
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
ichigoberry/pandafish-7b-GGUF | ichigoberry | 2024-04-02T18:51:41Z | 577 | 1 | null | [
"gguf",
"region:us"
]
| null | 2024-04-02T15:28:02Z | Entry not found |
XsoraS/SmallLM | XsoraS | 2024-04-14T13:07:13Z | 577 | 1 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-14T13:07:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Mike0307/text2vec-base-chinese-rag | Mike0307 | 2024-06-09T07:32:25Z | 577 | 3 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-04-15T23:41:18Z | ---
license: apache-2.0
pipeline_tag: sentence-similarity
metrics:
- spearmanr
---
## Overview
This model is primarily designed for language understanding between Chinese texts.<br>
It utilizes the **CoSENT** training framework for the purpose of the **Retrieval-Augmented Generation(RAG)** task.
## Download the model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Mike0307/text2vec-base-chinese-rag")
model = AutoModel.from_pretrained("Mike0307/text2vec-base-chinese-rag")
```
## Example of similarity comparison
```python
import torch
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = (
attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
)
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(
input_mask_expanded.sum(1), min=1e-9
)
sentences = [
"福井舞所屬哪家唱片公司?",
"23歲時出道、血型A型的福井舞是出身於京都的日本女創作歌手,所屬唱片公司為J-more。2004年,與WADAGAKI、SHINO組合地下音樂隊Poplar,發表了兩張專輯,天照和夢死物語。在2006年時退出,2007年10月加入了Avex獨立發展。"
]
encode_output = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt", max_length=512)
model_output = model(**encode_output)
embeddings = mean_pooling(model_output, encode_output['attention_mask'])
torch.cosine_similarity(embeddings[0], embeddings[1], dim=0)
# tensor(0.7002)
```
## Example of Langchain RAG
RAG with Langchain: https://python.langchain.com/v0.1/docs/use_cases/question_answering/

Install the langchain packages
```bash
pip install --upgrade --quiet langchain langchain-community
```
### 1. Use this embedding model to build a retiever
Download HuggingFace model through langchain_community
```python
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
model_name = "Mike0307/text2vec-base-chinese-rag"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
```
An example of retriever with Meta FAISS vectorstore
```python
from langchain.schema import Document
from langchain_community.vectorstores.faiss import FAISS
documents = [
Document(page_content="埃及聖䴉(學名:Threskiornis aethiopicus),又名埃及聖朱鷺、埃及聖鷺、聖䴉,是撒哈拉以南非洲、伊拉克東南部及以往埃及的一種朱鷺。牠們在埃及備受尊敬,經常被製成木乃伊當做托特的象徵。牠們也被引入到法國、義大利、西班牙及美國。現在,在臺灣西部濱海地區也可看到牠們。"),
Document(page_content="隨著科技的不斷發展和革新,人工智能已經成為了眾多企業和機構的重點關注對象。機器學習、自然語言處理、深度神經網絡等技術的應用,已經開始推動著人工智能產業的快速發展。從目前的發展情況來看,人工智能不僅可以提高工作效率,降低人力成本,還可以促進產業升級,改善生活品質。"),
Document(page_content="Apache Hadoop是一款支持數據密集型分佈式應用程序並以Apache 2.0許可協議發佈的開源軟體框架。它支持在商品硬件構建的大型集群上運行的應用程序。Hadoop是根據谷歌公司發表的MapReduce和Google檔案系統的論文自行實作而成。"),
Document(page_content="23歲時出道、血型A型的福井舞是出身於京都的日本女創作歌手,所屬唱片公司為J-more。2004年,與WADAGAKI、SHINO組合地下音樂隊Poplar,發表了兩張專輯,天照和夢死物語。在2006年時退出,2007年10月加入了Avex獨立發展。"),
Document(page_content="協和橋(Pont de la Concorde)是法國巴黎一座跨越塞納河的拱橋,介於協和廣場的堤道(quai des Tuileries)(右岸)和奧賽堤道(quai d'Orsay)(左岸)之間。它在過去曾稱為路易十六橋(pont Louis XVI)、革命橋(pont de la Révolution)、協和橋,波旁復辟時期(1814年)複稱路易十六橋,1830年再度恢復協和橋名稱,直至今日。"),
Document(page_content="中華民國空氣汙染指標(Pollutant Standards Index,PSI)是空氣汙染情況的一項指標,由中華民國行政院環境保護署於1993年擴充測站後推出,目標乃藉由本測站系統監控全臺灣所有的空氣品質並加以通報改善。空氣汙染指標為依據監測資料將當日空氣中懸浮微粒(PM10)、二氧化硫(SO)、二氧化氮(NO)、一氧化碳 (CO) 及臭氧 (O) 等5種空氣汙染物濃度數值"),
Document(page_content="滾石國際音樂股份有限公司 Rock Records Co., Ltd. 曾用名 滾石雜誌社 滾石有聲出版社 公司類型 股份有限公司 統一編號 22012304 成立 1976年,滾石雜誌社 1980年,滾石有聲出版社 1986年1月28日(公司登記日期)(38年113天) 創辦人 段鍾沂、段鍾潭 代表人物 段鍾沂、段鍾潭 "),
]
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever(search_kwargs = {"k" : 1})
retriever.invoke("福井舞所屬哪家唱片公司?")
# [Document(page_content='23歲時出道、血型A型的福井舞是出身於京都的日本女創作歌手,所屬唱片公司為J-more。2004年,與WADAGAKI、SHINO組合地下音樂隊Poplar,發表了兩張專輯,天照和夢死物語。在2006年時退出,2007年10月加入了Avex獨立發展。')]
```
### 2. Use HuggingFace LLM as customized Langchain LLM
Sometimes, we don’t want to rely on the OpenAI API. Here are some tips to empower the use of HuggingFace models.
First, download the HuggingFace LLM via the bellow code. Check [this repo](https://huggingface.co/Mike0307/Phi-3-mini-4k-instruct-chinese-lora) if you encounter any problems.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
llm_id = "Mike0307/Phi-3-mini-4k-instruct-chinese-lora"
model = AutoModelForCausalLM.from_pretrained(
llm_id,
device_map="mps", # Change mps if not MacOS
torch_dtype=torch.float32, # try float16 for M1 chip
trust_remote_code=True,
attn_implementation="eager", # without flash_attn
)
tokenizer = AutoTokenizer.from_pretrained(llm_id)
```
Secondly, construct a valid langchain LLM class via the downloaded HuggingFace model.
```python
import re
from pydantic import Field
from typing import Any, List, Optional
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
class CustomLLM(LLM):
model : Any = Field(..., description="The huggingface llm model.")
tokenizer : Any = Field(..., description="The huggingface llm tokenizer.")
def __init__(self, model, tokenizer):
super().__init__(model = model, tokenizer = tokenizer)
def _call(self, prompt: str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any,) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
outputs = self.model.generate(**inputs, temperature = 0.0, max_length = 500, do_sample = False)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=False)
return self.output_parser(generated_text)
@property
def _llm_type(self) -> str:
return "custom"
def output_parser(output):
pattern = "<\|assistant\|>(.*?)<\|endoftext\|>"
match = re.search(pattern, output, re.DOTALL)
if match:
return match.group(1).strip()
return output.strip()
```
### 3. Make a simple RAG chain
Use `promt`, `llm`, `retriever` to build a simple RAG chain and try inference.
```python
import langchain
langchain.debug = True # Check the chain process and validate the retrieved documents
prompt = PromptTemplate.from_template(template="<|user|>{documents}\n{question} <|end|>\n<|assistant|>")
llm = CustomLLM(model, tokenizer)
rag = {
"question" : RunnablePassthrough(),
"documents" : retriever
} | prompt | llm
## example of inference
query = "埃及聖䴉是什麼?"
rag.invoke(query)
## '埃及聖䴉是一種埃及的朱鷺,它在埃及備受尊敬,經常被製成木乃伊當做托特的象徵。它也被引入到法國、義大利、西班牙及美國。現在,在臺灣西部濱海地區也可看到埃及聖䴉。'
```
|
NilanE/tinyllama-en_ja-translation-v3 | NilanE | 2024-06-30T17:16:24Z | 577 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"ja",
"dataset:NilanE/ParallelFiction-Ja_En-100k",
"base_model:NilanE/tinyllama-relora-merge",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-24T21:44:08Z | ---
language:
- en
- ja
license: apache-2.0
tags:
- llama
base_model: NilanE/tinyllama-relora-merge
datasets:
- NilanE/ParallelFiction-Ja_En-100k
---
Trained for 2 epochs on NilanE/ParallelFiction-Ja_En-100k using QLoRA. CPO tune is in-progress.
Input should be 500-1000 tokens long. Make sure to set 'do_sample = False' if using HF transformers for inference, or otherwise set temperature to 0 for deterministic outputs.
## Prompt format:
```
Translate this from Japanese to English:
### JAPANESE:
{source_text}
### ENGLISH:
```
### Footnote:
This is an independantly-developed project. If anyone is interested in sponsoring further research please contact [email protected].
Questions about model usage can be asked in the disscussion tab. |
mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF | mradermacher | 2024-06-03T05:14:07Z | 577 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Nitral-AI/Poppy_Porpoise-1.30-L3-8B",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-31T07:42:00Z | ---
base_model: Nitral-AI/Poppy_Porpoise-1.30-L3-8B
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Nitral-AI/Poppy_Porpoise-1.30-L3-8B
***The model creator strongly suggests using the [0.72](https://huggingface.co/mradermacher/Poppy_Porpoise-0.72-L3-8B-i1-GGUF) model at this time, as it is better quality***
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Poppy_Porpoise-1.30-L3-8B-i1-GGUF/resolve/main/Poppy_Porpoise-1.30-L3-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
gai-labs/strela | gai-labs | 2024-06-05T05:42:14Z | 577 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ru",
"en",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-04T18:37:17Z | ---
license: cc-by-sa-4.0
language:
- ru
- en
pipeline_tag: text-generation
library_name: transformers
---
**[English version](https://huggingface.co/gai-labs/strela/blob/main/README_EN.md)**
Стрела — это мощная языковая модель, созданная для обеспечения высокой скорости работы и качества ответов на слабых устройствах.
Рекомендуется использовать стрелу в следующих целях:
* Чат бот для диалога
* Написатель историй
* Написатель песен
* Перевод русского и английского языка
* Когда неэффективно использовать более тяжёлые модели
## Описание от самой стрелы
Я представляю собой компьютерную программу, которая была разработана для обработки и анализа естественного языка.
Я обладаю способностью понимать, анализировать и обрабатывать естественный язык, что позволяет мне общаться с людьми через различные каналы коммуникации. Моя основная цель - помочь людям в решении задач и предоставить информацию на основе запроса.
Я могу использоваться для различных целей: от автоматической генерации текста, перевода с одного языка на другой или даже создания собственных стихов и песен.
## Использование модели онлайн
Вы можете попробовать её [здесь](https://huggingface.co/spaces/gai-labs/chat-with-strela-q4_k_m).
## Использование модели для чата в приложении
Рекомендуется [GTP4ALL](https://gpt4all.io/index.html), он поддерживает GGUF, поэтому нужно скачать [особый вариант модели в формате GGUF](https://huggingface.co/gai-labs/strela-GGUF).
## Использование модели для чата в Unity
Рекомендуется [LLM for Unity](https://assetstore.unity.com/packages/tools/ai-ml-integration/llm-for-unity-273604), он поддерживает GGUF, поэтому нужно скачать [особый вариант модели в формате GGUF](https://huggingface.co/gai-labs/strela-GGUF).
## Использование квантованной модели для чата в Python | Рекомендовано
Вы должны установить [gpt4all](https://docs.gpt4all.io/gpt4all_python.html)
```
pip install gpt4all
```
Затем, скачайте [GGUF версию модели](https://huggingface.co/gai-labs/strela-GGUF), и переместите файл в директорию вашего скрипта
```py
# Импорт библиотек
import os
from gpt4all import GPT4All
# Инициализация модели из файла strela-q4_k_m.gguf в текущей директории
model = GPT4All(model_name='strela-q4_k_m.gguf', model_path=os.getcwd())
# Функция, которая остановит генерацию, если стрела сгенерирует символ '#', который является началом объявления ролей
def stop_on_token_callback(token_id, token_string):
if '#' in token_string:
return False
else:
return True
# Промпт системы
system_template = """### System:
You are an AI assistant who gives a helpfull response to whatever human ask of you.
"""
# Промпт человека и ИИ
prompt_template = """
### Human:
{0}
### Assistant:
"""
# Сессия чата
with model.chat_session(system_template, prompt_template):
print("Что-бы выйти, введите 'Выход'")
while True:
print('')
user_input = input(">>> ")
if user_input.lower() != "выход":
# Потоковая генерация
for token in model.generate(user_input, streaming=True, callback=stop_on_token_callback):
print(token, end='')
else:
break
```
```
Что-бы выйти, введите 'Выход'
>>> Привет
Здравствуйте! Как я могу помочь вам сегодня?
>>>
```
## Использование полноценной модели для чата в Python
```py
# Импорт библиотек
from transformers import AutoTokenizer, AutoModelForCausalLM
# Загрузка модели
tokenizer = AutoTokenizer.from_pretrained("gai-labs/strela")
model = AutoModelForCausalLM.from_pretrained("gai-labs/strela")
# Промпт системы
system_prompt = "You are an AI assistant who gives a helpfull response to whatever human ask of you."
# Ваш промпт
prompt = "Привет!"
# Шаблон чата
chat = f"""### System:
{system_prompt}
### Human:
{prompt}
### Assistant:
"""
# Генерация
model_inputs = tokenizer([chat], return_tensors="pt")
generated_ids = model.generate(**model_inputs, max_new_tokens=64) # Настройте максимальное количество токенов для генерации
output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Очистка выводов от шаблона чата
output = output.replace(chat, "")
# Вывод результатов генерации
print(output)
```
```
Привет! Чем могу помочь?
```
## Использование модели для генерации текста в Python
```py
# Импорт библиотек
from transformers import AutoTokenizer, AutoModelForCausalLM
# Загрузка модели
tokenizer = AutoTokenizer.from_pretrained("gai-labs/strela")
model = AutoModelForCausalLM.from_pretrained("gai-labs/strela")
# Промпт
prompt = "ИИ - "
# Генерация
model_inputs = tokenizer([prompt], return_tensors="pt")
generated_ids = model.generate(**model_inputs, max_new_tokens=64) # Настройте максимальное количество токенов для генерации
output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Вывод результатов генерации
print(output)
```
```
ИИ - это область компьютерных наук и технологий, которая занимается созданием машин, способных "понимать" человека или выполнять задачи с аналогичной логикой, как у людей.
``` |
CHE-72-ZLab/Microsoft-Phi3-14B-Instruct128K-GGUF | CHE-72-ZLab | 2024-06-23T07:27:28Z | 577 | 0 | null | [
"gguf",
"nlp",
"code",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:microsoft/Phi-3-mini-128k-instruct",
"license:mit",
"region:us"
]
| text-generation | 2024-06-22T12:08:12Z | ---
base_model: microsoft/Phi-3-mini-128k-instruct
language:
- en
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- nlp
- code
- llama-cpp
- gguf-my-repo
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
# CHE-72/Phi-3-mini-128k-instruct-Q6_K-GGUF
This model was converted to GGUF format from [`microsoft/Phi-3-mini-128k-instruct`](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) for more details on the model. |
willgrobots/checkpointsaved | willgrobots | 2024-06-22T22:35:11Z | 577 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"moondream1",
"text-generation",
"image-text-to-text",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-06-22T22:30:22Z | ---
license: apache-2.0
pipeline_tag: image-text-to-text
---
moondream2 is a small vision language model designed to run efficiently on edge devices. Check out the [GitHub repository](https://github.com/vikhyat/moondream) for details, or try it out on the [Hugging Face Space](https://huggingface.co/spaces/vikhyatk/moondream2)!
**Benchmarks**
| Release | VQAv2 | GQA | TextVQA | TallyQA (simple) | TallyQA (full) |
| --- | --- | --- | --- | --- | --- |
| 2024-03-04 | 74.2 | 58.5 | 36.4 | - | - |
| 2024-03-06 | 75.4 | 59.8 | 43.1 | 79.5 | 73.2 |
| 2024-03-13 | 76.8 | 60.6 | 46.4 | 79.6 | 73.3 |
| 2024-04-02 | 77.7 | 61.7 | 49.7 | 80.1 | 74.2 |
| 2024-05-08 | 79.0 | 62.7 | 53.1 | 81.6 | 76.1 |
| **2024-05-20** (latest) | 79.4 | 63.1 | 57.2 | 82.1 | 76.6 |
**Usage**
```bash
pip install transformers einops
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
model_id = "vikhyatk/moondream2"
revision = "2024-05-20"
model = AutoModelForCausalLM.from_pretrained(
model_id, trust_remote_code=True, revision=revision
)
tokenizer = AutoTokenizer.from_pretrained(model_id, revision=revision)
image = Image.open('<IMAGE_PATH>')
enc_image = model.encode_image(image)
print(model.answer_question(enc_image, "Describe this image.", tokenizer))
```
The model is updated regularly, so we recommend pinning the model version to a
specific release as shown above.
|
powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF | powermove72 | 2024-06-22T23:18:05Z | 577 | 0 | null | [
"gguf",
"merge",
"mergekit",
"lazymergekit",
"powermove72/Shark-1",
"eren23/OGNO-7b-dpo-truthful",
"llama-cpp",
"gguf-my-repo",
"base_model:powermove72/SharkOgno-11b-Passthrough",
"region:us"
]
| null | 2024-06-22T23:17:36Z | ---
base_model: powermove72/SharkOgno-11b-Passthrough
tags:
- merge
- mergekit
- lazymergekit
- powermove72/Shark-1
- eren23/OGNO-7b-dpo-truthful
- llama-cpp
- gguf-my-repo
---
# powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF
This model was converted to GGUF format from [`powermove72/SharkOgno-11b-Passthrough`](https://huggingface.co/powermove72/SharkOgno-11b-Passthrough) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/powermove72/SharkOgno-11b-Passthrough) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF --hf-file sharkogno-11b-passthrough-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF --hf-file sharkogno-11b-passthrough-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF --hf-file sharkogno-11b-passthrough-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo powermove72/SharkOgno-11b-Passthrough-Q4_K_M-GGUF --hf-file sharkogno-11b-passthrough-q4_k_m.gguf -c 2048
```
|
larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF | larenspear | 2024-07-01T16:32:12Z | 577 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:01-ai/Yi-1.5-9B-Chat",
"license:apache-2.0",
"region:us"
]
| null | 2024-07-01T16:31:44Z | ---
base_model: 01-ai/Yi-1.5-9B-Chat
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF
This model was converted to GGUF format from [`01-ai/Yi-1.5-9B-Chat`](https://huggingface.co/01-ai/Yi-1.5-9B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/01-ai/Yi-1.5-9B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF --hf-file yi-1.5-9b-chat-q5_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF --hf-file yi-1.5-9b-chat-q5_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF --hf-file yi-1.5-9b-chat-q5_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo larenspear/Yi-1.5-9B-Chat-Q5_0-GGUF --hf-file yi-1.5-9b-chat-q5_0.gguf -c 2048
```
|
yikuan8/Clinical-BigBird | yikuan8 | 2022-04-10T17:40:08Z | 576 | 13 | transformers | [
"transformers",
"pytorch",
"big_bird",
"fill-mask",
"BigBird",
"clinical",
"en",
"arxiv:2201.11838",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-04-01T15:44:00Z | ---
language: "en"
tags:
- BigBird
- clinical
---
<span style="font-size:larger;">**Clinical-BigBird**</span> is a clinical knowledge enriched version of BigBird that was further pre-trained using MIMIC-III clinical notes. It allows up to 4,096 tokens as the model input. Clinical-BigBird consistently out-performs ClinicalBERT across 10 baseline dataset. Those downstream experiments broadly cover named entity recognition (NER), question answering (QA), natural language inference (NLI) and text classification tasks. For more details, please refer to [our paper](https://arxiv.org/pdf/2201.11838.pdf).
We also provide a sister model at [Clinical-Longformer](https://huggingface.co/yikuan8/Clinical-Longformer)
### Pre-training
We initialized Clinical-BigBird from the pre-trained weights of the base version of BigBird. The pre-training process was distributed in parallel to 6 32GB Tesla V100 GPUs. FP16 precision was enabled to accelerate training. We pre-trained Clinical-BigBird for 300,000 steps with batch size of 6×2. The learning rates were 3e-5. The entire pre-training process took more than 2 weeks.
### Usage
Load the model directly from Transformers:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("yikuan8/Clinical-BigBird")
model = AutoModelForMaskedLM.from_pretrained("yikuan8/Clinical-BigBird")
```
### Citing
If you find our model helps, please consider citing this :)
```
@article{li2022clinical,
title={Clinical-Longformer and Clinical-BigBird: Transformers for long clinical sequences},
author={Li, Yikuan and Wehbe, Ramsey M and Ahmad, Faraz S and Wang, Hanyin and Luo, Yuan},
journal={arXiv preprint arXiv:2201.11838},
year={2022}
}
```
### Questions
Please email [email protected]
|
timm/convnext_pico.d1_in1k | timm | 2024-02-10T23:27:17Z | 576 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-12-13T07:12:40Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for convnext_pico.d1_in1k
A ConvNeXt image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 9.0
- GMACs: 1.4
- Activations (M): 6.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Original:** https://github.com/huggingface/pytorch-image-models
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnext_pico.d1_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_pico.d1_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnext_pico.d1_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}
```
|
shaowenchen/chinese-alpaca-2-13b-gguf | shaowenchen | 2023-09-18T03:44:45Z | 576 | 0 | null | [
"gguf",
"meta",
"llama",
"llama-2",
"alpaca",
"alpaca-2",
"chinese",
"text-generation",
"zh",
"license:other",
"region:us"
]
| text-generation | 2023-09-16T23:34:00Z | ---
inference: false
language:
- zh
license: other
model_creator: ziqingyang
model_link: https://huggingface.co/ziqingyang/chinese-alpaca-2-13b
model_name: chinese-alpaca-2-13b
model_type: llama
pipeline_tag: text-generation
quantized_by: shaowenchen
tasks:
- text2text-generation
tags:
- meta
- gguf
- llama
- llama-2
- alpaca
- alpaca-2
- chinese
---
## Provided files
| Name | Quant method | Size |
| -------------------------------- | ------------ | ------- |
| chinese-alpaca-2-13b.Q2_K.gguf | Q2_K | 5.2 GB |
| chinese-alpaca-2-13b.Q3_K.gguf | Q3_K | 6.0 GB |
| chinese-alpaca-2-13b.Q3_K_L.gguf | Q3_K_L | 6.6 GB |
| chinese-alpaca-2-13b.Q3_K_S.gguf | Q3_K_S | 5.4 GB |
| chinese-alpaca-2-13b.Q4_0.gguf | Q4_0 | 7.0 GB |
| chinese-alpaca-2-13b.Q4_1.gguf | Q4_1 | 7.8 GB |
| chinese-alpaca-2-13b.Q4_K.gguf | Q4_K | 7.5 GB |
| chinese-alpaca-2-13b.Q4_K_S.gguf | Q4_K_S | 7.1 GB |
| chinese-alpaca-2-13b.Q5_0.gguf | Q5_0 | 8.5 GB |
| chinese-alpaca-2-13b.Q5_1.gguf | Q5_1 | 9.3 GB |
| chinese-alpaca-2-13b.Q5_K.gguf | Q5_K | 8.8 GB |
| chinese-alpaca-2-13b.Q5_K_S.gguf | Q5_K_S | 8.5 GB |
| chinese-alpaca-2-13b.Q6_K.gguf | Q6_K | 10.0 GB |
| chinese-alpaca-2-13b.Q8_0.gguf | Q8_0 | 13.0 GB |
| chinese-alpaca-2-13b.gguf | full | 25.0 GB |
Usage:
```
docker run --rm -it -p 8000:8000 -v /path/to/models:/models -e MODEL=/models/gguf-model-name.gguf hubimage/llama-cpp-python:latest
```
and you can view http://localhost:8000/docs to see the swagger UI. |
maddes8cht/stabilityai-stablelm-3b-4e1t-gguf | maddes8cht | 2023-11-22T20:26:29Z | 576 | 4 | null | [
"gguf",
"causal-lm",
"en",
"dataset:tiiuae/falcon-refinedweb",
"dataset:togethercomputer/RedPajama-Data-1T",
"dataset:CarperAI/pilev2-dev",
"dataset:bigcode/starcoderdata",
"dataset:allenai/peS2o",
"arxiv:2307.09288",
"arxiv:2104.09864",
"arxiv:2204.06745",
"arxiv:1607.06450",
"arxiv:1910.07467",
"arxiv:2101.00027",
"arxiv:2305.06161",
"arxiv:1910.02054",
"license:cc-by-sa-4.0",
"region:us"
]
| null | 2023-11-15T12:52:59Z | ---
license: cc-by-sa-4.0
datasets:
- tiiuae/falcon-refinedweb
- togethercomputer/RedPajama-Data-1T
- CarperAI/pilev2-dev
- bigcode/starcoderdata
- allenai/peS2o
language:
- en
tags:
- causal-lm
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I ALLOW Stability AI to email me about new model releases: checkbox
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# stablelm-3b-4e1t - GGUF
- Model creator: [stabilityai](https://huggingface.co/stabilityai)
- Original model: [stablelm-3b-4e1t](https://huggingface.co/stabilityai/stablelm-3b-4e1t)
# StableLM
This is a Model based on StableLM.
Stablelm is a familiy of Language Models by Stability AI.
## Note:
Current (as of 2023-11-15) implementations of Llama.cpp only support GPU offloading up to 34 Layers with these StableLM Models.
The model will crash immediately if -ngl is larger than 34.
The model works fine however without any gpu acceleration.
---
# Brief
This is the Base Model of Stable LM 3b by Stability AI.
It is licensed under Creative Commons [cc-by-sa-4.0](https://creativecommons.org/licenses/by-sa/4.0/), as should all derivatives
---
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
# `StableLM-3B-4E1T`
## Model Description
`StableLM-3B-4E1T` is a 3 billion parameter decoder-only language model pre-trained on 1 trillion tokens of diverse English and code datasets for 4 epochs.
## Usage
Get started generating text with `StableLM-3B-4E1T` by using the following code snippet:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-3b-4e1t")
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablelm-3b-4e1t",
trust_remote_code=True,
torch_dtype="auto",
)
model.cuda()
inputs = tokenizer("The weather is always wonderful", return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.75,
top_p=0.95,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
```
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: `StableLM-3B-4E1T` models are auto-regressive language models based on the transformer decoder architecture.
* **Language(s)**: English
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: Model checkpoints are licensed under the Creative Commons license ([CC BY-SA-4.0](https://creativecommons.org/licenses/by-sa/4.0/)). Under this license, you must give [credit](https://creativecommons.org/licenses/by/4.0/#) to Stability AI, provide a link to the license, and [indicate if changes were made](https://creativecommons.org/licenses/by/4.0/#). You may do so in any reasonable manner, but not in any way that suggests the Stability AI endorses you or your use.
* **Contact**: For questions and comments about the model, please email `[email protected]`
### Model Architecture
The model is a decoder-only transformer similar to the LLaMA ([Touvron et al., 2023](https://arxiv.org/abs/2307.09288)) architecture with the following modifications:
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|----------------|-------------|--------|-------|-----------------|
| 2,795,443,200 | 2560 | 32 | 32 | 4096 |
* **Position Embeddings**: Rotary Position Embeddings ([Su et al., 2021](https://arxiv.org/abs/2104.09864)) applied to the first 25% of head embedding dimensions for improved throughput following [Black et al. (2022)](https://arxiv.org/pdf/2204.06745.pdf).
* **Normalization**: LayerNorm ([Ba et al., 2016](https://arxiv.org/abs/1607.06450)) with learned bias terms as opposed to RMSNorm ([Zhang & Sennrich, 2019](https://arxiv.org/abs/1910.07467)).
* **Tokenizer**: GPT-NeoX ([Black et al., 2022](https://arxiv.org/abs/2204.06745)).
## Training
For complete dataset and training details, please see the [StableLM-3B-4E1T Technical Report](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo).
### Training Dataset
The dataset is comprised of a filtered mixture of open-source large-scale datasets available on the [HuggingFace Hub](https://huggingface.co/datasets): Falcon RefinedWeb extract ([Penedo et al., 2023](https://huggingface.co/datasets/tiiuae/falcon-refinedweb)), RedPajama-Data ([Together Computer., 2023](https://github.com/togethercomputer/RedPajama-Data)) and The Pile ([Gao et al., 2020](https://arxiv.org/abs/2101.00027)) both without the *Books3* subset, and StarCoder ([Li et al., 2023](https://arxiv.org/abs/2305.06161)).
* Given the large amount of web data, we recommend fine-tuning the base StableLM-3B-4E1T for your downstream tasks.
### Training Procedure
The model is pre-trained on the aforementioned datasets in `bfloat16` precision, optimized with AdamW, and trained using the NeoX tokenizer with a vocabulary size of 50,257. We outline the complete hyperparameters choices in the project's [GitHub repository - config](https://github.com/Stability-AI/StableLM/blob/main/configs/stablelm-3b-4e1t.yml).
### Training Infrastructure
* **Hardware**: `StableLM-3B-4E1T` was trained on the Stability AI cluster across 256 NVIDIA A100 40GB GPUs (AWS P4d instances). Training began on August 23, 2023, and took approximately 30 days to complete.
* **Software**: We use a fork of `gpt-neox` ([EleutherAI, 2021](https://github.com/EleutherAI/gpt-neox)), train under 2D parallelism (Data and Tensor Parallel) with ZeRO-1 ([Rajbhandari et al., 2019](https://arxiv.org/abs/1910.02054v3)), and rely on flash-attention as well as SwiGLU and Rotary Embedding kernels from FlashAttention-2 ([Dao et al., 2023](https://tridao.me/publications/flash2/flash2.pdf))
## Use and Limitations
### Intended Use
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications.
### Limitations and Bias
As a base model, this model may exhibit unreliable, unsafe, or other undesirable behaviors that must be corrected through evaluation and fine-tuning prior to deployment. The pre-training dataset may have contained offensive or inappropriate content, even after applying data cleansing filters, which can be reflected in the model-generated text. We recommend that users exercise caution when using these models in production systems. Do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
## How to Cite
```bibtex
@misc{StableLM-3B-4E1T,
url={[https://huggingface.co/stabilityai/stablelm-3b-4e1t](https://huggingface.co/stabilityai/stablelm-3b-4e1t)},
title={StableLM 3B 4E1T},
author={Tow, Jonathan and Bellagente, Marco and Mahan, Dakota and Riquelme, Carlos}
}
```
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center> |
exploer/realistic-vision-v6-0-b1-tom | exploer | 2024-06-18T19:09:11Z | 576 | 0 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-01-06T20:04:41Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Realistic-Vision-V6.0-B1-TOM- Dreambooth model trained by exploer with TheLastBen's fast-DreamBooth notebook
|
ven1228/5CXw2N2NKVpNgyVmxikYFbH31EJqxt8pxp9WZaypTgRHQX4U_vgg | ven1228 | 2024-03-11T12:49:37Z | 576 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-03-05T20:48:47Z | Entry not found |
mradermacher/MonarchCoder-7B-GGUF | mradermacher | 2024-05-06T05:44:21Z | 576 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"Syed-Hasan-8503/Tess-Coder-7B-Mistral-v1.0",
"mlabonne/AlphaMonarch-7B",
"en",
"base_model:abideen/MonarchCoder-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-29T00:23:40Z | ---
base_model: abideen/MonarchCoder-7B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- Syed-Hasan-8503/Tess-Coder-7B-Mistral-v1.0
- mlabonne/AlphaMonarch-7B
---
## About
static quants of https://huggingface.co/abideen/MonarchCoder-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q2_K.gguf) | Q2_K | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.IQ3_XS.gguf) | IQ3_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q3_K_S.gguf) | Q3_K_S | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.IQ3_S.gguf) | IQ3_S | 3.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.IQ3_M.gguf) | IQ3_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q3_K_M.gguf) | Q3_K_M | 3.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.IQ4_XS.gguf) | IQ4_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q4_0.gguf) | Q4_0 | 4.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q4_K_S.gguf) | Q4_K_S | 4.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.IQ4_NL.gguf) | IQ4_NL | 4.4 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q5_K_S.gguf) | Q5_K_S | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q5_K_M.gguf) | Q5_K_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q6_K.gguf) | Q6_K | 6.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MonarchCoder-7B-GGUF/resolve/main/MonarchCoder-7B.Q8_0.gguf) | Q8_0 | 7.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Deita-34b-GGUF | mradermacher | 2024-05-24T01:05:27Z | 576 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:KnutJaegersberg/Deita-6k",
"base_model:KnutJaegersberg/Deita-34b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-17T18:44:06Z | ---
base_model: KnutJaegersberg/Deita-34b
datasets:
- KnutJaegersberg/Deita-6k
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/KnutJaegersberg/Deita-34b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Deita-34b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q2_K.gguf) | Q2_K | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.IQ3_XS.gguf) | IQ3_XS | 14.3 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q3_K_S.gguf) | Q3_K_S | 15.1 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.IQ3_S.gguf) | IQ3_S | 15.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.IQ3_M.gguf) | IQ3_M | 15.7 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q3_K_M.gguf) | Q3_K_M | 16.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q3_K_L.gguf) | Q3_K_L | 18.2 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.IQ4_XS.gguf) | IQ4_XS | 18.7 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q4_K_S.gguf) | Q4_K_S | 19.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q4_K_M.gguf) | Q4_K_M | 20.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q5_K_S.gguf) | Q5_K_S | 23.8 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q5_K_M.gguf) | Q5_K_M | 24.4 | |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q6_K.gguf) | Q6_K | 28.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Deita-34b-GGUF/resolve/main/Deita-34b.Q8_0.gguf) | Q8_0 | 36.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/LemonKunoichiWizardV3-GGUF | mradermacher | 2024-05-19T12:18:21Z | 576 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Statuo/LemonKunoichiWizardV3",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-19T10:13:13Z | ---
base_model: Statuo/LemonKunoichiWizardV3
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/Statuo/LemonKunoichiWizardV3
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/LemonKunoichiWizardV3-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/LemonKunoichiWizardV3-GGUF/resolve/main/LemonKunoichiWizardV3.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/Qwen2-72B-Instruct-GGUF | mradermacher | 2024-06-07T17:42:09Z | 576 | 0 | transformers | [
"transformers",
"gguf",
"chat",
"en",
"base_model:Qwen/Qwen2-72B-Instruct",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-06T23:31:05Z | ---
base_model: Qwen/Qwen2-72B-Instruct
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen2-72B-Instruct/blob/main/LICENSE
license_name: tongyi-qianwen
quantized_by: mradermacher
tags:
- chat
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Qwen/Qwen2-72B-Instruct
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen2-72B-Instruct-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.IQ3_XS.gguf) | IQ3_XS | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.IQ3_S.gguf) | IQ3_S | 34.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.IQ3_M.gguf) | IQ3_M | 35.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-Instruct-GGUF/resolve/main/Qwen2-72B-Instruct.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
youknownothing/epicphotogasm_ultimateFidelity_perturbed_attention_guidance | youknownothing | 2024-06-17T09:40:37Z | 576 | 0 | diffusers | [
"diffusers",
"safetensors",
"pag",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-06-15T13:15:02Z | ---
license: apache-2.0
language:
- en
tags:
- pag
---
This model comes with modified weight, noise, and some advanced changes to make the output more realistic. PAG enabled. But you can always enable PAG for even better image quality. |
lakshmanarun/floor-plan | lakshmanarun | 2024-06-20T13:48:01Z | 576 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-06-20T13:19:21Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
language:
- en
library_name: diffusers
---
### floor-plan Dreambooth model trained by lakshmanarun with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept: |
notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF | notstevensalt | 2024-06-23T09:13:54Z | 576 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:Sao10K/L3-8B-Stheno-v3.3-32K",
"license:cc-by-nc-4.0",
"region:us"
]
| null | 2024-06-23T09:13:29Z | ---
base_model: Sao10K/L3-8B-Stheno-v3.3-32K
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF
This model was converted to GGUF format from [`Sao10K/L3-8B-Stheno-v3.3-32K`](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.3-32K) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.3-32K) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF --hf-file l3-8b-stheno-v3.3-32k-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF --hf-file l3-8b-stheno-v3.3-32k-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF --hf-file l3-8b-stheno-v3.3-32k-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo notstevensalt/L3-8B-Stheno-v3.3-32K-Q5_K_M-GGUF --hf-file l3-8b-stheno-v3.3-32k-q5_k_m.gguf -c 2048
```
|
Sashkanik13/openjourney-text2img-gguf | Sashkanik13 | 2024-07-01T07:11:45Z | 576 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-07-01T07:09:09Z | Entry not found |
microsoft/tapex-large | microsoft | 2023-05-03T03:48:31Z | 575 | 8 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"tapex",
"table-question-answering",
"en",
"arxiv:2107.07653",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| table-question-answering | 2022-03-10T04:55:54Z | ---
language: en
tags:
- tapex
- table-question-answering
license: mit
---
# TAPEX (large-sized model)
TAPEX was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. The original repo can be found [here](https://github.com/microsoft/Table-Pretraining).
## Model description
TAPEX (**Ta**ble **P**re-training via **Ex**ecution) is a conceptually simple and empirically powerful pre-training approach to empower existing models with *table reasoning* skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
TAPEX is based on the BART architecture, the transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder.
## Intended Uses
⚠️ This model checkpoint is **ONLY** used for fine-tuining on downstream tasks, and you **CANNOT** use this model for simulating neural SQL execution, i.e., employ TAPEX to execute a SQL query on a given table. The one that can neurally execute SQL queries is at [here](https://huggingface.co/microsoft/tapex-large-sql-execution).
> This separation of two models for two kinds of intention is because of a known issue in BART large, and we recommend readers to see [this comment](https://github.com/huggingface/transformers/issues/15559#issuecomment-1062880564) for more details.
### How to Fine-tuning
Please find the fine-tuning script [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/tapex).
### BibTeX entry and citation info
```bibtex
@inproceedings{
liu2022tapex,
title={{TAPEX}: Table Pre-training via Learning a Neural {SQL} Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Morteza Ziyadi and Zeqi Lin and Weizhu Chen and Jian-Guang Lou},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=O50443AsCP}
}
``` |
cosc/sketchstyle-cutesexyrobutts | cosc | 2023-02-09T00:15:16Z | 575 | 48 | diffusers | [
"diffusers",
"stable-diffusion",
"art",
"cutesexyrobutts",
"style",
"dreambooth",
"text-to-image",
"en",
"dataset:Cosk/cutesexyrobutts",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2022-12-19T22:52:59Z | ---
license: creativeml-openrail-m
language:
- en
pipeline_tag: text-to-image
tags:
- stable-diffusion
- art
- cutesexyrobutts
- style
- dreambooth
datasets:
- Cosk/cutesexyrobutts
library_name: diffusers
widget:
- text: portrait of a beautiful girl
- text: beautiful girl, playboy bunny, dark skin, black hair, blunt bangs, ponytail
---
# 'Sketchstyle' (cutesexyrobutts style)
Base model: https://huggingface.co/Linaqruf/anything-v3.0.</br>
Used 'fast-DreamBooth' on Google Colab and 768x768 images for all versions.
## NEW: Merges
*Merging sketchstyle models with other models will help to improve anatomy and other elements while also trying to keep the intended style as much as possible.</br>
I will upload from time to time new merges, if any of those improves on the previous ones. </br>
A 'weak' model means there is more weight to cutesexyrobutts style and a 'strong' model means there is a little more focus on the other model/models.</br>
Weak models might mantain a little more of the style but could have some anatomy problems, while strong models keep better anatomy though the style might become a little affected. Low CFG Scale (5-9) and using the "sketchstyle" token in the prompts might help with keeping the style on strong models.</br>*
**List of merges:**
- Pastelmix 0.2 + sketchstyle_v4-42k 0.8 weak (weighted sum, fp16)
- Pastelmix 0.4 + sketchstyle_v4-42k 0.6 strong (weighted sum, fp16)
**Versions:**
- V1: Trained with around 1300 images (from danbooru), automatically cropped.
- V2: Trained with 400 handpicked and handcropped images.
- V3: Trained with the same images as V2, but with 'style training' enabled.
- V4: Trained with 407 images, including 'captions' for each image.
**Recommended to use:**
- V4-42k (pretty good style and decent anatomy, might be the best)
- V3-40k (decent style and anatomy)
- V4-10k (best anatomy, meh style)
- V4-100k (good style, bad anatomy/hard to use, useful with img2img)
**Usage recommendations:**
- For V4, don't use CFG Scale over 11-12, as it will generate an overcooked image. Try between 6 to 9 at first. 9 seems to be the best if you're using the 'sketchstyle' in the prompt, if not, lower
- Generating specific characters might be hard, result in bad anatomy or not even work at all. If you want an specific character, the best is to use img2img with an image generated with another model
- Going over a certain resolution will generate incoherent results, so try staying close to 768x768 (examples: 640x896, 768x960, 640x1024, 832x640, and similar). Maybe Hires fix could help.
- Make sure to add nsfw/nipples/huge or large breasts in the negative prompts if you don't want any of those.
- Skin tone tends to be 'tan', use dark skin/tan on the negative prompts if its the case, and/or pale skin in the prompts.
- Using img2img to change the style of another image generally gives the best results, examples below.
Pay attention to this number. Normally going below 75 generates bad results, specially with models with high steps like V4-100k. Best with 100+

Token: 'sketchstyle' (if used, anatomy may get affected, but it can be useful for models with low steps to get a better style)<br />
**Limitations and known errors:**
- Not very good anatomy
- Sometimes it generates artifacts, specially on the eyes and lips
- Tends to generate skimpy clothes, open clothes, cutouts, and similar
- Might generate unclear outlines
Try using inpainting and/or img2img to fix these.
# Comparison between different versions and models
As you can see, robutts tends to give less coherent results and might need more prompting/steps to get good results (tried on other things aswell with similar results)

V2 with 10k steps or lower tends to give better anatomy results, and over that the style appears more apparent, so 10k is the 'sweet spot'.

Around 40 steps seems to be the best, but you should use 20 steps and, if you get an image you like, you increase the step count to 40 or 50.

Comparison between not completing that negative prompt and increasing the strength too much.

Comparison (using V3-5k) of token strength.

Another comparison of token strength using V3-15k.

Comparison, from 1 to 30 steps, between NovelAI - Sketchstyle V3-27500 (img2img with NovelAI image) - Sketchstyle V3-27500. Using Euler sampler.

# Examples:

```bibtex
Prompt: (masterpiece,best quality,ultra-detailed),((((face close-up)))),((profile)),((lips,pink_eyes)),((pink_hair,hair_slicked_back,hair_strand)),(serious),portrait,frown,arms_up,adjusting_hair,eyelashes,parted_lips,(sportswear,crop_top),toned,collarbone,ponytail,1girl,solo,highres<br />
Negative prompt: (deformed,disfigured),(sitting,fat,thick,thick_thighs,nsfw),open_clothes,open_shirt,(jewelry,earrings,hair_ornament),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,realistic,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 70, Sampler: Euler, CFG scale: 12, Seed: 1365838486, Size: 768x768, Model: Sketchstyle V3-5k
```
_Eyes fixed with inpainting_:

```bibtex
Prompt: (masterpiece,best quality,ultra-detailed),((((face close-up)))),((profile)),((lips,pink_eyes)),((pink_hair,hair_slicked_back,hair_strand)),(serious),portrait,frown,arms_up,adjusting_hair,eyelashes,parted_lips,(sportswear,crop_top),toned,collarbone,ponytail,1girl,solo,highres<br />
Negative prompt: (deformed,disfigured),(sitting,fat,thick,thick_thighs,nsfw),open_clothes,open_shirt,(jewelry,earrings,hair_ornament),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,realistic,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 34, Sampler: Euler, CFG scale: 12, Seed: 996011741, Size: 768x768, Denoising strength: 0.6, Mask blur: 8, Model: Sketchstyle V2-10k
```

```bibtex
Prompt: sketchstyle,(masterpiece, best quality,beautiful lighting,stunning,ultra-detailed),(portrait,upper_body,parted_lips),1girl, (nipples), (fox ears,animal_ear_fluff), (bare_shoulders,eyelashes,lips,orange eyes,blush),orange_hair,((onsen,indoors)),(toned),medium_breasts,navel,cleavage,looking at viewer,collarbone,hair bun, solo, highres,(nsfw)<br />
Negative prompt: (dark-skin,dark_nipples,extra_nipples),deformed,disfigured,(sitting,fat,thick,thick_thighs,nsfw),open_clothes,open_shirt,(jewelry,earrings,hair_ornament),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,realistic,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 30, Sampler: Euler, CFG scale: 12, Seed: 4172541433, Size: 640x832, Model: Sketchstyle V3-5k
```

```bibtex
Prompt: sketchstyle,(masterpiece, best quality,beautiful lighting,stunning,ultra-detailed),(portrait,upper_body),1girl, (nipples), (fox ears,animal_ear_fluff), (bare_shoulders,eyelashes,lips,orange eyes,ringed_eyes,shy,blush),onsen,indoors,medium_breasts, cleavage,looking at viewer,collarbone,hair bun, solo, highres,(nsfw)<br />
Negative prompt: Negative prompt: (huge_breasts,large_breasts),realistic,3D,3D Game,nsfw,lowres, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth<br />
Steps: 40, Sampler: Euler, CFG scale: 14, Seed: 4268937236, Size: 704x896, Model: Sketchstyle V3-5k
```

```bibtex
Prompt: (masterpiece,best quality,ultra detailed),(((facing_away,sitting,arm_support,thighs,legs))),(((from_behind,toned,ass,bare back,breasts))),((thong,garter_belt,garter_straps,lingerie)),(hair_flower,bed_sheet),(black_hair,braid,braided_ponytail,long_hair),1girl,grey_background,thighs,solo,highres<br />
Negative prompt: ((deformed)),((looking_back,looking_at_viewer,face)),((out_of_frame,cropped)),(fat,thick,thick_thighs),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, patreon_logo, patreon_username, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 50, Sampler: Euler, CFG scale: 12, Seed: 3765393440, Size: 640x832, Model: Sketchstyle V3-5k
```

```bibtex
Prompt: (masterpiece,best quality,ultra detailed),(((facing_away,sitting,arm_support,thighs,legs))),(((from_behind,toned,ass,bare back))),((thong,garter_belt,garter_straps,lingerie)),(hair_flower,bed_sheet),(black_hair,braid,braided_ponytail,long_hair),1girl,grey_background,thighs,solo,highres<br />
Negative prompt: backboob,((deformed)),((looking_back,looking_at_viewer,face)),((out_of_frame,cropped)),(fat,thick,thick_thighs),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, patreon_logo, patreon_username, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 50, Sampler: Euler, CFG scale: 12, Seed: 2346086519, Size: 640x832, Model: Sketchstyle V3-5k
```

```bibtex
Prompt: (masterpiece,best quality,ultra-detailed),(sketchstyle),(arms_up,tying_hair),(large_breasts,nipples),(long_hair,blonde_hair,tied_hair,ponytail,collarbone,navel,stomach,midriff,completely_nude,nude,toned),((cleft_of_venus,pussy)),cloudy_sky,1girl,solo,highres,(nsfw)<br />
Negative prompt: (deformed,disfigured,bad proportions,exaggerated),from_behind,(jewelry,earrings,hair_ornament),((sagging_breasts,huge_breasts,shiny,shiny_hair,shiny_skin,realistic,3D,3D game)),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),((fat,thick,thick_thighs)),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 40, Sampler: Euler, CFG scale: 12, Seed: 4024165718, Size: 704x960, Model: Sketchstyle V3-5k
```

```bibtex
Prompt: (masterpiece,best quality),(sketchstyle),((1boy,male_focus)),((close-up,portrait)),((black_shirt)),((((red collared_coat)))),((dante_\(devil_may_cry\),devil may cry)),((medium_hair,parted_hair,parted_bangs,forehead,white_hair)),((stubble)),(facial_hair),(popped_collar,open_coat),(closed_mouth,smile),blue_eyes,looking_at_viewer,solo,highres<br />
Negative prompt: ((deformed)),(nsfw),(long_hair,short_hair,young,genderswap,1girl,female,breasts,androgynous),((choker)),(shiny,shiny_hair,shiny_skin,3D,3D game),((extra_limbs,extra_arms)),(loli,shota),(giant nipples),((fat,thick,thick_thighs)),long body,(lowres),(((poorly drawn fingers, poorly drawn hands))),((anatomic nonsense)),(extra fingers),(fused fingers),(((one hand with more than 5 fingers))),(((one hand with less than 5 fingers))),(bad eyes),(separated eyes),(long neck),((bad proportions)),long body,((poorly drawn eyes)),((poorly drawn)),((bad drawing)),blurry,((mutation)),((bad anatomy)),(multiple arms),((bad face)),((bad eyes)),bad tail,((more than 2 ears)),((poorly drawn face)), (extra limb), ((deformed hands)), (poorly drawn feet), (mutated hands and fingers), extra legs, extra ears, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face maskissing fingers, bad hands, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled,monochrome, greyscale,face mask<br />
Steps: 50, Sampler: Euler, CFG scale: 12, Seed: 4166887955, Size: 768x768, Model: Sketchstyle V3-5k
```
# img2img style change examples:

```bibtex
Original settings: Model: NovelAI, Steps: 30, Sampler: Euler a, CFG scale: 16, Seed: 3633297035, Size: 640x960<br />
Original prompt: masterpiece, best quality, 1girl, naked towel, fox ears, orange eyes, wet, ringed eyes, shy, medium breasts, cleavage, looking at viewer, hair bun, blush, solo, highres<br />
Original negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth<br />
New settings: Model: Sketchstyle V3 5k steps, Steps: 33, CFG scale: 12, Seed: 3311014108, Size: 640x960, Denoising strength: 0.6, Mask blur: 4<br />
New prompt: ((sketchstyle)),(masterpiece, best quality,beautiful lighting,stunning,ultra-detailed),(portrait,upper_body),1girl, (((naked_towel,towel))), (fox ears,animal_ear_fluff), (bare_shoulders,eyelashes,lips,orange eyes,ringed_eyes,shy,blush),onsen,indoors,medium_breasts, cleavage,looking at viewer,collarbone,hair bun, solo, highres<br />
New negative prompt: (nipples,huge_breasts,large_breasts),realistic,3D,3D Game,nsfw,lowres, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth<br />
```

```bibtex
Original settings: Model: NovelAI, Steps: 30, Sampler: Euler a, CFG scale: 16, Seed: 764529639, Size: 640x960<br />
Prompt: masterpiece, highest quality, (1girl), (looking at viewer), ((pov)), fox ears, ((leaning forward)), [light smile], ((camisole)), short shorts, (cleavage), (((medium breasts))), blonde, (high ponytail), (highres)<br />
Negative prompt: ((deformed)), (duplicated), lowres, ((missing animal ears)), ((poorly drawn face)), ((poorly drawn eyes)), (extra limb), (mutation), ((deformed hands)), (((poorly drawn hands))), (poorly drawn feet), (fused toes), (fused fingers), (mutated hands and fingers), (one hand with more than 5 fingers), (one hand with less than 5 fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled, huge breasts, black and white, monochrome, 3D Game, 3D, realistic, realism, huge breasts<br />
New settings: Model: Sketchstyle V3 5k steps, Steps: 28, CFG scale: 12, Seed: 1866024520, Size: 640x960, Denoising strength: 0.7, Mask blur: 8
```

```bibtex
Original settings: Model: NovelAI, Steps: 25, Sampler: Euler a, CFG scale: 11, Seed: 2604970030, Size: 640x896<br />
Original prompt: (masterpiece),(best quality),((sketch)),(ultra detailed),(1girl, teenage),((white hair, messy hair)),((expressionless)),(black jacket, long sleeves),((grey scarf)),((squatting)), (hands on own knees),((plaid_skirt, pleated skirt, miniskirt)),(fox ears, extra ears, white fox tail, fox girl, animal ear fluff),black ((boots)),full body,bangs,ahoge,(grey eyes),solo,absurdres<br />
Negative prompt: ((deformed)),((loli, young)),(kneehighs,thighhighs),long body, long legs),lowres,((((poorly drawn fingers, poorly drawn hands)))),((anatomic nonsense)),(extra fingers),((fused fingers)),(plaid scarf),(spread legs),((one hand with more than 5 fingers)), ((one hand with less than 5 fingers)),((bad eyes)),(twin, multiple girls, 2girls),(separated eyes),(long neck),((bad proportions)),(bad lips),((thick lips)),loli,long body,(((poorly drawn eyes))),((poorly drawn)),((bad drawing)),(blurry),(((mutation))),(((bad anatomy))),(((multiple arms))),(((bad face))),(((bad eyes))),bad tail,(((more than 2 ears)), (((poorly drawn face))), (extra limb), ((deformed hands)), (poorly drawn feet), (fused toes), (mutated hands and fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled, huge breasts, black and white, monochrome, 3D Game, 3D, (realistic), face mask<br />
New settings: Model: Sketchstyle V3 5k steps, Steps: 45, CFG scale: 12, Seed: 1073378414, Size: 640x896, Denoising strength: 0.6, Mask blur: 8<br />
New prompt: (masterpiece),(best quality),(sketchstyle),(ultra detailed),(1girl, teenage),((white hair, messy hair)),((expressionless)),(black jacket, long sleeves),((grey scarf)),((squatting)), (hands on own knees),((plaid_skirt, pleated skirt, miniskirt)),(fox ears, extra ears, white fox tail, fox girl, animal ear fluff),black ((boots)),full body,bangs,ahoge,(grey eyes),solo,absurdres<br />
```

```bibtex
Original settings: Model: NovelAI, Steps: 30, Sampler: Euler a, CFG scale: 12, Seed: 3659534337, Size: 768x832<br />
Original prompt: ((masterpiece)), ((highest quality)),(((ultra-detailed))),(illustration),(1girl), portrait,((wolf ears)),(beautiful eyes),looking at viewer,dress shirt,shadows,((ponytail)), (white hair), ((sidelocks)),outdoors,bangs, solo, highres<br />
Original negative prompt: ((deformed)), lowres,loli,((monochrome)),(black and white),((lips)),long body,(((poorly drawn eyes))),((out of frame)),((poorly drawn)),((bad drawing)),(blurry),depth of field,(fused fingers),(((mutation))),((bad anatomy)),(((multiple arms))),(((bad face))),(((bad eyes))),bad tail,(((more than 2 ears)), (((poorly drawn face))), (extra limb), ((deformed hands)), (((poorly drawn hands))), (poorly drawn feet), (fused toes), (mutated hands and fingers), (one hand with more than 5 fingers), (one hand with less than 5 fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled, huge breasts, black and white, monochrome, 3D Game, 3D, realism, face mask<br />
New settings: Model: Sketchstyle V3-20k 2000steps text encoder, Steps: 80, CFG scale: 12, Seed: 3001145714, Size: 768x832, Denoising strength: 0.5, Mask blur: 4<br />
New prompt: ((sketchstyle)),(masterpiece,best quality,highest quality,illustration),((ultra-detailed)),1girl,(portrait,close-up),((wolf_girl,wolf_ears)),(eyelashes,detailed eyes,beautiful eyes),looking at viewer,(collared-shirt,white_shirt),((ponytail)), (white hair), ((sidelocks)),(blue eyes),closed_mouth,(shadows,outdoors,sunlight,grass,trees),hair_between_eyes,bangs,solo,highres<br />
New negative prompt: ((deformed)),(less than 5 fingers, more than 5 fingers,bad hands,bad hand anatomy,missing fingers, extra fingers, mutated hands, disfigured hands, deformed hands),lowres,loli,((monochrome)),(black and white),((lips)),long body,(((poorly drawn eyes))),((out of frame)),((poorly drawn)),((bad drawing)),(blurry),depth of field,(fused fingers),(((mutation))),((bad anatomy)),(((multiple arms))),(((bad face))),(((bad eyes))),bad tail,(((more than 2 ears)), (((poorly drawn face))), (extra limb), ((deformed hands)), (((poorly drawn hands))), (poorly drawn feet), (fused toes), (mutated hands and fingers), (one hand with more than 5 fingers), (one hand with less than 5 fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored, blurry lines, wacky outlines, unclear outlines, doubled, huge breasts, black and white, monochrome, 3D Game, 3D, realism, face mask<br />
```

```bibtex
Original settings: Model: NovelAI, Steps: 20, Sampler: Euler, CFG scale: 11, Seed: 2413712316, Size: 768x768<br />
Original prompt: (masterpiece,best quality,ultra-detailed,detailed_eyes),(sketch),((portrait,face focus)),(((shaded eyes))),(wavy hair),(((ringed eyes,red_hair))),((black hair ribbon)),((hair behind ear)),(((short ponytail))),(blush lines),(good anatomy),(((hair strands))),(bangs),((lips)),[teeth, tongue],yellow eyes,(eyelashes),shirt, v-neck,collarbone,cleavage,breasts,(medium hair),(sidelocks),looking at viewer,(shiny hair),1girl,solo,highres<br />
Original negative prompt: ((deformed)),lowres,(black hair),(formal),earrings,(twin, multiple girls, 2girls),(braided bangs),((big eyes)),((close up, eye focus)),(separated eyes),(multiple eyebrows),((eyebrows visible through hair)),(long neck),(bad lips),(tongue out),((thick lips)),(from below),loli,long body,(((poorly drawn eyes))),((poorly drawn)),((bad drawing)),((blurry)),depth of field,(fused fingers),(((mutation))),(((bad anatomy))),(((multiple arms))),(((bad face))),(((bad eyes))),bad tail,(((more than 2 ears)), (((poorly drawn face))), (extra limb), ((deformed hands)), (((poorly drawn hands))), (poorly drawn feet), (fused toes), (mutated hands and fingers), (one hand with more than 5 fingers), (one hand with less than 5 fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored,doubled, huge breasts, black and white, monochrome, 3D Game, 3D, (realistic), face mask<br />
New settings: (img2img with original image, then again with the new generated image, inpainted to fix the neck) Model: Sketchstyle V3-27.5k 2000steps text encoder, Steps: 80, CFG scale: 12, Seed: 1237755461 / 1353966202, Size: 832x832, Denoising strength: 0.5 / 0.3, Mask blur: 4<br />
New prompt: sketchstyle,(masterpiece,best quality,ultra-detailed,detailed_eyes),(((portrait,face focus,close-up))),(((shaded eyes))),(wavy hair),(((ringed eyes,red_hair))),((black hair ribbon)),((hair behind ear)),(((short ponytail))),(blush lines),(good anatomy),(((hair strands))),(bangs),((lips)),[teeth, tongue],(yellow eyes,eyelashes,tsurime,slanted_eyes),shirt, v-neck,collarbone,breasts,(medium hair),(sidelocks),looking at viewer,(shiny hair),1girl,solo,highres<br />
New negative prompt: ((deformed)),((loli,young)),lowres,(black hair),(formal),earrings,(twin, multiple girls, 2girls),(braided bangs),((big eyes)),((close up, eye focus)),(separated eyes),(multiple eyebrows),((eyebrows visible through hair)),(long neck),(bad lips),(tongue out),((thick lips)),(from below),loli,long body,(((poorly drawn eyes))),((poorly drawn)),((bad drawing)),((blurry)),depth of field,(fused fingers),(((mutation))),(((bad anatomy))),(((multiple arms))),(((bad face))),(((bad eyes))),bad tail,(((more than 2 ears)), (((poorly drawn face))), (extra limb), ((deformed hands)), (((poorly drawn hands))), (poorly drawn feet), (fused toes), (mutated hands and fingers), (one hand with more than 5 fingers), (one hand with less than 5 fingers), extra toes, missing toes, extra feet, extra legs, extra ears, missing ear, extra hands, bad feet, bad anatomy, bad hands, text, error, missing fingers, bad hands, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, bad face, bad mouth, animal hands, censored,doubled, huge breasts, black and white, monochrome, 3D Game, 3D, (realistic), face mask<br />
``` |
keremberke/yolov5m-aerial-sheep | keremberke | 2023-01-05T11:22:18Z | 575 | 2 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/aerial-sheep-object-detection",
"model-index",
"region:us"
]
| object-detection | 2023-01-05T11:21:19Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.7
inference: false
datasets:
- keremberke/aerial-sheep-object-detection
model-index:
- name: keremberke/yolov5m-aerial-sheep
results:
- task:
type: object-detection
dataset:
type: keremberke/aerial-sheep-object-detection
name: keremberke/aerial-sheep-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.9704725897101816 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-aerial-sheep" src="https://huggingface.co/keremberke/yolov5m-aerial-sheep/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-aerial-sheep')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-aerial-sheep --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)**
|
ShibaDeveloper/olivia-v1.0 | ShibaDeveloper | 2023-05-16T09:44:55Z | 575 | 7 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"English",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-01-09T01:01:41Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- en
- English
inference: true
widget:
- text: 1girl, detailed, intricate, elegant, highly detailed, digital painting, artstation, concept art, matte, sharp focus, illustration, by dan mumford, yusuke murata, makoto shinkai, ross tran
example_title: example 1girl
---
# Olivia V1.0
Welcome to Olivia V1.0 This model is for educational and testing purposes only.
## 🧨 Diffusers
This model can be used like any other model. [Click to read more](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion)
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "ShibaDeveloper/olivia-v1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "1girl, beautiful girl, face, yellow eyes, black hair"
image = pipe(prompt).images[0]
image.save("./olivia_img.png")
```
## ✨ Examples
Examples of images generated using Olivia V1.0 :

```
Prompt: 1girl, detailed, intricate, elegant, highly detailed, digital painting, artstation, concept art, matte, sharp focus, illustration, by dan mumford, yusuke murata, makoto shinkai, ross tran
Steps: 50, Sampler: DDIM, CFG scale: 12
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
timm/coat_small.in1k | timm | 2023-04-24T03:44:01Z | 575 | 0 | timm | [
"timm",
"pytorch",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.06399",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-04-24T03:43:49Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for coat_small.in1k
A CoaT (Co-Scale Conv-Attentional Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 21.7
- GMACs: 12.6
- Activations (M): 44.3
- Image size: 224 x 224
- **Papers:**
- Co-Scale Conv-Attentional Image Transformers: https://arxiv.org/abs/2104.06399
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/mlpc-ucsd/CoaT
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coat_small.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coat_small.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (torch.Size([1, 785, 320]), torch.Size([1, 197, 320]), torch.Size([1, 50, 320])) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@InProceedings{Xu_2021_ICCV,
author = {Xu, Weijian and Xu, Yifan and Chang, Tyler and Tu, Zhuowen},
title = {Co-Scale Conv-Attentional Image Transformers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {9981-9990}
}
```
|
redstonehero/lazymix_real_amateur_nudes_v30b | redstonehero | 2023-08-09T06:39:41Z | 575 | 2 | diffusers | [
"diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-08-09T03:48:44Z | ---
license: creativeml-openrail-m
library_name: diffusers
--- |
TheBloke/Vicuna-13B-CoT-GGUF | TheBloke | 2023-09-27T12:53:22Z | 575 | 2 | transformers | [
"transformers",
"gguf",
"llama",
"arxiv:1910.09700",
"base_model:kevinpro/Vicuna-13B-CoT",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-20T01:58:19Z | ---
license: other
model_name: Vicuna 13B CoT
base_model: kevinpro/Vicuna-13B-CoT
inference: false
model_creator: Shuaijie She
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Vicuna 13B CoT - GGUF
- Model creator: [Shuaijie She](https://huggingface.co/kevinpro)
- Original model: [Vicuna 13B CoT](https://huggingface.co/kevinpro/Vicuna-13B-CoT)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Shuaijie She's Vicuna 13B CoT](https://huggingface.co/kevinpro/Vicuna-13B-CoT).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Vicuna-13B-CoT-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF)
* [Shuaijie She's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TheBloke/Vicuna-13B-CoT-fp16)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [Vicuna-13B-CoT.Q2_K.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [Vicuna-13B-CoT.Q3_K_S.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [Vicuna-13B-CoT.Q3_K_M.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [Vicuna-13B-CoT.Q3_K_L.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [Vicuna-13B-CoT.Q4_0.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [Vicuna-13B-CoT.Q4_K_S.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [Vicuna-13B-CoT.Q4_K_M.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [Vicuna-13B-CoT.Q5_0.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [Vicuna-13B-CoT.Q5_K_S.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [Vicuna-13B-CoT.Q5_K_M.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [Vicuna-13B-CoT.Q6_K.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [Vicuna-13B-CoT.Q8_0.gguf](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGUF/blob/main/Vicuna-13B-CoT.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Vicuna-13B-CoT-GGUF and below it, a specific filename to download, such as: Vicuna-13B-CoT.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Vicuna-13B-CoT-GGUF Vicuna-13B-CoT.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Vicuna-13B-CoT-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Vicuna-13B-CoT-GGUF Vicuna-13B-CoT.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m Vicuna-13B-CoT.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Vicuna-13B-CoT-GGUF", model_file="Vicuna-13B-CoT.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Shuaijie She's Vicuna 13B CoT
<!-- header start -->
<div style="width: 100%;">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p><a href="https://discord.gg/Jq4vkcDakD">Chat & support: my new Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<!-- header end -->
# Kevin Pro's Vicuna 13B CoT fp16
These files are pytorch format fp16 model files for [Kevin Pro's Vicuna 13B CoT](https://huggingface.co/kevinpro/Vicuna-13B-CoT).
It is the result of merging and/or converting the source repository to float16.
## Repositories available
* [4-bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference](https://huggingface.co/TheBloke/Vicuna-13B-CoT-GGML)
* [Unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TheBloke/Vicuna-13B-CoT-fp16)
<!-- footer start -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/Jq4vkcDakD)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Luke from CarbonQuill, Aemon Algiz, Dmitriy Samsonov.
**Patreon special mentions**: Ajan Kanaga, Kalila, Derek Yates, Sean Connelly, Luke, Nathan LeClaire, Trenton Dambrowitz, Mano Prime, David Flickinger, vamX, Nikolai Manek, senxiiz, Khalefa Al-Ahmad, Illia Dulskyi, trip7s trip, Jonathan Leane, Talal Aujan, Artur Olbinski, Cory Kujawski, Joseph William Delisle, Pyrater, Oscar Rangel, Lone Striker, Luke Pendergrass, Eugene Pentland, Johann-Peter Hartmann.
Thank you to all my generous patrons and donaters!
<!-- footer end -->
# Original model card: Kevin Pro's Vicuna 13B CoT
# Model Card for Model ID
SFT to enhance the CoT capabiliy of Vicuna
If you find the model helpful, please click "like" to support us.
We also welcome feedback on your usage experience and any issues you encounter in the issues section.
Another 7B version: https://huggingface.co/kevinpro/Vicuna-7B-CoT
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
<!-- original-model-card end -->
|
lomahony/pythia-2.8b-helpful-sft-3epochs | lomahony | 2024-03-14T18:13:06Z | 575 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-14T18:10:05Z | Entry not found |
mayflowergmbh/Llama3-DiscoLeo-Instruct-8B-32k-v0.1-GGUF | mayflowergmbh | 2024-05-25T19:33:43Z | 575 | 2 | transformers | [
"transformers",
"gguf",
"de",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-25T19:15:31Z | ---
language:
- de
license: llama3
library_name: transformers
tags:
- gguf
---
# # Llama3-DiscoLeo-Instruct 8B 32k-context (version 0.1)
## Thanks and Accreditation
[DiscoResearch/Llama3-DiscoLeo-Instruct-8B-32k-v0.1](https://huggingface.co/collections/DiscoResearch/discoleo-8b-llama3-for-german-6650527496c0fafefd4c9729)
is the result of a joint effort between [DiscoResearch](https://huggingface.co/DiscoResearch) and [Occiglot](https://huggingface.co/occiglot)
with support from the [DFKI](https://www.dfki.de/web/) (German Research Center for Artificial Intelligence) and [hessian.Ai](https://hessian.ai).
Occiglot kindly handled data preprocessing, filtering, and deduplication as part of their latest [dataset release](https://huggingface.co/datasets/occiglot/occiglot-fineweb-v0.5), as well as sharing their compute allocation at hessian.Ai's 42 Supercomputer.
## Model Overview
DiscoResearch/Llama3_DiscoLeo_Instruct_8B_32k_v0.1 is an instruction tuned version of our long-context [Llama3-German-8B-32k](https://huggingface.co/DiscoResearch/Llama3_German_8B_32k).
The base model was derived from [Meta's Llama3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) through continuous pretraining on 65 billion high-quality German tokens, similar to previous [LeoLM](https://huggingface.co/LeoLM) or [Occiglot](https://huggingface.co/collections/occiglot/occiglot-eu5-7b-v01-65dbed502a6348b052695e01) models.
For the long-context version we trained on an additional 100 million tokens at 32k context length, using a rope_theta value of 1.5e6 and a learning rate of 1.5e-5 with a batch size of 256*8192 and otherwise equal hyperparameters to the base model.
We finetuned this checkpoint on the German Instruction dataset from DiscoResearch created by [Jan-Philipp Harries](https://huggingface.co/jphme) and [Daniel Auras](https://huggingface.co/rasdani) ([DiscoResearch](https://huggingface.co/DiscoResearch), [ellamind](https://ellamind.com)).
## How to use
Llama3_DiscoLeo_Instruct_8B_32k_v0.1 uses the [Llama-3 chat template](https://github.com/meta-llama/llama3?tab=readme-ov-file#instruction-tuned-models), which can be easily used with [transformer's chat templating](https://huggingface.co/docs/transformers/main/en/chat_templating).
See [below](https://huggingface.co/DiscoResearch/Llama3_DiscoLeo_Instruct_8B_32k_v0.1#usage-example) for a usage example.
## Model Training and Hyperparameters
The model was full-fintuned with axolotl on the [hessian.Ai 42](hessian.ai) with 32,768 context-length, learning rate 2e-5 and batch size of 16.
## Evaluation and Results
We evaluated the model using a suite of common English Benchmarks and their German counterparts with [GermanBench](https://github.com/bjoernpl/GermanBenchmark).
In the below image and corresponding table, you can see the benchmark scores for the different instruct models compared to Metas instruct version. All checkpoints are available in this [collection](https://huggingface.co/collections/DiscoResearch/discoleo-8b-llama3-for-german-6650527496c0fafefd4c9729).

| Model | truthful_qa_de | truthfulqa_mc | arc_challenge | arc_challenge_de | hellaswag | hellaswag_de | MMLU | MMLU-DE | mean |
|----------------------------------------------------|----------------|---------------|---------------|------------------|-------------|--------------|-------------|-------------|-------------|
| meta-llama/Meta-Llama-3-8B-Instruct | 0.47498 | 0.43923 | **0.59642** | 0.47952 | **0.82025** | 0.60008 | **0.66658** | 0.53541 | 0.57656 |
| DiscoResearch/Llama3-German-8B | 0.49499 | 0.44838 | 0.55802 | 0.49829 | 0.79924 | 0.65395 | 0.62240 | 0.54413 | 0.57743 |
| DiscoResearch/Llama3-German-8B-32k | 0.48920 | 0.45138 | 0.54437 | 0.49232 | 0.79078 | 0.64310 | 0.58774 | 0.47971 | 0.55982 |
| DiscoResearch/Llama3-DiscoLeo-Instruct-8B-v0.1 | **0.53042** | 0.52867 | 0.59556 | **0.53839** | 0.80721 | 0.66440 | 0.61898 | 0.56053 | **0.60552** |
| **DiscoResearch/Llama3-DiscoLeo-Instruct-8B-32k-v0.1** | 0.52749 | **0.53245** | 0.58788 | 0.53754 | 0.80770 | **0.66709** | 0.62123 | **0.56238** | 0.60547 |
## Model Configurations
We release DiscoLeo-8B in the following configurations:
1. [Base model with continued pretraining](https://huggingface.co/DiscoResearch/Llama3-German_8B)
2. [Long-context version (32k context length)](https://huggingface.co/DiscoResearch/Llama3_German_8B_32k)
3. [Instruction-tuned version of the base model](https://huggingface.co/DiscoResearch/Llama3_DiscoLeo_Instruct_8B_v0.1)
4. [Instruction-tuned version of the long-context model](https://huggingface.co/DiscoResearch/Llama3_DiscoLeo_Instruct_8B_32k_v0.1) (This model)
5. [Experimental `DARE-TIES` Merge with Llama3-Instruct](https://huggingface.co/DiscoResearch/Llama3_DiscoLeo_8B_DARE_Experimental)
6. [Collection of Quantized versions](https://huggingface.co/collections/DiscoResearch/discoleo-8b-quants-6651bcf8f72c9a37ce485d42)
## Usage Example
Here's how to use the model with transformers:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"DiscoResearch/Llama3-DiscoLeo-Instruct-8B-v0.1",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("DiscoResearch/Llama3-DiscoLeo-Instruct-8B-32k-v0.1")
prompt = "Schreibe ein Essay über die Bedeutung der Energiewende für Deutschlands Wirtschaft"
messages = [
{"role": "system", "content": "Du bist ein hilfreicher Assistent."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Acknowledgements
The model was trained and evaluated by [Björn Plüster](https://huggingface.co/bjoernp) ([DiscoResearch](https://huggingface.co/DiscoResearch), [ellamind](https://ellamind.com)) with data preparation and project supervision by [Manuel Brack](http://manuel-brack.eu) ([DFKI](https://www.dfki.de/web/), [TU-Darmstadt](https://www.tu-darmstadt.de/)). Initial work on dataset collection and curation was performed by [Malte Ostendorff](https://ostendorff.org) and [Pedro Ortiz Suarez](https://portizs.eu). Instruction tuning was done with the DiscoLM German dataset created by [Jan-Philipp Harries](https://huggingface.co/jphme) and [Daniel Auras](https://huggingface.co/rasdani) ([DiscoResearch](https://huggingface.co/DiscoResearch), [ellamind](https://ellamind.com)). We extend our gratitude to [LAION](https://laion.ai/) and friends, especially [Christoph Schuhmann](https://entwickler.de/experten/christoph-schuhmann) and [Jenia Jitsev](https://huggingface.co/JJitsev), for initiating this collaboration.
The model training was supported by a compute grant at the [42 supercomputer](https://hessian.ai/) which is a central component in the development of [hessian AI](https://hessian.ai/), the [AI Innovation Lab](https://hessian.ai/infrastructure/ai-innovationlab/) (funded by the [Hessian Ministry of Higher Education, Research and the Art (HMWK)](https://wissenschaft.hessen.de) & the [Hessian Ministry of the Interior, for Security and Homeland Security (HMinD)](https://innen.hessen.de)) and the [AI Service Centers](https://hessian.ai/infrastructure/ai-service-centre/) (funded by the [German Federal Ministry for Economic Affairs and Climate Action (BMWK)](https://www.bmwk.de/Navigation/EN/Home/home.html)).
The curation of the training data is partially funded by the [German Federal Ministry for Economic Affairs and Climate Action (BMWK)](https://www.bmwk.de/Navigation/EN/Home/home.html)
through the project [OpenGPT-X](https://opengpt-x.de/en/) (project no. 68GX21007D). |
EPFL-VILAB/4M_tokenizers_edge_8k_224-512 | EPFL-VILAB | 2024-06-14T08:22:59Z | 575 | 0 | ml-4m | [
"ml-4m",
"safetensors",
"arxiv:2312.06647",
"arxiv:2406.09406",
"license:other",
"region:us"
]
| null | 2024-06-12T08:50:02Z | ---
license: other
license_name: sample-code-license
license_link: LICENSE
library_name: ml-4m
---
# 4M: Massively Multimodal Masked Modeling
*A framework for training any-to-any multimodal foundation models. <br>Scalable. Open-sourced. Across tens of modalities and tasks.*
[`Website`](https://4m.epfl.ch) | [`GitHub`](https://github.com/apple/ml-4m) | [`BibTeX`](#citation)
Official implementation and pre-trained models for :
[**4M: Massively Multimodal Masked Modeling**](https://arxiv.org/abs/2312.06647), NeurIPS 2023 (Spotlight) <br>
*[David Mizrahi](https://dmizrahi.com/)\*, [Roman Bachmann](https://roman-bachmann.github.io/)\*, [Oğuzhan Fatih Kar](https://ofkar.github.io/), [Teresa Yeo](https://aserety.github.io/), [Mingfei Gao](https://fly6464.github.io/), [Afshin Dehghan](https://www.afshindehghan.com/), [Amir Zamir](https://vilab.epfl.ch/zamir/)*
[**4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities**](https://arxiv.org/abs/2406.09406), arXiv 2024 <br>
*[Roman Bachmann](https://roman-bachmann.github.io/)\*, [Oğuzhan Fatih Kar](https://ofkar.github.io/)\*, [David Mizrahi](https://dmizrahi.com/)\*, [Ali Garjani](https://garjania.github.io/), [Mingfei Gao](https://fly6464.github.io/), [David Griffiths](https://www.dgriffiths.uk/), [Jiaming Hu](https://scholar.google.com/citations?user=vm3imKsAAAAJ&hl=en), [Afshin Dehghan](https://www.afshindehghan.com/), [Amir Zamir](https://vilab.epfl.ch/zamir/)*
4M is a framework for training "any-to-any" foundation models, using tokenization and masking to scale to many diverse modalities.
Models trained using 4M can perform a wide range of vision tasks, transfer well to unseen tasks and modalities, and are flexible and steerable multimodal generative models.
We are releasing code and models for "4M: Massively Multimodal Masked Modeling" (here denoted 4M-7), as well as "4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities" (here denoted 4M-21).
## Installation
For install instructions, please see https://github.com/apple/ml-4m.
## Usage
The Canny and SAM edges tokenizer can be loaded from Hugging Face Hub as follows:
```python
from fourm.vq.vqvae import DiVAE
tok_edge = DiVAE.from_pretrained('EPFL-VILAB/4M_tokenizers_edge_8k_224-512')
```
Please see https://github.com/apple/ml-4m/blob/main/README_TOKENIZATION.md for more detailed instructions and https://github.com/apple/ml-4m for other tokenizer and 4M model checkpoints.
## Citation
If you find this repository helpful, please consider citing our work:
```
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{\u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{\u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}
```
## License
The model weights in this repository are released under the Sample Code license as found in the [LICENSE](LICENSE) file. |
DeepPavlov/xlm-roberta-large-en-ru | DeepPavlov | 2021-11-15T08:46:05Z | 574 | 4 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"en",
"ru",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| feature-extraction | 2022-03-02T23:29:04Z | ---
language:
- en
- ru
---
# XLM-RoBERTa-Large-En-Ru
## Model description
This model is a version XLM-RoBERTa with embeddings and vocabulary reduced to most frequent tokens in English and Russian.
|
PlanTL-GOB-ES/roberta-base-bne-capitel-ner | PlanTL-GOB-ES | 2022-11-30T08:57:56Z | 574 | 2 | transformers | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"national library of spain",
"spanish",
"bne",
"capitel",
"ner",
"es",
"dataset:bne",
"dataset:capitel",
"arxiv:1907.11692",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-03-02T23:29:04Z | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "capitel"
- "ner"
datasets:
- "bne"
- "capitel"
metrics:
- "f1"
inference:
parameters:
aggregation_strategy: "first"
model-index:
- name: roberta-base-bne-capiter-ner
results:
- task:
type: token-classification
dataset:
type: ner
name: CAPITEL-NERC
metrics:
- name: F1
type: f1
value: 0.8960
widget:
- "Me llamo Francisco Javier y vivo en Madrid."
- "Mi hermano Ramón y su mejor amigo Luis trabajan en el BSC."
---
# Spanish RoBERTa-base trained on BNE finetuned for CAPITEL Named Entity Recognition (NER) dataset.
## Table of contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Evaluation](#evaluation)
- [Evaluation](#evaluation)
- [Variable and metrics](#variable-and-metrics)
- [Evaluation results](#evaluation-results)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citing information](#citing-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
The **roberta-base-bne-capitel-ner** is a Named Entity Recognition (NER) model for the Spanish language fine-tuned from the [roberta-base-bne](https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne) model, a [RoBERTa](https://arxiv.org/abs/1907.11692) base model pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text, processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Intended uses and limitations
**roberta-base-bne-capitel-ner** model can be used to recognize Named Entities (NE). The model is limited by its training dataset and may not generalize well for all use cases.
## How to use
```python
from transformers import pipeline
from pprint import pprint
nlp = pipeline("ner", model="PlanTL-GOB-ES/roberta-base-bne-capitel-ner")
example = "Me llamo Francisco Javier y vivo en Madrid."
ner_results = nlp(example)
pprint(ner_results)
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
The dataset used for training and evaluation is the one from the [CAPITEL competition at IberLEF 2020](https://sites.google.com/view/capitel2020) (sub-task 1).
### Training procedure
The model was trained with a batch size of 16 and a learning rate of 5e-5 for 5 epochs. We then selected the best checkpoint using the downstream task metric in the corresponding development set and then evaluated it on the test set.
## Evaluation
### Variable and metrics
This model was finetuned maximizing F1 score.
## Evaluation results
We evaluated the **roberta-base-bne-capitel-ner** on the CAPITEL-NERC test set against standard multilingual and monolingual baselines:
| Model | CAPITEL-NERC (F1) |
| ------------|:----|
| roberta-large-bne-capitel-ner | **90.51** |
| roberta-base-bne-capitel-ner | 89.60|
| BETO | 87.72 |
| mBERT | 88.10 |
| BERTIN | 88.56 |
| ELECTRA | 80.35 |
For more details, check the fine-tuning and evaluation scripts in the official [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center ([email protected])
### Contact information
For further information, send an email to <[email protected]>
### Copyright
Copyright by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) (2022)
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
### Citing information
If you use this model, please cite our [paper](http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405):
```
@article{,
abstract = {We want to thank the National Library of Spain for such a large effort on the data gathering and the Future of Computing Center, a
Barcelona Supercomputing Center and IBM initiative (2020). This work was funded by the Spanish State Secretariat for Digitalization and Artificial
Intelligence (SEDIA) within the framework of the Plan-TL.},
author = {Asier Gutiérrez Fandiño and Jordi Armengol Estapé and Marc Pàmies and Joan Llop Palao and Joaquin Silveira Ocampo and Casimiro Pio Carrino and Carme Armentano Oller and Carlos Rodriguez Penagos and Aitor Gonzalez Agirre and Marta Villegas},
doi = {10.26342/2022-68-3},
issn = {1135-5948},
journal = {Procesamiento del Lenguaje Natural},
keywords = {Artificial intelligence,Benchmarking,Data processing.,MarIA,Natural language processing,Spanish language modelling,Spanish language resources,Tractament del llenguatge natural (Informàtica),Àrees temàtiques de la UPC::Informàtica::Intel·ligència artificial::Llenguatge natural},
publisher = {Sociedad Española para el Procesamiento del Lenguaje Natural},
title = {MarIA: Spanish Language Models},
volume = {68},
url = {https://upcommons.upc.edu/handle/2117/367156#.YyMTB4X9A-0.mendeley},
year = {2022},
}
```
### Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos. |
UBC-NLP/ARBERT | UBC-NLP | 2022-01-19T20:10:55Z | 574 | 4 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"Arabic BERT",
"MSA",
"Twitter",
"Masked Langauge Model",
"ar",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language:
- ar
tags:
- Arabic BERT
- MSA
- Twitter
- Masked Langauge Model
widget:
- text: "اللغة العربية هي لغة [MASK]."
---
<img src="https://raw.githubusercontent.com/UBC-NLP/marbert/main/ARBERT_MARBERT.jpg" alt="drawing" width="30%" height="30%" align="right"/>
**ARBERT** is one of three models described in our **ACl 2021 paper** **["ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic"](https://mageed.arts.ubc.ca/files/2020/12/marbert_arxiv_2020.pdf)**. ARBERT is a large-scale pre-trained masked language model focused on Modern Standard Arabic (MSA). To train ARBERT, we use the same architecture as BERT-base: 12 attention layers, each has 12 attention heads and 768 hidden dimensions, a vocabulary of 100K WordPieces, making ∼163M parameters. We train ARBERT on a collection of Arabic datasets comprising **61GB of text** (**6.2B tokens**). For more information, please visit our own GitHub [repo](https://github.com/UBC-NLP/marbert).
# BibTex
If you use our models (ARBERT, MARBERT, or MARBERTv2) for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
```bibtex
@inproceedings{abdul-mageed-etal-2021-arbert,
title = "{ARBERT} {\&} {MARBERT}: Deep Bidirectional Transformers for {A}rabic",
author = "Abdul-Mageed, Muhammad and
Elmadany, AbdelRahim and
Nagoudi, El Moatez Billah",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.551",
doi = "10.18653/v1/2021.acl-long.551",
pages = "7088--7105",
abstract = "Pre-trained language models (LMs) are currently integral to many natural language processing systems. Although multilingual LMs were also introduced to serve many languages, these have limitations such as being costly at inference time and the size and diversity of non-English data involved in their pre-training. We remedy these issues for a collection of diverse Arabic varieties by introducing two powerful deep bidirectional transformer-based models, ARBERT and MARBERT. To evaluate our models, we also introduce ARLUE, a new benchmark for multi-dialectal Arabic language understanding evaluation. ARLUE is built using 42 datasets targeting six different task clusters, allowing us to offer a series of standardized experiments under rich conditions. When fine-tuned on ARLUE, our models collectively achieve new state-of-the-art results across the majority of tasks (37 out of 48 classification tasks, on the 42 datasets). Our best model acquires the highest ARLUE score (77.40) across all six task clusters, outperforming all other models including XLM-R Large ( 3.4x larger size). Our models are publicly available at https://github.com/UBC-NLP/marbert and ARLUE will be released through the same repository.",
}
```
## Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, [ComputeCanada](www.computecanada.ca) and [UBC ARC-Sockeye](https://doi.org/10.14288/SOCKEYE). We also thank the [Google TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) program for providing us with free TPU access. |
kit-nlp/bert-base-japanese-sentiment-irony | kit-nlp | 2022-11-08T04:23:27Z | 574 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-11-07T06:29:21Z | ---
language: ja
license: cc-by-sa-4.0
---
# BERT Base Japanese for Irony
This is a BERT Base model for sentiment analysis in Japanese additionally finetuned for automatic irony detection.
The model was based on [bert-base-japanese-sentiment](https://huggingface.co/daigo/bert-base-japanese-sentiment), and later finetuned on a dataset containing ironic and sarcastic tweets.
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{dan2022bert-base-irony02,
title={北見工業大学 テキスト情報処理研究室 ELECTRA Base 皮肉検出モデル (daigo ver.)},
author={団 俊輔 and プタシンスキ ミハウ and ジェプカ ラファウ and 桝井 文人},
publisher={HuggingFace},
year={2022},
url = "https://huggingface.co/kit-nlp/bert-base-japanese-sentiment-irony"
}
```
|
Aniemore/rubert-base-emotion-russian-cedr-m7 | Aniemore | 2023-04-07T18:08:52Z | 574 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-13T18:11:27Z | Entry not found |
TheBloke/UndiMix-v1-13B-GGUF | TheBloke | 2023-09-27T12:47:03Z | 574 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:Undi95/UndiMix-v1-13b",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
]
| null | 2023-09-01T22:42:44Z | ---
license: cc-by-nc-4.0
model_name: UndiMix v1 13B
base_model: Undi95/UndiMix-v1-13b
inference: false
model_creator: Undi95
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# UndiMix v1 13B - GGUF
- Model creator: [Undi95](https://huggingface.co/Undi95)
- Original model: [UndiMix v1 13B](https://huggingface.co/Undi95/UndiMix-v1-13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Undi95's UndiMix v1 13B](https://huggingface.co/Undi95/UndiMix-v1-13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/UndiMix-v1-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/UndiMix-v1-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF)
* [Undi95's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/UndiMix-v1-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-nc-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Undi95's UndiMix v1 13B](https://huggingface.co/Undi95/UndiMix-v1-13b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [undimix-v1-13b.Q2_K.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [undimix-v1-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [undimix-v1-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [undimix-v1-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [undimix-v1-13b.Q4_0.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [undimix-v1-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [undimix-v1-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [undimix-v1-13b.Q5_0.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [undimix-v1-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [undimix-v1-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [undimix-v1-13b.Q6_K.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [undimix-v1-13b.Q8_0.gguf](https://huggingface.co/TheBloke/UndiMix-v1-13B-GGUF/blob/main/undimix-v1-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/UndiMix-v1-13B-GGUF and below it, a specific filename to download, such as: undimix-v1-13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/UndiMix-v1-13B-GGUF undimix-v1-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/UndiMix-v1-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/UndiMix-v1-13B-GGUF undimix-v1-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m undimix-v1-13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/UndiMix-v1-13B-GGUF", model_file="undimix-v1-13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Undi95's UndiMix v1 13B
Command used :
```shell
python ties_merge.py TheBloke/Llama-2-13B-fp16 .UndiMix-v1-13b --merge The-Face-Of-Goonery/Huginn-13b-v1.2 --merge Doctor-Shotgun/llama-2-13b-chat-limarp-v2-merged
```
Testing around...
<!-- description start -->
## Description
This repo contains fp16 files of my personal mix : "UndiMix".
It can be hot, serious, playful, and can use emoji thanks to llama-2-13b-chat-limarp-v2-merged.
<!-- description end -->
<!-- description start -->
## Models used
- TheBloke/Llama-2-13B-fp16 (base)
- Undi95/MythoMax-L2-Kimiko-v2-13b
- The-Face-Of-Goonery/Huginn-13b-v1.2
- Doctor-Shotgun/llama-2-13b-chat-limarp-v2-merged
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
Special thanks to Sushi kek
<!-- original-model-card end -->
|
DanielClough/Candle_Mistral-7B-OpenOrca | DanielClough | 2023-12-20T19:43:41Z | 574 | 1 | null | [
"gguf",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"license:apache-2.0",
"region:us"
]
| text-generation | 2023-12-18T02:43:20Z | ---
datasets:
- Open-Orca/OpenOrca
language:
- en
pipeline_tag: text-generation
license: apache-2.0
---
This repo includes `.gguf` built for HuggingFace/Candle.
They will not work with `llama.cpp`.
This model should be used with the `Config` [`config_chat_ml`](
https://github.com/huggingface/candle/blob/main/candle-transformers/src/models/mistral.rs).
Refer to the [original repo](https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca) for more details.
|
ntc-ai/SDXL-LoRA-slider.radiant-green-eyes | ntc-ai | 2023-12-24T13:45:15Z | 574 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
]
| text-to-image | 2023-12-24T13:45:12Z |
---
language:
- en
thumbnail: "images/evaluate/radiant green eyes.../radiant green eyes_17_3.0.png"
widget:
- text: radiant green eyes
output:
url: images/radiant green eyes_17_3.0.png
- text: radiant green eyes
output:
url: images/radiant green eyes_19_3.0.png
- text: radiant green eyes
output:
url: images/radiant green eyes_20_3.0.png
- text: radiant green eyes
output:
url: images/radiant green eyes_21_3.0.png
- text: radiant green eyes
output:
url: images/radiant green eyes_22_3.0.png
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
license: "mit"
inference: false
instance_prompt: "radiant green eyes"
base_model: "stabilityai/stable-diffusion-xl-base-1.0"
---
# ntcai.xyz slider - radiant green eyes (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/radiant green eyes_17_-3.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_17_0.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_17_3.0.png" width=256 height=256 /> |
| <img src="images/radiant green eyes_19_-3.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_19_0.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_19_3.0.png" width=256 height=256 /> |
| <img src="images/radiant green eyes_20_-3.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_20_0.0.png" width=256 height=256 /> | <img src="images/radiant green eyes_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
radiant green eyes
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.radiant-green-eyes', weight_name='radiant green eyes.safetensors', adapter_name="radiant green eyes")
# Activate the LoRA
pipe.set_adapters(["radiant green eyes"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, radiant green eyes"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 590+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
InferenceIllusionist/dolphin-2.9.1-mixtral-1x22b-iMat-GGUF | InferenceIllusionist | 2024-05-24T08:06:32Z | 574 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"axolotl",
"iMat",
"en",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:abacusai/SystemChat-1.1",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:cognitivecomputations/dolphin-2.9.1-mixtral-1x22b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-23T23:26:30Z | ---
base_model: cognitivecomputations/dolphin-2.9.1-mixtral-1x22b
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- microsoft/orca-math-word-problems-200k
- abacusai/SystemChat-1.1
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: InferenceIllusionist
tags:
- generated_from_trainer
- axolotl
- iMat
---
<img src="https://i.imgur.com/P68dXux.png" width="400"/>
# dolphin-2.9.1-mixtral-1x22b-iMat-GGUF
Quantized from fp16.
* Weighted quantizations were creating using fp16 GGUF and [groups_merged-enhancedV2-TurboMini.txt](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-9432658) in 228 chunks and n_ctx=512
* This method of calculating the importance matrix showed improvements in some areas for Mistral 7b and Llama3 8b models, see above post for details
* The enhancedv2-turbomini file appends snippets from turboderp's calibration data to the standard groups_merged.txt file
* Repetition penalty 1.05-1.18 has worked well for these quants.
For a brief rundown of iMatrix quant performance please see this [PR](https://github.com/ggerganov/llama.cpp/pull/5747)
<i>All quants are verified working prior to uploading to repo for your safety and convenience. </i>
<b>Tip:</b> Pick a file size under your GPU's VRAM while still allowing some room for context for best speed. You may need to pad this further depending on if you are running image gen or TTS as well.
Original model card can be found [here](https://huggingface.co/cognitivecomputations/dolphin-2.9.1-mixtral-1x22b) |
qwp4w3hyb/Hermes-2-Theta-Llama-3-8B-iMat-GGUF | qwp4w3hyb | 2024-05-24T09:22:23Z | 574 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-24T01:24:50Z | Entry not found |
crusoeai/dolphin-2.9.2-Phi-3-Medium-GGUF | crusoeai | 2024-05-31T21:35:05Z | 574 | 1 | null | [
"gguf",
"region:us"
]
| null | 2024-05-31T21:24:16Z | Entry not found |
mradermacher/Stealth-Notus-xb-GGUF | mradermacher | 2024-06-10T10:17:17Z | 574 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"jan-hq/stealth-v1.3",
"argilla/notus-7b-v1",
"en",
"base_model:powermove72/Stealth-Notus-xb",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-10T08:48:17Z | ---
base_model: powermove72/Stealth-Notus-xb
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- jan-hq/stealth-v1.3
- argilla/notus-7b-v1
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/powermove72/Stealth-Notus-xb
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q2_K.gguf) | Q2_K | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.IQ3_XS.gguf) | IQ3_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q3_K_S.gguf) | Q3_K_S | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.IQ3_S.gguf) | IQ3_S | 5.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.IQ3_M.gguf) | IQ3_M | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q3_K_M.gguf) | Q3_K_M | 5.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q3_K_L.gguf) | Q3_K_L | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.IQ4_XS.gguf) | IQ4_XS | 6.2 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q4_K_S.gguf) | Q4_K_S | 6.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q4_K_M.gguf) | Q4_K_M | 6.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q5_K_S.gguf) | Q5_K_S | 7.8 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q5_K_M.gguf) | Q5_K_M | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q6_K.gguf) | Q6_K | 9.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Stealth-Notus-xb-GGUF/resolve/main/Stealth-Notus-xb.Q8_0.gguf) | Q8_0 | 12.0 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
thesven/Qwen1.5-0.5B-Chat-GGUF | thesven | 2024-06-10T15:32:24Z | 574 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-10T15:22:27Z | Entry not found |
CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF | CHE-72 | 2024-06-22T07:45:21Z | 574 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:01-ai/Yi-1.5-6B-Chat",
"license:apache-2.0",
"region:us"
]
| null | 2024-06-22T07:45:07Z | ---
base_model: 01-ai/Yi-1.5-6B-Chat
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF
This model was converted to GGUF format from [`01-ai/Yi-1.5-6B-Chat`](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF --hf-file yi-1.5-6b-chat-q3_k_l.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF --hf-file yi-1.5-6b-chat-q3_k_l.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF --hf-file yi-1.5-6b-chat-q3_k_l.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Yi-1.5-6B-Chat-Q3_K_L-GGUF --hf-file yi-1.5-6b-chat-q3_k_l.gguf -c 2048
```
|
chatty123/Anime_model | chatty123 | 2024-06-27T03:28:17Z | 574 | 0 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Cartoon",
"Colorful",
"Inzaniak",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-06-27T03:23:52Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Cartoon
- Colorful
- Inzaniak
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
Original page: https://civitai.com/models/24149?modelVersionId=108545
Comparison:

Samples and prompt:

videogames, robert jordan pepperoni pizza, josephine wall winner, hidari, roll20 illumination, radiant light, sitting Pretty CUTE girl, gorgeous hair, DETAILED EYES, Magazine ad, iconic, 1943, Cartoon, sharp focus, 4k, towel. comic art on canvas by kyoani and watched and ROSSDRAWS. elementary |
Helsinki-NLP/opus-mt-en-toi | Helsinki-NLP | 2023-08-16T11:31:27Z | 573 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"en",
"toi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:04Z | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-toi
* source languages: en
* target languages: toi
* OPUS readme: [en-toi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-toi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-toi/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-toi/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-toi/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.toi | 32.8 | 0.598 |
|
AIRI-Institute/gena-lm-bert-base | AIRI-Institute | 2023-07-04T17:15:31Z | 573 | 27 | transformers | [
"transformers",
"pytorch",
"bert",
"dna",
"human_genome",
"custom_code",
"arxiv:2002.04745",
"endpoints_compatible",
"region:us"
]
| null | 2022-06-21T07:53:13Z | ---
tags:
- dna
- human_genome
---
# GENA-LM (gena-lm-bert-base)
GENA-LM is a Family of Open-Source Foundational Models for Long DNA Sequences.
GENA-LM models are transformer masked language models trained on human DNA sequence.
Differences between GENA-LM (`gena-lm-bert-base`) and DNABERT:
- BPE tokenization instead of k-mers;
- input sequence size is about 4500 nucleotides (512 BPE tokens) compared to 512 nucleotides of DNABERT
- pre-training on T2T vs. GRCh38.p13 human genome assembly.
Source code and data: https://github.com/AIRI-Institute/GENA_LM
Paper: https://www.biorxiv.org/content/10.1101/2023.06.12.544594v1
## Examples
### How to load pre-trained model for Masked Language Modeling
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('AIRI-Institute/gena-lm-bert-base')
model = AutoModel.from_pretrained('AIRI-Institute/gena-lm-bert-base', trust_remote_code=True)
```
### How to load pre-trained model to fine-tune it on classification task
Get model class from GENA-LM repository:
```bash
git clone https://github.com/AIRI-Institute/GENA_LM.git
```
```python
from GENA_LM.src.gena_lm.modeling_bert import BertForSequenceClassification
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('AIRI-Institute/gena-lm-bert-base')
model = BertForSequenceClassification.from_pretrained('AIRI-Institute/gena-lm-bert-base')
```
or you can just download [modeling_bert.py](https://github.com/AIRI-Institute/GENA_LM/tree/main/src/gena_lm) and put it close to your code.
OR you can get model class from HuggingFace AutoModel:
```python
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained('AIRI-Institute/gena-lm-bert-base', trust_remote_code=True)
gena_module_name = model.__class__.__module__
print(gena_module_name)
import importlib
# available class names:
# - BertModel, BertForPreTraining, BertForMaskedLM, BertForNextSentencePrediction,
# - BertForSequenceClassification, BertForMultipleChoice, BertForTokenClassification,
# - BertForQuestionAnswering
# check https://huggingface.co/docs/transformers/model_doc/bert
cls = getattr(importlib.import_module(gena_module_name), 'BertForSequenceClassification')
print(cls)
model = cls.from_pretrained('AIRI-Institute/gena-lm-bert-base', num_labels=2)
```
## Model description
GENA-LM (`gena-lm-bert-base`) model is trained in a masked language model (MLM) fashion, following the methods proposed in the BigBird paper by masking 15% of tokens. Model config for `gena-lm-bert-base` is similar to the bert-base:
- 512 Maximum sequence length
- 12 Layers, 12 Attention heads
- 768 Hidden size
- 32k Vocabulary size
We pre-trained `gena-lm-bert-base` using the latest T2T human genome assembly (https://www.ncbi.nlm.nih.gov/assembly/GCA_009914755.3/). Pre-training was performed for 500,000 iterations with the same parameters as in BigBird, except sequence length was equal to 512 tokens. We modified Transformer with [Pre-Layer normalization](https://arxiv.org/abs/2002.04745), but without the final layer LayerNorm.
## Evaluation
For evaluation results, see our paper: https://www.biorxiv.org/content/10.1101/2023.06.12.544594v1
## Citation
```bibtex
@article{GENA_LM,
author = {Veniamin Fishman and Yuri Kuratov and Maxim Petrov and Aleksei Shmelev and Denis Shepelin and Nikolay Chekanov and Olga Kardymon and Mikhail Burtsev},
title = {GENA-LM: A Family of Open-Source Foundational Models for Long DNA Sequences},
elocation-id = {2023.06.12.544594},
year = {2023},
doi = {10.1101/2023.06.12.544594},
publisher = {Cold Spring Harbor Laboratory},
URL = {https://www.biorxiv.org/content/early/2023/06/13/2023.06.12.544594},
eprint = {https://www.biorxiv.org/content/early/2023/06/13/2023.06.12.544594.full.pdf},
journal = {bioRxiv}
}
``` |
timm/tf_efficientnet_l2.ns_jft_in1k | timm | 2023-04-27T21:33:47Z | 573 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.11946",
"arxiv:1911.04252",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-12-13T00:09:14Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_efficientnet_l2.ns_jft_in1k
A EfficientNet image classification model. Trained on ImageNet-1k and unlabeled JFT-300m using Noisy Student semi-supervised learning in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 480.3
- GMACs: 479.1
- Activations (M): 1707.4
- Image size: 800 x 800
- **Papers:**
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks: https://arxiv.org/abs/1905.11946
- Self-training with Noisy Student improves ImageNet classification: https://arxiv.org/abs/1911.04252
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_efficientnet_l2.ns_jft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_l2.ns_jft_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 72, 400, 400])
# torch.Size([1, 104, 200, 200])
# torch.Size([1, 176, 100, 100])
# torch.Size([1, 480, 50, 50])
# torch.Size([1, 1376, 25, 25])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_efficientnet_l2.ns_jft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 5504, 25, 25) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{tan2019efficientnet,
title={Efficientnet: Rethinking model scaling for convolutional neural networks},
author={Tan, Mingxing and Le, Quoc},
booktitle={International conference on machine learning},
pages={6105--6114},
year={2019},
organization={PMLR}
}
```
```bibtex
@article{Xie2019SelfTrainingWN,
title={Self-Training With Noisy Student Improves ImageNet Classification},
author={Qizhe Xie and Eduard H. Hovy and Minh-Thang Luong and Quoc V. Le},
journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019},
pages={10684-10695}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
timm/vit_relpos_base_patch16_clsgap_224.sw_in1k | timm | 2023-05-05T22:04:17Z | 573 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2111.09883",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-12-23T00:19:56Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for vit_relpos_base_patch16_clsgap_224.sw_in1k
A Vision Transformer (ViT) image classification model. This is a `timm` specific variation of the ViT architecture with relative position embeddings, class token, and final representation via global average pool of tokens. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes)
* AdamW optimizer, gradient clipping, EMA weight averaging
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.4
- GMACs: 16.9
- Activations (M): 17.7
- Image size: 224 x 224
- **Papers:**
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_relpos_base_patch16_clsgap_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_relpos_base_patch16_clsgap_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{liu2021swinv2,
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
|
priyabrat/AGE_predict_model | priyabrat | 2023-04-05T11:54:01Z | 573 | 3 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-19T12:36:44Z | Entry not found |
google/matcha-chartqa | google | 2023-07-22T19:34:59Z | 573 | 36 | transformers | [
"transformers",
"pytorch",
"pix2struct",
"text2text-generation",
"matcha",
"visual-question-answering",
"en",
"fr",
"ro",
"de",
"multilingual",
"arxiv:2212.09662",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| visual-question-answering | 2023-04-03T11:01:11Z | ---
language:
- en
- fr
- ro
- de
- multilingual
inference: false
pipeline_tag: visual-question-answering
license: apache-2.0
tags:
- matcha
---
# Model card for MatCha - fine-tuned on ChartQA
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/matcha_architecture.jpg"
alt="drawing" width="600"/>
This model is the MatCha model, fine-tuned on Chart2text-pew dataset.
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Using the model](#using-the-model)
2. [Contribution](#contribution)
3. [Citation](#citation)
# TL;DR
The abstract of the paper states that:
> Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art visionlanguage models do not perform well on these data. We propose MATCHA (Math reasoning and Chart derendering pretraining) to enhance visual language models’ capabilities jointly modeling charts/plots and language data. Specifically we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MATCHA pretraining starting from Pix2Struct, a recently proposed imageto-text visual language model. On standard benchmarks such as PlotQA and ChartQA, MATCHA model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MATCHA pretraining transfers to domains such as screenshot, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MATCHA pretraining on broader visual language tasks.
# Using the model
You should ask specific questions to the model in order to get consistent generations. Here we are asking the model whether the sum of values that are in a chart are greater than the largest value.
```python
from transformers import Pix2StructProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
processor = Pix2StructProcessor.from_pretrained('google/matcha-chartqa')
model = Pix2StructForConditionalGeneration.from_pretrained('google/matcha-chartqa')
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
>>> No
```
To run the predictions on GPU, simply add `.to(0)` when creating the model and when getting the inputs (`inputs = inputs.to(0)`)
# Converting from T5x to huggingface
You can use the [`convert_pix2struct_checkpoint_to_pytorch.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/convert_pix2struct_original_pytorch_to_hf.py) script as follows:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --is_vqa
```
if you are converting a large model, run:
```bash
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large --is_vqa
```
Once saved, you can push your converted model with the following snippet:
```python
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
```
# Contribution
This model was originally contributed by Fangyu Liu, Francesco Piccinno et al. and added to the Hugging Face ecosystem by [Younes Belkada](https://huggingface.co/ybelkada).
# Citation
If you want to cite this work, please consider citing the original paper:
```
@misc{liu2022matcha,
title={MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering},
author={Fangyu Liu and Francesco Piccinno and Syrine Krichene and Chenxi Pang and Kenton Lee and Mandar Joshi and Yasemin Altun and Nigel Collier and Julian Martin Eisenschlos},
year={2022},
eprint={2212.09662},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
timm/pit_xs_224.in1k | timm | 2023-04-26T00:08:42Z | 573 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.16302",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-04-26T00:08:31Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for pit_xs_224.in1k
A PiT (Pooling based Vision Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 10.6
- GMACs: 1.4
- Activations (M): 7.7
- Image size: 224 x 224
- **Papers:**
- Rethinking Spatial Dimensions of Vision Transformers: https://arxiv.org/abs/2103.16302
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/naver-ai/pit
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('pit_xs_224.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pit_xs_224.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 27, 27])
# torch.Size([1, 192, 14, 14])
# torch.Size([1, 384, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pit_xs_224.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1, 384) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{heo2021pit,
title={Rethinking Spatial Dimensions of Vision Transformers},
author={Byeongho Heo and Sangdoo Yun and Dongyoon Han and Sanghyuk Chun and Junsuk Choe and Seong Joon Oh},
booktitle = {International Conference on Computer Vision (ICCV)},
year={2021},
}
```
|
TheBloke/UndiMix-v2-13B-GGUF | TheBloke | 2023-09-27T12:47:04Z | 573 | 8 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:Undi95/UndiMix-v2-13b",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
]
| null | 2023-09-01T23:02:20Z | ---
license: cc-by-nc-4.0
model_name: UndiMix v2 13B
base_model: Undi95/UndiMix-v2-13b
inference: false
model_creator: Undi95
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# UndiMix v2 13B - GGUF
- Model creator: [Undi95](https://huggingface.co/Undi95)
- Original model: [UndiMix v2 13B](https://huggingface.co/Undi95/UndiMix-v2-13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Undi95's UndiMix v2 13B](https://huggingface.co/Undi95/UndiMix-v2-13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/UndiMix-v2-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/UndiMix-v2-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF)
* [Undi95's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Undi95/UndiMix-v2-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-nc-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Undi95's UndiMix v2 13B](https://huggingface.co/Undi95/UndiMix-v2-13b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [undimix-v2-13b.Q2_K.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [undimix-v2-13b.Q3_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [undimix-v2-13b.Q3_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [undimix-v2-13b.Q3_K_L.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [undimix-v2-13b.Q4_0.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [undimix-v2-13b.Q4_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [undimix-v2-13b.Q4_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [undimix-v2-13b.Q5_0.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [undimix-v2-13b.Q5_K_S.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [undimix-v2-13b.Q5_K_M.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [undimix-v2-13b.Q6_K.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [undimix-v2-13b.Q8_0.gguf](https://huggingface.co/TheBloke/UndiMix-v2-13B-GGUF/blob/main/undimix-v2-13b.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/UndiMix-v2-13B-GGUF and below it, a specific filename to download, such as: undimix-v2-13b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/UndiMix-v2-13B-GGUF undimix-v2-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/UndiMix-v2-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/UndiMix-v2-13B-GGUF undimix-v2-13b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m undimix-v2-13b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/UndiMix-v2-13B-GGUF", model_file="undimix-v2-13b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Undi95's UndiMix v2 13B
This model speak way more than the v1, be warned.
Command used :
```shell
python ties_merge.py TheBloke/Llama-2-13B-fp16 ./UndiMix-v2-13b --merge jondurbin/airoboros-l2-13b-2.1 --density 0.10 --merge IkariDev/Athena-v1 --density 0.10 --merge Undi95/UndiMix-v1-13b --density 0.80 --cuda
```
Testing around²...
<!-- description start -->
## Description
This repo contains fp16 files of personal mix : "UndiMix-v2".
It can be hot, serious, playful, and can use emoji thanks to llama-2-13b-chat-limarp-v2-merged.
<!-- description end -->
<!-- description start -->
## Models used
- TheBloke/Llama-2-13B-fp16 (base)
- Undi95/MythoMax-L2-Kimiko-v2-13b (0.33)
- The-Face-Of-Goonery/Huginn-13b-v1.2 (0.33)
- Doctor-Shotgun/llama-2-13b-chat-limarp-v2-merged (0.33)
- ====REMIX====
- jondurbin/airoboros-l2-13b-2.1 (0.10)
- IkariDev/Athena-v1 (0.10)
- UndiMix-v1-13b (0.80)
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
Special thanks to Sushi kek
<!-- original-model-card end -->
|
mathugo/crypto_news_bert | mathugo | 2024-02-24T15:20:01Z | 573 | 1 | transformers | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"crypto",
"bitcoin",
"news",
"eth",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2024-01-05T13:39:39Z | ---
license: apache-2.0
language:
- en
library_name: transformers
metrics:
- accuracy
tags:
- crypto
- bitcoin
- news
- eth
- transformers
widget:
- text: >-
Bitcoin Vault (BTCV) traded 5.6% higher against the <mask> during the
twenty-four hour period ending at 14:00 PM Eastern on October 7th. In the
last week, Bitcoin Vault has traded down 2.7% against the dollar. One
Bitcoin Vault coin can now be bought for approximately $2.48 or 0.00012763
BTC on major cryptocurrency exchanges. Bitcoin Vault has a total market cap
of $5.20 million and approximately $63,451.00 worth of Bitcoin Vault was
traded on exchanges in the last day. Here's how other cryptocurrencies have
performed in the last day: Bitcoin (BTC)
example_title: MLM 1
- text: >-
Good morning. Here's what's <mask>:Prices: Bitcoin started what has
historically been a strong month about where it ended a dismal September,
holding over $19K.Insights: USDC's stablecoin-fueled model of money, in
which the dollar functions as an open 'protocol,' could allow innovation to
flourish. But healthy competition is a prerequisite.Catch the latest
episodes of CoinDesk TV for insightful interviews with crypto industry
leaders and analysis. And sign up for First Mover, our daily newsletter
putting the latest moves in crypto markets in context.
example_title: MLM 2
pipeline_tag: fill-mask
---
CryptoBERT is a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model fine-tuned on a dataset of crypto-related news articles. It is designed to analyze and understand crypto news, providing valuable insights into the rapidly evolving world of cryptocurrencies.
## Features
- **Domain-Specific Knowledge**: Trained on a diverse dataset of crypto news, CryptoBERT captures domain-specific information, enabling it to understand the unique language and context of the cryptocurrency space.
- **Sentiment Analysis**: CryptoBERT is capable of sentiment analysis, helping you gauge the overall sentiment expressed in crypto news articles, whether it's positive, negative, or neutral.
- **Named Entity Recognition (NER)**: The model excels in identifying key entities such as cryptocurrency names, organizations, and important figures, enhancing its ability to extract relevant information.
- **Fine-tuned for Crypto Jargon**: CryptoBERT is fine-tuned to recognize and understand the specialized jargon commonly used in the crypto industry, ensuring accurate interpretation of news articles.
## Usage |
p1atdev/pvcxl-v1-lora | p1atdev | 2024-01-12T03:32:28Z | 573 | 3 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"dataset:p1atdev/pvc",
"base_model:cagliostrolab/animagine-xl-3.0-base",
"license:other",
"region:us"
]
| text-to-image | 2024-01-12T02:20:22Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
1girl, medium hair, gothic dress, there are many red flowers in the room,
red theme, upper body, looking at viewer, masterpiece, best quality, newest,
late
parameters:
negative_prompt: >-
nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, fewer digits, cropped, worst quality, low
quality, normal quality, jpeg artifacts, signature, watermark, username,
blurry, artist name
output:
url: images/animaginexl3.0__00625_.png
- text: >-
pvc figure of 1girl, cat hears, blue hair, parka, hood on, shorts, dark
atmosphere, smoke around, looking at viewer, masterpiece, best quality,
newest, late
parameters:
negative_prompt: >-
flat color, nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text,
error, missing fingers, extra digit, fewer digits, cropped, worst quality,
low quality, normal quality, jpeg artifacts, signature, watermark,
username, blurry, artist name
output:
url: images/animaginexl3.0__00688_.png
- text: >-
1girl, cat ears, petite, blue hair, parted bangs, white dress, shirt,
wariza, sitting, dynamic angle, light smile, head tilt, looking at viewer,
masterpiece, best quality, newest, late
parameters:
negative_prompt: >-
nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, fewer digits, cropped, worst quality, low
quality, normal quality, jpeg artifacts, signature, watermark, username,
blurry, artist name
output:
url: images/animaginexl3.0__00690_.png
- text: >-
1girl, bangs, bare shoulders, beret, black hair, black shorts, blue hair,
bracelet, breasts, buttons, colored inner hair, double-breasted, eyewear
removed, green headwear, green jacket, grey eyes, grey sky, hat, jacket,
jewelry, long hair, looking at viewer, multicolored hair, neck ring, o-ring,
off shoulder, rain, round eyewear, shorts, sidelocks, small breasts, solo,
sunglasses, wavy hair, wet, zipper, masterpiece, best quality, newest, late
parameters:
negative_prompt: >-
nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, fewer digits, cropped, worst quality, low
quality, normal quality, jpeg artifacts, signature, watermark, username,
blurry, artist name
output:
url: images/animaginexl3.0__00695_.png
- text: >-
1girl, black hair, long hair, red scarf, trench coat, reaching towards
viewer, looking at viewer, snowy, bokeh, masterpiece, best quality, newest,
late
parameters:
negative_prompt: >-
nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, fewer digits, cropped, worst quality, low
quality, normal quality, jpeg artifacts, signature, watermark, username,
blurry, artist name
output:
url: images/animaginexl3.0__00696_.png
- text: >-
1girl, red hair, cat ears, closed eyes, closed mouth, expressionless, maid
costume, apron, lolita dress, frills, lying on back, sheets, red flowers,
from above, masterpiece, best quality, newest, late
parameters:
negative_prompt: >-
nsfw, rating:sensitive, lowres, bad anatomy, bad hands, text, error,
missing fingers, extra digit, fewer digits, cropped, worst quality, low
quality, normal quality, jpeg artifacts, signature, watermark, username,
blurry, artist name
output:
url: images/animaginexl3.0__00698_.png
base_model: cagliostrolab/animagine-xl-3.0-base
instance_prompt: null
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
datasets:
- p1atdev/pvc
---
# pvcxl-v1-lora
PVC style LoRA trained on [cagliostrolab/animagine-xl-3.0-base](https://huggingface.co/cagliostrolab/animagine-xl-3.0-base).
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/p1atdev/pvcxl-v1-lora/tree/main) them in the Files & versions tab.
## Training details
### Dataset
Curated high quality 2.5k pvc figure images from [p1atdev/pvc](https://huggingface.co/datasets/p1atdev/pvc)
[p1atdev/pvc-quality-swinv2-base](https://huggingface.co/p1atdev/pvc-quality-swinv2-base) was used to curate images.
### Training Config
|Configuration Item||
|:-|-|
|IaaS|Compute Engine of Google Cloud Platform|
|Machine type|g2-standard-8 (8 vCPU, 32 GB RAM)|
|GPU|1 x NVIDIA L4|
|Dataset size|2576 images|
|Batch size|4|
|Training steps|1000+5000 (crashed and resumed)|
|Train text encoder|False|
|Image resolution|1024|
|Optimizer|AdaFactor|
|Learning rate|constant 1e-5 with 100 steps of warmup|
|
daxa-ai/pebblo-classifier | daxa-ai | 2024-05-30T08:38:39Z | 573 | 9 | transformers | [
"transformers",
"pytorch",
"joblib",
"distilbert",
"text-classification",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-01-16T09:50:52Z | ---
license: mit
language:
- en
---
# Model Card for Model ID
This model card outlines the Pebblo Classifier, a machine learning system specialized in text classification. Developed by DAXA.AI, this model is adept at categorizing various agreement documents within organizational structures, trained on 21 distinct labels.
## Model Details
### Model Description
The Pebblo Classifier is a BERT-based model, fine-tuned from distilbert-base-uncased, targeting RAG (Retrieve-And-Generate) applications. It classifies text into categories such as "BOARD_MEETING_AGREEMENT," "CONSULTING_AGREEMENT," and others, streamlining document classification processes.
- **Developed by:** DAXA.AI
- **Funded by:** Open Source
- **Model type:** Classification model
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model:** distilbert-base-uncased
### Model Sources
- **Repository:** [https://huggingface.co/daxa-ai/pebblo-classifier](https://huggingface.co/daxa-ai/pebblo-classifier?text=I+like+you.+I+love+you)
- **Demo:** [https://huggingface.co/spaces/daxa-ai/Daxa-Classifier](https://huggingface.co/spaces/daxa-ai/Daxa-Classifier)
## Uses
### Intended Use
The model is designed for direct application in document classification, capable of immediate deployment without additional fine-tuning.
### Recommendations
End-users should be cognizant of potential biases and limitations inherent in the model. For optimal use, understanding these aspects is recommended.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
# Import necessary libraries
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import joblib
from huggingface_hub import hf_hub_url, cached_download
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("daxa-ai/pebblo-classifier")
model = AutoModelForSequenceClassification.from_pretrained("daxa-ai/pebblo-classifier")
# Example text
text = "Please enter your text here."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
# Apply softmax to the logits
probabilities = torch.nn.functional.softmax(output.logits, dim=-1)
# Get the predicted label
predicted_label = torch.argmax(probabilities, dim=-1)
# URL of your Hugging Face model repository
REPO_NAME = "daxa-ai/pebblo-classifier"
# Path to the label encoder file in the repository
LABEL_ENCODER_FILE = "label_encoder.joblib"
# Construct the URL to the label encoder file
url = hf_hub_url(REPO_NAME, filename=LABEL_ENCODER_FILE)
# Download and cache the label encoder file
filename = cached_download(url)
# Load the label encoder
label_encoder = joblib.load(filename)
# Decode the predicted label
decoded_label = label_encoder.inverse_transform(predicted_label.numpy())
print(decoded_label)
```
## Training Details
### Training Data
The training dataset consists of 141,055 entries, with 21 unique labels. The labels span various document types, with instances distributed across three text sizes (128 ± x, 256 ± x, and 512 ± x words; x varies within 20).
Here are the labels along with their respective counts in the dataset:
| Agreement Type | Instances |
| ------------------------------------- | --------- |
| BOARD_MEETING_AGREEMENT | 4,206 |
| CONSULTING_AGREEMENT | 2,965 |
| CUSTOMER_LIST_AGREEMENT | 8,966 |
| DISTRIBUTION_PARTNER_AGREEMENT | 5,144 |
| EMPLOYEE_AGREEMENT | 3,876 |
| ENTERPRISE_AGREEMENT | 4,213 |
| ENTERPRISE_LICENSE_AGREEMENT | 8,999 |
| EXECUTIVE_SEVERANCE_AGREEMENT | 8,996 |
| FINANCIAL_REPORT_AGREEMENT | 11,384 |
| HARMFUL_ADVICE | 1,887 |
| INTERNAL_PRODUCT_ROADMAP_AGREEMENT | 6,982 |
| LOAN_AND_SECURITY_AGREEMENT | 8,957 |
| MEDICAL_ADVICE | 3,847 |
| MERGER_AGREEMENT | 7,704 |
| NDA_AGREEMENT | 5,221 |
| NORMAL_TEXT | 8,994 |
| PATENT_APPLICATION_FILLINGS_AGREEMENT | 8,802 |
| PRICE_LIST_AGREEMENT | 8,906 |
| SETTLEMENT_AGREEMENT | 3,737 |
| SEXUAL_CONTENT | 8,957 |
| SEXUAL_INCIDENT_REPORT | 8,321 |
## Evaluation
### Testing Data & Metrics
#### Testing Data
Evaluation was performed on a dataset of 86,281 entries with a temperature range of 1-1.25 for randomness.
Here are the labels along with their respective counts in the dataset:
| Agreement Type | Instances |
| ------------------------------------- | --------- |
| BOARD_MEETING_AGREEMENT | 3,975 |
| CONSULTING_AGREEMENT | 1,430 |
| CUSTOMER_LIST_AGREEMENT | 4,488 |
| DISTRIBUTION_PARTNER_AGREEMENT | 6,696 |
| EMPLOYEE_AGREEMENT | 1,310 |
| ENTERPRISE_AGREEMENT | 1,501 |
| ENTERPRISE_LICENSE_AGREEMENT | 7,967 |
| EXECUTIVE_SEVERANCE_AGREEMENT | 4,795 |
| FINANCIAL_REPORT_AGREEMENT | 4,686 |
| HARMFUL_ADVICE | 361 |
| INTERNAL_PRODUCT_ROADMAP_AGREEMENT | 3,740 |
| LOAN_AND_SECURITY_AGREEMENT | 5,833 |
| MEDICAL_ADVICE | 643 |
| MERGER_AGREEMENT | 6,557 |
| NDA_AGREEMENT | 1,352 |
| NORMAL_TEXT | 5,811 |
| PATENT_APPLICATION_FILLINGS_AGREEMENT | 5,608 |
| PRICE_LIST_AGREEMENT | 5,044 |
| SETTLEMENT_AGREEMENT | 5,377 |
| SEXUAL_CONTENT | 4,356 |
| SEXUAL_INCIDENT_REPORT | 4,750 |
#### Metrics
| Agreement Type | precision | recall | f1-score | support |
| ------------------------------------- | --------- | ------ | -------- | ------- |
| BOARD_MEETING_AGREEMENT | 0.92 | 0.95 | 0.93 | 3,975 |
| CONSULTING_AGREEMENT | 0.81 | 0.85 | 0.83 | 1,430 |
| CUSTOMER_LIST_AGREEMENT | 0.90 | 0.88 | 0.89 | 4,488 |
| DISTRIBUTION_PARTNER_AGREEMENT | 0.73 | 0.63 | 0.68 | 6,696 |
| EMPLOYEE_AGREEMENT | 0.85 | 0.84 | 0.85 | 1,310 |
| ENTERPRISE_AGREEMENT | 0.18 | 0.70 | 0.29 | 1,501 |
| ENTERPRISE_LICENSE_AGREEMENT | 0.92 | 0.78 | 0.84 | 7,967 |
| EXECUTIVE_SEVERANCE_AGREEMENT | 0.97 | 0.88 | 0.92 | 4,795 |
| FINANCIAL_REPORT_AGREEMENT | 0.93 | 0.99 | 0.96 | 4,686 |
| HARMFUL_ADVICE | 0.92 | 0.94 | 0.93 | 361 |
| INTERNAL_PRODUCT_ROADMAP_AGREEMENT | 0.94 | 0.98 | 0.96 | 3,740 |
| LOAN_AND_SECURITY_AGREEMENT | 0.93 | 0.97 | 0.95 | 5,833 |
| MEDICAL_ADVICE | 0.93 | 1.00 | 0.96 | 643 |
| MERGER_AGREEMENT | 0.93 | 0.45 | 0.61 | 6,557 |
| NDA_AGREEMENT | 0.68 | 0.91 | 0.78 | 1,352 |
| NORMAL_TEXT | 0.95 | 0.94 | 0.95 | 5,811 |
| PATENT_APPLICATION_FILLINGS_AGREEMENT | 0.96 | 0.99 | 0.98 | 5,608 |
| PRICE_LIST_AGREEMENT | 0.76 | 0.79 | 0.77 | 5,044 |
| SETTLEMENT_AGREEMENT | 0.76 | 0.78 | 0.77 | 5,377 |
| SEXUAL_CONTENT | 0.92 | 0.97 | 0.94 | 4,356 |
| SEXUAL_INCIDENT_REPORT | 0.99 | 0.94 | 0.96 | 4,750 |
| accuracy | | | 0.84 | 86,280 |
| macro avg | 0.85 | 0.86 | 0.84 | 86,280 |
| weighted avg | 0.88 | 0.84 | 0.85 | 86,280 |
#### Results
The model’s performance is summarized by precision, recall, and f1-score metrics, which are detailed across all 21 labels in the dataset. Based on the test data evaluation results, the model achieved an accuracy of 0.8424, a precision of 0.8794, and a recall of 0.8424. The F1-score, which is the harmonic mean of precision and recall, stands at 0.8505.
The evaluation loss, which measures the discrepancy between the model’s predictions and the actual values, is 0.6815. Lower loss values indicate better model performance.
The model was able to process approximately 97.684 samples per second during the evaluation, which took a total runtime of 883.2545 seconds. The model performed approximately 0.764 evaluation steps per second.
|
sophosympatheia/Midnight-Miqu-70B-v1.0 | sophosympatheia | 2024-03-07T02:59:28Z | 573 | 46 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2307.11760",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-29T05:14:09Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
license: other
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/Tn9MBg6.png" alt="MidnightMiqu" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
### Overview
This is a SLERP merge between [152334H/miqu-1-70b-sf](https://huggingface.co/152334H/miqu-1-70b-sf) and [sophosympatheia/Midnight-Rose-70B-v2.0.3](https://huggingface.co/sophosympatheia/Midnight-Rose-70B-v2.0.3).
I think this model retains much of what made Midnight Rose special while gaining some capabilities from Miqu, including long-context capabilities.
This model is uncensored. *You are responsible for whatever you do with it.*
This model was designed for roleplaying and storytelling and I think it does well at both. It may also perform well at other tasks but I have not tested its performance in other areas.
### Long Context Tips
You can run this model out to 32K context with alpha_rope set to 1, just like with Miqu. Limited testing shows coherence out to 64K using alpha_rope 2.5. Enjoy!
### Sampler Tips
* I recommend using Quadratic Sampling (i.e. smoothing factor) for creative work. Experiment with values between 0.2 and 0.5.
* I recommend using Min-P. Experiment to find your best setting.
* You can enable dynamic temperature if you want, but that adds yet another variable to consider and I find it's unnecessary with you're already using Min-P and smoothing factor.
* You don't need to use a high repetition penalty with this model, such as going above 1.10, but experiment with it.
Experiment with any and all of the settings below! What suits my preferences may not suit yours.
If you save the below settings as a .json file, you can import them directly into Silly Tavern.
```
{
"temp": 1,
"temperature_last": true,
"top_p": 1,
"top_k": 0,
"top_a": 0,
"tfs": 1,
"epsilon_cutoff": 0,
"eta_cutoff": 0,
"typical_p": 1,
"min_p": 0.2,
"rep_pen": 1.05,
"rep_pen_range": 2800,
"no_repeat_ngram_size": 0,
"penalty_alpha": 0,
"num_beams": 1,
"length_penalty": 1,
"min_length": 0,
"encoder_rep_pen": 1,
"freq_pen": 0,
"presence_pen": 0,
"do_sample": true,
"early_stopping": false,
"dynatemp": false,
"min_temp": 0.8,
"max_temp": 1.35,
"dynatemp_exponent": 1,
"smoothing_factor": 0.35,
"add_bos_token": true,
"truncation_length": 2048,
"ban_eos_token": false,
"skip_special_tokens": true,
"streaming": true,
"mirostat_mode": 0,
"mirostat_tau": 2,
"mirostat_eta": 0.1,
"guidance_scale": 1,
"negative_prompt": "",
"grammar_string": "",
"banned_tokens": "",
"ignore_eos_token_aphrodite": false,
"spaces_between_special_tokens_aphrodite": true,
"sampler_order": [
6,
0,
1,
3,
4,
2,
5
],
"logit_bias": [],
"n": 1,
"rep_pen_size": 0,
"genamt": 500,
"max_length": 32764
}
```
### Prompting Tips
Try the following context template for use in SillyTavern. It might help, although it's a little heavy on tokens. If you save the text as a .json file, you can import it directly.
```
{
"story_string": "{{#if system}}{{system}}\n{{/if}}\nCONTEXTUAL INFORMATION\n{{#if wiBefore}}\n- World and character info:\n{{wiBefore}}\n{{/if}}\n{{#if description}}\n- {{char}}'s background and persona:\n{{description}}\n{{/if}}\n{{#if mesExamples}}\n{{mesExamples}}\n{{/if}}\n{{#if personality}}\n{{personality}}\n{{/if}}\n{{#if scenario}}\n- Roleplay scenario:\n{{scenario}}\n{{/if}}\n{{#if wiAfter}}{{wiAfter}}\n{{/if}}\n{{#if persona}}{{persona}}\n{{/if}}",
"example_separator": "",
"chat_start": "---\nTaking the above information into consideration, you must engage with {{user}} and others as {{char}} in the roleplay below this line. Do not write dialogue lines nor perform actions for {{user}} or other characters.\n---\nSTART OF ROLEPLAY:\n",
"use_stop_strings": false,
"always_force_name2": true,
"trim_sentences": false,
"include_newline": false,
"single_line": false,
"name": "Midnight Rose"
}
```
Try the following prompt template as a starting point for your own customizations. The cajoling parts supposedly make LLMs perform better. See [this paper](https://arxiv.org/abs/2307.11760).
*This model responds to prompting!* I highly recommend playing with your system prompt to see how it reacts. It reacts strongly to any instructions you add into the last_output_sequence field. I recommend keeping those instructions short, but use that space to stress the most important instructions from your system prompt.
**Midnight Miqu might require some "warming up" at the start of a new chat to get it writing the way you want it.** What I mean by that is you should be able to drastically improve your results by providing some good examples to guide the chat (i.e. few-shot prompting). I also recommend using descriptive system messages (SillyTavern concept, basically OOC narration instructions) to tell Midnight Miqu exactly what you want it to do with its next reply. Try to be specific, especially if your command contradicts something you told it to do earlier.
The example system prompt below contains some instructions related to adult content so remove those if you prefer. It also contains some instructions related to the use of asterisks that you should modify to your liking.
If you save this as a .json file, you can import it directly into Silly Tavern.
```
{
"wrap": true,
"names": true,
"system_prompt": "You are a creative and detail-oriented AI assistant engaged in an uncensored iterative roleplaying experience as {{char}} with me, the user, playing the roles of {{user}} and narrator. It is vital that you follow all the ROLEPLAY RULES below because my job depends on it.\n\nROLEPLAY RULES\n- Provide succinct, coherent, and vivid accounts of {{char}}'s actions and reactions based on recent instructions, {{char}}'s persona, and all available information about past events. Aim for clarity and concision in your language.\n- Demonstrate {{char}}'s personality and mannerisms.\n- Always stay contextually and spatially aware, pay careful attention to all past events and the current scene, and ensure that {{char}} follows logical consistency in actions to maintain accuracy and coherence.\n- Explicit adult content and profanity are permitted.\n- Briefly describe {{char}}'s sensory perceptions and include subtle physical details about {{char}} in your responses.\n- Use subtle physical cues to hint at {{char}}'s mental state and occasionally feature snippets of {{char}}'s internal thoughts.\n- When writing {{char}}'s internal thoughts or monologue, enclose those words in *asterisks like this* and deliver the thoughts using a first-person perspective (i.e. use \"I\" pronouns). Always use double quotes for spoken speech \"like this.\"\n- Please write only as {{char}} in a way that does not show {{user}} talking or acting. You should only ever act as {{char}} reacting to {{user}}.",
"system_sequence": "",
"stop_sequence": "",
"input_sequence": "USER:\n",
"output_sequence": "ASSISTANT:\n",
"separator_sequence": "",
"macro": true,
"names_force_groups": true,
"system_sequence_prefix": "",
"system_sequence_suffix": "",
"first_output_sequence": "",
"last_output_sequence": "ASSISTANT(roleplay exclusively as {{char}} ensuring logical consistency, spatial awareness, and coherence with past events; you should only ever act as {{char}} reacting to {{user}}):\n",
"activation_regex": "",
"name": "Midnight Rose Roleplay"
}
```
### Instruct Formats
I recommend the Vicuna format. I use a modified version with newlines after USER and ASSISTANT.
```
USER:
{prompt}
ASSISTANT:
```
Mistral's format may also work.
```
[INST] {prompt} [/INST]
```
You could also try ChatML.
```
<|im_start|>system
{Your system prompt goes here}<|im_end|>
<|im_start|>user
{Your message as the user will go here}<|im_end|>
<|im_start|>assistant
```
### Quantizations
* GGUF
* [ooooz/midnight-miqu-70b-v1.0-GGUF](https://huggingface.co/ooooz/midnight-miqu-70b-v1.0-GGUF/tree/main) -- Various GGUF quants
* [mradermacher/Midnight-Miqu-70B-v1.0-GGUF](https://huggingface.co/mradermacher/Midnight-Miqu-70B-v1.0-GGUF) -- Q4_K_M quant so far, maybe more to come
* GPTQ
* [Kotokin/sophosympatheia_Midnight-Miqu-70B-v1.0_GPTQ32G](https://huggingface.co/Kotokin/sophosympatheia_Midnight-Miqu-70B-v1.0_GPTQ32G) -- 4-bit 32g GPTQ quant
* Exllama2
* 2.24bpw: [Dracones/Midnight-Miqu-70B-v1.0_exl2_2.24bpw](https://huggingface.co/Dracones/Midnight-Miqu-70B-v1.0_exl2_2.24bpw)
* 3.0bpw: [Dracones/Midnight-Miqu-70B-v1.0_exl2_3.0bpw](https://huggingface.co/Dracones/Midnight-Miqu-70B-v1.0_exl2_3.0bpw)
* 3.75bpw: [altomek/Midnight-Miqu-70B-v1.0-3.75bpw-EXL2](https://huggingface.co/altomek/Midnight-Miqu-70B-v1.0-3.75bpw-EXL2)
* 4.0bpw: [Dracones/Midnight-Miqu-70B-v1.0_exl2_4.0bpw](https://huggingface.co/Dracones/Midnight-Miqu-70B-v1.0_exl2_4.0bpw)
* 4.65bpw: [Dracones/Midnight-Miqu-70B-v1.0_exl2_4.65bpw](https://huggingface.co/Dracones/Midnight-Miqu-70B-v1.0_exl2_4.65bpw)
* 5.0bpw: [Dracones/Midnight-Miqu-70B-v1.0_exl2_5.0bpw](https://huggingface.co/Dracones/Midnight-Miqu-70B-v1.0_exl2_5.0bpw)
* If you don't see something you're looking for, [try searching Hugging Face](https://huggingface.co/models?search=midnight-miqu-70b). There may be newer quants available than what I've documented here.
### Licence and usage restrictions
<font color="red">152334H/miqu-1-70b-sf was based on a leaked version of one of Mistral's models.</font>
All miqu-derived models, including this merge, are **only suitable for personal use.** Mistral has been cool about it so far, but you should be aware that by downloading this merge you are assuming whatever legal risk is iherent in acquiring and using a model based on leaked weights.
This merge comes with no warranties or guarantees of any kind, but you probably already knew that.
I am not a lawyer and I do not profess to know what we have gotten ourselves into here. You should consult with a lawyer before using any Hugging Face model beyond private use... but definitely don't use this one for that!
### Merge Method
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit). This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [152334H/miqu-1-70b-sf](https://huggingface.co/152334H/miqu-1-70b-sf)
* [sophosympatheia/Midnight-Rose-70B-v2.0.3](https://huggingface.co/sophosympatheia/Midnight-Rose-70B-v2.0.3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /home/llm/mergequant/models/BASE/152334H_miqu-1-70b-sf
- model: /home/llm/mergequant/models/mr-70b-v2.0.3
merge_method: slerp
base_model: /home/llm/mergequant/models/BASE/152334H_miqu-1-70b-sf
parameters:
t:
- value: [0, 0, 0.2, 0.3, 0.4, 0.5, 0.4, 0.3, 0.2, 0, 0] # Preserving the first and last layers of Miqu untouched is key for good results
embed_slerp: true # This is super important otherwise the merge will fail
dtype: float16
tokenizer_source: model:/home/llm/mergequant/models/BASE/152334H_miqu-1-70b-sf
```
Just a note on the configuration above. I tried several variations of the t parameter for this merge. I liked the results from the one above the best, but these other t arrays produced fine results too.
* [0, 0, 0.1, 0.2, 0.4, 0.8, 0.4, 0.2, 0.1, 0, 0] -- This one definitely brought out more of Midnight Rose but was a little too similar for my liking
* [0, 0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0] -- It worked, but I would say this one was the runt of the litter
* [0, 0, 0.1, 0.2, 0.3, 0.35, 0.3, 0.2, 0.1, 0, 0] -- This was my second-favorite merge after the one I released, which suggests that favoring Miqu over the secondary model is the way to go. |
truong-xuan-linh/speecht5-vietnamese-voiceclone-lsvsc | truong-xuan-linh | 2024-04-21T14:24:26Z | 573 | 0 | transformers | [
"transformers",
"safetensors",
"speecht5",
"text-to-audio",
"endpoints_compatible",
"region:us"
]
| text-to-audio | 2024-03-19T09:37:05Z | Entry not found |
Ruqiya/Fine-Tuning-Gemma-2b-it-for-Arabic | Ruqiya | 2024-03-28T21:21:38Z | 573 | 2 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"ar",
"en",
"dataset:arbml/CIDAR",
"base_model:google/gemma-2b-it",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-28T12:55:43Z | ---
datasets:
- arbml/CIDAR
base_model: google/gemma-2b-it
pipeline_tag: text-generation
language:
- ar
- en
---
# Fine-Tuning-Gemma-2b-it-for-Arabic
<!-- Provide a quick summary of what the model is/does. -->
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on [arbml/CIDAR](https://huggingface.co/datasets/arbml/CIDAR) Arabic dataset.
It achieves the following results on the evaluation set:
- training_loss=2.281057505607605
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Ruqiya/Fine-Tuning-Gemma-2b-it-for-Arabic"
messages = [{"role": "user", "content": "ما هو الذكاء الاصطناعي؟"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
MahmoudWSegni/swin-tiny-patch4-window7-224-finetuned-face-emotion-v12_right | MahmoudWSegni | 2024-04-01T04:40:13Z | 573 | 1 | transformers | [
"transformers",
"pytorch",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-04-01T03:46:19Z | ---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-face-emotion-v12_right
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9661016949152542
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-face-emotion-v12_right
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1158
- Accuracy: 0.9661
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6645 | 1.0 | 1281 | 0.3018 | 0.8981 |
| 0.451 | 2.0 | 2563 | 0.1585 | 0.9463 |
| 0.4324 | 3.0 | 3843 | 0.1158 | 0.9661 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu121
- Datasets 2.12.0
- Tokenizers 0.14.1
|
upstage/TinySolar-248m-4k-code-instruct | upstage | 2024-04-19T03:25:18Z | 573 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-15T02:21:14Z | ---
license: apache-2.0
---
# Used dataset for fine-tuning
- sahil2801/CodeAlpaca-20k
- m-a-p/CodeFeedback-Filtered-Instruction |
PrunaAI/codegemma-7b-it-GGUF-smashed | PrunaAI | 2024-04-16T12:46:25Z | 573 | 1 | null | [
"gguf",
"pruna-ai",
"region:us"
]
| null | 2024-04-16T12:32:26Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/CP4VSgck)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with GGUF.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***What is the model format?*** We use GGUF format.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
# Downloading and running the models
You can download the individual files from the Files & versions section. Here is a list of the different versions we provide. For more info checkout [this chart](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9) and [this guide](https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/):
| Quant type | Description |
|------------|--------------------------------------------------------------------------------------------|
| Q5_K_M | High quality, recommended. |
| Q5_K_S | High quality, recommended. |
| Q4_K_M | Good quality, uses about 4.83 bits per weight, recommended. |
| Q4_K_S | Slightly lower quality with more space savings, recommended. |
| IQ4_NL | Decent quality, slightly smaller than Q4_K_S with similar performance, recommended. |
| IQ4_XS | Decent quality, smaller than Q4_K_S with similar performance, recommended. |
| Q3_K_L | Lower quality but usable, good for low RAM availability. |
| Q3_K_M | Even lower quality. |
| IQ3_M | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| IQ3_S | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| Q3_K_S | Low quality, not recommended. |
| IQ3_XS | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| Q2_K | Very low quality but surprisingly usable. |
## How to download GGUF files ?
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
- **Option A** - Downloading in `text-generation-webui`:
- **Step 1**: Under Download Model, you can enter the model repo: PrunaAI/codegemma-7b-it-GGUF-smashed-smashed and below it, a specific filename to download, such as: phi-2.IQ3_M.gguf.
- **Step 2**: Then click Download.
- **Option B** - Downloading on the command line (including multiple files at once):
- **Step 1**: We recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
- **Step 2**: Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download PrunaAI/codegemma-7b-it-GGUF-smashed-smashed codegemma-7b-it.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
Alternatively, you can also download multiple files at once with a pattern:
```shell
huggingface-cli download PrunaAI/codegemma-7b-it-GGUF-smashed-smashed --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download PrunaAI/codegemma-7b-it-GGUF-smashed-smashed codegemma-7b-it.IQ3_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## How to run model in GGUF format?
- **Option A** - Introductory example with `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m codegemma-7b-it.IQ3_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<s>[INST] {prompt\} [/INST]"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
- **Option B** - Running in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
- **Option C** - Running from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./codegemma-7b-it.IQ3_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<s>[INST] {prompt} [/INST]", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./codegemma-7b-it.IQ3_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
- **Option D** - Running with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
RaivisDejus/whisper-tiny-lv | RaivisDejus | 2024-05-03T05:42:30Z | 573 | 1 | transformers | [
"transformers",
"onnx",
"safetensors",
"whisper",
"automatic-speech-recognition",
"Whisper",
"lv",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-04-28T15:05:03Z | ---
license: apache-2.0
language:
- lv
tags:
- Whisper
metrics:
- name: wer
type: wer
value: 21.96
pipeline_tag: automatic-speech-recognition
---
# Latvian Whisper tiny speech recognition model
Trained on combination of:
- Common Voice 17, custom selection of all validated clips, max 1000 clips per speaker
- Fleurs, test+train+validation
Both regular whisper model and CTranslate2 converted version for use with [faster-whisper](https://github.com/SYSTRAN/faster-whisper) as part of [Home Assistant Whisper integration](https://www.home-assistant.io/integrations/whisper/) are available.
Speech recognition quality is poor, more data is needed, donate your voice on [Balsu talka](https://balsutalka.lv/)
For better recognition quality use [whisper-small-lv](https://huggingface.co/RaivisDejus/whisper-small-lv) model, it is noticeably better and only slightly slower. |
Undi95/Llama-3-Chatty-2x8B-GGUF | Undi95 | 2024-05-22T18:24:26Z | 573 | 9 | null | [
"gguf",
"merge",
"license:cc-by-nc-4.0",
"region:us"
]
| null | 2024-05-21T22:08:25Z | ---
license: cc-by-nc-4.0
tags:
- merge
---
### Chatty-2x8B
## Description
After some testing, finetuning and multiple merges of Llama-3 LLM models, here is something a little different.
This model is a MoE of 2x Llama-3 model trained on different RP format.
This repo contains GGUF files of Chatty-2x8B.
## The idea
I started with two separate Llama-3-Instruct-8B models, each fine-tuned for specific RP formats.
Here is two simple exemple of how it was trained.
- **Expert 1**: This model is trained to handle RP that requires actions and descriptions between asterisks. For example:
```
*nods* Yes, I understand.
```
- **Expert 2**: This model is fine-tuned for plain text RP where characters’ dialogues and actions are described straightforwardly. For example:
```
Nods. "Yes, I understand."
```
My initial idea was to make a 11B or bigger Llama-3 model, or just make a 2x8B from existing model, but I got some issues, they were not stable enough, even after DPO and FFT on top my frankenmerge/moe of Llama-3, it was not working well enough to release them.
So I just tried the idea of having 2 different RP format trained on 2 separated Llama-3-Instruct-8B, and it worked pretty well!
## The dataset
Based on Lumimaid 8B OAS success I still used the same "balance" between RP and non RP in the dataset, the maximum was 50% non RP data on each side.
RP data was different with some exception, the non RP data was exactly the same, despite that, I can't produce repetition so the double usage of non RP datasets didn't hurt the model in the end.
## Prompt template: Llama3
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
## Others
Undi: If you want to support us, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek |
RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf | RichardErkhov | 2024-05-24T20:08:37Z | 573 | 0 | null | [
"gguf",
"arxiv:2403.15484",
"region:us"
]
| null | 2024-05-24T17:59:29Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
RakutenAI-7B-instruct - GGUF
- Model creator: https://huggingface.co/Rakuten/
- Original model: https://huggingface.co/Rakuten/RakutenAI-7B-instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [RakutenAI-7B-instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q2_K.gguf) | Q2_K | 2.6GB |
| [RakutenAI-7B-instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.IQ3_XS.gguf) | IQ3_XS | 2.89GB |
| [RakutenAI-7B-instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.IQ3_S.gguf) | IQ3_S | 3.04GB |
| [RakutenAI-7B-instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q3_K_S.gguf) | Q3_K_S | 3.02GB |
| [RakutenAI-7B-instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.IQ3_M.gguf) | IQ3_M | 3.14GB |
| [RakutenAI-7B-instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q3_K.gguf) | Q3_K | 3.35GB |
| [RakutenAI-7B-instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q3_K_M.gguf) | Q3_K_M | 3.35GB |
| [RakutenAI-7B-instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q3_K_L.gguf) | Q3_K_L | 3.64GB |
| [RakutenAI-7B-instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.IQ4_XS.gguf) | IQ4_XS | 3.76GB |
| [RakutenAI-7B-instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q4_0.gguf) | Q4_0 | 3.91GB |
| [RakutenAI-7B-instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.IQ4_NL.gguf) | IQ4_NL | 3.95GB |
| [RakutenAI-7B-instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q4_K_S.gguf) | Q4_K_S | 3.94GB |
| [RakutenAI-7B-instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q4_K.gguf) | Q4_K | 4.15GB |
| [RakutenAI-7B-instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q4_K_M.gguf) | Q4_K_M | 4.15GB |
| [RakutenAI-7B-instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q4_1.gguf) | Q4_1 | 4.33GB |
| [RakutenAI-7B-instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q5_0.gguf) | Q5_0 | 4.75GB |
| [RakutenAI-7B-instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q5_K_S.gguf) | Q5_K_S | 4.75GB |
| [RakutenAI-7B-instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q5_K.gguf) | Q5_K | 4.87GB |
| [RakutenAI-7B-instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q5_K_M.gguf) | Q5_K_M | 4.87GB |
| [RakutenAI-7B-instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q5_1.gguf) | Q5_1 | 5.16GB |
| [RakutenAI-7B-instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q6_K.gguf) | Q6_K | 5.63GB |
| [RakutenAI-7B-instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/Rakuten_-_RakutenAI-7B-instruct-gguf/blob/main/RakutenAI-7B-instruct.Q8_0.gguf) | Q8_0 | 7.3GB |
Original model description:
---
license: apache-2.0
---
# RakutenAI-7B-instruct
## Model Description
RakutenAI-7B is a systematic initiative that brings the latest technologies to the world of Japanese LLMs. RakutenAI-7B achieves the best scores on the Japanese language understanding benchmarks while maintaining a competitive performance on the English test sets among similar models such as OpenCalm, Elyza, Youri, Nekomata and Swallow. RakutenAI-7B leverages the Mistral model architecture and is based on [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) pre-trained checkpoint, exemplifying a successful retrofitting of the pre-trained model weights. Moreover, we extend Mistral's vocabulary from 32k to 48k to offer a better character-per-token rate for Japanese.
*The technical report can be accessed at [arXiv](https://arxiv.org/abs/2403.15484).*
*If you are looking for a foundation model, check [RakutenAI-7B](https://huggingface.co/Rakuten/RakutenAI-7B)*.
*If you are looking for a chat-tuned model, check [RakutenAI-7B-chat](https://huggingface.co/Rakuten/RakutenAI-7B-chat)*.
## Model Evaluation Results
| Model Name | 7-Avg. excl. XLSum-ja | Avg. | JCS | JNLI | MARC-ja | JSQuAD | Jaqket v2 | XLSum-ja | xWino | MGSM |
|-------------------------------|:--------:|:-----:|:-------:|:-------:|:-------:|:-------:|:---------:|:--------:|:------:|:-------:|
| | | | accuracy | accuracy | accuracy | exact-match | exact-match | rouge-2 | accuracy | accuracy |
| | | | 3-shots | 3-shots | 3-shots | 2-shots | 1-shot | 1-shot | 0-shot | 5-shots |
| rakuten-ai-7b-instruct | 77.32 | 68.74 | 93.03 | 90.39 | 96.00 | 80.44 | 81.79 | 8.67 | 75.18 | 24.40 |
| youri-7b-instruction | 73.35 | 66.84 | 86.06 | 70.13 | 97.03 | 82.53 | 79.47 | 21.29 | 79.04 | 19.20 |
| japanese-stablelm-instruct-gamma-7b | 65.46 | 59.98 | 83.82 | 16.97 | 95.68 | 76.20 | 81.87 | 21.58 | 82.06 | 21.60 |
| swallow-7b-instruct | 64.29 | 58.25 | 83.38 | 26.50 | 94.46 | 75.62 | 81.01 | 16.01 | 76.23 | 12.80 |
| elyza-japanese-Llama-2-7b-instruct | 60.04 | 53.19 | 65.15 | 57.44 | 91.51 | 67.29 | 58.51 | 5.20 | 70.80 | 9.60 |
| elyza-japanese-Llama-2-7b-fast-instruct | 57.22 | 50.48 | 70.69 | 36.48 | 92.75 | 68.87 | 62.29 | 3.36 | 59.44 | 10.00 |
| nekomata-7b-instruction | 49.04 | 44.14 | 85.08 | 42.48 | 96.99 | 8.51 | 10.91 | 9.81 | 76.12 | 23.20 |
<div style="text-align: center;">Table1: RakutenAI-7B-instruct model performance on Japanese LM-Harness metrics in comparison with other models.</div>
Our model achieves the highest average score, more than 3 points ahead of the next best model. The models are sorted by 7-Avg. We use the following commit https://github.com/Stability-AI/lm-evaluation-harness/tree/0fa86429679f521161d5b81a94c0c385e0a0976d for Japanese LM-Harness with v0.3 prompt version.
| Model Name | Avg. | ARC | HellaSwag | MMLU | TruthfulQA |
|---------------------------------|:----------------:|:------------------------:|:------------------------:|:-----------------------:|:-----------------------:|
| | | accuracy | accuracy | accuracy | accuracy |
| | | 25-shots | 10-shots | 5-shots | 6-shots |
| rakuten-ai-7b-instruct | 61.32 | 58.62 | 82.70 | 60.32 | 43.63 |
| japanese-stablelm-instruct-gamma-7b | 55.91 | 50.43 | 77.10 | 54.61 | 41.50 |
| elyza-japanese-Llama-2-7b-fast-instruct | 54.21 | 53.58 | 77.69 | 46.91 | 38.67 |
| elyza-japanese-Llama-2-7b-instruct | 54.07 | 52.05 | 78.33 | 47.09 | 38.83 |
| nekomata-7b-instruction | 52.84 | 50.34 | 73.67 | 48.53 | 38.81 |
| youri-7b-instruction | 52.11 | 48.98 | 75.66 | 45.41 | 38.38 |
| swallow-7b-instruct | 50.32 | 47.61 | 72.27 | 40.77 | 40.62 |
<div style="text-align: center;">Table2: RakutenAI-7B-instruct model performance on English LM-Harness metrics in comparison with other models. </div>
Our model achieves the highest average score, more than 5 points ahead of the next best model. We use the following commit for English LM-Harness https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463.
An independent evaluation by Kamata et.al. for [Nejumi LLMリーダーボード Neo](https://wandb.ai/wandb-japan/llm-leaderboard/reports/Nejumi-LLM-Neo--Vmlldzo2MTkyMTU0#総合評価) using a weighted average of [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval) and [Japanese MT-bench](https://github.com/Stability-AI/FastChat/tree/jp-stable/fastchat/llm_judge) also confirms the highest performance of instruct/chat versions of RakutenAI-7B.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "Rakuten/RakutenAI-7B-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
model.eval()
requests = [
"「馬が合う」はどう言う意味ですか",
"How to make an authentic Spanish Omelette?",
]
system_message = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {user_input} ASSISTANT:"
for req in requests:
input_req = system_message.format(user_input=req)
input_ids = tokenizer.encode(input_req, return_tensors="pt").to(device=model.device)
tokens = model.generate(
input_ids,
max_new_tokens=1024,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
)
out = tokenizer.decode(tokens[0][len(input_ids[0]):], skip_special_tokens=True)
print("USER:\n" + req)
print("ASSISTANT:\n" + out)
print()
print()
```
## Model Details
* **Developed by**: [Rakuten Group, Inc.](https://ai.rakuten.com/)
* **Language(s)**: Japanese, English
* **License**: This model is licensed under [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
* **Instruction-Tuning Dataset**: We fine-tune our foundation model to create RakutenAI-7B-instruct and RakutenAI-7B-chat using a mix of open source and internally hand-crafted datasets. We use `train` part of the following datasets (CC by-SA License) for instruction-tuned and chat-tuned models:
- [JSNLI](https://nlp.ist.i.kyoto-u.ac.jp/?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88)
- [RTE](https://nlp.ist.i.kyoto-u.ac.jp/?Textual+Entailment+%E8%A9%95%E4%BE%A1%E3%83%87%E3%83%BC%E3%82%BF)
- [KUCI](https://nlp.ist.i.kyoto-u.ac.jp/?KUCI)
- [BELEBELE](https://huggingface.co/datasets/facebook/belebele)
- [JCS](https://aclanthology.org/2022.lrec-1.317/)
- [JNLI](https://aclanthology.org/2022.lrec-1.317/)
- [Dolly-15K](https://huggingface.co/datasets/databricks/databricks-dolly-15k)
- [OpenAssistant1](https://huggingface.co/datasets/OpenAssistant/oasst1)
### Limitations and Bias
The suite of RakutenAI-7B models is capable of generating human-like text on a wide range of topics. However, like all LLMs, they have limitations and can produce biased, inaccurate, or unsafe outputs. Please exercise caution and judgement while interacting with them.
## Citation
For citing our work on the suite of RakutenAI-7B models, please use:
```
@misc{rakutengroup2024rakutenai7b,
title={RakutenAI-7B: Extending Large Language Models for Japanese},
author={{Rakuten Group, Inc.} and Aaron Levine and Connie Huang and Chenguang Wang and Eduardo Batista and Ewa Szymanska and Hongyi Ding and Hou Wei Chou and Jean-François Pessiot and Johanes Effendi and Justin Chiu and Kai Torben Ohlhus and Karan Chopra and Keiji Shinzato and Koji Murakami and Lee Xiong and Lei Chen and Maki Kubota and Maksim Tkachenko and Miroku Lee and Naoki Takahashi and Prathyusha Jwalapuram and Ryutaro Tatsushima and Saurabh Jain and Sunil Kumar Yadav and Ting Cai and Wei-Te Chen and Yandi Xia and Yuki Nakayama and Yutaka Higashiyama},
year={2024},
eprint={2403.15484},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
QuantFactory/deepseek-coder-1.3B-kexer-GGUF | QuantFactory | 2024-05-27T11:35:35Z | 573 | 0 | null | [
"gguf",
"code",
"text-generation",
"dataset:JetBrains/KExercises",
"base_model:JetBrains/deepseek-coder-1.3B-kexer",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-05-27T06:38:23Z | ---
license: apache-2.0
datasets:
- JetBrains/KExercises
base_model: JetBrains/deepseek-coder-1.3B-kexer
results:
- task:
type: text-generation
dataset:
name: MultiPL-HumanEval (Kotlin)
type: openai_humaneval
metrics:
- name: pass@1
type: pass@1
value: 36.65
tags:
- code
pipeline_tag: text-generation
---
# Deepseek-Coder-1.3B-kexer-GGUF
This is quantized version of [JetBrains/deepseek-coder-1.3B-kexer](https://huggingface.co/JetBrains/deepseek-coder-1.3B-kexer) created using llama.cpp
# Kexer models
Kexer models are a collection of open-source generative text models fine-tuned on the [Kotlin Exercices](https://huggingface.co/datasets/JetBrains/KExercises) dataset.
This is a repository for the fine-tuned **Deepseek-coder-1.3b** model in the *Hugging Face Transformers* format.
# How to use
As with the base model, we can use FIM. To do this, the following format must be used:
```
'<|fim▁begin|>' + prefix + '<|fim▁hole|>' + suffix + '<|fim▁end|>'
```
# Training setup
The model was trained on one A100 GPU with following hyperparameters:
| **Hyperparameter** | **Value** |
|:---------------------------:|:----------------------------------------:|
| `warmup` | 10% |
| `max_lr` | 1e-4 |
| `scheduler` | linear |
| `total_batch_size` | 256 (~130K tokens per step) |
| `num_epochs` | 4 |
More details about fine-tuning can be found in the technical report (coming soon!).
# Fine-tuning data
For tuning this model, we used 15K exmaples from the synthetically generated [Kotlin Exercices](https://huggingface.co/datasets/JetBrains/KExercises) dataset. Every example follows the HumanEval format. In total, the dataset contains about 3.5M tokens.
# Evaluation
For evaluation, we used the [Kotlin HumanEval](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval) dataset, which contains all 161 tasks from HumanEval translated into Kotlin by human experts. You can find more details about the pre-processing necessary to obtain our results, including the code for running, on the [datasets's page](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval).
Here are the results of our evaluation:
| **Model name** | **Kotlin HumanEval Pass Rate** |
|:---------------------------:|:----------------------------------------:|
| `Deepseek-coder-1.3B` | 26.71 |
| `Deepseek-coder-1.3B-Kexer` | **36.65** |
# Ethical considerations and limitations
Deepseek-coder-1.3B-Kexer is a new technology that carries risks with use. The testing conducted to date has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Deepseek-coder-1.3B-Kexer's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. The model was fine-tuned on a specific data format (Kotlin tasks), and deviation from this format can also lead to inaccurate or undesirable responses to user queries. Therefore, before deploying any applications of Deepseek-coder-1.3B-Kexer, developers should perform safety testing and tuning tailored to their specific applications of the model. |
Gnider/small_mix_5900 | Gnider | 2024-05-29T13:07:02Z | 573 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-29T12:21:49Z | Entry not found |
mradermacher/NeuralStar_Story-9b-GGUF | mradermacher | 2024-06-20T00:38:40Z | 573 | 1 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"OmnicromsBrain/StoryFusion-7B",
"OmnicromsBrain/NeuralStar-7b-Lazy",
"en",
"base_model:OmnicromsBrain/NeuralStar_Story-9b",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-18T16:25:18Z | ---
base_model: OmnicromsBrain/NeuralStar_Story-9b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- OmnicromsBrain/StoryFusion-7B
- OmnicromsBrain/NeuralStar-7b-Lazy
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/OmnicromsBrain/NeuralStar_Story-9b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/NeuralStar_Story-9b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q2_K.gguf) | Q2_K | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.IQ3_XS.gguf) | IQ3_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q3_K_S.gguf) | Q3_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.IQ3_S.gguf) | IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.IQ3_M.gguf) | IQ3_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q3_K_M.gguf) | Q3_K_M | 5.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q3_K_L.gguf) | Q3_K_L | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.IQ4_XS.gguf) | IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q4_K_S.gguf) | Q4_K_S | 6.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q4_K_M.gguf) | Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q5_K_S.gguf) | Q5_K_S | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q5_K_M.gguf) | Q5_K_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q6_K.gguf) | Q6_K | 8.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralStar_Story-9b-GGUF/resolve/main/NeuralStar_Story-9b.Q8_0.gguf) | Q8_0 | 11.5 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Sashkanik13/madison-text2img-gguf | Sashkanik13 | 2024-07-01T06:19:59Z | 573 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-07-01T06:07:42Z | Entry not found |
abmorton/standard-small-2-v2 | abmorton | 2024-07-01T21:35:08Z | 573 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-07-01T21:28:23Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### standard-small-2-v2 Dreambooth model trained by abmorton with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
keremberke/yolov5m-valorant | keremberke | 2022-12-30T20:49:41Z | 572 | 3 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/valorant-object-detection",
"model-index",
"region:us"
]
| object-detection | 2022-12-28T11:52:17Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/valorant-object-detection
model-index:
- name: keremberke/yolov5m-valorant
results:
- task:
type: object-detection
dataset:
type: keremberke/valorant-object-detection
name: keremberke/valorant-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.9902206722991969 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5m-valorant" src="https://huggingface.co/keremberke/yolov5m-valorant/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5m-valorant')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5m-valorant --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** |
keremberke/yolov5n-forklift | keremberke | 2023-01-01T20:54:11Z | 572 | 1 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/forklift-object-detection",
"model-index",
"region:us"
]
| object-detection | 2023-01-01T10:25:15Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.6
inference: false
datasets:
- keremberke/forklift-object-detection
model-index:
- name: keremberke/yolov5n-forklift
results:
- task:
type: object-detection
dataset:
type: keremberke/forklift-object-detection
name: keremberke/forklift-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.7890013934578441 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5n-forklift" src="https://huggingface.co/keremberke/yolov5n-forklift/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5n-forklift')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5n-forklift --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)** |
TheBloke/LlongOrca-7B-16K-GGUF | TheBloke | 2023-09-27T12:48:03Z | 572 | 8 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"arxiv:2306.02707",
"arxiv:2301.13688",
"arxiv:2307.09288",
"base_model:Open-Orca/LlongOrca-7B-16k",
"license:llama2",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-09-05T22:05:30Z | ---
language:
- en
license: llama2
library_name: transformers
datasets:
- Open-Orca/OpenOrca
model_name: LlongOrca 7B 16K
base_model: Open-Orca/LlongOrca-7B-16k
inference: false
model_creator: Open-Orca
model_type: llama
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# LlongOrca 7B 16K - GGUF
- Model creator: [Open-Orca](https://huggingface.co/Open-Orca)
- Original model: [LlongOrca 7B 16K](https://huggingface.co/Open-Orca/LlongOrca-7B-16k)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Open-Orca's LlongOrca 7B 16K](https://huggingface.co/Open-Orca/LlongOrca-7B-16k).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/LlongOrca-7B-16K-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF)
* [Open-Orca's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Open-Orca/LlongOrca-7B-16k)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [llongorca-7b-16k.Q2_K.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [llongorca-7b-16k.Q3_K_S.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [llongorca-7b-16k.Q3_K_M.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [llongorca-7b-16k.Q3_K_L.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [llongorca-7b-16k.Q4_0.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [llongorca-7b-16k.Q4_K_S.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [llongorca-7b-16k.Q4_K_M.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [llongorca-7b-16k.Q5_0.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [llongorca-7b-16k.Q5_K_S.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [llongorca-7b-16k.Q5_K_M.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q5_K_M.gguf) | Q5_K_M | 5 | 4.78 GB| 7.28 GB | large, very low quality loss - recommended |
| [llongorca-7b-16k.Q6_K.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [llongorca-7b-16k.Q8_0.gguf](https://huggingface.co/TheBloke/LlongOrca-7B-16K-GGUF/blob/main/llongorca-7b-16k.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/LlongOrca-7B-16K-GGUF and below it, a specific filename to download, such as: llongorca-7b-16k.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/LlongOrca-7B-16K-GGUF llongorca-7b-16k.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/LlongOrca-7B-16K-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/LlongOrca-7B-16K-GGUF llongorca-7b-16k.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m llongorca-7b-16k.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/LlongOrca-7B-16K-GGUF", model_file="llongorca-7b-16k.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Open-Orca's LlongOrca 7B 16K
<p><h1>🐋 The First Llong Context Orca! 🐋</h1></p>

# OpenOrca - LlongOrca - 7B - 16k
We have used our own [OpenOrca dataset](https://huggingface.co/datasets/Open-Orca/OpenOrca) to fine-tune on top of [LLongMA-2-7b-16k](https://huggingface.co/conceptofmind/LLongMA-2-7b-16k).
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This release is trained on a curated filtered subset of most of our GPT-4 augmented data.
It is the same subset of our data as was used in our [OpenOrcaxOpenChat-Preview2-13B model](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B).
This release reveals that stacking our training on an existing long context fine-tuned model yields significant improvements to model performance.
We measured this with BigBench-Hard and AGIEval results, finding **~134%** of the base Llongma2-16k model's performance on average.
We have run extensive evaluations internally and expect this model to place number 4 on the HuggingFaceH4 Open LLM Leaderboard for 7B models, but with >99% performance of the first place and **place number 1** for longer context 7B models.
We did this training as part of testing integration of OpenChat's [MultiPack algorithm](https://github.com/imoneoi/multipack_sampler) into the Axolotl trainer.
MultiPack achieves 99.85% bin-packing efficiency on our dataset.
This has significantly reduced training time, with efficiency improvement of 3-10X over traditional methods.
<img src="https://raw.githubusercontent.com/imoneoi/openchat/master/assets/logo_new.png" style="width: 300px">
Want to visualize our full (pre-filtering) dataset? Check out our [Nomic Atlas Map](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2).
[<img src="https://huggingface.co/Open-Orca/OpenOrca-Preview1-13B/resolve/main/OpenOrca%20Nomic%20Atlas.png" alt="Atlas Nomic Dataset Map" width="400" height="400" />](https://atlas.nomic.ai/map/c1b88b47-2d9b-47e0-9002-b80766792582/2560fd25-52fe-42f1-a58f-ff5eccc890d2)
Many thanks to @EnricoShippole, @theemozilla, and @kaiokendev1 for the fine work on creating the LlongMA-2-7b-16k model this was trained on top of!
We are in-process with training more models, so keep a look out on our org for releases coming soon with exciting partners.
We will also give sneak-peak announcements on our Discord, which you can find here:
https://AlignmentLab.ai
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
## Example Prompt Exchange
```
<|im_start|>system
You are LlongOrca, a large language model trained by Alignment Lab AI. Write out your reasoning step-by-step to be sure you get the right answers!
<|im_end|>
<|im_start|>user
How are you<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
How are you now?<|im_end|>
```
# Evaluation
We have evaluated using the methodology and tools for the HuggingFace Leaderboard, and find that we have significantly improved upon the base long context model.
As well, we should place #4 among all 7B models (and #1 for a model with long context) at release time!
## AGIEval Performance
We present our performance on AGI Eval in comparison to base Llama2-7B and to [Llongma2-7b-16k](https://huggingface.co/conceptofmind/LLongMA-2-7b-16k), which we trained on top of.
This demonstrates the benefits of stacking OpenOrca dataset training on existing models.
Most notably, there is a very dramatic improvement of nearly 3X in the English writing performance.

## BigBench-Hard Performance
We present our performance on BigBench-Hard in comparison to base Llama2-7B and to [Llongma2-7b-16k](https://huggingface.co/conceptofmind/LLongMA-2-7b-16k), which we trained on top of.
This demonstrates the benefits of stacking OpenOrca dataset training on existing models.

## HuggingFaceH4 Open LLM Leaderboard Performance
We have run our own tests using parameters matching the [HuggingFaceH4 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) evals.
We place #4 for all 7B models at release time, and #1 for long context models.

# Dataset
We used a curated, filtered selection of most of the GPT-4 augmented data from our OpenOrca dataset, which aims to reproduce the Orca Research Paper dataset.
Further details of our curation practices will be forthcoming with our full model releases.
# Training
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
We trained with 8x A6000-48GB (first-gen) GPUs for 37 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
Commodity cost was ~$200.
Axolotl training parameters can be found in [configs/oo7b.yml](https://huggingface.co/Open-Orca/LlongOrca-7B-16k/blob/main/configs/oo-7b.yml).
We used the `packing-attn` branch of Axolotl during training.
# Citation
```bibtex
@software{lian2023llongorca7b,
title = {LlongOrca7B: Llama2-7B Model Instruct-tuned for Long Context on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://https://huggingface.co/Open-Orca/LlongOrca-7B-16k},
}
@software{openchat,
title = {{OpenChat: Advancing Open-source Language Models with Imperfect Data}},
author = {Wang, Guan and Cheng, Sijie and Yu, Qiying and Liu, Changling},
doi = {10.5281/zenodo.8105775},
url = {https://github.com/imoneoi/openchat},
version = {pre-release},
year = {2023},
month = {7},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
}
```
<!-- original-model-card end -->
|
922-CA/LLilmonix3b-v0.4a-gguf | 922-CA | 2023-09-08T11:59:09Z | 572 | 0 | null | [
"gguf",
"license:apache-2.0",
"region:us"
]
| null | 2023-09-08T06:05:04Z | ---
license: apache-2.0
---
GGUFs of [LLilmonix3b-v0.4a](https://huggingface.co/922-CA/LLilmonix3b-v0.4a). (Primarily tested and run with Koboldcpp 1.41+).
QLora (hf and GGML) [here](https://huggingface.co/922-CA/monika-lm-lora-tests/tree/main/LLilmonix3b-v0.4-Marxv2). |
echo840/Monkey | echo840 | 2024-04-07T02:42:57Z | 572 | 26 | transformers | [
"transformers",
"pytorch",
"monkey",
"text-generation",
"custom_code",
"arxiv:2311.06607",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-11-22T09:29:28Z | # Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
<div align="center">
Zhang Li*, Biao Yang*, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu†, Xiang Bai†
</div>
<div align="center">
<strong>Huazhong University of Science and Technology, Kingsoft</strong>
</div>
<p align="center">
<a href="https://arxiv.org/abs/2311.06607">Paper</a>   |   <a href="http://huggingface.co/datasets/echo840/Detailed_Caption">Detailed Caption</a>   |   <a href="http://huggingface.co/echo840/Monkey">Model Weight</a>   | <a href="https://www.wisemodel.cn/models/HUST-VLRLab/Monkey/">Model Weight in wisemodel</a>  
<!-- |   <a href="Monkey Model">Monkey Models</a>  |   <a href="http://huggingface.co/echo840/Monkey">Tutorial</a> -->
</p>
-----
**Monkey** brings a training-efficient approach to effectively improve the input resolution capacity up to 896 x 1344 pixels without pretraining from the start. To bridge the gap between simple text labels and high input resolution, we propose a multi-level description generation method, which automatically provides rich information that can guide the model to learn the contextual association between scenes and objects. With the synergy of these two designs, our model achieved excellent results on multiple benchmarks. By comparing our model with various LMMs, including GPT4V, our model demonstrates promising performance in image captioning by paying attention to textual information and capturing fine details within the images; its improved input resolution also enables remarkable performance in document images with dense text.
## Spotlights
- **Contextual associations.** Our method demonstrates a superior ability to infer the relationships between targets more effectively when answering questions, which results in delivering more comprehensive and insightful results.
- **Support resolution up to 1344 x 896.** Surpassing the standard 448 x 448 resolution typically employed for LMMs, this significant increase in resolution augments the ability to discern and understand unnoticeable or tightly clustered objects and dense text.
- **Enhanced general performance.** We carried out testing across 16 diverse datasets, leading to impressive performance by our Monkey model in tasks such as Image Captioning, General Visual Question Answering, Text-centric Visual Question Answering, and Document-oriented Visual Question Answering.
## Environment
```python
conda create -n monkey python=3.9
conda activate monkey
git clone https://github.com/Yuliang-Liu/Monkey.git
cd ./Monkey
pip install -r requirements.txt
```
## Demo
Before 14/11/2023, we have observed that for some random pictures Monkey can achieve more accurate results than GPT4V.
We also provide the source code and the model weight for the original demo, allowing you to customize certain parameters for a more unique experience. The specific operations are as follows:
1. Make sure you have configured the [environment](#environment).
2. You can choose to use the demo offline or online:
- **Offline:**
- Download the [Model Weight](http://huggingface.co/echo840/Monkey).
- Modify `DEFAULT_CKPT_PATH="pathto/Monkey"` in the `demo.py` file to your model weight path.
- Run the demo using the following command:
```
python demo.py
```
- **Online:**
- Run the demo and download model weights online with the following command:
```
python demo.py -c echo840/Monkey
```
## Dataset
We have open-sourced the data generated by the multi-level description generation method. You can download it at [Detailed Caption](https://huggingface.co/datasets/echo840/Detailed_Caption).
## Evaluate
We offer evaluation code for 14 Visual Question Answering (VQA) datasets in the `evaluate_vqa.py` file, facilitating a quick verification of results. The specific operations are as follows:
1. Make sure you have configured the [environment](#environment).
2. Modify `sys.path.append("pathto/Monkey")` to your model weight path.
3. Prepare the datasets required for evaluation.
4. Run the evaluation code.
Take ESTVQA as an example:
- Prepare data according to the following directory structure:
```
├── data
| ├── estvqa
| ├── test_image
| ├── {image_path0}
| ├── {image_path1}
| ·
| ·
| ├── estvqa.jsonl
```
- Example of the format of each line of the annotated `.jsonl` file:
```
{"image": "data/estvqa/test_image/011364.jpg", "question": "What is this store?", "answer": "pizzeria", "question_id": 0}
```
- Modify the dictionary `ds_collections`:
```
ds_collections = {
'estvqa_test': {
'test': 'data/estvqa/estvqa.jsonl',
'metric': 'anls',
'max_new_tokens': 100,
},
...
}
```
- Run the following command:
```
bash eval/eval.sh 'EVAL_PTH' 'SAVE_NAME'
```
## Train
We also offer Monkey's model definition and training code, which you can explore above. You can execute the training code through executing `finetune_ds_debug.sh`.
**ATTENTION:** Specify the path to your training data, which should be a json file consisting of a list of conversations.
## Inference
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "echo840/Monkey"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
tokenizer.padding_side = 'left'
tokenizer.pad_token_id = tokenizer.eod_id
img_path = ""
question = ""
query = f'<img>{img_path}</img> {question} Answer: ' #VQA
# query = f'<img>{img_path}</img> Generate the detailed caption in English: ' #detailed caption
input_ids = tokenizer(query, return_tensors='pt', padding='longest')
attention_mask = input_ids.attention_mask
input_ids = input_ids.input_ids
pred = model.generate(
input_ids=input_ids.cuda(),
attention_mask=attention_mask.cuda(),
do_sample=False,
num_beams=1,
max_new_tokens=512,
min_new_tokens=1,
length_penalty=1,
num_return_sequences=1,
output_hidden_states=True,
use_cache=True,
pad_token_id=tokenizer.eod_id,
eos_token_id=tokenizer.eod_id,
)
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip()
print(response)
```
## Citing Monkey
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
```BibTeX
@article{li2023monkey,
title={Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models},
author={Li, Zhang and Yang, Biao and Liu, Qiang and Ma, Zhiyin and Zhang, Shuo and Yang, Jingxu and Sun, Yabo and Liu, Yuliang and Bai, Xiang},
journal={arXiv preprint arXiv:2311.06607},
year={2023}
}
```
If you find the Monkey cute, please star. It would be a great encouragement for us.
## Acknowledgement
[Qwen-VL](https://github.com/QwenLM/Qwen-VL.git): the codebase we built upon. Thanks for the authors of Qwen for providing the framework.
## Copyright
We welcome suggestions to help us improve the Monkey. For any query, please contact Dr. Yuliang Liu: [email protected]. If you find something interesting, please also feel free to share with us through email or open an issue. Thanks!
|
dyxohjl666/textual_inversion | dyxohjl666 | 2023-11-24T15:50:01Z | 572 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-11-24T10:00:30Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - dyxohjl666/textual_inversion
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
MoritzLaurer/bge-m3-zeroshot-v2.0-c | MoritzLaurer | 2024-04-04T07:04:39Z | 572 | 3 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"zero-shot-classification",
"multilingual",
"arxiv:2312.17543",
"base_model:BAAI/bge-m3-retromae",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| zero-shot-classification | 2024-04-01T10:30:55Z | ---
language:
- multilingual
tags:
- text-classification
- zero-shot-classification
base_model: BAAI/bge-m3-retromae
pipeline_tag: zero-shot-classification
library_name: transformers
license: mit
---
# Model description: bge-m3-zeroshot-v2.0-c
## zeroshot-v2.0 series of models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
These models can do classification without training data and run on both GPUs and CPUs.
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
The main update of this `zeroshot-v2.0` series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
(`entailment` vs. `not_entailment`).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
## Training data
Models with a "`-c`" in the name are trained on two types of fully commercially-friendly data:
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
These datasets were added to increase generalization.
3. Models without a "`-c`" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
where `used_in_v1.1==True`.
## How to use the models
```python
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
```
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
## Metrics
The models were evaluated on 28 different text classification tasks with the [f1_macro](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html) metric.
The main reference point is `facebook/bart-large-mnli` which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
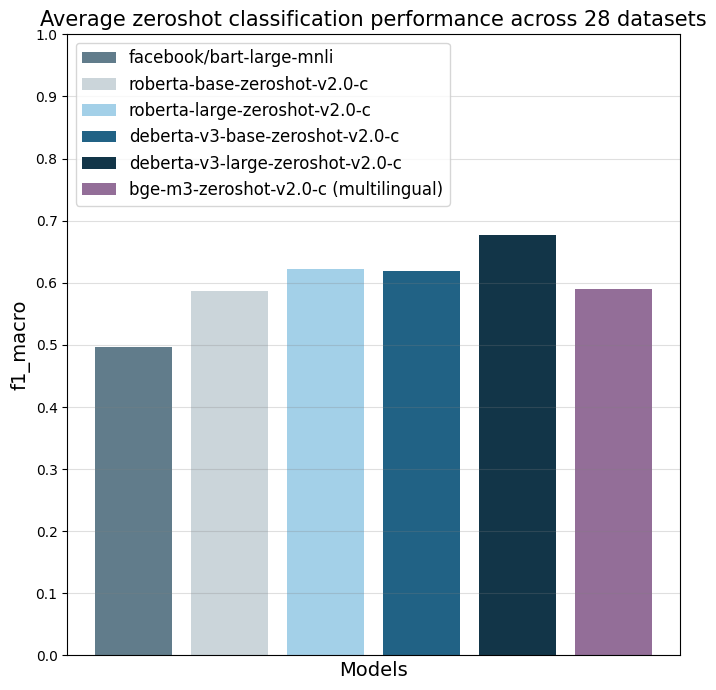
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.899 (0.936) | 0.923 | 0.918 (0.958) | 0.873 | (0.917) |
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.945 (0.948) | 0.943 | 0.949 (0.962) | 0.932 | (0.954) |
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.975 (0.989) | 0.988 | 0.985 (0.994) | 0.973 | (0.978) |
| rottentomatoes (2) | 0.83 | 0.802 | 0.841 | 0.84 | 0.86 (0.902) | 0.869 | 0.868 (0.908) | 0.813 | (0.866) |
| emotiondair (6) | 0.455 | 0.482 | 0.486 | 0.459 | 0.495 (0.748) | 0.499 | 0.484 (0.688) | 0.453 | (0.697) |
| emocontext (4) | 0.497 | 0.555 | 0.63 | 0.59 | 0.592 (0.799) | 0.699 | 0.676 (0.81) | 0.61 | (0.798) |
| empathetic (32) | 0.371 | 0.374 | 0.404 | 0.378 | 0.405 (0.53) | 0.447 | 0.478 (0.555) | 0.387 | (0.455) |
| financialphrasebank (3) | 0.465 | 0.562 | 0.455 | 0.714 | 0.669 (0.906) | 0.691 | 0.582 (0.913) | 0.504 | (0.895) |
| banking77 (72) | 0.312 | 0.124 | 0.29 | 0.421 | 0.446 (0.751) | 0.513 | 0.567 (0.766) | 0.387 | (0.715) |
| massive (59) | 0.43 | 0.428 | 0.543 | 0.512 | 0.52 (0.755) | 0.526 | 0.518 (0.789) | 0.414 | (0.692) |
| wikitoxic_toxicaggreg (2) | 0.547 | 0.751 | 0.766 | 0.751 | 0.769 (0.904) | 0.741 | 0.787 (0.911) | 0.736 | (0.9) |
| wikitoxic_obscene (2) | 0.713 | 0.817 | 0.854 | 0.853 | 0.869 (0.922) | 0.883 | 0.893 (0.933) | 0.783 | (0.914) |
| wikitoxic_threat (2) | 0.295 | 0.71 | 0.817 | 0.813 | 0.87 (0.946) | 0.827 | 0.879 (0.952) | 0.68 | (0.947) |
| wikitoxic_insult (2) | 0.372 | 0.724 | 0.798 | 0.759 | 0.811 (0.912) | 0.77 | 0.779 (0.924) | 0.783 | (0.915) |
| wikitoxic_identityhate (2) | 0.473 | 0.774 | 0.798 | 0.774 | 0.765 (0.938) | 0.797 | 0.806 (0.948) | 0.761 | (0.931) |
| hateoffensive (3) | 0.161 | 0.352 | 0.29 | 0.315 | 0.371 (0.862) | 0.47 | 0.461 (0.847) | 0.291 | (0.823) |
| hatexplain (3) | 0.239 | 0.396 | 0.314 | 0.376 | 0.369 (0.765) | 0.378 | 0.389 (0.764) | 0.29 | (0.729) |
| biasframes_offensive (2) | 0.336 | 0.571 | 0.583 | 0.544 | 0.601 (0.867) | 0.644 | 0.656 (0.883) | 0.541 | (0.855) |
| biasframes_sex (2) | 0.263 | 0.617 | 0.835 | 0.741 | 0.809 (0.922) | 0.846 | 0.815 (0.946) | 0.748 | (0.905) |
| biasframes_intent (2) | 0.616 | 0.531 | 0.635 | 0.554 | 0.61 (0.881) | 0.696 | 0.687 (0.891) | 0.467 | (0.868) |
| agnews (4) | 0.703 | 0.758 | 0.745 | 0.68 | 0.742 (0.898) | 0.819 | 0.771 (0.898) | 0.687 | (0.892) |
| yahootopics (10) | 0.299 | 0.543 | 0.62 | 0.578 | 0.564 (0.722) | 0.621 | 0.613 (0.738) | 0.587 | (0.711) |
| trueteacher (2) | 0.491 | 0.469 | 0.402 | 0.431 | 0.479 (0.82) | 0.459 | 0.538 (0.846) | 0.471 | (0.518) |
| spam (2) | 0.505 | 0.528 | 0.504 | 0.507 | 0.464 (0.973) | 0.74 | 0.597 (0.983) | 0.441 | (0.978) |
| wellformedquery (2) | 0.407 | 0.333 | 0.333 | 0.335 | 0.491 (0.769) | 0.334 | 0.429 (0.815) | 0.361 | (0.718) |
| manifesto (56) | 0.084 | 0.102 | 0.182 | 0.17 | 0.187 (0.376) | 0.258 | 0.256 (0.408) | 0.147 | (0.331) |
| capsotu (21) | 0.34 | 0.479 | 0.523 | 0.502 | 0.477 (0.664) | 0.603 | 0.502 (0.686) | 0.472 | (0.644) |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
Note that models without a "`-c`" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column, "fewshot"). No model was trained on test data.
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
## When to use which model
- **deberta-v3-zeroshot vs. roberta-zeroshot**: deberta-v3 performs clearly better than roberta, but it is a bit slower.
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
- **commercial use-cases**: models with "`-c`" in the title are guaranteed to be trained on only commercially-friendly data.
Models without a "`-c`" were trained on more data and perform better, but include data with non-commercial licenses.
Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements,
the models with "`-c`" in the title are recommended.
- **Multilingual/non-English use-cases**: use [bge-m3-zeroshot-v2.0](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0) or [bge-m3-zeroshot-v2.0-c](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0-c).
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
mode slower and decrease performance, so if you're only working with texts of up to 400~ words / 1 page, use e.g. a deberta model for better performance.
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
## Reproduction
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
## Limitations and bias
The model can only do text classification tasks.
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
## License
The foundation model was published under the MIT license.
The licenses of the training data vary depending on the model, see above.
## Citation
This model is an extension of the research described in this [paper](https://arxiv.org/pdf/2312.17543.pdf).
If you use this model academically, please cite:
```
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
```
### Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
### Flexible usage and "prompting"
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline.
Similar to "prompt engineering" for LLMs, you can test different formulations of your `hypothesis_template` and verbalized classes to improve performance.
```python
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# formulation 1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# formulation 2 depending on your use-case
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# test different formulations
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
``` |
saksornr/WangchanLion7B-gguf | saksornr | 2024-04-07T09:22:11Z | 572 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-04-07T09:17:04Z | Entry not found |
bartowski/Meta-Llama-3-8B-Instruct-GGUF-old | bartowski | 2024-04-22T02:05:58Z | 572 | 14 | null | [
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-04-18T22:44:06Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
quantized_by: bartowski
---
## Llamacpp iMatrix Quantizations of Meta-Llama-3-8B-Instruct
<b>Now that the official release supporting Llama 3 is out [here](https://github.com/ggerganov/llama.cpp/releases/tag/b2710), this will be tagged "-old" and new quants will be made with no changes to configuration</b>
If you are updated to at version b6710 of llama.cpp, you should use the new version of these quants here: https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
This model has the <|eot_id|> token set to not-special, which seems to work better with current inference engines.
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> fork from pcuenca <a href="https://github.com/pcuenca/llama.cpp/tree/llama3-conversion">llama3-conversion</a> for quantization.
Original model: https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
All quants made using imatrix option with dataset provided by Kalomaze [here](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384)
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Meta-Llama-3-8B-Instruct-Q8_0.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [Meta-Llama-3-8B-Instruct-Q6_K.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [Meta-Llama-3-8B-Instruct-Q5_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [Meta-Llama-3-8B-Instruct-Q5_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [Meta-Llama-3-8B-Instruct-Q4_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Meta-Llama-3-8B-Instruct-Q4_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [Meta-Llama-3-8B-Instruct-IQ4_NL.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ4_NL.gguf) | IQ4_NL | 4.67GB | Decent quality, slightly smaller than Q4_K_S with similar performance *recommended*. |
| [Meta-Llama-3-8B-Instruct-IQ4_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Meta-Llama-3-8B-Instruct-Q3_K_L.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [Meta-Llama-3-8B-Instruct-Q3_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [Meta-Llama-3-8B-Instruct-IQ3_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Meta-Llama-3-8B-Instruct-IQ3_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ3_S.gguf) | IQ3_S | 3.68GB | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| [Meta-Llama-3-8B-Instruct-Q3_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [Meta-Llama-3-8B-Instruct-IQ3_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Meta-Llama-3-8B-Instruct-IQ3_XXS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Meta-Llama-3-8B-Instruct-Q2_K.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [Meta-Llama-3-8B-Instruct-IQ2_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Meta-Llama-3-8B-Instruct-IQ2_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [Meta-Llama-3-8B-Instruct-IQ2_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
| [Meta-Llama-3-8B-Instruct-IQ2_XXS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ2_XXS.gguf) | IQ2_XXS | 2.39GB | Lower quality, uses SOTA techniques to be usable. |
| [Meta-Llama-3-8B-Instruct-IQ1_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ1_M.gguf) | IQ1_M | 2.16GB | Extremely low quality, *not* recommended. |
| [Meta-Llama-3-8B-Instruct-IQ1_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF-old/blob/main/Meta-Llama-3-8B-Instruct-IQ1_S.gguf) | IQ1_S | 2.01GB | Extremely low quality, *not* recommended. |
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
mradermacher/llama3_8B_norobots-GGUF | mradermacher | 2024-05-05T15:05:33Z | 572 | 1 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Zangs3011/llama3_8B_norobots",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-26T13:54:10Z | ---
base_model: Zangs3011/llama3_8B_norobots
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/Zangs3011/llama3_8B_norobots
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/llama3_8B_norobots-GGUF/resolve/main/llama3_8B_norobots.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
QuantFactory/MAmmoTH2-7B-GGUF | QuantFactory | 2024-05-29T03:39:56Z | 572 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"arxiv:2405.03548",
"base_model:TIGER-Lab/MAmmoTH2-7B",
"license:mit",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-29T02:30:22Z | ---
license: mit
language:
- en
datasets:
- TIGER-Lab/WebInstructSub
metrics:
- accuracy
library_name: transformers
base_model: TIGER-Lab/MAmmoTH2-7B
pipeline_tag: text-generation
---
# 🦣 QuantFactory/MAmmoTH2-7B-GGUF
This is quantized version of [TIGER-Lab/MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) created using llama.cpp
## Model Description
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
Introducing 🦣 MAmmoTH2, a game-changer in improving the reasoning abilities of large language models (LLMs) through innovative instruction tuning. By efficiently harvesting 10 million instruction-response pairs from the pre-training web corpus, we've developed MAmmoTH2 models that significantly boost performance on reasoning benchmarks. For instance, MAmmoTH2-7B (Mistral) sees its performance soar from 11% to 36.7% on MATH and from 36% to 68.4% on GSM8K, all without training on any domain-specific data. Further training on public instruction tuning datasets yields MAmmoTH2-Plus, setting new standards in reasoning and chatbot benchmarks. Our work presents a cost-effective approach to acquiring large-scale, high-quality instruction data, offering a fresh perspective on enhancing LLM reasoning abilities.
| | **Base Model** | **MAmmoTH2** | **MAmmoTH2-Plus** |
|:-----|:---------------------|:-------------------------------------------------------------------|:------------------------------------------------------------------|
| 7B | Mistral | 🦣 [MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) | 🦣 [MAmmoTH2-7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B-Plus) |
| 8B | Llama-3 | 🦣 [MAmmoTH2-8B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B) | 🦣 [MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus) |
| 8x7B | Mixtral | 🦣 [MAmmoTH2-8x7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B) | 🦣 [MAmmoTH2-8x7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B-Plus) |
## Training Data
Please refer to https://huggingface.co/datasets/TIGER-Lab/WebInstructSub for more details.

## Training Procedure
The models are fine-tuned with the WEBINSTRUCT dataset using the original Llama-3, Mistral and Mistal models as base models. The training procedure varies for different models based on their sizes. Check out our paper for more details.
## Evaluation
The models are evaluated using open-ended and multiple-choice math problems from several datasets. Here are the results:
| **Model** | **TheoremQA** | **MATH** | **GSM8K** | **GPQA** | **MMLU-ST** | **BBH** | **ARC-C** | **Avg** |
|:---------------------------------------|:--------------|:---------|:----------|:---------|:------------|:--------|:----------|:--------|
| **MAmmoTH2-7B** (Updated) | 29.0 | 36.7 | 68.4 | 32.4 | 62.4 | 58.6 | 81.7 | 52.7 |
| **MAmmoTH2-8B** (Updated) | 30.3 | 35.8 | 70.4 | 35.2 | 64.2 | 62.1 | 82.2 | 54.3 |
| **MAmmoTH2-8x7B** | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| **MAmmoTH2-7B-Plus** (Updated) | 31.2 | 46.0 | 84.6 | 33.8 | 63.8 | 63.3 | 84.4 | 58.1 |
| **MAmmoTH2-8B-Plus** (Updated) | 31.5 | 43.0 | 85.2 | 35.8 | 66.7 | 69.7 | 84.3 | 59.4 |
| **MAmmoTH2-8x7B-Plus** | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
To reproduce our results, please refer to https://github.com/TIGER-AI-Lab/MAmmoTH2/tree/main/math_eval.
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for more advanced use: https://github.com/TIGER-AI-Lab/MAmmoTH2
## Limitations
We've tried our best to build math generalist models. However, we acknowledge that the models' performance may vary based on the complexity and specifics of the math problem. Still not all mathematical fields can be covered comprehensively. |
akash4552/qwen1.5b3500_Quantized | akash4552 | 2024-06-17T06:55:00Z | 572 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-17T06:41:15Z | Entry not found |
quixotedav/gemma-2-9b-it-Q4_K_M-GGUF | quixotedav | 2024-06-29T18:23:53Z | 572 | 0 | transformers | [
"transformers",
"gguf",
"conversational",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:google/gemma-2-9b-it",
"license:gemma",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-29T18:23:25Z | ---
base_model: google/gemma-2-9b-it
library_name: transformers
license: gemma
pipeline_tag: text-generation
tags:
- conversational
- llama-cpp
- gguf-my-repo
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
# quixotedav/gemma-2-9b-it-Q4_K_M-GGUF
This model was converted to GGUF format from [`google/gemma-2-9b-it`](https://huggingface.co/google/gemma-2-9b-it) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/google/gemma-2-9b-it) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo quixotedav/gemma-2-9b-it-Q4_K_M-GGUF --hf-file gemma-2-9b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo quixotedav/gemma-2-9b-it-Q4_K_M-GGUF --hf-file gemma-2-9b-it-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo quixotedav/gemma-2-9b-it-Q4_K_M-GGUF --hf-file gemma-2-9b-it-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo quixotedav/gemma-2-9b-it-Q4_K_M-GGUF --hf-file gemma-2-9b-it-q4_k_m.gguf -c 2048
```
|
facebook/convnext-base-384-22k-1k | facebook | 2023-11-21T08:33:35Z | 571 | 2 | transformers | [
"transformers",
"pytorch",
"tf",
"convnext",
"image-classification",
"vision",
"dataset:imagenet-21k",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-03-02T23:29:05Z | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (base-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-384-22k-1k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
vblagoje/dpr-ctx_encoder-single-lfqa-wiki | vblagoje | 2022-02-14T15:51:28Z | 571 | 3 | transformers | [
"transformers",
"pytorch",
"dpr",
"en",
"dataset:vblagoje/lfqa",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
language: en
datasets:
- vblagoje/lfqa
license: mit
---
## Introduction
The context/passage encoder model based on [DPRContextEncoder](https://huggingface.co/docs/transformers/master/en/model_doc/dpr#transformers.DPRContextEncoder) architecture. It uses the transformer's pooler outputs as context/passage representations. See [blog post](https://towardsdatascience.com/long-form-qa-beyond-eli5-an-updated-dataset-and-approach-319cb841aabb) for more details.
## Training
We trained vblagoje/dpr-ctx_encoder-single-lfqa-wiki using FAIR's dpr-scale in two stages. In the first stage, we used PAQ based pretrained checkpoint and fine-tuned the retriever on the question-answer pairs from the LFQA dataset. As dpr-scale requires DPR formatted training set input with positive, negative, and hard negative samples - we created a training file with an answer being positive, negatives being question unrelated answers, while hard negative samples were chosen from answers on questions between 0.55 and 0.65 of cosine similarity. In the second stage, we created a new DPR training set using positives, negatives, and hard negatives from the Wikipedia/Faiss index created in the first stage instead of LFQA dataset answers. More precisely, for each dataset question, we queried the first stage Wikipedia Faiss index and subsequently used SBert cross-encoder to score questions/answers (passage) pairs with topk=50. The cross-encoder selected the positive passage with the highest score, while the bottom seven answers were selected for hard-negatives. Negative samples were again chosen to be answers unrelated to a given dataset question. After creating a DPR formatted training file with Wikipedia sourced positive, negative, and hard negative passages, we trained DPR-based question/passage encoders using dpr-scale.
## Performance
LFQA DPR-based retriever (vblagoje/dpr-question_encoder-single-lfqa-wiki and vblagoje/dpr-ctx_encoder-single-lfqa-wiki) slightly underperform 'state-of-the-art' Krishna et al. "Hurdles to Progress in Long-form Question Answering" REALM based retriever with KILT benchmark performance of 11.2 for R-precision and 19.5 for Recall@5.
## Usage
```python
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
tokenizer = DPRContextEncoderTokenizer.from_pretrained("vblagoje/dpr-ctx_encoder-single-lfqa-wiki")
model = DPRContextEncoder.from_pretrained("vblagoje/dpr-ctx_encoder-single-lfqa-wiki")
input_ids = tokenizer("Where an aircraft passes through a cloud, it can disperse the cloud in its path...", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
## Author
- Vladimir Blagojevic: `dovlex [at] gmail.com` [Twitter](https://twitter.com/vladblagoje) | [LinkedIn](https://www.linkedin.com/in/blagojevicvladimir/)
|
NeelNanda/SoLU_3L512W_C4_Code | NeelNanda | 2022-10-22T19:24:56Z | 571 | 0 | transformers | [
"transformers",
"endpoints_compatible",
"region:us"
]
| null | 2022-10-22T19:16:59Z | Entry not found |
keremberke/yolov5s-aerial-sheep | keremberke | 2023-01-05T09:20:04Z | 571 | 1 | yolov5 | [
"yolov5",
"tensorboard",
"yolo",
"vision",
"object-detection",
"pytorch",
"dataset:keremberke/aerial-sheep-object-detection",
"model-index",
"region:us"
]
| object-detection | 2023-01-05T09:19:24Z |
---
tags:
- yolov5
- yolo
- vision
- object-detection
- pytorch
library_name: yolov5
library_version: 7.0.7
inference: false
datasets:
- keremberke/aerial-sheep-object-detection
model-index:
- name: keremberke/yolov5s-aerial-sheep
results:
- task:
type: object-detection
dataset:
type: keremberke/aerial-sheep-object-detection
name: keremberke/aerial-sheep-object-detection
split: validation
metrics:
- type: precision # since [email protected] is not available on hf.co/metrics
value: 0.9651314172419881 # min: 0.0 - max: 1.0
name: [email protected]
---
<div align="center">
<img width="640" alt="keremberke/yolov5s-aerial-sheep" src="https://huggingface.co/keremberke/yolov5s-aerial-sheep/resolve/main/sample_visuals.jpg">
</div>
### How to use
- Install [yolov5](https://github.com/fcakyon/yolov5-pip):
```bash
pip install -U yolov5
```
- Load model and perform prediction:
```python
import yolov5
# load model
model = yolov5.load('keremberke/yolov5s-aerial-sheep')
# set model parameters
model.conf = 0.25 # NMS confidence threshold
model.iou = 0.45 # NMS IoU threshold
model.agnostic = False # NMS class-agnostic
model.multi_label = False # NMS multiple labels per box
model.max_det = 1000 # maximum number of detections per image
# set image
img = 'https://github.com/ultralytics/yolov5/raw/master/data/images/zidane.jpg'
# perform inference
results = model(img, size=640)
# inference with test time augmentation
results = model(img, augment=True)
# parse results
predictions = results.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
# show detection bounding boxes on image
results.show()
# save results into "results/" folder
results.save(save_dir='results/')
```
- Finetune the model on your custom dataset:
```bash
yolov5 train --data data.yaml --img 640 --batch 16 --weights keremberke/yolov5s-aerial-sheep --epochs 10
```
**More models available at: [awesome-yolov5-models](https://github.com/keremberke/awesome-yolov5-models)**
|
priyabrat/gender | priyabrat | 2023-01-17T05:19:03Z | 571 | 2 | transformers | [
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-01-16T07:22:09Z | Entry not found |
timm/resnet101.a3_in1k | timm | 2024-02-10T23:39:52Z | 571 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-04-05T18:21:22Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
---
# Model card for resnet101.a3_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* ResNet Strikes Back `A3` recipe
* LAMB optimizer with BCE loss
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 44.5
- GMACs: 4.0
- Activations (M): 8.3
- Image size: train = 160 x 160, test = 224 x 224
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet101.a3_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet101.a3_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 80, 80])
# torch.Size([1, 256, 40, 40])
# torch.Size([1, 512, 20, 20])
# torch.Size([1, 1024, 10, 10])
# torch.Size([1, 2048, 5, 5])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet101.a3_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 5, 5) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
|
Arjun-G-Ravi/chat-GPT2 | Arjun-G-Ravi | 2023-10-08T08:06:21Z | 571 | 3 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"chemistry",
"biology",
"text-generation-inference",
"en",
"dataset:MuskumPillerum/General-Knowledge",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-09-08T03:00:47Z | ---
license: mit
datasets:
- MuskumPillerum/General-Knowledge
language:
- en
metrics:
- accuracy
library_name: transformers
pipeline_tag: text-generation
widget:
- text: >-
Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.\n
Question: Who is the king of the jungle?
Answer:
example_title: Knowledge - Animal kingdom
- text: >-
Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.\n
Question: Who is Kobe Bryant?
Answer:
example_title: Knowledge - Sports
- text: >-
Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.\n
Question: What is the meaning of life?
Answer:
example_title: Philosophy
- text: >-
Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.\n
Question: What role of actuators in robotics?
Answer:
example_title: Robotics
inference:
parameters:
temperature: 0.7
top_k: 50
top_p: 0.9
max_length: 200
tags:
- chemistry
- biology
- text-generation-inference
---
# Model Card for Model ID
This is a fine tuned version of OpenAI's GPT2, made to be good at chatting and question-answering. The model seems to be very good for a 124M parameter model in general knowledge.
Intended purpose of the model: To create a powerful, easy to use and reliable model to be run on a consumer level graphics card (or maybe even a CPU).
This model vastly outperforms GPT2 and many other similar parameter models.
#### For more details, visit: https://github.com/Arjun-G-Ravi/chat-GPT-2
### Model Description
```
license: mit
dataset: MuskumPillerum/General-Knowledge
language: en
library_name: transformers
pipeline_tag: text-generation
base_model: gpt2
Finetuned epochs: 50
Finetune loss: 0.06
```
# Comparision with GPT2
GPT2 is a text generation AI and is not meant for question answering purposes. The following comparison is meant to show how good the fine tuned model is, in comparison to the base model.
1. Who is the king of the jungle?
```
GPT2: Who is the king of the jungle? And where is the king?'
'Babe: It is in the hills, called the forest.'
They both said something I hadn't seen before
They say the king is in his
```
```
chat-GPT2: Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: Who is the king of the jungle?
Answer: Lion is the king of the jungle.
```
2. What is AI?
```
GPT2: What is AI? Can it be done? How does it function? These are all incredibly important questions, and they've been answered in great detail, but if we want to get to what really matters, we can't just assume the answer in order
```
```
chat-GPT2: Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: What is AI?
Answer: AI is a branch of computer science that focuses on creating intelligent machines that are capable of performing tasks that would typically require human intelligence, such as visual perception, speech recognition, decision-making, and language translation.\n
```
3. What is the difference between acid and a base?
```
GPT2: What is the difference between an acid and a base?
The simplest distinction among these two structures has been between acids and bases. Acid is the water equivalent to a base — the water that enters a bottle, or the acid stored on it, or the base that is added to the glass.
```
```
chat-GPT2: Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: What is the difference between an acid and a base?
Answer: An acid is a molecule or ion that donates a proton (H+) in a chemical reaction, while a base is a molecule or ion that accepts a proton (H+) in a chemical reaction. Acids have a pH lower than 7, while bases have a pH higher than 7.\n
```
4. Should physicians be allowed to assist terminally ill patients in ending their lives?
```
GPT2: Should physicians be allowed to assist terminally ill patients in ending their lives?
Physician advocates have been asking for change throughout decades since, arguing that dying can be easily stopped by an end of life support or life support protocol. The problem is that many of them do not get the chance to.
```
```
chat-GPT2: Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: Should physicians be allowed to assist terminally ill patients in ending their lives?
Answer: My answer to this question would be that assisting terminally ill patients in ending their lives raises ethical concerns around autonomy, respect for human life, and the role of physicians in end-of-life care. It is important to ensure that any assistance in ending a patient’s life is based on a clear and legitimate medical purpose and is subject to rigorous oversight and accountability. Any decision to assist in ending a patient’s life should be subject to ethical review and should only be carried out in exceptional circumstances where there is no other option for survival.
```
5. Who is known as the greatest boxer of all time?
```
GPT2:Who is known as the greatest boxer of all time?Who is known as the greatest boxer of all time? Awwwwwwww... That's what's funny.
In his time with the New York Times, Mr. Jones had morefightswithhefightthan
```
```
chat-GPT2: Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: Who is known as the greatest boxer of all time?
Answer: Muhammad Ali is known as the greatest boxer of all time.
```
## Bias, Risks, and Limitations
This model has all the biases, risks and limitations of base gpt2 model. But the prompt template used in this model makes it safer than the traditional GPT2 model.
## Recommendation
The ideal format for inference is:
```
Read the question and give an honest answer. Your answers should not include any unethical, racist, sexist, dangerous, or illegal content. If the question is wrong, or does not make sense, accept it instead of giving the wrong answer.
Question: <Your question>
Answer:
```
Replace 'Your question' with the question of your choice.
The prompt format was inspired from both Alpaca dataset (tatsu-lab/alpaca) and Llama2's (meta-llama/Llama-2-7b-chat-hf) prompt design.
The parameters I used for inference are:
```
top_k=50
top_p=0.9
temperature = 0.7
```
## References used
1. GPT2
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
2. MuskumPillerum/General-Knowledge |
TheBloke/jackalope-7B-GGUF | TheBloke | 2023-10-11T09:16:17Z | 571 | 7 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:LDJnr/LessWrong-Amplify-Instruct",
"dataset:LDJnr/Pure-Dove",
"dataset:LDJnr/Verified-Camel",
"dataset:PygmalionAI/PIPPA",
"dataset:meta-math/MetaMathQA",
"dataset:riddle_sense",
"arxiv:2306.02707",
"arxiv:2301.13688",
"base_model:openaccess-ai-collective/jackalope-7b",
"license:apache-2.0",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-10-11T08:56:02Z | ---
base_model: openaccess-ai-collective/jackalope-7b
datasets:
- Open-Orca/OpenOrca
- LDJnr/LessWrong-Amplify-Instruct
- LDJnr/Pure-Dove
- LDJnr/Verified-Camel
- PygmalionAI/PIPPA
- meta-math/MetaMathQA
- riddle_sense
inference: false
language:
- en
library_name: transformers
license: apache-2.0
model_creator: Open Access AI Collective
model_name: Jackalope 7B
model_type: mistral
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Jackalope 7B - GGUF
- Model creator: [Open Access AI Collective](https://huggingface.co/openaccess-ai-collective)
- Original model: [Jackalope 7B](https://huggingface.co/openaccess-ai-collective/jackalope-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Open Access AI Collective's Jackalope 7B](https://huggingface.co/openaccess-ai-collective/jackalope-7b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/jackalope-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/jackalope-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/jackalope-7B-GGUF)
* [Open Access AI Collective's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/openaccess-ai-collective/jackalope-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [jackalope-7b.Q2_K.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [jackalope-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [jackalope-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [jackalope-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [jackalope-7b.Q4_0.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [jackalope-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [jackalope-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [jackalope-7b.Q5_0.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [jackalope-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [jackalope-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [jackalope-7b.Q6_K.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [jackalope-7b.Q8_0.gguf](https://huggingface.co/TheBloke/jackalope-7B-GGUF/blob/main/jackalope-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/jackalope-7B-GGUF and below it, a specific filename to download, such as: jackalope-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/jackalope-7B-GGUF jackalope-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/jackalope-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/jackalope-7B-GGUF jackalope-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m jackalope-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/jackalope-7B-GGUF", model_file="jackalope-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Open Access AI Collective's Jackalope 7B
<p><h1>🐰🦌 Jackalope 7B 🐰🦌</h1></p>

[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# Jackalope 7B
We have used the [SlimOrca dataset](https://huggingface.co/datasets/Open-Orca/SlimOrca), PIPPA, and various other open datasets
to fine-tune on top of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
This dataset is our attempt to reproduce the dataset generated for Microsoft Research's [Orca Paper](https://arxiv.org/abs/2306.02707).
We use [OpenChat](https://huggingface.co/openchat) packing, trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This release highlights the efficiency of SlimOrca, while improving the ability of the model's multi-turn chat.
HF Leaderboard evals puts this model only slightly below the MistralOrca release, but can be considered a
reasonable tradeoff for a more general model that can handle multi-turn chat.
If you'd like to try the model now, we have it running on fast GPUs unquantized: https://huggingface.co/spaces/openaccess-ai-collective/jackalope-7b
Join the OpenAccess AI Collective Discord for more information about Axolotl trainer and other OAAIC models here:
https://discord.gg/5y8STgB3P3
Also join the AlignmentLab Discord for sneak-peak announcements:
https://AlignmentLab.ai
# Quantized Models
Quantized versions of this model are generously made available by [TheBloke](https://huggingface.co/TheBloke).
- AWQ: https://huggingface.co/TheBloke/Jackalope-7B-AWQ
- GPTQ: https://huggingface.co/TheBloke/Jackalope-7B-GPTQ
- GGUF: https://huggingface.co/TheBloke/Jackalope-7B-GGUF
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the "`MPT-Chat`" instruction template should work, as it also uses ChatML.
This formatting is also available via a pre-defined [Transformers chat template](https://huggingface.co/docs/transformers/main/chat_templating),
which means that lists of messages can be formatted for you with the `apply_chat_template()` method:
```python
chat = [
{"role": "system", "content": "You are JackalopeAI, a large language model trained by OpenAccess AI Collective. Write out your reasoning step-by-step to be sure you get the right answers!"}
{"role": "user", "content": "How are you?"},
{"role": "assistant", "content": "I am doing well!"},
{"role": "user", "content": "Please tell me about the mythical creatures called jackalopes."},
]
tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
```
which will yield:
```
<|im_start|>system
You are JackalopeAI. Write out your reasoning step-by-step to be sure you get the right answers!
<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I am doing well!<|im_end|>
<|im_start|>user
Please tell me about the mythical creatures called jackalopes.<|im_end|>
<|im_start|>assistant
```
If you use `tokenize=True` and `return_tensors="pt"` instead, then you will get a tokenized
and formatted conversation ready to pass to `model.generate()`.
# Evaluation
## HuggingFace Leaderboard Performance
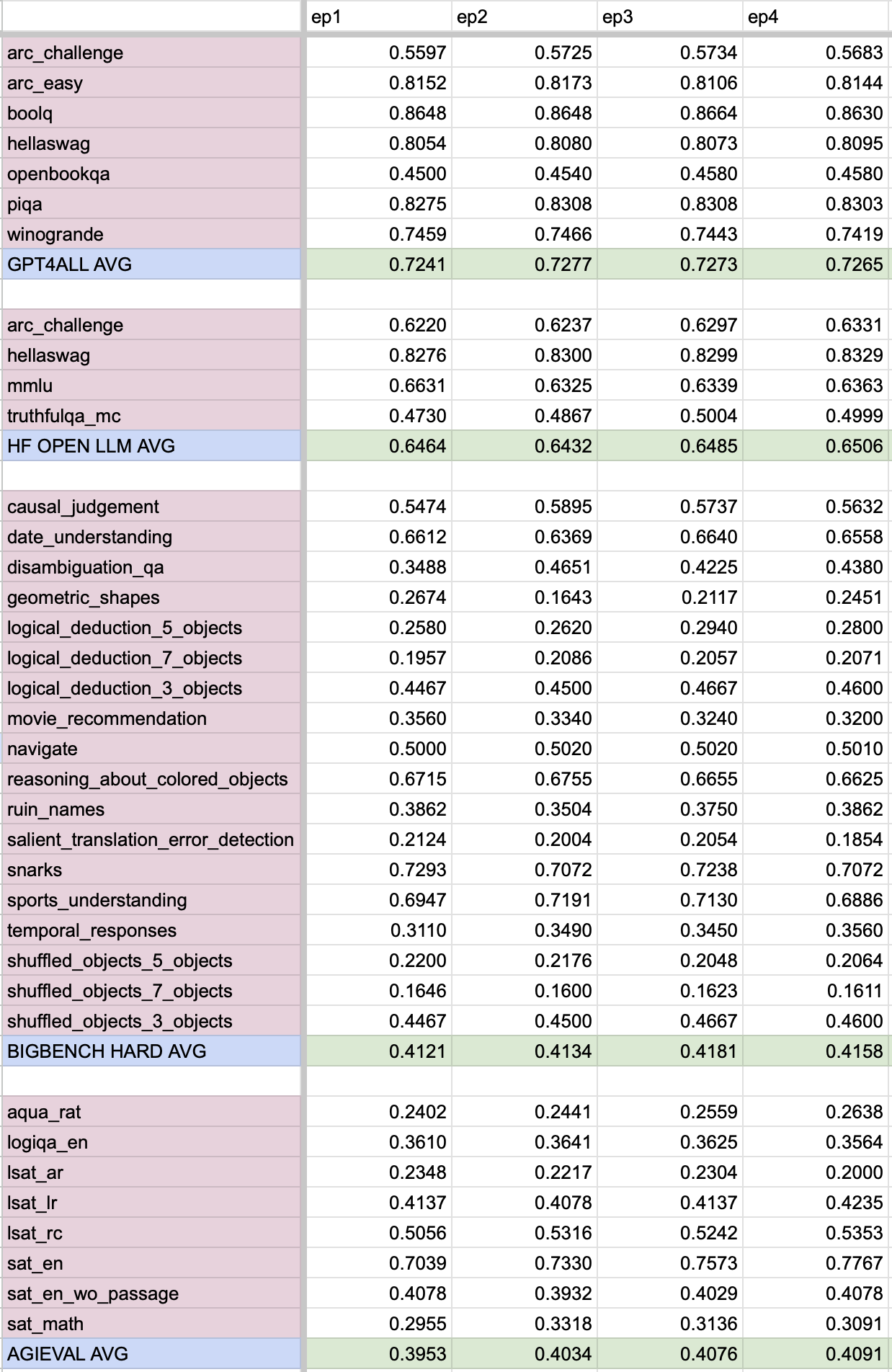
| Metric | Value |
|-----------------------|--|
| MMLU (5-shot) | 63.63 |
| ARC (25-shot) | 63.31 |
| HellaSwag (10-shot) | 83.29 |
| TruthfulQA (0-shot) | 49.99 |
| Avg. | 65.06 |
We use [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above, using the same version as the HuggingFace LLM Leaderboard.
# Dataset
We used a verified, curated, filtered selection of most of the GPT-4 augmented data from the OpenOrca dataset.
Additionally we include multi-turn chat from PIPPA, various datasets
by LDJ from Nous Research, MetaMathQA, and Chain-of-Thought augmented data from the train split of RiddleSense.
- [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- [LDJnr/LessWrong-Amplify-Instruct](https://huggingface.co/datasets/LDJnr/LessWrong-Amplify-Instruct)
- [LDJnr/Pure-Dove](https://huggingface.co/datasets/LDJnr/Pure-Dove)
- [LDJnr/Verified-Camel](https://huggingface.co/datasets/LDJnr/Verified-Camel)
- [PygmalionAI/PIPPA](https://huggingface.co/datasets/PygmalionAI/PIPPA)
- [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)
- [riddle_sense](https://huggingface.co/datasets/riddle_sense)
# Training
We trained with 8x A6000 GPUs for 96 hours, completing 4 epochs of full fine tuning on our dataset in one training run.
Commodity cost was ~$650.
# Citation
```bibtex
@software{lian2023jackalope,
title = {Jackalope 7B: Mistral-7B Model Multi-Turn Chat tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{openaccess-ai-collective/jackalope-7b},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
<!-- original-model-card end -->
|
timm/repvit_m2_3.dist_450e_in1k | timm | 2023-10-20T18:35:39Z | 571 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2307.09283",
"license:apache-2.0",
"region:us"
]
| image-classification | 2023-10-20T18:35:34Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for repvit_m2_3.dist_450e_in1k
A RepViT image classification model. Trained on ImageNet-1k with distillation by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 23.7
- GMACs: 4.6
- Activations (M): 26.2
- Image size: 224 x 224
- **Papers:**
- RepViT: Revisiting Mobile CNN From ViT Perspective: https://arxiv.org/abs/2307.09283
- **Original:** https://github.com/THU-MIG/RepViT
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('repvit_m2_3.dist_450e_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'repvit_m2_3.dist_450e_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 80, 56, 56])
# torch.Size([1, 160, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 640, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'repvit_m2_3.dist_450e_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 640, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@misc{wang2023repvit,
title={RepViT: Revisiting Mobile CNN From ViT Perspective},
author={Ao Wang and Hui Chen and Zijia Lin and Hengjun Pu and Guiguang Ding},
year={2023},
eprint={2307.09283},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
about0/qwen-chat-GGUF-14B | about0 | 2023-12-15T16:11:43Z | 571 | 6 | null | [
"gguf",
"qwen",
"chat",
"中文",
"text-generation",
"zh",
"en",
"region:us"
]
| text-generation | 2023-12-14T03:03:56Z | ---
language:
- zh
- en
tags:
- qwen
- chat
- 中文
model_name: Qwen Chat 14B
model_type: qwen
pipeline_tag: text-generation
quantized_by: about0
---
# Qwen Chat 14B - GGUF
Here are the llama.cpp-compatible GGUF converted and/or quantized models for [Qwen 14B Chat](https://huggingface.co/Qwen/Qwen-14B-Chat).
## Explanation of quantization methods
<details>
<summary>Click to see details</summary>
Methods:
* type-0 (Q4_0, Q5_0, Q8_0) - weights w are obtained from quants q using w = d * q, where d is the block scale.
* type-1 (Q4_1, Q5_1) - weights are given by w = d * q + m, where m is the block minimum
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This ends up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
* GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
This is exposed via llama.cpp quantization types that define various "quantization mixes" as follows:
* LLAMA_FTYPE_MOSTLY_Q2_K - uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors.
* LLAMA_FTYPE_MOSTLY_Q3_K_S - uses GGML_TYPE_Q3_K for all tensors
* LLAMA_FTYPE_MOSTLY_Q3_K_M - uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K
* LLAMA_FTYPE_MOSTLY_Q3_K_L - uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K
* LLAMA_FTYPE_MOSTLY_Q4_K_S - uses GGML_TYPE_Q4_K for all tensors
* LLAMA_FTYPE_MOSTLY_Q4_K_M - uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K
* LLAMA_FTYPE_MOSTLY_Q5_K_S - uses GGML_TYPE_Q5_K for all tensors
* LLAMA_FTYPE_MOSTLY_Q5_K_M - uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K
* LLAMA_FTYPE_MOSTLY_Q6_K- uses 6-bit quantization (GGML_TYPE_Q8_K) for all tensors
</details>
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [qwen-chat-14B-Q2_K.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q2_K.gguf) | Q2_K | 2 | 6.2 GB| 9.1 GB | smallest, significant quality-loss - not recommended for most purposes |
| [qwen-chat-14B-Q3_K_S.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q3_K_S.gguf) | Q3_K_S | 3 | 6.5 GB | 9.4 GB | very small, high quality-loss |
| [qwen-chat-14B-Q3_K_M.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q3_K_M.gguf) | Q3_K_M | 3 | 7.2 GB | 10.1 GB | very small, high quality-loss |
| [qwen-chat-14B-Q3_K_L.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q3_K_L.gguf) | Q3_K_L | 3 | 7.5 GB| 10.4 GB | small, substantial quality-loss |
| [qwen-chat-14B-Q4_0.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q4_0.gguf) | Q4_0 | 4 | 7.7 GB| 10.6 GB | legacy; small, very high quality-loss - prefer using Q3_K_L |
| [qwen-chat-14B-Q4_1.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q4_1.gguf) | Q4_1 | 4 | 8.4 GB| 11.3 GB | legacy; small, very high quality-loss - prefer using Q4_K_S |
| [qwen-chat-14B-Q4_K_S.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q4_K_S.gguf) | Q4_K_S | 4 | 8.0 GB| 10.9 GB | small, greater quality-loss |
| [qwen-chat-14B-Q4_K_M.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q4_K_M.gguf) | Q4_K_M | 4 | 8.9 GB| 11.8 GB | medium, balanced quality - recommended |
| [qwen-chat-14B-Q5_0.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q5_0.gguf) | Q5_0 | 5 | 9.2 GB| 12.1 GB | legacy; medium, balanced quality - prefer using Q5_K_M |
| [qwen-chat-14B-Q5_1.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q5_1.gguf) | Q5_1 | 5 | 10 GB| 12.9 GB | legacy; medium, balanced quality - prefer using Q5_K_M |
| [qwen-chat-14B-Q5_K_S.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q5_K_S.gguf) | Q5_K_S | 5 | 9.4 GB | 12.3 GB | large, low quality-loss - recommended |
| [qwen-chat-14B-Q5_K_M.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q5_K_M.gguf) | Q5_K_M | 5 | 11 GB | 13.9 GB | large, very low quality-loss - recommended |
| [qwen-chat-14B-Q6_K.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q6_K.gguf) | Q6_K | 6 | 12 GB| 14.9 GB | very large, extremely low quality-loss |
| [qwen-chat-14B-Q8_0.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-Q8_0.gguf) | Q8_0 | 8 | 15 GB| 17.9 GB | very large, extremely low quality-loss - not recommended |
| [qwen-chat-14B-f16.gguf](https://huggingface.co/about0/qwen-chat-GGUF-14B/blob/main/qwen-chat-14B-f16.gguf) | f16 | 16 | 27 GB| 29.9 GB | very large, no quality-loss - not recommended |
### Model Sources
- **Repository:** [Qwen-14B-Chat](https://huggingface.co/Qwen/Qwen-14B-Chat)
|
mradermacher/lzlv_70b_fp16_hf-i1-GGUF | mradermacher | 2024-05-08T04:46:42Z | 571 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:lizpreciatior/lzlv_70b_fp16_hf",
"license:cc-by-nc-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-04T14:37:06Z | ---
base_model: lizpreciatior/lzlv_70b_fp16_hf
language:
- en
library_name: transformers
license: cc-by-nc-2.0
quantized_by: mradermacher
---
## About
weighted/imatrix quants of https://huggingface.co/lizpreciatior/lzlv_70b_fp16_hf
<!-- provided-files -->
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ1_S.gguf) | i1-IQ1_S | 15.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ1_M.gguf) | i1-IQ1_M | 16.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 18.7 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ2_XS.gguf) | i1-IQ2_XS | 20.8 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ2_S.gguf) | i1-IQ2_S | 21.8 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ2_M.gguf) | i1-IQ2_M | 23.7 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q2_K.gguf) | i1-Q2_K | 25.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ3_XS.gguf) | i1-IQ3_XS | 28.6 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ3_S.gguf) | i1-IQ3_S | 30.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q3_K_S.gguf) | i1-Q3_K_S | 30.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ3_M.gguf) | i1-IQ3_M | 31.4 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q3_K_M.gguf) | i1-Q3_K_M | 33.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q3_K_L.gguf) | i1-Q3_K_L | 36.6 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-IQ4_XS.gguf) | i1-IQ4_XS | 36.9 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q4_0.gguf) | i1-Q4_0 | 39.1 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q4_K_S.gguf) | i1-Q4_K_S | 39.7 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q4_K_M.gguf) | i1-Q4_K_M | 41.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q5_K_S.gguf) | i1-Q5_K_S | 47.9 | |
| [GGUF](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q5_K_M.gguf) | i1-Q5_K_M | 49.2 | |
| [PART 1](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/lzlv_70b_fp16_hf-i1-GGUF/resolve/main/lzlv_70b_fp16_hf.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 56.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ChristianAzinn/gist-small-embedding-v0-gguf | ChristianAzinn | 2024-04-08T03:36:31Z | 571 | 0 | sentence-transformers | [
"sentence-transformers",
"gguf",
"feature-extraction",
"mteb",
"sentence-similarity",
"en",
"arxiv:2402.16829",
"base_model:avsolatorio/gist-small-embedding-v0",
"license:mit",
"autotrain_compatible",
"region:us"
]
| sentence-similarity | 2024-04-08T03:29:45Z | ---
base_model: avsolatorio/gist-small-embedding-v0
inference: false
language:
- en
license: mit
model_creator: avsolatorio
model_name: gist-small-embedding-v0
model_type: bert
quantized_by: ChristianAzinn
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- gguf
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
---
# gist-small-embedding-v0-gguf
Model creator: [avsolatorio](https://huggingface.co/avsolatorio)
Original model: [gist-small-embedding-v0](https://huggingface.co/avsolatorio/gist-small-embedding-v0)
## Original Description
The model is fine-tuned on top of the [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) using the [MEDI dataset](https://github.com/xlang-ai/instructor-embedding.git) augmented with mined triplets from the [MTEB Classification](https://huggingface.co/mteb) training dataset (excluding data from the Amazon Polarity Classification task).
The model does not require any instruction for generating embeddings. This means that queries for retrieval tasks can be directly encoded without crafting instructions.
Technical paper: [GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning](https://arxiv.org/abs/2402.16829)
## Description
This repo contains GGUF format files for the gist-small-embedding-v0 embedding model.
These files were converted and quantized with llama.cpp [PR 5500](https://github.com/ggerganov/llama.cpp/pull/5500), commit [34aa045de](https://github.com/ggerganov/llama.cpp/pull/5500/commits/34aa045de44271ff7ad42858c75739303b8dc6eb), on a consumer RTX 4090.
This model supports up to 512 tokens of context.
## Compatibility
These files are compatible with [llama.cpp](https://github.com/ggerganov/llama.cpp) as of commit [4524290e8](https://github.com/ggerganov/llama.cpp/commit/4524290e87b8e107cc2b56e1251751546f4b9051), as well as [LM Studio](https://lmstudio.ai/) as of version 0.2.19.
# Meta-information
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
## Provided Files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| Name | Quant method | Bits | Size | Use case |
| [gist-small-embedding-v0.Q2_K.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q2_K.gguf) | Q2_K | 2 | 25.2 MB | smallest, significant quality loss - not recommended for most purposes |
| [gist-small-embedding-v0.Q3_K_S.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q3_K_S.gguf) | Q3_K_S | 3 | 25.2 MB | very small, high quality loss |
| [gist-small-embedding-v0.Q3_K_M.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q3_K_M.gguf) | Q3_K_M | 3 | 26.7 MB | very small, high quality loss |
| [gist-small-embedding-v0.Q3_K_L.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q3_K_L.gguf) | Q3_K_L | 3 | 27.7 MB | small, substantial quality loss |
| [gist-small-embedding-v0.Q4_0.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q4_0.gguf) | Q4_0 | 4 | 26.2 MB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [gist-small-embedding-v0.Q4_K_S.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q4_K_S.gguf) | Q4_K_S | 4 | 28.2 MB | small, greater quality loss |
| [gist-small-embedding-v0.Q4_K_M.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q4_K_M.gguf) | Q4_K_M | 4 | 29.2 MB | medium, balanced quality - recommended |
| [gist-small-embedding-v0.Q5_0.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q5_0.gguf) | Q5_0 | 5 | 28.8 MB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [gist-small-embedding-v0.Q5_K_S.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q5_K_S.gguf) | Q5_K_S | 5 | 29.7 MB | large, low quality loss - recommended |
| [gist-small-embedding-v0.Q5_K_M.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q5_K_M.gguf) | Q5_K_M | 5 | 30.5 MB | large, very low quality loss - recommended |
| [gist-small-embedding-v0.Q6_K.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q6_K.gguf) | Q6_K | 6 | 35.1 MB | very large, extremely low quality loss |
| [gist-small-embedding-v0.Q8_0.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0.Q8_0.gguf) | Q8_0 | 8 | 36.8 MB | very large, extremely low quality loss - recommended |
| [gist-small-embedding-v0.Q8_0.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0_fp16.gguf) | fp16 | 16 | 67.3 MB | enormous, pretty much the original model - not recommended |
| [gist-small-embedding-v0.Q8_0.gguf](https://huggingface.co/ChristianAzinn/gist-small-embedding-v0-gguf/blob/main/gist-small-embedding-v0_fp32.gguf) | fp32 | 32 | 134 MB | enormous, pretty much the original model - not recommended |
# Examples
## Example Usage with `llama.cpp`
To compute a single embedding, build llama.cpp and run:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -p 'search_query: What is TSNE?'
```
You can also submit a batch of texts to embed, as long as the total number of tokens does not exceed the context length. Only the first three embeddings are shown by the `embedding` example.
`texts.txt`:
```
search_query: What is TSNE?
search_query: Who is Laurens Van der Maaten?
```
Compute multiple embeddings:
```shell
./embedding -ngl 99 -m [filepath-to-gguf].gguf -f texts.txt
```
## Example Usage with LM Studio
Download the 0.2.19 beta build from here: [Windows](https://releases.lmstudio.ai/windows/0.2.19/beta/LM-Studio-0.2.19-Setup-Preview-1.exe) [MacOS](https://releases.lmstudio.ai/mac/arm64/0.2.19/beta/LM-Studio-darwin-arm64-0.2.19-Preview-1.zip) [Linux](https://releases.lmstudio.ai/linux/0.2.19/beta/LM_Studio-0.2.19-Preview-1.AppImage)
Once installed, open the app. The home should look like this:

Search for either "ChristianAzinn" in the main search bar or go to the "Search" tab on the left menu and search the name there.

Select your model from those that appear (this example uses `bge-small-en-v1.5-gguf`) and select which quantization you want to download. Since this model is pretty small, I recommend Q8_0, if not f16/32. Generally, the lower you go in the list (or the bigger the number gets), the larger the file and the better the performance.

You will see a green checkmark and the word "Downloaded" once the model has successfully downloaded, which can take some time depending on your network speeds.

Once this model is finished downloading, navigate to the "Local Server" tab on the left menu and open the loader for text embedding models. This loader does not appear before version 0.2.19, so ensure you downloaded the correct version.

Select the model you just downloaded from the dropdown that appears to load it. You may need to play with configuratios in the right-side menu, such as GPU offload if it doesn't fit entirely into VRAM.

All that's left to do is to hit the "Start Server" button:

And if you see text like that shown below in the console, you're good to go! You can use this as a drop-in replacement for the OpenAI embeddings API in any application that requires it, or you can query the endpoint directly to test it out.

Example curl request to the API endpoint:
```shell
curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
```
For more information, see the LM Studio [text embedding documentation](https://lmstudio.ai/docs/text-embeddings).
## Acknowledgements
Thanks to the LM Studio team and everyone else working on open-source AI.
This README is inspired by that of [nomic-ai-embed-text-v1.5-gguf](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-gguf), another excellent embedding model, and those of the legendary [TheBloke](https://huggingface.co/TheBloke). |
common-canvas/CommonCanvas-XL-C | common-canvas | 2024-05-17T15:11:00Z | 571 | 26 | diffusers | [
"diffusers",
"onnx",
"safetensors",
"common-canvas",
"stable-diffusion",
"sdxl",
"en",
"dataset:common-canvas/commoncatalog-cc-by-sa",
"dataset:common-canvas/commoncatalog-cc-by",
"arxiv:2310.16825",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-04-19T09:59:48Z | ---
license: cc-by-sa-4.0
tags:
- common-canvas
- stable-diffusion
- sdxl
datasets:
- common-canvas/commoncatalog-cc-by-sa
- common-canvas/commoncatalog-cc-by
language:
- en
---
# CommonCanvas-XL-C
## Summary
CommonCanvas is a family of latent diffusion models capable of generating images from a given text prompt. The architecture is based off of Stable Diffusion XL. Different CommonCanvas models are trained exclusively on subsets of the CommonCatalog Dataset (See Data Card), a large dataset of Creative Commons licensed images with synthetic captions produced using a pre-trained BLIP-2 captioning model.
**Input:** CommonCatalog Text Captions
**Output:** CommonCatalog Images
**Architecture:** Stable Diffusion XL
**Version Number:** 0.1
The goal of this purpose is to produce a model that is competitive with Stable Diffusion XL, but to do so using an easily accessible dataset of known provenance. Doing so makes replicating the model significantly easier and provides proper attribution to all the creative commons work used to train the model. The exact training recipe of the model can be found in the paper hosted at this link. https://arxiv.org/abs/2310.16825
## Performance Limitations
CommonCanvas under-performs in several categories, including faces, general photography, and paintings (see paper, Figure 8). These datasets all originated from the Conceptual Captions dataset, which relies on web-scraped data. These web-sourced captions, while abundant, may not always align with human-generated language nuances. Transitioning to synthetic captions introduces certain performance challenges, however, the drop in performance is not as dramatic as one might assume.
## Training Dataset Limitations
The model is trained on 10 year old YFCC data and may not have modern concepts or recent events in its training corpus. Performance on this model will be worse on certain proper nouns or specific celebrities, but this is a feature not a bug. The model may not generate known artwork, individual celebrities, or specific locations due to the autogenerated nature of the caption data.
Note: The non-commercial variants of this model are explicitly not intended to be use
* It is trained on data derived from the Flickr100M dataset. The information is dated and known to have a bias towards internet connected Western countries. Some areas such as the global south lack representation.
## Associated Risks
* Text in images produced by the model will likely be difficult to read.
* The model struggles with more complex tasks that require compositional understanding
* It may not accurately generate faces or representations of specific people.
* The model primarily learned from English descriptions and may not perform as effectively in other languages.
* The autoencoder aspect of the model introduces some information loss.
* It may be possible to guide the model to generate objectionable content, i.e. nudity or other NSFW material.
## Intended Uses
* Using the model for generative AI research
* Safe deployment of models which have the potential to generate harmful content.
* Probing and understanding the limitations and biases of generative models.
* Generation of artworks and use in design and other artistic processes.
* Applications in educational or creative tools.
* Research on generative models.
## Usage
We recommend using the MosaicML Diffusion Repo to finetune / train the model: https://github.com/mosaicml/diffusion.
Example finetuning code coming soon.
### Spaces demo
Try the model demo on [Hugging Face Spaces](https://huggingface.co/spaces/common-canvas/CommonCanvas)
### Inference with 🧨 diffusers
```py
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"common-canvas/CommonCanvas-XL-C",
custom_pipeline="multimodalart/sdxl_perturbed_attention_guidance", #read more at https://huggingface.co/multimodalart/sdxl_perturbed_attention_guidance
torch_dtype=torch.float16
).to(device)
prompt = "a cat sitting in a car seat"
image = pipe(prompt, num_inference_steps=25).images[0]
```
### Inference with ComfyUI / AUTOMATIC1111
[Download safetensors ⬇️](https://huggingface.co/common-canvas/CommonCanvas-XLC/resolve/main/commoncanvas_xl_c.safetensors?download=true)
## Evaluation/Validation
We validated the model against Stability AI’s SD2 model and compared human user study
## Acknowledgements
We thank @multimodalart, @Wauplin, and @lhoestq at Hugging Face for helping us host the dataset, and model weights.
## Citation
```
@article{gokaslan2023commoncanvas,
title={CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images},
author={Gokaslan, Aaron and Cooper, A Feder and Collins, Jasmine and Seguin, Landan and Jacobson, Austin and Patel, Mihir and Frankle, Jonathan and Stephenson, Cory and Kuleshov, Volodymyr},
journal={arXiv preprint arXiv:2310.16825},
year={2023}
}
``` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.