
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 71 | null | language: kor
thumbnail: "Keywords to Sentences"
tags:
- keytotext
- k2t
- Keywords to Sentences
license: "MIT"
datasets:
- dataset.py
--- |
CAMeL-Lab/bert-base-arabic-camelbert-ca | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 580 | null | ---
license: mit
---
### UZUMAKI on Stable Diffusion
This is the `<NARUTO>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:
















|
CAMeL-Lab/bert-base-arabic-camelbert-da-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42 | null | ---
language:
- en
thumbnail: null
tags:
- automatic-speech-recognition
- CTC
- Attention
- pytorch
- speechbrain
license: apache-2.0
datasets:
- switchboard
metrics:
- wer
- cer
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# wav2vec 2.0 with CTC/Attention trained on Switchboard (No LM)
This repository provides all the necessary tools to perform automatic speech recognition from an end-to-end system pretrained on the Switchboard (EN) corpus within SpeechBrain.
For a better experience, we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io).
The performance of the model is the following:
| Release | Swbd CER | Callhome CER | Eval2000 CER | Swbd WER | Callhome WER | Eval2000 WER | GPUs |
|:--------:|:--------:|:------------:|:------------:|:--------:|:------------:|:------------:|:-----------:|
| 17-09-22 | 5.24 | 9.69 | 7.44 | 8 .76 | 14.67 | 11.78 | 4xA100 40GB |
## Pipeline Description
This ASR system is composed of 2 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units trained on the Switchboard training transcriptions and the Fisher corpus.
- Acoustic model (wav2vec2.0 + CTC). A pretrained wav2vec 2.0 model ([facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60)) is combined with a feature encoder consisting of three DNN layers and finetuned on Switchboard. The obtained final acoustic representation is given to a greedy CTC decoder.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling `transcribe_file` if needed.
## Install SpeechBrain
First of all, please install tranformers and SpeechBrain with the following command:
```
pip install speechbrain transformers
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Transcribing Your Own Audio Files
```python
from speechbrain.pretrained import EncoderASR
asr_model = EncoderASR.from_hparams(source="speechbrain/asr-wav2vec2-switchboard", savedir="pretrained_models/asr-wav2vec2-switchboard")
asr_model.transcribe_file('speechbrain/asr-wav2vec2-switchboard/example.wav')
```
## Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
## Training
The model was trained with SpeechBrain (commit hash: `70904d0`).
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/Switchboard/ASR/CTC
python train_with_wav2vec.py hparams/train_with_wav2vec.yaml --data_folder=your_data_folder
```
## Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Credits
This model was trained with resources provided by the [THN Center for AI](https://www.th-nuernberg.de/en/kiz).
# About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly.
Competitive or state-of-the-art performance is obtained in various domains.
- Website: https://speechbrain.github.io/
- GitHub: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# Citing SpeechBrain
Please cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 37 | null | ---
language:
- en
thumbnail: null
tags:
- automatic-speech-recognition
- CTC
- Attention
- Transformer
- pytorch
- speechbrain
license: apache-2.0
datasets:
- switchboard
metrics:
- wer
- cer
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Transformer for Switchboard (with Transformer LM)
This repository provides all the necessary tools to perform automatic speech
recognition from an end-to-end system pretrained on Switchboard (EN) within SpeechBrain.
For a better experience, we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io).
The performance of the model is the following:
| Release | Swbd WER | Callhome WER | Eval2000 WER | GPUs |
|:--------:|:--------:|:------------:|:------------:|:-----------:|
| 17-09-22 | 9.80 | 17.89 | 13.94 | 1xA100 40GB |
## Pipeline Description
This ASR system is composed of 3 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units trained on the Switchboard training transcriptions and the Fisher corpus.
- Neural language model (Transformer LM) trained on the Switchboard training transcriptions and the Fisher corpus.
- Acoustic model made of a transformer encoder and a joint decoder with CTC +
transformer. Hence, the decoding also incorporates the CTC probabilities.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling `transcribe_file` if needed.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Transcribing Your Own Audio Files
```python
from speechbrain.pretrained import EncoderDecoderASR
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-transformer-switchboard", savedir="pretrained_models/asr-transformer-switchboard")
asr_model.transcribe_file("speechbrain/asr-transformer-switchboard/example.wav")
```
## Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
## Parallel Inference on a Batch
Please, [see this Colab notebook](https://colab.research.google.com/drive/1hX5ZI9S4jHIjahFCZnhwwQmFoGAi3tmu?usp=sharing) to figure out how to transcribe in parallel a batch of input sentences using a pre-trained model.
## Training
The model was trained with SpeechBrain (commit hash: `70904d0`).
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/Switchboard/ASR/transformer
python train.py hparams/transformer.yaml --data_folder=your_data_folder
```
## Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Credits
This model was trained with resources provided by the [THN Center for AI](https://www.th-nuernberg.de/en/kiz).
# About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly.
Competitive or state-of-the-art performance is obtained in various domains.
- Website: https://speechbrain.github.io/
- GitHub: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# Citing SpeechBrain
Please cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.8450793650793651
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6176470588235294
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6261127596439169
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.7498610339077265
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.886
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.618421052631579
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6203703703703703
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9199939731806539
- name: F1 (macro)
type: f1_macro
value: 0.9158483158560947
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8457746478873239
- name: F1 (macro)
type: f1_macro
value: 0.6760195209742395
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6684723726977249
- name: F1 (macro)
type: f1_macro
value: 0.65910797043685
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.959379564582319
- name: F1 (macro)
type: f1_macro
value: 0.8779321856206035
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9031651519899718
- name: F1 (macro)
type: f1_macro
value: 0.9015700872047177
---
# relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.6176470588235294
- Accuracy on SAT: 0.6261127596439169
- Accuracy on BATS: 0.7498610339077265
- Accuracy on U2: 0.618421052631579
- Accuracy on U4: 0.6203703703703703
- Accuracy on Google: 0.886
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9199939731806539
- Micro F1 score on CogALexV: 0.8457746478873239
- Micro F1 score on EVALution: 0.6684723726977249
- Micro F1 score on K&H+N: 0.959379564582319
- Micro F1 score on ROOT09: 0.9031651519899718
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.8450793650793651
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average_no_mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: I wasn’t aware of this relationship, but I just read in the encyclopedia that <obj> is <subj>’s <mask>
- loss_function: nce_logout
- classification_loss: False
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 29
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-e-nce-conceptnet-validated/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 54 | null | ---
language:
- en
thumbnail: null
tags:
- automatic-speech-recognition
- CTC
- Attention
- pytorch
- speechbrain
license: "apache-2.0"
datasets:
- switchboard
metrics:
- wer
- cer
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# CRDNN with CTC/Attention trained on Switchboard (No LM)
This repository provides all the necessary tools to perform automatic speech recognition from an end-to-end system pretrained on Switchboard (EN) within SpeechBrain.
For a better experience we encourage you to learn more about [SpeechBrain](https://speechbrain.github.io).
The performance of the model is the following:
| Release | Swbd CER | Callhome CER | Eval2000 CER | Swbd WER | Callhome WER | Eval2000 WER | GPUs |
|:--------:|:--------:|:------------:|:------------:|:--------:|:------------:|:------------:|:-----------:|
| 17-09-22 | 9.89 | 16.30 | 13.17 | 16.01 | 25.12 | 20.71 | 1xA100 40GB |
## Pipeline description
This ASR system is composed with 2 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units trained on
the training transcriptions of the Switchboard and Fisher corpus.
- Acoustic model (CRDNN + CTC/Attention). The CRDNN architecture is made of
N blocks of convolutional neural networks with normalisation and pooling on the
frequency domain. Then, a bidirectional LSTM is connected to a final DNN to obtain
the final acoustic representation that is given to the CTC and attention decoders.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling `transcribe_file` if needed.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Note that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
## Transcribing Your Own Audio Files
```python
from speechbrain.pretrained import EncoderDecoderASR
asr_model = EncoderDecoderASR.from_hparams(source="speechbrain/asr-crdnn-switchboard", savedir="pretrained_models/speechbrain/asr-crdnn-switchboard")
asr_model.transcribe_file('speechbrain/asr-crdnn-switchboard/example.wav')
```
## Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
## Parallel Inference on a Batch
Please, [see this Colab notebook](https://colab.research.google.com/drive/1hX5ZI9S4jHIjahFCZnhwwQmFoGAi3tmu?usp=sharing) to figure out how to transcribe in parallel a batch of input sentences using a pre-trained model.
## Training
The model was trained with SpeechBrain (commit hash: `70904d0`).
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```bash
cd recipes/Switchboard/ASR/seq2seq
python train.py hparams/train_BPE_2000.yaml --data_folder=your_data_folder
```
## Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
## Credits
This model was trained with resources provided by the [THN Center for AI](https://www.th-nuernberg.de/en/kiz).
# About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly.
Competitive or state-of-the-art performance is obtained in various domains.
- Website: https://speechbrain.github.io/
- GitHub: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# Citing SpeechBrain
Please cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"has_space"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 19,850 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: mit-b2-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8523956723338485
- task:
type: image-classification
name: Image Classification
dataset:
type: custom
name: custom
split: test
metrics:
- type: f1
value: 0.8580847578266328
name: F1
- type: precision
value: 0.8587893412503379
name: Precision
- type: recall
value: 0.8593508500772797
name: Recall
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mit-b2-finetuned-memes
This model is a fine-tuned version of [aaraki/vit-base-patch16-224-in21k-finetuned-cifar10](https://huggingface.co/aaraki/vit-base-patch16-224-in21k-finetuned-cifar10) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4137
- Accuracy: 0.8524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9727 | 0.99 | 40 | 0.8400 | 0.7334 |
| 0.5305 | 1.99 | 80 | 0.5147 | 0.8284 |
| 0.3124 | 2.99 | 120 | 0.4698 | 0.8145 |
| 0.2263 | 3.99 | 160 | 0.3892 | 0.8563 |
| 0.1453 | 4.99 | 200 | 0.3874 | 0.8570 |
| 0.1255 | 5.99 | 240 | 0.4097 | 0.8470 |
| 0.0989 | 6.99 | 280 | 0.3860 | 0.8570 |
| 0.0755 | 7.99 | 320 | 0.4141 | 0.8539 |
| 0.08 | 8.99 | 360 | 0.4049 | 0.8594 |
| 0.0639 | 9.99 | 400 | 0.4137 | 0.8524 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CAMeL-Lab/bert-base-arabic-camelbert-da | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 449 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-base-patch4-window7-224-20epochs-finetuned-memes
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.847758887171561
- task:
type: image-classification
name: Image Classification
dataset:
type: custom
name: custom
split: test
metrics:
- type: f1
value: 0.8504084378729573
name: F1
- type: precision
value: 0.8519647060733512
name: Precision
- type: recall
value: 0.8523956723338485
name: Recall
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-base-patch4-window7-224-20epochs-finetuned-memes
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7090
- Accuracy: 0.8478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0238 | 0.99 | 40 | 0.9636 | 0.6445 |
| 0.777 | 1.99 | 80 | 0.6591 | 0.7666 |
| 0.4763 | 2.99 | 120 | 0.5381 | 0.8130 |
| 0.3215 | 3.99 | 160 | 0.5244 | 0.8253 |
| 0.2179 | 4.99 | 200 | 0.5123 | 0.8238 |
| 0.1868 | 5.99 | 240 | 0.5052 | 0.8308 |
| 0.154 | 6.99 | 280 | 0.5444 | 0.8338 |
| 0.1166 | 7.99 | 320 | 0.6318 | 0.8238 |
| 0.1099 | 8.99 | 360 | 0.5656 | 0.8338 |
| 0.0925 | 9.99 | 400 | 0.6057 | 0.8338 |
| 0.0779 | 10.99 | 440 | 0.5942 | 0.8393 |
| 0.0629 | 11.99 | 480 | 0.6112 | 0.8400 |
| 0.0742 | 12.99 | 520 | 0.6588 | 0.8331 |
| 0.0752 | 13.99 | 560 | 0.6143 | 0.8408 |
| 0.0577 | 14.99 | 600 | 0.6450 | 0.8516 |
| 0.0589 | 15.99 | 640 | 0.6787 | 0.8400 |
| 0.0555 | 16.99 | 680 | 0.6641 | 0.8454 |
| 0.052 | 17.99 | 720 | 0.7213 | 0.8524 |
| 0.0589 | 18.99 | 760 | 0.6917 | 0.8470 |
| 0.0506 | 19.99 | 800 | 0.7090 | 0.8478 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,860 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8766666666666667
- name: F1
type: f1
value: 0.877887788778878
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3275
- Accuracy: 0.8767
- F1: 0.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
tags:
- autotrain
- translation
language:
- tr
- en
datasets:
- Tritkoman/autotrain-data-qjnwjkwnw
co2_eq_emissions:
emissions: 148.66763338560511
---
# Model Trained Using AutoTrain
- Problem type: Translation
- Model ID: 1490354394
- CO2 Emissions (in grams): 148.6676
## Validation Metrics
- Loss: 2.112
- SacreBLEU: 8.676
- Gen len: 13.161 |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 132 | null | ---
license: mit
---
### Sorami style on Stable Diffusion
This is the `<sorami-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
CAMeL-Lab/bert-base-arabic-camelbert-mix | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"Arabic",
"Dialect",
"Egyptian",
"Gulf",
"Levantine",
"Classical Arabic",
"MSA",
"Modern Standard Arabic",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20,880 | null | ---
license: bigscience-bloom-rail-1.0
widget :
- text: "ആധുനിക ഭാരതം കണ്ട "
example_title: "ആധുനിക ഭാരതം"
- text : "മലയാളഭാഷ എഴുതുന്നതിനായി"
example_title: "മലയാളഭാഷ എഴുതുന്നതിനായി"
- text : "ഇന്ത്യയിൽ കേരള സംസ്ഥാനത്തിലും"
example_title : "ഇന്ത്യയിൽ കേരള"
---
# GPT2-Malayalam
## Model description
GPT2-Malayalam is a GPT-2 transformer model fine Tuned on a large corpus of Malayalam data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way with an automatic process to generate inputs and labels from those texts. More precisely, it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence, shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the predictions for the token i only uses the inputs from 1 to i but not the future tokens.
This way, the model learns an inner representation of the Malayalam language that can then be used to extract features useful for downstream tasks.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
## Usage
You can use this model for Malayalam text generation:
```python
>>> from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
>>> tokenizer = GPT2Tokenizer.from_pretrained("ashiqabdulkhader/GPT2-Malayalam")
>>> model = TFGPT2LMHeadModel.from_pretrained("ashiqabdulkhader/GPT2-Malayalam")
>>> text = "മലയാളത്തിലെ പ്രധാന ഭാഷയാണ്"
>>> encoded_text = tokenizer.encode(text, return_tensors='tf')
>>> beam_output = model.generate(
encoded_text,
max_length=100,
num_beams=5,
temperature=0.7,
no_repeat_ngram_size=2,
num_return_sequences=5
)
>>> print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
``` |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 75 | null | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: pegasus-model-3-x25
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-model-3-x25
This model is a fine-tuned version of [theojolliffe/pegasus-cnn_dailymail-v4-e1-e4-feedback](https://huggingface.co/theojolliffe/pegasus-cnn_dailymail-v4-e1-e4-feedback) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5668
- Rouge1: 61.9972
- Rouge2: 48.1531
- Rougel: 48.845
- Rougelsum: 59.5019
- Gen Len: 123.0814
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|:---------:|:--------:|
| 1.144 | 1.0 | 883 | 0.5668 | 61.9972 | 48.1531 | 48.845 | 59.5019 | 123.0814 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 229 | null | ---
tags:
- Pong-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pong-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pong-PLE-v0
type: Pong-PLE-v0
metrics:
- type: mean_reward
value: -16.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pong-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pong-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
tags:
- audio
- spectrograms
datasets:
- teticio/audio-diffusion-instrumental-hiphop-256
---
Denoising Diffusion Probabilistic Model trained on [teticio/audio-diffusion-instrumental-hiphop-256](https://huggingface.co/datasets/teticio/audio-diffusion-instrumental-hiphop-256) to generate mel spectrograms of 256x256 corresponding to 5 seconds of audio. The audio consists of samples of instrumental Hip Hop music. The code to convert from audio to spectrogram and vice versa can be found in https://github.com/teticio/audio-diffusion along with scripts to train and run inference.
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-quarter | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
tags:
- autotrain
- translation
language:
- en
- es
datasets:
- Tritkoman/autotrain-data-akakka
co2_eq_emissions:
emissions: 4.471184695619804
---
# Model Trained Using AutoTrain
- Problem type: Translation
- Model ID: 1492154441
- CO2 Emissions (in grams): 4.4712
## Validation Metrics
- Loss: 0.899
- SacreBLEU: 59.218
- Gen len: 9.889 |
CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 574 | null | ---
tags:
- autotrain
- translation
language:
- en
- es
datasets:
- Tritkoman/autotrain-data-akakka
co2_eq_emissions:
emissions: 0.26170356193686023
---
# Model Trained Using AutoTrain
- Problem type: Translation
- Model ID: 1492154444
- CO2 Emissions (in grams): 0.2617
## Validation Metrics
- Loss: 0.770
- SacreBLEU: 62.097
- Gen len: 8.635 |
CAMeL-Lab/bert-base-arabic-camelbert-msa-sixteenth | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.70
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="matemato/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
CAMeL-Lab/bert-base-arabic-camelbert-msa | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,967 | null | ---
license: mit
---
### lxj-o4 on Stable Diffusion
This is the `<csp>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
CBreit00/DialoGPT_small_Rick | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- text-classification
- generated_from_trainer
datasets:
- paws
metrics:
- f1
- precision
- recall
model-index:
- name: deberta-v3-large-finetuned-paws-paraphrase-detector
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: paws
type: paws
args: labeled_final
metrics:
- name: F1
type: f1
value: 0.9426698284279537
- name: Precision
type: precision
value: 0.9300853289292595
- name: Recall
type: recall
value: 0.9555995475113123
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large-finetuned-paws-paraphrase-detector
Feel free to use for paraphrase detection tasks!
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the paws dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3046
- F1: 0.9427
- Precision: 0.9301
- Recall: 0.9556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:---------:|:------:|
| 0.1492 | 1.0 | 6176 | 0.1650 | 0.9537 | 0.9385 | 0.9695 |
| 0.1018 | 2.0 | 12352 | 0.1968 | 0.9544 | 0.9427 | 0.9664 |
| 0.0482 | 3.0 | 18528 | 0.2419 | 0.9521 | 0.9388 | 0.9658 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
CL/safe-math-bot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### She-Hulk Law Art on Stable Diffusion
This is the `<shehulk-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
CLAck/indo-pure | [
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: mit
---
### led-toy on Stable Diffusion
This is the `<led-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
CLTL/MedRoBERTa.nl | [
"pytorch",
"roberta",
"fill-mask",
"nl",
"transformers",
"license:mit",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,988 | null | ---
license: mit
---
### durer style on Stable Diffusion
This is the `<drr-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:



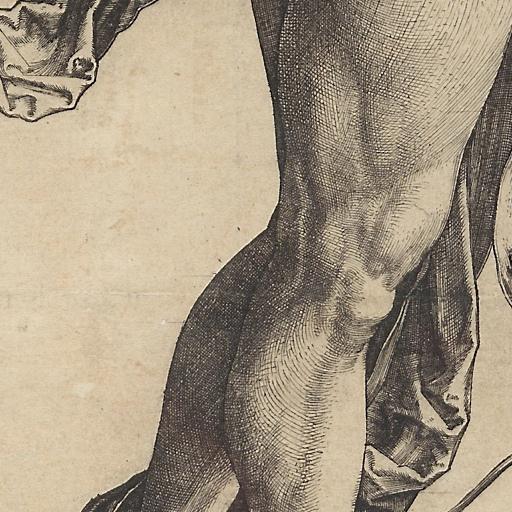

|
CLTL/icf-levels-stm | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
language: el
tags:
- summarization
license: apache-2.0
---
# Abstractive Greek Text Summarization
Application is deployed in [Hugging Face Spaces](https://huggingface.co/spaces/kriton/greek-text-summarization).<br>
We trained mT5-small for the downstream task of text summarization in Greek using this [News Article Dataset](https://www.kaggle.com/datasets/kpittos/news-articles).
```python
from transformers import AutoTokenizer
from transformers import AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("kriton/greek-text-summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("kriton/greek-text-summarization")
```
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="kriton/greek-text-summarization")
article = """ Στη ΔΕΘ πρόκειται να ανακοινωθεί και με τον πλέον επίσημο τρόπο το Food Pass - το τρίτο επίδομα που εξετάσει η κυβέρνηση έπειτα από τις επιδοτήσει σε καύσιμα και ηλεκτρικό ρεύμα.
Η επιταγή ακρίβειας για τρόφιμα θα δοθεί εφάπαξ σε οικογένειες, που πληρούν συγκεκριμένα κριτήρια, με στόχο να στηριχτούν όσοι πλήττονται περισσότερο από την αύξηση του πληθωρισμού και την ακρίβεια, όπως:
χαμηλοσυνταξιούχοι, άνεργοι και ευάλωτες κοινωνικές ομάδες.
Σύμφωνα με τις διαθέσιμες πληροφορίες, η πληρωμή θα γίνει κοντά στις γιορτές των Χριστουγέννων, όταν - σύμφωνα με εκτιμήσεις - θα έχει βαθύνει η ενεργειακή κρίση και θα έχουν αυξηθεί ακόμη παραπάνω οι ανάγκες των νοικοκυριών.
Ουσιαστικά, με τον τρόπο αυτό, η κυβέρνηση θα επιδοτήσει τις αγορές του σούπερ μάρκετ για έναν μήνα για ευάλωτες ομάδες.
Αντιδράσεις από τους κρεοπώλες
Υπενθυμίζεται πως την Πέμπτη η Πανελλήνια Ομοσπονδία Καταστηματαρχών Κρεοπωλών (ΠΟΚΚ) Οικονομικών - με επιστολή της προς τα συναρμόδια υπουργεία - διαμαρτυρήθηκε σχετικά με τη χορήγηση του Food Pass στα σούπερ μάρκετ.
Στην επιστολή της ομοσπονδίας, την οποία κοινοποίησε και στην Κεντρική Ένωση Επιμελητηρίων και στη ΓΣΕΒΕΕ, σημειώνεται ότι εάν το μέτρο εξαργύρωσης του επιδόματος τροφίμων αφορά μόνο στις αλυσίδες τροφίμων τότε απαξιώνεται ο κλάδος των κρεοπωλών και «εντείνεται ο αθέμιτος ανταγωνισμός, εφόσον κατευθύνεται ο καταναλωτή σε συγκεκριμένες επαγγελματικές κατηγορίες».
Στο πλαίσιο αυτό, οι κρεοπώλες ζητούν να διευθυνθεί η λίστα των επαγγελματιών όπου ο καταναλωτής θα μπορεί να εξαργυρώσει το εν λόγω βοήθημα.
"""
def genarate_summary(article):
inputs = tokenizer(
'summarize: ' + article,
return_tensors="pt",
max_length=1024,
truncation=True,
padding="max_length",
)
outputs = model.generate(
inputs["input_ids"],
max_length=512,
min_length=130,
length_penalty=3.0,
num_beams=8,
early_stopping=True,
repetition_penalty=3.0,
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
print(genarate_summary(article))
>>> `Το Food Pass - το τρίτο επίδομα που εξετάζει η κυβέρνηση έπειτα από τις επιδοτήσεις σε καύσιμα και ηλεκτρικό ρεύμα για έναν μήνα για ευάλωτες ομάδες. Σύμφωνα με πληροφορίες της Πανελλήνια Ομοσπονδίας Καταστηματαρχών Κρεοπωλών (ΠΟΚΚ) Οικονομικών, οι κρεοπώλες διαμαρτυρήθηκαν σχετικά με τη χορήγηση του «fast food pass» προκειμένου να αυξάνουν ακόμη περισσότερες κοινωνικές ανάγκους στο κλάδο`
``` |
Cameron/BERT-Jigsaw | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 35 | null | ---
license: mit
---
### Wish artist stile on Stable Diffusion
This is the `<wish-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
dccuchile/albert-xlarge-spanish-finetuned-pawsx | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
license: mit
---
# MagicPrompt - Dall-E 2
This is a model from the MagicPrompt series of models, which are [GPT-2](https://huggingface.co/gpt2) models intended to generate prompt texts for imaging AIs, in this case: [Dall-E 2](https://openai.com/dall-e-2/).
## 🖼️ Here's an example:
<img src="https://files.catbox.moe/h10plz.png">
This model was trained with a set of about 26k of data filtered and extracted from various places such as: [The Web Archive](https://web.archive.org/web/*/https://labs.openai.com/s/*), [The SubReddit for Dall-E 2](https://www.reddit.com/r/dalle2) and [dalle2.gallery](https://dalle2.gallery/#search). This may be a relatively small dataset, but we have to consider that Dall-E 2 is a closed service and we only have prompts from people who share it and have access to the service, for now. The set was trained with about 40,000 steps and I have plans to improve the model if possible.
If you want to test the model with a demo, you can go to: "[spaces/Gustavosta/MagicPrompt-Dalle](https://huggingface.co/spaces/Gustavosta/MagicPrompt-Dalle)".
## 💻 You can see other MagicPrompt models:
- For Stable Diffusion: [Gustavosta/MagicPrompt-Stable-Diffusion](https://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusion)
- For Midjourney: [Gustavosta/MagicPrompt-Midjourney](https://huggingface.co/Gustavosta/MagicPrompt-Midjourney) **[⚠️ In progress]**
- MagicPrompt full: [Gustavosta/MagicPrompt](https://huggingface.co/Gustavosta/MagicPrompt) **[⚠️ In progress]**
## ⚖️ Licence:
[MIT](https://huggingface.co/models?license=license:mit)
When using this model, please credit: [Gustavosta](https://huggingface.co/Gustavosta)
**Thanks for reading this far! :)**
|
dccuchile/distilbert-base-spanish-uncased-finetuned-mldoc | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.863677639046538
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1343
- F1: 0.8637
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2578 | 1.0 | 525 | 0.1562 | 0.8273 |
| 0.1297 | 2.0 | 1050 | 0.1330 | 0.8474 |
| 0.0809 | 3.0 | 1575 | 0.1343 | 0.8637 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
dccuchile/distilbert-base-spanish-uncased-finetuned-ner | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | 2022-09-18T07:18:08Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum-ss
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xsum
type: xsum
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 26.3663
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-ss
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5823
- Rouge1: 26.3663
- Rouge2: 6.4727
- Rougel: 20.538
- Rougelsum: 20.5411
- Gen Len: 18.8006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 2.8125 | 0.25 | 3189 | 2.5823 | 26.3663 | 6.4727 | 20.538 | 20.5411 | 18.8006 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Chaima/TunBerto | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
- summarization
model-index:
- name: bart-base-xsum
results:
- task:
type: summarization
name: Summarization
dataset:
name: xsum
type: xsum
config: default
split: test
metrics:
- type: rouge
value: 38.643
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2E1MTczZDhmODNjNjY2NzU5ZTJlYjM0ZWQ4YmUzN2NhYTExOGYxZTU5YmU5YThjM2FiZmVhMzU5OGE2NGZhNSIsInZlcnNpb24iOjF9.jdp1DkzoLLLpNknLrIC8oxcOKt0si9iK7r3qMuh2UVzSeHr8aG3kMNjpybMw3C9hhb2ebXzUpWok2ILvRSZTBw
- type: rouge
value: 17.7546
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDViMTgzYTQxNzFkZTg0NWY2MjgyNGQ0MmVhMDBkMjMyMTllZWM0YzE5ZjQyMmEwY2QxYTViMWMzMDQwNzdiNiIsInZlcnNpb24iOjF9.ja641EZwDrll0akyPOATo9Rqj1uaCpAftziHd0mi5ZuLqCUZsh8H0OLfjvZLNK1JwtkMi3n_P_8UYvmG1tuiAQ
- type: rouge
value: 32.2114
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWZhN2YxZTI5NGQ1MzRiYTEzZmI4YTRmYzY5NTMxYWVjZTRhODFjZTJlN2VkZWRkNzllOTE5ZTA5OTY2OGNiYiIsInZlcnNpb24iOjF9.hs2yl3ArmJuDo_N87MUWqcJ034sCjD8borR4kE_D91z0aL3NilFdpDk2iuyynE9pCn4JttetiGRLngpMvKekDw
- type: rouge
value: 32.2207
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWJkMTdmYmJlMGY3ZDg0ZGU4NTk3ZDRiMTg2ODUxZjU3ODJiMGNmZGZiOGFmNDhhZmRkMTE5MTM1YTMwNDI3NiIsInZlcnNpb24iOjF9.nTXRauPJTCmm1Ed4mp4LyIaWKd0OXhK94OAZEnIpN549pMZ19ufrNTuBeXQj6vLQAsaugbrPotBXBPe-Pbp3Dg
- type: loss
value: 1.8224396705627441
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDlhYTY5MzFkOGRlNGFjOGZiYzUyYmQ3ZWViNmY2ODZiYzhjNzYyYWZlN2ViZTJiZWEyMDFlYjE0YmIyODY2YyIsInZlcnNpb24iOjF9.96OPA94rxBtQpSiEEk7hBffOa30pe1TslYE9cpZiiwQb7GOCNGeUqjxWmzE0-R1_QluMN527k0dFL1G2KWQwAA
- type: gen_len
value: 19.7028
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzU1Njc2YmYxZGM4NjA3ZTMxZmY2YjBmNjhiZmE5YzA5Y2U2NDNjZDM0MWNjZjAwYjYxZWVmNDZjMDc5MGM2YyIsInZlcnNpb24iOjF9.j7cYnDB8LQ_stl35EaHKKJhqavj9mHVroOkzuk88rV8eRWhpksKg-n1FfbXERhxKIUBrQIWszyMUlEvAV5beBQ
- task:
type: summarization
name: Summarization
dataset:
name: xsum
type: xsum
config: default
split: validation
metrics:
- type: rouge
value: 38.7415
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjdhZTc4MGUyODM3ZDBjNmVhODRlNDMzNWJmYmNlM2NmZTEwNzc3ZDYwYjllMzc4ZWE4N2FlNWQwNDhjNGZlMiIsInZlcnNpb24iOjF9.a3dZeqsFupDVZOoSrw3FRC7ysZ04930QQKNLLyJkmoSbh6p9J1IVa5Xih3RTmQbYAN2XczTSbpQS7RqpOGE3Dg
- type: rouge
value: 17.8295
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTRmN2ZjMDM3NDgwYzVlODcwNmYwZjVlODcxMGE4ZDU5MDQ2ZDdjMjEzZWE2NmNiYzRiZGZmMzkzN2EzZThlYSIsInZlcnNpb24iOjF9.3E8u6Ia8_ri_qcNjshPFEPEyED3cK1dNJr027fdjn0_DjY7PDsnP6pmeNv4YJJSTWTX_itiX69zcdWK5m4WPCQ
- type: rouge
value: 32.2861
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzllOGNkYWI4MTdiZDc4MjgxZGUzNWZlYzkyNjlhNTQ3Y2JlMmE0NGZiNGRlMGMxNDkxZWViNjk2OTFmNmJiYyIsInZlcnNpb24iOjF9.cqrqGe65cej66-c3JjQebMx3kiM1nGOVMpN0ZbqnCRFoMdqqCIVG3ZjP-LJY3MptXRqk_sWY_O5kMximu5sgCg
- type: rouge
value: 32.2763
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGNkZWQzMzcwY2YyYjE3OWM1ZmJiMTExYmViNTU2NjExZDdmMTQ4OGZkOGZiYjk1OWQ0YTY5YjU5NTI0YjQwNiIsInZlcnNpb24iOjF9.pLFILxKJ33wPSDByZz-IQv_ujRzypMeblgc3C7_3eO5egte0_hTnjl4u-m8KLGYy7mfVXFHZPpvihwlShrARDg
- type: loss
value: 1.8132821321487427
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmRhM2UxMWRhNjk0NmIxODQyNjEyNmEwMzYyYTc3NGZlN2RlNWYyZjE1M2NlNDQyOTM1ZGU2MDQ1OWY1OTYyYyIsInZlcnNpb24iOjF9.ZTCMjc6AwjXjO7mHiVPCSyYX1eAPX5IDbWSckWIQpH7O9qk8Sm4WXST-q26Mtf4WOkn2u26Lf171ATBH5GyCCg
- type: gen_len
value: 19.7116
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2JjMzcxZTI0MDQ4ZDk3YTVhYTZjYmRiYmM5MWUwNDM0MjFkOWZiYTNlMWQ1NzA3MDMyNTI5MjY4OGY5ZGYwYiIsInZlcnNpb24iOjF9.JJ41buqEz-r4GSHAAB31_gofuzjEm0fgui9ovJJbJZLTcooGHAbYMBuDAZM8ojwFEu6S2VTR0fJE60OCs278Cg
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-xsum
**Training:** The model has been trained using the script provided in the following repository https://github.com/MorenoLaQuatra/transformers-tasks-templates
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on [xsum](https://huggingface.co/datasets/xsum) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8051
- R1: 0.5643
- R2: 0.3017
- Rl: 0.5427
- Rlsum: 0.5427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | R1 | R2 | Rl | Rlsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|
| 0.8983 | 1.0 | 6377 | 0.8145 | 0.5443 | 0.2724 | 0.5212 | 0.5211 |
| 0.8211 | 2.0 | 12754 | 0.7940 | 0.5519 | 0.2831 | 0.5295 | 0.5295 |
| 0.7701 | 3.0 | 19131 | 0.7839 | 0.5569 | 0.2896 | 0.5347 | 0.5348 |
| 0.7046 | 4.0 | 25508 | 0.7792 | 0.5615 | 0.2956 | 0.5394 | 0.5393 |
| 0.6837 | 5.0 | 31885 | 0.7806 | 0.5631 | 0.2993 | 0.5416 | 0.5416 |
| 0.6412 | 6.0 | 38262 | 0.7816 | 0.5643 | 0.301 | 0.5427 | 0.5426 |
| 0.6113 | 7.0 | 44639 | 0.7881 | 0.5645 | 0.3017 | 0.5428 | 0.5428 |
| 0.5855 | 8.0 | 51016 | 0.7921 | 0.5651 | 0.303 | 0.5433 | 0.5432 |
| 0.5636 | 9.0 | 57393 | 0.7972 | 0.5649 | 0.3032 | 0.5433 | 0.5433 |
| 0.5482 | 10.0 | 63770 | 0.7996 | 0.565 | 0.3036 | 0.5436 | 0.5435 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Chakita/KNUBert | [
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | ---
license: mit
---
### green-blue shanshui on Stable Diffusion
This is the `<green-blue shanshui>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
Cheatham/xlm-roberta-base-finetuned | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | git lfs install
git clone https://huggingface.co/cardiffnlp/twitter-roberta-base-emotion |
Chinat/test-classifier | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: train
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9307387862796834
- name: Recall
type: recall
value: 0.9498485358465163
- name: F1
type: f1
value: 0.9401965683824755
- name: Accuracy
type: accuracy
value: 0.9860187201977983
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0620
- Precision: 0.9307
- Recall: 0.9498
- F1: 0.9402
- Accuracy: 0.9860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0868 | 1.0 | 1756 | 0.0699 | 0.9197 | 0.9352 | 0.9274 | 0.9821 |
| 0.0324 | 2.0 | 3512 | 0.0659 | 0.9202 | 0.9455 | 0.9327 | 0.9849 |
| 0.0162 | 3.0 | 5268 | 0.0620 | 0.9307 | 0.9498 | 0.9402 | 0.9860 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ChoboAvenger/DialoGPT-small-DocBot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
model-index:
- name: bert_emo_classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_emo_classifier
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2652
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8874 | 0.25 | 500 | 0.4256 |
| 0.3255 | 0.5 | 1000 | 0.3233 |
| 0.2754 | 0.75 | 1500 | 0.2736 |
| 0.242 | 1.0 | 2000 | 0.2263 |
| 0.1661 | 1.25 | 2500 | 0.2118 |
| 0.1614 | 1.5 | 3000 | 0.1812 |
| 0.1434 | 1.75 | 3500 | 0.1924 |
| 0.1629 | 2.0 | 4000 | 0.1766 |
| 0.1066 | 2.25 | 4500 | 0.2100 |
| 0.1313 | 2.5 | 5000 | 0.1996 |
| 0.1113 | 2.75 | 5500 | 0.2185 |
| 0.115 | 3.0 | 6000 | 0.2406 |
| 0.0697 | 3.25 | 6500 | 0.2485 |
| 0.0835 | 3.5 | 7000 | 0.2391 |
| 0.0637 | 3.75 | 7500 | 0.2695 |
| 0.0707 | 4.0 | 8000 | 0.2652 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.10.3
|
ChoboAvenger/DialoGPT-small-joshua | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- uk
tags:
- text2text-generation
library_name: generic
license: mit
---
# Attribution
OPT-175B is licensed under the [OPT-175B license](https://github.com/facebookresearch/metaseq/blob/main/projects/OPT/MODEL_LICENSE.md), Copyright (c) Meta Platforms, Inc. All Rights Reserved. |
ChrisP/xlm-roberta-base-finetuned-marc-en | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: fr
license: mit
datasets:
- oscar
---
## Start with
* Model description
-> The model description provides basic details about the model. This includes the architecture, version, if it was introduced in a paper, if an original implementation is available, the author, and general information about the model. Any copyright should be attributed here. General information about training procedures, parameters, and important disclaimers can also be mentioned in this section.
* Intended uses & limitations
-> Here you describe the use cases the model is intended for, including the languages, fields, and domains where it can be applied. This section of the model card can also document areas that are known to be out of scope for the model, or where it is likely to perform suboptimally.
* How to use
-> This section should include some examples of how to use the model. This can showcase usage of the pipeline() function, usage of the model and tokenizer classes, and any other code you think might be helpful.
* Limitations and bias
-> This part should indicate which dataset(s) the model was trained on. A brief description of the dataset(s) is also welcome.
* Training data
-> In this section you should describe all the relevant aspects of training that are useful from a reproducibility perspective. This includes any preprocessing and postprocessing that were done on the data, as well as details such as the number of epochs the model was trained for, the batch size, the learning rate, and so on.
* Training procedure
-> Here you should describe the metrics you use for evaluation, and the different factors you are mesuring. Mentioning which metric(s) were used, on which dataset and which dataset split, makes it easy to compare you model’s performance compared to that of other models. These should be informed by the previous sections, such as the intended users and use cases.
* Evaluation results
-> Finally, provide an indication of how well the model performs on the evaluation dataset. If the model uses a decision threshold, either provide the decision threshold used in the evaluation, or provide details on evaluation at different thresholds for the intended uses.
https://github.com/huggingface/hub-docs/blame/main/modelcard.md |
ChristopherA08/IndoELECTRA | [
"pytorch",
"electra",
"pretraining",
"id",
"dataset:oscar",
"transformers"
] | null | {
"architectures": [
"ElectraForPreTraining"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: mit
---
### Rail Scene on Stable Diffusion
This is the `<rail-pov>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
Chuah/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
model-index:
- name: prot_bert_bfd-disoRNA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prot_bert_bfd-disoRNA
This model is a fine-tuned version of [Rostlab/prot_bert_bfd](https://huggingface.co/Rostlab/prot_bert_bfd) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0634
- Precision: 0.9746
- Recall: 0.9872
- F1: 0.9809
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.0627 | 1.0 | 61 | 0.0665 | 0.9746 | 0.9872 | 0.9809 |
| 0.0186 | 2.0 | 122 | 0.0644 | 0.9746 | 0.9872 | 0.9809 |
| 0.015 | 3.0 | 183 | 0.0634 | 0.9746 | 0.9872 | 0.9809 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ChukSamuels/DialoGPT-small-Dr.FauciBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9487096774193549
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3060
- Accuracy: 0.9487
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.643 | 1.0 | 318 | 1.9110 | 0.7452 |
| 1.4751 | 2.0 | 636 | 0.9678 | 0.8606 |
| 0.7736 | 3.0 | 954 | 0.5578 | 0.9168 |
| 0.4652 | 4.0 | 1272 | 0.4081 | 0.9352 |
| 0.3364 | 5.0 | 1590 | 0.3538 | 0.9442 |
| 0.2801 | 6.0 | 1908 | 0.3294 | 0.9465 |
| 0.2515 | 7.0 | 2226 | 0.3165 | 0.9471 |
| 0.2366 | 8.0 | 2544 | 0.3107 | 0.9487 |
| 0.2292 | 9.0 | 2862 | 0.3069 | 0.9490 |
| 0.2247 | 10.0 | 3180 | 0.3060 | 0.9487 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1.post200
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Chun/DialoGPT-large-dailydialog | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9255
- name: F1
type: f1
value: 0.9255179580374608
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2213
- Accuracy: 0.9255
- F1: 0.9255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8391 | 1.0 | 250 | 0.3177 | 0.9035 | 0.9006 |
| 0.2526 | 2.0 | 500 | 0.2213 | 0.9255 | 0.9255 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Chun/DialoGPT-small-dailydialog | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: 2-finetuned-xlm-r-masakhaner-swa-whole-word-phonetic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2-finetuned-xlm-r-masakhaner-swa-whole-word-phonetic
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 11.0492
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-08
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 61 | 39.7928 |
| No log | 2.0 | 122 | 39.8195 |
| No log | 3.0 | 183 | 39.8228 |
| No log | 4.0 | 244 | 39.0793 |
| No log | 5.0 | 305 | 38.6628 |
| No log | 6.0 | 366 | 37.4014 |
| No log | 7.0 | 427 | 36.8203 |
| No log | 8.0 | 488 | 36.2607 |
| 41.0436 | 9.0 | 549 | 35.9316 |
| 41.0436 | 10.0 | 610 | 34.3282 |
| 41.0436 | 11.0 | 671 | 33.3604 |
| 41.0436 | 12.0 | 732 | 32.4470 |
| 41.0436 | 13.0 | 793 | 31.5403 |
| 41.0436 | 14.0 | 854 | 30.9665 |
| 41.0436 | 15.0 | 915 | 29.4171 |
| 41.0436 | 16.0 | 976 | 28.4589 |
| 32.5506 | 17.0 | 1037 | 27.2699 |
| 32.5506 | 18.0 | 1098 | 26.0614 |
| 32.5506 | 19.0 | 1159 | 25.1529 |
| 32.5506 | 20.0 | 1220 | 24.3080 |
| 32.5506 | 21.0 | 1281 | 23.1511 |
| 32.5506 | 22.0 | 1342 | 22.3332 |
| 32.5506 | 23.0 | 1403 | 21.7154 |
| 32.5506 | 24.0 | 1464 | 20.7367 |
| 24.3212 | 25.0 | 1525 | 20.1804 |
| 24.3212 | 26.0 | 1586 | 19.5591 |
| 24.3212 | 27.0 | 1647 | 18.8760 |
| 24.3212 | 28.0 | 1708 | 18.3291 |
| 24.3212 | 29.0 | 1769 | 18.0296 |
| 24.3212 | 30.0 | 1830 | 17.4091 |
| 24.3212 | 31.0 | 1891 | 17.2150 |
| 24.3212 | 32.0 | 1952 | 16.6483 |
| 18.5662 | 33.0 | 2013 | 16.2697 |
| 18.5662 | 34.0 | 2074 | 16.1714 |
| 18.5662 | 35.0 | 2135 | 15.8008 |
| 18.5662 | 36.0 | 2196 | 15.2647 |
| 18.5662 | 37.0 | 2257 | 15.4195 |
| 18.5662 | 38.0 | 2318 | 14.9898 |
| 18.5662 | 39.0 | 2379 | 14.8599 |
| 18.5662 | 40.0 | 2440 | 14.6119 |
| 15.1141 | 41.0 | 2501 | 14.4644 |
| 15.1141 | 42.0 | 2562 | 14.3398 |
| 15.1141 | 43.0 | 2623 | 14.4107 |
| 15.1141 | 44.0 | 2684 | 13.9039 |
| 15.1141 | 45.0 | 2745 | 14.0043 |
| 15.1141 | 46.0 | 2806 | 13.9534 |
| 15.1141 | 47.0 | 2867 | 13.9267 |
| 15.1141 | 48.0 | 2928 | 13.5888 |
| 15.1141 | 49.0 | 2989 | 13.6313 |
| 13.182 | 50.0 | 3050 | 13.5405 |
| 13.182 | 51.0 | 3111 | 13.3378 |
| 13.182 | 52.0 | 3172 | 13.3160 |
| 13.182 | 53.0 | 3233 | 13.1356 |
| 13.182 | 54.0 | 3294 | 13.2483 |
| 13.182 | 55.0 | 3355 | 13.1259 |
| 13.182 | 56.0 | 3416 | 13.1775 |
| 13.182 | 57.0 | 3477 | 13.1118 |
| 12.1712 | 58.0 | 3538 | 12.9363 |
| 12.1712 | 59.0 | 3599 | 12.8765 |
| 12.1712 | 60.0 | 3660 | 12.7923 |
| 12.1712 | 61.0 | 3721 | 12.9732 |
| 12.1712 | 62.0 | 3782 | 12.8606 |
| 12.1712 | 63.0 | 3843 | 12.7897 |
| 12.1712 | 64.0 | 3904 | 12.6516 |
| 12.1712 | 65.0 | 3965 | 12.6242 |
| 11.5853 | 66.0 | 4026 | 12.5954 |
| 11.5853 | 67.0 | 4087 | 12.4505 |
| 11.5853 | 68.0 | 4148 | 12.5595 |
| 11.5853 | 69.0 | 4209 | 12.4287 |
| 11.5853 | 70.0 | 4270 | 12.4768 |
| 11.5853 | 71.0 | 4331 | 12.4003 |
| 11.5853 | 72.0 | 4392 | 12.4323 |
| 11.5853 | 73.0 | 4453 | 12.4179 |
| 11.25 | 74.0 | 4514 | 12.3767 |
| 11.25 | 75.0 | 4575 | 12.4342 |
| 11.25 | 76.0 | 4636 | 12.2565 |
| 11.25 | 77.0 | 4697 | 12.3128 |
| 11.25 | 78.0 | 4758 | 12.3749 |
| 11.25 | 79.0 | 4819 | 12.3565 |
| 11.25 | 80.0 | 4880 | 12.3288 |
| 11.25 | 81.0 | 4941 | 12.2014 |
| 11.0038 | 82.0 | 5002 | 12.1772 |
| 11.0038 | 83.0 | 5063 | 12.2690 |
| 11.0038 | 84.0 | 5124 | 12.1987 |
| 11.0038 | 85.0 | 5185 | 12.0654 |
| 11.0038 | 86.0 | 5246 | 12.1295 |
| 11.0038 | 87.0 | 5307 | 12.1560 |
| 11.0038 | 88.0 | 5368 | 11.9662 |
| 11.0038 | 89.0 | 5429 | 12.1134 |
| 11.0038 | 90.0 | 5490 | 12.0294 |
| 10.8283 | 91.0 | 5551 | 12.1112 |
| 10.8283 | 92.0 | 5612 | 12.0910 |
| 10.8283 | 93.0 | 5673 | 12.0087 |
| 10.8283 | 94.0 | 5734 | 11.9803 |
| 10.8283 | 95.0 | 5795 | 11.9094 |
| 10.8283 | 96.0 | 5856 | 12.1592 |
| 10.8283 | 97.0 | 5917 | 11.9361 |
| 10.8283 | 98.0 | 5978 | 11.9596 |
| 10.693 | 99.0 | 6039 | 11.9026 |
| 10.693 | 100.0 | 6100 | 12.0040 |
| 10.693 | 101.0 | 6161 | 11.8866 |
| 10.693 | 102.0 | 6222 | 11.9536 |
| 10.693 | 103.0 | 6283 | 11.8034 |
| 10.693 | 104.0 | 6344 | 11.6885 |
| 10.693 | 105.0 | 6405 | 11.8505 |
| 10.693 | 106.0 | 6466 | 11.8280 |
| 10.5875 | 107.0 | 6527 | 11.7874 |
| 10.5875 | 108.0 | 6588 | 11.7348 |
| 10.5875 | 109.0 | 6649 | 11.7765 |
| 10.5875 | 110.0 | 6710 | 11.7527 |
| 10.5875 | 111.0 | 6771 | 11.6816 |
| 10.5875 | 112.0 | 6832 | 11.7396 |
| 10.5875 | 113.0 | 6893 | 11.6475 |
| 10.5875 | 114.0 | 6954 | 11.7010 |
| 10.5114 | 115.0 | 7015 | 11.7049 |
| 10.5114 | 116.0 | 7076 | 11.7967 |
| 10.5114 | 117.0 | 7137 | 11.7248 |
| 10.5114 | 118.0 | 7198 | 11.6549 |
| 10.5114 | 119.0 | 7259 | 11.5194 |
| 10.5114 | 120.0 | 7320 | 11.6924 |
| 10.5114 | 121.0 | 7381 | 11.5194 |
| 10.5114 | 122.0 | 7442 | 11.6607 |
| 10.4791 | 123.0 | 7503 | 11.5189 |
| 10.4791 | 124.0 | 7564 | 11.5525 |
| 10.4791 | 125.0 | 7625 | 11.5226 |
| 10.4791 | 126.0 | 7686 | 11.4954 |
| 10.4791 | 127.0 | 7747 | 11.5944 |
| 10.4791 | 128.0 | 7808 | 11.7056 |
| 10.4791 | 129.0 | 7869 | 11.7464 |
| 10.4791 | 130.0 | 7930 | 11.4851 |
| 10.4791 | 131.0 | 7991 | 11.3106 |
| 10.4223 | 132.0 | 8052 | 11.6615 |
| 10.4223 | 133.0 | 8113 | 11.5130 |
| 10.4223 | 134.0 | 8174 | 11.5866 |
| 10.4223 | 135.0 | 8235 | 11.4999 |
| 10.4223 | 136.0 | 8296 | 11.5736 |
| 10.4223 | 137.0 | 8357 | 11.6101 |
| 10.4223 | 138.0 | 8418 | 11.6018 |
| 10.4223 | 139.0 | 8479 | 11.5062 |
| 10.3725 | 140.0 | 8540 | 11.4695 |
| 10.3725 | 141.0 | 8601 | 11.5745 |
| 10.3725 | 142.0 | 8662 | 11.2131 |
| 10.3725 | 143.0 | 8723 | 11.4861 |
| 10.3725 | 144.0 | 8784 | 11.3521 |
| 10.3725 | 145.0 | 8845 | 11.4302 |
| 10.3725 | 146.0 | 8906 | 11.3891 |
| 10.3725 | 147.0 | 8967 | 11.4948 |
| 10.3579 | 148.0 | 9028 | 11.4140 |
| 10.3579 | 149.0 | 9089 | 11.2809 |
| 10.3579 | 150.0 | 9150 | 11.5084 |
| 10.3579 | 151.0 | 9211 | 11.4942 |
| 10.3579 | 152.0 | 9272 | 11.4316 |
| 10.3579 | 153.0 | 9333 | 11.5054 |
| 10.3579 | 154.0 | 9394 | 11.4354 |
| 10.3579 | 155.0 | 9455 | 11.3708 |
| 10.3411 | 156.0 | 9516 | 11.6017 |
| 10.3411 | 157.0 | 9577 | 11.4415 |
| 10.3411 | 158.0 | 9638 | 11.6150 |
| 10.3411 | 159.0 | 9699 | 11.3789 |
| 10.3411 | 160.0 | 9760 | 11.3342 |
| 10.3411 | 161.0 | 9821 | 11.4761 |
| 10.3411 | 162.0 | 9882 | 11.3000 |
| 10.3411 | 163.0 | 9943 | 11.4109 |
| 10.3236 | 164.0 | 10004 | 11.4250 |
| 10.3236 | 165.0 | 10065 | 11.3250 |
| 10.3236 | 166.0 | 10126 | 11.4247 |
| 10.3236 | 167.0 | 10187 | 11.1662 |
| 10.3236 | 168.0 | 10248 | 11.4494 |
| 10.3236 | 169.0 | 10309 | 11.3871 |
| 10.3236 | 170.0 | 10370 | 11.2961 |
| 10.3236 | 171.0 | 10431 | 11.3576 |
| 10.3236 | 172.0 | 10492 | 11.4350 |
| 10.3059 | 173.0 | 10553 | 11.3612 |
| 10.3059 | 174.0 | 10614 | 11.3979 |
| 10.3059 | 175.0 | 10675 | 11.3716 |
| 10.3059 | 176.0 | 10736 | 11.4017 |
| 10.3059 | 177.0 | 10797 | 11.5342 |
| 10.3059 | 178.0 | 10858 | 11.2274 |
| 10.3059 | 179.0 | 10919 | 11.4326 |
| 10.3059 | 180.0 | 10980 | 11.4779 |
| 10.2637 | 181.0 | 11041 | 11.3424 |
| 10.2637 | 182.0 | 11102 | 11.2459 |
| 10.2637 | 183.0 | 11163 | 11.3178 |
| 10.2637 | 184.0 | 11224 | 11.3254 |
| 10.2637 | 185.0 | 11285 | 11.2635 |
| 10.2637 | 186.0 | 11346 | 11.2145 |
| 10.2637 | 187.0 | 11407 | 11.3280 |
| 10.2637 | 188.0 | 11468 | 11.3373 |
| 10.2837 | 189.0 | 11529 | 11.1808 |
| 10.2837 | 190.0 | 11590 | 11.2220 |
| 10.2837 | 191.0 | 11651 | 11.1251 |
| 10.2837 | 192.0 | 11712 | 11.3569 |
| 10.2837 | 193.0 | 11773 | 11.1888 |
| 10.2837 | 194.0 | 11834 | 11.2572 |
| 10.2837 | 195.0 | 11895 | 11.3158 |
| 10.2837 | 196.0 | 11956 | 11.2948 |
| 10.2404 | 197.0 | 12017 | 11.2186 |
| 10.2404 | 198.0 | 12078 | 11.2823 |
| 10.2404 | 199.0 | 12139 | 11.2506 |
| 10.2404 | 200.0 | 12200 | 11.5542 |
| 10.2404 | 201.0 | 12261 | 11.3140 |
| 10.2404 | 202.0 | 12322 | 11.2008 |
| 10.2404 | 203.0 | 12383 | 11.1571 |
| 10.2404 | 204.0 | 12444 | 11.2337 |
| 10.2304 | 205.0 | 12505 | 11.2708 |
| 10.2304 | 206.0 | 12566 | 11.3081 |
| 10.2304 | 207.0 | 12627 | 11.1103 |
| 10.2304 | 208.0 | 12688 | 11.1240 |
| 10.2304 | 209.0 | 12749 | 11.3450 |
| 10.2304 | 210.0 | 12810 | 11.0590 |
| 10.2304 | 211.0 | 12871 | 11.2573 |
| 10.2304 | 212.0 | 12932 | 11.2076 |
| 10.2304 | 213.0 | 12993 | 11.1813 |
| 10.2405 | 214.0 | 13054 | 11.3382 |
| 10.2405 | 215.0 | 13115 | 11.4096 |
| 10.2405 | 216.0 | 13176 | 11.1521 |
| 10.2405 | 217.0 | 13237 | 11.3125 |
| 10.2405 | 218.0 | 13298 | 11.1917 |
| 10.2405 | 219.0 | 13359 | 11.2792 |
| 10.2405 | 220.0 | 13420 | 11.1236 |
| 10.2405 | 221.0 | 13481 | 11.2397 |
| 10.2096 | 222.0 | 13542 | 11.1875 |
| 10.2096 | 223.0 | 13603 | 11.3117 |
| 10.2096 | 224.0 | 13664 | 11.1565 |
| 10.2096 | 225.0 | 13725 | 11.4165 |
| 10.2096 | 226.0 | 13786 | 11.1474 |
| 10.2096 | 227.0 | 13847 | 10.9854 |
| 10.2096 | 228.0 | 13908 | 11.1346 |
| 10.2096 | 229.0 | 13969 | 11.2123 |
| 10.1998 | 230.0 | 14030 | 11.2454 |
| 10.1998 | 231.0 | 14091 | 11.3353 |
| 10.1998 | 232.0 | 14152 | 11.3052 |
| 10.1998 | 233.0 | 14213 | 11.1773 |
| 10.1998 | 234.0 | 14274 | 11.1327 |
| 10.1998 | 235.0 | 14335 | 11.3109 |
| 10.1998 | 236.0 | 14396 | 11.1788 |
| 10.1998 | 237.0 | 14457 | 11.3767 |
| 10.1947 | 238.0 | 14518 | 11.2157 |
| 10.1947 | 239.0 | 14579 | 11.2102 |
| 10.1947 | 240.0 | 14640 | 11.1842 |
| 10.1947 | 241.0 | 14701 | 11.1392 |
| 10.1947 | 242.0 | 14762 | 11.1399 |
| 10.1947 | 243.0 | 14823 | 11.1630 |
| 10.1947 | 244.0 | 14884 | 11.1972 |
| 10.1947 | 245.0 | 14945 | 11.0548 |
| 10.1922 | 246.0 | 15006 | 11.1279 |
| 10.1922 | 247.0 | 15067 | 11.0969 |
| 10.1922 | 248.0 | 15128 | 11.2348 |
| 10.1922 | 249.0 | 15189 | 11.1151 |
| 10.1922 | 250.0 | 15250 | 11.5368 |
| 10.1922 | 251.0 | 15311 | 11.2244 |
| 10.1922 | 252.0 | 15372 | 11.2102 |
| 10.1922 | 253.0 | 15433 | 11.2735 |
| 10.1922 | 254.0 | 15494 | 11.3227 |
| 10.1994 | 255.0 | 15555 | 11.2377 |
| 10.1994 | 256.0 | 15616 | 11.2835 |
| 10.1994 | 257.0 | 15677 | 11.3475 |
| 10.1994 | 258.0 | 15738 | 11.2092 |
| 10.1994 | 259.0 | 15799 | 11.1936 |
| 10.1994 | 260.0 | 15860 | 11.0319 |
| 10.1994 | 261.0 | 15921 | 11.1916 |
| 10.1994 | 262.0 | 15982 | 11.1357 |
| 10.1883 | 263.0 | 16043 | 10.9732 |
| 10.1883 | 264.0 | 16104 | 11.1839 |
| 10.1883 | 265.0 | 16165 | 11.0701 |
| 10.1883 | 266.0 | 16226 | 11.1613 |
| 10.1883 | 267.0 | 16287 | 11.1302 |
| 10.1883 | 268.0 | 16348 | 11.0951 |
| 10.1883 | 269.0 | 16409 | 11.0579 |
| 10.1883 | 270.0 | 16470 | 11.1459 |
| 10.1863 | 271.0 | 16531 | 11.1969 |
| 10.1863 | 272.0 | 16592 | 11.1275 |
| 10.1863 | 273.0 | 16653 | 11.1115 |
| 10.1863 | 274.0 | 16714 | 11.1285 |
| 10.1863 | 275.0 | 16775 | 11.1053 |
| 10.1863 | 276.0 | 16836 | 11.0105 |
| 10.1863 | 277.0 | 16897 | 11.1378 |
| 10.1863 | 278.0 | 16958 | 11.0771 |
| 10.1614 | 279.0 | 17019 | 11.0620 |
| 10.1614 | 280.0 | 17080 | 10.9906 |
| 10.1614 | 281.0 | 17141 | 11.0771 |
| 10.1614 | 282.0 | 17202 | 11.0357 |
| 10.1614 | 283.0 | 17263 | 11.0417 |
| 10.1614 | 284.0 | 17324 | 11.0287 |
| 10.1614 | 285.0 | 17385 | 11.1172 |
| 10.1614 | 286.0 | 17446 | 10.9257 |
| 10.1717 | 287.0 | 17507 | 11.2312 |
| 10.1717 | 288.0 | 17568 | 11.3800 |
| 10.1717 | 289.0 | 17629 | 11.1386 |
| 10.1717 | 290.0 | 17690 | 11.1724 |
| 10.1717 | 291.0 | 17751 | 11.1628 |
| 10.1717 | 292.0 | 17812 | 11.1226 |
| 10.1717 | 293.0 | 17873 | 11.1955 |
| 10.1717 | 294.0 | 17934 | 11.1388 |
| 10.1717 | 295.0 | 17995 | 11.0874 |
| 10.1806 | 296.0 | 18056 | 11.0813 |
| 10.1806 | 297.0 | 18117 | 11.1475 |
| 10.1806 | 298.0 | 18178 | 11.1678 |
| 10.1806 | 299.0 | 18239 | 11.2450 |
| 10.1806 | 300.0 | 18300 | 11.1936 |
| 10.1806 | 301.0 | 18361 | 11.1021 |
| 10.1806 | 302.0 | 18422 | 11.1874 |
| 10.1806 | 303.0 | 18483 | 11.1719 |
| 10.1683 | 304.0 | 18544 | 11.1554 |
| 10.1683 | 305.0 | 18605 | 11.0771 |
| 10.1683 | 306.0 | 18666 | 11.0676 |
| 10.1683 | 307.0 | 18727 | 11.1280 |
| 10.1683 | 308.0 | 18788 | 11.0236 |
| 10.1683 | 309.0 | 18849 | 11.1440 |
| 10.1683 | 310.0 | 18910 | 11.1843 |
| 10.1683 | 311.0 | 18971 | 11.0474 |
| 10.1437 | 312.0 | 19032 | 11.0391 |
| 10.1437 | 313.0 | 19093 | 10.9148 |
| 10.1437 | 314.0 | 19154 | 11.0575 |
| 10.1437 | 315.0 | 19215 | 11.1955 |
| 10.1437 | 316.0 | 19276 | 11.0053 |
| 10.1437 | 317.0 | 19337 | 11.0810 |
| 10.1437 | 318.0 | 19398 | 11.1360 |
| 10.1437 | 319.0 | 19459 | 11.2291 |
| 10.1539 | 320.0 | 19520 | 11.0239 |
| 10.1539 | 321.0 | 19581 | 11.1216 |
| 10.1539 | 322.0 | 19642 | 11.2516 |
| 10.1539 | 323.0 | 19703 | 10.9759 |
| 10.1539 | 324.0 | 19764 | 11.0398 |
| 10.1539 | 325.0 | 19825 | 11.0431 |
| 10.1539 | 326.0 | 19886 | 10.9151 |
| 10.1539 | 327.0 | 19947 | 11.0905 |
| 10.1432 | 328.0 | 20008 | 11.0099 |
| 10.1432 | 329.0 | 20069 | 11.0893 |
| 10.1432 | 330.0 | 20130 | 11.1344 |
| 10.1432 | 331.0 | 20191 | 11.0682 |
| 10.1432 | 332.0 | 20252 | 10.9558 |
| 10.1432 | 333.0 | 20313 | 11.0669 |
| 10.1432 | 334.0 | 20374 | 11.0556 |
| 10.1432 | 335.0 | 20435 | 11.2097 |
| 10.1432 | 336.0 | 20496 | 11.0200 |
| 10.1343 | 337.0 | 20557 | 10.9683 |
| 10.1343 | 338.0 | 20618 | 10.9824 |
| 10.1343 | 339.0 | 20679 | 11.1563 |
| 10.1343 | 340.0 | 20740 | 11.1489 |
| 10.1343 | 341.0 | 20801 | 11.1389 |
| 10.1343 | 342.0 | 20862 | 11.1128 |
| 10.1343 | 343.0 | 20923 | 11.0437 |
| 10.1343 | 344.0 | 20984 | 11.1005 |
| 10.143 | 345.0 | 21045 | 11.1696 |
| 10.143 | 346.0 | 21106 | 11.1356 |
| 10.143 | 347.0 | 21167 | 11.0798 |
| 10.143 | 348.0 | 21228 | 10.9183 |
| 10.143 | 349.0 | 21289 | 11.0879 |
| 10.143 | 350.0 | 21350 | 10.9651 |
| 10.143 | 351.0 | 21411 | 11.0724 |
| 10.143 | 352.0 | 21472 | 11.0264 |
| 10.1456 | 353.0 | 21533 | 11.1398 |
| 10.1456 | 354.0 | 21594 | 11.2497 |
| 10.1456 | 355.0 | 21655 | 10.8898 |
| 10.1456 | 356.0 | 21716 | 10.9631 |
| 10.1456 | 357.0 | 21777 | 11.0734 |
| 10.1456 | 358.0 | 21838 | 11.1226 |
| 10.1456 | 359.0 | 21899 | 11.1686 |
| 10.1456 | 360.0 | 21960 | 11.0314 |
| 10.1345 | 361.0 | 22021 | 11.0940 |
| 10.1345 | 362.0 | 22082 | 10.9222 |
| 10.1345 | 363.0 | 22143 | 11.1036 |
| 10.1345 | 364.0 | 22204 | 11.1905 |
| 10.1345 | 365.0 | 22265 | 10.9741 |
| 10.1345 | 366.0 | 22326 | 10.9092 |
| 10.1345 | 367.0 | 22387 | 11.0564 |
| 10.1345 | 368.0 | 22448 | 11.0534 |
| 10.1354 | 369.0 | 22509 | 11.0307 |
| 10.1354 | 370.0 | 22570 | 11.1469 |
| 10.1354 | 371.0 | 22631 | 11.0560 |
| 10.1354 | 372.0 | 22692 | 11.0240 |
| 10.1354 | 373.0 | 22753 | 10.9869 |
| 10.1354 | 374.0 | 22814 | 11.0004 |
| 10.1354 | 375.0 | 22875 | 11.1373 |
| 10.1354 | 376.0 | 22936 | 11.0955 |
| 10.1354 | 377.0 | 22997 | 11.0542 |
| 10.1382 | 378.0 | 23058 | 10.9813 |
| 10.1382 | 379.0 | 23119 | 10.9874 |
| 10.1382 | 380.0 | 23180 | 10.9736 |
| 10.1382 | 381.0 | 23241 | 11.1295 |
| 10.1382 | 382.0 | 23302 | 10.8724 |
| 10.1382 | 383.0 | 23363 | 10.9367 |
| 10.1382 | 384.0 | 23424 | 11.0516 |
| 10.1382 | 385.0 | 23485 | 11.0275 |
| 10.1246 | 386.0 | 23546 | 11.0184 |
| 10.1246 | 387.0 | 23607 | 11.0570 |
| 10.1246 | 388.0 | 23668 | 11.0246 |
| 10.1246 | 389.0 | 23729 | 11.0131 |
| 10.1246 | 390.0 | 23790 | 11.0168 |
| 10.1246 | 391.0 | 23851 | 11.0817 |
| 10.1246 | 392.0 | 23912 | 10.8949 |
| 10.1246 | 393.0 | 23973 | 10.7698 |
| 10.1173 | 394.0 | 24034 | 11.0041 |
| 10.1173 | 395.0 | 24095 | 10.9257 |
| 10.1173 | 396.0 | 24156 | 10.9295 |
| 10.1173 | 397.0 | 24217 | 10.9476 |
| 10.1173 | 398.0 | 24278 | 11.0583 |
| 10.1173 | 399.0 | 24339 | 11.0006 |
| 10.1173 | 400.0 | 24400 | 10.9714 |
| 10.1173 | 401.0 | 24461 | 11.0480 |
| 10.1253 | 402.0 | 24522 | 11.0213 |
| 10.1253 | 403.0 | 24583 | 10.9636 |
| 10.1253 | 404.0 | 24644 | 10.9886 |
| 10.1253 | 405.0 | 24705 | 11.0664 |
| 10.1253 | 406.0 | 24766 | 11.0462 |
| 10.1253 | 407.0 | 24827 | 11.0122 |
| 10.1253 | 408.0 | 24888 | 10.8572 |
| 10.1253 | 409.0 | 24949 | 11.1382 |
| 10.1386 | 410.0 | 25010 | 11.0700 |
| 10.1386 | 411.0 | 25071 | 10.9676 |
| 10.1386 | 412.0 | 25132 | 11.1865 |
| 10.1386 | 413.0 | 25193 | 11.0785 |
| 10.1386 | 414.0 | 25254 | 11.0290 |
| 10.1386 | 415.0 | 25315 | 11.1383 |
| 10.1386 | 416.0 | 25376 | 11.1139 |
| 10.1386 | 417.0 | 25437 | 11.0185 |
| 10.1386 | 418.0 | 25498 | 11.0187 |
| 10.1491 | 419.0 | 25559 | 11.0893 |
| 10.1491 | 420.0 | 25620 | 11.0348 |
| 10.1491 | 421.0 | 25681 | 10.9932 |
| 10.1491 | 422.0 | 25742 | 11.0765 |
| 10.1491 | 423.0 | 25803 | 11.0488 |
| 10.1491 | 424.0 | 25864 | 11.0241 |
| 10.1491 | 425.0 | 25925 | 11.0695 |
| 10.1491 | 426.0 | 25986 | 10.8986 |
| 10.1184 | 427.0 | 26047 | 10.8433 |
| 10.1184 | 428.0 | 26108 | 10.8476 |
| 10.1184 | 429.0 | 26169 | 10.9747 |
| 10.1184 | 430.0 | 26230 | 10.9259 |
| 10.1184 | 431.0 | 26291 | 10.8647 |
| 10.1184 | 432.0 | 26352 | 11.0280 |
| 10.1184 | 433.0 | 26413 | 10.9582 |
| 10.1184 | 434.0 | 26474 | 10.9810 |
| 10.1396 | 435.0 | 26535 | 11.0491 |
| 10.1396 | 436.0 | 26596 | 11.0700 |
| 10.1396 | 437.0 | 26657 | 10.9878 |
| 10.1396 | 438.0 | 26718 | 10.9400 |
| 10.1396 | 439.0 | 26779 | 10.8682 |
| 10.1396 | 440.0 | 26840 | 10.9667 |
| 10.1396 | 441.0 | 26901 | 11.0117 |
| 10.1396 | 442.0 | 26962 | 11.0374 |
| 10.1337 | 443.0 | 27023 | 11.1337 |
| 10.1337 | 444.0 | 27084 | 10.9415 |
| 10.1337 | 445.0 | 27145 | 11.0174 |
| 10.1337 | 446.0 | 27206 | 11.0239 |
| 10.1337 | 447.0 | 27267 | 10.8979 |
| 10.1337 | 448.0 | 27328 | 10.9217 |
| 10.1337 | 449.0 | 27389 | 10.8926 |
| 10.1337 | 450.0 | 27450 | 11.1219 |
| 10.1168 | 451.0 | 27511 | 10.8931 |
| 10.1168 | 452.0 | 27572 | 11.0112 |
| 10.1168 | 453.0 | 27633 | 10.9823 |
| 10.1168 | 454.0 | 27694 | 11.1091 |
| 10.1168 | 455.0 | 27755 | 10.8694 |
| 10.1168 | 456.0 | 27816 | 10.9625 |
| 10.1168 | 457.0 | 27877 | 10.8553 |
| 10.1168 | 458.0 | 27938 | 10.9888 |
| 10.1168 | 459.0 | 27999 | 10.9296 |
| 10.1229 | 460.0 | 28060 | 10.8895 |
| 10.1229 | 461.0 | 28121 | 10.9803 |
| 10.1229 | 462.0 | 28182 | 11.0144 |
| 10.1229 | 463.0 | 28243 | 11.0257 |
| 10.1229 | 464.0 | 28304 | 10.9141 |
| 10.1229 | 465.0 | 28365 | 11.1346 |
| 10.1229 | 466.0 | 28426 | 11.0254 |
| 10.1229 | 467.0 | 28487 | 11.0384 |
| 10.1179 | 468.0 | 28548 | 10.8491 |
| 10.1179 | 469.0 | 28609 | 11.0469 |
| 10.1179 | 470.0 | 28670 | 10.9678 |
| 10.1179 | 471.0 | 28731 | 10.8902 |
| 10.1179 | 472.0 | 28792 | 10.9649 |
| 10.1179 | 473.0 | 28853 | 10.9252 |
| 10.1179 | 474.0 | 28914 | 11.1131 |
| 10.1179 | 475.0 | 28975 | 11.0267 |
| 10.1189 | 476.0 | 29036 | 10.8428 |
| 10.1189 | 477.0 | 29097 | 11.0314 |
| 10.1189 | 478.0 | 29158 | 11.0936 |
| 10.1189 | 479.0 | 29219 | 10.9968 |
| 10.1189 | 480.0 | 29280 | 10.8721 |
| 10.1189 | 481.0 | 29341 | 11.0153 |
| 10.1189 | 482.0 | 29402 | 11.1761 |
| 10.1189 | 483.0 | 29463 | 10.9840 |
| 10.1153 | 484.0 | 29524 | 10.9648 |
| 10.1153 | 485.0 | 29585 | 11.1140 |
| 10.1153 | 486.0 | 29646 | 11.0212 |
| 10.1153 | 487.0 | 29707 | 10.9197 |
| 10.1153 | 488.0 | 29768 | 10.9798 |
| 10.1153 | 489.0 | 29829 | 10.9047 |
| 10.1153 | 490.0 | 29890 | 11.0146 |
| 10.1153 | 491.0 | 29951 | 11.0575 |
| 10.1141 | 492.0 | 30012 | 11.0400 |
| 10.1141 | 493.0 | 30073 | 11.0898 |
| 10.1141 | 494.0 | 30134 | 10.9910 |
| 10.1141 | 495.0 | 30195 | 11.0579 |
| 10.1141 | 496.0 | 30256 | 10.8580 |
| 10.1141 | 497.0 | 30317 | 10.9450 |
| 10.1141 | 498.0 | 30378 | 11.0523 |
| 10.1141 | 499.0 | 30439 | 11.1228 |
| 10.1176 | 500.0 | 30500 | 11.0492 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Chun/w-en2zh-hsk | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2453
- Accuracy: 0.92
- F1: 0.9098
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Chun/w-en2zh-mtm | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: deberta-finetuned-ner-connll-late-stop
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
config: en
split: train
args: en
metrics:
- name: Precision
type: precision
value: 0.830192600803658
- name: Recall
type: recall
value: 0.8470945850417079
- name: F1
type: f1
value: 0.8385584324702589
- name: Accuracy
type: accuracy
value: 0.9228861596598961
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-finetuned-ner-connll-late-stop
This model is a fine-tuned version of [microsoft/deberta-base](https://huggingface.co/microsoft/deberta-base) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5259
- Precision: 0.8302
- Recall: 0.8471
- F1: 0.8386
- Accuracy: 0.9229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3408 | 1.0 | 1875 | 0.3639 | 0.7462 | 0.7887 | 0.7669 | 0.8966 |
| 0.2435 | 2.0 | 3750 | 0.2933 | 0.8104 | 0.8332 | 0.8217 | 0.9178 |
| 0.1822 | 3.0 | 5625 | 0.3034 | 0.8147 | 0.8388 | 0.8266 | 0.9221 |
| 0.1402 | 4.0 | 7500 | 0.3667 | 0.8275 | 0.8474 | 0.8374 | 0.9235 |
| 0.1013 | 5.0 | 9375 | 0.4290 | 0.8285 | 0.8448 | 0.8366 | 0.9227 |
| 0.0677 | 6.0 | 11250 | 0.4914 | 0.8259 | 0.8473 | 0.8365 | 0.9231 |
| 0.0439 | 7.0 | 13125 | 0.5259 | 0.8302 | 0.8471 | 0.8386 | 0.9229 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Chun/w-en2zh-otm | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ## Persian XLM-RoBERTA Large For Question Answering Task
XLM-RoBERTA is a multilingual language model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116v2) by Conneau et al. .
Multilingual [XLM-RoBERTa large for QA on various languages](https://huggingface.co/deepset/xlm-roberta-large-squad2) is fine-tuned on various QA datasets but PQuAD, which is the biggest persian QA dataset so far. This second model is our base model to be fine-tuned.
Paper presenting PQuAD dataset: [arXiv:2202.06219](https://arxiv.org/abs/2202.06219)
---
## Introduction
This model is fine-tuned on PQuAD Train set and is easily ready to use.
Its very long training time encouraged me to publish this model in order to make life easier for those who need.
## Hyperparameters of training
I set batch size to 4 due to the limitations of GPU memory in Google Colab.
```
batch_size = 4
n_epochs = 1
base_LM_model = "deepset/xlm-roberta-large-squad2"
max_seq_len = 256
learning_rate = 3e-5
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate = 3e-5,
warmup_ratio = 0.1,
gradient_accumulation_steps = 8,
weight_decay = 0.01,
```
## Performance
Evaluated on the PQuAD Persian test set with the [official PQuAD link](https://huggingface.co/datasets/newsha/PQuAD).
I trained for more than 1 epoch as well, but I get worse results.
Our XLM-Roberta outperforms [our ParsBert on PQuAD](https://huggingface.co/pedramyazdipoor/parsbert_question_answering_PQuAD), but the former is more than 3 times bigger than the latter one; so comparing these two is not fair.
### Question Answering On Test Set of PQuAD Dataset
| Metric | Our XLM-Roberta Large| Our ParsBert |
|:----------------:|:--------------------:|:-------------:|
| Exact Match | 66.56* | 47.44 |
| F1 | 87.31* | 81.96 |
## How to use
## Pytorch
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
path = 'pedramyazdipoor/persian_xlm_roberta_large'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForQuestionAnswering.from_pretrained(path)
```
## Inference
There are some considerations for inference:
1) Start index of answer must be smaller than end index.
2) The span of answer must be within the context.
3) The selected span must be the most probable choice among N pairs of candidates.
```python
def generate_indexes(start_logits, end_logits, N, min_index):
output_start = start_logits
output_end = end_logits
start_indexes = np.arange(len(start_logits))
start_probs = output_start
list_start = dict(zip(start_indexes, start_probs.tolist()))
end_indexes = np.arange(len(end_logits))
end_probs = output_end
list_end = dict(zip(end_indexes, end_probs.tolist()))
sorted_start_list = sorted(list_start.items(), key=lambda x: x[1], reverse=True) #Descending sort by probability
sorted_end_list = sorted(list_end.items(), key=lambda x: x[1], reverse=True)
final_start_idx, final_end_idx = [[] for l in range(2)]
start_idx, end_idx, prob = 0, 0, (start_probs.tolist()[0] + end_probs.tolist()[0])
for a in range(0,N):
for b in range(0,N):
if (sorted_start_list[a][1] + sorted_end_list[b][1]) > prob :
if (sorted_start_list[a][0] <= sorted_end_list[b][0]) and (sorted_start_list[a][0] > min_index) :
prob = sorted_start_list[a][1] + sorted_end_list[b][1]
start_idx = sorted_start_list[a][0]
end_idx = sorted_end_list[b][0]
final_start_idx.append(start_idx)
final_end_idx.append(end_idx)
return final_start_idx[0], final_end_idx[0]
```
```python
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.eval().to(device)
text = 'سلام من پدرامم 26 سالمه'
question = 'چند سالمه؟'
encoding = tokenizer(question,text,add_special_tokens = True,
return_token_type_ids = True,
return_tensors = 'pt',
padding = True,
return_offsets_mapping = True,
truncation = 'only_first',
max_length = 32)
out = model(encoding['input_ids'].to(device),encoding['attention_mask'].to(device), encoding['token_type_ids'].to(device))
#we had to change some pieces of code to make it compatible with one answer generation at a time
#If you have unanswerable questions, use out['start_logits'][0][0:] and out['end_logits'][0][0:] because <s> (the 1st token) is for this situation and must be compared with other tokens.
#you can initialize min_index in generate_indexes() to put force on tokens being chosen to be within the context(startindex must be greater than seperator token).
answer_start_index, answer_end_index = generate_indexes(out['start_logits'][0][1:], out['end_logits'][0][1:], 5, 0)
print(tokenizer.tokenize(text + question))
print(tokenizer.tokenize(text + question)[answer_start_index : (answer_end_index + 1)])
>>> ['▁سلام', '▁من', '▁پدر', 'ام', 'م', '▁26', '▁سالم', 'ه', 'نام', 'م', '▁چیست', '؟']
>>> ['▁26']
```
## Acknowledgments
We hereby, express our gratitude to the [Newsha Shahbodaghkhan](https://huggingface.co/datasets/newsha/PQuAD/tree/main) for facilitating dataset gathering.
## Contributors
- Pedram Yazdipoor : [Linkedin](https://www.linkedin.com/in/pedram-yazdipour/)
## Releases
### Release v0.2 (Sep 18, 2022)
This is the second version of our Persian XLM-Roberta-Large.
There were some problems using the previous version. |
Chun/w-zh2en-hsk | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- metrics:
- type: mean_reward
value: 1291.10 +/- 55.61
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Chun/w-zh2en-mto | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2269 | 1.0 | 5533 | 1.1705 |
| 0.9725 | 2.0 | 11066 | 1.1238 |
| 0.768 | 3.0 | 16599 | 1.1568 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Chungu424/qazwsx | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/triton7777/ddpm-butterflies-128/tensorboard?#scalars)
|
Ci/Pai | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### Lula 13 on Stable Diffusion
This is the `<lula-13>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
Cilan/dalle-knockoff | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### laala-character on Stable Diffusion
This is the `<laala>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
ClaudeCOULOMBE/RickBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ## ParsBert Fine-Tuned for Question Answering Task
ParsBERT is a monolingual language model based on Google’s BERT architecture. This model is pre-trained on large Persian corpora with various writing styles from numerous subjects (e.g., scientific, novels, news) with more than 3.9M documents, 73M sentences, and 1.3B words.
In this project I fine-tuned [ParsBert](https://huggingface.co/HooshvareLab/bert-fa-base-uncased) on [PQuAD dataset](https://huggingface.co/datasets/newsha/PQuAD/tree/main) for extractive question answering task.
Our source code is [here](https://github.com/pedramyazdipoor/ParsBert_QA_PQuAD).
Paper presenting ParsBert : [arXiv:2005.12515](https://arxiv.org/abs/2005.12515).
Paper presenting PQuAD dataset: [arXiv:2202.06219](https://arxiv.org/abs/2202.06219).
---
## Introduction
This model is fine-tuned on PQuAD Train set and is easily ready to use. Too long training time encouraged me to publish this model in order to make life easier for those who need.
## Hyperparameters
I set batch_size to 32 due to the limitations of GPU memory in Google Colab.
```
batch_size = 32,
n_epochs = 2,
max_seq_len = 256,
learning_rate = 5e-5
```
## Performance
Evaluated on the PQuAD Persian test set.
I trained for more than 2 epochs as well, but I get worse results.
Our [XLM-Roberta Large](https://huggingface.co/pedramyazdipoor/persian_xlm_roberta_large) outperforms our ParsBert, but the former is more than 3 times bigger than the latter one; so comparing these two is not fair.
### Question Answering On Test Set of PQuAD Dataset
| Metric | Our XLM-Roberta Large| Our ParsBert |
|:----------------:|:--------------------:|:-------------:|
| Exact Match | 66.56* | 47.44 |
| F1 | 87.31* | 81.96 |
## How to use
## Pytorch
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
path = 'pedramyazdipoor/parsbert_question_answering_PQuAD'
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForQuestionAnswering.from_pretrained(path)
```
## Tensorflow
```python
from transformers import AutoTokenizer, TFAutoModelForQuestionAnswering
path = 'pedramyazdipoor/parsbert_question_answering_PQuAD'
tokenizer = AutoTokenizer.from_pretrained(path)
model = TFAutoModelForQuestionAnswering.from_pretrained(path)
```
## Inference for pytorch
I leave Inference for tensorflow as an excercise for you :) .
There are some considerations for inference:
1) Start index of answer must be smaller than end index.
2) The span of answer must be within the context.
3) The selected span must be the most probable choice among N pairs of candidates.
```python
def generate_indexes(start_logits, end_logits, N, max_index):
output_start = start_logits
output_end = end_logits
start_indexes = np.arange(len(start_logits))
start_probs = output_start
list_start = dict(zip(start_indexes, start_probs.tolist()))
end_indexes = np.arange(len(end_logits))
end_probs = output_end
list_end = dict(zip(end_indexes, end_probs.tolist()))
sorted_start_list = sorted(list_start.items(), key=lambda x: x[1], reverse=True) #Descending sort by probability
sorted_end_list = sorted(list_end.items(), key=lambda x: x[1], reverse=True)
final_start_idx, final_end_idx = [[] for l in range(2)]
start_idx, end_idx, prob = 0, 0, (start_probs.tolist()[0] + end_probs.tolist()[0])
for a in range(0,N):
for b in range(0,N):
if (sorted_start_list[a][1] + sorted_end_list[b][1]) > prob :
if (sorted_start_list[a][0] <= sorted_end_list[b][0]) and (sorted_end_list[a][0] < max_index) :
prob = sorted_start_list[a][1] + sorted_end_list[b][1]
start_idx = sorted_start_list[a][0]
end_idx = sorted_end_list[b][0]
final_start_idx.append(start_idx)
final_end_idx.append(end_idx)
return final_start_idx[0], final_end_idx[0]
```
```python
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.eval().to(device)
text = 'سلام من پدرامم 26 سالمه'
question = 'چند سالمه؟'
encoding = tokenizer(text,question,add_special_tokens = True,
return_token_type_ids = True,
return_tensors = 'pt',
padding = True,
return_offsets_mapping = True,
truncation = 'only_first',
max_length = 32)
out = model(encoding['input_ids'].to(device),encoding['attention_mask'].to(device), encoding['token_type_ids'].to(device))
#we had to change some pieces of code to make it compatible with one answer generation at a time
#If you have unanswerable questions, use out['start_logits'][0][0:] and out['end_logits'][0][0:] because <s> (the 1st token) is for this situation and must be compared with other tokens.
#you can initialize max_index in generate_indexes() to put force on tokens being chosen to be within the context(end index must be less than seperator token).
answer_start_index, answer_end_index = generate_indexes(out['start_logits'][0][1:], out['end_logits'][0][1:], 5, 0)
print(tokenizer.tokenize(text + question))
print(tokenizer.tokenize(text + question)[answer_start_index : (answer_end_index + 1)])
>>> ['▁سلام', '▁من', '▁پدر', 'ام', 'م', '▁26', '▁سالم', 'ه', 'نام', 'م', '▁چیست', '؟']
>>> ['▁26']
```
## Acknowledgments
We did this project thanks to the fantastic job done by [HooshvareLab](https://huggingface.co/HooshvareLab/bert-fa-base-uncased).
We also express our gratitude to [Newsha Shahbodaghkhan](https://huggingface.co/datasets/newsha/PQuAD/tree/main) for facilitating dataset gathering.
## Contributors
- Pedram Yazdipoor : [Linkedin](https://www.linkedin.com/in/pedram-yazdipour/)
## Releases
### Release v0.2 (Sep 19, 2022)
This is the second version of our ParsBert for Question Answering on PQuAD.
|
ClaudeYang/awesome_fb_model | [
"pytorch",
"bart",
"text-classification",
"dataset:multi_nli",
"transformers",
"zero-shot-classification"
] | zero-shot-classification | {
"architectures": [
"BartForSequenceClassification"
],
"model_type": "bart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-imdb
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93092
- name: F1
type: f1
value: 0.931612085692789
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2368
- Accuracy: 0.9309
- F1: 0.9316
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CleveGreen/FieldClassifier_v2_gpt | [
"pytorch",
"gpt2",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"GPT2ForSequenceClassification"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- cord-layoutlmv3
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: LayoutLMv3-Finetuned-CORD_100
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: cord-layoutlmv3
type: cord-layoutlmv3
config: cord
split: train
args: cord
metrics:
- name: Precision
type: precision
value: 0.9524870081662955
- name: Recall
type: recall
value: 0.9603293413173652
- name: F1
type: f1
value: 0.9563920983973164
- name: Accuracy
type: accuracy
value: 0.9647707979626485
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3-Finetuned-CORD_100
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the cord-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1948
- Precision: 0.9525
- Recall: 0.9603
- F1: 0.9564
- Accuracy: 0.9648
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.1e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.56 | 250 | 0.9568 | 0.7298 | 0.7844 | 0.7561 | 0.7992 |
| 1.3271 | 3.12 | 500 | 0.5239 | 0.8398 | 0.8713 | 0.8553 | 0.8858 |
| 1.3271 | 4.69 | 750 | 0.3586 | 0.8945 | 0.9207 | 0.9074 | 0.9300 |
| 0.3495 | 6.25 | 1000 | 0.2716 | 0.9298 | 0.9416 | 0.9357 | 0.9410 |
| 0.3495 | 7.81 | 1250 | 0.2331 | 0.9198 | 0.9356 | 0.9276 | 0.9474 |
| 0.1725 | 9.38 | 1500 | 0.2134 | 0.9379 | 0.9499 | 0.9438 | 0.9529 |
| 0.1725 | 10.94 | 1750 | 0.2079 | 0.9401 | 0.9513 | 0.9457 | 0.9605 |
| 0.1116 | 12.5 | 2000 | 0.1992 | 0.9554 | 0.9618 | 0.9586 | 0.9656 |
| 0.1116 | 14.06 | 2250 | 0.1941 | 0.9517 | 0.9588 | 0.9553 | 0.9631 |
| 0.0762 | 15.62 | 2500 | 0.1966 | 0.9503 | 0.9588 | 0.9545 | 0.9639 |
| 0.0762 | 17.19 | 2750 | 0.1951 | 0.9510 | 0.9588 | 0.9549 | 0.9626 |
| 0.0636 | 18.75 | 3000 | 0.1948 | 0.9525 | 0.9603 | 0.9564 | 0.9648 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Cloudy/DialoGPT-CJ-large | [
"pytorch",
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
tags:
- generated_from_trainer
model-index:
- name: finetuned-bertweetlarge-pheme
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-bertweetlarge-pheme
This model is a fine-tuned version of [vinai/bertweet-large](https://huggingface.co/vinai/bertweet-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8454
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.2347 | 4.9 | 500 | 0.5495 |
| 0.0318 | 9.8 | 1000 | 0.8454 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ClydeWasTaken/DialoGPT-small-joshua | [
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Ravneet/ddpm-butterflies-128/tensorboard?#scalars)
|
CoachCarter/distilbert-base-uncased-finetuned-squad | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-regression
widget:
structuredData:
Hour:
- 0
- 1
- 2
Lag_1:
- 4.215
- 3.741
- 3.38
Lag_2:
- 3.939
- 4.215
- 3.741
Lag_3:
- 4.222
- 3.939
- 4.215
Lag_4:
- 4.568
- 4.222
- 3.939
Temperature:
- 20.45
- 19.5
- 18.75
Weekday:
- 4
- 4
- 4
Weekofyear:
- 1
- 1
- 1
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|--------------------------|---------------|
| bootstrap | True |
| ccp_alpha | 0.0 |
| criterion | squared_error |
| max_depth | 10 |
| max_features | 1.0 |
| max_leaf_nodes | |
| max_samples | |
| min_impurity_decrease | 0.0 |
| min_samples_leaf | 1 |
| min_samples_split | 2 |
| min_weight_fraction_leaf | 0.0 |
| n_estimators | 50 |
| n_jobs | |
| oob_score | False |
| random_state | 59 |
| verbose | 0 |
| warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-container-id-2 {color: black;background-color: white;}#sk-container-id-2 pre{padding: 0;}#sk-container-id-2 div.sk-toggleable {background-color: white;}#sk-container-id-2 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-2 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-2 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-2 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-2 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-2 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-2 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-2 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-2 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-2 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-2 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-2 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-2 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-2 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-2 div.sk-item {position: relative;z-index: 1;}#sk-container-id-2 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-2 div.sk-item::before, #sk-container-id-2 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-2 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-2 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-2 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-2 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-2 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-2 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-2 div.sk-label-container {text-align: center;}#sk-container-id-2 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-2 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-2" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>RandomForestRegressor(max_depth=10, n_estimators=50, random_state=59)</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-2" type="checkbox" checked><label for="sk-estimator-id-2" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestRegressor</label><div class="sk-toggleable__content"><pre>RandomForestRegressor(max_depth=10, n_estimators=50, random_state=59)</pre></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|---------|
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
[More Information Needed]
```
</details>
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
``` |
CodeDanCode/CartmenBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: model-2-bart-reverse-raw
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model-2-bart-reverse-raw
This model is a fine-tuned version of [eugenesiow/bart-paraphrase](https://huggingface.co/eugenesiow/bart-paraphrase) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1556
- Rouge1: 63.5215
- Rouge2: 58.8297
- Rougel: 60.5701
- Rougelsum: 63.2683
- Gen Len: 19.4672
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.1276 | 1.0 | 12767 | 0.1556 | 63.5215 | 58.8297 | 60.5701 | 63.2683 | 19.4672 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CodeDanCode/SP-KyleBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft_rs1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft_rs1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0789
- F1: 0.9267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2742 | 1.0 | 101 | 0.0959 | 0.8413 |
| 0.0698 | 2.0 | 202 | 0.0635 | 0.8923 |
| 0.0335 | 3.0 | 303 | 0.0630 | 0.9013 |
| 0.0171 | 4.0 | 404 | 0.0635 | 0.9133 |
| 0.0096 | 5.0 | 505 | 0.0671 | 0.9171 |
| 0.0058 | 6.0 | 606 | 0.0701 | 0.9210 |
| 0.0037 | 7.0 | 707 | 0.0762 | 0.9231 |
| 0.0034 | 8.0 | 808 | 0.0771 | 0.9168 |
| 0.0021 | 9.0 | 909 | 0.0751 | 0.9268 |
| 0.0013 | 10.0 | 1010 | 0.0770 | 0.9277 |
| 0.0011 | 11.0 | 1111 | 0.0784 | 0.9259 |
| 0.0008 | 12.0 | 1212 | 0.0789 | 0.9267 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CodeMonkey98/distilroberta-base-finetuned-wikitext2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### margo on Stable Diffusion
This is the `<dog-margo>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
CodeNinja1126/bert-q-encoder | [
"pytorch"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft_rs2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft_rs2
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0945
- F1: 0.9185
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2719 | 1.0 | 101 | 0.0878 | 0.8458 |
| 0.0682 | 2.0 | 202 | 0.0678 | 0.8838 |
| 0.0321 | 3.0 | 303 | 0.0617 | 0.9041 |
| 0.0149 | 4.0 | 404 | 0.0709 | 0.9061 |
| 0.0097 | 5.0 | 505 | 0.0766 | 0.9114 |
| 0.0059 | 6.0 | 606 | 0.0803 | 0.9174 |
| 0.0035 | 7.0 | 707 | 0.0845 | 0.9160 |
| 0.0023 | 8.0 | 808 | 0.0874 | 0.9158 |
| 0.0016 | 9.0 | 909 | 0.0928 | 0.9188 |
| 0.0016 | 10.0 | 1010 | 0.0951 | 0.9108 |
| 0.0011 | 11.0 | 1111 | 0.0938 | 0.9178 |
| 0.0009 | 12.0 | 1212 | 0.0945 | 0.9185 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CodeNinja1126/koelectra-model | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-18T21:07:39Z | ---
tags:
- generated_from_trainer
datasets:
- squad_bn
model-index:
- name: banglabert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# banglabert-finetuned-squad
This model is a fine-tuned version of [csebuetnlp/banglabert](https://huggingface.co/csebuetnlp/banglabert) on the squad_bn dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4421
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3649 | 1.0 | 7397 | 1.4421 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
CodeNinja1126/test-model | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
license: creativeml-openrail-m
---
Ported from weights hosted on original model repo: https://huggingface.co/CompVis/stable-diffusion-v1-4 |
CoderBoy432/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 40 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 40,
"warmup_steps": 4,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
CoderEFE/DialoGPT-marxbot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational",
"has_space"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-09-18T21:28:18Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- gem
model-index:
- name: OUT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OUT
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the gem dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 25
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 14
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CoderEFE/DialoGPT-medium-marx | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: LeKazuha/distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# LeKazuha/distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.1946
- Train End Logits Accuracy: 0.6778
- Train Start Logits Accuracy: 0.6365
- Validation Loss: 1.1272
- Validation End Logits Accuracy: 0.6948
- Validation Start Logits Accuracy: 0.6569
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 11064, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.1946 | 0.6778 | 0.6365 | 1.1272 | 0.6948 | 0.6569 | 0 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.7.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
CoffeeAddict93/gpt1-modest-proposal | [
"pytorch",
"openai-gpt",
"text-generation",
"transformers",
"has_space"
] | text-generation | {
"architectures": [
"OpenAIGPTLMHeadModel"
],
"model_type": "openai-gpt",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-09-18T21:58:03Z | ---
license: cc-by-4.0
tags:
- generated_from_trainer
model-index:
- name: electra-base-squad2-ta-qna-electra
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-base-squad2-ta-qna-electra
This model is a fine-tuned version of [deepset/electra-base-squad2](https://huggingface.co/deepset/electra-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1644
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 44 | 0.2352 |
| No log | 2.0 | 88 | 0.1644 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CoffeeAddict93/gpt2-call-of-the-wild | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: model2-bart-reverse
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model2-bart-reverse
This model is a fine-tuned version of [theojolliffe/model-2-bart-reverse-raw](https://huggingface.co/theojolliffe/model-2-bart-reverse-raw) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5768
- Rouge1: 50.0024
- Rouge2: 44.5149
- Rougel: 50.408
- Rougelsum: 50.0015
- Gen Len: 20.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 160 | 0.5107 | 54.2246 | 50.7271 | 51.1954 | 54.4944 | 20.0 |
| No log | 2.0 | 320 | 0.5895 | 48.1317 | 43.4207 | 48.6594 | 48.4308 | 20.0 |
| No log | 3.0 | 480 | 0.5833 | 51.7747 | 46.8312 | 52.47 | 52.1239 | 20.0 |
| 0.4286 | 4.0 | 640 | 0.5768 | 50.0024 | 44.5149 | 50.408 | 50.0015 | 20.0 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CoffeeAddict93/gpt2-medium-modest-proposal | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
---
### CarrasCharacter on Stable Diffusion
This is the `<Carras>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
CoffeeAddict93/gpt2-modest-proposal | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
license: mit
---
### vietstoneking on Stable Diffusion
This is the `<vietstoneking>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
CohleM/bert-nepali-tokenizer | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Access to model sd-concepts-library/rhizomuse-machine-bionic-sculpture is restricted and you are not in the authorized list. Visit https://huggingface.co/sd-concepts-library/rhizomuse-machine-bionic-sculpture to ask for access. |
CohleM/mbert-nepali-tokenizer | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-19T00:12:56Z | ---
license: mit
---
### rcrumb portraits style on Stable Diffusion
This is the `<rcrumb-portraits>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:










|
Connorvr/BrightBot-small | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-09-19T02:05:33Z | ---
tags:
- Pong-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: pong-policy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pong-PLE-v0
type: Pong-PLE-v0
metrics:
- type: mean_reward
value: -16.00 +/- 0.00
name: mean_reward
verified: false
---
## parameters
pong_hyperparameters = { <br>
"h_size": 64,<br>
"n_training_episodes": 20000,<br>
"n_evaluation_episodes": 10,<br>
"max_t": 5000,<br>
"gamma": 0.99,<br>
"lr": 1e-2,<br>
"env_id": env_id,<br>
"state_space": s_size,<br>
"action_space": a_size,<br>
}<br>
|
Connorvr/TeachingGen | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-09-19T02:08:45Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 14.50 +/- 12.34
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga CoreyMorris -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga CoreyMorris
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Contrastive-Tension/BERT-Base-CT | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
language:
- ko
license:
- mit
widget:
source_sentence: "대한민국의 수도는 서울입니다."
sentences:
- "미국의 수도는 뉴욕이 아닙니다."
- "대한민국의 수도 요금은 저렴한 편입니다."
- "서울은 대한민국의 수도입니다."
---
# smartmind/roberta-ko-small-tsdae
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 256 dimensional dense vector space and can be used for tasks like clustering or semantic search.
Korean roberta small model pretrained with [TSDAE](https://arxiv.org/abs/2104.06979).
[TSDAE](https://arxiv.org/abs/2104.06979)로 사전학습된 한국어 roberta모델입니다. 모델의 구조는 [lassl/roberta-ko-small](https://huggingface.co/lassl/roberta-ko-small)과 동일합니다. 토크나이저는 다릅니다.
sentence-similarity를 구하는 용도로 바로 사용할 수도 있고, 목적에 맞게 파인튜닝하여 사용할 수도 있습니다.
## Usage (Sentence-Transformers)
[sentence-transformers](https://www.SBERT.net)를 설치한 뒤, 모델을 바로 불러올 수 있습니다.
```
pip install -U sentence-transformers
```
이후 다음처럼 모델을 사용할 수 있습니다.
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('smartmind/roberta-ko-small-tsdae')
embeddings = model.encode(sentences)
print(embeddings)
```
다음은 sentence-transformers의 기능을 사용하여 여러 문장의 유사도를 구하는 예시입니다.
```python
from sentence_transformers import util
sentences = [
"대한민국의 수도는 서울입니다.",
"미국의 수도는 뉴욕이 아닙니다.",
"대한민국의 수도 요금은 저렴한 편입니다.",
"서울은 대한민국의 수도입니다.",
"오늘 서울은 하루종일 맑음",
]
paraphrase = util.paraphrase_mining(model, sentences)
for score, i, j in paraphrase:
print(f"{sentences[i]}\t\t{sentences[j]}\t\t{score:.4f}")
```
```
대한민국의 수도는 서울입니다. 서울은 대한민국의 수도입니다. 0.7616
대한민국의 수도는 서울입니다. 미국의 수도는 뉴욕이 아닙니다. 0.7031
대한민국의 수도는 서울입니다. 대한민국의 수도 요금은 저렴한 편입니다. 0.6594
미국의 수도는 뉴욕이 아닙니다. 서울은 대한민국의 수도입니다. 0.6445
대한민국의 수도 요금은 저렴한 편입니다. 서울은 대한민국의 수도입니다. 0.4915
미국의 수도는 뉴욕이 아닙니다. 대한민국의 수도 요금은 저렴한 편입니다. 0.4785
서울은 대한민국의 수도입니다. 오늘 서울은 하루종일 맑음 0.4119
대한민국의 수도는 서울입니다. 오늘 서울은 하루종일 맑음 0.3520
미국의 수도는 뉴욕이 아닙니다. 오늘 서울은 하루종일 맑음 0.2550
대한민국의 수도 요금은 저렴한 편입니다. 오늘 서울은 하루종일 맑음 0.1896
```
## Usage (HuggingFace Transformers)
[sentence-transformers](https://www.SBERT.net)를 설치하지 않은 상태로는 다음처럼 사용할 수 있습니다.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('smartmind/roberta-ko-small-tsdae')
model = AutoModel.from_pretrained('smartmind/roberta-ko-small-tsdae')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
[klue](https://huggingface.co/datasets/klue) STS 데이터에 대해 다음 점수를 얻었습니다. 이 데이터에 대해 파인튜닝하지 **않은** 상태로 구한 점수입니다.
|split|cosine_pearson|cosine_spearman|euclidean_pearson|euclidean_spearman|manhattan_pearson|manhattan_spearman|dot_pearson|dot_spearman|
|-----|--------------|---------------|-----------------|------------------|-----------------|------------------|-----------|------------|
|train|0.8735|0.8676|0.8268|0.8357|0.8248|0.8336|0.8449|0.8383|
|validation|0.5409|0.5349|0.4786|0.4657|0.4775|0.4625|0.5284|0.5252|
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 508, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 256, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Contrastive-Tension/BERT-Base-Swe-CT-STSb | [
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 126 | 2022-09-22T05:38:57Z | ```
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('truongpdd/vi-en-roberta-base')
model = AutoModel.from_pretrained('truongpdd/vi-en-roberta-base', from_flax=True)
``` |
Contrastive-Tension/BERT-Distil-NLI-CT | [
"pytorch",
"tf",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 609.50 +/- 193.33
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga CoreyMorris -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga CoreyMorris
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Contrastive-Tension/BERT-Large-CT-STSb | [
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-09-19T03:39:24Z | ---
tags:
- automatic-speech-recognition
- gary109/AI_Light_Dance
- generated_from_trainer
model-index:
- name: ai-light-dance_singing4_ft_wav2vec2-large-xlsr-53-5gram-v4-2-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ai-light-dance_singing4_ft_wav2vec2-large-xlsr-53-5gram-v4-2-1
This model is a fine-tuned version of [gary109/ai-light-dance_singing4_ft_wav2vec2-large-xlsr-53-5gram-v4-2](https://huggingface.co/gary109/ai-light-dance_singing4_ft_wav2vec2-large-xlsr-53-5gram-v4-2) on the GARY109/AI_LIGHT_DANCE - ONSET-SINGING4 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2219
- Wer: 0.0976
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.4531 | 1.0 | 72 | 0.2317 | 0.1021 |
| 0.4479 | 2.0 | 144 | 0.2335 | 0.1014 |
| 0.4475 | 3.0 | 216 | 0.2340 | 0.1000 |
| 0.4432 | 4.0 | 288 | 0.2372 | 0.0993 |
| 0.447 | 5.0 | 360 | 0.2350 | 0.1008 |
| 0.4318 | 6.0 | 432 | 0.2332 | 0.0989 |
| 0.4162 | 7.0 | 504 | 0.2338 | 0.1002 |
| 0.4365 | 8.0 | 576 | 0.2321 | 0.0990 |
| 0.4318 | 9.0 | 648 | 0.2313 | 0.0992 |
| 0.4513 | 10.0 | 720 | 0.2336 | 0.0994 |
| 0.4257 | 11.0 | 792 | 0.2310 | 0.0982 |
| 0.418 | 12.0 | 864 | 0.2316 | 0.0989 |
| 0.4122 | 13.0 | 936 | 0.2341 | 0.0971 |
| 0.4265 | 14.0 | 1008 | 0.2322 | 0.0992 |
| 0.4477 | 15.0 | 1080 | 0.2334 | 0.0987 |
| 0.4023 | 16.0 | 1152 | 0.2351 | 0.0971 |
| 0.4095 | 17.0 | 1224 | 0.2304 | 0.0977 |
| 0.42 | 18.0 | 1296 | 0.2313 | 0.0976 |
| 0.3988 | 19.0 | 1368 | 0.2299 | 0.0984 |
| 0.4078 | 20.0 | 1440 | 0.2310 | 0.0970 |
| 0.4131 | 21.0 | 1512 | 0.2293 | 0.1007 |
| 0.4209 | 22.0 | 1584 | 0.2313 | 0.0998 |
| 0.3931 | 23.0 | 1656 | 0.2351 | 0.1014 |
| 0.406 | 24.0 | 1728 | 0.2336 | 0.0992 |
| 0.3998 | 25.0 | 1800 | 0.2355 | 0.1009 |
| 0.4197 | 26.0 | 1872 | 0.2346 | 0.0996 |
| 0.4289 | 27.0 | 1944 | 0.2283 | 0.1001 |
| 0.4197 | 28.0 | 2016 | 0.2281 | 0.1000 |
| 0.4107 | 29.0 | 2088 | 0.2327 | 0.1007 |
| 0.442 | 30.0 | 2160 | 0.2279 | 0.0985 |
| 0.4315 | 31.0 | 2232 | 0.2284 | 0.0993 |
| 0.4095 | 32.0 | 2304 | 0.2275 | 0.0998 |
| 0.4277 | 33.0 | 2376 | 0.2281 | 0.0996 |
| 0.4114 | 34.0 | 2448 | 0.2267 | 0.1008 |
| 0.4311 | 35.0 | 2520 | 0.2274 | 0.0982 |
| 0.4193 | 36.0 | 2592 | 0.2259 | 0.0987 |
| 0.421 | 37.0 | 2664 | 0.2277 | 0.0989 |
| 0.4084 | 38.0 | 2736 | 0.2268 | 0.0992 |
| 0.4302 | 39.0 | 2808 | 0.2287 | 0.0996 |
| 0.4379 | 40.0 | 2880 | 0.2281 | 0.0984 |
| 0.415 | 41.0 | 2952 | 0.2270 | 0.1006 |
| 0.4035 | 42.0 | 3024 | 0.2299 | 0.0992 |
| 0.4103 | 43.0 | 3096 | 0.2257 | 0.0987 |
| 0.4187 | 44.0 | 3168 | 0.2260 | 0.0975 |
| 0.4254 | 45.0 | 3240 | 0.2273 | 0.0985 |
| 0.415 | 46.0 | 3312 | 0.2312 | 0.1000 |
| 0.4069 | 47.0 | 3384 | 0.2270 | 0.1003 |
| 0.4085 | 48.0 | 3456 | 0.2230 | 0.0978 |
| 0.4287 | 49.0 | 3528 | 0.2241 | 0.0989 |
| 0.4227 | 50.0 | 3600 | 0.2233 | 0.0994 |
| 0.3998 | 51.0 | 3672 | 0.2268 | 0.0991 |
| 0.4139 | 52.0 | 3744 | 0.2224 | 0.0987 |
| 0.409 | 53.0 | 3816 | 0.2256 | 0.1001 |
| 0.4191 | 54.0 | 3888 | 0.2264 | 0.0991 |
| 0.4156 | 55.0 | 3960 | 0.2237 | 0.0993 |
| 0.4252 | 56.0 | 4032 | 0.2250 | 0.0988 |
| 0.4207 | 57.0 | 4104 | 0.2246 | 0.0989 |
| 0.4143 | 58.0 | 4176 | 0.2248 | 0.0981 |
| 0.4261 | 59.0 | 4248 | 0.2237 | 0.0973 |
| 0.4212 | 60.0 | 4320 | 0.2243 | 0.0976 |
| 0.426 | 61.0 | 4392 | 0.2230 | 0.0983 |
| 0.4257 | 62.0 | 4464 | 0.2230 | 0.0977 |
| 0.4102 | 63.0 | 4536 | 0.2219 | 0.0976 |
| 0.4133 | 64.0 | 4608 | 0.2221 | 0.0984 |
| 0.4257 | 65.0 | 4680 | 0.2236 | 0.0982 |
| 0.4006 | 66.0 | 4752 | 0.2231 | 0.0992 |
| 0.404 | 67.0 | 4824 | 0.2227 | 0.0983 |
| 0.409 | 68.0 | 4896 | 0.2235 | 0.0991 |
| 0.4075 | 69.0 | 4968 | 0.2242 | 0.0978 |
| 0.4167 | 70.0 | 5040 | 0.2248 | 0.0989 |
| 0.4026 | 71.0 | 5112 | 0.2242 | 0.0985 |
| 0.404 | 72.0 | 5184 | 0.2236 | 0.0989 |
| 0.4162 | 73.0 | 5256 | 0.2241 | 0.0986 |
| 0.4094 | 74.0 | 5328 | 0.2244 | 0.0991 |
| 0.4147 | 75.0 | 5400 | 0.2247 | 0.0989 |
| 0.4096 | 76.0 | 5472 | 0.2244 | 0.0983 |
| 0.4112 | 77.0 | 5544 | 0.2236 | 0.0981 |
| 0.3987 | 78.0 | 5616 | 0.2242 | 0.0982 |
| 0.3953 | 79.0 | 5688 | 0.2259 | 0.0983 |
| 0.4093 | 80.0 | 5760 | 0.2239 | 0.0991 |
| 0.406 | 81.0 | 5832 | 0.2238 | 0.0980 |
| 0.4149 | 82.0 | 5904 | 0.2240 | 0.0995 |
| 0.4017 | 83.0 | 5976 | 0.2240 | 0.0987 |
| 0.4065 | 84.0 | 6048 | 0.2245 | 0.0979 |
| 0.4315 | 85.0 | 6120 | 0.2249 | 0.0978 |
| 0.421 | 86.0 | 6192 | 0.2239 | 0.0977 |
| 0.4061 | 87.0 | 6264 | 0.2243 | 0.0974 |
| 0.4096 | 88.0 | 6336 | 0.2244 | 0.0982 |
| 0.4171 | 89.0 | 6408 | 0.2246 | 0.0974 |
| 0.4189 | 90.0 | 6480 | 0.2240 | 0.0980 |
| 0.4106 | 91.0 | 6552 | 0.2236 | 0.0978 |
| 0.408 | 92.0 | 6624 | 0.2234 | 0.0983 |
| 0.4218 | 93.0 | 6696 | 0.2239 | 0.0985 |
| 0.3997 | 94.0 | 6768 | 0.2237 | 0.0983 |
| 0.4173 | 95.0 | 6840 | 0.2238 | 0.0980 |
| 0.4134 | 96.0 | 6912 | 0.2235 | 0.0982 |
| 0.3959 | 97.0 | 6984 | 0.2237 | 0.0979 |
| 0.4149 | 98.0 | 7056 | 0.2238 | 0.0982 |
| 0.4125 | 99.0 | 7128 | 0.2238 | 0.0983 |
| 0.4111 | 100.0 | 7200 | 0.2235 | 0.0982 |
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.9.1+cu102
- Datasets 2.3.3.dev0
- Tokenizers 0.12.1
|
Cooker/cicero-similis | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- ko
- en
widget:
source_sentence: "대한민국의 수도는?"
sentences:
- "서울특별시는 한국이 정치,경제,문화 중심 도시이다."
- "부산은 대한민국의 제2의 도시이자 최대의 해양 물류 도시이다."
- "제주도는 대한민국에서 유명한 관광지이다"
- "Seoul is the capital of Korea"
- "울산광역시는 대한민국 남동부 해안에 있는 광역시이다"
---
# moco-sentencebertV2.0
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
- 이 모델은 [bongsoo/mbertV2.0](https://huggingface.co/bongsoo/mbertV2.0) MLM 모델을
<br>sentencebert로 만든 후,추가적으로 STS Tearch-student 증류 학습 시켜 만든 모델 입니다.
- **vocab: 152,537 개**(기존 119,548 vocab 에 32,989 신규 vocab 추가)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence_transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('bongsoo/moco-sentencebertV2.0')
embeddings = model.encode(sentences)
print(embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(embeddings[0].reshape(1,-1), embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
[[ 0.16649279 -0.2933038 -0.00391259 ... 0.00720964 0.18175027 -0.21052675]
[ 0.10106096 -0.11454111 -0.00378215 ... -0.009032 -0.2111504 -0.15030429]]
*cosine_score:0.3352515697479248
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
- 평균 폴링(mean_pooling) 방식 사용. ([cls 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-cls-token), [max 폴링](https://huggingface.co/sentence-transformers/bert-base-nli-max-tokens))
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('bongsoo/moco-sentencebertV2.0')
model = AutoModel.from_pretrained('bongsoo/moco-sentencebertV2.0')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
# sklearn 을 이용하여 cosine_scores를 구함
# => 입력값 embeddings 은 (1,768) 처럼 2D 여야 함.
from sklearn.metrics.pairwise import paired_cosine_distances, paired_euclidean_distances, paired_manhattan_distances
cosine_scores = 1 - (paired_cosine_distances(sentence_embeddings[0].reshape(1,-1), sentence_embeddings[1].reshape(1,-1)))
print(f'*cosine_score:{cosine_scores[0]}')
```
#### 출력(Outputs)
```
Sentence embeddings:
tensor([[ 0.1665, -0.2933, -0.0039, ..., 0.0072, 0.1818, -0.2105],
[ 0.1011, -0.1145, -0.0038, ..., -0.0090, -0.2112, -0.1503]])
*cosine_score:0.3352515697479248
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
- 성능 측정을 위한 말뭉치는, 아래 한국어 (kor), 영어(en) 평가 말뭉치를 이용함
<br> 한국어 : **korsts(1,379쌍문장)** 와 **klue-sts(519쌍문장)**
<br> 영어 : [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt)(1,376쌍문장) 와 [glue:stsb](https://huggingface.co/datasets/glue/viewer/stsb/validation) (1,500쌍문장)
- 성능 지표는 **cosin.spearman** 측정하여 비교함.
- 평가 측정 코드는 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-test.ipynb) 참조
|모델 |korsts|klue-sts|korsts+klue-sts|stsb_multi_mt|glue(stsb)
|:--------|------:|--------:|--------------:|------------:|-----------:|
|distiluse-base-multilingual-cased-v2|0.747|0.785|0.577|0.807|0.819|
|paraphrase-multilingual-mpnet-base-v2|0.820|0.799|0.711|0.868|0.890|
|bongsoo/sentencedistilbertV1.2|0.819|0.858|0.630|0.837|0.873|
|bongsoo/moco-sentencedistilbertV2.0|0.812|0.847|0.627|0.837|0.877|
|bongsoo/moco-sentencebertV2.0|0.824|0.841|0.635|0.843|0.879|
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training(훈련 과정)
The model was trained with the parameters:
**1. MLM 훈련**
- 입력 모델 : bert-base-multilingual-cased
- 말뭉치 : 훈련 : bongsoo/moco-corpus-kowiki2022(7.6M) , 평가: bongsoo/bongevalsmall
- HyperParameter : LearningRate : 5e-5, epochs: 8, batchsize: 32, max_token_len : 128
- vocab : 152,537개 (기존 119,548 에 32,989 신규 vocab 추가)
- 출력 모델 : mbertV2.0 (size: 813MB)
- 훈련시간 : 90h/1GPU (24GB/19.6GB use)
- loss : 훈련loss: 2.258400, 평가loss: 3.102096, perplexity: 19.78158(bong_eval:1,500)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/bert/bert-MLM-Trainer-V1.2.ipynb) 참조
**2. STS 훈련**
=>bert를 sentencebert로 만듬.
- 입력 모델 : mbertV2.0
- 말뭉치 : korsts + kluestsV1.1 + stsb_multi_mt + mteb/sickr-sts (총:33,093)
- HyperParameter : LearningRate : 3e-5, epochs: 200, batchsize: 32, max_token_len : 128
- 출력 모델 : sbert-mbertV2.0 (size: 813MB)
- 훈련시간 : 9h20m/1GPU (24GB/9.0GB use)
- loss(cosin_spearman) : 0.799(말뭉치:korsts(tune_test.tsv))
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
**3.증류(distilation) 훈련**
- 학생 모델 : sbert-mbertV2.0
- 교사 모델 : paraphrase-multilingual-mpnet-base-v2
- 말뭉치 : en_ko_train.tsv(한국어-영어 사회과학분야 병렬 말뭉치 : 1.1M)
- HyperParameter : LearningRate : 5e-5, epochs: 40, batchsize: 128, max_token_len : 128
- 출력 모델 : sbert-mlbertV2.0-distil
- 훈련시간 : 17h/1GPU (24GB/18.6GB use)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sbert-distillaton.ipynb) 참조
**4.STS 훈련**
=> sentencebert 모델을 sts 훈련시킴
- 입력 모델 : sbert-mlbertV2.0-distil
- 말뭉치 : korsts(5,749) + kluestsV1.1(11,668) + stsb_multi_mt(5,749) + mteb/sickr-sts(9,927) + glue stsb(5,749) (총:38,842)
- HyperParameter : LearningRate : 3e-5, epochs: 800, batchsize: 64, max_token_len : 128
- 출력 모델 : moco-sentencebertV2.0
- 훈련시간 : 25h/1GPU (24GB/13GB use)
- 훈련코드 [여기](https://github.com/kobongsoo/BERT/blob/master/sbert/sentece-bert-sts.ipynb) 참조
<br>모델 제작 과정에 대한 자세한 내용은 [여기](https://github.com/kobongsoo/BERT/tree/master)를 참조 하세요.
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1035 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Config**:
```
{
"_name_or_path": "../../data11/model/sbert/sbert-mbertV2.0-distil",
"architectures": [
"BertModel"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"torch_dtype": "float32",
"transformers_version": "4.21.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 152537
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
bongsoo |
Cool/Demo | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-19T04:43:03Z | ---
license: mit
---
### mu-sadr on Stable Diffusion
This is the `<783463b>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:









|
CopymySkill/DialoGPT-medium-atakan | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language:
- zh
license: apache-2.0
tags:
- chinese poem
- 中文
- 写诗
- 唐诗
- 宋词
widget:
- text: "作诗:百花 模仿:李清照"
---
# 2023 update: Check new version at https://huggingface.co/hululuzhu/chinese-poem-t5-v2
# 一个好玩的中文AI写诗模型
- 两种模式仿写唐宋古诗
- 无特定风格输入格式 `作诗:您的标题`,比如 `作诗:秋思`
- 无特定风格输入格式 `作诗:您的标题 模仿:唐宋诗人名字`,比如 `作诗:秋思 模仿:李清照`
- 如果你想尝试
- 如果自己有GPU环境,可以参考我放在huggingface的[示例代码](https://huggingface.co/hululuzhu/chinese-poem-t5-mengzi-finetune#%E8%BF%90%E8%A1%8C%E4%BB%A3%E7%A0%81%E7%A4%BA%E4%BE%8B)
- 或者使用Google Colab,用这个[简化版colab](https://colab.research.google.com/github/hululuzhu/chinese-ai-writing-share/blob/main/inference/2022_simple_poem_inference_huggingface.ipynb)来玩我的T5写诗模型
- 训练代码请参考[我的github链接](https://github.com/hululuzhu/chinese-ai-writing-share)
- 如果想了解一些背景和讨论,可以看我的[slides](https://github.com/hululuzhu/chinese-ai-writing-share/tree/main/slides)
## 架构
- 预训练使用 [澜舟科技的孟子 T5](https://huggingface.co/Langboat/mengzi-t5-base)
- 我只训练了3-4个epoch,看loss的下降速度应该还有提升空间
## 数据来源
- 唐诗宋词 https://github.com/chinese-poetry/chinese-poetry
- 2022 T5 方案考虑了 `标题 -> 诗歌`,或者 `标题+诗人 -> 诗歌`
- 标题长度限制12token,诗人4token,诗歌64token,结尾用句号,具体参考training下面的notebook
## 语言支持
- 默认简体中文
- 2022 T5 inference 支持繁体中文,需要标记 `is_input_traditional_chinese=True`
- 如需要训练繁体中文模型,查找`chinese_converter.to_simplified`改为`chinese_converter.to_traditional`
## 训练
- 我是用 Google Colab Pro(推荐,16G的GPU一个月随便用才9.99!)
- transformer方案使用TF2 keras,用TPU训练,模型训练时间~10小时
- T5因为使用simplet5 (pytorch + huggingface 的一个封装),所以使用GPU训练,模型训练时间~6-8小时
## 运行代码示例
```python
# 安装以下2个包方便文字处理和模型生成
# !pip install -q simplet5
# !pip install -q chinese-converter
# 具体代码
import torch
from simplet5 import SimpleT5
from transformers import T5Tokenizer, T5ForConditionalGeneration
import chinese_converter
MODEL_PATH = "hululuzhu/chinese-poem-t5-mengzi-finetune"
class PoemModel(SimpleT5):
def __init__(self) -> None:
super().__init__()
self.device = torch.device("cuda")
def load_my_model(self):
self.tokenizer = T5Tokenizer.from_pretrained(MODEL_PATH)
self.model = T5ForConditionalGeneration.from_pretrained(MODEL_PATH)
# 有一些预先设定参数
AUTHOR_PROMPT = "模仿:"
TITLE_PROMPT = "作诗:"
EOS_TOKEN = '</s>'
poem_model = PoemModel()
poem_model.load_my_model()
poem_model.model = poem_model.model.to('cuda')
MAX_AUTHOR_CHAR = 4
MAX_TITLE_CHAR = 12
MIN_CONTENT_CHAR = 10
MAX_CONTENT_CHAR = 64
def poem(title_str, opt_author=None, model=poem_model,
is_input_traditional_chinese=False):
model.model = model.model.to('cuda')
if opt_author:
in_request = TITLE_PROMPT + title_str[:MAX_TITLE_CHAR] + EOS_TOKEN + AUTHOR_PROMPT + opt_author[:MAX_AUTHOR_CHAR]
else:
in_request = TITLE_PROMPT + title_str[:MAX_TITLE_CHAR]
if is_input_traditional_chinese:
in_request = chinese_converter.to_simplified(in_request)
out = model.predict(in_request,
max_length=MAX_CONTENT_CHAR)[0].replace(",", ",")
if is_input_traditional_chinese:
out = chinese_converter.to_traditional(out)
print(f"標題: {in_request.replace('</s>', ' ')}\n詩歌: {out}")
else:
print(f"标题: {in_request.replace('</s>', ' ')}\n诗歌: {out}")
```
## 简体中文示例
```
for title in ['秋思', "百花", '佳人有约']:
# Empty author means general style
for author in ['', "杜甫", "李白", "李清照", "苏轼"]:
poem(title, author)
print()
标题: 作诗:秋思
诗歌: 秋思不可奈,况复值新晴。露叶红犹湿,风枝翠欲倾。客愁随日薄,归夢逐云轻。独倚阑干久,西风吹雁声。
标题: 作诗:秋思 模仿:杜甫
诗歌: 西风动高树,落叶满空庭。白露侵肌冷,青灯照眼青。客愁随暮角,归夢逐残星。独坐还成感,秋声不可听。
标题: 作诗:秋思 模仿:李白
诗歌: 秋色满空山,秋风动客衣。浮云不到处,明月自来归。
标题: 作诗:秋思 模仿:李清照
诗歌: 秋思不可奈,况复在天涯。客路逢寒食,家书报早炊。风霜侵鬓发,天地入诗脾。欲寄南飞雁,归期未有期。
标题: 作诗:秋思 模仿:苏轼
诗歌: 西风吹雨过江城,独倚阑干思不胜。黄叶满庭秋意动,碧梧当户夜寒生。故园夢断人千里,新雁书来雁一行。莫怪衰翁无业,一樽聊复慰平生。
标题: 作诗:百花
诗歌: 百花开尽绿阴成,红紫妖红照眼明。谁道东风无意思,一枝春色爲谁荣。
标题: 作诗:百花 模仿:杜甫
诗歌: 百花开尽绿阴成,独有江梅照眼明。莫道春光无别意,只应留得一枝横。
标题: 作诗:百花 模仿:李白
诗歌: 百花如锦树,春色满芳洲。日暖花争发,风轻絮乱流。香飘金谷露,艳拂玉山楼。谁道无情物,年年爲客愁。
标题: 作诗:百花 模仿:李清照
诗歌: 百花如锦水如蓝,春到园林处处堪。谁道东风不相识,一枝开尽绿阴南。
标题: 作诗:百花 模仿:苏轼
诗歌: 百花开尽绿阴成,谁道春风不世情。若使此花无俗韵,世间那得有芳名。
标题: 作诗:佳人有约
诗歌: 佳人约我共登台,笑指花前酒半杯。莫道春光无分到,且看红日上楼来。
标题: 作诗:佳人有约 模仿:杜甫
诗歌: 佳人有约到江干,共约寻春入肺肝。红杏绿桃相映发,白苹红蓼不胜寒。花前醉舞春风裏,月下狂歌夜漏残。莫怪相逢不相识,只应清夢在长安。
标题: 作诗:佳人有约 模仿:李白
诗歌: 佳人有约在瑶台,花落花开不待开。莫道春风无分到,且看明月照楼台。
标题: 作诗:佳人有约 模仿:李清照
诗歌: 佳人约我共登台,花下相携醉不回。莫道春归无觅处,桃花依旧笑人来。
标题: 作诗:佳人有约 模仿:苏轼
诗歌: 佳人约我共清欢,笑指花前醉玉盘。莫道春归无觅处,且看红日上栏干。
```
# 繁体中文
```
for title in ['春節', "中秋", "春秋战国"]:
# Empty author means general style
for author in ['', "杜甫", "李白", "李清照", "蘇軾"]:
poem(title, author, is_input_traditional_chinese=True)
print()
標題: 作诗:春节
詩歌: 去年今日到江干,家在青山綠水間。老去心情渾似舊,春來情緒只如閒。
標題: 作诗:春节 模仿:杜甫
詩歌: 江上春歸早,山中客到稀。亂花隨處發,細草向人飛。節物催年老,生涯逐日非。故園桃李樹,猶得及芳菲。
標題: 作诗:春节 模仿:李白
詩歌: 去年今日來,花發滿城開。今歲明朝去,明年依舊來。
標題: 作诗:春节 模仿:李清照
詩歌: 去年今日是今朝,不覺今年又一宵。但有梅花堪共醉,何須柳絮更相撩。
標題: 作诗:春节 模仿:苏轼
詩歌: 今年春色到江干,柳眼桃腮次第看。但得此身長健在,不須回首歎凋殘。
標題: 作诗:中秋
詩歌: 秋氣侵肌骨,寒光入鬢毛。雲收千里月,風送一帆高。
標題: 作诗:中秋 模仿:杜甫
詩歌: 秋色滿江天,清光萬里懸。雲開見海月,水落見沙田。白露侵肌冷,青苔滿鬢鮮。何當一樽酒,共醉玉壺前。
標題: 作诗:中秋 模仿:李白
詩歌: 中秋月色好,況復是中秋。玉兔擣藥杵,金烏搗藥。雲開天似水,風起海如漚。此夜何人見,長歌淚不流。
標題: 作诗:中秋 模仿:李清照
詩歌: 秋氣侵肌骨,寒光入鬢毛。客愁隨日減,詩思逐風高。露重衣襟溼,天高雁影豪。何當一樽酒,來此醉陶陶。
標題: 作诗:中秋 模仿:苏轼
詩歌: 月從海上生,照我庭下影。不知此何夕,但見天宇靜。
標題: 作诗:春秋战国
詩歌: 秦皇不識趙高祖,魯國何嘗有霸臣。若使當時無孔子,豈知今日是前身。
標題: 作诗:春秋战国 模仿:杜甫
詩歌: 秦王不戰楚人驕,魯國亡秦勢亦銷。若使當時無霸業,豈能終始是英豪。
標題: 作诗:春秋战国 模仿:李白
詩歌: 魯國亡家事可哀,秦王不戰亦須哀。當時若使齊公子,何用區區爲禍胎。
標題: 作诗:春秋战国 模仿:李清照
詩歌: 秦皇不識趙高祖,魯國何須問大鈞。若使當時無孔子,豈知今日有秦人。
標題: 作诗:春秋战国 模仿:苏轼
詩歌: 秦皇不識趙高祖,魯國何如鄭子真。若使當時無孔子,豈知今日有張巡。
``` |
Corvus/DialoGPT-medium-CaptainPrice | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
---
### bozo 22 on Stable Diffusion
This is the `<bozo-22>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:











|
CouchCat/ma_mlc_v7_distil | [
"pytorch",
"distilbert",
"text-classification",
"en",
"transformers",
"multi-label",
"license:mit"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 29 | null | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
model-index:
- name: prot_bert_bfd-disoanno
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prot_bert_bfd-disoanno
This model is a fine-tuned version of [Rostlab/prot_bert_bfd](https://huggingface.co/Rostlab/prot_bert_bfd) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4253
- Precision: 0.8161
- Recall: 0.8234
- F1: 0.8146
## Model description
This is a token classification model designed to predict the intrinsically disordered regions of amino acid sequences.
## Intended uses & limitations
This model works on amino acid sequences that are spaced between characters.
'0': No disorder
'1': Disordered
Example Inputs :
M S A I Q N L H S F D P F A D A S K G D D L L P A G T E D Y I H I R I Q Q R N G R K T L T T V Q G I A D D Y D K K K L V K A F K K K F A C N G T V I E H P E Y G E V I Q L Q G D Q R K N I C Q F L V E I G L A K D D Q L K V H G F
M A S R Q N N K Q E L D E R A R Q G E T V V P G G T G G K S L E A Q Q H L A E G R S K G G Q T R K E Q L G T E G Y Q E M G R K G G L S T V E K S G E E R A Q E E G I G I D E S K F R T G N N K N Q N Q N E D Q D K
M P P I A T R R G Q Y E P K V Q Q A K L S P D T I P L N P A D K T K D P L A R A D S L H H H V E S D S Q E D D K A A E E P P L S R K R W Q N R T F R R K G R R Q A P Y K H K
S G S D G G V C P K I L K K C R R D S D C P G A C I C R G N G Y C G
M G G K W S K S S V V G W P T V R E R M R R A E P A A D G V G A A S R D L E K H G A I T S S N T A A T N A A C A W L E A Q E E E E V G F P V T P Q V P L R P M T Y K A A V D L S H F L K E K G G L E G L I H S Q R R Q D I L D L W I Y H T Q G Y F P D W Q N Y T P G P G V R Y P L T F G W C Y K L V P V E P D K V E E A N K G E N T S L L H P V S L H G M D D P E R E V L E W R F D S R L A F H H V A R E L H P E Y F K N C
M R Y T D S R K L T P E T D A N H K T A S P Q P I R R I S S Q T L L G P D G K L I I D H D G Q E Y L L R K T Q A G K L L L T K
## Training and evaluation data
Training and evaluation data were retrieved from https://www.csuligroup.com/DeepDISOBind/#Materials (Accessed March 2022).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.4895 | 1.0 | 61 | 0.4415 | 0.8257 | 0.8317 | 0.8262 |
| 0.5881 | 2.0 | 122 | 0.4242 | 0.8124 | 0.8201 | 0.8119 |
| 0.562 | 3.0 | 183 | 0.4253 | 0.8161 | 0.8234 | 0.8146 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
CouchCat/ma_ner_v6_distil | [
"pytorch",
"distilbert",
"token-classification",
"en",
"transformers",
"ner",
"license:mit",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags:
- roberta
- adapter-transformers
datasets:
- glue
language:
- en
---
# Adapter `WillHeld/pfadapter-roberta-base-mnli` for roberta-base
An [adapter](https://adapterhub.ml) for the `roberta-base` model that was trained on the [glue](https://huggingface.co/datasets/glue/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("roberta-base")
adapter_name = model.load_adapter("WillHeld/pfadapter-roberta-base-mnli", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here --> |
CouchCat/ma_ner_v7_distil | [
"pytorch",
"distilbert",
"token-classification",
"en",
"transformers",
"ner",
"license:mit",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
license: mit
---
### SkyFalls on Stable Diffusion
This is the `<SkyFalls>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
CouchCat/ma_sa_v7_distil | [
"pytorch",
"distilbert",
"text-classification",
"en",
"transformers",
"sentiment-analysis",
"license:mit"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 38 | null | ---
language:
- multilingual
license: apache-2.0
inference: false
tags:
- youtube
- video
- pytorch
---
# YouTube video semantic similarity model (WT = with transcripts)
This YouTube video semantic similarity model was developed as part of the RegretsReporter research project at Mozilla Foundation. You can read more about the project [here](https://foundation.mozilla.org/en/youtube/user-controls/) and about the semantic similarity model [here](https://foundation.mozilla.org/en/blog/the-regretsreporter-user-controls-study-machine-learning-to-measure-semantic-similarity-of-youtube-videos/).
You can also easily try this model with this [Spaces demo app](https://huggingface.co/spaces/mozilla-foundation/youtube_video_similarity). Just provide two YouTube video links and you can see how similar those two videos are according to the model. For your convenience, the demo also includes a few predefined video pair examples.
## Model description
This model is custom PyTorch model for predicting whether a pair of YouTube videos are similar or not. The model does not take video data itself as an input but instead it relies on video metadata to save computing resources. The input for the model consists of video titles, descriptions, transcripts and YouTube channel-equality signal of video pairs. As illustrated below, the model includes three [cross-encoders](https://www.sbert.net/examples/applications/cross-encoder/README.html) for determining the similarity of each of the text components of the videos, which are then connected directly, along with a channel-equality signal into a single linear layer with a sigmoid output. The output is a similarity probability as follows:
- If the output is close to 1, the model is very confident that the videos are similar
- If the output is close to 0, the model is very confident that the videos are not similar
- If the output is close to 0.5, the model is uncertain

For pretrained cross-encoders, [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) was used to be further trained as part of this model.
**Note**: sometimes YouTube videos lack transcripts so actually there are two different versions of this model trained: a model with trascripts (WT = with transcripts) and a model without transcripts (NT = no transcripts). This model is with transcripts and the model without transcripts is available [here](https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_nt).
**Note**: Possible model architecture enhancements are discussed a bit on [this blog post](https://foundation.mozilla.org/en/blog/the-regretsreporter-user-controls-study-machine-learning-to-measure-semantic-similarity-of-youtube-videos/) and some of the ideas were implemented and tried on experimental v2 version of the model which code is available on the RegretsReporter [GitHub repository](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/semsim). Based on the test set evaluation, the experimental v2 model didn't significantly improve the results. Thus, it was decided that more complex v2 model weights are not released at this time.
## Intended uses & limitations
This model is intended to be used for analyzing whether a pair of YouTube videos are similar or not. We hope that this model will prove valuable to other researchers investigating YouTube.
### How to use
As this model is a custom PyTorch model, not normal transformers model, you need to clone this model repository first. The repository contains model code in `RRUM` class (RRUM stands for RegretsReporter Unified Model) in `unifiedmodel.py` file. For loading the model from Hugging Face model hub, there also is a Hugging Face model wrapper named `YoutubeVideoSimilarityModel` in `huggingface_model_wrapper.py` file. Needed Python requirements are specified in `requirements.txt` file. To load the model, follow these steps:
1. `git clone https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_wt`
2. `pip install -r requirements.txt`
And finally load the model with the following example code:
```python
from huggingface_model_wrapper import YoutubeVideoSimilarityModel
model = YoutubeVideoSimilarityModel.from_pretrained('mozilla-foundation/youtube_video_similarity_model_wt')
```
For loading and preprocessing input data into correct format, the `unifiedmodel.py` file also contains a `RRUMDataset` class. To use the loaded model for predicting video pair similarity, you can use the following example code:
```python
import torch
import pandas as pd
from torch.utils.data import DataLoader
from unifiedmodel import RRUMDataset
video1_channel = "Mozilla"
video1_title = "YouTube Regrets"
video1_description = "Are your YouTube recommendations sometimes lies? Conspiracy theories? Or just weird as hell?\n\n\nYou’re not alone. That’s why Mozilla and 37,380 YouTube users conducted a study to better understand harmful YouTube recommendations. This is what we learned about YouTube regrets: https://foundation.mozilla.org/regrets/"
video1_transcript = "Everyone loves YouTube.\nAn endless library of great videos you can\nwatch for free.\nBut we don’t all love YouTube’s recommendations,\nand 70% of viewing time on the platform is\ndriven by videos they suggest.\nSometimes the videos YouTube recommends are\nweird or off-topic.\nBut sometimes they are downright harmful.\nMozilla has heard from people who were recommended\nanti-LGBT content.\nVideos that encourage eating disorders, claims\nabout fraudulent elections, and much more.\nYouTube says it’s improved its algorithm,\nbut Mozilla’s latest research finds it still\nsuggests videos that are racist, misogynistic,\nconspiratorial or misinformation.\nSometimes it even suggests videos that breach\nYouTube’s very own content guidelines.\nVideos that YouTube later removed for being\nharmful, dangerous or deceptive.\nIt’s got to stop.\nFind out more and learn how you can take action\nat foundation.mozilla.org/regrets"
video2_channel = "Mozilla"
video2_title = "YouTube Regrets Reporter"
video2_description = "Are you choosing what to watch, or is YouTube choosing for you?\n\nTheir algorithm is responsible for over 70% of viewing time, which can include recommending harmful videos.\n\nHelp us hold them responsible. Install RegretsReporter: https://mzl.la/37BT2vA"
video2_transcript = "are your youtube recommendations\nsometimes conspiracy theories low-key\nhateful or just weird as hell\nwe're investigating youtube's\nrecommendation engine\nand we need your help join our\ncrowdsourced campaign by installing\nregrets reporter today"
df = pd.DataFrame([[video1_title, video1_description, video1_transcript] + [video2_title, video2_description, video2_transcript] + [int(video1_channel == video2_channel)]], columns=['regret_title', 'regret_description', 'regret_transcript', 'recommendation_title', 'recommendation_description', 'recommendation_transcript', 'channel_sim'])
dataset = RRUMDataset(df, with_transcript=True, label_col=None, cross_encoder_model_name_or_path=model.cross_encoder_model_name_or_path)
data_loader = DataLoader(dataset.test_dataset)
with torch.inference_mode():
prediction = model(next(iter(data_loader)))
prediction = torch.special.expit(prediction).squeeze().tolist()
```
Some more code and examples are also available at RegretsReporter [GitHub repository](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/semsim).
### Limitations and bias
The cross-encoders that we use to determine similarity of texts are also trained on texts that inevitably reflect social bias. To understand the implications of this, we need to consider the application of the model: to determine if videos are semantically similar or not. So the concern is that our model may, in some systematic way, think certain kinds of videos are more or less similar to each other.
For example, it's possible that the models have encoded a social bias that certain ethnicities are more often involved in violent situations. If this were the case, it is possible that videos about people of one ethnicity may be more likely to be rated similar to videos about violent situations. This could be evaluated by applying the model to synthetic video pairs crafted to test these situations. There is also [active research](https://www.aaai.org/AAAI22Papers/AISI-7742.KanekoM.pdf) in measuring bias in language models, as part of the broader field of [AI fairness](https://facctconference.org/2022/index.html).
We have not analyzed the biases in our model as, for our original application, potential for harm was extremely low. Care should be taken in future applications.
A more difficult issue is the multilingual nature of our data. For the pretrained cross-encoders in our model, we used the [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) model which supports a set of 100 languages (the original mMiniLMv2 base model) including English, German, Spanish and Chinese. However, it is reasonable to expect that the model's performance varies among the languages that it supports. The impact can vary — the model may fail either with false positives, in which it thinks a dissimilar pair is similar, or false negatives, in which it thinks a similar pair is dissimilar. We performed a basic analysis to evaluate the performance of our model in different languages and it suggested that our model performs well across languages, but the potential differences in the quality of our labels between languages reduced our confidence.
## Training data
Since the RegretsReporter project operates without YouTube's support, we were limited to the publicly available data we could fetch from YouTube. The RegretsReporter project developed a browser extension that our volunteer project participants used to send us data about their YouTube usage and what videos YouTube recommended for them. We also used automated methods to acquire additional needed model training data (title, channel, description, transcript) for videos from the YouTube site directly.
To get labeled training data, we contracted 24 research assistants, all graduate students at Exeter University, to perform 20 hours each, classifying gathered video pairs using a [classification tool](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/classification) that we developed. There are many subtleties in defining similarity of two videos, so we are not able to precisely describe what we mean by "similar", but we developed a [policy](https://docs.google.com/document/d/1VB7YAENmuMDMW_kPPUbuDPbHfQBDhF5ylzHA3cAZywg/) to guide our research assistants in classifying video pairs. Research assistants all read the classification policy and worked with Dr. Chico Camargo, who ensured they had all the support they needed to contribute to this work. These research assistants were partners in our research and are named for their contributions in our [final report](https://foundation.mozilla.org/en/research/library/user-controls/report/).
Thanks to our research assistants, we had 44,434 labeled video pairs to train our model (although about 3% of these were labeled "unsure" and so unused). For each of these pairs, the research assistant determined whether the videos are similar or not, and our model is able to learn from these examples.
## Training procedure
### Preprocessing
Our training data of YouTube video titles, descriptions and transcripts tend to include a lot of noisy text having, for example, URLs, emojis and other potential noise. Thus, we used text cleaning functions to clean some of the noise. Text cleaning seemed to improve the model accuracy on test set but the text cleaning was disabled in the end because it added extra latency to the data preprocessing which would have made the project's model prediction run slower when predictions were ran for hundreds of millions of video pairs. The data loading and preprocessing class `RRUMDataset` in `unifiedmodel.py` file still includes text cleaning option by setting the parameter `clean_text=True` on the class initialization.
The text data was tokenized with [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) cross-encoder's SentencePiece tokenizer having a vocabulary size of 250,002. Tokenization was done with maximum length of 128 tokens.
### Training
The model was trained using [PyTorch Lightning](https://pytorch-lightning.readthedocs.io/en/stable/) on NVIDIA A100 GPU. The model can also be trained on lower resources, for example with the free T4 GPU on Google Colab. The optimizer used was a Adam with learning rate 5e-3, learning rate warmup for 5% steps of total training steps and linear decay of the learning rate after. The model was trained with batch size of 128 for 15 epochs. Based on per epoch evaluation, the final model uses the checkpoint from epoch 10.
## Evaluation results
With the final test set, our models were achieving following scores presented on the table below:
| Metric | Model with transcripts | Model without transcripts |
|--------------------------------|------------------------|---------------------------|
| Accuracy | 0.93 | 0.92 |
| Precision | 0.81 | 0.81 |
| Recall | 0.91 | 0.87 |
| AUROC | 0.97 | 0.96 |
## Acknowledgements
We're grateful to Chico Camargo and Ranadheer Malla from the University of Exeter for leading the analysis of RegretsReporter data. Thank you to the research assistants at the University of Exeter for analyzing the video data: Josh Adebayo, Sharon Choi, Henry Cook, Alex Craig, Bee Dally, Seb Dixon, Aditi Dutta, Ana Lucia Estrada Jaramillo, Jamie Falla, Alice Gallagher Boyden, Adriano Giunta, Lisa Greghi, Keanu Hambali, Clare Keeton Graddol, Kien Khuong, Mitran Malarvannan, Zachary Marre, Inês Mendes de Sousa, Dario Notarangelo, Izzy Sebire, Tawhid Shahrior, Shambhavi Shivam, Marti Toneva, Anthime Valin, and Ned Westwood.
Finally, we're so grateful for the 22,722 RegretsReporter participants who contributed their data.
## Contact
If these models are useful to you, we'd love to hear from you. Please write to [email protected]
|
CoveJH/ConBot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- multilingual
license: apache-2.0
inference: false
tags:
- youtube
- video
- pytorch
---
# YouTube video semantic similarity model (NT = no transcripts)
This YouTube video semantic similarity model was developed as part of the RegretsReporter research project at Mozilla Foundation. You can read more about the project [here](https://foundation.mozilla.org/en/youtube/user-controls/) and about the semantic similarity model [here](https://foundation.mozilla.org/en/blog/the-regretsreporter-user-controls-study-machine-learning-to-measure-semantic-similarity-of-youtube-videos/).
You can also easily try this model with this [Spaces demo app](https://huggingface.co/spaces/mozilla-foundation/youtube_video_similarity). Just provide two YouTube video links and you can see how similar those two videos are according to the model. For your convenience, the demo also includes a few predefined video pair examples.
## Model description
This model is custom PyTorch model for predicting whether a pair of YouTube videos are similar or not. The model does not take video data itself as an input but instead it relies on video metadata to save computing resources. The input for the model consists of video titles, descriptions, transcripts and YouTube channel-equality signal of video pairs. As illustrated below, the model includes three [cross-encoders](https://www.sbert.net/examples/applications/cross-encoder/README.html) for determining the similarity of each of the text components of the videos, which are then connected directly, along with a channel-equality signal into a single linear layer with a sigmoid output. The output is a similarity probability as follows:
- If the output is close to 1, the model is very confident that the videos are similar
- If the output is close to 0, the model is very confident that the videos are not similar
- If the output is close to 0.5, the model is uncertain

For pretrained cross-encoders, [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) was used to be further trained as part of this model.
**Note**: sometimes YouTube videos lack transcripts so actually there are two different versions of this model trained: a model with trascripts (WT = with transcripts) and a model without transcripts (NT = no transcripts). This model is without transcripts and the model with transcripts is available [here](https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_wt).
**Note**: Possible model architecture enhancements are discussed a bit on [this blog post](https://foundation.mozilla.org/en/blog/the-regretsreporter-user-controls-study-machine-learning-to-measure-semantic-similarity-of-youtube-videos/) and some of the ideas were implemented and tried on experimental v2 version of the model which code is available on the RegretsReporter [GitHub repository](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/semsim). Based on the test set evaluation, the experimental v2 model didn't significantly improve the results. Thus, it was decided that more complex v2 model weights are not released at this time.
## Intended uses & limitations
This model is intended to be used for analyzing whether a pair of YouTube videos are similar or not. We hope that this model will prove valuable to other researchers investigating YouTube.
### How to use
As this model is a custom PyTorch model, not normal transformers model, you need to clone this model repository first. The repository contains model code in `RRUM` class (RRUM stands for RegretsReporter Unified Model) in `unifiedmodel.py` file. For loading the model from Hugging Face model hub, there also is a Hugging Face model wrapper named `YoutubeVideoSimilarityModel` in `huggingface_model_wrapper.py` file. Needed Python requirements are specified in `requirements.txt` file. To load the model, follow these steps:
1. `git clone https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_nt`
2. `pip install -r requirements.txt`
And finally load the model with the following example code:
```python
from huggingface_model_wrapper import YoutubeVideoSimilarityModel
model = YoutubeVideoSimilarityModel.from_pretrained('mozilla-foundation/youtube_video_similarity_model_nt')
```
For loading and preprocessing input data into correct format, the `unifiedmodel.py` file also contains a `RRUMDataset` class. To use the loaded model for predicting video pair similarity, you can use the following example code:
```python
import torch
import pandas as pd
from torch.utils.data import DataLoader
from unifiedmodel import RRUMDataset
video1_channel = "Mozilla"
video1_title = "YouTube Regrets"
video1_description = "Are your YouTube recommendations sometimes lies? Conspiracy theories? Or just weird as hell?\n\n\nYou’re not alone. That’s why Mozilla and 37,380 YouTube users conducted a study to better understand harmful YouTube recommendations. This is what we learned about YouTube regrets: https://foundation.mozilla.org/regrets/"
video2_channel = "Mozilla"
video2_title = "YouTube Regrets Reporter"
video2_description = "Are you choosing what to watch, or is YouTube choosing for you?\n\nTheir algorithm is responsible for over 70% of viewing time, which can include recommending harmful videos.\n\nHelp us hold them responsible. Install RegretsReporter: https://mzl.la/37BT2vA"
df = pd.DataFrame([[video1_title, video1_description, None] + [video2_title, video2_description, None] + [int(video1_channel == video2_channel)]], columns=['regret_title', 'regret_description', 'regret_transcript', 'recommendation_title', 'recommendation_description', 'recommendation_transcript', 'channel_sim'])
dataset = RRUMDataset(df, with_transcript=False, label_col=None, cross_encoder_model_name_or_path=model.cross_encoder_model_name_or_path)
data_loader = DataLoader(dataset.test_dataset)
with torch.inference_mode():
prediction = model(next(iter(data_loader)))
prediction = torch.special.expit(prediction).squeeze().tolist()
```
Some more code and examples are also available at RegretsReporter [GitHub repository](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/semsim).
### Limitations and bias
The cross-encoders that we use to determine similarity of texts are also trained on texts that inevitably reflect social bias. To understand the implications of this, we need to consider the application of the model: to determine if videos are semantically similar or not. So the concern is that our model may, in some systematic way, think certain kinds of videos are more or less similar to each other.
For example, it's possible that the models have encoded a social bias that certain ethnicities are more often involved in violent situations. If this were the case, it is possible that videos about people of one ethnicity may be more likely to be rated similar to videos about violent situations. This could be evaluated by applying the model to synthetic video pairs crafted to test these situations. There is also [active research](https://www.aaai.org/AAAI22Papers/AISI-7742.KanekoM.pdf) in measuring bias in language models, as part of the broader field of [AI fairness](https://facctconference.org/2022/index.html).
We have not analyzed the biases in our model as, for our original application, potential for harm was extremely low. Care should be taken in future applications.
A more difficult issue is the multilingual nature of our data. For the pretrained cross-encoders in our model, we used the [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) model which supports a set of 100 languages (the original mMiniLMv2 base model) including English, German, Spanish and Chinese. However, it is reasonable to expect that the model's performance varies among the languages that it supports. The impact can vary — the model may fail either with false positives, in which it thinks a dissimilar pair is similar, or false negatives, in which it thinks a similar pair is dissimilar. We performed a basic analysis to evaluate the performance of our model in different languages and it suggested that our model performs well across languages, but the potential differences in the quality of our labels between languages reduced our confidence.
## Training data
Since the RegretsReporter project operates without YouTube's support, we were limited to the publicly available data we could fetch from YouTube. The RegretsReporter project developed a browser extension that our volunteer project participants used to send us data about their YouTube usage and what videos YouTube recommended for them. We also used automated methods to acquire additional needed model training data (title, channel, description, transcript) for videos from the YouTube site directly.
To get labeled training data, we contracted 24 research assistants, all graduate students at Exeter University, to perform 20 hours each, classifying gathered video pairs using a [classification tool](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/classification) that we developed. There are many subtleties in defining similarity of two videos, so we are not able to precisely describe what we mean by "similar", but we developed a [policy](https://docs.google.com/document/d/1VB7YAENmuMDMW_kPPUbuDPbHfQBDhF5ylzHA3cAZywg/) to guide our research assistants in classifying video pairs. Research assistants all read the classification policy and worked with Dr. Chico Camargo, who ensured they had all the support they needed to contribute to this work. These research assistants were partners in our research and are named for their contributions in our [final report](https://foundation.mozilla.org/en/research/library/user-controls/report/).
Thanks to our research assistants, we had 44,434 labeled video pairs to train our model (although about 3% of these were labeled "unsure" and so unused). For each of these pairs, the research assistant determined whether the videos are similar or not, and our model is able to learn from these examples.
## Training procedure
### Preprocessing
Our training data of YouTube video titles, descriptions and transcripts tend to include a lot of noisy text having, for example, URLs, emojis and other potential noise. Thus, we used text cleaning functions to clean some of the noise. Text cleaning seemed to improve the model accuracy on test set but the text cleaning was disabled in the end because it added extra latency to the data preprocessing which would have made the project's model prediction run slower when predictions were ran for hundreds of millions of video pairs. The data loading and preprocessing class `RRUMDataset` in `unifiedmodel.py` file still includes text cleaning option by setting the parameter `clean_text=True` on the class initialization.
The text data was tokenized with [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) cross-encoder's SentencePiece tokenizer having a vocabulary size of 250,002. Tokenization was done with maximum length of 128 tokens.
### Training
The model was trained using [PyTorch Lightning](https://pytorch-lightning.readthedocs.io/en/stable/) on NVIDIA A100 GPU. The model can also be trained on lower resources, for example with the free T4 GPU on Google Colab. The optimizer used was a Adam with learning rate 5e-3, learning rate warmup for 5% steps of total training steps and linear decay of the learning rate after. The model was trained with batch size of 128 for 15 epochs. Based on per epoch evaluation, the final model uses the checkpoint from epoch 13.
## Evaluation results
With the final test set, our models were achieving following scores presented on the table below:
| Metric | Model with transcripts | Model without transcripts |
|--------------------------------|------------------------|---------------------------|
| Accuracy | 0.93 | 0.92 |
| Precision | 0.81 | 0.81 |
| Recall | 0.91 | 0.87 |
| AUROC | 0.97 | 0.96 |
## Acknowledgements
We're grateful to Chico Camargo and Ranadheer Malla from the University of Exeter for leading the analysis of RegretsReporter data. Thank you to the research assistants at the University of Exeter for analyzing the video data: Josh Adebayo, Sharon Choi, Henry Cook, Alex Craig, Bee Dally, Seb Dixon, Aditi Dutta, Ana Lucia Estrada Jaramillo, Jamie Falla, Alice Gallagher Boyden, Adriano Giunta, Lisa Greghi, Keanu Hambali, Clare Keeton Graddol, Kien Khuong, Mitran Malarvannan, Zachary Marre, Inês Mendes de Sousa, Dario Notarangelo, Izzy Sebire, Tawhid Shahrior, Shambhavi Shivam, Marti Toneva, Anthime Valin, and Ned Westwood.
Finally, we're so grateful for the 22,722 RegretsReporter participants who contributed their data.
## Contact
If these models are useful to you, we'd love to hear from you. Please write to [email protected] |
Coverage/sakurajimamai | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
---
### zk on Stable Diffusion
This is the `zk` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









|
Coyotl/DialoGPT-test-last-arthurmorgan | [
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: other
commercial: no
inference: false
---
# OPT 2.7B - Erebus
## Model description
This is the second generation of the original Shinen made by Mr. Seeker. The full dataset consists of 6 different sources, all surrounding the "Adult" theme. The name "Erebus" comes from the greek mythology, also named "darkness". This is in line with Shin'en, or "deep abyss". For inquiries, please contact the KoboldAI community. **Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.**
## Training data
The data can be divided in 6 different datasets:
- Literotica (everything with 4.5/5 or higher)
- Sexstories (everything with 90 or higher)
- Dataset-G (private dataset of X-rated stories)
- Doc's Lab (all stories)
- Pike Dataset (novels with "adult" rating)
- SoFurry (collection of various animals)
The dataset uses `[Genre: <comma-separated list of genres>]` for tagging.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/OPT-2.7B-Erebus')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
## Limitations and biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion). **Warning: This model has a very strong NSFW bias!**
### License
OPT-6.7B is licensed under the OPT-175B license, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### BibTeX entry and citation info
```
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Coyotl/DialoGPT-test2-arthurmorgan | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: mit
---
### tudisco on Stable Diffusion
This is the `<cat-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
Coyotl/DialoGPT-test3-arthurmorgan | [
"conversational"
] | conversational | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="pikodemo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Craak/GJ0001 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.78
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
CracklesCreeper/Piglin-Talks-Harry-Potter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: en
license: other
commercial: no
---
# OPT 2.7B - Nerys
## Model Description
OPT 2.7B-Nerys is a finetune created using Facebook's OPT model.
## Training data
The training data contains around 2500 ebooks in various genres (the "Pike" dataset), a CYOA dataset called "CYS" and 50 Asian "Light Novels" (the "Manga-v1" dataset).
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
This dataset has been cleaned in the same way as fairseq-dense-13B-Nerys-v2
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/OPT-2.7B-Nerys-v2')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### License
OPT-6B is licensed under the OPT-175B license, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### BibTeX entry and citation info
```
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Craftified/Bob | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- zeroth_korean_asr
model-index:
- name: wav2vec2-large-xls-r-300m-korean-third
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-korean-third
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the zeroth_korean_asr dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
Craig/mGqFiPhu | [
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | feature-extraction | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-09-19T07:05:01Z | ---
language:
- ko
tags:
- albert
---
# smartmind/albert-kor-base-tweak
[kykim/albert-kor-base](https://huggingface.co/kykim/albert-kor-base)와 동일한 모델입니다.
`AutoTokenizer`로 토크나이저를 불러올 수 있도록 조정했습니다. |
Craig/paraphrase-MiniLM-L6-v2 | [
"pytorch",
"bert",
"arxiv:1908.10084",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,026 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-cased-hate-speech
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-hate-speech
**Training:** The model has been trained using the script provided in the following repository https://github.com/MorenoLaQuatra/transformers-tasks-templates
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on [hate speech](https://huggingface.co/datasets/ucberkeley-dlab/measuring-hate-speech) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6837
- Mae: 1.9686
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.6857 | 1.0 | 3389 | 0.6471 | 1.9725 |
| 0.3645 | 2.0 | 6778 | 0.4359 | 1.9725 |
| 0.2266 | 3.0 | 10167 | 0.3664 | 1.9725 |
| 0.1476 | 4.0 | 13556 | 0.3253 | 1.9725 |
| 0.0992 | 5.0 | 16945 | 0.3047 | 1.9725 |
| 0.0737 | 6.0 | 20334 | 0.2869 | 1.9725 |
| 0.0537 | 7.0 | 23723 | 0.2709 | 1.9725 |
| 0.0458 | 8.0 | 27112 | 0.2667 | 1.9725 |
| 0.0313 | 9.0 | 30501 | 0.2589 | 1.9725 |
| 0.027 | 10.0 | 33890 | 0.2540 | 1.9725 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
CrisLeaf/generador-de-historias-de-tolkien | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaK6_Arabidopsis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaK6_Arabidopsis
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7194
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 600001
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:------:|:---------------:|
| 4.6174 | 6.12 | 20000 | 1.9257 |
| 1.8873 | 12.24 | 40000 | 1.8098 |
| 1.8213 | 18.36 | 60000 | 1.7952 |
| 1.8042 | 24.48 | 80000 | 1.7888 |
| 1.7945 | 30.6 | 100000 | 1.7861 |
| 1.7873 | 36.72 | 120000 | 1.7772 |
| 1.782 | 42.84 | 140000 | 1.7757 |
| 1.7761 | 48.96 | 160000 | 1.7632 |
| 1.7714 | 55.08 | 180000 | 1.7685 |
| 1.7677 | 61.2 | 200000 | 1.7568 |
| 1.7637 | 67.32 | 220000 | 1.7570 |
| 1.7585 | 73.44 | 240000 | 1.7442 |
| 1.7554 | 79.56 | 260000 | 1.7556 |
| 1.7515 | 85.68 | 280000 | 1.7505 |
| 1.7483 | 91.8 | 300000 | 1.7463 |
| 1.745 | 97.92 | 320000 | 1.7425 |
| 1.7427 | 104.04 | 340000 | 1.7425 |
| 1.7398 | 110.16 | 360000 | 1.7359 |
| 1.7377 | 116.28 | 380000 | 1.7369 |
| 1.7349 | 122.4 | 400000 | 1.7340 |
| 1.7325 | 128.52 | 420000 | 1.7313 |
| 1.731 | 134.64 | 440000 | 1.7256 |
| 1.7286 | 140.76 | 460000 | 1.7238 |
| 1.7267 | 146.88 | 480000 | 1.7324 |
| 1.7247 | 153.0 | 500000 | 1.7247 |
| 1.7228 | 159.12 | 520000 | 1.7185 |
| 1.7209 | 165.24 | 540000 | 1.7166 |
| 1.7189 | 171.36 | 560000 | 1.7206 |
| 1.7181 | 177.48 | 580000 | 1.7190 |
| 1.7159 | 183.6 | 600000 | 1.7194 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Crisblair/Wkwk | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: other
commercial: no
---
# OPT 13B - Nerys
## Model Description
OPT 13B-Nerys is a finetune created using Facebook's OPT model.
## Training data
The training data contains around 2500 ebooks in various genres (the "Pike" dataset), a CYOA dataset called "CYS" and 50 Asian "Light Novels" (the "Manga-v1" dataset).
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
This dataset has been cleaned in the same way as fairseq-dense-13B-Nerys-v2
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/OPT-13B-Nerys-v2')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### License
OPT-6B is licensed under the OPT-175B license, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
### BibTeX entry and citation info
```
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Crispy/dialopt-small-kratos | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- generated_from_trainer
model-index:
- name: DNADebertaK6_Worm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DNADebertaK6_Worm
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 600001
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:------:|:---------------:|
| 4.5653 | 7.26 | 20000 | 1.8704 |
| 1.8664 | 14.53 | 40000 | 1.7762 |
| 1.7803 | 21.79 | 60000 | 1.7429 |
| 1.7502 | 29.06 | 80000 | 1.7305 |
| 1.7329 | 36.32 | 100000 | 1.7185 |
| 1.7191 | 43.59 | 120000 | 1.7073 |
| 1.7065 | 50.85 | 140000 | 1.6925 |
| 1.6945 | 58.12 | 160000 | 1.6877 |
| 1.6862 | 65.38 | 180000 | 1.6792 |
| 1.6788 | 72.65 | 200000 | 1.6712 |
| 1.6729 | 79.91 | 220000 | 1.6621 |
| 1.6679 | 87.18 | 240000 | 1.6608 |
| 1.6632 | 94.44 | 260000 | 1.6586 |
| 1.6582 | 101.71 | 280000 | 1.6585 |
| 1.6551 | 108.97 | 300000 | 1.6564 |
| 1.6507 | 116.24 | 320000 | 1.6449 |
| 1.6481 | 123.5 | 340000 | 1.6460 |
| 1.6448 | 130.77 | 360000 | 1.6411 |
| 1.6425 | 138.03 | 380000 | 1.6408 |
| 1.6387 | 145.3 | 400000 | 1.6358 |
| 1.6369 | 152.56 | 420000 | 1.6373 |
| 1.6337 | 159.83 | 440000 | 1.6364 |
| 1.6312 | 167.09 | 460000 | 1.6303 |
| 1.6298 | 174.36 | 480000 | 1.6346 |
| 1.6273 | 181.62 | 500000 | 1.6272 |
| 1.6244 | 188.88 | 520000 | 1.6268 |
| 1.6225 | 196.15 | 540000 | 1.6295 |
| 1.6207 | 203.41 | 560000 | 1.6206 |
| 1.6186 | 210.68 | 580000 | 1.6277 |
| 1.6171 | 217.94 | 600000 | 1.6161 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.2
- Tokenizers 0.12.1
|
CrypticT1tan/DialoGPT-medium-harrypotter | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
tags:
- emotion-classification
datasets:
- go-emotions
- bdotloh/empathetic-dialogues-contexts
---
# Model Description
Yet another Transformer model fine-tuned for approximating another non-linear mapping between X and Y? That's right!
This is your good ol' emotion classifier - given an input text, the model outputs a probability distribution over a set of pre-selected emotion words. In this case, it is 32, which is the number of emotion classes in the [Empathetic Dialogues](https://huggingface.co/datasets/bdotloh/empathetic-dialogues-contexts) dataset.
This model is built "on top of" a [distilbert-base-uncased model fine-tuned on the go-emotions dataset](https://huggingface.co/bhadresh-savani/bert-base-go-emotion). Y'all should really check out that model, it even contains a jupyter notebook file that illustrates how the model was trained (bhadresh-savani if you see this, thank you!).
## Training data
## Training procedure
### Preprocessing
## Evaluation results
### Limitations and bias
Well where should we begin...
EmpatheticDialogues:
1) Unable to ascertain the degree of cultural specificity for the context that a respondent described when given an emotion label (i.e., p(description | emotion, *culture*))
2) ...
|
Cryptikdw/DialoGPT-small-rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 40 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 40,
"warmup_steps": 4,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Culmenus/IceBERT-finetuned-ner | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"dataset:mim_gold_ner",
"transformers",
"generated_from_trainer",
"license:gpl-3.0",
"model-index",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-large-finetuned-ours-DS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-ours-DS
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9568
- Accuracy: 0.71
- Precision: 0.6689
- Recall: 0.6607
- F1: 0.6637
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.6820964947491663e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.9953 | 1.99 | 199 | 0.7955 | 0.66 | 0.7533 | 0.5971 | 0.5352 |
| 0.6638 | 3.98 | 398 | 0.8043 | 0.735 | 0.7068 | 0.6782 | 0.6846 |
| 0.3457 | 5.97 | 597 | 0.9568 | 0.71 | 0.6689 | 0.6607 | 0.6637 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Culmenus/XLMR-ENIS-finetuned-ner | [
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"dataset:mim_gold_ner",
"transformers",
"generated_from_trainer",
"license:agpl-3.0",
"model-index",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: mit
---
### Ori Toor on Stable Diffusion
This is the `<ori-toor>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.