
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/app.rs | use crate::console_log;
use crate::worker::{ModelData, Worker, WorkerInput, WorkerOutput};
use std::str::FromStr;
use wasm_bindgen::prelude::*;
use wasm_bindgen_futures::JsFuture;
use yew::{html, Component, Context, Html};
use yew_agent::{Bridge, Bridged};
async fn fetch_url(url: &str) -> Result<Vec<u8>, JsValue> {
use web_sys::{Request, RequestCache, RequestInit, RequestMode, Response};
let window = web_sys::window().ok_or("window")?;
let opts = RequestInit::new();
opts.set_method("GET");
opts.set_mode(RequestMode::Cors);
opts.set_cache(RequestCache::NoCache);
let request = Request::new_with_str_and_init(url, &opts)?;
let resp_value = JsFuture::from(window.fetch_with_request(&request)).await?;
// `resp_value` is a `Response` object.
assert!(resp_value.is_instance_of::<Response>());
let resp: Response = resp_value.dyn_into()?;
let data = JsFuture::from(resp.blob()?).await?;
let blob = web_sys::Blob::from(data);
let array_buffer = JsFuture::from(blob.array_buffer()).await?;
let data = js_sys::Uint8Array::new(&array_buffer).to_vec();
Ok(data)
}
pub enum Msg {
Refresh,
Run,
UpdateStatus(String),
SetModel(ModelData),
WorkerIn(WorkerInput),
WorkerOut(Result<WorkerOutput, String>),
}
pub struct CurrentDecode {
start_time: Option<f64>,
}
pub struct App {
status: String,
loaded: bool,
temperature: std::rc::Rc<std::cell::RefCell<f64>>,
top_p: std::rc::Rc<std::cell::RefCell<f64>>,
prompt: std::rc::Rc<std::cell::RefCell<String>>,
generated: String,
n_tokens: usize,
current_decode: Option<CurrentDecode>,
worker: Box<dyn Bridge<Worker>>,
}
async fn model_data_load() -> Result<ModelData, JsValue> {
let tokenizer = fetch_url("tokenizer.json").await?;
let model = fetch_url("model.bin").await?;
console_log!("{}", model.len());
Ok(ModelData { tokenizer, model })
}
fn performance_now() -> Option<f64> {
let window = web_sys::window()?;
let performance = window.performance()?;
Some(performance.now() / 1000.)
}
impl Component for App {
type Message = Msg;
type Properties = ();
fn create(ctx: &Context<Self>) -> Self {
let status = "loading weights".to_string();
let cb = {
let link = ctx.link().clone();
move |e| link.send_message(Self::Message::WorkerOut(e))
};
let worker = Worker::bridge(std::rc::Rc::new(cb));
Self {
status,
n_tokens: 0,
temperature: std::rc::Rc::new(std::cell::RefCell::new(0.)),
top_p: std::rc::Rc::new(std::cell::RefCell::new(1.0)),
prompt: std::rc::Rc::new(std::cell::RefCell::new("".to_string())),
generated: String::new(),
current_decode: None,
worker,
loaded: false,
}
}
fn rendered(&mut self, ctx: &Context<Self>, first_render: bool) {
if first_render {
ctx.link().send_future(async {
match model_data_load().await {
Err(err) => {
let status = format!("{err:?}");
Msg::UpdateStatus(status)
}
Ok(model_data) => Msg::SetModel(model_data),
}
});
}
}
fn update(&mut self, ctx: &Context<Self>, msg: Self::Message) -> bool {
match msg {
Msg::SetModel(md) => {
self.status = "weights loaded successfully!".to_string();
self.loaded = true;
console_log!("loaded weights");
self.worker.send(WorkerInput::ModelData(md));
true
}
Msg::Run => {
if self.current_decode.is_some() {
self.status = "already generating some sample at the moment".to_string()
} else {
let start_time = performance_now();
self.current_decode = Some(CurrentDecode { start_time });
self.status = "generating...".to_string();
self.n_tokens = 0;
self.generated.clear();
let temp = *self.temperature.borrow();
let top_p = *self.top_p.borrow();
let prompt = self.prompt.borrow().clone();
console_log!("temp: {}, top_p: {}, prompt: {}", temp, top_p, prompt);
ctx.link()
.send_message(Msg::WorkerIn(WorkerInput::Run(temp, top_p, prompt)))
}
true
}
Msg::WorkerOut(output) => {
match output {
Ok(WorkerOutput::WeightsLoaded) => self.status = "weights loaded!".to_string(),
Ok(WorkerOutput::GenerationDone(Err(err))) => {
self.status = format!("error in worker process: {err}");
self.current_decode = None
}
Ok(WorkerOutput::GenerationDone(Ok(()))) => {
let dt = self.current_decode.as_ref().and_then(|current_decode| {
current_decode.start_time.and_then(|start_time| {
performance_now().map(|stop_time| stop_time - start_time)
})
});
self.status = match dt {
None => "generation succeeded!".to_string(),
Some(dt) => format!(
"generation succeeded in {:.2}s ({:.1} ms/token)",
dt,
dt * 1000.0 / (self.n_tokens as f64)
),
};
self.current_decode = None
}
Ok(WorkerOutput::Generated(token)) => {
self.n_tokens += 1;
self.generated.push_str(&token)
}
Err(err) => {
self.status = format!("error in worker {err:?}");
}
}
true
}
Msg::WorkerIn(inp) => {
self.worker.send(inp);
true
}
Msg::UpdateStatus(status) => {
self.status = status;
true
}
Msg::Refresh => true,
}
}
fn view(&self, ctx: &Context<Self>) -> Html {
use yew::TargetCast;
let temperature = self.temperature.clone();
let oninput_temperature = ctx.link().callback(move |e: yew::InputEvent| {
let input: web_sys::HtmlInputElement = e.target_unchecked_into();
if let Ok(temp) = f64::from_str(&input.value()) {
*temperature.borrow_mut() = temp
}
Msg::Refresh
});
let top_p = self.top_p.clone();
let oninput_top_p = ctx.link().callback(move |e: yew::InputEvent| {
let input: web_sys::HtmlInputElement = e.target_unchecked_into();
if let Ok(top_p_input) = f64::from_str(&input.value()) {
*top_p.borrow_mut() = top_p_input
}
Msg::Refresh
});
let prompt = self.prompt.clone();
let oninput_prompt = ctx.link().callback(move |e: yew::InputEvent| {
let input: web_sys::HtmlInputElement = e.target_unchecked_into();
*prompt.borrow_mut() = input.value();
Msg::Refresh
});
html! {
<div style="margin: 2%;">
<div><p>{"Running "}
<a href="https://github.com/karpathy/llama2.c" target="_blank">{"llama2.c"}</a>
{" in the browser using rust/wasm with "}
<a href="https://github.com/huggingface/candle" target="_blank">{"candle!"}</a>
</p>
<p>{"Once the weights have loaded, click on the run button to start generating content."}
</p>
</div>
{"temperature \u{00a0} "}
<input type="range" min="0." max="1.2" step="0.1" value={self.temperature.borrow().to_string()} oninput={oninput_temperature} id="temp"/>
{format!(" \u{00a0} {}", self.temperature.borrow())}
<br/ >
{"top_p \u{00a0} "}
<input type="range" min="0." max="1.0" step="0.05" value={self.top_p.borrow().to_string()} oninput={oninput_top_p} id="top_p"/>
{format!(" \u{00a0} {}", self.top_p.borrow())}
<br/ >
{"prompt: "}<input type="text" value={self.prompt.borrow().to_string()} oninput={oninput_prompt} id="prompt"/>
<br/ >
{
if self.loaded{
html!(<button class="button" onclick={ctx.link().callback(move |_| Msg::Run)}> { "run" }</button>)
}else{
html! { <progress id="progress-bar" aria-label="Loading weights..."></progress> }
}
}
<br/ >
<h3>
{&self.status}
</h3>
{
if self.current_decode.is_some() {
html! { <progress id="progress-bar" aria-label="generating…"></progress> }
} else {
html! {}
}
}
<blockquote>
<p> { self.generated.chars().map(|c|
if c == '\r' || c == '\n' {
html! { <br/> }
} else {
html! { {c} }
}).collect::<Html>()
} </p>
</blockquote>
</div>
}
}
}
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c/src | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/bin/m.rs | use candle::{Device, Tensor};
use candle_transformers::generation::LogitsProcessor;
use candle_wasm_example_llama2::worker::{Model as M, ModelData};
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub struct Model {
inner: M,
logits_processor: LogitsProcessor,
tokens: Vec<u32>,
repeat_penalty: f32,
}
impl Model {
fn process(&mut self, tokens: &[u32]) -> candle::Result<String> {
const REPEAT_LAST_N: usize = 64;
let dev = Device::Cpu;
let input = Tensor::new(tokens, &dev)?.unsqueeze(0)?;
let logits = self.inner.llama.forward(&input, tokens.len())?;
let logits = logits.squeeze(0)?;
let logits = if self.repeat_penalty == 1. || tokens.is_empty() {
logits
} else {
let start_at = self.tokens.len().saturating_sub(REPEAT_LAST_N);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&self.tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
self.tokens.push(next_token);
let text = match self.inner.tokenizer.id_to_token(next_token) {
Some(text) => text.replace('▁', " ").replace("<0x0A>", "\n"),
None => "".to_string(),
};
Ok(text)
}
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn new(weights: Vec<u8>, tokenizer: Vec<u8>) -> Result<Model, JsError> {
let model = M::load(ModelData {
tokenizer,
model: weights,
});
let logits_processor = LogitsProcessor::new(299792458, None, None);
match model {
Ok(inner) => Ok(Self {
inner,
logits_processor,
tokens: vec![],
repeat_penalty: 1.,
}),
Err(e) => Err(JsError::new(&e.to_string())),
}
}
#[wasm_bindgen]
pub fn get_seq_len(&mut self) -> usize {
self.inner.config.seq_len
}
#[wasm_bindgen]
pub fn init_with_prompt(
&mut self,
prompt: String,
temp: f64,
top_p: f64,
repeat_penalty: f32,
seed: u64,
) -> Result<String, JsError> {
// First reset the cache.
{
let mut cache = self.inner.cache.kvs.lock().unwrap();
for elem in cache.iter_mut() {
*elem = None
}
}
let temp = if temp <= 0. { None } else { Some(temp) };
let top_p = if top_p <= 0. || top_p >= 1. {
None
} else {
Some(top_p)
};
self.logits_processor = LogitsProcessor::new(seed, temp, top_p);
self.repeat_penalty = repeat_penalty;
self.tokens.clear();
let tokens = self
.inner
.tokenizer
.encode(prompt, true)
.map_err(|m| JsError::new(&m.to_string()))?
.get_ids()
.to_vec();
let text = self
.process(&tokens)
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
#[wasm_bindgen]
pub fn next_token(&mut self) -> Result<String, JsError> {
let last_token = *self.tokens.last().unwrap();
let text = self
.process(&[last_token])
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
}
fn main() {}
| 1 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c/src | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/bin/worker.rs | use yew_agent::PublicWorker;
fn main() {
console_error_panic_hook::set_once();
candle_wasm_example_llama2::Worker::register();
}
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c/src | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/bin/app.rs | fn main() {
wasm_logger::init(wasm_logger::Config::new(log::Level::Trace));
console_error_panic_hook::set_once();
yew::Renderer::<candle_wasm_example_llama2::App>::new().render();
}
| 3 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-core/LICENSE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 4 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-core/Cargo.toml | [package]
name = "candle-core"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
accelerate-src = { workspace = true, optional = true }
byteorder = { workspace = true }
candle-kernels = { workspace = true, optional = true }
candle-metal-kernels = { workspace = true, optional = true }
metal = { workspace = true, optional = true}
cudarc = { workspace = true, optional = true }
gemm = { workspace = true }
half = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
libc = { workspace = true, optional = true }
memmap2 = { workspace = true }
num-traits = { workspace = true }
num_cpus = { workspace = true }
rand = { workspace = true }
rand_distr = { workspace = true }
rayon = { workspace = true }
safetensors = { workspace = true }
thiserror = { workspace = true }
ug = { workspace = true }
ug-cuda = { workspace = true, optional = true }
ug-metal = { workspace = true, optional = true }
yoke = { workspace = true }
zip = { workspace = true }
[dev-dependencies]
anyhow = { workspace = true }
clap = { workspace = true }
criterion = { workspace = true }
[features]
default = []
cuda = ["cudarc", "dep:candle-kernels", "dep:ug-cuda"]
cudnn = ["cuda", "cudarc/cudnn"]
mkl = ["dep:libc", "dep:intel-mkl-src"]
accelerate = ["dep:libc", "dep:accelerate-src"]
metal = ["dep:metal", "dep:candle-metal-kernels", "dep:ug-metal"]
[[bench]]
name = "bench_main"
harness = false
[[example]]
name = "metal_basics"
required-features = ["metal"]
| 5 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-core/README.md | # candle
Minimalist ML framework for Rust
| 6 |
0 | hf_public_repos/candle/candle-core | hf_public_repos/candle/candle-core/src/scalar.rs | //! TensorScalar Enum and Trait
//!
use crate::{Result, Tensor, WithDType};
pub enum TensorScalar {
Tensor(Tensor),
Scalar(Tensor),
}
pub trait TensorOrScalar {
fn to_tensor_scalar(self) -> Result<TensorScalar>;
}
impl TensorOrScalar for &Tensor {
fn to_tensor_scalar(self) -> Result<TensorScalar> {
Ok(TensorScalar::Tensor(self.clone()))
}
}
impl<T: WithDType> TensorOrScalar for T {
fn to_tensor_scalar(self) -> Result<TensorScalar> {
let scalar = Tensor::new(self, &crate::Device::Cpu)?;
Ok(TensorScalar::Scalar(scalar))
}
}
| 7 |
0 | hf_public_repos/candle/candle-core | hf_public_repos/candle/candle-core/src/npy.rs | //! Numpy support for tensors.
//!
//! The spec for the npy format can be found in
//! [npy-format](https://docs.scipy.org/doc/numpy-1.14.2/neps/npy-format.html).
//! The functions from this module can be used to read tensors from npy/npz files
//! or write tensors to these files. A npy file contains a single tensor (unnamed)
//! whereas a npz file can contain multiple named tensors. npz files are also compressed.
//!
//! These two formats are easy to use in Python using the numpy library.
//!
//! ```python
//! import numpy as np
//! x = np.arange(10)
//!
//! # Write a npy file.
//! np.save("test.npy", x)
//!
//! # Read a value from the npy file.
//! x = np.load("test.npy")
//!
//! # Write multiple values to a npz file.
//! values = { "x": x, "x_plus_one": x + 1 }
//! np.savez("test.npz", **values)
//!
//! # Load multiple values from a npz file.
//! values = np.loadz("test.npz")
//! ```
use crate::{DType, Device, Error, Result, Shape, Tensor};
use byteorder::{LittleEndian, ReadBytesExt};
use half::{bf16, f16, slice::HalfFloatSliceExt};
use std::collections::HashMap;
use std::fs::File;
use std::io::{BufReader, Read, Write};
use std::path::Path;
const NPY_MAGIC_STRING: &[u8] = b"\x93NUMPY";
const NPY_SUFFIX: &str = ".npy";
fn read_header<R: Read>(reader: &mut R) -> Result<String> {
let mut magic_string = vec![0u8; NPY_MAGIC_STRING.len()];
reader.read_exact(&mut magic_string)?;
if magic_string != NPY_MAGIC_STRING {
return Err(Error::Npy("magic string mismatch".to_string()));
}
let mut version = [0u8; 2];
reader.read_exact(&mut version)?;
let header_len_len = match version[0] {
1 => 2,
2 => 4,
otherwise => return Err(Error::Npy(format!("unsupported version {otherwise}"))),
};
let mut header_len = vec![0u8; header_len_len];
reader.read_exact(&mut header_len)?;
let header_len = header_len
.iter()
.rev()
.fold(0_usize, |acc, &v| 256 * acc + v as usize);
let mut header = vec![0u8; header_len];
reader.read_exact(&mut header)?;
Ok(String::from_utf8_lossy(&header).to_string())
}
#[derive(Debug, PartialEq)]
struct Header {
descr: DType,
fortran_order: bool,
shape: Vec<usize>,
}
impl Header {
fn shape(&self) -> Shape {
Shape::from(self.shape.as_slice())
}
fn to_string(&self) -> Result<String> {
let fortran_order = if self.fortran_order { "True" } else { "False" };
let mut shape = self
.shape
.iter()
.map(|x| x.to_string())
.collect::<Vec<_>>()
.join(",");
let descr = match self.descr {
DType::BF16 => Err(Error::Npy("bf16 is not supported".into()))?,
DType::F16 => "f2",
DType::F32 => "f4",
DType::F64 => "f8",
DType::I64 => "i8",
DType::U32 => "u4",
DType::U8 => "u1",
};
if !shape.is_empty() {
shape.push(',')
}
Ok(format!(
"{{'descr': '<{descr}', 'fortran_order': {fortran_order}, 'shape': ({shape}), }}"
))
}
// Hacky parser for the npy header, a typical example would be:
// {'descr': '<f8', 'fortran_order': False, 'shape': (128,), }
fn parse(header: &str) -> Result<Header> {
let header =
header.trim_matches(|c: char| c == '{' || c == '}' || c == ',' || c.is_whitespace());
let mut parts: Vec<String> = vec![];
let mut start_index = 0usize;
let mut cnt_parenthesis = 0i64;
for (index, c) in header.chars().enumerate() {
match c {
'(' => cnt_parenthesis += 1,
')' => cnt_parenthesis -= 1,
',' => {
if cnt_parenthesis == 0 {
parts.push(header[start_index..index].to_owned());
start_index = index + 1;
}
}
_ => {}
}
}
parts.push(header[start_index..].to_owned());
let mut part_map: HashMap<String, String> = HashMap::new();
for part in parts.iter() {
let part = part.trim();
if !part.is_empty() {
match part.split(':').collect::<Vec<_>>().as_slice() {
[key, value] => {
let key = key.trim_matches(|c: char| c == '\'' || c.is_whitespace());
let value = value.trim_matches(|c: char| c == '\'' || c.is_whitespace());
let _ = part_map.insert(key.to_owned(), value.to_owned());
}
_ => return Err(Error::Npy(format!("unable to parse header {header}"))),
}
}
}
let fortran_order = match part_map.get("fortran_order") {
None => false,
Some(fortran_order) => match fortran_order.as_ref() {
"False" => false,
"True" => true,
_ => return Err(Error::Npy(format!("unknown fortran_order {fortran_order}"))),
},
};
let descr = match part_map.get("descr") {
None => return Err(Error::Npy("no descr in header".to_string())),
Some(descr) => {
if descr.is_empty() {
return Err(Error::Npy("empty descr".to_string()));
}
if descr.starts_with('>') {
return Err(Error::Npy(format!("little-endian descr {descr}")));
}
// the only supported types in tensor are:
// float64, float32, float16,
// complex64, complex128,
// int64, int32, int16, int8,
// uint8, and bool.
match descr.trim_matches(|c: char| c == '=' || c == '<' || c == '|') {
"e" | "f2" => DType::F16,
"f" | "f4" => DType::F32,
"d" | "f8" => DType::F64,
// "i" | "i4" => DType::S32,
"q" | "i8" => DType::I64,
// "h" | "i2" => DType::S16,
// "b" | "i1" => DType::S8,
"B" | "u1" => DType::U8,
"I" | "u4" => DType::U32,
"?" | "b1" => DType::U8,
// "F" | "F4" => DType::C64,
// "D" | "F8" => DType::C128,
descr => return Err(Error::Npy(format!("unrecognized descr {descr}"))),
}
}
};
let shape = match part_map.get("shape") {
None => return Err(Error::Npy("no shape in header".to_string())),
Some(shape) => {
let shape = shape.trim_matches(|c: char| c == '(' || c == ')' || c == ',');
if shape.is_empty() {
vec![]
} else {
shape
.split(',')
.map(|v| v.trim().parse::<usize>())
.collect::<std::result::Result<Vec<_>, _>>()?
}
}
};
Ok(Header {
descr,
fortran_order,
shape,
})
}
}
impl Tensor {
// TODO: Add the possibility to read directly to a device?
pub(crate) fn from_reader<R: std::io::Read>(
shape: Shape,
dtype: DType,
reader: &mut R,
) -> Result<Self> {
let elem_count = shape.elem_count();
match dtype {
DType::BF16 => {
let mut data_t = vec![bf16::ZERO; elem_count];
reader.read_u16_into::<LittleEndian>(data_t.reinterpret_cast_mut())?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::F16 => {
let mut data_t = vec![f16::ZERO; elem_count];
reader.read_u16_into::<LittleEndian>(data_t.reinterpret_cast_mut())?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::F32 => {
let mut data_t = vec![0f32; elem_count];
reader.read_f32_into::<LittleEndian>(&mut data_t)?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::F64 => {
let mut data_t = vec![0f64; elem_count];
reader.read_f64_into::<LittleEndian>(&mut data_t)?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::U8 => {
let mut data_t = vec![0u8; elem_count];
reader.read_exact(&mut data_t)?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::U32 => {
let mut data_t = vec![0u32; elem_count];
reader.read_u32_into::<LittleEndian>(&mut data_t)?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
DType::I64 => {
let mut data_t = vec![0i64; elem_count];
reader.read_i64_into::<LittleEndian>(&mut data_t)?;
Tensor::from_vec(data_t, shape, &Device::Cpu)
}
}
}
/// Reads a npy file and return the stored multi-dimensional array as a tensor.
pub fn read_npy<T: AsRef<Path>>(path: T) -> Result<Self> {
let mut reader = File::open(path.as_ref())?;
let header = read_header(&mut reader)?;
let header = Header::parse(&header)?;
if header.fortran_order {
return Err(Error::Npy("fortran order not supported".to_string()));
}
Self::from_reader(header.shape(), header.descr, &mut reader)
}
/// Reads a npz file and returns the stored multi-dimensional arrays together with their names.
pub fn read_npz<T: AsRef<Path>>(path: T) -> Result<Vec<(String, Self)>> {
let zip_reader = BufReader::new(File::open(path.as_ref())?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut result = vec![];
for i in 0..zip.len() {
let mut reader = zip.by_index(i)?;
let name = {
let name = reader.name();
name.strip_suffix(NPY_SUFFIX).unwrap_or(name).to_owned()
};
let header = read_header(&mut reader)?;
let header = Header::parse(&header)?;
if header.fortran_order {
return Err(Error::Npy("fortran order not supported".to_string()));
}
let s = Self::from_reader(header.shape(), header.descr, &mut reader)?;
result.push((name, s))
}
Ok(result)
}
/// Reads a npz file and returns the stored multi-dimensional arrays for some specified names.
pub fn read_npz_by_name<T: AsRef<Path>>(path: T, names: &[&str]) -> Result<Vec<Self>> {
let zip_reader = BufReader::new(File::open(path.as_ref())?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut result = vec![];
for name in names.iter() {
let mut reader = match zip.by_name(&format!("{name}{NPY_SUFFIX}")) {
Ok(reader) => reader,
Err(_) => Err(Error::Npy(format!(
"no array for {name} in {:?}",
path.as_ref()
)))?,
};
let header = read_header(&mut reader)?;
let header = Header::parse(&header)?;
if header.fortran_order {
return Err(Error::Npy("fortran order not supported".to_string()));
}
let s = Self::from_reader(header.shape(), header.descr, &mut reader)?;
result.push(s)
}
Ok(result)
}
fn write<T: Write>(&self, f: &mut T) -> Result<()> {
f.write_all(NPY_MAGIC_STRING)?;
f.write_all(&[1u8, 0u8])?;
let header = Header {
descr: self.dtype(),
fortran_order: false,
shape: self.dims().to_vec(),
};
let mut header = header.to_string()?;
let pad = 16 - (NPY_MAGIC_STRING.len() + 5 + header.len()) % 16;
for _ in 0..pad % 16 {
header.push(' ')
}
header.push('\n');
f.write_all(&[(header.len() % 256) as u8, (header.len() / 256) as u8])?;
f.write_all(header.as_bytes())?;
self.write_bytes(f)
}
/// Writes a multi-dimensional array in the npy format.
pub fn write_npy<T: AsRef<Path>>(&self, path: T) -> Result<()> {
let mut f = File::create(path.as_ref())?;
self.write(&mut f)
}
/// Writes multiple multi-dimensional arrays using the npz format.
pub fn write_npz<S: AsRef<str>, T: AsRef<Tensor>, P: AsRef<Path>>(
ts: &[(S, T)],
path: P,
) -> Result<()> {
let mut zip = zip::ZipWriter::new(File::create(path.as_ref())?);
let options: zip::write::FileOptions<()> =
zip::write::FileOptions::default().compression_method(zip::CompressionMethod::Stored);
for (name, tensor) in ts.iter() {
zip.start_file(format!("{}.npy", name.as_ref()), options)?;
tensor.as_ref().write(&mut zip)?
}
Ok(())
}
}
/// Lazy tensor loader.
pub struct NpzTensors {
index_per_name: HashMap<String, usize>,
path: std::path::PathBuf,
// We do not store a zip reader as it needs mutable access to extract data. Instead we
// re-create a zip reader for each tensor.
}
impl NpzTensors {
pub fn new<T: AsRef<Path>>(path: T) -> Result<Self> {
let path = path.as_ref().to_owned();
let zip_reader = BufReader::new(File::open(&path)?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut index_per_name = HashMap::new();
for i in 0..zip.len() {
let file = zip.by_index(i)?;
let name = {
let name = file.name();
name.strip_suffix(NPY_SUFFIX).unwrap_or(name).to_owned()
};
index_per_name.insert(name, i);
}
Ok(Self {
index_per_name,
path,
})
}
pub fn names(&self) -> Vec<&String> {
self.index_per_name.keys().collect()
}
/// This only returns the shape and dtype for a named tensor. Compared to `get`, this avoids
/// reading the whole tensor data.
pub fn get_shape_and_dtype(&self, name: &str) -> Result<(Shape, DType)> {
let index = match self.index_per_name.get(name) {
None => crate::bail!("cannot find tensor {name}"),
Some(index) => *index,
};
let zip_reader = BufReader::new(File::open(&self.path)?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut reader = zip.by_index(index)?;
let header = read_header(&mut reader)?;
let header = Header::parse(&header)?;
Ok((header.shape(), header.descr))
}
pub fn get(&self, name: &str) -> Result<Option<Tensor>> {
let index = match self.index_per_name.get(name) {
None => return Ok(None),
Some(index) => *index,
};
// We hope that the file has not changed since first reading it.
let zip_reader = BufReader::new(File::open(&self.path)?);
let mut zip = zip::ZipArchive::new(zip_reader)?;
let mut reader = zip.by_index(index)?;
let header = read_header(&mut reader)?;
let header = Header::parse(&header)?;
if header.fortran_order {
return Err(Error::Npy("fortran order not supported".to_string()));
}
let tensor = Tensor::from_reader(header.shape(), header.descr, &mut reader)?;
Ok(Some(tensor))
}
}
#[cfg(test)]
mod tests {
use super::Header;
#[test]
fn parse() {
let h = "{'descr': '<f8', 'fortran_order': False, 'shape': (128,), }";
assert_eq!(
Header::parse(h).unwrap(),
Header {
descr: crate::DType::F64,
fortran_order: false,
shape: vec![128]
}
);
let h = "{'descr': '<f4', 'fortran_order': True, 'shape': (256,1,128), }";
let h = Header::parse(h).unwrap();
assert_eq!(
h,
Header {
descr: crate::DType::F32,
fortran_order: true,
shape: vec![256, 1, 128]
}
);
assert_eq!(
h.to_string().unwrap(),
"{'descr': '<f4', 'fortran_order': True, 'shape': (256,1,128,), }"
);
let h = Header {
descr: crate::DType::U32,
fortran_order: false,
shape: vec![],
};
assert_eq!(
h.to_string().unwrap(),
"{'descr': '<u4', 'fortran_order': False, 'shape': (), }"
);
}
}
| 8 |
0 | hf_public_repos/candle/candle-core | hf_public_repos/candle/candle-core/src/op.rs | //! Tensor Opertion Enums and Traits
//!
#![allow(clippy::redundant_closure_call)]
use crate::Tensor;
use half::{bf16, f16};
use num_traits::float::Float;
#[derive(Clone, Copy, PartialEq, Eq)]
pub enum CmpOp {
Eq,
Ne,
Le,
Ge,
Lt,
Gt,
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum ReduceOp {
Sum,
Min,
Max,
ArgMin,
ArgMax,
}
impl ReduceOp {
pub(crate) fn name(&self) -> &'static str {
match self {
Self::ArgMax => "argmax",
Self::ArgMin => "argmin",
Self::Min => "min",
Self::Max => "max",
Self::Sum => "sum",
}
}
}
// These ops return the same type as their input type.
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum BinaryOp {
Add,
Mul,
Sub,
Div,
Maximum,
Minimum,
}
// Unary ops with no argument
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum UnaryOp {
Exp,
Log,
Sin,
Cos,
Abs,
Neg,
Recip,
Sqr,
Sqrt,
Gelu,
GeluErf,
Erf,
Relu,
Silu,
Tanh,
Floor,
Ceil,
Round,
Sign,
}
#[derive(Clone)]
pub enum Op {
Binary(Tensor, Tensor, BinaryOp),
Unary(Tensor, UnaryOp),
Cmp(Tensor, CmpOp),
// The third argument is the reduced shape with `keepdim=true`.
Reduce(Tensor, ReduceOp, Vec<usize>),
Matmul(Tensor, Tensor),
Gather(Tensor, Tensor, usize),
ScatterAdd(Tensor, Tensor, Tensor, usize),
IndexSelect(Tensor, Tensor, usize),
IndexAdd(Tensor, Tensor, Tensor, usize),
WhereCond(Tensor, Tensor, Tensor),
#[allow(dead_code)]
Conv1D {
arg: Tensor,
kernel: Tensor,
padding: usize,
stride: usize,
dilation: usize,
},
#[allow(dead_code)]
ConvTranspose1D {
arg: Tensor,
kernel: Tensor,
padding: usize,
output_padding: usize,
stride: usize,
dilation: usize,
},
#[allow(dead_code)]
Conv2D {
arg: Tensor,
kernel: Tensor,
padding: usize,
stride: usize,
dilation: usize,
},
#[allow(dead_code)]
ConvTranspose2D {
arg: Tensor,
kernel: Tensor,
padding: usize,
output_padding: usize,
stride: usize,
dilation: usize,
},
AvgPool2D {
arg: Tensor,
kernel_size: (usize, usize),
stride: (usize, usize),
},
MaxPool2D {
arg: Tensor,
kernel_size: (usize, usize),
stride: (usize, usize),
},
UpsampleNearest1D {
arg: Tensor,
target_size: usize,
},
UpsampleNearest2D {
arg: Tensor,
target_h: usize,
target_w: usize,
},
Cat(Vec<Tensor>, usize),
#[allow(dead_code)] // add is currently unused.
Affine {
arg: Tensor,
mul: f64,
add: f64,
},
ToDType(Tensor),
Copy(Tensor),
Broadcast(Tensor),
Narrow(Tensor, usize, usize, usize),
SliceScatter0(Tensor, Tensor, usize),
Reshape(Tensor),
ToDevice(Tensor),
Transpose(Tensor, usize, usize),
Permute(Tensor, Vec<usize>),
Elu(Tensor, f64),
Powf(Tensor, f64),
CustomOp1(
Tensor,
std::sync::Arc<Box<dyn crate::CustomOp1 + Send + Sync>>,
),
CustomOp2(
Tensor,
Tensor,
std::sync::Arc<Box<dyn crate::CustomOp2 + Send + Sync>>,
),
CustomOp3(
Tensor,
Tensor,
Tensor,
std::sync::Arc<Box<dyn crate::CustomOp3 + Send + Sync>>,
),
}
pub trait UnaryOpT {
const NAME: &'static str;
const KERNEL: &'static str;
const V: Self;
fn bf16(v1: bf16) -> bf16;
fn f16(v1: f16) -> f16;
fn f32(v1: f32) -> f32;
fn f64(v1: f64) -> f64;
fn u8(v1: u8) -> u8;
fn u32(v1: u32) -> u32;
fn i64(v1: i64) -> i64;
// There is no very good way to represent optional function in traits so we go for an explicit
// boolean flag to mark the function as existing.
const BF16_VEC: bool = false;
fn bf16_vec(_xs: &[bf16], _ys: &mut [bf16]) {}
const F16_VEC: bool = false;
fn f16_vec(_xs: &[f16], _ys: &mut [f16]) {}
const F32_VEC: bool = false;
fn f32_vec(_xs: &[f32], _ys: &mut [f32]) {}
const F64_VEC: bool = false;
fn f64_vec(_xs: &[f64], _ys: &mut [f64]) {}
}
pub trait BinaryOpT {
const NAME: &'static str;
const KERNEL: &'static str;
const V: Self;
fn bf16(v1: bf16, v2: bf16) -> bf16;
fn f16(v1: f16, v2: f16) -> f16;
fn f32(v1: f32, v2: f32) -> f32;
fn f64(v1: f64, v2: f64) -> f64;
fn u8(v1: u8, v2: u8) -> u8;
fn u32(v1: u32, v2: u32) -> u32;
fn i64(v1: i64, v2: i64) -> i64;
const BF16_VEC: bool = false;
fn bf16_vec(_xs1: &[bf16], _xs2: &[bf16], _ys: &mut [bf16]) {}
const F16_VEC: bool = false;
fn f16_vec(_xs1: &[f16], _xs2: &[f16], _ys: &mut [f16]) {}
const F32_VEC: bool = false;
fn f32_vec(_xs1: &[f32], _xs2: &[f32], _ys: &mut [f32]) {}
const F64_VEC: bool = false;
fn f64_vec(_xs1: &[f64], _xs2: &[f64], _ys: &mut [f64]) {}
const U8_VEC: bool = false;
fn u8_vec(_xs1: &[u8], _xs2: &[u8], _ys: &mut [u8]) {}
const U32_VEC: bool = false;
fn u32_vec(_xs1: &[u32], _xs2: &[u32], _ys: &mut [u32]) {}
const I64_VEC: bool = false;
fn i64_vec(_xs1: &[i64], _xs2: &[i64], _ys: &mut [i64]) {}
}
pub(crate) struct Add;
pub(crate) struct Div;
pub(crate) struct Mul;
pub(crate) struct Sub;
pub(crate) struct Maximum;
pub(crate) struct Minimum;
pub(crate) struct Exp;
pub(crate) struct Log;
pub(crate) struct Sin;
pub(crate) struct Cos;
pub(crate) struct Abs;
pub(crate) struct Neg;
pub(crate) struct Recip;
pub(crate) struct Sqr;
pub(crate) struct Sqrt;
pub(crate) struct Gelu;
pub(crate) struct GeluErf;
pub(crate) struct Erf;
pub(crate) struct Relu;
pub(crate) struct Silu;
pub(crate) struct Tanh;
pub(crate) struct Floor;
pub(crate) struct Ceil;
pub(crate) struct Round;
pub(crate) struct Sign;
macro_rules! bin_op {
($op:ident, $name: literal, $e: expr, $f32_vec: ident, $f64_vec: ident) => {
impl BinaryOpT for $op {
const NAME: &'static str = $name;
const KERNEL: &'static str = concat!("b", $name);
const V: Self = $op;
#[inline(always)]
fn bf16(v1: bf16, v2: bf16) -> bf16 {
$e(v1, v2)
}
#[inline(always)]
fn f16(v1: f16, v2: f16) -> f16 {
$e(v1, v2)
}
#[inline(always)]
fn f32(v1: f32, v2: f32) -> f32 {
$e(v1, v2)
}
#[inline(always)]
fn f64(v1: f64, v2: f64) -> f64 {
$e(v1, v2)
}
#[inline(always)]
fn u8(v1: u8, v2: u8) -> u8 {
$e(v1, v2)
}
#[inline(always)]
fn u32(v1: u32, v2: u32) -> u32 {
$e(v1, v2)
}
#[inline(always)]
fn i64(v1: i64, v2: i64) -> i64 {
$e(v1, v2)
}
#[cfg(feature = "mkl")]
const F32_VEC: bool = true;
#[cfg(feature = "mkl")]
const F64_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f32_vec(xs1: &[f32], xs2: &[f32], ys: &mut [f32]) {
crate::mkl::$f32_vec(xs1, xs2, ys)
}
#[cfg(feature = "mkl")]
#[inline(always)]
fn f64_vec(xs1: &[f64], xs2: &[f64], ys: &mut [f64]) {
crate::mkl::$f64_vec(xs1, xs2, ys)
}
#[cfg(feature = "accelerate")]
const F32_VEC: bool = true;
#[cfg(feature = "accelerate")]
const F64_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f32_vec(xs1: &[f32], xs2: &[f32], ys: &mut [f32]) {
crate::accelerate::$f32_vec(xs1, xs2, ys)
}
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f64_vec(xs1: &[f64], xs2: &[f64], ys: &mut [f64]) {
crate::accelerate::$f64_vec(xs1, xs2, ys)
}
}
};
}
bin_op!(Add, "add", |v1, v2| v1 + v2, vs_add, vd_add);
bin_op!(Sub, "sub", |v1, v2| v1 - v2, vs_sub, vd_sub);
bin_op!(Mul, "mul", |v1, v2| v1 * v2, vs_mul, vd_mul);
bin_op!(Div, "div", |v1, v2| v1 / v2, vs_div, vd_div);
bin_op!(
Minimum,
"minimum",
|v1, v2| if v1 > v2 { v2 } else { v1 },
vs_min,
vd_min
);
bin_op!(
Maximum,
"maximum",
|v1, v2| if v1 < v2 { v2 } else { v1 },
vs_max,
vd_max
);
#[allow(clippy::redundant_closure_call)]
macro_rules! unary_op {
($op: ident, $name: literal, $a: ident, $e: expr) => {
impl UnaryOpT for $op {
const NAME: &'static str = $name;
const KERNEL: &'static str = concat!("u", $name);
const V: Self = $op;
#[inline(always)]
fn bf16($a: bf16) -> bf16 {
$e
}
#[inline(always)]
fn f16($a: f16) -> f16 {
$e
}
#[inline(always)]
fn f32($a: f32) -> f32 {
$e
}
#[inline(always)]
fn f64($a: f64) -> f64 {
$e
}
#[inline(always)]
fn u8(_: u8) -> u8 {
todo!("no unary function for u8")
}
#[inline(always)]
fn u32(_: u32) -> u32 {
todo!("no unary function for u32")
}
#[inline(always)]
fn i64(_: i64) -> i64 {
todo!("no unary function for i64")
}
}
};
($op: ident, $name: literal, $a: ident, $e: expr, $f32_vec:ident, $f64_vec:ident) => {
impl UnaryOpT for $op {
const NAME: &'static str = $name;
const KERNEL: &'static str = concat!("u", $name);
const V: Self = $op;
#[inline(always)]
fn bf16($a: bf16) -> bf16 {
$e
}
#[inline(always)]
fn f16($a: f16) -> f16 {
$e
}
#[inline(always)]
fn f32($a: f32) -> f32 {
$e
}
#[inline(always)]
fn f64($a: f64) -> f64 {
$e
}
#[inline(always)]
fn u8(_: u8) -> u8 {
todo!("no unary function for u8")
}
#[inline(always)]
fn u32(_: u32) -> u32 {
todo!("no unary function for u32")
}
#[inline(always)]
fn i64(_: i64) -> i64 {
todo!("no unary function for i64")
}
#[cfg(feature = "mkl")]
const F32_VEC: bool = true;
#[cfg(feature = "mkl")]
const F64_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::mkl::$f32_vec(xs, ys)
}
#[cfg(feature = "mkl")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::mkl::$f64_vec(xs, ys)
}
#[cfg(feature = "accelerate")]
const F32_VEC: bool = true;
#[cfg(feature = "accelerate")]
const F64_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::accelerate::$f32_vec(xs, ys)
}
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::accelerate::$f64_vec(xs, ys)
}
}
};
}
unary_op!(Exp, "exp", v, v.exp(), vs_exp, vd_exp);
unary_op!(Log, "log", v, v.ln(), vs_ln, vd_ln);
unary_op!(Sin, "sin", v, v.sin(), vs_sin, vd_sin);
unary_op!(Cos, "cos", v, v.cos(), vs_cos, vd_cos);
unary_op!(Tanh, "tanh", v, v.tanh(), vs_tanh, vd_tanh);
unary_op!(Neg, "neg", v, -v);
unary_op!(Recip, "recip", v, v.recip());
unary_op!(Sqr, "sqr", v, v * v, vs_sqr, vd_sqr);
unary_op!(Sqrt, "sqrt", v, v.sqrt(), vs_sqrt, vd_sqrt);
// Hardcode the value for sqrt(2/pi)
// https://github.com/huggingface/candle/issues/1982
#[allow(clippy::excessive_precision)]
const SQRT_TWO_OVER_PI_F32: f32 = 0.79788456080286535587989211986876373;
#[allow(clippy::excessive_precision)]
const SQRT_TWO_OVER_PI_F64: f64 = 0.79788456080286535587989211986876373;
/// Tanh based approximation of the `gelu` operation
/// GeluErf is the more precise one.
/// <https://en.wikipedia.org/wiki/Activation_function#Comparison_of_activation_functions>
impl UnaryOpT for Gelu {
const NAME: &'static str = "gelu";
const V: Self = Gelu;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
bf16::from_f32_const(0.5)
* v
* (bf16::ONE
+ bf16::tanh(
bf16::from_f32_const(SQRT_TWO_OVER_PI_F32)
* v
* (bf16::ONE + bf16::from_f32_const(0.044715) * v * v),
))
}
#[inline(always)]
fn f16(v: f16) -> f16 {
f16::from_f32_const(0.5)
* v
* (f16::ONE
+ f16::tanh(
f16::from_f32_const(SQRT_TWO_OVER_PI_F32)
* v
* (f16::ONE + f16::from_f32_const(0.044715) * v * v),
))
}
#[inline(always)]
fn f32(v: f32) -> f32 {
0.5 * v * (1.0 + f32::tanh(SQRT_TWO_OVER_PI_F32 * v * (1.0 + 0.044715 * v * v)))
}
#[inline(always)]
fn f64(v: f64) -> f64 {
0.5 * v * (1.0 + f64::tanh(SQRT_TWO_OVER_PI_F64 * v * (1.0 + 0.044715 * v * v)))
}
#[inline(always)]
fn u8(_: u8) -> u8 {
0
}
#[inline(always)]
fn u32(_: u32) -> u32 {
0
}
#[inline(always)]
fn i64(_: i64) -> i64 {
0
}
const KERNEL: &'static str = "ugelu";
#[cfg(feature = "mkl")]
const F32_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::mkl::vs_gelu(xs, ys)
}
#[cfg(feature = "mkl")]
const F64_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::mkl::vd_gelu(xs, ys)
}
#[cfg(feature = "accelerate")]
const F32_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::accelerate::vs_gelu(xs, ys)
}
#[cfg(feature = "accelerate")]
const F64_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::accelerate::vd_gelu(xs, ys)
}
}
/// `erf` operation
/// <https://en.wikipedia.org/wiki/Error_function>
impl UnaryOpT for Erf {
const NAME: &'static str = "erf";
const KERNEL: &'static str = "uerf";
const V: Self = Erf;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
bf16::from_f64(Self::f64(v.to_f64()))
}
#[inline(always)]
fn f16(v: f16) -> f16 {
f16::from_f64(Self::f64(v.to_f64()))
}
#[inline(always)]
fn f32(v: f32) -> f32 {
Self::f64(v as f64) as f32
}
#[inline(always)]
fn f64(v: f64) -> f64 {
crate::cpu::erf::erf(v)
}
#[inline(always)]
fn u8(_: u8) -> u8 {
0
}
#[inline(always)]
fn u32(_: u32) -> u32 {
0
}
#[inline(always)]
fn i64(_: i64) -> i64 {
0
}
}
/// Silu operation
impl UnaryOpT for Silu {
const NAME: &'static str = "silu";
const V: Self = Silu;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v / (bf16::ONE + (-v).exp())
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v / (f16::ONE + (-v).exp())
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v / (1.0 + (-v).exp())
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v / (1.0 + (-v).exp())
}
#[inline(always)]
fn u8(_: u8) -> u8 {
0
}
#[inline(always)]
fn u32(_: u32) -> u32 {
0
}
#[inline(always)]
fn i64(_: i64) -> i64 {
0
}
const KERNEL: &'static str = "usilu";
#[cfg(feature = "mkl")]
const F32_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::mkl::vs_silu(xs, ys)
}
#[cfg(feature = "mkl")]
const F64_VEC: bool = true;
#[cfg(feature = "mkl")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::mkl::vd_silu(xs, ys)
}
#[cfg(feature = "accelerate")]
const F32_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f32_vec(xs: &[f32], ys: &mut [f32]) {
crate::accelerate::vs_silu(xs, ys)
}
#[cfg(feature = "accelerate")]
const F64_VEC: bool = true;
#[cfg(feature = "accelerate")]
#[inline(always)]
fn f64_vec(xs: &[f64], ys: &mut [f64]) {
crate::accelerate::vd_silu(xs, ys)
}
}
impl UnaryOpT for Abs {
const NAME: &'static str = "abs";
const KERNEL: &'static str = "uabs";
const V: Self = Abs;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v.abs()
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v.abs()
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v.abs()
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v.abs()
}
#[inline(always)]
fn u8(v: u8) -> u8 {
v
}
#[inline(always)]
fn u32(v: u32) -> u32 {
v
}
#[inline(always)]
fn i64(v: i64) -> i64 {
v.abs()
}
}
impl UnaryOpT for Ceil {
const NAME: &'static str = "ceil";
const KERNEL: &'static str = "uceil";
const V: Self = Ceil;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v.ceil()
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v.ceil()
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v.ceil()
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v.ceil()
}
#[inline(always)]
fn u8(v: u8) -> u8 {
v
}
#[inline(always)]
fn u32(v: u32) -> u32 {
v
}
#[inline(always)]
fn i64(v: i64) -> i64 {
v
}
}
impl UnaryOpT for Floor {
const NAME: &'static str = "floor";
const KERNEL: &'static str = "ufloor";
const V: Self = Floor;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v.floor()
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v.floor()
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v.floor()
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v.floor()
}
#[inline(always)]
fn u8(v: u8) -> u8 {
v
}
#[inline(always)]
fn u32(v: u32) -> u32 {
v
}
#[inline(always)]
fn i64(v: i64) -> i64 {
v
}
}
impl UnaryOpT for Round {
const NAME: &'static str = "round";
const KERNEL: &'static str = "uround";
const V: Self = Round;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v.round()
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v.round()
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v.round()
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v.round()
}
#[inline(always)]
fn u8(v: u8) -> u8 {
v
}
#[inline(always)]
fn u32(v: u32) -> u32 {
v
}
#[inline(always)]
fn i64(v: i64) -> i64 {
v
}
}
impl UnaryOpT for GeluErf {
const NAME: &'static str = "gelu_erf";
const KERNEL: &'static str = "ugelu_erf";
const V: Self = GeluErf;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
bf16::from_f64(Self::f64(v.to_f64()))
}
#[inline(always)]
fn f16(v: f16) -> f16 {
f16::from_f64(Self::f64(v.to_f64()))
}
#[inline(always)]
fn f32(v: f32) -> f32 {
Self::f64(v as f64) as f32
}
#[inline(always)]
fn f64(v: f64) -> f64 {
(crate::cpu::erf::erf(v / 2f64.sqrt()) + 1.) * 0.5 * v
}
#[inline(always)]
fn u8(_: u8) -> u8 {
0
}
#[inline(always)]
fn u32(_: u32) -> u32 {
0
}
#[inline(always)]
fn i64(_: i64) -> i64 {
0
}
}
impl UnaryOpT for Relu {
const NAME: &'static str = "relu";
const KERNEL: &'static str = "urelu";
const V: Self = Relu;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
v.max(bf16::ZERO)
}
#[inline(always)]
fn f16(v: f16) -> f16 {
v.max(f16::ZERO)
}
#[inline(always)]
fn f32(v: f32) -> f32 {
v.max(0f32)
}
#[inline(always)]
fn f64(v: f64) -> f64 {
v.max(0f64)
}
#[inline(always)]
fn u8(v: u8) -> u8 {
v
}
#[inline(always)]
fn u32(v: u32) -> u32 {
v
}
#[inline(always)]
fn i64(v: i64) -> i64 {
v
}
}
/// `BackpropOp` is a wrapper around `Option<Op>`. The main goal is to ensure that dependencies are
/// properly checked when creating a new value
#[derive(Clone)]
pub struct BackpropOp(Option<Op>);
impl BackpropOp {
pub(crate) fn none() -> Self {
BackpropOp(None)
}
pub(crate) fn new1(arg: &Tensor, f: impl Fn(Tensor) -> Op) -> Self {
let op = if arg.track_op() {
Some(f(arg.clone()))
} else {
None
};
Self(op)
}
pub(crate) fn new2(arg1: &Tensor, arg2: &Tensor, f: impl Fn(Tensor, Tensor) -> Op) -> Self {
let op = if arg1.track_op() || arg2.track_op() {
Some(f(arg1.clone(), arg2.clone()))
} else {
None
};
Self(op)
}
pub(crate) fn new3(
arg1: &Tensor,
arg2: &Tensor,
arg3: &Tensor,
f: impl Fn(Tensor, Tensor, Tensor) -> Op,
) -> Self {
let op = if arg1.track_op() || arg2.track_op() || arg3.track_op() {
Some(f(arg1.clone(), arg2.clone(), arg3.clone()))
} else {
None
};
Self(op)
}
pub(crate) fn new<A: AsRef<Tensor>>(args: &[A], f: impl Fn(Vec<Tensor>) -> Op) -> Self {
let op = if args.iter().any(|arg| arg.as_ref().track_op()) {
let args: Vec<Tensor> = args.iter().map(|arg| arg.as_ref().clone()).collect();
Some(f(args))
} else {
None
};
Self(op)
}
pub(crate) fn is_none(&self) -> bool {
self.0.is_none()
}
}
impl std::ops::Deref for BackpropOp {
type Target = Option<Op>;
fn deref(&self) -> &Self::Target {
&self.0
}
}
impl UnaryOpT for Sign {
const NAME: &'static str = "sign";
const KERNEL: &'static str = "usign";
const V: Self = Sign;
#[inline(always)]
fn bf16(v: bf16) -> bf16 {
bf16::from((v > bf16::ZERO) as i8) - bf16::from((v < bf16::ZERO) as i8)
}
#[inline(always)]
fn f16(v: f16) -> f16 {
f16::from((v > f16::ZERO) as i8) - f16::from((v < f16::ZERO) as i8)
}
#[inline(always)]
fn f32(v: f32) -> f32 {
f32::from(v > 0.) - f32::from(v < 0.)
}
#[inline(always)]
fn f64(v: f64) -> f64 {
f64::from(v > 0.) - f64::from(v < 0.)
}
#[inline(always)]
fn u8(v: u8) -> u8 {
u8::min(1, v)
}
#[inline(always)]
fn u32(v: u32) -> u32 {
u32::min(1, v)
}
#[inline(always)]
fn i64(v: i64) -> i64 {
(v > 0) as i64 - (v < 0) as i64
}
}
| 9 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/pair_class.yml | task: sentence-transformers:pair_class
base_model: google-bert/bert-base-uncased
project_name: autotrain-st-pair-class
log: tensorboard
backend: local
data:
path: sentence-transformers/all-nli
train_split: pair-class:train
valid_split: pair-class:test
column_mapping:
sentence1_column: premise
sentence2_column: hypothesis
target_column: label
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 0 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/sentence_transformers/triplet.yml | task: sentence-transformers:triplet
base_model: microsoft/mpnet-base
project_name: autotrain-st-triplet
log: tensorboard
backend: local
data:
path: sentence-transformers/all-nli
train_split: triplet:train
valid_split: triplet:dev
column_mapping:
sentence1_column: anchor
sentence2_column: positive
sentence3_column: negative
params:
max_seq_length: 512
epochs: 5
batch_size: 8
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 1 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/vlm/paligemma_vqa.yml | task: vlm:vqa
base_model: google/paligemma-3b-pt-224
project_name: autotrain-paligemma-finetuned-vqa
log: tensorboard
backend: local
data:
path: abhishek/vqa_small
train_split: train
valid_split: validation
column_mapping:
image_column: image
text_column: multiple_choice_answer
prompt_text_column: question
params:
epochs: 3
batch_size: 2
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
peft: true
quantization: int4
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 2 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/image_classification/local.yml | task: image_classification
base_model: google/vit-base-patch16-224
project_name: autotrain-image-classification-model
log: tensorboard
backend: local
data:
path: data/
train_split: train # this folder inside data/ will be used for training, it contains the images in subfolders.
valid_split: null
column_mapping:
image_column: image
target_column: label
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 3 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/image_classification/hub_dataset.yml | task: image_classification
base_model: google/vit-base-patch16-224
project_name: autotrain-cats-vs-dogs-finetuned
log: tensorboard
backend: local
data:
path: cats_vs_dogs
train_split: train
valid_split: null
column_mapping:
image_column: image
target_column: labels
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 4 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/seq2seq/local.yml | task: seq2seq
base_model: google/flan-t5-base
project_name: autotrain-seq2seq-local
log: tensorboard
backend: local
data:
path: path/to/your/dataset csv/jsonl files
train_split: train
valid_split: test
column_mapping:
text_column: text
target_column: target
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: none
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 5 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/seq2seq/hub_dataset.yml | task: seq2seq
base_model: google/flan-t5-base
project_name: autotrain-seq2seq-hub-dataset
log: tensorboard
backend: local
data:
path: samsum
train_split: train
valid_split: test
column_mapping:
text_column: dialogue
target_column: summary
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: none
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 6 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/image_scoring/local.yml | task: image_regression
base_model: google/vit-base-patch16-224
project_name: autotrain-image-regression-model
log: tensorboard
backend: local
data:
path: data/
train_split: train # this folder inside data/ will be used for training, it contains the images and metadata.jsonl
valid_split: valid # this folder inside data/ will be used for validation, it contains the images and metadata.jsonl. can be set to null
# column mapping should not be changed for local datasets
column_mapping:
image_column: image
target_column: target
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 7 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/image_scoring/hub_dataset.yml | task: image_regression
base_model: google/vit-base-patch16-224
project_name: autotrain-cats-vs-dogs-finetuned
log: tensorboard
backend: local
data:
path: cats_vs_dogs
train_split: train
valid_split: null
column_mapping:
image_column: image
target_column: labels
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 8 |
0 | hf_public_repos/autotrain-advanced/configs | hf_public_repos/autotrain-advanced/configs/image_scoring/image_quality.yml | task: image_regression
base_model: microsoft/resnet-50
project_name: autotrain-img-quality-resnet50
log: tensorboard
backend: local
data:
path: abhishek/img-quality-full
train_split: train
valid_split: null
column_mapping:
image_column: image
target_column: target
params:
epochs: 10
batch_size: 8
lr: 2e-3
optimizer: adamw_torch
scheduler: cosine
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true | 9 |
0 | hf_public_repos | hf_public_repos/blog/chatbot-amd-gpu.md | ---
title: "Run a Chatgpt-like Chatbot on a Single GPU with ROCm"
thumbnail: /blog/assets/chatbot-amd-gpu/thumbnail.png
authors:
- user: andyll7772
guest: true
---
# Run a Chatgpt-like Chatbot on a Single GPU with ROCm
## Introduction
ChatGPT, OpenAI's groundbreaking language model, has become an
influential force in the realm of artificial intelligence, paving the
way for a multitude of AI applications across diverse sectors. With its
staggering ability to comprehend and generate human-like text, ChatGPT
has transformed industries, from customer support to creative writing,
and has even served as an invaluable research tool.
Various efforts have been made to provide
open-source large language models which demonstrate great capabilities
but in smaller sizes, such as
[OPT](https://huggingface.co/docs/transformers/model_doc/opt),
[LLAMA](https://github.com/facebookresearch/llama),
[Alpaca](https://github.com/tatsu-lab/stanford_alpaca) and
[Vicuna](https://github.com/lm-sys/FastChat).
In this blog, we will delve into the world of Vicuna, and explain how to
run the Vicuna 13B model on a single AMD GPU with ROCm.
**What is Vicuna?**
Vicuna is an open-source chatbot with 13 billion parameters, developed
by a team from UC Berkeley, CMU, Stanford, and UC San Diego. To create
Vicuna, a LLAMA base model was fine-tuned using about 70K user-shared
conversations collected from ShareGPT.com via public APIs. According to
initial assessments where GPT-4 is used as a reference, Vicuna-13B has
achieved over 90%\* quality compared to OpenAI ChatGPT.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/01.png" style="width: 60%; height: auto;">
</p>
It was released on [Github](https://github.com/lm-sys/FastChat) on Apr
11, just a few weeks ago. It is worth mentioning that the data set,
training code, evaluation metrics, training cost are known for Vicuna. Its total training cost was just
around \$300, making it a cost-effective solution for the general public.
For more details about Vicuna, please check out
<https://vicuna.lmsys.org>.
**Why do we need a quantized GPT model?**
Running Vicuna-13B model in fp16 requires around 28GB GPU RAM. To
further reduce the memory footprint, optimization techniques are
required. There is a recent research paper GPTQ published, which
proposed accurate post-training quantization for GPT models with lower
bit precision. As illustrated below, for models with parameters larger
than 10B, the 4-bit or 3-bit GPTQ can achieve comparable accuracy
with fp16.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/02.png" style="width: 70%; height: auto;">
</p>
Moreover, large parameters of these models also have a severely negative
effect on GPT latency because GPT token generation is more limited by
memory bandwidth (GB/s) than computation (TFLOPs or TOPs) itself. For this
reason, a quantized model does not degrade
token generation latency when the GPU is under a memory bound situation.
Refer to [the GPTQ quantization papers](<https://arxiv.org/abs/2210.17323>) and [github repo](<https://github.com/IST-DASLab/gptq>).
By leveraging this technique, several 4-bit quantized Vicuna models are
available from Hugging Face as follows,
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/03.png" style="width: 50%; height: auto;">
</p>
## Running Vicuna 13B Model on AMD GPU with ROCm
To run the Vicuna 13B model on an AMD GPU, we need to leverage the power
of ROCm (Radeon Open Compute), an open-source software platform that
provides AMD GPU acceleration for deep learning and high-performance
computing applications.
Here's a step-by-step guide on how to set up and run the Vicuna 13B
model on an AMD GPU with ROCm:
**System Requirements**
Before diving into the installation process, ensure that your system
meets the following requirements:
- An AMD GPU that supports ROCm (check the compatibility list on
docs.amd.com page)
- A Linux-based operating system, preferably Ubuntu 18.04 or 20.04
- Conda or Docker environment
- Python 3.6 or higher
For more information, please check out <https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/Prerequisites.html>.
This example has been tested on [**Instinct
MI210**](https://www.amd.com/en/products/server-accelerators/amd-instinct-mi210)
and [**Radeon
RX6900XT**](https://www.amd.com/en/products/graphics/amd-radeon-rx-6900-xt)
GPUs with ROCm5.4.3 and Pytorch2.0.
**Quick Start**
**1 ROCm installation and Docker container setup (Host machine)**
**1.1 ROCm** **installation**
The following is for ROCm5.4.3 and Ubuntu 22.04. Please modify
according to your target ROCm and Ubuntu version from:
<https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.4.3/page/How_to_Install_ROCm.html>
```
sudo apt update && sudo apt upgrade -y
wget https://repo.radeon.com/amdgpu-install/5.4.3/ubuntu/jammy/amdgpu-install_5.4.50403-1_all.deb
sudo apt-get install ./amdgpu-install_5.4.50403-1_all.deb
sudo amdgpu-install --usecase=hiplibsdk,rocm,dkms
sudo amdgpu-install --list-usecase
sudo reboot
```
**1.2 ROCm installation verification**
```
rocm-smi
sudo rocminfo
```
**1.3 Docker image pull and run a Docker container**
The following uses Pytorch2.0 on ROCm5.4.2. Please use the
appropriate docker image according to your target ROCm and Pytorch
version: <https://hub.docker.com/r/rocm/pytorch/tags>
```
docker pull rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
sudo docker run --device=/dev/kfd --device=/dev/dri --group-add video \
--shm-size=8g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined \
--ipc=host -it --name vicuna_test -v ${PWD}:/workspace -e USER=${USER} \
rocm/pytorch:rocm5.4.2_ubuntu20.04_py3.8_pytorch_2.0.0_preview
```
**2 Model** **quantization and Model inference (Inside the docker)**
You can either download quantized Vicuna-13b model from Huggingface or
quantize the floating-point model. Please check out **Appendix - GPTQ
model quantization** if you want to quantize the floating-point model.
**2.1 Download the quantized Vicuna-13b model**
Use download-model.py script from the following git repo.
```
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
python download-model.py anon8231489123/vicuna-13b-GPTQ-4bit-128g
```
2. **Running the Vicuna 13B GPTQ Model on AMD GPU**
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa
python setup_cuda.py install
```
These commands will compile and link HIPIFIED CUDA-equivalent kernel
binaries to
python as C extensions. The kernels of this implementation are composed
of dequantization + FP32 Matmul. If you want to use dequantization +
FP16 Matmul for additional speed-up, please check out **Appendix - GPTQ
Dequantization + FP16 Mamul kernel for AMD GPUs**
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
cd GPTQ-for-LLaMa/
python setup_cuda.py install
# model inference
python llama_inference.py ../../models/vicuna-13b --wbits 4 --load \
../../models/vicuna-13b/vicuna-13b_4_actorder.safetensors --groupsize 128 --text “You input text here”
```
Now that you have everything set up, it's time to run the Vicuna 13B
model on your AMD GPU. Use the commands above to run the model. Replace
*"Your input text here"* with the text you want to use as input for
the model. If everything is set up correctly, you should see the model
generating output text based on your input.
**3. Expose the quantized Vicuna model to the Web API server**
Change the path of GPTQ python modules (GPTQ-for-LLaMa) in the following
line:
<https://github.com/thisserand/FastChat/blob/4a57c928a906705404eae06f7a44b4da45828487/fastchat/serve/load_gptq_model.py#L7>
To launch Web UXUI from the gradio library, you need to set up the
controller, worker (Vicunal model worker), web_server by running them as
background jobs.
```
nohup python0 -W ignore::UserWarning -m fastchat.serve.controller &
nohup python0 -W ignore::UserWarning -m fastchat.serve.model_worker --model-path /path/to/quantized_vicuna_weights \
--model-name vicuna-13b-quantization --wbits 4 --groupsize 128 &
nohup python0 -W ignore::UserWarning -m fastchat.serve.gradio_web_server &
```
Now the 4-bit quantized Vicuna-13B model can be fitted in RX6900XT GPU
DDR memory, which has 16GB DDR. Only 7.52GB of DDR (46% of 16GB) is
needed to run 13B models whereas the model needs more than 28GB of DDR
space in fp16 datatype. The latency penalty and accuracy penalty are
also very minimal and the related metrics are provided at the end of
this article.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/04.png" style="width: 60%; height: auto;">
</p>
**Test the quantized Vicuna model in the Web API server**
Let us give it a try. First, let us use fp16 Vicuna model for language
translation.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/05.png" style="width: 80%; height: auto;">
</p>
It does a better job than me. Next, let us ask something about soccer. The answer looks good to me.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/06.png" style="width: 80%; height: auto;">
</p>
When we switch to the 4-bit model, for the same question, the answer is
a bit different. There is a duplicated “Lionel Messi” in it.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/07.png" style="width: 80%; height: auto;">
</p>
**Vicuna fp16 and 4bit quantized model comparison**
Test environment:
\- GPU: Instinct MI210, RX6900XT
\- python: 3.10
\- pytorch: 2.1.0a0+gitfa08e54
\- rocm: 5.4.3
**Metrics - Model size (GB)**
- Model parameter size. When the models are preloaded to GPU DDR, the
actual DDR size consumption is larger than model itself due to caching
for Input and output token spaces.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/08.png" style="width: 70%; height: auto;">
</p>
**Metrics – Accuracy (PPL: Perplexity)**
- Measured on 2048 examples of C4
(<https://paperswithcode.com/dataset/c4>) dataset
- Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul
- Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul
- Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/09.png" style="width: 70%; height: auto;">
</p>
**Metrics – Latency (Token generation latency, ms)**
- Measured during token generation phases.
- Vicuna 13b – baseline: fp16 datatype parameter, fp16 Matmul
- Vicuna 13b – quant (4bit/fp32): 4bits datatype parameter, fp32 Matmul
- Vicuna 13b – quant (4bit/fp16): 4bits datatype parameter, fp16 Matmul
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/10.png" style="width: 70%; height: auto;">
</p>
## Conclusion
Large language models (LLMs) have made significant advancements in
chatbot systems, as seen in OpenAI’s ChatGPT. Vicuna-13B, an open-source
LLM model has been developed and demonstrated excellent capability and quality.
By following this guide, you should now have a better understanding of
how to set up and run the Vicuna 13B model on an AMD GPU with ROCm. This
will enable you to unlock the full potential of this cutting-edge
language model for your research and personal projects.
Thanks for reading!
## Appendix - GPTQ model quantization
**Building Vicuna quantized model from the floating-point LLaMA model**
**a. Download LLaMA and Vicuna delta models from Huggingface**
The developers of Vicuna (lmsys) provide only delta-models that can be
applied to the LLaMA model. Download LLaMA in huggingface format and
Vicuna delta parameters from Huggingface individually. Currently, 7b and
13b delta models of Vicuna are available.
<https://huggingface.co/models?sort=downloads&search=huggyllama>
<https://huggingface.co/models?sort=downloads&search=lmsys>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/13.png" style="width: 60%; height: auto;">
</p>
**b. Convert LLaMA to Vicuna by using Vicuna-delta model**
```
git clone https://github.com/lm-sys/FastChat
cd FastChat
```
Convert the LLaMA parameters by using this command:
(Note: do not use vicuna-{7b, 13b}-\*delta-v0 because it’s vocab_size is
different from that of LLaMA and the model cannot be converted)
```
python -m fastchat.model.apply_delta --base /path/to/llama-13b --delta lmsys/vicuna-13b-delta-v1.1 \
--target ./vicuna-13b
```
Now Vicuna-13b model is ready.
**c. Quantize Vicuna to 2/3/4 bits**
To apply the GPTQ to LLaMA and Vicuna,
```
git clone https://github.com/oobabooga/GPTQ-for-LLaMa -b cuda
cd GPTQ-for-LLaMa
```
(Note, do not use <https://github.com/qwopqwop200/GPTQ-for-LLaMa> for
now. Because 2,3,4bit quantization + MatMul kernels implemented in this
repo does not parallelize the dequant+matmul and hence shows lower token
generation performance)
Quantize Vicuna-13b model with this command. QAT is done based on c4
data-set but you can also use other data-sets, such as wikitext2
(Note. Change group size with different combinations as long as the
model accuracy increases significantly. Under some combination of wbit
and groupsize, model accuracy can be increased significantly.)
```
python llama.py ./Vicuna-13b c4 --wbits 4 --true-sequential --act-order \
--save_safetensors Vicuna-13b-4bit-act-order.safetensors
```
Now the model is ready and saved as
**Vicuna-13b-4bit-act-order.safetensors**.
**GPTQ Dequantization + FP16 Mamul kernel for AMD GPUs**
The more optimized kernel implementation in
<https://github.com/oobabooga/GPTQ-for-LLaMa/blob/57a26292ed583528d9941e79915824c5af012279/quant_cuda_kernel.cu#L891>
targets at A100 GPU and not compatible with ROCM5.4.3 HIPIFY
toolkits. It needs to be modified as follows. The same for
VecQuant2MatMulKernelFaster, VecQuant3MatMulKernelFaster,
VecQuant4MatMulKernelFaster kernels.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chatbot-amd-gpu/14.png" style="width: 100%; height: auto;">
For convenience, All the modified codes are available in [Github Gist](https://gist.github.com/seungrokjung/110943b70503732c4a398607e1cbdd6c).
| 0 |
0 | hf_public_repos | hf_public_repos/blog/daily-papers.md | ---
title: "Exploring the Daily Papers Page on Hugging Face"
thumbnail: /blog/assets/daily-papers/thumbnail.png
authors:
- user: AdinaY
---
# Exploring the Daily Papers Page on Hugging Face
In the fast-paced world of research, staying up-to-date with the latest advancements is crucial. To help developers and researchers keep a pulse on the cutting-edge of AI, Hugging Face introduced the [Daily Papers](https://huggingface.co/papers) page. Since its launch, Daily Papers has featured high-quality research selected by [AK](https://huggingface.co/akhaliq) and researchers from the community. Over the past year, more than 3,700 papers have been featured, and the page has grown to over 12k subscribers!
However, many people may not have fully explored all of the features Daily Papers offers. This article will guide you through some hidden functionalities to help you make the most of this platform.
## 📑 Claim your Papers

On the Daily Papers page, you’ll notice author names listed under the title of each paper. If you're one of the authors and have a Hugging Face account, you can [claim your paper](https://huggingface.co/docs/hub/paper-pages#claiming-authorship-to-a-paper) with a single click! After claiming, the paper will be automatically linked to your account, adding visibility to your research and helping build your personal brand in the community.
This feature makes it easy for the community to connect with you and your work, creating more opportunities for collaboration and interaction.
## ⏫ Submit Papers

The paper submission feature is open to all users who’ve claimed a paper. Users don’t have to limit submissions to their own work, they can also share interesting research papers that would benefit the community.
This allows Hugging Face Papers to maintain an up-to-date and ever-expanding collection of research in the AI field, curated by the community!
## 💬 Chat with Authors

Under each paper, there is a discussion section where users can leave comments and engage in direct conversations with the authors. Tagging the authors (@username) can lead to real-time feedback, questions or discussion of the research.
This feature fosters interaction, bringing together researchers from the whole community. Everyone, from beginners to experts, can contribute their ideas, making the global AI community even more connected and inclusive.
Whether to ask clarification questions or share constructive feedback, it opens the door to meaningful dialogue and can even spark new ideas or collaborations.
## 🔗 All You Need in One Page

On each paper’s page, you’ll find related [resources](https://huggingface.co/docs/hub/paper-pages#linking-a-paper-to-a-model-dataset-or-space), such as models, datasets, demos and other useful collections, all linked on the right side.
Authors can easily associate their models or datasets with their paper by simply adding the paper's arXiv URL to the README.md file of their resources. This feature allows authors to highlight their work and helps users access everything they need in one convenient place.
## 🗳 Show Your Support with Upvotes

You can support the paper by clicking the upvote button in the top-right corner. This allows the community to recommend the paper and support the author's work. The upvote feature highlights influential and innovative research, helping more people discover and focus on excellent papers.
For authors, each upvote acts as a recognition of their efforts and can be a source of motivation to continue producing high-quality research.
## 🙋 Recommend Similar Papers

If you type @librarian-bot in the comment section, the system will automatically suggest related papers. This feature is great for those looking to dive deeper into a topic or explore similar ideas. It’s like having a personal AI-powered research assistant!
## 🔠 Multilingual Comments and Translation

At Hugging Face, we value diversity, and that extends to language as well. On the Daily Papers page, users can leave comments in any language, and our built-in translation feature will ensure everyone can understand and contribute.
Whether you’re providing feedback, discussing a question, or exchanging ideas, this feature helps break down language barriers, making global collaboration even easier.
## ✅ Subscription

You can subscribe to Daily Papers by clicking the "Subscribe" button at the top of the page. You'll receive daily updates (excluding weekends) with the latest papers straight to your inbox. 📩
This feature makes it easy to browse the latest titles at a glance and jump into any research that catches your eye.
## 💡 Interactive Features with arXiv

There’s also some cool integration between Paper Pages and arXiv. For example, you can easily check if a paper on arXiv has already been featured on Hugging Face's Daily Papers page. If you spot the familiar emoji 🤗 on the page, you can click it to jump straight to the paper page on Daily Papers and explore all the features mentioned above.
To use the arXiv to HF Paper Pages feature, you'll need to install an extention, which you can find here: https://chromewebstore.google.com/detail/arxiv-to-hf/icfbnjkijgggnhmlikeppnoehoalpcpp.

On arXiv, you can also check if a paper has a demo hosted on Hugging Face Spaces. If the author has added a link, you can click it to jump directly to the Space and try out the demo yourself!
We hope this guide helps you make the most of [Daily Papers](https://huggingface.co/docs/hub/paper-pages) on Hugging Face. By utilizing all these features, you can stay up-to-date with the latest research, engage with authors, and contribute to the growing AI community. Whether you're a researcher, developer or curious beginner, Daily Papers is here to help you connect with the top AI research!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/fasttext.md | ---
title: "Welcome fastText to the Hugging Face Hub"
thumbnail: /blog/assets/147_fasttext/thumbnail.png
authors:
- user: sheonhan
- user: juanpino
guest: true
---
# Welcome fastText to the Hugging Face Hub
[fastText](https://fasttext.cc/) is a library for efficient learning of text representation and classification. [Open-sourced](https://fasttext.cc/blog/2016/08/18/blog-post.html) by Meta AI in 2016, fastText integrates key ideas that have been influential in natural language processing and machine learning over the past few decades: representing sentences using bag of words and bag of n-grams, using subword information, and utilizing a hidden representation to share information across classes.
To speed up computation, fastText uses hierarchical softmax, capitalizing on the imbalanced distribution of classes. All these techniques offer users scalable solutions for text representation and classification.
Hugging Face is now hosting official mirrors of word vectors of all 157 languages and the latest model for language identification. This means that using Hugging Face, you can easily download and use the models with a few commands.
### Finding models
Word vectors for 157 languages and the language identification model can be found in the [Meta AI](https://huggingface.co/facebook) org. For example, you can find the model page for English word vectors [here](https://huggingface.co/facebook/fasttext-en-vectors) and the language identification model [here](https://huggingface.co/facebook/fasttext-language-identification).
### Widgets
This integration includes support for text classification and feature extraction widgets. Try out the language identification widget [here](https://huggingface.co/facebook/fasttext-language-identification) and feature extraction widget [here](https://huggingface.co/facebook/fasttext-en-vectors)!


### How to use
Here is how to load and use a pre-trained vectors:
```python
>>> import fasttext
>>> from huggingface_hub import hf_hub_download
>>> model_path = hf_hub_download(repo_id="facebook/fasttext-en-vectors", filename="model.bin")
>>> model = fasttext.load_model(model_path)
>>> model.words
['the', 'of', 'and', 'to', 'in', 'a', 'that', 'is', ...]
>>> len(model.words)
145940
>>> model['bread']
array([ 4.89417791e-01, 1.60882145e-01, -2.25947708e-01, -2.94273376e-01,
-1.04577184e-01, 1.17962055e-01, 1.34821936e-01, -2.41778508e-01, ...])
```
Here is how to use this model to query nearest neighbors of an English word vector:
```python
>>> import fasttext
>>> from huggingface_hub import hf_hub_download
>>> model_path = hf_hub_download(repo_id="facebook/fasttext-en-nearest-neighbors", filename="model.bin")
>>> model = fasttext.load_model(model_path)
>>> model.get_nearest_neighbors("bread", k=5)
[(0.5641006231307983, 'butter'),
(0.48875734210014343, 'loaf'),
(0.4491206705570221, 'eat'),
(0.42444291710853577, 'food'),
(0.4229326844215393, 'cheese')]
```
Here is how to use this model to detect the language of a given text:
```python
>>> import fasttext
>>> from huggingface_hub import hf_hub_download
>>> model_path = hf_hub_download(repo_id="facebook/fasttext-language-identification", filename="model.bin")
>>> model = fasttext.load_model(model_path)
>>> model.predict("Hello, world!")
(('__label__eng_Latn',), array([0.81148803]))
>>> model.predict("Hello, world!", k=5)
(('__label__eng_Latn', '__label__vie_Latn', '__label__nld_Latn', '__label__pol_Latn', '__label__deu_Latn'),
array([0.61224753, 0.21323682, 0.09696738, 0.01359863, 0.01319415]))
```
## Would you like to integrate your library to the Hub?
This integration is possible thanks to our collaboration with [Meta AI](https://ai.facebook.com/) and the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library, which enables all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co/docs/hub/models-adding-libraries) for you!
| 2 |
0 | hf_public_repos | hf_public_repos/blog/fine-tune-w2v2-bert.md | ---
title: "Fine-Tune W2V2-Bert for low-resource ASR with 🤗 Transformers"
thumbnail: /blog/assets/fine-tune-w2v2-bert/w2v_thumbnail.png
authors:
- user: ylacombe
---
# **Fine-Tune W2V2-Bert for low-resource ASR with 🤗 Transformers**
<!-- {blog_metadata} -->
<!-- {authors} -->
<a target="_blank" href="https://colab.research.google.com/github/ylacombe/scripts_and_notebooks/blob/main/Fine_Tune_W2V2_BERT_on_CV16_Mongolian.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
***New (01/2024)***: *This blog post is strongly inspired by "[Fine-tuning XLS-R on Multi-Lingual ASR](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)" and ["Fine-tuning MMS Adapter Models for Multi-Lingual ASR"](https://huggingface.co/blog/mms_adapters)*.
## Introduction
Last month, MetaAI released [Wav2Vec2-BERT](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2-bert), as a building block of their [Seamless Communication](https://ai.meta.com/research/seamless-communication/), a family of AI translation models.
[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2-bert) is the result of a series of improvements based on an original model: **Wav2Vec2**, a pre-trained model for Automatic Speech Recognition (ASR) released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by *Alexei Baevski, Michael Auli, and Alex Conneau*. With as little as 10 minutes of labeled audio data, Wav2Vec2 could be fine-tuned to achieve 5% word-error rate performance on the [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) dataset, demonstrating for the first time low-resource transfer learning for ASR.
Following a series of multilingual improvements ([XLSR](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2), [XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r) and [MMS](https://huggingface.co/docs/transformers/model_doc/mms)), Wav2Vec2-BERT is a 580M-parameters versatile audio model that has been pre-trained on **4.5M** hours of unlabeled audio data covering **more than 143 languages**. For comparison, **XLS-R** used almost **half a million** hours of audio data in **128 languages** and **MMS** checkpoints were pre-trained on more than **half a million hours of audio** in over **1,400 languages**. Boosting to millions of hours enables Wav2Vec2-BERT to achieve even more competitive results in speech-related tasks, whatever the language.
To use it for ASR, Wav2Vec2-BERT can be fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems, such as ASR and handwriting recognition. We highly recommend reading the well-written blog post [*Sequence Modeling with CTC (2017)*](https://distill.pub/2017/ctc/) by Awni Hannun, to learn more about the CTC algorithm.
The aim of this notebook is to give you all the elements you need to train Wav2Vec2-BERT model - more specifically the pre-trained checkpoint [**facebook/w2v-bert-2.0**](https://huggingface.co/facebook/w2v-bert-2.0) - on ASR tasks, using open-source tools and models. It first presents the complete pre-processing pipeline, then performs a little fine-tuning of the W2V2-BERT. The final section gathers training tips from Hugging Face experts to scale-up CTC training.
For demonstration purposes, we fine-tune the model on the low resource Mongolian ASR dataset of [Common Voice 16.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_0) that contains *ca.* 14h of validated training data.
## Motivation
[Whisper](https://huggingface.co/blog/fine-tune-whisper#introduction) is a suite of ASR models, commonly accepted as the best performing models for the ASR task. It provides state-of-the-art performance for English ASR, while being well suited to multilingual fine-tuning from limited resources.
However, when it comes to "resource-poor" languages such as Mongolian, Whisper performs poorly, as seen in section D.2.2 of the [Whisper paper](https://cdn.openai.com/papers/whisper.pdf) - Mongolian or Malayalam achieved over 100% WER at every Whisper checkpoint. The checkpoint available also have a limited vocabulary and therefore cannot be fine-tuned on a language whose alphabet does not overlap with this vocabulary.
In addition, Whisper is a sequence-to-sequence model that performs ASR autoregressively, making it inherently "slow". Whisper's slowness is exacerbated for languages whose characteristics are infrequent in the training dataset. In this case, Whisper has to generate on average more tokens per word, and therefore takes longer.
Faced with limited resources - both in terms of training data availability and inference constraints - more "frugal" models are needed. In this case, Wav2Vec2-BERT is just the thing.
**Wav2Vec2-BERT** predicts ASR in a single pass, making it much faster than Whisper. As this notebook will show, it requires **little data** to achieve **competitive performance**, is **easily adaptable** to any alphabet, and is **more resource-efficient**.
In fact, it achieves **similar WER performance** on Mongolian ASR compared with [Whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) after similar fine-tuning, while being over **10x to 30x faster** and **2.5x more resource-efficient**.
**Note**: The benchmark was carried out with a 16GB V100 on Google Colab, using batch sizes ranging from 1 to 8 on the Mongolian CV16 test set.
## Notebook Setup
Before we start, let's install `datasets` and `transformers`. Also, we need `accelerate` for training, `torchaudio` to load audio files and `jiwer` to evaluate our fine-tuned model using the [word error rate (WER)](https://huggingface.co/metrics/wer) metric.
```bash
%%capture
!pip install datasets
!pip install --upgrade transformers
!pip install torchaudio
!pip install jiwer
!pip install accelerate -U
```
We strongly suggest to upload your training checkpoints directly to the [🤗 Hub](https://huggingface.co/) while training. The [🤗 Hub](https://huggingface.co/) provides:
- Integrated version control: you can be sure that no model checkpoint is lost during training.
- Tensorboard logs: track important metrics over the course of training.
- Model cards: document what a model does and its intended use cases.
- Community: an easy way to share and collaborate with the community!
To do so, you have to store your authentication token from the Hugging Face website (sign up [here](https://huggingface.co/join) if you haven't already!). This is done by entering your Hub authentication token when prompted below. Find your Hub authentication token [here](https://huggingface.co/settings/tokens):
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Prepare Data, Tokenizer, Feature Extractor
ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, *e.g.* a feature vector, and a tokenizer that processes the model's output format to text.
In 🤗 Transformers, the Wav2Vec2-BERT model is thus accompanied by both a tokenizer, called [Wav2Vec2CTCTokenizer](https://huggingface.co/transformers/master/model_doc/wav2vec2.html#wav2vec2ctctokenizer), and a feature extractor, called [SeamlessM4TFeatureExtractor](https://huggingface.co/docs/transformers/v4.36.1/en/model_doc/seamless_m4t#transformers.SeamlessM4TFeatureExtractor) that the model shares with the [first](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t) and [second](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4_v2t) versions of Seamless-M4T, as they all process audio in the same way.
Let's start by creating the tokenizer to decode the predicted output classes to the output transcription.
### Create `Wav2Vec2CTCTokenizer`
Remember that Wav2Vec2-like models fine-tuned on CTC transcribe an audio file with a single forward pass by first processing the audio input into a sequence of processed context representations and then using the final vocabulary output layer to classify each context representation to a character that represents the transcription.
The output size of this layer corresponds to the number of tokens in the vocabulary, and therefore only on the labeled dataset used for fine-tuning. So in the first step, we will take a look at the chosen dataset of Common Voice and define a vocabulary based on the transcriptions.
For this notebook, we will use [Common Voice's 16.0 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_0) for Mongolian. Mongolian corresponds to the language code `"mn"`.
Now we can use 🤗 Datasets' simple API to download the data. The dataset name is `"mozilla-foundation/common_voice_16_0"`, the configuration name corresponds to the language code, which is `"mn"` in our case.
**Note**: Before being able to download the dataset, you have to access it by logging into your Hugging Face account, going on the [dataset repo page](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_0) and clicking on "Agree and Access repository"
Common Voice has many different splits including `invalidated`, which refers to data that was not rated as "clean enough" to be considered useful. In this notebook, we will only make use of the splits `"train"`, `"validation"` and `"test"`.
Because the Mongolian dataset is so small, we will merge both the validation and training data into a training dataset and only use the test data for validation.
```python
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_16_0", "mn", split="train+validation", use_auth_token=True)
common_voice_test = load_dataset("mozilla-foundation/common_voice_16_0", "mn", split="test", use_auth_token=True)
```
Many ASR datasets only provide the target text, `'sentence'` for each audio array `'audio'` and file `'path'`. Common Voice actually provides much more information about each audio file, such as the `'accent'`, etc. Keeping the notebook as general as possible, we only consider the transcribed text for fine-tuning.
```python
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
```
Let's write a short function to display some random samples of the dataset and run it a couple of times to get a feeling for the transcriptions.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10)
```
Alright! The transcriptions look fairly clean. Having translated the transcribed sentences, it seems that the language corresponds more to written-out text than noisy dialogue. This makes sense considering that [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_0) is a crowd-sourced read speech corpus.
We can see that the transcriptions contain some special characters, such as `,.?!;:`. Without a language model, it is much harder to classify speech chunks to such special characters because they don't really correspond to a characteristic sound unit. *E.g.*, the letter `"s"` has a more or less clear sound, whereas the special character `"."` does not.
Also in order to understand the meaning of a speech signal, it is usually not necessary to include special characters in the transcription.
Let's simply remove all characters that don't contribute to the meaning of a word and cannot really be represented by an acoustic sound and normalize the text.
```python
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\'\»\«]'
def remove_special_characters(batch):
# remove special characters
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
```
Let's look at the processed text labels again.
```python
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
```
```bash
Хойч үе юуны төлөө тэмцэлдэхийг би мэдэхгүй.
Тэр өвдгөн дээрээ толгойгоо тавиад сулхан гиншинэ.
Эхнэргүй ганц бие хүн гэсэн санагдана.
Дамиран хотод төрж өссөн хээнцэр залуусын нэг билээ.
Мөн судлаачид шинжлэх ухааны үндэстэй тайлбар хайдаг.
Судалгааны ажил нь бүтэлгүй болсонд л гутарч маргааш илүү ажиллах тухай бодсон бололтой.
Ийм зөрчлөөс гэтлэх гарц "Оноосон нэрийн сан"-г үүсгэснээр шийдвэрлэгдэнэ.
Үүлтэй тэнгэрийн доогуур үзүүртэй моддын дээгүүр дүүлэн нисэх сэн.
Та нар ямар юмаа ингэж булаацалдаа вэ?
Тэд амьд хэлтрээ болов уу яагаа бол гэхээс одоо ч дотор арзганан бачуурдаг юм.
```
In CTC, it is common to classify speech chunks into letters, so we will do the same here.
Let's extract all distinct letters of the training and test data and build our vocabulary from this set of letters.
We write a mapping function that concatenates all transcriptions into one long transcription and then transforms the string into a set of chars.
It is important to pass the argument `batched=True` to the `map(...)` function so that the mapping function has access to all transcriptions at once.
```python
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
```
Now, we create the union of all distinct letters in the training dataset and test dataset and convert the resulting list into an enumerated dictionary.
```python
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
```bash
{' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'g': 6,
'h': 7,
'i': 8,
'l': 9,
'n': 10,
'o': 11,
'r': 12,
't': 13,
'x': 14,
'а': 15,
'б': 16,
'в': 17,
'г': 18,
'д': 19,
'е': 20,
'ж': 21,
'з': 22,
'и': 23,
'й': 24,
'к': 25,
'л': 26,
'м': 27,
'н': 28,
'о': 29,
'п': 30,
'р': 31,
'с': 32,
'т': 33,
'у': 34,
'ф': 35,
'х': 36,
'ц': 37,
'ч': 38,
'ш': 39,
'ъ': 40,
'ы': 41,
'ь': 42,
'э': 43,
'ю': 44,
'я': 45,
'ё': 46,
'ү': 47,
'ө': 48}
```
Cleaning up a dataset is a back-and-forth process that needs to be done with care.
Looking at the separate letters in the training and test datasets, we see a mix of Latin and Mongolian Cyrillic characters. After discussing with a native speaker of the target language (thanks [Mishig](https://github.com/mishig25) for taking a look), we'll remove the Latin characters for two reasons:
1. the CTC algorithm benefits from reduced vocabulary size, so it is recommended to remove redundant characters
2. in this example, we are concentrating entirely on the Mongolian alphabet.
```python
def remove_latin_characters(batch):
batch["sentence"] = re.sub(r'[a-z]+', '', batch["sentence"])
return batch
# remove latin characters
common_voice_train = common_voice_train.map(remove_latin_characters)
common_voice_test = common_voice_test.map(remove_latin_characters)
# extract unique characters again
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
```
```bash
{' ': 0,
'а': 1,
'б': 2,
'в': 3,
'г': 4,
'д': 5,
'е': 6,
'ж': 7,
'з': 8,
'и': 9,
'й': 10,
'к': 11,
'л': 12,
'м': 13,
'н': 14,
'о': 15,
'п': 16,
'р': 17,
'с': 18,
'т': 19,
'у': 20,
'ф': 21,
'х': 22,
'ц': 23,
'ч': 24,
'ш': 25,
'ъ': 26,
'ы': 27,
'ь': 28,
'э': 29,
'ю': 30,
'я': 31,
'ё': 32,
'ү': 33,
'ө': 34}
```
Cool, we see that all letters of the Mongolian alphabet occur in the dataset (which is not really surprising) and we also extracted the special character `" "`. Note that we did not exclude this special character because:
the model has to learn to predict when a word is finished or else the model prediction would always be a sequence of chars which would make it impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important step before training your model. E.g., we don't want our model to differentiate between `a` and `A` just because we forgot to normalize the data. The difference between `a` and `A` does not depend on the "sound" of the letter at all, but more on grammatical rules - *e.g.* use a capitalized letter at the beginning of the sentence. So it is sensible to remove the difference between capitalized and non-capitalized letters so that the model has an easier time learning to transcribe speech. You can read more about the effects of pre-processing on the ASR task in the [Audio Transformers Course](https://huggingface.co/learn/audio-course/chapter5/evaluation#normalisation).
To make it clearer that `" "` has its own token class, we give it a more visible character `|`. In addition, we also add an "unknown" token so that the model can later deal with characters not encountered in Common Voice's training set.
```python
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
```
Finally, we also add a padding token that corresponds to CTC's "*blank token*". The "blank token" is a core component of the CTC algorithm. For more information, please take a look at the "Alignment" section of this [blog post](https://distill.pub/2017/ctc/).
```python
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
```
```bash
37
```
Cool, now our vocabulary is complete and consists of 37 tokens, which means that the linear layer that we will add on top of the pre-trained Wav2Vec2-BERT checkpoint will have an output dimension of 37.
Let's now save the vocabulary as a json file.
```python
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
```
In a final step, we use the json file to load the vocabulary into an instance of the `Wav2Vec2CTCTokenizer` class
```python
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
```
If one wants to re-use the just created tokenizer with the fine-tuned model of this notebook, it is strongly advised to upload the `tokenizer` to the [🤗 Hub](https://huggingface.co/). Let's call the repo to which we will upload the files
`"w2v-bert-2.0-mongolian-colab-CV16.0"`:
```python
repo_name = "w2v-bert-2.0-mongolian-colab-CV16.0"
```
and upload the tokenizer to the [🤗 Hub](https://huggingface.co/).
```python
tokenizer.push_to_hub(repo_name)
```
Great, you can see the just created repository under `https://huggingface.co/<your-username>/w2v-bert-2.0-mongolian-colab-CV16.0`
### Create `SeamlessM4TFeatureExtractor`
The role of the `SeamlessM4TFeatureExtractor` is to prepare the raw audio input in a format that the model can "understand". It therefore maps the sequence of one-dimensional amplitude values (aka the raw audio input) to a two-dimensional matrix of log-mel spectrogram values. The latter encodes the signal frequency information as a function of time. See [this section](https://huggingface.co/learn/audio-course/chapter1/audio_data#the-frequency-spectrum) from the Audio Transformers course to learn more about spectrograms and why they are important.
Unlike the tokenizer, the feature extractor doesn't need to be "learned" from the data, so we can load it directly from the [initial model checkpoint](https://huggingface.co/facebook/w2v-bert-2.0).
```python
from transformers import SeamlessM4TFeatureExtractor
feature_extractor = SeamlessM4TFeatureExtractor.from_pretrained("facebook/w2v-bert-2.0")
```
Great, Wav2Vec2-BERT's feature extraction pipeline is thereby fully defined!
For improved user-friendliness, the feature extractor and tokenizer are *wrapped* into a single `Wav2Vec2BertProcessor` class so that one only needs a `model` and `processor` object.
```python
from transformers import Wav2Vec2BertProcessor
processor = Wav2Vec2BertProcessor(feature_extractor=feature_extractor, tokenizer=tokenizer)
processor.push_to_hub(repo_name)
```
Next, we can prepare the dataset.
### Preprocess Data
So far, we have not looked at the actual values of the speech signal but just the transcription. In addition to `sentence`, our datasets include two more column names `path` and `audio`. `path` states the absolute path of the audio file. Let's take a look.
```python
common_voice_train[0]["path"]
```
```bash
/root/.cache/huggingface/datasets/downloads/extracted/276aa682ce2b6a24934bc401b1f30e004c3fb178dd41d6295b273329f592844a/mn_train_0/common_voice_mn_18578097.mp3
```
Wav2Vec2-BERT expects the input in the format of a 1-dimensional array of 16 kHz. This means that the audio file has to be loaded and resampled.
Thankfully, `datasets` does this automatically by calling the other column `audio`. Let try it out.
```python
common_voice_train[0]["audio"]
```
```bash
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/276aa682ce2b6a24934bc401b1f30e004c3fb178dd41d6295b273329f592844a/mn_train_0/common_voice_mn_18578097.mp3',
'array': array([ 0.00000000e+00, -1.64773251e-14, 1.81765166e-13, ...,
-3.23167333e-05, 2.20304846e-05, 3.26883201e-05]),
'sampling_rate': 48000}
```
Great, we can see that the audio file has automatically been loaded. This is thanks to the new [`"Audio"` feature](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=audio#datasets.Audio) introduced in `datasets == 4.13.3`, which loads and resamples audio files on-the-fly upon calling.
In the example above we can see that the audio data is loaded with a sampling rate of 48kHz whereas Wav2Vec2-BERT was pre-trained at a sampling rate of 16kHz. The sampling rate plays an important role in that it defines how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the *real* speech signal but also necessitates more values per second.
A pre-trained checkpoint expects its input data to have been sampled more or less from the same distribution as the data it was trained on. The same speech signals sampled at two different rates have a very different distribution, *e.g.*, doubling the sampling rate results in data points being twice as long. Thus,
before fine-tuning a pre-trained checkpoint of an ASR model, it is crucial to verify that the sampling rate of the data that was used to pre-train the model matches the sampling rate of the dataset used to fine-tune the model.
Luckily, we can set the audio feature to the correct sampling rate by making use of [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=cast_column#datasets.DatasetDict.cast_column):
```python
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
```
Let's take a look at `"audio"` again:
```python
common_voice_train[0]["audio"]
```
```bash
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/276aa682ce2b6a24934bc401b1f30e004c3fb178dd41d6295b273329f592844a/mn_train_0/common_voice_mn_18578097.mp3',
'array': array([ 9.09494702e-12, -2.27373675e-13, 5.45696821e-12, ...,
-5.22854862e-06, -1.21556368e-05, -9.76262163e-06]),
'sampling_rate': 16000}
```
This seemed to have worked! Let's listen to a couple of audio files to better understand the dataset and verify that the audio was correctly loaded.
```python
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(common_voice_train)-1)
print(common_voice_train[rand_int]["sentence"])
ipd.Audio(data=common_voice_train[rand_int]["audio"]["array"], autoplay=True, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fine-tune-w2v2-bert/mongolian_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
It seems like the data is now correctly loaded and resampled.
It can be heard, that the speakers change along with their speaking rate, accent, and background environment, etc. Overall, the recordings sound acceptably clear though, which is to be expected from a crowd-sourced read speech corpus.
Let's do a final check that the data is correctly prepared, by printing the shape of the speech input, its transcription, and the corresponding sampling rate.
```python
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
```
```bash
Target text: энэ бол тэдний амжилтын бодит нууц
Input array shape: (74496,)
Sampling rate: 16000
```
Good! Everything looks fine - the data is a 1-dimensional array, the sampling rate always corresponds to 16kHz, and the target text is normalized.
Finally, we can leverage `Wav2Vec2BertProcessor` to process the data to the format expected by `Wav2Vec2BertForCTC` for training. To do so let's make use of Dataset's [`map(...)`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=map#datasets.DatasetDict.map) function.
First, we load and resample the audio data, simply by calling `batch["audio"]`.
Second, we extract the `input_features` from the loaded audio file. In our case, the `Wav2Vec2BertProcessor` creates a more complex representation as the raw waveform, known as [Log-Mel feature extraction](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum).
Third, we encode the transcriptions to label ids.
```python
def prepare_dataset(batch):
audio = batch["audio"]
batch["input_features"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
batch["input_length"] = len(batch["input_features"])
batch["labels"] = processor(text=batch["sentence"]).input_ids
return batch
```
Let's apply the data preparation function to all examples.
```python
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
```
Note**: `datasets` automatically takes care of audio loading and resampling. If you wish to implement your own costumized data loading/sampling, feel free to just make use of the `"path"` column instead and disregard the `"audio"` column.
Awesome, now we are ready to start training!
## Training
The data is processed so that we are ready to start setting up the training pipeline. We will make use of 🤗 Transformer's [Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer) class, for which we essentially need to do the following:
- Define a data collator. In contrast to most NLP models, Wav2Vec2-BERT has a much larger input length than output length. Given the large input sizes, it is much more efficient to pad the training batches dynamically meaning that all training samples should only be padded to the longest sample in their batch and not the overall longest sample. Therefore, fine-tuning Wav2Vec2-BERT requires a special padding data collator, which we will define below.
- Evaluation metric. During training, the model should be evaluated on the word error rate. We should define a `compute_metrics` function accordingly
- Load a pre-trained checkpoint. We need to load a pre-trained checkpoint and configure it correctly for training.
- Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the test data and verify that it has indeed learned to correctly transcribe speech.
### Set-up Trainer
Let's start by defining the data collator. The code for the data collator was copied from [this example](https://github.com/huggingface/transformers/blob/7e61d56a45c19284cfda0cee8995fb552f6b1f4e/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L219).
Without going into too many details, in contrast to the common data collators, this data collator treats the `input_features` and `labels` differently and thus applies to separate padding functions on them. This is necessary because in speech input and output are of different modalities meaning that they should not be treated by the same padding function.
Analogous to the common data collators, the padding tokens in the labels with `-100` so that those tokens are **not** taken into account when computing the loss.
```python
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
processor: Wav2Vec2BertProcessor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_features": feature["input_features"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
```
Next, the evaluation metric is defined. As mentioned earlier, the
predominant metric in ASR is the word error rate (WER), hence we will use it in this notebook as well.
```python
wer_metric = load_metric("wer")
```
The model will return a sequence of logit vectors:
\\( \mathbf{y}_1, \ldots, \mathbf{y}_m \\) with \\( \mathbf{y}_1 = f_{\theta}(x_1, \ldots, x_n)[0] \\) and \\( n >> m \\).
A logit vector \\( \mathbf{y}_1 \\) contains the log-odds for each word in the vocabulary we defined earlier, thus \\( \text{len}(\mathbf{y}_i) = \\) `config.vocab_size`. We are interested in the most likely prediction of the model and thus take the `argmax(...)` of the logits. Also, we transform the encoded labels back to the original string by replacing `-100` with the `pad_token_id` and decoding the ids while making sure that consecutive tokens are **not** grouped to the same token in CTC style \\( {}^1 \\).
```python
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
Now, we can load the main pre-trained [checkpoint](https://huggingface.co/facebook/w2v-bert-2.0). The tokenizer's `pad_token_id` must be to define the model's `pad_token_id` or in the case of `Wav2Vec2BertForCTC` also CTC's *blank token* \\( {}^2 \\). To save GPU memory, we enable PyTorch's [gradient checkpointing](https://pytorch.org/docs/stable/checkpoint.html) and also set the loss reduction to "*mean*".
Since, we're only training a small subset of weights, the model is not prone to overfitting. Therefore, we make sure to disable all dropout layers.
**Note**: When using this notebook to train Wav2Vec2-BERT on another language of Common Voice those hyper-parameter settings might not work very well. Feel free to adapt those depending on your use case.
```python
from transformers import Wav2Vec2BertForCTC
model = Wav2Vec2BertForCTC.from_pretrained(
"facebook/w2v-bert-2.0",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
mask_time_prob=0.0,
layerdrop=0.0,
ctc_loss_reduction="mean",
add_adapter=True,
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
)
```
In a final step, we define all parameters related to training.
To give more explanation on some of the parameters:
- `group_by_length` makes training more efficient by grouping training samples of similar input length into one batch. This can significantly speed up training time by heavily reducing the overall number of useless padding tokens that are passed through the model
- `learning_rate` was heuristically tuned until fine-tuning has become stable. Note that those parameters strongly depend on the Common Voice dataset and might be suboptimal for other speech datasets.
For more explanations on other parameters, one can take a look at the [docs](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer#trainingarguments).
During training, a checkpoint will be uploaded asynchronously to the hub every 600 training steps. It allows you to also play around with the demo widget even while your model is still training.
**Note**: If one does not want to upload the model checkpoints to the hub, simply set `push_to_hub=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=2,
evaluation_strategy="steps",
num_train_epochs=10,
gradient_checkpointing=True,
fp16=True,
save_steps=600,
eval_steps=300,
logging_steps=300,
learning_rate=5e-5,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
```
------------------------------------------------------------------------
\\( {}^1 \\) To allow models to become independent of the speaker rate, in CTC, consecutive tokens that are identical are simply grouped as a single token. However, the encoded labels should not be grouped when decoding since they don't correspond to the predicted tokens of the model, which is why the `group_tokens=False` parameter has to be passed. If we wouldn't pass this parameter a word like `"hello"` would incorrectly be encoded, and decoded as `"helo"`.
\\( {}^2 \\) The blank token allows the model to predict a word, such as `"hello"` by forcing it to insert the blank token between the two l's. A CTC-conform prediction of `"hello"` of our model would be `[PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]`.
### Training
Training will take multiple hours depending on the GPU allocated to this notebook. While the trained model yields somewhat satisfying results on *Common Voice*'s test data of Mongolian, it is by no means an optimally fine-tuned model. The purpose of this notebook is just to demonstrate how to fine-tune Wav2Vec2-BERT on an ASR dataset.
```python
trainer.train()
```
| Step | Training Loss | Validation Loss | Wer |
|:-------------:|:----:|:---------------:|:------:|
| 300 | 1.712700 | 0.647740 | 0.517892 |
| 600 | 0.349300 | 0.615849 | 0.442027 |
| 900 | 0.180500 | 0.525088 | 0.367305 |
| 1200 | 0.075400 | 0.528768 | 0.324016 |
The training loss and validation WER go down nicely. In comparison, the same training with [whisper-large-v3](https://huggingface.co/openai/whisper-large-v3), the commonly recognized state-of-the-art ASR model from OpenAI, has a final WER of 33.3%. You can find the resulting Whisper checkpoint [here](https://huggingface.co/sanchit-gandhi/whisper-large-v3-ft-cv16-mn). This shows that Wav2Vec2-Bert can achieve performance close to or **equivalent to that of the state of the art in low-resource languages**.
You can now upload the result of the training to the 🤗 Hub, just execute this instruction:
```python
trainer.push_to_hub()
```
You can now share this model with all your friends, family, favorite pets: they can all load it with the identifier "your-username/the-name-you-picked" so for instance:
```python
from transformers import AutoModelForCTC, Wav2Vec2BertProcessor
model = AutoModelForCTC.from_pretrained("ylacombe/w2v-bert-2.0-mongolian-colab-CV16.0")
processor = Wav2Vec2BertProcessor.from_pretrained("ylacombe/w2v-bert-2.0-mongolian-colab-CV16.0")
```
For more examples of how Wav2Vec2-BERT can be fine-tuned, please take a look at the [official speech recognition examples](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition#examples).
### Evaluation
As a final check, let's load the model and verify that it indeed has learned to transcribe Mongolian speech.
Let's first load the pre-trained checkpoint.
```python
model = Wav2Vec2BertForCTC.from_pretrained(repo_name).to("cuda")
processor = Wav2Vec2BertProcessor.from_pretrained(repo_name)
```
Let's process the audio, run a forward pass and predict the ids.
```python
sample = common_voice_test[0]
input_features = torch.tensor(sample["input_features"]).to("cuda").unsqueeze(0)
with torch.no_grad():
logits = model(input_features).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
```
Finally, we can decode the example from the predicted tokens and compare it to the reference transcription:
```python
print(processor.decode(pred_ids))
print(processor.decode(input_dict["labels"]).lower())
```
```bash
эрчүүдийн ганцаардлыг эмэхтэйчүүд ойлгох нь ховор юм
эрчүдийн ганцардлыг эмэгтэйчүд ойлгох нь ховор юм
```
Alright! The transcription can definitely be recognized from our prediction, but it is not perfect yet. Training the model a bit longer, spending more time on the data pre-processing, and especially using a [language model](https://huggingface.co/blog/wav2vec2-with-ngram) for decoding would certainly improve the model's overall performance.
For a demonstration model on a low-resource language, the results are quite acceptable however 🤗.
## Scaling-up the training
We've shown in this blogpost how Meta's `w2v-bert-2.0` fine-tuning can give near state-of-the-art performance on low-resource languages.
To take things a step further, I've put together a set of tips and pointers given by my colleagues at Hugging Face on how to scale up training for this model. These tips came to light when I showed them this blog post [training run](https://huggingface.co/hf-audio/w2v-bert-2.0-mongolian-colab-CV16.0#training-results), as well as other training attempts ([here](https://wandb.ai/ylacombe/huggingface/runs/nasaux7f?workspace=user-ylacombe) and [here](https://wandb.ai/ylacombe/huggingface/runs/4y8pd2gq)).
Many thanks to [Patrick](https://huggingface.co/patrickvonplaten), [Sanchit](https://huggingface.co/sanchit-gandhi) and [Pablo](https://huggingface.co/Molbap) for their valuable expertise and help 🤗
Note that Common Voice newest version ([CV16](https://huggingface.co/datasets/mozilla-foundation/common_voice_16_0)) provides many more hours of data and for may languages and thus provides fertile ground for much more efficient models in many low-resource languages.
### Datasets-related tips
CTC ASR is typically done with lower-case, un-punctuated transcriptions. This simplifies the CTC task since the model is considered as "acoustic only", meaning that it makes prediction largely based on the phonetics sounds of the audio, rather than any language modelling context of the spoken sentence.
Very low-frequency characters can significantly affect loss during learning by causing loss spikes via erroneous targets. By default, the CTC tokenizer created in this blog post would add them to the vocabulary even if their frequency is negligible compared to more frequent characters. We can treat these characters as "errors" in the dataset annotation, so that they can be removed from the vocabulary, and simply classified as `"[UNK]"` during training.
It is therefore absolutely necessary to recheck the tokenizer vocabulary and remove all low-frequency characters, in much the same way as we removed Latin characters when creating the tokenizer.
Note that the Common Voice dataset is particularly prone to such "wrong" characters, for example characters from other languages (阪).
### Training-related tips
**Average duration seen by each CTC token:** through experimentation, we found the ideal ratio of duration seen per CTC token is 10 to 35 ms. In other words, to be able to learn and predict correctly, the duration of the acoustic information a CTC token needs to see should be neither too low nor too high. In fact, it should more or less correspond to a fraction of the time it takes us humans to pronounce a phoneme.
[One](https://wandb.ai/ylacombe/huggingface/runs/4y8pd2gq) of my training runs had a loss curve initially going nicely downwards, as expected, but at some point it started to explode. I realized that I had been using a [basic checkpoint with no architecture changes](https://huggingface.co/facebook/w2v-bert-2.0), and that each CTC token was seeing a piece of the signal for 30 to 60 ms. Adding an convolutional [adapter layer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert#transformers.Wav2Vec2BertConfig.add_adapter) to sub-sample the encoder hidden-states along the time dimension was enough to reduce the signal chunk sampling to the desired duration and to prevent this type of loss curve.
**Under-training:** My colleagues quickly noticed when looking at my training runs that the models was severely under-trained, something that could have been spotted by looking at the loss curve, which looks like it was stopped in the middle of a steep descent. This pointed out other issues as well, notably the loss curve not being smooth enough, a sign of wrong hyper-parameters settings.
Here are a few ways to solve under-training in our case:
- the warm-up rate might be too high, causing the learning rate to drop too quickly. A way to solve this would be keep the warmup ratio to 5 to 15% and scale up the number of epochs. The warm-up steps are essential to gradually bring the new language-model head weights into alignment with the pre-trained model.
- Loss curve lack of smoothness can be played around thanks to [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)'s \\( \beta_2 \\) which can typically set from 0.95 to 0.98 by default.
*Related posts and additional links are listed here:*
- [**Official paper**](https://huggingface.co/papers/2305.13516)
- [**Original cobebase**](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/)
- [**Transformers Docs**](https://huggingface.co/docs/transformers/main/en/model_doc/wav2vec2-bert)
- [**Related XLS-R blog post**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)
- [**Related MMS blog post**](https://huggingface.co/blog/mms_adapters)
| 3 |
0 | hf_public_repos | hf_public_repos/blog/introducing-private-hub.md | ---
title: "Introducing the Private Hub: A New Way to Build With Machine Learning"
thumbnail: /blog/assets/92_introducing_private_hub/thumbnail.png
authors:
- user: federicopascual
---
# Introducing the Private Hub: A New Way to Build With Machine Learning
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
> [!TIP]
> June 2023 Update: The Private Hub is now called **Enterprise Hub**.
>
> The Enterprise Hub is a hosted solution that combines the best of Cloud Managed services (SaaS) and Enterprise security. It lets customers deploy specific services like <b>Inference Endpoints</b> on a wide scope of compute options, from on-cloud to on-prem. It offers advanced user administration and access controls through SSO.
>
> **We no longer offer Private Hub on-prem deployments as this experiment is now discontinued.**
>
> Get in touch with our [Enterprise team](/support) to find the best solution for your company.
Machine learning is changing how companies are building technology. From powering a new generation of disruptive products to enabling smarter features in well-known applications we all use and love, ML is at the core of the development process.
But with every technology shift comes new challenges.
Around [90% of machine learning models never make it into production](https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/). Unfamiliar tools and non-standard workflows slow down ML development. Efforts get duplicated as models and datasets aren't shared internally, and similar artifacts are built from scratch across teams all the time. Data scientists find it hard to show their technical work to business stakeholders, who struggle to share precise and timely feedback. And machine learning teams waste time on Docker/Kubernetes and optimizing models for production.
With this in mind, we launched the [Private Hub](https://huggingface.co/platform) (PH), a new way to build with machine learning. From research to production, it provides a unified set of tools to accelerate each step of the machine learning lifecycle in a secure and compliant way. PH brings various ML tools together in one place, making collaborating in machine learning simpler, more fun and productive.
In this blog post, we will deep dive into what is the Private Hub, why it's useful, and how customers are accelerating their ML roadmaps with it.
Read along or feel free to jump to the section that sparks 🌟 your interest:
1. [What is the Hugging Face Hub?](#1-what-is-the-hugging-face-hub)
2. [What is the Private Hub?](#2-what-is-the-private-hub)
3. [How are companies using the Private Hub to accelerate their ML roadmap?](#3-how-are-companies-using-the-private-hub-to-accelerate-their-ml-roadmap)
Let's get started! 🚀
## 1. What is the Hugging Face Hub?
Before diving into the Private Hub, let's first take a look at the Hugging Face Hub, which is a central part of the PH.
The [Hugging Face Hub](https://huggingface.co/docs/hub/index) offers over 60K models, 6K datasets, and 6K ML demo apps, all open source and publicly available, in an online platform where people can easily collaborate and build ML together. The Hub works as a central place where anyone can explore, experiment, collaborate and build technology with machine learning.
On the Hugging Face Hub, you’ll be able to create or discover the following ML assets:
- [Models](https://huggingface.co/models): hosting the latest state-of-the-art models for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more.
- [Datasets](https://huggingface.co/datasets): featuring a wide variety of data for different domains, modalities and languages.
- [Spaces](https://huggingface.co/spaces): interactive apps for showcasing ML models directly in your browser.
Each model, dataset or space uploaded to the Hub is a [Git-based repository](https://huggingface.co/docs/hub/repositories), which are version-controlled places that can contain all your files. You can use the traditional git commands to pull, push, clone, and/or manipulate your files. You can see the commit history for your models, datasets and spaces, and see who did what and when.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Commit history on a machine learning model" src="assets/92_introducing_private_hub/commit-history.png"></medium-zoom>
<figcaption>Commit history on a model</figcaption>
</figure>
The Hugging Face Hub is also a central place for feedback and development in machine learning. Teams use [pull requests and discussions](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to support peer reviews on models, datasets, and spaces, improve collaboration and accelerate their ML work.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Pull requests and discussions on a model" src="assets/92_introducing_private_hub/pull-requests-and-discussions.png"></medium-zoom>
<figcaption>Pull requests and discussions on a model</figcaption>
</figure>
The Hub allows users to create [Organizations](https://huggingface.co/docs/hub/organizations), that is, team accounts to manage models, datasets, and spaces collaboratively. An organization’s repositories will be featured on the organization’s page and admins can set roles to control access to these repositories. Every member of the organization can contribute to models, datasets and spaces given the right permissions. Here at Hugging Face, we believe having the right tools to collaborate drastically accelerates machine learning development! 🔥
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Organization in the Hub for BigScience" src="assets/92_introducing_private_hub/organizations.png"></medium-zoom>
<figcaption>Organization in the Hub for <a href="https://huggingface.co/bigscience">BigScience</a></figcaption>
</figure>
Now that we have covered the basics, let's dive into the specific characteristics of models, datasets and spaces hosted on the Hugging Face Hub.
### Models
[Transfer learning](https://www.youtube.com/watch?v=BqqfQnyjmgg&ab_channel=HuggingFace) has changed the way companies approach machine learning problems. Traditionally, companies needed to train models from scratch, which requires a lot of time, data, and resources. Now machine learning teams can use a pre-trained model and [fine-tune it for their own use case](https://huggingface.co/course/chapter3/1?fw=pt) in a fast and cost-effective way. This dramatically accelerates the process of getting accurate and performant models.
On the Hub, you can find 60,000+ state-of-the-art open source pre-trained models for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more. You can use the search bar or filter by tasks, libraries, licenses and other tags to find the right model for your particular use case:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="60,000+ models available on the Hub" src="assets/92_introducing_private_hub/models.png"></medium-zoom>
<figcaption>60,000+ models available on the Hub</figcaption>
</figure>
These models span 180 languages and support up to 25 ML libraries (including Transformers, Keras, spaCy, Timm and others), so there is a lot of flexibility in terms of the type of models, languages and libraries.
Each model has a [model card](https://huggingface.co/docs/hub/models-cards), a simple markdown file with a description of the model itself. This includes what it's intended for, what data that model has been trained on, code samples, information on potential bias and potential risks associated with the model, metrics, related research papers, you name it. Model cards are a great way to understand what the model is about, but they also are useful for identifying the right pre-trained model as a starting point for your ML project:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Model card" src="assets/92_introducing_private_hub/model-card.png"></medium-zoom>
<figcaption>Model card</figcaption>
</figure>
Besides improving models' discoverability and reusability, model cards also make it easier for model risk management (MRM) processes. ML teams are often required to provide information about the machine learning models they build so compliance teams can identify, measure and mitigate model risks. Through model cards, organizations can set up a template with all the required information and streamline the MRM conversations between the ML and compliance teams right within the models.
The Hub also provides an [Inference Widget](https://huggingface.co/docs/hub/models-widgets) to easily test models right from your browser! It's a really good way to get a feeling if a particular model is a good fit and something you wanna dive into:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Inference widget" src="assets/92_introducing_private_hub/inference-widget.png"></medium-zoom>
<figcaption>Inference widget</figcaption>
</figure>
### Datasets
Data is a key part of building machine learning models; without the right data, you won't get accurate models. The 🤗 Hub hosts more than [6,000 open source, ready-to-use datasets for ML models](https://huggingface.co/datasets) with fast, easy-to-use and efficient data manipulation tools. Like with models, you can find the right dataset for your use case by using the search bar or filtering by tags. For example, you can easily find 96 models for sentiment analysis by filtering by the task "sentiment-classification":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Datasets available for sentiment classification" src="assets/92_introducing_private_hub/filtering-datasets.png"></medium-zoom>
<figcaption>Datasets available for sentiment classification</figcaption>
</figure>
Similar to models, datasets uploaded to the 🤗 Hub have [Dataset Cards](https://huggingface.co/docs/hub/datasets-cards#dataset-cards) to help users understand the contents of the dataset, how the dataset should be used, how it was created and know relevant considerations for using the dataset. You can use the [Dataset Viewer](https://huggingface.co/docs/hub/datasets-viewer) to easily view the data and quickly understand if a particular dataset is useful for your machine learning project:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Super Glue dataset preview" src="assets/92_introducing_private_hub/dataset-preview.png"></medium-zoom>
<figcaption>Super Glue dataset preview</figcaption>
</figure>
### Spaces
A few months ago, we introduced a new feature on the 🤗 Hub called [Spaces](https://huggingface.co/spaces/launch). It's a simple way to build and host machine learning apps. Spaces allow you to easily showcase your ML models to business stakeholders and get the feedback you need to move your ML project forward.
If you've been generating funny images with [DALL-E mini](https://huggingface.co/spaces/dalle-mini/dalle-mini), then you have used Spaces. This space showcase the [DALL-E mini model](https://huggingface.co/dalle-mini/dalle-mini), a machine learning model to generate images based on text prompts:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Space for DALL-E mini" src="assets/92_introducing_private_hub/dalle-mini.png"></medium-zoom>
<figcaption>Space for DALL-E mini</figcaption>
</figure>
## 2. What is the Private Hub?
The [Private Hub](https://huggingface.co/platform) allows companies to use Hugging Face’s complete ecosystem in their own private and compliant environment to accelerate their machine learning development. It brings ML tools for every step of the ML lifecycle together in one place to make collaborating in ML simpler and more productive, while having a compliant environment that companies need for building ML securely:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The Private Hub" src="assets/92_introducing_private_hub/private-hub.png"></medium-zoom>
<figcaption>The Private Hub</figcaption>
</figure>
With the Private Hub, data scientists can seamlessly work with [Transformers](https://github.com/huggingface/transformers), [Datasets](https://github.com/huggingface/datasets) and other [open source libraries](https://github.com/huggingface) with models, datasets and spaces privately and securely hosted on your own servers, and get machine learning done faster by leveraging the Hub features:
- [AutoTrain](https://huggingface.co/autotrain): you can use our AutoML no-code solution to train state-of-the-art models, automatically fine-tuned, evaluated and deployed in your own servers.
- [Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator): evaluate any model on any dataset on the Private Hub with any metric without writing a single line of code.
- [Spaces](https://huggingface.co/spaces/launch): easily host an ML demo app to show your ML work to business stakeholders, get feedback early and build faster.
- [Inference API](https://huggingface.co/inference-api): every private model created on the Private Hub is deployed for inference in your own infrastructure via simple API calls.
- [PRs and Discussions](https://huggingface.co/blog/community-update): support peer reviews on models, datasets, and spaces to improve collaboration across teams.
From research to production, your data never leaves your servers. The Private Hub runs in your own compliant server. It provides enterprise security features like security scans, audit trail, SSO, and control access to keep your models and data secure.
We provide flexible options for deploying your Private Hub in your private, compliant environment, including:
- **Managed Private Hub (SaaS)**: runs in segregated virtual private servers (VPCs) owned by Hugging Face. You can enjoy the full Hugging Face experience on your own private Hub without having to manage any infrastructure.
- **On-cloud Private Hub**: runs in a cloud account on AWS, Azure or GCP owned by the customer. This deployment option gives you full administrative control of the underlying cloud infrastructure and lets you achieve stronger security and compliance.
- **On-prem Private Hub**: on-premise deployment of the Hugging Face Hub on your own infrastructure. For customers with strict compliance rules and/or workloads where they don't want or are not allowed to run on a public cloud.
Now that we have covered the basics of what the Private Hub is, let's go over how companies are using it to accelerate their ML development.
## 3. How Are Companies Using the Private Hub to Accelerate Their ML Roadmap?
[🤗 Transformers](https://github.com/huggingface/transformers) is one of the [fastest growing open source projects of all time](https://star-history.com/#tensorflow/tensorflow&nodejs/node&kubernetes/kubernetes&pytorch/pytorch&huggingface/transformers&Timeline). We now offer [25+ open source libraries](https://github.com/huggingface) and over 10,000 companies are now using Hugging Face to build technology with machine learning.
Being at the heart of the open source AI community, we had thousands of conversations with machine learning and data science teams, giving us a unique perspective on the most common problems and challenges companies are facing when building machine learning.
Through these conversations, we discovered that the current workflow for building machine learning is broken. Duplicated efforts, poor feedback loops, high friction to collaborate across teams, non-standard processes and tools, and difficulty optimizing models for production are common and slow down ML development.
We built the Private Hub to change this. Like Git and GitHub forever changed how companies build software, the Private Hub changes how companies build machine learning:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Before and after using The Private Hub" src="assets/92_introducing_private_hub/before-and-after.png"></medium-zoom>
<figcaption>Before and after using The Private Hub</figcaption>
</figure>
In this section, we'll go through a demo example of how customers are leveraging the PH to accelerate their ML lifecycle. We will go over the step-by-step process of building an ML app to automatically analyze financial analyst 🏦 reports.
First, we will search for a pre-trained model relevant to our use case and fine-tune it on a custom dataset for sentiment analysis. Next, we will build an ML web app to show how this model works to business stakeholders. Finally, we will use the Inference API to run inferences with an infrastructure that can handle production-level loads. All artifacts for this ML demo app can be found in this [organization on the Hub](https://huggingface.co/FinanceInc).
### Training accurate models faster
#### Leveraging a pre-trained model from the Hub
Instead of training models from scratch, transfer learning now allows you to build more accurate models 10x faster ⚡️by fine-tuning pre-trained models available on the Hub for your particular use case.
For our demo example, one of the requirements for building this ML app for financial analysts is doing sentiment analysis. Business stakeholders want to automatically get a sense of a company's performance as soon as financial docs and analyst reports are available.
So as a first step towards creating this ML app, we dive into the [🤗 Hub](https://huggingface.co/models) and explore what pre-trained models are available that we can fine-tune for sentiment analysis. The search bar and tags will let us filter and discover relevant models very quickly. Soon enough, we come across [FinBERT](https://huggingface.co/yiyanghkust/finbert-pretrain), a BERT model pre-trained on corporate reports, earnings call transcripts and financial analyst reports:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Finbert model" src="assets/92_introducing_private_hub/finbert-pretrain.png"></medium-zoom>
<figcaption>Finbert model</figcaption>
</figure>
We [clone the model](https://huggingface.co/FinanceInc/finbert-pretrain) in our own Private Hub, so it's available to other teammates. We also add the required information to the model card to streamline the model risk management process with the compliance team.
#### Fine-tuning a pre-trained model with a custom dataset
Now that we have a great pre-trained model for financial data, the next step is to fine-tune it using our own data for doing sentiment analysis!
So, we first upload a [custom dataset for sentiment analysis](https://huggingface.co/datasets/FinanceInc/auditor_sentiment) that we built internally with the team to our Private Hub. This dataset has several thousand sentences from financial news in English and proprietary financial data manually categorized by our team according to their sentiment. This data contains sensitive information, so our compliance team only allows us to upload this data on our own servers. Luckily, this is not an issue as we run the Private Hub on our own AWS instance.
Then, we use [AutoTrain](https://huggingface.co/autotrain) to quickly fine-tune the FinBert model with our custom sentiment analysis dataset. We can do this straight from the datasets page on our Private Hub:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Fine-tuning a pre-trained model with AutoTrain" src="assets/92_introducing_private_hub/train-in-autotrain.png"></medium-zoom>
<figcaption>Fine-tuning a pre-trained model with AutoTrain</figcaption>
</figure>
Next, we select "manual" as the model choice and choose our [cloned Finbert model](https://huggingface.co/FinanceInc/finbert-pretrain) as the model to fine-tune with our dataset:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Creating a new project with AutoTrain" src="assets/92_introducing_private_hub/autotrain-new-project.png"></medium-zoom>
<figcaption>Creating a new project with AutoTrain</figcaption>
</figure>
Finally, we select the number of candidate models to train with our data. We choose 25 models and voila! After a few minutes, AutoTrain has automatically fine-tuned 25 finbert models with our own sentiment analysis data, showing the performance metrics for all the different models 🔥🔥🔥
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="25 fine-tuned models with AutoTrain" src="assets/92_introducing_private_hub/autotrain-trained-models.png"></medium-zoom>
<figcaption>25 fine-tuned models with AutoTrain</figcaption>
</figure>
Besides the performance metrics, we can easily test the [fine-tuned models](https://huggingface.co/FinanceInc/auditor_sentiment_finetuned) using the inference widget right from our browser to get a sense of how good they are:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Testing the fine-tuned models with the Inference Widget" src="assets/92_introducing_private_hub/auto-train-inference-widget.png"></medium-zoom>
<figcaption>Testing the fine-tuned models with the Inference Widget</figcaption>
</figure>
### Easily demo models to relevant stakeholders
Now that we have trained our custom model for analyzing financial documents, as a next step, we want to build a machine learning demo with [Spaces](https://huggingface.co/spaces/launch) to validate our MVP with our business stakeholders. This demo app will use our custom sentiment analysis model, as well as a second FinBERT model we fine-tuned for [detecting forward-looking statements](https://huggingface.co/FinanceInc/finbert_fls) from financial reports. This interactive demo app will allow us to get feedback sooner, iterate faster, and improve the models so we can use them in production. ✅
In less than 20 minutes, we were able to build an [interactive demo app](https://huggingface.co/spaces/FinanceInc/Financial_Analyst_AI) that any business stakeholder can easily test right from their browsers:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Space for our financial demo app" src="assets/92_introducing_private_hub/financial-analyst-space.png"></medium-zoom>
<figcaption>Space for our financial demo app</figcaption>
</figure>
If you take a look at the [app.py file](https://huggingface.co/spaces/FinanceInc/Financial_Analyst_AI/blob/main/app.py), you'll see it's quite simple:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Code for our ML demo app" src="assets/92_introducing_private_hub/spaces-code.png"></medium-zoom>
<figcaption>Code for our ML demo app</figcaption>
</figure>
51 lines of code are all it took to get this ML demo app up and running! 🤯
### Scale inferences while staying out of MLOps
By now, our business stakeholders have provided great feedback that allowed us to improve these models. Compliance teams assessed potential risks through the information provided via the model cards and green-lighted our project for production. Now, we are ready to put these models to work and start analyzing financial reports at scale! 🎉
Instead of wasting time on Docker/Kubernetes, setting up a server for running these models or optimizing models for production, all we need to do is to leverage the [Inference API](https://huggingface.co/inference-api). We don't need to worry about deployment or scalability issues, we can easily integrate our custom models via simple API calls.
Models uploaded to the Hub and/or created with AutoTrain are instantly deployed to production, ready to make inferences at scale and in real-time. And all it takes to run inferences is 12 lines of code!
To get the code snippet to run inferences with our [sentiment analysis model](https://huggingface.co/FinanceInc/auditor_sentiment_finetuned), we click on "Deploy" and "Accelerated Inference":
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Leveraging the Inference API to run inferences on our custom model" src="assets/92_introducing_private_hub/deploy.png"></medium-zoom>
<figcaption>Leveraging the Inference API to run inferences on our custom model</figcaption>
</figure>
This will show us the following code to make HTTP requests to the Inference API and start analyzing data with our custom model:
```python
import requests
API_URL = "https://api-inference.huggingface.co/models/FinanceInc/auditor_sentiment_finetuned"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Operating profit jumped to EUR 47 million from EUR 6.6 million",
})
```
With just 12 lines of code, we are up and running in running inferences with an infrastructure that can handle production-level loads at scale and in real-time 🚀. Pretty cool, right?
## Last Words
Machine learning is becoming the default way to build technology, mostly thanks to open-source and open-science.
But building machine learning is still hard. Many ML projects are rushed and never make it to production. ML development is slowed down by non-standard workflows. ML teams get frustrated with duplicated work, low collaboration across teams, and a fragmented ecosystem of ML tooling.
At Hugging Face, we believe there is a better way to build machine learning. And this is why we created the [Private Hub](https://huggingface.co/platform). We think that providing a unified set of tools for every step of the machine learning development and the right tools to collaborate will lead to better ML work, bring more ML solutions to production, and help ML teams spark innovation.
Interested in learning more? [Request a demo](https://huggingface.co/platform#form) to see how you can leverage the Private Hub to accelerate ML development within your organization.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/langchain.md | ---
title: "Hugging Face x LangChain : A new partner package"
thumbnail: /blog/assets/langchain_huggingface/thumbnail.png
authors:
- user: jofthomas
- user: kkondratenko
guest: true
- user: efriis
guest: true
org: langchain-ai
---
# Hugging Face x LangChain : A new partner package in LangChain
We are thrilled to announce the launch of **`langchain_huggingface`**, a partner package in LangChain jointly maintained by Hugging Face and LangChain. This new Python package is designed to bring the power of the latest development of Hugging Face into LangChain and keep it up to date.
# From the community, for the community
All Hugging Face-related classes in LangChain were coded by the community, and while we thrived on this, over time, some of them became deprecated because of the lack of an insider’s perspective.
By becoming a partner package, we aim to reduce the time it takes to bring new features available in the Hugging Face ecosystem to LangChain's users.
**`langchain-huggingface`** integrates seamlessly with LangChain, providing an efficient and effective way to utilize Hugging Face models within the LangChain ecosystem. This partnership is not just about sharing technology but also about a joint commitment to maintain and continually improve this integration.
## **Getting Started**
Getting started with **`langchain-huggingface`** is straightforward. Here’s how you can install and begin using the [package](https://github.com/langchain-ai/langchain/tree/master/libs/partners/huggingface):
```python
pip install langchain-huggingface
```
Now that the package is installed, let’s have a tour of what’s inside !
## The LLMs
### HuggingFacePipeline
Among `transformers`, the [Pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) is the most versatile tool in the Hugging Face toolbox. LangChain being designed primarily to address RAG and Agent use cases, the scope of the pipeline here is reduced to the following text-centric tasks: `“text-generation"`, `“text2text-generation"`, `“summarization”`, `“translation”`.
Models can be loaded directly with the `from_model_id` method:
```python
from langchain_huggingface import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(
model_id="microsoft/Phi-3-mini-4k-instruct",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 100,
"top_k": 50,
"temperature": 0.1,
},
)
llm.invoke("Hugging Face is")
```
Or you can also define the pipeline yourself before passing it to the class:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
model_id = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
#attn_implementation="flash_attention_2", # if you have an ampere GPU
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=100, top_k=50, temperature=0.1)
llm = HuggingFacePipeline(pipeline=pipe)
llm.invoke("Hugging Face is")
```
When using this class, the model will be loaded in cache and use your computer’s hardware; thus, you may be limited by the available resources on your computer.
### HuggingFaceEndpoint
There are also two ways to use this class. You can specify the model with the `repo_id` parameter. Those endpoints use the [serverless API](https://huggingface.co/inference-api/serverless), which is particularly beneficial to people using [pro accounts](https://huggingface.co/subscribe/pro) or [enterprise hub](https://huggingface.co/enterprise). Still, regular users can already have access to a fair amount of request by connecting with their HF token in the environment where they are executing the code.
```python
from langchain_huggingface import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Meta-Llama-3-8B-Instruct",
task="text-generation",
max_new_tokens=100,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
```python
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
Under the hood, this class uses the [InferenceClient](https://huggingface.co/docs/huggingface_hub/en/package_reference/inference_client) to be able to serve a wide variety of use-case, serverless API to deployed TGI instances.
### ChatHuggingFace
Every model has its own special tokens with which it works best. Without those tokens added to your prompt, your model will greatly underperform
When going from a list of messages to a completion prompt, there is an attribute that exists in most LLM tokenizers called [chat_template](https://huggingface.co/docs/transformers/chat_templating).
To learn more about chat_template in the different models, visit this [space](https://huggingface.co/spaces/Jofthomas/Chat_template_viewer) I made!
This class is wrapper around the other LLMs. It takes as input a list of messages an then creates the correct completion prompt by using the `tokenizer.apply_chat_template` method.
```python
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm_engine_hf = ChatHuggingFace(llm=llm)
llm_engine_hf.invoke("Hugging Face is")
```
The code above is equivalent to :
```python
# with mistralai/Mistral-7B-Instruct-v0.2
llm.invoke("<s>[INST] Hugging Face is [/INST]")
# with meta-llama/Meta-Llama-3-8B-Instruct
llm.invoke("""<|begin_of_text|><|start_header_id|>user<|end_header_id|>Hugging Face is<|eot_id|><|start_header_id|>assistant<|end_header_id|>""")
```
## The Embeddings
Hugging Face is filled with very powerful embedding models than you can directly leverage in your pipeline.
First choose your model. One good resource for choosing an embedding model is the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
### HuggingFaceEmbeddings
This class uses [sentence-transformers](https://sbert.net/) embeddings. It computes the embedding locally, hence using your computer resources.
```python
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
model_name = "mixedbread-ai/mxbai-embed-large-v1"
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
### HuggingFaceEndpointEmbeddings
`HuggingFaceEndpointEmbeddings` is very similar to what `HuggingFaceEndpoint` does for the LLM, in the sense that it also uses the InferenceClient under the hood to compute the embeddings.
It can be used with models on the hub, and TEI instances whether they are deployed locally or online.
```python
from langchain_huggingface.embeddings import HuggingFaceEndpointEmbeddings
hf_embeddings = HuggingFaceEndpointEmbeddings(
model= "mixedbread-ai/mxbai-embed-large-v1",
task="feature-extraction",
huggingfacehub_api_token="<HF_TOKEN>",
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
## Conclusion
We are committed to making **`langchain-huggingface`** better by the day. We will be actively monitoring feedback and issues and working to address them as quickly as possible. We will also be adding new features and functionality and expanding the package to support an even wider range of the community's use cases. We strongly encourage you to try this package and to give your opinion, as it will pave the way for the package's future.
| 5 |
0 | hf_public_repos | hf_public_repos/blog/how-to-generate.md | ---
title: "How to generate text: using different decoding methods for language generation with Transformers"
thumbnail: /blog/assets/02_how-to-generate/thumbnail.png
authors:
- user: patrickvonplaten
---
# How to generate text: using different decoding methods for language generation with Transformers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Note**: Edited on July 2023 with up-to-date references and examples.
## Introduction
In recent years, there has been an increasing interest in open-ended
language generation thanks to the rise of large transformer-based
language models trained on millions of webpages, including OpenAI's [ChatGPT](https://openai.com/blog/chatgpt)
and Meta's [LLaMA](https://ai.meta.com/blog/large-language-model-llama-meta-ai/).
The results on conditioned open-ended language generation are impressive, having shown to
[generalize to new tasks](https://ai.googleblog.com/2021/10/introducing-flan-more-generalizable.html),
[handle code](https://huggingface.co/blog/starcoder),
or [take non-text data as input](https://openai.com/research/whisper).
Besides the improved transformer architecture and massive unsupervised
training data, **better decoding methods** have also played an important
role.
This blog post gives a brief overview of different decoding strategies
and more importantly shows how *you* can implement them with very little
effort using the popular `transformers` library\!
All of the following functionalities can be used for **auto-regressive**
language generation ([here](http://jalammar.github.io/illustrated-gpt2/)
a refresher). In short, *auto-regressive* language generation is based
on the assumption that the probability distribution of a word sequence
can be decomposed into the product of conditional next word
distributions:
$$ P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, $$
and \\(W_0\\) being the initial *context* word sequence. The length \\(T\\)
of the word sequence is usually determined *on-the-fly* and corresponds
to the timestep \\(t=T\\) the EOS token is generated from \\(P(w_{t} | w_{1: t-1}, W_{0})\\).
We will give a tour of the currently most prominent decoding methods,
mainly *Greedy search*, *Beam search*, and *Sampling*.
Let's quickly install transformers and load the model. We will use GPT2
in PyTorch for demonstration, but the API is 1-to-1 the same for
TensorFlow and JAX.
``` python
!pip install -q transformers
```
``` python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = AutoModelForCausalLM.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id).to(torch_device)
```
## Greedy Search
Greedy search is the simplest decoding method.
It selects the word with the highest probability as
its next word: \\(w_t = argmax_{w}P(w | w_{1:t-1})\\) at each timestep
\\(t\\). The following sketch shows greedy search.
<img src="/blog/assets/02_how-to-generate/greedy_search.png" alt="greedy search" style="margin: auto; display: block;">
Starting from the word \\(\text{"The"},\\) the algorithm greedily chooses
the next word of highest probability \\(\text{"nice"}\\) and so on, so
that the final generated word sequence is \\((\text{"The"}, \text{"nice"}, \text{"woman"})\\)
having an overall probability of \\(0.5 \times 0.4 = 0.2\\) .
In the following we will generate word sequences using GPT2 on the
context \\((\text{"I"}, \text{"enjoy"}, \text{"walking"}, \text{"with"}, \text{"my"}, \text{"cute"}, \text{"dog"})\\). Let's
see how greedy search can be used in `transformers`:
``` python
# encode context the generation is conditioned on
model_inputs = tokenizer('I enjoy walking with my cute dog', return_tensors='pt').to(torch_device)
# generate 40 new tokens
greedy_output = model.generate(**model_inputs, max_new_tokens=40)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure
```
Alright\! We have generated our first short text with GPT2 😊. The
generated words following the context are reasonable, but the model
quickly starts repeating itself\! This is a very common problem in
language generation in general and seems to be even more so in greedy
and beam search - check out [Vijayakumar et
al., 2016](https://arxiv.org/abs/1610.02424) and [Shao et
al., 2017](https://arxiv.org/abs/1701.03185).
The major drawback of greedy search though is that it misses high
probability words hidden behind a low probability word as can be seen in
our sketch above:
The word \\(\text{"has"}\\)
with its high conditional probability of \\(0.9\\)
is hidden behind the word \\(\text{"dog"}\\), which has only the
second-highest conditional probability, so that greedy search misses the
word sequence \\(\text{"The"}, \text{"dog"}, \text{"has"}\\) .
Thankfully, we have beam search to alleviate this problem\!
## Beam search
Beam search reduces the risk of missing hidden high probability word
sequences by keeping the most likely `num_beams` of hypotheses at each
time step and eventually choosing the hypothesis that has the overall
highest probability. Let's illustrate with `num_beams=2`:
<img src="/blog/assets/02_how-to-generate/beam_search.png" alt="beam search" style="margin: auto; display: block;">
At time step 1, besides the most likely hypothesis \\((\text{"The"}, \text{"nice"})\\),
beam search also keeps track of the second
most likely one \\((\text{"The"}, \text{"dog"})\\).
At time step 2, beam search finds that the word sequence \\((\text{"The"}, \text{"dog"}, \text{"has"})\\),
has with \\(0.36\\)
a higher probability than \\((\text{"The"}, \text{"nice"}, \text{"woman"})\\),
which has \\(0.2\\) . Great, it has found the most likely word sequence in
our toy example\!
Beam search will always find an output sequence with higher probability
than greedy search, but is not guaranteed to find the most likely
output.
Let's see how beam search can be used in `transformers`. We set
`num_beams > 1` and `early_stopping=True` so that generation is finished
when all beam hypotheses reached the EOS token.
``` python
# activate beam search and early_stopping
beam_output = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure
```
While the result is arguably more fluent, the output still includes
repetitions of the same word sequences.
One of the available remedies is to introduce *n-grams* (*a.k.a* word sequences of
n words) penalties as introduced by [Paulus et al.
(2017)](https://arxiv.org/abs/1705.04304) and [Klein et al.
(2017)](https://arxiv.org/abs/1701.02810). The most common *n-grams*
penalty makes sure that no *n-gram* appears twice by manually setting
the probability of next words that could create an already seen *n-gram*
to 0.
Let's try it out by setting `no_repeat_ngram_size=2` so that no *2-gram*
appears twice:
``` python
# set no_repeat_ngram_size to 2
beam_output = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to
```
Nice, that looks much better\! We can see that the repetition does not
appear anymore. Nevertheless, *n-gram* penalties have to be used with
care. An article generated about the city *New York* should not use a
*2-gram* penalty or otherwise, the name of the city would only appear
once in the whole text\!
Another important feature about beam search is that we can compare the
top beams after generation and choose the generated beam that fits our
purpose best.
In `transformers`, we simply set the parameter `num_return_sequences` to
the number of highest scoring beams that should be returned. Make sure
though that `num_return_sequences <= num_beams`\!
``` python
# set return_num_sequences > 1
beam_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
```
```
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's a good idea to
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time to take a
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's a good idea.
```
As can be seen, the five beam hypotheses are only marginally different
to each other - which should not be too surprising when using only 5
beams.
In open-ended generation, a couple of reasons have been brought
forward why beam search might not be the best possible option:
- Beam search can work very well in tasks where the length of the
desired generation is more or less predictable as in machine
translation or summarization - see [Murray et al.
(2018)](https://arxiv.org/abs/1808.10006) and [Yang et al.
(2018)](https://arxiv.org/abs/1808.09582). But this is not the case
for open-ended generation where the desired output length can vary
greatly, e.g. dialog and story generation.
- We have seen that beam search heavily suffers from repetitive
generation. This is especially hard to control with *n-gram*- or
other penalties in story generation since finding a good trade-off
between inhibiting repetition and repeating cycles of identical
*n-grams* requires a lot of finetuning.
- As argued in [Ari Holtzman et al.
(2019)](https://arxiv.org/abs/1904.09751), high quality human
language does not follow a distribution of high probability next
words. In other words, as humans, we want generated text to surprise
us and not to be boring/predictable. The authors show this nicely by
plotting the probability, a model would give to human text vs. what
beam search does.
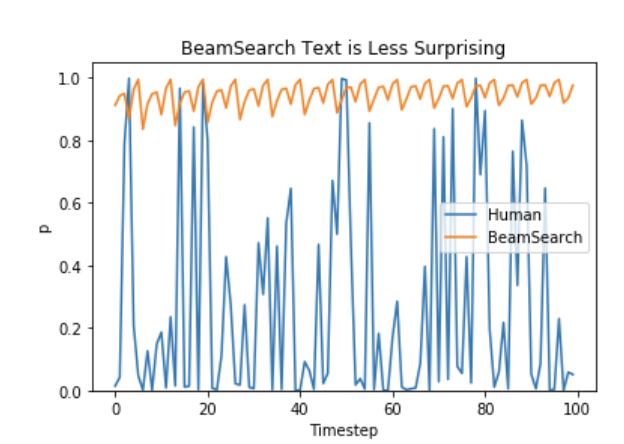
So let's stop being boring and introduce some randomness 🤪.
## Sampling
In its most basic form, sampling means randomly picking the next word \\(w_t\\) according to its conditional probability distribution:
$$ w_t \sim P(w|w_{1:t-1}) $$
Taking the example from above, the following graphic visualizes language
generation when sampling.
<img src="/blog/assets/02_how-to-generate/sampling_search.png" alt="sampling search" style="margin: auto; display: block;">
It becomes obvious that language generation using sampling is not
*deterministic* anymore. The word \\((\text{"car"})\\) is sampled from the
conditioned probability distribution \\(P(w | \text{"The"})\\), followed
by sampling \\((\text{"drives"})\\) from
\\(P(w | \text{"The"}, \text{"car"})\\) .
In `transformers`, we set `do_sample=True` and deactivate *Top-K*
sampling (more on this later) via `top_k=0`. In the following, we will
fix the random seed for illustration purposes. Feel free to change the
`set_seed` argument to obtain different results, or to remove it for non-determinism.
``` python
# set seed to reproduce results. Feel free to change the seed though to get different results
from transformers import set_seed
set_seed(42)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this had me staying in an unusual room and not going on nights out with friends (which will always be wondered for a mere minute or so at this point).
```
Interesting\! The text seems alright - but when taking a closer look, it
is not very coherent and doesn't sound like it was written by a
human. That is the big problem when sampling word sequences: The models
often generate incoherent gibberish, *cf.* [Ari Holtzman et al.
(2019)](https://arxiv.org/abs/1904.09751).
A trick is to make the distribution \\(P(w|w_{1:t-1})\\) sharper
(increasing the likelihood of high probability words and decreasing the
likelihood of low probability words) by lowering the so-called
`temperature` of the
[softmax](https://en.wikipedia.org/wiki/Softmax_function#Smooth_arg_max).
An illustration of applying temperature to our example from above could
look as follows.
<img src="/blog/assets/02_how-to-generate/sampling_search_with_temp.png" alt="sampling temp search" style="margin: auto; display: block;">
The conditional next word distribution of step \\(t=1\\) becomes much
sharper leaving almost no chance for word \\((\text{"car"})\\) to be
selected.
Let's see how we can cool down the distribution in the library by
setting `temperature=0.6`:
``` python
# set seed to reproduce results. Feel free to change the seed though to get different results
set_seed(42)
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=0,
temperature=0.6,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to chew on it. I like to eat it and not chew on it. I like to be able to walk with my dog."
So how did you decide
```
OK. There are less weird n-grams and the output is a bit more coherent
now\! While applying temperature can make a distribution less random, in
its limit, when setting `temperature` \\(\to 0\\), temperature scaled
sampling becomes equal to greedy decoding and will suffer from the same
problems as before.
### Top-K Sampling
[Fan et. al (2018)](https://arxiv.org/pdf/1805.04833.pdf) introduced a
simple, but very powerful sampling scheme, called ***Top-K*** sampling.
In *Top-K* sampling, the *K* most likely next words are filtered and the
probability mass is redistributed among only those *K* next words. GPT2
adopted this sampling scheme, which was one of the reasons for its
success in story generation.
We extend the range of words used for both sampling steps in the example
above from 3 words to 10 words to better illustrate *Top-K* sampling.
<img src="/blog/assets/02_how-to-generate/top_k_sampling.png" alt="Top K sampling" style="margin: auto; display: block;">
Having set \\(K = 6\\), in both sampling steps we limit our sampling pool
to 6 words. While the 6 most likely words, defined as
\\(V_{\text{top-K}}\\) encompass only *ca.* two-thirds of the whole
probability mass in the first step, it includes almost all of the
probability mass in the second step. Nevertheless, we see that it
successfully eliminates the rather weird candidates \\((\text{``not"}, \text{``the"}, \text{``small"}, \text{``told"})\\) in the second sampling step.
Let's see how *Top-K* can be used in the library by setting `top_k=50`:
``` python
# set seed to reproduce results. Feel free to change the seed though to get different results
set_seed(42)
# set top_k to 50
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this time it was hard for me to figure out what to do with it. (One reason I asked this for a few months back is that I had a
```
Not bad at all\! The text is arguably the most *human-sounding* text so
far. One concern though with *Top-K* sampling is that it does not
dynamically adapt the number of words that are filtered from the next
word probability distribution \\(P(w|w_{1:t-1})\\). This can be
problematic as some words might be sampled from a very sharp
distribution (distribution on the right in the graph above), whereas
others from a much more flat distribution (distribution on the left in
the graph above).
In step \\(t=1\\), *Top-K* eliminates the possibility to sample
\\((\text{"people"}, \text{"big"}, \text{"house"}, \text{"cat"})\\), which seem like reasonable
candidates. On the other hand, in step \\(t=2\\) the method includes the
arguably ill-fitted words \\((\text{"down"}, \text{"a"})\\) in the sample pool of
words. Thus, limiting the sample pool to a fixed size *K* could endanger
the model to produce gibberish for sharp distributions and limit the
model's creativity for flat distribution. This intuition led [Ari
Holtzman et al. (2019)](https://arxiv.org/abs/1904.09751) to create
***Top-p***- or ***nucleus***-sampling.
### Top-p (nucleus) sampling
Instead of sampling only from the most likely *K* words, in *Top-p*
sampling chooses from the smallest possible set of words whose
cumulative probability exceeds the probability *p*. The probability mass
is then redistributed among this set of words. This way, the size of the
set of words (*a.k.a* the number of words in the set) can dynamically
increase and decrease according to the next word's probability
distribution. Ok, that was very wordy, let's visualize.
<img src="/blog/assets/02_how-to-generate/top_p_sampling.png" alt="Top p sampling" style="margin: auto; display: block;">
Having set \\(p=0.92\\), *Top-p* sampling picks the *minimum* number of
words to exceed together \\(p=92\%\\) of the probability mass, defined as
\\(V_{\text{top-p}}\\). In the first example, this included the 9 most
likely words, whereas it only has to pick the top 3 words in the second
example to exceed 92%. Quite simple actually\! It can be seen that it
keeps a wide range of words where the next word is arguably less
predictable, *e.g.* \\(P(w | \text{"The''})\\), and only a few words when
the next word seems more predictable, *e.g.*
\\(P(w | \text{"The"}, \text{"car"})\\).
Alright, time to check it out in `transformers`\! We activate *Top-p*
sampling by setting `0 < top_p < 1`:
``` python
# set seed to reproduce results. Feel free to change the seed though to get different results
set_seed(42)
# set top_k to 50
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
```
```
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this had me staying in an unusual room and not going on nights out with friends (which will always be my yearning for such a spacious screen on my desk
```
Great, that sounds like it could have been written by a human. Well,
maybe not quite yet.
While in theory, *Top-p* seems more elegant than *Top-K*, both methods
work well in practice. *Top-p* can also be used in combination with
*Top-K*, which can avoid very low ranked words while allowing for some
dynamic selection.
Finally, to get multiple independently sampled outputs, we can *again*
set the parameter `num_return_sequences > 1`:
``` python
# set seed to reproduce results. Feel free to change the seed though to get different results
set_seed(42)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
```
```
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog for the rest of the day, but this time it was hard for me to figure out what to do with it. When I finally looked at this for a few moments, I immediately thought, "
1: I enjoy walking with my cute dog. The only time I felt like walking was when I was working, so it was awesome for me. I didn't want to walk for days. I am really curious how she can walk with me
2: I enjoy walking with my cute dog (Chama-I-I-I-I-I), and I really enjoy running. I play in a little game I play with my brother in which I take pictures of our houses.
```
Cool, now you should have all the tools to let your model write your
stories with `transformers`!
## Conclusion
As *ad-hoc* decoding methods, *top-p* and *top-K* sampling seem to
produce more fluent text than traditional *greedy* - and *beam* search
on open-ended language generation. There is
evidence that the apparent flaws of *greedy* and *beam* search -
mainly generating repetitive word sequences - are caused by the model
(especially the way the model is trained), rather than the decoding
method, *cf.* [Welleck et al.
(2019)](https://arxiv.org/pdf/1908.04319.pdf). Also, as demonstrated in
[Welleck et al. (2020)](https://arxiv.org/abs/2002.02492), it looks as
*top-K* and *top-p* sampling also suffer from generating repetitive word
sequences.
In [Welleck et al. (2019)](https://arxiv.org/pdf/1908.04319.pdf), the
authors show that according to human evaluations, *beam* search can
generate more fluent text than *Top-p* sampling, when adapting the
model's training objective.
Open-ended language generation is a rapidly evolving field of research
and as it is often the case there is no one-size-fits-all method here,
so one has to see what works best in one's specific use case.
Fortunately, *you* can try out all the different decoding methods in
`transfomers` 🤗 -- you can have an overview of the available methods
[here](https://huggingface.co/docs/transformers/generation_strategies#decoding-strategies).
Thanks to everybody, who has contributed to the blog post: Alexander Rush, Julien Chaumand, Thomas Wolf, Victor Sanh, Sam Shleifer, Clément Delangue, Yacine Jernite, Oliver Åstrand and John de Wasseige.
## Appendix
`generate` has evolved into a highly composable method, with flags to manipulate the resulting text in many
directions that were not covered in this blog post. Here are a few helpful pages to guide you:
- [How to parameterize `generate`](https://huggingface.co/docs/transformers/generation_strategies#default-text-generation-configuration)
- [How to stream the output](https://huggingface.co/docs/transformers/generation_strategies#streaming)
- [Full list of decoding options](https://huggingface.co/docs/transformers/en/main_classes/text_generation#transformers.GenerationConfig)
- [`generate` API reference](https://huggingface.co/docs/transformers/en/main_classes/text_generation#transformers.GenerationMixin.generate)
- [LLM score leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
If you find that navigating our docs is challenging and you can't easily find what you're looking for, drop us a message in [this GitHub issue](https://github.com/huggingface/transformers/issues/24575). Your feedback is critical to set our future direction! 🤗
| 6 |
0 | hf_public_repos | hf_public_repos/blog/datasets-docs-update.md | ---
title: "Introducing new audio and vision documentation in 🤗 Datasets"
thumbnail: /blog/assets/87_datasets-docs-update/thumbnail.gif
authors:
- user: stevhliu
---
# Introducing new audio and vision documentation in 🤗 Datasets
Open and reproducible datasets are essential for advancing good machine learning. At the same time, datasets have grown tremendously in size as rocket fuel for large language models. In 2020, Hugging Face launched 🤗 Datasets, a library dedicated to:
1. Providing access to standardized datasets with a single line of code.
2. Tools for rapidly and efficiently processing large-scale datasets.
Thanks to the community, we added hundreds of NLP datasets in many languages and dialects during the [Datasets Sprint](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)! 🤗 ❤️
But text datasets are just the beginning. Data is represented in richer formats like 🎵 audio, 📸 images, and even a combination of audio and text or image and text. Models trained on these datasets enable awesome applications like describing what is in an image or answering questions about an image.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://salesforce-blip.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
The 🤗 Datasets team has been building tools and features to make working with these dataset types as simple as possible for the best developer experience. We added new documentation along the way to help you learn more about loading and processing audio and image datasets.
## Quickstart
The [Quickstart](https://huggingface.co/docs/datasets/quickstart) is one of the first places new users visit for a TLDR about a library’s features. That’s why we updated the Quickstart to include how you can use 🤗 Datasets to work with audio and image datasets. Choose a dataset modality you want to work with and see an end-to-end example of how to load and process the dataset to get it ready for training with either PyTorch or TensorFlow.
Also new in the Quickstart is the `to_tf_dataset` function which takes care of converting a dataset into a `tf.data.Dataset` like a mama bear taking care of her cubs. This means you don’t have to write any code to shuffle and load batches from your dataset to get it to play nicely with TensorFlow. Once you’ve converted your dataset into a `tf.data.Dataset`, you can train your model with the usual TensorFlow or Keras methods.
Check out the [Quickstart](https://huggingface.co/docs/datasets/quickstart) today to learn how to work with different dataset modalities and try out the new `to_tf_dataset` function!
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="Cards with links to end-to-end examples for how to process audio, vision, and NLP datasets" src="assets/87_datasets-docs-update/quickstart.png" />
<figcaption>Choose your dataset adventure!</figcaption>
</figure>
## Dedicated guides
Each dataset modality has specific nuances on how to load and process them. For example, when you load an audio dataset, the audio signal is automatically decoded and resampled on-the-fly by the `Audio` feature. This is quite different from loading a text dataset!
To make all of the modality-specific documentation more discoverable, there are new dedicated sections with guides focused on showing you how to load and process each modality. If you’re looking for specific information about working with a dataset modality, take a look at these dedicated sections first. Meanwhile, functions that are non-specific and can be used broadly are documented in the General Usage section. Reorganizing the documentation in this way will allow us to better scale to other dataset types we plan to support in the future.
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="An overview of the how-to guides page that displays five new sections of the guides: general usage, audio, vision, text, and dataset repository." src="assets/87_datasets-docs-update/overview.png" />
<figcaption>The guides are organized into sections that cover the most essential aspects of 🤗 Datasets.</figcaption>
</figure>
Check out the [dedicated guides](https://huggingface.co/docs/datasets/how_to) to learn more about loading and processing datasets for different modalities.
## ImageFolder
Typically, 🤗 Datasets users [write a dataset loading script](https://huggingface.co/docs/datasets/dataset_script) to download and generate a dataset with the appropriate `train` and `test` splits. With the `ImageFolder` dataset builder, you don’t need to write any code to download and generate an image dataset. Loading an image dataset for image classification is as simple as ensuring your dataset is organized in a folder like:
```py
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
```
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="A table of images of dogs and their associated label." src="assets/87_datasets-docs-update/good_boi_pics.png" />
<figcaption>Your 🐶 dataset should look something like this once you've uploaded it to the Hub and preview it.</figcaption>
</figure>
Image labels are generated in a `label` column based on the directory name. `ImageFolder` allows you to get started instantly with an image dataset, eliminating the time and effort required to write a dataset loading script.
But wait, it gets even better! If you have a file containing some metadata about your image dataset, `ImageFolder` can be used for other image tasks like image captioning and object detection. For example, object detection datasets commonly have *bounding boxes*, coordinates in an image that identify where an object is. `ImageFolder` can use this file to link the metadata about the bounding box and category for each image to the corresponding images in the folder:
```py
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
You can use `ImageFolder` to load an image dataset for nearly any type of image task if you have a metadata file with the required information. Check out the [ImageFolder](https://huggingface.co/docs/datasets/image_load) guide to learn more.
## What’s next?
Similar to how the first iteration of the 🤗 Datasets library standardized text datasets and made them super easy to download and process, we are very excited to bring this same level of user-friendliness to audio and image datasets. In doing so, we hope it’ll be easier for users to train, build, and evaluate models and applications across all different modalities.
In the coming months, we’ll continue to add new features and tools to support working with audio and image datasets. Word on the 🤗 Hugging Face street is that there’ll be something called `AudioFolder` coming soon! 🤫 While you wait, feel free to take a look at the [audio processing guide](https://huggingface.co/docs/datasets/audio_process) and then get hands-on with an audio dataset like [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech).
---
Join the [forum](https://discuss.huggingface.co/) for any questions and feedback about working with audio and image datasets. If you discover any bugs, please open a [GitHub Issue](https://github.com/huggingface/datasets/issues/new/choose), so we can take care of it.
Feeling a little more adventurous? Contribute to the growing community-driven collection of audio and image datasets on the [Hub](https://huggingface.co/datasets)! [Create a dataset repository](https://huggingface.co/docs/datasets/upload_dataset) on the Hub and upload your dataset. If you need a hand, open a discussion on your repository’s **Community tab** and ping one of the 🤗 Datasets team members to help you cross the finish line!
| 7 |
0 | hf_public_repos | hf_public_repos/blog/fine-tune-segformer.md | ---
title: Fine-Tune a Semantic Segmentation Model with a Custom Dataset
thumbnail: /blog/assets/56_fine_tune_segformer/thumb.png
authors:
- user: tobiasc
guest: true
- user: nielsr
---
# Fine-Tune a Semantic Segmentation Model with a Custom Dataset
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/56_fine_tune_segformer.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**This guide shows how you can fine-tune Segformer, a state-of-the-art semantic segmentation model. Our goal is to build a model for a pizza delivery robot, so it can see where to drive and recognize obstacles 🍕🤖. We'll first label a set of sidewalk images on [Segments.ai](https://segments.ai?utm_source=hf&utm_medium=colab&utm_campaign=sem_seg). Then we'll fine-tune a pre-trained SegFormer model by using [`🤗 transformers`](https://huggingface.co/transformers), an open-source library that offers easy-to-use implementations of state-of-the-art models. Along the way, you'll learn how to work with the Hugging Face Hub, the largest open-source catalog of models and datasets.**
Semantic segmentation is the task of classifying each pixel in an image. You can see it as a more precise way of classifying an image. It has a wide range of use cases in fields such as medical imaging and autonomous driving. For example, for our pizza delivery robot, it is important to know exactly where the sidewalk is in an image, not just whether there is a sidewalk or not.
Because semantic segmentation is a type of classification, the network architectures used for image classification and semantic segmentation are very similar. In 2014, [a seminal paper](https://arxiv.org/abs/1411.4038) by Long et al. used convolutional neural networks for semantic segmentation. More recently, Transformers have been used for image classification (e.g. [ViT](https://huggingface.co/blog/fine-tune-vit)), and now they're also being used for semantic segmentation, pushing the state-of-the-art further.
[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer) is a model for semantic segmentation introduced by Xie et al. in 2021. It has a hierarchical Transformer encoder that doesn't use positional encodings (in contrast to ViT) and a simple multi-layer perceptron decoder. SegFormer achieves state-of-the-art performance on multiple common datasets. Let's see how our pizza delivery robot performs for sidewalk images.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Pizza delivery robot segmenting a scene" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/pizza-scene.png"></medium-zoom>
</figure>
Let's get started by installing the necessary dependencies. Because we're going to push our dataset and model to the Hugging Face Hub, we need to install [Git LFS](https://git-lfs.github.com/) and log in to Hugging Face.
The installation of `git-lfs` might be different on your system. Note that Google Colab has Git LFS pre-installed.
```bash
pip install -q transformers datasets evaluate segments-ai
apt-get install git-lfs
git lfs install
huggingface-cli login
```
## 1. Create/choose a dataset
The first step in any ML project is assembling a good dataset. In order to train a semantic segmentation model, we need a dataset with semantic segmentation labels. We can either use an existing dataset from the Hugging Face Hub, such as [ADE20k](https://huggingface.co/datasets/scene_parse_150), or create our own dataset.
For our pizza delivery robot, we could use an existing autonomous driving dataset such as [CityScapes](https://www.cityscapes-dataset.com/) or [BDD100K](https://bdd100k.com/). However, these datasets were captured by cars driving on the road. Since our delivery robot will be driving on the sidewalk, there will be a mismatch between the images in these datasets and the data our robot will see in the real world.
We don't want our delivery robot to get confused, so we'll create our own semantic segmentation dataset using images captured on sidewalks. We'll show how you can label the images we captured in the next steps. If you just want to use our finished, labeled dataset, you can skip the ["Create your own dataset"](#create-your-own-dataset) section and continue from ["Use a dataset from the Hub"](#use-a-dataset-from-the-hub).
### Create your own dataset
To create your semantic segmentation dataset, you'll need two things:
1. images covering the situations your model will encounter in the real world
2. segmentation labels, i.e. images where each pixel represents a class/category.
We went ahead and captured a thousand images of sidewalks in Belgium. Collecting and labeling such a dataset can take a long time, so you can start with a smaller dataset and expand it if the model does not perform well enough.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Example images from the sidewalk dataset" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/sidewalk-examples.png"></medium-zoom>
<figcaption>Some examples of the raw images in the sidewalk dataset.</figcaption>
</figure>
To obtain segmentation labels, we need to indicate the classes of all the regions/objects in these images. This can be a time-consuming endeavour, but using the right tools can speed up the task significantly. For labeling, we'll use [Segments.ai](https://segments.ai?utm_source=hf&utm_medium=colab&utm_campaign=sem_seg), since it has smart labeling tools for image segmentation and an easy-to-use Python SDK.
#### Set up the labeling task on Segments.ai
First, create an account at [https://segments.ai/join](https://segments.ai/join?utm_source=hf&utm_medium=colab&utm_campaign=sem_seg).
Next, create a new dataset and upload your images. You can either do this from the web interface or via the Python SDK (see the [notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/56_fine_tune_segformer.ipynb)).
#### Label the images
Now that the raw data is loaded, go to [segments.ai/home](https://segments.ai/home) and open the newly created dataset. Click "Start labeling" and create segmentation masks. You can use the ML-powered superpixel and autosegment tools to label faster.
<figure class="image table text-center m-0">
<video
alt="Labeling a sidewalk image on Segments.ai"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/sidewalk-labeling-crop.mp4" poster="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/sidewalk-labeling-crop-poster.png" type="video/mp4">
</video>
<figcaption>Tip: when using the superpixel tool, scroll to change the superpixel size, and click and drag to select segments.</figcaption>
</figure>
#### Push the result to the Hugging Face Hub
When you're done labeling, create a new dataset release containing the labeled data. You can either do this on the releases tab on Segments.ai, or programmatically through the SDK as shown in the notebook.
Note that creating the release can take a few seconds. You can check the releases tab on Segments.ai to check if your release is still being created.
Now, we'll convert the release to a [Hugging Face dataset](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset) via the Segments.ai Python SDK. If you haven't set up the Segments Python client yet, follow the instructions in the "Set up the labeling task on Segments.ai" section of the [notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/56_fine_tune_segformer.ipynb#scrollTo=9T2Jr9t9y4HD).
*Note that the conversion can take a while, depending on the size of your dataset.*
```python
from segments.huggingface import release2dataset
release = segments_client.get_release(dataset_identifier, release_name)
hf_dataset = release2dataset(release)
```
If we inspect the features of the new dataset, we can see the image column and the corresponding label. The label consists of two parts: a list of annotations and a segmentation bitmap. The annotation corresponds to the different objects in the image. For each object, the annotation contains an `id` and a `category_id`. The segmentation bitmap is an image where each pixel contains the `id` of the object at that pixel. More information can be found in the [relevant docs](https://docs.segments.ai/reference/sample-and-label-types/label-types#segmentation-labels).
For semantic segmentation, we need a semantic bitmap that contains a `category_id` for each pixel. We'll use the `get_semantic_bitmap` function from the Segments.ai SDK to convert the bitmaps to semantic bitmaps. To apply this function to all the rows in our dataset, we'll use [`dataset.map`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map).
```python
from segments.utils import get_semantic_bitmap
def convert_segmentation_bitmap(example):
return {
"label.segmentation_bitmap":
get_semantic_bitmap(
example["label.segmentation_bitmap"],
example["label.annotations"],
id_increment=0,
)
}
semantic_dataset = hf_dataset.map(
convert_segmentation_bitmap,
)
```
You can also rewrite the `convert_segmentation_bitmap` function to use batches and pass `batched=True` to `dataset.map`. This will significantly speed up the mapping, but you might need to tweak the `batch_size` to ensure the process doesn't run out of memory.
The SegFormer model we're going to fine-tune later expects specific names for the features. For convenience, we'll match this format now. Thus, we'll rename the `image` feature to `pixel_values` and the `label.segmentation_bitmap` to `label` and discard the other features.
```python
semantic_dataset = semantic_dataset.rename_column('image', 'pixel_values')
semantic_dataset = semantic_dataset.rename_column('label.segmentation_bitmap', 'label')
semantic_dataset = semantic_dataset.remove_columns(['name', 'uuid', 'status', 'label.annotations'])
```
We can now push the transformed dataset to the Hugging Face Hub. That way, your team and the Hugging Face community can make use of it. In the next section, we'll see how you can load the dataset from the Hub.
```python
hf_dataset_identifier = f"{hf_username}/{dataset_name}"
semantic_dataset.push_to_hub(hf_dataset_identifier)
```
### Use a dataset from the Hub
If you don't want to create your own dataset, but found a suitable dataset for your use case on the Hugging Face Hub, you can define the identifier here.
For example, you can use the full labeled sidewalk dataset. Note that you can check out the examples [directly in your browser](https://huggingface.co/datasets/segments/sidewalk-semantic).
```python
hf_dataset_identifier = "segments/sidewalk-semantic"
```
## 2. Load and prepare the Hugging Face dataset for training
Now that we've created a new dataset and pushed it to the Hugging Face Hub, we can load the dataset in a single line.
```python
from datasets import load_dataset
ds = load_dataset(hf_dataset_identifier)
```
Let's shuffle the dataset and split the dataset in a train and test set.
```python
ds = ds.shuffle(seed=1)
ds = ds["train"].train_test_split(test_size=0.2)
train_ds = ds["train"]
test_ds = ds["test"]
```
We'll extract the number of labels and the human-readable ids, so we can configure the segmentation model correctly later on.
```python
import json
from huggingface_hub import hf_hub_download
repo_id = f"datasets/{hf_dataset_identifier}"
filename = "id2label.json"
id2label = json.load(open(hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset"), "r"))
id2label = {int(k): v for k, v in id2label.items()}
label2id = {v: k for k, v in id2label.items()}
num_labels = len(id2label)
```
### Image processor & data augmentation
A SegFormer model expects the input to be of a certain shape. To transform our training data to match the expected shape, we can use `SegFormerImageProcessor`. We could use the `ds.map` function to apply the image processor to the whole training dataset in advance, but this can take up a lot of disk space. Instead, we'll use a *transform*, which will only prepare a batch of data when that data is actually used (on-the-fly). This way, we can start training without waiting for further data preprocessing.
In our transform, we'll also define some data augmentations to make our model more resilient to different lighting conditions. We'll use the [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) function from `torchvision` to randomly change the brightness, contrast, saturation, and hue of the images in the batch.
```python
from torchvision.transforms import ColorJitter
from transformers import SegformerImageProcessor
processor = SegformerImageProcessor()
jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
def train_transforms(example_batch):
images = [jitter(x) for x in example_batch['pixel_values']]
labels = [x for x in example_batch['label']]
inputs = processor(images, labels)
return inputs
def val_transforms(example_batch):
images = [x for x in example_batch['pixel_values']]
labels = [x for x in example_batch['label']]
inputs = processor(images, labels)
return inputs
# Set transforms
train_ds.set_transform(train_transforms)
test_ds.set_transform(val_transforms)
```
## 3. Fine-tune a SegFormer model
### Load the model to fine-tune
The SegFormer authors define 5 models with increasing sizes: B0 to B5. The following chart (taken from the original paper) shows the performance of these different models on the ADE20K dataset, compared to other models.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="SegFormer model variants compared with other segmentation models" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/segformer.png"></medium-zoom>
<figcaption><a href="https://arxiv.org/abs/2105.15203">Source</a></figcaption>
</figure>
Here, we'll load the smallest SegFormer model (B0), pre-trained on ImageNet-1k. It's only about 14MB in size!
Using a small model will make sure that our model can run smoothly on our pizza delivery robot.
```python
from transformers import SegformerForSemanticSegmentation
pretrained_model_name = "nvidia/mit-b0"
model = SegformerForSemanticSegmentation.from_pretrained(
pretrained_model_name,
id2label=id2label,
label2id=label2id
)
```
### Set up the Trainer
To fine-tune the model on our data, we'll use Hugging Face's [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer). We need to set up the training configuration and an evalutation metric to use a Trainer.
First, we'll set up the [`TrainingArguments`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments). This defines all training hyperparameters, such as learning rate and the number of epochs, frequency to save the model and so on. We also specify to push the model to the hub after training (`push_to_hub=True`) and specify a model name (`hub_model_id`).
```python
from transformers import TrainingArguments
epochs = 50
lr = 0.00006
batch_size = 2
hub_model_id = "segformer-b0-finetuned-segments-sidewalk-2"
training_args = TrainingArguments(
"segformer-b0-finetuned-segments-sidewalk-outputs",
learning_rate=lr,
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
save_total_limit=3,
evaluation_strategy="steps",
save_strategy="steps",
save_steps=20,
eval_steps=20,
logging_steps=1,
eval_accumulation_steps=5,
load_best_model_at_end=True,
push_to_hub=True,
hub_model_id=hub_model_id,
hub_strategy="end",
)
```
Next, we'll define a function that computes the evaluation metric we want to work with. Because we're doing semantic segmentation, we'll use the [mean Intersection over Union (mIoU)](https://huggingface.co/spaces/evaluate-metric/mean_iou), directly accessible in the [`evaluate` library](https://huggingface.co/docs/evaluate/index). IoU represents the overlap of segmentation masks. Mean IoU is the average of the IoU of all semantic classes. Take a look at [this blogpost](https://www.jeremyjordan.me/evaluating-image-segmentation-models/) for an overview of evaluation metrics for image segmentation.
Because our model outputs logits with dimensions height/4 and width/4, we have to upscale them before we can compute the mIoU.
```python
import torch
from torch import nn
import evaluate
metric = evaluate.load("mean_iou")
def compute_metrics(eval_pred):
with torch.no_grad():
logits, labels = eval_pred
logits_tensor = torch.from_numpy(logits)
# scale the logits to the size of the label
logits_tensor = nn.functional.interpolate(
logits_tensor,
size=labels.shape[-2:],
mode="bilinear",
align_corners=False,
).argmax(dim=1)
pred_labels = logits_tensor.detach().cpu().numpy()
metrics = metric.compute(
predictions=pred_labels,
references=labels,
num_labels=len(id2label),
ignore_index=0,
reduce_labels=processor.do_reduce_labels,
)
# add per category metrics as individual key-value pairs
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
per_category_iou = metrics.pop("per_category_iou").tolist()
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
return metrics
```
Finally, we can instantiate a `Trainer` object.
```python
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
```
Now that our trainer is set up, training is as simple as calling the `train` function. We don't need to worry about managing our GPU(s), the trainer will take care of that.
```python
trainer.train()
```
When we're done with training, we can push our fine-tuned model and the image processor to the Hub.
This will also automatically create a model card with our results. We'll supply some extra information in `kwargs` to make the model card more complete.
```python
kwargs = {
"tags": ["vision", "image-segmentation"],
"finetuned_from": pretrained_model_name,
"dataset": hf_dataset_identifier,
}
processor.push_to_hub(hub_model_id)
trainer.push_to_hub(**kwargs)
```
## 4. Inference
Now comes the exciting part, using our fine-tuned model! In this section, we'll show how you can load your model from the hub and use it for inference.
However, you can also try out your model directly on the Hugging Face Hub, thanks to the cool widgets powered by the [hosted inference API](https://api-inference.huggingface.co/docs/python/html/index.html). If you pushed your model to the Hub in the previous step, you should see an inference widget on your model page. You can add default examples to the widget by defining example image URLs in your model card. See [this model card](https://huggingface.co/tobiasc/segformer-b0-finetuned-segments-sidewalk/blob/main/README.md) as an example.
<figure class="image table text-center m-0 w-full">
<video
alt="The interactive widget of the model"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/widget.mp4" poster="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/widget-poster.png" type="video/mp4">
</video>
</figure>
### Use the model from the Hub
We'll first load the model from the Hub using `SegformerForSemanticSegmentation.from_pretrained()`.
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained(f"{hf_username}/{hub_model_id}")
```
Next, we'll load an image from our test dataset.
```python
image = test_ds[0]['pixel_values']
gt_seg = test_ds[0]['label']
image
```
To segment this test image, we first need to prepare the image using the image processor. Then we forward it through the model.
We also need to remember to upscale the output logits to the original image size. In order to get the actual category predictions, we just have to apply an `argmax` on the logits.
```python
from torch import nn
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
# First, rescale logits to original image size
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1], # (height, width)
mode='bilinear',
align_corners=False
)
# Second, apply argmax on the class dimension
pred_seg = upsampled_logits.argmax(dim=1)[0]
```
Now it's time to display the result. We'll display the result next to the ground-truth mask.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(1,1,1,1)" alt="SegFormer prediction vs the ground truth" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/56_fine_tune_segformer/output.png"></medium-zoom>
</figure>
What do you think? Would you send our pizza delivery robot on the road with this segmentation information?
The result might not be perfect yet, but we can always expand our dataset to make the model more robust. We can now also go train a larger SegFormer model, and see how it stacks up.
## 5. Conclusion
That's it! You now know how to create your own image segmentation dataset and how to use it to fine-tune a semantic segmentation model.
We introduced you to some useful tools along the way, such as:
* [Segments.ai](https://segments.ai) for labeling your data
* [🤗 datasets](https://huggingface.co/docs/datasets/) for creating and sharing a dataset
* [🤗 transformers](https://huggingface.co/transformers) for easily fine-tuning a state-of-the-art segmentation model
* [Hugging Face Hub](https://huggingface.co/docs/hub/main) for sharing our dataset and model, and for creating an inference widget for our model
We hope you enjoyed this post and learned something. Feel free to share your own model with us on Twitter ([@TobiasCornille](https://twitter.com/tobiascornille), [@NielsRogge](https://twitter.com/nielsrogge), and [@huggingface](https://twitter.com/huggingface)).
| 8 |
0 | hf_public_repos | hf_public_repos/blog/stable-diffusion-inference-intel.md | ---
title: "Accelerating Stable Diffusion Inference on Intel CPUs"
thumbnail: /blog/assets/136_stable_diffusion_inference_intel/01.png
authors:
- user: juliensimon
- user: echarlaix
---
# Accelerating Stable Diffusion Inference on Intel CPUs
Recently, we introduced the latest generation of [Intel Xeon](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html) CPUs (code name Sapphire Rapids), its new hardware features for deep learning acceleration, and how to use them to accelerate [distributed fine-tuning](https://huggingface.co/blog/intel-sapphire-rapids) and [inference](https://huggingface.co/blog/intel-sapphire-rapids-inference) for natural language processing Transformers.
In this post, we're going to show you different techniques to accelerate Stable Diffusion models on Sapphire Rapids CPUs. A follow-up post will do the same for distributed fine-tuning.
At the time of writing, the simplest way to get your hands on a Sapphire Rapids server is to use the Amazon EC2 [R7iz](https://aws.amazon.com/ec2/instance-types/r7iz/) instance family. As it's still in preview, you have to [sign up](https://pages.awscloud.com/R7iz-Preview.html) to get access. Like in previous posts, I'm using an `r7iz.metal-16xl` instance (64 vCPU, 512GB RAM) with an Ubuntu 20.04 AMI (`ami-07cd3e6c4915b2d18`).
Let's get started! Code samples are available on [Gitlab](https://gitlab.com/juliensimon/huggingface-demos/-/tree/main/optimum/stable_diffusion_intel).
## The Diffusers library
The [Diffusers](https://huggingface.co/docs/diffusers/index) library makes it extremely simple to generate images with Stable Diffusion models. If you're not familiar with these models, here's a great [illustrated introduction](https://jalammar.github.io/illustrated-stable-diffusion/).
First, let's create a virtual environment with the required libraries: Transformers, Diffusers, Accelerate, and PyTorch.
```
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers accelerate torch==1.13.1
```
Then, we write a simple benchmarking function that repeatedly runs inference, and returns the average latency for a single-image generation.
```python
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
```
Now, let's build a `StableDiffusionPipeline` with the default `float32` data type, and measure its inference latency.
```python
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
```
The average latency is **32.3 seconds**. As demonstrated by this [Intel Space](https://huggingface.co/spaces/Intel/Stable-Diffusion-Side-by-Side), the same code runs on a previous generation Intel Xeon (code name Ice Lake) in about 45 seconds.
Out of the box, we can see that Sapphire Rapids CPUs are quite faster without any code change!
Now, let's accelerate!
## Optimum Intel and OpenVINO
[Optimum Intel](https://huggingface.co/docs/optimum/intel/index) accelerates end-to-end pipelines on Intel architectures. Its API is extremely similar to the vanilla [Diffusers](https://huggingface.co/docs/diffusers/index) API, making it trivial to adapt existing code.
Optimum Intel supports [OpenVINO](https://docs.openvino.ai/latest/index.html), an Intel open-source toolkit for high-performance inference.
Optimum Intel and OpenVINO can be installed as follows:
```
pip install optimum[openvino]
```
Starting from the code above, we only need to replace `StableDiffusionPipeline` with `OVStableDiffusionPipeline`. To load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True` when loading your model.
```python
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
# Don't forget to save the exported model
ov_pipe.save_pretrained("./openvino")
```
OpenVINO automatically optimizes the model for the `bfloat16` format. Thanks to this, the average latency is now **16.7 seconds**, a sweet 2x speedup.
The pipeline above support dynamic input shapes, with no restriction on the number of images or their resolution. With Stable Diffusion, your application is usually restricted to one (or a few) different output resolutions, such as 512x512, or 256x256. Thus, it makes a lot of sense to unlock significant acceleration by reshaping the pipeline to a fixed resolution. If you need more than one output resolution, you can simply maintain a few pipeline instances, one for each resolution.
```python
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
```
With a static shape, average latency is slashed to **4.7 seconds**, an additional 3.5x speedup.
As you can see, OpenVINO is a simple and efficient way to accelerate Stable Diffusion inference. When combined with a Sapphire Rapids CPU, it delivers almost 10x speedup compared to vanilla inference on Ice Lake Xeons.
If you can't or don't want to use OpenVINO, the rest of this post will show you a series of other optimization techniques. Fasten your seatbelt!
## System-level optimization
Diffuser models are large multi-gigabyte models, and image generation is a memory-intensive operation. By installing a high-performance memory allocation library, we should be able to speed up memory operations and parallelize them across the Xeon cores. Please note that this will change the default memory allocation library on your system. Of course, you can go back to the default library by uninstalling the new one.
[jemalloc](https://jemalloc.net/) and [tcmalloc](https://github.com/gperftools/gperftools) are equally interesting. Here, I'm installing `jemalloc` as my tests give it a slight performance edge. It can also be tweaked for a particular workload, for example to maximize CPU utilization. You can refer to the [tuning guide](https://github.com/jemalloc/jemalloc/blob/dev/TUNING.md) for details.
```
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
```
Next, we install the `libiomp` library to optimize parallel processing. It's part of [Intel OpenMP* Runtime](https://www.intel.com/content/www/us/en/docs/cpp-compiler/developer-guide-reference/2021-8/openmp-run-time-library-routines.html).
```
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
```
Finally, we install the [numactl](https://github.com/numactl/numactl) command line tool. This lets us pin our Python process to specific cores, and avoid some of the overhead related to context switching.
```
numactl -C 0-31 python sd_blog_1.py
```
Thanks to these optimizations, our original Diffusers code now predicts in **11.8 seconds**. That's almost 3x faster, without any code change. These tools are certainly working great on our 32-core Xeon.
We're far from done. Let's add the Intel Extension for PyTorch to the mix.
## IPEX and BF16
The [Intel Extension for Pytorch](https://intel.github.io/intel-extension-for-pytorch/) (IPEX) extends PyTorch and takes advantage of hardware acceleration features present on Intel CPUs, such as [AVX-512](https://en.wikipedia.org/wiki/AVX-512) Vector Neural Network Instructions (AVX512 VNNI) and [Advanced Matrix Extensions](https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions) (AMX).
Let's install it.
```
pip install intel_extension_for_pytorch==1.13.100
```
We then update our code to optimize each pipeline element with IPEX (you can list them by printing the `pipe` object). This requires converting them to the channels-last format.
```python
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
# to channels last
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
# Create random input to enable JIT compilation
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
# optimize with IPEX
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
```
We also enable the `bloat16` data format to leverage the AMX tile matrix multiply unit (TMMU) accelerator present on Sapphire Rapids CPUs.
```python
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
```
With this updated version, inference latency is further reduced from 11.9 seconds to **5.4 seconds**. That's more than 2x acceleration thanks to IPEX and AMX.
Can we extract a bit more performance? Yes, with schedulers!
## Schedulers
The Diffusers library lets us attach a [scheduler](https://huggingface.co/docs/diffusers/using-diffusers/schedulers) to a Stable Diffusion pipeline. Schedulers try to find the best trade-off between denoising speed and denoising quality.
According to the documentation: "*At the time of writing this doc DPMSolverMultistepScheduler gives arguably the best speed/quality trade-off and can be run with as little as 20 steps.*"
Let's try it.
```python
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
```
With this final version, inference latency is now down to **5.05 seconds**. Compared to our initial Sapphire Rapids baseline (32.3 seconds), this is almost 6.5x faster!
<kbd>
<img src="assets/136_stable_diffusion_inference_intel/01.png">
</kbd>
*Environment: Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7*
## Conclusion
The ability to generate high-quality images in seconds should work well for a lot of use cases, such as customer apps, content generation for marketing and media, or synthetic data for dataset augmentation.
Here are some resources to help you get started:
* Diffusers [documentation](https://huggingface.co/docs/diffusers)
* Optimum Intel [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference)
* [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub
* [Developer resources](https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html) from Intel and Hugging Face.
If you have questions or feedback, we'd love to read them on the [Hugging Face forum](https://discuss.huggingface.co/).
Thanks for reading!
| 9 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim192_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 192, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim192<cutlass::half_t, false>(params, stream);
}
| 0 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/philox.cuh | // Pytorch also has an implementation of Philox RNG: https://github.com/pytorch/pytorch/blob/8ca3c881db3e3510fcb7725389f6a0633c9b992c/torch/csrc/jit/tensorexpr/cuda_random.h
#pragma once
// Philox CUDA.
namespace flash {
struct ull2 {
unsigned long long x;
unsigned long long y;
};
__forceinline__ __device__ uint2 mulhilo32(const unsigned int a, const unsigned int b) {
uint2 *res;
unsigned long long tmp;
asm ("mul.wide.u32 %0, %1, %2;\n\t"
: "=l"(tmp)
: "r"(a), "r"(b));
res = (uint2*)(&tmp);
return *res;
}
__forceinline__ __device__ uint4 philox_single_round(const uint4 ctr, const uint2 key) {
constexpr unsigned long kPhiloxSA = 0xD2511F53;
constexpr unsigned long kPhiloxSB = 0xCD9E8D57;
uint2 res0 = mulhilo32(kPhiloxSA, ctr.x);
uint2 res1 = mulhilo32(kPhiloxSB, ctr.z);
uint4 ret = {res1.y ^ ctr.y ^ key.x, res1.x, res0.y ^ ctr.w ^ key.y, res0.x};
return ret;
}
__forceinline__ __device__ uint4 philox(unsigned long long seed,
unsigned long long subsequence,
unsigned long long offset) {
constexpr unsigned long kPhilox10A = 0x9E3779B9;
constexpr unsigned long kPhilox10B = 0xBB67AE85;
uint2 key = reinterpret_cast<uint2&>(seed);
uint4 counter;
ull2 *tmp = reinterpret_cast<ull2*>(&counter);
tmp->x = offset;
tmp->y = subsequence;
#pragma unroll
for (int i = 0; i < 6; i++) {
counter = philox_single_round(counter, key);
key.x += (kPhilox10A);
key.y += (kPhilox10B);
}
uint4 output = philox_single_round(counter, key);
return output;
}
} // namespace flash
| 1 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim160_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 160, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim160<cutlass::half_t, false>(params, stream);
}
| 2 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim96_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 96, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim96<cutlass::half_t, true>(params, stream);
}
| 3 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/softmax.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include <cmath>
#include <cute/tensor.hpp>
#include <cutlass/numeric_types.h>
#include "philox.cuh"
#include "utils.h"
namespace flash {
using namespace cute;
////////////////////////////////////////////////////////////////////////////////////////////////////
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ __forceinline__ void thread_reduce_(Tensor<Engine0, Layout0> const &tensor, Tensor<Engine1, Layout1> &summary, Operator &op) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(summary) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); mi++) {
summary(mi) = zero_init ? tensor(mi, 0) : op(summary(mi), tensor(mi, 0));
#pragma unroll
for (int ni = 1; ni < size<1>(tensor); ni++) {
summary(mi) = op(summary(mi), tensor(mi, ni));
}
}
}
template<typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ __forceinline__ void quad_allreduce_(Tensor<Engine0, Layout0> &dst, Tensor<Engine1, Layout1> &src, Operator &op) {
CUTE_STATIC_ASSERT_V(size(dst) == size(src));
#pragma unroll
for (int i = 0; i < size(dst); i++){
dst(i) = Allreduce<4>::run(src(i), op);
}
}
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ __forceinline__ void reduce_(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &summary, Operator &op) {
thread_reduce_<zero_init>(tensor, summary, op);
quad_allreduce_(summary, summary, op);
}
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__device__ __forceinline__ void reduce_max(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &max){
MaxOp<float> max_op;
reduce_<zero_init>(tensor, max, max_op);
}
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__device__ __forceinline__ void reduce_sum(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &sum){
SumOp<float> sum_op;
thread_reduce_<zero_init>(tensor, sum, sum_op);
}
// Apply the exp to all the elements.
template <bool Scale_max=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__forceinline__ __device__ void scale_apply_exp2(Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> const &max, const float scale) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(max) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
// If max is -inf, then all elements must have been -inf (possibly due to masking).
// We don't want (-inf - (-inf)) since that would give NaN.
// If we don't have float around M_LOG2E the multiplication is done in fp64.
const float max_scaled = max(mi) == -INFINITY ? 0.f : max(mi) * (Scale_max ? scale : float(M_LOG2E));
#pragma unroll
for (int ni = 0; ni < size<1>(tensor); ++ni) {
// Instead of computing exp(x - max), we compute exp2(x * log_2(e) -
// max * log_2(e)) This allows the compiler to use the ffma
// instruction instead of fadd and fmul separately.
// The following macro will disable the use of fma.
// See: https://github.com/pytorch/pytorch/issues/121558 for more details
// This macro is set in PyTorch and not FlashAttention
#ifdef UNFUSE_FMA
tensor(mi, ni) = exp2f(__fmul_rn(tensor(mi, ni), scale) - max_scaled);
#else
tensor(mi, ni) = exp2f(tensor(mi, ni) * scale - max_scaled);
#endif
}
}
}
// Apply the exp to all the elements.
template <bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__forceinline__ __device__ void max_scale_exp2_sum(Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> &max, Tensor<Engine1, Layout1> &sum, const float scale) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(max) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
MaxOp<float> max_op;
max(mi) = zero_init ? tensor(mi, 0) : max_op(max(mi), tensor(mi, 0));
#pragma unroll
for (int ni = 1; ni < size<1>(tensor); ni++) {
max(mi) = max_op(max(mi), tensor(mi, ni));
}
max(mi) = Allreduce<4>::run(max(mi), max_op);
// If max is -inf, then all elements must have been -inf (possibly due to masking).
// We don't want (-inf - (-inf)) since that would give NaN.
const float max_scaled = max(mi) == -INFINITY ? 0.f : max(mi) * scale;
sum(mi) = 0;
#pragma unroll
for (int ni = 0; ni < size<1>(tensor); ++ni) {
// Instead of computing exp(x - max), we compute exp2(x * log_2(e) -
// max * log_2(e)) This allows the compiler to use the ffma
// instruction instead of fadd and fmul separately.
tensor(mi, ni) = exp2f(tensor(mi, ni) * scale - max_scaled);
sum(mi) += tensor(mi, ni);
}
SumOp<float> sum_op;
sum(mi) = Allreduce<4>::run(sum(mi), sum_op);
}
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template <int kNRows>
struct Softmax {
using TensorT = decltype(make_tensor<float>(Shape<Int<kNRows>>{}));
TensorT row_max, row_sum;
__forceinline__ __device__ Softmax() {};
template<bool Is_first, bool Check_inf=false, typename Tensor0, typename Tensor1>
__forceinline__ __device__ void softmax_rescale_o(Tensor0 &acc_s, Tensor1 &acc_o, float softmax_scale_log2) {
// Reshape acc_s from (MMA=4, MMA_M, MMA_N) to (nrow=(2, MMA_M), ncol=(2, MMA_N))
Tensor scores = make_tensor(acc_s.data(), flash::convert_layout_acc_rowcol(acc_s.layout()));
static_assert(decltype(size<0>(scores))::value == kNRows);
if (Is_first) {
flash::template reduce_max</*zero_init=*/true>(scores, row_max);
flash::scale_apply_exp2(scores, row_max, softmax_scale_log2);
flash::reduce_sum</*zero_init=*/true>(scores, row_sum);
} else {
Tensor scores_max_prev = make_fragment_like(row_max);
cute::copy(row_max, scores_max_prev);
flash::template reduce_max</*zero_init=*/false>(scores, row_max);
// Reshape acc_o from (MMA=4, MMA_M, MMA_K) to (nrow=(2, MMA_M), ncol=(2, MMA_K))
Tensor acc_o_rowcol = make_tensor(acc_o.data(), flash::convert_layout_acc_rowcol(acc_o.layout()));
static_assert(decltype(size<0>(acc_o_rowcol))::value == kNRows);
#pragma unroll
for (int mi = 0; mi < size(row_max); ++mi) {
float scores_max_cur = !Check_inf
? row_max(mi)
: (row_max(mi) == -INFINITY ? 0.0f : row_max(mi));
float scores_scale = exp2f((scores_max_prev(mi) - scores_max_cur) * softmax_scale_log2);
row_sum(mi) *= scores_scale;
#pragma unroll
for (int ni = 0; ni < size<1>(acc_o_rowcol); ++ni) { acc_o_rowcol(mi, ni) *= scores_scale; }
}
flash::scale_apply_exp2(scores, row_max, softmax_scale_log2);
// We don't do the reduce across threads here since we don't need to use the row_sum.
// We do that reduce at the end when we need to normalize the softmax.
flash::reduce_sum</*zero_init=*/false>(scores, row_sum);
}
};
template<bool Is_dropout=false, bool Split=false, typename Tensor0>
__forceinline__ __device__ TensorT normalize_softmax_lse(Tensor0 &acc_o, float softmax_scale, float rp_dropout=1.0) {
SumOp<float> sum_op;
quad_allreduce_(row_sum, row_sum, sum_op);
TensorT lse = make_fragment_like(row_sum);
Tensor acc_o_rowcol = make_tensor(acc_o.data(), flash::convert_layout_acc_rowcol(acc_o.layout()));
static_assert(decltype(size<0>(acc_o_rowcol))::value == kNRows);
#pragma unroll
for (int mi = 0; mi < size<0>(acc_o_rowcol); ++mi) {
float sum = row_sum(mi);
float inv_sum = (sum == 0.f || sum != sum) ? 1.f : 1.f / sum;
lse(mi) = (sum == 0.f || sum != sum) ? (Split ? -INFINITY : INFINITY) : row_max(mi) * softmax_scale + __logf(sum);
float scale = !Is_dropout ? inv_sum : inv_sum * rp_dropout;
#pragma unroll
for (int ni = 0; ni < size<1>(acc_o_rowcol); ++ni) { acc_o_rowcol(mi, ni) *= scale; }
}
return lse;
};
};
} // namespace flash
| 4 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/mask.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include <cute/tensor.hpp>
namespace flash {
using namespace cute;
template <typename Engine, typename Layout>
__forceinline__ __device__ void apply_mask(Tensor<Engine, Layout> &tensor, const int max_seqlen_k,
const int col_idx_offset_ = 0) {
// tensor has shape (nrow=(2, MMA_M), ncol=(2, MMA_N))
static_assert(Layout::rank == 2, "Only support 2D Tensor");
const int lane_id = threadIdx.x % 32;
const int col_idx_offset = col_idx_offset_ + (lane_id % 4) * 2;
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
if (col_idx >= max_seqlen_k) {
// Without the "make_coord" we get wrong results
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
tensor(mi, make_coord(j, nj)) = -INFINITY;
}
}
}
}
}
template <bool HasWSLeft=true, typename Engine, typename Layout>
__forceinline__ __device__ void apply_mask_local(Tensor<Engine, Layout> &tensor, const int col_idx_offset_,
const int max_seqlen_k, const int row_idx_offset,
const int max_seqlen_q, const int warp_row_stride,
const int window_size_left, const int window_size_right) {
// tensor has shape (nrow=(2, MMA_M), ncol=(2, MMA_N))
static_assert(Layout::rank == 2, "Only support 2D Tensor");
const int lane_id = threadIdx.x % 32;
const int col_idx_offset = col_idx_offset_ + (lane_id % 4) * 2;
#pragma unroll
for (int mi = 0; mi < size<0, 1>(tensor); ++mi) {
const int row_idx_base = row_idx_offset + mi * warp_row_stride;
#pragma unroll
for (int i = 0; i < size<0, 0>(tensor); ++i) {
const int row_idx = row_idx_base + i * 8;
const int col_idx_limit_left = std::max(0, row_idx + max_seqlen_k - max_seqlen_q - window_size_left);
const int col_idx_limit_right = std::min(max_seqlen_k, row_idx + 1 + max_seqlen_k - max_seqlen_q + window_size_right);
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
if (col_idx >= col_idx_limit_right || (HasWSLeft && col_idx < col_idx_limit_left)) {
tensor(make_coord(i, mi), make_coord(j, nj)) = -INFINITY;
}
}
}
// if (cute::thread0()) {
// printf("mi = %d, i = %d, row_idx = %d, max_seqlen_k = %d\n", mi, i, row_idx, max_seqlen_k);
// print(tensor(make_coord(i, mi), _));
// // print(tensor(_, j + nj * size<1, 0>(tensor)));
// }
}
}
}
template <typename Engine, typename Layout>
__forceinline__ __device__ void apply_mask_causal(Tensor<Engine, Layout> &tensor, const int col_idx_offset_,
const int max_seqlen_k, const int row_idx_offset,
const int max_seqlen_q, const int warp_row_stride) {
// Causal masking is equivalent to local masking with window_size_left = infinity and window_size_right = 0
apply_mask_local</*HasWSLeft=*/false>(tensor, col_idx_offset_, max_seqlen_k, row_idx_offset,
max_seqlen_q, warp_row_stride, -1, 0);
}
template <typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__forceinline__ __device__ void apply_mask_causal_w_idx(
Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> const &idx_rowcol,
const int col_idx_offset_, const int max_seqlen_k, const int row_idx_offset)
{
// tensor has shape (nrow=(2, MMA_M), ncol=(2, MMA_N))
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 2, "Only support 2D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(tensor) == size<0>(idx_rowcol));
CUTE_STATIC_ASSERT_V(size<1>(tensor) == size<1>(idx_rowcol));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
const int col_idx_limit = std::min(max_seqlen_k, 1 + row_idx_offset + get<0>(idx_rowcol(mi, 0)));
#pragma unroll
for (int ni = 0; ni < size<1, 1>(tensor); ++ni) {
if (col_idx_offset_ + get<1>(idx_rowcol(0, ni)) >= col_idx_limit) {
tensor(mi, ni) = -INFINITY;
}
}
// if (cute::thread0()) {
// printf("ni = %d, j = %d, col_idx = %d, max_seqlen_k = %d\n", ni, j, col_idx, max_seqlen_k);
// print(tensor(_, make_coord(j, ni)));
// // print(tensor(_, j + ni * size<1, 0>(tensor)));
// }
}
}
template <bool Is_causal, bool Is_local, bool Has_alibi>
struct Mask {
const int max_seqlen_k, max_seqlen_q;
const int window_size_left, window_size_right;
const float alibi_slope;
__forceinline__ __device__ Mask(const int max_seqlen_k, const int max_seqlen_q,
const int window_size_left, const int window_size_right,
const float alibi_slope=0.f)
: max_seqlen_k(max_seqlen_k)
, max_seqlen_q(max_seqlen_q)
, window_size_left(window_size_left)
, window_size_right(window_size_right)
, alibi_slope(!Has_alibi ? 0.0 : alibi_slope) {
};
// Causal_mask: whether this particular iteration needs causal masking
template <bool Causal_mask=false, bool Is_even_MN=true, typename Engine, typename Layout>
__forceinline__ __device__ void apply_mask(Tensor<Engine, Layout> &tensor_,
const int col_idx_offset_,
const int row_idx_offset,
const int warp_row_stride) {
static_assert(!(Causal_mask && Is_local), "Cannot be both causal and local");
static_assert(Layout::rank == 3, "Only support 3D Tensor");
static_assert(decltype(size<0>(tensor_))::value == 4, "First dimension must be 4");
static constexpr bool Need_masking = Has_alibi || Causal_mask || Is_local || !Is_even_MN;
// if (cute::thread0()) { printf("Has_alibi = %d, Causal_mask=%d, Is_local=%d, Is_even_MN = %d, Need_masking = %d\n", Has_alibi, Causal_mask, Is_local, Is_even_MN, Need_masking); }
if constexpr (Need_masking) {
// Reshape tensor_ from (MMA=4, MMA_M, MMA_N) to (nrow=(2, MMA_M), ncol=(2, MMA_N))
Tensor tensor = make_tensor(tensor_.data(), flash::convert_layout_acc_rowcol(tensor_.layout()));
// Do we need both row and column indices, or just column incides?
static constexpr bool Col_idx_only = !(Has_alibi && !Is_causal) && !Is_local && !Causal_mask;
const int lane_id = threadIdx.x % 32;
const int col_idx_offset = col_idx_offset_ + (lane_id % 4) * 2;
if constexpr (Col_idx_only) {
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
// No causal, no local
if constexpr (Has_alibi) {
tensor(mi, make_coord(j, nj)) += alibi_slope * col_idx;
}
if constexpr (!Is_even_MN) {
if (col_idx >= max_seqlen_k) { tensor(mi, make_coord(j, nj)) = -INFINITY; }
}
}
}
}
} else {
#pragma unroll
for (int mi = 0; mi < size<0, 1>(tensor); ++mi) {
const int row_idx_base = row_idx_offset + mi * warp_row_stride;
#pragma unroll
for (int i = 0; i < size<0, 0>(tensor); ++i) {
const int row_idx = row_idx_base + i * 8;
const int col_idx_limit_left = std::max(0, row_idx + max_seqlen_k - max_seqlen_q - window_size_left);
const int col_idx_limit_right = std::min(max_seqlen_k, row_idx + 1 + max_seqlen_k - max_seqlen_q + window_size_right);
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
if constexpr (Has_alibi) {
if constexpr (Is_causal) {
tensor(make_coord(i, mi), make_coord(j, nj)) += alibi_slope * col_idx;
} else {
tensor(make_coord(i, mi), make_coord(j, nj)) -= alibi_slope * abs(row_idx + max_seqlen_k - max_seqlen_q - col_idx);
}
}
if constexpr (Causal_mask) {
if (col_idx >= col_idx_limit_right) {
tensor(make_coord(i, mi), make_coord(j, nj)) = -INFINITY;
}
}
if constexpr (Is_local) {
if (col_idx >= col_idx_limit_right || col_idx < col_idx_limit_left) {
tensor(make_coord(i, mi), make_coord(j, nj)) = -INFINITY;
}
}
if constexpr (!Causal_mask && !Is_local && !Is_even_MN) {
// Causal and Local already handles MN masking
if (col_idx >= max_seqlen_k) {
tensor(make_coord(i, mi), make_coord(j, nj)) = -INFINITY;
}
}
}
}
}
}
}
}
};
};
} // namespace flash
| 5 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim64_bf16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 64, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim64<cutlass::bfloat16_t, false>(params, stream);
}
| 6 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/kernel_traits_sm90.h | /******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
#include "cute/algorithm/copy.hpp"
#include "cutlass/cutlass.h"
#include "cutlass/layout/layout.h"
#include <cutlass/numeric_types.h>
using namespace cute;
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_, typename elem_type=cutlass::half_t>
struct Flash_kernel_traits_sm90 {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
using Element = elem_type;
static constexpr bool Has_cp_async = true;
#else
using Element = cutlass::half_t;
static constexpr bool Has_cp_async = false;
#endif
using ElementAccum = float;
using index_t = uint32_t;
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
using MMA_Atom_Arch = std::conditional_t<
std::is_same_v<elem_type, cutlass::half_t>,
MMA_Atom<SM80_16x8x16_F32F16F16F32_TN>,
MMA_Atom<SM80_16x8x16_F32BF16BF16F32_TN>
>;
using ValLayoutMNK = Layout<Shape<_1, _2, _1>>;
#else
using MMA_Atom_Arch = MMA_Atom<SM75_16x8x8_F32F16F16F32_TN>;
using ValLayoutMNK = Layout<Shape<_1, _2, _2>>;
#endif
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 750
using SmemCopyAtom = Copy_Atom<SM75_U32x4_LDSM_N, elem_type>;
using SmemCopyAtomTransposed = Copy_Atom<SM75_U16x8_LDSM_T, elem_type>;
#else
using SmemCopyAtom = Copy_Atom<DefaultCopy, elem_type>;
using SmemCopyAtomTransposed = Copy_Atom<DefaultCopy, elem_type>;
#endif
};
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_, bool Is_Q_in_regs_=false, bool Share_Q_K_smem_=false, typename elem_type=cutlass::half_t,
typename Base=Flash_kernel_traits_sm90<kHeadDim_, kBlockM_, kBlockN_, kNWarps_, elem_type> >
struct Flash_fwd_kernel_traits : public Base {
using Element = typename Base::Element;
using ElementAccum = typename Base::ElementAccum;
using index_t = typename Base::index_t;
static constexpr bool Has_cp_async = Base::Has_cp_async;
using SmemCopyAtom = typename Base::SmemCopyAtom;
using SmemCopyAtomTransposed = typename Base::SmemCopyAtomTransposed;
static constexpr bool Share_Q_K_smem = Share_Q_K_smem_;
static constexpr bool Is_Q_in_regs = Is_Q_in_regs_ || Share_Q_K_smem;
// The number of threads.
static constexpr int kNWarps = kNWarps_;
static constexpr int kNThreads = kNWarps * 32;
static constexpr int kBlockM = kBlockM_;
static constexpr int kBlockN = kBlockN_;
static constexpr int kHeadDim = kHeadDim_;
static_assert(kHeadDim % 32 == 0);
static constexpr int kBlockKSmem = kHeadDim % 64 == 0 ? 64 : 32;
static constexpr int kBlockKGmem = kHeadDim % 128 == 0 ? 128 : (kHeadDim % 64 == 0 ? 64 : 32);
static constexpr int kSwizzle = kBlockKSmem == 32 ? 2 : 3;
using TiledMma = TiledMMA<
typename Base::MMA_Atom_Arch,
Layout<Shape<Int<kNWarps>,_1,_1>>, // 4x1x1 or 8x1x1 thread group
typename Base::ValLayoutMNK>; // 1x2x1 or 1x2x2 value group for 16x16x16 MMA and LDSM
using SmemLayoutAtomQ = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
// This has to be kBlockKSmem, using kHeadDim gives wrong results for d=128
Layout<Shape<_8, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutQ = decltype(tile_to_shape(
SmemLayoutAtomQ{},
Shape<Int<kBlockM>, Int<kHeadDim>>{}));
using SmemLayoutKV = decltype(tile_to_shape(
SmemLayoutAtomQ{},
Shape<Int<kBlockN>, Int<kHeadDim>>{}));
using SmemLayoutAtomVtransposed = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
// This has to be kBlockN and not 8, otherwise we get wrong results for d=128
Layout<Shape<Int<kBlockKSmem>, Int<kBlockN>>,
Stride<_1, Int<kBlockKSmem>>>{}));
using SmemLayoutVtransposed = decltype(tile_to_shape(
SmemLayoutAtomVtransposed{},
Shape<Int<kHeadDim>, Int<kBlockN>>{}));
// Maybe the VtransposeNoSwizzle just needs to have the right shape
// And the strides don't matter?
using SmemLayoutVtransposedNoSwizzle = decltype(SmemLayoutVtransposed{}.layout_fn());
using SmemLayoutAtomO = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<Int<8>, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutO = decltype(tile_to_shape(
SmemLayoutAtomO{},
Shape<Int<kBlockM>, Int<kHeadDim>>{}));
using SmemCopyAtomO = Copy_Atom<DefaultCopy, elem_type>;
static constexpr int kSmemQCount = size(SmemLayoutQ{});
static constexpr int kSmemKVCount = size(SmemLayoutKV{}) * 2;
static constexpr int kSmemQSize = kSmemQCount * sizeof(Element);
static constexpr int kSmemKVSize = kSmemKVCount * sizeof(Element);
static constexpr int kSmemSize = Share_Q_K_smem ? std::max(kSmemQSize, kSmemKVSize) : kSmemQSize + kSmemKVSize;
static constexpr int kGmemElemsPerLoad = sizeof(cute::uint128_t) / sizeof(Element);
static_assert(kHeadDim % kGmemElemsPerLoad == 0, "kHeadDim must be a multiple of kGmemElemsPerLoad");
// Using kBlockKSmem here is 6-10% faster than kBlockKGmem for d=128 because of bank conflicts.
// For example, for d=128, smem is split into 2 "pages", each page takes care of columns
// 0-63 and 64-127. If we have 16 threads per row for gmem read, when we write to smem,
// thread 0 - 7 will write to the first page and thread 8 - 15 will write to the second page,
// to the same banks.
static constexpr int kGmemThreadsPerRow = kBlockKSmem / kGmemElemsPerLoad;
static_assert(kNThreads % kGmemThreadsPerRow == 0, "kNThreads must be a multiple of kGmemThreadsPerRow");
using GmemLayoutAtom = Layout<Shape <Int<kNThreads / kGmemThreadsPerRow>, Int<kGmemThreadsPerRow>>,
Stride<Int<kGmemThreadsPerRow>, _1>>;
// We use CACHEGLOBAL instead of CACHEALWAYS for both Q and K/V, since we won't be reading
// from the same address by the same threadblock. This is slightly faster.
using Gmem_copy_struct = std::conditional_t<
Has_cp_async,
SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>,
DefaultCopy
>;
using GmemTiledCopyQKV = decltype(
make_tiled_copy(Copy_Atom<Gmem_copy_struct, elem_type>{},
GmemLayoutAtom{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per read
using GmemTiledCopyO = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, elem_type>{},
GmemLayoutAtom{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per store
static constexpr int kGmemThreadsPerRowP = kBlockN / kGmemElemsPerLoad;
static_assert(kNThreads % kGmemThreadsPerRowP == 0, "kNThreads must be a multiple of kGmemThreadsPerRowP");
using GmemLayoutAtomP = Layout<Shape <Int<kNThreads / kGmemThreadsPerRowP>, Int<kGmemThreadsPerRowP>>,
Stride<Int<kGmemThreadsPerRowP>, _1>>;
using GmemTiledCopyP = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, elem_type>{},
GmemLayoutAtomP{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per store
};
////////////////////////////////////////////////////////////////////////////////////////////////////
| 7 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim160_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 160, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim160<cutlass::half_t, true>(params, stream);
}
| 8 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim160_bf16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 160, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim160<cutlass::bfloat16_t, true>(params, stream);
}
| 9 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/distributed_inference.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Distributed inference
Distributed inference can fall into three brackets:
1. Loading an entire model onto each GPU and sending chunks of a batch through each GPU's model copy at a time
2. Loading parts of a model onto each GPU and processing a single input at one time
3. Loading parts of a model onto each GPU and using what is called scheduled Pipeline Parallelism to combine the two prior techniques.
We're going to go through the first and the last bracket, showcasing how to do each as they are more realistic scenarios.
## Sending chunks of a batch automatically to each loaded model
This is the most memory-intensive solution, as it requires each GPU to keep a full copy of the model in memory at a given time.
Normally when doing this, users send the model to a specific device to load it from the CPU, and then move each prompt to a different device.
A basic pipeline using the `diffusers` library might look something like so:
```python
import torch
import torch.distributed as dist
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
```
Followed then by performing inference based on the specific prompt:
```python
def run_inference(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
pipe.to(rank)
if torch.distributed.get_rank() == 0:
prompt = "a dog"
elif torch.distributed.get_rank() == 1:
prompt = "a cat"
result = pipe(prompt).images[0]
result.save(f"result_{rank}.png")
```
One will notice how we have to check the rank to know what prompt to send, which can be a bit tedious.
A user might then also think that with Accelerate, using the `Accelerator` to prepare a dataloader for such a task might also be
a simple way to manage this. (To learn more, check out the relevant section in the [Quick Tour](../quicktour#distributed-evaluation))
Can it manage it? Yes. Does it add unneeded extra code however: also yes.
With Accelerate, we can simplify this process by using the [`Accelerator.split_between_processes`] context manager (which also exists in `PartialState` and `AcceleratorState`).
This function will automatically split whatever data you pass to it (be it a prompt, a set of tensors, a dictionary of the prior data, etc.) across all the processes (with a potential
to be padded) for you to use right away.
Let's rewrite the above example using this context manager:
```python
from accelerate import PartialState # Can also be Accelerator or AcceleratorState
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
distributed_state = PartialState()
pipe.to(distributed_state.device)
# Assume two processes
with distributed_state.split_between_processes(["a dog", "a cat"]) as prompt:
result = pipe(prompt).images[0]
result.save(f"result_{distributed_state.process_index}.png")
```
And then to launch the code, we can use the Accelerate:
If you have generated a config file to be used using `accelerate config`:
```bash
accelerate launch distributed_inference.py
```
If you have a specific config file you want to use:
```bash
accelerate launch --config_file my_config.json distributed_inference.py
```
Or if don't want to make any config files and launch on two GPUs:
> Note: You will get some warnings about values being guessed based on your system. To remove these you can do `accelerate config default` or go through `accelerate config` to create a config file.
```bash
accelerate launch --num_processes 2 distributed_inference.py
```
We've now reduced the boilerplate code needed to split this data to a few lines of code quite easily.
But what if we have an odd distribution of prompts to GPUs? For example, what if we have 3 prompts, but only 2 GPUs?
Under the context manager, the first GPU would receive the first two prompts and the second GPU the third, ensuring that
all prompts are split and no overhead is needed.
*However*, what if we then wanted to do something with the results of *all the GPUs*? (Say gather them all and perform some kind of post processing)
You can pass in `apply_padding=True` to ensure that the lists of prompts are padded to the same length, with extra data being taken
from the last sample. This way all GPUs will have the same number of prompts, and you can then gather the results.
<Tip>
This is only needed when trying to perform an action such as gathering the results, where the data on each device
needs to be the same length. Basic inference does not require this.
</Tip>
For instance:
```python
from accelerate import PartialState # Can also be Accelerator or AcceleratorState
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
distributed_state = PartialState()
pipe.to(distributed_state.device)
# Assume two processes
with distributed_state.split_between_processes(["a dog", "a cat", "a chicken"], apply_padding=True) as prompt:
result = pipe(prompt).images
```
On the first GPU, the prompts will be `["a dog", "a cat"]`, and on the second GPU it will be `["a chicken", "a chicken"]`.
Make sure to drop the final sample, as it will be a duplicate of the previous one.
You can find more complex examples [here](https://github.com/huggingface/accelerate/tree/main/examples/inference/distributed) such as how to use it with LLMs.
## Memory-efficient pipeline parallelism (experimental)
This next part will discuss using *pipeline parallelism*. This is an **experimental** API that utilizes [torch.distributed.pipelining](https://pytorch.org/docs/stable/distributed.pipelining.html#) as a native solution.
The general idea with pipeline parallelism is: say you have 4 GPUs and a model big enough it can be *split* on four GPUs using `device_map="auto"`. With this method you can send in 4 inputs at a time (for example here, any amount works) and each model chunk will work on an input, then receive the next input once the prior chunk finished, making it *much* more efficient **and faster** than the method described earlier. Here's a visual taken from the PyTorch repository:

To illustrate how you can use this with Accelerate, we have created an [example zoo](https://github.com/huggingface/accelerate/tree/main/examples/inference) showcasing a number of different models and situations. In this tutorial, we'll show this method for GPT2 across two GPUs.
Before you proceed, please make sure you have the latest PyTorch version installed by running the following:
```bash
pip install torch
```
Start by creating the model on the CPU:
```{python}
from transformers import GPT2ForSequenceClassification, GPT2Config
config = GPT2Config()
model = GPT2ForSequenceClassification(config)
model.eval()
```
Next you'll need to create some example inputs to use. These help `torch.distributed.pipelining` trace the model.
<Tip warning={true}>
However you make this example will determine the relative batch size that will be used/passed
through the model at a given time, so make sure to remember how many items there are!
</Tip>
```{python}
input = torch.randint(
low=0,
high=config.vocab_size,
size=(2, 1024), # bs x seq_len
device="cpu",
dtype=torch.int64,
requires_grad=False,
)
```
Next we need to actually perform the tracing and get the model ready. To do so, use the [`inference.prepare_pippy`] function and it will fully wrap the model for pipeline parallelism automatically:
```{python}
from accelerate.inference import prepare_pippy
example_inputs = {"input_ids": input}
model = prepare_pippy(model, example_args=(input,))
```
<Tip>
There are a variety of parameters you can pass through to `prepare_pippy`:
* `split_points` lets you determine what layers to split the model at. By default we use wherever `device_map="auto" declares, such as `fc` or `conv1`.
* `num_chunks` determines how the batch will be split and sent to the model itself (so `num_chunks=1` with four split points/four GPUs will have a naive MP where a single input gets passed between the four layer split points)
</Tip>
From here, all that's left is to actually perform the distributed inference!
<Tip warning={true}>
When passing inputs, we highly recommend to pass them in as a tuple of arguments. Using `kwargs` is supported, however, this approach is experimental.
</Tip>
```{python}
args = some_more_arguments
with torch.no_grad():
output = model(*args)
```
When finished all the data will be on the last process only:
```{python}
from accelerate import PartialState
if PartialState().is_last_process:
print(output)
```
<Tip>
If you pass in `gather_output=True` to [`inference.prepare_pippy`], the output will be sent
across to all the GPUs afterwards without needing the `is_last_process` check. This is
`False` by default as it incurs a communication call.
</Tip>
And that's it! To explore more, please check out the inference examples in the [Accelerate repo](https://github.com/huggingface/accelerate/tree/main/examples/inference/pippy) and our [documentation](../package_reference/inference) as we work to improving this integration.
| 0 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/megatron_lm.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Megatron-LM
[Megatron-LM](https://github.com/NVIDIA/Megatron-LM) enables training large transformer language models at scale.
It provides efficient tensor, pipeline and sequence based model parallelism for pre-training transformer based
Language Models such as [GPT](https://arxiv.org/abs/2005.14165) (Decoder Only), [BERT](https://arxiv.org/pdf/1810.04805.pdf) (Encoder Only) and [T5](https://arxiv.org/abs/1910.10683) (Encoder-Decoder).
For detailed information and how things work behind the scene please refer the github [repo](https://github.com/NVIDIA/Megatron-LM).
## What is integrated?
Accelerate integrates following feature of Megatron-LM to enable large scale pre-training/finetuning
of BERT (Encoder), GPT (Decoder) or T5 models (Encoder and Decoder):
a. **Tensor Parallelism (TP)**: Reduces memory footprint without much additional communication on intra-node ranks.
Each tensor is split into multiple chunks with each shard residing on separate GPU. At each step, the same mini-batch of data is processed
independently and in parallel by each shard followed by syncing across all GPUs (`all-reduce` operation).
In a simple transformer layer, this leads to 2 `all-reduces` in the forward path and 2 in the backward path.
For more details, please refer research paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using
Model Parallelism](https://arxiv.org/pdf/1909.08053.pdf) and
this section of blogpost [The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed#tensor-parallelism).
b. **Pipeline Parallelism (PP)**: Reduces memory footprint and enables large scale training via inter-node parallelization.
Reduces the bubble of naive PP via PipeDream-Flush schedule/1F1B schedule and Interleaved 1F1B schedule.
Layers are distributed uniformly across PP stages. For example, if a model has `24` layers and we have `4` GPUs for
pipeline parallelism, each GPU will have `6` layers (24/4). For more details on schedules to reduce the idle time of PP,
please refer to the research paper [Efficient Large-Scale Language Model Training on GPU Clusters
Using Megatron-LM](https://arxiv.org/pdf/2104.04473.pdf) and
this section of blogpost [The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed#pipeline-parallelism).
c. **Sequence Parallelism (SP)**: Reduces memory footprint without any additional communication. Only applicable when using TP.
It reduces activation memory required as it prevents the same copies to be on the tensor parallel ranks
post `all-reduce` by replacing then with `reduce-scatter` and `no-op` operation would be replaced by `all-gather`.
As `all-reduce = reduce-scatter + all-gather`, this saves a ton of activation memory at no added communication cost.
To put it simply, it shards the outputs of each transformer layer along sequence dimension, e.g.,
if the sequence length is `1024` and the TP size is `4`, each GPU will have `256` tokens (1024/4) for each sample.
This increases the batch size that can be supported for training. For more details, please refer to the research paper
[Reducing Activation Recomputation in Large Transformer Models](https://arxiv.org/pdf/2205.05198.pdf).
d. **Data Parallelism (DP)** via Distributed Optimizer: Reduces the memory footprint by sharding optimizer states and gradients across DP ranks
(versus the traditional method of replicating the optimizer state across data parallel ranks).
For example, when using Adam optimizer with mixed-precision training, each parameter accounts for 12 bytes of memory.
This gets distributed equally across the GPUs, i.e., each parameter would account for 3 bytes (12/4) if we have 4 GPUs.
For more details, please refer the research paper [ZeRO: Memory Optimizations Toward Training Trillion
Parameter Models](https://arxiv.org/pdf/1910.02054.pdf) and following section of blog
[The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed#zero-data-parallelism).
e. **Selective Activation Recomputation**: Reduces the memory footprint of activations significantly via smart activation checkpointing.
It doesn't store activations occupying large memory while being fast to recompute thereby achieving great tradeoff between memory and recomputation.
For example, for GPT-3, this leads to 70% reduction in required memory for activations at the expense of
only 2.7% FLOPs overhead for recomputation of activations. For more details, please refer to the research paper
[Reducing Activation Recomputation in Large Transformer Models](https://arxiv.org/pdf/2205.05198.pdf).
f. **Fused Kernels**: Fused Softmax, Mixed Precision Fused Layer Norm and Fused gradient accumulation to weight gradient computation of linear layer.
PyTorch JIT compiled Fused GeLU and Fused Bias+Dropout+Residual addition.
g. **Support for Indexed datasets**: Efficient binary format of datasets for large scale training. Support for the `mmap`, `cached` index file and the `lazy` loader format.
h. **Checkpoint reshaping and interoperability**: Utility for reshaping Megatron-LM checkpoints of variable
tensor and pipeline parallel sizes to the beloved Transformers sharded checkpoints as it has great support with plethora of tools
such as Accelerate Big Model Inference, Megatron-DeepSpeed Inference etc.
Support is also available for converting Transformers sharded checkpoints to Megatron-LM checkpoint of variable tensor and pipeline parallel sizes
for large scale training.
## Pre-Requisites
You will need to install the latest pytorch, cuda, nccl, and NVIDIA [APEX](https://github.com/NVIDIA/apex#quick-start) releases and the nltk library.
See [documentation](https://github.com/NVIDIA/Megatron-LM#setup) for more details.
Another way to setup the environment is to pull an NVIDIA PyTorch Container that comes with all the required installations from NGC.
Below is a step-by-step method to set up the conda environment:
1. Create a virtual environment
```
conda create --name ml
```
2. Assuming that the machine has CUDA 11.3 installed, installing the corresponding PyTorch GPU Version
```
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
```
3. Install Nvidia APEX
```
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
cd ..
```
4. Installing Megatron-LM
```
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.5.0
pip install --no-use-pep517 -e .
```
## Accelerate Megatron-LM Plugin
Important features are directly supported via the `accelerate config` command.
An example of the corresponding questions for using Megatron-LM features is shown below:
```bash
:~$ accelerate config --config_file "megatron_gpt_config.yaml"
In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 0
Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU): 2
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]: yes
What is the Tensor Parallelism degree/size? [1]:2
Do you want to enable Sequence Parallelism? [YES/no]:
What is the Pipeline Parallelism degree/size? [1]:2
What is the number of micro-batches? [1]:2
Do you want to enable selective activation recomputation? [YES/no]:
Do you want to use distributed optimizer which shards optimizer state and gradients across data parallel ranks? [YES/no]:
What is the gradient clipping value based on global L2 Norm (0 to disable)? [1.0]:
How many GPU(s) should be used for distributed training? [1]:4
Do you wish to use FP16 or BF16 (mixed precision)? [NO/fp16/bf16]: bf16
```
The resulting config is shown below:
```
~$ cat megatron_gpt_config.yaml
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: MEGATRON_LM
downcast_bf16: 'no'
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config:
megatron_lm_gradient_clipping: 1.0
megatron_lm_num_micro_batches: 2
megatron_lm_pp_degree: 2
megatron_lm_recompute_activations: true
megatron_lm_sequence_parallelism: true
megatron_lm_tp_degree: 2
megatron_lm_use_distributed_optimizer: true
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
use_cpu: false
```
We will take the example of GPT pre-training. The minimal changes required to the official `run_clm_no_trainer.py`
to use Megatron-LM are as follows:
1. As Megatron-LM uses its own implementation of Optimizer, the corresponding scheduler compatible with it needs to be used.
As such, support for only the Megatron-LM's scheduler is present. User will need to create `accelerate.utils.MegatronLMDummyScheduler`.
Example is given below:
```python
from accelerate.utils import MegatronLMDummyScheduler
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
lr_scheduler = MegatronLMDummyScheduler(
optimizer=optimizer,
total_num_steps=args.max_train_steps,
warmup_num_steps=args.num_warmup_steps,
)
else:
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
```
2. Getting the details of the total batch size now needs to be cognization of tensor and pipeline parallel sizes.
Example of getting the effective total batch size is shown below:
```python
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
total_batch_size = accelerator.state.megatron_lm_plugin.global_batch_size
else:
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
```
3. When using Megatron-LM, the losses are already averaged across the data parallel group
```python
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
losses.append(loss)
else:
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
losses = torch.tensor(losses)
else:
losses = torch.cat(losses)
```
4. For Megatron-LM, we need to save the model using `accelerator.save_state`
```python
if accelerator.distributed_type == DistributedType.MEGATRON_LM:
accelerator.save_state(args.output_dir)
else:
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
```
That's it! We are good to go 🚀. Please find the example script in the examples folder at the path `accelerate/examples/by_feature/megatron_lm_gpt_pretraining.py`.
Let's run it for `gpt-large` model architecture using 4 A100-80GB GPUs.
```bash
accelerate launch --config_file megatron_gpt_config.yaml \
examples/by_feature/megatron_lm_gpt_pretraining.py \
--config_name "gpt2-large" \
--tokenizer_name "gpt2-large" \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--block_size 1024 \
--learning_rate 5e-5 \
--per_device_train_batch_size 24 \
--per_device_eval_batch_size 24 \
--num_train_epochs 5 \
--with_tracking \
--report_to "wandb" \
--output_dir "awesome_model"
```
Below are some important excerpts from the output logs:
```bash
Loading extension module fused_dense_cuda...
>>> done with compiling and loading fused kernels. Compilation time: 3.569 seconds
> padded vocab (size: 50257) with 175 dummy tokens (new size: 50432)
Building gpt model in the pre-training mode.
The Megatron LM model weights are initialized at random in `accelerator.prepare`. Please use `accelerator.load_checkpoint` to load a pre-trained checkpoint matching the distributed setup.
Preparing dataloader
Preparing dataloader
Preparing model
> number of parameters on (tensor, pipeline) model parallel rank (1, 0): 210753280
> number of parameters on (tensor, pipeline) model parallel rank (1, 1): 209445120
> number of parameters on (tensor, pipeline) model parallel rank (0, 0): 210753280
> number of parameters on (tensor, pipeline) model parallel rank (0, 1): 209445120
Preparing optimizer
Preparing scheduler
> learning rate decay style: linear
10/10/2022 22:57:22 - INFO - __main__ - ***** Running training *****
10/10/2022 22:57:22 - INFO - __main__ - Num examples = 2318
10/10/2022 22:57:22 - INFO - __main__ - Num Epochs = 5
10/10/2022 22:57:22 - INFO - __main__ - Instantaneous batch size per device = 24
10/10/2022 22:57:22 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 48
10/10/2022 22:57:22 - INFO - __main__ - Gradient Accumulation steps = 1
10/10/2022 22:57:22 - INFO - __main__ - Total optimization steps = 245
20%|████████████▍ | 49/245 [01:04<04:09, 1.27s/it]
10/10/2022 22:58:29 - INFO - __main__ - epoch 0: perplexity: 1222.1594275215962 eval_loss: 7.10837459564209
40%|████████████████████████▊ | 98/245 [02:10<03:07, 1.28s/it]
10/10/2022 22:59:35 - INFO - __main__ - epoch 1: perplexity: 894.5236583794557 eval_loss: 6.796291351318359
60%|████████████████████████████████████▌ | 147/245 [03:16<02:05, 1.28s/it]
10/10/2022 23:00:40 - INFO - __main__ - epoch 2: perplexity: 702.8458788508042 eval_loss: 6.555137634277344
80%|████████████████████████████████████████████████▊ | 196/245 [04:22<01:02, 1.28s/it]
10/10/2022 23:01:46 - INFO - __main__ - epoch 3: perplexity: 600.3220028695281 eval_loss: 6.39746618270874
100%|█████████████████████████████████████████████████████████████| 245/245 [05:27<00:00, 1.28s/it]
```
There are a large number of other options/features that one can set using `accelerate.utils.MegatronLMPlugin`.
## Advanced features to leverage writing custom train step and Megatron-LM Indexed Datasets
For leveraging more features, please go through below details.
1. Below is an example of changes required to customize the Train Step while using Megatron-LM.
You will implement the `accelerate.utils.AbstractTrainStep` or inherit from their corresponding children
`accelerate.utils.GPTTrainStep`, `accelerate.utils.BertTrainStep` or `accelerate.utils.T5TrainStep`.
```python
from accelerate.utils import MegatronLMDummyScheduler, GPTTrainStep, avg_losses_across_data_parallel_group
# Custom loss function for the Megatron model
class GPTTrainStepWithCustomLoss(GPTTrainStep):
def __init__(self, megatron_args, **kwargs):
super().__init__(megatron_args)
self.kwargs = kwargs
def get_loss_func(self):
def loss_func(inputs, loss_mask, output_tensor):
batch_size, seq_length = output_tensor.shape
losses = output_tensor.float()
loss_mask = loss_mask.view(-1).float()
loss = losses.view(-1) * loss_mask
# Resize and average loss per sample
loss_per_sample = loss.view(batch_size, seq_length).sum(axis=1)
loss_mask_per_sample = loss_mask.view(batch_size, seq_length).sum(axis=1)
loss_per_sample = loss_per_sample / loss_mask_per_sample
# Calculate and scale weighting
weights = torch.stack([(inputs == kt).float() for kt in self.kwargs["keytoken_ids"]]).sum(axis=[0, 2])
weights = 1.0 + self.kwargs["alpha"] * weights
# Calculate weighted average
weighted_loss = (loss_per_sample * weights).mean()
# Reduce loss across data parallel groups
averaged_loss = avg_losses_across_data_parallel_group([weighted_loss])
return weighted_loss, {"lm loss": averaged_loss[0]}
return loss_func
def get_forward_step_func(self):
def forward_step(data_iterator, model):
"""Forward step."""
# Get the batch.
tokens, labels, loss_mask, attention_mask, position_ids = self.get_batch(data_iterator)
output_tensor = model(tokens, position_ids, attention_mask, labels=labels)
return output_tensor, partial(self.loss_func, tokens, loss_mask)
return forward_step
def main():
# Custom loss function for the Megatron model
keytoken_ids = []
keywords = ["plt", "pd", "sk", "fit", "predict", " plt", " pd", " sk", " fit", " predict"]
for keyword in keywords:
ids = tokenizer([keyword]).input_ids[0]
if len(ids) == 1:
keytoken_ids.append(ids[0])
accelerator.print(f"Keytoken ids: {keytoken_ids}")
accelerator.state.megatron_lm_plugin.custom_train_step_class = GPTTrainStepWithCustomLoss
accelerator.state.megatron_lm_plugin.custom_train_step_kwargs = {
"keytoken_ids": keytoken_ids,
"alpha": 0.25,
}
```
2. For using the Megatron-LM datasets, a few more changes are required. Dataloaders for these datasets
are available only on rank 0 of each tensor parallel group. As such, there are rank where dataloader won't be
available and this requires tweaks to the training loop. Being able to do all this shows how
flexible and extensible Accelerate is. The changes required are as follows.
a. For Megatron-LM indexed datasets, we need to use `MegatronLMDummyDataLoader`
and pass the required dataset args to it such as `data_path`, `seq_length` etc.
See [here](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/arguments.py#L804) for the list of available args.
```python
from accelerate.utils import MegatronLMDummyDataLoader
megatron_dataloader_config = {
"data_path": args.data_path,
"splits_string": args.splits_string,
"seq_length": args.block_size,
"micro_batch_size": args.per_device_train_batch_size,
}
megatron_dataloader = MegatronLMDummyDataLoader(**megatron_dataloader_config)
accelerator.state.megatron_lm_plugin.megatron_dataset_flag = True
```
b. `megatron_dataloader` is repeated 3 times to get training, validation and test dataloaders
as per the `args.splits_string` proportions
```python
model, optimizer, lr_scheduler, train_dataloader, eval_dataloader, _ = accelerator.prepare(
model, optimizer, lr_scheduler, megatron_dataloader, megatron_dataloader, megatron_dataloader
)
```
c. Changes to training and evaluation loops as dataloader is only available on tensor parallel ranks 0
So, we need to iterate only if the dataloader isn't `None` else provide empty dict
As such, we loop using `while` loop and break when `completed_steps` is equal to `args.max_train_steps`
This is similar to the Megatron-LM setup wherein user has to provide `max_train_steps` when using Megaton-LM indexed datasets.
This displays how flexible and extensible Accelerate is.
```python
while completed_steps < args.max_train_steps:
model.train()
batch = next(train_dataloader) if train_dataloader is not None else {}
outputs = model(**batch)
loss = outputs.loss
...
if completed_steps % eval_interval == 0:
eval_completed_steps = 0
losses = []
while eval_completed_steps < eval_iters:
model.eval()
with torch.no_grad():
batch = next(eval_dataloader) if eval_dataloader is not None else {}
outputs = model(**batch)
```
## Utility for Checkpoint reshaping and interoperability
1. The scripts for these are present in Transformers library under respective models.
Currently, it is available for GPT model [checkpoint_reshaping_and_interoperability.py](https://github.com/huggingface/transformers/blob/main/src/transformers/models/megatron_gpt2/checkpoint_reshaping_and_interoperability.py)
2. Below is an example of conversion of checkpoint from Megatron-LM to universal Transformers sharded checkpoint.
```bash
python checkpoint_reshaping_and_interoperability.py \
--convert_checkpoint_from_megatron_to_transformers \
--load_path "gpt/iter_0005000" \
--save_path "gpt/trfs_checkpoint" \
--max_shard_size "200MB" \
--tokenizer_name "gpt2" \
--print-checkpoint-structure
```
3. Conversion of checkpoint from transformers to megatron with `tp_size=2`, `pp_size=2` and `dp_size=2`.
```bash
python checkpoint_utils/megatgron_gpt2/checkpoint_reshaping_and_interoperability.py \
--load_path "gpt/trfs_checkpoint" \
--save_path "gpt/megatron_lm_checkpoint" \
--target_tensor_model_parallel_size 2 \
--target_pipeline_model_parallel_size 2 \
--target_data_parallel_size 2 \
--target_params_dtype "bf16" \
--make_vocab_size_divisible_by 128 \
--use_distributed_optimizer \
--print-checkpoint-structure
```
## Megatron-LM GPT models support returning logits and `megatron_generate` function for text generation
1. Returning logits require setting `require_logits=True` in MegatronLMPlugin as shown below.
These would be available on the in the last stage of pipeline.
```python
megatron_lm_plugin = MegatronLMPlugin(return_logits=True)
```
2. `megatron_generate` method for Megatron-LM GPT model: This will use Tensor and Pipeline Parallelism to complete
generations for a batch of inputs when using greedy with/without top_k/top_p sampling and for individual prompt inputs when using beam search decoding.
Only a subset of features of transformers generate is supported. This will help in using large models via tensor and pipeline parallelism
for generation (already does key-value caching and uses fused kernels by default).
This requires data parallel size to be 1, sequence parallelism and activation checkpointing to be disabled.
It also requires specifying path to tokenizer's vocab file and merges file.
Below example shows how to configure and use `megatron_generate` method for Megatron-LM GPT model.
```python
# specifying tokenizer's vocab and merges file
vocab_file = os.path.join(args.resume_from_checkpoint, "vocab.json")
merge_file = os.path.join(args.resume_from_checkpoint, "merges.txt")
other_megatron_args = {"vocab_file": vocab_file, "merge_file": merge_file}
megatron_lm_plugin = MegatronLMPlugin(other_megatron_args=other_megatron_args)
# inference using `megatron_generate` functionality
tokenizer.pad_token = tokenizer.eos_token
max_new_tokens = 64
batch_texts = [
"Are you human?",
"The purpose of life is",
"The arsenal was constructed at the request of",
"How are you doing these days?",
]
batch_encodings = tokenizer(batch_texts, return_tensors="pt", padding=True)
# top-p sampling
generated_tokens = model.megatron_generate(
batch_encodings["input_ids"],
batch_encodings["attention_mask"],
max_new_tokens=max_new_tokens,
top_p=0.8,
top_p_decay=0.5,
temperature=0.9,
)
decoded_preds = tokenizer.batch_decode(generated_tokens.cpu().numpy())
accelerator.print(decoded_preds)
# top-k sampling
generated_tokens = model.megatron_generate(
batch_encodings["input_ids"],
batch_encodings["attention_mask"],
max_new_tokens=max_new_tokens,
top_k=50,
temperature=0.9,
)
decoded_preds = tokenizer.batch_decode(generated_tokens.cpu().numpy())
accelerator.print(decoded_preds)
# adding `bos` token at the start
generated_tokens = model.megatron_generate(
batch_encodings["input_ids"], batch_encodings["attention_mask"], max_new_tokens=max_new_tokens, add_BOS=True
)
decoded_preds = tokenizer.batch_decode(generated_tokens.cpu().numpy())
accelerator.print(decoded_preds)
# beam search => only takes single prompt
batch_texts = ["The purpose of life is"]
batch_encodings = tokenizer(batch_texts, return_tensors="pt", padding=True)
generated_tokens = model.megatron_generate(
batch_encodings["input_ids"],
batch_encodings["attention_mask"],
max_new_tokens=max_new_tokens,
num_beams=20,
length_penalty=1.5,
)
decoded_preds = tokenizer.batch_decode(generated_tokens.cpu().numpy())
accelerator.print(decoded_preds)
```
3. An end-to-end example of using `megatron_generate` method for Megatron-LM GPT model is available at
[megatron_gpt2_generation.py](https://github.com/pacman100/accelerate-megatron-test/blob/main/src/inference/megatron_gpt2_generation.py) with
config file [megatron_lm_gpt_generate_config.yaml](https://github.com/pacman100/accelerate-megatron-test/blob/main/src/Configs/megatron_lm_gpt_generate_config.yaml).
The bash script with accelerate launch command is available at [megatron_lm_gpt_generate.sh](https://github.com/pacman100/accelerate-megatron-test/blob/main/megatron_lm_gpt_generate.sh).
The output logs of the script are available at [megatron_lm_gpt_generate.log](https://github.com/pacman100/accelerate-megatron-test/blob/main/output_logs/megatron_lm_gpt_generate.log).
## Support for ROPE and ALiBi Positional embeddings and Multi-Query Attention
1. For ROPE/ALiBi attention, pass `position_embedding_type` with `("absolute" | "rotary" | "alibi")` to `MegatronLMPlugin` as shown below.
```python
other_megatron_args = {"position_embedding_type": "alibi"}
megatron_lm_plugin = MegatronLMPlugin(other_megatron_args=other_megatron_args)
```
2. For Multi-Query Attention, pass `attention_head_type` with `("multihead" | "multiquery")` to `MegatronLMPlugin` as shown below.
```python
other_megatron_args = {"attention_head_type": "multiquery"}
megatron_lm_plugin = MegatronLMPlugin(other_megatron_args=other_megatron_args)
```
## Caveats
1. Supports Transformers GPT2, Megatron-BERT and T5 models.
This covers Decoder only, Encode only and Encoder-Decoder model classes.
2. Only loss is returned from model forward pass as
there is quite complex interplay of pipeline, tensor and data parallelism behind the scenes.
The `model(**batch_data)` call return loss(es) averaged across the data parallel ranks.
This is fine for most cases wherein pre-training jobs are run using Megatron-LM features and
you can easily compute the `perplexity` using the loss.
For GPT model, returning logits in addition to loss(es) is supported.
These logits aren't gathered across data parallel ranks. Use `accelerator.utils.gather_across_data_parallel_groups`
to gather logits across data parallel ranks. These logits along with labels can be used for computing various
performance metrics.
3. The main process is the last rank as the losses/logits are available in the last stage of pipeline.
`accelerator.is_main_process` and `accelerator.is_local_main_process` return `True` for last rank when using
Megatron-LM integration.
4. In `accelerator.prepare` call, a Megatron-LM model corresponding to a given Transformers model is created
with random weights. Please use `accelerator.load_state` to load the Megatron-LM checkpoint with matching TP, PP and DP partitions.
5. Currently, checkpoint reshaping and interoperability support is only available for GPT.
Soon it will be extended to BERT and T5.
6. `gradient_accumulation_steps` needs to be 1. When using Megatron-LM, micro batches in pipeline parallelism
setting is synonymous with gradient accumulation.
7. When using Megatron-LM, use `accelerator.save_state` and `accelerator.load_state` for saving and loading checkpoints.
8. Below are the mapping from Megatron-LM model architectures to the the equivalent transformers model architectures.
Only these transformers model architectures are supported.
a. Megatron-LM [BertModel](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/bert_model.py) :
transformers models with `megatron-bert` in config's model type, e.g.,
[MegatronBERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)
b. Megatron-LM [GPTModel](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py) :
transformers models with `gpt2` in config's model type, e.g.,
[OpenAI GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)
c. Megatron-LM [T5Model](https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/t5_model.py) :
transformers models with `t5` in config's model type, e.g.,
[T5](https://huggingface.co/docs/transformers/model_doc/t5) and
[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)
| 1 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/training_zoo.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Example Zoo
Below contains a non-exhaustive list of tutorials and scripts showcasing Accelerate.
## Official Accelerate Examples:
### Basic Examples
These examples showcase the base features of Accelerate and are a great starting point
- [Barebones NLP example](https://github.com/huggingface/accelerate/blob/main/examples/nlp_example.py)
- [Barebones distributed NLP example in a Jupyter Notebook](https://github.com/huggingface/notebooks/blob/main/examples/accelerate_examples/simple_nlp_example.ipynb)
- [Barebones computer vision example](https://github.com/huggingface/accelerate/blob/main/examples/cv_example.py)
- [Barebones distributed computer vision example in a Jupyter Notebook](https://github.com/huggingface/notebooks/blob/main/examples/accelerate_examples/simple_cv_example.ipynb)
- [Using Accelerate in Kaggle](https://www.kaggle.com/code/muellerzr/multi-gpu-and-accelerate)
### Feature Specific Examples
These examples showcase specific features that the Accelerate framework offers
- [Automatic memory-aware gradient accumulation](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/automatic_gradient_accumulation.py)
- [Checkpointing states](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/checkpointing.py)
- [Cross validation](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/cross_validation.py)
- [DeepSpeed](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/deepspeed_with_config_support.py)
- [Fully Sharded Data Parallelism](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/fsdp_with_peak_mem_tracking.py)
- [Gradient accumulation](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/gradient_accumulation.py)
- [Memory-aware batch size finder](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/memory.py)
- [Metric Computation](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/multi_process_metrics.py)
- [Using Trackers](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/tracking.py)
- [Using Megatron-LM](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/megatron_lm_gpt_pretraining.py)
### Full Examples
These examples showcase every feature in Accelerate at once that was shown in "Feature Specific Examples"
- [Complete NLP example](https://github.com/huggingface/accelerate/blob/main/examples/complete_nlp_example.py)
- [Complete computer vision example](https://github.com/huggingface/accelerate/blob/main/examples/complete_cv_example.py)
- [Very complete and extensible vision example showcasing SLURM, hydra, and a very extensible usage of the framework](https://github.com/yuvalkirstain/PickScore)
- [Causal language model fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm_no_trainer.py)
- [Masked language model fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm_no_trainer.py)
- [Speech pretraining example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py)
- [Translation fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/translation/run_translation_no_trainer.py)
- [Text classification fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue_no_trainer.py)
- [Semantic segmentation fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py)
- [Question answering fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_no_trainer.py)
- [Beam search question answering fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py)
- [Multiple choice question answering fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/multiple-choice/run_swag_no_trainer.py)
- [Named entity recognition fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner_no_trainer.py)
- [Image classification fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification_no_trainer.py)
- [Summarization fine-tuning example](https://github.com/huggingface/transformers/blob/main/examples/pytorch/summarization/run_summarization_no_trainer.py)
- [End-to-end examples on how to use AWS SageMaker integration of Accelerate](https://github.com/huggingface/notebooks/blob/main/sagemaker/22_accelerate_sagemaker_examples/README.md)
- [Megatron-LM examples for various NLp tasks](https://github.com/pacman100/accelerate-megatron-test)
## Integration Examples
These are tutorials from libraries that integrate with Accelerate:
> Don't find your integration here? Make a PR to include it!
### Amphion
- [Training Text-to-Speech Models with Amphion](https://github.com/open-mmlab/Amphion/blob/main/egs/tts/README.md)
- [Training Singing Voice Conversion Models with Amphion](https://github.com/open-mmlab/Amphion/blob/main/egs/svc/README.md)
- [Training Vocoders with Amphion](https://github.com/open-mmlab/Amphion/blob/main/egs/vocoder/README.md)
### Catalyst
- [Distributed training tutorial with Catalyst](https://catalyst-team.github.io/catalyst/tutorials/ddp.html)
### DALLE2-pytorch
- [Fine-tuning DALLE2](https://github.com/lucidrains/DALLE2-pytorch#usage)
### Diffusers
- [Performing textual inversion with diffusers](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion)
- [Training DreamBooth with diffusers](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth)
### fastai
- [Distributed training from Jupyter Notebooks with fastai](https://docs.fast.ai/tutorial.distributed.html)
- [Basic distributed training examples with fastai](https://docs.fast.ai/examples/distributed_app_examples.html)
### GradsFlow
- [Auto Image Classification with GradsFlow](https://docs.gradsflow.com/en/latest/examples/nbs/01-ImageClassification/)
### imagen-pytorch
- [Fine-tuning Imagen](https://github.com/lucidrains/imagen-pytorch#usage)
### Kornia
- [Fine-tuning vision models with Kornia's Trainer](https://kornia.readthedocs.io/en/latest/get-started/training.html)
### PyTorch Accelerated
- [Quickstart distributed training tutorial with PyTorch Accelerated](https://pytorch-accelerated.readthedocs.io/en/latest/quickstart.html)
### PyTorch3D
- [Perform Deep Learning with 3D data](https://pytorch3d.org/tutorials/)
### Stable-Dreamfusion
- [Training with Stable-Dreamfusion to convert text to a 3D model](https://colab.research.google.com/drive/1MXT3yfOFvO0ooKEfiUUvTKwUkrrlCHpF?usp=sharing)
### Tez
- [Leaf disease detection with Tez and Accelerate](https://www.kaggle.com/code/abhishek/tez-faster-and-easier-training-for-leaf-detection/notebook)
### trlx
- [How to implement a sentiment learning task with trlx](https://github.com/CarperAI/trlx#example-how-to-add-a-task)
### Comfy-UI
- [Enabling using large Stable Diffusion Models in low-vram settings using Accelerate](https://github.com/comfyanonymous/ComfyUI/blob/master/comfy/model_management.py#L291-L296)
## In Science
Below contains a non-exhaustive list of papers utilizing Accelerate.
> Don't find your paper here? Make a PR to include it!
* Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, Omer Levy: “Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation”, 2023; [arXiv:2305.01569](http://arxiv.org/abs/2305.01569).
* Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, Ee-Peng Lim: “Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models”, 2023; [arXiv:2305.04091](http://arxiv.org/abs/2305.04091).
* Arthur Câmara, Claudia Hauff: “Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models”, 2022; [arXiv:2205.08343](http://arxiv.org/abs/2205.08343).
* Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, Ce Zhang: “High-throughput Generative Inference of Large Language Models with a Single GPU”, 2023; [arXiv:2303.06865](http://arxiv.org/abs/2303.06865).
* Peter Melchior, Yan Liang, ChangHoon Hahn, Andy Goulding: “Autoencoding Galaxy Spectra I: Architecture”, 2022; [arXiv:2211.07890](http://arxiv.org/abs/2211.07890).
* Jiaao Chen, Aston Zhang, Mu Li, Alex Smola, Diyi Yang: “A Cheaper and Better Diffusion Language Model with Soft-Masked Noise”, 2023; [arXiv:2304.04746](http://arxiv.org/abs/2304.04746).
* Ayaan Haque, Matthew Tancik, Alexei A. Efros, Aleksander Holynski, Angjoo Kanazawa: “Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions”, 2023; [arXiv:2303.12789](http://arxiv.org/abs/2303.12789).
* Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, Andrea Vedaldi: “RealFusion: 360° Reconstruction of Any Object from a Single Image”, 2023; [arXiv:2302.10663](http://arxiv.org/abs/2302.10663).
* Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li: “Better Aligning Text-to-Image Models with Human Preference”, 2023; [arXiv:2303.14420](http://arxiv.org/abs/2303.14420).
* Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang: “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace”, 2023; [arXiv:2303.17580](http://arxiv.org/abs/2303.17580).
* Yue Yang, Wenlin Yao, Hongming Zhang, Xiaoyang Wang, Dong Yu, Jianshu Chen: “Z-LaVI: Zero-Shot Language Solver Fueled by Visual Imagination”, 2022; [arXiv:2210.12261](http://arxiv.org/abs/2210.12261).
* Sheng-Yen Chou, Pin-Yu Chen, Tsung-Yi Ho: “How to Backdoor Diffusion Models?”, 2022; [arXiv:2212.05400](http://arxiv.org/abs/2212.05400).
* Junyoung Seo, Wooseok Jang, Min-Seop Kwak, Jaehoon Ko, Hyeonsu Kim, Junho Kim, Jin-Hwa Kim, Jiyoung Lee, Seungryong Kim: “Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation”, 2023; [arXiv:2303.07937](http://arxiv.org/abs/2303.07937).
* Or Patashnik, Daniel Garibi, Idan Azuri, Hadar Averbuch-Elor, Daniel Cohen-Or: “Localizing Object-level Shape Variations with Text-to-Image Diffusion Models”, 2023; [arXiv:2303.11306](http://arxiv.org/abs/2303.11306).
* Dídac Surís, Sachit Menon, Carl Vondrick: “ViperGPT: Visual Inference via Python Execution for Reasoning”, 2023; [arXiv:2303.08128](http://arxiv.org/abs/2303.08128).
* Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, Qifeng Chen: “FateZero: Fusing Attentions for Zero-shot Text-based Video Editing”, 2023; [arXiv:2303.09535](http://arxiv.org/abs/2303.09535).
* Sean Welleck, Jiacheng Liu, Ximing Lu, Hannaneh Hajishirzi, Yejin Choi: “NaturalProver: Grounded Mathematical Proof Generation with Language Models”, 2022; [arXiv:2205.12910](http://arxiv.org/abs/2205.12910).
* Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, Daniel Cohen-Or: “TEXTure: Text-Guided Texturing of 3D Shapes”, 2023; [arXiv:2302.01721](http://arxiv.org/abs/2302.01721).
* Puijin Cheng, Li Lin, Yijin Huang, Huaqing He, Wenhan Luo, Xiaoying Tang: “Learning Enhancement From Degradation: A Diffusion Model For Fundus Image Enhancement”, 2023; [arXiv:2303.04603](http://arxiv.org/abs/2303.04603).
* Shun Shao, Yftah Ziser, Shay Cohen: “Erasure of Unaligned Attributes from Neural Representations”, 2023; [arXiv:2302.02997](http://arxiv.org/abs/2302.02997).
* Seonghyeon Ye, Hyeonbin Hwang, Sohee Yang, Hyeongu Yun, Yireun Kim, Minjoon Seo: “In-Context Instruction Learning”, 2023; [arXiv:2302.14691](http://arxiv.org/abs/2302.14691).
* Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, Anima Anandkumar: “Prismer: A Vision-Language Model with An Ensemble of Experts”, 2023; [arXiv:2303.02506](http://arxiv.org/abs/2303.02506).
* Haoyu Chen, Zhihua Wang, Yang Yang, Qilin Sun, Kede Ma: “Learning a Deep Color Difference Metric for Photographic Images”, 2023; [arXiv:2303.14964](http://arxiv.org/abs/2303.14964).
* Van-Hoang Le, Hongyu Zhang: “Log Parsing with Prompt-based Few-shot Learning”, 2023; [arXiv:2302.07435](http://arxiv.org/abs/2302.07435).
* Keito Kudo, Yoichi Aoki, Tatsuki Kuribayashi, Ana Brassard, Masashi Yoshikawa, Keisuke Sakaguchi, Kentaro Inui: “Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?”, 2023; [arXiv:2302.07866](http://arxiv.org/abs/2302.07866).
* Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, Prithviraj Ammanabrolu: “Behavior Cloned Transformers are Neurosymbolic Reasoners”, 2022; [arXiv:2210.07382](http://arxiv.org/abs/2210.07382).
* Martin Wessel, Tomáš Horych, Terry Ruas, Akiko Aizawa, Bela Gipp, Timo Spinde: “Introducing MBIB -- the first Media Bias Identification Benchmark Task and Dataset Collection”, 2023; [arXiv:2304.13148](http://arxiv.org/abs/2304.13148). DOI: [https://dx.doi.org/10.1145/3539618.3591882 10.1145/3539618.3591882].
* Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, Daniel Cohen-Or: “Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models”, 2023; [arXiv:2301.13826](http://arxiv.org/abs/2301.13826).
* Marcio Fonseca, Yftah Ziser, Shay B. Cohen: “Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents”, 2022; [arXiv:2205.12486](http://arxiv.org/abs/2205.12486).
* Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, Daniel Cohen-Or: “TEXTure: Text-Guided Texturing of 3D Shapes”, 2023; [arXiv:2302.01721](http://arxiv.org/abs/2302.01721).
* Tianxing He, Jingyu Zhang, Tianle Wang, Sachin Kumar, Kyunghyun Cho, James Glass, Yulia Tsvetkov: “On the Blind Spots of Model-Based Evaluation Metrics for Text Generation”, 2022; [arXiv:2212.10020](http://arxiv.org/abs/2212.10020).
* Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham: “In-Context Retrieval-Augmented Language Models”, 2023; [arXiv:2302.00083](http://arxiv.org/abs/2302.00083).
* Dacheng Li, Rulin Shao, Hongyi Wang, Han Guo, Eric P. Xing, Hao Zhang: “MPCFormer: fast, performant and private Transformer inference with MPC”, 2022; [arXiv:2211.01452](http://arxiv.org/abs/2211.01452).
* Baolin Peng, Michel Galley, Pengcheng He, Chris Brockett, Lars Liden, Elnaz Nouri, Zhou Yu, Bill Dolan, Jianfeng Gao: “GODEL: Large-Scale Pre-Training for Goal-Directed Dialog”, 2022; [arXiv:2206.11309](http://arxiv.org/abs/2206.11309).
* Egil Rønningstad, Erik Velldal, Lilja Øvrelid: “Entity-Level Sentiment Analysis (ELSA): An exploratory task survey”, 2023, Proceedings of the 29th International Conference on Computational Linguistics, 2022, pages 6773-6783; [arXiv:2304.14241](http://arxiv.org/abs/2304.14241).
* Charlie Snell, Ilya Kostrikov, Yi Su, Mengjiao Yang, Sergey Levine: “Offline RL for Natural Language Generation with Implicit Language Q Learning”, 2022; [arXiv:2206.11871](http://arxiv.org/abs/2206.11871).
* Zhiruo Wang, Shuyan Zhou, Daniel Fried, Graham Neubig: “Execution-Based Evaluation for Open-Domain Code Generation”, 2022; [arXiv:2212.10481](http://arxiv.org/abs/2212.10481).
* Minh-Long Luu, Zeyi Huang, Eric P. Xing, Yong Jae Lee, Haohan Wang: “Expeditious Saliency-guided Mix-up through Random Gradient Thresholding”, 2022; [arXiv:2212.04875](http://arxiv.org/abs/2212.04875).
* Jun Hao Liew, Hanshu Yan, Daquan Zhou, Jiashi Feng: “MagicMix: Semantic Mixing with Diffusion Models”, 2022; [arXiv:2210.16056](http://arxiv.org/abs/2210.16056).
* Yaqing Wang, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, Jianfeng Gao: “LiST: Lite Prompted Self-training Makes Parameter-Efficient Few-shot Learners”, 2021; [arXiv:2110.06274](http://arxiv.org/abs/2110.06274).
| 2 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/model_size_estimator.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Model memory estimator
One very difficult aspect when exploring potential models to use on your machine is knowing just how big of a model will *fit* into memory with your current graphics card (such as loading the model onto CUDA).
To help alleviate this, Accelerate has a CLI interface through `accelerate estimate-memory`. This tutorial will
help walk you through using it, what to expect, and at the end link to the interactive demo hosted on the Hub which will
even let you post those results directly on the model repo!
Currently we support searching for models that can be used in `timm` and `transformers`.
<Tip>
This API will load the model into memory on the `meta` device, so we are not actually downloading
and loading the full weights of the model into memory, nor do we need to. As a result it's
perfectly fine to measure 8 billion parameter models (or more), without having to worry about
if your CPU can handle it!
</Tip>
## Gradio Demos
Below are a few gradio demos related to what was described above. The first is the official Hugging Face memory estimation space, utilizing Accelerate directly:
<div class="block dark:hidden">
<iframe
src="https://hf-accelerate-model-memory-usage.hf.space?__theme=light"
width="850"
height="1600"
></iframe>
</div>
<div class="hidden dark:block">
<iframe
src="https://hf-accelerate-model-memory-usage.hf.space?__theme=dark"
width="850"
height="1600"
></iframe>
</div>
A community member has taken the idea and expanded it further, allowing you to filter models directly and see if you can run a particular LLM given GPU constraints and LoRA configurations. To play with it, see [here](https://huggingface.co/spaces/Vokturz/can-it-run-llm) for more details.
## The Command
When using `accelerate estimate-memory`, you need to pass in the name of the model you want to use, potentially the framework
that model utilizing (if it can't be found automatically), and the data types you want the model to be loaded in with.
For example, here is how we can calculate the memory footprint for `bert-base-cased`:
```bash
accelerate estimate-memory bert-base-cased
```
This will download the `config.json` for `bert-based-cased`, load the model on the `meta` device, and report back how much space
it will use:
Memory Usage for loading `bert-base-cased`:
| dtype | Largest Layer | Total Size | Training using Adam |
|---------|---------------|------------|---------------------|
| float32 | 84.95 MB | 418.18 MB | 1.61 GB |
| float16 | 42.47 MB | 206.59 MB | 826.36 MB |
| int8 | 21.24 MB | 103.29 MB | 413.18 MB |
| int4 | 10.62 MB | 51.65 MB | 206.59 MB |
By default it will return all the supported dtypes (`int4` through `float32`), but if you are interested in specific ones these can be filtered.
### Specific libraries
If the source library cannot be determined automatically (like it could in the case of `bert-base-cased`), a library name can
be passed in.
```bash
accelerate estimate-memory HuggingFaceM4/idefics-80b-instruct --library_name transformers
```
Memory Usage for loading `HuggingFaceM4/idefics-80b-instruct`:
| dtype | Largest Layer | Total Size | Training using Adam |
|---------|---------------|------------|---------------------|
| float32 | 3.02 GB | 297.12 GB | 1.16 TB |
| float16 | 1.51 GB | 148.56 GB | 594.24 GB |
| int8 | 772.52 MB | 74.28 GB | 297.12 GB |
| int4 | 386.26 MB | 37.14 GB | 148.56 GB |
```bash
accelerate estimate-memory timm/resnet50.a1_in1k --library_name timm
```
Memory Usage for loading `timm/resnet50.a1_in1k`:
| dtype | Largest Layer | Total Size | Training using Adam |
|---------|---------------|------------|---------------------|
| float32 | 9.0 MB | 97.7 MB | 390.78 MB |
| float16 | 4.5 MB | 48.85 MB | 195.39 MB |
| int8 | 2.25 MB | 24.42 MB | 97.7 MB |
| int4 | 1.12 MB | 12.21 MB | 48.85 MB |
### Specific dtypes
As mentioned earlier, while we return `int4` through `float32` by default, any dtype can be used from `float32`, `float16`, `int8`, and `int4`.
To do so, pass them in after specifying `--dtypes`:
```bash
accelerate estimate-memory bert-base-cased --dtypes float32 float16
```
Memory Usage for loading `bert-base-cased`:
| dtype | Largest Layer | Total Size | Training using Adam |
|---------|---------------|------------|---------------------|
| float32 | 84.95 MB | 413.18 MB | 1.61 GB |
| float16 | 42.47 MB | 206.59 MB | 826.36 MB |
## Caveats with this calculator
This calculator will tell you how much memory is needed to purely load the model in, *not* to perform inference.
This calculation is accurate within a few % of the actual value, so it is a very good view of just how much memory it will take. For instance loading `bert-base-cased` actually takes `413.68 MB` when loaded on CUDA in full precision, and the calculator estimates `413.18 MB`.
When performing inference you can expect to add up to an additional 20% as found by [EleutherAI](https://blog.eleuther.ai/transformer-math/). We'll be conducting research into finding a more accurate estimate to these values, and will update
this calculator once done.
| 3 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/local_sgd.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Using Local SGD with Accelerate
Local SGD is a technique for distributed training where gradients are not synchronized every step. Thus, each process updates its own version of the model weights and after a given number of steps these weights are synchronized by averaging across all processes. This improves communication efficiency and can lead to substantial training speed up especially when a computer lacks a faster interconnect such as NVLink.
Unlike gradient accumulation (where improving communication efficiency requires increasing the effective batch size), Local SGD does not require changing a batch size or a learning rate / schedule. However, if necessary, Local SGD can be combined with gradient accumulation as well.
In this tutorial you will see how to quickly setup Local SGD Accelerate. Compared to a standard Accelerate setup, this requires only two extra lines of code.
This example will use a very simplistic PyTorch training loop that performs gradient accumulation every two batches:
```python
device = "cuda"
model.to(device)
gradient_accumulation_steps = 2
for index, batch in enumerate(training_dataloader):
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss = loss / gradient_accumulation_steps
loss.backward()
if (index + 1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
## Converting it to Accelerate
First the code shown earlier will be converted to use Accelerate with neither a LocalSGD or a gradient accumulation helper:
```diff
+ from accelerate import Accelerator
+ accelerator = Accelerator()
+ model, optimizer, training_dataloader, scheduler = accelerator.prepare(
+ model, optimizer, training_dataloader, scheduler
+ )
for index, batch in enumerate(training_dataloader):
inputs, targets = batch
- inputs = inputs.to(device)
- targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss = loss / gradient_accumulation_steps
+ accelerator.backward(loss)
if (index+1) % gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step()
```
## Letting Accelerate handle model synchronization
All that is left now is to let Accelerate handle model parameter synchronization **and** the gradient accumulation for us. For simplicity let us assume we need to synchronize every 8 steps. This is
achieved by adding one `with LocalSGD` statement and one call `local_sgd.step()` after every optimizer step:
```diff
+local_sgd_steps=8
+with LocalSGD(accelerator=accelerator, model=model, local_sgd_steps=8, enabled=True) as local_sgd:
for batch in training_dataloader:
with accelerator.accumulate(model):
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
+ local_sgd.step()
```
Under the hood, the Local SGD code **disables** automatic gradient synchronization (but accumulation still works as expected!). Instead it averages model parameters every `local_sgd_steps` steps (as well as at the end of the training loop).
## Limitations
The current implementation works only with basic multi-GPU (or multi-CPU) training without, e.g., [DeepSpeed.](https://github.com/microsoft/DeepSpeed).
## References
Although we are not aware of the true origins of this simple approach, the idea of local SGD is quite old and goes
back to at least:
Zhang, J., De Sa, C., Mitliagkas, I., & Ré, C. (2016). [Parallel SGD: When does averaging help?. arXiv preprint
arXiv:1606.07365.](https://arxiv.org/abs/1606.07365)
We credit the term Local SGD to the following paper (but there might be earlier references we are not aware of).
Stich, Sebastian Urban. ["Local SGD Converges Fast and Communicates Little." ICLR 2019-International Conference on
Learning Representations. No. CONF. 2019.](https://arxiv.org/abs/1805.09767)
| 4 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/sagemaker.md | <!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Amazon SageMaker
Hugging Face and Amazon introduced new [Hugging Face Deep Learning Containers (DLCs)](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers) to
make it easier than ever to train Hugging Face Transformer models in [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
## Getting Started
### Setup & Installation
Before you can run your Accelerate scripts on Amazon SageMaker you need to sign up for an AWS account. If you do not
have an AWS account yet learn more [here](https://docs.aws.amazon.com/sagemaker/latest/dg/gs-set-up.html).
After you have your AWS Account you need to install the `sagemaker` sdk for Accelerate with:
```bash
pip install "accelerate[sagemaker]" --upgrade
```
Accelerate currently uses the DLCs, with `transformers`, `datasets` and `tokenizers` pre-installed. Accelerate is not in the DLC yet (will soon be added!) so to use it within Amazon SageMaker you need to create a
`requirements.txt` in the same directory where your training script is located and add it as dependency:
```
accelerate
```
You should also add any other dependencies you have to this `requirements.txt`.
### Configure Accelerate
You can configure the launch configuration for Amazon SageMaker the same as you do for non SageMaker training jobs with
the Accelerate CLI:
```bash
accelerate config
# In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 1
```
Accelerate will go through a questionnaire about your Amazon SageMaker setup and create a config file you can edit.
<Tip>
Accelerate is not saving any of your credentials.
</Tip>
### Prepare a Accelerate fine-tuning script
The training script is very similar to a training script you might run outside of SageMaker, but to save your model
after training you need to specify either `/opt/ml/model` or use `os.environ["SM_MODEL_DIR"]` as your save
directory. After training, artifacts in this directory are uploaded to S3:
```diff
- torch.save('/opt/ml/model`)
+ accelerator.save('/opt/ml/model')
```
<Tip warning={true}>
SageMaker doesn’t support argparse actions. If you want to use, for example, boolean hyperparameters, you need to
specify type as bool in your script and provide an explicit True or False value for this hyperparameter. [[REF]](https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html#prepare-a-pytorch-training-script).
</Tip>
### Launch Training
You can launch your training with Accelerate CLI with:
```
accelerate launch path_to_script.py --args_to_the_script
```
This will launch your training script using your configuration. The only thing you have to do is provide all the
arguments needed by your training script as named arguments.
**Examples**
<Tip>
If you run one of the example scripts, don't forget to add `accelerator.save('/opt/ml/model')` to it.
</Tip>
```bash
accelerate launch ./examples/sagemaker_example.py
```
Outputs:
```
Configuring Amazon SageMaker environment
Converting Arguments to Hyperparameters
Creating Estimator
2021-04-08 11:56:50 Starting - Starting the training job...
2021-04-08 11:57:13 Starting - Launching requested ML instancesProfilerReport-1617883008: InProgress
.........
2021-04-08 11:58:54 Starting - Preparing the instances for training.........
2021-04-08 12:00:24 Downloading - Downloading input data
2021-04-08 12:00:24 Training - Downloading the training image..................
2021-04-08 12:03:39 Training - Training image download completed. Training in progress..
........
epoch 0: {'accuracy': 0.7598039215686274, 'f1': 0.8178438661710037}
epoch 1: {'accuracy': 0.8357843137254902, 'f1': 0.882249560632689}
epoch 2: {'accuracy': 0.8406862745098039, 'f1': 0.8869565217391304}
........
2021-04-08 12:05:40 Uploading - Uploading generated training model
2021-04-08 12:05:40 Completed - Training job completed
Training seconds: 331
Billable seconds: 331
You can find your model data at: s3://your-bucket/accelerate-sagemaker-1-2021-04-08-11-56-47-108/output/model.tar.gz
```
## Advanced Features
### Distributed Training: Data Parallelism
Set up the accelerate config by running `accelerate config` and answer the SageMaker questions and set it up.
To use SageMaker DDP, select it when asked
`What is the distributed mode? ([0] No distributed training, [1] data parallelism):`.
Example config below:
```yaml
base_job_name: accelerate-sagemaker-1
compute_environment: AMAZON_SAGEMAKER
distributed_type: DATA_PARALLEL
ec2_instance_type: ml.p3.16xlarge
iam_role_name: xxxxx
image_uri: null
mixed_precision: fp16
num_machines: 1
profile: xxxxx
py_version: py38
pytorch_version: 1.10.2
region: us-east-1
transformers_version: 4.17.0
use_cpu: false
```
### Distributed Training: Model Parallelism
*currently in development, will be supported soon.*
### Python packages and dependencies
Accelerate currently uses the DLCs, with `transformers`, `datasets` and `tokenizers` pre-installed. If you
want to use different/other Python packages you can do this by adding them to the `requirements.txt`. These packages
will be installed before your training script is started.
### Local Training: SageMaker Local mode
The local mode in the SageMaker SDK allows you to run your training script locally inside the HuggingFace DLC (Deep Learning container)
or using your custom container image. This is useful for debugging and testing your training script inside the final container environment.
Local mode uses Docker compose (*Note: Docker Compose V2 is not supported yet*). The SDK will handle the authentication against ECR
to pull the DLC to your local environment. You can emulate CPU (single and multi-instance) and GPU (single instance) SageMaker training jobs.
To use local mode, you need to set your `ec2_instance_type` to `local`.
```yaml
ec2_instance_type: local
```
### Advanced configuration
The configuration allows you to override parameters for the [Estimator](https://sagemaker.readthedocs.io/en/stable/api/training/estimators.html).
These settings have to be applied in the config file and are not part of `accelerate config`. You can control many additional aspects of the training job, e.g. use Spot instances, enable network isolation and many more.
```yaml
additional_args:
# enable network isolation to restrict internet access for containers
enable_network_isolation: True
```
You can find all available configuration [here](https://sagemaker.readthedocs.io/en/stable/api/training/estimators.html).
### Use Spot Instances
You can use Spot Instances e.g. using (see [Advanced configuration](#advanced-configuration)):
```yaml
additional_args:
use_spot_instances: True
max_wait: 86400
```
*Note: Spot Instances are subject to be terminated and training to be continued from a checkpoint. This is not handled in Accelerate out of the box. Contact us if you would like this feature.*
### Remote scripts: Use scripts located on Github
*undecided if feature is needed. Contact us if you would like this feature.* | 5 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/fsdp.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fully Sharded Data Parallel
To accelerate training huge models on larger batch sizes, we can use a fully sharded data parallel model.
This type of data parallel paradigm enables fitting more data and larger models by sharding the optimizer states, gradients and parameters.
To read more about it and the benefits, check out the [Fully Sharded Data Parallel blog](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/).
We have integrated the latest PyTorch's Fully Sharded Data Parallel (FSDP) training feature.
All you need to do is enable it through the config.
## How it works out of the box
On your machine(s) just run:
```bash
accelerate config
```
and answer the questions asked. This will generate a config file that will be used automatically to properly set the
default options when doing
```bash
accelerate launch my_script.py --args_to_my_script
```
For instance, here is how you would run `examples/nlp_example.py` (from the root of the repo) with FSDP enabled:
```bash
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: false
fsdp_cpu_ram_efficient_loading: true
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
```bash
accelerate launch examples/nlp_example.py
```
Currently, `Accelerate` supports the following config through the CLI:
`fsdp_sharding_strategy`: [1] FULL_SHARD (shards optimizer states, gradients and parameters), [2] SHARD_GRAD_OP (shards optimizer states and gradients), [3] NO_SHARD (DDP), [4] HYBRID_SHARD (shards optimizer states, gradients and parameters within each node while each node has full copy), [5] HYBRID_SHARD_ZERO2 (shards optimizer states and gradients within each node while each node has full copy). For more information, please refer the official [PyTorch docs](https://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.ShardingStrategy).
`fsdp_offload_params` : Decides Whether to offload parameters and gradients to CPU
`fsdp_auto_wrap_policy`: [1] TRANSFORMER_BASED_WRAP, [2] SIZE_BASED_WRAP, [3] NO_WRAP
`fsdp_transformer_layer_cls_to_wrap`: Only applicable for Transformers. When using `fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP`, a user may provide a comma-separated string of transformer layer class names (case-sensitive) to wrap, e.g., `BertLayer`, `GPTJBlock`, `T5Block`, `BertLayer,BertEmbeddings,BertSelfOutput`. This is important because submodules that share weights (e.g., embedding layers) should not end up in different FSDP wrapped units. Using this policy, wrapping happens for each block containing Multi-Head Attention followed by a couple of MLP layers. Remaining layers including the shared embeddings are conveniently wrapped in same outermost FSDP unit. Therefore, use this for transformer-based models. You can use the `model._no_split_modules` for Transformer models by answering `yes` to `Do you want to use the model's `_no_split_modules` to wrap. It will try to use `model._no_split_modules` when possible.
`fsdp_min_num_params`: minimum number of parameters when using `fsdp_auto_wrap_policy=SIZE_BASED_WRAP`.
`fsdp_backward_prefetch_policy`: [1] BACKWARD_PRE, [2] BACKWARD_POST, [3] NO_PREFETCH
`fsdp_forward_prefetch`: if True, then FSDP explicitly prefetches the next upcoming all-gather while executing in the forward pass. Should only be used for static-graph models since the prefetching follows the first iteration’s execution order. i.e., if the sub-modules' order changes dynamically during the model's execution do not enable this feature.
`fsdp_state_dict_type`: [1] FULL_STATE_DICT, [2] LOCAL_STATE_DICT, [3] SHARDED_STATE_DICT
`fsdp_use_orig_params`: If True, allows non-uniform `requires_grad` during init, which means support for interspersed frozen and trainable parameters. This setting is useful in cases such as parameter-efficient fine-tuning as discussed in [this post](https://dev-discuss.pytorch.org/t/rethinking-pytorch-fully-sharded-data-parallel-fsdp-from-first-principles/1019). This option also allows one to have multiple optimizer param groups. This should be `True` when creating an optimizer before preparing/wrapping the model with FSDP.
`fsdp_cpu_ram_efficient_loading`: Only applicable for Transformers models. If True, only the first process loads the pretrained model checkpoint while all other processes have empty weights. This should be set to False if you experience errors when loading the pretrained Transformers model via `from_pretrained` method. When this setting is True `fsdp_sync_module_states` also must to be True, otherwise all the processes except the main process would have random weights leading to unexpected behaviour during training. For this to work, make sure the distributed process group is initialized before calling Transformers `from_pretrained` method. When using Trainer API, the distributed process group is initialized when you create an instance of `TrainingArguments` class.
`fsdp_sync_module_states`: If True, each individually wrapped FSDP unit will broadcast module parameters from rank 0.
For additional and more nuanced control, you can specify other FSDP parameters via `FullyShardedDataParallelPlugin`.
When creating `FullyShardedDataParallelPlugin` object, pass it the parameters that weren't part of the accelerate config or if you want to override them.
The FSDP parameters will be picked based on the accelerate config file or launch command arguments and other parameters that you will pass directly through the `FullyShardedDataParallelPlugin` object will set/override that.
Below is an example:
```py
from accelerate import FullyShardedDataParallelPlugin
from torch.distributed.fsdp.fully_sharded_data_parallel import FullOptimStateDictConfig, FullStateDictConfig
fsdp_plugin = FullyShardedDataParallelPlugin(
state_dict_config=FullStateDictConfig(offload_to_cpu=False, rank0_only=False),
optim_state_dict_config=FullOptimStateDictConfig(offload_to_cpu=False, rank0_only=False),
)
accelerator = Accelerator(fsdp_plugin=fsdp_plugin)
```
## Saving and loading
The new recommended way of checkpointing when using FSDP models is to use `SHARDED_STATE_DICT` as `StateDictType` when setting up the accelerate config.
Below is the code snippet to save using `save_state` utility of accelerate.
```py
accelerator.save_state("ckpt")
```
Inspect the checkpoint folder to see model and optimizer as shards per process:
```
ls ckpt
# optimizer_0 pytorch_model_0 random_states_0.pkl random_states_1.pkl scheduler.bin
cd ckpt
ls optimizer_0
# __0_0.distcp __1_0.distcp
ls pytorch_model_0
# __0_0.distcp __1_0.distcp
```
To load them back for resuming the training, use the `load_state` utility of accelerate
```py
accelerator.load_state("ckpt")
```
When using transformers `save_pretrained`, pass `state_dict=accelerator.get_state_dict(model)` to save the model state dict.
Below is an example:
```diff
unwrapped_model.save_pretrained(
args.output_dir,
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
+ state_dict=accelerator.get_state_dict(model),
)
```
### State Dict
`accelerator.get_state_dict` will call the underlying `model.state_dict` implementation using `FullStateDictConfig(offload_to_cpu=True, rank0_only=True)` context manager to get the state dict only for rank 0 and it will be offloaded to CPU.
You can then pass `state` into the `save_pretrained` method. There are several modes for `StateDictType` and `FullStateDictConfig` that you can use to control the behavior of `state_dict`. For more information, see the [PyTorch documentation](https://pytorch.org/docs/stable/fsdp.html).
If you choose to use `StateDictType.SHARDED_STATE_DICT`, the weights of the model during `Accelerator.save_state` will be split into `n` files for each sub-split on the model. To merge them back into
a single dictionary to load back into the model later after training you can use the `merge_weights` utility:
```py
from accelerate.utils import merge_fsdp_weights
# Our weights are saved usually in a `pytorch_model_fsdp_{model_number}` folder
merge_fsdp_weights("pytorch_model_fsdp_0", "output_path", safe_serialization=True)
```
The final output will then either be saved to `model.safetensors` or `pytorch_model.bin` (if `safe_serialization=False` is passed).
This can also be called using the CLI:
```bash
accelerate merge-weights pytorch_model_fsdp_0/ output_path
```
## Mapping between FSDP sharding strategies and DeepSpeed ZeRO Stages
* `FULL_SHARD` maps to the DeepSpeed `ZeRO Stage-3`. Shards optimizer states, gradients and parameters.
* `SHARD_GRAD_OP` maps to the DeepSpeed `ZeRO Stage-2`. Shards optimizer states and gradients.
* `NO_SHARD` maps to `ZeRO Stage-0`. No sharding wherein each GPU has full copy of model, optimizer states and gradients.
* `HYBRID_SHARD` maps to `ZeRO++ Stage-3` wherein `zero_hpz_partition_size=<num_gpus_per_node>`. Here, this will shard optimizer states, gradients and parameters within each node while each node has full copy.
## A few caveats to be aware of
- In case of multiple models, pass the optimizers to the prepare call in the same order as corresponding models else `accelerator.save_state()` and `accelerator.load_state()` will result in wrong/unexpected behaviour.
- This feature is incompatible with `--predict_with_generate` in the `run_translation.py` script of `Transformers` library.
For more control, users can leverage the `FullyShardedDataParallelPlugin`. After creating an instance of this class, users can pass it to the Accelerator class instantiation.
For more information on these options, please refer to the PyTorch [FullyShardedDataParallel](https://github.com/pytorch/pytorch/blob/0df2e863fbd5993a7b9e652910792bd21a516ff3/torch/distributed/fsdp/fully_sharded_data_parallel.py#L236) code.
<Tip>
For those interested in the similarities and differences between FSDP and DeepSpeed, please check out the [concept guide here](../concept_guides/fsdp_and_deepspeed)!
</Tip> | 6 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/deepspeed_multiple_model.md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Using multiple models with DeepSpeed
<Tip warning={true}>
This guide assumes that you have read and understood the [DeepSpeed usage guide](./deepspeed.md).
</Tip>
Running multiple models with Accelerate and DeepSpeed is useful for:
* Knowledge distillation
* Post-training techniques like RLHF (see the [TRL](https://github.com/huggingface/trl) library for more examples)
* Training multiple models at once
Currently, Accelerate has a **very experimental API** to help you use multiple models.
This tutorial will focus on two common use cases:
1. Knowledge distillation, where a smaller student model is trained to mimic a larger, better-performing teacher. If the student model fits on a single GPU, we can use ZeRO-2 for training and ZeRO-3 to shard the teacher for inference. This is significantly faster than using ZeRO-3 for both models.
2. Training multiple *disjoint* models at once.
## Knowledge distillation
Knowledge distillation is a good example of using multiple models, but only training one of them.
Normally, you would use a single [`utils.DeepSpeedPlugin`] for both models. However, in this case, there are two separate configurations. Accelerate allows you to create and use multiple plugins **if and only if** they are in a `dict` so that you can reference and enable the proper plugin when needed.
```python
from accelerate.utils import DeepSpeedPlugin
zero2_plugin = DeepSpeedPlugin(hf_ds_config="zero2_config.json")
zero3_plugin = DeepSpeedPlugin(hf_ds_config="zero3_config.json")
deepspeed_plugins = {"student": zero2_plugin, "teacher": zero3_plugin}
```
The `zero2_config.json` should be configured for full training (so specify `scheduler` and `optimizer` if you are not utilizing your own), while `zero3_config.json` should only be configured for the inference model, as shown in the example below.
```json
{
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": "auto",
"stage3_max_reuse_distance": "auto",
},
"train_micro_batch_size_per_gpu": 1
}
```
An example `zero2_config.json` configuration is shown below.
```json
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
```
<Tip>
DeepSpeed will raise an error if `train_micro_batch_size_per_gpu` isn't specified, even if this particular model isn't being trained.
</Tip>
From here, create a single [`Accelerator`] and pass in both configurations.
```python
from accelerate import Accelerator
accelerator = Accelerator(deepspeed_plugins=deepspeed_plugins)
```
Now let's see how to use them.
### Student model
By default, Accelerate sets the first item in the `dict` as the default or enabled plugin (`"student"` plugin). Verify this by using the [`utils.deepspeed.get_active_deepspeed_plugin`] function to see which plugin is enabled.
```python
active_plugin = get_active_deepspeed_plugin(accelerator.state)
assert active_plugin is deepspeed_plugins["student"]
```
[`AcceleratorState`] also keeps the active DeepSpeed plugin saved in `state.deepspeed_plugin`.
```python
assert active_plugin is accelerator.deepspeed_plugin
```
Since `student` is the currently active plugin, let's go ahead and prepare the model, optimizer, and scheduler.
```python
student_model, optimizer, scheduler = ...
student_model, optimizer, scheduler, train_dataloader = accelerator.prepare(student_model, optimizer, scheduler, train_dataloader)
```
Now it's time to deal with the teacher model.
### Teacher model
First, you need to specify in [`Accelerator`] that the `zero3_config.json` configuration should be used.
```python
accelerator.state.select_deepspeed_plugin("teacher")
```
This disables the `"student"` plugin and enables the `"teacher"` plugin instead. The
DeepSpeed stateful config inside of Transformers is updated, and it changes which plugin configuration gets called when using
`deepspeed.initialize()`. This allows you to use the automatic `deepspeed.zero.Init` context manager integration Transformers provides.
```python
teacher_model = AutoModel.from_pretrained(...)
teacher_model = accelerator.prepare(teacher_model)
```
Otherwise, you should manually initialize the model with `deepspeed.zero.Init`.
```python
with deepspeed.zero.Init(accelerator.deepspeed_plugin.config):
model = MyModel(...)
```
### Training
From here, your training loop can be whatever you like, as long as `teacher_model` is never being trained on.
```python
teacher_model.eval()
student_model.train()
for batch in train_dataloader:
with torch.no_grad():
output_teacher = teacher_model(**batch)
output_student = student_model(**batch)
# Combine the losses or modify it in some way
loss = output_teacher.loss + output_student.loss
accelerator.backward(loss)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
## Train multiple disjoint models
Training multiple models is a more complicated scenario.
In its current state, we assume each model is **completely disjointed** from the other during training.
This scenario still requires two [`utils.DeepSpeedPlugin`]'s to be made. However, you also need a second [`Accelerator`], since different `deepspeed` engines are being called at different times. A single [`Accelerator`] can only carry one instance at a time.
Since the [`state.AcceleratorState`] is a stateful object though, it is already aware of both [`utils.DeepSpeedPlugin`]'s available. You can just instantiate a second [`Accelerator`] with no extra arguments.
```python
first_accelerator = Accelerator(deepspeed_plugins=deepspeed_plugins)
second_accelerator = Accelerator()
```
You can call either `first_accelerator.state.select_deepspeed_plugin()` to enable or disable
a particular plugin, and then call [`prepare`].
```python
# can be `accelerator_0`, `accelerator_1`, or by calling `AcceleratorState().select_deepspeed_plugin(...)`
first_accelerator.state.select_deepspeed_plugin("first_model")
first_model = AutoModel.from_pretrained(...)
# For this example, `get_training_items` is a nonexistent function that gets the setup we need for training
first_optimizer, first_scheduler, train_dl, eval_dl = get_training_items(model1)
first_model, first_optimizer, first_scheduler, train_dl, eval_dl = accelerator.prepare(
first_model, first_optimizer, first_scheduler, train_dl, eval_dl
)
second_accelerator.state.select_deepspeed_plugin("second_model")
second_model = AutoModel.from_pretrained(...)
# For this example, `get_training_items` is a nonexistent function that gets the setup we need for training
second_optimizer, second_scheduler, _, _ = get_training_items(model2)
second_model, second_optimizer, second_scheduler = accelerator.prepare(
second_model, second_optimizer, second_scheduler
)
```
And now you can train:
```python
for batch in dl:
outputs1 = first_model(**batch)
first_accelerator.backward(outputs1.loss)
first_optimizer.step()
first_scheduler.step()
first_optimizer.zero_grad()
outputs2 = model2(**batch)
second_accelerator.backward(outputs2.loss)
second_optimizer.step()
second_scheduler.step()
second_optimizer.zero_grad()
```
## Resources
To see more examples, please check out the [related tests](https://github.com/huggingface/accelerate/blob/main/src/accelerate/test_utils/scripts/external_deps/test_ds_multiple_model.py) currently in [Accelerate].
| 7 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/explore.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Start Here!
Please use the interactive tool below to help you get started with learning about a particular
feature of Accelerate and how to utilize it! It will provide you with a code diff, an explanation
towards what is going on, as well as provide you with some useful links to explore more within
the documentation!
Most code examples start from the following python code before integrating Accelerate in some way:
```python
for batch in dataloader:
optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step()
```
<div class="block dark:hidden">
<iframe
src="https://hf-accelerate-accelerate-examples.hf.space?__theme=light"
width="850"
height="1600"
></iframe>
</div>
<div class="hidden dark:block">
<iframe
src="https://hf-accelerate-accelerate-examples.hf.space?__theme=dark"
width="850"
height="1600"
></iframe>
</div>
| 8 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/usage_guides/ddp_comm_hook.md | <!--
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DDP Communication Hooks
Distributed Data Parallel (DDP) communication hooks provide a generic interface to control how gradients are communicated across workers by overriding the vanilla allreduce in `DistributedDataParallel`. A few built-in communication hooks are provided, and users can easily apply any of these hooks to optimize communication.
- **FP16 Compression Hook**: Compresses gradients by casting them to half-precision floating-point format (`torch.float16`), reducing communication overhead.
- **BF16 Compression Hook**: Similar to FP16, but uses the Brain Floating Point format (`torch.bfloat16`), which can be more efficient on certain hardware.
- **PowerSGD Hook**: An advanced gradient compression algorithm that provides high compression rates and can accelerate bandwidth-bound distributed training.
In this tutorial, you will see how to quickly set up DDP communication hooks and perform training with the utilities provided in Accelerate, which can be as simple as adding just one new line of code! This demonstrates how to use DDP communication hooks to optimize gradient communication in distributed training with the Accelerate library.
## FP16 Compression Hook
<hfoptions id="fp16">
<hfoption id="PyTorch">
```python
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.algorithms.ddp_comm_hooks import default_hooks
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
model = MyModel()
model = DDP(model, device_ids=[torch.cuda.current_device()])
model.register_comm_hook(state=None, hook=default_hooks.fp16_compress_hook)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
<hfoption id="Accelerate">
```python
from accelerate import Accelerator, DDPCommunicationHookType, DistributedDataParallelKwargs
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
# DDP Communication Hook setup
ddp_kwargs = DistributedDataParallelKwargs(comm_hook=DDPCommunicationHookType.FP16)
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
model = MyModel()
optimizer = torch.optim.Adam(model.parameters())
data_loader = DataLoader(dataset, batch_size=16)
model, optimizer, data_loader = accelerator.prepare(model, optimizer, data_loader)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
</hfoptions>
### BF16 Compression Hook
<Tip warning={true}>
BF16 Compression Hook API is experimental, and it requires NCCL version later than 2.9.6.
</Tip>
<hfoptions id="bf16">
<hfoption id="PyTorch">
```python
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.algorithms.ddp_comm_hooks import default_hooks
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
model = MyModel()
model = DDP(model, device_ids=[torch.cuda.current_device()])
model.register_comm_hook(state=None, hook=default_hooks.bf16_compress_hook)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
<hfoption id="Accelerate">
```python
from accelerate import Accelerator, DDPCommunicationHookType, DistributedDataParallelKwargs
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
# DDP Communication Hook setup
ddp_kwargs = DistributedDataParallelKwargs(comm_hook=DDPCommunicationHookType.BF16)
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
model = MyModel()
optimizer = torch.optim.Adam(model.parameters())
data_loader = DataLoader(dataset, batch_size=16)
model, optimizer, data_loader = accelerator.prepare(model, optimizer, data_loader)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
</hfoptions>
### PowerSGD Hook
<Tip warning={true}>
PowerSGD typically requires extra memory of the same size as the model’s gradients to enable error feedback, which can compensate for biased compressed communication and improve accuracy.
</Tip>
<hfoptions id="powerSGD">
<hfoption id="PyTorch">
```python
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.algorithms.ddp_comm_hooks import powerSGD_hook
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
model = MyModel()
model = DDP(model, device_ids=[torch.cuda.current_device()])
state = powerSGD_hook.PowerSGDState(process_group=None)
model.register_comm_hook(state=state, hook=powerSGD_hook.powerSGD_hook)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
<hfoption id="Accelerate">
```python
from accelerate import Accelerator, DDPCommunicationHookType, DistributedDataParallelKwargs
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
# DDP Communication Hook setup
ddp_kwargs = DistributedDataParallelKwargs(comm_hook=DDPCommunicationHookType.POWER_SGD)
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
model = MyModel()
optimizer = torch.optim.Adam(model.parameters())
data_loader = DataLoader(dataset, batch_size=16)
model, optimizer, data_loader = accelerator.prepare(model, optimizer, data_loader)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
```
</hfoption>
</hfoptions>
## DDP Communication Hooks utilities
There are two additional utilities for supporting optional functionalities with the communication hooks.
### comm_wrapper
`comm_wrapper` is an option to wrap a communication hook with additional functionality. For example, it can be used to combine FP16 compression with other communication strategies. Currently supported wrappers are `no`, `fp16`, and `bf16`.
```python
from accelerate import Accelerator, DDPCommunicationHookType, DistributedDataParallelKwargs
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
# DDP Communication Hook setup
ddp_kwargs = DistributedDataParallelKwargs(
comm_hook=DDPCommunicationHookType.POWER_SGD,
comm_wrapper=DDPCommunicationHookType.FP16
)
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
model = MyModel()
optimizer = torch.optim.Adam(model.parameters())
data_loader = DataLoader(dataset, batch_size=16)
model, optimizer, data_loader = accelerator.prepare(model, optimizer, data_loader)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
```
### comm_state_option
`comm_state_option` allows you to pass additional state information required by certain communication hooks. This is particularly useful for stateful hooks like `PowerSGD`, which require maintaining hyperparameters and internal states across training steps. Below is an example showcasing the use of `comm_state_option` with the `PowerSGD` hook.
```python
from accelerate import Accelerator, DDPCommunicationHookType, DistributedDataParallelKwargs
import torch
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
# DDP Communication Hook setup
ddp_kwargs = DistributedDataParallelKwargs(
comm_hook=DDPCommunicationHookType.POWER_SGD,
comm_state_option={"matrix_approximation_rank": 2}
)
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
model = MyModel()
optimizer = torch.optim.Adam(model.parameters())
data_loader = DataLoader(dataset, batch_size=16)
model, optimizer, data_loader = accelerator.prepare(model, optimizer, data_loader)
# Training loop
for data, targets in data_loader:
outputs = model(data)
loss = criterion(outputs, targets)
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
```
For more advanced usage and additional hooks, refer to the [PyTorch DDP Communication Hooks documentation](https://pytorch.org/docs/stable/ddp_comm_hooks.html).
| 9 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mmdit/projections.rs | use candle::{Module, Result, Tensor};
use candle_nn as nn;
pub struct Qkv {
pub q: Tensor,
pub k: Tensor,
pub v: Tensor,
}
pub struct Mlp {
fc1: nn::Linear,
act: nn::Activation,
fc2: nn::Linear,
}
impl Mlp {
pub fn new(
in_features: usize,
hidden_features: usize,
vb: candle_nn::VarBuilder,
) -> Result<Self> {
let fc1 = nn::linear(in_features, hidden_features, vb.pp("fc1"))?;
let act = nn::Activation::GeluPytorchTanh;
let fc2 = nn::linear(hidden_features, in_features, vb.pp("fc2"))?;
Ok(Self { fc1, act, fc2 })
}
}
impl Module for Mlp {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = self.fc1.forward(x)?;
let x = self.act.forward(&x)?;
self.fc2.forward(&x)
}
}
pub struct QkvOnlyAttnProjections {
qkv: nn::Linear,
head_dim: usize,
}
impl QkvOnlyAttnProjections {
pub fn new(dim: usize, num_heads: usize, vb: nn::VarBuilder) -> Result<Self> {
let head_dim = dim / num_heads;
let qkv = nn::linear(dim, dim * 3, vb.pp("qkv"))?;
Ok(Self { qkv, head_dim })
}
pub fn pre_attention(&self, x: &Tensor) -> Result<Qkv> {
let qkv = self.qkv.forward(x)?;
split_qkv(&qkv, self.head_dim)
}
}
pub struct AttnProjections {
head_dim: usize,
qkv: nn::Linear,
ln_k: Option<candle_nn::RmsNorm>,
ln_q: Option<candle_nn::RmsNorm>,
proj: nn::Linear,
}
impl AttnProjections {
pub fn new(dim: usize, num_heads: usize, vb: nn::VarBuilder) -> Result<Self> {
let head_dim = dim / num_heads;
let qkv = nn::linear(dim, dim * 3, vb.pp("qkv"))?;
let proj = nn::linear(dim, dim, vb.pp("proj"))?;
let (ln_k, ln_q) = if vb.contains_tensor("ln_k.weight") {
let ln_k = candle_nn::rms_norm(head_dim, 1e-6, vb.pp("ln_k"))?;
let ln_q = candle_nn::rms_norm(head_dim, 1e-6, vb.pp("ln_q"))?;
(Some(ln_k), Some(ln_q))
} else {
(None, None)
};
Ok(Self {
head_dim,
qkv,
proj,
ln_k,
ln_q,
})
}
pub fn pre_attention(&self, x: &Tensor) -> Result<Qkv> {
let qkv = self.qkv.forward(x)?;
let Qkv { q, k, v } = split_qkv(&qkv, self.head_dim)?;
let q = match self.ln_q.as_ref() {
None => q,
Some(l) => {
let (b, t, h) = q.dims3()?;
l.forward(&q.reshape((b, t, (), self.head_dim))?)?
.reshape((b, t, h))?
}
};
let k = match self.ln_k.as_ref() {
None => k,
Some(l) => {
let (b, t, h) = k.dims3()?;
l.forward(&k.reshape((b, t, (), self.head_dim))?)?
.reshape((b, t, h))?
}
};
Ok(Qkv { q, k, v })
}
pub fn post_attention(&self, x: &Tensor) -> Result<Tensor> {
self.proj.forward(x)
}
}
fn split_qkv(qkv: &Tensor, head_dim: usize) -> Result<Qkv> {
let (batch_size, seq_len, _) = qkv.dims3()?;
let qkv = qkv.reshape((batch_size, seq_len, 3, (), head_dim))?;
let q = qkv.get_on_dim(2, 0)?;
let q = q.reshape((batch_size, seq_len, ()))?;
let k = qkv.get_on_dim(2, 1)?;
let k = k.reshape((batch_size, seq_len, ()))?;
let v = qkv.get_on_dim(2, 2)?;
Ok(Qkv { q, k, v })
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/whisper/mod.rs | //! Whisper Model Implementation
//!
//! Whisper is an automatic speech recognition (ASR) system trained on large amounts
//! of multilingual and multitask supervised data collected from the web. It can be used to
//! convert audio files (in the `.wav` format) to text. Supported features include
//! language detection as well as multilingual speech recognition.
//!
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-whisper)
//! - 💻 [GH Link](https://github.com/openai/whisper)
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py)
//!
//!
pub mod audio;
pub mod model;
pub mod quantized_model;
use serde::Deserialize;
// The names in comments correspond to the original implementation:
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L17
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub num_mel_bins: usize, // n_mels
pub max_source_positions: usize, // n_audio_ctx
pub d_model: usize, // n_audio_state
pub encoder_attention_heads: usize, // n_audio_head
pub encoder_layers: usize, // n_audio_layer
pub vocab_size: usize, // n_vocab
pub max_target_positions: usize, // n_text_ctx
// pub n_text_state: usize,
pub decoder_attention_heads: usize, // n_text_head
pub decoder_layers: usize, // n_text_layer
#[serde(default)]
pub suppress_tokens: Vec<u32>,
}
pub const DTYPE: candle::DType = candle::DType::F32;
// Audio parameters.
pub const SAMPLE_RATE: usize = 16000;
pub const N_FFT: usize = 400;
pub const HOP_LENGTH: usize = 160;
pub const CHUNK_LENGTH: usize = 30;
pub const N_SAMPLES: usize = CHUNK_LENGTH * SAMPLE_RATE; // 480000 samples in a 30-second chunk
pub const N_FRAMES: usize = N_SAMPLES / HOP_LENGTH; // 3000 frames in a mel spectrogram input
pub const NO_SPEECH_THRESHOLD: f64 = 0.6;
pub const LOGPROB_THRESHOLD: f64 = -1.0;
pub const TEMPERATURES: [f64; 6] = [0.0, 0.2, 0.4, 0.6, 0.8, 1.0];
pub const COMPRESSION_RATIO_THRESHOLD: f64 = 2.4;
// Tokenizer dependent bits.
pub const SOT_TOKEN: &str = "<|startoftranscript|>";
pub const TRANSCRIBE_TOKEN: &str = "<|transcribe|>";
pub const TRANSLATE_TOKEN: &str = "<|translate|>";
pub const NO_TIMESTAMPS_TOKEN: &str = "<|notimestamps|>";
pub const EOT_TOKEN: &str = "<|endoftext|>";
pub const NO_SPEECH_TOKENS: [&str; 2] = ["<|nocaptions|>", "<|nospeech|>"];
| 1 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/whisper/audio.rs | // Audio processing code, adapted from whisper.cpp
// https://github.com/ggerganov/whisper.cpp
use candle::utils::get_num_threads;
use std::sync::Arc;
use std::thread;
pub trait Float:
num_traits::Float + num_traits::FloatConst + num_traits::NumAssign + Send + Sync
{
}
impl Float for f32 {}
impl Float for f64 {}
// https://github.com/ggerganov/whisper.cpp/blob/4774d2feb01a772a15de81ffc34b34a1f294f020/whisper.cpp#L2357
fn fft<T: Float>(inp: &[T]) -> Vec<T> {
let n = inp.len();
let zero = T::zero();
if n == 1 {
return vec![inp[0], zero];
}
if n % 2 == 1 {
return dft(inp);
}
let mut out = vec![zero; n * 2];
let mut even = Vec::with_capacity(n / 2);
let mut odd = Vec::with_capacity(n / 2);
for (i, &inp) in inp.iter().enumerate() {
if i % 2 == 0 {
even.push(inp)
} else {
odd.push(inp);
}
}
let even_fft = fft(&even);
let odd_fft = fft(&odd);
let two_pi = T::PI() + T::PI();
let n_t = T::from(n).unwrap();
for k in 0..n / 2 {
let k_t = T::from(k).unwrap();
let theta = two_pi * k_t / n_t;
let re = theta.cos();
let im = -theta.sin();
let re_odd = odd_fft[2 * k];
let im_odd = odd_fft[2 * k + 1];
out[2 * k] = even_fft[2 * k] + re * re_odd - im * im_odd;
out[2 * k + 1] = even_fft[2 * k + 1] + re * im_odd + im * re_odd;
out[2 * (k + n / 2)] = even_fft[2 * k] - re * re_odd + im * im_odd;
out[2 * (k + n / 2) + 1] = even_fft[2 * k + 1] - re * im_odd - im * re_odd;
}
out
}
// https://github.com/ggerganov/whisper.cpp/blob/4774d2feb01a772a15de81ffc34b34a1f294f020/whisper.cpp#L2337
fn dft<T: Float>(inp: &[T]) -> Vec<T> {
let zero = T::zero();
let n = inp.len();
let two_pi = T::PI() + T::PI();
let mut out = Vec::with_capacity(2 * n);
let n_t = T::from(n).unwrap();
for k in 0..n {
let k_t = T::from(k).unwrap();
let mut re = zero;
let mut im = zero;
for (j, &inp) in inp.iter().enumerate() {
let j_t = T::from(j).unwrap();
let angle = two_pi * k_t * j_t / n_t;
re += inp * angle.cos();
im -= inp * angle.sin();
}
out.push(re);
out.push(im);
}
out
}
#[allow(clippy::too_many_arguments)]
// https://github.com/ggerganov/whisper.cpp/blob/4774d2feb01a772a15de81ffc34b34a1f294f020/whisper.cpp#L2414
fn log_mel_spectrogram_w<T: Float>(
ith: usize,
hann: &[T],
samples: &[T],
filters: &[T],
fft_size: usize,
fft_step: usize,
speed_up: bool,
n_len: usize,
n_mel: usize,
n_threads: usize,
) -> Vec<T> {
let n_fft = if speed_up {
1 + fft_size / 4
} else {
1 + fft_size / 2
};
let zero = T::zero();
let half = T::from(0.5).unwrap();
let mut fft_in = vec![zero; fft_size];
let mut mel = vec![zero; n_len * n_mel];
let n_samples = samples.len();
let end = std::cmp::min(n_samples / fft_step + 1, n_len);
for i in (ith..end).step_by(n_threads) {
let offset = i * fft_step;
// apply Hanning window
for j in 0..std::cmp::min(fft_size, n_samples - offset) {
fft_in[j] = hann[j] * samples[offset + j];
}
// fill the rest with zeros
if n_samples - offset < fft_size {
fft_in[n_samples - offset..].fill(zero);
}
// FFT
let mut fft_out: Vec<T> = fft(&fft_in);
// Calculate modulus^2 of complex numbers
for j in 0..fft_size {
fft_out[j] = fft_out[2 * j] * fft_out[2 * j] + fft_out[2 * j + 1] * fft_out[2 * j + 1];
}
for j in 1..fft_size / 2 {
let v = fft_out[fft_size - j];
fft_out[j] += v;
}
if speed_up {
// scale down in the frequency domain results in a speed up in the time domain
for j in 0..n_fft {
fft_out[j] = half * (fft_out[2 * j] + fft_out[2 * j + 1]);
}
}
// mel spectrogram
for j in 0..n_mel {
let mut sum = zero;
let mut k = 0;
// Unroll loop
while k < n_fft.saturating_sub(3) {
sum += fft_out[k] * filters[j * n_fft + k]
+ fft_out[k + 1] * filters[j * n_fft + k + 1]
+ fft_out[k + 2] * filters[j * n_fft + k + 2]
+ fft_out[k + 3] * filters[j * n_fft + k + 3];
k += 4;
}
// Handle remainder
while k < n_fft {
sum += fft_out[k] * filters[j * n_fft + k];
k += 1;
}
mel[j * n_len + i] = T::max(sum, T::from(1e-10).unwrap()).log10();
}
}
mel
}
pub fn log_mel_spectrogram_<T: Float>(
samples: &[T],
filters: &[T],
fft_size: usize,
fft_step: usize,
n_mel: usize,
speed_up: bool,
) -> Vec<T> {
let zero = T::zero();
let two_pi = T::PI() + T::PI();
let half = T::from(0.5).unwrap();
let one = T::from(1.0).unwrap();
let four = T::from(4.0).unwrap();
let fft_size_t = T::from(fft_size).unwrap();
let hann: Vec<T> = (0..fft_size)
.map(|i| half * (one - ((two_pi * T::from(i).unwrap()) / fft_size_t).cos()))
.collect();
let n_len = samples.len() / fft_step;
// pad audio with at least one extra chunk of zeros
let pad = 100 * super::CHUNK_LENGTH / 2;
let n_len = if n_len % pad != 0 {
(n_len / pad + 1) * pad
} else {
n_len
};
let n_len = n_len + pad;
let samples = {
let mut samples_padded = samples.to_vec();
let to_add = n_len * fft_step - samples.len();
samples_padded.extend(std::iter::repeat(zero).take(to_add));
samples_padded
};
// ensure that the number of threads is even and less than 12
let n_threads = std::cmp::min(get_num_threads() - get_num_threads() % 2, 12);
let hann = Arc::new(hann);
let samples = Arc::new(samples);
let filters = Arc::new(filters);
// use scope to allow for non static references to be passed to the threads
// and directly collect the results into a single vector
let all_outputs = thread::scope(|s| {
(0..n_threads)
// create threads and return their handles
.map(|thread_id| {
let hann = Arc::clone(&hann);
let samples = Arc::clone(&samples);
let filters = Arc::clone(&filters);
// spawn new thread and start work
s.spawn(move || {
log_mel_spectrogram_w(
thread_id, &hann, &samples, &filters, fft_size, fft_step, speed_up, n_len,
n_mel, n_threads,
)
})
})
.collect::<Vec<_>>()
.into_iter()
// wait for each thread to finish and collect their results
.map(|handle| handle.join().expect("Thread failed"))
.collect::<Vec<_>>()
});
let l = all_outputs[0].len();
let mut mel = vec![zero; l];
// iterate over mel spectrogram segments, dividing work by threads.
for segment_start in (0..l).step_by(n_threads) {
// go through each thread's output.
for thread_output in all_outputs.iter() {
// add each thread's piece to our mel spectrogram.
for offset in 0..n_threads {
let mel_index = segment_start + offset; // find location in mel.
if mel_index < mel.len() {
// Make sure we don't go out of bounds.
mel[mel_index] += thread_output[mel_index];
}
}
}
}
let mmax = mel
.iter()
.max_by(|&u, &v| u.partial_cmp(v).unwrap_or(std::cmp::Ordering::Greater))
.copied()
.unwrap_or(zero)
- T::from(8).unwrap();
for m in mel.iter_mut() {
let v = T::max(*m, mmax);
*m = v / four + one
}
mel
}
pub fn pcm_to_mel<T: Float>(cfg: &super::Config, samples: &[T], filters: &[T]) -> Vec<T> {
log_mel_spectrogram_(
samples,
filters,
super::N_FFT,
super::HOP_LENGTH,
cfg.num_mel_bins,
false,
)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_fft() {
let input = vec![0.0, 1.0, 0.0, 0.0];
let output = fft(&input);
assert_eq!(
output,
vec![
1.0,
0.0,
6.123233995736766e-17,
-1.0,
-1.0,
0.0,
-6.123233995736766e-17,
1.0
]
);
}
#[test]
fn test_dft() {
let input = vec![0.0, 1.0, 0.0, 0.0];
let output = dft(&input);
assert_eq!(
output,
vec![
1.0,
0.0,
6.123233995736766e-17,
-1.0,
-1.0,
-1.2246467991473532e-16,
-1.8369701987210297e-16,
1.0
]
);
}
#[test]
fn test_log_mel_spectrogram() {
let samples = vec![0.0; 1000];
let filters = vec![0.0; 1000];
let output = log_mel_spectrogram_(&samples, &filters, 100, 10, 10, false);
assert_eq!(output.len(), 30_000);
}
#[test]
fn test_tiny_log_mel_spectrogram() {
let samples = vec![0.0; 100];
let filters = vec![0.0; 100];
let output = log_mel_spectrogram_(&samples, &filters, 20, 2, 2, false);
assert_eq!(output.len(), 6_000);
}
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/whisper/model.rs | use super::Config;
use crate::models::with_tracing::{linear, linear_no_bias, Linear};
use candle::{Device, IndexOp, Result, Tensor, D};
use candle_nn::{embedding, Conv1d, Conv1dConfig, Embedding, LayerNorm, Module, VarBuilder};
fn conv1d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
config: Conv1dConfig,
vb: VarBuilder,
) -> Result<Conv1d> {
let weight = vb.get((out_channels, in_channels, kernel_size), "weight")?;
let bias = vb.get(out_channels, "bias")?;
Ok(Conv1d::new(weight, Some(bias), config))
}
fn layer_norm(size: usize, vb: VarBuilder) -> Result<LayerNorm> {
let weight = vb.get(size, "weight")?;
let bias = vb.get(size, "bias")?;
Ok(LayerNorm::new(weight, bias, 1e-5))
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L62
#[derive(Debug, Clone)]
struct MultiHeadAttention {
query: Linear,
key: Linear,
value: Linear,
out: Linear,
n_head: usize,
span: tracing::Span,
softmax_span: tracing::Span,
matmul_span: tracing::Span,
kv_cache: Option<(Tensor, Tensor)>,
}
impl MultiHeadAttention {
fn load(n_state: usize, n_head: usize, vb: VarBuilder) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "multi-head-attn");
let softmax_span = tracing::span!(tracing::Level::TRACE, "multi-head-attn-softmax");
let matmul_span = tracing::span!(tracing::Level::TRACE, "multi-head-attn-matmul");
let query = linear(n_state, n_state, vb.pp("q_proj"))?;
let value = linear(n_state, n_state, vb.pp("v_proj"))?;
let key = linear_no_bias(n_state, n_state, vb.pp("k_proj"))?;
let out = linear(n_state, n_state, vb.pp("out_proj"))?;
Ok(Self {
query,
key,
value,
out,
n_head,
span,
softmax_span,
matmul_span,
kv_cache: None,
})
}
fn forward(
&mut self,
x: &Tensor,
xa: Option<&Tensor>,
mask: Option<&Tensor>,
flush_cache: bool,
) -> Result<Tensor> {
let _enter = self.span.enter();
let q = self.query.forward(x)?;
let (k, v) = match xa {
None => {
let k = self.key.forward(x)?;
let v = self.value.forward(x)?;
(k, v)
}
Some(x) => {
if flush_cache {
self.kv_cache = None;
}
if let Some((k, v)) = &self.kv_cache {
(k.clone(), v.clone())
} else {
let k = self.key.forward(x)?;
let v = self.value.forward(x)?;
self.kv_cache = Some((k.clone(), v.clone()));
(k, v)
}
}
};
let wv = self.qkv_attention(&q, &k, &v, mask)?;
let out = self.out.forward(&wv)?;
Ok(out)
}
fn reshape_head(&self, x: &Tensor) -> Result<Tensor> {
let (n_batch, n_ctx, n_state) = x.dims3()?;
let target_dims = &[n_batch, n_ctx, self.n_head, n_state / self.n_head];
x.reshape(target_dims)?.transpose(1, 2)
}
fn qkv_attention(
&self,
q: &Tensor,
k: &Tensor,
v: &Tensor,
mask: Option<&Tensor>,
) -> Result<Tensor> {
let (_, n_ctx, n_state) = q.dims3()?;
let scale = ((n_state / self.n_head) as f64).powf(-0.25);
let q = (self.reshape_head(q)? * scale)?;
let k = (self.reshape_head(k)?.transpose(2, 3)? * scale)?;
let v = self.reshape_head(v)?.contiguous()?;
let mut qk = {
let _enter = self.matmul_span.enter();
q.matmul(&k)?
};
if let Some(mask) = mask {
let mask = mask.i((0..n_ctx, 0..n_ctx))?;
qk = qk.broadcast_add(&mask)?
}
let w = {
let _enter = self.softmax_span.enter();
candle_nn::ops::softmax_last_dim(&qk)?
};
let wv = {
let _enter = self.matmul_span.enter();
w.matmul(&v)?
}
.transpose(1, 2)?
.flatten_from(2)?;
Ok(wv)
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None;
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L111
#[derive(Debug, Clone)]
struct ResidualAttentionBlock {
attn: MultiHeadAttention,
attn_ln: LayerNorm,
cross_attn: Option<(MultiHeadAttention, LayerNorm)>,
mlp_linear1: Linear,
mlp_linear2: Linear,
mlp_ln: LayerNorm,
span: tracing::Span,
}
impl ResidualAttentionBlock {
fn load(n_state: usize, n_head: usize, ca: bool, vb: VarBuilder) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "residual-attn");
let attn = MultiHeadAttention::load(n_state, n_head, vb.pp("self_attn"))?;
let attn_ln = layer_norm(n_state, vb.pp("self_attn_layer_norm"))?;
let cross_attn = if ca {
let cross_attn = MultiHeadAttention::load(n_state, n_head, vb.pp("encoder_attn"))?;
let cross_attn_ln = layer_norm(n_state, vb.pp("encoder_attn_layer_norm"))?;
Some((cross_attn, cross_attn_ln))
} else {
None
};
let n_mlp = n_state * 4;
let mlp_linear1 = linear(n_state, n_mlp, vb.pp("fc1"))?;
let mlp_linear2 = linear(n_mlp, n_state, vb.pp("fc2"))?;
let mlp_ln = layer_norm(n_state, vb.pp("final_layer_norm"))?;
Ok(Self {
attn,
attn_ln,
cross_attn,
mlp_linear1,
mlp_linear2,
mlp_ln,
span,
})
}
fn forward(
&mut self,
x: &Tensor,
xa: Option<&Tensor>,
mask: Option<&Tensor>,
flush_kv_cache: bool,
) -> Result<Tensor> {
let _enter = self.span.enter();
let attn = self
.attn
.forward(&self.attn_ln.forward(x)?, None, mask, flush_kv_cache)?;
let mut x = (x + attn)?;
if let Some((attn, ln)) = &mut self.cross_attn {
x = (&x + attn.forward(&ln.forward(&x)?, xa, None, flush_kv_cache)?)?;
}
let mlp = self.mlp_linear2.forward(
&self
.mlp_linear1
.forward(&self.mlp_ln.forward(&x)?)?
.gelu()?,
)?;
x + mlp
}
fn reset_kv_cache(&mut self) {
self.attn.reset_kv_cache();
if let Some((attn, _)) = &mut self.cross_attn {
attn.reset_kv_cache();
}
}
}
fn sinusoids(length: usize, channels: usize, device: &Device) -> Result<Tensor> {
let max_timescale = 10000f32;
let log_timescale_increment = max_timescale.ln() / (channels / 2 - 1) as f32;
let inv_timescales: Vec<_> = (0..channels / 2)
.map(|i| (i as f32 * (-log_timescale_increment)).exp())
.collect();
let inv_timescales = Tensor::new(inv_timescales.as_slice(), device)?.unsqueeze(0)?;
let arange = Tensor::arange(0, length as u32, device)?
.to_dtype(candle::DType::F32)?
.unsqueeze(1)?;
let sh = (length, channels / 2);
let scaled_time = (arange.broadcast_as(sh)? * inv_timescales.broadcast_as(sh)?)?;
let sincos = Tensor::cat(&[scaled_time.sin()?, scaled_time.cos()?], 1)?;
Ok(sincos)
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L143
#[derive(Debug, Clone)]
pub struct AudioEncoder {
conv1: Conv1d,
conv2: Conv1d,
positional_embedding: Tensor,
blocks: Vec<ResidualAttentionBlock>,
ln_post: LayerNorm,
span: tracing::Span,
conv1_span: tracing::Span,
conv2_span: tracing::Span,
}
impl AudioEncoder {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "audio-encoder");
let conv1_span = tracing::span!(tracing::Level::TRACE, "conv1");
let conv2_span = tracing::span!(tracing::Level::TRACE, "conv2");
let n_state = cfg.d_model;
let n_head = cfg.encoder_attention_heads;
let n_ctx = cfg.max_source_positions;
let cfg1 = Conv1dConfig {
padding: 1,
stride: 1,
groups: 1,
dilation: 1,
};
let cfg2 = Conv1dConfig {
padding: 1,
stride: 2,
groups: 1,
dilation: 1,
};
let conv1 = conv1d(cfg.num_mel_bins, n_state, 3, cfg1, vb.pp("conv1"))?;
let conv2 = conv1d(n_state, n_state, 3, cfg2, vb.pp("conv2"))?;
let positional_embedding = sinusoids(n_ctx, n_state, vb.device())?;
let blocks = (0..cfg.encoder_layers)
.map(|i| {
ResidualAttentionBlock::load(n_state, n_head, false, vb.pp(format!("layers.{i}")))
})
.collect::<Result<Vec<_>>>()?;
let ln_post = layer_norm(n_state, vb.pp("layer_norm"))?;
Ok(Self {
conv1,
conv2,
positional_embedding,
blocks,
ln_post,
conv1_span,
conv2_span,
span,
})
}
pub fn forward(&mut self, x: &Tensor, flush_kv_cache: bool) -> Result<Tensor> {
let _enter = self.span.enter();
let x = {
let _enter = self.conv1_span.enter();
self.conv1.forward(x)?.gelu()?
};
let x = {
let _enter = self.conv2_span.enter();
self.conv2.forward(&x)?.gelu()?
};
let x = x.transpose(1, 2)?;
let (_bsize, seq_len, _hidden) = x.dims3()?;
let positional_embedding = self.positional_embedding.narrow(0, 0, seq_len)?;
let mut x = x.broadcast_add(&positional_embedding)?;
for block in self.blocks.iter_mut() {
x = block.forward(&x, None, None, flush_kv_cache)?
}
let x = self.ln_post.forward(&x)?;
Ok(x)
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L176
#[derive(Debug, Clone)]
pub struct TextDecoder {
token_embedding: Embedding,
positional_embedding: Tensor,
blocks: Vec<ResidualAttentionBlock>,
ln: LayerNorm,
mask: Tensor,
span: tracing::Span,
span_final: tracing::Span,
}
impl TextDecoder {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "text-decoder");
let span_final = tracing::span!(tracing::Level::TRACE, "text-decoder-final");
let n_state = cfg.d_model;
let n_head = cfg.decoder_attention_heads;
let n_ctx = cfg.max_target_positions;
let token_embedding = embedding(cfg.vocab_size, n_state, vb.pp("embed_tokens"))?;
let positional_embedding = vb.get((n_ctx, n_state), "embed_positions.weight")?;
let blocks = (0..cfg.decoder_layers)
.map(|i| {
ResidualAttentionBlock::load(n_state, n_head, true, vb.pp(format!("layers.{i}")))
})
.collect::<Result<Vec<_>>>()?;
let ln = layer_norm(n_state, vb.pp("layer_norm"))?;
let mask: Vec<_> = (0..n_ctx)
.flat_map(|i| (0..n_ctx).map(move |j| if j > i { f32::NEG_INFINITY } else { 0f32 }))
.collect();
let mask = Tensor::from_vec(mask, (n_ctx, n_ctx), vb.device())?;
Ok(Self {
token_embedding,
positional_embedding,
blocks,
ln,
mask,
span,
span_final,
})
}
pub fn forward(&mut self, x: &Tensor, xa: &Tensor, flush_kv_cache: bool) -> Result<Tensor> {
let _enter = self.span.enter();
let last = x.dim(D::Minus1)?;
let token_embedding = self.token_embedding.forward(x)?;
let positional_embedding = self.positional_embedding.narrow(0, 0, last)?;
let mut x = token_embedding.broadcast_add(&positional_embedding)?;
for block in self.blocks.iter_mut() {
x = block.forward(&x, Some(xa), Some(&self.mask), flush_kv_cache)?;
}
self.ln.forward(&x)
}
pub fn final_linear(&self, x: &Tensor) -> Result<Tensor> {
let b_size = x.dim(0)?;
let w = self.token_embedding.embeddings().broadcast_left(b_size)?;
let logits = {
let _enter = self.span_final.enter();
x.matmul(&w.t()?)?
};
Ok(logits)
}
pub fn reset_kv_cache(&mut self) {
for block in self.blocks.iter_mut() {
block.reset_kv_cache();
}
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L221
#[derive(Debug, Clone)]
pub struct Whisper {
pub encoder: AudioEncoder,
pub decoder: TextDecoder,
pub config: Config,
}
impl Whisper {
pub fn load(vb: &VarBuilder, config: Config) -> Result<Self> {
let encoder = AudioEncoder::load(vb.pp("model.encoder"), &config)?;
let decoder = TextDecoder::load(vb.pp("model.decoder"), &config)?;
Ok(Self {
encoder,
decoder,
config,
})
}
pub fn reset_kv_cache(&mut self) {
self.encoder
.blocks
.iter_mut()
.for_each(|b| b.reset_kv_cache());
self.decoder.reset_kv_cache();
}
}
| 3 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/whisper/quantized_model.rs | use super::Config;
use crate::quantized_nn::{layer_norm, linear, linear_no_bias, Embedding, Linear};
pub use crate::quantized_var_builder::VarBuilder;
use candle::{Device, IndexOp, Result, Tensor, D};
use candle_nn::{Conv1d, Conv1dConfig, LayerNorm, Module};
fn conv1d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
config: Conv1dConfig,
vb: VarBuilder,
) -> Result<Conv1d> {
let weight = vb
.get((out_channels, in_channels, kernel_size), "weight")?
.dequantize(vb.device())?;
let bias = vb.get(out_channels, "bias")?.dequantize(vb.device())?;
Ok(Conv1d::new(weight, Some(bias), config))
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L62
#[derive(Debug, Clone)]
struct MultiHeadAttention {
query: Linear,
key: Linear,
value: Linear,
out: Linear,
n_head: usize,
span: tracing::Span,
softmax_span: tracing::Span,
matmul_span: tracing::Span,
kv_cache: Option<(Tensor, Tensor)>,
}
impl MultiHeadAttention {
fn load(n_state: usize, n_head: usize, vb: VarBuilder) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "multi-head-attn");
let softmax_span = tracing::span!(tracing::Level::TRACE, "multi-head-attn-softmax");
let matmul_span = tracing::span!(tracing::Level::TRACE, "multi-head-attn-matmul");
let query = linear(n_state, n_state, vb.pp("q_proj"))?;
let value = linear(n_state, n_state, vb.pp("v_proj"))?;
let key = linear_no_bias(n_state, n_state, vb.pp("k_proj"))?;
let out = linear(n_state, n_state, vb.pp("out_proj"))?;
Ok(Self {
query,
key,
value,
out,
n_head,
span,
softmax_span,
matmul_span,
kv_cache: None,
})
}
fn forward(
&mut self,
x: &Tensor,
xa: Option<&Tensor>,
mask: Option<&Tensor>,
flush_cache: bool,
) -> Result<Tensor> {
let _enter = self.span.enter();
let q = self.query.forward(x)?;
let (k, v) = match xa {
None => {
let k = self.key.forward(x)?;
let v = self.value.forward(x)?;
(k, v)
}
Some(x) => {
if flush_cache {
self.kv_cache = None;
}
if let Some((k, v)) = &self.kv_cache {
(k.clone(), v.clone())
} else {
let k = self.key.forward(x)?;
let v = self.value.forward(x)?;
self.kv_cache = Some((k.clone(), v.clone()));
(k, v)
}
}
};
let wv = self.qkv_attention(&q, &k, &v, mask)?;
let out = self.out.forward(&wv)?;
Ok(out)
}
fn reshape_head(&self, x: &Tensor) -> Result<Tensor> {
let (n_batch, n_ctx, n_state) = x.dims3()?;
let target_dims = &[n_batch, n_ctx, self.n_head, n_state / self.n_head];
x.reshape(target_dims)?.transpose(1, 2)
}
fn qkv_attention(
&self,
q: &Tensor,
k: &Tensor,
v: &Tensor,
mask: Option<&Tensor>,
) -> Result<Tensor> {
let (_, n_ctx, n_state) = q.dims3()?;
let scale = ((n_state / self.n_head) as f64).powf(-0.25);
let q = (self.reshape_head(q)? * scale)?;
let k = (self.reshape_head(k)?.transpose(2, 3)? * scale)?;
let v = self.reshape_head(v)?.contiguous()?;
let mut qk = {
let _enter = self.matmul_span.enter();
q.matmul(&k)?
};
if let Some(mask) = mask {
let mask = mask.i((0..n_ctx, 0..n_ctx))?;
qk = qk.broadcast_add(&mask)?
}
let w = {
let _enter = self.softmax_span.enter();
candle_nn::ops::softmax_last_dim(&qk)?
};
let wv = {
let _enter = self.matmul_span.enter();
w.matmul(&v)?
}
.transpose(1, 2)?
.flatten_from(2)?;
Ok(wv)
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None;
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L111
#[derive(Debug, Clone)]
struct ResidualAttentionBlock {
attn: MultiHeadAttention,
attn_ln: LayerNorm,
cross_attn: Option<(MultiHeadAttention, LayerNorm)>,
mlp_linear1: Linear,
mlp_linear2: Linear,
mlp_ln: LayerNorm,
span: tracing::Span,
}
impl ResidualAttentionBlock {
fn load(n_state: usize, n_head: usize, ca: bool, vb: VarBuilder) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "residual-attn");
let attn = MultiHeadAttention::load(n_state, n_head, vb.pp("self_attn"))?;
let attn_ln = layer_norm(n_state, 1e-5, vb.pp("self_attn_layer_norm"))?;
let cross_attn = if ca {
let cross_attn = MultiHeadAttention::load(n_state, n_head, vb.pp("encoder_attn"))?;
let cross_attn_ln = layer_norm(n_state, 1e-5, vb.pp("encoder_attn_layer_norm"))?;
Some((cross_attn, cross_attn_ln))
} else {
None
};
let n_mlp = n_state * 4;
let mlp_linear1 = linear(n_state, n_mlp, vb.pp("fc1"))?;
let mlp_linear2 = linear(n_mlp, n_state, vb.pp("fc2"))?;
let mlp_ln = layer_norm(n_state, 1e-5, vb.pp("final_layer_norm"))?;
Ok(Self {
attn,
attn_ln,
cross_attn,
mlp_linear1,
mlp_linear2,
mlp_ln,
span,
})
}
fn forward(
&mut self,
x: &Tensor,
xa: Option<&Tensor>,
mask: Option<&Tensor>,
flush_kv_cache: bool,
) -> Result<Tensor> {
let _enter = self.span.enter();
let attn = self
.attn
.forward(&self.attn_ln.forward(x)?, None, mask, flush_kv_cache)?;
let mut x = (x + attn)?;
if let Some((attn, ln)) = &mut self.cross_attn {
x = (&x + attn.forward(&ln.forward(&x)?, xa, None, flush_kv_cache)?)?;
}
let mlp = x
.apply(&self.mlp_ln)?
.apply(&self.mlp_linear1)?
.gelu()?
.apply(&self.mlp_linear2)?;
x + mlp
}
fn reset_kv_cache(&mut self) {
self.attn.reset_kv_cache();
if let Some((attn, _)) = &mut self.cross_attn {
attn.reset_kv_cache();
}
}
}
fn sinusoids(length: usize, channels: usize, device: &Device) -> Result<Tensor> {
let max_timescale = 10000f32;
let log_timescale_increment = max_timescale.ln() / (channels / 2 - 1) as f32;
let inv_timescales: Vec<_> = (0..channels / 2)
.map(|i| (i as f32 * (-log_timescale_increment)).exp())
.collect();
let inv_timescales = Tensor::new(inv_timescales.as_slice(), device)?.unsqueeze(0)?;
let arange = Tensor::arange(0, length as u32, device)?
.to_dtype(candle::DType::F32)?
.unsqueeze(1)?;
let sh = (length, channels / 2);
let scaled_time = (arange.broadcast_as(sh)? * inv_timescales.broadcast_as(sh)?)?;
let sincos = Tensor::cat(&[scaled_time.sin()?, scaled_time.cos()?], 1)?;
Ok(sincos)
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L143
#[derive(Debug, Clone)]
pub struct AudioEncoder {
conv1: Conv1d,
conv2: Conv1d,
positional_embedding: Tensor,
blocks: Vec<ResidualAttentionBlock>,
ln_post: LayerNorm,
span: tracing::Span,
conv1_span: tracing::Span,
conv2_span: tracing::Span,
}
impl AudioEncoder {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "audio-encoder");
let conv1_span = tracing::span!(tracing::Level::TRACE, "conv1");
let conv2_span = tracing::span!(tracing::Level::TRACE, "conv2");
let n_state = cfg.d_model;
let n_head = cfg.encoder_attention_heads;
let n_ctx = cfg.max_source_positions;
let cfg1 = Conv1dConfig {
padding: 1,
stride: 1,
groups: 1,
dilation: 1,
};
let cfg2 = Conv1dConfig {
padding: 1,
stride: 2,
groups: 1,
dilation: 1,
};
let conv1 = conv1d(cfg.num_mel_bins, n_state, 3, cfg1, vb.pp("conv1"))?;
let conv2 = conv1d(n_state, n_state, 3, cfg2, vb.pp("conv2"))?;
let positional_embedding = sinusoids(n_ctx, n_state, vb.device())?;
let blocks = (0..cfg.encoder_layers)
.map(|i| {
ResidualAttentionBlock::load(n_state, n_head, false, vb.pp(format!("layers.{i}")))
})
.collect::<Result<Vec<_>>>()?;
let ln_post = layer_norm(n_state, 1e-5, vb.pp("layer_norm"))?;
Ok(Self {
conv1,
conv2,
positional_embedding,
blocks,
ln_post,
conv1_span,
conv2_span,
span,
})
}
pub fn forward(&mut self, x: &Tensor, flush_kv_cache: bool) -> Result<Tensor> {
let _enter = self.span.enter();
let x = {
let _enter = self.conv1_span.enter();
self.conv1.forward(x)?.gelu()?
};
let x = {
let _enter = self.conv2_span.enter();
self.conv2.forward(&x)?.gelu()?
};
let x = x.transpose(1, 2)?;
let (_bsize, seq_len, _hidden) = x.dims3()?;
let positional_embedding = self.positional_embedding.narrow(0, 0, seq_len)?;
let mut x = x.broadcast_add(&positional_embedding)?;
for block in self.blocks.iter_mut() {
x = block.forward(&x, None, None, flush_kv_cache)?
}
let x = self.ln_post.forward(&x)?;
Ok(x)
}
pub fn reset_kv_cache(&mut self) {
for block in self.blocks.iter_mut() {
block.reset_kv_cache();
}
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L176
#[derive(Debug, Clone)]
pub struct TextDecoder {
token_embedding: Embedding,
positional_embedding: Tensor,
blocks: Vec<ResidualAttentionBlock>,
ln: LayerNorm,
mask: Tensor,
span: tracing::Span,
span_final: tracing::Span,
}
impl TextDecoder {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "text-decoder");
let span_final = tracing::span!(tracing::Level::TRACE, "text-decoder-final");
let n_state = cfg.d_model;
let n_head = cfg.decoder_attention_heads;
let n_ctx = cfg.max_target_positions;
let token_embedding = Embedding::new(cfg.vocab_size, n_state, vb.pp("embed_tokens"))?;
let positional_embedding = vb
.get((n_ctx, n_state), "embed_positions.weight")?
.dequantize(vb.device())?;
let blocks = (0..cfg.decoder_layers)
.map(|i| {
ResidualAttentionBlock::load(n_state, n_head, true, vb.pp(format!("layers.{i}")))
})
.collect::<Result<Vec<_>>>()?;
let ln = layer_norm(n_state, 1e-5, vb.pp("layer_norm"))?;
let mask: Vec<_> = (0..n_ctx)
.flat_map(|i| (0..n_ctx).map(move |j| if j > i { f32::NEG_INFINITY } else { 0f32 }))
.collect();
let mask = Tensor::from_vec(mask, (n_ctx, n_ctx), vb.device())?;
Ok(Self {
token_embedding,
positional_embedding,
blocks,
ln,
mask,
span,
span_final,
})
}
pub fn forward(&mut self, x: &Tensor, xa: &Tensor, flush_kv_cache: bool) -> Result<Tensor> {
let _enter = self.span.enter();
let last = x.dim(D::Minus1)?;
let token_embedding = self.token_embedding.forward(x)?;
let positional_embedding = self.positional_embedding.narrow(0, 0, last)?;
let mut x = token_embedding.broadcast_add(&positional_embedding)?;
for block in self.blocks.iter_mut() {
x = block.forward(&x, Some(xa), Some(&self.mask), flush_kv_cache)?;
}
self.ln.forward(&x)
}
pub fn final_linear(&self, x: &Tensor) -> Result<Tensor> {
let b_size = x.dim(0)?;
let w = self.token_embedding.embeddings().broadcast_left(b_size)?;
let logits = {
let _enter = self.span_final.enter();
x.matmul(&w.t()?)?
};
Ok(logits)
}
pub fn reset_kv_cache(&mut self) {
for block in self.blocks.iter_mut() {
block.reset_kv_cache();
}
}
}
// https://github.com/openai/whisper/blob/f572f2161ba831bae131364c3bffdead7af6d210/whisper/model.py#L221
#[derive(Debug, Clone)]
pub struct Whisper {
pub encoder: AudioEncoder,
pub decoder: TextDecoder,
pub config: Config,
}
impl Whisper {
pub fn load(vb: &VarBuilder, config: Config) -> Result<Self> {
let encoder = AudioEncoder::load(vb.pp("model.encoder"), &config)?;
let decoder = TextDecoder::load(vb.pp("model.decoder"), &config)?;
Ok(Self {
encoder,
decoder,
config,
})
}
pub fn reset_kv_cache(&mut self) {
self.encoder.reset_kv_cache();
self.decoder.reset_kv_cache();
}
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/flux/mod.rs | //! Flux Model
//!
//! Flux is a 12B rectified flow transformer capable of generating images from text descriptions.
//!
//! - 🤗 [Hugging Face Model](https://huggingface.co/black-forest-labs/FLUX.1-schnell)
//! - 💻 [GitHub Repository](https://github.com/black-forest-labs/flux)
//! - 📝 [Blog Post](https://blackforestlabs.ai/announcing-black-forest-labs/)
//!
//! # Usage
//!
//! ```bash
//! cargo run --features cuda \
//! --example flux -r -- \
//! --height 1024 --width 1024 \
//! --prompt "a rusty robot walking on a beach holding a small torch, \
//! the robot has the word \"rust\" written on it, high quality, 4k"
//! ```
//!
//! <div align=center>
//! <img src="https://github.com/huggingface/candle/raw/main/candle-examples/examples/flux/assets/flux-robot.jpg" alt="" width=320>
//! </div>
//!
use candle::{Result, Tensor};
pub trait WithForward {
#[allow(clippy::too_many_arguments)]
fn forward(
&self,
img: &Tensor,
img_ids: &Tensor,
txt: &Tensor,
txt_ids: &Tensor,
timesteps: &Tensor,
y: &Tensor,
guidance: Option<&Tensor>,
) -> Result<Tensor>;
}
pub mod autoencoder;
pub mod model;
pub mod quantized_model;
pub mod sampling;
| 5 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/flux/model.rs | use candle::{DType, IndexOp, Result, Tensor, D};
use candle_nn::{LayerNorm, Linear, RmsNorm, VarBuilder};
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/model.py#L12
#[derive(Debug, Clone)]
pub struct Config {
pub in_channels: usize,
pub vec_in_dim: usize,
pub context_in_dim: usize,
pub hidden_size: usize,
pub mlp_ratio: f64,
pub num_heads: usize,
pub depth: usize,
pub depth_single_blocks: usize,
pub axes_dim: Vec<usize>,
pub theta: usize,
pub qkv_bias: bool,
pub guidance_embed: bool,
}
impl Config {
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/util.py#L32
pub fn dev() -> Self {
Self {
in_channels: 64,
vec_in_dim: 768,
context_in_dim: 4096,
hidden_size: 3072,
mlp_ratio: 4.0,
num_heads: 24,
depth: 19,
depth_single_blocks: 38,
axes_dim: vec![16, 56, 56],
theta: 10_000,
qkv_bias: true,
guidance_embed: true,
}
}
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/util.py#L64
pub fn schnell() -> Self {
Self {
in_channels: 64,
vec_in_dim: 768,
context_in_dim: 4096,
hidden_size: 3072,
mlp_ratio: 4.0,
num_heads: 24,
depth: 19,
depth_single_blocks: 38,
axes_dim: vec![16, 56, 56],
theta: 10_000,
qkv_bias: true,
guidance_embed: false,
}
}
}
fn layer_norm(dim: usize, vb: VarBuilder) -> Result<LayerNorm> {
let ws = Tensor::ones(dim, vb.dtype(), vb.device())?;
Ok(LayerNorm::new_no_bias(ws, 1e-6))
}
fn scaled_dot_product_attention(q: &Tensor, k: &Tensor, v: &Tensor) -> Result<Tensor> {
let dim = q.dim(D::Minus1)?;
let scale_factor = 1.0 / (dim as f64).sqrt();
let mut batch_dims = q.dims().to_vec();
batch_dims.pop();
batch_dims.pop();
let q = q.flatten_to(batch_dims.len() - 1)?;
let k = k.flatten_to(batch_dims.len() - 1)?;
let v = v.flatten_to(batch_dims.len() - 1)?;
let attn_weights = (q.matmul(&k.t()?)? * scale_factor)?;
let attn_scores = candle_nn::ops::softmax_last_dim(&attn_weights)?.matmul(&v)?;
batch_dims.push(attn_scores.dim(D::Minus2)?);
batch_dims.push(attn_scores.dim(D::Minus1)?);
attn_scores.reshape(batch_dims)
}
fn rope(pos: &Tensor, dim: usize, theta: usize) -> Result<Tensor> {
if dim % 2 == 1 {
candle::bail!("dim {dim} is odd")
}
let dev = pos.device();
let theta = theta as f64;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / theta.powf(i as f64 / dim as f64) as f32)
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, 1, inv_freq_len), dev)?;
let inv_freq = inv_freq.to_dtype(pos.dtype())?;
let freqs = pos.unsqueeze(2)?.broadcast_mul(&inv_freq)?;
let cos = freqs.cos()?;
let sin = freqs.sin()?;
let out = Tensor::stack(&[&cos, &sin.neg()?, &sin, &cos], 3)?;
let (b, n, d, _ij) = out.dims4()?;
out.reshape((b, n, d, 2, 2))
}
fn apply_rope(x: &Tensor, freq_cis: &Tensor) -> Result<Tensor> {
let dims = x.dims();
let (b_sz, n_head, seq_len, n_embd) = x.dims4()?;
let x = x.reshape((b_sz, n_head, seq_len, n_embd / 2, 2))?;
let x0 = x.narrow(D::Minus1, 0, 1)?;
let x1 = x.narrow(D::Minus1, 1, 1)?;
let fr0 = freq_cis.get_on_dim(D::Minus1, 0)?;
let fr1 = freq_cis.get_on_dim(D::Minus1, 1)?;
(fr0.broadcast_mul(&x0)? + fr1.broadcast_mul(&x1)?)?.reshape(dims.to_vec())
}
pub(crate) fn attention(q: &Tensor, k: &Tensor, v: &Tensor, pe: &Tensor) -> Result<Tensor> {
let q = apply_rope(q, pe)?.contiguous()?;
let k = apply_rope(k, pe)?.contiguous()?;
let x = scaled_dot_product_attention(&q, &k, v)?;
x.transpose(1, 2)?.flatten_from(2)
}
pub(crate) fn timestep_embedding(t: &Tensor, dim: usize, dtype: DType) -> Result<Tensor> {
const TIME_FACTOR: f64 = 1000.;
const MAX_PERIOD: f64 = 10000.;
if dim % 2 == 1 {
candle::bail!("{dim} is odd")
}
let dev = t.device();
let half = dim / 2;
let t = (t * TIME_FACTOR)?;
let arange = Tensor::arange(0, half as u32, dev)?.to_dtype(candle::DType::F32)?;
let freqs = (arange * (-MAX_PERIOD.ln() / half as f64))?.exp()?;
let args = t
.unsqueeze(1)?
.to_dtype(candle::DType::F32)?
.broadcast_mul(&freqs.unsqueeze(0)?)?;
let emb = Tensor::cat(&[args.cos()?, args.sin()?], D::Minus1)?.to_dtype(dtype)?;
Ok(emb)
}
#[derive(Debug, Clone)]
pub struct EmbedNd {
#[allow(unused)]
dim: usize,
theta: usize,
axes_dim: Vec<usize>,
}
impl EmbedNd {
pub fn new(dim: usize, theta: usize, axes_dim: Vec<usize>) -> Self {
Self {
dim,
theta,
axes_dim,
}
}
}
impl candle::Module for EmbedNd {
fn forward(&self, ids: &Tensor) -> Result<Tensor> {
let n_axes = ids.dim(D::Minus1)?;
let mut emb = Vec::with_capacity(n_axes);
for idx in 0..n_axes {
let r = rope(
&ids.get_on_dim(D::Minus1, idx)?,
self.axes_dim[idx],
self.theta,
)?;
emb.push(r)
}
let emb = Tensor::cat(&emb, 2)?;
emb.unsqueeze(1)
}
}
#[derive(Debug, Clone)]
pub struct MlpEmbedder {
in_layer: Linear,
out_layer: Linear,
}
impl MlpEmbedder {
fn new(in_sz: usize, h_sz: usize, vb: VarBuilder) -> Result<Self> {
let in_layer = candle_nn::linear(in_sz, h_sz, vb.pp("in_layer"))?;
let out_layer = candle_nn::linear(h_sz, h_sz, vb.pp("out_layer"))?;
Ok(Self {
in_layer,
out_layer,
})
}
}
impl candle::Module for MlpEmbedder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.in_layer)?.silu()?.apply(&self.out_layer)
}
}
#[derive(Debug, Clone)]
pub struct QkNorm {
query_norm: RmsNorm,
key_norm: RmsNorm,
}
impl QkNorm {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let query_norm = vb.get(dim, "query_norm.scale")?;
let query_norm = RmsNorm::new(query_norm, 1e-6);
let key_norm = vb.get(dim, "key_norm.scale")?;
let key_norm = RmsNorm::new(key_norm, 1e-6);
Ok(Self {
query_norm,
key_norm,
})
}
}
struct ModulationOut {
shift: Tensor,
scale: Tensor,
gate: Tensor,
}
impl ModulationOut {
fn scale_shift(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&(&self.scale + 1.)?)?
.broadcast_add(&self.shift)
}
fn gate(&self, xs: &Tensor) -> Result<Tensor> {
self.gate.broadcast_mul(xs)
}
}
#[derive(Debug, Clone)]
struct Modulation1 {
lin: Linear,
}
impl Modulation1 {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let lin = candle_nn::linear(dim, 3 * dim, vb.pp("lin"))?;
Ok(Self { lin })
}
fn forward(&self, vec_: &Tensor) -> Result<ModulationOut> {
let ys = vec_
.silu()?
.apply(&self.lin)?
.unsqueeze(1)?
.chunk(3, D::Minus1)?;
if ys.len() != 3 {
candle::bail!("unexpected len from chunk {ys:?}")
}
Ok(ModulationOut {
shift: ys[0].clone(),
scale: ys[1].clone(),
gate: ys[2].clone(),
})
}
}
#[derive(Debug, Clone)]
struct Modulation2 {
lin: Linear,
}
impl Modulation2 {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let lin = candle_nn::linear(dim, 6 * dim, vb.pp("lin"))?;
Ok(Self { lin })
}
fn forward(&self, vec_: &Tensor) -> Result<(ModulationOut, ModulationOut)> {
let ys = vec_
.silu()?
.apply(&self.lin)?
.unsqueeze(1)?
.chunk(6, D::Minus1)?;
if ys.len() != 6 {
candle::bail!("unexpected len from chunk {ys:?}")
}
let mod1 = ModulationOut {
shift: ys[0].clone(),
scale: ys[1].clone(),
gate: ys[2].clone(),
};
let mod2 = ModulationOut {
shift: ys[3].clone(),
scale: ys[4].clone(),
gate: ys[5].clone(),
};
Ok((mod1, mod2))
}
}
#[derive(Debug, Clone)]
pub struct SelfAttention {
qkv: Linear,
norm: QkNorm,
proj: Linear,
num_heads: usize,
}
impl SelfAttention {
fn new(dim: usize, num_heads: usize, qkv_bias: bool, vb: VarBuilder) -> Result<Self> {
let head_dim = dim / num_heads;
let qkv = candle_nn::linear_b(dim, dim * 3, qkv_bias, vb.pp("qkv"))?;
let norm = QkNorm::new(head_dim, vb.pp("norm"))?;
let proj = candle_nn::linear(dim, dim, vb.pp("proj"))?;
Ok(Self {
qkv,
norm,
proj,
num_heads,
})
}
fn qkv(&self, xs: &Tensor) -> Result<(Tensor, Tensor, Tensor)> {
let qkv = xs.apply(&self.qkv)?;
let (b, l, _khd) = qkv.dims3()?;
let qkv = qkv.reshape((b, l, 3, self.num_heads, ()))?;
let q = qkv.i((.., .., 0))?.transpose(1, 2)?;
let k = qkv.i((.., .., 1))?.transpose(1, 2)?;
let v = qkv.i((.., .., 2))?.transpose(1, 2)?;
let q = q.apply(&self.norm.query_norm)?;
let k = k.apply(&self.norm.key_norm)?;
Ok((q, k, v))
}
#[allow(unused)]
fn forward(&self, xs: &Tensor, pe: &Tensor) -> Result<Tensor> {
let (q, k, v) = self.qkv(xs)?;
attention(&q, &k, &v, pe)?.apply(&self.proj)
}
}
#[derive(Debug, Clone)]
struct Mlp {
lin1: Linear,
lin2: Linear,
}
impl Mlp {
fn new(in_sz: usize, mlp_sz: usize, vb: VarBuilder) -> Result<Self> {
let lin1 = candle_nn::linear(in_sz, mlp_sz, vb.pp("0"))?;
let lin2 = candle_nn::linear(mlp_sz, in_sz, vb.pp("2"))?;
Ok(Self { lin1, lin2 })
}
}
impl candle::Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.lin1)?.gelu()?.apply(&self.lin2)
}
}
#[derive(Debug, Clone)]
pub struct DoubleStreamBlock {
img_mod: Modulation2,
img_norm1: LayerNorm,
img_attn: SelfAttention,
img_norm2: LayerNorm,
img_mlp: Mlp,
txt_mod: Modulation2,
txt_norm1: LayerNorm,
txt_attn: SelfAttention,
txt_norm2: LayerNorm,
txt_mlp: Mlp,
}
impl DoubleStreamBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let h_sz = cfg.hidden_size;
let mlp_sz = (h_sz as f64 * cfg.mlp_ratio) as usize;
let img_mod = Modulation2::new(h_sz, vb.pp("img_mod"))?;
let img_norm1 = layer_norm(h_sz, vb.pp("img_norm1"))?;
let img_attn = SelfAttention::new(h_sz, cfg.num_heads, cfg.qkv_bias, vb.pp("img_attn"))?;
let img_norm2 = layer_norm(h_sz, vb.pp("img_norm2"))?;
let img_mlp = Mlp::new(h_sz, mlp_sz, vb.pp("img_mlp"))?;
let txt_mod = Modulation2::new(h_sz, vb.pp("txt_mod"))?;
let txt_norm1 = layer_norm(h_sz, vb.pp("txt_norm1"))?;
let txt_attn = SelfAttention::new(h_sz, cfg.num_heads, cfg.qkv_bias, vb.pp("txt_attn"))?;
let txt_norm2 = layer_norm(h_sz, vb.pp("txt_norm2"))?;
let txt_mlp = Mlp::new(h_sz, mlp_sz, vb.pp("txt_mlp"))?;
Ok(Self {
img_mod,
img_norm1,
img_attn,
img_norm2,
img_mlp,
txt_mod,
txt_norm1,
txt_attn,
txt_norm2,
txt_mlp,
})
}
fn forward(
&self,
img: &Tensor,
txt: &Tensor,
vec_: &Tensor,
pe: &Tensor,
) -> Result<(Tensor, Tensor)> {
let (img_mod1, img_mod2) = self.img_mod.forward(vec_)?; // shift, scale, gate
let (txt_mod1, txt_mod2) = self.txt_mod.forward(vec_)?; // shift, scale, gate
let img_modulated = img.apply(&self.img_norm1)?;
let img_modulated = img_mod1.scale_shift(&img_modulated)?;
let (img_q, img_k, img_v) = self.img_attn.qkv(&img_modulated)?;
let txt_modulated = txt.apply(&self.txt_norm1)?;
let txt_modulated = txt_mod1.scale_shift(&txt_modulated)?;
let (txt_q, txt_k, txt_v) = self.txt_attn.qkv(&txt_modulated)?;
let q = Tensor::cat(&[txt_q, img_q], 2)?;
let k = Tensor::cat(&[txt_k, img_k], 2)?;
let v = Tensor::cat(&[txt_v, img_v], 2)?;
let attn = attention(&q, &k, &v, pe)?;
let txt_attn = attn.narrow(1, 0, txt.dim(1)?)?;
let img_attn = attn.narrow(1, txt.dim(1)?, attn.dim(1)? - txt.dim(1)?)?;
let img = (img + img_mod1.gate(&img_attn.apply(&self.img_attn.proj)?))?;
let img = (&img
+ img_mod2.gate(
&img_mod2
.scale_shift(&img.apply(&self.img_norm2)?)?
.apply(&self.img_mlp)?,
)?)?;
let txt = (txt + txt_mod1.gate(&txt_attn.apply(&self.txt_attn.proj)?))?;
let txt = (&txt
+ txt_mod2.gate(
&txt_mod2
.scale_shift(&txt.apply(&self.txt_norm2)?)?
.apply(&self.txt_mlp)?,
)?)?;
Ok((img, txt))
}
}
#[derive(Debug, Clone)]
pub struct SingleStreamBlock {
linear1: Linear,
linear2: Linear,
norm: QkNorm,
pre_norm: LayerNorm,
modulation: Modulation1,
h_sz: usize,
mlp_sz: usize,
num_heads: usize,
}
impl SingleStreamBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let h_sz = cfg.hidden_size;
let mlp_sz = (h_sz as f64 * cfg.mlp_ratio) as usize;
let head_dim = h_sz / cfg.num_heads;
let linear1 = candle_nn::linear(h_sz, h_sz * 3 + mlp_sz, vb.pp("linear1"))?;
let linear2 = candle_nn::linear(h_sz + mlp_sz, h_sz, vb.pp("linear2"))?;
let norm = QkNorm::new(head_dim, vb.pp("norm"))?;
let pre_norm = layer_norm(h_sz, vb.pp("pre_norm"))?;
let modulation = Modulation1::new(h_sz, vb.pp("modulation"))?;
Ok(Self {
linear1,
linear2,
norm,
pre_norm,
modulation,
h_sz,
mlp_sz,
num_heads: cfg.num_heads,
})
}
fn forward(&self, xs: &Tensor, vec_: &Tensor, pe: &Tensor) -> Result<Tensor> {
let mod_ = self.modulation.forward(vec_)?;
let x_mod = mod_.scale_shift(&xs.apply(&self.pre_norm)?)?;
let x_mod = x_mod.apply(&self.linear1)?;
let qkv = x_mod.narrow(D::Minus1, 0, 3 * self.h_sz)?;
let (b, l, _khd) = qkv.dims3()?;
let qkv = qkv.reshape((b, l, 3, self.num_heads, ()))?;
let q = qkv.i((.., .., 0))?.transpose(1, 2)?;
let k = qkv.i((.., .., 1))?.transpose(1, 2)?;
let v = qkv.i((.., .., 2))?.transpose(1, 2)?;
let mlp = x_mod.narrow(D::Minus1, 3 * self.h_sz, self.mlp_sz)?;
let q = q.apply(&self.norm.query_norm)?;
let k = k.apply(&self.norm.key_norm)?;
let attn = attention(&q, &k, &v, pe)?;
let output = Tensor::cat(&[attn, mlp.gelu()?], 2)?.apply(&self.linear2)?;
xs + mod_.gate(&output)
}
}
#[derive(Debug, Clone)]
pub struct LastLayer {
norm_final: LayerNorm,
linear: Linear,
ada_ln_modulation: Linear,
}
impl LastLayer {
fn new(h_sz: usize, p_sz: usize, out_c: usize, vb: VarBuilder) -> Result<Self> {
let norm_final = layer_norm(h_sz, vb.pp("norm_final"))?;
let linear = candle_nn::linear(h_sz, p_sz * p_sz * out_c, vb.pp("linear"))?;
let ada_ln_modulation = candle_nn::linear(h_sz, 2 * h_sz, vb.pp("adaLN_modulation.1"))?;
Ok(Self {
norm_final,
linear,
ada_ln_modulation,
})
}
fn forward(&self, xs: &Tensor, vec: &Tensor) -> Result<Tensor> {
let chunks = vec.silu()?.apply(&self.ada_ln_modulation)?.chunk(2, 1)?;
let (shift, scale) = (&chunks[0], &chunks[1]);
let xs = xs
.apply(&self.norm_final)?
.broadcast_mul(&(scale.unsqueeze(1)? + 1.0)?)?
.broadcast_add(&shift.unsqueeze(1)?)?;
xs.apply(&self.linear)
}
}
#[derive(Debug, Clone)]
pub struct Flux {
img_in: Linear,
txt_in: Linear,
time_in: MlpEmbedder,
vector_in: MlpEmbedder,
guidance_in: Option<MlpEmbedder>,
pe_embedder: EmbedNd,
double_blocks: Vec<DoubleStreamBlock>,
single_blocks: Vec<SingleStreamBlock>,
final_layer: LastLayer,
}
impl Flux {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let img_in = candle_nn::linear(cfg.in_channels, cfg.hidden_size, vb.pp("img_in"))?;
let txt_in = candle_nn::linear(cfg.context_in_dim, cfg.hidden_size, vb.pp("txt_in"))?;
let mut double_blocks = Vec::with_capacity(cfg.depth);
let vb_d = vb.pp("double_blocks");
for idx in 0..cfg.depth {
let db = DoubleStreamBlock::new(cfg, vb_d.pp(idx))?;
double_blocks.push(db)
}
let mut single_blocks = Vec::with_capacity(cfg.depth_single_blocks);
let vb_s = vb.pp("single_blocks");
for idx in 0..cfg.depth_single_blocks {
let sb = SingleStreamBlock::new(cfg, vb_s.pp(idx))?;
single_blocks.push(sb)
}
let time_in = MlpEmbedder::new(256, cfg.hidden_size, vb.pp("time_in"))?;
let vector_in = MlpEmbedder::new(cfg.vec_in_dim, cfg.hidden_size, vb.pp("vector_in"))?;
let guidance_in = if cfg.guidance_embed {
let mlp = MlpEmbedder::new(256, cfg.hidden_size, vb.pp("guidance_in"))?;
Some(mlp)
} else {
None
};
let final_layer =
LastLayer::new(cfg.hidden_size, 1, cfg.in_channels, vb.pp("final_layer"))?;
let pe_dim = cfg.hidden_size / cfg.num_heads;
let pe_embedder = EmbedNd::new(pe_dim, cfg.theta, cfg.axes_dim.to_vec());
Ok(Self {
img_in,
txt_in,
time_in,
vector_in,
guidance_in,
pe_embedder,
double_blocks,
single_blocks,
final_layer,
})
}
}
impl super::WithForward for Flux {
#[allow(clippy::too_many_arguments)]
fn forward(
&self,
img: &Tensor,
img_ids: &Tensor,
txt: &Tensor,
txt_ids: &Tensor,
timesteps: &Tensor,
y: &Tensor,
guidance: Option<&Tensor>,
) -> Result<Tensor> {
if txt.rank() != 3 {
candle::bail!("unexpected shape for txt {:?}", txt.shape())
}
if img.rank() != 3 {
candle::bail!("unexpected shape for img {:?}", img.shape())
}
let dtype = img.dtype();
let pe = {
let ids = Tensor::cat(&[txt_ids, img_ids], 1)?;
ids.apply(&self.pe_embedder)?
};
let mut txt = txt.apply(&self.txt_in)?;
let mut img = img.apply(&self.img_in)?;
let vec_ = timestep_embedding(timesteps, 256, dtype)?.apply(&self.time_in)?;
let vec_ = match (self.guidance_in.as_ref(), guidance) {
(Some(g_in), Some(guidance)) => {
(vec_ + timestep_embedding(guidance, 256, dtype)?.apply(g_in))?
}
_ => vec_,
};
let vec_ = (vec_ + y.apply(&self.vector_in))?;
// Double blocks
for block in self.double_blocks.iter() {
(img, txt) = block.forward(&img, &txt, &vec_, &pe)?
}
// Single blocks
let mut img = Tensor::cat(&[&txt, &img], 1)?;
for block in self.single_blocks.iter() {
img = block.forward(&img, &vec_, &pe)?;
}
let img = img.i((.., txt.dim(1)?..))?;
self.final_layer.forward(&img, &vec_)
}
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/flux/sampling.rs | use candle::{Device, Result, Tensor};
pub fn get_noise(
num_samples: usize,
height: usize,
width: usize,
device: &Device,
) -> Result<Tensor> {
let height = (height + 15) / 16 * 2;
let width = (width + 15) / 16 * 2;
Tensor::randn(0f32, 1., (num_samples, 16, height, width), device)
}
#[derive(Debug, Clone)]
pub struct State {
pub img: Tensor,
pub img_ids: Tensor,
pub txt: Tensor,
pub txt_ids: Tensor,
pub vec: Tensor,
}
impl State {
pub fn new(t5_emb: &Tensor, clip_emb: &Tensor, img: &Tensor) -> Result<Self> {
let dtype = img.dtype();
let (bs, c, h, w) = img.dims4()?;
let dev = img.device();
let img = img.reshape((bs, c, h / 2, 2, w / 2, 2))?; // (b, c, h, ph, w, pw)
let img = img.permute((0, 2, 4, 1, 3, 5))?; // (b, h, w, c, ph, pw)
let img = img.reshape((bs, h / 2 * w / 2, c * 4))?;
let img_ids = Tensor::stack(
&[
Tensor::full(0u32, (h / 2, w / 2), dev)?,
Tensor::arange(0u32, h as u32 / 2, dev)?
.reshape(((), 1))?
.broadcast_as((h / 2, w / 2))?,
Tensor::arange(0u32, w as u32 / 2, dev)?
.reshape((1, ()))?
.broadcast_as((h / 2, w / 2))?,
],
2,
)?
.to_dtype(dtype)?;
let img_ids = img_ids.reshape((1, h / 2 * w / 2, 3))?;
let img_ids = img_ids.repeat((bs, 1, 1))?;
let txt = t5_emb.repeat(bs)?;
let txt_ids = Tensor::zeros((bs, txt.dim(1)?, 3), dtype, dev)?;
let vec = clip_emb.repeat(bs)?;
Ok(Self {
img,
img_ids,
txt,
txt_ids,
vec,
})
}
}
fn time_shift(mu: f64, sigma: f64, t: f64) -> f64 {
let e = mu.exp();
e / (e + (1. / t - 1.).powf(sigma))
}
/// `shift` is a triple `(image_seq_len, base_shift, max_shift)`.
pub fn get_schedule(num_steps: usize, shift: Option<(usize, f64, f64)>) -> Vec<f64> {
let timesteps: Vec<f64> = (0..=num_steps)
.map(|v| v as f64 / num_steps as f64)
.rev()
.collect();
match shift {
None => timesteps,
Some((image_seq_len, y1, y2)) => {
let (x1, x2) = (256., 4096.);
let m = (y2 - y1) / (x2 - x1);
let b = y1 - m * x1;
let mu = m * image_seq_len as f64 + b;
timesteps
.into_iter()
.map(|v| time_shift(mu, 1., v))
.collect()
}
}
}
pub fn unpack(xs: &Tensor, height: usize, width: usize) -> Result<Tensor> {
let (b, _h_w, c_ph_pw) = xs.dims3()?;
let height = (height + 15) / 16;
let width = (width + 15) / 16;
xs.reshape((b, height, width, c_ph_pw / 4, 2, 2))? // (b, h, w, c, ph, pw)
.permute((0, 3, 1, 4, 2, 5))? // (b, c, h, ph, w, pw)
.reshape((b, c_ph_pw / 4, height * 2, width * 2))
}
#[allow(clippy::too_many_arguments)]
pub fn denoise<M: super::WithForward>(
model: &M,
img: &Tensor,
img_ids: &Tensor,
txt: &Tensor,
txt_ids: &Tensor,
vec_: &Tensor,
timesteps: &[f64],
guidance: f64,
) -> Result<Tensor> {
let b_sz = img.dim(0)?;
let dev = img.device();
let guidance = Tensor::full(guidance as f32, b_sz, dev)?;
let mut img = img.clone();
for window in timesteps.windows(2) {
let (t_curr, t_prev) = match window {
[a, b] => (a, b),
_ => continue,
};
let t_vec = Tensor::full(*t_curr as f32, b_sz, dev)?;
let pred = model.forward(&img, img_ids, txt, txt_ids, &t_vec, vec_, Some(&guidance))?;
img = (img + pred * (t_prev - t_curr))?
}
Ok(img)
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/flux/quantized_model.rs | use super::model::{attention, timestep_embedding, Config, EmbedNd};
use crate::quantized_nn::{linear, linear_b, Linear};
use crate::quantized_var_builder::VarBuilder;
use candle::{DType, IndexOp, Result, Tensor, D};
use candle_nn::{LayerNorm, RmsNorm};
fn layer_norm(dim: usize, vb: VarBuilder) -> Result<LayerNorm> {
let ws = Tensor::ones(dim, DType::F32, vb.device())?;
Ok(LayerNorm::new_no_bias(ws, 1e-6))
}
#[derive(Debug, Clone)]
pub struct MlpEmbedder {
in_layer: Linear,
out_layer: Linear,
}
impl MlpEmbedder {
fn new(in_sz: usize, h_sz: usize, vb: VarBuilder) -> Result<Self> {
let in_layer = linear(in_sz, h_sz, vb.pp("in_layer"))?;
let out_layer = linear(h_sz, h_sz, vb.pp("out_layer"))?;
Ok(Self {
in_layer,
out_layer,
})
}
}
impl candle::Module for MlpEmbedder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.in_layer)?.silu()?.apply(&self.out_layer)
}
}
#[derive(Debug, Clone)]
pub struct QkNorm {
query_norm: RmsNorm,
key_norm: RmsNorm,
}
impl QkNorm {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let query_norm = vb.get(dim, "query_norm.scale")?.dequantize(vb.device())?;
let query_norm = RmsNorm::new(query_norm, 1e-6);
let key_norm = vb.get(dim, "key_norm.scale")?.dequantize(vb.device())?;
let key_norm = RmsNorm::new(key_norm, 1e-6);
Ok(Self {
query_norm,
key_norm,
})
}
}
struct ModulationOut {
shift: Tensor,
scale: Tensor,
gate: Tensor,
}
impl ModulationOut {
fn scale_shift(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&(&self.scale + 1.)?)?
.broadcast_add(&self.shift)
}
fn gate(&self, xs: &Tensor) -> Result<Tensor> {
self.gate.broadcast_mul(xs)
}
}
#[derive(Debug, Clone)]
struct Modulation1 {
lin: Linear,
}
impl Modulation1 {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let lin = linear(dim, 3 * dim, vb.pp("lin"))?;
Ok(Self { lin })
}
fn forward(&self, vec_: &Tensor) -> Result<ModulationOut> {
let ys = vec_
.silu()?
.apply(&self.lin)?
.unsqueeze(1)?
.chunk(3, D::Minus1)?;
if ys.len() != 3 {
candle::bail!("unexpected len from chunk {ys:?}")
}
Ok(ModulationOut {
shift: ys[0].clone(),
scale: ys[1].clone(),
gate: ys[2].clone(),
})
}
}
#[derive(Debug, Clone)]
struct Modulation2 {
lin: Linear,
}
impl Modulation2 {
fn new(dim: usize, vb: VarBuilder) -> Result<Self> {
let lin = linear(dim, 6 * dim, vb.pp("lin"))?;
Ok(Self { lin })
}
fn forward(&self, vec_: &Tensor) -> Result<(ModulationOut, ModulationOut)> {
let ys = vec_
.silu()?
.apply(&self.lin)?
.unsqueeze(1)?
.chunk(6, D::Minus1)?;
if ys.len() != 6 {
candle::bail!("unexpected len from chunk {ys:?}")
}
let mod1 = ModulationOut {
shift: ys[0].clone(),
scale: ys[1].clone(),
gate: ys[2].clone(),
};
let mod2 = ModulationOut {
shift: ys[3].clone(),
scale: ys[4].clone(),
gate: ys[5].clone(),
};
Ok((mod1, mod2))
}
}
#[derive(Debug, Clone)]
pub struct SelfAttention {
qkv: Linear,
norm: QkNorm,
proj: Linear,
num_heads: usize,
}
impl SelfAttention {
fn new(dim: usize, num_heads: usize, qkv_bias: bool, vb: VarBuilder) -> Result<Self> {
let head_dim = dim / num_heads;
let qkv = linear_b(dim, dim * 3, qkv_bias, vb.pp("qkv"))?;
let norm = QkNorm::new(head_dim, vb.pp("norm"))?;
let proj = linear(dim, dim, vb.pp("proj"))?;
Ok(Self {
qkv,
norm,
proj,
num_heads,
})
}
fn qkv(&self, xs: &Tensor) -> Result<(Tensor, Tensor, Tensor)> {
let qkv = xs.apply(&self.qkv)?;
let (b, l, _khd) = qkv.dims3()?;
let qkv = qkv.reshape((b, l, 3, self.num_heads, ()))?;
let q = qkv.i((.., .., 0))?.transpose(1, 2)?;
let k = qkv.i((.., .., 1))?.transpose(1, 2)?;
let v = qkv.i((.., .., 2))?.transpose(1, 2)?;
let q = q.apply(&self.norm.query_norm)?;
let k = k.apply(&self.norm.key_norm)?;
Ok((q, k, v))
}
#[allow(unused)]
fn forward(&self, xs: &Tensor, pe: &Tensor) -> Result<Tensor> {
let (q, k, v) = self.qkv(xs)?;
attention(&q, &k, &v, pe)?.apply(&self.proj)
}
}
#[derive(Debug, Clone)]
struct Mlp {
lin1: Linear,
lin2: Linear,
}
impl Mlp {
fn new(in_sz: usize, mlp_sz: usize, vb: VarBuilder) -> Result<Self> {
let lin1 = linear(in_sz, mlp_sz, vb.pp("0"))?;
let lin2 = linear(mlp_sz, in_sz, vb.pp("2"))?;
Ok(Self { lin1, lin2 })
}
}
impl candle::Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.lin1)?.gelu()?.apply(&self.lin2)
}
}
#[derive(Debug, Clone)]
pub struct DoubleStreamBlock {
img_mod: Modulation2,
img_norm1: LayerNorm,
img_attn: SelfAttention,
img_norm2: LayerNorm,
img_mlp: Mlp,
txt_mod: Modulation2,
txt_norm1: LayerNorm,
txt_attn: SelfAttention,
txt_norm2: LayerNorm,
txt_mlp: Mlp,
}
impl DoubleStreamBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let h_sz = cfg.hidden_size;
let mlp_sz = (h_sz as f64 * cfg.mlp_ratio) as usize;
let img_mod = Modulation2::new(h_sz, vb.pp("img_mod"))?;
let img_norm1 = layer_norm(h_sz, vb.pp("img_norm1"))?;
let img_attn = SelfAttention::new(h_sz, cfg.num_heads, cfg.qkv_bias, vb.pp("img_attn"))?;
let img_norm2 = layer_norm(h_sz, vb.pp("img_norm2"))?;
let img_mlp = Mlp::new(h_sz, mlp_sz, vb.pp("img_mlp"))?;
let txt_mod = Modulation2::new(h_sz, vb.pp("txt_mod"))?;
let txt_norm1 = layer_norm(h_sz, vb.pp("txt_norm1"))?;
let txt_attn = SelfAttention::new(h_sz, cfg.num_heads, cfg.qkv_bias, vb.pp("txt_attn"))?;
let txt_norm2 = layer_norm(h_sz, vb.pp("txt_norm2"))?;
let txt_mlp = Mlp::new(h_sz, mlp_sz, vb.pp("txt_mlp"))?;
Ok(Self {
img_mod,
img_norm1,
img_attn,
img_norm2,
img_mlp,
txt_mod,
txt_norm1,
txt_attn,
txt_norm2,
txt_mlp,
})
}
fn forward(
&self,
img: &Tensor,
txt: &Tensor,
vec_: &Tensor,
pe: &Tensor,
) -> Result<(Tensor, Tensor)> {
let (img_mod1, img_mod2) = self.img_mod.forward(vec_)?; // shift, scale, gate
let (txt_mod1, txt_mod2) = self.txt_mod.forward(vec_)?; // shift, scale, gate
let img_modulated = img.apply(&self.img_norm1)?;
let img_modulated = img_mod1.scale_shift(&img_modulated)?;
let (img_q, img_k, img_v) = self.img_attn.qkv(&img_modulated)?;
let txt_modulated = txt.apply(&self.txt_norm1)?;
let txt_modulated = txt_mod1.scale_shift(&txt_modulated)?;
let (txt_q, txt_k, txt_v) = self.txt_attn.qkv(&txt_modulated)?;
let q = Tensor::cat(&[txt_q, img_q], 2)?;
let k = Tensor::cat(&[txt_k, img_k], 2)?;
let v = Tensor::cat(&[txt_v, img_v], 2)?;
let attn = attention(&q, &k, &v, pe)?;
let txt_attn = attn.narrow(1, 0, txt.dim(1)?)?;
let img_attn = attn.narrow(1, txt.dim(1)?, attn.dim(1)? - txt.dim(1)?)?;
let img = (img + img_mod1.gate(&img_attn.apply(&self.img_attn.proj)?))?;
let img = (&img
+ img_mod2.gate(
&img_mod2
.scale_shift(&img.apply(&self.img_norm2)?)?
.apply(&self.img_mlp)?,
)?)?;
let txt = (txt + txt_mod1.gate(&txt_attn.apply(&self.txt_attn.proj)?))?;
let txt = (&txt
+ txt_mod2.gate(
&txt_mod2
.scale_shift(&txt.apply(&self.txt_norm2)?)?
.apply(&self.txt_mlp)?,
)?)?;
Ok((img, txt))
}
}
#[derive(Debug, Clone)]
pub struct SingleStreamBlock {
linear1: Linear,
linear2: Linear,
norm: QkNorm,
pre_norm: LayerNorm,
modulation: Modulation1,
h_sz: usize,
mlp_sz: usize,
num_heads: usize,
}
impl SingleStreamBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let h_sz = cfg.hidden_size;
let mlp_sz = (h_sz as f64 * cfg.mlp_ratio) as usize;
let head_dim = h_sz / cfg.num_heads;
let linear1 = linear(h_sz, h_sz * 3 + mlp_sz, vb.pp("linear1"))?;
let linear2 = linear(h_sz + mlp_sz, h_sz, vb.pp("linear2"))?;
let norm = QkNorm::new(head_dim, vb.pp("norm"))?;
let pre_norm = layer_norm(h_sz, vb.pp("pre_norm"))?;
let modulation = Modulation1::new(h_sz, vb.pp("modulation"))?;
Ok(Self {
linear1,
linear2,
norm,
pre_norm,
modulation,
h_sz,
mlp_sz,
num_heads: cfg.num_heads,
})
}
fn forward(&self, xs: &Tensor, vec_: &Tensor, pe: &Tensor) -> Result<Tensor> {
let mod_ = self.modulation.forward(vec_)?;
let x_mod = mod_.scale_shift(&xs.apply(&self.pre_norm)?)?;
let x_mod = x_mod.apply(&self.linear1)?;
let qkv = x_mod.narrow(D::Minus1, 0, 3 * self.h_sz)?;
let (b, l, _khd) = qkv.dims3()?;
let qkv = qkv.reshape((b, l, 3, self.num_heads, ()))?;
let q = qkv.i((.., .., 0))?.transpose(1, 2)?;
let k = qkv.i((.., .., 1))?.transpose(1, 2)?;
let v = qkv.i((.., .., 2))?.transpose(1, 2)?;
let mlp = x_mod.narrow(D::Minus1, 3 * self.h_sz, self.mlp_sz)?;
let q = q.apply(&self.norm.query_norm)?;
let k = k.apply(&self.norm.key_norm)?;
let attn = attention(&q, &k, &v, pe)?;
let output = Tensor::cat(&[attn, mlp.gelu()?], 2)?.apply(&self.linear2)?;
xs + mod_.gate(&output)
}
}
#[derive(Debug, Clone)]
pub struct LastLayer {
norm_final: LayerNorm,
linear: Linear,
ada_ln_modulation: Linear,
}
impl LastLayer {
fn new(h_sz: usize, p_sz: usize, out_c: usize, vb: VarBuilder) -> Result<Self> {
let norm_final = layer_norm(h_sz, vb.pp("norm_final"))?;
let linear_ = linear(h_sz, p_sz * p_sz * out_c, vb.pp("linear"))?;
let ada_ln_modulation = linear(h_sz, 2 * h_sz, vb.pp("adaLN_modulation.1"))?;
Ok(Self {
norm_final,
linear: linear_,
ada_ln_modulation,
})
}
fn forward(&self, xs: &Tensor, vec: &Tensor) -> Result<Tensor> {
let chunks = vec.silu()?.apply(&self.ada_ln_modulation)?.chunk(2, 1)?;
let (shift, scale) = (&chunks[0], &chunks[1]);
let xs = xs
.apply(&self.norm_final)?
.broadcast_mul(&(scale.unsqueeze(1)? + 1.0)?)?
.broadcast_add(&shift.unsqueeze(1)?)?;
xs.apply(&self.linear)
}
}
#[derive(Debug, Clone)]
pub struct Flux {
img_in: Linear,
txt_in: Linear,
time_in: MlpEmbedder,
vector_in: MlpEmbedder,
guidance_in: Option<MlpEmbedder>,
pe_embedder: EmbedNd,
double_blocks: Vec<DoubleStreamBlock>,
single_blocks: Vec<SingleStreamBlock>,
final_layer: LastLayer,
}
impl Flux {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let img_in = linear(cfg.in_channels, cfg.hidden_size, vb.pp("img_in"))?;
let txt_in = linear(cfg.context_in_dim, cfg.hidden_size, vb.pp("txt_in"))?;
let mut double_blocks = Vec::with_capacity(cfg.depth);
let vb_d = vb.pp("double_blocks");
for idx in 0..cfg.depth {
let db = DoubleStreamBlock::new(cfg, vb_d.pp(idx))?;
double_blocks.push(db)
}
let mut single_blocks = Vec::with_capacity(cfg.depth_single_blocks);
let vb_s = vb.pp("single_blocks");
for idx in 0..cfg.depth_single_blocks {
let sb = SingleStreamBlock::new(cfg, vb_s.pp(idx))?;
single_blocks.push(sb)
}
let time_in = MlpEmbedder::new(256, cfg.hidden_size, vb.pp("time_in"))?;
let vector_in = MlpEmbedder::new(cfg.vec_in_dim, cfg.hidden_size, vb.pp("vector_in"))?;
let guidance_in = if cfg.guidance_embed {
let mlp = MlpEmbedder::new(256, cfg.hidden_size, vb.pp("guidance_in"))?;
Some(mlp)
} else {
None
};
let final_layer =
LastLayer::new(cfg.hidden_size, 1, cfg.in_channels, vb.pp("final_layer"))?;
let pe_dim = cfg.hidden_size / cfg.num_heads;
let pe_embedder = EmbedNd::new(pe_dim, cfg.theta, cfg.axes_dim.to_vec());
Ok(Self {
img_in,
txt_in,
time_in,
vector_in,
guidance_in,
pe_embedder,
double_blocks,
single_blocks,
final_layer,
})
}
}
impl super::WithForward for Flux {
#[allow(clippy::too_many_arguments)]
fn forward(
&self,
img: &Tensor,
img_ids: &Tensor,
txt: &Tensor,
txt_ids: &Tensor,
timesteps: &Tensor,
y: &Tensor,
guidance: Option<&Tensor>,
) -> Result<Tensor> {
if txt.rank() != 3 {
candle::bail!("unexpected shape for txt {:?}", txt.shape())
}
if img.rank() != 3 {
candle::bail!("unexpected shape for img {:?}", img.shape())
}
let dtype = img.dtype();
let pe = {
let ids = Tensor::cat(&[txt_ids, img_ids], 1)?;
ids.apply(&self.pe_embedder)?
};
let mut txt = txt.apply(&self.txt_in)?;
let mut img = img.apply(&self.img_in)?;
let vec_ = timestep_embedding(timesteps, 256, dtype)?.apply(&self.time_in)?;
let vec_ = match (self.guidance_in.as_ref(), guidance) {
(Some(g_in), Some(guidance)) => {
(vec_ + timestep_embedding(guidance, 256, dtype)?.apply(g_in))?
}
_ => vec_,
};
let vec_ = (vec_ + y.apply(&self.vector_in))?;
// Double blocks
for block in self.double_blocks.iter() {
(img, txt) = block.forward(&img, &txt, &vec_, &pe)?
}
// Single blocks
let mut img = Tensor::cat(&[&txt, &img], 1)?;
for block in self.single_blocks.iter() {
img = block.forward(&img, &vec_, &pe)?;
}
let img = img.i((.., txt.dim(1)?..))?;
self.final_layer.forward(&img, &vec_)
}
}
| 8 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/flux/autoencoder.rs | use candle::{Result, Tensor, D};
use candle_nn::{conv2d, group_norm, Conv2d, GroupNorm, VarBuilder};
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/modules/autoencoder.py#L9
#[derive(Debug, Clone)]
pub struct Config {
pub resolution: usize,
pub in_channels: usize,
pub ch: usize,
pub out_ch: usize,
pub ch_mult: Vec<usize>,
pub num_res_blocks: usize,
pub z_channels: usize,
pub scale_factor: f64,
pub shift_factor: f64,
}
impl Config {
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/util.py#L47
pub fn dev() -> Self {
Self {
resolution: 256,
in_channels: 3,
ch: 128,
out_ch: 3,
ch_mult: vec![1, 2, 4, 4],
num_res_blocks: 2,
z_channels: 16,
scale_factor: 0.3611,
shift_factor: 0.1159,
}
}
// https://github.com/black-forest-labs/flux/blob/727e3a71faf37390f318cf9434f0939653302b60/src/flux/util.py#L79
pub fn schnell() -> Self {
Self {
resolution: 256,
in_channels: 3,
ch: 128,
out_ch: 3,
ch_mult: vec![1, 2, 4, 4],
num_res_blocks: 2,
z_channels: 16,
scale_factor: 0.3611,
shift_factor: 0.1159,
}
}
}
fn scaled_dot_product_attention(q: &Tensor, k: &Tensor, v: &Tensor) -> Result<Tensor> {
let dim = q.dim(D::Minus1)?;
let scale_factor = 1.0 / (dim as f64).sqrt();
let attn_weights = (q.matmul(&k.t()?)? * scale_factor)?;
candle_nn::ops::softmax_last_dim(&attn_weights)?.matmul(v)
}
#[derive(Debug, Clone)]
struct AttnBlock {
q: Conv2d,
k: Conv2d,
v: Conv2d,
proj_out: Conv2d,
norm: GroupNorm,
}
impl AttnBlock {
fn new(in_c: usize, vb: VarBuilder) -> Result<Self> {
let q = conv2d(in_c, in_c, 1, Default::default(), vb.pp("q"))?;
let k = conv2d(in_c, in_c, 1, Default::default(), vb.pp("k"))?;
let v = conv2d(in_c, in_c, 1, Default::default(), vb.pp("v"))?;
let proj_out = conv2d(in_c, in_c, 1, Default::default(), vb.pp("proj_out"))?;
let norm = group_norm(32, in_c, 1e-6, vb.pp("norm"))?;
Ok(Self {
q,
k,
v,
proj_out,
norm,
})
}
}
impl candle::Module for AttnBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let init_xs = xs;
let xs = xs.apply(&self.norm)?;
let q = xs.apply(&self.q)?;
let k = xs.apply(&self.k)?;
let v = xs.apply(&self.v)?;
let (b, c, h, w) = q.dims4()?;
let q = q.flatten_from(2)?.t()?.unsqueeze(1)?;
let k = k.flatten_from(2)?.t()?.unsqueeze(1)?;
let v = v.flatten_from(2)?.t()?.unsqueeze(1)?;
let xs = scaled_dot_product_attention(&q, &k, &v)?;
let xs = xs.squeeze(1)?.t()?.reshape((b, c, h, w))?;
xs.apply(&self.proj_out)? + init_xs
}
}
#[derive(Debug, Clone)]
struct ResnetBlock {
norm1: GroupNorm,
conv1: Conv2d,
norm2: GroupNorm,
conv2: Conv2d,
nin_shortcut: Option<Conv2d>,
}
impl ResnetBlock {
fn new(in_c: usize, out_c: usize, vb: VarBuilder) -> Result<Self> {
let conv_cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let norm1 = group_norm(32, in_c, 1e-6, vb.pp("norm1"))?;
let conv1 = conv2d(in_c, out_c, 3, conv_cfg, vb.pp("conv1"))?;
let norm2 = group_norm(32, out_c, 1e-6, vb.pp("norm2"))?;
let conv2 = conv2d(out_c, out_c, 3, conv_cfg, vb.pp("conv2"))?;
let nin_shortcut = if in_c == out_c {
None
} else {
Some(conv2d(
in_c,
out_c,
1,
Default::default(),
vb.pp("nin_shortcut"),
)?)
};
Ok(Self {
norm1,
conv1,
norm2,
conv2,
nin_shortcut,
})
}
}
impl candle::Module for ResnetBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let h = xs
.apply(&self.norm1)?
.apply(&candle_nn::Activation::Swish)?
.apply(&self.conv1)?
.apply(&self.norm2)?
.apply(&candle_nn::Activation::Swish)?
.apply(&self.conv2)?;
match self.nin_shortcut.as_ref() {
None => xs + h,
Some(c) => xs.apply(c)? + h,
}
}
}
#[derive(Debug, Clone)]
struct Downsample {
conv: Conv2d,
}
impl Downsample {
fn new(in_c: usize, vb: VarBuilder) -> Result<Self> {
let conv_cfg = candle_nn::Conv2dConfig {
stride: 2,
..Default::default()
};
let conv = conv2d(in_c, in_c, 3, conv_cfg, vb.pp("conv"))?;
Ok(Self { conv })
}
}
impl candle::Module for Downsample {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = xs.pad_with_zeros(D::Minus1, 0, 1)?;
let xs = xs.pad_with_zeros(D::Minus2, 0, 1)?;
xs.apply(&self.conv)
}
}
#[derive(Debug, Clone)]
struct Upsample {
conv: Conv2d,
}
impl Upsample {
fn new(in_c: usize, vb: VarBuilder) -> Result<Self> {
let conv_cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let conv = conv2d(in_c, in_c, 3, conv_cfg, vb.pp("conv"))?;
Ok(Self { conv })
}
}
impl candle::Module for Upsample {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let (_, _, h, w) = xs.dims4()?;
xs.upsample_nearest2d(h * 2, w * 2)?.apply(&self.conv)
}
}
#[derive(Debug, Clone)]
struct DownBlock {
block: Vec<ResnetBlock>,
downsample: Option<Downsample>,
}
#[derive(Debug, Clone)]
pub struct Encoder {
conv_in: Conv2d,
mid_block_1: ResnetBlock,
mid_attn_1: AttnBlock,
mid_block_2: ResnetBlock,
norm_out: GroupNorm,
conv_out: Conv2d,
down: Vec<DownBlock>,
}
impl Encoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let conv_cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let mut block_in = cfg.ch;
let conv_in = conv2d(cfg.in_channels, block_in, 3, conv_cfg, vb.pp("conv_in"))?;
let mut down = Vec::with_capacity(cfg.ch_mult.len());
let vb_d = vb.pp("down");
for (i_level, ch_mult) in cfg.ch_mult.iter().enumerate() {
let mut block = Vec::with_capacity(cfg.num_res_blocks);
let vb_d = vb_d.pp(i_level);
let vb_b = vb_d.pp("block");
let in_ch_mult = if i_level == 0 {
1
} else {
cfg.ch_mult[i_level - 1]
};
block_in = cfg.ch * in_ch_mult;
let block_out = cfg.ch * ch_mult;
for i_block in 0..cfg.num_res_blocks {
let b = ResnetBlock::new(block_in, block_out, vb_b.pp(i_block))?;
block.push(b);
block_in = block_out;
}
let downsample = if i_level != cfg.ch_mult.len() - 1 {
Some(Downsample::new(block_in, vb_d.pp("downsample"))?)
} else {
None
};
let block = DownBlock { block, downsample };
down.push(block)
}
let mid_block_1 = ResnetBlock::new(block_in, block_in, vb.pp("mid.block_1"))?;
let mid_attn_1 = AttnBlock::new(block_in, vb.pp("mid.attn_1"))?;
let mid_block_2 = ResnetBlock::new(block_in, block_in, vb.pp("mid.block_2"))?;
let conv_out = conv2d(block_in, 2 * cfg.z_channels, 3, conv_cfg, vb.pp("conv_out"))?;
let norm_out = group_norm(32, block_in, 1e-6, vb.pp("norm_out"))?;
Ok(Self {
conv_in,
mid_block_1,
mid_attn_1,
mid_block_2,
norm_out,
conv_out,
down,
})
}
}
impl candle_nn::Module for Encoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut h = xs.apply(&self.conv_in)?;
for block in self.down.iter() {
for b in block.block.iter() {
h = h.apply(b)?
}
if let Some(ds) = block.downsample.as_ref() {
h = h.apply(ds)?
}
}
h.apply(&self.mid_block_1)?
.apply(&self.mid_attn_1)?
.apply(&self.mid_block_2)?
.apply(&self.norm_out)?
.apply(&candle_nn::Activation::Swish)?
.apply(&self.conv_out)
}
}
#[derive(Debug, Clone)]
struct UpBlock {
block: Vec<ResnetBlock>,
upsample: Option<Upsample>,
}
#[derive(Debug, Clone)]
pub struct Decoder {
conv_in: Conv2d,
mid_block_1: ResnetBlock,
mid_attn_1: AttnBlock,
mid_block_2: ResnetBlock,
norm_out: GroupNorm,
conv_out: Conv2d,
up: Vec<UpBlock>,
}
impl Decoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let conv_cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let mut block_in = cfg.ch * cfg.ch_mult.last().unwrap_or(&1);
let conv_in = conv2d(cfg.z_channels, block_in, 3, conv_cfg, vb.pp("conv_in"))?;
let mid_block_1 = ResnetBlock::new(block_in, block_in, vb.pp("mid.block_1"))?;
let mid_attn_1 = AttnBlock::new(block_in, vb.pp("mid.attn_1"))?;
let mid_block_2 = ResnetBlock::new(block_in, block_in, vb.pp("mid.block_2"))?;
let mut up = Vec::with_capacity(cfg.ch_mult.len());
let vb_u = vb.pp("up");
for (i_level, ch_mult) in cfg.ch_mult.iter().enumerate().rev() {
let block_out = cfg.ch * ch_mult;
let vb_u = vb_u.pp(i_level);
let vb_b = vb_u.pp("block");
let mut block = Vec::with_capacity(cfg.num_res_blocks + 1);
for i_block in 0..=cfg.num_res_blocks {
let b = ResnetBlock::new(block_in, block_out, vb_b.pp(i_block))?;
block.push(b);
block_in = block_out;
}
let upsample = if i_level != 0 {
Some(Upsample::new(block_in, vb_u.pp("upsample"))?)
} else {
None
};
let block = UpBlock { block, upsample };
up.push(block)
}
up.reverse();
let norm_out = group_norm(32, block_in, 1e-6, vb.pp("norm_out"))?;
let conv_out = conv2d(block_in, cfg.out_ch, 3, conv_cfg, vb.pp("conv_out"))?;
Ok(Self {
conv_in,
mid_block_1,
mid_attn_1,
mid_block_2,
norm_out,
conv_out,
up,
})
}
}
impl candle_nn::Module for Decoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let h = xs.apply(&self.conv_in)?;
let mut h = h
.apply(&self.mid_block_1)?
.apply(&self.mid_attn_1)?
.apply(&self.mid_block_2)?;
for block in self.up.iter().rev() {
for b in block.block.iter() {
h = h.apply(b)?
}
if let Some(us) = block.upsample.as_ref() {
h = h.apply(us)?
}
}
h.apply(&self.norm_out)?
.apply(&candle_nn::Activation::Swish)?
.apply(&self.conv_out)
}
}
#[derive(Debug, Clone)]
pub struct DiagonalGaussian {
sample: bool,
chunk_dim: usize,
}
impl DiagonalGaussian {
pub fn new(sample: bool, chunk_dim: usize) -> Result<Self> {
Ok(Self { sample, chunk_dim })
}
}
impl candle_nn::Module for DiagonalGaussian {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let chunks = xs.chunk(2, self.chunk_dim)?;
if self.sample {
let std = (&chunks[1] * 0.5)?.exp()?;
&chunks[0] + (std * chunks[0].randn_like(0., 1.))?
} else {
Ok(chunks[0].clone())
}
}
}
#[derive(Debug, Clone)]
pub struct AutoEncoder {
encoder: Encoder,
decoder: Decoder,
reg: DiagonalGaussian,
shift_factor: f64,
scale_factor: f64,
}
impl AutoEncoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let encoder = Encoder::new(cfg, vb.pp("encoder"))?;
let decoder = Decoder::new(cfg, vb.pp("decoder"))?;
let reg = DiagonalGaussian::new(true, 1)?;
Ok(Self {
encoder,
decoder,
reg,
scale_factor: cfg.scale_factor,
shift_factor: cfg.shift_factor,
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let z = xs.apply(&self.encoder)?.apply(&self.reg)?;
(z - self.shift_factor)? * self.scale_factor
}
pub fn decode(&self, xs: &Tensor) -> Result<Tensor> {
let xs = ((xs / self.scale_factor)? + self.shift_factor)?;
xs.apply(&self.decoder)
}
}
impl candle::Module for AutoEncoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.decode(&self.encode(xs)?)
}
}
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/trocr/image_processor.rs | use image::{DynamicImage, ImageBuffer};
use serde::Deserialize;
use std::collections::HashMap;
use candle::{DType, Device, Result, Tensor};
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct ProcessorConfig {
do_resize: bool,
height: u32,
width: u32,
do_rescale: bool,
do_normalize: bool,
image_mean: Vec<f32>,
image_std: Vec<f32>,
}
impl Default for ProcessorConfig {
fn default() -> Self {
Self {
do_resize: true,
height: 384,
width: 384,
do_rescale: true,
do_normalize: true,
image_mean: vec![0.5, 0.5, 0.5],
image_std: vec![0.5, 0.5, 0.5],
}
}
}
pub struct ViTImageProcessor {
do_resize: bool,
height: u32,
width: u32,
do_normalize: bool,
image_mean: Vec<f32>,
image_std: Vec<f32>,
}
impl ViTImageProcessor {
pub fn new(config: &ProcessorConfig) -> Self {
Self {
do_resize: config.do_resize,
height: config.height,
width: config.width,
do_normalize: config.do_normalize,
image_mean: config.image_mean.clone(),
image_std: config.image_std.clone(),
}
}
pub fn preprocess(&self, images: Vec<&str>) -> Result<Tensor> {
let height = self.height as usize;
let width = self.width as usize;
let channels = 3;
let images = self.load_images(images)?;
let resized_images: Vec<DynamicImage> = if self.do_resize {
images
.iter()
.map(|image| self.resize(image.clone(), None).unwrap())
.collect()
} else {
images
};
let normalized_images: Vec<Tensor> = if self.do_normalize {
resized_images
.iter()
.map(|image| self.normalize(image.clone(), None, None).unwrap())
.collect()
} else {
let resized_images: Vec<ImageBuffer<image::Rgb<u8>, Vec<u8>>> =
resized_images.iter().map(|image| image.to_rgb8()).collect();
let data = resized_images
.into_iter()
.map(|image| image.into_raw())
.collect::<Vec<Vec<u8>>>();
data.iter()
.map(|image| {
Tensor::from_vec(image.clone(), (height, width, channels), &Device::Cpu)
.unwrap()
.permute((2, 0, 1))
.unwrap()
})
.collect::<Vec<Tensor>>()
};
Tensor::stack(&normalized_images, 0)
}
fn resize(
&self,
image: image::DynamicImage,
size: Option<HashMap<String, u32>>,
) -> Result<image::DynamicImage> {
let (height, width) = match &size {
Some(size) => (size.get("height").unwrap(), size.get("width").unwrap()),
None => (&self.height, &self.width),
};
let resized_image =
image.resize_exact(*width, *height, image::imageops::FilterType::Triangle);
Ok(resized_image)
}
fn normalize(
&self,
image: image::DynamicImage,
mean: Option<Vec<f32>>,
std: Option<Vec<f32>>,
) -> Result<Tensor> {
let mean = match mean {
Some(mean) => mean,
None => self.image_mean.clone(),
};
let std = match std {
Some(std) => std,
None => self.image_std.clone(),
};
let mean = Tensor::from_vec(mean, (3, 1, 1), &Device::Cpu)?;
let std = Tensor::from_vec(std, (3, 1, 1), &Device::Cpu)?;
let image = image.to_rgb8();
let data = image.into_raw();
let height = self.height as usize;
let width = self.width as usize;
let channels = 3;
let data =
Tensor::from_vec(data, &[height, width, channels], &Device::Cpu)?.permute((2, 0, 1))?;
(data.to_dtype(DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
}
pub fn load_images(&self, image_path: Vec<&str>) -> Result<Vec<image::DynamicImage>> {
let mut images: Vec<image::DynamicImage> = Vec::new();
for path in image_path {
let img = image::ImageReader::open(path)?.decode().unwrap();
images.push(img);
}
Ok(images)
}
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/glm4/main.rs | use candle_transformers::models::glm4::*;
use clap::Parser;
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{Repo, RepoType};
use tokenizers::Tokenizer;
struct TextGeneration {
model: Model,
device: Device,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
dtype: DType,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
device: &Device,
dtype: DType,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer,
logits_processor,
repeat_penalty,
repeat_last_n,
verbose_prompt,
device: device.clone(),
dtype,
}
}
fn run(&mut self, sample_len: usize) -> anyhow::Result<()> {
use std::io::BufRead;
use std::io::BufReader;
use std::io::Write;
println!("starting the inference loop");
println!("[欢迎使用GLM-4,请输入prompt]");
let stdin = std::io::stdin();
let reader = BufReader::new(stdin);
for line in reader.lines() {
let line = line.expect("Failed to read line");
let tokens = self.tokenizer.encode(line, true).expect("tokens error");
if tokens.is_empty() {
panic!("Empty prompts are not supported in the chatglm model.")
}
if self.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let eos_token = match self.tokenizer.get_vocab(true).get("<|endoftext|>") {
Some(token) => *token,
None => panic!("cannot find the endoftext token"),
};
let mut tokens = tokens.get_ids().to_vec();
let mut generated_tokens = 0usize;
std::io::stdout().flush().expect("output flush error");
let start_gen = std::time::Instant::now();
let mut count = 0;
let mut result = vec![];
for index in 0..sample_len {
count += 1;
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input)?;
let logits = logits.squeeze(0)?.to_dtype(self.dtype)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
let token = self
.tokenizer
.decode(&[next_token], true)
.expect("Token error");
if self.verbose_prompt {
println!(
"[Count: {}] [Raw Token: {}] [Decode Token: {}]",
count, next_token, token
);
}
result.push(token);
std::io::stdout().flush()?;
}
let dt = start_gen.elapsed();
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
println!("Result:");
for tokens in result {
print!("{tokens}");
}
self.model.reset_kv_cache(); // clean the cache
}
Ok(())
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(name = "cache", short, long, default_value = ".")]
cache_path: String,
#[arg(long)]
cpu: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 8192)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
weight_file: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.2)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> anyhow::Result<()> {
let args = Args::parse();
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.6),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
println!("cache path {}", args.cache_path);
let api = hf_hub::api::sync::ApiBuilder::from_cache(hf_hub::Cache::new(args.cache_path.into()))
.build()
.map_err(anyhow::Error::msg)?;
let model_id = match args.model_id {
Some(model_id) => model_id.to_string(),
None => "THUDM/glm-4-9b".to_string(),
};
let revision = match args.revision {
Some(rev) => rev.to_string(),
None => "main".to_string(),
};
let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let tokenizer_filename = match args.tokenizer {
Some(file) => std::path::PathBuf::from(file),
None => api
.model("THUDM/codegeex4-all-9b".to_string())
.get("tokenizer.json")
.map_err(anyhow::Error::msg)?,
};
let filenames = match args.weight_file {
Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],
None => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).expect("Tokenizer Error");
let start = std::time::Instant::now();
let config = Config::glm4();
let device = candle_examples::device(args.cpu)?;
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Model::new(&config, vb)?;
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
args.verbose_prompt,
&device,
dtype,
);
pipeline.run(args.sample_len)?;
Ok(())
}
| 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/glm4/README.org | * GLM4
GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu AI.
- [[https://github.com/THUDM/GLM4][Github]]
- [[https://huggingface.co/THUDM/glm-4-9b][huggingface]]
** Running with ~cuda~
#+begin_src shell
cargo run --example glm4 --release --features cuda
#+end_src
** Running with ~cpu~
#+begin_src shell
cargo run --example glm4 --release -- --cpu
#+end_src
** Output Example
#+begin_src shell
cargo run --example glm4 --release --features cuda -- --sample-len 500 --cache .
Finished release [optimized] target(s) in 0.24s
Running `/root/candle/target/release/examples/glm4 --sample-len 500 --cache .`
avx: true, neon: false, simd128: false, f16c: true
temp: 0.60 repeat-penalty: 1.20 repeat-last-n: 64
cache path .
retrieved the files in 6.88963ms
loaded the model in 6.113752297s
starting the inference loop
[欢迎使用GLM-4,请输入prompt]
请你告诉我什么是FFT
266 tokens generated (34.50 token/s)
Result:
。Fast Fourier Transform (FFT) 是一种快速计算离散傅里叶变换(DFT)的方法,它广泛应用于信号处理、图像处理和数据分析等领域。
具体来说,FFT是一种将时域数据转换为频域数据的算法。在数字信号处理中,我们通常需要知道信号的频率成分,这就需要进行傅立叶变换。传统的傅立叶变换的计算复杂度较高,而 FFT 则大大提高了计算效率,使得大规模的 DFT 换成为可能。
以下是使用 Python 中的 numpy 进行 FFT 的简单示例:
```python
import numpy as np
# 创建一个时域信号
t = np.linspace(0, 1, num=100)
f = np.sin(2*np.pi*5*t) + 3*np.cos(2*np.pi*10*t)
# 对该信号做FFT变换,并计算其幅值谱
fft_result = np.fft.fftshift(np.abs(np.fft.fft(f)))
```
在这个例子中,我们首先创建了一个时域信号 f。然后我们对这个信号进行了 FFT 换,得到了一个频域结果 fft_result。
#+end_src
This example will read prompt from stdin
* Citation
#+begin_src
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
#+end_src
#+begin_src
@misc{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
#+end_src
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/efficientvit/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::efficientvit;
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
M0,
M1,
M2,
M3,
M4,
M5,
}
impl Which {
fn model_filename(&self) -> String {
let name = match self {
Self::M0 => "m0",
Self::M1 => "m1",
Self::M2 => "m2",
Self::M3 => "m3",
Self::M4 => "m4",
Self::M5 => "m5",
};
format!("timm/efficientvit_{}.r224_in1k", name)
}
fn config(&self) -> efficientvit::Config {
match self {
Self::M0 => efficientvit::Config::m0(),
Self::M1 => efficientvit::Config::m1(),
Self::M2 => efficientvit::Config::m2(),
Self::M3 => efficientvit::Config::m3(),
Self::M4 => efficientvit::Config::m4(),
Self::M5 => efficientvit::Config::m5(),
}
}
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(value_enum, long, default_value_t=Which::M0)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let model_name = args.which.model_filename();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = efficientvit::efficientvit(&args.which.config(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/efficientvit/README.md | # candle-efficientvit
[EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention](https://arxiv.org/abs/2305.07027).
This candle implementation uses a pre-trained EfficientViT (from Microsoft Research Asia) network for inference.
The classification head has been trained on the ImageNet dataset and returns the probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example efficientvit --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg --which m1
loaded image Tensor[dims 3, 224, 224; f32]
model built
mountain bike, all-terrain bike, off-roader: 69.80%
unicycle, monocycle : 13.03%
bicycle-built-for-two, tandem bicycle, tandem: 9.28%
crash helmet : 2.25%
alp : 0.46%
```
| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/codegeex4-9b/main.rs | use candle_transformers::models::codegeex4_9b::*;
use clap::Parser;
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{Repo, RepoType};
use tokenizers::Tokenizer;
struct TextGeneration {
model: Model,
device: Device,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
dtype: DType,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
device: &Device,
dtype: DType,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer,
logits_processor,
repeat_penalty,
repeat_last_n,
verbose_prompt,
device: device.clone(),
dtype,
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> anyhow::Result<()> {
use std::io::Write;
println!("starting the inference loop");
let tokens = self.tokenizer.encode(prompt, true).expect("tokens error");
if tokens.is_empty() {
panic!("Empty prompts are not supported in the chatglm model.")
}
if self.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let eos_token = match self.tokenizer.get_vocab(true).get("<|endoftext|>") {
Some(token) => *token,
None => panic!("cannot find the endoftext token"),
};
let mut tokens = tokens.get_ids().to_vec();
let mut generated_tokens = 0usize;
print!("{prompt}");
std::io::stdout().flush().expect("output flush error");
let start_gen = std::time::Instant::now();
println!("\n start_gen");
println!("samplelen {}", sample_len);
let mut count = 0;
let mut result = vec![];
for index in 0..sample_len {
count += 1;
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input)?;
let logits = logits.squeeze(0)?.to_dtype(self.dtype)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
let token = self
.tokenizer
.decode(&[next_token], true)
.expect("Token error");
if self.verbose_prompt {
println!(
"[Count: {}] [Raw Token: {}] [Decode Token: {}]",
count, next_token, token
);
}
result.push(token);
std::io::stdout().flush()?;
}
let dt = start_gen.elapsed();
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
println!("Result:");
for tokens in result {
print!("{tokens}");
}
Ok(())
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(name = "cache", short, long, default_value = ".")]
cache_path: String,
#[arg(long)]
cpu: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 5000)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
weight_file: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> anyhow::Result<()> {
let args = Args::parse();
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.95),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
println!("cache path {}", args.cache_path);
let api = hf_hub::api::sync::ApiBuilder::from_cache(hf_hub::Cache::new(args.cache_path.into()))
.build()
.map_err(anyhow::Error::msg)?;
let model_id = match args.model_id {
Some(model_id) => model_id.to_string(),
None => "THUDM/codegeex4-all-9b".to_string(),
};
let revision = match args.revision {
Some(rev) => rev.to_string(),
None => "main".to_string(),
};
let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let tokenizer_filename = match args.tokenizer {
Some(file) => std::path::PathBuf::from(file),
None => api
.model("THUDM/codegeex4-all-9b".to_string())
.get("tokenizer.json")
.map_err(anyhow::Error::msg)?,
};
let filenames = match args.weight_file {
Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],
None => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).expect("Tokenizer Error");
let start = std::time::Instant::now();
let config = Config::codegeex4();
let device = candle_examples::device(args.cpu)?;
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = Model::new(&config, vb)?;
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
args.verbose_prompt,
&device,
dtype,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/codegeex4-9b/README.org | * candle-codegeex4_9b
THUDM/CodeGeeX4 is a versatile model for all AI software development scenarios, including code completion, code interpreter, web search, function calling, repository-level Q&A and much more.
- [[https://github.com/THUDM/CodeGeeX4][Github]]
- [[https://codegeex.cn/][HomePage]]
- [[https://huggingface.co/THUDM/codegeex4-all-9b][huggingface]]
** Running with ~cuda~
#+begin_src shell
cargo run --example codegeex4-9b --release --features cuda -- --prompt "please write a insertion sort in rust" --sample-len 300
#+end_src
** Running with ~cpu~
#+begin_src shell
cargo run --example codegeex4-9b --release --cpu -- --prompt "please write a insertion sort in rust" --sample-len 300
#+end_src
** Output_Example
*** Input
#+begin_src shell
cargo run --release --features cuda -- --prompt 'please write a FFT in rust' --sample-len 500 --cache /root/autodl-tmp
#+end_src
*** Output
#+begin_src shell
avx: false, neon: false, simd128: false, f16c: false
temp: 0.95 repeat-penalty: 1.10 repeat-last-n: 64
cache path /root/autodl-tmp
Prompt: [please write a FFT in rust]
Using Seed 11511762269791786684
DType is BF16
transofrmer layers create
模型加载完毕 4
starting the inference loop
开始生成
samplelen 500
500 tokens generated (34.60 token/s)
Result:
Sure, I can help you with that. Here's an example of a Fast Fourier Transform (FFT) implementation in Rust:
```rust
use num_complex::Complex;
fn fft(input: &[Complex<f64> > ] ) -> Vec<Complex<f64> > > {
let n = input.len();
if n == 1 {
return vec![input[0]]];
}
let mut even = vec![];
let mut odd = vec![];
for i in 0..n {
if i % 2 == 0 {
even.push(input[i]);
} else {
odd.push(input[i]);
}
}
let even_fft = fft(&even);
let odd_fft = fft(&odd);
let mut output = vec![];
for k in 0..n/2 {
let t = Complex::new(0.0, -2.0 * std::f64::consts::PI * (k as f64) / (n as f64))) ).exp();
output.push(even_fft[k] + odd_fft[k] * t]);
output.push(even_fft[k] - odd_fft[k] * t]);
}
return output;
}
```
This implementation uses the Cooley-Tukey algorithm to perform the FFT. The function takes an array of complex numbers and returns an array of complex numbers which is the result of the FFT.
#+end_src
* Citation
#+begin_src
@inproceedings{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
booktitle={Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining},
pages={5673--5684},
year={2023}
}
#+end_src
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/marian-mt/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::Error as E;
use clap::{Parser, ValueEnum};
use candle::{DType, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::models::marian;
use tokenizers::Tokenizer;
#[derive(Clone, Debug, Copy, ValueEnum)]
enum Which {
Base,
Big,
}
// TODO: Maybe add support for the conditional prompt.
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
#[arg(long)]
tokenizer_dec: Option<String>,
/// Choose the variant of the model to run.
#[arg(long, default_value = "big")]
which: Which,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Use the quantized version of the model.
#[arg(long)]
quantized: bool,
/// Text to be translated
#[arg(long)]
text: String,
}
pub fn main() -> anyhow::Result<()> {
use hf_hub::api::sync::Api;
let args = Args::parse();
let config = match args.which {
Which::Base => marian::Config::opus_mt_fr_en(),
Which::Big => marian::Config::opus_mt_tc_big_fr_en(),
};
let tokenizer = {
let tokenizer = match args.tokenizer {
Some(tokenizer) => std::path::PathBuf::from(tokenizer),
None => {
let name = match args.which {
Which::Base => "tokenizer-marian-base-fr.json",
Which::Big => "tokenizer-marian-fr.json",
};
Api::new()?
.model("lmz/candle-marian".to_string())
.get(name)?
}
};
Tokenizer::from_file(&tokenizer).map_err(E::msg)?
};
let tokenizer_dec = {
let tokenizer = match args.tokenizer_dec {
Some(tokenizer) => std::path::PathBuf::from(tokenizer),
None => {
let name = match args.which {
Which::Base => "tokenizer-marian-base-en.json",
Which::Big => "tokenizer-marian-en.json",
};
Api::new()?
.model("lmz/candle-marian".to_string())
.get(name)?
}
};
Tokenizer::from_file(&tokenizer).map_err(E::msg)?
};
let mut tokenizer_dec = TokenOutputStream::new(tokenizer_dec);
let device = candle_examples::device(args.cpu)?;
let vb = {
let model = match args.model {
Some(model) => std::path::PathBuf::from(model),
None => match args.which {
Which::Base => Api::new()?
.repo(hf_hub::Repo::with_revision(
"Helsinki-NLP/opus-mt-fr-en".to_string(),
hf_hub::RepoType::Model,
"refs/pr/4".to_string(),
))
.get("model.safetensors")?,
Which::Big => Api::new()?
.model("Helsinki-NLP/opus-mt-tc-big-fr-en".to_string())
.get("model.safetensors")?,
},
};
unsafe { VarBuilder::from_mmaped_safetensors(&[&model], DType::F32, &device)? }
};
let mut model = marian::MTModel::new(&config, vb)?;
let mut logits_processor =
candle_transformers::generation::LogitsProcessor::new(1337, None, None);
let encoder_xs = {
let mut tokens = tokenizer
.encode(args.text, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
tokens.push(config.eos_token_id);
let tokens = Tensor::new(tokens.as_slice(), &device)?.unsqueeze(0)?;
model.encoder().forward(&tokens, 0)?
};
let mut token_ids = vec![config.decoder_start_token_id];
for index in 0..1000 {
let context_size = if index >= 1 { 1 } else { token_ids.len() };
let start_pos = token_ids.len().saturating_sub(context_size);
let input_ids = Tensor::new(&token_ids[start_pos..], &device)?.unsqueeze(0)?;
let logits = model.decode(&input_ids, &encoder_xs, start_pos)?;
let logits = logits.squeeze(0)?;
let logits = logits.get(logits.dim(0)? - 1)?;
let token = logits_processor.sample(&logits)?;
token_ids.push(token);
if let Some(t) = tokenizer_dec.next_token(token)? {
use std::io::Write;
print!("{t}");
std::io::stdout().flush()?;
}
if token == config.eos_token_id || token == config.forced_eos_token_id {
break;
}
}
if let Some(rest) = tokenizer_dec.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
println!();
Ok(())
}
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/marian-mt/convert_slow_tokenizer.py | # coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utilities to convert slow tokenizers in their fast tokenizers counterparts.
All the conversions are grouped here to gather SentencePiece dependencies outside of the fast tokenizers files and
allow to make our dependency on SentencePiece optional.
"""
import warnings
from typing import Dict, List, Tuple
from packaging import version
from pathlib import Path
from tokenizers import AddedToken, Regex, Tokenizer, decoders, normalizers, pre_tokenizers, processors
from tokenizers.models import BPE, Unigram, WordPiece
from transformers.utils import is_protobuf_available, requires_backends
from transformers.utils.import_utils import PROTOBUF_IMPORT_ERROR
def import_protobuf(error_message=""):
if is_protobuf_available():
import google.protobuf
if version.parse(google.protobuf.__version__) < version.parse("4.0.0"):
from transformers.utils import sentencepiece_model_pb2
else:
from transformers.utils import sentencepiece_model_pb2_new as sentencepiece_model_pb2
return sentencepiece_model_pb2
else:
raise ImportError(PROTOBUF_IMPORT_ERROR.format(error_message))
def _get_prepend_scheme(add_prefix_space: bool, original_tokenizer) -> str:
if add_prefix_space:
prepend_scheme = "always"
if hasattr(original_tokenizer, "legacy") and not original_tokenizer.legacy:
prepend_scheme = "first"
else:
prepend_scheme = "never"
return prepend_scheme
class SentencePieceExtractor:
"""
Extractor implementation for SentencePiece trained models. https://github.com/google/sentencepiece
"""
def __init__(self, model: str):
requires_backends(self, "sentencepiece")
from sentencepiece import SentencePieceProcessor
self.sp = SentencePieceProcessor()
self.sp.Load(model)
def extract(self, vocab_scores=None) -> Tuple[Dict[str, int], List[Tuple]]:
"""
By default will return vocab and merges with respect to their order, by sending `vocab_scores` we're going to
order the merges with respect to the piece scores instead.
"""
sp = self.sp
vocab = {sp.id_to_piece(index): index for index in range(sp.GetPieceSize())}
if vocab_scores is not None:
vocab_scores, reverse = dict(vocab_scores), True
else:
vocab_scores, reverse = vocab, False
# Merges
merges = []
for merge, piece_score in vocab_scores.items():
local = []
for index in range(1, len(merge)):
piece_l, piece_r = merge[:index], merge[index:]
if piece_l in vocab and piece_r in vocab:
local.append((piece_l, piece_r, piece_score))
local = sorted(local, key=lambda x: (vocab[x[0]], vocab[x[1]]))
merges.extend(local)
merges = sorted(merges, key=lambda val: val[2], reverse=reverse)
merges = [(val[0], val[1]) for val in merges]
return vocab, merges
def check_number_comma(piece: str) -> bool:
return len(piece) < 2 or piece[-1] != "," or not piece[-2].isdigit()
class Converter:
def __init__(self, original_tokenizer):
self.original_tokenizer = original_tokenizer
def converted(self) -> Tokenizer:
raise NotImplementedError()
class BertConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
tokenize_chinese_chars = False
strip_accents = False
do_lower_case = False
if hasattr(self.original_tokenizer, "basic_tokenizer"):
tokenize_chinese_chars = self.original_tokenizer.basic_tokenizer.tokenize_chinese_chars
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:0 $A:0 {sep}:0",
pair=f"{cls}:0 $A:0 {sep}:0 $B:1 {sep}:1",
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class SplinterConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
tokenize_chinese_chars = False
strip_accents = False
do_lower_case = False
if hasattr(self.original_tokenizer, "basic_tokenizer"):
tokenize_chinese_chars = self.original_tokenizer.basic_tokenizer.tokenize_chinese_chars
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
question = str(self.original_tokenizer.question_token)
dot = "."
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
question_token_id = self.original_tokenizer.question_token_id
dot_token_id = self.original_tokenizer.convert_tokens_to_ids(".")
if self.original_tokenizer.padding_side == "right":
pair = f"{cls}:0 $A:0 {question} {dot} {sep}:0 $B:1 {sep}:1"
else:
pair = f"{cls}:0 $A:0 {sep}:0 $B:1 {question} {dot} {sep}:1"
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:0 $A:0 {sep}:0",
pair=pair,
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
(question, question_token_id),
(dot, dot_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class FunnelConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
tokenize_chinese_chars = False
strip_accents = False
do_lower_case = False
if hasattr(self.original_tokenizer, "basic_tokenizer"):
tokenize_chinese_chars = self.original_tokenizer.basic_tokenizer.tokenize_chinese_chars
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:2 $A:0 {sep}:0", # token_type_id is 2 for Funnel transformer
pair=f"{cls}:2 $A:0 {sep}:0 $B:1 {sep}:1",
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class MPNetConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
tokenize_chinese_chars = False
strip_accents = False
do_lower_case = False
if hasattr(self.original_tokenizer, "basic_tokenizer"):
tokenize_chinese_chars = self.original_tokenizer.basic_tokenizer.tokenize_chinese_chars
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:0 $A:0 {sep}:0",
pair=f"{cls}:0 $A:0 {sep}:0 {sep}:0 $B:1 {sep}:1", # MPNet uses two [SEP] tokens
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class OpenAIGPTConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
merges = list(self.original_tokenizer.bpe_ranks.keys())
unk_token = self.original_tokenizer.unk_token
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
unk_token=str(unk_token),
end_of_word_suffix="</w>",
fuse_unk=False,
)
)
if tokenizer.token_to_id(str(unk_token)) is not None:
tokenizer.add_special_tokens([str(unk_token)])
tokenizer.normalizer = normalizers.BertNormalizer(lowercase=True)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
tokenizer.decoder = decoders.BPEDecoder(suffix="</w>")
return tokenizer
class GPT2Converter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
merges = list(self.original_tokenizer.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=self.original_tokenizer.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
if self.original_tokenizer.add_bos_token:
bos = self.original_tokenizer.bos_token
bos_token_id = self.original_tokenizer.bos_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{bos}:0 $A:0",
pair=f"{bos}:0 $A:0 $B:1",
special_tokens=[
(bos, bos_token_id),
],
)
else:
# XXX trim_offsets=False actually means this post_processor doesn't
# really do anything.
tokenizer.post_processor = processors.ByteLevel(trim_offsets=False)
return tokenizer
class HerbertConverter(Converter):
def converted(self) -> Tokenizer:
tokenizer_info_str = "#version:"
token_suffix = "</w>"
vocab = self.original_tokenizer.encoder
merges = list(self.original_tokenizer.bpe_ranks.keys())
if tokenizer_info_str in merges[0][0]:
merges = merges[1:]
tokenizer = Tokenizer(
BPE(
vocab,
merges,
dropout=None,
unk_token=self.original_tokenizer.unk_token,
end_of_word_suffix=token_suffix,
)
)
tokenizer.normalizer = normalizers.BertNormalizer(lowercase=False, strip_accents=False)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
tokenizer.decoder = decoders.BPEDecoder(suffix=token_suffix)
tokenizer.post_processor = processors.BertProcessing(
sep=(self.original_tokenizer.sep_token, self.original_tokenizer.sep_token_id),
cls=(self.original_tokenizer.cls_token, self.original_tokenizer.cls_token_id),
)
return tokenizer
class RobertaConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
vocab = ot.encoder
merges = list(ot.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=ot.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.RobertaProcessing(
sep=(ot.sep_token, ot.sep_token_id),
cls=(ot.cls_token, ot.cls_token_id),
add_prefix_space=ot.add_prefix_space,
trim_offsets=True, # True by default on Roberta (historical)
)
return tokenizer
class RoFormerConverter(Converter):
def converted(self) -> Tokenizer:
from .models.roformer.tokenization_utils import JiebaPreTokenizer
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
strip_accents = False
do_lower_case = False
if hasattr(self.original_tokenizer, "basic_tokenizer"):
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=False,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.PreTokenizer.custom(JiebaPreTokenizer(vocab))
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:0 $A:0 {sep}:0",
pair=f"{cls}:0 $A:0 {sep}:0 $B:1 {sep}:1",
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class DebertaConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
vocab = ot.encoder
merges = list(ot.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=ot.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.TemplateProcessing(
single="[CLS]:0 $A:0 [SEP]:0",
pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[
("[CLS]", self.original_tokenizer.convert_tokens_to_ids("[CLS]")),
("[SEP]", self.original_tokenizer.convert_tokens_to_ids("[SEP]")),
],
)
return tokenizer
class SpmConverter(Converter):
def __init__(self, *args):
requires_backends(self, "protobuf")
super().__init__(*args)
# from .utils import sentencepiece_model_pb2 as model_pb2
model_pb2 = import_protobuf()
m = model_pb2.ModelProto()
with open(self.original_tokenizer.vocab_file, "rb") as f:
m.ParseFromString(f.read())
self.proto = m
if self.proto.trainer_spec.byte_fallback:
if not getattr(self, "handle_byte_fallback", None):
warnings.warn(
"The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option"
" which is not implemented in the fast tokenizers. In practice this means that the fast version of the"
" tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these "
"unknown tokens into a sequence of byte tokens matching the original piece of text."
)
def vocab(self, proto):
return [(piece.piece, piece.score) for piece in proto.pieces]
def unk_id(self, proto):
return proto.trainer_spec.unk_id
def tokenizer(self, proto):
model_type = proto.trainer_spec.model_type
vocab_scores = self.vocab(proto)
unk_id = self.unk_id(proto)
if model_type == 1:
tokenizer = Tokenizer(Unigram(vocab_scores, unk_id))
elif model_type == 2:
_, merges = SentencePieceExtractor(self.original_tokenizer.vocab_file).extract()
bpe_vocab = {word: i for i, (word, score) in enumerate(vocab_scores)}
tokenizer = Tokenizer(
BPE(
bpe_vocab,
merges,
unk_token=proto.trainer_spec.unk_piece,
fuse_unk=True,
)
)
else:
raise Exception(
"You're trying to run a `Unigram` model but you're file was trained with a different algorithm"
)
return tokenizer
def normalizer(self, proto):
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
if not precompiled_charsmap:
return normalizers.Sequence([normalizers.Replace(Regex(" {2,}"), " ")])
else:
return normalizers.Sequence(
[normalizers.Precompiled(precompiled_charsmap), normalizers.Replace(Regex(" {2,}"), " ")]
)
def pre_tokenizer(self, replacement, add_prefix_space):
prepend_scheme = _get_prepend_scheme(add_prefix_space, self.original_tokenizer)
return pre_tokenizers.Metaspace(replacement=replacement, prepend_scheme=prepend_scheme)
def post_processor(self):
return None
def decoder(self, replacement, add_prefix_space):
prepend_scheme = _get_prepend_scheme(add_prefix_space, self.original_tokenizer)
return decoders.Metaspace(replacement=replacement, prepend_scheme=prepend_scheme)
def converted(self) -> Tokenizer:
tokenizer = self.tokenizer(self.proto)
# Tokenizer assemble
normalizer = self.normalizer(self.proto)
if normalizer is not None:
tokenizer.normalizer = normalizer
replacement = "▁"
add_prefix_space = True
pre_tokenizer = self.pre_tokenizer(replacement, add_prefix_space)
if pre_tokenizer is not None:
tokenizer.pre_tokenizer = pre_tokenizer
tokenizer.decoder = self.decoder(replacement, add_prefix_space)
post_processor = self.post_processor()
if post_processor:
tokenizer.post_processor = post_processor
return tokenizer
class AlbertConverter(SpmConverter):
def vocab(self, proto):
return [
(piece.piece, piece.score) if check_number_comma(piece.piece) else (piece.piece, piece.score - 100)
for piece in proto.pieces
]
def normalizer(self, proto):
list_normalizers = [
normalizers.Replace("``", '"'),
normalizers.Replace("''", '"'),
]
if not self.original_tokenizer.keep_accents:
list_normalizers.append(normalizers.NFKD())
list_normalizers.append(normalizers.StripAccents())
if self.original_tokenizer.do_lower_case:
list_normalizers.append(normalizers.Lowercase())
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
if precompiled_charsmap:
list_normalizers.append(normalizers.Precompiled(precompiled_charsmap))
list_normalizers.append(normalizers.Replace(Regex(" {2,}"), " "))
return normalizers.Sequence(list_normalizers)
def post_processor(self):
return processors.TemplateProcessing(
single="[CLS]:0 $A:0 [SEP]:0",
pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[
("[CLS]", self.original_tokenizer.convert_tokens_to_ids("[CLS]")),
("[SEP]", self.original_tokenizer.convert_tokens_to_ids("[SEP]")),
],
)
class BarthezConverter(SpmConverter):
def unk_id(self, proto):
unk_id = 3
return unk_id
def post_processor(self):
return processors.TemplateProcessing(
single="<s> $A </s>",
pair="<s> $A </s> </s> $B </s>",
special_tokens=[
("<s>", self.original_tokenizer.convert_tokens_to_ids("<s>")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class CamembertConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>NOTUSED", 0.0),
("<pad>", 0.0),
("</s>NOTUSED", 0.0),
("<unk>", 0.0),
("<unk>NOTUSED", -100),
]
# We down-grade the original SentencePiece by -100 to avoid using it and use our added token instead
vocab += [(piece.piece, piece.score) for piece in proto.pieces[1:]]
vocab += [("<mask>", 0.0)]
return vocab
def unk_id(self, proto):
# See vocab unk position
return 3
def post_processor(self):
return processors.TemplateProcessing(
single="<s> $A </s>",
pair="<s> $A </s> </s> $B </s>",
special_tokens=[
("<s>", self.original_tokenizer.convert_tokens_to_ids("<s>")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class DebertaV2Converter(SpmConverter):
def pre_tokenizer(self, replacement, add_prefix_space):
list_pretokenizers = []
if self.original_tokenizer.split_by_punct:
list_pretokenizers.append(pre_tokenizers.Punctuation(behavior="isolated"))
prepend_scheme = _get_prepend_scheme(add_prefix_space, self.original_tokenizer)
list_pretokenizers.append(pre_tokenizers.Metaspace(replacement=replacement, prepend_scheme=prepend_scheme))
return pre_tokenizers.Sequence(list_pretokenizers)
def normalizer(self, proto):
list_normalizers = []
if self.original_tokenizer.do_lower_case:
list_normalizers.append(normalizers.Lowercase())
list_normalizers.append(normalizers.Strip())
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
if precompiled_charsmap:
list_normalizers.append(normalizers.Precompiled(precompiled_charsmap))
list_normalizers.append(normalizers.Replace(Regex(" {2,}"), " "))
return normalizers.Sequence(list_normalizers)
def post_processor(self):
return processors.TemplateProcessing(
single="[CLS]:0 $A:0 [SEP]:0",
pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[
("[CLS]", self.original_tokenizer.convert_tokens_to_ids("[CLS]")),
("[SEP]", self.original_tokenizer.convert_tokens_to_ids("[SEP]")),
],
)
class MBartConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>", 0.0),
("<pad>", 0.0),
("</s>", 0.0),
("<unk>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
vocab += [
("ar_AR", 0.0),
("cs_CZ", 0.0),
("de_DE", 0.0),
("en_XX", 0.0),
("es_XX", 0.0),
("et_EE", 0.0),
("fi_FI", 0.0),
("fr_XX", 0.0),
("gu_IN", 0.0),
("hi_IN", 0.0),
("it_IT", 0.0),
("ja_XX", 0.0),
("kk_KZ", 0.0),
("ko_KR", 0.0),
("lt_LT", 0.0),
("lv_LV", 0.0),
("my_MM", 0.0),
("ne_NP", 0.0),
("nl_XX", 0.0),
("ro_RO", 0.0),
("ru_RU", 0.0),
("si_LK", 0.0),
("tr_TR", 0.0),
("vi_VN", 0.0),
("zh_CN", 0.0),
]
vocab += [("<mask>", 0.0)]
return vocab
def unk_id(self, proto):
return 3
def post_processor(self):
return processors.TemplateProcessing(
single="$A </s> en_XX",
pair="$A $B </s> en_XX",
special_tokens=[
("en_XX", self.original_tokenizer.convert_tokens_to_ids("en_XX")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class MBart50Converter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>", 0.0),
("<pad>", 0.0),
("</s>", 0.0),
("<unk>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
# fmt: off
vocab += [("ar_AR", 0.0), ("cs_CZ", 0.0), ("de_DE", 0.0), ("en_XX", 0.0), ("es_XX", 0.0), ("et_EE", 0.0), ("fi_FI", 0.0), ("fr_XX", 0.0), ("gu_IN", 0.0), ("hi_IN", 0.0), ("it_IT", 0.0), ("ja_XX", 0.0), ("kk_KZ", 0.0), ("ko_KR", 0.0), ("lt_LT", 0.0), ("lv_LV", 0.0), ("my_MM", 0.0), ("ne_NP", 0.0), ("nl_XX", 0.0), ("ro_RO", 0.0), ("ru_RU", 0.0), ("si_LK", 0.0), ("tr_TR", 0.0), ("vi_VN", 0.0), ("zh_CN", 0.0), ("af_ZA", 0.0), ("az_AZ", 0.0), ("bn_IN", 0.0), ("fa_IR", 0.0), ("he_IL", 0.0), ("hr_HR", 0.0), ("id_ID", 0.0), ("ka_GE", 0.0), ("km_KH", 0.0), ("mk_MK", 0.0), ("ml_IN", 0.0), ("mn_MN", 0.0), ("mr_IN", 0.0), ("pl_PL", 0.0), ("ps_AF", 0.0), ("pt_XX", 0.0), ("sv_SE", 0.0), ("sw_KE", 0.0), ("ta_IN", 0.0), ("te_IN", 0.0), ("th_TH", 0.0), ("tl_XX", 0.0), ("uk_UA", 0.0), ("ur_PK", 0.0), ("xh_ZA", 0.0), ("gl_ES", 0.0), ("sl_SI", 0.0)]
# fmt: on
vocab += [("<mask>", 0.0)]
return vocab
def unk_id(self, proto):
return 3
def post_processor(self):
return processors.TemplateProcessing(
single="en_XX $A </s>",
pair="en_XX $A $B </s>",
special_tokens=[
("en_XX", self.original_tokenizer.convert_tokens_to_ids("en_XX")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class NllbConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>", 0.0),
("<pad>", 0.0),
("</s>", 0.0),
("<unk>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
vocab += [
# fmt: off
('ace_Arab', 0.0), ('ace_Latn', 0.0), ('acm_Arab', 0.0), ('acq_Arab', 0.0), ('aeb_Arab', 0.0), ('afr_Latn', 0.0), ('ajp_Arab', 0.0), ('aka_Latn', 0.0), ('amh_Ethi', 0.0), ('apc_Arab', 0.0), ('arb_Arab', 0.0), ('ars_Arab', 0.0), ('ary_Arab', 0.0), ('arz_Arab', 0.0), ('asm_Beng', 0.0), ('ast_Latn', 0.0), ('awa_Deva', 0.0), ('ayr_Latn', 0.0), ('azb_Arab', 0.0), ('azj_Latn', 0.0), ('bak_Cyrl', 0.0), ('bam_Latn', 0.0), ('ban_Latn', 0.0), ('bel_Cyrl', 0.0), ('bem_Latn', 0.0), ('ben_Beng', 0.0), ('bho_Deva', 0.0), ('bjn_Arab', 0.0), ('bjn_Latn', 0.0), ('bod_Tibt', 0.0), ('bos_Latn', 0.0), ('bug_Latn', 0.0), ('bul_Cyrl', 0.0), ('cat_Latn', 0.0), ('ceb_Latn', 0.0), ('ces_Latn', 0.0), ('cjk_Latn', 0.0), ('ckb_Arab', 0.0), ('crh_Latn', 0.0), ('cym_Latn', 0.0), ('dan_Latn', 0.0), ('deu_Latn', 0.0), ('dik_Latn', 0.0), ('dyu_Latn', 0.0), ('dzo_Tibt', 0.0), ('ell_Grek', 0.0), ('eng_Latn', 0.0), ('epo_Latn', 0.0), ('est_Latn', 0.0), ('eus_Latn', 0.0), ('ewe_Latn', 0.0), ('fao_Latn', 0.0), ('pes_Arab', 0.0), ('fij_Latn', 0.0), ('fin_Latn', 0.0), ('fon_Latn', 0.0), ('fra_Latn', 0.0), ('fur_Latn', 0.0), ('fuv_Latn', 0.0), ('gla_Latn', 0.0), ('gle_Latn', 0.0), ('glg_Latn', 0.0), ('grn_Latn', 0.0), ('guj_Gujr', 0.0), ('hat_Latn', 0.0), ('hau_Latn', 0.0), ('heb_Hebr', 0.0), ('hin_Deva', 0.0), ('hne_Deva', 0.0), ('hrv_Latn', 0.0), ('hun_Latn', 0.0), ('hye_Armn', 0.0), ('ibo_Latn', 0.0), ('ilo_Latn', 0.0), ('ind_Latn', 0.0), ('isl_Latn', 0.0), ('ita_Latn', 0.0), ('jav_Latn', 0.0), ('jpn_Jpan', 0.0), ('kab_Latn', 0.0), ('kac_Latn', 0.0), ('kam_Latn', 0.0), ('kan_Knda', 0.0), ('kas_Arab', 0.0), ('kas_Deva', 0.0), ('kat_Geor', 0.0), ('knc_Arab', 0.0), ('knc_Latn', 0.0), ('kaz_Cyrl', 0.0), ('kbp_Latn', 0.0), ('kea_Latn', 0.0), ('khm_Khmr', 0.0), ('kik_Latn', 0.0), ('kin_Latn', 0.0), ('kir_Cyrl', 0.0), ('kmb_Latn', 0.0), ('kon_Latn', 0.0), ('kor_Hang', 0.0), ('kmr_Latn', 0.0), ('lao_Laoo', 0.0), ('lvs_Latn', 0.0), ('lij_Latn', 0.0), ('lim_Latn', 0.0), ('lin_Latn', 0.0), ('lit_Latn', 0.0), ('lmo_Latn', 0.0), ('ltg_Latn', 0.0), ('ltz_Latn', 0.0), ('lua_Latn', 0.0), ('lug_Latn', 0.0), ('luo_Latn', 0.0), ('lus_Latn', 0.0), ('mag_Deva', 0.0), ('mai_Deva', 0.0), ('mal_Mlym', 0.0), ('mar_Deva', 0.0), ('min_Latn', 0.0), ('mkd_Cyrl', 0.0), ('plt_Latn', 0.0), ('mlt_Latn', 0.0), ('mni_Beng', 0.0), ('khk_Cyrl', 0.0), ('mos_Latn', 0.0), ('mri_Latn', 0.0), ('zsm_Latn', 0.0), ('mya_Mymr', 0.0), ('nld_Latn', 0.0), ('nno_Latn', 0.0), ('nob_Latn', 0.0), ('npi_Deva', 0.0), ('nso_Latn', 0.0), ('nus_Latn', 0.0), ('nya_Latn', 0.0), ('oci_Latn', 0.0), ('gaz_Latn', 0.0), ('ory_Orya', 0.0), ('pag_Latn', 0.0), ('pan_Guru', 0.0), ('pap_Latn', 0.0), ('pol_Latn', 0.0), ('por_Latn', 0.0), ('prs_Arab', 0.0), ('pbt_Arab', 0.0), ('quy_Latn', 0.0), ('ron_Latn', 0.0), ('run_Latn', 0.0), ('rus_Cyrl', 0.0), ('sag_Latn', 0.0), ('san_Deva', 0.0), ('sat_Beng', 0.0), ('scn_Latn', 0.0), ('shn_Mymr', 0.0), ('sin_Sinh', 0.0), ('slk_Latn', 0.0), ('slv_Latn', 0.0), ('smo_Latn', 0.0), ('sna_Latn', 0.0), ('snd_Arab', 0.0), ('som_Latn', 0.0), ('sot_Latn', 0.0), ('spa_Latn', 0.0), ('als_Latn', 0.0), ('srd_Latn', 0.0), ('srp_Cyrl', 0.0), ('ssw_Latn', 0.0), ('sun_Latn', 0.0), ('swe_Latn', 0.0), ('swh_Latn', 0.0), ('szl_Latn', 0.0), ('tam_Taml', 0.0), ('tat_Cyrl', 0.0), ('tel_Telu', 0.0), ('tgk_Cyrl', 0.0), ('tgl_Latn', 0.0), ('tha_Thai', 0.0), ('tir_Ethi', 0.0), ('taq_Latn', 0.0), ('taq_Tfng', 0.0), ('tpi_Latn', 0.0), ('tsn_Latn', 0.0), ('tso_Latn', 0.0), ('tuk_Latn', 0.0), ('tum_Latn', 0.0), ('tur_Latn', 0.0), ('twi_Latn', 0.0), ('tzm_Tfng', 0.0), ('uig_Arab', 0.0), ('ukr_Cyrl', 0.0), ('umb_Latn', 0.0), ('urd_Arab', 0.0), ('uzn_Latn', 0.0), ('vec_Latn', 0.0), ('vie_Latn', 0.0), ('war_Latn', 0.0), ('wol_Latn', 0.0), ('xho_Latn', 0.0), ('ydd_Hebr', 0.0), ('yor_Latn', 0.0), ('yue_Hant', 0.0), ('zho_Hans', 0.0), ('zho_Hant', 0.0), ('zul_Latn', 0.0)
# fmt: on
]
vocab += [("<mask>", 0.0)]
return vocab
def unk_id(self, proto):
return 3
def post_processor(self):
return processors.TemplateProcessing(
single="eng_Latn $A </s>",
pair="eng_Latn $A $B </s>",
special_tokens=[
("eng_Latn", self.original_tokenizer.convert_tokens_to_ids("eng_Latn")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class SeamlessM4TConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<pad>", 0.0),
("<unk>", 0.0),
("<s>", 0.0),
("</s>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
return vocab
def unk_id(self, proto):
return self.original_tokenizer.unk_token_id
def post_processor(self):
return processors.TemplateProcessing(
single="__eng__ $A </s>",
pair="__eng__ $A $B </s>",
special_tokens=[
("__eng__", self.original_tokenizer.convert_tokens_to_ids("__eng__")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class XLMRobertaConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>", 0.0),
("<pad>", 0.0),
("</s>", 0.0),
("<unk>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
vocab += [("<mask>", 0.0)]
return vocab
def unk_id(self, proto):
unk_id = 3
return unk_id
def post_processor(self):
return processors.TemplateProcessing(
single="<s> $A </s>",
pair="<s> $A </s> </s> $B </s>",
special_tokens=[
("<s>", self.original_tokenizer.convert_tokens_to_ids("<s>")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class XLNetConverter(SpmConverter):
def vocab(self, proto):
return [
(piece.piece, piece.score) if check_number_comma(piece.piece) else (piece.piece, piece.score - 100)
for piece in proto.pieces
]
def normalizer(self, proto):
list_normalizers = [
normalizers.Replace("``", '"'),
normalizers.Replace("''", '"'),
]
if not self.original_tokenizer.keep_accents:
list_normalizers.append(normalizers.NFKD())
list_normalizers.append(normalizers.StripAccents())
if self.original_tokenizer.do_lower_case:
list_normalizers.append(normalizers.Lowercase())
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
if precompiled_charsmap:
list_normalizers.append(normalizers.Precompiled(precompiled_charsmap))
list_normalizers.append(normalizers.Replace(Regex(" {2,}"), " "))
return normalizers.Sequence(list_normalizers)
def post_processor(self):
return processors.TemplateProcessing(
single="$A:0 <sep>:0 <cls>:2",
pair="$A:0 <sep>:0 $B:1 <sep>:1 <cls>:2",
special_tokens=[
("<sep>", self.original_tokenizer.convert_tokens_to_ids("<sep>")),
("<cls>", self.original_tokenizer.convert_tokens_to_ids("<cls>")),
],
)
class ReformerConverter(SpmConverter):
pass
class RemBertConverter(SpmConverter):
# Inspired from AlbertConverter
def normalizer(self, proto):
list_normalizers = [
normalizers.Replace("``", '"'),
normalizers.Replace("''", '"'),
normalizers.Replace(Regex(" {2,}"), " "),
]
if not self.original_tokenizer.keep_accents:
list_normalizers.append(normalizers.NFKD())
list_normalizers.append(normalizers.StripAccents())
if self.original_tokenizer.do_lower_case:
list_normalizers.append(normalizers.Lowercase())
precompiled_charsmap = proto.normalizer_spec.precompiled_charsmap
if precompiled_charsmap:
list_normalizers.append(normalizers.Precompiled(precompiled_charsmap))
return normalizers.Sequence(list_normalizers)
def post_processor(self):
return processors.TemplateProcessing(
single="[CLS]:0 $A:0 [SEP]:0",
pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[
("[CLS]", self.original_tokenizer.convert_tokens_to_ids("[CLS]")),
("[SEP]", self.original_tokenizer.convert_tokens_to_ids("[SEP]")),
],
)
class BertGenerationConverter(SpmConverter):
pass
class PegasusConverter(SpmConverter):
def vocab(self, proto):
vocab = [
(self.original_tokenizer.pad_token, 0.0),
(self.original_tokenizer.eos_token, 0.0),
]
if self.original_tokenizer.mask_token_sent is not None:
vocab += [(self.original_tokenizer.mask_token_sent, 0.0)]
if (
self.original_tokenizer.mask_token is not None
and self.original_tokenizer.mask_token_id < self.original_tokenizer.offset
):
vocab += [(self.original_tokenizer.mask_token, 0.0)]
vocab += [(f"<unk_{i}>", -100.0) for i in range(2, self.original_tokenizer.offset)]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[2:]]
return vocab
def unk_id(self, proto):
return proto.trainer_spec.unk_id + self.original_tokenizer.offset
def pre_tokenizer(self, replacement, add_prefix_space):
prepend_scheme = _get_prepend_scheme(add_prefix_space, self.original_tokenizer)
return pre_tokenizers.Sequence(
[
pre_tokenizers.WhitespaceSplit(),
pre_tokenizers.Metaspace(replacement=replacement, prepend_scheme=prepend_scheme),
]
)
def post_processor(self):
eos = self.original_tokenizer.eos_token
special_tokens = [
(eos, self.original_tokenizer.eos_token_id),
]
return processors.TemplateProcessing(single=["$A", eos], pair=["$A", "$B", eos], special_tokens=special_tokens)
class T5Converter(SpmConverter):
def vocab(self, proto):
num_extra_ids = self.original_tokenizer._extra_ids
vocab = [(piece.piece, piece.score) for piece in proto.pieces]
vocab += [(f"<extra_id_{i}>", 0.0) for i in range(num_extra_ids - 1, -1, -1)]
return vocab
def post_processor(self):
return processors.TemplateProcessing(
single=["$A", "</s>"],
pair=["$A", "</s>", "$B", "</s>"],
special_tokens=[
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class WhisperConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
merges = list(self.original_tokenizer.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=self.original_tokenizer.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
prefix_token_ids = self.original_tokenizer.prefix_tokens
prefixes = self.original_tokenizer.convert_ids_to_tokens(prefix_token_ids)
eos = self.original_tokenizer.eos_token
eos_token_id = self.original_tokenizer.eos_token_id
prefix_template = " ".join([f"{token}:0" for token in prefixes])
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{prefix_template} $A:0 {eos}:0",
pair=f"{prefix_template} $A:0 $B:1 {eos}:1",
special_tokens=[
(eos, eos_token_id),
*zip(prefixes, prefix_token_ids),
],
)
return tokenizer
class BigBirdConverter(SpmConverter):
def post_processor(self):
return processors.TemplateProcessing(
single="[CLS]:0 $A:0 [SEP]:0",
pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
special_tokens=[
("[CLS]", self.original_tokenizer.convert_tokens_to_ids("[CLS]")),
("[SEP]", self.original_tokenizer.convert_tokens_to_ids("[SEP]")),
],
)
class CLIPConverter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.encoder
merges = list(self.original_tokenizer.bpe_ranks.keys())
unk_token = self.original_tokenizer.unk_token
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="</w>",
fuse_unk=False,
unk_token=str(unk_token),
)
)
tokenizer.normalizer = normalizers.Sequence(
[normalizers.NFC(), normalizers.Replace(Regex(r"\s+"), " "), normalizers.Lowercase()]
)
tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
[
pre_tokenizers.Split(
Regex(r"""'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+"""),
behavior="removed",
invert=True,
),
pre_tokenizers.ByteLevel(add_prefix_space=False),
]
)
tokenizer.decoder = decoders.ByteLevel()
# Hack to have a ByteLevel and TemplaceProcessor
tokenizer.post_processor = processors.RobertaProcessing(
sep=(self.original_tokenizer.eos_token, self.original_tokenizer.eos_token_id),
cls=(self.original_tokenizer.bos_token, self.original_tokenizer.bos_token_id),
add_prefix_space=False,
trim_offsets=False,
)
return tokenizer
class LayoutLMv2Converter(Converter):
def converted(self) -> Tokenizer:
vocab = self.original_tokenizer.vocab
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(self.original_tokenizer.unk_token)))
tokenize_chinese_chars = False
strip_accents = False
do_lower_case = True
if hasattr(self.original_tokenizer, "basic_tokenizer"):
tokenize_chinese_chars = self.original_tokenizer.basic_tokenizer.tokenize_chinese_chars
strip_accents = self.original_tokenizer.basic_tokenizer.strip_accents
do_lower_case = self.original_tokenizer.basic_tokenizer.do_lower_case
tokenizer.normalizer = normalizers.BertNormalizer(
clean_text=True,
handle_chinese_chars=tokenize_chinese_chars,
strip_accents=strip_accents,
lowercase=do_lower_case,
)
tokenizer.pre_tokenizer = pre_tokenizers.BertPreTokenizer()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls}:0 $A:0 {sep}:0",
pair=f"{cls}:0 $A:0 {sep}:0 $B:1 {sep}:1",
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
tokenizer.decoder = decoders.WordPiece(prefix="##")
return tokenizer
class BlenderbotConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
vocab = ot.encoder
merges = list(ot.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=ot.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.TemplateProcessing(
single=f"$A:0 {ot.eos_token}:0",
special_tokens=[
(ot.eos_token, ot.eos_token_id),
],
)
return tokenizer
class XGLMConverter(SpmConverter):
def vocab(self, proto):
vocab = [
("<s>", 0.0),
("<pad>", 0.0),
("</s>", 0.0),
("<unk>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
# fmt: off
vocab += [("<madeupword0>", 0.0), ("<madeupword1>", 0.0), ("<madeupword2>", 0.0), ("<madeupword3>", 0.0), ("<madeupword4>", 0.0), ("<madeupword5>", 0.0), ("<madeupword6>", 0.0)]
# fmt: on
return vocab
def unk_id(self, proto):
unk_id = 3
return unk_id
def post_processor(self):
return processors.TemplateProcessing(
single="</s> $A",
pair="</s> $A </s> </s> $B",
special_tokens=[
("<s>", self.original_tokenizer.convert_tokens_to_ids("<s>")),
("</s>", self.original_tokenizer.convert_tokens_to_ids("</s>")),
],
)
class LlamaConverter(SpmConverter):
handle_byte_fallback = True
def vocab(self, proto):
vocab = [
("<unk>", 0.0),
("<s>", 0.0),
("</s>", 0.0),
]
vocab += [(piece.piece, piece.score) for piece in proto.pieces[3:]]
return vocab
def unk_id(self, proto):
unk_id = 0
return unk_id
def decoder(self, replacement, add_prefix_space):
return decoders.Sequence(
[
decoders.Replace("▁", " "),
decoders.ByteFallback(),
decoders.Fuse(),
decoders.Strip(content=" ", left=1),
]
)
def tokenizer(self, proto):
model_type = proto.trainer_spec.model_type
vocab_scores = self.vocab(proto)
if model_type == 1:
import tokenizers
if version.parse(tokenizers.__version__) < version.parse("0.14.0"):
tokenizer = Tokenizer(Unigram(vocab_scores, 0))
else:
tokenizer = Tokenizer(Unigram(vocab_scores, 0, byte_fallback=True))
elif model_type == 2:
_, merges = SentencePieceExtractor(self.original_tokenizer.vocab_file).extract(vocab_scores)
bpe_vocab = {word: i for i, (word, _score) in enumerate(vocab_scores)}
tokenizer = Tokenizer(
BPE(bpe_vocab, merges, unk_token=proto.trainer_spec.unk_piece, fuse_unk=True, byte_fallback=True)
)
tokenizer.add_special_tokens(
[
AddedToken("<unk>", normalized=False, special=True),
AddedToken("<s>", normalized=False, special=True),
AddedToken("</s>", normalized=False, special=True),
]
)
else:
raise Exception(
"You're trying to run a `Unigram` model but you're file was trained with a different algorithm"
)
return tokenizer
def normalizer(self, proto):
return normalizers.Sequence(
[
normalizers.Prepend(prepend="▁"),
normalizers.Replace(pattern=" ", content="▁"),
]
)
def pre_tokenizer(self, replacement, add_prefix_space):
return None
def post_processor(self):
# the processor is defined in the LlamaTokenizerFast class.
return None
class MarkupLMConverter(Converter):
def converted(self) -> Tokenizer:
ot = self.original_tokenizer
vocab = ot.encoder
merges = list(ot.bpe_ranks.keys())
tokenizer = Tokenizer(
BPE(
vocab=vocab,
merges=merges,
dropout=None,
continuing_subword_prefix="",
end_of_word_suffix="",
fuse_unk=False,
unk_token=self.original_tokenizer.unk_token,
)
)
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=ot.add_prefix_space)
tokenizer.decoder = decoders.ByteLevel()
cls = str(self.original_tokenizer.cls_token)
sep = str(self.original_tokenizer.sep_token)
cls_token_id = self.original_tokenizer.cls_token_id
sep_token_id = self.original_tokenizer.sep_token_id
tokenizer.post_processor = processors.TemplateProcessing(
single=f"{cls} $A {sep}",
pair=f"{cls} $A {sep} $B {sep}",
special_tokens=[
(cls, cls_token_id),
(sep, sep_token_id),
],
)
return tokenizer
class MarianConverter(SpmConverter):
def __init__(self, *args, index: int = 0):
requires_backends(self, "protobuf")
super(SpmConverter, self).__init__(*args)
# from .utils import sentencepiece_model_pb2 as model_pb2
model_pb2 = import_protobuf()
m = model_pb2.ModelProto()
print(self.original_tokenizer.spm_files)
with open(self.original_tokenizer.spm_files[index], "rb") as f:
m.ParseFromString(f.read())
self.proto = m
print(self.original_tokenizer)
#with open(self.original_tokenizer.vocab_path, "r") as f:
dir_path = Path(self.original_tokenizer.spm_files[0]).parents[0]
with open(dir_path / "vocab.json", "r") as f:
import json
self._vocab = json.load(f)
if self.proto.trainer_spec.byte_fallback:
if not getattr(self, "handle_byte_fallback", None):
warnings.warn(
"The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option"
" which is not implemented in the fast tokenizers. In practice this means that the fast version of the"
" tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these "
"unknown tokens into a sequence of byte tokens matching the original piece of text."
)
def vocab(self, proto):
vocab_size = max(self._vocab.values()) + 1
vocab = [("<NIL>", -100) for _ in range(vocab_size)]
for piece in proto.pieces:
try:
index = self._vocab[piece.piece]
except Exception:
print(f"Ignored missing piece {piece.piece}")
vocab[index] = (piece.piece, piece.score)
return vocab
SLOW_TO_FAST_CONVERTERS = {
"AlbertTokenizer": AlbertConverter,
"BartTokenizer": RobertaConverter,
"BarthezTokenizer": BarthezConverter,
"BertTokenizer": BertConverter,
"BigBirdTokenizer": BigBirdConverter,
"BlenderbotTokenizer": BlenderbotConverter,
"CamembertTokenizer": CamembertConverter,
"CLIPTokenizer": CLIPConverter,
"CodeGenTokenizer": GPT2Converter,
"ConvBertTokenizer": BertConverter,
"DebertaTokenizer": DebertaConverter,
"DebertaV2Tokenizer": DebertaV2Converter,
"DistilBertTokenizer": BertConverter,
"DPRReaderTokenizer": BertConverter,
"DPRQuestionEncoderTokenizer": BertConverter,
"DPRContextEncoderTokenizer": BertConverter,
"ElectraTokenizer": BertConverter,
"FNetTokenizer": AlbertConverter,
"FunnelTokenizer": FunnelConverter,
"GPT2Tokenizer": GPT2Converter,
"HerbertTokenizer": HerbertConverter,
"LayoutLMTokenizer": BertConverter,
"LayoutLMv2Tokenizer": BertConverter,
"LayoutLMv3Tokenizer": RobertaConverter,
"LayoutXLMTokenizer": XLMRobertaConverter,
"LongformerTokenizer": RobertaConverter,
"LEDTokenizer": RobertaConverter,
"LxmertTokenizer": BertConverter,
"MarkupLMTokenizer": MarkupLMConverter,
"MBartTokenizer": MBartConverter,
"MBart50Tokenizer": MBart50Converter,
"MPNetTokenizer": MPNetConverter,
"MobileBertTokenizer": BertConverter,
"MvpTokenizer": RobertaConverter,
"NllbTokenizer": NllbConverter,
"OpenAIGPTTokenizer": OpenAIGPTConverter,
"PegasusTokenizer": PegasusConverter,
"RealmTokenizer": BertConverter,
"ReformerTokenizer": ReformerConverter,
"RemBertTokenizer": RemBertConverter,
"RetriBertTokenizer": BertConverter,
"RobertaTokenizer": RobertaConverter,
"RoFormerTokenizer": RoFormerConverter,
"SeamlessM4TTokenizer": SeamlessM4TConverter,
"SqueezeBertTokenizer": BertConverter,
"T5Tokenizer": T5Converter,
"WhisperTokenizer": WhisperConverter,
"XLMRobertaTokenizer": XLMRobertaConverter,
"XLNetTokenizer": XLNetConverter,
"SplinterTokenizer": SplinterConverter,
"XGLMTokenizer": XGLMConverter,
"LlamaTokenizer": LlamaConverter,
"CodeLlamaTokenizer": LlamaConverter,
}
def convert_slow_tokenizer(transformer_tokenizer) -> Tokenizer:
"""
Utilities to convert a slow tokenizer instance in a fast tokenizer instance.
Args:
transformer_tokenizer ([`~tokenization_utils_base.PreTrainedTokenizer`]):
Instance of a slow tokenizer to convert in the backend tokenizer for
[`~tokenization_utils_base.PreTrainedTokenizerFast`].
Return:
A instance of [`~tokenizers.Tokenizer`] to be used as the backend tokenizer of a
[`~tokenization_utils_base.PreTrainedTokenizerFast`]
"""
tokenizer_class_name = transformer_tokenizer.__class__.__name__
if tokenizer_class_name not in SLOW_TO_FAST_CONVERTERS:
raise ValueError(
f"An instance of tokenizer class {tokenizer_class_name} cannot be converted in a Fast tokenizer instance."
" No converter was found. Currently available slow->fast convertors:"
f" {list(SLOW_TO_FAST_CONVERTERS.keys())}"
)
converter_class = SLOW_TO_FAST_CONVERTERS[tokenizer_class_name]
return converter_class(transformer_tokenizer).converted()
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/marian-mt/README.md | # candle-marian-mt
`marian-mt` is a neural machine translation model. In this example it is used to
translate text from French to English. See the associated [model
card](https://huggingface.co/Helsinki-NLP/opus-mt-tc-big-fr-en) for details on
the model itself.
## Running an example
```bash
cargo run --example marian-mt --release -- \
--text "Demain, dès l'aube, à l'heure où blanchit la campagne, Je partirai. Vois-tu, je sais que tu m'attends. J'irai par la forêt, j'irai par la montagne. Je ne puis demeurer loin de toi plus longtemps."
```
```
<NIL> Tomorrow, at dawn, at the time when the country is whitening, I will go. See,
I know you are waiting for me. I will go through the forest, I will go through the
mountain. I cannot stay far from you any longer.</s>
```
## Generating the tokenizer.json files
You can use the following script to generate the `tokenizer.json` config files
from the hf-hub repos. This requires the `tokenizers` and `sentencepiece`
packages to be install and use the `convert_slow_tokenizer.py` script from this
directory.
```python
from convert_slow_tokenizer import MarianConverter
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-fr-en", use_fast=False)
fast_tokenizer = MarianConverter(tokenizer, index=0).converted()
fast_tokenizer.save(f"tokenizer-marian-base-fr.json")
fast_tokenizer = MarianConverter(tokenizer, index=1).converted()
fast_tokenizer.save(f"tokenizer-marian-base-en.json")
```
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.feature_extraction import FeatureExtractionPipeline
from app.pipelines.sentence_similarity import SentenceSimilarityPipeline
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app | hf_public_repos/api-inference-community/docker_images/sentence_transformers/app/pipelines/feature_extraction.py | import os
from typing import List
from app.pipelines import Pipeline
from sentence_transformers import SentenceTransformer
class FeatureExtractionPipeline(Pipeline):
def __init__(
self,
model_id: str,
):
self.model = SentenceTransformer(
model_id, use_auth_token=os.getenv("HF_API_TOKEN")
)
def __call__(self, inputs: str) -> List[float]:
"""
Args:
inputs (:obj:`str`):
a string to get the features of.
Return:
A :obj:`list` of floats: The features computed by the model.
"""
return self.model.encode(inputs).tolist()
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers | hf_public_repos/api-inference-community/docker_images/sentence_transformers/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers | hf_public_repos/api-inference-community/docker_images/sentence_transformers/tests/test_api_sentence_similarity.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"feature-extraction" not in ALLOWED_TASKS,
"feature-extraction not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["sentence-similarity"]]
)
class SentenceSimilarityTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "sentence-similarity"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
source_sentence = "I am a very happy man"
sentences = [
"What is this?",
"I am a super happy man",
"I am a sad man",
"I am a happy dog",
]
inputs = {"source_sentence": source_sentence, "sentences": sentences}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
def test_missing_input_sentences(self):
source_sentence = "I am a very happy man"
inputs = {"source_sentence": source_sentence}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
400,
)
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers | hf_public_repos/api-inference-community/docker_images/sentence_transformers/tests/test_api.py | import os
from typing import Dict, List
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, List[str]] = {
"feature-extraction": ["bert-base-uncased"],
"sentence-similarity": [
"sentence-transformers/paraphrase-distilroberta-base-v1",
"sentence-transformers/paraphrase-xlm-r-multilingual-v1",
],
}
ALL_TASKS = {
"automatic-speech-recognition",
"audio-source-separation",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"text-generation",
"text-to-speech",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
with self.assertRaises(EnvironmentError):
get_pipeline(unsupported_task, model_id="XX")
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/sentence_transformers | hf_public_repos/api-inference-community/docker_images/sentence_transformers/tests/test_api_feature_extraction.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"feature-extraction" not in ALLOWED_TASKS,
"feature-extraction not implemented",
)
class FeatureExtractionTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["feature-extraction"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "feature-extraction"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "Hello, my name is John and I live in New York"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
def test_malformed_sentence(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 6 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/doctr/requirements.txt | starlette==0.27.0
api-inference-community==0.0.23
python-doctr[torch]==0.5.1
huggingface_hub==0.5.1
| 7 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/doctr/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
RUN apt-get update -y && apt-get install libgl1-mesa-glx -y
RUN pip install --no-cache-dir -U pip
RUN pip install --no-cache-dir torch==1.11 torchvision==0.12
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
ENV TORCH_HOME=/data/torch_hub/
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 8 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/doctr/prestart.sh | python app/main.py
| 9 |
0 | hf_public_repos | hf_public_repos/blog/nystromformer.md | ---
title: "Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method"
thumbnail: /blog/assets/86_nystromformer/thumbnail.png
authors:
- user: asi
guest: true
---
# Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## Introduction
Transformers have exhibited remarkable performance on various Natural Language Processing and Computer Vision tasks. Their success can be attributed to the self-attention mechanism, which captures the pairwise interactions between all the tokens in an input. However, the standard self-attention mechanism has a time and memory complexity of \\(O(n^2)\\) (where \\(n\\) is the length of the input sequence), making it expensive to train on long input sequences.
The [Nyströmformer](https://arxiv.org/abs/2102.03902) is one of many efficient Transformer models that approximates standard self-attention with \\(O(n)\\) complexity. Nyströmformer exhibits competitive performance on various downstream NLP and CV tasks while improving upon the efficiency of standard self-attention. The aim of this blog post is to give readers an overview of the Nyström method and how it can be adapted to approximate self-attention.
## Nyström method for matrix approximation
At the heart of Nyströmformer is the Nyström method for matrix approximation. It allows us to approximate a matrix by sampling some of its rows and columns. Let's consider a matrix \\(P^{n \times n}\\), which is expensive to compute in its entirety. So, instead, we approximate it using the Nyström method. We start by sampling \\(m\\) rows and columns from \\(P\\). We can then arrange the sampled rows and columns as follows:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Representing P as a block matrix" src="assets/86_nystromformer/p_block.png"></medium-zoom>
<figcaption>Representing P as a block matrix</figcaption>
</figure>
We now have four submatrices: \\(A_P, B_P, F_P,\\) and \\(C_P\\), with sizes \\(m \times m, m \times (n - m), (n - m) \times m\\) and
\\((n - m) \times (n - m)\\) respectively. The \\(m\\) sampled columns are contained in \\(A_P\\) and \\(F_P\\), whereas the \\(m\\) sampled rows are contained in \\(A_P\\) and \\(B_P\\). So, the entries of \\(A_P, B_P,\\) and \\(F_P\\) are known to us, and we will estimate \\(C_P\\). According to the Nyström method, \\(C_P\\) is given by:
$$C_P = F_P A_P^+ B_P$$
Here, \\(+\\) denotes the Moore-Penrose inverse (or pseudoinverse).
Thus, the Nyström approximation of \\(P, \hat{P}\\) can be written as:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of P" src="assets/86_nystromformer/p_hat.png"></medium-zoom>
<figcaption>Nyström approximation of P</figcaption>
</figure>
As shown in the second line, \\(\hat{P}\\) can be expressed as a product of three matrices. The reason for doing so will become clear later.
## Can we approximate self-attention with the Nyström method?
Our goal is to ultimately approximate the softmax matrix in standard self attention: S = softmax \\( \frac{QK^T}{\sqrt{d}} \\)
Here, \\(Q\\) and \\(K\\) denote the queries and keys respectively. Following the procedure discussed above, we would sample \\(m\\) rows and columns from \\(S\\), form four submatrices, and obtain \\(\hat{S}\\):
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of S" src="assets/86_nystromformer/s_hat.png"></medium-zoom>
<figcaption>Nyström approximation of S</figcaption>
</figure>
But, what does it mean to sample a column from \\(S\\)? It means we select one element from each row. Recall how S is calculated: the final operation is a row-wise softmax. To find a single entry in a row, we must access all other entries (for the denominator in softmax). So, sampling one column requires us to know all other columns in the matrix. Therefore, we cannot directly apply the Nyström method to approximate the softmax matrix.
## How can we adapt the Nyström method to approximate self-attention?
Instead of sampling from \\(S\\), the authors propose to sample landmarks (or Nyström points) from queries and keys. We denote the query landmarks and key landmarks as \\(\tilde{Q}\\) and \\(\tilde{K}\\) respectively. \\(\tilde{Q}\\) and \\(\tilde{K}\\) can be used to construct three matrices corresponding to those in the Nyström approximation of \\(S\\). We define the following matrices:
$$\tilde{F} = softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) \hspace{40pt} \tilde{A} = softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ \hspace{40pt} \tilde{B} = softmax(\frac{\tilde{Q}K^T}{\sqrt{d}})$$
The sizes of \\(\tilde{F}\\), \\(\tilde{A}\\), and \\(\tilde{B}) are \\(n \times m, m \times m,\\) and \\(m \times n\\) respectively.
We replace the three matrices in the Nyström approximation of \\(S\\) with the new matrices we have defined to obtain an alternative Nyström approximation:
$$\begin{aligned}\hat{S} &= \tilde{F} \tilde{A} \tilde{B} \\ &= softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ softmax(\frac{\tilde{Q}K^T}{\sqrt{d}}) \end{aligned}$$
This is the Nyström approximation of the softmax matrix in the self-attention mechanism. We multiply this matrix with the values ( \\(V\\)) to obtain a linear approximation of self-attention. Note that we never calculated the product \\(QK^T\\), avoiding the \\(O(n^2)\\) complexity.
## How do we select landmarks?
Instead of sampling \\(m\\) rows from \\(Q\\) and \\(K\\), the authors propose to construct \\(\tilde{Q}\\) and \\(\tilde{K}\\)
using segment means. In this procedure, \\(n\\) tokens are grouped into \\(m\\) segments, and the mean of each segment is computed. Ideally, \\(m\\) is much smaller than \\(n\\). According to experiments from the paper, selecting just \\(32\\) or \\(64\\) landmarks produces competetive performance compared to standard self-attention and other efficient attention mechanisms, even for long sequences lengths ( \\(n=4096\\) or \\(8192\\)).
The overall algorithm is summarised by the following figure from the paper:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Efficient self-attention with the Nyström method" src="assets/86_nystromformer/paper_figure.png"></medium-zoom>
<figcaption>Efficient self-attention with the Nyström method</figcaption>
</figure>
The three orange matrices above correspond to the three matrices we constructed using the key and query landmarks. Also, notice that there is a DConv box. This corresponds to a skip connection added to the values using a 1D depthwise convolution.
## How is Nyströmformer implemented?
The original implementation of Nyströmformer can be found [here](https://github.com/mlpen/Nystromformer) and the HuggingFace implementation can be found [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/nystromformer/modeling_nystromformer.py). Let's take a look at a few lines of code (with some comments added) from the HuggingFace implementation. Note that some details such as normalization, attention masking, and depthwise convolution are avoided for simplicity.
```python
key_layer = self.transpose_for_scores(self.key(hidden_states)) # K
value_layer = self.transpose_for_scores(self.value(hidden_states)) # V
query_layer = self.transpose_for_scores(mixed_query_layer) # Q
q_landmarks = query_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{Q}
k_landmarks = key_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{K}
kernel_1 = torch.nn.functional.softmax(torch.matmul(query_layer, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{F}
kernel_2 = torch.nn.functional.softmax(torch.matmul(q_landmarks, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{A} before pseudo-inverse
attention_scores = torch.matmul(q_landmarks, key_layer.transpose(-1, -2)) # \tilde{B} before softmax
kernel_3 = nn.functional.softmax(attention_scores, dim=-1) # \tilde{B}
attention_probs = torch.matmul(kernel_1, self.iterative_inv(kernel_2)) # \tilde{F} * \tilde{A}
new_value_layer = torch.matmul(kernel_3, value_layer) # \tilde{B} * V
context_layer = torch.matmul(attention_probs, new_value_layer) # \tilde{F} * \tilde{A} * \tilde{B} * V
```
## Using Nyströmformer with HuggingFace
Nyströmformer for Masked Language Modeling (MLM) is available on HuggingFace. Currently, there are 4 checkpoints, corresponding to various sequence lengths: [`nystromformer-512`](https://huggingface.co/uw-madison/nystromformer-512), [`nystromformer-1024`](https://huggingface.co/uw-madison/nystromformer-1024), [`nystromformer-2048`](https://huggingface.co/uw-madison/nystromformer-2048), and [`nystromformer-4096`](https://huggingface.co/uw-madison/nystromformer-4096). The number of landmarks, \\(m\\), can be controlled using the `num_landmarks` parameter in the [`NystromformerConfig`](https://huggingface.co/docs/transformers/v4.18.0/en/model_doc/nystromformer#transformers.NystromformerConfig). Let's take a look at a minimal example of Nyströmformer for MLM:
```python
from transformers import AutoTokenizer, NystromformerForMaskedLM
import torch
tokenizer = AutoTokenizer.from_pretrained("uw-madison/nystromformer-512")
model = NystromformerForMaskedLM.from_pretrained("uw-madison/nystromformer-512")
inputs = tokenizer("Paris is the [MASK] of France.", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# retrieve index of [MASK]
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
capital
</div>
Alternatively, we can use the [pipeline API](https://huggingface.co/docs/transformers/main_classes/pipelines) (which handles all the complexity for us):
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='uw-madison/nystromformer-512')
unmasker("Paris is the [MASK] of France.")
```
<div class="output stream stdout">
Output:
----------------------------------------------------------------------------------------------------
[{'score': 0.829957902431488,
'token': 1030,
'token_str': 'capital',
'sequence': 'paris is the capital of france.'},
{'score': 0.022157637402415276,
'token': 16081,
'token_str': 'birthplace',
'sequence': 'paris is the birthplace of france.'},
{'score': 0.01904447190463543,
'token': 197,
'token_str': 'name',
'sequence': 'paris is the name of france.'},
{'score': 0.017583081498742104,
'token': 1107,
'token_str': 'kingdom',
'sequence': 'paris is the kingdom of france.'},
{'score': 0.005948934704065323,
'token': 148,
'token_str': 'city',
'sequence': 'paris is the city of france.'}]
</div>
## Conclusion
Nyströmformer offers an efficient approximation to the standard self-attention mechanism, while outperforming other linear self-attention schemes. In this blog post, we went over a high-level overview of the Nyström method and how it can be leveraged for self-attention. Readers interested in deploying or fine-tuning Nyströmformer for downstream tasks can find the HuggingFace documentation [here](https://huggingface.co/docs/transformers/model_doc/nystromformer).
| 0 |
0 | hf_public_repos | hf_public_repos/blog/cosmopedia.md | ---
title: "Cosmopedia: how to create large-scale synthetic data for pre-training Large Language Models"
thumbnail: /blog/assets/cosmopedia/thumbnail.png
authors:
- user: loubnabnl
- user: anton-l
- user: davanstrien
---
# Cosmopedia: how to create large-scale synthetic data for pre-training
In this blog post, we outline the challenges and solutions involved in generating a synthetic dataset with billions of tokens to replicate [Phi-1.5](https://arxiv.org/abs/2309.05463), leading to the creation of [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia). Synthetic data has become a central topic in Machine Learning. It refers to artificially generated data, for instance by large language models (LLMs), to mimic real-world data.
Traditionally, creating datasets for supervised fine-tuning and instruction-tuning required the costly and time-consuming process of hiring human annotators. This practice entailed significant resources, limiting the development of such datasets to a few key players in the field. However, the landscape has recently changed. We've seen hundreds of high-quality synthetic fine-tuning datasets developed, primarily using GPT-3.5 and GPT-4. The community has also supported this development with numerous publications that guide the process for various domains, and address the associated challenges [[1](https://arxiv.org/abs/2305.14233)][[2](https://arxiv.org/abs/2312.02120)][[3](https://arxiv.org/abs/2402.10176)][[4](https://arxiv.org/abs/2304.12244)][[5](https://huggingface.co/blog/synthetic-data-save-costs)].
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/data.png" alt="number of datasets with synthetic tag" style="width: 90%; height: auto;"><br>
<em>Figure 1. Datasets on Hugging Face hub with the tag synthetic.</em>
</p>
However, this is not another blog post on generating synthetic instruction-tuning datasets, a subject the community is already extensively exploring. We focus on scaling from a **few thousand** to **millions** of samples that can be used for **pre-training LLMs from scratch**. This presents a unique set of challenges.
## Why Cosmopedia?
Microsoft pushed this field with their series of Phi models [[6](https://arxiv.org/abs/2306.11644)][[7](https://arxiv.org/abs/2309.05463)][[8](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)], which were predominantly trained on synthetic data. They surpassed larger models that were trained much longer on web datasets. [Phi-2](https://huggingface.co/microsoft/phi-2) was downloaded over 617k times in the past month and is among the top 20 most-liked models on the Hugging Face hub.
While the technical reports of the Phi models, such as the [“Textbooks Are All You Need”](https://arxiv.org/abs/2306.11644) paper, shed light on the models’ remarkable performance and creation, they leave out substantial details regarding the curation of their synthetic training datasets. Furthermore, the datasets themselves are not released. This sparks debate among enthusiasts and skeptics alike. Some praise the models' capabilities, while critics argue they may simply be overfitting benchmarks; some of them even label the approach of pre-training models on synthetic data as [« garbage in, garbage out»](https://x.com/Grady_Booch/status/1760042033761378431?s=20). Yet, the idea of having full control over the data generation process and replicating the high-performance of Phi models is intriguing and worth exploring.
This is the motivation for developing [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia), which aims to reproduce the training data used for Phi-1.5. In this post we share our initial findings and discuss some plans to improve on the current dataset. We delve into the methodology for creating the dataset, offering an in-depth look at the approach to prompt curation and the technical stack. Cosmopedia is fully open: we release the [code](https://github.com/huggingface/cosmopedia) for our end-to-end pipeline, the [dataset](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia), and a 1B model trained on it called [cosmo-1b](https://huggingface.co/HuggingFaceTB/cosmo-1b). This enables the community to reproduce the results and build upon them.
## Behind the scenes of Cosmopedia’s creation
Besides the lack of information about the creation of the Phi datasets, another downside is that they use proprietary models to generate the data. To address these shortcomings, we introduce Cosmopedia, a dataset of synthetic textbooks, blog posts, stories, posts, and WikiHow articles generated by [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1). It contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
Heads up: If you are anticipating tales about deploying large-scale generation tasks across hundreds of H100 GPUs, in reality most of the time for Cosmopedia was spent on meticulous prompt engineering.
### Prompts curation
Generating synthetic data might seem straightforward, but maintaining diversity, which is crucial for optimal performance, becomes significantly challenging when scaling up. Therefore, it's essential to curate diverse prompts that cover a wide range of topics and minimize duplicate outputs, as we don’t want to spend compute on generating billions of textbooks only to discard most because they resemble each other closely. Before we launched the generation on hundreds of GPUs, we spent a lot of time iterating on the prompts with tools like [HuggingChat](https://huggingface.co/chat/). In this section, we'll go over the process of creating over 30 million prompts for Cosmopedia, spanning hundreds of topics and achieving less than 1% duplicate content.
Cosmopedia aims to generate a vast quantity of high-quality synthetic data with broad topic coverage. According to the Phi-1.5 [technical report](https://arxiv.org/abs/2309.05463), the authors curated 20,000 topics to produce 20 billion tokens of synthetic textbooks while using samples from web datasets for diversity, stating:
> We carefully selected 20K topics to seed the generation of this new synthetic data. In our generation prompts, we use samples from web datasets for diversity.
>
Assuming an average file length of 1000 tokens, this suggests using approximately 20 million distinct prompts. However, the methodology behind combining topics and web samples for increased diversity remains unclear.
We combine two approaches to build Cosmopedia’s prompts: conditioning on curated sources and conditioning on web data. We refer to the source of the data we condition on as “seed data”.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/piecharts.png" alt="piecharts of data sources" style="width: 90%; height: auto;"><br>
<em>Figure 2. The distribution of data sources for building Cosmopedia prompts (left plot) and the distribution of sources inside the Curated sources category (right plot).</em>
</p>
#### Curated Sources
We use topics from reputable educational sources such as Stanford courses, Khan Academy, OpenStax, and WikiHow. These resources cover many valuable topics for an LLM to learn. For instance, we extracted the outlines of various Stanford courses and constructed prompts that request the model to generate textbooks for individual units within those courses. An example of such a prompt is illustrated in figure 3.
Although this approach yields high-quality content, its main limitation is scalability. We are constrained by the number of resources and the topics available within each source. For example, we can extract only 16,000 unique units from OpenStax and 250,000 from Stanford. Considering our goal of generating 20 billion tokens, we need at least 20 million prompts!
##### Leverage diversity in audience and style
One strategy to increase the variety of generated samples is to leverage the diversity of audience and style: a single topic can be repurposed multiple times by altering the target audience (e.g., young children vs. college students) and the generation style (e.g., academic textbook vs. blog post). However, we discovered that simply modifying the prompt from "Write a detailed course unit for a textbook on 'Why Go To Space?' intended for college students" to "Write a detailed blog post on 'Why Go To Space?'" or "Write a textbook on 'Why Go To Space?' for young children" was insufficient to prevent a high rate of duplicate content. To mitigate this, we emphasized changes in audience and style, providing specific instructions on how the format and content should differ.
Figure 3 illustrates how we adapt a prompt based on the same topic for different audiences.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/textbooks.png" alt="comparison of prompts" style="width: 90%; height: auto;"><br>
<em>Figure 3. Prompts for generating the same textbook for young children vs for professionals and researchers vs for high school students.</em>
</p>
By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles), we can get up to 12 times the number of prompts. However, we might want to include other topics not covered in these resources, and the small volume of these sources still limits this approach and is very far from the 20+ million prompts we are targeting. That’s when web data comes in handy; what if we were to generate textbooks covering all the web topics? In the next section, we’ll explain how we selected topics and used web data to build millions of prompts.
#### Web data
Using web data to construct prompts proved to be the most scalable, contributing to over 80% of the prompts used in Cosmopedia. We clustered millions of web samples, using a dataset like [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), into 145 clusters, and identified the topic of each cluster by providing extracts from 10 random samples and asking Mixtral to find their common topic. More details on this clustering are available in the Technical Stack section.
We inspected the clusters and excluded any deemed of low educational value. Examples of removed content include explicit adult material, celebrity gossip, and obituaries. The full list of the 112 topics retained and those removed can be found [here](https://github.com/huggingface/cosmopedia/blob/dd5cd1f7fcfae255c9cfbe704ba2187965523457/prompts/web_samples/filter_and_classify_clusters.py).
We then built prompts by instructing the model to generate a textbook related to a web sample within the scope of the topic it belongs to based on the clustering. Figure 4 provides an example of a web-based prompt. To enhance diversity and account for any incompleteness in topic labeling, we condition the prompts on the topic only 50% of the time, and change the audience and generation styles, as explained in the previous section. We ultimately built 23 million prompts using this approach. Figure 5 shows the final distribution of seed data, generation formats, and audiences in Cosmopedia.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/web_samples.png" alt="web prompt" style="width: 90%; height: auto;"><br>
<em>Figure 4. Example of a web extract and the associated prompt.</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/histograms.png" alt="histogram" style="width: 90%; height: auto;"><br>
<em>Figure 5. The distribution of seed data, generation format and target audiences in Cosmopedia dataset.</em>
</p>
In addition to random web files, we used samples from AutoMathText, a carefully curated dataset of Mathematical texts with the goal of including more scientific content.
#### Instruction datasets and stories
In our initial assessments of models trained using the generated textbooks, we observed a lack of common sense and fundamental knowledge typical of grade school education. To address this, we created stories incorporating day-to-day knowledge and basic common sense using texts from the [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) and [OpenHermes2.5](https://huggingface.co/datasets/teknium/OpenHermes-2.5) instruction-tuning datasets as seed data for the prompts. These datasets span a broad range of subjects. For instance, from UltraChat, we used the "Questions about the world" subset, which covers 30 meta-concepts about the world. For OpenHermes2.5, another diverse and high-quality instruction-tuning dataset, we omitted sources and categories unsuitable for storytelling, such as glaive-code-assist for programming and camelai for advanced chemistry. Figure 6 shows examples of prompts we used to generate these stories.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/stories.png" alt="stories prompts" style="width: 90%; height: auto;"><br>
<em>Figure 6. Prompts for generating stories from UltraChat and OpenHermes samples for young children vs a general audience vs reddit forums.</em>
</p>
That's the end of our prompt engineering story for building 30+ million diverse prompts that provide content with very few duplicates. The figure below shows the clusters present in Cosmopedia, this distribution resembles the clusters in the web data. You can also find a clickable map from [Nomic](https://www.nomic.ai/) [here](https://atlas.nomic.ai/map/cosmopedia).
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/clusters.png" alt="clusters" style="width: 90%; height: auto;"><br>
<em>Figure 7. The clusters of Cosmopedia, annotated using Mixtral.</em>
</p>
You can use the dataset [viewer](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/viewer/stanford) to investigate the dataset yourself:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/viewer.png" alt="dataset viewer" style="width: 90%; height: auto;"><br>
<em>Figure 8. Cosmopedia's dataset viewer.</em>
</p>
### Technical stack
We release all the code used to build Cosmopedia in: [https://github.com/huggingface/cosmopedia](https://github.com/huggingface/cosmopedia)
In this section we'll highlight the technical stack used for text clustering, text generation at scale and for training cosmo-1b model.
#### Topics clustering
We used [text-clustering](https://github.com/huggingface/text-clustering/) repository to implement the topic clustering for the web data used in Cosmopedia prompts. The plot below illustrates the pipeline for finding and labeling the clusters. We additionally asked Mixtral to give the cluster an educational score out of 10 in the labeling step; this helped us in the topics inspection step. You can find a demo of the web clusters and their scores in this [demo](https://huggingface.co/spaces/HuggingFaceTB/inspect_web_clusters).
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/text_clustering.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>Figure 9. The pipleline of text-clustering.</em>
</p>
#### Textbooks generation at scale
We leverage the [llm-swarm](https://github.com/huggingface/llm-swarm) library to generate 25 billion tokens of synthetic content using [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1). This is a scalable synthetic data generation tool using local LLMs or inference endpoints on the Hugging Face Hub. It supports [TGI](https://github.com/huggingface/text-generation-inference) and [vLLM](https://github.com/vllm-project/vllm) inference libraries. We deployed Mixtral-8x7B locally on H100 GPUs from the Hugging Face Science cluster with TGI. The total compute time for generating Cosmopedia was over 10k GPU hours.
Here's an example to run generations with Mixtral on 100k Cosmopedia prompts using 2 TGI instances on a Slurm cluster:
```bash
# clone the repo and follow installation requirements
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples -1 \
--checkpoint_path "./tests_data" \
--repo_id "HuggingFaceTB/generations_cosmopedia_100k" \
--checkpoint_interval 500
```
You can even track the generations with `wandb` to monitor the throughput and number of generated tokens.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/wandb.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>Figure 10. Wandb plots for an llm-swarm run.</em>
</p>
**Note:**
We used HuggingChat for the initial iterations on the prompts. Then, we generated a few hundred samples for each prompt using `llm-swarm` to spot unusual patterns. For instance, the model used very similar introductory phrases for textbooks and frequently began stories with the same phrases, like "Once upon a time" and "The sun hung low in the sky". Explicitly asking the model to avoid these introductory statements and to be creative fixed the issue; they were still used but less frequently.
#### Benchmark decontamination
Given that we generate synthetic data, there is a possibility of benchmark contamination within the seed samples or the model's training data. To address this, we implement a decontamination pipeline to ensure our dataset is free of any samples from the test benchmarks.
Similar to Phi-1, we identify potentially contaminated samples using a 10-gram overlap. After retrieving the candidates, we employ [`difflib.SequenceMatcher`](https://docs.python.org/3/library/difflib.html) to compare the dataset sample against the benchmark sample. If the ratio of `len(matched_substrings)` to `len(benchmark_sample)` exceeds 0.5, we discard the sample. This decontamination process is applied across all benchmarks evaluated with the Cosmo-1B model, including MMLU, HellaSwag, PIQA, SIQA, Winogrande, OpenBookQA, ARC-Easy, and ARC-Challenge.
We report the number of contaminated samples removed from each dataset split, as well as the number of unique benchmark samples that they correspond to (in brackets):
<div align="center">
| Dataset group | ARC | BoolQ | HellaSwag | PIQA |
| --- | --- | --- | --- | --- |
| web data + stanford + openstax | 49 (16) | 386 (41) | 6 (5) | 5 (3) |
| auto_math_text + khanacademy | 17 (6) | 34 (7) | 1 (1) | 0 (0) |
| stories | 53 (32) | 27 (21) | 3 (3) | 6 (4) |
</div>
We find less than 4 contaminated samples for MMLU, OpenBookQA and WinoGrande.
#### Training stack
We trained a 1B LLM using Llama2 architecure on Cosmopedia to assess its quality: [https://huggingface.co/HuggingFaceTB/cosmo-1b](https://huggingface.co/HuggingFaceTB/cosmo-1b).
We used [datatrove](https://github.com/huggingface/datatrove) library for data deduplication and tokenization, [nanotron](https://github.com/huggingface/nanotron/tree/main) for model training, and [lighteval](https://github.com/huggingface/lighteval-harness) for evaluation.
The model performs better than TinyLlama 1.1B on ARC-easy, ARC-challenge, OpenBookQA, and MMLU and is comparable to Qwen-1.5-1B on ARC-challenge and OpenBookQA. However, we notice some performance gaps compared to Phi-1.5, suggesting a better synthetic generation quality, which can be related to the LLM used for generation, topic coverage, or prompts.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/evals.png" alt="evaluation results" style="width: 60%; height: auto;"><br>
<em>Figure 10. Evaluation results of Cosmo-1B.</em>
</p>
## Conclusion & next steps
In this blog post, we outlined our approach for creating Cosmopedia, a large synthetic dataset designed for pre-training models, with the goal of replicating the Phi datasets. We highlighted the significance of meticulously crafting prompts to cover a wide range of topics, ensuring the generation of diverse content. Additionally, we have shared and open-sourced our technical stack, which allows for scaling the generation process across hundreds of GPUs.
However, this is just the initial version of Cosmopedia, and we are actively working on enhancing the quality of the generated content. The accuracy and reliability of the generations largely depends on the model used in the generation. Specifically, Mixtral may sometimes hallucinate and produce incorrect information, for example when it comes to historical facts or mathematical reasoning within the AutoMathText and KhanAcademy subsets. One strategy to mitigate the issue of hallucinations is the use of retrieval augmented generation (RAG). This involves retrieving information related to the seed sample, for example from Wikipedia, and incorporating it into the context. Hallucination measurement methods could also help assess which topics or domains suffer the most from it [[9]](https://arxiv.org/abs/2303.08896). It would also be interesting to compare Mixtral’s generations to other open models.
The potential for synthetic data is immense, and we are eager to see what the community will build on top of Cosmopedia.
## References
[1] Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. URL [https://arxiv.org/abs/2305.14233](https://arxiv.org/abs/2305.14233)
[2] Wei et al. Magicoder: Source Code Is All You Need. URL [https://arxiv.org/abs/2312.02120](https://arxiv.org/abs/2312.02120)
[3] Toshniwal et al. OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset. URL [https://arxiv.org/abs/2402.10176](https://arxiv.org/abs/2402.10176)
[4] Xu et al. WizardLM: Empowering Large Language Models to Follow Complex Instructions. URL [https://arxiv.org/abs/2304.12244](https://arxiv.org/abs/2304.12244)
[5] Moritz Laurer. Synthetic data: save money, time and carbon with open source. URL [https://huggingface.co/blog/synthetic-data-save-cost](https://huggingface.co/blog/synthetic-data-save-cost)
[6] Gunasekar et al. Textbooks Are All You Need. URL [https://arxiv.org/abs/2306.11644](https://arxiv.org/abs/2306.11644)
[7] Li et al. Textbooks are all you need ii: phi-1.5 technical report. URL [https://arxiv.org/abs/2309.05463](https://arxiv.org/abs/2309.05463)
[8] Phi-2 blog post. URL [https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)
[9] Manakul, Potsawee and Liusie, Adian and Gales, Mark JF. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. URL [https://arxiv.org/abs/2303.08896](https://arxiv.org/abs/2303.08896)
| 1 |
0 | hf_public_repos | hf_public_repos/blog/ml-for-games-2.md | ---
title: "AI for Game Development: Creating a Farming Game in 5 Days. Part 2"
thumbnail: /blog/assets/124_ml-for-games/thumbnail2.png
authors:
- user: dylanebert
---
# AI for Game Development: Creating a Farming Game in 5 Days. Part 2
**Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7186551685035085098). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 2: Game Design
In [Part 1](https://huggingface.co/blog/ml-for-games-1) of this tutorial series, we used **AI for Art Style**. More specifically, we used Stable Diffusion to generate concept art and develop the visual style of our game.
In this part, we'll be using AI for Game Design. In [The Short Version](#the-short-version), I'll talk about how I used ChatGPT as a tool to help develop game ideas. But more importantly, what is actually going on here? Keep reading for background on [Language Models](#language-models) and their broader [Uses in Game Development](#uses-in-game-development).
### The Short Version
The short version is straightforward: ask [ChatGPT](https://chat.openai.com/chat) for advice, and follow its advice at your own discretion. In the case of the farming game, I asked ChatGPT:
> You are a professional game designer, designing a simple farming game. What features are most important to making the farming game fun and engaging?
The answer given includes (summarized):
1. Variety of crops
2. A challenging and rewarding progression system
3. Dynamic and interactive environments
4. Social and multiplayer features
5. A strong and immersive story or theme
Given that I only have 5 days, I decided to [gray-box](https://en.wikipedia.org/wiki/Gray-box_testing) the first two points. You can play the result [here](https://individualkex.itch.io/ml-for-game-dev-2), and view the source code [here](https://github.com/dylanebert/FarmingGame).
I'm not going to go into detail on how I implemented these mechanics, since the focus of this series is how to use AI tools in your own game development process, not how to implement a farming game. Instead, I'll talk about what ChatGPT is (a language model), how these models actually work, and what this means for game development.
### Language Models
ChatGPT, despite being a major breakthrough in adoption, is an iteration on tech that has existed for a while: *language models*.
Language models are a type of AI that are trained to predict the likelihood of a sequence of words. For example, if I were to write "The cat chases the ____", a language model would be trained to predict "mouse". This training process can then be applied to a wide variety of tasks. For example, translation: "the French word for cat is ____". This setup, while successful at some natural language tasks, wasn't anywhere near the level of performance seen today. This is, until the introduction of **transformers**.
**Transformers**, [introduced in 2017](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), are a neural network architecture that use a self-attention mechanism to predict the entire sequence all at once. This is the tech behind modern language models like ChatGPT. Want to learn more about how they work? Check out our [Introduction to Transformers](https://huggingface.co/course/chapter1/1) course, available free here on Hugging Face.
So why is ChatGPT so successful compared to previous language models? It's impossible to answer this in its entirety, since ChatGPT is not open source. However, one of the reasons is Reinforcement Learning from Human Feedback (RLHF), where human feedback is used to improve the language model. Check out this [blog post](https://huggingface.co/blog/rlhf) for more information on RLHF: how it works, open-source tools for doing it, and its future.
This area of AI is constantly changing, and likely to see an explosion of creativity as it becomes part of the open source community, including in uses for game development. If you're reading this, you're probably ahead of the curve already.
### Uses in Game Development
In [The Short Version](#the-short-version), I talked about how I used ChatGPT to help develop game ideas. There is a lot more you can do with it though, like using it to [code an entire game](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex). You can use it for pretty much anything you can think of. Something that might be a bit more helpful is to talk about what it *can't* do.
#### Limitations
ChatGPT often sounds very convincing, while being wrong. Here is an [archive of ChatGPT failures](https://github.com/giuven95/chatgpt-failures). The reason for these is that ChatGPT doesn't *know* what it's talking about the way a human does. It's a very large [Language Model](#language-models) that predicts likely outputs, but doesn't really understand what it's saying. One of my personal favorite examples of these failures (especially relevant to game development) is this explanation of quaternions from [Reddit](https://www.reddit.com/r/Unity3D/comments/zcps1f/eli5_quaternion_by_chatgpt/):
<figure class="image text-center">
<img src="/blog/assets/124_ml-for-games/quaternion.png" alt="ChatGPT Quaternion Explanation">
</figure>
This explanation, while sounding excellent, is completely wrong. This is a great example of why ChatGPT, while very useful, shouldn't be used as a definitive knowledge base.
#### Suggestions
If ChatGPT fails a lot, should you use it? I would argue that it's still extremely useful as a tool, rather than as a replacement. In the example of Game Design, I could have followed up on ChatGPT's answer, and asked it to implement all of its suggestions for me. As I mentioned before, [others have done this](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex), and it somewhat works. However, I would suggest using ChatGPT more as a tool for brainstorming and acceleration, rather than as a complete replacement for steps in the development process.
Click [here](https://huggingface.co/blog/ml-for-games-3) to read Part 3, where we use **AI for 3D Assets**.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/using-ml-for-disasters.md | ---
title: "Using Machine Learning to Aid Survivors and Race through Time"
thumbnail: /blog/assets/using-ml-for-disasters/thumbnail.png
authors:
- user: merve
- user: adirik
---
# Using Machine Learning to Aid Survivors and Race through Time
On February 6, 2023, earthquakes measuring 7.7 and 7.6 hit South Eastern Turkey, affecting 10 cities and resulting in more than 42,000 deaths and 120,000 injured as of February 21.
A few hours after the earthquake, a group of programmers started a Discord server to roll out an application called *afetharita*, literally meaning, *disaster map*. This application would serve search & rescue teams and volunteers to find survivors and bring them help. The need for such an app arose when survivors posted screenshots of texts with their addresses and what they needed (including rescue) on social media. Some survivors also tweeted what they needed so their relatives knew they were alive and that they need rescue. Needing to extract information from these tweets, we developed various applications to turn them into structured data and raced against time in developing and deploying these apps.
When I got invited to the discord server, there was quite a lot of chaos regarding how we (volunteers) would operate and what we would do. We decided to collaboratively train models so we needed a model and dataset registry. We opened a Hugging Face organization account and collaborated through pull requests as to build ML-based applications to receive and process information.
We had been told by volunteers in other teams that there's a need for an application to post screenshots, extract information from the screenshots, structure it and write the structured information to the database. We started developing an application that would take a given image, extract the text first, and from text, extract a name, telephone number, and address and write these informations to a database that would be handed to authorities. After experimenting with various open-source OCR tools, we started using `easyocr` for OCR part and `Gradio` for building an interface for this application. We were asked to build a standalone application for OCR as well so we opened endpoints from the interface. The text output from OCR is parsed using transformers-based fine-tuned NER model.
To collaborate and improve the application, we hosted it on Hugging Face Spaces and we've received a GPU grant to keep the application up and running. Hugging Face Hub team has set us up a CI bot for us to have an ephemeral environment, so we could see how a pull request would affect the Space, and it helped us during pull request reviews.
Later on, we were given labeled content from various channels (e.g. twitter, discord) with raw tweets of survivors' calls for help, along with the addresses and personal information extracted from them. We started experimenting both with few-shot prompting of closed-source models and fine-tuning our own token classification model from transformers. We’ve used [bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) as a base model for token classification and came up with the first address extraction model.
The model was later used in `afetharita` to extract addresses. The parsed addresses would be sent to a geocoding API to obtain longitude and latitude, and the geolocation would then be displayed on the front-end map. For inference, we have used Inference API, which is an API that hosts model for inference and is automatically enabled when the model is pushed to Hugging Face Hub. Using Inference API for serving has saved us from pulling the model, writing an app, building a docker image, setting up CI/CD, and deploying the model to a cloud instance, where it would be extra overhead work for the DevOps and cloud teams as well. Hugging Face teams have provided us with more replicas so that there would be no downtime and the application would be robust against a lot of traffic.
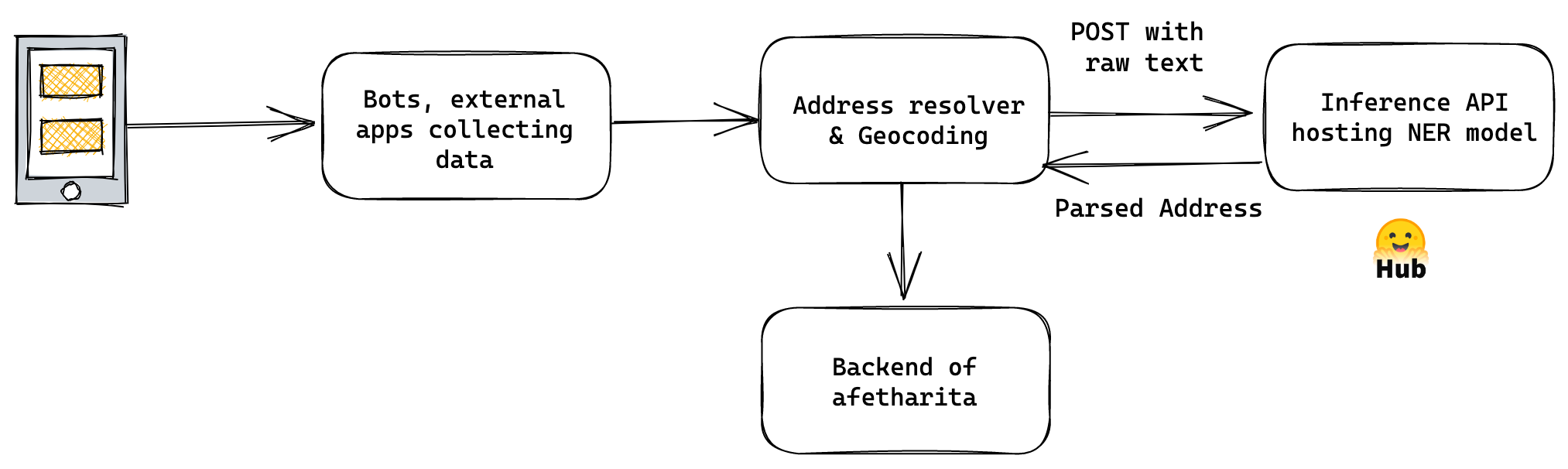
Later on, we were asked if we could extract what earthquake survivors need from a given tweet. We were given data with multiple labels for multiple needs in a given tweet, and these needs could be shelter, food, or logistics, as it was freezing cold over there. We’ve started experimenting first with zero-shot experimentations with open-source NLI models on Hugging Face Hub and few-shot experimentations with closed-source generative model endpoints. We have tried [xlm-roberta-large-xnli](https://huggingface.co/joeddav/xlm-roberta-large-xnli) and [convbert-base-turkish-mc4-cased-allnli_tr](https://huggingface.co/emrecan/convbert-base-turkish-mc4-cased-allnli_tr). NLI models were particularly useful as we could directly infer with candidate labels and change the labels as data drift occurs, whereas generative models could have made up labels and cause mismatches when giving responses to the backend. We initially didn’t have labeled data so anything would work.
In the end, we decided to fine-tune our own model as it would take roughly three minutes to fine-tune BERT’s text classification head on a single GPU. We had a labelling effort to develop the dataset to train this model. We logged our experiments in the model card’s metadata so we could later come up with a leaderboard to keep track of which model should be deployed to production. For base model, we have tried [bert-base-turkish-uncased](https://huggingface.co/loodos/bert-base-turkish-uncased) and [bert-base-turkish-128k-cased](https://huggingface.co/dbmdz/bert-base-turkish-128k-cased) and realized they perform better than [bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased). You can find our leaderboard [here](https://huggingface.co/spaces/deprem-ml/intent-leaderboard).
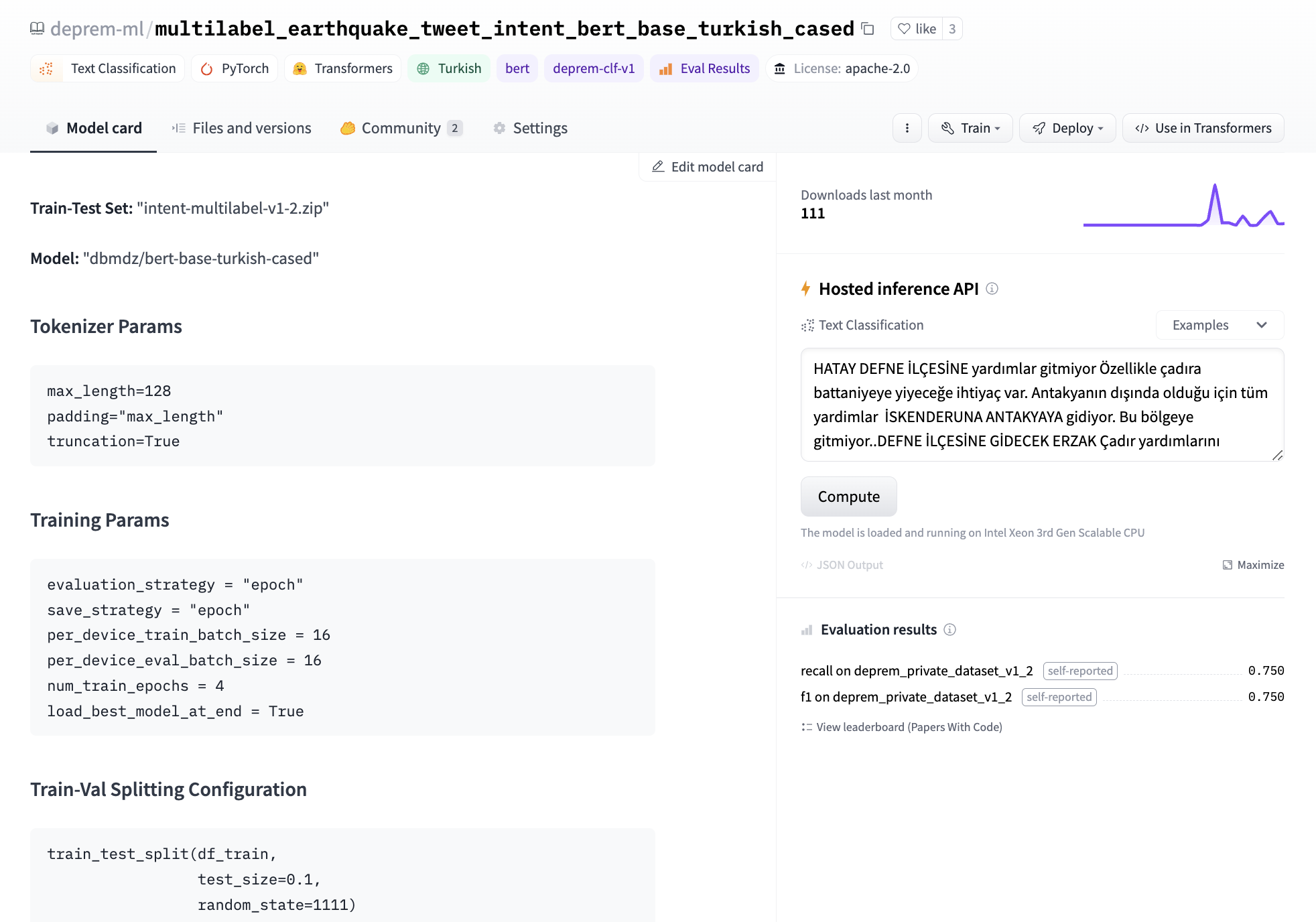
Considering the task at hand and the imbalance of our data classes, we focused on eliminating false negatives and created a Space to benchmark the recall and F1-scores of all models. To do this, we added the metadata tag `deprem-clf-v1` to all relevant model repos and used this tag to automatically retrieve the logged F1 and recall scores and rank models. We had a separate benchmark set to avoid leakage to the train set and consistently benchmark our models. We also benchmarked each model to identify the best threshold per label for deployment.
We wanted our NER model to be evaluated and crowd-sourced the effort because the data labelers were working to give us better and updated intent datasets. To evaluate the NER model, we’ve set up a labeling interface using `Argilla` and `Gradio`, where people could input a tweet and flag the output as correct/incorrect/ambiguous.
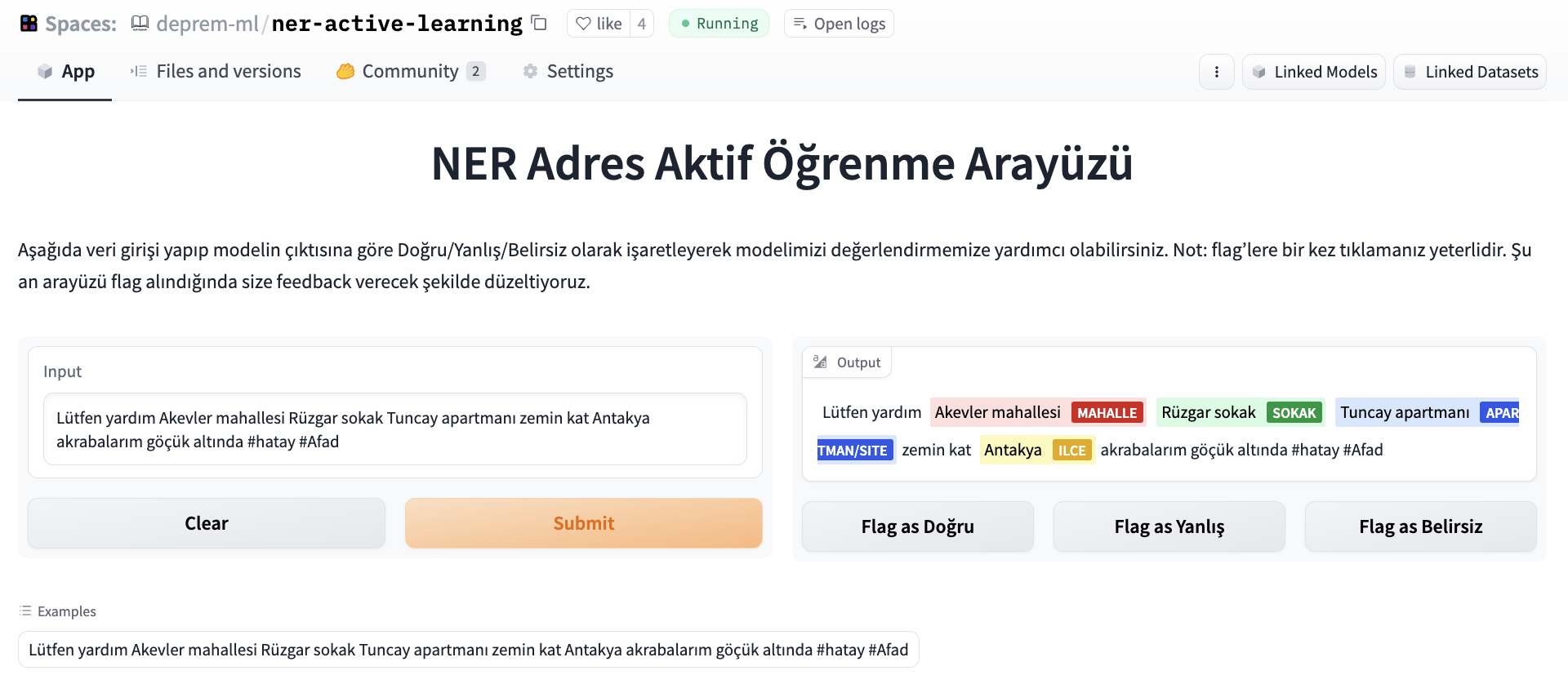
Later, the dataset was deduplicated and used to benchmark our further experiments.
Another team under machine learning has worked with generative models (behind a gated API) to get the specific needs (as labels were too broad) as free text and pass the text as an additional context to each posting. For this, they’ve done prompt engineering and wrapped the API endpoints as a separate API, and deployed them on the cloud. We found that using few-shot prompting with LLMs helps adjust to fine-grained needs in the presence of rapidly developing data drift, as the only thing we need to adjust is the prompt and we do not need any labeled data for this.
These models are currently being used in production to create the points in the heat map below so that volunteers and search and rescue teams can bring the needs to survivors.
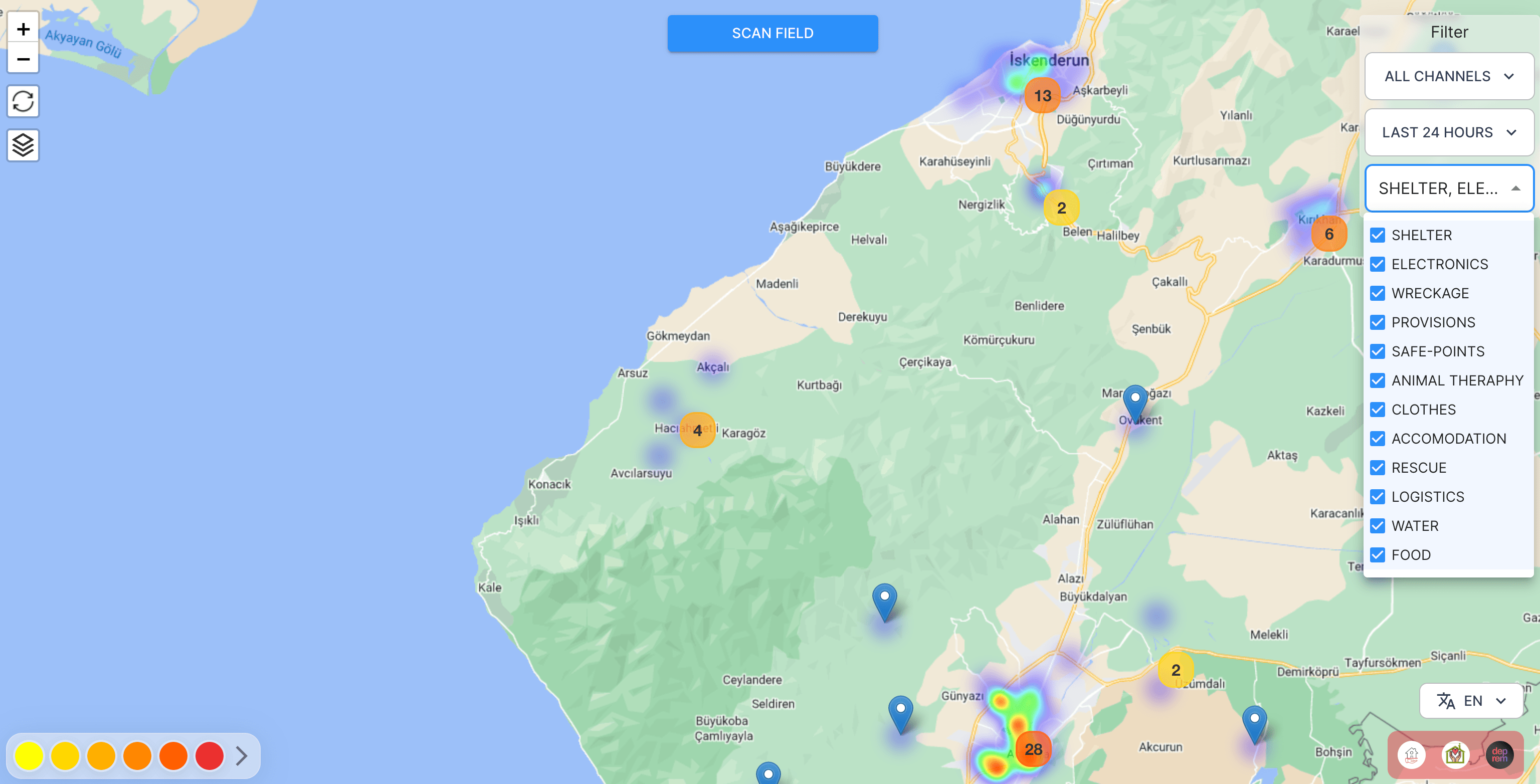
We’ve realized that if it wasn’t for Hugging Face Hub and the ecosystem, we wouldn’t be able to collaborate, prototype, and deploy this fast. Below is our MLOps pipeline for address recognition and intent classification models.
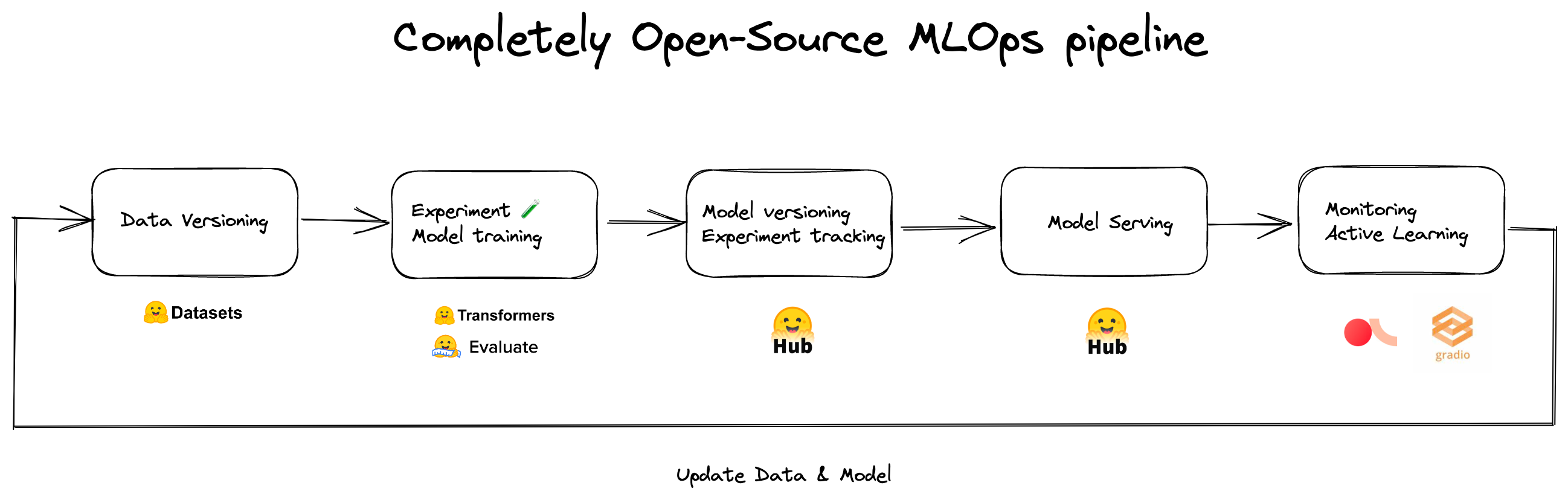
There are tens of volunteers behind this application and its individual components, who worked with no sleep to get these out in such a short time.
## Remote Sensing Applications
Other teams worked on remote sensing applications to assess the damage to buildings and infrastructure in an effort to direct search and rescue operations. The lack of electricity and stable mobile networks during the first 48 hours of the earthquake, combined with collapsed roads, made it extremely difficult to assess the extent of the damage and where help was needed. The search and rescue operations were also heavily affected by false reports of collapsed and damaged buildings due to the difficulties in communication and transportation.
To address these issues and create open source tools that can be leveraged in the future, we started by collecting pre and post-earthquake satellite images of the affected zones from Planet Labs, Maxar and Copernicus Open Access Hub.

Our initial approach was to rapidly label satellite images for object detection and instance segmentation, with a single category for "buildings". The aim was to evaluate the extent of damage by comparing the number of surviving buildings in pre- and post-earthquake images collected from the same area. In order to make it easier to train models, we started by cropping 1080x1080 satellite images into smaller 640x640 chunks. Next, we fine-tuned [YOLOv5](https://huggingface.co/spaces/deprem-ml/deprem_satellite_test), YOLOv8 and EfficientNet models for building detection and a [SegFormer](https://huggingface.co/spaces/deprem-ml/deprem_satellite_semantic_whu) model for semantic segmentation of buildings, and deployed these apps as Hugging Face Spaces.
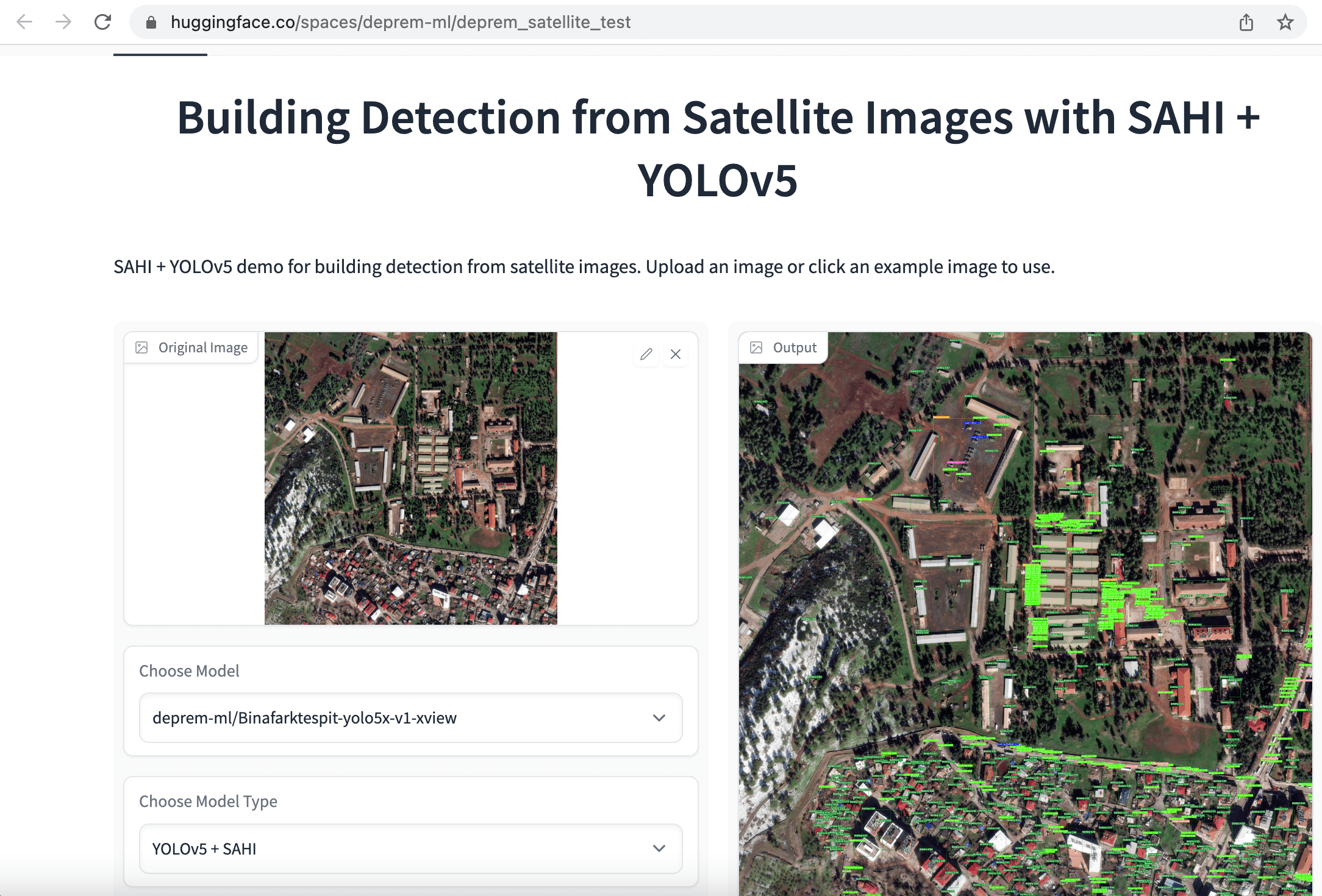
Once again, dozens of volunteers worked on labeling, preparing data, and training models. In addition to individual volunteers, companies like [Co-One](https://co-one.co/) volunteered to label satellite data with more detailed annotations for buildings and infrastructure, including *no damage*, *destroyed*, *damaged*, *damaged facility,* and *undamaged facility* labels. Our current objective is to release an extensive open-source dataset that can expedite search and rescue operations worldwide in the future.

## Wrapping Up
For this extreme use case, we had to move fast and optimize over classification metrics where even one percent improvement mattered. There were many ethical discussions in the progress, as even picking the metric to optimize over was an ethical question. We have seen how open-source machine learning and democratization enables individuals to build life-saving applications.
We are thankful for the community behind Hugging Face for releasing these models and datasets, and team at Hugging Face for their infrastructure and MLOps support. | 3 |
0 | hf_public_repos | hf_public_repos/blog/accelerate-transformers-with-inferentia2.md | ---
title: "Accelerating Hugging Face Transformers with AWS Inferentia2"
thumbnail: /blog/assets/140_accelerate_transformers_with_inferentia2/thumbnail.png
authors:
- user: philschmid
- user: juliensimon
---
# Accelerating Hugging Face Transformers with AWS Inferentia2
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
In the last five years, Transformer models [[1](https://arxiv.org/abs/1706.03762)] have become the _de facto_ standard for many machine learning (ML) tasks, such as natural language processing (NLP), computer vision (CV), speech, and more. Today, many data scientists and ML engineers rely on popular transformer architectures like BERT [[2](https://arxiv.org/abs/1810.04805)], RoBERTa [[3](https://arxiv.org/abs/1907.11692)], the Vision Transformer [[4](https://arxiv.org/abs/2010.11929)], or any of the 130,000+ pre-trained models available on the [Hugging Face](https://huggingface.co) hub to solve complex business problems with state-of-the-art accuracy.
However, for all their greatness, Transformers can be challenging to deploy in production. On top of the infrastructure plumbing typically associated with model deployment, which we largely solved with our [Inference Endpoints](https://huggingface.co/inference-endpoints) service, Transformers are large models which routinely exceed the multi-gigabyte mark. Large language models (LLMs) like [GPT-J-6B](https://huggingface.co/EleutherAI/gpt-j-6B), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), or [Opt-30B](https://huggingface.co/facebook/opt-30b) are in the tens of gigabytes, not to mention behemoths like [BLOOM](https://huggingface.co/bigscience/bloom), our very own LLM, which clocks in at 350 gigabytes.
Fitting these models on a single accelerator can be quite difficult, let alone getting the high throughput and low inference latency that applications require, like conversational applications and search. So far, ML experts have designed complex manual techniques to slice large models, distribute them on a cluster of accelerators, and optimize their latency. Unfortunately, this work is extremely difficult, time-consuming, and completely out of reach for many ML practitioners.
At Hugging Face, we're democratizing ML and always looking to partner with companies who also believe that every developer and organization should benefit from state-of-the-art models. For this purpose, we're excited to partner with Amazon Web Services to optimize Hugging Face Transformers for AWS [Inferentia 2](https://aws.amazon.com/machine-learning/inferentia/)! It’s a new purpose-built inference accelerator that delivers unprecedented levels of throughput, latency, performance per watt, and scalability.
## Introducing AWS Inferentia2
AWS Inferentia2 is the next generation to Inferentia1 launched in 2019. Powered by Inferentia1, Amazon EC2 Inf1 instances delivered 25% higher throughput and 70% lower cost than comparable G5 instances based on NVIDIA A10G GPU, and with Inferentia2, AWS is pushing the envelope again.
The new Inferentia2 chip delivers a 4x throughput increase and a 10x latency reduction compared to Inferentia. Likewise, the new [Amazon EC2 Inf2](https://aws.amazon.com/de/ec2/instance-types/inf2/) instances have up to 2.6x better throughput, 8.1x lower latency, and 50% better performance per watt than comparable G5 instances. Inferentia 2 gives you the best of both worlds: cost-per-inference optimization thanks to high throughput and response time for your application thanks to low inference latency.
Inf2 instances are available in multiple sizes, which are equipped with between 1 to 12 Inferentia 2 chips. When several chips are present, they are interconnected by a blazing-fast direct Inferentia2 to Inferentia2 connectivity for distributed inference on large models. For example, the largest instance size, inf2.48xlarge, has 12 chips and enough memory to load a 175-billion parameter model like GPT-3 or BLOOM.
Thankfully none of this comes at the expense of development complexity. With [optimum neuron](https://github.com/huggingface/optimum-neuron), you don't need to slice or modify your model. Because of the native integration in [AWS Neuron SDK](https://github.com/aws-neuron/aws-neuron-sdk), all it takes is a single line of code to compile your model for Inferentia 2. You can experiment in minutes! Test the performance your model could reach on Inferentia 2 and see for yourself.
Speaking of, let’s show you how several Hugging Face models run on Inferentia 2. Benchmarking time!
## Benchmarking Hugging Face Models on AWS Inferentia 2
We evaluated some of the most popular NLP models from the [Hugging Face Hub](https://huggingface.co/models) including BERT, RoBERTa, DistilBERT, and vision models like Vision Transformers.
The first benchmark compares the performance of Inferentia, Inferentia 2, and GPUs. We ran all experiments on AWS with the following instance types:
* Inferentia1 - [inf1.2xlarge](https://aws.amazon.com/ec2/instance-types/inf1/?nc1=h_ls) powered by a single Inferentia chip.
* Inferentia2 - [inf2.xlarge](https://aws.amazon.com/ec2/instance-types/inf2/?nc1=h_ls) powered by a single Inferentia2 chip.
* GPU - [g5.2xlarge](https://aws.amazon.com/ec2/instance-types/g5/) powered by a single NVIDIA A10G GPU.
_Note: that we did not optimize the model for the GPU environment, the models were evaluated in fp32._
When it comes to benchmarking Transformer models, there are two metrics that are most adopted:
* **Latency**: the time it takes for the model to perform a single prediction (pre-process, prediction, post-process).
* **Throughput**: the number of executions performed in a fixed amount of time for one benchmark configuration
We looked at latency across different setups and models to understand the benefits and tradeoffs of the new Inferentia2 instance. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/aws-neuron-samples/tree/main/benchmark) with all the information and scripts to do so.
### Results
The benchmark confirms that the performance improvements claimed by AWS can be reproduced and validated by real use-cases and examples. On average, AWS Inferentia2 delivers 4.5x better latency than NVIDIA A10G GPUs and 4x better latency than Inferentia1 instances.
We ran 144 experiments on 6 different model architectures:
* Accelerators: Inf1, Inf2, NVIDIA A10G
* Models: [BERT-base](https://huggingface.co/bert-base-uncased), [BERT-Large](https://huggingface.co/bert-large-uncased), [RoBERTa-base](https://huggingface.co/roberta-base), [DistilBERT](https://huggingface.co/distilbert-base-uncased), [ALBERT-base](https://huggingface.co/albert-base-v2), [ViT-base](https://huggingface.co/google/vit-base-patch16-224)
* Sequence length: 8, 16, 32, 64, 128, 256, 512
* Batch size: 1
In each experiment, we collected numbers for p95 latency. You can find the full details of the benchmark in this spreadsheet: [HuggingFace: Benchmark Inferentia2](https://docs.google.com/spreadsheets/d/1AULEHBu5Gw6ABN8Ls6aSB2CeZyTIP_y5K7gC7M3MXqs/edit?usp=sharing).
Let’s highlight a few insights of the benchmark.
### BERT-base
Here is the latency comparison for running [BERT-base](https://huggingface.co/bert-base-uncased) on each of the infrastructure setups, with a logarithmic scale for latency. It is remarkable to see how Inferentia2 outperforms all other setups by ~6x for sequence lengths up to 256.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="BERT-base p95 latency" src="assets/140_accelerate_transformers_with_inferentia2/bert.png"></medium-zoom>
<figcaption>Figure 1. BERT-base p95 latency</figcaption>
</figure>
<br>
### Vision Transformer
Here is the latency comparison for running [ViT-base](https://huggingface.co/google/vit-base-patch16-224) on the different infrastructure setups. Inferentia2 delivers 2x better latency than the NVIDIA A10G, with the potential to greatly help companies move from traditional architectures, like CNNs, to Transformers for - real-time applications.
<br>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="ViT p95 latency" src="assets/140_accelerate_transformers_with_inferentia2/vit.png"></medium-zoom>
<figcaption>Figure 1. ViT p95 latency</figcaption>
</figure>
<br>
## Conclusion
Transformer models have emerged as the go-to solution for many machine learning tasks. However, deploying them in production has been challenging due to their large size and latency requirements. Thanks to AWS Inferentia2 and the collaboration between Hugging Face and AWS, developers and organizations can now leverage the benefits of state-of-the-art models without the prior need for extensive machine learning expertise. You can start testing for as low as 0.76$/h.
The initial benchmarking results are promising, and show that Inferentia2 delivers superior latency performance when compared to both Inferentia and NVIDIA A10G GPUs. This latest breakthrough promises high-quality machine learning models can be made available to a much broader audience delivering AI accessibility to everyone. | 4 |
0 | hf_public_repos | hf_public_repos/blog/gradio-spaces.md | ---
title: "Showcase Your Projects in Spaces using Gradio"
thumbnail: /blog/assets/28_gradio-spaces/thumbnail.png
authors:
- user: merve
---
# Showcase Your Projects in Spaces using Gradio
It's so easy to demonstrate a Machine Learning project thanks to [Gradio](https://gradio.app/).
In this blog post, we'll walk you through:
- the recent Gradio integration that helps you demo models from the Hub seamlessly with few lines of code leveraging the [Inference API](https://huggingface.co/inference-api).
- how to use Hugging Face Spaces to host demos of your own models.
## Hugging Face Hub Integration in Gradio
You can demonstrate your models in the Hub easily. You only need to define the [Interface](https://gradio.app/docs#interface) that includes:
- The repository ID of the model you want to infer with
- A description and title
- Example inputs to guide your audience
After defining your Interface, just call `.launch()` and your demo will start running. You can do this in Colab, but if you want to share it with the community a great option is to use Spaces!
Spaces are a simple, free way to host your ML demo apps in Python. To do so, you can create a repository at https://huggingface.co/new-space and select Gradio as the SDK. Once done, you can create a file called `app.py`, copy the code below, and your app will be up and running in a few seconds!
```python
import gradio as gr
description = "Story generation with GPT-2"
title = "Generate your own story"
examples = [["Adventurer is approached by a mysterious stranger in the tavern for a new quest."]]
interface = gr.Interface.load("huggingface/pranavpsv/gpt2-genre-story-generator",
description=description,
examples=examples
)
interface.launch()
```
You can play with the Story Generation model [here](https://huggingface.co/spaces/merve/GPT-2-story-gen)

Under the hood, Gradio calls the Inference API which supports Transformers as well as other popular ML frameworks such as spaCy, SpeechBrain and Asteroid. This integration supports different types of models, `image-to-text`, `speech-to-text`, `text-to-speech` and more. You can check out this example BigGAN ImageNet `text-to-image` model [here](https://huggingface.co/spaces/merve/BigGAN-ImageNET). Implementation is below.
```python
import gradio as gr
description = "BigGAN text-to-image demo."
title = "BigGAN ImageNet"
interface = gr.Interface.load("huggingface/osanseviero/BigGAN-deep-128",
description=description,
title = title,
examples=[["american robin"]]
)
interface.launch()
```

## Serving Custom Model Checkpoints with Gradio in Hugging Face Spaces
You can serve your models in Spaces even if the Inference API does not support your model. Just wrap your model inference in a Gradio `Interface` as described below and put it in Spaces.

## Mix and Match Models!
Using Gradio Series, you can mix-and-match different models! Here, we've put a French to English translation model on top of the story generator and a English to French translation model at the end of the generator model to simply make a French story generator.
```python
import gradio as gr
from gradio.mix import Series
description = "Generate your own D&D story!"
title = "French Story Generator using Opus MT and GPT-2"
translator_fr = gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-fr-en")
story_gen = gr.Interface.load("huggingface/pranavpsv/gpt2-genre-story-generator")
translator_en = gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-en-fr")
examples = [["L'aventurier est approché par un mystérieux étranger, pour une nouvelle quête."]]
Series(translator_fr, story_gen, translator_en, description = description,
title = title,
examples=examples, inputs = gr.inputs.Textbox(lines = 10)).launch()
```
You can check out the French Story Generator [here](https://huggingface.co/spaces/merve/french-story-gen)

## Uploading your Models to the Spaces
You can serve your demos in Hugging Face thanks to Spaces! To do this, simply create a new Space, and then drag and drop your demos or use Git.

Easily build your first demo with Spaces [here](https://huggingface.co/spaces)! | 5 |
0 | hf_public_repos | hf_public_repos/blog/duckdb-nsql-7b.md | ---
title: "Text2SQL using Hugging Face Dataset Viewer API and Motherduck DuckDB-NSQL-7B"
thumbnail: /blog/assets/duckdb-nsql-7b/thumbnail.png
authors:
- user: asoria
- user: tdoehmen
guest: true
org: motherduckdb
- user: senwu
guest: true
org: NumbersStation
- user: lorr
guest: true
org: NumbersStation
---
# Text2SQL using Hugging Face Dataset Viewer API and Motherduck DuckDB-NSQL-7B
Today, integrating AI-powered features, particularly leveraging Large Language Models (LLMs), has become increasingly prevalent across various tasks such as text generation, classification, image-to-text, image-to-image transformations, etc.
Developers are increasingly recognizing these applications' potential benefits, particularly in enhancing core tasks such as scriptwriting, web development, and, now, interfacing with data. Historically, crafting insightful SQL queries for data analysis was primarily the domain of data analysts, SQL developers, data engineers, or professionals in related fields, all navigating the nuances of SQL dialect syntax. However, with the advent of AI-powered solutions, the landscape is evolving. These advanced models offer new avenues for interacting with data, potentially streamlining processes and uncovering insights with greater efficiency and depth.
What if you could unlock fascinating insights from your dataset without diving deep into coding? To glean valuable information, one would need to craft a specialized `SELECT` statement, considering which columns to display, the source table, filtering conditions for selected rows, aggregation methods, and sorting preferences. This traditional approach involves a sequence of commands: `SELECT`, `FROM`, `WHERE`, `GROUP`, and `ORDER`.
But what if you’re not a seasoned developer and still want to harness the power of your data? In such cases, seeking assistance from SQL specialists becomes necessary, highlighting a gap in accessibility and usability.
This is where groundbreaking advancements in AI and LLM technology step in to bridge the divide. Imagine conversing with your data effortlessly, simply stating your information needs in plain language and having the model translate your request into a query.
In recent months, significant strides have been made in this arena. [MotherDuck](https://motherduck.com/) and [Numbers Station](https://numbersstation.ai/) unveiled their latest innovation: [DuckDB-NSQL-7B](https://huggingface.co/motherduckdb/DuckDB-NSQL-7B-v0.1), a state-of-the-art LLM designed specifically for [DuckDB SQL](https://duckdb.org/). What is this model’s mission? To empower users with the ability to unlock insights from their data effortlessly.
Initially fine-tuned from Meta’s original [Llama-2–7b](https://huggingface.co/meta-llama/Llama-2-7b) model using a broad dataset covering general SQL queries, DuckDB-NSQL-7B underwent further refinement with DuckDB text-to-SQL pairs. Notably, its capabilities extend beyond crafting `SELECT` statements; it can generate a wide range of valid DuckDB SQL statements, including official documentation and extensions, making it a versatile tool for data exploration and analysis.
In this article, we will learn how to deal with text2sql tasks using the DuckDB-NSQL-7B model, the Hugging Face dataset viewer API for parquet files and duckdb for data retrieval.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/text2sql-flow.png" alt="text2sql flow"><br>
<em>text2sql flow</em>
</p>
### How to use the model
- Using Hugging Face `transformers` pipeline
```python
from transformers import pipeline
pipe = pipeline("text-generation", model="motherduckdb/DuckDB-NSQL-7B-v0.1")
```
- Using transformers tokenizer and model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
```
- Using `llama.cpp` to load the model in `GGUF`
```python
from llama_cpp import Llama
llama = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf", # Path to local model
n_gpu_layers=-1,
)
```
The main goal of `llama.cpp` is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware - locally and in the cloud. We will use this approach.
### Hugging Face Dataset Viewer API for more than 120K datasets
Data is a crucial component in any Machine Learning endeavor. Hugging Face is a valuable resource, offering access to over 120,000 free and open datasets spanning various formats, including CSV, Parquet, JSON, audio, and image files.
Each dataset hosted by Hugging Face comes equipped with a comprehensive dataset viewer. This viewer provides users essential functionalities such as statistical insights, data size assessment, full-text search capabilities, and efficient filtering options. This feature-rich interface empowers users to easily explore and evaluate datasets, facilitating informed decision-making throughout the machine learning workflow.
For this demo, we will be using the [world-cities-geo](https://huggingface.co/datasets/jamescalam/world-cities-geo) dataset.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/dataset-viewer.png" alt="dataset viewer"><br>
<em>Dataset viewer of world-cities-geo dataset</em>
</p>
Behind the scenes, each dataset in the Hub is processed by the [Hugging Face dataset viewer API](https://huggingface.co/docs/datasets-server/index), which gets useful information and serves functionalities like:
- List the dataset **splits, column names and data types**
- Get the dataset **size** (in number of rows or bytes)
- Download and view **rows at any index** in the dataset
- **Search** a word in the dataset
- **Filter** rows based on a query string
- Get insightful **statistics** about the data
- Access the dataset as **parquet files** to use in your favorite processing or analytics framework
In this demo, we will use the last functionality, auto-converted parquet files.
### Generate SQL queries from text instructions
First, [download](https://huggingface.co/motherduckdb/DuckDB-NSQL-7B-v0.1-GGUF/blob/main/DuckDB-NSQL-7B-v0.1-q8_0.gguf) the quantized models version of DuckDB-NSQL-7B-v0.1
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/download.png" alt="download model"><br>
<em>Downloading the model</em>
</p>
Alternatively, you can execute the following code:
```
huggingface-cli download motherduckdb/DuckDB-NSQL-7B-v0.1-GGUF DuckDB-NSQL-7B-v0.1-q8_0.gguf --local-dir . --local-dir-use-symlinks False
```
Now, lets install the needed dependencies:
```
pip install llama-cpp-python
pip install duckdb
```
For the text-to-SQL model, we will use a prompt with the following structure:
```
### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Question:
{query_input}
### Response (use duckdb shorthand if possible):
```
- **ddl_create** will be the dataset schema as a SQL `CREATE` command
- **query_input** will be the user instructions, expressed with natural language
So, we need to tell to the model about the schema of the Hugging Face dataset. For that, we are going to get the first parquet file for [jamescalam/world-cities-geo](https://huggingface.co/datasets/jamescalam/world-cities-geo) dataset:
```
GET https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet
```
```
{
"default":{
"train":[
"https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet"
]
}
}
```
The [parquet file](https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet) is hosted in Hugging Face viewer under `refs/convert/parquet` revision:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/parquet.png" alt="parquet file"><br>
<em>Parquet file</em>
</p>
- Simulate a [DuckDB](https://duckdb.org/) table creation from the first row of the parquet file
```python
import duckdb
con = duckdb.connect()
con.execute(f"CREATE TABLE data as SELECT * FROM '{first_parquet_url}' LIMIT 1;")
result = con.sql("SELECT sql FROM duckdb_tables() where table_name ='data';").df()
ddl_create = result.iloc[0,0]
con.close()
```
The `CREATE` schema DDL is:
```
CREATE TABLE "data"(
city VARCHAR,
country VARCHAR,
region VARCHAR,
continent VARCHAR,
latitude DOUBLE,
longitude DOUBLE,
x DOUBLE,
y DOUBLE,
z DOUBLE
);
```
And, as you can see, it matches the columns in the dataset viewer:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/columns.png" alt="dataset columns"><br>
<em>Dataset columns</em>
</p>
- Now, we can construct the prompt with the **ddl_create** and the **query** input
```python
prompt = """### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Question:
{query_input}
### Response (use duckdb shorthand if possible):
"""
```
If the user wants to know the **Cities from Albania country**, the prompt will look like this:
```python
query = "Cities from Albania country"
prompt = prompt.format(ddl_create=ddl_create, query_input=query)
```
So the expanded prompt that will be sent to the LLM looks like this:
```
### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
CREATE TABLE "data"(city VARCHAR, country VARCHAR, region VARCHAR, continent VARCHAR, latitude DOUBLE, longitude DOUBLE, x DOUBLE, y DOUBLE, z DOUBLE);
### Question:
Cities from Albania country
### Response (use duckdb shorthand if possible):
```
- It is time to send the prompt to the model
```python
from llama_cpp import Llama
llm = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf",
n_ctx=2048,
n_gpu_layers=50
)
pred = llm(prompt, temperature=0.1, max_tokens=1000)
sql_output = pred["choices"][0]["text"]
```
The output SQL command will point to a `data` table, but since we don't have a real table but just a reference to the parquet file, we will replace all `data` occurrences by the `first_parquet_url`:
```python
sql_output = sql_output.replace("FROM data", f"FROM '{first_parquet_url}'")
```
And the final output will be:
```
SELECT city FROM 'https://huggingface.co/api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet' WHERE country = 'Albania'
```
- Now, it is time to finally execute our generated SQL directly in the dataset, so, lets use once again DuckDB powers:
```python
con = duckdb.connect()
try:
query_result = con.sql(sql_output).df()
except Exception as error:
print(f"❌ Could not execute SQL query {error=}")
finally:
con.close()
```
And here we have the results (100 rows):
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/result.png" alt="sql command result"><br>
<em>Execution result (100 rows)</em>
</p>
Let's compare this result with the dataset viewer using the "search function" for **Albania** country, it should be the same:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/search.png" alt="search result"><br>
<em>Search result for Albania country</em>
</p>
You can also get the same result calling directly to the search or filter API:
- Using [/search](https://huggingface.co/docs/datasets-server/search?code=python#search-text-in-a-dataset) API
```python
import requests
API_URL = "https://datasets-server.huggingface.co/search?dataset=jamescalam/world-cities-geo&config=default&split=train&query=Albania"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
- Using [filter](https://huggingface.co/docs/datasets-server/filter) API
```python
import requests
API_URL = "https://datasets-server.huggingface.co/filter?dataset=jamescalam/world-cities-geo&config=default&split=train&where=country='Albania'"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
Our final demo will be a Hugging Face space that looks like this:
<figure class="image table text-center m-0 w-full">
<video
alt="Demo"
style="max-width: 95%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/demo.mp4" type="video/mp4">
</video>
</figure>
You can see the notebook with the code [here](https://colab.research.google.com/drive/1hOyQ_Lp5wwC2z9HYhEzBHuRuqy-5plDO?usp=sharing).
And the Hugging Face Space [here](https://huggingface.co/spaces/asoria/datasets-text2sql) | 6 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-contextual.md | ---
title: "Introducing ConTextual: How well can your Multimodal model jointly reason over text and image in text-rich scenes?"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_contextual.png
authors:
- user: rohan598
guest: true
- user: hbXNov
guest: true
- user: kaiweichang
guest: true
- user: violetpeng
guest: true
- user: clefourrier
---
# Introducing ConTextual: How well can your Multimodal model jointly reason over text and image in text-rich scenes?
Models are becoming quite good at understanding text on its own, but what about text in images, which gives important contextual information? For example, navigating a map, or understanding a meme? The ability to reason about the interactions between the text and visual context in images can power many real-world applications, such as AI assistants, or tools to assist the visually impaired.
We refer to these tasks as "context-sensitive text-rich visual reasoning tasks".
At the moment, most evaluations of instruction-tuned large multimodal models (LMMs) focus on testing how well models can respond to human instructions posed as questions or imperative sentences (“Count this”, “List that”, etc) over images... but not how well they understand context-sensitive text-rich scenes!
That’s why we (researchers from University of California Los Angeles) created ConTextual, a Context-sensitive Text-rich visuaL reasoning dataset for evaluating LMMs. We also released a leaderboard, so that the community can see for themselves which models are the best at this task.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="ucla-contextual/contextual_leaderboard"></gradio-app>
For an in-depth dive, you can also check these additional resources: [paper](https://arxiv.org/abs/2401.13311), [code](https://github.com/rohan598/ConTextual), [dataset](https://huggingface.co/datasets/ucla-contextual/contextual_all), [validation dataset](https://huggingface.co/datasets/ucla-contextual/contextual_val), and [leaderboard](https://huggingface.co/spaces/ucla-contextual/contextual_leaderboard).
## What is ConTextual
ConTextual is a Context-sensitive Text-rich visual reasoning dataset consisting of 506 challenging instructions for LMM evaluation. We create a diverse set of instructions on text-rich images with the constraint that they should require context-sensitive joint reasoning over the textual and visual cues in the image.
It covers 8 real-world visual scenarios - Time Reading, Shopping, Navigation, Abstract Scenes, Mobile Application, Webpages, Infographics and Miscellaneous Natural Scenes. (See the figure for a sample of each dataset).

Each sample consists of:
- A text-rich image
- A human-written instruction (question or imperative task)
- A human-written reference response
The dataset is released in two forms:
- (a) a validation set of 100 instances from the complete dataset with instructions, images, and reference answers to the instructions.
- (b) a test dataset with instructions and images only.
The leaderboard contains model results both on the validation and test datasets (the information is also present in the paper). The development set allows the practitioners to test and iterate on their approaches easily. The evaluation sandbox is present in our github.
## Experiments
For our initial experiments, our benchmark assessed the performance of 13 models. We divided them into three categories:
- **Augmented LLM approach**: GPT4 + visual information in the form of OCR of the image and/or dense image captions;
- **Closed-Source LMMs**: GPT4V(ision) and Gemini-Vision-Pro;
- **Open-Source LMMs**: LLaVA-v1.5-13B, ShareGPT4V-7B, Instruct-Blip-Vicuna-7B, mPlugOwl-v2-7B, Bliva-Vicuna-7B, Qwen-VL-7B and Idefics-9B.
Our dataset includes a reference response for each instruction, allowing us to test various automatic evaluation methods. For evaluation, we use an LLM-as-a-judge approach, and prompt GPT-4 with the instruction, reference response, and predicted response. The model has to return whether the predicted response is acceptable or not. (GPT4 was chosen as it correlated the most with human judgement in our experiments.)
Let's look at some examples!
[Example 1](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/leaderboards-on-the-hub/contextual-qualitative-ex-1.png)
In this instance, GPT-4V provides an incorrect response to the instruction, despite its logical reasoning. The use of green indicates responses that match the reference, while red highlights errors in the responses. Additionally, a Summarized Reasoning is provided to outline the rationale used by GPT-4V to arrive at its answer.
[Example 2](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/leaderboards-on-the-hub/contextual-qualitative-ex-2.png)
In this example, GPT-4V correctly responds to the instruction. However, ShareGPT-4V-7B (best performing open-source LMM) and GPT-4 w/ Layout-aware OCR + Caption (Augmented LLM) produce a wrong response, due to lack of joint reasoning over text and image.
You’ll find more examples like this in the Appendix section of our [paper](https://arxiv.org/abs/2401.13311)!
## Key Takeaways!
While working on this, we found that:
- Modern LMMs (proprietary and open models) struggle to perform on ConTextual dataset while humans are good at it, hinting at the possibility of model improvement to enhance reasoning over text-rich images, a domain with significant real-world applications.
- Proprietary LMMs perform poorly in infographics reasoning that involves time reading, indicating a gap in their capabilities compared to humans. Notably, GPT-4V, the best performing model, surpasses humans in abstract reasoning, potentially due to exposure to memes and quotes data, but struggles in time-related tasks where humans excel.
- For open-source models such as LLaVA-1.5-13B and ShareGPT-4V-7B, there is a strong gap between the domains on which they achieve acceptable human ratings (abstract and natural scene contexts) and the other domains ((time-reading, infographics, navigation, shopping, web, and mobile usage). It's therefore likely that many of the domains we cover in our samples are out-of-distribution for these models. Open-source models should therefore aim to increase the diversity in their training data.
- Augmenting an LMMs with a Large Language Model, which receives visual information converted into text via OCR or captions, performs notably badly, with an human approval rate of 17.2%. Our samples need a combination of precise visual perception along with fine-grained nuanced vision-language alignment to be solved.
Our analysis suggests promising next steps include:
- developing enhanced image encoders,
- creating highly accurate image descriptions,
- facilitating fine-grained vision-language alignment to improve the model's perception and mitigate the occurrence of hallucinations.
This, in turn, will lead to more effective context-sensitive text-rich visual reasoning.
## What’s next?
We’d love to evaluate your models too, to help collectively advance the state of vision language models! To submit, please follow our guidelines below.
We hope that this benchmark will help in developing nuanced vision-language alignment techniques and welcome any kind of collaboration! You can contact us here: [Rohan]([email protected]) and [Hritik]([email protected]), and know more about the team here: [Rohan](https://web.cs.ucla.edu/~rwadhawan7/), [Hritik](https://sites.google.com/view/hbansal), [Kai-Wei Chang](https://web.cs.ucla.edu/~kwchang/), [Nanyun (Violet) Peng](https://vnpeng.net/).
## How to Submit?
We are accepting submissions for both the test and validation sets. Please, follow the corresponding procedure below.
### Validation Set Submission
To submit your validation results to the leaderboard, you can run our auto-evaluation code (Evaluation Pipeline with GPT4), following [these instructions](https://github.com/rohan598/ConTextual?tab=readme-ov-file#-evaluation-pipeline-gpt-4).
We expect submissions to be json format as shown below:
```json
{"model_name": {"img_url": "The boolean score of your model on the image, 1 for success and 0 for failure"}}
```
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is either 0 or 1 (int)
There should be 100 predictions, corresponding to the 100 urls of the val set.
To make the submission please go to the [leaderboard](https://huggingface.co/spaces/ucla-contextual/contextual_leaderboard) hosted on HuggingFace and fill up the Submission form.
### Test Set Submission
Once you are happy with your validation results, you can send your model predictions to [Rohan]([email protected]) and [Hritik]([email protected]).
Please include in your email:
- A name for your model.
- Organization (affiliation).
- (Optionally) GitHub repo or paper link.
We expect submissions to be json format similar to val set as shown below:
```json
{"model_name": {"img_url": "predicted response"}}
```
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is the predicted response for that instance (string)
There should be 506 predictions, corresponding to the 506 urls of the test set.
| 7 |
0 | hf_public_repos | hf_public_repos/blog/japanese-stable-diffusion.md | ---
title: "Japanese Stable Diffusion"
thumbnail: /blog/assets/106_japanese_stable_diffusion/jsd_thumbnail.png
authors:
- user: mshing
guest: true
- user: keisawada
guest: true
---
# Japanese Stable Diffusion
<a target="_blank" href="https://huggingface.co/spaces/rinna/japanese-stable-diffusion" target="_parent"><img src="https://img.shields.io/badge/🤗 Hugging Face-Spaces-blue" alt="Open In Hugging Face Spaces"/></a>
<a target="_blank" href="https://colab.research.google.com/github/rinnakk/japanese-stable-diffusion/blob/master/scripts/txt2img.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Stable Diffusion, developed by [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), has generated a great deal of interest due to its ability to generate highly accurate images by simply entering text prompts. Stable Diffusion mainly uses the English subset [LAION2B-en](https://huggingface.co/datasets/laion/laion2B-en) of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset for its training data and, as a result, requires English text prompts to be entered producing images that tend to be more oriented towards Western culture.
[rinna Co., Ltd](https://rinna.co.jp/). has developed a Japanese-specific text-to-image model named "Japanese Stable Diffusion" by fine-tuning Stable Diffusion on Japanese-captioned images. Japanese Stable Diffusion accepts Japanese text prompts and generates images that reflect the culture of the Japanese-speaking world which may be difficult to express through translation.
In this blog, we will discuss the background of the development of Japanese Stable Diffusion and its learning methodology.
Japanese Stable Diffusion is available on Hugging Face and GitHub. The code is based on [🧨 Diffusers](https://huggingface.co/docs/diffusers/index).
- Hugging Face model card: https://huggingface.co/rinna/japanese-stable-diffusion
- Hugging Face Spaces: https://huggingface.co/spaces/rinna/japanese-stable-diffusion
- GitHub: https://github.com/rinnakk/japanese-stable-diffusion
## Stable Diffusion
Recently diffusion models have been reported to be very effective in artificial synthesis, even more so than GANs (Generative Adversarial Networks) for images. Hugging Face explains how diffusion models work in the following articles:
- [The Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
Generally, a text-to-image model consists of a text encoder that interprets text and a generative model that generates an image from its output.
Stable Diffusion uses CLIP, the language-image pre-training model from OpenAI, as its text encoder and a latent diffusion model, which is an improved version of the diffusion model, as the generative model. Stable Diffusion was trained mainly on the English subset of LAION-5B and can generate high-performance images simply by entering text prompts. In addition to its high performance, Stable Diffusion is also easy to use with inference running at a computing cost of about 10GB VRAM GPU.
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="300"/>
</p>
*from [Stable Diffusion with 🧨 Diffusers](https://huggingface.co/blog/stable_diffusion)*
## Japanese Stable Diffusion
### Why do we need Japanese Stable Diffusion?
Stable Diffusion is a very powerful text-to-image model not only in terms of quality but also in terms of computational cost. Because Stable Diffusion was trained on an English dataset, it is required to translate non-English prompts to English first. Surprisingly, Stable Diffusion can sometimes generate proper images even when using non-English prompts.
So, why do we need a language-specific Stable Diffusion? The answer is because we want a text-to-image model that can understand Japanese culture, identity, and unique expressions including slang. For example, one of the more common Japanese terms re-interpreted from the English word businessman is "salary man" which we most often imagine as a man wearing a suit. Stable Diffusion cannot understand such Japanese unique words correctly because Japanese is not their target.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/sd.jpeg" alt="salary man of stable diffusion" title="salary man of stable diffusion">
</p>
*"salary man, oil painting" from the original Stable Diffusion*
So, this is why we made a language-specific version of Stable Diffusion. Japanese Stable Diffusion can achieve the following points compared to the original Stable Diffusion.
- Generate Japanese-style images
- Understand Japanese words adapted from English
- Understand Japanese unique onomatope
- Understand Japanese proper noun
### Training Data
We used approximately 100 million images with Japanese captions, including the Japanese subset of [LAION-5B](https://laion.ai/blog/laion-5b/). In addition, to remove low quality samples, we used [japanese-cloob-vit-b-16](https://huggingface.co/rinna/japanese-cloob-vit-b-16) published by rinna Co., Ltd. as a preprocessing step to remove samples whose scores were lower than a certain threshold.
### Training Details
The biggest challenge in making a Japanese-specific text-to-image model is the size of the dataset. Non-English datasets are much smaller than English datasets, and this causes performance degradation in deep learning-based models. The dataset used to train Japanese Stable Diffusion is 1/20th the size of the dataset on which Stable Diffusion is trained. To make a good model with such a small dataset, we fine-tuned the powerful [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion-v1-4) trained on the English dataset, rather than training a text-to-image model from scratch.
To make a good language-specific text-to-image model, we did not simply fine-tune but applied 2 training stages following the idea of [PITI](https://arxiv.org/abs/2205.12952).
#### 1st stage: Train a Japanese-specific text encoder
In the 1st stage, the latent diffusion model is fixed and we replaced the English text encoder with a Japanese-specific text encoder, which is trained. At this time, our Japanese sentencepiece tokenizer is used as the tokenizer. If the CLIP tokenizer is used as it is, Japanese texts are tokenized bytes, which makes it difficult to learn the token dependency, and the number of tokens becomes unnecessarily large. For example, if we tokenize "サラリーマン 油絵", we get `['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>']` which are uninterpretable tokens.
```python
from transformers import CLIPTokenizer
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text = "サラリーマン 油絵"
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵
```
On the other hand, by using our Japanese tokenizer, the prompt is split into interpretable tokens and the number of tokens is reduced. For example, "サラリーマン 油絵" can be tokenized as `['▁', 'サラリーマン', '▁', '油', '絵']`, which is correctly tokenized in Japanese.
```python
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-stable-diffusion", subfolder="tokenizer", use_auth_token=True)
tokenizer.do_lower_case = True
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['▁', 'サラリーマン', '▁', '油', '絵']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵
```
This stage enables the model to understand Japanese prompts but does not still output Japanese-style images because the latent diffusion model has not been changed at all. In other words, the Japanese word "salary man" can be interpreted as the English word "businessman," but the generated result is a businessman with a Western face, as shown below.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/jsd-stage1.jpeg" alt="salary man of japanese stable diffusion at stage 1" title="salary man of japanese stable diffusion at stage 1">
</p>
*"サラリーマン 油絵", which means exactly "salary man, oil painting", from the 1st-stage Japanese Stable Diffusion*
Therefore, in the 2nd stage, we train to output more Japanese-style images.
#### 2nd stage: Fine-tune the text encoder and the latent diffusion model jointly
In the 2nd stage, we will train both the text encoder and the latent diffusion model to generate Japanese-style images. This stage is essential to make the model become a more language-specific model. After this, the model can finally generate a businessman with a Japanese face, as shown in the image below.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/jsd-stage2.jpeg" alt="salary man of japanese stable diffusion" title="salary man of japanese stable diffusion">
</p>
*"サラリーマン 油絵", which means exactly "salary man, oil painting", from the 2nd-stage Japanese Stable Diffusion*
## rinna’s Open Strategy
Numerous research institutes are releasing their research results based on the idea of democratization of AI, aiming for a world where anyone can easily use AI. In particular, recently, pre-trained models with a large number of parameters based on large-scale training data have become the mainstream, and there are concerns about a monopoly of high-performance AI by research institutes with computational resources. Still, fortunately, many pre-trained models have been released and are contributing to the development of AI technology. However, pre-trained models on text often target English, the world's most popular language. For a world in which anyone can easily use AI, we believe that it is desirable to be able to use state-of-the-art AI in languages other than English.
Therefore, rinna Co., Ltd. has released [GPT](https://huggingface.co/rinna/japanese-gpt-1b), [BERT](https://huggingface.co/rinna/japanese-roberta-base), and [CLIP](https://huggingface.co/rinna/japanese-clip-vit-b-16), which are specialized for Japanese, and now have also released [Japanese Stable Diffusion](https://huggingface.co/rinna/japanese-stable-diffusion). By releasing a pre-trained model specialized for Japanese, we hope to make AI that is not biased toward the cultures of the English-speaking world but also incorporates the culture of the Japanese-speaking world. Making it available to everyone will help to democratize an AI that guarantees Japanese cultural identity.
## What’s Next?
Compared to Stable Diffusion, Japanese Stable Diffusion is not as versatile and still has some accuracy issues. However, through the development and release of Japanese Stable Diffusion, we hope to communicate to the research community the importance and potential of language-specific model development.
rinna Co., Ltd. has released GPT and BERT models for Japanese text, and CLIP, CLOOB, and Japanese Stable Diffusion models for Japanese text and images. We will continue to improve these models and next we will consider releasing models based on self-supervised learning specialized for Japanese speech.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/clipseg-zero-shot.md | ---
title: Zero-shot image segmentation with CLIPSeg
thumbnail: /blog/assets/123_clipseg-zero-shot/thumb.png
authors:
- user: tobiasc
guest: true
- user: nielsr
---
# Zero-shot image segmentation with CLIPSeg
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/123_clipseg-zero-shot.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**This guide shows how you can use [CLIPSeg](https://huggingface.co/docs/transformers/main/en/model_doc/clipseg), a zero-shot image segmentation model, using [`🤗 transformers`](https://huggingface.co/transformers). CLIPSeg creates rough segmentation masks that can be used for robot perception, image inpainting, and many other tasks. If you need more precise segmentation masks, we’ll show how you can refine the results of CLIPSeg on [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).**
Image segmentation is a well-known task within the field of computer vision. It allows a computer to not only know what is in an image (classification), where objects are in the image (detection), but also what the outlines of those objects are. Knowing the outlines of objects is essential in fields such as robotics and autonomous driving. For example, a robot has to know the shape of an object to grab it correctly. Segmentation can also be combined with [image inpainting](https://t.co/5q8YHSOfx7) to allow users to describe which part of the image they want to replace.
One limitation of most image segmentation models is that they only work with a fixed list of categories. For example, you cannot simply use a segmentation model trained on oranges to segment apples. To teach the segmentation model an additional category, you have to label data of the new category and train a new model, which can be costly and time-consuming. But what if there was a model that can already segment almost any kind of object, without any further training? That’s exactly what [CLIPSeg](https://arxiv.org/abs/2112.10003), a zero-shot segmentation model, achieves.
Currently, CLIPSeg still has its limitations. For example, the model uses images of 352 x 352 pixels, so the output is quite low-resolution. This means we cannot expect pixel-perfect results when we work with images from modern cameras. If we want more precise segmentations, we can fine-tune a state-of-the-art segmentation model, as shown in [our previous blog post](https://huggingface.co/blog/fine-tune-segformer). In that case, we can still use CLIPSeg to generate some rough labels, and then refine them in a labeling tool such as [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg). Before we describe how to do that, let’s first take a look at how CLIPSeg works.
## CLIP: the magic model behind CLIPSeg
[CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip), which stands for **C**ontrastive **L**anguage–**I**mage **P**re-training, is a model developed by OpenAI in 2021. You can give CLIP an image or a piece of text, and CLIP will output an abstract *representation* of your input. This abstract representation, also called an *embedding*, is really just a vector (a list of numbers). You can think of this vector as a point in high-dimensional space. CLIP is trained so that the representations of similar pictures and texts are similar as well. This means that if we input an image and a text description that fits that image, the representations of the image and the text will be similar (i.e., the high-dimensional points will be close together).
At first, this might not seem very useful, but it is actually very powerful. As an example, let’s take a quick look at how CLIP can be used to classify images without ever having been trained on that task. To classify an image, we input the image and the different categories we want to choose from to CLIP (e.g. we input an image and the words “apple”, “orange”, …). CLIP then gives us back an embedding of the image and of each category. Now, we simply have to check which category embedding is closest to the embedding of the image, et voilà! Feels like magic, doesn’t it?
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clip-tv-example.png"></medium-zoom>
<figcaption>Example of image classification using CLIP (<a href="https://openai.com/blog/clip/">source</a>).</figcaption>
</figure>
What’s more, CLIP is not only useful for classification, but it can also be used for [image search](https://huggingface.co/spaces/DrishtiSharma/Text-to-Image-search-using-CLIP) (can you see how this is similar to classification?), [text-to-image models](https://huggingface.co/spaces/kamiyamai/stable-diffusion-webui) ([DALL-E 2](https://openai.com/dall-e-2/) is powered by CLIP), [object detection](https://segments.ai/zeroshot?utm_source=hf&utm_medium=blog&utm_campaign=clipseg) ([OWL-ViT](https://arxiv.org/abs/2205.06230)), and most importantly for us: image segmentation. Now you see why CLIP was truly a breakthrough in machine learning.
The reason why CLIP works so well is that the model was trained on a huge dataset of images with text captions. The dataset contained a whopping 400 million image-text pairs taken from the internet. These images contain a wide variety of objects and concepts, and CLIP is great at creating a representation for each of them.
## CLIPSeg: image segmentation with CLIP
[CLIPSeg](https://arxiv.org/abs/2112.10003) is a model that uses CLIP representations to create image segmentation masks. It was published by Timo Lüddecke and Alexander Ecker. They achieved zero-shot image segmentation by training a Transformer-based decoder on top of the CLIP model, which is kept frozen. The decoder takes in the CLIP representation of an image, and the CLIP representation of the thing you want to segment. Using these two inputs, the CLIPSeg decoder creates a binary segmentation mask. To be more precise, the decoder doesn’t only use the final CLIP representation of the image we want to segment, but it also uses the outputs of some of the layers of CLIP.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clipseg-overview.png"></medium-zoom>
<figcaption><a href="https://arxiv.org/abs/2112.10003">Source</a></figcaption>
</figure>
The decoder is trained on the [PhraseCut dataset](https://arxiv.org/abs/2008.01187), which contains over 340,000 phrases with corresponding image segmentation masks. The authors also experimented with various augmentations to expand the size of the dataset. The goal here is not only to be able to segment the categories that are present in the dataset, but also to segment unseen categories. Experiments indeed show that the decoder can generalize to unseen categories.
One interesting feature of CLIPSeg is that both the query (the image we want to segment) and the prompt (the thing we want to segment in the image) are input as CLIP embeddings. The CLIP embedding for the prompt can either come from a piece of text (the category name), **or from another image**. This means you can segment oranges in a photo by giving CLIPSeg an example image of an orange.
This technique, which is called "visual prompting", is really helpful when the thing you want to segment is hard to describe. For example, if you want to segment a logo in a picture of a t-shirt, it's not easy to describe the shape of the logo, but CLIPSeg allows you to simply use the image of the logo as the prompt.
The CLIPSeg paper contains some tips on improving the effectiveness of visual prompting. They find that cropping the query image (so that it only contains the object you want to segment) helps a lot. Blurring and darkening the background of the query image also helps a little bit. In the next section, we'll show how you can try out visual prompting yourself using [`🤗 transformers`](https://huggingface.co/transformers).
## Using CLIPSeg with Hugging Face Transformers
Using Hugging Face Transformers, you can easily download and run a
pre-trained CLIPSeg model on your images. Let's start by installing
transformers.
```python
!pip install -q transformers
```
To download the model, simply instantiate it.
```python
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
```
Now we can load an image to try out the segmentation. We\'ll choose a
picture of a delicious breakfast taken by [Calum
Lewis](https://unsplash.com/@calumlewis).
```python
from PIL import Image
import requests
url = "https://unsplash.com/photos/8Nc_oQsc2qQ/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjcxMjAwNzI0&force=true&w=640"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a pancake breakfast." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/73d97c93dc0f5545378e433e956509b8acafb8d9.png"></medium-zoom>
</figure>
### Text prompting
Let's start by defining some text categories we want to segment.
```python
prompts = ["cutlery", "pancakes", "blueberries", "orange juice"]
```
Now that we have our inputs, we can process them and input them to the
model.
```python
import torch
inputs = processor(text=prompts, images=[image] * len(prompts), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
preds = outputs.logits.unsqueeze(1)
```
Finally, let's visualize the output.
```python
import matplotlib.pyplot as plt
_, ax = plt.subplots(1, len(prompts) + 1, figsize=(3*(len(prompts) + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len(prompts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(prompts)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/14c048ea92645544c1bbbc9e55f3c620eaab8886.png"></medium-zoom>
</figure>
### Visual prompting
As mentioned before, we can also use images as the input prompts (i.e.
in place of the category names). This can be especially useful if it\'s
not easy to describe the thing you want to segment. For this example,
we\'ll use a picture of a coffee cup taken by [Daniel
Hooper](https://unsplash.com/@dan_fromyesmorecontent).
```python
url = "https://unsplash.com/photos/Ki7sAc8gOGE/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTJ8fGNvZmZlJTIwdG8lMjBnb3xlbnwwfHx8fDE2NzExOTgzNDQ&force=true&w=640"
prompt = Image.open(requests.get(url, stream=True).raw)
prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a paper coffee cup." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7931f9db82ab07af7d161f0cfbfc347645da6646.png"></medium-zoom>
</figure>
We can now process the input image and prompt image and input them to
the model.
```python
encoded_image = processor(images=[image], return_tensors="pt")
encoded_prompt = processor(images=[prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
Then, we can visualize the results as before.
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/fbde45fc65907d17de38b0db3eb262bdec1f1784.png"></medium-zoom>
</figure>
Let's try one last time by using the visual prompting tips described in
the paper, i.e. cropping the image and darkening the background.
```python
url = "https://i.imgur.com/mRSORqz.jpg"
alternative_prompt = Image.open(requests.get(url, stream=True).raw)
alternative_prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A cropped version of the image of the coffee cup with a darker background." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/915a97da22131e0ab6ff4daa78ffe3f1889e3386.png"></medium-zoom>
</figure>
```python
encoded_alternative_prompt = processor(images=[alternative_prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_alternative_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7f75badfc245fc3a75e0e05058b8c4b6a3a991fa.png"></medium-zoom>
</figure>
In this case, the result is pretty much the same. This is probably
because the coffee cup was already separated well from the background in
the original image.
## Using CLIPSeg to pre-label images on Segments.ai
As you can see, the results from CLIPSeg are a little fuzzy and very
low-res. If we want to obtain better results, you can fine-tune a
state-of-the-art segmentation model, as explained in [our previous
blogpost](https://huggingface.co/blog/fine-tune-segformer). To finetune
the model, we\'ll need labeled data. In this section, we\'ll show you
how you can use CLIPSeg to create some rough segmentation masks and then
refine them on
[Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg),
a labeling platform with smart labeling tools for image segmentation.
First, create an account at
[https://segments.ai/join](https://segments.ai/join?utm_source=hf&utm_medium=blog&utm_campaign=clipseg)
and install the Segments Python SDK. Then you can initialize the
Segments.ai Python client using an API key. This key can be found on
[the account page](https://segments.ai/account?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
!pip install -q segments-ai
```
```python
from segments import SegmentsClient
from getpass import getpass
api_key = getpass('Enter your API key: ')
segments_client = SegmentsClient(api_key)
```
Next, let\'s load an image from a dataset using the Segments client.
We\'ll use the [a2d2 self-driving
dataset](https://www.a2d2.audi/a2d2/en.html). You can also create your
own dataset by following [these
instructions](https://docs.segments.ai/tutorials/getting-started?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
samples = segments_client.get_samples("admin-tobias/clipseg")
# Use the last image as an example
sample = samples[1]
image = Image.open(requests.get(sample.attributes.image.url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a street with cars from the a2d2 dataset." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/a0ca3accab5a40547f16b2abc05edd4558818bdf.png"></medium-zoom>
</figure>
We also need to get the category names from the dataset attributes.
```python
dataset = segments_client.get_dataset("admin-tobias/clipseg")
category_names = [category.name for category in dataset.task_attributes.categories]
```
Now we can use CLIPSeg on the image as before. This time, we\'ll also
scale up the outputs so that they match the input image\'s size.
```python
from torch import nn
inputs = processor(text=category_names, images=[image] * len(category_names), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
# resize the outputs
preds = nn.functional.interpolate(
outputs.logits.unsqueeze(1),
size=(image.size[1], image.size[0]),
mode="bilinear"
)
```
And we can visualize the results again.
```python
len_cats = len(category_names)
_, ax = plt.subplots(1, len_cats + 1, figsize=(3*(len_cats + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len_cats)];
[ax[i+1].text(0, -15, category_name) for i, category_name in enumerate(category_names)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the street image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7782da300097ce4dcb3891257db7cc97ccf1deb3.png"></medium-zoom>
</figure>
Now we have to combine the predictions to a single segmented image.
We\'ll simply do this by taking the category with the greatest sigmoid
value for each patch. We\'ll also make sure that all the values under a
certain threshold do not count.
```python
threshold = 0.1
flat_preds = torch.sigmoid(preds.squeeze()).reshape((preds.shape[0], -1))
# Initialize a dummy "unlabeled" mask with the threshold
flat_preds_with_treshold = torch.full((preds.shape[0] + 1, flat_preds.shape[-1]), threshold)
flat_preds_with_treshold[1:preds.shape[0]+1,:] = flat_preds
# Get the top mask index for each pixel
inds = torch.topk(flat_preds_with_treshold, 1, dim=0).indices.reshape((preds.shape[-2], preds.shape[-1]))
```
Let\'s quickly visualize the result.
```python
plt.imshow(inds)
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A combined segmentation label of the street image." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/b92dc12452108a0b2769ddfc1d7f79909e65144b.png"></medium-zoom>
</figure>
Lastly, we can upload the prediction to Segments.ai. To do that, we\'ll
first convert the bitmap to a png file, then we\'ll upload this file to
the Segments, and finally we\'ll add the label to the sample.
```python
from segments.utils import bitmap2file
import numpy as np
inds_np = inds.numpy().astype(np.uint32)
unique_inds = np.unique(inds_np).tolist()
f = bitmap2file(inds_np, is_segmentation_bitmap=True)
asset = segments_client.upload_asset(f, "clipseg_prediction.png")
attributes = {
'format_version': '0.1',
'annotations': [{"id": i, "category_id": i} for i in unique_inds if i != 0],
'segmentation_bitmap': { 'url': asset.url },
}
segments_client.add_label(sample.uuid, 'ground-truth', attributes)
```
If you take a look at the [uploaded prediction on
Segments.ai](https://segments.ai/admin-tobias/clipseg/samples/71a80d39-8cf3-4768-a097-e81e0b677517/ground-truth),
you can see that it\'s not perfect. However, you can manually correct
the biggest mistakes, and then you can use the corrected dataset to
train a better model than CLIPSeg.
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="Thumbnails of the final segmentation labels on Segments.ai." src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/segments-thumbs.png"></medium-zoom>
</figure>
## Conclusion
CLIPSeg is a zero-shot segmentation model that works with both text and image prompts. The model adds a decoder to CLIP and can segment almost anything. However, the output segmentation masks are still very low-res for now, so you’ll probably still want to fine-tune a different segmentation model if accuracy is important.
Note that there's more research on zero-shot segmentation currently being conducted, so you can expect more models to be added in the near future. One example is [GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit), which is already available in 🤗 Transformers. To stay up to date with the latest news in segmentation research, you can follow us on Twitter: [@TobiasCornille](https://twitter.com/tobiascornille), [@NielsRogge](https://twitter.com/nielsrogge), and [@huggingface](https://twitter.com/huggingface).
If you’re interested in learning how to fine-tune a state-of-the-art segmentation model, check out our previous blog post: [https://huggingface.co/blog/fine-tune-segformer](https://huggingface.co/blog/fine-tune-segformer).
| 9 |
0 | hf_public_repos | hf_public_repos/blog/space-secrets-disclosure.md | ---
title: Space secrets security update
thumbnail: /blog/assets/space-secrets-security-update/space-secrets-security-update.png
authors:
- user: huggingface
---
# Space secrets leak disclosure
Earlier this week our team detected unauthorized access to our Spaces platform, specifically related to Spaces secrets. As a consequence, we have suspicions that a subset of Spaces’ secrets could have been accessed without authorization.
As a first step of remediation, we have revoked a number of HF tokens present in those secrets. Users whose tokens have been revoked already received an email notice. **We recommend you refresh any key or token and consider switching your HF tokens to fine-grained access tokens which are the new default.**
We are working with outside cyber security forensic specialists, to investigate the issue as well as review our security policies and procedures.
Over the past few days, we have made other significant improvements to the security of the Spaces infrastructure, including completely removing org tokens (resulting in increased traceability and audit capabilities), implementing key management service (KMS) for Spaces secrets, robustifying and expanding our system’s ability to identify leaked tokens and proactively invalidate them, and more generally improving our security across the board. We also plan on completely deprecating “classic” read and write tokens in the near future, as soon as fine-grained access tokens reach feature parity. We will continue to investigate any possible related incident.
Finally, we have also reported this incident to law enforcement agencies and Data protection authorities.
We deeply regret the disruption this incident may have caused and understand the inconvenience it may have posed to you. We pledge to use this as an opportunity to strengthen the security of our entire infrastructure. For any question, please contact us at [email protected].
| 0 |
0 | hf_public_repos | hf_public_repos/blog/chinese-language-blog.md | ---
title: "Introducing HuggingFace blog for Chinese speakers: Fostering Collaboration with the Chinese AI community"
thumbnail: /blog/assets/chinese-language-blog/thumbnail.png
forceLinkToOtherLanguage: on
authors:
- user: xianbao
- user: adinayakefu
- user: chenglu
guest: true
---
# Introducing HuggingFace blog for Chinese speakers: Fostering Collaboration with the Chinese AI community
## Welcome to our blog for Chinese speakers!
We are delighted to introduce Hugging Face’s new blog for Chinese speakers: [hf.co/blog/zh](https://huggingface.co/blog/zh)! A committed group of volunteers has made this possible by translating our invaluable resources, including blog posts and comprehensive courses on transformers, diffusion, and reinforcement learning. This step aims to make our content accessible to the ever-growing Chinese AI community, fostering mutual learning and collaboration.
## Recognizing the Chinese AI Community’s Accomplishments
We want to highlight the remarkable achievements and contributions of the Chinese AI community, which has demonstrated exceptional talent and innovation. Groundbreaking advancements like [HuggingGPT](https://huggingface.co/spaces/microsoft/HuggingGPT), [ChatGLM](https://huggingface.co/THUDM/chatglm-6b), [RWKV](https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B), [ChatYuan](https://huggingface.co/spaces/ClueAI/ChatYuan-large-v2), [ModelScope text-to-video models](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis) as well as [IDEA CCNL](https://huggingface.co/IDEA-CCNL) and [BAAI](https://huggingface.co/BAAI)’s contributions underscore the incredible potential within the community.
In addition, the Chinese AI community has been actively engaged in creating trendy Spaces, such as [Chuanhu GPT](https://huggingface.co/spaces/jdczlx/ChatGPT-chuanhu) and [GPT Academy](https://huggingface.co/spaces/qingxu98/gpt-academic), further demonstrating its enthusiasm and creativity.
We have been collaborating with organizations such as [PaddlePaddle](https://huggingface.co/blog/paddlepaddle) to ensure seamless integration with Hugging Face, empowering more collaborative efforts in the realm of Machine Learning.
## Strengthening Collaborative Ties and Future Events
We are proud of our collaborative history with our Chinese collaborators, having worked together on various events that have enabled knowledge exchange and collaboration, propelling the AI community forward. Some of our collaborative efforts include:
- [Online ChatGPT course, in collaboration with DataWhale (ongoing)](https://mp.weixin.qq.com/s/byR2n-5QJmy34Jq0W3ECDg)
- [First offline meetup in Beijing for JAX/Diffusers community sprint](https://twitter.com/huggingface/status/1648986159580876800)
- [Organizing a Prompt engineering hackathon alongside Baixing AI](https://mp.weixin.qq.com/s/M5vjicNG1uBdCQzQtQU9yw)
- [Fine-tuning Lora models in collaboration with PaddlePaddle](https://aistudio.baidu.com/aistudio/competition/detail/860/0/introduction)
- [Fine-tuning stable diffusion models in an event with HeyWhale](https://www.heywhale.com/home/competition/63bbfb98de6c0e9cdb0d9dd5)
We are excited to announce that we will continue to strengthen our ties with the Chinese AI community by fostering more collaborations and joint efforts. These initiatives will create opportunities for knowledge sharing and expertise exchange, promoting collaborative open-source machine learning across our communities, and tackling the challenges and opportunities in the field of cooperative OS ML.
## Beyond Boundaries: Embracing a Diverse AI Community
As we embark on this new chapter, our collaboration with the Chinese AI community will serve as a platform to bridge cultural and linguistic barriers, fostering innovation and cooperation in the AI domain. At Hugging Face, we value diverse perspectives and voices, aiming to create a welcoming and inclusive community that promotes ethical and equitable AI development.
Join us on this exciting journey, and stay tuned for more updates on our blog about Chinese community advancements and future collaborative endeavors!
You may also find us here:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chinese-language-blog/wechat.jpg">
</figure>
[BAAI](https://hub.baai.ac.cn/users/45017), [Bilibili](https://space.bilibili.com/1740664937/), [CNBlogs](https://www.cnblogs.com/huggingface), [CSDN](https://huggingface.blog.csdn.net/), [Juejin](https://juejin.cn/user/611789528634712), [OS China](https://my.oschina.net/HuggingFace), [SegmentFault](https://segmentfault.com/u/huggingface), [Zhihu](https://www.zhihu.com/org/huggingface)
| 1 |
0 | hf_public_repos | hf_public_repos/blog/fast-diffusers-coreml.md | ---
title: Faster Stable Diffusion with Core ML on iPhone, iPad, and Mac
thumbnail: /blog/assets/149_fast_diffusers_coreml/thumbnail.png
authors:
- user: pcuenq
---
# Faster Stable Diffusion with Core ML on iPhone, iPad, and Mac
WWDC’23 (Apple Worldwide Developers Conference) was held last week. A lot of the news focused on the Vision Pro announcement during the keynote, but there’s much more to it. Like every year, WWDC week is packed with more than 200 technical sessions that dive deep inside the upcoming features across Apple operating systems and frameworks. This year we are particularly excited about changes in Core ML devoted to compression and optimization techniques. These changes make running [models](https://huggingface.co/apple) such as Stable Diffusion faster and with less memory use! As a taste, consider the following test I ran on my [iPhone 13 back in December](https://huggingface.co/blog/diffusers-coreml), compared with the current speed using 6-bit palettization:
<img style="border:none;" alt="Stable Diffusion on iPhone, back in December and now using 6-bit palettization" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/before-after-1600.jpg" />
<small>Stable Diffusion on iPhone, back in December and now with 6-bit palettization</small>
## Contents
* [New Core ML Optimizations](#new-core-ml-optimizations)
* [Using Quantized and Optimized Stable Diffusion Models](#using-quantized-and-optimized-stable-diffusion-models)
* [Converting and Optimizing Custom Models](#converting-and-optimizing-custom-models)
* [Using Less than 6 bits](#using-less-than-6-bits)
* [Conclusion](#conclusion)
## New Core ML Optimizations
Core ML is a mature framework that allows machine learning models to run efficiently on-device, taking advantage of all the compute hardware in Apple devices: the CPU, the GPU, and the Neural Engine specialized in ML tasks. On-device execution is going through a period of extraordinary interest triggered by the popularity of models such as Stable Diffusion and Large Language Models with chat interfaces. Many people want to run these models on their hardware for a variety of reasons, including convenience, privacy, and API cost savings. Naturally, many developers are exploring ways to run these models efficiently on-device and creating new apps and use cases. Core ML improvements that contribute to achieving that goal are big news for the community!
The Core ML optimization changes encompass two different (but complementary) software packages:
* The Core ML framework itself. This is the engine that runs ML models on Apple hardware and is part of the operating system. Models have to be exported in a special format supported by the framework, and this format is also referred to as “Core ML”.
* The `coremltools` conversion package. This is an [open-source Python module](https://github.com/apple/coremltools) whose mission is to convert PyTorch or Tensorflow models to the Core ML format.
`coremltools` now includes a new submodule called `coremltools.optimize` with all the compression and optimization tools. For full details on this package, please take a look at [this WWDC session](https://developer.apple.com/wwdc23/10047). In the case of Stable Diffusion, we’ll be using _6-bit palettization_, a type of quantization that compresses model weights from a 16-bit floating-point representation to just 6 bits per parameter. The name “palettization” refers to a technique similar to the one used in computer graphics to work with a limited set of colors: the color table (or “palette”) contains a fixed number of colors, and the colors in the image are replaced with the indexes of the closest colors available in the palette. This immediately provides the benefit of drastically reducing storage size, and thus reducing download time and on-device disk use.
<img style="border:none;" alt="Illustration of 2-bit palettization. Image credit: Apple WWDC’23 Session 'Use Core ML Tools for machine learning model compression'" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/palettization_illustration.png" />
<small>Illustration of 2-bit palettization. Image credit: Apple WWDC’23 Session <i><a href="https://developer.apple.com/wwdc23/10047">Use Core ML Tools for machine learning model compression</a></i>.</small>
The compressed 6-bit _weights_ cannot be used for computation, because they are just indices into a table and no longer represent the magnitude of the original weights. Therefore, Core ML needs to uncompress the palletized weights before use. In previous versions of Core ML, uncompression took place when the model was first loaded from disk, so the amount of memory used was equal to the uncompressed model size. With the new improvements, weights are kept as 6-bit numbers and converted on the fly as inference progresses from layer to layer. This might seem slow – an inference run requires a lot of uncompressing operations –, but it’s typically more efficient than preparing all the weights in 16-bit mode! The reason is that memory transfers are in the critical path of execution, and transferring less memory is faster than transferring uncompressed data.
## Using Quantized and Optimized Stable Diffusion Models
[Last December](https://huggingface.co/blog/diffusers-coreml), Apple introduced [`ml-stable-diffusion`](https://github.com/apple/ml-stable-diffusion), an open-source repo based on [diffusers](https://github.com/huggingface/diffusers) to easily convert Stable Diffusion models to Core ML. It also applies [optimizations to the transformers attention layers](https://machinelearning.apple.com/research/neural-engine-transformers) that make inference faster on the Neural Engine (on devices where it’s available). `ml-stable-diffusion` has just been updated after WWDC with the following:
* Quantization is supported using `--quantize-nbits` during conversion. You can quantize to 8, 6, 4, or even 2 bits! For best results, we recommend using 6-bit quantization, as the precision loss is small while achieving fast inference and significant memory savings. If you want to go lower than that, please check [this section](#using-less-than-6-bits) for advanced techniques.
* Additional optimizations of the attention layers that achieve even better performance on the Neural Engine! The trick is to split the query sequences into chunks of 512 to avoid the creation of large intermediate tensors. This method is called `SPLIT_EINSUM_V2` in the code and can improve performance between 10% to 30%.
In order to make it easy for everyone to take advantage of these improvements, we have converted the four official Stable Diffusion models and pushed them to the [Hub](https://huggingface.co/apple). These are all the variants:
| Model | Uncompressed | Palettized |
|---------------------------|-------------------|---------------------------|
| Stable Diffusion 1.4 | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-v1-4) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-1-4-palettized) |
| Stable Diffusion 1.5 | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-v1-5) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-v1-5-palettized) |
| Stable Diffusion 2 base | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-2-base) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-2-base-palettized) |
| Stable Diffusion 2.1 base | [Core ML, `float16`](https://huggingface.co/apple/coreml-stable-diffusion-2-1-base) | [Core ML, 6-bit palettized](https://huggingface.co/apple/coreml-stable-diffusion-2-1-base-palettized) |
<br>
<div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;">
In order to use 6-bit models, you need the development versions of iOS/iPadOS 17 or macOS 14 (Sonoma) because those are the ones that contain the latest Core ML framework. You can download them from the [Apple developer site](https://developer.apple.com) if you are a registered developer, or you can sign up for the public beta that will be released in a few weeks.
</div>
<br>
Note that each variant is available in Core ML format and also as a `zip` archive. Zip files are ideal for native apps, such as our [open-source demo app](https://github.com/huggingface/swift-coreml-diffusers) and other [third party tools](https://github.com/godly-devotion/MochiDiffusion). If you just want to run the models on your own hardware, the easiest way is to use our demo app and select the quantized model you want to test. You need to compile the app using Xcode, but an update will be available for download in the App Store soon. For more details, check [our previous post](https://huggingface.co/blog/fast-mac-diffusers).
<img style="border:none;" alt="Running 6-bit stable-diffusion-2-1-base model in demo app" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/fast-diffusers-coreml/diffusers_mac_screenshot.png" />
<small>Running 6-bit stable-diffusion-2-1-base model in demo app</small>
If you want to download a particular Core ML package to integrate it in your own Xcode project, you can clone the repos or just download the version of interest using code like the following.
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-2-1-base-palettized"
variant = "original/packages"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
## Converting and Optimizing Custom Models
If you want to use a personalized Stable Diffusion model (for example, if you have fine-tuned or dreamboothed your own models), you can use Apple’s ml-stable-diffusion repo to do the conversion yourself. This is a brief summary of how you’d go about it, but we recommend you read [the documentation details](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).
<br>
<div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;">
If you want to apply quantization, you need the latest versions of `coremltools`, `apple/ml-stable-diffusion` and Xcode in order to do the conversion.
* Download `coremltools` 7.0 beta from [the releases page in GitHub](https://github.com/apple/coremltools/releases).
* Download Xcode 15.0 beta from [Apple developer site](https://developer.apple.com/).
* Download `apple/ml-stable-diffusion` [from the repo](https://github.com/apple/ml-stable-diffusion) and follow the installation instructions.
</div>
<br>
1. Select the model you want to convert. You can train your own or choose one from the [Hugging Face Diffusers Models Gallery](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery). For example, let’s convert [`prompthero/openjourney-v4`](https://huggingface.co/prompthero/openjourney-v4).
2. Install `apple/ml-stable-diffusion` and run a first conversion using the `ORIGINAL` attention implementation like this:
```bash
python -m python_coreml_stable_diffusion.torch2coreml \
--model-version prompthero/openjourney-v4 \
--convert-unet \
--convert-text-encoder \
--convert-vae-decoder \
--convert-vae-encoder \
--convert-safety-checker \
--quantize-nbits 6 \
--attention-implementation ORIGINAL \
--compute-unit CPU_AND_GPU \
--bundle-resources-for-swift-cli \
--check-output-correctness \
-o models/original/openjourney-6-bit
```
<br>
<div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;">
* Use `--convert-vae-encoder` if you want to use image-to-image tasks.
* Do _not_ use `--chunk-unet` with `--quantized-nbits 6` (or less), as the quantized model is small enough to work fine on both iOS and macOS.
</div>
<br>
3. Repeat the conversion for the `SPLIT_EINSUM_V2` attention implementation:
```bash
python -m python_coreml_stable_diffusion.torch2coreml \
--model-version prompthero/openjourney-v4 \
--convert-unet \
--convert-text-encoder \
--convert-vae-decoder \
--convert-safety-checker \
--quantize-nbits 6 \
--attention-implementation SPLIT_EINSUM_V2 \
--compute-unit ALL \
--bundle-resources-for-swift-cli \
--check-output-correctness \
-o models/split_einsum_v2/openjourney-6-bit
```
4. Test the converted models on the desired hardware. As a rule of thumb, the `ORIGINAL` version usually works better on macOS, whereas `SPLIT_EINSUM_V2` is usually faster on iOS. For more details and additional data points, see [these tests contributed by the community](https://github.com/huggingface/swift-coreml-diffusers/issues/31) on the previous version of Stable Diffusion for Core ML.
5. To integrate the desired model in your own app:
* If you are going to distribute the model inside the app, use the `.mlpackage` files. Note that this will increase the size of your app binary.
* Otherwise, you can use the compiled `Resources` to download them dynamically when your app starts.
<br>
<div style="background-color: #f0fcf0; padding: 8px 32px 1px; outline: 1px solid; border-radius: 10px;">
If you don’t use the `--quantize-nbits` option, weights will be represented as 16-bit floats. This is compatible with the current version of Core ML so you won’t need to install the betas of iOS, macOS or Xcode.
</div>
<br>
## Using Less than 6 bits
6-bit quantization is a sweet spot between model quality, model size and convenience – you just need to provide a conversion option in order to be able to quantize any pre-trained model. This is an example of _post-training compression_.
The beta version of `coremltools` released last week also includes _training-time_ compression methods. The idea here is that you can fine-tune a pre-trained Stable Diffusion model and perform the weights compression while fine-tuning is taking place. This allows you to use 4- or even 2-bit compression while minimizing the loss in quality. The reason this works is because weight clustering is performed using a differentiable algorithm, and therefore we can apply the usual training optimizers to find the quantization table while minimizing model loss.
We have plans to evaluate this method soon, and can’t wait to see how 4-bit optimized models work and how fast they run. If you beat us to it, please drop us a note and we’ll be happy to check 🙂
## Conclusion
Quantization methods can be used to reduce the size of Stable Diffusion models, make them run faster on-device and consume less resources. The latest versions of Core ML and `coremltools` support techniques like 6-bit palettization that are easy to apply and that have a minimal impact on quality. We have added 6-bit palettized [models to the Hub](https://huggingface.co/apple), which are small enough to run on both iOS and macOS. We've also shown how you can convert fine-tuned models yourself, and can't wait to see what you do with these tools and techniques!
| 2 |
0 | hf_public_repos | hf_public_repos/blog/inference-endpoints-embeddings.md | ---
title: Deploy Embedding Models with Hugging Face Inference Endpoints
thumbnail: /blog/assets/168_inference_endpoints_embeddings/thumbnail.jpg
authors:
- user: philschmid
---
# Deploy Embedding Models with Hugging Face Inference Endpoints
The rise of Generative AI and LLMs like ChatGPT has increased the interest and importance of embedding models for a variety of tasks especially for retrievel augemented generation, like search or chat with your data. Embeddings are helpful since they represent sentences, images, words, etc. as numeric vector representations, which allows us to map semantically related items and retrieve helpful information. This helps us to provide relevant context for our prompt to improve the quality and specificity of generation.
Compared to LLMs are Embedding Models smaller in size and faster for inference. That is very important since you need to recreate your embeddings after you changed your model or improved your model fine-tuning. Additionally, is it important that the whole retrieval augmentation process is as fast as possible to provide a good user experience.
In this blog post, we will show you how to deploy open-source Embedding Models to [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) using [Text Embedding Inference](https://github.com/huggingface/text-embeddings-inference), our managed SaaS solution that makes it easy to deploy models. Additionally, we will teach you how to run large scale batch requests.
1. [What is Hugging Face Inference Endpoints](#1-what-is-hugging-face-inference-endpoints)
2. [What is Text Embedding Inference](#2-what-is-text-embeddings-inference)
3. [Deploy Embedding Model as Inference Endpoint](#3-deploy-embedding-model-as-inference-endpoint)
4. [Send request to endpoint and create embeddings](#4-send-request-to-endpoint-and-create-embeddings)
Before we start, let's refresh our knowledge about Inference Endpoints.
## 1. What is Hugging Face Inference Endpoints?
[Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists to create Generative AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security.
Here are some of the most important features:
1. [Easy Deployment](https://huggingface.co/docs/inference-endpoints/index): Deploy models as production-ready APIs with just a few clicks, eliminating the need to handle infrastructure or MLOps.
2. [Cost Efficiency](https://huggingface.co/docs/inference-endpoints/autoscaling): Benefit from automatic scale to zero capability, reducing costs by scaling down the infrastructure when the endpoint is not in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness.
3. [Enterprise Security](https://huggingface.co/docs/inference-endpoints/security): Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance.
4. [LLM Optimization](https://huggingface.co/text-generation-inference): Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference
5. [Comprehensive Task Support](https://huggingface.co/docs/inference-endpoints/supported_tasks): Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and easy customization to enable advanced tasks like speaker diarization or any Machine Learning task and library.
You can get started with Inference Endpoints at: https://ui.endpoints.huggingface.co/
## 2. What is Text Embeddings Inference?
[Text Embeddings Inference (TEI)](https://github.com/huggingface/text-embeddings-inference#text-embeddings-inference) is a purpose built solution for deploying and serving open source text embeddings models. TEI is build for high-performance extraction supporting the most popular models. TEI supports all top 10 models of the [Massive Text Embedding Benchmark (MTEB) Leaderboard](https://huggingface.co/spaces/mteb/leaderboard), including FlagEmbedding, Ember, GTE and E5. TEI currently implements the following performance optimizing features:
- No model graph compilation step
- Small docker images and fast boot times. Get ready for true serverless!
- Token based dynamic batching
- Optimized transformers code for inference using [Flash Attention](https://github.com/HazyResearch/flash-attention), [Candle](https://github.com/huggingface/candle) and [cuBLASLt](https://docs.nvidia.com/cuda/cublas/#using-the-cublaslt-api)
- [Safetensors](https://github.com/huggingface/safetensors) weight loading
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
Those feature enabled industry-leading performance on throughput and cost. In a benchmark for [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) on an Nvidia A10G Inference Endpoint with a sequence length of 512 tokens and a batch size of 32, we achieved a throughput of 450+ req/sec resulting into a cost of 0.00156$ / 1M tokens or 0.00000156$ / 1k tokens. That is 64x cheaper than OpenAI Embeddings ($0.0001 / 1K tokens).
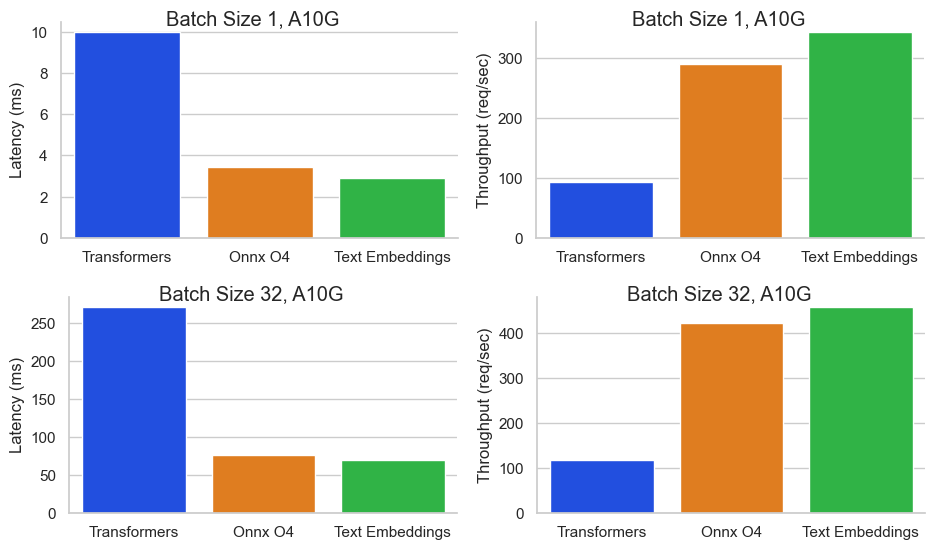
## 3. Deploy Embedding Model as Inference Endpoint
To get started, you need to be logged in with a User or Organization account with a payment method on file (you can add one [here](https://huggingface.co/settings/billing)), then access Inference Endpoints at [https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints)
Then, click on “New endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case `BAAI/bge-base-en-v1.5`.
Inference Endpoints suggest an instance type based on the model size, which should be big enough to run the model. Here `Intel Ice Lake 2 vCPU`. To get the performance for the benchmark we ran you, change the instance to `1x Nvidia A10G`.
*Note: If the instance type cannot be selected, you need to [contact us](mailto:[email protected]?subject=Quota%20increase%20HF%20Endpoints&body=Hello,%0D%0A%0D%0AI%20would%20like%20to%20request%20access/quota%20increase%20for%20%7BINSTANCE%20TYPE%7D%20for%20the%20following%20account%20%7BHF%20ACCOUNT%7D.) and request an instance quota.*

You can then deploy your model with a click on “Create Endpoint”. After 1-3 minutes, the Endpoint should be online and available to serve requests.
## 4. Send request to endpoint and create embeddings
The Endpoint overview provides access to the Inference Widget, which can be used to manually send requests. This allows you to quickly test your Endpoint with different inputs and share it with team members.
*Note: TEI is currently is not automatically truncating the input. You can enable this by setting `truncate: true` in your request.*
In addition to the widget the overview provides an code snippet for cURL, Python and Javascript, which you can use to send request to the model. The code snippet shows you how to send a single request, but TEI also supports batch requests, which allows you to send multiple document at the same to increase utilization of your endpoint. Below is an example on how to send a batch request with truncation set to true.
```python
import requests
API_URL = "https://l2skjfwp9punv393.us-east-1.aws.endpoints.huggingface.cloud"
headers = {
"Authorization": "Bearer YOUR TOKEN",
"Content-Type": "application/json"
}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": ["sentence 1", "sentence 2", "sentence 3"],
"truncate": True
})
# output [[0.334, ...], [-0.234, ...]]
```
## Conclusion
TEI on Hugging Face Inference Endpoints enables blazing fast and ultra cost-efficient deployment of state-of-the-art embeddings models. With industry-leading throughput of 450+ requests per second and costs as low as $0.00000156 / 1k tokens, Inference Endpoints delivers 64x cost savings compared to OpenAI Embeddings.
For developers and companies leveraging text embeddings to enable semantic search, chatbots, recommendations, and more, Hugging Face Inference Endpoints eliminates infrastructure overhead and delivers high throughput at lowest cost streamlining the process from research to production.
---
Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/). | 3 |
0 | hf_public_repos | hf_public_repos/blog/inferentia-inference-endpoints.md | ---
title: "Deploy models on AWS Inferentia2 from Hugging Face"
thumbnail: /blog/assets/inferentia-inference-endpoints/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
---
# Deploy models on AWS Inferentia2 from Hugging Face

[AWS Inferentia2](https://aws.amazon.com/machine-learning/inferentia/) is the latest AWS machine learning chip available through the [Amazon EC2 Inf2 instances](https://aws.amazon.com/ec2/instance-types/inf2/) on Amazon Web Services. Designed from the ground up for AI workloads, Inf2 instances offer great performance and cost/performance for production workloads.
We have been working for over a year with the product and engineering teams at AWS to make the performance and cost-efficiency of AWS Trainium and Inferentia chips available to Hugging Face users. Our open-source library <code>[optimum-neuron](https://huggingface.co/docs/optimum-neuron/index)</code> makes it easy to train and deploy Hugging Face models on these accelerators. You can read more about our work [accelerating transformers](https://huggingface.co/blog/accelerate-transformers-with-inferentia2), [large language models](https://huggingface.co/blog/inferentia-llama2) and [text-generation-inference](https://huggingface.co/blog/text-generation-inference-on-inferentia2) (TGI).
Today, we are making the power of Inferentia2 directly and widely available to Hugging Face Hub users.
## Enabling over 100,000 models on AWS Inferentia2 with Amazon SageMaker
A few months ago, we introduced a new way to deploy Large Language Models (LLMs) on SageMaker, with a new Inferentia/Trainium option for supported models, like Meta [Llama 3](https://huggingface.co/meta-llama/Meta-Llama-3-8B?sagemaker_deploy=true). You can deploy a Llama3 model on Inferentia2 instances on SageMaker to serve inference at scale and benefit from SageMaker’s complete set of fully managed features for building and fine-tuning models, MLOps, and governance.

Today, we are expanding support for this deployment experience to over 100,000 public models available on Hugging Face, including 14 new model architectures (`albert`,`bert`,`camembert`,`convbert`,`deberta`,`deberta-v2`,`distilbert`,`electra`,`roberta`,`mobilebert`,`mpnet`,`vit`,`xlm`,`xlm-roberta`), and 6 new machine learning tasks (`text-classification`,`text-generation`,`token-classification`,`fill-mask`,`question-answering`,`feature-extraction`).
Following these simple code snippets, AWS customers will be able to easily deploy the models on Inferentia2 instances in Amazon SageMaker.
## Hugging Face Inference Endpoints introduces support for AWS Inferentia2
The easiest option to deploy models from the Hub is [Hugging Face Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated). Today, we are happy to introduce new Inferentia 2 instances for Hugging Face Inference Endpoints. So now, when you find a model in Hugging Face you are interested in, you can deploy it in just a few clicks on Inferentia2. All you need to do is select the model you want to deploy, select the new Inf2 instance option under the Amazon Web Services instance configuration, and you’re off to the races.
For supported models like Llama 3, you can select 2 flavors:
* Inf2-small, with 2 cores and 32 GB memory ($0.75/hour) perfect for Llama 3 8B
* Inf2-xlarge, with 24 cores and 384 GB memory ($12/hour) perfect for Llama 3 70B
Hugging Face Inference Endpoints are billed by the second of capacity used, with cost scaling up with replica autoscaling, and down to zero with scale to zero - both automated and enabled with easy to use settings.

Inference Endpoints uses [Text Generation Inference for Neuron](https://huggingface.co/blog/text-generation-inference-on-inferentia2) (TGI) to run Llama 3 on AWS Inferentia. TGI is a purpose-built solution for deploying and serving Large Language Models (LLMs) for production workloads at scale, supporting continuous batching, streaming and much more. In addition, LLMs deployed with Text Generation Inference are compatible with the OpenAI SDK Messages API, so if you already have Gen AI applications integrated with LLMs, you don’t need to change the code of your application, and just have to point to your new endpoint deployed with Hugging Face Inference Endpoints.
After you deploy your endpoint on Inferentia2, you can send requests using the Widget provided in the UI or the OpenAI SDK.
## Whats Next
We are working hard to expand the scope of models enabled for deployment on AWS Inferentia2 with Hugging Face Inference Endpoints. Next, we want to add support for Diffusion and Embedding models, so you can generate images and build semantic search and recommendation systems leveraging the acceleration of AWS Inferentia2 and the ease of use of Hugging Face Inference Endpoints.
In addition, we continue our work to improve performance for Text Generation Inference (TGI) on Neuronx, ensuring faster and more efficient LLM deployments on AWS Inferentia 2 in our open source libraries. Stay tuned for these updates as we continue to enhance our capabilities and optimize your deployment experience!
| 4 |
0 | hf_public_repos | hf_public_repos/blog/classification-use-cases.md | ---
title: "How Hugging Face Accelerated Development of Witty Works Writing Assistant"
thumbnail: /blog/assets/78_ml_director_insights/witty-works.png
authors:
- user: juliensimon
- user: Violette
- user: florentgbelidji
- user: oknerazan
guest: true
- user: lsmith
guest: true
---
# How Hugging Face Accelerated Development of Witty Works Writing Assistant
## The Success Story of Witty Works with the Hugging Face Expert Acceleration Program.
_If you're interested in building ML solutions faster, visit the [Expert Acceleration Program](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case) landing page and contact us [here](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case#form)!_
### Business Context
As IT continues to evolve and reshape our world, creating a more diverse and inclusive environment within the industry is imperative. [Witty Works](https://www.witty.works/) was built in 2018 to address this challenge. Starting as a consulting company advising organizations on becoming more diverse, Witty Works first helped them write job ads using inclusive language. To scale this effort, in 2019, they built a web app to assist users in writing inclusive job ads in English, French and German. They enlarged the scope rapidly with a writing assistant working as a browser extension that automatically fixes and explains potential bias in emails, Linkedin posts, job ads, etc. The aim was to offer a solution for internal and external communication that fosters a cultural change by providing micro-learning bites that explain the underlying bias of highlighted words and phrases.
<p align="center">
<img src="/blog/assets/78_ml_director_insights/wittyworks.png"><br>
<em>Example of suggestions by the writing assistant</em>
</p>
### First experiments
Witty Works first chose a basic machine learning approach to build their assistant from scratch. Using transfer learning with pre-trained spaCy models, the assistant was able to:
- Analyze text and transform words into lemmas,
- Perform a linguistic analysis,
- Extract the linguistic features from the text (plural and singular forms, gender), part-of-speech tags (pronouns, verbs, nouns, adjectives, etc.), word dependencies labels, named entity recognition, etc.
By detecting and filtering words according to a specific knowledge base using linguistic features, the assistant could highlight non-inclusive words and suggest alternatives in real-time.
### Challenge
The vocabulary had around 2300 non-inclusive words and idioms in German and English correspondingly. And the above described basic approach worked well for 85% of the vocabulary but failed for context-dependent words. Therefore the task was to build a context-dependent classifier of non-inclusive words. Such a challenge (understanding the context rather than recognizing linguistic features) led to using Hugging Face transformers.
```diff
Example of context dependent non-inclusive words:
Fossil fuels are not renewable resources. Vs He is an old fossil
You will have a flexible schedule. Vs You should keep your schedule flexible.
```
### Solutions provided by the [Hugging Face Experts](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case)
- #### **Get guidance for deciding on the right ML approach.**
The initial chosen approach was vanilla transformers (used to extract token embeddings of specific non-inclusive words). The Hugging Face Expert recommended switching from contextualized word embeddings to contextualized sentence embeddings. In this approach, the representation of each word in a sentence depends on its surrounding context.
Hugging Face Experts suggested the use of a [Sentence Transformers](https://www.sbert.net/) architecture. This architecture generates embeddings for sentences as a whole. The distance between semantically similar sentences is minimized and maximized for distant sentences.
In this approach, Sentence Transformers use Siamese networks and triplet network structures to modify the pre-trained transformer models to generate “semantically meaningful” sentence embeddings.
The resulting sentence embedding serves as input for a classical classifier based on KNN or logistic regression to build a context-dependent classifier of non-inclusive words.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“We generate contextualized embedding vectors for every word depending on its
sentence (BERT embedding). Then, we keep only the embedding for the “problem”
word’s token, and calculate the smallest angle (cosine similarity)”
```
To fine-tune a vanilla transformers-based classifier, such as a simple BERT model, Witty Works would have needed a substantial amount of annotated data. Hundreds of samples for each category of flagged words would have been necessary. However, such an annotation process would have been costly and time-consuming, which Witty Works couldn’t afford.
- #### **Get guidance on selecting the right ML library.**
The Hugging Face Expert suggested using the Sentence Transformers Fine-tuning library (aka [SetFit](https://github.com/huggingface/setfit)), an efficient framework for few-shot fine-tuning of Sentence Transformers models. Combining contrastive learning and semantic sentence similarity, SetFit achieves high accuracy on text classification tasks with very little labeled data.
```diff
Julien Simon, Chief Evangelist at Hugging Face:
“SetFit for text classification tasks is a great tool to add to the ML toolbox”
```
The Witty Works team found the performance was adequate with as little as 15-20 labeled sentences per specific word.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“At the end of the day, we saved time and money by not creating this large data set”
```
Reducing the number of sentences was essential to ensure that model training remained fast and that running the model was efficient. However, it was also necessary for another reason: Witty explicitly takes a highly supervised/rule-based approach to [actively manage bias](https://www.witty.works/en/blog/is-chatgpt-able-to-generate-inclusive-language). Reducing the number of sentences is very important to reduce the effort in manually reviewing the training sentences.
- #### **Get guidance on selecting the right ML models.**
One major challenge for Witty Works was deploying a model with low latency. No one expects to wait 3 minutes to get suggestions to improve one’s text! Both Hugging Face and Witty Works experimented with a few sentence transformers models and settled for [mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) combined with logistic regression and KNN.
After a first test on Google Colab, the Hugging Face experts guided Witty Works on deploying the model on Azure. No optimization was necessary as the model was fast enough.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“Working with Hugging Face saved us a lot of time and money.
One can feel lost when implementing complex text classification use cases.
As it is one of the most popular tasks, there are a lot of models on the Hub.
The Hugging Face experts guided me through the massive amount of transformer-based
models to choose the best possible approach.
Plus, I felt very well supported during the model deployment”
```
### **Results and conclusion**
The number of training sentences dropped from 100-200 per word to 15-20 per word. Witty Works achieved an accuracy of 0.92 and successfully deployed a custom model on Azure with minimal DevOps effort!
```diff
Lukas Kahwe Smith CTO & Co-founder of Witty Works:
“Working on an IT project by oneself can be challenging and even if
the EAP is a significant investment for a startup, it is the cheaper
and most meaningful way to get a sparring partner“
```
With the guidance of the Hugging Face experts, Witty Works saved time and money by implementing a new ML workflow in the Hugging Face way.
```diff
Julien Simon, Chief Evangelist at Hugging Face:
“The Hugging way to build workflows:
find open-source pre-trained models,
evaluate them right away,
see what works, see what does not.
By iterating, you start learning things immediately”
```
---
🤗 If you or your team are interested in accelerating your ML roadmap with Hugging Face Experts, please visit [hf.co/support](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case) to learn more.
| 5 |
0 | hf_public_repos | hf_public_repos/blog/cv_state.md | ---
title: The State of Computer Vision at Hugging Face 🤗
thumbnail: /blog/assets/cv_state/thumbnail.png
authors:
- user: sayakpaul
---
# The State of Computer Vision at Hugging Face 🤗
At Hugging Face, we pride ourselves on democratizing the field of artificial intelligence together with the community. As a part of that mission, we began focusing our efforts on computer vision over the last year. What started as a [PR for having Vision Transformers (ViT) in 🤗 Transformers](https://github.com/huggingface/transformers/pull/10950) has now grown into something much bigger – 8 core vision tasks, over 3000 models, and over 100 datasets on the Hugging Face Hub.
A lot of exciting things have happened since ViTs joined the Hub. In this blog post, we’ll summarize what went down and what’s coming to support the continuous progress of Computer Vision from the 🤗 ecosystem.
Here is a list of things we’ll cover:
- [Supported vision tasks and Pipelines](#support-for-pipelines)
- [Training your own vision models](#training-your-own-models)
- [Integration with `timm`](#🤗-🤝-timm)
- [Diffusers](#🧨-diffusers)
- [Support for third-party libraries](#support-for-third-party-libraries)
- [Deployment](#deployment)
- and much more!
## Enabling the community: One task at a time 👁
The Hugging Face Hub is home to over 100,000 public models for different tasks such as next-word prediction, mask filling, token classification, sequence classification, and so on. As of today, we support [8 core vision tasks](https://huggingface.co/tasks) providing many model checkpoints:
- Image classification
- Image segmentation
- (Zero-shot) object detection
- Video classification
- Depth estimation
- Image-to-image synthesis
- Unconditional image generation
- Zero-shot image classification
Each of these tasks comes with at least 10 model checkpoints on the Hub for you to explore. Furthermore, we support [tasks](https://huggingface.co/tasks) that lie at the intersection of vision and language such as:
- Image-to-text (image captioning, OCR)
- Text-to-image
- Document question-answering
- Visual question-answering
These tasks entail not only state-of-the-art Transformer-based architectures such as [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin](https://huggingface.co/docs/transformers/model_doc/swin), [DETR](https://huggingface.co/docs/transformers/model_doc/detr) but also *pure convolutional* architectures like [ConvNeXt](https://huggingface.co/docs/transformers/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/model_doc/resnet), [RegNet](https://huggingface.co/docs/transformers/model_doc/regnet), and more! Architectures like ResNets are still very much relevant for a myriad of industrial use cases and hence the support of these non-Transformer architectures in 🤗 Transformers.
It’s also important to note that the models on the Hub are not just from the Transformers library but also from other third-party libraries. For example, even though we support tasks like unconditional image generation on the Hub, we don’t have any models supporting that task in Transformers yet (such as [this](https://huggingface.co/ceyda/butterfly_cropped_uniq1K_512)). Supporting all ML tasks, whether they are solved with Transformers or a third-party library is a part of our mission to foster a collaborative open-source Machine Learning ecosystem.
## Support for Pipelines
We developed [Pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines) to equip practitioners with the tools they need to easily incorporate machine learning into their toolbox. They provide an easy way to perform inference on a given input with respect to a task. We have support for [seven vision tasks](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#computer-vision) in Pipelines. Here is an example of using Pipelines for depth estimation:
```py
from transformers import pipeline
depth_estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
output = depth_estimator("http://images.cocodataset.org/val2017/000000039769.jpg")
# This is a tensor with the values being the depth expressed
# in meters for each pixel
output["depth"]
```
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/depth_estimation_output.png"/>
</div>
The interface remains the same even for tasks like visual question-answering:
```py
from transformers import pipeline
oracle = pipeline(model="dandelin/vilt-b32-finetuned-vqa")
image_url = "https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg"
oracle(question="What's the animal doing?", image=image_url, top_k=1)
# [{'score': 0.778620, 'answer': 'laying down'}]
```
## Training your own models
While being able to use a model for off-the-shelf inference is a great way to get started, fine-tuning is where the community gets the most benefits. This is especially true when your datasets are custom, and you’re not getting good performance out of the pre-trained models.
Transformers provides a [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) for everything related to training. Currently, `Trainer` seamlessly supports the following tasks: image classification, image segmentation, video classification, object detection, and depth estimation. Fine-tuning models for other vision tasks are also supported, just not by `Trainer`.
As long as the loss computation is included in a model from Transformers computes loss for a given task, it should be eligible for fine-tuning for the task. If you find issues, please [report](https://github.com/huggingface/transformers/issues) them on GitHub.
**Where do I find the code?**
- [Model documentation](https://huggingface.co/docs/transformers/index#supported-models)
- [Hugging Face notebooks](https://github.com/huggingface/notebooks)
- [Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples)
- [Task pages](https://huggingface.co/tasks)
[Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples) include different [self-supervised pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) like [MAE](https://arxiv.org/abs/2111.06377), and [contrastive image-text pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) like [CLIP](https://arxiv.org/abs/2103.00020). These scripts are valuable resources for the research community as well as for practitioners willing to run pre-training from scratch on custom data corpora.
Some tasks are not inherently meant for fine-tuning, though. Examples include zero-shot image classification (such as [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip)), zero-shot object detection (such as [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit)), and zero-shot segmentation (such as [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)). We’ll revisit these models in this post.
## Integrations with Datasets
[Datasets](https://huggingface.co/docs/datasets) provides easy access to thousands of datasets of different modalities. As mentioned earlier, the Hub has over 100 datasets for computer vision. Some examples worth noting here: [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k), [Scene Parsing](https://huggingface.co/datasets/scene_parse_150), [NYU Depth V2](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2), [COYO-700M](https://huggingface.co/datasets/kakaobrain/coyo-700m), and [LAION-400M](https://huggingface.co/datasets/laion/laion400m). With these datasets being on the Hub, one can easily load them with just two lines of code:
```py
from datasets import load_dataset
dataset = load_dataset("scene_parse_150")
```
Besides these datasets, we provide integration support with augmentation libraries like [albumentations](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) and [Kornia](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb). The community can take advantage of the flexibility and performance of Datasets and powerful augmentation transformations provided by these libraries. In addition to these, we also provide [dedicated data-loading guides](https://huggingface.co/docs/datasets/image_load) for core vision tasks: image classification, image segmentation, object detection, and depth estimation.
## 🤗 🤝 timm
`timm`, also known as [pytorch-image-models](https://github.com/rwightman/pytorch-image-models), is an open-source collection of state-of-the-art PyTorch image models, pre-trained weights, and utility scripts for training, inference, and validation.
We have over 200 models from `timm` on the Hub and more are on the way. Check out the [documentation](https://huggingface.co/docs/timm/index) to know more about this integration.
## 🧨 Diffusers
[Diffusers](https://huggingface.co/docs/diffusers) provides pre-trained vision and audio diffusion models, and serves as a modular toolbox for inference and training. With this library, you can generate plausible images from natural language inputs amongst other creative use cases. Here is an example:
```py
from diffusers import DiffusionPipeline
generator = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
generator.to(“cuda”)
image = generator("An image of a squirrel in Picasso style").images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/sd_output.png"/>
</div>
This type of technology can empower a new generation of creative applications and also aid artists coming from different backgrounds. To know more about Diffusers and the different use cases, check out the [official documentation](https://huggingface.co/docs/diffusers).
The literature on Diffusion-based models is developing at a rapid pace which is why we partnered with [Jonathan Whitaker](https://github.com/johnowhitaker) to develop a course on it. The course is free, and you can check it out [here](https://github.com/huggingface/diffusion-models-class).
## Support for third-party libraries
Central to the Hugging Face ecosystem is the [Hugging Face Hub](https://huggingface.co/docs/hub), which lets people collaborate effectively on Machine Learning. As mentioned earlier, we not only support models from 🤗 Transformers on the Hub but also models from other third-party libraries. To this end, we provide [several utilities](https://huggingface.co/docs/hub/models-adding-libraries) so that you can integrate your own library with the Hub. One of the primary advantages of doing this is that it becomes very easy to share artifacts (such as models and datasets) with the community, thereby making it easier for your users to try out your models.
When you have your models hosted on the Hub, you can also [add custom inference widgets](https://github.com/huggingface/api-inference-community) for them. Inference widgets allow users to quickly check out the models. This helps with improving user engagement.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/task_widget_generation.png"/>
</div>
## Spaces for computer vision demos
With [Spaces](https://huggingface.co/docs/hub/spaces-overview), one can easily demonstrate their Machine Learning models. Spaces support direct integrations with [Gradio](https://gradio.app/), [Streamlit](https://streamlit.io/), and [Docker](https://www.docker.com/) empowering practitioners to have a great amount of flexibility while showcasing their models. You can bring in your own Machine Learning framework to build a demo with Spaces.
The Gradio library provides several components for building Computer Vision applications on Spaces such as [Video](https://gradio.app/docs/#video), [Gallery](https://gradio.app/docs/#gallery), and [Model3D](https://gradio.app/docs/#model3d). The community has been hard at work building some amazing Computer Vision applications that are powered by Spaces:
- [Generate 3D voxels from a predicted depth map of an input image](https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-voxels)
- [Open vocabulary semantic segmentation](https://huggingface.co/spaces/facebook/ov-seg)
- [Narrate videos by generating captions](https://huggingface.co/spaces/nateraw/lavila)
- [Classify videos from YouTube](https://huggingface.co/spaces/fcakyon/video-classification)
- [Zero-shot video classification](https://huggingface.co/spaces/fcakyon/zero-shot-video-classification)
- [Visual question-answering](https://huggingface.co/spaces/nielsr/vilt-vqa)
- [Use zero-shot image classification to find best captions for an image to generate similar images](https://huggingface.co/spaces/pharma/CLIP-Interrogator)
## 🤗 AutoTrain
[AutoTrain](https://huggingface.co/autotrain) provides a “no-code” solution to train state-of-the-art Machine Learning models for tasks like text classification, text summarization, named entity recognition, and more. For Computer Vision, we currently support [image classification](https://huggingface.co/blog/autotrain-image-classification), but one can expect more task coverage.
AutoTrain also enables [automatic model evaluation](https://huggingface.co/spaces/autoevaluate/model-evaluator). This application allows you to evaluate 🤗 Transformers [models](https://huggingface.co/models?library=transformers&sort=downloads) across a wide variety of [datasets](https://huggingface.co/datasets) on the Hub. The results of your evaluation will be displayed on the [public leaderboards](https://huggingface.co/spaces/autoevaluate/leaderboards). You can check [this blog post](https://huggingface.co/blog/eval-on-the-hub) for more details.
## The technical philosophy
In this section, we wanted to share our philosophy behind adding support for Computer Vision in 🤗 Transformers so that the community is aware of the design choices specific to this area.
Even though Transformers started with NLP, we support multiple modalities today, for example – vision, audio, vision-language, and Reinforcement Learning. For all of these modalities, all the corresponding models from Transformers enjoy some common benefits:
- Easy model download with a single line of code with `from_pretrained()`
- Easy model upload with `push_to_hub()`
- Support for loading huge checkpoints with efficient checkpoint sharding techniques
- Optimization support (with tools like [Optimum](https://huggingface.co/docs/optimum))
- Initialization from model configurations
- Support for both PyTorch and TensorFlow (non-exhaustive)
- and many more
Unlike tokenizers, we have preprocessors (such as [this](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTImageProcessor)) that take care of preparing data for the vision models. We have worked hard to ensure the user experience of using a vision model still feels easy and similar:
```py
from transformers import ViTImageProcessor, ViTForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
# Egyptian cat
```
Even for a difficult task like object detection, the user experience doesn’t change very much:
```py
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(
outputs, threshold=0.5, target_sizes=target_sizes
)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
Leads to:
```bash
Detected remote with confidence 0.833 at location [38.31, 72.1, 177.63, 118.45]
Detected cat with confidence 0.831 at location [9.2, 51.38, 321.13, 469.0]
Detected cat with confidence 0.804 at location [340.3, 16.85, 642.93, 370.95]
Detected remote with confidence 0.683 at location [334.48, 73.49, 366.37, 190.01]
Detected couch with confidence 0.535 at location [0.52, 1.19, 640.35, 475.1]
```
## Zero-shot models for vision
There’s been a surge of models that reformulate core vision tasks like segmentation and detection in interesting ways and introduce even more flexibility. We support a few of those from Transformers:
- [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip) that enables zero-shot image classification with prompts. Given an image, you’d prompt the CLIP model with a natural language query like “an image of {}”. The hope is to get the class label as the answer.
- [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit) that allows for language-conditioned zero-shot object detection and image-conditioned one-shot object detection. This means you can detect objects in an image even if the underlying model didn’t learn to detect them during training! You can refer to [this notebook](https://github.com/huggingface/notebooks/tree/main/examples#:~:text=zeroshot_object_detection_with_owlvit.ipynb) to know more.
- [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg) that supports language-conditioned zero-shot image segmentation and image-conditioned one-shot image segmentation. This means you can segment objects in an image even if the underlying model didn’t learn to segment them during training! You can refer to [this blog post](https://huggingface.co/blog/clipseg-zero-shot) that illustrates this idea. [GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit) also supports the task of zero-shot segmentation.
- [X-CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/xclip) that showcases zero-shot generalization to videos. Precisely, it supports zero-shot video classification. Check out [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Zero_shot_classify_a_YouTube_video_with_X_CLIP.ipynb) for more details.
The community can expect to see more zero-shot models for computer vision being supported from 🤗Transformers in the coming days.
## Deployment
As our CTO Julien says - “real artists ship” 🚀
We support the deployment of these vision models through [🤗Inference Endpoints](https://huggingface.co/inference-endpoints). Inference Endpoints integrates directly with compatible models pertaining to image classification, object detection, and image segmentation. For other tasks, you can use the [custom handlers](https://huggingface.co/docs/inference-endpoints/guides/custom_handler). Since we also provide many vision models in TensorFlow from 🤗Transformers for their deployment, we either recommend using the custom handlers or following these resources:
- [Deploying TensorFlow Vision Models in Hugging Face with TF Serving](https://huggingface.co/blog/tf-serving-vision)
- [Deploying 🤗 ViT on Kubernetes with TF Serving](https://huggingface.co/blog/deploy-tfserving-kubernetes)
- [Deploying 🤗 ViT on Vertex AI](https://huggingface.co/blog/deploy-vertex-ai)
- [Deploying ViT with TFX and Vertex AI](https://github.com/deep-diver/mlops-hf-tf-vision-models)
## Conclusion
In this post, we gave you a rundown of the things currently supported from the Hugging Face ecosystem to empower the next generation of Computer Vision applications. We hope you’ll enjoy using these offerings to build reliably and responsibly.
There is a lot to be done, though. Here are some things you can expect to see:
- Direct support of videos from 🤗 Datasets
- Supporting more industry-relevant tasks like image similarity
- Interoperability of the image datasets with TensorFlow
- A course on Computer Vision from the 🤗 community
As always, we welcome your patches, PRs, model checkpoints, datasets, and other contributions! 🤗
*Acknowlegements: Thanks to Omar Sanseviero, Nate Raw, Niels Rogge, Alara Dirik, Amy Roberts, Maria Khalusova, and Lysandre Debut for their rigorous and timely reviews on the blog draft. Thanks to Chunte Lee for creating the blog thumbnail.*
| 6 |
0 | hf_public_repos | hf_public_repos/blog/setfit-absa.md | ---
title: "SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit"
thumbnail: /blog/assets/setfit-absa/intel_hf_logo_2.png
authors:
- user: ronenlap
guest: true
- user: tomaarsen
- user: lewtun
- user: danielkorat
guest: true
- user: orenpereg
guest: true
- user: moshew
guest: true
---
# SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=500>
</p>
<p align="center">
<em>SetFitABSA is an efficient technique to detect the sentiment towards specific aspects within the text.</em>
</p>
Aspect-Based Sentiment Analysis (ABSA) is the task of detecting the sentiment towards specific aspects within the text. For example, in the sentence, "This phone has a great screen, but its battery is too small", the _aspect_ terms are "screen" and "battery" and the sentiment polarities towards them are Positive and Negative, respectively.
ABSA is widely used by organizations for extracting valuable insights by analyzing customer feedback towards aspects of products or services in various domains. However, labeling training data for ABSA is a tedious task because of the fine-grained nature (token level) of manually identifying aspects within the training samples.
Intel Labs and Hugging Face are excited to introduce SetFitABSA, a framework for few-shot training of domain-specific ABSA models; SetFitABSA is competitive and even outperforms generative models such as Llama2 and T5 in few-shot scenarios.
Compared to LLM based methods, SetFitABSA has two unique advantages:
<p>🗣 <strong>No prompts needed:</strong> few-shot in-context learning with LLMs requires handcrafted prompts which make the results brittle, sensitive to phrasing and dependent on user expertise. SetFitABSA dispenses with prompts altogether by generating rich embeddings directly from a small number of labeled text examples.</p>
<p>🏎 <strong>Fast to train:</strong> SetFitABSA requires only a handful of labeled training samples; in addition, it uses a simple training data format, eliminating the need for specialized tagging tools. This makes the data labeling process fast and easy.</p>
In this blog post, we'll explain how SetFitABSA works and how to train your very own models using the [SetFit library](https://github.com/huggingface/setfit). Let's dive in!
## How does it work?
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=700>
</p>
<p align="center">
<em>SetFitABSA's three-stage training process</em>
</p>
SetFitABSA is comprised of three steps. The first step extracts aspect candidates from the text, the second one yields the aspects by classifying the aspect candidates as aspects or non-aspects, and the final step associates a sentiment polarity to each extracted aspect. Steps two and three are based on SetFit models.
### Training
**1. Aspect candidate extraction**
In this work we assume that aspects, which are usually features of products and services, are mostly nouns or noun compounds (strings of consecutive nouns). We use [spaCy](https://spacy.io/) to tokenize and extract nouns/noun compounds from the sentences in the (few-shot) training set. Since not all extracted nouns/noun compounds are aspects, we refer to them as aspect candidates.
**2. Aspect/Non-aspect classification**
Now that we have aspect candidates, we need to train a model to be able to distinguish between nouns that are aspects and nouns that are non-aspects. For this purpose, we need training samples with aspect/no-aspect labels. This is done by considering aspects in the training set as `True` aspects, while other non-overlapping candidate aspects are considered non-aspects and therefore labeled as `False`:
* **Training sentence:** "Waiters aren't friendly but the cream pasta is out of this world."
* **Tokenized:** [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
* **Extracted aspect candidates:** [<strong style="color:orange">Waiters</strong>, are, n't, friendly, but, the, <strong style="color:orange">cream</strong>, <strong style="color:orange">pasta</strong>, is, out, of, this, <strong style="color:orange">world</strong>, .]
* **Gold labels from training set, in [BIO format](https://en.wikipedia.org/wiki/Inside–outside–beginning_(tagging)):** [B-ASP, O, O, O, O, O, B-ASP, I-ASP, O, O, O, O, O, .]
* **Generated aspect/non-aspect Labels:** [<strong style="color:green">Waiters</strong>, are, n't, friendly, but, the, <strong style="color:green">cream</strong>, <strong style="color:green">pasta</strong>, is, out, of, this, <strong style="color:red">world</strong>, .]
Now that we have all the aspect candidates labeled, how do we use it to train the candidate aspect classification model? In other words, how do we use SetFit, a sentence classification framework, to classify individual tokens? Well, this is the trick: each aspect candidate is concatenated with the entire training sentence to create a training instance using the following template:
```
aspect_candidate:training_sentence
```
Applying the template to the example above will generate 3 training instances – two with `True` labels representing aspect training instances, and one with `False` label representing non-aspect training instance:
| Text | Label |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| world:Waiters aren't friendly but the cream pasta is out of this world. | 0 |
| ... | ... |
After generating the training instances, we are ready to use the power of SetFit to train a few-shot domain-specific binary classifier to extract aspects from an input text review. This will be our first fine-tuned SetFit model.
**3. Sentiment polarity classification**
Once the system extracts the aspects from the text, it needs to associate a sentiment polarity (e.g., positive, negative or neutral) to each aspect. For this purpose, we use a 2nd SetFit model and train it in a similar fashion to the aspect extraction model as illustrated in the following example:
* **Training sentence:** "Waiters aren't friendly but the cream pasta is out of this world."
* **Tokenized:** [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
* **Gold labels from training set:** [NEG, O, O, O, O, O, POS, POS, O, O, O, O, O, .]
| Text | Label |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | NEG |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | POS |
| ... | ... |
Note that as opposed to the aspect extraction model, we don't include non-aspects in this training set because the goal is to classify the sentiment polarity towards real aspects.
## Running inference
At inference time, the test sentence passes through the spaCy aspect candidate extraction phase, resulting in test instances using the template `aspect_candidate:test_sentence`. Next, non-aspects are filtered by the aspect/non-aspect classifier. Finally, the extracted aspects are fed to the sentiment polarity classifier that predicts the sentiment polarity per aspect.
In practice, this means the model can receive normal text as input, and output aspects and their sentiments:
**Model Input:**
```
"their dinner specials are fantastic."
```
**Model Output:**
```
[{'span': 'dinner specials', 'polarity': 'positive'}]
```
## Benchmarking
SetFitABSA was benchmarked against the recent state-of-the-art work by [AWS AI Labs](https://arxiv.org/pdf/2210.06629.pdf) and [Salesforce AI Research](https://arxiv.org/pdf/2204.05356.pdf) that finetune T5 and GPT2 using prompts. To get a more complete picture, we also compare our model to the Llama-2-chat model using in-context learning.
We use the popular Laptop14 and Restaurant14 ABSA [datasets](https://huggingface.co/datasets/alexcadillon/SemEval2014Task4) from the Semantic Evaluation Challenge 2014 ([SemEval14](https://aclanthology.org/S14-2004.pdf)).
SetFitABSA is evaluated both on the intermediate task of aspect term extraction (SB1) and on the full ABSA task of aspect extraction along with their sentiment polarity predictions (SB1+SB2).
### Model size comparison
| Model | Size (params) |
|:------------------:|:-------------:|
| Llama-2-chat | 7B |
| T5-base | 220M |
| GPT2-base | 124M |
| GPT2-medium | 355M |
| **SetFit (MPNet)** | 2x 110M |
Note that for the SB1 task, SetFitABSA is 110M parameters, for SB2 it is 110M parameters, and for SB1+SB2 SetFitABSA consists of 220M parameters.
### Performance comparison
We see a clear advantage of SetFitABSA when the number of training instances is low, despite being 2x smaller than T5 and x3 smaller than GPT2-medium. Even when compared to Llama 2, which is x64 larger, the performance is on par or better.
**SetFitABSA vs GPT2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_GPT2.png" width=700>
</p>
**SetFitABSA vs T5**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_T5.png" width=700>
</p>
Note that for fair comparison, we conducted comparisons with SetFitABSA against exactly the dataset splits used by the various baselines (GPT2, T5, etc.).
**SetFitABSA vs Llama2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_Llama2.png" width=700>
</p>
We notice that increasing the number of in-context training samples for Llama2 did not result in improved performance. This phenomenon [has been shown for ChatGPT before](https://www.analyticsvidhya.com/blog/2023/09/power-of-llms-zero-shot-and-few-shot-prompting/), and we think it should be further investigated.
## Training your own model
SetFitABSA is part of the SetFit framework. To train an ABSA model, start by installing `setfit` with the `absa` option enabled:
```shell
python -m pip install -U "setfit[absa]"
```
Additionally, we must install the `en_core_web_lg` spaCy model:
```shell
python -m spacy download en_core_web_lg
```
We continue by preparing the training set. The format of the training set is a `Dataset` with the columns `text`, `span`, `label`, `ordinal`:
* **text**: The full sentence or text containing the aspects.
* **span**: An aspect from the full sentence. Can be multiple words. For example: "food".
* **label**: The (polarity) label corresponding to the aspect span. For example: "positive". The label names can be chosen arbitrarily when tagging the collected training data.
* **ordinal**: If the aspect span occurs multiple times in the text, then this ordinal represents the index of those occurrences. Often this is just 0, as each aspect usually appears only once in the input text.
For example, the training text "Restaurant with wonderful food but worst service I ever seen" contains two aspects, so will add two lines to the training set table:
| Text | Span | Label | Ordinal |
|:-------------------------------------------------------------|:--------|:---------|:--------|
| Restaurant with wonderful food but worst service I ever seen | food | positive | 0 |
| Restaurant with wonderful food but worst service I ever seen | service | negative | 0 |
| ... | ... | ... | ... |
Once we have the training dataset ready we can create an ABSA trainer and execute the training. SetFit models are fairly efficient to train, but as SetFitABSA involves two models trained sequentially, it is recommended to use a GPU for training to keep the training time low. For example, the following training script trains a full SetFitABSA model in about 10 minutes with the free Google Colab T4 GPU.
```python
from datasets import load_dataset
from setfit import AbsaTrainer, AbsaModel
# Create a training dataset as above
# For convenience we will use an already prepared dataset here
train_dataset = load_dataset("tomaarsen/setfit-absa-semeval-restaurants", split="train[:128]")
# Create a model with a chosen sentence transformer from the Hub
model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create a trainer:
trainer = AbsaTrainer(model, train_dataset=train_dataset)
# Execute training:
trainer.train()
```
That's it! We have trained a domain-specific ABSA model. We can save our trained model to disk or upload it to the Hugging Face hub. Bear in mind that the model contains two submodels, so each is given its own path:
```python
model.save_pretrained(
"models/setfit-absa-model-aspect",
"models/setfit-absa-model-polarity"
)
# or
model.push_to_hub(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
Now we can use our trained model for inference. We start by loading the model:
```python
from setfit import AbsaModel
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
Then, we use the predict API to run inference. The input is a list of strings, each representing a textual review:
```python
preds = model.predict([
"Best pizza outside of Italy and really tasty.",
"The food variations are great and the prices are absolutely fair.",
"Unfortunately, you have to expect some waiting time and get a note with a waiting number if it should be very full."
])
print(preds)
# [
# [{'span': 'pizza', 'polarity': 'positive'}],
# [{'span': 'food variations', 'polarity': 'positive'}, {'span': 'prices', 'polarity': 'positive'}],
# [{'span': 'waiting time', 'polarity': 'neutral'}, {'span': 'waiting number', 'polarity': 'neutral'}]
# ]
```
For more details on training options, saving and loading models, and inference see the SetFit [docs](https://huggingface.co/docs/setfit/how_to/absa).
## References
* Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35.
* Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, Dan Roth, 2023 "Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2210.06629
* Ehsan Hosseini-Asl, Wenhao Liu, Caiming Xiong, 2022. "A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2204.05356
* Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. "Efficient Few-Shot Learning Without Prompts". https://arxiv.org/abs/2209.11055
| 7 |
0 | hf_public_repos | hf_public_repos/blog/deploy-with-openvino.md | ---
title: Optimize and deploy with Optimum-Intel and OpenVINO GenAI
authors:
- user: AlexKoff88
guest: true
org: Intel
- user: MrOpenVINO
guest: true
org: Intel
- user: katuni4ka
guest: true
org: Intel
- user: sandye51
guest: true
org: Intel
- user: raymondlo84
guest: true
org: Intel
- user: helenai
guest: true
org: Intel
- user: echarlaix
---
# Optimize and deploy models with Optimum-Intel and OpenVINO GenAI
Deploying Transformers models at the edge or client-side requires careful consideration of performance and compatibility. Python, though powerful, is not always ideal for such deployments, especially in environments dominated by C++. This blog will guide you through optimizing and deploying Hugging Face Transformers models using Optimum-Intel and OpenVINO™ GenAI, ensuring efficient AI inference with minimal dependencies.
## Table of Contents
1. Why Use OpenVINO™ for Edge Deployment
2. Step 1: Setting Up the Environment
3. Step 2: Exporting Models to OpenVINO IR
4. Step 3: Model Optimization
5. Step 4: Deploying with OpenVINO GenAI API
6. Conclusion
## Why Use OpenVINO™ for Edge Deployment
OpenVINO™ was originally developed as a C++ AI inference solution, making it ideal for edge and client deployment where minimizing dependencies is crucial. With the introduction of the GenAI API, integrating large language models (LLMs) into C++ or Python applications has become even more straightforward, with features designed to simplify deployment and enhance performance.
## Step 1: Setting Up the Environment
## Pre-requisites
To start, ensure your environment is properly configured with both Python and C++. Install the necessary Python packages:
```sh
pip install --upgrade --upgrade-strategy eager "optimum[openvino]"
```
Here are the specific packages used in this blog post:
```
transformers==4.44
openvino==24.3
openvino-tokenizers==24.3
optimum-intel==1.20
lm-eval==0.4.3
```
For GenAI C++ libraries installation follow the instruction [here](https://docs.openvino.ai/2024/get-started/install-openvino/install-openvino-genai.html).
## Step 2: Exporting Models to OpenVINO IR
Hugging Face and Intel's collaboration has led to the [Optimum-Intel](https://huggingface.co/docs/optimum/en/intel/index) project. It is designed to optimize Transformers models for inference on Intel HW. Optimum-Intel supports OpenVINO as an inference backend and its API has wrappers for various model architectures built on top of OpenVINO inference API. All of these wrappers start from `OV` prefix, for example, `OVModelForCausalLM`. Otherwise, it is similar to the API of 🤗 Transformers library.
To export Transformers models to OpenVINO Intermediate Representation (IR) one can use two options: This can be done using Python’s `.from_pretrained()` method or the Optimum command-line interface (CLI). Below are examples using both methods:
### Using Python API
```python
from optimum.intel import OVModelForCausalLM
model_id = "meta-llama/Meta-Llama-3.1-8B"
model = OVModelForCausalLM.from_pretrained(model_id, export=True)
model.save_pretrained("./llama-3.1-8b-ov")
```
### Using Command Line Interface (CLI)
```sh
optimum-cli export openvino -m meta-llama/Meta-Llama-3.1-8B ./llama-3.1-8b-ov
```
The `./llama-3.1-8b-ov` folder will contain `.xml` and `bin` IR model files and required configuration files that come from the source model. 🤗 tokenizer will be also converted to the format of `openvino-tokenizers` library and corresponding configuration files will be created in the same folder.
## Step 3: Model Optimization
When running LLMs on the resource constrained edge and client devices, model optimization is highly recommended step. Weight-only quantization is a mainstream approach that significantly reduces latency and model footprint. Optimum-Intel offers weight-only quantization through the Neural Network Compression Framework (NNCF), which has a variety of optimization techniques designed specifically for LLMs: from data-free INT8 and INT4 weight quantization to data-aware methods such as [AWQ](https://huggingface.co/docs/transformers/main/en/quantization/awq), [GPTQ](https://huggingface.co/docs/transformers/main/en/quantization/gptq), quantization scale estimation, mixed-precision quantization.
By default, weights of the models that are larger than one billion parameters are quantized to INT8 precision which is safe in terms of accuracy. It means that the export steps described above lead to the model with 8-bit weights. However, 4-bit integer weight-only quantization allows achieving a better accuracy-performance trade-off.
For `meta-llama/Meta-Llama-3.1-8B` model we recommend stacking AWQ, quantization scale estimation along with mixed-precision INT4/INT8 quantization of weights using a calibration dataset that reflects a deployment use case. As in the case of export, there are two options on how to apply 4-bit weight-only quantization to LLM model:
### Using Python API
- Specify `quantization_config` parameter in the `.from_pretrained()` method. In this case `OVWeightQuantizationConfig` object should be created and set to this parameter as follows:
```python
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
MODEL_ID = "meta-llama/Meta-Llama-3.1-8B"
quantization_config = OVWeightQuantizationConfig(bits=4, awq=True, scale_estimation=True, group_size=64, dataset="c4")
model = OVModelForCausalLM.from_pretrained(MODEL_ID, export=True, quantization_config=quantization_config)
model.save_pretrained("./llama-3.1-8b-ov")
```
### Using Command Line Interface (CLI):
```sh
optimum-cli export openvino -m meta-llama/Meta-Llama-3.1-8B --weight-format int4 --awq --scale-estimation --group-size 64 --dataset wikitext2 ./llama-3.1-8b-ov
```
>**Note**: The model optimization process can take time as it and applies several methods subsequently and uses model inference over the specified dataset.
Model optimization with API is more flexible as it allows using custom datasets that can be passed as an iterable object, for example, and instance of `Dataset` object of 🤗 library or just a list of strings.
Weight quantization usually introduces some degradation of the accuracy metric. To compare optimized and source models we report Word Perplexity metric measured on the [Wikitext](https://huggingface.co/datasets/EleutherAI/wikitext_document_level) dataset with [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness.git) project which support both 🤗 Transformers and Optimum-Intel models out-of-the-box.
| Model | PPL PyTorch FP32 | OpenVINO INT8 | OpenVINO INT4 |
| :--------------------------- | :--------------: | :-----------: | :-----------: |
| meta-llama/Meta-Llama-3.1-8B | 7.3366 | 7.3463 | 7.8288 |
## Step 4: Deploying with OpenVINO GenAI API
After conversion and optimization, deploying the model using OpenVINO GenAI is straightforward. The LLMPipeline class in OpenVINO GenAI provides both Python and C++ APIs, supporting various text generation methods with minimal dependencies.
### Python API Example
```python
import argparse
import openvino_genai
device = "CPU" # GPU can be used as well
pipe = openvino_genai.LLMPipeline(args.model_dir, device)
config = openvino_genai.GenerationConfig()
config.max_new_tokens = 100
print(pipe.generate(args.prompt, config))
```
To run this example you need minimum dependencies to be installed into the Python enviroment as OpenVINO GenAI is designed to provide a lightweight deployment. You can install OpenVINO GenAI package to the same Python environment or create a separate one to compare the application footprint:
```sh
pip install openvino-genai==24.3
```
### C++ API Example
Let's see how to run the same pipilene with OpenVINO GenAI C++ API. The GenAI API is designed to be intuitive and provides a seamless migration from 🤗 Transformers API.
>**Note**: In the below example, any other available device in your environment can be specified for "device" variable. For example, if you are using an Intel CPU with integrated graphics, "GPU" is be a good option to try with. To check the available devices, you can use ov::Core::get_available_devices method (refer to [query-device-properties](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/query-device-properties.html)).
```cpp
#include "openvino/genai/llm_pipeline.hpp"
#include <iostream>
int main(int argc, char* argv[]) {
std::string model_path = "./llama-3.1-8b-ov";
std::string device = "CPU" // GPU can be used as well
ov::genai::LLMPipeline pipe(model_path, device);
std::cout << pipe.generate("What is LLM model?", ov::genai::max_new_tokens(256));
}
```
### Customizing Generation Config
`LLMPipeline` also allows specifying custom generation options by means of `ov::genai::GenerationConfig`:
```cpp
ov::genai::GenerationConfig config;
config.max_new_tokens = 256;
std::string result = pipe.generate(prompt, config);
```
With the LLMPipieline, users can not only effortlessly leverage various decoding algorithms such as Beam Search but also construct an interactive chat scenario with a Streamer as in the below example. Moreover, one can take advantage of enhanced internal optimizations with LLMPipeline, such as reduced prompt processing time with utilization of KV cache of previous chat history with the chat methods : start_chat() and finish_chat() (refer to [using-genai-in-chat-scenario](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html#using-genai-in-chat-scenario)).
```cpp
ov::genai::GenerationConfig config;
config.max_new_tokens = 100;
config.do_sample = true;
config.top_p = 0.9;
config.top_k = 30;
auto streamer = [](std::string subword) {
std::cout << subword << std::flush;
return false;
};
// Since the streamer is set, the results will
// be printed each time a new token is generated.
pipe.generate(prompt, config, streamer);
```
And finally let's see how to use LLMPipeline in the chat scenario:
```cpp
pipe.start_chat()
for (size_t i = 0; i < questions.size(); i++) {
std::cout << "question:\n";
std::getline(std::cin, prompt);
std::cout << pipe.generate(prompt) << std::endl;
}
pipe.finish_chat();
```
## Conclusion
The combination of Optimum-Intel and OpenVINO™ GenAI offers a powerful, flexible solution for deploying Hugging Face models at the edge. By following these steps, you can achieve optimized, high-performance AI inference in environments where Python may not be ideal, ensuring your applications run smoothly across Intel hardware.
## Additional Resources
1. You can find more details in this [tutorial](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html).
2. To build the C++ examples above refer to this [document](https://github.com/openvinotoolkit/openvino.genai/blob/releases/2024/3/src/docs/BUILD.md).
3. [OpenVINO Documentation](docs.openvino.ai)
4. [Jupyter Notebooks](https://docs.openvino.ai/2024/learn-openvino/interactive-tutorials-python.html)
5. [Optimum Documentation](https://huggingface.co/docs/optimum/main/en/intel/index)
 | 8 |
0 | hf_public_repos | hf_public_repos/blog/dedup.md | ---
title: "Large-scale Near-deduplication Behind BigCode"
thumbnail: /blog/assets/dedup/thumbnail.png
authors:
- user: chenghao
---
# Large-scale Near-deduplication Behind BigCode
## Intended Audience
People who are interested in document-level near-deduplication at a large scale, and have some understanding of hashing, graph and text processing.
## Motivations
It is important to take care of our data before feeding it to the model, at least Large Language Model in our case, as the old saying goes, garbage in, garbage out. Even though it's increasingly difficult to do so with headline-grabbing models (or should we say APIs) creating an illusion that data quality matters less.
One of the problems we face in both BigScience and BigCode for data quality is duplication, including possible benchmark contamination. It has been shown that models tend to output training data verbatim when there are many duplicates[[1]](#1) (though it is less clear in some other domains[[2]](#2)), and it also makes the model vulnerable to privacy attacks[[1]](#1). Additionally, some typical advantages of deduplication also include:
1. Efficient training: You can achieve the same, and sometimes better, performance with less training steps[[3]](#3) [[4]](#4).
2. Prevent possible data leakage and benchmark contamination: Non-zero duplicates discredit your evaluations and potentially make so-called improvement a false claim.
3. Accessibility. Most of us cannot afford to download or transfer thousands of gigabytes of text repeatedly, not to mention training a model with it. Deduplication, for a fix-sized dataset, makes it easier to study, transfer and collaborate with.
## From BigScience to BigCode
Allow me to share a story first on how I jumped on this near-deduplication quest, how the results have progressed, and what lessons I have learned along the way.
It all started with a conversation on LinkedIn when [BigScience](https://bigscience.huggingface.co/) had already started for a couple of months. Huu Nguyen approached me when he noticed my pet project on GitHub, asking me if I were interested in working on deduplication for BigScience. Of course, my answer was a yes, completely ignorant of just how much effort will be required alone due to the sheer mount of the data.
It was fun and challenging at the same time. It is challenging in a sense that I didn't really have much research experience with that sheer scale of data, and everyone was still welcoming and trusting you with thousands of dollars of cloud compute budget. Yes, I had to wake up from my sleep to double-check that I had turned off those machines several times. As a result, I had to learn on the job through all the trials and errors, which in the end opened me to a new perspective that I don't think I would ever have if it weren't for BigScience.
Moving forward, one year later, I am putting what I have learned back into [BigCode](https://www.bigcode-project.org/), working on even bigger datasets. In addition to LLMs that are trained for English[[3]](#3), we have confirmed that deduplication improves code models too[[4]](#4), while using a much smaller dataset. And now, I am sharing what I have learned with you, my dear reader, and hopefully, you can also get a sense of what is happening behind the scene of BigCode through the lens of deduplication.
In case you are interested, here is an updated version of the deduplication comparison that we started in BigScience:
| Dataset | Input Size | Output Size or Deduction | Level | Method | Parameters | Language | Time |
| ------------------------------------ | -------------------------------- | --------------------------------------------------------------- | --------------------- | --------------------------------------------- | ---------------------------------------------------------------- | ------------ | ------------------- |
| OpenWebText2[[5]](#5) | After URL dedup: 193.89 GB (69M) | After MinHashLSH: 65.86 GB (17M) | URL + Document | URL(Exact) + Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | |
| Pile-CC[[5]](#5) | _~306 GB_ | _227.12 GiB (~55M)_ | Document | Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | "several days" |
| BNE5[[6]](#6) | 2TB | 570 GB | Document | Onion | 5-gram | Spanish | |
| MassiveText[[7]](#7) | | 0.001 TB ~ 2.1 TB | Document | Document(Exact + MinHash LSH) | \\( (?, 0.8, 13, ?, ?) \\) | English | |
| CC100-XL[[8]](#8) | | 0.01 GiB ~ 3324.45 GiB | URL + Paragraph | URL(Exact) + Paragraph(Exact) | SHA-1 | Multilingual | |
| C4[[3]](#3) | 806.92 GB (364M) | 3.04% ~ 7.18% **↓** (train) | Substring or Document | Substring(Suffix Array) or Document(MinHash) | Suffix Array: 50-token, MinHash: \\( (9000, 0.8, 5, 20, 450) \\) | English | |
| Real News[[3]](#3) | ~120 GiB | 13.63% ~ 19.4% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| LM1B[[3]](#3) | ~4.40 GiB (30M) | 0.76% ~ 4.86% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| WIKI40B[[3]](#3) | ~2.9M | 0.39% ~ 2.76% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| The BigScience ROOTS Corpus[[9]](#9) | | 0.07% ~ 2.7% **↓** (document) + 10.61%~32.30% **↓** (substring) | Document + Substring | Document (SimHash) + Substring (Suffix Array) | SimHash: 6-grams, hamming distance of 4, Suffix Array: 50-token | Multilingual | 12 hours ~ few days |
This is the one for code datasets we created for BigCode as well. Model names are used when the dataset name isn't available.
| Model | Method | Parameters | Level |
| --------------------- | -------------------- | -------------------------------------- | -------- |
| InCoder[[10]](#10) | Exact | Alphanumeric tokens/md5 + Bloom filter | Document |
| CodeGen[[11]](#11) | Exact | SHA256 | Document |
| AlphaCode[[12]](#12) | Exact | ignore whiespaces | Document |
| PolyCode[[13]](#13) | Exact | SHA256 | Document |
| PaLM Coder[[14]](#14) | Levenshtein distance | | Document |
| CodeParrot[[15]](#15) | MinHash + LSH | \\( (256, 0.8, 1) \\) | Document |
| The Stack[[16]](#16) | MinHash + LSH | \\( (256, 0.7, 5) \\) | Document |
MinHash + LSH parameters \\( (P, T, K, B, R) \\):
1. \\( P \\) number of permutations/hashes
2. \\( T \\) Jaccard similarity threshold
3. \\( K \\) n-gram/shingle size
4. \\( B \\) number of bands
5. \\( R \\) number of rows
To get a sense of how those parameters might impact your results, here is a simple demo to illustrate the computation mathematically: [MinHash Math Demo](https://huggingface.co/spaces/bigcode/near-deduplication).
## MinHash Walkthrough
In this section, we will cover each step of MinHash, the one used in BigCode, and potential scaling issues and solutions. We will demonstrate the workflow via one example of three documents in English:
| doc_id | content |
| ------ | ---------------------------------------- |
| 0 | Deduplication is so much fun! |
| 1 | Deduplication is so much fun and easy! |
| 2 | I wish spider dog[[17]](#17) is a thing. |
The typical workflow of MinHash is as follows:
1. Shingling (tokenization) and fingerprinting (MinHashing), where we map each document into a set of hashes.
2. Locality-sensitive hashing (LSH). This step is to reduce the number of comparisons by grouping documents with similar bands together.
3. Duplicate removal. This step is where we decide which duplicated documents to keep or remove.
### Shingles
Like in most applications involving text, we need to begin with tokenization. N-grams, a.k.a. shingles, are often used. In our example, we will be using word-level tri-grams, without any punctuations. We will circle back to how the size of ngrams impacts the performance in a later section.
| doc_id | shingles |
| ------ | ------------------------------------------------------------------------------- |
| 0 | {"Deduplication is so", "is so much", "so much fun"} |
| 1 | {'so much fun', 'fun and easy', 'Deduplication is so', 'is so much'} |
| 2 | {'dog is a', 'is a thing', 'wish spider dog', 'spider dog is', 'I wish spider'} |
This operation has a time complexity of \\( \mathcal{O}(NM) \\) where \\( N \\) is the number of documents and \\( M \\) is the length of the document. In other words, it is linearly dependent on the size of the dataset. This step can be easily scaled by parallelization by multiprocessing or distributed computation.
### Fingerprint Computation
In MinHash, each shingle will typically either be 1) hashed multiple times with different hash functions, or 2) permuted multiple times using one hash function. Here, we choose to permute each hash 5 times. More variants of MinHash can be found in [MinHash - Wikipedia](https://en.wikipedia.org/wiki/MinHash?useskin=vector).
| shingle | permuted hashes |
| ------------------- | ----------------------------------------------------------- |
| Deduplication is so | [403996643, 2764117407, 3550129378, 3548765886, 2353686061] |
| is so much | [3594692244, 3595617149, 1564558780, 2888962350, 432993166] |
| so much fun | [1556191985, 840529008, 1008110251, 3095214118, 3194813501] |
Taking the minimum value of each column within each document — the "Min" part of the "MinHash", we arrive at the final MinHash for this document:
| doc_id | minhash |
| ------ | ---------------------------------------------------------- |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] |
Technically, we don't have to use the minimum value of each column, but the minimum value is the most common choice. Other order statistics such as maximum, kth smallest, or kth largest can be used as well[[21]](#21).
In implementation, you can easily vectorize these steps with `numpy` and expect to have a time complexity of \\( \mathcal{O}(NMK) \\) where \\( K \\) is your number of permutations. Code modified based on [Datasketch](https://github.com/ekzhu/datasketch).
```python
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}
```
If you are familiar with [Datasketch](https://github.com/ekzhu/datasketch), you might ask, why do we bother to strip all the nice high-level functions the library provides? It is not because we want to avoid adding dependencies, but because we intend to squeeze as much CPU computation as possible during parallelization. Fusing few steps into one function call enables us to utilize our compute resources better.
Since one document's calculation is not dependent on anything else. A good parallelization choice would be using the `map` function from the `datasets` library:
```python
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)
```
After the fingerprint calculation, one particular document is mapped to one array of integer values. To figure out what documents are similar to each other, we need to group them based on such fingerprints. Entering the stage, **Locality Sensitive Hashing (LSH)**.
### Locality Sensitive Hashing
LSH breaks the fingerprint array into bands, each band containing the same number of rows. If there is any hash values left, it will be ignored. Let's use \\( b=2 \\) bands and \\( r=2 \\) rows to group those documents:
| doc_id | minhash | bands |
| ------ | ---------------------------------------------------------- | ------------------------------------------------------ |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 2888962350]] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 1998729813]] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | [0:[166417565, 213933364], 1:[1129612544, 1419614622]] |
If two documents share the same hashes in a band at a particular location (band index), they will be clustered into the same bucket and will be considered as candidates.
| band index | band value | doc_ids |
| ---------- | ------------------------ | ------- |
| 0 | [403996643, 840529008] | 0, 1 |
| 1 | [1008110251, 2888962350] | 0 |
| 1 | [1008110251, 1998729813] | 1 |
| 0 | [166417565, 213933364] | 2 |
| 1 | [1129612544, 1419614622] | 2 |
For each row in the `doc_ids` column, we can generate candidate pairs by pairing every two of them. From the above table, we can generate one candidate pair: `(0, 1)`.
### Beyond Duplicate Pairs
This is where many deduplication descriptions in papers or tutorials stop. We are still left with the question of what to do with them. Generally, we can proceed with two options:
1. Double-check their actual Jaccard similarities by calculating their shingle overlap, due to the estimation nature of MinHash. The Jaccard Similarity of two sets is defined as the size of the intersection divided by the size of the union. And now it becomes much more doable than computing all-pair similarities, because we can focus only for documents within a cluster. This is also what we initially did for BigCode, which worked reasonably well.
2. Treat them as true positives. You probably already noticed the issue here: the Jaccard similarity isn't transitive, meaning \\( A \\) is similar to \\( B \\) and \\( B \\) is similar to \\( C \\), but \\( A \\) and \\( C \\) do not necessary share the similarity. However, our experiments from The Stack show that treating all of them as duplicates improves the downstream model's performance the best. And now we gradually moved towards this method instead, and it saves time as well. But to apply this to your dataset, we still recommend going over your dataset and looking at your duplicates, and then making a data-driven decision.
From such pairs, whether they are validated or not, we can now construct a graph with those pairs as edges, and duplicates will be clustered into communities or connected components. In terms of implementation, unfortunately, this is where `datasets` couldn't help much because now we need something like a `groupby` where we can cluster documents based on their _band offset_ and _band values_. Here are some options we have tried:
**Option 1: Iterate the datasets the old-fashioned way and collect edges. Then use a graph library to do community detection or connected component detection.**
This did not scale well in our tests, and the reasons are multifold. First, iterating the whole dataset is slow and memory consuming at a large scale. Second, popular graph libraries like `graphtool` or `networkx` have a lot of overhead for graph creation.
**Option 2: Use popular python frameworks such as `dask` to allow more efficient `groupby` operations**.
But then you still have problems of slow iteration and slow graph creation.
**Option 3: Iterate the dataset, but use a union find data structure to cluster documents.**
This adds negligible overhead to the iteration, and it works relatively well for medium datasets.
```python
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Clustering..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)
```
**Option 4: For large datasets, use Spark.**
We already know that steps up to the LSH part can be parallelized, which is also achievable in Spark. In addition to that, Spark supports distributed `groupBy` out of the box, and it is also straightforward to implement algorithms like [[18]](#18) for connected component detection. If you are wondering why we didn't use Spark's implementation of MinHash, the answer is that all our experiments so far stemmed from [Datasketch](https://github.com/ekzhu/datasketch), which uses an entirely different implementation than Spark, and we want to ensure that we carry on the lessons and insights learned from that without going into another rabbit hole of ablation experiments.
```python
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x: (x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)
```
A simple connected component algorithm based on [[18]](#18) implemented in Spark.
```python
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()
```
Additionally, thanks to cloud providers, we can set up Spark clusters like a breeze with services like GCP DataProc. **In the end, we can comfortably run the program to deduplicate 1.4 TB of data in just under 4 hours with a budget of $15 an hour.**
## Quality Matters
Scaling a ladder doesn't get us to the moon. That's why we need to make sure this is the right direction, and we are using it the right way.
Early on, our parameters were largely inherited from the CodeParrot experiments, and our ablation experiment indicated that those settings did improve the model's downstream performance[[16]](#16). We then set to further explore this path and can confirm that[[4]](#4):
1. Near-deduplication improves the model's downstream performance with a much smaller dataset (6 TB VS. 3 TB)
2. We haven't figured out the limit yet, but a more aggressive deduplication (6 TB VS. 2.4 TB) can improve the performance even more:
1. Lower the similarity threshold
2. Increase the shingle size (unigram → 5-gram)
3. Ditch false positive checking because we can afford to lose a small percentage of false positives
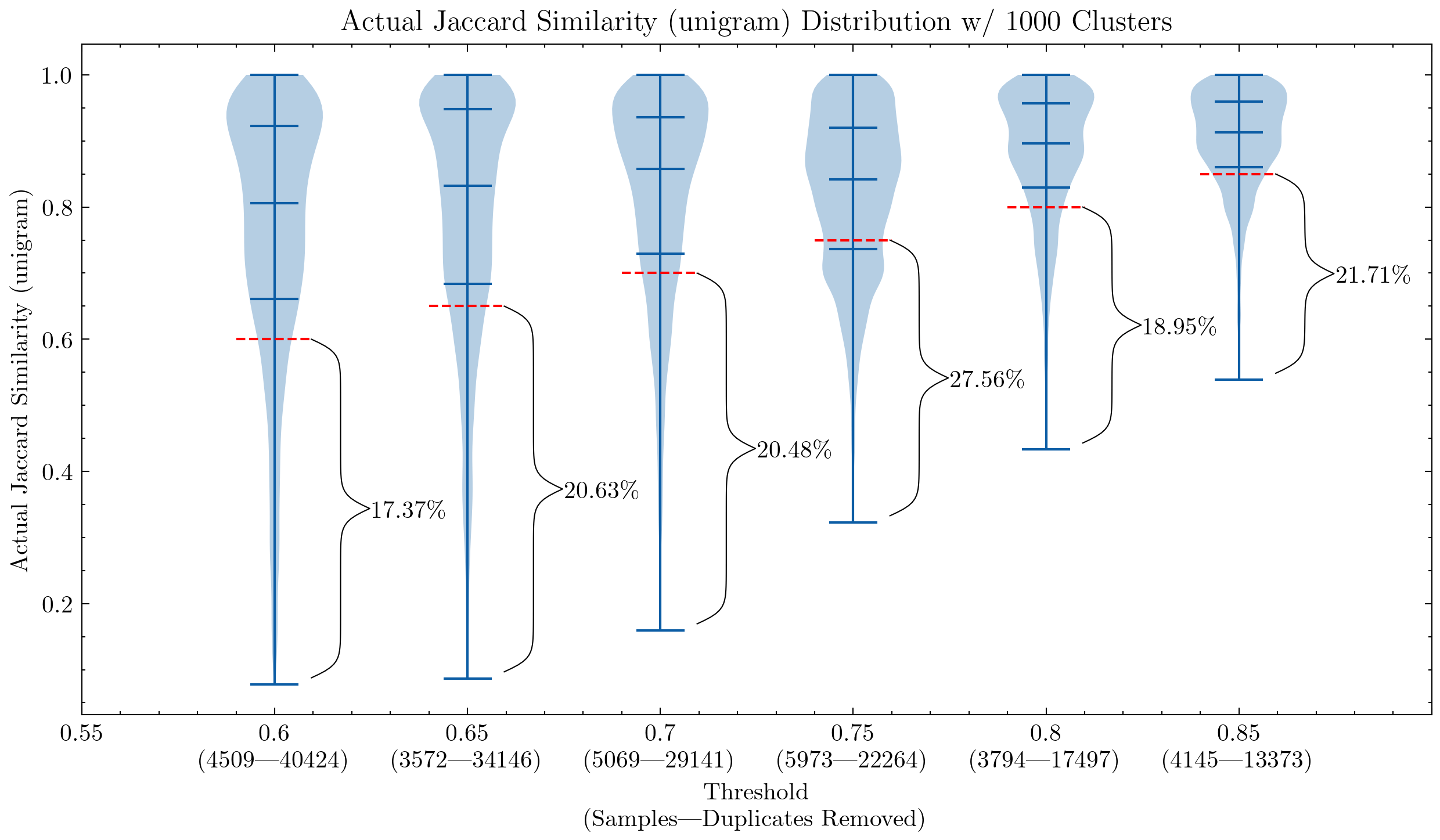
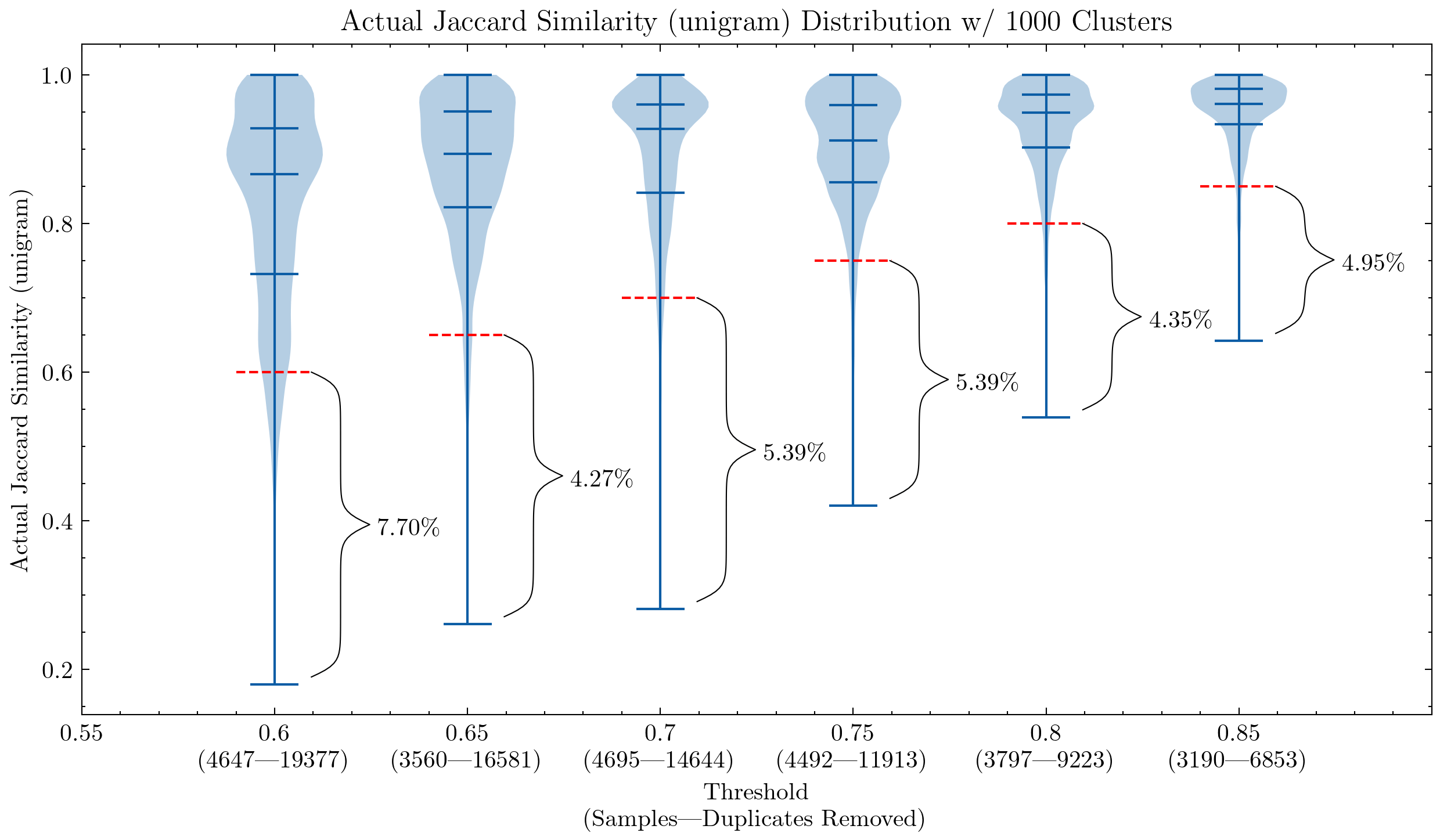
<center>
Image: Two graphs showing the impact of similarity threshold and shingle size, the first one is using unigram and the second one 5-gram. The red dash line shows the similarity cutoff: any documents below would be considered as false positives — their similarities with other documents within a cluster are lower than the threshold.
</center>
These graphs can help us understand why it was necessary to double-check the false positives for CodeParrot and early version of the Stack: using unigram creates many false positives; They also demonstrate that by increasing the shingle size to 5-gram, the percentage of false positives decreases significantly. A smaller threshold is desired if we want to keep the deduplication aggressiveness.
Additional experiments also showed that lowering the threshold removes more documents that have high similarity pairs, meaning an increased recall in the segment we actually would like to remove the most.
## Scaling
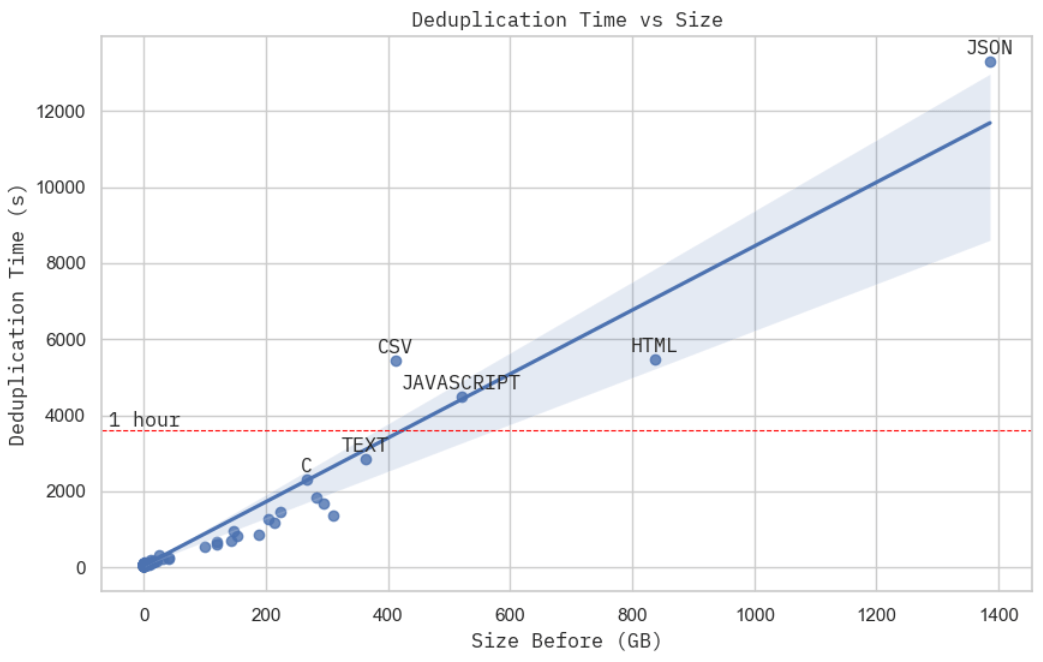
<center>Image: Deduplication time versus raw dataset size. This is achieved with 15 worker c2d-standard-16 machines on GCP, and each costed around $0.7 per hour. </center>

<center>Image: CPU usage screenshot for the cluster during processing JSON dataset.</center>
This isn't the most rigorous scaling proof you can find, but the deduplication time, given a fixed computation budget, looks practically linear to the physical size of the dataset. When you take a closer look at the cluster resource usage when processing JSON dataset, the largest subset in the Stack, you can see the MinHash + LSH (stage 2) dominated the total real computation time (stage 2 + 3), which from our previous analysis is \\( \mathcal{O}(NM) \\) — linear to the dataset physical volume.
## Proceed with Caution
Deduplication doesn't exempt you from thorough data exploration and analysis. In addition, these deduplication discoveries hold true for the Stack, but it does not mean it is readily applicable to other datasets or languages. It is a good first step towards building a better dataset, and further investigations such as data quality filtering (e.g., vulnerability, toxicity, bias, generated templates, PII) are still much needed.
We still encourage you to perform similar analysis on your datasets before training. For example, it might not be very helpful to do deduplication if you have tight time and compute budget: [@geiping_2022](http://arxiv.org/abs/2212.14034) mentions that substring deduplication didn't improve their model's downstream performance. Existing datasets might also require thorough examination before use, for example, [@gao_2020](http://arxiv.org/abs/2101.00027) states that they only made sure the Pile itself, along with its splits, are deduplicated, and they won't proactively deduplicating for any downstream benchmarks and leave that decision to readers.
In terms of data leakage and benchmark contamination, there is still much to explore. We had to retrain our code models because HumanEval was published in one of the GitHub repos in Python. Early near-deduplication results also suggest that MBPP[[19]](#19), one of the most popular benchmarks for coding, shares a lot of similarity with many Leetcode problems (e.g., task 601 in MBPP is basically Leetcode 646, task 604 ≃ Leetcode 151.). And we all know GitHub is no short of those coding challenges and solutions. It will be even more difficult if someone with bad intentions upload all the benchmarks in the form of python scripts, or other less obvious ways, and pollute all your training data.
## Future Directions
1. Substring deduplication. Even though it showed some benefits for English[[3]](#3), it is not clear yet if this should be applied to code data as well;
2. Repetition: paragraphs that are repeated multiple times in one document. [@rae_2021](http://arxiv.org/abs/2112.11446) shared some interesting heuristics on how to detect and remove them.
3. Using model embeddings for semantic deduplication. It is another whole research question with scaling, cost, ablation experiments, and trade-off with near-deduplication. There are some intriguing takes on this[[20]](#20), but we still need more situated evidence to draw a conclusion (e.g, [@abbas_2023](http://arxiv.org/abs/2303.09540)'s only text deduplication reference is [@lee_2022a](http://arxiv.org/abs/2107.06499), whose main claim is deduplicating helps instead of trying to be SOTA).
4. Optimization. There is always room for optimization: better quality evaluation, scaling, downstream performance impact analysis etc.
5. Then there is another direction to look at things: To what extent near-deduplication starts to hurt performance? To what extent similarity is needed for diversity instead of being considered as redundancy?
## Credits
The banner image contains emojis (hugging face, Santa, document, wizard, and wand) from Noto Emoji (Apache 2.0). This blog post is proudly written without any generative APIs.
Huge thanks to Huu Nguyen @Huu and Hugo Laurençon @HugoLaurencon for the collaboration in BigScience and everyone at BigCode for the help along the way! If you ever find any error, feel free to contact me: mouchenghao at gmail dot com.
## Supporting Resources
- [Datasketch](https://github.com/ekzhu/datasketch) (MIT)
- [simhash-py](https://github.com/seomoz/simhash-py/tree/master/simhash) and [simhash-cpp](https://github.com/seomoz/simhash-cpp) (MIT)
- [Deduplicating Training Data Makes Language Models Better](https://github.com/google-research/deduplicate-text-datasets) (Apache 2.0)
- [Gaoya](https://github.com/serega/gaoya) (MIT)
- [BigScience](https://github.com/bigscience-workshop) (Apache 2.0)
- [BigCode](https://github.com/bigcode-project) (Apache 2.0)
## References
- <a id="1">[1]</a> : Nikhil Kandpal, Eric Wallace, Colin Raffel, [Deduplicating Training Data Mitigates Privacy Risks in Language Models](http://arxiv.org/abs/2202.06539), 2022
- <a id="2">[2]</a> : Gowthami Somepalli, et al., [Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models](http://arxiv.org/abs/2212.03860), 2022
- <a id="3">[3]</a> : Katherine Lee, Daphne Ippolito, et al., [Deduplicating Training Data Makes Language Models Better](http://arxiv.org/abs/2107.06499), 2022
- <a id="4">[4]</a> : Loubna Ben Allal, Raymond Li, et al., [SantaCoder: Don't reach for the stars!](http://arxiv.org/abs/2301.03988), 2023
- <a id="5">[5]</a> : Leo Gao, Stella Biderman, et al., [The Pile: An 800GB Dataset of Diverse Text for Language Modeling](http://arxiv.org/abs/2101.00027), 2020
- <a id="6">[6]</a> : Asier Gutiérrez-Fandiño, Jordi Armengol-Estapé, et al., [MarIA: Spanish Language Models](http://arxiv.org/abs/2107.07253), 2022
- <a id="7">[7]</a> : Jack W. Rae, Sebastian Borgeaud, et al., [Scaling Language Models: Methods, Analysis & Insights from Training Gopher](http://arxiv.org/abs/2112.11446), 2021
- <a id="8">[8]</a> : Xi Victoria Lin, Todor Mihaylov, et al., [Few-shot Learning with Multilingual Language Models](http://arxiv.org/abs/2112.10668), 2021
- <a id="9">[9]</a> : Hugo Laurençon, Lucile Saulnier, et al., [The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset](https://openreview.net/forum?id=UoEw6KigkUn), 2022
- <a id="10">[10]</a> : Daniel Fried, Armen Aghajanyan, et al., [InCoder: A Generative Model for Code Infilling and Synthesis](http://arxiv.org/abs/2204.05999), 2022
- <a id="11">[11]</a> : Erik Nijkamp, Bo Pang, et al., [CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis](http://arxiv.org/abs/2203.13474), 2023
- <a id="12">[12]</a> : Yujia Li, David Choi, et al., [Competition-Level Code Generation with AlphaCode](http://arxiv.org/abs/2203.07814), 2022
- <a id="13">[13]</a> : Frank F. Xu, Uri Alon, et al., [A Systematic Evaluation of Large Language Models of Code](http://arxiv.org/abs/2202.13169), 2022
- <a id="14">[14]</a> : Aakanksha Chowdhery, Sharan Narang, et al., [PaLM: Scaling Language Modeling with Pathways](http://arxiv.org/abs/2204.02311), 2022
- <a id="15">[15]</a> : Lewis Tunstall, Leandro von Werra, Thomas Wolf, [Natural Language Processing with Transformers, Revised Edition](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/), 2022
- <a id="16">[16]</a> : Denis Kocetkov, Raymond Li, et al., [The Stack: 3 TB of permissively licensed source code](http://arxiv.org/abs/2211.15533), 2022
- <a id="17">[17]</a> : [Rocky | Project Hail Mary Wiki | Fandom](https://projecthailmary.fandom.com/wiki/Rocky)
- <a id="18">[18]</a> : Raimondas Kiveris, Silvio Lattanzi, et al., [Connected Components in MapReduce and Beyond](https://doi.org/10.1145/2670979.2670997), 2014
- <a id="19">[19]</a> : Jacob Austin, Augustus Odena, et al., [Program Synthesis with Large Language Models](http://arxiv.org/abs/2108.07732), 2021
- <a id="20">[20]</a>: Amro Abbas, Kushal Tirumala, et al., [SemDeDup: Data-efficient learning at web-scale through semantic deduplication](http://arxiv.org/abs/2303.09540), 2023
- <a id="21">[21]</a>: Edith Cohen, [MinHash Sketches : A Brief Survey](http://www.cohenwang.com/edith/Surveys/minhash.pdf), 2016
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.