
code
stringlengths 2.5k
6.36M
| kind
stringclasses 2
values | parsed_code
stringlengths 0
404k
| quality_prob
float64 0
0.98
| learning_prob
float64 0.03
1
|
|---|---|---|---|---|
```
import time
import os
import pandas as pd
import numpy as np
np.set_printoptions(precision=6, suppress=True)
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras import *
tf.__version__
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
from tensorflow.keras.metrics import Metric
class RSquare(Metric):
"""Compute R^2 score.
This is also called as coefficient of determination.
It tells how close are data to the fitted regression line.
- Highest score can be 1.0 and it indicates that the predictors
perfectly accounts for variation in the target.
- Score 0.0 indicates that the predictors do not
account for variation in the target.
- It can also be negative if the model is worse.
Usage:
```python
actuals = tf.constant([1, 4, 3], dtype=tf.float32)
preds = tf.constant([2, 4, 4], dtype=tf.float32)
result = tf.keras.metrics.RSquare()
result.update_state(actuals, preds)
print('R^2 score is: ', r1.result().numpy()) # 0.57142866
```
"""
def __init__(self, name='r_square', dtype=tf.float32):
super(RSquare, self).__init__(name=name, dtype=dtype)
self.squared_sum = self.add_weight("squared_sum", initializer="zeros")
self.sum = self.add_weight("sum", initializer="zeros")
self.res = self.add_weight("residual", initializer="zeros")
self.count = self.add_weight("count", initializer="zeros")
def update_state(self, y_true, y_pred):
y_true = tf.convert_to_tensor(y_true, tf.float32)
y_pred = tf.convert_to_tensor(y_pred, tf.float32)
self.squared_sum.assign_add(tf.reduce_sum(y_true**2))
self.sum.assign_add(tf.reduce_sum(y_true))
self.res.assign_add(
tf.reduce_sum(tf.square(tf.subtract(y_true, y_pred))))
self.count.assign_add(tf.cast(tf.shape(y_true)[0], tf.float32))
def result(self):
mean = self.sum / self.count
total = self.squared_sum - 2 * self.sum * mean + self.count * mean**2
return 1 - (self.res / total)
def reset_states(self):
# The state of the metric will be reset at the start of each epoch.
self.squared_sum.assign(0.0)
self.sum.assign(0.0)
self.res.assign(0.0)
self.count.assign(0.0)
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = ((8/2.54), (6/2.54))
plt.rcParams["font.family"] = "Arial"
plt.rcParams["mathtext.default"] = "rm"
plt.rcParams.update({'font.size': 11})
MARKER_SIZE = 15
cmap_m = ["#f4a6ad", "#f6957e", "#fccfa2", "#8de7be", "#86d6f2", "#24a9e4", "#b586e0", "#d7f293"]
cmap = ["#e94d5b", "#ef4d28", "#f9a54f", "#25b575", "#1bb1e7", "#1477a2", "#a662e5", "#c2f442"]
plt.rcParams['axes.spines.top'] = False
# plt.rcParams['axes.edgecolor'] =
plt.rcParams['axes.linewidth'] = 1
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['xtick.major.width'] = 1
plt.rcParams['xtick.minor.width'] = 1
plt.rcParams['ytick.major.width'] = 1
plt.rcParams['ytick.minor.width'] = 1
```
# Model training
## hyperparameters
```
SIZE = 50
LOSS_RATES = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
DISP_STEPS = 100
TRAINING_EPOCHS = 500
BATCH_SIZE = 32
LEARNING_RATE = 0.001
class ConvBlock(layers.Layer):
def __init__(self, filters, kernel_size, dropout_rate):
super(ConvBlock, self).__init__()
self.filters = filters
self.kernel_size = kernel_size
self.dropout_rate = dropout_rate
self.conv1 = layers.Conv2D(self.filters, self.kernel_size,
activation='relu', kernel_initializer='he_normal', padding='same')
self.batch1 = layers.BatchNormalization()
self.drop = layers.Dropout(self.dropout_rate)
self.conv2 = layers.Conv2D(self.filters, self.kernel_size,
activation='relu', kernel_initializer='he_normal', padding='same')
self.batch2 = layers.BatchNormalization()
def call(self, inp):
inp = self.batch1(self.conv1(inp))
inp = self.drop(inp)
inp = self.batch2(self.conv2(inp))
return inp
class DeconvBlock(layers.Layer):
def __init__(self, filters, kernel_size, strides):
super(DeconvBlock, self).__init__()
self.filters = filters
self.kernel_size = kernel_size
self.strides = strides
self.deconv1 = layers.Conv2DTranspose(self.filters, self.kernel_size, strides=self.strides, padding='same')
def call(self, inp):
inp = self.deconv1(inp)
return inp
class UNet(Model):
def __init__(self):
super(UNet, self).__init__()
self.conv_block1 = ConvBlock(64, (2, 2), 0.1)
self.pool1 = layers.MaxPooling2D()
self.conv_block2 = ConvBlock(128, (2, 2), 0.2)
self.pool2 = layers.MaxPooling2D()
self.conv_block3 = ConvBlock(256, (2, 2), 0.2)
self.deconv_block1 = DeconvBlock(128, (2, 2), (2, 2))
self.conv_block4 = ConvBlock(128, (2, 2), 0.2)
self.deconv_block2 = DeconvBlock(32, (2, 2), (2, 2))
self.padding = layers.ZeroPadding2D(((1, 0), (0, 1)))
self.conv_block5 = ConvBlock(64, (2, 2), 0.1)
self.output_conv = layers.Conv2D(1, (1, 1), activation='sigmoid')
def call(self, inp):
conv1 = self.conv_block1(inp)
pooled1 = self.pool1(conv1)
conv2 = self.conv_block2(pooled1)
pooled2 = self.pool2(conv2)
bottom = self.conv_block3(pooled2)
deconv1 = self.padding(self.deconv_block1(bottom))
deconv1 = layers.concatenate([deconv1, conv2])
deconv1 = self.conv_block4(deconv1)
deconv2 = self.deconv_block2(deconv1)
deconv2 = layers.concatenate([deconv2, conv1])
deconv2 = self.conv_block5(deconv2)
return self.output_conv(deconv2)
#loss inputs should be masked.
loss_object = tf.keras.losses.MeanSquaredError()
def loss_function(model, inp, tar):
masked_real = tar * (1 - inp[..., 1:2])
masked_pred = model(inp) * (1 - inp[..., 1:2])
return loss_object(masked_real, masked_pred)
```
# Mining
```
for LOSS_RATE in LOSS_RATES:
l = np.load('./data/tot_dataset_loss_%.2f.npz' % LOSS_RATE)
raw_input = l['raw_input']
raw_label = l['raw_label']
test_input = l['test_input']
test_label = l['test_label']
MAXS = l['MAXS']
MINS = l['MINS']
SCREEN_SIZE = l['SCREEN_SIZE']
raw_input = raw_input.astype(np.float32)
raw_label = raw_label.astype(np.float32)
test_input = test_input.astype(np.float32)
test_label = test_label.astype(np.float32)
num_train = int(raw_input.shape[0]*.7)
raw_input, raw_label = shuffle(raw_input, raw_label, random_state=4574)
train_input, train_label = raw_input[:num_train, ...], raw_label[:num_train, ...]
val_input, val_label = raw_input[num_train:, ...], raw_label[num_train:, ...]
train_dataset = tf.data.Dataset.from_tensor_slices((train_input, train_label))
train_dataset = train_dataset.cache().shuffle(BATCH_SIZE*50).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((val_input, val_label))
val_dataset = val_dataset.cache().shuffle(BATCH_SIZE*50).batch(BATCH_SIZE)
test_dataset = tf.data.Dataset.from_tensor_slices((test_input, test_label))
test_dataset = test_dataset.batch(BATCH_SIZE)
print('Training for loss rate %.2f start.' % LOSS_RATE)
BEST_PATH = './checkpoints/UNet_best_loss_%.2fp' % LOSS_RATE
@tf.function
def train(loss_function, model, opt, inp, tar):
with tf.GradientTape() as tape:
gradients = tape.gradient(loss_function(model, inp, tar), model.trainable_variables)
gradient_variables = zip(gradients, model.trainable_variables)
opt.apply_gradients(gradient_variables)
unet_model = UNet()
opt = tf.optimizers.Adam(learning_rate=LEARNING_RATE)
checkpoint_path = BEST_PATH
ckpt = tf.train.Checkpoint(unet_model=unet_model, opt=opt)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=10)
writer = tf.summary.create_file_writer('tmp')
prev_test_loss = 100.0
early_stop_buffer = 500
with writer.as_default():
with tf.summary.record_if(True):
for epoch in range(TRAINING_EPOCHS):
for step, (inp, tar) in enumerate(train_dataset):
train(loss_function, unet_model, opt, inp, tar)
loss_values = loss_function(unet_model, inp, tar)
tf.summary.scalar('loss', loss_values, step=step)
if step % DISP_STEPS == 0:
test_loss = 0
for step_, (inp_, tar_) in enumerate(test_dataset):
test_loss += loss_function(unet_model, inp_, tar_)
if step_ > DISP_STEPS:
test_loss /= DISP_STEPS
break
if test_loss.numpy() < prev_test_loss:
ckpt_save_path = ckpt_manager.save()
prev_test_loss = test_loss.numpy()
print('Saving checkpoint at {}'.format(ckpt_save_path))
else:
early_stop_buffer -= 1
print('Epoch {} batch {} train loss: {:.4f} test loss: {:.4f}'
.format(epoch, step, loss_values.numpy(), test_loss.numpy()))
if early_stop_buffer <= 0:
print('early stop.')
break
if early_stop_buffer <= 0:
break
i = -1
if ckpt_manager.checkpoints:
ckpt.restore(ckpt_manager.checkpoints[i])
print ('Checkpoint ' + ckpt_manager.checkpoints[i][-2:] +' restored!!')
unet_model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
loss = tf.keras.losses.MeanSquaredError())
test_loss = unet_model.evaluate(test_dataset)
pred_result = unet_model.predict(test_dataset)
avg_pred = []
OUTLIER = 2
for __ in range(5):
temp = []
for _ in range(int(pred_result.shape[1]/5)):
temp.append(pred_result[..., _*5:(_+1)*5, 0][..., __])
temp = np.stack(temp, axis=2)
temp.sort(axis=2)
avg_pred.append(temp[..., OUTLIER:-OUTLIER].mean(axis=2))
avg_pred = np.stack(avg_pred, axis=2)
masking = test_input[..., 1]
avg_masking = masking[..., :5]
masked_pred = np.ma.array(pred_result[..., 0], mask=masking)
masked_avg_pred = np.ma.array(avg_pred, mask=avg_masking)
masked_label = np.ma.array(test_label[..., 0], mask=masking)
plot_label = ((MAXS[:5]-MINS[:5])*masked_label[..., :5] + MINS[:5])
plot_label.fill_value = np.nan
plot_avg_pred = ((MAXS[:5]-MINS[:5])*masked_avg_pred[..., :5] + MINS[:5])
plot_avg_pred.fill_value = np.nan
f = open('./results/UNet_best_loss_%.2fp.npz' % LOSS_RATE, 'wb')
np.savez(f,
test_label = plot_label.filled(),
test_pred = plot_avg_pred.filled()
)
f.close()
```
|
github_jupyter
|
import time
import os
import pandas as pd
import numpy as np
np.set_printoptions(precision=6, suppress=True)
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
import tensorflow as tf
from tensorflow.keras import *
tf.__version__
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
from tensorflow.keras.metrics import Metric
class RSquare(Metric):
"""Compute R^2 score.
This is also called as coefficient of determination.
It tells how close are data to the fitted regression line.
- Highest score can be 1.0 and it indicates that the predictors
perfectly accounts for variation in the target.
- Score 0.0 indicates that the predictors do not
account for variation in the target.
- It can also be negative if the model is worse.
Usage:
```python
actuals = tf.constant([1, 4, 3], dtype=tf.float32)
preds = tf.constant([2, 4, 4], dtype=tf.float32)
result = tf.keras.metrics.RSquare()
result.update_state(actuals, preds)
print('R^2 score is: ', r1.result().numpy()) # 0.57142866
```
"""
def __init__(self, name='r_square', dtype=tf.float32):
super(RSquare, self).__init__(name=name, dtype=dtype)
self.squared_sum = self.add_weight("squared_sum", initializer="zeros")
self.sum = self.add_weight("sum", initializer="zeros")
self.res = self.add_weight("residual", initializer="zeros")
self.count = self.add_weight("count", initializer="zeros")
def update_state(self, y_true, y_pred):
y_true = tf.convert_to_tensor(y_true, tf.float32)
y_pred = tf.convert_to_tensor(y_pred, tf.float32)
self.squared_sum.assign_add(tf.reduce_sum(y_true**2))
self.sum.assign_add(tf.reduce_sum(y_true))
self.res.assign_add(
tf.reduce_sum(tf.square(tf.subtract(y_true, y_pred))))
self.count.assign_add(tf.cast(tf.shape(y_true)[0], tf.float32))
def result(self):
mean = self.sum / self.count
total = self.squared_sum - 2 * self.sum * mean + self.count * mean**2
return 1 - (self.res / total)
def reset_states(self):
# The state of the metric will be reset at the start of each epoch.
self.squared_sum.assign(0.0)
self.sum.assign(0.0)
self.res.assign(0.0)
self.count.assign(0.0)
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = ((8/2.54), (6/2.54))
plt.rcParams["font.family"] = "Arial"
plt.rcParams["mathtext.default"] = "rm"
plt.rcParams.update({'font.size': 11})
MARKER_SIZE = 15
cmap_m = ["#f4a6ad", "#f6957e", "#fccfa2", "#8de7be", "#86d6f2", "#24a9e4", "#b586e0", "#d7f293"]
cmap = ["#e94d5b", "#ef4d28", "#f9a54f", "#25b575", "#1bb1e7", "#1477a2", "#a662e5", "#c2f442"]
plt.rcParams['axes.spines.top'] = False
# plt.rcParams['axes.edgecolor'] =
plt.rcParams['axes.linewidth'] = 1
plt.rcParams['lines.linewidth'] = 1.5
plt.rcParams['xtick.major.width'] = 1
plt.rcParams['xtick.minor.width'] = 1
plt.rcParams['ytick.major.width'] = 1
plt.rcParams['ytick.minor.width'] = 1
SIZE = 50
LOSS_RATES = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
DISP_STEPS = 100
TRAINING_EPOCHS = 500
BATCH_SIZE = 32
LEARNING_RATE = 0.001
class ConvBlock(layers.Layer):
def __init__(self, filters, kernel_size, dropout_rate):
super(ConvBlock, self).__init__()
self.filters = filters
self.kernel_size = kernel_size
self.dropout_rate = dropout_rate
self.conv1 = layers.Conv2D(self.filters, self.kernel_size,
activation='relu', kernel_initializer='he_normal', padding='same')
self.batch1 = layers.BatchNormalization()
self.drop = layers.Dropout(self.dropout_rate)
self.conv2 = layers.Conv2D(self.filters, self.kernel_size,
activation='relu', kernel_initializer='he_normal', padding='same')
self.batch2 = layers.BatchNormalization()
def call(self, inp):
inp = self.batch1(self.conv1(inp))
inp = self.drop(inp)
inp = self.batch2(self.conv2(inp))
return inp
class DeconvBlock(layers.Layer):
def __init__(self, filters, kernel_size, strides):
super(DeconvBlock, self).__init__()
self.filters = filters
self.kernel_size = kernel_size
self.strides = strides
self.deconv1 = layers.Conv2DTranspose(self.filters, self.kernel_size, strides=self.strides, padding='same')
def call(self, inp):
inp = self.deconv1(inp)
return inp
class UNet(Model):
def __init__(self):
super(UNet, self).__init__()
self.conv_block1 = ConvBlock(64, (2, 2), 0.1)
self.pool1 = layers.MaxPooling2D()
self.conv_block2 = ConvBlock(128, (2, 2), 0.2)
self.pool2 = layers.MaxPooling2D()
self.conv_block3 = ConvBlock(256, (2, 2), 0.2)
self.deconv_block1 = DeconvBlock(128, (2, 2), (2, 2))
self.conv_block4 = ConvBlock(128, (2, 2), 0.2)
self.deconv_block2 = DeconvBlock(32, (2, 2), (2, 2))
self.padding = layers.ZeroPadding2D(((1, 0), (0, 1)))
self.conv_block5 = ConvBlock(64, (2, 2), 0.1)
self.output_conv = layers.Conv2D(1, (1, 1), activation='sigmoid')
def call(self, inp):
conv1 = self.conv_block1(inp)
pooled1 = self.pool1(conv1)
conv2 = self.conv_block2(pooled1)
pooled2 = self.pool2(conv2)
bottom = self.conv_block3(pooled2)
deconv1 = self.padding(self.deconv_block1(bottom))
deconv1 = layers.concatenate([deconv1, conv2])
deconv1 = self.conv_block4(deconv1)
deconv2 = self.deconv_block2(deconv1)
deconv2 = layers.concatenate([deconv2, conv1])
deconv2 = self.conv_block5(deconv2)
return self.output_conv(deconv2)
#loss inputs should be masked.
loss_object = tf.keras.losses.MeanSquaredError()
def loss_function(model, inp, tar):
masked_real = tar * (1 - inp[..., 1:2])
masked_pred = model(inp) * (1 - inp[..., 1:2])
return loss_object(masked_real, masked_pred)
for LOSS_RATE in LOSS_RATES:
l = np.load('./data/tot_dataset_loss_%.2f.npz' % LOSS_RATE)
raw_input = l['raw_input']
raw_label = l['raw_label']
test_input = l['test_input']
test_label = l['test_label']
MAXS = l['MAXS']
MINS = l['MINS']
SCREEN_SIZE = l['SCREEN_SIZE']
raw_input = raw_input.astype(np.float32)
raw_label = raw_label.astype(np.float32)
test_input = test_input.astype(np.float32)
test_label = test_label.astype(np.float32)
num_train = int(raw_input.shape[0]*.7)
raw_input, raw_label = shuffle(raw_input, raw_label, random_state=4574)
train_input, train_label = raw_input[:num_train, ...], raw_label[:num_train, ...]
val_input, val_label = raw_input[num_train:, ...], raw_label[num_train:, ...]
train_dataset = tf.data.Dataset.from_tensor_slices((train_input, train_label))
train_dataset = train_dataset.cache().shuffle(BATCH_SIZE*50).batch(BATCH_SIZE)
val_dataset = tf.data.Dataset.from_tensor_slices((val_input, val_label))
val_dataset = val_dataset.cache().shuffle(BATCH_SIZE*50).batch(BATCH_SIZE)
test_dataset = tf.data.Dataset.from_tensor_slices((test_input, test_label))
test_dataset = test_dataset.batch(BATCH_SIZE)
print('Training for loss rate %.2f start.' % LOSS_RATE)
BEST_PATH = './checkpoints/UNet_best_loss_%.2fp' % LOSS_RATE
@tf.function
def train(loss_function, model, opt, inp, tar):
with tf.GradientTape() as tape:
gradients = tape.gradient(loss_function(model, inp, tar), model.trainable_variables)
gradient_variables = zip(gradients, model.trainable_variables)
opt.apply_gradients(gradient_variables)
unet_model = UNet()
opt = tf.optimizers.Adam(learning_rate=LEARNING_RATE)
checkpoint_path = BEST_PATH
ckpt = tf.train.Checkpoint(unet_model=unet_model, opt=opt)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=10)
writer = tf.summary.create_file_writer('tmp')
prev_test_loss = 100.0
early_stop_buffer = 500
with writer.as_default():
with tf.summary.record_if(True):
for epoch in range(TRAINING_EPOCHS):
for step, (inp, tar) in enumerate(train_dataset):
train(loss_function, unet_model, opt, inp, tar)
loss_values = loss_function(unet_model, inp, tar)
tf.summary.scalar('loss', loss_values, step=step)
if step % DISP_STEPS == 0:
test_loss = 0
for step_, (inp_, tar_) in enumerate(test_dataset):
test_loss += loss_function(unet_model, inp_, tar_)
if step_ > DISP_STEPS:
test_loss /= DISP_STEPS
break
if test_loss.numpy() < prev_test_loss:
ckpt_save_path = ckpt_manager.save()
prev_test_loss = test_loss.numpy()
print('Saving checkpoint at {}'.format(ckpt_save_path))
else:
early_stop_buffer -= 1
print('Epoch {} batch {} train loss: {:.4f} test loss: {:.4f}'
.format(epoch, step, loss_values.numpy(), test_loss.numpy()))
if early_stop_buffer <= 0:
print('early stop.')
break
if early_stop_buffer <= 0:
break
i = -1
if ckpt_manager.checkpoints:
ckpt.restore(ckpt_manager.checkpoints[i])
print ('Checkpoint ' + ckpt_manager.checkpoints[i][-2:] +' restored!!')
unet_model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
loss = tf.keras.losses.MeanSquaredError())
test_loss = unet_model.evaluate(test_dataset)
pred_result = unet_model.predict(test_dataset)
avg_pred = []
OUTLIER = 2
for __ in range(5):
temp = []
for _ in range(int(pred_result.shape[1]/5)):
temp.append(pred_result[..., _*5:(_+1)*5, 0][..., __])
temp = np.stack(temp, axis=2)
temp.sort(axis=2)
avg_pred.append(temp[..., OUTLIER:-OUTLIER].mean(axis=2))
avg_pred = np.stack(avg_pred, axis=2)
masking = test_input[..., 1]
avg_masking = masking[..., :5]
masked_pred = np.ma.array(pred_result[..., 0], mask=masking)
masked_avg_pred = np.ma.array(avg_pred, mask=avg_masking)
masked_label = np.ma.array(test_label[..., 0], mask=masking)
plot_label = ((MAXS[:5]-MINS[:5])*masked_label[..., :5] + MINS[:5])
plot_label.fill_value = np.nan
plot_avg_pred = ((MAXS[:5]-MINS[:5])*masked_avg_pred[..., :5] + MINS[:5])
plot_avg_pred.fill_value = np.nan
f = open('./results/UNet_best_loss_%.2fp.npz' % LOSS_RATE, 'wb')
np.savez(f,
test_label = plot_label.filled(),
test_pred = plot_avg_pred.filled()
)
f.close()
| 0.825414 | 0.674855 |
<a href="https://colab.research.google.com/github/prachi-lad17/Python-Case-Studies/blob/main/Case_Study_2%3A%20Figuring_out_which_customer_may_leave.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# **Figuring out which customer may leave**
```
```
# Figuring Our Which Customers May Leave - Churn Analysis
### About our Dataset
Source - https://www.kaggle.com/blastchar/telco-customer-churn
1. We have customer information for a Telecommunications company
2. We've got customer IDs, general customer info, the servies they've subscribed too, type of contract and monthly charges.
3. This is a historic customer information so we have a field stating whether that customer has **churnded**
**Field Descriptions**
- customerID - Customer ID
- gender - Whether the customer is a male or a female
- SeniorCitizen - Whether the customer is a senior citizen or not (1, 0)
- Partner - Whether the customer has a partner or not (Yes, No)
- Dependents - Whether the customer has dependents or not (Yes, No)
- tenure - Number of months the customer has stayed with the company
- PhoneService - Whether the customer has a phone service or not (Yes, No)
- MultipleLines - Whether the customer has multiple lines or not (Yes, No, No phone service)
- InternetService - Customer’s internet service provider (DSL, Fiber optic, No)
- OnlineSecurity - Whether the customer has online security or not (Yes, No, No internet service)
- OnlineBackup - Whether the customer has online backup or not (Yes, No, No internet service)
- DeviceProtection - Whether the customer has device protection or not (Yes, No, No internet service)
- TechSupport - Whether the customer has tech support or not (Yes, No, No internet service)
- StreamingTV - Whether the customer has streaming TV or not (Yes, No, No internet service)
- StreamingMovies - Whether the customer has streaming movies or not (Yes, No, No internet service)
- Contract - The contract term of the customer (Month-to-month, One year, Two year)
- PaperlessBilling - Whether the customer has paperless billing or not (Yes, No)
- PaymentMethod - The customer’s payment method (Electronic check, Mailed check Bank transfer (automatic), Credit card (automatic))
- MonthlyCharges - The amount charged to the customer monthly
- TotalCharges - The total amount charged to the customer
- Churn - Whether the customer churned or not (Yes or No)
***Customer Churn*** - churn is when an existing customer, user, player, subscriber or any kind of return client stops doing business or ends the relationship with a company.
**Aim -** is to figure our which customers may likely churn in future
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
## Loading files
file_name = "https://raw.githubusercontent.com/rajeevratan84/datascienceforbusiness/master/WA_Fn-UseC_-Telco-Customer-Churn.csv"
churn_df = pd.read_csv(file_name)
# Using .head() function to check if file is uploaded. It will print first 5 records.
churn_df.head()
## To check last 5 records, we use .tail() funtion
churn_df.tail()
## To get summary on numeric columns
churn_df.describe()
## To get summary on each column
churn_df.describe(include="all")
## TO check categorical variables in dataset
churn_df.select_dtypes(exclude=['int64','float']).columns
## To check numerical variables
churn_df.select_dtypes(exclude=['object']).columns
## To check the unique values
churn_df.SeniorCitizen.unique()
## To check unique levels of tenure
churn_df.tenure.unique()
## Printing unique levels of Churn variable
churn_df.Churn.unique()
## How many unique values are there in MonthlyChaerges variable
len(churn_df.MonthlyCharges.unique())
## How many unique values are there in Churn variable
len(churn_df.Churn.unique())
## Another way of showing information of data in a single output
print("No_of_Rows: ", churn_df.shape[0])
print()
print("No_of_Columns: ", churn_df.shape[1])
print()
print("Features: ", churn_df.columns.to_list)
print("\nMissing_Values: ", churn_df.isnull().sum().values.sum())
print("\nMissing_Values: ", churn_df.isnull().sum())
print("\nUnique_Values: \n", churn_df.nunique())
## Print how many churn and not churn
churn_df['Churn'].value_counts(sort = False)
```
## **Exporatory Data Analysis**
```
## It is a best practice to keep a copy, in case we need to check at original dataset in future
churn_df_copy = churn_df.copy()
## Dropping the columns which are not necessary for the plots we are gonna do.
churn_df_copy.drop(['customerID','MonthlyCharges', 'TotalCharges', 'tenure'], axis=1, inplace=True)
churn_df_copy.head()
```
### **pd.crosstab() == if we want to work upon more variable at a time then we use pd.crosstab()**
* The pandas crosstab function builds a cross-tabulation table that can show the frequency with which certain groups of data appear.
* The crosstab function can operate on numpy arrays, series or columns in a dataframe.
* Pandas does that work behind the scenes to count how many occurrences there are of each combination.
* The pandas crosstab function is a useful tool for summarizing data. The functionality overlaps with some of the other pandas tools but it occupies a useful place in your data analysis toolbox.
```
## By using this code we can apply crosstab function for each column
summary = pd.concat([pd.crosstab(churn_df_copy[x], churn_df_copy.Churn) for x in churn_df_copy.columns[:-1]], keys=churn_df_copy.columns[:-1])
summary
## Printing churn rate by gender
pd.crosstab(churn_df_copy['Churn'],churn_df_copy['gender'])
## Printing churn rate by gender with margins
pd.crosstab(churn_df_copy['Churn'],churn_df_copy['gender'],margins=True,margins_name="Total",normalize=True)
## Checking margins
pd.concat([pd.crosstab(churn_df_copy[x], churn_df_copy.Churn,margins=True,margins_name="Total",normalize=True) for x in churn_df_copy.columns[:-1]], keys=churn_df_copy.columns[:-1])
"""Making a % column for summary"""
summary['Churn_%'] = summary['Yes'] / summary['No'] + summary['Yes']
summary
```
## **Visualization and EDA**
```
import matplotlib.pyplot as plt # this is used for the plot the graph
import seaborn as sns # used for plot interactive graph.
from pylab import rcParams # Customize Matplotlib plots using rcParams
# Data to plot
labels = churn_df['Churn'].value_counts(sort = True).index
sizes = churn_df['Churn'].value_counts(sort = True)
colors = ["pink","lightblue"]
explode = (0.05,0) # explode 1st slice
rcParams['figure.figsize'] = 7,7
# Plot
plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', shadow=True, startangle=90,)
plt.title('Customer Churn Breakdown')
plt.show()
# Correlation plot doesn't end up being too informative
import matplotlib.pyplot as plt
def plot_corr(df,size=10):
'''Function plots a graphical correlation matrix for each pair of columns in the dataframe.
Input:
df: pandas DataFrame
size: vertical and horizontal size of the plot'''
corr = df.corr()
fig, ax = plt.subplots(figsize=(size, size))
ax.legend()
cax = ax.matshow(corr)
fig.colorbar(cax)
plt.xticks(range(len(corr.columns)), corr.columns, rotation='vertical')
plt.yticks(range(len(corr.columns)), corr.columns)
plot_corr(churn_df)
# Create a Violin Plot showing how monthy charges relate to Churn
# We an see that Churned customers tend to be higher paying customers
g = sns.factorplot(x="Churn", y = "MonthlyCharges",data = churn_df, kind="violin", palette = "Pastel1")
# Let's look at Tenure
g = sns.factorplot(x="Churn", y = "tenure",data = churn_df, kind="violin", palette = "Pastel1")
plt.figure(figsize= (10,10))
sns.countplot(churn_df['Churn'])
```
## **Preparing our dataset for Machine Learning**
```
# Check for empty fields, Note, " " is not Null but a spaced character
len(churn_df[churn_df['TotalCharges'] == " "])
## Drop missing data
churn_df = churn_df[churn_df['TotalCharges'] != " "]
len(churn_df[churn_df['TotalCharges'] == " "])
## Here we are making diff col - id_col, target_col,
## Next we are writing a code to check the unique levels in each categorical variable and if it is <6 then it is applying label encoding.
## Label Encoding takes binary column and changes the values to 0 and 1. We do label encoding because our can only understand 0 and 1 language.
## cat_col - will store categorical variables which are having less than 6 unique levels
## id_col - stores customerID column
## target_col - stores Churn column
## num_cols - stores all the numerical columns except id_cols, target_cols, cat_col
## bin_cols - stores the binary variables
## multi_cols - stores the categorical columns which are not binary
## Then next we do label encoding for binary columns
## And duplicating columns for multi value columns
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
#customer id col
id_col = ['customerID']
#Target columns
target_col = ["Churn"]
#categorical columns
cat_cols = churn_df.nunique()[churn_df.nunique() < 6].keys().tolist()
cat_cols = [x for x in cat_cols if x not in target_col]
#numerical columns
num_cols = [x for x in churn_df.columns if x not in cat_cols + target_col + id_col]
#Binary columns with 2 values
bin_cols = churn_df.nunique()[churn_df.nunique() == 2].keys().tolist()
#Columns more than 2 values
multi_cols = [i for i in cat_cols if i not in bin_cols]
#Label encoding Binary columns
le = LabelEncoder()
for i in bin_cols :
churn_df[i] = le.fit_transform(churn_df[i])
#Duplicating columns for multi value columns
churn_df = pd.get_dummies(data = churn_df, columns = multi_cols )
churn_df.head()
len(churn_df.columns)
num_cols
id_col
cat_cols
## Scaling Numerical columns
std = StandardScaler()
## Scale data
scaled = std.fit_transform(churn_df[num_cols])
scaled = pd.DataFrame(scaled,columns = num_cols)
## Dropping original values merging scaled values for numerical columns
df_telcom_og = churn_df.copy()
churn_df = churn_df.drop(columns = num_cols,axis = 1)
churn_df = churn_df.merge(scaled, left_index = True, right_index = True, how = "left")
## Churn_df.info()
churn_df.head()
churn_df.drop(['customerID'], axis=1, inplace=True)
churn_df.head()
churn_df[churn_df.isnull().any(axis=1)]
print(len(churn_df.isnull().sum()))
## Since there are only 11 NA values, we drop them.
churn_df = churn_df.dropna()
# Double check that nulls have been removed
churn_df[churn_df.isnull().any(axis=1)]
```
# **Splitting into training and testing**
```
from sklearn.model_selection import train_test_split
# We remove our label values from train data
X = churn_df.drop(['Churn'],axis=1).values
# We assigned our label variable to test data
Y = churn_df['Churn'].values
# Split it to a 70:30 Ratio Train:Test
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
type(x_train)
df_train = pd.DataFrame(x_train)
df_train.head()
print(len(churn_df.columns))
churn_df.columns
churn_df.head()
```
# **Training LOGISTIC REGRESSION model**
```
from sklearn.linear_model import LogisticRegression
### creating a model
classifier_model = LogisticRegression()
### passing training data to model
classifier_model.fit(x_train,y_train)
### predicting values x_test using model and storing the values in y_pred
y_pred = classifier_model.predict(x_test)
### interception and coefficient of model
print(classifier_model.intercept_)
print(classifier_model.coef_)
print()
### printing values for better understanding
print(list(zip(y_test, y_pred)))
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
### creating and printing confusion matrix
conf_matrix = confusion_matrix(y_test,y_pred)
print(conf_matrix)
### Creating and printing classification report
print("Classification Report: ")
print(classification_report(y_test,y_pred))
### Creating and printing accuracy score
acc = accuracy_score(y_test,y_pred)
print("Accuracy {0:.2f}%".format(100*accuracy_score(y_pred, y_test)))
```
## **Feature Importance using Logistic Regression**
```
# Let's see what features mattered most i.e. Feature Importance
# We sort on the co-efficients with the largest weights as those impact the resulting output the most
coef = classifier_model.coef_[0]
coef = [abs(number) for number in coef]
print(coef)
# Finding and deleting the label column
cols = list(churn_df.columns)
cols.index('Churn')
del cols[6]
cols
# Sorting on Feature Importance
sorted_index = sorted(range(len(coef)), key = lambda k: coef[k], reverse = True)
for idx in sorted_index:
print(cols[idx])
```
## **Try Random Forests**
```
from sklearn.ensemble import RandomForestClassifier
random_forest_model = RandomForestClassifier(n_estimators=100,random_state=10) ## it will built 100 DT in background
#fit the model on the data and predict the values
random_forest_model.fit(x_train,y_train)
y_pred_rf = random_forest_model.predict(x_test)
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
### creating and printing confusion matrix
conf_matrix_rf = confusion_matrix(y_test,y_pred_rf)
print(conf_matrix_rf)
### Creating and printing classification report
print("Classification Report: ")
print(classification_report(y_test,y_pred_rf))
### Creating and printing accuracy score
acc = accuracy_score(y_test,y_pred_rf)
print("Accuracy {0:.2f}%".format(100*accuracy_score(y_pred_rf, y_test)))
```
# **Saving a model**
```
import pickle
# save
with open('model.pkl','wb') as f:
pickle.dump(random_forest_model, f)
# load
with open('model.pkl', 'rb') as f:
loaded_model_rf = pickle.load(f)
predictions = loaded_model_rf.predict(x_test)
predictions
```
# **Deep Learning Model**
```
## Using the newest version of Tensorflow 2.0
%tensorflow_version 2.x
## Checking to ensure we are using our GPU
import tensorflow as tf
tf.test.gpu_device_name()
# Create a simple model
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(20, kernel_initializer = "uniform",activation = "relu", input_dim=40))
model.add(Dense(1, kernel_initializer = "uniform",activation = "sigmoid"))
model.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])
# Display Model Summary and Show Parameters
model.summary()
# Start Training Our Classifier
batch_size = 64
epochs = 25
history = model.fit(x_train,
y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
predictions = model.predict(x_test)
predictions = (predictions > 0.5)
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
```
# **Saving Model**
```
## Simple cnn = simple convolutional neural network
## You mean a HDF5/H5 file, which is a file format to store structured data, its not a model by itself.
## Keras saves models in this format as it can easily store the weights and model configuration in a single file.
model.save("simple_cnn_25_epochs.h5")
## Loading our model
from tensorflow.keras.models import load_model
classifier_DL_simple_cnn = load_model('simple_cnn_25_epochs.h5')
```
# **Trying deeper models, checkpoints and stopping early.**
```
from tensorflow.keras.regularizers import l2
from tensorflow.keras.layers import Dropout
from tensorflow.keras.callbacks import ModelCheckpoint
model2 = Sequential()
# Hidden Layer 1
model2.add(Dense(2000, activation='relu', input_dim=40, kernel_regularizer=l2(0.01)))
model2.add(Dropout(0.3, noise_shape=None, seed=None))
# Hidden Layer 2
model2.add(Dense(1000, activation='relu', input_dim=18, kernel_regularizer=l2(0.01)))
model2.add(Dropout(0.3, noise_shape=None, seed=None))
# Hidden Layer 3
model2.add(Dense(500, activation = 'relu', kernel_regularizer=l2(0.01)))
model2.add(Dropout(0.3, noise_shape=None, seed=None))
model2.add(Dense(1, activation='sigmoid'))
model2.summary()
# Create our checkpoint so that we save model after each epoch
checkpoint = ModelCheckpoint("deep_model_checkpoint.h5",
monitor="val_loss",
mode="min",
save_best_only = True,
verbose=1)
model2.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Defining our early stoppping criteria
from tensorflow.keras.callbacks import EarlyStopping
earlystop = EarlyStopping(monitor = 'val_loss', # value being monitored for improvement
min_delta = 0, #Abs value and is the min change required before we stop
patience = 2, #Number of epochs we wait before stopping
verbose = 1,
restore_best_weights = True) #keeps the best weigths once stopped
# we put our call backs into a callback list
callbacks = [earlystop, checkpoint]
batch_size = 32
epochs = 10
history = model2.fit(x_train,
y_train,
batch_size = batch_size,
epochs = epochs,
verbose = 1,
# NOTE We are adding our callbacks here
callbacks = callbacks,
validation_data = (x_test, y_test))
score = model2.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
```
|
github_jupyter
|
```
# Figuring Our Which Customers May Leave - Churn Analysis
### About our Dataset
Source - https://www.kaggle.com/blastchar/telco-customer-churn
1. We have customer information for a Telecommunications company
2. We've got customer IDs, general customer info, the servies they've subscribed too, type of contract and monthly charges.
3. This is a historic customer information so we have a field stating whether that customer has **churnded**
**Field Descriptions**
- customerID - Customer ID
- gender - Whether the customer is a male or a female
- SeniorCitizen - Whether the customer is a senior citizen or not (1, 0)
- Partner - Whether the customer has a partner or not (Yes, No)
- Dependents - Whether the customer has dependents or not (Yes, No)
- tenure - Number of months the customer has stayed with the company
- PhoneService - Whether the customer has a phone service or not (Yes, No)
- MultipleLines - Whether the customer has multiple lines or not (Yes, No, No phone service)
- InternetService - Customer’s internet service provider (DSL, Fiber optic, No)
- OnlineSecurity - Whether the customer has online security or not (Yes, No, No internet service)
- OnlineBackup - Whether the customer has online backup or not (Yes, No, No internet service)
- DeviceProtection - Whether the customer has device protection or not (Yes, No, No internet service)
- TechSupport - Whether the customer has tech support or not (Yes, No, No internet service)
- StreamingTV - Whether the customer has streaming TV or not (Yes, No, No internet service)
- StreamingMovies - Whether the customer has streaming movies or not (Yes, No, No internet service)
- Contract - The contract term of the customer (Month-to-month, One year, Two year)
- PaperlessBilling - Whether the customer has paperless billing or not (Yes, No)
- PaymentMethod - The customer’s payment method (Electronic check, Mailed check Bank transfer (automatic), Credit card (automatic))
- MonthlyCharges - The amount charged to the customer monthly
- TotalCharges - The total amount charged to the customer
- Churn - Whether the customer churned or not (Yes or No)
***Customer Churn*** - churn is when an existing customer, user, player, subscriber or any kind of return client stops doing business or ends the relationship with a company.
**Aim -** is to figure our which customers may likely churn in future
## **Exporatory Data Analysis**
### **pd.crosstab() == if we want to work upon more variable at a time then we use pd.crosstab()**
* The pandas crosstab function builds a cross-tabulation table that can show the frequency with which certain groups of data appear.
* The crosstab function can operate on numpy arrays, series or columns in a dataframe.
* Pandas does that work behind the scenes to count how many occurrences there are of each combination.
* The pandas crosstab function is a useful tool for summarizing data. The functionality overlaps with some of the other pandas tools but it occupies a useful place in your data analysis toolbox.
## **Visualization and EDA**
## **Preparing our dataset for Machine Learning**
# **Splitting into training and testing**
# **Training LOGISTIC REGRESSION model**
## **Feature Importance using Logistic Regression**
## **Try Random Forests**
# **Saving a model**
# **Deep Learning Model**
# **Saving Model**
# **Trying deeper models, checkpoints and stopping early.**
| 0.719285 | 0.934634 |
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import f1_score
from sklearn.tree import DecisionTreeClassifier
# reading data files and storing them in a dataframe
df = pd.read_csv('Downloads/Features_Variant_1.csv')
df.info()
df.columns = ['likes','Page_Checkins','Page_talking_about','Page_Category','Derived5','Derived6','Derived7','Derived8','Derived9','Derived10','Derived11','Derived12','Derived13','Derived14','Derived15','Derived16','Derived17','Derived18','Derived19','Derived20','Derived21','Derived22','Derived23','Derived24','Derived25','Derived26','Derived27','Derived28','Derived29','CC1','CC2','CC3','CC4','CC5','Base time','Post_length','Post_Share_Count','Post_Promotion_Status','H_Local','Post published weekday40','Post published weekday41','Post published weekday42','Post published weekday43','Post published weekday44','Post published weekday45','Post published weekday46','Base DateTime weekday47','Base DateTime weekday48','Base DateTime weekday49','Base DateTime weekday50','Base DateTime weekday51','Base DateTime weekday52','Base DateTime weekday53','Target Variable']
df.describe()
df.corr().head()
f,ax = plt.subplots(figsize=(18, 18))
sns.heatmap(train_data.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
plt.show()
from sklearn import linear_model, metrics
from sklearn.model_selection import train_test_split
X = df[['likes','Page_Checkins','Page_talking_about','Page_Category','Derived5','Derived6','Derived7','Derived8','Derived9','Derived10','Derived11','Derived12','Derived13','Derived14','Derived15','Derived16','Derived17','Derived18','Derived19','Derived20','Derived21','Derived22','Derived23','Derived24','Derived25','Derived26','Derived27','Derived28','Derived29','CC1','CC2','CC3','CC4','CC5','Base time','Post_length','Post_Share_Count','Post_Promotion_Status','H_Local','Post published weekday40','Post published weekday41','Post published weekday42','Post published weekday43','Post published weekday44','Post published weekday45','Post published weekday46','Base DateTime weekday47','Base DateTime weekday48','Base DateTime weekday49','Base DateTime weekday50','Base DateTime weekday51','Base DateTime weekday52','Base DateTime weekday53']]
y=df['Target Variable']
#Standardization
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
X_train_std=sc.fit_transform(x_train)
X_test=sc.transform(x_test)
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.1,random_state=1)
Linear_model = linear_model.LinearRegression()
Linear_model.fit(x_train, y_train)
print(Linear_model.intercept_)
print(Linear_model.coef_)
y_predcited = Linear_model.predict(x_test)
print(y_predcited)
print(metrics.mean_squared_error(y_test,y_predcited))
print(np.sqrt(metrics.mean_squared_error(y_test,y_predcited)))
from sklearn.metrics import r2_score
print(r2_score(y_test,y_predcited ) )
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
tree_reg = tree.DecisionTreeRegressor(max_depth=6)
tree_reg.fit(x_train, y_train)
print(tree_reg.score(x_test,y_test))
y_pred = regressor.predict(x_test)
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
important = tree_reg.feature_importances_
print(important)
tree.plot_tree(tree_reg)
```
|
github_jupyter
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import f1_score
from sklearn.tree import DecisionTreeClassifier
# reading data files and storing them in a dataframe
df = pd.read_csv('Downloads/Features_Variant_1.csv')
df.info()
df.columns = ['likes','Page_Checkins','Page_talking_about','Page_Category','Derived5','Derived6','Derived7','Derived8','Derived9','Derived10','Derived11','Derived12','Derived13','Derived14','Derived15','Derived16','Derived17','Derived18','Derived19','Derived20','Derived21','Derived22','Derived23','Derived24','Derived25','Derived26','Derived27','Derived28','Derived29','CC1','CC2','CC3','CC4','CC5','Base time','Post_length','Post_Share_Count','Post_Promotion_Status','H_Local','Post published weekday40','Post published weekday41','Post published weekday42','Post published weekday43','Post published weekday44','Post published weekday45','Post published weekday46','Base DateTime weekday47','Base DateTime weekday48','Base DateTime weekday49','Base DateTime weekday50','Base DateTime weekday51','Base DateTime weekday52','Base DateTime weekday53','Target Variable']
df.describe()
df.corr().head()
f,ax = plt.subplots(figsize=(18, 18))
sns.heatmap(train_data.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax)
plt.show()
from sklearn import linear_model, metrics
from sklearn.model_selection import train_test_split
X = df[['likes','Page_Checkins','Page_talking_about','Page_Category','Derived5','Derived6','Derived7','Derived8','Derived9','Derived10','Derived11','Derived12','Derived13','Derived14','Derived15','Derived16','Derived17','Derived18','Derived19','Derived20','Derived21','Derived22','Derived23','Derived24','Derived25','Derived26','Derived27','Derived28','Derived29','CC1','CC2','CC3','CC4','CC5','Base time','Post_length','Post_Share_Count','Post_Promotion_Status','H_Local','Post published weekday40','Post published weekday41','Post published weekday42','Post published weekday43','Post published weekday44','Post published weekday45','Post published weekday46','Base DateTime weekday47','Base DateTime weekday48','Base DateTime weekday49','Base DateTime weekday50','Base DateTime weekday51','Base DateTime weekday52','Base DateTime weekday53']]
y=df['Target Variable']
#Standardization
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
X_train_std=sc.fit_transform(x_train)
X_test=sc.transform(x_test)
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.1,random_state=1)
Linear_model = linear_model.LinearRegression()
Linear_model.fit(x_train, y_train)
print(Linear_model.intercept_)
print(Linear_model.coef_)
y_predcited = Linear_model.predict(x_test)
print(y_predcited)
print(metrics.mean_squared_error(y_test,y_predcited))
print(np.sqrt(metrics.mean_squared_error(y_test,y_predcited)))
from sklearn.metrics import r2_score
print(r2_score(y_test,y_predcited ) )
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
tree_reg = tree.DecisionTreeRegressor(max_depth=6)
tree_reg.fit(x_train, y_train)
print(tree_reg.score(x_test,y_test))
y_pred = regressor.predict(x_test)
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
important = tree_reg.feature_importances_
print(important)
tree.plot_tree(tree_reg)
| 0.538255 | 0.309682 |
```
from esper.prelude import *
def get_fps_map(vids):
from query.models import Video
vs = Video.objects.filter(id__in=vids)
return {v.id: v.fps for v in vs}
def frame_second_conversion(c, mode='f2s'):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import Interval3D
fps_map = get_fps_map(set(c.get_grouped_intervals().keys()))
def second_to_frame(fps):
def map_fn(intrvl):
i2 = intrvl.copy()
t1,t2 = intrvl.t
i2.t = (int(t1*fps), int(t2*fps))
return i2
return map_fn
def frame_to_second(fps):
def map_fn(intrvl):
i2 = intrvl.copy()
t1,t2 = intrvl.t
i2.t = (int(t1/fps), int(t2/fps))
return i2
return map_fn
if mode=='f2s':
fn = frame_to_second
if mode=='s2f':
fn = second_to_frame
output = {}
for vid, intervals in c.get_grouped_intervals().items():
output[vid] = intervals.map(fn(fps_map[vid]))
return DomainIntervalCollection(output)
def frame_to_second_collection(c):
return frame_second_conversion(c, 'f2s')
def second_to_frame_collection(c):
return frame_second_conversion(c, 's2f')
def convert_to_1d_collection(collection):
from rekall.interval_list import Interval
from rekall.video_interval_collection import VideoIntervalCollection
video_map = collection.get_grouped_intervals()
return VideoIntervalCollection({vid: [Interval(
i.t[0], i.t[1], None) for i in video_map[vid].get_intervals()] for vid in video_map})
def display_result(collection_1d):
from esper.rekall import intrvllists_to_result
results = intrvllists_to_result(collection_1d.get_allintervals())
return esper_widget(results,
crop_bboxes=False, show_middle_frame=False, disable_captions=False,
results_per_page=25, jupyter_keybindings=True)
def topN(gen,n=25):
from tqdm import tqdm_notebook as tqdm
from rekall.runtime import disjoint_domain_combiner
result = None
count = 0
with tqdm(total=n) as pbar:
for collection in gen:
delta = len(collection.get_grouped_intervals())
pbar.update(delta)
count += delta
if result is None:
result = collection
else:
result = disjoint_domain_combiner(result, collection)
if count >= n:
break
return result
# time dimension in seconds
def get_commercial_intervals_in_vids(vids, in_seconds=True):
from query.models import Commercial
from rekall.domain_interval_collection import DomainIntervalCollection
qs = Commercial.objects.filter(video_id__in=vids)
commercials = DomainIntervalCollection.from_django_qs(qs)
if in_seconds:
return frame_to_second_collection(commercials)
return commercials
```
# Interviews
```
GUEST_LIST = [name.lower() for name in ['Barack Obama', 'Donald Trump', 'Ted Cruz', 'John Kasich', 'Marco Rubio', 'Ben Carson', 'Jeb Bush',
'Jim Gilmore', 'Chris Christie', 'Carly Fiorina', 'Rick Santorum', 'Rand Paul', 'Mike Huckabee',
'Hillary Clinton', 'Bernie Sanders', 'Lincoln Chafee', 'Martin O’Malley', 'Jim Webb',
'Sarah Palin', 'John Boehner', 'Paul Ryan', 'Newt Gingrich','Nancy Pelosi','Elizabeth Warren', 'Mitch McConnell',
'Chuck Schumer','Harry Reid','Joe Biden', 'Kevin McCarthy', 'Steve Scalise', 'Bobby Jindal', 'John Cornyn',
'Dick Durbin','Orrin Hatch', 'Lindsey Graham', 'Mitt Romney', 'Michelle Obama' ,'Bill Clinton',
'George W Bush', 'Tim Kaine' ]]
HOST_LIST = list(set([h.name for s in CanonicalShow.objects.exclude(hosts=None) for h in s.hosts.all()]))
VIDEOS = sorted([v.id for v in Video.objects.exclude(show__hosts=None)])
def get_name_to_labeler_id(names):
from tqdm import tqdm
def get_labeler_ids(n):
from query.models import Labeler
labeler_names = ['face-identity:'+n, 'face-identity-converted:'+n, 'face-identity-uncommon:'+n]
return [l.id for l in Labeler.objects.filter(name__in=labeler_names)]
output = {}
for n in tqdm(names):
output[n] = get_labeler_ids(n)
return output
NAME_TO_LABELER_ID = get_name_to_labeler_id(GUEST_LIST+HOST_LIST)
def name_to_id(name):
from query.models import Identity
return Identity.objects.get(name=name).id
GUEST_IDS=[name_to_id(n) for n in GUEST_LIST]
HOST_IDS=[name_to_id(n) for n in HOST_LIST]
# time dimension in seconds
# Outputs a dictionary from name to video interval collection
def get_person_intervals_in_vids(person_names, vids, probability=0.7, min_height=None):
from query.models import FaceIdentity
from django.db.models import F,Q
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import P
SAMPLE_RATE = 3 # Every 3s
lids = []
for n in person_names:
lids.extend(NAME_TO_LABELER_ID[n])
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=lids,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
frame_number=F('face__frame__number'),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
faces = DomainIntervalCollection.from_django_qs(face_id_qs, {
't1':'frame_number',
't2':'frame_number',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, with_payload=lambda row: row.labeler_name.split(':')[1], progress=False)
fps_map = get_fps_map(set(faces.get_grouped_intervals().keys()))
names_to_collection = {}
for n in person_names:
faces_one_person = faces.filter(P(lambda p: p==n))
output = {}
for vid, intervals in faces_one_person.get_grouped_intervals().items():
fps = fps_map[vid]
eps = round(fps * SAMPLE_RATE)
output[vid] = intervals.temporal_coalesce(epsilon=eps)
names_to_collection[n] = frame_to_second_collection(DomainIntervalCollection(output))
return names_to_collection
# Returns interview_IS<person_only_IS<>, host_only_IS<>, person_with_host_IS<>>
def interview_query(guest, hosts, commercials):
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import T, P, or_preds, overlap_bound
from rekall.temporal_predicates import overlaps, before, after
SEGMENT_LENGTH=30
OVERLAP_LAX=60
HOST_GUEST_GAP=120
MIN_LENGTH=240
SMALL_FACE_THRESHOLD=0.3
MIN_GUEST_TIME_RATIO=0.35
MAX_SMALL_GUEST_RATIO=0.7
fuzzy_overlap = or_preds(overlaps(), before(max_dist=OVERLAP_LAX), after(max_dist=OVERLAP_LAX))
interview_candidates = hosts.merge(guest, T(fuzzy_overlap), time_window=OVERLAP_LAX).temporal_coalesce()
interviews = interview_candidates.temporal_coalesce(
epsilon=HOST_GUEST_GAP
).filter_size(min_size=MIN_LENGTH
).minus(commercials
).filter_size(min_size=MIN_LENGTH)
def select_second(p):
return p[1]
# Interview<Guest<height>>
interview_with_guest = interviews.collect_by_interval(
guest,
T(overlaps()),
filter_empty=True,
time_window=0,
).map_payload(
select_second)
def total_time(intervals):
return intervals.fold(lambda s, i: s+i.length(), 0)
def filter_time(interview):
guest = interview.payload
small_guest = guest.filter_size(max_size=SMALL_FACE_THRESHOLD, axis='Y')
small_guest_time = total_time(small_guest)
total_guest_time = total_time(guest)
segment_time = interview.length()
return (total_guest_time / segment_time > MIN_GUEST_TIME_RATIO and
small_guest_time / total_guest_time < MAX_SMALL_GUEST_RATIO)
# Interview<Guest<height>>
interviews = interview_with_guest.filter(filter_time)
# Guest<height>
guest_in_interviews = guest.filter_against(interviews, T(overlaps()), time_window=0)
# HostAndGuest<(Host, Guest)>
guest_with_host = guest_in_interviews.join(
hosts,
T(overlaps()),
lambda guest, host: [Interval3D(overlap_bound(guest.t, host.t), payload=(guest, host))],
time_window=0)
guest_only = guest_in_interviews.minus(guest_with_host)
hosts_in_interviews = hosts.filter_against(interviews, T(overlaps()), time_window=0)
hosts_only = hosts_in_interviews.minus(guest_with_host)
interview_with_metadata = interviews.collect_by_interval(
guest_only,
T(overlaps()),
filter_empty=False,
time_window=0
).map_payload(select_second).collect_by_interval(
hosts_only,
T(overlaps()),
filter_empty=False,
time_window=0
).collect_by_interval(
guest_with_host,
T(overlaps()),
filter_empty=False,
time_window=0
).map_payload(lambda p: (p[0][0],p[0][1],p[1]))
return interview_with_metadata
def get_interviews_for_vids(vids):
from rekall.domain_interval_collection import DomainIntervalCollection
from tqdm import tqdm
people_to_intervals = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
hosts = DomainIntervalCollection({})
for host_name in HOST_LIST:
hosts = hosts.union(people_to_intervals[host_name])
commercials = get_commercial_intervals_in_vids(vids)
ret = DomainIntervalCollection({})
for guest_name in tqdm(GUEST_LIST):
guest = people_to_intervals[guest_name]
interviews = interview_query(guest, hosts, commercials)
ret = ret.union(interviews)
return ret
```
## Run on a few videos
```
vids = VIDEOS[::10000]
answer = get_interviews_for_vids(vids)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
```
## Run On All of TVNews
```
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
vids = VIDEOS[:10000]
answer,_ = rt.run(get_interviews_for_vids, vids, randomize=False, chunksize=20, progress=True)
# pickle.dump(answer, open('../data/interviews/interviews{0}-{1}.pkl'.format(vids[0],vids[-1]), 'wb'))
```
## Run with Streaming
```
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer = topN(rt.get_result_iterator(get_interviews_for_vids, VIDEOS, randomize=True),n=25)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
```
# Faces in a Row
```
VIDEOS = sorted([v.id for v in Video.objects.all()])
def get_faces_in_a_row_for_vids(vids):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d_utils import P, XY, and_preds
from rekall.bbox_predicates import left_of, same_value
from tqdm import tqdm
MIN_NUM_FACES = 10
MIN_HEIGHT = 0.1
EPSILON = 0.05
qs = Face.objects.filter(frame__video_id__in=vids).annotate(
video_id=F("frame__video_id"),
min_frame=F("frame__number"),
max_frame=F("frame__number") + 1,
height=F('bbox_y2')-F('bbox_y1'),
).filter(height__gte=MIN_HEIGHT)
faces = DomainIntervalCollection.from_django_qs(qs, DomainIntervalCollection.django_bbox_default_schema(),
progress=True)
def has_enough_faces(n):
def pred(faces):
return faces.size() >= n
return pred
def get_pattern(n):
assert(n>1)
constraints = []
for i in range(n-1):
name1 = str(i)
name2 = str(i+1)
constraints.append(([name1, name2],[XY(
and_preds(
left_of(),
same_value('y1', epsilon=EPSILON),
same_value('y2', epsilon=EPSILON)))]))
return constraints
def faces_aligned():
def pred(faces):
pattern = get_pattern(faces.size())
return len(faces.match(pattern, exact=True)) > 0
return pred
commercials = get_commercial_intervals_in_vids(vids, in_seconds=False)
aligned_faces_in_frames = faces.minus(commercials).group_by_time().filter(P(and_preds(
has_enough_faces(MIN_NUM_FACES),
faces_aligned())))
return aligned_faces_in_frames
```
## Run on a few videos
```
vids = VIDEOS[::10003]
answer = get_faces_in_a_row_for_vids(vids)
display_result(convert_to_1d_collection(answer))
```
## Run On All of TVNews
```
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
vids = VIDEOS[4::100]
answer,_ = rt.run(get_faces_in_a_row_for_vids, vids, randomize=False, chunksize=15, progress=True)
print("Total results:", sum(answer.size().values()))
def filter_vids(c, vids=None):
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
if vids is None or len(vids)==0:
return c
d = c.get_allintervals()
ret = {}
for v in vids:
if v in d:
ret[v] = d[v]
return VideoIntervalCollection3D(ret)
display_result(convert_to_1d_collection(filter_vids(answer,[])))
```
# Donald Trump on All Channels
```
TRUMP_FACE_LABELER_IDS = get_name_to_labeler_id(['donald trump'])['donald trump']
def get_video_ids_for_dates(dates):
assert(len(dates)>0)
import datetime as dt
from django.db.models import Q
from query.models import Video
one_day = dt.timedelta(days=1)
f = None
for d in dates:
new_term = Q(time__gte=d) & Q(time__lt=d+one_day)
if f is None:
f = new_term
else:
f = f | new_term
return [v.id for v in Video.objects.filter(duplicate=False, corrupted=False).filter(f)]
def get_donald_faces_on_dates(dates, probability=0.7, min_height=None):
SAMPLING_RATE = 3.0
from query.models import FaceIdentity
from django.db.models import F, FloatField
from django.db.models.functions import Cast
from rekall.runtime import Runtime
from rekall.domain_interval_collection import DomainIntervalCollection
vids = get_video_ids_for_dates(dates)
print("{0} videos found".format(len(vids)))
def get_faces_for_vid(vs):
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vs,
face__frame__shot_boundary=False,
labeler_id__in=TRUMP_FACE_LABELER_IDS,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
video_id=F('face__frame__video_id'),
start=Cast(F('face__frame__number') / F('face__frame__video__fps'),
FloatField()),
end=Cast(F('face__frame__number') / F('face__frame__video__fps') + SAMPLING_RATE,
FloatField()),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2')
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
faces = DomainIntervalCollection.from_django_qs(face_id_qs, {
't1':'start',
't2':'end',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, progress=False)
return faces
if len(vids) == 0:
return DomainIntervalCollection({})
# Read from Django in small batches, otherwise it gets stuck
faces,_ = Runtime.inline().run(get_faces_for_vid, vids, chunksize=10, progress=True)
return faces
# Time dimension will be unix timestamp
# Outputs one IntervalSet3D<VideoID, ChannelName>
def convert_to_absolute_time_and_add_channel(collection):
from query.models import Video
from rekall.interval_set_3d import IntervalSet3D, Interval3D
vids = collection.get_grouped_intervals().keys()
vs = Video.objects.filter(id__in=vids)
# Seconds since Unix Epoch
start_time_map = {v.id: v.time.timestamp() for v in vs}
channel_map = {v.id: v.channel.name for v in vs}
faces = collection.add_domain_to_payload().get_flattened_intervalset()
# Interval<VideoID, ChannelName>
def convert(interval):
vid = interval.payload[1]
start = start_time_map[vid]
channel = channel_map[vid]
return Interval3D((interval.t[0]+start, interval.t[1]+start),
interval.x, interval.y, payload=(vid, channel))
return faces.map(convert)
# intervals: IntervalSet<(VideoID,...)>, in absolute time
# Outputs a collection grouped by video id, in relative time (seconds)
def group_by_video_and_use_relative_time(intervals):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import IntervalSet3D
by_vids = DomainIntervalCollection.from_intervalset(intervals, lambda i: i.payload[0])
vids = by_vids.get_grouped_intervals().keys()
start_time_map = {v.id: v.time.timestamp() for v in Video.objects.filter(id__in=vids)}
def convert_time(i):
vid = i.payload[0]
start = start_time_map[vid]
j = i.copy()
j.t = i.t[0]-start, i.t[1]-start
return j
return by_vids.map(convert_time)
# Returns Interval<Faces>
def donald_on_all_channels(dates):
MIN_FACE_PROB = 0.7
MIN_FACE_HEIGHT = 0.3
MIN_NUM_CHANNELS = 3
from rekall.temporal_predicates import overlaps
from rekall.interval_set_3d import Interval3D, IntervalSet3D
from rekall.interval_set_3d_utils import T, overlap_bound
from rekall.domain_interval_collection import DomainIntervalCollection
faces = get_donald_faces_on_dates(
dates,
probability=MIN_FACE_PROB,
min_height=MIN_FACE_HEIGHT)
print("got faces")
# Face<VideoID, Channel>
faces_with_channel = convert_to_absolute_time_and_add_channel(faces)
print("converted to absolute time")
faces_per_channel = DomainIntervalCollection.from_intervalset(faces_with_channel, lambda i: i.payload[1])
if len(faces_per_channel.get_grouped_intervals()) < MIN_NUM_CHANNELS:
return IntervalSet3D([])
output = None
for channel, faces in faces_per_channel.get_grouped_intervals().items():
if output is None:
output = faces.map(lambda i: Interval3D(i.t, payload=[i]))
else:
output = output.join(
faces,
T(overlaps()),
lambda f1, f2: [
Interval3D(overlap_bound(f1.t,f2.t), payload=f1.payload + [f2])
],
time_window=0,
)
print("{0} intervals found".format(output.size()))
if output is None:
return IntervalSet3D([])
output = output.map_payload(lambda p: group_by_video_and_use_relative_time(IntervalSet3D(p)))
return output
```
## run on a few dates
```
import datetime
NUM_DATES=1
dates = [datetime.date(2017,1,20)+ i*datetime.timedelta(days=1) for i in range(NUM_DATES)]
answer = donald_on_all_channels(dates)
display_result(convert_to_1d_collection(second_to_frame_collection(answer.get_intervals()[0].payload)))
```
## Run on one Year
```
YEAR = 2015
is_leap = YEAR % 4 == 0 and (YEAR % 100 != 0 or YEAR % 400 == 0)
start = datetime.date(YEAR,1,1)
delta = datetime.timedelta(days=1)
dates = [start + delta * i for i in range(366 if is_leap else 365)]
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer,_ = rt.run(donald_on_all_channels, dates, randomize=False, chunksize=10, progress=True)
print("Total results:", answer.size())
```
## Run on entire dataset
```
YEARS = range(2009,2019)
dates = []
for y in YEARS:
is_leap = y % 4 == 0 and (y % 100 != 0 or y % 400 == 0)
start = datetime.date(y,1,1)
delta = datetime.timedelta(days=1)
dates.extend([start + delta * i for i in range(366 if is_leap else 365)])
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer,_ = rt.run(donald_on_all_channels, dates, randomize=False, chunksize=5, progress=True)
print("Total results:", answer.size())
```
# Scratchpad
```
vids = [763, 3769, 5281, 8220, 9901, 12837, 13141, 26386, 33004, 33004, 34642, 38275, 42756, 50164, 50164, 50164, 50164, 50164, 50164, 50164, 52075, 52945, 54377, 54377, 59122, 59122, 59398, 59398, 59398, 59398]
answer = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
display_result(convert_to_1d_collection(second_to_frame_collection(answer['bernie sanders'])))
display_result(convert_to_1d_collection(second_to_frame_collection(answer['jake tapper'])))
answer = get_interviews_for_vids(vids)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
ls=[l.name for l in Labeler.objects.all() if l.name.startswith('face-identity:') or l.name.startswith('face-identity-converted:') or l.name.startswith('face-identity-uncommon:')]
ls=[l.split(':')[1] for l in ls]
for g in GUEST_LIST:
if g not in ls:
print(g)
for h in HOST_LIST:
if h not in ls:
print(h)
ls
sorted(HOST_LIST)
interviews = LabeledInterview.objects \
.annotate(fps=F('video__fps')) \
.annotate(min_frame=F('fps') * F('start')) \
.annotate(max_frame=F('fps') * F('end')) \
.filter(guest1="bernie sanders", original=True)
print([i.video.id for i in interviews])
len(vids)
answer.get_allintervals()[10]
answer
len(VIDEOS)
VIDEOS[:100]
Video.objects.count()
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
vids = [188346]
people_to_intervals = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
hosts = VideoIntervalCollection3D({})
for host_name in HOST_LIST:
hosts = hosts.union(people_to_intervals[host_name])
display_result(convert_to_1d_collection(second_to_frame_collection(hosts)))
import pickle
a = pickle.load(open('../data/interviews/paper/interview_10y-all.pkl', 'rb'))
a['John Kasich'][188346]
VIDEOS.index(188346)
people_to_intervals['john kasich'].get_allintervals()[188346]
Video.objects.get(id=188346).fps * 3
def get_person_intervals_in_vids_frames(person_names, vids, probability=0.7, min_height=None):
from query.models import FaceIdentity
from django.db.models import F,Q
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import P
SAMPLE_RATE = 3 # Every 3s
lids = []
for n in person_names:
lids.extend(NAME_TO_LABELER_ID[n])
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=lids,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
frame_number=F('face__frame__number'),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
total = face_id_qs.count()
faces = VideoIntervalCollection3D.from_django_qs(face_id_qs, {
't1':'frame_number',
't2':'frame_number',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, with_payload=lambda row: row.labeler_name.split(':')[1], progress=True, total=total)
fps_map = get_fps_map(set(faces.get_allintervals().keys()))
names_to_collection = {}
for n in person_names:
faces_one_person = faces.filter(P(lambda p: p==n))
output = {}
for vid, intervals in faces_one_person.get_allintervals().items():
fps = fps_map[vid]
eps = fps * SAMPLE_RATE
output[vid] = intervals.temporal_coalesce(epsilon=eps)
names_to_collection[n] = VideoIntervalCollection3D(output)
return names_to_collection
jk = get_person_intervals_in_vids_frames(['john kasich'], [188346], probability=0.7, min_height=0.2)
jk['john kasich'].get_allintervals()
len(answer.get_allintervals())
answer.get_allintervals()[42341].map_payload(lambda _:None)
answer.get_allintervals()[42341].split(lambda i:i.payload[2])
len(vids)
keys = answer.get_allintervals().keys()
[(k, answer.get_allintervals()[k].)]
def discard(p):
return None
frame_to_second_collection(answer).get_allintervals()[128907].map_payload(discard)
Video.objects.get(id=1).time.timestamp()
import datetime
date = datetime.date(2016,12,16)
vs=Video.objects.filter(time__gte=date, time__lt=date+datetime.timedelta(days=1), duplicate=False, corrupted=False)
vs.count()
[v.time for v in vs.filter(channel_id=1).order_by('time')]
Labeler.objects.filter(name__contains='donald trump')
TRUMP_FACE_LABELER_ID
FaceIdentity.objects.filter(labeler_id=TRUMP_FACE_LABELER_ID, face__frame__video_id)
vids = list(range(10))
probability=0.7
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=[419],
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
start=Cast(F('face__frame__number') / F('face__frame__video__fps'),
FloatField()),
end=F('start') + 3.0,
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
time=F('face__frame__video__time')
).filter(height__gte=0.4)
face_id_qs[0].face.frame.video
date
answer.get_intervals()[0]
answer.get_intervals()[0].payload
sorted(answer.get_allintervals().keys())
answer.get_allintervals()['2009-10-28']
display_result(convert_to_1d_collection(second_to_frame_collection(sort_by_video(answer.get_intervals()[1].payload))))
```
|
github_jupyter
|
from esper.prelude import *
def get_fps_map(vids):
from query.models import Video
vs = Video.objects.filter(id__in=vids)
return {v.id: v.fps for v in vs}
def frame_second_conversion(c, mode='f2s'):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import Interval3D
fps_map = get_fps_map(set(c.get_grouped_intervals().keys()))
def second_to_frame(fps):
def map_fn(intrvl):
i2 = intrvl.copy()
t1,t2 = intrvl.t
i2.t = (int(t1*fps), int(t2*fps))
return i2
return map_fn
def frame_to_second(fps):
def map_fn(intrvl):
i2 = intrvl.copy()
t1,t2 = intrvl.t
i2.t = (int(t1/fps), int(t2/fps))
return i2
return map_fn
if mode=='f2s':
fn = frame_to_second
if mode=='s2f':
fn = second_to_frame
output = {}
for vid, intervals in c.get_grouped_intervals().items():
output[vid] = intervals.map(fn(fps_map[vid]))
return DomainIntervalCollection(output)
def frame_to_second_collection(c):
return frame_second_conversion(c, 'f2s')
def second_to_frame_collection(c):
return frame_second_conversion(c, 's2f')
def convert_to_1d_collection(collection):
from rekall.interval_list import Interval
from rekall.video_interval_collection import VideoIntervalCollection
video_map = collection.get_grouped_intervals()
return VideoIntervalCollection({vid: [Interval(
i.t[0], i.t[1], None) for i in video_map[vid].get_intervals()] for vid in video_map})
def display_result(collection_1d):
from esper.rekall import intrvllists_to_result
results = intrvllists_to_result(collection_1d.get_allintervals())
return esper_widget(results,
crop_bboxes=False, show_middle_frame=False, disable_captions=False,
results_per_page=25, jupyter_keybindings=True)
def topN(gen,n=25):
from tqdm import tqdm_notebook as tqdm
from rekall.runtime import disjoint_domain_combiner
result = None
count = 0
with tqdm(total=n) as pbar:
for collection in gen:
delta = len(collection.get_grouped_intervals())
pbar.update(delta)
count += delta
if result is None:
result = collection
else:
result = disjoint_domain_combiner(result, collection)
if count >= n:
break
return result
# time dimension in seconds
def get_commercial_intervals_in_vids(vids, in_seconds=True):
from query.models import Commercial
from rekall.domain_interval_collection import DomainIntervalCollection
qs = Commercial.objects.filter(video_id__in=vids)
commercials = DomainIntervalCollection.from_django_qs(qs)
if in_seconds:
return frame_to_second_collection(commercials)
return commercials
GUEST_LIST = [name.lower() for name in ['Barack Obama', 'Donald Trump', 'Ted Cruz', 'John Kasich', 'Marco Rubio', 'Ben Carson', 'Jeb Bush',
'Jim Gilmore', 'Chris Christie', 'Carly Fiorina', 'Rick Santorum', 'Rand Paul', 'Mike Huckabee',
'Hillary Clinton', 'Bernie Sanders', 'Lincoln Chafee', 'Martin O’Malley', 'Jim Webb',
'Sarah Palin', 'John Boehner', 'Paul Ryan', 'Newt Gingrich','Nancy Pelosi','Elizabeth Warren', 'Mitch McConnell',
'Chuck Schumer','Harry Reid','Joe Biden', 'Kevin McCarthy', 'Steve Scalise', 'Bobby Jindal', 'John Cornyn',
'Dick Durbin','Orrin Hatch', 'Lindsey Graham', 'Mitt Romney', 'Michelle Obama' ,'Bill Clinton',
'George W Bush', 'Tim Kaine' ]]
HOST_LIST = list(set([h.name for s in CanonicalShow.objects.exclude(hosts=None) for h in s.hosts.all()]))
VIDEOS = sorted([v.id for v in Video.objects.exclude(show__hosts=None)])
def get_name_to_labeler_id(names):
from tqdm import tqdm
def get_labeler_ids(n):
from query.models import Labeler
labeler_names = ['face-identity:'+n, 'face-identity-converted:'+n, 'face-identity-uncommon:'+n]
return [l.id for l in Labeler.objects.filter(name__in=labeler_names)]
output = {}
for n in tqdm(names):
output[n] = get_labeler_ids(n)
return output
NAME_TO_LABELER_ID = get_name_to_labeler_id(GUEST_LIST+HOST_LIST)
def name_to_id(name):
from query.models import Identity
return Identity.objects.get(name=name).id
GUEST_IDS=[name_to_id(n) for n in GUEST_LIST]
HOST_IDS=[name_to_id(n) for n in HOST_LIST]
# time dimension in seconds
# Outputs a dictionary from name to video interval collection
def get_person_intervals_in_vids(person_names, vids, probability=0.7, min_height=None):
from query.models import FaceIdentity
from django.db.models import F,Q
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import P
SAMPLE_RATE = 3 # Every 3s
lids = []
for n in person_names:
lids.extend(NAME_TO_LABELER_ID[n])
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=lids,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
frame_number=F('face__frame__number'),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
faces = DomainIntervalCollection.from_django_qs(face_id_qs, {
't1':'frame_number',
't2':'frame_number',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, with_payload=lambda row: row.labeler_name.split(':')[1], progress=False)
fps_map = get_fps_map(set(faces.get_grouped_intervals().keys()))
names_to_collection = {}
for n in person_names:
faces_one_person = faces.filter(P(lambda p: p==n))
output = {}
for vid, intervals in faces_one_person.get_grouped_intervals().items():
fps = fps_map[vid]
eps = round(fps * SAMPLE_RATE)
output[vid] = intervals.temporal_coalesce(epsilon=eps)
names_to_collection[n] = frame_to_second_collection(DomainIntervalCollection(output))
return names_to_collection
# Returns interview_IS<person_only_IS<>, host_only_IS<>, person_with_host_IS<>>
def interview_query(guest, hosts, commercials):
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import T, P, or_preds, overlap_bound
from rekall.temporal_predicates import overlaps, before, after
SEGMENT_LENGTH=30
OVERLAP_LAX=60
HOST_GUEST_GAP=120
MIN_LENGTH=240
SMALL_FACE_THRESHOLD=0.3
MIN_GUEST_TIME_RATIO=0.35
MAX_SMALL_GUEST_RATIO=0.7
fuzzy_overlap = or_preds(overlaps(), before(max_dist=OVERLAP_LAX), after(max_dist=OVERLAP_LAX))
interview_candidates = hosts.merge(guest, T(fuzzy_overlap), time_window=OVERLAP_LAX).temporal_coalesce()
interviews = interview_candidates.temporal_coalesce(
epsilon=HOST_GUEST_GAP
).filter_size(min_size=MIN_LENGTH
).minus(commercials
).filter_size(min_size=MIN_LENGTH)
def select_second(p):
return p[1]
# Interview<Guest<height>>
interview_with_guest = interviews.collect_by_interval(
guest,
T(overlaps()),
filter_empty=True,
time_window=0,
).map_payload(
select_second)
def total_time(intervals):
return intervals.fold(lambda s, i: s+i.length(), 0)
def filter_time(interview):
guest = interview.payload
small_guest = guest.filter_size(max_size=SMALL_FACE_THRESHOLD, axis='Y')
small_guest_time = total_time(small_guest)
total_guest_time = total_time(guest)
segment_time = interview.length()
return (total_guest_time / segment_time > MIN_GUEST_TIME_RATIO and
small_guest_time / total_guest_time < MAX_SMALL_GUEST_RATIO)
# Interview<Guest<height>>
interviews = interview_with_guest.filter(filter_time)
# Guest<height>
guest_in_interviews = guest.filter_against(interviews, T(overlaps()), time_window=0)
# HostAndGuest<(Host, Guest)>
guest_with_host = guest_in_interviews.join(
hosts,
T(overlaps()),
lambda guest, host: [Interval3D(overlap_bound(guest.t, host.t), payload=(guest, host))],
time_window=0)
guest_only = guest_in_interviews.minus(guest_with_host)
hosts_in_interviews = hosts.filter_against(interviews, T(overlaps()), time_window=0)
hosts_only = hosts_in_interviews.minus(guest_with_host)
interview_with_metadata = interviews.collect_by_interval(
guest_only,
T(overlaps()),
filter_empty=False,
time_window=0
).map_payload(select_second).collect_by_interval(
hosts_only,
T(overlaps()),
filter_empty=False,
time_window=0
).collect_by_interval(
guest_with_host,
T(overlaps()),
filter_empty=False,
time_window=0
).map_payload(lambda p: (p[0][0],p[0][1],p[1]))
return interview_with_metadata
def get_interviews_for_vids(vids):
from rekall.domain_interval_collection import DomainIntervalCollection
from tqdm import tqdm
people_to_intervals = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
hosts = DomainIntervalCollection({})
for host_name in HOST_LIST:
hosts = hosts.union(people_to_intervals[host_name])
commercials = get_commercial_intervals_in_vids(vids)
ret = DomainIntervalCollection({})
for guest_name in tqdm(GUEST_LIST):
guest = people_to_intervals[guest_name]
interviews = interview_query(guest, hosts, commercials)
ret = ret.union(interviews)
return ret
vids = VIDEOS[::10000]
answer = get_interviews_for_vids(vids)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
vids = VIDEOS[:10000]
answer,_ = rt.run(get_interviews_for_vids, vids, randomize=False, chunksize=20, progress=True)
# pickle.dump(answer, open('../data/interviews/interviews{0}-{1}.pkl'.format(vids[0],vids[-1]), 'wb'))
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer = topN(rt.get_result_iterator(get_interviews_for_vids, VIDEOS, randomize=True),n=25)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
VIDEOS = sorted([v.id for v in Video.objects.all()])
def get_faces_in_a_row_for_vids(vids):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d_utils import P, XY, and_preds
from rekall.bbox_predicates import left_of, same_value
from tqdm import tqdm
MIN_NUM_FACES = 10
MIN_HEIGHT = 0.1
EPSILON = 0.05
qs = Face.objects.filter(frame__video_id__in=vids).annotate(
video_id=F("frame__video_id"),
min_frame=F("frame__number"),
max_frame=F("frame__number") + 1,
height=F('bbox_y2')-F('bbox_y1'),
).filter(height__gte=MIN_HEIGHT)
faces = DomainIntervalCollection.from_django_qs(qs, DomainIntervalCollection.django_bbox_default_schema(),
progress=True)
def has_enough_faces(n):
def pred(faces):
return faces.size() >= n
return pred
def get_pattern(n):
assert(n>1)
constraints = []
for i in range(n-1):
name1 = str(i)
name2 = str(i+1)
constraints.append(([name1, name2],[XY(
and_preds(
left_of(),
same_value('y1', epsilon=EPSILON),
same_value('y2', epsilon=EPSILON)))]))
return constraints
def faces_aligned():
def pred(faces):
pattern = get_pattern(faces.size())
return len(faces.match(pattern, exact=True)) > 0
return pred
commercials = get_commercial_intervals_in_vids(vids, in_seconds=False)
aligned_faces_in_frames = faces.minus(commercials).group_by_time().filter(P(and_preds(
has_enough_faces(MIN_NUM_FACES),
faces_aligned())))
return aligned_faces_in_frames
vids = VIDEOS[::10003]
answer = get_faces_in_a_row_for_vids(vids)
display_result(convert_to_1d_collection(answer))
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
vids = VIDEOS[4::100]
answer,_ = rt.run(get_faces_in_a_row_for_vids, vids, randomize=False, chunksize=15, progress=True)
print("Total results:", sum(answer.size().values()))
def filter_vids(c, vids=None):
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
if vids is None or len(vids)==0:
return c
d = c.get_allintervals()
ret = {}
for v in vids:
if v in d:
ret[v] = d[v]
return VideoIntervalCollection3D(ret)
display_result(convert_to_1d_collection(filter_vids(answer,[])))
TRUMP_FACE_LABELER_IDS = get_name_to_labeler_id(['donald trump'])['donald trump']
def get_video_ids_for_dates(dates):
assert(len(dates)>0)
import datetime as dt
from django.db.models import Q
from query.models import Video
one_day = dt.timedelta(days=1)
f = None
for d in dates:
new_term = Q(time__gte=d) & Q(time__lt=d+one_day)
if f is None:
f = new_term
else:
f = f | new_term
return [v.id for v in Video.objects.filter(duplicate=False, corrupted=False).filter(f)]
def get_donald_faces_on_dates(dates, probability=0.7, min_height=None):
SAMPLING_RATE = 3.0
from query.models import FaceIdentity
from django.db.models import F, FloatField
from django.db.models.functions import Cast
from rekall.runtime import Runtime
from rekall.domain_interval_collection import DomainIntervalCollection
vids = get_video_ids_for_dates(dates)
print("{0} videos found".format(len(vids)))
def get_faces_for_vid(vs):
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vs,
face__frame__shot_boundary=False,
labeler_id__in=TRUMP_FACE_LABELER_IDS,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
video_id=F('face__frame__video_id'),
start=Cast(F('face__frame__number') / F('face__frame__video__fps'),
FloatField()),
end=Cast(F('face__frame__number') / F('face__frame__video__fps') + SAMPLING_RATE,
FloatField()),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2')
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
faces = DomainIntervalCollection.from_django_qs(face_id_qs, {
't1':'start',
't2':'end',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, progress=False)
return faces
if len(vids) == 0:
return DomainIntervalCollection({})
# Read from Django in small batches, otherwise it gets stuck
faces,_ = Runtime.inline().run(get_faces_for_vid, vids, chunksize=10, progress=True)
return faces
# Time dimension will be unix timestamp
# Outputs one IntervalSet3D<VideoID, ChannelName>
def convert_to_absolute_time_and_add_channel(collection):
from query.models import Video
from rekall.interval_set_3d import IntervalSet3D, Interval3D
vids = collection.get_grouped_intervals().keys()
vs = Video.objects.filter(id__in=vids)
# Seconds since Unix Epoch
start_time_map = {v.id: v.time.timestamp() for v in vs}
channel_map = {v.id: v.channel.name for v in vs}
faces = collection.add_domain_to_payload().get_flattened_intervalset()
# Interval<VideoID, ChannelName>
def convert(interval):
vid = interval.payload[1]
start = start_time_map[vid]
channel = channel_map[vid]
return Interval3D((interval.t[0]+start, interval.t[1]+start),
interval.x, interval.y, payload=(vid, channel))
return faces.map(convert)
# intervals: IntervalSet<(VideoID,...)>, in absolute time
# Outputs a collection grouped by video id, in relative time (seconds)
def group_by_video_and_use_relative_time(intervals):
from rekall.domain_interval_collection import DomainIntervalCollection
from rekall.interval_set_3d import IntervalSet3D
by_vids = DomainIntervalCollection.from_intervalset(intervals, lambda i: i.payload[0])
vids = by_vids.get_grouped_intervals().keys()
start_time_map = {v.id: v.time.timestamp() for v in Video.objects.filter(id__in=vids)}
def convert_time(i):
vid = i.payload[0]
start = start_time_map[vid]
j = i.copy()
j.t = i.t[0]-start, i.t[1]-start
return j
return by_vids.map(convert_time)
# Returns Interval<Faces>
def donald_on_all_channels(dates):
MIN_FACE_PROB = 0.7
MIN_FACE_HEIGHT = 0.3
MIN_NUM_CHANNELS = 3
from rekall.temporal_predicates import overlaps
from rekall.interval_set_3d import Interval3D, IntervalSet3D
from rekall.interval_set_3d_utils import T, overlap_bound
from rekall.domain_interval_collection import DomainIntervalCollection
faces = get_donald_faces_on_dates(
dates,
probability=MIN_FACE_PROB,
min_height=MIN_FACE_HEIGHT)
print("got faces")
# Face<VideoID, Channel>
faces_with_channel = convert_to_absolute_time_and_add_channel(faces)
print("converted to absolute time")
faces_per_channel = DomainIntervalCollection.from_intervalset(faces_with_channel, lambda i: i.payload[1])
if len(faces_per_channel.get_grouped_intervals()) < MIN_NUM_CHANNELS:
return IntervalSet3D([])
output = None
for channel, faces in faces_per_channel.get_grouped_intervals().items():
if output is None:
output = faces.map(lambda i: Interval3D(i.t, payload=[i]))
else:
output = output.join(
faces,
T(overlaps()),
lambda f1, f2: [
Interval3D(overlap_bound(f1.t,f2.t), payload=f1.payload + [f2])
],
time_window=0,
)
print("{0} intervals found".format(output.size()))
if output is None:
return IntervalSet3D([])
output = output.map_payload(lambda p: group_by_video_and_use_relative_time(IntervalSet3D(p)))
return output
import datetime
NUM_DATES=1
dates = [datetime.date(2017,1,20)+ i*datetime.timedelta(days=1) for i in range(NUM_DATES)]
answer = donald_on_all_channels(dates)
display_result(convert_to_1d_collection(second_to_frame_collection(answer.get_intervals()[0].payload)))
YEAR = 2015
is_leap = YEAR % 4 == 0 and (YEAR % 100 != 0 or YEAR % 400 == 0)
start = datetime.date(YEAR,1,1)
delta = datetime.timedelta(days=1)
dates = [start + delta * i for i in range(366 if is_leap else 365)]
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer,_ = rt.run(donald_on_all_channels, dates, randomize=False, chunksize=10, progress=True)
print("Total results:", answer.size())
YEARS = range(2009,2019)
dates = []
for y in YEARS:
is_leap = y % 4 == 0 and (y % 100 != 0 or y % 400 == 0)
start = datetime.date(y,1,1)
delta = datetime.timedelta(days=1)
dates.extend([start + delta * i for i in range(366 if is_leap else 365)])
import ipyparallel as ipp
from esper.rekall_parallel import get_runtime_for_ipython_cluster
import pickle
c = ipp.Client(profile='local')
rt = get_runtime_for_ipython_cluster(c)
answer,_ = rt.run(donald_on_all_channels, dates, randomize=False, chunksize=5, progress=True)
print("Total results:", answer.size())
vids = [763, 3769, 5281, 8220, 9901, 12837, 13141, 26386, 33004, 33004, 34642, 38275, 42756, 50164, 50164, 50164, 50164, 50164, 50164, 50164, 52075, 52945, 54377, 54377, 59122, 59122, 59398, 59398, 59398, 59398]
answer = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
display_result(convert_to_1d_collection(second_to_frame_collection(answer['bernie sanders'])))
display_result(convert_to_1d_collection(second_to_frame_collection(answer['jake tapper'])))
answer = get_interviews_for_vids(vids)
display_result(convert_to_1d_collection(second_to_frame_collection(answer)))
ls=[l.name for l in Labeler.objects.all() if l.name.startswith('face-identity:') or l.name.startswith('face-identity-converted:') or l.name.startswith('face-identity-uncommon:')]
ls=[l.split(':')[1] for l in ls]
for g in GUEST_LIST:
if g not in ls:
print(g)
for h in HOST_LIST:
if h not in ls:
print(h)
ls
sorted(HOST_LIST)
interviews = LabeledInterview.objects \
.annotate(fps=F('video__fps')) \
.annotate(min_frame=F('fps') * F('start')) \
.annotate(max_frame=F('fps') * F('end')) \
.filter(guest1="bernie sanders", original=True)
print([i.video.id for i in interviews])
len(vids)
answer.get_allintervals()[10]
answer
len(VIDEOS)
VIDEOS[:100]
Video.objects.count()
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
vids = [188346]
people_to_intervals = get_person_intervals_in_vids(HOST_LIST + GUEST_LIST, vids, 0.7,0.2)
hosts = VideoIntervalCollection3D({})
for host_name in HOST_LIST:
hosts = hosts.union(people_to_intervals[host_name])
display_result(convert_to_1d_collection(second_to_frame_collection(hosts)))
import pickle
a = pickle.load(open('../data/interviews/paper/interview_10y-all.pkl', 'rb'))
a['John Kasich'][188346]
VIDEOS.index(188346)
people_to_intervals['john kasich'].get_allintervals()[188346]
Video.objects.get(id=188346).fps * 3
def get_person_intervals_in_vids_frames(person_names, vids, probability=0.7, min_height=None):
from query.models import FaceIdentity
from django.db.models import F,Q
from rekall.video_interval_collection_3d import VideoIntervalCollection3D
from rekall.interval_set_3d import Interval3D
from rekall.interval_set_3d_utils import P
SAMPLE_RATE = 3 # Every 3s
lids = []
for n in person_names:
lids.extend(NAME_TO_LABELER_ID[n])
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=lids,
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
frame_number=F('face__frame__number'),
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
)
if min_height is not None:
face_id_qs = face_id_qs.filter(height__gte=min_height)
total = face_id_qs.count()
faces = VideoIntervalCollection3D.from_django_qs(face_id_qs, {
't1':'frame_number',
't2':'frame_number',
'x1':'x1','x2':'x2','y1':'y1','y2':'y2',
}, with_payload=lambda row: row.labeler_name.split(':')[1], progress=True, total=total)
fps_map = get_fps_map(set(faces.get_allintervals().keys()))
names_to_collection = {}
for n in person_names:
faces_one_person = faces.filter(P(lambda p: p==n))
output = {}
for vid, intervals in faces_one_person.get_allintervals().items():
fps = fps_map[vid]
eps = fps * SAMPLE_RATE
output[vid] = intervals.temporal_coalesce(epsilon=eps)
names_to_collection[n] = VideoIntervalCollection3D(output)
return names_to_collection
jk = get_person_intervals_in_vids_frames(['john kasich'], [188346], probability=0.7, min_height=0.2)
jk['john kasich'].get_allintervals()
len(answer.get_allintervals())
answer.get_allintervals()[42341].map_payload(lambda _:None)
answer.get_allintervals()[42341].split(lambda i:i.payload[2])
len(vids)
keys = answer.get_allintervals().keys()
[(k, answer.get_allintervals()[k].)]
def discard(p):
return None
frame_to_second_collection(answer).get_allintervals()[128907].map_payload(discard)
Video.objects.get(id=1).time.timestamp()
import datetime
date = datetime.date(2016,12,16)
vs=Video.objects.filter(time__gte=date, time__lt=date+datetime.timedelta(days=1), duplicate=False, corrupted=False)
vs.count()
[v.time for v in vs.filter(channel_id=1).order_by('time')]
Labeler.objects.filter(name__contains='donald trump')
TRUMP_FACE_LABELER_ID
FaceIdentity.objects.filter(labeler_id=TRUMP_FACE_LABELER_ID, face__frame__video_id)
vids = list(range(10))
probability=0.7
face_id_qs = FaceIdentity.objects.filter(
probability__gte=probability,
face__frame__video_id__in=vids,
face__frame__shot_boundary=False,
labeler_id__in=[419],
).annotate(
height=F('face__bbox_y2')-F('face__bbox_y1'),
labeler_name=F('labeler__name'),
video_id=F('face__frame__video_id'),
start=Cast(F('face__frame__number') / F('face__frame__video__fps'),
FloatField()),
end=F('start') + 3.0,
x1=F('face__bbox_x1'),
x2=F('face__bbox_x2'),
y1=F('face__bbox_y1'),
y2=F('face__bbox_y2'),
time=F('face__frame__video__time')
).filter(height__gte=0.4)
face_id_qs[0].face.frame.video
date
answer.get_intervals()[0]
answer.get_intervals()[0].payload
sorted(answer.get_allintervals().keys())
answer.get_allintervals()['2009-10-28']
display_result(convert_to_1d_collection(second_to_frame_collection(sort_by_video(answer.get_intervals()[1].payload))))
| 0.41561 | 0.450601 |
```
import pandas as pd
import numpy as np
import math
import sklearn.datasets
from sklearn.model_selection import train_test_split
import sklearn.tree
##Seaborn for fancy plots.
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams["figure.figsize"] = (8,8)
```
## Decision Trees
One classification algorithm we can use is a decision tree. A DT is one of the algorithms that is easiest to visualize and understand, it can be represented as a series of simple decisions, in the shape of a tree.
The tree effectively looks at each feature and splits the records based on that feature's value. It repeats this until every record is grouped into one of the target
First we'll load some data and take a quick look at it, not a full eda. The pairplot is slow and large, but serves to visually highlight what we are doing in the classification - we want to effectively draw a line separating the blues from the oranges in those scatter plots. The plots show a 2d slice, the full classification does it in 30 dimensions, but the concept is the same, draw a line that splits the groups as accurately as we can. Note the sklearn_to_df function below, the sklearn datasets aren't returned in nice clean dataframes like we're used to. This function just formats them to be so. This would be a good addition to the utility file is you're so inclined.
```
def sklearn_to_df(sklearn_dataset):
df = pd.DataFrame(sklearn_dataset.data, columns=sklearn_dataset.feature_names)
df['target'] = pd.Series(sklearn_dataset.target)
return df
#Swap datasets for a more complex example
df = sklearn_to_df(sklearn.datasets.load_breast_cancer())
#df = sklearn_to_df(sklearn.datasets.load_iris())
df.head()
# This serves an illustrative point, but is slow
# Comment out if running frequently
#sns.pairplot(data=df.sample(100), hue="target")
```
<h3>Create Tree Model and Plot it</h3>
```
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
#Trees don't theoretically require dummies, but sklearns implemention does.
df2 = pd.get_dummies(df, drop_first=True)
y = np.array(df2["target"]).reshape(-1,1)
X = np.array(df2.drop(columns={"target"}))
X_train, X_test, y_train, y_test = train_test_split(X, y)
clf = DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
```
### Feature Importance
Since the decision tree is a model we can look at in detail, we can also extract the feature importance. We'll do more with this in the feature selection part in a couple of weeks.
```
importances = clf.feature_importances_
feat_imp = pd.Series(importances, index=df2.drop(columns={"target"}).columns)
feat_imp.sort_values(ascending=False)[0:5]
```
##### Change Split Criteria
We can repeat with entropy to see what results from that, and if there's a real difference.
```
#Tree with entropy
clf = DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
```
### Fancy Visualizations
We can use the export_graphviz to make a nicer visualization, but it is a little bit of a process. You may need to install it (pip install python-graphviz or conda install python-graphviz). The command below will generate a file that we can then visualize. Open it and copy it into an online tool such as: https://dreampuf.github.io/GraphvizOnline There are also vscode plugins that you can try to picture things in the IDE.
This is optional.
```
from sklearn.tree import export_graphviz
export_graphviz(clf,
out_file="tree.dot",
feature_names = df.drop(columns={"target"}).columns,
class_names=["0","1"],
filled = True)
```
<h2>Decision Tree Decisions</h2>
The splits that the decision tree makes are decided by one of the criteria that we talked about in the powerpoint: gini or entropy. The tree constuction is a recursive process, each of the processes below looks at one leaf at a time, treating it like its own tree.
<h3>Gini and Entropy</h3>
<h4>Gini Impurity and Gini Gain</h4>
Gini is the default criteria for measuring the quality of a split. When using Gini, at each node the tree algorith will choose the split that maximizes the Gini Gain.
The Gini impurity is defined as the probability that you would misclassify a randomly selected item, when classifying according to the distribution in the dataset. This is intuitively pretty simple, check here for a good illustration: https://victorzhou.com/blog/gini-impurity/. The formual is:
$ H(Q_m) = \sum_k p_{mk} (1 - p_{mk}) $
The Gini gain takes this idea and builds on it. It is defined as the total impurity minus the weighted impurity after a split - or basically how much impurity was removed by splitting. The link above also illustrates this well. At each node of the tree, the algorithm looks at the data and chooses the split that has the highest Gini gain, that's how the decisions are chosen, ordered, and structured into a tree.
<h4>Entropy and Information Gain</h4>
Entropy is the alternate method for measuring the quality of a split. It is similar in concept to Gini but a little more mathmatically complex (that we don't need to derive). The formula for entropy is:
$ H(Q_m) = - \sum_k p_{mk} \log(p_{mk}) $
The probability of each item being selected multiplied by the log base 2 of that probability.
An illustrated example of entropy and information gain is here: https://victorzhou.com/blog/information-gain/
Information gain is very similar to Gini gain at this point, we take the current entropy and subtract the weighted average of the entropy of each branch after the split. The algorithm finds the split that maximises this, and uses it to create the tree.
<h3>Tree Fitting</h3>
Decision trees have a few considerations, one is how many levels should the tree be? The more levels (splits) we have, the more granular our decisions will be. However, what if our tree gets so granular that it becomes too specific? The algorithm chases accuracy, and if there is a way that it can get more accuracy, it will. In practice, this may look like a tree with many, many levels - going down into very specifc sets of critera to divide the data. In one sense, this is good - we are creating a model that does an excellent job in dividing our data between classes; in another sense it can be bad - we may get a model that is very well suited to one set of data, but does poorly if we were to provide it another dataset. Since we want to make predictions for new data that we don't already have, this is bad.
<b>This leads us to the idea of overfitting and underfitting, which we will get into in more depth in a few days. In short, we want a model that is tailored to our data, to make accurate predictions, but not so customized to our specific data that it is too customized to be accurate with other situations with new data. </b>
<h3>Combatting Tree Overfitting</h3>
<h4>Pre-Construction</h4>
With a tree, one thing that we can do to limit the potential for overfitting is to cap the number of levels that the algorithm is allowed to create. If we do so, the model generated will have to seek the most accuracy when limited to X number of decisions. This will help prevent the model from being overfitted. In scenarios where there are lots of features, trees are often prone to overfitting.
Decision trees also have other options, such as min_samples_split - the minimum number of results that need to be in a leaf before it is allowed to be split, that will have a similar impact. If a leaf can split if there are only 2 items (default), it can be very customized to the data as it can just split if there are two outcomes in a node. If we limit this we effectively force the tree to be more general - even if there's a difference in values in a node, it can't split those until there are X number of values there.
There are a couple more options that are similar, such as max_features which will limit how many features a tree is able to consider.
We will modify these options in more depth when doing grid searches next(ish) time.
```
#limit depth
clf = DecisionTreeClassifier(max_depth=3)
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
```
Limiting depth is simple, as above. Depending on the data this may have negligable or significant impacts on the overall accuracy.
How deep should the tree be? The theoretical maximum is n-1, but that's not very practical. On a very small scale such as this one, you might just see what happens by default, then dial it back 1 or 2 or 3.... If we take that concept a bit further, we can construct what's called a Grid Search. The Grid Search will try multiple values for max depth, and give us back all the results.
<h3>Hyperparamaters</h3>
This also introduces us to the idea of a Hyperparamater - a paramater that controls the learning process of the algorithm. In this case max depth is a hyperpararmater (the criteria, min_split_size, and max_features are all other ones) - whatever we set it to will control how the model is created, and the impact of changing it isn't always determinable in advance. Hyperparamaters will come up in most algorithms that we use to create models, and the process for selecting what they should be is often based on trial and error. We will dig into Hyperparamaters more soon - hyperparamater tuning is one of the ways that we can maximize accuracy of our models through selection of the optimum combination of hyperparamater settings.
In general, many of the things that you can provide as arguments to create the models are hyperparamaters. HP are special because they aren't things that are learned during model training (like which splits to make in a tree), they have to be set ahead of time.
## Post-Construction Tools to Combat Overfitting - Pruning
Another thing we can do is called pruning, as the name suggests it is basically trimming off the excess to get a nice clean tree. The pruning in sklearn is called ccp_alpha or cost complexity pruning. The premise is that it will look for the highest impurities and then cut the tree back.
<h4>Cost Complexity Pruning</h4>
We don't need to spend an excess of time looking at the details of pruning, be we should cover the basic math and logic behind it. The base of the concept is something called a Cost Complexity Measure for a given tree:
$ R_\alpha(T) = R(T) + \alpha|\widetilde{T}| $
Where:
$ R(T) $ is the misclassification rate of the tree.
$ |\widetilde{T}| $ is the number of terminal nodes.
If you look at a single node (T = 1), then the formula is:
$ R_\alpha(t)=R(t)+\alpha $
So alpha is the value needed to raise the cost complexity of the node (right side of the equation) to match the cost complexity of the branch (left side). Ideally we want the branches to reduce our impurity - we want the branches to have a lower amount of misclassification. The pruning algoritm picks off the nodes with the lowest alpha, or those that are least improved by splitting, until that alpha value reaches whatever limit is specified. As nodes are killed off, the tree gets smaller and less deep, the end result being the same as if we limited it via a hyperparamater.
We can use some sklearn demo stuff to illustrate the differences with different alpha levels, and thus different 'aggressiveness' of pruning. This demonstrates he idea of managing accuracy in the training set vs the testing set to combat overfitting, something that will come up regularly. Here we are purposefully limiting how accurate the model can get during training in order to ensure it does not become overfitted.
```
#limit depth
clf = DecisionTreeClassifier()
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
fig, ax = plt.subplots()
ax.plot(ccp_alphas[:-1], impurities[:-1], marker="o", drawstyle="steps-post")
ax.set_xlabel("effective alpha")
ax.set_ylabel("total impurity of leaves")
ax.set_title("Total Impurity vs effective alpha for training set")
```
In the chart above, the more alpha we allow, the more pruning is done, the less tailored to the data the model is allowed to become during training.
```
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]
fig, ax = plt.subplots(2, 1)
ax[0].plot(ccp_alphas, node_counts, marker="o", drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")
ax[1].plot(ccp_alphas, depth, marker="o", drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth of tree")
ax[1].set_title("Depth vs alpha")
fig.tight_layout()
```
The alpha value acts as a limiter, we can see in the graphs above, the higher alpha gets the more simple the tree is forced to become - less depth and fewer nodes. The impact is the same as if we were to use the HP to set limits here.
```
train_scores = [clf.score(X_train, y_train) for clf in clfs]
test_scores = [clf.score(X_test, y_test) for clf in clfs]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("accuracy")
ax.set_title("Accuracy vs alpha for training and testing sets")
ax.plot(ccp_alphas, train_scores, marker="o", label="train", drawstyle="steps-post")
ax.plot(ccp_alphas, test_scores, marker="o", label="test", drawstyle="steps-post")
ax.legend()
plt.show()
```
Here's the important bit - the impact on the test data predictions. As we saw above, if we let the tree get more and more specific (more nodes and more depth) the training accuracy will get higher and higher, and the impurity lower and lower. This is what the algorithm "wants" to do, it is trying to be as accurate as it possibly can. There's too much of a good thing here, as the model can become overfitted to the specific training data, and not as useful in general situations.
By limiting the algorithm's ability to chase that accuracy we can stop it before that training becomes too specialized - here we are doing so with the pruning functionality, next we'll do so with tuning the HP.
This idea comes up regularly, we want to train the model to be really accurate, but kill that process once it begins to get too specific.
# Working Example
## Load Dataset - heart.csv
```
#Load Data
df_ = pd.read_csv("data/heart.csv")
df_.head()
#Do some exploration
```
## Create and Fit Model, View Tree
Also try a few options and observe accuracy and tree size.
```
#Model
#View Tree
```
## Use Pruning
```
#Model with Pruning
#Find best alpha
#Plot
#Model pruned best
```
|
github_jupyter
|
import pandas as pd
import numpy as np
import math
import sklearn.datasets
from sklearn.model_selection import train_test_split
import sklearn.tree
##Seaborn for fancy plots.
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams["figure.figsize"] = (8,8)
def sklearn_to_df(sklearn_dataset):
df = pd.DataFrame(sklearn_dataset.data, columns=sklearn_dataset.feature_names)
df['target'] = pd.Series(sklearn_dataset.target)
return df
#Swap datasets for a more complex example
df = sklearn_to_df(sklearn.datasets.load_breast_cancer())
#df = sklearn_to_df(sklearn.datasets.load_iris())
df.head()
# This serves an illustrative point, but is slow
# Comment out if running frequently
#sns.pairplot(data=df.sample(100), hue="target")
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
#Trees don't theoretically require dummies, but sklearns implemention does.
df2 = pd.get_dummies(df, drop_first=True)
y = np.array(df2["target"]).reshape(-1,1)
X = np.array(df2.drop(columns={"target"}))
X_train, X_test, y_train, y_test = train_test_split(X, y)
clf = DecisionTreeClassifier()
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
importances = clf.feature_importances_
feat_imp = pd.Series(importances, index=df2.drop(columns={"target"}).columns)
feat_imp.sort_values(ascending=False)[0:5]
#Tree with entropy
clf = DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
from sklearn.tree import export_graphviz
export_graphviz(clf,
out_file="tree.dot",
feature_names = df.drop(columns={"target"}).columns,
class_names=["0","1"],
filled = True)
#limit depth
clf = DecisionTreeClassifier(max_depth=3)
clf = clf.fit(X_train, y_train)
print(clf.get_depth())
print(clf.score(X_test, y_test))
plot_tree(clf)
#limit depth
clf = DecisionTreeClassifier()
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
fig, ax = plt.subplots()
ax.plot(ccp_alphas[:-1], impurities[:-1], marker="o", drawstyle="steps-post")
ax.set_xlabel("effective alpha")
ax.set_ylabel("total impurity of leaves")
ax.set_title("Total Impurity vs effective alpha for training set")
clfs = []
for ccp_alpha in ccp_alphas:
clf = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, y_train)
clfs.append(clf)
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]
fig, ax = plt.subplots(2, 1)
ax[0].plot(ccp_alphas, node_counts, marker="o", drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")
ax[1].plot(ccp_alphas, depth, marker="o", drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth of tree")
ax[1].set_title("Depth vs alpha")
fig.tight_layout()
train_scores = [clf.score(X_train, y_train) for clf in clfs]
test_scores = [clf.score(X_test, y_test) for clf in clfs]
fig, ax = plt.subplots()
ax.set_xlabel("alpha")
ax.set_ylabel("accuracy")
ax.set_title("Accuracy vs alpha for training and testing sets")
ax.plot(ccp_alphas, train_scores, marker="o", label="train", drawstyle="steps-post")
ax.plot(ccp_alphas, test_scores, marker="o", label="test", drawstyle="steps-post")
ax.legend()
plt.show()
#Load Data
df_ = pd.read_csv("data/heart.csv")
df_.head()
#Do some exploration
#Model
#View Tree
#Model with Pruning
#Find best alpha
#Plot
#Model pruned best
| 0.535584 | 0.940243 |
# 04 - Full waveform inversion with Devito and Dask
## Introduction
In this tutorial we show how [Devito](http://www.devitoproject.org/devito-public) and [scipy.optimize.minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) are used with [Dask](https://dask.pydata.org/en/latest/#dask) to perform [full waveform inversion](https://www.slim.eos.ubc.ca/research/inversion) (FWI) on distributed memory parallel computers.
## scipy.optimize.minimize
In this tutorial we use [scipy.optimize.minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) to solve the FWI gradient based minimization problem rather than the simple grdient decent algorithm in the previous tutorial.
```python
scipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)
```
> Minimization of scalar function of one or more variables.
>
> In general, the optimization problems are of the form:
>
> minimize f(x) subject to
>
> g_i(x) >= 0, i = 1,...,m
> h_j(x) = 0, j = 1,...,p
> where x is a vector of one or more variables. g_i(x) are the inequality constraints. h_j(x) are the equality constrains.
[scipy.optimize.minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) provides a wide variety of methods for solving minimization problems depending on the context. Here we are going to focus on using L-BFGS via [scipy.optimize.minimize(method=’L-BFGS-B’)](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb)
```python
scipy.optimize.minimize(fun, x0, args=(), method='L-BFGS-B', jac=None, bounds=None, tol=None, callback=None, options={'disp': None, 'maxls': 20, 'iprint': -1, 'gtol': 1e-05, 'eps': 1e-08, 'maxiter': 15000, 'ftol': 2.220446049250313e-09, 'maxcor': 10, 'maxfun': 15000})```
The argument `fun` is a callable function that returns the misfit between the simulated and the observed data. If `jac` is a Boolean and is `True`, `fun` is assumed to return the gradient along with the objective function - as is our case when applying the adjoint-state method.
## What is Dask?
> [Dask](https://dask.pydata.org/en/latest/#dask) is a flexible parallel computing library for analytic computing.
>
> Dask is composed of two components:
>
> * Dynamic task scheduling optimized for computation...
> * “Big Data” collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments. These parallel collections run on top of the dynamic task schedulers.
>
> Dask emphasizes the following virtues:
>
> * Familiar: Provides parallelized NumPy array and Pandas DataFrame objects
> * Flexible: Provides a task scheduling interface for more custom workloads and integration with other projects.
> * Native: Enables distributed computing in Pure Python with access to the PyData stack.
> * Fast: Operates with low overhead, low latency, and minimal serialization necessary for fast numerical algorithms
> * Scales up: Runs resiliently on clusters with 1000s of cores
> * Scales down: Trivial to set up and run on a laptop in a single process
> * Responsive: Designed with interactive computing in mind it provides rapid feedback and diagnostics to aid humans
**We are going to use it here to parallelise the computation of the functional and gradient as this is the vast bulk of the computational expense of FWI and it is trivially parallel over data shots.**
## Setting up (synthetic) data
In a real world scenario we work with collected seismic data; for the tutorial we know what the actual solution is and we are using the workers to also generate the synthetic data.
```
#NBVAL_IGNORE_OUTPUT
# Set up inversion parameters.
param = {'t0': 0.,
'tn': 1000., # Simulation last 1 second (1000 ms)
'f0': 0.010, # Source peak frequency is 10Hz (0.010 kHz)
'nshots': 5, # Number of shots to create gradient from
'm_bounds': (0.08, 0.25), # Set the min and max slowness
'shape': (101, 101), # Number of grid points (nx, nz).
'spacing': (10., 10.), # Grid spacing in m. The domain size is now 1km by 1km.
'origin': (0, 0), # Need origin to define relative source and receiver locations.
'nbl': 40} # nbl thickness.
import numpy as np
import scipy
from scipy import signal, optimize
from devito import Grid
from distributed import Client, LocalCluster, wait
import cloudpickle as pickle
# Import acoustic solver, source and receiver modules.
from examples.seismic import Model, demo_model, AcquisitionGeometry, Receiver
from examples.seismic.acoustic import AcousticWaveSolver
from examples.seismic import AcquisitionGeometry
# Import convenience function for plotting results
from examples.seismic import plot_image
def get_true_model():
''' Define the test phantom; in this case we are using
a simple circle so we can easily see what is going on.
'''
return demo_model('circle-isotropic', vp=3.0, vp_background=2.5,
origin=param['origin'], shape=param['shape'],
spacing=param['spacing'], nbl=param['nbl'])
def get_initial_model():
'''The initial guess for the subsurface model.
'''
# Make sure both model are on the same grid
grid = get_true_model().grid
return demo_model('circle-isotropic', vp=2.5, vp_background=2.5,
origin=param['origin'], shape=param['shape'],
spacing=param['spacing'], nbl=param['nbl'],
grid=grid)
def wrap_model(x, astype=None):
'''Wrap a flat array as a subsurface model.
'''
model = get_initial_model()
if astype:
model.vp = x.astype(astype).reshape(model.vp.data.shape)
else:
model.vp = x.reshape(model.vp.data.shape)
return model
def load_model(filename):
""" Returns the current model. This is used by the
worker to get the current model.
"""
pkl = pickle.load(open(filename, "rb"))
return pkl['model']
def dump_model(filename, model):
''' Dump model to disk.
'''
pickle.dump({'model':model}, open(filename, "wb"))
def load_shot_data(shot_id, dt):
''' Load shot data from disk, resampling to the model time step.
'''
pkl = pickle.load(open("shot_%d.p"%shot_id, "rb"))
return pkl['geometry'].resample(dt), pkl['rec'].resample(dt)
def dump_shot_data(shot_id, rec, geometry):
''' Dump shot data to disk.
'''
pickle.dump({'rec':rec, 'geometry': geometry}, open('shot_%d.p'%shot_id, "wb"))
def generate_shotdata_i(param):
""" Inversion crime alert! Here the worker is creating the
'observed' data using the real model. For a real case
the worker would be reading seismic data from disk.
"""
true_model = get_true_model()
shot_id = param['shot_id']
src_coordinates = np.empty((1, len(param['shape'])))
src_coordinates[0, :] = [30, param['shot_id']*1000./(param['nshots']-1)]
# Number of receiver locations per shot.
nreceivers = 101
# Set up receiver data and geometry.
rec_coordinates = np.empty((nreceivers, len(param['shape'])))
rec_coordinates[:, 1] = np.linspace(0, true_model.domain_size[0], num=nreceivers)
rec_coordinates[:, 0] = 980. # 20m from the right end
# Geometry
geometry = AcquisitionGeometry(true_model, rec_coordinates, src_coordinates,
param['t0'], param['tn'], src_type='Ricker',
f0=param['f0'])
# Set up solver.
solver = AcousticWaveSolver(true_model, geometry, space_order=4)
# Generate synthetic receiver data from true model.
true_d, _, _ = solver.forward(vp=true_model.vp)
dump_shot_data(shot_id, true_d, geometry)
def generate_shotdata(param):
# Define work list
work = [dict(param) for i in range(param['nshots'])]
for i in range(param['nshots']):
work[i]['shot_id'] = i
generate_shotdata_i(work[i])
# Map worklist to cluster
futures = client.map(generate_shotdata_i, work)
# Wait for all futures
wait(futures)
#NBVAL_IGNORE_OUTPUT
# Start Dask cluster
cluster = LocalCluster(n_workers=2, death_timeout=600)
client = Client(cluster)
# Generate shot data.
generate_shotdata(param)
```
## Dask specifics
Previously we defined a function to calculate the individual contribution to the functional and gradient for each shot, which was then used in a loop over all shots. However, when using distributed frameworks such as Dask we instead think in terms of creating a worklist which gets *mapped* onto the worker pool. The sum reduction is also performed in parallel. For now however we assume that the scipy.optimize.minimize itself is running on the *master* process; this is a reasonable simplification because the computational cost of calculating (f, g) far exceeds the other compute costs.
Because we want to be able to use standard reduction operators such as sum on (f, g) we first define it as a type so that we can define the `__add__` (and `__rand__` method).
```
# Define a type to store the functional and gradient.
class fg_pair:
def __init__(self, f, g):
self.f = f
self.g = g
def __add__(self, other):
f = self.f + other.f
g = self.g + other.g
return fg_pair(f, g)
def __radd__(self, other):
if other == 0:
return self
else:
return self.__add__(other)
```
## Create operators for gradient based inversion
To perform the inversion we are going to use [scipy.optimize.minimize(method=’L-BFGS-B’)](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb).
First we define the functional, ```f```, and gradient, ```g```, operator (i.e. the function ```fun```) for a single shot of data. This is the work that is going to be performed by the worker on a unit of data.
```
from devito import Function
# Create FWI gradient kernel for a single shot
def fwi_gradient_i(param):
# Load the current model and the shot data for this worker.
# Note, unlike the serial example the model is not passed in
# as an argument. Broadcasting large datasets is considered
# a programming anti-pattern and at the time of writing it
# it only worked relaiably with Dask master. Therefore, the
# the model is communicated via a file.
model0 = load_model(param['model'])
dt = model0.critical_dt
geometry, rec = load_shot_data(param['shot_id'], dt)
geometry.model = model0
# Set up solver.
solver = AcousticWaveSolver(model0, geometry, space_order=4)
# Compute simulated data and full forward wavefield u0
d, u0, _ = solver.forward(save=True)
# Compute the data misfit (residual) and objective function
residual = Receiver(name='rec', grid=model0.grid,
time_range=geometry.time_axis,
coordinates=geometry.rec_positions)
residual.data[:] = d.data[:residual.shape[0], :] - rec.data[:residual.shape[0], :]
f = .5*np.linalg.norm(residual.data.flatten())**2
# Compute gradient using the adjoint-state method. Note, this
# backpropagates the data misfit through the model.
grad = Function(name="grad", grid=model0.grid)
solver.gradient(rec=residual, u=u0, grad=grad)
# Copying here to avoid a (probably overzealous) destructor deleting
# the gradient before Dask has had a chance to communicate it.
g = np.array(grad.data[:])
# return the objective functional and gradient.
return fg_pair(f, g)
```
Define the global functional-gradient operator. This does the following:
* Maps the worklist (shots) to the workers so that the invidual contributions to (f, g) are computed.
* Sum individual contributions to (f, g) and returns the result.
```
def fwi_gradient(model, param):
# Dump a copy of the current model for the workers
# to pick up when they are ready.
param['model'] = "model_0.p"
dump_model(param['model'], wrap_model(model))
# Define work list
work = [dict(param) for i in range(param['nshots'])]
for i in range(param['nshots']):
work[i]['shot_id'] = i
# Distribute worklist to workers.
fgi = client.map(fwi_gradient_i, work, retries=1)
# Perform reduction.
fg = client.submit(sum, fgi).result()
# L-BFGS in scipy expects a flat array in 64-bit floats.
return fg.f, -fg.g.flatten().astype(np.float64)
```
## FWI with L-BFGS-B
Equipped with a function to calculate the functional and gradient, we are finally ready to define the optimization function.
```
from scipy import optimize
# Define bounding box constraints on the solution.
def apply_box_constraint(vp):
# Maximum possible 'realistic' velocity is 3.5 km/sec
# Minimum possible 'realistic' velocity is 2 km/sec
return np.clip(vp, 2.0, 3.5)
# Many optimization methods in scipy.optimize.minimize accept a callback
# function that can operate on the solution after every iteration. Here
# we use this to apply box constraints and to monitor the true relative
# solution error.
relative_error = []
def fwi_callbacks(x):
# Apply boundary constraint
x.data[:] = apply_box_constraint(x)
# Calculate true relative error
true_x = get_true_model().vp.data.flatten()
relative_error.append(np.linalg.norm((x-true_x)/true_x))
def fwi(model, param, ftol=0.1, maxiter=5):
result = optimize.minimize(fwi_gradient,
model.vp.data.flatten().astype(np.float64),
args=(param, ), method='L-BFGS-B', jac=True,
callback=fwi_callbacks,
options={'ftol':ftol,
'maxiter':maxiter,
'disp':True})
return result
```
We now apply our FWI function and have a look at the result.
```
#NBVAL_IGNORE_OUTPUT
model0 = get_initial_model()
# Baby steps
result = fwi(model0, param)
# Print out results of optimizer.
print(result)
#NBVAL_SKIP
# Show what the update does to the model
from examples.seismic import plot_image, plot_velocity
model0.vp = result.x.astype(np.float32).reshape(model0.vp.data.shape)
plot_velocity(model0)
#NBVAL_SKIP
# Plot percentage error
plot_image(100*np.abs(model0.vp.data-get_true_model().vp.data)/get_true_model().vp.data, vmax=15, cmap="hot")
#NBVAL_SKIP
import matplotlib.pyplot as plt
# Plot objective function decrease
plt.figure()
plt.loglog(relative_error)
plt.xlabel('Iteration number')
plt.ylabel('True relative error')
plt.title('Convergence')
plt.show()
```
<sup>This notebook is part of the tutorial "Optimised Symbolic Finite Difference Computation with Devito" presented at the Intel® HPC Developer Conference 2017.</sup>
|
github_jupyter
|
scipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)
scipy.optimize.minimize(fun, x0, args=(), method='L-BFGS-B', jac=None, bounds=None, tol=None, callback=None, options={'disp': None, 'maxls': 20, 'iprint': -1, 'gtol': 1e-05, 'eps': 1e-08, 'maxiter': 15000, 'ftol': 2.220446049250313e-09, 'maxcor': 10, 'maxfun': 15000})```
The argument `fun` is a callable function that returns the misfit between the simulated and the observed data. If `jac` is a Boolean and is `True`, `fun` is assumed to return the gradient along with the objective function - as is our case when applying the adjoint-state method.
## What is Dask?
> [Dask](https://dask.pydata.org/en/latest/#dask) is a flexible parallel computing library for analytic computing.
>
> Dask is composed of two components:
>
> * Dynamic task scheduling optimized for computation...
> * “Big Data” collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to larger-than-memory or distributed environments. These parallel collections run on top of the dynamic task schedulers.
>
> Dask emphasizes the following virtues:
>
> * Familiar: Provides parallelized NumPy array and Pandas DataFrame objects
> * Flexible: Provides a task scheduling interface for more custom workloads and integration with other projects.
> * Native: Enables distributed computing in Pure Python with access to the PyData stack.
> * Fast: Operates with low overhead, low latency, and minimal serialization necessary for fast numerical algorithms
> * Scales up: Runs resiliently on clusters with 1000s of cores
> * Scales down: Trivial to set up and run on a laptop in a single process
> * Responsive: Designed with interactive computing in mind it provides rapid feedback and diagnostics to aid humans
**We are going to use it here to parallelise the computation of the functional and gradient as this is the vast bulk of the computational expense of FWI and it is trivially parallel over data shots.**
## Setting up (synthetic) data
In a real world scenario we work with collected seismic data; for the tutorial we know what the actual solution is and we are using the workers to also generate the synthetic data.
## Dask specifics
Previously we defined a function to calculate the individual contribution to the functional and gradient for each shot, which was then used in a loop over all shots. However, when using distributed frameworks such as Dask we instead think in terms of creating a worklist which gets *mapped* onto the worker pool. The sum reduction is also performed in parallel. For now however we assume that the scipy.optimize.minimize itself is running on the *master* process; this is a reasonable simplification because the computational cost of calculating (f, g) far exceeds the other compute costs.
Because we want to be able to use standard reduction operators such as sum on (f, g) we first define it as a type so that we can define the `__add__` (and `__rand__` method).
## Create operators for gradient based inversion
To perform the inversion we are going to use [scipy.optimize.minimize(method=’L-BFGS-B’)](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb).
First we define the functional, ```f```, and gradient, ```g```, operator (i.e. the function ```fun```) for a single shot of data. This is the work that is going to be performed by the worker on a unit of data.
Define the global functional-gradient operator. This does the following:
* Maps the worklist (shots) to the workers so that the invidual contributions to (f, g) are computed.
* Sum individual contributions to (f, g) and returns the result.
## FWI with L-BFGS-B
Equipped with a function to calculate the functional and gradient, we are finally ready to define the optimization function.
We now apply our FWI function and have a look at the result.
| 0.857231 | 0.968081 |
# Code
**Date: February, 2017**
```
%matplotlib inline
import numpy as np
import scipy as sp
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# For linear regression
from scipy.stats import multivariate_normal
from scipy.integrate import dblquad
# Shut down warnings for nicer output
import warnings
warnings.filterwarnings('ignore')
colors = sns.color_palette()
plt.rc('text', usetex=True)
plt.rc('font', family='serif')
```
**Coin tossing example**
```
#===================================================
# FUNCTIONS
#===================================================
def relative_entropy(theta0, a):
return theta0 * np.log(theta0/a) + (1 - theta0) * np.log((1 - theta0)/(1 - a))
def quadratic_loss(theta0, a):
return (a - theta0)**2
def loss_distribution(l, dr, loss, true_dist, theta0, y_grid):
"""
Uses the formula for the change of discrete random variable. It takes care of the
fact that relative entropy is not monotone.
"""
eps = 1e-16
if loss == 'relative_entropy':
a1 = sp.optimize.bisect(lambda a: relative_entropy(theta0, a) - l, a = eps, b = theta0)
a2 = sp.optimize.bisect(lambda a: relative_entropy(theta0, a) - l, a = theta0, b = 1 - eps)
elif loss == 'quadratic':
a1 = theta0 - np.sqrt(l)
a2 = theta0 + np.sqrt(l)
if np.isclose(a1, dr).any():
y1 = y_grid[np.isclose(a1, dr)][0]
prob1 = true_dist.pmf(y1)
else:
prob1 = 0.0
if np.isclose(a2, dr).any():
y2 = y_grid[np.isclose(a2, dr)][0]
prob2 = true_dist.pmf(y2)
else:
prob2 = 0.0
if np.isclose(a1, a2):
# around zero loss, the two sides might find the same a
return prob1
else:
return prob1 + prob2
def risk_quadratic(theta0, n, alpha=0, beta=0):
"""
See Casella and Berger, p.332
"""
first_term = n * theta0 * (1 - theta0)/(alpha + beta + n)**2
second_term = ((n * theta0 + alpha)/(alpha + beta + n) - theta0)**2
return first_term + second_term
def loss_figures(theta0, n, alpha, beta, mle=True, entropy=True):
true_dist = stats.binom(n, theta0)
y_grid = np.arange(n + 1) # sum of ones in a sample
a_grid = np.linspace(0, 1, 100) # action space represented as [0, 1]
# The two decision functions (as a function of Y)
decision_rule = y_grid/n
decision_rule_bayes = (y_grid + alpha)/(n + alpha + beta)
if mle and entropy:
"""
MLE with relative entropy loss
"""
loss = relative_entropy(theta0, decision_rule)
loss_dist = np.asarray([loss_distribution(i, decision_rule, "relative_entropy",
true_dist, theta0,
y_grid) for i in loss[1:-1]])
loss_dist = np.hstack([true_dist.pmf(y_grid[0]), loss_dist, true_dist.pmf(y_grid[-1])])
risk = loss @ loss_dist
elif mle and not entropy:
"""
MLE with quadratic loss
"""
loss = quadratic_loss(theta0, decision_rule)
loss_dist = np.asarray([loss_distribution(i, decision_rule, "quadratic",
true_dist, theta0,
y_grid) for i in loss])
risk = risk_quadratic(theta0, n)
elif not mle and entropy:
"""
Bayes with realtive entropy loss
"""
loss = relative_entropy(theta0, decision_rule_bayes)
loss_dist = np.asarray([loss_distribution(i, decision_rule_bayes, "relative_entropy",
true_dist, theta0, y_grid) for i in loss])
risk = loss @ loss_dist
elif not mle and not entropy:
"""
Bayes with quadratic loss
"""
loss = quadratic_loss(theta0, decision_rule_bayes)
loss_dist = np.asarray([loss_distribution(i, decision_rule_bayes, "quadratic",
true_dist, theta0, y_grid) for i in loss])
risk = risk_quadratic(theta0, n, alpha, beta)
return loss, loss_dist, risk
theta0 = .79
n = 25
alpha, beta = 7, 2
#=========================
# Elements of Figure 1
#=========================
true_dist = stats.binom(n, theta0)
y_grid = np.arange(n + 1) # sum of ones in a sample
a_grid = np.linspace(0, 1, 100) # action space represented as [0, 1]
rel_ent = relative_entropy(theta0, a_grid) # form of the loss function
quadratic = quadratic_loss(theta0, a_grid) # form of the loss function
#=========================
# Elements of Figure 2
#=========================
theta0_alt = .39
true_dist_alt = stats.binom(n, theta0_alt)
# The two decision functions (as a function of Y)
decision_rule = y_grid/n
decision_rule_bayes = (y_grid + alpha)/(n + alpha + beta)
#=========================
# Elements of Figure 3
#=========================
loss_re_mle, loss_dist_re_mle, risk_re_mle = loss_figures(theta0, n, alpha, beta)
loss_quad_mle, loss_dist_quad_mle, risk_quad_mle = loss_figures(theta0, n, alpha, beta,
entropy=False)
loss_re_bayes, loss_dist_re_bayes, risk_re_bayes = loss_figures(theta0, n, alpha, beta,
mle=False)
loss_quad_bayes, loss_dist_quad_bayes, risk_quad_bayes = loss_figures(theta0, n, alpha, beta,
mle=False, entropy=False)
loss_re_mle_alt, loss_dist_re_mle_alt, risk_re_mle_alt = loss_figures(theta0_alt,
n, alpha, beta)
loss_quad_mle_alt, loss_dist_quad_mle_alt, risk_quad_mle_alt = loss_figures(theta0_alt, n,
alpha, beta, entropy=False)
loss_re_bayes_alt, loss_dist_re_bayes_alt, risk_re_bayes_alt = loss_figures(theta0_alt, n,
alpha, beta, mle=False)
loss_quad_bayes_alt, loss_dist_quad_bayes_alt, risk_quad_bayes_alt = loss_figures(theta0_alt,
n, alpha, beta,
mle=False, entropy=False)
fig, ax = plt.subplots(1, 2, figsize = (12, 4))
ax[0].set_title('True distribution over Y', fontsize = 14)
ax[0].plot(y_grid, true_dist.pmf(y_grid), 'o', color = sns.color_palette()[3])
ax[0].vlines(y_grid, 0, true_dist.pmf(y_grid), lw = 4, color = sns.color_palette()[3], alpha = .7)
ax[0].set_xlabel(r'Number of ones in the sample', fontsize = 12)
ax[1].set_title('Loss functions over the action space', fontsize = 14)
ax[1].plot(a_grid, rel_ent, lw = 2, label = 'relative entropy loss')
ax[1].plot(a_grid, quadratic, lw = 2, label = 'quadratic loss')
ax[1].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
ax[1].legend(loc = 'best', fontsize = 12)
ax[1].set_xlabel(r'Actions $(a)$', fontsize = 12)
plt.tight_layout()
plt.savefig("./example1_fig1.png", dpi=800)
fig, ax = plt.subplots(1, 2, figsize = (12, 4))
ax[0].set_title('Induced action distribution of the MLE estimator', fontsize = 14)
# Small bias
ax[0].plot(decision_rule, true_dist.pmf(y_grid), 'o')
ax[0].vlines(decision_rule, 0, true_dist.pmf(y_grid), lw = 5, alpha = .9, color = sns.color_palette()[0])
ax[0].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
# Large bias for Bayes
ax[0].plot(decision_rule, true_dist_alt.pmf(y_grid), 'o', color = sns.color_palette()[0], alpha = .4)
ax[0].vlines(decision_rule, 0, true_dist_alt.pmf(y_grid), lw = 4, alpha = .4, color = sns.color_palette()[0])
ax[0].axvline(theta0_alt, color = sns.color_palette()[2], lw = 2, alpha = .4,
label = r'$\theta=${t}'.format(t=theta0_alt))
ax[0].legend(loc = 'best', fontsize = 12)
ax[0].set_ylim([0, .2])
ax[0].set_xlim([0, 1])
ax[0].set_xlabel(r'Actions $(a)$', fontsize = 12)
ax[1].set_title('Induced action distribution of the Bayes estimator', fontsize = 14)
# Small bias
ax[1].plot(decision_rule_bayes, true_dist.pmf(y_grid), 'o', color = sns.color_palette()[1])
ax[1].vlines(decision_rule_bayes, 0, true_dist.pmf(y_grid), lw = 5, alpha = .9,
color = sns.color_palette()[1])
ax[1].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
# Large bias for Bayes
ax[1].plot(decision_rule_bayes, true_dist_alt.pmf(y_grid), 'o', color = sns.color_palette()[1], alpha = .4)
ax[1].vlines(decision_rule_bayes, 0, true_dist_alt.pmf(y_grid), lw = 4, alpha = .4,
color = sns.color_palette()[1])
ax[1].axvline(theta0_alt, color = sns.color_palette()[2], lw = 2, alpha = .4,
label = r'$\theta=${t}'.format(t=theta0_alt))
ax[1].legend(loc = 'best', fontsize = 12)
ax[1].set_ylim([0, .2])
ax[1].set_xlim([0, 1])
ax[1].set_xlabel(r'Actions $(a)$', fontsize = 12)
plt.tight_layout()
plt.savefig("./example1_fig2.png", dpi=800)
fig, ax = plt.subplots(2, 2, figsize = (12, 6))
ax[0, 0].set_title('Induced entropy loss distribution (MLE estimator)', fontsize = 14)
ax[0, 0].vlines(loss_re_mle, 0, loss_dist_re_mle, lw = 9, alpha = .9, color = sns.color_palette()[0])
ax[0, 0].axvline(risk_re_mle, lw = 3, linestyle = '--',
color = sns.color_palette()[0], label = r"Entropy risk ($\theta_0={t}$)".format(t=theta0))
ax[0, 0].vlines(loss_re_mle_alt, 0, loss_dist_re_mle_alt, lw = 9, alpha = .3, color = sns.color_palette()[0])
ax[0, 0].axvline(risk_re_mle_alt, lw = 3, linestyle = '--', alpha = .4,
color = sns.color_palette()[0], label = r"Entropy risk ($\theta={t}$)".format(t=theta0_alt))
ax[0, 0].set_xlim([0, .1])
ax[0, 0].set_ylim([0, .2])
ax[0, 0].set_xlabel('Loss', fontsize=12)
ax[0, 0].legend(loc = 'best', fontsize = 12)
ax[1, 0].set_title('Induced entropy loss distribution (Bayes estimator)', fontsize=14)
ax[1, 0].vlines(loss_re_bayes, 0, loss_dist_re_bayes, lw=9, alpha=.9, color=sns.color_palette()[1])
ax[1, 0].axvline(risk_re_bayes, lw=3, linestyle='--',
color = sns.color_palette()[1], label=r"Entropy risk ($\theta_0={t}$)".format(t=theta0))
ax[1, 0].vlines(loss_re_bayes_alt, 0, loss_dist_re_bayes_alt, lw=9, alpha=.3, color=sns.color_palette()[1])
ax[1, 0].axvline(risk_re_bayes_alt, lw=3, linestyle='--', alpha=.4, color=sns.color_palette()[1],
label=r"Entropy risk ($\theta={t}$)".format(t=theta0_alt))
ax[1, 0].set_xlim([0, .1])
ax[1, 0].set_ylim([0, .2])
ax[1, 0].set_xlabel('Loss')
ax[1, 0].legend(loc='best', fontsize=12)
ax[0, 1].set_title('Induced quadratic loss distribution (MLE estimator)', fontsize=14)
ax[0, 1].vlines(loss_quad_mle, 0, loss_dist_quad_mle, lw=9, alpha=.9, color=sns.color_palette()[0])
ax[0, 1].axvline(risk_quad_mle, lw=3, linestyle='--',
color = sns.color_palette()[0], label=r"Quadratic risk ($\theta_0={t}$)".format(t=theta0))
ax[0, 1].vlines(loss_quad_mle_alt, 0, loss_dist_quad_mle_alt, lw=9, alpha=.3, color=sns.color_palette()[0])
ax[0, 1].axvline(risk_quad_mle_alt, lw=3, linestyle='--', alpha=.4,
color=sns.color_palette()[0], label=r"Quadratic risk ($\theta={t}$)".format(t=theta0_alt))
ax[0, 1].set_xlim([0, .05])
ax[0, 1].set_ylim([0, .2])
ax[0, 1].set_xlabel('Loss', fontsize=12)
ax[0, 1].legend(loc='best', fontsize=12)
ax[1, 1].set_title('Induced quadratic loss distribution (Bayes estimator)', fontsize=14)
ax[1, 1].vlines(loss_quad_bayes, 0, loss_dist_quad_bayes, lw=9, alpha=.9, color=sns.color_palette()[1])
ax[1, 1].axvline(risk_quad_bayes, lw=3, linestyle='--',
color = sns.color_palette()[1], label=r"Quadratic risk ($\theta_0={t}$)".format(t=theta0))
ax[1, 1].vlines(loss_quad_bayes_alt, 0, loss_dist_quad_bayes_alt, lw=9, alpha=.3, color=sns.color_palette()[1])
ax[1, 1].axvline(risk_quad_bayes_alt, lw=3, linestyle = '--', alpha=.4,
color=sns.color_palette()[1], label=r"Quadratic risk ($\theta={t}$)".format(t=theta0_alt))
ax[1, 1].set_xlim([0, .05])
ax[1, 1].set_ylim([0, .2])
ax[1, 1].set_xlabel('Loss', fontsize=12)
ax[1, 1].legend(loc='best', fontsize=12)
plt.tight_layout()
plt.savefig("./example1_fig3.png", dpi=800)
```
**Bayes OLS example**
```
mu = np.array([1, 3]) # mean
sigma = np.array([[4, 1], [1, 8]]) # covariance matrix
n = 50 # sample size
# Bayes priors
mu_bayes = np.array([2, 2])
precis_bayes = np.array([[6, -3], [-3, 6]])
# joint normal rv for (Y,X)
mvnorm = multivariate_normal(mu, sigma)
# decision rule -- OLS estimator
def d_OLS(Z, n):
Y = Z[:, 0]
X = np.stack((np.ones(n), Z[:,1]), axis=-1)
return np.linalg.inv(X.T @ X) @ X.T @ Y
# decision rule -- Bayes
def d_bayes(Z, n):
Y = Z[:, 0]
X = np.stack((np.ones(n), Z[:,1]), axis=-1)
return np.linalg.inv(X.T @ X + precis_bayes) @ (precis_bayes @ mu_bayes + X.T @ Y)
# loss -- define integrand
def loss_int(y, x, b):
'''Defines the integrand under mvnorm distribution.'''
return (y - b[0] - b[1]*x)**2*mvnorm.pdf((y,x))
# simulate distribution over actions and over losses
B_OLS = []
L_OLS = []
B_bayes = []
L_bayes = []
for i in range(1000):
# generate sample
Z = mvnorm.rvs(n)
# get OLS action corrsponding to realized sample
b_OLS = d_OLS(Z, n)
# get Bayes action
b_bayes = d_bayes(Z, n)
# get loss through integration
l_OLS = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_OLS,)) # get loss
l_bayes = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_bayes,)) # get loss
# record action
B_OLS.append(b_OLS)
B_bayes.append(b_bayes)
# record loss
L_OLS.append(l_OLS)
L_bayes.append(l_bayes)
# take first column if integrating
L_OLS = np.array(L_OLS)[:, 0]
L_bayes = np.array(L_bayes)[:, 0]
B_OLS = pd.DataFrame(B_OLS, columns=["$\\beta_0$", "$\\beta_1$"])
B_bayes = pd.DataFrame(B_bayes, columns=["$\\beta_0$", "$\\beta_1$"])
g1 = sns.jointplot(x = "$\\beta_0$", y = "$\\beta_1$", data=B_OLS, kind="kde",
space=0.3, color = sns.color_palette()[0], size=5, xlim = (-.5, 1.6), ylim = (-.1, .4))
g1.ax_joint.plot([mu[0] - sigma[0,1]/sigma[1,1]*mu[1]],[sigma[0,1]/sigma[1,1]], 'ro', color='r', label='best-in-class')
g1.set_axis_labels(r'$\beta_0$', r'$\beta_1$', fontsize=14)
g1.fig.suptitle('Induced action distribution -- OLS', fontsize=14, y=1.04)
plt.savefig("./example2_fig1a.png", dpi=800)
g2 = sns.jointplot(x = "$\\beta_0$", y = "$\\beta_1$", data=B_bayes, kind="kde",
space=0.3, color = sns.color_palette()[0], size=5, xlim = (-.5, 1.6), ylim = (-.1, .4))
g2.ax_joint.plot([mu[0] - sigma[0,1]/sigma[1,1]*mu[1]],[sigma[0,1]/sigma[1,1]], 'ro', color='r', label='best-in-class')
g2.set_axis_labels(r'$\beta_0$', r'$\beta_1$', fontsize=14)
g2.fig.suptitle('Induced action distribution -- Bayes', fontsize=14, y=1.04)
plt.savefig("./example2_fig1b.png", dpi=800)
plt.show()
b_best = [mu[0] - sigma[0,1]/sigma[1,1]*mu[1], sigma[0,1]/sigma[1,1]]
l_best = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_best,))
print(l_best[0])
plt.figure(figsize=(11, 5))
plt.axvline(x=l_best[0], ymin=0, ymax=1, linewidth=3, color = colors[4], label='Best-in-class loss')
plt.axvline(x=L_OLS.mean(), ymin=0, ymax=1, linewidth=3, color = colors[2], label='Risk of OLS')
plt.axvline(x=L_bayes.mean(), ymin=0, ymax=1, linewidth=3, color = colors[3], label='Risk of Bayes')
sns.distplot(L_OLS, bins=50, kde=False, color = colors[0], label='OLS')
sns.distplot(L_bayes, bins=50, kde=False, color = colors[1], label='Bayes')
plt.title('Induced loss distribution', fontsize = 14, y=1.02)
plt.legend(fontsize=12)
plt.xlabel('Loss', fontsize=12)
plt.xlim([3.8, 4.5])
plt.tight_layout()
plt.savefig("./example2_fig2.png", dpi=800)
beta_0 = mu[0] - sigma[0,1]/sigma[1,1]*mu[1]
beta_1 = sigma[0,1]/sigma[1,1]
print('Bias of OLS')
print('==========================')
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_0, B_OLS.mean()[0], beta_0 - B_OLS.mean()[0]))
print('{:.4f} - {:.4f} = {:.4f}\n\n'.format(beta_1, B_OLS.mean()[1], beta_1 - B_OLS.mean()[1]))
print('Bias of Bayes')
print('==========================')
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_0, B_bayes.mean()[0], beta_0 - B_bayes.mean()[0]))
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_1, B_bayes.mean()[1], beta_1 - B_bayes.mean()[1]))
print('Variance of OLS')
print('======================')
print(B_OLS.var())
print('\n\nVarinace of Bayes')
print('======================')
print(B_bayes.var())
print('Risk of OLS: {:.4f} \nRisk of Bayes: {:.4f}'.format(L_OLS.mean(), L_bayes.mean()))
```
|
github_jupyter
|
%matplotlib inline
import numpy as np
import scipy as sp
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# For linear regression
from scipy.stats import multivariate_normal
from scipy.integrate import dblquad
# Shut down warnings for nicer output
import warnings
warnings.filterwarnings('ignore')
colors = sns.color_palette()
plt.rc('text', usetex=True)
plt.rc('font', family='serif')
#===================================================
# FUNCTIONS
#===================================================
def relative_entropy(theta0, a):
return theta0 * np.log(theta0/a) + (1 - theta0) * np.log((1 - theta0)/(1 - a))
def quadratic_loss(theta0, a):
return (a - theta0)**2
def loss_distribution(l, dr, loss, true_dist, theta0, y_grid):
"""
Uses the formula for the change of discrete random variable. It takes care of the
fact that relative entropy is not monotone.
"""
eps = 1e-16
if loss == 'relative_entropy':
a1 = sp.optimize.bisect(lambda a: relative_entropy(theta0, a) - l, a = eps, b = theta0)
a2 = sp.optimize.bisect(lambda a: relative_entropy(theta0, a) - l, a = theta0, b = 1 - eps)
elif loss == 'quadratic':
a1 = theta0 - np.sqrt(l)
a2 = theta0 + np.sqrt(l)
if np.isclose(a1, dr).any():
y1 = y_grid[np.isclose(a1, dr)][0]
prob1 = true_dist.pmf(y1)
else:
prob1 = 0.0
if np.isclose(a2, dr).any():
y2 = y_grid[np.isclose(a2, dr)][0]
prob2 = true_dist.pmf(y2)
else:
prob2 = 0.0
if np.isclose(a1, a2):
# around zero loss, the two sides might find the same a
return prob1
else:
return prob1 + prob2
def risk_quadratic(theta0, n, alpha=0, beta=0):
"""
See Casella and Berger, p.332
"""
first_term = n * theta0 * (1 - theta0)/(alpha + beta + n)**2
second_term = ((n * theta0 + alpha)/(alpha + beta + n) - theta0)**2
return first_term + second_term
def loss_figures(theta0, n, alpha, beta, mle=True, entropy=True):
true_dist = stats.binom(n, theta0)
y_grid = np.arange(n + 1) # sum of ones in a sample
a_grid = np.linspace(0, 1, 100) # action space represented as [0, 1]
# The two decision functions (as a function of Y)
decision_rule = y_grid/n
decision_rule_bayes = (y_grid + alpha)/(n + alpha + beta)
if mle and entropy:
"""
MLE with relative entropy loss
"""
loss = relative_entropy(theta0, decision_rule)
loss_dist = np.asarray([loss_distribution(i, decision_rule, "relative_entropy",
true_dist, theta0,
y_grid) for i in loss[1:-1]])
loss_dist = np.hstack([true_dist.pmf(y_grid[0]), loss_dist, true_dist.pmf(y_grid[-1])])
risk = loss @ loss_dist
elif mle and not entropy:
"""
MLE with quadratic loss
"""
loss = quadratic_loss(theta0, decision_rule)
loss_dist = np.asarray([loss_distribution(i, decision_rule, "quadratic",
true_dist, theta0,
y_grid) for i in loss])
risk = risk_quadratic(theta0, n)
elif not mle and entropy:
"""
Bayes with realtive entropy loss
"""
loss = relative_entropy(theta0, decision_rule_bayes)
loss_dist = np.asarray([loss_distribution(i, decision_rule_bayes, "relative_entropy",
true_dist, theta0, y_grid) for i in loss])
risk = loss @ loss_dist
elif not mle and not entropy:
"""
Bayes with quadratic loss
"""
loss = quadratic_loss(theta0, decision_rule_bayes)
loss_dist = np.asarray([loss_distribution(i, decision_rule_bayes, "quadratic",
true_dist, theta0, y_grid) for i in loss])
risk = risk_quadratic(theta0, n, alpha, beta)
return loss, loss_dist, risk
theta0 = .79
n = 25
alpha, beta = 7, 2
#=========================
# Elements of Figure 1
#=========================
true_dist = stats.binom(n, theta0)
y_grid = np.arange(n + 1) # sum of ones in a sample
a_grid = np.linspace(0, 1, 100) # action space represented as [0, 1]
rel_ent = relative_entropy(theta0, a_grid) # form of the loss function
quadratic = quadratic_loss(theta0, a_grid) # form of the loss function
#=========================
# Elements of Figure 2
#=========================
theta0_alt = .39
true_dist_alt = stats.binom(n, theta0_alt)
# The two decision functions (as a function of Y)
decision_rule = y_grid/n
decision_rule_bayes = (y_grid + alpha)/(n + alpha + beta)
#=========================
# Elements of Figure 3
#=========================
loss_re_mle, loss_dist_re_mle, risk_re_mle = loss_figures(theta0, n, alpha, beta)
loss_quad_mle, loss_dist_quad_mle, risk_quad_mle = loss_figures(theta0, n, alpha, beta,
entropy=False)
loss_re_bayes, loss_dist_re_bayes, risk_re_bayes = loss_figures(theta0, n, alpha, beta,
mle=False)
loss_quad_bayes, loss_dist_quad_bayes, risk_quad_bayes = loss_figures(theta0, n, alpha, beta,
mle=False, entropy=False)
loss_re_mle_alt, loss_dist_re_mle_alt, risk_re_mle_alt = loss_figures(theta0_alt,
n, alpha, beta)
loss_quad_mle_alt, loss_dist_quad_mle_alt, risk_quad_mle_alt = loss_figures(theta0_alt, n,
alpha, beta, entropy=False)
loss_re_bayes_alt, loss_dist_re_bayes_alt, risk_re_bayes_alt = loss_figures(theta0_alt, n,
alpha, beta, mle=False)
loss_quad_bayes_alt, loss_dist_quad_bayes_alt, risk_quad_bayes_alt = loss_figures(theta0_alt,
n, alpha, beta,
mle=False, entropy=False)
fig, ax = plt.subplots(1, 2, figsize = (12, 4))
ax[0].set_title('True distribution over Y', fontsize = 14)
ax[0].plot(y_grid, true_dist.pmf(y_grid), 'o', color = sns.color_palette()[3])
ax[0].vlines(y_grid, 0, true_dist.pmf(y_grid), lw = 4, color = sns.color_palette()[3], alpha = .7)
ax[0].set_xlabel(r'Number of ones in the sample', fontsize = 12)
ax[1].set_title('Loss functions over the action space', fontsize = 14)
ax[1].plot(a_grid, rel_ent, lw = 2, label = 'relative entropy loss')
ax[1].plot(a_grid, quadratic, lw = 2, label = 'quadratic loss')
ax[1].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
ax[1].legend(loc = 'best', fontsize = 12)
ax[1].set_xlabel(r'Actions $(a)$', fontsize = 12)
plt.tight_layout()
plt.savefig("./example1_fig1.png", dpi=800)
fig, ax = plt.subplots(1, 2, figsize = (12, 4))
ax[0].set_title('Induced action distribution of the MLE estimator', fontsize = 14)
# Small bias
ax[0].plot(decision_rule, true_dist.pmf(y_grid), 'o')
ax[0].vlines(decision_rule, 0, true_dist.pmf(y_grid), lw = 5, alpha = .9, color = sns.color_palette()[0])
ax[0].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
# Large bias for Bayes
ax[0].plot(decision_rule, true_dist_alt.pmf(y_grid), 'o', color = sns.color_palette()[0], alpha = .4)
ax[0].vlines(decision_rule, 0, true_dist_alt.pmf(y_grid), lw = 4, alpha = .4, color = sns.color_palette()[0])
ax[0].axvline(theta0_alt, color = sns.color_palette()[2], lw = 2, alpha = .4,
label = r'$\theta=${t}'.format(t=theta0_alt))
ax[0].legend(loc = 'best', fontsize = 12)
ax[0].set_ylim([0, .2])
ax[0].set_xlim([0, 1])
ax[0].set_xlabel(r'Actions $(a)$', fontsize = 12)
ax[1].set_title('Induced action distribution of the Bayes estimator', fontsize = 14)
# Small bias
ax[1].plot(decision_rule_bayes, true_dist.pmf(y_grid), 'o', color = sns.color_palette()[1])
ax[1].vlines(decision_rule_bayes, 0, true_dist.pmf(y_grid), lw = 5, alpha = .9,
color = sns.color_palette()[1])
ax[1].axvline(theta0, color = sns.color_palette()[2], lw = 2, label = r'$\theta_0=${t}'.format(t=theta0))
# Large bias for Bayes
ax[1].plot(decision_rule_bayes, true_dist_alt.pmf(y_grid), 'o', color = sns.color_palette()[1], alpha = .4)
ax[1].vlines(decision_rule_bayes, 0, true_dist_alt.pmf(y_grid), lw = 4, alpha = .4,
color = sns.color_palette()[1])
ax[1].axvline(theta0_alt, color = sns.color_palette()[2], lw = 2, alpha = .4,
label = r'$\theta=${t}'.format(t=theta0_alt))
ax[1].legend(loc = 'best', fontsize = 12)
ax[1].set_ylim([0, .2])
ax[1].set_xlim([0, 1])
ax[1].set_xlabel(r'Actions $(a)$', fontsize = 12)
plt.tight_layout()
plt.savefig("./example1_fig2.png", dpi=800)
fig, ax = plt.subplots(2, 2, figsize = (12, 6))
ax[0, 0].set_title('Induced entropy loss distribution (MLE estimator)', fontsize = 14)
ax[0, 0].vlines(loss_re_mle, 0, loss_dist_re_mle, lw = 9, alpha = .9, color = sns.color_palette()[0])
ax[0, 0].axvline(risk_re_mle, lw = 3, linestyle = '--',
color = sns.color_palette()[0], label = r"Entropy risk ($\theta_0={t}$)".format(t=theta0))
ax[0, 0].vlines(loss_re_mle_alt, 0, loss_dist_re_mle_alt, lw = 9, alpha = .3, color = sns.color_palette()[0])
ax[0, 0].axvline(risk_re_mle_alt, lw = 3, linestyle = '--', alpha = .4,
color = sns.color_palette()[0], label = r"Entropy risk ($\theta={t}$)".format(t=theta0_alt))
ax[0, 0].set_xlim([0, .1])
ax[0, 0].set_ylim([0, .2])
ax[0, 0].set_xlabel('Loss', fontsize=12)
ax[0, 0].legend(loc = 'best', fontsize = 12)
ax[1, 0].set_title('Induced entropy loss distribution (Bayes estimator)', fontsize=14)
ax[1, 0].vlines(loss_re_bayes, 0, loss_dist_re_bayes, lw=9, alpha=.9, color=sns.color_palette()[1])
ax[1, 0].axvline(risk_re_bayes, lw=3, linestyle='--',
color = sns.color_palette()[1], label=r"Entropy risk ($\theta_0={t}$)".format(t=theta0))
ax[1, 0].vlines(loss_re_bayes_alt, 0, loss_dist_re_bayes_alt, lw=9, alpha=.3, color=sns.color_palette()[1])
ax[1, 0].axvline(risk_re_bayes_alt, lw=3, linestyle='--', alpha=.4, color=sns.color_palette()[1],
label=r"Entropy risk ($\theta={t}$)".format(t=theta0_alt))
ax[1, 0].set_xlim([0, .1])
ax[1, 0].set_ylim([0, .2])
ax[1, 0].set_xlabel('Loss')
ax[1, 0].legend(loc='best', fontsize=12)
ax[0, 1].set_title('Induced quadratic loss distribution (MLE estimator)', fontsize=14)
ax[0, 1].vlines(loss_quad_mle, 0, loss_dist_quad_mle, lw=9, alpha=.9, color=sns.color_palette()[0])
ax[0, 1].axvline(risk_quad_mle, lw=3, linestyle='--',
color = sns.color_palette()[0], label=r"Quadratic risk ($\theta_0={t}$)".format(t=theta0))
ax[0, 1].vlines(loss_quad_mle_alt, 0, loss_dist_quad_mle_alt, lw=9, alpha=.3, color=sns.color_palette()[0])
ax[0, 1].axvline(risk_quad_mle_alt, lw=3, linestyle='--', alpha=.4,
color=sns.color_palette()[0], label=r"Quadratic risk ($\theta={t}$)".format(t=theta0_alt))
ax[0, 1].set_xlim([0, .05])
ax[0, 1].set_ylim([0, .2])
ax[0, 1].set_xlabel('Loss', fontsize=12)
ax[0, 1].legend(loc='best', fontsize=12)
ax[1, 1].set_title('Induced quadratic loss distribution (Bayes estimator)', fontsize=14)
ax[1, 1].vlines(loss_quad_bayes, 0, loss_dist_quad_bayes, lw=9, alpha=.9, color=sns.color_palette()[1])
ax[1, 1].axvline(risk_quad_bayes, lw=3, linestyle='--',
color = sns.color_palette()[1], label=r"Quadratic risk ($\theta_0={t}$)".format(t=theta0))
ax[1, 1].vlines(loss_quad_bayes_alt, 0, loss_dist_quad_bayes_alt, lw=9, alpha=.3, color=sns.color_palette()[1])
ax[1, 1].axvline(risk_quad_bayes_alt, lw=3, linestyle = '--', alpha=.4,
color=sns.color_palette()[1], label=r"Quadratic risk ($\theta={t}$)".format(t=theta0_alt))
ax[1, 1].set_xlim([0, .05])
ax[1, 1].set_ylim([0, .2])
ax[1, 1].set_xlabel('Loss', fontsize=12)
ax[1, 1].legend(loc='best', fontsize=12)
plt.tight_layout()
plt.savefig("./example1_fig3.png", dpi=800)
mu = np.array([1, 3]) # mean
sigma = np.array([[4, 1], [1, 8]]) # covariance matrix
n = 50 # sample size
# Bayes priors
mu_bayes = np.array([2, 2])
precis_bayes = np.array([[6, -3], [-3, 6]])
# joint normal rv for (Y,X)
mvnorm = multivariate_normal(mu, sigma)
# decision rule -- OLS estimator
def d_OLS(Z, n):
Y = Z[:, 0]
X = np.stack((np.ones(n), Z[:,1]), axis=-1)
return np.linalg.inv(X.T @ X) @ X.T @ Y
# decision rule -- Bayes
def d_bayes(Z, n):
Y = Z[:, 0]
X = np.stack((np.ones(n), Z[:,1]), axis=-1)
return np.linalg.inv(X.T @ X + precis_bayes) @ (precis_bayes @ mu_bayes + X.T @ Y)
# loss -- define integrand
def loss_int(y, x, b):
'''Defines the integrand under mvnorm distribution.'''
return (y - b[0] - b[1]*x)**2*mvnorm.pdf((y,x))
# simulate distribution over actions and over losses
B_OLS = []
L_OLS = []
B_bayes = []
L_bayes = []
for i in range(1000):
# generate sample
Z = mvnorm.rvs(n)
# get OLS action corrsponding to realized sample
b_OLS = d_OLS(Z, n)
# get Bayes action
b_bayes = d_bayes(Z, n)
# get loss through integration
l_OLS = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_OLS,)) # get loss
l_bayes = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_bayes,)) # get loss
# record action
B_OLS.append(b_OLS)
B_bayes.append(b_bayes)
# record loss
L_OLS.append(l_OLS)
L_bayes.append(l_bayes)
# take first column if integrating
L_OLS = np.array(L_OLS)[:, 0]
L_bayes = np.array(L_bayes)[:, 0]
B_OLS = pd.DataFrame(B_OLS, columns=["$\\beta_0$", "$\\beta_1$"])
B_bayes = pd.DataFrame(B_bayes, columns=["$\\beta_0$", "$\\beta_1$"])
g1 = sns.jointplot(x = "$\\beta_0$", y = "$\\beta_1$", data=B_OLS, kind="kde",
space=0.3, color = sns.color_palette()[0], size=5, xlim = (-.5, 1.6), ylim = (-.1, .4))
g1.ax_joint.plot([mu[0] - sigma[0,1]/sigma[1,1]*mu[1]],[sigma[0,1]/sigma[1,1]], 'ro', color='r', label='best-in-class')
g1.set_axis_labels(r'$\beta_0$', r'$\beta_1$', fontsize=14)
g1.fig.suptitle('Induced action distribution -- OLS', fontsize=14, y=1.04)
plt.savefig("./example2_fig1a.png", dpi=800)
g2 = sns.jointplot(x = "$\\beta_0$", y = "$\\beta_1$", data=B_bayes, kind="kde",
space=0.3, color = sns.color_palette()[0], size=5, xlim = (-.5, 1.6), ylim = (-.1, .4))
g2.ax_joint.plot([mu[0] - sigma[0,1]/sigma[1,1]*mu[1]],[sigma[0,1]/sigma[1,1]], 'ro', color='r', label='best-in-class')
g2.set_axis_labels(r'$\beta_0$', r'$\beta_1$', fontsize=14)
g2.fig.suptitle('Induced action distribution -- Bayes', fontsize=14, y=1.04)
plt.savefig("./example2_fig1b.png", dpi=800)
plt.show()
b_best = [mu[0] - sigma[0,1]/sigma[1,1]*mu[1], sigma[0,1]/sigma[1,1]]
l_best = dblquad(loss_int, -np.inf, np.inf, lambda x: -np.inf, lambda x: np.inf, args=(b_best,))
print(l_best[0])
plt.figure(figsize=(11, 5))
plt.axvline(x=l_best[0], ymin=0, ymax=1, linewidth=3, color = colors[4], label='Best-in-class loss')
plt.axvline(x=L_OLS.mean(), ymin=0, ymax=1, linewidth=3, color = colors[2], label='Risk of OLS')
plt.axvline(x=L_bayes.mean(), ymin=0, ymax=1, linewidth=3, color = colors[3], label='Risk of Bayes')
sns.distplot(L_OLS, bins=50, kde=False, color = colors[0], label='OLS')
sns.distplot(L_bayes, bins=50, kde=False, color = colors[1], label='Bayes')
plt.title('Induced loss distribution', fontsize = 14, y=1.02)
plt.legend(fontsize=12)
plt.xlabel('Loss', fontsize=12)
plt.xlim([3.8, 4.5])
plt.tight_layout()
plt.savefig("./example2_fig2.png", dpi=800)
beta_0 = mu[0] - sigma[0,1]/sigma[1,1]*mu[1]
beta_1 = sigma[0,1]/sigma[1,1]
print('Bias of OLS')
print('==========================')
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_0, B_OLS.mean()[0], beta_0 - B_OLS.mean()[0]))
print('{:.4f} - {:.4f} = {:.4f}\n\n'.format(beta_1, B_OLS.mean()[1], beta_1 - B_OLS.mean()[1]))
print('Bias of Bayes')
print('==========================')
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_0, B_bayes.mean()[0], beta_0 - B_bayes.mean()[0]))
print('{:.4f} - {:.4f} = {:.4f}'.format(beta_1, B_bayes.mean()[1], beta_1 - B_bayes.mean()[1]))
print('Variance of OLS')
print('======================')
print(B_OLS.var())
print('\n\nVarinace of Bayes')
print('======================')
print(B_bayes.var())
print('Risk of OLS: {:.4f} \nRisk of Bayes: {:.4f}'.format(L_OLS.mean(), L_bayes.mean()))
| 0.713232 | 0.832849 |
## CNN-Project-Exercise
We'll be using the CIFAR-10 dataset, which is very famous dataset for image recognition!
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.
### Follow the Instructions in Bold, if you get stuck somewhere, view the solutions video! Most of the challenge with this project is actually dealing with the data and its dimensions, not from setting up the CNN itself!
## Step 0: Get the Data
** *Note: If you have trouble with this just watch the solutions video. This doesn't really have anything to do with the exercise, its more about setting up your data. Please make sure to watch the solutions video before posting any QA questions.* **
** Download the data for CIFAR from here: https://www.cs.toronto.edu/~kriz/cifar.html **
**Specifically the CIFAR-10 python version link: https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz **
** Remember the directory you save the file in! **
```
# Put file path as a string here
CIFAR_DIR = ''
```
The archive contains the files data_batch_1, data_batch_2, ..., data_batch_5, as well as test_batch. Each of these files is a Python "pickled" object produced with cPickle.
** Load the Data. Use the Code Below to load the data: **
```
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
cifar_dict = pickle.load(fo, encoding='bytes')
return cifar_dict
dirs = ['batches.meta','data_batch_1','data_batch_2','data_batch_3','data_batch_4','data_batch_5','test_batch']
all_data = [0,1,2,3,4,5,6]
for i,direc in zip(all_data,dirs):
all_data[i] = unpickle(CIFAR_DIR+direc)
batch_meta = all_data[0]
data_batch1 = all_data[1]
data_batch2 = all_data[2]
data_batch3 = all_data[3]
data_batch4 = all_data[4]
data_batch5 = all_data[5]
test_batch = all_data[6]
batch_meta
```
** Why the 'b's in front of the string? **
Bytes literals are always prefixed with 'b' or 'B'; they produce an instance of the bytes type instead of the str type. They may only contain ASCII characters; bytes with a numeric value of 128 or greater must be expressed with escapes.
https://stackoverflow.com/questions/6269765/what-does-the-b-character-do-in-front-of-a-string-literal
```
data_batch1.keys()
```
Loaded in this way, each of the batch files contains a dictionary with the following elements:
* data -- a 10000x3072 numpy array of uint8s. Each row of the array stores a 32x32 colour image. The first 1024 entries contain the red channel values, the next 1024 the green, and the final 1024 the blue. The image is stored in row-major order, so that the first 32 entries of the array are the red channel values of the first row of the image.
* labels -- a list of 10000 numbers in the range 0-9. The number at index i indicates the label of the ith image in the array data.
The dataset contains another file, called batches.meta. It too contains a Python dictionary object. It has the following entries:
* label_names -- a 10-element list which gives meaningful names to the numeric labels in the labels array described above. For example, label_names[0] == "airplane", label_names[1] == "automobile", etc.
### Display a single image using matplotlib.
** Grab a single image from data_batch1 and display it with plt.imshow(). You'll need to reshape and transpose the numpy array inside the X = data_batch[b'data'] dictionary entry.**
** It should end up looking like this: **
# Array of all images reshaped and formatted for viewing
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("uint8")
```
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# Put the code here that transforms the X array!
plt.imshow(X[0])
plt.imshow(X[1])
plt.imshow(X[4])
```
# Helper Functions for Dealing With Data.
** Use the provided code below to help with dealing with grabbing the next batch once you've gotten ready to create the Graph Session. Can you break down how it works? **
```
def one_hot_encode(vec, vals=10):
'''
For use to one-hot encode the 10- possible labels
'''
n = len(vec)
out = np.zeros((n, vals))
out[range(n), vec] = 1
return out
class CifarHelper():
def __init__(self):
self.i = 0
# Grabs a list of all the data batches for training
self.all_train_batches = [data_batch1,data_batch2,data_batch3,data_batch4,data_batch5]
# Grabs a list of all the test batches (really just one batch)
self.test_batch = [test_batch]
# Intialize some empty variables for later on
self.training_images = None
self.training_labels = None
self.test_images = None
self.test_labels = None
def set_up_images(self):
print("Setting Up Training Images and Labels")
# Vertically stacks the training images
self.training_images = np.vstack([d[b"data"] for d in self.all_train_batches])
train_len = len(self.training_images)
# Reshapes and normalizes training images
self.training_images = self.training_images.reshape(train_len,3,32,32).transpose(0,2,3,1)/255
# One hot Encodes the training labels (e.g. [0,0,0,1,0,0,0,0,0,0])
self.training_labels = one_hot_encode(np.hstack([d[b"labels"] for d in self.all_train_batches]), 10)
print("Setting Up Test Images and Labels")
# Vertically stacks the test images
self.test_images = np.vstack([d[b"data"] for d in self.test_batch])
test_len = len(self.test_images)
# Reshapes and normalizes test images
self.test_images = self.test_images.reshape(test_len,3,32,32).transpose(0,2,3,1)/255
# One hot Encodes the test labels (e.g. [0,0,0,1,0,0,0,0,0,0])
self.test_labels = one_hot_encode(np.hstack([d[b"labels"] for d in self.test_batch]), 10)
def next_batch(self, batch_size):
# Note that the 100 dimension in the reshape call is set by an assumed batch size of 100
x = self.training_images[self.i:self.i+batch_size].reshape(100,32,32,3)
y = self.training_labels[self.i:self.i+batch_size]
self.i = (self.i + batch_size) % len(self.training_images)
return x, y
```
** How to use the above code: **
```
# Before Your tf.Session run these two lines
ch = CifarHelper()
ch.set_up_images()
# During your session to grab the next batch use this line
# (Just like we did for mnist.train.next_batch)
# batch = ch.next_batch(100)
```
## Creating the Model
** Import tensorflow **
** Create 2 placeholders, x and y_true. Their shapes should be: **
* x shape = [None,32,32,3]
* y_true shape = [None,10]
** Create one more placeholder called hold_prob. No need for shape here. This placeholder will just hold a single probability for the dropout. **
### Helper Functions
** Grab the helper functions from MNIST with CNN (or recreate them here yourself for a hard challenge!). You'll need: **
* init_weights
* init_bias
* conv2d
* max_pool_2by2
* convolutional_layer
* normal_full_layer
### Create the Layers
** Create a convolutional layer and a pooling layer as we did for MNIST. **
** Its up to you what the 2d size of the convolution should be, but the last two digits need to be 3 and 32 because of the 3 color channels and 32 pixels. So for example you could use:**
convo_1 = convolutional_layer(x,shape=[4,4,3,32])
** Create the next convolutional and pooling layers. The last two dimensions of the convo_2 layer should be 32,64 **
** Now create a flattened layer by reshaping the pooling layer into [-1,8 \* 8 \* 64] or [-1,4096] **
```
8*8*64
```
** Create a new full layer using the normal_full_layer function and passing in your flattend convolutional 2 layer with size=1024. (You could also choose to reduce this to something like 512)**
** Now create the dropout layer with tf.nn.dropout, remember to pass in your hold_prob placeholder. **
** Finally set the output to y_pred by passing in the dropout layer into the normal_full_layer function. The size should be 10 because of the 10 possible labels**
### Loss Function
** Create a cross_entropy loss function **
### Optimizer
** Create the optimizer using an Adam Optimizer. **
** Create a variable to intialize all the global tf variables. **
## Graph Session
** Perform the training and test print outs in a Tf session and run your model! **
|
github_jupyter
|
# Put file path as a string here
CIFAR_DIR = ''
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
cifar_dict = pickle.load(fo, encoding='bytes')
return cifar_dict
dirs = ['batches.meta','data_batch_1','data_batch_2','data_batch_3','data_batch_4','data_batch_5','test_batch']
all_data = [0,1,2,3,4,5,6]
for i,direc in zip(all_data,dirs):
all_data[i] = unpickle(CIFAR_DIR+direc)
batch_meta = all_data[0]
data_batch1 = all_data[1]
data_batch2 = all_data[2]
data_batch3 = all_data[3]
data_batch4 = all_data[4]
data_batch5 = all_data[5]
test_batch = all_data[6]
batch_meta
data_batch1.keys()
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
# Put the code here that transforms the X array!
plt.imshow(X[0])
plt.imshow(X[1])
plt.imshow(X[4])
def one_hot_encode(vec, vals=10):
'''
For use to one-hot encode the 10- possible labels
'''
n = len(vec)
out = np.zeros((n, vals))
out[range(n), vec] = 1
return out
class CifarHelper():
def __init__(self):
self.i = 0
# Grabs a list of all the data batches for training
self.all_train_batches = [data_batch1,data_batch2,data_batch3,data_batch4,data_batch5]
# Grabs a list of all the test batches (really just one batch)
self.test_batch = [test_batch]
# Intialize some empty variables for later on
self.training_images = None
self.training_labels = None
self.test_images = None
self.test_labels = None
def set_up_images(self):
print("Setting Up Training Images and Labels")
# Vertically stacks the training images
self.training_images = np.vstack([d[b"data"] for d in self.all_train_batches])
train_len = len(self.training_images)
# Reshapes and normalizes training images
self.training_images = self.training_images.reshape(train_len,3,32,32).transpose(0,2,3,1)/255
# One hot Encodes the training labels (e.g. [0,0,0,1,0,0,0,0,0,0])
self.training_labels = one_hot_encode(np.hstack([d[b"labels"] for d in self.all_train_batches]), 10)
print("Setting Up Test Images and Labels")
# Vertically stacks the test images
self.test_images = np.vstack([d[b"data"] for d in self.test_batch])
test_len = len(self.test_images)
# Reshapes and normalizes test images
self.test_images = self.test_images.reshape(test_len,3,32,32).transpose(0,2,3,1)/255
# One hot Encodes the test labels (e.g. [0,0,0,1,0,0,0,0,0,0])
self.test_labels = one_hot_encode(np.hstack([d[b"labels"] for d in self.test_batch]), 10)
def next_batch(self, batch_size):
# Note that the 100 dimension in the reshape call is set by an assumed batch size of 100
x = self.training_images[self.i:self.i+batch_size].reshape(100,32,32,3)
y = self.training_labels[self.i:self.i+batch_size]
self.i = (self.i + batch_size) % len(self.training_images)
return x, y
# Before Your tf.Session run these two lines
ch = CifarHelper()
ch.set_up_images()
# During your session to grab the next batch use this line
# (Just like we did for mnist.train.next_batch)
# batch = ch.next_batch(100)
8*8*64
| 0.568296 | 0.987067 |
# Unsupervised clustering on rock properties
Sometimes we don't have labels, but would like to discover structure in a dataset. This is what clustering algorithms attempt to do. They don't require labels from us — they are 'unsupervised'.
We'll use a subset of the [Rock Property Catalog](http://subsurfwiki.org/wiki/Rock_Property_Catalog) data, licensed CC-BY Agile Scientific. Note that the data have been preprocessed, including the addition of noise. See the notebook [RPC_for_regression_and_classification.ipynb](RPC_for_regression_and_classification.ipynb).
We'll use two unsupervised techniques:
- k-means clustering
- DBSCAN
We do have lithology labels for this dataset, so we can use those as a measure of how well we're doing with the clustering.
```
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
uid = "1TMqV0d6zEqhP-gK_jQlagTuPN7pFEI5rhkVN0xJIx4g"
url = f"https://docs.google.com/spreadsheets/d/{uid}/export?format=csv"
df = pd.read_csv(url)
```
Notice that the count of `Rho` values is smaller than for the other properties.
Pairplots are a good way to see how the various features are distributed with respect to each other:
```
cols = ['Vp', 'Vs', 'Rho_n']
sns.pairplot(df.dropna(), vars=cols, hue='Lithology', plot_kws={'edgecolor': None})
```
## Clustering with _k_-means
From [the Wikipedia article](https://en.wikipedia.org/wiki/K-means_clustering):
> k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells.
```
from sklearn.cluster import KMeans
clu =
df['K means'] = clu.predict(df[cols].values)
for name, group in df.groupby('K means'):
plt.scatter(group.Vp, group.Rho_n, label=name)
plt.legend()
```
We actually do have the labels, so let's compare...
```
for name, group in df.groupby('Lithology'):
plt.scatter(group.Vp, group.Rho_n, label=name)
plt.legend()
```
## Measuring the accuracy
There are metrics for comparing clusterings. For example, `adjusted_rand_score` — from the scikit-learn docs:
> The Rand Index computes a similarity measure between two clusterings by considering all pairs of samples and counting pairs that are assigned in the same or different clusters in the predicted and true clusterings.
>
> The raw RI score is then “adjusted for chance” into the ARI score using the following scheme:
>
> ARI = (RI - Expected_RI) / (max(RI) - Expected_RI)
>
> The adjusted Rand index is thus ensured to have a value close to 0.0 for random labeling independently of the number of clusters and samples and exactly 1.0 when the clusterings are identical (up to a permutation).
```
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(df.Lithology, df['K means'])
```
That is not a good score.
## Clustering with DBSCAN
DBSCAN has nothing to do with databases. From [the Wikipedia article](https://en.wikipedia.org/wiki/DBSCAN):
> Density-based spatial clustering of applications with noise (DBSCAN) is [...] a density-based clustering algorithm: given a set of points in some space, it groups together points that are closely packed together (points with many nearby neighbors), marking as outliers points that lie alone in low-density regions (whose nearest neighbors are too far away). DBSCAN is one of the most common clustering algorithms and also most cited in scientific literature.
```
from sklearn.cluster import DBSCAN
DBSCAN()
```
There are two important hyperparameters:
- `eps`, the maximum distance between points in the same cluster.
- `min_samples`, the minimum number of samples in a cluster.
```
clu = DBSCAN(eps=150, min_samples=10)
clu.fit(df[cols].values)
df['DBSCAN'] = clu.labels_
for name, group in df.groupby('DBSCAN'):
plt.scatter(group.Vp, group.Rho_n, label=name)
```
It's a bit hard to juggle the two parameters... let's make an interactive widget:
Now we can apply this idea to our problem:
```
@interact(eps=(10, 250, 10))
def plot(eps):
clu = DBSCAN(eps=eps)
clu.fit(df[cols].values)
df['DBSCAN'] = clu.labels_
for name, group in df.groupby('DBSCAN'):
plt.scatter(group.Vp, group.Rho_n, label=name)
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(df.Lithology, df.DBSCAN)
```
### Exercises
- Can you make the interactive widget display the Rand score? Use `plt.text(x, y, "Text")`.
- Can you write a loop to find the value of `eps` giving the highest Rand score?
- Can you add the `min_samples` parameter to the widget?
- Explore some of [the other clustering algorithms](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.cluster).
- Try some clustering on one of your own datasets (or use something from [sklearn](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets), e.g. `sklearn.datasets.load_iris`).
|
github_jupyter
|
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
uid = "1TMqV0d6zEqhP-gK_jQlagTuPN7pFEI5rhkVN0xJIx4g"
url = f"https://docs.google.com/spreadsheets/d/{uid}/export?format=csv"
df = pd.read_csv(url)
cols = ['Vp', 'Vs', 'Rho_n']
sns.pairplot(df.dropna(), vars=cols, hue='Lithology', plot_kws={'edgecolor': None})
from sklearn.cluster import KMeans
clu =
df['K means'] = clu.predict(df[cols].values)
for name, group in df.groupby('K means'):
plt.scatter(group.Vp, group.Rho_n, label=name)
plt.legend()
for name, group in df.groupby('Lithology'):
plt.scatter(group.Vp, group.Rho_n, label=name)
plt.legend()
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(df.Lithology, df['K means'])
from sklearn.cluster import DBSCAN
DBSCAN()
clu = DBSCAN(eps=150, min_samples=10)
clu.fit(df[cols].values)
df['DBSCAN'] = clu.labels_
for name, group in df.groupby('DBSCAN'):
plt.scatter(group.Vp, group.Rho_n, label=name)
@interact(eps=(10, 250, 10))
def plot(eps):
clu = DBSCAN(eps=eps)
clu.fit(df[cols].values)
df['DBSCAN'] = clu.labels_
for name, group in df.groupby('DBSCAN'):
plt.scatter(group.Vp, group.Rho_n, label=name)
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(df.Lithology, df.DBSCAN)
| 0.575588 | 0.985524 |
## Classes
```
from abc import ABC, abstractmethod
class Account(ABC):
def __init__(self, account_number, balance):
self._account_number = account_number
self._balance = balance
def deposit(self, value):
if value > 0:
self._balance += value
else:
print("Invalid value to deposit:", value)
def withdraw(self, value):
if value > 0 and value <= self._balance:
self._balance -= value
else:
print("Invalid value to withdraw:", value)
@property
def account_number(self):
return self._account_number
@property
def balance(self):
return self._balance
@abstractmethod
def description(self):
pass
class SavingsAccount(Account):
def __init__(self, account_number, balance, interest=0.02):
super().__init__(account_number, balance)
self._interest = interest
def annual_interest(self):
return self.balance * self._interest
@property
def interest(self):
'''
This method is not part of the exercise
'''
return self._interest
def description(self):
return "savings"
class CurrentAccount(Account):
def __init__(self, account_number, balance, overdraft=100):
super().__init__(account_number, balance)
self._overdraft = overdraft
def withdraw(self, value):
if value > 0 and value <= (self._balance + self._overdraft):
self._balance -= value
else:
print("Invalid value to withdraw:", value)
@property
def overdraft(self):
'''
This method is not part of the exercise
'''
return self._overdraft
def description(self):
return "current"
```
## Testing
```
s = SavingsAccount("1", 1000)
s.balance
s.interest
s.annual_interest()
c = CurrentAccount("2", 50)
c.balance
c.overdraft
c.withdraw(200)
```
## List of Accounts
```
accounts = []
# let's add some accounts
accounts.append(SavingsAccount("1000", 1000))
accounts.append(SavingsAccount("1001", 5000))
accounts.append(CurrentAccount("2000", 10000, 1000))
accounts.append(CurrentAccount("2001", 500))
accounts.append(SavingsAccount("1002", 10, 0.1))
accounts.append(SavingsAccount("1003", 100000, 0.05))
accounts.append(CurrentAccount("2002", 10, 0.0))
accounts.append(CurrentAccount("2003", 50, 100))
accounts.append(CurrentAccount("2004", 5))
accounts.append(CurrentAccount("2005", 1000, 10))
accounts.append(CurrentAccount("2006", 500, 1000))
for account in accounts:
if isinstance(account, CurrentAccount):
if account.overdraft > account.balance:
print("Account", account.account_number, ": overdraft =", account.overdraft, ", balance = ", account.balance)
```
|
github_jupyter
|
from abc import ABC, abstractmethod
class Account(ABC):
def __init__(self, account_number, balance):
self._account_number = account_number
self._balance = balance
def deposit(self, value):
if value > 0:
self._balance += value
else:
print("Invalid value to deposit:", value)
def withdraw(self, value):
if value > 0 and value <= self._balance:
self._balance -= value
else:
print("Invalid value to withdraw:", value)
@property
def account_number(self):
return self._account_number
@property
def balance(self):
return self._balance
@abstractmethod
def description(self):
pass
class SavingsAccount(Account):
def __init__(self, account_number, balance, interest=0.02):
super().__init__(account_number, balance)
self._interest = interest
def annual_interest(self):
return self.balance * self._interest
@property
def interest(self):
'''
This method is not part of the exercise
'''
return self._interest
def description(self):
return "savings"
class CurrentAccount(Account):
def __init__(self, account_number, balance, overdraft=100):
super().__init__(account_number, balance)
self._overdraft = overdraft
def withdraw(self, value):
if value > 0 and value <= (self._balance + self._overdraft):
self._balance -= value
else:
print("Invalid value to withdraw:", value)
@property
def overdraft(self):
'''
This method is not part of the exercise
'''
return self._overdraft
def description(self):
return "current"
s = SavingsAccount("1", 1000)
s.balance
s.interest
s.annual_interest()
c = CurrentAccount("2", 50)
c.balance
c.overdraft
c.withdraw(200)
accounts = []
# let's add some accounts
accounts.append(SavingsAccount("1000", 1000))
accounts.append(SavingsAccount("1001", 5000))
accounts.append(CurrentAccount("2000", 10000, 1000))
accounts.append(CurrentAccount("2001", 500))
accounts.append(SavingsAccount("1002", 10, 0.1))
accounts.append(SavingsAccount("1003", 100000, 0.05))
accounts.append(CurrentAccount("2002", 10, 0.0))
accounts.append(CurrentAccount("2003", 50, 100))
accounts.append(CurrentAccount("2004", 5))
accounts.append(CurrentAccount("2005", 1000, 10))
accounts.append(CurrentAccount("2006", 500, 1000))
for account in accounts:
if isinstance(account, CurrentAccount):
if account.overdraft > account.balance:
print("Account", account.account_number, ": overdraft =", account.overdraft, ", balance = ", account.balance)
| 0.6488 | 0.646446 |
# String formatting
In many of the scripts in this series of lessons, you'll see something like this:
```python
msg_tmp = 'Hello, {}!'
print(msg_tmp.format('Matt'))
# => "Hello, Matt!"
```
Notice two things: the curly brackets `{}`, which is a placeholder, and the `.format()` method, which is where you specify what values should replace the curly bracket placeholders.
This is Python's built-in string formatting specification, and it's really handy for creating text templates. Here's another example:
```
greeting = 'Hello, my name is {}. I am {} years old, and I live in {}.'
my_name = 'Cody'
my_age = 33
my_state = 'Colorado'
print(greeting.format(my_name, my_age, my_state))
```
When you use `format()` like this, _order matters_. Check out what happens when we switch it up:
```
print(greeting.format(my_age, my_state, my_name))
```
### Using keywords instead
In the same way that dictionaries and lists [have a different way of accessing bits of data](Python%20data%20types%20and%20basic%20syntax.ipynb#Collections-of-data) -- indexing by position versus indexing by keyword -- you can use position-based formatting or keyword-based formatting. Here's an example:
```
mad_lib = 'The {noun} went to {city} and {ed_verb} for hours.'
my_noun = 'gorilla'
my_city = 'Denver'
my_verb = 'danced'
my_sentence = mad_lib.format(noun=my_noun,
city=my_city,
ed_verb=my_verb)
print(my_sentence)
```
I prefer this approach because I find it easier to keep track of what's going on -- it's more explicit -- but it's largely a matter of preference, and in some circumstances the other approach might make more sense.
### Let's start a chain of family-style restaurants
We'll start with three employees.
```
employees = ['Bob', 'Barb', 'Dana']
```
We are friendly folk, and we want to say hello to each of our employees. We _could_ do this:
```
print('Hello,', employees[0] + '! Are you wearing the appropriate amount of flair?')
print('Hello,', employees[1] + '! Are you wearing the appropriate amount of flair?')
print('Hello,', employees[2] + '! Are you wearing the appropriate amount of flair?')
```
Everything about that makes me want to vomit forever. The basic problem: We aren't being lazy enough!
First, we should be using a [`for loop`](Python%20data%20types%20and%20basic%20syntax.ipynb#for-loops) to burn through that list.
Second, we should be using a template to construct our employee greeting.
```
greet = 'Hello, {valued_employee}! Are you wearing the appropriate amount of flair?'
for emp in employees:
print(greet.format(valued_employee=emp))
```
_Much_ less typing for us, and it's extensible should we ever decide to hire more than three employees.
### Let's go nuts and loop over a list of dictionaries
We've collected more data on our employees, including the number of pieces of flair on each of their suspenders, and we're storing this data as a list of dictionaries.
While we're at it, let's use some conditional logic (an `if` statement) to give a hard time to employees who aren't giving us 110%.
👉 Forget how `if` statements work? [Check this notebook](Python%20data%20types%20and%20basic%20syntax.ipynb#if-statements).
```
employees = [
{'name': 'Bob', 'position': 'server', 'flair_pieces': 10},
{'name': 'Barb', 'position': 'hostess', 'flair_pieces': 3},
{'name': 'Dana', 'position': 'server', 'flair_pieces': 30},
]
# it's in the employee handbook, folks
FLAIR_MINIMUM = 10
greeting = 'Hello, {name}! {msg}'
for emp in employees:
if emp['flair_pieces'] < FLAIR_MINIMUM:
print(greeting.format(name=emp['name'], msg='WHY ARE YOU WEARING LESS THAN THE REQUIRED AMOUNT OF FLAIR.'))
elif emp['flair_pieces'] == FLAIR_MINIMUM:
print(greeting.format(name=emp['name'], msg='Congratulations on doing the absolute minimum, SLACKER.'))
else:
print(greeting.format(name=emp['name'], msg='You are a valued member of this team. Expect a promotion soon!'))
```
### Formatting numbers
Just like in Excel, you can change the formatting of a piece of data for display purposes without changing the underlying data itself. Here are a couple of the more common recipes for formatting numbers:
```
my_number = 1902323820.823
```
#### Add thousand-separator commas
```
'{:,}'.format(my_number)
```
#### Increase or decrease decimal precision
```
# no decimal places
'{:0.0f}'.format(my_number)
# two decimal places
'{:0.2f}'.format(my_number)
# two decimal places ~and~ commas
'{:,.2f}'.format(my_number)
# add a dollar sign to that
'${:,.2f}'.format(my_number)
# add a british pound sign to that
'£{:,.2f}'.format(my_number)
# add an emoji to that
'😬{:,.2f}'.format(my_number)
# add an emoji to that ... in a sentence
'I have 😬{:,.2f} in GrimaceCoin, my new cryptocurrency.'.format(my_number)
```
|
github_jupyter
|
msg_tmp = 'Hello, {}!'
print(msg_tmp.format('Matt'))
# => "Hello, Matt!"
greeting = 'Hello, my name is {}. I am {} years old, and I live in {}.'
my_name = 'Cody'
my_age = 33
my_state = 'Colorado'
print(greeting.format(my_name, my_age, my_state))
print(greeting.format(my_age, my_state, my_name))
mad_lib = 'The {noun} went to {city} and {ed_verb} for hours.'
my_noun = 'gorilla'
my_city = 'Denver'
my_verb = 'danced'
my_sentence = mad_lib.format(noun=my_noun,
city=my_city,
ed_verb=my_verb)
print(my_sentence)
employees = ['Bob', 'Barb', 'Dana']
print('Hello,', employees[0] + '! Are you wearing the appropriate amount of flair?')
print('Hello,', employees[1] + '! Are you wearing the appropriate amount of flair?')
print('Hello,', employees[2] + '! Are you wearing the appropriate amount of flair?')
greet = 'Hello, {valued_employee}! Are you wearing the appropriate amount of flair?'
for emp in employees:
print(greet.format(valued_employee=emp))
employees = [
{'name': 'Bob', 'position': 'server', 'flair_pieces': 10},
{'name': 'Barb', 'position': 'hostess', 'flair_pieces': 3},
{'name': 'Dana', 'position': 'server', 'flair_pieces': 30},
]
# it's in the employee handbook, folks
FLAIR_MINIMUM = 10
greeting = 'Hello, {name}! {msg}'
for emp in employees:
if emp['flair_pieces'] < FLAIR_MINIMUM:
print(greeting.format(name=emp['name'], msg='WHY ARE YOU WEARING LESS THAN THE REQUIRED AMOUNT OF FLAIR.'))
elif emp['flair_pieces'] == FLAIR_MINIMUM:
print(greeting.format(name=emp['name'], msg='Congratulations on doing the absolute minimum, SLACKER.'))
else:
print(greeting.format(name=emp['name'], msg='You are a valued member of this team. Expect a promotion soon!'))
my_number = 1902323820.823
'{:,}'.format(my_number)
# no decimal places
'{:0.0f}'.format(my_number)
# two decimal places
'{:0.2f}'.format(my_number)
# two decimal places ~and~ commas
'{:,.2f}'.format(my_number)
# add a dollar sign to that
'${:,.2f}'.format(my_number)
# add a british pound sign to that
'£{:,.2f}'.format(my_number)
# add an emoji to that
'😬{:,.2f}'.format(my_number)
# add an emoji to that ... in a sentence
'I have 😬{:,.2f} in GrimaceCoin, my new cryptocurrency.'.format(my_number)
| 0.197599 | 0.890199 |
```
import pandas as pd
docs = pd.read_table('SMSSpamCollection', header=None, names=['Class', 'sms'])
docs.head()
#df.column_name.value_counts() - gives no. of unique inputs in that columns
docs.Class.value_counts()
ham_spam=docs.Class.value_counts()
ham_spam
print("Spam % is ",(ham_spam[1]/float(ham_spam[0]+ham_spam[1]))*100)
# mapping labels to 1 and 0
docs['label'] = docs.Class.map({'ham':0, 'spam':1})
docs.head()
X=docs.sms
y=docs.label
X = docs.sms
y = docs.label
print(X.shape)
print(y.shape)
# splitting into test and train
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
X_train.head()
from sklearn.feature_extraction.text import CountVectorizer
# vectorising the text
vect = CountVectorizer(stop_words='english')
vect.fit(X_train)
vect.vocabulary_
vect.get_feature_names()
# transform
X_train_transformed = vect.transform(X_train)
X_test_tranformed =vect.transform(X_test)
from sklearn.naive_bayes import BernoulliNB
# instantiate bernoulli NB object
bnb = BernoulliNB()
# fit
bnb.fit(X_train_transformed,y_train)
# predict class
y_pred_class = bnb.predict(X_test_tranformed)
# predict probability
y_pred_proba =bnb.predict_proba(X_test_tranformed)
# accuracy
from sklearn import metrics
metrics.accuracy_score(y_test, y_pred_class)
bnb
metrics.confusion_matrix(y_test, y_pred_class)
confusion = metrics.confusion_matrix(y_test, y_pred_class)
print(confusion)
#[row, column]
TN = confusion[0, 0]
FP = confusion[0, 1]
FN = confusion[1, 0]
TP = confusion[1, 1]
sensitivity = TP / float(FN + TP)
print("sensitivity",sensitivity)
specificity = TN / float(TN + FP)
print("specificity",specificity)
precision = TP / float(TP + FP)
print("precision",precision)
print(metrics.precision_score(y_test, y_pred_class))
print("precision",precision)
print("PRECISION SCORE :",metrics.precision_score(y_test, y_pred_class))
print("RECALL SCORE :", metrics.recall_score(y_test, y_pred_class))
print("F1 SCORE :",metrics.f1_score(y_test, y_pred_class))
y_pred_proba
from sklearn.metrics import confusion_matrix as sk_confusion_matrix
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_pred_proba[:,1])
roc_auc = auc(false_positive_rate, true_positive_rate)
print (roc_auc)
print(true_positive_rate)
print(false_positive_rate)
print(thresholds)
%matplotlib inline
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('ROC')
plt.plot(false_positive_rate, true_positive_rate)
```
|
github_jupyter
|
import pandas as pd
docs = pd.read_table('SMSSpamCollection', header=None, names=['Class', 'sms'])
docs.head()
#df.column_name.value_counts() - gives no. of unique inputs in that columns
docs.Class.value_counts()
ham_spam=docs.Class.value_counts()
ham_spam
print("Spam % is ",(ham_spam[1]/float(ham_spam[0]+ham_spam[1]))*100)
# mapping labels to 1 and 0
docs['label'] = docs.Class.map({'ham':0, 'spam':1})
docs.head()
X=docs.sms
y=docs.label
X = docs.sms
y = docs.label
print(X.shape)
print(y.shape)
# splitting into test and train
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
X_train.head()
from sklearn.feature_extraction.text import CountVectorizer
# vectorising the text
vect = CountVectorizer(stop_words='english')
vect.fit(X_train)
vect.vocabulary_
vect.get_feature_names()
# transform
X_train_transformed = vect.transform(X_train)
X_test_tranformed =vect.transform(X_test)
from sklearn.naive_bayes import BernoulliNB
# instantiate bernoulli NB object
bnb = BernoulliNB()
# fit
bnb.fit(X_train_transformed,y_train)
# predict class
y_pred_class = bnb.predict(X_test_tranformed)
# predict probability
y_pred_proba =bnb.predict_proba(X_test_tranformed)
# accuracy
from sklearn import metrics
metrics.accuracy_score(y_test, y_pred_class)
bnb
metrics.confusion_matrix(y_test, y_pred_class)
confusion = metrics.confusion_matrix(y_test, y_pred_class)
print(confusion)
#[row, column]
TN = confusion[0, 0]
FP = confusion[0, 1]
FN = confusion[1, 0]
TP = confusion[1, 1]
sensitivity = TP / float(FN + TP)
print("sensitivity",sensitivity)
specificity = TN / float(TN + FP)
print("specificity",specificity)
precision = TP / float(TP + FP)
print("precision",precision)
print(metrics.precision_score(y_test, y_pred_class))
print("precision",precision)
print("PRECISION SCORE :",metrics.precision_score(y_test, y_pred_class))
print("RECALL SCORE :", metrics.recall_score(y_test, y_pred_class))
print("F1 SCORE :",metrics.f1_score(y_test, y_pred_class))
y_pred_proba
from sklearn.metrics import confusion_matrix as sk_confusion_matrix
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_pred_proba[:,1])
roc_auc = auc(false_positive_rate, true_positive_rate)
print (roc_auc)
print(true_positive_rate)
print(false_positive_rate)
print(thresholds)
%matplotlib inline
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('ROC')
plt.plot(false_positive_rate, true_positive_rate)
| 0.616936 | 0.544378 |
## Summary
**Notes:**
This notebook should be run on a machine with > 32G of memory.
---
## Imports
```
import os
from pathlib import Path
import crc32c
import pyarrow as pa
import pyarrow.parquet as pq
from tqdm.notebook import tqdm
```
## Parameters
```
NOTEBOOK_NAME = "01_load_data"
NOTEBOOK_DIR = Path(NOTEBOOK_NAME).resolve()
NOTEBOOK_DIR.mkdir(exist_ok=True)
NOTEBOOK_DIR
if "DATAPKG_OUTPUT_DIR" in os.environ:
DATAPKG_OUTPUT_DIR = Path(os.getenv("DATAPKG_OUTPUT_DIR")).resolve()
else:
DATAPKG_OUTPUT_DIR = NOTEBOOK_DIR
DATAPKG_OUTPUT_DIR.mkdir(exist_ok=True)
DATAPKG_OUTPUT_DIR
if "DATAPKG_OUTPUT_DIR" in os.environ:
OUTPUT_DIR = Path(os.getenv("DATAPKG_OUTPUT_DIR")).joinpath("elaspic2").resolve()
else:
OUTPUT_DIR = NOTEBOOK_DIR.parent
OUTPUT_DIR.mkdir(exist_ok=True)
OUTPUT_DIR
```
## Datasets
```
resources = {
# === Core ===
"elaspic-training-set-core": DATAPKG_OUTPUT_DIR.joinpath(
"elaspic-training-set", "02_export_data_core", "elaspic-training-set-core.parquet"
),
"protherm-dagger-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "protherm_dagger", "mutation-by-sequence.parquet"
),
"rocklin-2017-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "rocklin_2017", "mutation-ssm2.parquet"
),
"dunham-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "dunham_2020_tianyu", "monomers.parquet"
),
"starr-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "starr_2020_domain", "stability.parquet"
),
"cagi5-frataxin-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "cagi5_frataxin", "1ekg-ddg.parquet"
),
"huang-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "huang_2020", "2jie-ddg.parquet"
),
# === Interface ===
"elaspic-training-set-interface": DATAPKG_OUTPUT_DIR.joinpath(
"elaspic-training-set", "02_export_data_interface", "elaspic-training-set-interface.parquet"
),
"skempi-v2-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "skempi_v2", "skempi-v2.parquet"
),
# "intact-mutations-interface": DATAPKG_OUTPUT_DIR.joinpath(
# "protein-folding-energy", "intact_mutations", "intact-mutations.parquet"
# ),
"dunham-2020-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "dunham_2020_tianyu", "dimers.parquet"
),
"starr-2020-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "starr_2020_domain", "affinity.parquet"
),
}
row_group_sizes = {
"dunham-2020-core": 1,
"dunham-2020-interface": 1,
"starr-2020-core": 1,
"starr-2020-interface": 1,
"huang-2020-core": 1,
}
for name, path in resources.items():
assert Path(path).is_file(), path
```
## Load data
```
columns = [
"unique_id",
"dataset",
"name",
"protein_sequence",
"ligand_sequence",
"mutation",
"effect",
"effect_type",
"protein_structure",
]
extra_columns = [
"provean_score",
"foldx_score",
"elaspic_score",
]
def get_unique_id(dataset, effect_type, protein_sequence, ligand_sequence):
if ligand_sequence is not None:
key = f"{dataset}|{effect_type}|{protein_sequence}|{ligand_sequence}"
else:
key = f"{dataset}|{effect_type}|{protein_sequence}"
return crc32c.crc32c(key.encode("utf-8"))
def get_unique_id_2(dataset, name, effect_type, protein_sequence, ligand_sequence):
if ligand_sequence is not None:
key = f"{dataset}|{name}|{effect_type}|{protein_sequence}|{ligand_sequence}"
else:
key = f"{dataset}|{name}|{effect_type}|{protein_sequence}"
return crc32c.crc32c(key.encode("utf-8"))
output_dir = OUTPUT_DIR.joinpath(NOTEBOOK_NAME).resolve()
output_dir.mkdir(exist_ok=True)
output_dir
_seen = {
"core": set(),
"interface": set(),
}
for dataset_name, dataset_file in resources.items():
print(dataset_name)
coi = dataset_name.rsplit("-", 1)[-1]
assert coi in ["core", "interface"]
df = (
pq.read_table(dataset_file)
.to_pandas(integer_object_nulls=True)
.rename(columns={"mutations": "mutation"})
)
print(f"Read {len(df)} rows.")
# Remove unneeded data
mask = df["mutation"].apply(len) >= 2
print(f"Removing {(~mask).sum()} rows with fewer than two mutations.")
df = df[mask]
mask = df["effect"].apply(lambda x: len(set(x))) >= 2
print(f"Removing {(~mask).sum()} rows with fewer than two unique effects.")
df = df[mask]
if "dataset" not in df:
df["dataset"] = dataset_name
if "ligand_sequence" not in df:
df["ligand_sequence"] = None
# Add a unique id
df["unique_id"] = [
get_unique_id(dataset, effect_type, protein_sequence, ligand_sequence)
for dataset, effect_type, protein_sequence, ligand_sequence in df[
["dataset", "effect_type", "protein_sequence", "ligand_sequence"]
].values
]
unique_ids = set(df["unique_id"].values)
if len(unique_ids) != len(df):
df["unique_id"] = [
get_unique_id_2(dataset, name, effect_type, protein_sequence, ligand_sequence)
for dataset, name, effect_type, protein_sequence, ligand_sequence in df[
["dataset", "name", "effect_type", "protein_sequence", "ligand_sequence"]
].values
]
unique_ids = set(df["unique_id"].values)
assert len(unique_ids) == len(df)
assert not set(unique_ids) & _seen[coi]
_seen[coi].update(unique_ids)
columns_all = columns + [c for c in extra_columns if c in df]
df_out = df[columns_all]
# Write output
output_file = output_dir.joinpath(f"{dataset_name}.parquet")
# if output_file.is_file():
# print(f"Refusing to overwrite existing file: {output_file}.\n")
# continue
pq.write_table(
pa.Table.from_pandas(df_out, preserve_index=False),
output_file,
row_group_size=row_group_sizes.get(dataset_name, 100),
)
del df, df_out
print()
```
|
github_jupyter
|
import os
from pathlib import Path
import crc32c
import pyarrow as pa
import pyarrow.parquet as pq
from tqdm.notebook import tqdm
NOTEBOOK_NAME = "01_load_data"
NOTEBOOK_DIR = Path(NOTEBOOK_NAME).resolve()
NOTEBOOK_DIR.mkdir(exist_ok=True)
NOTEBOOK_DIR
if "DATAPKG_OUTPUT_DIR" in os.environ:
DATAPKG_OUTPUT_DIR = Path(os.getenv("DATAPKG_OUTPUT_DIR")).resolve()
else:
DATAPKG_OUTPUT_DIR = NOTEBOOK_DIR
DATAPKG_OUTPUT_DIR.mkdir(exist_ok=True)
DATAPKG_OUTPUT_DIR
if "DATAPKG_OUTPUT_DIR" in os.environ:
OUTPUT_DIR = Path(os.getenv("DATAPKG_OUTPUT_DIR")).joinpath("elaspic2").resolve()
else:
OUTPUT_DIR = NOTEBOOK_DIR.parent
OUTPUT_DIR.mkdir(exist_ok=True)
OUTPUT_DIR
resources = {
# === Core ===
"elaspic-training-set-core": DATAPKG_OUTPUT_DIR.joinpath(
"elaspic-training-set", "02_export_data_core", "elaspic-training-set-core.parquet"
),
"protherm-dagger-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "protherm_dagger", "mutation-by-sequence.parquet"
),
"rocklin-2017-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "rocklin_2017", "mutation-ssm2.parquet"
),
"dunham-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "dunham_2020_tianyu", "monomers.parquet"
),
"starr-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "starr_2020_domain", "stability.parquet"
),
"cagi5-frataxin-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "cagi5_frataxin", "1ekg-ddg.parquet"
),
"huang-2020-core": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "huang_2020", "2jie-ddg.parquet"
),
# === Interface ===
"elaspic-training-set-interface": DATAPKG_OUTPUT_DIR.joinpath(
"elaspic-training-set", "02_export_data_interface", "elaspic-training-set-interface.parquet"
),
"skempi-v2-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "skempi_v2", "skempi-v2.parquet"
),
# "intact-mutations-interface": DATAPKG_OUTPUT_DIR.joinpath(
# "protein-folding-energy", "intact_mutations", "intact-mutations.parquet"
# ),
"dunham-2020-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "dunham_2020_tianyu", "dimers.parquet"
),
"starr-2020-interface": DATAPKG_OUTPUT_DIR.joinpath(
"protein-folding-energy", "starr_2020_domain", "affinity.parquet"
),
}
row_group_sizes = {
"dunham-2020-core": 1,
"dunham-2020-interface": 1,
"starr-2020-core": 1,
"starr-2020-interface": 1,
"huang-2020-core": 1,
}
for name, path in resources.items():
assert Path(path).is_file(), path
columns = [
"unique_id",
"dataset",
"name",
"protein_sequence",
"ligand_sequence",
"mutation",
"effect",
"effect_type",
"protein_structure",
]
extra_columns = [
"provean_score",
"foldx_score",
"elaspic_score",
]
def get_unique_id(dataset, effect_type, protein_sequence, ligand_sequence):
if ligand_sequence is not None:
key = f"{dataset}|{effect_type}|{protein_sequence}|{ligand_sequence}"
else:
key = f"{dataset}|{effect_type}|{protein_sequence}"
return crc32c.crc32c(key.encode("utf-8"))
def get_unique_id_2(dataset, name, effect_type, protein_sequence, ligand_sequence):
if ligand_sequence is not None:
key = f"{dataset}|{name}|{effect_type}|{protein_sequence}|{ligand_sequence}"
else:
key = f"{dataset}|{name}|{effect_type}|{protein_sequence}"
return crc32c.crc32c(key.encode("utf-8"))
output_dir = OUTPUT_DIR.joinpath(NOTEBOOK_NAME).resolve()
output_dir.mkdir(exist_ok=True)
output_dir
_seen = {
"core": set(),
"interface": set(),
}
for dataset_name, dataset_file in resources.items():
print(dataset_name)
coi = dataset_name.rsplit("-", 1)[-1]
assert coi in ["core", "interface"]
df = (
pq.read_table(dataset_file)
.to_pandas(integer_object_nulls=True)
.rename(columns={"mutations": "mutation"})
)
print(f"Read {len(df)} rows.")
# Remove unneeded data
mask = df["mutation"].apply(len) >= 2
print(f"Removing {(~mask).sum()} rows with fewer than two mutations.")
df = df[mask]
mask = df["effect"].apply(lambda x: len(set(x))) >= 2
print(f"Removing {(~mask).sum()} rows with fewer than two unique effects.")
df = df[mask]
if "dataset" not in df:
df["dataset"] = dataset_name
if "ligand_sequence" not in df:
df["ligand_sequence"] = None
# Add a unique id
df["unique_id"] = [
get_unique_id(dataset, effect_type, protein_sequence, ligand_sequence)
for dataset, effect_type, protein_sequence, ligand_sequence in df[
["dataset", "effect_type", "protein_sequence", "ligand_sequence"]
].values
]
unique_ids = set(df["unique_id"].values)
if len(unique_ids) != len(df):
df["unique_id"] = [
get_unique_id_2(dataset, name, effect_type, protein_sequence, ligand_sequence)
for dataset, name, effect_type, protein_sequence, ligand_sequence in df[
["dataset", "name", "effect_type", "protein_sequence", "ligand_sequence"]
].values
]
unique_ids = set(df["unique_id"].values)
assert len(unique_ids) == len(df)
assert not set(unique_ids) & _seen[coi]
_seen[coi].update(unique_ids)
columns_all = columns + [c for c in extra_columns if c in df]
df_out = df[columns_all]
# Write output
output_file = output_dir.joinpath(f"{dataset_name}.parquet")
# if output_file.is_file():
# print(f"Refusing to overwrite existing file: {output_file}.\n")
# continue
pq.write_table(
pa.Table.from_pandas(df_out, preserve_index=False),
output_file,
row_group_size=row_group_sizes.get(dataset_name, 100),
)
del df, df_out
print()
| 0.321353 | 0.678338 |
# Computation Biology Summer Program Hackathon
This [Jupyter notebook](https://jupyter.org/) gives examples on how to use the various [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) web services from the [Knowledge Systems Group](https://www.mskcc.org/research-areas/labs/nikolaus-schultz). In this hackathon we will pull data from those APIs to make visualizations.
## How to run the notebook
This notebook can be executed on your own machine after installing Jupyter. Please install the Python 3 version of anaconda: https://www.anaconda.com/download/. After having that set up you can install Jupyter with:
```bash
conda install jupyter
```
For these examples we also require the [Swagger API](https://swagger.io/specification/) client `bravado`.
```bash
conda install -c conda-forge bravado
```
And the popular data analysis libraries pandas, matplotlib and seaborn:
```
conda install pandas matplotlib seaborn
```
Then clone this repo:
```
git clone https://github.com/mskcc/cbsp-hackathon
```
And run Jupyter in this folder
```
cd cbsp-hackathon/0-introduction
jupyter
```
That should open Jupyter in a new browser window and you should be able to open this notebook using the web interface. You can then follow along with the next steps.
## How to use the notebook
The notebook consists of cells which can be executed by clicking on one and pressing shift+f. In the toolbar at the top there is a dropdown which indicates what type of cell you have selected e.g. `Code` or [Markdown](https://en.wikipedia.org/wiki/Markdown). The former will be executed as raw Python code the latter is a markup language and will be run through a Markdown parser. Both generate HTML that will be printed directly to the notebook page.
There a few keyboard shortcuts that are good to know. That is: `b` creates a new cell below the one you've selected and `a` above the one you selected. Editing a cell can be done with a single click for a code cell and a double click for a Markdown cell. A complete list of all keyboard shortcuts can be found by pressing the keyboard icon in the toolbar at the top.
Give it a shot by editing one of the cells and pressing shift+f.
## Using the REST APIs
All [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) web services from the [Knowledge Systems Group](https://www.mskcc.org/research-areas/labs/nikolaus-schultz) we will be using in this tutorial have their REST APIs defined following the [Open API / Swagger specification](https://swagger.io/specification/). This allows us to use `bravado` to connect to them directly, and explore the API interactively.
For example this is how to connect to the [cBioPortal](https://www.cbioportal.org) API:
```
from bravado.client import SwaggerClient
cbioportal = SwaggerClient.from_url('https://www.cbioportal.org/api/api-docs',
config={"validate_requests":False,"validate_responses":False})
print(cbioportal)
```
You can now explore the API by using code completion, press `Tab` after typing `cbioportal.`:
```
cbioportal.
```
This will give a dropdown with all the different APIs, similar to how you can see them here on the cBioPortal website: https://www.cbioportal.org/api/swagger-ui.html#/.
You can also get the parameters to a specific endpoint by pressing shift+tab twice after typing the name of the specific endpoint e.g.:
```
cbioportal.A_Cancer_Types.getCancerTypeUsingGET(
```
That shows one of the parameters is `cancerTypeId` of type `string`, the example `acc` is mentioned:
```
acc = cbioportal.Cancer_Types.getCancerTypeUsingGET(cancerTypeId='acc').result()
print(acc)
```
You can see that the JSON output returned by the cBioPortal API gets automatically converted into an object called `TypeOfCancer`. This object can be explored interactively as well by pressing tab after typing `acc.`:
```
acc.
```
### cBioPortal API
[cBioPortal](https://www.cbioportal.org) stores cancer genomics data from a large number of published studies. Let's figure out:
- how many studies are there?
- how many cancer types do they span?
- how many samples in total?
- which study has the largest number of samples?
```
studies = cbioportal.Studies.getAllStudiesUsingGET().result()
cancer_types = cbioportal.Cancer_Types.getAllCancerTypesUsingGET().result()
print("In total there are {} studies in cBioPortal, spanning {} different types of cancer.".format(
len(studies),
len(cancer_types)
))
```
To get the total number of samples in each study we have to look a bit more at the response of the studies endpoint:
```
dir(studies[0])
```
We can sum the `allSampleCount` values of each study in cBioPortal:
```
print("The total number of samples in all studies is: {}".format(sum([x.allSampleCount for x in studies])))
```
Let's see which study has the largest number of samples:
```
sorted_studies = sorted(studies, key=lambda x: x.allSampleCount)
sorted_studies[-1]
```
Make it as little easier to read using pretty print:
```
from pprint import pprint
pprint(vars(sorted_studies[-1])['_Model__dict'])
```
Now that we've answered the inital questions we can dig a little deeper into this specific study:
- How many patients are in this study?
- What gene is most commonly mutated across the different samples?
- Does this study span one or more types of cancer?
The description of the study with id `msk_impact_2017` study mentions there are 10,000 patients sequenced. Can we find this data in the cBioPortal?
```
patients = cbioportal.Patients.getAllPatientsInStudyUsingGET(studyId='msk_impact_2017').result()
print("The msk_impact_2017 study spans {} patients".format(len(patients)))
```
Now let's try to figure out what gene is most commonly mutated. For this we can check the endpoints in the group `K_Mutations`. When looking at these endpoints it seems that a study can have multiple molecular profiles. This is because samples might have been sequenced using different assays (e.g. targeting a subset of genes or all genes). An example for the `acc_tcga` study is given for a molecular profile (`acc_tcga_mutations`) and a collection of samples (`msk_impact_2017_all`). We can use the same approach for the `msk_impact_2017` study. This will take a few seconds. You can use the command `%%time` to time a cell):
```
%%time
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='msk_impact_2017_mutations',
sampleListId='msk_impact_2017_all'
).result()
```
We can explore what the mutation data structure looks like:
```
pprint(vars(mutations[0])['_Model__dict'])
```
It seems that the `gene` field is not filled in. To keep the response size of the API small, the API uses a parameter called `projection` that indicates whether or not to return all fields of an object or only a portion of the fields. By default it will use the `SUMMARY` projection. But because in this case we want to `gene` information, we'll use the `DETAILED` projection instead, so let's update the previous statement:
```
%%time
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='msk_impact_2017_mutations',
sampleListId='msk_impact_2017_all',
projection='DETAILED'
).result()
```
You can see the response time is slightly slower. Let's check if the gene field is filled in now:
```
pprint(vars(mutations[0])['_Model__dict'])
```
Now that we have the gene field we can check what gene is most commonly mutated:
```
from collections import Counter
mutation_counts = Counter([m.gene.hugoGeneSymbol for m in mutations])
mutation_counts.most_common(5)
```
We can verify that these results are correct by looking at the study view of the MSK-IMPACT study on the cBioPortal website: https://www.cbioportal.org/study/summary?id=msk_impact_2017. Note that the website uses the REST API we've been using in this hackathon, so we would expect those numbers to be the same, but good to do a sanity check. We see that the number of patients is indeed 10,336. But the number of samples with a mutation in TP53 is 4,561 instead of 4,985. Can you spot why they differ?
Next question:
- How many samples have a TP53 mutation?
For this exercise it might be useful to use a [pandas dataframe](https://pandas.pydata.org/) to be able to do grouping operations. You can convert the mutations result to a dataframe like this:
```
import pandas as pd
mdf = pd.DataFrame.from_dict([
# python magic that combines two dictionaries:
dict(
m.__dict__['_Model__dict'],
**m.__dict__['_Model__dict']['gene'].__dict__['_Model__dict'])
# create one item in the list for each mutation
for m in mutations
])
```
The DataFrame is a data type originally from `Matlab` and `R` that makes it easier to work with columnar data. Pandas brings that data type to Python. There are also several performance optimizations by it using the data types from [numpy](https://www.numpy.org/).
Now that you have the data in a Dataframe you can group the mutations by the gene name and count the number of unique samples in TP53:
```
sample_count_per_gene = mdf.groupby('hugoGeneSymbol')['uniqueSampleKey'].nunique()
print("There are {} samples with a mutation in TP53".format(
sample_count_per_gene['TP53']
))
```
It would be nice to visualize this result in context of the other genes by plotting the top 10 most mutated genes. For this you can use the matplotlib interface that integrates with pandas.
First inline plotting in the notebook:
```
%matplotlib inline
sample_count_per_gene.sort_values(ascending=False).head(10).plot(kind='bar')
```
Make it look a little nicer by importing seaborn:
```
import seaborn as sns
sns.set_style("white")
sns.set_context('notebook')
sample_count_per_gene.sort_values(ascending=False).head(10).plot(kind='bar')
sns.despine(trim=False)
```
You can further change the plot a bit by using the arguments to the plot function or using the matplotlib interface directly:
```
import matplotlib.pyplot as plt
sample_count_per_gene.sort_values(ascending=False).head(10).plot(
kind='bar',
ylim=[0,5000],
color='green'
)
sns.despine(trim=False)
plt.xlabel('')
plt.xticks(rotation=300)
plt.ylabel('Number of samples',labelpad=20)
plt.title('Number of mutations in genes in MSK-IMPACT (2017)',pad=25)
```
A further extension of this plot could be to color the bar chart by the type of mutation in that sample (`mdf.mutationType`) and to include copy number alterations (see `Discrete Copy Number Alterations` endpoints).
### Genome Nexus API
[Genome Nexus](https://www.genomenexus.org) is a web service that aggregates all cancer related information about a particular mutation. Similarly to cBioPortal it provides a REST API following the [Swagger / OpenAPI specification](https://swagger.io/specification/).
```
from bravado.client import SwaggerClient
gn = SwaggerClient.from_url('https://www.genomenexus.org/v2/api-docs',
config={"validate_requests":False,
"validate_responses":False,
"validate_swagger_spec":False})
print(gn)
```
To look up annotations for a single variant, one can use the following endpoint:
```
variant = gn.annotation_controller.fetchVariantAnnotationByGenomicLocationGET(
genomicLocation='7,140453136,140453136,A,T',
# adds extra annotation resources, not included in default response:
fields='hotspots mutation_assessor annotation_summary'.split()
).result()
```
You can see a lot of information is provided for that particular variant if you type tab after `variant.`:
```
variant.
```
For this example we will focus on the hotspot annotation and ignore the others. [Cancer hotspots](https://www.cancerhotspots.org/) is a popular web resource which indicates whether particular variants have been found to be recurrently mutated in large scale cancer genomics data.
The example variant above is a hotspot:
```
variant.hotspots
```
Let's see how many hotspot mutations there are in the Cholangiocarcinoma (TCGA, PanCancer Atlas) study with study id `chol_tcga_pan_can_atlas_2018` from the cBioPortal:
```
%%time
cbioportal = SwaggerClient.from_url('https://www.cbioportal.org/api/api-docs',
config={"validate_requests":False,"validate_responses":False})
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='chol_tcga_pan_can_atlas_2018_mutations',
sampleListId='chol_tcga_pan_can_atlas_2018_all',
projection='DETAILED'
).result()
```
Convert the results to a dataframe again:
```
import pandas as pd
mdf = pd.DataFrame.from_dict([
# python magic that combines two dictionaries:
dict(
m.__dict__['_Model__dict'],
**m.__dict__['_Model__dict']['gene'].__dict__['_Model__dict'])
# create one item in the list for each mutation
for m in mutations
])
```
Then get only the unique mutations, to avoid calling the web service with the same variants:
```
variants = mdf['chromosome startPosition endPosition referenceAllele variantAllele'.split()]\
.drop_duplicates()\
.dropna(how='any',axis=0)\
.reset_index()
```
Convert them to input that genome nexus will understand:
```
variants = variants.rename(columns={'chr','chromosome','startPosition':'start','endPosition':'end'})\
.to_dict(orient='records')
# remove the index field
for v in variants:
del v['index']
print("There are {} mutations left to annotate".format(len(variants)))
```
Annotate them with genome nexus:
```
%%time
variants_annotated = gn.annotation_controller.fetchVariantAnnotationByGenomicLocationPOST(
genomicLocations=variants,
fields='hotspots annotation_summary'.split()
).result()
```
Index the variants to make it easier to query them:
```
gn_dict = {
"{},{},{},{},{}".format(
v.annotation_summary.genomicLocation.chromosome,
v.annotation_summary.genomicLocation.start,
v.annotation_summary.genomicLocation.end,
v.annotation_summary.genomicLocation.referenceAllele,
v.annotation_summary.genomicLocation.variantAllele)
:
v for v in variants_annotated
}
```
Add a new column to indicate whether something is a hotspot
```
def is_hotspot(x):
"""TODO: Current structure for hotspots in Genome Nexus is a little funky.
Need to check whether all lists in the annotation field are empty."""
if x:
return sum([len(a) for a in x.hotspots.annotation]) > 0
else:
return False
def create_dict_query_key(x):
return "{},{},{},{},{}".format(
x.chromosome, x.startPosition, x.endPosition, x.referenceAllele, x.variantAllele
)
mdf['is_hotspot'] = mdf.apply(lambda x: is_hotspot(gn_dict.get(create_dict_query_key(x), None)), axis=1)
```
Then plot the results:
```
%matplotlib inline
import seaborn as sns
sns.set_style("white")
sns.set_context('notebook')
import matplotlib.pyplot as plt
mdf.groupby('hugoGeneSymbol').is_hotspot.sum().sort_values(ascending=False).head(10).plot(kind='bar')
sns.despine(trim=False)
plt.xlabel('')
plt.xticks(rotation=300)
plt.ylabel('Number of non-unique hotspots',labelpad=20)
plt.title('Hotspots in Cholangiocarcinoma (TCGA, PanCancer Atlas)',pad=25)
```
### OncoKB API
[OncoKB](https://oncokb.org) is is a precision oncology knowledge base and contains information about the effects and treatment implications of specific cancer gene alterations. Similarly to cBioPortal and Genome Nexus it provides a REST API following the [Swagger / OpenAPI specification](https://swagger.io/specification/).
```
oncokb = SwaggerClient.from_url('https://www.oncokb.org/api/v1/v2/api-docs',
config={"validate_requests":False,
"validate_responses":False,
"validate_swagger_spec":False})
print(oncokb)
```
To look up annotations for a variant, one can use the following endpoint:
```
variant = oncokb.Annotations.annotateMutationsByGenomicChangeGetUsingGET(
genomicLocation='7,140453136,140453136,A,T',
).result()
```
You can see a lot of information is provided for that particular variant if you type tab after `variant.`:
```
variant.
```
For instance we can see the summary information about it:
```
variant.variantSummary
```
If you look up this variant on the OncoKB website: https://www.oncokb.org/gene/BRAF/V600E. You can see that there are various combinations of drugs and their level of evidence listed. This is a classification system for indicating how much we know about whether or not a patient might respond to a particular treatment. Please see https://www.oncokb.org/levels for more information about the levels of evidence for therapeutic biomarkers.
We can use the same `variants` we pulled from cBioPortal in the previous section to figure out the highest level of each variant.
```
%%time
variants_annotated = oncokb.Annotations.annotateMutationsByGenomicChangePostUsingPOST(
body=[
{"genomicLocation":"{chromosome},{start},{end},{referenceAllele},{variantAllele}".format(**v)}
for v in variants
],
).result()
```
Count the highes level for each variant
```
from collections import Counter
counts_per_level = Counter([va.highestSensitiveLevel for va in variants_annotated if va.highestSensitiveLevel])
```
Then plot them
```
pd.DataFrame(counts_per_level,index=[0]).plot(kind='bar', colors=['#4D8834','#2E2E2C','#753579'])
plt.xticks([])
plt.ylabel('Number of variants')
plt.title('Actionable variants in chol_tcga_pan_can_atlas_2018')
sns.despine()
```
The current plot could be more useful. See the idea listed here for one example of how to improve it: https://github.com/mskcc/cbsp-hackathon/tree/master/1-ideas/annotate-oncokb-barchart.
|
github_jupyter
|
conda install jupyter
conda install -c conda-forge bravado
conda install pandas matplotlib seaborn
git clone https://github.com/mskcc/cbsp-hackathon
cd cbsp-hackathon/0-introduction
jupyter
from bravado.client import SwaggerClient
cbioportal = SwaggerClient.from_url('https://www.cbioportal.org/api/api-docs',
config={"validate_requests":False,"validate_responses":False})
print(cbioportal)
cbioportal.
cbioportal.A_Cancer_Types.getCancerTypeUsingGET(
acc = cbioportal.Cancer_Types.getCancerTypeUsingGET(cancerTypeId='acc').result()
print(acc)
acc.
studies = cbioportal.Studies.getAllStudiesUsingGET().result()
cancer_types = cbioportal.Cancer_Types.getAllCancerTypesUsingGET().result()
print("In total there are {} studies in cBioPortal, spanning {} different types of cancer.".format(
len(studies),
len(cancer_types)
))
dir(studies[0])
print("The total number of samples in all studies is: {}".format(sum([x.allSampleCount for x in studies])))
sorted_studies = sorted(studies, key=lambda x: x.allSampleCount)
sorted_studies[-1]
from pprint import pprint
pprint(vars(sorted_studies[-1])['_Model__dict'])
patients = cbioportal.Patients.getAllPatientsInStudyUsingGET(studyId='msk_impact_2017').result()
print("The msk_impact_2017 study spans {} patients".format(len(patients)))
%%time
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='msk_impact_2017_mutations',
sampleListId='msk_impact_2017_all'
).result()
pprint(vars(mutations[0])['_Model__dict'])
%%time
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='msk_impact_2017_mutations',
sampleListId='msk_impact_2017_all',
projection='DETAILED'
).result()
pprint(vars(mutations[0])['_Model__dict'])
from collections import Counter
mutation_counts = Counter([m.gene.hugoGeneSymbol for m in mutations])
mutation_counts.most_common(5)
import pandas as pd
mdf = pd.DataFrame.from_dict([
# python magic that combines two dictionaries:
dict(
m.__dict__['_Model__dict'],
**m.__dict__['_Model__dict']['gene'].__dict__['_Model__dict'])
# create one item in the list for each mutation
for m in mutations
])
sample_count_per_gene = mdf.groupby('hugoGeneSymbol')['uniqueSampleKey'].nunique()
print("There are {} samples with a mutation in TP53".format(
sample_count_per_gene['TP53']
))
%matplotlib inline
sample_count_per_gene.sort_values(ascending=False).head(10).plot(kind='bar')
import seaborn as sns
sns.set_style("white")
sns.set_context('notebook')
sample_count_per_gene.sort_values(ascending=False).head(10).plot(kind='bar')
sns.despine(trim=False)
import matplotlib.pyplot as plt
sample_count_per_gene.sort_values(ascending=False).head(10).plot(
kind='bar',
ylim=[0,5000],
color='green'
)
sns.despine(trim=False)
plt.xlabel('')
plt.xticks(rotation=300)
plt.ylabel('Number of samples',labelpad=20)
plt.title('Number of mutations in genes in MSK-IMPACT (2017)',pad=25)
from bravado.client import SwaggerClient
gn = SwaggerClient.from_url('https://www.genomenexus.org/v2/api-docs',
config={"validate_requests":False,
"validate_responses":False,
"validate_swagger_spec":False})
print(gn)
variant = gn.annotation_controller.fetchVariantAnnotationByGenomicLocationGET(
genomicLocation='7,140453136,140453136,A,T',
# adds extra annotation resources, not included in default response:
fields='hotspots mutation_assessor annotation_summary'.split()
).result()
variant.
variant.hotspots
%%time
cbioportal = SwaggerClient.from_url('https://www.cbioportal.org/api/api-docs',
config={"validate_requests":False,"validate_responses":False})
mutations = cbioportal.Mutations.getMutationsInMolecularProfileBySampleListIdUsingGET(
molecularProfileId='chol_tcga_pan_can_atlas_2018_mutations',
sampleListId='chol_tcga_pan_can_atlas_2018_all',
projection='DETAILED'
).result()
import pandas as pd
mdf = pd.DataFrame.from_dict([
# python magic that combines two dictionaries:
dict(
m.__dict__['_Model__dict'],
**m.__dict__['_Model__dict']['gene'].__dict__['_Model__dict'])
# create one item in the list for each mutation
for m in mutations
])
variants = mdf['chromosome startPosition endPosition referenceAllele variantAllele'.split()]\
.drop_duplicates()\
.dropna(how='any',axis=0)\
.reset_index()
variants = variants.rename(columns={'chr','chromosome','startPosition':'start','endPosition':'end'})\
.to_dict(orient='records')
# remove the index field
for v in variants:
del v['index']
print("There are {} mutations left to annotate".format(len(variants)))
%%time
variants_annotated = gn.annotation_controller.fetchVariantAnnotationByGenomicLocationPOST(
genomicLocations=variants,
fields='hotspots annotation_summary'.split()
).result()
gn_dict = {
"{},{},{},{},{}".format(
v.annotation_summary.genomicLocation.chromosome,
v.annotation_summary.genomicLocation.start,
v.annotation_summary.genomicLocation.end,
v.annotation_summary.genomicLocation.referenceAllele,
v.annotation_summary.genomicLocation.variantAllele)
:
v for v in variants_annotated
}
def is_hotspot(x):
"""TODO: Current structure for hotspots in Genome Nexus is a little funky.
Need to check whether all lists in the annotation field are empty."""
if x:
return sum([len(a) for a in x.hotspots.annotation]) > 0
else:
return False
def create_dict_query_key(x):
return "{},{},{},{},{}".format(
x.chromosome, x.startPosition, x.endPosition, x.referenceAllele, x.variantAllele
)
mdf['is_hotspot'] = mdf.apply(lambda x: is_hotspot(gn_dict.get(create_dict_query_key(x), None)), axis=1)
%matplotlib inline
import seaborn as sns
sns.set_style("white")
sns.set_context('notebook')
import matplotlib.pyplot as plt
mdf.groupby('hugoGeneSymbol').is_hotspot.sum().sort_values(ascending=False).head(10).plot(kind='bar')
sns.despine(trim=False)
plt.xlabel('')
plt.xticks(rotation=300)
plt.ylabel('Number of non-unique hotspots',labelpad=20)
plt.title('Hotspots in Cholangiocarcinoma (TCGA, PanCancer Atlas)',pad=25)
oncokb = SwaggerClient.from_url('https://www.oncokb.org/api/v1/v2/api-docs',
config={"validate_requests":False,
"validate_responses":False,
"validate_swagger_spec":False})
print(oncokb)
variant = oncokb.Annotations.annotateMutationsByGenomicChangeGetUsingGET(
genomicLocation='7,140453136,140453136,A,T',
).result()
variant.
variant.variantSummary
%%time
variants_annotated = oncokb.Annotations.annotateMutationsByGenomicChangePostUsingPOST(
body=[
{"genomicLocation":"{chromosome},{start},{end},{referenceAllele},{variantAllele}".format(**v)}
for v in variants
],
).result()
from collections import Counter
counts_per_level = Counter([va.highestSensitiveLevel for va in variants_annotated if va.highestSensitiveLevel])
pd.DataFrame(counts_per_level,index=[0]).plot(kind='bar', colors=['#4D8834','#2E2E2C','#753579'])
plt.xticks([])
plt.ylabel('Number of variants')
plt.title('Actionable variants in chol_tcga_pan_can_atlas_2018')
sns.despine()
| 0.499268 | 0.988624 |
Straightforward translation of https://github.com/rmeinl/apricot-julia/blob/5f130f846f8b7f93bb4429e2b182f0765a61035c/notebooks/python_reimpl.ipynb
See also https://github.com/genkuroki/public/blob/main/0016/apricot/python_reimpl.ipynb
```
using Seaborn
using ScikitLearn: @sk_import
@sk_import datasets: fetch_covtype
using Random
using StatsBase: sample
digits_data = fetch_covtype()
X_digits = permutedims(abs.(digits_data["data"]))
summary(X_digits)
"""`calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)` mutates `gains` only"""
function calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)
Threads.@threads for i in eachindex(idxs)
@inbounds idx = idxs[i]
@inbounds gains[i] = sum(j -> sqrt(current_values[j] + X[j, idx]), axes(X, 1))
end
gains .-= current_concave_values_sum
end
@doc calculate_gains!
function fit(X, k; calculate_gains! = calculate_gains!)
d, n = size(X)
cost = 0.0
ranking = Int[]
total_gains = Float64[]
current_values = zeros(d)
current_concave_values_sum = sum(sqrt, current_values)
idxs = collect(1:n)
gains = zeros(n)
while cost < k
calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)
idx = argmax(gains)
best_idx = idxs[idx]
curr_cost = 1.0
cost + curr_cost > k && break
cost += curr_cost
# Calculate gains
gain = gains[idx] * curr_cost
# Select next
current_values .+= @view X[:, best_idx]
current_concave_values_sum = sum(sqrt, current_values)
push!(ranking, best_idx)
push!(total_gains, gain)
popat!(idxs, idx)
end
return ranking, total_gains
end
k = 1000
@time ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!);
@time ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!);
tic = time()
ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!)
toc0 = time() - tic
toc0
@time begin
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
end;
@time begin
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
end;
tic = time()
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
toc1 = time() - tic
toc1
plt.figure(figsize=(9, 4.5))
plt.subplot(121)
plt.plot(cumsum(gains0), label="Naive")
plt.plot(gains1, label="Random")
plt.ylabel("F(S)")
plt.xlabel("Subset Size")
plt.legend()
plt.grid(lw=0.3)
plt.subplot(122)
plt.bar(1:2, [toc0, toc1])
plt.ylabel("Time (s)")
plt.xticks(1:2, ["Naive", "Random"], rotation=90)
plt.grid(lw=0.3)
plt.title("Julia 1.6.2")
plt.tight_layout()
#plt.show()
```
|
github_jupyter
|
using Seaborn
using ScikitLearn: @sk_import
@sk_import datasets: fetch_covtype
using Random
using StatsBase: sample
digits_data = fetch_covtype()
X_digits = permutedims(abs.(digits_data["data"]))
summary(X_digits)
"""`calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)` mutates `gains` only"""
function calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)
Threads.@threads for i in eachindex(idxs)
@inbounds idx = idxs[i]
@inbounds gains[i] = sum(j -> sqrt(current_values[j] + X[j, idx]), axes(X, 1))
end
gains .-= current_concave_values_sum
end
@doc calculate_gains!
function fit(X, k; calculate_gains! = calculate_gains!)
d, n = size(X)
cost = 0.0
ranking = Int[]
total_gains = Float64[]
current_values = zeros(d)
current_concave_values_sum = sum(sqrt, current_values)
idxs = collect(1:n)
gains = zeros(n)
while cost < k
calculate_gains!(X, gains, current_values, idxs, current_concave_values_sum)
idx = argmax(gains)
best_idx = idxs[idx]
curr_cost = 1.0
cost + curr_cost > k && break
cost += curr_cost
# Calculate gains
gain = gains[idx] * curr_cost
# Select next
current_values .+= @view X[:, best_idx]
current_concave_values_sum = sum(sqrt, current_values)
push!(ranking, best_idx)
push!(total_gains, gain)
popat!(idxs, idx)
end
return ranking, total_gains
end
k = 1000
@time ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!);
@time ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!);
tic = time()
ranking0, gains0 = fit(X_digits, k; calculate_gains! = calculate_gains!)
toc0 = time() - tic
toc0
@time begin
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
end;
@time begin
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
end;
tic = time()
idxs = sample(axes(X_digits, 2), k; replace=false)
X_subset = X_digits[:, idxs]
gains1 = cumsum(X_subset; dims=2)
gains1 = vec(sum(sqrt, gains1; dims=1))
toc1 = time() - tic
toc1
plt.figure(figsize=(9, 4.5))
plt.subplot(121)
plt.plot(cumsum(gains0), label="Naive")
plt.plot(gains1, label="Random")
plt.ylabel("F(S)")
plt.xlabel("Subset Size")
plt.legend()
plt.grid(lw=0.3)
plt.subplot(122)
plt.bar(1:2, [toc0, toc1])
plt.ylabel("Time (s)")
plt.xticks(1:2, ["Naive", "Random"], rotation=90)
plt.grid(lw=0.3)
plt.title("Julia 1.6.2")
plt.tight_layout()
#plt.show()
| 0.66454 | 0.868882 |
# Setup
```
import os
import pandas as pd
import numpy as np
import torch
from transformers import BertModel, BertTokenizer
from transformers import RobertaModel, RobertaTokenizer
import utils
import vsm
VSM_HOME = os.path.join('data', 'vsmdata')
DATA_HOME = os.path.join('data', 'wordrelatedness')
utils.fix_random_seeds()
dev_df = pd.read_csv(
os.path.join(DATA_HOME, "cs224u-wordrelatedness-dev.csv"))
```
# BERT
When evaluating subword pooling methods, in this case BERT, our first big consideration was which approach to take: decontextualized or aggregated. We decided to focus on the decontextualized approach because it does not require a corpus and, as stated in lecture, produced comparable results to the aggreagated approach.
Following this, we evaluated our model using various pooling functions, distance functions, and numbers of layers. In lecture and based on the papers discussed, the conclusions drawn were that fewer layers and a mean pooling function typically produced the best results. Nevertheless, we decided to test a variety of combinations of the previously stated factors.
# Decontextualized Approach Model
There are many different options for pre-trained weights. We chose to use 'bert-base-uncased' for our experiments.
```
bert_weights_name = 'bert-base-uncased'
bert_tokenizer = BertTokenizer.from_pretrained(bert_weights_name)
bert_model = BertModel.from_pretrained(bert_weights_name)
```
The following is our implementation of some of the distance functions we tried. This includes kNearestNeighbors, as well as a function that returns the negative values of the jaccard score. We are utilizing the negative value because `vsm.create_subword_pooling_vsm` returns `-d` where `d` is the value computed by `distfunc`, since it assumes that `distfunc` is a distance value of some kind rather than a relatedness/similarity value.
```
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
neigh = KNeighborsRegressor()
def knn_distance(u, v):
return neigh.predict(np.concatenate((u,v), axis=1))
def create_knn_model(vsm_df, dev_df, test_size=0.20):
X = knn_feature_matrix(vsm_df, dev_df)
y = dev_df['score']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
neigh.fit(X_train, y_train)
print(X_train.shape)
def knn_feature_matrix(vsm_df, rel_df):
matrix = np.zeros((len(rel_df), len(vsm_df.columns)*2))
for ind in rel_df.index:
matrix[ind] = knn_represent(rel_df['word1'][ind], rel_df['word2'][ind], vsm_df)
return matrix
def knn_represent(word1, word2, vsm_df):
return np.concatenate((vsm_df.loc[word1], vsm_df.loc[word2]), axis=None)
def neg_jaccard(u,v):
return -vsm.jaccard(u,v)
```
The following is our implementation of the decontextualized appraoch to BERT, in which we were able to alter the pooling function, number of layers, and distance function.
```
def apply_bert(rel_df, layer, pool_func):
vocab = set(rel_df.word1.values) | set(rel_df.word2.values)
pooled_df = vsm.create_subword_pooling_vsm(vocab, bert_tokenizer, bert_model, layer, pool_func)
return pooled_df
def evaluate_pooled_bert(rel_df, layer, pool_func):
pooled_df = apply_bert(rel_df, layer, pool_func)
return vsm.word_relatedness_evaluation(rel_df, pooled_df, distfunc=neg_jaccard)
pool_func = vsm.mean_pooling
for val in range(1,4):
layer = val
pred_df, rho = evaluate_pooled_bert(dev_df, layer, pool_func)
print(layer, rho)
```
Record of pooling function, distance function, number of layers, and resulting rho
| pooling func| distfunc | layer | rho |
| --- | ---| --- | --- |
| max | cosine | 1 | 0.2707496460162731 |
| max | cosine | 2 | 0.20702414483988724 |
| max | cosine | 3 | 0.17744729074571614 |
| mean | cosine | 1 | 0.2757425333620801 |
| mean | cosine | 2 | 0.217700456830832 |
| mean | cosine | 3 | 0.18617500500667575 |
| mean | euclidean | 1 | 0.28318140326817176 |
| mean | euclidean | 2 | 0.19286314385117495 |
| mean | euclidean | 3 | 0.1681594482646394 |
| mean | jaccard | 1 | 0.43622599933657347 |
| mean | jaccard | 2 | 0.3473368495338 |
| mean | jaccard | 3 | 0.3279460629681185 |
| min | cosine | 1 | 0.28747309266119614 |
| min | cosine | 2 | 0.2211592952130484 |
| min | cosine | 3 | 0.19272403506986122 |
| min | euclidean | 1 | 0.23831264619930617 |
| min | euclidean | 2 | 0.16104191516635505 |
| min | euclidean | 3 | 0.1326673152179109 |
| last | cosine | 1 | 0.26255946375943245 |
| last | cosine | 2 | 0.20210332109799414 |
| last | cosine | 3 | 0.1720367373470963 |
|
github_jupyter
|
import os
import pandas as pd
import numpy as np
import torch
from transformers import BertModel, BertTokenizer
from transformers import RobertaModel, RobertaTokenizer
import utils
import vsm
VSM_HOME = os.path.join('data', 'vsmdata')
DATA_HOME = os.path.join('data', 'wordrelatedness')
utils.fix_random_seeds()
dev_df = pd.read_csv(
os.path.join(DATA_HOME, "cs224u-wordrelatedness-dev.csv"))
bert_weights_name = 'bert-base-uncased'
bert_tokenizer = BertTokenizer.from_pretrained(bert_weights_name)
bert_model = BertModel.from_pretrained(bert_weights_name)
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
neigh = KNeighborsRegressor()
def knn_distance(u, v):
return neigh.predict(np.concatenate((u,v), axis=1))
def create_knn_model(vsm_df, dev_df, test_size=0.20):
X = knn_feature_matrix(vsm_df, dev_df)
y = dev_df['score']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
neigh.fit(X_train, y_train)
print(X_train.shape)
def knn_feature_matrix(vsm_df, rel_df):
matrix = np.zeros((len(rel_df), len(vsm_df.columns)*2))
for ind in rel_df.index:
matrix[ind] = knn_represent(rel_df['word1'][ind], rel_df['word2'][ind], vsm_df)
return matrix
def knn_represent(word1, word2, vsm_df):
return np.concatenate((vsm_df.loc[word1], vsm_df.loc[word2]), axis=None)
def neg_jaccard(u,v):
return -vsm.jaccard(u,v)
def apply_bert(rel_df, layer, pool_func):
vocab = set(rel_df.word1.values) | set(rel_df.word2.values)
pooled_df = vsm.create_subword_pooling_vsm(vocab, bert_tokenizer, bert_model, layer, pool_func)
return pooled_df
def evaluate_pooled_bert(rel_df, layer, pool_func):
pooled_df = apply_bert(rel_df, layer, pool_func)
return vsm.word_relatedness_evaluation(rel_df, pooled_df, distfunc=neg_jaccard)
pool_func = vsm.mean_pooling
for val in range(1,4):
layer = val
pred_df, rho = evaluate_pooled_bert(dev_df, layer, pool_func)
print(layer, rho)
| 0.54359 | 0.866246 |
# Programming with Python
## Episode 3 - Storing Multiple Values in Lists
Teaching: 30 min,
Exercises: 30 min
## Objectives
- Explain what a list is.
- Create and index lists of simple values.
- Change the values of individual elements
- Append values to an existing list
- Reorder and slice list elements
- Create and manipulate nested lists
#### How can I store many values together?
Just as a `for loop` is a way to do operations many times, a list is a way to store many values. Unlike NumPy arrays, lists are built into the language (so we don't have to load a library to use them). We create a list by putting values inside square brackets and separating the values with commas:
```
odds = [1, 3, 5, 7]
print('odds are:', odds)
```
```
odds = [1, 3, 5, 7]
print('odds are:', odds)
```
We can access elements of a list using indices – numbered positions of elements in the list. These positions are numbered starting at 0, so the first element has an index of 0.
```
print('first element:', odds[0])
print('last element:', odds[3])
print('"-1" element:', odds[-1])
```
```
print('first element:', odds[0])
print('last element:', odds[3])
print('"-1" element:', odds[-1])
```
Yes, we can use negative numbers as indices in Python. When we do so, the index `-1` gives us the last element in the list, `-2` the second to last, and so on.
Because of this, `odds[3]` and `odds[-1]` point to the same element here.
If we loop over a list, the loop variable is assigned elements one at a time:
for number in odds:
print(number)
```
word = 'lead'
print(word[0])
print(word[1])
print(word[2])
print(word[3])
word = 'lead'
for char in word:
print(char)
```
There is one important difference between lists and strings: we can change the values in a list, but we cannot change individual characters in a string. For example:
```
names = ['Curie', 'Darwing', 'Turing'] # typo in Darwin's name
print('names is originally:', names)
names[1] = 'Darwin' # correct the name
print('final value of names:', names)
```
works, but:
```
name = 'Darwin'
name[0] = 'd'
```
doesn't.
### Ch-Ch-Ch-Ch-Changes
Data which can be modified in place is called *mutable*, while data which cannot be modified is called *immutable*. Strings and numbers are immutable. This does not mean that variables with string or number values are constants, but when we want to change the value of a string or number variable, we can only replace the old value with a completely new value.
Lists and arrays, on the other hand, are mutable: we can modify them after they have been created. We can change individual elements, append new elements, or reorder the whole list. For some operations, like sorting, we can choose whether to use a function that modifies the data in-place or a function that returns a modified copy and leaves the original unchanged.
Be careful when modifying data in-place. If two variables refer to the same list, and you modify the list value, it will change for both variables!
```
salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
my_salsa = salsa # <-- my_salsa and salsa point to the *same* list data in memory
salsa[0] = 'hot peppers'
print('Ingredients in salsa:', salsa)
print('Ingredients in my salsa:', my_salsa)
```
If you want variables with mutable values to be independent, you must make a copy of the value when you assign it.
```
salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
my_salsa = list(salsa) # <-- makes a *copy* of the list
salsa[0] = 'hot peppers'
print('Ingredients in salsa:', salsa)
print('Ingredients in my salsa:', my_salsa)
```
Because of pitfalls like this, code which modifies data in place can be more difficult to understand. However, it is often far more efficient to modify a large data structure in place than to create a modified copy for every small change. You should consider both of these aspects when writing your code.
### Nested Lists
Since lists can contain any Python variable type, it can even contain other lists.
For example, we could represent the products in the shelves of a small grocery shop:
```
shop = [['pepper', 'zucchini', 'onion'],
['cabbage', 'lettuce', 'garlic'],
['apple', 'pear', 'banana']]
```
Here is an example of how indexing a list of lists works:
The first element of our list is another list representing the first shelf:
```
print(shop[0])
```
to reference a particular item on a particular shelf (e.g. the third item on the second shelf - i.e. the `garlic`) we'd use extra `[` `]`'s
```
print(shop[1][2])
```
don't forget the zero index thing ...
### Heterogeneous Lists
Lists in Python can contain elements of different types. Example:
```
sample_ages = [10, 12.5, 'Unknown']
```
There are many ways to change the contents of lists besides assigning new values to individual elements:
```
odds.append(11)
print('odds after adding a value:', odds)
del odds[0]
print('odds after removing the first element:', odds)
odds.reverse()
print('odds after reversing:', odds)
```
While modifying in place, it is useful to remember that Python treats lists in a slightly counter-intuitive way.
If we make a list and (attempt to) copy it then modify in place, we can cause all sorts of trouble:
```
odds = [1, 3, 5, 7]
primes = odds
primes.append(2)
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7, 2]
```
This is because Python stores a list in memory, and then can use multiple names to refer to the same list. If all we want to do is copy a (simple) list, we can use the list function, so we do not modify a list we did not mean to:
```
odds = [1, 3, 5, 7]
primes = list(odds)
primes.append(2)
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7]
```
### Turn a String Into a List
Use a `for loop` to convert the string "hello" into a list of letters: `["h", "e", "l", "l", "o"]`
Hint: You can create an empty list like this:
my_list = []
Subsets of lists and strings can be accessed by specifying ranges of values in brackets, similar to how we accessed ranges of positions in a NumPy array. This is commonly referred to as *slicing* the list/string.
```
binomial_name = "Drosophila melanogaster"
group = binomial_name[0:10]
print("group:", group)
species = binomial_name[11:24]
print("species:", species)
chromosomes = ["X", "Y", "2", "3", "4"]
autosomes = chromosomes[2:5]
print("autosomes:", autosomes)
last = chromosomes[-1]
print("last:", last)
```
### Slicing From the End
Use slicing to access only the last four characters of a string or entries of a list.
```
string_for_slicing = "Observation date: 02-Feb-2013"
list_for_slicing = [["fluorine", "F"],
["chlorine", "Cl"],
["bromine", "Br"],
["iodine", "I"],
["astatine", "At"]]
```
Would your solution work regardless of whether you knew beforehand the length of the string or list (e.g. if you wanted to apply the solution to a set of lists of different lengths)? If not, try to change your approach to make it more robust.
Hint: Remember that indices can be negative as well as positive
### Non-Continuous Slices
So far we've seen how to use slicing to take single blocks of successive entries from a sequence. But what if we want to take a subset of entries that aren't next to each other in the sequence?
You can achieve this by providing a third argument to the range within the brackets, called the step size. The example below shows how you can take every third entry in a list:
```
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[0:12:3]
print("subset", subset)
```
Notice that the slice taken begins with the first entry in the range, followed by entries taken at equally-spaced intervals (the steps) thereafter. If you wanted to begin the subset with the third entry, you would need to specify that as the starting point of the sliced range:
```
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[2:12:3]
print("subset", subset)
```
Use the step size argument to create a new string that contains only every second character in the string "In an octopus's garden in the shade"
Start with:
```
beatles = "In an octopus's garden in the shade"
```
and print:
```
I notpssgre ntesae
```
If you want to take a slice from the beginning of a sequence, you can omit the first index in the range:
```
date = "Monday 4 January 2016"
day = date[0:6]
print("Using 0 to begin range:", day)
day = date[:6]
print("Omitting beginning index:", day)
```
And similarly, you can omit the ending index in the range to take a slice to the end of the sequence:
```
months = ["jan", "feb", "mar", "apr", "may", "jun", "jul", "aug", "sep", "oct", "nov", "dec"]
q4 = months[8:12]
print("With specified start and end position:", q4)
q4 = months[8:len(months)]
print("Using len() to get last entry:", q4)
q4 = months[8:]
print("Omitting ending index:", q4)
```
### Overloading
`+` usually means addition, but when used on strings or lists, it means "concatenate". Given that, what do you think the multiplication operator * does on lists? In particular, what will be the output of the following code?
```
counts = [2, 4, 6, 8, 10]
repeats = counts * 2
print(repeats)
```
The technical term for this is operator overloading. A single operator, like `+` or `*`, can do different things depending on what it's applied to.
is this the same as:
```
counts + counts
```
and what might:
```
counts / 2
```
mean ?
## Key Points
- [value1, value2, value3, ...] creates a list.
- Lists can contain any Python object, including lists (i.e., list of lists).
- Lists are indexed and sliced with square brackets (e.g., list[0] and list[2:9]), in the same way as strings and arrays.
- Lists are mutable (i.e., their values can be changed in place).
- Strings are immutable (i.e., the characters in them cannot be changed).
### Save, and version control your changes
- save your work: `File -> Save`
- add all your changes to your local repository: `Terminal -> git add .`
- commit your updates a new Git version: `Terminal -> git commit -m "End of Episode 3"`
- push your latest commits to GitHub: `Terminal -> git push`
|
github_jupyter
|
odds = [1, 3, 5, 7]
print('odds are:', odds)
odds = [1, 3, 5, 7]
print('odds are:', odds)
print('first element:', odds[0])
print('last element:', odds[3])
print('"-1" element:', odds[-1])
print('first element:', odds[0])
print('last element:', odds[3])
print('"-1" element:', odds[-1])
word = 'lead'
print(word[0])
print(word[1])
print(word[2])
print(word[3])
word = 'lead'
for char in word:
print(char)
names = ['Curie', 'Darwing', 'Turing'] # typo in Darwin's name
print('names is originally:', names)
names[1] = 'Darwin' # correct the name
print('final value of names:', names)
name = 'Darwin'
name[0] = 'd'
salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
my_salsa = salsa # <-- my_salsa and salsa point to the *same* list data in memory
salsa[0] = 'hot peppers'
print('Ingredients in salsa:', salsa)
print('Ingredients in my salsa:', my_salsa)
salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']
my_salsa = list(salsa) # <-- makes a *copy* of the list
salsa[0] = 'hot peppers'
print('Ingredients in salsa:', salsa)
print('Ingredients in my salsa:', my_salsa)
shop = [['pepper', 'zucchini', 'onion'],
['cabbage', 'lettuce', 'garlic'],
['apple', 'pear', 'banana']]
print(shop[0])
print(shop[1][2])
sample_ages = [10, 12.5, 'Unknown']
odds.append(11)
print('odds after adding a value:', odds)
del odds[0]
print('odds after removing the first element:', odds)
odds.reverse()
print('odds after reversing:', odds)
odds = [1, 3, 5, 7]
primes = odds
primes.append(2)
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7, 2]
odds = [1, 3, 5, 7]
primes = list(odds)
primes.append(2)
print('primes:', primes)
print('odds:', odds)
primes: [1, 3, 5, 7, 2]
odds: [1, 3, 5, 7]
binomial_name = "Drosophila melanogaster"
group = binomial_name[0:10]
print("group:", group)
species = binomial_name[11:24]
print("species:", species)
chromosomes = ["X", "Y", "2", "3", "4"]
autosomes = chromosomes[2:5]
print("autosomes:", autosomes)
last = chromosomes[-1]
print("last:", last)
string_for_slicing = "Observation date: 02-Feb-2013"
list_for_slicing = [["fluorine", "F"],
["chlorine", "Cl"],
["bromine", "Br"],
["iodine", "I"],
["astatine", "At"]]
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[0:12:3]
print("subset", subset)
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]
subset = primes[2:12:3]
print("subset", subset)
beatles = "In an octopus's garden in the shade"
I notpssgre ntesae
date = "Monday 4 January 2016"
day = date[0:6]
print("Using 0 to begin range:", day)
day = date[:6]
print("Omitting beginning index:", day)
months = ["jan", "feb", "mar", "apr", "may", "jun", "jul", "aug", "sep", "oct", "nov", "dec"]
q4 = months[8:12]
print("With specified start and end position:", q4)
q4 = months[8:len(months)]
print("Using len() to get last entry:", q4)
q4 = months[8:]
print("Omitting ending index:", q4)
counts = [2, 4, 6, 8, 10]
repeats = counts * 2
print(repeats)
counts + counts
counts / 2
| 0.327776 | 0.98551 |
# Using Astronomer Airflow with Snowflake
### Prerequisites
1) A valid Snowflake and S3 account
2) The Astronomer CLI or a running version of Airflow. (This guide was written to work with Airflow on Astronomer, but the same code should work for vanilla Airflow as well)
Navigate here to get set up:
https://github.com/astronomerio/astro-cli
### Getting Started
Navigate to a project directory and run `astro airflow init` in a terminal.
This will generate a skeleton file directory:
```
.
├── dags
│ └── example-dag.py
├── Dockerfile
├── include
├── packages.txt
├── plugins
```
Clone this repository into your plugins folder:
https://github.com/airflow-plugins/snowflake_plugin
This gives you the Airflow plugins needed to interact with Snowflake. For a full list of community contributed plugins, check out:
- https://github.com/apache/incubator-airflow/tree/master/airflow
- https://github.com/airflow-plugins/
### Start a local Airflow Instance:
Before you can spin up Airflow, you will need to specify that your image builds with all of the dependencies necessary to snowflake and Amazon S3.
Add the following to your `packages.txt` and `requirements.txt`:
packages.txt
musl
gcc
make
g++
lz4-dev
cyrus-sasl-dev
openssl-dev
python3-dev
requirements.txt
azure-common==1.1.14
azure-nspkg==2.0.0
azure-storage==0.36.0
ijson==2.3
pycryptodome==3.6.4
snowflake-connector-python==1.6.5
<br>
Now run
`astro airflow start`
<br>
This should spin up a few docker containers on your machine. Run `docker ps` and you should see:
```
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1fc88586da10 notebook/airflow:latest "tini -- /entrypoint…" 5 seconds ago Up 5 seconds 5555/tcp, 8793/tcp, 0.0.0.0:8080->8080/tcp notebook_webserver_1
a1d02ea75c2b notebook/airflow:latest "tini -- /entrypoint…" 6 seconds ago Up 1 second 5555/tcp, 8080/tcp, 8793/tcp notebook_scheduler_1
d0edb1f6c497 postgres:10.1-alpine "docker-entrypoint.s…" 6 seconds ago Up 6 seconds 0.0.0.0:5432->5432/tcp notebook_postgres_1
```
### Enter your Connection Credentials
Navigate to Admin-->Connections-->Create and create a new connection within your Airflow instance. The `conn_id` will be used to refer to your connection.
This will be your local development environment. Navigate to `localhost:8080` to see your Airflow dashboard.
<br> 
<br>
Do the same thing for your S3 connection.
### Write your DAG
Because the `snowflake_plugin` was added to the `plugins` directory, it can be imported as an airflow plugin.
See the attached example for what this could look like. DAG files should go in the `dags` folder.
### Deploy your DAG
Once you get your DAG working locally and your Astronomer cluster deployed, you can authenticate and start deploying!
Run
astro auth login
You should be prompted to log into your instance. Once you've authenticated, run
astro airflow deploy
and chose which Airflow instance you want to deploy to.
The deploy will packages the entire project directory (dags, plugins, and all the requirements and packages needed for the code to run) into a Docker image and push it to the your Kubernetes Cluster.
Once you enter all your credentials in your production instance, everything is good to go.

|
github_jupyter
|
.
├── dags
│ └── example-dag.py
├── Dockerfile
├── include
├── packages.txt
├── plugins
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1fc88586da10 notebook/airflow:latest "tini -- /entrypoint…" 5 seconds ago Up 5 seconds 5555/tcp, 8793/tcp, 0.0.0.0:8080->8080/tcp notebook_webserver_1
a1d02ea75c2b notebook/airflow:latest "tini -- /entrypoint…" 6 seconds ago Up 1 second 5555/tcp, 8080/tcp, 8793/tcp notebook_scheduler_1
d0edb1f6c497 postgres:10.1-alpine "docker-entrypoint.s…" 6 seconds ago Up 6 seconds 0.0.0.0:5432->5432/tcp notebook_postgres_1
| 0.454472 | 0.918114 |
**Pandas Exercises - With the NY Times Covid data**
Run the cell below to pull get the data from the nytimes github
```
!git clone https://github.com/nytimes/covid-19-data.git
```
**1. Import Pandas and Check your Version of Pandas**
```
import pandas as pd
pd.__version__
```
**2. Read the *us-counties.csv* data into a new Dataframe**
```
covid_data = pd.read_csv('/content/covid-19-data/us-counties.csv')
```
**3. Display the first 5 Rows**
```
covid_data.head(5)
```
**4. Drop the 'fips' Column**
```
covid_data = covid_data.drop('fips', axis=1)
```
**5. Check dtypes of the data**
```
covid_data.dtypes
```
**6. Change the 'date' column to Date dtype**
```
covid_data.date = pd.to_datetime(covid_data.date)
```
**7. Set the data index to 'date'**
```
covid_data = covid_data.set_index('date')
```
**8. Find how many weeks worth of data we have**
```
print('Weeks:', (covid_data.index.max() - covid_data.index.min()).days / 7)
```
**9. Create a seperate Dataframe representing only California and display the first 5 data entries**
```
CA_data = covid_data[covid_data['state'].str.contains("California")]
CA_data.head()
```
**10. How many counties in California do we have data for?**
```
CA_data['county'].nunique()
```
**11. How many data entries do we have for each county?**
```
CA_data['county'].value_counts()
# Alternatively the count and totals can be done with collections Counter
from collections import Counter
count = Counter(CA_data['county'])
count
```
**12. How many counties in California have experienced over 1000 cases?**
```
len(CA_data[CA_data['cases'] > 1000]['county'].value_counts())
# nunique will tell you how for each Column
CA_data[CA_data['cases'] > 1000].nunique()
```
**13. Which county has experienced the highest death toll?**
```
CA_data[CA_data['deaths'] > max(CA_data['deaths']) - 1]
```
**14. Slice the Data for that County Seperately into a new Dataframe**
```
la_ca_data = CA_data[CA_data['county'].str.contains('Los Angeles')]
```
**15. Create and populate new Columns for New Cases per Day and Deaths per day**
```
# Creating a New Column this way will Raise a SettingWithCopyWarning
pd.set_option('mode.chained_assignment',None)
# The Code above surpresses that warning
la_ca_data['cases_per_day'] = la_ca_data['cases'].diff(1).fillna(0)
la_ca_data['deaths_per_day'] = la_ca_data['deaths'].diff(1).fillna(0)
# This code turns the warning back on
# See the Pandas documentation here for more on SettingWithCopyWarning
# https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
pd.set_option('mode.chained_assignment', 'warn')
```
**16. What date had the most cases for LA county?**
```
la_ca_data[la_ca_data['cases_per_day'] > max(la_ca_data['cases_per_day']) - 1]
```
**17. Inspect the data in the month of April for Los Angeles County**
```
april_la_ca_data = la_ca_data['2020-04-01':'2020-04-30']
april_la_ca_data
```
**18. Find the mean [cases per day] for April**
```
april_la_ca_data = la_ca_data['2020-04-01':'2020-04-30']
april_la_ca_data.describe()
```
**19. Plot cases per day for the month of April in Los Angeles county**
```
la_cases_plot = april_la_ca_data['cases_per_day'].plot(title='LA County Cases per Day')
fig = la_cases_plot.get_figure()
fig.set_size_inches(8,4)
```
**20. Plot Deaths per Day for the month of March**
```
march_la_ca_data = la_ca_data['2020-03-01':'2020-03-31']
la_march_plot = march_la_ca_data['deaths_per_day'].plot(title='LA County Deaths per Day')
fig = la_march_plot.get_figure()
fig.set_size_inches(8,4)
```
**Armed with basics in Pandas - Answer your own questions about the data! Happy exploring**
Don't hesitate to send me suggestions / a message / or make change requests. There is more than one way to do everything here!
```
```
|
github_jupyter
|
!git clone https://github.com/nytimes/covid-19-data.git
import pandas as pd
pd.__version__
covid_data = pd.read_csv('/content/covid-19-data/us-counties.csv')
covid_data.head(5)
covid_data = covid_data.drop('fips', axis=1)
covid_data.dtypes
covid_data.date = pd.to_datetime(covid_data.date)
covid_data = covid_data.set_index('date')
print('Weeks:', (covid_data.index.max() - covid_data.index.min()).days / 7)
CA_data = covid_data[covid_data['state'].str.contains("California")]
CA_data.head()
CA_data['county'].nunique()
CA_data['county'].value_counts()
# Alternatively the count and totals can be done with collections Counter
from collections import Counter
count = Counter(CA_data['county'])
count
len(CA_data[CA_data['cases'] > 1000]['county'].value_counts())
# nunique will tell you how for each Column
CA_data[CA_data['cases'] > 1000].nunique()
CA_data[CA_data['deaths'] > max(CA_data['deaths']) - 1]
la_ca_data = CA_data[CA_data['county'].str.contains('Los Angeles')]
# Creating a New Column this way will Raise a SettingWithCopyWarning
pd.set_option('mode.chained_assignment',None)
# The Code above surpresses that warning
la_ca_data['cases_per_day'] = la_ca_data['cases'].diff(1).fillna(0)
la_ca_data['deaths_per_day'] = la_ca_data['deaths'].diff(1).fillna(0)
# This code turns the warning back on
# See the Pandas documentation here for more on SettingWithCopyWarning
# https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
pd.set_option('mode.chained_assignment', 'warn')
la_ca_data[la_ca_data['cases_per_day'] > max(la_ca_data['cases_per_day']) - 1]
april_la_ca_data = la_ca_data['2020-04-01':'2020-04-30']
april_la_ca_data
april_la_ca_data = la_ca_data['2020-04-01':'2020-04-30']
april_la_ca_data.describe()
la_cases_plot = april_la_ca_data['cases_per_day'].plot(title='LA County Cases per Day')
fig = la_cases_plot.get_figure()
fig.set_size_inches(8,4)
march_la_ca_data = la_ca_data['2020-03-01':'2020-03-31']
la_march_plot = march_la_ca_data['deaths_per_day'].plot(title='LA County Deaths per Day')
fig = la_march_plot.get_figure()
fig.set_size_inches(8,4)
| 0.65202 | 0.966505 |
## Welcome to Coding Exercise 5.
We'll only have 2 questions and both of them will be difficult. You may import other libraries to help you here. Clue: find out more about the ```itertools``` and ```math``` library.
### Question 1.
* List item
* List item
### "Greatest Possible Combination"
We have a function as such:
```f(x1, x2, x3) = (x1^2 + x2 * x3) modulo 20 ```
Given 3 list/array/vector containing possible values of x1, x2, and x3, find the maximum output possible.
#### Explanation:
If x1 = 2, x2 = 5, x3 = 3, then...
The function's output is: (2^2 + 5 * 3) modulo 20 = (4 + 15) modulo 20 = 19 modulo 20 = 19.
If x1 = 3, x2 = 5, x3 = 3, then...
The function's output is: (3^2 + 5 * 3) modulo 20 = (9 + 15) modulo 20 = 24 modulo 20 = 4.
In this case, since 19 > 4, the combination of (X1 = 2, X2 = 5, X3 = 3) gives a *greater* output value than the combination of (X1 = 3, X2 = 5, X3 = 3).
#### Example:
- Array X1: [2, 4]
- Array X2: [1, 2, 3]
- Array x3: [5, 6]
How many combinations do we have?
1. X1 = 2, X2 = 1, X3 = 5. Output = (2^2 + 1 * 5) modulo 20 = 9 modulo 20 = 9.
2. X1 = 2, X2 = 1, X3 = 6. Output = 10
3. X1 = 2, X2 = 2, X3 = 5. Output = 14
4. X1 = 2, X2 = 2, X3 = 6. Output = 16
5. X1 = 2, X2 = 3, X3 = 5. Output = 19
6. X1 = 2, X2 = 3, X3 = 6. Output = (2^2 + 3 * 6) modulo 20 = 22 modulo 20 = 2
7. X1 = 4, X2 = 1, X3 = 5. Output = 1
8. X1 = 4, X2 = 1, X3 = 6. Output = 2
9. X1 = 4, X2 = 2, X3 = 5. Output = 6
10. X1 = 4, X2 = 2, X3 = 6. Output = 8
11. X1 = 4, X2 = 3, X3 = 5. Output = 11
12. X1 = 4, X2 = 3, X3 = 6. Output = 14
Out of these 12 combinations, what is the maximum output of our function?
The maximum output is 19, achieved with X1 = 2, X2 = 3, X3 = 5.
Answer : 19
(No need to specify the values of X1, X2, X3).
```
### Write your solution here ###
def maximum(x1, x2, x3):
return
```
### Question 2.
### "Position in Repeating Series"
Your function will be called ```position``` and it has 3 inputs.
This problem has 3 inputs:
- The first input, (n), is the maximum number in our series
- The second input, (r), is how many times our series will be repeated
- The third input, (p), is the position of the desired output.
Here are a few examples:
- If n = 3, and r = 1, then our series will be: 1,2,3,2,1
- If n = 4, and r = 1, then our series will be: 1,2,3,4,3,2,1
- If n = 3, and r = 2, then our series will be: 1,2,3,2,1,2,3,2,1
- If n = 4, and r = 2, then our series will be: 1,2,3,4,3,2,1,2,3,4,3,2,1
- If n = 5, and r = 3, then our series will be: 1,2,3,4,5,4,3,2,1,2,3,4,5,4,3,2,1,2,3,4,5,4,3,2,1
Now, what is the meaning of the third input?
We want to know what's the value of the number in the position of p. The first number in the series is the first position. This is not the same as index! Indexing in Python starts at 0, and indexing in R starts at 1, so we want to make a standard that applies to both Python and R.
#### Example 1
n = 3, r = 1, p = 4
The series is : 1, 2, 3, 2, 1
The 4th number of the series = suku ke - 4 dari barisan tersebut = 2.
Answer = 2.
#### Example 2
n = 3, r = 2, p = 7
The series is : 1, 2, 3, 2, 1, 2, 3, 2, 1
The 7th number of the series = suku ke - 7 dari barisan tersebut = 3.
Answer = 3.
#### Example 3
n = 4, r = 2, p = 7
The series is : 1, 2, 3, 4, 3, 2, 1, 2, 3, 4, 3, 2, 1
The 7th number of the series = suku ke - 7 dari barisan tersebut = 1.
Answer = 1.
```
### Write your solution here ###
def position(n, r, p):
return
```
|
github_jupyter
|
Given 3 list/array/vector containing possible values of x1, x2, and x3, find the maximum output possible.
#### Explanation:
If x1 = 2, x2 = 5, x3 = 3, then...
The function's output is: (2^2 + 5 * 3) modulo 20 = (4 + 15) modulo 20 = 19 modulo 20 = 19.
If x1 = 3, x2 = 5, x3 = 3, then...
The function's output is: (3^2 + 5 * 3) modulo 20 = (9 + 15) modulo 20 = 24 modulo 20 = 4.
In this case, since 19 > 4, the combination of (X1 = 2, X2 = 5, X3 = 3) gives a *greater* output value than the combination of (X1 = 3, X2 = 5, X3 = 3).
#### Example:
- Array X1: [2, 4]
- Array X2: [1, 2, 3]
- Array x3: [5, 6]
How many combinations do we have?
1. X1 = 2, X2 = 1, X3 = 5. Output = (2^2 + 1 * 5) modulo 20 = 9 modulo 20 = 9.
2. X1 = 2, X2 = 1, X3 = 6. Output = 10
3. X1 = 2, X2 = 2, X3 = 5. Output = 14
4. X1 = 2, X2 = 2, X3 = 6. Output = 16
5. X1 = 2, X2 = 3, X3 = 5. Output = 19
6. X1 = 2, X2 = 3, X3 = 6. Output = (2^2 + 3 * 6) modulo 20 = 22 modulo 20 = 2
7. X1 = 4, X2 = 1, X3 = 5. Output = 1
8. X1 = 4, X2 = 1, X3 = 6. Output = 2
9. X1 = 4, X2 = 2, X3 = 5. Output = 6
10. X1 = 4, X2 = 2, X3 = 6. Output = 8
11. X1 = 4, X2 = 3, X3 = 5. Output = 11
12. X1 = 4, X2 = 3, X3 = 6. Output = 14
Out of these 12 combinations, what is the maximum output of our function?
The maximum output is 19, achieved with X1 = 2, X2 = 3, X3 = 5.
Answer : 19
(No need to specify the values of X1, X2, X3).
### Question 2.
### "Position in Repeating Series"
Your function will be called ```position``` and it has 3 inputs.
This problem has 3 inputs:
- The first input, (n), is the maximum number in our series
- The second input, (r), is how many times our series will be repeated
- The third input, (p), is the position of the desired output.
Here are a few examples:
- If n = 3, and r = 1, then our series will be: 1,2,3,2,1
- If n = 4, and r = 1, then our series will be: 1,2,3,4,3,2,1
- If n = 3, and r = 2, then our series will be: 1,2,3,2,1,2,3,2,1
- If n = 4, and r = 2, then our series will be: 1,2,3,4,3,2,1,2,3,4,3,2,1
- If n = 5, and r = 3, then our series will be: 1,2,3,4,5,4,3,2,1,2,3,4,5,4,3,2,1,2,3,4,5,4,3,2,1
Now, what is the meaning of the third input?
We want to know what's the value of the number in the position of p. The first number in the series is the first position. This is not the same as index! Indexing in Python starts at 0, and indexing in R starts at 1, so we want to make a standard that applies to both Python and R.
#### Example 1
n = 3, r = 1, p = 4
The series is : 1, 2, 3, 2, 1
The 4th number of the series = suku ke - 4 dari barisan tersebut = 2.
Answer = 2.
#### Example 2
n = 3, r = 2, p = 7
The series is : 1, 2, 3, 2, 1, 2, 3, 2, 1
The 7th number of the series = suku ke - 7 dari barisan tersebut = 3.
Answer = 3.
#### Example 3
n = 4, r = 2, p = 7
The series is : 1, 2, 3, 4, 3, 2, 1, 2, 3, 4, 3, 2, 1
The 7th number of the series = suku ke - 7 dari barisan tersebut = 1.
Answer = 1.
| 0.883324 | 0.989977 |
```
"""Bond Breaking"""
__authors__ = "Victor H. Chavez", "Lyudmila Slipchenko"
__credits__ = ["Victor H. Chavez", "Lyudmila Slipchenko"]
__email__ = ["[email protected]", "[email protected]"]
__copyright__ = "(c) 2008-2019, The Psi4Education Developers"
__license__ = "BSD-3-Clause"
__date__ = "2019-11-18"
```
---
## Lab 2. Bond-breaking in $H_2$
In this lab, you will:
* Investigate the bond-breaking reaction in $H_2$ molecule.
* Compare the performance of restricted and unrestricted Hartree-Fock, and Density Functional Theory for bond breaking.
* Benchmark these results with respect to the Full Configuration Interaction (FCI) values obtained using the coupled cluster with single and double excitations (CCSD) calculations, which give the exact answer for the two-electron system.
* Calculate the correlation energy.
* Distinguish dynamic and static contributions to the correlation energy.
Authors: Lyudmila Slipchenko ([email protected]; ORCID: 0000-0002-0445-2990) and Victor H. Chavez ([email protected]; ORCID: 0000-0003-3765-2961).
***
```
#Import modules
import psi4
import numpy as np
import os
import matplotlib.pyplot as plt
```
***
To perform a basic calculation we use the ```psi4.energy``` function. The function needs to know what method and basis set to use, and what molecule you are interested in (if you have defined more than one geometry inside your Jupyter Notebook). Let say that we want to get the HF energy of the Helium atom. We would need to do the following:
```
#Define Helium Geometry
#The first line referst to the charge and spin multiplicity.
he_geo = psi4.geometry("""
0 1
He 0.0 0.0 0.0
""")
#Request the HF calculation using the correlation consistent basis set cc-pvdz.
e = psi4.energy("HF/cc-pvdz", molecule=he_geo)
#Print the energy. The units are given in atomic units or hartrees.
print(f"The HF energy of He is {e}")
#We made us of *f-strings* which allow us to combine strings and numbers in a print statement.
```
If you were to try the Helium example on a Hydrogen atom as it is, you would find that Psi4 will throw an error. This is because when running a calculation, Psi4 defaults to a *Restricted Hartree-Fock* or *RHF*, (i.e. a system with an even number of electrons where all electrons are paired). This means that electrons of opposite spin occupy (or are "restricted") to the same spatial orbital.
In cases like Hydrogen, where the numbers of alpha and beta spin electrons are different, we lift this restriction allowing both electrons to have different spatial orbitals.
<br>
<img src="./restricted.png">
<br>
We need to tell Psi4 that we want an UHF calculation. This is done by setting the global option "reference" as "UHF". In the cell below, type: ```psi4.set_options({"reference" : "UHF"})```. You may need to switch between UHF and RHF many times throughout the lab.
***
We want to produce a binding energy curve for the $H_2$ molecule using different levels of theory. The binding energy is given by:
$$E_{bind} = E(H_2) - 2E(H) \tag{1} $$
For a molecule with one degree of freedom, just like the $H_2$ molecule, the potential energy surface is just a 1D curve. Notice that the second term on the right hand side of the equation is just constant that is equal to two times the energy of the Hydrogen atom. Your first task is to obtain this value for each method:
### Part 1
#### **1.** Calculate and store the energy of a single H atom with the methods: HF, PBE, B3LYP and CCSD. Use 6-31G** basis for all the calculation in this lab. Change the reference and multiplicity of the atom accordingly.
<div class="alert alert-info">
Hint: Notice that the first argument of `psi4.energy` is a string. You could quickly go through the calculations by creating a list with the different methods and then use them in a for loop to to run each of them. Consider that the string also contains the basis set. In order to overcome this predicament, remember that strings can be concatenated by using the `+` operator (e.g. "HF"+"/cc-pvdz").
</div>
#### **2.** Explain the origin of errors in each method and why HF and CCSD energies are the same for the H atom.
```
### RESPONSE
```
---
Let us now concentrate on the first term of equation 1. We require to run a series of calculations for each method at different H-H separations in Angstroms (e.g. 0.3, 0.4, 0.5, ... ,4.9, 5.0).
<div class="alert alert-info">
Hint : Given that the argument of a psi4.geometry is a string, we can take advantage of that by looking at the following example:
</div>
```
#Define string with psi4.geometry syntax.
#Identify what you want to change and use a particular label that you know that won't get repeated.
molecule = """
**atom1** 0.0 0.0 0.0
"""
#Create a list with the things that you want to go through.
atoms = [ "H", "He", "Li" ]
#Cycle through them.
for atom in atoms:
print(molecule.replace("**atom1**", atom))
```
#### **3.** Using the previous example and the following distances, write a snippet that will calculate the energy at each separation for a **RHF** calculation. You will need to change the reference to "RHF" (Psi4 still thinks you want to run UHF calculations).
Make sure you store the wavefunction object for each separation since it will be used later in the lab: ```energy, wfn = psi4.energy("method/basis", return_wfn=True)```
```
#We use more points closer to where we would expect to have the ground state geometry to create a nice and smooth function.
distances = np.zeros(20)
distances[0:16] = np.linspace(0.3, 2.5, 16)
distances[16:] = np.linspace(2.7, 5.0, 4)
```
Here we are using the `numpy` library first to create an empty array filled with zeros using `np.zeros`, where the argument specifies the size of the array. The other function `np.linspace` creates a sequence of evenly spaced values within an interval. This means, we generated a linear space with 16 points from 0.3 to 2.5 and one with 4 points from 2.7 to 5.0.
```
#RESPONSE:
```
---
#### **4.** Calculate the energies at the same distances at the **UHF** level. You can recycle the code that you just wrote (just remember to change the name of your variables). We will need extra information that can ony be found in the output.
In order to save the output to a file we require the additional option: ```psi4.core.set_output_file("filename.txt", True)```.
<div class="alert alert-info">
Hint: In order to obtain the correct UHF energies, we need to set the extra following options:
<\div>
```
psi4.set_options({'reference' : 'UHF',
'guess_mix' : True,
'guess' : "gwh"})
#RESPONSE
```
#### **5.** Store the values for $S^2$. This information is found in each outputfile close to the end of your calculation (look for Spin Contamination Metric).
You can go through each of the files and copy the value, but you can also think about how can you let python automatize this process. Think carefully about the steps required for this. Given a path you would need to import the file ( `f = open(path, 'r')` ) and proceed to extract the lines ( `f.read().splitlines()` ). With those lines available, you may concentrate on determining whether or not each line contains the `S^2` string.
If you require a more thorough review of parsing files. You can look at [this tutorial](https://education.molssi.org/python_scripting_cms/02-file_parsing/index.html) to learn more about file parsing.
```
#Response
```
#### **6.** Make a table or plot of $S^2$ values from the UHF calculations. Explain why $S^2$ deteriorates when the H-H bond is stretched.
```
#Response
```
---
#### 7. Calculate the same potential energy surface at the DFT level. Use the PBE functional and a restricted wavefunction.
```
#RESPONSE
```
#### **8.** Calculate the same potential energy surface at the FCI level.
For a two-electron system, the FCI results may be obtained by using the CCSD method. This is true because CCSD includes determinants that are singly and doubly excited. For a two electron system that includes all electrons available, thus CCSD includes all possible excitations in the system.
#### **9.** You will need to save the output file generated by Psi4 again. From the output file, record total CCSD ampltitudes: CCSD $T_1^2$ and $T_2^2$, and the value of the largest $T_2$ amplitude for the ground state geometry and for a split geometry.
Consider T as a sum of operators that that act on a reference determinant. In CCSD $T = T_1 + T_2$ where $T_1$ refers with single excitations and $T_2$ with double excitations.
The values of amplitudes show a relative weight of singly and doubly excited determinants in the wavefunction. If $T_1$ and/or $T_2$ are large (generally speaking, if a particular |$T_2| > 0.1$), the wavefunction is considered to be multi-configurational, i.e., containing several important Slater determinants. In other words, this is a region where non-dynamic (static) correlation is significant. Several small $T_1$ and $T_2$ amplitudes tell about (almost always present) dynamic correlation.
In each output you should look at the values of *Largest {TIA, Tia, TIjAb} Amplitudes*, where the $T$ refers to the previously mentioned operator, and the following indices refer to the orbitals used according to the notation:
| | Occupied Molecular Orbitals | Virtual Molecular Orbitals | | |
|-------|-----------------------------|----------------------------|---|---|
| Alpha | i,j | a, b | | |
| Beta | I, J | A, B | | |
```
#RESPONSE
```
---
#### **10.** Plot on the same graph the RHF, DFT and FCI binding energies in $H_2$ versus the separation distance. Plot in kcal/mol energy units (1 Hartree = 627.5 kcal/mol)
```
#Response
```
#### **11.** Using your results, compare CCSD, UHF and RHF dissociation energies.
```
#RESPONSE
```
---
#### **12.** Comment on the behaviour of RHF with respect to FCI at short (around 0.7 Angstroms) and long distances. For more information, you can read paragraph 3.8.7 from Reference 1 (found below) for a discussion of RHF and UHF solutions.
#RESPONSE
---
#### **13.** Plot the first two $H_2$ molecular orbitals from your RHF and UHF calculations at equilibrium , 0.7 and 5.0 Angstroms. Remember to use the appropriate global settings. Comment on qualitative changes in the shape of the orbitals.
##### You may use the function `generate_orbitals` from the orbital_helper file in the same directory to plot both HOMO and HOMO for the $H_2$ molecule. The syntax is the following:
```
from orbital_helper import generate_orbitals
x, alpha_orbitals, beta_orbitals = generate_orbitals(wfn, [1,2,3])
#Where the arguments are the wavefunction object and the integer values of the orbitals.
#The function returns a numpy array with the domain, and a set of lists with alpha and beta orbitals.
```
##### If you have the package `moly` installed. You may visualize the orbitals in 3D with the following:
```
import moly
fig = moly.Figure(figsize=(300,500))
fig.add_orbital("Name", wfn, orbital_number, iso, colorscale="portland_r")
fig.show()
```
```
from orbital_helper import generate_orbitals
#RESPONSE
```
---
#### **14.** Difference between FCI and HF energies is the correlation energy. What is the nature of the correlation energy (dynamic vs non-dynamic) in $H_2$ at equilibrium and long distances? At what distance does the non-dynamic correlation become important?
#RESPONSE
---
#### **15.** Comment on the behaviour of DFT at equilibrium and long distances. What is the reason of DFT failure for bond-breaking?
#RESPONSE
---
#### **Bonus.** From the previously computed energy of a Hydrogen atom with the hybrid B3LYP functional. Compare the energy of the atom computed with HF, B3LYP and the exact energy. Do you see any discrepancy with B3LYP? If so, what is/are the reasons for such discrepancies?
```
#RESPONSE
```
***
## Part 2
Your friend, who is an experimental chemist, seeks your help knowing that you have expertise in running quantum chemistry simulations. Their research group has measured the singlet-triplet gap of ozone recently. They want to see if computational simulations can support their measurement. How will you measure the singlet-triplet gap in ozone?
Use the ideas from the previous part of this lab and the follwoing hints:
**1.** Assume that the singlet and triplet ozone molecules have the same geometry.
**2.** You will have to optimize the geometry of ozone to start with. Psi4 can let you import geometries from PubChem. The sytax is: `h2o_geometry = psi4.geometry("pubchem:water")`. You may use the common name or its molecular formula. Alternatively, you can use a database such as [CCCBDB](https://cccbdb.nist.gov/).
**3.** Use RHF/6-31G* for simulating the singlet ozone molecule. Use UHF/6-31G* for simulating the triplet ozone molecule. Use the energy difference to compute the gap.
**4.** Write the electronic energies corresponding to singlet and triplet ozone molecules. the singlet-triplet gap in eV, and the $<S^2>$ value for triplet ozone. Information about spin contamination is given by $<S^2>$ and can be found close to the end of your calculation (look for Spin Contamination Metric).
```
#Response
```
---
Now, compute the singlet-triplet gap between the $^1\Delta_g$ and $^3\Sigma_g$ states of oxygen molecule and report it in eV. Compare the singlet-triplet gap you computed in this lab with the ones availiable in CCBDB. Is it an exact match (http://cccbdb.nist.gov/stgap1.asp)?
<img src="./ozone.png">
##### Compare the expected $<S^2>$ with observed $<S^2>$ and respond: Of all the four cases you have computed so far, which one suffers the most spin contamination?
```
#RESPONSE
```
---
Bonus. Compute the singlet-triplet gap between $^1\Sigma_g ^+$ and $^3\Sigma_g ^-$ states of oxygen atom.
<div class="alert alert-info">
Hint: Start with $^1 \Delta_g$ geometry. Use the maximum overlap method (MOM) to force the highest beta electron to occupy the second $\pi^*$ ortibal: ```psi4.set_options({"MOM_START":1})```
</div>
```
#Response
```
# ---
## Further Reading:
#### General:
1. Szabo, A., & Ostlund, N. S. (2012). Modern quantum chemistry: introduction to advanced electronic structure theory. Courier Corporation.
2. Cramer, Christopher J. Essentials of computational chemistry: theories and models. John Wiley & Sons, 2013.
3. Krylov. A. Theory and Practice of Molecular Electronic Structure: [link](http://iopenshell.usc.edu/chem545/lectures2016/chem545_2016.pdf)
4. Sherrill. D. Non-Dynamical (Static) Electron Correlation: Bond Breaking in Quantum Chemistry [link](https://youtu.be/coGVX7HCCQE)
#### Bond stretching:
1. Dutta, Antara, and C. David Sherrill. "Full configuration interaction potential energy curves for breaking bonds to hydrogen: An assessment of single-reference correlation methods." The Journal of chemical physics 118.4 (2003): 1610-1619.
#### Singlet-triplet gaps:
1. Slipchenko, Lyudmila V., and Anna I. Krylov. "Singlet-triplet gaps in diradicals by the spin-flip approach: A benchmark study." The Journal of chemical physics 117.10 (2002): 4694-4708.
|
github_jupyter
|
"""Bond Breaking"""
__authors__ = "Victor H. Chavez", "Lyudmila Slipchenko"
__credits__ = ["Victor H. Chavez", "Lyudmila Slipchenko"]
__email__ = ["[email protected]", "[email protected]"]
__copyright__ = "(c) 2008-2019, The Psi4Education Developers"
__license__ = "BSD-3-Clause"
__date__ = "2019-11-18"
#Import modules
import psi4
import numpy as np
import os
import matplotlib.pyplot as plt
#Define Helium Geometry
#The first line referst to the charge and spin multiplicity.
he_geo = psi4.geometry("""
0 1
He 0.0 0.0 0.0
""")
#Request the HF calculation using the correlation consistent basis set cc-pvdz.
e = psi4.energy("HF/cc-pvdz", molecule=he_geo)
#Print the energy. The units are given in atomic units or hartrees.
print(f"The HF energy of He is {e}")
#We made us of *f-strings* which allow us to combine strings and numbers in a print statement.
### RESPONSE
#Define string with psi4.geometry syntax.
#Identify what you want to change and use a particular label that you know that won't get repeated.
molecule = """
**atom1** 0.0 0.0 0.0
"""
#Create a list with the things that you want to go through.
atoms = [ "H", "He", "Li" ]
#Cycle through them.
for atom in atoms:
print(molecule.replace("**atom1**", atom))
Here we are using the `numpy` library first to create an empty array filled with zeros using `np.zeros`, where the argument specifies the size of the array. The other function `np.linspace` creates a sequence of evenly spaced values within an interval. This means, we generated a linear space with 16 points from 0.3 to 2.5 and one with 4 points from 2.7 to 5.0.
---
#### **4.** Calculate the energies at the same distances at the **UHF** level. You can recycle the code that you just wrote (just remember to change the name of your variables). We will need extra information that can ony be found in the output.
In order to save the output to a file we require the additional option: ```psi4.core.set_output_file("filename.txt", True)```.
<div class="alert alert-info">
Hint: In order to obtain the correct UHF energies, we need to set the extra following options:
<\div>
#### **5.** Store the values for $S^2$. This information is found in each outputfile close to the end of your calculation (look for Spin Contamination Metric).
You can go through each of the files and copy the value, but you can also think about how can you let python automatize this process. Think carefully about the steps required for this. Given a path you would need to import the file ( `f = open(path, 'r')` ) and proceed to extract the lines ( `f.read().splitlines()` ). With those lines available, you may concentrate on determining whether or not each line contains the `S^2` string.
If you require a more thorough review of parsing files. You can look at [this tutorial](https://education.molssi.org/python_scripting_cms/02-file_parsing/index.html) to learn more about file parsing.
#### **6.** Make a table or plot of $S^2$ values from the UHF calculations. Explain why $S^2$ deteriorates when the H-H bond is stretched.
---
#### 7. Calculate the same potential energy surface at the DFT level. Use the PBE functional and a restricted wavefunction.
#### **8.** Calculate the same potential energy surface at the FCI level.
For a two-electron system, the FCI results may be obtained by using the CCSD method. This is true because CCSD includes determinants that are singly and doubly excited. For a two electron system that includes all electrons available, thus CCSD includes all possible excitations in the system.
#### **9.** You will need to save the output file generated by Psi4 again. From the output file, record total CCSD ampltitudes: CCSD $T_1^2$ and $T_2^2$, and the value of the largest $T_2$ amplitude for the ground state geometry and for a split geometry.
Consider T as a sum of operators that that act on a reference determinant. In CCSD $T = T_1 + T_2$ where $T_1$ refers with single excitations and $T_2$ with double excitations.
The values of amplitudes show a relative weight of singly and doubly excited determinants in the wavefunction. If $T_1$ and/or $T_2$ are large (generally speaking, if a particular |$T_2| > 0.1$), the wavefunction is considered to be multi-configurational, i.e., containing several important Slater determinants. In other words, this is a region where non-dynamic (static) correlation is significant. Several small $T_1$ and $T_2$ amplitudes tell about (almost always present) dynamic correlation.
In each output you should look at the values of *Largest {TIA, Tia, TIjAb} Amplitudes*, where the $T$ refers to the previously mentioned operator, and the following indices refer to the orbitals used according to the notation:
| | Occupied Molecular Orbitals | Virtual Molecular Orbitals | | |
|-------|-----------------------------|----------------------------|---|---|
| Alpha | i,j | a, b | | |
| Beta | I, J | A, B | | |
---
#### **10.** Plot on the same graph the RHF, DFT and FCI binding energies in $H_2$ versus the separation distance. Plot in kcal/mol energy units (1 Hartree = 627.5 kcal/mol)
#### **11.** Using your results, compare CCSD, UHF and RHF dissociation energies.
---
#### **12.** Comment on the behaviour of RHF with respect to FCI at short (around 0.7 Angstroms) and long distances. For more information, you can read paragraph 3.8.7 from Reference 1 (found below) for a discussion of RHF and UHF solutions.
#RESPONSE
---
#### **13.** Plot the first two $H_2$ molecular orbitals from your RHF and UHF calculations at equilibrium , 0.7 and 5.0 Angstroms. Remember to use the appropriate global settings. Comment on qualitative changes in the shape of the orbitals.
##### You may use the function `generate_orbitals` from the orbital_helper file in the same directory to plot both HOMO and HOMO for the $H_2$ molecule. The syntax is the following:
##### If you have the package `moly` installed. You may visualize the orbitals in 3D with the following:
---
#### **14.** Difference between FCI and HF energies is the correlation energy. What is the nature of the correlation energy (dynamic vs non-dynamic) in $H_2$ at equilibrium and long distances? At what distance does the non-dynamic correlation become important?
#RESPONSE
---
#### **15.** Comment on the behaviour of DFT at equilibrium and long distances. What is the reason of DFT failure for bond-breaking?
#RESPONSE
---
#### **Bonus.** From the previously computed energy of a Hydrogen atom with the hybrid B3LYP functional. Compare the energy of the atom computed with HF, B3LYP and the exact energy. Do you see any discrepancy with B3LYP? If so, what is/are the reasons for such discrepancies?
***
## Part 2
Your friend, who is an experimental chemist, seeks your help knowing that you have expertise in running quantum chemistry simulations. Their research group has measured the singlet-triplet gap of ozone recently. They want to see if computational simulations can support their measurement. How will you measure the singlet-triplet gap in ozone?
Use the ideas from the previous part of this lab and the follwoing hints:
**1.** Assume that the singlet and triplet ozone molecules have the same geometry.
**2.** You will have to optimize the geometry of ozone to start with. Psi4 can let you import geometries from PubChem. The sytax is: `h2o_geometry = psi4.geometry("pubchem:water")`. You may use the common name or its molecular formula. Alternatively, you can use a database such as [CCCBDB](https://cccbdb.nist.gov/).
**3.** Use RHF/6-31G* for simulating the singlet ozone molecule. Use UHF/6-31G* for simulating the triplet ozone molecule. Use the energy difference to compute the gap.
**4.** Write the electronic energies corresponding to singlet and triplet ozone molecules. the singlet-triplet gap in eV, and the $<S^2>$ value for triplet ozone. Information about spin contamination is given by $<S^2>$ and can be found close to the end of your calculation (look for Spin Contamination Metric).
---
Now, compute the singlet-triplet gap between the $^1\Delta_g$ and $^3\Sigma_g$ states of oxygen molecule and report it in eV. Compare the singlet-triplet gap you computed in this lab with the ones availiable in CCBDB. Is it an exact match (http://cccbdb.nist.gov/stgap1.asp)?
<img src="./ozone.png">
##### Compare the expected $<S^2>$ with observed $<S^2>$ and respond: Of all the four cases you have computed so far, which one suffers the most spin contamination?
---
Bonus. Compute the singlet-triplet gap between $^1\Sigma_g ^+$ and $^3\Sigma_g ^-$ states of oxygen atom.
<div class="alert alert-info">
Hint: Start with $^1 \Delta_g$ geometry. Use the maximum overlap method (MOM) to force the highest beta electron to occupy the second $\pi^*$ ortibal: ```psi4.set_options({"MOM_START":1})```
</div>
| 0.79657 | 0.925095 |
```
import batoid
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
telescope = batoid.Optic.fromYaml("HSC.yaml")
def pupil(thx, thy, nside=512):
rays = batoid.RayVector.asGrid(
optic=telescope, wavelength=750e-9,
theta_x=thx, theta_y=thy,
nx=nside, ny=nside
)
rays2 = rays.copy()
telescope.stopSurface.interact(rays2)
telescope.trace(rays)
w = ~rays.vignetted
return rays2.x[w], rays2.y[w]
def drawCircle(ax, cx, cy, r, **kwargs):
t = np.linspace(0, 2*np.pi, 1000)
x = r*np.cos(t)+cx
y = r*np.sin(t)+cy
ax.plot(x, y, **kwargs)
def drawRay(ax, cx, cy, width, theta, **kwargs):
R = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]])
dx = np.linspace(0, 4.1, 1000)
dy = np.ones_like(dx)*width/2
bx = np.copy(dx)
by = -dy
dx, dy = R.dot(np.vstack([dx, dy]))
bx, by = R.dot(np.vstack([bx, by]))
dx += cx
dy += cy
bx += cx
by += cy
ax.plot(dx, dy, **kwargs)
ax.plot(bx, by, **kwargs)
def drawRectangle(ax, cx, cy, width, height, **kwargs):
x = width/2*np.array([-1,-1,1,1,-1])
y = height/2*np.array([-1,1,1,-1,-1])
x += cx
y += cy
ax.plot(x, y, **kwargs)
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
def modelPlot(thx, thy):
fig, ax = plt.subplots(1, 1, figsize=(30, 30))
ax.scatter(*pupil(thx,thy), s=0.1, c='k')
ax.set_aspect('equal')
# Primary mirror
drawCircle(ax, 0, 0, 4.1, c='r')
# Camera shadow
drawCircle(ax, 17*thx, 17*thy, 0.95, c='r')
# G1 cutoff
drawCircle(ax, -142*thx, -142*thy, 4.25, c='r')
# G4 cutoff
thr = np.hypot(thx, thy)
if thr > np.deg2rad(0.75):
thph = np.arctan2(thy, thx)
cr = -17.76 - 2e3*(thr-np.deg2rad(0.76)) - 1.8e5*(thr-np.deg2rad(0.76))*(thr-np.deg2rad(0.8))
drawCircle(ax, cr*np.cos(thph), cr*np.sin(thph), 20.0, c='r')
# spider
alpha = 6.75
# TopRing
trRate = 14
drawRay(ax, 0.45+trRate*thx, 0.45+trRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.45+trRate*thx, 0.45+trRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.45+trRate*thx, -0.45+trRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.45+trRate*thx, -0.45+trRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# TertiarySpiderFirstPass
tsfpRate = 2
drawRay(ax, 0.45+tsfpRate*thx, 0.45+tsfpRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.45+tsfpRate*thx, 0.45+tsfpRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.45+tsfpRate*thx, -0.45+tsfpRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.45+tsfpRate*thx, -0.45+tsfpRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# TertiarySpiderSecondPass
tsspRate = -2
drawRay(ax, 0.51+tsspRate*thx, 0.51+tsspRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.51+tsspRate*thx, 0.51+tsspRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.51+tsspRate*thx, -0.51+tsspRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.51+tsspRate*thx, -0.51+tsspRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# FEU
drawRectangle(ax, 15*thx, 15*thy, 0.84, 2.28, c='r')
ax.set_xlim(-5,5)
ax.set_ylim(-5,5)
ax.axvline(c='k')
ax.axhline(c='k')
fig.show()
telescope.itemDict['SubaruHSC.TopRing'].skip=False
telescope.itemDict['SubaruHSC.BottomRing'].skip=False
telescope.itemDict['SubaruHSC.TertiarySpiderFirstPass'].skip=False
telescope.itemDict['SubaruHSC.TertiarySpiderSecondPass'].skip=False
telescope.itemDict['SubaruHSC.FEU'].skip=False
# modelPlot(0, np.deg2rad(-0.82))
# modelPlot(0, np.deg2rad(-0.77))
# modelPlot(0, np.deg2rad(-0.7))
# modelPlot(0, np.deg2rad(-0.35))
# modelPlot(0, np.deg2rad(0))
# modelPlot(0, np.deg2rad(0.35))
# modelPlot(0, np.deg2rad(0.7))
# modelPlot(0, np.deg2rad(0.77))
# modelPlot(np.deg2rad(-0.77), 0)
# modelPlot(np.deg2rad(-0.7), 0)
# modelPlot(np.deg2rad(-0.35), 0)
# modelPlot(np.deg2rad(0), 0)
# modelPlot(np.deg2rad(0.35), 0)
# modelPlot(np.deg2rad(0.7), 0)
# modelPlot(np.deg2rad(0.77), 0)
# modelPlot(np.deg2rad(-0.5), np.deg2rad(-0.5))
# modelPlot(np.deg2rad(-0.35), np.deg2rad(-0.35))
# modelPlot(np.deg2rad(-0.2), np.deg2rad(-0.2))
# modelPlot(np.deg2rad(0.5), np.deg2rad(-0.5))
# modelPlot(np.deg2rad(0.35), np.deg2rad(-0.35))
# modelPlot(np.deg2rad(0.2), np.deg2rad(-0.2))
modelPlot(np.deg2rad(0.55), np.deg2rad(0.55))
```
|
github_jupyter
|
import batoid
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
telescope = batoid.Optic.fromYaml("HSC.yaml")
def pupil(thx, thy, nside=512):
rays = batoid.RayVector.asGrid(
optic=telescope, wavelength=750e-9,
theta_x=thx, theta_y=thy,
nx=nside, ny=nside
)
rays2 = rays.copy()
telescope.stopSurface.interact(rays2)
telescope.trace(rays)
w = ~rays.vignetted
return rays2.x[w], rays2.y[w]
def drawCircle(ax, cx, cy, r, **kwargs):
t = np.linspace(0, 2*np.pi, 1000)
x = r*np.cos(t)+cx
y = r*np.sin(t)+cy
ax.plot(x, y, **kwargs)
def drawRay(ax, cx, cy, width, theta, **kwargs):
R = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]])
dx = np.linspace(0, 4.1, 1000)
dy = np.ones_like(dx)*width/2
bx = np.copy(dx)
by = -dy
dx, dy = R.dot(np.vstack([dx, dy]))
bx, by = R.dot(np.vstack([bx, by]))
dx += cx
dy += cy
bx += cx
by += cy
ax.plot(dx, dy, **kwargs)
ax.plot(bx, by, **kwargs)
def drawRectangle(ax, cx, cy, width, height, **kwargs):
x = width/2*np.array([-1,-1,1,1,-1])
y = height/2*np.array([-1,1,1,-1,-1])
x += cx
y += cy
ax.plot(x, y, **kwargs)
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
def modelPlot(thx, thy):
fig, ax = plt.subplots(1, 1, figsize=(30, 30))
ax.scatter(*pupil(thx,thy), s=0.1, c='k')
ax.set_aspect('equal')
# Primary mirror
drawCircle(ax, 0, 0, 4.1, c='r')
# Camera shadow
drawCircle(ax, 17*thx, 17*thy, 0.95, c='r')
# G1 cutoff
drawCircle(ax, -142*thx, -142*thy, 4.25, c='r')
# G4 cutoff
thr = np.hypot(thx, thy)
if thr > np.deg2rad(0.75):
thph = np.arctan2(thy, thx)
cr = -17.76 - 2e3*(thr-np.deg2rad(0.76)) - 1.8e5*(thr-np.deg2rad(0.76))*(thr-np.deg2rad(0.8))
drawCircle(ax, cr*np.cos(thph), cr*np.sin(thph), 20.0, c='r')
# spider
alpha = 6.75
# TopRing
trRate = 14
drawRay(ax, 0.45+trRate*thx, 0.45+trRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.45+trRate*thx, 0.45+trRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.45+trRate*thx, -0.45+trRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.45+trRate*thx, -0.45+trRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# TertiarySpiderFirstPass
tsfpRate = 2
drawRay(ax, 0.45+tsfpRate*thx, 0.45+tsfpRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.45+tsfpRate*thx, 0.45+tsfpRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.45+tsfpRate*thx, -0.45+tsfpRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.45+tsfpRate*thx, -0.45+tsfpRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# TertiarySpiderSecondPass
tsspRate = -2
drawRay(ax, 0.51+tsspRate*thx, 0.51+tsspRate*thy, 0.18, np.deg2rad(90+alpha), c='r')
drawRay(ax, 0.51+tsspRate*thx, 0.51+tsspRate*thy, 0.18, np.deg2rad(-alpha), c='r')
drawRay(ax, -0.51+tsspRate*thx, -0.51+tsspRate*thy, 0.18, np.deg2rad(180-alpha), c='r')
drawRay(ax, -0.51+tsspRate*thx, -0.51+tsspRate*thy, 0.18, np.deg2rad(270+alpha), c='r')
# FEU
drawRectangle(ax, 15*thx, 15*thy, 0.84, 2.28, c='r')
ax.set_xlim(-5,5)
ax.set_ylim(-5,5)
ax.axvline(c='k')
ax.axhline(c='k')
fig.show()
telescope.itemDict['SubaruHSC.TopRing'].skip=False
telescope.itemDict['SubaruHSC.BottomRing'].skip=False
telescope.itemDict['SubaruHSC.TertiarySpiderFirstPass'].skip=False
telescope.itemDict['SubaruHSC.TertiarySpiderSecondPass'].skip=False
telescope.itemDict['SubaruHSC.FEU'].skip=False
# modelPlot(0, np.deg2rad(-0.82))
# modelPlot(0, np.deg2rad(-0.77))
# modelPlot(0, np.deg2rad(-0.7))
# modelPlot(0, np.deg2rad(-0.35))
# modelPlot(0, np.deg2rad(0))
# modelPlot(0, np.deg2rad(0.35))
# modelPlot(0, np.deg2rad(0.7))
# modelPlot(0, np.deg2rad(0.77))
# modelPlot(np.deg2rad(-0.77), 0)
# modelPlot(np.deg2rad(-0.7), 0)
# modelPlot(np.deg2rad(-0.35), 0)
# modelPlot(np.deg2rad(0), 0)
# modelPlot(np.deg2rad(0.35), 0)
# modelPlot(np.deg2rad(0.7), 0)
# modelPlot(np.deg2rad(0.77), 0)
# modelPlot(np.deg2rad(-0.5), np.deg2rad(-0.5))
# modelPlot(np.deg2rad(-0.35), np.deg2rad(-0.35))
# modelPlot(np.deg2rad(-0.2), np.deg2rad(-0.2))
# modelPlot(np.deg2rad(0.5), np.deg2rad(-0.5))
# modelPlot(np.deg2rad(0.35), np.deg2rad(-0.35))
# modelPlot(np.deg2rad(0.2), np.deg2rad(-0.2))
modelPlot(np.deg2rad(0.55), np.deg2rad(0.55))
| 0.569494 | 0.697849 |
# Álgebra matricial
En este libro tratamos de minimizar la notación matemática tanto como sea posible. Además, evitamos usar el cálculo para motivar conceptos estadísticos. Sin embargo, Matrix Algebra (también conocida como Linear Algebra) y su notación matemática facilita enormemente la exposición de las técnicas avanzadas de análisis de datos cubiertas en el resto de este libro. Por lo tanto, dedicamos un capítulo de este libro a la introducción de Matrix Algebra. Hacemos esto en el contexto del análisis de datos y utilizando una de las principales aplicaciones: Modelos lineales.
Describiremos tres ejemplos de las ciencias de la vida: uno de la física, uno relacionado con la genética y otro de un experimento con ratones. Son muy diferentes, pero terminamos usando la misma técnica estadística: ajustar modelos lineales. Los modelos lineales normalmente se enseñan y describen en el lenguaje del álgebra matricial.
```
library(rafalib)
```
## Ejemplos motivadores
#### Objetos que caen
Imagina que eres Galileo en el siglo XVI tratando de describir la velocidad de un objeto que cae. Un asistente sube a la Torre de Pisa y deja caer una pelota, mientras varios otros asistentes registran la posición en diferentes momentos. Simulemos algunos datos usando las ecuaciones que conocemos hoy y agregando algún error de medición:
```
set.seed(1)
g <- 9.8 ##meters per second
n <- 25
tt <- seq(0,3.4,len=n) ##time in secs, note: we use tt because t is a base function
#rands = s.randi(0, 1, n, seed=1)
d <- 56.67 - 0.5*g*tt^2 + rnorm(n,sd=1) ##meters
```
Los asistentes entregan los datos a Galileo y esto es lo que ve:
```
mypar()
plot(tt,d,ylab="Distancia en metros",xlab="Tiempo en segundos")
```
No conoce la ecuación exacta, pero al observar el gráfico anterior deduce que la posición debe seguir una parábola. Así que modela los datos con:
$$ Y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \varepsilon_i, i=1,\dots,n $$
Con $Y_i$ representando la ubicación, $x_i$ representando el tiempo y $\varepsilon_i$ representando el error de medición. Este es un modelo lineal porque es una combinación lineal de cantidades conocidas (las $x$) denominadas predictores o covariables y parámetros desconocidos (las $\beta$).
#### Alturas de padre e hijo
Ahora imagina que eres Francis Galton en el siglo XIX y recopilas datos de altura emparejados de padres e hijos. Sospechas que la altura se hereda. Tu información:
```
father.son = read.csv('https://raw.githubusercontent.com/jabernalv/Father-Son-height/master/Pearson.csv')
x=father.son$fheight
y=father.son$sheight
```
Se ve como esto:
```
plot(x,y,xlab="Altura de los padres",ylab="Altura de los hijos")
```
Las alturas de los hijos parecen aumentar linealmente con las alturas de los padres. En este caso, un modelo que describe los datos es el siguiente:
$$ Y_i = \beta_0 + \beta_1 x_i + \varepsilon_i, i=1,\dots,N $$
Este también es un modelo lineal con $x_i$ y $Y_i$, las alturas del padre y el hijo respectivamente, para el $i$-ésimo par y $\varepsilon_i$ un término para tener en cuenta la variabilidad adicional. Aquí pensamos en las alturas de los padres como predictores y siendo fijos (no aleatorios), por lo que usamos minúsculas. El error de medición por sí solo no puede explicar toda la variabilidad observada en $\varepsilon_i$. Esto tiene sentido ya que hay otras variables que no están en el modelo, por ejemplo, la estatura de las madres, la aleatoriedad genética y los factores ambientales.
#### Muestras aleatorias de múltiples poblaciones
Aquí leemos datos de peso corporal de ratones que fueron alimentados con dos dietas diferentes: alta en grasas y control (chow). Tenemos una muestra aleatoria de 12 ratones para cada uno. Nos interesa determinar si la dieta tiene efecto sobre el peso. Aquí están los datos:
```
library(downloader)
url <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/femaleMiceWeights.csv"
dat <- read.csv(url)
mypar(1,1)
stripchart(Bodyweight~Diet,data=dat,vertical=TRUE,method="jitter",pch=1,main="Mice weights")
```
Queremos estimar la diferencia en el peso promedio entre las poblaciones. Demostramos cómo hacer esto usando pruebas t e intervalos de confianza, basados en la diferencia en los promedios de las muestras. Podemos obtener los mismos resultados exactos usando un modelo lineal:
$$ Y_i = \beta_0 + \beta_1 x_{i} + \varepsilon_i$$
con $\beta_0$ el peso promedio de la dieta chow, $\beta_1$ la diferencia entre los promedios, $x_i = 1$ cuando el ratón $i$ recibe la dieta alta en grasas (hf), $x_i = 0$ cuando recibe la dieta chow , y $\varepsilon_i$ explica las diferencias entre ratones de la misma población.
#### Modelos lineales en general
Hemos visto tres ejemplos muy diferentes en los que se pueden utilizar modelos lineales. Un modelo general que engloba todos los ejemplos anteriores es el siguiente:
$$ Y_i = \beta_0 + \beta_1 x_{i,1} + \beta_2 x_{i,2} + \dots + \beta_2 x_{i,p} + \varepsilon_i, i=1,\dots,n $$
$$ Y_i = \beta_0 + \sum_{j=1}^p \beta_j x_{i,j} + \varepsilon_i, i=1,\dots,n $$
Tenga en cuenta que tenemos un número general de predictores $p$. El álgebra matricial proporciona un lenguaje compacto y un marco matemático para calcular y hacer derivaciones con cualquier modelo lineal que se ajuste al marco anterior.
<a name="estimaciones"></a>
#### Estimación de parámetros
Para que los modelos anteriores sean útiles, tenemos que estimar los $\beta$ s desconocidos. En el primer ejemplo, queremos describir un proceso físico para el cual no podemos tener parámetros desconocidos. En el segundo ejemplo, entendemos mejor la herencia al estimar cuánto, en promedio, la altura del padre afecta la altura del hijo. En el ejemplo final, queremos determinar si de hecho hay una diferencia: si $\beta_1 \neq 0$.
El enfoque estándar en ciencia es encontrar los valores que minimizan la distancia del modelo ajustado a los datos. La siguiente se llama ecuación de mínimos cuadrados (LS) y la veremos a menudo en este capítulo:
$$ \sum_{i=1}^n \left\{ Y_i - \left(\beta_0 + \sum_{j=1}^p \beta_j x_{i,j}\right)\right\}^2 $$
Una vez que encontremos el mínimo, llamaremos a los valores estimaciones de mínimos cuadrados (LSE) y los denotaremos con $\hat{\beta}$. La cantidad obtenida al evaluar la ecuación de mínimos cuadrados en las estimaciones se denomina suma residual de cuadrados (RSS). Como todas estas cantidades dependen de $Y$, *son variables aleatorias*. Los $\hat{\beta}$ s son variables aleatorias y eventualmente realizaremos inferencias sobre ellas.
#### Ejemplo de caída de objetos revisado
Gracias a mi profesor de física de la escuela secundaria, sé que la ecuación de la trayectoria de un objeto que cae es:
$$d = h_0 + v_0 t - 0.5 \times 9.8 t^2$$
con $h_0$ y $v_0$ la altura inicial y la velocidad respectivamente. Los datos que simulamos arriba siguieron esta ecuación y agregaron el error de medición para simular `n` observaciones para dejar caer la pelota $(v_0=0)$ desde la torre de Pisa $(h_0=56.67)$. Es por eso que usamos este código para simular datos:
```
g <- 9.8 ##meters per second
n <- 25
tt <- seq(0,3.4,len=n) ##time in secs, t is a base function
f <- 56.67 - 0.5*g*tt^2
y <- f + rnorm(n,sd=1)
```
Así es como se ven los datos con la línea sólida que representa la trayectoria real:
```
plot(tt,y,ylab="Distancia en metros",xlab="Tiempo en segundos")
lines(tt,f,col=2)
```
Pero pretendíamos ser Galileo, por lo que no conocemos los parámetros del modelo. Los datos sugieren que es una parábola, así que la modelamos como tal:
$$ Y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \varepsilon_i, i=1,\dots,n $$
¿Cómo encontramos la LSE?
#### La función `lm`
En R podemos ajustar este modelo simplemente usando la función `lm`. Describiremos esta función en detalle más adelante, pero aquí hay una vista previa:
```
tt2 <-tt^2
fit <- lm(y~tt+tt2)
summary(fit)$coef
```
Nos da la LSE, así como los errores estándar y los valores de p.
Parte de lo que hacemos en esta sección es explicar las matemáticas detrás de esta función.
#### La estimación de mínimos cuadrados (LSE)
Escribamos una función que calcule el RSS para cualquier vector $\beta$:
```
rss <- function(Beta0,Beta1,Beta2){
r <- y - (Beta0+Beta1*tt+Beta2*tt^2)
return(sum(r^2))
}
```
Así que para cualquier vector tridimensional obtenemos un RSS. Aquí hay una gráfica del RSS como una función de $\beta_2$ cuando mantenemos los otros dos fijos:
```
Beta2s<- seq(-10,0,len=100)
plot(Beta2s,sapply(Beta2s,rss,Beta0=55,Beta1=0),
ylab="RSS",xlab="Beta2",type="l")
##Let's add another curve fixing another pair:
Beta2s<- seq(-10,0,len=100)
lines(Beta2s,sapply(Beta2s,rss,Beta0=65,Beta1=0),col=2)
```
Prueba y error aquí no va a funcionar. En su lugar, podemos usar el cálculo: tomar las derivadas parciales, ponerlas a 0 y resolver. Por supuesto, si tenemos muchos parámetros, estas ecuaciones pueden volverse bastante complejas. El álgebra lineal proporciona una forma compacta y general de resolver este problema.
#### Más sobre Galton (avanzado)
Al estudiar los datos de padre e hijo, Galton hizo un descubrimiento fascinante mediante el análisis exploratorio.
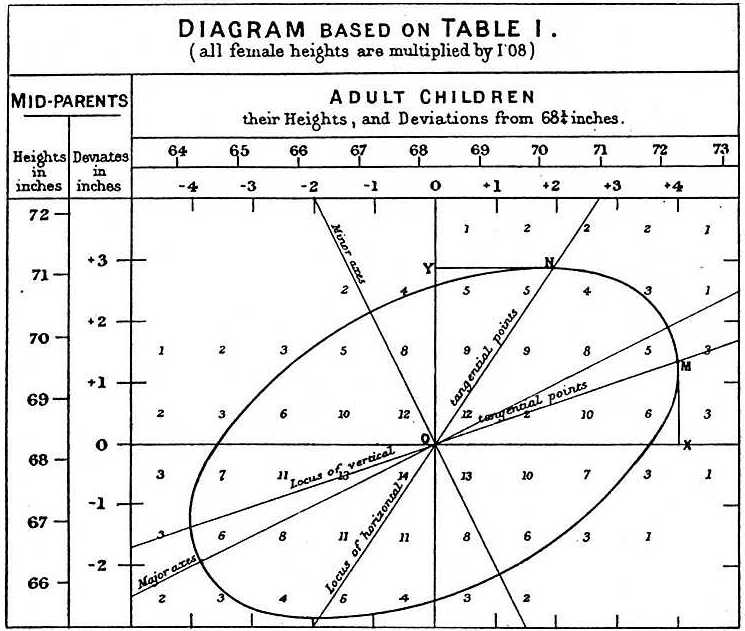
Observó que si tabulaba el número de pares de estatura padre-hijo y seguía todos los valores x,y que tenían los mismos totales en la tabla, formaban una elipse. En el gráfico de arriba, hecho por Galton, ves la elipse formada por los pares que tienen 3 casos. Esto luego llevó a modelar estos datos como normal bivariado correlacionado que describimos anteriormente:
$$
Pr(X<a,Y<b) =
$$
$$
\int_{-\infty}^{a} \int_{-\infty}^{b} \frac{1}{2\pi\sigma_x\sigma_y\sqrt{1-\rho^2}}
\exp{ \left\{
\frac{1}{2(1-\rho^2)}
\left[\left(\frac{x-\mu_x}{\sigma_x}\right)^2 -
2\rho\left(\frac{x-\mu_x}{\sigma_x}\right)\left(\frac{y-\mu_y}{\sigma_y}\right)+
\left(\frac{y-\mu_y}{\sigma_y}\right)^2
\right]
\right\}
}
$$
Describimos cómo podemos usar las matemáticas para mostrar que si mantiene fijo $X$ (la condición es que sea $x$), la distribución de $Y$ se distribuye normalmente con la media: $\mu_x +\sigma_y \rho \left(\frac {x-\mu_x}{\sigma_x}\right)$ y desviación estándar $\sigma_y \sqrt{1-\rho^2}$. Tenga en cuenta que $\rho$ es la correlación entre $Y$ y $X$, lo que implica que si fijamos $X=x$, $Y$ de hecho sigue un modelo lineal. Los parámetros $\beta_0$ y $\beta_1$ en nuestro modelo lineal simple se pueden expresar en términos de $\mu_x,\mu_y,\sigma_x,\sigma_y$ y $\rho$.
|
github_jupyter
|
library(rafalib)
set.seed(1)
g <- 9.8 ##meters per second
n <- 25
tt <- seq(0,3.4,len=n) ##time in secs, note: we use tt because t is a base function
#rands = s.randi(0, 1, n, seed=1)
d <- 56.67 - 0.5*g*tt^2 + rnorm(n,sd=1) ##meters
mypar()
plot(tt,d,ylab="Distancia en metros",xlab="Tiempo en segundos")
father.son = read.csv('https://raw.githubusercontent.com/jabernalv/Father-Son-height/master/Pearson.csv')
x=father.son$fheight
y=father.son$sheight
plot(x,y,xlab="Altura de los padres",ylab="Altura de los hijos")
library(downloader)
url <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/femaleMiceWeights.csv"
dat <- read.csv(url)
mypar(1,1)
stripchart(Bodyweight~Diet,data=dat,vertical=TRUE,method="jitter",pch=1,main="Mice weights")
g <- 9.8 ##meters per second
n <- 25
tt <- seq(0,3.4,len=n) ##time in secs, t is a base function
f <- 56.67 - 0.5*g*tt^2
y <- f + rnorm(n,sd=1)
plot(tt,y,ylab="Distancia en metros",xlab="Tiempo en segundos")
lines(tt,f,col=2)
tt2 <-tt^2
fit <- lm(y~tt+tt2)
summary(fit)$coef
rss <- function(Beta0,Beta1,Beta2){
r <- y - (Beta0+Beta1*tt+Beta2*tt^2)
return(sum(r^2))
}
Beta2s<- seq(-10,0,len=100)
plot(Beta2s,sapply(Beta2s,rss,Beta0=55,Beta1=0),
ylab="RSS",xlab="Beta2",type="l")
##Let's add another curve fixing another pair:
Beta2s<- seq(-10,0,len=100)
lines(Beta2s,sapply(Beta2s,rss,Beta0=65,Beta1=0),col=2)
| 0.355216 | 0.983166 |
```
import pandas as pd
result = pd.read_csv('editeddata.csv')
result
from nltk.classify import NaiveBayesClassifier
import nltk.classify.util as cu
import random
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.corpus import stopwords
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
```
#### TF-IDF, bigram, on 'stem'
```
vcBayesInput = []
vec_tfidf_bi = TfidfVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['stem'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
```
#### CountVectorizer, bigram, on 'stem'
```
vcBayesInput = []
vec_tfidf_bi = CountVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['stem'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
```
#### TF-IDF, bigram, on 'lemm'
```
vcBayesInput = []
vec_tfidf_bi = TfidfVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['lemm'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
```
#### CountVectorizer, bigram, on 'lemm'
```
vcBayesInput = []
vec_tfidf_bi = CountVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['lemm'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
```
|
github_jupyter
|
import pandas as pd
result = pd.read_csv('editeddata.csv')
result
from nltk.classify import NaiveBayesClassifier
import nltk.classify.util as cu
import random
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.corpus import stopwords
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
vcBayesInput = []
vec_tfidf_bi = TfidfVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['stem'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
vcBayesInput = []
vec_tfidf_bi = CountVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['stem'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
vcBayesInput = []
vec_tfidf_bi = TfidfVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['lemm'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
vcBayesInput = []
vec_tfidf_bi = CountVectorizer(analyzer = 'word', ngram_range=(1,2),stop_words='english')
x=result['lemm'].values
y=result['newstype'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0,test_size=0.25)
for i in range(len(x_train)):
word_count = {}
X = vec_tfidf_bi.fit_transform([x_train[i]]).toarray()
features = vec_tfidf_bi.get_feature_names()
for j in range(len(features)):
word_count[features[j]] = X[0][j]
vcBayesInput.append((word_count, "fake" if y_train[i] == 0 else "true"))
random.seed(12)
random.shuffle(vcBayesInput)
size = len(vcBayesInput)
train_size = int(0.8 * size)
train_set, test_set = vcBayesInput[0:train_size], vcBayesInput[train_size:size]
model = NaiveBayesClassifier.train(train_set)
ac = cu.accuracy(model, test_set)
print(ac)
model.show_most_informative_features(20)
| 0.204183 | 0.683091 |
# Named Entity Recognition using Transformers
**Author:** [Varun Singh](https://www.linkedin.com/in/varunsingh2/)<br>
**Date created:** Jun 23, 2021<br>
**Last modified:** Jun 24, 2021<br>
**Description:** NER using the Transformers and data from CoNLL 2003 shared task.
## Introduction
Named Entity Recognition (NER) is the process of identifying named entities in text.
Example of named entities are: "Person", "Location", "Organization", "Dates" etc. NER is
essentially a token classification task where every token is classified into one or more
predetermined categories.
In this exercise, we will train a simple Transformer based model to perform NER. We will
be using the data from CoNLL 2003 shared task. For more information about the dataset,
please visit [the dataset website](https://www.clips.uantwerpen.be/conll2003/ner/).
However, since obtaining this data requires an additional step of getting a free license, we will be using
HuggingFace's datasets library which contains a processed version of this dataset.
## Install the open source datasets library from HuggingFace
```
!pip3 install datasets
!wget https://raw.githubusercontent.com/sighsmile/conlleval/master/conlleval.py
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from datasets import load_dataset
from collections import Counter
from conlleval import evaluate
```
We will be using the transformer implementation from this fantastic
[example](https://keras.io/examples/nlp/text_classification_with_transformer/).
Let's start by defining a `TransformerBlock` layer:
```
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = keras.layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.ffn = keras.Sequential(
[
keras.layers.Dense(ff_dim, activation="relu"),
keras.layers.Dense(embed_dim),
]
)
self.layernorm1 = keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = keras.layers.Dropout(rate)
self.dropout2 = keras.layers.Dropout(rate)
def call(self, inputs, training=False):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
```
Next, let's define a `TokenAndPositionEmbedding` layer:
```
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = keras.layers.Embedding(
input_dim=vocab_size, output_dim=embed_dim
)
self.pos_emb = keras.layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, inputs):
maxlen = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
position_embeddings = self.pos_emb(positions)
token_embeddings = self.token_emb(inputs)
return token_embeddings + position_embeddings
```
## Build the NER model class as a `keras.Model` subclass
```
class NERModel(keras.Model):
def __init__(
self, num_tags, vocab_size, maxlen=128, embed_dim=32, num_heads=2, ff_dim=32
):
super(NERModel, self).__init__()
self.embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
self.transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
self.dropout1 = layers.Dropout(0.1)
self.ff = layers.Dense(ff_dim, activation="relu")
self.dropout2 = layers.Dropout(0.1)
self.ff_final = layers.Dense(num_tags, activation="softmax")
def call(self, inputs, training=False):
x = self.embedding_layer(inputs)
x = self.transformer_block(x)
x = self.dropout1(x, training=training)
x = self.ff(x)
x = self.dropout2(x, training=training)
x = self.ff_final(x)
return x
```
## Load the CoNLL 2003 dataset from the datasets library and process it
```
conll_data = load_dataset("conll2003")
```
We will export this data to a tab-separated file format which will be easy to read as a
`tf.data.Dataset` object.
```
def export_to_file(export_file_path, data):
with open(export_file_path, "w") as f:
for record in data:
ner_tags = record["ner_tags"]
tokens = record["tokens"]
f.write(
str(len(tokens))
+ "\t"
+ "\t".join(tokens)
+ "\t"
+ "\t".join(map(str, ner_tags))
+ "\n"
)
os.mkdir("data")
export_to_file("./data/conll_train.txt", conll_data["train"])
export_to_file("./data/conll_val.txt", conll_data["validation"])
```
## Make the NER label lookup table
NER labels are usually provided in IOB, IOB2 or IOBES formats. Checkout this link for
more information:
[Wikipedia](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging))
Note that we start our label numbering from 1 since 0 will be reserved for padding. We
have a total of 10 labels: 9 from the NER dataset and one for padding.
```
def make_tag_lookup_table():
iob_labels = ["B", "I"]
ner_labels = ["PER", "ORG", "LOC", "MISC"]
all_labels = [(label1, label2) for label2 in ner_labels for label1 in iob_labels]
all_labels = ["-".join([a, b]) for a, b in all_labels]
all_labels = ["[PAD]", "O"] + all_labels
return dict(zip(range(0, len(all_labels) + 1), all_labels))
mapping = make_tag_lookup_table()
print(mapping)
```
Get a list of all tokens in the training dataset. This will be used to create the
vocabulary.
```
all_tokens = sum(conll_data["train"]["tokens"], [])
all_tokens_array = np.array(list(map(str.lower, all_tokens)))
counter = Counter(all_tokens_array)
print(len(counter))
num_tags = len(mapping)
vocab_size = 20000
# We only take (vocab_size - 2) most commons words from the training data since
# the `StringLookup` class uses 2 additional tokens - one denoting an unknown
# token and another one denoting a masking token
vocabulary = [token for token, count in counter.most_common(vocab_size - 2)]
# The StringLook class will convert tokens to token IDs
lookup_layer = keras.layers.experimental.preprocessing.StringLookup(
vocabulary=vocabulary
)
```
Create 2 new `Dataset` objects from the training and validation data
```
train_data = tf.data.TextLineDataset("./data/conll_train.txt")
val_data = tf.data.TextLineDataset("./data/conll_val.txt")
```
Print out one line to make sure it looks good. The first record in the line is the number of tokens.
After that we will have all the tokens followed by all the ner tags.
```
print(list(train_data.take(1).as_numpy_iterator()))
```
We will be using the following map function to transform the data in the dataset:
```
def map_record_to_training_data(record):
record = tf.strings.split(record, sep="\t")
length = tf.strings.to_number(record[0], out_type=tf.int32)
tokens = record[1 : length + 1]
tags = record[length + 1 :]
tags = tf.strings.to_number(tags, out_type=tf.int64)
tags += 1
return tokens, tags
def lowercase_and_convert_to_ids(tokens):
tokens = tf.strings.lower(tokens)
return lookup_layer(tokens)
# We use `padded_batch` here because each record in the dataset has a
# different length.
batch_size = 32
train_dataset = (
train_data.map(map_record_to_training_data)
.map(lambda x, y: (lowercase_and_convert_to_ids(x), y))
.padded_batch(batch_size)
)
val_dataset = (
val_data.map(map_record_to_training_data)
.map(lambda x, y: (lowercase_and_convert_to_ids(x), y))
.padded_batch(batch_size)
)
ner_model = NERModel(num_tags, vocab_size, embed_dim=32, num_heads=4, ff_dim=64)
```
We will be using a custom loss function that will ignore the loss from padded tokens.
```
class CustomNonPaddingTokenLoss(keras.losses.Loss):
def __init__(self, name="custom_ner_loss"):
super().__init__(name=name)
def call(self, y_true, y_pred):
loss_fn = keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction=keras.losses.Reduction.NONE
)
loss = loss_fn(y_true, y_pred)
mask = tf.cast((y_true > 0), dtype=tf.float32)
loss = loss * mask
return tf.reduce_sum(loss) / tf.reduce_sum(mask)
loss = CustomNonPaddingTokenLoss()
```
## Compile and fit the model
```
ner_model.compile(optimizer="adam", loss=loss)
ner_model.fit(train_dataset, epochs=10)
def tokenize_and_convert_to_ids(text):
tokens = text.split()
return lowercase_and_convert_to_ids(tokens)
# Sample inference using the trained model
sample_input = tokenize_and_convert_to_ids(
"eu rejects german call to boycott british lamb"
)
sample_input = tf.reshape(sample_input, shape=[1, -1])
print(sample_input)
output = ner_model.predict(sample_input)
prediction = np.argmax(output, axis=-1)[0]
prediction = [mapping[i] for i in prediction]
# eu -> B-ORG, german -> B-MISC, british -> B-MISC
print(prediction)
```
## Metrics calculation
Here is a function to calculate the metrics. The function calculates F1 score for the
overall NER dataset as well as individual scores for each NER tag.
```
def calculate_metrics(dataset):
all_true_tag_ids, all_predicted_tag_ids = [], []
for x, y in dataset:
output = ner_model.predict(x)
predictions = np.argmax(output, axis=-1)
predictions = np.reshape(predictions, [-1])
true_tag_ids = np.reshape(y, [-1])
mask = (true_tag_ids > 0) & (predictions > 0)
true_tag_ids = true_tag_ids[mask]
predicted_tag_ids = predictions[mask]
all_true_tag_ids.append(true_tag_ids)
all_predicted_tag_ids.append(predicted_tag_ids)
all_true_tag_ids = np.concatenate(all_true_tag_ids)
all_predicted_tag_ids = np.concatenate(all_predicted_tag_ids)
predicted_tags = [mapping[tag] for tag in all_predicted_tag_ids]
real_tags = [mapping[tag] for tag in all_true_tag_ids]
evaluate(real_tags, predicted_tags)
calculate_metrics(val_dataset)
```
## Conclusions
In this exercise, we created a simple transformer based named entity recognition model.
We trained it on the CoNLL 2003 shared task data and got an overall F1 score of around 70%.
State of the art NER models fine-tuned on pretrained models such as BERT or ELECTRA can easily
get much higher F1 score -between 90-95% on this dataset owing to the inherent knowledge
of words as part of the pretraining process and the usage of subword tokenization.
|
github_jupyter
|
!pip3 install datasets
!wget https://raw.githubusercontent.com/sighsmile/conlleval/master/conlleval.py
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from datasets import load_dataset
from collections import Counter
from conlleval import evaluate
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = keras.layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.ffn = keras.Sequential(
[
keras.layers.Dense(ff_dim, activation="relu"),
keras.layers.Dense(embed_dim),
]
)
self.layernorm1 = keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = keras.layers.Dropout(rate)
self.dropout2 = keras.layers.Dropout(rate)
def call(self, inputs, training=False):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
class TokenAndPositionEmbedding(layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = keras.layers.Embedding(
input_dim=vocab_size, output_dim=embed_dim
)
self.pos_emb = keras.layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
def call(self, inputs):
maxlen = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=maxlen, delta=1)
position_embeddings = self.pos_emb(positions)
token_embeddings = self.token_emb(inputs)
return token_embeddings + position_embeddings
class NERModel(keras.Model):
def __init__(
self, num_tags, vocab_size, maxlen=128, embed_dim=32, num_heads=2, ff_dim=32
):
super(NERModel, self).__init__()
self.embedding_layer = TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim)
self.transformer_block = TransformerBlock(embed_dim, num_heads, ff_dim)
self.dropout1 = layers.Dropout(0.1)
self.ff = layers.Dense(ff_dim, activation="relu")
self.dropout2 = layers.Dropout(0.1)
self.ff_final = layers.Dense(num_tags, activation="softmax")
def call(self, inputs, training=False):
x = self.embedding_layer(inputs)
x = self.transformer_block(x)
x = self.dropout1(x, training=training)
x = self.ff(x)
x = self.dropout2(x, training=training)
x = self.ff_final(x)
return x
conll_data = load_dataset("conll2003")
def export_to_file(export_file_path, data):
with open(export_file_path, "w") as f:
for record in data:
ner_tags = record["ner_tags"]
tokens = record["tokens"]
f.write(
str(len(tokens))
+ "\t"
+ "\t".join(tokens)
+ "\t"
+ "\t".join(map(str, ner_tags))
+ "\n"
)
os.mkdir("data")
export_to_file("./data/conll_train.txt", conll_data["train"])
export_to_file("./data/conll_val.txt", conll_data["validation"])
def make_tag_lookup_table():
iob_labels = ["B", "I"]
ner_labels = ["PER", "ORG", "LOC", "MISC"]
all_labels = [(label1, label2) for label2 in ner_labels for label1 in iob_labels]
all_labels = ["-".join([a, b]) for a, b in all_labels]
all_labels = ["[PAD]", "O"] + all_labels
return dict(zip(range(0, len(all_labels) + 1), all_labels))
mapping = make_tag_lookup_table()
print(mapping)
all_tokens = sum(conll_data["train"]["tokens"], [])
all_tokens_array = np.array(list(map(str.lower, all_tokens)))
counter = Counter(all_tokens_array)
print(len(counter))
num_tags = len(mapping)
vocab_size = 20000
# We only take (vocab_size - 2) most commons words from the training data since
# the `StringLookup` class uses 2 additional tokens - one denoting an unknown
# token and another one denoting a masking token
vocabulary = [token for token, count in counter.most_common(vocab_size - 2)]
# The StringLook class will convert tokens to token IDs
lookup_layer = keras.layers.experimental.preprocessing.StringLookup(
vocabulary=vocabulary
)
train_data = tf.data.TextLineDataset("./data/conll_train.txt")
val_data = tf.data.TextLineDataset("./data/conll_val.txt")
print(list(train_data.take(1).as_numpy_iterator()))
def map_record_to_training_data(record):
record = tf.strings.split(record, sep="\t")
length = tf.strings.to_number(record[0], out_type=tf.int32)
tokens = record[1 : length + 1]
tags = record[length + 1 :]
tags = tf.strings.to_number(tags, out_type=tf.int64)
tags += 1
return tokens, tags
def lowercase_and_convert_to_ids(tokens):
tokens = tf.strings.lower(tokens)
return lookup_layer(tokens)
# We use `padded_batch` here because each record in the dataset has a
# different length.
batch_size = 32
train_dataset = (
train_data.map(map_record_to_training_data)
.map(lambda x, y: (lowercase_and_convert_to_ids(x), y))
.padded_batch(batch_size)
)
val_dataset = (
val_data.map(map_record_to_training_data)
.map(lambda x, y: (lowercase_and_convert_to_ids(x), y))
.padded_batch(batch_size)
)
ner_model = NERModel(num_tags, vocab_size, embed_dim=32, num_heads=4, ff_dim=64)
class CustomNonPaddingTokenLoss(keras.losses.Loss):
def __init__(self, name="custom_ner_loss"):
super().__init__(name=name)
def call(self, y_true, y_pred):
loss_fn = keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction=keras.losses.Reduction.NONE
)
loss = loss_fn(y_true, y_pred)
mask = tf.cast((y_true > 0), dtype=tf.float32)
loss = loss * mask
return tf.reduce_sum(loss) / tf.reduce_sum(mask)
loss = CustomNonPaddingTokenLoss()
ner_model.compile(optimizer="adam", loss=loss)
ner_model.fit(train_dataset, epochs=10)
def tokenize_and_convert_to_ids(text):
tokens = text.split()
return lowercase_and_convert_to_ids(tokens)
# Sample inference using the trained model
sample_input = tokenize_and_convert_to_ids(
"eu rejects german call to boycott british lamb"
)
sample_input = tf.reshape(sample_input, shape=[1, -1])
print(sample_input)
output = ner_model.predict(sample_input)
prediction = np.argmax(output, axis=-1)[0]
prediction = [mapping[i] for i in prediction]
# eu -> B-ORG, german -> B-MISC, british -> B-MISC
print(prediction)
def calculate_metrics(dataset):
all_true_tag_ids, all_predicted_tag_ids = [], []
for x, y in dataset:
output = ner_model.predict(x)
predictions = np.argmax(output, axis=-1)
predictions = np.reshape(predictions, [-1])
true_tag_ids = np.reshape(y, [-1])
mask = (true_tag_ids > 0) & (predictions > 0)
true_tag_ids = true_tag_ids[mask]
predicted_tag_ids = predictions[mask]
all_true_tag_ids.append(true_tag_ids)
all_predicted_tag_ids.append(predicted_tag_ids)
all_true_tag_ids = np.concatenate(all_true_tag_ids)
all_predicted_tag_ids = np.concatenate(all_predicted_tag_ids)
predicted_tags = [mapping[tag] for tag in all_predicted_tag_ids]
real_tags = [mapping[tag] for tag in all_true_tag_ids]
evaluate(real_tags, predicted_tags)
calculate_metrics(val_dataset)
| 0.889966 | 0.936807 |
# Machine Learning
> A Summary of lecture "Introduction to Computational Thinking and Data Science", via MITx-6.00.2x (edX)
- toc: true
- badges: true
- comments: true
- author: Chanseok Kang
- categories: [Python, edX, Machine_Learning]
- image: images/ml_block.png
- What is Machine Learning
- Many useful programs learn something
> Note: "Field of study that gives computers the ability to learn without being explicitly programmed" - Arthur Samuel
- Modern statistics meets optimization

- Basic Paradigm
- Observe set of examples: **training data**
- Infer something about process that generated that data
- Use inference to make predictions about previously unseen data: **test data**
- All ML Methods Require
- Representation of the features
- Distance metric for feature vectors
- Objective function and constraints
- Optimization method for learning the model
- Evaluation method
- Supervised Learning
- Start with set of feature vector / value pairs
- Goal : find a model that predicts a value for a previously unseen feature vector
- **Regression** models predict a real
- E.g. linear regression
- **Classification** models predict a label (chosen from a finite set of labels)
- Unsupervied Learning
- Start with a set of feature vectors
- Goal : uncover some latent structure in the set of feature vectors
- **Clustering** the most common technique
- Define some metric that captures how similar one feature vector is to another
- Group examples based on this metric
- Choosing Features
- Features never fully describe the situation
- Feature Engineering
- Represent examples by feature vectors that will facilitate generalization
- Suppose I want to use 100 examples from past to predict which students will pass the final exam
- Some features surely helpful, e.g., their grade on the midterm, did they do the problem sets, etc.
- Others might cause me to overfit, e.g., birth month
- Whant to maximize ratio of useful input to irrelevant input
- Signal-to-Noise Ratio (SNR)
- K-Nearest Neighbors
- Distance between vectors
- Minkowski metric
$$ dist(X_1, X_2, p) = (\sum_{k=1}^{len}abs({X_1}_k - {X_2}_k)^p)^{\frac{1}{p}} \\
p=1 : \text{Manhattan Distance} \\
p=2 : \text{Euclidean Distance}$$
```
from lecture12_segment2 import *
cobra = Animal('cobra', [1,1,1,1,0])
rattlesnake = Animal('rattlesnake', [1,1,1,1,0])
boa = Animal('boa\nconstrictor', [0,1,0,1,0])
chicken = Animal('chicken', [1,1,0,1,2])
alligator = Animal('alligator', [1,1,0,1,4])
dartFrog = Animal('dart frog', [1,0,1,0,4])
zebra = Animal('zebra', [0,0,0,0,4])
python = Animal('python', [1,1,0,1,0])
guppy = Animal('guppy', [0,1,0,0,0])
animals = [cobra, rattlesnake, boa, chicken, guppy,
dartFrog, zebra, python, alligator]
compareAnimals(animals, 3) # k=3
```
- Using Distance Matrix for classification
- Simplest approach is probably nearest neighbor
- Remember training data
- When predicting the label of a new example
- Find the nearest example in the training data
- Predict the label associated with that example
- Advantage and Disadvantage of KNN
- Advantages
- Learning fase, no explicit training
- No theory required
- Easy to explain method and results
- Disadvantages
- Memory intensive and predictions can take a long time
- Are better algorithms than brute force
- No model to shed light on process that generated data
```
# Applying scaling
cobra = Animal('cobra', [1,1,1,1,0])
rattlesnake = Animal('rattlesnake', [1,1,1,1,0])
boa = Animal('boa\nconstrictor', [0,1,0,1,0])
chicken = Animal('chicken', [1,1,0,1,2])
alligator = Animal('alligator', [1,1,0,1,1])
dartFrog = Animal('dart frog', [1,0,1,0,1])
zebra = Animal('zebra', [0,0,0,0,1])
python = Animal('python', [1,1,0,1,0])
guppy = Animal('guppy', [0,1,0,0,0])
animals = [cobra, rattlesnake, boa, chicken, guppy,
dartFrog, zebra, python, alligator]
compareAnimals(animals, 3) k = 3
```
- A more General Approach: Scaling
- Z-scaling
- Each feature has a mean of 0 & a standard deviation of 1
- Interpolation
- Map minimum value to 0, maximum value to 1, and linearly interpolate
```python
def zScaleFeatures(vals):
"""Assumes vals is a sequence of floats"""
result = np.array(vals)
mean = np.mean(vals)
result = result - mean
return result/np.std(result)
def iScaleFeatures(vals):
"""Assumes vals is a sequence of floats"""
minVal, maxVal = min(vals), max(vals)
fit = np.polyfit([minVal, maxVal], [0, 1], 1)
return np.polyval(fit, vals)
```
- Clustering
- Partition examples into groups (clusters) such that examples in a group are more similar to each other than to examples in other groups
- Unlike classification, there is not typically a "right answer"
- Answer dictated by feature vector and distance metric, not by a group truth label
- Optimization Problem
$$ variability(c) = \sum_{e \in c} distance(mean(c), e)^2 \\
dissimilarity(C) = \sum_{c \in C} variability(c) \\
c :\text{one cluster} \\
C : \text{all of the clusters}$$
- Why not divide variability by size of cluster?
- Big and bad worse than small and bad
- Is optimization problem finding a $C$ that minimizes $dissimilarity(C)$?
- No, otherwise could put each example in its own cluster
- Need constraints, e.g.
- Minimum distance between clusters
- Number of clusters
- K-means Clustering
- Constraint: exactly k non-empty clusters
- Use a greedy algorithm to find an approximation to minimizing objective function
- Algorithm
```
randomly chose k examples as initial centroids
while true:
create k clusters by assigning each example to closest centroid
compute k new centroids by averaging examples in each cluster
if centroids don`t change:
break
```
```
from lecture12_segment3 import *
centers = [(2, 3), (4, 6), (7, 4), (7,7)]
examples = []
random.seed(0)
for c in centers:
for i in range(5):
xVal = (c[0] + random.gauss(0, .5))
yVal = (c[1] + random.gauss(0, .5))
name = str(c) + '-' + str(i)
example = Example(name, pylab.array([xVal, yVal]))
examples.append(example)
xVals, yVals = [], []
for e in examples:
xVals.append(e.getFeatures()[0])
yVals.append(e.getFeatures()[1])
random.seed(2)
kmeans(examples, 4, True)
```
- Mitigating Dependence on Initial Centroids
```python
best = kMeans(points)
for t in range(numTrials):
C = kMeans(points)
if dissimilarity(C) < dissimilarity(best):
best = C
return best
```
- A Pretty Example
- User k-means to cluster groups of pixels in an image by their color
- Get the color associated with the centroid of each cluster, i.e., the average color of the cluster
- For each pixel in the original image, find the centroid that is its nearest neighbor
- Replaced the pixel by that centroid
|
github_jupyter
|
from lecture12_segment2 import *
cobra = Animal('cobra', [1,1,1,1,0])
rattlesnake = Animal('rattlesnake', [1,1,1,1,0])
boa = Animal('boa\nconstrictor', [0,1,0,1,0])
chicken = Animal('chicken', [1,1,0,1,2])
alligator = Animal('alligator', [1,1,0,1,4])
dartFrog = Animal('dart frog', [1,0,1,0,4])
zebra = Animal('zebra', [0,0,0,0,4])
python = Animal('python', [1,1,0,1,0])
guppy = Animal('guppy', [0,1,0,0,0])
animals = [cobra, rattlesnake, boa, chicken, guppy,
dartFrog, zebra, python, alligator]
compareAnimals(animals, 3) # k=3
# Applying scaling
cobra = Animal('cobra', [1,1,1,1,0])
rattlesnake = Animal('rattlesnake', [1,1,1,1,0])
boa = Animal('boa\nconstrictor', [0,1,0,1,0])
chicken = Animal('chicken', [1,1,0,1,2])
alligator = Animal('alligator', [1,1,0,1,1])
dartFrog = Animal('dart frog', [1,0,1,0,1])
zebra = Animal('zebra', [0,0,0,0,1])
python = Animal('python', [1,1,0,1,0])
guppy = Animal('guppy', [0,1,0,0,0])
animals = [cobra, rattlesnake, boa, chicken, guppy,
dartFrog, zebra, python, alligator]
compareAnimals(animals, 3) k = 3
def zScaleFeatures(vals):
"""Assumes vals is a sequence of floats"""
result = np.array(vals)
mean = np.mean(vals)
result = result - mean
return result/np.std(result)
def iScaleFeatures(vals):
"""Assumes vals is a sequence of floats"""
minVal, maxVal = min(vals), max(vals)
fit = np.polyfit([minVal, maxVal], [0, 1], 1)
return np.polyval(fit, vals)
randomly chose k examples as initial centroids
while true:
create k clusters by assigning each example to closest centroid
compute k new centroids by averaging examples in each cluster
if centroids don`t change:
break
from lecture12_segment3 import *
centers = [(2, 3), (4, 6), (7, 4), (7,7)]
examples = []
random.seed(0)
for c in centers:
for i in range(5):
xVal = (c[0] + random.gauss(0, .5))
yVal = (c[1] + random.gauss(0, .5))
name = str(c) + '-' + str(i)
example = Example(name, pylab.array([xVal, yVal]))
examples.append(example)
xVals, yVals = [], []
for e in examples:
xVals.append(e.getFeatures()[0])
yVals.append(e.getFeatures()[1])
random.seed(2)
kmeans(examples, 4, True)
best = kMeans(points)
for t in range(numTrials):
C = kMeans(points)
if dissimilarity(C) < dissimilarity(best):
best = C
return best
| 0.641759 | 0.984246 |
# Retrieve Tweets
Takes a list of tweet IDs and outputs the full tweet dataset. When the script hits Twitter's API limit, it will automatically wait and restart after the appropriate amount of time. Because of the API rate limiting, this script could take up to a few hours.
```
import pandas as pd
import tweepy
import csv
# Insert your Twitter API key here
consumer_key = ''
consumer_secret = ''
access_token = ''
access_secret = ''
def retrieve_tweets(input_file, output_file):
"""
Takes an input filename/path of tweetIDs and outputs the full tweet data to a csv
"""
# Authorization with Twitter
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True, retry_count=3, retry_delay=5, retry_errors=set([401, 404, 500, 503]))
# Read input file
df = pd.read_csv(input_file)
# Create output file
csvFile = open(output_file, 'w')
csvWriter = csv.writer(csvFile)
csvWriter.writerow(["text",
"created_at",
"geo",
"lang",
"place",
"coordinates",
"user.favourites_count",
"user.statuses_count",
"user.description",
"user.location",
"user.id",
"user.created_at",
"user.verified",
"user.following",
"user.url",
"user.listed_count",
"user.followers_count",
"user.default_profile_image",
"user.utc_offset",
"user.friends_count",
"user.default_profile",
"user.name",
"user.lang",
"user.screen_name",
"user.geo_enabled",
"user.profile_background_color",
"user.profile_image_url",
"user.time_zone",
"id",
"favorite_count",
"retweeted",
"source",
"favorited",
"retweet_count"])
# Append tweets to output file
for tweetid in df.iloc[:,0]:
csvFile = open(output_file, 'a')
csvWriter = csv.writer(csvFile)
try:
status = api.get_status(tweetid)
csvWriter.writerow([status.text,
status.created_at,
status.geo,
status.lang,
status.place,
status.coordinates,
status.user.favourites_count,
status.user.statuses_count,
status.user.description,
status.user.location,
status.user.id,
status.user.created_at,
status.user.verified,
status.user.following,
status.user.url,
status.user.listed_count,
status.user.followers_count,
status.user.default_profile_image,
status.user.utc_offset,
status.user.friends_count,
status.user.default_profile,
status.user.name,
status.user.lang,
status.user.screen_name,
status.user.geo_enabled,
status.user.profile_background_color,
status.user.profile_image_url,
status.user.time_zone,
status.id,
status.favorite_count,
status.retweeted,
status.source,
status.favorited,
status.retweet_count])
except Exception as e:
print(e)
pass
retrieve_tweets('clean_data/clean_data.csv', 'full_tweets.csv')
```
|
github_jupyter
|
import pandas as pd
import tweepy
import csv
# Insert your Twitter API key here
consumer_key = ''
consumer_secret = ''
access_token = ''
access_secret = ''
def retrieve_tweets(input_file, output_file):
"""
Takes an input filename/path of tweetIDs and outputs the full tweet data to a csv
"""
# Authorization with Twitter
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True, retry_count=3, retry_delay=5, retry_errors=set([401, 404, 500, 503]))
# Read input file
df = pd.read_csv(input_file)
# Create output file
csvFile = open(output_file, 'w')
csvWriter = csv.writer(csvFile)
csvWriter.writerow(["text",
"created_at",
"geo",
"lang",
"place",
"coordinates",
"user.favourites_count",
"user.statuses_count",
"user.description",
"user.location",
"user.id",
"user.created_at",
"user.verified",
"user.following",
"user.url",
"user.listed_count",
"user.followers_count",
"user.default_profile_image",
"user.utc_offset",
"user.friends_count",
"user.default_profile",
"user.name",
"user.lang",
"user.screen_name",
"user.geo_enabled",
"user.profile_background_color",
"user.profile_image_url",
"user.time_zone",
"id",
"favorite_count",
"retweeted",
"source",
"favorited",
"retweet_count"])
# Append tweets to output file
for tweetid in df.iloc[:,0]:
csvFile = open(output_file, 'a')
csvWriter = csv.writer(csvFile)
try:
status = api.get_status(tweetid)
csvWriter.writerow([status.text,
status.created_at,
status.geo,
status.lang,
status.place,
status.coordinates,
status.user.favourites_count,
status.user.statuses_count,
status.user.description,
status.user.location,
status.user.id,
status.user.created_at,
status.user.verified,
status.user.following,
status.user.url,
status.user.listed_count,
status.user.followers_count,
status.user.default_profile_image,
status.user.utc_offset,
status.user.friends_count,
status.user.default_profile,
status.user.name,
status.user.lang,
status.user.screen_name,
status.user.geo_enabled,
status.user.profile_background_color,
status.user.profile_image_url,
status.user.time_zone,
status.id,
status.favorite_count,
status.retweeted,
status.source,
status.favorited,
status.retweet_count])
except Exception as e:
print(e)
pass
retrieve_tweets('clean_data/clean_data.csv', 'full_tweets.csv')
| 0.260578 | 0.582966 |
#### New to Plotly?
Plotly's Python library is free and open source! [Get started](https://plot.ly/python/getting-started/) by downloading the client and [reading the primer](https://plot.ly/python/getting-started/).
<br>You can set up Plotly to work in [online](https://plot.ly/python/getting-started/#initialization-for-online-plotting) or [offline](https://plot.ly/python/getting-started/#initialization-for-offline-plotting) mode, or in [jupyter notebooks](https://plot.ly/python/getting-started/#start-plotting-online).
<br>We also have a quick-reference [cheatsheet](https://images.plot.ly/plotly-documentation/images/python_cheat_sheet.pdf) (new!) to help you get started!
#### Version Check
Plotly's python package is updated frequently. Run `pip install plotly --upgrade` to use the latest version.
```
import plotly
plotly.__version__
```
### Basic Time Series Plot
```
import datetime
import matplotlib.pyplot as plt
import numpy as np
import plotly.plotly as py
import plotly.tools as tls
# Learn about API authentication here: https://plot.ly/python/getting-started
# Find your api_key here: https://plot.ly/settings/api
x = np.array([datetime.datetime(2014, i, 9) for i in range(1,13)])
y = np.random.randint(100, size=x.shape)
plt.plot(x,y)
plt.tight_layout()
fig = plt.gcf()
plotly_fig = tls.mpl_to_plotly( fig )
py.iplot(plotly_fig, filename='mpl-time-series')
```
### Time Series With Custom Axis Rnage
```
import datetime
import matplotlib.pyplot as plt
import numpy as np
import plotly.plotly as py
import plotly.tools as tls
# Learn about API authentication here: https://plot.ly/python/getting-started
# Find your api_key here: https://plot.ly/settings/api
x = np.array([datetime.datetime(2014, i, 9) for i in range(1,13)])
y = np.random.randint(100, size=x.shape)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(x,y)
ax1.set_title('Setting Custom Axis Range for time series')
plotly_fig = tls.mpl_to_plotly( fig )
plotly_fig['layout']['xaxis1']['range'] = [1357669800000, 1449599400000]
py.iplot(plotly_fig, filename='mpl-time-series-custom-axis')
```
#### Reference
See [https://plot.ly/python/reference/#layout-xaxis-rangeslider](https://plot.ly/python/reference/#layout-xaxis-rangeslider) and
[https://plot.ly/python/reference/#layout-xaxis-rangeselector](https://plot.ly/python/reference/#layout-xaxis-rangeselector) for more information and chart attribute options!
```
from IPython.display import display, HTML
display(HTML('<link href="//fonts.googleapis.com/css?family=Open+Sans:600,400,300,200|Inconsolata|Ubuntu+Mono:400,700" rel="stylesheet" type="text/css" />'))
display(HTML('<link rel="stylesheet" type="text/css" href="http://help.plot.ly/documentation/all_static/css/ipython-notebook-custom.css">'))
! pip install git+https://github.com/plotly/publisher.git --upgrade
import publisher
publisher.publish(
'matplotlib_timeseries.ipynb', '/matplotlib/time-series/', 'Matplotlib Time Series',
'How to make time series plots in Matplotlib with Plotly.',
title = 'Matplotlib Time Series | Plotly',
has_thumbnail='true', thumbnail='thumbnail/time-series.jpg',
language='matplotlib',
page_type='example_index',
display_as='basic', order=7)
```
|
github_jupyter
|
import plotly
plotly.__version__
import datetime
import matplotlib.pyplot as plt
import numpy as np
import plotly.plotly as py
import plotly.tools as tls
# Learn about API authentication here: https://plot.ly/python/getting-started
# Find your api_key here: https://plot.ly/settings/api
x = np.array([datetime.datetime(2014, i, 9) for i in range(1,13)])
y = np.random.randint(100, size=x.shape)
plt.plot(x,y)
plt.tight_layout()
fig = plt.gcf()
plotly_fig = tls.mpl_to_plotly( fig )
py.iplot(plotly_fig, filename='mpl-time-series')
import datetime
import matplotlib.pyplot as plt
import numpy as np
import plotly.plotly as py
import plotly.tools as tls
# Learn about API authentication here: https://plot.ly/python/getting-started
# Find your api_key here: https://plot.ly/settings/api
x = np.array([datetime.datetime(2014, i, 9) for i in range(1,13)])
y = np.random.randint(100, size=x.shape)
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(x,y)
ax1.set_title('Setting Custom Axis Range for time series')
plotly_fig = tls.mpl_to_plotly( fig )
plotly_fig['layout']['xaxis1']['range'] = [1357669800000, 1449599400000]
py.iplot(plotly_fig, filename='mpl-time-series-custom-axis')
from IPython.display import display, HTML
display(HTML('<link href="//fonts.googleapis.com/css?family=Open+Sans:600,400,300,200|Inconsolata|Ubuntu+Mono:400,700" rel="stylesheet" type="text/css" />'))
display(HTML('<link rel="stylesheet" type="text/css" href="http://help.plot.ly/documentation/all_static/css/ipython-notebook-custom.css">'))
! pip install git+https://github.com/plotly/publisher.git --upgrade
import publisher
publisher.publish(
'matplotlib_timeseries.ipynb', '/matplotlib/time-series/', 'Matplotlib Time Series',
'How to make time series plots in Matplotlib with Plotly.',
title = 'Matplotlib Time Series | Plotly',
has_thumbnail='true', thumbnail='thumbnail/time-series.jpg',
language='matplotlib',
page_type='example_index',
display_as='basic', order=7)
| 0.568296 | 0.919027 |
```
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from processwx import select_stn, process_stn
%matplotlib inline
%config InlineBackend.figure_format='retina'
```
# EDA with Teton avalanche observations and hazard forecasts
I've already preprocessed the avalanche events and forecasts, so we'll just load them into dataframes here:
```
events_df = pd.read_csv('btac_events.csv.gz', compression='gzip',
index_col=[0], parse_dates = [2])
hzrd_df = pd.read_csv('btac_nowcast_teton.csv.gz', compression='gzip',
index_col=[0], parse_dates=[0])
```
Since we dont't have hazard forecasts for non-Jackson regions, let's filter events in those areas out. I infer the
list of zones from the [BTAC obs page](http://jhavalanche.org/observations/viewObs).
```
zones = ['101','102','103','104','105','106','JHMR','GT','SK']
df1 = events_df[events_df['zone'].isin(zones)]
```
Let's take a look at the event data. The first 10 columns contain data on the time, location, and characteristics of the slide path:
```
df1[df1.columns[0:10]].head(10)
```
These fields are largely self explanatory; elevation is reported in feet above mean sea level.
After that, we get details on the size, type, and trigger for the avalanche, as well as the number of people killed:
```
df1[df1.columns[10:16]].head(10)
```
A guide to avalanche terminology and codes is available [here](http://www.americanavalancheassociation.org/pdf/Avalanche_data_codes.pdf). Destructive size and relative size describe the magnitude of the slide, depth is the initial thickness in inches of the snow slab that slides. The trigger describes the source of the disturbance causing the slide, while type describes the nature of the slab.
Finally, we get notes and info on the reporting individual, if available:
```
df1[df1.columns[16:]].head(10)
```
Let's look at a quick count of the events in our database by year:
```
per = df1['event_date'].dt.to_period("M");
g = df1.groupby(per);
s1 = g['ID'].count();
fig, ax = plt.subplots(1,1,figsize=(16,6));
s1 = s1.resample('M').sum();
s1.plot(kind='bar', ax=ax, title='Avalanche event counts', rot=65);
ticks = ax.xaxis.get_ticklocs();
ticklabels = [l.get_text() for l in ax.xaxis.get_ticklabels()];
ax.xaxis.set_ticks(ticks[::3]);
ax.xaxis.set_ticklabels(ticklabels[::3]);
ax.set_xlabel('date');
ax.set_ylabel('count');
```
What's going on here? It turns out initially, the only events in our data are serious accidents. In the winter of 2009-2010, the ski patrol at Jackson Hole began reporting the results of their avalanche control work, and a broader range of non-accident reports from skiers and snowmobilers are included. The raw observation counts are thus tricky to compare from year to year.
```
per = df1['event_date'].dt.to_period("M");
g = df1.groupby(per);
s2 = g['fatality'].sum().astype(int);
fig, ax = plt.subplots(1,1,figsize=(16,6));
s2 = s2.resample('M').sum();
s2.plot(kind='bar', ax=ax, title='Monthly fatal avalanche events', rot=65);
ticks = ax.xaxis.get_ticklocs();
ticklabels = [l.get_text() for l in ax.xaxis.get_ticklabels()];
ax.xaxis.set_ticks(ticks[::3]);
ax.xaxis.set_ticklabels(ticklabels[::3]);
ax.set_xlabel('date');
ax.set_ylabel('count');
print("Total fatalities:",s2.sum())
```
So in our 16 year record, we have 25 avalanche fatalities in the jackson hole region. With such a small sample, hard to see any particular pattern.
Let's start examining these events in the context of the avalanche forecasts. First, the data (last 5 days shown):
```
hzrd_df.tail(10)
```
Each column is for a specific terrain elevation (atl is "above treeline", tl is "treeline", btl is "below treeline"), representing the forecast hazard level from 1-5 (low to extreme). The equivalent elevation bands are 6000-7500ft, 7500-9000ft, and 9000-10500ft. The daily bulletin gives an expected hazard for the morning and afternoon - in late winter and spring, the longer days and warming temperatures can create significant intrady increases in hazard. This is what the hazard looked like over the course of the 2008-2009 season:
```
s = ('2008-10-31','2009-5-31')
#s = ('2013-10-31','2014-5-31')
#s =('2016-10-31','2017-5-31')
ax = hzrd_df.loc[s[0]:s[1],['atl','tl','btl']].plot(figsize=(16,6),rot=45);
ax.set_ylim([0,5]);
ax.set_ylabel('Avalanche Danger');
```
Peak hazard occurred in late December to early January. The increased intraday variation in hazard is visible from March forward, with higher hazard in the afternoons.
What forecast conditions have the highest number of fatalities? We don't have a very impressive sample with just one region of a single state, but we can at least see how to approach it. We want to extract the appropriate forecast hazard for the date and elevation where fatalities occurred.
First, we make a function to categorize elevations:
```
def elevation_category(elevation):
if (6000. < elevation <= 7500.):
return 'btl'
elif (7500. < elevation <= 9000.):
return 'tl'
elif (9000. < elevation <= 10500.):
return 'atl'
else:
return None
```
Next we augment the event frame with the elevation category in which the slide occurred:
```
df1.is_copy=False
df1['el_cat'] = df1['elevation'].apply(lambda x: elevation_category(x))
```
We next average the morning and afternoon hazard levels, then stack and reindex the hazard frame in preparation for a left outer join with the event frame:
```
df2 = hzrd_df[['atl','tl','btl']].resample('D').mean().stack()
df2 = df2.reset_index()
df2.columns = ['event_date','el_cat','hazard']
df2.head()
```
Finally, we merge these frames, then restrict the analysis to fatal accidents. While the sample size is small, we recover the frequently noted result that more fatal accidents occur during "Considerable" forecast hazard than "High" or "Extreme". This is both the result of the underlying hazard frequency (there are more "Considerable" days than "High" or "Extreme" days) and psychology (fewer people choose to recreate in avalanche terrain when the forecast danger is above "Considerable").
```
df3 = pd.merge(df1, df2, how='left', left_on=['event_date','el_cat'], right_on=['event_date','el_cat'])
df4 = df3[df3['fatality']>0]
df4['hazard'].plot(kind='hist', title='Fatalities by avalanche forecast hazard',
xlim=[0,5], bins=20, figsize=(6,6));
```
The stacked histogram of forecast avalanche danger by elevation category has a lognormal character.
```
hzrd_df[['atl','tl','btl']].plot(kind='hist', stacked=True,
xlim=[0,5], bins=20, figsize=(6,6));
```
The raw count of avalanches by hazard rating is given below:
```
g = df3.groupby(by='hazard');
g['ID'].count()
```
and here, raw counts of forecasts per hazard rating
```
atl1, b = np.histogram(hzrd_df['atl'], bins=20);
tl1, _ = np.histogram(hzrd_df['tl'], bins=20);
btl1, _ = np.histogram(hzrd_df['btl'], bins=20);
atl1 + tl1 + btl1
b
```
While this is "quick and dirty", the forecast frequence weighted avalanche occurrence suggests there are about three events per fcst at "high" and "extreme" hazard, about one per forecast at "considerable", less than 1/3 per forecast at "moderate", and 1/40 per forecast at "low".
A quick addendum, adding thresholds for destructive size:
```
g = df3[(1 < df3['hazard']) & (df3['hazard'] <= 2)].groupby(by='destructive_size');
sz_2 = g['ID'].count()
g = df3[(2 < df3['hazard']) & (df3['hazard'] <= 3)].groupby(by='destructive_size');
sz_3 = g['ID'].count()
g = df3[(3 < df3['hazard']) & (df3['hazard'] <= 4)].groupby(by='destructive_size');
sz_4 = g['ID'].count()
g = df3[(4 < df3['hazard']) & (df3['hazard'] <= 5)].groupby(by='destructive_size');
sz_5 = g['ID'].count()
print(sz_2,sz_3,sz_4,sz_5)
```
# Weather
Having examined avalanche forecasts and observations, the next challenge is to address the driving variable: weather. We'll take a quick look at some station data from Jackson Hole.
First, let's look at the data sources available. I've coded a handy utility to help pick out useful stations. Let's find the ten nearest Jackson Hole, with (lat, lon) = (43.572236,-110.8496103):
```
df = select_stn('./wxdata',{'k_nrst': 10, 'lat_lon': (43.572236,-110.8496103)}, return_df=True)
df.head(10)
wx_df = process_stn('./wxdata', 'JHR');
```
Let's look at air temp during the winter of 2008-2009:
```
wx_df.loc['2008-10-31':'2009-05-31','air_temp_set_1'].plot(figsize=(16,6));
```
That looks pretty good. If we look at the whole series though, there are some issues:
```
wx_df['air_temp_set_1'].plot(figsize=(16,6));
```
At this resolution, we basically see the annual cycle for the period when the temperature sensor is reporting, but there are some obvious issues. Let's look at the period of 2011-2014 to explore this:
```
wx_df.loc['2011-10-31':'2014-05-31','air_temp_set_1'].plot(figsize=(16,6));
```
Odds are pretty good that those spikes down to -15C in July of 2012 are non physical. We'd like a method for outlier detection. First pass will use median absolute deviation:
|
github_jupyter
|
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from processwx import select_stn, process_stn
%matplotlib inline
%config InlineBackend.figure_format='retina'
events_df = pd.read_csv('btac_events.csv.gz', compression='gzip',
index_col=[0], parse_dates = [2])
hzrd_df = pd.read_csv('btac_nowcast_teton.csv.gz', compression='gzip',
index_col=[0], parse_dates=[0])
zones = ['101','102','103','104','105','106','JHMR','GT','SK']
df1 = events_df[events_df['zone'].isin(zones)]
df1[df1.columns[0:10]].head(10)
df1[df1.columns[10:16]].head(10)
df1[df1.columns[16:]].head(10)
per = df1['event_date'].dt.to_period("M");
g = df1.groupby(per);
s1 = g['ID'].count();
fig, ax = plt.subplots(1,1,figsize=(16,6));
s1 = s1.resample('M').sum();
s1.plot(kind='bar', ax=ax, title='Avalanche event counts', rot=65);
ticks = ax.xaxis.get_ticklocs();
ticklabels = [l.get_text() for l in ax.xaxis.get_ticklabels()];
ax.xaxis.set_ticks(ticks[::3]);
ax.xaxis.set_ticklabels(ticklabels[::3]);
ax.set_xlabel('date');
ax.set_ylabel('count');
per = df1['event_date'].dt.to_period("M");
g = df1.groupby(per);
s2 = g['fatality'].sum().astype(int);
fig, ax = plt.subplots(1,1,figsize=(16,6));
s2 = s2.resample('M').sum();
s2.plot(kind='bar', ax=ax, title='Monthly fatal avalanche events', rot=65);
ticks = ax.xaxis.get_ticklocs();
ticklabels = [l.get_text() for l in ax.xaxis.get_ticklabels()];
ax.xaxis.set_ticks(ticks[::3]);
ax.xaxis.set_ticklabels(ticklabels[::3]);
ax.set_xlabel('date');
ax.set_ylabel('count');
print("Total fatalities:",s2.sum())
hzrd_df.tail(10)
s = ('2008-10-31','2009-5-31')
#s = ('2013-10-31','2014-5-31')
#s =('2016-10-31','2017-5-31')
ax = hzrd_df.loc[s[0]:s[1],['atl','tl','btl']].plot(figsize=(16,6),rot=45);
ax.set_ylim([0,5]);
ax.set_ylabel('Avalanche Danger');
def elevation_category(elevation):
if (6000. < elevation <= 7500.):
return 'btl'
elif (7500. < elevation <= 9000.):
return 'tl'
elif (9000. < elevation <= 10500.):
return 'atl'
else:
return None
df1.is_copy=False
df1['el_cat'] = df1['elevation'].apply(lambda x: elevation_category(x))
df2 = hzrd_df[['atl','tl','btl']].resample('D').mean().stack()
df2 = df2.reset_index()
df2.columns = ['event_date','el_cat','hazard']
df2.head()
df3 = pd.merge(df1, df2, how='left', left_on=['event_date','el_cat'], right_on=['event_date','el_cat'])
df4 = df3[df3['fatality']>0]
df4['hazard'].plot(kind='hist', title='Fatalities by avalanche forecast hazard',
xlim=[0,5], bins=20, figsize=(6,6));
hzrd_df[['atl','tl','btl']].plot(kind='hist', stacked=True,
xlim=[0,5], bins=20, figsize=(6,6));
g = df3.groupby(by='hazard');
g['ID'].count()
atl1, b = np.histogram(hzrd_df['atl'], bins=20);
tl1, _ = np.histogram(hzrd_df['tl'], bins=20);
btl1, _ = np.histogram(hzrd_df['btl'], bins=20);
atl1 + tl1 + btl1
b
g = df3[(1 < df3['hazard']) & (df3['hazard'] <= 2)].groupby(by='destructive_size');
sz_2 = g['ID'].count()
g = df3[(2 < df3['hazard']) & (df3['hazard'] <= 3)].groupby(by='destructive_size');
sz_3 = g['ID'].count()
g = df3[(3 < df3['hazard']) & (df3['hazard'] <= 4)].groupby(by='destructive_size');
sz_4 = g['ID'].count()
g = df3[(4 < df3['hazard']) & (df3['hazard'] <= 5)].groupby(by='destructive_size');
sz_5 = g['ID'].count()
print(sz_2,sz_3,sz_4,sz_5)
df = select_stn('./wxdata',{'k_nrst': 10, 'lat_lon': (43.572236,-110.8496103)}, return_df=True)
df.head(10)
wx_df = process_stn('./wxdata', 'JHR');
wx_df.loc['2008-10-31':'2009-05-31','air_temp_set_1'].plot(figsize=(16,6));
wx_df['air_temp_set_1'].plot(figsize=(16,6));
wx_df.loc['2011-10-31':'2014-05-31','air_temp_set_1'].plot(figsize=(16,6));
| 0.25945 | 0.920861 |
# Workshop 12: Introduction to Numerical ODE Solutions
*Source: Eric Ayars, PHYS 312 @ CSU Chico*
**Submit this notebook to bCourses to receive a grade for this Workshop.**
Please complete workshop activities in code cells in this iPython notebook. The activities titled **Practice** are purely for you to explore Python, and no particular output is expected. Some of them have some code written, and you should try to modify it in different ways to understand how it works. Although no particular output is expected at submission time, it is _highly_ recommended that you read and work through the practice activities before or alongside the exercises. However, the activities titled **Exercise** have specific tasks and specific outputs expected. Include comments in your code when necessary. Enter your name in the cell at the top of the notebook.
**The workshop should be submitted on bCourses under the Assignments tab (both the .ipynb and .pdf files).**
```
# Run this cell before preceding
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
```
## Ordinary Differential Equation (ODE)
An ordinary differential equation is an equation that takes the following form:
$$F(t,x,x',x'',\dots) = 0$$
where $x$ is a function of $t$ and the $'$ symbol denotes derivatives:
$$x' = \frac{dx}{dt}$$
$$x'' = \frac{d^2x}{dt^2}$$
$$\vdots$$
An example is
$$x' + x = 0$$
To solve such an equation, we need to specify an *initial condition*: a set of values $(t_0, x_0)$ that our solution must pass through. This is because there are multiple solutions which can satisfy that equation. Any solution of the form
$$x(t) = Ae^{-t}$$
satisfies the differential equation above. So by requiring that this curve pass through a particular point $(t_0, x_0)$, we can determine $A$:
$$A = \frac{x_0}{e^{-t_0}}$$
Another way to visualize is this is with the aid of a "slope field": a plot that, for various points $(t,x)$ shows what $x(t)$ must look like locally by evaluating the derivative $x'$ at that point:
```
# Initial condition
t0 = 0.0
x0 = 0.75
# Make a grid of x,t values
t_values = np.linspace(t0, t0+3, 20)
x_values = np.linspace(-np.abs(x0)*1.2, np.abs(x0)*1.2, 20)
t, x = np.meshgrid(t_values, x_values)
# Evaluate derivative at each x point
xdot = -x
plt.figure()
# Plot slope field arrows
plt.quiver(t,x, np.ones(t.shape), xdot,color='b')
# Plot solution
A = x0 / np.exp(-t0)
plt.plot(t_values,A * np.exp(-t_values),color='r')
# Plot initial condition
plt.plot(t0,x0,'go',markersize=8)
plt.xlabel('t')
plt.ylabel('x(t)')
plt.title("Slope field and a solution of $x'=x$")
plt.show()
```
With those two pieces of information--the differential equation and an initial condition--we are able to write down a closed-form solution $x(t)$. But for a general differential equation, even if you have an initial condition, it is difficult to write down $x(t)$ in closed form. For example, if the equation is nonlinear or, if you have a set of *coupled* differential equations, as we frequently encounter in physics, numerical methods are indispensable.
## Outline of this Workshop
1. Basic setup and numerical solution of a first-order ODE
2. Set up a second-order ODE--the harmonic oscillator
3. Numerical stability issue
4. Phase portraits
## Euler method
### Definition of the Euler method
Suppose we have the differential equation
$$\frac{dx}{dt} = f(x,t)$$
This means that, given a point in the system $(x_0, t_0)$, we have a way to compute the derivative $dx/dt$ at that point. But it may be difficult or impossible to analytically integrate $f(x,t)$ to find a closed form for $x(t)$. Instead, we rely on numerical methods to estimate solutions. More specifically, given an *initial condition* $(x_0, t_0)$, where $x(t_0) = x_0$, the goal is to find a numerical method to calculate $x(t)$ for $t > t_0$.
The most basic Euler method is based on the simple observation that
$$x(t+\Delta t) = x(t) + \int_{t}^{t+\Delta t} \left(\frac{dx}{dt}\right) dt = x(t) + \int_{t}^{t+\Delta t} f(x(t),t) dt $$
If we cannot explicitly take that integral, but we have a way to calculate $f(x,t)$, then the first thing we would try is
$$x(t+\Delta t) \approx x(t) + f(x(t), t) \cdot \Delta t$$
Now let us try to make this into code. Suppose we have a list of times $\{t_i\}$ such that $t_{i+1} - t_i = \Delta t$ (generated by `np.arange` or `np.linspace`, for example). Then given $x_0$ at $t_0$, we calculate $x_i$ according to the rule
$$x_i = x_{i-1} + f(x_{i-1},t_{i-1})\Delta t$$
So as long as we can write the first derivative in the form above, we have a way to attack this problem.
For example, we can numerically solve a problem like
$$v' = 1-v^2$$
$$\rightarrow v_i = v_{i-1} + f(v_{i-1}, t_{i-1}) \Delta t = v_{i-1} + (1-v_{i-1}^2)\Delta t$$
Given an initial $(t_0, v_0)$, we can use the Euler method to solve this equation, which describes the velocity (denoted $v$ here) of a particle falling but experiencing a drag force (see lecture). We know that the solution of such an equation should be that the velocity of the particle should increase quickly at first (due to constant gravitational force) but then asymptote to some terminal value because the drag force increases with velocity. Let's see this:
```
# Basic example of Euler method
t_0 = 0.0 # initial time condition
v_0 = 0.0 # initial velocity condition
# Generate some times t_i
t_data = np.linspace(0,100,1000)
# Placeholder array for velocities v_i
v_data = np.zeros(1000)
v_data[0] = v_0
N = len(t_data)
# use Euler method to estimate v_i for each i
for i in range(1,N):
f = 1 - v_data[i-1]**2 # f(v_{i-1})
dt = t_data[i] - t_data[i-1] # time interval
v_data[i] = v_data[i-1] + f * dt # calculate v_i
# Plot results
plt.figure()
plt.plot(t_data, v_data)
plt.xlabel("Time")
plt.ylabel("Velocity")
plt.title("Velocity of particle falling and experiencing drag")
plt.show()
```
So we have established a technique to approximate solutions to some first-order differential equations. Note that these solutions still have some error--flip back to the workshop on integration techniques to remind yourself of this.
At first, being able to solve only first-order differential equations seems very restrictive. But actually, it is enough for us to start modeling real systems and observing interesting behaviors. First, let us try to convert a second order differential equation, such as Newton's second law, into a set of first order differential equations, which we now know how to solve.
### Example: Euler Method and a Second-Order ODE
Commonly we have a set of *second-order* differential equations. For example, the harmonic oscillator takes this form:
$$F = ma = m\frac{d^2x}{dt^2} = -kx$$
$$\rightarrow \frac{d^2x}{dt^2} + \frac{k}{m}x = 0$$
But we can rewrite as a set of first-order differential equations by noting that
$$a = \frac{dv}{dt}$$
and
$$v = \frac{dx}{dt}$$
So the force equation above becomes a pair of equations:
\begin{align}
x' &= \frac{dx}{dt} = v \\
v' &= \frac{dv}{dt} = -\frac{k}{m}x
\end{align}
This means that to form a solution, we need three numbers for the initial condition, $(t_0, x_0, v_0)$ where $x(t_0) = x_0$ and $v(t_0) = v_0$. As we did above, let us write this down in terms of the values $x_i$, $v_i$, and $t_i$:
\begin{align}
x_i &= x_{i-1} + v_{i-1} \Delta t \\
v_i &= v_{i-1} + \left(-\frac{k}{m}x_{i-1}\right)\Delta t
\end{align}
In the examples below, I will continue to take $t_0 = 0$
```
# Use Euler method to solve coupled first order ODE
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
km = 0.3 # value of k / m
# Initial conditions
x_0 = 1.0
v_0 = 0.0
# Number of timesteps
T = 1000
dt = 0.1 #size of time step (Delta t)
def Euler(t0, x0, v0, T, dt):
x_data = np.zeros(T)
v_data = np.zeros(T)
t_data = np.arange(T) * dt + t0
x_data[0] = x0
v_data[0] = v0
for i in range(1,T):
x_data[i] = x_data[i-1] + v_data[i-1] * dt
v_data[i] = v_data[i-1] + (-km * x_data[i-1]) * dt
return t_data, x_data, v_data
t_data, x_data, v_data = Euler(0.0, x_0, v_0, T, dt)
# Analytical solutions for (x(t), v(t)) assuming x_0 = 1.0, v_0 = 0, t_0 = 0
analytical_x = np.cos(np.sqrt(km)*t_data)
analytical_v = -np.sqrt(km)*np.sin(np.sqrt(km)*t_data)
plt.figure(figsize=(8,8))
plt.subplot(211)
plt.plot(t_data, x_data, label="numerical")
plt.plot(t_data, analytical_x,label="analytical")
plt.ylabel("Position")
plt.legend()
plt.title("Position of the mass on spring")
plt.subplot(212)
plt.plot(t_data, v_data, label="numerical")
plt.plot(t_data, analytical_v, label="analytical")
plt.ylabel("Velocity")
plt.xlabel("Time")
plt.legend()
plt.title("Velocity of the mass on spring")
# Plot error in position as a function of time
plt.figure()
plt.plot(t_data, np.abs(x_data - analytical_x))
plt.ylabel("$|x_i - x_{analytical}|$")
plt.xlabel("Time")
plt.title("Absolute error in position")
plt.show()
```
### Exercise 1:
The damped harmonic oscillator (DHO) satisfies the following differential equation:
$$\frac{d^2x}{dt^2}+\frac{c}{m}\frac{dx}{dt}+\frac{k}{m}x = 0$$
It differs from the previous example by the addition of the $(c/m) dx/dt$ term. Like we did above, we can unwrap this second-order ODE into two first-order ODEs using two separate variables $x(t)$ and $v(t)$
\begin{align}
x' &= v \\
v' &= -\frac{c}{m}v - \frac{k}{m}x
\end{align}
1. Like in the example above, write down the update rules for $x_i$ and $v_i$.
1. Then write some code to implement your rules to estimate a numerical solution for $x(t)$ and $v(t)$ for a given initial condition $x_0$ and $v_0$ (you can assume $t_0 = 0$ like above).
1. Plot your results for $x(t)$ and $v(t)$ and make sure that they make sense. You may use the code in the example as a template.
*Hint*: Recall that the qualitative behavior of the oscillator is different depending on the (dimensionless) value of the ratio
$$\frac{(c/m)^2}{k/m}$$
So you should be able to see the effect of this by trying out different values for $c/m$ and $k/m$.
```
# Code for Exercise 1
```
## But wait...
But you know that for a closed system, like the SHO, we actually have a special constraint on the system--the total energy (kinetic + potential) must be constant! So at every point of our solution, we should check whether this is true. How do we evaluate the total energy?
$$E = T + U = \frac{1}{2}mv^2 + \frac{1}{2}kx^2$$
Let's define a rescaled energy $\tilde{E}$ as $(1/m)E$:
$$\tilde{E} = \frac{1}{2}v^2 + \frac{1}{2}\frac{k}{m} x^2$$
### Exercise 2:
1. Copy the code from the example using the SHO above, in which we solved the SHO using the Euler Method. Add code to calculate the rescaled energy $\tilde{E}_i$ for each time step.
1. Plot $\tilde{E}(t)$ vs. the time. Does the energy stay constant, fluctuate around some constant value, or does it diverge/decay?
```
# Code for Exercise 2
```
## Euler-Cromer/Symplectic Euler Method
There exists a way to keep the energy fluctuations from growing, using a just a slight variant of the update rules described above. This update rule is called the
\begin{align}
v_i &= v_{i-1} + \left(-\frac{k}{m}x_{i-1}\right)\Delta t \\
x_i &= x_{i-1} + v_{i} \Delta t
\end{align}
In this version, you use the approximate velocity at time $t_i$ instead of the velocity at time $t_{i-1}$ to calculate $x_i$.
### Exercise 3:
1. Modify the code from Exercise 2 to instead implement the update rule in the Euler-Cromer method. You can either modify the it in-place or copy it to the cell below and modify it.
1. Now run your code to calculate and plot $x(t)$, $v(t)$, and $\tilde{E}(t)$. Does the energy stay constant, fluctuate around some constant value, or does it diverge/decay?
```
# Code for Exercise 3
```
There are also higher order ODE integration schemes, like Runge-Kutta, which make better estimates of the change in $(x(t),v(t)...)$ between $t_{i-1}$ and $t_i$. The shortcoming of our simple method above is that we are typically using the value of the derivative ($x'$ or $v'$) at $t_i$ or $t_{i-1}$ as a subsitute for the derivative over the entire interval $(t_{i-1}, t_i)$. These higher order schemes try to make better estimates of the derivatives inside this interval to make a better estimate of $\Delta x$ and $\Delta v$.
## Visualizing Phase Space
Here we generalize the use of the slope field above to visualize our error in the Euler method. The tool below is called a phase portrait and is ubiquitous in physics and mathematics, and students studying dynamical systems for their capstone projects may find it useful as a nice visualization. In the cell below, we examine the phase portrait of the SHO and study the numerical and analytical solutions. Before you run this cell, run the SHO example cell again with `x_0 = 1.0` and `v_0 = 0.0` so that `km`, `x_data`, and `v_data` are properly populated.
```
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
xvalues, yvalues = np.meshgrid(np.arange(min(x_data),max(x_data), 0.2), np.arange(min(v_data), max(v_data), 0.5))
xdot = yvalues
ydot = - km * xvalues
plt.figure(figsize=(8,8))
plt.streamplot(xvalues, yvalues, xdot, ydot)
plt.plot(x_data[0],v_data[0],'go',markersize=8)
plt.plot(x_data, v_data,color='r', label="numerical")
plt.plot(analytical_x, analytical_v, color='k', label="analytical")
plt.ylabel("Velocity")
plt.xlabel("Position")
plt.title("Phase Portrait")
plt.legend()
plt.grid()
plt.show()
```
You can make phase portraits for just about any system! Here's a phase portrait for the DHO. How does the phase portrait change qualitatively, as you vary $c/m$ and $k/m$?
```
cm = 0.2 # c / m
km = 0.3 # k / m
xvalues, yvalues = np.meshgrid(np.arange(-3,3, 0.5), np.arange(-3,3, 0.5))
xdot = yvalues
ydot = - cm * yvalues - km * xvalues
plt.figure(figsize=(8,8))
plt.streamplot(xvalues, yvalues, xdot, ydot)
plt.ylabel("Velocity")
plt.xlabel("Position")
plt.title("Phase Portrait")
plt.grid()
plt.show()
```
|
github_jupyter
|
# Run this cell before preceding
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# Initial condition
t0 = 0.0
x0 = 0.75
# Make a grid of x,t values
t_values = np.linspace(t0, t0+3, 20)
x_values = np.linspace(-np.abs(x0)*1.2, np.abs(x0)*1.2, 20)
t, x = np.meshgrid(t_values, x_values)
# Evaluate derivative at each x point
xdot = -x
plt.figure()
# Plot slope field arrows
plt.quiver(t,x, np.ones(t.shape), xdot,color='b')
# Plot solution
A = x0 / np.exp(-t0)
plt.plot(t_values,A * np.exp(-t_values),color='r')
# Plot initial condition
plt.plot(t0,x0,'go',markersize=8)
plt.xlabel('t')
plt.ylabel('x(t)')
plt.title("Slope field and a solution of $x'=x$")
plt.show()
# Basic example of Euler method
t_0 = 0.0 # initial time condition
v_0 = 0.0 # initial velocity condition
# Generate some times t_i
t_data = np.linspace(0,100,1000)
# Placeholder array for velocities v_i
v_data = np.zeros(1000)
v_data[0] = v_0
N = len(t_data)
# use Euler method to estimate v_i for each i
for i in range(1,N):
f = 1 - v_data[i-1]**2 # f(v_{i-1})
dt = t_data[i] - t_data[i-1] # time interval
v_data[i] = v_data[i-1] + f * dt # calculate v_i
# Plot results
plt.figure()
plt.plot(t_data, v_data)
plt.xlabel("Time")
plt.ylabel("Velocity")
plt.title("Velocity of particle falling and experiencing drag")
plt.show()
# Use Euler method to solve coupled first order ODE
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
km = 0.3 # value of k / m
# Initial conditions
x_0 = 1.0
v_0 = 0.0
# Number of timesteps
T = 1000
dt = 0.1 #size of time step (Delta t)
def Euler(t0, x0, v0, T, dt):
x_data = np.zeros(T)
v_data = np.zeros(T)
t_data = np.arange(T) * dt + t0
x_data[0] = x0
v_data[0] = v0
for i in range(1,T):
x_data[i] = x_data[i-1] + v_data[i-1] * dt
v_data[i] = v_data[i-1] + (-km * x_data[i-1]) * dt
return t_data, x_data, v_data
t_data, x_data, v_data = Euler(0.0, x_0, v_0, T, dt)
# Analytical solutions for (x(t), v(t)) assuming x_0 = 1.0, v_0 = 0, t_0 = 0
analytical_x = np.cos(np.sqrt(km)*t_data)
analytical_v = -np.sqrt(km)*np.sin(np.sqrt(km)*t_data)
plt.figure(figsize=(8,8))
plt.subplot(211)
plt.plot(t_data, x_data, label="numerical")
plt.plot(t_data, analytical_x,label="analytical")
plt.ylabel("Position")
plt.legend()
plt.title("Position of the mass on spring")
plt.subplot(212)
plt.plot(t_data, v_data, label="numerical")
plt.plot(t_data, analytical_v, label="analytical")
plt.ylabel("Velocity")
plt.xlabel("Time")
plt.legend()
plt.title("Velocity of the mass on spring")
# Plot error in position as a function of time
plt.figure()
plt.plot(t_data, np.abs(x_data - analytical_x))
plt.ylabel("$|x_i - x_{analytical}|$")
plt.xlabel("Time")
plt.title("Absolute error in position")
plt.show()
# Code for Exercise 1
# Code for Exercise 2
# Code for Exercise 3
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
xvalues, yvalues = np.meshgrid(np.arange(min(x_data),max(x_data), 0.2), np.arange(min(v_data), max(v_data), 0.5))
xdot = yvalues
ydot = - km * xvalues
plt.figure(figsize=(8,8))
plt.streamplot(xvalues, yvalues, xdot, ydot)
plt.plot(x_data[0],v_data[0],'go',markersize=8)
plt.plot(x_data, v_data,color='r', label="numerical")
plt.plot(analytical_x, analytical_v, color='k', label="analytical")
plt.ylabel("Velocity")
plt.xlabel("Position")
plt.title("Phase Portrait")
plt.legend()
plt.grid()
plt.show()
cm = 0.2 # c / m
km = 0.3 # k / m
xvalues, yvalues = np.meshgrid(np.arange(-3,3, 0.5), np.arange(-3,3, 0.5))
xdot = yvalues
ydot = - cm * yvalues - km * xvalues
plt.figure(figsize=(8,8))
plt.streamplot(xvalues, yvalues, xdot, ydot)
plt.ylabel("Velocity")
plt.xlabel("Position")
plt.title("Phase Portrait")
plt.grid()
plt.show()
| 0.828766 | 0.989928 |
<img src="ku_logo_uk_v.png" alt="drawing" width="130" style="float:right"/>
# <span style="color:#2c061f"> Exercise 5 </span>
<br>
## <span style="color:#374045"> Introduction to Programming and Numerical Analysis </span>
#### <span style="color:#d89216"> <br> Sebastian Honoré </span>
## Plan for today
<br>
1. Welcome
2. Interactive plotting
3. Solving an exchange model
4. Problemset 2
**Note: The inuagural project is now live! Deadline 27/3.**
# 2. Interactive plotting
Last time i showed you how to plot static functions. Today, we are going to be plotting interactively. This means that the plots will change dynamically once you change model parameters. This requires that you formulate your plot as a function. Let's try it out:
```
# Imports
import ipywidgets as widgets
import matplotlib.pyplot as plt
import numpy as np
import OLG_trans as OLG #OLG transition functions
#Center images in notebook (optional)
from IPython.core.display import HTML
HTML("""
<style>
.output_png {
display: table-cell;
text-align: center;
vertical-align: middle;
}
</style>
""")
# Figure to plot
def fig(rho,alpha):
"""
Returns:
Plots the transition curve
Args:
rho(float): Timepreference parameter
"""
#parameters
alpha = alpha
rho = rho #Time preference parameter (value not defined)
n = 0.2
#transition curve
k_1, k_2 = OLG.transition_curve(alpha,rho,n,T=1000,k_min=1e-20,k_max=6)
fig = plt.figure(figsize=(9,9))
ax = fig.add_subplot(1,1,1)
ax.plot(k_1,k_2, label="Transition curve") #transition curve
ax.plot(k_1,k_1, '--', color='grey',label="45 degree") #45 degree line
ax.set_xlabel('$k_t$')
ax.set_ylabel('$k_t+1$')
ax.set_title('Transition curve')
ax.legend()
ax.set_xlim([0,0.2])
ax.set_ylim([0,0.2]);
return
# Interactive plot
import ipywidgets as widgets
widgets.interact(fig,
rho = widgets.FloatSlider(description='rho', min=0, max=16, step=0.01, value=0.5),
alpha = widgets.FloatSlider
)
```
# Widget types
Before we used the `FloatSlider` argument. However, there are several others you can use. These include:
- `IntSlider` discrete version of `FloatSlider`
- `Dropdown` creates a dropdown menu of things to choose from
- `ToggleButtons` creates buttons you can click on to change the plot
Remember: Your plot function needs to be able to accomodate these elements!
# 3. Solving an exchange model
Here are some tips on how to solve the exchange model in PS2.
1. You may define a dictionary of model parameters or options. I think this is less confusing and makes your functions simpler. Instead of:
```
N = 10000
mu = 0.5
sigma = 0.2
mu_low = 0.1
mu_high = 0.9
beta1 = 1.3
beta2 = 2.1
seed = 1986
```
Store them in a dictionary and use this a single input to the function:
```
mp = {"N":1000,
"mu":0.5,
"sigma":0.2,
"mu_low":0.1,
"mu_high":0.9,
"beta1":1.3,
"beta2":2.1,
"seed":1986}
# Function example:
def f(x1,x2,mp):
y=x1*mp["beta1"]+x2*mp["beta2"]
return y
```
# 3. Solving an exchange model
2. Utilize Walras's law which implies that excess demand should be zero in equilibrium
3. Construct a while-loop that iterates towards the equilibrium by adjusting price
Pseudo code:
1) Calculate current excess demand
2) Check if the excess demand is approximately zero
3) If it is not zero adjust the price marginally
4) Continue until excess demand is zero
## Your turn to shine
Work on problemset 2 and ask for help if needed.
|
github_jupyter
|
# Imports
import ipywidgets as widgets
import matplotlib.pyplot as plt
import numpy as np
import OLG_trans as OLG #OLG transition functions
#Center images in notebook (optional)
from IPython.core.display import HTML
HTML("""
<style>
.output_png {
display: table-cell;
text-align: center;
vertical-align: middle;
}
</style>
""")
# Figure to plot
def fig(rho,alpha):
"""
Returns:
Plots the transition curve
Args:
rho(float): Timepreference parameter
"""
#parameters
alpha = alpha
rho = rho #Time preference parameter (value not defined)
n = 0.2
#transition curve
k_1, k_2 = OLG.transition_curve(alpha,rho,n,T=1000,k_min=1e-20,k_max=6)
fig = plt.figure(figsize=(9,9))
ax = fig.add_subplot(1,1,1)
ax.plot(k_1,k_2, label="Transition curve") #transition curve
ax.plot(k_1,k_1, '--', color='grey',label="45 degree") #45 degree line
ax.set_xlabel('$k_t$')
ax.set_ylabel('$k_t+1$')
ax.set_title('Transition curve')
ax.legend()
ax.set_xlim([0,0.2])
ax.set_ylim([0,0.2]);
return
# Interactive plot
import ipywidgets as widgets
widgets.interact(fig,
rho = widgets.FloatSlider(description='rho', min=0, max=16, step=0.01, value=0.5),
alpha = widgets.FloatSlider
)
N = 10000
mu = 0.5
sigma = 0.2
mu_low = 0.1
mu_high = 0.9
beta1 = 1.3
beta2 = 2.1
seed = 1986
mp = {"N":1000,
"mu":0.5,
"sigma":0.2,
"mu_low":0.1,
"mu_high":0.9,
"beta1":1.3,
"beta2":2.1,
"seed":1986}
# Function example:
def f(x1,x2,mp):
y=x1*mp["beta1"]+x2*mp["beta2"]
return y
| 0.80969 | 0.975762 |
dataset: https://www.kaggle.com/blastchar/telco-customer-churn
```
from google.colab import drive # Import a library named google.colab
drive.mount('/content/drive', force_remount=True) # mount the content to the directory `/content/drive`
%cd /content/drive/MyDrive/Tensorflow_Practice
# !mkdir HW13 # I HAVE MADE IT.
import tensorflow as tf
from tensorflow import keras # a high api
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
df.head()
```
data exploration
```
df.drop("customerID", axis="columns", inplace=True) # remove the unuseful information
df.dtypes # see the data type of each columns
# because MonthlyCharges is type of float64, TotalCharges is type object
# we have to convert object to float
pd.to_numeric(df.TotalCharges, errors='coerce').isnull() # numeric make the invalid data to Nan
# to get the index of invalid data
df[pd.to_numeric(df.TotalCharges, errors='coerce').isnull()]
df.iloc[488]["TotalCharges"]
# df1 = df[df.TotalCharges != ' ']
indexes = df[pd.to_numeric(df.TotalCharges, errors='coerce').isnull()].index
print(indexes)
df1 = df.drop(indexes, axis = 'rows')
df1.shape
df1.dtypes
df1.TotalCharges = pd.to_numeric(df1.TotalCharges)
df1.TotalCharges
tenure_churn_no = df1[df1.Churn=='No'].tenure
tenure_churn_yes = df1[df1.Churn=='Yes'].tenure
plt.xlabel("tenure")
plt.ylabel("Number Of Customers")
plt.title("Customer Churn Prediction Visualiztion")
plt.hist([tenure_churn_yes, tenure_churn_no], rwidth=0.95, color=['blue', 'yellow'], label=['Churn=Yes', 'Churn=No'])
plt.legend() # about the label
mc_churn_no = df1[df1.Churn=='No'].MonthlyCharges
mc_churn_yes = df1[df1.Churn=='Yes'].MonthlyCharges
plt.xlabel("Monthly Charges")
plt.ylabel("Number Of Customers")
plt.title("Customer Churn Prediction Visualiztion")
plt.hist([mc_churn_yes, mc_churn_no], rwidth=0.95,color=['blue', 'yellow'], label=['Churn=Yes', 'Churn=No'])
plt.legend()
def print_unique_col_values(df):
for column in df:
if df[column].dtypes=='object':
print(f'{column}: {df[column].unique()}')
print_unique_col_values(df1)
df1.replace({'No internet service': 'No','No phone service': 'No'},inplace=True)
print_unique_col_values(df1)
yes_no_collumns = [ "Partner", 'Dependents', 'PhoneService', 'MultipleLines', 'OnlineSecurity',
'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', "PaperlessBilling", "Churn"]
for col in yes_no_collumns:
df1[col].replace({'Yes' : 1, 'No' : 0}, inplace=True)
print_unique_col_values(df1)
df1["gender"].replace({'Female':0, 'Male':1 }, inplace=True)
df2 = pd.get_dummies(data=df1, columns=["InternetService", "Contract", "PaymentMethod"])
df2.head()
df2.dtypes
cols_to_scale = ['tenure', 'MonthlyCharges', 'TotalCharges']
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df2[cols_to_scale] = scaler.fit_transform(df2[cols_to_scale])
for col in df2:
print(f'{col} : {df2[col].unique() } ' )
X = df2.drop("Churn", axis='columns')
y = df2.Churn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5)
X_train.shape
# input shape equals to the number of columns
model = keras.Sequential([
keras.layers.Dense(26, input_shape=(26,), activation='relu'),
keras.layers.Dense(20, activation='relu'),
keras.layers.Dense(15, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
# tf.keras.optimizers.Adam(
# learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
# name='Adam', **kwargs
# )
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=100)
model.evaluate(X_test, y_test)
yp = model.predict(X_test)
yp
y_pred = []
for ele in yp:
if ele >= 0.5:
y_pred.append(1)
else:
y_pred.append(0)
from sklearn.metrics import confusion_matrix, classification_report
print(classification_report(y_test, y_pred))
import seaborn as sn
cm = tf.math.confusion_matrix(labels=y_test, predictions=y_pred)
# plt.figure
plt.figure(figsize = (10,5))
sn.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Truth')
print("The number of classification report")
# Accuracy
print(round((821+237)/(821+178+171+237), 2))
# Precision for 0 class
print(round(821/(821+171), 2))
# Precision for 1 class
print(round(229/(229+137), 2))
# Recall fo 0 class
print(round(821/(821+178), 2))
# Recall for 1 class
print(round(237/(171+237), 2))
```
|
github_jupyter
|
from google.colab import drive # Import a library named google.colab
drive.mount('/content/drive', force_remount=True) # mount the content to the directory `/content/drive`
%cd /content/drive/MyDrive/Tensorflow_Practice
# !mkdir HW13 # I HAVE MADE IT.
import tensorflow as tf
from tensorflow import keras # a high api
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("WA_Fn-UseC_-Telco-Customer-Churn.csv")
df.head()
df.drop("customerID", axis="columns", inplace=True) # remove the unuseful information
df.dtypes # see the data type of each columns
# because MonthlyCharges is type of float64, TotalCharges is type object
# we have to convert object to float
pd.to_numeric(df.TotalCharges, errors='coerce').isnull() # numeric make the invalid data to Nan
# to get the index of invalid data
df[pd.to_numeric(df.TotalCharges, errors='coerce').isnull()]
df.iloc[488]["TotalCharges"]
# df1 = df[df.TotalCharges != ' ']
indexes = df[pd.to_numeric(df.TotalCharges, errors='coerce').isnull()].index
print(indexes)
df1 = df.drop(indexes, axis = 'rows')
df1.shape
df1.dtypes
df1.TotalCharges = pd.to_numeric(df1.TotalCharges)
df1.TotalCharges
tenure_churn_no = df1[df1.Churn=='No'].tenure
tenure_churn_yes = df1[df1.Churn=='Yes'].tenure
plt.xlabel("tenure")
plt.ylabel("Number Of Customers")
plt.title("Customer Churn Prediction Visualiztion")
plt.hist([tenure_churn_yes, tenure_churn_no], rwidth=0.95, color=['blue', 'yellow'], label=['Churn=Yes', 'Churn=No'])
plt.legend() # about the label
mc_churn_no = df1[df1.Churn=='No'].MonthlyCharges
mc_churn_yes = df1[df1.Churn=='Yes'].MonthlyCharges
plt.xlabel("Monthly Charges")
plt.ylabel("Number Of Customers")
plt.title("Customer Churn Prediction Visualiztion")
plt.hist([mc_churn_yes, mc_churn_no], rwidth=0.95,color=['blue', 'yellow'], label=['Churn=Yes', 'Churn=No'])
plt.legend()
def print_unique_col_values(df):
for column in df:
if df[column].dtypes=='object':
print(f'{column}: {df[column].unique()}')
print_unique_col_values(df1)
df1.replace({'No internet service': 'No','No phone service': 'No'},inplace=True)
print_unique_col_values(df1)
yes_no_collumns = [ "Partner", 'Dependents', 'PhoneService', 'MultipleLines', 'OnlineSecurity',
'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', "PaperlessBilling", "Churn"]
for col in yes_no_collumns:
df1[col].replace({'Yes' : 1, 'No' : 0}, inplace=True)
print_unique_col_values(df1)
df1["gender"].replace({'Female':0, 'Male':1 }, inplace=True)
df2 = pd.get_dummies(data=df1, columns=["InternetService", "Contract", "PaymentMethod"])
df2.head()
df2.dtypes
cols_to_scale = ['tenure', 'MonthlyCharges', 'TotalCharges']
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df2[cols_to_scale] = scaler.fit_transform(df2[cols_to_scale])
for col in df2:
print(f'{col} : {df2[col].unique() } ' )
X = df2.drop("Churn", axis='columns')
y = df2.Churn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5)
X_train.shape
# input shape equals to the number of columns
model = keras.Sequential([
keras.layers.Dense(26, input_shape=(26,), activation='relu'),
keras.layers.Dense(20, activation='relu'),
keras.layers.Dense(15, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
# tf.keras.optimizers.Adam(
# learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False,
# name='Adam', **kwargs
# )
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt, loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=100)
model.evaluate(X_test, y_test)
yp = model.predict(X_test)
yp
y_pred = []
for ele in yp:
if ele >= 0.5:
y_pred.append(1)
else:
y_pred.append(0)
from sklearn.metrics import confusion_matrix, classification_report
print(classification_report(y_test, y_pred))
import seaborn as sn
cm = tf.math.confusion_matrix(labels=y_test, predictions=y_pred)
# plt.figure
plt.figure(figsize = (10,5))
sn.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Truth')
print("The number of classification report")
# Accuracy
print(round((821+237)/(821+178+171+237), 2))
# Precision for 0 class
print(round(821/(821+171), 2))
# Precision for 1 class
print(round(229/(229+137), 2))
# Recall fo 0 class
print(round(821/(821+178), 2))
# Recall for 1 class
print(round(237/(171+237), 2))
| 0.381335 | 0.669384 |
<!--NAVIGATION-->
< [Combining Datasets: Merge and Join](03.07-Merge-and-Join.ipynb) | [Contents](Index.ipynb) | [Pivot Tables](03.09-Pivot-Tables.ipynb) >
# Aggregation and Grouping
An essential piece of analysis of large data is efficient summarization: computing aggregations like ``sum()``, ``mean()``, ``median()``, ``min()``, and ``max()``, in which a single number gives insight into the nature of a potentially large dataset.
In this section, we'll explore aggregations in Pandas, from simple operations akin to what we've seen on NumPy arrays, to more sophisticated operations based on the concept of a ``groupby``.
For convenience, we'll use the same ``display`` magic function that we've seen in previous sections:
```
import numpy as np
import pandas as pd
class display(object):
"""Display HTML representation of multiple objects"""
template = """<div style="float: left; padding: 10px;">
<p style='font-family:"Courier New", Courier, monospace'>{0}</p>{1}
</div>"""
def __init__(self, *args):
self.args = args
def _repr_html_(self):
return '\n'.join(self.template.format(a, eval(a)._repr_html_())
for a in self.args)
def __repr__(self):
return '\n\n'.join(a + '\n' + repr(eval(a))
for a in self.args)
```
## Planets Data
Here we will use the Planets dataset, available via the [Seaborn package](http://seaborn.pydata.org/) (see [Visualization With Seaborn](04.14-Visualization-With-Seaborn.ipynb)).
It gives information on planets that astronomers have discovered around other stars (known as *extrasolar planets* or *exoplanets* for short). It can be downloaded with a simple Seaborn command:
```
import seaborn as sns
planets = sns.load_dataset('planets')
planets.shape
planets.head()
```
This has some details on the 1,000+ extrasolar planets discovered up to 2014.
## Simple Aggregation in Pandas
Earlier, we explored some of the data aggregations available for NumPy arrays (["Aggregations: Min, Max, and Everything In Between"](02.04-Computation-on-arrays-aggregates.ipynb)).
As with a one-dimensional NumPy array, for a Pandas ``Series`` the aggregates return a single value:
```
rng = np.random.RandomState(42)
ser = pd.Series(rng.rand(5))
ser
ser.sum()
ser.mean()
```
For a ``DataFrame``, by default the aggregates return results within each column:
```
df = pd.DataFrame({'A': rng.rand(5),
'B': rng.rand(5)})
df
i = pd.date_range('2019-06-11', periods=9, freq='2D')
ts = pd.DataFrame({'A': [1,2,3,4,6,7,8,9,10]}, index=i)
print(ts,"Data Sets")
print(ts.first('3D'),"First Data")
print(ts.last('3D'),"Last Data")
df.mean()
```
By specifying the ``axis`` argument, you can instead aggregate within each row:
```
df.mean(axis='columns')
```
Pandas ``Series`` and ``DataFrame``s include all of the common aggregates mentioned in [Aggregations: Min, Max, and Everything In Between](02.04-Computation-on-arrays-aggregates.ipynb); in addition, there is a convenience method ``describe()`` that computes several common aggregates for each column and returns the result.
Let's use this on the Planets data, for now dropping rows with missing values:
```
planets.dropna().describe()
```
This can be a useful way to begin understanding the overall properties of a dataset.
For example, we see in the ``year`` column that although exoplanets were discovered as far back as 1989, half of all known expolanets were not discovered until 2010 or after.
This is largely thanks to the *Kepler* mission, which is a space-based telescope specifically designed for finding eclipsing planets around other stars.
The following table summarizes some other built-in Pandas aggregations:
| Aggregation | Description |
|--------------------------|---------------------------------|
| ``count()`` | Total number of items |
| ``first()``, ``last()`` | First and last item |
| ``mean()``, ``median()`` | Mean and median |
| ``min()``, ``max()`` | Minimum and maximum |
| ``std()``, ``var()`` | Standard deviation and variance |
| ``mad()`` | Mean absolute deviation |
| ``prod()`` | Product of all items |
| ``sum()`` | Sum of all items |
These are all methods of ``DataFrame`` and ``Series`` objects.
To go deeper into the data, however, simple aggregates are often not enough.
The next level of data summarization is the ``groupby`` operation, which allows you to quickly and efficiently compute aggregates on subsets of data.
## GroupBy: Split, Apply, Combine
Simple aggregations can give you a flavor of your dataset, but often we would prefer to aggregate conditionally on some label or index: this is implemented in the so-called ``groupby`` operation.
The name "group by" comes from a command in the SQL database language, but it is perhaps more illuminative to think of it in the terms first coined by Hadley Wickham of Rstats fame: *split, apply, combine*.
### Split, apply, combine
A canonical example of this split-apply-combine operation, where the "apply" is a summation aggregation, is illustrated in this figure:

[figure source in Appendix](06.00-Figure-Code.ipynb#Split-Apply-Combine)
This makes clear what the ``groupby`` accomplishes:
- The *split* step involves breaking up and grouping a ``DataFrame`` depending on the value of the specified key.
- The *apply* step involves computing some function, usually an aggregate, transformation, or filtering, within the individual groups.
- The *combine* step merges the results of these operations into an output array.
While this could certainly be done manually using some combination of the masking, aggregation, and merging commands covered earlier, an important realization is that *the intermediate splits do not need to be explicitly instantiated*. Rather, the ``GroupBy`` can (often) do this in a single pass over the data, updating the sum, mean, count, min, or other aggregate for each group along the way.
The power of the ``GroupBy`` is that it abstracts away these steps: the user need not think about *how* the computation is done under the hood, but rather thinks about the *operation as a whole*.
As a concrete example, let's take a look at using Pandas for the computation shown in this diagram.
We'll start by creating the input ``DataFrame``:
```
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C','D'],
'data': range(7)}, columns=['key', 'data'])
df
```
The most basic split-apply-combine operation can be computed with the ``groupby()`` method of ``DataFrame``s, passing the name of the desired key column:
```
a = df.groupby('key')
a
```
Notice that what is returned is not a set of ``DataFrame``s, but a ``DataFrameGroupBy`` object.
This object is where the magic is: you can think of it as a special view of the ``DataFrame``, which is poised to dig into the groups but does no actual computation until the aggregation is applied.
This "lazy evaluation" approach means that common aggregates can be implemented very efficiently in a way that is almost transparent to the user.
To produce a result, we can apply an aggregate to this ``DataFrameGroupBy`` object, which will perform the appropriate apply/combine steps to produce the desired result:
```
df.groupby('key').sum()
```
The ``sum()`` method is just one possibility here; you can apply virtually any common Pandas or NumPy aggregation function, as well as virtually any valid ``DataFrame`` operation, as we will see in the following discussion.
### The GroupBy object
The ``GroupBy`` object is a very flexible abstraction.
In many ways, you can simply treat it as if it's a collection of ``DataFrame``s, and it does the difficult things under the hood. Let's see some examples using the Planets data.
Perhaps the most important operations made available by a ``GroupBy`` are *aggregate*, *filter*, *transform*, and *apply*.
We'll discuss each of these more fully in ["Aggregate, Filter, Transform, Apply"](#Aggregate,-Filter,-Transform,-Apply), but before that let's introduce some of the other functionality that can be used with the basic ``GroupBy`` operation.
#### Column indexing
The ``GroupBy`` object supports column indexing in the same way as the ``DataFrame``, and returns a modified ``GroupBy`` object.
For example:
```
planets.head()
planets.groupby('method')
planets.groupby('method')['orbital_period']
```
Here we've selected a particular ``Series`` group from the original ``DataFrame`` group by reference to its column name.
As with the ``GroupBy`` object, no computation is done until we call some aggregate on the object:
```
planets.groupby('method')['orbital_period'].median()
```
This gives an idea of the general scale of orbital periods (in days) that each method is sensitive to.
#### Iteration over groups
The ``GroupBy`` object supports direct iteration over the groups, returning each group as a ``Series`` or ``DataFrame``:
```
for (method, group) in planets.groupby('method'):
print("{0:50s} shape={1}".format(method, group.shape))
```
This can be useful for doing certain things manually, though it is often much faster to use the built-in ``apply`` functionality, which we will discuss momentarily.
#### Dispatch methods
Through some Python class magic, any method not explicitly implemented by the ``GroupBy`` object will be passed through and called on the groups, whether they are ``DataFrame`` or ``Series`` objects.
For example, you can use the ``describe()`` method of ``DataFrame``s to perform a set of aggregations that describe each group in the data:
```
planets.stack()
planets.groupby('method').describe().unstack()
```
Looking at this table helps us to better understand the data: for example, the vast majority of planets have been discovered by the Radial Velocity and Transit methods, though the latter only became common (due to new, more accurate telescopes) in the last decade.
The newest methods seem to be Transit Timing Variation and Orbital Brightness Modulation, which were not used to discover a new planet until 2011.
This is just one example of the utility of dispatch methods.
Notice that they are applied *to each individual group*, and the results are then combined within ``GroupBy`` and returned.
Again, any valid ``DataFrame``/``Series`` method can be used on the corresponding ``GroupBy`` object, which allows for some very flexible and powerful operations!
### Aggregate, filter, transform, apply
The preceding discussion focused on aggregation for the combine operation, but there are more options available.
In particular, ``GroupBy`` objects have ``aggregate()``, ``filter()``, ``transform()``, and ``apply()`` methods that efficiently implement a variety of useful operations before combining the grouped data.
For the purpose of the following subsections, we'll use this ``DataFrame``:
```
rng = np.random.RandomState(0)
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': range(6),
'data2': rng.randint(0, 10, 6)},
columns = ['key', 'data1', 'data2'])
df
```
#### Aggregation
We're now familiar with ``GroupBy`` aggregations with ``sum()``, ``median()``, and the like, but the ``aggregate()`` method allows for even more flexibility.
It can take a string, a function, or a list thereof, and compute all the aggregates at once.
Here is a quick example combining all these:
```
df.groupby('key').aggregate(['min', np.median, max])
```
Another useful pattern is to pass a dictionary mapping column names to operations to be applied on that column:
```
df.groupby('key').aggregate({'data1': 'min',
'data2': 'max'})
```
#### Filtering
A filtering operation allows you to drop data based on the group properties.
For example, we might want to keep all groups in which the standard deviation is larger than some critical value:
```
def filter_func(x):
return x['data2'].std() > 4
display('df', "df.groupby('key').std()", "df.groupby('key').filter(filter_func)")
df.groupby('key').std()
df.groupby('key').filter(filter_func)
```
The filter function should return a Boolean value specifying whether the group passes the filtering. Here because group A does not have a standard deviation greater than 4, it is dropped from the result.
#### Transformation
While aggregation must return a reduced version of the data, transformation can return some transformed version of the full data to recombine.
For such a transformation, the output is the same shape as the input.
A common example is to center the data by subtracting the group-wise mean:
```
df.groupby('key').transform(lambda x: x - x.mean())
```
#### The apply() method
The ``apply()`` method lets you apply an arbitrary function to the group results.
The function should take a ``DataFrame``, and return either a Pandas object (e.g., ``DataFrame``, ``Series``) or a scalar; the combine operation will be tailored to the type of output returned.
For example, here is an ``apply()`` that normalizes the first column by the sum of the second:
```
def norm_by_data2(x):
# x is a DataFrame of group values
x['data1'] /= x['data2'].sum()
return x
display('df', "df.groupby('key').apply(norm_by_data2)")
df.groupby('key').apply(norm_by_data2)
```
``apply()`` within a ``GroupBy`` is quite flexible: the only criterion is that the function takes a ``DataFrame`` and returns a Pandas object or scalar; what you do in the middle is up to you!
### Specifying the split key
In the simple examples presented before, we split the ``DataFrame`` on a single column name.
This is just one of many options by which the groups can be defined, and we'll go through some other options for group specification here.
#### A list, array, series, or index providing the grouping keys
The key can be any series or list with a length matching that of the ``DataFrame``. For example:
```
L = [0, 1, 0, 1, 2, 0]
display('df', 'df.groupby(L).sum()')
df.groupby(L).sum()
```
Of course, this means there's another, more verbose way of accomplishing the ``df.groupby('key')`` from before:
```
display('df', "df.groupby(df['key']).sum()")
```
#### A dictionary or series mapping index to group
Another method is to provide a dictionary that maps index values to the group keys:
```
df2 = df.set_index('key')
mapping = {'A': 'vowel', 'B': 'consonant', 'C': 'consonant'}
display('df2', 'df2.groupby(mapping).sum()')
df2.groupby(mapping).sum()
```
#### Any Python function
Similar to mapping, you can pass any Python function that will input the index value and output the group:
```
display('df2', 'df2.groupby(str.lower).mean()')
df2.groupby(str.lower).mean()
```
#### A list of valid keys
Further, any of the preceding key choices can be combined to group on a multi-index:
```
df2.groupby([str.lower, mapping]).mean()
```
### Grouping example
As an example of this, in a couple lines of Python code we can put all these together and count discovered planets by method and by decade:
```
decade = 10 * (planets['year'] // 10)
decade = decade.astype(str) + 's'
decade.name = 'decade'
planets.groupby(['method', decade])['number'].sum().unstack().fillna(0)
```
This shows the power of combining many of the operations we've discussed up to this point when looking at realistic datasets.
We immediately gain a coarse understanding of when and how planets have been discovered over the past several decades!
Here I would suggest digging into these few lines of code, and evaluating the individual steps to make sure you understand exactly what they are doing to the result.
It's certainly a somewhat complicated example, but understanding these pieces will give you the means to similarly explore your own data.
<!--NAVIGATION-->
< [Combining Datasets: Merge and Join](03.07-Merge-and-Join.ipynb) | [Contents](Index.ipynb) | [Pivot Tables](03.09-Pivot-Tables.ipynb) >
|
github_jupyter
|
import numpy as np
import pandas as pd
class display(object):
"""Display HTML representation of multiple objects"""
template = """<div style="float: left; padding: 10px;">
<p style='font-family:"Courier New", Courier, monospace'>{0}</p>{1}
</div>"""
def __init__(self, *args):
self.args = args
def _repr_html_(self):
return '\n'.join(self.template.format(a, eval(a)._repr_html_())
for a in self.args)
def __repr__(self):
return '\n\n'.join(a + '\n' + repr(eval(a))
for a in self.args)
import seaborn as sns
planets = sns.load_dataset('planets')
planets.shape
planets.head()
rng = np.random.RandomState(42)
ser = pd.Series(rng.rand(5))
ser
ser.sum()
ser.mean()
df = pd.DataFrame({'A': rng.rand(5),
'B': rng.rand(5)})
df
i = pd.date_range('2019-06-11', periods=9, freq='2D')
ts = pd.DataFrame({'A': [1,2,3,4,6,7,8,9,10]}, index=i)
print(ts,"Data Sets")
print(ts.first('3D'),"First Data")
print(ts.last('3D'),"Last Data")
df.mean()
df.mean(axis='columns')
planets.dropna().describe()
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C','D'],
'data': range(7)}, columns=['key', 'data'])
df
a = df.groupby('key')
a
df.groupby('key').sum()
planets.head()
planets.groupby('method')
planets.groupby('method')['orbital_period']
planets.groupby('method')['orbital_period'].median()
for (method, group) in planets.groupby('method'):
print("{0:50s} shape={1}".format(method, group.shape))
planets.stack()
planets.groupby('method').describe().unstack()
rng = np.random.RandomState(0)
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C'],
'data1': range(6),
'data2': rng.randint(0, 10, 6)},
columns = ['key', 'data1', 'data2'])
df
df.groupby('key').aggregate(['min', np.median, max])
df.groupby('key').aggregate({'data1': 'min',
'data2': 'max'})
def filter_func(x):
return x['data2'].std() > 4
display('df', "df.groupby('key').std()", "df.groupby('key').filter(filter_func)")
df.groupby('key').std()
df.groupby('key').filter(filter_func)
df.groupby('key').transform(lambda x: x - x.mean())
def norm_by_data2(x):
# x is a DataFrame of group values
x['data1'] /= x['data2'].sum()
return x
display('df', "df.groupby('key').apply(norm_by_data2)")
df.groupby('key').apply(norm_by_data2)
L = [0, 1, 0, 1, 2, 0]
display('df', 'df.groupby(L).sum()')
df.groupby(L).sum()
display('df', "df.groupby(df['key']).sum()")
df2 = df.set_index('key')
mapping = {'A': 'vowel', 'B': 'consonant', 'C': 'consonant'}
display('df2', 'df2.groupby(mapping).sum()')
df2.groupby(mapping).sum()
display('df2', 'df2.groupby(str.lower).mean()')
df2.groupby(str.lower).mean()
df2.groupby([str.lower, mapping]).mean()
decade = 10 * (planets['year'] // 10)
decade = decade.astype(str) + 's'
decade.name = 'decade'
planets.groupby(['method', decade])['number'].sum().unstack().fillna(0)
| 0.558207 | 0.987496 |
# Python para Data Science: Introdução à linguagem e Numpy - parte 2
```
import numpy as np
from numpy import arange
np.arange(10)
km = np.array([1000, 2300, 4985, 1400, 6482])
km
type(km)
km.dtype
km = np.loadtxt(fname = 'carros-km.txt', dtype = int)
km
km.dtype
dados = [
['Rodas de liga', 'Travas elétricas', 'Piloto automático', 'Bancos de couro', 'Ar condicionado', 'Sensor de estacionamento', 'Sensor crepuscular', 'Sensor de chuva'],
['Central multimídia', 'Teto panorâmico', 'Freios ABS', '4 X 4', 'Painel digital', 'Piloto automático', 'Bancos de couro', 'Câmera de estacionamento'],
['Piloto automático', 'Controle de estabilidade', 'Sensor crepuscular', 'Freios ABS', 'Câmbio automático', 'Bancos de couro', 'Central multimídia', 'Vidros elétricos']
]
dados
Acessorios = np.array(dados)
Acessorios
# 258 linhas
km.shape
# 3 linhas e 8 colunas
Acessorios.shape
np_array = np.arange(10000000)
py_list = list(range(10000000))
# Ver desempenho da linha de codigo que esta sendo execultada
%time for _ in range (100): np_array *= 2
%time for _ in range(100): py_list = [x * 2 for x in py_list]
# Calculo idade com Numpy
km = np.array([44410, 5712, 37123, 0, 25757])
anos = np.array([2003, 1991, 1990, 2019, 2006])
idade = 2019 - anos
idade
#Operações entre array
km_media = km / idade
km_media
#Operações com array de duas dimensões
dados = np.array([km, anos])
dados
dados.shape
dados[0] [0]
km_media = dados[0] / (2019 - dados[1])
km_media
#Seleções com arrays
contador = np.arange(10)
contador
#mostrar item especifico, seleciona o 6 pra mostrar o 5
item = 6
index = item -1
contador[index]
contador [-1]
dados[0]
dados[1]
dados[1][2]
dados[1, 2]
#Fatiamento i: onde inicia j:ponto de parada k: passo
contador = np.arange(10)
contador
contador[1:4]
contador[1:8:2]
#Varrendo toda a array de dois em dois
contador[::2]
dados[:, 1:3]
dados[:, 1:3] [0]
dados[0]/ (2019 - dados[1])
contador = np.arange(20)
contador
contador > 5
contador[contador > 5]
dados
dados [1] > 2000
dados [:, dados[1] > 2000]
dados = np.array(
[
['Roberto', 'casado', 'masculino'],
['Sheila', 'solteiro', 'feminino'],
['Bruno', 'solteiro', 'masculino'],
['Rita', 'casado', 'feminino']
]
)
dados[0::2, :2]
dados = np.array([[44410, 5712, 37123, 0, 25757] ,
[2003, 1991, 1990, 2019, 2006]])
dados
# 2 linhas 5 colunas
dados.shape
# Array com duas dimensões
dados.ndim
#Numero de elementos
dados.size
# Rtorna o tipi dos elementos do array
dados.dtype
#Transforma o array de linha para coluna e vice versa
dados.T
#Transforma o array de linha para coluna e vice versa
dados.transpose()
# transforma o array em uma lista
dados.tolist()
contador = np.arange(10)
contador
#Retorna um array com os mesmo dados em uma nova forma
contador.reshape((5, 2))
#Retorna um array com os mesmo dados em uma nova forma Ordenada
contador.reshape((5, 2), order='F')
km = [44410, 5712, 37123, 0 , 25757]
anos = [2003, 19910, 1990, 2019, 2006]
#Concatenação
info_carros = km + anos
info_carros
np.array(info_carros).reshape((2, 5))
np.array(info_carros).reshape((5, 2), order='F')
dados_new = dados.copy()
dados_new
dados_new.resize((3, 5), refcheck=False)
dados_new
dados_new[2] = dados_new[0] / (2019 - dados_new[1])
dados_new
anos = np.loadtxt(fname= "carros-anos.txt", dtype = int)
km = np.loadtxt (fname= "carros-km.txt")
valor = np.loadtxt(fname = "carros-valor.txt")
# array de uma dimesão com 258 linhas
anos.shape
#Transforma arrays unidimensionais em um array bidimensionais
dataset = np.column_stack((anos, km, valor))
dataset
dataset.shape
np.mean(dataset)
#media da kilometragem
np.mean(dataset[:,1])
np.mean(dataset[:,2])
#desvio padrão
np.std(dataset[:,2])
#Somatorios, passa o eixo em que estar trabalhando
dataset.sum(axis=0)
dataset[:, 1].sum()
np.sum(dataset, axis = 0)
np.sum(dataset[:, 2])
```
|
github_jupyter
|
import numpy as np
from numpy import arange
np.arange(10)
km = np.array([1000, 2300, 4985, 1400, 6482])
km
type(km)
km.dtype
km = np.loadtxt(fname = 'carros-km.txt', dtype = int)
km
km.dtype
dados = [
['Rodas de liga', 'Travas elétricas', 'Piloto automático', 'Bancos de couro', 'Ar condicionado', 'Sensor de estacionamento', 'Sensor crepuscular', 'Sensor de chuva'],
['Central multimídia', 'Teto panorâmico', 'Freios ABS', '4 X 4', 'Painel digital', 'Piloto automático', 'Bancos de couro', 'Câmera de estacionamento'],
['Piloto automático', 'Controle de estabilidade', 'Sensor crepuscular', 'Freios ABS', 'Câmbio automático', 'Bancos de couro', 'Central multimídia', 'Vidros elétricos']
]
dados
Acessorios = np.array(dados)
Acessorios
# 258 linhas
km.shape
# 3 linhas e 8 colunas
Acessorios.shape
np_array = np.arange(10000000)
py_list = list(range(10000000))
# Ver desempenho da linha de codigo que esta sendo execultada
%time for _ in range (100): np_array *= 2
%time for _ in range(100): py_list = [x * 2 for x in py_list]
# Calculo idade com Numpy
km = np.array([44410, 5712, 37123, 0, 25757])
anos = np.array([2003, 1991, 1990, 2019, 2006])
idade = 2019 - anos
idade
#Operações entre array
km_media = km / idade
km_media
#Operações com array de duas dimensões
dados = np.array([km, anos])
dados
dados.shape
dados[0] [0]
km_media = dados[0] / (2019 - dados[1])
km_media
#Seleções com arrays
contador = np.arange(10)
contador
#mostrar item especifico, seleciona o 6 pra mostrar o 5
item = 6
index = item -1
contador[index]
contador [-1]
dados[0]
dados[1]
dados[1][2]
dados[1, 2]
#Fatiamento i: onde inicia j:ponto de parada k: passo
contador = np.arange(10)
contador
contador[1:4]
contador[1:8:2]
#Varrendo toda a array de dois em dois
contador[::2]
dados[:, 1:3]
dados[:, 1:3] [0]
dados[0]/ (2019 - dados[1])
contador = np.arange(20)
contador
contador > 5
contador[contador > 5]
dados
dados [1] > 2000
dados [:, dados[1] > 2000]
dados = np.array(
[
['Roberto', 'casado', 'masculino'],
['Sheila', 'solteiro', 'feminino'],
['Bruno', 'solteiro', 'masculino'],
['Rita', 'casado', 'feminino']
]
)
dados[0::2, :2]
dados = np.array([[44410, 5712, 37123, 0, 25757] ,
[2003, 1991, 1990, 2019, 2006]])
dados
# 2 linhas 5 colunas
dados.shape
# Array com duas dimensões
dados.ndim
#Numero de elementos
dados.size
# Rtorna o tipi dos elementos do array
dados.dtype
#Transforma o array de linha para coluna e vice versa
dados.T
#Transforma o array de linha para coluna e vice versa
dados.transpose()
# transforma o array em uma lista
dados.tolist()
contador = np.arange(10)
contador
#Retorna um array com os mesmo dados em uma nova forma
contador.reshape((5, 2))
#Retorna um array com os mesmo dados em uma nova forma Ordenada
contador.reshape((5, 2), order='F')
km = [44410, 5712, 37123, 0 , 25757]
anos = [2003, 19910, 1990, 2019, 2006]
#Concatenação
info_carros = km + anos
info_carros
np.array(info_carros).reshape((2, 5))
np.array(info_carros).reshape((5, 2), order='F')
dados_new = dados.copy()
dados_new
dados_new.resize((3, 5), refcheck=False)
dados_new
dados_new[2] = dados_new[0] / (2019 - dados_new[1])
dados_new
anos = np.loadtxt(fname= "carros-anos.txt", dtype = int)
km = np.loadtxt (fname= "carros-km.txt")
valor = np.loadtxt(fname = "carros-valor.txt")
# array de uma dimesão com 258 linhas
anos.shape
#Transforma arrays unidimensionais em um array bidimensionais
dataset = np.column_stack((anos, km, valor))
dataset
dataset.shape
np.mean(dataset)
#media da kilometragem
np.mean(dataset[:,1])
np.mean(dataset[:,2])
#desvio padrão
np.std(dataset[:,2])
#Somatorios, passa o eixo em que estar trabalhando
dataset.sum(axis=0)
dataset[:, 1].sum()
np.sum(dataset, axis = 0)
np.sum(dataset[:, 2])
| 0.264453 | 0.904355 |
# Exploratory data analysis for vtalks.net
## Table of contents:
* [Introduction](#introduction)
* [Setup & Configuration](#setup-and-configuration)
* [Load the Data Set](#load-the-data-set)
* [Youtube Statistics Analysis](#youtube-statistics-analysis)
* [Youtube Views](#youtube-views)
* [Youtube Likes](#youtube-likes)
* [Youtube Dislikes](#youtube-dislikes)
* [Youtube Favorites](#youtube-favorites)
* [Statistics Analysis](#statistics-analysis)
* [Views](#views)
* [Likes](#likes)
* [Dislikes](#dislikes)
* [Favorites](#favorites)
* [Youtube Statistics Histograms](#youtube-statistics-histograms)
* [Youtube Views Histogram](#youtube-views-histogram)
* [Youtube Likes Histogram](#youtube-likes-histogram)
* [Youtube Dislikes Histogram](#youtube-dislikes-histogram)
* [Youtube Favorites Histogram](#youtube-favorites-histogram)
* [Statistics Histograms](#statistics-histograms)
* [Views Histogram](#views-histogram)
* [Likes Histogram](#likes-histogram)
* [Dislikes Histogram](#dislikes-histogram)
* [Favorites Histogram](#favorites-histogram)
## Introduction <a class="anchor" id="introduction"></a>
This jupyter network describes an exploratory data analysis for a data set of talks published on [vtalks.net](http://www.vtalks.net) website.
We are going to use numpy and pandas to load and analyze our dataset, and we will use matplotlib python libraries for
plotting the results.
```
!pwd
```
### Setup & Configuration <a class="anchor" id="setup-and-configuration"></a>
```
import numpy as np
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
import seaborn
```
Now we configure matplotlib to ensure we have somne pretty plots :)
```
%matplotlib inline
seaborn.set()
plt.rc('figure', figsize=(16,8))
plt.style.use('bmh')
plt.style.available
```
### Load the Data Set <a class="anchor" id="load-the-dataset"></a>
And finally load our dataset. Notice that there are different data sets available.
The first one is a general data set with all the information available from the start (around mid 2010) until now. Then there are the same data sets but splitted by year.
```
data_source = "../../.dataset/vtalks_dataset_2018.csv"
# data_source = "../../.dataset/vtalks_dataset_2017.csv"
# data_source = "../../.dataset/vtalks_dataset_2016.csv"
# data_source = "../../.dataset/vtalks_dataset_2015.csv"
# data_source = "../../.dataset/vtalks_dataset_2014.csv"
# data_source = "../../.dataset/vtalks_dataset_2013.csv"
# data_source = "../../.dataset/vtalks_dataset_2012.csv"
# data_source = "../../.dataset/vtalks_dataset_2011.csv"
# data_source = "../../.dataset/vtalks_dataset_2010.csv"
# data_source = "../../.dataset/vtalks_dataset_all.csv"
data_set = pd.read_csv(
data_source,
parse_dates=[1],
dtype={
'id': int,
'youtube_view_count': int,
'youtube_like_count': int,
'youtube_dislike_count': int,
'youtube_favorite_count': int,
'view_count': int,
'like_count': int,
'dislike_count': int,
'favorite_count': int,
})
data_set.dtypes
data_set.info()
data_set.head()
data_set.describe()
pp.ProfileReport(data_set)
```
## Youtube Statistics Analysis <a class="anchor" id="youtube-statistics-analysis"></a>
### Youtube Views <a class="anchor" id="youtube-views"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_views': data_set.youtube_view_count,
})
```
#### Descriptive analysis:
##### Count
```
count = data_set.youtube_view_count.count()
"Count: {:d}".format(count)
```
##### Minimum, Index Minimum, Maximum, Index Maximum
```
min = data_set.youtube_view_count.min()
max = data_set.youtube_view_count.max()
index_min = data_set.youtube_view_count.idxmin()
index_max = data_set.youtube_view_count.idxmax()
"Minimum: {:d} Index Minimum: {:d} - Maximum {:d} Index Maximum: {:d}".format(min, index_min, max, index_max)
```
##### Quantile 50%
```
quantile = data_set.youtube_view_count.quantile()
"Quantile 50%: {:f}".format(quantile)
```
##### Sum
```
sum = data_set.youtube_view_count.sum()
"Sum: {:d}".format(sum)
```
##### Mean
```
mean = data_set.youtube_view_count.mean()
"Mean: {:f}".format(mean)
```
##### Arithmetic median (50% quantile) of values
```
median = data_set.youtube_view_count.median()
"Arithmetic median (50% quantile) of values {:f}".format(median)
```
##### Mean absolute deviation from mean value
```
mad = data_set.youtube_view_count.mad()
"Mean absolute deviation from mean value {:f}".format(mad)
```
##### Product of all values
```
prod = data_set.youtube_view_count.prod()
"Product of all values {:f}".format(prod)
```
##### Sample variance of values
```
var = data_set.youtube_view_count.var()
"Sample variance of values {:f}".format(var)
```
##### Sample standard deviation of values
```
std = data_set.youtube_view_count.std()
"Sample standard deviation of values {:f}".format(std)
```
##### Sample skewness (third moment) of values
```
skew = data_set.youtube_view_count.skew()
"Sample skewness (third moment) of values {:f}".format(skew)
```
##### Sample kurtosis (fourth moment) of values
```
kurt = data_set.youtube_view_count.kurt()
"Sample kurtosis (fourth moment) of values {:f}".format(kurt)
```
##### Cumsum
```
cumsum = data_set.youtube_view_count.cumsum()
cumsum.head()
```
##### Cummin
```
cummin = data_set.youtube_view_count.cummin()
cummin.head()
```
##### Cummax
```
cummax = data_set.youtube_view_count.cummin()
cummax.head()
```
##### Cumprod
```
cumprod = data_set.youtube_view_count.cumprod()
cumprod.head()
```
##### Diff
```
diff = data_set.youtube_view_count.diff()
diff.head()
```
##### Percent change
```
pct_change = data_set.youtube_view_count.pct_change()
pct_change.head()
```
#### Bar Plot
```
plot_data_set.plot(x='created');
```
### Youtube Likes <a class="anchor" id="youtube-likes"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_likes': data_set.youtube_like_count,
})
plot_data_set.plot(x='created');
```
### Youtube Dislikes <a class="anchor" id="youtube-dislikes"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_dislikes': data_set.youtube_dislike_count,
})
plot_data_set.plot(x='created');
```
### Youtube Favorites <a class="anchor" id="youtube-favorites"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_favorites': data_set.youtube_favorite_count,
})
plot_data_set.plot(x='created');
```
## Statistics Analysis <a class="anchor" id="statistics-analysis"></a>
### Views <a class="anchor" id="views"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'view_count': data_set.view_count,
})
plot_data_set.plot(x='created');
```
### Likes <a class="anchor" id="likes"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'like_count': data_set.like_count,
})
plot_data_set.plot(x='created');
```
### Dislikes <a class="anchor" id="dislikes"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'dislike_count': data_set.dislike_count,
})
plot_data_set.plot(x='created');
```
### Favorites <a class="anchor" id="favorites"></a>
```
plot_data_set = pd.DataFrame({
'created': data_set.created,
'favorite_count': data_set.favorite_count,
})
plot_data_set.plot(x='created');
```
## Youtube Statistics Histograms <a class="anchor" id="youtube-statistics-histograms"></a>
A histogram is an accurate graphical representation of the distribution of numerical data. It is an estimate of the probability distribution of a continuous variable (quantitative variable).
Basically, histograms are used to represent data given in form of some groups. X-axis is about bin ranges where Y-axis talks about frequency.
### Youtube Views Histogram <a class="anchor" id="youtube-views-histogram"></a>
```
plot_data_set = pd.DataFrame({'youtube_view_count': data_set.youtube_view_count}, columns=['youtube_view_count'])
plot_data_set.hist(bins=150);
```
### Youtube Like Histogram <a class="anchor" id="youtube-likes-histogram"></a>
```
plot_data_set = pd.DataFrame({'youtube_like_count': data_set.youtube_like_count}, columns=['youtube_like_count'])
plot_data_set.hist(bins=150);
```
### Youtube Dislike Histogram <a class="anchor" id="youtube-dislikes-histogram"></a>
```
plot_data_set = pd.DataFrame({'youtube_dislike_count': data_set.youtube_dislike_count}, columns=['youtube_dislike_count'])
plot_data_set.hist(bins=150);
```
### Youtube Favorite Histogram <a class="anchor" id="youtube-favorites-histogram"></a>
```
plot_data_set = pd.DataFrame({'youtube_favorite_count': data_set.youtube_favorite_count}, columns=['youtube_favorite_count'])
plot_data_set.hist(bins=150);
```
## Statistics Histograms <a class="anchor" id="statistics-histogram"></a>
### View Histogram <a class="anchor" id="views-histogram"></a>
```
plot_data_set = pd.DataFrame({'view_count': data_set.view_count}, columns=['view_count'])
plot_data_set.hist(bins=150);
```
### Likes Histogram <a class="anchor" id="likes-histogram"></a>
```
plot_data_set = pd.DataFrame({'like_count': data_set.like_count}, columns=['like_count'])
plot_data_set.hist(bins=150);
```
### Dislikes Histogram <a class="anchor" id="dislikes-histogram"></a>
```
plot_data_set = pd.DataFrame({'dislike_count': data_set.dislike_count}, columns=['dislike_count'])
plot_data_set.hist(bins=150);
```
### Favorites Histogram <a class="anchor" id="favorites-histogram"></a>
```
plot_data_set = pd.DataFrame({'favorite_count': data_set.favorite_count}, columns=['favorite_count'])
plot_data_set.hist(bins=150);
```
|
github_jupyter
|
!pwd
import numpy as np
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
import seaborn
%matplotlib inline
seaborn.set()
plt.rc('figure', figsize=(16,8))
plt.style.use('bmh')
plt.style.available
data_source = "../../.dataset/vtalks_dataset_2018.csv"
# data_source = "../../.dataset/vtalks_dataset_2017.csv"
# data_source = "../../.dataset/vtalks_dataset_2016.csv"
# data_source = "../../.dataset/vtalks_dataset_2015.csv"
# data_source = "../../.dataset/vtalks_dataset_2014.csv"
# data_source = "../../.dataset/vtalks_dataset_2013.csv"
# data_source = "../../.dataset/vtalks_dataset_2012.csv"
# data_source = "../../.dataset/vtalks_dataset_2011.csv"
# data_source = "../../.dataset/vtalks_dataset_2010.csv"
# data_source = "../../.dataset/vtalks_dataset_all.csv"
data_set = pd.read_csv(
data_source,
parse_dates=[1],
dtype={
'id': int,
'youtube_view_count': int,
'youtube_like_count': int,
'youtube_dislike_count': int,
'youtube_favorite_count': int,
'view_count': int,
'like_count': int,
'dislike_count': int,
'favorite_count': int,
})
data_set.dtypes
data_set.info()
data_set.head()
data_set.describe()
pp.ProfileReport(data_set)
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_views': data_set.youtube_view_count,
})
count = data_set.youtube_view_count.count()
"Count: {:d}".format(count)
min = data_set.youtube_view_count.min()
max = data_set.youtube_view_count.max()
index_min = data_set.youtube_view_count.idxmin()
index_max = data_set.youtube_view_count.idxmax()
"Minimum: {:d} Index Minimum: {:d} - Maximum {:d} Index Maximum: {:d}".format(min, index_min, max, index_max)
quantile = data_set.youtube_view_count.quantile()
"Quantile 50%: {:f}".format(quantile)
sum = data_set.youtube_view_count.sum()
"Sum: {:d}".format(sum)
mean = data_set.youtube_view_count.mean()
"Mean: {:f}".format(mean)
median = data_set.youtube_view_count.median()
"Arithmetic median (50% quantile) of values {:f}".format(median)
mad = data_set.youtube_view_count.mad()
"Mean absolute deviation from mean value {:f}".format(mad)
prod = data_set.youtube_view_count.prod()
"Product of all values {:f}".format(prod)
var = data_set.youtube_view_count.var()
"Sample variance of values {:f}".format(var)
std = data_set.youtube_view_count.std()
"Sample standard deviation of values {:f}".format(std)
skew = data_set.youtube_view_count.skew()
"Sample skewness (third moment) of values {:f}".format(skew)
kurt = data_set.youtube_view_count.kurt()
"Sample kurtosis (fourth moment) of values {:f}".format(kurt)
cumsum = data_set.youtube_view_count.cumsum()
cumsum.head()
cummin = data_set.youtube_view_count.cummin()
cummin.head()
cummax = data_set.youtube_view_count.cummin()
cummax.head()
cumprod = data_set.youtube_view_count.cumprod()
cumprod.head()
diff = data_set.youtube_view_count.diff()
diff.head()
pct_change = data_set.youtube_view_count.pct_change()
pct_change.head()
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_likes': data_set.youtube_like_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_dislikes': data_set.youtube_dislike_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'youtube_favorites': data_set.youtube_favorite_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'view_count': data_set.view_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'like_count': data_set.like_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'dislike_count': data_set.dislike_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({
'created': data_set.created,
'favorite_count': data_set.favorite_count,
})
plot_data_set.plot(x='created');
plot_data_set = pd.DataFrame({'youtube_view_count': data_set.youtube_view_count}, columns=['youtube_view_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'youtube_like_count': data_set.youtube_like_count}, columns=['youtube_like_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'youtube_dislike_count': data_set.youtube_dislike_count}, columns=['youtube_dislike_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'youtube_favorite_count': data_set.youtube_favorite_count}, columns=['youtube_favorite_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'view_count': data_set.view_count}, columns=['view_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'like_count': data_set.like_count}, columns=['like_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'dislike_count': data_set.dislike_count}, columns=['dislike_count'])
plot_data_set.hist(bins=150);
plot_data_set = pd.DataFrame({'favorite_count': data_set.favorite_count}, columns=['favorite_count'])
plot_data_set.hist(bins=150);
| 0.550124 | 0.979823 |
<a href="https://colab.research.google.com/github/SauravMaheshkar/trax/blob/SauravMaheshkar-example-1/examples/Deep_N_Gram_Models.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#@title
# Copyright 2020 Google LLC.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# https://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
Author - [@SauravMaheshkar](https://github.com/SauravMaheshkar)
# Downloading the Trax Package
[Trax](https://trax-ml.readthedocs.io/en/latest/) is an end-to-end library for deep learning that focuses on clear code and speed. It is actively used and maintained in the [Google Brain team](https://research.google/teams/brain/). This notebook ([run it in colab](https://colab.research.google.com/github/google/trax/blob/master/trax/intro.ipynb)) shows how to use Trax and where you can find more information.
```
%%capture
!pip install trax
```
# Importing Packages
In this notebook we will use the following packages:
* [**Pandas**](https://pandas.pydata.org/) is a fast, powerful, flexible and easy to use open-source data analysis and manipulation tool, built on top of the Python programming language. It offers a fast and efficient DataFrame object for data manipulation with integrated indexing.
* [**os**](https://docs.python.org/3/library/os.html) module provides a portable way of using operating system dependent functionality.
* [**trax**](https://trax-ml.readthedocs.io/en/latest/trax.html) is an end-to-end library for deep learning that focuses on clear code and speed.
* [**random**](https://docs.python.org/3/library/random.html) module implements pseudo-random number generators for various distributions.
* [**itertools**](https://docs.python.org/3/library/itertools.html) module implements a number of iterator building blocks inspired by constructs from APL, Haskell, and SML. Each has been recast in a form suitable for Python.
```
import pandas as pd
import os
import trax
import trax.fastmath.numpy as np
import random as rnd
from trax import fastmath
from trax import layers as tl
```
# Loading the Data
For this project, I've used the [gothic-literature](https://www.kaggle.com/charlesaverill/gothic-literature), [shakespeare-plays](https://www.kaggle.com/kingburrito666/shakespeare-plays) and [shakespeareonline](https://www.kaggle.com/kewagbln/shakespeareonline) datasets from the Kaggle library.
We perform the following steps for loading in the data:
* Iterate over all the directories in the `/kaggle/input/` directory
* Filter out `.txt` files
* Make a `lines` list containing the individual lines from all the datasets combined
```
directories = os.listdir('/kaggle/input/')
lines = []
for directory in directories:
for filename in os.listdir(os.path.join('/kaggle/input',directory)):
if filename.endswith(".txt"):
with open(os.path.join(os.path.join('/kaggle/input',directory), filename)) as files:
for line in files:
processed_line = line.strip()
if processed_line:
lines.append(processed_line)
```
## Pre-Processing
### Converting to Lowercase
Converting all the characters in the `lines` list to **lowercase**.
```
for i, line in enumerate(lines):
lines[i] = line.lower()
```
### Converting into Tensors
Creating a function to convert each line into a tensor by converting each character into it's ASCII value. And adding a optional `EOS`(**End of statement**) character.
```
def line_to_tensor(line, EOS_int=1):
tensor = []
for c in line:
c_int = ord(c)
tensor.append(c_int)
tensor.append(EOS_int)
return tensor
```
### Creating a Batch Generator
Here, we create a `batch_generator()` function to yield a batch and mask generator. We perform the following steps:
* Shuffle the lines if not shuffled
* Convert the lines into a Tensor
* Pad the lines if it's less than the maximum length
* Generate a mask
```
def data_generator(batch_size, max_length, data_lines, line_to_tensor=line_to_tensor, shuffle=True):
index = 0
cur_batch = []
num_lines = len(data_lines)
lines_index = [*range(num_lines)]
if shuffle:
rnd.shuffle(lines_index)
while True:
if index >= num_lines:
index = 0
if shuffle:
rnd.shuffle(lines_index)
line = data_lines[lines_index[index]]
if len(line) < max_length:
cur_batch.append(line)
index += 1
if len(cur_batch) == batch_size:
batch = []
mask = []
for li in cur_batch:
tensor = line_to_tensor(li)
pad = [0] * (max_length - len(tensor))
tensor_pad = tensor + pad
batch.append(tensor_pad)
example_mask = [0 if t == 0 else 1 for t in tensor_pad]
mask.append(example_mask)
batch_np_arr = np.array(batch)
mask_np_arr = np.array(mask)
yield batch_np_arr, batch_np_arr, mask_np_arr
cur_batch = []
```
# Defining the Model
## Gated Recurrent Unit
This function generates a GRU Language Model, consisting of the following layers:
* ShiftRight()
* Embedding()
* GRU Units(Number specified by the `n_layers` parameter)
* Dense() Layer
* LogSoftmax() Activation
```
def GRULM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.GRU(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
```
## Long Short Term Memory
This function generates a LSTM Language Model, consisting of the following layers:
* ShiftRight()
* Embedding()
* LSTM Units(Number specified by the `n_layers` parameter)
* Dense() Layer
* LogSoftmax() Activation
```
def LSTMLM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.LSTM(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
```
## Simple Recurrent Unit
This function generates a SRU Language Model, consisting of the following layers:
* ShiftRight()
* Embedding()
* SRU Units(Number specified by the `n_layers` parameter)
* Dense() Layer
* LogSoftmax() Activation
```
def SRULM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.SRU(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
GRUmodel = GRULM(n_layers = 5)
LSTMmodel = LSTMLM(n_layers = 5)
SRUmodel = SRULM(n_layers = 5)
print(GRUmodel)
print(LSTMmodel)
print(SRUmodel)
```
## Hyperparameters
Here, we declare `the batch_size` and the `max_length` hyperparameters for the model.
```
batch_size = 32
max_length = 64
```
# Creating Evaluation and Training Dataset
```
eval_lines = lines[-1000:] # Create a holdout validation set
lines = lines[:-1000] # Leave the rest for training
```
# Training the Models
Here, we create a function to train the models. This function does the following:
* Creating a Train and Evaluation Generator that cycles infinetely using the `itertools` module
* Train the Model using Adam Optimizer
* Use the Accuracy Metric for Evaluation
```
from trax.supervised import training
import itertools
def train_model(model, data_generator, batch_size=32, max_length=64, lines=lines, eval_lines=eval_lines, n_steps=10, output_dir = 'model/'):
bare_train_generator = data_generator(batch_size, max_length, data_lines=lines)
infinite_train_generator = itertools.cycle(bare_train_generator)
bare_eval_generator = data_generator(batch_size, max_length, data_lines=eval_lines)
infinite_eval_generator = itertools.cycle(bare_eval_generator)
train_task = training.TrainTask(
labeled_data=infinite_train_generator,
loss_layer=tl.CrossEntropyLoss(),
optimizer=trax.optimizers.Adam(0.0005),
n_steps_per_checkpoint=1
)
eval_task = training.EvalTask(
labeled_data=infinite_eval_generator,
metrics=[tl.CrossEntropyLoss(), tl.Accuracy()],
n_eval_batches=1
)
training_loop = training.Loop(model,
train_task,
eval_tasks=[eval_task],
output_dir = output_dir
)
training_loop.run(n_steps=n_steps)
return training_loop
GRU_training_loop = train_model(GRUmodel, data_generator,n_steps=10, output_dir = 'model/GRU')
LSTM_training_loop = train_model(LSTMmodel, data_generator, n_steps = 10, output_dir = 'model/LSTM')
SRU_training_loop = train_model(SRUmodel, data_generator, n_steps = 10, output_dir = 'model/SRU')
```
|
github_jupyter
|
#@title
# Copyright 2020 Google LLC.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# https://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
%%capture
!pip install trax
import pandas as pd
import os
import trax
import trax.fastmath.numpy as np
import random as rnd
from trax import fastmath
from trax import layers as tl
directories = os.listdir('/kaggle/input/')
lines = []
for directory in directories:
for filename in os.listdir(os.path.join('/kaggle/input',directory)):
if filename.endswith(".txt"):
with open(os.path.join(os.path.join('/kaggle/input',directory), filename)) as files:
for line in files:
processed_line = line.strip()
if processed_line:
lines.append(processed_line)
for i, line in enumerate(lines):
lines[i] = line.lower()
def line_to_tensor(line, EOS_int=1):
tensor = []
for c in line:
c_int = ord(c)
tensor.append(c_int)
tensor.append(EOS_int)
return tensor
def data_generator(batch_size, max_length, data_lines, line_to_tensor=line_to_tensor, shuffle=True):
index = 0
cur_batch = []
num_lines = len(data_lines)
lines_index = [*range(num_lines)]
if shuffle:
rnd.shuffle(lines_index)
while True:
if index >= num_lines:
index = 0
if shuffle:
rnd.shuffle(lines_index)
line = data_lines[lines_index[index]]
if len(line) < max_length:
cur_batch.append(line)
index += 1
if len(cur_batch) == batch_size:
batch = []
mask = []
for li in cur_batch:
tensor = line_to_tensor(li)
pad = [0] * (max_length - len(tensor))
tensor_pad = tensor + pad
batch.append(tensor_pad)
example_mask = [0 if t == 0 else 1 for t in tensor_pad]
mask.append(example_mask)
batch_np_arr = np.array(batch)
mask_np_arr = np.array(mask)
yield batch_np_arr, batch_np_arr, mask_np_arr
cur_batch = []
def GRULM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.GRU(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
def LSTMLM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.LSTM(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
def SRULM(vocab_size=256, d_model=512, n_layers=2, mode='train'):
model = tl.Serial(
tl.ShiftRight(mode=mode),
tl.Embedding( vocab_size = vocab_size, d_feature = d_model),
[tl.SRU(n_units=d_model) for _ in range(n_layers)],
tl.Dense(n_units = vocab_size),
tl.LogSoftmax()
)
return model
GRUmodel = GRULM(n_layers = 5)
LSTMmodel = LSTMLM(n_layers = 5)
SRUmodel = SRULM(n_layers = 5)
print(GRUmodel)
print(LSTMmodel)
print(SRUmodel)
batch_size = 32
max_length = 64
eval_lines = lines[-1000:] # Create a holdout validation set
lines = lines[:-1000] # Leave the rest for training
from trax.supervised import training
import itertools
def train_model(model, data_generator, batch_size=32, max_length=64, lines=lines, eval_lines=eval_lines, n_steps=10, output_dir = 'model/'):
bare_train_generator = data_generator(batch_size, max_length, data_lines=lines)
infinite_train_generator = itertools.cycle(bare_train_generator)
bare_eval_generator = data_generator(batch_size, max_length, data_lines=eval_lines)
infinite_eval_generator = itertools.cycle(bare_eval_generator)
train_task = training.TrainTask(
labeled_data=infinite_train_generator,
loss_layer=tl.CrossEntropyLoss(),
optimizer=trax.optimizers.Adam(0.0005),
n_steps_per_checkpoint=1
)
eval_task = training.EvalTask(
labeled_data=infinite_eval_generator,
metrics=[tl.CrossEntropyLoss(), tl.Accuracy()],
n_eval_batches=1
)
training_loop = training.Loop(model,
train_task,
eval_tasks=[eval_task],
output_dir = output_dir
)
training_loop.run(n_steps=n_steps)
return training_loop
GRU_training_loop = train_model(GRUmodel, data_generator,n_steps=10, output_dir = 'model/GRU')
LSTM_training_loop = train_model(LSTMmodel, data_generator, n_steps = 10, output_dir = 'model/LSTM')
SRU_training_loop = train_model(SRUmodel, data_generator, n_steps = 10, output_dir = 'model/SRU')
| 0.785966 | 0.960952 |
# **Decision Trees**
The Wisconsin Breast Cancer Dataset(WBCD) can be found here(https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data)
This dataset describes the characteristics of the cell nuclei of various patients with and without breast cancer. The task is to classify a decision tree to predict if a patient has a benign or a malignant tumour based on these features.
Attribute Information:
```
# Attribute Domain
-- -----------------------------------------
1. Sample code number id number
2. Clump Thickness 1 - 10
3. Uniformity of Cell Size 1 - 10
4. Uniformity of Cell Shape 1 - 10
5. Marginal Adhesion 1 - 10
6. Single Epithelial Cell Size 1 - 10
7. Bare Nuclei 1 - 10
8. Bland Chromatin 1 - 10
9. Normal Nucleoli 1 - 10
10. Mitoses 1 - 10
11. Class: (2 for benign, 4 for malignant)
```
```
import pandas as pd
headers = ["ID","CT","UCSize","UCShape","MA","SECSize","BN","BC","NN","Mitoses","Diagnosis"]
data = pd.read_csv('./data/breast-cancer-wisconsin.data', na_values='?',
header=None, index_col=['ID'], names = headers)
data = data.reset_index(drop=True)
data = data.fillna(0)
data.describe()
print(data.loc[:698,data.columns != "Diagnosis"].shape)
train_X = data.loc[:599,data.columns != "Diagnosis"]
train_Y = data.loc[:599:,"Diagnosis"]
test_X = data.loc[600 :,data.columns != "Diagnosis"]
test_Y = data.loc[600 :,"Diagnosis"]
print(train_X.shape)
print(test_Y.shape)
print(test_X.shape)
print(test_Y.shape)
```
1. a) Implement a decision tree (you can use decision tree implementation from existing libraries).
```
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
tree_gini = DecisionTreeClassifier(criterion = "gini",random_state=0)
tree_entropy = DecisionTreeClassifier(criterion = "entropy",random_state=0)
```
1. b) Train a decision tree object of the above class on the WBC dataset using misclassification rate, entropy and Gini as the splitting metrics.
```
import time
t1 = time.time()
tree_gini.fit(train_X,train_Y)
t2 = time.time()
tree_entropy.fit(train_X,train_Y)
t3 = time.time()
print("Time to train gini Tree : {0} and entropy Tree : {1}".format(t2 - t1,t3 - t2))
```
1. c) Report the accuracies in each of the above splitting metrics and give the best result.
```
print("Train Accuracy for gini: ",accuracy_score(tree_gini.predict(train_X), train_Y))
print("Train Accuracy for entropy: ",accuracy_score(tree_entropy.predict(train_X),train_Y))
print("Test Accuracy for gini: ",accuracy_score(tree_gini.predict(test_X), test_Y))
print("Test Accuracy for entropy: ",accuracy_score(tree_entropy.predict(test_X),test_Y))
```
Gini gives slightly better results
1. d) Experiment with different approaches to decide when to terminate the tree (number of layers, purity measure, etc). Report and give explanations for all approaches.
```
#Number of Layes
depth = [i for i in range(2,15)]
entropy_test = []
gini_test = []
gini_train = []
entropy_train = []
for d in depth:
new_tree_entropy = DecisionTreeClassifier(criterion="entropy",max_depth=d)
new_tree_gini = DecisionTreeClassifier(criterion="gini",max_depth=d)
new_tree_entropy.fit(train_X,train_Y)
new_tree_gini.fit(train_X,train_Y)
etest = accuracy_score(new_tree_entropy.predict(test_X),test_Y)
gtest = accuracy_score(new_tree_gini.predict(test_X),test_Y)
etrain = accuracy_score(new_tree_entropy.predict(train_X),train_Y)
gtrain = accuracy_score(new_tree_gini.predict(train_X), train_Y)
print("Maximum Depth : {0}".format(d))
print("Train Accuracy for gini: ",gtrain)
print("Train Accuracy for entropy: ",etrain)
print("Test Accuracy for gini: ",gtest)
print("Test Accuracy for entropy: ",etest)
entropy_test.append(etest)
entropy_train.append(etrain)
gini_test.append(gtest)
gini_train.append(gtrain)
import matplotlib.pyplot as plt
plt.plot(depth,entropy_test,'g--',label = "Test Accuracy of Tree using Gini")
plt.plot(depth,gini_test,'b--',label = "Test Accuracy of Tree using Entropy")
plt.title("Test Accuracy vs Max Depth")
plt.xlabel("Maximum Depth")
plt.ylabel("Accuracy")
plt.legend()
```
Depth 9 is optimal for using Entropy.While 4-5 depth is the optimal range when using Gini.
```
#using impurity to stop
impurity_val = [0.001,0.005,0.01,0.02,0.04,0.05,0.1,0.5,1,2]
test_acc = []
for impurity in impurity_val:
new_tree = DecisionTreeClassifier(criterion="entropy",min_impurity_decrease= impurity)
new_tree.fit(train_X,train_Y)
etest = accuracy_score(new_tree.predict(test_X),test_Y)
print("Test Accuracy for entropy: ",etest)
test_acc.append(etest)
print(test_acc)
print(impurity_val)
plt.plot(impurity_val,test_acc,label = "Test Accuracy")
plt.xlabel("Max Inpurity")
plt.ylabel("Accuracy")
plt.legend()
```
Best Value for min_impurity change is 0.005 and 0.01 which gives 97 % Accuracy
2. What is boosting, bagging and stacking?
Which class does random forests belong to and why?
Answer:
Boosting , bagging and stacking are different methods to perform ensembling.The key idea behind ensembling is that while one model can be prone to biases,or high variance,combining a x number of model together to arrive at a decision gives a more robust and more accurate performance
Bagging : In bagging a multiple editions of training data is created with typically the same size of original training data.This is done by allowing repetitions of data points in each set.Then a model typically of the same type(Homogenous) is trained for eachs set of the created training edition.Finally decisions are taken by some sort of deterministic voting mechanism.This prevents Variance as each model is dependent on the training data,but together they can come to a more reasonable and more robust outcomes.
Boosting :Boosting in contrast to Bagging focusses more on reducing bias although it can decrease variances as well.In Boosting the constituent models are not trained independently of each other,the model at any point is trained with a special focus on data points which are misclassified uptil that point.Hence models are dependent on the base models.
Stacking : In stacking multiple model is trained on the data independently ,but unlike other methods they are combined by using another "meta model" which learns how to weight the weaker model's output for each data point.Essentially the meta model learns which model are accurate for which data points.
Random Forest is a Bagging Method.
3. Implement random forest algorithm using different decision trees .
```
class Random_Forest:
def __init__(self,n_trees = 50, n_features = 2 , max_depth = 10, min_size = 2,criterion = "gini"):
self.n_features = n_features
self.n_trees = n_trees
self.max_depth = max_depth
self.min_size = min_size
self.criterion = "gini"
self.model = []
def train(self,test_X,test_Y):
for i in range(self.n_trees):
cur_tree = DecisionTreeClassifier(criterion = self.criterion,max_depth = self.max_depth, min_samples_split = self.min_size,
max_features = self.n_features)
cur_tree.fit(train_X,train_Y)
self.model.append(cur_tree)
def predict(self,test_X):
votes = [{} for i in range(test_X.shape[0])]
max_vote = [0 for i in range(test_X.shape[0])]
max_label = [-1 for i in range(test_X.shape[0])]
sz = len(votes)
for i in range(self.n_trees):
pred = self.model[i].predict(test_X)
for j in range(sz):
if pred[j] in votes[j].keys():
votes[j][pred[j]] += 1
else:
votes[j][pred[j]] = 1
if votes[j][pred[j]] > max_vote[j]:
max_vote[j] = votes[j][pred[j]]
max_label[j] = pred[j]
return max_label
model = Random_Forest(n_trees = 100, n_features = 2 , max_depth = 6, min_size = 2,criterion = "entropy")
t1 = time.time()
model.train(train_X,train_Y)
t2 = time.time()
print("Time taken for training : {0}".format(t2 - t1))
#print(test_X[1])
#print(model.predict(test_X[1]))
#results = [model.predict(data) for data in test_X]
#accuracy_score = accuracy_score(results,test_Y)
print("The Accuracy Score is {0}".format(accuracy_score(model.predict(test_X),test_Y)))
```
4. Report the accuracies obtained after using the Random forest algorithm and compare it with the best accuracies obtained with the decision trees.
As can be seen above the Random Forest gives the highest scored seen till now of 0.989898 of roughly 99% accuracy
5. Submit your solution as a separate pdf in the final zip file of your submission
Compute a decision tree with the goal to predict the food review based on its smell, taste and portion size.
(a) Compute the entropy of each rule in the first stage.
(b) Show the final decision tree. Clearly draw it.
Submit a handwritten response. Clearly show all the steps.
|
github_jupyter
|
# Attribute Domain
-- -----------------------------------------
1. Sample code number id number
2. Clump Thickness 1 - 10
3. Uniformity of Cell Size 1 - 10
4. Uniformity of Cell Shape 1 - 10
5. Marginal Adhesion 1 - 10
6. Single Epithelial Cell Size 1 - 10
7. Bare Nuclei 1 - 10
8. Bland Chromatin 1 - 10
9. Normal Nucleoli 1 - 10
10. Mitoses 1 - 10
11. Class: (2 for benign, 4 for malignant)
import pandas as pd
headers = ["ID","CT","UCSize","UCShape","MA","SECSize","BN","BC","NN","Mitoses","Diagnosis"]
data = pd.read_csv('./data/breast-cancer-wisconsin.data', na_values='?',
header=None, index_col=['ID'], names = headers)
data = data.reset_index(drop=True)
data = data.fillna(0)
data.describe()
print(data.loc[:698,data.columns != "Diagnosis"].shape)
train_X = data.loc[:599,data.columns != "Diagnosis"]
train_Y = data.loc[:599:,"Diagnosis"]
test_X = data.loc[600 :,data.columns != "Diagnosis"]
test_Y = data.loc[600 :,"Diagnosis"]
print(train_X.shape)
print(test_Y.shape)
print(test_X.shape)
print(test_Y.shape)
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
tree_gini = DecisionTreeClassifier(criterion = "gini",random_state=0)
tree_entropy = DecisionTreeClassifier(criterion = "entropy",random_state=0)
import time
t1 = time.time()
tree_gini.fit(train_X,train_Y)
t2 = time.time()
tree_entropy.fit(train_X,train_Y)
t3 = time.time()
print("Time to train gini Tree : {0} and entropy Tree : {1}".format(t2 - t1,t3 - t2))
print("Train Accuracy for gini: ",accuracy_score(tree_gini.predict(train_X), train_Y))
print("Train Accuracy for entropy: ",accuracy_score(tree_entropy.predict(train_X),train_Y))
print("Test Accuracy for gini: ",accuracy_score(tree_gini.predict(test_X), test_Y))
print("Test Accuracy for entropy: ",accuracy_score(tree_entropy.predict(test_X),test_Y))
#Number of Layes
depth = [i for i in range(2,15)]
entropy_test = []
gini_test = []
gini_train = []
entropy_train = []
for d in depth:
new_tree_entropy = DecisionTreeClassifier(criterion="entropy",max_depth=d)
new_tree_gini = DecisionTreeClassifier(criterion="gini",max_depth=d)
new_tree_entropy.fit(train_X,train_Y)
new_tree_gini.fit(train_X,train_Y)
etest = accuracy_score(new_tree_entropy.predict(test_X),test_Y)
gtest = accuracy_score(new_tree_gini.predict(test_X),test_Y)
etrain = accuracy_score(new_tree_entropy.predict(train_X),train_Y)
gtrain = accuracy_score(new_tree_gini.predict(train_X), train_Y)
print("Maximum Depth : {0}".format(d))
print("Train Accuracy for gini: ",gtrain)
print("Train Accuracy for entropy: ",etrain)
print("Test Accuracy for gini: ",gtest)
print("Test Accuracy for entropy: ",etest)
entropy_test.append(etest)
entropy_train.append(etrain)
gini_test.append(gtest)
gini_train.append(gtrain)
import matplotlib.pyplot as plt
plt.plot(depth,entropy_test,'g--',label = "Test Accuracy of Tree using Gini")
plt.plot(depth,gini_test,'b--',label = "Test Accuracy of Tree using Entropy")
plt.title("Test Accuracy vs Max Depth")
plt.xlabel("Maximum Depth")
plt.ylabel("Accuracy")
plt.legend()
#using impurity to stop
impurity_val = [0.001,0.005,0.01,0.02,0.04,0.05,0.1,0.5,1,2]
test_acc = []
for impurity in impurity_val:
new_tree = DecisionTreeClassifier(criterion="entropy",min_impurity_decrease= impurity)
new_tree.fit(train_X,train_Y)
etest = accuracy_score(new_tree.predict(test_X),test_Y)
print("Test Accuracy for entropy: ",etest)
test_acc.append(etest)
print(test_acc)
print(impurity_val)
plt.plot(impurity_val,test_acc,label = "Test Accuracy")
plt.xlabel("Max Inpurity")
plt.ylabel("Accuracy")
plt.legend()
class Random_Forest:
def __init__(self,n_trees = 50, n_features = 2 , max_depth = 10, min_size = 2,criterion = "gini"):
self.n_features = n_features
self.n_trees = n_trees
self.max_depth = max_depth
self.min_size = min_size
self.criterion = "gini"
self.model = []
def train(self,test_X,test_Y):
for i in range(self.n_trees):
cur_tree = DecisionTreeClassifier(criterion = self.criterion,max_depth = self.max_depth, min_samples_split = self.min_size,
max_features = self.n_features)
cur_tree.fit(train_X,train_Y)
self.model.append(cur_tree)
def predict(self,test_X):
votes = [{} for i in range(test_X.shape[0])]
max_vote = [0 for i in range(test_X.shape[0])]
max_label = [-1 for i in range(test_X.shape[0])]
sz = len(votes)
for i in range(self.n_trees):
pred = self.model[i].predict(test_X)
for j in range(sz):
if pred[j] in votes[j].keys():
votes[j][pred[j]] += 1
else:
votes[j][pred[j]] = 1
if votes[j][pred[j]] > max_vote[j]:
max_vote[j] = votes[j][pred[j]]
max_label[j] = pred[j]
return max_label
model = Random_Forest(n_trees = 100, n_features = 2 , max_depth = 6, min_size = 2,criterion = "entropy")
t1 = time.time()
model.train(train_X,train_Y)
t2 = time.time()
print("Time taken for training : {0}".format(t2 - t1))
#print(test_X[1])
#print(model.predict(test_X[1]))
#results = [model.predict(data) for data in test_X]
#accuracy_score = accuracy_score(results,test_Y)
print("The Accuracy Score is {0}".format(accuracy_score(model.predict(test_X),test_Y)))
| 0.483648 | 0.984411 |
# Bile Acids
Compare placebo v. letrozole and letrozole v. let-co-housed at time points 2 and 5.
```
library(tidyverse)
library(magrittr)
source("/Users/cayla/ANCOM/scripts/ancom_v2.1.R")
counts <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/Bile_Acids_Cutoff.csv')
head(counts, n=1)
counts$OTUs <- as.factor(counts$OTUs)
metadata <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/Mapping_file_w_og.csv')
head(metadata, n=1)
metadata %<>% select(SampleID, Week, Category)
indices <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/taxonomy_cutoff.csv')
head(indices, n=1)
indices$OTUs <- as.factor(indices$OTUs)
indices %<>% rename(BA = Domain)
indices[,3:8] <- NULL
# subset data and metadata
meta.t2.PvL <- metadata %>% filter(Week == '2', Category == 'Placebo' | Category == 'Letrozole')
t2.PvL <- counts %>% select(OTUs, any_of(meta.t2.PvL$SampleID)) %>% column_to_rownames('OTUs')
meta.t2.LvLCH <- metadata %>% filter(Week == '2', Category == 'Co-L' | Category == 'Letrozole')
t2.LvLCH <- counts %>% select(OTUs, any_of(meta.t2.LvLCH$SampleID)) %>% column_to_rownames('OTUs')
meta.t5.PvL <- metadata %>% filter(Week == '5', Category == 'Placebo' | Category == 'Letrozole')
t5.PvL <- counts %>% select(OTUs, any_of(meta.t5.PvL$SampleID)) %>% column_to_rownames('OTUs')
meta.t5.LvLCH <- metadata %>% filter(Week == '5', Category == 'Co-L' | Category == 'Letrozole')
t5.LvLCH <- counts %>% select(OTUs, any_of(meta.t5.LvLCH$SampleID)) %>% column_to_rownames('OTUs')
```
## Time Point 2
### Placebo v. Letrozole
```
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t2.PvL
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t2.PvL, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table1 <- prepro$feature_table
# Preprocessed metadata
meta_data1 <- prepro$meta_data
# Structural zero info
struc_zero1 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res <- ANCOM(feature_table1, meta_data1, struc_zero1, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res$out, "2021-07-26_BAs_T2_PvL_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero1), nrow(feature_table1), sum(apply(struc_zero1, 1, sum) == 0))
res$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T2_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T2_PvL.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T2_PvL.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T2_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
```
### Letrozole v. Let-co-housed
```
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t2.LvLCH
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t2.LvLCH, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table2 <- prepro$feature_table
# Preprocessed metadata
meta_data2 <- prepro$meta_data
# Structural zero info
struc_zero2 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res2 <- ANCOM(feature_table2, meta_data2, struc_zero2, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
#write_csv(res2$out, "2021-07-26_BAs_T2_LvLCH_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero2), nrow(feature_table2), sum(apply(struc_zero2, 1, sum) == 0))
res2$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T2_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res2$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T2_LvLCH.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res2$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T2_LvLCH.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T2_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
```
## Time Point 5
### Placebo v. Letrozole
```
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t5.PvL
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t5.PvL, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table3 <- prepro$feature_table
# Preprocessed metadata
meta_data3 <- prepro$meta_data
# Structural zero info
struc_zero3 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res3 <- ANCOM(feature_table3, meta_data3, struc_zero3, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res3$out, "2021-07-26_BAs_T5_PvL_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero3), nrow(feature_table3), sum(apply(struc_zero3, 1, sum) == 0))
res3$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T5_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res3$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T5_PvL.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res3$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T5_PvL.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T5_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
```
### Letrozole v. Let-co-housed
```
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t5.LvLCH
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t5.LvLCH, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table4 <- prepro$feature_table
# Preprocessed metadata
meta_data4 <- prepro$meta_data
# Structural zero info
struc_zero4 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res4 <- ANCOM(feature_table4, meta_data4, struc_zero4, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res4$out, "2021-07-26_BAs_T5_LvLCH_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero4), nrow(feature_table4), sum(apply(struc_zero4, 1, sum) == 0))
res4$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T5_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res4$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T5_LvLCH.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res4$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T5_LvLCH.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T5_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
```
|
github_jupyter
|
library(tidyverse)
library(magrittr)
source("/Users/cayla/ANCOM/scripts/ancom_v2.1.R")
counts <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/Bile_Acids_Cutoff.csv')
head(counts, n=1)
counts$OTUs <- as.factor(counts$OTUs)
metadata <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/Mapping_file_w_og.csv')
head(metadata, n=1)
metadata %<>% select(SampleID, Week, Category)
indices <- read_csv('https://github.com/bryansho/PCOS_WGS_16S_metabolome/raw/master/DESEQ2/Bile_Acids/taxonomy_cutoff.csv')
head(indices, n=1)
indices$OTUs <- as.factor(indices$OTUs)
indices %<>% rename(BA = Domain)
indices[,3:8] <- NULL
# subset data and metadata
meta.t2.PvL <- metadata %>% filter(Week == '2', Category == 'Placebo' | Category == 'Letrozole')
t2.PvL <- counts %>% select(OTUs, any_of(meta.t2.PvL$SampleID)) %>% column_to_rownames('OTUs')
meta.t2.LvLCH <- metadata %>% filter(Week == '2', Category == 'Co-L' | Category == 'Letrozole')
t2.LvLCH <- counts %>% select(OTUs, any_of(meta.t2.LvLCH$SampleID)) %>% column_to_rownames('OTUs')
meta.t5.PvL <- metadata %>% filter(Week == '5', Category == 'Placebo' | Category == 'Letrozole')
t5.PvL <- counts %>% select(OTUs, any_of(meta.t5.PvL$SampleID)) %>% column_to_rownames('OTUs')
meta.t5.LvLCH <- metadata %>% filter(Week == '5', Category == 'Co-L' | Category == 'Letrozole')
t5.LvLCH <- counts %>% select(OTUs, any_of(meta.t5.LvLCH$SampleID)) %>% column_to_rownames('OTUs')
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t2.PvL
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t2.PvL, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table1 <- prepro$feature_table
# Preprocessed metadata
meta_data1 <- prepro$meta_data
# Structural zero info
struc_zero1 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res <- ANCOM(feature_table1, meta_data1, struc_zero1, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res$out, "2021-07-26_BAs_T2_PvL_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero1), nrow(feature_table1), sum(apply(struc_zero1, 1, sum) == 0))
res$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T2_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T2_PvL.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T2_PvL.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T2_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t2.LvLCH
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t2.LvLCH, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table2 <- prepro$feature_table
# Preprocessed metadata
meta_data2 <- prepro$meta_data
# Structural zero info
struc_zero2 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res2 <- ANCOM(feature_table2, meta_data2, struc_zero2, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
#write_csv(res2$out, "2021-07-26_BAs_T2_LvLCH_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero2), nrow(feature_table2), sum(apply(struc_zero2, 1, sum) == 0))
res2$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T2_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res2$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T2_LvLCH.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res2$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T2_LvLCH.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T2_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t5.PvL
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t5.PvL, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table3 <- prepro$feature_table
# Preprocessed metadata
meta_data3 <- prepro$meta_data
# Structural zero info
struc_zero3 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res3 <- ANCOM(feature_table3, meta_data3, struc_zero3, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res3$out, "2021-07-26_BAs_T5_PvL_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero3), nrow(feature_table3), sum(apply(struc_zero3, 1, sum) == 0))
res3$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T5_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res3$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T5_PvL.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res3$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T5_PvL.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T5_PvL.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# Data Preprocessing
# feature_table is a df/matrix with features as rownames and samples in columns
feature_table <- t5.LvLCH
sample_var <- "SampleID"
group_var <- "Category"
out_cut <- 0.05
zero_cut <- 0.90
lib_cut <- 0
neg_lb <- TRUE
prepro <- feature_table_pre_process(feature_table, meta.t5.LvLCH, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
# Preprocessed feature table
feature_table4 <- prepro$feature_table
# Preprocessed metadata
meta_data4 <- prepro$meta_data
# Structural zero info
struc_zero4 <- prepro$structure_zeros
# Run ANCOM
main_var <- "Category"
p_adj_method <- "BH" # number of taxa > 10, therefore use Benjamini-Hochberg correction
alpha <- 0.05
adj_formula <- NULL
rand_formula <- NULL
t_start <- Sys.time()
res4 <- ANCOM(feature_table4, meta_data4, struc_zero4, main_var, p_adj_method,
alpha, adj_formula, rand_formula)
t_end <- Sys.time()
t_end - t_start
# write output to file
# output contains the "W" statistic for each taxa - a count of the number of times
# the null hypothesis is rejected for each taxa
# detected_x are logicals indicating detection at specified FDR cut-off
write_csv(res4$out, "2021-07-26_BAs_T5_LvLCH_ANCOM_data.csv")
n_taxa <- ifelse(is.null(struc_zero4), nrow(feature_table4), sum(apply(struc_zero4, 1, sum) == 0))
res4$fig + scale_y_continuous(sec.axis = sec_axis(~ . * 100 / n_taxa, name = 'W proportion'))
ggsave(filename = paste(lubridate::today(),'volcano_BAs_T5_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
# save features with W > 0
non.zero <- res4$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
mutate(W.proportion = y/(n_taxa-1)) %>% # add W
filter(W.proportion > 0) %>%
rowid_to_column()
write.csv(non.zero, paste(lubridate::today(),'NonZeroW_Features_BileAcids_T5_LvLCH.csv',sep='_'))
# to find most significant taxa, I will sort the data
# 1) y (W statistic)
# 2) according to the absolute value of CLR mean difference
sig <- res4$fig$data %>%
arrange(desc(y), desc(abs(x))) %>%
left_join(indices, by = c('taxa_id' = 'OTUs')) %>%
filter(y >= (0.7*n_taxa)) # keep significant taxa
write.csv(sig, paste(lubridate::today(),'SigFeatures_BAs_T5_LvLCH.csv',sep='_'))
# plot top 20 taxa
sig %>%
slice_head(n=20) %>%
mutate(taxa_id = fct_reorder(taxa_id, (abs(x)))) %>%
ggplot(aes(x, taxa_id)) +
geom_point(aes(size = 1)) +
theme_bw(base_size = 16) +
guides(size = "none") +
labs(x = 'CLR Mean Difference', y = NULL)
ggsave(filename = paste(lubridate::today(),'Top20_BAs_T5_LvLCH.pdf',sep='_'), bg = 'transparent', device = 'pdf', dpi = 'retina')
| 0.423696 | 0.837321 |
```
%matplotlib notebook
import control as c
import ipywidgets as w
import numpy as np
from IPython.display import display, HTML
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.transforms as transforms
import matplotlib.animation as animation
display(HTML('<script> $(document).ready(function() { $("div.input").hide(); }); </script>'))
```
## Control design for a Ball and Beam system
The following example is a control design task for a ball and beam system. The structure consists of a ball or cylinder rolling atop of a straight beam, rotated either by direct position input or through a driving mechanism. The objective is to control the ball's position.
<br><br>
<table><tbody><tr>
<td><center><img src="Images/bbdir.png" width="65%" /></center></td>
<td><center><img src="Images/bbmech.png" width="65%" /></center></td>
</tr>
<tr>
<td><center>Direct drive</center></td><td><center>Drive through mechanism</center></td>
</tr></tbody></table>
<br>
While the system is non-linear, thus falls outside of the reach of classical control, after linearization and a set of simplifications, it is still possible to control it near to its steady state. Keep in mind, though, that results containing larger movements will violate these assumptions.
The linearized motion equations are:
<br>
$$\left(\frac{J}{r^2}+m\right)\cdot\ddot x=-m\cdot g\cdot\alpha\qquad\left(\frac{J}{r^2}+m\right)\cdot\ddot x=-\frac{m\cdot g\cdot d}{L}\cdot\varphi$$
<br>
Where:
<br>
$$J=\frac{2}{5}m\cdot r^2$$
<br>
After the Laplace transformation of the differential equations, the transfer functions can be expressed as:
<br>
$$G_{dir}(s)=-\frac{m\cdot g}{\left(\frac{J}{r^2}+m\right)\cdot s^2}\qquad G_{mech}(s)=-\frac{m\cdot g\cdot d}{L\cdot\left(\frac{J}{r^2}+m\right)\cdot s^2}$$
<br>
Your task is to choose a controller type, and tune it to acceptable levels of performance!
<b>First, choose a system model!</b><br>
Toggle between different realistic models with randomly preselected values (buttons *Model 1* - *Model 6*). By clicking the *Preset* button default, valid predetermined controller parameters are set and cannot be tuned further.
The two types are formally equivalent due to the simplifications.
```
# Model selector buttons
typeSelect = w.ToggleButtons(
options=[('Direct drive', 0), ('Drive mechanism', 1),],
description='System: ')
display(typeSelect)
# System parameters
g = 9.81 # m/s^2 - gravitational acceleration
# Figure definition
fig1, ((f1_ax1), (f1_ax2)) = plt.subplots(2, 1)
fig1.set_size_inches((9.8, 5))
fig1.set_tight_layout(True)
f1_line1, = f1_ax1.plot([], [])
f1_line2, = f1_ax2.plot([], [])
f1_ax1.grid(which='both', axis='both', color='lightgray')
f1_ax2.grid(which='both', axis='both', color='lightgray')
f1_ax1.autoscale(enable=True, axis='both', tight=True)
f1_ax2.autoscale(enable=True, axis='both', tight=True)
f1_ax1.set_title('Bode magnitude plot', fontsize=11)
f1_ax1.set_xscale('log')
f1_ax1.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=10)
f1_ax1.set_ylabel(r'$A\/$[dB]', labelpad=0, fontsize=10)
f1_ax1.tick_params(axis='both', which='both', pad=0, labelsize=8)
f1_ax2.set_title('Bode phase plot', fontsize=11)
f1_ax2.set_xscale('log')
f1_ax2.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=10)
f1_ax2.set_ylabel(r'$\phi\/$[°]', labelpad=0, fontsize=10)
f1_ax2.tick_params(axis='both', which='both', pad=0, labelsize=8)
def build_base_model(m, r, d, L, type_select):
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
print('System transfer function:')
print(W_sys)
# System analysis
poles = c.pole(W_sys) # Poles
print('System poles:\n')
print(poles)
global f1_line1, f1_line2
f1_ax1.lines.remove(f1_line1)
f1_ax2.lines.remove(f1_line2)
mag, phase, omega = c.bode_plot(W_sys, Plot=False) # Bode-plot
f1_line1, = f1_ax1.plot(omega/2/np.pi, 20*np.log10(mag), lw=1, color='blue')
f1_line2, = f1_ax2.plot(omega/2/np.pi, phase*180/np.pi, lw=1, color='blue')
f1_ax1.relim()
f1_ax2.relim()
f1_ax1.autoscale_view()
f1_ax2.autoscale_view()
def update_sliders(index, model):
global m_slider, r_slider, d_slider, L_slider
mval = [0.05, 0.05, 0.1, 0.1, 0.5, 0.5, 0.25]
rval = [0.01, 0.05, 0.05, 0.1, 0.1, 0.15, 0.075]
dval = [0.025, 0.01, 0.05, 0.2, 0.2, 0.4, 0.2]
Lval = [0.1, 0.1, 0.5, 1, 2, 2, 1]
m_slider.value = mval[index]
r_slider.value = rval[index]
d_slider.value = dval[index]
L_slider.value = Lval[index]
if index == -1:
m_slider.disabled = True;
r_slider.disabled = True;
d_slider.disabled = True;
L_slider.disabled = True;
else:
m_slider.disabled = False;
r_slider.disabled = False;
if model == 0:
d_slider.disabled = False;
L_slider.disabled = False;
else:
d_slider.disabled = True;
L_slider.disabled = True;
# GUI widgets
typeSelect2 = w.ToggleButtons(
options=[('Model 1', 0), ('Model 2', 1), ('Model 3', 2), ('Model 4', 3), ('Model 5', 4), ('Model 6', 5),
('Preset', -1)],
value=-1, description='System: ', layout=w.Layout(width='60%'))
m_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=1, description='m [kg] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
r_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=0, description='r [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
d_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=0, description='d [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
L_slider = w.FloatLogSlider(value=0, base=10, min=-1, max=2, description='L [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
input_data = w.interactive_output(build_base_model, {'m':m_slider, 'r':r_slider, 'd':d_slider, 'L':L_slider,
'type_select':typeSelect})
input_data2 = w.interactive_output(update_sliders, {'index':typeSelect2, 'model':typeSelect})
display(typeSelect2, input_data2)
display(w.HBox([w.VBox([m_slider, r_slider], layout=w.Layout(width='45%')),
w.VBox([d_slider, L_slider], layout=w.Layout(width='45%'))]), input_data)
```
Due to the massive simplifications, the system is reduced to an ideal double integrator.<br>
<b>Select an appropriate controller configuration! Which one is the best for your system? Why?<br>
Set up your controller for the fastest settling time with no overshoot!</b>
You can turn on/off each of the I and D components, and if D is active, you can apply the first-order filter as well, based on the derivating time constant.
```
# PID ball balancer
fig2, ((f2_ax1, f2_ax2, f2_ax3), (f2_ax4, f2_ax5, f2_ax6)) = plt.subplots(2, 3)
fig2.set_size_inches((9.8, 5))
fig2.set_tight_layout(True)
f2_line1, = f2_ax1.plot([], [])
f2_line2, = f2_ax2.plot([], [])
f2_line3, = f2_ax3.plot([], [])
f2_line4, = f2_ax4.plot([], [])
f2_line5, = f2_ax5.plot([], [])
f2_line6, = f2_ax6.plot([], [])
f2_ax1.grid(which='both', axis='both', color='lightgray')
f2_ax2.grid(which='both', axis='both', color='lightgray')
f2_ax3.grid(which='both', axis='both', color='lightgray')
f2_ax4.grid(which='both', axis='both', color='lightgray')
f2_ax5.grid(which='both', axis='both', color='lightgray')
f2_ax6.grid(which='both', axis='both', color='lightgray')
f2_ax1.autoscale(enable=True, axis='both', tight=True)
f2_ax2.autoscale(enable=True, axis='both', tight=True)
f2_ax3.autoscale(enable=True, axis='both', tight=True)
f2_ax4.autoscale(enable=True, axis='both', tight=True)
f2_ax5.autoscale(enable=True, axis='both', tight=True)
f2_ax6.autoscale(enable=True, axis='both', tight=True)
f2_ax1.set_title('Closed loop step response', fontsize=9)
f2_ax1.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax1.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax1.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax2.set_title('Nyquist diagram', fontsize=9)
f2_ax2.set_xlabel(r'Re', labelpad=0, fontsize=8)
f2_ax2.set_ylabel(r'Im', labelpad=0, fontsize=8)
f2_ax2.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax3.set_title('Bode magniture plot', fontsize=9)
f2_ax3.set_xscale('log')
f2_ax3.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=8)
f2_ax3.set_ylabel(r'$A\/$[dB]', labelpad=0, fontsize=8)
f2_ax3.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax4.set_title('Closed loop impulse response', fontsize=9)
f2_ax4.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax4.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax4.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax5.set_title('Load transfer step response', fontsize=9)
f2_ax5.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax5.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax5.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax6.set_title('Bode phase plot', fontsize=9)
f2_ax6.set_xscale('log')
f2_ax6.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=8)
f2_ax6.set_ylabel(r'$\phi\/$[°]', labelpad=0, fontsize=8)
f2_ax6.tick_params(axis='both', which='both', pad=0, labelsize=6)
def position_control(Kp, Ti, Td, Fd, Ti0, Td0, m, r, d, L, type_select):
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
# PID Controller
P = Kp # Proportional term
I = Kp / Ti # Integral term
D = Kp * Td # Derivative term
Td_f = Td / Fd # Derivative term filter
W_PID = c.parallel(c.tf([P], [1]),
c.tf([I * Ti0], [1 * Ti0, 1 * (not Ti0)]),
c.tf([D * Td0, 0], [Td_f * Td0, 1])) # PID controller in time constant format
W_open = c.series(W_PID, W_sys) # Open loop
W_closed = c.feedback(W_open, 1, -1) # Closed loop with negative feedback
if type_select: # Disturbance transfer
W_load = c.feedback (c.tf([1], [J/r/r+m, 0, 0]), c.series(c.tf([m*g*d], [L]), W_PID), -1)
else:
W_load = c.feedback (c.tf([1], [J/r/r+m, 0, 0]), c.series(c.tf([m*g], [1]), W_PID), -1)
# Display
global f2_line1, f2_line2, f2_line3, f2_line4, f2_line5, f2_line6
f2_ax1.lines.remove(f2_line1)
f2_ax2.lines.remove(f2_line2)
f2_ax3.lines.remove(f2_line3)
f2_ax4.lines.remove(f2_line4)
f2_ax5.lines.remove(f2_line5)
f2_ax6.lines.remove(f2_line6)
tout, yout = c.step_response(W_closed)
f2_line1, = f2_ax1.plot(tout, yout, lw=1, color='blue')
_, _, ob = c.nyquist_plot(W_open, Plot=False) # Small resolution plot to determine bounds
real, imag, freq = c.nyquist_plot(W_open, omega=np.logspace(np.log10(ob[0]), np.log10(ob[-1]), 1000), Plot=False)
f2_line2, = f2_ax2.plot(real, imag, lw=1, color='blue')
mag, phase, omega = c.bode_plot(W_open, Plot=False)
f2_line3, = f2_ax3.plot(omega/2/np.pi, 20*np.log10(mag), lw=1, color='blue')
f2_line6, = f2_ax6.plot(omega/2/np.pi, phase*180/np.pi, lw=1, color='blue')
tout, yout = c.impulse_response(W_closed)
f2_line4, = f2_ax4.plot(tout, yout, lw=1, color='blue')
tout, yout = c.step_response(W_load)
f2_line5, = f2_ax5.plot(tout, yout, lw=1, color='blue')
f2_ax1.relim()
f2_ax2.relim()
f2_ax3.relim()
f2_ax4.relim()
f2_ax5.relim()
f2_ax6.relim()
f2_ax1.autoscale_view()
f2_ax2.autoscale_view()
f2_ax3.autoscale_view()
f2_ax4.autoscale_view()
f2_ax5.autoscale_view()
f2_ax6.autoscale_view()
def update_controller(index):
global Kp_slider, Ti_slider, Td_slider, Fd_slider, Ti_button, Td_button
if index == -1:
Kp_slider.value = 100
Td_slider.value = 0.05
Fd_slider.value = 5
Ti_button.value = False
Td_button.value = True
Kp_slider.disabled = True
Ti_slider.disabled = True
Td_slider.disabled = True
Fd_slider.disabled = True
Ti_button.disabled = True
Td_button.disabled = True
else:
Kp_slider.disabled = False
Ti_slider.disabled = False
Td_slider.disabled = False
Fd_slider.disabled = False
Ti_button.disabled = False
Td_button.disabled = False
# GUI widgets
Kp_slider = w.FloatLogSlider(value=2, base=10, min=-3, max=5, description='Kp:', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Ti_slider = w.FloatLogSlider(value=0.0035, base=10, min=-4, max=1, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Td_slider = w.FloatLogSlider(value=0.25, base=10, min=-4, max=1, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Fd_slider = w.FloatLogSlider(value=1, base=10, min=0, max=3, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Ti_button = w.ToggleButton(value=False, description='Ti',
layout=w.Layout(width='auto', flex='1 1 0%'))
Td_button = w.ToggleButton(value=True, description='Td',
layout=w.Layout(width='auto', flex='1 1 0%'))
input_data = w.interactive_output(position_control, {'Kp': Kp_slider, 'Ti': Ti_slider, 'Td': Td_slider,
'Fd': Fd_slider, 'Ti0' : Ti_button, 'Td0': Td_button,
'm':m_slider, 'r':r_slider,
'd':d_slider, 'L':L_slider, 'type_select':typeSelect})
w.interactive_output(update_controller, {'index': typeSelect2})
display(w.HBox([Kp_slider, Ti_button, Ti_slider, Td_button, Td_slider, Fd_slider]), input_data)
```
In the following simulation, you can observe the movement of your system based on your controller setup. You can create reference signals and even apply some disturbance and see how the system reacts.
<b>Is your configuration suitable for signal-following? Readjust your controller so that it can follow a sine wave acceptably!</b>
<br><br>
<i>(The animations are scaled to fit the frame through the whole simulation. Because of this, unstable solutions might not seem to move until the very last second.)</i>
```
# Simulation
anim_fig = plt.figure()
anim_fig.set_size_inches((9.8, 6))
anim_fig.set_tight_layout(True)
anim_ax1 = anim_fig.add_subplot(211)
anim_ax2 = anim_ax1.twinx()
frame_count=1000
l1 = anim_ax1.plot([], [], lw=1, color='blue')
l2 = anim_ax1.plot([], [], lw=2, color='red')
l3 = anim_ax2.plot([], [], lw=1, color='grey')
line1 = l1[0]
line2 = l2[0]
line3 = l3[0]
anim_ax1.legend(l1+l2+l3, ['Reference [m]', 'Output [m]', 'Load [N]'], loc=1)
anim_ax1.set_title('Time response simulation', fontsize=12)
anim_ax1.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=10)
anim_ax1.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=10)
anim_ax1.tick_params(axis='both', which='both', pad=0, labelsize=8)
anim_ax2.set_ylabel(r'$F\/$[N]', labelpad=0, fontsize=10)
anim_ax2.tick_params(axis='both', which='both', pad=0, labelsize=8)
anim_ax1.grid(which='both', axis='both', color='lightgray')
T_plot = []
X_plot = []
D_plot = []
R_plot = []
P_plot = []
# Scene data
scene_ax = anim_fig.add_subplot(212)
scene_ax.set_xlim((-4.75, 4.75))
scene_ax.set_ylim((-1.5, 1.5))
scene_ax.axis('off')
rotation_transform = transforms.Affine2D()
scene_ax.add_patch(patches.Polygon(np.stack(([-3.5, -3.5, -0.5, 0.5, 3.5, 3.5, -3.5],
[0.25, 0.1, -0.25, -0.25, 0.1, 0.25, 0.25])).T,
fill = True, lw=1, ec='black', fc='lightgray', zorder=5,
transform=rotation_transform + scene_ax.transData))
scene_ax.add_patch(patches.Polygon(np.stack(([-0.7, -0.7, 0.7, 0.7, 0.25, -0.25, -0.7],
[-1.1, -1.4, -1.4, -1.1, 0, 0, -1.1])).T,
fill = True, lw=1, ec='black', fc='darkgoldenrod', zorder=0))
scene_ax.add_patch(patches.Circle((0, 0), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=20))
ball = patches.Circle((0, 0.5), fill=True, radius=0.25, ec='black', fc='orange', lw=1,
zorder=5, transform=rotation_transform + scene_ax.transData)
gleam = patches.Wedge((0, 0.5), 0.2, fill=True, width=0.075, theta1=215, theta2=235, lw=0,
ec='white', fc='white', zorder=10, transform=rotation_transform + scene_ax.transData)
scene_ax.add_patch(ball)
scene_ax.add_patch(gleam)
center_drive_belt, = scene_ax.plot([-0.42, -0.15, 0.15, 0.42], [-0.8, 0.05, 0.05, -0.8], color='black', lw=3, zorder=10)
center_drive_1 = patches.Circle((0, 0), fill=True, radius=0.18, ec='black', fc='lawngreen', lw=1, zorder=15)
center_drive_2 = patches.Circle((0, -0.85), fill=True, radius=0.45, ec='black', fc='lawngreen', lw=1, zorder=15)
center_drive_shaft = patches.Circle((0, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25)
center_drive_mark_1 = patches.Wedge((0, -0.85), 0.40, theta1=260, theta2=280, width=0.32,
fill=True, ec='black', fc='white', lw=1, zorder=20)
center_drive_mark_2 = patches.Wedge((0, -0.85), 0.40, theta1=80, theta2=100, width=0.32,
fill=True, ec='black', fc='white', lw=1, zorder=20)
scene_ax.add_patch(center_drive_1)
scene_ax.add_patch(center_drive_2)
scene_ax.add_patch(center_drive_shaft)
scene_ax.add_patch(center_drive_mark_1)
scene_ax.add_patch(center_drive_mark_2)
wheel_transform = transforms.Affine2D()
drive_rod_outline, = scene_ax.plot([3.5, 3.4], [-0.85, 0.175], color='black', solid_capstyle='round', lw=8, zorder=15,
visible=False)
drive_rod, = scene_ax.plot([3.5, 3.4], [-0.85, 0.175], color='deepskyblue', solid_capstyle='round', lw=6, zorder=20,
visible=False)
drive_wheel_rod_outline, = scene_ax.plot([3.05, 3.5], [-0.85, -0.85], color='black', solid_capstyle='round', lw=12, zorder=0,
visible=False)
drive_wheel_rod, = scene_ax.plot([3.05, 3.5], [-0.85, -0.85], color='cyan', solid_capstyle='round', lw=10, zorder=10,
visible=False)
drive_motor_grate, = scene_ax.plot([2.5, 2.5, 2.5833, 2.5833, 2.6666, 2.6666, 2.75],
[-1, -1.25, -1, -1.25, -1, -1.25, -1],
color='black', solid_capstyle='round', lw=1, zorder=5, visible=False)
drive_rod_p1 = patches.Circle((3.4, 0.175), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25,
transform=rotation_transform + scene_ax.transData, visible=False)
drive_rod_p2 = patches.Circle((3.5, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25,
transform=wheel_transform + scene_ax.transData, visible=False)
drive_wheel = patches.Circle((3.05, -0.85), fill=True, radius=0.25, ec='black', fc='cyan', lw=1, zorder=5, visible=False)
drive_wheel_p = patches.Circle((3.05, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25, visible=False)
drive_motor = patches.Polygon(np.stack(([2.3, 3.2, 3.2, 2.6, 2.3, 2.3],
[-1.4, -1.4, -0.7, -0.7, -0.85, -1.4])).T,
fill = True, lw=1, ec='black', fc='firebrick', zorder=0, visible=False)
scene_ax.add_patch(drive_rod_p1)
scene_ax.add_patch(drive_rod_p2)
scene_ax.add_patch(drive_wheel)
scene_ax.add_patch(drive_wheel_p)
scene_ax.add_patch(drive_motor)
x_arrow = scene_ax.arrow(0, 0.05, 0, 0.15, ec='black', fc='blue', head_width=0.1,
length_includes_head=True, lw=1, fill=True, zorder=10,
transform=rotation_transform + scene_ax.transData)
r_arrow = scene_ax.arrow(0, 0.05, 0, 0.15, ec='black', fc='red', head_width=0.1,
length_includes_head=True, lw=1, fill=True, zorder=10,
transform=rotation_transform + scene_ax.transData)
base_arrow = x_arrow.xy
rot_pos = []
ball_pos = []
ref_pos = []
ball_rot = []
sys_type = 0
#Simulation function
def simulation(Kp, Ti, Td, Fd, Ti0, Td0, m, r, d, L, type_select, T, dt, X, Xf, Xa, Xo, F, Ff, Fa, Fo):
# Controller
P = Kp # Proportional term
I = Kp / Ti # Integral term
D = Kp * Td # Derivative term
Td_f = Td / Fd # Derivative term filter
W_PID = c.parallel(c.tf([P], [1]),
c.tf([I * Ti0], [1 * Ti0, 1 * (not Ti0)]),
c.tf([D * Td0, 0], [Td_f * Td0, 1])) # PID controller
# System
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
# Model
W_open = c.series(W_PID, W_sys) # Open loop
W_closed = c.feedback(W_open, 1, -1) # Closed loop with negative feedback
if type_select: # Disturbance transfer
W_s1 = c.tf([m*g*d], [L])
else:
W_s1 = c.tf([m*g], [1])
W_s2 = c.tf([1], [J/r/r+m, 0, 0])
W_load = c.feedback(W_s2, c.series(W_PID, W_s1), -1)
W_cont_sys = c.feedback(W_PID, W_sys, -1) # Control signal (angle) system component
W_cont_load = c.feedback(c.series(W_s2, c.negate(W_PID)), W_s1, 1) # Control signal (angle) load component
# Reference and disturbance signals
T_sim = np.arange(0, T, dt, dtype=np.float64)
if X == 0: # Constant reference
X_sim = np.full_like(T_sim, Xa * Xo)
elif X == 1: # Sine wave reference
X_sim = (np.sin(2 * np.pi * Xf * T_sim) + Xo) * Xa
elif X == 2: # Square wave reference
X_sim = (np.sign(np.sin(2 * np.pi * Xf * T_sim)) + Xo) * Xa
if F == 0: # Constant load
F_sim = np.full_like(T_sim, Fa * Fo)
elif F == 1: # Sine wave load
F_sim = (np.sin(2 * np.pi * Ff * T_sim) + Fo) * Fa
elif F == 2: # Square wave load
F_sim = (np.sign(np.sin(2 * np.pi * Ff * T_sim)) + Fo) * Fa
elif F == 3: # Noise form load
F_sim = np.interp(T_sim, np.linspace(0, T, int(T * Ff) + 2),
np.random.normal(loc=(Fo * Fa), scale=Fa, size=int(T * Ff) + 2))
# System response
Tx, youtx, xoutx = c.forced_response(W_closed, T_sim, X_sim)
Tf, youtf, xoutf = c.forced_response(W_load, T_sim, F_sim)
R_sim = np.nan_to_num(youtx + youtf)
Tcx, youtcx, xoutcx = c.forced_response(W_cont_sys, T_sim, X_sim)
Tcf, youtcf, xoutcf = c.forced_response(W_cont_load, T_sim, F_sim)
P_sim = np.nan_to_num(youtcx + youtcf)
# Display
XR_max = max(np.amax(np.absolute(np.concatenate((X_sim, R_sim)))), Xa)
F_max = max(np.amax(np.absolute(F_sim)), Fa)
P_max = np.amax(np.absolute(P_sim))
anim_ax1.set_xlim((0, T))
anim_ax1.set_ylim((-1.2 * XR_max, 1.2 * XR_max))
anim_ax2.set_ylim((-1.5 * F_max, 1.5 * F_max))
global T_plot, X_plot, F_plot, R_plot, P_plot, rot_pos, ball_pos, ref_pos, ball_rot, sys_type
T_plot = np.linspace(0, T, frame_count, dtype=np.float32)
X_plot = np.interp(T_plot, T_sim, X_sim)
F_plot = np.interp(T_plot, T_sim, F_sim)
R_plot = np.interp(T_plot, T_sim, R_sim)
P_plot = np.interp(T_plot, T_sim, P_sim)
rot_pos = P_plot / P_max * -10 # The constant sets the apparent maximal tilt of the animation in degrees
ball_pos = R_plot / XR_max * 3.4
ref_pos = X_plot / XR_max * 3.4
ball_rot = ball_pos / np.pi * -360
sys_type = type_select
def anim_init():
line1.set_data([], [])
line2.set_data([], [])
line3.set_data([], [])
ball.set_center((0, 0.5))
gleam.set_center((0, 0.5))
gleam.set_theta1(215)
gleam.set_theta2(235)
center_drive_mark_1.set_theta1(260)
center_drive_mark_1.set_theta2(280)
center_drive_mark_2.set_theta1(80)
center_drive_mark_2.set_theta2(100)
drive_rod_outline.set_data([3.5, 3.4], [-0.85, 0.175])
drive_rod.set_data([3.5, 3.4], [-0.85, 0.175])
drive_wheel_rod_outline.set_data([3.05, 3.5], [-0.85, -0.85])
drive_wheel_rod.set_data([3.05, 3.5], [-0.85, -0.85])
x_arrow.set_xy(base_arrow)
r_arrow.set_xy(base_arrow)
rotation_transform.clear()
wheel_transform.clear()
if sys_type:
center_drive_1.set_visible(False)
center_drive_2.set_visible(False)
center_drive_shaft.set_visible(False)
center_drive_belt.set_visible(False)
center_drive_mark_1.set_visible(False)
center_drive_mark_2.set_visible(False)
drive_rod.set_visible(True)
drive_rod_outline.set_visible(True)
drive_wheel_rod.set_visible(True)
drive_wheel_rod_outline.set_visible(True)
drive_wheel.set_visible(True)
drive_motor.set_visible(True)
drive_rod_p1.set_visible(True)
drive_rod_p2.set_visible(True)
drive_wheel_p.set_visible(True)
drive_motor_grate.set_visible(True)
else:
center_drive_1.set_visible(True)
center_drive_2.set_visible(True)
center_drive_shaft.set_visible(True)
center_drive_belt.set_visible(True)
center_drive_mark_1.set_visible(True)
center_drive_mark_2.set_visible(True)
drive_rod.set_visible(False)
drive_rod_outline.set_visible(False)
drive_wheel_rod.set_visible(False)
drive_wheel_rod_outline.set_visible(False)
drive_wheel.set_visible(False)
drive_motor.set_visible(False)
drive_rod_p1.set_visible(False)
drive_rod_p2.set_visible(False)
drive_wheel_p.set_visible(False)
drive_motor_grate.set_visible(False)
return (line1, line2, line3, ball, gleam, x_arrow, r_arrow, center_drive_1, center_drive_2,
center_drive_shaft, center_drive_belt, center_drive_mark_1, center_drive_mark_2,
drive_rod_outline, drive_rod, drive_wheel_rod_outline, drive_wheel_rod, drive_wheel, drive_motor,
drive_rod_p1, drive_rod_p2, drive_wheel_p, drive_motor_grate,)
def animate(i):
line1.set_data(T_plot[0:i], X_plot[0:i])
line2.set_data(T_plot[0:i], R_plot[0:i])
line3.set_data(T_plot[0:i], F_plot[0:i])
ball.set_center((ball_pos[i], 0.5))
gleam.set_center((ball_pos[i], 0.5))
gleam.set_theta1(215 + ball_rot[i])
gleam.set_theta2(235 + ball_rot[i])
if sys_type:
center_drive_1.set_visible(False)
center_drive_2.set_visible(False)
center_drive_shaft.set_visible(False)
center_drive_belt.set_visible(False)
center_drive_mark_1.set_visible(False)
center_drive_mark_2.set_visible(False)
drive_rod.set_visible(True)
drive_rod_outline.set_visible(True)
drive_wheel_rod.set_visible(True)
drive_wheel_rod_outline.set_visible(True)
drive_wheel.set_visible(True)
drive_motor.set_visible(True)
drive_rod_p1.set_visible(True)
drive_rod_p2.set_visible(True)
drive_wheel_p.set_visible(True)
drive_motor_grate.set_visible(True)
else:
center_drive_1.set_visible(True)
center_drive_2.set_visible(True)
center_drive_shaft.set_visible(True)
center_drive_belt.set_visible(True)
center_drive_mark_1.set_visible(True)
center_drive_mark_2.set_visible(True)
drive_rod.set_visible(False)
drive_rod_outline.set_visible(False)
drive_wheel_rod.set_visible(False)
drive_wheel_rod_outline.set_visible(False)
drive_wheel.set_visible(False)
drive_motor.set_visible(False)
drive_rod_p1.set_visible(False)
drive_rod_p2.set_visible(False)
drive_wheel_p.set_visible(False)
drive_motor_grate.set_visible(False)
center_drive_mark_1.set_theta1(260 + rot_pos[i] / 2.5)
center_drive_mark_1.set_theta2(280 + rot_pos[i] / 2.5)
center_drive_mark_2.set_theta1(80 + rot_pos[i] / 2.5)
center_drive_mark_2.set_theta2(100 + rot_pos[i] / 2.5)
x_arrow.set_xy(base_arrow + [ref_pos[i], 0])
r_arrow.set_xy(base_arrow + [ball_pos[i], 0])
rotation_transform.clear().rotate_deg_around(0, 0, rot_pos[i])
wheel_transform.clear().rotate_deg_around(3.05, -0.85, rot_pos[i] * 9)
drive_rod_outline.set_data(np.stack((wheel_transform.transform_point([3.5, -0.85]),
rotation_transform.transform_point([3.4, 0.175]))).T)
drive_rod.set_data(np.stack((wheel_transform.transform_point([3.5, -0.85]),
rotation_transform.transform_point([3.4, 0.175]))).T)
drive_wheel_rod_outline.set_data(np.stack(([3.05, -0.85], wheel_transform.transform_point([3.5, -0.85]))).T)
drive_wheel_rod.set_data(np.stack(([3.05, -0.85], wheel_transform.transform_point([3.5, -0.85]))).T)
return (line1, line2, line3, ball, gleam, x_arrow, r_arrow, center_drive_1, center_drive_2,
center_drive_shaft, center_drive_belt, center_drive_mark_1, center_drive_mark_2,
drive_rod_outline, drive_rod, drive_wheel_rod_outline, drive_wheel_rod, drive_wheel, drive_motor,
drive_rod_p1, drive_rod_p2, drive_wheel_p, drive_motor_grate,)
anim = animation.FuncAnimation(anim_fig, animate, init_func=anim_init,
frames=frame_count, interval=10, blit=True,
repeat=True)
# Controllers
T_slider = w.FloatLogSlider(value=10, base=10, min=-0.7, max=1, step=0.01,
description='Duration [s]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
dt_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=-1, step=0.01,
description='Timestep [s]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
X_type = w.Dropdown(options=[('Constant', 0), ('Sine', 1), ('Square', 2)], value=1,
description='Reference: ', continuous_update=False, layout=w.Layout(width='auto', flex='3 3 auto'))
Xf_slider = w.FloatLogSlider(value=0.5, base=10, min=-2, max=2, step=0.01,
description='Frequency [Hz]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Xa_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=2, step=0.01,
description='Amplitude [m]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Xo_slider = w.FloatSlider(value=0, min=-10, max=10, description='Offset/Ampl:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
F_type = w.Dropdown(options=[('Constant', 0), ('Sine', 1), ('Square', 2), ('Noise', 3)], value=2,
description='Disturbance: ', continuous_update=False, layout=w.Layout(width='auto', flex='3 3 auto'))
Ff_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=2, step=0.01,
description='Frequency [Hz]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Fa_slider = w.FloatLogSlider(value=0.1, base=10, min=-2, max=2, step=0.01,
description='Amplitude [N]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Fo_slider = w.FloatSlider(value=0, min=-10, max=10, description='Offset/Ampl:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
input_data = w.interactive_output(simulation, {'Kp': Kp_slider, 'Ti': Ti_slider, 'Td': Td_slider,
'Fd': Fd_slider, 'Ti0' : Ti_button, 'Td0': Td_button,
'm':m_slider, 'r':r_slider, 'd':d_slider, 'L':L_slider,
'type_select':typeSelect,
'T': T_slider, 'dt': dt_slider,
'X': X_type, 'Xf': Xf_slider, 'Xa': Xa_slider, 'Xo': Xo_slider,
'F': F_type, 'Ff': Ff_slider, 'Fa': Fa_slider, 'Fo': Fo_slider})
display(w.HBox([w.HBox([T_slider, dt_slider], layout=w.Layout(width='25%')),
w.Box([], layout=w.Layout(width='5%')),
w.VBox([X_type, w.HBox([Xf_slider, Xa_slider, Xo_slider])], layout=w.Layout(width='30%')),
w.Box([], layout=w.Layout(width='5%')),
w.VBox([F_type, w.HBox([Ff_slider, Fa_slider, Fo_slider])], layout=w.Layout(width='30%'))],
layout=w.Layout(width='100%', justify_content='center')), input_data)
```
The duration parameter controls the simulated timeframe and does not affect the runtime of the animation. In contrast, the timestep controls the model sampling and can refine the results in exchange for higher computational resources.
|
github_jupyter
|
%matplotlib notebook
import control as c
import ipywidgets as w
import numpy as np
from IPython.display import display, HTML
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.transforms as transforms
import matplotlib.animation as animation
display(HTML('<script> $(document).ready(function() { $("div.input").hide(); }); </script>'))
# Model selector buttons
typeSelect = w.ToggleButtons(
options=[('Direct drive', 0), ('Drive mechanism', 1),],
description='System: ')
display(typeSelect)
# System parameters
g = 9.81 # m/s^2 - gravitational acceleration
# Figure definition
fig1, ((f1_ax1), (f1_ax2)) = plt.subplots(2, 1)
fig1.set_size_inches((9.8, 5))
fig1.set_tight_layout(True)
f1_line1, = f1_ax1.plot([], [])
f1_line2, = f1_ax2.plot([], [])
f1_ax1.grid(which='both', axis='both', color='lightgray')
f1_ax2.grid(which='both', axis='both', color='lightgray')
f1_ax1.autoscale(enable=True, axis='both', tight=True)
f1_ax2.autoscale(enable=True, axis='both', tight=True)
f1_ax1.set_title('Bode magnitude plot', fontsize=11)
f1_ax1.set_xscale('log')
f1_ax1.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=10)
f1_ax1.set_ylabel(r'$A\/$[dB]', labelpad=0, fontsize=10)
f1_ax1.tick_params(axis='both', which='both', pad=0, labelsize=8)
f1_ax2.set_title('Bode phase plot', fontsize=11)
f1_ax2.set_xscale('log')
f1_ax2.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=10)
f1_ax2.set_ylabel(r'$\phi\/$[°]', labelpad=0, fontsize=10)
f1_ax2.tick_params(axis='both', which='both', pad=0, labelsize=8)
def build_base_model(m, r, d, L, type_select):
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
print('System transfer function:')
print(W_sys)
# System analysis
poles = c.pole(W_sys) # Poles
print('System poles:\n')
print(poles)
global f1_line1, f1_line2
f1_ax1.lines.remove(f1_line1)
f1_ax2.lines.remove(f1_line2)
mag, phase, omega = c.bode_plot(W_sys, Plot=False) # Bode-plot
f1_line1, = f1_ax1.plot(omega/2/np.pi, 20*np.log10(mag), lw=1, color='blue')
f1_line2, = f1_ax2.plot(omega/2/np.pi, phase*180/np.pi, lw=1, color='blue')
f1_ax1.relim()
f1_ax2.relim()
f1_ax1.autoscale_view()
f1_ax2.autoscale_view()
def update_sliders(index, model):
global m_slider, r_slider, d_slider, L_slider
mval = [0.05, 0.05, 0.1, 0.1, 0.5, 0.5, 0.25]
rval = [0.01, 0.05, 0.05, 0.1, 0.1, 0.15, 0.075]
dval = [0.025, 0.01, 0.05, 0.2, 0.2, 0.4, 0.2]
Lval = [0.1, 0.1, 0.5, 1, 2, 2, 1]
m_slider.value = mval[index]
r_slider.value = rval[index]
d_slider.value = dval[index]
L_slider.value = Lval[index]
if index == -1:
m_slider.disabled = True;
r_slider.disabled = True;
d_slider.disabled = True;
L_slider.disabled = True;
else:
m_slider.disabled = False;
r_slider.disabled = False;
if model == 0:
d_slider.disabled = False;
L_slider.disabled = False;
else:
d_slider.disabled = True;
L_slider.disabled = True;
# GUI widgets
typeSelect2 = w.ToggleButtons(
options=[('Model 1', 0), ('Model 2', 1), ('Model 3', 2), ('Model 4', 3), ('Model 5', 4), ('Model 6', 5),
('Preset', -1)],
value=-1, description='System: ', layout=w.Layout(width='60%'))
m_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=1, description='m [kg] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
r_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=0, description='r [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
d_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=0, description='d [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
L_slider = w.FloatLogSlider(value=0, base=10, min=-1, max=2, description='L [m] :', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
input_data = w.interactive_output(build_base_model, {'m':m_slider, 'r':r_slider, 'd':d_slider, 'L':L_slider,
'type_select':typeSelect})
input_data2 = w.interactive_output(update_sliders, {'index':typeSelect2, 'model':typeSelect})
display(typeSelect2, input_data2)
display(w.HBox([w.VBox([m_slider, r_slider], layout=w.Layout(width='45%')),
w.VBox([d_slider, L_slider], layout=w.Layout(width='45%'))]), input_data)
# PID ball balancer
fig2, ((f2_ax1, f2_ax2, f2_ax3), (f2_ax4, f2_ax5, f2_ax6)) = plt.subplots(2, 3)
fig2.set_size_inches((9.8, 5))
fig2.set_tight_layout(True)
f2_line1, = f2_ax1.plot([], [])
f2_line2, = f2_ax2.plot([], [])
f2_line3, = f2_ax3.plot([], [])
f2_line4, = f2_ax4.plot([], [])
f2_line5, = f2_ax5.plot([], [])
f2_line6, = f2_ax6.plot([], [])
f2_ax1.grid(which='both', axis='both', color='lightgray')
f2_ax2.grid(which='both', axis='both', color='lightgray')
f2_ax3.grid(which='both', axis='both', color='lightgray')
f2_ax4.grid(which='both', axis='both', color='lightgray')
f2_ax5.grid(which='both', axis='both', color='lightgray')
f2_ax6.grid(which='both', axis='both', color='lightgray')
f2_ax1.autoscale(enable=True, axis='both', tight=True)
f2_ax2.autoscale(enable=True, axis='both', tight=True)
f2_ax3.autoscale(enable=True, axis='both', tight=True)
f2_ax4.autoscale(enable=True, axis='both', tight=True)
f2_ax5.autoscale(enable=True, axis='both', tight=True)
f2_ax6.autoscale(enable=True, axis='both', tight=True)
f2_ax1.set_title('Closed loop step response', fontsize=9)
f2_ax1.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax1.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax1.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax2.set_title('Nyquist diagram', fontsize=9)
f2_ax2.set_xlabel(r'Re', labelpad=0, fontsize=8)
f2_ax2.set_ylabel(r'Im', labelpad=0, fontsize=8)
f2_ax2.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax3.set_title('Bode magniture plot', fontsize=9)
f2_ax3.set_xscale('log')
f2_ax3.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=8)
f2_ax3.set_ylabel(r'$A\/$[dB]', labelpad=0, fontsize=8)
f2_ax3.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax4.set_title('Closed loop impulse response', fontsize=9)
f2_ax4.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax4.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax4.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax5.set_title('Load transfer step response', fontsize=9)
f2_ax5.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=8)
f2_ax5.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=8)
f2_ax5.tick_params(axis='both', which='both', pad=0, labelsize=6)
f2_ax6.set_title('Bode phase plot', fontsize=9)
f2_ax6.set_xscale('log')
f2_ax6.set_xlabel(r'$f\/$[Hz]', labelpad=0, fontsize=8)
f2_ax6.set_ylabel(r'$\phi\/$[°]', labelpad=0, fontsize=8)
f2_ax6.tick_params(axis='both', which='both', pad=0, labelsize=6)
def position_control(Kp, Ti, Td, Fd, Ti0, Td0, m, r, d, L, type_select):
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
# PID Controller
P = Kp # Proportional term
I = Kp / Ti # Integral term
D = Kp * Td # Derivative term
Td_f = Td / Fd # Derivative term filter
W_PID = c.parallel(c.tf([P], [1]),
c.tf([I * Ti0], [1 * Ti0, 1 * (not Ti0)]),
c.tf([D * Td0, 0], [Td_f * Td0, 1])) # PID controller in time constant format
W_open = c.series(W_PID, W_sys) # Open loop
W_closed = c.feedback(W_open, 1, -1) # Closed loop with negative feedback
if type_select: # Disturbance transfer
W_load = c.feedback (c.tf([1], [J/r/r+m, 0, 0]), c.series(c.tf([m*g*d], [L]), W_PID), -1)
else:
W_load = c.feedback (c.tf([1], [J/r/r+m, 0, 0]), c.series(c.tf([m*g], [1]), W_PID), -1)
# Display
global f2_line1, f2_line2, f2_line3, f2_line4, f2_line5, f2_line6
f2_ax1.lines.remove(f2_line1)
f2_ax2.lines.remove(f2_line2)
f2_ax3.lines.remove(f2_line3)
f2_ax4.lines.remove(f2_line4)
f2_ax5.lines.remove(f2_line5)
f2_ax6.lines.remove(f2_line6)
tout, yout = c.step_response(W_closed)
f2_line1, = f2_ax1.plot(tout, yout, lw=1, color='blue')
_, _, ob = c.nyquist_plot(W_open, Plot=False) # Small resolution plot to determine bounds
real, imag, freq = c.nyquist_plot(W_open, omega=np.logspace(np.log10(ob[0]), np.log10(ob[-1]), 1000), Plot=False)
f2_line2, = f2_ax2.plot(real, imag, lw=1, color='blue')
mag, phase, omega = c.bode_plot(W_open, Plot=False)
f2_line3, = f2_ax3.plot(omega/2/np.pi, 20*np.log10(mag), lw=1, color='blue')
f2_line6, = f2_ax6.plot(omega/2/np.pi, phase*180/np.pi, lw=1, color='blue')
tout, yout = c.impulse_response(W_closed)
f2_line4, = f2_ax4.plot(tout, yout, lw=1, color='blue')
tout, yout = c.step_response(W_load)
f2_line5, = f2_ax5.plot(tout, yout, lw=1, color='blue')
f2_ax1.relim()
f2_ax2.relim()
f2_ax3.relim()
f2_ax4.relim()
f2_ax5.relim()
f2_ax6.relim()
f2_ax1.autoscale_view()
f2_ax2.autoscale_view()
f2_ax3.autoscale_view()
f2_ax4.autoscale_view()
f2_ax5.autoscale_view()
f2_ax6.autoscale_view()
def update_controller(index):
global Kp_slider, Ti_slider, Td_slider, Fd_slider, Ti_button, Td_button
if index == -1:
Kp_slider.value = 100
Td_slider.value = 0.05
Fd_slider.value = 5
Ti_button.value = False
Td_button.value = True
Kp_slider.disabled = True
Ti_slider.disabled = True
Td_slider.disabled = True
Fd_slider.disabled = True
Ti_button.disabled = True
Td_button.disabled = True
else:
Kp_slider.disabled = False
Ti_slider.disabled = False
Td_slider.disabled = False
Fd_slider.disabled = False
Ti_button.disabled = False
Td_button.disabled = False
# GUI widgets
Kp_slider = w.FloatLogSlider(value=2, base=10, min=-3, max=5, description='Kp:', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Ti_slider = w.FloatLogSlider(value=0.0035, base=10, min=-4, max=1, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Td_slider = w.FloatLogSlider(value=0.25, base=10, min=-4, max=1, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Fd_slider = w.FloatLogSlider(value=1, base=10, min=0, max=3, description='', continuous_update=False,
layout=w.Layout(width='auto', flex='5 5 auto'))
Ti_button = w.ToggleButton(value=False, description='Ti',
layout=w.Layout(width='auto', flex='1 1 0%'))
Td_button = w.ToggleButton(value=True, description='Td',
layout=w.Layout(width='auto', flex='1 1 0%'))
input_data = w.interactive_output(position_control, {'Kp': Kp_slider, 'Ti': Ti_slider, 'Td': Td_slider,
'Fd': Fd_slider, 'Ti0' : Ti_button, 'Td0': Td_button,
'm':m_slider, 'r':r_slider,
'd':d_slider, 'L':L_slider, 'type_select':typeSelect})
w.interactive_output(update_controller, {'index': typeSelect2})
display(w.HBox([Kp_slider, Ti_button, Ti_slider, Td_button, Td_slider, Fd_slider]), input_data)
# Simulation
anim_fig = plt.figure()
anim_fig.set_size_inches((9.8, 6))
anim_fig.set_tight_layout(True)
anim_ax1 = anim_fig.add_subplot(211)
anim_ax2 = anim_ax1.twinx()
frame_count=1000
l1 = anim_ax1.plot([], [], lw=1, color='blue')
l2 = anim_ax1.plot([], [], lw=2, color='red')
l3 = anim_ax2.plot([], [], lw=1, color='grey')
line1 = l1[0]
line2 = l2[0]
line3 = l3[0]
anim_ax1.legend(l1+l2+l3, ['Reference [m]', 'Output [m]', 'Load [N]'], loc=1)
anim_ax1.set_title('Time response simulation', fontsize=12)
anim_ax1.set_xlabel(r'$t\/$[s]', labelpad=0, fontsize=10)
anim_ax1.set_ylabel(r'$x\/$[m]', labelpad=0, fontsize=10)
anim_ax1.tick_params(axis='both', which='both', pad=0, labelsize=8)
anim_ax2.set_ylabel(r'$F\/$[N]', labelpad=0, fontsize=10)
anim_ax2.tick_params(axis='both', which='both', pad=0, labelsize=8)
anim_ax1.grid(which='both', axis='both', color='lightgray')
T_plot = []
X_plot = []
D_plot = []
R_plot = []
P_plot = []
# Scene data
scene_ax = anim_fig.add_subplot(212)
scene_ax.set_xlim((-4.75, 4.75))
scene_ax.set_ylim((-1.5, 1.5))
scene_ax.axis('off')
rotation_transform = transforms.Affine2D()
scene_ax.add_patch(patches.Polygon(np.stack(([-3.5, -3.5, -0.5, 0.5, 3.5, 3.5, -3.5],
[0.25, 0.1, -0.25, -0.25, 0.1, 0.25, 0.25])).T,
fill = True, lw=1, ec='black', fc='lightgray', zorder=5,
transform=rotation_transform + scene_ax.transData))
scene_ax.add_patch(patches.Polygon(np.stack(([-0.7, -0.7, 0.7, 0.7, 0.25, -0.25, -0.7],
[-1.1, -1.4, -1.4, -1.1, 0, 0, -1.1])).T,
fill = True, lw=1, ec='black', fc='darkgoldenrod', zorder=0))
scene_ax.add_patch(patches.Circle((0, 0), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=20))
ball = patches.Circle((0, 0.5), fill=True, radius=0.25, ec='black', fc='orange', lw=1,
zorder=5, transform=rotation_transform + scene_ax.transData)
gleam = patches.Wedge((0, 0.5), 0.2, fill=True, width=0.075, theta1=215, theta2=235, lw=0,
ec='white', fc='white', zorder=10, transform=rotation_transform + scene_ax.transData)
scene_ax.add_patch(ball)
scene_ax.add_patch(gleam)
center_drive_belt, = scene_ax.plot([-0.42, -0.15, 0.15, 0.42], [-0.8, 0.05, 0.05, -0.8], color='black', lw=3, zorder=10)
center_drive_1 = patches.Circle((0, 0), fill=True, radius=0.18, ec='black', fc='lawngreen', lw=1, zorder=15)
center_drive_2 = patches.Circle((0, -0.85), fill=True, radius=0.45, ec='black', fc='lawngreen', lw=1, zorder=15)
center_drive_shaft = patches.Circle((0, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25)
center_drive_mark_1 = patches.Wedge((0, -0.85), 0.40, theta1=260, theta2=280, width=0.32,
fill=True, ec='black', fc='white', lw=1, zorder=20)
center_drive_mark_2 = patches.Wedge((0, -0.85), 0.40, theta1=80, theta2=100, width=0.32,
fill=True, ec='black', fc='white', lw=1, zorder=20)
scene_ax.add_patch(center_drive_1)
scene_ax.add_patch(center_drive_2)
scene_ax.add_patch(center_drive_shaft)
scene_ax.add_patch(center_drive_mark_1)
scene_ax.add_patch(center_drive_mark_2)
wheel_transform = transforms.Affine2D()
drive_rod_outline, = scene_ax.plot([3.5, 3.4], [-0.85, 0.175], color='black', solid_capstyle='round', lw=8, zorder=15,
visible=False)
drive_rod, = scene_ax.plot([3.5, 3.4], [-0.85, 0.175], color='deepskyblue', solid_capstyle='round', lw=6, zorder=20,
visible=False)
drive_wheel_rod_outline, = scene_ax.plot([3.05, 3.5], [-0.85, -0.85], color='black', solid_capstyle='round', lw=12, zorder=0,
visible=False)
drive_wheel_rod, = scene_ax.plot([3.05, 3.5], [-0.85, -0.85], color='cyan', solid_capstyle='round', lw=10, zorder=10,
visible=False)
drive_motor_grate, = scene_ax.plot([2.5, 2.5, 2.5833, 2.5833, 2.6666, 2.6666, 2.75],
[-1, -1.25, -1, -1.25, -1, -1.25, -1],
color='black', solid_capstyle='round', lw=1, zorder=5, visible=False)
drive_rod_p1 = patches.Circle((3.4, 0.175), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25,
transform=rotation_transform + scene_ax.transData, visible=False)
drive_rod_p2 = patches.Circle((3.5, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25,
transform=wheel_transform + scene_ax.transData, visible=False)
drive_wheel = patches.Circle((3.05, -0.85), fill=True, radius=0.25, ec='black', fc='cyan', lw=1, zorder=5, visible=False)
drive_wheel_p = patches.Circle((3.05, -0.85), fill=True, radius=0.03, ec='black', fc='gray', lw=1, zorder=25, visible=False)
drive_motor = patches.Polygon(np.stack(([2.3, 3.2, 3.2, 2.6, 2.3, 2.3],
[-1.4, -1.4, -0.7, -0.7, -0.85, -1.4])).T,
fill = True, lw=1, ec='black', fc='firebrick', zorder=0, visible=False)
scene_ax.add_patch(drive_rod_p1)
scene_ax.add_patch(drive_rod_p2)
scene_ax.add_patch(drive_wheel)
scene_ax.add_patch(drive_wheel_p)
scene_ax.add_patch(drive_motor)
x_arrow = scene_ax.arrow(0, 0.05, 0, 0.15, ec='black', fc='blue', head_width=0.1,
length_includes_head=True, lw=1, fill=True, zorder=10,
transform=rotation_transform + scene_ax.transData)
r_arrow = scene_ax.arrow(0, 0.05, 0, 0.15, ec='black', fc='red', head_width=0.1,
length_includes_head=True, lw=1, fill=True, zorder=10,
transform=rotation_transform + scene_ax.transData)
base_arrow = x_arrow.xy
rot_pos = []
ball_pos = []
ref_pos = []
ball_rot = []
sys_type = 0
#Simulation function
def simulation(Kp, Ti, Td, Fd, Ti0, Td0, m, r, d, L, type_select, T, dt, X, Xf, Xa, Xo, F, Ff, Fa, Fo):
# Controller
P = Kp # Proportional term
I = Kp / Ti # Integral term
D = Kp * Td # Derivative term
Td_f = Td / Fd # Derivative term filter
W_PID = c.parallel(c.tf([P], [1]),
c.tf([I * Ti0], [1 * Ti0, 1 * (not Ti0)]),
c.tf([D * Td0, 0], [Td_f * Td0, 1])) # PID controller
# System
J=2/5*m*r*r
if type_select:
W_sys = c.tf([m*g*d], [L*(J/(r*r)+m), 0, 0])
else:
W_sys = c.tf([m*g], [J/(r*r)+m, 0, 0])
# Model
W_open = c.series(W_PID, W_sys) # Open loop
W_closed = c.feedback(W_open, 1, -1) # Closed loop with negative feedback
if type_select: # Disturbance transfer
W_s1 = c.tf([m*g*d], [L])
else:
W_s1 = c.tf([m*g], [1])
W_s2 = c.tf([1], [J/r/r+m, 0, 0])
W_load = c.feedback(W_s2, c.series(W_PID, W_s1), -1)
W_cont_sys = c.feedback(W_PID, W_sys, -1) # Control signal (angle) system component
W_cont_load = c.feedback(c.series(W_s2, c.negate(W_PID)), W_s1, 1) # Control signal (angle) load component
# Reference and disturbance signals
T_sim = np.arange(0, T, dt, dtype=np.float64)
if X == 0: # Constant reference
X_sim = np.full_like(T_sim, Xa * Xo)
elif X == 1: # Sine wave reference
X_sim = (np.sin(2 * np.pi * Xf * T_sim) + Xo) * Xa
elif X == 2: # Square wave reference
X_sim = (np.sign(np.sin(2 * np.pi * Xf * T_sim)) + Xo) * Xa
if F == 0: # Constant load
F_sim = np.full_like(T_sim, Fa * Fo)
elif F == 1: # Sine wave load
F_sim = (np.sin(2 * np.pi * Ff * T_sim) + Fo) * Fa
elif F == 2: # Square wave load
F_sim = (np.sign(np.sin(2 * np.pi * Ff * T_sim)) + Fo) * Fa
elif F == 3: # Noise form load
F_sim = np.interp(T_sim, np.linspace(0, T, int(T * Ff) + 2),
np.random.normal(loc=(Fo * Fa), scale=Fa, size=int(T * Ff) + 2))
# System response
Tx, youtx, xoutx = c.forced_response(W_closed, T_sim, X_sim)
Tf, youtf, xoutf = c.forced_response(W_load, T_sim, F_sim)
R_sim = np.nan_to_num(youtx + youtf)
Tcx, youtcx, xoutcx = c.forced_response(W_cont_sys, T_sim, X_sim)
Tcf, youtcf, xoutcf = c.forced_response(W_cont_load, T_sim, F_sim)
P_sim = np.nan_to_num(youtcx + youtcf)
# Display
XR_max = max(np.amax(np.absolute(np.concatenate((X_sim, R_sim)))), Xa)
F_max = max(np.amax(np.absolute(F_sim)), Fa)
P_max = np.amax(np.absolute(P_sim))
anim_ax1.set_xlim((0, T))
anim_ax1.set_ylim((-1.2 * XR_max, 1.2 * XR_max))
anim_ax2.set_ylim((-1.5 * F_max, 1.5 * F_max))
global T_plot, X_plot, F_plot, R_plot, P_plot, rot_pos, ball_pos, ref_pos, ball_rot, sys_type
T_plot = np.linspace(0, T, frame_count, dtype=np.float32)
X_plot = np.interp(T_plot, T_sim, X_sim)
F_plot = np.interp(T_plot, T_sim, F_sim)
R_plot = np.interp(T_plot, T_sim, R_sim)
P_plot = np.interp(T_plot, T_sim, P_sim)
rot_pos = P_plot / P_max * -10 # The constant sets the apparent maximal tilt of the animation in degrees
ball_pos = R_plot / XR_max * 3.4
ref_pos = X_plot / XR_max * 3.4
ball_rot = ball_pos / np.pi * -360
sys_type = type_select
def anim_init():
line1.set_data([], [])
line2.set_data([], [])
line3.set_data([], [])
ball.set_center((0, 0.5))
gleam.set_center((0, 0.5))
gleam.set_theta1(215)
gleam.set_theta2(235)
center_drive_mark_1.set_theta1(260)
center_drive_mark_1.set_theta2(280)
center_drive_mark_2.set_theta1(80)
center_drive_mark_2.set_theta2(100)
drive_rod_outline.set_data([3.5, 3.4], [-0.85, 0.175])
drive_rod.set_data([3.5, 3.4], [-0.85, 0.175])
drive_wheel_rod_outline.set_data([3.05, 3.5], [-0.85, -0.85])
drive_wheel_rod.set_data([3.05, 3.5], [-0.85, -0.85])
x_arrow.set_xy(base_arrow)
r_arrow.set_xy(base_arrow)
rotation_transform.clear()
wheel_transform.clear()
if sys_type:
center_drive_1.set_visible(False)
center_drive_2.set_visible(False)
center_drive_shaft.set_visible(False)
center_drive_belt.set_visible(False)
center_drive_mark_1.set_visible(False)
center_drive_mark_2.set_visible(False)
drive_rod.set_visible(True)
drive_rod_outline.set_visible(True)
drive_wheel_rod.set_visible(True)
drive_wheel_rod_outline.set_visible(True)
drive_wheel.set_visible(True)
drive_motor.set_visible(True)
drive_rod_p1.set_visible(True)
drive_rod_p2.set_visible(True)
drive_wheel_p.set_visible(True)
drive_motor_grate.set_visible(True)
else:
center_drive_1.set_visible(True)
center_drive_2.set_visible(True)
center_drive_shaft.set_visible(True)
center_drive_belt.set_visible(True)
center_drive_mark_1.set_visible(True)
center_drive_mark_2.set_visible(True)
drive_rod.set_visible(False)
drive_rod_outline.set_visible(False)
drive_wheel_rod.set_visible(False)
drive_wheel_rod_outline.set_visible(False)
drive_wheel.set_visible(False)
drive_motor.set_visible(False)
drive_rod_p1.set_visible(False)
drive_rod_p2.set_visible(False)
drive_wheel_p.set_visible(False)
drive_motor_grate.set_visible(False)
return (line1, line2, line3, ball, gleam, x_arrow, r_arrow, center_drive_1, center_drive_2,
center_drive_shaft, center_drive_belt, center_drive_mark_1, center_drive_mark_2,
drive_rod_outline, drive_rod, drive_wheel_rod_outline, drive_wheel_rod, drive_wheel, drive_motor,
drive_rod_p1, drive_rod_p2, drive_wheel_p, drive_motor_grate,)
def animate(i):
line1.set_data(T_plot[0:i], X_plot[0:i])
line2.set_data(T_plot[0:i], R_plot[0:i])
line3.set_data(T_plot[0:i], F_plot[0:i])
ball.set_center((ball_pos[i], 0.5))
gleam.set_center((ball_pos[i], 0.5))
gleam.set_theta1(215 + ball_rot[i])
gleam.set_theta2(235 + ball_rot[i])
if sys_type:
center_drive_1.set_visible(False)
center_drive_2.set_visible(False)
center_drive_shaft.set_visible(False)
center_drive_belt.set_visible(False)
center_drive_mark_1.set_visible(False)
center_drive_mark_2.set_visible(False)
drive_rod.set_visible(True)
drive_rod_outline.set_visible(True)
drive_wheel_rod.set_visible(True)
drive_wheel_rod_outline.set_visible(True)
drive_wheel.set_visible(True)
drive_motor.set_visible(True)
drive_rod_p1.set_visible(True)
drive_rod_p2.set_visible(True)
drive_wheel_p.set_visible(True)
drive_motor_grate.set_visible(True)
else:
center_drive_1.set_visible(True)
center_drive_2.set_visible(True)
center_drive_shaft.set_visible(True)
center_drive_belt.set_visible(True)
center_drive_mark_1.set_visible(True)
center_drive_mark_2.set_visible(True)
drive_rod.set_visible(False)
drive_rod_outline.set_visible(False)
drive_wheel_rod.set_visible(False)
drive_wheel_rod_outline.set_visible(False)
drive_wheel.set_visible(False)
drive_motor.set_visible(False)
drive_rod_p1.set_visible(False)
drive_rod_p2.set_visible(False)
drive_wheel_p.set_visible(False)
drive_motor_grate.set_visible(False)
center_drive_mark_1.set_theta1(260 + rot_pos[i] / 2.5)
center_drive_mark_1.set_theta2(280 + rot_pos[i] / 2.5)
center_drive_mark_2.set_theta1(80 + rot_pos[i] / 2.5)
center_drive_mark_2.set_theta2(100 + rot_pos[i] / 2.5)
x_arrow.set_xy(base_arrow + [ref_pos[i], 0])
r_arrow.set_xy(base_arrow + [ball_pos[i], 0])
rotation_transform.clear().rotate_deg_around(0, 0, rot_pos[i])
wheel_transform.clear().rotate_deg_around(3.05, -0.85, rot_pos[i] * 9)
drive_rod_outline.set_data(np.stack((wheel_transform.transform_point([3.5, -0.85]),
rotation_transform.transform_point([3.4, 0.175]))).T)
drive_rod.set_data(np.stack((wheel_transform.transform_point([3.5, -0.85]),
rotation_transform.transform_point([3.4, 0.175]))).T)
drive_wheel_rod_outline.set_data(np.stack(([3.05, -0.85], wheel_transform.transform_point([3.5, -0.85]))).T)
drive_wheel_rod.set_data(np.stack(([3.05, -0.85], wheel_transform.transform_point([3.5, -0.85]))).T)
return (line1, line2, line3, ball, gleam, x_arrow, r_arrow, center_drive_1, center_drive_2,
center_drive_shaft, center_drive_belt, center_drive_mark_1, center_drive_mark_2,
drive_rod_outline, drive_rod, drive_wheel_rod_outline, drive_wheel_rod, drive_wheel, drive_motor,
drive_rod_p1, drive_rod_p2, drive_wheel_p, drive_motor_grate,)
anim = animation.FuncAnimation(anim_fig, animate, init_func=anim_init,
frames=frame_count, interval=10, blit=True,
repeat=True)
# Controllers
T_slider = w.FloatLogSlider(value=10, base=10, min=-0.7, max=1, step=0.01,
description='Duration [s]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
dt_slider = w.FloatLogSlider(value=0.1, base=10, min=-3, max=-1, step=0.01,
description='Timestep [s]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
X_type = w.Dropdown(options=[('Constant', 0), ('Sine', 1), ('Square', 2)], value=1,
description='Reference: ', continuous_update=False, layout=w.Layout(width='auto', flex='3 3 auto'))
Xf_slider = w.FloatLogSlider(value=0.5, base=10, min=-2, max=2, step=0.01,
description='Frequency [Hz]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Xa_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=2, step=0.01,
description='Amplitude [m]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Xo_slider = w.FloatSlider(value=0, min=-10, max=10, description='Offset/Ampl:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
F_type = w.Dropdown(options=[('Constant', 0), ('Sine', 1), ('Square', 2), ('Noise', 3)], value=2,
description='Disturbance: ', continuous_update=False, layout=w.Layout(width='auto', flex='3 3 auto'))
Ff_slider = w.FloatLogSlider(value=1, base=10, min=-2, max=2, step=0.01,
description='Frequency [Hz]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Fa_slider = w.FloatLogSlider(value=0.1, base=10, min=-2, max=2, step=0.01,
description='Amplitude [N]:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
Fo_slider = w.FloatSlider(value=0, min=-10, max=10, description='Offset/Ampl:', continuous_update=False,
orientation='vertical', layout=w.Layout(width='auto', height='auto', flex='1 1 auto'))
input_data = w.interactive_output(simulation, {'Kp': Kp_slider, 'Ti': Ti_slider, 'Td': Td_slider,
'Fd': Fd_slider, 'Ti0' : Ti_button, 'Td0': Td_button,
'm':m_slider, 'r':r_slider, 'd':d_slider, 'L':L_slider,
'type_select':typeSelect,
'T': T_slider, 'dt': dt_slider,
'X': X_type, 'Xf': Xf_slider, 'Xa': Xa_slider, 'Xo': Xo_slider,
'F': F_type, 'Ff': Ff_slider, 'Fa': Fa_slider, 'Fo': Fo_slider})
display(w.HBox([w.HBox([T_slider, dt_slider], layout=w.Layout(width='25%')),
w.Box([], layout=w.Layout(width='5%')),
w.VBox([X_type, w.HBox([Xf_slider, Xa_slider, Xo_slider])], layout=w.Layout(width='30%')),
w.Box([], layout=w.Layout(width='5%')),
w.VBox([F_type, w.HBox([Ff_slider, Fa_slider, Fo_slider])], layout=w.Layout(width='30%'))],
layout=w.Layout(width='100%', justify_content='center')), input_data)
| 0.47171 | 0.919208 |
# Advanced Circuits
```
import numpy as np
from qiskit import *
```
## Opaque gates
```
from qiskit.circuit import Gate
my_gate = Gate(name='my_gate', num_qubits=2, params=[])
qr = QuantumRegister(3, 'q')
circ = QuantumCircuit(qr)
circ.append(my_gate, [qr[0], qr[1]])
circ.append(my_gate, [qr[1], qr[2]])
circ.draw()
```
## Composite Gates
```
# Build a sub-circuit
sub_q = QuantumRegister(2)
sub_circ = QuantumCircuit(sub_q, name='sub_circ')
sub_circ.h(sub_q[0])
sub_circ.crz(1, sub_q[0], sub_q[1])
sub_circ.barrier()
sub_circ.id(sub_q[1])
sub_circ.u(1, 2, -2, sub_q[0])
# Convert to a gate and stick it into an arbitrary place in the bigger circuit
sub_inst = sub_circ.to_instruction()
qr = QuantumRegister(3, 'q')
circ = QuantumCircuit(qr)
circ.h(qr[0])
circ.cx(qr[0], qr[1])
circ.cx(qr[1], qr[2])
circ.append(sub_inst, [qr[1], qr[2]])
circ.draw()
```
Circuits are not immediately decomposed upon conversion `to_instruction` to allow circuit design at higher levels of abstraction.
When desired, or before compilation, sub-circuits will be decomposed via the `decompose` method.
```
decomposed_circ = circ.decompose() # Does not modify original circuit
decomposed_circ.draw()
```
## Parameterized circuits
```
from qiskit.circuit import Parameter
theta = Parameter('θ')
n = 5
qc = QuantumCircuit(5, 1)
qc.h(0)
for i in range(n-1):
qc.cx(i, i+1)
qc.barrier()
qc.rz(theta, range(5))
qc.barrier()
for i in reversed(range(n-1)):
qc.cx(i, i+1)
qc.h(0)
qc.measure(0, 0)
qc.draw('mpl')
```
We can inspect the circuit's parameters
```
print(qc.parameters)
```
### Binding parameters to values
All circuit parameters must be bound before sending the circuit to a backend. This can be done as follows:
- The `bind_parameters` method accepts a dictionary mapping `Parameter`s to values, and returns a new circuit with each parameter replaced by its corresponding value. Partial binding is supported, in which case the returned circuit will be parameterized by any `Parameter`s that were not mapped to a value.
```
import numpy as np
theta_range = np.linspace(0, 2 * np.pi, 128)
circuits = [qc.bind_parameters({theta: theta_val})
for theta_val in theta_range]
circuits[-1].draw()
backend = BasicAer.get_backend('qasm_simulator')
job = backend.run(transpile(circuits, backend))
counts = job.result().get_counts()
```
In the example circuit, we apply a global $R_z(\theta)$ rotation on a five-qubit entangled state, and so expect to see oscillation in qubit-0 at $5\theta$.
```
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111)
ax.plot(theta_range, list(map(lambda c: c.get('0', 0), counts)), '.-', label='0')
ax.plot(theta_range, list(map(lambda c: c.get('1', 0), counts)), '.-', label='1')
ax.set_xticks([i * np.pi / 2 for i in range(5)])
ax.set_xticklabels(['0', r'$\frac{\pi}{2}$', r'$\pi$', r'$\frac{3\pi}{2}$', r'$2\pi$'], fontsize=14)
ax.set_xlabel('θ', fontsize=14)
ax.set_ylabel('Counts', fontsize=14)
ax.legend(fontsize=14)
```
### Reducing compilation cost
Compiling over a parameterized circuit prior to binding can, in some cases, significantly reduce compilation time as compared to compiling over a set of bound circuits.
```
import time
from itertools import combinations
from qiskit.compiler import assemble
from qiskit.test.mock import FakeVigo
start = time.time()
qcs = []
theta_range = np.linspace(0, 2*np.pi, 32)
for n in theta_range:
qc = QuantumCircuit(5)
for k in range(8):
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qc.rz(n, range(5))
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qcs.append(qc)
compiled_circuits = transpile(qcs, backend=FakeVigo())
qobj = assemble(compiled_circuits, backend=FakeVigo())
end = time.time()
print('Time compiling over set of bound circuits: ', end-start)
start = time.time()
qc = QuantumCircuit(5)
theta = Parameter('theta')
for k in range(8):
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qc.rz(theta, range(5))
for i,j in combinations(range(5), 2):
qc.cx(i,j)
transpiled_qc = transpile(qc, backend=FakeVigo())
qobj = assemble([transpiled_qc.bind_parameters({theta: n})
for n in theta_range], backend=FakeVigo())
end = time.time()
print('Time compiling over parameterized circuit, then binding: ', end-start)
```
### Composition
Parameterized circuits can be composed like standard `QuantumCircuit`s.
Generally, when composing two parameterized circuits, the resulting circuit will be parameterized by the union of the parameters of the input circuits.
However, parameter names must be unique within a given circuit.
When attempting to add a parameter whose name is already present in the target circuit:
- if the source and target share the same `Parameter` instance, the parameters will be assumed to be the same and combined
- if the source and target have different `Parameter` instances, an error will be raised
```
phi = Parameter('phi')
sub_circ1 = QuantumCircuit(2, name='sc_1')
sub_circ1.rz(phi, 0)
sub_circ1.rx(phi, 1)
sub_circ2 = QuantumCircuit(2, name='sc_2')
sub_circ2.rx(phi, 0)
sub_circ2.rz(phi, 1)
qc = QuantumCircuit(4)
qr = qc.qregs[0]
qc.append(sub_circ1.to_instruction(), [qr[0], qr[1]])
qc.append(sub_circ2.to_instruction(), [qr[0], qr[1]])
qc.append(sub_circ2.to_instruction(), [qr[2], qr[3]])
print(qc.draw())
# The following raises an error: "QiskitError: 'Name conflict on adding parameter: phi'"
# phi2 = Parameter('phi')
# qc.u3(0.1, phi2, 0.3, 0)
```
To insert a subcircuit under a different parameterization, the `to_instruction` method accepts an optional argument (`parameter_map`) which, when present, will generate instructions with the source parameter replaced by a new parameter.
```
p = Parameter('p')
qc = QuantumCircuit(3, name='oracle')
qc.rz(p, 0)
qc.cx(0, 1)
qc.rz(p, 1)
qc.cx(1, 2)
qc.rz(p, 2)
theta = Parameter('theta')
phi = Parameter('phi')
gamma = Parameter('gamma')
qr = QuantumRegister(9)
larger_qc = QuantumCircuit(qr)
larger_qc.append(qc.to_instruction({p: theta}), qr[0:3])
larger_qc.append(qc.to_instruction({p: phi}), qr[3:6])
larger_qc.append(qc.to_instruction({p: gamma}), qr[6:9])
print(larger_qc.draw())
print(larger_qc.decompose().draw())
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
|
github_jupyter
|
import numpy as np
from qiskit import *
from qiskit.circuit import Gate
my_gate = Gate(name='my_gate', num_qubits=2, params=[])
qr = QuantumRegister(3, 'q')
circ = QuantumCircuit(qr)
circ.append(my_gate, [qr[0], qr[1]])
circ.append(my_gate, [qr[1], qr[2]])
circ.draw()
# Build a sub-circuit
sub_q = QuantumRegister(2)
sub_circ = QuantumCircuit(sub_q, name='sub_circ')
sub_circ.h(sub_q[0])
sub_circ.crz(1, sub_q[0], sub_q[1])
sub_circ.barrier()
sub_circ.id(sub_q[1])
sub_circ.u(1, 2, -2, sub_q[0])
# Convert to a gate and stick it into an arbitrary place in the bigger circuit
sub_inst = sub_circ.to_instruction()
qr = QuantumRegister(3, 'q')
circ = QuantumCircuit(qr)
circ.h(qr[0])
circ.cx(qr[0], qr[1])
circ.cx(qr[1], qr[2])
circ.append(sub_inst, [qr[1], qr[2]])
circ.draw()
decomposed_circ = circ.decompose() # Does not modify original circuit
decomposed_circ.draw()
from qiskit.circuit import Parameter
theta = Parameter('θ')
n = 5
qc = QuantumCircuit(5, 1)
qc.h(0)
for i in range(n-1):
qc.cx(i, i+1)
qc.barrier()
qc.rz(theta, range(5))
qc.barrier()
for i in reversed(range(n-1)):
qc.cx(i, i+1)
qc.h(0)
qc.measure(0, 0)
qc.draw('mpl')
print(qc.parameters)
import numpy as np
theta_range = np.linspace(0, 2 * np.pi, 128)
circuits = [qc.bind_parameters({theta: theta_val})
for theta_val in theta_range]
circuits[-1].draw()
backend = BasicAer.get_backend('qasm_simulator')
job = backend.run(transpile(circuits, backend))
counts = job.result().get_counts()
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111)
ax.plot(theta_range, list(map(lambda c: c.get('0', 0), counts)), '.-', label='0')
ax.plot(theta_range, list(map(lambda c: c.get('1', 0), counts)), '.-', label='1')
ax.set_xticks([i * np.pi / 2 for i in range(5)])
ax.set_xticklabels(['0', r'$\frac{\pi}{2}$', r'$\pi$', r'$\frac{3\pi}{2}$', r'$2\pi$'], fontsize=14)
ax.set_xlabel('θ', fontsize=14)
ax.set_ylabel('Counts', fontsize=14)
ax.legend(fontsize=14)
import time
from itertools import combinations
from qiskit.compiler import assemble
from qiskit.test.mock import FakeVigo
start = time.time()
qcs = []
theta_range = np.linspace(0, 2*np.pi, 32)
for n in theta_range:
qc = QuantumCircuit(5)
for k in range(8):
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qc.rz(n, range(5))
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qcs.append(qc)
compiled_circuits = transpile(qcs, backend=FakeVigo())
qobj = assemble(compiled_circuits, backend=FakeVigo())
end = time.time()
print('Time compiling over set of bound circuits: ', end-start)
start = time.time()
qc = QuantumCircuit(5)
theta = Parameter('theta')
for k in range(8):
for i,j in combinations(range(5), 2):
qc.cx(i,j)
qc.rz(theta, range(5))
for i,j in combinations(range(5), 2):
qc.cx(i,j)
transpiled_qc = transpile(qc, backend=FakeVigo())
qobj = assemble([transpiled_qc.bind_parameters({theta: n})
for n in theta_range], backend=FakeVigo())
end = time.time()
print('Time compiling over parameterized circuit, then binding: ', end-start)
phi = Parameter('phi')
sub_circ1 = QuantumCircuit(2, name='sc_1')
sub_circ1.rz(phi, 0)
sub_circ1.rx(phi, 1)
sub_circ2 = QuantumCircuit(2, name='sc_2')
sub_circ2.rx(phi, 0)
sub_circ2.rz(phi, 1)
qc = QuantumCircuit(4)
qr = qc.qregs[0]
qc.append(sub_circ1.to_instruction(), [qr[0], qr[1]])
qc.append(sub_circ2.to_instruction(), [qr[0], qr[1]])
qc.append(sub_circ2.to_instruction(), [qr[2], qr[3]])
print(qc.draw())
# The following raises an error: "QiskitError: 'Name conflict on adding parameter: phi'"
# phi2 = Parameter('phi')
# qc.u3(0.1, phi2, 0.3, 0)
p = Parameter('p')
qc = QuantumCircuit(3, name='oracle')
qc.rz(p, 0)
qc.cx(0, 1)
qc.rz(p, 1)
qc.cx(1, 2)
qc.rz(p, 2)
theta = Parameter('theta')
phi = Parameter('phi')
gamma = Parameter('gamma')
qr = QuantumRegister(9)
larger_qc = QuantumCircuit(qr)
larger_qc.append(qc.to_instruction({p: theta}), qr[0:3])
larger_qc.append(qc.to_instruction({p: phi}), qr[3:6])
larger_qc.append(qc.to_instruction({p: gamma}), qr[6:9])
print(larger_qc.draw())
print(larger_qc.decompose().draw())
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
| 0.381335 | 0.954732 |
# MLB Power Rankings and Casino Odds
> Part 3 - adding power rankings and odds into the MLB prediction model
- toc: false
- badges: true
- comments: true
- categories: [baseball, webscraping, Elo, Trueskill, Glick, machine learning]
- image: images/chart-preview.png
|MLB Baseball Prediction Series:|[Part 1](https://rdpharr.github.io/project_notes/baseball/benchmark/webscraping/brier/accuracy/calibration/machine%20learning/2020/09/20/baseball_project.html)|[Part 2](https://rdpharr.github.io/project_notes/baseball/webscraping/xgboost/brier/accuracy/calibration/machine%20learning/2020/09/21/MLB-Part2-First-Model.html)|Part 3|[Part 4](https://rdpharr.github.io/project_notes/baseball/hyperopt/xgboost/machine%20learning/2020/09/24/model-optimization.html)|[Part 5](https://rdpharr.github.io/project_notes/baseball/webscraping/kelly%20criterion/xgboost/machine%20learning/2020/09/26/predictions-and-betting-strategy.html)|
|-----|------|-----------|---------|----------|------|
Last time, we created a model that performs pretty well just based on the statistics that we downloaded from [baseball-reference.com](http://baseball-reference.com). In this post, we'll extend that model by adding power rankings and casino odds to the model.
> Important: You can run this notebook from Colab or Binder using the buttons above, but you'll also need the files we created in Part 2.
## Power Rankings
The 538 Blog has famously modified the [Elo system](https://en.wikipedia.org/wiki/Elo_rating_system) from chess to make [their baseball rankings](https://projects.fivethirtyeight.com/2020-mlb-predictions/). The Elo system tries to determine the relative skill level of a player based on the skill levels of the other players encountered. If you beat a person with a high skill level, your skill level is going to improve more than if you win against a player of the same or lower skill level than you. And if your skill level is higher than your opponent's then you will probably win the match.
If 538 thinks Elo is foundational, then we should definitely put it in our model. The trouble is that not everyone agrees on how to implement it. In fact there are a whole family of different power ranking systems out there. In this project we're going to add four: 2 varieties of Elo ([slow and fast changing](https://en.wikipedia.org/wiki/Elo_rating_system#Most_accurate_K-factor)), [Glicko](https://en.wikipedia.org/wiki/Glicko_rating_system), and [Trueskill](https://en.wikipedia.org/wiki/TrueSkill). Luckily people have created libraries to help us get the code right.
>Important: If you are running this notebook online, you may need to install the additional libraries. [Here's how to do it on Colab](https://colab.research.google.com/notebooks/snippets/importing_libraries.ipynb).
Let's get to it. We'll start by importing our dataframe from Part 2.
```
import pickle
df = pickle.load(open("dataframe.pkl","rb"))
```
### Elo Rankings
For Elo rankings, we're going to use the [elote library](https://github.com/helton-tech/elote), primarily because it's named after the Mexican habit of eating corn on the cob with mayonnaise (yuck!). Install it like this:
```
pip install elote
```
```
from elote import EloCompetitor
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=EloCompetitor()
for x in df.away_team_abbr.unique():
ratings[x]=EloCompetitor()
home_team_elo = []
away_team_elo = []
elo_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pre-game ratings
elo_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_elo.append(ratings[r.home_team_abbr].rating)
away_team_elo.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['elo_exp'] = elo_exp
df['home_team_elo'] = home_team_elo
df['away_team_elo'] = away_team_elo
```
Now we'll do the slow changing version, where we decrease the k-factor.
```
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=EloCompetitor()
ratings[x]._k_score=16
for x in df.away_team_abbr.unique():
ratings[x]=EloCompetitor()
ratings[x]._k_score=16
home_team_elo = []
away_team_elo = []
elo_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pregame ratings
elo_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_elo.append(ratings[r.home_team_abbr].rating)
away_team_elo.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['elo_slow_exp'] = elo_exp
df['home_team_elo_slow'] = home_team_elo
df['away_team_elo_slow'] = away_team_elo
```
### Glicko Ratings
Glicko can be calculated using the same library.
```
from elote import GlickoCompetitor
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=GlickoCompetitor()
for x in df.away_team_abbr.unique():
ratings[x]=GlickoCompetitor()
home_team_glick = []
away_team_glick = []
glick_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pregame ratings
glick_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_glick.append(ratings[r.home_team_abbr].rating)
away_team_glick.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['glick_exp'] = glick_exp
df['home_team_glick'] = home_team_glick
df['away_team_glick'] = away_team_glick
```
### Trueskill Ratings
Trueskill was invented for Microsoft video games on the XBox. It's something you need to license if you are going to use it for commercial purposes. Trueskill ratings are a little bit more complex, because we have the opportunity to include the starting pitcher skill as well. Install the [python package](https://trueskill.org/) like this:
```
pip install trueskill
```
```
from trueskill import Rating, quality, rate
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=Rating(25)
for x in df.away_team_abbr.unique():
ratings[x]=Rating(25)
for x in df.home_pitcher.unique():
ratings[x]=Rating(25)
for x in df.away_pitcher.unique():
ratings[x]=Rating(25)
ts_quality = []
pitcher_ts_diff = []
team_ts_diff = []
home_pitcher_ts = []
away_pitcher_ts = []
home_team_ts = []
away_team_ts = []
df = df.sort_values(by='date').copy()
for i, r in df.iterrows():
# get pre-match trueskill ratings from dict
match = [(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])]
ts_quality.append(quality(match))
pitcher_ts_diff.append(ratings[r.home_pitcher].mu-ratings[r.away_pitcher].mu)
team_ts_diff.append(ratings[r.home_team_abbr].mu-ratings[r.away_team_abbr].mu)
home_pitcher_ts.append(ratings[r.home_pitcher].mu)
away_pitcher_ts.append(ratings[r.away_pitcher].mu)
home_team_ts.append(ratings[r.home_team_abbr].mu)
away_team_ts.append(ratings[r.away_team_abbr].mu)
if r.date < df.date.max():
# update ratings dictionary with post-match ratings
if r.home_team_win==1:
match = [(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])]
[(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])] = rate(match)
else:
match = [(ratings[r.away_team_abbr], ratings[r.away_pitcher]),
(ratings[r.home_team_abbr], ratings[r.home_pitcher])]
[(ratings[r.away_team_abbr], ratings[r.away_pitcher]),
(ratings[r.home_team_abbr], ratings[r.home_pitcher])] = rate(match)
df['ts_game_quality'] = ts_quality
df['pitcher_ts_diff'] = pitcher_ts_diff
df['team_ts_diff'] = team_ts_diff
df['home_pitcher_ts'] = home_pitcher_ts
df['away_pitcher_ts'] = away_pitcher_ts
df['home_team_ts'] = home_team_ts
df['away_team_ts'] = away_team_ts
```
That's all we need for power rankings. Let's move on.
## Casino Odds
Having the casino odds in our model is really going to improve its predictions, but getting them in there is kind of a pain in the ass. The problem is that we need to match the games from two different systems (baseball-reference.com and covers.com). These systems don't use the same team abbreviations and don't even agree on what time the games started. So there's a bit of code to compensate.
But it starts the same as in Part 1 of this blog series - we need to find out which days to download odds data for. We'll use our dataframe to get this list.
```
import pandas as pd
dates = pd.to_datetime(df['date'], unit='s')
game_days = dates.dt.strftime('%Y-%m-%d').unique()
print("Days of odds data needed:", len(game_days))
```
The below code is largely the same from Part 1, except we are also grabbing team abbreviations from the data
```
import requests
from bs4 import BeautifulSoup as bs
import datetime as dt
game_data = []
for d in game_days:
# get the web page with game data on it
url = f'https://www.covers.com/Sports/MLB/Matchups?selectedDate={d}'
resp = requests.get(url)
# parse the games
scraped_games = bs(resp.text).findAll('div',{'class':'cmg_matchup_game_box'})
for g in scraped_games:
game = {}
game['home_moneyline'] = g['data-game-odd']
game['date'] = g['data-game-date']
game['away_team_abbr'] = g['data-away-team-shortname-search']
game['home_team_abbr'] = g['data-home-team-shortname-search']
try:
game['home_score'] =g.find('div',{'class':'cmg_matchup_list_score_home'}).text.strip()
game['away_score'] =g.find('div',{'class':'cmg_matchup_list_score_away'}).text.strip()
except:
game['home_score'] =''
game['away_score'] =''
game_data.append(game)
if len(game_data) % 1000==0:
#show progress
print(dt.datetime.now(), d, len(game_data))
print("Done! Games downloaded:", len(game_data))
```
So slow. Let's save this so we don't have to go through that again.
```
import pickle
pickle.dump(game_data, open('covers_data_2.pkl','wb'))
```
We'll do some prepping and cleaning of the data.
```
import pickle
game_data = pickle.load(open('covers_data_2.pkl','rb'))
import numpy as np
import pandas as pd
odds = pd.DataFrame(game_data)
odds['home_moneyline'].replace('', np.nan, inplace=True)
odds.dropna(subset=['home_moneyline'], inplace=True)
odds.home_moneyline = pd.to_numeric(odds.home_moneyline)
odds.date = pd.to_datetime(odds.date).dt.date
```
Now we convert the team names to be the same as baseball-reference.com
```
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter(action='ignore', category=FutureWarning)
odds.home_team_abbr[odds.home_team_abbr=='SF']='SFG'
odds.home_team_abbr[odds.home_team_abbr=='TB']='TBR'
odds.home_team_abbr[odds.home_team_abbr=='WAS']='WSN'
odds.home_team_abbr[odds.home_team_abbr=='KC']='KCR'
odds.home_team_abbr[odds.home_team_abbr=='SD']='SDP'
odds.away_team_abbr[odds.away_team_abbr=='SF']='SFG'
odds.away_team_abbr[odds.away_team_abbr=='TB']='TBR'
odds.away_team_abbr[odds.away_team_abbr=='WAS']='WSN'
odds.away_team_abbr[odds.away_team_abbr=='KC']='KCR'
odds.away_team_abbr[odds.away_team_abbr=='SD']='SDP'
```
Finally, convert the moneyline odds to probabilities
```
odds['odds_proba']=np.nan
odds['odds_proba'][odds.home_moneyline<0] = -odds.home_moneyline/(-odds.home_moneyline + 100)
odds['odds_proba'][odds.home_moneyline>0] = (100/(odds.home_moneyline + 100))
```
Because the game times aren't exact, we'll use [pandas merge_asof](https://pandas.pydata.org/docs/reference/api/pandas.merge_asof.html) to find the closest match. The syntax is that you the fields in "by" parameter need to be exact, and it will find the closest by the "on" parameter. I think this feature is awesome, and another reason I love pandas.
```
print('dataframe shape before merge:', df.shape)
# get dates into the same format
odds['date'] = (pd.to_datetime(pd.to_datetime(odds['date'])) - pd.Timestamp("1970-01-01")) // pd.Timedelta('1s')
# do the merge
df = pd.merge_asof(left=df.sort_values(by='date'),
right=odds[['home_team_abbr','date', 'away_team_abbr','odds_proba']].sort_values(by='date'),
by=['home_team_abbr','away_team_abbr'],
on='date')
df = df.sort_values(by='date').copy().reset_index(drop=True)
print('dataframe shape after merge:', df.shape)
```
Things look good now. Let's save this dataframe before we move on
```
import pickle
pickle.dump(df, open('dataframe_part3.pkl','wb'))
```
## Run The Model
This is almost the exact code we ran in part 2
```
import pickle
df = pickle.load(open('dataframe_part3.pkl','rb'))
import xgboost as xgb
# target encoding
encode_me = [x for x in df.keys() if 'object' in str(df[x].dtype)]
for x in encode_me:
df[x] = df.groupby(x)['home_team_win'].apply(lambda x:x.rolling(180).mean()).shift(1)
# create test, train splits
df = df.sort_values(by='date').copy().reset_index(drop=True)
X = df.drop(columns=['home_team_win', 'game_id'])
y = df.home_team_win
X_train = X[:-1000]
y_train = y[:-1000]
X_valid = X[-1000:-500]
y_valid = y[-1000:-500]
X_test = X[-500:]
y_test = y[-500:]
```
Run the model
```
params = {'learning_rate': 0.035,'max_depth': 1}
gbm = xgb.XGBClassifier(**params)
model = gbm.fit(X_train, y_train,
eval_set = [[X_train, y_train],
[X_valid, y_valid]],
eval_metric='logloss',
early_stopping_rounds=10)
xgb_test_preds = model.predict(X_test)
xgb_test_proba = model.predict_proba(X_test)[:,1]
```
Since we now know the casino odds for these specific games, we can directly compare our model preditions with on the same games. Peviously we'd been comparing our results against how the casino predicted 2019 games.
```
#collapse-hide
from sklearn.calibration import calibration_curve
from sklearn.metrics import accuracy_score, brier_score_loss
import matplotlib.pyplot as plt
import pickle
def cal_curve(data, bins):
# adapted from:
#https://scikit-learn.org/stable/auto_examples/calibration/plot_calibration_curve.html
fig = plt.figure(1, figsize=(12, 8))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax2 = plt.subplot2grid((3, 1), (2, 0))
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
for y_test, y_pred, y_proba, name in data:
brier = brier_score_loss(y_test, y_proba)
print("{}\t\tAccuracy:{:.4f}\t Brier Loss: {:.4f}".format(
name, accuracy_score(y_test, y_pred), brier))
fraction_of_positives, mean_predicted_value = \
calibration_curve(y_test, y_proba, n_bins=bins)
ax1.plot(mean_predicted_value, fraction_of_positives,
label="%s (%1.4f)" % (name, brier))
ax2.hist(y_proba, range=(0, 1), bins=bins, label=name,
histtype="step", lw=2)
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliability curve)')
ax2.set_xlabel("Mean predicted value")
ax2.set_ylabel("Count")
ax2.legend(loc="lower right")
plt.tight_layout()
plt.show()
casino_proba = X_test['odds_proba']
casino_preds = X_test['odds_proba']>.5
data = [
(y_test, casino_preds, casino_proba, 'Casino'),
(y_test,xgb_test_preds, xgb_test_proba, 'XGBoost')
]
cal_curve(data, 15)
```
Now we're talking. Our accuracy in our test data is 0.6% better than the oddsmakers and our calibration is virtually the same. It's a concern that to get these results, I needed to set the max depth to 1. That is very low, and implies that we are susceptible to overfitting. One way to fix that is to get more data...
## Next up
In [Part 4](https://rdpharr.github.io/project_notes/baseball/hyperopt/xgboost/machine%20learning/2020/09/24/model-optimization.html), we're going to train this thing for real, and try to squeak out a few more % through downloading more data and hyperparameter optimization. You may want to run the next notebook overnight...
|
github_jupyter
|
import pickle
df = pickle.load(open("dataframe.pkl","rb"))
pip install elote
from elote import EloCompetitor
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=EloCompetitor()
for x in df.away_team_abbr.unique():
ratings[x]=EloCompetitor()
home_team_elo = []
away_team_elo = []
elo_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pre-game ratings
elo_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_elo.append(ratings[r.home_team_abbr].rating)
away_team_elo.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['elo_exp'] = elo_exp
df['home_team_elo'] = home_team_elo
df['away_team_elo'] = away_team_elo
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=EloCompetitor()
ratings[x]._k_score=16
for x in df.away_team_abbr.unique():
ratings[x]=EloCompetitor()
ratings[x]._k_score=16
home_team_elo = []
away_team_elo = []
elo_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pregame ratings
elo_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_elo.append(ratings[r.home_team_abbr].rating)
away_team_elo.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['elo_slow_exp'] = elo_exp
df['home_team_elo_slow'] = home_team_elo
df['away_team_elo_slow'] = away_team_elo
from elote import GlickoCompetitor
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=GlickoCompetitor()
for x in df.away_team_abbr.unique():
ratings[x]=GlickoCompetitor()
home_team_glick = []
away_team_glick = []
glick_exp = []
df = df.sort_values(by='date').reset_index(drop=True)
for i, r in df.iterrows():
# get pregame ratings
glick_exp.append(ratings[r.home_team_abbr].expected_score(ratings[r.away_team_abbr]))
home_team_glick.append(ratings[r.home_team_abbr].rating)
away_team_glick.append(ratings[r.away_team_abbr].rating)
# update ratings
if r.home_team_win:
ratings[r.home_team_abbr].beat(ratings[r.away_team_abbr])
else:
ratings[r.away_team_abbr].beat(ratings[r.home_team_abbr])
df['glick_exp'] = glick_exp
df['home_team_glick'] = home_team_glick
df['away_team_glick'] = away_team_glick
pip install trueskill
from trueskill import Rating, quality, rate
ratings = {}
for x in df.home_team_abbr.unique():
ratings[x]=Rating(25)
for x in df.away_team_abbr.unique():
ratings[x]=Rating(25)
for x in df.home_pitcher.unique():
ratings[x]=Rating(25)
for x in df.away_pitcher.unique():
ratings[x]=Rating(25)
ts_quality = []
pitcher_ts_diff = []
team_ts_diff = []
home_pitcher_ts = []
away_pitcher_ts = []
home_team_ts = []
away_team_ts = []
df = df.sort_values(by='date').copy()
for i, r in df.iterrows():
# get pre-match trueskill ratings from dict
match = [(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])]
ts_quality.append(quality(match))
pitcher_ts_diff.append(ratings[r.home_pitcher].mu-ratings[r.away_pitcher].mu)
team_ts_diff.append(ratings[r.home_team_abbr].mu-ratings[r.away_team_abbr].mu)
home_pitcher_ts.append(ratings[r.home_pitcher].mu)
away_pitcher_ts.append(ratings[r.away_pitcher].mu)
home_team_ts.append(ratings[r.home_team_abbr].mu)
away_team_ts.append(ratings[r.away_team_abbr].mu)
if r.date < df.date.max():
# update ratings dictionary with post-match ratings
if r.home_team_win==1:
match = [(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])]
[(ratings[r.home_team_abbr], ratings[r.home_pitcher]),
(ratings[r.away_team_abbr], ratings[r.away_pitcher])] = rate(match)
else:
match = [(ratings[r.away_team_abbr], ratings[r.away_pitcher]),
(ratings[r.home_team_abbr], ratings[r.home_pitcher])]
[(ratings[r.away_team_abbr], ratings[r.away_pitcher]),
(ratings[r.home_team_abbr], ratings[r.home_pitcher])] = rate(match)
df['ts_game_quality'] = ts_quality
df['pitcher_ts_diff'] = pitcher_ts_diff
df['team_ts_diff'] = team_ts_diff
df['home_pitcher_ts'] = home_pitcher_ts
df['away_pitcher_ts'] = away_pitcher_ts
df['home_team_ts'] = home_team_ts
df['away_team_ts'] = away_team_ts
import pandas as pd
dates = pd.to_datetime(df['date'], unit='s')
game_days = dates.dt.strftime('%Y-%m-%d').unique()
print("Days of odds data needed:", len(game_days))
import requests
from bs4 import BeautifulSoup as bs
import datetime as dt
game_data = []
for d in game_days:
# get the web page with game data on it
url = f'https://www.covers.com/Sports/MLB/Matchups?selectedDate={d}'
resp = requests.get(url)
# parse the games
scraped_games = bs(resp.text).findAll('div',{'class':'cmg_matchup_game_box'})
for g in scraped_games:
game = {}
game['home_moneyline'] = g['data-game-odd']
game['date'] = g['data-game-date']
game['away_team_abbr'] = g['data-away-team-shortname-search']
game['home_team_abbr'] = g['data-home-team-shortname-search']
try:
game['home_score'] =g.find('div',{'class':'cmg_matchup_list_score_home'}).text.strip()
game['away_score'] =g.find('div',{'class':'cmg_matchup_list_score_away'}).text.strip()
except:
game['home_score'] =''
game['away_score'] =''
game_data.append(game)
if len(game_data) % 1000==0:
#show progress
print(dt.datetime.now(), d, len(game_data))
print("Done! Games downloaded:", len(game_data))
import pickle
pickle.dump(game_data, open('covers_data_2.pkl','wb'))
import pickle
game_data = pickle.load(open('covers_data_2.pkl','rb'))
import numpy as np
import pandas as pd
odds = pd.DataFrame(game_data)
odds['home_moneyline'].replace('', np.nan, inplace=True)
odds.dropna(subset=['home_moneyline'], inplace=True)
odds.home_moneyline = pd.to_numeric(odds.home_moneyline)
odds.date = pd.to_datetime(odds.date).dt.date
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter(action='ignore', category=FutureWarning)
odds.home_team_abbr[odds.home_team_abbr=='SF']='SFG'
odds.home_team_abbr[odds.home_team_abbr=='TB']='TBR'
odds.home_team_abbr[odds.home_team_abbr=='WAS']='WSN'
odds.home_team_abbr[odds.home_team_abbr=='KC']='KCR'
odds.home_team_abbr[odds.home_team_abbr=='SD']='SDP'
odds.away_team_abbr[odds.away_team_abbr=='SF']='SFG'
odds.away_team_abbr[odds.away_team_abbr=='TB']='TBR'
odds.away_team_abbr[odds.away_team_abbr=='WAS']='WSN'
odds.away_team_abbr[odds.away_team_abbr=='KC']='KCR'
odds.away_team_abbr[odds.away_team_abbr=='SD']='SDP'
odds['odds_proba']=np.nan
odds['odds_proba'][odds.home_moneyline<0] = -odds.home_moneyline/(-odds.home_moneyline + 100)
odds['odds_proba'][odds.home_moneyline>0] = (100/(odds.home_moneyline + 100))
print('dataframe shape before merge:', df.shape)
# get dates into the same format
odds['date'] = (pd.to_datetime(pd.to_datetime(odds['date'])) - pd.Timestamp("1970-01-01")) // pd.Timedelta('1s')
# do the merge
df = pd.merge_asof(left=df.sort_values(by='date'),
right=odds[['home_team_abbr','date', 'away_team_abbr','odds_proba']].sort_values(by='date'),
by=['home_team_abbr','away_team_abbr'],
on='date')
df = df.sort_values(by='date').copy().reset_index(drop=True)
print('dataframe shape after merge:', df.shape)
import pickle
pickle.dump(df, open('dataframe_part3.pkl','wb'))
import pickle
df = pickle.load(open('dataframe_part3.pkl','rb'))
import xgboost as xgb
# target encoding
encode_me = [x for x in df.keys() if 'object' in str(df[x].dtype)]
for x in encode_me:
df[x] = df.groupby(x)['home_team_win'].apply(lambda x:x.rolling(180).mean()).shift(1)
# create test, train splits
df = df.sort_values(by='date').copy().reset_index(drop=True)
X = df.drop(columns=['home_team_win', 'game_id'])
y = df.home_team_win
X_train = X[:-1000]
y_train = y[:-1000]
X_valid = X[-1000:-500]
y_valid = y[-1000:-500]
X_test = X[-500:]
y_test = y[-500:]
params = {'learning_rate': 0.035,'max_depth': 1}
gbm = xgb.XGBClassifier(**params)
model = gbm.fit(X_train, y_train,
eval_set = [[X_train, y_train],
[X_valid, y_valid]],
eval_metric='logloss',
early_stopping_rounds=10)
xgb_test_preds = model.predict(X_test)
xgb_test_proba = model.predict_proba(X_test)[:,1]
#collapse-hide
from sklearn.calibration import calibration_curve
from sklearn.metrics import accuracy_score, brier_score_loss
import matplotlib.pyplot as plt
import pickle
def cal_curve(data, bins):
# adapted from:
#https://scikit-learn.org/stable/auto_examples/calibration/plot_calibration_curve.html
fig = plt.figure(1, figsize=(12, 8))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax2 = plt.subplot2grid((3, 1), (2, 0))
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
for y_test, y_pred, y_proba, name in data:
brier = brier_score_loss(y_test, y_proba)
print("{}\t\tAccuracy:{:.4f}\t Brier Loss: {:.4f}".format(
name, accuracy_score(y_test, y_pred), brier))
fraction_of_positives, mean_predicted_value = \
calibration_curve(y_test, y_proba, n_bins=bins)
ax1.plot(mean_predicted_value, fraction_of_positives,
label="%s (%1.4f)" % (name, brier))
ax2.hist(y_proba, range=(0, 1), bins=bins, label=name,
histtype="step", lw=2)
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliability curve)')
ax2.set_xlabel("Mean predicted value")
ax2.set_ylabel("Count")
ax2.legend(loc="lower right")
plt.tight_layout()
plt.show()
casino_proba = X_test['odds_proba']
casino_preds = X_test['odds_proba']>.5
data = [
(y_test, casino_preds, casino_proba, 'Casino'),
(y_test,xgb_test_preds, xgb_test_proba, 'XGBoost')
]
cal_curve(data, 15)
| 0.092191 | 0.850717 |
# Obtaining deflection in time for a sinc excited tip interacting with a viscoelastic solid (Standard Linear Solid)
```
import numpy as np
from numba import jit
from AFM_simulations import MDR_SLS_sinc, SLS_parabolic_LR_sinc, Hertzian_sinc
import matplotlib.pyplot as plt
from AFM_calculations import derivative_cd, av_dt
%matplotlib inline
A = -1.36e-9 #amplitude of the sinc excitation
R = 10.0e-9 #radius of curvature of the parabolic tip apex
startprint = 0.0
simultime = 1200.0e-6 #total simulation time
fo1 =20.0e3 #cantilever 1st mode resonance frequency
omega = 2.0*np.pi*fo1
period1 = 1.0/fo1 #fundamental period
to =7.0*period1 #centered time of the sinc excitation
fo2 = 6.27*fo1
fo3 = 17.6*fo1
Q1 = 2.0 #cantilever's 1st mode quality factor
Q2 = 8.0
Q3 = 12.0
BW = 2.5*fo1*2.0 #excitation bandwith of sinc function
k_m1 = 0.25 #cantilever's 1st mode stiffness
zb = 3.85e-9 #cantilever equilibrium position
period2 = 1.0/fo2
period3 = 1.0/fo3
dt= period3/1.0e4 #simulation timestep
printstep = dt*10.0 #timestep in the saved time array
```
## Interconversion of SLS parameters between Voigt and Maxwell configuration
```
nu = 0.3 #time independent Poisson's ratio
G_v = 1.0e-1/(1.2*R) #modulus of the spring in the Voigt unit that is in series with the upper spring
Gg_v = 10.0e6 /(2*(1+nu)) #Glassy modulus in the Voigt-SLS configuration reported in the grid
Jg = 1.0/Gg_v #glassy compliance
tau_v = 0.1/omega #retardation time reported in simulation grid
J = 1.0/G_v #compliance of the spring in the Voigt unit that is in series with the upper spring
eta = tau_v*G_v
phi = 1.0/eta #fluidity of the dashpot in the Voigt unit that is in series with the upper spring
Je = J+Jg
# Now converting to the Maxwell SLS configuration: spring in parallel with Maxwell unit, note that these two models are mechanical analogs showing quantitatively the same behavior
Ge = 1.0/(Je)
G = J/(Jg*Je)
Gg = (G+Ge)
tau_m = tau_v*(Ge/Gg)
eta = tau_m*G
```
## Runing simulation with Lee and Radok formulation
```
sls_jit = jit()(SLS_parabolic_LR_sinc)
zb = 3.85e-9 #cantilever equilibrium position
t_lr, tip_lr, Fts_lr, xb_lr = sls_jit(A, to, BW, G, tau_m, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Ge, Q1, Q2, Q3, nu)
```
## Runing simulation with Hertzian solution
```
hertz_jit = jit()(Hertzian_sinc)
t_h, tp_h, Fts_h = hertz_jit(A, to, BW, Gg, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Q1, Q2, Q3, nu)
```
## Runing simulation for the Method of dimensionality reduction (aligned with Ting's theory)
```
MDR_jit = jit()(MDR_SLS_sinc)
t_m, tip_m, Fts_m, ca_m = MDR_jit(A, to, BW, G, tau_m, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Ge, Q1, Q2, Q3, nu, 1000, 10.0e-9)
```
## Comparing Lee and Radok with Ting's solution (obtained with MDR method)
```
xb_dot = derivative_cd((-xb_lr)**1.5, t_lr) #derivative of the sample displacement
G_rel = np.zeros(len(t_lr))
G_rel = Ge + G*np.exp(-t_lr/tau_m) #relaxation modulus of the SLS model
dt_lr = av_dt(t_lr)
conv = np.convolve(G_rel, xb_dot, mode='full')*dt_lr #convolution of the relaxation modulus with the derivative of sample displacement
conv = conv[:len(xb_lr)]
plt.plot((tip_lr - zb)*1.0e9, Fts_lr, 'y', lw=5, label = 'python-LR')
plt.plot( (tip_m-zb)*1.0e9, Fts_m, 'b', lw=4, label = 'MDR' )
alfa = 8.0/3.0*np.sqrt(R)/(1.0-nu)
#plt.plot((tip_lr - zb)*1.0e9, conv*alfa, 'r', lw=1.0, label='convolution-LR')
plt.plot((tp_h-zb)*1.0e9, Fts_h, 'g--', lw=2.0, label = 'Hertz')
plt.xlim(-5,-2)
plt.legend(loc=1)
```
|
github_jupyter
|
import numpy as np
from numba import jit
from AFM_simulations import MDR_SLS_sinc, SLS_parabolic_LR_sinc, Hertzian_sinc
import matplotlib.pyplot as plt
from AFM_calculations import derivative_cd, av_dt
%matplotlib inline
A = -1.36e-9 #amplitude of the sinc excitation
R = 10.0e-9 #radius of curvature of the parabolic tip apex
startprint = 0.0
simultime = 1200.0e-6 #total simulation time
fo1 =20.0e3 #cantilever 1st mode resonance frequency
omega = 2.0*np.pi*fo1
period1 = 1.0/fo1 #fundamental period
to =7.0*period1 #centered time of the sinc excitation
fo2 = 6.27*fo1
fo3 = 17.6*fo1
Q1 = 2.0 #cantilever's 1st mode quality factor
Q2 = 8.0
Q3 = 12.0
BW = 2.5*fo1*2.0 #excitation bandwith of sinc function
k_m1 = 0.25 #cantilever's 1st mode stiffness
zb = 3.85e-9 #cantilever equilibrium position
period2 = 1.0/fo2
period3 = 1.0/fo3
dt= period3/1.0e4 #simulation timestep
printstep = dt*10.0 #timestep in the saved time array
nu = 0.3 #time independent Poisson's ratio
G_v = 1.0e-1/(1.2*R) #modulus of the spring in the Voigt unit that is in series with the upper spring
Gg_v = 10.0e6 /(2*(1+nu)) #Glassy modulus in the Voigt-SLS configuration reported in the grid
Jg = 1.0/Gg_v #glassy compliance
tau_v = 0.1/omega #retardation time reported in simulation grid
J = 1.0/G_v #compliance of the spring in the Voigt unit that is in series with the upper spring
eta = tau_v*G_v
phi = 1.0/eta #fluidity of the dashpot in the Voigt unit that is in series with the upper spring
Je = J+Jg
# Now converting to the Maxwell SLS configuration: spring in parallel with Maxwell unit, note that these two models are mechanical analogs showing quantitatively the same behavior
Ge = 1.0/(Je)
G = J/(Jg*Je)
Gg = (G+Ge)
tau_m = tau_v*(Ge/Gg)
eta = tau_m*G
sls_jit = jit()(SLS_parabolic_LR_sinc)
zb = 3.85e-9 #cantilever equilibrium position
t_lr, tip_lr, Fts_lr, xb_lr = sls_jit(A, to, BW, G, tau_m, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Ge, Q1, Q2, Q3, nu)
hertz_jit = jit()(Hertzian_sinc)
t_h, tp_h, Fts_h = hertz_jit(A, to, BW, Gg, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Q1, Q2, Q3, nu)
MDR_jit = jit()(MDR_SLS_sinc)
t_m, tip_m, Fts_m, ca_m = MDR_jit(A, to, BW, G, tau_m, R, dt, startprint, simultime, fo1, k_m1, zb, printstep, Ge, Q1, Q2, Q3, nu, 1000, 10.0e-9)
xb_dot = derivative_cd((-xb_lr)**1.5, t_lr) #derivative of the sample displacement
G_rel = np.zeros(len(t_lr))
G_rel = Ge + G*np.exp(-t_lr/tau_m) #relaxation modulus of the SLS model
dt_lr = av_dt(t_lr)
conv = np.convolve(G_rel, xb_dot, mode='full')*dt_lr #convolution of the relaxation modulus with the derivative of sample displacement
conv = conv[:len(xb_lr)]
plt.plot((tip_lr - zb)*1.0e9, Fts_lr, 'y', lw=5, label = 'python-LR')
plt.plot( (tip_m-zb)*1.0e9, Fts_m, 'b', lw=4, label = 'MDR' )
alfa = 8.0/3.0*np.sqrt(R)/(1.0-nu)
#plt.plot((tip_lr - zb)*1.0e9, conv*alfa, 'r', lw=1.0, label='convolution-LR')
plt.plot((tp_h-zb)*1.0e9, Fts_h, 'g--', lw=2.0, label = 'Hertz')
plt.xlim(-5,-2)
plt.legend(loc=1)
| 0.452536 | 0.945349 |
```
import os
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision import models
import numpy as np
import pandas as pd
import math
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
```
### Load Best Model
```
# Create a feedforward NN with:
# 1 hidden layer with self.first_hidden_size neurons and Relu activation function.
# 1 output layer with 3 neurons and softmax activation function.
class MLP(torch.nn.Module):
def __init__(self, input_size, first_hidden_size):
super(MLP, self).__init__()
self.input_size = input_size
self.first_hidden_size = first_hidden_size
self.fc1 = torch.nn.Linear(self.input_size, self.first_hidden_size)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(self.first_hidden_size, 3)
self.softmax = torch.nn.Softmax(dim = 1)
def forward(self, x):
first_hidden = self.fc1(x)
first_relu = self.relu(first_hidden)
output = self.fc2(first_relu)
output = self.softmax(output)
return output
```
### Test MLP
```
# Computes the accuracy.
def compute_accuracy(predictions, labels):
# Take the max value and the max index of every vector in predictions.
max_values, max_indexes = torch.max(predictions.data, 1)
# Compute the accuracy.
accuracy = (((max_indexes == labels).sum().item()) / labels.shape[0]) * 100
return accuracy
def test_model(model, data, actual_labels):
# Set evaluation mode.
model.eval()
# Compute predicted labels.
predicted_test_labels = model(data)
# Compute accuracy.
final_accuracy = compute_accuracy(predicted_test_labels, actual_labels)
return final_accuracy, predicted_test_labels
# A list that has the names of all cases.
cases_folder_names = ['\\case01', '\\case02', '\\case03', '\\case04', '\\case05', '\\case06', '\\case07', '\\case08',
'\\case09', '\\case10', '\\case11', '\\case12', '\\case13', '\\case14', '\\case15', '\\case16',
'\\case17', '\\case18', '\\case19', '\\case20', '\\case21', '\\case22', '\\case23']
embeddings_directory = r"C:\Nikolaos Sintoris\Education\MEng CSE - UOI\Diploma Thesis\Training Results\Layer 4\Embeddings\ResNet50 Classifier"
best_model_directory = r"C:\Nikolaos Sintoris\Education\MEng CSE - UOI\Diploma Thesis\Training Results\Layer 4\Best Model\ResNet50 Classifier"
for current_case_name in cases_folder_names:
print("Current Case Name: ", current_case_name)
#===============================================================
#==================== Load Test Dataset ==========================
current_case_embeddings_directory = embeddings_directory + current_case_name
test_data_np = np.loadtxt(current_case_embeddings_directory + '\\test_data.csv', delimiter = ',')
test_data = torch.from_numpy(test_data_np) # It does not create a copy. Uses the same memory.
test_data = test_data.float()
print("\tTest data shape: ", test_data.shape)
actual_test_labels_np = np.loadtxt(current_case_embeddings_directory + '\\actual_test_labels.csv', delimiter = ',')
actual_test_labels = torch.from_numpy(actual_test_labels_np) # It does not create a copy. Uses the same memory.
actual_test_labels = actual_test_labels.long()
print("\tActual test labels shape: ", actual_test_labels.shape)
#===============================================================
#===============================================================
#===============================================================
#==================== Load Best Model ==========================
current_case_best_model_directory = best_model_directory + current_case_name + "\\state_dict_model.pt"
# Load the model with the maximum validation accuracy.
input_layer_size = test_data.shape[1]
first_hidden_layer_size = round(math.sqrt(input_layer_size * 3))
my_model = MLP(input_layer_size, first_hidden_layer_size)
my_model.load_state_dict(torch.load(current_case_best_model_directory))
#===============================================================
#===============================================================
#===============================================================
#==================== Compute Accuracy ==========================
test_accuracy, predicted_test_labels = test_model(my_model, test_data, actual_test_labels)
print("\tTest accuracy: ", test_accuracy)
#===============================================================
#===============================================================
#===============================================================
#==================== Compute F1 Score ==========================
_, final_predicted_test_labels = torch.max(predicted_test_labels.data, 1)
final_predicted_test_labels_np = final_predicted_test_labels.numpy()
test_f1_score = f1_score(actual_test_labels_np, final_predicted_test_labels_np, average = 'macro')
print("\tTest F1-Score: ", test_f1_score)
#===============================================================
#===============================================================
#===============================================================
#==================== Save Results ==========================
# Save test accuracy and F1-score to a csv file.
test_results_np = np.array( [test_accuracy, test_f1_score] )
np.savetxt(best_model_directory + current_case_name + "\\accuracy_f1_score.csv", test_results_np, delimiter = ',')
#===============================================================
#===============================================================
```
|
github_jupyter
|
import os
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torchvision import models
import numpy as np
import pandas as pd
import math
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
# Create a feedforward NN with:
# 1 hidden layer with self.first_hidden_size neurons and Relu activation function.
# 1 output layer with 3 neurons and softmax activation function.
class MLP(torch.nn.Module):
def __init__(self, input_size, first_hidden_size):
super(MLP, self).__init__()
self.input_size = input_size
self.first_hidden_size = first_hidden_size
self.fc1 = torch.nn.Linear(self.input_size, self.first_hidden_size)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(self.first_hidden_size, 3)
self.softmax = torch.nn.Softmax(dim = 1)
def forward(self, x):
first_hidden = self.fc1(x)
first_relu = self.relu(first_hidden)
output = self.fc2(first_relu)
output = self.softmax(output)
return output
# Computes the accuracy.
def compute_accuracy(predictions, labels):
# Take the max value and the max index of every vector in predictions.
max_values, max_indexes = torch.max(predictions.data, 1)
# Compute the accuracy.
accuracy = (((max_indexes == labels).sum().item()) / labels.shape[0]) * 100
return accuracy
def test_model(model, data, actual_labels):
# Set evaluation mode.
model.eval()
# Compute predicted labels.
predicted_test_labels = model(data)
# Compute accuracy.
final_accuracy = compute_accuracy(predicted_test_labels, actual_labels)
return final_accuracy, predicted_test_labels
# A list that has the names of all cases.
cases_folder_names = ['\\case01', '\\case02', '\\case03', '\\case04', '\\case05', '\\case06', '\\case07', '\\case08',
'\\case09', '\\case10', '\\case11', '\\case12', '\\case13', '\\case14', '\\case15', '\\case16',
'\\case17', '\\case18', '\\case19', '\\case20', '\\case21', '\\case22', '\\case23']
embeddings_directory = r"C:\Nikolaos Sintoris\Education\MEng CSE - UOI\Diploma Thesis\Training Results\Layer 4\Embeddings\ResNet50 Classifier"
best_model_directory = r"C:\Nikolaos Sintoris\Education\MEng CSE - UOI\Diploma Thesis\Training Results\Layer 4\Best Model\ResNet50 Classifier"
for current_case_name in cases_folder_names:
print("Current Case Name: ", current_case_name)
#===============================================================
#==================== Load Test Dataset ==========================
current_case_embeddings_directory = embeddings_directory + current_case_name
test_data_np = np.loadtxt(current_case_embeddings_directory + '\\test_data.csv', delimiter = ',')
test_data = torch.from_numpy(test_data_np) # It does not create a copy. Uses the same memory.
test_data = test_data.float()
print("\tTest data shape: ", test_data.shape)
actual_test_labels_np = np.loadtxt(current_case_embeddings_directory + '\\actual_test_labels.csv', delimiter = ',')
actual_test_labels = torch.from_numpy(actual_test_labels_np) # It does not create a copy. Uses the same memory.
actual_test_labels = actual_test_labels.long()
print("\tActual test labels shape: ", actual_test_labels.shape)
#===============================================================
#===============================================================
#===============================================================
#==================== Load Best Model ==========================
current_case_best_model_directory = best_model_directory + current_case_name + "\\state_dict_model.pt"
# Load the model with the maximum validation accuracy.
input_layer_size = test_data.shape[1]
first_hidden_layer_size = round(math.sqrt(input_layer_size * 3))
my_model = MLP(input_layer_size, first_hidden_layer_size)
my_model.load_state_dict(torch.load(current_case_best_model_directory))
#===============================================================
#===============================================================
#===============================================================
#==================== Compute Accuracy ==========================
test_accuracy, predicted_test_labels = test_model(my_model, test_data, actual_test_labels)
print("\tTest accuracy: ", test_accuracy)
#===============================================================
#===============================================================
#===============================================================
#==================== Compute F1 Score ==========================
_, final_predicted_test_labels = torch.max(predicted_test_labels.data, 1)
final_predicted_test_labels_np = final_predicted_test_labels.numpy()
test_f1_score = f1_score(actual_test_labels_np, final_predicted_test_labels_np, average = 'macro')
print("\tTest F1-Score: ", test_f1_score)
#===============================================================
#===============================================================
#===============================================================
#==================== Save Results ==========================
# Save test accuracy and F1-score to a csv file.
test_results_np = np.array( [test_accuracy, test_f1_score] )
np.savetxt(best_model_directory + current_case_name + "\\accuracy_f1_score.csv", test_results_np, delimiter = ',')
#===============================================================
#===============================================================
| 0.871557 | 0.887595 |
I refered the K-means Clustering on website : "https://machinelearningcoban.com/2017/01/01/kmeans/" while doing this
homework, so there will be similarities in the codebase.
Trying to follow the given paths.
Import libraries:
Note: Set seed = 200
```
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
import logging
np.random.seed(200)
```
The below function will display the graph, i set the markersize equal to 1 to have a better visualization
Set the scale to equal, that means 1 unit horizontal == 1 unit vertical in the plot
```
def display(dataset, label):
x0 = dataset[label == 0, :]
x1 = dataset[label == 1, :]
x2 = dataset[label == 2, :]
plt.plot(x0[:, 0], x0[:, 1], 'b^', markersize = 1)
plt.plot(x1[:, 0], x1[:, 1], 'go', markersize = 1)
plt.plot(x2[:, 0], x2[:, 1], 'rs', markersize = 1)
plt.axis('equal')
plt.plot()
plt.show()
```
The below function choose random point in the cluster as initial centers
```
def choose_centers(dataset, k):
return dataset[np.random.choice(dataset.shape[0], k, replace=False)]
```
The below function assign the label for points in clusters by the distance between that point and all of the centers
The label for a point in a cluster is the label of the center which is closest to the point
```
def assign_labels(dataset, centers):
D = cdist(dataset, centers)
D2 = centers[0] - dataset
D3 = centers[1] - dataset
D4 = centers[2] - dataset
# print(D2)
# print(D)
# print('Distance between center and points:',D2)
return np.argmin(D, axis = 1)
```
The below function is to update the center to minimize the total average distance between center and all the points in
the cluster.
```
def update_centers(dataset, labels, k):
centers = np.zeros((k, dataset.shape[1]))
print(centers)
for index in range(k):
Xk = dataset[labels == index, :]
centers[index,:] = np.mean(Xk, axis = 0)
return centers
```
The below function check if converged, if converged -> 2 set contain old centers and new centers+ are the same
-> New and center are the same -> same set
Alternative way -> set threshold that is a very small number, if the distance between old and new center are smaller
than that threshold -> converged. Else return False
```
def converged(centers, new_centers):
# logging.info([tuple(a) for a in centers])
return (set([tuple(a) for a in centers]) == set([tuple(a) for a in new_centers]))
```
The below function will first choose 3 random points and set it as the 3 initial centers
Assume that point is a center of the cluster, add that point into the list named "labels" to label the point
accordingly, test if that point satisfies that the average distance between that point and all the points in the cluster
is the smallest. If that point satisfies, break and return
```
def kmeans(dataset, k):
centers = [choose_centers(dataset, k)]
labels = []
it = 0
# print(dataset)
# print('center:',centers)
while True:
labels.append(assign_labels(dataset, centers[-1]))
new_centers = update_centers(dataset, labels[-1], k)
if converged(centers[-1], new_centers):
break
centers.append(new_centers)
it += 1
return centers, labels, it
```
Clusters created with multivariate_normal() function in numpy.random to ensure data follows
multivariate normal distribution
Working with 3 clusters, if you want to work with more custers, modify the code, create more means and clusters
REMEMBER TO KEEP THE SAME COVARIANCE!!! Well you actually can change the covariance, but each cluster would not be as
round as the value $$ \begin{bmatrix}1 & 0\\0 & 1\end{bmatrix} $$
```
means = [[-1, -1], [4, 4], [8, 12]]
cov = [[1, 0], [0, 1]]
n = int(input('Enter size of cluster'))
x0 = np.random.multivariate_normal(mean=means[0], cov=cov, size=n)
x1 = np.random.multivariate_normal(mean=means[1], cov=cov, size=n)
x2 = np.random.multivariate_normal(mean=means[2], cov=cov, size=n)
```
Concatenate all generated data into one array using np.concatenate, axis = 0 -> stack on each other
Create labels using number * the length of each cluster, then transpose it into a [m*1] matrix, with m = the number of
elements in each cluster time the number of clusters, if you add more clusters to the game, add more label to the
original_label
```
dataset = np.concatenate((x0, x1, x2), axis = 0)
k = 3
original_label = np.asarray([0]*n + [1]*n + [2]*n).T
```
Preview the first 10 rows of the dataset:
```
print(x0[:10])
print(x1[:10])
print(x2[:10])
centers, labels, it = kmeans(dataset, k)
print('The algorithm took :',it, 'iterations')
print('Centers found:')
final_centers = centers[-1]
print(centers)
display(dataset, labels[-1])
```
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
import logging
np.random.seed(200)
def display(dataset, label):
x0 = dataset[label == 0, :]
x1 = dataset[label == 1, :]
x2 = dataset[label == 2, :]
plt.plot(x0[:, 0], x0[:, 1], 'b^', markersize = 1)
plt.plot(x1[:, 0], x1[:, 1], 'go', markersize = 1)
plt.plot(x2[:, 0], x2[:, 1], 'rs', markersize = 1)
plt.axis('equal')
plt.plot()
plt.show()
def choose_centers(dataset, k):
return dataset[np.random.choice(dataset.shape[0], k, replace=False)]
def assign_labels(dataset, centers):
D = cdist(dataset, centers)
D2 = centers[0] - dataset
D3 = centers[1] - dataset
D4 = centers[2] - dataset
# print(D2)
# print(D)
# print('Distance between center and points:',D2)
return np.argmin(D, axis = 1)
def update_centers(dataset, labels, k):
centers = np.zeros((k, dataset.shape[1]))
print(centers)
for index in range(k):
Xk = dataset[labels == index, :]
centers[index,:] = np.mean(Xk, axis = 0)
return centers
def converged(centers, new_centers):
# logging.info([tuple(a) for a in centers])
return (set([tuple(a) for a in centers]) == set([tuple(a) for a in new_centers]))
def kmeans(dataset, k):
centers = [choose_centers(dataset, k)]
labels = []
it = 0
# print(dataset)
# print('center:',centers)
while True:
labels.append(assign_labels(dataset, centers[-1]))
new_centers = update_centers(dataset, labels[-1], k)
if converged(centers[-1], new_centers):
break
centers.append(new_centers)
it += 1
return centers, labels, it
means = [[-1, -1], [4, 4], [8, 12]]
cov = [[1, 0], [0, 1]]
n = int(input('Enter size of cluster'))
x0 = np.random.multivariate_normal(mean=means[0], cov=cov, size=n)
x1 = np.random.multivariate_normal(mean=means[1], cov=cov, size=n)
x2 = np.random.multivariate_normal(mean=means[2], cov=cov, size=n)
dataset = np.concatenate((x0, x1, x2), axis = 0)
k = 3
original_label = np.asarray([0]*n + [1]*n + [2]*n).T
print(x0[:10])
print(x1[:10])
print(x2[:10])
centers, labels, it = kmeans(dataset, k)
print('The algorithm took :',it, 'iterations')
print('Centers found:')
final_centers = centers[-1]
print(centers)
display(dataset, labels[-1])
| 0.276495 | 0.980692 |
# Decision Tree
Mateus Victor<br>
GitHub: <a href="https://github.com/mateusvictor">mateusvictor</a>
## Setup
```
import numpy as np
import pandas as pd
# To model the desision tree
from sklearn.tree import DecisionTreeClassifier
# Transform the data
from sklearn import preprocessing
# To create a train and test set
from sklearn.model_selection import train_test_split
# Metrics to evaluating
from sklearn import metrics
# For ploting
import matplotlib.pyplot as plt
from io import StringIO
import pydotplus
import matplotlib.image as mpimg
from sklearn import tree
%matplotlib inline
!wget -O drug200.csv https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-ML0101EN-SkillsNetwork/labs/Module%203/data/drug200.csv
```
<h2>About the dataset</h2>
Imagine that you are a medical researcher compiling data for a study. You have collected data about a set of patients, all of whom suffered from the same illness. During their course of treatment, each patient responded to one of 5 medications, Drug A, Drug B, Drug c, Drug x and y.
Part of your job is to build a model to find out which drug might be appropriate for a future patient with the same illness. The feature sets of this dataset are Age, Sex, Blood Pressure, and Cholesterol of patients, and the target is the drug that each patient responded to.
It is a sample of multiclass classifier, and you can use the training part of the dataset
to build a decision tree, and then use it to predict the class of a unknown patient, or to prescribe it to a new patient.
```
df = pd.read_csv('drug200.csv')
print(f"Size of the data: {df.shape}")
df.head()
```
## Decision Tree
```
# Independent variables
X = df[['Age', 'Sex', 'BP', 'Cholesterol', 'Na_to_K']].values
X[0:5]
# Independent variable (target)
Y = df['Drug']
Y[:5]
```
### Normalizing the data
```
# We have to convert categorical variables to dummy/indicator variables
le_sex = preprocessing.LabelEncoder()
le_sex.fit(['F', 'M'])
X[:,1] = le_sex.transform(X[:,1])
le_BP = preprocessing.LabelEncoder()
le_BP.fit(['LOW', 'NORMAL', 'HIGH'])
X[:,2] = le_BP.transform(X[:,2])
le_Chol = preprocessing.LabelEncoder()
le_Chol.fit(['NORMAL', 'HIGH'])
X[:,3] = le_Chol.transform(X[:,3])
# Data transformed:
X[:5]
```
### Train Test Split
```
# 70% of the data will be the train data and the rest wiill be the test data
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=3)
print(f"Train set: {X_train.shape}; {Y_train.shape}")
print(f"Test set: {X_test.shape}; {Y_test.shape}")
```
### Training and predicting
```
# Specifying criterion="entropy" so we can see the infromation gain of each node
decTree = DecisionTreeClassifier(criterion="entropy", max_depth=4)
decTree.fit(X_train, Y_train)
# Predicting
predTree = decTree.predict(X_test)
print(f"Predicted values: {predTree[0:5]}")
print(f"Actual values: {Y_test[:5]}")
```
### Evaluation
```
print("DecisionTree's Accuracy: ", metrics.accuracy_score(Y_test, predTree))
```
### Vizualization
```
dot_data = StringIO()
filename = "drugtree.png"
featuresNames = df.columns[:5]
targetNames = df['Drug'].unique().tolist()
out = tree.export_graphviz(decTree, feature_names=featuresNames, out_file=dot_data, class_names=np.unique(Y_train), filled=True, special_characters=True, rotate=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png(filename)
img = mpimg.imread(filename)
plt.figure(figsize=(100, 200))
plt.imshow(img, interpolation='nearest')
```
|
github_jupyter
|
import numpy as np
import pandas as pd
# To model the desision tree
from sklearn.tree import DecisionTreeClassifier
# Transform the data
from sklearn import preprocessing
# To create a train and test set
from sklearn.model_selection import train_test_split
# Metrics to evaluating
from sklearn import metrics
# For ploting
import matplotlib.pyplot as plt
from io import StringIO
import pydotplus
import matplotlib.image as mpimg
from sklearn import tree
%matplotlib inline
!wget -O drug200.csv https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-ML0101EN-SkillsNetwork/labs/Module%203/data/drug200.csv
df = pd.read_csv('drug200.csv')
print(f"Size of the data: {df.shape}")
df.head()
# Independent variables
X = df[['Age', 'Sex', 'BP', 'Cholesterol', 'Na_to_K']].values
X[0:5]
# Independent variable (target)
Y = df['Drug']
Y[:5]
# We have to convert categorical variables to dummy/indicator variables
le_sex = preprocessing.LabelEncoder()
le_sex.fit(['F', 'M'])
X[:,1] = le_sex.transform(X[:,1])
le_BP = preprocessing.LabelEncoder()
le_BP.fit(['LOW', 'NORMAL', 'HIGH'])
X[:,2] = le_BP.transform(X[:,2])
le_Chol = preprocessing.LabelEncoder()
le_Chol.fit(['NORMAL', 'HIGH'])
X[:,3] = le_Chol.transform(X[:,3])
# Data transformed:
X[:5]
# 70% of the data will be the train data and the rest wiill be the test data
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=3)
print(f"Train set: {X_train.shape}; {Y_train.shape}")
print(f"Test set: {X_test.shape}; {Y_test.shape}")
# Specifying criterion="entropy" so we can see the infromation gain of each node
decTree = DecisionTreeClassifier(criterion="entropy", max_depth=4)
decTree.fit(X_train, Y_train)
# Predicting
predTree = decTree.predict(X_test)
print(f"Predicted values: {predTree[0:5]}")
print(f"Actual values: {Y_test[:5]}")
print("DecisionTree's Accuracy: ", metrics.accuracy_score(Y_test, predTree))
dot_data = StringIO()
filename = "drugtree.png"
featuresNames = df.columns[:5]
targetNames = df['Drug'].unique().tolist()
out = tree.export_graphviz(decTree, feature_names=featuresNames, out_file=dot_data, class_names=np.unique(Y_train), filled=True, special_characters=True, rotate=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png(filename)
img = mpimg.imread(filename)
plt.figure(figsize=(100, 200))
plt.imshow(img, interpolation='nearest')
| 0.740925 | 0.964656 |
# Título 1
## Título 2

```
print("Hola Mundo!")
# No tipado!
# Variables primitivas
entero = 4
decimales = 1.1
nombre = "Jeff"
segundo_nombre = "Otro nombre" #no camel case
casado = False
profesor = True
hijos = None
apellido = 'Velasquez'
print(type(entero))
print(type(decimales))
print(type(nombre))
print(type(segundo_nombre))
print(type(casado))
print(type(profesor))
print(type(hijos))
print(type(apellido))
print(type('nan')) #Not A Number
cadena_de_texto = """
El programa "Coursera para la Escuela Politécnica Nacional" ofrece alrededor de 4.000 cursos y especializaciones dirigidos por profesores e instructores de prestigiosas universidades y empresas multinacionales. Es una gran oportunidad para fortalecer el desarrollo académico y profesional de los participantes.
Usted se ha registrado en el Coursera para la Escuela Politécnica Nacional de Coursera. Aproveche los cursos, especializaciones y proyectos guiados (de corta duración) que le ofrece este programa.
Saludos,
"""
print(cadena_de_texto)
entero = 4
decimales = 1.1
nombre = "Jeff"
segundo_nombre = "Otro nombre" #no camel case
casado = False
profesor = True
hijos = None
apellido = 'Velasquez'
print(entero)
entero = decimales
entero = hijos
entero = casado
entero = nombre
print(entero)
#Truty y Falsy
tuplas = (1,2,3) #Arreglo que no se pueden modificar
listas = [4,5,6] #Arreglos que se pueden modificar
diccionario = {
"nombre": "Jeff"
}
if('Jeff'): #truty
print('Truty')
else:
print('Falsy')
if(''):
print('Truty')
else:
print('Falsy')
variable = None
if(variable):
print("Truty")
else:
print("falsy")
if(1):
print("Truty")
else:
print("falsy")
if(0):
print("Truty")
else:
print("falsy")
if(-1):
print("Truty")
else:
print("falsy")
if(-1.2):
print("Truty")
else:
print("falsy")
if(1.1):
print("Truty")
else:
print("falsy")
if(()):
print("Truty")
else:
print("falsy")
if((1,2,3)):
print("Truty")
else:
print("falsy")
if([]):
print("Truty")
else:
print("falsy")
if([1,2,3]):
print("Truty")
else:
print("falsy")
if({}):
print("Truty")
else:
print("falsy")
if({"nombre": "Jeff"}):
print("Truty")
else:
print("falsy")
arreglo = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
arreglo[0:5] #[0,3[
arreglo[2:] #Hasta el final
arreglo[:4] #Desde el principio
arreglo[-1] #lee desde el final
arreglo[-10] #índice negativo empieza desde el final
arreglo[3:-2]
arreglo[-8:8]
arreglo[-4:-1]
arreglo[-7:]
arreglo[:-3]
arreglo[:]
arregloTupla = (1,2,3,4,5,6,7,8,9,10)
arregloTupla[4:9]
diccionario = {
"nombre": "Jeff",
"apellido": "Velasquez",
"otroCampo": "otro"
}
diccionario["nombre"]
"12" in arreglo
print(type(12 in arreglo))
9 in arreglo
len(arreglo)
len(arregloTupla)
len(diccionario)
"nombre" in diccionario #solo valida las llaves
"Jeff" in diccionario
#arregloTupla[0] = 2 #tuplas elementos solo de lectura
arreglo[9] = 11
arreglo
#metodos arreglos
#arreglo.pop
#arreglo.append
#arreglo.insert
#entre otros
for numeroLista in arreglo:
print(numeroLista)
for key in diccionario:
print(key)
contador = 0
while contador < 10:
print(contador)
contador+=1
jeff = {
True:"Jeff",
False: "otro",
1: 12.2,
1.2:34,
'edad': 23,
"mascotas": [{"nombre":"Pelusa"}],
None: None
}
jeff[1]
jeff['edad'] = 25
jeff['apellido'] = "velasquez"
jeff["mascotas"][0]["nombre"] = "Panda"
jeff
jeff.keys()
jeff.values()
type(jeff.keys())
type(jeff.values())
for llave in jeff.keys():
print(llave)
for valor in jeff.values():
print(valor)
1==1 or 2==2
1!=1 and 2!=2
```
|
github_jupyter
|
print("Hola Mundo!")
# No tipado!
# Variables primitivas
entero = 4
decimales = 1.1
nombre = "Jeff"
segundo_nombre = "Otro nombre" #no camel case
casado = False
profesor = True
hijos = None
apellido = 'Velasquez'
print(type(entero))
print(type(decimales))
print(type(nombre))
print(type(segundo_nombre))
print(type(casado))
print(type(profesor))
print(type(hijos))
print(type(apellido))
print(type('nan')) #Not A Number
cadena_de_texto = """
El programa "Coursera para la Escuela Politécnica Nacional" ofrece alrededor de 4.000 cursos y especializaciones dirigidos por profesores e instructores de prestigiosas universidades y empresas multinacionales. Es una gran oportunidad para fortalecer el desarrollo académico y profesional de los participantes.
Usted se ha registrado en el Coursera para la Escuela Politécnica Nacional de Coursera. Aproveche los cursos, especializaciones y proyectos guiados (de corta duración) que le ofrece este programa.
Saludos,
"""
print(cadena_de_texto)
entero = 4
decimales = 1.1
nombre = "Jeff"
segundo_nombre = "Otro nombre" #no camel case
casado = False
profesor = True
hijos = None
apellido = 'Velasquez'
print(entero)
entero = decimales
entero = hijos
entero = casado
entero = nombre
print(entero)
#Truty y Falsy
tuplas = (1,2,3) #Arreglo que no se pueden modificar
listas = [4,5,6] #Arreglos que se pueden modificar
diccionario = {
"nombre": "Jeff"
}
if('Jeff'): #truty
print('Truty')
else:
print('Falsy')
if(''):
print('Truty')
else:
print('Falsy')
variable = None
if(variable):
print("Truty")
else:
print("falsy")
if(1):
print("Truty")
else:
print("falsy")
if(0):
print("Truty")
else:
print("falsy")
if(-1):
print("Truty")
else:
print("falsy")
if(-1.2):
print("Truty")
else:
print("falsy")
if(1.1):
print("Truty")
else:
print("falsy")
if(()):
print("Truty")
else:
print("falsy")
if((1,2,3)):
print("Truty")
else:
print("falsy")
if([]):
print("Truty")
else:
print("falsy")
if([1,2,3]):
print("Truty")
else:
print("falsy")
if({}):
print("Truty")
else:
print("falsy")
if({"nombre": "Jeff"}):
print("Truty")
else:
print("falsy")
arreglo = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
arreglo[0:5] #[0,3[
arreglo[2:] #Hasta el final
arreglo[:4] #Desde el principio
arreglo[-1] #lee desde el final
arreglo[-10] #índice negativo empieza desde el final
arreglo[3:-2]
arreglo[-8:8]
arreglo[-4:-1]
arreglo[-7:]
arreglo[:-3]
arreglo[:]
arregloTupla = (1,2,3,4,5,6,7,8,9,10)
arregloTupla[4:9]
diccionario = {
"nombre": "Jeff",
"apellido": "Velasquez",
"otroCampo": "otro"
}
diccionario["nombre"]
"12" in arreglo
print(type(12 in arreglo))
9 in arreglo
len(arreglo)
len(arregloTupla)
len(diccionario)
"nombre" in diccionario #solo valida las llaves
"Jeff" in diccionario
#arregloTupla[0] = 2 #tuplas elementos solo de lectura
arreglo[9] = 11
arreglo
#metodos arreglos
#arreglo.pop
#arreglo.append
#arreglo.insert
#entre otros
for numeroLista in arreglo:
print(numeroLista)
for key in diccionario:
print(key)
contador = 0
while contador < 10:
print(contador)
contador+=1
jeff = {
True:"Jeff",
False: "otro",
1: 12.2,
1.2:34,
'edad': 23,
"mascotas": [{"nombre":"Pelusa"}],
None: None
}
jeff[1]
jeff['edad'] = 25
jeff['apellido'] = "velasquez"
jeff["mascotas"][0]["nombre"] = "Panda"
jeff
jeff.keys()
jeff.values()
type(jeff.keys())
type(jeff.values())
for llave in jeff.keys():
print(llave)
for valor in jeff.values():
print(valor)
1==1 or 2==2
1!=1 and 2!=2
| 0.046638 | 0.708326 |
# Exercise 11.1 - Solution
## Air-shower reconstruction
Follow the description of a cosmic-ray observatory in Example 11.2 and Fig. 11.2(b).
The simulated data contain 9 × 9 detector stations which record traversing particles from the cosmic-ray induced air shower.
Each station measures two quantities, which are stored in the form of a map (2D array) corresponding to the station positions in offset coordinates:
- arrival time `T`: time point of detection in seconds
- signal `S`: signal strength in arbitrary units
The following shower properties need to be reconstructed:
- `axis`: x, y, z unit vector of the shower arrival direction
- `core`: position of the shower core in meters
- `logE`: $\log_{10} (E / \mathrm{eV})$, energy of the cosmic ray
Reconstruct the properties of the arriving cosmic rays by analyzing their
air showers:
### Tasks
1. Set up a multi-task regression network for simultaneously predicting shower direction, shower core position, and energy. The network should consist of a common part to the three properties, followed by an individual subnetwork for each property. Combine the mean squared errors of the different properties using weights $w_j$.
2. Train the model to the following precisions:
- Better than $1.5^\circ$ angular resolution
- Better than $25$ m core position resolution
- Better than $7\%$ relative energy uncertainty $\left(\frac{E_\mathrm{pred} - E_\mathrm{true}}{E_\mathrm{true}}\right)$
Estimate what these requirements mean in terms of the mean squared error loss and adjust the relative weights in the objective function accordingly.
3. Plot and interpret the resulting training curves, both with and without the weights $w_j$ in the objective function.
##### Hint: using a GPU for this task may be advantageous!
```
from tensorflow import keras
import numpy as np
from matplotlib import pyplot as plt
layers = keras.layers
print("keras", keras.__version__)
```
### Download data
```
import os
import gdown
url = "https://drive.google.com/u/0/uc?export=download&confirm=HgGH&id=1nQDddS36y4AcJ87ocoMjyx46HGueiU6k"
output = 'airshowers.npz'
if os.path.exists(output) == False:
gdown.download(url, output, quiet=True)
f = np.load(output)
```
### Input 1: arrival times
```
# time map
T = f['time']
T -= np.nanmean(T)
T /= np.nanstd(T)
T[np.isnan(T)] = 0
print(T.shape)
```
#### Plot four example arrival time maps
```
nsamples=len(T)
random_samples = np.random.choice(nsamples, 4)
def rectangular_array(n=9):
""" Return x,y coordinates for rectangular array with n^2 stations. """
n0 = (n - 1) / 2
return (np.mgrid[0:n, 0:n].astype(float) - n0)
for i,j in enumerate(random_samples):
plt.subplot(2,2,i+1)
footprint=T[j,...]
xd, yd = rectangular_array()
mask = footprint != 0
mask[5, 5] = True
marker_size = 50 * footprint[mask]
plot = plt.scatter(xd, yd, c='grey', s=10, alpha=0.3, label="silent")
circles = plt.scatter(xd[mask], yd[mask], c=footprint[mask],
cmap="viridis", alpha=1, label="loud")
cbar = plt.colorbar(circles)
cbar.set_label('normalized time [a.u.]')
plt.grid(True)
plt.tight_layout()
plt.show()
```
### Input 2: signals
```
# signal map
S = f['signal']
S = np.log10(1 + S)
S -= np.nanmin(S)
S /= np.nanmax(S)
S[np.isnan(S)] = 0
print(S.shape)
for i,j in enumerate(random_samples):
plt.subplot(2,2,i+1)
footprint=S[j,...]
xd, yd = rectangular_array()
mask = footprint != 0
mask[5, 5] = True
marker_size = 200 * footprint[mask] + 20
plot = plt.scatter(xd, yd, c='grey', s=10, alpha=0.3, label="silent")
circles = plt.scatter(xd[mask], yd[mask], c=footprint[mask], s=marker_size,
cmap="autumn_r", alpha=1, label="loud")
cbar = plt.colorbar(circles)
cbar.set_label('normalized signals [a.u.]')
plt.grid(True)
plt.tight_layout()
plt.show()
```
Combine inputs
```
X = np.stack([T, S], axis=-1)
```
### Labels
```
axis = f['showeraxis']
core = f['showercore'][:, 0:2]
core /= 750
# energy - log10(E/eV) in range [18.5, 20]
logE = f['logE']
logE -= 19.25
X_train, X_test = np.split(X, [-20000])
axis_train, axis_test = np.split(axis, [-20000])
core_train, core_test = np.split(core, [-20000])
logE_train, logE_test = np.split(logE, [-20000])
```
## Define Model
## Task
Set up a multi-task regression network for simultaneously predicting shower direction, shower core position, and energy. The network should consist of a common part to the three properties, followed by an individual subnetwork for each property.
```
# define towers for the individual targets
def tower(z, nout, name):
zt = layers.Conv2D(32, (3, 3), name=name + '-conv1', **kwargs)(z)
zt = layers.Conv2D(32, (3, 3), name=name + '-conv2', **kwargs)(zt)
zt = layers.Conv2D(48, (3, 3), name=name + '-conv3', **kwargs)(zt)
zt = layers.Flatten(name=name + '-flat')(zt)
zt = layers.Dense(10 * nout, name=name + '-dense', **kwargs)(zt)
return layers.Dense(nout, name=name)(zt)
input1 = layers.Input(shape=(9, 9, 2))
kwargs = dict(activation='relu', kernel_initializer='he_normal')
z = layers.SeparableConv2D(8, (3, 3), padding="same", **kwargs)(input1)
# common densely connected block
zlist = [z]
for i in range(5):
z = layers.Conv2D(16, (1, 1), padding='same', **kwargs)(z)
z = layers.SeparableConv2D(16, (3, 3), padding='same', **kwargs)(z)
zlist.append(z)
z = layers.concatenate(zlist[:], axis=-1)
z1 = tower(z, 3, 'axis')
z2 = tower(z, 2, 'core')
z3 = tower(z, 1, 'energy')
model = keras.models.Model(inputs=[input1], outputs=[z1, z2, z3])
print(model.summary())
```
### Task
Train the model to the following precisions:
- Better than $1.5^\circ$ angular resolution
- Better than $25$ m core position resolution
- Better than $7\%$ relative energy uncertainty $\left(\frac{E_\mathrm{pred} - E_\mathrm{true}}{E_\mathrm{true}}\right)$
Estimate what these requirements mean in terms of the mean squared error loss and adjust the relative weights in the objective function accordingly.
<em>The total objective function is $\mathcal{L}_\mathrm{tot} = w_1 \cdot \mathcal{L}_1 + w_2 \cdot \mathcal{L}_2 + w_3 \cdot \mathcal{L}_3$, where $\mathcal{L}$ are the mean squared error (MSE) objectives of the reconstruction tasks for the arrivaldirection, core position and energy, respectively.
#### shower axis
$\mathcal{L}_1 = \frac{1}{N} \sum_i^N ( \vec{a}_{\mathrm{pred},i} - \vec{a}_{\mathrm{true},i} )^2$,
where the $\vec{a}$ vectors denote the (unit) shower axis (x,y,z).
#### shower core
$\mathcal{L}_2 = \frac{1}{N} \sum_i^N \left( \frac{\vec{c}_{\mathrm{pred},i} - \vec{c}_{\mathrm{true},i}}{750\mathrm{m}}\right)^2$,
with $\vec{c}$ denote the 2D core position / 750 m.
#### energy
$\mathcal{L}_3 = \frac{1}{N} \sum_i^N \left( \log_{10}\frac{E_{\mathrm{pred},i}}{10^{19.25} \mathrm{eV}} - \log_{10}\frac{E_{\mathrm{true},i}}{10^{19.25} \mathrm{eV}}\right)^2$
Since the objectives can be solved to different precision, we need to apply
individual weights, such that
$\mathcal{L}_\mathrm{tot} = w_1 \cdot \mathcal{L}_1 + w_2 \cdot \mathcal{L}_2 + w_3 \cdot \mathcal{L}_3$.
We can derive the weights from the correspondence between the MSE and the negative log-likelihood for a Gaussian distribution.
$-2 \ln(\mathcal{J}_\mathrm{tot}) = -2\cdot\ln(\mathcal{J}_1) - 2\cdot\ln(\mathcal{J}_2) - 2\cdot\ln(\mathcal{J}_3)$
$-2 \ln(\mathcal{L}_\mathrm{tot}) = \frac{N\cdot\mathcal{L}_1 }{\sigma_1^{2}} + \frac{N\cdot\mathcal{L}_2 }{\sigma_2^{2}} + \frac{N\cdot\mathcal{L}_3}{\sigma_3^{2}}$
$-2 \ln(\mathcal{L}_\mathrm{tot}) = w_1 \cdot \mathcal{L}_1 + w_2 \cdot \mathcal{L}_2 + w_3 \cdot \mathcal{L}_3$,
where the number of samples $N$ is irrelevant for the optimum parameters.
Hence, the weights according to the specified resolutions read:
##### arrival direction: $$w_1 \sim 1/\sigma_1^2 = 1/(1.5^\circ)^2 ~\sim 1500$$
##### core position: $$w_2 \sim 1/\sigma_2^2 \sim 1/(25m/750m)^2 \sim 900$$
##### energy: $$w_3 \sim 1/\sigma_3^2 = 1/(7\%)**2 = 50$$
or simply $w_1 = 15,\;w_2 = 9,\; w_3 = 1$.
Alternatively to this calculation, we can monitor the training loss and adjust
the weights such that the contribution to the total objective is similar for all
objectives.</em>
```
loss_weights=[15, 9, 2]
model.compile(
loss=['mse', 'mse', 'mse'],
loss_weights=loss_weights,
optimizer=keras.optimizers.Adam(lr=1e-3))
fit = model.fit(
X_train,
[axis_train, core_train, logE_train],
batch_size=128,
epochs=40,
verbose=2,
validation_split=0.1,
callbacks=[keras.callbacks.ReduceLROnPlateau(factor=0.67, patience=10, verbose=1),
keras.callbacks.EarlyStopping(patience=5, verbose=1)]
)
```
### Plot training curves
```
def plot_history(history, weighted=False):
fig, ax = plt.subplots(1)
n = np.arange(len(history['loss']))
for i, s in enumerate(['axis', 'core', 'energy']):
w = loss_weights[i] if weighted else 1
l1 = w * np.array(history['%s_loss' % s])
l2 = w * np.array(history['val_%s_loss' % s])
color = 'C%i' % i
ax.plot(n, l1, c=color, ls='--')
ax.plot(n, l2, c=color, label=s)
ax.plot(n, history['loss'], ls='--', c='k')
ax.plot(n, history['val_loss'], label='sum', c='k')
ax.set_xlabel('Epoch')
ax.set_ylabel('Weighted Loss' if weighted else 'Loss')
ax.legend()
ax.semilogy()
ax.grid()
plt.show()
```
#### Unweighted losses
```
plot_history(fit.history, weighted=False)
```
#### Weighted losses
```
plot_history(fit.history, weighted=True)
```
## Study performance of the DNN
```
axis_pred, core_pred, logE_pred = model.predict(X_test, batch_size=128, verbose=1)
logE_pred = logE_pred[:,0] # remove keras dummy axis
```
### Reconstruction performance of the shower axis
```
d = np.sum(axis_pred * axis_test, axis=1) / np.sum(axis_pred**2, axis=1)**.5
d = np.arccos(np.clip(d, 0, 1)) * 180 / np.pi
reso = np.percentile(d, 68)
plt.figure()
plt.hist(d, bins=np.linspace(0, 3, 41))
plt.axvline(reso, color='C1')
plt.text(0.95, 0.95, '$\sigma_{68} = %.2f^\circ$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel(r'$\Delta \alpha$ [deg]')
plt.ylabel('#')
plt.grid()
plt.tight_layout()
```
### Reconstruction performance of the shower core
```
d = np.sum((750 * (core_test - core_pred))**2, axis=1)**.5
reso = np.percentile(d, 68)
plt.figure()
plt.hist(d, bins=np.linspace(0, 40, 41))
plt.axvline(reso, color='C1')
plt.text(0.95, 0.95, '$\sigma_{68} = %.2f m$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel('$\Delta r$ [m]')
plt.ylabel('#')
plt.grid()
plt.tight_layout()
```
### Reconstruction performance of the shower energy
```
d = 10**(logE_pred - logE_test) - 1
reso = np.std(d)
plt.figure()
plt.hist(d, bins=np.linspace(-0.3, 0.3, 41))
plt.xlabel('($E_\mathrm{rec} - E_\mathrm{true}) / E_\mathrm{true}$')
plt.ylabel('#')
plt.text(0.95, 0.95, '$\sigma_\mathrm{rel} = %.3f$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.grid()
plt.tight_layout()
plt.figure()
plt.scatter(19.25 + logE_test, 19.25 + logE_pred, s=2, alpha=0.3)
plt.plot([18.5, 20], [18.5, 20], color='black')
plt.xlabel('$\log_{10}(E_\mathrm{true}/\mathrm{eV})$')
plt.ylabel('$\log_{10}(E_\mathrm{rec}/\mathrm{eV})$')
plt.grid()
plt.tight_layout()
```
|
github_jupyter
|
from tensorflow import keras
import numpy as np
from matplotlib import pyplot as plt
layers = keras.layers
print("keras", keras.__version__)
import os
import gdown
url = "https://drive.google.com/u/0/uc?export=download&confirm=HgGH&id=1nQDddS36y4AcJ87ocoMjyx46HGueiU6k"
output = 'airshowers.npz'
if os.path.exists(output) == False:
gdown.download(url, output, quiet=True)
f = np.load(output)
# time map
T = f['time']
T -= np.nanmean(T)
T /= np.nanstd(T)
T[np.isnan(T)] = 0
print(T.shape)
nsamples=len(T)
random_samples = np.random.choice(nsamples, 4)
def rectangular_array(n=9):
""" Return x,y coordinates for rectangular array with n^2 stations. """
n0 = (n - 1) / 2
return (np.mgrid[0:n, 0:n].astype(float) - n0)
for i,j in enumerate(random_samples):
plt.subplot(2,2,i+1)
footprint=T[j,...]
xd, yd = rectangular_array()
mask = footprint != 0
mask[5, 5] = True
marker_size = 50 * footprint[mask]
plot = plt.scatter(xd, yd, c='grey', s=10, alpha=0.3, label="silent")
circles = plt.scatter(xd[mask], yd[mask], c=footprint[mask],
cmap="viridis", alpha=1, label="loud")
cbar = plt.colorbar(circles)
cbar.set_label('normalized time [a.u.]')
plt.grid(True)
plt.tight_layout()
plt.show()
# signal map
S = f['signal']
S = np.log10(1 + S)
S -= np.nanmin(S)
S /= np.nanmax(S)
S[np.isnan(S)] = 0
print(S.shape)
for i,j in enumerate(random_samples):
plt.subplot(2,2,i+1)
footprint=S[j,...]
xd, yd = rectangular_array()
mask = footprint != 0
mask[5, 5] = True
marker_size = 200 * footprint[mask] + 20
plot = plt.scatter(xd, yd, c='grey', s=10, alpha=0.3, label="silent")
circles = plt.scatter(xd[mask], yd[mask], c=footprint[mask], s=marker_size,
cmap="autumn_r", alpha=1, label="loud")
cbar = plt.colorbar(circles)
cbar.set_label('normalized signals [a.u.]')
plt.grid(True)
plt.tight_layout()
plt.show()
X = np.stack([T, S], axis=-1)
axis = f['showeraxis']
core = f['showercore'][:, 0:2]
core /= 750
# energy - log10(E/eV) in range [18.5, 20]
logE = f['logE']
logE -= 19.25
X_train, X_test = np.split(X, [-20000])
axis_train, axis_test = np.split(axis, [-20000])
core_train, core_test = np.split(core, [-20000])
logE_train, logE_test = np.split(logE, [-20000])
# define towers for the individual targets
def tower(z, nout, name):
zt = layers.Conv2D(32, (3, 3), name=name + '-conv1', **kwargs)(z)
zt = layers.Conv2D(32, (3, 3), name=name + '-conv2', **kwargs)(zt)
zt = layers.Conv2D(48, (3, 3), name=name + '-conv3', **kwargs)(zt)
zt = layers.Flatten(name=name + '-flat')(zt)
zt = layers.Dense(10 * nout, name=name + '-dense', **kwargs)(zt)
return layers.Dense(nout, name=name)(zt)
input1 = layers.Input(shape=(9, 9, 2))
kwargs = dict(activation='relu', kernel_initializer='he_normal')
z = layers.SeparableConv2D(8, (3, 3), padding="same", **kwargs)(input1)
# common densely connected block
zlist = [z]
for i in range(5):
z = layers.Conv2D(16, (1, 1), padding='same', **kwargs)(z)
z = layers.SeparableConv2D(16, (3, 3), padding='same', **kwargs)(z)
zlist.append(z)
z = layers.concatenate(zlist[:], axis=-1)
z1 = tower(z, 3, 'axis')
z2 = tower(z, 2, 'core')
z3 = tower(z, 1, 'energy')
model = keras.models.Model(inputs=[input1], outputs=[z1, z2, z3])
print(model.summary())
loss_weights=[15, 9, 2]
model.compile(
loss=['mse', 'mse', 'mse'],
loss_weights=loss_weights,
optimizer=keras.optimizers.Adam(lr=1e-3))
fit = model.fit(
X_train,
[axis_train, core_train, logE_train],
batch_size=128,
epochs=40,
verbose=2,
validation_split=0.1,
callbacks=[keras.callbacks.ReduceLROnPlateau(factor=0.67, patience=10, verbose=1),
keras.callbacks.EarlyStopping(patience=5, verbose=1)]
)
def plot_history(history, weighted=False):
fig, ax = plt.subplots(1)
n = np.arange(len(history['loss']))
for i, s in enumerate(['axis', 'core', 'energy']):
w = loss_weights[i] if weighted else 1
l1 = w * np.array(history['%s_loss' % s])
l2 = w * np.array(history['val_%s_loss' % s])
color = 'C%i' % i
ax.plot(n, l1, c=color, ls='--')
ax.plot(n, l2, c=color, label=s)
ax.plot(n, history['loss'], ls='--', c='k')
ax.plot(n, history['val_loss'], label='sum', c='k')
ax.set_xlabel('Epoch')
ax.set_ylabel('Weighted Loss' if weighted else 'Loss')
ax.legend()
ax.semilogy()
ax.grid()
plt.show()
plot_history(fit.history, weighted=False)
plot_history(fit.history, weighted=True)
axis_pred, core_pred, logE_pred = model.predict(X_test, batch_size=128, verbose=1)
logE_pred = logE_pred[:,0] # remove keras dummy axis
d = np.sum(axis_pred * axis_test, axis=1) / np.sum(axis_pred**2, axis=1)**.5
d = np.arccos(np.clip(d, 0, 1)) * 180 / np.pi
reso = np.percentile(d, 68)
plt.figure()
plt.hist(d, bins=np.linspace(0, 3, 41))
plt.axvline(reso, color='C1')
plt.text(0.95, 0.95, '$\sigma_{68} = %.2f^\circ$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel(r'$\Delta \alpha$ [deg]')
plt.ylabel('#')
plt.grid()
plt.tight_layout()
d = np.sum((750 * (core_test - core_pred))**2, axis=1)**.5
reso = np.percentile(d, 68)
plt.figure()
plt.hist(d, bins=np.linspace(0, 40, 41))
plt.axvline(reso, color='C1')
plt.text(0.95, 0.95, '$\sigma_{68} = %.2f m$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel('$\Delta r$ [m]')
plt.ylabel('#')
plt.grid()
plt.tight_layout()
d = 10**(logE_pred - logE_test) - 1
reso = np.std(d)
plt.figure()
plt.hist(d, bins=np.linspace(-0.3, 0.3, 41))
plt.xlabel('($E_\mathrm{rec} - E_\mathrm{true}) / E_\mathrm{true}$')
plt.ylabel('#')
plt.text(0.95, 0.95, '$\sigma_\mathrm{rel} = %.3f$' % reso, ha='right', va='top', transform=plt.gca().transAxes)
plt.grid()
plt.tight_layout()
plt.figure()
plt.scatter(19.25 + logE_test, 19.25 + logE_pred, s=2, alpha=0.3)
plt.plot([18.5, 20], [18.5, 20], color='black')
plt.xlabel('$\log_{10}(E_\mathrm{true}/\mathrm{eV})$')
plt.ylabel('$\log_{10}(E_\mathrm{rec}/\mathrm{eV})$')
plt.grid()
plt.tight_layout()
| 0.785432 | 0.97506 |
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
```
## Does nn.Conv2d init work well?
[Jump_to lesson 9 video](https://course.fast.ai/videos/?lesson=9&t=21)
```
#export
from exp.nb_02 import *
def get_data():
path = datasets.download_data(MNIST_URL, ext='.gz')
with gzip.open(path, 'rb') as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(tensor, (x_train,y_train,x_valid,y_valid))
def normalize(x, m, s): return (x-m)/s
torch.nn.modules.conv._ConvNd.reset_parameters??
x_train,y_train,x_valid,y_valid = get_data()
train_mean,train_std = x_train.mean(),x_train.std()
x_train = normalize(x_train, train_mean, train_std)
x_valid = normalize(x_valid, train_mean, train_std)
x_train = x_train.view(-1,1,28,28)
x_valid = x_valid.view(-1,1,28,28)
x_train.shape,x_valid.shape
n,*_ = x_train.shape
c = y_train.max()+1
nh = 32
n,c
l1 = nn.Conv2d(1, nh, 5)
x = x_valid[:100]
x.shape
def stats(x): return x.mean(),x.std()
l1.weight.shape
stats(l1.weight),stats(l1.bias)
t = l1(x)
stats(t)
init.kaiming_normal_(l1.weight, a=1.)
stats(l1(x))
import torch.nn.functional as F
def f1(x,a=0): return F.leaky_relu(l1(x),a)
init.kaiming_normal_(l1.weight, a=0)
stats(f1(x))
l1 = nn.Conv2d(1, nh, 5)
stats(f1(x))
l1.weight.shape
# receptive field size
rec_fs = l1.weight[0,0].numel()
rec_fs
nf,ni,*_ = l1.weight.shape
nf,ni
fan_in = ni*rec_fs
fan_out = nf*rec_fs
fan_in,fan_out
def gain(a): return math.sqrt(2.0 / (1 + a**2))
gain(1),gain(0),gain(0.01),gain(0.1),gain(math.sqrt(5.))
torch.zeros(10000).uniform_(-1,1).std()
1/math.sqrt(3.)
def kaiming2(x,a, use_fan_out=False):
nf,ni,*_ = x.shape
rec_fs = x[0,0].shape.numel()
fan = nf*rec_fs if use_fan_out else ni*rec_fs
std = gain(a) / math.sqrt(fan)
bound = math.sqrt(3.) * std
x.data.uniform_(-bound,bound)
kaiming2(l1.weight, a=0);
stats(f1(x))
kaiming2(l1.weight, a=math.sqrt(5.))
stats(f1(x))
class Flatten(nn.Module):
def forward(self,x): return x.view(-1)
m = nn.Sequential(
nn.Conv2d(1,8, 5,stride=2,padding=2), nn.ReLU(),
nn.Conv2d(8,16,3,stride=2,padding=1), nn.ReLU(),
nn.Conv2d(16,32,3,stride=2,padding=1), nn.ReLU(),
nn.Conv2d(32,1,3,stride=2,padding=1),
nn.AdaptiveAvgPool2d(1),
Flatten(),
)
y = y_valid[:100].float()
t = m(x)
stats(t)
l = mse(t,y)
l.backward()
stats(m[0].weight.grad)
init.kaiming_uniform_??
for l in m:
if isinstance(l,nn.Conv2d):
init.kaiming_uniform_(l.weight)
l.bias.data.zero_()
t = m(x)
stats(t)
l = mse(t,y)
l.backward()
stats(m[0].weight.grad)
```
## Export
```
!./notebook2script.py 02a_why_sqrt5.ipynb
```
|
github_jupyter
|
%load_ext autoreload
%autoreload 2
%matplotlib inline
#export
from exp.nb_02 import *
def get_data():
path = datasets.download_data(MNIST_URL, ext='.gz')
with gzip.open(path, 'rb') as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
return map(tensor, (x_train,y_train,x_valid,y_valid))
def normalize(x, m, s): return (x-m)/s
torch.nn.modules.conv._ConvNd.reset_parameters??
x_train,y_train,x_valid,y_valid = get_data()
train_mean,train_std = x_train.mean(),x_train.std()
x_train = normalize(x_train, train_mean, train_std)
x_valid = normalize(x_valid, train_mean, train_std)
x_train = x_train.view(-1,1,28,28)
x_valid = x_valid.view(-1,1,28,28)
x_train.shape,x_valid.shape
n,*_ = x_train.shape
c = y_train.max()+1
nh = 32
n,c
l1 = nn.Conv2d(1, nh, 5)
x = x_valid[:100]
x.shape
def stats(x): return x.mean(),x.std()
l1.weight.shape
stats(l1.weight),stats(l1.bias)
t = l1(x)
stats(t)
init.kaiming_normal_(l1.weight, a=1.)
stats(l1(x))
import torch.nn.functional as F
def f1(x,a=0): return F.leaky_relu(l1(x),a)
init.kaiming_normal_(l1.weight, a=0)
stats(f1(x))
l1 = nn.Conv2d(1, nh, 5)
stats(f1(x))
l1.weight.shape
# receptive field size
rec_fs = l1.weight[0,0].numel()
rec_fs
nf,ni,*_ = l1.weight.shape
nf,ni
fan_in = ni*rec_fs
fan_out = nf*rec_fs
fan_in,fan_out
def gain(a): return math.sqrt(2.0 / (1 + a**2))
gain(1),gain(0),gain(0.01),gain(0.1),gain(math.sqrt(5.))
torch.zeros(10000).uniform_(-1,1).std()
1/math.sqrt(3.)
def kaiming2(x,a, use_fan_out=False):
nf,ni,*_ = x.shape
rec_fs = x[0,0].shape.numel()
fan = nf*rec_fs if use_fan_out else ni*rec_fs
std = gain(a) / math.sqrt(fan)
bound = math.sqrt(3.) * std
x.data.uniform_(-bound,bound)
kaiming2(l1.weight, a=0);
stats(f1(x))
kaiming2(l1.weight, a=math.sqrt(5.))
stats(f1(x))
class Flatten(nn.Module):
def forward(self,x): return x.view(-1)
m = nn.Sequential(
nn.Conv2d(1,8, 5,stride=2,padding=2), nn.ReLU(),
nn.Conv2d(8,16,3,stride=2,padding=1), nn.ReLU(),
nn.Conv2d(16,32,3,stride=2,padding=1), nn.ReLU(),
nn.Conv2d(32,1,3,stride=2,padding=1),
nn.AdaptiveAvgPool2d(1),
Flatten(),
)
y = y_valid[:100].float()
t = m(x)
stats(t)
l = mse(t,y)
l.backward()
stats(m[0].weight.grad)
init.kaiming_uniform_??
for l in m:
if isinstance(l,nn.Conv2d):
init.kaiming_uniform_(l.weight)
l.bias.data.zero_()
t = m(x)
stats(t)
l = mse(t,y)
l.backward()
stats(m[0].weight.grad)
!./notebook2script.py 02a_why_sqrt5.ipynb
| 0.734976 | 0.81538 |
# The $\chi^2$ Distribution
## $\chi^2$ Test Statistic
If we make $n$ ranom samples (observations) from Gaussian (Normal) distributions with known means, $\mu_i$, and known variances, $\sigma_i^2$, it is seen that the total squared deviation,
$$
\chi^2 = \sum_{i=1}^{n} \left(\frac{x_i - \mu_i}{\sigma_i}\right)^2\,,
$$
follows a $\chi^2$ distribution with $n$ degrees of freedom.
## Probability Distribution Function
The $\chi^2$ probability distribution function for $k$ degrees of freedom (the number of parameters that are allowed to vary) is given by
$$
f\left(\chi^2\,;k\right) = \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, \chi^{k-2}\,e^{-\chi^2/2}\,,
$$
where if there are no constrained variables the number of degrees of freedom, $k$, is equal to the number of observations, $k=n$. The p.d.f. is often abbreviated in notation from $f\left(\chi^2\,;k\right)$ to $\chi^2_k$.
A reminder that for integer values of $k$, the Gamma function is $\Gamma\left(k\right) = \left(k-1\right)!$, and that $\Gamma\left(x+1\right) = x\Gamma\left(x\right)$, and $\Gamma\left(1/2\right) = \sqrt{\pi}$.
## Mean
Letting $\chi^2=z$, and noting that the form of the Gamma function is
$$
\Gamma\left(z\right) = \int\limits_{0}^{\infty} x^{z-1}\,e^{-x}\,dx,
$$
it is seen that the mean of the $\chi^2$ distribution $f\left(\chi^2 ; k\right)$ is
$$
\begin{align}
\mu &= \textrm{E}\left[z\right] = \displaystyle\int\limits_{0}^{\infty} z\, \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, z^{k/2-1}\,e^{-z\,/2}\,dz \\
&= \displaystyle \frac{\displaystyle 1}{\displaystyle \Gamma\left(k\,/2\right)} \int\limits_{0}^{\infty} \left(\frac{z}{2}\right)^{k/2}\,e^{-z\,/2}\,dz = \displaystyle \frac{\displaystyle 1}{\displaystyle \Gamma\left(k\,/2\right)} \int\limits_{0}^{\infty} x^{k/2}\,e^{-x}\,2 \,dx \\
&= \displaystyle \frac{\displaystyle 2 \,\Gamma\left(k\,/2 + 1\right)}{\displaystyle \Gamma\left(k\,/2\right)} \\
&= \displaystyle 2 \frac{k}{2} \frac{\displaystyle \Gamma\left(k\,/2\right)}{\displaystyle \Gamma\left(k\,/2\right)} \\
&= k.
\end{align}
$$
## Variance
Likewise, the variance is
$$
\begin{align}
\textrm{Var}\left[z\right] &= \textrm{E}\left[\left(z-\textrm{E}\left[z\right]\right)^2\right] = \displaystyle\int\limits_{0}^{\infty} \left(z - k\right)^2\, \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, z^{k/2-1}\,e^{-z\,/2}\,dz \\
&= \displaystyle\int\limits_{0}^{\infty} z^2\, f\left(z \,; k\right)\,dz - 2k\int\limits_{0}^{\infty} z\,\,f\left(z \,; k\right)\,dz + k^2\int\limits_{0}^{\infty} f\left(z \,; k\right)\,dz \\
&= \displaystyle\int\limits_{0}^{\infty} z^2 \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, z^{k/2-1}\,e^{-z\,/2}\,dz - 2k^2 + k^2\\
&= \displaystyle\int\limits_{0}^{\infty} \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, z^{k/2+1}\,e^{-z\,/2}\,dz - k^2\\
&= \frac{\displaystyle 2}{\displaystyle \Gamma\left(k\,/2\right)} \displaystyle\int\limits_{0}^{\infty} \left(\frac{z}{2}\right)^{k/2+1}\,e^{-z\,/2}\,dz - k^2 = \frac{\displaystyle 2}{\displaystyle \Gamma\left(k\,/2\right)} \displaystyle\int\limits_{0}^{\infty} x^{k/2+1}\,e^{-x}\,2\,dx - k^2 \\
&= \displaystyle \frac{\displaystyle 4 \,\Gamma\left(k\,/2 + 2\right)}{\displaystyle \Gamma\left(k\,/2\right)} - k^2 \\
&= \displaystyle 4 \left(\frac{k}{2} + 1\right) \frac{\displaystyle \Gamma\left(k\,/2 + 1\right)}{\displaystyle \Gamma\left(k\,/2\right)} - k^2 \\
&= \displaystyle 4 \left(\frac{k}{2} + 1\right) \frac{k}{2} - k^2 \\
&= k^2 + 2k - k^2 \\
&= 2k,
\end{align}
$$
such that the standard deviation is
$$
\sigma = \sqrt{2k}\,.
$$
Given this information we now plot the $\chi^2$ p.d.f. with various numbers of degrees of freedom to visualize how the distribution's behaviour
```
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# Plot the chi^2 distribution
x = np.linspace(0., 10., num=1000)
[plt.plot(x, stats.chi2.pdf(x, df=ndf), label=r'$k = ${}'.format(ndf))
for ndf in range(1, 7)]
plt.ylim(-0.01, 0.5)
plt.xlabel(r'$x=\chi^2$')
plt.ylabel(r'$f\left(x;k\right)$')
plt.title(r'$\chi^2$ distribution for various degrees of freedom')
plt.legend(loc='best')
plt.show();
```
## Cumulative Distribution Function
The cumulative distribution function (CDF) for the $\chi^2$ distribution is (letting $z=\chi^2$)
$$
\begin{split}
F_{\chi^2}\left(x\,; k\right) &= \int\limits_{0}^{x} f_{\chi^2}\left(z\,; k\right) \,dz \\
&= \int\limits_{0}^{x} \frac{\displaystyle 1}{\displaystyle 2^{k/2} \,\Gamma\left(k\,/2\right)}\, z^{k/2-1}\,e^{-z/2} \,dz \\
&= \int\limits_{0}^{x} \frac{\displaystyle 1}{\displaystyle 2 \,\Gamma\left(k\,/2\right)}\, \left(\frac{z}{2}\right)^{k/2-1}\,e^{-z/2} \,dz = \frac{1}{\displaystyle 2 \,\Gamma\left(k\,/2\right)}\int\limits_{0}^{x/2} t^{k/2-1}\,e^{-t} \,2\,dt \\
&= \frac{1}{\displaystyle \Gamma\left(k\,/2\right)}\int\limits_{0}^{x/2} t^{k/2-1}\,e^{-t} \,dt
\end{split}
$$
Noting the form of the [lower incomplete gamma function](https://en.wikipedia.org/wiki/Incomplete_gamma_function) is
$$
\gamma\left(s,x\right) = \int\limits_{0}^{x} t^{s-1}\,e^{-t} \,dt\,,
$$
and the form of the [regularized Gamma function](https://en.wikipedia.org/wiki/Incomplete_gamma_function#Regularized_Gamma_functions_and_Poisson_random_variables) is
$$
P\left(s,x\right) = \frac{\gamma\left(s,x\right)}{\Gamma\left(s\right)}\,,
$$
it is seen that
$$
\begin{split}
F_{\chi^2}\left(x\,; k\right) &= \frac{1}{\displaystyle \Gamma\left(k\,/2\right)}\int\limits_{0}^{x/2} t^{k/2-1}\,e^{-t} \,dt \\
&= \frac{\displaystyle \gamma\left(\frac{k}{2},\frac{x}{2}\right)}{\displaystyle \Gamma\left(\frac{k}{2}\right)} \\
&= P\left(\frac{k}{2},\frac{x}{2}\right)\,.
\end{split}
$$
Thus, it is seen that the compliment to the CDF (the complementary cumulative distribution function (CCDF)),
$$
\bar{F}_{\chi^2}\left(x\,; k\right) = 1-F_{\chi^2}\left(x\,; k\right),
$$
represents a one-sided (one-tailed) $p$-value for observing a $\chi^2$ given a model — that is, the probability to observe a $\chi^2$ value greater than or equal to that which was observed.
```
def chi2_ccdf(x, df):
"""The complementary cumulative distribution function
Args:
x: the value of chi^2
df: the number of degrees of freedom
Returns:
1 - the cumulative distribution function
"""
return 1. - stats.chi2.cdf(x=x, df=df)
x = np.linspace(0., 10., num=1000)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 4.5))
for ndf in range(1,7):
axes[0].plot(x, stats.chi2.cdf(x, df=ndf),
label=r'$k = ${}'.format(ndf))
axes[1].plot(x, chi2_ccdf(x, df=ndf),
label=r'$k = ${}'.format(ndf))
axes[0].set_xlabel(r'$x=\chi^2$')
axes[0].set_ylabel(r'$F\left(x;k\right)$')
axes[0].set_title(r'$\chi^2$ CDF for various degrees of freedom')
axes[0].legend(loc='best')
axes[1].set_xlabel(r'$x=\chi^2$')
axes[1].set_ylabel(r'$\bar{F}\left(x;k\right) = p$-value')
axes[1].set_title(r'$\chi^2$ CCDF ($p$-value) for various degrees of freedom')
axes[1].legend(loc='best')
plt.show();
```
## Binned $\chi^2$ per Degree of Freedom
TODO
## References
- \[1\] G. Cowan, _Statistical Data Analysis_, Oxford University Press, 1998
- \[2\] G. Cowan, "Goodness of fit and Wilk's theorem", Notes, 2013
|
github_jupyter
|
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# Plot the chi^2 distribution
x = np.linspace(0., 10., num=1000)
[plt.plot(x, stats.chi2.pdf(x, df=ndf), label=r'$k = ${}'.format(ndf))
for ndf in range(1, 7)]
plt.ylim(-0.01, 0.5)
plt.xlabel(r'$x=\chi^2$')
plt.ylabel(r'$f\left(x;k\right)$')
plt.title(r'$\chi^2$ distribution for various degrees of freedom')
plt.legend(loc='best')
plt.show();
def chi2_ccdf(x, df):
"""The complementary cumulative distribution function
Args:
x: the value of chi^2
df: the number of degrees of freedom
Returns:
1 - the cumulative distribution function
"""
return 1. - stats.chi2.cdf(x=x, df=df)
x = np.linspace(0., 10., num=1000)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 4.5))
for ndf in range(1,7):
axes[0].plot(x, stats.chi2.cdf(x, df=ndf),
label=r'$k = ${}'.format(ndf))
axes[1].plot(x, chi2_ccdf(x, df=ndf),
label=r'$k = ${}'.format(ndf))
axes[0].set_xlabel(r'$x=\chi^2$')
axes[0].set_ylabel(r'$F\left(x;k\right)$')
axes[0].set_title(r'$\chi^2$ CDF for various degrees of freedom')
axes[0].legend(loc='best')
axes[1].set_xlabel(r'$x=\chi^2$')
axes[1].set_ylabel(r'$\bar{F}\left(x;k\right) = p$-value')
axes[1].set_title(r'$\chi^2$ CCDF ($p$-value) for various degrees of freedom')
axes[1].legend(loc='best')
plt.show();
| 0.877896 | 0.993063 |
# Visualisation of critical points
---
## Use of TensorFlow optimizers to locate function minima
***Author: Piotr Skalski***
### Imports
```
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
```
### Settings
```
# learning rate
LR = 0.005
# parameters a and b of the real function
REAL_PARAMS = [1, 1]
# starting point for gradient descent
INIT_PARAMS = [1, 0]
# output directory (the folder must be created on the drive)
OUTPUT_DIR = "saddle_point"
```
### Performing the simulation
```
def find_optimization_path(tf_function, init_point, iterations):
x, y = [tf.Variable(initial_value=p, dtype=tf.float32) for p in init_point]
function = tf_function(x, y)
train_op = tf.train.GradientDescentOptimizer(LR).minimize(function)
x_list, y_list, cost_list = [], [], []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for t in range(iterations):
x_, y_, function_ = sess.run([x, y, function])
x_list.append(x_); y_list.append(y_); cost_list.append(function_)
result, _ = sess.run([function, train_op])
return x_list, y_list, cost_list
```
### Create a blank chart
```
def create_blank_chart_with_styling(plot_size):
# my favorite styling kit
plt.style.use('dark_background')
# determining the size of the graph
fig = plt.figure(figsize=plot_size)
# 3D mode
ax = Axes3D(fig)
# transparent axis pane background
ax.xaxis.pane.fill = False
ax.yaxis.pane.fill = False
ax.zaxis.pane.fill = False
# setting chart axis names
ax.set(xlabel="$x$", ylabel="$y$")
return (fig, ax)
```
### Create animation
```
def create_animation(tf_function, np_function, init_point, iterations, plot_name, file_name, dir_name):
# 3D cost figure
for angle in range(iterations):
fix, ax = create_blank_chart_with_styling((6, 6))
x_list, y_list, cost_list = find_optimization_path(tf_function, init_point, iterations)
# parameter space
a3D, b3D = np.meshgrid(np.linspace(-1, 1, 100), np.linspace(-1, 1, 100))
cost3D = np.array([np_function(x_, y_) for x_, y_ in zip(a3D.flatten(), b3D.flatten())]).reshape(a3D.shape)
ax.plot_surface(a3D, b3D, cost3D, rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'), alpha=1.0)
# initial parameter place
ax.scatter(x_list[0], y_list[0], zs=cost_list[0], s=200, c='r')
# plot 3D gradient descent
ax.plot(x_list[:angle], y_list[:angle], zs=cost_list[:angle], zdir='z', c='r', lw=3)
# graph rotation
ax.view_init(30, 45 + angle*2)
# addition of a title
ax.set_title(plot_name, fontsize=20)
# saving a file
plt.savefig("./{}/{}_{:05}.png".format(dir_name, file_name, angle))
plt.close()
tf_fun = lambda x, y: x**3 - 3*x*y**2
np_fun = lambda x, y: x**3 - 3*x*y**2
create_animation(tf_fun, np_fun, INIT_PARAMS, 180, "Saddle point", "saddle_point", OUTPUT_DIR)
tf_fun = lambda x, y: 3*(1-x)**2*tf.exp(-(x**2) - (y+1)**2) - 10*(x/5 - x**3 - y**5)*tf.exp(-x**2-y**2) - 1/3*tf.exp(-(x+1)**2 - y**2)
np_fun = lambda x, y: 3*(1-x)**2*np.exp(-(x**2) - (y+1)**2) - 10*(x/5 - x**3 - y**5)*np.exp(-x**2-y**2) - 1/3*np.exp(-(x+1)**2 - y**2)
create_animation(tf_fun, np_fun, INIT_PARAMS, 180, "Local minimum", "local_minimum", OUTPUT_DIR)
```
### Expected results
Go to OUTPUT_DIR, which should now be filled with subsequent keyframes of our animation. All the resulting images look more or less like this.
Now all you need to do is enter OUTPUT_DIR and use ImageMagick to create a final gift with one command.
```bash
convert -delay 10 -loop 0 *.png keras_class_boundaries.gif
```
## Thank you
---
|
github_jupyter
|
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# learning rate
LR = 0.005
# parameters a and b of the real function
REAL_PARAMS = [1, 1]
# starting point for gradient descent
INIT_PARAMS = [1, 0]
# output directory (the folder must be created on the drive)
OUTPUT_DIR = "saddle_point"
def find_optimization_path(tf_function, init_point, iterations):
x, y = [tf.Variable(initial_value=p, dtype=tf.float32) for p in init_point]
function = tf_function(x, y)
train_op = tf.train.GradientDescentOptimizer(LR).minimize(function)
x_list, y_list, cost_list = [], [], []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for t in range(iterations):
x_, y_, function_ = sess.run([x, y, function])
x_list.append(x_); y_list.append(y_); cost_list.append(function_)
result, _ = sess.run([function, train_op])
return x_list, y_list, cost_list
def create_blank_chart_with_styling(plot_size):
# my favorite styling kit
plt.style.use('dark_background')
# determining the size of the graph
fig = plt.figure(figsize=plot_size)
# 3D mode
ax = Axes3D(fig)
# transparent axis pane background
ax.xaxis.pane.fill = False
ax.yaxis.pane.fill = False
ax.zaxis.pane.fill = False
# setting chart axis names
ax.set(xlabel="$x$", ylabel="$y$")
return (fig, ax)
def create_animation(tf_function, np_function, init_point, iterations, plot_name, file_name, dir_name):
# 3D cost figure
for angle in range(iterations):
fix, ax = create_blank_chart_with_styling((6, 6))
x_list, y_list, cost_list = find_optimization_path(tf_function, init_point, iterations)
# parameter space
a3D, b3D = np.meshgrid(np.linspace(-1, 1, 100), np.linspace(-1, 1, 100))
cost3D = np.array([np_function(x_, y_) for x_, y_ in zip(a3D.flatten(), b3D.flatten())]).reshape(a3D.shape)
ax.plot_surface(a3D, b3D, cost3D, rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'), alpha=1.0)
# initial parameter place
ax.scatter(x_list[0], y_list[0], zs=cost_list[0], s=200, c='r')
# plot 3D gradient descent
ax.plot(x_list[:angle], y_list[:angle], zs=cost_list[:angle], zdir='z', c='r', lw=3)
# graph rotation
ax.view_init(30, 45 + angle*2)
# addition of a title
ax.set_title(plot_name, fontsize=20)
# saving a file
plt.savefig("./{}/{}_{:05}.png".format(dir_name, file_name, angle))
plt.close()
tf_fun = lambda x, y: x**3 - 3*x*y**2
np_fun = lambda x, y: x**3 - 3*x*y**2
create_animation(tf_fun, np_fun, INIT_PARAMS, 180, "Saddle point", "saddle_point", OUTPUT_DIR)
tf_fun = lambda x, y: 3*(1-x)**2*tf.exp(-(x**2) - (y+1)**2) - 10*(x/5 - x**3 - y**5)*tf.exp(-x**2-y**2) - 1/3*tf.exp(-(x+1)**2 - y**2)
np_fun = lambda x, y: 3*(1-x)**2*np.exp(-(x**2) - (y+1)**2) - 10*(x/5 - x**3 - y**5)*np.exp(-x**2-y**2) - 1/3*np.exp(-(x+1)**2 - y**2)
create_animation(tf_fun, np_fun, INIT_PARAMS, 180, "Local minimum", "local_minimum", OUTPUT_DIR)
convert -delay 10 -loop 0 *.png keras_class_boundaries.gif
| 0.542136 | 0.948632 |
```
import QC_Library as qc
file='/Users/oz/downloads/kaneohe_all.json'
retDict_SST_7_20 = qc.outliers.analyze(file, 'sst', gross_range=[1, 35],verbosity=1)
qc.outliers.diagnostic_plots(retDict_SST_7_20['parameter'], retDict_SST_7_20['data'], retDict_SST_7_20['times'],
xlabel='Time')
qc.outliers.diagnostic_plots(retDict_SST_7_20['parameter'], retDict_SST_7_20['data'], retDict_SST_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_SST_7_20['gross_range_flags'],
'spike_flags' : retDict_SST_7_20['spike_flags']}, yrange=[0, 35], title="SST", ylabel= 'SST',
xlabel='Time')
retDict_Sal_7_20 = qc.outliers.analyze(file, 'sal', gross_range=[20, 40],verbosity=1)
qc.outliers.diagnostic_plots(retDict_Sal_7_20['parameter'], retDict_Sal_7_20['data'],
retDict_Sal_7_20['times'], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_Sal_7_20['parameter'], retDict_Sal_7_20['data'], retDict_Sal_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_Sal_7_20['gross_range_flags'],
'spike_flags' : retDict_Sal_7_20['spike_flags']}, yrange=[20, 40], title="SSS",
ylabel= 'SSS', xlabel='Time')
retDict_O2_7_20 = qc.outliers.analyze(file, 'sc_o2_umolkg', gross_range=[50, 500], verbosity=1)
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
yrange=[0, 500], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_O2_7_20['gross_range_flags'],
'spike_flags' : retDict_O2_7_20['spike_flags']}, yrange=[0, 500], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_O2_7_20['gross_range_flags'],
'spike_flags' : retDict_O2_7_20['spike_flags']}, yrange=[0, 500], xlabel='Time',
time_range=['2014-07-01','2014-11-01'])
retDict_Chl_7_20 = qc.outliers.analyze(file, 'chl', gross_range=[0, 50],verbosity=1)
qc.outliers.diagnostic_plots(retDict_Chl_7_20['parameter'], retDict_Chl_7_20['data'], retDict_Chl_7_20['times'],
xlabel='Time')
qc.outliers.diagnostic_plots(retDict_Chl_7_20['parameter'], retDict_Chl_7_20['data'], retDict_Chl_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_Chl_7_20['gross_range_flags'],
'spike_flags' : retDict_Chl_7_20['spike_flags']}, yrange=[0, 50], xlabel='Time')
```
|
github_jupyter
|
import QC_Library as qc
file='/Users/oz/downloads/kaneohe_all.json'
retDict_SST_7_20 = qc.outliers.analyze(file, 'sst', gross_range=[1, 35],verbosity=1)
qc.outliers.diagnostic_plots(retDict_SST_7_20['parameter'], retDict_SST_7_20['data'], retDict_SST_7_20['times'],
xlabel='Time')
qc.outliers.diagnostic_plots(retDict_SST_7_20['parameter'], retDict_SST_7_20['data'], retDict_SST_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_SST_7_20['gross_range_flags'],
'spike_flags' : retDict_SST_7_20['spike_flags']}, yrange=[0, 35], title="SST", ylabel= 'SST',
xlabel='Time')
retDict_Sal_7_20 = qc.outliers.analyze(file, 'sal', gross_range=[20, 40],verbosity=1)
qc.outliers.diagnostic_plots(retDict_Sal_7_20['parameter'], retDict_Sal_7_20['data'],
retDict_Sal_7_20['times'], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_Sal_7_20['parameter'], retDict_Sal_7_20['data'], retDict_Sal_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_Sal_7_20['gross_range_flags'],
'spike_flags' : retDict_Sal_7_20['spike_flags']}, yrange=[20, 40], title="SSS",
ylabel= 'SSS', xlabel='Time')
retDict_O2_7_20 = qc.outliers.analyze(file, 'sc_o2_umolkg', gross_range=[50, 500], verbosity=1)
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
yrange=[0, 500], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_O2_7_20['gross_range_flags'],
'spike_flags' : retDict_O2_7_20['spike_flags']}, yrange=[0, 500], xlabel='Time')
qc.outliers.diagnostic_plots(retDict_O2_7_20['parameter'], retDict_O2_7_20['data'], retDict_O2_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_O2_7_20['gross_range_flags'],
'spike_flags' : retDict_O2_7_20['spike_flags']}, yrange=[0, 500], xlabel='Time',
time_range=['2014-07-01','2014-11-01'])
retDict_Chl_7_20 = qc.outliers.analyze(file, 'chl', gross_range=[0, 50],verbosity=1)
qc.outliers.diagnostic_plots(retDict_Chl_7_20['parameter'], retDict_Chl_7_20['data'], retDict_Chl_7_20['times'],
xlabel='Time')
qc.outliers.diagnostic_plots(retDict_Chl_7_20['parameter'], retDict_Chl_7_20['data'], retDict_Chl_7_20['times'],
flag_arrays={'gross_range_flags' : retDict_Chl_7_20['gross_range_flags'],
'spike_flags' : retDict_Chl_7_20['spike_flags']}, yrange=[0, 50], xlabel='Time')
| 0.229104 | 0.281492 |
TSG095 - Hadoop namenode logs
=============================
Steps
-----
### Parameters
```
import re
tail_lines = 2000
pod = None # All
container = "hadoop"
log_files = [ "/var/log/supervisor/log/namenode*.log" ]
expressions_to_analyze = [
re.compile(".{23} WARN "),
re.compile(".{23} ERROR ")
]
```
### Instantiate Kubernetes client
```
# Instantiate the Python Kubernetes client into 'api' variable
import os
try:
from kubernetes import client, config
from kubernetes.stream import stream
if "KUBERNETES_SERVICE_PORT" in os.environ and "KUBERNETES_SERVICE_HOST" in os.environ:
config.load_incluster_config()
else:
config.load_kube_config()
api = client.CoreV1Api()
print('Kubernetes client instantiated')
except ImportError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [SOP059 - Install Kubernetes Python module](../install/sop059-install-kubernetes-module.ipynb) to resolve this issue.'))
raise
```
### Get the namespace for the big data cluster
Get the namespace of the big data cluster from the Kuberenetes API.
NOTE: If there is more than one big data cluster in the target
Kubernetes cluster, then set \[0\] to the correct value for the big data
cluster.
```
# Place Kubernetes namespace name for BDC into 'namespace' variable
try:
namespace = api.list_namespace(label_selector='MSSQL_CLUSTER').items[0].metadata.name
except IndexError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))
raise
print('The kubernetes namespace for your big data cluster is: ' + namespace)
```
### Get tail for log
```
# Display the last 'tail_lines' of files in 'log_files' list
pods = api.list_namespaced_pod(namespace)
entries_for_analysis = []
for p in pods.items:
if pod is None or p.metadata.name == pod:
for c in p.spec.containers:
if container is None or c.name == container:
for log_file in log_files:
print (f"- LOGS: '{log_file}' for CONTAINER: '{c.name}' in POD: '{p.metadata.name}'")
try:
output = stream(api.connect_get_namespaced_pod_exec, p.metadata.name, namespace, command=['/bin/sh', '-c', f'tail -n {tail_lines} {log_file}'], container=c.name, stderr=True, stdout=True)
except Exception:
print (f"FAILED to get LOGS for CONTAINER: {c.name} in POD: {p.metadata.name}")
else:
for line in output.split('\n'):
for expression in expressions_to_analyze:
if expression.match(line):
entries_for_analysis.append(line)
print(line)
print("")
print(f"{len(entries_for_analysis)} log entries found for further analysis.")
```
### Analyze log entries and suggest relevant Troubleshooting Guides
```
# Analyze log entries and suggest further relevant troubleshooting guides
from IPython.display import Markdown
tsgs = []
suggestions = 0
for entry in entries_for_analysis:
print (entry)
for tsg in tsgs:
if entry.find(tsg[0]) != -1:
display(Markdown(f'SUGGEST: Use [{tsg[2]}](tsg[1]) to resolve this issue.'))
suggestions = suggestions + 1
print("")
print(f"{len(entries_for_analysis)} log entries analyzed. {suggestions} further troubleshooting suggestions made inline.")
print('Notebook execution complete.')
```
|
github_jupyter
|
import re
tail_lines = 2000
pod = None # All
container = "hadoop"
log_files = [ "/var/log/supervisor/log/namenode*.log" ]
expressions_to_analyze = [
re.compile(".{23} WARN "),
re.compile(".{23} ERROR ")
]
# Instantiate the Python Kubernetes client into 'api' variable
import os
try:
from kubernetes import client, config
from kubernetes.stream import stream
if "KUBERNETES_SERVICE_PORT" in os.environ and "KUBERNETES_SERVICE_HOST" in os.environ:
config.load_incluster_config()
else:
config.load_kube_config()
api = client.CoreV1Api()
print('Kubernetes client instantiated')
except ImportError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [SOP059 - Install Kubernetes Python module](../install/sop059-install-kubernetes-module.ipynb) to resolve this issue.'))
raise
# Place Kubernetes namespace name for BDC into 'namespace' variable
try:
namespace = api.list_namespace(label_selector='MSSQL_CLUSTER').items[0].metadata.name
except IndexError:
from IPython.display import Markdown
display(Markdown(f'SUGGEST: Use [TSG081 - Get namespaces (Kubernetes)](../monitor-k8s/tsg081-get-kubernetes-namespaces.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [TSG010 - Get configuration contexts](../monitor-k8s/tsg010-get-kubernetes-contexts.ipynb) to resolve this issue.'))
display(Markdown(f'SUGGEST: Use [SOP011 - Set kubernetes configuration context](../common/sop011-set-kubernetes-context.ipynb) to resolve this issue.'))
raise
print('The kubernetes namespace for your big data cluster is: ' + namespace)
# Display the last 'tail_lines' of files in 'log_files' list
pods = api.list_namespaced_pod(namespace)
entries_for_analysis = []
for p in pods.items:
if pod is None or p.metadata.name == pod:
for c in p.spec.containers:
if container is None or c.name == container:
for log_file in log_files:
print (f"- LOGS: '{log_file}' for CONTAINER: '{c.name}' in POD: '{p.metadata.name}'")
try:
output = stream(api.connect_get_namespaced_pod_exec, p.metadata.name, namespace, command=['/bin/sh', '-c', f'tail -n {tail_lines} {log_file}'], container=c.name, stderr=True, stdout=True)
except Exception:
print (f"FAILED to get LOGS for CONTAINER: {c.name} in POD: {p.metadata.name}")
else:
for line in output.split('\n'):
for expression in expressions_to_analyze:
if expression.match(line):
entries_for_analysis.append(line)
print(line)
print("")
print(f"{len(entries_for_analysis)} log entries found for further analysis.")
# Analyze log entries and suggest further relevant troubleshooting guides
from IPython.display import Markdown
tsgs = []
suggestions = 0
for entry in entries_for_analysis:
print (entry)
for tsg in tsgs:
if entry.find(tsg[0]) != -1:
display(Markdown(f'SUGGEST: Use [{tsg[2]}](tsg[1]) to resolve this issue.'))
suggestions = suggestions + 1
print("")
print(f"{len(entries_for_analysis)} log entries analyzed. {suggestions} further troubleshooting suggestions made inline.")
print('Notebook execution complete.')
| 0.36557 | 0.723566 |
```
import pandas as pd
from pySankey.sankey import sankey
import plotly.graph_objects as go
from datetime import datetime as DateTime
```
## Proceso
### Adquisición de datos
```
## Cargamos los datos
df = pd.read_csv('data/TB_HOSP_VAC_FALLECIDOS.csv')
df.head(5)
df.columns
```
### Limpieza y transformación de datos
```
## Generamos las columnas necesarias para graficar
df['UCI'] = 'NO UCI'
df.loc[df[df['flag_uci'] == 1].index,'UCI'] = 'UCI'
df['FALLECIDO'] = 'NO FALLECIDO'
df.loc[df[df['cdc_fallecido_covid'] == 1].index,'FALLECIDO'] = 'FALLECIDO'
df['DOSIS'] = 'SIN VACUNA'
df.loc[df[df['fecha_dosis1'].notna()].index,'DOSIS'] = 'DOSIS: 1'
df.loc[df[df['fecha_dosis2'].notna()].index,'DOSIS'] = 'DOSIS: 2'
df.loc[df[df['fecha_dosis3'].notna()].index,'DOSIS'] = 'DOSIS: 3'
df[['flag_vacuna','fecha_dosis1','fecha_dosis2','fecha_dosis3','DOSIS','flag_uci','UCI','cdc_fallecido_covid','FALLECIDO']].head(10)
df.sort_values('DOSIS', inplace=True)
```
## Resultados
```
colors = {
"SIN VACUNA": "#f71b1b",
"DOSIS: 2": "#f3f71b",
"DOSIS: 3": "#12e23f",
"DOSIS: 1": "#f78c1b",
"FALLECIDO": "#000000",
"UCI": "#000000",
"NO UCI": "#1b7ef7",
"NO FALLECIDO": "#1b7ef7"
}
sankey(df["DOSIS"], df["UCI"], colorDict=colors)
novacunados_uci_count = len(df[(df['flag_vacuna']==0) & (df['UCI']=='UCI')])
novacunados_nouci_count = len(df[(df['flag_vacuna']==0) & (df['UCI']=='NO UCI')])
dosis1_uci_count = len(df[(df['flag_vacuna']==1) & (df['UCI']=='UCI')])
dosis1_nouci_count = len(df[(df['flag_vacuna']==1) & (df['UCI']=='NO UCI')])
dosis2_uci_count = len(df[(df['flag_vacuna']==2) & (df['UCI']=='UCI')])
dosis2_nouci_count = len(df[(df['flag_vacuna']==2) & (df['UCI']=='NO UCI')])
dosis3_uci_count = len(df[(df['flag_vacuna']==3) & (df['UCI']=='UCI')])
dosis3_nouci_count = len(df[(df['flag_vacuna']==3) & (df['UCI']=='NO UCI')])
vacunados_uci_count = len(df[(df['flag_vacuna']>0) & (df['UCI']=='UCI')])
vacunados_nouci_count = len(df[(df['flag_vacuna']>0) & (df['UCI']=='NO UCI')])
print(f'novacunados_uci_count: {novacunados_uci_count}')
print(f'novacunados_nouci_count: {novacunados_nouci_count}')
print(f'dosis1_uci_count: {dosis1_uci_count}')
print(f'dosis1_nouci_count: {dosis1_nouci_count}')
print(f'dosis2_uci_count: {dosis2_uci_count}')
print(f'dosis2_nouci_count: {dosis2_nouci_count}')
print(f'dosis3_uci_count: {dosis3_uci_count}')
print(f'dosis3_nouci_count: {dosis3_nouci_count}')
print(f'vacunados_uci_count: {vacunados_uci_count}')
print(f'vacunados_nouci_count: {vacunados_nouci_count}')
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 15,
thickness = 15,
line = dict(color = "black", width = 0.5),
label = ['SIN VACUNA','DOSIS: 1','DOSIS: 2','DOSIS: 3','UCI','NO UCI'],
color = ['#f71b1b','#f78c1b','#f3f71b','#12e23f','#000000','#1b7ef7']
),
link = dict(
source = [0, 1, 2, 3, 0, 1, 2, 3],
target = [4, 4, 4, 4, 5, 5, 5, 5],
value = [8910, 774, 3800, 4824, 44257, 5482, 30842, 38633],
color = ['lightcoral','peachpuff','lemonchiffon','lightgreen','lightcoral','peachpuff','lemonchiffon','lightgreen']
))])
fig.update_layout(title_text="FLUJO DE PACIENTES QUE LLEGAN A UCI SEGÚN ESTADO DE VACUNACIÓN",
width=1024,
height=768,
font_size=14)
fig.add_annotation(go.layout.Annotation(
showarrow=False,
text="""Fuente: https://www.datosabiertos.gob.pe/dataset/hospitalizados-vacunados-y-fallecidos-por-covid-19<br>
Autor: https://malexandersalazar.github.io/, Moisés Alexander Salazar Vila, """ + f'{DateTime.now():%Y-%m-%d}',
xanchor='right',
x=1,
yanchor='top',
y=0,
align='right'
))
fig.show()
sankey(df["DOSIS"], df["FALLECIDO"], colorDict=colors)
novacunados_fallecido_count = len(df[(df['flag_vacuna']==0) & (df['FALLECIDO']=='FALLECIDO')])
novacunados_nofallecido_count = len(df[(df['flag_vacuna']==0) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis1_fallecido_count = len(df[(df['flag_vacuna']==1) & (df['FALLECIDO']=='FALLECIDO')])
dosis1_nofallecido_count = len(df[(df['flag_vacuna']==1) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis2_fallecido_count = len(df[(df['flag_vacuna']==2) & (df['FALLECIDO']=='FALLECIDO')])
dosis2_nofallecido_count = len(df[(df['flag_vacuna']==2) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis3_fallecido_count = len(df[(df['flag_vacuna']==3) & (df['FALLECIDO']=='FALLECIDO')])
dosis3_nofallecido_count = len(df[(df['flag_vacuna']==3) & (df['FALLECIDO']=='NO FALLECIDO')])
vacunados_fallecido_count = len(df[(df['flag_vacuna']>0) & (df['FALLECIDO']=='FALLECIDO')])
vacunados_nofallecido_count = len(df[(df['flag_vacuna']>0) & (df['FALLECIDO']=='NO FALLECIDO')])
print(f'novacunados_fallecido_count: {novacunados_fallecido_count}')
print(f'novacunados_nofallecido_count: {novacunados_nofallecido_count}')
print(f'dosis1_fallecido_count: {dosis1_fallecido_count}')
print(f'dosis1_nofallecido_count: {dosis1_nofallecido_count}')
print(f'dosis2_fallecido_count: {dosis2_fallecido_count}')
print(f'dosis2_nofallecido_count: {dosis2_nofallecido_count}')
print(f'dosis3_fallecido_count: {dosis3_fallecido_count}')
print(f'dosis3_nofallecido_count: {dosis3_nofallecido_count}')
print(f'vacunados_fallecido_count: {vacunados_fallecido_count}')
print(f'vacunados_nofallecido_count: {vacunados_nofallecido_count}')
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 15,
thickness = 15,
line = dict(color = "black", width = 0.5),
label = ['SIN VACUNA','DOSIS: 1','DOSIS: 2','DOSIS: 3','FALLECIDO','NO FALLECIDO'],
color = ['#f71b1b','#f78c1b','#f3f71b','#12e23f','#000000','#1b7ef7']
),
link = dict(
source = [0, 1, 2, 3, 0, 1, 2, 3],
target = [4, 4, 4, 4, 5, 5, 5, 5],
value = [35254, 959, 1347, 261, 17913, 5297, 33295, 43196],
color = ['lightcoral','peachpuff','lemonchiffon','lightgreen','lightcoral','peachpuff','lemonchiffon','lightgreen']
))])
fig.update_layout(title_text="FLUJO DE PACIENTES QUE FALLECEN SEGÚN ESTADO DE VACUNACIÓN",
width=1024,
height=768,
font_size=14)
fig.add_annotation(go.layout.Annotation(
showarrow=False,
text="""Fuente: https://www.datosabiertos.gob.pe/dataset/hospitalizados-vacunados-y-fallecidos-por-covid-19<br>
Autor: https://malexandersalazar.github.io/, Moisés Alexander Salazar Vila, """ + f'{DateTime.now():%Y-%m-%d}',
xanchor='right',
x=1,
yanchor='top',
y=0,
align='right'
))
fig.show()
ratio = novacunados_fallecido_count / vacunados_fallecido_count
print(ratio)
```
|
github_jupyter
|
import pandas as pd
from pySankey.sankey import sankey
import plotly.graph_objects as go
from datetime import datetime as DateTime
## Cargamos los datos
df = pd.read_csv('data/TB_HOSP_VAC_FALLECIDOS.csv')
df.head(5)
df.columns
## Generamos las columnas necesarias para graficar
df['UCI'] = 'NO UCI'
df.loc[df[df['flag_uci'] == 1].index,'UCI'] = 'UCI'
df['FALLECIDO'] = 'NO FALLECIDO'
df.loc[df[df['cdc_fallecido_covid'] == 1].index,'FALLECIDO'] = 'FALLECIDO'
df['DOSIS'] = 'SIN VACUNA'
df.loc[df[df['fecha_dosis1'].notna()].index,'DOSIS'] = 'DOSIS: 1'
df.loc[df[df['fecha_dosis2'].notna()].index,'DOSIS'] = 'DOSIS: 2'
df.loc[df[df['fecha_dosis3'].notna()].index,'DOSIS'] = 'DOSIS: 3'
df[['flag_vacuna','fecha_dosis1','fecha_dosis2','fecha_dosis3','DOSIS','flag_uci','UCI','cdc_fallecido_covid','FALLECIDO']].head(10)
df.sort_values('DOSIS', inplace=True)
colors = {
"SIN VACUNA": "#f71b1b",
"DOSIS: 2": "#f3f71b",
"DOSIS: 3": "#12e23f",
"DOSIS: 1": "#f78c1b",
"FALLECIDO": "#000000",
"UCI": "#000000",
"NO UCI": "#1b7ef7",
"NO FALLECIDO": "#1b7ef7"
}
sankey(df["DOSIS"], df["UCI"], colorDict=colors)
novacunados_uci_count = len(df[(df['flag_vacuna']==0) & (df['UCI']=='UCI')])
novacunados_nouci_count = len(df[(df['flag_vacuna']==0) & (df['UCI']=='NO UCI')])
dosis1_uci_count = len(df[(df['flag_vacuna']==1) & (df['UCI']=='UCI')])
dosis1_nouci_count = len(df[(df['flag_vacuna']==1) & (df['UCI']=='NO UCI')])
dosis2_uci_count = len(df[(df['flag_vacuna']==2) & (df['UCI']=='UCI')])
dosis2_nouci_count = len(df[(df['flag_vacuna']==2) & (df['UCI']=='NO UCI')])
dosis3_uci_count = len(df[(df['flag_vacuna']==3) & (df['UCI']=='UCI')])
dosis3_nouci_count = len(df[(df['flag_vacuna']==3) & (df['UCI']=='NO UCI')])
vacunados_uci_count = len(df[(df['flag_vacuna']>0) & (df['UCI']=='UCI')])
vacunados_nouci_count = len(df[(df['flag_vacuna']>0) & (df['UCI']=='NO UCI')])
print(f'novacunados_uci_count: {novacunados_uci_count}')
print(f'novacunados_nouci_count: {novacunados_nouci_count}')
print(f'dosis1_uci_count: {dosis1_uci_count}')
print(f'dosis1_nouci_count: {dosis1_nouci_count}')
print(f'dosis2_uci_count: {dosis2_uci_count}')
print(f'dosis2_nouci_count: {dosis2_nouci_count}')
print(f'dosis3_uci_count: {dosis3_uci_count}')
print(f'dosis3_nouci_count: {dosis3_nouci_count}')
print(f'vacunados_uci_count: {vacunados_uci_count}')
print(f'vacunados_nouci_count: {vacunados_nouci_count}')
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 15,
thickness = 15,
line = dict(color = "black", width = 0.5),
label = ['SIN VACUNA','DOSIS: 1','DOSIS: 2','DOSIS: 3','UCI','NO UCI'],
color = ['#f71b1b','#f78c1b','#f3f71b','#12e23f','#000000','#1b7ef7']
),
link = dict(
source = [0, 1, 2, 3, 0, 1, 2, 3],
target = [4, 4, 4, 4, 5, 5, 5, 5],
value = [8910, 774, 3800, 4824, 44257, 5482, 30842, 38633],
color = ['lightcoral','peachpuff','lemonchiffon','lightgreen','lightcoral','peachpuff','lemonchiffon','lightgreen']
))])
fig.update_layout(title_text="FLUJO DE PACIENTES QUE LLEGAN A UCI SEGÚN ESTADO DE VACUNACIÓN",
width=1024,
height=768,
font_size=14)
fig.add_annotation(go.layout.Annotation(
showarrow=False,
text="""Fuente: https://www.datosabiertos.gob.pe/dataset/hospitalizados-vacunados-y-fallecidos-por-covid-19<br>
Autor: https://malexandersalazar.github.io/, Moisés Alexander Salazar Vila, """ + f'{DateTime.now():%Y-%m-%d}',
xanchor='right',
x=1,
yanchor='top',
y=0,
align='right'
))
fig.show()
sankey(df["DOSIS"], df["FALLECIDO"], colorDict=colors)
novacunados_fallecido_count = len(df[(df['flag_vacuna']==0) & (df['FALLECIDO']=='FALLECIDO')])
novacunados_nofallecido_count = len(df[(df['flag_vacuna']==0) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis1_fallecido_count = len(df[(df['flag_vacuna']==1) & (df['FALLECIDO']=='FALLECIDO')])
dosis1_nofallecido_count = len(df[(df['flag_vacuna']==1) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis2_fallecido_count = len(df[(df['flag_vacuna']==2) & (df['FALLECIDO']=='FALLECIDO')])
dosis2_nofallecido_count = len(df[(df['flag_vacuna']==2) & (df['FALLECIDO']=='NO FALLECIDO')])
dosis3_fallecido_count = len(df[(df['flag_vacuna']==3) & (df['FALLECIDO']=='FALLECIDO')])
dosis3_nofallecido_count = len(df[(df['flag_vacuna']==3) & (df['FALLECIDO']=='NO FALLECIDO')])
vacunados_fallecido_count = len(df[(df['flag_vacuna']>0) & (df['FALLECIDO']=='FALLECIDO')])
vacunados_nofallecido_count = len(df[(df['flag_vacuna']>0) & (df['FALLECIDO']=='NO FALLECIDO')])
print(f'novacunados_fallecido_count: {novacunados_fallecido_count}')
print(f'novacunados_nofallecido_count: {novacunados_nofallecido_count}')
print(f'dosis1_fallecido_count: {dosis1_fallecido_count}')
print(f'dosis1_nofallecido_count: {dosis1_nofallecido_count}')
print(f'dosis2_fallecido_count: {dosis2_fallecido_count}')
print(f'dosis2_nofallecido_count: {dosis2_nofallecido_count}')
print(f'dosis3_fallecido_count: {dosis3_fallecido_count}')
print(f'dosis3_nofallecido_count: {dosis3_nofallecido_count}')
print(f'vacunados_fallecido_count: {vacunados_fallecido_count}')
print(f'vacunados_nofallecido_count: {vacunados_nofallecido_count}')
fig = go.Figure(data=[go.Sankey(
node = dict(
pad = 15,
thickness = 15,
line = dict(color = "black", width = 0.5),
label = ['SIN VACUNA','DOSIS: 1','DOSIS: 2','DOSIS: 3','FALLECIDO','NO FALLECIDO'],
color = ['#f71b1b','#f78c1b','#f3f71b','#12e23f','#000000','#1b7ef7']
),
link = dict(
source = [0, 1, 2, 3, 0, 1, 2, 3],
target = [4, 4, 4, 4, 5, 5, 5, 5],
value = [35254, 959, 1347, 261, 17913, 5297, 33295, 43196],
color = ['lightcoral','peachpuff','lemonchiffon','lightgreen','lightcoral','peachpuff','lemonchiffon','lightgreen']
))])
fig.update_layout(title_text="FLUJO DE PACIENTES QUE FALLECEN SEGÚN ESTADO DE VACUNACIÓN",
width=1024,
height=768,
font_size=14)
fig.add_annotation(go.layout.Annotation(
showarrow=False,
text="""Fuente: https://www.datosabiertos.gob.pe/dataset/hospitalizados-vacunados-y-fallecidos-por-covid-19<br>
Autor: https://malexandersalazar.github.io/, Moisés Alexander Salazar Vila, """ + f'{DateTime.now():%Y-%m-%d}',
xanchor='right',
x=1,
yanchor='top',
y=0,
align='right'
))
fig.show()
ratio = novacunados_fallecido_count / vacunados_fallecido_count
print(ratio)
| 0.160595 | 0.516778 |
# Education theme - all audits - all data excluding PDF contents - including phrases and lemmas
This experiment used 8697 pages from GOV.UK related to the education theme. We extracted the following content from those pages:
- Title
- Description
- Indexable content (i.e. the body of the document stored in Search)
- Existing topic names
- Exiting organisation names
In order to do so, we used a combination of data from the search index and the content store. We then run Latent Dirichlet allocation (LDA) with the following parameters:
- we asked for 10 topics
- we let LDA run with 50 iterations
We included both phrases and lemmas.
The code wasn't commited as this was a one-off run. It was run against commit 47bff4eab1110d259edc7da10139c3b0bdf44e9a with this patch:
```
diff --git a/corpus_building.py b/corpus_building.py
index 76ddc0c..af12da1 100644
--- a/corpus_building.py
+++ b/corpus_building.py
@@ -39,12 +39,10 @@ class CorpusReader(object):
"""
Extract some kind of n-grams from a document
"""
- if self.use_phrasemachine:
- phrases = self._phrases_in_raw_text_via_phrasemachine(raw_text)
- else:
- phrases = self._phrases_in_raw_text_via_lemmatisation(raw_text)
+ phrases_1 = self._phrases_in_raw_text_via_phrasemachine(raw_text)
+ phrases_2 = self._phrases_in_raw_text_via_lemmatisation(raw_text)
- return phrases
+ return phrases_1 + phrases_2
def fetch_document_bigrams(self, document_lemmas, number_of_bigrams=100):
"""
@@ -102,7 +100,7 @@ class CorpusReader(object):
Builds a list of phrases from raw text using phrasemachine.
"""
# This returns a Dictionary of counts
- phrase_counts = phrasemachine.get_phrases(raw_text)['counts']
+ phrase_counts = phrasemachine.get_phrases(raw_text.decode('ascii', 'ignore'))['counts']
print("Found the following phrases: {}".format(phrase_counts))
```
The outcome of this experiment can be seen below. In order to run the script again, use this:
```shell
python train_lda.py --output-topics experiments/phrasemachine_and_lemmas_nopdf_topics.csv --output-tags experiments/phrasemachine_and_lemmas_nopdf_tags.csv --vis-filename experiments/phrasemachine_and_lemmas_nopdf_vis.html --numtopics 10 --use-phrasemachine import expanded_audits/all_audits_for_education_words_nopdf.csv
```
## Dictionary
LDA constructs a dictionary of words it collects from the documents. This dictionary has information on word frequencies. The dictionary for this can be seen [here](model/2016-11-09_13-25-45_592588_dict.csv).
```
# This code is required so we can display the visualisation
import pyLDAvis
from IPython.core.display import display, HTML
# Changing the cell widths
display(HTML("<style>.container { width:100% !important; }</style>"))
# Setting the max number of rows
pd.options.display.max_rows = 30
# Setting the max number of columns
pd.options.display.max_columns = 50
pyLDAvis.enable_notebook()
```
## Interactive topic model visualisation
The page below displays the topics generated by the algorithm and allows us to interact with them in order to discover what words make up each topic.
```
from IPython.display import HTML
HTML(filename='phrasemachine_and_lemmas_nopdf_vis.html')
```
## Sample of tagged documents
Below we list a sample of the education links and the correspondent topics the algorithm chose to tag it with. This is useful in order to see if the algorithm is tagging those documents with meaningful topics.
For a complete list, please see [here](phrasemachine_and_lemmas_nopdf_tags.csv.csv).
### https://www.gov.uk/guidance/express-logistics-apprenticeships
- Topic 8 (67%)
- Topic 3 (32%)
### https://www.gov.uk/government/news/hi-tech-skills
- Topic 8 (91%)
- Topic 5 (9%)
### https://www.gov.uk/government/news/180-million-new-bursary-scheme-to-help-the-most-vulnerable-16-to-19-year-olds
- Topic 2 (34%)
- Topic 3 (28%)
- Topic 9 (23%)
### https://www.gov.uk/government/publications/school-census-autumn-2014-term-on-term-user-guide
- Topic 6 (86%)
- Topic 9 (8%)
- Topic 1 (4%)
### https://www.gov.uk/government/publications/teacher-misconduct-panel-outcome-miss-rakhi-patel
- Topic 6 (99%)
### https://www.gov.uk/government/news/1-million-from-adoption-support-fund-helps-over-160-families
- Topic 2 (98%)
### https://www.gov.uk/government/publications/applying-for-powers-to-award-taught-degrees-research-degrees-and-university-title
- Topic 5 (80%)
- Topic 1 (18%)
### https://www.gov.uk/government/news/launch-of-national-college-for-teaching-and-leadership
- Topic 7 (76%)
- Topic 2 (13%)
- Topic 1 (4%)
### https://www.gov.uk/government/collections/phonics-choosing-a-programme
- Topic 4 (88%)
- Topic 6 (6%)
- Topic 9 (4%)
### https://www.gov.uk/government/publications/how-to-write-a-winning-apprenticeship-application
- Topic 0 (87%)
- Topic 1 (11%)
### https://www.gov.uk/government/publications/key-stage-1-tests-modified-test-administration-guidance-mtag
- Topic 3 (49%)
- Topic 6 (36%)
- Topic 7 (15%)
### https://www.gov.uk/government/publications/24-advanced-learning-loans-policy-overview
- Topic 9 (100%)
### https://www.gov.uk/government/publications/the-impact-of-short-breaks-on-families-with-a-disabled-child-over-time-the-second-report-from-the-quantitative-study
- Topic 4 (55%)
- Topic 2 (37%)
- Topic 6 (6%)
### https://www.gov.uk/government/publications/co-ordinated-admissions-2017-series-13-files
- Topic 5 (62%)
- Topic 1 (26%)
- Topic 6 (11%)
### https://www.gov.uk/government/publications/inspecting-schools-leaflet-for-schools
- Topic 2 (94%)
### https://www.gov.uk/government/publications/further-education-reforms-review-of-loans-system
- Topic 8 (89%)
- Topic 9 (9%)
- Topic 0 (2%)
### https://www.gov.uk/government/statistics/permanent-and-fixed-period-exclusions-in-england-2013-to-2014
- Topic 1 (76%)
- Topic 2 (14%)
- Topic 6 (9%)
### https://www.gov.uk/government/statistics/early-years-foundation-stage-profile-results-in-england-academic-year-2010-to-2011
- Topic 6 (93%)
- Topic 4 (5%)
- Topic 9 (1%)
### https://www.gov.uk/government/publications/letter-from-the-secretary-of-state-for-education-to-leighton-andrews-and-john-odowd
- Topic 7 (70%)
- Topic 4 (14%)
- Topic 0 (9%)
### https://www.gov.uk/government/news/two-million-apprenticeships-in-this-parliament
- Topic 5 (65%)
- Topic 0 (34%)
|
github_jupyter
|
diff --git a/corpus_building.py b/corpus_building.py
index 76ddc0c..af12da1 100644
--- a/corpus_building.py
+++ b/corpus_building.py
@@ -39,12 +39,10 @@ class CorpusReader(object):
"""
Extract some kind of n-grams from a document
"""
- if self.use_phrasemachine:
- phrases = self._phrases_in_raw_text_via_phrasemachine(raw_text)
- else:
- phrases = self._phrases_in_raw_text_via_lemmatisation(raw_text)
+ phrases_1 = self._phrases_in_raw_text_via_phrasemachine(raw_text)
+ phrases_2 = self._phrases_in_raw_text_via_lemmatisation(raw_text)
- return phrases
+ return phrases_1 + phrases_2
def fetch_document_bigrams(self, document_lemmas, number_of_bigrams=100):
"""
@@ -102,7 +100,7 @@ class CorpusReader(object):
Builds a list of phrases from raw text using phrasemachine.
"""
# This returns a Dictionary of counts
- phrase_counts = phrasemachine.get_phrases(raw_text)['counts']
+ phrase_counts = phrasemachine.get_phrases(raw_text.decode('ascii', 'ignore'))['counts']
print("Found the following phrases: {}".format(phrase_counts))
python train_lda.py --output-topics experiments/phrasemachine_and_lemmas_nopdf_topics.csv --output-tags experiments/phrasemachine_and_lemmas_nopdf_tags.csv --vis-filename experiments/phrasemachine_and_lemmas_nopdf_vis.html --numtopics 10 --use-phrasemachine import expanded_audits/all_audits_for_education_words_nopdf.csv
# This code is required so we can display the visualisation
import pyLDAvis
from IPython.core.display import display, HTML
# Changing the cell widths
display(HTML("<style>.container { width:100% !important; }</style>"))
# Setting the max number of rows
pd.options.display.max_rows = 30
# Setting the max number of columns
pd.options.display.max_columns = 50
pyLDAvis.enable_notebook()
from IPython.display import HTML
HTML(filename='phrasemachine_and_lemmas_nopdf_vis.html')
| 0.579281 | 0.804098 |
<a href="https://colab.research.google.com/github/wwangwe/labour-market-analysis/blob/working/notebooks/Web_Scrapping.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Real-time Kenyan Labour Market Analysis
## Web Scrapping
```
import json
import time
from datetime import datetime
from random import randint
import requests
from bs4 import BeautifulSoup
headers = [
({
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}),
({
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5)AppleWebKit/605.1.15 (KHTML, like Gecko)Version/12.1.1 Safari/605.1.15',
}),
({
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
}),
({
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.8 (KHTML, like Gecko)',
}),
({
'User-Agent':
'Mozilla/5.0 (iPhone; CPU iPhone OS 13_5_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 [FBAN/FBIOS;FBDV/iPhone9,1;FBMD/iPhone;FBSN/iOS;FBSV/13.5.1;FBSS/2;FBID/phone;FBLC/en_US;FBOP/5]'
})
]
def header(headers: list) -> dict:
"""Generate a random header.
Args:
headers (list): List of headers.
Returns:
random_header (dict): Random header from the list of headers.
"""
random_int = randint(0, len(headers) - 1)
random_header = headers[random_int]
return random_header
def prepare_soup(url: str) -> 'BeautifulSoup':
"""Process url to a Beautiful Soup object.
Args:
url (str): Link to jobs page.
Raises:
ValueError: Raised when requests.get fails.
Returns:
soup: Browsable bs4 object.
"""
response = requests.get(url, header(headers), timeout=5)
status_code = response.status_code
if status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
return soup
else:
raise ValueError("Soup Not Created! Status Code: ", status_code)
def fetch_jobs(url: str) -> list:
"""Get job detail urls for all the jobs in current page(url).
Args:
url (str): Current page with jobs.
Returns:
list_data (list): List of job detail urls.
"""
soup = prepare_soup(url)
string_data = soup.find_all("script", type="application/ld+json")[0].text
json_data = json.loads(string_data)['itemListElement']
list_data = [data['url'] for data in json_data]
pages = soup.find('ul', 'pagination').find_all('li')[-2].find_all(['a', 'span'])[0].text
return (list_data, pages)
def fetch_job_details(soup: 'BeautifulSoup', url) -> dict:
"""Fetch details for each job.
Each dictionary contains details about only one job. Try Except
used to handle possible errors due to change in selectors.
Args:
soup (BeautifulSoup): Browsable bs4 object.
Returns:
dict: Dictionary of job details.
"""
details = {}
try:
details['title'] = soup.find('h1', 'job-header__title').text
except AttributeError:
details['title'] = 'None'
try:
details['job_function'] = soup.find(
'div', 'hide-under-lg').find_all('h2')[1].text
except AttributeError:
details['job_function'] = 'None'
try:
details['location'] = soup.find('a', 'job-header__location').text
except AttributeError:
details['location'] = 'None'
try:
details['industry'] = soup.find('span',
'job-header__location').find('a').text
except AttributeError:
details['industry'] = 'None'
try:
details['description'] = soup.find_all(
'div', 'customer-card__content-segment')[0].find('p').text
except AttributeError:
details['description'] = 'None'
try:
details['qualifications'] = soup.find(
'div', 'description-content__content').text
except AttributeError:
details['qualifications'] = 'None'
details['hyperlink'] = url
return details
url = "https://www.brightermonday.co.ke/jobs"
def main(url):
page = 1
while True:
current_url = url+f'?page={page}'
page += 1
job_data = []
job_urls = fetch_jobs(current_url)[0]
total_pages = int(fetch_jobs(current_url)[1])
for job_url in job_urls:
soup = prepare_soup(job_url)
if soup != None:
job_details = fetch_job_details(soup, job_url)
job_data.append(job_details)
print(job_details)
else:
break
if page <= total_pages:
time.sleep(randint(1, 5))
else:
break
return job_data
main(url)
```
|
github_jupyter
|
import json
import time
from datetime import datetime
from random import randint
import requests
from bs4 import BeautifulSoup
headers = [
({
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}),
({
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5)AppleWebKit/605.1.15 (KHTML, like Gecko)Version/12.1.1 Safari/605.1.15',
}),
({
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
}),
({
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.8 (KHTML, like Gecko)',
}),
({
'User-Agent':
'Mozilla/5.0 (iPhone; CPU iPhone OS 13_5_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 [FBAN/FBIOS;FBDV/iPhone9,1;FBMD/iPhone;FBSN/iOS;FBSV/13.5.1;FBSS/2;FBID/phone;FBLC/en_US;FBOP/5]'
})
]
def header(headers: list) -> dict:
"""Generate a random header.
Args:
headers (list): List of headers.
Returns:
random_header (dict): Random header from the list of headers.
"""
random_int = randint(0, len(headers) - 1)
random_header = headers[random_int]
return random_header
def prepare_soup(url: str) -> 'BeautifulSoup':
"""Process url to a Beautiful Soup object.
Args:
url (str): Link to jobs page.
Raises:
ValueError: Raised when requests.get fails.
Returns:
soup: Browsable bs4 object.
"""
response = requests.get(url, header(headers), timeout=5)
status_code = response.status_code
if status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
return soup
else:
raise ValueError("Soup Not Created! Status Code: ", status_code)
def fetch_jobs(url: str) -> list:
"""Get job detail urls for all the jobs in current page(url).
Args:
url (str): Current page with jobs.
Returns:
list_data (list): List of job detail urls.
"""
soup = prepare_soup(url)
string_data = soup.find_all("script", type="application/ld+json")[0].text
json_data = json.loads(string_data)['itemListElement']
list_data = [data['url'] for data in json_data]
pages = soup.find('ul', 'pagination').find_all('li')[-2].find_all(['a', 'span'])[0].text
return (list_data, pages)
def fetch_job_details(soup: 'BeautifulSoup', url) -> dict:
"""Fetch details for each job.
Each dictionary contains details about only one job. Try Except
used to handle possible errors due to change in selectors.
Args:
soup (BeautifulSoup): Browsable bs4 object.
Returns:
dict: Dictionary of job details.
"""
details = {}
try:
details['title'] = soup.find('h1', 'job-header__title').text
except AttributeError:
details['title'] = 'None'
try:
details['job_function'] = soup.find(
'div', 'hide-under-lg').find_all('h2')[1].text
except AttributeError:
details['job_function'] = 'None'
try:
details['location'] = soup.find('a', 'job-header__location').text
except AttributeError:
details['location'] = 'None'
try:
details['industry'] = soup.find('span',
'job-header__location').find('a').text
except AttributeError:
details['industry'] = 'None'
try:
details['description'] = soup.find_all(
'div', 'customer-card__content-segment')[0].find('p').text
except AttributeError:
details['description'] = 'None'
try:
details['qualifications'] = soup.find(
'div', 'description-content__content').text
except AttributeError:
details['qualifications'] = 'None'
details['hyperlink'] = url
return details
url = "https://www.brightermonday.co.ke/jobs"
def main(url):
page = 1
while True:
current_url = url+f'?page={page}'
page += 1
job_data = []
job_urls = fetch_jobs(current_url)[0]
total_pages = int(fetch_jobs(current_url)[1])
for job_url in job_urls:
soup = prepare_soup(job_url)
if soup != None:
job_details = fetch_job_details(soup, job_url)
job_data.append(job_details)
print(job_details)
else:
break
if page <= total_pages:
time.sleep(randint(1, 5))
else:
break
return job_data
main(url)
| 0.470737 | 0.585783 |
```
x="India"
x
X <- "Hello, World!"
X
x=10
y=20
x+y
x-y
x*y
x/y
# Interest (I) of a principal amount (P) of 10000 for 4 years with an interest rate (R) of 8 %
P=10000
N=4
R=8/100
I=P*N*R
I
x=10
y="India"
x+y
x <- TRUE
class(x)
x<- 23.5
class(x)
x<- 23
class(x)
x<- 23+75i
class(x)
x<- "india"
class(x)
x<- TRUE
class(x)
x<- True
class(x)
x = c(5,10,15)
max(x)
min(x)
mean(x)
sqrt(x)
x = c(5.5,10.7,15.2)
ceiling(x)
floor(x)
x = "Lorem ipsum dolor sit amet,
consectetur adipiscing elit,
sed do eiusmod tempor incididunt
ut labore et dolore magna aliqua."
x
x="Hello World!"
nchar(x)
x <- "Hello"
y <- "World"
paste(x,y)
x = readline();
print(x)
class(x)
x=as.integer(readline())
class(x)
x=as.integer(readline(prompt = "Enter any number : "))
x
class(x)
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
if (x <10) {
print("x is less than 10")
}
if (x == 10) {
print("x is = 10")
}
i = 0
while (i < 10) {
print(i)
i = i + 1
}
i = 0
while (i < 10) {
print("Hello")
i = i + 1
}
for (x in 1:10) {
print(x)
}
my_function = function(fname)
{
paste(fname, "Griffin")
}
my_function("Peter")
my_function("Lois")
my_function("Stewie")
plot(1, 3)
x=c(1,2,3,4,5)
y=c(1,3,5,7,9)
plot(x,y)
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales")
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red")
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red",cex=2)
```

```
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red",cex=2,pch=25)
x <- c(10,20,30,40)
pie(x)
x <- c(10,20,30,40)
mylabel <- c("Apples", "Bananas", "Cherries", "Dates")
pie(x, label = mylabel, main = "Fruits")
x <- c(10,20,30,40)
mylabel <- c("Apples", "Bananas", "Cherries", "Dates")
colors <- c("blue", "yellow", "green", "black")
pie(x, label = mylabel, main = "Fruits", col = colors)
x <- c("A", "B", "C", "D")
y <- c(2, 4, 6, 8)
barplot(y, names.arg = x)
x <- c("A", "B", "C", "D")
y <- c(2, 4, 6, 8)
barplot(y, names.arg = x, col = "red")
x <- rnorm(100)
x
hist(x, breaks = 10)
x <- c(1,2,3,4)
y <- c(1,3,5,7)
plot(x,y,type = "S")
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
print(x*10/100)
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
print((x-250000)*10/100)
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x <= 250000) {
print("You are not taxable")
}
if (250000<x && x<500000)
{
print("You are taxable")
print((x-250000)*10/100)
}
if (x>500000)
{
print("You are taxable")
print(((x-500000)*20/100)+(x-500000-25000)*10/100)
}
```
|
github_jupyter
|
x="India"
x
X <- "Hello, World!"
X
x=10
y=20
x+y
x-y
x*y
x/y
# Interest (I) of a principal amount (P) of 10000 for 4 years with an interest rate (R) of 8 %
P=10000
N=4
R=8/100
I=P*N*R
I
x=10
y="India"
x+y
x <- TRUE
class(x)
x<- 23.5
class(x)
x<- 23
class(x)
x<- 23+75i
class(x)
x<- "india"
class(x)
x<- TRUE
class(x)
x<- True
class(x)
x = c(5,10,15)
max(x)
min(x)
mean(x)
sqrt(x)
x = c(5.5,10.7,15.2)
ceiling(x)
floor(x)
x = "Lorem ipsum dolor sit amet,
consectetur adipiscing elit,
sed do eiusmod tempor incididunt
ut labore et dolore magna aliqua."
x
x="Hello World!"
nchar(x)
x <- "Hello"
y <- "World"
paste(x,y)
x = readline();
print(x)
class(x)
x=as.integer(readline())
class(x)
x=as.integer(readline(prompt = "Enter any number : "))
x
class(x)
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
x=as.integer(readline(prompt = "Enter any number : "))
if (x >10) {
print("x is greater than 10")
}
if (x <10) {
print("x is less than 10")
}
if (x == 10) {
print("x is = 10")
}
i = 0
while (i < 10) {
print(i)
i = i + 1
}
i = 0
while (i < 10) {
print("Hello")
i = i + 1
}
for (x in 1:10) {
print(x)
}
my_function = function(fname)
{
paste(fname, "Griffin")
}
my_function("Peter")
my_function("Lois")
my_function("Stewie")
plot(1, 3)
x=c(1,2,3,4,5)
y=c(1,3,5,7,9)
plot(x,y)
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales")
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red")
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red",cex=2)
plot(x,y, main="Plot a value", xlab="Days", ylab="Sales", col="red",cex=2,pch=25)
x <- c(10,20,30,40)
pie(x)
x <- c(10,20,30,40)
mylabel <- c("Apples", "Bananas", "Cherries", "Dates")
pie(x, label = mylabel, main = "Fruits")
x <- c(10,20,30,40)
mylabel <- c("Apples", "Bananas", "Cherries", "Dates")
colors <- c("blue", "yellow", "green", "black")
pie(x, label = mylabel, main = "Fruits", col = colors)
x <- c("A", "B", "C", "D")
y <- c(2, 4, 6, 8)
barplot(y, names.arg = x)
x <- c("A", "B", "C", "D")
y <- c(2, 4, 6, 8)
barplot(y, names.arg = x, col = "red")
x <- rnorm(100)
x
hist(x, breaks = 10)
x <- c(1,2,3,4)
y <- c(1,3,5,7)
plot(x,y,type = "S")
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
print(x*10/100)
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x >250000) {
print("You are taxable")
print((x-250000)*10/100)
}
if (x <= 250000) {
print("You are not taxable")
}
x=as.integer(readline(prompt = "Enter any Salary : "))
if (x <= 250000) {
print("You are not taxable")
}
if (250000<x && x<500000)
{
print("You are taxable")
print((x-250000)*10/100)
}
if (x>500000)
{
print("You are taxable")
print(((x-500000)*20/100)+(x-500000-25000)*10/100)
}
| 0.151153 | 0.479747 |
```
from pprint import pprint
import numpy as np
import matplotlib.pyplot as plt
```
# The Qiskit Cold Atom Provider
The qiskit-cold-atom module comes with a provider that manages access to cold atomic backends.
This tutorial shows the workflow of how a user interfaces with this provider.
<div class="alert alert-block alert-info">
<b>Note:</b> To run the cells in this tutorial that interface with a remote device backend, you'll need to have a registered account with a valid username and token for this backend.</div>
## Credential management
The `ColdAtomProvider` comes with an account system similar to the `IBMQ`-account, which will look familiar to many Qiskit users. This manages the access to all the backends that are available to the user.
The necessary credentials to access remote backends can be saved to disk or used in a session and never saved. The main methods to manage credentials with the provider are the following:
- `enable_account(urls, username, token)`: Enable your account in the current session.
- `save_account(urls, username, token)`: Save your account credentials to disk for future use.
- `load_account()`: Load account using stored credentials.
- `stored_account()`: List the account credentials stored to disk.
- `active_account()`: List the account credentials currently in the session.
- `delete_account()`: Delete the saved account credentials from disk.
To access remote backends via the provider, the account credentials have to specify the third-party `url` of the desired backend and a valid `username` and `token` as a password.
```
from qiskit_cold_atom.providers import ColdAtomProvider
# save an account to disk
# ColdAtomProvider.save_account(url = ["url_of_backend_1", "url_of_backend_2"], username="JohnDoe",token="123456")
# load the stored account
provider = ColdAtomProvider.load_account()
```
## Backends
Backends of the `ColdAtomProvider` represent either simulators or a real experimental hardware based on cold atomic experiments. A user may run suitable quantum circuits on these backends and retrieve the results.
The backends of the provider can be retrieved with the following methods:
- `provider.backends()`: Returns all backend objects known to the provider.
- `provider.get_backend(NAME)`: Returns the named backend.
```
print(provider.backends())
```
The provider currently includes simulators of a fermionic tweezer hardware (introduced [here](./03_fermionic_tweezer_hardware.ipynb)) and a collective spin hardware (introduced [here](./04_collective_spin_hardware.ipynb)).
As a first real device, an experimental system of collective spins is available, which is maintained by the Jendrzejewski group of the ["Synthetic Quantum Systems (SYNQS)"](https://www.synqs.org/) collaboration located at Heidelberg University (Germany):
```
spin_device_backend = provider.get_backend("SYNQS_SoPa_backend")
```
The `status` of this backend can be queried to see whether it is currently online and how many jobs are queued:
```
spin_device_backend.status().to_dict()
```
The backend `configuration` tells the user which quantum gates the backend can implement:
```
spin_device_backend.configuration().supported_instructions
```
The gates and instructions made available by the backend naturally depend on the hardware developments happening on the backend. With future versions of the backend, additional gates that manipulate the collective spins in the hardware will be added.
## Jobs:
The submission of circuits to execute on the backend is handled via `Job` instances. Circuits are submitted to the backend via the `run()` method which returns a `ColdAtomJob` object related to this submission.
The user can interact with this job to gain information about the submitted circuits with the following methods:
- `status()`: Returns the status of the job.
- `backend()`: Returns the backend the job was run on.
- `job_id()`: Gets the job_id.
- `cancel()`: Cancels the job.
- `result()`: Gets the results from the circuit run.
Let's submit some very simple example circuits on the remote backend as a toy example.
The following circuits describe the loading of atoms into a trap during the `delay` instruction. Upon measurement, the total number of atoms in the trap is measured. This should increase with increasing loading time and eventually saturate at the traps limit.
```
from qiskit.circuit import QuantumCircuit, Parameter
import numpy as np
t = Parameter("t")
circuit = QuantumCircuit(1, 1)
circuit.delay(duration = t, unit='s', qarg=0)
circuit.measure(0, 0)
circuit.draw(output='mpl')
# create a list of circuits with variable loading times:
load_times = np.arange(0.1, 15, 2)
circuit_list =[circuit.bind_parameters({t: load_time}) for load_time in load_times]
# send the list of circuits to the backend and execute with 5 shots each
# demo_job = spin_device_backend.run(circuit_list, shots = 5)
```
The job gets a unique `job_id` attached by the backend server which can be queried using the method `demo_job.job_id`.
### Retrieving jobs:
A job that has been run in a previous session can also be retrieved from the backend by providing the `job_id`:
```
job_retrieved = spin_device_backend.retrieve_job(job_id = "20210520_171502_89aec")
print("job status: ", job_retrieved.status())
```
The result of the job can be accessed by directly calling `job.result()` which returns a `Qiskit.Result` object:
```
result = job_retrieved.result()
print(type(result))
```
Let's look at the results of the previously submitted demo_job in detail:
```
outcomes = [result.get_memory(i) for i in range(len(circuit_list))]
atom_numbers = [np.mean(np.array(counts, dtype=float)) for counts in outcomes]
atom_stds = [np.std(np.array(counts, dtype=float)) for counts in outcomes]
import matplotlib.pyplot as plt
plt.errorbar(load_times, atom_numbers, yerr=atom_stds, fmt='x--')
plt.grid(alpha=0.5)
plt.title("loading of atoms in cold atomic device through Qiskit")
plt.xlabel("loading time [s]")
plt.ylabel("atom number in trap [a.u.]")
plt.show()
```
The entire result object can also be viewed as a dictionary:
```
result.to_dict()
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
|
github_jupyter
|
from pprint import pprint
import numpy as np
import matplotlib.pyplot as plt
from qiskit_cold_atom.providers import ColdAtomProvider
# save an account to disk
# ColdAtomProvider.save_account(url = ["url_of_backend_1", "url_of_backend_2"], username="JohnDoe",token="123456")
# load the stored account
provider = ColdAtomProvider.load_account()
print(provider.backends())
spin_device_backend = provider.get_backend("SYNQS_SoPa_backend")
spin_device_backend.status().to_dict()
spin_device_backend.configuration().supported_instructions
from qiskit.circuit import QuantumCircuit, Parameter
import numpy as np
t = Parameter("t")
circuit = QuantumCircuit(1, 1)
circuit.delay(duration = t, unit='s', qarg=0)
circuit.measure(0, 0)
circuit.draw(output='mpl')
# create a list of circuits with variable loading times:
load_times = np.arange(0.1, 15, 2)
circuit_list =[circuit.bind_parameters({t: load_time}) for load_time in load_times]
# send the list of circuits to the backend and execute with 5 shots each
# demo_job = spin_device_backend.run(circuit_list, shots = 5)
job_retrieved = spin_device_backend.retrieve_job(job_id = "20210520_171502_89aec")
print("job status: ", job_retrieved.status())
result = job_retrieved.result()
print(type(result))
outcomes = [result.get_memory(i) for i in range(len(circuit_list))]
atom_numbers = [np.mean(np.array(counts, dtype=float)) for counts in outcomes]
atom_stds = [np.std(np.array(counts, dtype=float)) for counts in outcomes]
import matplotlib.pyplot as plt
plt.errorbar(load_times, atom_numbers, yerr=atom_stds, fmt='x--')
plt.grid(alpha=0.5)
plt.title("loading of atoms in cold atomic device through Qiskit")
plt.xlabel("loading time [s]")
plt.ylabel("atom number in trap [a.u.]")
plt.show()
result.to_dict()
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
| 0.424889 | 0.984575 |
<!--BOOK_INFORMATION-->
<img align="left" style="padding-right:10px;" src="fig/cover-small.jpg">
*This notebook contains an excerpt from the [Whirlwind Tour of Python](http://www.oreilly.com/programming/free/a-whirlwind-tour-of-python.csp) by Jake VanderPlas; the content is available [on GitHub](https://github.com/jakevdp/WhirlwindTourOfPython).*
*The text and code are released under the [CC0](https://github.com/jakevdp/WhirlwindTourOfPython/blob/master/LICENSE) license; see also the companion project, the [Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook).*
<!--NAVIGATION-->
< [Errors and Exceptions](09-Errors-and-Exceptions.ipynb) | [Contents](Index.ipynb) | [List Comprehensions](11-List-Comprehensions.ipynb) >
# Iterators
Often an important piece of data analysis is repeating a similar calculation, over and over, in an automated fashion.
For example, you may have a table of a names that you'd like to split into first and last, or perhaps of dates that you'd like to convert to some standard format.
One of Python's answers to this is the *iterator* syntax.
We've seen this already with the ``range`` iterator:
```
for i in range(10):
print(i, end=' ')
```
Here we're going to dig a bit deeper.
It turns out that in Python 3, ``range`` is not a list, but is something called an *iterator*, and learning how it works is key to understanding a wide class of very useful Python functionality.
## Iterating over lists
Iterators are perhaps most easily understood in the concrete case of iterating through a list.
Consider the following:
```
for value in [2, 4, 6, 8, 10]:
# do some operation
print(value + 1, end=' ')
```
The familiar "``for x in y``" syntax allows us to repeat some operation for each value in the list.
The fact that the syntax of the code is so close to its English description ("*for [each] value in [the] list*") is just one of the syntactic choices that makes Python such an intuitive language to learn and use.
But the face-value behavior is not what's *really* happening.
When you write something like "``for val in L``", the Python interpreter checks whether it has an *iterator* interface, which you can check yourself with the built-in ``iter`` function:
```
iter([2, 4, 6, 8, 10])
```
It is this iterator object that provides the functionality required by the ``for`` loop.
The ``iter`` object is a container that gives you access to the next object for as long as it's valid, which can be seen with the built-in function ``next``:
```
I = iter([2, 4, 6, 8, 10])
print(next(I))
print(next(I))
print(next(I))
```
What is the purpose of this level of indirection?
Well, it turns out this is incredibly useful, because it allows Python to treat things as lists that are *not actually lists*.
## ``range()``: A List Is Not Always a List
Perhaps the most common example of this indirect iteration is the ``range()`` function in Python 3 (named ``xrange()`` in Python 2), which returns not a list, but a special ``range()`` object:
```
range(10)
```
``range``, like a list, exposes an iterator:
```
iter(range(10))
```
So Python knows to treat it *as if* it's a list:
```
for i in range(10):
print(i, end=' ')
```
The benefit of the iterator indirection is that *the full list is never explicitly created!*
We can see this by doing a range calculation that would overwhelm our system memory if we actually instantiated it (note that in Python 2, ``range`` creates a list, so running the following will not lead to good things!):
```
N = 10 ** 12
for i in range(N):
if i >= 10: break
print(i, end=', ')
```
If ``range`` were to actually create that list of one trillion values, it would occupy tens of terabytes of machine memory: a waste, given the fact that we're ignoring all but the first 10 values!
In fact, there's no reason that iterators ever have to end at all!
Python's ``itertools`` library contains a ``count`` function that acts as an infinite range:
```
from itertools import count
for i in count():
if i >= 10:
break
print(i, end=', ')
```
Had we not thrown-in a loop break here, it would go on happily counting until the process is manually interrupted or killed (using, for example, ``ctrl-C``).
## Useful Iterators
This iterator syntax is used nearly universally in Python built-in types as well as the more data science-specific objects we'll explore in later sections.
Here we'll cover some of the more useful iterators in the Python language:
### ``enumerate``
Often you need to iterate not only the values in an array, but also keep track of the index.
You might be tempted to do things this way:
```
L = [2, 4, 6, 8, 10]
for i in range(len(L)):
print(i, L[i])
```
Although this does work, Python provides a cleaner syntax using the ``enumerate`` iterator:
```
for i, val in enumerate(L):
print(i, val)
```
This is the more "Pythonic" way to enumerate the indices and values in a list.
### Exercise
Consider whether enumerate could be used to determine all the positions in a list, which contain the maximal element.
### ``zip``
Other times, you may have multiple lists that you want to iterate over simultaneously.
You could certainly iterate over the index as in the non-Pythonic example we looked at previously, but it is better to use the ``zip`` iterator, which zips together iterables:
```
L = [2, 4, 6, 8, 10]
R = [3, 6, 9, 12, 15]
for lval, rval in zip(L, R):
print(lval, rval)
```
Any number of iterables can be zipped together, and if they are different lengths, the shortest will determine the length of the ``zip``.
### ``map`` and ``filter``
The ``map`` iterator takes a function and applies it to the values in an iterator:
```
# find the first 10 square numbers
square = lambda x: x ** 2
for val in map(square, range(10)):
print(val, end=' ')
```
The ``filter`` iterator looks similar, except it only passes-through values for which the filter function evaluates to True:
```
# find values up to 10 for which x % 2 is zero
is_even = lambda x: x % 2 == 0
for val in filter(is_even, range(10)):
print(val, end=' ')
```
The ``map`` and ``filter`` functions, along with the ``reduce`` function (which lives in Python's ``functools`` module) are fundamental components of the *functional programming* style, which, while not a dominant programming style in the Python world, has its outspoken proponents (see, for example, the [pytoolz](https://toolz.readthedocs.org/en/latest/) library).
### Exercise
A perfect number is a positive integer that is equal to the sum of its positive divisors, excluding the number itself. Write a function which determines whether a number is perfect. Print out all the perfect numbers until 1000.
### Iterators as function arguments
We saw in [``*args`` and ``**kwargs``: Flexible Arguments](#*args-and-**kwargs:-Flexible-Arguments). that ``*args`` and ``**kwargs`` can be used to pass sequences and dictionaries to functions.
It turns out that the ``*args`` syntax works not just with sequences, but with any iterator:
```
print(*range(10))
```
So, for example, we can get tricky and compress the ``map`` example from before into the following:
```
print(*map(lambda x: x ** 2, range(10)))
```
Using this trick lets us answer the age-old question that comes up in Python learners' forums: why is there no ``unzip()`` function which does the opposite of ``zip()``?
If you lock yourself in a dark closet and think about it for a while, you might realize that the opposite of ``zip()`` is... ``zip()``! The key is that ``zip()`` can zip-together any number of iterators or sequences. Observe:
```
L1 = (1, 2, 3, 4)
L2 = ('a', 'b', 'c', 'd')
z = zip(L1, L2)
print(*z)
z = zip(L1, L2)
new_L1, new_L2 = zip(*z)
print(new_L1, new_L2)
```
Ponder this for a while. If you understand why it works, you'll have come a long way in understanding Python iterators!
## Specialized Iterators: ``itertools``
We briefly looked at the infinite ``range`` iterator, ``itertools.count``.
The ``itertools`` module contains a whole host of useful iterators; it's well worth your while to explore the module to see what's available.
As an example, consider the ``itertools.permutations`` function, which iterates over all permutations of a sequence:
```
from itertools import permutations
p = permutations(range(3))
print(*p)
```
Similarly, the ``itertools.combinations`` function iterates over all unique combinations of ``N`` values within a list:
```
from itertools import combinations
c = combinations(range(4), 2)
print(*c)
```
Somewhat related is the ``product`` iterator, which iterates over all sets of pairs between two or more iterables:
```
from itertools import product
p = product('ab', range(3))
print(*p)
```
Many more useful iterators exist in ``itertools``: the full list can be found, along with some examples, in Python's [online documentation](https://docs.python.org/3.5/library/itertools.html).
<!--NAVIGATION-->
< [Errors and Exceptions](09-Errors-and-Exceptions.ipynb) | [Contents](Index.ipynb) | [List Comprehensions](11-List-Comprehensions.ipynb)>
|
github_jupyter
|
for i in range(10):
print(i, end=' ')
for value in [2, 4, 6, 8, 10]:
# do some operation
print(value + 1, end=' ')
iter([2, 4, 6, 8, 10])
I = iter([2, 4, 6, 8, 10])
print(next(I))
print(next(I))
print(next(I))
range(10)
iter(range(10))
for i in range(10):
print(i, end=' ')
N = 10 ** 12
for i in range(N):
if i >= 10: break
print(i, end=', ')
from itertools import count
for i in count():
if i >= 10:
break
print(i, end=', ')
L = [2, 4, 6, 8, 10]
for i in range(len(L)):
print(i, L[i])
for i, val in enumerate(L):
print(i, val)
L = [2, 4, 6, 8, 10]
R = [3, 6, 9, 12, 15]
for lval, rval in zip(L, R):
print(lval, rval)
# find the first 10 square numbers
square = lambda x: x ** 2
for val in map(square, range(10)):
print(val, end=' ')
# find values up to 10 for which x % 2 is zero
is_even = lambda x: x % 2 == 0
for val in filter(is_even, range(10)):
print(val, end=' ')
print(*range(10))
print(*map(lambda x: x ** 2, range(10)))
L1 = (1, 2, 3, 4)
L2 = ('a', 'b', 'c', 'd')
z = zip(L1, L2)
print(*z)
z = zip(L1, L2)
new_L1, new_L2 = zip(*z)
print(new_L1, new_L2)
from itertools import permutations
p = permutations(range(3))
print(*p)
from itertools import combinations
c = combinations(range(4), 2)
print(*c)
from itertools import product
p = product('ab', range(3))
print(*p)
| 0.074471 | 0.962356 |
<a href="http://cocl.us/pytorch_link_top">
<img src="https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DL0110EN/notebook_images%20/Pytochtop.png" width="750" alt="IBM Product " />
</a>
<img src="https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DL0110EN/notebook_images%20/cc-logo-square.png" width="200" alt="cognitiveclass.ai logo" />
<h1>Neural Networks More Hidden Neutrons</h1>
<h2>Objective</h2><ul><li> How to create complex Neural Network in pytorch.</li></ul>
<h2>Table of Contents</h2>
<ul>
<li><a href="#Prep">Preperation</a></li>
<li><a href="#Data">Get Our Data</a></li>
<li><a href="#Train">Define the Neural Network, Optimizer, and Train the Model</a></li>
</ul>
<p>Estimated Time Needed: <strong>25 min</strong></p>
<hr>
<h2 id="Prep">Preparation</h2>
We'll need to import the following libraries for this lab.
```
import torch
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
```
Define the plotting functions.
```
def get_hist(model,data_set):
activations=model.activation(data_set.x)
for i,activation in enumerate(activations):
plt.hist(activation.numpy(),4,density=True)
plt.title("Activation layer " + str(i+1))
plt.xlabel("Activation")
plt.xlabel("Activation")
plt.legend()
plt.show()
def PlotStuff(X,Y,model=None,leg=False):
plt.plot(X[Y==0].numpy(),Y[Y==0].numpy(),'or',label='training points y=0 ' )
plt.plot(X[Y==1].numpy(),Y[Y==1].numpy(),'ob',label='training points y=1 ' )
if model!=None:
plt.plot(X.numpy(),model(X).detach().numpy(),label='neral network ')
plt.legend()
plt.show()
```
<h2 id="Data">Get Our Data</h2>
Define the class to get our dataset.
```
class Data(Dataset):
def __init__(self):
self.x=torch.linspace(-20, 20, 100).view(-1,1)
self.y=torch.zeros(self.x.shape[0])
self.y[(self.x[:,0]>-10)& (self.x[:,0]<-5)]=1
self.y[(self.x[:,0]>5)& (self.x[:,0]<10)]=1
self.y=self.y.view(-1,1)
self.len=self.x.shape[0]
def __getitem__(self,index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
```
<h2 id="Train">Define the Neural Network, Optimizer and Train the Model</h2>
Define the class for creating our model.
```
class Net(nn.Module):
def __init__(self,D_in,H,D_out):
super(Net,self).__init__()
self.linear1=nn.Linear(D_in,H)
self.linear2=nn.Linear(H,D_out)
def forward(self,x):
x=torch.sigmoid(self.linear1(x))
x=torch.sigmoid(self.linear2(x))
return x
```
Create the function to train our model, which accumulate lost for each iteration to obtain the cost.
```
def train(data_set,model,criterion, train_loader, optimizer, epochs=5,plot_number=10):
cost=[]
for epoch in range(epochs):
total=0
for x,y in train_loader:
optimizer.zero_grad()
yhat=model(x)
loss=criterion(yhat,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total+=loss.item()
if epoch%plot_number==0:
PlotStuff(data_set.x,data_set.y,model)
cost.append(total)
plt.figure()
plt.plot(cost)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
return cost
data_set=Data()
PlotStuff(data_set.x,data_set.y,leg=False)
```
Create our model with 9
neurons in the hidden layer. And then create a BCE loss and an Adam optimizer.
```
torch.manual_seed(0)
model=Net(1,9,1)
learning_rate=0.1
criterion=nn.BCELoss()
optimizer=torch.optim.Adam(model.parameters(), lr=learning_rate)
train_loader=DataLoader(dataset=data_set,batch_size=100)
COST=train(data_set,model,criterion, train_loader, optimizer, epochs=600,plot_number=200)
```
```
plt.plot(COST)
```
<a href="http://cocl.us/pytorch_link_bottom">
<img src="https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DL0110EN/notebook_images%20/notebook_bottom%20.png" width="750" alt="PyTorch Bottom" />
</a>
<h2>About the Authors:</h2>
<a href="https://www.linkedin.com/in/joseph-s-50398b136/">Joseph Santarcangelo</a> has a PhD in Electrical Engineering, his research focused on using machine learning, signal processing, and computer vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.
Other contributors: <a href="https://www.linkedin.com/in/michelleccarey/">Michelle Carey</a>, <a href="www.linkedin.com/in/jiahui-mavis-zhou-a4537814a">Mavis Zhou</a>, <a href="https://www.linkedin.com/in/fanjiang0619/">Fan Jiang</a>, <a href="https://www.linkedin.com/in/yi-leng-yao-84451275/">Yi Leng Yao</a>, <a href="https://www.linkedin.com/in/sacchitchadha/">Sacchit Chadha</a>
## Change Log
| Date (YYYY-MM-DD) | Version | Changed By | Change Description |
| ----------------- | ------- | ---------- | ----------------------------------------------------------- |
| 2020-09-23 | 2.0 | Shubham | Migrated Lab to Markdown and added to course repo in GitLab |
Copyright © 2018 <a href="cognitiveclass.ai?utm_source=bducopyrightlink&utm_medium=dswb&utm_campaign=bdu">cognitiveclass.ai</a>. This notebook and its source code are released under the terms of the <a href="https://bigdatauniversity.com/mit-license/">MIT License</a>.
|
github_jupyter
|
import torch
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
def get_hist(model,data_set):
activations=model.activation(data_set.x)
for i,activation in enumerate(activations):
plt.hist(activation.numpy(),4,density=True)
plt.title("Activation layer " + str(i+1))
plt.xlabel("Activation")
plt.xlabel("Activation")
plt.legend()
plt.show()
def PlotStuff(X,Y,model=None,leg=False):
plt.plot(X[Y==0].numpy(),Y[Y==0].numpy(),'or',label='training points y=0 ' )
plt.plot(X[Y==1].numpy(),Y[Y==1].numpy(),'ob',label='training points y=1 ' )
if model!=None:
plt.plot(X.numpy(),model(X).detach().numpy(),label='neral network ')
plt.legend()
plt.show()
class Data(Dataset):
def __init__(self):
self.x=torch.linspace(-20, 20, 100).view(-1,1)
self.y=torch.zeros(self.x.shape[0])
self.y[(self.x[:,0]>-10)& (self.x[:,0]<-5)]=1
self.y[(self.x[:,0]>5)& (self.x[:,0]<10)]=1
self.y=self.y.view(-1,1)
self.len=self.x.shape[0]
def __getitem__(self,index):
return self.x[index],self.y[index]
def __len__(self):
return self.len
class Net(nn.Module):
def __init__(self,D_in,H,D_out):
super(Net,self).__init__()
self.linear1=nn.Linear(D_in,H)
self.linear2=nn.Linear(H,D_out)
def forward(self,x):
x=torch.sigmoid(self.linear1(x))
x=torch.sigmoid(self.linear2(x))
return x
def train(data_set,model,criterion, train_loader, optimizer, epochs=5,plot_number=10):
cost=[]
for epoch in range(epochs):
total=0
for x,y in train_loader:
optimizer.zero_grad()
yhat=model(x)
loss=criterion(yhat,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total+=loss.item()
if epoch%plot_number==0:
PlotStuff(data_set.x,data_set.y,model)
cost.append(total)
plt.figure()
plt.plot(cost)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
return cost
data_set=Data()
PlotStuff(data_set.x,data_set.y,leg=False)
torch.manual_seed(0)
model=Net(1,9,1)
learning_rate=0.1
criterion=nn.BCELoss()
optimizer=torch.optim.Adam(model.parameters(), lr=learning_rate)
train_loader=DataLoader(dataset=data_set,batch_size=100)
COST=train(data_set,model,criterion, train_loader, optimizer, epochs=600,plot_number=200)
plt.plot(COST)
| 0.843444 | 0.914099 |
```
from billboard import ChartData
import pandas as pd
import lyricsgenius as lg
# initialize the Genius API
genius = lg.Genius("1nVXMraHD3ieBaMJteYrKT4eqenseJ0WP78V85wRZ3sa1W9FSVUL-9Fg6WlpVon-")
genius.skip_non_songs = True
#create a list of dates given number of years. Will return dates in January, April, August, December
#Format: YYYY-MM-DD
def create_date_list(curr_year, num_years):
#make sure charts exist
start_year = curr_year - 1
end_year = start_year - num_years
months = ["01-01","02-01","03-01","04-01","05-01","06-01","07-01","08-01","09-01","10-01","11-01","12-01"]
total_dates = []
#moving backwards through years
for i in range(start_year, end_year, -1):
for month in months:
total_dates.append(str(i)+ "-" + month)
return total_dates
def split_entry(entry):
arr = entry.split("by")
return [arr[0].strip().strip('\''), arr[1].strip()]
#parse a chart to enter into a dataframe
def parse_chart(chart):
chart_dict = {}
for index in range(len(chart)):
curr_song = split_entry(str(chart[index]))
song_dict = {}
song_dict["Title"] = curr_song[0]
song_dict["Artist"] = curr_song[1]
chart_dict[index]= song_dict
return chart_dict
#will return a dataframe containing all song's title and artist from the start year and backwards num_years at 4 times
#througout the year
def chart_main(chart_name, start_year, num_years):
#initialize complete DataFrame
data = pd.DataFrame(columns = ["Title", "Artist"])
#get list of dates to get charts from
dates_list = create_date_list(start_year, num_years)
#get all charts at dates in date_list and parse into dataframe
for date in dates_list:
try:
chart = ChartData(chart_name, date)
except:
continue
entry = parse_chart(chart)
for i in range(len(entry)):
data = data.append(entry[i], ignore_index=True)
return data
genre_arr = []
chart_names = ["r-b-hip-hop-songs","pop-songs","rock-songs","country-songs"]
hip_hop = chart_main(chart_names[0], 2020, 10)
pop = chart_main(chart_names[1], 2020, 10)
rock = chart_main(chart_names[2], 2020, 10)
country = chart_main(chart_names[3], 2020, 10)
hip_hop.to_csv("Hip_Hop_songs.csv", index=False)
pop.to_csv("Pop_songs.csv", index=False)
rock.to_csv("Rock_songs.csv", index=False)
country.to_csv("Country_songs.csv", index=False)
hip_hop = pd.read_csv("cleaned_songs/hiphop_songs_cleaned.csv")
pop = pd.read_csv("cleaned_songs/pop_songs_cleaned.csv")
rock = pd.read_csv("cleaned_songs/rock_songs_cleaned.csv")
country = pd.read_csv("cleaned_songs/country_songs_cleaned.csv")
#function that returns a dictionary of lyrics keyed by song and artist
def get_lyrics(df):
lyric_dict = {}
for index, data in df.iterrows():
if ((data["Title"]+data["Artist"]) not in [*lyric_dict]):
try:
curr_lyric = genius.search_song(data["Title"], data["Artist"])
if (type(curr_lyric) is None):
continue
else:
lyric_dict[data["Title"]+data["Artist"]] = curr_lyric.lyrics
except:
continue
return lyric_dict
def count_occurence(df):
occurrence_dict = {}
for index, data in df.iterrows():
data[data["Title"]+data["Artist"]] = data.get((data["Title"]+data["Artist"]),0) + 1
return occurrence_dict
hip_hop_lyics = get_lyrics(hip_hop)
pop_lyrics = get_lyrics(pop)
rock_lyrics = get_lyrics(rock)
country_lyrics = get_lyrics(country)
#hip_hop_df = pd.DataFrame.from_dict(hip_hop_lyrics, orient='index')
#pop_df = pd.DataFrame.from_dict(pop_lyrics, orient='index')
#rock_df = pd.DataFrame.from_dict(rock_lyrics, orient='index')
country_df = pd.DataFrame.from_dict(country_lyrics, orient='index')
#hip_hop_df.to_csv("hiphop_lyrics.csv")
#pop_df.to_csv("pop_lyrics.csv")
#rock_df.to_csv("rock_lyrics.csv")
country_df.to_csv("country_lyrics.csv")
```
|
github_jupyter
|
from billboard import ChartData
import pandas as pd
import lyricsgenius as lg
# initialize the Genius API
genius = lg.Genius("1nVXMraHD3ieBaMJteYrKT4eqenseJ0WP78V85wRZ3sa1W9FSVUL-9Fg6WlpVon-")
genius.skip_non_songs = True
#create a list of dates given number of years. Will return dates in January, April, August, December
#Format: YYYY-MM-DD
def create_date_list(curr_year, num_years):
#make sure charts exist
start_year = curr_year - 1
end_year = start_year - num_years
months = ["01-01","02-01","03-01","04-01","05-01","06-01","07-01","08-01","09-01","10-01","11-01","12-01"]
total_dates = []
#moving backwards through years
for i in range(start_year, end_year, -1):
for month in months:
total_dates.append(str(i)+ "-" + month)
return total_dates
def split_entry(entry):
arr = entry.split("by")
return [arr[0].strip().strip('\''), arr[1].strip()]
#parse a chart to enter into a dataframe
def parse_chart(chart):
chart_dict = {}
for index in range(len(chart)):
curr_song = split_entry(str(chart[index]))
song_dict = {}
song_dict["Title"] = curr_song[0]
song_dict["Artist"] = curr_song[1]
chart_dict[index]= song_dict
return chart_dict
#will return a dataframe containing all song's title and artist from the start year and backwards num_years at 4 times
#througout the year
def chart_main(chart_name, start_year, num_years):
#initialize complete DataFrame
data = pd.DataFrame(columns = ["Title", "Artist"])
#get list of dates to get charts from
dates_list = create_date_list(start_year, num_years)
#get all charts at dates in date_list and parse into dataframe
for date in dates_list:
try:
chart = ChartData(chart_name, date)
except:
continue
entry = parse_chart(chart)
for i in range(len(entry)):
data = data.append(entry[i], ignore_index=True)
return data
genre_arr = []
chart_names = ["r-b-hip-hop-songs","pop-songs","rock-songs","country-songs"]
hip_hop = chart_main(chart_names[0], 2020, 10)
pop = chart_main(chart_names[1], 2020, 10)
rock = chart_main(chart_names[2], 2020, 10)
country = chart_main(chart_names[3], 2020, 10)
hip_hop.to_csv("Hip_Hop_songs.csv", index=False)
pop.to_csv("Pop_songs.csv", index=False)
rock.to_csv("Rock_songs.csv", index=False)
country.to_csv("Country_songs.csv", index=False)
hip_hop = pd.read_csv("cleaned_songs/hiphop_songs_cleaned.csv")
pop = pd.read_csv("cleaned_songs/pop_songs_cleaned.csv")
rock = pd.read_csv("cleaned_songs/rock_songs_cleaned.csv")
country = pd.read_csv("cleaned_songs/country_songs_cleaned.csv")
#function that returns a dictionary of lyrics keyed by song and artist
def get_lyrics(df):
lyric_dict = {}
for index, data in df.iterrows():
if ((data["Title"]+data["Artist"]) not in [*lyric_dict]):
try:
curr_lyric = genius.search_song(data["Title"], data["Artist"])
if (type(curr_lyric) is None):
continue
else:
lyric_dict[data["Title"]+data["Artist"]] = curr_lyric.lyrics
except:
continue
return lyric_dict
def count_occurence(df):
occurrence_dict = {}
for index, data in df.iterrows():
data[data["Title"]+data["Artist"]] = data.get((data["Title"]+data["Artist"]),0) + 1
return occurrence_dict
hip_hop_lyics = get_lyrics(hip_hop)
pop_lyrics = get_lyrics(pop)
rock_lyrics = get_lyrics(rock)
country_lyrics = get_lyrics(country)
#hip_hop_df = pd.DataFrame.from_dict(hip_hop_lyrics, orient='index')
#pop_df = pd.DataFrame.from_dict(pop_lyrics, orient='index')
#rock_df = pd.DataFrame.from_dict(rock_lyrics, orient='index')
country_df = pd.DataFrame.from_dict(country_lyrics, orient='index')
#hip_hop_df.to_csv("hiphop_lyrics.csv")
#pop_df.to_csv("pop_lyrics.csv")
#rock_df.to_csv("rock_lyrics.csv")
country_df.to_csv("country_lyrics.csv")
| 0.292696 | 0.302433 |
```
import os
import pandas as pd
os.getcwd()
a=pd.read_csv('D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\DND_U_Id_Class.tsv', sep='\t')
a
a['1017147974999146496']
a['1017147974999146496'].to_csv('D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\depressive_tweet_id.csv',index=False)
#This code creates the dataset from Corpus.csv which is downloadable from the
#internet well known dataset which is labeled manually by hand. But for the text
#of tweets you need to fetch them with their IDs.
import tweepy
# Twitter Developer keys here
# It is CENSORED
consumer_key = 'u9L8y92xb1S0OrqydndNzM3Al'
consumer_key_secret = 'UD0Rt625HHjnMwWKc5PH0YPLO2JE8aOzuGq39vLfVBU9zYWlm4'
access_token = '1308707110281195521-kYVJKftHmUlBEGNPIDzgH6iBuVBaxH'
access_token_secret = 'VuvHmZ52CSTleeiFAnUXnF00rK9LmToi0zZRQiZRkuDGQ'
auth = tweepy.OAuthHandler(consumer_key, consumer_key_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# This method creates the training set
def createTrainingSet(corpusFile, targetResultFile):
import csv
import time
counter = 0
corpus = []
with open(corpusFile, 'r') as csvfile:
lineReader = csv.reader(csvfile, delimiter=',', quotechar="\"")
for row in lineReader:
corpus.append({"tweet_id": row[0], "label": row[0], "topic": row[0]})
sleepTime = 2
trainingDataSet = []
for tweet in corpus:
try:
tweetFetched = api.get_status(tweet["tweet_id"])
print("Tweet fetched" + tweetFetched.text)
tweet["text"] = tweetFetched.text
trainingDataSet.append(tweet)
time.sleep(sleepTime)
except:
print("Inside the exception - no:2")
continue
with open(targetResultFile, 'w') as csvfile:
linewriter = csv.writer(csvfile, delimiter=',', quotechar="\"")
for tweet in trainingDataSet:
try:
linewriter.writerow([tweet["tweet_id"], tweet["text"], tweet["label"], tweet["topic"]])
except Exception as e:
print(e)
return trainingDataSet
# Code starts here
# This is corpus dataset
corpusFile = "D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\depressive_tweet_id.csv"
# This is my target file
targetResultFile = "D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\tweet_text.csv"
# Call the method
resultFile = createTrainingSet(corpusFile, targetResultFile)
tweetFetched = api.get_status(tweet["tweet_id"])
```
|
github_jupyter
|
import os
import pandas as pd
os.getcwd()
a=pd.read_csv('D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\DND_U_Id_Class.tsv', sep='\t')
a
a['1017147974999146496']
a['1017147974999146496'].to_csv('D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\depressive_tweet_id.csv',index=False)
#This code creates the dataset from Corpus.csv which is downloadable from the
#internet well known dataset which is labeled manually by hand. But for the text
#of tweets you need to fetch them with their IDs.
import tweepy
# Twitter Developer keys here
# It is CENSORED
consumer_key = 'u9L8y92xb1S0OrqydndNzM3Al'
consumer_key_secret = 'UD0Rt625HHjnMwWKc5PH0YPLO2JE8aOzuGq39vLfVBU9zYWlm4'
access_token = '1308707110281195521-kYVJKftHmUlBEGNPIDzgH6iBuVBaxH'
access_token_secret = 'VuvHmZ52CSTleeiFAnUXnF00rK9LmToi0zZRQiZRkuDGQ'
auth = tweepy.OAuthHandler(consumer_key, consumer_key_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# This method creates the training set
def createTrainingSet(corpusFile, targetResultFile):
import csv
import time
counter = 0
corpus = []
with open(corpusFile, 'r') as csvfile:
lineReader = csv.reader(csvfile, delimiter=',', quotechar="\"")
for row in lineReader:
corpus.append({"tweet_id": row[0], "label": row[0], "topic": row[0]})
sleepTime = 2
trainingDataSet = []
for tweet in corpus:
try:
tweetFetched = api.get_status(tweet["tweet_id"])
print("Tweet fetched" + tweetFetched.text)
tweet["text"] = tweetFetched.text
trainingDataSet.append(tweet)
time.sleep(sleepTime)
except:
print("Inside the exception - no:2")
continue
with open(targetResultFile, 'w') as csvfile:
linewriter = csv.writer(csvfile, delimiter=',', quotechar="\"")
for tweet in trainingDataSet:
try:
linewriter.writerow([tweet["tweet_id"], tweet["text"], tweet["label"], tweet["topic"]])
except Exception as e:
print(e)
return trainingDataSet
# Code starts here
# This is corpus dataset
corpusFile = "D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\depressive_tweet_id.csv"
# This is my target file
targetResultFile = "D:\Project\Twitter_depression_detector\data\Depression_Annotated_Data (1)\Depression_Annotated_Data\tweet_text.csv"
# Call the method
resultFile = createTrainingSet(corpusFile, targetResultFile)
tweetFetched = api.get_status(tweet["tweet_id"])
| 0.148325 | 0.207998 |
# Crash course in Jupyter and Python
- Introduction to Jupyter
- Using Markdown
- Magic functions
- REPL
- Saving and exporting Jupyter notebooks
- Python
- Data types
- Operators
- Collections
- Functions and methods
- Control flow
- Loops, comprehension
- Packages and namespace
- Coding style
- Understanding error messages
- Getting help
## Class Repository
Course material will be posted here. Please make any personal modifications to a **copy** of the notebook to avoid merge conflicts.
https://github.com/cliburn/sta-663-2020.git
## Introduction to Jupyter
- [Official Jupyter docs](https://jupyter.readthedocs.io/en/latest/)
- User interface and kernels
- Notebook, editor, terminal
- Literate programming
- Code and markdown cells
- Menu and toolbar
- Key bindings
- Polyglot programming
```
%load_ext rpy2.ipython
import warnings
warnings.simplefilter('ignore', FutureWarning)
df = %R iris
df.head()
%%R -i df -o res
library(tidyverse)
res <- df %>% group_by(Species) %>% summarize_all(mean)
res
```
### Using Markdown
- What is markdown?
- Headers
- Formatting text
- Syntax-highlighted code
- Lists
- Hyperlinks and images
- LaTeX
See `Help | Markdown`
### Magic functions
- [List of magic functions](https://ipython.readthedocs.io/en/stable/interactive/magics.html)
- `%magic`
- Shell access
- Convenience functions
- Quick and dirty text files
```
%magic
```
### REPL
- Read, Eval, Print, Loop
- Learn by experimentation
```
1 + 2
```
### Saving and exporting Jupyter notebooks
- The File menu item
- Save and Checkpoint
- Exporting
- Close and Halt
- Cleaning up with the Running tab
## Introduction to Python
- [Official Python docs](https://docs.python.org/3/)
- [Why Python?](https://insights.stackoverflow.com/trends?tags=python%2Cjavascript%2Cjava%2Cc%2B%2B%2Cr%2Cjulia-lang%2Cscala&utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link&utm_term=incredible-growth-python)
- General purpose language (web, databases, introductory programming classes)
- Language for scientific computation (physics, engineering, statistics, ML, AI)
- Human readable
- Interpreted
- Dynamic typing
- Strong typing
- Multi-paradigm
- Implementations (CPython, PyPy, Jython, IronPython)
### Data types
- boolean
- int, double, complex
- strings
- None
```
True, False
1, 2, 3
import numpy as np
np.pi, np.e
3 + 4j
'hello, world'
"hell's bells"
"""三轮车跑的快
上面坐个老太太
要五毛给一块
你说奇怪不奇怪"""
None
None is None
```
### Operators
- mathematical
- logical
- bitwise
- membership
- identity
- assignment and in-place operators
- operator precedence
#### Arithmetic
```
2 ** 3
11 / 3
11 // 3
11 % 3
```
#### Logical
```
True and False
True or False
not (True or False)
```
#### Relational
```
2 == 2, 2 == 3, 2 != 3, 2 < 3, 2 <= 3, 2 > 3, 2 >= 3
```
#### Bitwise
```
format(10, '04b')
format(7, '04b')
x = 10 & 7
x, format(x, '04b')
x = 10 | 7
x, format(x, '04b')
x = 10 ^ 7
x, format(x, '04b')
```
#### Membership
```
'hell' in 'hello'
3 in range(5), 7 in range(5)
'a' in dict(zip('abc', range(3)))
```
#### Identity
```
x = [2,3]
y = [2,3]
x == y, x is y
id(x), id(y)
x = 'hello'
y = 'hello'
x == y, x is y
id(x), id(y)
```
#### Assignment
```
x = 2
x = x + 2
x
x *= 2
x
```
### Collections
- Sequence containers - list, tuple
- Mapping containers - set, dict
- The [`collections`](https://docs.python.org/2/library/collections.html) module
#### Lists
```
xs = [1,2,3]
xs[0], xs[-1]
xs[1] = 9
xs
```
#### Tuples
```
ys = (1,2,3)
ys[0], ys[-1]
try:
ys[1] = 9
except TypeError as e:
print(e)
```
#### Sets
```
zs = [1,1,2,2,2,3,3,3,3]
set(zs)
```
#### Dictionaries
```
{'a': 0, 'b': 1, 'c': 2}
dict(a=0, b=1, c=2)
dict(zip('abc', range(3)))
```
### Functions and methods
- Anatomy of a function
- Docstrings
- Class methods
```
list(range(10))
[item for item in dir() if not item.startswith('_')]
def f(a, b):
"""Do something with a and b.
Assume that the + and * operatores are defined for a and b.
"""
return 2*a + 3*b
f(2, 3)
f(3, 2)
f(b=3, a=2)
f(*(2,3))
f(**dict(a=2, b=3))
f('hello', 'world')
f([1,2,3], ['a', 'b', 'c'])
```
### Control flow
- if and the ternary operator
- Checking conditions - what evaluates as true/false?
- if-elif-else
- while
- break, continue
- pass
```
if 1 + 1 == 2:
print("Phew!")
'vegan' if 1 + 1 == 2 else 'carnivore'
'vegan' if 1 + 1 == 3 else 'carnivore'
if 1+1 == 3:
print("oops")
else:
print("Phew!")
for grade in [94, 79, 81, 57]:
if grade > 90:
print('A')
elif grade > 80:
print('B')
elif grade > 70:
print('C')
else:
print('Are you in the right class?')
i = 10
while i > 0:
print(i)
i -= 1
for i in range(1, 10):
if i % 2 == 0:
continue
print(i)
for i in range(1, 10):
if i % 2 == 0:
break
print(i)
for i in range(1, 10):
if i % 2 == 0:
pass
else:
print(i)
```
### Loops and comprehensions
- for, range, enumerate
- lazy and eager evaluation
- list, set, dict comprehensions
- generator expression
```
for i in range(1,5):
print(i**2, end=',')
for i, x in enumerate(range(1,5)):
print(i, x**2)
for i, x in enumerate(range(1,5), start=10):
print(i, x**2)
range(5)
list(range(5))
```
#### Comprehensions
```
[x**3 % 3 for x in range(10)]
{x**3 % 3 for x in range(10)}
{k: v for k, v in enumerate('abcde')}
(x**3 for x in range(10))
list(x**3 for x in range(10))
```
### Packages and namespace
- Modules (file)
- Package (hierarchical modules)
- Namespace and naming conflicts
- Using `import`
- [Batteries included](https://docs.python.org/3/library/index.html)
```
%%file foo.py
def foo(x):
return f"And FOO you too, {x}"
import foo
foo.foo("Winnie the Pooh")
from foo import foo
foo("Winnie the Pooh")
import numpy as np
np.random.randint(0, 10, (5,5))
```
### Coding style
- [PEP 8 — the Style Guide for Python Code](https://pep8.org/)
- Many code editors can be used with linters to check if your code conforms to PEP 8 style guidelines.
- E.g. see [jupyter-autopep8](https://github.com/kenkoooo/jupyter-autopep8)
### Understanding error messages
- [Built-in exceptions](https://docs.python.org/3/library/exceptions.html)
```
try:
1 / 0
except ZeroDivisionError as e:
print(e)
```
### Getting help
- `?foo`, `foo?`, `help(foo)`
- Use a search engine
- Use `StackOverflow`
- Ask your TA
```
help(help)
```
|
github_jupyter
|
%load_ext rpy2.ipython
import warnings
warnings.simplefilter('ignore', FutureWarning)
df = %R iris
df.head()
%%R -i df -o res
library(tidyverse)
res <- df %>% group_by(Species) %>% summarize_all(mean)
res
%magic
1 + 2
True, False
1, 2, 3
import numpy as np
np.pi, np.e
3 + 4j
'hello, world'
"hell's bells"
"""三轮车跑的快
上面坐个老太太
要五毛给一块
你说奇怪不奇怪"""
None
None is None
2 ** 3
11 / 3
11 // 3
11 % 3
True and False
True or False
not (True or False)
2 == 2, 2 == 3, 2 != 3, 2 < 3, 2 <= 3, 2 > 3, 2 >= 3
format(10, '04b')
format(7, '04b')
x = 10 & 7
x, format(x, '04b')
x = 10 | 7
x, format(x, '04b')
x = 10 ^ 7
x, format(x, '04b')
'hell' in 'hello'
3 in range(5), 7 in range(5)
'a' in dict(zip('abc', range(3)))
x = [2,3]
y = [2,3]
x == y, x is y
id(x), id(y)
x = 'hello'
y = 'hello'
x == y, x is y
id(x), id(y)
x = 2
x = x + 2
x
x *= 2
x
xs = [1,2,3]
xs[0], xs[-1]
xs[1] = 9
xs
ys = (1,2,3)
ys[0], ys[-1]
try:
ys[1] = 9
except TypeError as e:
print(e)
zs = [1,1,2,2,2,3,3,3,3]
set(zs)
{'a': 0, 'b': 1, 'c': 2}
dict(a=0, b=1, c=2)
dict(zip('abc', range(3)))
list(range(10))
[item for item in dir() if not item.startswith('_')]
def f(a, b):
"""Do something with a and b.
Assume that the + and * operatores are defined for a and b.
"""
return 2*a + 3*b
f(2, 3)
f(3, 2)
f(b=3, a=2)
f(*(2,3))
f(**dict(a=2, b=3))
f('hello', 'world')
f([1,2,3], ['a', 'b', 'c'])
if 1 + 1 == 2:
print("Phew!")
'vegan' if 1 + 1 == 2 else 'carnivore'
'vegan' if 1 + 1 == 3 else 'carnivore'
if 1+1 == 3:
print("oops")
else:
print("Phew!")
for grade in [94, 79, 81, 57]:
if grade > 90:
print('A')
elif grade > 80:
print('B')
elif grade > 70:
print('C')
else:
print('Are you in the right class?')
i = 10
while i > 0:
print(i)
i -= 1
for i in range(1, 10):
if i % 2 == 0:
continue
print(i)
for i in range(1, 10):
if i % 2 == 0:
break
print(i)
for i in range(1, 10):
if i % 2 == 0:
pass
else:
print(i)
for i in range(1,5):
print(i**2, end=',')
for i, x in enumerate(range(1,5)):
print(i, x**2)
for i, x in enumerate(range(1,5), start=10):
print(i, x**2)
range(5)
list(range(5))
[x**3 % 3 for x in range(10)]
{x**3 % 3 for x in range(10)}
{k: v for k, v in enumerate('abcde')}
(x**3 for x in range(10))
list(x**3 for x in range(10))
%%file foo.py
def foo(x):
return f"And FOO you too, {x}"
import foo
foo.foo("Winnie the Pooh")
from foo import foo
foo("Winnie the Pooh")
import numpy as np
np.random.randint(0, 10, (5,5))
try:
1 / 0
except ZeroDivisionError as e:
print(e)
help(help)
| 0.23467 | 0.958226 |
```
import numpy as np
from scipy import optimize, interpolate
import pandas as pd
from collections import namedtuple
import os
import shutil
import rwforcReader, rbdoutReader
def read_test_results(fileName):
"""
ToDO
"""
tests_dict = {}
excel = pd.ExcelFile(fileName)
for sheet in excel.sheet_names:
df = excel.parse(sheet)
value = df.values
#print(sheet)
#print(value.shape)
tests_dict[sheet] = value
return tests_dict
test = read_test_results('Z.xlsx')
def make_curve(A, n):
"""
TODO
"""
lt_zero = np.arange(-1, 0, 0.1)
lt_zero_stress = -0.2 * lt_zero
gt_zero = np.arange(0, 1, 0.01)
gt_zero_stress = A * np.power(gt_zero, n)
x = np.hstack([lt_zero, gt_zero])
y = np.hstack([lt_zero_stress, gt_zero_stress])
return np.hstack([x.reshape(-1,1), y.reshape(-1,1)])
def write_curve(fileName, curve, lcid):
"""
TODO
"""
with open(fileName, 'w+') as f:
f.write("*KEYWORD\n")
f.write("*DEFINE_CURVE\n")
f.write("{0}".format(str(int(lcid)))+"\n")
f.write("$#\n")
for p in curve:
f.write("{:.4f}, {:.4f}\n".format(p[0], p[1]))
f.write("*END")
def prepare_files(folder_name, files):
"""
TODO
"""
if not os.path.exists(folder_name):
os.mkdir(folder_name)
for f in files:
shutil.copy(os.path.join(owd,f), os.path.join(owd, folder_name, f))#os.path.join(owd,folder_name,f), os.path.join(owd,f))
os.chdir(folder_name)
def execute_calculation(exe_path, main_file):
os.system(exe_path + " i=" + main_file + " NCPU=8 Memory=2000m")
os.chdir
def get_result(rgb_id, rw_id):
rwf = rwforcReader.rwforcReader('JellyRoll_Z.rwforc')
#print(res[0]["1"])#
rbd = rbdoutReader.rbdoutReader('JellyRoll_Z.rbdout')
# print(res[0]['time'], res[1]['2'])
d_x = np.array(rbd[1][str(rgb_id)]).reshape(-1, 1)
forc = np.array(rwf[1][str(rw_id)]).reshape(-1, 1)
assert d_x.shape[0] == forc.shape[0]
return np.hstack([d_x, forc])
def func_simulation(param):
"""
TODO
"""
global cur_num
with open ("param.txt", "a+") as f:
f.write("{0:d},{1:.4f},{2:.4f}\n".format(cur_num, param[0], param[1]))
curve = make_curve(param[0], param[1])
prepare_files(str(cur_num), ['JellyRoll.blk', 'JellyRoll.mat', 'JellyRoll_punch.dyn'])
write_curve('2100.k', curve, 2100)
#execute_calculation('D:\LSDYNA\program\ls-dyna_smp_s_R11_0_winx64_ifort131.exe', 'JellyRoll_punch.dyn')
simu = get_result(2, 3)
print(simu)
os.chdir(owd)
cur_num += 1
return simu
def err_func(param, test):
print(test)
simu = func_simulation(param)
funcSim = interpolate.interp1d(simu[:,0], simu[:,1], bounds_error=False)
funcTest = interpolate.interp1d(test['Y'][:,0], test['Y'][:,1], bounds_error=False)
if np.max(test['Y'][:,0]) > np.max(simu[:,0]):
top = np.max(simu[:,0])
else:
top = np.max(test['Y'][:,0])
#print(top)
if np.min(test['Y'][:,0]) > np.min(simu[:,0]):
lower = np.min(test["Y"][:,0])
else:
lower = np.min(simu[:,0])
inter_sim = funcSim(np.arange(lower,top, 0.001))
inter_test = funcTest(np.arange(lower,top, 0.001))
print(inter_sim)
return inter_sim - inter_test
def do_inverse(test):
"""
TODO
"""
try:
res = optimize.leastsq(err_func, (300, 1.5), args=[test], epsfcn=0.01)
print(res)
except ValueError as e:
print(res)
finally:
os.chdir(owd)
return res
cur_num = 1
owd = os.getcwd()
err_func((200,1), test)
```
|
github_jupyter
|
import numpy as np
from scipy import optimize, interpolate
import pandas as pd
from collections import namedtuple
import os
import shutil
import rwforcReader, rbdoutReader
def read_test_results(fileName):
"""
ToDO
"""
tests_dict = {}
excel = pd.ExcelFile(fileName)
for sheet in excel.sheet_names:
df = excel.parse(sheet)
value = df.values
#print(sheet)
#print(value.shape)
tests_dict[sheet] = value
return tests_dict
test = read_test_results('Z.xlsx')
def make_curve(A, n):
"""
TODO
"""
lt_zero = np.arange(-1, 0, 0.1)
lt_zero_stress = -0.2 * lt_zero
gt_zero = np.arange(0, 1, 0.01)
gt_zero_stress = A * np.power(gt_zero, n)
x = np.hstack([lt_zero, gt_zero])
y = np.hstack([lt_zero_stress, gt_zero_stress])
return np.hstack([x.reshape(-1,1), y.reshape(-1,1)])
def write_curve(fileName, curve, lcid):
"""
TODO
"""
with open(fileName, 'w+') as f:
f.write("*KEYWORD\n")
f.write("*DEFINE_CURVE\n")
f.write("{0}".format(str(int(lcid)))+"\n")
f.write("$#\n")
for p in curve:
f.write("{:.4f}, {:.4f}\n".format(p[0], p[1]))
f.write("*END")
def prepare_files(folder_name, files):
"""
TODO
"""
if not os.path.exists(folder_name):
os.mkdir(folder_name)
for f in files:
shutil.copy(os.path.join(owd,f), os.path.join(owd, folder_name, f))#os.path.join(owd,folder_name,f), os.path.join(owd,f))
os.chdir(folder_name)
def execute_calculation(exe_path, main_file):
os.system(exe_path + " i=" + main_file + " NCPU=8 Memory=2000m")
os.chdir
def get_result(rgb_id, rw_id):
rwf = rwforcReader.rwforcReader('JellyRoll_Z.rwforc')
#print(res[0]["1"])#
rbd = rbdoutReader.rbdoutReader('JellyRoll_Z.rbdout')
# print(res[0]['time'], res[1]['2'])
d_x = np.array(rbd[1][str(rgb_id)]).reshape(-1, 1)
forc = np.array(rwf[1][str(rw_id)]).reshape(-1, 1)
assert d_x.shape[0] == forc.shape[0]
return np.hstack([d_x, forc])
def func_simulation(param):
"""
TODO
"""
global cur_num
with open ("param.txt", "a+") as f:
f.write("{0:d},{1:.4f},{2:.4f}\n".format(cur_num, param[0], param[1]))
curve = make_curve(param[0], param[1])
prepare_files(str(cur_num), ['JellyRoll.blk', 'JellyRoll.mat', 'JellyRoll_punch.dyn'])
write_curve('2100.k', curve, 2100)
#execute_calculation('D:\LSDYNA\program\ls-dyna_smp_s_R11_0_winx64_ifort131.exe', 'JellyRoll_punch.dyn')
simu = get_result(2, 3)
print(simu)
os.chdir(owd)
cur_num += 1
return simu
def err_func(param, test):
print(test)
simu = func_simulation(param)
funcSim = interpolate.interp1d(simu[:,0], simu[:,1], bounds_error=False)
funcTest = interpolate.interp1d(test['Y'][:,0], test['Y'][:,1], bounds_error=False)
if np.max(test['Y'][:,0]) > np.max(simu[:,0]):
top = np.max(simu[:,0])
else:
top = np.max(test['Y'][:,0])
#print(top)
if np.min(test['Y'][:,0]) > np.min(simu[:,0]):
lower = np.min(test["Y"][:,0])
else:
lower = np.min(simu[:,0])
inter_sim = funcSim(np.arange(lower,top, 0.001))
inter_test = funcTest(np.arange(lower,top, 0.001))
print(inter_sim)
return inter_sim - inter_test
def do_inverse(test):
"""
TODO
"""
try:
res = optimize.leastsq(err_func, (300, 1.5), args=[test], epsfcn=0.01)
print(res)
except ValueError as e:
print(res)
finally:
os.chdir(owd)
return res
cur_num = 1
owd = os.getcwd()
err_func((200,1), test)
| 0.240239 | 0.416144 |
```
%matplotlib inline
import os
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
HOUSING_PATH = os.path.join("datasets", "housing")
def load_housing_data(housing_path=HOUSING_PATH):
'''
return pandas dataframe with all housing data
'''
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing_data = load_housing_data()
housing_data.head()
housing_data.info()
housing_data["ocean_proximity"].value_counts()
housing_data.describe()
housing_data.hist(bins=50, figsize=(20, 15))
plt.show()
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing_data, test_size=0.2, random_state=42)
#create income category to use with strata sampling
#the division by 1.5 is to limit the number of categories
housing_data["income_cat"] = np.ceil(housing_data["median_income"] / 1.5)
housing_data["income_cat"].where(housing_data["income_cat"] < 5, 5.0, inplace=True)
housing_data["income_cat"].hist()
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_idx, test_idx in split.split(housing_data, housing_data["income_cat"]):
strat_train_set = housing_data.loc[train_idx]
strat_test_set = housing_data.loc[test_idx]
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
for set_ in (strat_test_set, strat_train_set):
set_.drop("income_cat", axis=1, inplace=True)
housing_data.plot(kind="scatter", x="longitude", y="latitude")
housing_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
housing_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing_data["population"]/100, label="population", figsize=(10,7)
, c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True)
#correlation matrix (Pearson's r)
corr_matrix = housing_data.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing_data[attributes], figsize=(12, 8))
housing_data.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1)
# working around empty values
# option 1: drop null values
# housing_data.dropna(subset=["total_bedrooms"])
# option 2: drop the whole column
# housing_data.drop("total_bedrooms", axis=1)
# option 3: replace empty with median
# median = housing_data["total_bedrooms"].median()
# housing_data["total_bedrooms"].fillna(median, inplace=True)
# handle missing data with scikit-learn imputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
# get only numerical set
housing = train_set.drop("median_house_value", axis=1)
housing_labels = train_set["median_house_value"].copy()
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
print(imputer.statistics_)
X = imputer.transform(housing_num) # numpy array
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
# transform categorical strings to one hot encoded categories
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
housing_cat_1hot = encoder.fit_transform(housing_data["ocean_proximity"].values.reshape(-1,1))
print(housing_cat_1hot.toarray())
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median"))
, ('std_scalar', StandardScaler())
])
housing_tr = num_pipeline.fit_transform(housing_num)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_tr, housing_labels)
some_data = num_pipeline.transform(housing_num.iloc[:5])
some_labels = housing_labels.iloc[:5]
preds = lin_reg.predict(some_data)
print(preds)
#print(some_labels)
# model evaluation with cross validation
from sklearn.model_selection import cross_val_score
scores = cross_val_score(lin_reg, housing_tr, housing_labels, scoring='neg_mean_squared_error', cv=10)
scores_u = np.sqrt(-scores)
print(scores_u, scores_u.mean(), scores_u.std())
```
|
github_jupyter
|
%matplotlib inline
import os
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
HOUSING_PATH = os.path.join("datasets", "housing")
def load_housing_data(housing_path=HOUSING_PATH):
'''
return pandas dataframe with all housing data
'''
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing_data = load_housing_data()
housing_data.head()
housing_data.info()
housing_data["ocean_proximity"].value_counts()
housing_data.describe()
housing_data.hist(bins=50, figsize=(20, 15))
plt.show()
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing_data, test_size=0.2, random_state=42)
#create income category to use with strata sampling
#the division by 1.5 is to limit the number of categories
housing_data["income_cat"] = np.ceil(housing_data["median_income"] / 1.5)
housing_data["income_cat"].where(housing_data["income_cat"] < 5, 5.0, inplace=True)
housing_data["income_cat"].hist()
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_idx, test_idx in split.split(housing_data, housing_data["income_cat"]):
strat_train_set = housing_data.loc[train_idx]
strat_test_set = housing_data.loc[test_idx]
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
for set_ in (strat_test_set, strat_train_set):
set_.drop("income_cat", axis=1, inplace=True)
housing_data.plot(kind="scatter", x="longitude", y="latitude")
housing_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
housing_data.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing_data["population"]/100, label="population", figsize=(10,7)
, c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True)
#correlation matrix (Pearson's r)
corr_matrix = housing_data.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing_data[attributes], figsize=(12, 8))
housing_data.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1)
# working around empty values
# option 1: drop null values
# housing_data.dropna(subset=["total_bedrooms"])
# option 2: drop the whole column
# housing_data.drop("total_bedrooms", axis=1)
# option 3: replace empty with median
# median = housing_data["total_bedrooms"].median()
# housing_data["total_bedrooms"].fillna(median, inplace=True)
# handle missing data with scikit-learn imputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
# get only numerical set
housing = train_set.drop("median_house_value", axis=1)
housing_labels = train_set["median_house_value"].copy()
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)
print(imputer.statistics_)
X = imputer.transform(housing_num) # numpy array
housing_tr = pd.DataFrame(X, columns=housing_num.columns)
# transform categorical strings to one hot encoded categories
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
housing_cat_1hot = encoder.fit_transform(housing_data["ocean_proximity"].values.reshape(-1,1))
print(housing_cat_1hot.toarray())
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median"))
, ('std_scalar', StandardScaler())
])
housing_tr = num_pipeline.fit_transform(housing_num)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_tr, housing_labels)
some_data = num_pipeline.transform(housing_num.iloc[:5])
some_labels = housing_labels.iloc[:5]
preds = lin_reg.predict(some_data)
print(preds)
#print(some_labels)
# model evaluation with cross validation
from sklearn.model_selection import cross_val_score
scores = cross_val_score(lin_reg, housing_tr, housing_labels, scoring='neg_mean_squared_error', cv=10)
scores_u = np.sqrt(-scores)
print(scores_u, scores_u.mean(), scores_u.std())
| 0.57081 | 0.691002 |
```
%matplotlib inline
import gym
import itertools
import matplotlib
import numpy as np
import pandas as pd
import sys
if "../" not in sys.path:
sys.path.append("../")
from collections import defaultdict
from lib.envs.windy_gridworld import WindyGridworldEnv
from lib import plotting
matplotlib.style.use('ggplot')
env = WindyGridworldEnv()
def make_epsilon_greedy_policy(Q, epsilon, nA):
"""
Creates an epsilon-greedy policy based on a given Q-function and epsilon.
Args:
Q: A dictionary that maps from state -> action-values.
Each value is a numpy array of length nA (see below)
epsilon: The probability to select a random action . float between 0 and 1.
nA: Number of actions in the environment.
Returns:
A function that takes the observation as an argument and returns
the probabilities for each action in the form of a numpy array of length nA.
"""
def policy_fn(observation):
A = np.ones(nA, dtype=float) * epsilon / nA
best_action = np.argmax(Q[observation])
A[best_action] += (1.0 - epsilon)
return A
return policy_fn
def sarsa(env, num_episodes, discount_factor=1.0, alpha=0.5, epsilon=0.1):
"""
SARSA algorithm: On-policy TD control. Finds the optimal epsilon-greedy policy.
Args:
env: OpenAI environment.
num_episodes: Number of episodes to run for.
discount_factor: Gamma discount factor.
alpha: TD learning rate.
epsilon: Chance the sample a random action. Float betwen 0 and 1.
Returns:
A tuple (Q, stats).
Q is the optimal action-value function, a dictionary mapping state -> action values.
stats is an EpisodeStats object with two numpy arrays for episode_lengths and episode_rewards.
"""
# The final action-value function.
# A nested dictionary that maps state -> (action -> action-value).
Q = defaultdict(lambda: np.zeros(env.action_space.n))
gamma = discount_factor
# Keeps track of useful statistics
stats = plotting.EpisodeStats(
episode_lengths=np.zeros(num_episodes),
episode_rewards=np.zeros(num_episodes))
# The policy we're following
policy = make_epsilon_greedy_policy(Q, epsilon, env.action_space.n)
for i_episode in range(num_episodes):
# Print out which episode we're on, useful for debugging.
if (i_episode + 1) % 100 == 0:
print("\rEpisode {}/{}.".format(i_episode + 1, num_episodes), end="")
sys.stdout.flush()
s_t = env.reset()
a_probs = policy(s_t)
a_t = np.random.choice(np.arange(len(a_probs)), p=a_probs)
stats.episode_lengths[i_episode] += 1
while True:
s_t_1, r_t, done, _ = env.step(a_t)
a_probs = policy(s_t_1)
a_t_1 = np.random.choice(np.arange(len(a_probs)), p=a_probs)
Q[s_t][a_t] = Q[s_t][a_t] + alpha * (r_t + gamma * Q[s_t_1][a_t_1] - Q[s_t][a_t])
s_t = s_t_1
a_t = a_t_1
# Update statistics
stats.episode_rewards[i_episode] += r_t
stats.episode_lengths[i_episode] += 1
if done:
break
# Implement this!
return Q, stats
Q, stats = sarsa(env, 200)
```
这三个图其实意思都差不多
- 图1:Episode的长度 随 时间的变化。Episode的长度越短,代表越快到达 G,这说明 PI 逐渐找到了最优解。
- 图2:和图1意思差不多,Episode的长度 = -1 * Episode Reward
- 图3:和图1的意思也差不多,曲线越陡,代表一个Episode所用的timestep越少,即episode越短
```
plotting.plot_episode_stats(stats)
```
|
github_jupyter
|
%matplotlib inline
import gym
import itertools
import matplotlib
import numpy as np
import pandas as pd
import sys
if "../" not in sys.path:
sys.path.append("../")
from collections import defaultdict
from lib.envs.windy_gridworld import WindyGridworldEnv
from lib import plotting
matplotlib.style.use('ggplot')
env = WindyGridworldEnv()
def make_epsilon_greedy_policy(Q, epsilon, nA):
"""
Creates an epsilon-greedy policy based on a given Q-function and epsilon.
Args:
Q: A dictionary that maps from state -> action-values.
Each value is a numpy array of length nA (see below)
epsilon: The probability to select a random action . float between 0 and 1.
nA: Number of actions in the environment.
Returns:
A function that takes the observation as an argument and returns
the probabilities for each action in the form of a numpy array of length nA.
"""
def policy_fn(observation):
A = np.ones(nA, dtype=float) * epsilon / nA
best_action = np.argmax(Q[observation])
A[best_action] += (1.0 - epsilon)
return A
return policy_fn
def sarsa(env, num_episodes, discount_factor=1.0, alpha=0.5, epsilon=0.1):
"""
SARSA algorithm: On-policy TD control. Finds the optimal epsilon-greedy policy.
Args:
env: OpenAI environment.
num_episodes: Number of episodes to run for.
discount_factor: Gamma discount factor.
alpha: TD learning rate.
epsilon: Chance the sample a random action. Float betwen 0 and 1.
Returns:
A tuple (Q, stats).
Q is the optimal action-value function, a dictionary mapping state -> action values.
stats is an EpisodeStats object with two numpy arrays for episode_lengths and episode_rewards.
"""
# The final action-value function.
# A nested dictionary that maps state -> (action -> action-value).
Q = defaultdict(lambda: np.zeros(env.action_space.n))
gamma = discount_factor
# Keeps track of useful statistics
stats = plotting.EpisodeStats(
episode_lengths=np.zeros(num_episodes),
episode_rewards=np.zeros(num_episodes))
# The policy we're following
policy = make_epsilon_greedy_policy(Q, epsilon, env.action_space.n)
for i_episode in range(num_episodes):
# Print out which episode we're on, useful for debugging.
if (i_episode + 1) % 100 == 0:
print("\rEpisode {}/{}.".format(i_episode + 1, num_episodes), end="")
sys.stdout.flush()
s_t = env.reset()
a_probs = policy(s_t)
a_t = np.random.choice(np.arange(len(a_probs)), p=a_probs)
stats.episode_lengths[i_episode] += 1
while True:
s_t_1, r_t, done, _ = env.step(a_t)
a_probs = policy(s_t_1)
a_t_1 = np.random.choice(np.arange(len(a_probs)), p=a_probs)
Q[s_t][a_t] = Q[s_t][a_t] + alpha * (r_t + gamma * Q[s_t_1][a_t_1] - Q[s_t][a_t])
s_t = s_t_1
a_t = a_t_1
# Update statistics
stats.episode_rewards[i_episode] += r_t
stats.episode_lengths[i_episode] += 1
if done:
break
# Implement this!
return Q, stats
Q, stats = sarsa(env, 200)
plotting.plot_episode_stats(stats)
| 0.693992 | 0.759983 |
# Making Scalable Graphs with Python
* Importing the MatPlotLib PyPlot tools as plt
* Inline graph display vs saving a graph
* Your created graph will in in the same directory as the notebook that you created it in
* Each time you run the creation cell, you will overwrite the save file
* Basic line graphs, titles, and axis labels
```
import matplotlib.pyplot as plt
```
By using the **as** command, we can now call the tools from **matplotlib.plyplot** using plt.*tool*
For example to graph x -coordinates (1, 2, 3, 4, 5) with y-coordinates (6, 7, 8, 9, 10) which gives the points (1, 6), (2, 7), (3, 8), (4, 9), and (5, 10) I would do the following:
```
plt.plot([1,2,3,4,5], [6, 7,8, 9, 3])
plt.show()
```
### You try:
Plot the points (1, 2), (3, 4), (5, 6), (7, 1), (8, 9) in the cell below
```
# Write the code to plot the points given in the cell above here
```
I can create my x points and y points as separate lists rather than include them in the plot command.
I can also use simple commands to label the axis and title the graph. Study the examples below to see how this works.
```
x = [1,2,3,4,5]
y = [5,7,4,8,6]
plt.plot(x, y)
plt.xlabel('x Axis Label Example')
plt.ylabel("y Axis Label Example")
plt.title('Graph Title Example')
plt.show()
```
### You try:
* Make a list of x coordinates and a list of y coordinates (different from the lists above)
* Use the plot command with those lists
* Create labels for each axis and a title for the graph
* use the show command to display your labeled graph
```
# Create your labeled graph according to the directions above here
```
You may want multiple lines and a legend. Study the code below:
```
x = [1,2,3,4,5]
y = [4,6,5,7,3]
y2 = [6,2,4,5,1]
plt.plot(x, y, label='First Line')
plt.plot(x, y2, label='Second Line')
plt.xlabel('X Label')
plt.ylabel("Y Label")
plt.title('Multiple Lines and Legends Example')
plt.legend()
plt.savefig("plt01example.png") # this line saves this as a PNG file. You can p[review this from the jupyter file manager
plt.savefig("plt01example.svg") # This saves the figure as an SVG. This format won't pixelate when enlarged.
plt.show()
```
For your science project graphs, you probably want to save the graph as an svg (scalable vector graphics) file. You can do that as shown below. Note how you can name the file and how you can change the type you save it as. PNG and PDF are also possible save types. See above for saving as PNG and SVG. Matplotlib figures out the format based on your filename extensions. You must save the figure befopre showing it, but after defining all of the parts you want.
Imagine you were measuring plant growth under bright and low light conditions over 5 weeks.
* Make a list for the x axis consisting of the numbers zero through five for start (zerop) and each following week
* Make two lists of y coordinates representing height in inches over the weeks, one each for your high and low light conditions.
* Plot each line with a label based ont he light condition it represents.
* Label the x axis "Week"
* Label the y axis "Height in inches"
* Title the graph appropriately for the experiment.
* Save your graph in both png and svg formats with files named "experiment.png" and "experiment.svg"
* Display your graph
* When finished upload your notebook and both graphs.
|
github_jupyter
|
import matplotlib.pyplot as plt
plt.plot([1,2,3,4,5], [6, 7,8, 9, 3])
plt.show()
# Write the code to plot the points given in the cell above here
x = [1,2,3,4,5]
y = [5,7,4,8,6]
plt.plot(x, y)
plt.xlabel('x Axis Label Example')
plt.ylabel("y Axis Label Example")
plt.title('Graph Title Example')
plt.show()
# Create your labeled graph according to the directions above here
x = [1,2,3,4,5]
y = [4,6,5,7,3]
y2 = [6,2,4,5,1]
plt.plot(x, y, label='First Line')
plt.plot(x, y2, label='Second Line')
plt.xlabel('X Label')
plt.ylabel("Y Label")
plt.title('Multiple Lines and Legends Example')
plt.legend()
plt.savefig("plt01example.png") # this line saves this as a PNG file. You can p[review this from the jupyter file manager
plt.savefig("plt01example.svg") # This saves the figure as an SVG. This format won't pixelate when enlarged.
plt.show()
| 0.693577 | 0.990505 |
```
import igraph as ig
import numpy as np
from sympy.solvers import nsolve
from sympy import *
from scipy.stats import norm
from __future__ import division
import powerlaw as pl
%matplotlib inline
import matplotlib.pyplot as plt
from sympy.solvers import nsolve
from sympy import *
from scipy import special
from scipy import stats
import pandas as pd
import scipy as sp
from scipy import stats
from scipy.spatial import distance
def dist(v1,v2):
dist = distance.euclidean((v1[0],v1[1]),(v2[0],v2[1]))
return dist
aggragate=pd.read_csv('final_table_galicia.csv')
x_coords = (aggragate['X'].values).reshape(550,1)
y_coords = (aggragate['Y'].values).reshape(550,1)
population = ((aggragate['population_y'].values).reshape(550,1)).tolist()
coords = np.concatenate([x_coords,y_coords],axis=1)
n = len(x_coords)
alldist = []
A = np.zeros((n,n))
A_binom = np.zeros((n,n))
count=0
for i in range(0,n):
for j in range(i+1,n):
m = (population[i][0]*population[j][0])/(dist(coords[i],coords[j]))**2
A[i][j] = m
A[j][i] = m
Dt = np.sum(A,axis=1).tolist()
DD = np.diag(Dt)
L = A - DD
q = np.linalg.eigvals(L) ### eigenvalue ditribution
qsorted = sorted(q,reverse=True)
q = qsorted
q = np.real(q)
qq = q
qq[0] = 0.
#coefficients in lotka volterra model
c = 0.5
ax = 1
ay = 1
sx = 1
sy = 1
d1 = 0.01
d2 = 0.01
x0 = ay*sx*(c*sy +ax)/(ax*ay + sx*sy*c**2 )
y0 = ax*sy*(-c*sx +ay)/(ax*ay + sx*sy*c**2 )
x, y = symbols('x y ')
f_x = diff(x*(1-x) + c*x*y ,x)
f_y = diff( x*(1-x) + c*x*y,y)
g_x = diff(y*(1-y) - c*x*y,x)
g_y = diff(y*(1-y) - c*x*y,y)
fx = np.array([(f_x.subs(x,x0)).subs(y,y0)],dtype='float')[0]
fy = np.array([(f_y.subs(x,x0)).subs(y,y0)],dtype='float')[0]
gx = np.array([(g_x.subs(x,x0)).subs(y,y0)],dtype='float')[0]
gy = np.array([(g_y.subs(x,x0)).subs(y,y0)],dtype='float')[0]
J = [[fx,fy],[gx,gy]]### Jacobian matrix
d1 = 0.01
d2 = 0.01
a12 = 2.1
a21 = 0.0
D = [[d1 + a12*y0,a12*x0],[a21*y0, d2 + a21*x0]]
J = [[fx,fy],[gx,gy]]
trj = np.trace(J)
trd = np.trace(D)
detj = np.linalg.det(J)
detd = np.linalg.det(D)
bb=(fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])
aa=detd
cc = detj
print((-bb/(2*aa)))
lambda1 = ((-bb - np.sqrt(bb**2 - 4*aa*cc))/(2*aa))
lambda2 = ((-bb + np.sqrt(bb**2 - 4*aa*cc))/(2*aa))
lambda1
lambda2
bth = []
cth=[]
xq = np.linspace(-240,0,700)
for i in range(len(xq)):
bth.append(-(trj + trd*xq[i]))
cth.append(detj + (fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])*xq[i] + detd*xq[i]**2)
solth = []
for j in range(len(xq)):
if (bth[j]*bth[j] - 4*cth[j]) > 0:
solth.append((-bth[j] + np.sqrt(bth[j]*bth[j] - 4*cth[j]))/2)
if (bth[j]*bth[j] - 4*cth[j]) < 0:
solth.append(-bth[j]/2)
b1 = []
c1=[]
for i in range(len(qq)):
b1.append(-(trj + trd*qq[i]))
c1.append(detj + (fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])*q[i] + detd*q[i]**2)
sol = []
for j in range(len(q)):
if (b1[j]*b1[j] - 4*c1[j]) > 0:
sol.append((-b1[j] + np.sqrt(b1[j]*b1[j] - 4*c1[j]))/2)
if (b1[j]*b1[j] - 4*c1[j]) < 0:
sol.append(-b1[j]/2)
f = plt.figure(figsize=[2*6.4, 2*4.8])
font0 = FontProperties()
font1 = font0.copy()
font1.set_weight('bold')
font1.set_size('large')
font1.set_family('sans-serif')
ax1 = plt.subplot(2,2,1)
plt.text(0.05, 0.93, '(a)',
verticalalignment='center', horizontalalignment='center',color='black',fontproperties=font1,fontsize=20,transform=ax1.transAxes)
plt.plot(xq,solth,'--',color='brown')
#plt.plot(qq,sol,'.',color = '#6495ED',label = 'Complete Graph')
plt.plot(qq,sol,'.',color = 'black')
plt.plot(lambda1,0,'o',color = 'red')
plt.plot(lambda2,0,'o',color = 'red')
plt.annotate(r'$\Lambda_{\alpha_1}^G$', xy=(lambda1, 0), xytext=(-17, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.annotate(r'$\Lambda_{\alpha_2}^G$', xy=(lambda2, 0), xytext=(-6, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.xlabel(r'$\Lambda_{\alpha}$',fontsize=15)
plt.ylabel(r'$Re (\lambda_{\alpha})$',fontsize=15)
plt.tick_params(axis='both', which='major', labelsize=15)
plt.xlim(-40,5)
plt.ylim(-0.8,0.2)
ax2 = plt.subplot(2,2,2)
plt.text(0.05, 0.93, '(b)',
verticalalignment='center', horizontalalignment='center',color='black',fontproperties=font1,fontsize=20,transform=ax2.transAxes)
plt.plot(xq_c,solth_c,'--',color='brown')
#plt.plot(qq,sol,'.',color = '#6495ED',label = 'Complete Graph')
plt.plot(qq_c,sol_c,'.',color = 'black')
plt.plot(lambda1_c,0,'o',color = 'red')
plt.plot(lambda2_c,0,'o',color = 'red')
plt.annotate(r'$\Lambda_{\alpha_1}^C$', xy=(lambda1_c, 0), xytext=(-2, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.annotate(r'$\Lambda_{\alpha_2}^C$', xy=(lambda2_c, 0), xytext=(-1, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.xlabel(r'$\Lambda_{\alpha}$',fontsize=15)
plt.ylabel(r'$Re (\lambda_{\alpha})$',fontsize=15)
plt.tick_params(axis='both', which='major', labelsize=15)
plt.xlim(-6,1)
plt.ylim(-0.8,0.2)
plt.tight_layout()
#plt.savefig('esi_eig_dist.pdf',bbox_inches='tight')
unew2y = []
stdnew2y = []
for i in range(len(degree)):
unew2y.append(mean2y[degree[i]][0])
stdnew2y.append(std2y[degree[i]][0])
plt.errorbar(np.linspace(0,549,550),np.array(unew2y),yerr=np.array(stdnew2y), fmt='.',elinewidth=0.4,ecolor='grey',color='black')
plt.xlabel(r'node index $i$',fontsize = 12)
plt.ylabel(r'$\langle v_i \rangle$',fontsize = 12)
#plt.ylim(0,1.4)
```
|
github_jupyter
|
import igraph as ig
import numpy as np
from sympy.solvers import nsolve
from sympy import *
from scipy.stats import norm
from __future__ import division
import powerlaw as pl
%matplotlib inline
import matplotlib.pyplot as plt
from sympy.solvers import nsolve
from sympy import *
from scipy import special
from scipy import stats
import pandas as pd
import scipy as sp
from scipy import stats
from scipy.spatial import distance
def dist(v1,v2):
dist = distance.euclidean((v1[0],v1[1]),(v2[0],v2[1]))
return dist
aggragate=pd.read_csv('final_table_galicia.csv')
x_coords = (aggragate['X'].values).reshape(550,1)
y_coords = (aggragate['Y'].values).reshape(550,1)
population = ((aggragate['population_y'].values).reshape(550,1)).tolist()
coords = np.concatenate([x_coords,y_coords],axis=1)
n = len(x_coords)
alldist = []
A = np.zeros((n,n))
A_binom = np.zeros((n,n))
count=0
for i in range(0,n):
for j in range(i+1,n):
m = (population[i][0]*population[j][0])/(dist(coords[i],coords[j]))**2
A[i][j] = m
A[j][i] = m
Dt = np.sum(A,axis=1).tolist()
DD = np.diag(Dt)
L = A - DD
q = np.linalg.eigvals(L) ### eigenvalue ditribution
qsorted = sorted(q,reverse=True)
q = qsorted
q = np.real(q)
qq = q
qq[0] = 0.
#coefficients in lotka volterra model
c = 0.5
ax = 1
ay = 1
sx = 1
sy = 1
d1 = 0.01
d2 = 0.01
x0 = ay*sx*(c*sy +ax)/(ax*ay + sx*sy*c**2 )
y0 = ax*sy*(-c*sx +ay)/(ax*ay + sx*sy*c**2 )
x, y = symbols('x y ')
f_x = diff(x*(1-x) + c*x*y ,x)
f_y = diff( x*(1-x) + c*x*y,y)
g_x = diff(y*(1-y) - c*x*y,x)
g_y = diff(y*(1-y) - c*x*y,y)
fx = np.array([(f_x.subs(x,x0)).subs(y,y0)],dtype='float')[0]
fy = np.array([(f_y.subs(x,x0)).subs(y,y0)],dtype='float')[0]
gx = np.array([(g_x.subs(x,x0)).subs(y,y0)],dtype='float')[0]
gy = np.array([(g_y.subs(x,x0)).subs(y,y0)],dtype='float')[0]
J = [[fx,fy],[gx,gy]]### Jacobian matrix
d1 = 0.01
d2 = 0.01
a12 = 2.1
a21 = 0.0
D = [[d1 + a12*y0,a12*x0],[a21*y0, d2 + a21*x0]]
J = [[fx,fy],[gx,gy]]
trj = np.trace(J)
trd = np.trace(D)
detj = np.linalg.det(J)
detd = np.linalg.det(D)
bb=(fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])
aa=detd
cc = detj
print((-bb/(2*aa)))
lambda1 = ((-bb - np.sqrt(bb**2 - 4*aa*cc))/(2*aa))
lambda2 = ((-bb + np.sqrt(bb**2 - 4*aa*cc))/(2*aa))
lambda1
lambda2
bth = []
cth=[]
xq = np.linspace(-240,0,700)
for i in range(len(xq)):
bth.append(-(trj + trd*xq[i]))
cth.append(detj + (fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])*xq[i] + detd*xq[i]**2)
solth = []
for j in range(len(xq)):
if (bth[j]*bth[j] - 4*cth[j]) > 0:
solth.append((-bth[j] + np.sqrt(bth[j]*bth[j] - 4*cth[j]))/2)
if (bth[j]*bth[j] - 4*cth[j]) < 0:
solth.append(-bth[j]/2)
b1 = []
c1=[]
for i in range(len(qq)):
b1.append(-(trj + trd*qq[i]))
c1.append(detj + (fx*D[1][1] + gy*D[0][0] - D[1][0]*fy - gx*D[0][1])*q[i] + detd*q[i]**2)
sol = []
for j in range(len(q)):
if (b1[j]*b1[j] - 4*c1[j]) > 0:
sol.append((-b1[j] + np.sqrt(b1[j]*b1[j] - 4*c1[j]))/2)
if (b1[j]*b1[j] - 4*c1[j]) < 0:
sol.append(-b1[j]/2)
f = plt.figure(figsize=[2*6.4, 2*4.8])
font0 = FontProperties()
font1 = font0.copy()
font1.set_weight('bold')
font1.set_size('large')
font1.set_family('sans-serif')
ax1 = plt.subplot(2,2,1)
plt.text(0.05, 0.93, '(a)',
verticalalignment='center', horizontalalignment='center',color='black',fontproperties=font1,fontsize=20,transform=ax1.transAxes)
plt.plot(xq,solth,'--',color='brown')
#plt.plot(qq,sol,'.',color = '#6495ED',label = 'Complete Graph')
plt.plot(qq,sol,'.',color = 'black')
plt.plot(lambda1,0,'o',color = 'red')
plt.plot(lambda2,0,'o',color = 'red')
plt.annotate(r'$\Lambda_{\alpha_1}^G$', xy=(lambda1, 0), xytext=(-17, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.annotate(r'$\Lambda_{\alpha_2}^G$', xy=(lambda2, 0), xytext=(-6, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.xlabel(r'$\Lambda_{\alpha}$',fontsize=15)
plt.ylabel(r'$Re (\lambda_{\alpha})$',fontsize=15)
plt.tick_params(axis='both', which='major', labelsize=15)
plt.xlim(-40,5)
plt.ylim(-0.8,0.2)
ax2 = plt.subplot(2,2,2)
plt.text(0.05, 0.93, '(b)',
verticalalignment='center', horizontalalignment='center',color='black',fontproperties=font1,fontsize=20,transform=ax2.transAxes)
plt.plot(xq_c,solth_c,'--',color='brown')
#plt.plot(qq,sol,'.',color = '#6495ED',label = 'Complete Graph')
plt.plot(qq_c,sol_c,'.',color = 'black')
plt.plot(lambda1_c,0,'o',color = 'red')
plt.plot(lambda2_c,0,'o',color = 'red')
plt.annotate(r'$\Lambda_{\alpha_1}^C$', xy=(lambda1_c, 0), xytext=(-2, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.annotate(r'$\Lambda_{\alpha_2}^C$', xy=(lambda2_c, 0), xytext=(-1, -0.25),
arrowprops=dict(arrowstyle="->"),fontsize=15)
plt.xlabel(r'$\Lambda_{\alpha}$',fontsize=15)
plt.ylabel(r'$Re (\lambda_{\alpha})$',fontsize=15)
plt.tick_params(axis='both', which='major', labelsize=15)
plt.xlim(-6,1)
plt.ylim(-0.8,0.2)
plt.tight_layout()
#plt.savefig('esi_eig_dist.pdf',bbox_inches='tight')
unew2y = []
stdnew2y = []
for i in range(len(degree)):
unew2y.append(mean2y[degree[i]][0])
stdnew2y.append(std2y[degree[i]][0])
plt.errorbar(np.linspace(0,549,550),np.array(unew2y),yerr=np.array(stdnew2y), fmt='.',elinewidth=0.4,ecolor='grey',color='black')
plt.xlabel(r'node index $i$',fontsize = 12)
plt.ylabel(r'$\langle v_i \rangle$',fontsize = 12)
#plt.ylim(0,1.4)
| 0.262275 | 0.426202 |
### Model
- 3 VGG Blocks
- Regularization: Dropout 20%
- Optimizer: SGD
- Loss: categorical_crossentropy
### Dataset
- Images cropped and resized
- Original Colorscheme
- Scaled in Generator and resized to 300x300x3
```
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras_preprocessing.image import ImageDataGenerator
from keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras import regularizers, optimizers
from tensorflow.keras.callbacks import EarlyStopping
from keras.optimizers import SGD
df = pd.read_csv('/content/drive/MyDrive/Multi_Class/train4_small.csv')
df.head()
df["labels"].replace({"macular degeneration": "md"}, inplace=True)
df.labels.value_counts()
```
### ImageGenerator
```
from sklearn.utils import shuffle
#df = shuffle(df)
# Directory
indir = '/content/drive/MyDrive/Datensätze/four'
datagen = ImageDataGenerator(rescale=1./255., validation_split = 0.25)
train_gen = datagen.flow_from_dataframe(dataframe = df,
directory = indir,
x_col = "filename",
y_col = 'labels',
batch_size = 10,
seed = 2,
shuffle = True,
class_mode = "categorical",
classes = ['opacity', 'glaucoma','md', 'normal'],
target_size = (300,300),
subset='training')
val_gen = datagen.flow_from_dataframe(dataframe = df,
directory = indir,
x_col = "filename",
y_col = 'labels',
batch_size = 10,
seed = 2,
shuffle = True,
class_mode = "categorical",
classes = ['opacity', 'glaucoma','md', 'normal'],
target_size = (300,300),
subset='validation')
imgs, labels = next(train_gen)
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20,20))
axes = axes.flatten()
for img, ax in zip( images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
plotImages(imgs)
print(labels)
```
### Model
```
early_stopping = EarlyStopping(patience=5)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(300, 300, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.2))
model.add(Dense(4, activation='softmax'))
opt = SGD(learning_rate=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
step_size_train = train_gen.n//train_gen.batch_size
step_size_val = val_gen.n//val_gen.batch_size
history = model.fit(x=train_gen, validation_data=val_gen, steps_per_epoch=step_size_train,
validation_steps=step_size_val, epochs=100, callbacks=[early_stopping],verbose=2)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(19)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
```
|
github_jupyter
|
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras_preprocessing.image import ImageDataGenerator
from keras.layers import Dense, Activation, Flatten, Dropout, BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
from keras import regularizers, optimizers
from tensorflow.keras.callbacks import EarlyStopping
from keras.optimizers import SGD
df = pd.read_csv('/content/drive/MyDrive/Multi_Class/train4_small.csv')
df.head()
df["labels"].replace({"macular degeneration": "md"}, inplace=True)
df.labels.value_counts()
from sklearn.utils import shuffle
#df = shuffle(df)
# Directory
indir = '/content/drive/MyDrive/Datensätze/four'
datagen = ImageDataGenerator(rescale=1./255., validation_split = 0.25)
train_gen = datagen.flow_from_dataframe(dataframe = df,
directory = indir,
x_col = "filename",
y_col = 'labels',
batch_size = 10,
seed = 2,
shuffle = True,
class_mode = "categorical",
classes = ['opacity', 'glaucoma','md', 'normal'],
target_size = (300,300),
subset='training')
val_gen = datagen.flow_from_dataframe(dataframe = df,
directory = indir,
x_col = "filename",
y_col = 'labels',
batch_size = 10,
seed = 2,
shuffle = True,
class_mode = "categorical",
classes = ['opacity', 'glaucoma','md', 'normal'],
target_size = (300,300),
subset='validation')
imgs, labels = next(train_gen)
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20,20))
axes = axes.flatten()
for img, ax in zip( images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
plotImages(imgs)
print(labels)
early_stopping = EarlyStopping(patience=5)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(300, 300, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.2))
model.add(Dense(4, activation='softmax'))
opt = SGD(learning_rate=0.001, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
step_size_train = train_gen.n//train_gen.batch_size
step_size_val = val_gen.n//val_gen.batch_size
history = model.fit(x=train_gen, validation_data=val_gen, steps_per_epoch=step_size_train,
validation_steps=step_size_val, epochs=100, callbacks=[early_stopping],verbose=2)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(19)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
| 0.758063 | 0.804713 |
```
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torchvision import datasets, models, transforms
import torchvision
import matplotlib.pyplot as plt
import time
import os
import copy
import json
from sklearn.metrics import roc_curve
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# Get model outputs and calculate loss
# Special case for inception because in training it has an auxiliary output. In train
# mode we calculate the loss by summing the final output and the auxiliary output
# but in testing we only consider the final output.
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'valid':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history, outputs, labels
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# Initialize these variables which will be set in this if statement. Each of these
# variables is model specific.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
from google.colab import drive
drive.mount('/content/gdrive')
!ls '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/'
# Top level data directory. Here we assume the format of the directory conforms
# to the ImageFolder structure
data_dir = "/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1"
#test_data_dir = "../input/hackathon-blossom-flower-classification/"
# Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "inception"
# Number of classes in the dataset
num_classes = 2
# Batch size for training (change depending on how much memory you have)
batch_size = 16
# Number of epochs to train for
num_epochs = 15
# Flag for feature extracting. When False, we finetune the whole model,
# when True we only update the reshaped layer params
feature_extract = False
# Initialize the model for this run
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# Print the model we just instantiated
#print(model_ft)
print("Model Loading Process Done")
data_transforms = {
'transform': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
#print(len(datasets.ImageFolder(data_dir + '/train')))
full_dataset = datasets.ImageFolder(data_dir + '/train', data_transforms['transform'])
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
#print(train_size)
#print(test_size)
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
image_datasets = {
'train':train_dataset,
'valid':test_dataset
}
dataloaders_dict = {
'train':torch.utils.data.DataLoader(image_datasets['train'], batch_size=batch_size, shuffle=True, num_workers=4),
'valid':torch.utils.data.DataLoader(image_datasets['valid'], batch_size=batch_size, shuffle=True, num_workers=4)
}
# Detect if we have a GPU available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# Send the model to GPU
model_ft = model_ft.to(device)
# Gather the parameters to be optimized/updated in this run. If we are
# finetuning we will be updating all parameters. However, if we are
# doing feature extract method, we will only update the parameters
# that we have just initialized, i.e. the parameters with requires_grad
# is True.
params_to_update = model_ft.parameters()
#print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
#print("\t",name)
pass
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
#print("\t",name)
pass
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
#optimizer_ft = optim.Adam(params_to_update,lr=0.0001)
# Setup the loss fxn
criterion = nn.CrossEntropyLoss()
# Train and evaluate
model_ft, hist, out, lab = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft, num_epochs=15, is_inception=(model_name=="inception"))
def save_checkpoint():
checkpoint = {
'model':model_ft,
'state_dict':model_ft.state_dict(),
'optimizer':optimizer_ft.state_dict()
}
torch.save(checkpoint, '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/checkpoint.pt')
def load_checkpoint(filepath, inference = False):
checkpoint = torch.load(filepath + 'checkpoint.pt')
model = checkpoint['model']
if inference:
for parameter in model.parameter():
parameter.require_grad = False
model.eval()
model.to(device)
return model
save_checkpoint()
model_ft = load_checkpoint(filepath='/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/')
!ls '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/test/'
test_data_dir ="/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/"
data_transforms = {
'testing': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
test_image_datasets = {x: datasets.ImageFolder(os.path.join('/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/test/'), data_transforms[x]) for x in ['testing']}
test_dataloaders_dict = {x: torch.utils.data.DataLoader(test_image_datasets[x], batch_size=batch_size, shuffle=False, num_workers=4) for x in ['testing']}
output = []
for inputs, labels in test_dataloaders_dict['testing']:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model_ft(inputs)
_, predicted = torch.max(outputs, 1)
#print(predicted)
for i in predicted:
output.append(int(i))
output
```
|
github_jupyter
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torchvision import datasets, models, transforms
import torchvision
import matplotlib.pyplot as plt
import time
import os
import copy
import json
from sklearn.metrics import roc_curve
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# Get model outputs and calculate loss
# Special case for inception because in training it has an auxiliary output. In train
# mode we calculate the loss by summing the final output and the auxiliary output
# but in testing we only consider the final output.
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'valid':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history, outputs, labels
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# Initialize these variables which will be set in this if statement. Each of these
# variables is model specific.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
from google.colab import drive
drive.mount('/content/gdrive')
!ls '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/'
# Top level data directory. Here we assume the format of the directory conforms
# to the ImageFolder structure
data_dir = "/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1"
#test_data_dir = "../input/hackathon-blossom-flower-classification/"
# Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "inception"
# Number of classes in the dataset
num_classes = 2
# Batch size for training (change depending on how much memory you have)
batch_size = 16
# Number of epochs to train for
num_epochs = 15
# Flag for feature extracting. When False, we finetune the whole model,
# when True we only update the reshaped layer params
feature_extract = False
# Initialize the model for this run
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# Print the model we just instantiated
#print(model_ft)
print("Model Loading Process Done")
data_transforms = {
'transform': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
#print(len(datasets.ImageFolder(data_dir + '/train')))
full_dataset = datasets.ImageFolder(data_dir + '/train', data_transforms['transform'])
train_size = int(0.8 * len(full_dataset))
test_size = len(full_dataset) - train_size
#print(train_size)
#print(test_size)
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
image_datasets = {
'train':train_dataset,
'valid':test_dataset
}
dataloaders_dict = {
'train':torch.utils.data.DataLoader(image_datasets['train'], batch_size=batch_size, shuffle=True, num_workers=4),
'valid':torch.utils.data.DataLoader(image_datasets['valid'], batch_size=batch_size, shuffle=True, num_workers=4)
}
# Detect if we have a GPU available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# Send the model to GPU
model_ft = model_ft.to(device)
# Gather the parameters to be optimized/updated in this run. If we are
# finetuning we will be updating all parameters. However, if we are
# doing feature extract method, we will only update the parameters
# that we have just initialized, i.e. the parameters with requires_grad
# is True.
params_to_update = model_ft.parameters()
#print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
#print("\t",name)
pass
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
#print("\t",name)
pass
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
#optimizer_ft = optim.Adam(params_to_update,lr=0.0001)
# Setup the loss fxn
criterion = nn.CrossEntropyLoss()
# Train and evaluate
model_ft, hist, out, lab = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft, num_epochs=15, is_inception=(model_name=="inception"))
def save_checkpoint():
checkpoint = {
'model':model_ft,
'state_dict':model_ft.state_dict(),
'optimizer':optimizer_ft.state_dict()
}
torch.save(checkpoint, '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/checkpoint.pt')
def load_checkpoint(filepath, inference = False):
checkpoint = torch.load(filepath + 'checkpoint.pt')
model = checkpoint['model']
if inference:
for parameter in model.parameter():
parameter.require_grad = False
model.eval()
model.to(device)
return model
save_checkpoint()
model_ft = load_checkpoint(filepath='/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/')
!ls '/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/test/'
test_data_dir ="/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/"
data_transforms = {
'testing': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
test_image_datasets = {x: datasets.ImageFolder(os.path.join('/content/gdrive/My Drive/anomaly/Dataset2/MURA-v1.1/test/'), data_transforms[x]) for x in ['testing']}
test_dataloaders_dict = {x: torch.utils.data.DataLoader(test_image_datasets[x], batch_size=batch_size, shuffle=False, num_workers=4) for x in ['testing']}
output = []
for inputs, labels in test_dataloaders_dict['testing']:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model_ft(inputs)
_, predicted = torch.max(outputs, 1)
#print(predicted)
for i in predicted:
output.append(int(i))
output
| 0.780202 | 0.471649 |
```
import nltk
import random
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
import pickle
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
stop_words = stopwords.words("english")
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)
]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
```
## Making a frequency distribution of the words
```
all_words = nltk.FreqDist(all_words)
all_words.most_common(20)
feature_words = list(all_words.keys())[:5000]
def find_features(document):
words = set(document)
feature = {}
for w in feature_words:
feature[w] = (w in words)
return feature
feature_sets = [(find_features(rev), category) for (rev, category) in documents]
```
### Training the classifier
```
training_set = feature_sets[:1900]
testing_set = feature_sets[1900:]
## TO-DO: To build own naive bayes algorithm
# classifier = nltk.NaiveBayesClassifier.train(training_set)
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
## saving it in a pickle
MNB_pickle = open("MNB_pickle.pickle", "wb")
pickle.dump(MNB_classifier, MNB_pickle)
MNB_pickle.close()
print("Multinomial classifier accuracy : ", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
## BernoulliNB
BNB_classifier = SklearnClassifier(BernoulliNB())
BNB_classifier.train(training_set)
BNB_pickle = open("BNB_pickle.pickle", "wb")
pickle.dump(BNB_classifier, BNB_pickle)
BNB_pickle.close()
print("Bernoulli classifier accuracy : ", (nltk.classify.accuracy(BNB_classifier, testing_set))*100)
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
LogisticRegression_pickle = open("LogisticRegression.pickle", "wb")
pickle.dump(LogisticRegression_classifier, LogisticRegression_pickle)
LogisticRegression_pickle.close()
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
SGDClassifier_classifier = SklearnClassifier(SGDClassifier())
SGDClassifier_classifier.train(training_set)
SGDClassifier_pickle = open("SGDClassifier.pickle", "wb")
pickle.dump(SGDClassifier_classifier, SGDClassifier_pickle)
SGDClassifier_pickle.close()
print("SGDClassifier_classifier accuracy percent:", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)
SVC_classifier = SklearnClassifier(SVC())
SVC_classifier.train(training_set)
SVC_classifier_pickle = open("SVC_classifier.pickle", "wb")
pickle.dump(SVC_classifier, SVC_classifier_pickle)
SVC_classifier_pickle.close()
print("SVC_classifier accuracy percent:", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
LinearSVC_pickle = open("LinearSVC.pickle", "wb")
pickle.dump(LinearSVC_classifier, LinearSVC_pickle)
LinearSVC_pickle.close()
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
NuSVC_classifier = SklearnClassifier(NuSVC())
NuSVC_classifier.train(training_set)
NuSVC_pickle = open("LinearSVC.pickle", "wb")
pickle.dump(NuSVC_classifier, NuSVC_pickle)
NuSVC_pickle.close()
print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
### using the old naive_bayes classifier
naive_bayes_pickle = open("naivebayes.pickle", "rb")
naive_bayes_classifier = pickle.load(naive_bayes_pickle)
naive_bayes_pickle.close()
print("Naive bayes classifier accuracy percent:", (nltk.classify.accuracy(naive_bayes_classifier, testing_set))*100)
```
## Putting it all together to make a voting system for increasing accuracy
### Check out voting_system.ipynb
|
github_jupyter
|
import nltk
import random
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
import pickle
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
stop_words = stopwords.words("english")
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)
]
random.shuffle(documents)
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
all_words = nltk.FreqDist(all_words)
all_words.most_common(20)
feature_words = list(all_words.keys())[:5000]
def find_features(document):
words = set(document)
feature = {}
for w in feature_words:
feature[w] = (w in words)
return feature
feature_sets = [(find_features(rev), category) for (rev, category) in documents]
training_set = feature_sets[:1900]
testing_set = feature_sets[1900:]
## TO-DO: To build own naive bayes algorithm
# classifier = nltk.NaiveBayesClassifier.train(training_set)
MNB_classifier = SklearnClassifier(MultinomialNB())
MNB_classifier.train(training_set)
## saving it in a pickle
MNB_pickle = open("MNB_pickle.pickle", "wb")
pickle.dump(MNB_classifier, MNB_pickle)
MNB_pickle.close()
print("Multinomial classifier accuracy : ", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)
## BernoulliNB
BNB_classifier = SklearnClassifier(BernoulliNB())
BNB_classifier.train(training_set)
BNB_pickle = open("BNB_pickle.pickle", "wb")
pickle.dump(BNB_classifier, BNB_pickle)
BNB_pickle.close()
print("Bernoulli classifier accuracy : ", (nltk.classify.accuracy(BNB_classifier, testing_set))*100)
LogisticRegression_classifier = SklearnClassifier(LogisticRegression())
LogisticRegression_classifier.train(training_set)
LogisticRegression_pickle = open("LogisticRegression.pickle", "wb")
pickle.dump(LogisticRegression_classifier, LogisticRegression_pickle)
LogisticRegression_pickle.close()
print("LogisticRegression_classifier accuracy percent:", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)
SGDClassifier_classifier = SklearnClassifier(SGDClassifier())
SGDClassifier_classifier.train(training_set)
SGDClassifier_pickle = open("SGDClassifier.pickle", "wb")
pickle.dump(SGDClassifier_classifier, SGDClassifier_pickle)
SGDClassifier_pickle.close()
print("SGDClassifier_classifier accuracy percent:", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)
SVC_classifier = SklearnClassifier(SVC())
SVC_classifier.train(training_set)
SVC_classifier_pickle = open("SVC_classifier.pickle", "wb")
pickle.dump(SVC_classifier, SVC_classifier_pickle)
SVC_classifier_pickle.close()
print("SVC_classifier accuracy percent:", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)
LinearSVC_classifier = SklearnClassifier(LinearSVC())
LinearSVC_classifier.train(training_set)
LinearSVC_pickle = open("LinearSVC.pickle", "wb")
pickle.dump(LinearSVC_classifier, LinearSVC_pickle)
LinearSVC_pickle.close()
print("LinearSVC_classifier accuracy percent:", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)
NuSVC_classifier = SklearnClassifier(NuSVC())
NuSVC_classifier.train(training_set)
NuSVC_pickle = open("LinearSVC.pickle", "wb")
pickle.dump(NuSVC_classifier, NuSVC_pickle)
NuSVC_pickle.close()
print("NuSVC_classifier accuracy percent:", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)
### using the old naive_bayes classifier
naive_bayes_pickle = open("naivebayes.pickle", "rb")
naive_bayes_classifier = pickle.load(naive_bayes_pickle)
naive_bayes_pickle.close()
print("Naive bayes classifier accuracy percent:", (nltk.classify.accuracy(naive_bayes_classifier, testing_set))*100)
| 0.501221 | 0.402451 |
```
import pandas as pd
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix,accuracy_score, roc_curve, auc
import matplotlib.pyplot as plt
from tqdm import tqdm
tqdm.pandas()
```
# Summary
We will apply ensemble learning for face recognition models supported in [deepface for python](https://github.com/serengil/deepface).
Human beings have 97.53% score in face recognition task based on the [Facebook study](https://research.fb.com/publications/deepface-closing-the-gap-to-human-level-performance-in-face-verification/).
So, can ensemble of the most popular face recognition models have a higher score than human beings?
# Data set
```
# Ref: https://github.com/serengil/deepface/tree/master/tests/dataset
idendities = {
"Angelina": ["img1.jpg", "img2.jpg", "img4.jpg", "img5.jpg", "img6.jpg", "img7.jpg", "img10.jpg", "img11.jpg"],
"Scarlett": ["img8.jpg", "img9.jpg", "img47.jpg", "img48.jpg", "img49.jpg", "img50.jpg", "img51.jpg"],
"Jennifer": ["img3.jpg", "img12.jpg", "img53.jpg", "img54.jpg", "img55.jpg", "img56.jpg"],
"Mark": ["img13.jpg", "img14.jpg", "img15.jpg", "img57.jpg", "img58.jpg"],
"Jack": ["img16.jpg", "img17.jpg", "img59.jpg", "img61.jpg", "img62.jpg"],
"Elon": ["img18.jpg", "img19.jpg", "img67.jpg"],
"Jeff": ["img20.jpg", "img21.jpg"],
"Marissa": ["img22.jpg", "img23.jpg"],
"Sundar": ["img24.jpg", "img25.jpg"],
"Katy": ["img26.jpg", "img27.jpg", "img28.jpg", "img42.jpg", "img43.jpg", "img44.jpg", "img45.jpg", "img46.jpg"],
"Matt": ["img29.jpg", "img30.jpg", "img31.jpg", "img32.jpg", "img33.jpg"],
"Leonardo": ["img34.jpg", "img35.jpg", "img36.jpg", "img37.jpg"],
"George": ["img38.jpg", "img39.jpg", "img40.jpg", "img41.jpg"]
}
```
# Positive samples
Find different photos of same people
```
positives = []
for key, values in idendities.items():
#print(key)
for i in range(0, len(values)-1):
for j in range(i+1, len(values)):
#print(values[i], " and ", values[j])
positive = []
positive.append(values[i])
positive.append(values[j])
positives.append(positive)
positives = pd.DataFrame(positives, columns = ["file_x", "file_y"])
positives["decision"] = "Yes"
positives.shape
```
# Negative samples
Compare photos of different people
```
samples_list = list(idendities.values())
negatives = []
for i in range(0, len(idendities) - 1):
for j in range(i+1, len(idendities)):
#print(samples_list[i], " vs ",samples_list[j])
cross_product = itertools.product(samples_list[i], samples_list[j])
cross_product = list(cross_product)
#print(cross_product)
for cross_sample in cross_product:
#print(cross_sample[0], " vs ", cross_sample[1])
negative = []
negative.append(cross_sample[0])
negative.append(cross_sample[1])
negatives.append(negative)
negatives = pd.DataFrame(negatives, columns = ["file_x", "file_y"])
negatives["decision"] = "No"
negatives = negatives.sample(positives.shape[0])
negatives.shape
```
# Merge Positives and Negative Samples
```
df = pd.concat([positives, negatives]).reset_index(drop = True)
df.shape
df.decision.value_counts()
df.file_x = "deepface/tests/dataset/"+df.file_x
df.file_y = "deepface/tests/dataset/"+df.file_y
```
# DeepFace
```
#!pip install deepface
from deepface import DeepFace
from deepface.basemodels import VGGFace, OpenFace, Facenet, FbDeepFace
pretrained_models = {}
pretrained_models["VGG-Face"] = VGGFace.loadModel()
print("VGG-Face loaded")
pretrained_models["Facenet"] = Facenet.loadModel()
print("Facenet loaded")
pretrained_models["OpenFace"] = OpenFace.loadModel()
print("OpenFace loaded")
pretrained_models["DeepFace"] = FbDeepFace.loadModel()
print("FbDeepFace loaded")
instances = df[["file_x", "file_y"]].values.tolist()
models = ['VGG-Face', 'Facenet', 'OpenFace', 'DeepFace']
metrics = ['cosine', 'euclidean', 'euclidean_l2']
if True:
for model in models:
for metric in metrics:
print("Processing ",model," ",metric)
if model == 'OpenFace' and metric == 'euclidean': #this returns same with openface euclidean l2
continue
else:
resp_obj = DeepFace.verify(instances
, model_name = model
, model = pretrained_models[model]
, distance_metric = metric)
distances = []
for i in range(0, len(instances)):
distance = round(resp_obj["pair_%s" % (i+1)]["distance"], 4)
distances.append(distance)
df['%s_%s' % (model, metric)] = distances
df.to_csv("face-recognition-pivot.csv", index = False)
else:
#Ref: https://github.com/serengil/deepface/blob/master/tests/dataset/face-recognition-pivot.csv
df = pd.read_csv("face-recognition-pivot.csv")
df_raw = df.copy()
df.head()
```
# Distribution
```
fig = plt.figure(figsize=(15, 15))
figure_idx = 1
for model in models:
for metric in metrics:
if model == 'OpenFace' and metric == 'euclidean': #this returns same with openface euclidean l2
metric = 'euclidean_l2'
feature = '%s_%s' % (model, metric)
ax1 = fig.add_subplot(4, 3, figure_idx)
df[df.decision == "Yes"][feature].plot(kind='kde', title = feature, label = 'Yes', legend = True)
df[df.decision == "No"][feature].plot(kind='kde', title = feature, label = 'No', legend = True)
figure_idx = figure_idx + 1
plt.show()
```
# Pre-processing for model
```
columns = []
for model in models:
for metric in metrics:
if model == 'OpenFace' and metric == 'euclidean':
continue
else:
feature = '%s_%s' % (model, metric)
columns.append(feature)
columns.append("decision")
df = df[columns]
df.loc[df[df.decision == 'Yes'].index, 'decision'] = 1
df.loc[df[df.decision == 'No'].index, 'decision'] = 0
df.head()
```
# Train test split
```
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df, test_size=0.50, random_state=34)
#df_test, df_val = train_test_split(df_test, test_size=0.50, random_state=17)
target_name = "decision"
y_train = df_train[target_name].values
x_train = df_train.drop(columns=[target_name]).values
y_test = df_test[target_name].values
x_test = df_test.drop(columns=[target_name]).values
```
# LightGBM
```
import lightgbm as lgb
features = df.drop(columns=[target_name]).columns.tolist()
lgb_train = lgb.Dataset(x_train, y_train, feature_name = features)
lgb_test = lgb.Dataset(x_test, y_test, feature_name = features)
#lgb_val = lgb.Dataset(x_val, y_val, feature_name = features)
params = {
'task': 'train'
, 'boosting_type': 'gbdt'
, 'objective': 'multiclass'
, 'num_class': 2
, 'metric': 'multi_logloss'
}
gbm = lgb.train(params, lgb_train, num_boost_round=250, early_stopping_rounds = 15 , valid_sets=[lgb_test])
#Ref: https://github.com/serengil/deepface/blob/master/models/face-recognition-ensemble-model.txt
gbm.save_model("face-recognition-ensemble-model.txt")
```
# Evaluation
```
predictions = gbm.predict(x_test)
prediction_classes = []
classified = 0
index = 0
for prediction in predictions:
prediction_class = np.argmax(prediction)
prediction_classes.append(prediction_class)
actual = y_test[index]
#print("prediction is ",prediction_class," whereas actual is ",actual)
if actual == prediction_class:
classified = classified + 1
index = index + 1
#print(classified," instances are classified in ",len(predictions)," instances")
print("accuracy: ",round(100*classified/len(predictions),2),"%")
cm = confusion_matrix(y_test, prediction_classes)
cm
tn, fp, fn, tp = cm.ravel()
tn, fp, fn, tp
recall = tp / (tp + fn)
precision = tp / (tp + fp)
accuracy = (tp + tn)/(tn + fp + fn + tp)
f1 = 2 * (precision * recall) / (precision + recall)
print("Precision: ", 100*precision,"%")
print("Recall: ", 100*recall,"%")
print("F1 score ",100*f1, "%")
print("Accuracy: ", 100*accuracy,"%")
human_limit = 97.53
if 100*accuracy > human_limit:
print("ensemble method is more successful than human beings!")
else:
print("human beings are still more successful than the ensemble of face recognition models")
```
# Interpretability
```
plt.figure(figsize=(7,7))
ax = lgb.plot_importance(gbm, max_num_features=20)
plt.show()
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin'
plt.rcParams["figure.figsize"] = [20, 20]
for i in range(0, gbm.num_trees()):
ax = lgb.plot_tree(gbm, tree_index = i)
plt.show()
if i == 2:
break
```
# ROC Curve
```
y_pred_proba = predictions[::,1]
from sklearn import metrics
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
plt.figure(figsize=(6,4))
plt.plot(fpr,tpr,label="data 1, auc="+str(auc))
```
# Running ensemble model directly
```
#Ref: https://github.com/serengil/deepface/blob/master/models/face-recognition-ensemble-model.txt
deepface_ensemble = lgb.Booster(model_file= 'face-recognition-ensemble-model.txt')
#bulk predictions
#bulk_predictions = deepface_ensemble.predict(x_test)
#single prediction
idx = 0
verified = np.argmax(deepface_ensemble.predict(np.expand_dims(df.iloc[idx].values[0:-1], axis=0).shape)[0]) == 1
print("verified: ", verified)
```
|
github_jupyter
|
import pandas as pd
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix,accuracy_score, roc_curve, auc
import matplotlib.pyplot as plt
from tqdm import tqdm
tqdm.pandas()
# Ref: https://github.com/serengil/deepface/tree/master/tests/dataset
idendities = {
"Angelina": ["img1.jpg", "img2.jpg", "img4.jpg", "img5.jpg", "img6.jpg", "img7.jpg", "img10.jpg", "img11.jpg"],
"Scarlett": ["img8.jpg", "img9.jpg", "img47.jpg", "img48.jpg", "img49.jpg", "img50.jpg", "img51.jpg"],
"Jennifer": ["img3.jpg", "img12.jpg", "img53.jpg", "img54.jpg", "img55.jpg", "img56.jpg"],
"Mark": ["img13.jpg", "img14.jpg", "img15.jpg", "img57.jpg", "img58.jpg"],
"Jack": ["img16.jpg", "img17.jpg", "img59.jpg", "img61.jpg", "img62.jpg"],
"Elon": ["img18.jpg", "img19.jpg", "img67.jpg"],
"Jeff": ["img20.jpg", "img21.jpg"],
"Marissa": ["img22.jpg", "img23.jpg"],
"Sundar": ["img24.jpg", "img25.jpg"],
"Katy": ["img26.jpg", "img27.jpg", "img28.jpg", "img42.jpg", "img43.jpg", "img44.jpg", "img45.jpg", "img46.jpg"],
"Matt": ["img29.jpg", "img30.jpg", "img31.jpg", "img32.jpg", "img33.jpg"],
"Leonardo": ["img34.jpg", "img35.jpg", "img36.jpg", "img37.jpg"],
"George": ["img38.jpg", "img39.jpg", "img40.jpg", "img41.jpg"]
}
positives = []
for key, values in idendities.items():
#print(key)
for i in range(0, len(values)-1):
for j in range(i+1, len(values)):
#print(values[i], " and ", values[j])
positive = []
positive.append(values[i])
positive.append(values[j])
positives.append(positive)
positives = pd.DataFrame(positives, columns = ["file_x", "file_y"])
positives["decision"] = "Yes"
positives.shape
samples_list = list(idendities.values())
negatives = []
for i in range(0, len(idendities) - 1):
for j in range(i+1, len(idendities)):
#print(samples_list[i], " vs ",samples_list[j])
cross_product = itertools.product(samples_list[i], samples_list[j])
cross_product = list(cross_product)
#print(cross_product)
for cross_sample in cross_product:
#print(cross_sample[0], " vs ", cross_sample[1])
negative = []
negative.append(cross_sample[0])
negative.append(cross_sample[1])
negatives.append(negative)
negatives = pd.DataFrame(negatives, columns = ["file_x", "file_y"])
negatives["decision"] = "No"
negatives = negatives.sample(positives.shape[0])
negatives.shape
df = pd.concat([positives, negatives]).reset_index(drop = True)
df.shape
df.decision.value_counts()
df.file_x = "deepface/tests/dataset/"+df.file_x
df.file_y = "deepface/tests/dataset/"+df.file_y
#!pip install deepface
from deepface import DeepFace
from deepface.basemodels import VGGFace, OpenFace, Facenet, FbDeepFace
pretrained_models = {}
pretrained_models["VGG-Face"] = VGGFace.loadModel()
print("VGG-Face loaded")
pretrained_models["Facenet"] = Facenet.loadModel()
print("Facenet loaded")
pretrained_models["OpenFace"] = OpenFace.loadModel()
print("OpenFace loaded")
pretrained_models["DeepFace"] = FbDeepFace.loadModel()
print("FbDeepFace loaded")
instances = df[["file_x", "file_y"]].values.tolist()
models = ['VGG-Face', 'Facenet', 'OpenFace', 'DeepFace']
metrics = ['cosine', 'euclidean', 'euclidean_l2']
if True:
for model in models:
for metric in metrics:
print("Processing ",model," ",metric)
if model == 'OpenFace' and metric == 'euclidean': #this returns same with openface euclidean l2
continue
else:
resp_obj = DeepFace.verify(instances
, model_name = model
, model = pretrained_models[model]
, distance_metric = metric)
distances = []
for i in range(0, len(instances)):
distance = round(resp_obj["pair_%s" % (i+1)]["distance"], 4)
distances.append(distance)
df['%s_%s' % (model, metric)] = distances
df.to_csv("face-recognition-pivot.csv", index = False)
else:
#Ref: https://github.com/serengil/deepface/blob/master/tests/dataset/face-recognition-pivot.csv
df = pd.read_csv("face-recognition-pivot.csv")
df_raw = df.copy()
df.head()
fig = plt.figure(figsize=(15, 15))
figure_idx = 1
for model in models:
for metric in metrics:
if model == 'OpenFace' and metric == 'euclidean': #this returns same with openface euclidean l2
metric = 'euclidean_l2'
feature = '%s_%s' % (model, metric)
ax1 = fig.add_subplot(4, 3, figure_idx)
df[df.decision == "Yes"][feature].plot(kind='kde', title = feature, label = 'Yes', legend = True)
df[df.decision == "No"][feature].plot(kind='kde', title = feature, label = 'No', legend = True)
figure_idx = figure_idx + 1
plt.show()
columns = []
for model in models:
for metric in metrics:
if model == 'OpenFace' and metric == 'euclidean':
continue
else:
feature = '%s_%s' % (model, metric)
columns.append(feature)
columns.append("decision")
df = df[columns]
df.loc[df[df.decision == 'Yes'].index, 'decision'] = 1
df.loc[df[df.decision == 'No'].index, 'decision'] = 0
df.head()
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df, test_size=0.50, random_state=34)
#df_test, df_val = train_test_split(df_test, test_size=0.50, random_state=17)
target_name = "decision"
y_train = df_train[target_name].values
x_train = df_train.drop(columns=[target_name]).values
y_test = df_test[target_name].values
x_test = df_test.drop(columns=[target_name]).values
import lightgbm as lgb
features = df.drop(columns=[target_name]).columns.tolist()
lgb_train = lgb.Dataset(x_train, y_train, feature_name = features)
lgb_test = lgb.Dataset(x_test, y_test, feature_name = features)
#lgb_val = lgb.Dataset(x_val, y_val, feature_name = features)
params = {
'task': 'train'
, 'boosting_type': 'gbdt'
, 'objective': 'multiclass'
, 'num_class': 2
, 'metric': 'multi_logloss'
}
gbm = lgb.train(params, lgb_train, num_boost_round=250, early_stopping_rounds = 15 , valid_sets=[lgb_test])
#Ref: https://github.com/serengil/deepface/blob/master/models/face-recognition-ensemble-model.txt
gbm.save_model("face-recognition-ensemble-model.txt")
predictions = gbm.predict(x_test)
prediction_classes = []
classified = 0
index = 0
for prediction in predictions:
prediction_class = np.argmax(prediction)
prediction_classes.append(prediction_class)
actual = y_test[index]
#print("prediction is ",prediction_class," whereas actual is ",actual)
if actual == prediction_class:
classified = classified + 1
index = index + 1
#print(classified," instances are classified in ",len(predictions)," instances")
print("accuracy: ",round(100*classified/len(predictions),2),"%")
cm = confusion_matrix(y_test, prediction_classes)
cm
tn, fp, fn, tp = cm.ravel()
tn, fp, fn, tp
recall = tp / (tp + fn)
precision = tp / (tp + fp)
accuracy = (tp + tn)/(tn + fp + fn + tp)
f1 = 2 * (precision * recall) / (precision + recall)
print("Precision: ", 100*precision,"%")
print("Recall: ", 100*recall,"%")
print("F1 score ",100*f1, "%")
print("Accuracy: ", 100*accuracy,"%")
human_limit = 97.53
if 100*accuracy > human_limit:
print("ensemble method is more successful than human beings!")
else:
print("human beings are still more successful than the ensemble of face recognition models")
plt.figure(figsize=(7,7))
ax = lgb.plot_importance(gbm, max_num_features=20)
plt.show()
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin'
plt.rcParams["figure.figsize"] = [20, 20]
for i in range(0, gbm.num_trees()):
ax = lgb.plot_tree(gbm, tree_index = i)
plt.show()
if i == 2:
break
y_pred_proba = predictions[::,1]
from sklearn import metrics
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
plt.figure(figsize=(6,4))
plt.plot(fpr,tpr,label="data 1, auc="+str(auc))
#Ref: https://github.com/serengil/deepface/blob/master/models/face-recognition-ensemble-model.txt
deepface_ensemble = lgb.Booster(model_file= 'face-recognition-ensemble-model.txt')
#bulk predictions
#bulk_predictions = deepface_ensemble.predict(x_test)
#single prediction
idx = 0
verified = np.argmax(deepface_ensemble.predict(np.expand_dims(df.iloc[idx].values[0:-1], axis=0).shape)[0]) == 1
print("verified: ", verified)
| 0.449151 | 0.808521 |
# The dataset object
The dataset object reads standard csv files, checks the frequency, and creates the cross validation indicies for training. It is an interface between the data in csv format and then transform function that converts the dataset into an input appropriate for a particular algorithm.
```
import os
import pandas as pd
import athena
```
There are several inputs:
- The filename of the data to read. This can be an absolute or relative path, or it may be the name of the file in the environment variable ATHENA_DATA_PATH.
- `index`: The column in the csv that contains the timestamp information that will serve as an index.
- `freq`: The sample rate of the data.
- `max_days`: Optional. Maximum number of days to use.
- `max_training_days`: Optional. The max number of training days to include with each cross validation set.
- `prediction_length`: How many future observations are we forecasting?
- `test_start_values`: List of datetime values where cross validation starts.
- `test_sequence_length`: The number of steps forward from each `test_start_values` to include in the cross validation.
Here are a few examples.
max_training_days=10
predition_length=48 #an entire day
test_sequence_length=1
```
ds = athena.Dataset("../test/data/dfw_demand.csv.gz",
index="timestamp",
freq="30min",
max_days=500,
max_training_days=10,
predition_length=48,
test_start_values=['2019-07-01 00:00:00', '2019-07-03 00:00:00', '2019-07-05 00:00:00'],
test_sequence_length=1
)
ds.plot_cv()
```
Because the `test_sequence_length` is one, there are only three cross validation tests. The test sets (blue) are 48 observations long. The training sets are 48*10 (`max_training_days=10`) observations long.
```
ds = athena.Dataset("../test/data/dfw_demand.csv.gz",
index="timestamp",
freq="30min",
max_days=500,
max_training_days=1,
predition_length=1,
test_start_values=['2019-07-01 00:00:00'],
test_sequence_length=20
)
ds.plot_cv()
```
Here, the `test_sequence_length=20` determines the number of CV sets. The predition length is 1, so only a single observation is included. The `max_training_days=1` is set to a small value so that we can still observe the prediction_length.
This creates 20 sequential tests that forecast a single step foreward for the day defined by `test_start_values[0]`.
|
github_jupyter
|
import os
import pandas as pd
import athena
ds = athena.Dataset("../test/data/dfw_demand.csv.gz",
index="timestamp",
freq="30min",
max_days=500,
max_training_days=10,
predition_length=48,
test_start_values=['2019-07-01 00:00:00', '2019-07-03 00:00:00', '2019-07-05 00:00:00'],
test_sequence_length=1
)
ds.plot_cv()
ds = athena.Dataset("../test/data/dfw_demand.csv.gz",
index="timestamp",
freq="30min",
max_days=500,
max_training_days=1,
predition_length=1,
test_start_values=['2019-07-01 00:00:00'],
test_sequence_length=20
)
ds.plot_cv()
| 0.189859 | 0.989791 |
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib as mpl
import warnings
import sklearn
sklearn.set_config(print_changed_only=True)
mpl.rcParams['legend.numpoints'] = 1
warnings.filterwarnings('ignore', category=DeprecationWarning)
warnings.filterwarnings('ignore', category=FutureWarning)
```
## Evaluation Metrics and scoring
### Metrics for binary classification
```
from sklearn.model_selection import train_test_split
data = pd.read_csv("data/bank-campaign.csv")
X = data.drop("target", axis=1).values
y = data.target.values
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dummy_majority = DummyClassifier(strategy='most_frequent').fit(X_train, y_train)
pred_most_frequent = dummy_majority.predict(X_test)
print("predicted labels: %s" % np.unique(pred_most_frequent))
print("score: %f" % dummy_majority.score(X_test, y_test))
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=2).fit(X_train, y_train)
pred_tree = tree.predict(X_test)
tree.score(X_test, y_test)
from sklearn.linear_model import LogisticRegression
dummy = DummyClassifier(strategy='most_frequent').fit(X_train, y_train)
pred_dummy = dummy.predict(X_test)
print("dummy score: %f" % dummy.score(X_test, y_test))
logreg = LogisticRegression(C=0.1).fit(X_train, y_train)
pred_logreg = logreg.predict(X_test)
print("logreg score: %f" % logreg.score(X_test, y_test))
```
# Confusion matrices
```
from sklearn.metrics import confusion_matrix
confusion = confusion_matrix(y_test, pred_logreg)
print(confusion)
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(logreg, X_test, y_test, values_format=".2g")
print("Most frequent class:")
print(confusion_matrix(y_test, pred_most_frequent))
print("\nDummy model:")
print(confusion_matrix(y_test, pred_dummy))
print("\nDecision tree:")
print(confusion_matrix(y_test, pred_tree))
print("\nLogistic Regression")
print(confusion_matrix(y_test, pred_logreg))
from sklearn.metrics import f1_score
print("f1 score most frequent: %.2f" % f1_score(y_test, pred_most_frequent, pos_label="yes"))
print("f1 score dummy: %.2f" % f1_score(y_test, pred_dummy, pos_label="yes"))
print("f1 score tree: %.2f" % f1_score(y_test, pred_tree, pos_label="yes"))
print("f1 score logreg: %.2f" % f1_score(y_test, pred_logreg, pos_label="yes"))
from sklearn.metrics import classification_report
print(classification_report(y_test, pred_most_frequent,
target_names=["no", "yes"]))
print(classification_report(y_test, pred_tree,
target_names=["no", "yes"]))
print(classification_report(y_test, pred_logreg,
target_names=["no", "yes"]))
```
# Taking uncertainty into account
## Precision-Recall curves and ROC curves
```
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.metrics import plot_precision_recall_curve
# create a similar dataset as before, but with more samples to get a smoother curve
X, y = make_blobs(n_samples=8000, centers=2, cluster_std=[7.0, 2], random_state=22, shuffle=False)
X, y = X[:4500], y[:4500]
# build an imbalanced synthetic dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
svc = SVC(gamma=.05).fit(X_train, y_train)
pr_svc = plot_precision_recall_curve(svc, X_test, y_test)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0, max_features=2)
rf.fit(X_train, y_train)
# RandomForestClassifier has predict_proba, but not decision_function
pr_rf = plot_precision_recall_curve(rf, X_test, y_test)
# plot both in the same axes
ax = plt.gca()
pr_rf.plot(ax=ax)
pr_svc.plot(ax=ax)
print("f1_score of random forest: %f" % f1_score(y_test, rf.predict(X_test)))
print("f1_score of svc: %f" % f1_score(y_test, svc.predict(X_test)))
from sklearn.metrics import average_precision_score
ap_rf = average_precision_score(y_test, rf.predict_proba(X_test)[:, 1])
ap_svc = average_precision_score(y_test, svc.decision_function(X_test))
print("average precision of random forest: %f" % ap_rf)
print("average precision of svc: %f" % ap_svc)
print("average precision of svc: %f" % pr_svc.average_precision)
```
# Receiver Operating Characteristics (ROC) and AUC
\begin{equation}
\text{FPR} = \frac{\text{FP}}{\text{FP} + \text{TN}}
\end{equation}
```
from sklearn.metrics import plot_roc_curve
roc_svc = plot_roc_curve(svc, X_test, y_test)
roc_svc.plot()
roc_rf = plot_roc_curve(rf, X_test, y_test, ax=roc_svc.ax_)
from sklearn.metrics import roc_auc_score
rf_auc = roc_auc_score(y_test, rf.predict_proba(X_test)[:, 1])
svc_auc = roc_auc_score(y_test, svc.decision_function(X_test))
print("AUC for Random Forest: %f" % rf_auc)
print("AUC for SVC: %f" % svc_auc)
```
## Using evaluation metrics in model selection
```
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import scale
cancer = load_breast_cancer()
# being lazy to simplify notebook, we should be using pipelines
X, y = scale(cancer.data), cancer.target
# default scoring for classification is accuracy
print("default scoring ",
cross_val_score(LogisticRegression(), X, y))
# providing scoring="accuracy" doesn't change the results
explicit_accuracy = cross_val_score(LogisticRegression(), X, y,
scoring="accuracy")
print("explicit accuracy scoring ", explicit_accuracy)
ap = cross_val_score(LogisticRegression(), X, y,
scoring="average_precision")
print("average precision", ap)
from sklearn.model_selection import cross_validate
res = cross_validate(SVC(), X, y,
scoring=["accuracy", "average_precision", "recall_macro"],
return_train_score=True, cv=5)
display(pd.DataFrame(res))
from sklearn.metrics.scorer import SCORERS
print(sorted(SCORERS.keys()))
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
data = pd.read_csv("data/bank-campaign.csv")
# back to the bank campaign
X = data.drop("target", axis=1).values
y = data.target.values == "no"
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=.1, test_size=.1, random_state=0)
param_grid = {'logisticregression__C': [0.0001, 0.01, 0.1, 1, 10]}
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=1000))
# using AUC scoring instead:
grid = GridSearchCV(model, param_grid=param_grid,
scoring=["roc_auc", 'average_precision', 'accuracy'],
refit='roc_auc')
grid.fit(X_train, y_train)
print("\nGrid-Search with AUC")
print("Best parameters:", grid.best_params_)
print("Best cross-validation score (AUC):", grid.best_score_)
print("Test set AUC: %.3f" % grid.score(X_test, y_test))
res = pd.DataFrame(grid.cv_results_)
res[['mean_test_roc_auc', 'mean_test_accuracy', 'mean_test_average_precision']].plot()
```
# Exercise
Load the adult dataset from ``data/adult.csv`` (or pick another dataset), and split it into training and test set.
Apply grid-search to the training set, searching for the best C for Logistic Regression using AUC.
Plot the ROC curve and precision-recall curve of the best model on the test set.
|
github_jupyter
|
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib as mpl
import warnings
import sklearn
sklearn.set_config(print_changed_only=True)
mpl.rcParams['legend.numpoints'] = 1
warnings.filterwarnings('ignore', category=DeprecationWarning)
warnings.filterwarnings('ignore', category=FutureWarning)
from sklearn.model_selection import train_test_split
data = pd.read_csv("data/bank-campaign.csv")
X = data.drop("target", axis=1).values
y = data.target.values
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dummy_majority = DummyClassifier(strategy='most_frequent').fit(X_train, y_train)
pred_most_frequent = dummy_majority.predict(X_test)
print("predicted labels: %s" % np.unique(pred_most_frequent))
print("score: %f" % dummy_majority.score(X_test, y_test))
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=2).fit(X_train, y_train)
pred_tree = tree.predict(X_test)
tree.score(X_test, y_test)
from sklearn.linear_model import LogisticRegression
dummy = DummyClassifier(strategy='most_frequent').fit(X_train, y_train)
pred_dummy = dummy.predict(X_test)
print("dummy score: %f" % dummy.score(X_test, y_test))
logreg = LogisticRegression(C=0.1).fit(X_train, y_train)
pred_logreg = logreg.predict(X_test)
print("logreg score: %f" % logreg.score(X_test, y_test))
from sklearn.metrics import confusion_matrix
confusion = confusion_matrix(y_test, pred_logreg)
print(confusion)
from sklearn.metrics import plot_confusion_matrix
plot_confusion_matrix(logreg, X_test, y_test, values_format=".2g")
print("Most frequent class:")
print(confusion_matrix(y_test, pred_most_frequent))
print("\nDummy model:")
print(confusion_matrix(y_test, pred_dummy))
print("\nDecision tree:")
print(confusion_matrix(y_test, pred_tree))
print("\nLogistic Regression")
print(confusion_matrix(y_test, pred_logreg))
from sklearn.metrics import f1_score
print("f1 score most frequent: %.2f" % f1_score(y_test, pred_most_frequent, pos_label="yes"))
print("f1 score dummy: %.2f" % f1_score(y_test, pred_dummy, pos_label="yes"))
print("f1 score tree: %.2f" % f1_score(y_test, pred_tree, pos_label="yes"))
print("f1 score logreg: %.2f" % f1_score(y_test, pred_logreg, pos_label="yes"))
from sklearn.metrics import classification_report
print(classification_report(y_test, pred_most_frequent,
target_names=["no", "yes"]))
print(classification_report(y_test, pred_tree,
target_names=["no", "yes"]))
print(classification_report(y_test, pred_logreg,
target_names=["no", "yes"]))
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.metrics import plot_precision_recall_curve
# create a similar dataset as before, but with more samples to get a smoother curve
X, y = make_blobs(n_samples=8000, centers=2, cluster_std=[7.0, 2], random_state=22, shuffle=False)
X, y = X[:4500], y[:4500]
# build an imbalanced synthetic dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
svc = SVC(gamma=.05).fit(X_train, y_train)
pr_svc = plot_precision_recall_curve(svc, X_test, y_test)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0, max_features=2)
rf.fit(X_train, y_train)
# RandomForestClassifier has predict_proba, but not decision_function
pr_rf = plot_precision_recall_curve(rf, X_test, y_test)
# plot both in the same axes
ax = plt.gca()
pr_rf.plot(ax=ax)
pr_svc.plot(ax=ax)
print("f1_score of random forest: %f" % f1_score(y_test, rf.predict(X_test)))
print("f1_score of svc: %f" % f1_score(y_test, svc.predict(X_test)))
from sklearn.metrics import average_precision_score
ap_rf = average_precision_score(y_test, rf.predict_proba(X_test)[:, 1])
ap_svc = average_precision_score(y_test, svc.decision_function(X_test))
print("average precision of random forest: %f" % ap_rf)
print("average precision of svc: %f" % ap_svc)
print("average precision of svc: %f" % pr_svc.average_precision)
from sklearn.metrics import plot_roc_curve
roc_svc = plot_roc_curve(svc, X_test, y_test)
roc_svc.plot()
roc_rf = plot_roc_curve(rf, X_test, y_test, ax=roc_svc.ax_)
from sklearn.metrics import roc_auc_score
rf_auc = roc_auc_score(y_test, rf.predict_proba(X_test)[:, 1])
svc_auc = roc_auc_score(y_test, svc.decision_function(X_test))
print("AUC for Random Forest: %f" % rf_auc)
print("AUC for SVC: %f" % svc_auc)
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import scale
cancer = load_breast_cancer()
# being lazy to simplify notebook, we should be using pipelines
X, y = scale(cancer.data), cancer.target
# default scoring for classification is accuracy
print("default scoring ",
cross_val_score(LogisticRegression(), X, y))
# providing scoring="accuracy" doesn't change the results
explicit_accuracy = cross_val_score(LogisticRegression(), X, y,
scoring="accuracy")
print("explicit accuracy scoring ", explicit_accuracy)
ap = cross_val_score(LogisticRegression(), X, y,
scoring="average_precision")
print("average precision", ap)
from sklearn.model_selection import cross_validate
res = cross_validate(SVC(), X, y,
scoring=["accuracy", "average_precision", "recall_macro"],
return_train_score=True, cv=5)
display(pd.DataFrame(res))
from sklearn.metrics.scorer import SCORERS
print(sorted(SCORERS.keys()))
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
data = pd.read_csv("data/bank-campaign.csv")
# back to the bank campaign
X = data.drop("target", axis=1).values
y = data.target.values == "no"
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=.1, test_size=.1, random_state=0)
param_grid = {'logisticregression__C': [0.0001, 0.01, 0.1, 1, 10]}
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=1000))
# using AUC scoring instead:
grid = GridSearchCV(model, param_grid=param_grid,
scoring=["roc_auc", 'average_precision', 'accuracy'],
refit='roc_auc')
grid.fit(X_train, y_train)
print("\nGrid-Search with AUC")
print("Best parameters:", grid.best_params_)
print("Best cross-validation score (AUC):", grid.best_score_)
print("Test set AUC: %.3f" % grid.score(X_test, y_test))
res = pd.DataFrame(grid.cv_results_)
res[['mean_test_roc_auc', 'mean_test_accuracy', 'mean_test_average_precision']].plot()
| 0.697712 | 0.819641 |
```
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/husein/t5/prepare/mesolitica-tpu.json'
os.environ['CUDA_VISIBLE_DEVICES'] = ''
import tensorflow as tf
from pegasus import transformer
vocab_size = 32000
hidden_size = 512
filter_size = 3072
num_encoder_layers = 6
num_decoder_layers = 6
num_heads = 8
label_smoothing = 0.0
dropout = 0.1
model = transformer.TransformerEncoderDecoderModel(vocab_size, hidden_size,
filter_size, num_heads,
num_encoder_layers,
num_decoder_layers,
label_smoothing, dropout)
X = tf.placeholder(tf.int64, (None, None))
top_p = tf.placeholder(tf.float32, None, name = 'top_p')
temperature = tf.placeholder(tf.float32, None, name = 'temperature')
outputs = model.predict({"inputs": X,}, tf.shape(X)[1], beam_size = 1,
top_p = top_p, temperature = temperature)
logits = tf.identity(outputs['outputs'], name = 'logits')
logits
import tokenization
tokenizer = tokenization.FullTokenizer(
vocab_file='pegasus.wordpiece', do_lower_case=False
)
import tensorflow as tf
ckpt_path = tf.train.latest_checkpoint('gs://mesolitica-tpu-general/pegasus-summarization-small')
ckpt_path
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, ckpt_path)
import re
from unidecode import unidecode
def cleaning(string):
return re.sub(r'[ ]+', ' ', unidecode(string.replace('\n', ' '))).strip()
string = """
Tidak ada apa-apa mengenai mesyuarat fakulti biologi Jumaat lalu di University of Alabama di Huntsville yang membayangkan pembunuhan yang akan berlaku, Profesor Debra Moriarity memberitahu wartawan Rabu. "Ia sebenarnya adalah satu-satunya mesyuarat fakulti yang sangat santai dan biasa," ahli biokim memberitahu CNN affiliate WAAY mengenai 13 orang yang duduk di sekitar meja bujur di Bilik 369 di Shelby Centre for Science and Technology. "Peristiwa akan datang, kelas penjadualan, belanjawan. Ia sebenarnya merupakan salah satu daripada mesyuarat fakulti yang paling mudah yang kami ada." Antara peserta adalah Amy Bishop, seorang ahli genetik yang terlatih Harvard dengan siapa Moriarity telah membangun hubungan profesional yang dipupuk oleh hakikat bahawa kedua-dua wanita bekerja dengan budaya sel. "Kadang-kadang anda meminjam sesuatu dari satu sama lain," katanya. "Kami telah bercakap mengenai cadangan pemberian cadangan bersama." Selepas kira-kira sejam, sebelum 4hb, Bishop - yang baru-baru ini dinafikan tempohnya - menamatkan tenang. "Secara tiba-tiba, dia hanya berdiri dan ditembak," kata Moriarity. Moriarity bertindak balas dengan cepat, menjatuhkan ke tangan dan lututnya di atas permaidani kelabu. "Hanya jatuh ke lantai dan merangkak di bawah meja dan merangkak ke arah Amy," kata Moriarity, yang memberi tumpuan kepada satu perkara. "Maksud saya, kamu merangkak di bawah meja, kamu melihat kaki orang yang menembak di atas meja, saya merangkul kakinya dan, saya tidak tahu apa yang saya fikirkan, saya tidak memikirkan apa-apa. hanya berfikir: \'Ambil dia!\' "Dan dia menghalang saya. Maksud saya, dia menarik kaki kakinya percuma dan saya berada di ambang pintu dengan belakang saya jenisnya. Dan saya fikir dia cuba menembak saya, tetapi ketika saya mula berteriak kepadanya, \'Amy, Amy, berfikir tentang cucu saya, berfikir tentang anak perempuan saya! Ini saya! Saya telah membantu anda sebelum ini; Saya akan membantu anda lagi! Jangan buat Amy ini! Jangan lakukan ini! \'"Uskup kemudian melangkah masuk ke dalam dewan, menunjuk pistol di Moriarity dan menarik pencetus, kata ahli biologi." Ia diklik, dan ia diklik lagi, dan saya merangkak kembali ke dalam bilik dan menutup pintu dan dia ditinggalkan di dalam dewan. "Orang-orang yang terselamat itu beraksi. Satu orang mengunci pintu kayu, satu lagi mengetuk meja ke atasnya, yang lain memindahkan peti sejuk ke tempatnya untuk menghalang pintu, yang lain dipanggil 911, yang lain berpindah ke Tiga orang yang maut, tiga lagi yang cedera, dua daripadanya kekal dirawat di rumah sakit pada hari Rabu dalam keadaan kritikal, menurut seorang jurubicara Hospital Huntsville, yang ketiga dilepaskan, Moriarity, yang menyertai fakulti sekolah pada tahun 1984, mengatakan bahawa mangsa tidak menjejaskan rancangannya untuk kekal di sekolah dan dia menolak apa-apa cadangan bahawa peranannya untuk mendapatkan Bishop di luar bilik itu adalah heroik. "Dia mengikuti saya di dewan dan kemudian senjata itu macet dan saya boleh mendapatkan ba ck di dalam bilik, "kata Moriarity. "Itu bukan seorang pahlawan. Itu hanya Tuhan yang melihat kamu." Dia berkata dia mempunyai sedikit masa untuk berfikir. "Dari awal hingga akhirnya kami mendapat sesuatu yang tidak dapat dibendung, ia tidak boleh melebihi 20 saat," katanya. Moriarity terus menolak cadangan bahawa apa-apa boleh dilakukan untuk melindungi mangsa. "Tidak ada cara untuk menjangka ini," katanya. "Dan tiada apa yang dapat dilakukan untuk menghentikannya, semuanya berlaku terlalu pantas." Dan dia bimbang bahawa apa-apa cubaan untuk mengetatkan keselamatan boleh membawa kesan negatif. "Ada kejahatan di dunia, malangnya orang baik disakiti oleh itu, tetapi universiti adalah tempat pemikiran bebas dan kebebasan untuk meneroka idea-idea dan mencari pengetahuan baru dan anda tidak mahu meletakkan sesuatu di tempat yang meredakannya. " Moriarity kembali ke pejabatnya pada hari Rabu dan berkata dia merancang untuk meneruskan pengajaran minggu depan. Dia meramalkan bahawa, dengan bantuan ubat anti-kecemasan, dia akan dapat tidur malam Rabu. "Saya telah bercakap dengan keluarga dan kawan-kawan dan hanya mendapatkan sokongan mereka membantu anda menanganinya," katanya. "Saya fikir sekarang kebanyakan dari kita mahu kembali ke sana dan mendapatkan sesuatu yang berlaku, membuat rancangan untuk siapa yang akan menutup kelas." Satu perkhidmatan peringatan untuk menghormati kehidupan orang mati - ahli fakulti Maria Davis, Adriel Johnson dan Gopi Podila - akan diadakan pada hari Jumaat.
"""
string2 = """
Gabungan parti Warisan, Pakatan Harapan, dan Upko hari ini mendedahkan calon-calon masing-masing untuk pilihan raya negeri Sabah, tetapi ketika pengumuman itu berlangsung, perwakilan PKR di dewan itu dilihat ‘gelisah’ seperti ‘tidak senang duduk’.
Sekumpulan anggota PKR kemudian dilihat meninggalkan dewan di Pusat Konvensyen Antarabangsa Sabah di Kota Kinabalu selepas berbincang dengan ketua PKR Sabah Christina Liew.
Semakan senarai-senarai calon berkenaan mendapati PKR hanya memperolehi separuh daripada jumlah kerusi yang diharapkan.
Semalam, PKR Sabah mengumumkan akan bertanding di 14 kerusi tetapi ketika Presiden Warisan Shafie Apdal mengumumkan calon gabungan tersebut hari ini, PKR hanya diberikan tujuh kerusi untuk bertanding.
Kerusi yang diberikan adalah Api-Api, Inanam, Tempasuk, Tamparuli, Matunggong, Klias, dan Sook.
Klias dan Sook adalah dua kerusi yang diberikan kepada PKR, sementara lima kerusi selebihnya pernah ditandingi oleh PKR pada pilihan raya umum 2018.
Dalam pengumuman PKR Sabah semalam, parti itu menjangkakan Warisan akan turut menyerahkan kerusi Kemabong, Membakut, dan Petagas kepada mereka.
Walau bagaimanapun, Warisan menyerahkan kerusi Kemabong kepada Upko dan mengekalkan bertanding untuk kerusi Membakut dan Petagas.
PKR juga menuntut empat daripada 13 kerusi baru yang diperkenalkan iaitu Segama, Limbahau, Sungai Manila, dan Pintasan tetapi Warisan membolot semua kerusi itu.
Sebagai pertukaran untuk kerusi yang diintainya, PKR bersedia untuk menyerahkan kerusi Kadaimaian, Kuala Penyu, dan Karanaan. Namun, ini dijangka tidak akan berlaku memandangkan parti tersebut tidak berpuas hati dengan agihan kerusi seperti yang diharapkan itu.
Selepas perwakilan dari PKR dan Liew keluar dari dewan tersebut, wartawan kemudian menyusuri Liew untuk mendapatkan penjelasannya.
Walau bagaimanapun, Liew enggan memberikan sebarang komen dan berkata bahawa dia ingin ke tandas.
Liew dan perwakilan PKR kemudian tidak kembali ke dalam dewan tersebut.
Apabila calon pilihan raya yang diumumkan diminta naik ke atas pentas untuk sesi bergambar, Liew tidak kelihatan.
Bilangan kerusi yang ditandingi oleh PKR kali ini hanya kurang satu kerusi daripada yang ditandingi parti itu pada PRU 2018.
Dalam perkembangan berkaitan, DAP dan Amanah dikatakan tidak mempunyai sebarang masalah dengan kerusi yang diberikan untuk PRN Sabah.
Sementara itu, Presiden Upko Madius Tangau enggan mengulas adakah dia berpuas hati dengan agihan kerusi tersebut. Madius kekal di majlis tersebut sehingga ia berakhir.
Partinya diberikan 12 kerusi, iaitu lebih tujuh kerusi berbanding PRU lalu.
DAP dan Amanah akan bertanding di bawah logo Warisan sementara PKR dan Upko akan menggunakan logo masing-masing.
DAP akan bertanding di tujuh kerusi, jumlah yang sama seperti yang mereka tandingi pada PRU lalu, sementara Amanah diberi satu kerusi.
Warisan akan bertanding sebanyak 54 kerusi.
Perkembangan terbaru ini mungkin mencetuskan pergeseran di antara PKR dan Warisan. PKR boleh memilih untuk bertanding di lebih banyak kerusi daripada 14 yang dituntutnya manakala Warisan juga boleh bertanding di kerusi sekutunya.
Barisan pemimpin tertinggi PKR dan Warisan hanya mempunyai dua hari sebelum hari penamaan calon pada Sabtu untuk mengurangkan pergeseran.
"""
string3 = """
Penubuhan universiti sukan seperti diutarakan Ketua Unit Sukan Kementerian Pengajian Tinggi, Dr Pekan Ramli dan disokong Pakar Pembangunan Sukan dan Reakreasi Luar, Universiti Pendidikan Sultan Idris (UPSI), Prof Dr Md Amin Md Taaf seperti disiarkan akhbar ini, memberikan sinar harapan kepada kewujudan institusi sedemikian.
Ia menjadi impian atlet negara untuk mengejar kejayaan dalam bidang sukan dan kecemerlangan dalam akademik untuk menjamin masa depan lebih baik apabila bersara daripada arena sukan kelak.
Pelbagai pandangan, idea, kaedah, bukti dan cadangan dilontarkan pakar berikutan pentingnya universiti sukan yang akan memberi impak besar sama ada pada peringkat kebangsaan mahupun antarabangsa.
Negara lain sudah lama meraih laba dengan kewujudan universiti sukan seperti China, Korea, Japan, Taiwan, India dan Vietnam. Mereka menghasilkan atlet universiti yang mempamerkan keputusan cemerlang pada peringkat tinggi seperti Sukan Olimpik, Kejohanan Dunia dan Sukan Asia.
Justeru, kejayaan mereka perlu dijadikan rujukan demi memajukan sukan tanah air. Jika kita merujuk pendekatan Asia, kewujudan universiti sukan penting dan memberi kesan positif dalam melonjakkan prestasi sukan lebih optimum.
Namun, jika kita melihat pendekatan Eropah, universiti sukan bukan antara organisasi atau institusi penting yang diberi perhatian dalam menyumbang kepada pemenang pingat.
Antara isu dalam universiti sukan ialah kos tinggi, lokasi, prasarana sukan, pertindihan kursus dengan universiti sedia ada dan impak terhadap dunia sukan negara hingga mengundang persoalan kewajaran dan kerelevanan penubuhannya.
Namun sebagai bekas atlet memanah negara dan Olympian (OLY) di Sukan Olimpik 2004 di Athens, Greece serta bekas pelajar Sekolah Sukan Bukit Jalil hingga berjaya dalam dunia akademik, saya mendapati terdapat beberapa faktor sering menjadi halangan dalam rutin harian mereka.
Antaranya, faktor masa yang terpaksa bergegas menghadiri kuliah selepas tamat sesi latihan yang mengambil masa 15 hingga 20 minit dengan menunggang motosikal; kereta (20-30 minit) atau pengangkutan disediakan Majlis Sukan Negara (MSN) ke Universiti Putra Malaysia (UPM).
Jika mereka menuntut di Universiti Teknologi MARA (UiTM) atau Universiti Malaya (UM), ia mungkin lebih lama.
Walaupun di universiti tersedia dengan kemudahan kolej dan kemudahan sukan, mereka memilih pulang ke MSN untuk menjalani latihan bersama pasukan dan jurulatih di padang atau gelanggang latihan rasmi.
Ini berlanjutan selagi bergelar atlet negara yang perlu memastikan prestasi sentiasa meningkat dari semasa ke semasa tanpa mengabaikan tugas sebagai pelajar.
Alangkah baiknya jika sebahagian Sekolah Sukan Bukit Jalil itu sendiri dijadikan Kolej atau Universiti Sukan Malaysia kerana lengkap dari segi kemudahan prasarana sukannya dan proses pengajaran dan pembelajaran (PdP) dalam bidang Sains Sukan, Kejurulatihan, Pendidikan Jasmani dan setaraf dengannya.
Pengambilan setiap semester pula hanya terhad kepada atlet berstatus kebangsaan dan antarabangsa sahaja supaya hasrat melahirkan lebih ramai atlet bertaraf Olimpik mudah direalisasikan.
Contohnya, bekas atlet lompat bergalah negara, Roslinda Samsu yang juga pemenang pingat perak Sukan Asia Doha 2006 dan Penerima Anugerah Khas Majlis Anugerah Sukan KPT 2012, terpaksa mengambil masa lebih kurang sembilan tahun untuk menamatkan ijazah Sarjana Muda Pendidikan Jasmani di UPM sepanjang 14 tahun terbabit dalam sukan olahraga.
Sepanjang tempoh bergelar atlet kebangsaan dan mahasiswa, beliau juga memenangi pingat Emas Sukan SEA empat siri berturut-turut pada 2005, 2007, 2009 dan 2011.
Begitu juga atlet kebangsaan seperti Leong Mun Yee (UPM); Pandalela Renong (UM); Bryan Nickson Lomas (UM); Cheng Chu Sian (UPM); Marbawi Sulaiman (UiTM) dan Norasheela Khalid (UPM).
Jika disenaraikan, mungkin lebih ramai lagi. Namun, pernah terlintas di fikiran mengapa hanya atlet dari sukan terjun yang dapat memenangi pingat di Sukan Olimpik? Bagaimana dengan atlet lain yang juga layak secara merit? Apakah kekangan atau masalah dihadapi sebagai atlet dan mahasiswa?
Adakah kewujudan universiti sukan akan memberi impak besar kepada kemajuan sukan negara? Jika dirancang dan diatur dengan cekap dan sistematik, ia perkara tidak mustahil dicapai.
"""
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string)))
%%time
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.0, temperature: 0.0})
def merge_ids_to_string(tokenizer, ids):
tokens = tokenizer.convert_ids_to_tokens(ids)
new_tokens = []
n_tokens = len(tokens)
i = 0
while i < n_tokens:
current_token = tokens[i]
if current_token.startswith('##'):
previous_token = new_tokens.pop()
merged_token = previous_token
while current_token.startswith('##'):
merged_token = merged_token + current_token.replace('##', '')
i = i + 1
current_token = tokens[i]
new_tokens.append(merged_token)
else:
new_tokens.append(current_token)
i = i + 1
words = [
i
for i in new_tokens
if i not in ['[CLS]', '[SEP]', '[PAD]']
]
return ' '.join(words)
merge_ids_to_string(tokenizer, l[0])
%%time
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string2)))
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.8, temperature: 0.1})
merge_ids_to_string(tokenizer, l[0])
%%time
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string3)))
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.8, temperature: 0.1})
merge_ids_to_string(tokenizer, l[0])
saver = tf.train.Saver(tf.trainable_variables())
saver.save(sess, 'output/model.ckpt')
strings = ','.join(
[
n.name
for n in tf.get_default_graph().as_graph_def().node
if ('Variable' in n.op
or 'Placeholder' in n.name
or 'top_p' in n.name
or 'temperature' in n.name
or 'logits' in n.name
or 'alphas' in n.name
or 'self/Softmax' in n.name)
and 'adam' not in n.name
and 'beta' not in n.name
and 'global_step' not in n.name
and 'gradients' not in n.name
]
)
strings.split(',')
def freeze_graph(model_dir, output_node_names):
if not tf.gfile.Exists(model_dir):
raise AssertionError(
"Export directory doesn't exists. Please specify an export "
'directory: %s' % model_dir
)
checkpoint = tf.train.get_checkpoint_state(model_dir)
input_checkpoint = checkpoint.model_checkpoint_path
absolute_model_dir = '/'.join(input_checkpoint.split('/')[:-1])
output_graph = absolute_model_dir + '/frozen_model.pb'
clear_devices = True
with tf.Session(graph = tf.Graph()) as sess:
saver = tf.train.import_meta_graph(
input_checkpoint + '.meta', clear_devices = clear_devices
)
saver.restore(sess, input_checkpoint)
output_graph_def = tf.graph_util.convert_variables_to_constants(
sess,
tf.get_default_graph().as_graph_def(),
output_node_names.split(','),
)
with tf.gfile.GFile(output_graph, 'wb') as f:
f.write(output_graph_def.SerializeToString())
print('%d ops in the final graph.' % len(output_graph_def.node))
freeze_graph('output', strings)
from tensorflow.tools.graph_transforms import TransformGraph
transforms = ['add_default_attributes',
'remove_nodes(op=Identity, op=CheckNumerics, op=Dropout)',
'fold_batch_norms',
'fold_old_batch_norms',
'quantize_weights(fallback_min=-10, fallback_max=10)',
'strip_unused_nodes',
'sort_by_execution_order']
pb = 'output/frozen_model.pb'
input_graph_def = tf.GraphDef()
with tf.gfile.FastGFile(pb, 'rb') as f:
input_graph_def.ParseFromString(f.read())
inputs = ['Placeholder', 'top_p', 'temperature']
transformed_graph_def = TransformGraph(input_graph_def,
inputs,
['logits'], transforms)
with tf.gfile.GFile(f'{pb}.quantized', 'wb') as f:
f.write(transformed_graph_def.SerializeToString())
def load_graph(frozen_graph_filename, **kwargs):
with tf.gfile.GFile(frozen_graph_filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# https://github.com/onnx/tensorflow-onnx/issues/77#issuecomment-445066091
# to fix import T5
for node in graph_def.node:
if node.op == 'RefSwitch':
node.op = 'Switch'
for index in xrange(len(node.input)):
if 'moving_' in node.input[index]:
node.input[index] = node.input[index] + '/read'
elif node.op == 'AssignSub':
node.op = 'Sub'
if 'use_locking' in node.attr:
del node.attr['use_locking']
elif node.op == 'AssignAdd':
node.op = 'Add'
if 'use_locking' in node.attr:
del node.attr['use_locking']
elif node.op == 'Assign':
node.op = 'Identity'
if 'use_locking' in node.attr:
del node.attr['use_locking']
if 'validate_shape' in node.attr:
del node.attr['validate_shape']
if len(node.input) == 2:
node.input[0] = node.input[1]
del node.input[1]
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def)
return graph
g = load_graph('output/frozen_model.pb')
x = g.get_tensor_by_name('import/Placeholder:0')
top_p = g.get_tensor_by_name('import/top_p:0')
temperature = g.get_tensor_by_name('import/temperature:0')
logits = g.get_tensor_by_name('import/logits:0')
test_sess = tf.Session(graph = g)
%%time
l = test_sess.run(logits, feed_dict = {x: [encoded], top_p: 0.0, temperature: 0.0})
```
|
github_jupyter
|
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/husein/t5/prepare/mesolitica-tpu.json'
os.environ['CUDA_VISIBLE_DEVICES'] = ''
import tensorflow as tf
from pegasus import transformer
vocab_size = 32000
hidden_size = 512
filter_size = 3072
num_encoder_layers = 6
num_decoder_layers = 6
num_heads = 8
label_smoothing = 0.0
dropout = 0.1
model = transformer.TransformerEncoderDecoderModel(vocab_size, hidden_size,
filter_size, num_heads,
num_encoder_layers,
num_decoder_layers,
label_smoothing, dropout)
X = tf.placeholder(tf.int64, (None, None))
top_p = tf.placeholder(tf.float32, None, name = 'top_p')
temperature = tf.placeholder(tf.float32, None, name = 'temperature')
outputs = model.predict({"inputs": X,}, tf.shape(X)[1], beam_size = 1,
top_p = top_p, temperature = temperature)
logits = tf.identity(outputs['outputs'], name = 'logits')
logits
import tokenization
tokenizer = tokenization.FullTokenizer(
vocab_file='pegasus.wordpiece', do_lower_case=False
)
import tensorflow as tf
ckpt_path = tf.train.latest_checkpoint('gs://mesolitica-tpu-general/pegasus-summarization-small')
ckpt_path
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess, ckpt_path)
import re
from unidecode import unidecode
def cleaning(string):
return re.sub(r'[ ]+', ' ', unidecode(string.replace('\n', ' '))).strip()
string = """
Tidak ada apa-apa mengenai mesyuarat fakulti biologi Jumaat lalu di University of Alabama di Huntsville yang membayangkan pembunuhan yang akan berlaku, Profesor Debra Moriarity memberitahu wartawan Rabu. "Ia sebenarnya adalah satu-satunya mesyuarat fakulti yang sangat santai dan biasa," ahli biokim memberitahu CNN affiliate WAAY mengenai 13 orang yang duduk di sekitar meja bujur di Bilik 369 di Shelby Centre for Science and Technology. "Peristiwa akan datang, kelas penjadualan, belanjawan. Ia sebenarnya merupakan salah satu daripada mesyuarat fakulti yang paling mudah yang kami ada." Antara peserta adalah Amy Bishop, seorang ahli genetik yang terlatih Harvard dengan siapa Moriarity telah membangun hubungan profesional yang dipupuk oleh hakikat bahawa kedua-dua wanita bekerja dengan budaya sel. "Kadang-kadang anda meminjam sesuatu dari satu sama lain," katanya. "Kami telah bercakap mengenai cadangan pemberian cadangan bersama." Selepas kira-kira sejam, sebelum 4hb, Bishop - yang baru-baru ini dinafikan tempohnya - menamatkan tenang. "Secara tiba-tiba, dia hanya berdiri dan ditembak," kata Moriarity. Moriarity bertindak balas dengan cepat, menjatuhkan ke tangan dan lututnya di atas permaidani kelabu. "Hanya jatuh ke lantai dan merangkak di bawah meja dan merangkak ke arah Amy," kata Moriarity, yang memberi tumpuan kepada satu perkara. "Maksud saya, kamu merangkak di bawah meja, kamu melihat kaki orang yang menembak di atas meja, saya merangkul kakinya dan, saya tidak tahu apa yang saya fikirkan, saya tidak memikirkan apa-apa. hanya berfikir: \'Ambil dia!\' "Dan dia menghalang saya. Maksud saya, dia menarik kaki kakinya percuma dan saya berada di ambang pintu dengan belakang saya jenisnya. Dan saya fikir dia cuba menembak saya, tetapi ketika saya mula berteriak kepadanya, \'Amy, Amy, berfikir tentang cucu saya, berfikir tentang anak perempuan saya! Ini saya! Saya telah membantu anda sebelum ini; Saya akan membantu anda lagi! Jangan buat Amy ini! Jangan lakukan ini! \'"Uskup kemudian melangkah masuk ke dalam dewan, menunjuk pistol di Moriarity dan menarik pencetus, kata ahli biologi." Ia diklik, dan ia diklik lagi, dan saya merangkak kembali ke dalam bilik dan menutup pintu dan dia ditinggalkan di dalam dewan. "Orang-orang yang terselamat itu beraksi. Satu orang mengunci pintu kayu, satu lagi mengetuk meja ke atasnya, yang lain memindahkan peti sejuk ke tempatnya untuk menghalang pintu, yang lain dipanggil 911, yang lain berpindah ke Tiga orang yang maut, tiga lagi yang cedera, dua daripadanya kekal dirawat di rumah sakit pada hari Rabu dalam keadaan kritikal, menurut seorang jurubicara Hospital Huntsville, yang ketiga dilepaskan, Moriarity, yang menyertai fakulti sekolah pada tahun 1984, mengatakan bahawa mangsa tidak menjejaskan rancangannya untuk kekal di sekolah dan dia menolak apa-apa cadangan bahawa peranannya untuk mendapatkan Bishop di luar bilik itu adalah heroik. "Dia mengikuti saya di dewan dan kemudian senjata itu macet dan saya boleh mendapatkan ba ck di dalam bilik, "kata Moriarity. "Itu bukan seorang pahlawan. Itu hanya Tuhan yang melihat kamu." Dia berkata dia mempunyai sedikit masa untuk berfikir. "Dari awal hingga akhirnya kami mendapat sesuatu yang tidak dapat dibendung, ia tidak boleh melebihi 20 saat," katanya. Moriarity terus menolak cadangan bahawa apa-apa boleh dilakukan untuk melindungi mangsa. "Tidak ada cara untuk menjangka ini," katanya. "Dan tiada apa yang dapat dilakukan untuk menghentikannya, semuanya berlaku terlalu pantas." Dan dia bimbang bahawa apa-apa cubaan untuk mengetatkan keselamatan boleh membawa kesan negatif. "Ada kejahatan di dunia, malangnya orang baik disakiti oleh itu, tetapi universiti adalah tempat pemikiran bebas dan kebebasan untuk meneroka idea-idea dan mencari pengetahuan baru dan anda tidak mahu meletakkan sesuatu di tempat yang meredakannya. " Moriarity kembali ke pejabatnya pada hari Rabu dan berkata dia merancang untuk meneruskan pengajaran minggu depan. Dia meramalkan bahawa, dengan bantuan ubat anti-kecemasan, dia akan dapat tidur malam Rabu. "Saya telah bercakap dengan keluarga dan kawan-kawan dan hanya mendapatkan sokongan mereka membantu anda menanganinya," katanya. "Saya fikir sekarang kebanyakan dari kita mahu kembali ke sana dan mendapatkan sesuatu yang berlaku, membuat rancangan untuk siapa yang akan menutup kelas." Satu perkhidmatan peringatan untuk menghormati kehidupan orang mati - ahli fakulti Maria Davis, Adriel Johnson dan Gopi Podila - akan diadakan pada hari Jumaat.
"""
string2 = """
Gabungan parti Warisan, Pakatan Harapan, dan Upko hari ini mendedahkan calon-calon masing-masing untuk pilihan raya negeri Sabah, tetapi ketika pengumuman itu berlangsung, perwakilan PKR di dewan itu dilihat ‘gelisah’ seperti ‘tidak senang duduk’.
Sekumpulan anggota PKR kemudian dilihat meninggalkan dewan di Pusat Konvensyen Antarabangsa Sabah di Kota Kinabalu selepas berbincang dengan ketua PKR Sabah Christina Liew.
Semakan senarai-senarai calon berkenaan mendapati PKR hanya memperolehi separuh daripada jumlah kerusi yang diharapkan.
Semalam, PKR Sabah mengumumkan akan bertanding di 14 kerusi tetapi ketika Presiden Warisan Shafie Apdal mengumumkan calon gabungan tersebut hari ini, PKR hanya diberikan tujuh kerusi untuk bertanding.
Kerusi yang diberikan adalah Api-Api, Inanam, Tempasuk, Tamparuli, Matunggong, Klias, dan Sook.
Klias dan Sook adalah dua kerusi yang diberikan kepada PKR, sementara lima kerusi selebihnya pernah ditandingi oleh PKR pada pilihan raya umum 2018.
Dalam pengumuman PKR Sabah semalam, parti itu menjangkakan Warisan akan turut menyerahkan kerusi Kemabong, Membakut, dan Petagas kepada mereka.
Walau bagaimanapun, Warisan menyerahkan kerusi Kemabong kepada Upko dan mengekalkan bertanding untuk kerusi Membakut dan Petagas.
PKR juga menuntut empat daripada 13 kerusi baru yang diperkenalkan iaitu Segama, Limbahau, Sungai Manila, dan Pintasan tetapi Warisan membolot semua kerusi itu.
Sebagai pertukaran untuk kerusi yang diintainya, PKR bersedia untuk menyerahkan kerusi Kadaimaian, Kuala Penyu, dan Karanaan. Namun, ini dijangka tidak akan berlaku memandangkan parti tersebut tidak berpuas hati dengan agihan kerusi seperti yang diharapkan itu.
Selepas perwakilan dari PKR dan Liew keluar dari dewan tersebut, wartawan kemudian menyusuri Liew untuk mendapatkan penjelasannya.
Walau bagaimanapun, Liew enggan memberikan sebarang komen dan berkata bahawa dia ingin ke tandas.
Liew dan perwakilan PKR kemudian tidak kembali ke dalam dewan tersebut.
Apabila calon pilihan raya yang diumumkan diminta naik ke atas pentas untuk sesi bergambar, Liew tidak kelihatan.
Bilangan kerusi yang ditandingi oleh PKR kali ini hanya kurang satu kerusi daripada yang ditandingi parti itu pada PRU 2018.
Dalam perkembangan berkaitan, DAP dan Amanah dikatakan tidak mempunyai sebarang masalah dengan kerusi yang diberikan untuk PRN Sabah.
Sementara itu, Presiden Upko Madius Tangau enggan mengulas adakah dia berpuas hati dengan agihan kerusi tersebut. Madius kekal di majlis tersebut sehingga ia berakhir.
Partinya diberikan 12 kerusi, iaitu lebih tujuh kerusi berbanding PRU lalu.
DAP dan Amanah akan bertanding di bawah logo Warisan sementara PKR dan Upko akan menggunakan logo masing-masing.
DAP akan bertanding di tujuh kerusi, jumlah yang sama seperti yang mereka tandingi pada PRU lalu, sementara Amanah diberi satu kerusi.
Warisan akan bertanding sebanyak 54 kerusi.
Perkembangan terbaru ini mungkin mencetuskan pergeseran di antara PKR dan Warisan. PKR boleh memilih untuk bertanding di lebih banyak kerusi daripada 14 yang dituntutnya manakala Warisan juga boleh bertanding di kerusi sekutunya.
Barisan pemimpin tertinggi PKR dan Warisan hanya mempunyai dua hari sebelum hari penamaan calon pada Sabtu untuk mengurangkan pergeseran.
"""
string3 = """
Penubuhan universiti sukan seperti diutarakan Ketua Unit Sukan Kementerian Pengajian Tinggi, Dr Pekan Ramli dan disokong Pakar Pembangunan Sukan dan Reakreasi Luar, Universiti Pendidikan Sultan Idris (UPSI), Prof Dr Md Amin Md Taaf seperti disiarkan akhbar ini, memberikan sinar harapan kepada kewujudan institusi sedemikian.
Ia menjadi impian atlet negara untuk mengejar kejayaan dalam bidang sukan dan kecemerlangan dalam akademik untuk menjamin masa depan lebih baik apabila bersara daripada arena sukan kelak.
Pelbagai pandangan, idea, kaedah, bukti dan cadangan dilontarkan pakar berikutan pentingnya universiti sukan yang akan memberi impak besar sama ada pada peringkat kebangsaan mahupun antarabangsa.
Negara lain sudah lama meraih laba dengan kewujudan universiti sukan seperti China, Korea, Japan, Taiwan, India dan Vietnam. Mereka menghasilkan atlet universiti yang mempamerkan keputusan cemerlang pada peringkat tinggi seperti Sukan Olimpik, Kejohanan Dunia dan Sukan Asia.
Justeru, kejayaan mereka perlu dijadikan rujukan demi memajukan sukan tanah air. Jika kita merujuk pendekatan Asia, kewujudan universiti sukan penting dan memberi kesan positif dalam melonjakkan prestasi sukan lebih optimum.
Namun, jika kita melihat pendekatan Eropah, universiti sukan bukan antara organisasi atau institusi penting yang diberi perhatian dalam menyumbang kepada pemenang pingat.
Antara isu dalam universiti sukan ialah kos tinggi, lokasi, prasarana sukan, pertindihan kursus dengan universiti sedia ada dan impak terhadap dunia sukan negara hingga mengundang persoalan kewajaran dan kerelevanan penubuhannya.
Namun sebagai bekas atlet memanah negara dan Olympian (OLY) di Sukan Olimpik 2004 di Athens, Greece serta bekas pelajar Sekolah Sukan Bukit Jalil hingga berjaya dalam dunia akademik, saya mendapati terdapat beberapa faktor sering menjadi halangan dalam rutin harian mereka.
Antaranya, faktor masa yang terpaksa bergegas menghadiri kuliah selepas tamat sesi latihan yang mengambil masa 15 hingga 20 minit dengan menunggang motosikal; kereta (20-30 minit) atau pengangkutan disediakan Majlis Sukan Negara (MSN) ke Universiti Putra Malaysia (UPM).
Jika mereka menuntut di Universiti Teknologi MARA (UiTM) atau Universiti Malaya (UM), ia mungkin lebih lama.
Walaupun di universiti tersedia dengan kemudahan kolej dan kemudahan sukan, mereka memilih pulang ke MSN untuk menjalani latihan bersama pasukan dan jurulatih di padang atau gelanggang latihan rasmi.
Ini berlanjutan selagi bergelar atlet negara yang perlu memastikan prestasi sentiasa meningkat dari semasa ke semasa tanpa mengabaikan tugas sebagai pelajar.
Alangkah baiknya jika sebahagian Sekolah Sukan Bukit Jalil itu sendiri dijadikan Kolej atau Universiti Sukan Malaysia kerana lengkap dari segi kemudahan prasarana sukannya dan proses pengajaran dan pembelajaran (PdP) dalam bidang Sains Sukan, Kejurulatihan, Pendidikan Jasmani dan setaraf dengannya.
Pengambilan setiap semester pula hanya terhad kepada atlet berstatus kebangsaan dan antarabangsa sahaja supaya hasrat melahirkan lebih ramai atlet bertaraf Olimpik mudah direalisasikan.
Contohnya, bekas atlet lompat bergalah negara, Roslinda Samsu yang juga pemenang pingat perak Sukan Asia Doha 2006 dan Penerima Anugerah Khas Majlis Anugerah Sukan KPT 2012, terpaksa mengambil masa lebih kurang sembilan tahun untuk menamatkan ijazah Sarjana Muda Pendidikan Jasmani di UPM sepanjang 14 tahun terbabit dalam sukan olahraga.
Sepanjang tempoh bergelar atlet kebangsaan dan mahasiswa, beliau juga memenangi pingat Emas Sukan SEA empat siri berturut-turut pada 2005, 2007, 2009 dan 2011.
Begitu juga atlet kebangsaan seperti Leong Mun Yee (UPM); Pandalela Renong (UM); Bryan Nickson Lomas (UM); Cheng Chu Sian (UPM); Marbawi Sulaiman (UiTM) dan Norasheela Khalid (UPM).
Jika disenaraikan, mungkin lebih ramai lagi. Namun, pernah terlintas di fikiran mengapa hanya atlet dari sukan terjun yang dapat memenangi pingat di Sukan Olimpik? Bagaimana dengan atlet lain yang juga layak secara merit? Apakah kekangan atau masalah dihadapi sebagai atlet dan mahasiswa?
Adakah kewujudan universiti sukan akan memberi impak besar kepada kemajuan sukan negara? Jika dirancang dan diatur dengan cekap dan sistematik, ia perkara tidak mustahil dicapai.
"""
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string)))
%%time
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.0, temperature: 0.0})
def merge_ids_to_string(tokenizer, ids):
tokens = tokenizer.convert_ids_to_tokens(ids)
new_tokens = []
n_tokens = len(tokens)
i = 0
while i < n_tokens:
current_token = tokens[i]
if current_token.startswith('##'):
previous_token = new_tokens.pop()
merged_token = previous_token
while current_token.startswith('##'):
merged_token = merged_token + current_token.replace('##', '')
i = i + 1
current_token = tokens[i]
new_tokens.append(merged_token)
else:
new_tokens.append(current_token)
i = i + 1
words = [
i
for i in new_tokens
if i not in ['[CLS]', '[SEP]', '[PAD]']
]
return ' '.join(words)
merge_ids_to_string(tokenizer, l[0])
%%time
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string2)))
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.8, temperature: 0.1})
merge_ids_to_string(tokenizer, l[0])
%%time
encoded = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(cleaning(string3)))
l = sess.run(logits, feed_dict = {X: [encoded], top_p: 0.8, temperature: 0.1})
merge_ids_to_string(tokenizer, l[0])
saver = tf.train.Saver(tf.trainable_variables())
saver.save(sess, 'output/model.ckpt')
strings = ','.join(
[
n.name
for n in tf.get_default_graph().as_graph_def().node
if ('Variable' in n.op
or 'Placeholder' in n.name
or 'top_p' in n.name
or 'temperature' in n.name
or 'logits' in n.name
or 'alphas' in n.name
or 'self/Softmax' in n.name)
and 'adam' not in n.name
and 'beta' not in n.name
and 'global_step' not in n.name
and 'gradients' not in n.name
]
)
strings.split(',')
def freeze_graph(model_dir, output_node_names):
if not tf.gfile.Exists(model_dir):
raise AssertionError(
"Export directory doesn't exists. Please specify an export "
'directory: %s' % model_dir
)
checkpoint = tf.train.get_checkpoint_state(model_dir)
input_checkpoint = checkpoint.model_checkpoint_path
absolute_model_dir = '/'.join(input_checkpoint.split('/')[:-1])
output_graph = absolute_model_dir + '/frozen_model.pb'
clear_devices = True
with tf.Session(graph = tf.Graph()) as sess:
saver = tf.train.import_meta_graph(
input_checkpoint + '.meta', clear_devices = clear_devices
)
saver.restore(sess, input_checkpoint)
output_graph_def = tf.graph_util.convert_variables_to_constants(
sess,
tf.get_default_graph().as_graph_def(),
output_node_names.split(','),
)
with tf.gfile.GFile(output_graph, 'wb') as f:
f.write(output_graph_def.SerializeToString())
print('%d ops in the final graph.' % len(output_graph_def.node))
freeze_graph('output', strings)
from tensorflow.tools.graph_transforms import TransformGraph
transforms = ['add_default_attributes',
'remove_nodes(op=Identity, op=CheckNumerics, op=Dropout)',
'fold_batch_norms',
'fold_old_batch_norms',
'quantize_weights(fallback_min=-10, fallback_max=10)',
'strip_unused_nodes',
'sort_by_execution_order']
pb = 'output/frozen_model.pb'
input_graph_def = tf.GraphDef()
with tf.gfile.FastGFile(pb, 'rb') as f:
input_graph_def.ParseFromString(f.read())
inputs = ['Placeholder', 'top_p', 'temperature']
transformed_graph_def = TransformGraph(input_graph_def,
inputs,
['logits'], transforms)
with tf.gfile.GFile(f'{pb}.quantized', 'wb') as f:
f.write(transformed_graph_def.SerializeToString())
def load_graph(frozen_graph_filename, **kwargs):
with tf.gfile.GFile(frozen_graph_filename, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# https://github.com/onnx/tensorflow-onnx/issues/77#issuecomment-445066091
# to fix import T5
for node in graph_def.node:
if node.op == 'RefSwitch':
node.op = 'Switch'
for index in xrange(len(node.input)):
if 'moving_' in node.input[index]:
node.input[index] = node.input[index] + '/read'
elif node.op == 'AssignSub':
node.op = 'Sub'
if 'use_locking' in node.attr:
del node.attr['use_locking']
elif node.op == 'AssignAdd':
node.op = 'Add'
if 'use_locking' in node.attr:
del node.attr['use_locking']
elif node.op == 'Assign':
node.op = 'Identity'
if 'use_locking' in node.attr:
del node.attr['use_locking']
if 'validate_shape' in node.attr:
del node.attr['validate_shape']
if len(node.input) == 2:
node.input[0] = node.input[1]
del node.input[1]
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def)
return graph
g = load_graph('output/frozen_model.pb')
x = g.get_tensor_by_name('import/Placeholder:0')
top_p = g.get_tensor_by_name('import/top_p:0')
temperature = g.get_tensor_by_name('import/temperature:0')
logits = g.get_tensor_by_name('import/logits:0')
test_sess = tf.Session(graph = g)
%%time
l = test_sess.run(logits, feed_dict = {x: [encoded], top_p: 0.0, temperature: 0.0})
| 0.305697 | 0.223652 |
Precursors!
```
import os, subprocess
if not os.path.isfile('data/hg19.ml.fa'):
subprocess.call('curl -o data/hg19.ml.fa https://storage.googleapis.com/basenji_tutorial_data/hg19.ml.fa', shell=True)
subprocess.call('curl -o data/hg19.ml.fa.fai https://storage.googleapis.com/basenji_tutorial_data/hg19.ml.fa.fai', shell=True)
if not os.path.isdir('models/heart'):
os.mkdir('models/heart')
if not os.path.isfile('models/heart/model_best.tf.meta'):
subprocess.call('curl -o models/heart/model_best.tf.index https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.index', shell=True)
subprocess.call('curl -o models/heart/model_best.tf.meta https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.meta', shell=True)
subprocess.call('curl -o models/heart/model_best.tf.data-00000-of-00001 https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.data-00000-of-00001', shell=True)
samples_out = open('data/heart_wigs_index.txt', 'w')
print('0\tCNhs11760\tdata/CNhs11760.bw\taorta', file=samples_out)
print('1\tCNhs12843\tdata/CNhs12843.bw\tartery', file=samples_out)
print('2\tCNhs12856\tdata/CNhs12856.bw\tpulmonic valve', file=samples_out)
samples_out.close()
```
Analyzing noncoding variation associated with disease is a major application of Basenji. I now offer several tools to enable that analysis. If you have a small set of variants and know what datasets are most relevant, [basenji_sat_vcf.py](https://github.com/calico/basenji/blob/master/bin/basenji_sat_vcf.py) lets you perform a saturation mutagenesis of the variant and surrounding region to see the relevant nearby motifs.
If you want scores measuring the influence of those variants on all datasets,
* [basenji_sad.py](https://github.com/calico/basenji/blob/master/bin/basenji_sad.py) computes my SNP activity difference (SAD) score--the predicted change in aligned fragments to the region.
* [basenji_sed.py](https://github.com/calico/basenji/blob/master/bin/basenji_sed.py) computes my SNP expression difference (SED) score--the predicted change in aligned fragments to gene TSS's.
Here, I'll demonstrate those two programs. You'll need
* Trained model
* Input file (FASTA or HDF5 with test_in/test_out)
First, you can either train your own model in the [Train/test tutorial](https://github.com/calico/basenji/blob/master/tutorials/train_test.ipynb) or use one that I pre-trained from the models subdirectory.
As an example, we'll study a prostate cancer susceptibility allele of rs339331 that increases RFX6 expression by modulating HOXB13 chromatin binding (http://www.nature.com/ng/journal/v46/n2/full/ng.2862.html).
First, we'll use [basenji_sad.py](https://github.com/calico/basenji/blob/master/bin/basenji_sad.py) to predict across the region for each allele and compute stats about the mean and max differences.
The most relevant options are:
| Option/Argument | Value | Note |
|:---|:---|:---|
| -f | data/hg19.ml.fa | Genome fasta. |
| -g | data/human.hg19.genome | Genome assembly chromosome length to bound gene sequences. |
| -l | 131072 | Saturation mutagenesis region in the center of the given sequence(s) |
| -o | rfx6_sad | Outplot plot directory. |
| --rc | | Predict forward and reverse complement versions and average the results. |
| -t | data/heart_wigs.txt | Target labels. |
| params_file | models/params_small.txt | Table of parameters to setup the model architecture and optimization parameters. |
| model_file | models/heart/model_best.tf | Trained saved model prefix. |
| vcf_file | data/rs339331.vcf | VCF file specifying variants to score. |
```
! basenji_sad.py -f data/hg19.ml.fa -g data/human.hg19.genome -l 131072 -o output/rfx6_sad --rc -t data/heart_wigs_index.txt models/params_small.txt models/heart/model_best.tf data/rs339331.vcf
```
rfx6_sad/sad_table.txt now contains a table describing the results.
The *u* in *upred* and *usad* refers to taking the mean across the sequence, whereas *x* in *xpred* and *xsad* refers to the maximum position.
Then *sad* refers to subtracting the alt allele prediction from the ref allele, and *sar* refers to adding a pseudocount 1 and taking log2 of their ratio.
```
! cat output/rfx6_sad/sad_table.txt
```
We can sort by *xsar* to get an idea of the datasets where Basenji sees the largest difference between the two alleles.
```
! sort -k13 -g output/rfx6_sad/sad_table.txt
! sort -k13 -gr output/rfx6_sad/sad_table.txt
```
These are inconclusive small effect sizes, not surprising given that we're only studying heart CAGE. The proper cell types and experiments would shed more light.
Alternatively, we can directly query the predictions at gene TSS's using [basenji_sed.py](https://github.com/calico/basenji/blob/master/bin/basenji_sed.py).
[basenji_sed.py](https://github.com/calico/basenji/blob/master/bin/basenji_sed.py) takes as input the gene sequence HDF5 format described in [genes.ipynb](https://github.com/calico/basenji/blob/master/tutorials/genes.ipynb). There's no harm to providing an HDF5 that describes all genes, but it's too big to easily move around so I constructed one that focuses on RFX6.
The most relevant options are:
| Option/Argument | Value | Note |
|:---|:---|:---|
| -g | data/human.hg19.genome | Genome assembly chromosome length to bound gene sequences. |
| -o | rfx6_sed | Outplot plot directory. |
| --rc | | Predict forward and reverse complement versions and average the results. |
| -w | 128 | Sequence bin width at which predictions are made. |
| params_file | models/params_med.txt | Table of parameters to setup the model architecture and optimization parameters. |
| model_file | models/gm12878.tf | Trained saved model prefix. |
| genes_hdf5_file | data/rfx6.h5 | HDF5 file specifying gene sequences to query. |
| vcf_file | data/rs339331.vcf | VCF file specifying variants to score. |
Before running [basenji_sed.py](https://github.com/calico/basenji/blob/master/bin/basenji_sed.py), we need to generate an input data file for RFX6. Using an included GTF file that contains only RFX6, one can use [basenji_hdf5_genes.py]((https://github.com/calico/basenji/blob/master/bin/basenji_hdf5_genes.py) to create the required format.
```
! basenji_hdf5_genes.py -g data/human.hg19.genome -l 131072 -c 0.333 -w 128 data/hg19.ml.fa data/rfx6.gtf data/rfx6.h5
! basenji_sed.py -a -g data/human.hg19.genome -o output/rfx6_sed --rc models/params_small.txt models/heart/model_best.tf data/rfx6.h5 data/rs339331.vcf
! sort -k9 -g output/rfx6_sed/sed_gene.txt
! sort -k9 -gr output/rfx6_sed/sed_gene.txt
```
|
github_jupyter
|
import os, subprocess
if not os.path.isfile('data/hg19.ml.fa'):
subprocess.call('curl -o data/hg19.ml.fa https://storage.googleapis.com/basenji_tutorial_data/hg19.ml.fa', shell=True)
subprocess.call('curl -o data/hg19.ml.fa.fai https://storage.googleapis.com/basenji_tutorial_data/hg19.ml.fa.fai', shell=True)
if not os.path.isdir('models/heart'):
os.mkdir('models/heart')
if not os.path.isfile('models/heart/model_best.tf.meta'):
subprocess.call('curl -o models/heart/model_best.tf.index https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.index', shell=True)
subprocess.call('curl -o models/heart/model_best.tf.meta https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.meta', shell=True)
subprocess.call('curl -o models/heart/model_best.tf.data-00000-of-00001 https://storage.googleapis.com/basenji_tutorial_data/model_best.tf.data-00000-of-00001', shell=True)
samples_out = open('data/heart_wigs_index.txt', 'w')
print('0\tCNhs11760\tdata/CNhs11760.bw\taorta', file=samples_out)
print('1\tCNhs12843\tdata/CNhs12843.bw\tartery', file=samples_out)
print('2\tCNhs12856\tdata/CNhs12856.bw\tpulmonic valve', file=samples_out)
samples_out.close()
! basenji_sad.py -f data/hg19.ml.fa -g data/human.hg19.genome -l 131072 -o output/rfx6_sad --rc -t data/heart_wigs_index.txt models/params_small.txt models/heart/model_best.tf data/rs339331.vcf
! cat output/rfx6_sad/sad_table.txt
! sort -k13 -g output/rfx6_sad/sad_table.txt
! sort -k13 -gr output/rfx6_sad/sad_table.txt
! basenji_hdf5_genes.py -g data/human.hg19.genome -l 131072 -c 0.333 -w 128 data/hg19.ml.fa data/rfx6.gtf data/rfx6.h5
! basenji_sed.py -a -g data/human.hg19.genome -o output/rfx6_sed --rc models/params_small.txt models/heart/model_best.tf data/rfx6.h5 data/rs339331.vcf
! sort -k9 -g output/rfx6_sed/sed_gene.txt
! sort -k9 -gr output/rfx6_sed/sed_gene.txt
| 0.255251 | 0.744912 |
<div style="width: 100%; clear: both;">
<div style="float: left; width: 50%;">
<img src="http://www.uoc.edu/portal/_resources/common/imatges/marca_UOC/UOC_Masterbrand.jpg", align="left">
</div>
<div style="float: right; width: 50%;">
<p style="margin: 0; padding-top: 22px; text-align:right;">M2.851 - Tipología y ciclo de vida de los datos aula 1 · Práctica 1</p>
<p style="margin: 0; text-align:right;">2018 · Máster universitario en Ciencia de datos (Data science)</p>
<p style="margin: 0; text-align:right;">Prof. Colaboradora: <b>Laia Subirats Maté</b></p>
<p style="margin: 0; text-align:right; padding-button: 100px;">Alumno: <b>Fernando Antonio Barbeiro Campos</b> - <a href="">[email protected]</a></p>
</div>
</div>
<div style="width:100%;"> </div>
### Dataset
Historial de eventos del UFC (*Ultimate Fighting Championship*)
### Descripción
Un dataset completo con todos los eventos deportivos de MMA (*mixed martial arts*) más famoso del mundo, los deportistas, resultados, entre otros.
### Imagen identificativa
<img src="ufc-results.jpg" alt="UFC results" style="width: 700px;"/>
<center>Figura 1: Resultados y card de peleas de un evento de UFC.</center>
### Contexto
El conjunto de datos se trata de todos los eventos deportivos de MMA realizados desde la creación del UFC (primer evento en el **12 de Noviembre de 1993**) hasta el último que ocurrió en el **27 de Octubre de 2018**, o sea, **454 eventos**, bien como el resultado de cada una de las peleas que ocurrieron en cada evento - precisamente **4869 luchas**.
### Contenido
El dataset tiene un contenido bastante sencillo que consiste en:
* [String] *event_name:* Nombre del evento
* [String] *weight_class:* Categoría de peso de la pelea
* [String] *fighter_1:* Nombre del competidor 1
* [String] *action:* Acción que ejecutó el competidor 1 sobre el oponente / resultado
* [String] *fighter_2:* Nombre del oponente
* [Integer] *round:* *Round* en que acabó la lucha
* [String] *time:* Tiempo en el *round* que acabó la lucha
* [String] *method:* Como ha sido el método utilizado para ganar
El intervalo de tiempo fuera mencionado arriba, vale resaltar que en cada evento hay una media de 10.7 luchas. La estrategia utilizada para recoger los datos es el resultado de iteraciones en listas:
* Inicialmente, pillamos la [lista de todos los eventos del UFC](https://en.wikipedia.org/wiki/List_of_UFC_events)
* Hacemos un `for` loop en la lista completa y extraemos (con uso de BeautifulSoup) las URLs individuales de cada evento
* Finalmente también haremos una lectura de tabla para finalmente recolectar los datos.
### Agradecimientos
En análisis se realizó entre **17 y 20 de Octubre** y específicamente el enfoque era encontrar puntos donde pudiera haber ilegalidad en la extracción de información de las fuentes de datos. Para ello, estuve mirando especialmente los ficheros de [robots.txt de Wikipedia](https://en.wikipedia.org/robots.txt), que dicho, es nuestra fuente de información, al cual dejamos el agradecimiento y sugiero donaciones para la iniciativa.
Las URLs de lectura no estaban *Disallowed* en el fichero de Robots, por lo tanto, no habría problemas explorarlas. Aun así, he aplicado técnicas como sleep recomienda **[4] Miller, C. (2017)** para evitar la sobrecarga (*throttling*) de la webpage.
### Inspiración
Desde mi punto de vista, el conjunto de datos es interesante porque el ámbito de su aplicación es bastante amplio, para comprobar, voy a describir escenarios de su aplicación:
1. Primeramente, una aplicación podría ser para uso en periodismo deportivo - para enseñar datos y patrones del deporte.
2. Un deportista, que compete o no en el evento, podría sacar informaciones de métodos más comúnmente utilizados para encerrar una lucha y, de esa manera, prepararse para evitar que hicieran con él o mismo practicar las técnicas para intentar aplicarlas cuando esté competiendo.
3. La preparación física en un deporte es un punto clave. Entender donde suele pasar la mayor parte de fines de luchas puede también ayudar los profesionales de preparación física a entrenar sus atletas para que en cansancio no les quite la oportunidad de victoria.
4. Podríamos identificar patrones de acuerdo con el peso (categoría) de los atletas, es decir, puede que en una categoría más ligera estén acostumbrados a pelearse más de pie, mientras en otras categorías más pasadas suele ocurrir grappling (lucha de suelo).
Seguramente hay otras numerosas posibilidades de aplicación.
### Licencia
Haciendo un breve estudio de las licencias presentadas, creo que la que se aplicaría más ampliamente a mi estudio sería **CC BY-NC-SA 4.0**, me explico: la licencia en cuestión permite:
* *Compartir*: copiar y redistribuir el material
* *Adaptar*: transformar y cambiar el material
Sin embargo, no permite el uso comercial del mismo - el que, siendo un trabajo de máster, tiene fines más académicos.
Abajo, una imagen de que trata la licencia elegida:
<img src="license.png" alt="License" style="width: 500px; height: 400px;"/>
<center>Figura 2: CC BY-NC-SA 4.0.</center>
P.D.: Como el los repositorios de Github no había disponibilidad de utilizar la dicha licencia, por allí he definido el uso de **BSD 3-Clause** que básicamente define que las redistribuciones de generadas con base en el proyecto en cuestión deben ser hechas con notificación a priori. Ademas, garantiza que los nombres de los creadores del proyecto inicial no pueden ser usados para promover productos derivados del proyecto inicial.
### Código
En ese apartado, tendremos el código utilizado para la extracción de los datos y al final para la generación del CSV.
```
import sys
print(sys.version)
# Not necessary at all, but to demonstrate that I'm aware that BeautifulSoup4 must be installed
!{sys.executable} -m pip install --upgrade pip
!{sys.executable} -m pip install BeautifulSoup4
from bs4 import BeautifulSoup
from IPython.core.display import display, HTML
from time import sleep
import requests
import pandas as pd
import os
Events = []
base_url = 'https://en.wikipedia.org'
main_url = base_url + '/wiki/List_of_UFC_events'
def perform_http_get(url):
"""
Note:
This is a simple function that performs an http_get and if the result code is 200 proceed the return.
Args:
url (str): A string.
Returns:
BeautifulSoup: a version parsed of the request content
"""
r = requests.get(url)
if r.status_code == 200:
return BeautifulSoup(r.content, 'html.parser')
def extract_cell(cells, id_td):
"""
Note:
This method is aimed for returning the content of a given cell (td) decoded and without
additional blank spaces.
Args:
cells (list): A list representing the table row.
id_td (int): The index of the wanted cell
Returns:
String: the real content of the cell.
"""
return cells[id_td].renderContents().decode().strip()
def append_fighter_names(cells_event, info):
"""
Note:
This method presents some logic that will be briefly explained here. It turns out that some
fighters don't have their own wikipedia page, in these cases, there is no link (<a>) within
their names. Therefore, returning just the content of the cell where this info is present
is enough. In other cases, where the link is there, we must extract to update our dictionary.
Args:
cells_event (list): A list representing the table row.
info (dict): The dictionary to be updated
"""
fighter1 = ''
fighter2 = ''
if len(cells_event[1].findAll('a')) == 0:
fighter1 = extract_cell(cells_event, 1)
else:
fighter1 = cells_event[1].find('a').renderContents().decode().strip()
if len(cells_event[3].findAll('a')) == 0:
fighter2 = extract_cell(cells_event, 3)
else:
fighter2 = cells_event[3].find('a').renderContents().decode().strip()
info.update({"fighter_1" : fighter1})
info.update({"fighter_2" : fighter2})
def extract_row(cells_event, link):
"""
Note:
The goal here is to create a dictionary for the given events and also
to update in our events list (Events.append). We realize that within
the method we are also invoking the append_fighter_names that will call
the aforementioned method to treat the fighters' name.
Args:
cells_event (list): A list representing the table row.
link (str): Basically the event name
"""
info = {
"event_name": link.contents[0],
"weight_class": extract_cell(cells_event, 0),
"action": extract_cell(cells_event, 2),
"method": extract_cell(cells_event, 4),
"round": extract_cell(cells_event, 5),
"time": extract_cell(cells_event, 6)
}
append_fighter_names(cells_event, info)
Events.append(info)
def download_event_image(individual_event, link):
"""
Note:
The method's name is pretty clear here, however, the objective is to
download the images of each event in order to present them at the bottom
of this current document. In a nutshell, the behaviour expected here
is to create all the recovered images in a folder called pictures
which, by the way, we can observe that will be created.
Args:
individual_event (BeautifulSoup): A BeautifulSoup representing the page of a single event.
"""
event_images = individual_event.select('table.infobox a.image img[src]')
if len(event_images) > 0:
for img in event_images:
img_url = 'http:' + img['src']
r = requests.get(img_url)
with open('pictures/' + link.contents[0], "wb") as code:
code.write(r.content)
def extract_info_individual_event(link):
"""
Note:
As you will see, this is the second part of a for loop that I will summarize here:
First we iterate over the list of UFC events presented in the main web-page (
https://en.wikipedia.org/wiki/List_of_UFC_events). From the data gathered there
each individual event will be accessed and we'll collect data from these events.
Needless to say that I'm not iterating over a single web-page, but instead, more than
450 different web pages, being the first of them the "master one", and this individual
ones.
Args:
link (url): The URL for the individual web-pages of a given list.
"""
individual_event = perform_http_get(base_url + link.get('href'))
table = individual_event.find('table',{'class': 'toccolours'})
download_event_image(individual_event, link)
if table is not None:
rows_event = table.findAll('tr')
for row_event in rows_event:
cells_event = row_event.findAll('td')
if len(cells_event) > 0 :
extract_row(cells_event, link)
"""
From my perspective this is a key part of the program and it will trigger
the execution and the invocation of the previous methods.
Basically we are collecting the "Past Events" of a table in one page and
for each event in this table (currently 454), we will read another
information as previously explained in different web pages.
By reading another information, I mean: download the event image, read
the card and the results of the event and so on.
Apart from the behaviour expected, in this part of the code, I also tried
to avoid throtling the Wikipedia source by adding some sleeps within each
iteration - it will slow down the process and avoid some common problems.
"""
Events = []
soup = perform_http_get(main_url)
table_past_events = soup.find('table', {'id': 'Past_events'})
rows = table_past_events.findAll('tr')
for row in rows:
#sleep(10) # Wait 10 sec, recommendations explained by [4] Miller, C. (2017)
cells = row.findAll('td')
if len(cells) > 0 :
links = cells[1].findAll('a')
for link in links:
extract_info_individual_event(link)
"""
Once we have a list of dict in Events attributes, it's high time we defined
a panda dataframe to properly store the info.
It is done here and we present a glimpse of the data with the df.head() below.
"""
print(len(Events), ' eventos fueron añadidos')
df = pd.DataFrame(Events)
df = df[['event_name', 'weight_class', 'fighter_1', 'action', 'fighter_2', 'round', 'time', 'method' ]]
df.head(15)
"""
This is particularly a visual part of the presentation of the data.
For each event, I'm presenting the folder advertising it.
Remembering that we download each of these pictures in a method
explained before
"""
df_imgs = df['event_name'].drop_duplicates()
print('Imagenes: ', len(df_imgs))
display(HTML('<table style="width:100%; border: 1px solid black;"><tr>'))
i = 0
row = ''
for img in df_imgs:
img_src = 'pictures/' + img
if i == 20:
row = '{}<td><img src=\'{}\' alt=\'{}\' /></td></tr>'.format(row, img_src, img)
display(HTML(row))
row = '<tr>'
i = 0
else:
row = '{}<td><img src=\'{}\' /></td>'.format(row, img_src)
i += 1
display(HTML('</tr></table>'))
```
### Dataset: Dataset en formato CSV
Por aquí generamos el dataset que podrá ser consultado en el repositorio.
```
"""
Last but not least, we are storing the dataframe in a CSV file
"""
file_name = 'ufc-events.csv'
df.to_csv(file_name)
```
### Referencias
<p style="text-align: justify">
[1] <b>Subirats, L., Calvo, M. (2018).</b> "<i>Web Scraping</i>". Editorial UOC. Barcelona: Universitat Autònoma de Barcelona.<p>
<p style="text-align: justify">
[2] <b>Masip, D. (?).</b> "<i>El lenguaje Python</i>". Editorial UOC. Barcelona: Universitat Autònoma de Barcelona.<p>
<p style="text-align: justify">
[3] <b>Lawson, R. (2015).</b> "<i>Web Scraping with Python</i>". Packt Publishing Ltd. Chapter 2. Scraping the Data.<p>
<p style="text-align: justify">
[4] <b>Miller, C. (2017).</b> "<i>Data Acquisition and Manipulation with Python - Acquire, Analyse, and Play with Data</i>". Packt Publishing Ltd. Chapter 2. Web Scraping with BeautifulSoup.<p>
<p style="text-align: justify">
[5] <b>Chhibber, A. (2018).</b> "<i>Web Scraping Using Python</i>". Technics Publications.<p>
|
github_jupyter
|
import sys
print(sys.version)
# Not necessary at all, but to demonstrate that I'm aware that BeautifulSoup4 must be installed
!{sys.executable} -m pip install --upgrade pip
!{sys.executable} -m pip install BeautifulSoup4
from bs4 import BeautifulSoup
from IPython.core.display import display, HTML
from time import sleep
import requests
import pandas as pd
import os
Events = []
base_url = 'https://en.wikipedia.org'
main_url = base_url + '/wiki/List_of_UFC_events'
def perform_http_get(url):
"""
Note:
This is a simple function that performs an http_get and if the result code is 200 proceed the return.
Args:
url (str): A string.
Returns:
BeautifulSoup: a version parsed of the request content
"""
r = requests.get(url)
if r.status_code == 200:
return BeautifulSoup(r.content, 'html.parser')
def extract_cell(cells, id_td):
"""
Note:
This method is aimed for returning the content of a given cell (td) decoded and without
additional blank spaces.
Args:
cells (list): A list representing the table row.
id_td (int): The index of the wanted cell
Returns:
String: the real content of the cell.
"""
return cells[id_td].renderContents().decode().strip()
def append_fighter_names(cells_event, info):
"""
Note:
This method presents some logic that will be briefly explained here. It turns out that some
fighters don't have their own wikipedia page, in these cases, there is no link (<a>) within
their names. Therefore, returning just the content of the cell where this info is present
is enough. In other cases, where the link is there, we must extract to update our dictionary.
Args:
cells_event (list): A list representing the table row.
info (dict): The dictionary to be updated
"""
fighter1 = ''
fighter2 = ''
if len(cells_event[1].findAll('a')) == 0:
fighter1 = extract_cell(cells_event, 1)
else:
fighter1 = cells_event[1].find('a').renderContents().decode().strip()
if len(cells_event[3].findAll('a')) == 0:
fighter2 = extract_cell(cells_event, 3)
else:
fighter2 = cells_event[3].find('a').renderContents().decode().strip()
info.update({"fighter_1" : fighter1})
info.update({"fighter_2" : fighter2})
def extract_row(cells_event, link):
"""
Note:
The goal here is to create a dictionary for the given events and also
to update in our events list (Events.append). We realize that within
the method we are also invoking the append_fighter_names that will call
the aforementioned method to treat the fighters' name.
Args:
cells_event (list): A list representing the table row.
link (str): Basically the event name
"""
info = {
"event_name": link.contents[0],
"weight_class": extract_cell(cells_event, 0),
"action": extract_cell(cells_event, 2),
"method": extract_cell(cells_event, 4),
"round": extract_cell(cells_event, 5),
"time": extract_cell(cells_event, 6)
}
append_fighter_names(cells_event, info)
Events.append(info)
def download_event_image(individual_event, link):
"""
Note:
The method's name is pretty clear here, however, the objective is to
download the images of each event in order to present them at the bottom
of this current document. In a nutshell, the behaviour expected here
is to create all the recovered images in a folder called pictures
which, by the way, we can observe that will be created.
Args:
individual_event (BeautifulSoup): A BeautifulSoup representing the page of a single event.
"""
event_images = individual_event.select('table.infobox a.image img[src]')
if len(event_images) > 0:
for img in event_images:
img_url = 'http:' + img['src']
r = requests.get(img_url)
with open('pictures/' + link.contents[0], "wb") as code:
code.write(r.content)
def extract_info_individual_event(link):
"""
Note:
As you will see, this is the second part of a for loop that I will summarize here:
First we iterate over the list of UFC events presented in the main web-page (
https://en.wikipedia.org/wiki/List_of_UFC_events). From the data gathered there
each individual event will be accessed and we'll collect data from these events.
Needless to say that I'm not iterating over a single web-page, but instead, more than
450 different web pages, being the first of them the "master one", and this individual
ones.
Args:
link (url): The URL for the individual web-pages of a given list.
"""
individual_event = perform_http_get(base_url + link.get('href'))
table = individual_event.find('table',{'class': 'toccolours'})
download_event_image(individual_event, link)
if table is not None:
rows_event = table.findAll('tr')
for row_event in rows_event:
cells_event = row_event.findAll('td')
if len(cells_event) > 0 :
extract_row(cells_event, link)
"""
From my perspective this is a key part of the program and it will trigger
the execution and the invocation of the previous methods.
Basically we are collecting the "Past Events" of a table in one page and
for each event in this table (currently 454), we will read another
information as previously explained in different web pages.
By reading another information, I mean: download the event image, read
the card and the results of the event and so on.
Apart from the behaviour expected, in this part of the code, I also tried
to avoid throtling the Wikipedia source by adding some sleeps within each
iteration - it will slow down the process and avoid some common problems.
"""
Events = []
soup = perform_http_get(main_url)
table_past_events = soup.find('table', {'id': 'Past_events'})
rows = table_past_events.findAll('tr')
for row in rows:
#sleep(10) # Wait 10 sec, recommendations explained by [4] Miller, C. (2017)
cells = row.findAll('td')
if len(cells) > 0 :
links = cells[1].findAll('a')
for link in links:
extract_info_individual_event(link)
"""
Once we have a list of dict in Events attributes, it's high time we defined
a panda dataframe to properly store the info.
It is done here and we present a glimpse of the data with the df.head() below.
"""
print(len(Events), ' eventos fueron añadidos')
df = pd.DataFrame(Events)
df = df[['event_name', 'weight_class', 'fighter_1', 'action', 'fighter_2', 'round', 'time', 'method' ]]
df.head(15)
"""
This is particularly a visual part of the presentation of the data.
For each event, I'm presenting the folder advertising it.
Remembering that we download each of these pictures in a method
explained before
"""
df_imgs = df['event_name'].drop_duplicates()
print('Imagenes: ', len(df_imgs))
display(HTML('<table style="width:100%; border: 1px solid black;"><tr>'))
i = 0
row = ''
for img in df_imgs:
img_src = 'pictures/' + img
if i == 20:
row = '{}<td><img src=\'{}\' alt=\'{}\' /></td></tr>'.format(row, img_src, img)
display(HTML(row))
row = '<tr>'
i = 0
else:
row = '{}<td><img src=\'{}\' /></td>'.format(row, img_src)
i += 1
display(HTML('</tr></table>'))
"""
Last but not least, we are storing the dataframe in a CSV file
"""
file_name = 'ufc-events.csv'
df.to_csv(file_name)
| 0.522933 | 0.870542 |
# Analysis of teams
This notebook contains analyses of teams that participated at the **`Copa America 2021`**. The analyses included are: `Goal contribution`, `Goal scoring`, `Progressive actions`, `Defensive actions`, and others. Inspiration is primarly taken from [@TalkingUnited](https://twitter.com/TalkingUnited).
## Load libraries
```
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import matplotlib.patheffects as path_effects
import seaborn as sns
from highlight_text import htext
from matplotlib.offsetbox import OffsetImage,AnchoredOffsetbox
from PIL import Image
pd.set_option('display.max_columns', 100)
```
## Set constants
```
countries = ['argentina', 'bolivia', 'brazil', 'colombia', 'chile', 'ecuador', 'paraguay', 'peru',
'uruguay', 'venezuela']
```
## 1. Goal contribution
This analysis is inspired in [@TaIkingUnited](https://twitter.com/TaIkingUnited) who published the analysis [here](https://twitter.com/TaIkingUnited/status/1470815092170231809). It involves data about `npxG` and `xA`.
### Load data
```
analysis_df = pd.DataFrame()
for country in countries:
if analysis_df.size > 0:
aux_analysis_df = pd.read_csv(f"data/{country}_standard.csv")
aux_analysis_df['country'] = country
analysis_df = analysis_df.append(aux_analysis_df, ignore_index=True, sort=False)
else:
analysis_df = pd.read_csv(f"data/{country}_standard.csv")
analysis_df['country'] = country
```
### Check data
```
print(f"The dataset contains {analysis_df.shape[0]} rows and {analysis_df.shape[1]} columns")
analysis_df.head()
```
### Filter data
**Remove goalkeepers**
```
analysis_df = analysis_df[analysis_df['pos'] != 'GK']
print(f"After removing GKs the dataset contains {analysis_df.shape[0]} players")
```
**Remove players who play less than 50% of the team's played minutes**
```
min_teams_played = analysis_df.loc[analysis_df['player']=='Squad Total', ['country', 'playingtime_90s']]
analysis_fdf = pd.DataFrame()
for country in countries:
team = analysis_df[analysis_df['country']==country]
min_team_played = min_teams_played.loc[min_teams_played['country']==country, 'playingtime_90s'].values[0]
if analysis_fdf.size > 0:
analysis_fdf = analysis_fdf.append(team[team['playingtime_90s'] >= (min_team_played/2)], ignore_index=True,
sort=False)
else:
analysis_fdf = team[team['playingtime_90s'] >= (min_team_played/2)]
```
**Remove summary rows**
```
analysis_fdf = analysis_fdf[analysis_fdf['player']!='Squad Total']
analysis_fdf = analysis_fdf[analysis_fdf['player']!='Opponent Total']
```
**Select columns**
```
analysis_fdf = analysis_fdf[['player','pos', 'country', 'per90minutes_xa', 'per90minutes_npxg']]
analysis_fdf.head()
analysis_fdf.index
```
### Draw scatterplots
```
title_font = "Alegreya Sans"
body_font = "Open Sans"
text_color = "black"
background = "white"
filler = "grey"
mpl.rcParams['xtick.color'] = text_color
mpl.rcParams['ytick.color'] = text_color
mpl.rcParams['xtick.labelsize'] = 10
mpl.rcParams['ytick.labelsize'] = 10
fig, axs = plt.subplots(nrows=5, ncols=2, figsize=(15,30))
fig.set_facecolor(background)
colors = {'argentina':'#4A8ABD', 'bolivia':'#C8C656', 'brazil':'#61AA4F', 'colombia':'#919191' ,
'chile':'#D25041', 'ecuador': '#F49845', 'paraguay': '#976C60', 'peru': '#F3B0AB', 'uruguay': '#60B9C7',
'venezuela': '#9F81C5'}
idx = 0
for i in range(0,5):
for j in range(0,2):
# set figure's params
axs[i][j].patch.set_alpha(0)
axs[i][j].grid(ls="dotted",lw="0.5",color="lightgrey", zorder=1)
axs[i][j].tick_params(axis="both",length=0)
spines = ["top","right", "bottom", "left"]
for s in spines:
if s in ["top","right"]:
axs[i][j].spines[s].set_visible(False)
else:
axs[i][j].spines[s].set_color(text_color)
team = analysis_fdf[analysis_fdf['country']==countries[idx]]
x = team['per90minutes_npxg'].values
y = team['per90minutes_xa'].values
axs[i][j].scatter(x, y, s=120, color=colors[countries[idx]], alpha=0.8, lw=1, zorder=2, edgecolor='black')
# add players' names
x_25 = team['per90minutes_npxg'].describe()['25%']
y_25 = team['per90minutes_xa'].describe()['25%']
for k, player_name in enumerate(team['player']):
if y[k] < y_25 or x[k] < x_25:
continue
if countries[idx] == 'argentina':
delta_x = 0.02
delta_y = 0
elif countries[idx] == 'bolivia':
delta_x = 0
delta_y = 0
else:
delta_x = -0.01
delta_y = 0.01
f_player_name = player_name
if ' ' in f_player_name:
f_player_name = f"{f_player_name[0]}. {' '.join(f_player_name.split(' ')[1:])}"
axs[i][j].annotate(f_player_name, (x[k]+delta_x, y[k]+delta_y), fontfamily=body_font,
fontweight="regular", fontsize=9, color=text_color, zorder=3)
# add axis labels
axs[i][j].set_xlabel(f"Non-penalty expected goal x 90 (npxG x90)", fontfamily=body_font, fontweight="bold",
fontsize=14, color=text_color)
axs[i][j].set_ylabel(f"Expected assists x 90 (xA x90)", fontfamily=body_font, fontweight="bold", fontsize=14,
color=text_color)
# add logo
if countries[idx] == 'uruguay':
loc='lower center'
else:
loc='upper center'
img = Image.open(f"imgs/logos/{countries[idx]}.png")
imagebox = OffsetImage(img, zoom=0.3)
ab = AnchoredOffsetbox(loc=loc, child=imagebox, frameon=False)
axs[i][j].add_artist(ab)
axs[i][j].annotate('Grandes\nasistidores',(0.05, 0.35), fontfamily=body_font, fontweight="bold", fontsize=10,
color='gray', zorder=3)
axs[i][j].annotate('Grandes\nasistidores\ny goleadores',
(0.8, 0.35), fontfamily=body_font, fontweight="bold", fontsize=10, color='gray', zorder=3)
axs[i][j].annotate('Grandes\ngoleadores', (0.8, 0.05), fontfamily=body_font,
fontweight="bold", fontsize=10, color='gray', zorder=3)
# add horizontal lines
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['25%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['50%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['75%'], color='gray', linestyle='dotted', lw=1)
# add vertical lines
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['25%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['50%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['75%'], color='gray', linestyle='dotted', lw=1)
idx += 1
## add title
fig.text(0.12,1.06,"Contribuciones en ataque por equipo",fontweight="bold", fontsize=28,fontfamily=title_font, color=text_color)
fig.text(0.12,1.045,"Copa América Brasil 2021",fontweight="regular", fontsize=20,fontfamily=body_font, color=text_color)
## add logo
ax2 = fig.add_axes([0.02,1,0.10,0.10]) # badge
ax2.axis("off")
img = Image.open("imgs/Brasil2021ca.png")
ax2.imshow(img)
## add footer
s = "Creado por Jorge Saldivar (@jorgesaldivar)"
fig.text(0.05, -0.025, s, fontweight="bold", fontsize=10, fontfamily=body_font, color=text_color)
s = "Datos de FBREF excluyendo arqueros e incluyendo solo jugadores que hayan participado en al menos 50% del total de minutos jugados por sus equipos"
fig.text(0.05, -0.018, s, fontstyle="italic",fontsize=9, fontfamily=body_font, color=text_color)
plt.tight_layout()
plt.show()
```
|
github_jupyter
|
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import matplotlib.patheffects as path_effects
import seaborn as sns
from highlight_text import htext
from matplotlib.offsetbox import OffsetImage,AnchoredOffsetbox
from PIL import Image
pd.set_option('display.max_columns', 100)
countries = ['argentina', 'bolivia', 'brazil', 'colombia', 'chile', 'ecuador', 'paraguay', 'peru',
'uruguay', 'venezuela']
analysis_df = pd.DataFrame()
for country in countries:
if analysis_df.size > 0:
aux_analysis_df = pd.read_csv(f"data/{country}_standard.csv")
aux_analysis_df['country'] = country
analysis_df = analysis_df.append(aux_analysis_df, ignore_index=True, sort=False)
else:
analysis_df = pd.read_csv(f"data/{country}_standard.csv")
analysis_df['country'] = country
print(f"The dataset contains {analysis_df.shape[0]} rows and {analysis_df.shape[1]} columns")
analysis_df.head()
analysis_df = analysis_df[analysis_df['pos'] != 'GK']
print(f"After removing GKs the dataset contains {analysis_df.shape[0]} players")
min_teams_played = analysis_df.loc[analysis_df['player']=='Squad Total', ['country', 'playingtime_90s']]
analysis_fdf = pd.DataFrame()
for country in countries:
team = analysis_df[analysis_df['country']==country]
min_team_played = min_teams_played.loc[min_teams_played['country']==country, 'playingtime_90s'].values[0]
if analysis_fdf.size > 0:
analysis_fdf = analysis_fdf.append(team[team['playingtime_90s'] >= (min_team_played/2)], ignore_index=True,
sort=False)
else:
analysis_fdf = team[team['playingtime_90s'] >= (min_team_played/2)]
analysis_fdf = analysis_fdf[analysis_fdf['player']!='Squad Total']
analysis_fdf = analysis_fdf[analysis_fdf['player']!='Opponent Total']
analysis_fdf = analysis_fdf[['player','pos', 'country', 'per90minutes_xa', 'per90minutes_npxg']]
analysis_fdf.head()
analysis_fdf.index
title_font = "Alegreya Sans"
body_font = "Open Sans"
text_color = "black"
background = "white"
filler = "grey"
mpl.rcParams['xtick.color'] = text_color
mpl.rcParams['ytick.color'] = text_color
mpl.rcParams['xtick.labelsize'] = 10
mpl.rcParams['ytick.labelsize'] = 10
fig, axs = plt.subplots(nrows=5, ncols=2, figsize=(15,30))
fig.set_facecolor(background)
colors = {'argentina':'#4A8ABD', 'bolivia':'#C8C656', 'brazil':'#61AA4F', 'colombia':'#919191' ,
'chile':'#D25041', 'ecuador': '#F49845', 'paraguay': '#976C60', 'peru': '#F3B0AB', 'uruguay': '#60B9C7',
'venezuela': '#9F81C5'}
idx = 0
for i in range(0,5):
for j in range(0,2):
# set figure's params
axs[i][j].patch.set_alpha(0)
axs[i][j].grid(ls="dotted",lw="0.5",color="lightgrey", zorder=1)
axs[i][j].tick_params(axis="both",length=0)
spines = ["top","right", "bottom", "left"]
for s in spines:
if s in ["top","right"]:
axs[i][j].spines[s].set_visible(False)
else:
axs[i][j].spines[s].set_color(text_color)
team = analysis_fdf[analysis_fdf['country']==countries[idx]]
x = team['per90minutes_npxg'].values
y = team['per90minutes_xa'].values
axs[i][j].scatter(x, y, s=120, color=colors[countries[idx]], alpha=0.8, lw=1, zorder=2, edgecolor='black')
# add players' names
x_25 = team['per90minutes_npxg'].describe()['25%']
y_25 = team['per90minutes_xa'].describe()['25%']
for k, player_name in enumerate(team['player']):
if y[k] < y_25 or x[k] < x_25:
continue
if countries[idx] == 'argentina':
delta_x = 0.02
delta_y = 0
elif countries[idx] == 'bolivia':
delta_x = 0
delta_y = 0
else:
delta_x = -0.01
delta_y = 0.01
f_player_name = player_name
if ' ' in f_player_name:
f_player_name = f"{f_player_name[0]}. {' '.join(f_player_name.split(' ')[1:])}"
axs[i][j].annotate(f_player_name, (x[k]+delta_x, y[k]+delta_y), fontfamily=body_font,
fontweight="regular", fontsize=9, color=text_color, zorder=3)
# add axis labels
axs[i][j].set_xlabel(f"Non-penalty expected goal x 90 (npxG x90)", fontfamily=body_font, fontweight="bold",
fontsize=14, color=text_color)
axs[i][j].set_ylabel(f"Expected assists x 90 (xA x90)", fontfamily=body_font, fontweight="bold", fontsize=14,
color=text_color)
# add logo
if countries[idx] == 'uruguay':
loc='lower center'
else:
loc='upper center'
img = Image.open(f"imgs/logos/{countries[idx]}.png")
imagebox = OffsetImage(img, zoom=0.3)
ab = AnchoredOffsetbox(loc=loc, child=imagebox, frameon=False)
axs[i][j].add_artist(ab)
axs[i][j].annotate('Grandes\nasistidores',(0.05, 0.35), fontfamily=body_font, fontweight="bold", fontsize=10,
color='gray', zorder=3)
axs[i][j].annotate('Grandes\nasistidores\ny goleadores',
(0.8, 0.35), fontfamily=body_font, fontweight="bold", fontsize=10, color='gray', zorder=3)
axs[i][j].annotate('Grandes\ngoleadores', (0.8, 0.05), fontfamily=body_font,
fontweight="bold", fontsize=10, color='gray', zorder=3)
# add horizontal lines
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['25%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['50%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axhline(y=team['per90minutes_xa'].describe()['75%'], color='gray', linestyle='dotted', lw=1)
# add vertical lines
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['25%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['50%'], color='gray', linestyle='dotted', lw=1)
#axs[i][j].axvline(x=team['per90minutes_npxg'].describe()['75%'], color='gray', linestyle='dotted', lw=1)
idx += 1
## add title
fig.text(0.12,1.06,"Contribuciones en ataque por equipo",fontweight="bold", fontsize=28,fontfamily=title_font, color=text_color)
fig.text(0.12,1.045,"Copa América Brasil 2021",fontweight="regular", fontsize=20,fontfamily=body_font, color=text_color)
## add logo
ax2 = fig.add_axes([0.02,1,0.10,0.10]) # badge
ax2.axis("off")
img = Image.open("imgs/Brasil2021ca.png")
ax2.imshow(img)
## add footer
s = "Creado por Jorge Saldivar (@jorgesaldivar)"
fig.text(0.05, -0.025, s, fontweight="bold", fontsize=10, fontfamily=body_font, color=text_color)
s = "Datos de FBREF excluyendo arqueros e incluyendo solo jugadores que hayan participado en al menos 50% del total de minutos jugados por sus equipos"
fig.text(0.05, -0.018, s, fontstyle="italic",fontsize=9, fontfamily=body_font, color=text_color)
plt.tight_layout()
plt.show()
| 0.210036 | 0.837885 |
# Quality metrics
There are two different pruning methods:
- validation,
- direct.
The first group works on trees that is already built. The direct method works while building the tree. In both cases we need to set a testing data set to validate the accuracy.
```
%store -r labels
%store -r data_set
test_labels = [1,1,-1,-1,1,1,1,-1]
test_data_set = [[1,1,2,2],[3,2,1,2],[2,3,1,2],
[2,2,1,2],[1,3,2,2],[2,1,1,2],
[3,1,2,1],[2,1,2,2]]
```
## Validation pruning - Reduced Error Pruning
This method checks the tree after it's build for leafs that does not impact on the accuracy or impact on the accuracy by reducing it.
Let's build the tree first.
```
import math
import numpy as np
import pydot
import copy
from math import log
class BinaryLeaf:
def __init__(self, elements, labels, ids):
self.L = None
self.R = None
self.elements = elements
self.split_feature = None
self.split_value = None
self.labels = labels
self.completed = False
self.ids = ids
self.validated = False
def set_R(self, Rleaf):
self.R = Rleaf
def set_L(self, Lleaf):
self.L = Lleaf
def set_elements(self, elements):
self.elements = elements
def get_elements(self):
return self.elements
def set_p(self, threshold):
self.p = threshold
def get_L(self):
return self.L
def get_R(self):
return self.R
def set_completed(self):
self.completed = True
def is_completed(self):
return self.completed
def get_labels(self):
return self.labels
def set_split(self, feature):
self.split_feature = feature
def get_split(self):
return self.split_feature
def set_split_value(self, value):
self.split_value = value
def get_split_value(self):
return self.split_value
def set_validated(self):
self.validated = True
def is_validated(self):
return self.validated
def set_ids(self, ids):
self.ids = ids
def get_ids(self):
return self.ids
labels_count = len(np.unique(labels))
ids = list(range(len(data_set)))
root = BinaryLeaf(data_set, labels, ids)
current_node = root
def get_unique_labels(labels):
return np.unique(np.array(labels)).tolist()
def get_unique_values(elements):
features_number = len(elements[0])
unique = []
for i in range(features_number):
features_list = []
for j in range(len(elements)):
features_list.append(elements[j][i])
unique.append(np.unique(np.array(features_list)))
return unique
def is_leaf_completed(node):
if node.is_completed():
if node.get_L() != None and not node.get_L().is_completed():
return node.get_L()
elif node.get_R() != None and not node.get_R().is_completed():
return node.get_R()
elif node.get_L() == None and node.get_R() == None:
return None
elif node.get_L().is_completed() or node.get_R().is_completed():
new_node = is_leaf_completed(node.get_L())
if new_node == None:
return is_leaf_completed(node.get_R())
else:
return new_node
else:
return None
return node
def find_leaf_not_completed(root):
return is_leaf_completed(root)
def get_split_candidates(unique_values):
split_list = []
for i in range(len(unique_values)):
current_list = []
temp_list = copy.deepcopy(unique_values)
current_list.append(temp_list[i])
del temp_list[i]
current_list.append(temp_list)
split_list.append(current_list)
return split_list
def get_number_of_labels_for_value(elements, column_id, label):
count = 0
if not isinstance(elements, list):
elements_list = [elements]
else:
elements_list = elements
column_elements = get_node_elements_column(column_id)
for i in range(len(elements_list)):
for j in range(len(column_elements)):
if column_elements[j] == elements_list[i]:
if current_node.labels[j] == label:
count = count + 1
return count
def get_node_elements_column(column_id):
return np.array(current_node.elements)[..., column_id].tolist()
def count_number_of_elements(elements, column_id):
count = 0
if isinstance(elements, list):
column_elements = get_node_elements_column(column_id)
for i in range(len(elements)):
count = count + column_elements.count(elements[i])
else:
count = count + get_node_elements_column(column_id).count(elements)
return count
def calculate_omega(elements, column_id):
t_l = count_number_of_elements(elements[0], column_id)
t_r = count_number_of_elements(elements[1], column_id)
p_l = t_l * 1.0 / len(current_node.elements) * 1.0
p_r = t_r * 1.0 / len(current_node.elements) * 1.0
sum_p = 0
labels = get_unique_labels(current_node.labels)
for i in range(labels_count):
p_class_t_l = (get_number_of_labels_for_value(elements[0], column_id, labels[i]) * 1.0) / (
count_number_of_elements(elements[0], column_id) * 1.0)
p_class_t_r = (get_number_of_labels_for_value(elements[1], column_id, labels[i]) * 1.0) / (
count_number_of_elements(elements[1], column_id) * 1.0)
sum_p = sum_p + math.fabs(p_class_t_l - p_class_t_r)
return 2.0 * p_l * p_r * sum_p
def check_completed(labels, elements):
ratio = len(get_unique_labels(labels))
if ratio == 1:
return True
elements = sorted(elements)
duplicated = [elements[i] for i in range(len(elements)) if i == 0 or elements[i] != elements[i - 1]]
if len(duplicated) == 1:
return True
return False
def split_node(current_node, value, split_id, split_history):
left_leaf = []
left_leaf_labels = []
left_leaf_ids = []
right_leaf = []
right_leaf_labels = []
right_leaf_ids = []
for i in range(len(current_node.elements)):
if current_node.elements[i][split_id] == value:
left_leaf.append(current_node.elements[i])
left_leaf_labels.append(current_node.labels[i])
left_leaf_ids.append(current_node.ids[i])
else:
right_leaf.append(current_node.elements[i])
right_leaf_labels.append(current_node.labels[i])
right_leaf_ids.append(current_node.ids[i])
if len(right_leaf_labels) == 0 or len(left_leaf_labels) == 0:
current_node.set_completed()
return current_node, split_history
split_history.append([str(current_node.ids), str(left_leaf_ids)])
split_history.append([str(current_node.ids), str(right_leaf_ids)])
current_node.set_L(BinaryLeaf(left_leaf, left_leaf_labels, left_leaf_ids))
current_node.set_R(BinaryLeaf(right_leaf, right_leaf_labels, right_leaf_ids))
current_node.set_split(split_id)
current_node.set_completed()
if check_completed(left_leaf_labels, left_leaf):
current_node.L.set_completed()
if check_completed(right_leaf_labels, right_leaf):
current_node.R.set_completed()
return current_node, split_history
def get_current_node():
return find_leaf_not_completed()
def build(root_node):
current_node = root_node
stop_criterion = False
split_history = []
while stop_criterion == False:
unique_values = get_unique_values(current_node.get_elements())
max_unique_id = 0
max_split_id = 0
max_value = 0
for i in range(len(unique_values)):
if len(unique_values[i]) == 1:
continue
split_candidates = get_split_candidates(unique_values[i].tolist())
for j in range(len(split_candidates)):
current_value = calculate_omega(split_candidates[j], i)
if max_value < current_value:
max_unique_id = i
max_split_id = j
max_value = current_value
current_node, split_history = split_node(current_node, unique_values[max_unique_id][max_split_id], max_unique_id, split_history)
new_node = find_leaf_not_completed(root_node)
if new_node != None:
current_node = new_node
else:
stop_criterion = True
return root_node, split_history
cart_tree, split_history_cart = build(current_node)
```
The current level methods returns the leafs of a given node:
```
def get_current_level(node):
if type(node) is not list:
return [node]
level = []
for leaf in node:
if leaf.get_R() != None:
level.append(leaf.get_R())
if leaf.get_L() != None:
level.append(leaf.get_L())
return level
```
Accuracy is calcualated on the tree that is temporarly pruned (changed) to check if the accuracy is greater or less compared to the full version of the tree.
```
def get_accuracy(cart_tree, test_data_set, test_labels):
predictions = []
for sample in test_data_set:
current_node = cart_tree
while current_node.get_R() != None or current_node.get_L() != None:
split_feature = current_node.get_split()
split_value = current_node.get_split_value()
if sample[split_feature] == split_value:
current_node = current_node.get_L()
else:
current_node = current_node.get_R()
prediction = int(np.sign(np.sum(current_node.get_labels())))
if prediction == 0:
prediction = -1
predictions.append(prediction)
accuracy = np.sum(np.array(predictions) == np.array(test_labels))
return predictions, accuracy / len(test_labels)
```
The validation method goes through the tree and cut/prune nodes on a given level. Next, it check the accuracy change with such a pruned tree.
```
def validate_rep(cart_tree, test_data_set, test_labels):
old_prediction, old_accuracy = get_accuracy(cart_tree, data_set, labels)
print("Train accuracy: "+ str(old_accuracy))
old_accuracy = 0.0
level = [cart_tree]
levels = [level]
while level != []:
level = get_current_level(levels[-1])
if level != []:
levels.append(level)
for i, level in enumerate(levels):
print("level ", i)
for j, leaf in enumerate(level):
print(" leaf ", j, ", ", leaf.ids)
if leaf.get_L() != None:
right_child = leaf.get_R()
left_child = leaf.get_L()
leaf.set_R(None)
leaf.set_L(None)
prediction, accuracy = get_accuracy(cart_tree, test_data_set, test_labels)
if i != 0:
print("Leaf: " + str(leaf.ids)+": post prunning accuracy is greater or equal than pre prunning accuracy: " + str(accuracy) + ">=" + str(old_accuracy))
else:
if accuracy < old_accuracy:
leaf.set_R(right_child)
leaf.set_L(left_child)
prediction, old_accuracy = get_accuracy(cart_tree, test_data_set, test_labels)
else:
old_accuracy = accuracy
leaf.set_completed()
validate_rep(cart_tree, test_data_set, test_labels)
```
|
github_jupyter
|
%store -r labels
%store -r data_set
test_labels = [1,1,-1,-1,1,1,1,-1]
test_data_set = [[1,1,2,2],[3,2,1,2],[2,3,1,2],
[2,2,1,2],[1,3,2,2],[2,1,1,2],
[3,1,2,1],[2,1,2,2]]
import math
import numpy as np
import pydot
import copy
from math import log
class BinaryLeaf:
def __init__(self, elements, labels, ids):
self.L = None
self.R = None
self.elements = elements
self.split_feature = None
self.split_value = None
self.labels = labels
self.completed = False
self.ids = ids
self.validated = False
def set_R(self, Rleaf):
self.R = Rleaf
def set_L(self, Lleaf):
self.L = Lleaf
def set_elements(self, elements):
self.elements = elements
def get_elements(self):
return self.elements
def set_p(self, threshold):
self.p = threshold
def get_L(self):
return self.L
def get_R(self):
return self.R
def set_completed(self):
self.completed = True
def is_completed(self):
return self.completed
def get_labels(self):
return self.labels
def set_split(self, feature):
self.split_feature = feature
def get_split(self):
return self.split_feature
def set_split_value(self, value):
self.split_value = value
def get_split_value(self):
return self.split_value
def set_validated(self):
self.validated = True
def is_validated(self):
return self.validated
def set_ids(self, ids):
self.ids = ids
def get_ids(self):
return self.ids
labels_count = len(np.unique(labels))
ids = list(range(len(data_set)))
root = BinaryLeaf(data_set, labels, ids)
current_node = root
def get_unique_labels(labels):
return np.unique(np.array(labels)).tolist()
def get_unique_values(elements):
features_number = len(elements[0])
unique = []
for i in range(features_number):
features_list = []
for j in range(len(elements)):
features_list.append(elements[j][i])
unique.append(np.unique(np.array(features_list)))
return unique
def is_leaf_completed(node):
if node.is_completed():
if node.get_L() != None and not node.get_L().is_completed():
return node.get_L()
elif node.get_R() != None and not node.get_R().is_completed():
return node.get_R()
elif node.get_L() == None and node.get_R() == None:
return None
elif node.get_L().is_completed() or node.get_R().is_completed():
new_node = is_leaf_completed(node.get_L())
if new_node == None:
return is_leaf_completed(node.get_R())
else:
return new_node
else:
return None
return node
def find_leaf_not_completed(root):
return is_leaf_completed(root)
def get_split_candidates(unique_values):
split_list = []
for i in range(len(unique_values)):
current_list = []
temp_list = copy.deepcopy(unique_values)
current_list.append(temp_list[i])
del temp_list[i]
current_list.append(temp_list)
split_list.append(current_list)
return split_list
def get_number_of_labels_for_value(elements, column_id, label):
count = 0
if not isinstance(elements, list):
elements_list = [elements]
else:
elements_list = elements
column_elements = get_node_elements_column(column_id)
for i in range(len(elements_list)):
for j in range(len(column_elements)):
if column_elements[j] == elements_list[i]:
if current_node.labels[j] == label:
count = count + 1
return count
def get_node_elements_column(column_id):
return np.array(current_node.elements)[..., column_id].tolist()
def count_number_of_elements(elements, column_id):
count = 0
if isinstance(elements, list):
column_elements = get_node_elements_column(column_id)
for i in range(len(elements)):
count = count + column_elements.count(elements[i])
else:
count = count + get_node_elements_column(column_id).count(elements)
return count
def calculate_omega(elements, column_id):
t_l = count_number_of_elements(elements[0], column_id)
t_r = count_number_of_elements(elements[1], column_id)
p_l = t_l * 1.0 / len(current_node.elements) * 1.0
p_r = t_r * 1.0 / len(current_node.elements) * 1.0
sum_p = 0
labels = get_unique_labels(current_node.labels)
for i in range(labels_count):
p_class_t_l = (get_number_of_labels_for_value(elements[0], column_id, labels[i]) * 1.0) / (
count_number_of_elements(elements[0], column_id) * 1.0)
p_class_t_r = (get_number_of_labels_for_value(elements[1], column_id, labels[i]) * 1.0) / (
count_number_of_elements(elements[1], column_id) * 1.0)
sum_p = sum_p + math.fabs(p_class_t_l - p_class_t_r)
return 2.0 * p_l * p_r * sum_p
def check_completed(labels, elements):
ratio = len(get_unique_labels(labels))
if ratio == 1:
return True
elements = sorted(elements)
duplicated = [elements[i] for i in range(len(elements)) if i == 0 or elements[i] != elements[i - 1]]
if len(duplicated) == 1:
return True
return False
def split_node(current_node, value, split_id, split_history):
left_leaf = []
left_leaf_labels = []
left_leaf_ids = []
right_leaf = []
right_leaf_labels = []
right_leaf_ids = []
for i in range(len(current_node.elements)):
if current_node.elements[i][split_id] == value:
left_leaf.append(current_node.elements[i])
left_leaf_labels.append(current_node.labels[i])
left_leaf_ids.append(current_node.ids[i])
else:
right_leaf.append(current_node.elements[i])
right_leaf_labels.append(current_node.labels[i])
right_leaf_ids.append(current_node.ids[i])
if len(right_leaf_labels) == 0 or len(left_leaf_labels) == 0:
current_node.set_completed()
return current_node, split_history
split_history.append([str(current_node.ids), str(left_leaf_ids)])
split_history.append([str(current_node.ids), str(right_leaf_ids)])
current_node.set_L(BinaryLeaf(left_leaf, left_leaf_labels, left_leaf_ids))
current_node.set_R(BinaryLeaf(right_leaf, right_leaf_labels, right_leaf_ids))
current_node.set_split(split_id)
current_node.set_completed()
if check_completed(left_leaf_labels, left_leaf):
current_node.L.set_completed()
if check_completed(right_leaf_labels, right_leaf):
current_node.R.set_completed()
return current_node, split_history
def get_current_node():
return find_leaf_not_completed()
def build(root_node):
current_node = root_node
stop_criterion = False
split_history = []
while stop_criterion == False:
unique_values = get_unique_values(current_node.get_elements())
max_unique_id = 0
max_split_id = 0
max_value = 0
for i in range(len(unique_values)):
if len(unique_values[i]) == 1:
continue
split_candidates = get_split_candidates(unique_values[i].tolist())
for j in range(len(split_candidates)):
current_value = calculate_omega(split_candidates[j], i)
if max_value < current_value:
max_unique_id = i
max_split_id = j
max_value = current_value
current_node, split_history = split_node(current_node, unique_values[max_unique_id][max_split_id], max_unique_id, split_history)
new_node = find_leaf_not_completed(root_node)
if new_node != None:
current_node = new_node
else:
stop_criterion = True
return root_node, split_history
cart_tree, split_history_cart = build(current_node)
def get_current_level(node):
if type(node) is not list:
return [node]
level = []
for leaf in node:
if leaf.get_R() != None:
level.append(leaf.get_R())
if leaf.get_L() != None:
level.append(leaf.get_L())
return level
def get_accuracy(cart_tree, test_data_set, test_labels):
predictions = []
for sample in test_data_set:
current_node = cart_tree
while current_node.get_R() != None or current_node.get_L() != None:
split_feature = current_node.get_split()
split_value = current_node.get_split_value()
if sample[split_feature] == split_value:
current_node = current_node.get_L()
else:
current_node = current_node.get_R()
prediction = int(np.sign(np.sum(current_node.get_labels())))
if prediction == 0:
prediction = -1
predictions.append(prediction)
accuracy = np.sum(np.array(predictions) == np.array(test_labels))
return predictions, accuracy / len(test_labels)
def validate_rep(cart_tree, test_data_set, test_labels):
old_prediction, old_accuracy = get_accuracy(cart_tree, data_set, labels)
print("Train accuracy: "+ str(old_accuracy))
old_accuracy = 0.0
level = [cart_tree]
levels = [level]
while level != []:
level = get_current_level(levels[-1])
if level != []:
levels.append(level)
for i, level in enumerate(levels):
print("level ", i)
for j, leaf in enumerate(level):
print(" leaf ", j, ", ", leaf.ids)
if leaf.get_L() != None:
right_child = leaf.get_R()
left_child = leaf.get_L()
leaf.set_R(None)
leaf.set_L(None)
prediction, accuracy = get_accuracy(cart_tree, test_data_set, test_labels)
if i != 0:
print("Leaf: " + str(leaf.ids)+": post prunning accuracy is greater or equal than pre prunning accuracy: " + str(accuracy) + ">=" + str(old_accuracy))
else:
if accuracy < old_accuracy:
leaf.set_R(right_child)
leaf.set_L(left_child)
prediction, old_accuracy = get_accuracy(cart_tree, test_data_set, test_labels)
else:
old_accuracy = accuracy
leaf.set_completed()
validate_rep(cart_tree, test_data_set, test_labels)
| 0.313105 | 0.810591 |
```
from google.colab import drive
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import urllib.request
import imageio
import glob
from skimage import io
import cv2 as cv
from google.colab.patches import cv2_imshow
# use GPU for computations if possible
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def load_warwick(folder_path):
train_images = []
train_labels = []
test_images = []
test_labels = []
for image_path in sorted(glob.glob(str(folder_path) + "/Train/image_*.png")):
image = imageio.imread(image_path)
train_images.append(image)
for label_path in sorted(glob.glob(str(folder_path) + "/Train/label_*.png")):
label = imageio.imread(label_path)
train_labels.append(label)
for image_path in sorted(glob.glob(str(folder_path) + "/Test/image_*.png")):
image = imageio.imread(image_path)
test_images.append(image)
for label_path in sorted(glob.glob(str(folder_path) + "/Test/label_*.png")):
label = imageio.imread(label_path)
test_labels.append(label)
X_train = torch.tensor(np.array(train_images), dtype=torch.float, requires_grad=True).permute(0,3,1,2)
Y_train = torch.tensor(np.array(train_labels)/255.0, dtype=torch.long)
X_test = torch.tensor(np.array(test_images), dtype=torch.float, requires_grad=True).permute(0,3,1,2)
Y_test = torch.tensor(np.array(test_labels)/255.0, dtype=torch.long)
return X_train, Y_train, X_test, Y_test
class semanticSegmentation_cnn(nn.Module):
def __init__(self):
super(semanticSegmentation_cnn, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.conv2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.conv3 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.convTranspose1 = nn.ConvTranspose2d(in_channels=32, out_channels=16, kernel_size=4, stride=2, padding=1)
self.convTranspose2 = nn.ConvTranspose2d(in_channels=16+16, out_channels=8, kernel_size=4, stride=2, padding=1)
self.conv1x1_out = nn.Conv2d(in_channels=8+8, out_channels=2, kernel_size=1, stride=1, bias=True)
def forward(self, x):
l1 = F.relu(self.conv1(x))
l2 = self.maxpool(l1)
l3 = F.relu(self.conv2(l2))
l4 = self.maxpool(l3)
l5 = F.relu(self.conv3(l4))
l6 = F.relu(self.convTranspose1(l5))
l7 = F.relu(self.convTranspose2(torch.cat((l3,l6),dim=1)))
return self.conv1x1_out(torch.cat((l1,l7),dim=1))
def accuracy(predictions, Y, coefficient=False):
predictions = torch.max(predictions, 1)[1]
return dice_loss(predictions, Y, coefficient)
def dice_loss(predictions, Y, coefficient=False,smooth=1):
batch_size = predictions.size(0)
predictions_flat = predictions.view(batch_size, -1)
Y_flat = Y.view(batch_size, -1)
intersection = (predictions_flat * Y_flat).sum(1)
unionset = predictions_flat.sum(1) + Y_flat.sum(1)
coef = 2 * (intersection + smooth) / (unionset + smooth)
if coefficient == False:
return coef.sum() / batch_size
else:
return coef
def plot_cost_iteration(training_loss, test_loss, iterations):
plt.plot(np.arange(start=0, stop=iterations, step= 1), training_loss, label='Training data')
plt.plot(np.arange(start=0, stop=iterations, step= 1), test_loss, label='Test data')
plt.xlabel('Iteration')
plt.ylabel('Cost')
plt.title('Cost per Iteration')
plt.legend()
plt.show()
def plot_accuracy_iteration(training_accuracy, test_accuracy, iterations):
plt.plot(np.arange(start=1, stop=iterations+1, step= 1), training_accuracy, label='Training data')
plt.plot(np.arange(start=1, stop=iterations+1, step= 1), test_accuracy, label='Test data')
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
plt.title('Accuracy per Iteration')
plt.legend()
plt.show()
warwick_path = '/content/drive/MyDrive/Colab Notebooks/Deep Learning for Image Analysis/warwick_dataset'
X_train, Y_train, X_test, Y_test = load_warwick(warwick_path)
training_dataset = torch.utils.data.TensorDataset(X_train, Y_train)
test_dataset = torch.utils.data.TensorDataset(X_test, Y_test)
# Initialise hyperparameters
minibatch_size = 85
learning_rate = 0.001
iterations = 1000
# Data structures to hold accuracy and loss values throughout the iterations
training_accuracy = []
training_loss = []
test_accuracy = []
test_loss = []
# Load the training and test dataset without shuffling
train_dataLoader = torch.utils.data.DataLoader(training_dataset, batch_size=minibatch_size, shuffle=False)
test_dataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=len(test_dataset), shuffle=False)
# Create the network
segmentation_cnn = semanticSegmentation_cnn()
segmentation_cnn.to(device)
# Use Stochastic Gradient Descent optimiser
optimiser = optim.Adam(segmentation_cnn.parameters(), lr=learning_rate)
loss_funtion = nn.CrossEntropyLoss()
# Training
for epoch in range(0, iterations):
epoch_loss = 0
epoch_accuracy = 0
for (x_batch, y_batch) in train_dataLoader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
optimiser.zero_grad()
predictions = segmentation_cnn(x_batch) # Forward pass on training batch
batch_accuracy = accuracy(predictions, y_batch) # Compute accuracy on training batch
epoch_accuracy += batch_accuracy.item()
loss = loss_funtion(torch.squeeze(predictions), y_batch) # Compute loss on training batch
batch_loss = loss.item()
epoch_loss += batch_loss
loss.backward() # Back propagation
optimiser.step() # Parameters update
training_accuracy.append(epoch_accuracy / len(train_dataLoader))
training_loss.append(epoch_loss / len(train_dataLoader))
with torch.no_grad():
for (x_test, y_test) in test_dataLoader:
x_test, y_test = x_test.to(device), y_test.to(device)
predictions = segmentation_cnn(x_test) # Forward pass on test dataset
test_accuracy.append(accuracy(predictions, y_test).item()) # Compute accuracy on test dataset
test_loss.append(loss_funtion(torch.squeeze(predictions), y_test).item()) # Compute loss on test dataset
if (epoch + 1) % 5 == 0:
print(f'Epoch {epoch+1:5d}: train loss {training_loss[-1]:5.2f} train accuracy {100*training_accuracy[-1]:6.2f} '\
f'test loss {test_loss[-1]:5.2f} test accuracy {100*test_accuracy[-1]:6.2f}')
# Plotting
plot_cost_iteration(training_loss, test_loss, iterations)
plot_accuracy_iteration(training_accuracy, test_accuracy, iterations)
image_index = 8
image_pred = predictions[image_index].cpu()
image_pred = torch.max(image_pred, 0)[1]
plt.imshow(image_pred, interpolation='bilinear')
image_label = y_test[image_index].cpu().numpy()
plt.imshow(image_label, interpolation='bilinear')
```
|
github_jupyter
|
from google.colab import drive
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import urllib.request
import imageio
import glob
from skimage import io
import cv2 as cv
from google.colab.patches import cv2_imshow
# use GPU for computations if possible
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def load_warwick(folder_path):
train_images = []
train_labels = []
test_images = []
test_labels = []
for image_path in sorted(glob.glob(str(folder_path) + "/Train/image_*.png")):
image = imageio.imread(image_path)
train_images.append(image)
for label_path in sorted(glob.glob(str(folder_path) + "/Train/label_*.png")):
label = imageio.imread(label_path)
train_labels.append(label)
for image_path in sorted(glob.glob(str(folder_path) + "/Test/image_*.png")):
image = imageio.imread(image_path)
test_images.append(image)
for label_path in sorted(glob.glob(str(folder_path) + "/Test/label_*.png")):
label = imageio.imread(label_path)
test_labels.append(label)
X_train = torch.tensor(np.array(train_images), dtype=torch.float, requires_grad=True).permute(0,3,1,2)
Y_train = torch.tensor(np.array(train_labels)/255.0, dtype=torch.long)
X_test = torch.tensor(np.array(test_images), dtype=torch.float, requires_grad=True).permute(0,3,1,2)
Y_test = torch.tensor(np.array(test_labels)/255.0, dtype=torch.long)
return X_train, Y_train, X_test, Y_test
class semanticSegmentation_cnn(nn.Module):
def __init__(self):
super(semanticSegmentation_cnn, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.conv2 = nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.conv3 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1, bias=True, padding_mode='reflect')
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.convTranspose1 = nn.ConvTranspose2d(in_channels=32, out_channels=16, kernel_size=4, stride=2, padding=1)
self.convTranspose2 = nn.ConvTranspose2d(in_channels=16+16, out_channels=8, kernel_size=4, stride=2, padding=1)
self.conv1x1_out = nn.Conv2d(in_channels=8+8, out_channels=2, kernel_size=1, stride=1, bias=True)
def forward(self, x):
l1 = F.relu(self.conv1(x))
l2 = self.maxpool(l1)
l3 = F.relu(self.conv2(l2))
l4 = self.maxpool(l3)
l5 = F.relu(self.conv3(l4))
l6 = F.relu(self.convTranspose1(l5))
l7 = F.relu(self.convTranspose2(torch.cat((l3,l6),dim=1)))
return self.conv1x1_out(torch.cat((l1,l7),dim=1))
def accuracy(predictions, Y, coefficient=False):
predictions = torch.max(predictions, 1)[1]
return dice_loss(predictions, Y, coefficient)
def dice_loss(predictions, Y, coefficient=False,smooth=1):
batch_size = predictions.size(0)
predictions_flat = predictions.view(batch_size, -1)
Y_flat = Y.view(batch_size, -1)
intersection = (predictions_flat * Y_flat).sum(1)
unionset = predictions_flat.sum(1) + Y_flat.sum(1)
coef = 2 * (intersection + smooth) / (unionset + smooth)
if coefficient == False:
return coef.sum() / batch_size
else:
return coef
def plot_cost_iteration(training_loss, test_loss, iterations):
plt.plot(np.arange(start=0, stop=iterations, step= 1), training_loss, label='Training data')
plt.plot(np.arange(start=0, stop=iterations, step= 1), test_loss, label='Test data')
plt.xlabel('Iteration')
plt.ylabel('Cost')
plt.title('Cost per Iteration')
plt.legend()
plt.show()
def plot_accuracy_iteration(training_accuracy, test_accuracy, iterations):
plt.plot(np.arange(start=1, stop=iterations+1, step= 1), training_accuracy, label='Training data')
plt.plot(np.arange(start=1, stop=iterations+1, step= 1), test_accuracy, label='Test data')
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
plt.title('Accuracy per Iteration')
plt.legend()
plt.show()
warwick_path = '/content/drive/MyDrive/Colab Notebooks/Deep Learning for Image Analysis/warwick_dataset'
X_train, Y_train, X_test, Y_test = load_warwick(warwick_path)
training_dataset = torch.utils.data.TensorDataset(X_train, Y_train)
test_dataset = torch.utils.data.TensorDataset(X_test, Y_test)
# Initialise hyperparameters
minibatch_size = 85
learning_rate = 0.001
iterations = 1000
# Data structures to hold accuracy and loss values throughout the iterations
training_accuracy = []
training_loss = []
test_accuracy = []
test_loss = []
# Load the training and test dataset without shuffling
train_dataLoader = torch.utils.data.DataLoader(training_dataset, batch_size=minibatch_size, shuffle=False)
test_dataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=len(test_dataset), shuffle=False)
# Create the network
segmentation_cnn = semanticSegmentation_cnn()
segmentation_cnn.to(device)
# Use Stochastic Gradient Descent optimiser
optimiser = optim.Adam(segmentation_cnn.parameters(), lr=learning_rate)
loss_funtion = nn.CrossEntropyLoss()
# Training
for epoch in range(0, iterations):
epoch_loss = 0
epoch_accuracy = 0
for (x_batch, y_batch) in train_dataLoader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
optimiser.zero_grad()
predictions = segmentation_cnn(x_batch) # Forward pass on training batch
batch_accuracy = accuracy(predictions, y_batch) # Compute accuracy on training batch
epoch_accuracy += batch_accuracy.item()
loss = loss_funtion(torch.squeeze(predictions), y_batch) # Compute loss on training batch
batch_loss = loss.item()
epoch_loss += batch_loss
loss.backward() # Back propagation
optimiser.step() # Parameters update
training_accuracy.append(epoch_accuracy / len(train_dataLoader))
training_loss.append(epoch_loss / len(train_dataLoader))
with torch.no_grad():
for (x_test, y_test) in test_dataLoader:
x_test, y_test = x_test.to(device), y_test.to(device)
predictions = segmentation_cnn(x_test) # Forward pass on test dataset
test_accuracy.append(accuracy(predictions, y_test).item()) # Compute accuracy on test dataset
test_loss.append(loss_funtion(torch.squeeze(predictions), y_test).item()) # Compute loss on test dataset
if (epoch + 1) % 5 == 0:
print(f'Epoch {epoch+1:5d}: train loss {training_loss[-1]:5.2f} train accuracy {100*training_accuracy[-1]:6.2f} '\
f'test loss {test_loss[-1]:5.2f} test accuracy {100*test_accuracy[-1]:6.2f}')
# Plotting
plot_cost_iteration(training_loss, test_loss, iterations)
plot_accuracy_iteration(training_accuracy, test_accuracy, iterations)
image_index = 8
image_pred = predictions[image_index].cpu()
image_pred = torch.max(image_pred, 0)[1]
plt.imshow(image_pred, interpolation='bilinear')
image_label = y_test[image_index].cpu().numpy()
plt.imshow(image_label, interpolation='bilinear')
| 0.846356 | 0.599544 |
# Geometry and Linear Algebraic Operations
:label:`sec_geometry-linear-algebraic-ops`
In :numref:`sec_linear-algebra`, we encountered the basics of linear algebra
and saw how it could be used to express common operations for transforming our data.
Linear algebra is one of the key mathematical pillars
underlying much of the work that we do in deep learning
and in machine learning more broadly.
While :numref:`sec_linear-algebra` contained enough machinery
to communicate the mechanics of modern deep learning models,
there is a lot more to the subject.
In this section, we will go deeper,
highlighting some geometric interpretations of linear algebra operations,
and introducing a few fundamental concepts, including of eigenvalues and eigenvectors.
## Geometry of Vectors
First, we need to discuss the two common geometric interpretations of vectors,
as either points or directions in space.
Fundamentally, a vector is a list of numbers such as the Python list below.
```
v = [1, 7, 0, 1]
```
Mathematicians most often write this as either a *column* or *row* vector, which is to say either as
$$
\mathbf{x} = \begin{bmatrix}1\\7\\0\\1\end{bmatrix},
$$
or
$$
\mathbf{x}^\top = \begin{bmatrix}1 & 7 & 0 & 1\end{bmatrix}.
$$
These often have different interpretations,
where data examples are column vectors
and weights used to form weighted sums are row vectors.
However, it can be beneficial to be flexible.
As we have described in :numref:`sec_linear-algebra`,
though a single vector's default orientation is a column vector,
for any matrix representing a tabular dataset,
treating each data example as a row vector
in the matrix
is more conventional.
Given a vector, the first interpretation
that we should give it is as a point in space.
In two or three dimensions, we can visualize these points
by using the components of the vectors to define
the location of the points in space compared
to a fixed reference called the *origin*. This can be seen in :numref:`fig_grid`.

:label:`fig_grid`
This geometric point of view allows us to consider the problem on a more abstract level.
No longer faced with some insurmountable seeming problem
like classifying pictures as either cats or dogs,
we can start considering tasks abstractly
as collections of points in space and picturing the task
as discovering how to separate two distinct clusters of points.
In parallel, there is a second point of view
that people often take of vectors: as directions in space.
Not only can we think of the vector $\mathbf{v} = [3,2]^\top$
as the location $3$ units to the right and $2$ units up from the origin,
we can also think of it as the direction itself
to take $3$ steps to the right and $2$ steps up.
In this way, we consider all the vectors in figure :numref:`fig_arrow` the same.

:label:`fig_arrow`
One of the benefits of this shift is that
we can make visual sense of the act of vector addition.
In particular, we follow the directions given by one vector,
and then follow the directions given by the other, as is seen in :numref:`fig_add-vec`.

:label:`fig_add-vec`
Vector subtraction has a similar interpretation.
By considering the identity that $\mathbf{u} = \mathbf{v} + (\mathbf{u}-\mathbf{v})$,
we see that the vector $\mathbf{u}-\mathbf{v}$ is the direction
that takes us from the point $\mathbf{v}$ to the point $\mathbf{u}$.
## Dot Products and Angles
As we saw in :numref:`sec_linear-algebra`,
if we take two column vectors $\mathbf{u}$ and $\mathbf{v}$,
we can form their dot product by computing:
$$\mathbf{u}^\top\mathbf{v} = \sum_i u_i\cdot v_i.$$
:eqlabel:`eq_dot_def`
Because :eqref:`eq_dot_def` is symmetric, we will mirror the notation
of classical multiplication and write
$$
\mathbf{u}\cdot\mathbf{v} = \mathbf{u}^\top\mathbf{v} = \mathbf{v}^\top\mathbf{u},
$$
to highlight the fact that exchanging the order of the vectors will yield the same answer.
The dot product :eqref:`eq_dot_def` also admits a geometric interpretation: it is closely related to the angle between two vectors. Consider the angle shown in :numref:`fig_angle`.

:label:`fig_angle`
To start, let us consider two specific vectors:
$$
\mathbf{v} = (r,0) \; \text{and} \; \mathbf{w} = (s\cos(\theta), s \sin(\theta)).
$$
The vector $\mathbf{v}$ is length $r$ and runs parallel to the $x$-axis,
and the vector $\mathbf{w}$ is of length $s$ and at angle $\theta$ with the $x$-axis.
If we compute the dot product of these two vectors, we see that
$$
\mathbf{v}\cdot\mathbf{w} = rs\cos(\theta) = \|\mathbf{v}\|\|\mathbf{w}\|\cos(\theta).
$$
With some simple algebraic manipulation, we can rearrange terms to obtain
$$
\theta = \arccos\left(\frac{\mathbf{v}\cdot\mathbf{w}}{\|\mathbf{v}\|\|\mathbf{w}\|}\right).
$$
In short, for these two specific vectors,
the dot product combined with the norms tell us the angle between the two vectors. This same fact is true in general. We will not derive the expression here, however,
if we consider writing $\|\mathbf{v} - \mathbf{w}\|^2$ in two ways:
one with the dot product, and the other geometrically using the law of cosines,
we can obtain the full relationship.
Indeed, for any two vectors $\mathbf{v}$ and $\mathbf{w}$,
the angle between the two vectors is
$$\theta = \arccos\left(\frac{\mathbf{v}\cdot\mathbf{w}}{\|\mathbf{v}\|\|\mathbf{w}\|}\right).$$
:eqlabel:`eq_angle_forumla`
This is a nice result since nothing in the computation references two-dimensions.
Indeed, we can use this in three or three million dimensions without issue.
As a simple example, let us see how to compute the angle between a pair of vectors:
```
%matplotlib inline
from d2l import torch as d2l
from IPython import display
import torch
from torchvision import transforms
import torchvision
def angle(v, w):
return torch.acos(v.dot(w) / (torch.norm(v) * torch.norm(w)))
angle(torch.tensor([0, 1, 2], dtype=torch.float32), torch.tensor([2.0, 3, 4]))
```
We will not use it right now, but it is useful to know
that we will refer to vectors for which the angle is $\pi/2$
(or equivalently $90^{\circ}$) as being *orthogonal*.
By examining the equation above, we see that this happens when $\theta = \pi/2$,
which is the same thing as $\cos(\theta) = 0$.
The only way this can happen is if the dot product itself is zero,
and two vectors are orthogonal if and only if $\mathbf{v}\cdot\mathbf{w} = 0$.
This will prove to be a helpful formula when understanding objects geometrically.
It is reasonable to ask: why is computing the angle useful?
The answer comes in the kind of invariance we expect data to have.
Consider an image, and a duplicate image,
where every pixel value is the same but $10\%$ the brightness.
The values of the individual pixels are in general far from the original values.
Thus, if one computed the distance between the original image and the darker one,
the distance can be large.
However, for most ML applications, the *content* is the same---it is still
an image of a cat as far as a cat/dog classifier is concerned.
However, if we consider the angle, it is not hard to see
that for any vector $\mathbf{v}$, the angle
between $\mathbf{v}$ and $0.1\cdot\mathbf{v}$ is zero.
This corresponds to the fact that scaling vectors
keeps the same direction and just changes the length.
The angle considers the darker image identical.
Examples like this are everywhere.
In text, we might want the topic being discussed
to not change if we write twice as long of document that says the same thing.
For some encoding (such as counting the number of occurrences of words in some vocabulary), this corresponds to a doubling of the vector encoding the document,
so again we can use the angle.
### Cosine Similarity
In ML contexts where the angle is employed
to measure the closeness of two vectors,
practitioners adopt the term *cosine similarity*
to refer to the portion
$$
\cos(\theta) = \frac{\mathbf{v}\cdot\mathbf{w}}{\|\mathbf{v}\|\|\mathbf{w}\|}.
$$
The cosine takes a maximum value of $1$
when the two vectors point in the same direction,
a minimum value of $-1$ when they point in opposite directions,
and a value of $0$ when the two vectors are orthogonal.
Note that if the components of high-dimensional vectors
are sampled randomly with mean $0$,
their cosine will nearly always be close to $0$.
## Hyperplanes
In addition to working with vectors, another key object
that you must understand to go far in linear algebra
is the *hyperplane*, a generalization to higher dimensions
of a line (two dimensions) or of a plane (three dimensions).
In an $d$-dimensional vector space, a hyperplane has $d-1$ dimensions
and divides the space into two half-spaces.
Let us start with an example.
Suppose that we have a column vector $\mathbf{w}=[2,1]^\top$. We want to know, "what are the points $\mathbf{v}$ with $\mathbf{w}\cdot\mathbf{v} = 1$?"
By recalling the connection between dot products and angles above :eqref:`eq_angle_forumla`,
we can see that this is equivalent to
$$
\|\mathbf{v}\|\|\mathbf{w}\|\cos(\theta) = 1 \; \iff \; \|\mathbf{v}\|\cos(\theta) = \frac{1}{\|\mathbf{w}\|} = \frac{1}{\sqrt{5}}.
$$

:label:`fig_vector-project`
If we consider the geometric meaning of this expression,
we see that this is equivalent to saying
that the length of the projection of $\mathbf{v}$
onto the direction of $\mathbf{w}$ is exactly $1/\|\mathbf{w}\|$, as is shown in :numref:`fig_vector-project`.
The set of all points where this is true is a line
at right angles to the vector $\mathbf{w}$.
If we wanted, we could find the equation for this line
and see that it is $2x + y = 1$ or equivalently $y = 1 - 2x$.
If we now look at what happens when we ask about the set of points with
$\mathbf{w}\cdot\mathbf{v} > 1$ or $\mathbf{w}\cdot\mathbf{v} < 1$,
we can see that these are cases where the projections
are longer or shorter than $1/\|\mathbf{w}\|$, respectively.
Thus, those two inequalities define either side of the line.
In this way, we have found a way to cut our space into two halves,
where all the points on one side have dot product below a threshold,
and the other side above as we see in :numref:`fig_space-division`.

:label:`fig_space-division`
The story in higher dimension is much the same.
If we now take $\mathbf{w} = [1,2,3]^\top$
and ask about the points in three dimensions with $\mathbf{w}\cdot\mathbf{v} = 1$,
we obtain a plane at right angles to the given vector $\mathbf{w}$.
The two inequalities again define the two sides of the plane as is shown in :numref:`fig_higher-division`.

:label:`fig_higher-division`
While our ability to visualize runs out at this point,
nothing stops us from doing this in tens, hundreds, or billions of dimensions.
This occurs often when thinking about machine learned models.
For instance, we can understand linear classification models
like those from :numref:`sec_softmax`,
as methods to find hyperplanes that separate the different target classes.
In this context, such hyperplanes are often referred to as *decision planes*.
The majority of deep learned classification models end
with a linear layer fed into a softmax,
so one can interpret the role of the deep neural network
to be to find a non-linear embedding such that the target classes
can be separated cleanly by hyperplanes.
To give a hand-built example, notice that we can produce a reasonable model
to classify tiny images of t-shirts and trousers from the Fashion MNIST dataset
(seen in :numref:`sec_fashion_mnist`)
by just taking the vector between their means to define the decision plane
and eyeball a crude threshold. First we will load the data and compute the averages.
```
# Load in the dataset
trans = []
trans.append(transforms.ToTensor())
trans = transforms.Compose(trans)
train = torchvision.datasets.FashionMNIST(root="../data", transform=trans,
train=True, download=True)
test = torchvision.datasets.FashionMNIST(root="../data", transform=trans,
train=False, download=True)
X_train_0 = torch.stack(
[x[0] * 256 for x in train if x[1] == 0]).type(torch.float32)
X_train_1 = torch.stack(
[x[0] * 256 for x in train if x[1] == 1]).type(torch.float32)
X_test = torch.stack(
[x[0] * 256 for x in test if x[1] == 0 or x[1] == 1]).type(torch.float32)
y_test = torch.stack([torch.tensor(x[1]) for x in test
if x[1] == 0 or x[1] == 1]).type(torch.float32)
# Compute averages
ave_0 = torch.mean(X_train_0, axis=0)
ave_1 = torch.mean(X_train_1, axis=0)
```
It can be informative to examine these averages in detail, so let us plot what they look like. In this case, we see that the average indeed resembles a blurry image of a t-shirt.
```
# Plot average t-shirt
d2l.set_figsize()
d2l.plt.imshow(ave_0.reshape(28, 28).tolist(), cmap='Greys')
d2l.plt.show()
```
In the second case, we again see that the average resembles a blurry image of trousers.
```
# Plot average trousers
d2l.plt.imshow(ave_1.reshape(28, 28).tolist(), cmap='Greys')
d2l.plt.show()
```
In a fully machine learned solution, we would learn the threshold from the dataset. In this case, I simply eyeballed a threshold that looked good on the training data by hand.
```
# Print test set accuracy with eyeballed threshold
w = (ave_1 - ave_0).T
# '@' is Matrix Multiplication operator in pytorch.
predictions = X_test.reshape(2000, -1) @ (w.flatten()) > -1500000
# Accuracy
torch.mean(predictions.type(y_test.dtype) == y_test, dtype=torch.float64)
```
## Geometry of Linear Transformations
Through :numref:`sec_linear-algebra` and the above discussions,
we have a solid understanding of the geometry of vectors, lengths, and angles.
However, there is one important object we have omitted discussing,
and that is a geometric understanding of linear transformations represented by matrices. Fully internalizing what matrices can do to transform data
between two potentially different high dimensional spaces takes significant practice,
and is beyond the scope of this appendix.
However, we can start building up intuition in two dimensions.
Suppose that we have some matrix:
$$
\mathbf{A} = \begin{bmatrix}
a & b \\ c & d
\end{bmatrix}.
$$
If we want to apply this to an arbitrary vector
$\mathbf{v} = [x, y]^\top$,
we multiply and see that
$$
\begin{aligned}
\mathbf{A}\mathbf{v} & = \begin{bmatrix}a & b \\ c & d\end{bmatrix}\begin{bmatrix}x \\ y\end{bmatrix} \\
& = \begin{bmatrix}ax+by\\ cx+dy\end{bmatrix} \\
& = x\begin{bmatrix}a \\ c\end{bmatrix} + y\begin{bmatrix}b \\d\end{bmatrix} \\
& = x\left\{\mathbf{A}\begin{bmatrix}1\\0\end{bmatrix}\right\} + y\left\{\mathbf{A}\begin{bmatrix}0\\1\end{bmatrix}\right\}.
\end{aligned}
$$
This may seem like an odd computation,
where something clear became somewhat impenetrable.
However, it tells us that we can write the way
that a matrix transforms *any* vector
in terms of how it transforms *two specific vectors*:
$[1,0]^\top$ and $[0,1]^\top$.
This is worth considering for a moment.
We have essentially reduced an infinite problem
(what happens to any pair of real numbers)
to a finite one (what happens to these specific vectors).
These vectors are an example a *basis*,
where we can write any vector in our space
as a weighted sum of these *basis vectors*.
Let us draw what happens when we use the specific matrix
$$
\mathbf{A} = \begin{bmatrix}
1 & 2 \\
-1 & 3
\end{bmatrix}.
$$
If we look at the specific vector $\mathbf{v} = [2, -1]^\top$,
we see this is $2\cdot[1,0]^\top + -1\cdot[0,1]^\top$,
and thus we know that the matrix $A$ will send this to
$2(\mathbf{A}[1,0]^\top) + -1(\mathbf{A}[0,1])^\top = 2[1, -1]^\top - [2,3]^\top = [0, -5]^\top$.
If we follow this logic through carefully,
say by considering the grid of all integer pairs of points,
we see that what happens is that the matrix multiplication
can skew, rotate, and scale the grid,
but the grid structure must remain as you see in :numref:`fig_grid-transform`.

:label:`fig_grid-transform`
This is the most important intuitive point
to internalize about linear transformations represented by matrices.
Matrices are incapable of distorting some parts of space differently than others.
All they can do is take the original coordinates on our space
and skew, rotate, and scale them.
Some distortions can be severe. For instance the matrix
$$
\mathbf{B} = \begin{bmatrix}
2 & -1 \\ 4 & -2
\end{bmatrix},
$$
compresses the entire two-dimensional plane down to a single line.
Identifying and working with such transformations are the topic of a later section,
but geometrically we can see that this is fundamentally different
from the types of transformations we saw above.
For instance, the result from matrix $\mathbf{A}$ can be "bent back" to the original grid. The results from matrix $\mathbf{B}$ cannot
because we will never know where the vector $[1,2]^\top$ came from---was
it $[1,1]^\top$ or $[0, -1]^\top$?
While this picture was for a $2\times2$ matrix,
nothing prevents us from taking the lessons learned into higher dimensions.
If we take similar basis vectors like $[1,0, \ldots,0]$
and see where our matrix sends them,
we can start to get a feeling for how the matrix multiplication
distorts the entire space in whatever dimension space we are dealing with.
## Linear Dependence
Consider again the matrix
$$
\mathbf{B} = \begin{bmatrix}
2 & -1 \\ 4 & -2
\end{bmatrix}.
$$
This compresses the entire plane down to live on the single line $y = 2x$.
The question now arises: is there some way we can detect this
just looking at the matrix itself?
The answer is that indeed we can.
Let us take $\mathbf{b}_1 = [2,4]^\top$ and $\mathbf{b}_2 = [-1, -2]^\top$
be the two columns of $\mathbf{B}$.
Remember that we can write everything transformed by the matrix $\mathbf{B}$
as a weighted sum of the columns of the matrix:
like $a_1\mathbf{b}_1 + a_2\mathbf{b}_2$.
We call this a *linear combination*.
The fact that $\mathbf{b}_1 = -2\cdot\mathbf{b}_2$
means that we can write any linear combination of those two columns
entirely in terms of say $\mathbf{b}_2$ since
$$
a_1\mathbf{b}_1 + a_2\mathbf{b}_2 = -2a_1\mathbf{b}_2 + a_2\mathbf{b}_2 = (a_2-2a_1)\mathbf{b}_2.
$$
This means that one of the columns is, in a sense, redundant
because it does not define a unique direction in space.
This should not surprise us too much
since we already saw that this matrix
collapses the entire plane down into a single line.
Moreover, we see that the linear dependence
$\mathbf{b}_1 = -2\cdot\mathbf{b}_2$ captures this.
To make this more symmetrical between the two vectors, we will write this as
$$
\mathbf{b}_1 + 2\cdot\mathbf{b}_2 = 0.
$$
In general, we will say that a collection of vectors
$\mathbf{v}_1, \ldots, \mathbf{v}_k$ are *linearly dependent*
if there exist coefficients $a_1, \ldots, a_k$ *not all equal to zero* so that
$$
\sum_{i=1}^k a_i\mathbf{v_i} = 0.
$$
In this case, we can solve for one of the vectors
in terms of some combination of the others,
and effectively render it redundant.
Thus, a linear dependence in the columns of a matrix
is a witness to the fact that our matrix
is compressing the space down to some lower dimension.
If there is no linear dependence we say the vectors are *linearly independent*.
If the columns of a matrix are linearly independent,
no compression occurs and the operation can be undone.
## Rank
If we have a general $n\times m$ matrix,
it is reasonable to ask what dimension space the matrix maps into.
A concept known as the *rank* will be our answer.
In the previous section, we noted that a linear dependence
bears witness to compression of space into a lower dimension
and so we will be able to use this to define the notion of rank.
In particular, the rank of a matrix $\mathbf{A}$
is the largest number of linearly independent columns
amongst all subsets of columns. For example, the matrix
$$
\mathbf{B} = \begin{bmatrix}
2 & 4 \\ -1 & -2
\end{bmatrix},
$$
has $\mathrm{rank}(B)=1$, since the two columns are linearly dependent,
but either column by itself is not linearly dependent.
For a more challenging example, we can consider
$$
\mathbf{C} = \begin{bmatrix}
1& 3 & 0 & -1 & 0 \\
-1 & 0 & 1 & 1 & -1 \\
0 & 3 & 1 & 0 & -1 \\
2 & 3 & -1 & -2 & 1
\end{bmatrix},
$$
and show that $\mathbf{C}$ has rank two since, for instance,
the first two columns are linearly independent,
however any of the four collections of three columns are dependent.
This procedure, as described, is very inefficient.
It requires looking at every subset of the columns of our given matrix,
and thus is potentially exponential in the number of columns.
Later we will see a more computationally efficient way
to compute the rank of a matrix, but for now,
this is sufficient to see that the concept
is well defined and understand the meaning.
## Invertibility
We have seen above that multiplication by a matrix with linearly dependent columns
cannot be undone, i.e., there is no inverse operation that can always recover the input. However, multiplication by a full-rank matrix
(i.e., some $\mathbf{A}$ that is $n \times n$ matrix with rank $n$),
we should always be able to undo it. Consider the matrix
$$
\mathbf{I} = \begin{bmatrix}
1 & 0 & \cdots & 0 \\
0 & 1 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & 1
\end{bmatrix}.
$$
which is the matrix with ones along the diagonal, and zeros elsewhere.
We call this the *identity* matrix.
It is the matrix which leaves our data unchanged when applied.
To find a matrix which undoes what our matrix $\mathbf{A}$ has done,
we want to find a matrix $\mathbf{A}^{-1}$ such that
$$
\mathbf{A}^{-1}\mathbf{A} = \mathbf{A}\mathbf{A}^{-1} = \mathbf{I}.
$$
If we look at this as a system, we have $n \times n$ unknowns
(the entries of $\mathbf{A}^{-1}$) and $n \times n$ equations
(the equality that needs to hold between every entry of the product $\mathbf{A}^{-1}\mathbf{A}$ and every entry of $\mathbf{I}$)
so we should generically expect a solution to exist.
Indeed, in the next section we will see a quantity called the *determinant*,
which has the property that as long as the determinant is not zero, we can find a solution. We call such a matrix $\mathbf{A}^{-1}$ the *inverse* matrix.
As an example, if $\mathbf{A}$ is the general $2 \times 2$ matrix
$$
\mathbf{A} = \begin{bmatrix}
a & b \\
c & d
\end{bmatrix},
$$
then we can see that the inverse is
$$
\frac{1}{ad-bc} \begin{bmatrix}
d & -b \\
-c & a
\end{bmatrix}.
$$
We can test to see this by seeing that multiplying
by the inverse given by the formula above works in practice.
```
M = torch.tensor([[1, 2], [1, 4]], dtype=torch.float32)
M_inv = torch.tensor([[2, -1], [-0.5, 0.5]])
M_inv @ M
```
### Numerical Issues
While the inverse of a matrix is useful in theory,
we must say that most of the time we do not wish
to *use* the matrix inverse to solve a problem in practice.
In general, there are far more numerically stable algorithms
for solving linear equations like
$$
\mathbf{A}\mathbf{x} = \mathbf{b},
$$
than computing the inverse and multiplying to get
$$
\mathbf{x} = \mathbf{A}^{-1}\mathbf{b}.
$$
Just as division by a small number can lead to numerical instability,
so can inversion of a matrix which is close to having low rank.
Moreover, it is common that the matrix $\mathbf{A}$ is *sparse*,
which is to say that it contains only a small number of non-zero values.
If we were to explore examples, we would see
that this does not mean the inverse is sparse.
Even if $\mathbf{A}$ was a $1$ million by $1$ million matrix
with only $5$ million non-zero entries
(and thus we need only store those $5$ million),
the inverse will typically have almost every entry non-negative,
requiring us to store all $1\text{M}^2$ entries---that is $1$ trillion entries!
While we do not have time to dive all the way into the thorny numerical issues
frequently encountered when working with linear algebra,
we want to provide you with some intuition about when to proceed with caution,
and generally avoiding inversion in practice is a good rule of thumb.
## Determinant
The geometric view of linear algebra gives an intuitive way
to interpret a fundamental quantity known as the *determinant*.
Consider the grid image from before, but now with a highlighted region (:numref:`fig_grid-filled`).

:label:`fig_grid-filled`
Look at the highlighted square. This is a square with edges given
by $(0, 1)$ and $(1, 0)$ and thus it has area one.
After $\mathbf{A}$ transforms this square,
we see that it becomes a parallelogram.
There is no reason this parallelogram should have the same area
that we started with, and indeed in the specific case shown here of
$$
\mathbf{A} = \begin{bmatrix}
1 & 2 \\
-1 & 3
\end{bmatrix},
$$
it is an exercise in coordinate geometry to compute
the area of this parallelogram and obtain that the area is $5$.
In general, if we have a matrix
$$
\mathbf{A} = \begin{bmatrix}
a & b \\
c & d
\end{bmatrix},
$$
we can see with some computation that the area
of the resulting parallelogram is $ad-bc$.
This area is referred to as the *determinant*.
Let us check this quickly with some example code.
```
torch.det(torch.tensor([[1, -1], [2, 3]], dtype=torch.float32))
```
The eagle-eyed amongst us will notice
that this expression can be zero or even negative.
For the negative term, this is a matter of convention
taken generally in mathematics:
if the matrix flips the figure,
we say the area is negated.
Let us see now that when the determinant is zero, we learn more.
Let us consider
$$
\mathbf{B} = \begin{bmatrix}
2 & 4 \\ -1 & -2
\end{bmatrix}.
$$
If we compute the determinant of this matrix,
we get $2\cdot(-2 ) - 4\cdot(-1) = 0$.
Given our understanding above, this makes sense.
$\mathbf{B}$ compresses the square from the original image
down to a line segment, which has zero area.
And indeed, being compressed into a lower dimensional space
is the only way to have zero area after the transformation.
Thus we see the following result is true:
a matrix $A$ is invertible if and only if
the determinant is not equal to zero.
As a final comment, imagine that we have any figure drawn on the plane.
Thinking like computer scientists, we can decompose
that figure into a collection of little squares
so that the area of the figure is in essence
just the number of squares in the decomposition.
If we now transform that figure by a matrix,
we send each of these squares to parallelograms,
each one of which has area given by the determinant.
We see that for any figure, the determinant gives the (signed) number
that a matrix scales the area of any figure.
Computing determinants for larger matrices can be laborious,
but the intuition is the same.
The determinant remains the factor
that $n\times n$ matrices scale $n$-dimensional volumes.
## Tensors and Common Linear Algebra Operations
In :numref:`sec_linear-algebra` the concept of tensors was introduced.
In this section, we will dive more deeply into tensor contractions
(the tensor equivalent of matrix multiplication),
and see how it can provide a unified view
on a number of matrix and vector operations.
With matrices and vectors we knew how to multiply them to transform data.
We need to have a similar definition for tensors if they are to be useful to us.
Think about matrix multiplication:
$$
\mathbf{C} = \mathbf{A}\mathbf{B},
$$
or equivalently
$$ c_{i, j} = \sum_{k} a_{i, k}b_{k, j}.$$
This pattern is one we can repeat for tensors.
For tensors, there is no one case of what
to sum over that can be universally chosen,
so we need specify exactly which indices we want to sum over.
For instance we could consider
$$
y_{il} = \sum_{jk} x_{ijkl}a_{jk}.
$$
Such a transformation is called a *tensor contraction*.
It can represent a far more flexible family of transformations
that matrix multiplication alone.
As a often-used notational simplification,
we can notice that the sum is over exactly those indices
that occur more than once in the expression,
thus people often work with *Einstein notation*,
where the summation is implicitly taken over all repeated indices.
This gives the compact expression:
$$
y_{il} = x_{ijkl}a_{jk}.
$$
### Common Examples from Linear Algebra
Let us see how many of the linear algebraic definitions
we have seen before can be expressed in this compressed tensor notation:
* $\mathbf{v} \cdot \mathbf{w} = \sum_i v_iw_i$
* $\|\mathbf{v}\|_2^{2} = \sum_i v_iv_i$
* $(\mathbf{A}\mathbf{v})_i = \sum_j a_{ij}v_j$
* $(\mathbf{A}\mathbf{B})_{ik} = \sum_j a_{ij}b_{jk}$
* $\mathrm{tr}(\mathbf{A}) = \sum_i a_{ii}$
In this way, we can replace a myriad of specialized notations with short tensor expressions.
### Expressing in Code
Tensors may flexibly be operated on in code as well.
As seen in :numref:`sec_linear-algebra`,
we can create tensors as is shown below.
```
# Define tensors
B = torch.tensor([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
A = torch.tensor([[1, 2], [3, 4]])
v = torch.tensor([1, 2])
# Print out the shapes
A.shape, B.shape, v.shape
```
Einstein summation has been implemented directly.
The indices that occurs in the Einstein summation can be passed as a string,
followed by the tensors that are being acted upon.
For instance, to implement matrix multiplication,
we can consider the Einstein summation seen above
($\mathbf{A}\mathbf{v} = a_{ij}v_j$)
and strip out the indices themselves to get the implementation:
```
# Reimplement matrix multiplication
torch.einsum("ij, j -> i", A, v), A@v
```
This is a highly flexible notation.
For instance if we want to compute
what would be traditionally written as
$$
c_{kl} = \sum_{ij} \mathbf{b}_{ijk}\mathbf{a}_{il}v_j.
$$
it can be implemented via Einstein summation as:
```
torch.einsum("ijk, il, j -> kl", B, A, v)
```
This notation is readable and efficient for humans,
however bulky if for whatever reason
we need to generate a tensor contraction programmatically.
For this reason, `einsum` provides an alternative notation
by providing integer indices for each tensor.
For example, the same tensor contraction can also be written as:
```
# PyTorch doesn't support this type of notation.
```
Either notation allows for concise and efficient representation of tensor contractions in code.
## Summary
* Vectors can be interpreted geometrically as either points or directions in space.
* Dot products define the notion of angle to arbitrarily high-dimensional spaces.
* Hyperplanes are high-dimensional generalizations of lines and planes. They can be used to define decision planes that are often used as the last step in a classification task.
* Matrix multiplication can be geometrically interpreted as uniform distortions of the underlying coordinates. They represent a very restricted, but mathematically clean, way to transform vectors.
* Linear dependence is a way to tell when a collection of vectors are in a lower dimensional space than we would expect (say you have $3$ vectors living in a $2$-dimensional space). The rank of a matrix is the size of the largest subset of its columns that are linearly independent.
* When a matrix's inverse is defined, matrix inversion allows us to find another matrix that undoes the action of the first. Matrix inversion is useful in theory, but requires care in practice owing to numerical instability.
* Determinants allow us to measure how much a matrix expands or contracts a space. A nonzero determinant implies an invertible (non-singular) matrix and a zero-valued determinant means that the matrix is non-invertible (singular).
* Tensor contractions and Einstein summation provide for a neat and clean notation for expressing many of the computations that are seen in machine learning.
## Exercises
1. What is the angle between
$$
\vec v_1 = \begin{bmatrix}
1 \\ 0 \\ -1 \\ 2
\end{bmatrix}, \qquad \vec v_2 = \begin{bmatrix}
3 \\ 1 \\ 0 \\ 1
\end{bmatrix}?
$$
2. True or false: $\begin{bmatrix}1 & 2\\0&1\end{bmatrix}$ and $\begin{bmatrix}1 & -2\\0&1\end{bmatrix}$ are inverses of one another?
3. Suppose that we draw a shape in the plane with area $100\mathrm{m}^2$. What is the area after transforming the figure by the matrix
$$
\begin{bmatrix}
2 & 3\\
1 & 2
\end{bmatrix}.
$$
4. Which of the following sets of vectors are linearly independent?
* $\left\{\begin{pmatrix}1\\0\\-1\end{pmatrix}, \begin{pmatrix}2\\1\\-1\end{pmatrix}, \begin{pmatrix}3\\1\\1\end{pmatrix}\right\}$
* $\left\{\begin{pmatrix}3\\1\\1\end{pmatrix}, \begin{pmatrix}1\\1\\1\end{pmatrix}, \begin{pmatrix}0\\0\\0\end{pmatrix}\right\}$
* $\left\{\begin{pmatrix}1\\1\\0\end{pmatrix}, \begin{pmatrix}0\\1\\-1\end{pmatrix}, \begin{pmatrix}1\\0\\1\end{pmatrix}\right\}$
5. Suppose that you have a matrix written as $A = \begin{bmatrix}c\\d\end{bmatrix}\cdot\begin{bmatrix}a & b\end{bmatrix}$ for some choice of values $a, b, c$, and $d$. True or false: the determinant of such a matrix is always $0$?
6. The vectors $e_1 = \begin{bmatrix}1\\0\end{bmatrix}$ and $e_2 = \begin{bmatrix}0\\1\end{bmatrix}$ are orthogonal. What is the condition on a matrix $A$ so that $Ae_1$ and $Ae_2$ are orthogonal?
7. How can you write $\mathrm{tr}(\mathbf{A}^4)$ in Einstein notation for an arbitrary matrix $A$?
[Discussions](https://discuss.d2l.ai/t/1084)
|
github_jupyter
|
v = [1, 7, 0, 1]
%matplotlib inline
from d2l import torch as d2l
from IPython import display
import torch
from torchvision import transforms
import torchvision
def angle(v, w):
return torch.acos(v.dot(w) / (torch.norm(v) * torch.norm(w)))
angle(torch.tensor([0, 1, 2], dtype=torch.float32), torch.tensor([2.0, 3, 4]))
# Load in the dataset
trans = []
trans.append(transforms.ToTensor())
trans = transforms.Compose(trans)
train = torchvision.datasets.FashionMNIST(root="../data", transform=trans,
train=True, download=True)
test = torchvision.datasets.FashionMNIST(root="../data", transform=trans,
train=False, download=True)
X_train_0 = torch.stack(
[x[0] * 256 for x in train if x[1] == 0]).type(torch.float32)
X_train_1 = torch.stack(
[x[0] * 256 for x in train if x[1] == 1]).type(torch.float32)
X_test = torch.stack(
[x[0] * 256 for x in test if x[1] == 0 or x[1] == 1]).type(torch.float32)
y_test = torch.stack([torch.tensor(x[1]) for x in test
if x[1] == 0 or x[1] == 1]).type(torch.float32)
# Compute averages
ave_0 = torch.mean(X_train_0, axis=0)
ave_1 = torch.mean(X_train_1, axis=0)
# Plot average t-shirt
d2l.set_figsize()
d2l.plt.imshow(ave_0.reshape(28, 28).tolist(), cmap='Greys')
d2l.plt.show()
# Plot average trousers
d2l.plt.imshow(ave_1.reshape(28, 28).tolist(), cmap='Greys')
d2l.plt.show()
# Print test set accuracy with eyeballed threshold
w = (ave_1 - ave_0).T
# '@' is Matrix Multiplication operator in pytorch.
predictions = X_test.reshape(2000, -1) @ (w.flatten()) > -1500000
# Accuracy
torch.mean(predictions.type(y_test.dtype) == y_test, dtype=torch.float64)
M = torch.tensor([[1, 2], [1, 4]], dtype=torch.float32)
M_inv = torch.tensor([[2, -1], [-0.5, 0.5]])
M_inv @ M
torch.det(torch.tensor([[1, -1], [2, 3]], dtype=torch.float32))
# Define tensors
B = torch.tensor([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
A = torch.tensor([[1, 2], [3, 4]])
v = torch.tensor([1, 2])
# Print out the shapes
A.shape, B.shape, v.shape
# Reimplement matrix multiplication
torch.einsum("ij, j -> i", A, v), A@v
torch.einsum("ijk, il, j -> kl", B, A, v)
# PyTorch doesn't support this type of notation.
| 0.902446 | 0.995104 |
```
import math
import random
import os
import numpy as np
from comet_ml import API
from matplotlib import pyplot as plt
import pandas as pd
from scipy import stats
COMET_API_KEY="bSyRm6vJpAwfehizXic7Fo0bY"
COMET_REST_API_KEY="S3g50KZWG8zEgk1PLzKUn0eEq"
def smooth(y, box_pts):
box = np.ones(box_pts)/box_pts
y_smooth = np.convolve(y, box, mode='same')
return y_smooth
```
# DQN - Gridworld
```
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {},
'distral': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
env_params = ''
for exp in client.get("jh-jl-rlfl/dqn-gridworldenv"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
if 'env_params' not in [p['name'] for p in params]:
continue
env = next(p for p in params if p['name'] == 'env_params')['valueMax']
if env != '[4,5,7]':
continue
env_params = env
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
env_params = [int(n) for n in env_params.replace("'",'').replace(']','').replace('[','').split(',')]
colors = [['red', 'darkred', 'brown'],['blue', 'darkblue', 'aqua'], ['green', 'darkgreen', 'lightgreen']]
fig, axs = plt.subplots(1,3, figsize=(20,5), sharey=True)
for color_idx, algorithm in enumerate(['baseline','fame','distral']):
for idx, (key, result_set) in enumerate(results[algorithm].items()):
result_set = [s for s in result_set if len(s) == 300]
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
axs[color_idx].plot(xs, smooth(ys_mean,15), label=f'{algorithm}-{env_params[idx]}', color=colors[color_idx][idx])
axs[color_idx].fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[color_idx][idx], interpolate=True, alpha=0.2)
axs[color_idx].set_title(f"Gridworld - {algorithm}")
axs[color_idx].grid()
axs[color_idx].legend()
axs[color_idx].set_xlim(1,300)
plt.show()
results['fame']
#fig, axs = plt.subplots(1,1, figsize=(20,5), sharey=True)
for color_idx, algorithm in enumerate(['baseline','fame','distral']):
for idx, (key, result_set) in enumerate(results[algorithm].items()):
print(result_set)
```
# DDPG - Gravity Pendulum
```
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
for exp in client.get("jh-jl-rlfl/ddpg-gravitypendulum"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
env_params = next(p for p in params if p['name'] == 'env_params')['valueMax']
# if env_params != '[7,10,13]':
if env_params != '[7,10,13]':
next
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
fig, ax = plt.subplots(figsize=(10,5))
colors = ['red', 'darkred', 'brown']
for idx, (key, result_set) in enumerate(results['fame'].items()):
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
colors = ['blue', 'darkblue', 'lightblue']
for idx, (key, result_set) in enumerate(results['baseline'].items()):
result_set = [s[:299] for s in result_set]
xs = np.arange(len(result_set[0]))
xs = xs
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Pendulum - F.A.M.E. vs Baseline")
#ax.set_xlabel("Gravity (Inverse Pendulum)", fontsize=13)
#ax.set_ylabel("Trailing 5-Episode Average Reward (5K frames)", fontsize=13)
ax.grid()
ax.legend()
ax.set_xlim(10,300)
plt.show()
```
# DDPG-Mountain Car
```
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
for exp in client.get("jh-jl-rlfl/ddpg-mountaincarcontinuous"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
fig, ax = plt.subplots(figsize=(10,5))
colors = ['red', 'blue', 'green']
def smooth(y, box_pts):
box = np.ones(box_pts)/box_pts
y_smooth = np.convolve(y, box, mode='same')
return y_smooth
for idx, (key, result_set) in enumerate(results['fame'].items()):
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Mountain Car - F.A.M.E. vs Baseline")
ax.grid()
ax.legend()
ax.set_xlim(0,300)
plt.show()
fig, ax = plt.subplots(figsize=(10,5))
for idx, (key, result_set) in enumerate(results['baseline'].items()):
result_set = [s[:299] for s in result_set]
xs = np.arange(len(result_set[0]))
xs = xs
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Mountain Car - F.A.M.E. vs Baseline")
#ax.set_xlabel("Gravity (Inverse Pendulum)", fontsize=13)
#ax.set_ylabel("Trailing 5-Episode Average Reward (5K frames)", fontsize=13)
ax.grid()
ax.legend()
ax.set_xlim(0,300)
plt.show()
a = [2,3,4,5,6][:2]
a
```
|
github_jupyter
|
import math
import random
import os
import numpy as np
from comet_ml import API
from matplotlib import pyplot as plt
import pandas as pd
from scipy import stats
COMET_API_KEY="bSyRm6vJpAwfehizXic7Fo0bY"
COMET_REST_API_KEY="S3g50KZWG8zEgk1PLzKUn0eEq"
def smooth(y, box_pts):
box = np.ones(box_pts)/box_pts
y_smooth = np.convolve(y, box, mode='same')
return y_smooth
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {},
'distral': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
env_params = ''
for exp in client.get("jh-jl-rlfl/dqn-gridworldenv"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
if 'env_params' not in [p['name'] for p in params]:
continue
env = next(p for p in params if p['name'] == 'env_params')['valueMax']
if env != '[4,5,7]':
continue
env_params = env
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
env_params = [int(n) for n in env_params.replace("'",'').replace(']','').replace('[','').split(',')]
colors = [['red', 'darkred', 'brown'],['blue', 'darkblue', 'aqua'], ['green', 'darkgreen', 'lightgreen']]
fig, axs = plt.subplots(1,3, figsize=(20,5), sharey=True)
for color_idx, algorithm in enumerate(['baseline','fame','distral']):
for idx, (key, result_set) in enumerate(results[algorithm].items()):
result_set = [s for s in result_set if len(s) == 300]
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
axs[color_idx].plot(xs, smooth(ys_mean,15), label=f'{algorithm}-{env_params[idx]}', color=colors[color_idx][idx])
axs[color_idx].fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[color_idx][idx], interpolate=True, alpha=0.2)
axs[color_idx].set_title(f"Gridworld - {algorithm}")
axs[color_idx].grid()
axs[color_idx].legend()
axs[color_idx].set_xlim(1,300)
plt.show()
results['fame']
#fig, axs = plt.subplots(1,1, figsize=(20,5), sharey=True)
for color_idx, algorithm in enumerate(['baseline','fame','distral']):
for idx, (key, result_set) in enumerate(results[algorithm].items()):
print(result_set)
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
for exp in client.get("jh-jl-rlfl/ddpg-gravitypendulum"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
env_params = next(p for p in params if p['name'] == 'env_params')['valueMax']
# if env_params != '[7,10,13]':
if env_params != '[7,10,13]':
next
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
fig, ax = plt.subplots(figsize=(10,5))
colors = ['red', 'darkred', 'brown']
for idx, (key, result_set) in enumerate(results['fame'].items()):
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
colors = ['blue', 'darkblue', 'lightblue']
for idx, (key, result_set) in enumerate(results['baseline'].items()):
result_set = [s[:299] for s in result_set]
xs = np.arange(len(result_set[0]))
xs = xs
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Pendulum - F.A.M.E. vs Baseline")
#ax.set_xlabel("Gravity (Inverse Pendulum)", fontsize=13)
#ax.set_ylabel("Trailing 5-Episode Average Reward (5K frames)", fontsize=13)
ax.grid()
ax.legend()
ax.set_xlim(10,300)
plt.show()
client = API(api_key=COMET_API_KEY, rest_api_key=COMET_REST_API_KEY)
results = {
'fame': {},
'baseline': {}
}
reward_keys = ['episode_reward.n0', 'episode_reward.n1', 'episode_reward.n2']
for tag in results.keys():
for ep_reward_key in reward_keys:
results[tag][ep_reward_key] = []
for exp in client.get("jh-jl-rlfl/ddpg-mountaincarcontinuous"):
params = client.get_experiment_parameters(exp)
metrics = client.get_experiment_metrics_raw(exp)
tag = client.get_experiment_tags(exp)[0]
rewards = {}
for ep_reward_key in reward_keys:
rewards[ep_reward_key] = []
for metric in metrics:
if metric['metricName'] in reward_keys:
rewards[metric['metricName']].append(float(metric['metricValue']))
for ep_reward_key in reward_keys:
# now that we have all the episode rewards, copy them to the root results:
results[tag][ep_reward_key].append(rewards[ep_reward_key])
fig, ax = plt.subplots(figsize=(10,5))
colors = ['red', 'blue', 'green']
def smooth(y, box_pts):
box = np.ones(box_pts)/box_pts
y_smooth = np.convolve(y, box, mode='same')
return y_smooth
for idx, (key, result_set) in enumerate(results['fame'].items()):
xs = np.arange(len(result_set[0]))
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Mountain Car - F.A.M.E. vs Baseline")
ax.grid()
ax.legend()
ax.set_xlim(0,300)
plt.show()
fig, ax = plt.subplots(figsize=(10,5))
for idx, (key, result_set) in enumerate(results['baseline'].items()):
result_set = [s[:299] for s in result_set]
xs = np.arange(len(result_set[0]))
xs = xs
ys_mean = np.mean(result_set, axis=0)
std = np.std(result_set, axis=0)
upper = [ys_mean[idx] + std for idx,std in enumerate(std)]
lower = [ys_mean[idx] - std for idx,std in enumerate(std)]
plt.plot(xs, smooth(ys_mean,15), label=key, color=colors[idx])
plt.fill_between(xs, smooth(upper,15), smooth(lower,15), where=upper>=lower, facecolor=colors[idx], interpolate=True, alpha=0.2)
ax.set_title("Mountain Car - F.A.M.E. vs Baseline")
#ax.set_xlabel("Gravity (Inverse Pendulum)", fontsize=13)
#ax.set_ylabel("Trailing 5-Episode Average Reward (5K frames)", fontsize=13)
ax.grid()
ax.legend()
ax.set_xlim(0,300)
plt.show()
a = [2,3,4,5,6][:2]
a
| 0.388386 | 0.472805 |
# Train-Valid-Test Split EDA / Sanity Check
```
# Import libraries
import numpy as np
import pandas as pd
# Load pickled data
train_df = pd.read_pickle("data/train.pkl")
valid_df = pd.read_pickle("data/val.pkl")
test_df = pd.read_pickle("data/test.pkl")
```
# Assert no users in multiple sets
```
# Unique users in each set
train_users = set(train_df['user_id'])
valid_users = set(valid_df['user_id'])
test_users = set(test_df['user_id'])
# Assert no overlap
null_set = set()
assert(train_users.intersection(valid_users) == null_set)
assert(train_users.intersection(test_users) == null_set)
assert(valid_users.intersection(test_users) == null_set)
```
# Assert no businesses in multiple sets
```
# Unique businesses in each set
train_bis = set(train_df['business_id'])
valid_bis = set(valid_df['business_id'])
test_bis = set(test_df['business_id'])
# Assert no overlap
null_set = set()
assert(train_bis.intersection(valid_bis) == null_set)
assert(train_bis.intersection(test_bis) == null_set)
assert(valid_bis.intersection(test_bis) == null_set)
```
# Assert no reviews in multiple sets
```
# Unique reviews in each set
train_rev = set(train_df['review_id_r'])
valid_rev = set(valid_df['review_id_r'])
test_rev = set(test_df['review_id_r'])
# Assert no overlap
null_set = set()
assert(train_rev.intersection(valid_rev) == null_set)
assert(train_rev.intersection(test_rev) == null_set)
assert(valid_rev.intersection(test_rev) == null_set)
```
# Summary Statistics
## Number of Users
```
print("Users in train set: {}".format(len(train_users)))
print("Users in valid set: {}".format(len(valid_users)))
print("Users in test set: {}".format(len(test_users)))
```
## Number of Businesses
```
print("Businesses in train set: {}".format(len(train_bis)))
print("Businesses in valid set: {}".format(len(valid_bis)))
print("Businesses in test set: {}".format(len(test_bis)))
```
## Number of Reviews
```
print("Reviews in train set: {}".format(train_df.shape[0]))
print("Reviews in valid set: {}".format(valid_df.shape[0]))
print("Reviews in test set: {}".format(test_df.shape[0]))
```
## Percentage of 5 Star Reviews
```
train_p = train_df[train_df['stars_r']==5].shape[0] / train_df.shape[0]
valid_p = valid_df[valid_df['stars_r']==5].shape[0] / valid_df.shape[0]
test_p = test_df[test_df['stars_r']==5].shape[0] / test_df.shape[0]
print("Percentage of 5 star reviews in train set: {:.3f}".format(train_p))
print("Percentage of 5 star reviews in valid set: {:.3f}".format(valid_p))
print("Percentage of 5 star reviews in test set: {:.3f}".format(test_p))
```
|
github_jupyter
|
# Import libraries
import numpy as np
import pandas as pd
# Load pickled data
train_df = pd.read_pickle("data/train.pkl")
valid_df = pd.read_pickle("data/val.pkl")
test_df = pd.read_pickle("data/test.pkl")
# Unique users in each set
train_users = set(train_df['user_id'])
valid_users = set(valid_df['user_id'])
test_users = set(test_df['user_id'])
# Assert no overlap
null_set = set()
assert(train_users.intersection(valid_users) == null_set)
assert(train_users.intersection(test_users) == null_set)
assert(valid_users.intersection(test_users) == null_set)
# Unique businesses in each set
train_bis = set(train_df['business_id'])
valid_bis = set(valid_df['business_id'])
test_bis = set(test_df['business_id'])
# Assert no overlap
null_set = set()
assert(train_bis.intersection(valid_bis) == null_set)
assert(train_bis.intersection(test_bis) == null_set)
assert(valid_bis.intersection(test_bis) == null_set)
# Unique reviews in each set
train_rev = set(train_df['review_id_r'])
valid_rev = set(valid_df['review_id_r'])
test_rev = set(test_df['review_id_r'])
# Assert no overlap
null_set = set()
assert(train_rev.intersection(valid_rev) == null_set)
assert(train_rev.intersection(test_rev) == null_set)
assert(valid_rev.intersection(test_rev) == null_set)
print("Users in train set: {}".format(len(train_users)))
print("Users in valid set: {}".format(len(valid_users)))
print("Users in test set: {}".format(len(test_users)))
print("Businesses in train set: {}".format(len(train_bis)))
print("Businesses in valid set: {}".format(len(valid_bis)))
print("Businesses in test set: {}".format(len(test_bis)))
print("Reviews in train set: {}".format(train_df.shape[0]))
print("Reviews in valid set: {}".format(valid_df.shape[0]))
print("Reviews in test set: {}".format(test_df.shape[0]))
train_p = train_df[train_df['stars_r']==5].shape[0] / train_df.shape[0]
valid_p = valid_df[valid_df['stars_r']==5].shape[0] / valid_df.shape[0]
test_p = test_df[test_df['stars_r']==5].shape[0] / test_df.shape[0]
print("Percentage of 5 star reviews in train set: {:.3f}".format(train_p))
print("Percentage of 5 star reviews in valid set: {:.3f}".format(valid_p))
print("Percentage of 5 star reviews in test set: {:.3f}".format(test_p))
| 0.493653 | 0.716727 |
# TITANIC: Wrangling the Passenger Manifest
## Exploratory Analysis with ```Pandas```
On April 15, 1912, the RMS Titanic sunk after hitting an iceberg, killing 1502 out of 2224 passengers and crew about during her maiden voyage. While luck did play a role in the survival of some passengers, certain groups—women and childen—were much more likely to survive.
In this tutorial you will gain experience using ```pandas``` to visualize and clean data from the Titanic's passenger manifest. Afterwards it is also recommended that you complete the "additional_wrangling_challenge" notebook, which expands on these skills and is included in this course's repository.
**Be sure to read the README before you begin!** In addition, you may also find these resources helpful:
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/
https://chrisalbon.com/python/data_wrangling/pandas_dataframe_descriptive_stats/
*This tutorial is based on the Kaggle Competition, "Predicting Survival Aboard the Titanic" https://www.kaggle.com/c/titanic*
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
```
## Load the Data
The file we'll be exploring today, ```train.csv```, represents a subset of the Titanic's passenger manifest. It was downloaded when you cloned X503's GitHub repo and is located in the ```Data``` folder. The remaining data from the passenger manifest is in ```test.csv```, which is saved in the same folder and we'll use later on in the Machine Learning course. But for now, let's load the ```train.csv``` file and start exploring the data.
=> Load the ```train.csv``` file into a ```pandas``` ```DataFrame```.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
```
# Read the train.csv file as a dataframe using pandas: df
df =
```
## Exploring the Data
=> Use ```pandas``` to view the "head" of the file with the first 10 rows.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.head.html
```
# Use pandas to view the first 10 rows of the file.
```
*What did you see? When exploring a new data set, these are some of the first questions you should try to answer.*
* Are there any missing values?
* What kinds of values/numbers/text are there?
* Are the values continuous or categorical?
* Are some variables more sparse than others?
* Are there multiple values in a single column?
#### Summary Statistics
__=>__ Use ```pandas``` to get summary statistics on the numerical fields in the data.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html
```
# Use pandas to get the summary statistics on the data.
```
*What can we infer from the summary statistics?*
* How many missing values does the ```Age``` column have?
* What percentage of the passengers survived?
* How many passengers traveled in Class 3?
* Are there any outliers in the ```Fare``` column?
__=>__ Use ```pandas``` to get the median of the ```Age``` column.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.median.html
```
# Use pandas to get the median of the Age column.
```
__=>__ Use ```pandas``` to find the number of unique values in the ```Ticket``` column.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.nunique.html
```
# Use pandas to find the number of unique values in the Ticket column.
```
The ```Ticket``` column has a large number of unique values. As we saw above in our initial exploration of the data, this feature includes a combination of text and numerical data. Therefore, let's use ```value_counts()``` to generate a frequency distribution of the ```Ticket``` values, so we can see whether this data will be useful for our models.
__=>__ Use ```pandas``` to count the number of each unique value in the ```Ticket``` column.
Documentation: http://pandas.pydata.org/pandas-docs/version/0.20.3/generated/pandas.Series.value_counts.html
```
# Use pandas to count the number of each unique Ticket value.
```
## Visualize the Data
Now let's look at two histograms of the ```Fare``` data. In the first, we'll set ```bins=10``` and in the second ```bin=50```. Which one do you find the most helpful? What are you able to tell about the range of fares paid by the passengers from the histograms?
```
fig = plt.figure(figsize=(7,10))
ax = fig.add_subplot(211)
ax.hist(df['Fare'], bins=10, range=(df['Fare'].min(),df['Fare'].max()))
plt.title('Fare Distribution with 10 Bins')
plt.xlabel('Fare')
plt.ylabel('Count of Passengers')
plt.show()
fig = plt.figure(figsize=(7,10))
ax = fig.add_subplot(212)
ax.hist(df['Fare'], bins=50, range=(df['Fare'].min(),df['Fare'].max()))
plt.title('Fare Distribution with 50 Bins')
plt.xlabel('Fare')
plt.ylabel('Count of Passengers')
plt.show()
```
## Data Wrangling
It's important to wrangle your data before building your models, since ```scikit-learn``` cannot process missing values and only accepts numerical data. Outliers should also be dealt with beforehand, since they will negatively impact the performance of most machine learning models.
### Outliers
When examining the histograms of the ```Fare``` data, did you notice any potential outliers? Since there is a relationship between the cost of a ticket and the class the passenger was traveling in, let's look at a box plot of this data to investigate further.
```
f, ax = plt.subplots(figsize=(9,7))
sns.boxplot(x='Pclass', y='Fare', data=df, palette='vlag')
sns.swarmplot(x='Pclass', y='Fare', data=df, size=2, color='0.3')
plt.title('Ticket Cost By Class', size=14)
plt.xlabel('Ticket Class', size=12)
plt.ylabel('Fares', size=12)
plt.show()
```
We can quickly see that there a few first-class fares that are much higher than the others. Let's sort the data set by the ```Fare``` column so we can see the cost of the most expensive tickets.
```
df.sort_values(by='Fare', ascending=False).head(10)
```
Since the ```$512``` fares appear to be outliers, let's replace them with ```$213```, since it is the second highest value and much closer to the other data points.
```
for idx in df.index:
if df.loc[idx].Fare > 500:
df.set_value(idx, 'Fare', 263.0000)
```
### Dealing with Missing Data
When deciding how to handle missing values, it is important to know how prevalent they are in your data. Let's use ```pandas``` to find out how many ```Cabin``` values are missing from our data set.
__=>__ Use ```pandas``` to get the sum of all the null values in the ```Cabin``` column.
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.isnull.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sum.html
```
# Sum the number of null Cabin values.
```
### Deleting a Feature
__=>__ Since most of the ```Cabin``` values are missing, let's use ```pandas``` to drop the column. We will also drop the ```Ticket``` column, since as we saw earlier, it contains of a mix of text and numeric data that doesn't appear to contain any useful information. *HINT: remember to set ```axis=1```.*
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html
https://chrisalbon.com/python/pandas_dropping_column_and_rows.html
```
# Use pandas to drop the Cabin and Ticket columns.
```
### Filling in Missing Data
While the ```Age``` column also contains null values, it is missing far fewer than the ```Cabin``` column, so we will fill those in rather than drop the column. The simplest approach, which we'll use here, is to replace the null values with the mean age of the passengers.
__=>__ First use ```pandas``` to calculate and save the mean age of the passengers. Then replace the null values in the ```Age``` column with that number.
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.mean.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.fillna.html
```
# First, use pandas to find the mean age of the passengers: mean_age
mean_age =
# ...and then fill in the null Age values with mean_age.
# Check that there are no more null values in the Age column.
```
### Save Your Work
...you will need it in a few weeks!
```
import pandas.io.sql as pd_sql
import sqlite3 as sql
# Create a sqlite3 database to store the data.
con = sql.connect('titanic.db')
```
__=>__ Use ```pandas``` to write your ```DataFrame``` to the ```sqlite``` database.
Documenation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
```
# Use pandas to save your dataframe to a sqlite database name 'training_data'.
```
|
github_jupyter
|
On April 15, 1912, the RMS Titanic sunk after hitting an iceberg, killing 1502 out of 2224 passengers and crew about during her maiden voyage. While luck did play a role in the survival of some passengers, certain groups—women and childen—were much more likely to survive.
In this tutorial you will gain experience using ```pandas``` to visualize and clean data from the Titanic's passenger manifest. Afterwards it is also recommended that you complete the "additional_wrangling_challenge" notebook, which expands on these skills and is included in this course's repository.
**Be sure to read the README before you begin!** In addition, you may also find these resources helpful:
https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/
https://chrisalbon.com/python/data_wrangling/pandas_dataframe_descriptive_stats/
*This tutorial is based on the Kaggle Competition, "Predicting Survival Aboard the Titanic" https://www.kaggle.com/c/titanic*
## Load the Data
The file we'll be exploring today, ```train.csv```, represents a subset of the Titanic's passenger manifest. It was downloaded when you cloned X503's GitHub repo and is located in the ```Data``` folder. The remaining data from the passenger manifest is in ```test.csv```, which is saved in the same folder and we'll use later on in the Machine Learning course. But for now, let's load the ```train.csv``` file and start exploring the data.
=> Load the ```train.csv``` file into a ```pandas``` ```DataFrame```.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
## Exploring the Data
=> Use ```pandas``` to view the "head" of the file with the first 10 rows.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.head.html
*What did you see? When exploring a new data set, these are some of the first questions you should try to answer.*
* Are there any missing values?
* What kinds of values/numbers/text are there?
* Are the values continuous or categorical?
* Are some variables more sparse than others?
* Are there multiple values in a single column?
#### Summary Statistics
__=>__ Use ```pandas``` to get summary statistics on the numerical fields in the data.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html
*What can we infer from the summary statistics?*
* How many missing values does the ```Age``` column have?
* What percentage of the passengers survived?
* How many passengers traveled in Class 3?
* Are there any outliers in the ```Fare``` column?
__=>__ Use ```pandas``` to get the median of the ```Age``` column.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.median.html
__=>__ Use ```pandas``` to find the number of unique values in the ```Ticket``` column.
Documentation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.nunique.html
The ```Ticket``` column has a large number of unique values. As we saw above in our initial exploration of the data, this feature includes a combination of text and numerical data. Therefore, let's use ```value_counts()``` to generate a frequency distribution of the ```Ticket``` values, so we can see whether this data will be useful for our models.
__=>__ Use ```pandas``` to count the number of each unique value in the ```Ticket``` column.
Documentation: http://pandas.pydata.org/pandas-docs/version/0.20.3/generated/pandas.Series.value_counts.html
## Visualize the Data
Now let's look at two histograms of the ```Fare``` data. In the first, we'll set ```bins=10``` and in the second ```bin=50```. Which one do you find the most helpful? What are you able to tell about the range of fares paid by the passengers from the histograms?
## Data Wrangling
It's important to wrangle your data before building your models, since ```scikit-learn``` cannot process missing values and only accepts numerical data. Outliers should also be dealt with beforehand, since they will negatively impact the performance of most machine learning models.
### Outliers
When examining the histograms of the ```Fare``` data, did you notice any potential outliers? Since there is a relationship between the cost of a ticket and the class the passenger was traveling in, let's look at a box plot of this data to investigate further.
We can quickly see that there a few first-class fares that are much higher than the others. Let's sort the data set by the ```Fare``` column so we can see the cost of the most expensive tickets.
Since the ```$512``` fares appear to be outliers, let's replace them with ```$213```, since it is the second highest value and much closer to the other data points.
### Dealing with Missing Data
When deciding how to handle missing values, it is important to know how prevalent they are in your data. Let's use ```pandas``` to find out how many ```Cabin``` values are missing from our data set.
__=>__ Use ```pandas``` to get the sum of all the null values in the ```Cabin``` column.
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.isnull.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sum.html
### Deleting a Feature
__=>__ Since most of the ```Cabin``` values are missing, let's use ```pandas``` to drop the column. We will also drop the ```Ticket``` column, since as we saw earlier, it contains of a mix of text and numeric data that doesn't appear to contain any useful information. *HINT: remember to set ```axis=1```.*
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html
https://chrisalbon.com/python/pandas_dropping_column_and_rows.html
### Filling in Missing Data
While the ```Age``` column also contains null values, it is missing far fewer than the ```Cabin``` column, so we will fill those in rather than drop the column. The simplest approach, which we'll use here, is to replace the null values with the mean age of the passengers.
__=>__ First use ```pandas``` to calculate and save the mean age of the passengers. Then replace the null values in the ```Age``` column with that number.
Documentation:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.mean.html
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.fillna.html
### Save Your Work
...you will need it in a few weeks!
__=>__ Use ```pandas``` to write your ```DataFrame``` to the ```sqlite``` database.
Documenation: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
| 0.836688 | 0.987142 |
```
%run ../utils.ipynb
from bs4 import BeautifulSoup
import requests
import sys
import time
import pandas as pd
import numpy as np
import urllib.robotparser as urobot
from tqdm import tqdm_notebook as tqdm
import validators
import os
import threading
import logging
import random
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Safari/605.1.15'}
urls = [
"https://www.magazineluiza.com.br",
"https://www.colombo.com.br",
"https://www.amazon.com.br",
"https://www.taqi.com.br",
"https://www.kabum.com.br",
"https://www.ricardoeletro.com.br",
"https://www.cissamagazine.com.br",
"https://www.promobit.com.br",
"https://www.havan.com.br",
"https://www.avenida.com.br"]
#urls = ["https://www.avenida.com.br"]
#to control concurrent executions
LOCK = threading.Lock()
#configures logger to track progress of the threads
logger = logging.getLogger()
logger.setLevel(logging.INFO)
#Class definition of the heuristic_crawler
class heuristic_crawler:
def __init__(self, url):
self.url = url
self.robotParser = getRobot(url) #robot parser to check if a link is valid or not
self.links_list = [] #list of allowed links
self.invalid_links = [] #list of invalid links
self.file_name = set_file_name(url) #name of the files generate by the crawler
def get_links(self):
actual_link = self.url
link_count = 0
number_of_links = 1000
next_links = []
total_links = 0
with LOCK:
print("Starts crawler on: {}".format(self.url))
pbar = tqdm(total=number_of_links)
while (len(self.links_list) < number_of_links):
try:
req = requests.get(actual_link, headers=header)
if(req.status_code == 200):
soup = BeautifulSoup(req.text)
pageLinks = soup.findAll("a", href=True)
for a in pageLinks:
#formata o link na tentativa de obter um link válido
link = format_link(self.url, a["href"])
print(link)
if(link not in next_links and link not in self.links_list):
next_links.append(link)
total_links += 1
#print(link)
#verifica se o link é valido
if(not validators.url(link)):
if(link not in self.invalid_links):
self.invalid_links.append(link)
#adiciona na lista de links do crawler caso seja um link não visitado, válido e que o robots.txt permita
elif((self.robotParser.can_fetch("*", link)) and (link != self.url) and (self.heuristic_check(link))):
#print("{} - {}".format(link_count, link))
self.links_list.append(link)
link_count += 1
pbar.update(1)
if(len(self.links_list) >= number_of_links):
break
except Exception:
if(link not in self.invalid_links):
self.invalid_links.append(link)
finally:
if(len(next_links) < 1 or len(self.links_list) >= number_of_links):
logging.info("****END: {}****".format(self.url))
with LOCK:
#saves the results to a file stats.csv; columns: site,valid_links,invalid_links
content = "{},{},{},{}\n".format(self.url.split(".")[1],len(self.links_list),len(self.invalid_links),total_links)
save_file(content, "./", "stats.csv", mode="a")
pbar.close()
return
actual_link = next_links.pop(0)
#print("Link Atual: {}".format(actual_link))
time.sleep(random.randint(1,5))
#saves the links as csv
def save_as_csv(self):
folders = ["links", "invalid_links"]
for folder in folders:
if not os.path.exists(folder):
os.makedirs(folder)
#saves valid links
ID = np.arange(len(self.links_list))
dictionary = {'id' : ID, 'links' : self.links_list}
df = pd.DataFrame(dictionary)
df.to_csv(('links/' + self.file_name + '.csv'),header=True, index=False, encoding='utf-8')
#saves invalid links
ID = np.arange(len(self.invalid_links))
dictionary = {'id' : ID, 'links' : self.invalid_links}
df = pd.DataFrame(dictionary)
df.to_csv(('invalid_links/' + self.file_name + '.csv'),header=True, index=False, encoding='utf-8')
#save the robots from a url
def save_robot(self):
robot_url = self.url + "/robots.txt"
req = requests.get(robot_url,headers=header)
content = req.text
save_file(content, "robots", (self.file_name + ".txt"))
#verifies if a link passes in the coditions of the heuristic
def heuristic_check(self, link):
KEYWORDS = ["Celular", "celular", "Smartphone",
"smartphone","iphone", "Telefon",
"telefon"]
BADWORDS = ["televenda", "Televenda",
"sac", "carr", "javascript",
"acessorio", "Acessorio"]
result = False
for word in KEYWORDS:
if(word in link):
result = True
for bad_word in BADWORDS:
if(bad_word in link):
result = False
return result
#getters and setters methods
def get_url(self):
return self.url
def set_url(self, url):
self.url = url
def get_links_list(self):
return self.links_list
def set_links_list(self, links):
self.links_list = links
#Saves the links from each site
def save_links(crawler):
crawler = heuristic_crawler(url)
crawler.save_robot()
crawler.get_links()
crawler.save_as_csv()
```
# Parallel saves the links in .csv
```
#configures logger to track progress of the threads
logger = logging.getLogger()
logger.setLevel(logging.INFO)
threads = []
for url in urls:
thread_name = url.split(".")[1]
crawler = heuristic_crawler(url)
thread = threading.Thread(target=save_links, args=(crawler,), name=thread_name)
threads.append(thread)
print("Starts crawler on: {}".format(url))
thread.start()
time.sleep(0.2)
for thread in tqdm(threads):
thread.join()
logging.info("finished thread: {}".format(thread.name))
```
# Saves the links from one site
```
url = urls[5]
crawler = heuristic_crawler(url)
save_links(url)
```
|
github_jupyter
|
%run ../utils.ipynb
from bs4 import BeautifulSoup
import requests
import sys
import time
import pandas as pd
import numpy as np
import urllib.robotparser as urobot
from tqdm import tqdm_notebook as tqdm
import validators
import os
import threading
import logging
import random
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Safari/605.1.15'}
urls = [
"https://www.magazineluiza.com.br",
"https://www.colombo.com.br",
"https://www.amazon.com.br",
"https://www.taqi.com.br",
"https://www.kabum.com.br",
"https://www.ricardoeletro.com.br",
"https://www.cissamagazine.com.br",
"https://www.promobit.com.br",
"https://www.havan.com.br",
"https://www.avenida.com.br"]
#urls = ["https://www.avenida.com.br"]
#to control concurrent executions
LOCK = threading.Lock()
#configures logger to track progress of the threads
logger = logging.getLogger()
logger.setLevel(logging.INFO)
#Class definition of the heuristic_crawler
class heuristic_crawler:
def __init__(self, url):
self.url = url
self.robotParser = getRobot(url) #robot parser to check if a link is valid or not
self.links_list = [] #list of allowed links
self.invalid_links = [] #list of invalid links
self.file_name = set_file_name(url) #name of the files generate by the crawler
def get_links(self):
actual_link = self.url
link_count = 0
number_of_links = 1000
next_links = []
total_links = 0
with LOCK:
print("Starts crawler on: {}".format(self.url))
pbar = tqdm(total=number_of_links)
while (len(self.links_list) < number_of_links):
try:
req = requests.get(actual_link, headers=header)
if(req.status_code == 200):
soup = BeautifulSoup(req.text)
pageLinks = soup.findAll("a", href=True)
for a in pageLinks:
#formata o link na tentativa de obter um link válido
link = format_link(self.url, a["href"])
print(link)
if(link not in next_links and link not in self.links_list):
next_links.append(link)
total_links += 1
#print(link)
#verifica se o link é valido
if(not validators.url(link)):
if(link not in self.invalid_links):
self.invalid_links.append(link)
#adiciona na lista de links do crawler caso seja um link não visitado, válido e que o robots.txt permita
elif((self.robotParser.can_fetch("*", link)) and (link != self.url) and (self.heuristic_check(link))):
#print("{} - {}".format(link_count, link))
self.links_list.append(link)
link_count += 1
pbar.update(1)
if(len(self.links_list) >= number_of_links):
break
except Exception:
if(link not in self.invalid_links):
self.invalid_links.append(link)
finally:
if(len(next_links) < 1 or len(self.links_list) >= number_of_links):
logging.info("****END: {}****".format(self.url))
with LOCK:
#saves the results to a file stats.csv; columns: site,valid_links,invalid_links
content = "{},{},{},{}\n".format(self.url.split(".")[1],len(self.links_list),len(self.invalid_links),total_links)
save_file(content, "./", "stats.csv", mode="a")
pbar.close()
return
actual_link = next_links.pop(0)
#print("Link Atual: {}".format(actual_link))
time.sleep(random.randint(1,5))
#saves the links as csv
def save_as_csv(self):
folders = ["links", "invalid_links"]
for folder in folders:
if not os.path.exists(folder):
os.makedirs(folder)
#saves valid links
ID = np.arange(len(self.links_list))
dictionary = {'id' : ID, 'links' : self.links_list}
df = pd.DataFrame(dictionary)
df.to_csv(('links/' + self.file_name + '.csv'),header=True, index=False, encoding='utf-8')
#saves invalid links
ID = np.arange(len(self.invalid_links))
dictionary = {'id' : ID, 'links' : self.invalid_links}
df = pd.DataFrame(dictionary)
df.to_csv(('invalid_links/' + self.file_name + '.csv'),header=True, index=False, encoding='utf-8')
#save the robots from a url
def save_robot(self):
robot_url = self.url + "/robots.txt"
req = requests.get(robot_url,headers=header)
content = req.text
save_file(content, "robots", (self.file_name + ".txt"))
#verifies if a link passes in the coditions of the heuristic
def heuristic_check(self, link):
KEYWORDS = ["Celular", "celular", "Smartphone",
"smartphone","iphone", "Telefon",
"telefon"]
BADWORDS = ["televenda", "Televenda",
"sac", "carr", "javascript",
"acessorio", "Acessorio"]
result = False
for word in KEYWORDS:
if(word in link):
result = True
for bad_word in BADWORDS:
if(bad_word in link):
result = False
return result
#getters and setters methods
def get_url(self):
return self.url
def set_url(self, url):
self.url = url
def get_links_list(self):
return self.links_list
def set_links_list(self, links):
self.links_list = links
#Saves the links from each site
def save_links(crawler):
crawler = heuristic_crawler(url)
crawler.save_robot()
crawler.get_links()
crawler.save_as_csv()
#configures logger to track progress of the threads
logger = logging.getLogger()
logger.setLevel(logging.INFO)
threads = []
for url in urls:
thread_name = url.split(".")[1]
crawler = heuristic_crawler(url)
thread = threading.Thread(target=save_links, args=(crawler,), name=thread_name)
threads.append(thread)
print("Starts crawler on: {}".format(url))
thread.start()
time.sleep(0.2)
for thread in tqdm(threads):
thread.join()
logging.info("finished thread: {}".format(thread.name))
url = urls[5]
crawler = heuristic_crawler(url)
save_links(url)
| 0.165323 | 0.247919 |
# Women Techsters Fellowship 2021
## Group 3 Mini-project
### Proposal for NLP Search Engine APP
# Project Goals, Scope and Functionality
# Problem
Virtual assistants powered by artificial intelligence have become a commmon feature of the big-data revolution.
Cortana, Google assistant, and Siri are some of the most popular assistants available on mobile devices and PCs. These assistants which primarily take natural voice as the input have been instrumental for children, people with disabilites and all users in general.
While the available ones have excellent utility, gaps are still available to build specific and tailor made assitants because the "one-size-fits-all" does not always apply.
In this project we sought to find out how Search Engines with text to speech and speech to text functionalities work and then we sought to build our very own search engine complete with a voice capturing capability, display ability as well as a user interface.
The search engine used Speech to text capabilities and displayed the same using Tkinter, a Graphical User Interface available on Python hence the name Tkinter_search Engine.
## Goals
OVERALL OBJECTIVE
The objective is to have an NLP search engine that outputs results for any search. The search engine will be enabled to recognize speech and text effciently with regard to grammar and different accents.
SPECIFIC OBJECTIVES
1. Understand NLP work
2. Build a text to speech functionality
3. Build a speech to text functionality
4. Define and process Keywords using NLP python package
5. Visualize results through a GUI on Tkinter
## Development method
While we have a limited timeframe, we will adopt the agile approach where we will consult users and team members at sprint/cycle to ger new insights and ideas into improving our product. The agile method is illustrated below.

## Tools
1. Jupyter notebook - code,writeup
2. NLP
3. Python Libraries such as tkinter, speech recognition, Google Text to speech among others.
4. Youtube videos
5. Data science sites- geeks4geeks, Kaggle, codecademy, datacamp, analytics vidhya
## Prototype screenshots
### Product 1

### Product 2

## References
1. https://www.kaggle.com/
2. https://www.analyticsvidhya.com/
3. https://www.datacamp.com/
4. https://www.youtube.com/watch?v=IWDC9vcBIFQ
# #WomenWhoCode
|
github_jupyter
|
# Women Techsters Fellowship 2021
## Group 3 Mini-project
### Proposal for NLP Search Engine APP
# Project Goals, Scope and Functionality
# Problem
Virtual assistants powered by artificial intelligence have become a commmon feature of the big-data revolution.
Cortana, Google assistant, and Siri are some of the most popular assistants available on mobile devices and PCs. These assistants which primarily take natural voice as the input have been instrumental for children, people with disabilites and all users in general.
While the available ones have excellent utility, gaps are still available to build specific and tailor made assitants because the "one-size-fits-all" does not always apply.
In this project we sought to find out how Search Engines with text to speech and speech to text functionalities work and then we sought to build our very own search engine complete with a voice capturing capability, display ability as well as a user interface.
The search engine used Speech to text capabilities and displayed the same using Tkinter, a Graphical User Interface available on Python hence the name Tkinter_search Engine.
## Goals
OVERALL OBJECTIVE
The objective is to have an NLP search engine that outputs results for any search. The search engine will be enabled to recognize speech and text effciently with regard to grammar and different accents.
SPECIFIC OBJECTIVES
1. Understand NLP work
2. Build a text to speech functionality
3. Build a speech to text functionality
4. Define and process Keywords using NLP python package
5. Visualize results through a GUI on Tkinter
## Development method
While we have a limited timeframe, we will adopt the agile approach where we will consult users and team members at sprint/cycle to ger new insights and ideas into improving our product. The agile method is illustrated below.

## Tools
1. Jupyter notebook - code,writeup
2. NLP
3. Python Libraries such as tkinter, speech recognition, Google Text to speech among others.
4. Youtube videos
5. Data science sites- geeks4geeks, Kaggle, codecademy, datacamp, analytics vidhya
## Prototype screenshots
### Product 1

### Product 2

## References
1. https://www.kaggle.com/
2. https://www.analyticsvidhya.com/
3. https://www.datacamp.com/
4. https://www.youtube.com/watch?v=IWDC9vcBIFQ
# #WomenWhoCode
| 0.575349 | 0.810104 |
## Step 3 - Climate Analysis and Exploration
You are now ready to use Python and SQLAlchemy to do basic climate analysis and data exploration on your new weather station tables. All of the following analysis should be completed using SQLAlchemy ORM queries, Pandas, and Matplotlib.
* Create a Jupyter Notebook file called `climate_analysis.ipynb` and use it to complete your climate analysis and data exporation.
* Choose a start date and end date for your trip. Make sure that your vacation range is approximately 3-15 days total.
* Use SQLAlchemy `create_engine` to connect to your sqlite database.
* Use SQLAlchemy `automap_base()` to reflect your tables into classes and save a reference to those classes called `Station` and `Measurement`.
### Precipitation Analysis
* Design a query to retrieve the last 12 months of precipitation data.
* Select only the `date` and `prcp` values.
* Load the query results into a Pandas DataFrame and set the index to the date column.
* Plot the results using the DataFrame `plot` method.
* Use Pandas to print the summary statistics for the precipitation data.
### Station Analysis
* Design a query to calculate the total number of stations.
* Design a query to find the most active stations.
* List the stations and observation counts in descending order
* Which station has the highest number of observations?
* Design a query to retrieve the last 12 months of temperature observation data (tobs).
* Filter by the station with the highest number of observations.
* Plot the results as a histogram with `bins=12`.
### Temperature Analysis
* Write a function called `calc_temps` that will accept a start date and end date in the format `%Y-%m-%d` and return the minimum, average, and maximum temperatures for that range of dates.
* Use the `calc_temps` function to calculate the min, avg, and max temperatures for your trip using the matching dates from the previous year (i.e. use "2017-01-01" if your trip start date was "2018-01-01")
* Plot the min, avg, and max temperature from your previous query as a bar chart.
* Use the average temperature as the bar height.
* Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr).
```
# Dependencies and boilerplate
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sqlalchemy import Column, Float, Integer, String
import sqlalchemy
from sqlalchemy.ext.automap import automap_base
from sqlalchemy.sql.expression import func
import datetime as dt
# # Use a Session to test the ORM classes for each table
from sqlalchemy import create_engine, MetaData
from sqlalchemy.orm import Session
# Create an engine to a database file called "hawaii.sqlite"
engine = create_engine('sqlite:///hawaii.sqlite')
# Use SQLAlchemy automap_base() to reflect your tables into
# classes and save a reference to those classes called Station and Measurement.
Base = automap_base()
Base.prepare(engine, reflect=True)
Base.classes.keys()
# Assign the measurement and station classes to a variable called `Measurement` and 'Station'
Measurement = Base.classes.measurement
Station = Base.classes.station
# Create a session
session = Session(engine)
#Check to see if all of the data was loaded and as what type
meas = session.query(Measurement).all()
len(meas), type(meas)
# Display the row's columns and data in dictionary format
first_row = session.query(Measurement).first()
first_row.__dict__
stat = session.query(Station).all()
len(stat), type(stat)
#Precipitation Analysis
precipitation= session.query(Measurement.date, Measurement.prcp)\
.filter(Measurement.date >= (dt.date.today() - dt.timedelta(days=365))).all()
type(precipitation), len(precipitation)
# convert into dataframe
prec_df=pd.DataFrame(precipitation).set_index('date')
prec_df.head()
#Plot the results using the DataFrame plot method.
x = range(len(prec_df.index.values))
y = prec_df["prcp"]
plt.bar(x, y,width=20)
labels= prec_df.index.values
plt.xticks(range(len(prec_df.index.values)), labels, rotation=45)
plt.title("Precipitation")
plt.legend(prec_df)
plt.locator_params(nbins=12, axis= "x")
plt.ylabel('Inches')
sns.set()
plt.show()
# Design a query to calculate the total number of stations.
stat = session.query(Station).all()
len(stat)
# Design a query to find the most active stations.
# List the stations and observation counts in descending order
# Which station has the highest number of observations?
precipitation2= session.query(Measurement.station,func.sum(Measurement.tobs))\
.group_by(Measurement.station).order_by(func.sum(Measurement.tobs).desc()).all()
precipitation2
# Design a query to retrieve the last 12 months of temperature observation data (tobs).
# Filter by the station with the highest number of observations.
# Plot the results as a histogram with `bins=12`.
tobs_12_months= session.query(Measurement.date, Measurement.tobs)\
.filter(Measurement.station == "USC00519397").filter(Measurement.date >= (dt.date.today()\
- dt.timedelta(days=365))).all()
tobs_12_months
type(tobs_12_months)
tobs12 = pd.DataFrame(tobs_12_months).set_index('date')
tobs12.head()
# Plot the results as a histogram with `bins=12`.
bins = 12
x= tobs12['tobs']
plt.hist(x,bins, color='orange')
plt.legend(tobs12)
plt.ylabel('Number of Observations')
plt.show()
# Write a function called calc_temps that will accept a start date and end date in the
# format %Y-%m-%d and return the minimum, average, and maximum temperatures for that range of dates.
start_date='2017-03-15'
end_date='2017-03-31'
def calc_temps (start, end):
min_temp = session.query(func.min(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
avg_temp = session.query(func.avg(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
max_temp = session.query(func.max(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
return min_temp, max_temp, avg_temp
temperature = calc_temps(start_date, end_date)
temperature
#Plot the min, avg, and max temperature from your previous query as a bar chart.
#Use the average temperature as the bar height.
#Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr).
avgb= temperature[2][0][0]
maxb= temperature[1][0][0]
minb= temperature[0][0][0]
tbs= maxb-minb
tbs
plt.bar(maxb,height=avgb, yerr=tbs, color='orange')
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.title('Trip Avg Temp')
plt.ylabel('Temp (F)')
plt.show()
```
|
github_jupyter
|
# Dependencies and boilerplate
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sqlalchemy import Column, Float, Integer, String
import sqlalchemy
from sqlalchemy.ext.automap import automap_base
from sqlalchemy.sql.expression import func
import datetime as dt
# # Use a Session to test the ORM classes for each table
from sqlalchemy import create_engine, MetaData
from sqlalchemy.orm import Session
# Create an engine to a database file called "hawaii.sqlite"
engine = create_engine('sqlite:///hawaii.sqlite')
# Use SQLAlchemy automap_base() to reflect your tables into
# classes and save a reference to those classes called Station and Measurement.
Base = automap_base()
Base.prepare(engine, reflect=True)
Base.classes.keys()
# Assign the measurement and station classes to a variable called `Measurement` and 'Station'
Measurement = Base.classes.measurement
Station = Base.classes.station
# Create a session
session = Session(engine)
#Check to see if all of the data was loaded and as what type
meas = session.query(Measurement).all()
len(meas), type(meas)
# Display the row's columns and data in dictionary format
first_row = session.query(Measurement).first()
first_row.__dict__
stat = session.query(Station).all()
len(stat), type(stat)
#Precipitation Analysis
precipitation= session.query(Measurement.date, Measurement.prcp)\
.filter(Measurement.date >= (dt.date.today() - dt.timedelta(days=365))).all()
type(precipitation), len(precipitation)
# convert into dataframe
prec_df=pd.DataFrame(precipitation).set_index('date')
prec_df.head()
#Plot the results using the DataFrame plot method.
x = range(len(prec_df.index.values))
y = prec_df["prcp"]
plt.bar(x, y,width=20)
labels= prec_df.index.values
plt.xticks(range(len(prec_df.index.values)), labels, rotation=45)
plt.title("Precipitation")
plt.legend(prec_df)
plt.locator_params(nbins=12, axis= "x")
plt.ylabel('Inches')
sns.set()
plt.show()
# Design a query to calculate the total number of stations.
stat = session.query(Station).all()
len(stat)
# Design a query to find the most active stations.
# List the stations and observation counts in descending order
# Which station has the highest number of observations?
precipitation2= session.query(Measurement.station,func.sum(Measurement.tobs))\
.group_by(Measurement.station).order_by(func.sum(Measurement.tobs).desc()).all()
precipitation2
# Design a query to retrieve the last 12 months of temperature observation data (tobs).
# Filter by the station with the highest number of observations.
# Plot the results as a histogram with `bins=12`.
tobs_12_months= session.query(Measurement.date, Measurement.tobs)\
.filter(Measurement.station == "USC00519397").filter(Measurement.date >= (dt.date.today()\
- dt.timedelta(days=365))).all()
tobs_12_months
type(tobs_12_months)
tobs12 = pd.DataFrame(tobs_12_months).set_index('date')
tobs12.head()
# Plot the results as a histogram with `bins=12`.
bins = 12
x= tobs12['tobs']
plt.hist(x,bins, color='orange')
plt.legend(tobs12)
plt.ylabel('Number of Observations')
plt.show()
# Write a function called calc_temps that will accept a start date and end date in the
# format %Y-%m-%d and return the minimum, average, and maximum temperatures for that range of dates.
start_date='2017-03-15'
end_date='2017-03-31'
def calc_temps (start, end):
min_temp = session.query(func.min(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
avg_temp = session.query(func.avg(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
max_temp = session.query(func.max(Measurement.tobs)).filter(Measurement.date >= start).filter(Measurement.date <= end).all()
return min_temp, max_temp, avg_temp
temperature = calc_temps(start_date, end_date)
temperature
#Plot the min, avg, and max temperature from your previous query as a bar chart.
#Use the average temperature as the bar height.
#Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr).
avgb= temperature[2][0][0]
maxb= temperature[1][0][0]
minb= temperature[0][0][0]
tbs= maxb-minb
tbs
plt.bar(maxb,height=avgb, yerr=tbs, color='orange')
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.title('Trip Avg Temp')
plt.ylabel('Temp (F)')
plt.show()
| 0.793746 | 0.980337 |
imports - numpy just to read data
```
import numpy as np
import pandas as pd
from keras.layers import Dense
from keras.models import Sequential
from keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
```
parameter 'patience' is the number of epochs to proceed without improvement
```
early_stopping_monitor = EarlyStopping(patience=3)
```
read the data so we can find the number of nodes in the input layer (n_cols)
```
data_file = 'hourly_wages.csv'
```
use pandas to examine the file since we had a problem loading into numpy
```
df = pd.read_csv(data_file)
df = df.reindex(np.random.permutation(df.index))
df.columns
df.plot(x='education_yrs', y='wage_per_hour',kind='scatter')
```
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corr.html
```
df.corr()
df.describe()
```
first row was a text headers which numpy could not handle.
had to add "skiprows=1" parameter to get the loadtxt method to work
```
# predictors = np.loadtxt(data_file, delimiter=',', skiprows=1)
df.info()
df.union = df.union.astype('bool')
df.female = df.female.astype('bool')
df.marr = df.marr.astype('bool')
df.south = df.south.astype('bool')
df.manufacturing = df.manufacturing.astype('bool')
df.construction = df.construction.astype('bool')
df.columns
df = (df-df.mean())/df.std()
predictors = df.drop(['union','education_yrs','experience_yrs',
'age', 'female', 'marr', 'south', 'manufacturing','construction',
], axis=1)
# predictors = df.drop(['wage_per_hour','union','education_yrs','experience_yrs',
# 'age', 'female', 'marr', 'south', 'manufacturing','construction',
# ], axis=1)
df.head()
```
based on correlation, use only education_yrs and age for features
```
df.plot()
target = df.wage_per_hour
n_cols = predictors.shape[1]
n_cols
```
Sequential model - each layer connected only to the previous layer
```
from keras import optimizers
adam = optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model = Sequential()
```
build up model layer at a time - 'Dense' layers are fully connected
```
model.add(Dense(100, activation='relu', input_shape = (n_cols,)))
model.add(Dense(100, activation='relu'))
model.add(Dense(1))
```
dump out the model configuration
```
model.get_config()
```
'adam' is a good, general purpose optimizer that adjusts the learning rate as it goes
```
model.compile(optimizer=adam, loss='mean_squared_error', metrics=['accuracy'])
# model.compile(optimizer=adam, loss='mean_squared_error')
# model.compile(optimizer='adam', loss='mean_squared_error')
```
need to split out the target column from the data
```
model.fit(predictors, target, validation_split=0.3, epochs=20)
model.fit(predictors, target, validation_split=0.3, epochs=20,
callbacks = [early_stopping_monitor])
```
this model is not doing very well. Maybe need to look at scaling the data.
Find the mean of each feature and divide by standard deviation.
```
from keras.models import load_model
model.save('model_file.h5')
my_model = load_model('model_file.h5')
```
|
github_jupyter
|
import numpy as np
import pandas as pd
from keras.layers import Dense
from keras.models import Sequential
from keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
early_stopping_monitor = EarlyStopping(patience=3)
data_file = 'hourly_wages.csv'
df = pd.read_csv(data_file)
df = df.reindex(np.random.permutation(df.index))
df.columns
df.plot(x='education_yrs', y='wage_per_hour',kind='scatter')
df.corr()
df.describe()
# predictors = np.loadtxt(data_file, delimiter=',', skiprows=1)
df.info()
df.union = df.union.astype('bool')
df.female = df.female.astype('bool')
df.marr = df.marr.astype('bool')
df.south = df.south.astype('bool')
df.manufacturing = df.manufacturing.astype('bool')
df.construction = df.construction.astype('bool')
df.columns
df = (df-df.mean())/df.std()
predictors = df.drop(['union','education_yrs','experience_yrs',
'age', 'female', 'marr', 'south', 'manufacturing','construction',
], axis=1)
# predictors = df.drop(['wage_per_hour','union','education_yrs','experience_yrs',
# 'age', 'female', 'marr', 'south', 'manufacturing','construction',
# ], axis=1)
df.head()
df.plot()
target = df.wage_per_hour
n_cols = predictors.shape[1]
n_cols
from keras import optimizers
adam = optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model = Sequential()
model.add(Dense(100, activation='relu', input_shape = (n_cols,)))
model.add(Dense(100, activation='relu'))
model.add(Dense(1))
model.get_config()
model.compile(optimizer=adam, loss='mean_squared_error', metrics=['accuracy'])
# model.compile(optimizer=adam, loss='mean_squared_error')
# model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(predictors, target, validation_split=0.3, epochs=20)
model.fit(predictors, target, validation_split=0.3, epochs=20,
callbacks = [early_stopping_monitor])
from keras.models import load_model
model.save('model_file.h5')
my_model = load_model('model_file.h5')
| 0.751648 | 0.893402 |
# IMDB movie review sentiment classification with CNNs
In this notebook, we'll train a convolutional neural network (CNN, ConvNet) for sentiment classification using Keras. Keras version $\ge$ 2 is required. This notebook is largely based on the [`imdb_cnn.py` script](https://github.com/keras-team/keras/blob/master/examples/imdb_cnn.py) in the Keras examples.
First, the needed imports. Keras tells us which backend (Theano, Tensorflow, CNTK) it will be using.
```
%matplotlib inline
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D
from keras.datasets import imdb
from distutils.version import LooseVersion as LV
from keras import __version__
from keras import backend as K
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
print('Using Keras version:', __version__, 'backend:', K.backend())
assert(LV(__version__) >= LV("2.0.0"))
```
## IMDB data set
Next we'll load the IMDB data set. First time we may have to download the data, which can take a while.
The dataset contains 50000 movies reviews from the Internet Movie Database, split into 25000 reviews for training and 25000 reviews for testing. Half of the reviews are positive (1) and half are negative (0).
The dataset has already been preprocessed, and each word has been replaced by an integer index.
The reviews are thus represented as varying-length sequences of integers.
(Word indices begin at "3", as "1" is used to mark the start of a review and "2" represents all out-of-vocabulary words. "0" will be used later to pad shorter reviews to a fixed size.)
```
# number of most-frequent words to use
nb_words = 10000
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=nb_words)
word_index = imdb.get_word_index()
print('IMDB data loaded:')
print('x_train:', x_train.shape)
print('y_train:', y_train.shape, 'positive:', np.sum(y_train))
print('x_test:', x_test.shape)
print('y_test:', y_test.shape, 'positive:', np.sum(y_test))
```
The first movie review in the training set:
```
print("First review in the training set:\n", x_train[0], "length:", len(x_train[0]), "class:", y_train[0])
```
As a sanity check, we can convert the review back to text:
```
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in x_train[0]])
print(decoded_review)
```
The training data consists of lists of word indices of varying length. Let's inspect the distribution of the length of the training movie reviews:
```
l = []
for i in range(len(x_train)):
l.append(len(x_train[i]))
plt.figure()
plt.title('Length of training reviews')
plt.hist(l,100);
```
Let's truncate the reviews to `maxlen` first words, and pad any shorter reviews with zeros at the end.
```
maxlen = 400
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen,
padding='post', truncating='post')
x_test = sequence.pad_sequences(x_test, maxlen=maxlen,
padding='post', truncating='post')
print('x_train:', x_train.shape)
print('x_test:', x_test.shape)
print("First review in the training set:\n", x_train[0], 'length:', len(x_train[0]))
l = []
for i in range(len(x_train)):
l.append(len(x_train[i]))
plt.figure()
plt.title('Length of training reviews')
plt.hist(l,100);
```
## Initialization
Let's create a 1D CNN model that has one (or optionally two) convolutional layers with *relu* as the activation function, followed by a *Dense* layer. The first layer in the network is an *Embedding* layer that converts integer indices to dense vectors of length `embedding_dims`. Dropout is applied after embedding and dense layers, and max pooling after the convolutional layers. The output layer contains a single neuron and *sigmoid* non-linearity to match the binary groundtruth (`y_train`).
Finally, we `compile()` the model, using *binary crossentropy* as the loss function and [*RMSprop*](https://keras.io/optimizers/#rmsprop) as the optimizer.
```
# model parameters:
embedding_dims = 50
cnn_filters = 100
cnn_kernel_size = 5
dense_hidden_dims = 200
print('Build model...')
model = Sequential()
model.add(Embedding(nb_words,
embedding_dims,
input_length=maxlen))
model.add(Dropout(0.2))
## uncomment these if you want to use two convolutional layers:
#model.add(Conv1D(cnn_filters, cnn_kernel_size,
# padding='valid', activation='relu'))
#model.add(MaxPooling1D(5))
model.add(Conv1D(cnn_filters, cnn_kernel_size,
padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(dense_hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
print(model.summary())
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
```
## Learning
Now we are ready to train our model. An *epoch* means one pass through the whole training data. Note also that we are using a fraction of the training data as our validation set.
```
%%time
epochs = 10
validation_split = 0.2
history = model.fit(x_train, y_train, batch_size=128,
epochs=epochs,
validation_split=validation_split)
```
Let's plot the data to see how the training progressed. A big gap between training and validation accuracies would suggest overfitting.
```
plt.figure(figsize=(5,3))
plt.plot(history.epoch,history.history['loss'], label='training')
plt.plot(history.epoch,history.history['val_loss'], label='validation')
plt.title('loss')
plt.legend(loc='best')
plt.figure(figsize=(5,3))
plt.plot(history.epoch,history.history['acc'], label='training')
plt.plot(history.epoch,history.history['val_acc'], label='validation')
plt.title('accuracy')
plt.legend(loc='best');
```
## Inference
For a better measure of the quality of the model, let's see the model accuracy for the test data.
```
scores = model.evaluate(x_test, y_test, verbose=2)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
```
We can also use the learned model to predict sentiments for new reviews:
```
myreviewtext = 'this movie was the worst i have ever seen and the actors were horrible'
#myreviewtext = 'this movie is great and i madly love the plot from beginning to end'
myreview = np.zeros((1,maxlen), dtype=int)
myreview[0, 0] = 1
for i, w in enumerate(myreviewtext.split()):
if w in word_index and word_index[w]+3<nb_words:
myreview[0, i+1] = word_index[w]+3
else:
print('word not in vocabulary:', w)
myreview[0, i+1] = 2
print(myreview, "shape:", myreview.shape)
p = model.predict(myreview, batch_size=1) # values close to "0" mean negative, close to "1" positive
print('Predicted sentiment: {:.10f}'.format(p[0,0]))
```
# Model tuning
Modify the model. Try to improve the classification accuracy on the test set, or experiment with the effects of different parameters.
You can also consult the Keras documentation at https://keras.io/.
|
github_jupyter
|
%matplotlib inline
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D
from keras.datasets import imdb
from distutils.version import LooseVersion as LV
from keras import __version__
from keras import backend as K
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
print('Using Keras version:', __version__, 'backend:', K.backend())
assert(LV(__version__) >= LV("2.0.0"))
# number of most-frequent words to use
nb_words = 10000
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=nb_words)
word_index = imdb.get_word_index()
print('IMDB data loaded:')
print('x_train:', x_train.shape)
print('y_train:', y_train.shape, 'positive:', np.sum(y_train))
print('x_test:', x_test.shape)
print('y_test:', y_test.shape, 'positive:', np.sum(y_test))
print("First review in the training set:\n", x_train[0], "length:", len(x_train[0]), "class:", y_train[0])
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in x_train[0]])
print(decoded_review)
l = []
for i in range(len(x_train)):
l.append(len(x_train[i]))
plt.figure()
plt.title('Length of training reviews')
plt.hist(l,100);
maxlen = 400
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen,
padding='post', truncating='post')
x_test = sequence.pad_sequences(x_test, maxlen=maxlen,
padding='post', truncating='post')
print('x_train:', x_train.shape)
print('x_test:', x_test.shape)
print("First review in the training set:\n", x_train[0], 'length:', len(x_train[0]))
l = []
for i in range(len(x_train)):
l.append(len(x_train[i]))
plt.figure()
plt.title('Length of training reviews')
plt.hist(l,100);
# model parameters:
embedding_dims = 50
cnn_filters = 100
cnn_kernel_size = 5
dense_hidden_dims = 200
print('Build model...')
model = Sequential()
model.add(Embedding(nb_words,
embedding_dims,
input_length=maxlen))
model.add(Dropout(0.2))
## uncomment these if you want to use two convolutional layers:
#model.add(Conv1D(cnn_filters, cnn_kernel_size,
# padding='valid', activation='relu'))
#model.add(MaxPooling1D(5))
model.add(Conv1D(cnn_filters, cnn_kernel_size,
padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(dense_hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
print(model.summary())
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
%%time
epochs = 10
validation_split = 0.2
history = model.fit(x_train, y_train, batch_size=128,
epochs=epochs,
validation_split=validation_split)
plt.figure(figsize=(5,3))
plt.plot(history.epoch,history.history['loss'], label='training')
plt.plot(history.epoch,history.history['val_loss'], label='validation')
plt.title('loss')
plt.legend(loc='best')
plt.figure(figsize=(5,3))
plt.plot(history.epoch,history.history['acc'], label='training')
plt.plot(history.epoch,history.history['val_acc'], label='validation')
plt.title('accuracy')
plt.legend(loc='best');
scores = model.evaluate(x_test, y_test, verbose=2)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
myreviewtext = 'this movie was the worst i have ever seen and the actors were horrible'
#myreviewtext = 'this movie is great and i madly love the plot from beginning to end'
myreview = np.zeros((1,maxlen), dtype=int)
myreview[0, 0] = 1
for i, w in enumerate(myreviewtext.split()):
if w in word_index and word_index[w]+3<nb_words:
myreview[0, i+1] = word_index[w]+3
else:
print('word not in vocabulary:', w)
myreview[0, i+1] = 2
print(myreview, "shape:", myreview.shape)
p = model.predict(myreview, batch_size=1) # values close to "0" mean negative, close to "1" positive
print('Predicted sentiment: {:.10f}'.format(p[0,0]))
| 0.725357 | 0.978508 |
SICP 习题 (2.10)解题总结: 区间除法中除于零的问题
SICP 习题 2.10 要求我们处理区间除法运算中除于零的问题。
题中讲到一个专业程序员Ben Bitdiddle看了Alyssa的工作后提出了除于零的问题,大家留意一下这个叫Ben的人,后面会不断出现这个人,只要是这个人提到的事情一般是对的,他的角色定位是个计算机牛人,不过是办公室经常能看到的那种牛人,后面还有更牛的。
对于区间运算的除于零的问题,处理起来也比较简单,只需要判断除数是不是为零,除数为零就报错。对于一个区间来讲,所谓为零就是这个区间横跨0,再直接一点讲就是起点是负数,终点是正数。
理解了以后写代码就很简单了:
```
(define (div-interval x y)
(if (< (* (upper-bound y) (lower-bound y)) 0)
(error "div-interval" "Div 0: the input y is ~s" y))
(mul-interval x
(make-interval (/ 1.0 (upper-bound y))
(/ 1.0 (lower-bound y)))))
```
好,解题结束。
```
(define (make-interval a b)
(cons a b))
(define (lower-bound x)
(car x))
(define (upper-bound x)
(cdr x))
(define (add-interval x y)
(make-interval (+ (lower-bound x) (lower-bound y))
(+ (upper-bound x) (upper-bound y))))
(define (sub-interval x y)
(make-interval (- (lower-bound x) (lower-bound y))
(- (upper-bound x) (upper-bound y))))
(define (mul-interval x y)
(if (> (lower-bound x) 0)
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (upper-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (upper-bound y)) (* (lower-bound x) (upper-bound y)))))
(if (> (upper-bound x) 0)
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (upper-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))))
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y))))) )))
(define (div-interval x y)
(if (< (* (upper-bound y) (lower-bound y)) 0)
(error "div-interval" "Div 0: the input y is ~s" y))
(mul-interval x
(make-interval (/ 1.0 (upper-bound y))
(/ 1.0 (lower-bound y)))))
(define (interval-width interval)
(/ (- (upper-bound interval) (lower-bound interval)) 2))
(define (start-test-2-10)
(div-interval (make-interval 1 2) (make-interval -1 3)))
(start-test-2-10)
```
|
github_jupyter
|
(define (div-interval x y)
(if (< (* (upper-bound y) (lower-bound y)) 0)
(error "div-interval" "Div 0: the input y is ~s" y))
(mul-interval x
(make-interval (/ 1.0 (upper-bound y))
(/ 1.0 (lower-bound y)))))
(define (make-interval a b)
(cons a b))
(define (lower-bound x)
(car x))
(define (upper-bound x)
(cdr x))
(define (add-interval x y)
(make-interval (+ (lower-bound x) (lower-bound y))
(+ (upper-bound x) (upper-bound y))))
(define (sub-interval x y)
(make-interval (- (lower-bound x) (lower-bound y))
(- (upper-bound x) (upper-bound y))))
(define (mul-interval x y)
(if (> (lower-bound x) 0)
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (upper-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (upper-bound y)) (* (lower-bound x) (upper-bound y)))))
(if (> (upper-bound x) 0)
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (upper-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))))
(if (> (lower-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y)) (* (upper-bound x) (upper-bound y)))
(if (> (upper-bound y) 0)
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y)))
(make-interval (* (lower-bound x) (lower-bound y))
(* (upper-bound x) (upper-bound y))))) )))
(define (div-interval x y)
(if (< (* (upper-bound y) (lower-bound y)) 0)
(error "div-interval" "Div 0: the input y is ~s" y))
(mul-interval x
(make-interval (/ 1.0 (upper-bound y))
(/ 1.0 (lower-bound y)))))
(define (interval-width interval)
(/ (- (upper-bound interval) (lower-bound interval)) 2))
(define (start-test-2-10)
(div-interval (make-interval 1 2) (make-interval -1 3)))
(start-test-2-10)
| 0.098177 | 0.90599 |
<a href="https://colab.research.google.com/github/ajeyalingam/Pneumonia-Detection/blob/main/pneumonia_detection_old.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
### About Dataset
* The dataset consists of training data, validation data, and testing data.
* The training data consists of 5,216 chest x-ray images with 3,875 images shown to have pneumonia and 1,341 images shown to be normal.
* The validation data is relatively small with only 16 images with 8 cases of pneumonia and 8 normal cases.
* The testing data consists of 624 images split between 390 pneumonia cases and 234 normal cases.
### Import libraries
```
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Input, layers
from keras.preprocessing.image import ImageDataGenerator, load_img
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.core import Activation, Dropout, Flatten, Dense
from keras import backend as K
from keras import layers
import os
import numpy as np
import pandas as np
from random import randint
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
```
### Load the data
```
from google.colab import drive
drive.mount('/content/drive')
main_dir = '/content/drive/MyDrive/Data/'
train_data_dir = main_dir + "train/"
validation_data_dir = main_dir + "val/"
test_data_dir = main_dir + "test/"
print("Working Directory Contents:", os.listdir(main_dir))
train_n = train_data_dir+'NORMAL/'
train_p = train_data_dir+'PNEUMONIA/'
print("length of cases in training set:",len(os.listdir(train_p)) + len(os.listdir(train_n)))
print("length of pneumonia cases in training set:",len(os.listdir(train_p)))
print("length of normal cases in training set:",len(os.listdir(train_n)))
```
The actual sizes of the photos are so high that I set them to size 180x180.
```
img_height, img_width = 180, 180
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
nb_train_samples = 5216
nb_validation_samples = 16
epochs = 12
batch_size = 16
```
### Upload images
```
# Performing Image Augmentation to have more data samples
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
val_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = val_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
# Show some images after data augmentation
image_batch, label_batch = next(iter(train_generator))
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10, 10))
for n in range(15):
ax = plt.subplot(5, 5, n + 1)
plt.imshow(image_batch[n])
if label_batch[n]:
plt.title("PNEUMONIA")
else:
plt.title("NORMAL")
plt.axis("off")
show_batch(image_batch, label_batch)
```
### Build the CNN
```
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape, padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
```
### Train the model
```
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
!cat /proc/cpuinfo
```
### Fit the model
```
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
# evaluate the model
scores = model.evaluate_generator(test_generator)
print("Loss of the model: %.2f"%(scores[0]))
print("Test Accuracy: %.2f%%"%(scores[1] * 100))
prediction = model.predict(test_generator)
print(prediction[0])
if (prediction[0] > 0.5):
print("PNEUMONIA")
else:
print("NORMAL")
```
|
github_jupyter
|
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Input, layers
from keras.preprocessing.image import ImageDataGenerator, load_img
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers.core import Activation, Dropout, Flatten, Dense
from keras import backend as K
from keras import layers
import os
import numpy as np
import pandas as np
from random import randint
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
from google.colab import drive
drive.mount('/content/drive')
main_dir = '/content/drive/MyDrive/Data/'
train_data_dir = main_dir + "train/"
validation_data_dir = main_dir + "val/"
test_data_dir = main_dir + "test/"
print("Working Directory Contents:", os.listdir(main_dir))
train_n = train_data_dir+'NORMAL/'
train_p = train_data_dir+'PNEUMONIA/'
print("length of cases in training set:",len(os.listdir(train_p)) + len(os.listdir(train_n)))
print("length of pneumonia cases in training set:",len(os.listdir(train_p)))
print("length of normal cases in training set:",len(os.listdir(train_n)))
img_height, img_width = 180, 180
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
nb_train_samples = 5216
nb_validation_samples = 16
epochs = 12
batch_size = 16
# Performing Image Augmentation to have more data samples
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
val_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
validation_generator = val_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
# Show some images after data augmentation
image_batch, label_batch = next(iter(train_generator))
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10, 10))
for n in range(15):
ax = plt.subplot(5, 5, n + 1)
plt.imshow(image_batch[n])
if label_batch[n]:
plt.title("PNEUMONIA")
else:
plt.title("NORMAL")
plt.axis("off")
show_batch(image_batch, label_batch)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape, padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
!cat /proc/cpuinfo
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
# evaluate the model
scores = model.evaluate_generator(test_generator)
print("Loss of the model: %.2f"%(scores[0]))
print("Test Accuracy: %.2f%%"%(scores[1] * 100))
prediction = model.predict(test_generator)
print(prediction[0])
if (prediction[0] > 0.5):
print("PNEUMONIA")
else:
print("NORMAL")
| 0.450601 | 0.911967 |
# When To Invest?
I was wondering how import is timing when making an investment particularly if you have a longer holding period.
We are going to use the data from the the Federal Reserve Bank of St. Louis website more commonly known as FRED. There is a handy function available in the pandas module that will allow us to get the data directly and put it into a DataFrame.
```
%matplotlib inline
import datetime as dt
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import numpy as np
import pandas as pd
import datetime as dt
import json
import os
import urllib.request
import pandas as pd
import sp500
def get_fed(data_id: str, start_date: str=None, end_date: str=None) -> pd.DataFrame:
"""
get_fed can be a model for other json requests. The req string can be built
to suit other api purposes. The creation of the DataFrame may require only a
change in the name of the column from observations to something appropriate
Parameters
----------
data_id: str
The name of the data item from the FRED. Example SP500 for the S&P 500.
start_date: str
Data start date in the format of %Y-%m-%d, e.g. 2015-12-31. The default
start date is 10 years prior to the current day.
end_date: str
Data end date in the format of %Y-%m-%d, e.g. 2015-12-31. The default
end date is today.
Returns
-------
df: pandas DataFrame
"""
filename = data_id + '.csv'
if start_date is None:
start_date = (dt.datetime.today() - dt.timedelta(days=3650)).strftime('%Y-%m-%d')
if end_date is None:
end_date = dt.datetime.today().strftime('%Y-%m-%d')
if not os.path.exists(filename) or stale_file(filename, 7):
ACCESS_KEY = sp500.fred_api
req = urllib.request.urlopen('https://api.stlouisfed.org/fred/series/observations'
+ '?series_id=' + data_id
+ '&observation_start=' + start_date
+ '&observation_end=' + end_date
+ '&api_key=' + ACCESS_KEY
+ '&file_type=json').read().decode('utf-8')
df = pd.DataFrame(json.loads(req)['observations'])
df['value'] = pd.to_numeric(df['value'], errors='coerce') # 'value' is an object
df = df.set_index(pd.to_datetime(df['date']))
df.rename(columns={'value' : data_id}, inplace=True)
df.to_csv(data_id + '.csv')
return df[[data_id]]
else:
return(pd.read_csv(data_id+'.csv', index_col=0, parse_dates=True))
def stale_file(filename: str, age_limit: int) -> bool:
"""
Checks to see if a file is stale
Parameters
----------
filename: str
age_limit: int
The maximum age in days before a file is considered stale
Returns
-------
True if the file is stale or False if it isn't
"""
m_date = dt.datetime.fromtimestamp(os.stat('SP500.csv')
.st_mtime).strftime('%Y%m%d')
today = dt.datetime.today().strftime('%Y%m%d')
if (dt.datetime.today()
- dt.datetime.fromtimestamp(os.stat(filename).st_mtime)).days > age_limit:
return True
data_id, start_date = 'SP500', '1999-12-31'
df = get_fed(data_id, start_date)
df.head()
df[['SP500']].plot(figsize=(14,6))
plt.title('S&P 500 Index')
plt.ylabel('Index Level')
plt.xlabel('Year');
```
We have 10 years of daily data. Now we want to get the month end index levels and from those we will calculate calendar monthly returns.
```
df['return'] = np.log(df[data_id]) - np.log(df[data_id].shift(1))
monthly = df[['return']].resample('M').sum()
monthly.plot(figsize=(14,6))
plt.title('S&P 500 - Monthly Returns')
plt.ylabel('Return')
plt.xlabel('Year');
```
## Rolling 1 Year Return or When Should I Buy?
This seems to imply that most of the time you can buy the S&P 500 and in a year, you will still have a postive return. We can calculate the proportion of positive 1 year holding periods to negative 1 year holding periods.
```
df['1 yr return'] = df['return'].resample('D').sum().rolling(250).sum()
df['1 yr return'].plot(figsize=(14,6))
plt.title('S&P 500 - 12 Month Rolling Return')
plt.ylabel('Return')
plt.xlabel('Year');
for ret in range(12):
print('Exp return: {:0.1%} Probability: {:0.2%}'.format(ret/100, len(df[df['1 yr return'] > ret/100]) /
(len(df[df['1 yr return'] > ret/100]) + len(df[df['1 yr return'] < ret/100]))))
```
# Calendar Study
## Months
Are there any patterns to the monthly returns? Does earnings season have an impact? Does the year end have an impact? Is there window dressing and tax loss effects? By studying the month-end returns we hope to answer these questions and uncover any other patterns.
Using the pivot_table command we change our monthly table that had each month and year represented in a row into one that has each month represented by row and each year represented by a column. The values in the table correspond to the monthly return.
```
pivoted = monthly.pivot_table('return', index=monthly.index.month, columns=monthly.index.year)
pivoted
```
In the chart below, each line represents a year and the months are represented by the x-axis.
```
pivoted.plot(legend=False, figsize=(15,6))
plt.title('S&P 500 - Monthly Returns Each Year')
plt.ylabel('Return')
plt.xlabel('Month');
```
Using the describe() function we can calculate summary statistics for each month.
```
by_month = pivoted.transpose().describe()
by_month.rename(columns={1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr', 5: 'May',
6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct',
11: 'Nov', 12: 'Dec'}, inplace=True)
by_month
```
There appear to be some definite calendar effects based on the average returns we see for each month. Whether or not these are significant statistically using a p-value such as 2.0 or 2.5 is unlikely given the standard deviation, but we can determine if they are signifcantly different above or below zero.
**Some obervations:**
- January is the only onth with a decidely negative return. This could be the result of unwinding year-end window dressing as evidenced by the positive return in December.
- July has the highest monthly return followed by March.
- It appears the months following quarter-ends: April, July, and October (although less in October) enjoy strong positive monthly returns.
- During the actual earnings season which starts 40 days after the quarter end or May for March, August for April, and November for September returns are less than 1%.
## Days
Are there any day of week patterns in the S&P 500 returns. Is there evidence of the week-end effect prinicpally short covering?
Using the pivot_table() function we convert our df dataframe that had each row represent a specific day into one that represents a single day of the week and each column is a week in the time period. The values are the average return for each day over 52 weeks, e.g. date 0/date 1 is the average of Monday return of the first week of the year for 11 years.
```
# pivoted_d = df.pivot_table('return', index=df.index.dat, columns=df.index.month)
# df.index.weekday_name also works but the rows are sorted alphabetically
pivoted_d = df.pivot_table('return', index=df.index.weekday, columns=df.index.week)
pivoted_d
pivoted_d.plot(legend=False, figsize=(12,6), alpha=0.3)
plt.title('S&P 500 - Daily Returns Each Week');
```
From the plot above it appears that day 1 or Tuesday has the greatest variability. Day 4 or Friday has the largest positive return. Using the describe command on the data we can calculate some basic statistics about each of the days.
```
by_days = pivoted_d.transpose().describe()
by_days.rename(columns={0: 'Mon', 1: 'Tue', 2: 'Wed', 3: 'Thu', 4: 'Fri'}, inplace=True)
by_days
```
**Some observations:**
- Friday does indeed have the highest daily average return at 4.5 bps, but it has the lowest standard deviation at 37 bps.
- Tuesday shares the highest daily average return with Friday, but it also has the largest standard deviation at 57 bps.
- Wednesday is generally pretty flat with a virtual 0 average return.
- Only Monday has a negative daily average return at 2 bps.
<br><br>
How significant is Friday's performance? We can check that by running a simulation which we will do later.
|
github_jupyter
|
%matplotlib inline
import datetime as dt
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import numpy as np
import pandas as pd
import datetime as dt
import json
import os
import urllib.request
import pandas as pd
import sp500
def get_fed(data_id: str, start_date: str=None, end_date: str=None) -> pd.DataFrame:
"""
get_fed can be a model for other json requests. The req string can be built
to suit other api purposes. The creation of the DataFrame may require only a
change in the name of the column from observations to something appropriate
Parameters
----------
data_id: str
The name of the data item from the FRED. Example SP500 for the S&P 500.
start_date: str
Data start date in the format of %Y-%m-%d, e.g. 2015-12-31. The default
start date is 10 years prior to the current day.
end_date: str
Data end date in the format of %Y-%m-%d, e.g. 2015-12-31. The default
end date is today.
Returns
-------
df: pandas DataFrame
"""
filename = data_id + '.csv'
if start_date is None:
start_date = (dt.datetime.today() - dt.timedelta(days=3650)).strftime('%Y-%m-%d')
if end_date is None:
end_date = dt.datetime.today().strftime('%Y-%m-%d')
if not os.path.exists(filename) or stale_file(filename, 7):
ACCESS_KEY = sp500.fred_api
req = urllib.request.urlopen('https://api.stlouisfed.org/fred/series/observations'
+ '?series_id=' + data_id
+ '&observation_start=' + start_date
+ '&observation_end=' + end_date
+ '&api_key=' + ACCESS_KEY
+ '&file_type=json').read().decode('utf-8')
df = pd.DataFrame(json.loads(req)['observations'])
df['value'] = pd.to_numeric(df['value'], errors='coerce') # 'value' is an object
df = df.set_index(pd.to_datetime(df['date']))
df.rename(columns={'value' : data_id}, inplace=True)
df.to_csv(data_id + '.csv')
return df[[data_id]]
else:
return(pd.read_csv(data_id+'.csv', index_col=0, parse_dates=True))
def stale_file(filename: str, age_limit: int) -> bool:
"""
Checks to see if a file is stale
Parameters
----------
filename: str
age_limit: int
The maximum age in days before a file is considered stale
Returns
-------
True if the file is stale or False if it isn't
"""
m_date = dt.datetime.fromtimestamp(os.stat('SP500.csv')
.st_mtime).strftime('%Y%m%d')
today = dt.datetime.today().strftime('%Y%m%d')
if (dt.datetime.today()
- dt.datetime.fromtimestamp(os.stat(filename).st_mtime)).days > age_limit:
return True
data_id, start_date = 'SP500', '1999-12-31'
df = get_fed(data_id, start_date)
df.head()
df[['SP500']].plot(figsize=(14,6))
plt.title('S&P 500 Index')
plt.ylabel('Index Level')
plt.xlabel('Year');
df['return'] = np.log(df[data_id]) - np.log(df[data_id].shift(1))
monthly = df[['return']].resample('M').sum()
monthly.plot(figsize=(14,6))
plt.title('S&P 500 - Monthly Returns')
plt.ylabel('Return')
plt.xlabel('Year');
df['1 yr return'] = df['return'].resample('D').sum().rolling(250).sum()
df['1 yr return'].plot(figsize=(14,6))
plt.title('S&P 500 - 12 Month Rolling Return')
plt.ylabel('Return')
plt.xlabel('Year');
for ret in range(12):
print('Exp return: {:0.1%} Probability: {:0.2%}'.format(ret/100, len(df[df['1 yr return'] > ret/100]) /
(len(df[df['1 yr return'] > ret/100]) + len(df[df['1 yr return'] < ret/100]))))
pivoted = monthly.pivot_table('return', index=monthly.index.month, columns=monthly.index.year)
pivoted
pivoted.plot(legend=False, figsize=(15,6))
plt.title('S&P 500 - Monthly Returns Each Year')
plt.ylabel('Return')
plt.xlabel('Month');
by_month = pivoted.transpose().describe()
by_month.rename(columns={1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr', 5: 'May',
6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct',
11: 'Nov', 12: 'Dec'}, inplace=True)
by_month
# pivoted_d = df.pivot_table('return', index=df.index.dat, columns=df.index.month)
# df.index.weekday_name also works but the rows are sorted alphabetically
pivoted_d = df.pivot_table('return', index=df.index.weekday, columns=df.index.week)
pivoted_d
pivoted_d.plot(legend=False, figsize=(12,6), alpha=0.3)
plt.title('S&P 500 - Daily Returns Each Week');
by_days = pivoted_d.transpose().describe()
by_days.rename(columns={0: 'Mon', 1: 'Tue', 2: 'Wed', 3: 'Thu', 4: 'Fri'}, inplace=True)
by_days
| 0.759136 | 0.90291 |
## Basic training functionality
```
from fastai.basic_train import *
from fastai.gen_doc.nbdoc import *
from fastai.vision import *
from fastai.distributed import *
```
[`basic_train`](/basic_train.html#basic_train) wraps together the data (in a [`DataBunch`](/basic_data.html#DataBunch) object) with a PyTorch model to define a [`Learner`](/basic_train.html#Learner) object. Here the basic training loop is defined for the [`fit`](/basic_train.html#fit) method. The [`Learner`](/basic_train.html#Learner) object is the entry point of most of the [`Callback`](/callback.html#Callback) objects that will customize this training loop in different ways. Some of the most commonly used customizations are available through the [`train`](/train.html#train) module, notably:
- [`Learner.lr_find`](/train.html#lr_find) will launch an LR range test that will help you select a good learning rate.
- [`Learner.fit_one_cycle`](/train.html#fit_one_cycle) will launch a training using the 1cycle policy to help you train your model faster.
- [`Learner.to_fp16`](/train.html#to_fp16) will convert your model to half precision and help you launch a training in mixed precision.
```
show_doc(Learner, title_level=2)
```
The main purpose of [`Learner`](/basic_train.html#Learner) is to train `model` using [`Learner.fit`](/basic_train.html#Learner.fit). After every epoch, all *metrics* will be printed and also made available to callbacks.
The default weight decay will be `wd`, which will be handled using the method from [Fixing Weight Decay Regularization in Adam](https://arxiv.org/abs/1711.05101) if `true_wd` is set (otherwise it's L2 regularization). If `true_wd` is set it will affect all optimizers, not only Adam. If `bn_wd` is `False`, then weight decay will be removed from batchnorm layers, as recommended in [Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour](https://arxiv.org/abs/1706.02677). If `train_bn`, batchnorm layer learnable params are trained even for frozen layer groups.
To use [discriminative layer training](#Discriminative-layer-training), pass a list of [`nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) as `layer_groups`; each [`nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) will be used to customize the optimization of the corresponding layer group.
If `path` is provided, all the model files created will be saved in `path`/`model_dir`; if not, then they will be saved in `data.path`/`model_dir`.
You can pass a list of [`callback`](/callback.html#callback)s that you have already created, or (more commonly) simply pass a list of callback functions to `callback_fns` and each function will be called (passing `self`) on object initialization, with the results stored as callback objects. For a walk-through, see the [training overview](/training.html) page. You may also want to use an [application](applications.html) specific model. For example, if you are dealing with a vision dataset, here the MNIST, you might want to use the [`cnn_learner`](/vision.learner.html#cnn_learner) method:
```
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
```
### Model fitting methods
```
show_doc(Learner.lr_find)
```
Runs the learning rate finder defined in [`LRFinder`](/callbacks.lr_finder.html#LRFinder), as discussed in [Cyclical Learning Rates for Training Neural Networks](https://arxiv.org/abs/1506.01186).
```
learn.lr_find()
learn.recorder.plot()
show_doc(Learner.fit)
```
Uses [discriminative layer training](#Discriminative-layer-training) if multiple learning rates or weight decay values are passed. To control training behaviour, use the [`callback`](/callback.html#callback) system or one or more of the pre-defined [`callbacks`](/callbacks.html#callbacks).
```
learn.fit(1)
show_doc(Learner.fit_one_cycle)
```
Use cycle length `cyc_len`, a per cycle maximal learning rate `max_lr`, momentum `moms`, division factor `div_factor`, weight decay `wd`, and optional callbacks [`callbacks`](/callbacks.html#callbacks). Uses the [`OneCycleScheduler`](/callbacks.one_cycle.html#OneCycleScheduler) callback. Please refer to [What is 1-cycle](/callbacks.one_cycle.html#What-is-1cycle?) for a conceptual background of 1-cycle training policy and more technical details on what do the method's arguments do.
```
learn.fit_one_cycle(1)
```
### See results
```
show_doc(Learner.predict)
```
`predict` can be used to get a single prediction from the trained learner on one specific piece of data you are interested in.
```
learn.data.train_ds[0]
```
Each element of the dataset is a tuple, where the first element is the data itself, while the second element is the target label. So to get the data, we need to index one more time.
```
data = learn.data.train_ds[0][0]
data
pred = learn.predict(data)
pred
```
The first two elements of the tuple are, respectively, the predicted class and label. Label here is essentially an internal representation of each class, since class name is a string and cannot be used in computation. To check what each label corresponds to, run:
```
learn.data.classes
```
So category 0 is 3 while category 1 is 7.
```
probs = pred[2]
```
The last element in the tuple is the predicted probabilities. For a categorization dataset, the number of probabilities returned is the same as the number of classes; `probs[i]` is the probability that the `item` belongs to `learn.data.classes[i]`.
```
learn.data.valid_ds[0][0]
```
You could always check yourself if the probabilities given make sense.
```
show_doc(Learner.get_preds)
```
It will run inference using the learner on all the data in the `ds_type` dataset and return the predictions; if `n_batch` is not specified, it will run the predictions on the default batch size. If `with_loss`, it will also return the loss on each prediction.
Here is how you check the default batch size.
```
learn.data.batch_size
preds = learn.get_preds()
preds
```
The first element of the tuple is a tensor that contains all the predictions.
```
preds[0]
```
While the second element of the tuple is a tensor that contains all the target labels.
```
preds[1]
preds[1][0]
```
For more details about what each number mean, refer to the documentation of [`predict`](/basic_train.html#predict).
Since [`get_preds`](/basic_train.html#get_preds) gets predictions on all the data in the `ds_type` dataset, here the number of predictions will be equal to the number of data in the validation dataset.
```
len(learn.data.valid_ds)
len(preds[0]), len(preds[1])
```
To get predictions on the entire training dataset, simply set the `ds_type` argument accordingly.
```
learn.get_preds(ds_type=DatasetType.Train)
```
To also get prediction loss along with the predictions and the targets, set `with_loss=True` in the arguments.
```
learn.get_preds(with_loss=True)
```
Note that the third tensor in the output tuple contains the losses.
```
show_doc(Learner.validate)
```
Return the calculated loss and the metrics of the current model on the given data loader `dl`. The default data loader `dl` is the validation dataloader.
You can check the default metrics of the learner using:
```
str(learn.metrics)
learn.validate()
learn.validate(learn.data.valid_dl)
learn.validate(learn.data.train_dl)
show_doc(Learner.show_results)
```
Note that the text number on the top is the ground truth, or the target label, the one in the middle is the prediction, while the image number on the bottom is the image data itself.
```
learn.show_results()
learn.show_results(ds_type=DatasetType.Train)
show_doc(Learner.pred_batch)
```
Note that the number of predictions given equals to the batch size.
```
learn.data.batch_size
preds = learn.pred_batch()
len(preds)
```
Since the total number of predictions is too large, we will only look at a part of them.
```
preds[:10]
item = learn.data.train_ds[0][0]
item
batch = learn.data.one_item(item)
batch
learn.pred_batch(batch=batch)
show_doc(Learner.interpret, full_name='interpret')
jekyll_note('This function only works in the vision application.')
```
For more details, refer to [ClassificationInterpretation](/vision.learner.html#ClassificationInterpretation)
### Model summary
```
show_doc(Learner.summary)
```
### Test time augmentation
```
show_doc(Learner.TTA, full_name = 'TTA')
```
Applies Test Time Augmentation to `learn` on the dataset `ds_type`. We take the average of our regular predictions (with a weight `beta`) with the average of predictions obtained through augmented versions of the training set (with a weight `1-beta`). The transforms decided for the training set are applied with a few changes `scale` controls the scale for zoom (which isn't random), the cropping isn't random but we make sure to get the four corners of the image. Flipping isn't random but applied once on each of those corner images (so that makes 8 augmented versions total).
### Gradient clipping
```
show_doc(Learner.clip_grad)
```
### Mixed precision training
```
show_doc(Learner.to_fp16)
```
Uses the [`MixedPrecision`](/callbacks.fp16.html#MixedPrecision) callback to train in mixed precision (i.e. forward and backward passes using fp16, with weight updates using fp32), using all [NVIDIA recommendations](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html) for ensuring speed and accuracy.
```
show_doc(Learner.to_fp32)
```
### Distributed training
If you want to use ditributed training or [`torch.nn.DataParallel`](https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel) these will directly wrap the model for you.
```
show_doc(Learner.to_distributed, full_name='to_distributed')
show_doc(Learner.to_parallel, full_name='to_parallel')
```
### Discriminative layer training
When fitting a model you can pass a list of learning rates (and/or weight decay amounts), which will apply a different rate to each *layer group* (i.e. the parameters of each module in `self.layer_groups`). See the [Universal Language Model Fine-tuning for Text Classification](https://arxiv.org/abs/1801.06146) paper for details and experimental results in NLP (we also frequently use them successfully in computer vision, but have not published a paper on this topic yet). When working with a [`Learner`](/basic_train.html#Learner) on which you've called `split`, you can set hyperparameters in four ways:
1. `param = [val1, val2 ..., valn]` (n = number of layer groups)
2. `param = val`
3. `param = slice(start,end)`
4. `param = slice(end)`
If we chose to set it in way 1, we must specify a number of values exactly equal to the number of layer groups. If we chose to set it in way 2, the chosen value will be repeated for all layer groups. See [`Learner.lr_range`](/basic_train.html#Learner.lr_range) for an explanation of the `slice` syntax).
Here's an example of how to use discriminative learning rates (note that you don't actually need to manually call [`Learner.split`](/basic_train.html#Learner.split) in this case, since fastai uses this exact function as the default split for `resnet18`; this is just to show how to customize it):
```
# creates 3 layer groups
learn.split(lambda m: (m[0][6], m[1]))
# only randomly initialized head now trainable
learn.freeze()
learn.fit_one_cycle(1)
# all layers now trainable
learn.unfreeze()
# optionally, separate LR and WD for each group
learn.fit_one_cycle(1, max_lr=(1e-4, 1e-3, 1e-2), wd=(1e-4,1e-4,1e-1))
show_doc(Learner.lr_range)
```
Rather than manually setting an LR for every group, it's often easier to use [`Learner.lr_range`](/basic_train.html#Learner.lr_range). This is a convenience method that returns one learning rate for each layer group. If you pass `slice(start,end)` then the first group's learning rate is `start`, the last is `end`, and the remaining are evenly geometrically spaced.
If you pass just `slice(end)` then the last group's learning rate is `end`, and all the other groups are `end/10`. For instance (for our learner that has 3 layer groups):
```
learn.lr_range(slice(1e-5,1e-3)), learn.lr_range(slice(1e-3))
show_doc(Learner.unfreeze)
```
Sets every layer group to *trainable* (i.e. `requires_grad=True`).
```
show_doc(Learner.freeze)
```
Sets every layer group except the last to *untrainable* (i.e. `requires_grad=False`).
What does '**the last layer group**' mean?
In the case of transfer learning, such as `learn = cnn_learner(data, models.resnet18, metrics=error_rate)`, `learn.model`will print out two large groups of layers: (0) Sequential and (1) Sequental in the following structure. We can consider the last conv layer as the break line between the two groups.
```
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
...
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten()
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25)
(4): Linear(in_features=1024, out_features=512, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
(8): Linear(in_features=512, out_features=12, bias=True)
)
)
```
`learn.freeze` freezes the first group and keeps the second or last group free to train, including multiple layers inside (this is why calling it 'group'), as you can see in `learn.summary()` output. How to read the table below, please see [model summary docs](/callbacks.hooks.html#model_summary).
```
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
...
...
...
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
AdaptiveAvgPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
AdaptiveMaxPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
Flatten [1, 1024] 0 False
______________________________________________________________________
BatchNorm1d [1, 1024] 2,048 True
______________________________________________________________________
Dropout [1, 1024] 0 False
______________________________________________________________________
Linear [1, 512] 524,800 True
______________________________________________________________________
ReLU [1, 512] 0 False
______________________________________________________________________
BatchNorm1d [1, 512] 1,024 True
______________________________________________________________________
Dropout [1, 512] 0 False
______________________________________________________________________
Linear [1, 12] 6,156 True
______________________________________________________________________
Total params: 11,710,540
Total trainable params: 543,628
Total non-trainable params: 11,166,912
```
```
show_doc(Learner.freeze_to)
```
From above we know what is layer group, but **what exactly does `freeze_to` do behind the scenes**?
The `freeze_to` source code can be understood as the following pseudo-code:
```python
def freeze_to(self, n:int)->None:
for g in self.layer_groups[:n]: freeze
for g in self.layer_groups[n:]: unfreeze
```
In other words, for example, `freeze_to(1)` is to freeze layer group 0 and unfreeze the rest layer groups, and `freeze_to(3)` is to freeze layer groups 0, 1, and 2 but unfreeze the rest layer groups (if there are more layer groups left).
Both `freeze` and `unfreeze` [sources](https://github.com/fastai/fastai/blob/master/fastai/basic_train.py#L216) are defined using `freeze_to`:
- When we say `freeze`, we mean that in the specified layer groups the [`requires_grad`](/torch_core.html#requires_grad) of all layers with weights (except BatchNorm layers) are set `False`, so the layer weights won't be updated during training.
- when we say `unfreeze`, we mean that in the specified layer groups the [`requires_grad`](/torch_core.html#requires_grad) of all layers with weights (except BatchNorm layers) are set `True`, so the layer weights will be updated during training.
```
show_doc(Learner.split)
```
A convenience method that sets `layer_groups` based on the result of [`split_model`](/torch_core.html#split_model). If `split_on` is a function, it calls that function and passes the result to [`split_model`](/torch_core.html#split_model) (see above for example).
### Saving and loading models
Simply call [`Learner.save`](/basic_train.html#Learner.save) and [`Learner.load`](/basic_train.html#Learner.load) to save and load models. Only the parameters are saved, not the actual architecture (so you'll need to create your model in the same way before loading weights back in). Models are saved to the `path`/`model_dir` directory.
```
show_doc(Learner.save)
```
If argument `file` is a pathlib object that's an absolute path, it'll override the default base directory (`learn.path`), otherwise the model will be saved in a file relative to `learn.path`.
```
learn.save("trained_model")
learn.save("trained_model", return_path=True)
show_doc(Learner.load)
```
This method only works after `save` (don't confuse with `export`/[`load_learner`](/basic_train.html#load_learner) pair).
If the `purge` argument is `True` (default) `load` internally calls `purge` with `clear_opt=False` to presever `learn.opt`.
```
learn = learn.load("trained_model")
```
### Deploying your model
When you are ready to put your model in production, export the minimal state of your [`Learner`](/basic_train.html#Learner) with:
```
show_doc(Learner.export)
```
If argument `fname` is a pathlib object that's an absolute path, it'll override the default base directory (`learn.path`), otherwise the model will be saved in a file relative to `learn.path`.
Passing `destroy=True` will destroy the [`Learner`](/basic_train.html#Learner), freeing most of its memory consumption. For specifics see [`Learner.destroy`](/basic_train.html#Learner.destroy).
This method only works with the [`Learner`](/basic_train.html#Learner) whose [`data`](/vision.data.html#vision.data) was created through the [data block API](/data_block.html).
Otherwise, you will have to create a [`Learner`](/basic_train.html#Learner) yourself at inference and load the model with [`Learner.load`](/basic_train.html#Learner.load).
```
learn.export()
learn.export('trained_model.pkl')
path = learn.path
path
show_doc(load_learner)
```
This function only works after `export` (don't confuse with `save`/`load` pair).
The `db_kwargs` will be passed to the call to `databunch` so you can specify a `bs` for the test set, or `num_workers`.
```
learn = load_learner(path)
learn = load_learner(path, 'trained_model.pkl')
```
WARNING: If you used any customized classes when creating your learner, you must first define these classes first before executing [`load_learner`](/basic_train.html#load_learner).
You can find more information and multiple examples in [this tutorial](/tutorial.inference.html).
### Freeing memory
If you want to be able to do more without needing to restart your notebook, the following methods are designed to free memory when it's no longer needed.
Refer to [this tutorial](/tutorial.resources.html) to learn how and when to use these methods.
```
show_doc(Learner.purge)
```
If `learn.path` is read-only, you can set `model_dir` attribute in Learner to a full `libpath` path that is writable (by setting `learn.model_dir` or passing `model_dir` argument in the [`Learner`](/basic_train.html#Learner) constructor).
```
show_doc(Learner.destroy)
```
If you need to free the memory consumed by the [`Learner`](/basic_train.html#Learner) object, call this method.
It can also be automatically invoked through [`Learner.export`](/basic_train.html#Learner.export) via its `destroy=True` argument.
### Other methods
```
show_doc(Learner.init)
```
Initializes all weights (except batchnorm) using function `init`, which will often be from PyTorch's [`nn.init`](https://pytorch.org/docs/stable/nn.html#torch-nn-init) module.
```
show_doc(Learner.mixup)
```
Uses [`MixUpCallback`](/callbacks.mixup.html#MixUpCallback).
```
show_doc(Learner.backward)
show_doc(Learner.create_opt)
```
You generally won't need to call this yourself - it's used to create the [`optim`](https://pytorch.org/docs/stable/optim.html#module-torch.optim) optimizer before fitting the model.
```
show_doc(Learner.dl)
learn.dl()
learn.dl(DatasetType.Train)
show_doc(Recorder, title_level=2)
```
A [`Learner`](/basic_train.html#Learner) creates a [`Recorder`](/basic_train.html#Recorder) object automatically - you do not need to explicitly pass it to `callback_fns` - because other callbacks rely on it being available. It stores the smoothed loss, hyperparameter values, and metrics for each batch, and provides plotting methods for each. Note that [`Learner`](/basic_train.html#Learner) automatically sets an attribute with the snake-cased name of each callback, so you can access this through `Learner.recorder`, as shown below.
### Plotting methods
```
show_doc(Recorder.plot)
```
This is mainly used with the learning rate finder, since it shows a scatterplot of loss vs learning rate.
```
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
learn.lr_find()
learn.recorder.plot()
show_doc(Recorder.plot_losses)
```
Note that validation losses are only calculated once per epoch, whereas training losses are calculated after every batch.
```
learn.fit_one_cycle(5)
learn.recorder.plot_losses()
show_doc(Recorder.plot_lr)
learn.recorder.plot_lr()
learn.recorder.plot_lr(show_moms=True)
show_doc(Recorder.plot_metrics)
```
Note that metrics are only collected at the end of each epoch, so you'll need to train at least two epochs to have anything to show here.
```
learn.recorder.plot_metrics()
```
### Callback methods
You don't call these yourself - they're called by fastai's [`Callback`](/callback.html#Callback) system automatically to enable the class's functionality. Refer to [`Callback`](/callback.html#Callback) for more details.
```
show_doc(Recorder.on_backward_begin)
show_doc(Recorder.on_batch_begin)
show_doc(Recorder.on_epoch_end)
show_doc(Recorder.on_train_begin)
```
### Inner functions
The following functions are used along the way by the [`Recorder`](/basic_train.html#Recorder) or can be called by other callbacks.
```
show_doc(Recorder.add_metric_names)
show_doc(Recorder.format_stats)
```
## Module functions
Generally you'll want to use a [`Learner`](/basic_train.html#Learner) to train your model, since they provide a lot of functionality and make things easier. However, for ultimate flexibility, you can call the same underlying functions that [`Learner`](/basic_train.html#Learner) calls behind the scenes:
```
show_doc(fit)
```
Note that you have to create the [`Optimizer`](https://pytorch.org/docs/stable/optim.html#torch.optim.Optimizer) yourself if you call this function, whereas [`Learn.fit`](/basic_train.html#fit) creates it for you automatically.
```
show_doc(train_epoch)
```
You won't generally need to call this yourself - it's what [`fit`](/basic_train.html#fit) calls for each epoch.
```
show_doc(validate)
```
This is what [`fit`](/basic_train.html#fit) calls after each epoch. You can call it if you want to run inference on a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) manually.
```
show_doc(get_preds)
show_doc(loss_batch)
```
You won't generally need to call this yourself - it's what [`fit`](/basic_train.html#fit) and [`validate`](/basic_train.html#validate) call for each batch. It only does a backward pass if you set `opt`.
## Other classes
```
show_doc(LearnerCallback, title_level=3)
show_doc(RecordOnCPU, title_level=3)
```
## Open This Notebook
<button style="display: flex; align-item: center; padding: 4px 8px; font-size: 14px; font-weight: 700; color: #1976d2; cursor: pointer;" onclick="window.location.href = 'https://console.cloud.google.com/mlengine/notebooks/deploy-notebook?q=download_url%3Dhttps%253A%252F%252Fraw.githubusercontent.com%252Ffastai%252Ffastai%252Fmaster%252Fdocs_src%252Fbasic_train.ipynb';"><img src="https://www.gstatic.com/images/branding/product/1x/cloud_24dp.png" /><span style="line-height: 24px; margin-left: 10px;">Open in GCP Notebooks</span></button>
## Undocumented Methods - Methods moved below this line will intentionally be hidden
```
show_doc(Learner.tta_only)
show_doc(Learner.TTA)
show_doc(RecordOnCPU.on_batch_begin)
```
## New Methods - Please document or move to the undocumented section
|
github_jupyter
|
from fastai.basic_train import *
from fastai.gen_doc.nbdoc import *
from fastai.vision import *
from fastai.distributed import *
show_doc(Learner, title_level=2)
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
show_doc(Learner.lr_find)
learn.lr_find()
learn.recorder.plot()
show_doc(Learner.fit)
learn.fit(1)
show_doc(Learner.fit_one_cycle)
learn.fit_one_cycle(1)
show_doc(Learner.predict)
learn.data.train_ds[0]
data = learn.data.train_ds[0][0]
data
pred = learn.predict(data)
pred
learn.data.classes
probs = pred[2]
learn.data.valid_ds[0][0]
show_doc(Learner.get_preds)
learn.data.batch_size
preds = learn.get_preds()
preds
preds[0]
preds[1]
preds[1][0]
len(learn.data.valid_ds)
len(preds[0]), len(preds[1])
learn.get_preds(ds_type=DatasetType.Train)
learn.get_preds(with_loss=True)
show_doc(Learner.validate)
str(learn.metrics)
learn.validate()
learn.validate(learn.data.valid_dl)
learn.validate(learn.data.train_dl)
show_doc(Learner.show_results)
learn.show_results()
learn.show_results(ds_type=DatasetType.Train)
show_doc(Learner.pred_batch)
learn.data.batch_size
preds = learn.pred_batch()
len(preds)
preds[:10]
item = learn.data.train_ds[0][0]
item
batch = learn.data.one_item(item)
batch
learn.pred_batch(batch=batch)
show_doc(Learner.interpret, full_name='interpret')
jekyll_note('This function only works in the vision application.')
show_doc(Learner.summary)
show_doc(Learner.TTA, full_name = 'TTA')
show_doc(Learner.clip_grad)
show_doc(Learner.to_fp16)
show_doc(Learner.to_fp32)
show_doc(Learner.to_distributed, full_name='to_distributed')
show_doc(Learner.to_parallel, full_name='to_parallel')
# creates 3 layer groups
learn.split(lambda m: (m[0][6], m[1]))
# only randomly initialized head now trainable
learn.freeze()
learn.fit_one_cycle(1)
# all layers now trainable
learn.unfreeze()
# optionally, separate LR and WD for each group
learn.fit_one_cycle(1, max_lr=(1e-4, 1e-3, 1e-2), wd=(1e-4,1e-4,1e-1))
show_doc(Learner.lr_range)
learn.lr_range(slice(1e-5,1e-3)), learn.lr_range(slice(1e-3))
show_doc(Learner.unfreeze)
show_doc(Learner.freeze)
Sequential(
(0): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
...
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(1): Sequential(
(0): AdaptiveConcatPool2d(
(ap): AdaptiveAvgPool2d(output_size=1)
(mp): AdaptiveMaxPool2d(output_size=1)
)
(1): Flatten()
(2): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25)
(4): Linear(in_features=1024, out_features=512, bias=True)
(5): ReLU(inplace)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5)
(8): Linear(in_features=512, out_features=12, bias=True)
)
)
======================================================================
Layer (type) Output Shape Param # Trainable
======================================================================
...
...
...
______________________________________________________________________
Conv2d [1, 512, 4, 4] 2,359,296 False
______________________________________________________________________
BatchNorm2d [1, 512, 4, 4] 1,024 True
______________________________________________________________________
AdaptiveAvgPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
AdaptiveMaxPool2d [1, 512, 1, 1] 0 False
______________________________________________________________________
Flatten [1, 1024] 0 False
______________________________________________________________________
BatchNorm1d [1, 1024] 2,048 True
______________________________________________________________________
Dropout [1, 1024] 0 False
______________________________________________________________________
Linear [1, 512] 524,800 True
______________________________________________________________________
ReLU [1, 512] 0 False
______________________________________________________________________
BatchNorm1d [1, 512] 1,024 True
______________________________________________________________________
Dropout [1, 512] 0 False
______________________________________________________________________
Linear [1, 12] 6,156 True
______________________________________________________________________
Total params: 11,710,540
Total trainable params: 543,628
Total non-trainable params: 11,166,912
show_doc(Learner.freeze_to)
def freeze_to(self, n:int)->None:
for g in self.layer_groups[:n]: freeze
for g in self.layer_groups[n:]: unfreeze
show_doc(Learner.split)
show_doc(Learner.save)
learn.save("trained_model")
learn.save("trained_model", return_path=True)
show_doc(Learner.load)
learn = learn.load("trained_model")
show_doc(Learner.export)
learn.export()
learn.export('trained_model.pkl')
path = learn.path
path
show_doc(load_learner)
learn = load_learner(path)
learn = load_learner(path, 'trained_model.pkl')
show_doc(Learner.purge)
show_doc(Learner.destroy)
show_doc(Learner.init)
show_doc(Learner.mixup)
show_doc(Learner.backward)
show_doc(Learner.create_opt)
show_doc(Learner.dl)
learn.dl()
learn.dl(DatasetType.Train)
show_doc(Recorder, title_level=2)
show_doc(Recorder.plot)
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy)
learn.lr_find()
learn.recorder.plot()
show_doc(Recorder.plot_losses)
learn.fit_one_cycle(5)
learn.recorder.plot_losses()
show_doc(Recorder.plot_lr)
learn.recorder.plot_lr()
learn.recorder.plot_lr(show_moms=True)
show_doc(Recorder.plot_metrics)
learn.recorder.plot_metrics()
show_doc(Recorder.on_backward_begin)
show_doc(Recorder.on_batch_begin)
show_doc(Recorder.on_epoch_end)
show_doc(Recorder.on_train_begin)
show_doc(Recorder.add_metric_names)
show_doc(Recorder.format_stats)
show_doc(fit)
show_doc(train_epoch)
show_doc(validate)
show_doc(get_preds)
show_doc(loss_batch)
show_doc(LearnerCallback, title_level=3)
show_doc(RecordOnCPU, title_level=3)
show_doc(Learner.tta_only)
show_doc(Learner.TTA)
show_doc(RecordOnCPU.on_batch_begin)
| 0.792504 | 0.951549 |

# Field Deployment : step by step
## • Step 1 : Mechanical position
### a) Use a bubble level on the mast to ensure the verticality

### b) Move the instrument into a horizontal position and adjust tilt if necessary (instrument must be horizontal when 90 or -90 asked position)
Edit config : http://10.42.0.1:8888/edit/config_hypernets.ini
```
from ipywidgets import HBox, VBox, FloatText, Button
from IPython.display import display
pan = FloatText(description="Pan :")
tilt = FloatText(description="Tilt :")
power = Button(description="Power Relay On")
move = Button(description="Move Pan-Tilt")
@power.on_click
def power_relay_on(_):
from hypernets.scripts.relay_command import set_state_relay
set_state_relay(2, "on")
set_state_relay(3, "on")
set_state_relay(4, "on") # pan-tilt is on relay4 at lov
@move.on_click
def move_pan_tilt(_):
from hypernets.scripts.pan_tilt import move_to
move_to(None, pan.value, tilt.value, verbose=False, wait=False)
display(HBox((VBox((power, move)), VBox((pan, tilt)))))
```
## • Step 2 : Yoctopuce
### (meteo / GPS)
```
from ipywidgets import HBox, Button, Label
from IPython.display import display
gps_show = Button(description="Get GPS location")
meteo = Button(description="Get Meteo Data")
gps_lbl = Label(value="")
meteo_lbl = Label(value="")
@gps_show.on_click
def show_gps_coords(_):
from hypernets.scripts.yocto_gps import get_gps
gps_lbl.value = get_gps(return_float=False)
@meteo.on_click
def show_meteo(_):
from hypernets.scripts.yocto_meteo import get_meteo
v_meteo = " ".join([str(val) + unit for val, unit in get_meteo()])
meteo_lbl.value = v_meteo
display(VBox((HBox((gps_show, gps_lbl)), HBox((meteo, meteo_lbl)))))
```
## • Step 3 : Point to the Sun :
```
from hypernets.scripts.pan_tilt import move_to
from hypernets.scripts.spa.spa_hypernets import spa_from_datetime
from ipywidgets import HBox, Button, Label
from IPython.display import display
# point_gps = Button(description="Point to the sun")
point_datetime = Button(description="Point to the Sun")
# sun_gps_lbl = Label(value="")
sun_datetime_lbl = Label(value="")
@point_datetime.on_click
def point_sun_datetime(_):
azimuth_sun, zenith_sun = spa_from_datetime()
sun_datetime_lbl.value = f"Sun position : {azimuth_sun}, {zenith_sun}"
move_to(None, azimuth_sun, 180-zenith_sun, verbose=False, wait=False)
# display(VBox((HBox((point_gps, sun_gps_lbl)), HBox((point_datetime, sun_datetime_lbl)))))
display((HBox((point_datetime, sun_datetime_lbl))))
```
## • Step 4 : Take a Picture
```
from hypernets.scripts.call_radiometer import take_picture
from IPython.display import Image
from ipywidgets import HBox, Button, Label
from IPython.display import display
power_inst = Button(description="Power on Instrument")
take_pic = Button(description="Take a picture")
output_lbl = Label(value="")
@power_inst.on_click
def power_relay_on(_):
from hypernets.scripts.relay_command import set_state_relay
set_state_relay(2, "on")
@take_pic.on_click
def take_picture_action(_):
# stream = take_picture(return_stream=True)
# pic_sun = Image(stream)
if take_picture():
output_lbl.value = "ok (see http://10.42.0.1:8888/tree/DATA)"
else:
output_lbl.value = "error"
# display(pic_sun)
display(HBox((power_inst, take_pic, output_lbl)))
```
## • Take Spectrum (in progress...)
```
from ipywidgets import Combobox, ToggleButtons, Dropdown, VBox, HBox
radiometer = Dropdown(description='Radiometer', options=['VNIR', 'SWIR', 'BOTH'])
entrance = Dropdown(description='Entrance', options=['Radiance', 'Irradiance', 'Dark'])
IT_Vnir = Dropdown(description='IT_Vnir', options=tuple([0]+[pow(2, i) for i in range(16)]))
IT_Swir = Dropdown(description='IT_Swir', options=tuple([0]+[pow(2, i) for i in range(16)]))
out = HBox([VBox([radiometer, entrance]), VBox([IT_Vnir, IT_Swir])])
display(out)
```
|
github_jupyter
|
from ipywidgets import HBox, VBox, FloatText, Button
from IPython.display import display
pan = FloatText(description="Pan :")
tilt = FloatText(description="Tilt :")
power = Button(description="Power Relay On")
move = Button(description="Move Pan-Tilt")
@power.on_click
def power_relay_on(_):
from hypernets.scripts.relay_command import set_state_relay
set_state_relay(2, "on")
set_state_relay(3, "on")
set_state_relay(4, "on") # pan-tilt is on relay4 at lov
@move.on_click
def move_pan_tilt(_):
from hypernets.scripts.pan_tilt import move_to
move_to(None, pan.value, tilt.value, verbose=False, wait=False)
display(HBox((VBox((power, move)), VBox((pan, tilt)))))
from ipywidgets import HBox, Button, Label
from IPython.display import display
gps_show = Button(description="Get GPS location")
meteo = Button(description="Get Meteo Data")
gps_lbl = Label(value="")
meteo_lbl = Label(value="")
@gps_show.on_click
def show_gps_coords(_):
from hypernets.scripts.yocto_gps import get_gps
gps_lbl.value = get_gps(return_float=False)
@meteo.on_click
def show_meteo(_):
from hypernets.scripts.yocto_meteo import get_meteo
v_meteo = " ".join([str(val) + unit for val, unit in get_meteo()])
meteo_lbl.value = v_meteo
display(VBox((HBox((gps_show, gps_lbl)), HBox((meteo, meteo_lbl)))))
from hypernets.scripts.pan_tilt import move_to
from hypernets.scripts.spa.spa_hypernets import spa_from_datetime
from ipywidgets import HBox, Button, Label
from IPython.display import display
# point_gps = Button(description="Point to the sun")
point_datetime = Button(description="Point to the Sun")
# sun_gps_lbl = Label(value="")
sun_datetime_lbl = Label(value="")
@point_datetime.on_click
def point_sun_datetime(_):
azimuth_sun, zenith_sun = spa_from_datetime()
sun_datetime_lbl.value = f"Sun position : {azimuth_sun}, {zenith_sun}"
move_to(None, azimuth_sun, 180-zenith_sun, verbose=False, wait=False)
# display(VBox((HBox((point_gps, sun_gps_lbl)), HBox((point_datetime, sun_datetime_lbl)))))
display((HBox((point_datetime, sun_datetime_lbl))))
from hypernets.scripts.call_radiometer import take_picture
from IPython.display import Image
from ipywidgets import HBox, Button, Label
from IPython.display import display
power_inst = Button(description="Power on Instrument")
take_pic = Button(description="Take a picture")
output_lbl = Label(value="")
@power_inst.on_click
def power_relay_on(_):
from hypernets.scripts.relay_command import set_state_relay
set_state_relay(2, "on")
@take_pic.on_click
def take_picture_action(_):
# stream = take_picture(return_stream=True)
# pic_sun = Image(stream)
if take_picture():
output_lbl.value = "ok (see http://10.42.0.1:8888/tree/DATA)"
else:
output_lbl.value = "error"
# display(pic_sun)
display(HBox((power_inst, take_pic, output_lbl)))
from ipywidgets import Combobox, ToggleButtons, Dropdown, VBox, HBox
radiometer = Dropdown(description='Radiometer', options=['VNIR', 'SWIR', 'BOTH'])
entrance = Dropdown(description='Entrance', options=['Radiance', 'Irradiance', 'Dark'])
IT_Vnir = Dropdown(description='IT_Vnir', options=tuple([0]+[pow(2, i) for i in range(16)]))
IT_Swir = Dropdown(description='IT_Swir', options=tuple([0]+[pow(2, i) for i in range(16)]))
out = HBox([VBox([radiometer, entrance]), VBox([IT_Vnir, IT_Swir])])
display(out)
| 0.522689 | 0.796649 |
#1. Install Dependencies
First install the libraries needed to execute recipes, this only needs to be done once, then click play.
```
!pip install git+https://github.com/google/starthinker
```
#2. Get Cloud Project ID
To run this recipe [requires a Google Cloud Project](https://github.com/google/starthinker/blob/master/tutorials/cloud_project.md), this only needs to be done once, then click play.
```
CLOUD_PROJECT = 'PASTE PROJECT ID HERE'
print("Cloud Project Set To: %s" % CLOUD_PROJECT)
```
#3. Get Client Credentials
To read and write to various endpoints requires [downloading client credentials](https://github.com/google/starthinker/blob/master/tutorials/cloud_client_installed.md), this only needs to be done once, then click play.
```
CLIENT_CREDENTIALS = 'PASTE CREDENTIALS HERE'
print("Client Credentials Set To: %s" % CLIENT_CREDENTIALS)
```
#4. Enter Federal Reserve Series Data Parameters
Download federal reserve series.
1. Specify the values for a <a href='https://fred.stlouisfed.org/docs/api/fred/series_observations.html' target='_blank'>Fred observations API call</a>.
1. A table will appear in the dataset.
Modify the values below for your use case, can be done multiple times, then click play.
```
FIELDS = {
'auth': 'service', # Credentials used for writing data.
'fred_api_key': '', # 32 character alpha-numeric lowercase string.
'fred_series_id': '', # Series ID to pull data from.
'fred_units': 'lin', # A key that indicates a data value transformation.
'fred_frequency': '', # An optional parameter that indicates a lower frequency to aggregate values to.
'fred_aggregation_method': 'avg', # A key that indicates the aggregation method used for frequency aggregation.
'project': '', # Existing BigQuery project.
'dataset': '', # Existing BigQuery dataset.
}
print("Parameters Set To: %s" % FIELDS)
```
#5. Execute Federal Reserve Series Data
This does NOT need to be modified unless you are changing the recipe, click play.
```
from starthinker.util.configuration import Configuration
from starthinker.util.configuration import commandline_parser
from starthinker.util.configuration import execute
from starthinker.util.recipe import json_set_fields
USER_CREDENTIALS = '/content/user.json'
TASKS = [
{
'fred': {
'auth': 'user',
'api_key': {'field': {'name': 'fred_api_key','kind': 'string','order': 1,'default': '','description': '32 character alpha-numeric lowercase string.'}},
'frequency': {'field': {'name': 'fred_frequency','kind': 'choice','order': 4,'default': '','description': 'An optional parameter that indicates a lower frequency to aggregate values to.','choices': ['','d','w','bw','m','q','sa','a','wef','weth','wew','wetu','wem','wesu','wesa','bwew','bwem']}},
'series': [
{
'series_id': {'field': {'name': 'fred_series_id','kind': 'string','order': 2,'default': '','description': 'Series ID to pull data from.'}},
'units': {'field': {'name': 'fred_units','kind': 'choice','order': 3,'default': 'lin','description': 'A key that indicates a data value transformation.','choices': ['lin','chg','ch1','pch','pc1','pca','cch','cca','log']}},
'aggregation_method': {'field': {'name': 'fred_aggregation_method','kind': 'choice','order': 5,'default': 'avg','description': 'A key that indicates the aggregation method used for frequency aggregation.','choices': ['avg','sum','eop']}}
}
],
'out': {
'bigquery': {
'project': {'field': {'name': 'project','kind': 'string','order': 10,'default': '','description': 'Existing BigQuery project.'}},
'dataset': {'field': {'name': 'dataset','kind': 'string','order': 11,'default': '','description': 'Existing BigQuery dataset.'}}
}
}
}
}
]
json_set_fields(TASKS, FIELDS)
execute(Configuration(project=CLOUD_PROJECT, client=CLIENT_CREDENTIALS, user=USER_CREDENTIALS, verbose=True), TASKS, force=True)
```
|
github_jupyter
|
!pip install git+https://github.com/google/starthinker
CLOUD_PROJECT = 'PASTE PROJECT ID HERE'
print("Cloud Project Set To: %s" % CLOUD_PROJECT)
CLIENT_CREDENTIALS = 'PASTE CREDENTIALS HERE'
print("Client Credentials Set To: %s" % CLIENT_CREDENTIALS)
FIELDS = {
'auth': 'service', # Credentials used for writing data.
'fred_api_key': '', # 32 character alpha-numeric lowercase string.
'fred_series_id': '', # Series ID to pull data from.
'fred_units': 'lin', # A key that indicates a data value transformation.
'fred_frequency': '', # An optional parameter that indicates a lower frequency to aggregate values to.
'fred_aggregation_method': 'avg', # A key that indicates the aggregation method used for frequency aggregation.
'project': '', # Existing BigQuery project.
'dataset': '', # Existing BigQuery dataset.
}
print("Parameters Set To: %s" % FIELDS)
from starthinker.util.configuration import Configuration
from starthinker.util.configuration import commandline_parser
from starthinker.util.configuration import execute
from starthinker.util.recipe import json_set_fields
USER_CREDENTIALS = '/content/user.json'
TASKS = [
{
'fred': {
'auth': 'user',
'api_key': {'field': {'name': 'fred_api_key','kind': 'string','order': 1,'default': '','description': '32 character alpha-numeric lowercase string.'}},
'frequency': {'field': {'name': 'fred_frequency','kind': 'choice','order': 4,'default': '','description': 'An optional parameter that indicates a lower frequency to aggregate values to.','choices': ['','d','w','bw','m','q','sa','a','wef','weth','wew','wetu','wem','wesu','wesa','bwew','bwem']}},
'series': [
{
'series_id': {'field': {'name': 'fred_series_id','kind': 'string','order': 2,'default': '','description': 'Series ID to pull data from.'}},
'units': {'field': {'name': 'fred_units','kind': 'choice','order': 3,'default': 'lin','description': 'A key that indicates a data value transformation.','choices': ['lin','chg','ch1','pch','pc1','pca','cch','cca','log']}},
'aggregation_method': {'field': {'name': 'fred_aggregation_method','kind': 'choice','order': 5,'default': 'avg','description': 'A key that indicates the aggregation method used for frequency aggregation.','choices': ['avg','sum','eop']}}
}
],
'out': {
'bigquery': {
'project': {'field': {'name': 'project','kind': 'string','order': 10,'default': '','description': 'Existing BigQuery project.'}},
'dataset': {'field': {'name': 'dataset','kind': 'string','order': 11,'default': '','description': 'Existing BigQuery dataset.'}}
}
}
}
}
]
json_set_fields(TASKS, FIELDS)
execute(Configuration(project=CLOUD_PROJECT, client=CLIENT_CREDENTIALS, user=USER_CREDENTIALS, verbose=True), TASKS, force=True)
| 0.52342 | 0.783575 |
# Setting up Enviroment
```
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.keras.backend as K
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import plot_model
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input
%matplotlib inline
tf.__version__
tf.test.is_gpu_available()
```
**Using Half Precision FP-16**
```
dtype='float16'
K.set_floatx(dtype)
# default is 1e-7 which is too small for float16. Without adjusting the epsilon, we will get NaN predictions because of divide by zero problems
K.set_epsilon(1e-4)
```
# Getting the Data
```
filenames = os.listdir("train")
print("No of images: ", len(filenames))
category = []
for file in filenames:
if file[0] == 'd':
category.append('1')
if file[0] == 'c':
category.append('0')
data = pd.DataFrame({'Photo': filenames, 'Class': category})
data = data.sample(frac = 1, replace = False, random_state = 0)
data.reset_index(drop = True, inplace = True)
data.head()
```
# Displaying 10 examples
```
fig = plt.figure(figsize = (20,10))
for i in range(10):
img = plt.imread("train/" + data['Photo'].iloc[i])
plt.subplot(2,5,i+1)
plt.imshow(img)
plt.show()
```
# Splitting the Data into Train and Validation
```
train_data = data.iloc[:20000]
valid_data = data.iloc[20000:]
train_data.head()
valid_data.head()
```
# Number of Trainable layers in a model
```
def num_trainable_layers(model):
count = 0
for layer in model.layers:
if layer.trainable == True:
count += 1
print("Number of Trainable Layers: ", count)
```
# Creating the Train and Validation Image Generators
```
train_datagen = ImageDataGenerator(rotation_range = 30,
width_shift_range = 0.25,
height_shift_range = 0.25,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
brightness_range = [0.75, 1.25],
preprocessing_function = preprocess_input)
valid_datagen = ImageDataGenerator(preprocessing_function = preprocess_input)
train_generator = train_datagen.flow_from_dataframe(train_data,
directory = 'train/',
x_col = 'Photo',
y_col = 'Class',
target_size = (299,299),
class_mode = 'binary',
seed = 42,
batch_size = 64)
validation_generator = valid_datagen.flow_from_dataframe(valid_data,
directory = 'train/',
x_col = 'Photo',
y_col = 'Class',
target_size = (299,299),
class_mode = 'binary',
seed = 42,
batch_size = 64)
```
# Using InceptionV3 as the base CNN model
```
inceptionv3 = InceptionV3(include_top = False,
weights = 'imagenet',
input_shape = (299, 299, 3),
pooling = 'avg',
classes = 2)
```
**Freezing the Base Model**
```
inceptionv3.trainable = False
```
**Adding Dense Layer at the end**
```
out = Dense(1, activation = 'sigmoid')(inceptionv3.output)
model = Model(inputs = inceptionv3.inputs, outputs = out)
num_trainable_layers(model)
model.summary()
```
# Compiling and Training the Model
```
optim = tf.keras.optimizers.Adam(lr = 0.001)
model.compile(optimizer = optim, loss = 'binary_crossentropy', metrics = ['accuracy'])
```
**Training only the Last (Dense) layer**
```
hist = model.fit_generator(train_generator,
steps_per_epoch = len(train_generator),
epochs = 20,
validation_data = validation_generator,
verbose = 2,
validation_steps = len(validation_generator),
validation_freq = 1)
```
# Saving the Model
```
model.save("model_before_finetuning.h5")
```
We save the model, in case we want to finetune the model at a later time. In that case, re-run the first cell to import the necessary modules and also initialize the Training and Validation Image Data Genartors. Then we load the saved model by running the following cell.
# Loading the Model
```
model = load_model("model_before_finetuning.h5")
```
# Finetuning the Model
**Unfreezing the Base Model**
```
model.trainable = True
num_trainable_layers(model)
```
**Using Checkpoints**
```
checkpoint = ModelCheckpoint('checkpoint.h5',
monitor = 'val_accuracy',
verbose = 0,
save_best_only = True,
save_weights_only = False,
mode = 'max',
save_freq = 'epoch')
```
**Re-Compiling the Model**
```
optim = tf.keras.optimizers.Adam(lr = 0.00001)
model.compile(optimizer = optim, loss = 'binary_crossentropy', metrics = ['accuracy'])
```
**Training all the layers**
```
hist = model.fit_generator(train_generator,
steps_per_epoch = len(train_generator),
epochs = 30,
callbacks = [checkpoint],
validation_data = validation_generator,
verbose = 2,
validation_steps = len(validation_generator),
validation_freq = 1)
```
# Saving the Final Model
Since after the last epoch, we see that model has attained its best score in terms of both Training and Validation Accuracy, we are going to save the model and use it to predict the Test Cases.
```
model.save("final_model.h5")
```
# Evaluating the Model
```
train_loss, train_acc = model.evaluate_generator(train_generator, steps = len(train_generator))
print("Train Loss: ", train_loss)
print("Train Acc: ", train_acc)
validation_loss, validation_acc = model.evaluate_generator(validation_generator, steps = len(validation_generator))
print("Validation Loss: ", validation_loss)
print("Validation Acc: ", validation_acc)
```
# Getting the Test Data
```
test_filenames = os.listdir("test")
print("No of images: ", len(test_filenames))
test_data = pd.DataFrame({'Photo': test_filenames})
test_data.reset_index(drop = True, inplace = True)
test_data.head()
```
# Creating the Test Image Generators
```
test_datagen = ImageDataGenerator(preprocessing_function = preprocess_input)
test_generator = test_datagen.flow_from_dataframe(test_data,
directory = 'test',
x_col = 'Photo',
target_size = (299,299),
class_mode = None,
shuffle = False,
batch_size = 64)
```
# Predicting the Test Examples
```
out = model.predict_generator(test_generator,
steps = len(test_generator),
verbose=0)
print("Shape of Test Prediction Array:", out.shape)
```
# Creating the Output CSV
```
df = pd.DataFrame({'id': test_filenames, 'label':out.squeeze()})
df.head()
df['id'] = df['id'].str.split(".", expand = True).iloc[:,0].astype(int)
df = df.sort_values('id').reset_index(drop = True)
df.head()
df.to_csv("out.csv", index = False)
```
**This model gave a score (LogLoss) of 0.14932 on the Test Dataset.**
|
github_jupyter
|
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.keras.backend as K
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import plot_model
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.inception_v3 import InceptionV3, preprocess_input
%matplotlib inline
tf.__version__
tf.test.is_gpu_available()
dtype='float16'
K.set_floatx(dtype)
# default is 1e-7 which is too small for float16. Without adjusting the epsilon, we will get NaN predictions because of divide by zero problems
K.set_epsilon(1e-4)
filenames = os.listdir("train")
print("No of images: ", len(filenames))
category = []
for file in filenames:
if file[0] == 'd':
category.append('1')
if file[0] == 'c':
category.append('0')
data = pd.DataFrame({'Photo': filenames, 'Class': category})
data = data.sample(frac = 1, replace = False, random_state = 0)
data.reset_index(drop = True, inplace = True)
data.head()
fig = plt.figure(figsize = (20,10))
for i in range(10):
img = plt.imread("train/" + data['Photo'].iloc[i])
plt.subplot(2,5,i+1)
plt.imshow(img)
plt.show()
train_data = data.iloc[:20000]
valid_data = data.iloc[20000:]
train_data.head()
valid_data.head()
def num_trainable_layers(model):
count = 0
for layer in model.layers:
if layer.trainable == True:
count += 1
print("Number of Trainable Layers: ", count)
train_datagen = ImageDataGenerator(rotation_range = 30,
width_shift_range = 0.25,
height_shift_range = 0.25,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
brightness_range = [0.75, 1.25],
preprocessing_function = preprocess_input)
valid_datagen = ImageDataGenerator(preprocessing_function = preprocess_input)
train_generator = train_datagen.flow_from_dataframe(train_data,
directory = 'train/',
x_col = 'Photo',
y_col = 'Class',
target_size = (299,299),
class_mode = 'binary',
seed = 42,
batch_size = 64)
validation_generator = valid_datagen.flow_from_dataframe(valid_data,
directory = 'train/',
x_col = 'Photo',
y_col = 'Class',
target_size = (299,299),
class_mode = 'binary',
seed = 42,
batch_size = 64)
inceptionv3 = InceptionV3(include_top = False,
weights = 'imagenet',
input_shape = (299, 299, 3),
pooling = 'avg',
classes = 2)
inceptionv3.trainable = False
out = Dense(1, activation = 'sigmoid')(inceptionv3.output)
model = Model(inputs = inceptionv3.inputs, outputs = out)
num_trainable_layers(model)
model.summary()
optim = tf.keras.optimizers.Adam(lr = 0.001)
model.compile(optimizer = optim, loss = 'binary_crossentropy', metrics = ['accuracy'])
hist = model.fit_generator(train_generator,
steps_per_epoch = len(train_generator),
epochs = 20,
validation_data = validation_generator,
verbose = 2,
validation_steps = len(validation_generator),
validation_freq = 1)
model.save("model_before_finetuning.h5")
model = load_model("model_before_finetuning.h5")
model.trainable = True
num_trainable_layers(model)
checkpoint = ModelCheckpoint('checkpoint.h5',
monitor = 'val_accuracy',
verbose = 0,
save_best_only = True,
save_weights_only = False,
mode = 'max',
save_freq = 'epoch')
optim = tf.keras.optimizers.Adam(lr = 0.00001)
model.compile(optimizer = optim, loss = 'binary_crossentropy', metrics = ['accuracy'])
hist = model.fit_generator(train_generator,
steps_per_epoch = len(train_generator),
epochs = 30,
callbacks = [checkpoint],
validation_data = validation_generator,
verbose = 2,
validation_steps = len(validation_generator),
validation_freq = 1)
model.save("final_model.h5")
train_loss, train_acc = model.evaluate_generator(train_generator, steps = len(train_generator))
print("Train Loss: ", train_loss)
print("Train Acc: ", train_acc)
validation_loss, validation_acc = model.evaluate_generator(validation_generator, steps = len(validation_generator))
print("Validation Loss: ", validation_loss)
print("Validation Acc: ", validation_acc)
test_filenames = os.listdir("test")
print("No of images: ", len(test_filenames))
test_data = pd.DataFrame({'Photo': test_filenames})
test_data.reset_index(drop = True, inplace = True)
test_data.head()
test_datagen = ImageDataGenerator(preprocessing_function = preprocess_input)
test_generator = test_datagen.flow_from_dataframe(test_data,
directory = 'test',
x_col = 'Photo',
target_size = (299,299),
class_mode = None,
shuffle = False,
batch_size = 64)
out = model.predict_generator(test_generator,
steps = len(test_generator),
verbose=0)
print("Shape of Test Prediction Array:", out.shape)
df = pd.DataFrame({'id': test_filenames, 'label':out.squeeze()})
df.head()
df['id'] = df['id'].str.split(".", expand = True).iloc[:,0].astype(int)
df = df.sort_values('id').reset_index(drop = True)
df.head()
df.to_csv("out.csv", index = False)
| 0.564459 | 0.885384 |
<a href="https://colab.research.google.com/github/aniketsharma00411/sign-language-to-text-translator/blob/main/metric_evaluation.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Initialization
```
from google.colab import drive
drive.mount('/content/drive')
from google.colab import files
import os
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras.applications import efficientnet
from keras.applications import mobilenet
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
from tqdm import tqdm
from scipy.stats import mode
os.chdir('./drive/My Drive/Sign Language to Text Translator')
```
# Loading Models
```
baseline_model = models.load_model('asl_basic.h5')
baseline_model_augmented = models.load_model('asl_basic_data_augmentation.h5')
efficient_net = models.load_model('asl_efficient_net_b0.h5')
mobilenet_augmented = models.load_model('asl_mobilenet_data_augmentation.h5')
ensemble = [models.load_model('asl_basic_ensemble_0.h5'),
models.load_model('asl_basic_ensemble_1.h5'),
models.load_model('asl_basic_ensemble_2.h5'),
models.load_model('asl_basic_ensemble_3.h5'),
models.load_model('asl_basic_ensemble_4.h5')]
```
# ASL Dataset
```
if not os.path.exists(os.path.expanduser('~')+'/.kaggle'):
! mkdir ~/.kaggle
if not os.path.exists(os.path.expanduser('~')+'/.kaggle/kaggle.json'):
kaggle_api_file = files.upload()
! mv kaggle.json ~/.kaggle
! kaggle datasets download -d grassknoted/asl-alphabet
! mv asl-alphabet.zip ~/.kaggle
! unzip -q ~/.kaggle/asl-alphabet.zip -d ~/.kaggle
! rm -rf ~/.kaggle/asl_alphabet_train/asl_alphabet_train/del
true_labels_data = [num//3000 for num in range(84000)]
```
## Baseline Models
```
image_gen = ImageDataGenerator(rescale=1/255)
data_gen = image_gen.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_baseline_model_data = baseline_model.predict(data_gen, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_baseline_model_data, axis=1), output_dict=True)
```
## Baseline Model data augmented
```
image_gen_aug = ImageDataGenerator(rescale=1/255)
data_gen_aug = image_gen_aug.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_augmented_model_data = baseline_model_augmented.predict(data_gen_aug, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_augmented_model_data, axis=1), output_dict=True)
```
## Efficient Net
```
image_gen_efficient_net = ImageDataGenerator(preprocessing_function=efficientnet.preprocess_input)
data_gen_efficient_net = image_gen_efficient_net.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_efficient_net_data = efficient_net.predict(data_gen_efficient_net, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_efficient_net_data, axis=1), output_dict=True)
```
## Mobilenet
```
image_gen_mobilenet = ImageDataGenerator(preprocessing_function=mobilenet.preprocess_input)
data_gen_mobilenet = image_gen_mobilenet.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_mobilenet_data = mobilenet_augmented.predict(data_gen_mobilenet, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_mobilenet_data, axis=1), output_dict=True)
```
## Ensemble
```
image_gen_ensemble = ImageDataGenerator(rescale=1/255)
data_gen_ensemble = image_gen_ensemble.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_ensemble_data = mode([np.argmax(model.predict(data_gen_ensemble, verbose=1), axis=1) for model in ensemble])[0][0]
classification_report(true_labels_data, predictions_ensemble_data, output_dict=True)
```
# ASL Alphabets
```
true_labels_alpha = [num//32 for num in range(832)]
```
## Baseline Models
```
image_gen2 = ImageDataGenerator(rescale=1/255)
data_gen2 = image_gen2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_baseline_model_alpha = baseline_model.predict(data_gen2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_baseline_model_alpha, axis=1), output_dict=True)
```
## Baseline Model data augmented
```
image_gen_aug2 = ImageDataGenerator(rescale=1/255)
data_gen_aug2 = image_gen_aug2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_augmented_model_alpha = baseline_model_augmented.predict(data_gen_aug2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_augmented_model_alpha, axis=1), output_dict=True)
```
## Efficient Net
```
image_gen_efficient_net2 = ImageDataGenerator(preprocessing_function=efficientnet.preprocess_input)
data_gen_efficient_net2 = image_gen_efficient_net2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_efficient_net_alpha = efficient_net.predict(data_gen_efficient_net2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_efficient_net_alpha, axis=1), output_dict=True)
```
## Mobilenet
```
image_gen_mobilenet2 = ImageDataGenerator(preprocessing_function=mobilenet.preprocess_input)
data_gen_mobilenet2 = image_gen_mobilenet2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_mobilenet_alpha = mobilenet_augmented.predict(data_gen_mobilenet2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_mobilenet_alpha, axis=1), output_dict=True)
```
## Ensemble
```
image_gen_ensemble2 = ImageDataGenerator(rescale=1/255)
data_gen_ensemble2 = image_gen_ensemble2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_ensemble_alpha = mode([np.argmax(model.predict(data_gen_ensemble2, verbose=1), axis=1) for model in ensemble])[0][0]
classification_report(true_labels_alpha, predictions_ensemble_alpha, output_dict=True)
```
|
github_jupyter
|
from google.colab import drive
drive.mount('/content/drive')
from google.colab import files
import os
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras.applications import efficientnet
from keras.applications import mobilenet
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
from tqdm import tqdm
from scipy.stats import mode
os.chdir('./drive/My Drive/Sign Language to Text Translator')
baseline_model = models.load_model('asl_basic.h5')
baseline_model_augmented = models.load_model('asl_basic_data_augmentation.h5')
efficient_net = models.load_model('asl_efficient_net_b0.h5')
mobilenet_augmented = models.load_model('asl_mobilenet_data_augmentation.h5')
ensemble = [models.load_model('asl_basic_ensemble_0.h5'),
models.load_model('asl_basic_ensemble_1.h5'),
models.load_model('asl_basic_ensemble_2.h5'),
models.load_model('asl_basic_ensemble_3.h5'),
models.load_model('asl_basic_ensemble_4.h5')]
if not os.path.exists(os.path.expanduser('~')+'/.kaggle'):
! mkdir ~/.kaggle
if not os.path.exists(os.path.expanduser('~')+'/.kaggle/kaggle.json'):
kaggle_api_file = files.upload()
! mv kaggle.json ~/.kaggle
! kaggle datasets download -d grassknoted/asl-alphabet
! mv asl-alphabet.zip ~/.kaggle
! unzip -q ~/.kaggle/asl-alphabet.zip -d ~/.kaggle
! rm -rf ~/.kaggle/asl_alphabet_train/asl_alphabet_train/del
true_labels_data = [num//3000 for num in range(84000)]
image_gen = ImageDataGenerator(rescale=1/255)
data_gen = image_gen.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_baseline_model_data = baseline_model.predict(data_gen, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_baseline_model_data, axis=1), output_dict=True)
image_gen_aug = ImageDataGenerator(rescale=1/255)
data_gen_aug = image_gen_aug.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_augmented_model_data = baseline_model_augmented.predict(data_gen_aug, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_augmented_model_data, axis=1), output_dict=True)
image_gen_efficient_net = ImageDataGenerator(preprocessing_function=efficientnet.preprocess_input)
data_gen_efficient_net = image_gen_efficient_net.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_efficient_net_data = efficient_net.predict(data_gen_efficient_net, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_efficient_net_data, axis=1), output_dict=True)
image_gen_mobilenet = ImageDataGenerator(preprocessing_function=mobilenet.preprocess_input)
data_gen_mobilenet = image_gen_mobilenet.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_mobilenet_data = mobilenet_augmented.predict(data_gen_mobilenet, verbose=1)
classification_report(true_labels_data, np.argmax(predictions_mobilenet_data, axis=1), output_dict=True)
image_gen_ensemble = ImageDataGenerator(rescale=1/255)
data_gen_ensemble = image_gen_ensemble.flow_from_directory(
os.path.expanduser('~')+'/.kaggle/asl_alphabet_train/asl_alphabet_train',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_ensemble_data = mode([np.argmax(model.predict(data_gen_ensemble, verbose=1), axis=1) for model in ensemble])[0][0]
classification_report(true_labels_data, predictions_ensemble_data, output_dict=True)
true_labels_alpha = [num//32 for num in range(832)]
image_gen2 = ImageDataGenerator(rescale=1/255)
data_gen2 = image_gen2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_baseline_model_alpha = baseline_model.predict(data_gen2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_baseline_model_alpha, axis=1), output_dict=True)
image_gen_aug2 = ImageDataGenerator(rescale=1/255)
data_gen_aug2 = image_gen_aug2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_augmented_model_alpha = baseline_model_augmented.predict(data_gen_aug2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_augmented_model_alpha, axis=1), output_dict=True)
image_gen_efficient_net2 = ImageDataGenerator(preprocessing_function=efficientnet.preprocess_input)
data_gen_efficient_net2 = image_gen_efficient_net2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_efficient_net_alpha = efficient_net.predict(data_gen_efficient_net2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_efficient_net_alpha, axis=1), output_dict=True)
image_gen_mobilenet2 = ImageDataGenerator(preprocessing_function=mobilenet.preprocess_input)
data_gen_mobilenet2 = image_gen_mobilenet2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_mobilenet_alpha = mobilenet_augmented.predict(data_gen_mobilenet2, verbose=1)
classification_report(true_labels_alpha, np.argmax(predictions_mobilenet_alpha, axis=1), output_dict=True)
image_gen_ensemble2 = ImageDataGenerator(rescale=1/255)
data_gen_ensemble2 = image_gen_ensemble2.flow_from_directory(
'asl_alphabets',
target_size=(224, 224),
class_mode=None,
color_mode='rgb',
shuffle=False
)
predictions_ensemble_alpha = mode([np.argmax(model.predict(data_gen_ensemble2, verbose=1), axis=1) for model in ensemble])[0][0]
classification_report(true_labels_alpha, predictions_ensemble_alpha, output_dict=True)
| 0.393968 | 0.656493 |
# Classificação de Imagem
O Serviço Cognitivo ***Computer Vision*** fornece modelos pré-construídos úteis para trabalhar com imagens, mas você vai ter que, com certa frequência, treinar o seu próprio modelo de visão computacional. Por exemplo, suponha que a empresa Northwind Traders quer criar um sistema de pagamento automático nas suas lojas que identifique os produtos que os clientes estão comprando se baseando em uma imagem capturada por uma câmera posicionada próxima ao caixa da loja. Para fazer isso, você terá que treinar um modelo de classificação de imagem que possa classificar as imagems para identificar os itens sendo comprados.

No Azure, você pode usar o serviço cognitivo ***Custom Vision*** para treinar um modelo baseado em imagens existentes. Há dois elementos na criação de uma solução de classificação de imagem. Primeiro, você precisa treinar um modelo para reconhecer diferentes classes usando imagens existentes. Então, quando o modelo estiver treinado, você precisa publicar o modelo como serviço para poder ser consumido pela sua aplicação.
## Crie um recurso de Custom Vision
TPara usar o serviço de ***Custom Vision*** (Visão Customizada), você precisa de um recurso Azure que você pode usar para **treinar** o modelo e um recurso com o qual você pode **publicar** o modelo para a sua aplicação poder usar. O recurso para cada tarefa (ou ambas) pode ser um recurso ***Cognitive Services*** genérico, ou um recurso específico de ***Custom Vision***. Você pode usar o mesmo recurso de Serviço Cognitivo para cada uma destas tarefas, ou você pode usar recursos diferentes (na mesma região) para cada tarefa para gerenciar os custos separadamente.
Siga as instruções a seguir para criar um novo recurso de ***Custom Vision***.
1. Em uma aba do seu navegador, abra o portal do Azure em [https://portal.azure.com](https://portal.azure.com), e faça login com a sua conta Microsfot associada à sua assinatura Azure.
2. Selecione o botão ***+Create a resource***, pesquise por *custom vision*, e crie um recurso ***Custom Vision*** com as seguintes configurações:
- **Create options**: Ambas
- **Subscription**: *Sua assinatura Azure*
- **Resource group**: *Selecione um resource group ou crie um com nome único*
- **Name**: *Entre um nome único*
- **Training location**: *Selecione qualquer região disponível*
- **Training pricing tier**: F0
- **Prediction location**: *A mesma região da **Training Location***
- **Prediction pricing tier**: F0
> **Nota**: Se você já tiver um serviço de *Custom Vision* F0 na sua assinatura, selecione **S0** para este serviço.
3. Espere até que os recursos sejam criados, e note que dois recursos de ***Custom Vision*** são disponibilizados; um para treinamento e outro para predição. Você pode visualizá-los navegando até o *resource group* onde você criou eles.
## Crie um projeto de ***Custom Vision***
Para treinar um modelo de detecção de objetos, você precisa criar um projeto de ***Custom Vision*** baseado no seu recurso de treinamento. Para fazer isso, você vai precisar usar o portal ***Custom Vision***.
1. Baixe e extraia as imagens de treinamento do link https://aka.ms/fruit-images.
2. Em outra aba do navegador, abra o portal ***Custom Vision*** em [https://customvision.ai](https://customvision.ai). Se questionado, entre com a sua conta Microsoft associada com a sua assinatura Azure e concorde com os termos de serviço.
3. No portal ***Custom Vision***, crie um novo projeto com as configurações a seguir:
- **Name**: *Grocery Checkout* (ou *Pagamento de Compras*, caso prefira em português)
- **Description**: Classificação de imagem para compras
- **Resource**: *O recurso de Custom Vision que você criou anteriormente*
- **Project Types**: *Classification* (Classificação)
- **Classification Types**: *Multiclass (single tag per image)* (Multiclasse (etiqueta única por imagem))
- **Domains**: *Food* (Comida)
4. Clique em **\[+\] Add images**, e selecione todos os arquivos na pasta **apple** que você extraiu anteriormente. Então faça upload dos arquivos de imagem e especifique a tag *apple* (ou *maçã*, se você preferir manter em português), assim:

5. Repita os passos anteriores para enviar as imagens na pasta **banana** com a tag *banana*, e as imagens na pasta **orange** com a tag *orange* (ou *laranja*, caso prefira).
6. Explore as imagens que você enviou no projeto de ***Custom Vision*** - deve haver 15 imagens de cada classe, assim:

7. No projeto ***Custom Vision***, acima das imagens, treine o modelo de classificação usando as imagens etiquetadas cliando em **Train**. Selecione a opção **Quick Training**, e então espere até que a iteração de treinamento esteja completa (isso pode levar alguns minutos).
8. Quando a iteração do modelo tiver sido treinada, revise as métricas de *Precision*, *Recall* e *AP* - elas medem a precisão do modelo de classificação, todas devem ser altas.
## Teste o modelo
Antes de publicar essa iteração do modelo para a sua aplicação utlizar, você deve testá-lo.
1. Acima das métricas de performance, clique em ***Quick Test***.
2. Na caixa ***Image URL***, digite `https://aka.ms/apple-image` e clique ➔
3. Veja as predições retornadas pelo seu modelo - a classificação de probabilidade para *maçã* deve ser a mais alta, assim:

4. Feche a janela do ***Quick Test***.
## Publique e consuma o modelo de classificação de imagem
Agora você está pronto para publicar o seu modelo treinado e para usá-lo por uma aplicação cliente.
9. Clique em **🗸 Publish** para publicar o modelo treinado com as configurações a seguir:
- **Model name**: *groceries* (ou *compras* caso queira manter em português)
- **Prediction Resource**: *O recurso de predicão que você criou anteriormente*.
### (!) Verifique
Você usou o mesmo nome do modelo: **groceries**?
10. Após publicar, clique no ícone *settings* (⚙ Configurações) na parte superior direita da página de **Performance** para ver as configurações do projeto. Então, sob **General** (na esquerda), copie o **Project Id** (Id do Projeto). Role este notebook para baixo e cole o Id do Projeto na célular de código abaixo do passo 13 substituindo **ID_DO_PROJETO**.

> _**Nota**: Caso você tenha usado o recurso **Cognitive Services** ao invés de criar um recurso **Custom Vision** no comeo deste exercício, você pode copiar a sua chave e endpoint do lado direito das configurações do seu projeto, colar isso na célula de código abaixo, e rodar para ver os resultados. Caso contrário, continue completando os passos abaixo para pegar a chave e endpoint para o seu recurso de predição Custom Vision._
11. Na parte superior esquerda da página **Project Settings**, clique no ícone *Projects Gallery* (👁) para retornar à página inicial do portal ***Custom Vision***, onde o seu projeto agora está listado.
12. Na página inicial do portal ***Custom Vision***, na parte superior direita, clique no ícone *settings* (⚙ Configurações) para visualizar as configurações do seu serviço ***Custom Vision***. Então, sob **Resources**, expanda o recurso **prediction** (<u>não</u> o recurso de treinamento) e copie os valores da sua **Key** (Chave) e **Endpoint** e cole na célula de código abaixo do passo 13, substituindo **SUA_CHAVE** e **SEU_ENDPOINT**.
### (!) Verifique
Se você estiver usando um recurso ***Custom Vision***, você usou o recurso ***prediction*** (<u>não</u> o recurso de treinamento)?

13. Rode a célula de código abaixo clicando no botão **Run cell** (▷) (à esquerda da célular) para configurar as variáveis com os valores do id do seu projeto, chave e o endpoint.
```
project_id = 'ID_DO_PROJETO'
cv_key = 'SUA_CHAVE'
cv_endpoint = 'SEU_ENDPOINT'
model_name = 'groceries' # esse valor deve ser idêntico ao nome do modelo de quando você publica a iteração do seu modelo (é case-sensitive)
print('Pronto para fazer predição usando o modelo {} no projeto {}'.format(model_name, project_id))
```
Agora você pode usar sua chave e endpoint como um cliente ***Custom Vision*** para conectar ao seu modelo de classificação.model.
Rode a célula de código a seguir para classificar uma seleção de imagens de teste usando o seu modelo publicado.
> **Nota**: Não se precoupe muito com os detalhes do código. Ele usa a SDK de Computer Vision para Python para pegar uma classe de predição para cada imagem na pasta /data/image-classification/test-fruit .
```
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
from msrest.authentication import ApiKeyCredentials
import matplotlib.pyplot as plt
from PIL import Image
import os
%matplotlib inline
# Pega as imagens de teste na pasta data/image-classification/test-fruit
test_folder = os.path.join('data', 'image-classification', 'test-fruit')
test_images = os.listdir(test_folder)
# Cria uma instância do serviço de predição
credentials = ApiKeyCredentials(in_headers={"Prediction-key": cv_key})
custom_vision_client = CustomVisionPredictionClient(endpoint=cv_endpoint, credentials=credentials)
# Cria uma figura para exibir os resultados
fig = plt.figure(figsize=(16, 8))
# Pega as imagens e exibe as classes para cada uma
print('Classificando as imagens em {} ...'.format(test_folder))
for i in range(len(test_images)):
# Abre a imagem e usa o modelo de Custom Vision para classificá-la
image_contents = open(os.path.join(test_folder, test_images[i]), "rb")
classification = custom_vision_client.classify_image(project_id, model_name, image_contents.read())
# Os resultados incluem a probabilidade para cada tag, em ordem descendente de probabilidade - pega a primeira
prediction = classification.predictions[0].tag_name
# Exibe a imagem com a sua classe mais provável
img = Image.open(os.path.join(test_folder, test_images[i]))
a=fig.add_subplot(len(test_images)/3, 3,i+1)
a.axis('off')
imgplot = plt.imshow(img)
a.set_title(prediction)
plt.show()
```
Muito provavelmente o seu modelo de classificação de imagem identificou corretamente as compras nas imagens.
## Saiba mais
O serviço ***Custom Vision*** oferece mais capacidades do que exploramos neste exercício. Por exemplo, você pode também usar o serviço de ***Custom Vision*** para criar modelos de *Deteção de Objetos*; que não apenas classificam objetos em imagens, mas também retornam *bounding boxes* (caixas de contorno) que mostram a localização do objeto na imagem.
Para saber mais sobre o serviço cognitivo ***Custom Vision***, veja a [documentação do Custom Vision](https://docs.microsoft.com/azure/cognitive-services/custom-vision-service/home)
|
github_jupyter
|
project_id = 'ID_DO_PROJETO'
cv_key = 'SUA_CHAVE'
cv_endpoint = 'SEU_ENDPOINT'
model_name = 'groceries' # esse valor deve ser idêntico ao nome do modelo de quando você publica a iteração do seu modelo (é case-sensitive)
print('Pronto para fazer predição usando o modelo {} no projeto {}'.format(model_name, project_id))
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
from msrest.authentication import ApiKeyCredentials
import matplotlib.pyplot as plt
from PIL import Image
import os
%matplotlib inline
# Pega as imagens de teste na pasta data/image-classification/test-fruit
test_folder = os.path.join('data', 'image-classification', 'test-fruit')
test_images = os.listdir(test_folder)
# Cria uma instância do serviço de predição
credentials = ApiKeyCredentials(in_headers={"Prediction-key": cv_key})
custom_vision_client = CustomVisionPredictionClient(endpoint=cv_endpoint, credentials=credentials)
# Cria uma figura para exibir os resultados
fig = plt.figure(figsize=(16, 8))
# Pega as imagens e exibe as classes para cada uma
print('Classificando as imagens em {} ...'.format(test_folder))
for i in range(len(test_images)):
# Abre a imagem e usa o modelo de Custom Vision para classificá-la
image_contents = open(os.path.join(test_folder, test_images[i]), "rb")
classification = custom_vision_client.classify_image(project_id, model_name, image_contents.read())
# Os resultados incluem a probabilidade para cada tag, em ordem descendente de probabilidade - pega a primeira
prediction = classification.predictions[0].tag_name
# Exibe a imagem com a sua classe mais provável
img = Image.open(os.path.join(test_folder, test_images[i]))
a=fig.add_subplot(len(test_images)/3, 3,i+1)
a.axis('off')
imgplot = plt.imshow(img)
a.set_title(prediction)
plt.show()
| 0.278944 | 0.74556 |
# VacationPy
----
#### Note
* Keep an eye on your API usage. Use https://developers.google.com/maps/reporting/gmp-reporting as reference for how to monitor your usage and billing.
* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.
```
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
import json
# Import API key
from api_keys import g_key
```
### Store Part I results into DataFrame
* Load the csv exported in Part I to a DataFrame
```
weather_df =pd.read_csv('../WeatherPy/output_data/output_data_cities.csv')
# weather_df
# Remove extra index
del weather_df['Unnamed: 0']
weather_df
```
### Humidity Heatmap
* Configure gmaps.
* Use the Lat and Lng as locations and Humidity as the weight.
* Add Heatmap layer to map.
```
# Configure gmaps with unique API key
gmaps.configure(api_key=g_key)
# Store latitude and longitude in location, and humidity as humidity
location = weather_df[["Lat", "Lng"]]
humidity = weather_df["Humidity"].astype(float)
# Create heat map of all cities based on humidity.
# Define the heatmap parameters
fig=gmaps.figure(center = [0,0] ,zoom_level = 2)
# Create and add heat layer
heat_layer = gmaps.heatmap_layer(location, weights=humidity,
dissipating=False, max_intensity=200,
point_radius = 4)
fig.add_layer(heat_layer)
# Display figure
fig
```
### Create new DataFrame fitting weather criteria
* Narrow down the cities to fit weather conditions.
* Drop any rows will null values.
```
# New DataFrame Narrow down the cities to fit weather conditions.
ideal_weather_df = weather_df[weather_df['Max Temp'] <=80]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Max Temp'] >=70]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Wind Speed'] <=10]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Cloudiness'] ==0]
ideal_weather_df = ideal_weather_df.dropna()
ideal_weather_df = ideal_weather_df.reset_index()
ideal_weather_df
```
### Hotel Map
* Store into variable named `hotel_df`.
* Add a "Hotel Name" column to the DataFrame.
* Set parameters to search for hotels with 5000 meters.
* Hit the Google Places API for each city's coordinates.
* Store the first Hotel result into the DataFrame.
* Plot markers on top of the heatmap.
```
hotel_df = ideal_weather_df
# Add column for Hotel Name
hotel_df['Hotel Name'] = ""
hotel_df['Hotel Address'] = ''
hotel_df = hotel_df.drop(columns='index')
hotel_df
# Params dictionary to update each iteration for hotels with 5000 meters
params = {
"radius": 5000,
"types": "lodging",
"key": g_key
}
# Use the lat/lng we recovered to identify hotels
for index, row in hotel_df.iterrows():
#get lat, lng from df
lat = row["Lat"]
lng = row["Lng"]
# change location each iteration while leaving original params in place
params["location"] = f"{lat},{lng}"
# Use the search term: "hotel" and our lat/lng
base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
# make request and print url
name_address = requests.get(base_url, params=params)
# convert to json
name_address = name_address.json()
# Since some data may be missing we incorporate a try-except to skip any that are missing a data point.
try:
hotel_df.loc[index, "Hotel Name"] = name_address["results"][0]["name"]
hotel_df.loc[index, "Hotel Address"] = name_address["results"][0]["vicinity"]
except (KeyError, IndexError):
print("Missing field/result... skipping.")
hotel_df
# NOTE: Do not change any of the code in this cell
# Using the template add the hotel marks to the heatmap
info_box_template = """
<dl>
<dt>Name</dt><dd>{Hotel Name}</dd>
<dt>City</dt><dd>{City}</dd>
<dt>Country</dt><dd>{Country}</dd>
</dl>
"""
# Store the DataFrame Row
# NOTE: be sure to update with your DataFrame name
hotel_info = [info_box_template.format(**row) for index, row in hotel_df.iterrows()]
locations = hotel_df[["Lat", "Lng"]]
# Add marker layer ontop of heat map
fig=gmaps.figure(center = [0,0] ,zoom_level = 2)
heat_layer = gmaps.heatmap_layer(location, weights=humidity,
dissipating=False, max_intensity=200,
point_radius = 4)
hotel_layer = gmaps.symbol_layer(locations, fill_color='rgba(0, 150, 0, 0.4)',
stroke_color='rgba(0, 0, 150, 0.4)', scale=2,info_box_content=hotel_info)
markers = gmaps.marker_layer(locations, info_box_content=hotel_info)
# Display figure
fig.add_layer(heat_layer)
fig.add_layer(markers)
fig.add_layer(hotel_layer)
fig
```
|
github_jupyter
|
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import requests
import gmaps
import os
import json
# Import API key
from api_keys import g_key
weather_df =pd.read_csv('../WeatherPy/output_data/output_data_cities.csv')
# weather_df
# Remove extra index
del weather_df['Unnamed: 0']
weather_df
# Configure gmaps with unique API key
gmaps.configure(api_key=g_key)
# Store latitude and longitude in location, and humidity as humidity
location = weather_df[["Lat", "Lng"]]
humidity = weather_df["Humidity"].astype(float)
# Create heat map of all cities based on humidity.
# Define the heatmap parameters
fig=gmaps.figure(center = [0,0] ,zoom_level = 2)
# Create and add heat layer
heat_layer = gmaps.heatmap_layer(location, weights=humidity,
dissipating=False, max_intensity=200,
point_radius = 4)
fig.add_layer(heat_layer)
# Display figure
fig
# New DataFrame Narrow down the cities to fit weather conditions.
ideal_weather_df = weather_df[weather_df['Max Temp'] <=80]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Max Temp'] >=70]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Wind Speed'] <=10]
ideal_weather_df = ideal_weather_df[ideal_weather_df['Cloudiness'] ==0]
ideal_weather_df = ideal_weather_df.dropna()
ideal_weather_df = ideal_weather_df.reset_index()
ideal_weather_df
hotel_df = ideal_weather_df
# Add column for Hotel Name
hotel_df['Hotel Name'] = ""
hotel_df['Hotel Address'] = ''
hotel_df = hotel_df.drop(columns='index')
hotel_df
# Params dictionary to update each iteration for hotels with 5000 meters
params = {
"radius": 5000,
"types": "lodging",
"key": g_key
}
# Use the lat/lng we recovered to identify hotels
for index, row in hotel_df.iterrows():
#get lat, lng from df
lat = row["Lat"]
lng = row["Lng"]
# change location each iteration while leaving original params in place
params["location"] = f"{lat},{lng}"
# Use the search term: "hotel" and our lat/lng
base_url = "https://maps.googleapis.com/maps/api/place/nearbysearch/json"
# make request and print url
name_address = requests.get(base_url, params=params)
# convert to json
name_address = name_address.json()
# Since some data may be missing we incorporate a try-except to skip any that are missing a data point.
try:
hotel_df.loc[index, "Hotel Name"] = name_address["results"][0]["name"]
hotel_df.loc[index, "Hotel Address"] = name_address["results"][0]["vicinity"]
except (KeyError, IndexError):
print("Missing field/result... skipping.")
hotel_df
# NOTE: Do not change any of the code in this cell
# Using the template add the hotel marks to the heatmap
info_box_template = """
<dl>
<dt>Name</dt><dd>{Hotel Name}</dd>
<dt>City</dt><dd>{City}</dd>
<dt>Country</dt><dd>{Country}</dd>
</dl>
"""
# Store the DataFrame Row
# NOTE: be sure to update with your DataFrame name
hotel_info = [info_box_template.format(**row) for index, row in hotel_df.iterrows()]
locations = hotel_df[["Lat", "Lng"]]
# Add marker layer ontop of heat map
fig=gmaps.figure(center = [0,0] ,zoom_level = 2)
heat_layer = gmaps.heatmap_layer(location, weights=humidity,
dissipating=False, max_intensity=200,
point_radius = 4)
hotel_layer = gmaps.symbol_layer(locations, fill_color='rgba(0, 150, 0, 0.4)',
stroke_color='rgba(0, 0, 150, 0.4)', scale=2,info_box_content=hotel_info)
markers = gmaps.marker_layer(locations, info_box_content=hotel_info)
# Display figure
fig.add_layer(heat_layer)
fig.add_layer(markers)
fig.add_layer(hotel_layer)
fig
| 0.52683 | 0.856812 |
```
!pip -q install PyGeodesy
!pip -q install numpy
!pip -q install polliwog
!pip -q install folium
from math import pi, sqrt, radians, degrees
import numpy as np
from pygeodesy.datum import Ellipsoid, Ellipsoids
from pygeodesy.vector3d import Vector3Tuple
WGS84 = Ellipsoids.WGS84
KM = 1000
from polliwog.transform.composite import CompositeTransform
from polliwog.transform.rotation import rotation_from_up_and_look, euler
import folium
class SpaceObject:
def __str__(self):
return """
Lat (deg): {}
Lon (deg): {}
Alt (m): {}
""".format(self.lat_d, self.lon_d, self.alt)
class Beam(SpaceObject):
def __init__(self):
self.alt = 0.0
self.width_d = 0.5
def dist(a, b):
return sqrt((b[0] - a[0])**2 + (b[1] - a[1])**2 + (b[2] - a[2])**2)
def normalized(array):
return array/np.linalg.norm(array)
def los_to_earth(position, pointing, ellipsoid):
"""
Adapted from Stephen Hartzell
"""
pointing_norm = normalized(pointing)
a = ellipsoid.a
b = ellipsoid.b
c = ellipsoid.c
x = position[0]
y = position[1]
z = position[2]
u = pointing_norm[0]
v = pointing_norm[1]
w = pointing_norm[2]
value = -a**2*b**2*w*z - a**2*c**2*v*y - b**2*c**2*u*x
radical = a**2*b**2*w**2 + a**2*c**2*v**2 - a**2*v**2*z**2 + \
2*a**2*v*w*y*z - a**2*w**2*y**2 + b**2*c**2*u**2 - b**2*u**2*z**2 + \
2*b**2*u*w*x*z - b**2*w**2*x**2 - c**2*u**2*y**2 + 2*c**2*u*v*x*y - c**2*v**2*x**2
magnitude = a**2*b**2*w**2 + a**2*c**2*v**2 + b**2*c**2*u**2
if radical < 0:
return (None, False)
d = (value - a*b*c*np.sqrt(radical)) / magnitude
if d < 0:
return (None, False)
result = np.array([
x + d * u,
y + d * v,
z + d * w,
])
return (result, True)
def ecef_forward(geopoint):
(x, y, z, _, _, _, _, _, _) = WGS84.ecef().forward(geopoint.lat_d, geopoint.lon_d, geopoint.alt)
return np.array([x, y, z])
def ecef_reverse(ecef_point):
(_, _, _, lat, lon, height, _, _, _) = WGS84.ecef().reverse(ecef_point[0], ecef_point[1], ecef_point[2])
o = SpaceObject()
o.lat_d = lat
o.lon_d = lon
o.alt = height
return o
def beam_shifter(sat, beam):
center = np.array([0.0, 0.0, 0.0])
r = WGS84.Rgeocentric(beam.lat_d)
r0 = WGS84.Rgeocentric(lat=0.0)
sat_ecef = ecef_forward(sat)
beam_ecef = ecef_forward(beam)
z_up = np.array([0.0, 0.0, 1.0])
towards = normalized(beam_ecef - sat_ecef)
to_sat_frame = CompositeTransform()
to_sat_frame.translate(-sat_ecef)
to_sat_frame.append_transform3(
rotation_from_up_and_look(
z_up,
towards
)
)
beam_sat_frame = to_sat_frame(beam_ecef)
def shifted_beam(sx, sy):
shift = CompositeTransform()
shift.append_transform3(euler([-sx, -sy, 0.0]))
beam_shift_sat_frame = shift(beam_sat_frame)
shifted_beam_ecef = to_sat_frame(beam_shift_sat_frame, reverse=True)
shifted_beam_isect_ecef, ok = los_to_earth(sat_ecef, shifted_beam_ecef - sat_ecef, WGS84)
if not ok:
return (None, ok)
return (ecef_reverse(shifted_beam_isect_ecef), True)
return shifted_beam
def footprint(sat, beam):
shifter = beam_shifter(sat, beam)
rotate_rad = np.linspace(0, 2*pi, 150)
shift_x_rad = np.arctan(np.sin(rotate_rad)*np.tan(radians(beam.width_d)))
shift_y_rad = np.arctan(np.cos(rotate_rad)*np.tan(radians(beam.width_d)))
result = [shifter(degrees(shift_x_rad[i]), degrees(shift_y_rad[i])) for i in range(len(rotate_rad))]
return [p for (p, ok) in result if ok]
def footprint_json(footprint):
json = {
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"scalerank": 5,
"featurecla": "Footprint 1"
},
"geometry": {
"type": "LineString",
"coordinates": [
[
point.lon_d,
point.lat_d
]
for point in footprint
] +
[
[
footprint[0].lon_d,
footprint[0].lat_d
]
]
}
}
]
}
return json
def add_marker(m, spaceobject):
folium.Marker([spaceobject.lat_d, spaceobject.lon_d]).add_to(m)
def render_footprint(m, sat, beam):
fp = footprint(sat, beam)
folium.GeoJson(footprint_json(fp), name='geojson').add_to(m)
def render_beam(m, lat_d = 0.0, lon_d = 0.0, beam = None):
if beam == None:
beam = Beam()
beam.lat_d = lat_d
beam.lon_d = lon_d
add_marker(m, beam)
render_footprint(m, sat, beam)
m = folium.Map(location=[55.0, 37.0], zoom_start=5)
sat = SpaceObject()
sat.lat_d = 0.0
sat.lon_d = 120.0
sat.alt = 35786*KM
beam_0 = Beam()
beam_0.lat_d = sat.lat_d
beam_0.lon_d = sat.lon_d
render_beam(m, beam=beam_0)
[
render_beam(m, lat_d=65.0, lon_d=-70.0 + delta*11)
for delta in range(9)
]
[
render_beam(m, lat_d=55.0, lon_d=-70.0 + delta*11)
for delta in range(9)
]
folium.LayerControl().add_to(m)
```
### Визуализация
```
m
```
|
github_jupyter
|
!pip -q install PyGeodesy
!pip -q install numpy
!pip -q install polliwog
!pip -q install folium
from math import pi, sqrt, radians, degrees
import numpy as np
from pygeodesy.datum import Ellipsoid, Ellipsoids
from pygeodesy.vector3d import Vector3Tuple
WGS84 = Ellipsoids.WGS84
KM = 1000
from polliwog.transform.composite import CompositeTransform
from polliwog.transform.rotation import rotation_from_up_and_look, euler
import folium
class SpaceObject:
def __str__(self):
return """
Lat (deg): {}
Lon (deg): {}
Alt (m): {}
""".format(self.lat_d, self.lon_d, self.alt)
class Beam(SpaceObject):
def __init__(self):
self.alt = 0.0
self.width_d = 0.5
def dist(a, b):
return sqrt((b[0] - a[0])**2 + (b[1] - a[1])**2 + (b[2] - a[2])**2)
def normalized(array):
return array/np.linalg.norm(array)
def los_to_earth(position, pointing, ellipsoid):
"""
Adapted from Stephen Hartzell
"""
pointing_norm = normalized(pointing)
a = ellipsoid.a
b = ellipsoid.b
c = ellipsoid.c
x = position[0]
y = position[1]
z = position[2]
u = pointing_norm[0]
v = pointing_norm[1]
w = pointing_norm[2]
value = -a**2*b**2*w*z - a**2*c**2*v*y - b**2*c**2*u*x
radical = a**2*b**2*w**2 + a**2*c**2*v**2 - a**2*v**2*z**2 + \
2*a**2*v*w*y*z - a**2*w**2*y**2 + b**2*c**2*u**2 - b**2*u**2*z**2 + \
2*b**2*u*w*x*z - b**2*w**2*x**2 - c**2*u**2*y**2 + 2*c**2*u*v*x*y - c**2*v**2*x**2
magnitude = a**2*b**2*w**2 + a**2*c**2*v**2 + b**2*c**2*u**2
if radical < 0:
return (None, False)
d = (value - a*b*c*np.sqrt(radical)) / magnitude
if d < 0:
return (None, False)
result = np.array([
x + d * u,
y + d * v,
z + d * w,
])
return (result, True)
def ecef_forward(geopoint):
(x, y, z, _, _, _, _, _, _) = WGS84.ecef().forward(geopoint.lat_d, geopoint.lon_d, geopoint.alt)
return np.array([x, y, z])
def ecef_reverse(ecef_point):
(_, _, _, lat, lon, height, _, _, _) = WGS84.ecef().reverse(ecef_point[0], ecef_point[1], ecef_point[2])
o = SpaceObject()
o.lat_d = lat
o.lon_d = lon
o.alt = height
return o
def beam_shifter(sat, beam):
center = np.array([0.0, 0.0, 0.0])
r = WGS84.Rgeocentric(beam.lat_d)
r0 = WGS84.Rgeocentric(lat=0.0)
sat_ecef = ecef_forward(sat)
beam_ecef = ecef_forward(beam)
z_up = np.array([0.0, 0.0, 1.0])
towards = normalized(beam_ecef - sat_ecef)
to_sat_frame = CompositeTransform()
to_sat_frame.translate(-sat_ecef)
to_sat_frame.append_transform3(
rotation_from_up_and_look(
z_up,
towards
)
)
beam_sat_frame = to_sat_frame(beam_ecef)
def shifted_beam(sx, sy):
shift = CompositeTransform()
shift.append_transform3(euler([-sx, -sy, 0.0]))
beam_shift_sat_frame = shift(beam_sat_frame)
shifted_beam_ecef = to_sat_frame(beam_shift_sat_frame, reverse=True)
shifted_beam_isect_ecef, ok = los_to_earth(sat_ecef, shifted_beam_ecef - sat_ecef, WGS84)
if not ok:
return (None, ok)
return (ecef_reverse(shifted_beam_isect_ecef), True)
return shifted_beam
def footprint(sat, beam):
shifter = beam_shifter(sat, beam)
rotate_rad = np.linspace(0, 2*pi, 150)
shift_x_rad = np.arctan(np.sin(rotate_rad)*np.tan(radians(beam.width_d)))
shift_y_rad = np.arctan(np.cos(rotate_rad)*np.tan(radians(beam.width_d)))
result = [shifter(degrees(shift_x_rad[i]), degrees(shift_y_rad[i])) for i in range(len(rotate_rad))]
return [p for (p, ok) in result if ok]
def footprint_json(footprint):
json = {
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"scalerank": 5,
"featurecla": "Footprint 1"
},
"geometry": {
"type": "LineString",
"coordinates": [
[
point.lon_d,
point.lat_d
]
for point in footprint
] +
[
[
footprint[0].lon_d,
footprint[0].lat_d
]
]
}
}
]
}
return json
def add_marker(m, spaceobject):
folium.Marker([spaceobject.lat_d, spaceobject.lon_d]).add_to(m)
def render_footprint(m, sat, beam):
fp = footprint(sat, beam)
folium.GeoJson(footprint_json(fp), name='geojson').add_to(m)
def render_beam(m, lat_d = 0.0, lon_d = 0.0, beam = None):
if beam == None:
beam = Beam()
beam.lat_d = lat_d
beam.lon_d = lon_d
add_marker(m, beam)
render_footprint(m, sat, beam)
m = folium.Map(location=[55.0, 37.0], zoom_start=5)
sat = SpaceObject()
sat.lat_d = 0.0
sat.lon_d = 120.0
sat.alt = 35786*KM
beam_0 = Beam()
beam_0.lat_d = sat.lat_d
beam_0.lon_d = sat.lon_d
render_beam(m, beam=beam_0)
[
render_beam(m, lat_d=65.0, lon_d=-70.0 + delta*11)
for delta in range(9)
]
[
render_beam(m, lat_d=55.0, lon_d=-70.0 + delta*11)
for delta in range(9)
]
folium.LayerControl().add_to(m)
m
| 0.881793 | 0.514583 |
<small><small><i>
All of these python notebooks are available at https://github.com/kipkurui/Python4Bioinformatics
# Working with strings
## The Print Statement
As seen previously, The **print()** function prints all of its arguments as strings, separated by spaces and follows by a linebreak:
- print("Hello World")
- print("Hello",'World')
- print("Hello", <Variable Containing the String>)
Note that **print** is different in old versions of Python (2.7) where it was a statement and did not need parenthesis around its arguments.
```
print("Hello","World")
```
The print has some optional arguments to control where and how to print. This includes `sep` the separator (default space) and `end` (end charcter) and `file` to write to a file.
```
dna="ACGTATA"
dna.count(A)
print("Hello","World",sep='...',end='!!')
```
You can find the additional arguments, and help on usage of print, and any other function, by appending a ? before it.
```
?print()
```
## String Formatting
There are lots of methods for formatting and manipulating strings built into python. Some of these are illustrated here.
String concatenation is the "addition" of two strings. Observe that while concatenating there will be no space between the strings.
```
string1='World'
string2='!'
print('Hello' + " "+ string1 + string2 + str(267.00))
```
The **%** operator is used to format a string inserting the value that comes after. It relies on the string containing a format specifier that identifies where to insert the value. The most common types of format specifiers are:
- %s -> string
- %d -> Integer
- %f -> Float
- %o -> Octal
- %x -> Hexadecimal
- %e -> exponential
```
print("Hello %s" % string1)
print("Actual Number = %d" %18)
print("Float of the number = %.3f" % 18.87687)
print("Exponential equivalent of the number = %e" %18)
```
When referring to multiple variables parenthesis is used. Values are inserted in the order they appear in the paranthesis (more on tuples in the next lecture)
```
print("Hello %s %s. This meaning of life is %d" %(string1,string2,42))
```
We can also specify the width of the field and the number of decimal places to be used. For example:
```
print('Print width 10: |%10s|'%'my')
print('Print width 10: |%10s|'%'name') # left justified
print("The number pi = %.2f to 2 decimal places"%3.1415)
print("More space pi = %10.2f"%3.1415)
print("Pad pi with 0 = %010.2f"%3.1415) # pad with zeros
```
## Other String Methods
Multiplying a string by an integer simply repeats it
```
print("Hello World! "*5)
```
Strings can be tranformed by a variety of functions:
Let's get back to our trna example.
```
s="hello wOrld"
print(s.capitalize())
print(s.upper())
print(s.lower())
print('|%s|' % "Hello World".center(30)) # center in 30 characters
print('|%s|'% " lots of space ".strip()) # remove leading and trailing whitespace
print("Hello World".replace("World","Class"))
```
There are also lots of ways to inspect or check strings. Examples of a few of these are given here:
```
help(str)
trna='AAGGGCTTAGCTTAATTAAAGTGGCTGATTTGCGTTCAGTTGATGCAGAGTGGGGTTTTGCAGTCCTTA'
print("The length of the sequence is %i" % len(trna),"nucleotides") # len() gives length
#count strings
print("There are %d 'G's but only %d C's in the sequence" % (trna.count('G'),trna.count('C')))
print('The "ATTAA" motif is at index',trna.find('ATTAA')) #index from 0 or -1
```
### Exercise
Calculate the % GC and % AT content in the trna sequence
```
A_count=trna.count('A')
C_count=trna.count('C')
G_count=trna.count('G')
T_count=trna.count('T')
```
## String comparison operations
Strings can be compared in lexicographical order with the usual comparisons. In addition the `in` operator checks for substrings:
```
'abc' < 'bbc' <= 'bbc'
"ABC" in "This is the ABC of Python"
```
## Accessing parts of strings
Strings can be indexed with square brackets. Indexing starts from zero in Python.
```
s = 'AAGGGCTTAGCTTAATTAAAGTGGCTGATTTGCGTTCAGTTGATGCAGAGTGGGGTTTTGCAGTCCTT'
print('First nucleotide of the sequence is',s[0])
print('Last nucleotide of the sequence is',s[len(s)-1])
```
Negative indices can be used to start counting from the back
```
print('First nucleotide of the sequence is',s[-len(s)])
print('Last nucleotide of the sequence is',s[-1])
```
#### Slicing
Finally a substring (range of characters) can be specified as using $a:b$ to specify the characters at index $a,a+1,\ldots,b-1$. Note that the last charcter is *not* included. Now we can find the first codon in the sequence:
```
print("First codon in the sequence is",s[0:3])
print("The secodn codon in the sequence is",s[3:6])
```
An empty beginning and end of the range denotes the beginning/end of the string:
```
print("First codon in the sequence is", s[:3])
print("Last codon in the sequence is", s[-3:])
```
A colon without an index, returns the whole string.
```
s[:]
```
## Strings are immutable
It is important that strings are constant, immutable values in Python. While new strings can easily be created it is not possible to modify a string:
```
s='012345'
sX=s[:2]+'X'+s[3:] # this creates a new string with 2 replaced by X
print("creating new string",sX,"OK")
sX=s.replace('2','X') # the same thing
print(sX,"still OK")
s[2] = 'X' # an error!!!
```
### Exercise:
1. Given the following amino acid sequence (MNKMDLVADVAEKTDLSKAKATEVIDAVFA), find the first, last and the 5th amino acids in the sequence.
2. The above amino acid is a bacterial restriction enzyme that recognizes "TCCGGA". Find the first restriction site in the following sequence: AAAAATCCCGAGGCGGCTATATAGGGCTCCGGAGGCGTAATATAAAA
|
github_jupyter
|
print("Hello","World")
dna="ACGTATA"
dna.count(A)
print("Hello","World",sep='...',end='!!')
?print()
string1='World'
string2='!'
print('Hello' + " "+ string1 + string2 + str(267.00))
print("Hello %s" % string1)
print("Actual Number = %d" %18)
print("Float of the number = %.3f" % 18.87687)
print("Exponential equivalent of the number = %e" %18)
print("Hello %s %s. This meaning of life is %d" %(string1,string2,42))
print('Print width 10: |%10s|'%'my')
print('Print width 10: |%10s|'%'name') # left justified
print("The number pi = %.2f to 2 decimal places"%3.1415)
print("More space pi = %10.2f"%3.1415)
print("Pad pi with 0 = %010.2f"%3.1415) # pad with zeros
print("Hello World! "*5)
s="hello wOrld"
print(s.capitalize())
print(s.upper())
print(s.lower())
print('|%s|' % "Hello World".center(30)) # center in 30 characters
print('|%s|'% " lots of space ".strip()) # remove leading and trailing whitespace
print("Hello World".replace("World","Class"))
help(str)
trna='AAGGGCTTAGCTTAATTAAAGTGGCTGATTTGCGTTCAGTTGATGCAGAGTGGGGTTTTGCAGTCCTTA'
print("The length of the sequence is %i" % len(trna),"nucleotides") # len() gives length
#count strings
print("There are %d 'G's but only %d C's in the sequence" % (trna.count('G'),trna.count('C')))
print('The "ATTAA" motif is at index',trna.find('ATTAA')) #index from 0 or -1
A_count=trna.count('A')
C_count=trna.count('C')
G_count=trna.count('G')
T_count=trna.count('T')
'abc' < 'bbc' <= 'bbc'
"ABC" in "This is the ABC of Python"
s = 'AAGGGCTTAGCTTAATTAAAGTGGCTGATTTGCGTTCAGTTGATGCAGAGTGGGGTTTTGCAGTCCTT'
print('First nucleotide of the sequence is',s[0])
print('Last nucleotide of the sequence is',s[len(s)-1])
print('First nucleotide of the sequence is',s[-len(s)])
print('Last nucleotide of the sequence is',s[-1])
print("First codon in the sequence is",s[0:3])
print("The secodn codon in the sequence is",s[3:6])
print("First codon in the sequence is", s[:3])
print("Last codon in the sequence is", s[-3:])
s[:]
s='012345'
sX=s[:2]+'X'+s[3:] # this creates a new string with 2 replaced by X
print("creating new string",sX,"OK")
sX=s.replace('2','X') # the same thing
print(sX,"still OK")
s[2] = 'X' # an error!!!
| 0.205296 | 0.944125 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.