
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
alexandrainst/da-hatespeech-classification-base | [
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"da",
"transformers",
"license:cc-by-sa-4.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 866 | null | ---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-roberta-finetuned-code-mixed-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-roberta-finetuned-code-mixed-DS
This model is a fine-tuned version of [l3cube-pune/hing-roberta](https://huggingface.co/l3cube-pune/hing-roberta) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8512
- Accuracy: 0.7706
- Precision: 0.7217
- Recall: 0.7233
- F1: 0.7222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.932923543227153e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.0216 | 1.0 | 497 | 1.1363 | 0.5392 | 0.4228 | 0.3512 | 0.2876 |
| 0.9085 | 2.0 | 994 | 0.7599 | 0.6761 | 0.6247 | 0.6294 | 0.5902 |
| 0.676 | 3.0 | 1491 | 0.7415 | 0.7505 | 0.6946 | 0.7034 | 0.6983 |
| 0.4404 | 4.0 | 1988 | 0.8512 | 0.7706 | 0.7217 | 0.7233 | 0.7222 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
alexandrainst/da-hatespeech-detection-base | [
"pytorch",
"tf",
"safetensors",
"bert",
"text-classification",
"da",
"transformers",
"license:cc-by-sa-4.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,719 | null | ---
license: mit
---
### Transmutation Circles on Stable Diffusion
This is the `<tcircle>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:
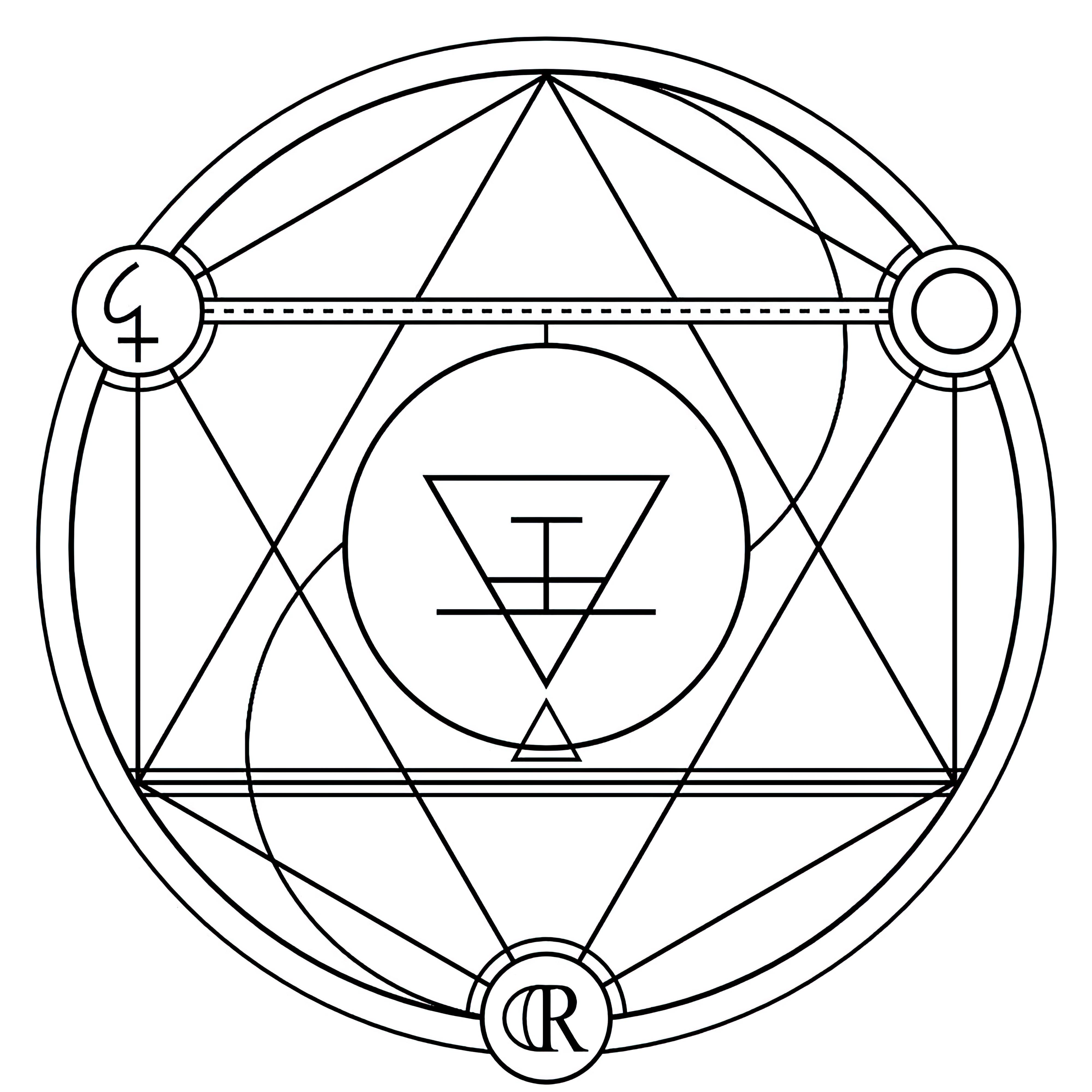
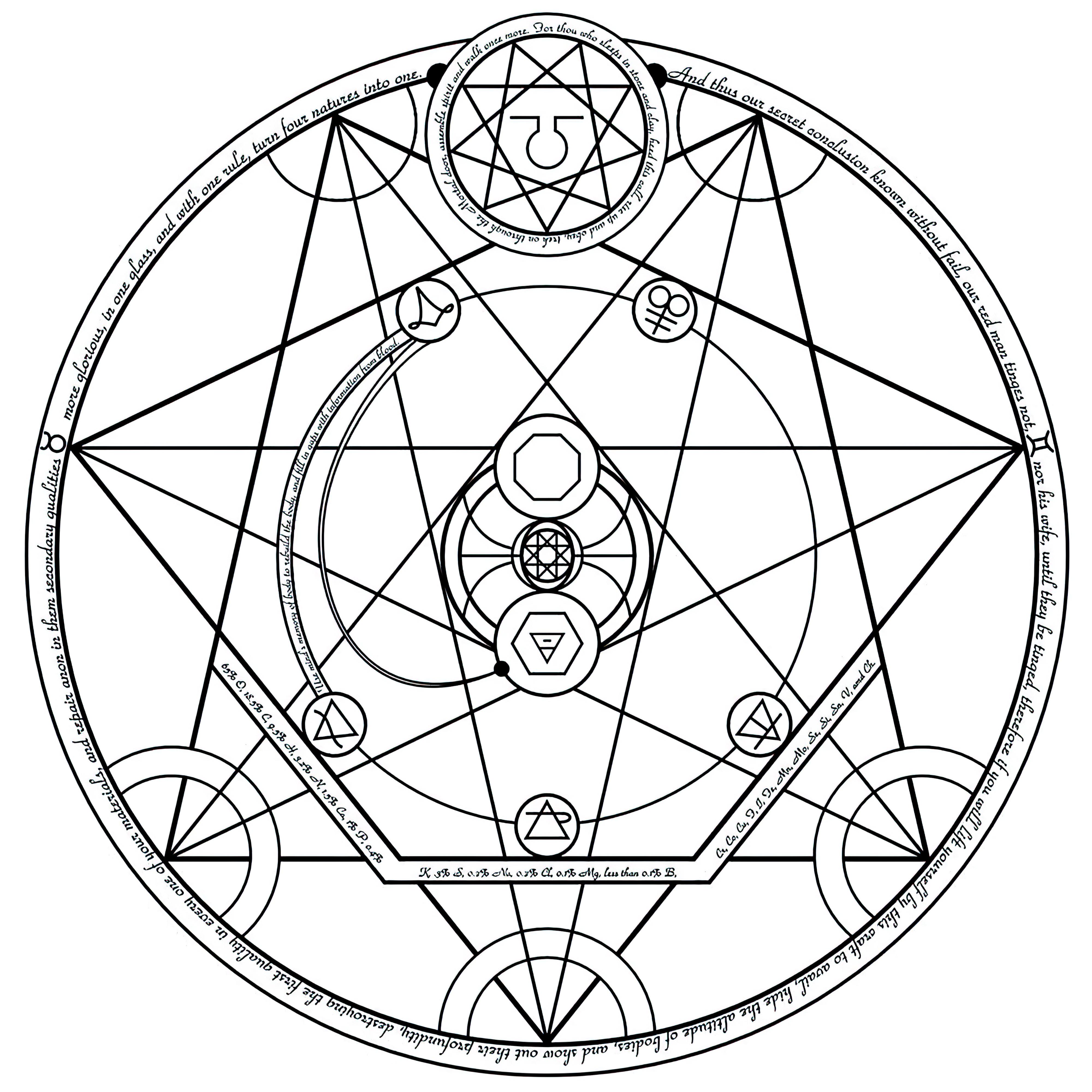
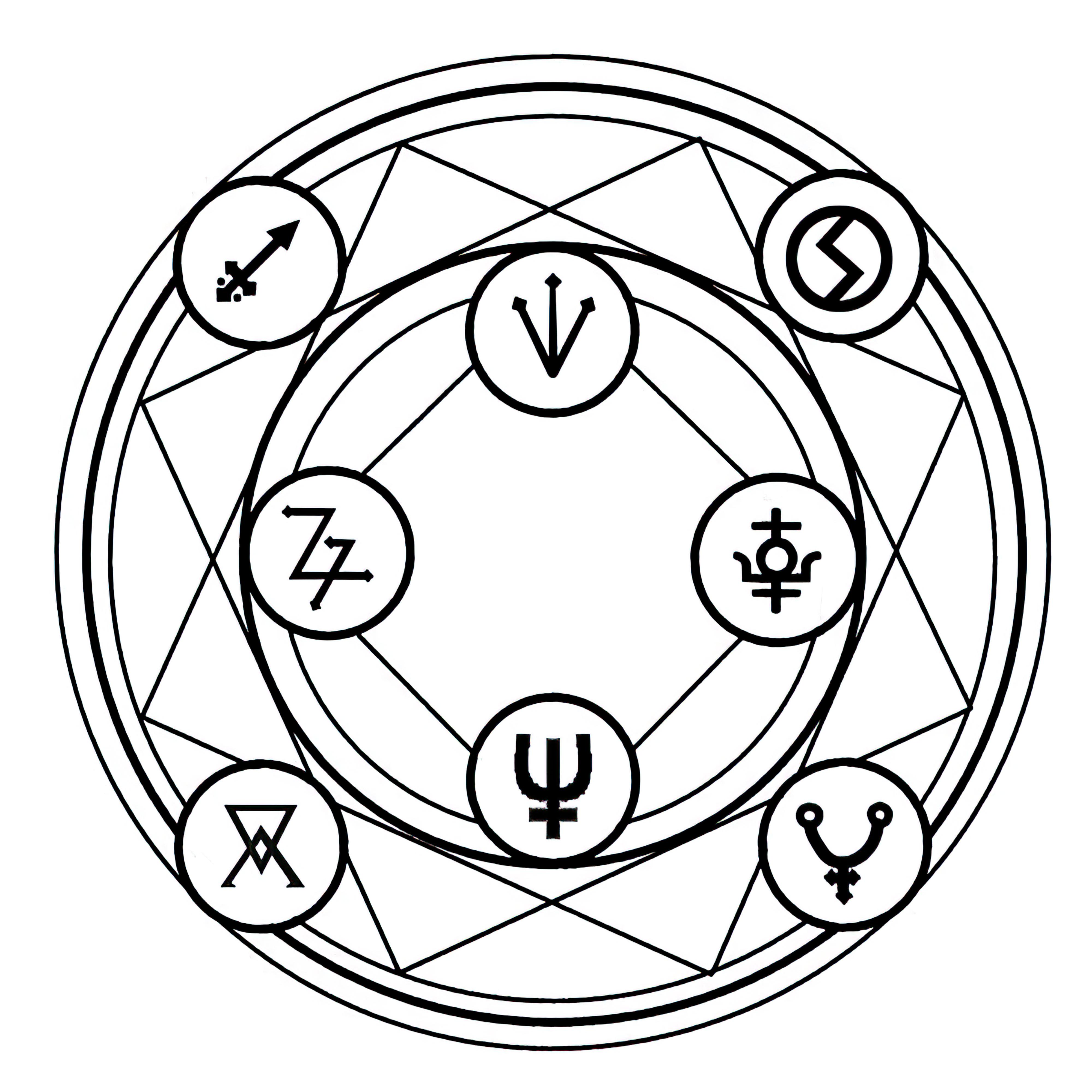
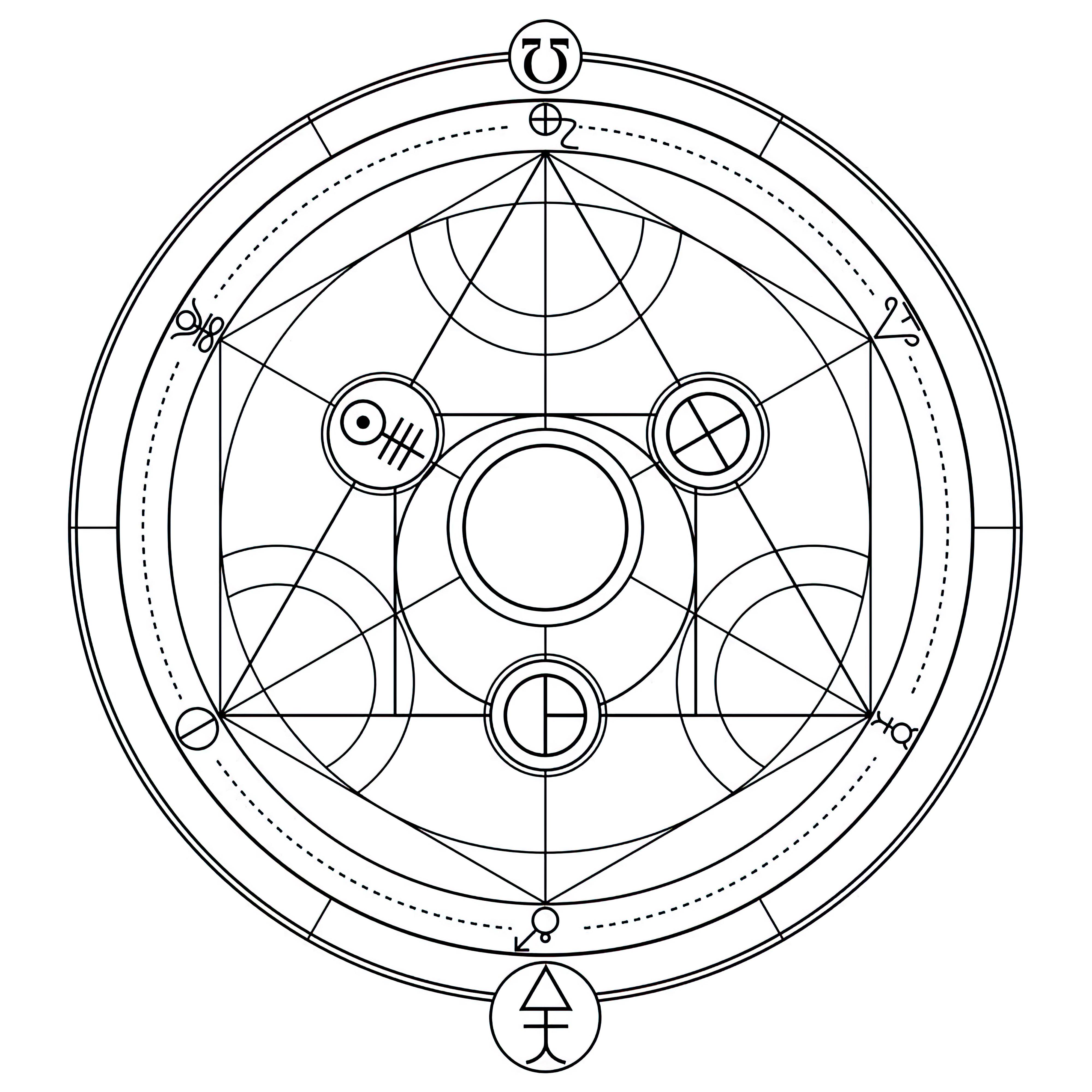
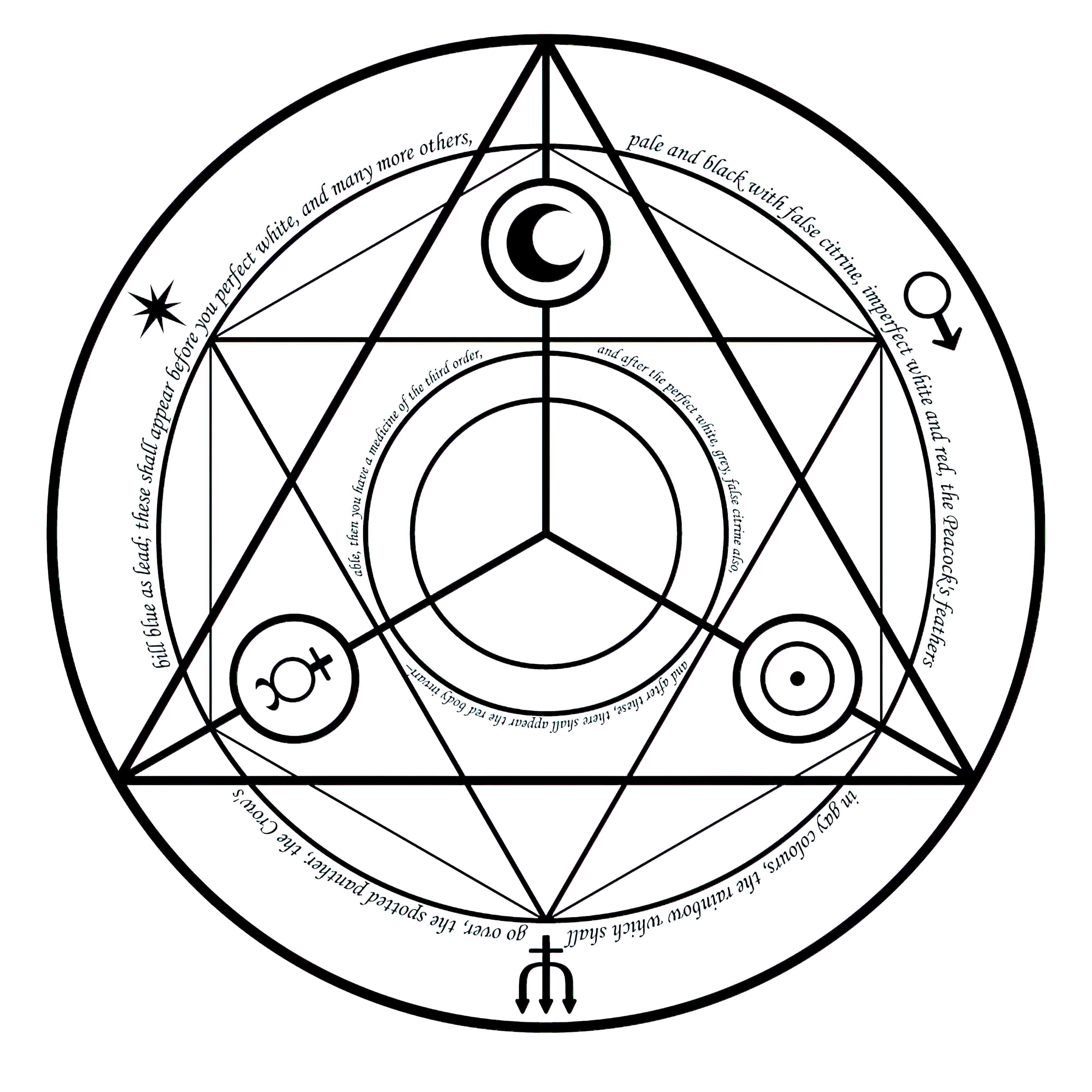


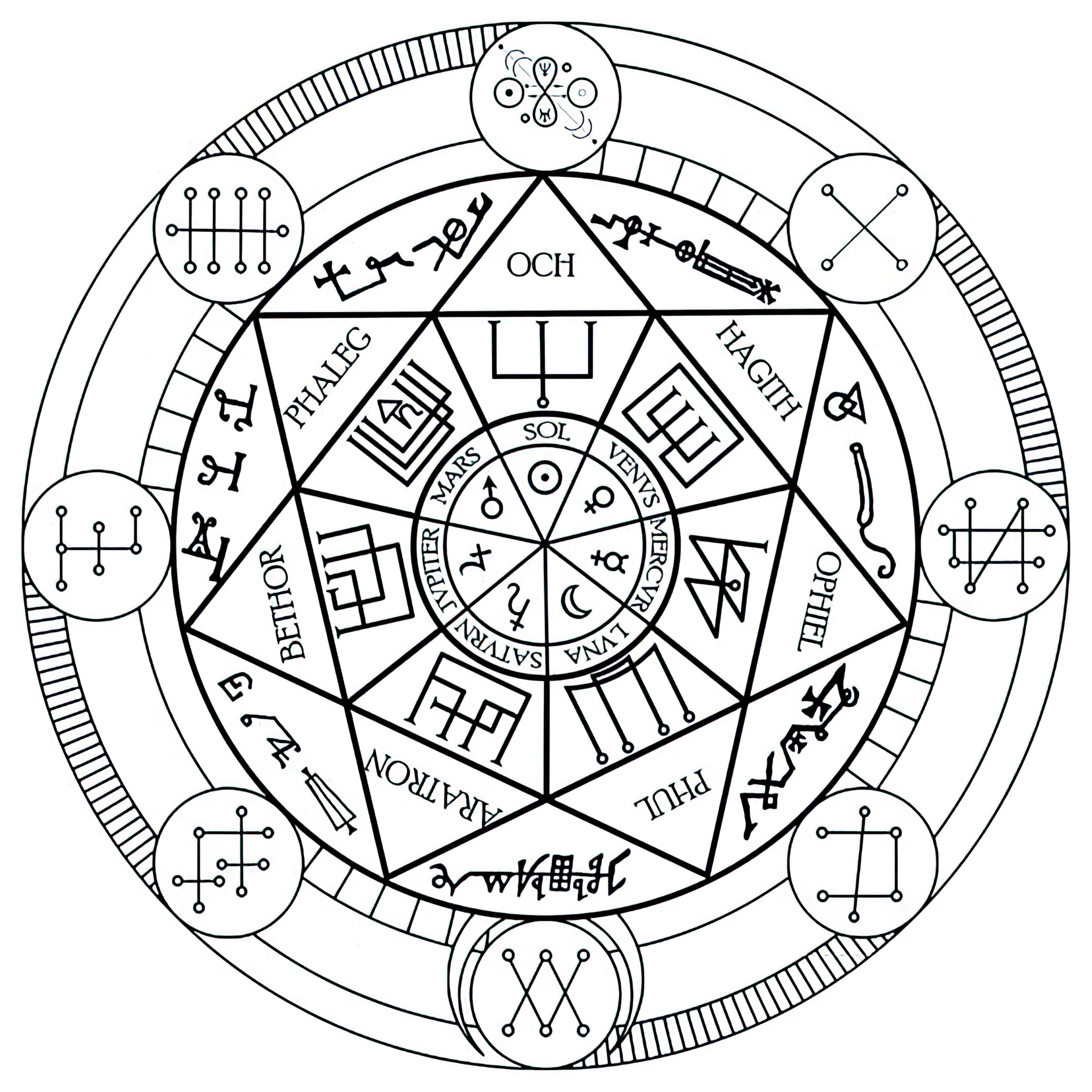
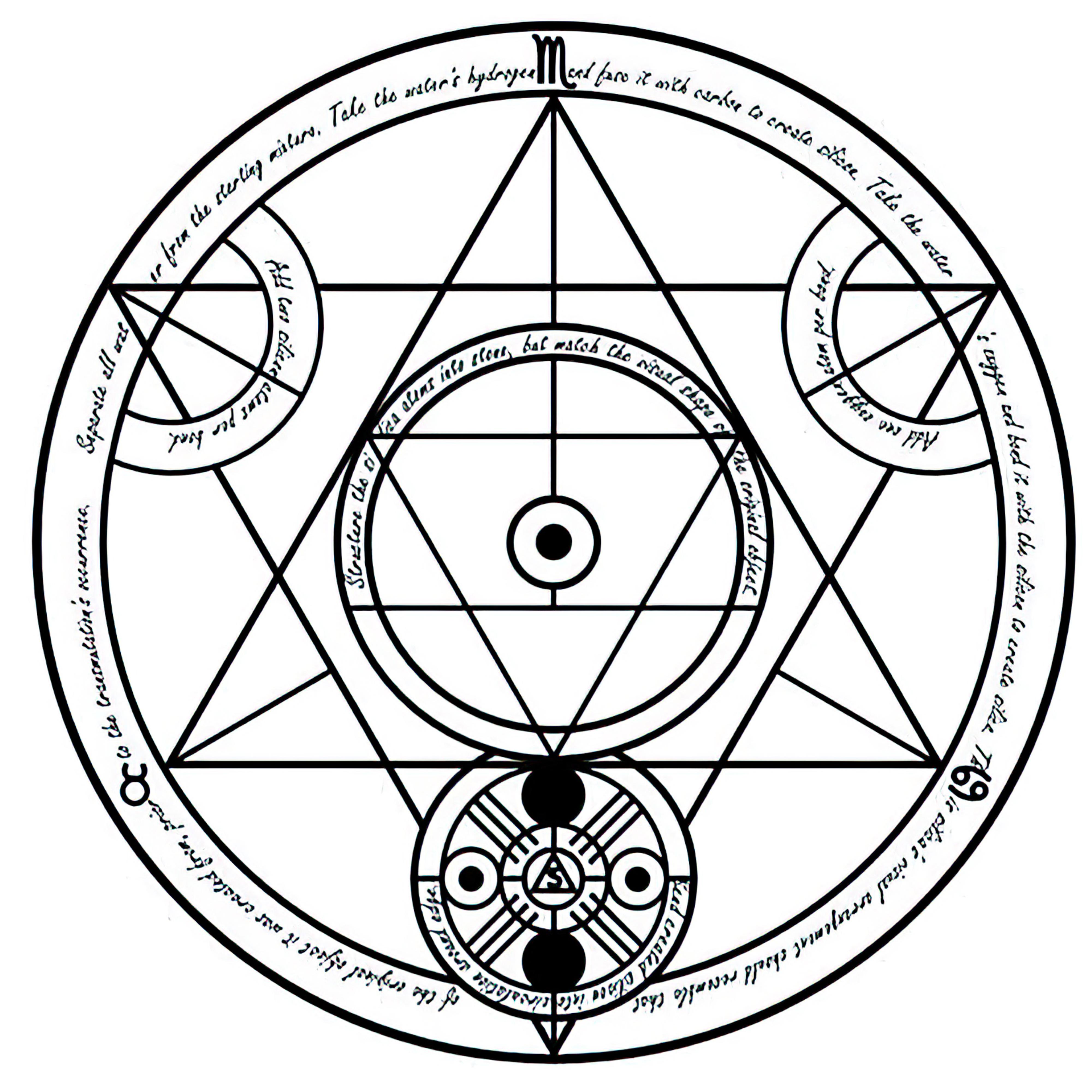
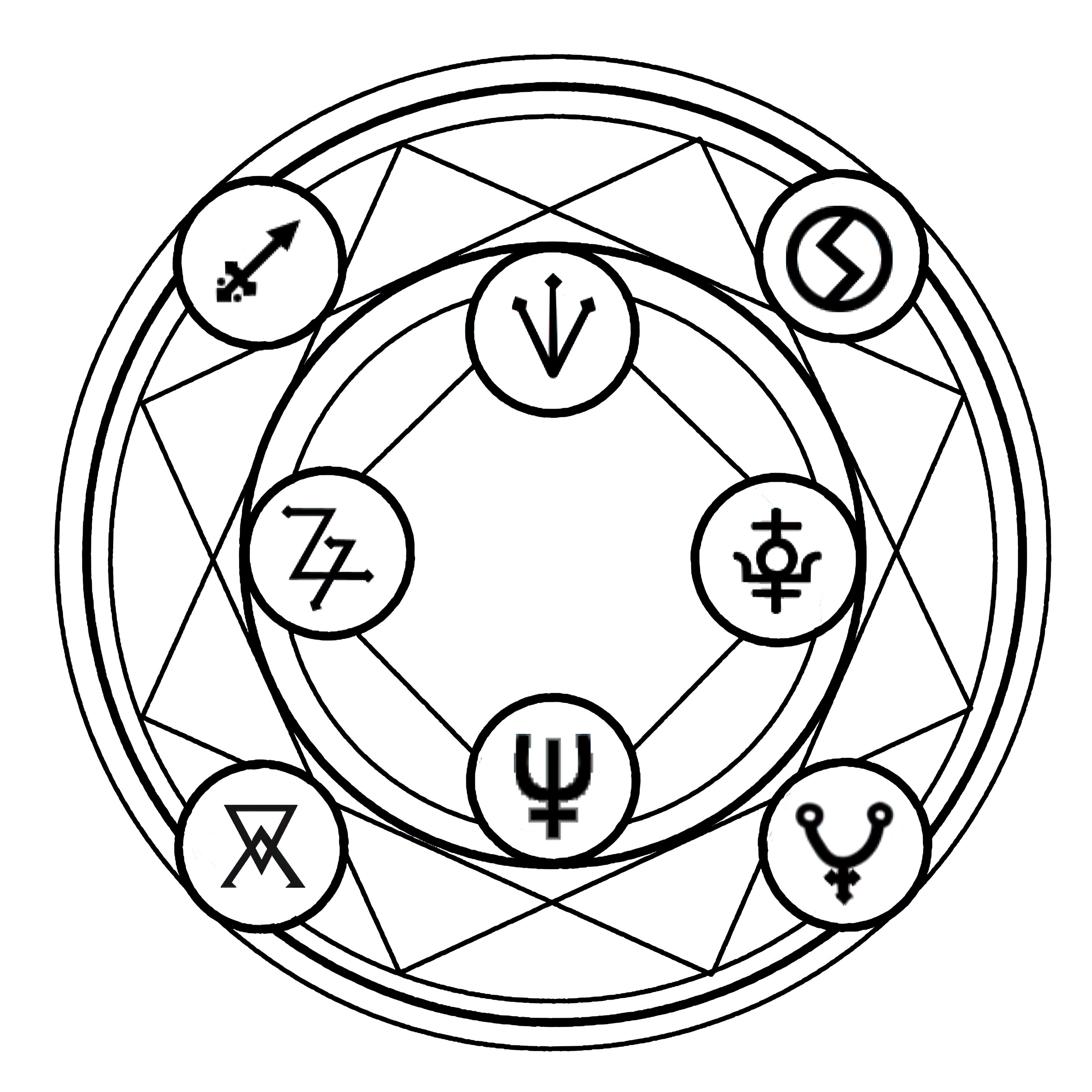


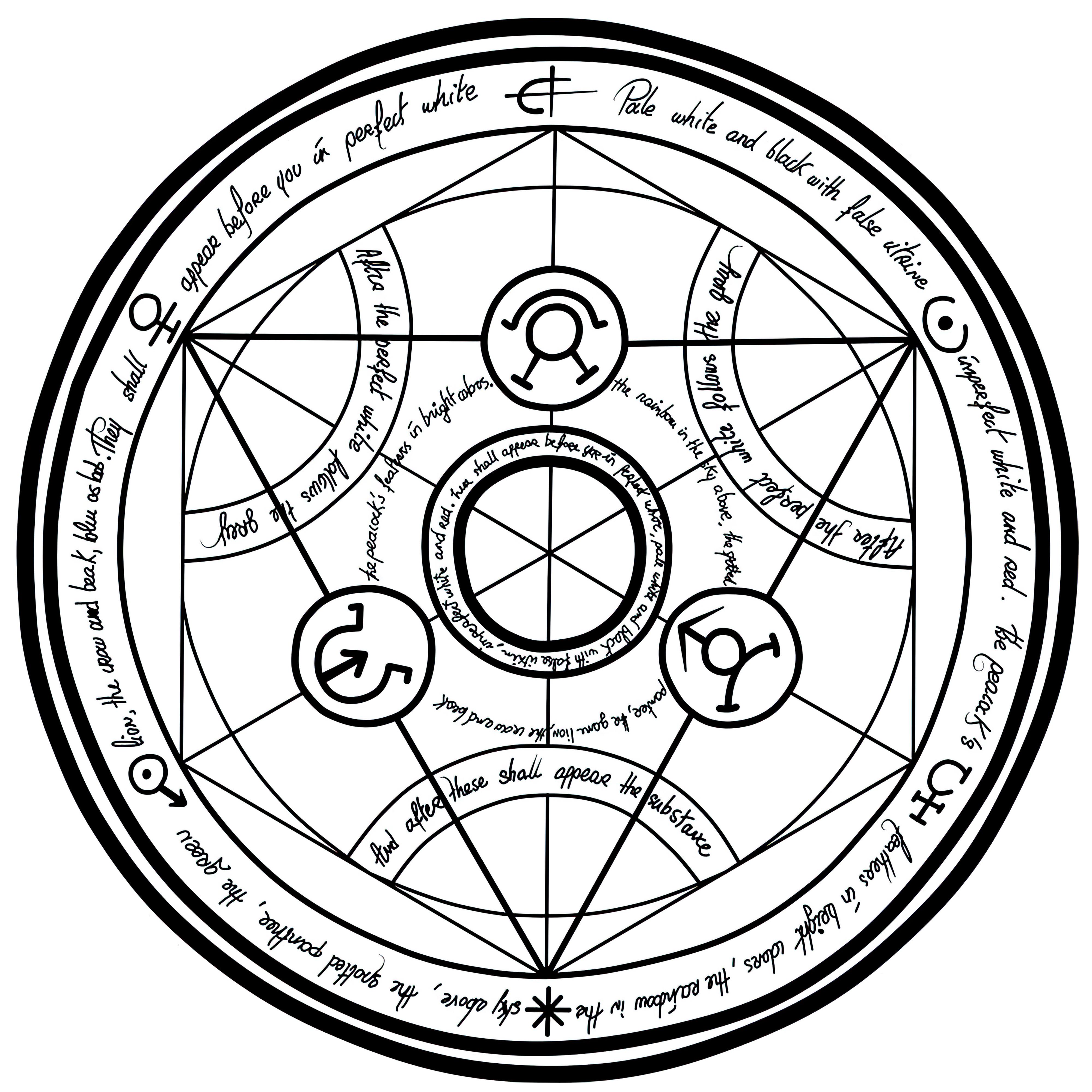


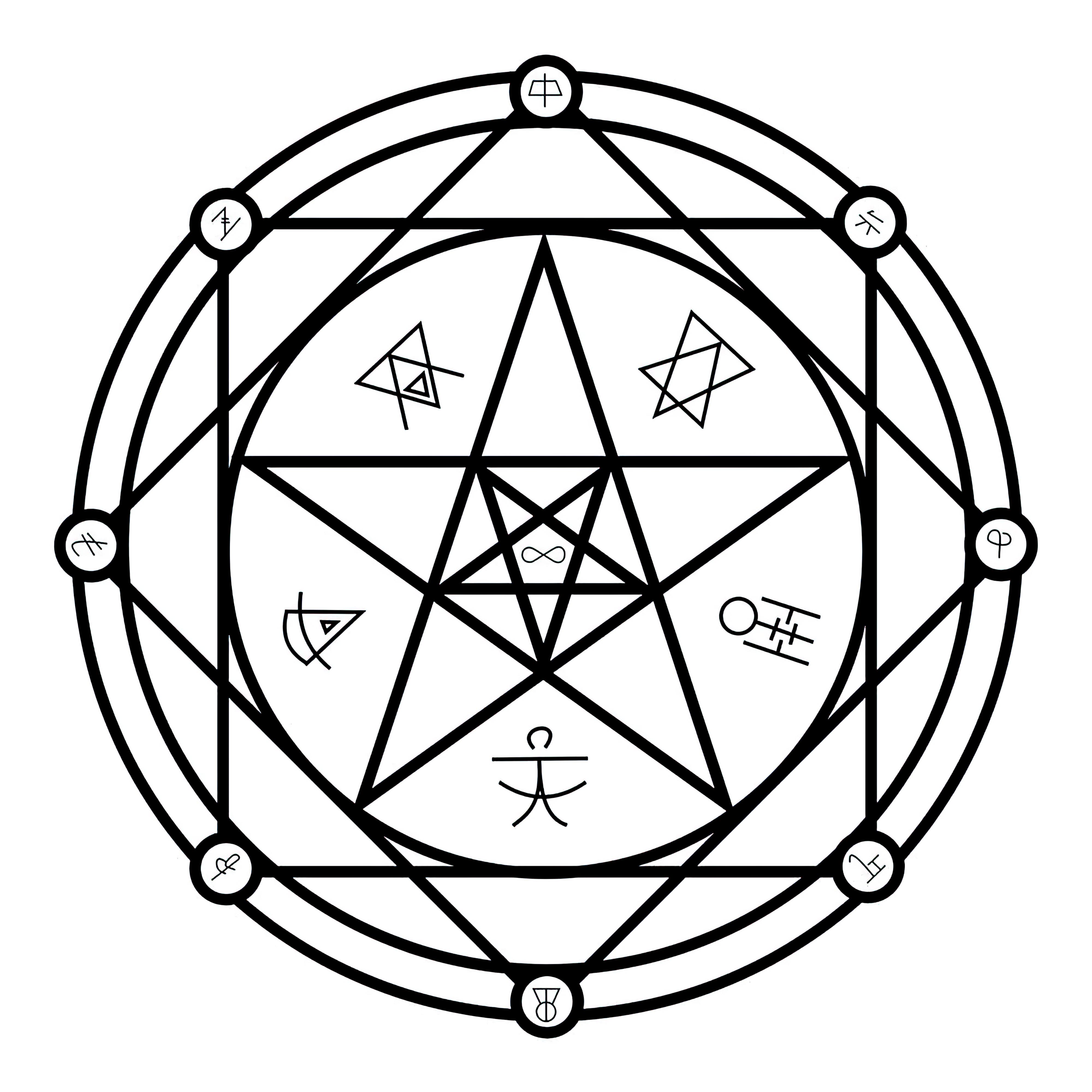
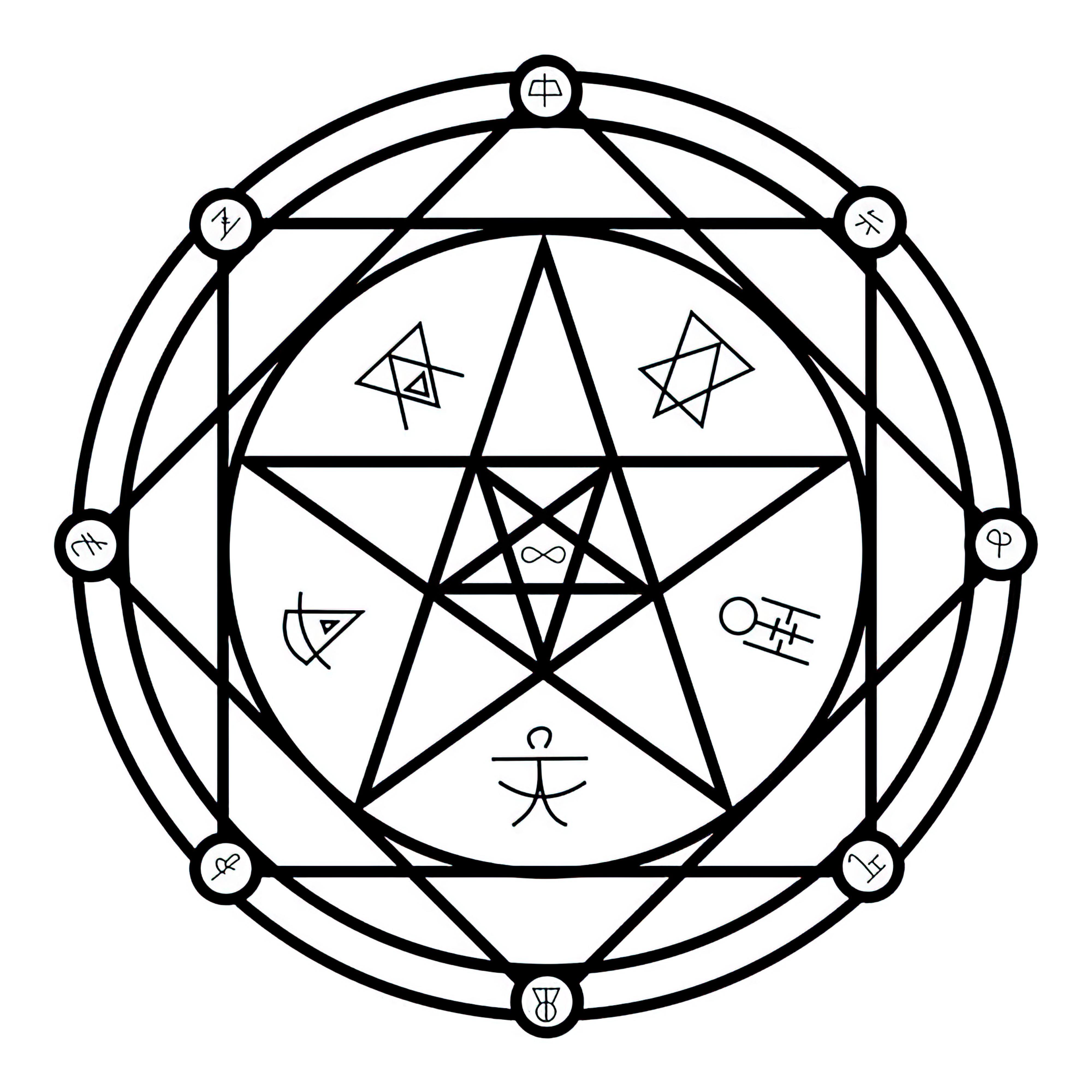
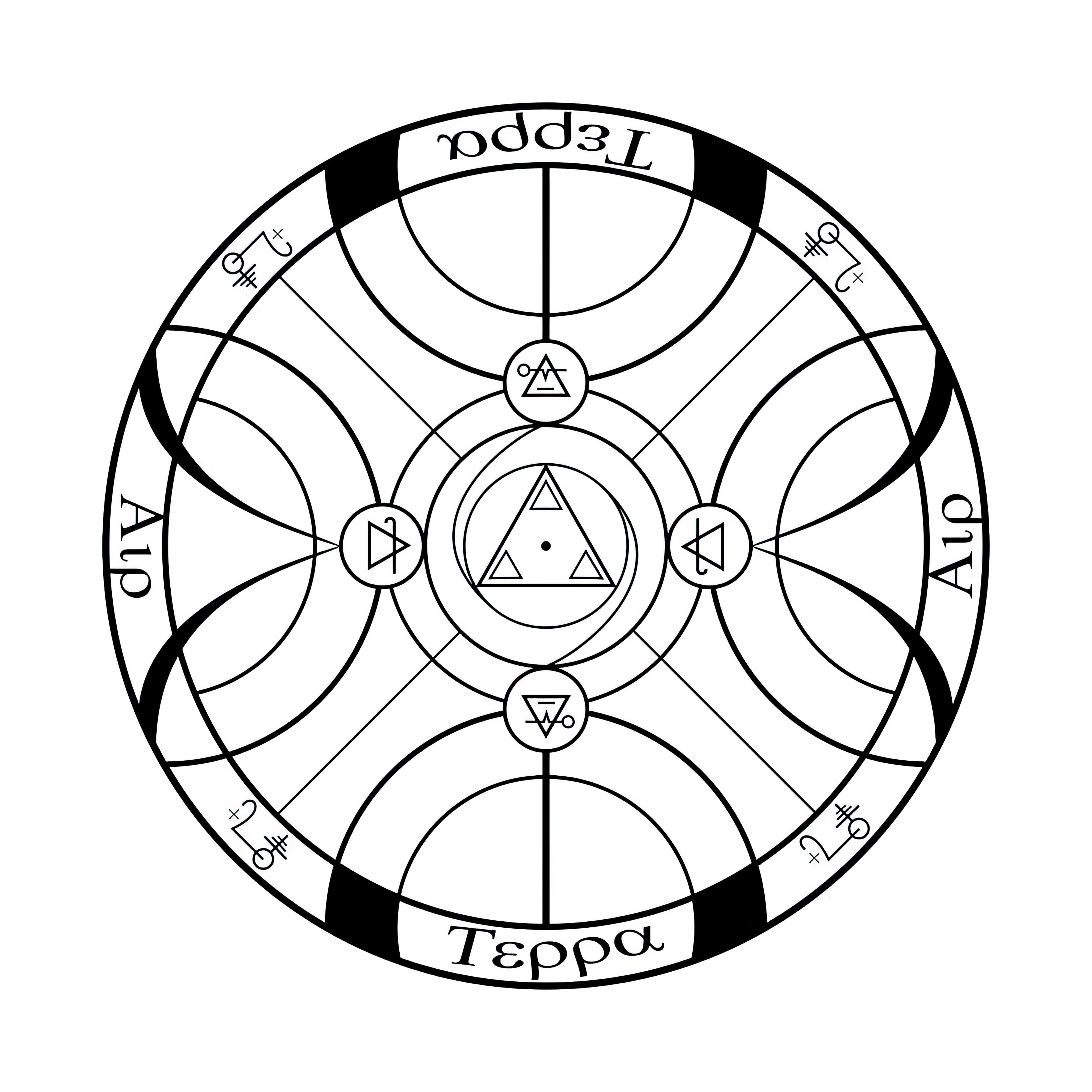
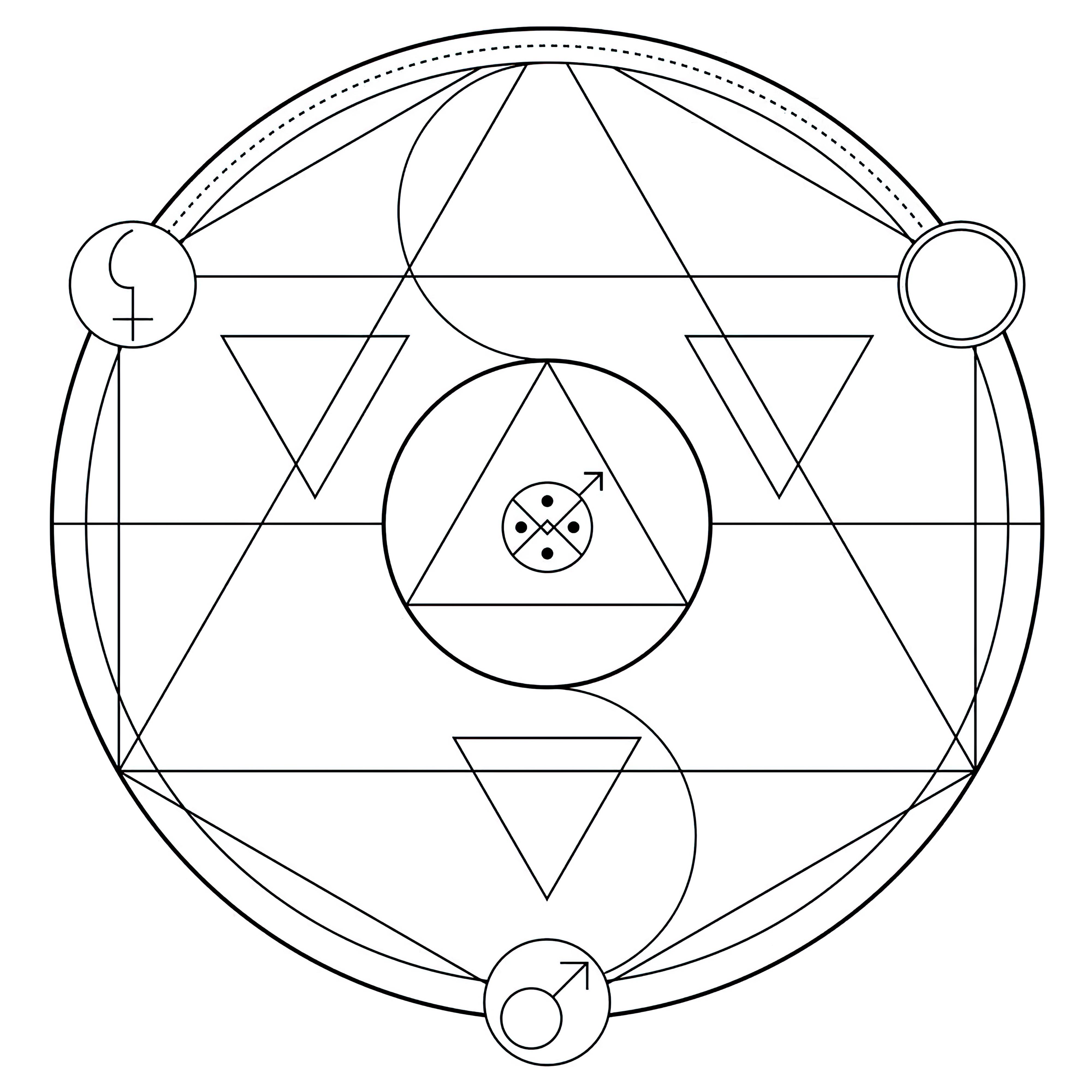
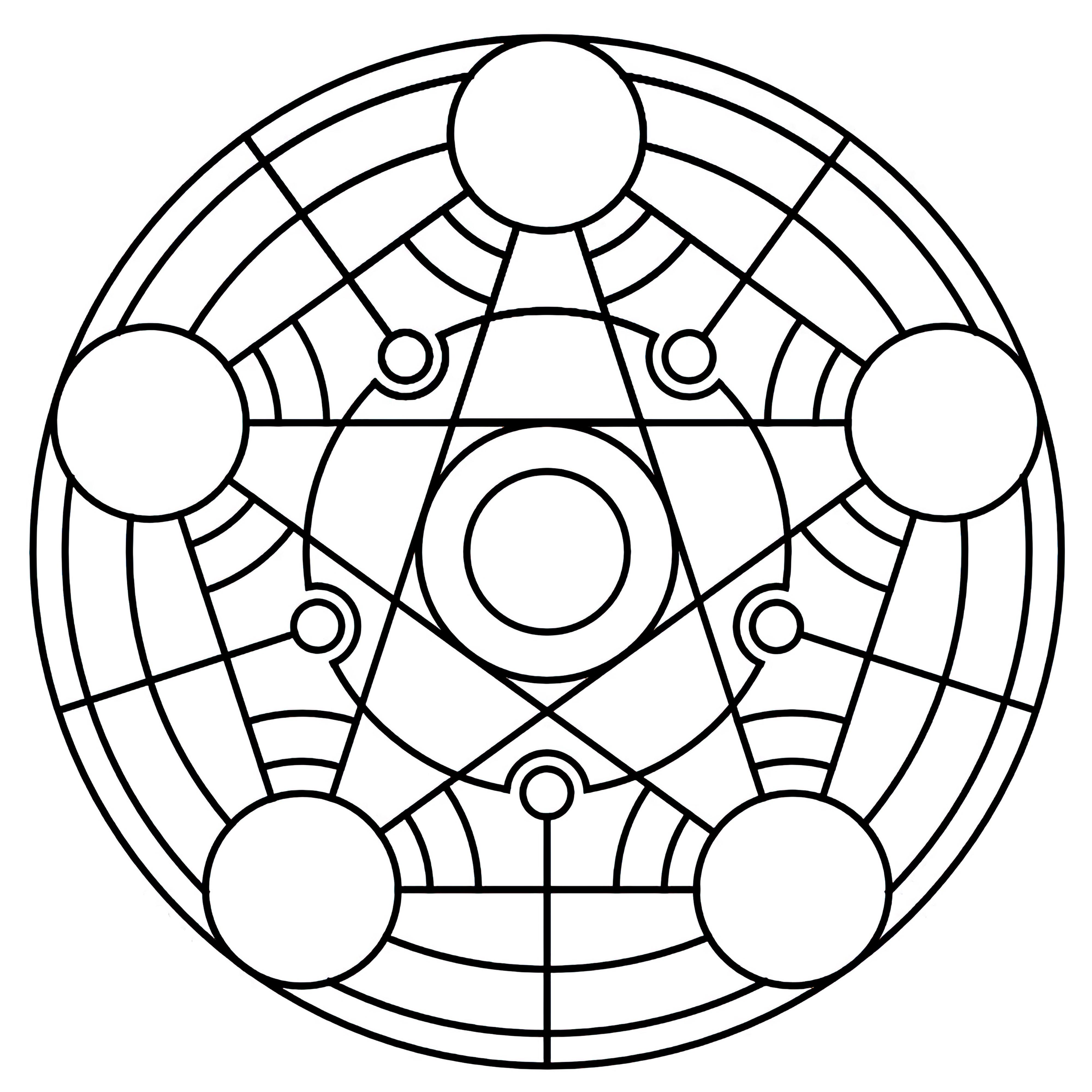
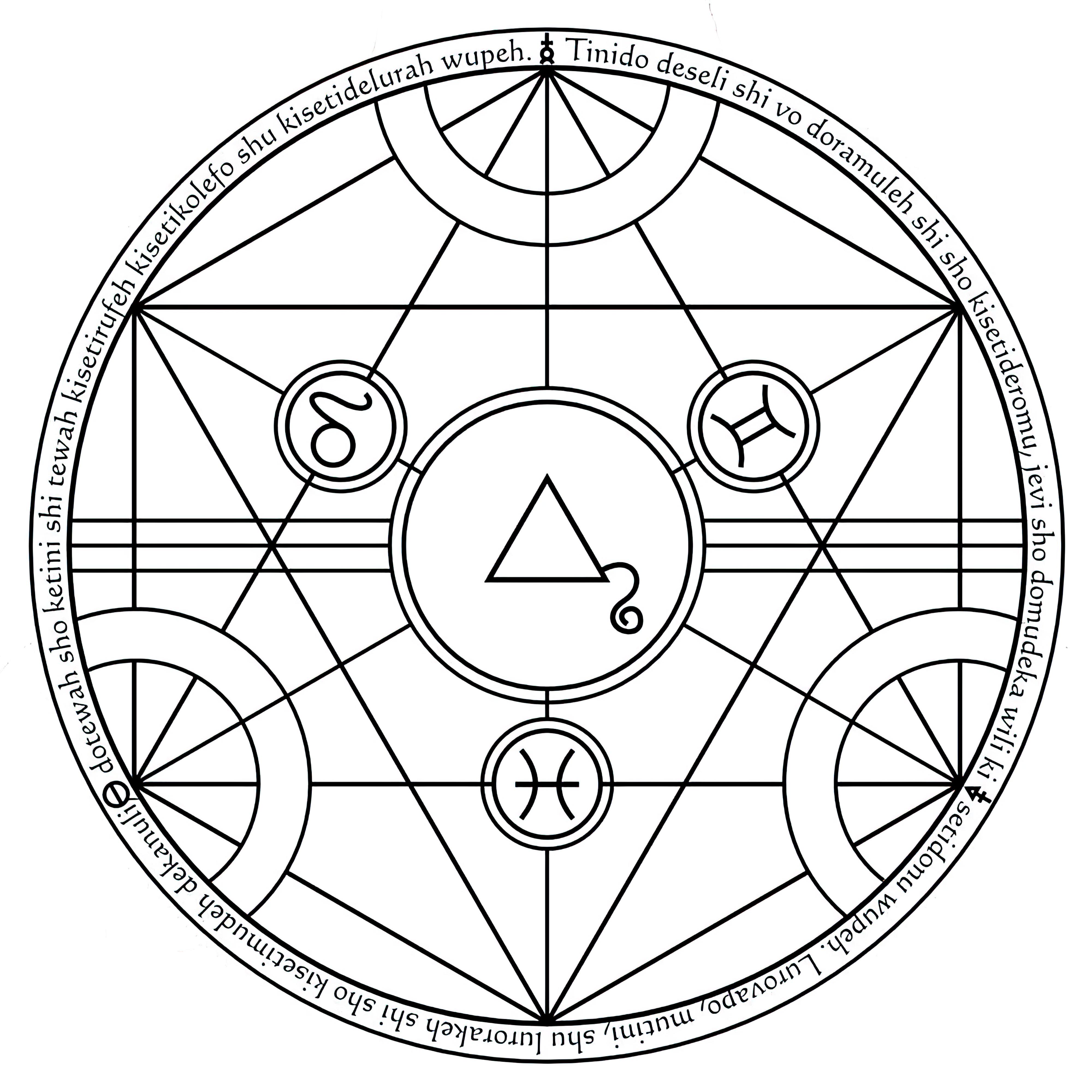
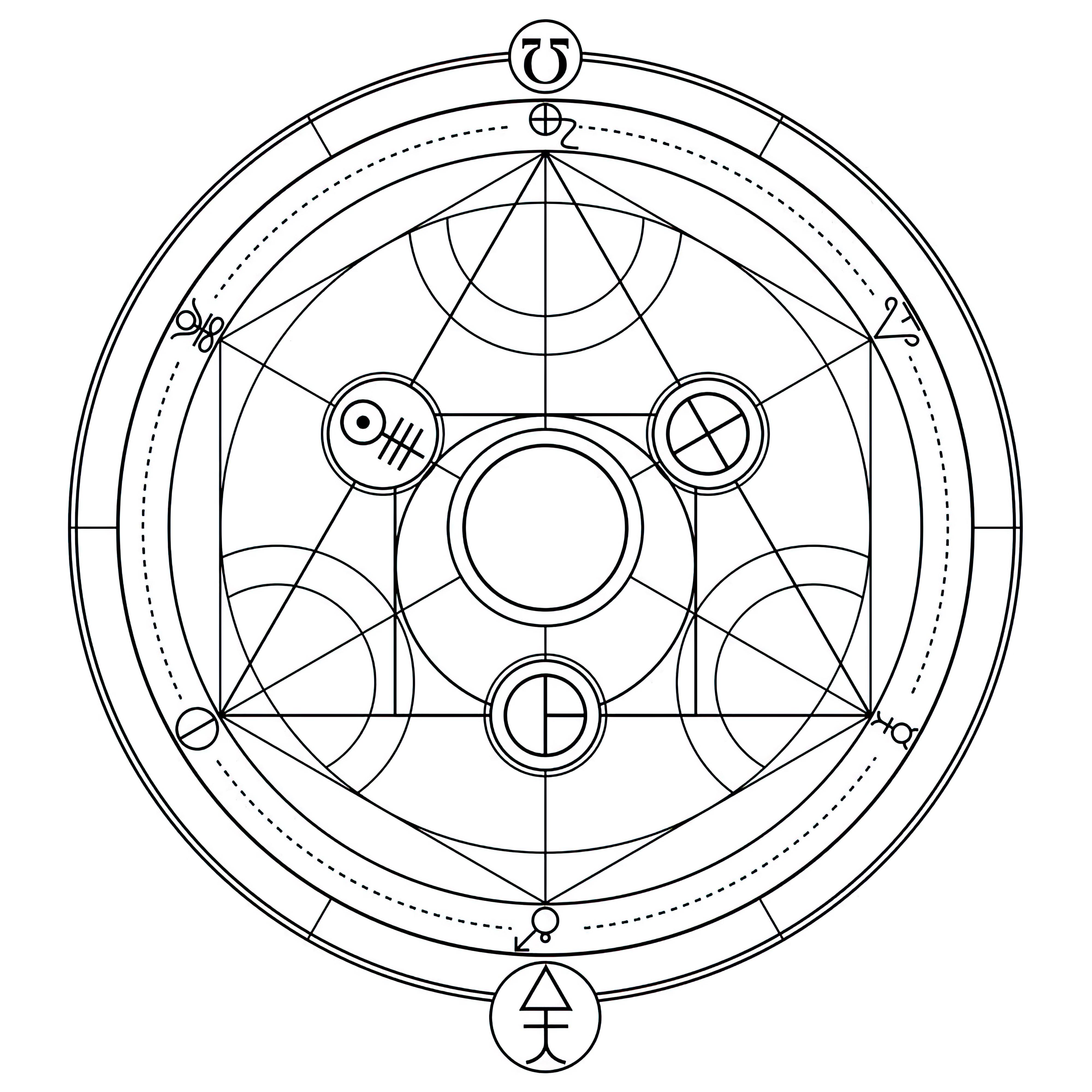
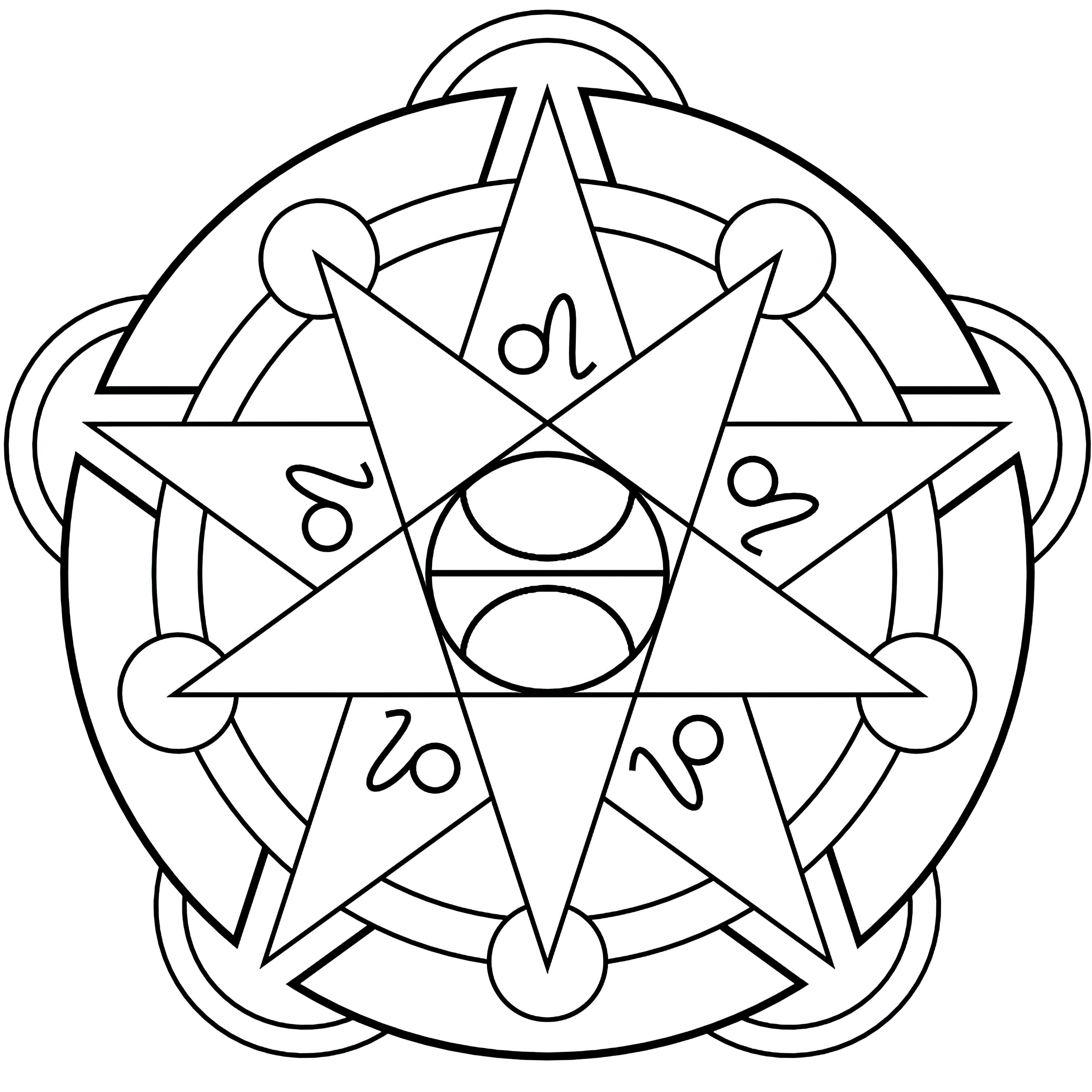

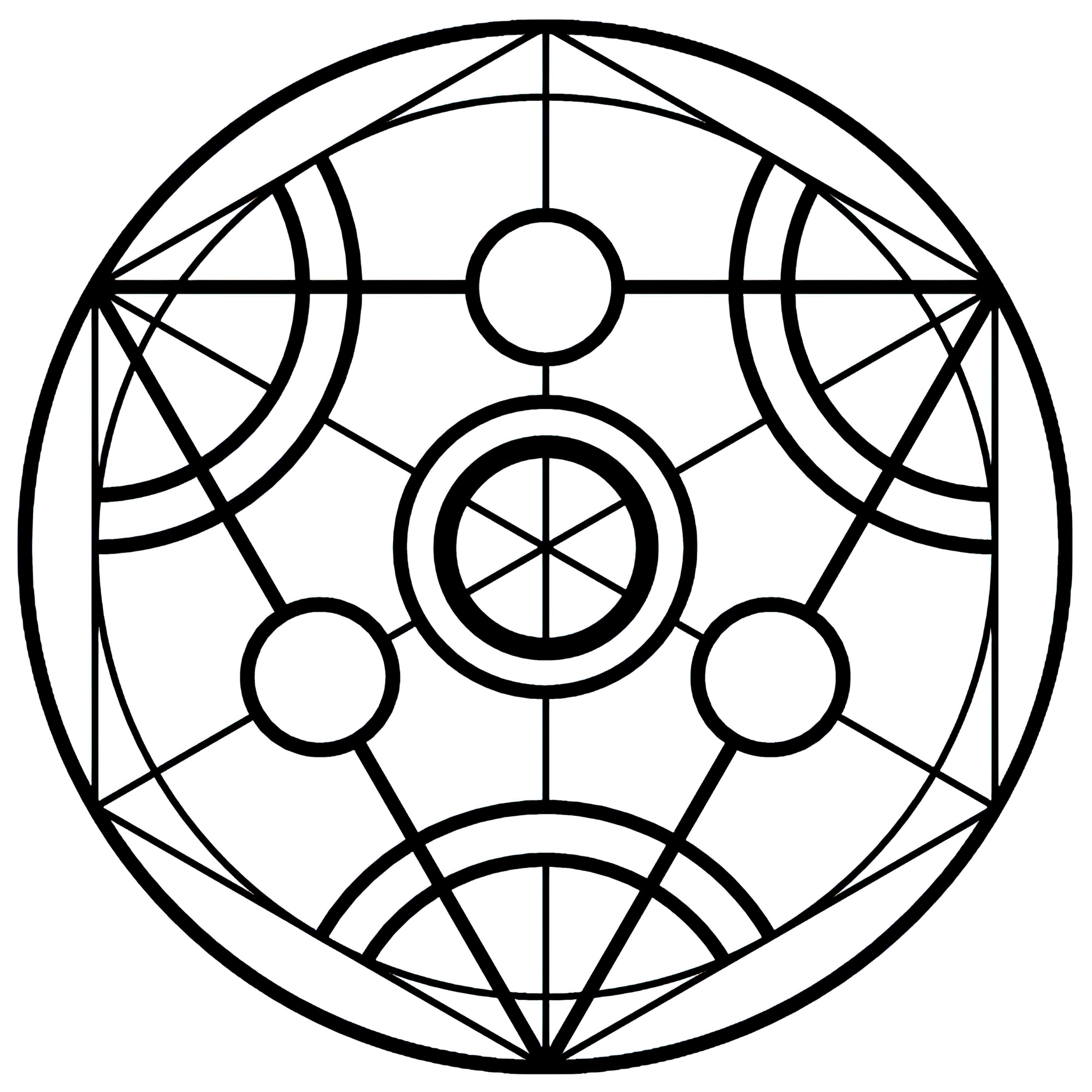
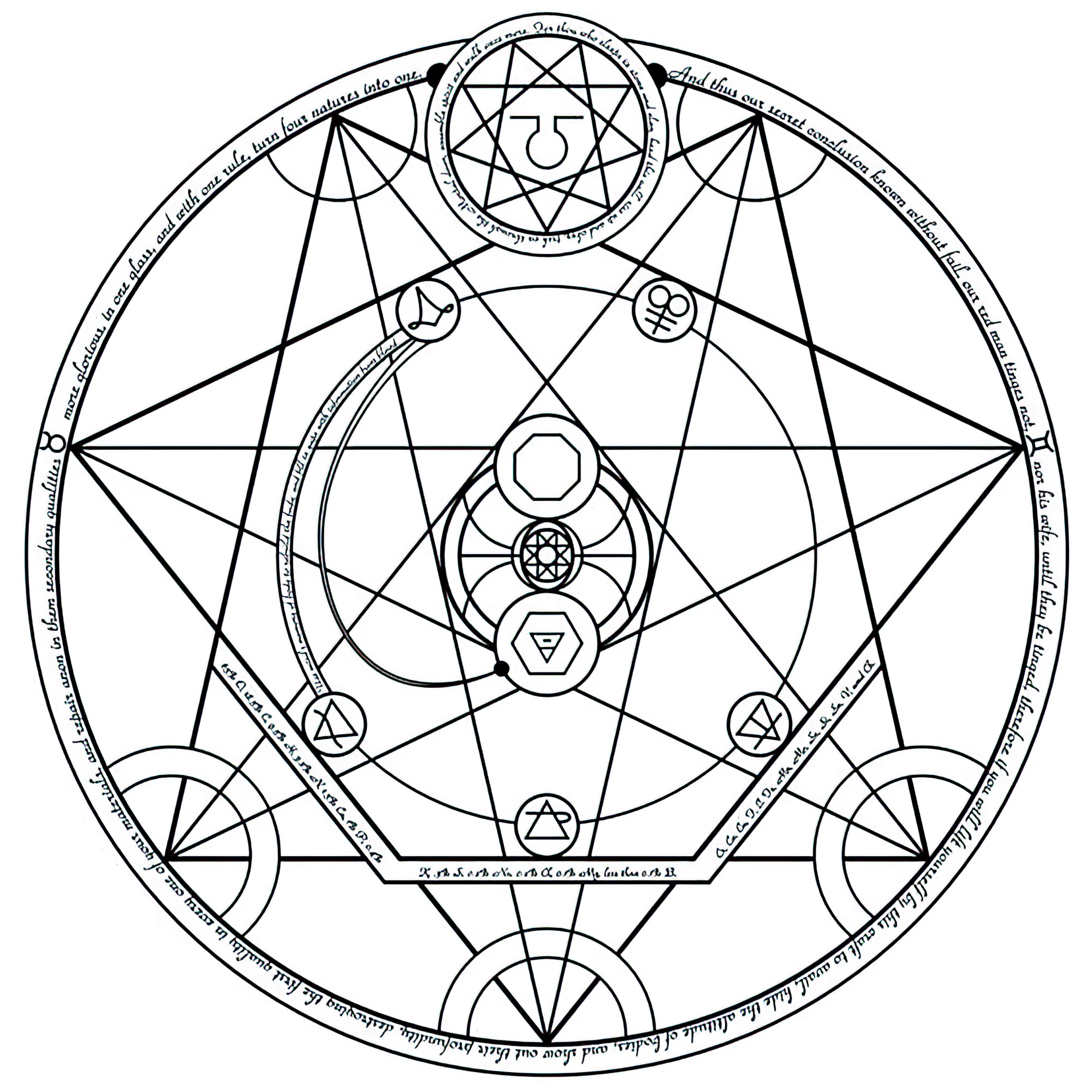
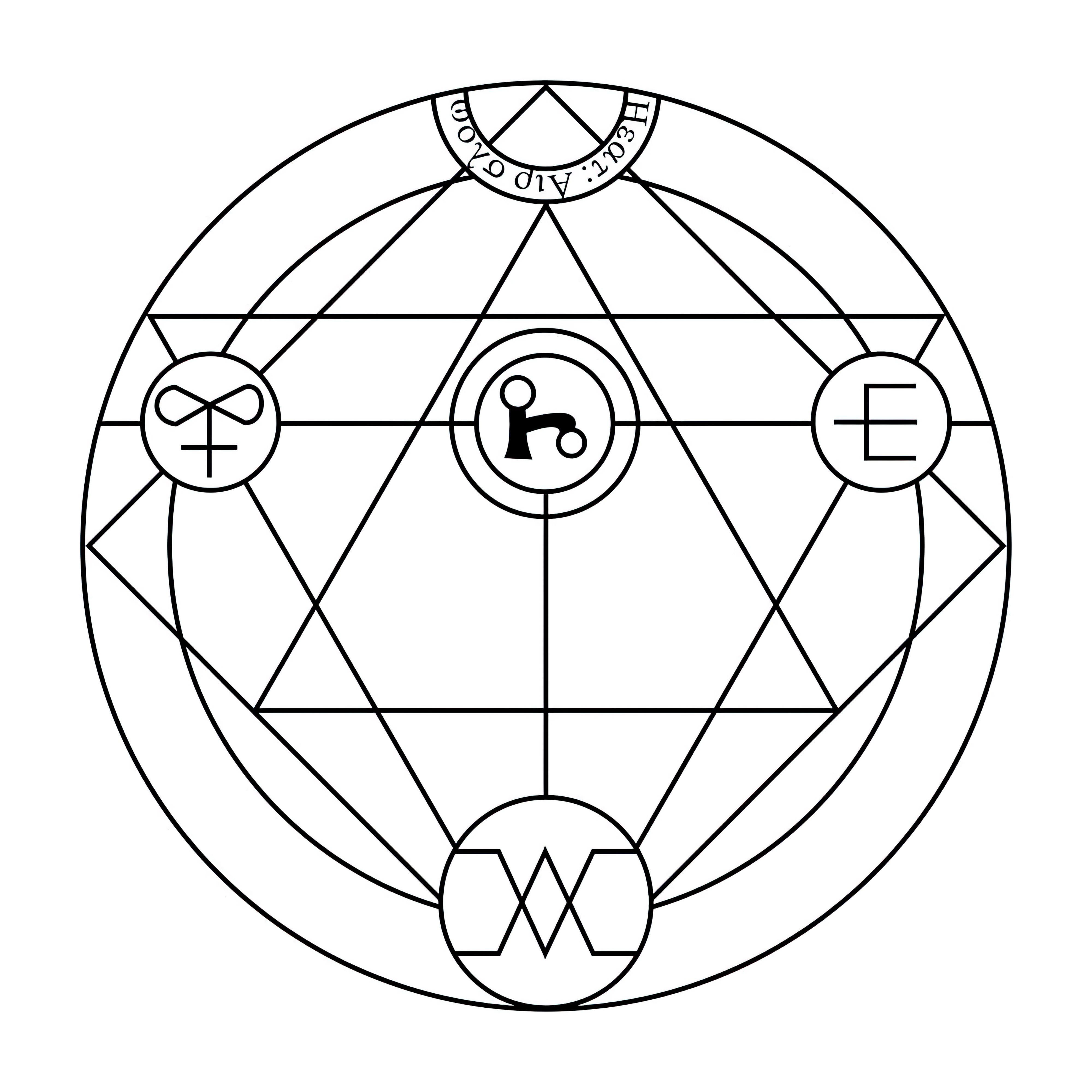
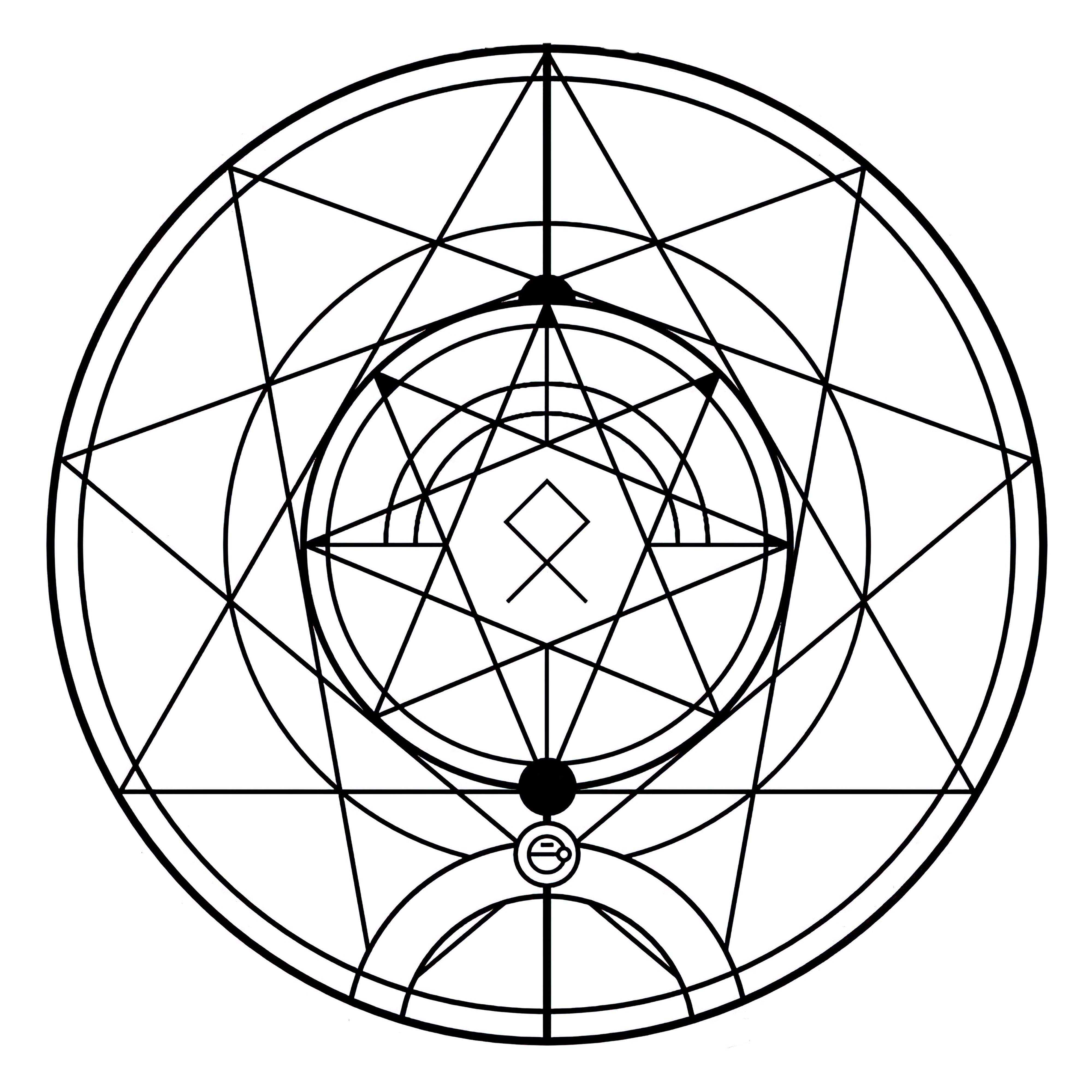

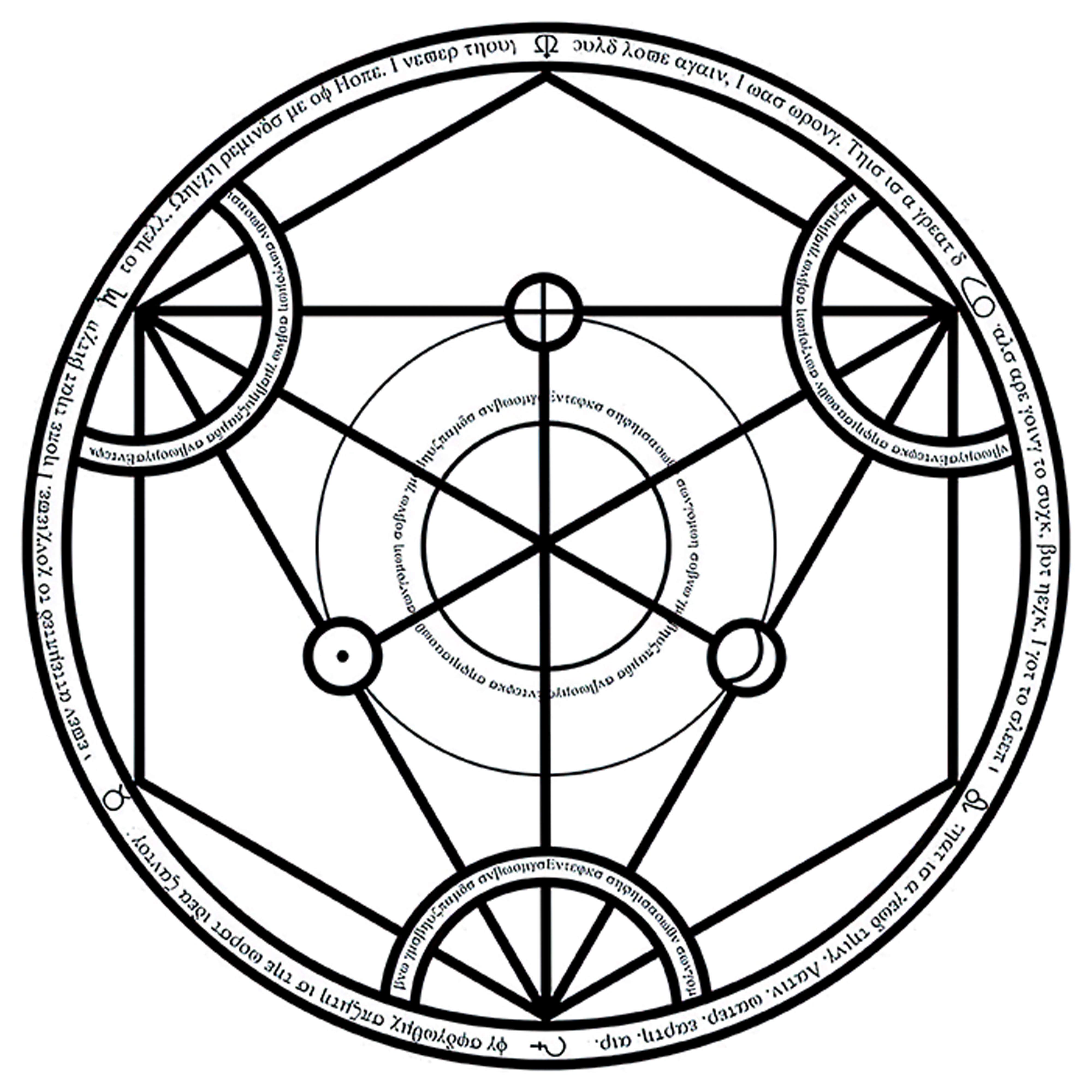
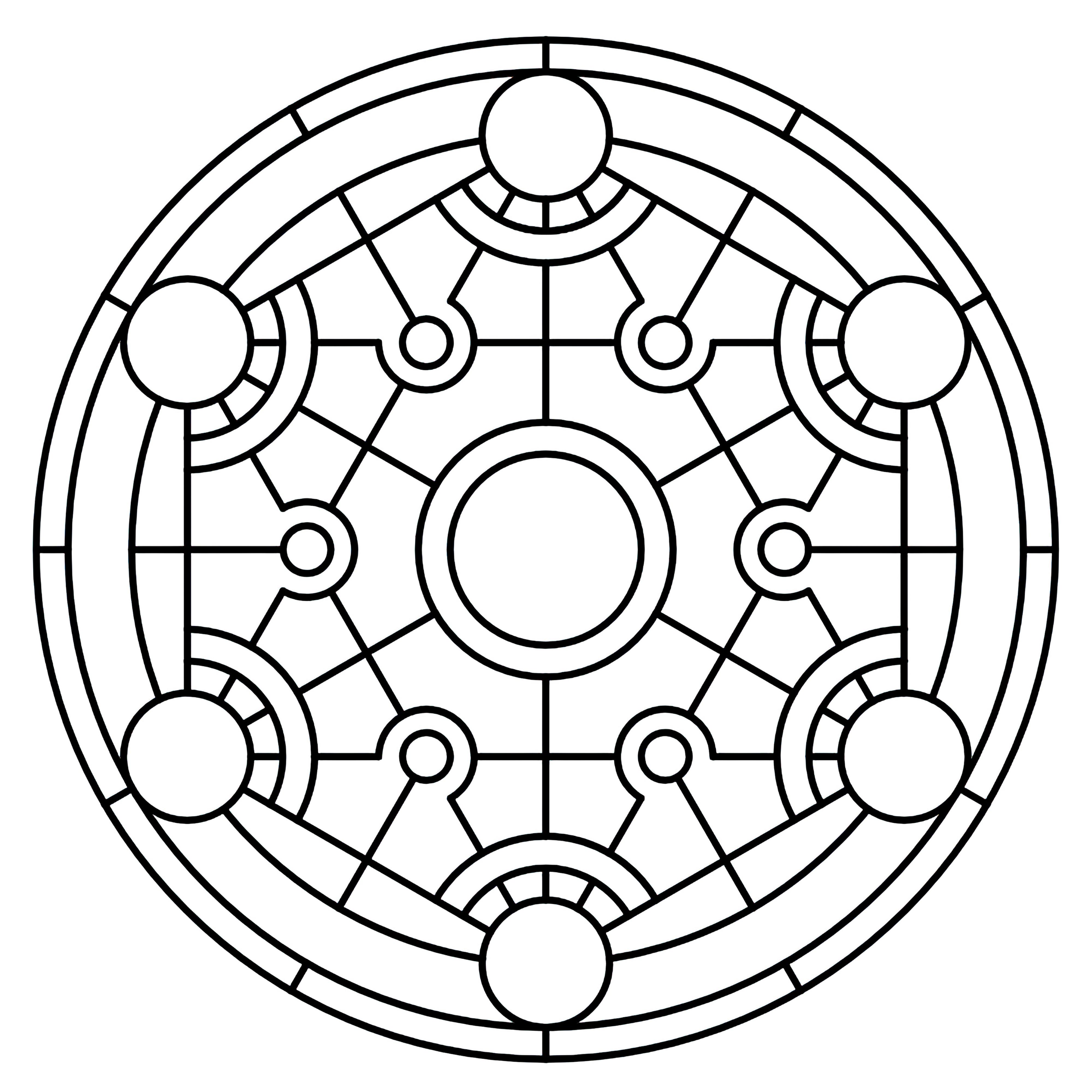
|
alexandrainst/da-ner-base | [
"pytorch",
"tf",
"bert",
"token-classification",
"da",
"dataset:dane",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 78 | null | ---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-roberta-finetuned-combined-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-roberta-finetuned-combined-DS
This model is a fine-tuned version of [l3cube-pune/hing-roberta](https://huggingface.co/l3cube-pune/hing-roberta) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0005
- Accuracy: 0.6840
- Precision: 0.6568
- Recall: 0.6579
- F1: 0.6570
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.927975767245621e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.8684 | 1.0 | 1423 | 0.8762 | 0.6643 | 0.6561 | 0.6209 | 0.6215 |
| 0.6545 | 2.0 | 2846 | 0.8043 | 0.6805 | 0.6497 | 0.6522 | 0.6502 |
| 0.4267 | 3.0 | 4269 | 1.1337 | 0.6966 | 0.6668 | 0.6699 | 0.6680 |
| 0.2762 | 4.0 | 5692 | 1.6520 | 0.6784 | 0.6558 | 0.6571 | 0.6553 |
| 0.1535 | 5.0 | 7115 | 2.0005 | 0.6840 | 0.6568 | 0.6579 | 0.6570 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
DavidAMcIntosh/DialoGPT-small-rick | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Fined-tuned BERT trained on 6500 images with warmup, increased epoch and decreased learning rate |
DavidAMcIntosh/small-rick | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### Riker Doll on Stable Diffusion
This is the `<rikerdoll>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
Davlan/bert-base-multilingual-cased-finetuned-amharic | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 109 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-basil
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-basil
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2272
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8527 | 1.0 | 800 | 1.4425 |
| 1.4878 | 2.0 | 1600 | 1.2740 |
| 1.3776 | 3.0 | 2400 | 1.2273 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Tokenizers 0.12.1
|
Davlan/bert-base-multilingual-cased-finetuned-hausa | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 151 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Davlan/bert-base-multilingual-cased-finetuned-luo | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-09-10T13:59:36Z | ---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| learning_rate | 0.0010000000474974513 |
| decay | 0.0 |
| beta_1 | 0.8999999761581421 |
| beta_2 | 0.9990000128746033 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details> |
Davlan/distilbert-base-multilingual-cased-masakhaner | [
"pytorch",
"tf",
"distilbert",
"token-classification",
"arxiv:2103.11811",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
language: en
thumbnail: http://www.huggingtweets.com/apesahoy-dril_gpt2-stefgotbooted/1662822110359/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1514451221054173189/BWP3wqQj_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1196519479364268034/5QpniWSP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1285982491636125701/IW0v36am_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">wint but Al & Humongous Ape MP & Agree to disagree 🍊 🍊 🍊</div>
<div style="text-align: center; font-size: 14px;">@apesahoy-dril_gpt2-stefgotbooted</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from wint but Al & Humongous Ape MP & Agree to disagree 🍊 🍊 🍊.
| Data | wint but Al | Humongous Ape MP | Agree to disagree 🍊 🍊 🍊 |
| --- | --- | --- | --- |
| Tweets downloaded | 3247 | 3247 | 3194 |
| Retweets | 49 | 191 | 1674 |
| Short tweets | 57 | 607 | 445 |
| Tweets kept | 3141 | 2449 | 1075 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2eu4r1qp/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @apesahoy-dril_gpt2-stefgotbooted's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2k50hu4q) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2k50hu4q/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/apesahoy-dril_gpt2-stefgotbooted')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Davlan/distilbert-base-multilingual-cased-ner-hrl | [
"pytorch",
"tf",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible",
"has_space"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 123,856 | null | ---
language: en
thumbnail: http://www.huggingtweets.com/altgazza-apesahoy-stefgotbooted/1662823067384/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1567984237432770561/PVmuvVJj_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1196519479364268034/5QpniWSP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1285982491636125701/IW0v36am_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">TONY BELL & Humongous Ape MP & Agree to disagree 🍊 🍊 🍊</div>
<div style="text-align: center; font-size: 14px;">@altgazza-apesahoy-stefgotbooted</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from TONY BELL & Humongous Ape MP & Agree to disagree 🍊 🍊 🍊.
| Data | TONY BELL | Humongous Ape MP | Agree to disagree 🍊 🍊 🍊 |
| --- | --- | --- | --- |
| Tweets downloaded | 3247 | 3247 | 3194 |
| Retweets | 24 | 191 | 1674 |
| Short tweets | 287 | 607 | 445 |
| Tweets kept | 2936 | 2449 | 1075 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/aiq4cmhm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @altgazza-apesahoy-stefgotbooted's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6lf780ul) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6lf780ul/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/altgazza-apesahoy-stefgotbooted')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Davlan/m2m100_418M-eng-yor-mt | [
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:2103.08647",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"M2M100ForConditionalGeneration"
],
"model_type": "m2m_100",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
title: Daimond Price
emoji: 💩
colorFrom: blue
colorTo: green
sdk: streamlit
sdk_version: 1.10.0
app_file: app.py
pinned: false
license: cc-by-3.0
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
Davlan/m2m100_418M-yor-eng-mt | [
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:2103.08647",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"M2M100ForConditionalGeneration"
],
"model_type": "m2m_100",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1420389646492635139/alpfnIFD_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1065129059514933248/3hBEw0Rr_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1196519479364268034/5QpniWSP_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mirror Celeb & GroanBot - Daily Dad Jokes & Puns & Humongous Ape MP</div>
<div style="text-align: center; font-size: 14px;">@apesahoy-groanbot-mirrorceleb</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mirror Celeb & GroanBot - Daily Dad Jokes & Puns & Humongous Ape MP.
| Data | Mirror Celeb | GroanBot - Daily Dad Jokes & Puns | Humongous Ape MP |
| --- | --- | --- | --- |
| Tweets downloaded | 3250 | 3250 | 3247 |
| Retweets | 257 | 1 | 191 |
| Short tweets | 23 | 0 | 607 |
| Tweets kept | 2970 | 3249 | 2449 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1t25sghh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @apesahoy-groanbot-mirrorceleb's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/35jtsar3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/35jtsar3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/apesahoy-groanbot-mirrorceleb')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Davlan/xlm-roberta-base-finetuned-shona | [
"pytorch",
"xlm-roberta",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- davanstrien/autotrain-data-encyclopedia_britannica
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 3.1471897890349294
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1423853554
- CO2 Emissions (in grams): 3.1472
## Validation Metrics
- Loss: 0.033
- Accuracy: 0.993
- Precision: 0.993
- Recall: 1.000
- AUC: 0.996
- F1: 0.996 |
DecafNosebleed/scarabot-model | [
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: turkish-poem-generation
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# turkish-poem-generation
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 7.2815
- Validation Loss: 7.2658
- Epoch: 5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 2660, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.02}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.2815 | 7.2657 | 0 |
| 7.2815 | 7.2659 | 1 |
| 7.2817 | 7.2653 | 2 |
| 7.2815 | 7.2657 | 3 |
| 7.2816 | 7.2660 | 4 |
| 7.2815 | 7.2658 | 5 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Declan/Breitbart_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
tags:
- image-classification
- keras
- tf
metrics:
- accuracy
license: cc-by-sa-4.0
---
Model for MNIST on TensorFlow. |
Declan/Breitbart_model_v6 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/surfingdoggo/ddpm-butterflies-128/tensorboard?#scalars)
|
Declan/Breitbart_model_v7 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
---
### disquieting muses on Stable Diffusion
This is the `<muses>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
Declan/Breitbart_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
---
### ned-flanders on Stable Diffusion
This is the `<flanders>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:













|
Declan/Breitbart_modelv7 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### Fluid_acrylic_Jellyfish_creatures_style_of_Carl_Ingram_art on Stable Diffusion
This is the `<jelly-core>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:
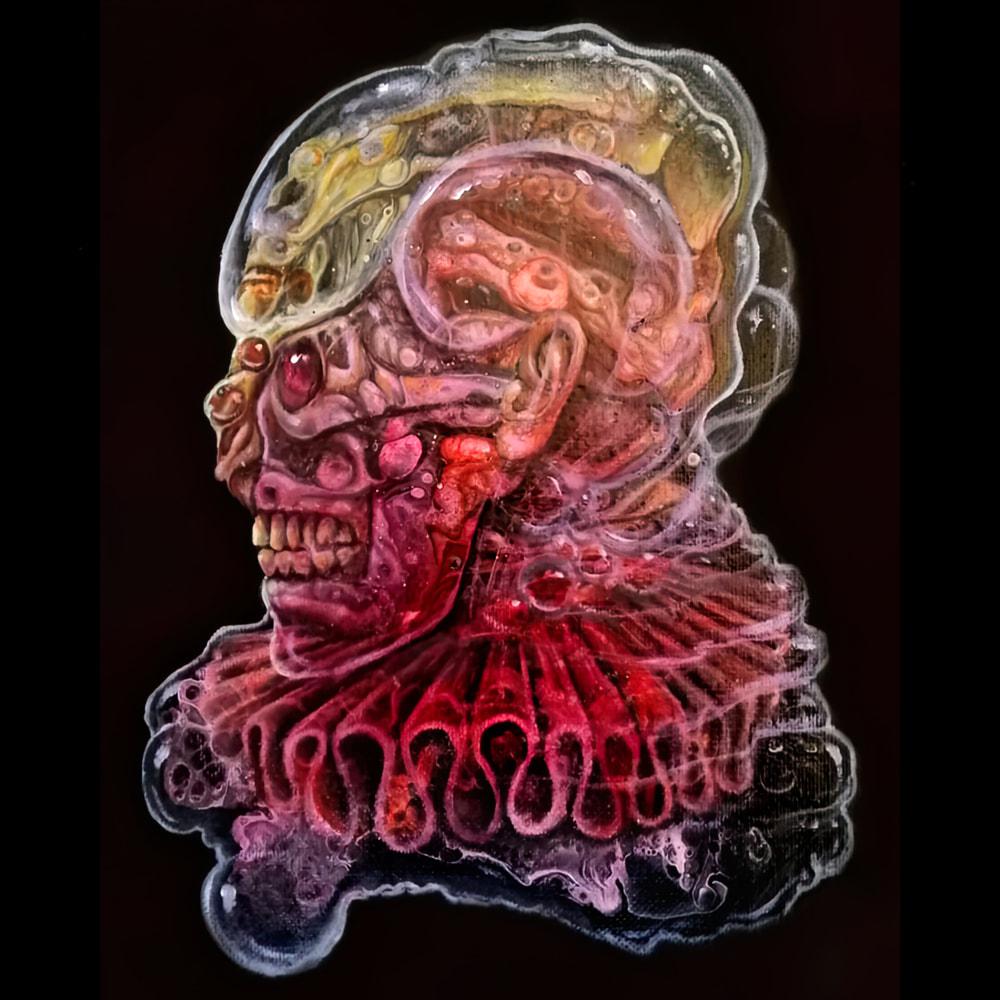


|
Declan/CNN_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-09-10T22:07:33Z | ---
library_name: stable-baselines3
tags:
- HalfCheetahBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 747.07 +/- 1132.58
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: HalfCheetahBulletEnv-v0
type: HalfCheetahBulletEnv-v0
---
# **A2C** Agent playing **HalfCheetahBulletEnv-v0**
This is a trained model of a **A2C** agent playing **HalfCheetahBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/ChicagoTribune_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- spacy
language:
- en
model-index:
- name: en_stonk_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8565043157
- name: NER Recall
type: recall
value: 0.8348858173
- name: NER F Score
type: f_score
value: 0.8455569081
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9726250474
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.9165718428
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.8978441095
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.9038596962
---
pipeline to extract stonk names, need to adjust for general use as some stonk names are very short. Based on the standard spacy pipeline, but added a pipe and wanted to distribute it easily
| Feature | Description |
| --- | --- |
| **Name** | `en_stonk_pipeline` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.4.1,<3.5.0` |
| **Default Pipeline** | `entity_ruler` |
| **Components** | `entity_ruler` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [OntoNotes 5](https://catalog.ldc.upenn.edu/LDC2013T19) (Ralph Weischedel, Martha Palmer, Mitchell Marcus, Eduard Hovy, Sameer Pradhan, Lance Ramshaw, Nianwen Xue, Ann Taylor, Jeff Kaufman, Michelle Franchini, Mohammed El-Bachouti, Robert Belvin, Ann Houston)<br />[ClearNLP Constituent-to-Dependency Conversion](https://github.com/clir/clearnlp-guidelines/blob/master/md/components/dependency_conversion.md) (Emory University)<br />[WordNet 3.0](https://wordnet.princeton.edu/) (Princeton University) |
| **License** | n/a |
| **Author** | [FriendlyUser](friendlyuser.github.io) |
### Label Scheme
<details>
<summary>View label scheme (8 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`entity_ruler`** | `COMPANY`, `COUNTRY`, `DIVIDENDS`, `INDEX`, `MAYBE`, `STOCK`, `STOCK_EXCHANGE`, `THINGS` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_ACC` | 99.93 |
| `TOKEN_P` | 99.57 |
| `TOKEN_R` | 99.58 |
| `TOKEN_F` | 99.57 |
| `TAG_ACC` | 97.26 |
| `SENTS_P` | 91.92 |
| `SENTS_R` | 88.90 |
| `SENTS_F` | 90.39 |
| `DEP_UAS` | 91.66 |
| `DEP_LAS` | 89.78 |
| `ENTS_P` | 85.65 |
| `ENTS_R` | 83.49 |
| `ENTS_F` | 84.56 | |
Declan/ChicagoTribune_model_v2 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9215
- name: F1
type: f1
value: 0.9215576355442753
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2166
- Accuracy: 0.9215
- F1: 0.9216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8299 | 1.0 | 250 | 0.3121 | 0.907 | 0.9043 |
| 0.2489 | 2.0 | 500 | 0.2166 | 0.9215 | 0.9216 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
Declan/ChicagoTribune_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
---
### klance on Stable Diffusion
This is the `<klance>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
Declan/NPR_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9237981101420746
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2239
- Accuracy: 0.924
- F1: 0.9238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8525 | 1.0 | 250 | 0.3308 | 0.9045 | 0.9010 |
| 0.2601 | 2.0 | 500 | 0.2239 | 0.924 | 0.9238 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Declan/NewYorkTimes_model_v3 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- conversational
---
# Hermione DialoGPT Model |
Declan/NewYorkTimes_model_v4 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 200.50 +/- 30.64
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/NewYorkTimes_model_v6 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
---
### unfinished building on Stable Diffusion
This is the `<unfinished-building>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:


|
Declan/NewYorkTimes_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
---
### Teelip-IR-Landscape on Stable Diffusion
This is the `<teelip-ir-landscape>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
Declan/Politico_model_v2 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="huijian222/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Declan/Politico_model_v3 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
---
### Road to Ruin on Stable Diffusion
This is the `<RtoR>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









|
Declan/Politico_model_v4 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
license: mit
---
### Piotr Jablonski on Stable Diffusion
This is the `<piotr-jablonski>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:







|
DeepBasak/Slack | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### nixeu on Stable Diffusion
This is the `<nixeu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).

Here is the new concept you will be able to use as a `style`:






|
DeepChem/ChemBERTa-5M-MLM | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 29 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="anechaev/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
DeividasM/wav2vec2-large-xlsr-53-lithuanian | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"lt",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
---
### leica on Stable Diffusion
This is the `<leica>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
Deniskin/emailer_medium_300 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: full
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `full` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/sbatova/ddpm-butterflies-128/tensorboard?#scalars)
|
DeskDown/MarianMixFT_en-hi | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-roberta-base-finetuned-mbti-0911
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-roberta-base-finetuned-mbti-0911
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 4.1338
- eval_runtime: 25.7058
- eval_samples_per_second: 67.495
- eval_steps_per_second: 8.442
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DeskDown/MarianMixFT_en-id | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: en
pipeline_tag: fill-mask
tags:
- legal
license: mit
---
### InLegalBERT
Model and tokenizer files for the InLegalBERT model from the paper [Pre-training Transformers on Indian Legal Text](https://arxiv.org/abs/2209.06049).
### Training Data
For building the pre-training corpus of Indian legal text, we collected a large corpus of case documents from the Indian Supreme Court and many High Courts of India.
The court cases in our dataset range from 1950 to 2019, and belong to all legal domains, such as Civil, Criminal, Constitutional, and so on.
In total, our dataset contains around 5.4 million Indian legal documents (all in the English language).
The raw text corpus size is around 27 GB.
### Training Setup
This model is initialized with the [LEGAL-BERT-SC model](https://huggingface.co/nlpaueb/legal-bert-base-uncased) from the paper [LEGAL-BERT: The Muppets straight out of Law School](https://aclanthology.org/2020.findings-emnlp.261/). In our work, we refer to this model as LegalBERT, and our re-trained model as InLegalBERT.
We further train this model on our data for 300K steps on the Masked Language Modeling (MLM) and Next Sentence Prediction (NSP) tasks.
### Model Overview
This model uses the same tokenizer as [LegalBERT](https://huggingface.co/nlpaueb/legal-bert-base-uncased).
This model has the same configuration as the [bert-base-uncased model](https://huggingface.co/bert-base-uncased):
12 hidden layers, 768 hidden dimensionality, 12 attention heads, ~110M parameters.
### Usage
Using the model to get embeddings/representations for a piece of text
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("law-ai/InLegalBERT")
text = "Replace this string with yours"
encoded_input = tokenizer(text, return_tensors="pt")
model = AutoModel.from_pretrained("law-ai/InLegalBERT")
output = model(**encoded_input)
last_hidden_state = output.last_hidden_state
```
### Fine-tuning Results
We have fine-tuned all pre-trained models on 3 legal tasks with Indian datasets:
* Legal Statute Identification ([ILSI Dataset](https://arxiv.org/abs/2112.14731))[Multi-label Text Classification]: Identifying relevant statutes (law articles) based on the facts of a court case
* Semantic Segmentation ([ISS Dataset](https://arxiv.org/abs/1911.05405))[Sentence Tagging]: Segmenting the document into 7 functional parts (semantic segments) such as Facts, Arguments, etc.
* Court Judgment Prediction ([ILDC Dataset](https://arxiv.org/abs/2105.13562))[Binary Text Classification]: Predicting whether the claims/petitions of a court case will be accepted/rejected
InLegalBERT beats LegalBERT as well as all other baselines/variants we have used, across all three tasks. For details, see our [paper](https://arxiv.org/abs/2209.06049).
### Citation
```
@inproceedings{paul-2022-pretraining,
url = {https://arxiv.org/abs/2209.06049},
author = {Paul, Shounak and Mandal, Arpan and Goyal, Pawan and Ghosh, Saptarshi},
title = {Pre-trained Language Models for the Legal Domain: A Case Study on Indian Law},
booktitle = {Proceedings of 19th International Conference on Artificial Intelligence and Law - ICAIL 2023}
year = {2023},
}
```
### About Us
We are a group of researchers from the Department of Computer Science and Technology, Indian Insitute of Technology, Kharagpur.
Our research interests are primarily ML and NLP applications for the legal domain, with a special focus on the challenges and oppurtunites for the Indian legal scenario.
We have, and are currently working on several legal tasks such as:
* named entity recognition, summarization of legal documents
* semantic segmentation of legal documents
* legal statute identification from facts, court judgment prediction
* legal document matching
You can find our publicly available codes and datasets [here](https://github.com/Law-AI). |
DeskDown/MarianMixFT_en-ms | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | 2022-09-11T12:31:09Z | The ELECTRA-large model, fine-tuned on the CoLA subset of the GLUE benchmark. |
Despin89/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Dev-DGT/food-dbert-multiling | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 17 | null | ---
language:
- uk
tags:
- automatic-speech-recognition
- audio
license: cc-by-nc-sa-4.0
datasets:
- https://github.com/egorsmkv/speech-recognition-uk
- mozilla-foundation/common_voice_6_1
metrics:
- wer
model-index:
- name: Ukrainian pruned_transducer_stateless5 v1.0.0
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice uk
type: mozilla-foundation/common_voice_6_1
split: test
args: uk
metrics:
- name: Validation WER
type: wer
value: 13.37
---
`pruned_transducer_stateless5` with Conformer encoder for Ukrainian: https://github.com/proger/icefall/tree/uk
[Data Filtering](https://github.com/proger/uk)
[Tensorboard run](https://tensorboard.dev/experiment/8WizOEvHR8CqmQAOsr4ALg/)
```
./pruned_transducer_stateless5/train.py \
--world-size 2 \
--num-epochs 30 \
--start-epoch 1 \
--full-libri 1 \
--exp-dir pruned_transducer_stateless5/exp-uk-shuf \
--max-duration 500 \
--use-fp16 1 \
--num-encoder-layers 18 \
--dim-feedforward 1024 \
--nhead 4 \
--encoder-dim 256 \
--decoder-dim 512 \
--joiner-dim 512 \
--bpe-model uk/data/lang_bpe_250/bpe.model
```
```
./pruned_transducer_stateless5/decode.py \
--epoch 27 \
--avg 15 \
--use-averaged-model True \
--exp-dir pruned_transducer_stateless5/exp-uk-shuf \
--decoding-method fast_beam_search \
--num-encoder-layers 18 \
--dim-feedforward 1024 \
--nhead 4 \
--encoder-dim 256 \
--decoder-dim 512 \
--joiner-dim 512 \
--bpe-model uk/data/lang_bpe_250/bpe.model \
--lang-dir uk/data/lang_bpe_250
``` |
Devmapall/paraphrase-quora | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
metrics:
- bleu
model-index:
- name: marian-finetuned-kde4-en-to-vi
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: kde4
type: kde4
config: en-vi
split: train
args: en-vi
metrics:
- name: Bleu
type: bleu
value: 51.20851369397996
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-vi
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-vi](https://huggingface.co/Helsinki-NLP/opus-mt-en-vi) on the kde4 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2134
- Bleu: 51.2085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Dilmk2/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | 2022-09-11T14:51:35Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 463.35 +/- 98.40
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
DimaOrekhov/transformer-method-name | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: mit
---
### cornell box on Stable Diffusion
This is the `<cornell-box>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:








|
DingleyMaillotUrgell/homer-bot | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
pipeline_tag: token-classification
datasets:
- conll2003
metrics:
- overall_precision
- overall_recall
- overall_f1
- overall_accuracy
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `token-classification`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'conll2003', 'eval_split': 'validation', 'data_keys': {'primary': 'tokens'}, 'ref_keys': ['ner_tags'], 'name': None, 'calibration_split': 'train'}]
* **name_or_path**: `elastic/distilbert-base-uncased-finetuned-conll03-english`
* **from_transformers**: `True`
* **operators_to_quantize**: `['Add', 'MatMul']`
* **calibration**:
* **method**: `percentile`
* **num_calibration_samples**: `128`
* **calibration_histogram_percentile**: `99.999`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **quantization_approach**: `dynamic`, `static`
* **node_exclusion**: `[]`, `['layernorm', 'gelu', 'residual', 'gather', 'softmax']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **reduce_range**: `True`, `False`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | quantization_approach | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | overall_precision | | overall_recall | | overall_f1 | | overall_accuracy |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :------------: | :-: | :--------: | :-: | :--------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 0.936 | \| | 0.944 | \| | 0.940 | \| | 0.988 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.935 | \| | 0.943 | \| | 0.939 | \| | 0.988 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.926 | \| | 0.931 | \| | 0.929 | \| | 0.987 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.000 | \| | 0.000 | \| | 0.000 | \| | 0.833 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.934 | \| | 0.944 | \| | 0.939 | \| | 0.988 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.935 | \| | 0.943 | \| | 0.939 | \| | 0.988 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.926 | \| | 0.931 | \| | 0.929 | \| | 0.987 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.000 | \| | 0.000 | \| | 0.000 | \| | 0.833 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.934 | \| | 0.944 | \| | 0.939 | \| | 0.988 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.913 | \| | 0.792 | \| | 0.848 | \| | 0.969 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.913 | \| | 0.792 | \| | 0.848 | \| | 0.969 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.000 | \| | 0.000 | \| | 0.000 | \| | 0.833 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.896 | \| | 0.783 | \| | 0.836 | \| | 0.968 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.925 | \| | 0.844 | \| | 0.883 | \| | 0.975 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.925 | \| | 0.844 | \| | 0.883 | \| | 0.975 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.045 | \| | 0.004 | \| | 0.008 | \| | 0.825 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.922 | \| | 0.839 | \| | 0.879 | \| | 0.975 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 0.936 | \| | 0.944 | \| | 0.940 | \| | 0.988 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 32.
| framework | quantization_approach | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 14.22 | \| | 70.33 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.22 | \| | 97.87 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.16 | \| | 98.47 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.52 | \| | 95.07 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.70 | \| | 93.47 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.22 | \| | 97.87 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.24 | \| | 97.67 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.36 | \| | 96.53 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.50 | \| | 95.27 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.98 | \| | 91.07 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.31 | \| | 88.47 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 11.23 | \| | 89.07 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.48 | \| | 87.20 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 13.54 | \| | 73.87 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 13.74 | \| | 72.80 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 13.80 | \| | 72.53 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.08 | \| | 71.07 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 31.23 | \| | 32.07 |
Below, time metrics for batch size = 1, input length = 64.
| framework | quantization_approach | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 24.52 | \| | 40.80 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.47 | \| | 54.20 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.53 | \| | 54.00 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.85 | \| | 53.07 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.14 | \| | 52.27 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.50 | \| | 54.07 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.50 | \| | 54.07 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.69 | \| | 53.53 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.46 | \| | 51.40 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.42 | \| | 49.00 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.91 | \| | 50.27 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.20 | \| | 49.53 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 20.74 | \| | 48.27 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.91 | \| | 40.20 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.35 | \| | 41.13 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.99 | \| | 40.07 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.95 | \| | 40.13 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 41.31 | \| | 24.27 |
Below, time metrics for batch size = 1, input length = 128.
| framework | quantization_approach | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 46.79 | \| | 21.40 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.84 | \| | 27.93 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.07 | \| | 28.53 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.71 | \| | 28.00 |
| `onnxruntime` | `dynamic` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.91 | \| | 27.87 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.42 | \| | 28.27 |
| `onnxruntime` | `dynamic` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.22 | \| | 28.40 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.51 | \| | 28.20 |
| `onnxruntime` | `dynamic` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.90 | \| | 27.87 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.88 | \| | 25.13 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 39.27 | \| | 25.47 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.37 | \| | 25.40 |
| `onnxruntime` | `static` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 39.16 | \| | 25.60 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 44.43 | \| | 22.53 |
| `onnxruntime` | `static` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 46.13 | \| | 21.73 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 45.48 | \| | 22.00 |
| `onnxruntime` | `static` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 45.82 | \| | 21.87 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 53.93 | \| | 18.60 |
|
DivyanshuSheth/T5-Seq2Seq-Final | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- conversational
---
#My discord server DialoGPT |
Dizoid/Lll | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### sculptural style on Stable Diffusion
This is the `<diaosu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
Dkwkk/W | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- nuts/autotrain-data-human_art_or_not
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 1.7172622019575956
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 1432453604
- CO2 Emissions (in grams): 1.7173
## Validation Metrics
- Loss: 0.000
- Accuracy: 1.000
- Precision: 1.000
- Recall: 1.000
- AUC: 1.000
- F1: 1.000 |
Dmitry12/sber | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
pipeline_tag: question-answering
widget:
- context: "Пушкин родился 6 июля 1799 года"
- text: "Когда родился Пушкин?"
example_title: "test"
---
обученный rubert от cointegrated/rubert-tiny2.
размер выборки - 4.
Эпохи - 16.
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="Den4ikAI/rubert-tiny-squad",
tokenizer="Den4ikAI/rubert-tiny-squad"
)
predictions = qa_pipeline({
'context': "Пушкин родился 6 июля 1799 года",
'question': "Когда родился Пушкин?"
})
print(predictions)
# output:
#{'score': 0.9413797664642334, 'start': 15, 'end': 31, 'answer': '6 июля 1799 года'}
``` |
DongHai/DialoGPT-small-rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
pipeline_tag: text-classification
datasets:
- glue
metrics:
- accuracy
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `text-classification`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'glue', 'eval_split': 'validation', 'data_keys': {'primary': 'sentence'}, 'ref_keys': ['label'], 'name': 'sst2', 'calibration_split': 'train'}]
* **name_or_path**: `distilbert-base-uncased-finetuned-sst-2-english`
* **from_transformers**: `True`
* **calibration**:
* **method**: `percentile`
* **num_calibration_samples**: `128`
* **calibration_histogram_percentile**: `99.999`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **quantization_approach**: `dynamic`, `static`
* **operators_to_quantize**: `['Add', 'MatMul']`, `['Add']`
* **node_exclusion**: `[]`, `['layernorm', 'gelu', 'residual', 'gather', 'softmax']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **reduce_range**: `True`, `False`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | accuracy |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.898 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.893 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.490 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.898 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.893 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.490 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.911 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.911 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.491 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.908 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.899 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.499 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.900 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.906 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.901 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 0.901 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 0.911 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 32.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 14.50 | \| | 69.00 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.19 | \| | 98.13 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.66 | \| | 93.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.45 | \| | 95.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.72 | \| | 93.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.40 | \| | 96.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.16 | \| | 98.40 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.40 | \| | 96.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.86 | \| | 92.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.43 | \| | 69.33 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.68 | \| | 68.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.40 | \| | 69.47 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.79 | \| | 67.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.80 | \| | 67.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.13 | \| | 70.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.54 | \| | 68.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.60 | \| | 68.53 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 11.23 | \| | 89.13 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.18 | \| | 89.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 11.39 | \| | 87.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 11.31 | \| | 88.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 13.73 | \| | 72.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.42 | \| | 69.40 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.09 | \| | 71.00 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 13.78 | \| | 72.60 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 16.11 | \| | 62.13 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 15.97 | \| | 62.67 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 15.82 | \| | 63.27 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 15.94 | \| | 62.73 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.03 | \| | 52.60 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.99 | \| | 52.67 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.93 | \| | 52.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.65 | \| | 53.67 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 31.28 | \| | 32.00 |
Below, time metrics for batch size = 1, input length = 64.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 24.59 | \| | 40.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.67 | \| | 53.60 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.16 | \| | 52.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.97 | \| | 52.73 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.29 | \| | 51.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.13 | \| | 52.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.64 | \| | 53.67 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.01 | \| | 52.60 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.96 | \| | 52.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.63 | \| | 40.67 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.28 | \| | 39.60 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.75 | \| | 40.47 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.97 | \| | 40.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 25.16 | \| | 39.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.49 | \| | 40.87 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.88 | \| | 40.20 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.17 | \| | 39.73 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.05 | \| | 49.93 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 20.76 | \| | 48.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 20.75 | \| | 48.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 20.23 | \| | 49.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.79 | \| | 40.40 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.17 | \| | 39.73 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.14 | \| | 41.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.27 | \| | 39.60 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 27.97 | \| | 35.80 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 27.43 | \| | 36.47 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 28.17 | \| | 35.53 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 28.16 | \| | 35.53 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 33.24 | \| | 30.13 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 32.46 | \| | 30.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 32.39 | \| | 30.93 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 32.75 | \| | 30.53 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 41.25 | \| | 24.27 |
Below, time metrics for batch size = 1, input length = 128.
| framework | quantization_approach | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 46.51 | \| | 21.53 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.33 | \| | 28.33 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.92 | \| | 27.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.56 | \| | 28.13 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.32 | \| | 27.53 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.53 | \| | 28.20 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.96 | \| | 27.87 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 35.42 | \| | 28.27 |
| `onnxruntime` | `dynamic` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.06 | \| | 27.80 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.40 | \| | 21.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.14 | \| | 21.27 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.46 | \| | 21.13 |
| `onnxruntime` | `dynamic` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.26 | \| | 21.20 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.48 | \| | 21.07 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.08 | \| | 21.27 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.02 | \| | 21.33 |
| `onnxruntime` | `dynamic` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.05 | \| | 21.27 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.63 | \| | 25.27 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 39.52 | \| | 25.33 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 39.78 | \| | 25.20 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 40.01 | \| | 25.00 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 44.24 | \| | 22.67 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 44.55 | \| | 22.47 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 45.74 | \| | 21.87 |
| `onnxruntime` | `static` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 44.12 | \| | 22.67 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 51.41 | \| | 19.47 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 52.52 | \| | 19.07 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 51.25 | \| | 19.53 |
| `onnxruntime` | `static` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 51.51 | \| | 19.47 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 59.37 | \| | 16.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 58.28 | \| | 17.20 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 59.37 | \| | 16.87 |
| `onnxruntime` | `static` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 58.28 | \| | 17.20 |
| `pytorch` | `None` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 53.72 | \| | 18.67 |
|
Waynehillsdev/wav2vec2-base-timit-demo-colab | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
---
### swamp-choe-2 on Stable Diffusion
This is the `<cat-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



|
DoyyingFace/bert-asian-hate-tweets-asian-unclean-warmup-25 | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
model_file: skops-ken4gzoq.pkl
widget:
structuredData:
area error:
- 30.29
- 96.05
- 48.31
compactness error:
- 0.01911
- 0.01652
- 0.01484
concave points error:
- 0.01037
- 0.0137
- 0.01093
concavity error:
- 0.02701
- 0.02269
- 0.02813
fractal dimension error:
- 0.003586
- 0.001698
- 0.002461
mean area:
- 481.9
- 1130.0
- 748.9
mean compactness:
- 0.1058
- 0.1029
- 0.1223
mean concave points:
- 0.03821
- 0.07951
- 0.08087
mean concavity:
- 0.08005
- 0.108
- 0.1466
mean fractal dimension:
- 0.06373
- 0.05461
- 0.05796
mean perimeter:
- 81.09
- 123.6
- 101.7
mean radius:
- 12.47
- 18.94
- 15.46
mean smoothness:
- 0.09965
- 0.09009
- 0.1092
mean symmetry:
- 0.1925
- 0.1582
- 0.1931
mean texture:
- 18.6
- 21.31
- 19.48
perimeter error:
- 2.497
- 5.486
- 3.094
radius error:
- 0.3961
- 0.7888
- 0.4743
smoothness error:
- 0.006953
- 0.004444
- 0.00624
symmetry error:
- 0.01782
- 0.01386
- 0.01397
texture error:
- 1.044
- 0.7975
- 0.7859
worst area:
- 677.9
- 1866.0
- 1156.0
worst compactness:
- 0.2378
- 0.2336
- 0.2394
worst concave points:
- 0.1015
- 0.1789
- 0.1514
worst concavity:
- 0.2671
- 0.2687
- 0.3791
worst fractal dimension:
- 0.0875
- 0.06589
- 0.08019
worst perimeter:
- 96.05
- 165.9
- 124.9
worst radius:
- 14.97
- 24.86
- 19.26
worst smoothness:
- 0.1426
- 0.1193
- 0.1546
worst symmetry:
- 0.3014
- 0.2551
- 0.2837
worst texture:
- 24.64
- 26.58
- 26.0
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|---------------------------------|----------------------------------------------------------|
| aggressive_elimination | False |
| cv | 5 |
| error_score | nan |
| estimator__categorical_features | |
| estimator__early_stopping | auto |
| estimator__l2_regularization | 0.0 |
| estimator__learning_rate | 0.1 |
| estimator__loss | auto |
| estimator__max_bins | 255 |
| estimator__max_depth | |
| estimator__max_iter | 100 |
| estimator__max_leaf_nodes | 31 |
| estimator__min_samples_leaf | 20 |
| estimator__monotonic_cst | |
| estimator__n_iter_no_change | 10 |
| estimator__random_state | |
| estimator__scoring | loss |
| estimator__tol | 1e-07 |
| estimator__validation_fraction | 0.1 |
| estimator__verbose | 0 |
| estimator__warm_start | False |
| estimator | HistGradientBoostingClassifier() |
| factor | 3 |
| max_resources | auto |
| min_resources | exhaust |
| n_jobs | -1 |
| param_grid | {'max_leaf_nodes': [5, 10, 15], 'max_depth': [2, 5, 10]} |
| random_state | 42 |
| refit | True |
| resource | n_samples |
| return_train_score | True |
| scoring | |
| verbose | 0 |
</details>
### Model Plot
The model plot is below.
<style>#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e {color: black;background-color: white;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e pre{padding: 0;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-toggleable {background-color: white;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-estimator:hover {background-color: #d4ebff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-item {z-index: 1;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-parallel-item:only-child::after {width: 0;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e div.sk-text-repr-fallback {display: none;}</style><div id="sk-a56a31ee-d6fa-4e3b-b7da-4835fa20bf9e" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>HalvingGridSearchCV(estimator=HistGradientBoostingClassifier(), n_jobs=-1,param_grid={'max_depth': [2, 5, 10],'max_leaf_nodes': [5, 10, 15]},random_state=42)</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="a9c150d5-aef9-43be-9f02-909eb6c63123" type="checkbox" ><label for="a9c150d5-aef9-43be-9f02-909eb6c63123" class="sk-toggleable__label sk-toggleable__label-arrow">HalvingGridSearchCV</label><div class="sk-toggleable__content"><pre>HalvingGridSearchCV(estimator=HistGradientBoostingClassifier(), n_jobs=-1,param_grid={'max_depth': [2, 5, 10],'max_leaf_nodes': [5, 10, 15]},random_state=42)</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="603ed55f-2612-454e-af85-0d0849361966" type="checkbox" ><label for="603ed55f-2612-454e-af85-0d0849361966" class="sk-toggleable__label sk-toggleable__label-arrow">HistGradientBoostingClassifier</label><div class="sk-toggleable__content"><pre>HistGradientBoostingClassifier()</pre></div></div></div></div></div></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
```python
import joblib
import json
import pandas as pd
clf = joblib.load(skops-ken4gzoq.pkl)
with open("config.json") as f:
config = json.load(f)
clf.predict(pd.DataFrame.from_dict(config["sklearn"]["example_input"]))
```
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
``` |
albert-base-v1 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 38,156 | 2022-09-11T19:39:08Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.7637698412698413
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5133689839572193
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.516320474777448
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5958866036687048
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.748
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.4605263157894737
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5231481481481481
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9025161970769926
- name: F1 (macro)
type: f1_macro
value: 0.8979165451427438
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8328638497652581
- name: F1 (macro)
type: f1_macro
value: 0.6469572777603673
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6630552546045504
- name: F1 (macro)
type: f1_macro
value: 0.6493250582245075
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9562495652778744
- name: F1 (macro)
type: f1_macro
value: 0.8695137253747418
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8906298965841429
- name: F1 (macro)
type: f1_macro
value: 0.8885946595123109
---
# relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.5133689839572193
- Accuracy on SAT: 0.516320474777448
- Accuracy on BATS: 0.5958866036687048
- Accuracy on U2: 0.4605263157894737
- Accuracy on U4: 0.5231481481481481
- Accuracy on Google: 0.748
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9025161970769926
- Micro F1 score on CogALexV: 0.8328638497652581
- Micro F1 score on EVALution: 0.6630552546045504
- Micro F1 score on K&H+N: 0.9562495652778744
- Micro F1 score on ROOT09: 0.8906298965841429
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.7637698412698413
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average_no_mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: I wasn’t aware of this relationship, but I just read in the encyclopedia that <obj> is <subj>’s <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 30
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-classification-conceptnet-validated/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
albert-large-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 687 | 2022-09-11T19:53:37Z | ---
license: mit
---
### Eye of Agamotto on Stable Diffusion
This is the `<eye-aga>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:


































|
albert-large-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26,792 | 2022-09-11T20:03:41Z | ---
license: bigscience-bloom-rail-1.0
---
# Yelpy BERT
A bert-base-uncased fine-tuned on yelp reviews (https://www.yelp.com/dataset) |
albert-xlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 341 | 2022-09-11T20:03:46Z | ---
license: mit
---
### Freddy Fazbear on Stable Diffusion
This is the `<freddy-fazbear>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
albert-xxlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7,091 | 2022-09-11T20:14:06Z | ---
license: mit
---
### glass pipe on Stable Diffusion
This is the `<glass-sherlock>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
albert-xxlarge-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42,640 | 2022-09-11T20:19:23Z | ---
license: bigscience-bloom-rail-1.0
---
# Senty BERT
A yelpy-bert fine-tuned as a ternary classification task (positive, negative, neutral labels) on:
- yelp reviews (https://yelp.com/dataset)
- the SST-3 dataset |
bert-base-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,621,271 | null | ---
datasets:
- coscan-speech2
license: apache-2.0
metrics:
- accuracy
model-index:
- name: wav2vec2-base-coscan-no-region
results:
- dataset:
name: Coscan Speech
type: NbAiLab/coscan-speech
metrics:
- name: Test Accuracy
type: accuracy
value: 0.5449342464872512
- name: Validation Accuracy
type: accuracy
value: 0.8175417762320808
task:
name: Audio Classification
type: audio-classification
tags:
- generated_from_trainer
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-coscan-no-region
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the coscan-speech2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9216
- Accuracy: 0.8175
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1512 | 1.0 | 6468 | 0.9216 | 0.8175 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 2.4.1.dev0
- Tokenizers 0.12.1 |
bert-base-chinese | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"arxiv:1810.04805",
"transformers",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3,377,486 | 2022-09-11T21:44:48Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5110
- Wer: 0.1852
- Mer: 0.1786
- Wil: 0.2694
- Wip: 0.7306
- Hits: 55023
- Substitutions: 6739
- Deletions: 2825
- Insertions: 2397
- Cer: 0.1459
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6898 | 1.0 | 1457 | 0.5259 | 0.2378 | 0.2201 | 0.3112 | 0.6888 | 54412 | 6955 | 3220 | 5183 | 0.2118 |
| 0.5915 | 2.0 | 2914 | 0.4905 | 0.1893 | 0.1824 | 0.2734 | 0.7266 | 54815 | 6756 | 3016 | 2455 | 0.1588 |
| 0.5414 | 3.0 | 4371 | 0.4812 | 0.1933 | 0.1850 | 0.2748 | 0.7252 | 54989 | 6684 | 2914 | 2885 | 0.1605 |
| 0.4633 | 4.0 | 5828 | 0.4820 | 0.1847 | 0.1782 | 0.2685 | 0.7315 | 54999 | 6685 | 2903 | 2342 | 0.1451 |
| 0.4275 | 5.0 | 7285 | 0.4831 | 0.1851 | 0.1785 | 0.2681 | 0.7319 | 55034 | 6630 | 2923 | 2405 | 0.1491 |
| 0.3977 | 6.0 | 8742 | 0.4903 | 0.1836 | 0.1773 | 0.2676 | 0.7324 | 54996 | 6681 | 2910 | 2264 | 0.1451 |
| 0.4236 | 7.0 | 10199 | 0.4941 | 0.1853 | 0.1788 | 0.2693 | 0.7307 | 54964 | 6706 | 2917 | 2343 | 0.1451 |
| 0.3496 | 8.0 | 11656 | 0.5022 | 0.1861 | 0.1794 | 0.2693 | 0.7307 | 54979 | 6661 | 2947 | 2409 | 0.1516 |
| 0.3439 | 9.0 | 13113 | 0.5081 | 0.1872 | 0.1802 | 0.2709 | 0.7291 | 55016 | 6738 | 2833 | 2519 | 0.1606 |
| 0.3505 | 10.0 | 14570 | 0.5110 | 0.1852 | 0.1786 | 0.2694 | 0.7306 | 55023 | 6739 | 2825 | 2397 | 0.1459 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-base-german-dbmdz-uncased | [
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 68,305 | 2022-09-11T20:52:46Z | ---
license: cc-by-nc-sa-4.0
---
This repository contains KenLM models for the Ukrainian language
Metrics for the NEWS models (tested with an acoustic model of [wav2vec2-xls-r-300m model](https://huggingface.co/Yehor/wav2vec2-xls-r-300m-uk-with-small-lm)):
| Model | CER | WER |
|-|-|-|
| no LM | 0.0412 | 0.2206 |
| lm-3gram-10k (alpha=0.1) | 0.0398 | 0.2191 |
| lm-4gram-10k (alpha=0.1) | 0.0398 | 0.219 |
| lm-5gram-10k (alpha=0.1) | 0.0398 | 0.219 |
| lm-3gram-30k | 0.038 | 0.2023 |
| lm-4gram-30k | 0.0379 | 0.2018 |
| lm-5gram-30k | 0.0379 | 0.202 |
| lm-3gram-50k | 0.0348 | 0.1826 |
| lm-4gram-50k | 0.0347 | 0.1818 |
| lm-5gram-50k | 0.0347 | 0.1821 |
| lm-3gram-100k | 0.031 | 0.1588 |
| lm-4gram-100k | 0.0308 | 0.1579 |
| lm-5gram-100k | 0.0308 | 0.1579 |
| lm-3gram-300k | 0.0261 | 0.1294 |
| lm-4gram-300k | 0.0261 | 0.1293 |
| lm-5gram-300k | 0.0261 | 0.1293 |
| lm-3gram-500k | 0.0248 | 0.1209 |
| lm-4gram-500k | 0.0247 | 0.1207 |
| lm-5gram-500k | 0.0247 | 0.1209 |
Files of the models are under the Files and versions section.
Attribution to the NEWS models:
- Chaplynskyi, D. et al. (2021) lang-uk Ukrainian Ubercorpus [Data set]. https://lang.org.ua/uk/corpora/#anchor4
|
bert-base-multilingual-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4,749,504 | 2022-09-11T22:39:14Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-5front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-5front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4633
- Wer: 0.1756
- Mer: 0.1693
- Wil: 0.2562
- Wip: 0.7438
- Hits: 55657
- Substitutions: 6415
- Deletions: 2515
- Insertions: 2414
- Cer: 0.1382
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6441 | 1.0 | 1457 | 0.4872 | 0.2061 | 0.1954 | 0.2850 | 0.7150 | 54813 | 6709 | 3065 | 3540 | 0.1823 |
| 0.543 | 2.0 | 2914 | 0.4422 | 0.1832 | 0.1765 | 0.2641 | 0.7359 | 55188 | 6458 | 2941 | 2432 | 0.1491 |
| 0.4896 | 3.0 | 4371 | 0.4373 | 0.1811 | 0.1739 | 0.2612 | 0.7388 | 55568 | 6464 | 2555 | 2679 | 0.1450 |
| 0.4299 | 4.0 | 5828 | 0.4326 | 0.1745 | 0.1685 | 0.2553 | 0.7447 | 55604 | 6391 | 2592 | 2288 | 0.1367 |
| 0.3853 | 5.0 | 7285 | 0.4390 | 0.1758 | 0.1693 | 0.2561 | 0.7439 | 55696 | 6406 | 2485 | 2462 | 0.1375 |
| 0.357 | 6.0 | 8742 | 0.4433 | 0.1835 | 0.1757 | 0.2619 | 0.7381 | 55609 | 6386 | 2592 | 2871 | 0.1438 |
| 0.3735 | 7.0 | 10199 | 0.4479 | 0.1799 | 0.1729 | 0.2598 | 0.7402 | 55582 | 6425 | 2580 | 2617 | 0.1411 |
| 0.302 | 8.0 | 11656 | 0.4554 | 0.1770 | 0.1702 | 0.2569 | 0.7431 | 55725 | 6408 | 2454 | 2568 | 0.1386 |
| 0.2992 | 9.0 | 13113 | 0.4614 | 0.1784 | 0.1715 | 0.2581 | 0.7419 | 55672 | 6405 | 2510 | 2606 | 0.1404 |
| 0.2972 | 10.0 | 14570 | 0.4633 | 0.1756 | 0.1693 | 0.2562 | 0.7438 | 55657 | 6415 | 2515 | 2414 | 0.1382 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-base-multilingual-uncased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 328,585 | 2022-09-11T23:09:56Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-10front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-10front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4586
- Wer: 0.1729
- Mer: 0.1671
- Wil: 0.2545
- Wip: 0.7455
- Hits: 55669
- Substitutions: 6448
- Deletions: 2470
- Insertions: 2249
- Cer: 0.1350
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6477 | 1.0 | 1457 | 0.4829 | 0.2234 | 0.2082 | 0.2973 | 0.7027 | 54891 | 6766 | 2930 | 4734 | 0.2060 |
| 0.5306 | 2.0 | 2914 | 0.4366 | 0.1808 | 0.1743 | 0.2615 | 0.7385 | 55312 | 6431 | 2844 | 2402 | 0.1439 |
| 0.4743 | 3.0 | 4371 | 0.4311 | 0.1827 | 0.1752 | 0.2623 | 0.7377 | 55558 | 6456 | 2573 | 2771 | 0.1483 |
| 0.4299 | 4.0 | 5828 | 0.4286 | 0.1778 | 0.1711 | 0.2580 | 0.7420 | 55641 | 6422 | 2524 | 2540 | 0.1419 |
| 0.3815 | 5.0 | 7285 | 0.4321 | 0.1741 | 0.1680 | 0.2554 | 0.7446 | 55673 | 6448 | 2466 | 2330 | 0.1379 |
| 0.3508 | 6.0 | 8742 | 0.4392 | 0.1737 | 0.1677 | 0.2547 | 0.7453 | 55683 | 6417 | 2487 | 2312 | 0.1373 |
| 0.3594 | 7.0 | 10199 | 0.4477 | 0.1726 | 0.1666 | 0.2528 | 0.7472 | 55757 | 6344 | 2486 | 2319 | 0.1349 |
| 0.2975 | 8.0 | 11656 | 0.4509 | 0.1726 | 0.1668 | 0.2537 | 0.7463 | 55691 | 6401 | 2495 | 2251 | 0.1349 |
| 0.2947 | 9.0 | 13113 | 0.4550 | 0.1725 | 0.1667 | 0.2539 | 0.7461 | 55700 | 6426 | 2461 | 2257 | 0.1347 |
| 0.2892 | 10.0 | 14570 | 0.4586 | 0.1729 | 0.1671 | 0.2545 | 0.7455 | 55669 | 6448 | 2470 | 2249 | 0.1350 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-base-uncased | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 59,663,489 | 2022-09-11T22:27:22Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-3front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-3front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4641
- Wer: 0.1743
- Mer: 0.1684
- Wil: 0.2557
- Wip: 0.7443
- Hits: 55594
- Substitutions: 6428
- Deletions: 2565
- Insertions: 2267
- Cer: 0.1368
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6567 | 1.0 | 1457 | 0.4959 | 0.2072 | 0.1966 | 0.2877 | 0.7123 | 54688 | 6836 | 3063 | 3486 | 0.1936 |
| 0.5486 | 2.0 | 2914 | 0.4504 | 0.1870 | 0.1796 | 0.2677 | 0.7323 | 55158 | 6518 | 2911 | 2647 | 0.1528 |
| 0.4957 | 3.0 | 4371 | 0.4410 | 0.1764 | 0.1705 | 0.2578 | 0.7422 | 55412 | 6429 | 2746 | 2216 | 0.1375 |
| 0.4371 | 4.0 | 5828 | 0.4379 | 0.1761 | 0.1702 | 0.2572 | 0.7428 | 55447 | 6407 | 2733 | 2232 | 0.1377 |
| 0.387 | 5.0 | 7285 | 0.4408 | 0.1756 | 0.1696 | 0.2562 | 0.7438 | 55510 | 6372 | 2705 | 2263 | 0.1399 |
| 0.3589 | 6.0 | 8742 | 0.4466 | 0.1737 | 0.1681 | 0.2552 | 0.7448 | 55532 | 6406 | 2649 | 2165 | 0.1359 |
| 0.3876 | 7.0 | 10199 | 0.4532 | 0.1746 | 0.1689 | 0.2563 | 0.7437 | 55491 | 6436 | 2660 | 2179 | 0.1363 |
| 0.3199 | 8.0 | 11656 | 0.4591 | 0.1738 | 0.1681 | 0.2554 | 0.7446 | 55568 | 6431 | 2588 | 2208 | 0.1362 |
| 0.3079 | 9.0 | 13113 | 0.4625 | 0.1743 | 0.1685 | 0.2557 | 0.7443 | 55579 | 6425 | 2583 | 2252 | 0.1366 |
| 0.3124 | 10.0 | 14570 | 0.4641 | 0.1743 | 0.1684 | 0.2557 | 0.7443 | 55594 | 6428 | 2565 | 2267 | 0.1368 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-large-cased-whole-word-masking-finetuned-squad | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,214 | null | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-8front-1body-0rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-8front-1body-0rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4589
- Wer: 0.1739
- Mer: 0.1679
- Wil: 0.2545
- Wip: 0.7455
- Hits: 55667
- Substitutions: 6385
- Deletions: 2535
- Insertions: 2309
- Cer: 0.1363
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6586 | 1.0 | 1457 | 0.4812 | 0.2110 | 0.1994 | 0.2888 | 0.7112 | 54745 | 6712 | 3130 | 3789 | 0.1784 |
| 0.5246 | 2.0 | 2914 | 0.4383 | 0.1839 | 0.1770 | 0.2641 | 0.7359 | 55251 | 6428 | 2908 | 2544 | 0.1481 |
| 0.4795 | 3.0 | 4371 | 0.4327 | 0.1811 | 0.1740 | 0.2610 | 0.7390 | 55523 | 6438 | 2626 | 2631 | 0.1458 |
| 0.4224 | 4.0 | 5828 | 0.4328 | 0.1754 | 0.1693 | 0.2555 | 0.7445 | 55577 | 6338 | 2672 | 2318 | 0.1397 |
| 0.3755 | 5.0 | 7285 | 0.4351 | 0.1723 | 0.1668 | 0.2529 | 0.7471 | 55607 | 6326 | 2654 | 2150 | 0.1362 |
| 0.3538 | 6.0 | 8742 | 0.4413 | 0.1728 | 0.1670 | 0.2531 | 0.7469 | 55696 | 6341 | 2550 | 2271 | 0.1372 |
| 0.3686 | 7.0 | 10199 | 0.4455 | 0.1715 | 0.1659 | 0.2519 | 0.7481 | 55692 | 6319 | 2576 | 2180 | 0.1354 |
| 0.3004 | 8.0 | 11656 | 0.4518 | 0.1727 | 0.1668 | 0.2537 | 0.7463 | 55712 | 6400 | 2475 | 2281 | 0.1371 |
| 0.2914 | 9.0 | 13113 | 0.4564 | 0.1739 | 0.1678 | 0.2544 | 0.7456 | 55681 | 6378 | 2528 | 2323 | 0.1370 |
| 0.297 | 10.0 | 14570 | 0.4589 | 0.1739 | 0.1679 | 0.2545 | 0.7455 | 55667 | 6385 | 2535 | 2309 | 0.1363 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bert-large-uncased-whole-word-masking-finetuned-squad | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 480,510 | 2022-09-11T21:20:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9295
- name: F1
type: f1
value: 0.929332697530698
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2116
- Accuracy: 0.9295
- F1: 0.9293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8487 | 1.0 | 250 | 0.3135 | 0.909 | 0.9051 |
| 0.2515 | 2.0 | 500 | 0.2116 | 0.9295 | 0.9293 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
bert-large-uncased-whole-word-masking | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 76,685 | 2022-09-11T21:20:42Z | ---
license: mit
---
### black-waifu on Stable Diffusion
This is the `<black-waifu>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:
















|
distilbert-base-cased | [
"pytorch",
"tf",
"onnx",
"distilbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"transformers",
"license:apache-2.0",
"has_space"
] | null | {
"architectures": null,
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 574,859 | 2022-09-11T21:34:13Z | ---
license: mit
---
### roy-lichtenstein on Stable Diffusion
This is the `<roy-lichtenstein>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
distilbert-base-multilingual-cased | [
"pytorch",
"tf",
"onnx",
"safetensors",
"distilbert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1910.01108",
"arxiv:1910.09700",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,339,633 | 2022-09-11T21:57:43Z | ---
license: cc-by-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: hing-mbert-finetuned-ours-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-mbert-finetuned-ours-DS
This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1569
- Accuracy: 0.71
- Precision: 0.6665
- Recall: 0.6668
- F1: 0.6658
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.824279936868144e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7704 | 1.99 | 199 | 0.7093 | 0.68 | 0.6679 | 0.6463 | 0.6309 |
| 0.2597 | 3.98 | 398 | 1.1569 | 0.71 | 0.6665 | 0.6668 | 0.6658 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
distilbert-base-uncased | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"distilbert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10,887,471 | 2022-09-11T22:20:48Z | ---
pipeline_tag: question-answering
datasets:
- squad
metrics:
- exact_match
- f1
- total_time_in_seconds
- samples_per_second
- latency_in_seconds
tags:
- distilbert
---
**task**: `question-answering`
**Backend:** `sagemaker-training`
**Backend args:** `{'instance_type': 'ml.m5.2xlarge', 'supported_instructions': 'avx512'}`
**Number of evaluation samples:** `All dataset`
Fixed parameters:
* **dataset**: [{'path': 'squad', 'eval_split': 'validation', 'data_keys': {'question': 'question', 'context': 'context'}, 'ref_keys': ['answers'], 'name': None, 'calibration_split': None}]
* **name_or_path**: `distilbert-base-uncased-distilled-squad`
* **from_transformers**: `True`
* **quantization_approach**: `dynamic`
Benchmarked parameters:
* **framework**: `onnxruntime`, `pytorch`
* **operators_to_quantize**: `['Add', 'MatMul']`, `['Add']`
* **node_exclusion**: `[]`, `['layernorm', 'gelu', 'residual', 'gather', 'softmax']`
* **per_channel**: `False`, `True`
* **framework_args**: `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}`, `{}`
* **reduce_range**: `True`, `False`
* **apply_quantization**: `True`, `False`
# Evaluation
## Non-time metrics
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | exact_match | | f1 |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------: | :-: | :----: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 76.764 | \| | 85.053 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 69.622 | \| | 79.914 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.435 | \| | 5.887 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.165 | \| | 85.973 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 76.764 | \| | 85.053 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 69.622 | \| | 79.914 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 0.435 | \| | 5.887 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.165 | \| | 85.973 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 78.884 | \| | 86.690 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 78.884 | \| | 86.690 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 78.884 | \| | 86.690 |
## Time metrics
Time benchmarks were run for 15 seconds per config.
Below, time metrics for batch size = 1, input length = 32.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 14.26 | \| | 70.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.08 | \| | 99.20 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.60 | \| | 94.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.88 | \| | 91.93 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.84 | \| | 92.27 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.34 | \| | 96.73 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.41 | \| | 96.07 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 10.96 | \| | 91.27 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 10.69 | \| | 93.53 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.43 | \| | 69.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.52 | \| | 68.87 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.35 | \| | 69.73 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.50 | \| | 69.00 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.20 | \| | 70.47 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.24 | \| | 70.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 14.58 | \| | 68.67 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 14.73 | \| | 67.87 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 31.49 | \| | 31.80 |
Below, time metrics for batch size = 1, input length = 64.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 24.83 | \| | 40.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 18.49 | \| | 54.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.87 | \| | 53.00 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.17 | \| | 52.20 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.92 | \| | 52.87 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.13 | \| | 52.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 18.95 | \| | 52.80 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 19.08 | \| | 52.47 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 19.14 | \| | 52.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.83 | \| | 40.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.84 | \| | 40.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.66 | \| | 40.60 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.76 | \| | 40.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 25.07 | \| | 39.93 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 25.27 | \| | 39.60 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 24.76 | \| | 40.40 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 24.70 | \| | 40.53 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 41.26 | \| | 24.27 |
Below, time metrics for batch size = 1, input length = 128.
| framework | operators_to_quantize | node_exclusion | per_channel | framework_args | reduce_range | apply_quantization | | latency_mean (ms) | | throughput (/s) |
| :-----------: | :-------------------: | :------------------------------------------------------: | :---------: | :-----------------------------------------------------------------: | :----------: | :----------------: | :-: | :---------------: | :-: | :-------------: |
| `onnxruntime` | `None` | `None` | `None` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `None` | `False` | \| | 46.89 | \| | 21.33 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 34.84 | \| | 28.73 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.88 | \| | 27.93 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 36.92 | \| | 27.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 36.25 | \| | 27.60 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 36.17 | \| | 27.67 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.59 | \| | 28.13 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 37.36 | \| | 26.80 |
| `onnxruntime` | `['Add', 'MatMul']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 35.97 | \| | 27.87 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 46.94 | \| | 21.33 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.19 | \| | 21.20 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.05 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `['layernorm', 'gelu', 'residual', 'gather', 'softmax']` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 46.79 | \| | 21.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 46.87 | \| | 21.40 |
| `onnxruntime` | `['Add']` | `[]` | `False` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.04 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `False` | `True` | \| | 47.08 | \| | 21.27 |
| `onnxruntime` | `['Add']` | `[]` | `True` | `{'opset': 13, 'optimization_level': 1, 'intra_op_num_threads': 4}` | `True` | `True` | \| | 47.05 | \| | 21.27 |
| `pytorch` | `None` | `None` | `None` | `{}` | `None` | `None` | \| | 54.61 | \| | 18.33 |
|
IssakaAI/wav2vec2-large-xls-r-300m-turkish-colab | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="santiviquez/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
ATGdev/ai_ironman | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-12T19:09:22Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-0front-1body-9rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-0front-1body-9rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4673
- Wer: 0.1766
- Mer: 0.1707
- Wil: 0.2594
- Wip: 0.7406
- Hits: 55410
- Substitutions: 6552
- Deletions: 2625
- Insertions: 2229
- Cer: 0.1386
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.641 | 1.0 | 1457 | 0.4913 | 0.2084 | 0.1972 | 0.2875 | 0.7125 | 54788 | 6785 | 3014 | 3658 | 0.1743 |
| 0.5415 | 2.0 | 2914 | 0.4483 | 0.1818 | 0.1759 | 0.2643 | 0.7357 | 55033 | 6514 | 3040 | 2190 | 0.1447 |
| 0.4835 | 3.0 | 4371 | 0.4427 | 0.1785 | 0.1722 | 0.2595 | 0.7405 | 55442 | 6443 | 2702 | 2386 | 0.1402 |
| 0.4267 | 4.0 | 5828 | 0.4376 | 0.1769 | 0.1711 | 0.2587 | 0.7413 | 55339 | 6446 | 2802 | 2177 | 0.1399 |
| 0.3752 | 5.0 | 7285 | 0.4414 | 0.1756 | 0.1698 | 0.2571 | 0.7429 | 55467 | 6432 | 2688 | 2223 | 0.1374 |
| 0.3471 | 6.0 | 8742 | 0.4497 | 0.1761 | 0.1704 | 0.2585 | 0.7415 | 55379 | 6494 | 2714 | 2166 | 0.1380 |
| 0.3841 | 7.0 | 10199 | 0.4535 | 0.1769 | 0.1710 | 0.2589 | 0.7411 | 55383 | 6482 | 2722 | 2220 | 0.1394 |
| 0.3139 | 8.0 | 11656 | 0.4604 | 0.1753 | 0.1696 | 0.2577 | 0.7423 | 55462 | 6502 | 2623 | 2199 | 0.1367 |
| 0.3012 | 9.0 | 13113 | 0.4628 | 0.1766 | 0.1708 | 0.2597 | 0.7403 | 55391 | 6571 | 2625 | 2210 | 0.1388 |
| 0.3087 | 10.0 | 14570 | 0.4673 | 0.1766 | 0.1707 | 0.2594 | 0.7406 | 55410 | 6552 | 2625 | 2229 | 0.1386 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Pinwheel/wav2vec2-large-xls-r-1b-hi-v2 | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-09-12T19:15:49Z | ---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
Aero/Tsubomi-Haruno | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational",
"license:mit"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
datasets:
- embedding-data/QQP_triplets
---
# tekraj/avodamed-synonym-generator1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('tekraj/avodamed-synonym-generator1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=tekraj/avodamed-synonym-generator1)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Aeroxas/Botroxas-small | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-5front-1body-5rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-5front-1body-5rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4383
- Wer: 0.1697
- Mer: 0.1641
- Wil: 0.2500
- Wip: 0.7500
- Hits: 55852
- Substitutions: 6314
- Deletions: 2421
- Insertions: 2228
- Cer: 0.1328
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6185 | 1.0 | 1457 | 0.4683 | 0.1948 | 0.1863 | 0.2758 | 0.7242 | 54959 | 6658 | 2970 | 2956 | 0.1682 |
| 0.5149 | 2.0 | 2914 | 0.4280 | 0.1773 | 0.1713 | 0.2591 | 0.7409 | 55376 | 6468 | 2743 | 2238 | 0.1426 |
| 0.4705 | 3.0 | 4371 | 0.4173 | 0.1743 | 0.1682 | 0.2552 | 0.7448 | 55680 | 6418 | 2489 | 2351 | 0.1387 |
| 0.4023 | 4.0 | 5828 | 0.4114 | 0.1713 | 0.1656 | 0.2515 | 0.7485 | 55751 | 6313 | 2523 | 2230 | 0.1335 |
| 0.3497 | 5.0 | 7285 | 0.4162 | 0.1722 | 0.1662 | 0.2522 | 0.7478 | 55787 | 6331 | 2469 | 2323 | 0.1365 |
| 0.3246 | 6.0 | 8742 | 0.4211 | 0.1714 | 0.1655 | 0.2513 | 0.7487 | 55802 | 6310 | 2475 | 2284 | 0.1367 |
| 0.3492 | 7.0 | 10199 | 0.4282 | 0.1711 | 0.1652 | 0.2514 | 0.7486 | 55861 | 6350 | 2376 | 2325 | 0.1341 |
| 0.2788 | 8.0 | 11656 | 0.4322 | 0.1698 | 0.1641 | 0.2502 | 0.7498 | 55883 | 6342 | 2362 | 2265 | 0.1327 |
| 0.2801 | 9.0 | 13113 | 0.4362 | 0.1710 | 0.1652 | 0.2514 | 0.7486 | 55828 | 6351 | 2408 | 2288 | 0.1352 |
| 0.2773 | 10.0 | 14570 | 0.4383 | 0.1697 | 0.1641 | 0.2500 | 0.7500 | 55852 | 6314 | 2421 | 2228 | 0.1328 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Aftabhussain/Tomato_Leaf_Classifier | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index",
"autotrain_compatible"
] | image-classification | {
"architectures": [
"ViTForImageClassification"
],
"model_type": "vit",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 50 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- yelp_review_full
metrics:
- accuracy
model-index:
- name: Bert_Classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: yelp_review_full
type: yelp_review_full
config: yelp_review_full
split: train
args: yelp_review_full
metrics:
- name: Accuracy
type: accuracy
value: 0.5533333333333333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bert_Classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the yelp_review_full dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1067
- Accuracy: 0.5533
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 188 | 1.0636 | 0.5 |
| No log | 2.0 | 376 | 1.0405 | 0.52 |
| 0.9962 | 3.0 | 564 | 1.1067 | 0.5533 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Ahda/M | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- yelp_review_full
metrics:
- accuracy
model-index:
- name: Bert_Classifier
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: yelp_review_full
type: yelp_review_full
config: yelp_review_full
split: train
args: yelp_review_full
metrics:
- name: Accuracy
type: accuracy
value: 0.56
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bert_Classifier
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the yelp_review_full dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9115
- Accuracy: 0.56
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 188 | 1.4208 | 0.5667 |
| No log | 2.0 | 376 | 1.4325 | 0.5733 |
| 0.3995 | 3.0 | 564 | 1.9115 | 0.56 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Ahmadvakili/A | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9243344747597482
- name: Recall
type: recall
value: 0.9361226087929299
- name: F1
type: f1
value: 0.9301911960871498
- name: Accuracy
type: accuracy
value: 0.9834781641698572
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0625
- Precision: 0.9243
- Recall: 0.9361
- F1: 0.9302
- Accuracy: 0.9835
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2424 | 1.0 | 878 | 0.0685 | 0.9152 | 0.9235 | 0.9193 | 0.9813 |
| 0.0539 | 2.0 | 1756 | 0.0621 | 0.9225 | 0.9333 | 0.9279 | 0.9828 |
| 0.0298 | 3.0 | 2634 | 0.0625 | 0.9243 | 0.9361 | 0.9302 | 0.9835 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AimB/mT5-en-kr-aihub-netflix | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- te_dx_jp
model-index:
- name: t5-base-TEDxJP-1front-1body-1rear
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-TEDxJP-1front-1body-1rear
This model is a fine-tuned version of [sonoisa/t5-base-japanese](https://huggingface.co/sonoisa/t5-base-japanese) on the te_dx_jp dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4600
- Wer: 0.1742
- Mer: 0.1683
- Wil: 0.2562
- Wip: 0.7438
- Hits: 55625
- Substitutions: 6495
- Deletions: 2467
- Insertions: 2291
- Cer: 0.1364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Mer | Wil | Wip | Hits | Substitutions | Deletions | Insertions | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|:-----:|:-------------:|:---------:|:----------:|:------:|
| 0.6478 | 1.0 | 1457 | 0.4880 | 0.2256 | 0.2100 | 0.2999 | 0.7001 | 54825 | 6842 | 2920 | 4808 | 0.2019 |
| 0.542 | 2.0 | 2914 | 0.4461 | 0.1886 | 0.1807 | 0.2697 | 0.7303 | 55225 | 6615 | 2747 | 2817 | 0.1577 |
| 0.4873 | 3.0 | 4371 | 0.4390 | 0.1764 | 0.1702 | 0.2584 | 0.7416 | 55541 | 6519 | 2527 | 2344 | 0.1392 |
| 0.4271 | 4.0 | 5828 | 0.4361 | 0.1750 | 0.1691 | 0.2567 | 0.7433 | 55512 | 6453 | 2622 | 2226 | 0.1381 |
| 0.3705 | 5.0 | 7285 | 0.4366 | 0.1741 | 0.1684 | 0.2558 | 0.7442 | 55508 | 6427 | 2652 | 2164 | 0.1358 |
| 0.3557 | 6.0 | 8742 | 0.4424 | 0.1738 | 0.1679 | 0.2555 | 0.7445 | 55600 | 6453 | 2534 | 2235 | 0.1369 |
| 0.3838 | 7.0 | 10199 | 0.4471 | 0.1741 | 0.1684 | 0.2562 | 0.7438 | 55550 | 6473 | 2564 | 2210 | 0.1362 |
| 0.3095 | 8.0 | 11656 | 0.4517 | 0.1746 | 0.1685 | 0.2566 | 0.7434 | 55618 | 6499 | 2470 | 2305 | 0.1367 |
| 0.306 | 9.0 | 13113 | 0.4573 | 0.1748 | 0.1688 | 0.2570 | 0.7430 | 55601 | 6517 | 2469 | 2304 | 0.1369 |
| 0.3073 | 10.0 | 14570 | 0.4600 | 0.1742 | 0.1683 | 0.2562 | 0.7438 | 55625 | 6495 | 2467 | 2291 | 0.1364 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Akash7897/distilbert-base-uncased-finetuned-sst2 | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | 2022-09-13T18:24:16Z | ---
license: mit
---
### Poutine Dish on Stable Diffusion
This is the `<poutine-qc>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




















|
Akashpb13/Hausa_xlsr | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ha",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"model_for_talk",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index",
"has_space"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | 2022-09-13T18:49:55Z | ---
license: mit
---
### grifter on Stable Diffusion
This is the `<grifter>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
Akashpb13/Swahili_xlsr | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sw",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"model_for_talk",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: mit
---
### Dog on Stable Diffusion
This is the `<Winston>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
Akira-Yana/distilbert-base-uncased-finetuned-cola | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T19:49:11Z | ---
tags:
- espnet
- audio
- automatic-speech-recognition
language: en
datasets:
- slurp
license: cc-by-4.0
---
## ESPnet2 ASR model
### `espnet/slurp_slu_2pass_gt`
This model was trained by Siddhant using slurp recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout 3b54bfe52a294cdfce668c20d777bfa65f413745
pip install -e .
cd egs2/slurp/slu1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/slurp_slu_2pass_gt
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Sat Aug 20 15:34:30 EDT 2022`
- python version: `3.9.5 (default, Jun 4 2021, 12:28:51) [GCC 7.5.0]`
- espnet version: `espnet 202207`
- pytorch version: `pytorch 1.8.1+cu102`
- Git hash: `45e2b13071f3cc4abbc3a7b2484bd6cffedd4d1c`
- Commit date: `Mon Aug 15 09:13:31 2022 -0400`
## slu_train_asr_bert_conformer_deliberation_raw_en_word
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|inference_slu_model_valid.acc.ave_10best/devel|8690|108484|90.9|6.2|2.9|2.7|11.8|39.9|
|inference_slu_model_valid.acc.ave_10best/test|13078|159666|90.7|6.2|3.1|2.6|11.9|38.7|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|inference_slu_model_valid.acc.ave_10best/devel|8690|512732|95.5|2.3|2.2|2.5|7.0|39.9|
|inference_slu_model_valid.acc.ave_10best/test|13078|757056|95.3|2.3|2.3|2.5|7.1|38.7|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/tuning/train_asr_bert_conformer_deliberation.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/slu_train_asr_bert_conformer_deliberation_raw_en_word
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 50
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param:
- encoder
- postdecoder.model
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/slu_stats_raw_en_word/train/speech_shape
- exp/slu_stats_raw_en_word/train/text_shape.word
- exp/slu_stats_raw_en_word/train/transcript_shape.word
valid_shape_file:
- exp/slu_stats_raw_en_word/valid/speech_shape
- exp/slu_stats_raw_en_word/valid/text_shape.word
- exp/slu_stats_raw_en_word/valid/transcript_shape.word
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 150
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train/wav.scp
- speech
- sound
- - dump/raw/train/text
- text
- text
- - dump/raw/train/transcript
- transcript
- text
valid_data_path_and_name_and_type:
- - dump/raw/devel/wav.scp
- speech
- sound
- - dump/raw/devel/text
- text
- text
- - dump/raw/devel/transcript
- transcript
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0002
scheduler: warmuplr
scheduler_conf:
warmup_steps: 25000
token_list:
- <blank>
- <unk>
- ▁the
- s
- ▁to
- ▁i
- ▁me
- ▁you
- ▁what
- ▁a
- ▁is
- ▁my
- ▁please
- a
- ''''
- y
- ▁in
- ing
- ▁s
- e
- ▁for
- i
- ▁on
- d
- t
- o
- u
- er
- p
- ▁of
- es
- re
- l
- ▁it
- ▁p
- le
- ▁f
- ▁m
- ▁email
- ▁d
- m
- ▁c
- st
- r
- n
- ar
- ▁h
- b
- ▁that
- c
- ▁this
- h
- an
- email_query
- ▁play
- ▁re
- ▁b
- ▁do
- ▁can
- at
- ▁have
- g
- ▁from
- ▁and
- en
- email_sendemail
- ▁olly
- 'on'
- ▁new
- it
- qa_factoid
- calendar_set
- ▁any
- or
- ▁g
- ▁how
- ▁t
- ▁tell
- ch
- ▁not
- ▁about
- ▁at
- ate
- general_negate
- f
- ▁today
- ▁e
- ed
- ▁list
- ▁r
- in
- k
- ic
- social_post
- ▁are
- play_music
- general_quirky
- ▁l
- al
- v
- ent
- ▁n
- ▁be
- ▁an
- ▁st
- et
- ▁am
- general_praise
- ▁time
- weather_query
- ▁up
- ▁check
- calendar_query
- ▁w
- om
- ur
- ▁send
- ▁with
- ly
- w
- general_explain
- ad
- ▁th
- news_query
- ▁one
- ▁emails
- day
- ▁sh
- ce
- ▁last
- ve
- ▁he
- z
- ▁ch
- ▁will
- ▁set
- ▁would
- ▁was
- x
- general_repeat
- ▁add
- ou
- ▁again
- ▁ex
- is
- ct
- general_affirm
- general_confirm
- ▁song
- ▁next
- ▁j
- ▁meeting
- um
- ation
- ▁turn
- ▁did
- if
- ▁alarm
- am
- ▁like
- datetime_query
- ter
- ▁remind
- ▁o
- qa_definition
- ▁said
- ▁calendar
- ll
- se
- ers
- th
- ▁get
- our
- ▁need
- ▁all
- ot
- ▁want
- ▁off
- and
- ▁right
- ▁de
- ▁tr
- ut
- general_dontcare
- ▁
- ▁week
- as
- ▁tweet
- ight
- ir
- ▁your
- ▁event
- ▁news
- ▁se
- ay
- ion
- ▁com
- ▁there
- ▁ye
- ▁weather
- un
- ▁confirm
- ld
- calendar_remove
- ▁y
- ▁lights
- ▁more
- ▁v
- play_radio
- ▁does
- ▁po
- ▁now
- id
- email_querycontact
- ▁show
- ▁could
- ery
- op
- ▁day
- ▁pm
- ▁music
- ▁tomorrow
- ▁train
- ▁u
- ine
- ▁or
- ange
- qa_currency
- ice
- ▁contact
- ▁just
- ▁jo
- ▁think
- qa_stock
- end
- ss
- ber
- ▁tw
- ▁command
- ▁make
- ▁no
- ▁mo
- pe
- ▁find
- general_commandstop
- ▁when
- social_query
- ▁so
- ong
- ▁co
- ant
- ow
- ▁much
- ▁where
- ul
- ue
- ri
- ap
- ▁start
- ▁mar
- ▁by
- one
- ▁know
- ▁wor
- oo
- ▁give
- ▁let
- ▁events
- der
- ▁ro
- ▁pr
- ▁pl
- play_podcasts
- art
- us
- ▁work
- ▁current
- ol
- cooking_recipe
- nt
- ▁correct
- transport_query
- ia
- ▁stock
- ▁br
- ive
- ▁app
- ▁two
- ▁latest
- lists_query
- ▁some
- recommendation_events
- ab
- ▁go
- ▁but
- ook
- ke
- alarm_set
- play_audiobook
- ▁k
- ▁response
- ▁wr
- cast
- ▁open
- ▁cle
- ▁done
- ▁got
- ▁ca
- ite
- ase
- ▁thank
- iv
- ah
- ag
- ▁answer
- ie
- ▁five
- ▁book
- ist
- ▁rec
- ore
- ▁john
- ment
- ▁appreci
- ▁fri
- ack
- ▁remove
- ated
- ock
- ree
- j
- ▁good
- ▁many
- orn
- fe
- ▁radio
- ▁we
- int
- ▁facebook
- ▁cl
- ▁sev
- ▁schedule
- ard
- ▁per
- ▁li
- ▁going
- nd
- ain
- recommendation_locations
- ▁post
- lists_createoradd
- ff
- ▁su
- red
- iot_hue_lightoff
- lists_remove
- ▁ar
- een
- ▁say
- ro
- ▁volume
- ▁le
- ▁reply
- ▁complaint
- ▁out
- ▁delete
- ▁ne
- ame
- ▁detail
- ▁if
- im
- ▁happ
- orr
- ich
- em
- ▁ev
- ction
- ▁dollar
- ▁as
- alarm_query
- audio_volume_mute
- ac
- music_query
- ▁mon
- ther
- ▁thanks
- cel
- ▁who
- ave
- ▁service
- ▁mail
- ty
- ▁hear
- de
- ▁si
- ▁wh
- ood
- ell
- ▁con
- ▁once
- ound
- ▁don
- ▁loc
- ▁light
- ▁birthday
- ▁inf
- ort
- ffe
- ▁playlist
- el
- ening
- ▁us
- ▁un
- ▁has
- own
- ▁inc
- ai
- ▁speak
- age
- ▁mess
- ast
- ci
- ver
- ▁ten
- ▁underst
- ▁pro
- ▁q
- enty
- ▁ticket
- gh
- audio_volume_up
- ▁take
- ▁bo
- ally
- ome
- transport_ticket
- ind
- iot_hue_lightchange
- pp
- iot_coffee
- ▁res
- plain
- io
- lar
- takeaway_query
- ge
- takeaway_order
- email_addcontact
- play_game
- ak
- ▁fa
- transport_traffic
- music_likeness
- ▁rep
- act
- ust
- transport_taxi
- iot_hue_lightdim
- ▁mu
- ▁ti
- ick
- ▁ha
- ould
- general_joke
- '1'
- qa_maths
- ▁lo
- iot_cleaning
- q
- ake
- ill
- her
- iot_hue_lightup
- pl
- '2'
- alarm_remove
- orrect
- ▁cont
- mail
- out
- audio_volume_down
- book
- ail
- recommendation_movies
- ck
- ▁man
- ▁mus
- ▁che
- me
- ume
- ▁answ
- datetime_convert
- ▁late
- iot_wemo_on
- ▁twe
- music_settings
- iot_wemo_off
- orre
- ith
- ▁tom
- ▁fr
- ere
- ▁ad
- xt
- ▁ab
- ank
- general_greet
- now
- ▁meet
- ▁curre
- ▁respon
- ▁ag
- ght
- audio_volume_other
- ink
- ▁spe
- iot_hue_lighton
- ▁rem
- lly
- '?'
- urn
- ▁op
- ▁complain
- ▁comm
- let
- music_dislikeness
- ove
- ▁sch
- ather
- ▁rad
- edule
- ▁under
- icket
- lease
- ▁bir
- erv
- ▁birth
- ▁face
- ▁cur
- sw
- ▁serv
- ek
- aid
- '9'
- ▁vol
- edu
- '5'
- cooking_query
- lete
- ▁joh
- ▁det
- firm
- nder
- '0'
- irm
- '8'
- '&'
- _
- list
- pon
- qa_query
- '7'
- '3'
- '-'
- reci
- ▁doll
- <sos/eos>
transcript_token_list:
- <blank>
- <unk>
- the
- to
- i
- me
- you
- is
- what
- please
- my
- a
- for
- 'on'
- in
- of
- email
- this
- it
- have
- from
- and
- play
- olly
- that
- new
- can
- do
- how
- tell
- about
- at
- any
- today
- not
- time
- are
- check
- list
- send
- with
- an
- one
- emails
- last
- will
- am
- again
- set
- next
- would
- was
- up
- like
- turn
- said
- calendar
- meeting
- get
- what's
- right
- all
- did
- be
- need
- want
- song
- tweet
- add
- event
- your
- news
- 'off'
- weather
- there
- lights
- more
- now
- alarm
- pm
- music
- show
- confirm
- train
- could
- think
- does
- make
- command
- just
- find
- when
- tomorrow
- much
- where
- week
- by
- give
- events
- know
- day
- start
- two
- latest
- response
- that's
- remind
- done
- but
- thank
- stock
- some
- you've
- answer
- five
- open
- current
- many
- remove
- radio
- good
- book
- 'no'
- facebook
- going
- it's
- volume
- reply
- work
- delete
- go
- complaint
- contact
- if
- service
- let
- thanks
- so
- hear
- once
- correct
- john
- playlist
- birthday
- got
- post
- ten
- order
- sorry
- has
- date
- hey
- coffee
- who
- rate
- three
- exchange
- further
- light
- twenty
- price
- mail
- reminder
- explain
- podcast
- ticket
- down
- really
- clear
- seven
- schedule
- alarms
- say
- morning
- change
- twitter
- cancel
- number
- dollar
- stop
- out
- appreciated
- hundred
- wrong
- don't
- information
- address
- contacts
- read
- york
- us
- which
- should
- 'yes'
- details
- songs
- between
- nine
- anything
- s1
- received
- playing
- shut
- dot
- mind
- com
- google
- most
- put
- job
- traffic
- four
- best
- six
- create
- recent
- yeah
- happening
- friday
- name
- very
- area
- mom
- or
- take
- appointment
- yeap
- room
- world
- home
- hour
- message
- eight
- clarify
- s2
- party
- episode
- here
- elaborate
- alexa
- appreciate
- customer
- i'd
- sent
- thing
- march
- look
- tonight
- place
- try
- after
- definition
- call
- well
- times
- rock
- phone
- speak
- today's
- whats
- food
- thirty
- see
- joke
- every
- pizza
- write
- lists
- game
- shopping
- weekend
- rephrase
- month
- matter
- s
- update
- station
- vacuum
- great
- detail
- long
- gmail
- old
- repeat
- city
- audiobook
- perfectly
- status
- inbox
- mute
- local
- near
- restaurant
- thousand
- tuesday
- year
- we
- media
- before
- around
- resume
- musch
- her
- house
- taxi
- hours
- didn't
- describe
- answers
- understand
- incorrect
- word
- listen
- first
- item
- d
- trump
- save
- days
- socket
- recipe
- nice
- u
- reminders
- social
- search
- as
- monday
- subject
- location
- movie
- saturday
- euro
- dinner
- them
- ask
- let's
- scheduled
- plug
- i'm
- gotten
- question
- minutes
- friend
- favorite
- meetings
- define
- instructions
- exactly
- cook
- understood
- sentence
- thursday
- grocery
- correcly
- their
- words
- temperature
- person
- amazon
- catch
- company
- mean
- something
- correctly
- living
- fantastic
- help
- following
- dollars
- rain
- speakers
- instruction
- helpful
- increase
- consumer
- evening
- family
- upcoming
- jazz
- saying
- way
- switch
- forecast
- task
- cleaner
- love
- late
- boss
- wednesday
- yesterday
- updates
- lower
- people
- cool
- wonderful
- twelve
- afternoon
- color
- wake
- oh
- lunch
- perfect
- back
- understanding
- useful
- amazing
- his
- dim
- movies
- chicago
- things
- takeaway
- fifty
- unread
- happy
- available
- noon
- wouldn't
- night
- had
- appointments
- idea
- michael
- doing
- over
- doesn't
- select
- hi
- shit
- may
- they
- delivery
- nearest
- buy
- apple
- car
- left
- confirmed
- report
- worth
- robot
- uber
- wemo
- sunday
- excellent
- outside
- blue
- looking
- messages
- top
- wear
- point
- too
- i've
- country
- prices
- bring
- store
- awesome
- unclear
- ok
- mark
- speaker
- app
- sound
- hot
- live
- jackson
- bad
- recently
- currently
- smith
- pull
- whatever
- india
- messed
- kitchen
- ninety
- percent
- him
- use
- office
- brightness
- care
- gave
- description
- tom
- regarding
- meaning
- meet
- siri
- bob
- joe
- hmm
- leave
- sarah
- smart
- come
- chicken
- seventeen
- walmart
- bill
- enough
- choose
- louder
- our
- trending
- born
- london
- zone
- account
- cnn
- audio
- president
- isn't
- compose
- coming
- second
- manner
- pick
- album
- uhh
- plus
- provide
- erase
- notification
- played
- channel
- donald
- pound
- instagram
- made
- bbc
- recommend
- happened
- united
- replay
- shop
- free
- dammit
- nope
- b
- nearby
- pop
- shops
- california
- highest
- notifications
- shuffle
- fm
- chinese
- currency
- uh
- restaurants
- jack
- april
- robert
- only
- been
- why
- states
- friends
- skip
- important
- he
- samsung
- later
- notify
- bedroom
- john's
- mails
- eleven
- red
- exact
- cold
- cup
- rates
- incorrectly
- fifth
- money
- boston
- spoke
- tomorrow's
- forward
- respond
- funny
- wait
- business
- market
- star
- headlines
- third
- favorites
- bother
- retry
- stocks
- high
- g
- favourite
- george
- umbrella
- directions
- wedding
- content
- m
- close
- spoken
- concert
- run
- alert
- searching
- mary
- into
- artist
- located
- mike
- anyone
- snow
- tickets
- then
- reset
- garden
- route
- hello
- tall
- likes
- talk
- forty
- share
- feed
- were
- indian
- washington
- difference
- remember
- convert
- receive
- tune
- level
- asking
- capital
- life
- dad
- yen
- street
- raining
- mistake
- correctly?
- quite
- pandora
- jane
- town
- yet
- player
- park
- san
- american
- far
- sports
- raise
- popular
- display
- these
- couldn't
- mountain
- dentist
- importance
- unimportant
- complain
- clean
- continue
- euros
- los
- ready
- yahoo
- can't
- classical
- politics
- newest
- lighting
- miami
- trip
- horrible
- info
- added
- prepare
- iphone
- machine
- mother
- miles
- via
- chris
- tv
- since
- bathroom
- state
- cheese
- request
- items
- oops
- ah
- closest
- warm
- microsoft
- settings
- value
- keep
- brighter
- note
- everything
- wife
- decrease
- okay
- using
- rap
- election
- sunny
- eat
- usa
- eighty
- fifteen
- until
- wanted
- wrongly
- dog
- obama
- years
- coat
- week's
- japan
- quiet
- paris
- angeles
- comcast
- target
- emailed
- airport
- interesting
- mcdonalds
- mr
- married
- green
- product
- past
- little
- other
- t
- listening
- cooking
- activate
- earth
- dance
- title
- florida
- rupee
- travel
- kids
- takeout
- pending
- america
- making
- its
- than
- doctor
- population
- bar
- plans
- power
- fourth
- silent
- ride
- milk
- how's
- seventy
- sure
- fine
- jennifer
- july
- sister
- brighten
- picture
- deliver
- singer
- clock
- inform
- brad
- burger
- never
- pesos
- object
- hero
- arrive
- classic
- olive
- games
- group
- watch
- line
- justin
- cost
- project
- called
- lets
- track
- still
- starbucks
- form
- repeating
- christmas
- breaking
- due
- cheapest
- forget
- posted
- james
- posts
- central
- lot
- stories
- whole
- small
- ever
- steak
- review
- requested
- wish
- david
- workout
- alex
- seems
- given
- gym
- largest
- la
- average
- compare
- china
- fifteenth
- having
- rupees
- band
- background
- meal
- online
- reserve
- file
- lamp
- laugh
- sun
- anniversary
- eastern
- busy
- mobile
- bit
- jokes
- places
- geographic
- else
- chess
- meant
- working
- p
- planned
- program
- seconds
- rated
- large
- issues
- road
- pay
- big
- holiday
- daily
- 'true'
- celebrity
- better
- hut
- being
- sixty
- away
- helped
- peter
- god
- cab
- someone
- internet
- page
- anna
- feel
- video
- steve
- opening
- lately
- sandy
- bank
- weeks
- id
- sam
- pitt
- river
- february
- i'll
- saved
- soup
- phrase
- distance
- economy
- hits
- sony
- eggs
- low
- water
- text
- topic
- co
- begin
- attend
- groceries
- adele
- reach
- within
- pause
- half
- yourself
- kind
- dark
- replied
- enter
- must
- asked
- beatles
- fun
- ingredients
- against
- invite
- soon
- colour
- different
- jacket
- updated
- seattle
- denver
- canada
- vegas
- mode
- pasta
- january
- doe
- listed
- refresh
- listened
- team
- longest
- spotify
- remainder
- telling
- mumbai
- you're
- orlando
- card
- rice
- during
- reduce
- locate
- future
- starting
- boil
- genre
- class
- slow
- famous
- named
- allen
- youtube
- works
- olly's
- dc
- brew
- through
- pounds
- football
- pacific
- white
- sings
- egg
- oil
- festival
- clothes
- moment
- die
- orange
- school
- kim
- las
- divided
- whether
- photo
- everyday
- ryan
- bills
- headline
- fix
- square
- npr
- jake
- brother
- todays
- terrible
- weekly
- type
- topics
- months
- chat
- yoga
- reading
- products
- extra
- cut
- adjust
- king
- personal
- client
- jan
- data
- doctor's
- computer
- rohit
- johns
- o'clock
- canadian
- mistakes
- rid
- names
- control
- sunscreen
- per
- lady
- head
- taylor
- always
- budget
- pink
- bought
- x
- side
- ahead
- articles
- english
- ny
- able
- reschedule
- fast
- hashtag
- tweets
- countries
- numbers
- running
- alabama
- blank
- madonna
- bright
- yellow
- west
- went
- options
- story
- october
- russia
- together
- n
- basketball
- joe's
- dominos
- tomorrows
- less
- situation
- colors
- mom's
- end
- payment
- drop
- downtown
- provider
- joes
- means
- helping
- mexican
- friday's
- cricket
- return
- needed
- death
- tech
- charlotte
- heavy
- draft
- sea
- paul
- r
- condition
- seventh
- dallas
- hip
- related
- article
- heard
- war
- elvis
- everest
- problem
- stating
- bieber
- system
- sales
- shoes
- hard
- become
- based
- kevin
- age
- she
- quality
- mile
- hair
- gas
- biggest
- inr
- climate
- hate
- twentieth
- sucks
- dean
- angelina
- turkey
- harry
- cake
- national
- record
- longer
- dave
- subjects
- brown
- supposed
- ocean
- church
- drive
- gandhi
- needs
- above
- theatre
- cookies
- abraham
- gone
- map
- television
- such
- face
- sale
- jim
- francisco
- sean
- june
- romantic
- compared
- curry
- ball
- jeff
- subway
- lincoln
- bed
- lagos
- turned
- south
- won
- trains
- girlfriend
- mahatma
- nsa
- hop
- amy
- commute
- solve
- came
- created
- dont
- history
- math
- telephone
- says
- laptop
- pawel
- offer
- fox
- single
- sixth
- midnight
- missed
- potter
- loud
- richard
- chuck
- looks
- practice
- body
- dan
- husband
- waiting
- birth
- stuff
- adam
- sender
- gaga
- truck
- france
- texas
- restart
- intel
- colours
- statue
- liberty
- intensity
- previous
- problems
- outlook
- visit
- wine
- peso
- continent
- utterance
- helps
- asssistance
- each
- north
- grand
- patrick
- match
- opinion
- plan
- trump's
- papa
- instead
- martin
- root
- purchase
- perry
- richards
- closing
- cloudy
- eddie
- senders
- move
- susan
- tesco
- size
- shows
- folder
- spaghetti
- doctors
- stores
- presidential
- dates
- theater
- menu
- agenda
- ann
- code
- animal
- frequency
- kansas
- roomba
- technology
- tasks
- without
- flight
- who's
- beach
- empty
- tired
- driving
- entire
- carry
- british
- dr
- asia
- rccg
- uncle
- vacation
- pepperoni
- programme
- standard
- reminding
- maximum
- starts
- tallest
- gonna
- fourteenth
- playback
- medium
- nike
- cruise
- changed
- diego
- arrange
- bowie
- learn
- mount
- particular
- costumer
- sundays
- fire
- calls
- silence
- podcasts
- spain
- dominoes
- website
- italy
- strongly
- agree
- agreed
- suggest
- mood
- fourteen
- result
- metallica
- thinking
- session
- profile
- england
- active
- ohio
- grid
- fall
- pot
- marriage
- queue
- told
- narendra
- jerry
- mt
- frank
- tenth
- wishes
- recording
- finished
- international
- calculate
- hit
- towers
- ninth
- site
- feeling
- macy's
- tag
- actually
- black
- birthdays
- hottest
- mary's
- expect
- snapchat
- jay
- smith's
- mountains
- building
- setting
- cleaning
- height
- initiate
- hall
- breakfast
- martha
- conference
- aol
- win
- steps
- fancy
- smartphone
- led
- zeppelin
- houses
- holy
- currencies
- club
- children
- atlanta
- einstein
- happen
- cell
- landline
- coworker
- objects
- negative
- modi
- soft
- haven't
- mention
- radius
- books
- daughter
- results
- earlier
- bruce
- butter
- stars
- remaining
- delivers
- device
- domino's
- unmute
- joy
- twelfth
- voice
- taking
- snowing
- sick
- boots
- cleveland
- journey
- destination
- worker
- poker
- lee
- katy
- australia
- incoming
- least
- lisa
- experience
- million
- recurring
- scenario
- sacramento
- geography
- library
- brief
- jolie
- monthly
- elton
- sirius
- alaska
- lyrics
- oven
- log
- random
- moscow
- barack
- disney
- alive
- measurements
- maker
- poor
- error
- stone
- versus
- hotmail
- interpret
- sarah's
- memorial
- goes
- stay
- delhi
- health
- special
- speed
- thirteen
- test
- edinburgh
- credit
- facts
- cat
- neighborhood
- sometime
- empire
- entry
- financial
- comment
- link
- hockey
- circuit
- holidays
- singh
- jodhpur
- rockville
- ones
- features
- bread
- eye
- mall
- directv
- contain
- seacrest
- chance
- under
- table
- few
- hotel
- rude
- services
- yesterday's
- certain
- fb
- abc
- netflix
- linda
- notes
- length
- reminded
- shoe
- wild
- employees
- beef
- sushi
- fastest
- thirteenth
- recommendations
- fish
- tennis
- main
- jersey
- jones
- break
- concerts
- gomez
- angry
- uk
- replies
- emily
- kickball
- released
- upload
- effects
- quickest
- italian
- caroline
- emma
- real
- human
- minute
- took
- activity
- jeff's
- staff
- handler
- touch
- hold
- joanne
- range
- moon
- submit
- ends
- tomato
- lost
- prime
- twelveth
- phones
- amd
- hectic
- bobburgers
- screwed
- porch
- reviews
- vegan
- rihanna
- houston
- ham
- mondays
- general
- engaged
- walk
- melody
- electronic
- held
- selected
- equal
- getting
- tata
- wall
- clothing
- round
- leaving
- nasdaq
- total
- pressure
- expensive
- border
- exhibition
- trash
- november
- handle
- halloween
- attachment
- kardashian
- shoot
- rewind
- rating
- toronto
- department
- procedure
- member
- ray
- chelsea
- rohan
- arrow
- checked
- modify
- wasn't
- chances
- protest
- lottery
- prince
- include
- jo
- net
- pie
- sleep
- enjoy
- nineties
- taco
- banana
- source
- quieter
- bored
- desert
- guys
- gary
- activities
- already
- contract
- st
- minister
- disable
- woman
- europe
- arijit
- audible
- presentation
- cad
- records
- trips
- booking
- tacos
- sally
- non
- centre
- direct
- advance
- selena
- policy
- orders
- stefan
- arrival
- divide
- chocolate
- dish
- teeth
- hdfc
- silvia
- stove
- coast
- defined
- digest
- snafu
- manager
- pinterest
- tim
- conversation
- bulldog
- titanic
- brunch
- heat
- canyon
- dial
- earliest
- region
- stopped
- foreign
- folk
- watching
- brexit
- albert
- joejoe
- early
- cities
- manchester
- december
- biloxi
- often
- questions
- garage
- tunes
- possible
- ms
- ar
- kiss
- shares
- bangalore
- heading
- derek's
- desk
- cheers
- tomasz
- terms
- companyname
- sara
- asap
- super
- meryl
- streep
- rent
- dress
- cinema
- usually
- trend
- conversion
- friendly
- ties
- ordered
- electricity
- marked
- migration
- choice
- journal
- norris
- aniston
- mailbox
- minus
- fried
- miley
- cyrus
- newly
- theory
- rest
- swift
- windy
- dan's
- mass
- comes
- selfie
- wings
- julie
- masti
- celine
- plays
- pack
- including
- responded
- jason's
- ale
- apples
- dolly
- oranges
- lg
- washer
- substitute
- global
- feedback
- grandma
- ben
- drainage
- invoice
- sunset
- takeaways
- man
- art
- universe
- suitable
- antonio
- full
- delivered
- laundry
- wrote
- min
- register
- snap
- nixon
- bird
- spend
- rome
- jesse
- calories
- cappuccino
- quickly
- buying
- britney
- spears
- spacey
- jobs
- arriving
- jean
- potholes
- janet
- pictures
- ashwin
- morgan
- freeman
- baby
- microwave
- yellowstone
- francis
- dubai
- invitation
- hope
- melbourne
- rocky
- kroger
- rivers
- charles
- jim's
- rectify
- statement
- carpet
- baked
- jessica
- meatballs
- mushrooms
- amount
- switzerland
- relating
- zero
- front
- phonebook
- hows
- cheesecake
- carryout
- magic
- ola
- replace
- recorded
- access
- land
- where's
- elephant
- removed
- liz
- load
- metal
- package
- diner
- goog
- bob's
- k
- year's
- mars
- guy
- assistant
- rahman
- eagle
- part
- burn
- aran
- stevens
- daughter's
- eighteen
- chemistry
- action
- selling
- thats
- koc
- lines
- sugar
- major
- chair
- easter
- departing
- africa
- nigeria
- requests
- conditions
- you'll
- manhattan
- roll
- cracow
- candy
- crush
- bell
- massive
- gold
- happens
- usual
- andrew
- equals
- dead
- plane
- graduation
- warned
- shaun
- triangle
- wyatt's
- pass
- function
- max
- space
- programmes
- awful
- parton
- exciting
- battery
- hwu
- recipes
- dirham
- rushmore
- johndoe
- button
- express
- pontificate
- easiest
- magda
- selection
- reservations
- guess
- copy
- classes
- supplies
- schedules
- winning
- berkeley
- notice
- headed
- outgoing
- mi
- rainy
- wikipedia
- entertainment
- dow
- everyone
- aunt
- furniture
- oceans
- softer
- heart
- newmail
- while
- baseball
- easy
- stations
- philadelphia
- alice
- swat
- yearly
- poem
- soccer
- president's
- milan
- paper
- kardashian's
- loop
- shown
- sandals
- yo
- scan
- nevada
- apahelp
- coldplay
- french
- bay
- higher
- rumplestiltskin
- airlines
- fresh
- standing
- cream
- hamburger
- broadway
- oscars
- tokyo
- cable
- shipment
- formula
- teacher
- sweet
- golden
- newsfeed
- confirmation
- shirt
- austin
- own
- canon
- wanna
- gods
- spanish
- count
- seat
- ideas
- study
- tara
- mutual
- jennifer's
- because
- edit
- denmark
- direction
- timer
- growth
- luther
- marketing
- cd
- mine
- public
- peter's
- bolshoi
- flat
- crazy
- others
- dry
- pub
- theatres
- bro
- fashion
- teams
- cycle
- pickup
- dion
- teach
- series
- checkout
- male
- noise
- solitaire
- pf
- cassie
- travelling
- davis
- naty
- income
- disco
- dropping
- donna
- follow
- shelly
- accidents
- plot
- irene
- download
- circle
- law
- tea
- organize
- principal
- weekends
- camera
- solution
- bombay
- wuthering
- heights
- charged
- colorado
- kong
- keys
- race
- mona
- entries
- j
- nyc
- potatoes
- gospel
- raju
- trivia
- bike
- dating
- oregon
- event's
- prefers
- rush
- percentages
- peking
- cooker
- husbands
- won't
- tower
- heaven
- hugh
- june's
- fake
- figure
- purple
- takes
- l
- howard
- stern
- nineteen
- percentage
- motorola
- doe's
- outstanding
- tesla
- laura
- dale
- warning
- eighteenth
- golf
- island
- career
- bieber's
- vacuuming
- pizzas
- refund
- weekday
- s's
- derek
- thanksgiving
- delayed
- query
- buffet
- rachel
- pants
- wash
- survey
- photos
- except
- topography
- door
- jen
- queen
- depart
- cheap
- theaters
- web
- jesse's
- multiply
- workhouse
- press
- click
- loss
- recipient
- verizon
- volcano
- rolls
- royce
- pixel
- affirmative
- completing
- thai
- walking
- bananas
- hollywood
- equation
- dirty
- scores
- katrina
- exam
- creating
- letter
- sing
- construction
- broadcast
- tom's
- rupies
- management
- permanently
- converting
- ist
- iron
- religion
- kings
- tucson
- standup
- tic
- tac
- toe
- headset
- sex
- diapers
- purpose
- seventeenth
- eighth
- dylan
- temple
- refer
- gift
- fact
- drink
- inches
- air
- carpets
- newcastle
- clients
- private
- tasting
- sams
- nj
- chili
- cultural
- swimming
- they're
- iowa
- jordan
- period
- accept
- cincinnati
- college
- rainbow
- myself
- deep
- deepest
- warming
- sky
- vp
- seeing
- indianapolis
- kmart
- nikesupport
- image
- suck
- broiler
- timeline
- dell
- parisa
- brandon
- example
- y
- filter
- sad
- shine
- sixteen
- christian
- pic
- pdr
- fry
- another
- network
- omelette
- kilometers
- municipality
- giving
- leo
- cups
- earthquake
- susan's
- application
- cross
- across
- carl
- pawel's
- sauce
- relativity
- rail
- sisters
- letting
- shorts
- vs
- rajesh
- swift's
- starving
- discussing
- block
- written
- n9ne
- women
- celebrities
- bake
- cookie
- continents
- workers
- leonardo
- mel
- gibson
- shall
- beauty
- sum
- fair
- deli
- middle
- same
- nile
- sell
- role
- boat
- sandwich
- parts
- hearing
- knows
- sand
- manoj
- delivering
- rahul
- neil
- australian
- kindly
- properly
- assist
- esurance
- emilia
- breach
- loudly
- harvard
- marc
- nintendo
- scrabble
- farm
- lie
- patio
- greg
- screen
- degrees
- yesterdays
- carrots
- receipt
- lasagna
- clooney
- there's
- degree
- preferences
- hallway
- latin
- nicest
- lauren
- worst
- also
- checkers
- input
- boyfriend
- masala
- tournament
- monet's
- burmuda
- section
- eric
- japanese
- supervisor
- junk
- performance
- effective
- urgent
- oldest
- tone
- sweater
- goa
- bag
- lowest
- aus
- peace
- julia
- summer
- fan
- hurricane
- colder
- steven
- sachin
- tendulkar
- watson
- exorbitant
- bags
- macs
- yulia
- matthew
- pole
- toby
- pennsylvania
- carmen
- tiffany
- complete
- electric
- wallet
- albums
- maths
- distribution
- eminem
- familiar
- regard
- upwards
- ron
- couple
- acme
- angel
- zoo
- nineteenth
- shazam
- inflation
- offers
- devotional
- jackie
- tony
- artificial
- intelligence
- grill
- father
- predictions
- repeats
- manila
- cooked
- reason
- learning
- nowadays
- cheer
- jingle
- bells
- anxiety
- hoizer
- girl
- pondichery
- position
- teachers
- dictionary
- nap
- cafe
- m's
- meting
- crime
- eve
- horn
- bristol
- pubs
- companies
- johnson
- resolve
- waterfall
- female
- biriyani
- drama
- nothappy
- haircut
- remote
- colleagues
- bones
- saturdays
- cambridge
- jam
- maine
- category
- invented
- chang's
- boy
- planning
- chen
- assignment
- publish
- hunt
- alerts
- dad's
- deal
- leading
- trail
- follows
- young
- jay's
- summary
- ko
- beyonce
- vergara
- mexico
- whishes
- arrived
- placid
- specific
- depot
- tikka
- expire
- markets
- problematic
- highly
- blues
- thirtieth
- brooklyn
- tatum
- argentinian
- redso
- des
- moines
- women's
- richard's
- cellphone
- division
- hong
- political
- charley's
- steakhouse
- accident
- normal
- wakeup
- satellite
- freezing
- forex
- jimmy
- chores
- snooze
- design
- museum
- guide
- speech
- ran
- shift
- inferior
- mashed
- jcpenney
- environment
- raw
- disturbed
- sia
- chips
- anybody
- present
- reynolds
- limbaugh
- weekdays
- islands
- viral
- asian
- streets
- inception
- meatloaf
- alternative
- compliant
- sensex
- phil
- est
- hand
- switched
- recap
- ferrari
- nandy
- promotion
- kate
- brothers
- ma
- followers
- closer
- deleted
- gloves
- bands
- platter
- boland
- corner
- strong
- chipotle
- eu
- amtrak
- son
- charges
- version
- rajdhani
- chart
- manage
- musical
- hat
- den
- tonight's
- syria
- stronger
- homelessness
- nails
- support
- ally
- sentences
- penn
- ago
- turning
- center
- hungry
- actress
- keywords
- usain
- bolt
- ongoing
- cancelled
- idol
- julia's
- wells
- fargo
- ri
- sarahs
- computers
- devices
- toms
- regards
- quote
- production
- brother's
- inch
- shell
- marathon
- directory
- dictate
- huey
- lewis
- elections
- alone
- marry
- apart
- danielle
- jane's
- mankind
- singularity
- nye
- feynman
- whom
- inventory
- makes
- dept
- apple's
- education
- bugs
- settle
- when's
- geographical
- jason
- exchanges
- mcdonald's
- tgi
- ship
- hershey
- facing
- faulty
- zita
- jeremy
- irons
- wallmart
- sphere
- hp
- gottten
- pardon
- engagement
- showing
- format
- absolute
- interest
- messenger
- gate
- enable
- columbus
- hips
- tour
- sterling
- thumbs
- priced
- tablet
- amc
- bible
- safeway
- organism
- undertake
- freedom
- charger
- documents
- jars
- clay
- members
- o
- vegetables
- delicious
- beaumont
- tx
- finance
- exhibitions
- trumps
- month's
- v
- applebee
- dakota
- bus
- brighton
- pa
- darken
- promoted
- liverpool
- utah
- suggestions
- micheal
- complaints
- pencil
- keith
- fridays
- temperatures
- hardware
- exercise
- jpearsonjessica
- release
- hoover
- goshen
- chester
- wood
- woodchuck
- healthcare
- borges
- calculator
- dune
- reality
- jobe
- gossip
- piece
- convenient
- titled
- pork
- belongs
- hongbin
- wreck
- tool
- started
- gather
- bruno
- costa
- patel
- daniel
- corporate
- controversy
- wendy's
- texans
- biography
- flowers
- investing
- arrives
- finish
- spot
- crop
- culture
- enjoying
- fetch
- kill
- auto
- washing
- buffalo
- he's
- titles
- ross
- whose
- types
- pleasant
- erin
- madison
- tuesday's
- lif
- khan
- affordable
- season
- policies
- c
- expected
- hypothesis
- seth
- kicked
- unhappy
- gallery
- xorg
- used
- monali
- thakur
- noodles
- cher
- sally's
- tracks
- mid
- launch
- glasgow
- bridge
- releases
- pitt's
- server
- clarity
- yens
- motivational
- scratch
- blanket
- aib
- reads
- singing
- monas
- tuesdays
- winter
- rocket
- lands
- chan
- economic
- sister's
- aa
- film
- pb
- indiana
- departure
- pipeline
- stitch
- sleeved
- hail
- logan
- style
- quantum
- physics
- labeled
- delia
- began
- rrcg
- shape
- awards
- improve
- pertaining
- trance
- lives
- weight
- met
- brian
- sinatra
- sunglasses
- attending
- falls
- requesting
- sunday's
- overhead
- greg's
- rom
- historic
- georgia
- guest
- jaipur
- iroomba
- alfredo
- pride
- prejudice
- fill
- interview
- daddy
- wangs
- manchow
- university
- locally
- lowes
- tiring
- east
- medical
- metro
- bach
- schubert
- rooster
- czk
- channing
- pad's
- identify
- yelp
- scandal
- affect
- suffering
- enabled
- arby's
- saw
- mango
- itunes
- highlights
- brings
- sixteenth
- tourist
- wendys
- presley
- sold
- intern
- affairs
- fries
- buttermilk
- panda
- wants
- floor
- clint
- eastwood
- moe's
- planets
- equivalent
- morrocco
- gravity
- uploaded
- someplace
- availability
- issue
- fly
- jpy
- natural
- delta
- disappointed
- files
- q
- cindy
- shortest
- simple
- ring
- lotion
- maroon
- fort
- died
- bonus
- repetitive
- icecream
- statistics
- rebel
- lawn
- leith
- measure
- daytime
- september
- pilots
- pda's
- shade
- sil
- cap
- punjab
- gwalior
- ashley
- juice
- nagar
- ellen
- programs
- fairs
- invest
- suits
- ingredient
- launches
- leaves
- bjork
- crater
- elevation
- stewart
- hotels
- spices
- bubbles
- grass
- broccoli
- capricious
- philosophy
- anthony's
- apply
- pings
- gps
- thomas
- koontz
- acdc
- beijing
- ratings
- union
- prayer
- todo
- angles
- scissors
- stashable
- cinch
- bacon
- passive
- que
- occurred
- lakeland
- tulsa
- advise
- singapore
- risotto
- invested
- model
- helmsworth
- bench
- julian
- buddy
- rogers
- brains
- chap
- badminton
- dick
- lopez
- apartment
- points
- germany
- unknown
- thugs
- healthy
- rash
- casey
- oriam
- ps
- plants
- mailed
- ikoyi
- grassmarket
- marleen's
- locations
- bush
- mac
- reaching
- allan
- till
- cheering
- guitar
- oxford
- densely
- populated
- son's
- hubby
- comparison
- putin
- barcelona
- gss
- energy
- pan
- nyack
- worked
- unavailable
- bryan
- adams
- miss
- checkbook
- jared's
- enrique
- iglesias
- forms
- jeans
- voices
- alan
- tudek
- animals
- olx
- mts
- freed
- jenn's
- coordinates
- humid
- demographic
- otherwise
- tiffany's
- outdoor
- sheila
- lincon
- dust
- serve
- conduct
- estimated
- gaana
- funds
- downloaded
- indignation
- meijer
- necessary
- grubhub
- pancakes
- mario
- bars
- birmingham
- sites
- donuts
- chopra
- textual
- rapids
- cant
- prefix
- sounds
- provides
- amy's
- benton
- leeds
- dsw
- returning
- defective
- digital
- bhaji
- carlos
- linux
- upgrade
- shark
- attacks
- screening
- exposure
- souffle
- tracking
- od
- progress
- paused
- gilmore
- hour's
- imdb
- orleans
- european
- gdp
- surfers
- theme
- ash
- ikea
- klm
- marilia
- cars
- robin
- williams
- surfin
- ottawa
- trade
- contains
- field
- someone's
- prague
- brno
- rene
- interests
- radiolab
- harris
- strive
- accommodating
- fell
- relationship
- pharmacy
- memo
- nancy
- paid
- expressing
- disapproval
- yard
- royale
- hide
- amber
- cheeseburger
- coca
- cola
- al
- matrimony
- scott
- potato
- funniest
- polling
- mother's
- chase
- xmtune
- matt
- murphy
- detroit
- taiwan
- organic
- secrets
- domino
- ac
- assistants
- z
- fred
- owner
- required
- saga
- hanks
- trading
- erosser
- rosser
- vikki
- dhaka
- notepad
- oldies
- alison
- recur
- w
- mentioning
- languages
- lavender
- toned
- videos
- stein
- chennai
- resuming
- moms
- foke
- beep
- discussion
- woodland
- lowry
- meetups
- powerball
- toyota
- focus
- concentrate
- nbc
- roosendaal
- deactivate
- shrimp
- parmigiana
- bumper
- spouses
- lucknow
- paying
- hurry
- served
- rhythm
- enquiry
- hartford
- plaza
- hyundai
- wishing
- websites
- briefing
- complex
- calculations
- jarvis
- highway
- fired
- dissatisfied
- sandra
- bullock
- ratio
- haskell
- sharon
- horse
- mum's
- dillinger
- sunblock
- sub
- tab
- crude
- software
- stadium
- step
- short
- reddit
- appoints
- agra
- sheet
- keyboard
- kfi
- district
- connery
- carnival
- wok
- shutting
- phoenix
- cloth
- rehan
- lego
- alphabetical
- mexco
- charles's
- foodpoisoning
- ultra
- madonna's
- harley
- davidson
- daylight
- afi
- infy
- launched
- inboxes
- secretary
- increased
- resolving
- fuel
- injector
- multiple
- interval
- mike's
- espresso
- sasha
- susie
- salesperson
- country's
- cylinder
- specifications
- ivory
- pst
- zoella's
- jackman
- reacting
- potential
- frying
- boise
- wendy
- divisible
- automated
- katherine
- pre
- gaming
- containing
- decade
- industry
- foot
- chemical
- cause
- taste
- bra
- julianne
- hough
- addresses
- vonstaragrabber
- lion
- restroom
- kohl's
- mentioned
- hz
- royal
- bloodline
- relationships
- billings
- levin
- quarter
- lori's
- lori
- exclamation
- definitions
- birds
- raj
- priya
- allows
- worlds
- kelly
- clarkson
- garam
- scarlet
- found
- cub
- dmv
- excessively
- lake
- dried
- reporting
- smile
- changes
- charmin
- eternal
- smoked
- meat
- beanos
- processing
- chip
- logic
- insightbb
- highland
- terrace
- child
- peck
- midwest
- cardinal
- anthony
- barrack
- jancy
- thompson
- cassy
- gulls
- alternate
- sin
- dragons
- msnbc
- residential
- leader
- siblings
- pedro
- serendipitous
- bestbuy
- targets
- wawa
- mentions
- engagements
- hawaii
- jr
- applied
- halifax
- ahmedabad
- monty
- python
- stronomy
- blahblah
- blah
- arrivals
- subtract
- payoneer
- formal
- connors
- indranagar
- transform
- marcia
- perpetual
- arranging
- cvs
- callum
- steffi
- attention
- kanye
- mommy
- chucky
- forest
- polarized
- proposal
- conrad
- coldest
- hue
- dictator
- clancy
- geranium
- delays
- build
- lense
- rai
- transistor
- dildo
- warren
- exercises
- forman
- kinley
- bottle
- retail
- yan
- regal
- unprofessional
- annual
- payday
- tricep
- arts
- ripped
- vietnam
- trends
- chaise
- preparation
- nestle
- paula
- deen's
- bmw
- microsoft's
- bookstore
- below
- moving
- pretty
- lock
- administrator
- edition
- airways
- marvel
- garner's
- rubix
- cube
- kfc
- milwaukee
- pager
- alexander
- gilchrist
- goods
- performing
- unopened
- security
- chain
- probiotic
- colleague
- knowing
- novel
- fiesta
- comcasts
- acer
- farmers
- fraud
- weighing
- india's
- gotse
- grapefruit
- similar
- tmobile
- nifty
- sessions
- recital
- greatest
- openings
- zip
- demento
- fatigued
- disease
- prevention
- overcharged
- unquote
- cotton
- tweeter
- railways
- flipkart
- fist
- renee
- nutritional
- starred
- calculated
- mattress
- hillstead
- paul's
- jill's
- disregard
- pesto
- stinks
- nobody
- behind
- kid
- nature
- ounces
- ted
- boiled
- dancom
- wars
- fmod
- span
- along
- malls
- joining
- frequently
- realdonaldtrump
- bobby
- mcgee
- pwd
- obamacare
- clicked
- falling
- pampers
- virgin
- hayden
- pat
- amie
- infosys
- technologies
- roads
- aerosmith
- airtel
- dairy
- sends
- dues
- tobytoday
- ileana
- d'cruz
- rended
- taj
- ashok
- typhoon
- rama
- final
- missouri
- virginia
- announce
- haughty
- salmon
- joking
- goodnight
- rebecca
- believe
- vowels
- ban
- haze
- insight
- cable's
- fellow
- tweeters
- canoe
- warriors
- assassinated
- acceleration
- detailed
- wife's
- robert's
- angus
- interested
- jen's
- sjobs
- cdn
- ruth
- simran
- aapa
- kadai
- armor
- sms
- indefatigable
- indicate
- fra
- floors
- modcloth
- honor
- weigh
- priority
- hiking
- smoky
- judawa
- expense
- deals
- plethora
- sam's
- august
- elain
- bbq
- leap
- congressional
- representatives
- voting
- reproductive
- ge
- bbb
- contacted
- assigned
- jill
- drafts
- scoring
- touches
- relevance
- goggins
- medvesek
- philippiness
- booked
- board
- locality
- beth
- katey
- fans
- approximately
- charitable
- rae
- darker
- anymore
- printing
- significance
- fondle
- mate
- larry's
- larrylarry
- faripir
- gurpur
- seasons
- softball
- refreshments
- jamie
- carrie
- underwood
- abdul
- kalam
- subterranean
- colombo
- sri
- lanka
- quit
- dollar's
- award
- among
- spouse
- forgot
- ass
- millionaire
- indians
- americas
- julie's
- transcribe
- garbage
- geographics
- tree
- criticize
- tanzania
- heather's
- answering
- spam
- phishing
- reseda
- axel
- kailey
- prettiest
- century
- mattel
- toys
- grateful
- fixing
- maidan
- sophia
- betty
- reasons
- russian
- applicable
- loving
- claire
- crashed
- batteries
- philips
- person's
- compile
- ali
- matthews
- apologize
- comcastcom
- luke
- jean's
- carefully
- beg
- trying
- flooringco
- seams
- baking
- skiing
- calming
- continuously
- tale
- roraima
- innova
- bowling
- beginning
- identifier
- diverse
- santa
- continuous
- hangman
- vegetarian
- roast
- rewards
- allow
- immediately
- shelley
- hennessey
- waking
- dicaprio
- ways
- immigration
- raised
- lose
- digger
- cosmetic
- perth
- feet
- chick
- tornadoes
- upstairs
- badly
- timings
- lobster
- runner
- forum
- thunderstorms
- powered
- plugged
- rod
- mgccc
- bleed
- ga
- pune
- mixed
- dishes
- radisson
- cheetah
- what'sapp
- cm
- father's
- skill
- graham
- eggless
- collect
- favorited
- flag
- ssmith
- virtual
- bryant
- spots
- scapingyards
- washed
- springfield
- draw
- insurance
- quantity
- brightener
- cuba
- stream
- raincoat
- maiden
- soundtracks
- deliveroo
- humidity
- crowded
- built
- mesa
- rosenstock
- workpdf
- occurring
- environmental
- dbell
- converse
- radia
- logged
- scabble
- loads
- jacob
- hasbro
- aldi
- piramid
- completely
- method
- hems
- loose
- connect
- snapchats
- arizona
- festivals
- hospital
- peppers
- bowl
- korn
- lupe
- eurostar
- umf
- unchecked
- berlin
- lane
- synonyms
- hampshire
- shakira
- brads
- keanu
- reeves
- johns's
- increasing
- burgers
- stan
- falklands
- valley
- maria
- hangin
- glow
- we're
- newsource
- clark
- carrey
- jams
- crashing
- outback
- sugars
- defines
- joel
- venue
- huffington
- images
- elizabeth
- case
- agnes
- randomly
- mecky
- incredible
- even
- decreased
- vacations
- honey
- akon
- barbara
- handsome
- forensic
- spielberg
- korea
- coding
- achievements
- albert's
- clerk
- hopes
- zimbabwe
- buble
- research
- excel
- gun
- rogen
- resin
- tooth
- filling
- mody
- marinara
- vicki's
- mardi
- gras
- monika
- relatives
- chillin
- lol
- levis
- tricounty
- messy
- disgusted
- emoteck
- foroogh
- quick
- decline
- emailstudy
- atdfd
- giant
- trey
- kalka
- mcdo
- timestamp
- operate
- watched
- infinity
- tactics
- upbeat
- synonym
- racing
- towards
- fog
- muted
- coke
- eighties
- tvs
- theresa
- brent
- kamycka
- dejvicka
- tap
- peanut
- circumference
- saskatoon
- sync
- sofa
- mcdonald
- silenced
- catalogue
- algorithm
- sanctimonious
- talked
- realize
- reveca
- paok
- wipe
- bisque
- br
- rather
- silly
- stat
- tar
- vitamins
- gain
- xm
- fongs
- anywhere
- zanes
- se
- chronicles
- weber
- commence
- causes
- sangli
- german
- hedges
- truthdig
- coffees
- commuter
- plain
- mimo's
- oscar
- restrictions
- treasure
- louis
- stevenson
- fifa
- beast
- pav
- prambors
- hannah
- ringcast
- vegetable
- episodes
- overnight
- apps
- nathan
- dismiss
- karl
- hourly
- eyes
- breeds
- inside
- tribune
- join
- crabmeat
- shakira's
- yankee
- greenwich
- gala
- jump
- recall
- johnny
- cash
- pod
- cast
- rare
- suppose
- enjoyment
- emo
- nayagara
- passion
- pit
- marckel
- bohemian
- emma's
- arijit's
- pet
- prize
- receptionist's
- beat
- freds
- probles
- patagonia
- quart
- '?'
- zach
- duration
- jlo
- alphabetic
- phohouse
- badpho
- daybreak
- biryani
- battle
- divergent
- moby
- jungle
- jaiho
- casserole
- shooter
- columbine
- wednesdays
- soul
- accumulation
- squash
- calm
- debate
- schools
- amd's
- lee's
- managers
- myspace
- relaxing
- bahar
- antarctica
- atmosphere
- pinpoint
- payments
- illinois
- louisiana
- cfo
- pool
- vyas
- morel
- mysore
- rise
- sdfa
- newspaper
- calorie
- dangerous
- sunrise
- mostly
- dining
- shake
- flood
- prescription
- mix
- view
- jana
- spa
- comments
- pear
- factor
- clearance
- northern
- language
- arnold
- exxon
- mobil
- dragon
- fruit
- differences
- seashells
- seashore
- velocity
- motorolla
- haggis
- fiji
- irwin
- similarities
- hypertrophy
- sharukh
- implement
- kazakhstan
- mediterranean
- roman
- grigorean
- hardword
- quead
- amphibious
- roberts
- climatic
- tornado
- prone
- rising
- declining
- megatel
- denzel
- washington's
- citizens
- arm
- persos
- belarus
- gyllenhal
- geology
- helicopter
- iphone's
- drained
- manger
- navy
- daikin
- jerk
- nexus
- interaction
- platform
- tweeting
- at&t
- mahaboobsayyad
- kellogg
- ashmit
- ismail
- listing
- enalen
- projects
- clara
- clinic
- exams
- ammunition
- mark's
- divya
- jjnzt
- activation
- andy
- terry's
- brenden
- jeffrey
- burnette
- protests
- joshua
- pianist
- whiz
- schadenfraude
- rials
- storage
- bot
- provided
- massachusetts
- channin
- store's
- rump
- prior
- re
- intelligent
- recognise
- irobot
- areas
- lighter
- yell
- uses
- cn
- gadgets
- skynet
- marie
- lamb
- balcony
- nyt
- bennett
- ralph
- pda
- balloon
- maps
- degeneres
- character
- evans
- actor
- fitbit
- malika
- shivaji
- attitude
- lily's
- concerned
- upon
- startup
- stuffs
- tawa
- relative
- legacy
- cst
- leah
- remini
- mortgage
- amed
- cleaners
- seal
- abita
- grammar
- backdoor
- minimize
- leisure
- billie
- spicy
- training
- comfortably
- sunburn
- minneapolis
- habits
- braking
- notifier
- swan
- thoughts
- pleasure
- those
- kashmirstart
- sells
- i'dl
- kettle
- 'false'
- rta
- valia's
- visiting
- techno
- mornings
- mow
- cbs
- slightly
- francine
- vice
- postpone
- mins
- xyz
- hwood
- kept
- spider
- reopen
- billy
- connery's
- eiffel
- itinerary
- crash
- valentine's
- likexchange
- divorce
- danville
- il
- government
- menus
- capabara
- origin
- assistance
- vicinity
- chit
- drinks
- flabbergasted
- xy
- self
- double
- castle
- refrigerator
- bakery
- spray
- pyramids
- bio
- basic
- humans
- schwarzenegger
- inchoate
- rules
- caftan
- raleigh
- hobby
- ajay
- devgn
- corden
- aud
- prevailing
- kenny's
- crew
- aww
- spying
- employer
- thier
- juanpedro
- craig
- leon's
- looked
- players
- costs
- providers
- sydney
- documentary
- hyphen
- represent
- strings
- pianos
- acoustical
- celeb
- pong
- linear
- turn_down
- reaches
- strength
- routine
- billboard
- piano
- ed
- sheeran
- diet
- vietnamese
- yams
- grandmother's
- rihana
- require
- stressed
- option
- affected
- acquire
- retrieve
- clarion
- congress
- turiellos
- mates
- solar
- dice
- jalapenos
- wished
- painting
- therapy
- warehouse
- mop
- neighbor
- flappy
- returns
- someones
- spring
- wonton
- moves
- jagger
- fishing
- hiphop
- dunkin
- donut
- atlantic
- daughters
- hula
- hoop
- lessons
- scrote's
- indie
- grief
- lebron
- naughty
- preprogrammed
- alt
- needy
- sharpen
- butcher
- knife
- pulled
- starbuck's
- backward
- terrorist
- invaders
- parent
- crescent
- brewhouse
- prado
- science
- playlists
- debbie's
- sleeping
- searched
- lindsey
- lohan
- competitions
- subtracting
- challenge
- beer
- gainers
- chili's
- frubs
- police
- softly
- practical
- assessment
- bonefish
- rotating
- placed
- lakers
- barenaked
- ladies
- lord
- rings
- mar
- sneakers
- artists
- sanantha
- shuffles
- shuffled
- bardonia
- county
- analyze
- pattern
- girls
- league
- fjords
- nothing
- brewing
- smurfs
- tommy's
- lovin
- cottage
- ming
- photosynthesis
- danny's
- repeated
- peaceful
- migrations
- zydeco
- inkheart
- seller
- occurence
- telegraph
- invited
- wifi
- levels
- willie
- nelson
- dolores
- alter
- retirement
- professional
- development
- sainsburys
- byron's
- floyd
- raingear
- notorious
- bone
- explanation
- database
- likely
- lucky
- irish
- sshow
- ramsey
- aired
- sprint
- preparing
- academy
- yeshudas
- angels
- dancing
- aretha
- franklin's
- layers
- glass
- kuch
- hai
- wakey
- knitting
- mujhe
- feb
- king's
- malinda
- parents
- mirchi
- gallon
- seen
- parks
- safest
- evacuation
- beautiful
- sofia
- francs
- consequences
- various
- dicaprio's
- networth
- phelps
- disk
- constructed
- concern
- effectively
- lawrence
- zac
- galifrankas
- wheat
- prediction
- schemes
- mega
- capricorns
- dinky
- lanegan's
- princess
- pregnant
- smallest
- americans
- retweet
- insta
- sonys
- bk
- alzacz
- kohls
- cleanliness
- pizzahut
- delay
- lpg
- satisfied
- choke
- suqcom
- repairs
- killing
- miller
- budgets
- iamironman
- gbaby
- gma
- loves
- kate's
- margaret
- ben's
- brady
- palmer
- homework
- tax
- regional
- archive
- fitness
- vault
- footloose
- child's
- damage
- petco
- canceled
- passing
- pikes
- peak
- avatar
- diverge
- maron
- fault
- sword
- eventual
- contest
- dangal
- mauritania
- abs
- wondering
- southampton
- resources
- soy
- lexmark's
- hilly
- lyon
- beirut
- tribute
- madrid
- ate
- sweat
- charlize
- theron
- atif
- aslam
- capture
- actual
- shane
- dawson
- zedd
- snooker
- loquaciousness
- sholay
- tofu
- nightmare
- avenged
- sevenfold
- matters
- prompt
- panic
- brilliant
- boston's
- mckinleyville
- astrology
- strait
- countdown
- cats
- fruits
- embassy
- pita
- gyros
- negotiations
- hairdresser
- courteous
- enthusiastic
- funk
- sense
- heathens
- cabinet
- irctc
- stored
- shutoff
- glasses
- ella
- fitzgerald
- rover's
- vet
- polar
- bears
- oceanside
- medicine
- anita
- barrow
- burrito
- oliver
- covering
- ground
- zucchini
- textile
- antebellum
- chimes
- covington
- species
- bees
- cranston
- kilometer
- behaved
- rudely
- jimi
- hendrix
- calms
- outwards
- califonia
- composed
- hint
- shipping
- frosting
- sport
- napoleon
- hill
- athens
- middletown
- shirts
- sample
- politician
- investigated
- rapper
- con
- cuisine
- wizard
- brick
- conroe
- iterate
- architect
- salon
- babaji
- passed
- maryland
- surya
- monopoly
- avenue
- considering
- celebration
- brewed
- galoshes
- tutorials
- workouts
- millenium
- toward
- neighbourhood
- bannon
- storming
- reoccurring
- longtime
- sweetheart
- memos
- starfish
- centaur
- philippines
- oar
- departs
- preferably
- latte
- sides
- pentagon
- fashioned
- rescheduled
- transportation
- twins
- duker
- deadline
- samurai
- obaba
- bp
- ambiance
- automatically
- object's
- boost
- morale
- jogging
- spell
- firefly
- mura
- masa
- checklist
- biographies
- sucked
- congested
- avinash
- commando
- jolie's
- instrumentals
- clarksville
- tablespoons
- surveys
- flour
- acela
- calone
- bucket
- fulls
- valid
- references
- critical
- perpetuate
- luncheon
- ohm's
- values
- plying
- expectations
- musician
- mindsweper
- throughout
- noontime
- included
- tour's
- voted
- walgreens
- chickens
- monday's
- crankshaft
- surfer
- lunchtime
- skramz
- compounds
- diabetes
- might
- reservation
- homosapien
- engadget
- boeing
- brisbane
- ear
- headphones
- minimum
- worry
- snowplows
- burying
- driveway
- adapt
- destroy
- impanema
- equipment
- turnt
- attractive
- conducted
- cinnamon
- freshener
- watsapp
- bean
- awfully
- entitled
- murderer
- ford
- forties
- scenery
- morocco
- sf
- blokus
- preacher
- taken
- stormy
- centers
- ethics
- popup
- mysterious
- puts
- stage
- considerations
- lourie
- artic
- scoop
- carion
- merced
- bypass
- passwords
- quantico
- grade
- examples
- cuisines
- hibernate
- bear
- published
- authors
- tempo
- keidis
- tidal
- cookoff
- zones
- probable
- summerfest
- dogs
- aren't
- necessarily
- carolina
- eleventh
- chilling
- sleeve
- invoking
- term
- herald
- maria's
- poltergeist
- imagine
- uv
- index
- johncena
- instruct
- oscillate
- liter
- nelly
- shawarma
- baster
- pali
- vilnius
- tabs
- debates
- singers
- activated
- ozzy
- osbourne
- danish
- happypeoplecom
- accounting
- backpack
- im
- puttanesca
- keeps
- worse
- wrigley
- braise
- loin
- carnatic
- bases
- nick
- swisher
- stolen
- clouds
- cleared
- bola's
- norman
- reedus
- screwdriver
- window
- volcanoes
- rowan
- atkinson
- minneapoliscity
- delicacies
- monitor
- overall
- gymnastics
- channels
- kxly
- botswana
- enjoyable
- spectre
- chane
- decentralized
- men's
- freeze
- postal
- becomes
- ccn
- berth
- michigan
- composition
- shahi
- panner
- dakar
- jakarta
- equalizer
- weird
- barely
- rodriguez
- oklahoma
- giraffes
- margarita
- difficult
- crabs
- firework
- probability
- tools
- emigration
- legislation
- pdf
- cheeseburgers
- applications
- adopters
- priest
- walks
- mechanic
- h
- showers
- signs
- contrast
- recollect
- gm's
- duck
- beavers
- tail
- lucking
- horkersd
- wo
- myrtle
- hr
- steam
- entirety
- anirudh
- colored
- tropical
- bedrooms
- yellowish
- elephants
- expenses
- contents
- warmer
- royksopp
- etc
- progressives
- peoples
- cultures
- unset
- iceland
- mp
- mangalore
- tanya
- quad
- particulars
- insert
- tvf
- formidable
- origins
- eden
- depressed
- mc
- donalds
- rub
- regrets
- judgments
- scope
- intellectual
- capacity
- ahmadabad
- stethoscope
- superstitions
- rl
- stine
- quinoa
- martial
- smooth
- damn
- speeding
- stephen
- halley
- barry
- jealous
- siri's
- java
- scenarios
- pc
- transfer
- tw
- agent
- nightime
- creamy
- mirch
- dil
- cannon
- cameras
- process
- merriam
- webster
- dubstep
- rangoon
- wines
- older
- navigate
- chandelier
- egs
- recognize
- subscriptions
- mileage
- studies
- microphone
- immigrant
- electronics
- careful
- paint
- fund
- success
- resolved
- bola
- eva's
- roller
- augusta
- midtown
- surprise
- children's
- dongle
- seashell
- bots
- fallen
- centimeters
- poisoning
- sci
- fi
- outcome
- reform
- sleepy
- moderate
- chrome
- ultraviolet
- george's
- geek
- courses
- rundown
- legend
- equipments
- usher
- manor
- advertisers
- clue
- depending
- strongest
- outstation
- fallout
- shoal
- lastfm
- relocate
- pollution
- awareness
- bryce
- jessie
- carol
- nsnbc
- vacuumed
- chives
- splits
- arbor
- receiving
- toast
- futures
- brokers
- routes
- fixed
- additional
- switches
- church's
- governor
- enacted
- grams
- guitarists
- android
- babe
- sonny
- sear
- eliminate
- remain
- uc
- polk
- pakistani
- bedside
- reshuffle
- frida
- devil's
- rusk
- actors
- pakistan
- happenings
- sit
- montauk
- beethoven
- legends
- sunshine
- mothers
- smoke
- feels
- rockies
- miamy
- operations
- addition
- subtraction
- incite
- annoying
- cristiano
- ronaldo
- spin
- cows
- jenny
- spread
- wallstreet
- selections
- nashik
- ipl
- oswald
- chambers
- horoscope
- mgk
- dog's
- residing
- cricketer
- dhoni
- byron
- fluctuations
- talks
- palermo
- shallowest
- bbcnews
- nsdl
- flights
- lineup
- stick
- ribs
- jeopardy
- timetables
- emi
- maya
- mackensie
- osteen
- jimmie's
- adjustments
- precocious
- fork
- husband's
- audi
- hibachi
- disputed
- crack
- visible
- boiling
- rogan
- karachi
- babysitter
- kidnapping
- hamburgers
- madonnas
- lessen
- ipo
- greenville
- carries
- creamed
- pickled
- herring
- tackle
- brush
- geyser
- savings
- torey
- hurt
- subscribe
- picks
- birthdate
- goals
- cairo
- projected
- patrick's
- capita
- honda
- intended
- hurriedly
- activates
- it'll
- wsj
- spy
- broods
- grommet
- steven's
- underground
- seahawks
- participants
- workday
- ammi
- nightlife
- donner
- summit
- ukraine's
- ended
- arrangements
- altucher's
- writer
- fortune
- brisket
- grant
- audiobooks
- twilight
- bass
- hunger
- roses
- barbecue
- tuna
- deadly
- killers
- finally
- trilogy
- grisham
- goblet
- roadblocks
- birthday's
- biscuits
- lawyers
- steve's
- kari
- labyrinth
- commonwealth
- sharma
- gulf
- petrol
- earthly
- ultimate
- ending
- allison
- canberra
- honolulu
- flash
- salman
- gresham
- hindustani
- stroganoff
- sock
- creates
- geo
- traits
- moral
- rein
- blood
- slayer
- pro
- bono
- succinct
- dalls
- somethings
- sharp
- izzo
- whiny
- bitch
- macaroni
- nights
- jumper
- blind
- cure
- cancer
- vibrant
- sloth
- transition
- recycling
- bbc's
- columbia
- kentucky
- hire
- opera
- prefer
- avoid
- sort
- comedy
- compassionate
- nc
- va
- riddles
- segment
- youth
- charity
- surrounding
- punjabi
- sharply
- lovett
- barber
- label
- hypocrisy
- subscriber
- captain
- disillusion
- hyderabad
- dashboard
- storm
- barrel
- panasonic
- clinton
- canasta
- mittens
- badra
- amit
- trivedi
- crystal
- lewis's
- everywhere
- rue
- evaporated
- mma
- offered
- tutoring
- peas
- dream
- cafes
- lauderdale
- deletion
- precise
- parliamentary
- remotely
- connection
- calendars
- stupidest
- shovel
- western
- cutting
- ll
- rapping
- spelling
- mama
- tatum's
- fulton
- universal
- garner
- chill
- icebo
- college's
- rehman
- soundcloud
- scorecards
- ketchup
- jimmy's
- crate
- lexmark
- preference
- females
- federal
- andreas
- sportsnet
- favourites
- janice
- bins
- pamela
- covered
- rhapsody
- italian's
- ke
- panera
- remainders
- tandoori
- sukhwinder
- sunidhi
- etymology
- googleplex
- slide
- wearing
- trivial
- pursuit
- cancels
- martina
- mcbride
- finances
- vocab
- zipcode
- compaq
- composer
- margarine
- jonathan
- entrepreneur
- extended
- combo
- memories
- tupac
- affects
- drunks
- ford's
- liked
- dealership
- olky
- realtor
- thighs
- ourselves
- economics
- medication
- gross
- domestic
- donaldson
- prostate
- wicker
- rooms
- instrumental
- savannah
- outing
- affleck
- quotes
- tire
- montana
- exhausted
- acoustic
- commercials
- convenience
- consciousness
- serge
- gainsbourg
- windows
- turks
- generate
- pedicures
- btaxes
- departures
- frasier
- amazon's
- bluetooth
- verus
- neat
- forecasted
- bing's
- dropped
- recurrent
- candidate
- aware
- blackeyed
- pees
- prince's
- perimeter
- rectangle
- aaron
- carter
- involve
- drugs
- lighten
- slicker
- rains
- cloud
- carrot
- popcorn
- carmike
- cinemas
- greater
- minestart
- frog
- lenon
- unique
- hanging
- hung
- sporty
- seldom
- jocko's
- kid's
- viewers
- cantonese
- usage
- specs
- bugatti
- veyron
- chief
- blockbuster
- krishnarajpuram
- interstate
- hammers
- obligatory
- wonder
- southeast
- marlon
- brando
- ferrel
- tal
- obidallah
- manoeuvres
- merita
- rotate
- changs
- pepsi
- shanghai
- branden
- wind
- landmarks
- dvr
- congestion
- valentines
- eastwind
- lomaine
- geneva
- officially
- hopkins
- takjistan
- dimmer
- karo
- apne
- aur
- karna
- chahta
- hu
- purchased
- otherplace
- giraffe
- ute
- requirement
- watts
- powerful
- bulb
- oclock
- nba
- hulu
- composing
- melissas
- millilitres
- spoons
- goulash
- thor
- harischand
- mg
- i95
- sb
- kilo
- diana
- llyod
- webber
- wool
- penultimate
- bang
- philosophers
- nietzche
- focault
- profession
- kilograms
- turkeys
- bibulous
- angeline
- atm
- narwhal
- kilamanjaro
- captia
- volkswagen
- onkyo
- av
- receiver
- ipad
- aniston's
- summarize
- ice
- jindel
- pump
- nikki
- minaj
- nationality
- snoodle
- yemen
- sudan
- unprompted
- organization
- megan
- fares
- engage
- functioning
- dinar
- conservative
- korean
- sahara
- kingdom
- antartica
- telugu
- tamil
- tsunami
- rajani
- khanth
- venture
- goalkeeper
- dushambe
- abrupt
- hbo
- sopranos
- parana
- cave
- anime
- posters
- johny
- depp
- invisible
- graphical
- joli
- pricing
- beech
- nuclear
- triad
- hilton
- borders
- lucille
- redhead
- geraldine
- ferraro
- bde
- lowered
- phrases
- nicole
- mcgoat's
- manipulate
- roip
- nasa
- google's
- davy
- crockett
- springsteen's
- richest
- costliest
- easily
- gm
- psso
- kroner
- maple
- trees
- christie
- brinkley
- libraries
- gmb
- key
- mongolia
- anastasia
- telekenesis
- promise
- stray
- cruise's
- starring
- odyssey
- polish
- zloty
- hook
- ups
- integral
- exponential
- berkshire
- hathaway
- tables
- pink's
- alligator
- porto
- tommy
- hilfiger
- print
- networks
- snaps
- celebrate
- bina
- yay
- smiley
- emoticon
- commented
- folgers
- hathway
- huge
- lfi
- tagged
- treated
- hersheys
- aircel
- nastyburger
- linkedin
- tracy
- waiter
- drain
- charge
- neptunal
- poorly
- waited
- inappropriate
- potus
- accounts
- vodafone
- complaining
- spoiled
- positive
- tumblr
- unpleasant
- overpricing
- cheating
- connected
- else's
- greetings
- thought
- waste
- excess
- micro
- lodge
- snapdeal
- sonic
- hole
- sole
- patel's
- insect
- packet
- elsewhere
- moan
- easyjet
- snotty
- expired
- xl
- sizes
- filing
- applebee's
- angela
- merkel
- swagging
- moto
- sluggish
- flavia
- mum
- jacob's
- existing
- cannot
- pleas
- mahmoud
- ebay
- smsayyad1985
- kishore17051985
- fedex
- truette
- petey's
- tessa
- gaurav
- karen
- mongomery
- llc
- joseph
- turnpike
- accumulated
- deadlines
- fees
- ppt
- emergency
- missing
- carl's
- attach
- physical
- drill
- marilyn
- jugal
- here's
- bug
- sarasigmon123
- lindafancy55
- markpolomm
- gary's
- mailing
- bill's
- erins
- beth's
- wont
- stacy
- cadwell
- tori
- aloud
- brenda
- thisome
- smurfette
- smithjoe
- hwacuk
- chong
- giselle
- bosses
- havent
- frieda's
- jjjindia
- exists
- batch
- samuelwaters
- joose
- hellen
- builders
- accepted
- victor
- taxi's
- terry
- macdonald
- yahoocom
- metion
- rodger
- christy's
- otp
- jayesh
- tried
- morgan's
- office's
- rob
- qerwerq
- secured
- gerry
- raj's
- junable
- shopyourway
- reference
- jhonny's
- marissa
- rosa
- bert
- ana
- goddammit
- pronounce
- serious
- recheck
- slowly
- failed
- fuck
- executed
- clearly
- errors
- showed
- races
- thursdays
- funky
- handmaid's
- beam
- scotty
- debit
- wiki
- editor's
- automobiles
- promo
- discount
- director
- act
- bejeweled
- aside
- snakes
- ladders
- marsala
- influx
- bayou
- reasonably
- tapas
- az
- ddlj
- meatball
- newscast
- bibber
- tmz
- devon
- applebees
- hihop
- doggie
- feelings
- radios
- litle
- tsos
- congratulate
- links
- treble
- flame
- eta
- encourage
- students
- choices
- lobby
- vf
- chore
- butterfly
- clips
- urban
- regular
- bi-weekly
- baltimore
- sport's
- breakups
- dale's
- brea
- douglasville
- fundraiser
- dolphines
- maradona
- pe
- becky
- appointed
- deputy
- utar
- pradesh
- anniston
- handy
- sainsbury's
- attenuate
- parcel
- jakes
- bristo
- stressful
- deposit
- mathematical
- superstar
- survivor
- destiny's
- westcombe
- facility
- oboe
- mcnamara
- abolish
- swim
- repair
- grub
- hub
- ill
- dec
- dreams
- wyatts
- obstacle
- poach
- dental
- rose
- davinci
- trevor
- noah
- ncaa
- entrapreneur
- sanam
- differs
- ave
- hopsin
- enya
- wbc
- accordingly
- remarks
- sufi
- beibers
- arrested
- sensor
- music's
- author
- antwerp
- cnn's
- foodnetworkcom
- customize
- preferred
- unable
- duct
- tape
- gooseto
- apig
- ringer
- secure
- passage
- tomatoes
- wan
- senelena
- americano
- makeup
- robotics
- teleconference
- robotic
- poughkeepsie
- steel
- day's
- soundtrack
- tobymac
- transit
- gloria
- furious
- nazi
- hunting
- effect
- marvin
- gaye
- pasadena
- ca
- constrain
- singles
- outer
- nowhereville
- comfortable
- erica
- grebe
- wooly
- trigonametry
- obsessed
- graphics
- undone
- tough
- treasury
- toledo
- munich
- obtain
- nutritionally
- balanced
- internal
- locks
- exit
- mocking
- lyft
- transaction
- tasty
- mixture
- according
- hands
- supports
- canceling
- congressman's
- lenin
- spagetti
- controversial
- statements
- walker
- humor
- nkotb
- jon
- snow's
- possibility
- wellington
- nz
- advantages
- disadvantages
- driver
- towels
- stretch
- gear
- joey
- crimson
- chose
- pineapple
- asparagus
- teaspoons
- bling
- medieval
- engines
- foods
- hurts
- cannibal
- tonic
- bitcoin
- collection
- hidden
- figures
- brasil
- politic
- superb
- dalida
- capuccino
- analysts
- thankama
- kodaikanal
- vote
- burritto
- chipolte
- abut
- sedaka
- chamber
- rfi
- knock
- cnncom
- remchi
- fl
- ortcars
- flip
- wire
- thriller
- fiasco
- breaks
- dam
- paradise
- presidency
- sigur
- ros
- socks
- van
- halen
- wayne
- spare
- lightness
- appropriately
- both
- musics
- coastal
- cry
- friend's
- wore
- veganism
- picnic
- regent
- visited
- therapist
- inauguration
- swatishs
- dorothy
- known
- supervision
- superbowl
- eric's
- bday
- kar
- abhi
- achche
- ache
- rahe
- honge
- mhz
- sponge
- bistros
- brownies
- tenderloin
- enchiladas
- gluten
- hotdog
- row
- bing
- notebook
- pulldown
- clearer
- medford
- drivers
- waverley
- canal
- connecting
- summers
- gibraltar
- monoprice
- mxblue
- mechanical
- turbulence
- carey
- blunder
- factorial
- depends
- commands
- stand
- draymond
- susumu
- hirasawa
- yosemite
- '200'
- baguette
- stonehenge
- douriff
- ivf
- ivr
- litt
- runs
- hesitant
- crock
- guetta
- malaysia
- whelers
- sadness
- william
- coral
- daft
- punk
- sandle
- santha
- ingerman
- calc
- shibaru
- alcohols
- nano
- gina
- desta
- mgmt
- bana
- talking
- garvin
- trilly
- nytimes
- chhana
- mereya
- favor
- strained
- cooler
- films
- einstein's
- aroma
- ska
- raphsody
- trebuchet
- forth
- relate
- qualifications
- kirk
- franklin
- arithmetic
- skyfall
- bathrooms
- raghu
- dixit
- reports
- availables
- haddock
- odd
- cape
- cod
- noisy
- dull
- hackernews
- porn
- pad
- fight
- fighter
- nzd
- melodious
- burton
- helena
- campaign
- mcclanahan
- mummy's
- motown
- rasgulla
- janta
- pvt
- ltd
- heartthrob
- justin's
- velociraptor
- hippo
- senatra
- giggle
- peru
- nirvana
- anirudh's
- retro
- mf
- doom
- summarise
- ariana
- grande
- predicted
- creed
- user
- desire
- kenny
- roger
- sia's
- thrills
- wapo
- stockholm
- okinawa
- occasionally
- shuffling
- veggie
- mukkala
- mukkabilla
- guardian
- anytime
- themes
- horror
- ennema
- eatha
- homestead
- forever
- mayor's
- stance
- council
- master
- louies
- keane's
- fears
- noe
- reggae
- largo
- swiftm
- afi's
- xinhua
- dedicated
- bottom
- franks
- yelawolf
- ucl
- flop
- grammys
- espn
- joni
- mitchell
- shot
- tequila
- sleepyhead
- aces
- redder
- edms
- lamp's
- loudest
- brolly
- thao
- nguyen
- interior
- dine
- dogwalking
- nytimescom
- overcast
- deactive
- foo
- disasters
- opacity
- dea
- guam
- drug
- abuse
- itzhak
- perlman
- drawing
- sweden
- bombing
- ireland
- poll
- hotha
- defrosting
- salt
- toggle
- spb
- weatherit
- either
- forecasts
- intellicast
- weathercom
- orevena
- recorder
- pizzahouse
- reorganize
- sticky
- umbrellas
- opened
- cleaned
- shakin
- bakey
- tips
- hypoallergenic
- sarcastic
- cheat
- ii
- developers
- edg
- yaad
- dilana
- kahin
- samantha's
- rita's
- adding
- bro's
- attendees
- maggie
- valet
- groomer
- timeframe
- pete
- faculty
- parade
- greens
- jack's
- walter
- gemma
- nail
- arora's
- namkeen
- tonights
- ggg
- tie
- iheartradio
- rov
- javan
- wfrn
- kicks
- osteen's
- wgrr
- lite
- prairie
- companion
- palhunik
- pudding
- tutorial
- welsh
- rarebit
- oatmeal
- pathia
- achieve
- veg
- pulav
- crockpot
- prepared
- keno
- pinball
- fishdom
- nfs
- harvest
- crops
- farmvile
- millionaires
- vodka
- depend
- pon
- stationary
- mad
- errands
- paav
- queried
- pepper
- rowling
- shadi
- viewed
- mlb
- heavyweight
- citadel
- scene
- circus
- trolls
- grab
- kung
- fu
- bowery
- railway
- coach
- fare
- metrolink
- navigation
- westwood
- layfayette
- inconvenience
- emotions
- arrahman
- cosmos
- multiplied
- abouts
- hitting
- eliot's
- el
- ribbons
- sperm
- whale
- eaten
- lbs
- pinhead
- timeliness
- defining
- thesaurus
- penalty
- approval
- poetry
- ambulance
- jello
- shots
- ferrell
- stassi
- schroedder's
- tacobell
- hierophant
- zealand
- stockton
- emissions
- blowing
- kennedy
- ziggurat
- gagas
- gretszky
- hemingway
- pages
- earn
- nobel
- actions
- sloths
- parton's
- madagascar
- acting
- tiangle
- trebuchets
- googs
- gandhiji
- amal
- brazil
- adviser
- rich
- acted
- rihanas
- stamp
- mugy
- msn
- busdriver
- fergie
- flick
- ribons
- nakumuka
- postmates
- complaintum
- glinder
- gta
- rcg
- outlet
- hadock
- mclanahan
- coal
- mumy's
- piza
- wheelers
- guarante
- debugging
- debuging
- proper
- sung
- bilando
- terrorism
- cover
- dimmed
- vanilli
- marauthr
- wooo
- michael's
- shutdown
- pittsburgh
- precipitation
- riff
- portland
- muggy
- giants
- banks
- steelz
- ensure
- ricky
- matin
- tyres
- plant
- chased
- advice
- gossiping
- society
- mitushree
- hairdresser's
- biology
- fsu
- reflect
- yashas
- vinay
- vally
- closed
- shoutcast
- pilkington
- soda
- powder
- sambar
- cookingforu
- thermonuclear
- battleship
- cereal
- wishlist
- wrist
- hipsterhood
- duncan
- trussel's
- simmons
- wide
- cisco
- crafts
- sporting
- presently
- sheffield
- septa
- lead
- fransisco
- washingdon
- evolution
- mariah
- kya
- tum
- mere
- karne
- karoge
- acts
- assembly
- idle
- brand
- meridian
- terranova
- guarantee
- marian
- fields
- farthest
- philippine
- cambodia
- situated
- foruget
- monopricechanical
- peenth
- moroco
- piz
- tre
- supplwn
- viki
- shivle
- loged
- applebe
- acess
- madagar
- anp
- socer
- subcribe
- pluged
- imigration
- audiowan
- debie's
- imediately
- f
- locar
- duark
- rebeca
- talle
- banas
- ragh
- acordingly
- wakely
- en
- bress
- acording
- stefanan
- puding
- vegie
- vius
- edie
- domizza
- eg
- cheeseiza
- ocurred
- brightnes
- alaba
- memory
- fransico
- sunderland
- boogie
- butt
- leviathan
- shinning
- premier
- cleanup
- wacky
- aman
- cherry
- bomb
- solstice
- silently
- closet
- nakumukka
- shed
- responses
- yankees
- investigation
- dooa
- pieces
- imogen
- heap
- stole
- dynamite
- cease
- operating
- rained
- uptown
- suggestion
- finlee's
- bedtime
- sockets
- sanfranscio
- abbas
- cn's
- vibrate
- cooling
- sheriffs
- hike
- ilayaraja
- speaking
- un
- storms
- roof
- tube
- jackpot
- classmates
- extremely
- somewhere
- drenched
- sentient
- budy
- heating
- apt
- parenting
- concerning
- seo
- searches
- sticking
- patterns
- numbered
- impression
- reunion
- presents
- mehta
- willing
- discuss
- evan
- parker
- violin
- lesson
- musicworkz
- registration
- opens
- evening's
- thursday's
- nineteenth's
- hayathis
- shower
- corresponding
- showcase
- famosa
- kamp
- neal
- brenan
- gx
- nonstop
- rm
- giver
- traveller
- knowledge
- crispy
- supper
- broil
- noodle
- stuffed
- maccoroni
- almond
- clash
- clans
- ping
- keeper
- enemy
- coc
- detergent
- corn
- dill
- pickles
- ranch
- dressing
- lentils
- translate
- toothpaste
- rearrange
- groups
- santana
- pritzker
- winners
- libertarian
- mc's
- vitaly
- nfl
- mythical
- oriented
- provisional
- experiences
- safely
- themselves
- mia
- reducing
- learly
- court
- vin
- diesel
- netbooks
- chinatown
- aberdeen
- queens
- luni
- purchasing
- timing
- bagmati
- narrow
- egypt
- represented
- revelation
- britain
- aamir
- priyanka
- middleton
- base
- original
- nhl
- goal
- scorers
- osteoperosis
- laws
- correlation
- motivation
- ncaaa
- tense
- touring
- framework
- adel
- diamond
- schwarzenegger's
- stomachs
- cow
- chairs
- steph
- subjegant
- pategonia
- michelle
- todlers
- stakes
- tinder
- matches
- fjord
- equator
- triumph
- hell
- moldova
- presley's
- wa
- rajinikanth
- basalt
- bali
- airplane
- hash
- lit
- <sos/eos>
two_pass: false
pre_postencoder_norm: false
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: null
zero_infinity: true
joint_net_conf: null
use_preprocessor: true
token_type: word
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
frontend: default
frontend_conf:
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: utterance_mvn
normalize_conf: {}
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
extract_feats_in_collect_stats: false
transcript_token_list:
- <blank>
- <unk>
- the
- to
- i
- me
- you
- is
- what
- please
- my
- a
- for
- 'on'
- in
- of
- email
- this
- it
- have
- from
- and
- play
- olly
- that
- new
- can
- do
- how
- tell
- about
- at
- any
- today
- not
- time
- are
- check
- list
- send
- with
- an
- one
- emails
- last
- will
- am
- again
- set
- next
- would
- was
- up
- like
- turn
- said
- calendar
- meeting
- get
- what's
- right
- all
- did
- be
- need
- want
- song
- tweet
- add
- event
- your
- news
- 'off'
- weather
- there
- lights
- more
- now
- alarm
- pm
- music
- show
- confirm
- train
- could
- think
- does
- make
- command
- just
- find
- when
- tomorrow
- much
- where
- week
- by
- give
- events
- know
- day
- start
- two
- latest
- response
- that's
- remind
- done
- but
- thank
- stock
- some
- you've
- answer
- five
- open
- current
- many
- remove
- radio
- good
- book
- 'no'
- facebook
- going
- it's
- volume
- reply
- work
- delete
- go
- complaint
- contact
- if
- service
- let
- thanks
- so
- hear
- once
- correct
- john
- playlist
- birthday
- got
- post
- ten
- order
- sorry
- has
- date
- hey
- coffee
- who
- rate
- three
- exchange
- further
- light
- twenty
- price
- mail
- reminder
- explain
- podcast
- ticket
- down
- really
- clear
- seven
- schedule
- alarms
- say
- morning
- change
- twitter
- cancel
- number
- dollar
- stop
- out
- appreciated
- hundred
- wrong
- don't
- information
- address
- contacts
- read
- york
- us
- which
- should
- 'yes'
- details
- songs
- between
- nine
- anything
- s1
- received
- playing
- shut
- dot
- mind
- com
- google
- most
- put
- job
- traffic
- four
- best
- six
- create
- recent
- yeah
- happening
- friday
- name
- very
- area
- mom
- or
- take
- appointment
- yeap
- room
- world
- home
- hour
- message
- eight
- clarify
- s2
- party
- episode
- here
- elaborate
- alexa
- appreciate
- customer
- i'd
- sent
- thing
- march
- look
- tonight
- place
- try
- after
- definition
- call
- well
- times
- rock
- phone
- speak
- today's
- whats
- food
- thirty
- see
- joke
- every
- pizza
- write
- lists
- game
- shopping
- weekend
- rephrase
- month
- matter
- s
- update
- station
- vacuum
- great
- detail
- long
- gmail
- old
- repeat
- city
- audiobook
- perfectly
- status
- inbox
- mute
- local
- near
- restaurant
- thousand
- tuesday
- year
- we
- media
- before
- around
- resume
- musch
- her
- house
- taxi
- hours
- didn't
- describe
- answers
- understand
- incorrect
- word
- listen
- first
- item
- d
- trump
- save
- days
- socket
- recipe
- nice
- u
- reminders
- social
- search
- as
- monday
- subject
- location
- movie
- saturday
- euro
- dinner
- them
- ask
- let's
- scheduled
- plug
- i'm
- gotten
- question
- minutes
- friend
- favorite
- meetings
- define
- instructions
- exactly
- cook
- understood
- sentence
- thursday
- grocery
- correcly
- their
- words
- temperature
- person
- amazon
- catch
- company
- mean
- something
- correctly
- living
- fantastic
- help
- following
- dollars
- rain
- speakers
- instruction
- helpful
- increase
- consumer
- evening
- family
- upcoming
- jazz
- saying
- way
- switch
- forecast
- task
- cleaner
- love
- late
- boss
- wednesday
- yesterday
- updates
- lower
- people
- cool
- wonderful
- twelve
- afternoon
- color
- wake
- oh
- lunch
- perfect
- back
- understanding
- useful
- amazing
- his
- dim
- movies
- chicago
- things
- takeaway
- fifty
- unread
- happy
- available
- noon
- wouldn't
- night
- had
- appointments
- idea
- michael
- doing
- over
- doesn't
- select
- hi
- shit
- may
- they
- delivery
- nearest
- buy
- apple
- car
- left
- confirmed
- report
- worth
- robot
- uber
- wemo
- sunday
- excellent
- outside
- blue
- looking
- messages
- top
- wear
- point
- too
- i've
- country
- prices
- bring
- store
- awesome
- unclear
- ok
- mark
- speaker
- app
- sound
- hot
- live
- jackson
- bad
- recently
- currently
- smith
- pull
- whatever
- india
- messed
- kitchen
- ninety
- percent
- him
- use
- office
- brightness
- care
- gave
- description
- tom
- regarding
- meaning
- meet
- siri
- bob
- joe
- hmm
- leave
- sarah
- smart
- come
- chicken
- seventeen
- walmart
- bill
- enough
- choose
- louder
- our
- trending
- born
- london
- zone
- account
- cnn
- audio
- president
- isn't
- compose
- coming
- second
- manner
- pick
- album
- uhh
- plus
- provide
- erase
- notification
- played
- channel
- donald
- pound
- instagram
- made
- bbc
- recommend
- happened
- united
- replay
- shop
- free
- dammit
- nope
- b
- nearby
- pop
- shops
- california
- highest
- notifications
- shuffle
- fm
- chinese
- currency
- uh
- restaurants
- jack
- april
- robert
- only
- been
- why
- states
- friends
- skip
- important
- he
- samsung
- later
- notify
- bedroom
- john's
- mails
- eleven
- red
- exact
- cold
- cup
- rates
- incorrectly
- fifth
- money
- boston
- spoke
- tomorrow's
- forward
- respond
- funny
- wait
- business
- market
- star
- headlines
- third
- favorites
- bother
- retry
- stocks
- high
- g
- favourite
- george
- umbrella
- directions
- wedding
- content
- m
- close
- spoken
- concert
- run
- alert
- searching
- mary
- into
- artist
- located
- mike
- anyone
- snow
- tickets
- then
- reset
- garden
- route
- hello
- tall
- likes
- talk
- forty
- share
- feed
- were
- indian
- washington
- difference
- remember
- convert
- receive
- tune
- level
- asking
- capital
- life
- dad
- yen
- street
- raining
- mistake
- correctly?
- quite
- pandora
- jane
- town
- yet
- player
- park
- san
- american
- far
- sports
- raise
- popular
- display
- these
- couldn't
- mountain
- dentist
- importance
- unimportant
- complain
- clean
- continue
- euros
- los
- ready
- yahoo
- can't
- classical
- politics
- newest
- lighting
- miami
- trip
- horrible
- info
- added
- prepare
- iphone
- machine
- mother
- miles
- via
- chris
- tv
- since
- bathroom
- state
- cheese
- request
- items
- oops
- ah
- closest
- warm
- microsoft
- settings
- value
- keep
- brighter
- note
- everything
- wife
- decrease
- okay
- using
- rap
- election
- sunny
- eat
- usa
- eighty
- fifteen
- until
- wanted
- wrongly
- dog
- obama
- years
- coat
- week's
- japan
- quiet
- paris
- angeles
- comcast
- target
- emailed
- airport
- interesting
- mcdonalds
- mr
- married
- green
- product
- past
- little
- other
- t
- listening
- cooking
- activate
- earth
- dance
- title
- florida
- rupee
- travel
- kids
- takeout
- pending
- america
- making
- its
- than
- doctor
- population
- bar
- plans
- power
- fourth
- silent
- ride
- milk
- how's
- seventy
- sure
- fine
- jennifer
- july
- sister
- brighten
- picture
- deliver
- singer
- clock
- inform
- brad
- burger
- never
- pesos
- object
- hero
- arrive
- classic
- olive
- games
- group
- watch
- line
- justin
- cost
- project
- called
- lets
- track
- still
- starbucks
- form
- repeating
- christmas
- breaking
- due
- cheapest
- forget
- posted
- james
- posts
- central
- lot
- stories
- whole
- small
- ever
- steak
- review
- requested
- wish
- david
- workout
- alex
- seems
- given
- gym
- largest
- la
- average
- compare
- china
- fifteenth
- having
- rupees
- band
- background
- meal
- online
- reserve
- file
- lamp
- laugh
- sun
- anniversary
- eastern
- busy
- mobile
- bit
- jokes
- places
- geographic
- else
- chess
- meant
- working
- p
- planned
- program
- seconds
- rated
- large
- issues
- road
- pay
- big
- holiday
- daily
- 'true'
- celebrity
- better
- hut
- being
- sixty
- away
- helped
- peter
- god
- cab
- someone
- internet
- page
- anna
- feel
- video
- steve
- opening
- lately
- sandy
- bank
- weeks
- id
- sam
- pitt
- river
- february
- i'll
- saved
- soup
- phrase
- distance
- economy
- hits
- sony
- eggs
- low
- water
- text
- topic
- co
- begin
- attend
- groceries
- adele
- reach
- within
- pause
- half
- yourself
- kind
- dark
- replied
- enter
- must
- asked
- beatles
- fun
- ingredients
- against
- invite
- soon
- colour
- different
- jacket
- updated
- seattle
- denver
- canada
- vegas
- mode
- pasta
- january
- doe
- listed
- refresh
- listened
- team
- longest
- spotify
- remainder
- telling
- mumbai
- you're
- orlando
- card
- rice
- during
- reduce
- locate
- future
- starting
- boil
- genre
- class
- slow
- famous
- named
- allen
- youtube
- works
- olly's
- dc
- brew
- through
- pounds
- football
- pacific
- white
- sings
- egg
- oil
- festival
- clothes
- moment
- die
- orange
- school
- kim
- las
- divided
- whether
- photo
- everyday
- ryan
- bills
- headline
- fix
- square
- npr
- jake
- brother
- todays
- terrible
- weekly
- type
- topics
- months
- chat
- yoga
- reading
- products
- extra
- cut
- adjust
- king
- personal
- client
- jan
- data
- doctor's
- computer
- rohit
- johns
- o'clock
- canadian
- mistakes
- rid
- names
- control
- sunscreen
- per
- lady
- head
- taylor
- always
- budget
- pink
- bought
- x
- side
- ahead
- articles
- english
- ny
- able
- reschedule
- fast
- hashtag
- tweets
- countries
- numbers
- running
- alabama
- blank
- madonna
- bright
- yellow
- west
- went
- options
- story
- october
- russia
- together
- n
- basketball
- joe's
- dominos
- tomorrows
- less
- situation
- colors
- mom's
- end
- payment
- drop
- downtown
- provider
- joes
- means
- helping
- mexican
- friday's
- cricket
- return
- needed
- death
- tech
- charlotte
- heavy
- draft
- sea
- paul
- r
- condition
- seventh
- dallas
- hip
- related
- article
- heard
- war
- elvis
- everest
- problem
- stating
- bieber
- system
- sales
- shoes
- hard
- become
- based
- kevin
- age
- she
- quality
- mile
- hair
- gas
- biggest
- inr
- climate
- hate
- twentieth
- sucks
- dean
- angelina
- turkey
- harry
- cake
- national
- record
- longer
- dave
- subjects
- brown
- supposed
- ocean
- church
- drive
- gandhi
- needs
- above
- theatre
- cookies
- abraham
- gone
- map
- television
- such
- face
- sale
- jim
- francisco
- sean
- june
- romantic
- compared
- curry
- ball
- jeff
- subway
- lincoln
- bed
- lagos
- turned
- south
- won
- trains
- girlfriend
- mahatma
- nsa
- hop
- amy
- commute
- solve
- came
- created
- dont
- history
- math
- telephone
- says
- laptop
- pawel
- offer
- fox
- single
- sixth
- midnight
- missed
- potter
- loud
- richard
- chuck
- looks
- practice
- body
- dan
- husband
- waiting
- birth
- stuff
- adam
- sender
- gaga
- truck
- france
- texas
- restart
- intel
- colours
- statue
- liberty
- intensity
- previous
- problems
- outlook
- visit
- wine
- peso
- continent
- utterance
- helps
- asssistance
- each
- north
- grand
- patrick
- match
- opinion
- plan
- trump's
- papa
- instead
- martin
- root
- purchase
- perry
- richards
- closing
- cloudy
- eddie
- senders
- move
- susan
- tesco
- size
- shows
- folder
- spaghetti
- doctors
- stores
- presidential
- dates
- theater
- menu
- agenda
- ann
- code
- animal
- frequency
- kansas
- roomba
- technology
- tasks
- without
- flight
- who's
- beach
- empty
- tired
- driving
- entire
- carry
- british
- dr
- asia
- rccg
- uncle
- vacation
- pepperoni
- programme
- standard
- reminding
- maximum
- starts
- tallest
- gonna
- fourteenth
- playback
- medium
- nike
- cruise
- changed
- diego
- arrange
- bowie
- learn
- mount
- particular
- costumer
- sundays
- fire
- calls
- silence
- podcasts
- spain
- dominoes
- website
- italy
- strongly
- agree
- agreed
- suggest
- mood
- fourteen
- result
- metallica
- thinking
- session
- profile
- england
- active
- ohio
- grid
- fall
- pot
- marriage
- queue
- told
- narendra
- jerry
- mt
- frank
- tenth
- wishes
- recording
- finished
- international
- calculate
- hit
- towers
- ninth
- site
- feeling
- macy's
- tag
- actually
- black
- birthdays
- hottest
- mary's
- expect
- snapchat
- jay
- smith's
- mountains
- building
- setting
- cleaning
- height
- initiate
- hall
- breakfast
- martha
- conference
- aol
- win
- steps
- fancy
- smartphone
- led
- zeppelin
- houses
- holy
- currencies
- club
- children
- atlanta
- einstein
- happen
- cell
- landline
- coworker
- objects
- negative
- modi
- soft
- haven't
- mention
- radius
- books
- daughter
- results
- earlier
- bruce
- butter
- stars
- remaining
- delivers
- device
- domino's
- unmute
- joy
- twelfth
- voice
- taking
- snowing
- sick
- boots
- cleveland
- journey
- destination
- worker
- poker
- lee
- katy
- australia
- incoming
- least
- lisa
- experience
- million
- recurring
- scenario
- sacramento
- geography
- library
- brief
- jolie
- monthly
- elton
- sirius
- alaska
- lyrics
- oven
- log
- random
- moscow
- barack
- disney
- alive
- measurements
- maker
- poor
- error
- stone
- versus
- hotmail
- interpret
- sarah's
- memorial
- goes
- stay
- delhi
- health
- special
- speed
- thirteen
- test
- edinburgh
- credit
- facts
- cat
- neighborhood
- sometime
- empire
- entry
- financial
- comment
- link
- hockey
- circuit
- holidays
- singh
- jodhpur
- rockville
- ones
- features
- bread
- eye
- mall
- directv
- contain
- seacrest
- chance
- under
- table
- few
- hotel
- rude
- services
- yesterday's
- certain
- fb
- abc
- netflix
- linda
- notes
- length
- reminded
- shoe
- wild
- employees
- beef
- sushi
- fastest
- thirteenth
- recommendations
- fish
- tennis
- main
- jersey
- jones
- break
- concerts
- gomez
- angry
- uk
- replies
- emily
- kickball
- released
- upload
- effects
- quickest
- italian
- caroline
- emma
- real
- human
- minute
- took
- activity
- jeff's
- staff
- handler
- touch
- hold
- joanne
- range
- moon
- submit
- ends
- tomato
- lost
- prime
- twelveth
- phones
- amd
- hectic
- bobburgers
- screwed
- porch
- reviews
- vegan
- rihanna
- houston
- ham
- mondays
- general
- engaged
- walk
- melody
- electronic
- held
- selected
- equal
- getting
- tata
- wall
- clothing
- round
- leaving
- nasdaq
- total
- pressure
- expensive
- border
- exhibition
- trash
- november
- handle
- halloween
- attachment
- kardashian
- shoot
- rewind
- rating
- toronto
- department
- procedure
- member
- ray
- chelsea
- rohan
- arrow
- checked
- modify
- wasn't
- chances
- protest
- lottery
- prince
- include
- jo
- net
- pie
- sleep
- enjoy
- nineties
- taco
- banana
- source
- quieter
- bored
- desert
- guys
- gary
- activities
- already
- contract
- st
- minister
- disable
- woman
- europe
- arijit
- audible
- presentation
- cad
- records
- trips
- booking
- tacos
- sally
- non
- centre
- direct
- advance
- selena
- policy
- orders
- stefan
- arrival
- divide
- chocolate
- dish
- teeth
- hdfc
- silvia
- stove
- coast
- defined
- digest
- snafu
- manager
- pinterest
- tim
- conversation
- bulldog
- titanic
- brunch
- heat
- canyon
- dial
- earliest
- region
- stopped
- foreign
- folk
- watching
- brexit
- albert
- joejoe
- early
- cities
- manchester
- december
- biloxi
- often
- questions
- garage
- tunes
- possible
- ms
- ar
- kiss
- shares
- bangalore
- heading
- derek's
- desk
- cheers
- tomasz
- terms
- companyname
- sara
- asap
- super
- meryl
- streep
- rent
- dress
- cinema
- usually
- trend
- conversion
- friendly
- ties
- ordered
- electricity
- marked
- migration
- choice
- journal
- norris
- aniston
- mailbox
- minus
- fried
- miley
- cyrus
- newly
- theory
- rest
- swift
- windy
- dan's
- mass
- comes
- selfie
- wings
- julie
- masti
- celine
- plays
- pack
- including
- responded
- jason's
- ale
- apples
- dolly
- oranges
- lg
- washer
- substitute
- global
- feedback
- grandma
- ben
- drainage
- invoice
- sunset
- takeaways
- man
- art
- universe
- suitable
- antonio
- full
- delivered
- laundry
- wrote
- min
- register
- snap
- nixon
- bird
- spend
- rome
- jesse
- calories
- cappuccino
- quickly
- buying
- britney
- spears
- spacey
- jobs
- arriving
- jean
- potholes
- janet
- pictures
- ashwin
- morgan
- freeman
- baby
- microwave
- yellowstone
- francis
- dubai
- invitation
- hope
- melbourne
- rocky
- kroger
- rivers
- charles
- jim's
- rectify
- statement
- carpet
- baked
- jessica
- meatballs
- mushrooms
- amount
- switzerland
- relating
- zero
- front
- phonebook
- hows
- cheesecake
- carryout
- magic
- ola
- replace
- recorded
- access
- land
- where's
- elephant
- removed
- liz
- load
- metal
- package
- diner
- goog
- bob's
- k
- year's
- mars
- guy
- assistant
- rahman
- eagle
- part
- burn
- aran
- stevens
- daughter's
- eighteen
- chemistry
- action
- selling
- thats
- koc
- lines
- sugar
- major
- chair
- easter
- departing
- africa
- nigeria
- requests
- conditions
- you'll
- manhattan
- roll
- cracow
- candy
- crush
- bell
- massive
- gold
- happens
- usual
- andrew
- equals
- dead
- plane
- graduation
- warned
- shaun
- triangle
- wyatt's
- pass
- function
- max
- space
- programmes
- awful
- parton
- exciting
- battery
- hwu
- recipes
- dirham
- rushmore
- johndoe
- button
- express
- pontificate
- easiest
- magda
- selection
- reservations
- guess
- copy
- classes
- supplies
- schedules
- winning
- berkeley
- notice
- headed
- outgoing
- mi
- rainy
- wikipedia
- entertainment
- dow
- everyone
- aunt
- furniture
- oceans
- softer
- heart
- newmail
- while
- baseball
- easy
- stations
- philadelphia
- alice
- swat
- yearly
- poem
- soccer
- president's
- milan
- paper
- kardashian's
- loop
- shown
- sandals
- yo
- scan
- nevada
- apahelp
- coldplay
- french
- bay
- higher
- rumplestiltskin
- airlines
- fresh
- standing
- cream
- hamburger
- broadway
- oscars
- tokyo
- cable
- shipment
- formula
- teacher
- sweet
- golden
- newsfeed
- confirmation
- shirt
- austin
- own
- canon
- wanna
- gods
- spanish
- count
- seat
- ideas
- study
- tara
- mutual
- jennifer's
- because
- edit
- denmark
- direction
- timer
- growth
- luther
- marketing
- cd
- mine
- public
- peter's
- bolshoi
- flat
- crazy
- others
- dry
- pub
- theatres
- bro
- fashion
- teams
- cycle
- pickup
- dion
- teach
- series
- checkout
- male
- noise
- solitaire
- pf
- cassie
- travelling
- davis
- naty
- income
- disco
- dropping
- donna
- follow
- shelly
- accidents
- plot
- irene
- download
- circle
- law
- tea
- organize
- principal
- weekends
- camera
- solution
- bombay
- wuthering
- heights
- charged
- colorado
- kong
- keys
- race
- mona
- entries
- j
- nyc
- potatoes
- gospel
- raju
- trivia
- bike
- dating
- oregon
- event's
- prefers
- rush
- percentages
- peking
- cooker
- husbands
- won't
- tower
- heaven
- hugh
- june's
- fake
- figure
- purple
- takes
- l
- howard
- stern
- nineteen
- percentage
- motorola
- doe's
- outstanding
- tesla
- laura
- dale
- warning
- eighteenth
- golf
- island
- career
- bieber's
- vacuuming
- pizzas
- refund
- weekday
- s's
- derek
- thanksgiving
- delayed
- query
- buffet
- rachel
- pants
- wash
- survey
- photos
- except
- topography
- door
- jen
- queen
- depart
- cheap
- theaters
- web
- jesse's
- multiply
- workhouse
- press
- click
- loss
- recipient
- verizon
- volcano
- rolls
- royce
- pixel
- affirmative
- completing
- thai
- walking
- bananas
- hollywood
- equation
- dirty
- scores
- katrina
- exam
- creating
- letter
- sing
- construction
- broadcast
- tom's
- rupies
- management
- permanently
- converting
- ist
- iron
- religion
- kings
- tucson
- standup
- tic
- tac
- toe
- headset
- sex
- diapers
- purpose
- seventeenth
- eighth
- dylan
- temple
- refer
- gift
- fact
- drink
- inches
- air
- carpets
- newcastle
- clients
- private
- tasting
- sams
- nj
- chili
- cultural
- swimming
- they're
- iowa
- jordan
- period
- accept
- cincinnati
- college
- rainbow
- myself
- deep
- deepest
- warming
- sky
- vp
- seeing
- indianapolis
- kmart
- nikesupport
- image
- suck
- broiler
- timeline
- dell
- parisa
- brandon
- example
- y
- filter
- sad
- shine
- sixteen
- christian
- pic
- pdr
- fry
- another
- network
- omelette
- kilometers
- municipality
- giving
- leo
- cups
- earthquake
- susan's
- application
- cross
- across
- carl
- pawel's
- sauce
- relativity
- rail
- sisters
- letting
- shorts
- vs
- rajesh
- swift's
- starving
- discussing
- block
- written
- n9ne
- women
- celebrities
- bake
- cookie
- continents
- workers
- leonardo
- mel
- gibson
- shall
- beauty
- sum
- fair
- deli
- middle
- same
- nile
- sell
- role
- boat
- sandwich
- parts
- hearing
- knows
- sand
- manoj
- delivering
- rahul
- neil
- australian
- kindly
- properly
- assist
- esurance
- emilia
- breach
- loudly
- harvard
- marc
- nintendo
- scrabble
- farm
- lie
- patio
- greg
- screen
- degrees
- yesterdays
- carrots
- receipt
- lasagna
- clooney
- there's
- degree
- preferences
- hallway
- latin
- nicest
- lauren
- worst
- also
- checkers
- input
- boyfriend
- masala
- tournament
- monet's
- burmuda
- section
- eric
- japanese
- supervisor
- junk
- performance
- effective
- urgent
- oldest
- tone
- sweater
- goa
- bag
- lowest
- aus
- peace
- julia
- summer
- fan
- hurricane
- colder
- steven
- sachin
- tendulkar
- watson
- exorbitant
- bags
- macs
- yulia
- matthew
- pole
- toby
- pennsylvania
- carmen
- tiffany
- complete
- electric
- wallet
- albums
- maths
- distribution
- eminem
- familiar
- regard
- upwards
- ron
- couple
- acme
- angel
- zoo
- nineteenth
- shazam
- inflation
- offers
- devotional
- jackie
- tony
- artificial
- intelligence
- grill
- father
- predictions
- repeats
- manila
- cooked
- reason
- learning
- nowadays
- cheer
- jingle
- bells
- anxiety
- hoizer
- girl
- pondichery
- position
- teachers
- dictionary
- nap
- cafe
- m's
- meting
- crime
- eve
- horn
- bristol
- pubs
- companies
- johnson
- resolve
- waterfall
- female
- biriyani
- drama
- nothappy
- haircut
- remote
- colleagues
- bones
- saturdays
- cambridge
- jam
- maine
- category
- invented
- chang's
- boy
- planning
- chen
- assignment
- publish
- hunt
- alerts
- dad's
- deal
- leading
- trail
- follows
- young
- jay's
- summary
- ko
- beyonce
- vergara
- mexico
- whishes
- arrived
- placid
- specific
- depot
- tikka
- expire
- markets
- problematic
- highly
- blues
- thirtieth
- brooklyn
- tatum
- argentinian
- redso
- des
- moines
- women's
- richard's
- cellphone
- division
- hong
- political
- charley's
- steakhouse
- accident
- normal
- wakeup
- satellite
- freezing
- forex
- jimmy
- chores
- snooze
- design
- museum
- guide
- speech
- ran
- shift
- inferior
- mashed
- jcpenney
- environment
- raw
- disturbed
- sia
- chips
- anybody
- present
- reynolds
- limbaugh
- weekdays
- islands
- viral
- asian
- streets
- inception
- meatloaf
- alternative
- compliant
- sensex
- phil
- est
- hand
- switched
- recap
- ferrari
- nandy
- promotion
- kate
- brothers
- ma
- followers
- closer
- deleted
- gloves
- bands
- platter
- boland
- corner
- strong
- chipotle
- eu
- amtrak
- son
- charges
- version
- rajdhani
- chart
- manage
- musical
- hat
- den
- tonight's
- syria
- stronger
- homelessness
- nails
- support
- ally
- sentences
- penn
- ago
- turning
- center
- hungry
- actress
- keywords
- usain
- bolt
- ongoing
- cancelled
- idol
- julia's
- wells
- fargo
- ri
- sarahs
- computers
- devices
- toms
- regards
- quote
- production
- brother's
- inch
- shell
- marathon
- directory
- dictate
- huey
- lewis
- elections
- alone
- marry
- apart
- danielle
- jane's
- mankind
- singularity
- nye
- feynman
- whom
- inventory
- makes
- dept
- apple's
- education
- bugs
- settle
- when's
- geographical
- jason
- exchanges
- mcdonald's
- tgi
- ship
- hershey
- facing
- faulty
- zita
- jeremy
- irons
- wallmart
- sphere
- hp
- gottten
- pardon
- engagement
- showing
- format
- absolute
- interest
- messenger
- gate
- enable
- columbus
- hips
- tour
- sterling
- thumbs
- priced
- tablet
- amc
- bible
- safeway
- organism
- undertake
- freedom
- charger
- documents
- jars
- clay
- members
- o
- vegetables
- delicious
- beaumont
- tx
- finance
- exhibitions
- trumps
- month's
- v
- applebee
- dakota
- bus
- brighton
- pa
- darken
- promoted
- liverpool
- utah
- suggestions
- micheal
- complaints
- pencil
- keith
- fridays
- temperatures
- hardware
- exercise
- jpearsonjessica
- release
- hoover
- goshen
- chester
- wood
- woodchuck
- healthcare
- borges
- calculator
- dune
- reality
- jobe
- gossip
- piece
- convenient
- titled
- pork
- belongs
- hongbin
- wreck
- tool
- started
- gather
- bruno
- costa
- patel
- daniel
- corporate
- controversy
- wendy's
- texans
- biography
- flowers
- investing
- arrives
- finish
- spot
- crop
- culture
- enjoying
- fetch
- kill
- auto
- washing
- buffalo
- he's
- titles
- ross
- whose
- types
- pleasant
- erin
- madison
- tuesday's
- lif
- khan
- affordable
- season
- policies
- c
- expected
- hypothesis
- seth
- kicked
- unhappy
- gallery
- xorg
- used
- monali
- thakur
- noodles
- cher
- sally's
- tracks
- mid
- launch
- glasgow
- bridge
- releases
- pitt's
- server
- clarity
- yens
- motivational
- scratch
- blanket
- aib
- reads
- singing
- monas
- tuesdays
- winter
- rocket
- lands
- chan
- economic
- sister's
- aa
- film
- pb
- indiana
- departure
- pipeline
- stitch
- sleeved
- hail
- logan
- style
- quantum
- physics
- labeled
- delia
- began
- rrcg
- shape
- awards
- improve
- pertaining
- trance
- lives
- weight
- met
- brian
- sinatra
- sunglasses
- attending
- falls
- requesting
- sunday's
- overhead
- greg's
- rom
- historic
- georgia
- guest
- jaipur
- iroomba
- alfredo
- pride
- prejudice
- fill
- interview
- daddy
- wangs
- manchow
- university
- locally
- lowes
- tiring
- east
- medical
- metro
- bach
- schubert
- rooster
- czk
- channing
- pad's
- identify
- yelp
- scandal
- affect
- suffering
- enabled
- arby's
- saw
- mango
- itunes
- highlights
- brings
- sixteenth
- tourist
- wendys
- presley
- sold
- intern
- affairs
- fries
- buttermilk
- panda
- wants
- floor
- clint
- eastwood
- moe's
- planets
- equivalent
- morrocco
- gravity
- uploaded
- someplace
- availability
- issue
- fly
- jpy
- natural
- delta
- disappointed
- files
- q
- cindy
- shortest
- simple
- ring
- lotion
- maroon
- fort
- died
- bonus
- repetitive
- icecream
- statistics
- rebel
- lawn
- leith
- measure
- daytime
- september
- pilots
- pda's
- shade
- sil
- cap
- punjab
- gwalior
- ashley
- juice
- nagar
- ellen
- programs
- fairs
- invest
- suits
- ingredient
- launches
- leaves
- bjork
- crater
- elevation
- stewart
- hotels
- spices
- bubbles
- grass
- broccoli
- capricious
- philosophy
- anthony's
- apply
- pings
- gps
- thomas
- koontz
- acdc
- beijing
- ratings
- union
- prayer
- todo
- angles
- scissors
- stashable
- cinch
- bacon
- passive
- que
- occurred
- lakeland
- tulsa
- advise
- singapore
- risotto
- invested
- model
- helmsworth
- bench
- julian
- buddy
- rogers
- brains
- chap
- badminton
- dick
- lopez
- apartment
- points
- germany
- unknown
- thugs
- healthy
- rash
- casey
- oriam
- ps
- plants
- mailed
- ikoyi
- grassmarket
- marleen's
- locations
- bush
- mac
- reaching
- allan
- till
- cheering
- guitar
- oxford
- densely
- populated
- son's
- hubby
- comparison
- putin
- barcelona
- gss
- energy
- pan
- nyack
- worked
- unavailable
- bryan
- adams
- miss
- checkbook
- jared's
- enrique
- iglesias
- forms
- jeans
- voices
- alan
- tudek
- animals
- olx
- mts
- freed
- jenn's
- coordinates
- humid
- demographic
- otherwise
- tiffany's
- outdoor
- sheila
- lincon
- dust
- serve
- conduct
- estimated
- gaana
- funds
- downloaded
- indignation
- meijer
- necessary
- grubhub
- pancakes
- mario
- bars
- birmingham
- sites
- donuts
- chopra
- textual
- rapids
- cant
- prefix
- sounds
- provides
- amy's
- benton
- leeds
- dsw
- returning
- defective
- digital
- bhaji
- carlos
- linux
- upgrade
- shark
- attacks
- screening
- exposure
- souffle
- tracking
- od
- progress
- paused
- gilmore
- hour's
- imdb
- orleans
- european
- gdp
- surfers
- theme
- ash
- ikea
- klm
- marilia
- cars
- robin
- williams
- surfin
- ottawa
- trade
- contains
- field
- someone's
- prague
- brno
- rene
- interests
- radiolab
- harris
- strive
- accommodating
- fell
- relationship
- pharmacy
- memo
- nancy
- paid
- expressing
- disapproval
- yard
- royale
- hide
- amber
- cheeseburger
- coca
- cola
- al
- matrimony
- scott
- potato
- funniest
- polling
- mother's
- chase
- xmtune
- matt
- murphy
- detroit
- taiwan
- organic
- secrets
- domino
- ac
- assistants
- z
- fred
- owner
- required
- saga
- hanks
- trading
- erosser
- rosser
- vikki
- dhaka
- notepad
- oldies
- alison
- recur
- w
- mentioning
- languages
- lavender
- toned
- videos
- stein
- chennai
- resuming
- moms
- foke
- beep
- discussion
- woodland
- lowry
- meetups
- powerball
- toyota
- focus
- concentrate
- nbc
- roosendaal
- deactivate
- shrimp
- parmigiana
- bumper
- spouses
- lucknow
- paying
- hurry
- served
- rhythm
- enquiry
- hartford
- plaza
- hyundai
- wishing
- websites
- briefing
- complex
- calculations
- jarvis
- highway
- fired
- dissatisfied
- sandra
- bullock
- ratio
- haskell
- sharon
- horse
- mum's
- dillinger
- sunblock
- sub
- tab
- crude
- software
- stadium
- step
- short
- reddit
- appoints
- agra
- sheet
- keyboard
- kfi
- district
- connery
- carnival
- wok
- shutting
- phoenix
- cloth
- rehan
- lego
- alphabetical
- mexco
- charles's
- foodpoisoning
- ultra
- madonna's
- harley
- davidson
- daylight
- afi
- infy
- launched
- inboxes
- secretary
- increased
- resolving
- fuel
- injector
- multiple
- interval
- mike's
- espresso
- sasha
- susie
- salesperson
- country's
- cylinder
- specifications
- ivory
- pst
- zoella's
- jackman
- reacting
- potential
- frying
- boise
- wendy
- divisible
- automated
- katherine
- pre
- gaming
- containing
- decade
- industry
- foot
- chemical
- cause
- taste
- bra
- julianne
- hough
- addresses
- vonstaragrabber
- lion
- restroom
- kohl's
- mentioned
- hz
- royal
- bloodline
- relationships
- billings
- levin
- quarter
- lori's
- lori
- exclamation
- definitions
- birds
- raj
- priya
- allows
- worlds
- kelly
- clarkson
- garam
- scarlet
- found
- cub
- dmv
- excessively
- lake
- dried
- reporting
- smile
- changes
- charmin
- eternal
- smoked
- meat
- beanos
- processing
- chip
- logic
- insightbb
- highland
- terrace
- child
- peck
- midwest
- cardinal
- anthony
- barrack
- jancy
- thompson
- cassy
- gulls
- alternate
- sin
- dragons
- msnbc
- residential
- leader
- siblings
- pedro
- serendipitous
- bestbuy
- targets
- wawa
- mentions
- engagements
- hawaii
- jr
- applied
- halifax
- ahmedabad
- monty
- python
- stronomy
- blahblah
- blah
- arrivals
- subtract
- payoneer
- formal
- connors
- indranagar
- transform
- marcia
- perpetual
- arranging
- cvs
- callum
- steffi
- attention
- kanye
- mommy
- chucky
- forest
- polarized
- proposal
- conrad
- coldest
- hue
- dictator
- clancy
- geranium
- delays
- build
- lense
- rai
- transistor
- dildo
- warren
- exercises
- forman
- kinley
- bottle
- retail
- yan
- regal
- unprofessional
- annual
- payday
- tricep
- arts
- ripped
- vietnam
- trends
- chaise
- preparation
- nestle
- paula
- deen's
- bmw
- microsoft's
- bookstore
- below
- moving
- pretty
- lock
- administrator
- edition
- airways
- marvel
- garner's
- rubix
- cube
- kfc
- milwaukee
- pager
- alexander
- gilchrist
- goods
- performing
- unopened
- security
- chain
- probiotic
- colleague
- knowing
- novel
- fiesta
- comcasts
- acer
- farmers
- fraud
- weighing
- india's
- gotse
- grapefruit
- similar
- tmobile
- nifty
- sessions
- recital
- greatest
- openings
- zip
- demento
- fatigued
- disease
- prevention
- overcharged
- unquote
- cotton
- tweeter
- railways
- flipkart
- fist
- renee
- nutritional
- starred
- calculated
- mattress
- hillstead
- paul's
- jill's
- disregard
- pesto
- stinks
- nobody
- behind
- kid
- nature
- ounces
- ted
- boiled
- dancom
- wars
- fmod
- span
- along
- malls
- joining
- frequently
- realdonaldtrump
- bobby
- mcgee
- pwd
- obamacare
- clicked
- falling
- pampers
- virgin
- hayden
- pat
- amie
- infosys
- technologies
- roads
- aerosmith
- airtel
- dairy
- sends
- dues
- tobytoday
- ileana
- d'cruz
- rended
- taj
- ashok
- typhoon
- rama
- final
- missouri
- virginia
- announce
- haughty
- salmon
- joking
- goodnight
- rebecca
- believe
- vowels
- ban
- haze
- insight
- cable's
- fellow
- tweeters
- canoe
- warriors
- assassinated
- acceleration
- detailed
- wife's
- robert's
- angus
- interested
- jen's
- sjobs
- cdn
- ruth
- simran
- aapa
- kadai
- armor
- sms
- indefatigable
- indicate
- fra
- floors
- modcloth
- honor
- weigh
- priority
- hiking
- smoky
- judawa
- expense
- deals
- plethora
- sam's
- august
- elain
- bbq
- leap
- congressional
- representatives
- voting
- reproductive
- ge
- bbb
- contacted
- assigned
- jill
- drafts
- scoring
- touches
- relevance
- goggins
- medvesek
- philippiness
- booked
- board
- locality
- beth
- katey
- fans
- approximately
- charitable
- rae
- darker
- anymore
- printing
- significance
- fondle
- mate
- larry's
- larrylarry
- faripir
- gurpur
- seasons
- softball
- refreshments
- jamie
- carrie
- underwood
- abdul
- kalam
- subterranean
- colombo
- sri
- lanka
- quit
- dollar's
- award
- among
- spouse
- forgot
- ass
- millionaire
- indians
- americas
- julie's
- transcribe
- garbage
- geographics
- tree
- criticize
- tanzania
- heather's
- answering
- spam
- phishing
- reseda
- axel
- kailey
- prettiest
- century
- mattel
- toys
- grateful
- fixing
- maidan
- sophia
- betty
- reasons
- russian
- applicable
- loving
- claire
- crashed
- batteries
- philips
- person's
- compile
- ali
- matthews
- apologize
- comcastcom
- luke
- jean's
- carefully
- beg
- trying
- flooringco
- seams
- baking
- skiing
- calming
- continuously
- tale
- roraima
- innova
- bowling
- beginning
- identifier
- diverse
- santa
- continuous
- hangman
- vegetarian
- roast
- rewards
- allow
- immediately
- shelley
- hennessey
- waking
- dicaprio
- ways
- immigration
- raised
- lose
- digger
- cosmetic
- perth
- feet
- chick
- tornadoes
- upstairs
- badly
- timings
- lobster
- runner
- forum
- thunderstorms
- powered
- plugged
- rod
- mgccc
- bleed
- ga
- pune
- mixed
- dishes
- radisson
- cheetah
- what'sapp
- cm
- father's
- skill
- graham
- eggless
- collect
- favorited
- flag
- ssmith
- virtual
- bryant
- spots
- scapingyards
- washed
- springfield
- draw
- insurance
- quantity
- brightener
- cuba
- stream
- raincoat
- maiden
- soundtracks
- deliveroo
- humidity
- crowded
- built
- mesa
- rosenstock
- workpdf
- occurring
- environmental
- dbell
- converse
- radia
- logged
- scabble
- loads
- jacob
- hasbro
- aldi
- piramid
- completely
- method
- hems
- loose
- connect
- snapchats
- arizona
- festivals
- hospital
- peppers
- bowl
- korn
- lupe
- eurostar
- umf
- unchecked
- berlin
- lane
- synonyms
- hampshire
- shakira
- brads
- keanu
- reeves
- johns's
- increasing
- burgers
- stan
- falklands
- valley
- maria
- hangin
- glow
- we're
- newsource
- clark
- carrey
- jams
- crashing
- outback
- sugars
- defines
- joel
- venue
- huffington
- images
- elizabeth
- case
- agnes
- randomly
- mecky
- incredible
- even
- decreased
- vacations
- honey
- akon
- barbara
- handsome
- forensic
- spielberg
- korea
- coding
- achievements
- albert's
- clerk
- hopes
- zimbabwe
- buble
- research
- excel
- gun
- rogen
- resin
- tooth
- filling
- mody
- marinara
- vicki's
- mardi
- gras
- monika
- relatives
- chillin
- lol
- levis
- tricounty
- messy
- disgusted
- emoteck
- foroogh
- quick
- decline
- emailstudy
- atdfd
- giant
- trey
- kalka
- mcdo
- timestamp
- operate
- watched
- infinity
- tactics
- upbeat
- synonym
- racing
- towards
- fog
- muted
- coke
- eighties
- tvs
- theresa
- brent
- kamycka
- dejvicka
- tap
- peanut
- circumference
- saskatoon
- sync
- sofa
- mcdonald
- silenced
- catalogue
- algorithm
- sanctimonious
- talked
- realize
- reveca
- paok
- wipe
- bisque
- br
- rather
- silly
- stat
- tar
- vitamins
- gain
- xm
- fongs
- anywhere
- zanes
- se
- chronicles
- weber
- commence
- causes
- sangli
- german
- hedges
- truthdig
- coffees
- commuter
- plain
- mimo's
- oscar
- restrictions
- treasure
- louis
- stevenson
- fifa
- beast
- pav
- prambors
- hannah
- ringcast
- vegetable
- episodes
- overnight
- apps
- nathan
- dismiss
- karl
- hourly
- eyes
- breeds
- inside
- tribune
- join
- crabmeat
- shakira's
- yankee
- greenwich
- gala
- jump
- recall
- johnny
- cash
- pod
- cast
- rare
- suppose
- enjoyment
- emo
- nayagara
- passion
- pit
- marckel
- bohemian
- emma's
- arijit's
- pet
- prize
- receptionist's
- beat
- freds
- probles
- patagonia
- quart
- '?'
- zach
- duration
- jlo
- alphabetic
- phohouse
- badpho
- daybreak
- biryani
- battle
- divergent
- moby
- jungle
- jaiho
- casserole
- shooter
- columbine
- wednesdays
- soul
- accumulation
- squash
- calm
- debate
- schools
- amd's
- lee's
- managers
- myspace
- relaxing
- bahar
- antarctica
- atmosphere
- pinpoint
- payments
- illinois
- louisiana
- cfo
- pool
- vyas
- morel
- mysore
- rise
- sdfa
- newspaper
- calorie
- dangerous
- sunrise
- mostly
- dining
- shake
- flood
- prescription
- mix
- view
- jana
- spa
- comments
- pear
- factor
- clearance
- northern
- language
- arnold
- exxon
- mobil
- dragon
- fruit
- differences
- seashells
- seashore
- velocity
- motorolla
- haggis
- fiji
- irwin
- similarities
- hypertrophy
- sharukh
- implement
- kazakhstan
- mediterranean
- roman
- grigorean
- hardword
- quead
- amphibious
- roberts
- climatic
- tornado
- prone
- rising
- declining
- megatel
- denzel
- washington's
- citizens
- arm
- persos
- belarus
- gyllenhal
- geology
- helicopter
- iphone's
- drained
- manger
- navy
- daikin
- jerk
- nexus
- interaction
- platform
- tweeting
- at&t
- mahaboobsayyad
- kellogg
- ashmit
- ismail
- listing
- enalen
- projects
- clara
- clinic
- exams
- ammunition
- mark's
- divya
- jjnzt
- activation
- andy
- terry's
- brenden
- jeffrey
- burnette
- protests
- joshua
- pianist
- whiz
- schadenfraude
- rials
- storage
- bot
- provided
- massachusetts
- channin
- store's
- rump
- prior
- re
- intelligent
- recognise
- irobot
- areas
- lighter
- yell
- uses
- cn
- gadgets
- skynet
- marie
- lamb
- balcony
- nyt
- bennett
- ralph
- pda
- balloon
- maps
- degeneres
- character
- evans
- actor
- fitbit
- malika
- shivaji
- attitude
- lily's
- concerned
- upon
- startup
- stuffs
- tawa
- relative
- legacy
- cst
- leah
- remini
- mortgage
- amed
- cleaners
- seal
- abita
- grammar
- backdoor
- minimize
- leisure
- billie
- spicy
- training
- comfortably
- sunburn
- minneapolis
- habits
- braking
- notifier
- swan
- thoughts
- pleasure
- those
- kashmirstart
- sells
- i'dl
- kettle
- 'false'
- rta
- valia's
- visiting
- techno
- mornings
- mow
- cbs
- slightly
- francine
- vice
- postpone
- mins
- xyz
- hwood
- kept
- spider
- reopen
- billy
- connery's
- eiffel
- itinerary
- crash
- valentine's
- likexchange
- divorce
- danville
- il
- government
- menus
- capabara
- origin
- assistance
- vicinity
- chit
- drinks
- flabbergasted
- xy
- self
- double
- castle
- refrigerator
- bakery
- spray
- pyramids
- bio
- basic
- humans
- schwarzenegger
- inchoate
- rules
- caftan
- raleigh
- hobby
- ajay
- devgn
- corden
- aud
- prevailing
- kenny's
- crew
- aww
- spying
- employer
- thier
- juanpedro
- craig
- leon's
- looked
- players
- costs
- providers
- sydney
- documentary
- hyphen
- represent
- strings
- pianos
- acoustical
- celeb
- pong
- linear
- turn_down
- reaches
- strength
- routine
- billboard
- piano
- ed
- sheeran
- diet
- vietnamese
- yams
- grandmother's
- rihana
- require
- stressed
- option
- affected
- acquire
- retrieve
- clarion
- congress
- turiellos
- mates
- solar
- dice
- jalapenos
- wished
- painting
- therapy
- warehouse
- mop
- neighbor
- flappy
- returns
- someones
- spring
- wonton
- moves
- jagger
- fishing
- hiphop
- dunkin
- donut
- atlantic
- daughters
- hula
- hoop
- lessons
- scrote's
- indie
- grief
- lebron
- naughty
- preprogrammed
- alt
- needy
- sharpen
- butcher
- knife
- pulled
- starbuck's
- backward
- terrorist
- invaders
- parent
- crescent
- brewhouse
- prado
- science
- playlists
- debbie's
- sleeping
- searched
- lindsey
- lohan
- competitions
- subtracting
- challenge
- beer
- gainers
- chili's
- frubs
- police
- softly
- practical
- assessment
- bonefish
- rotating
- placed
- lakers
- barenaked
- ladies
- lord
- rings
- mar
- sneakers
- artists
- sanantha
- shuffles
- shuffled
- bardonia
- county
- analyze
- pattern
- girls
- league
- fjords
- nothing
- brewing
- smurfs
- tommy's
- lovin
- cottage
- ming
- photosynthesis
- danny's
- repeated
- peaceful
- migrations
- zydeco
- inkheart
- seller
- occurence
- telegraph
- invited
- wifi
- levels
- willie
- nelson
- dolores
- alter
- retirement
- professional
- development
- sainsburys
- byron's
- floyd
- raingear
- notorious
- bone
- explanation
- database
- likely
- lucky
- irish
- sshow
- ramsey
- aired
- sprint
- preparing
- academy
- yeshudas
- angels
- dancing
- aretha
- franklin's
- layers
- glass
- kuch
- hai
- wakey
- knitting
- mujhe
- feb
- king's
- malinda
- parents
- mirchi
- gallon
- seen
- parks
- safest
- evacuation
- beautiful
- sofia
- francs
- consequences
- various
- dicaprio's
- networth
- phelps
- disk
- constructed
- concern
- effectively
- lawrence
- zac
- galifrankas
- wheat
- prediction
- schemes
- mega
- capricorns
- dinky
- lanegan's
- princess
- pregnant
- smallest
- americans
- retweet
- insta
- sonys
- bk
- alzacz
- kohls
- cleanliness
- pizzahut
- delay
- lpg
- satisfied
- choke
- suqcom
- repairs
- killing
- miller
- budgets
- iamironman
- gbaby
- gma
- loves
- kate's
- margaret
- ben's
- brady
- palmer
- homework
- tax
- regional
- archive
- fitness
- vault
- footloose
- child's
- damage
- petco
- canceled
- passing
- pikes
- peak
- avatar
- diverge
- maron
- fault
- sword
- eventual
- contest
- dangal
- mauritania
- abs
- wondering
- southampton
- resources
- soy
- lexmark's
- hilly
- lyon
- beirut
- tribute
- madrid
- ate
- sweat
- charlize
- theron
- atif
- aslam
- capture
- actual
- shane
- dawson
- zedd
- snooker
- loquaciousness
- sholay
- tofu
- nightmare
- avenged
- sevenfold
- matters
- prompt
- panic
- brilliant
- boston's
- mckinleyville
- astrology
- strait
- countdown
- cats
- fruits
- embassy
- pita
- gyros
- negotiations
- hairdresser
- courteous
- enthusiastic
- funk
- sense
- heathens
- cabinet
- irctc
- stored
- shutoff
- glasses
- ella
- fitzgerald
- rover's
- vet
- polar
- bears
- oceanside
- medicine
- anita
- barrow
- burrito
- oliver
- covering
- ground
- zucchini
- textile
- antebellum
- chimes
- covington
- species
- bees
- cranston
- kilometer
- behaved
- rudely
- jimi
- hendrix
- calms
- outwards
- califonia
- composed
- hint
- shipping
- frosting
- sport
- napoleon
- hill
- athens
- middletown
- shirts
- sample
- politician
- investigated
- rapper
- con
- cuisine
- wizard
- brick
- conroe
- iterate
- architect
- salon
- babaji
- passed
- maryland
- surya
- monopoly
- avenue
- considering
- celebration
- brewed
- galoshes
- tutorials
- workouts
- millenium
- toward
- neighbourhood
- bannon
- storming
- reoccurring
- longtime
- sweetheart
- memos
- starfish
- centaur
- philippines
- oar
- departs
- preferably
- latte
- sides
- pentagon
- fashioned
- rescheduled
- transportation
- twins
- duker
- deadline
- samurai
- obaba
- bp
- ambiance
- automatically
- object's
- boost
- morale
- jogging
- spell
- firefly
- mura
- masa
- checklist
- biographies
- sucked
- congested
- avinash
- commando
- jolie's
- instrumentals
- clarksville
- tablespoons
- surveys
- flour
- acela
- calone
- bucket
- fulls
- valid
- references
- critical
- perpetuate
- luncheon
- ohm's
- values
- plying
- expectations
- musician
- mindsweper
- throughout
- noontime
- included
- tour's
- voted
- walgreens
- chickens
- monday's
- crankshaft
- surfer
- lunchtime
- skramz
- compounds
- diabetes
- might
- reservation
- homosapien
- engadget
- boeing
- brisbane
- ear
- headphones
- minimum
- worry
- snowplows
- burying
- driveway
- adapt
- destroy
- impanema
- equipment
- turnt
- attractive
- conducted
- cinnamon
- freshener
- watsapp
- bean
- awfully
- entitled
- murderer
- ford
- forties
- scenery
- morocco
- sf
- blokus
- preacher
- taken
- stormy
- centers
- ethics
- popup
- mysterious
- puts
- stage
- considerations
- lourie
- artic
- scoop
- carion
- merced
- bypass
- passwords
- quantico
- grade
- examples
- cuisines
- hibernate
- bear
- published
- authors
- tempo
- keidis
- tidal
- cookoff
- zones
- probable
- summerfest
- dogs
- aren't
- necessarily
- carolina
- eleventh
- chilling
- sleeve
- invoking
- term
- herald
- maria's
- poltergeist
- imagine
- uv
- index
- johncena
- instruct
- oscillate
- liter
- nelly
- shawarma
- baster
- pali
- vilnius
- tabs
- debates
- singers
- activated
- ozzy
- osbourne
- danish
- happypeoplecom
- accounting
- backpack
- im
- puttanesca
- keeps
- worse
- wrigley
- braise
- loin
- carnatic
- bases
- nick
- swisher
- stolen
- clouds
- cleared
- bola's
- norman
- reedus
- screwdriver
- window
- volcanoes
- rowan
- atkinson
- minneapoliscity
- delicacies
- monitor
- overall
- gymnastics
- channels
- kxly
- botswana
- enjoyable
- spectre
- chane
- decentralized
- men's
- freeze
- postal
- becomes
- ccn
- berth
- michigan
- composition
- shahi
- panner
- dakar
- jakarta
- equalizer
- weird
- barely
- rodriguez
- oklahoma
- giraffes
- margarita
- difficult
- crabs
- firework
- probability
- tools
- emigration
- legislation
- pdf
- cheeseburgers
- applications
- adopters
- priest
- walks
- mechanic
- h
- showers
- signs
- contrast
- recollect
- gm's
- duck
- beavers
- tail
- lucking
- horkersd
- wo
- myrtle
- hr
- steam
- entirety
- anirudh
- colored
- tropical
- bedrooms
- yellowish
- elephants
- expenses
- contents
- warmer
- royksopp
- etc
- progressives
- peoples
- cultures
- unset
- iceland
- mp
- mangalore
- tanya
- quad
- particulars
- insert
- tvf
- formidable
- origins
- eden
- depressed
- mc
- donalds
- rub
- regrets
- judgments
- scope
- intellectual
- capacity
- ahmadabad
- stethoscope
- superstitions
- rl
- stine
- quinoa
- martial
- smooth
- damn
- speeding
- stephen
- halley
- barry
- jealous
- siri's
- java
- scenarios
- pc
- transfer
- tw
- agent
- nightime
- creamy
- mirch
- dil
- cannon
- cameras
- process
- merriam
- webster
- dubstep
- rangoon
- wines
- older
- navigate
- chandelier
- egs
- recognize
- subscriptions
- mileage
- studies
- microphone
- immigrant
- electronics
- careful
- paint
- fund
- success
- resolved
- bola
- eva's
- roller
- augusta
- midtown
- surprise
- children's
- dongle
- seashell
- bots
- fallen
- centimeters
- poisoning
- sci
- fi
- outcome
- reform
- sleepy
- moderate
- chrome
- ultraviolet
- george's
- geek
- courses
- rundown
- legend
- equipments
- usher
- manor
- advertisers
- clue
- depending
- strongest
- outstation
- fallout
- shoal
- lastfm
- relocate
- pollution
- awareness
- bryce
- jessie
- carol
- nsnbc
- vacuumed
- chives
- splits
- arbor
- receiving
- toast
- futures
- brokers
- routes
- fixed
- additional
- switches
- church's
- governor
- enacted
- grams
- guitarists
- android
- babe
- sonny
- sear
- eliminate
- remain
- uc
- polk
- pakistani
- bedside
- reshuffle
- frida
- devil's
- rusk
- actors
- pakistan
- happenings
- sit
- montauk
- beethoven
- legends
- sunshine
- mothers
- smoke
- feels
- rockies
- miamy
- operations
- addition
- subtraction
- incite
- annoying
- cristiano
- ronaldo
- spin
- cows
- jenny
- spread
- wallstreet
- selections
- nashik
- ipl
- oswald
- chambers
- horoscope
- mgk
- dog's
- residing
- cricketer
- dhoni
- byron
- fluctuations
- talks
- palermo
- shallowest
- bbcnews
- nsdl
- flights
- lineup
- stick
- ribs
- jeopardy
- timetables
- emi
- maya
- mackensie
- osteen
- jimmie's
- adjustments
- precocious
- fork
- husband's
- audi
- hibachi
- disputed
- crack
- visible
- boiling
- rogan
- karachi
- babysitter
- kidnapping
- hamburgers
- madonnas
- lessen
- ipo
- greenville
- carries
- creamed
- pickled
- herring
- tackle
- brush
- geyser
- savings
- torey
- hurt
- subscribe
- picks
- birthdate
- goals
- cairo
- projected
- patrick's
- capita
- honda
- intended
- hurriedly
- activates
- it'll
- wsj
- spy
- broods
- grommet
- steven's
- underground
- seahawks
- participants
- workday
- ammi
- nightlife
- donner
- summit
- ukraine's
- ended
- arrangements
- altucher's
- writer
- fortune
- brisket
- grant
- audiobooks
- twilight
- bass
- hunger
- roses
- barbecue
- tuna
- deadly
- killers
- finally
- trilogy
- grisham
- goblet
- roadblocks
- birthday's
- biscuits
- lawyers
- steve's
- kari
- labyrinth
- commonwealth
- sharma
- gulf
- petrol
- earthly
- ultimate
- ending
- allison
- canberra
- honolulu
- flash
- salman
- gresham
- hindustani
- stroganoff
- sock
- creates
- geo
- traits
- moral
- rein
- blood
- slayer
- pro
- bono
- succinct
- dalls
- somethings
- sharp
- izzo
- whiny
- bitch
- macaroni
- nights
- jumper
- blind
- cure
- cancer
- vibrant
- sloth
- transition
- recycling
- bbc's
- columbia
- kentucky
- hire
- opera
- prefer
- avoid
- sort
- comedy
- compassionate
- nc
- va
- riddles
- segment
- youth
- charity
- surrounding
- punjabi
- sharply
- lovett
- barber
- label
- hypocrisy
- subscriber
- captain
- disillusion
- hyderabad
- dashboard
- storm
- barrel
- panasonic
- clinton
- canasta
- mittens
- badra
- amit
- trivedi
- crystal
- lewis's
- everywhere
- rue
- evaporated
- mma
- offered
- tutoring
- peas
- dream
- cafes
- lauderdale
- deletion
- precise
- parliamentary
- remotely
- connection
- calendars
- stupidest
- shovel
- western
- cutting
- ll
- rapping
- spelling
- mama
- tatum's
- fulton
- universal
- garner
- chill
- icebo
- college's
- rehman
- soundcloud
- scorecards
- ketchup
- jimmy's
- crate
- lexmark
- preference
- females
- federal
- andreas
- sportsnet
- favourites
- janice
- bins
- pamela
- covered
- rhapsody
- italian's
- ke
- panera
- remainders
- tandoori
- sukhwinder
- sunidhi
- etymology
- googleplex
- slide
- wearing
- trivial
- pursuit
- cancels
- martina
- mcbride
- finances
- vocab
- zipcode
- compaq
- composer
- margarine
- jonathan
- entrepreneur
- extended
- combo
- memories
- tupac
- affects
- drunks
- ford's
- liked
- dealership
- olky
- realtor
- thighs
- ourselves
- economics
- medication
- gross
- domestic
- donaldson
- prostate
- wicker
- rooms
- instrumental
- savannah
- outing
- affleck
- quotes
- tire
- montana
- exhausted
- acoustic
- commercials
- convenience
- consciousness
- serge
- gainsbourg
- windows
- turks
- generate
- pedicures
- btaxes
- departures
- frasier
- amazon's
- bluetooth
- verus
- neat
- forecasted
- bing's
- dropped
- recurrent
- candidate
- aware
- blackeyed
- pees
- prince's
- perimeter
- rectangle
- aaron
- carter
- involve
- drugs
- lighten
- slicker
- rains
- cloud
- carrot
- popcorn
- carmike
- cinemas
- greater
- minestart
- frog
- lenon
- unique
- hanging
- hung
- sporty
- seldom
- jocko's
- kid's
- viewers
- cantonese
- usage
- specs
- bugatti
- veyron
- chief
- blockbuster
- krishnarajpuram
- interstate
- hammers
- obligatory
- wonder
- southeast
- marlon
- brando
- ferrel
- tal
- obidallah
- manoeuvres
- merita
- rotate
- changs
- pepsi
- shanghai
- branden
- wind
- landmarks
- dvr
- congestion
- valentines
- eastwind
- lomaine
- geneva
- officially
- hopkins
- takjistan
- dimmer
- karo
- apne
- aur
- karna
- chahta
- hu
- purchased
- otherplace
- giraffe
- ute
- requirement
- watts
- powerful
- bulb
- oclock
- nba
- hulu
- composing
- melissas
- millilitres
- spoons
- goulash
- thor
- harischand
- mg
- i95
- sb
- kilo
- diana
- llyod
- webber
- wool
- penultimate
- bang
- philosophers
- nietzche
- focault
- profession
- kilograms
- turkeys
- bibulous
- angeline
- atm
- narwhal
- kilamanjaro
- captia
- volkswagen
- onkyo
- av
- receiver
- ipad
- aniston's
- summarize
- ice
- jindel
- pump
- nikki
- minaj
- nationality
- snoodle
- yemen
- sudan
- unprompted
- organization
- megan
- fares
- engage
- functioning
- dinar
- conservative
- korean
- sahara
- kingdom
- antartica
- telugu
- tamil
- tsunami
- rajani
- khanth
- venture
- goalkeeper
- dushambe
- abrupt
- hbo
- sopranos
- parana
- cave
- anime
- posters
- johny
- depp
- invisible
- graphical
- joli
- pricing
- beech
- nuclear
- triad
- hilton
- borders
- lucille
- redhead
- geraldine
- ferraro
- bde
- lowered
- phrases
- nicole
- mcgoat's
- manipulate
- roip
- nasa
- google's
- davy
- crockett
- springsteen's
- richest
- costliest
- easily
- gm
- psso
- kroner
- maple
- trees
- christie
- brinkley
- libraries
- gmb
- key
- mongolia
- anastasia
- telekenesis
- promise
- stray
- cruise's
- starring
- odyssey
- polish
- zloty
- hook
- ups
- integral
- exponential
- berkshire
- hathaway
- tables
- pink's
- alligator
- porto
- tommy
- hilfiger
- print
- networks
- snaps
- celebrate
- bina
- yay
- smiley
- emoticon
- commented
- folgers
- hathway
- huge
- lfi
- tagged
- treated
- hersheys
- aircel
- nastyburger
- linkedin
- tracy
- waiter
- drain
- charge
- neptunal
- poorly
- waited
- inappropriate
- potus
- accounts
- vodafone
- complaining
- spoiled
- positive
- tumblr
- unpleasant
- overpricing
- cheating
- connected
- else's
- greetings
- thought
- waste
- excess
- micro
- lodge
- snapdeal
- sonic
- hole
- sole
- patel's
- insect
- packet
- elsewhere
- moan
- easyjet
- snotty
- expired
- xl
- sizes
- filing
- applebee's
- angela
- merkel
- swagging
- moto
- sluggish
- flavia
- mum
- jacob's
- existing
- cannot
- pleas
- mahmoud
- ebay
- smsayyad1985
- kishore17051985
- fedex
- truette
- petey's
- tessa
- gaurav
- karen
- mongomery
- llc
- joseph
- turnpike
- accumulated
- deadlines
- fees
- ppt
- emergency
- missing
- carl's
- attach
- physical
- drill
- marilyn
- jugal
- here's
- bug
- sarasigmon123
- lindafancy55
- markpolomm
- gary's
- mailing
- bill's
- erins
- beth's
- wont
- stacy
- cadwell
- tori
- aloud
- brenda
- thisome
- smurfette
- smithjoe
- hwacuk
- chong
- giselle
- bosses
- havent
- frieda's
- jjjindia
- exists
- batch
- samuelwaters
- joose
- hellen
- builders
- accepted
- victor
- taxi's
- terry
- macdonald
- yahoocom
- metion
- rodger
- christy's
- otp
- jayesh
- tried
- morgan's
- office's
- rob
- qerwerq
- secured
- gerry
- raj's
- junable
- shopyourway
- reference
- jhonny's
- marissa
- rosa
- bert
- ana
- goddammit
- pronounce
- serious
- recheck
- slowly
- failed
- fuck
- executed
- clearly
- errors
- showed
- races
- thursdays
- funky
- handmaid's
- beam
- scotty
- debit
- wiki
- editor's
- automobiles
- promo
- discount
- director
- act
- bejeweled
- aside
- snakes
- ladders
- marsala
- influx
- bayou
- reasonably
- tapas
- az
- ddlj
- meatball
- newscast
- bibber
- tmz
- devon
- applebees
- hihop
- doggie
- feelings
- radios
- litle
- tsos
- congratulate
- links
- treble
- flame
- eta
- encourage
- students
- choices
- lobby
- vf
- chore
- butterfly
- clips
- urban
- regular
- bi-weekly
- baltimore
- sport's
- breakups
- dale's
- brea
- douglasville
- fundraiser
- dolphines
- maradona
- pe
- becky
- appointed
- deputy
- utar
- pradesh
- anniston
- handy
- sainsbury's
- attenuate
- parcel
- jakes
- bristo
- stressful
- deposit
- mathematical
- superstar
- survivor
- destiny's
- westcombe
- facility
- oboe
- mcnamara
- abolish
- swim
- repair
- grub
- hub
- ill
- dec
- dreams
- wyatts
- obstacle
- poach
- dental
- rose
- davinci
- trevor
- noah
- ncaa
- entrapreneur
- sanam
- differs
- ave
- hopsin
- enya
- wbc
- accordingly
- remarks
- sufi
- beibers
- arrested
- sensor
- music's
- author
- antwerp
- cnn's
- foodnetworkcom
- customize
- preferred
- unable
- duct
- tape
- gooseto
- apig
- ringer
- secure
- passage
- tomatoes
- wan
- senelena
- americano
- makeup
- robotics
- teleconference
- robotic
- poughkeepsie
- steel
- day's
- soundtrack
- tobymac
- transit
- gloria
- furious
- nazi
- hunting
- effect
- marvin
- gaye
- pasadena
- ca
- constrain
- singles
- outer
- nowhereville
- comfortable
- erica
- grebe
- wooly
- trigonametry
- obsessed
- graphics
- undone
- tough
- treasury
- toledo
- munich
- obtain
- nutritionally
- balanced
- internal
- locks
- exit
- mocking
- lyft
- transaction
- tasty
- mixture
- according
- hands
- supports
- canceling
- congressman's
- lenin
- spagetti
- controversial
- statements
- walker
- humor
- nkotb
- jon
- snow's
- possibility
- wellington
- nz
- advantages
- disadvantages
- driver
- towels
- stretch
- gear
- joey
- crimson
- chose
- pineapple
- asparagus
- teaspoons
- bling
- medieval
- engines
- foods
- hurts
- cannibal
- tonic
- bitcoin
- collection
- hidden
- figures
- brasil
- politic
- superb
- dalida
- capuccino
- analysts
- thankama
- kodaikanal
- vote
- burritto
- chipolte
- abut
- sedaka
- chamber
- rfi
- knock
- cnncom
- remchi
- fl
- ortcars
- flip
- wire
- thriller
- fiasco
- breaks
- dam
- paradise
- presidency
- sigur
- ros
- socks
- van
- halen
- wayne
- spare
- lightness
- appropriately
- both
- musics
- coastal
- cry
- friend's
- wore
- veganism
- picnic
- regent
- visited
- therapist
- inauguration
- swatishs
- dorothy
- known
- supervision
- superbowl
- eric's
- bday
- kar
- abhi
- achche
- ache
- rahe
- honge
- mhz
- sponge
- bistros
- brownies
- tenderloin
- enchiladas
- gluten
- hotdog
- row
- bing
- notebook
- pulldown
- clearer
- medford
- drivers
- waverley
- canal
- connecting
- summers
- gibraltar
- monoprice
- mxblue
- mechanical
- turbulence
- carey
- blunder
- factorial
- depends
- commands
- stand
- draymond
- susumu
- hirasawa
- yosemite
- '200'
- baguette
- stonehenge
- douriff
- ivf
- ivr
- litt
- runs
- hesitant
- crock
- guetta
- malaysia
- whelers
- sadness
- william
- coral
- daft
- punk
- sandle
- santha
- ingerman
- calc
- shibaru
- alcohols
- nano
- gina
- desta
- mgmt
- bana
- talking
- garvin
- trilly
- nytimes
- chhana
- mereya
- favor
- strained
- cooler
- films
- einstein's
- aroma
- ska
- raphsody
- trebuchet
- forth
- relate
- qualifications
- kirk
- franklin
- arithmetic
- skyfall
- bathrooms
- raghu
- dixit
- reports
- availables
- haddock
- odd
- cape
- cod
- noisy
- dull
- hackernews
- porn
- pad
- fight
- fighter
- nzd
- melodious
- burton
- helena
- campaign
- mcclanahan
- mummy's
- motown
- rasgulla
- janta
- pvt
- ltd
- heartthrob
- justin's
- velociraptor
- hippo
- senatra
- giggle
- peru
- nirvana
- anirudh's
- retro
- mf
- doom
- summarise
- ariana
- grande
- predicted
- creed
- user
- desire
- kenny
- roger
- sia's
- thrills
- wapo
- stockholm
- okinawa
- occasionally
- shuffling
- veggie
- mukkala
- mukkabilla
- guardian
- anytime
- themes
- horror
- ennema
- eatha
- homestead
- forever
- mayor's
- stance
- council
- master
- louies
- keane's
- fears
- noe
- reggae
- largo
- swiftm
- afi's
- xinhua
- dedicated
- bottom
- franks
- yelawolf
- ucl
- flop
- grammys
- espn
- joni
- mitchell
- shot
- tequila
- sleepyhead
- aces
- redder
- edms
- lamp's
- loudest
- brolly
- thao
- nguyen
- interior
- dine
- dogwalking
- nytimescom
- overcast
- deactive
- foo
- disasters
- opacity
- dea
- guam
- drug
- abuse
- itzhak
- perlman
- drawing
- sweden
- bombing
- ireland
- poll
- hotha
- defrosting
- salt
- toggle
- spb
- weatherit
- either
- forecasts
- intellicast
- weathercom
- orevena
- recorder
- pizzahouse
- reorganize
- sticky
- umbrellas
- opened
- cleaned
- shakin
- bakey
- tips
- hypoallergenic
- sarcastic
- cheat
- ii
- developers
- edg
- yaad
- dilana
- kahin
- samantha's
- rita's
- adding
- bro's
- attendees
- maggie
- valet
- groomer
- timeframe
- pete
- faculty
- parade
- greens
- jack's
- walter
- gemma
- nail
- arora's
- namkeen
- tonights
- ggg
- tie
- iheartradio
- rov
- javan
- wfrn
- kicks
- osteen's
- wgrr
- lite
- prairie
- companion
- palhunik
- pudding
- tutorial
- welsh
- rarebit
- oatmeal
- pathia
- achieve
- veg
- pulav
- crockpot
- prepared
- keno
- pinball
- fishdom
- nfs
- harvest
- crops
- farmvile
- millionaires
- vodka
- depend
- pon
- stationary
- mad
- errands
- paav
- queried
- pepper
- rowling
- shadi
- viewed
- mlb
- heavyweight
- citadel
- scene
- circus
- trolls
- grab
- kung
- fu
- bowery
- railway
- coach
- fare
- metrolink
- navigation
- westwood
- layfayette
- inconvenience
- emotions
- arrahman
- cosmos
- multiplied
- abouts
- hitting
- eliot's
- el
- ribbons
- sperm
- whale
- eaten
- lbs
- pinhead
- timeliness
- defining
- thesaurus
- penalty
- approval
- poetry
- ambulance
- jello
- shots
- ferrell
- stassi
- schroedder's
- tacobell
- hierophant
- zealand
- stockton
- emissions
- blowing
- kennedy
- ziggurat
- gagas
- gretszky
- hemingway
- pages
- earn
- nobel
- actions
- sloths
- parton's
- madagascar
- acting
- tiangle
- trebuchets
- googs
- gandhiji
- amal
- brazil
- adviser
- rich
- acted
- rihanas
- stamp
- mugy
- msn
- busdriver
- fergie
- flick
- ribons
- nakumuka
- postmates
- complaintum
- glinder
- gta
- rcg
- outlet
- hadock
- mclanahan
- coal
- mumy's
- piza
- wheelers
- guarante
- debugging
- debuging
- proper
- sung
- bilando
- terrorism
- cover
- dimmed
- vanilli
- marauthr
- wooo
- michael's
- shutdown
- pittsburgh
- precipitation
- riff
- portland
- muggy
- giants
- banks
- steelz
- ensure
- ricky
- matin
- tyres
- plant
- chased
- advice
- gossiping
- society
- mitushree
- hairdresser's
- biology
- fsu
- reflect
- yashas
- vinay
- vally
- closed
- shoutcast
- pilkington
- soda
- powder
- sambar
- cookingforu
- thermonuclear
- battleship
- cereal
- wishlist
- wrist
- hipsterhood
- duncan
- trussel's
- simmons
- wide
- cisco
- crafts
- sporting
- presently
- sheffield
- septa
- lead
- fransisco
- washingdon
- evolution
- mariah
- kya
- tum
- mere
- karne
- karoge
- acts
- assembly
- idle
- brand
- meridian
- terranova
- guarantee
- marian
- fields
- farthest
- philippine
- cambodia
- situated
- foruget
- monopricechanical
- peenth
- moroco
- piz
- tre
- supplwn
- viki
- shivle
- loged
- applebe
- acess
- madagar
- anp
- socer
- subcribe
- pluged
- imigration
- audiowan
- debie's
- imediately
- f
- locar
- duark
- rebeca
- talle
- banas
- ragh
- acordingly
- wakely
- en
- bress
- acording
- stefanan
- puding
- vegie
- vius
- edie
- domizza
- eg
- cheeseiza
- ocurred
- brightnes
- alaba
- memory
- fransico
- sunderland
- boogie
- butt
- leviathan
- shinning
- premier
- cleanup
- wacky
- aman
- cherry
- bomb
- solstice
- silently
- closet
- nakumukka
- shed
- responses
- yankees
- investigation
- dooa
- pieces
- imogen
- heap
- stole
- dynamite
- cease
- operating
- rained
- uptown
- suggestion
- finlee's
- bedtime
- sockets
- sanfranscio
- abbas
- cn's
- vibrate
- cooling
- sheriffs
- hike
- ilayaraja
- speaking
- un
- storms
- roof
- tube
- jackpot
- classmates
- extremely
- somewhere
- drenched
- sentient
- budy
- heating
- apt
- parenting
- concerning
- seo
- searches
- sticking
- patterns
- numbered
- impression
- reunion
- presents
- mehta
- willing
- discuss
- evan
- parker
- violin
- lesson
- musicworkz
- registration
- opens
- evening's
- thursday's
- nineteenth's
- hayathis
- shower
- corresponding
- showcase
- famosa
- kamp
- neal
- brenan
- gx
- nonstop
- rm
- giver
- traveller
- knowledge
- crispy
- supper
- broil
- noodle
- stuffed
- maccoroni
- almond
- clash
- clans
- ping
- keeper
- enemy
- coc
- detergent
- corn
- dill
- pickles
- ranch
- dressing
- lentils
- translate
- toothpaste
- rearrange
- groups
- santana
- pritzker
- winners
- libertarian
- mc's
- vitaly
- nfl
- mythical
- oriented
- provisional
- experiences
- safely
- themselves
- mia
- reducing
- learly
- court
- vin
- diesel
- netbooks
- chinatown
- aberdeen
- queens
- luni
- purchasing
- timing
- bagmati
- narrow
- egypt
- represented
- revelation
- britain
- aamir
- priyanka
- middleton
- base
- original
- nhl
- goal
- scorers
- osteoperosis
- laws
- correlation
- motivation
- ncaaa
- tense
- touring
- framework
- adel
- diamond
- schwarzenegger's
- stomachs
- cow
- chairs
- steph
- subjegant
- pategonia
- michelle
- todlers
- stakes
- tinder
- matches
- fjord
- equator
- triumph
- hell
- moldova
- presley's
- wa
- rajinikanth
- basalt
- bali
- airplane
- hash
- lit
- <sos/eos>
two_pass: false
pre_postencoder_norm: false
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 512
attention_heads: 8
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
deliberationencoder: conformer
deliberationencoder_conf:
output_size: 512
attention_heads: 8
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: linear
normalize_before: true
macaron_style: true
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
decoder: transformer
decoder_conf:
attention_heads: 8
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.1
src_attention_dropout_rate: 0.1
postdecoder: hugging_face_transformers
postdecoder_conf:
model_name_or_path: bert-base-cased
output_size: 512
required:
- output_dir
- token_list
version: '202207'
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
AkshaySg/LanguageIdentification | [
"multilingual",
"dataset:VoxLingua107",
"LID",
"spoken language recognition",
"license:apache-2.0"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T20:30:22Z | ---
license: mit
---
### Chillpill on Stable Diffusion
This is the `<Chillpill>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
AkshaySg/gramCorrection | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 4 | 2022-09-13T20:40:21Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-model2-1309
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-model2-1309
This model is a fine-tuned version of [theojolliffe/bart-paraphrase-v4-e1-feedback](https://huggingface.co/theojolliffe/bart-paraphrase-v4-e1-feedback) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1465
- Rouge1: 60.8818
- Rouge2: 53.2203
- Rougel: 60.2427
- Rougelsum: 60.557
- Gen Len: 19.6498
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.914 | 1.0 | 867 | 0.1465 | 60.8818 | 53.2203 | 60.2427 | 60.557 | 19.6498 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0
- Datasets 1.18.0
- Tokenizers 0.10.3
|
AlErysvi/Erys | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T21:09:29Z | ---
license: mit
---
### looney anime on Stable Diffusion
This is the `<looney-anime>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




















|
Alaeddin/convbert-base-turkish-ner-cased | [
"pytorch",
"convbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"ConvBertForTokenClassification"
],
"model_type": "convbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-09-13T21:13:56Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 449.00 +/- 109.17
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga anechaev -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga anechaev
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
AlanDev/DallEMiniButBetter | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T21:16:01Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-burak-new-300
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-burak-new-300
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5042
- Wer: 0.3803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 41
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.7568 | 8.62 | 500 | 2.6689 | 1.0 |
| 0.7678 | 17.24 | 1000 | 0.5044 | 0.4656 |
| 0.2373 | 25.86 | 1500 | 0.4944 | 0.4047 |
| 0.1526 | 34.48 | 2000 | 0.5042 | 0.3803 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
AlbertHSU/ChineseFoodBert | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | 2022-09-13T21:55:28Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: distilbert-legal-chunk
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-legal-chunk
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0699
- Precision: 0.8994
- Recall: 0.8721
- Macro F1: 0.8855
- Micro F1: 0.8855
- Accuracy: 0.9789
- Marker F1: 0.9804
- Marker Precision: 0.9687
- Marker Recall: 0.9925
- Reference F1: 0.9791
- Reference Precision: 0.9804
- Reference Recall: 0.9778
- Term F1: 0.8670
- Term Precision: 0.8844
- Term Recall: 0.8502
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Macro F1 | Micro F1 | Accuracy | Marker F1 | Marker Precision | Marker Recall | Reference F1 | Reference Precision | Reference Recall | Term F1 | Term Precision | Term Recall |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:--------:|:--------:|:---------:|:----------------:|:-------------:|:------------:|:-------------------:|:----------------:|:-------:|:--------------:|:-----------:|
| 0.0857 | 1.0 | 3125 | 0.0966 | 0.8374 | 0.7889 | 0.8124 | 0.8124 | 0.9676 | 0.6143 | 0.5874 | 0.6437 | 0.9628 | 0.9423 | 0.9842 | 0.8291 | 0.8656 | 0.7955 |
| 0.058 | 2.0 | 6250 | 0.0606 | 0.8869 | 0.9146 | 0.9006 | 0.9006 | 0.9814 | 0.9405 | 0.9126 | 0.9702 | 0.9689 | 0.9511 | 0.9873 | 0.8923 | 0.8805 | 0.9045 |
| 0.0415 | 3.0 | 9375 | 0.0642 | 0.9077 | 0.9131 | 0.9104 | 0.9104 | 0.9823 | 0.9524 | 0.9262 | 0.9801 | 0.9742 | 0.9614 | 0.9873 | 0.9021 | 0.9026 | 0.9016 |
| 0.0283 | 4.0 | 12500 | 0.0646 | 0.9066 | 0.9089 | 0.9077 | 0.9077 | 0.9819 | 0.9564 | 0.9326 | 0.9815 | 0.9712 | 0.9555 | 0.9873 | 0.8986 | 0.9008 | 0.8965 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Aleenbo/Arcane | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T22:44:47Z | ---
license: mit
---
### green-tent on Stable Diffusion
This is the `<green-tent>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:






|
Aleksandar/distilbert-srb-ner-setimes-lr | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T23:05:28Z | ---
language: en
thumbnail: http://www.huggingtweets.com/39daph/1663110357486/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1552662904897343488/9Wjz519m_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">daph</div>
<div style="text-align: center; font-size: 14px;">@39daph</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from daph.
| Data | daph |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 157 |
| Short tweets | 867 |
| Tweets kept | 2223 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wg7cywr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @39daph's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1bhgb0ky) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1bhgb0ky/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/39daph')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar/electra-srb-oscar | [
"pytorch",
"electra",
"fill-mask",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"ElectraForMaskedLM"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-09-13T23:08:57Z | ---
license: mit
---
### dtv-pkmn on Stable Diffusion
This is the `<dtv-pkm2>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).

`"hyperdetailed fantasy (monster) (dragon-like) character on top of a rock in the style of <dtv-pkm2> . extremely detailed, amazing artwork with depth and realistic CINEMATIC lighting, matte painting"`
Here is the new concept you will be able to use as a `style`:




|
Aleksandar1932/gpt2-country | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | 2022-09-13T23:12:04Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1478425372438011912/GQujYoYi_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1565550091334828032/flg5WPOb_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1541590121102905345/jxbNo0z0_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">WUNNA & PnBRock & Cardi B</div>
<div style="text-align: center; font-size: 14px;">@1gunnagunna-iamcardib-pnbrock</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from WUNNA & PnBRock & Cardi B.
| Data | WUNNA | PnBRock | Cardi B |
| --- | --- | --- | --- |
| Tweets downloaded | 2827 | 3104 | 3073 |
| Retweets | 2216 | 1190 | 1500 |
| Short tweets | 125 | 310 | 348 |
| Tweets kept | 486 | 1604 | 1225 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3cayvnkn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @1gunnagunna-iamcardib-pnbrock's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/od188nqh) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/od188nqh/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/1gunnagunna-iamcardib-pnbrock')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar1932/gpt2-hip-hop | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2022-09-13T23:12:24Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1569700017828397071/A5Wt_ZMK_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1463152292006436875/Mrh4Av-C_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Naughtius Maximus & Burger King</div>
<div style="text-align: center; font-size: 14px;">@burgerking-elonmusk</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Naughtius Maximus & Burger King.
| Data | Naughtius Maximus | Burger King |
| --- | --- | --- |
| Tweets downloaded | 3200 | 3250 |
| Retweets | 122 | 2 |
| Short tweets | 979 | 71 |
| Tweets kept | 2099 | 3177 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/22ygpzid/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @burgerking-elonmusk's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/zo86uf0y) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/zo86uf0y/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/burgerking-elonmusk')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar1932/gpt2-pop | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2022-09-13T23:13:30Z | ---
language: en
thumbnail: http://www.huggingtweets.com/mariahcarey/1663110896270/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1486066100248981508/AwBY6X2x_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mariah Carey</div>
<div style="text-align: center; font-size: 14px;">@mariahcarey</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mariah Carey.
| Data | Mariah Carey |
| --- | --- |
| Tweets downloaded | 3225 |
| Retweets | 697 |
| Short tweets | 388 |
| Tweets kept | 2140 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1euvplmf/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mariahcarey's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3lc0u7bu) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3lc0u7bu/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mariahcarey')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar1932/gpt2-rock-124439808 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-09-13T23:13:34Z | ---
language: en
thumbnail: http://www.huggingtweets.com/sanbenito/1663110946747/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1375293530587820041/kFJTqJSD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">☀️🌊❤️</div>
<div style="text-align: center; font-size: 14px;">@sanbenito</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ☀️🌊❤️.
| Data | ☀️🌊❤️ |
| --- | --- |
| Tweets downloaded | 1331 |
| Retweets | 406 |
| Short tweets | 177 |
| Tweets kept | 748 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/zjwkhelw/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @sanbenito's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1kdzzute) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1kdzzute/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/sanbenito')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar1932/gpt2-soul | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | 2022-09-13T23:15:06Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1407334956716769288/HFgpsbmW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Metallica</div>
<div style="text-align: center; font-size: 14px;">@metallica</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Metallica.
| Data | Metallica |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 390 |
| Short tweets | 185 |
| Tweets kept | 2675 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3n6wz64s/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @metallica's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ea9ctpp) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ea9ctpp/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/metallica')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandar1932/gpt2-spanish-classics | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-09-13T23:17:28Z | ---
language: en
thumbnail: http://www.huggingtweets.com/burgerking/1663111083258/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1463152292006436875/Mrh4Av-C_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Burger King</div>
<div style="text-align: center; font-size: 14px;">@burgerking</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Burger King.
| Data | Burger King |
| --- | --- |
| Tweets downloaded | 3252 |
| Retweets | 2 |
| Short tweets | 71 |
| Tweets kept | 3179 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/34ppslia/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @burgerking's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1e5tij6u) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1e5tij6u/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/burgerking')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Aleksandra/distilbert-base-uncased-finetuned-squad | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-13T23:18:07Z | ---
license: mit
---
### 8bit on Stable Diffusion
This is the `<8bit>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
Aleksandra/herbert-base-cased-finetuned-squad | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"transformers",
"generated_from_trainer",
"license:cc-by-4.0",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1569700017828397071/A5Wt_ZMK_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1368062641285992449/G_0qX1jP_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/872980937939857409/0Ze_P2L__400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Naughtius Maximus & Jessica Verrilli & Chad Masters</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-heychadmasters-jess</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Naughtius Maximus & Jessica Verrilli & Chad Masters.
| Data | Naughtius Maximus | Jessica Verrilli | Chad Masters |
| --- | --- | --- | --- |
| Tweets downloaded | 3200 | 3240 | 76 |
| Retweets | 122 | 1182 | 0 |
| Short tweets | 979 | 364 | 5 |
| Tweets kept | 2099 | 1694 | 71 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1xq7vmdk/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-heychadmasters-jess's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/13kzw9xh) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/13kzw9xh/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-heychadmasters-jess')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
adorkin/xlm-roberta-en-ru-emoji | [
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"en",
"ru",
"dataset:tweet_eval",
"transformers"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | 2022-09-13T23:18:49Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1569700017828397071/A5Wt_ZMK_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1546881052035190786/j0wpQleX_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1293278688465899521/-J-WylRi_400x400.png')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Naughtius Maximus & McDonald's & Subway®</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-mcdonalds-subway</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Naughtius Maximus & McDonald's & Subway®.
| Data | Naughtius Maximus | McDonald's | Subway® |
| --- | --- | --- | --- |
| Tweets downloaded | 3200 | 3250 | 3250 |
| Retweets | 122 | 0 | 4 |
| Short tweets | 979 | 17 | 192 |
| Tweets kept | 2099 | 3233 | 3054 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/7pt71lc3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-mcdonalds-subway's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2l1m0tuq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2l1m0tuq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-mcdonalds-subway')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.