
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/update.py | #!/usr/bin/env python
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from pathlib import Path
from .config_args import default_config_file, load_config_from_file
from .config_utils import SubcommandHelpFormatter
description = "Update an existing config file with the latest defaults while maintaining the old configuration."
def update_config(args):
"""
Update an existing config file with the latest defaults while maintaining the old configuration.
"""
config_file = args.config_file
if config_file is None and Path(default_config_file).exists():
config_file = default_config_file
elif not Path(config_file).exists():
raise ValueError(f"The passed config file located at {config_file} doesn't exist.")
config = load_config_from_file(config_file)
if config_file.endswith(".json"):
config.to_json_file(config_file)
else:
config.to_yaml_file(config_file)
return config_file
def update_command_parser(parser, parents):
parser = parser.add_parser("update", parents=parents, help=description, formatter_class=SubcommandHelpFormatter)
parser.add_argument(
"--config_file",
default=None,
help=(
"The path to the config file to update. Will default to a file named default_config.yaml in the cache "
"location, which is the content of the environment `HF_HOME` suffixed with 'accelerate', or if you don't have "
"such an environment variable, your cache directory ('~/.cache' or the content of `XDG_CACHE_HOME`) suffixed "
"with 'huggingface'."
),
)
parser.set_defaults(func=update_config_command)
return parser
def update_config_command(args):
config_file = update_config(args)
print(f"Sucessfully updated the configuration file at {config_file}.")
| 0 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/sagemaker.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
from ...utils.constants import SAGEMAKER_PARALLEL_EC2_INSTANCES, TORCH_DYNAMO_MODES
from ...utils.dataclasses import ComputeEnvironment, SageMakerDistributedType
from ...utils.imports import is_boto3_available
from .config_args import SageMakerConfig
from .config_utils import (
DYNAMO_BACKENDS,
_ask_field,
_ask_options,
_convert_dynamo_backend,
_convert_mixed_precision,
_convert_sagemaker_distributed_mode,
_convert_yes_no_to_bool,
)
if is_boto3_available():
import boto3 # noqa: F401
def _create_iam_role_for_sagemaker(role_name):
iam_client = boto3.client("iam")
sagemaker_trust_policy = {
"Version": "2012-10-17",
"Statement": [
{"Effect": "Allow", "Principal": {"Service": "sagemaker.amazonaws.com"}, "Action": "sts:AssumeRole"}
],
}
try:
# create the role, associated with the chosen trust policy
iam_client.create_role(
RoleName=role_name, AssumeRolePolicyDocument=json.dumps(sagemaker_trust_policy, indent=2)
)
policy_document = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sagemaker:*",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:GetAuthorizationToken",
"cloudwatch:PutMetricData",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:GetLogEvents",
"s3:CreateBucket",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:PutObject",
],
"Resource": "*",
}
],
}
# attach policy to role
iam_client.put_role_policy(
RoleName=role_name,
PolicyName=f"{role_name}_policy_permission",
PolicyDocument=json.dumps(policy_document, indent=2),
)
except iam_client.exceptions.EntityAlreadyExistsException:
print(f"role {role_name} already exists. Using existing one")
def _get_iam_role_arn(role_name):
iam_client = boto3.client("iam")
return iam_client.get_role(RoleName=role_name)["Role"]["Arn"]
def get_sagemaker_input():
credentials_configuration = _ask_options(
"How do you want to authorize?",
["AWS Profile", "Credentials (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY) "],
int,
)
aws_profile = None
if credentials_configuration == 0:
aws_profile = _ask_field("Enter your AWS Profile name: [default] ", default="default")
os.environ["AWS_PROFILE"] = aws_profile
else:
print(
"Note you will need to provide AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY when you launch you training script with,"
"`accelerate launch --aws_access_key_id XXX --aws_secret_access_key YYY`"
)
aws_access_key_id = _ask_field("AWS Access Key ID: ")
os.environ["AWS_ACCESS_KEY_ID"] = aws_access_key_id
aws_secret_access_key = _ask_field("AWS Secret Access Key: ")
os.environ["AWS_SECRET_ACCESS_KEY"] = aws_secret_access_key
aws_region = _ask_field("Enter your AWS Region: [us-east-1]", default="us-east-1")
os.environ["AWS_DEFAULT_REGION"] = aws_region
role_management = _ask_options(
"Do you already have an IAM Role for executing Amazon SageMaker Training Jobs?",
["Provide IAM Role name", "Create new IAM role using credentials"],
int,
)
if role_management == 0:
iam_role_name = _ask_field("Enter your IAM role name: ")
else:
iam_role_name = "accelerate_sagemaker_execution_role"
print(f'Accelerate will create an iam role "{iam_role_name}" using the provided credentials')
_create_iam_role_for_sagemaker(iam_role_name)
is_custom_docker_image = _ask_field(
"Do you want to use custom Docker image? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
docker_image = None
if is_custom_docker_image:
docker_image = _ask_field("Enter your Docker image: ", lambda x: str(x).lower())
is_sagemaker_inputs_enabled = _ask_field(
"Do you want to provide SageMaker input channels with data locations? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
sagemaker_inputs_file = None
if is_sagemaker_inputs_enabled:
sagemaker_inputs_file = _ask_field(
"Enter the path to the SageMaker inputs TSV file with columns (channel_name, data_location): ",
lambda x: str(x).lower(),
)
is_sagemaker_metrics_enabled = _ask_field(
"Do you want to enable SageMaker metrics? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
sagemaker_metrics_file = None
if is_sagemaker_metrics_enabled:
sagemaker_metrics_file = _ask_field(
"Enter the path to the SageMaker metrics TSV file with columns (metric_name, metric_regex): ",
lambda x: str(x).lower(),
)
distributed_type = _ask_options(
"What is the distributed mode?",
["No distributed training", "Data parallelism"],
_convert_sagemaker_distributed_mode,
)
dynamo_config = {}
use_dynamo = _ask_field(
"Do you wish to optimize your script with torch dynamo?[yes/NO]:",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
if use_dynamo:
prefix = "dynamo_"
dynamo_config[prefix + "backend"] = _ask_options(
"Which dynamo backend would you like to use?",
[x.lower() for x in DYNAMO_BACKENDS],
_convert_dynamo_backend,
default=2,
)
use_custom_options = _ask_field(
"Do you want to customize the defaults sent to torch.compile? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
if use_custom_options:
dynamo_config[prefix + "mode"] = _ask_options(
"Which mode do you want to use?",
TORCH_DYNAMO_MODES,
lambda x: TORCH_DYNAMO_MODES[int(x)],
default="default",
)
dynamo_config[prefix + "use_fullgraph"] = _ask_field(
"Do you want the fullgraph mode or it is ok to break model into several subgraphs? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
dynamo_config[prefix + "use_dynamic"] = _ask_field(
"Do you want to enable dynamic shape tracing? [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
ec2_instance_query = "Which EC2 instance type you want to use for your training?"
if distributed_type != SageMakerDistributedType.NO:
ec2_instance_type = _ask_options(
ec2_instance_query, SAGEMAKER_PARALLEL_EC2_INSTANCES, lambda x: SAGEMAKER_PARALLEL_EC2_INSTANCES[int(x)]
)
else:
ec2_instance_query += "? [ml.p3.2xlarge]:"
ec2_instance_type = _ask_field(ec2_instance_query, lambda x: str(x).lower(), default="ml.p3.2xlarge")
debug = False
if distributed_type != SageMakerDistributedType.NO:
debug = _ask_field(
"Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: ",
_convert_yes_no_to_bool,
default=False,
error_message="Please enter yes or no.",
)
num_machines = 1
if distributed_type in (SageMakerDistributedType.DATA_PARALLEL, SageMakerDistributedType.MODEL_PARALLEL):
num_machines = _ask_field(
"How many machines do you want use? [1]: ",
int,
default=1,
)
mixed_precision = _ask_options(
"Do you wish to use FP16 or BF16 (mixed precision)?",
["no", "fp16", "bf16", "fp8"],
_convert_mixed_precision,
)
if use_dynamo and mixed_precision == "no":
print(
"Torch dynamo used without mixed precision requires TF32 to be efficient. Accelerate will enable it by default when launching your scripts."
)
return SageMakerConfig(
image_uri=docker_image,
compute_environment=ComputeEnvironment.AMAZON_SAGEMAKER,
distributed_type=distributed_type,
use_cpu=False,
dynamo_config=dynamo_config,
ec2_instance_type=ec2_instance_type,
profile=aws_profile,
region=aws_region,
iam_role_name=iam_role_name,
mixed_precision=mixed_precision,
num_machines=num_machines,
sagemaker_inputs_file=sagemaker_inputs_file,
sagemaker_metrics_file=sagemaker_metrics_file,
debug=debug,
)
| 1 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/default.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from pathlib import Path
import torch
from ...utils import is_mlu_available, is_musa_available, is_npu_available, is_xpu_available
from .config_args import ClusterConfig, default_json_config_file
from .config_utils import SubcommandHelpFormatter
description = "Create a default config file for Accelerate with only a few flags set."
def write_basic_config(mixed_precision="no", save_location: str = default_json_config_file, use_xpu: bool = False):
"""
Creates and saves a basic cluster config to be used on a local machine with potentially multiple GPUs. Will also
set CPU if it is a CPU-only machine.
Args:
mixed_precision (`str`, *optional*, defaults to "no"):
Mixed Precision to use. Should be one of "no", "fp16", or "bf16"
save_location (`str`, *optional*, defaults to `default_json_config_file`):
Optional custom save location. Should be passed to `--config_file` when using `accelerate launch`. Default
location is inside the huggingface cache folder (`~/.cache/huggingface`) but can be overriden by setting
the `HF_HOME` environmental variable, followed by `accelerate/default_config.yaml`.
use_xpu (`bool`, *optional*, defaults to `False`):
Whether to use XPU if available.
"""
path = Path(save_location)
path.parent.mkdir(parents=True, exist_ok=True)
if path.exists():
print(
f"Configuration already exists at {save_location}, will not override. Run `accelerate config` manually or pass a different `save_location`."
)
return False
mixed_precision = mixed_precision.lower()
if mixed_precision not in ["no", "fp16", "bf16", "fp8"]:
raise ValueError(
f"`mixed_precision` should be one of 'no', 'fp16', 'bf16', or 'fp8'. Received {mixed_precision}"
)
config = {
"compute_environment": "LOCAL_MACHINE",
"mixed_precision": mixed_precision,
}
if is_mlu_available():
num_mlus = torch.mlu.device_count()
config["num_processes"] = num_mlus
config["use_cpu"] = False
if num_mlus > 1:
config["distributed_type"] = "MULTI_MLU"
else:
config["distributed_type"] = "NO"
elif is_musa_available():
num_musas = torch.musa.device_count()
config["num_processes"] = num_musas
config["use_cpu"] = False
if num_musas > 1:
config["distributed_type"] = "MULTI_MUSA"
else:
config["distributed_type"] = "NO"
elif torch.cuda.is_available():
num_gpus = torch.cuda.device_count()
config["num_processes"] = num_gpus
config["use_cpu"] = False
if num_gpus > 1:
config["distributed_type"] = "MULTI_GPU"
else:
config["distributed_type"] = "NO"
elif is_xpu_available() and use_xpu:
num_xpus = torch.xpu.device_count()
config["num_processes"] = num_xpus
config["use_cpu"] = False
if num_xpus > 1:
config["distributed_type"] = "MULTI_XPU"
else:
config["distributed_type"] = "NO"
elif is_npu_available():
num_npus = torch.npu.device_count()
config["num_processes"] = num_npus
config["use_cpu"] = False
if num_npus > 1:
config["distributed_type"] = "MULTI_NPU"
else:
config["distributed_type"] = "NO"
else:
num_xpus = 0
config["use_cpu"] = True
config["num_processes"] = 1
config["distributed_type"] = "NO"
config["debug"] = False
config["enable_cpu_affinity"] = False
config = ClusterConfig(**config)
config.to_json_file(path)
return path
def default_command_parser(parser, parents):
parser = parser.add_parser("default", parents=parents, help=description, formatter_class=SubcommandHelpFormatter)
parser.add_argument(
"--config_file",
default=default_json_config_file,
help=(
"The path to use to store the config file. Will default to a file named default_config.yaml in the cache "
"location, which is the content of the environment `HF_HOME` suffixed with 'accelerate', or if you don't have "
"such an environment variable, your cache directory ('~/.cache' or the content of `XDG_CACHE_HOME`) suffixed "
"with 'huggingface'."
),
dest="save_location",
)
parser.add_argument(
"--mixed_precision",
choices=["no", "fp16", "bf16"],
type=str,
help="Whether or not to use mixed precision training. "
"Choose between FP16 and BF16 (bfloat16) training. "
"BF16 training is only supported on Nvidia Ampere GPUs and PyTorch 1.10 or later.",
default="no",
)
parser.set_defaults(func=default_config_command)
return parser
def default_config_command(args):
config_file = write_basic_config(args.mixed_precision, args.save_location)
if config_file:
print(f"accelerate configuration saved at {config_file}")
| 2 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/__init__.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
from .config import config_command_parser
from .config_args import default_config_file, load_config_from_file # noqa: F401
from .default import default_command_parser
from .update import update_command_parser
def get_config_parser(subparsers=None):
parent_parser = argparse.ArgumentParser(add_help=False, allow_abbrev=False)
# The main config parser
config_parser = config_command_parser(subparsers)
# The subparser to add commands to
subcommands = config_parser.add_subparsers(title="subcommands", dest="subcommand")
# Then add other parsers with the parent parser
default_command_parser(subcommands, parents=[parent_parser])
update_command_parser(subcommands, parents=[parent_parser])
return config_parser
def main():
config_parser = get_config_parser()
args = config_parser.parse_args()
if not hasattr(args, "func"):
config_parser.print_help()
exit(1)
# Run
args.func(args)
if __name__ == "__main__":
main()
| 3 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/config_utils.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
from ...utils.dataclasses import (
ComputeEnvironment,
DistributedType,
DynamoBackend,
FP8BackendType,
PrecisionType,
SageMakerDistributedType,
)
from ..menu import BulletMenu
DYNAMO_BACKENDS = [
"EAGER",
"AOT_EAGER",
"INDUCTOR",
"AOT_TS_NVFUSER",
"NVPRIMS_NVFUSER",
"CUDAGRAPHS",
"OFI",
"FX2TRT",
"ONNXRT",
"TENSORRT",
"AOT_TORCHXLA_TRACE_ONCE",
"TORHCHXLA_TRACE_ONCE",
"IPEX",
"TVM",
]
def _ask_field(input_text, convert_value=None, default=None, error_message=None):
ask_again = True
while ask_again:
result = input(input_text)
try:
if default is not None and len(result) == 0:
return default
return convert_value(result) if convert_value is not None else result
except Exception:
if error_message is not None:
print(error_message)
def _ask_options(input_text, options=[], convert_value=None, default=0):
menu = BulletMenu(input_text, options)
result = menu.run(default_choice=default)
return convert_value(result) if convert_value is not None else result
def _convert_compute_environment(value):
value = int(value)
return ComputeEnvironment(["LOCAL_MACHINE", "AMAZON_SAGEMAKER"][value])
def _convert_distributed_mode(value):
value = int(value)
return DistributedType(
["NO", "MULTI_CPU", "MULTI_XPU", "MULTI_GPU", "MULTI_NPU", "MULTI_MLU", "MULTI_MUSA", "XLA"][value]
)
def _convert_dynamo_backend(value):
value = int(value)
return DynamoBackend(DYNAMO_BACKENDS[value]).value
def _convert_mixed_precision(value):
value = int(value)
return PrecisionType(["no", "fp16", "bf16", "fp8"][value])
def _convert_sagemaker_distributed_mode(value):
value = int(value)
return SageMakerDistributedType(["NO", "DATA_PARALLEL", "MODEL_PARALLEL"][value])
def _convert_fp8_backend(value):
value = int(value)
return FP8BackendType(["TE", "MSAMP"][value])
def _convert_yes_no_to_bool(value):
return {"yes": True, "no": False}[value.lower()]
class SubcommandHelpFormatter(argparse.RawDescriptionHelpFormatter):
"""
A custom formatter that will remove the usage line from the help message for subcommands.
"""
def _format_usage(self, usage, actions, groups, prefix):
usage = super()._format_usage(usage, actions, groups, prefix)
usage = usage.replace("<command> [<args>] ", "")
return usage
| 4 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/config/config_args.py | #!/usr/bin/env python
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
from dataclasses import dataclass
from enum import Enum
from typing import List, Optional, Union
import yaml
from ...utils import ComputeEnvironment, DistributedType, SageMakerDistributedType
from ...utils.constants import SAGEMAKER_PYTHON_VERSION, SAGEMAKER_PYTORCH_VERSION, SAGEMAKER_TRANSFORMERS_VERSION
hf_cache_home = os.path.expanduser(
os.environ.get("HF_HOME", os.path.join(os.environ.get("XDG_CACHE_HOME", "~/.cache"), "huggingface"))
)
cache_dir = os.path.join(hf_cache_home, "accelerate")
default_json_config_file = os.path.join(cache_dir, "default_config.yaml")
default_yaml_config_file = os.path.join(cache_dir, "default_config.yaml")
# For backward compatibility: the default config is the json one if it's the only existing file.
if os.path.isfile(default_yaml_config_file) or not os.path.isfile(default_json_config_file):
default_config_file = default_yaml_config_file
else:
default_config_file = default_json_config_file
def load_config_from_file(config_file):
if config_file is not None:
if not os.path.isfile(config_file):
raise FileNotFoundError(
f"The passed configuration file `{config_file}` does not exist. "
"Please pass an existing file to `accelerate launch`, or use the default one "
"created through `accelerate config` and run `accelerate launch` "
"without the `--config_file` argument."
)
else:
config_file = default_config_file
with open(config_file, encoding="utf-8") as f:
if config_file.endswith(".json"):
if (
json.load(f).get("compute_environment", ComputeEnvironment.LOCAL_MACHINE)
== ComputeEnvironment.LOCAL_MACHINE
):
config_class = ClusterConfig
else:
config_class = SageMakerConfig
return config_class.from_json_file(json_file=config_file)
else:
if (
yaml.safe_load(f).get("compute_environment", ComputeEnvironment.LOCAL_MACHINE)
== ComputeEnvironment.LOCAL_MACHINE
):
config_class = ClusterConfig
else:
config_class = SageMakerConfig
return config_class.from_yaml_file(yaml_file=config_file)
@dataclass
class BaseConfig:
compute_environment: ComputeEnvironment
distributed_type: Union[DistributedType, SageMakerDistributedType]
mixed_precision: str
use_cpu: bool
debug: bool
def to_dict(self):
result = self.__dict__
# For serialization, it's best to convert Enums to strings (or their underlying value type).
def _convert_enums(value):
if isinstance(value, Enum):
return value.value
if isinstance(value, dict):
if not bool(value):
return None
for key1, value1 in value.items():
value[key1] = _convert_enums(value1)
return value
for key, value in result.items():
result[key] = _convert_enums(value)
result = {k: v for k, v in result.items() if v is not None}
return result
@staticmethod
def process_config(config_dict):
"""
Processes `config_dict` and sets default values for any missing keys
"""
if "compute_environment" not in config_dict:
config_dict["compute_environment"] = ComputeEnvironment.LOCAL_MACHINE
if "distributed_type" not in config_dict:
raise ValueError("A `distributed_type` must be specified in the config file.")
if "num_processes" not in config_dict and config_dict["distributed_type"] == DistributedType.NO:
config_dict["num_processes"] = 1
if "mixed_precision" not in config_dict:
config_dict["mixed_precision"] = "fp16" if ("fp16" in config_dict and config_dict["fp16"]) else None
if "fp16" in config_dict: # Convert the config to the new format.
del config_dict["fp16"]
if "dynamo_backend" in config_dict: # Convert the config to the new format.
dynamo_backend = config_dict.pop("dynamo_backend")
config_dict["dynamo_config"] = {} if dynamo_backend == "NO" else {"dynamo_backend": dynamo_backend}
if "use_cpu" not in config_dict:
config_dict["use_cpu"] = False
if "debug" not in config_dict:
config_dict["debug"] = False
if "enable_cpu_affinity" not in config_dict:
config_dict["enable_cpu_affinity"] = False
return config_dict
@classmethod
def from_json_file(cls, json_file=None):
json_file = default_json_config_file if json_file is None else json_file
with open(json_file, encoding="utf-8") as f:
config_dict = json.load(f)
config_dict = cls.process_config(config_dict)
extra_keys = sorted(set(config_dict.keys()) - set(cls.__dataclass_fields__.keys()))
if len(extra_keys) > 0:
raise ValueError(
f"The config file at {json_file} had unknown keys ({extra_keys}), please try upgrading your `accelerate`"
" version or fix (and potentially remove) these keys from your config file."
)
return cls(**config_dict)
def to_json_file(self, json_file):
with open(json_file, "w", encoding="utf-8") as f:
content = json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
f.write(content)
@classmethod
def from_yaml_file(cls, yaml_file=None):
yaml_file = default_yaml_config_file if yaml_file is None else yaml_file
with open(yaml_file, encoding="utf-8") as f:
config_dict = yaml.safe_load(f)
config_dict = cls.process_config(config_dict)
extra_keys = sorted(set(config_dict.keys()) - set(cls.__dataclass_fields__.keys()))
if len(extra_keys) > 0:
raise ValueError(
f"The config file at {yaml_file} had unknown keys ({extra_keys}), please try upgrading your `accelerate`"
" version or fix (and potentially remove) these keys from your config file."
)
return cls(**config_dict)
def to_yaml_file(self, yaml_file):
with open(yaml_file, "w", encoding="utf-8") as f:
yaml.safe_dump(self.to_dict(), f)
def __post_init__(self):
if isinstance(self.compute_environment, str):
self.compute_environment = ComputeEnvironment(self.compute_environment)
if isinstance(self.distributed_type, str):
if self.compute_environment == ComputeEnvironment.AMAZON_SAGEMAKER:
self.distributed_type = SageMakerDistributedType(self.distributed_type)
else:
self.distributed_type = DistributedType(self.distributed_type)
if getattr(self, "dynamo_config", None) is None:
self.dynamo_config = {}
@dataclass
class ClusterConfig(BaseConfig):
num_processes: int = -1 # For instance if we use SLURM and the user manually passes it in
machine_rank: int = 0
num_machines: int = 1
gpu_ids: Optional[str] = None
main_process_ip: Optional[str] = None
main_process_port: Optional[int] = None
rdzv_backend: Optional[str] = "static"
same_network: Optional[bool] = False
main_training_function: str = "main"
enable_cpu_affinity: bool = False
# args for FP8 training
fp8_config: dict = None
# args for deepspeed_plugin
deepspeed_config: dict = None
# args for fsdp
fsdp_config: dict = None
# args for megatron_lm
megatron_lm_config: dict = None
# args for ipex
ipex_config: dict = None
# args for mpirun
mpirun_config: dict = None
# args for TPU
downcast_bf16: bool = False
# args for TPU pods
tpu_name: str = None
tpu_zone: str = None
tpu_use_cluster: bool = False
tpu_use_sudo: bool = False
command_file: str = None
commands: List[str] = None
tpu_vm: List[str] = None
tpu_env: List[str] = None
# args for dynamo
dynamo_config: dict = None
def __post_init__(self):
if self.deepspeed_config is None:
self.deepspeed_config = {}
if self.fsdp_config is None:
self.fsdp_config = {}
if self.megatron_lm_config is None:
self.megatron_lm_config = {}
if self.ipex_config is None:
self.ipex_config = {}
if self.mpirun_config is None:
self.mpirun_config = {}
if self.fp8_config is None:
self.fp8_config = {}
return super().__post_init__()
@dataclass
class SageMakerConfig(BaseConfig):
ec2_instance_type: str
iam_role_name: str
image_uri: Optional[str] = None
profile: Optional[str] = None
region: str = "us-east-1"
num_machines: int = 1
gpu_ids: str = "all"
base_job_name: str = f"accelerate-sagemaker-{num_machines}"
pytorch_version: str = SAGEMAKER_PYTORCH_VERSION
transformers_version: str = SAGEMAKER_TRANSFORMERS_VERSION
py_version: str = SAGEMAKER_PYTHON_VERSION
sagemaker_inputs_file: str = None
sagemaker_metrics_file: str = None
additional_args: dict = None
dynamo_config: dict = None
enable_cpu_affinity: bool = False
| 5 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/menu/keymap.py | # Copyright 2022 The HuggingFace Team and Brian Chao. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utilities relating to parsing raw characters from the keyboard, based on https://github.com/bchao1/bullet
"""
import os
import string
import sys
ARROW_KEY_FLAG = 1 << 8
KEYMAP = {
"tab": ord("\t"),
"newline": ord("\r"),
"esc": 27,
"up": 65 + ARROW_KEY_FLAG,
"down": 66 + ARROW_KEY_FLAG,
"right": 67 + ARROW_KEY_FLAG,
"left": 68 + ARROW_KEY_FLAG,
"mod_int": 91,
"undefined": sys.maxsize,
"interrupt": 3,
"insert": 50,
"delete": 51,
"pg_up": 53,
"pg_down": 54,
}
KEYMAP["arrow_begin"] = KEYMAP["up"]
KEYMAP["arrow_end"] = KEYMAP["left"]
if sys.platform == "win32":
WIN_CH_BUFFER = []
WIN_KEYMAP = {
b"\xe0H": KEYMAP["up"] - ARROW_KEY_FLAG,
b"\x00H": KEYMAP["up"] - ARROW_KEY_FLAG,
b"\xe0P": KEYMAP["down"] - ARROW_KEY_FLAG,
b"\x00P": KEYMAP["down"] - ARROW_KEY_FLAG,
b"\xe0M": KEYMAP["right"] - ARROW_KEY_FLAG,
b"\x00M": KEYMAP["right"] - ARROW_KEY_FLAG,
b"\xe0K": KEYMAP["left"] - ARROW_KEY_FLAG,
b"\x00K": KEYMAP["left"] - ARROW_KEY_FLAG,
}
for i in range(10):
KEYMAP[str(i)] = ord(str(i))
def get_raw_chars():
"Gets raw characters from inputs"
if os.name == "nt":
import msvcrt
encoding = "mbcs"
# Flush the keyboard buffer
while msvcrt.kbhit():
msvcrt.getch()
if len(WIN_CH_BUFFER) == 0:
# Read the keystroke
ch = msvcrt.getch()
# If it is a prefix char, get second part
if ch in (b"\x00", b"\xe0"):
ch2 = ch + msvcrt.getch()
# Translate actual Win chars to bullet char types
try:
chx = chr(WIN_KEYMAP[ch2])
WIN_CH_BUFFER.append(chr(KEYMAP["mod_int"]))
WIN_CH_BUFFER.append(chx)
if ord(chx) in (
KEYMAP["insert"] - 1 << 9,
KEYMAP["delete"] - 1 << 9,
KEYMAP["pg_up"] - 1 << 9,
KEYMAP["pg_down"] - 1 << 9,
):
WIN_CH_BUFFER.append(chr(126))
ch = chr(KEYMAP["esc"])
except KeyError:
ch = ch2[1]
else:
ch = ch.decode(encoding)
else:
ch = WIN_CH_BUFFER.pop(0)
elif os.name == "posix":
import termios
import tty
fd = sys.stdin.fileno()
old_settings = termios.tcgetattr(fd)
try:
tty.setraw(fd)
ch = sys.stdin.read(1)
finally:
termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
return ch
def get_character():
"Gets a character from the keyboard and returns the key code"
char = get_raw_chars()
if ord(char) in [KEYMAP["interrupt"], KEYMAP["newline"]]:
return char
elif ord(char) == KEYMAP["esc"]:
combo = get_raw_chars()
if ord(combo) == KEYMAP["mod_int"]:
key = get_raw_chars()
if ord(key) >= KEYMAP["arrow_begin"] - ARROW_KEY_FLAG and ord(key) <= KEYMAP["arrow_end"] - ARROW_KEY_FLAG:
return chr(ord(key) + ARROW_KEY_FLAG)
else:
return KEYMAP["undefined"]
else:
return get_raw_chars()
else:
if char in string.printable:
return char
else:
return KEYMAP["undefined"]
| 6 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/menu/input.py | # Copyright 2022 The HuggingFace Team and Brian Chao. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This file contains utilities for handling input from the user and registering specific keys to specific functions,
based on https://github.com/bchao1/bullet
"""
from typing import List
from .keymap import KEYMAP, get_character
def mark(key: str):
"""
Mark the function with the key code so it can be handled in the register
"""
def decorator(func):
handle = getattr(func, "handle_key", [])
handle += [key]
func.handle_key = handle
return func
return decorator
def mark_multiple(*keys: List[str]):
"""
Mark the function with the key codes so it can be handled in the register
"""
def decorator(func):
handle = getattr(func, "handle_key", [])
handle += keys
func.handle_key = handle
return func
return decorator
class KeyHandler(type):
"""
Metaclass that adds the key handlers to the class
"""
def __new__(cls, name, bases, attrs):
new_cls = super().__new__(cls, name, bases, attrs)
if not hasattr(new_cls, "key_handler"):
new_cls.key_handler = {}
new_cls.handle_input = KeyHandler.handle_input
for value in attrs.values():
handled_keys = getattr(value, "handle_key", [])
for key in handled_keys:
new_cls.key_handler[key] = value
return new_cls
@staticmethod
def handle_input(cls):
"Finds and returns the selected character if it exists in the handler"
char = get_character()
if char != KEYMAP["undefined"]:
char = ord(char)
handler = cls.key_handler.get(char)
if handler:
cls.current_selection = char
return handler(cls)
else:
return None
def register(cls):
"""Adds KeyHandler metaclass to the class"""
return KeyHandler(cls.__name__, cls.__bases__, cls.__dict__.copy())
| 7 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/menu/cursor.py | # Copyright 2022 The HuggingFace Team and Brian Chao. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A utility for showing and hiding the terminal cursor on Windows and Linux, based on https://github.com/bchao1/bullet
"""
import os
import sys
from contextlib import contextmanager
# Windows only
if os.name == "nt":
import ctypes
import msvcrt # noqa
class CursorInfo(ctypes.Structure):
# _fields is a specific attr expected by ctypes
_fields_ = [("size", ctypes.c_int), ("visible", ctypes.c_byte)]
def hide_cursor():
if os.name == "nt":
ci = CursorInfo()
handle = ctypes.windll.kernel32.GetStdHandle(-11)
ctypes.windll.kernel32.GetConsoleCursorInfo(handle, ctypes.byref(ci))
ci.visible = False
ctypes.windll.kernel32.SetConsoleCursorInfo(handle, ctypes.byref(ci))
elif os.name == "posix":
sys.stdout.write("\033[?25l")
sys.stdout.flush()
def show_cursor():
if os.name == "nt":
ci = CursorInfo()
handle = ctypes.windll.kernel32.GetStdHandle(-11)
ctypes.windll.kernel32.GetConsoleCursorInfo(handle, ctypes.byref(ci))
ci.visible = True
ctypes.windll.kernel32.SetConsoleCursorInfo(handle, ctypes.byref(ci))
elif os.name == "posix":
sys.stdout.write("\033[?25h")
sys.stdout.flush()
@contextmanager
def hide():
"Context manager to hide the terminal cursor"
try:
hide_cursor()
yield
finally:
show_cursor()
| 8 |
0 | hf_public_repos/accelerate/src/accelerate/commands | hf_public_repos/accelerate/src/accelerate/commands/menu/helpers.py | # Copyright 2022 The HuggingFace Team and Brian Chao. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A variety of helper functions and constants when dealing with terminal menu choices, based on
https://github.com/bchao1/bullet
"""
import enum
import shutil
import sys
TERMINAL_WIDTH, _ = shutil.get_terminal_size()
CURSOR_TO_CHAR = {"UP": "A", "DOWN": "B", "RIGHT": "C", "LEFT": "D"}
class Direction(enum.Enum):
UP = 0
DOWN = 1
def forceWrite(content, end=""):
sys.stdout.write(str(content) + end)
sys.stdout.flush()
def writeColor(content, color, end=""):
forceWrite(f"\u001b[{color}m{content}\u001b[0m", end)
def reset_cursor():
forceWrite("\r")
def move_cursor(num_lines: int, direction: str):
forceWrite(f"\033[{num_lines}{CURSOR_TO_CHAR[direction.upper()]}")
def clear_line():
forceWrite(" " * TERMINAL_WIDTH)
reset_cursor()
def linebreak():
reset_cursor()
forceWrite("-" * TERMINAL_WIDTH)
| 9 |
0 | hf_public_repos | hf_public_repos/blog/ort-accelerating-hf-models.md | ---
title: "Accelerating over 130,000 Hugging Face models with ONNX Runtime"
thumbnail: /blog/assets/ort_accelerating_hf_models/thumbnail.png
authors:
- user: sschoenmeyer
guest: true
- user: mfuntowicz
---
# Accelerating over 130,000 Hugging Face models with ONNX Runtime
## What is ONNX Runtime?
ONNX Runtime is a cross-platform machine learning tool that can be used to accelerate a wide variety of models, particularly those with ONNX support.
## Hugging Face ONNX Runtime Support
There are over 130,000 ONNX-supported models on Hugging Face, an open source community that allows users to build, train, and deploy hundreds of thousands of publicly available machine learning models.
These ONNX-supported models, which include many increasingly popular large language models (LLMs) and cloud models, can leverage ONNX Runtime to improve performance, along with other benefits.
For example, using ONNX Runtime to accelerate the whisper-tiny model can improve average latency per inference, with an up to 74.30% gain over PyTorch.
ONNX Runtime works closely with Hugging Face to ensure that the most popular models on the site are supported.
In total, over 90 Hugging Face model architectures are supported by ONNX Runtime, including the 11 most popular architectures (where popularity is determined by the corresponding number of models uploaded to the Hugging Face Hub):
| Model Architecture | Approximate No. of Models |
|:------------------:|:-------------------------:|
| BERT | 28180 |
| GPT2 | 14060 |
| DistilBERT | 11540 |
| RoBERTa | 10800 |
| T5 | 10450 |
| Wav2Vec2 | 6560 |
| Stable-Diffusion | 5880 |
| XLM-RoBERTa | 5100 |
| Whisper | 4400 |
| BART | 3590 |
| Marian | 2840 |
## Learn More
To learn more about accelerating Hugging Face models with ONNX Runtime, check out our recent post on the [Microsoft Open Source Blog](https://cloudblogs.microsoft.com/opensource/2023/10/04/accelerating-over-130000-hugging-face-models-with-onnx-runtime/). | 0 |
0 | hf_public_repos | hf_public_repos/blog/habana-gaudi-2-bloom.md | ---
title: "Fast Inference on Large Language Models: BLOOMZ on Habana Gaudi2 Accelerator"
thumbnail: /blog/assets/habana-gaudi-2-bloom/thumbnail.png
authors:
- user: regisss
---
# Fast Inference on Large Language Models: BLOOMZ on Habana Gaudi2 Accelerator
This article will show you how to easily deploy large language models with hundreds of billions of parameters like BLOOM on [Habana® Gaudi®2](https://habana.ai/training/gaudi2/) using 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/index), which is the bridge between Gaudi2 and the 🤗 Transformers library. As demonstrated in the benchmark presented in this post, this will enable you to **run inference faster than with any GPU currently available on the market**.
As models get bigger and bigger, deploying them into production to run inference has become increasingly challenging. Both hardware and software have seen a lot of innovations to address these challenges, so let's dive in to see how to efficiently overcome them!
## BLOOMZ
[BLOOM](https://arxiv.org/abs/2211.05100) is a 176-billion-parameter autoregressive model that was trained to complete sequences of text. It can handle 46 different languages and 13 programming languages. Designed and trained as part of the [BigScience](https://bigscience.huggingface.co/) initiative, BLOOM is an open-science project that involved a large number of researchers and engineers all over the world. More recently, another model with the exact same architecture was released: [BLOOMZ](https://arxiv.org/abs/2211.01786), which is a fine-tuned version of BLOOM on several tasks leading to better generalization and zero-shot[^1] capabilities.
Such large models raise new challenges in terms of memory and speed for both [training](https://huggingface.co/blog/bloom-megatron-deepspeed) and [inference](https://huggingface.co/blog/bloom-inference-optimization). Even in 16-bit precision, one instance requires 352 GB to fit! You will probably struggle to find any device with so much memory at the moment, but state-of-the-art hardware like Habana Gaudi2 does make it possible to perform inference on BLOOM and BLOOMZ models with low latencies.
## Habana Gaudi2
[Gaudi2](https://habana.ai/training/gaudi2/) is the second-generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices (called Habana Processing Units, or HPUs) with 96GB of memory each, which provides room to make very large models fit in. However, hosting the model is not very interesting if the computation is slow. Fortunately, Gaudi2 shines on that aspect: it differs from GPUs in that its architecture enables the accelerator to perform General Matrix Multiplication (GeMM) and other operations in parallel, which speeds up deep learning workflows. These features make Gaudi2 a great candidate for LLM training and inference.
Habana's SDK, SynapseAI™, supports PyTorch and DeepSpeed for accelerating LLM training and inference. The [SynapseAI graph compiler](https://docs.habana.ai/en/latest/Gaudi_Overview/SynapseAI_Software_Suite.html#graph-compiler-and-runtime) will optimize the execution of the operations accumulated in the graph (e.g. operator fusion, data layout management, parallelization, pipelining and memory management, and graph-level optimizations).
Moreover, support for [HPU graphs](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html) and [DeepSpeed-inference](https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/Inference_Using_DeepSpeed.html) have just recently been introduced in SynapseAI, and these are well-suited for latency-sensitive applications as shown in our benchmark below.
All these features are integrated into the 🤗 [Optimum Habana](https://github.com/huggingface/optimum-habana) library so that deploying your model on Gaudi is very simple. Check out the quick-start page [here](https://huggingface.co/docs/optimum/habana/quickstart).
If you would like to get access to Gaudi2, go to the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html) and follow [this guide](https://huggingface.co/blog/habana-gaudi-2-benchmark#how-to-get-access-to-gaudi2).
## Benchmarks
In this section, we are going to provide an early benchmark of BLOOMZ on Gaudi2, first-generation Gaudi and Nvidia A100 80GB. Although these devices have quite a lot of memory, the model is so large that a single device is not enough to contain a single instance of BLOOMZ. To solve this issue, we are going to use [DeepSpeed](https://www.deepspeed.ai/), which is a deep learning optimization library that enables many memory and speed improvements to accelerate the model and make it fit the device. In particular, we rely here on [DeepSpeed-inference](https://arxiv.org/abs/2207.00032): it introduces several features such as [model (or pipeline) parallelism](https://huggingface.co/blog/bloom-megatron-deepspeed#pipeline-parallelism) to make the most of the available devices. For Gaudi2, we use [Habana's DeepSpeed fork](https://github.com/HabanaAI/deepspeed) that adds support for HPUs.
### Latency
We measured latencies (batch of one sample) for two different sizes of BLOOMZ, both with multi-billion parameters:
- [176 billion](https://huggingface.co/bigscience/bloomz) parameters
- [7 billion](https://huggingface.co/bigscience/bloomz-7b1) parameters
Runs were performed with DeepSpeed-inference in 16-bit precision with 8 devices and using a [key-value cache](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/bloom#transformers.BloomForCausalLM.forward.use_cache). Note that while [CUDA graphs](https://developer.nvidia.com/blog/cuda-graphs/) are not currently compatible with model parallelism in DeepSpeed (DeepSpeed v0.8.2, see [here](https://github.com/microsoft/DeepSpeed/blob/v0.8.2/deepspeed/inference/engine.py#L158)), HPU graphs are supported in Habana's DeepSpeed fork. All benchmarks are doing [greedy generation](https://huggingface.co/blog/how-to-generate#greedy-search) of 100 token outputs. The input prompt is:
> "DeepSpeed is a machine learning framework"
which consists of 7 tokens with BLOOM's tokenizer.
The results for inference latency are displayed in the table below (the unit is *seconds*).
| Model | Number of devices | Gaudi2 latency (seconds) | A100-80GB latency (seconds) | First-gen Gaudi latency (seconds) |
|:-----------:|:-----------------:|:-------------------------:|:-----------------:|:----------------------------------:|
| BLOOMZ | 8 | 3.103 | 4.402 | / |
| BLOOMZ-7B | 8 | 0.734 | 2.417 | 3.321 |
| BLOOMZ-7B | 1 | 0.772 | 2.119 | 2.387 |
*Update: the numbers above were updated with the releases of Optimum Habana 1.6 and SynapseAI 1.10, leading to a* x*1.42 speedup on BLOOMZ with Gaudi2 compared to A100.*
The Habana team recently introduced support for DeepSpeed-inference in SynapseAI 1.8, and thereby quickly enabled inference for 100+ billion parameter models. **For the 176-billion-parameter checkpoint, Gaudi2 is 1.42x faster than A100 80GB**. Smaller checkpoints present interesting results too. **Gaudi2 is 2.89x faster than A100 for BLOOMZ-7B!** It is also interesting to note that it manages to benefit from model parallelism whereas A100 is faster on a single device.
We also ran these models on first-gen Gaudi. While it is slower than Gaudi2, it is interesting from a price perspective as a DL1 instance on AWS costs approximately 13\$ per hour. Latency for BLOOMZ-7B on first-gen Gaudi is 2.387 seconds. Thus, **first-gen Gaudi offers for the 7-billion checkpoint a better price-performance ratio than A100** which costs more than 30\$ per hour!
We expect the Habana team will optimize the performance of these models in the upcoming SynapseAI releases. For example, in our last benchmark, we saw that [Gaudi2 performs Stable Diffusion inference 2.2x faster than A100](https://huggingface.co/blog/habana-gaudi-2-benchmark#generating-images-from-text-with-stable-diffusion) and this has since been improved further to 2.37x with the latest optimizations provided by Habana. We will update these numbers as new versions of SynapseAI are released and integrated within Optimum Habana.
### Running inference on a complete dataset
The script we wrote enables using your model to complete sentences over a whole dataset. This is useful to try BLOOMZ inference on Gaudi2 on your own data.
Here is an example with the [*tldr_news*](https://huggingface.co/datasets/JulesBelveze/tldr_news/viewer/all/test) dataset. It contains both the headline and content of several articles (you can visualize it on the Hugging Face Hub). We kept only the *content* column and truncated each sample to the first 16 tokens so that the model generates the rest of the sequence with 50 new tokens. The first five samples look like:
```
Batch n°1
Input: ['Facebook has released a report that shows what content was most widely viewed by Americans between']
Output: ['Facebook has released a report that shows what content was most widely viewed by Americans between January and June of this year. The report, which is based on data from the company’s mobile advertising platform, shows that the most popular content on Facebook was news, followed by sports, entertainment, and politics. The report also shows that the most']
--------------------------------------------------------------------------------------------------
Batch n°2
Input: ['A quantum effect called superabsorption allows a collection of molecules to absorb light more']
Output: ['A quantum effect called superabsorption allows a collection of molecules to absorb light more strongly than the sum of the individual absorptions of the molecules. This effect is due to the coherent interaction of the molecules with the electromagnetic field. The superabsorption effect has been observed in a number of systems, including liquid crystals, liquid crystals in']
--------------------------------------------------------------------------------------------------
Batch n°3
Input: ['A SpaceX Starship rocket prototype has exploded during a pressure test. It was']
Output: ['A SpaceX Starship rocket prototype has exploded during a pressure test. It was the first time a Starship prototype had been tested in the air. The explosion occurred at the SpaceX facility in Boca Chica, Texas. The Starship prototype was being tested for its ability to withstand the pressure of flight. The explosion occurred at']
--------------------------------------------------------------------------------------------------
Batch n°4
Input: ['Scalene is a high-performance CPU and memory profiler for Python.']
Output: ['Scalene is a high-performance CPU and memory profiler for Python. It is designed to be a lightweight, portable, and easy-to-use profiler. Scalene is a Python package that can be installed on any platform that supports Python. Scalene is a lightweight, portable, and easy-to-use profiler']
--------------------------------------------------------------------------------------------------
Batch n°5
Input: ['With the rise of cheap small "Cube Satellites", startups are now']
Output: ['With the rise of cheap small "Cube Satellites", startups are now able to launch their own satellites for a fraction of the cost of a traditional launch. This has led to a proliferation of small satellites, which are now being used for a wide range of applications. The most common use of small satellites is for communications,']
```
In the next section, we explain how to use the script we wrote to perform this benchmark or to apply it on any dataset you like from the Hugging Face Hub!
### How to reproduce these results?
The script used for benchmarking BLOOMZ on Gaudi2 and first-gen Gaudi is available [here](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation). Before running it, please make sure that the latest versions of SynapseAI and the Gaudi drivers are installed following [the instructions given by Habana](https://docs.habana.ai/en/latest/Installation_Guide/index.html).
Then, run the following:
```bash
git clone https://github.com/huggingface/optimum-habana.git
cd optimum-habana && pip install . && cd examples/text-generation
pip install git+https://github.com/HabanaAI/[email protected]
```
Finally, you can launch the script as follows:
```bash
python ../gaudi_spawn.py --use_deepspeed --world_size 8 run_generation.py --model_name_or_path bigscience/bloomz --use_hpu_graphs --use_kv_cache --max_new_tokens 100
```
For multi-node inference, you can follow [this guide](https://huggingface.co/docs/optimum/habana/usage_guides/multi_node_training) from the documentation of Optimum Habana.
You can also load any dataset from the Hugging Face Hub to get prompts that will be used for generation using the argument `--dataset_name my_dataset_name`.
This benchmark was performed with Transformers v4.28.1, SynapseAI v1.9.0 and Optimum Habana v1.5.0.
For GPUs, [here](https://github.com/huggingface/transformers-bloom-inference/blob/main/bloom-inference-scripts/bloom-ds-inference.py) is the script that led to the results that were previously presented in [this blog post](https://huggingface.co/blog/bloom-inference-pytorch-scripts) (and [here](https://github.com/huggingface/transformers-bloom-inference/tree/main/bloom-inference-scripts#deepspeed-inference) are the instructions to use it). To use CUDA graphs, static shapes are necessary and this is not supported in 🤗 Transformers. You can use [this repo](https://github.com/HabanaAI/Model-References/tree/1.8.0/PyTorch/nlp/bloom) written by the Habana team to enable them.
## Conclusion
We see in this article that **Habana Gaudi2 performs BLOOMZ inference faster than Nvidia A100 80GB**. And there is no need to write a complicated script as 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/index) provides easy-to-use tools to run inference with multi-billion-parameter models on HPUs. Future releases of Habana's SynapseAI SDK are expected to speed up performance, so we will update this benchmark regularly as LLM inference optimizations on SynapseAI continue to advance. We are also looking forward to the performance benefits that will come with FP8 inference on Gaudi2.
We also presented the results achieved with first-generation Gaudi. For smaller models, it can perform on par with or even better than A100 for almost a third of its price. It is a good alternative option to using GPUs for running inference with such a big model like BLOOMZ.
If you are interested in accelerating your Machine Learning training and inference workflows using the latest AI hardware accelerators and software libraries, check out our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership and contact them here](https://huggingface.co/hardware/habana). To learn more about Hugging Face efforts to make AI hardware accelerators easy to use, check out our [Hardware Partner Program](https://huggingface.co/hardware).
### Related Topics
- [Faster Training and Inference: Habana Gaudi-2 vs Nvidia A100 80GB](https://huggingface.co/blog/habana-gaudi-2-benchmark)
- [Leverage DeepSpeed to Train Faster and Cheaper Large Scale Transformer Models with Hugging Face and Habana Labs Gaudi](https://developer.habana.ai/events/leverage-deepspeed-to-train-faster-and-cheaper-large-scale-transformer-models-with-hugging-face-and-habana-labs-gaudi/)
---
Thanks for reading! If you have any questions, feel free to contact me, either through [Github](https://github.com/huggingface/optimum-habana) or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [LinkedIn](https://www.linkedin.com/in/regispierrard/).
[^1]: “Zero-shot” refers to the ability of a model to complete a task on new or unseen input data, i.e. without having been provided any training examples of this kind of data. We provide the model with a prompt and a sequence of text that describes what we want our model to do, in natural language. Zero-shot classification excludes any examples of the desired task being completed. This differs from single or few-shot classification, as these tasks include a single or a few examples of the selected task.
| 1 |
0 | hf_public_repos | hf_public_repos/blog/diffusers-2nd-month.md | ---
title: What's new in Diffusers? 🎨
thumbnail: /blog/assets/102_diffusers_2nd_month/inpainting.png
authors:
- user: osanseviero
---
# What's new in Diffusers? 🎨
A month and a half ago we released `diffusers`, a library that provides a modular toolbox for diffusion models across modalities. A couple of weeks later, we released support for Stable Diffusion, a high quality text-to-image model, with a free demo for anyone to try out. Apart from burning lots of GPUs, in the last three weeks the team has decided to add one or two new features to the library that we hope the community enjoys! This blog post gives a high-level overview of the new features in `diffusers` version 0.3! Remember to give a ⭐ to the [GitHub repository](https://github.com/huggingface/diffusers).
- [Image to Image pipelines](#image-to-image-pipeline)
- [Textual Inversion](#textual-inversion)
- [Inpainting](#experimental-inpainting-pipeline)
- [Optimizations for Smaller GPUs](#optimizations-for-smaller-gpus)
- [Run on Mac](#diffusers-in-mac-os)
- [ONNX Exporter](#experimental-onnx-exporter-and-pipeline)
- [New docs](#new-docs)
- [Community](#community)
- [Generate videos with SD latent space](#stable-diffusion-videos)
- [Model Explainability](#diffusers-interpret)
- [Japanese Stable Diffusion](#japanese-stable-diffusion)
- [High quality fine-tuned model](#waifu-diffusion)
- [Cross Attention Control with Stable Diffusion](#cross-attention-control)
- [Reusable seeds](#reusable-seeds)
## Image to Image pipeline
One of the most requested features was to have image to image generation. This pipeline allows you to input an image and a prompt, and it will generate an image based on that!
Let's see some code based on the official Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb).
```python
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Download an initial image
# ...
init_image = preprocess(init_img)
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]
```
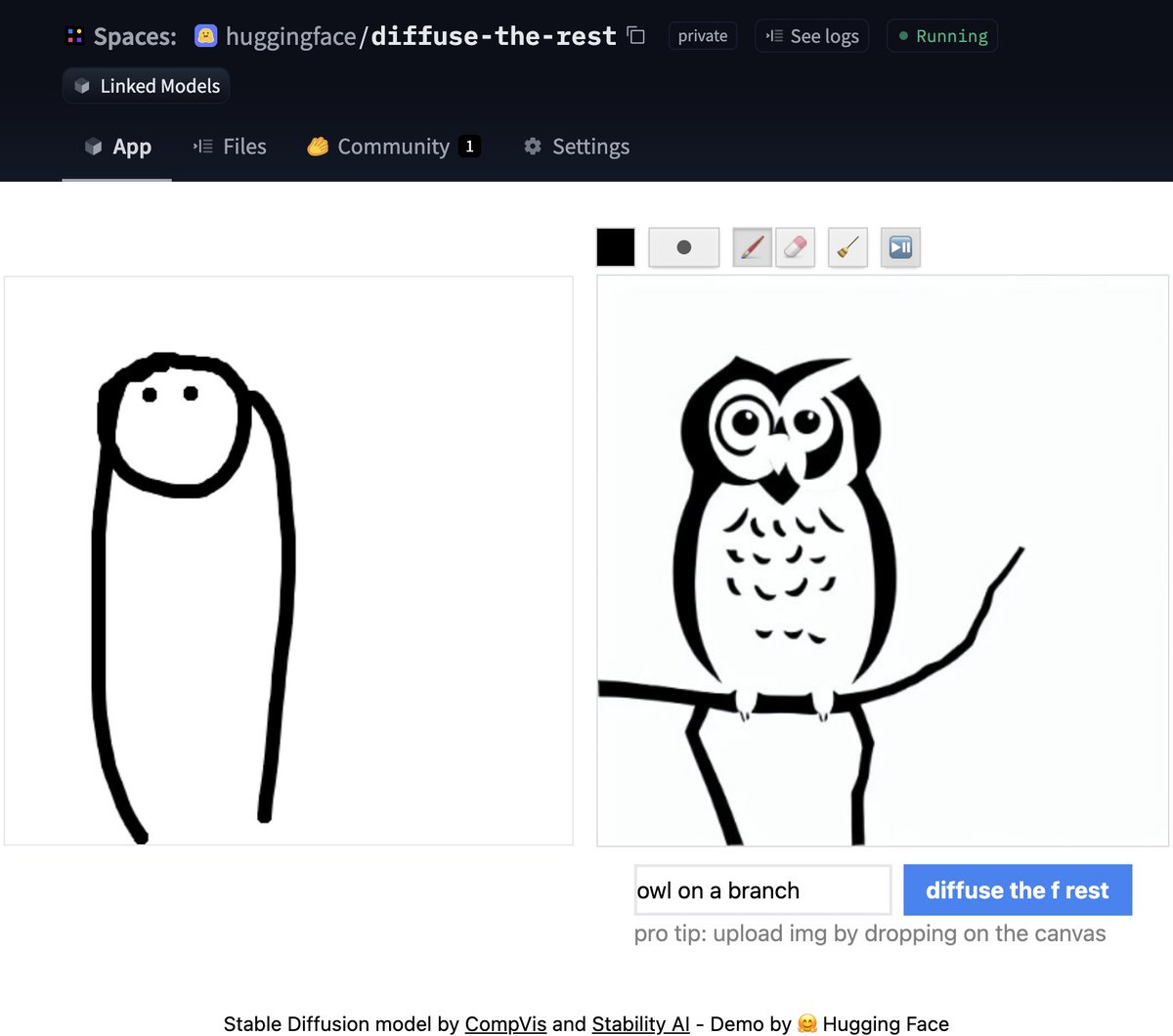
Don't have time for code? No worries, we also created a [Space demo](https://huggingface.co/spaces/huggingface/diffuse-the-rest) where you can try it out directly
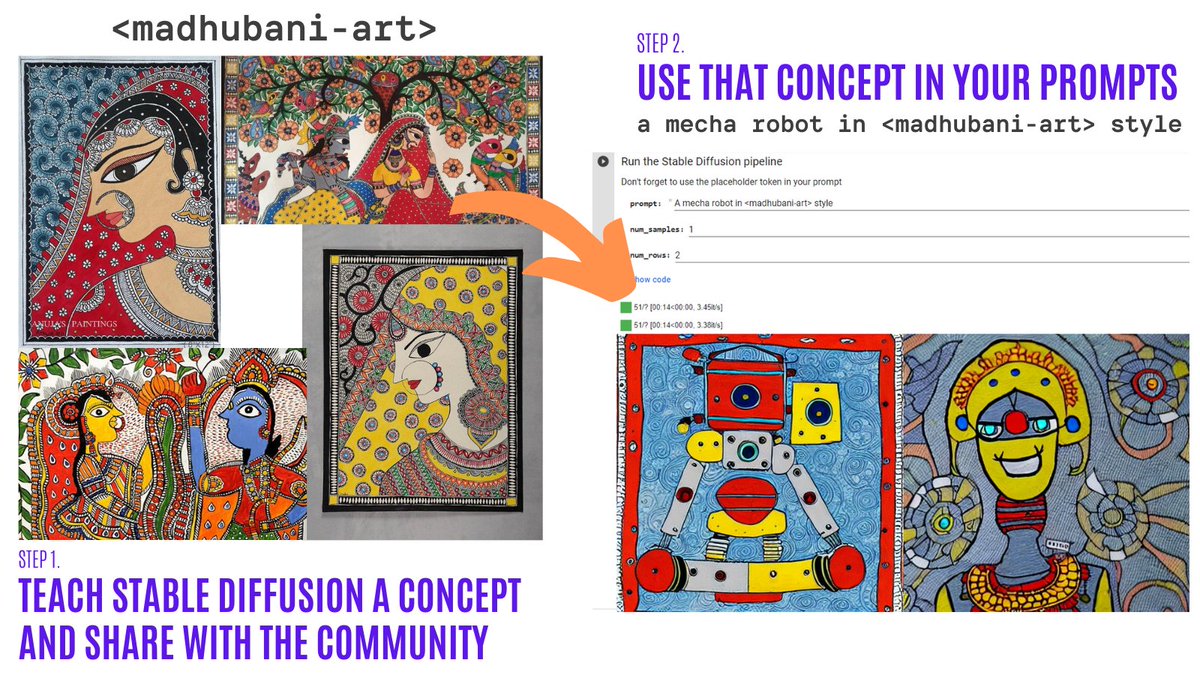
## Textual Inversion
Textual Inversion lets you personalize a Stable Diffusion model on your own images with just 3-5 samples. With this tool, you can train a model on a concept, and then share the concept with the rest of the community!
In just a couple of days, the community shared over 200 concepts! Check them out!
* [Organization](https://huggingface.co/sd-concepts-library) with the concepts.
* [Navigator Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_textual_inversion_library_navigator.ipynb): Browse visually and use over 150 concepts created by the community.
* [Training Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb): Teach Stable Diffusion a new concept and share it with the rest of the community.
* [Inference Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb): Run Stable Diffusion with the learned concepts.
## Experimental inpainting pipeline
Inpainting allows to provide an image, then select an area in the image (or provide a mask), and use Stable Diffusion to replace the mask. Here is an example:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/inpainting.png" alt="Example inpaint of owl being generated from an initial image and a prompt"/>
</figure>
You can try out a minimal Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) or check out the code below. A demo is coming soon!
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["a cat sitting on a bench"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).images
```
Please note this is experimental, so there is room for improvement.
## Optimizations for smaller GPUs
After some improvements, the diffusion models can take much less VRAM. 🔥 For example, Stable Diffusion only takes 3.2GB! This yields the exact same results at the expense of 10% of speed. Here is how to use these optimizations
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()
```
This is super exciting as this will reduce even more the barrier to use these models!
## Diffusers in Mac OS
🍎 That's right! Another widely requested feature was just released! Read the full instructions in the [official docs](https://huggingface.co/docs/diffusers/optimization/mps) (including performance comparisons, specs, and more).
Using the PyTorch mps device, people with M1/M2 hardware can run inference with Stable Diffusion. 🤯 This requires minimal setup for users, try it out!
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
## Experimental ONNX exporter and pipeline
The new experimental pipeline allows users to run Stable Diffusion on any hardware that supports ONNX. Here is an example of how to use it (note that the `onnx` revision is being used)
```python
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
Alternatively, you can also convert your SD checkpoints to ONNX directly with the exporter script.
```
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"
```
## New docs
All of the previous features are very cool. As maintainers of open-source libraries, we know about the importance of high quality documentation to make it as easy as possible for anyone to try out the library.
💅 Because of this, we did a Docs sprint and we're very excited to do a first release of our [documentation](https://huggingface.co/docs/diffusers/v0.3.0/en/index). This is a first version, so there are many things we plan to add (and contributions are always welcome!).
Some highlights of the docs:
* Techniques for [optimization](https://huggingface.co/docs/diffusers/optimization/fp16)
* The [training overview](https://huggingface.co/docs/diffusers/training/overview)
* A [contributing guide](https://huggingface.co/docs/diffusers/conceptual/contribution)
* In-depth API docs for [schedulers](https://huggingface.co/docs/diffusers/api/schedulers)
* In-depth API docs for [pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview)
## Community
And while we were doing all of the above, the community did not stay idle! Here are some highlights (although not exhaustive) of what has been done out there
### Stable Diffusion Videos
Create 🔥 videos with Stable Diffusion by exploring the latent space and morphing between text prompts. You can:
* Dream different versions of the same prompt
* Morph between different prompts
The [Stable Diffusion Videos](https://github.com/nateraw/stable-diffusion-videos) tool is pip-installable, comes with a Colab notebook and a Gradio notebook, and is super easy to use!
Here is an example
```python
from stable_diffusion_videos import walk
video_path = walk(['a cat', 'a dog'], [42, 1337], num_steps=3, make_video=True)
```
### Diffusers Interpret
[Diffusers interpret](https://github.com/JoaoLages/diffusers-interpret) is an explainability tool built on top of `diffusers`. It has cool features such as:
* See all the images in the diffusion process
* Analyze how each token in the prompt influences the generation
* Analyze within specified bounding boxes if you want to understand a part of the image
(Image from the tool repository)
```python
# pass pipeline to the explainer class
explainer = StableDiffusionPipelineExplainer(pipe)
# generate an image with `explainer`
prompt = "Corgi with the Eiffel Tower"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, attribution_percentage)
#[('corgi', 40),
# ('with', 5),
# ('the', 5),
# ('eiffel', 25),
# ('tower', 25)]
```
### Japanese Stable Diffusion
The name says it all! The goal of JSD was to train a model that also captures information about the culture, identity and unique expressions. It was trained with 100 million images with Japanese captions. You can read more about how the model was trained in the [model card](https://huggingface.co/rinna/japanese-stable-diffusion)
### Waifu Diffusion
[Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion) is a fine-tuned SD model for high-quality anime images generation.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/waifu.png" alt="Images of high quality anime"/>
</figure>
(Image from the tool repository)
### Cross Attention Control
[Cross Attention Control](https://github.com/bloc97/CrossAttentionControl) allows fine control of the prompts by modifying the attention maps of the diffusion models. Some cool things you can do:
* Replace a target in the prompt (e.g. replace cat by dog)
* Reduce or increase the importance of words in the prompt (e.g. if you want less attention to be given to "rocks")
* Easily inject styles
And much more! Check out the repo.
### Reusable Seeds
One of the most impressive early demos of Stable Diffusion was the reuse of seeds to tweak images. The idea is to use the seed of an image of interest to generate a new image, with a different prompt. This yields some cool results! Check out the [Colab](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
## Thanks for reading!
I hope you enjoy reading this! Remember to give a Star in our [GitHub Repository](https://github.com/huggingface/diffusers) and join the [Hugging Face Discord Server](https://hf.co/join/discord), where we have a category of channels just for Diffusion models. Over there the latest news in the library are shared!
Feel free to open issues with feature requests and bug reports! Everything that has been achieved couldn't have been done without such an amazing community.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/sovereign-data-solution-case-study.md | ---
title: "Banque des Territoires (CDC Group) x Polyconseil x Hugging Face: Enhancing a Major French Environmental Program with a Sovereign Data Solution"
thumbnail: /blog/assets/78_ml_director_insights/cdc_poly_hf.png
authors:
- user: AnthonyTruchet-Polyconseil
guest: true
- user: jcailton
guest: true
- user: StacyRamaherison
guest: true
- user: florentgbelidji
- user: Violette
---
# Banque des Territoires (CDC Group) x Polyconseil x Hugging Face: Enhancing a Major French Environmental Program with a Sovereign Data Solution
## Table of contents
- Case Study in English - Banque des Territoires (CDC Group) x Polyconseil x Hugging Face: Enhancing a Major French Environmental Program with a Sovereign Data Solution
- [Executive summary](#executive-summary)
- [The power of RAG to meet environmental objectives](#power-of-rag)
- [Industrializing while ensuring performance and sovereignty](#industrializing-ensuring-performance-sovereignty)
- [A modular solution to respond to a dynamic sector](#modular-solution-to-respond-to-a-dynamic-sector)
- [Key Success Factors Success Factors](#key-success-factors)
- Case Study in French - Banque des Territoires (Groupe CDC) x Polyconseil x Hugging Face : améliorer un programme environnemental français majeur grâce à une solution data souveraine
- [Résumé](#resume)
- [La puissance du RAG au service d'objectifs environnementaux](#puissance-rag)
- [Industrialiser en garantissant performance et souveraineté](#industrialiser-garantissant-performance-souverainete)
- [Une solution modulaire pour répondre au dynamisme du secteur](#solution-modulaire-repondre-dynamisme-secteur)
- [Facteurs clés de succès](#facteurs-cles-succes)
<a name="executive-summary"></a>
## Executive summary
The collaboration initiated last January between Banque des Territoires (part of the Caisse des Dépôts et Consignations group), Polyconseil, and Hugging Face illustrates the possibility of merging the potential of generative AI with the pressing demands of data sovereignty.
As the project's first phase has just finished, the tool developed is ultimately intended to support the national strategy for schools' environmental renovation. Specifically, the solution aims to optimize the support framework of Banque des Territoires’ EduRénov program, which is dedicated to the ecological renovation of 10,000 public school facilities (nurseries, grade/middle/high schools, and universities).
This article shares some key insights from a successful co-development between:
- A data science team from Banque des Territoires’ Loan Department, along with EduRénov’ Director ;
- A multidisciplinary team from Polyconseil, including developers, DevOps, and Product Managers ;
- A Hugging Face expert in Machine Learning and AI solutions deployment.
<a name="power-of-rag"></a>
## The power of RAG to meet environmental objectives
Launched by Banque des Territoires (BdT), EduRénov is a flagship program within France's ecological and energy transformation strategy. It aims to simplify, support, and finance the energetic renovation of public school buildings. Its ambition is reflected in challenging objectives: assisting 10,000 renovation projects, from nurseries to universities - representing 20% of the national pool of infrastructures - to achieve 40% energy savings within 5 years. Banque des Territoires mobilizes unprecedented means to meet this goal: 2 billion euros in loans to finance the work and 50 million euros dedicated to preparatory engineering. After just one year of operation, the program signed nearly 2,000 projects but aims to expand further. As program director Nicolas Turcat emphasizes:
> _EduRénov has found its projects and cruising speed; now we will enhance the relationship quality with local authorities while seeking many new projects. We share a common conviction with Polyconseil and Hugging Face: the challenge of ecological transition will be won by scaling up our actions._
The success of the EduRénov program involves numerous exchanges - notably emails - between experts from Banque des Territoires, Caisse des Dépôts Group (CDC) leading the program, and the communities owning the involved buildings. These interactions are crucial but particularly time-consuming and repetitive. However, responses to these emails rely on a large documentation shared between all BdT experts. Therefore, a Retrieval Augmented Generation (RAG) solution to facilitate these exchanges is particularly appropriate.
Since the launch of ChatGPT and the growing craze around generative AI, many companies have been interested in RAG systems that leverage their data using LLMs via commercial APIs. Public actors have shown more measured enthusiasm due to data sensitivity and strategic sovereignty issues.
In this context, LLMs and open-source technological ecosystems present significant advantages, especially as their generalist performances catch up with proprietary solutions currently leading the field. Thus, the CDC launched a pilot data transformation project around the EduRénov program, chosen for its operational criticality and potential impact, with an unyielding condition: to guarantee the sovereignty of compute services and models used.
<a name="industrializing-ensuring-performance-sovereignty"></a>
## Industrializing while ensuring performance and sovereignty
Before starting the project, CDC teams experimented with different models and frameworks, notably using open-source solutions proposed by Hugging Face (Text Generation Inference, Transformers, Sentence Transformers, Tokenizers, etc.). These tests validated the potential of a RAG approach. The CDC, therefore, wished to develop a secure application to improve the responsiveness of BdT's support to communities.
Given Caisse des Dépôts (CDC) status in the French public ecosystem and the need to ensure the solution’s sovereignty and security for manipulated data, the CDC chose a French consortium formed by Polyconseil and Hugging Face. Beyond their respective technical expertise, the complementarity of this collaboration was deemed particularly suited to the project's challenges.
- Polyconseil is a technology firm that provides digital innovation expertise through an Agile approach at every stage of technically-intensive projects. From large corporations to startups, Polyconseil partners with clients across all sectors, including ArianeGroup, Canal+, France Ministry of Culture, SNCF, and FDJ. Certified Service France Garanti, Polyconseil has demonstrated expertise in on-premise and cloud deployment ([AWS Advanced Tier Services partner and labeled Amazon EKS Delivery](https://www.linkedin.com/feed/update/urn:li:activity:7201588363357827072/), GCP Cloud Architect, Kubernetes CKA certified consultants, etc.). The firm thus possesses all the necessary resources to deploy large-scale digital projects, with teams composed of Data Scientists, Data Engineers, full-stack/DevOps developers, UI/UX Designers, Product Managers, etc. Its generative AI and LLM expertise is based on a dedicated practice: Alivia, through the [Alivia App](https://www.alivia.app/), plus custom support and implementation offers.
- Founded in 2016, Hugging Face has become, over the years, the most widely used platform for AI collaboration on a global scale. Initially specializing in Transformers and publisher of the famous open-source library of the same name, Hugging Face is now globally recognized for its platform, the 'Hub', which brings together the machine learning community. Hugging Face offers widely adopted libraries, more than 750,000 models, and over 175,000 datasets ready to use. Hugging Face has become, in a few years, an essential global player in artificial intelligence. With the mission to democratize machine learning, Hugging Face now counts more than 200,000 daily active users and 15,000 companies that build, train, and deploy models and datasets.
<a name="modular-solution-to-respond-to-a-dynamic-sector"></a>
## A modular solution to respond to a dynamic sector
The imagined solution consists of an application made available to BdT employees, allowing them to submit an email sent by a prospect and automatically generate a suitable and sourced project response based on EduRénov documentation. The agent can then edit the response before sending it to their interlocutor. This final step enables alignment with the agents' expectations using a method such as Reinforcement Learning from Human Feedback (RLHF).
The following diagram illustrates this:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/diagram_en.png" alt="RLHF" width=90%>
</p>
### Diagram explanation
1. A client sends a request by email through existing channels.
2. This request is transferred to the new user interface.
3. Call to the Orchestrator, which builds a query based on an email for the Retriever.
4. The Retriever module finds the relevant contextual elements indexed by their embeddings from the vector database.
5. The Orchestrator constructs a prompt incorporating the retrieved context and calls the Reader module by carefully tracing the documentary sources.
6. The Reader module uses an LLM to generate a response suggestion, which is returned to the agent via the user interface.
7. The agent evaluates the quality of the response in the interface, then corrects and validates it. This step allows for the collection of human intelligence feedback.
8. The response is transferred to the messaging system for sending.
9. The response is delivered to the client, mentioning references to certain sources.
10. The client can refer to the public repository of used documentary resources.
To implement this overall process, four main subsystems are distinguished:
- In green: the user interface for ingesting the documentary base and constituting qualitative datasets for fine-tuning and RLHF.
- In black: the messaging system and its interfacing.
- In purple: the Retrieval Augmented Generation system itself.
- In red: the entire pipeline and the fine-tuning and RLHF database.
<a name="key-success-factors"></a>
## Key Success Factors Success Factors
The state-of-the-art in the GenAI field evolves at a tremendous pace; making it critical to modify models during a project without significantly affecting the developed solution. Polyconseil designed a modular architecture where simple configuration changes can adjust the LLM, embedding model, and retrieval method. This lets data scientists easily test different configurations to optimize the solution's performance. Finally, this means that the optimal open and sovereign LLM solution to date can be available in production relatively simply.
We opted for a [modular monolith](https://www.milanjovanovic.tech/blog/what-is-a-modular-monolith) in [hexagonal architecture](https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/) to optimize the design workload. However, as the efficient evaluation of an LLM requires execution on a GPU, we outsourced LLM calls outside the monolith. We used Hugging Face's [Text Generation Inference (TGI)](https://huggingface.co/docs/text-generation-inference/index), which offers a highly performant and configurable dockerized service to host any LLM available on the Hub.
To ensure data independence and sovereignty, the solution primarily relies on open-source models deployed on a French cloud provider: [NumSpot](https://numspot.com/). This actor was chosen for its SecNumCloud qualification, backed by Outscale's IaaS, founded by Dassault Systèmes to meet its own security challenges.
Regarding open-source solutions, many French tools stand out. In particular, the unicorn [Mistral AI](https://mistral.ai/fr/) is one of them, whose [Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) model is currently used within the system’s Reader. However, other more discreet yet specific projects present strong potential to meet our challenges, such as [CroissantLLM](https://huggingface.co/blog/manu/croissant-llm-blog), which we are evaluating. This model results from a collaboration between the [MICS laboratory](https://www.mics.centralesupelec.fr/) of CentraleSupélec and [Illuin Technology](https://www.illuin.tech/). They aim to provide an ethical, responsible, and performant model tailored to French data.
Organizationally, we formed a single Agile team operating according to a flexible ScrumBan methodology, complemented by a weekly ritual of monitoring and training on AI breakthroughs. The latter is led by the Hugging Face expert from its [Expert Support program](https://huggingface.co/support). This structure facilitates a smooth transfer of skills and responsibilities to the BdT Data teams while ensuring regular and resilient deliveries amidst project context changes. Thus, we delivered an early naive MVP of the solution and both qualitative and quantitative evaluation notebooks. To this end, we utilize open-source libraries specializing in the evaluation of generative AI systems, such as RAGAS. This serves as the foundation upon which we iterate new features and performance improvements to the system.
Final Words from Hakim Lahlou, OLS Groups Innovation and Strategy Director at Banque des Territoires loan department:
> _We are delighted to work at Banque des Territoires alongside these experts, renowned both in France and internationally, on a cutting edge fully sovereign data solution. Based on this pilot program, this approach opens a new pathway: this is likely how public policies will be deployed in the territories in the future, along with the necessary financing for the country's ecological and energy transformation. Currently, this approach is the only one that enables massive, efficient, and precise deployment._
_Are you involved in a project that has sovereignty challenges? Do you want to develop a solution that leverages the capabilities of LLMs? Or do you simply have questions about our services or the project? Reach out to us directly at [email protected]._
_If you are interested in the Hugging Face Expert Support program for your company, please contact us [here](https://huggingface.co/contact/sales?from=support) - our sales team will get in touch to discuss your needs!_
---
# Banque des Territoires (Groupe CDC) x Polyconseil x Hugging Face : améliorer un programme environnemental français majeur grâce à une solution data souveraine
<a name="resume"></a>
## Résumé
La collaboration lancée en janvier dernier entre la Banque des Territoires de la Caisse des Dépôts et Consignations (CDC), Polyconseil et Hugging Face démontre qu’il est possible d’allier le potentiel de l’IA générative avec les enjeux de souveraineté.
Alors que la première phase du projet vient d’aboutir, l’outil développé doit, à terme, soutenir la stratégie nationale de rénovation environnementale des établissements scolaires. Plus précisément, la solution vise à optimiser le parcours d'accompagnement du Programme EduRénov de la Banque des Territoires (BdT), dédié à la rénovation écologique de 10 000 écoles, collèges et lycées.
Cet article partage quelques enseignements clés d'un co-développement fructueux entre :
- une équipe data science de la Direction des Prêts de la Banque des Territoires ainsi que le Directeur du Programme EduRénov ;
- une équipe pluridisciplinaire de Polyconseil comprenant développeurs, DevOps et Product Manager ;
- un expert Hugging Face en déploiement de solutions de Machine Learning et d’IA.
<a name="puissance-rag"></a>
## La puissance du RAG au service d'objectifs environnementaux
Mis en place par la Banque des Territoires, EduRénov est un programme phare de la stratégie de transformation écologique et énergétique française. Il vise à simplifier, accompagner et financer les démarches de rénovation énergétique des bâtiments scolaires publics. L’ambition se traduit par des objectifs exigeants : 10 000 projets de rénovation d’écoles, collèges, lycées, crèches ou universités - soit 20% du parc national - accompagnés afin qu’ils puissent réaliser 40% d’économie d’énergie en 5 ans. Pour y répondre, la Banque des Territoires mobilise des moyens d’action inédits : une enveloppe de 2 milliards d’euros de prêts pour financer les travaux et 50 millions d’euros dédiés à l’ingénierie préparatoire. Après seulement un an d’existence, le programme compte déjà presque 2 000 projets mais conforte les moyens de ses ambitions ; comme le souligne le directeur du programme Nicolas Turcat :
> _EduRénov a trouvé ses projets et son rythme de croisière, désormais nous allons intensifier la qualité de la relation avec les collectivités tout en allant chercher (beaucoup) de nouveaux projets. Nous portons une conviction commune avec Polyconseil et Hugging Face : le défi de la transition écologique se gagnera par la massification des moyens d’action._
Le succès du programme EduRénov passe par de nombreux échanges - notamment de courriels - entre les experts de la Banque des Territoires, le Groupe Caisse des Dépôts qui conduit le programme, et les collectivités qui détiennent ce patrimoine à rénover. Ces interactions sont cruciales, mais particulièrement chronophages et répétitives. Néanmoins, les réponses à ces courriels reposent sur une base documentaire large et commune à tous les experts de la BdT. Une solution à base de Retrieval Augmented Generation (RAG) pour faciliter ces échanges est donc particulièrement adaptée.
Depuis le lancement de ChatGPT et le début de l’engouement autour de l’IA générative, de nombreuses entreprises se sont intéressées aux systèmes RAG pour valoriser leurs bases documentaires en utilisant simplement des LLMs via leurs APIs commerciales. Compte tenu de la sensibilité de leurs données et d'enjeux stratégiques de souveraineté, l’enthousiasme est resté plus mesuré du côté des acteurs publics.
Dans ce contexte, les LLMs et les écosystèmes technologiques open source présentent des avantages significatifs, et ce d'autant plus que leurs performances généralistes rattrapent celles des solutions propriétaires, leaders du domaine. C'est ainsi que la CDC a décidé de lancer un projet de transformation data pilote autour du programme EduRénov, choisi pour sa criticité opérationnelle et son impact potentiel, en imposant une condition essentielle : garantir le caractère souverain du cloud et des modèles utilisés dans ce cadre.
<a name="industrialiser-garantissant-performance-souverainete"></a>
## Industrialiser en garantissant performance et souveraineté
À la genèse du projet, les équipes de la CDC ont expérimenté avec différents modèles et frameworks, notamment à l’aide des solutions open source proposées par Hugging Face (Text Generation Inference, Transformers, Sentence Transformers, Tokenizers, etc.). Ces tests ont validé le potentiel de l’approche RAG envisagée. La CDC a donc souhaité développer une application sécurisée permettant d’améliorer la réactivité d’accompagnement des collectivités par la Banque des Territoires.
Compte tenu du statut de la Caisse des Dépôts dans l’écosystème public français, et afin de garantir la souveraineté de la solution et la sécurité des données travaillées, elle a choisi de s’orienter vers le groupement français constitué par Polyconseil et Hugging Face. Au-delà des expertises techniques respectives, la complémentarité de cette collaboration a été jugée particulièrement adaptée aux enjeux du projet.
- Polyconseil est un cabinet d’experts en innovation numérique qui agit de manière Agile sur chaque étape de projets à forte composante technique. Du grand compte à la startup, Polyconseil intervient pour des clients de tous secteurs d’activité, tels que ArianeGroup, Canal+, le Ministère de la Culture, la SNCF, la FDJ, etc. Certifié Service France Garanti, Polyconseil dispose d’une expertise éprouvée sur le déploiement on-premise et sur clouds ([AWS Advanced Tier Services partner et labellisé Amazon EKS Delivery](https://www.linkedin.com/feed/update/urn:li:activity:7201588363357827072/), consultants certifiés GCP Cloud Architect, Kubernetes CKA, etc.). Le cabinet possède ainsi l’ensemble des ressources nécessaires au déploiement de projets numériques d’envergure, avec des équipes de Data Scientists, Data Engineers, développeurs full stack /DevOps, UI/UX Designers, Product Managers, etc. L’expertise en matière d’IA générative et de LLM repose sur une practice dédiée : Alivia, au travers de la solution [Alivia App](https://www.alivia.app/) et d’offres d’accompagnement et de mise en œuvre sur-mesure.
- Fondée en 2016, Hugging Face est devenue au fil des années la plateforme la plus utilisée pour la collaboration sur l’Intelligence Artificielle à l’échelle mondiale. Hugging Face, d’abord spécialiste des Transformers et éditeur de la célèbre librairie Open-Source éponyme, est maintenant reconnue mondialement pour sa plateforme, le « Hub », qui rassemble la communauté du machine learning. Proposant à la fois des bibliothèques très largement adoptées, plus de 750 000 modèles, et plus de 175 000 jeux de données (datasets) prêts à l'emploi, Hugging Face est devenue en quelques années un acteur mondial incontournable en intelligence artificielle. Avec pour mission de démocratiser le machine learning, Hugging Face compte aujourd'hui plus de 200 000 utilisateurs actifs quotidiens et 15 000 entreprises qui construisent, entraînent et déploient des modèles et des ensembles de données.
<a name="solution-modulaire-repondre-dynamisme-secteur"></a>
## Une solution modulaire pour répondre au dynamisme du secteur
La solution imaginée consiste en une application mise à disposition des collaborateurs de la Banque des Territoires, qui leur permet de soumettre un courriel envoyé par un prospect et de générer automatiquement un projet de réponse adapté et sourcé, basé sur la documentation métier. L’agent peut ensuite éditer la réponse avant de l’envoyer à son interlocuteur. Cette dernière étape permet d’envisager une phase d’alignement aux attentes des agents du système à l’aide grâce à différentes techniques comme “Reinforcement Learning from Human Feedback” (RLHF).
Elle est illustrée par le schéma suivant :
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llama2-non-engineers/diagram_fr.png" alt="RLHF" width=90%>
</p>
### Explication du schéma
1. Un client envoie une demande par courriel selon les canaux existants.
2. Cette demande est transférée dans la nouvelle interface utilisateur
3. Le module Retriever retrouve les éléments de contexte pertinents, indexés par leur embedding, depuis la base de données vectorielle.
4. The Retriever module finds the relevant contextual elements indexed by their embeddings from the vector database.
5. L'Orchestrateur construit un prompt incorporant le contexte récupéré et appelle le module Reader en retraçant soigneusement les sources documentaires.
6. Le module Reader mobilise un LLM pour générer une suggestion de réponse, qui est renvoyée à l'agent via l'interface utilisateur.
7. L'agent évalue dans l'interface la qualité de la réponse puis la corrige et la valide. Cette étape permet la collecte de feedback de l'intelligence humaine.
8. Transfert au système de messagerie pour envoi.
9. La réponse est acheminée au client et mentionne les références à certaines sources.
10. Le client peut se référer au référentiel public des ressources documentaires utilisées.
Pour implémenter ce processus d'ensemble on distingue 4 grands sous-systèmes :
- en vert : l'interface d'utilisation, d'ingestion de la base documentaire et de constitution des jeux de données qualitatifs pour le fine-tuning et le RLHF.
- en noir : le système de messagerie et son interfaçage.
- en violet : le système Retrieval Augmented Generation proprement dit.
- en rouge : l'ensemble du pipeline et de la base de données de fine-tuning et RLHF.
<a name="facteurs-cles-succes"></a>
## Facteurs clés de succès
L'état de l'art du domaine évolue à très grande vitesse ; il est donc critique de pouvoir changer de modèles en cours de projet sans remettre en cause significativement la solution développée. Polyconseil a donc conçu une architecture modulaire, dans laquelle le LLM, le modèle d'embedding et la méthode de retrieval peuvent être modifiés par une simple configuration. Ceci permet en outre aux data scientists d'itérer facilement sur différentes configurations pour optimiser la performance de la solution. Cela permet enfin plus globalement de disposer en production et assez simplement de la meilleure solution de LLM à date, ouverte et assurant le caractère souverain.
Dans une optique d’optimisation de la charge de conception, nous avons opté pour un [monolithe modulaire](https://www.milanjovanovic.tech/blog/what-is-a-modular-monolith) en [architecture hexagonale](https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/). Mais comme l'évaluation efficace d'un LLM demande une exécution sur un GPU nous avons déporté à l'extérieur du monolithe l'appel au LLM. Pour ce faire, nous avons utilisé [Text Generation Inference (TGI)](https://huggingface.co/docs/text-generation-inference/index) d’Hugging Face, qui offre un service dockerisé performant et configurable pour héberger n'importe quel LLM disponible sur le Hub.
Afin de garantir l’indépendance et la souveraineté des données, la solution s'appuie essentiellement sur des modèles open source, déployés sur un fournisseur de Cloud français : [NumSpot](https://numspot.com/). Cet acteur a été choisi pour sa qualification SecNumCloud, adossé à l'IaaS Outscale, fondée par Dassault Systèmes pour répondre à ses propres enjeux de sécurité.
Concernant les solutions open source, de nombreux outils français se démarquent. La licorne [Mistral AI](https://mistral.ai/fr/), dont nous utilisons actuellement le modèle [Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3), sort notamment du lot. Mais d’autres projets plus discrets mais plus spécifiques présentent un fort potentiel pour répondre à nos enjeux, tels que [CroissantLLM](https://huggingface.co/blog/manu/croissant-llm-blog) que nous évaluons. Ce modèle est issu d’une collaboration entre le [laboratoire MICS](https://www.mics.centralesupelec.fr/) de CentraleSupélec et [Illuin Technology](https://www.illuin.tech/). Il vise à offrir un modèle spécialisé sur des données en français, qui soit éthique, responsable et performant.
Sur le plan organisationnel, nous avons constitué une seule équipe Agile opérant selon une méthodologie de type ScrumBan souple, complétée par un rituel hebdomadaire de veille et de formation sur les avancées de l'IA. Ce dernier est conduit par l’expert Hugging Face du programme [Expert Support](https://huggingface.co/support). Cette organisation facilite un transfert fluide des compétences et des responsabilités vers les équipes Data de la BdT, tout en assurant des livraisons régulières et résilientes aux changements de contexte du projet. Ainsi nous avons livré tôt un MVP naïf de la solution et des notebooks d'évaluations qualitatives et quantitatives. Pour cela, nous utilisons des bibliothèques open source spécialisées dans l’évaluation des systèmes d’IA générative, telles que RAGAS. Ce travail constitue désormais le socle sur lequel nous itérons de nouvelles fonctionnalités et des améliorations de la performance du système.
Le mot de la fin, par Hakim Lahlou, Directeur Innovation et Stratégie Groupes OLS à la Direction des prêts de la Banque des Territoires :
> _Nous sommes heureux de travailler à la Banque des Territoires aux côtés de ces experts reconnus en France comme à l’international autour d’une solution data très innovante et pleinement souveraine. Sur la base de ce Programme pilote, cette approche ouvre une nouvelle voie : c’est probablement ainsi à l’avenir que se déploieront les politiques publiques dans les territoires ainsi que les financements nécessaires à la Transformation écologique et énergétique du pays. Cette approche est aujourd’hui la seule à permettre des déploiements massifs, efficaces et précis._
_Vous êtes concernés par un projet avec des enjeux de souveraineté ? Vous souhaitez mettre au point une solution qui tire profit des capacités des LLMs ? Ou vous avez tout simplement des questions sur nos services ou sur le projet ? Contactez-nous directement à [email protected]_
_Si vous êtes intéressé par le programme Hugging Face Expert Support pour votre entreprise, veuillez nous contacter [ici](https://huggingface.co/contact/sales?from=support) - notre équipe commerciale vous contactera pour discuter de vos besoins !_
| 3 |
0 | hf_public_repos | hf_public_repos/blog/gradio-reload.md | ---
title: "AI Apps in a Flash with Gradio's Reload Mode"
thumbnail: /blog/assets/gradio-reload/thumbnail_compressed.png
authors:
- user: freddyaboulton
---
# AI Apps in a Flash with Gradio's Reload Mode
In this post, I will show you how you can build a functional AI application quickly with Gradio's reload mode. But before we get to that, I want to explain what reload mode does and why Gradio implements its own auto-reloading logic. If you are already familiar with Gradio and want to get to building, please skip to the third [section](#building-a-document-analyzer-application).
## What Does Reload Mode Do?
To put it simply, it pulls in the latest changes from your source files without restarting the Gradio server. If that does not make sense yet, please continue reading.
Gradio is a popular Python library for creating interactive machine learning apps.
Gradio developers declare their UI layout entirely in Python and add some Python logic that triggers whenever a UI event happens. It's easy to learn if you know basic Python. Check out this [quickstart](https://www.gradio.app/guides/quickstart) if you are not familiar with Gradio yet.
Gradio applications are launched like any other Python script, just run `python app.py` (the file with the Gradio code can be called anything). This will start an HTTP server that renders your app's UI and responds to user actions. If you want to make changes to your app, you stop the server (typically with `Ctrl + C`), edit your source file, and then re-run the script.
Having to stop and relaunch the server can introduce a lot of latency while you are developing your app. It would be better if there was a way to pull in the latest code changes automatically so you can test new ideas instantly.
That's exactly what Gradio's reload mode does. Simply run `gradio app.py` instead of `python app.py` to launch your app in reload mode!
## Why Did Gradio Build Its Own Reloader?
Gradio applications are run with [uvicorn](https://www.uvicorn.org/), an asynchronous server for Python web frameworks. Uvicorn already offers [auto-reloading](https://www.uvicorn.org/) but Gradio implements its own logic for the following reasons:
1. **Faster Reloading**: Uvicorn's auto-reload will shut down the server and spin it back up. This is faster than doing it by hand, but it's too slow for developing a Gradio app. Gradio developers build their UI in Python so they should see how ther UI looks as soon as a change is made. This is standard in the Javascript ecosystem but it's new to Python.
2. **Selective Reloading**: Gradio applications are AI applications. This means they typically load an AI model into memory or connect to a datastore like a vector database. Relaunching the server during development will mean reloading that model or reconnecting to that database, which introduces too much latency between development cycles. To fix this issue, Gradio introduces an `if gr.NO_RELOAD:` code-block that you can use to mark code that should not be reloaded. This is only possible because Gradio implements its own reloading logic.
I will now show you how you can use Gradio reload mode to quickly build an AI App.
## Building a Document Analyzer Application
Our application will allow users to upload pictures of documents and ask questions about them. They will receive answers in natural language. We will use the free [Hugging Face Inference API](https://huggingface.co/docs/huggingface_hub/guides/inference) so you should be able to follow along from your computer. No GPU required!
To get started, let's create a barebones `gr.Interface`. Enter the following code in a file called `app.py` and launch it in reload mode with `gradio app.py`:
```python
import gradio as gr
demo = gr.Interface(lambda x: x, "text", "text")
if __name__ == "__main__":
demo.launch()
```
This creates the following simple UI.

Since I want to let users upload image files along with their questions, I will switch the input component to be a `gr.MultimodalTextbox()`. Notice how the UI updates instantly!
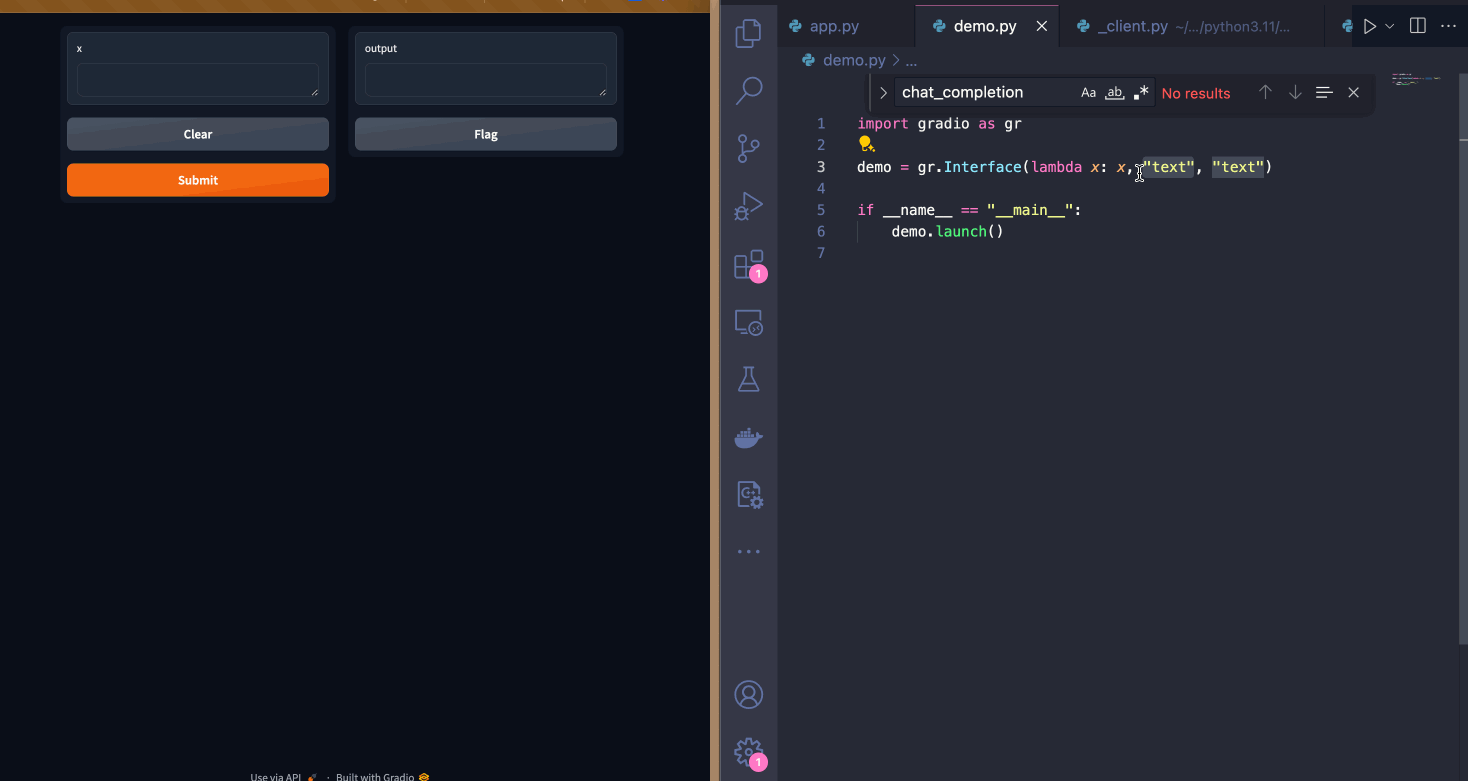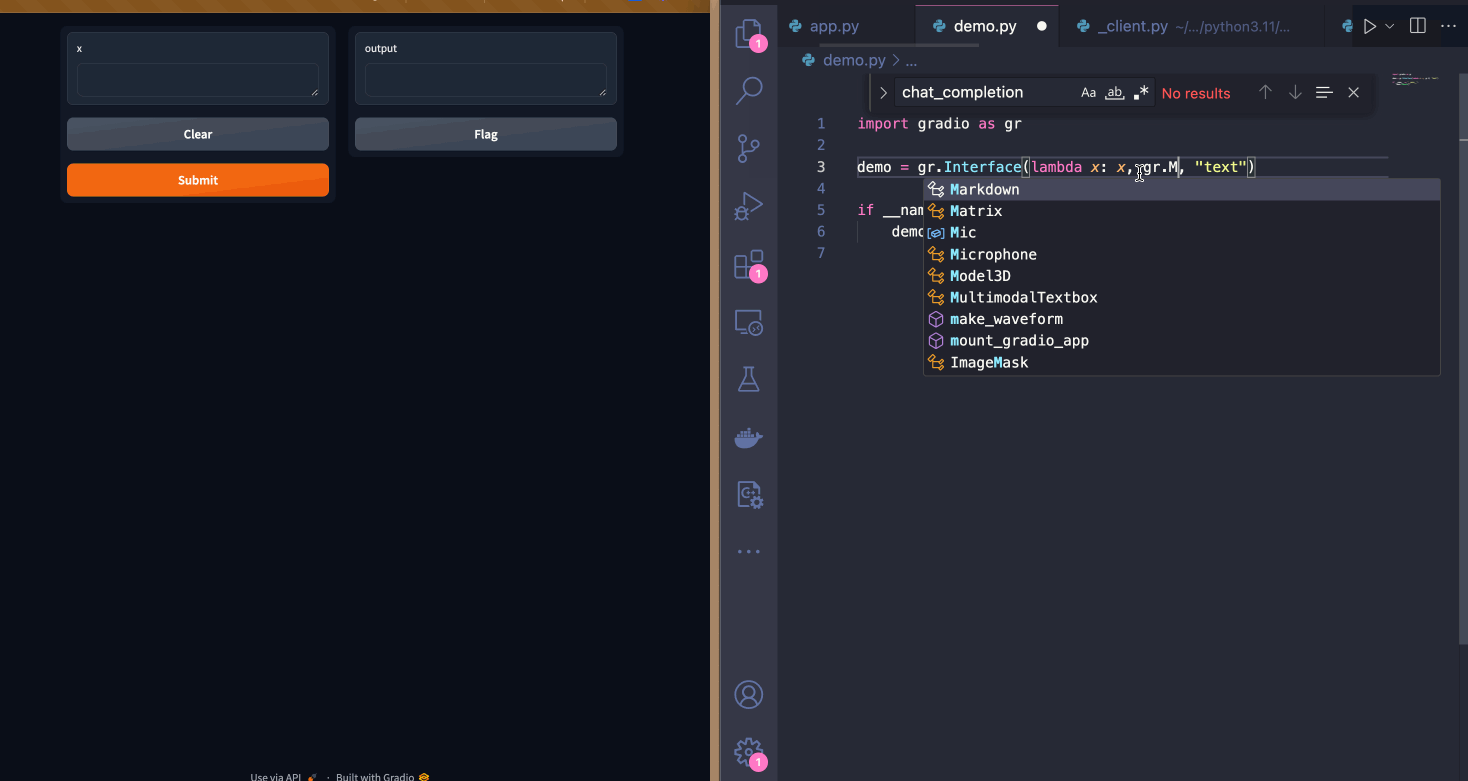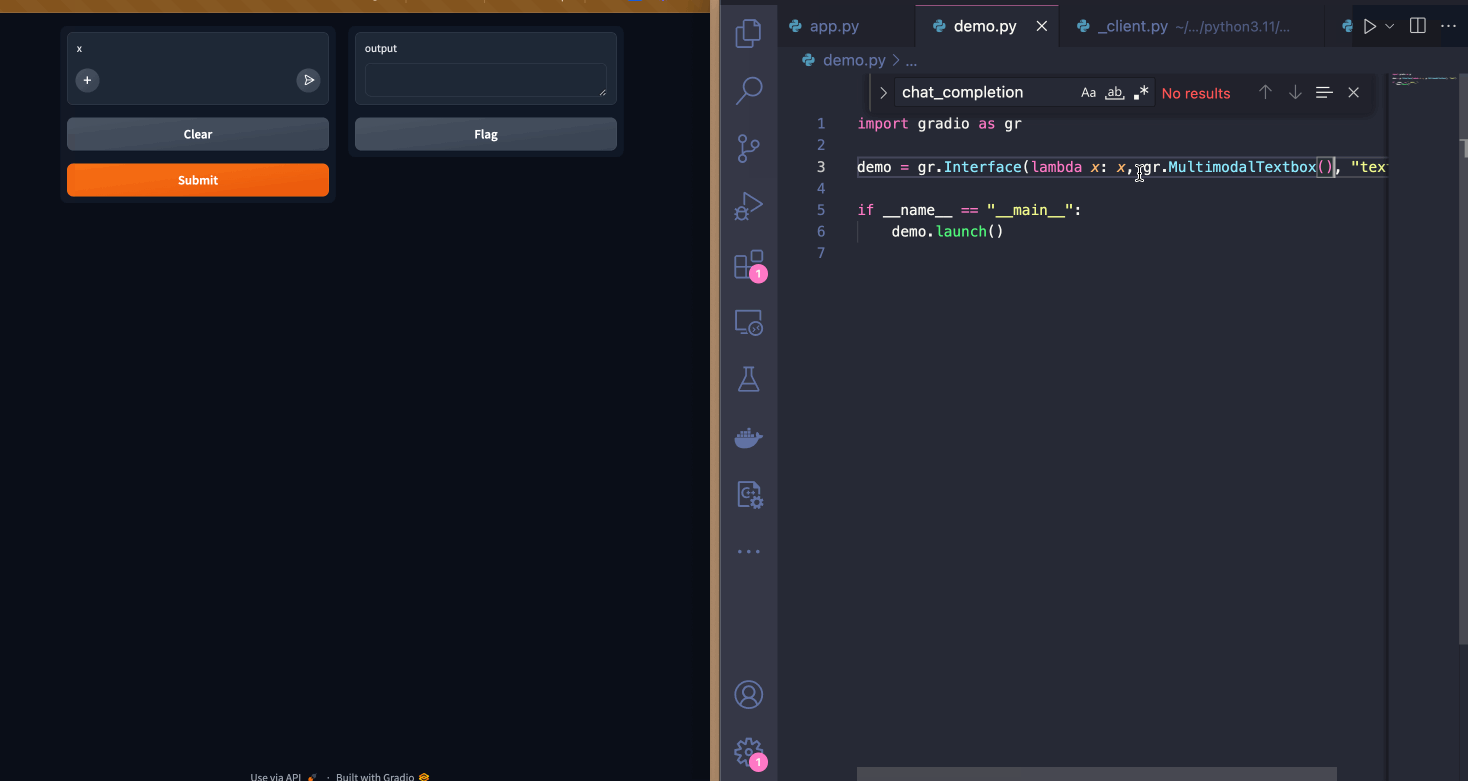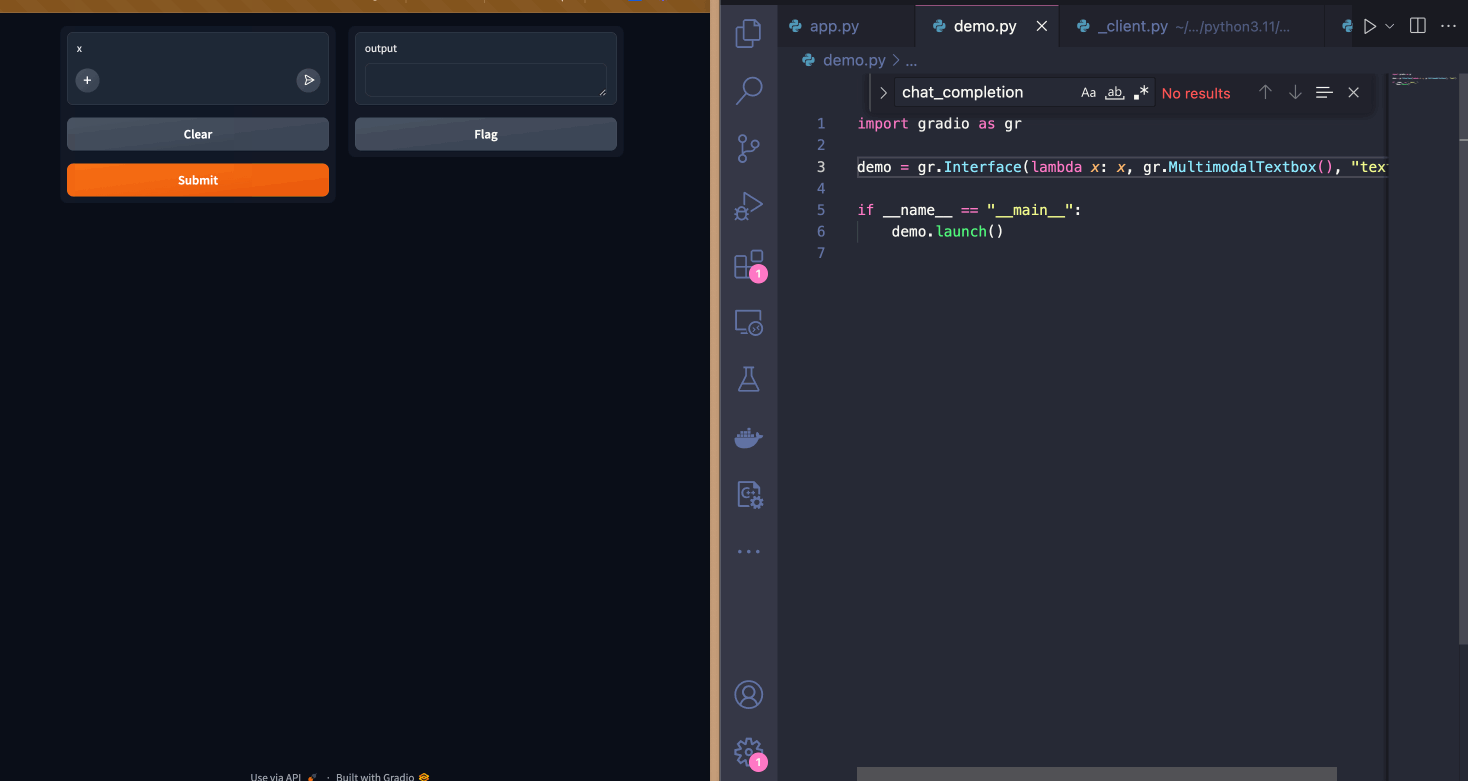
This UI works but, I think it would be better if the input textbox was below the output textbox. I can do this with the `Blocks` API. I'm also customizing the input textbox by adding a placeholder text to guide users.
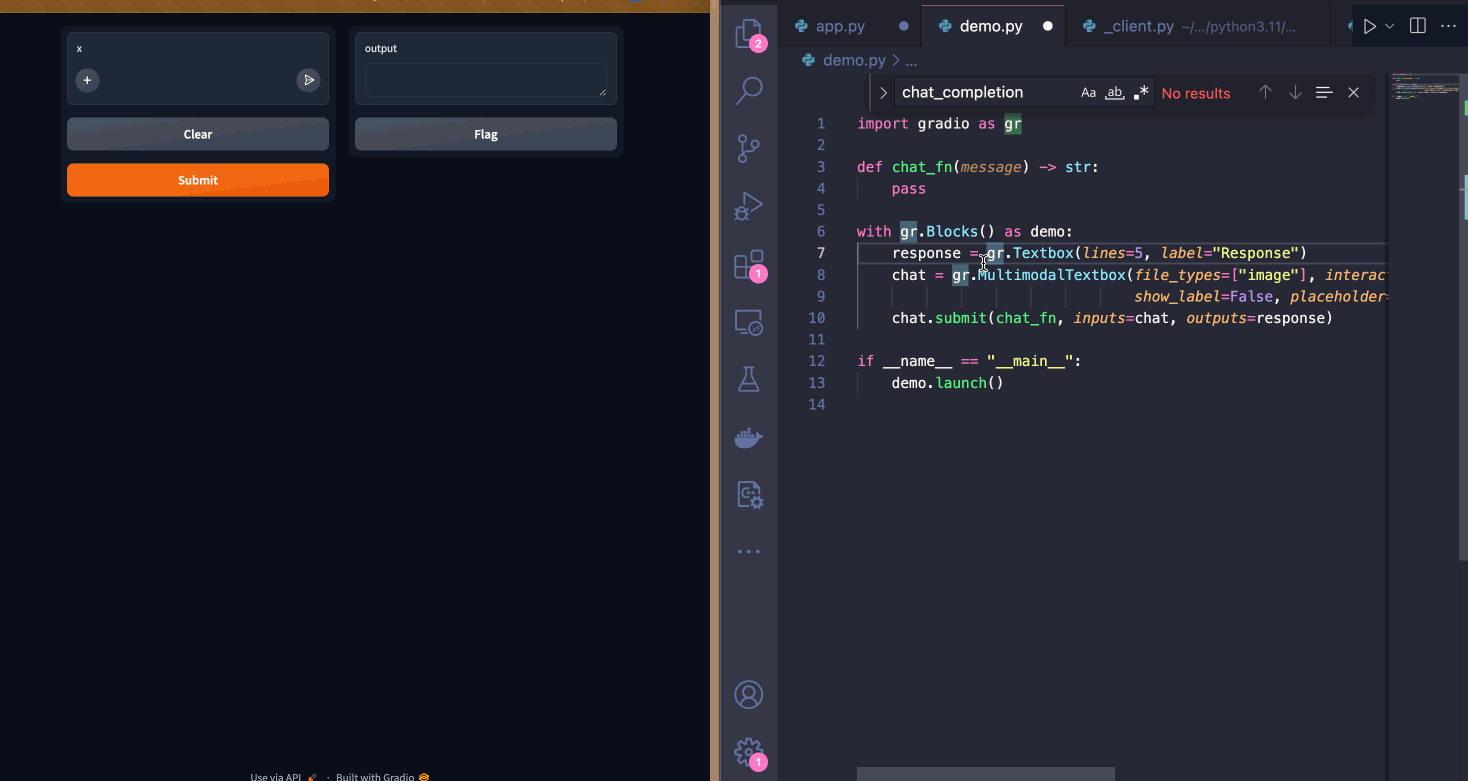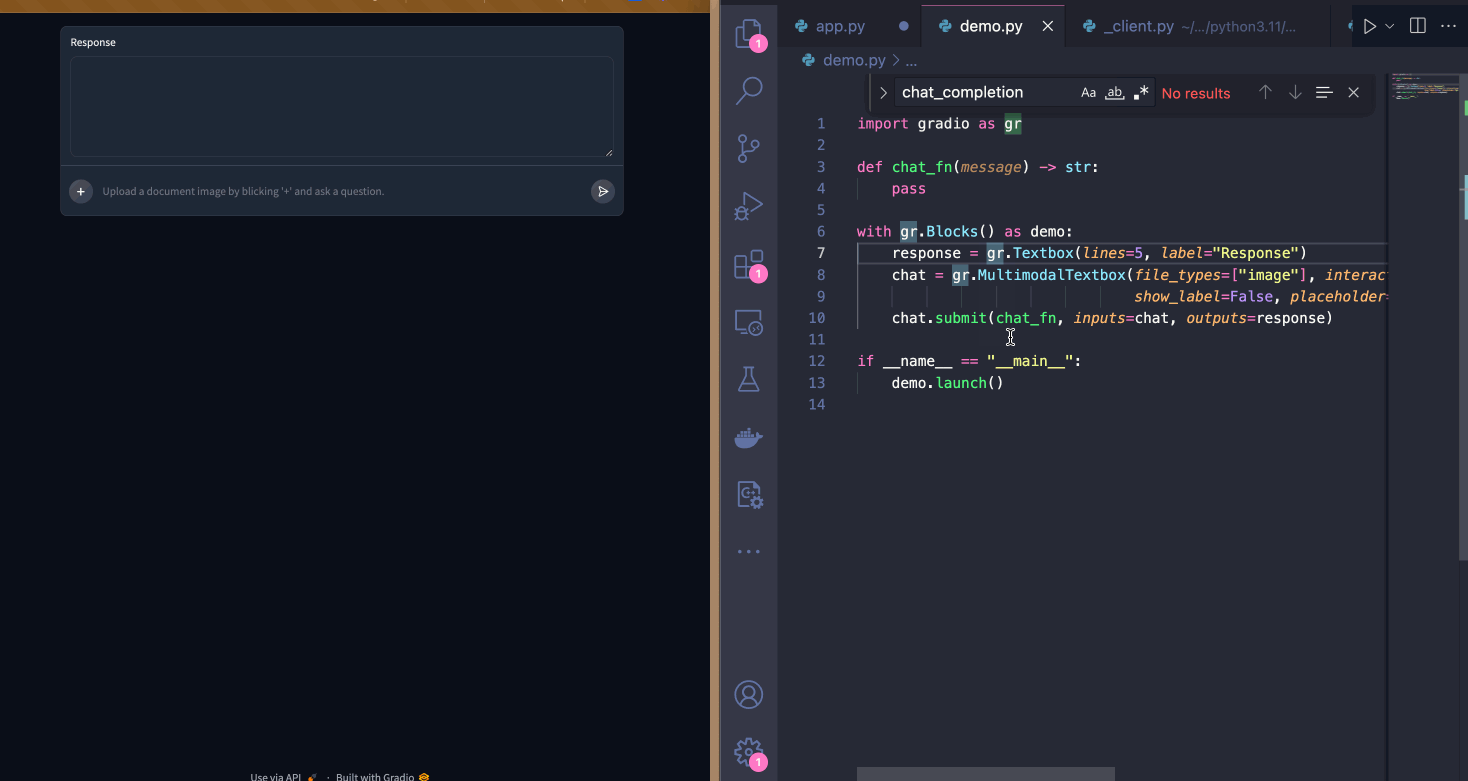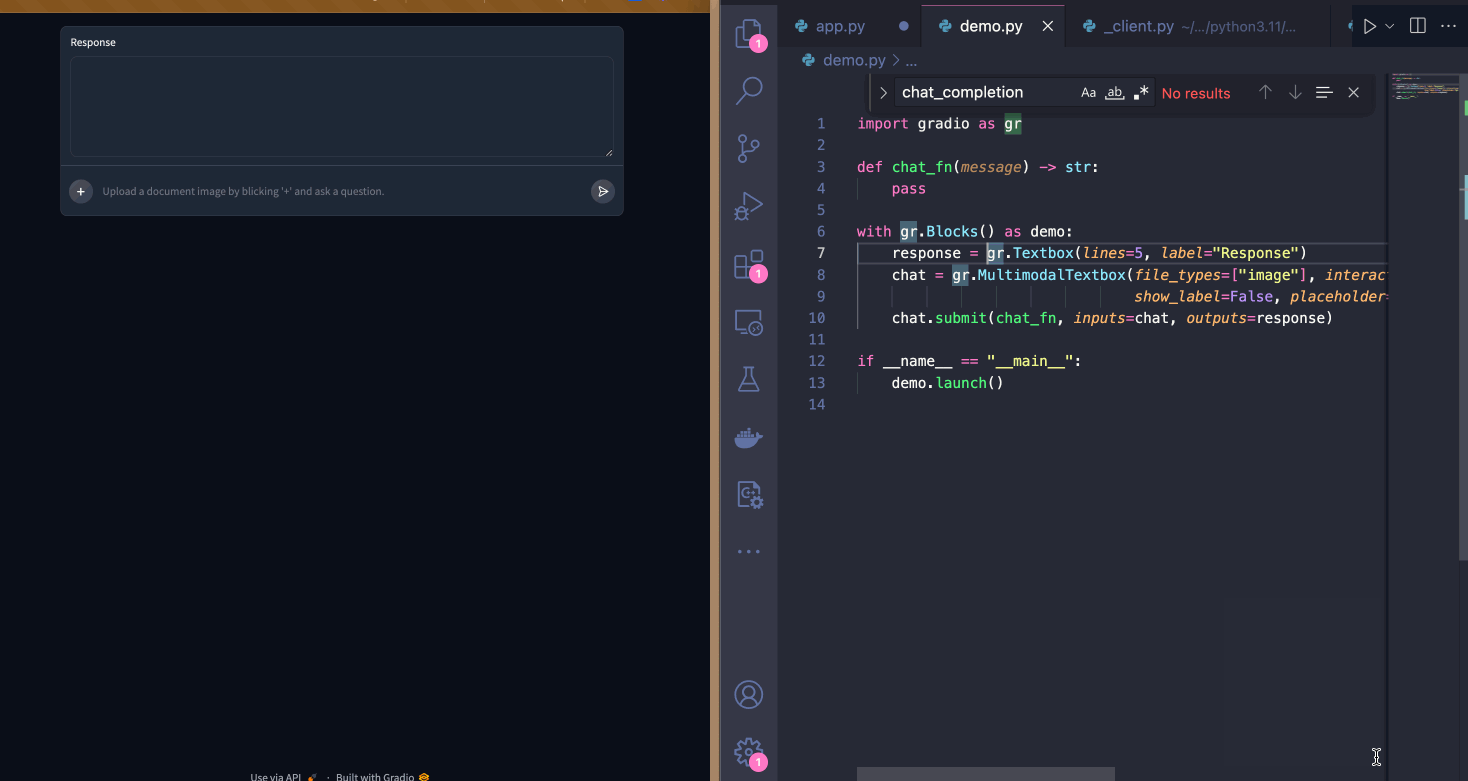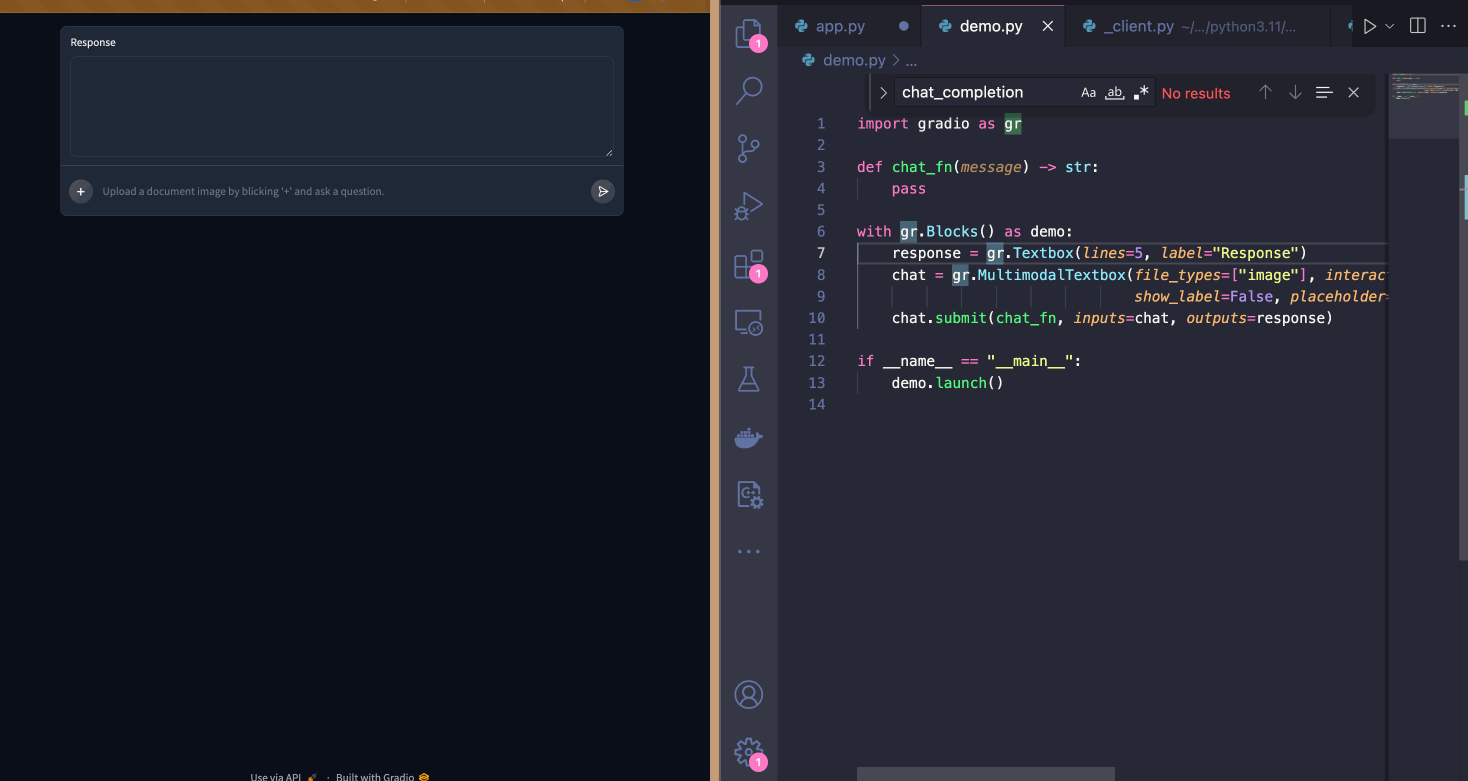
Now that I'm satisfied with the UI, I will start implementing the logic of the `chat_fn`.
Since I'll be using Hugging Face's Inference API, I will import the `InferenceClient` from the `huggingface_hub` package (it comes pre-installed with Gradio). I'll be using the [`impira/layouylm-document-qa`](https://huggingface.co/impira/layoutlm-document-qa) model to answer the user's question. I will then use the [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) LLM to provide a response in natural language.
```python
from huggingface_hub import InferenceClient
client = InferenceClient()
def chat_fn(multimodal_message):
question = multimodal_message["text"]
image = multimodal_message["files"][0]
answer = client.document_question_answering(image=image, question=question, model="impira/layoutlm-document-qa")
answer = [{"answer": a.answer, "confidence": a.score} for a in answer]
user_message = {"role": "user", "content": f"Question: {question}, answer: {answer}"}
message = ""
for token in client.chat_completion(messages=[user_message],
max_tokens=200,
stream=True,
model="HuggingFaceH4/zephyr-7b-beta"):
if token.choices[0].finish_reason is not None:
continue
message += token.choices[0].delta.content
yield message
```
Here is our demo in action!
I will also provide a system message so that the LLM keeps answers short and doesn't include the raw confidence scores. To avoid re-instantiating the `InferenceClient` on every change, I will place it inside a no reload code block.
```python
if gr.NO_RELOAD:
client = InferenceClient()
system_message = {
"role": "system",
"content": """
You are a helpful assistant.
You will be given a question and a set of answers along with a confidence score between 0 and 1 for each answer.
You job is to turn this information into a short, coherent response.
For example:
Question: "Who is being invoiced?", answer: {"answer": "John Doe", "confidence": 0.98}
You should respond with something like:
With a high degree of confidence, I can say John Doe is being invoiced.
Question: "What is the invoice total?", answer: [{"answer": "154.08", "confidence": 0.75}, {"answer": "155", "confidence": 0.25}
You should respond with something like:
I believe the invoice total is $154.08 but it can also be $155.
"""}
```
Here is our demo in action now! The system message really helped keep the bot's answers short and free of long decimals.
As a final improvement, I will add a markdown header to the page:
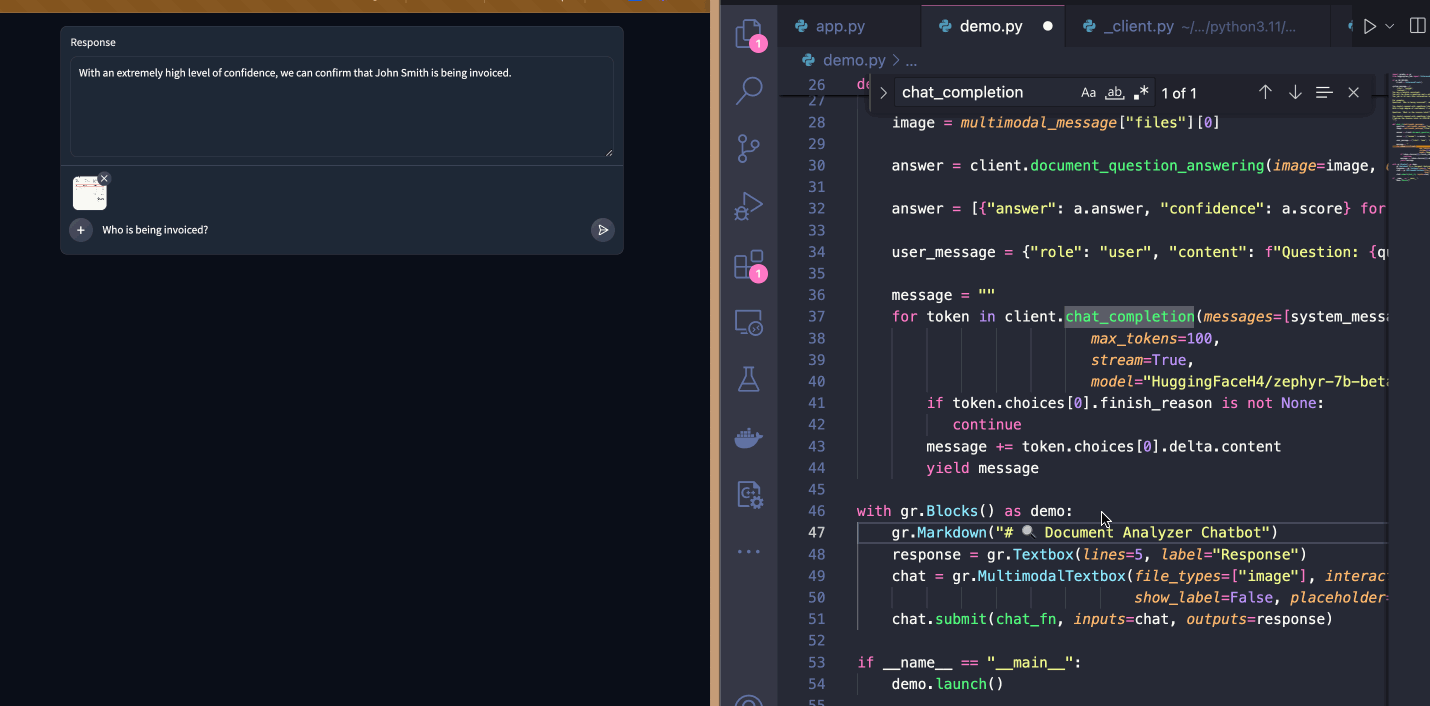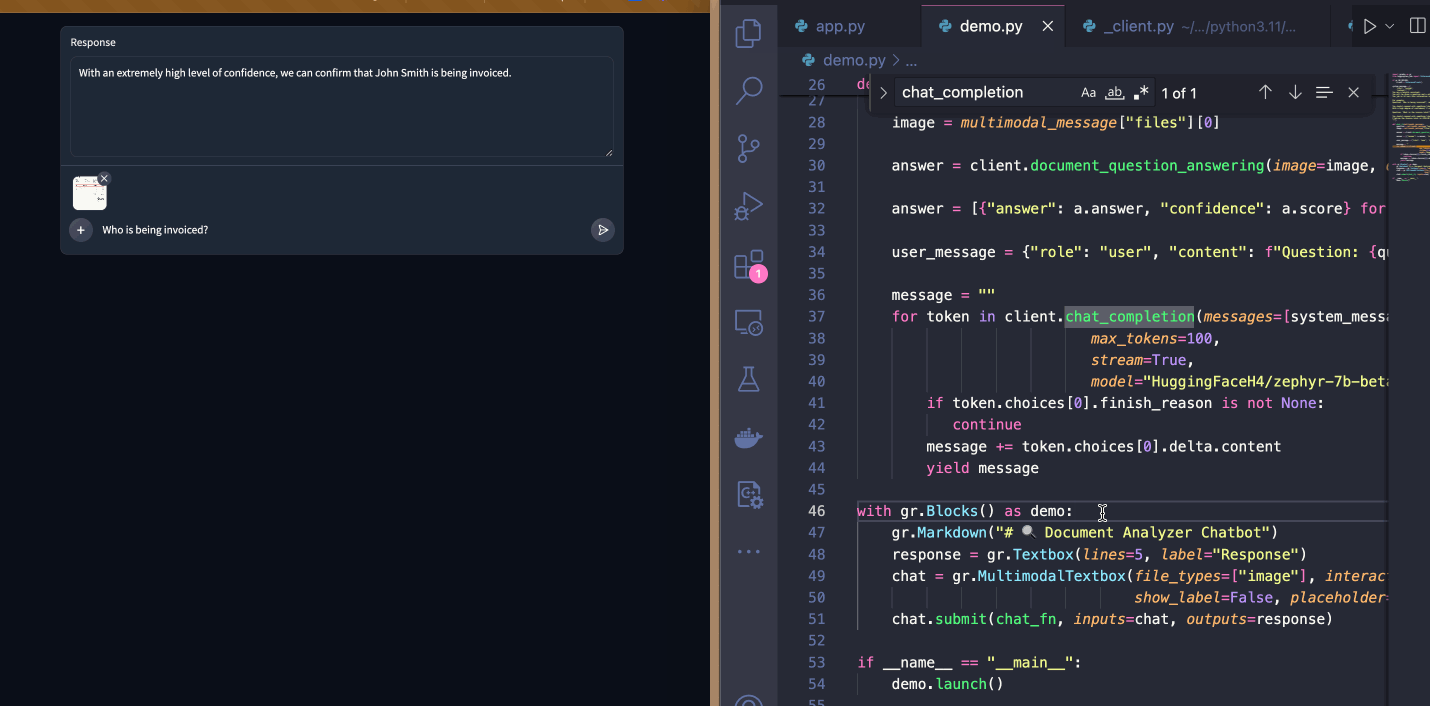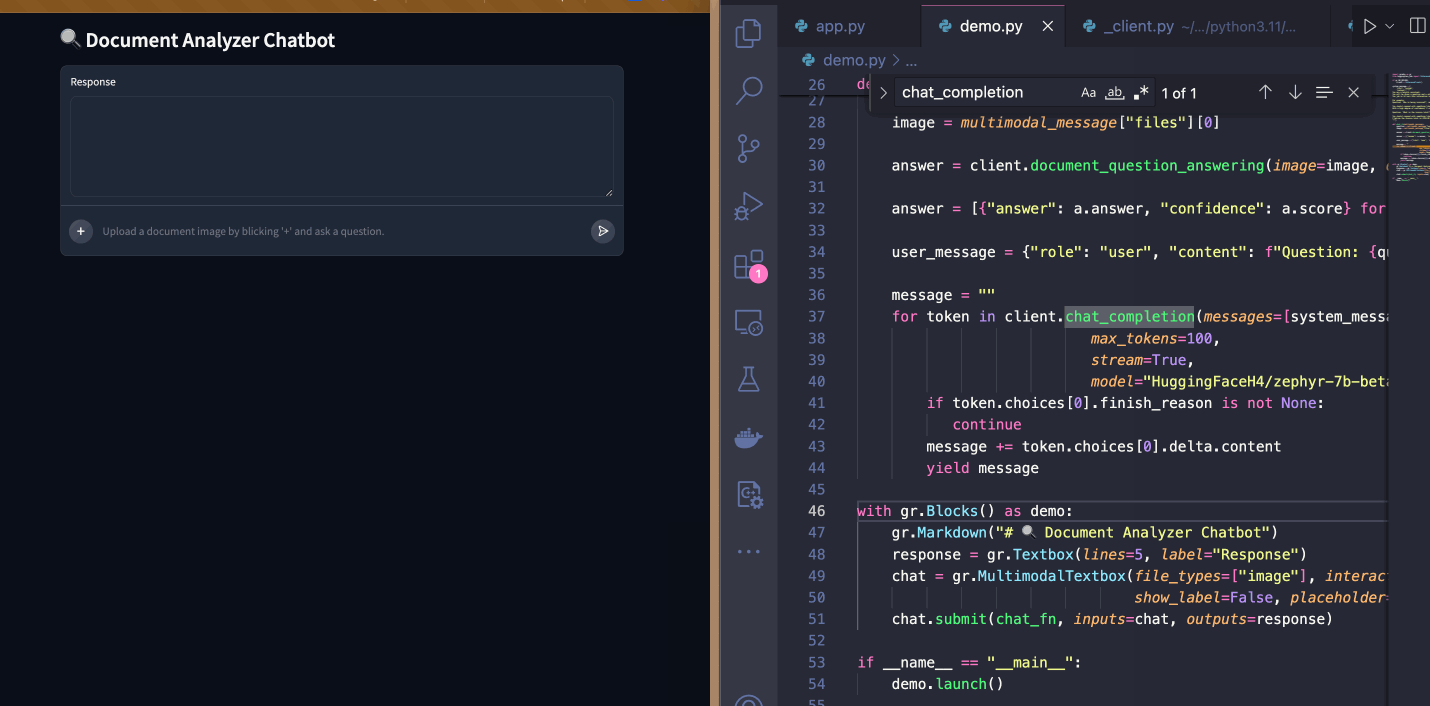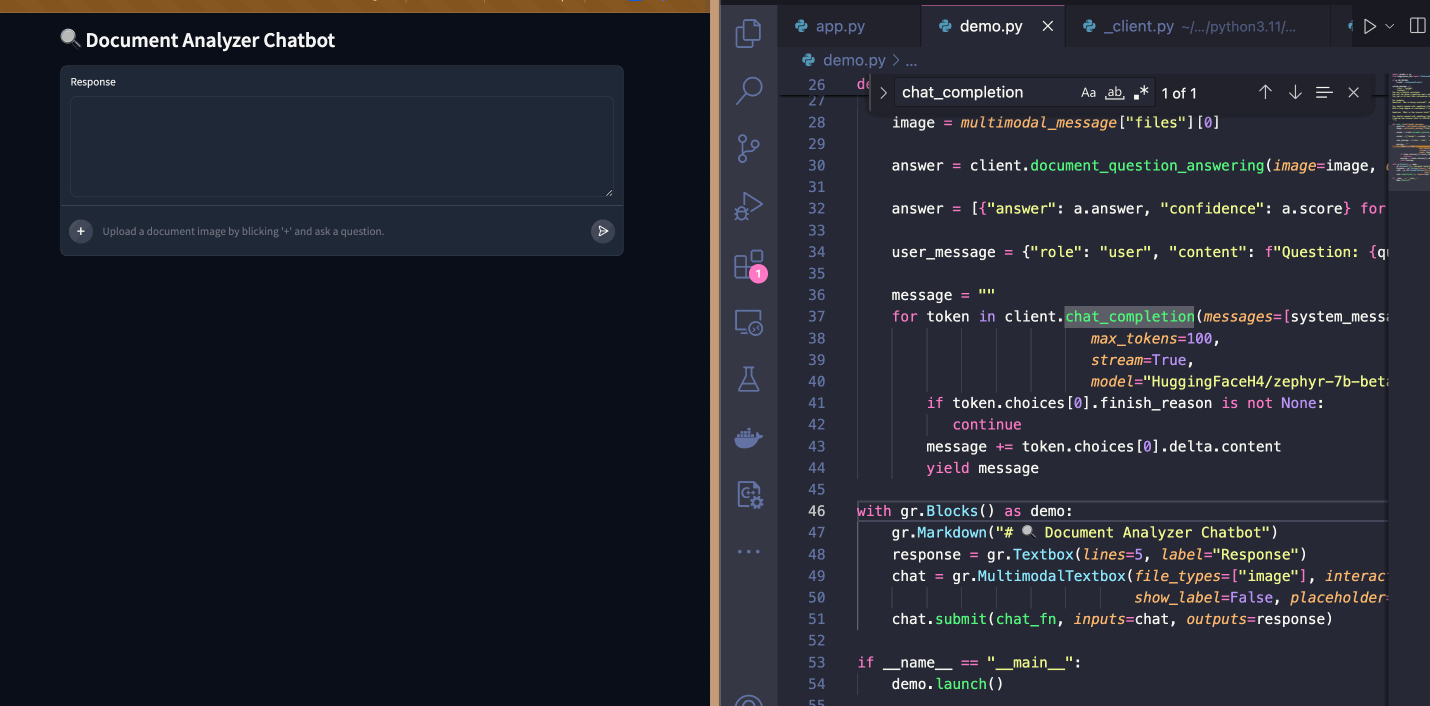
## Conclusion
In this post, I developed a working AI application with Gradio and the Hugging Face Inference API. When I started developing this, I didn't know what the final product would look like so having the UI and server logic reload instanty let me iterate on different ideas very quickly. It took me about an hour to develop this entire app!
If you'd like to see the entire code for this demo, please check out this [space](https://huggingface.co/spaces/freddyaboulton/document-analyzer)!
| 4 |
0 | hf_public_repos | hf_public_repos/blog/ml-director-insights-4.md | ---
title: "Director of Machine Learning Insights [Part 4]"
thumbnail: /blog/assets/78_ml_director_insights/part4.png
---
# Director of Machine Learning Insights [Part 4]
_If you're interested in building ML solutions faster visit: [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co/blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co/blog/ml-director-insights-2)
- [Director of Machine Learning Insights [Part 3 : Finance Edition]](https://huggingface.co/blog/ml-director-insights-3)
🚀 In this fourth installment, you’ll hear what the following top Machine Learning Directors say about Machine Learning’s impact on their respective industries: Javier Mansilla, Shaun Gittens, Samuel Franklin, and Evan Castle. —All are currently Directors of Machine Learning with rich field insights.
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Javier.png"></a>
### [Javier Mansilla](https://www.linkedin.com/in/javimansilla/?originalSubdomain=ar) - Director of Machine Learning, Marketing Science at [Mercado Libre](https://mercadolibre.com/)
**Background:** Seasoned entrepreneur and leader, Javier was co-founder and CTO of Machinalis, a high-end company building Machine Learning since 2010 (yes, before the breakthrough of neural nets). When Machinalis was acquired by Mercado Libre, that small team evolved to enable Machine Learning as a capability for a tech giant with more than 10k devs, impacting the lives of almost 100 million direct users. Daily, Javier leads not only the tech and product roadmap of their Machine Learning Platform (NASDAQ MELI), but also their users' tracking system, the AB Testing framework, and the open-source office. Javier is an active member & contributor of [Python-Argentina non-profit PyAr](https://www.python.org.ar/), he loves hanging out with family and friends, python, biking, football, carpentry, and slow-paced holidays in nature!
**Fun Fact:** I love reading science fiction, and my idea of retirement includes resuming the teenage dream of writing short stories.📚
**Mercado Libre:** The biggest company in Latam and the eCommerce & fintech omnipresent solution for the continent
#### **1. How has ML made a positive impact on e-commerce?**
I would say that ML made the impossible possible in specific cases like fraud prevention and optimized processes and flows in ways we couldn't have imagined in a vast majority of other areas.
In the middle, there are applications where ML enabled a next-level of UX that otherwise would be very expensive (but maybe possible). For example, the discovery and serendipity added to users' journey navigating between listings and offers.
We ran search, recommendations, ads, credit-scoring, moderations, forecasting of several key aspects, logistics, and a lot more core units with Machine Learning optimizing at least one of its fundamental metrics.
We even use ML to optimize the way we reserve and use infrastructure.
#### **2. What are the biggest ML challenges within e-commerce?**
Besides all the technical challenges ahead (for instance, more and more real timeless and personalization), the biggest challenge is the always present focus on the end-user.
E-commerce is scaling its share of the market year after year, and Machine Learning is always a probabilistic approach that doesn't provide 100% perfection. We need to be careful to keep optimizing our products while still paying attention to the long tail and the experience of each individual person.
Finally, a growing challenge is coordinating and fostering data (inputs and outputs) co-existence in a multi-channel and multi-business world—marketplace, logistics, credits, insurance, payments on brick-and-mortar stores, etc.
#### **3. A common mistake you see people make trying to integrate ML into e-commerce?**
The most common mistakes are related to using the wrong tool for the wrong problem.
For instance, starting complex instead of with the simplest baseline possible. For instance not measuring the with/without machine learning impact. For instance, investing in tech without having a clear clue of the boundaries of the expected gain.
Last but not least: thinking only in the short term, forgetting about the hidden impacts, technical debts, maintenance, and so on.
#### **4. What excites you most about the future of ML?**
Talking from the perspective of being on the trench crafting technology with our bare hands like we used to do ten years ago, definitely what I like the most is to see that we as an industry are solving most of the slow, repetitive and boring pieces of the challenge.
It’s of course an ever-moving target, and new difficulties arise.
But we are getting better at incorporating mature tools and practices that will lead to shorter cycles of model-building which, at the end of the day, reduces time to market.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Shaun.png"></a>
### [Shaun Gittens](https://www.linkedin.com/in/shaungittens/) - Director of Machine Learning at [MasterPeace Solutions](https://www.masterpeaceltd.com/)
**Background:** Dr. Shaun Gittens is the Director of the Machine Learning Capability of MasterPeace Solutions, Ltd., a company specializing in providing advanced technology and mission-critical cyber services to its clients. In this role, he is:
1. Growing the core of machine learning experts and practitioners at the company.
2. Increasing the knowledge of bleeding-edge machine learning practices among its existing employees.
3. Ensuring the delivery of effective machine learning solutions and consulting support not only to the company’s clientele but also to the start-up companies currently being nurtured from within MasterPeace.
Before joining MasterPeace, Dr. Gittens served as Principal Data Scientist for the Applied Technology Group, LLC. He built his career on training and deploying machine learning solutions on distributed big data and streaming platforms such as Apache Hadoop, Apache Spark, and Apache Storm. As a postdoctoral fellow at Auburn University, he investigated effective methods for visualizing the knowledge gained from trained non-linear machine-learned models.
**Fun Fact:** Addicted to playing tennis & Huge anime fan. 🎾
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on Engineering?**
Engineering is vast in its applications and can encompass a great many areas. That said, more recently, we are seeing ML affect a range of engineering facets addressing obvious fields such as robotics and automobile engineering to not-so-obvious fields such as chemical and civil engineering. ML is so broad in its application that merely the very existence of training data consisting of prior recorded labor processes is all required to attempt to have ML affect your bottom line. In essence, we are in an age where ML has significantly impacted the automation of all sorts of previously human-only-operated engineering processes.
#### **2. What are the biggest ML challenges within Engineering?**
1. The biggest challenges come with the operationalization and deployment of ML-trained solutions in a manner in which human operations can be replaced with minimal consequences. We’re seeing it now with fully self-driving automobiles. It’s challenging to automate processes with little to no fear of jeopardizing humans or processes that humans rely on. One of the most significant examples of this phenomenon that concerns me is ML and Bias. It is a reality that ML models trained on data containing, even if unaware, prejudiced decision-making can reproduce said bias in operation. Bias needs to be put front and center in the attempt to incorporate ML into engineering such that systemic racism isn’t propagated into future technological advances to then cause harm to disadvantaged populations. ML systems trained on data emanating from biased processes are doomed to repeat them, mainly if those training the ML solutions aren’t acutely aware of all forms of data present in the process to be automated.
2. Another critical challenge regarding ML in engineering is that the field is mainly categorized by the need for problem-solving, which often requires creativity. As of now, few great cases exist today of ML agents being truly “creative” and capable of “thinking out-of-the-box” since current ML solutions tend to result merely from a search through all possible solutions. In my humble opinion, though a great many solutions can be found via these methods, ML will have somewhat of a ceiling in engineering until the former can consistently demonstrate creativity in a variety of problem spaces. That said, that ceiling is still pretty high, and there is much left to be accomplished in ML applications in engineering.
#### **3. What’s a common mistake you see people make when trying to integrate ML into Engineering?**
Using an overpowered ML technique on a small problem dataset is one common mistake I see people making in integrating ML into Engineering. Deep Learning, for example, is moving AI and ML to heights unimagined in such a short period, but it may not be one’s best method for solving a problem, depending on your problem space. Often more straightforward methods work just as well or better when working with small training datasets on limited hardware.
Also, not setting up an effective CI/CD (continuous integration/ continuous deployment) structure for your ML solution is another mistake I see. Very often, a once-trained model won’t suffice not only because data changes over time but resources and personnel do as well. Today’s ML practitioner needs to:
1. secure consistent flow of data as it changes and continuously retrain new models to keep it accurate and useful,
2. ensure the structure is in place to allow for seamless replacement of older models by newly trained models while,
3. allowing for minimal disruption to the consumer of the ML model outputs.
#### **4. What excites you most about the future of ML?**
The future of ML continues to be exciting and seemingly every month there are advances reported in the field that even wow the experts to this day. As 1) ML techniques improve and become more accessible to established practitioners and novices alike, 2) everyday hardware becomes faster, 3) power consumption becomes less problematic for miniaturized edge devices, and 4) memory limitations diminish over time, the ceiling for ML in Engineering will be bright for years to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Samuel.png
"></a>
### [Samuel Franklin](https://www.linkedin.com/in/samuelcfranklin/) - Senior Director of Data Science & ML Engineering at [Pluralsight](https://www.pluralsight.com/)
**Background:** Samuel is a senior Data Science and ML Engineering leader at Pluralsight with a Ph.D. in cognitive science. He leads talented teams of Data Scientists and ML Engineers building intelligent services that power Pluralsight’s Skills platform.
Outside the virtual office, Dr. Franklin teaches Data Science and Machine Learning seminars for Emory University. He also serves as Chairman of the Board of Directors for the Atlanta Humane Society.
**Fun Fact:** I live in a log cabin on top of a mountain in the Appalachian range.
**Pluralsight:** We are a technology workforce development company and our Skills platform is used by 70% of the Fortune 500 to help their employees build business-critical tech skills.
#### **1. How has ML made a positive impact on Education?**
Online, on-demand educational content has made lifelong learning more accessible than ever for billions of people globally. Decades of cognitive research show that the relevance, format, and sequence of educational content significantly impact students’ success. Advances in deep learning content search and recommendation algorithms have greatly improved our ability to create customized, efficient learning paths at-scale that can adapt to individual student’s needs over time.
#### **2. What are the biggest ML challenges within Education?**
I see MLOps technology as a key opportunity area for improving ML across industries. The state of MLOps technology today reminds me of the Container Orchestration Wars circa 2015-16. There are competing visions for the ML Train-Deploy-Monitor stack, each evangelized by enthusiastic communities and supported by large organizations. If a predominant vision eventually emerges, then consensus on MLOps engineering patterns could follow, reducing the decision-making complexity that currently creates friction for ML teams.
#### **3. What’s a common mistake you see people make trying to integrate ML into existing products?**
There are two critical mistakes that I’ve seen organizations of all sizes make when getting started with ML. The first mistake is underestimating the importance of investing in senior leaders with substantial hands-on ML experience. ML strategy and operations leadership benefits from a depth of technical expertise beyond what is typically found in the BI / Analytics domain or provided by educational programs that offer a limited introduction to the field. The second mistake is waiting too long to design, test, and implement production deployment pipelines. Effective prototype models can languish in repos for months – even years – while waiting on ML pipeline development. This can impose significant opportunity costs on an organization and frustrate ML teams to the point of increasing attrition risk.
#### **4. What excites you most about the future of ML?**
I’m excited about the opportunity to mentor the next generation of ML leaders. My career began when cloud computing platforms were just getting started and ML tooling was much less mature than it is now. It was exciting to explore different engineering patterns for ML experimentation and deployment, since established best practices were rare. But, that exploration included learning too many technical and people leadership lessons the hard way. Sharing those lessons with the next generation of ML leaders will help empower them to advance the field farther and faster than what we’ve seen over the past 10+ years.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/evan.png"></a>
### [Evan Castle](https://www.linkedin.com/in/evan-castle-ai/) - Director of ML, Product Marketing, Elastic Stack at [Elastic](www.elastic.co)
**Background:** Over a decade of leadership experience in the intersection of data science, product, and strategy. Evan worked in various industries, from building risk models at Fortune 100s like Capital One to launching ML products at Sisense and Elastic.
**Fun Fact:** Met Paul McCarthy. 🎤
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on SaaS?**
Machine learning has become truly operational in SaaS, powering multiple uses from personalization, semantic and image search, recommendations to anomaly detection, and a ton of other business scenarios. The real impact is that ML comes baked right into more and more applications. It's becoming an expectation and more often than not it's invisible to end users.
For example, at Elastic we invested in ML for anomaly detection, optimized for endpoint security and SIEM. It delivers some heavy firepower out of the box with an amalgamation of different techniques like time series decomposition, clustering, correlation analysis, and Bayesian distribution modeling. The big benefit for security analysts is threat detection is automated in many different ways. So anomalies are quickly bubbled up related to temporal deviations, unusual geographic locations, statistical rarity, and many other factors. That's the huge positive impact of integrating ML.
#### **2. What are the biggest ML challenges within SaaS?**
To maximize the benefits of ML there is a double challenge of delivering value to users that are new to machine learning and also to seasoned data scientists. There's obviously a huge difference in demands for these two folks. If an ML capability is a total black box it's likely to be too rigid or simple to have a real impact. On the other hand, if you solely deliver a developer toolkit it's only useful if you have a data science team in-house. Striking the right balance is about making sure ML is open enough for the data science team to have transparency and control over models and also packing in battle-tested models that are easy to configure and deploy without being a pro.
#### **3. What’s a common mistake you see people make trying to integrate ML into SaaS?**
To get it right, any integrated model has to work at scale, which means support for massive data sets while ensuring results are still performant and accurate. Let's illustrate this with a real example. There has been a surge in interest in vector search. All sorts of things can be represented in vectors from text, and images to events. Vectors can be used to capture similarities between content and are great for things like search relevance and recommendations. The challenge is developing algorithms that can compare vectors taking into account trade-offs in speed, complexity, and cost.
At Elastic, we spent a lot of time evaluating and benchmarking the performance of models for vector search. We decided on an approach for the approximate nearest neighbor (ANN) algorithm called Hierarchical Navigable Small World graphs (HNSW), which basically maps vectors into a
graph based on their similarity to each other. HNSW delivers an order of magnitude increase in speed and accuracy across a variety of ANN-benchmarks. This is just one example of non-trivial decisions more and more product and engineering teams need to take to successfully integrate ML into their products.
#### **4. What excites you most about the future of ML?**
Machine learning will become as simple as ordering online. The big advances in NLP especially have made ML more human by understanding context, intent, and meaning. I think we are in an era of foundational models that will blossom into many interesting directions. At Elastic we are thrilled with our own integration to Hugging Face and excited to already see how our customers are leveraging NLP for observability, security, and search.
---
🤗 Thank you for joining us in this fourth installment of ML Director Insights.
Big thanks to Javier Mansilla, Shaun Gittens, Samuel Franklin, and Evan Castle for their brilliant insights and participation in this piece. We look forward to watching your continued success and will be cheering you on each step of the way. 🎉
If you're' interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) to learn more.
| 5 |
0 | hf_public_repos | hf_public_repos/blog/wav2vec2-with-ngram.md | ---
title: "Boosting Wav2Vec2 with n-grams in 🤗 Transformers"
thumbnail: /blog/assets/44_boost_wav2vec2_ngram/wav2vec2_ngram.png
authors:
- user: patrickvonplaten
---
# Boosting Wav2Vec2 with n-grams in 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Boosting_Wav2Vec2_with_n_grams_in_Transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Wav2Vec2** is a popular pre-trained model for speech recognition.
Released in [September 2020](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
by Meta AI Research, the novel architecture catalyzed progress in
self-supervised pretraining for speech recognition, *e.g.* [*G. Ng et
al.*, 2021](https://arxiv.org/pdf/2104.03416.pdf), [*Chen et al*,
2021](https://arxiv.org/abs/2110.13900), [*Hsu et al.*,
2021](https://arxiv.org/abs/2106.07447) and [*Babu et al.*,
2021](https://arxiv.org/abs/2111.09296). On the Hugging Face Hub,
Wav2Vec2's most popular pre-trained checkpoint currently amounts to
over [**250,000** monthly
downloads](https://huggingface.co/facebook/wav2vec2-base-960h).
Using Connectionist Temporal Classification (CTC), pre-trained
Wav2Vec2-like checkpoints are extremely easy to fine-tune on downstream
speech recognition tasks. In a nutshell, fine-tuning pre-trained
Wav2Vec2 checkpoints works as follows:
A single randomly initialized linear layer is stacked on top of the
pre-trained checkpoint and trained to classify raw audio input to a
sequence of letters. It does so by:
1. extracting audio representations from the raw audio (using CNN
layers),
2. processing the sequence of audio representations with a stack of
transformer layers, and,
3. classifying the processed audio representations into a sequence of
output letters.
Previously audio classification models required an additional language
model (LM) and a dictionary to transform the sequence of classified audio
frames to a coherent transcription. Wav2Vec2's architecture is based on
transformer layers, thus giving each processed audio representation
context from all other audio representations. In addition, Wav2Vec2
leverages the [CTC algorithm](https://distill.pub/2017/ctc/) for
fine-tuning, which solves the problem of alignment between a varying
"input audio length"-to-"output text length" ratio.
Having contextualized audio classifications and no alignment problems,
Wav2Vec2 does not require an external language model or dictionary to
yield acceptable audio transcriptions.
As can be seen in Appendix C of the [official
paper](https://arxiv.org/abs/2006.11477), Wav2Vec2 gives impressive
downstream performances on [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) without using a language model at
all. However, from the appendix, it also becomes clear that using Wav2Vec2
in combination with a language model can yield a significant
improvement, especially when the model was trained on only 10 minutes of
transcribed audio.
Until recently, the 🤗 Transformers library did not offer a simple user
interface to decode audio files with a fine-tuned Wav2Vec2 **and** a
language model. This has thankfully changed. 🤗 Transformers now offers
an easy-to-use integration with *Kensho Technologies'* [pyctcdecode
library](https://github.com/kensho-technologies/pyctcdecode). This blog
post is a step-by-step **technical** guide to explain how one can create
an **n-gram** language model and combine it with an existing fine-tuned
Wav2Vec2 checkpoint using 🤗 Datasets and 🤗 Transformers.
We start by:
1. How does decoding audio with an LM differ from decoding audio
without an LM?
2. How to get suitable data for a language model?
3. How to build an *n-gram* with KenLM?
4. How to combine the *n-gram* with a fine-tuned Wav2Vec2 checkpoint?
For a deep dive into how Wav2Vec2 functions - which is not necessary for
this blog post - the reader is advised to consult the following
material:
- [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations](https://arxiv.org/abs/2006.11477)
- [Fine-Tune Wav2Vec2 for English ASR with 🤗
Transformers](https://huggingface.co/blog/fine-tune-wav2vec2-english)
- [An Illustrated Tour of Wav2vec
2.0](https://jonathanbgn.com/2021/09/30/illustrated-wav2vec-2.html)
## **1. Decoding audio data with Wav2Vec2 and a language model**
As shown in 🤗 Transformers [exemple docs of
Wav2Vec2](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC),
audio can be transcribed as follows.
First, we install `datasets` and `transformers`.
```bash
pip install datasets transformers
```
Let's load a small excerpt of the [Librispeech
dataset](https://huggingface.co/datasets/librispeech_asr) to demonstrate
Wav2Vec2's speech transcription capabilities.
```python
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
dataset
```
**Output:**
```bash
Reusing dataset librispeech_asr (/root/.cache/huggingface/datasets/hf-internal-testing___librispeech_asr/clean/2.1.0/f2c70a4d03ab4410954901bde48c54b85ca1b7f9bf7d616e7e2a72b5ee6ddbfc)
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
We can pick one of the 73 audio samples and listen to it.
```python
audio_sample = dataset[2]
audio_sample["text"].lower()
```
**Output:**
```bash
he tells us that at this festive season of the year with christmas and roast beef looming before us similes drawn from eating and its results occur most readily to the mind
```
Having chosen a data sample, we now load the fine-tuned model and
processor.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h")
```
Next, we process the data
```python
inputs = processor(audio_sample["audio"]["array"], sampling_rate=audio_sample["audio"]["sampling_rate"], return_tensors="pt")
```
forward it to the model
```python
import torch
with torch.no_grad():
logits = model(**inputs).logits
```
and decode it
```python
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmaus and rose beef looming before us simalyis drawn from eating and its results occur most readily to the mind'
```
Comparing the transcription to the target transcription above, we can
see that some words *sound* correct, but are not *spelled* correctly,
*e.g.*:
- *christmaus* vs. *christmas*
- *rose* vs. *roast*
- *simalyis* vs. *similes*
Let's see whether combining Wav2Vec2 with an ***n-gram*** lnguage model
can help here.
First, we need to install `pyctcdecode` and `kenlm`.
```bash
pip install https://github.com/kpu/kenlm/archive/master.zip pyctcdecode
```
For demonstration purposes, we have prepared a new model repository
[patrickvonplaten/wav2vec2-base-100h-with-lm](https://huggingface.co/patrickvonplaten/wav2vec2-base-100h-with-lm)
which contains the same Wav2Vec2 checkpoint but has an additional
**4-gram** language model for English.
Instead of using `Wav2Vec2Processor`, this time we use
`Wav2Vec2ProcessorWithLM` to load the **4-gram** model in addition to
the feature extractor and tokenizer.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
```
In constrast to decoding the audio without language model, the processor
now directly receives the model's output `logits` instead of the
`argmax(logits)` (called `predicted_ids`) above. The reason is that when
decoding with a language model, at each time step, the processor takes
the probabilities of all possible output characters into account. Let's
take a look at the dimension of the `logits` output.
```python
logits.shape
```
**Output:**
```bash
torch.Size([1, 624, 32])
```
We can see that the `logits` correspond to a sequence of 624 vectors
each having 32 entries. Each of the 32 entries thereby stands for the
logit probability of one of the 32 possible output characters of the
model:
```python
" ".join(sorted(processor.tokenizer.get_vocab()))
```
**Output:**
```bash
"' </s> <pad> <s> <unk> A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |"
```
Intuitively, one can understand the decoding process of
`Wav2Vec2ProcessorWithLM` as applying beam search through a matrix of
size 624 $\times$ 32 probabilities while leveraging the probabilities of
the next letters as given by the *n-gram* language model.
OK, let's run the decoding step again. `pyctcdecode` language model
decoder does not automatically convert `torch` tensors to `numpy` so
we'll have to convert them ourselves before.
```python
transcription = processor.batch_decode(logits.numpy()).text
transcription[0].lower()
```
**Output:**
```bash
'he tells us that at this festive season of the year with christmas and rose beef looming before us similes drawn from eating and its results occur most readily to the mind'
```
Cool! Recalling the words `facebook/wav2vec2-base-100h` without a
language model transcribed incorrectly previously, *e.g.*,
> - *christmaus* vs. *christmas*
> - *rose* vs. *roast*
> - *simalyis* vs. *similes*
we can take another look at the transcription of
`facebook/wav2vec2-base-100h` **with** a 4-gram language model. 2 out of
3 errors are corrected; *christmas* and *similes* have been correctly
transcribed.
Interestingly, the incorrect transcription of *rose* persists. However,
this should not surprise us very much. Decoding audio without a language
model is much more prone to yield spelling mistakes, such as
*christmaus* or *similes* (those words don't exist in the English
language as far as I know). This is because the speech recognition
system almost solely bases its prediction on the acoustic input it was
given and not really on the language modeling context of previous and
successive predicted letters \\( {}^1 \\). If on the other hand, we add a
language model, we can be fairly sure that the speech recognition
system will heavily reduce spelling errors since a well-trained *n-gram*
model will surely not predict a word that has spelling errors. But the
word *rose* is a valid English word and therefore the 4-gram will
predict this word with a probability that is not insignificant.
The language model on its own most likely does favor the correct word
*roast* since the word sequence *roast beef* is much more common in
English than *rose beef*. Because the final transcription is derived
from a weighted combination of `facebook/wav2vec2-base-100h` output
probabilities and those of the *n-gram* language model, it is quite
common to see incorrectly transcribed words such as *rose*.
For more information on how you can tweak different parameters when
decoding with `Wav2Vec2ProcessorWithLM`, please take a look at the
official documentation
[here](https://huggingface.co/docs/transformers/master/en/model_doc/wav2vec2#transformers.Wav2Vec2ProcessorWithLM.batch_decode).
------------------------------------------------------------------------
\\({}^1 \\) Some research shows that a model such as
`facebook/wav2vec2-base-100h` - when sufficiently large and trained on
enough data - can learn language modeling dependencies between
intermediate audio representations similar to a language model.
Great, now that you have seen the advantages adding an *n-gram* language
model can bring, let's dive into how to create an *n-gram* and
`Wav2Vec2ProcessorWithLM` from scratch.
## **2. Getting data for your language model**
A language model that is useful for a speech recognition system should
support the acoustic model, *e.g.* Wav2Vec2, in predicting the next word
(or token, letter) and therefore model the following distribution:
\\( \mathbf{P}(w_n | \mathbf{w}_0^{t-1}) \\) with \\( w_n \\) being the next word
and \\( \mathbf{w}_0^{t-1} \\) being the sequence of all previous words since
the beginning of the utterance. Simply said, the language model should
be good at predicting the next word given all previously transcribed
words regardless of the audio input given to the speech recognition
system.
As always a language model is only as good as the data it is trained on.
In the case of speech recognition, we should therefore ask ourselves for
what kind of data, the speech recognition will be used for:
*conversations*, *audiobooks*, *movies*, *speeches*, *, etc*, \...?
The language model should be good at modeling language that corresponds
to the target transcriptions of the speech recognition system. For
demonstration purposes, we assume here that we have fine-tuned a
pre-trained
[`facebook/wav2vec2-xls-r-300m`](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
on [Common Voice
7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0)
in Swedish. The fine-tuned checkpoint can be found
[here](https://huggingface.co/hf-test/xls-r-300m-sv). Common Voice 7 is
a relatively crowd-sourced read-out audio dataset and we will evaluate
the model on its test data.
Let's now look for suitable text data on the Hugging Face Hub. We
search all datasets for those [that contain Swedish
data](https://huggingface.co/datasets?languages=languages:sv&sort=downloads).
Browsing a bit through the datasets, we are looking for a dataset that
is similar to Common Voice's read-out audio data. The obvious choices
of [oscar](https://huggingface.co/datasets/oscar) and
[mc4](https://huggingface.co/datasets/mc4) might not be the most
suitable here because they:
- are generated from crawling the web, which might not be very
clean and correspond well to spoken language
- require a lot of pre-processing
- are very large which is not ideal for demonstration purposes
here 😉
A dataset that seems sensible here and which is relatively clean and
easy to pre-process is
[europarl_bilingual](https://huggingface.co/datasets/europarl_bilingual)
as it's a dataset that is based on discussions and talks of the
European parliament. It should therefore be relatively clean and
correspond well to read-out audio data. The dataset is originally designed
for machine translation and can therefore only be accessed in
translation pairs. We will only extract the text of the target
language, Swedish (`sv`), from the *English-to-Swedish* translations.
```python
target_lang="sv" # change to your target lang
```
Let's download the data.
```python
from datasets import load_dataset
dataset = load_dataset("europarl_bilingual", lang1="en", lang2=target_lang, split="train")
```
We see that the data is quite large - it has over a million
translations. Since it's only text data, it should be relatively easy
to process though.
Next, let's look at how the data was preprocessed when training the
fine-tuned *XLS-R* checkpoint in Swedish. Looking at the [`run.sh`
file](https://huggingface.co/hf-test/xls-r-300m-sv/blob/main/run.sh), we
can see that the following characters were removed from the official
transcriptions:
```python
chars_to_ignore_regex = '[,?.!\-\;\:"“%‘”�—’…–]' # change to the ignored characters of your fine-tuned model
```
Let's do the same here so that the alphabet of our language model
matches the one of the fine-tuned acoustic checkpoints.
We can write a single map function to extract the Swedish text and
process it right away.
```python
import re
def extract_text(batch):
text = batch["translation"][target_lang]
batch["text"] = re.sub(chars_to_ignore_regex, "", text.lower())
return batch
```
Let's apply the `.map()` function. This should take roughly 5 minutes.
```python
dataset = dataset.map(extract_text, remove_columns=dataset.column_names)
```
Great. Let's upload it to the Hub so
that we can inspect and reuse it better.
You can log in by executing the following cell.
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
```
Next, we call 🤗 Hugging Face's
[`push_to_hub`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=push#datasets.Dataset.push_to_hub)
method to upload the dataset to the repo
`"sv_corpora_parliament_processed"`.
```python
dataset.push_to_hub(f"{target_lang}_corpora_parliament_processed", split="train")
```
That was easy! The dataset viewer is automatically enabled when
uploading a new dataset, which is very convenient. You can now directly
inspect the dataset online.
Feel free to look through our preprocessed dataset directly on
[`hf-test/sv_corpora_parliament_processed`](https://huggingface.co/datasets/hf-test/sv_corpora_parliament_processed).
Even if we are not a native speaker in Swedish, we can see that the data
is well processed and seems clean.
Next, let's use the data to build a language model.
## **3. Build an *n-gram* with KenLM**
While large language models based on the [Transformer architecture](https://jalammar.github.io/illustrated-transformer/) have become the standard in NLP, it is still very common to use an ***n-gram*** LM to boost speech recognition systems - as shown in Section 1.
Looking again at Table 9 of Appendix C of the [official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477), it can be noticed that using a *Transformer*-based LM for decoding clearly yields better results than using an *n-gram* model, but the difference between *n-gram* and *Transformer*-based LM is much less significant than the difference between *n-gram* and no LM.
*E.g.*, for the large Wav2Vec2 checkpoint that was fine-tuned on 10min only, an *n-gram* reduces the word error rate (WER) compared to no LM by *ca.* 80% while a *Transformer*-based LM *only* reduces the WER by another 23% compared to the *n-gram*. This relative WER reduction becomes less, the more data the acoustic model has been trained on. *E.g.*, for the large checkpoint a *Transformer*-based LM reduces the WER by merely 8% compared to an *n-gram* LM whereas the *n-gram* still yields a 21% WER reduction compared to no language model.
The reason why an *n-gram* is preferred over a *Transformer*-based LM is that *n-grams* come at a significantly smaller computational cost. For an *n-gram*, retrieving the probability of a word given previous words is almost only as computationally expensive as querying a look-up table or tree-like data storage - *i.e.* it's very fast compared to modern *Transformer*-based language models that would require a full forward pass to retrieve the next word probabilities.
For more information on how *n-grams* function and why they are (still) so useful for speech recognition, the reader is advised to take a look at [this excellent summary](https://web.stanford.edu/~jurafsky/slp3/3.pdf) from Stanford.
Great, let's see step-by-step how to build an *n-gram*. We will use the
popular [KenLM library](https://github.com/kpu/kenlm) to do so. Let's
start by installing the Ubuntu library prerequisites:
```bash
sudo apt install build-essential cmake libboost-system-dev libboost-thread-dev libboost-program-options-dev libboost-test-dev libeigen3-dev zlib1g-dev libbz2-dev liblzma-dev
```
before downloading and unpacking the KenLM repo.
```bash
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz
```
KenLM is written in C++, so we'll make use of `cmake` to build the
binaries.
```bash
mkdir kenlm/build && cd kenlm/build && cmake .. && make -j2
ls kenlm/build/bin
```
Great, as we can see, the executable functions have successfully
been built under `kenlm/build/bin/`.
KenLM by default computes an *n-gram* with [Kneser-Ney
smooting](https://en.wikipedia.org/wiki/Kneser%E2%80%93Ney_smoothing).
All text data used to create the *n-gram* is expected to be stored in a
text file. We download our dataset and save it as a `.txt` file.
```python
from datasets import load_dataset
username = "hf-test" # change to your username
dataset = load_dataset(f"{username}/{target_lang}_corpora_parliament_processed", split="train")
with open("text.txt", "w") as file:
file.write(" ".join(dataset["text"]))
```
Now, we just have to run KenLM's `lmplz` command to build our *n-gram*,
called `"5gram.arpa"`. As it's relatively common in speech recognition,
we build a *5-gram* by passing the `-o 5` parameter.
For more information on the different *n-gram* LM that can be built
with KenLM, one can take a look at the [official website of KenLM](https://kheafield.com/code/kenlm/).
Executing the command below might take a minute or so.
```bash
kenlm/build/bin/lmplz -o 5 <"text.txt" > "5gram.arpa"
```
**Output:**
```bash
=== 1/5 Counting and sorting n-grams ===
Reading /content/swedish_text.txt
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
tcmalloc: large alloc 1918697472 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b28c51e 0x55d40b26b2eb 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 8953896960 bytes == 0x55d47f6c0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b308 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
****************************************************************************************************
Unigram tokens 42153890 types 360209
=== 2/5 Calculating and sorting adjusted counts ===
Chain sizes: 1:4322508 2:1062772928 3:1992699264 4:3188318720 5:4649631744
tcmalloc: large alloc 4649631744 bytes == 0x55d40d0f0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26b8d7 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 1992704000 bytes == 0x55d561ce0000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
tcmalloc: large alloc 3188326400 bytes == 0x55d695a86000 @ 0x7fdccb1a91e7 0x55d40b2f17a2 0x55d40b2e07ca 0x55d40b2e1208 0x55d40b26bcdd 0x55d40b257066 0x7fdcc9342bf7 0x55d40b258baa
Statistics:
1 360208 D1=0.686222 D2=1.01595 D3+=1.33685
2 5476741 D1=0.761523 D2=1.06735 D3+=1.32559
3 18177681 D1=0.839918 D2=1.12061 D3+=1.33794
4 30374983 D1=0.909146 D2=1.20496 D3+=1.37235
5 37231651 D1=0.944104 D2=1.25164 D3+=1.344
Memory estimate for binary LM:
type MB
probing 1884 assuming -p 1.5
probing 2195 assuming -r models -p 1.5
trie 922 without quantization
trie 518 assuming -q 8 -b 8 quantization
trie 806 assuming -a 22 array pointer compression
trie 401 assuming -a 22 -q 8 -b 8 array pointer compression and quantization
=== 3/5 Calculating and sorting initial probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 4/5 Calculating and writing order-interpolated probabilities ===
Chain sizes: 1:4322496 2:87627856 3:363553620 4:728999592 5:1042486228
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
####################################################################################################
=== 5/5 Writing ARPA model ===
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Name:lmplz VmPeak:14181536 kB VmRSS:2199260 kB RSSMax:4160328 kB user:120.598 sys:26.6659 CPU:147.264 real:136.344
```
Great, we have built a *5-gram* LM! Let's inspect the first couple of
lines.
```bash
head -20 5gram.arpa
```
**Output:**
```bash
\data\
ngram 1=360208
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
-5.199537 avbrottet -0.43322718
```
There is a small problem that 🤗 Transformers will not be happy about
later on. The *5-gram* correctly includes a "Unknown" or `<unk>`, as
well as a *begin-of-sentence*, `<s>` token, but no *end-of-sentence*,
`</s>` token. This sadly has to be corrected currently after the build.
We can simply add the *end-of-sentence* token by adding the line
`0 </s> -0.11831701` below the *begin-of-sentence* token and increasing
the `ngram 1` count by 1. Because the file has roughly 100 million
lines, this command will take *ca.* 2 minutes.
```python
with open("5gram.arpa", "r") as read_file, open("5gram_correct.arpa", "w") as write_file:
has_added_eos = False
for line in read_file:
if not has_added_eos and "ngram 1=" in line:
count=line.strip().split("=")[-1]
write_file.write(line.replace(f"{count}", f"{int(count)+1}"))
elif not has_added_eos and "<s>" in line:
write_file.write(line)
write_file.write(line.replace("<s>", "</s>"))
has_added_eos = True
else:
write_file.write(line)
```
Let's now inspect the corrected *5-gram*.
```bash
head -20 5gram_correct.arpa
```
**Output:**
```bash
\data\
ngram 1=360209
ngram 2=5476741
ngram 3=18177681
ngram 4=30374983
ngram 5=37231651
\1-grams:
-6.770219 <unk> 0
0 <s> -0.11831701
0 </s> -0.11831701
-4.6095004 återupptagande -1.2174699
-2.2361007 av -0.79668784
-4.8163533 sessionen -0.37327805
-2.2251768 jag -1.4205662
-4.181505 förklarar -0.56261665
-3.5790775 europaparlamentets -0.63611007
-4.771945 session -0.3647111
-5.8043895 återupptagen -0.3058712
-2.8580177 efter -0.7557702
```
Great, this looks better! We're done at this point and all that is left
to do is to correctly integrate the `"ngram"` with
[`pyctcdecode`](https://github.com/kensho-technologies/pyctcdecode) and
🤗 Transformers.
## **4. Combine an *n-gram* with Wav2Vec2**
In a final step, we want to wrap the *5-gram* into a
`Wav2Vec2ProcessorWithLM` object to make the *5-gram* boosted decoding
as seamless as shown in Section 1. We start by downloading the currently
"LM-less" processor of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv).
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("hf-test/xls-r-300m-sv")
```
Next, we extract the vocabulary of its tokenizer as it represents the
`"labels"` of `pyctcdecode`'s `BeamSearchDecoder` class.
```python
vocab_dict = processor.tokenizer.get_vocab()
sorted_vocab_dict = {k.lower(): v for k, v in sorted(vocab_dict.items(), key=lambda item: item[1])}
```
The `"labels"` and the previously built `5gram_correct.arpa` file is all
that's needed to build the decoder.
```python
from pyctcdecode import build_ctcdecoder
decoder = build_ctcdecoder(
labels=list(sorted_vocab_dict.keys()),
kenlm_model_path="5gram_correct.arpa",
)
```
**Output:**
```bash
Found entries of length > 1 in alphabet. This is unusual unless style is BPE, but the alphabet was not recognized as BPE type. Is this correct?
Unigrams and labels don't seem to agree.
```
We can safely ignore the warning and all that is left to do now is to
wrap the just created `decoder`, together with the processor's
`tokenizer` and `feature_extractor` into a `Wav2Vec2ProcessorWithLM`
class.
```python
from transformers import Wav2Vec2ProcessorWithLM
processor_with_lm = Wav2Vec2ProcessorWithLM(
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
decoder=decoder
)
```
We want to directly upload the LM-boosted processor into the model
folder of
[`xls-r-300m-sv`](https://huggingface.co/hf-test/xls-r-300m-sv) to have
all relevant files in one place.
Let's clone the repo, add the new decoder files and upload them
afterward. First, we need to install `git-lfs`.
```bash
sudo apt-get install git-lfs tree
```
Cloning and uploading of modeling files can be done conveniently with
the `huggingface_hub`'s `Repository` class.
More information on how to use the `huggingface_hub` to upload any
files, please take a look at the [official
docs](https://huggingface.co/docs/huggingface_hub/how-to-upstream).
```python
from huggingface_hub import Repository
repo = Repository(local_dir="xls-r-300m-sv", clone_from="hf-test/xls-r-300m-sv")
```
**Output:**
```bash
Cloning https://huggingface.co/hf-test/xls-r-300m-sv into local empty directory.
```
Having cloned `xls-r-300m-sv`, let's save the new processor with LM
into it.
```python
processor_with_lm.save_pretrained("xls-r-300m-sv")
```
Let's inspect the local repository. The `tree` command conveniently can
also show the size of the different files.
```bash
tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [4.1G] 5gram_correct.arpa
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
As can be seen the *5-gram* LM is quite large - it amounts to more than
4 GB. To reduce the size of the *n-gram* and make loading faster,
`kenLM` allows converting `.arpa` files to binary ones using the
`build_binary` executable.
Let's make use of it here.
```bash
kenlm/build/bin/build_binary xls-r-300m-sv/language_model/5gram_correct.arpa xls-r-300m-sv/language_model/5gram.bin
```
**Output:**
```bash
Reading xls-r-300m-sv/language_model/5gram_correct.arpa
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
SUCCESS
```
Great, it worked! Let's remove the `.arpa` file and check the size of
the binary *5-gram* LM.
```bash
rm xls-r-300m-sv/language_model/5gram_correct.arpa && tree -h xls-r-300m-sv/
```
**Output:**
```bash
xls-r-300m-sv/
├── [ 23] added_tokens.json
├── [ 401] all_results.json
├── [ 253] alphabet.json
├── [2.0K] config.json
├── [ 304] emissions.csv
├── [ 226] eval_results.json
├── [4.0K] language_model
│ ├── [1.8G] 5gram.bin
│ ├── [ 78] attrs.json
│ └── [4.9M] unigrams.txt
├── [ 240] preprocessor_config.json
├── [1.2G] pytorch_model.bin
├── [3.5K] README.md
├── [4.0K] runs
│ └── [4.0K] Jan09_22-00-50_brutasse
│ ├── [4.0K] 1641765760.8871996
│ │ └── [4.6K] events.out.tfevents.1641765760.brutasse.31164.1
│ ├── [ 42K] events.out.tfevents.1641765760.brutasse.31164.0
│ └── [ 364] events.out.tfevents.1641794162.brutasse.31164.2
├── [1.2K] run.sh
├── [ 30K] run_speech_recognition_ctc.py
├── [ 502] special_tokens_map.json
├── [ 279] tokenizer_config.json
├── [ 29K] trainer_state.json
├── [2.9K] training_args.bin
├── [ 196] train_results.json
├── [ 319] vocab.json
└── [4.0K] wandb
├── [ 52] debug-internal.log -> run-20220109_220240-1g372i3v/logs/debug-internal.log
├── [ 43] debug.log -> run-20220109_220240-1g372i3v/logs/debug.log
├── [ 28] latest-run -> run-20220109_220240-1g372i3v
└── [4.0K] run-20220109_220240-1g372i3v
├── [4.0K] files
│ ├── [8.8K] conda-environment.yaml
│ ├── [140K] config.yaml
│ ├── [4.7M] output.log
│ ├── [5.4K] requirements.txt
│ ├── [2.1K] wandb-metadata.json
│ └── [653K] wandb-summary.json
├── [4.0K] logs
│ ├── [3.4M] debug-internal.log
│ └── [8.2K] debug.log
└── [113M] run-1g372i3v.wandb
9 directories, 34 files
```
Nice, we reduced the *n-gram* by more than half to less than 2GB now. In
the final step, let's upload all files.
```python
repo.push_to_hub(commit_message="Upload lm-boosted decoder")
```
**Output:**
```bash
Git LFS: (1 of 1 files) 1.85 GB / 1.85 GB
Counting objects: 9, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 1.23 MiB | 1.92 MiB/s, done.
Total 9 (delta 3), reused 0 (delta 0)
To https://huggingface.co/hf-test/xls-r-300m-sv
27d0c57..5a191e2 main -> main
```
That's it. Now you should be able to use the *5gram* for LM-boosted
decoding as shown in Section 1.
As can be seen on [`xls-r-300m-sv`'s model
card](https://huggingface.co/hf-test/xls-r-300m-sv#inference-with-lm)
our *5gram* LM-boosted decoder yields a WER of 18.85% on Common Voice's 7
test set which is a relative performance of *ca.* 30% 🔥.
| 6 |
0 | hf_public_repos | hf_public_repos/blog/simple_sdxl_optimizations.md | ---
title: "Exploring simple optimizations for SDXL"
thumbnail: /blog/assets/simple_sdxl_optimizations/thumbnail.png
authors:
- user: sayakpaul
- user: stevhliu
---
# Exploring simple optimizations for SDXL
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/exploring_simple%20optimizations_for_sdxl.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
[Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) is the latest latent diffusion model by Stability AI for generating high-quality super realistic images. It overcomes challenges of previous Stable Diffusion models like getting hands and text right as well as spatially correct compositions. In addition, SDXL is also more context aware and requires fewer words in its prompt to generate better looking images.
However, all of these improvements come at the expense of a significantly larger model. How much larger? The base SDXL model has 3.5B parameters (the UNet, in particular), which is approximately 3x larger than the previous Stable Diffusion model.
To explore how we can optimize SDXL for inference speed and memory use, we ran some tests on an A100 GPU (40 GB). For each inference run, we generate 4 images and repeat it 3 times. While computing the inference latency, we only consider the final iteration out of the 3 iterations.
So if you run SDXL out-of-the-box as is with full precision and use the default attention mechanism, it’ll consume 28GB of memory and take 72.2 seconds!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")
pipe.unet.set_default_attn_processor()
```
This isn’t very practical and can slow you down because you’re often generating more than 4 images. And if you don’t have a more powerful GPU, you’ll run into that frustrating out-of-memory error message. So how can we optimize SDXL to increase inference speed and reduce its memory-usage?
In 🤗 Diffusers, we have a bunch of optimization tricks and techniques to help you run memory-intensive models like SDXL and we'll show you how! The two things we’ll focus on are *inference speed* and *memory*.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
🧠 The techniques discussed in this post are applicable to all the <a href=https://huggingface.co/docs/diffusers/main/en/using-diffusers/pipeline_overview>pipelines</a>.
</div>
## Inference speed
Diffusion is a random process, so there's no guarantee you'll get an image you’ll like. Often times, you’ll need to run inference multiple times and iterate, and that’s why optimizing for speed is crucial. This section focuses on using lower precision weights and incorporating memory-efficient attention and `torch.compile` from PyTorch 2.0 to boost speed and reduce inference time.
### Lower precision
Model weights are stored at a certain *precision* which is expressed as a floating point data type. The standard floating point data type is float32 (fp32), which can accurately represent a wide range of floating numbers. For inference, you often don’t need to be as precise so you should use float16 (fp16) which captures a narrower range of floating numbers. This means fp16 only takes half the amount of memory to store compared to fp32, and is twice as fast because it is easier to calculate. In addition, modern GPU cards have optimized hardware to run fp16 calculations, making it even faster.
With 🤗 Diffusers, you can use fp16 for inference by specifying the `torch.dtype` parameter to convert the weights when the model is loaded:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet.set_default_attn_processor()
```
Compared to a completely unoptimized SDXL pipeline, using fp16 takes 21.7GB of memory and only 14.8 seconds. You’re almost speeding up inference by a full minute!
### Memory-efficient attention
The attention blocks used in transformers modules can be a huge bottleneck, because memory increases _quadratically_ as input sequences get longer. This can quickly take up a ton of memory and leave you with an out-of-memory error message. 😬
Memory-efficient attention algorithms seek to reduce the memory burden of calculating attention, whether it is by exploiting sparsity or tiling. These optimized algorithms used to be mostly available as third-party libraries that needed to be installed separately. But starting with PyTorch 2.0, this is no longer the case. PyTorch 2 introduced [scaled dot product attention (SDPA)](https://pytorch.org/blog/accelerated-diffusers-pt-20/), which offers fused implementations of [Flash Attention](https://huggingface.co/papers/2205.14135), [memory-efficient attention](https://huggingface.co/papers/2112.05682) (xFormers), and a PyTorch implementation in C++. SDPA is probably the easiest way to speed up inference: if you’re using PyTorch ≥ 2.0 with 🤗 Diffusers, it is automatically enabled by default!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
```
Compared to a completely unoptimized SDXL pipeline, using fp16 and SDPA takes the same amount of memory and the inference time improves to 11.4 seconds. Let’s use this as the new baseline we’ll compare the other optimizations to.
### torch.compile
PyTorch 2.0 also introduced the `torch.compile` API for just-in-time (JIT) compilation of your PyTorch code into more optimized kernels for inference. Unlike other compiler solutions, `torch.compile` requires minimal changes to your existing code and it is as easy as wrapping your model with the function.
With the `mode` parameter, you can optimize for memory overhead or inference speed during compilation, which gives you way more flexibility.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
Compared to the previous baseline (fp16 + SDPA), wrapping the UNet with `torch.compile` improves inference time to 10.2 seconds.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The first time you compile a model is slower, but once the model is compiled, all subsequent calls to it are much faster!
</div>
## Model memory footprint
Models today are growing larger and larger, making it a challenge to fit them into memory. This section focuses on how you can reduce the memory footprint of these enormous models so you can run them on consumer GPUs. These techniques include CPU offloading, decoding latents into images over several steps rather than all at once, and using a distilled version of the autoencoder.
### Model CPU offloading
Model offloading saves memory by loading the UNet into the GPU memory while the other components of the diffusion model (text encoders, VAE) are loaded onto the CPU. This way, the UNet can run for multiple iterations on the GPU until it is no longer needed.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.enable_model_cpu_offload()
```
Compared to the baseline, it now takes 20.2GB of memory which saves you 1.5GB of memory.
### Sequential CPU offloading
Another type of offloading which can save you more memory at the expense of slower inference is sequential CPU offloading. Rather than offloading an entire model - like the UNet - model weights stored in different UNet submodules are offloaded to the CPU and only loaded onto the GPU right before the forward pass. Essentially, you’re only loading parts of the model each time which allows you to save even more memory. The only downside is that it is significantly slower because you’re loading and offloading submodules many times.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.enable_sequential_cpu_offload()
```
Compared to the baseline, this takes 19.9GB of memory but the inference time increases to 67 seconds.
## Slicing
In SDXL, a variational encoder (VAE) decodes the refined latents (predicted by the UNet) into realistic images. The memory requirement of this step scales with the number of images being predicted (the batch size). Depending on the image resolution and the available GPU VRAM, it can be quite memory-intensive.
This is where “slicing” is useful. The input tensor to be decoded is split into slices and the computation to decode it is completed over several steps. This saves memory and allows larger batch sizes.
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_vae_slicing()
```
With sliced computations, we reduce the memory to 15.4GB. If we add sequential CPU offloading, it is further reduced to 11.45GB which lets you generate 4 images (1024x1024) per prompt. However, with sequential offloading, the inference latency also increases.
## Caching computations
Any text-conditioned image generation model typically uses a text encoder to compute embeddings from the input prompt. SDXL uses *two* text encoders! This contributes quite a bit to the inference latency. However, since these embeddings remain unchanged throughout the reverse diffusion process, we can precompute them and reuse them as we go. This way, after computing the text embeddings, we can remove the text encoders from memory.
First, load the text encoders and their corresponding tokenizers and compute the embeddings from the input prompt:
```python
tokenizers = [tokenizer, tokenizer_2]
text_encoders = [text_encoder, text_encoder_2]
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds
) = encode_prompt(tokenizers, text_encoders, prompt)
```
Next, flush the GPU memory to remove the text encoders:
```jsx
del text_encoder, text_encoder_2, tokenizer, tokenizer_2
flush()
```
Now the embeddings are good to go straight to the SDXL pipeline:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
text_encoder=None,
text_encoder_2=None,
tokenizer=None,
tokenizer_2=None,
torch_dtype=torch.float16,
).to("cuda")
call_args = dict(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=num_inference_steps,
)
image = pipe(**call_args).images[0]
```
Combined with SDPA and fp16, we can reduce the memory to 21.9GB. Other techniques discussed above for optimizing memory can also be used with cached computations.
## Tiny Autoencoder
As previously mentioned, a VAE decodes latents into images. Naturally, this step is directly bottlenecked by the size of the VAE. So, let’s just use a smaller autoencoder! The [Tiny Autoencoder by `madebyollin`](https://github.com/madebyollin/taesd), available [the Hub](https://huggingface.co/madebyollin/taesdxl) is just 10MB and it is distilled from the original VAE used by SDXL.
```python
from diffusers import AutoencoderTiny
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe.to("cuda")
```
With this setup, we reduce the memory requirement to 15.6GB while reducing the inference latency at the same time.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The Tiny Autoencoder can omit some of the more fine-grained details from images, which is why the Tiny AutoEncoder is more appropriate for image previews.
</div>
## Conclusion
To conclude and summarize the savings from our optimizations:
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ While profiling GPUs to measure the trade-off between inference latency and memory requirements, it is important to be aware of the hardware being used. The above findings may not translate equally from hardware to hardware. For example, `torch.compile` only seems to benefit modern GPUs, at least for SDXL.
</div>
| **Technique** | **Memory (GB)** | **Inference latency (ms)** |
| --- | --- | --- |
| unoptimized pipeline | 28.09 | 72200.5 |
| fp16 | 21.72 | 14800.9 |
| **fp16 + SDPA (default)** | **21.72** | **11413.0** |
| default + `torch.compile` | 21.73 | 10296.7 |
| default + model CPU offload | 20.21 | 16082.2 |
| default + sequential CPU offload | 19.91 | 67034.0 |
| **default + VAE slicing** | **15.40** | **11232.2** |
| default + VAE slicing + sequential CPU offload | 11.47 | 66869.2 |
| default + precomputed text embeddings | 21.85 | 11909.0 |
| default + Tiny Autoencoder | 15.48 | 10449.7 |
We hope these optimizations make it a breeze to run your favorite pipelines. Try these techniques out and share your images with us! 🤗
---
**Acknowledgements**: Thank you to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) for his helpful reviews on the draft.
| 7 |
0 | hf_public_repos | hf_public_repos/blog/google-cloud-model-garden.md | ---
title: "Making thousands of open LLMs bloom in the Vertex AI Model Garden"
thumbnail: /blog/assets/173_gcp-partnership/thumbnail.jpg
authors:
- user: philschmid
- user: jeffboudier
---
# Making thousands of open LLMs bloom in the Vertex AI Model Garden
Today, we are thrilled to announce the launch of **Deploy on Google Cloud**, a new integration on the Hugging Face Hub to deploy thousands of foundation models easily to Google Cloud using Vertex AI or Google Kubernetes Engine (GKE). Deploy on Google Cloud makes it easy to deploy open models as API Endpoints within your own Google Cloud account, either directly through Hugging Face model cards or within Vertex Model Garden, Google Cloud’s single place to discover, customize, and deploy a wide variety of models from Google and Google partners. Starting today, we are enabling the most popular open models on Hugging Face for inference powered by our production solution, [Text Generation Inference](https://github.com/huggingface/text-generation-inference/).
With Deploy on Google Cloud, developers can build production-ready Generative AI applications without managing infrastructure and servers, directly within their secure Google Cloud environment.
## A Collaboration for AI Builders
This new experience expands upon the [strategic partnership we announced earlier this year](https://huggingface.co/blog/gcp-partnership) to simplify the access and deployment of open Generative AI models for Google customers. One of the main problems developers and organizations face is the time and resources it takes to deploy models securely and reliably. Deploy on Google Cloud offers an easy, managed solution to these challenges, providing dedicated configurations and assets to Hugging Face Models. It’s a simple click-through experience to create a production-ready Endpoint on Google Cloud’s Vertex AI.
“Vertex AI’s Model Garden integration with the Hugging Face Hub makes it seamless to discover and deploy open models on Vertex AI and GKE, whether you start your journey on the Hub or directly in the Google Cloud Console” says Wenming Ye, Product Manager at Google. “We can’t wait to see what Google Developers build with Hugging Face models”.
## How it works - from the Hub
Deploying Hugging Face Models on Google Cloud is super easy. Below, you will find step-by-step instructions on how to deploy [Zephyr Gemma](https://console.cloud.google.com/vertex-ai/publishers/HuggingFaceH4/model-garden/zephyr-7b-gemma-v0.1;hfSource=true;action=deploy?authuser=1). Starting today, [all models with the “text-generation-inference”](https://huggingface.co/models?pipeline_tag=text-generation-inference&sort=trending) tag will be supported.
Open the “Deploy” menu, and select “Google Cloud”. This will now bring you straight into the Google Cloud Console, where you can deploy Zephyr Gemma in 1 click on Vertex AI, or GKE.
Once you are in the Vertex Model Garden, you can select Vertex AI or GKE as your deployment environment. With Vertex AI you can deploy the model with 1-click on “Deploy”. For GKE, you can follow instructions and manifest templates on how to deploy the model on a new or running Kubernetes Cluster.
## How it works - from Vertex Model Garden
Vertex Model Garden is where Google Developers can find ready-to-use models for their Generative AI projects. Starting today, the Vertex Model Garden offers a new experience to easily deploy the most popular open LLMs available on Hugging Face!
You can find the new “Deploy From Hugging Face” option inside Google Vertex AI Model Garden, which allows you to search and deploy Hugging Face models directly within your Google Cloud console.
When you click on “Deploy From Hugging Face”, a form will appear where you can quickly search for model IDs. Hundreds of the most popular open LLMs on Hugging Face are available with ready-to-use, tested hardware configurations.
Once you find the model you want to deploy, select it, and Vertex AI will prefill all required configurations to deploy your model to Vertex AI or GKE. You can even ensure you selected the right model by “viewing it on Hugging Face.” If you’re using a gated model, make sure to provide your Hugging Face access token so the model download can be authorized.
And that’s it! Deploying a model like Zephyr Gemma directly, from the Vertex Model Garden onto your own Google Cloud account is just a couple of clicks.
## We’re just getting started
We are excited to collaborate with Google Cloud to make AI more open and accessible for everyone. Deploying open models on Google Cloud has never been easier, whether you start from the Hugging Face Hub, or within the Google Cloud console. And we’re not going to stop there – stay tuned as we enable more experiences to build AI with open models on Google Cloud! | 8 |
0 | hf_public_repos | hf_public_repos/blog/scalable-data-inspection.md | ---
title: "Interactively explore your Huggingface dataset with one line of code"
thumbnail: /blog/assets/scalable-data-inspection/thumbnail.png
authors:
- user: sps44
guest: true
- user: druzsan
guest: true
- user: neindochoh
guest: true
- user: MarkusStoll
guest: true
---
# Interactively explore your Huggingface dataset with one line of code
The Hugging Face [*datasets* library](https://huggingface.co/docs/datasets/index) not only provides access to more than 70k publicly available datasets, but also offers very convenient data preparation pipelines for custom datasets.
[Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to create **interactive visualizations** to **identify critical clusters** in your data. Because Spotlight understands the data semantics within Hugging Face datasets, you can **[get started with just one line of code](https://renumics.com/docs)**:
```python
import datasets
from renumics import spotlight
ds = datasets.load_dataset('speech_commands', 'v0.01', split='validation')
spotlight.show(ds)
```
<p align="center"><a href="https://github.com/Renumics/spotlight"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/speech_commands_vis_s.gif" width="100%"/></a></p>
Spotlight allows to **leverage model results** such as predictions and embeddings to gain a deeper understanding in data segments and model failure modes:
```python
ds_results = datasets.load_dataset('renumics/speech_commands-ast-finetuned-results', 'v0.01', split='validation')
ds = datasets.concatenate_datasets([ds, ds_results], axis=1)
spotlight.show(ds, dtype={'embedding': spotlight.Embedding}, layout=spotlight.layouts.debug_classification(embedding='embedding', inspect={'audio': spotlight.dtypes.audio_dtype}))
```
Data inspection is a very important task in almost all ML development stages, but it can also be very time consuming.
> “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” — Greg Brockman
>
[Spotlight](https://renumics.com/docs) helps you to **make data inspection more scalable** along two dimensions: Setting up and maintaining custom data inspection workflows and finding relevant data samples and clusters to inspect. In the following sections we show some examples based on Hugging Face datasets.
## Spotlight 🤝 Hugging Face datasets
The *datasets* library has several features that makes it an ideal tool for working with ML datasets: It stores tabular data (e.g. metadata, labels) along with unstructured data (e.g. images, audio) in a common Arrows table. *Datasets* also describes important data semantics through features (e.g. images, audio) and additional task-specific metadata.
Spotlight directly works on top of the *datasets* library. This means that there is no need to copy or pre-process the dataset for data visualization and inspection. Spotlight loads the tabular data into memory to allow for efficient, client-side data analytics. Memory-intensive unstructured data samples (e.g. audio, images, video) are loaded lazily on demand. In most cases, data types and label mappings are inferred directly from the dataset. Here, we visualize the CIFAR-100 dataset with one line of code:
```python
ds = datasets.load_dataset('cifar100', split='test')
spotlight.show(ds)
```
In cases where the data types are ambiguous or not specified, the Spotlight API allows to manually assign them:
```python
label_mapping = dict(zip(ds.features['fine_label'].names, range(len(ds.features['fine_label'].names))))
spotlight.show(ds, dtype={'img': spotlight.Image, 'fine_label': spotlight.dtypes.CategoryDType(categories=label_mapping)})
```
## **Leveraging model results for data inspection**
Exploring raw unstructured datasets often yield little insights. Leveraging model results such as predictions or embeddings can help to uncover critical data samples and clusters. Spotlight has several visualization options (e.g. similarity map, confusion matrix) that specifically make use of model results.
We recommend storing your prediction results directly in a Hugging Face dataset. This not only allows you to take advantage of the batch processing capabilities of the datasets library, but also keeps label mappings.
We can use the [*transformers* library](https://huggingface.co/docs/transformers) to compute embeddings and predictions on the CIFAR-100 image classification problem. We install the libraries via pip:
```bash
pip install renumics-spotlight datasets transformers[torch]
```
Now we can compute the enrichment:
```python
import torch
import transformers
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_name = "Ahmed9275/Vit-Cifar100"
processor = transformers.ViTImageProcessor.from_pretrained(model_name)
cls_model = transformers.ViTForImageClassification.from_pretrained(model_name).to(device)
fe_model = transformers.ViTModel.from_pretrained(model_name).to(device)
def infer(batch):
images = [image.convert("RGB") for image in batch]
inputs = processor(images=images, return_tensors="pt").to(device)
with torch.no_grad():
outputs = cls_model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1).cpu().numpy()
embeddings = fe_model(**inputs).last_hidden_state[:, 0].cpu().numpy()
preds = probs.argmax(axis=-1)
return {"prediction": preds, "embedding": embeddings}
features = datasets.Features({**ds.features, "prediction": ds.features["fine_label"], "embedding": datasets.Sequence(feature=datasets.Value("float32"), length=768)})
ds_enriched = ds.map(infer, input_columns="img", batched=True, batch_size=2, features=features)
```
If you don’t want to perform the full inference run, you can alternatively download pre-computed model results for CIFAR-100 to follow this tutorial:
```python
ds_results = datasets.load_dataset('renumics/spotlight-cifar100-enrichment', split='test')
ds_enriched = datasets.concatenate_datasets([ds, ds_results], axis=1)
```
We can now use the results to interactively explore relevant data samples and clusters in Spotlight:
```python
layout = spotlight.layouts.debug_classification(label='fine_label', embedding='embedding', inspect={'img': spotlight.dtypes.image_dtype})
spotlight.show(ds_enriched, dtype={'embedding': spotlight.Embedding}, layout=layout)
```
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/cifar-100-model-debugging.png" alt="CIFAR-100 model debugging layout example.">
</figure>
## Customizing data inspection workflows
Visualization layouts can be interactively changed, saved and loaded in the GUI: You can select different widget types and configurations. The *Inspector* widget allows to represent multimodal data samples including text, image, audio, video and time series data.
You can also define layouts through the [Python API](https://renumics.com/api/spotlight/). This option is especially useful for building custom data inspection and curation workflows including EDA, model debugging and model monitoring tasks.
In combination with the data issues widget, the Python API offers a great way to integrate the results of existing scripts (e.g. data quality checks or model monitoring) into a scalable data inspection workflow.
## Using Spotlight on the Hugging Face hub
You can use Spotlight directly on your local NLP, audio, CV or multimodal dataset. If you would like to showcase your dataset or model results on the Hugging Face hub, you can use Hugging Face spaces to launch a Spotlight visualization for it.
We have already prepared [example spaces](https://huggingface.co/renumics) for many popular NLP, audio and CV datasets on the hub. You can simply duplicate one of these spaces and specify your dataset in the `HF_DATASET` variable.
You can optionally choose a dataset that contains model results and other configuration options such as splits, subsets or dataset revisions.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/space_duplication.png" alt="Creating a new dataset visualization with Spotlight by duplicating a Hugging Face space.">
</figure>
## What’s next?
With Spotlight you can create **interactive visualizations** and leverage data enrichments to **identify critical clusters** in your Hugging Face datasets. In this blog, we have seen both an audio ML and a computer vision example.
You can use Spotlight directly to explore and curate your NLP, audio, CV or multimodal dataset:
- Install Spotlight: *pip install renumics-spotlight*
- Check out the [documentation](https://renumics.com/docs) or open an issue on [Github](https://github.com/Renumics/spotlight)
- Join the [Spotlight community](https://discord.gg/VAQdFCU5YD) on Discord
- Follow us on [Twitter](https://twitter.com/renumics) and [LinkedIn](https://www.linkedin.com/company/renumics) | 9 |
0 | hf_public_repos/candle/candle-core | hf_public_repos/candle/candle-core/tests/quantized_tests.rs | use candle_core::{
bail,
quantized::{self, GgmlDType},
test_device,
test_utils::to_vec2_round,
DType, Device, IndexOp, Module, Result, Tensor,
};
use quantized::{k_quants, GgmlType};
use rand::prelude::*;
const GGML_TEST_SIZE: usize = 32 * 128;
const GGML_MAX_QUANTIZATION_TOTAL_ERROR: f32 = 0.002;
const GGML_MAX_QUANTIZATION_TOTAL_ERROR_2BITS: f32 = 0.0075;
const GGML_MAX_QUANTIZATION_TOTAL_ERROR_3BITS: f32 = 0.0040;
const GGML_MAX_DOT_PRODUCT_ERROR: f32 = 0.02;
fn test_matmul(
device: &Device,
(b, m, n, k): (usize, usize, usize, usize),
dtype: GgmlDType,
) -> Result<()> {
let lhs = (0..(m * k))
.map(|v| v as f32 / (m * k) as f32)
.collect::<Vec<_>>();
let rhs = (0..(k * n))
.map(|v| v as f32 / (n * k) as f32)
.collect::<Vec<_>>();
let lhs = Tensor::from_slice(&lhs, (m, k), device)?;
let rhs = Tensor::from_slice(&rhs, (k, n), device)?;
let mm = lhs.matmul(&rhs)?;
let qtensor = quantized::QTensor::quantize(&rhs.t()?, dtype)?;
let matmul = quantized::QMatMul::from_qtensor(qtensor)?;
let res = matmul.forward(&lhs)?;
let error: f32 = ((&mm - &res)?.abs()? / &mm.abs()?)?
.sum_all()?
.to_scalar()?;
let error = error / (b * m * n) as f32;
assert!(
error <= 0.02,
"Error {error} is too big. \nExpected:\n {mm} \nFound:\n {res}\n for {dtype:?}"
);
Ok(())
}
fn quantized_matmul(device: &Device) -> Result<()> {
let (m, k, n) = (3, 64, 4);
let lhs_s = (0..(m * k)).map(|v| v as f32).collect::<Vec<_>>();
let lhs = Tensor::from_slice(&lhs_s, (m, k), device)?;
let mut dst = vec![42.; 3 * 4];
let mut rhs_t = vec![k_quants::BlockQ4_0::zeros(); 8];
let rhs = (0..(k * n)).map(|v| v as f32).collect::<Vec<_>>();
k_quants::BlockQ4_0::from_float(&rhs, &mut rhs_t)?;
k_quants::matmul((m, k, n), &lhs_s, &rhs_t, &mut dst)?;
assert_eq!(
dst.iter().map(|x| x.round()).collect::<Vec<_>>(),
&[
85120.0, 214562.0, 345455.0, 474748.0, 213475.0, 604465.0, 1000686.0, 1388317.0,
341876.0, 994283.0, 1655709.0, 2301518.0
]
);
let tensor_rhs = Tensor::from_slice(&rhs, (n, k), device)?.t()?;
let mm = lhs.matmul(&tensor_rhs)?;
assert_eq!(
mm.to_vec2::<f32>()?,
&[
[85344.0, 214368.0, 343392.0, 472416.0],
[214368.0, 605536.0, 996704.0, 1387872.0],
[343392.0, 996704.0, 1650016.0, 2303328.0]
]
);
let qtensor = quantized::QTensor::quantize(&tensor_rhs.t()?, GgmlDType::Q4_0)?;
let matmul = quantized::QMatMul::from_qtensor(qtensor)?;
let res = matmul.forward(&lhs)?;
match device {
Device::Metal(_) => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[84946.0, 214126.0, 344757.0, 473798.0],
[213458.0, 604350.0, 1000469.0, 1387990.0],
[341970.0, 994574.0, 1656181.0, 2302182.0]
]
),
Device::Cuda(_) => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[84866.0, 214045.0, 344676.0, 473707.0],
[213425.0, 604313.0, 1000431.0, 1387960.0],
[342030.0, 994630.0, 1656248.0, 2302250.0]
]
),
Device::Cpu => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[85120.0, 214562.0, 345455.0, 474748.0],
[213475.0, 604465.0, 1000686.0, 1388317.0],
[341876.0, 994283.0, 1655709.0, 2301518.0]
]
),
}
test_matmul(device, (1, 3, 4, 256), GgmlDType::Q4_0)?;
Ok(())
}
fn quantized_matmul_neg(device: &Device) -> Result<()> {
let (m, k, n) = (3, 64, 4);
let lhs_s = (0..(m * k))
.map(|v| v as f32 - (m * k) as f32 / 2.0)
.collect::<Vec<_>>();
let lhs = Tensor::from_slice(&lhs_s, (m, k), device)?;
let mut dst = vec![42.; 3 * 4];
let mut rhs_t = vec![k_quants::BlockQ4_0::zeros(); 8];
let rhs = (0..k * n)
.map(|v| v as f32 - (k * n) as f32 / 3.0)
.collect::<Vec<_>>();
let tensor_rhs = Tensor::from_slice(&rhs, (n, k), device)?.t()?;
k_quants::BlockQ4_0::from_float(&rhs, &mut rhs_t)?;
k_quants::matmul((m, k, n), &lhs_s, &rhs_t, &mut dst)?;
assert_eq!(
dst.iter().map(|x| x.round()).collect::<Vec<_>>(),
&[
243524.0, -19596.0, -285051.0, -549815.0, 23777.0, 21651.0, 19398.0, 18367.0,
-196472.0, 63012.0, 324585.0, 587902.0
]
);
let mm = lhs.matmul(&tensor_rhs)?;
assert_eq!(
to_vec2_round(&mm, 0)?,
&[
[244064.0, -20128.0, -284320.0, -548512.0],
[23563.0, 21515.0, 19467.0, 17419.0],
[-196939.0, 63157.0, 323253.0, 583349.0]
]
);
let qtensor = quantized::QTensor::quantize(&tensor_rhs.t()?, GgmlDType::Q4_0)?;
let matmul = quantized::QMatMul::from_qtensor(qtensor)?;
let res = matmul.forward(&lhs)?;
match device {
Device::Metal(_) => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[243666.0, -19714.0, -285433.0, -550453.0],
[23782.0, 21654.0, 19400.0, 18369.0],
[-196102.0, 63022.0, 324233.0, 587191.0]
]
),
Device::Cuda(_) => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[243740.0, -19762.0, -285476.0, -550498.0],
[23774.0, 21645.0, 19395.0, 18364.0],
[-196045.0, 63030.0, 324120.0, 587079.0]
]
),
Device::Cpu => assert_eq!(
to_vec2_round(&res, 0)?,
&[
[243524.0, -19596.0, -285051.0, -549815.0],
[23777.0, 21651.0, 19398.0, 18367.0],
[-196472.0, 63012.0, 324585.0, 587902.0]
]
),
}
let lhs2 = Tensor::stack(&[&lhs, &lhs], 0)?;
let res2 = matmul.forward(&lhs2)?;
let res2 = res2.i(1)?;
let diff = (res - res2)?.abs()?.sum_all()?.to_vec0::<f32>()?;
if device.is_cuda() {
assert!(diff < 0.1);
} else {
assert_eq!(diff, 0.);
}
Ok(())
}
fn qmm_batch(dev: &Device) -> Result<()> {
let (lhs, rhs, _mm) = get_random_tensors(2, 256, 6, dev)?;
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q2K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.shape().dims(), [2, 6]);
let lhs2 = Tensor::cat(&[&lhs, &lhs], 0)?;
let mm2 = rhs.forward(&lhs2)?;
assert_eq!(mm2.shape().dims(), [4, 6]);
let diff2 = (mm2.i(2..)? - &mm)?.abs()?.sum_all()?.to_vec0::<f32>()?;
assert_eq!(diff2, 0.0);
let lhs3 = Tensor::cat(&[&lhs2, &lhs], 0)?;
let mm3 = rhs.forward(&lhs3)?;
assert_eq!(mm3.shape().dims(), [6, 6]);
let diff3 = (mm3.i(2..4)? - &mm)?.abs()?.sum_all()?.to_vec0::<f32>()?;
assert_eq!(diff3, 0.0);
let diff3 = (mm3.i(4..)? - &mm)?.abs()?.sum_all()?.to_vec0::<f32>()?;
assert_eq!(diff3, 0.0);
let lhs4 = Tensor::cat(&[&lhs3, &lhs3], 0)?;
let mm4 = rhs.forward(&lhs4)?;
assert_eq!(mm4.shape().dims(), [12, 6]);
let diff4 = (mm4.i(..6)? - &mm3)?.abs()?.sum_all()?.to_vec0::<f32>()?;
if dev.is_cuda() {
// We use a different kernel for sizes from 1 to 8 on cuda which explains
// the difference here.
assert!(0. < diff4 && diff4 < 1e-4)
} else {
assert_eq!(diff4, 0.0)
};
let diff4 = (mm4.i(6..)? - &mm4.i(..6)?)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff4, 0.0);
Ok(())
}
test_device!(quantized_matmul, qmm_cpu, qmm_cuda, qmm_metal);
test_device!(quantized_matmul_neg, qmm_n_cpu, qmm_n_cuda, qmm_n_metal);
test_device!(qmm_batch, qmm_b_cpu, qmm_b_cuda, qmm_b_metal);
fn quantize_q4_0(device: &Device) -> Result<()> {
let src = (0..32 * 4).map(|v| v as f32).collect::<Vec<_>>();
let src = Tensor::from_slice(&src, (32 * 4,), device)?;
let quant = quantized::QTensor::quantize(&src, GgmlDType::Q4_0)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
assert_eq!(
dst.to_vec1::<f32>()?,
&[
-0.0, -0.0, 3.875, 3.875, 3.875, 3.875, 7.75, 7.75, 7.75, 7.75, 11.625, 11.625, 11.625,
11.625, 15.5, 15.5, 15.5, 15.5, 19.375, 19.375, 19.375, 19.375, 23.25, 23.25, 23.25,
23.25, 27.125, 27.125, 27.125, 27.125, 31.0, 31.0, 31.5, 31.5, 31.5, 31.5, 39.375,
39.375, 39.375, 39.375, 39.375, 39.375, 39.375, 39.375, 47.25, 47.25, 47.25, 47.25,
47.25, 47.25, 47.25, 47.25, 55.125, 55.125, 55.125, 55.125, 55.125, 55.125, 55.125,
55.125, 63.0, 63.0, 63.0, 63.0, 59.375, 59.375, 71.25, 71.25, 71.25, 71.25, 71.25,
71.25, 71.25, 71.25, 71.25, 71.25, 71.25, 71.25, 83.125, 83.125, 83.125, 83.125,
83.125, 83.125, 83.125, 83.125, 83.125, 83.125, 83.125, 83.125, 95.0, 95.0, 95.0, 95.0,
95.0, 95.0, 95.25, 95.25, 95.25, 95.25, 95.25, 95.25, 95.25, 95.25, 111.125, 111.125,
111.125, 111.125, 111.125, 111.125, 111.125, 111.125, 111.125, 111.125, 111.125,
111.125, 111.125, 111.125, 111.125, 111.125, 127.0, 127.0, 127.0, 127.0, 127.0, 127.0,
127.0, 127.0
]
);
ggml_quantization_error_test(GgmlDType::Q4_0, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q4_1(device: &Device) -> Result<()> {
let src = (0..32 * 4).map(|v| v as f32).collect::<Vec<_>>();
let src = Tensor::from_slice(&src, (32 * 4,), device)?;
let quant = quantized::QTensor::quantize(&src, GgmlDType::Q4_1)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
assert_eq!(
round_vector(&dst.to_vec1::<f32>()?),
&[
0.0, 0.0, 2.066, 2.066, 4.133, 4.133, 6.199, 6.199, 8.266, 8.266, 10.332, 10.332,
12.398, 12.398, 14.465, 14.465, 16.531, 16.531, 18.598, 18.598, 20.664, 20.664, 22.73,
22.73, 24.797, 24.797, 26.863, 26.863, 28.93, 28.93, 30.996, 30.996, 32.0, 32.0,
34.066, 34.066, 36.133, 36.133, 38.199, 38.199, 40.266, 40.266, 42.332, 42.332, 44.398,
44.398, 46.465, 46.465, 48.531, 48.531, 50.598, 50.598, 52.664, 52.664, 54.73, 54.73,
56.797, 56.797, 58.863, 58.863, 60.93, 60.93, 62.996, 62.996, 64.0, 64.0, 66.066,
66.066, 68.133, 68.133, 70.199, 70.199, 72.266, 72.266, 74.332, 74.332, 76.398, 76.398,
78.465, 78.465, 80.531, 80.531, 82.598, 82.598, 84.664, 84.664, 86.73, 86.73, 88.797,
88.797, 90.863, 90.863, 92.93, 92.93, 94.996, 94.996, 96.0, 96.0, 98.066, 98.066,
100.133, 100.133, 102.199, 102.199, 104.266, 104.266, 106.332, 106.332, 108.398,
108.398, 110.465, 110.465, 112.531, 112.531, 114.598, 114.598, 116.664, 116.664,
118.73, 118.73, 120.797, 120.797, 122.863, 122.863, 124.93, 124.93, 126.996, 126.996
]
);
ggml_quantization_error_test(GgmlDType::Q4_1, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q5_0(device: &Device) -> Result<()> {
let src = (0..32 * 4).map(|v| v as f32).collect::<Vec<_>>();
let src = Tensor::from_slice(&src, (32 * 4,), device)?;
let quant = quantized::QTensor::quantize(&src, GgmlDType::Q5_0)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
assert_eq!(
round_vector(&dst.to_vec1::<f32>()?),
&[
-0.0, 1.938, 1.938, 3.875, 3.875, 5.813, 5.813, 7.75, 7.75, 9.688, 9.688, 11.625,
11.625, 13.563, 13.563, 15.5, 15.5, 17.438, 17.438, 19.375, 19.375, 21.313, 21.313,
23.25, 23.25, 25.188, 25.188, 27.125, 27.125, 29.063, 29.063, 31.0, 31.5, 31.5, 35.438,
35.438, 35.438, 35.438, 39.375, 39.375, 39.375, 39.375, 43.313, 43.313, 43.313, 43.313,
47.25, 47.25, 47.25, 47.25, 51.188, 51.188, 51.188, 51.188, 55.125, 55.125, 55.125,
55.125, 59.063, 59.063, 59.063, 59.063, 63.0, 63.0, 65.313, 65.313, 65.313, 65.313,
65.313, 71.25, 71.25, 71.25, 71.25, 71.25, 71.25, 77.188, 77.188, 77.188, 77.188,
77.188, 77.188, 83.125, 83.125, 83.125, 83.125, 83.125, 83.125, 89.063, 89.063, 89.063,
89.063, 89.063, 89.063, 95.0, 95.0, 95.0, 95.25, 95.25, 95.25, 95.25, 103.188, 103.188,
103.188, 103.188, 103.188, 103.188, 103.188, 103.188, 111.125, 111.125, 111.125,
111.125, 111.125, 111.125, 111.125, 111.125, 119.063, 119.063, 119.063, 119.063,
119.063, 119.063, 119.063, 119.063, 127.0, 127.0, 127.0, 127.0
]
);
ggml_quantization_error_test(GgmlDType::Q5_0, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q5_1(device: &Device) -> Result<()> {
let src = (0..32 * 4).map(|v| v as f32).collect::<Vec<_>>();
let src = Tensor::from_slice(&src, (32 * 4,), device)?;
let quant = quantized::QTensor::quantize(&src, GgmlDType::Q5_1)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
assert_eq!(
round_vector(&dst.to_vec1::<f32>()?),
&[
0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0,
16.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0,
30.0, 31.0, 32.0, 33.0, 34.0, 35.0, 36.0, 37.0, 38.0, 39.0, 40.0, 41.0, 42.0, 43.0,
44.0, 45.0, 46.0, 47.0, 48.0, 49.0, 50.0, 51.0, 52.0, 53.0, 54.0, 55.0, 56.0, 57.0,
58.0, 59.0, 60.0, 61.0, 62.0, 63.0, 64.0, 65.0, 66.0, 67.0, 68.0, 69.0, 70.0, 71.0,
72.0, 73.0, 74.0, 75.0, 76.0, 77.0, 78.0, 79.0, 80.0, 81.0, 82.0, 83.0, 84.0, 85.0,
86.0, 87.0, 88.0, 89.0, 90.0, 91.0, 92.0, 93.0, 94.0, 95.0, 96.0, 97.0, 98.0, 99.0,
100.0, 101.0, 102.0, 103.0, 104.0, 105.0, 106.0, 107.0, 108.0, 109.0, 110.0, 111.0,
112.0, 113.0, 114.0, 115.0, 116.0, 117.0, 118.0, 119.0, 120.0, 121.0, 122.0, 123.0,
124.0, 125.0, 126.0, 127.0
]
);
ggml_quantization_error_test(GgmlDType::Q5_1, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn get_test_vector2(bound: f32, size: usize, device: &Device) -> Result<Tensor> {
assert!(
size % crate::quantized::k_quants::QK_K == 0,
"size must be a multiple of {}",
crate::quantized::k_quants::QK_K
);
let src = (0..size)
.map(|v| (v as f32 - size as f32 / 2.) * bound / (size as f32 / 2.))
.collect::<Vec<_>>();
assert_eq!([src[0], src[size / 2]], [-bound, 0.0]);
Tensor::from_vec(src, (size,), device)
}
/// Round a vector
fn round_vector(values: &[f32]) -> Vec<f32> {
values
.iter()
.map(|x| (1000. * x).round() / 1000.)
.collect::<Vec<_>>()
}
fn compare_with_error(values: &[f32], expected: &[f32], tolerance: f32) {
for (i, (value, expected_value)) in values.iter().zip(expected.iter()).enumerate() {
let difference = (value - expected_value).abs();
assert!(
difference < tolerance,
"Error at index {}: value = {}, expected = {}. Difference = {} exceeds tolerance = {}.",
i,
value,
expected_value,
difference,
tolerance
);
}
}
/// Creates a vector similar to the ones used in GGML unit tests:
/// https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L26-L30
fn create_ggml_like_vector(offset: f32) -> Vec<f32> {
(0..GGML_TEST_SIZE)
.map(|i| 0.1 + 2.0 * (i as f32 + offset).cos())
.collect()
}
/// Calculates the root mean square error between two vectors
fn calculate_rmse(a: &[f32], b: &[f32]) -> f32 {
assert_eq!(a.len(), b.len());
let sum = a
.iter()
.zip(b)
.map(|(a, b)| (a - b).powi(2))
.sum::<f32>()
.sqrt();
sum / a.len() as f32
}
/// Similar to the GGML quantization unit test:
/// https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L43-L50
fn ggml_quantization_error_test(dtype: GgmlDType, device: &Device, max_error: f32) -> Result<()> {
let src = create_ggml_like_vector(0.0);
let src = Tensor::from_slice(&src, (GGML_TEST_SIZE,), device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let error = calculate_rmse(&src.to_vec1::<f32>()?, &dst.to_vec1::<f32>()?);
if error > max_error {
bail!(
"Quantization error {} exceeds max error {}",
error,
max_error
);
}
Ok(())
}
fn quantize_q2k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q2K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.1);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.499, -0.366, -0.249, 0.0, 0.295, 0.492]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 6.0);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR_2BITS)?;
Ok(())
}
fn quantize_q3k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q3K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.03);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.493, -0.37, -0.243, -0.0, 0.292, 0.492]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 3.5);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR_3BITS)?;
Ok(())
}
fn quantize_q4k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q4K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.017);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.5, -0.373, -0.25, 0.0, 0.288, 0.498]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 4.5);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q5k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q5K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.009);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.5, -0.373, -0.25, 0.0, 0.279, 0.499]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 2.5);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q6k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q6K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.008);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.497, -0.372, -0.25, -0.0, 0.284, 0.5]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 2.0);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
fn quantize_q8k(device: &Device) -> Result<()> {
let dtype = GgmlDType::Q8K;
let src = get_test_vector2(0.5, 1024, device)?;
let quant = quantized::QTensor::quantize(&src, dtype)?;
let dst = quant.dequantize(device)?;
let dst_f16 = quant.dequantize_f16(device)?;
let diff = (dst.to_dtype(DType::F16)? - dst_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src = src.to_vec1::<f32>()?;
let dst = dst.to_vec1::<f32>()?;
compare_with_error(dst.as_slice(), src.as_slice(), 0.008);
// Test some specific values
assert_eq!(
[src[0], src[128], src[256], src[512], src[800], src[1023]],
[-0.5, -0.375, -0.25, 0.0, 0.28125, 0.49902344]
);
let dst = round_vector(&dst);
assert_eq!(
[dst[0], dst[128], dst[256], dst[512], dst[800], dst[1023]],
[-0.5, -0.375, -0.25, -0.0, 0.281, 0.499]
);
let src_big = get_test_vector2(128.0, 1024, device)?;
let quant_big = quantized::QTensor::quantize(&src_big, dtype)?;
let dst_big = quant_big.dequantize(device)?;
let dst_big_f16 = quant_big.dequantize_f16(device)?;
let diff = (dst_big.to_dtype(DType::F16)? - dst_big_f16)?
.to_dtype(DType::F32)?
.abs()?
.sum_all()?
.to_vec0::<f32>()?;
assert_eq!(diff, 0.);
let src_big = src_big.to_vec1::<f32>()?;
let dst_big = dst_big.to_vec1::<f32>()?;
compare_with_error(dst_big.as_slice(), src_big.as_slice(), 0.6);
ggml_quantization_error_test(dtype, device, GGML_MAX_QUANTIZATION_TOTAL_ERROR)?;
Ok(())
}
test_device!(
quantize_q4_0,
quantize_q4_0_cpu,
quantize_q4_0_cuda,
quantize_q4_0_metal
);
test_device!(
quantize_q4_1,
quantize_q4_1_cpu,
quantize_q4_1_cuda,
quantize_q4_1_metal
);
test_device!(
quantize_q5_0,
quantize_q5_0_cpu,
quantize_q5_0_cuda,
quantize_q5_0_metal
);
test_device!(
quantize_q5_1,
quantize_q5_1_cpu,
quantize_q5_1_cuda,
quantize_q5_1_metal
);
test_device!(
quantize_q2k,
quantize_q2k_cpu,
quantize_q2k_cuda,
quantize_q2k_metal
);
test_device!(
quantize_q3k,
quantize_q3k_cpu,
quantize_q3k_cuda,
quantize_q3k_metal
);
test_device!(
quantize_q4k,
quantize_q4k_cpu,
quantize_q4k_cuda,
quantize_q4k_metal
);
test_device!(
quantize_q5k,
quantize_q5k_cpu,
quantize_q5k_cuda,
quantize_q5k_metal
);
test_device!(
quantize_q6k,
quantize_q6k_cpu,
quantize_q6k_cuda,
quantize_q6k_metal
);
test_device!(
quantize_q8k,
quantize_q8k_cpu,
quantize_q8k_cuda,
quantize_q8k_metal
);
/// Very simple dot product implementation
fn vec_dot_reference(a: &[f32], b: &[f32]) -> f32 {
a.iter().zip(b).map(|(a, b)| a * b).sum()
}
/// Returns the error achieved by the GGML matmul unit test.
fn ggml_reference_matmul_error(dtype: GgmlDType) -> Result<f32> {
let err = match dtype {
GgmlDType::F16 => 0.000010,
GgmlDType::Q2K => 0.004086,
GgmlDType::Q3K => 0.016148,
GgmlDType::Q4K => 0.002425,
GgmlDType::Q5K => 0.000740,
GgmlDType::Q6K => 0.000952,
GgmlDType::Q4_0 => 0.001143,
GgmlDType::Q4_1 => 0.008,
GgmlDType::Q5_0 => 0.001353,
GgmlDType::Q5_1 => 0.00149,
GgmlDType::Q8_0 => 0.000092,
// Not from the ggml repo.
GgmlDType::Q8K => 0.00065,
_ => bail!("No GGML results for quantization type {dtype:?}",),
};
Ok(err)
}
/// Similar to the GGML matmul unit test:
/// https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L76-L91
fn ggml_matmul_error_test<T: GgmlType>() -> Result<()> {
let a = create_ggml_like_vector(0.0);
let b = create_ggml_like_vector(1.0);
ggml_matmul_error_test_::<T>(a.as_slice(), b.as_slice(), 1.0)?;
// Another example that is more likely to trigger the overflow reported in #1526
let a = (0..GGML_TEST_SIZE)
.map(|i| i as f32 / GGML_TEST_SIZE as f32)
.collect::<Vec<_>>();
let b = (0..GGML_TEST_SIZE)
.map(|i| i as f32 / GGML_TEST_SIZE as f32)
.collect::<Vec<_>>();
ggml_matmul_error_test_::<T>(a.as_slice(), b.as_slice(), 2.0)?;
Ok(())
}
fn ggml_matmul_error_test_<T: GgmlType>(a: &[f32], b: &[f32], err_m: f32) -> Result<()> {
let length = a.len();
let mut a_quant = vec![T::zeros(); length / T::BLCK_SIZE];
let mut b_quant = vec![T::VecDotType::zeros(); length / T::VecDotType::BLCK_SIZE];
T::from_float(a, &mut a_quant)?;
T::VecDotType::from_float(b, &mut b_quant)?;
let result = T::vec_dot(length, &a_quant, &b_quant)?;
let result_unopt = T::vec_dot_unopt(length, &a_quant, &b_quant)?;
let reference_result = vec_dot_reference(a, b);
if (result - result_unopt).abs() / length as f32 > 1e-6 {
bail!(
"the opt and unopt vec-dot returned different values, opt {result}, unopt {result_unopt}"
)
}
let error = (result - reference_result).abs() / length as f32;
let ggml_error = ggml_reference_matmul_error(T::DTYPE)? * err_m;
if !error.is_finite() || error > GGML_MAX_DOT_PRODUCT_ERROR {
bail!("Dot product error {error} exceeds max error {GGML_MAX_DOT_PRODUCT_ERROR}",);
}
// We diverge slightly due to different rounding behavior / f16 to f32 conversions in GGML
// => we use a slightly higher error threshold
const ERROR_LENIENCY: f32 = 0.00001;
if error - ERROR_LENIENCY > ggml_error {
bail!(
"Dot product error {} exceeds ggml reference error {}",
error,
ggml_error
);
}
Ok(())
}
#[test]
fn quantized_mm() -> Result<()> {
ggml_matmul_error_test::<k_quants::BlockQ4_0>()?;
ggml_matmul_error_test::<k_quants::BlockQ4_1>()?;
ggml_matmul_error_test::<k_quants::BlockQ5_0>()?;
ggml_matmul_error_test::<k_quants::BlockQ5_1>()?;
ggml_matmul_error_test::<k_quants::BlockQ8_0>()?;
Ok(())
}
/// generates random tensors of size `m x k` and `n x k` and calculates their expected matrix multiplication result.
fn get_random_tensors(
m: usize,
k: usize,
n: usize,
device: &Device,
) -> Result<(Tensor, Tensor, Tensor)> {
let mut rng = StdRng::seed_from_u64(314159265358979);
let lhs = (0..m * k)
.map(|_| rng.gen::<f32>() - 0.5)
.collect::<Vec<_>>();
let rhs = (0..n * k)
.map(|_| rng.gen::<f32>() - 0.5)
.collect::<Vec<_>>();
let lhs = Tensor::from_vec(lhs, (m, k), device)?;
let rhs = Tensor::from_vec(rhs, (n, k), device)?;
let mm = lhs.matmul(&rhs.t()?)?;
Ok((lhs, rhs, mm))
}
#[macro_export]
macro_rules! quantized_matmul {
// TODO: Switch to generating the two last arguments automatically once concat_idents is
// stable. https://github.com/rust-lang/rust/issues/29599
($fn_name: ident, $fn_name_cpu: ident, $fn_name_cuda: ident, $fn_name_metal: ident, $dtype: expr) => {
fn $fn_name(device: &Device) -> Result<()> {
test_matmul(device, (1, 3, 4, 256), $dtype)?;
Ok(())
}
test_device!($fn_name, $fn_name_cpu, $fn_name_cuda, $fn_name_metal);
};
}
quantized_matmul!(
quantized_matmul_q4_0_bis,
quantized_matmul_q4_0_cpu,
quantized_matmul_q4_0_cuda,
quantized_matmul_q4_0_metal,
GgmlDType::Q4_0
);
quantized_matmul!(
quantized_matmul_q4_1_bis,
quantized_matmul_q4_1_cpu,
quantized_matmul_q4_1_cuda,
quantized_matmul_q4_1_metal,
GgmlDType::Q4_1
);
quantized_matmul!(
quantized_matmul_q5_0_bis,
quantized_matmul_q5_0_cpu,
quantized_matmul_q5_0_cuda,
quantized_matmul_q5_0_metal,
GgmlDType::Q5_0
);
quantized_matmul!(
quantized_matmul_q5_1_bis,
quantized_matmul_q5_1_cpu,
quantized_matmul_q5_1_cuda,
quantized_matmul_q5_1_metal,
GgmlDType::Q5_1
);
quantized_matmul!(
quantized_matmul_q8_0_bis,
quantized_matmul_q8_0_cpu,
quantized_matmul_q8_0_cuda,
quantized_matmul_q8_0_metal,
GgmlDType::Q8_0
);
// Not implemented in Ggml
// quantized_matmul!(
// quantized_matmul_q8_1_bis,
// quantized_matmul_q8_1_cpu,
// quantized_matmul_q8_1_cuda,
// quantized_matmul_q8_1_metal,
// GgmlDType::Q8_1
// );
// TODO This is bugged (also bugged in GGML
quantized_matmul!(
quantized_matmul_q2k_bis,
quantized_matmul_q2k_cpu,
quantized_matmul_q2k_cuda,
quantized_matmul_q2k_metal,
GgmlDType::Q2K
);
quantized_matmul!(
quantized_matmul_q3k_bis,
quantized_matmul_q3k_cpu,
quantized_matmul_q3k_cuda,
quantized_matmul_q3k_metal,
GgmlDType::Q3K
);
quantized_matmul!(
quantized_matmul_q4k_bis,
quantized_matmul_q4k_cpu,
quantized_matmul_q4k_cuda,
quantized_matmul_q4k_metal,
GgmlDType::Q4K
);
quantized_matmul!(
quantized_matmul_q5k_bis,
quantized_matmul_q5k_cpu,
quantized_matmul_q5k_cuda,
quantized_matmul_q5k_metal,
GgmlDType::Q5K
);
quantized_matmul!(
quantized_matmul_q6k_bis,
quantized_matmul_q6k_cpu,
quantized_matmul_q6k_cuda,
quantized_matmul_q6k_metal,
GgmlDType::Q6K
);
// Not implemented on metal
// quantized_matmul!(
// quantized_matmul_q8k_bis,
// quantized_matmul_q8k_cpu,
// quantized_matmul_q8k_cuda,
// quantized_matmul_q8k_metal,
// GgmlDType::Q8K
// );
#[test]
fn quantized_matmul_q2k() -> Result<()> {
use k_quants::BlockQ2K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q2K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [0.916, 0.422, 0.215, 1.668]);
ggml_matmul_error_test::<BlockQ2K>()?;
Ok(())
}
#[test]
fn quantized_matmul_q3k() -> Result<()> {
use k_quants::BlockQ3K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q3K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.029, 1.418, -0.314, 1.495]);
ggml_matmul_error_test::<BlockQ3K>()?;
Ok(())
}
#[test]
fn quantized_matmul_q4k() -> Result<()> {
use k_quants::BlockQ4K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q4K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.125, 1.435, -0.201, 1.589]);
ggml_matmul_error_test::<BlockQ4K>()?;
Ok(())
}
#[test]
fn quantized_matmul_q5k() -> Result<()> {
use k_quants::BlockQ5K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q5K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.192, 1.491, -0.18, 1.743]);
//Expected: 0.000740408897
ggml_matmul_error_test::<BlockQ5K>()?;
Ok(())
}
#[test]
fn quantized_matmul_q6k() -> Result<()> {
use k_quants::BlockQ6K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q6K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.324, 1.49, -0.164, 1.741]);
ggml_matmul_error_test::<BlockQ6K>()?;
Ok(())
}
#[test]
fn quantized_matmul_q8k() -> Result<()> {
use k_quants::BlockQ8K;
let cpu = &Device::Cpu;
let (m, k, n) = (11, 512, 21);
let (lhs, rhs, mm) = get_random_tensors(m, k, n, cpu)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.262, 1.513, -0.208, 1.702]);
let rhs = quantized::QTensor::quantize(&rhs, GgmlDType::Q8K)?;
let rhs = quantized::QMatMul::from_qtensor(rhs)?;
let mm = rhs.forward(&lhs)?;
assert_eq!(mm.dims(), [m, n]);
let dst = mm.flatten_all()?.to_vec1::<f32>()?;
let dst = round_vector(&[dst[0], dst[m * n / 3], dst[m * n * 2 / 3], dst[m * n - 1]]);
assert_eq!(dst, [1.266, 1.504, -0.204, 1.7]);
ggml_matmul_error_test::<BlockQ8K>()?;
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-core | hf_public_repos/candle/candle-core/tests/pth.py | import torch
from collections import OrderedDict
# Write a trivial tensor to a pt file
a= torch.tensor([[1,2,3,4], [5,6,7,8]])
o = OrderedDict()
o["test"] = a
# Write a trivial tensor to a pt file
torch.save(o, "test.pt")
############################################################################################################
# Write a trivial tensor to a pt file with a key
torch.save({"model_state_dict": o}, "test_with_key.pt")
############################################################################################################
# Create a tensor with fortran contiguous memory layout
import numpy as np
# Step 1: Create a 3D NumPy array with Fortran order using a range of numbers
# For example, creating a 2x3x4 array
array_fortran = np.asfortranarray(np.arange(1, 2*3*4 + 1).reshape(2, 3, 4))
# Verify the memory order
print("Is Fortran contiguous (F order):", array_fortran.flags['F_CONTIGUOUS']) # Should be True
print("Is C contiguous (C order):", array_fortran.flags['C_CONTIGUOUS']) # Should be False
# Step 2: Convert the NumPy array to a PyTorch tensor
tensor_fortran = torch.from_numpy(array_fortran)
# Verify the tensor layout
print("Tensor stride:", tensor_fortran.stride()) # Stride will reflect the Fortran memory layout
# Step 3: Save the PyTorch tensor to a .pth file
torch.save({"tensor_fortran": tensor_fortran}, 'fortran_tensor_3d.pth')
print("3D Tensor saved with Fortran layout.")
| 1 |
0 | hf_public_repos/candle | hf_public_repos/candle/.vscode/settings.json | {
"[python]": {
"editor.defaultFormatter": "ms-python.black-formatter"
},
"python.formatting.provider": "none",
"python.testing.pytestArgs": [
"candle-pyo3"
],
"python.testing.unittestEnabled": false,
"python.testing.pytestEnabled": true
} | 2 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-examples/build.rs | #![allow(unused)]
use anyhow::{Context, Result};
use std::io::Write;
use std::path::PathBuf;
struct KernelDirectories {
kernel_glob: &'static str,
rust_target: &'static str,
include_dirs: &'static [&'static str],
}
const KERNEL_DIRS: [KernelDirectories; 1] = [KernelDirectories {
kernel_glob: "examples/custom-ops/kernels/*.cu",
rust_target: "examples/custom-ops/cuda_kernels.rs",
include_dirs: &[],
}];
fn main() -> Result<()> {
println!("cargo:rerun-if-changed=build.rs");
#[cfg(feature = "cuda")]
{
for kdir in KERNEL_DIRS.iter() {
let builder = bindgen_cuda::Builder::default().kernel_paths_glob(kdir.kernel_glob);
println!("cargo:info={builder:?}");
let bindings = builder.build_ptx().unwrap();
bindings.write(kdir.rust_target).unwrap()
}
}
Ok(())
}
| 3 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-examples/Cargo.toml | [package]
name = "candle-examples"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
accelerate-src = { workspace = true, optional = true }
candle = { workspace = true }
candle-datasets = { workspace = true, optional = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
candle-flash-attn = { workspace = true, optional = true }
candle-onnx = { workspace = true, optional = true }
csv = "1.3.0"
cudarc = { workspace = true, optional = true }
half = { workspace = true, optional = true }
hf-hub = { workspace = true, features = ["tokio"] }
image = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
num-traits = { workspace = true }
palette = { version = "0.7.6", optional = true }
enterpolation = { version = "0.2.1", optional = true}
pyo3 = { version = "0.22.0", features = ["auto-initialize", "abi3-py311"], optional = true }
rayon = { workspace = true }
rubato = { version = "0.15.0", optional = true }
safetensors = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
symphonia = { version = "0.5.3", features = ["all"], optional = true }
tokenizers = { workspace = true, features = ["onig"] }
cpal = { version = "0.15.2", optional = true }
pdf2image = { version = "0.1.2" , optional = true}
[dev-dependencies]
anyhow = { workspace = true }
byteorder = { workspace = true }
clap = { workspace = true }
imageproc = { workspace = true }
memmap2 = { workspace = true }
rand = { workspace = true }
ab_glyph = { workspace = true }
tracing = { workspace = true }
tracing-chrome = { workspace = true }
tracing-subscriber = { workspace = true }
# Necessary to disambiguate with tokio in wasm examples which are 1.28.1
tokio = "1.29.1"
[build-dependencies]
anyhow = { workspace = true }
bindgen_cuda = { version = "0.1.1", optional = true }
[features]
default = []
accelerate = ["dep:accelerate-src", "candle/accelerate", "candle-nn/accelerate", "candle-transformers/accelerate"]
cuda = ["candle/cuda", "candle-nn/cuda", "candle-transformers/cuda", "dep:bindgen_cuda"]
cudnn = ["candle/cudnn"]
flash-attn = ["cuda", "candle-transformers/flash-attn", "dep:candle-flash-attn"]
mkl = ["dep:intel-mkl-src", "candle/mkl", "candle-nn/mkl", "candle-transformers/mkl"]
nccl = ["cuda", "cudarc/nccl", "dep:half"]
onnx = ["candle-onnx"]
metal = ["candle/metal", "candle-nn/metal"]
microphone = ["cpal", "rubato"]
encodec = ["cpal", "symphonia", "rubato"]
mimi = ["cpal", "symphonia", "rubato"]
depth_anything_v2 = ["palette", "enterpolation"]
[[example]]
name = "llama_multiprocess"
required-features = ["cuda", "nccl", "flash-attn"]
[[example]]
name = "reinforcement-learning"
required-features = ["pyo3"]
[[example]]
name = "onnx"
required-features = ["onnx"]
[[example]]
name = "onnx_basics"
required-features = ["onnx"]
[[example]]
name = "whisper"
required-features = ["symphonia"]
[[example]]
name = "whisper-microphone"
required-features = ["microphone"]
[[example]]
name = "mnist-training"
required-features = ["candle-datasets"]
[[example]]
name = "llama2-c"
required-features = ["candle-datasets"]
[[example]]
name = "mimi"
required-features = ["mimi"]
[[example]]
name = "encodec"
required-features = ["encodec"]
[[example]]
name = "depth_anything_v2"
required-features = ["depth_anything_v2"]
[[example]]
name = "silero-vad"
required-features = ["onnx"]
[[example]]
name = "colpali"
required-features = ["pdf2image"]
| 4 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-examples/README.md | # candle-examples
| 5 |
0 | hf_public_repos/candle/candle-examples | hf_public_repos/candle/candle-examples/src/lib.rs | pub mod audio;
pub mod bs1770;
pub mod coco_classes;
pub mod imagenet;
pub mod token_output_stream;
pub mod wav;
use candle::utils::{cuda_is_available, metal_is_available};
use candle::{Device, Result, Tensor};
pub fn device(cpu: bool) -> Result<Device> {
if cpu {
Ok(Device::Cpu)
} else if cuda_is_available() {
Ok(Device::new_cuda(0)?)
} else if metal_is_available() {
Ok(Device::new_metal(0)?)
} else {
#[cfg(all(target_os = "macos", target_arch = "aarch64"))]
{
println!(
"Running on CPU, to run on GPU(metal), build this example with `--features metal`"
);
}
#[cfg(not(all(target_os = "macos", target_arch = "aarch64")))]
{
println!("Running on CPU, to run on GPU, build this example with `--features cuda`");
}
Ok(Device::Cpu)
}
}
pub fn load_image<P: AsRef<std::path::Path>>(
p: P,
resize_longest: Option<usize>,
) -> Result<(Tensor, usize, usize)> {
let img = image::ImageReader::open(p)?
.decode()
.map_err(candle::Error::wrap)?;
let (initial_h, initial_w) = (img.height() as usize, img.width() as usize);
let img = match resize_longest {
None => img,
Some(resize_longest) => {
let (height, width) = (img.height(), img.width());
let resize_longest = resize_longest as u32;
let (height, width) = if height < width {
let h = (resize_longest * height) / width;
(h, resize_longest)
} else {
let w = (resize_longest * width) / height;
(resize_longest, w)
};
img.resize_exact(width, height, image::imageops::FilterType::CatmullRom)
}
};
let (height, width) = (img.height() as usize, img.width() as usize);
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (height, width, 3), &Device::Cpu)?.permute((2, 0, 1))?;
Ok((data, initial_h, initial_w))
}
pub fn load_image_and_resize<P: AsRef<std::path::Path>>(
p: P,
width: usize,
height: usize,
) -> Result<Tensor> {
let img = image::ImageReader::open(p)?
.decode()
.map_err(candle::Error::wrap)?
.resize_to_fill(
width as u32,
height as u32,
image::imageops::FilterType::Triangle,
);
let img = img.to_rgb8();
let data = img.into_raw();
Tensor::from_vec(data, (width, height, 3), &Device::Cpu)?.permute((2, 0, 1))
}
/// Saves an image to disk using the image crate, this expects an input with shape
/// (c, height, width).
pub fn save_image<P: AsRef<std::path::Path>>(img: &Tensor, p: P) -> Result<()> {
let p = p.as_ref();
let (channel, height, width) = img.dims3()?;
if channel != 3 {
candle::bail!("save_image expects an input of shape (3, height, width)")
}
let img = img.permute((1, 2, 0))?.flatten_all()?;
let pixels = img.to_vec1::<u8>()?;
let image: image::ImageBuffer<image::Rgb<u8>, Vec<u8>> =
match image::ImageBuffer::from_raw(width as u32, height as u32, pixels) {
Some(image) => image,
None => candle::bail!("error saving image {p:?}"),
};
image.save(p).map_err(candle::Error::wrap)?;
Ok(())
}
pub fn save_image_resize<P: AsRef<std::path::Path>>(
img: &Tensor,
p: P,
h: usize,
w: usize,
) -> Result<()> {
let p = p.as_ref();
let (channel, height, width) = img.dims3()?;
if channel != 3 {
candle::bail!("save_image expects an input of shape (3, height, width)")
}
let img = img.permute((1, 2, 0))?.flatten_all()?;
let pixels = img.to_vec1::<u8>()?;
let image: image::ImageBuffer<image::Rgb<u8>, Vec<u8>> =
match image::ImageBuffer::from_raw(width as u32, height as u32, pixels) {
Some(image) => image,
None => candle::bail!("error saving image {p:?}"),
};
let image = image::DynamicImage::from(image);
let image = image.resize_to_fill(w as u32, h as u32, image::imageops::FilterType::CatmullRom);
image.save(p).map_err(candle::Error::wrap)?;
Ok(())
}
/// Loads the safetensors files for a model from the hub based on a json index file.
pub fn hub_load_safetensors(
repo: &hf_hub::api::sync::ApiRepo,
json_file: &str,
) -> Result<Vec<std::path::PathBuf>> {
let json_file = repo.get(json_file).map_err(candle::Error::wrap)?;
let json_file = std::fs::File::open(json_file)?;
let json: serde_json::Value =
serde_json::from_reader(&json_file).map_err(candle::Error::wrap)?;
let weight_map = match json.get("weight_map") {
None => candle::bail!("no weight map in {json_file:?}"),
Some(serde_json::Value::Object(map)) => map,
Some(_) => candle::bail!("weight map in {json_file:?} is not a map"),
};
let mut safetensors_files = std::collections::HashSet::new();
for value in weight_map.values() {
if let Some(file) = value.as_str() {
safetensors_files.insert(file.to_string());
}
}
let safetensors_files = safetensors_files
.iter()
.map(|v| repo.get(v).map_err(candle::Error::wrap))
.collect::<Result<Vec<_>>>()?;
Ok(safetensors_files)
}
| 6 |
0 | hf_public_repos/candle/candle-examples | hf_public_repos/candle/candle-examples/src/bs1770.rs | // Copied from https://github.com/ruuda/bs1770/blob/master/src/lib.rs
// BS1770 -- Loudness analysis library conforming to ITU-R BS.1770
// Copyright 2020 Ruud van Asseldonk
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// A copy of the License has been included in the root of the repository.
//! Loudness analysis conforming to [ITU-R BS.1770-4][bs17704].
//!
//! This library offers the building blocks to perform BS.1770 loudness
//! measurements, but you need to put the pieces together yourself.
//!
//! [bs17704]: https://www.itu.int/rec/R-REC-BS.1770-4-201510-I/en
//!
//! # Stereo integrated loudness example
//!
//! ```ignore
//! # fn load_stereo_audio() -> [Vec<i16>; 2] {
//! # [vec![0; 48_000], vec![0; 48_000]]
//! # }
//! #
//! let sample_rate_hz = 44_100;
//! let bits_per_sample = 16;
//! let channel_samples: [Vec<i16>; 2] = load_stereo_audio();
//!
//! // When converting integer samples to float, note that the maximum amplitude
//! // is `1 << (bits_per_sample - 1)`, one bit is the sign bit.
//! let normalizer = 1.0 / (1_u64 << (bits_per_sample - 1)) as f32;
//!
//! let channel_power: Vec<_> = channel_samples.iter().map(|samples| {
//! let mut meter = bs1770::ChannelLoudnessMeter::new(sample_rate_hz);
//! meter.push(samples.iter().map(|&s| s as f32 * normalizer));
//! meter.into_100ms_windows()
//! }).collect();
//!
//! let stereo_power = bs1770::reduce_stereo(
//! channel_power[0].as_ref(),
//! channel_power[1].as_ref(),
//! );
//!
//! let gated_power = bs1770::gated_mean(
//! stereo_power.as_ref()
//! ).unwrap_or(bs1770::Power(0.0));
//! println!("Integrated loudness: {:.1} LUFS", gated_power.loudness_lkfs());
//! ```
use std::f32;
/// Coefficients for a 2nd-degree infinite impulse response filter.
///
/// Coefficient a0 is implicitly 1.0.
#[derive(Clone)]
struct Filter {
a1: f32,
a2: f32,
b0: f32,
b1: f32,
b2: f32,
// The past two input and output samples.
x1: f32,
x2: f32,
y1: f32,
y2: f32,
}
impl Filter {
/// Stage 1 of th BS.1770-4 pre-filter.
pub fn high_shelf(sample_rate_hz: f32) -> Filter {
// Coefficients taken from https://github.com/csteinmetz1/pyloudnorm/blob/
// 6baa64d59b7794bc812e124438692e7fd2e65c0c/pyloudnorm/meter.py#L135-L136.
let gain_db = 3.999_843_8;
let q = 0.707_175_25;
let center_hz = 1_681.974_5;
// Formula taken from https://github.com/csteinmetz1/pyloudnorm/blob/
// 6baa64d59b7794bc812e124438692e7fd2e65c0c/pyloudnorm/iirfilter.py#L134-L143.
let k = (f32::consts::PI * center_hz / sample_rate_hz).tan();
let vh = 10.0_f32.powf(gain_db / 20.0);
let vb = vh.powf(0.499_666_78);
let a0 = 1.0 + k / q + k * k;
Filter {
b0: (vh + vb * k / q + k * k) / a0,
b1: 2.0 * (k * k - vh) / a0,
b2: (vh - vb * k / q + k * k) / a0,
a1: 2.0 * (k * k - 1.0) / a0,
a2: (1.0 - k / q + k * k) / a0,
x1: 0.0,
x2: 0.0,
y1: 0.0,
y2: 0.0,
}
}
/// Stage 2 of th BS.1770-4 pre-filter.
pub fn high_pass(sample_rate_hz: f32) -> Filter {
// Coefficients taken from https://github.com/csteinmetz1/pyloudnorm/blob/
// 6baa64d59b7794bc812e124438692e7fd2e65c0c/pyloudnorm/meter.py#L135-L136.
let q = 0.500_327_05;
let center_hz = 38.135_47;
// Formula taken from https://github.com/csteinmetz1/pyloudnorm/blob/
// 6baa64d59b7794bc812e124438692e7fd2e65c0c/pyloudnorm/iirfilter.py#L145-L151
let k = (f32::consts::PI * center_hz / sample_rate_hz).tan();
Filter {
a1: 2.0 * (k * k - 1.0) / (1.0 + k / q + k * k),
a2: (1.0 - k / q + k * k) / (1.0 + k / q + k * k),
b0: 1.0,
b1: -2.0,
b2: 1.0,
x1: 0.0,
x2: 0.0,
y1: 0.0,
y2: 0.0,
}
}
/// Feed the next input sample, get the next output sample.
#[inline(always)]
pub fn apply(&mut self, x0: f32) -> f32 {
let y0 = 0.0 + self.b0 * x0 + self.b1 * self.x1 + self.b2 * self.x2
- self.a1 * self.y1
- self.a2 * self.y2;
self.x2 = self.x1;
self.x1 = x0;
self.y2 = self.y1;
self.y1 = y0;
y0
}
}
/// Compensated sum, for summing many values of different orders of magnitude
/// accurately.
#[derive(Copy, Clone, PartialEq)]
struct Sum {
sum: f32,
residue: f32,
}
impl Sum {
#[inline(always)]
fn zero() -> Sum {
Sum {
sum: 0.0,
residue: 0.0,
}
}
#[inline(always)]
fn add(&mut self, x: f32) {
let sum = self.sum + (self.residue + x);
self.residue = (self.residue + x) - (sum - self.sum);
self.sum = sum;
}
}
/// The mean of the squares of the K-weighted samples in a window of time.
///
/// K-weighted power is equivalent to K-weighted loudness, the only difference
/// is one of scale: power is quadratic in sample amplitudes, whereas loudness
/// units are logarithmic. `loudness_lkfs` and `from_lkfs` convert between power,
/// and K-weighted Loudness Units relative to nominal Full Scale (LKFS).
///
/// The term “LKFS” (Loudness Units, K-Weighted, relative to nominal Full Scale)
/// is used in BS.1770-4 to emphasize K-weighting, but the term is otherwise
/// interchangeable with the more widespread term “LUFS” (Loudness Units,
/// relative to Full Scale). Loudness units are related to decibels in the
/// following sense: boosting a signal that has a loudness of
/// -<var>L<sub>K</sub></var> LUFS by <var>L<sub>K</sub></var> dB (by
/// multiplying the amplitude by 10<sup><var>L<sub>K</sub></var>/20</sup>) will
/// bring the loudness to 0 LUFS.
///
/// K-weighting refers to a high-shelf and high-pass filter that model the
/// effect that humans perceive a certain amount of power in low frequencies to
/// be less loud than the same amount of power in higher frequencies. In this
/// library the `Power` type is used exclusively to refer to power after applying K-weighting.
///
/// The nominal “full scale” is the range [-1.0, 1.0]. Because the power is the
/// mean square of the samples, if no input samples exceeded the full scale, the
/// power will be in the range [0.0, 1.0]. However, the power delivered by
/// multiple channels, which is a weighted sum over individual channel powers,
/// can exceed this range, because the weighted sum is not normalized.
#[derive(Copy, Clone, PartialEq, PartialOrd)]
pub struct Power(pub f32);
impl Power {
/// Convert Loudness Units relative to Full Scale into a squared sample amplitude.
///
/// This is the inverse of `loudness_lkfs`.
pub fn from_lkfs(lkfs: f32) -> Power {
// The inverse of the formula below.
Power(10.0_f32.powf((lkfs + 0.691) * 0.1))
}
/// Return the loudness of this window in Loudness Units, K-weighted, relative to Full Scale.
///
/// This is the inverse of `from_lkfs`.
pub fn loudness_lkfs(&self) -> f32 {
// Equation 2 (p.5) of BS.1770-4.
-0.691 + 10.0 * self.0.log10()
}
}
/// A `T` value for non-overlapping windows of audio, 100ms in length.
///
/// The `ChannelLoudnessMeter` applies K-weighting and then produces the power
/// for non-overlapping windows of 100ms duration.
///
/// These non-overlapping 100ms windows can later be combined into overlapping
/// windows of 400ms, spaced 100ms apart, to compute instantaneous loudness or
/// to perform a gated measurement, or they can be combined into even larger
/// windows for a momentary loudness measurement.
#[derive(Copy, Clone, Debug)]
pub struct Windows100ms<T> {
pub inner: T,
}
impl<T> Windows100ms<T> {
/// Wrap a new empty vector.
pub fn new() -> Windows100ms<Vec<T>> {
Windows100ms { inner: Vec::new() }
}
/// Apply `as_ref` to the inner value.
pub fn as_ref(&self) -> Windows100ms<&[Power]>
where
T: AsRef<[Power]>,
{
Windows100ms {
inner: self.inner.as_ref(),
}
}
/// Apply `as_mut` to the inner value.
pub fn as_mut(&mut self) -> Windows100ms<&mut [Power]>
where
T: AsMut<[Power]>,
{
Windows100ms {
inner: self.inner.as_mut(),
}
}
#[allow(clippy::len_without_is_empty)]
/// Apply `len` to the inner value.
pub fn len(&self) -> usize
where
T: AsRef<[Power]>,
{
self.inner.as_ref().len()
}
}
/// Measures K-weighted power of non-overlapping 100ms windows of a single channel of audio.
///
/// # Output
///
/// The output of the meter is an intermediate result in the form of power for
/// 100ms non-overlapping windows. The windows need to be processed further to
/// get one of the instantaneous, momentary, and integrated loudness
/// measurements defined in BS.1770.
///
/// The windows can also be inspected directly; the data is meaningful
/// on its own (the K-weighted power delivered in that window of time), but it
/// is not something that BS.1770 defines a term for.
///
/// # Multichannel audio
///
/// To perform a loudness measurement of multichannel audio, construct a
/// `ChannelLoudnessMeter` per channel, and later combine the measured power
/// with e.g. `reduce_stereo`.
///
/// # Instantaneous loudness
///
/// The instantaneous loudness is the power over a 400ms window, so you can
/// average four 100ms windows. No special functionality is implemented to help
/// with that at this time. ([Pull requests would be accepted.][contribute])
///
/// # Momentary loudness
///
/// The momentary loudness is the power over a 3-second window, so you can
/// average thirty 100ms windows. No special functionality is implemented to
/// help with that at this time. ([Pull requests would be accepted.][contribute])
///
/// # Integrated loudness
///
/// Use `gated_mean` to perform an integrated loudness measurement:
///
/// ```ignore
/// # use std::iter;
/// # use bs1770::{ChannelLoudnessMeter, gated_mean};
/// # let sample_rate_hz = 44_100;
/// # let samples_per_100ms = sample_rate_hz / 10;
/// # let mut meter = ChannelLoudnessMeter::new(sample_rate_hz);
/// # meter.push((0..44_100).map(|i| (i as f32 * 0.01).sin()));
/// let integrated_loudness_lkfs = gated_mean(meter.as_100ms_windows())
/// .unwrap_or(bs1770::Power(0.0))
/// .loudness_lkfs();
/// ```
///
/// [contribute]: https://github.com/ruuda/bs1770/blob/master/CONTRIBUTING.md
#[derive(Clone)]
pub struct ChannelLoudnessMeter {
/// The number of samples that fit in 100ms of audio.
samples_per_100ms: u32,
/// Stage 1 filter (head effects, high shelf).
filter_stage1: Filter,
/// Stage 2 filter (high-pass).
filter_stage2: Filter,
/// Sum of the squares over non-overlapping windows of 100ms.
windows: Windows100ms<Vec<Power>>,
/// The number of samples in the current unfinished window.
count: u32,
/// The sum of the squares of the samples in the current unfinished window.
square_sum: Sum,
}
impl ChannelLoudnessMeter {
/// Construct a new loudness meter for the given sample rate.
pub fn new(sample_rate_hz: u32) -> ChannelLoudnessMeter {
ChannelLoudnessMeter {
samples_per_100ms: sample_rate_hz / 10,
filter_stage1: Filter::high_shelf(sample_rate_hz as f32),
filter_stage2: Filter::high_pass(sample_rate_hz as f32),
windows: Windows100ms::new(),
count: 0,
square_sum: Sum::zero(),
}
}
/// Feed input samples for loudness analysis.
///
/// # Full scale
///
/// Full scale for the input samples is the interval [-1.0, 1.0]. If your
/// input consists of signed integer samples, you can convert as follows:
///
/// ```ignore
/// # let mut meter = bs1770::ChannelLoudnessMeter::new(44_100);
/// # let bits_per_sample = 16_usize;
/// # let samples = &[0_i16];
/// // Note that the maximum amplitude is `1 << (bits_per_sample - 1)`,
/// // one bit is the sign bit.
/// let normalizer = 1.0 / (1_u64 << (bits_per_sample - 1)) as f32;
/// meter.push(samples.iter().map(|&s| s as f32 * normalizer));
/// ```
///
/// # Repeated calls
///
/// You can call `push` multiple times to feed multiple batches of samples.
/// This is equivalent to feeding a single chained iterator. The leftover of
/// samples that did not fill a full 100ms window is not discarded:
///
/// ```ignore
/// # use std::iter;
/// # use bs1770::ChannelLoudnessMeter;
/// let sample_rate_hz = 44_100;
/// let samples_per_100ms = sample_rate_hz / 10;
/// let mut meter = ChannelLoudnessMeter::new(sample_rate_hz);
///
/// meter.push(iter::repeat(0.0).take(samples_per_100ms as usize - 1));
/// assert_eq!(meter.as_100ms_windows().len(), 0);
///
/// meter.push(iter::once(0.0));
/// assert_eq!(meter.as_100ms_windows().len(), 1);
/// ```
pub fn push<I: Iterator<Item = f32>>(&mut self, samples: I) {
let normalizer = 1.0 / self.samples_per_100ms as f32;
// LLVM, if you could go ahead and inline those apply calls, and then
// unroll and vectorize the loop, that'd be terrific.
for x in samples {
let y = self.filter_stage1.apply(x);
let z = self.filter_stage2.apply(y);
self.square_sum.add(z * z);
self.count += 1;
// TODO: Should this branch be marked cold?
if self.count == self.samples_per_100ms {
let mean_squares = Power(self.square_sum.sum * normalizer);
self.windows.inner.push(mean_squares);
// We intentionally do not reset the residue. That way, leftover
// energy from this window is not lost, so for the file overall,
// the sum remains more accurate.
self.square_sum.sum = 0.0;
self.count = 0;
}
}
}
/// Return a reference to the 100ms windows analyzed so far.
pub fn as_100ms_windows(&self) -> Windows100ms<&[Power]> {
self.windows.as_ref()
}
/// Return all 100ms windows analyzed so far.
pub fn into_100ms_windows(self) -> Windows100ms<Vec<Power>> {
self.windows
}
}
/// Combine power for multiple channels by taking a weighted sum.
///
/// Note that BS.1770-4 defines power for a multi-channel signal as a weighted
/// sum over channels which is not normalized. This means that a stereo signal
/// is inherently louder than a mono signal. For a mono signal played back on
/// stereo speakers, you should therefore still apply `reduce_stereo`, passing
/// in the same signal for both channels.
pub fn reduce_stereo(
left: Windows100ms<&[Power]>,
right: Windows100ms<&[Power]>,
) -> Windows100ms<Vec<Power>> {
assert_eq!(
left.len(),
right.len(),
"Channels must have the same length."
);
let mut result = Vec::with_capacity(left.len());
for (l, r) in left.inner.iter().zip(right.inner) {
result.push(Power(l.0 + r.0));
}
Windows100ms { inner: result }
}
/// In-place version of `reduce_stereo` that stores the result in the former left channel.
pub fn reduce_stereo_in_place(left: Windows100ms<&mut [Power]>, right: Windows100ms<&[Power]>) {
assert_eq!(
left.len(),
right.len(),
"Channels must have the same length."
);
for (l, r) in left.inner.iter_mut().zip(right.inner) {
l.0 += r.0;
}
}
/// Perform gating and averaging for a BS.1770-4 integrated loudness measurement.
///
/// The integrated loudness measurement is not just the average power over the
/// entire signal. BS.1770-4 defines two stages of gating that exclude
/// parts of the signal, to ensure that silent parts do not contribute to the
/// loudness measurement. This function performs that gating, and returns the
/// average power over the windows that were not excluded.
///
/// The result of this function is the integrated loudness measurement.
///
/// When no signal remains after applying the gate, this function returns
/// `None`. In particular, this happens when all of the signal is softer than
/// -70 LKFS, including a signal that consists of pure silence.
pub fn gated_mean(windows_100ms: Windows100ms<&[Power]>) -> Option<Power> {
let mut gating_blocks = Vec::with_capacity(windows_100ms.len());
// Stage 1: an absolute threshold of -70 LKFS. (Equation 6, p.6.)
let absolute_threshold = Power::from_lkfs(-70.0);
// Iterate over all 400ms windows.
for window in windows_100ms.inner.windows(4) {
// Note that the sum over channels has already been performed at this point.
let gating_block_power = Power(0.25 * window.iter().map(|mean| mean.0).sum::<f32>());
if gating_block_power > absolute_threshold {
gating_blocks.push(gating_block_power);
}
}
if gating_blocks.is_empty() {
return None;
}
// Compute the loudness after applying the absolute gate, in order to
// determine the threshold for the relative gate.
let mut sum_power = Sum::zero();
for &gating_block_power in &gating_blocks {
sum_power.add(gating_block_power.0);
}
let absolute_gated_power = Power(sum_power.sum / (gating_blocks.len() as f32));
// Stage 2: Apply the relative gate.
let relative_threshold = Power::from_lkfs(absolute_gated_power.loudness_lkfs() - 10.0);
let mut sum_power = Sum::zero();
let mut n_blocks = 0_usize;
for &gating_block_power in &gating_blocks {
if gating_block_power > relative_threshold {
sum_power.add(gating_block_power.0);
n_blocks += 1;
}
}
if n_blocks == 0 {
return None;
}
let relative_gated_power = Power(sum_power.sum / n_blocks as f32);
Some(relative_gated_power)
}
| 7 |
0 | hf_public_repos/candle/candle-examples | hf_public_repos/candle/candle-examples/src/coco_classes.rs | pub const NAMES: [&str; 80] = [
"person",
"bicycle",
"car",
"motorbike",
"aeroplane",
"bus",
"train",
"truck",
"boat",
"traffic light",
"fire hydrant",
"stop sign",
"parking meter",
"bench",
"bird",
"cat",
"dog",
"horse",
"sheep",
"cow",
"elephant",
"bear",
"zebra",
"giraffe",
"backpack",
"umbrella",
"handbag",
"tie",
"suitcase",
"frisbee",
"skis",
"snowboard",
"sports ball",
"kite",
"baseball bat",
"baseball glove",
"skateboard",
"surfboard",
"tennis racket",
"bottle",
"wine glass",
"cup",
"fork",
"knife",
"spoon",
"bowl",
"banana",
"apple",
"sandwich",
"orange",
"broccoli",
"carrot",
"hot dog",
"pizza",
"donut",
"cake",
"chair",
"sofa",
"pottedplant",
"bed",
"diningtable",
"toilet",
"tvmonitor",
"laptop",
"mouse",
"remote",
"keyboard",
"cell phone",
"microwave",
"oven",
"toaster",
"sink",
"refrigerator",
"book",
"clock",
"vase",
"scissors",
"teddy bear",
"hair drier",
"toothbrush",
];
| 8 |
0 | hf_public_repos/candle/candle-examples | hf_public_repos/candle/candle-examples/src/audio.rs | use candle::{Result, Tensor};
// https://github.com/facebookresearch/audiocraft/blob/69fea8b290ad1b4b40d28f92d1dfc0ab01dbab85/audiocraft/data/audio_utils.py#L57
pub fn normalize_loudness(
wav: &Tensor,
sample_rate: u32,
loudness_compressor: bool,
) -> Result<Tensor> {
let energy = wav.sqr()?.mean_all()?.sqrt()?.to_vec0::<f32>()?;
if energy < 2e-3 {
return Ok(wav.clone());
}
let wav_array = wav.to_vec1::<f32>()?;
let mut meter = crate::bs1770::ChannelLoudnessMeter::new(sample_rate);
meter.push(wav_array.into_iter());
let power = meter.as_100ms_windows();
let loudness = match crate::bs1770::gated_mean(power) {
None => return Ok(wav.clone()),
Some(gp) => gp.loudness_lkfs() as f64,
};
let delta_loudness = -14. - loudness;
let gain = 10f64.powf(delta_loudness / 20.);
let wav = (wav * gain)?;
if loudness_compressor {
wav.tanh()
} else {
Ok(wav)
}
}
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter8/introduction.mdx | # Congratulations!
You have worked hard to reach this point, and we'd like to congratulate you on completing this Audio course!
Throughout this course, you gained foundational understanding of audio data, explored new concepts, and developed
practical skills working with Audio Transformers.
From the basics of working with audio data and pre-trained checkpoints via pipelines, to building real-world
audio applications, you have discovered how you can build systems that can not only understand sound but also create it.
As this field is dynamic and ever-evolving, we encourage you to stay curious and continuously explore new models, research
advancements, and new applications. When building your own new and exciting audio applications, make sure to always keep
ethical implications in mind, and carefully consider the potential impact on individuals and society as a whole.
Thank you for joining this audio course, we hope you thoroughly enjoyed this educational experience, as
much as we relished crafting it. Your feedback and contributions are welcome in
the [course GitHub repo](https://github.com/huggingface/audio-transformers-course).
To learn how you can obtain your well-deserved certificate of completion, if you successfully passed the hands-on assignments,
check out the [next page](certification).
Finally, to stay connected with the Audio Course Team, you can follow us on Twitter:
* Maria Khalusova: [@mariakhalusova](https://twitter.com/mariaKhalusova)
* Sanchit Gandhi: [@sanchitgandhi99](https://twitter.com/sanchitgandhi99)
* Matthijs Hollemans: [@mhollemans](https://twitter.com/mhollemans)
* Vaibhav (VB) Srivastav: [@reach_vb](https://twitter.com/reach_vb)
Stay curious and train Transformers! :)
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/choosing_dataset.mdx | # Choosing a dataset
As with any machine learning problem, our model is only as good as the data that we train it on. Speech recognition
datasets vary considerably in how they are curated and the domains that they cover. To pick the right dataset, we need
to match our criteria with the features that a dataset offers.
Before we pick a dataset, we first need to understand the key defining features.
## Features of speech datasets
### 1. Number of hours
Simply put, the number of training hours indicates how large the dataset is. It’s analogous to the number of training
examples in an NLP dataset. However, bigger datasets aren’t necessarily better. If we want a model that generalises well,
we want a **diverse** dataset with lots of different speakers, domains and speaking styles.
### 2. Domain
The domain entails where the data was sourced from, whether it be audiobooks, podcasts, YouTube or financial meetings.
Each domain has a different distribution of data. For example, audiobooks are recorded in high-quality studio conditions
(with no background noise) and text that is taken from written literature. Whereas for YouTube, the audio likely contains
more background noise and a more informal style of speech.
We need to match our domain to the conditions we anticipate at inference time. For instance, if we train our model on
audiobooks, we can’t expect it to perform well in noisy environments.
### 3. Speaking style
The speaking style falls into one of two categories:
* Narrated: read from a script
* Spontaneous: un-scripted, conversational speech
The audio and text data reflect the style of speaking. Since narrated text is scripted, it tends to be spoken articulately
and without any errors:
```
“Consider the task of training a model on a speech recognition dataset”
```
Whereas for spontaneous speech, we can expect a more colloquial style of speech, with the inclusion of repetitions,
hesitations and false-starts:
```
“Let’s uhh let's take a look at how you'd go about training a model on uhm a sp- speech recognition dataset”
```
### 4. Transcription style
The transcription style refers to whether the target text has punctuation, casing or both. If we want a system to generate
fully formatted text that could be used for a publication or meeting transcription, we require training data with punctuation
and casing. If we just require the spoken words in an un-formatted structure, neither punctuation nor casing are necessary.
In this case, we can either pick a dataset without punctuation or casing, or pick one that has punctuation and casing and
then subsequently remove them from the target text through pre-processing.
## A summary of datasets on the Hub
Here is a summary of the most popular English speech recognition datasets on the Hugging Face Hub:
| Dataset | Train Hours | Domain | Speaking Style | Casing | Punctuation | License | Recommended Use |
|-----------------------------------------------------------------------------------------|-------------|-----------------------------|-----------------------|--------|-------------|-----------------|----------------------------------|
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | Audiobook | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) | 3000 | Wikipedia | Narrated | ✅ | ✅ | CC0-1.0 | Non-native speakers |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | European Parliament | Oratory | ❌ | ✅ | CC0 | Non-native speakers |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | TED talks | Oratory | ❌ | ❌ | CC-BY-NC-ND 3.0 | Technical topics |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 10000 | Audiobook, podcast, YouTube | Narrated, spontaneous | ❌ | ✅ | apache-2.0 | Robustness over multiple domains |
| [SPGISpeech](https://huggingface.co/datasets/kensho/spgispeech) | 5000 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | User Agreement | Fully formatted transcriptions |
| [Earnings-22](https://huggingface.co/datasets/revdotcom/earnings22) | 119 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | CC-BY-SA-4.0 | Diversity of accents |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | Meetings | Spontaneous | ✅ | ✅ | CC-BY-4.0 | Noisy speech conditions |
This table serves as a reference for selecting a dataset based on your criterion. Below is an equivalent table for
multilingual speech recognition. Note that we omit the train hours column, since this varies depending on the language
for each dataset, and replace it with the number of languages per dataset:
| Dataset | Languages | Domain | Speaking Style | Casing | Punctuation | License | Recommended Usage |
|-----------------------------------------------------------------------------------------------|-----------|---------------------------------------|----------------|--------|-------------|-----------|-------------------------|
| [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 6 | Audiobooks | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 108 | Wikipedia text & crowd-sourced speech | Narrated | ✅ | ✅ | CC0-1.0 | Diverse speaker set |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 15 | European Parliament recordings | Spontaneous | ❌ | ✅ | CC0 | European languages |
| [FLEURS](https://huggingface.co/datasets/google/fleurs) | 101 | European Parliament recordings | Spontaneous | ❌ | ❌ | CC-BY-4.0 | Multilingual evaluation |
For a detailed breakdown of the audio datasets covered in both tables, refer to the blog post [A Complete Guide to Audio Datasets](https://huggingface.co/blog/audio-datasets#a-tour-of-audio-datasets-on-the-hub).
While there are over 180 speech recognition datasets on the Hub, it may be possible that there isn't a dataset that matches
your needs. In this case, it's also possible to use your own audio data with 🤗 Datasets. To create a custom audio dataset,
refer to the guide [Create an audio dataset](https://huggingface.co/docs/datasets/audio_dataset). When creating a custom
audio dataset, consider sharing the final dataset on the Hub so that others in the community can benefit from your
efforts - the audio community is inclusive and wide-ranging, and others will appreciate your work as you do theirs.
Alright! Now that we've gone through all the criterion for selecting an ASR dataset, let's pick one for the purpose of this tutorial.
We know that Whisper already does a pretty good job at transcribing data in high-resource languages (such as English and Spanish), so
we'll focus ourselves on low-resource multilingual transcription. We want to retain Whisper's ability to predict punctuation and casing,
so it seems from the second table that Common Voice 13 is a great candidate dataset!
## Common Voice 13
Common Voice 13 is a crowd-sourced dataset where speakers record text from Wikipedia in various languages. It forms part of
the Common Voice series, a collection of Common Voice datasets released by Mozilla Foundation. At the time of writing,
Common Voice 13 is the latest edition of the dataset, with the most languages and hours per language out of any release to date.
We can get the full list of languages for the Common Voice 13 dataset by checking-out the dataset page on the Hub:
[mozilla-foundation/common_voice_13_0](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0).
The first time you view this page, you'll be asked to accept the terms of use. After that, you'll be given full access to the dataset.
Once we've provided authentication to use the dataset, we'll be presented with the dataset preview. The dataset preview
shows us the first 100 samples of the dataset for each language. What's more, it's loaded up with audio samples ready for us
to listen to in real time. For this Unit, we'll select [_Dhivehi_](https://en.wikipedia.org/wiki/Maldivian_language)
(or _Maldivian_), an Indo-Aryan language spoken in the South Asian island country of the Maldives. While we're selecting
Dhivehi for this tutorial, the steps covered here apply to any one of the 108 languages in the Common Voice 13 dataset, and
more generally to any one of the 180+ audio datasets on the Hugging Face Hub, so there's no restriction on language or dialect.
We can select the Dhivehi subset of Common Voice 13 by setting the subset to `dv` using the dropdown menu (`dv` being the language
identifier code for Dhivehi):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/cv_13_dv_selection.png" alt="Selecting the Dhivehi split from the Dataset's Preview">
</div>
If we hit the play button on the first sample, we can listen to the audio and see the corresponding text. Have a scroll
through the samples for the train and test sets to get a better feel for the audio and text data that we're dealing with.
You can tell from the intonation and style that the recordings are taken from narrated speech. You'll also likely notice
the large variation in speakers and recording quality, a common trait of crowd-sourced data.
The Dataset Preview is a brilliant way of experiencing audio datasets before committing to using them. You can pick any
dataset on the Hub, scroll through the samples and listen to the audio for the different subsets and splits, gauging whether
it's the right dataset for your needs. Once you've selected a dataset, it's trivial to load the data so that you can
start using it.
Now, I personally don't speak Dhivehi, and expect the vast majority of readers not to either! To know if our fine-tuned model
is any good, we'll need a rigorous way of _evaluating_ it on unseen data and measuring its transcription accuracy.
We'll cover exactly this in the next section!
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/evaluation.mdx | # Evaluation metrics for ASR
If you're familiar with the [Levenshtein distance](https://en.wikipedia.org/wiki/Levenshtein_distance) from NLP, the
metrics for assessing speech recognition systems will be familiar! Don't worry if you're not, we'll go through the
explanations start-to-finish to make sure you know the different metrics and understand what they mean.
When assessing speech recognition systems, we compare the system's predictions to the target text transcriptions,
annotating any errors that are present. We categorise these errors into one of three categories:
1. Substitutions (S): where we transcribe the **wrong word** in our prediction ("sit" instead of "sat")
2. Insertions (I): where we add an **extra word** in our prediction
3. Deletions (D): where we **remove a word** in our prediction
These error categories are the same for all speech recognition metrics. What differs is the level at which we compute
these errors: we can either compute them on the _word level_ or on the _character level_.
We'll use a running example for each of the metric definitions. Here, we have a _ground truth_ or _reference_ text sequence:
```python
reference = "the cat sat on the mat"
```
And a predicted sequence from the speech recognition system that we're trying to assess:
```python
prediction = "the cat sit on the"
```
We can see that the prediction is pretty close, but some words are not quite right. We'll evaluate this prediction
against the reference for the three most popular speech recognition metrics and see what sort of numbers we get for each.
## Word Error Rate
The *word error rate (WER)* metric is the 'de facto' metric for speech recognition. It calculates substitutions,
insertions and deletions on the *word level*. This means errors are annotated on a word-by-word basis. Take our example:
| Reference: | the | cat | sat | on | the | mat |
|-------------|-----|-----|---------|-----|-----|-----|
| Prediction: | the | cat | **sit** | on | the | | |
| Label: | ✅ | ✅ | S | ✅ | ✅ | D |
Here, we have:
* 1 substitution ("sit" instead of "sat")
* 0 insertions
* 1 deletion ("mat" is missing)
This gives 2 errors in total. To get our error rate, we divide the number of errors by the total number of words in our
reference (N), which for this example is 6:
$$
\begin{aligned}
WER &= \frac{S + I + D}{N} \\
&= \frac{1 + 0 + 1}{6} \\
&= 0.333
\end{aligned}
$$
Alright! So we have a WER of 0.333, or 33.3%. Notice how the word "sit" only has one character that is wrong, but the
entire word is marked incorrect. This is a defining feature of the WER: spelling errors are penalised heavily, no matter
how minor they are.
The WER is defined such that *lower is better*: a lower WER means there are fewer errors in our prediction, so a perfect
speech recognition system would have a WER of zero (no errors).
Let's see how we can compute the WER using 🤗 Evaluate. We'll need two packages to compute our WER metric: 🤗 Evaluate
for the API interface, and JIWER to do the heavy lifting of running the calculation:
```
pip install --upgrade evaluate jiwer
```
Great! We can now load up the WER metric and compute the figure for our example:
```python
from evaluate import load
wer_metric = load("wer")
wer = wer_metric.compute(references=[reference], predictions=[prediction])
print(wer)
```
**Print Output:**
```
0.3333333333333333
```
0.33, or 33.3%, as expected! We now know what's going on under-the-hood with this WER calculation.
Now, here's something that's quite confusing... What do you think the upper limit of the WER is? You would expect it to be
1 or 100% right? Nuh uh! Since the WER is the ratio of errors to number of words (N), there is no upper limit on the WER!
Let's take an example were we predict 10 words and the target only has 2 words. If all of our predictions were wrong (10 errors),
we'd have a WER of 10 / 2 = 5, or 500%! This is something to bear in mind if you train an ASR system and see a WER of over
100%. Although if you're seeing this, something has likely gone wrong... 😅
## Word Accuracy
We can flip the WER around to give us a metric where *higher is better*. Rather than measuring the word error rate,
we can measure the *word accuracy (WAcc)* of our system:
$$
\begin{equation}
WAcc = 1 - WER \nonumber
\end{equation}
$$
The WAcc is also measured on the word-level, it's just the WER reformulated as an accuracy metric rather than an error
metric. The WAcc is very infrequently quoted in the speech literature - we think of our system predictions in terms of
word errors, and so prefer error rate metrics that are more associated with these error type annotations.
## Character Error Rate
It seems a bit unfair that we marked the entire word for "sit" wrong when in fact only one letter was incorrect.
That's because we were evaluating our system on the word level, thereby annotating errors on a word-by-word basis.
The *character error rate (CER)* assesses systems on the *character level*. This means we divide up our words into their
individual characters, and annotate errors on a character-by-character basis:
| Reference: | t | h | e | | c | a | t | | s | a | t | | o | n | | t | h | e | | m | a | t |
|-------------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
| Prediction: | t | h | e | | c | a | t | | s | **i** | t | | o | n | | t | h | e | | | | |
| Label: | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | S | ✅ | | ✅ | ✅ | | ✅ | ✅ | ✅ | | D | D | D |
We can see now that for the word "sit", the "s" and "t" are marked as correct. It's only the "i" which is labelled as a
substitution error (S). Thus, we reward our system for the partially correct prediction 🤝
In our example, we have 1 character substitution, 0 insertions, and 3 deletions. In total, we have 14 characters. So, our CER is:
$$
\begin{aligned}
CER &= \frac{S + I + D}{N} \\
&= \frac{1 + 0 + 3}{14} \\
&= 0.286
\end{aligned}
$$
Right! We have a CER of 0.286, or 28.6%. Notice how this is lower than our WER - we penalised the spelling error much less.
## Which metric should I use?
In general, the WER is used far more than the CER for assessing speech systems. This is because the WER requires systems
to have greater understanding of the context of the predictions. In our example, "sit" is in the wrong tense. A system
that understands the relationship between the verb and tense of the sentence would have predicted the correct verb tense
of "sat". We want to encourage this level of understanding from our speech systems. So although the WER is less forgiving than
the CER, it's also more conducive to the kinds of intelligible systems we want to develop. Therefore, we typically use
the WER and would encourage you to as well! However, there are circumstances where it is not possible to use the WER.
Certain languages, such as Mandarin and Japanese, have no notion of 'words', and so the WER is meaningless. Here, we revert
to using the CER.
In our example, we only used one sentence when computing the WER. We would typically use an entire test set consisting
of several thousand sentences when evaluating a real system. When evaluating over multiple sentences, we aggregate S, I, D
and N across all sentences, and then compute the WER according to the formula defined above. This gives a better estimate
of the WER for unseen data.
## Normalisation
If we train an ASR model on data with punctuation and casing, it will learn to predict casing and punctuation in its
transcriptions. This is great when we want to use our model for actual speech recognition applications, such as
transcribing meetings or dictation, since the predicted transcriptions will be fully formatted with casing and punctuation,
a style referred to as *orthographic*.
However, we also have the option of *normalising* the dataset to remove any casing and punctuation. Normalising the
dataset makes the speech recognition task easier: the model no longer needs to distinguish between upper and lower case
characters, or have to predict punctuation from the audio data alone (e.g. what sound does a semi-colon make?).
Because of this, the word error rates are naturally lower (meaning the results are better). The Whisper paper demonstrates
the drastic effect that normalising transcriptions can have on WER results (*c.f.* Section 4.4 of the [Whisper paper](https://cdn.openai.com/papers/whisper.pdf)).
While we get lower WERs, the model isn't necessarily better for production. The lack of casing and punctuation makes the predicted
text from the model significantly harder to read. Take the example from the [previous section](asr_models), where we ran
Wav2Vec2 and Whisper on the same audio sample from the LibriSpeech dataset. The Wav2Vec2 model predicts neither punctuation
nor casing, whereas Whisper predicts both. Comparing the transcriptions side-by-side, we see that the Whisper transcription
is far easier to read:
```
Wav2Vec2: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Whisper: He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.
```
The Whisper transcription is orthographic and thus ready to go - it's formatted as we'd expect for a meeting transcription
or dictation script with both punctuation and casing. On the contrary, we would need to use additional post-processing
to restore punctuation and casing in our Wav2Vec2 predictions if we wanted to use it for downstream applications.
There is a happy medium between normalising and not normalising: we can train our systems on orthographic transcriptions,
and then normalise the predictions and targets before computing the WER. This way, we train our systems to predict fully
formatted text, but also benefit from the WER improvements we get by normalising the transcriptions.
The Whisper model was released with a normaliser that effectively handles the normalisation of casing, punctuation and
number formatting among others. Let's apply the normaliser to the Whisper transcriptions to demonstrate how we can
normalise them:
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
prediction = " He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind."
normalized_prediction = normalizer(prediction)
normalized_prediction
```
**Output:**
```
' he tells us that at this festive season of the year with christmas and roast beef looming before us similarly is drawn from eating and its results occur most readily to the mind '
```
Great! We can see that the text has been fully lower-cased and all punctuation removed. Let's now define the reference
transcription and then compute the normalised WER between the reference and prediction:
```python
reference = "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"
normalized_referece = normalizer(reference)
wer = wer_metric.compute(
references=[normalized_referece], predictions=[normalized_prediction]
)
wer
```
**Output:**
```
0.0625
```
6.25% - that's about what we'd expect for the Whisper base model on the LibriSpeech validation set. As we see here,
we've predicted an orthographic transcription, but benefited from the WER boost obtained by normalising the reference and
prediction prior to computing the WER.
The choice of how you normalise the transcriptions is ultimately down to your needs. We recommend training on
orthographic text and evaluating on normalised text to get the best of both worlds.
## Putting it all together
Alright! We've covered three topics so far in this Unit: pre-trained models, dataset selection and evaluation.
Let's have some fun and put them together in one end-to-end example 🚀 We're going to set ourselves up for the next
section on fine-tuning by evaluating the pre-trained Whisper model on the Common Voice 13 Dhivehi test set. We'll use
the WER number we get as a _baseline_ for our fine-tuning run, or a target number that we'll try and beat 🥊
First, we'll load the pre-trained Whisper model using the `pipeline()` class. This process will be extremely familiar by now!
The only new thing we'll do is load the model in half-precision (float16) if running on a GPU - this will speed up
inference at almost no cost to WER accuracy.
```python
from transformers import pipeline
import torch
if torch.cuda.is_available():
device = "cuda:0"
torch_dtype = torch.float16
else:
device = "cpu"
torch_dtype = torch.float32
pipe = pipeline(
"automatic-speech-recognition",
model="openai/whisper-small",
torch_dtype=torch_dtype,
device=device,
)
```
Next, we'll load the Dhivehi test split of Common Voice 13. You'll remember from the previous section that the Common
Voice 13 is *gated*, meaning we had to agree to the dataset terms of use before gaining access to the dataset. We can
now link our Hugging Face account to our notebook, so that we have access to the dataset from the machine we're currently
using.
Linking the notebook to the Hub is straightforward - it simply requires entering your Hub authentication token when prompted.
Find your Hub authentication token [here](https://huggingface.co/settings/tokens) and enter it when prompted:
```python
from huggingface_hub import notebook_login
notebook_login()
```
Great! Once we've linked the notebook to our Hugging Face account, we can proceed with downloading the Common Voice
dataset. This will take a few minutes to download and pre-process, fetching the data from the Hugging Face Hub and
preparing it automatically on your notebook:
```python
from datasets import load_dataset
common_voice_test = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
```
<Tip>
If you face an authentication issue when loading the dataset, ensure that you have accepted the dataset's terms of use
on the Hugging Face Hub through the following link: https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0
</Tip>
Evaluating over an entire dataset can be done in much the same way as over a single example - all we have to do is **loop**
over the input audios, rather than inferring just a single sample. To do this, we first transform our dataset into a
`KeyDataset`. All this does is pick out the particular dataset column that we want to forward to the model (in our case, that's
the `"audio"` column), ignoring the rest (like the target transcriptions, which we don't want to use for inference). We
then iterate over this transformed datasets, appending the model outputs to a list to save the predictions. The
following code cell will take approximately five minutes if running on a GPU with half-precision, peaking at 12GB memory:
```python
from tqdm import tqdm
from transformers.pipelines.pt_utils import KeyDataset
all_predictions = []
# run streamed inference
for prediction in tqdm(
pipe(
KeyDataset(common_voice_test, "audio"),
max_new_tokens=128,
generate_kwargs={"task": "transcribe"},
batch_size=32,
),
total=len(common_voice_test),
):
all_predictions.append(prediction["text"])
```
<Tip>
If you experience a CUDA out-of-memory (OOM) when running the above cell, incrementally reduce the `batch_size` by
factors of 2 until you find a batch size that fits your device.
</Tip>
And finally, we can compute the WER. Let's first compute the orthographic WER, i.e. the WER without any post-processing:
```python
from evaluate import load
wer_metric = load("wer")
wer_ortho = 100 * wer_metric.compute(
references=common_voice_test["sentence"], predictions=all_predictions
)
wer_ortho
```
**Output:**
```
167.29577268612022
```
Okay... 167% essentially means our model is outputting garbage 😜 Not to worry, it'll be our aim to improve this by
fine-tuning the model on the Dhivehi training set!
Next, we'll evaluate the normalised WER, i.e. the WER with normalisation post-processing. We have to filter out samples
that would be empty after normalisation, as otherwise the total number of words in our reference (N) would be zero, which
would give a division by zero error in our calculation:
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
# compute normalised WER
all_predictions_norm = [normalizer(pred) for pred in all_predictions]
all_references_norm = [normalizer(label) for label in common_voice_test["sentence"]]
# filtering step to only evaluate the samples that correspond to non-zero references
all_predictions_norm = [
all_predictions_norm[i]
for i in range(len(all_predictions_norm))
if len(all_references_norm[i]) > 0
]
all_references_norm = [
all_references_norm[i]
for i in range(len(all_references_norm))
if len(all_references_norm[i]) > 0
]
wer = 100 * wer_metric.compute(
references=all_references_norm, predictions=all_predictions_norm
)
wer
```
**Output:**
```
125.69809089960707
```
Again we see the drastic reduction in WER we achieve by normalising our references and predictions: the baseline model
achieves an orthographic test WER of 168%, while the normalised WER is 126%.
Right then! These are the numbers that we want to try and beat when we fine-tune the model, in order to improve the Whisper
model for Dhivehi speech recognition. Continue reading to get hands-on with a fine-tuning example 🚀
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/supplemental_reading.mdx | # Supplemental reading and resources
This unit provided a hands-on introduction to speech recognition, one of the most popular tasks in the audio domain.
Want to learn more? Here you will find additional resources that will help you deepen your understanding of the topics and
enhance your learning experience.
* [Whisper Talk](https://www.youtube.com/live/fZMiD8sDzzg?feature=share) by Jong Wook Kim: a presentation on the Whisper model, explaining the motivation, architecture, training and results, delivered by Whisper author Jong Wook Kim
* [End-to-End Speech Benchmark (ESB)](https://arxiv.org/abs/2210.13352): a paper that comprehensively argues for using the orthographic WER as opposed to the normalised WER for evaluating ASR systems and presents an accompanying benchmark
* [Fine-Tuning Whisper for Multilingual ASR](https://huggingface.co/blog/fine-tune-whisper): an in-depth blog post that explains how the Whisper model works in more detail, and the pre- and post-processing steps involved with the feature extractor and tokenizer
* [Fine-tuning MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters): an end-to-end guide for fine-tuning Meta AI's new [MMS](https://ai.facebook.com/blog/multilingual-model-speech-recognition/) speech recognition models, freezing the base model weights and only fine-tuning a small number of *adapter* layers
* [Boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram): a blog post for combining CTC models with external language models (LMs) to combat spelling and punctuation errors
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/asr_models.mdx | # Pre-trained models for automatic speech recognition
In this section, we'll cover how to use the `pipeline()` to leverage pre-trained models for speech recognition. In [Unit 2](../chapter2/asr_pipeline),
we introduced the `pipeline()` as an easy way of running speech recognition tasks, with all pre- and post-processing handled under-the-hood
and the flexibility to quickly experiment with any pre-trained checkpoint on the Hugging Face Hub. In this Unit, we'll go a
level deeper and explore the different attributes of speech recognition models and how we can use them to tackle a range
of different tasks.
As detailed in Unit 3, speech recognition model broadly fall into one of two categories:
1. Connectionist Temporal Classification (CTC): _encoder-only_ models with a linear classification (CTC) head on top
2. Sequence-to-sequence (Seq2Seq): _encoder-decoder_ models, with a cross-attention mechanism between the encoder and decoder
Prior to 2022, CTC was the more popular of the two architectures, with encoder-only models such as Wav2Vec2, HuBERT and XLSR achieving
breakthoughs in the pre-training / fine-tuning paradigm for speech. Big corporations, such as Meta and Microsoft, pre-trained
the encoder on vast amounts of unlabelled audio data for many days or weeks. Users could then take a pre-trained checkpoint, and
fine-tune it with a CTC head on as little as **10 minutes** of labelled speech data to achieve strong performance on a downstream
speech recognition task.
However, CTC models have their shortcomings. Appending a simple linear layer to an encoder gives a small, fast overall model, but can
be prone to phonetic spelling errors. We'll demonstrate this for the Wav2Vec2 model below.
## Probing CTC Models
Let's load a small excerpt of the [LibriSpeech ASR](hf-internal-testing/librispeech_asr_dummy) dataset to demonstrate
Wav2Vec2's speech transcription capabilities:
```python
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
dataset
```
**Output:**
```
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
We can pick one of the 73 audio samples and inspect the audio sample as well as the transcription:
```python
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Output:**
```
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
Alright! Christmas and roast beef, sounds great! 🎄 Having chosen a data sample, we now load a fine-tuned checkpoint into
the `pipeline()`. For this, we'll use the official [Wav2Vec2 base](facebook/wav2vec2-base-100h) checkpoint fine-tuned on
100 hours of LibriSpeech data:
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")
```
Next, we'll take an example from the dataset and pass its raw data to the pipeline. Since the `pipeline` *consumes* any
dictionary that we pass it (meaning it cannot be re-used), we'll pass a copy of the data. This way, we can safely re-use
the same audio sample in the following examples:
```python
pipe(sample["audio"].copy())
```
**Output:**
```
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}
```
We can see that the Wav2Vec2 model does a pretty good job at transcribing this sample - at a first glance it looks generally correct.
Let's put the target and prediction side-by-side and highlight the differences:
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
Comparing the target text to the predicted transcription, we can see that all words _sound_ correct, but some are not spelled accurately. For example:
* _CHRISTMAUS_ vs. _CHRISTMAS_
* _ROSE_ vs. _ROAST_
* _SIMALYIS_ vs. _SIMILES_
This highlights the shortcoming of a CTC model. A CTC model is essentially an 'acoustic-only' model: it consists of an encoder
which forms hidden-state representations from the audio inputs, and a linear layer which maps the hidden-states to characters:
<!--- Need U3 to be merged before this figure is available:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/wav2vec2-ctc.png" alt="Transformer encoder with a CTC head on top">
</div>
--->
This means that the system almost entirely bases its prediction on the acoustic input it was given (the phonetic sounds of the audio),
and so has a tendency to transcribe the audio in a phonetic way (e.g. _CHRISTMAUS_). It gives less importance to the
language modelling context of previous and successive letters, and so is prone to phonetic spelling errors. A more intelligent model
would identify that _CHRISTMAUS_ is not a valid word in the English vocabulary, and correct it to _CHRISTMAS_ when making
its predictions. We're also missing two big features in our prediction - casing and punctuation - which limits the usefulness of
the model's transcriptions to real-world applications.
## Graduation to Seq2Seq
Cue Seq2Seq models! As outlined in Unit 3, Seq2Seq models are formed of an encoder and decoder linked via a cross-attention
mechanism. The encoder plays the same role as before, computing hidden-state representations of the audio inputs, while the decoder
plays the role of a **language model**. The decoder processes the entire sequence of hidden-state representations
from the encoder and generates the corresponding text transcriptions. With global context of the audio input, the decoder
is able to use language modelling context as it makes its predictions, correcting for spelling mistakes on-the-fly and thus
circumventing the issue of phonetic predictions.
There are two downsides to Seq2Seq models:
1. They are inherently slower at decoding, since the decoding process happens one step at a time, rather than all at once
2. They are more data hungry, requiring significantly more training data to reach convergence
In particular, the need for large amounts of training data has been a bottleneck in the advancement of Seq2Seq architectures for
speech. Labelled speech data is difficult to come by, with the largest annotated datasets at the time clocking in at just
10,000 hours. This all changed in 2022 upon the release of **Whisper**. Whisper is a pre-trained model for speech recognition
published in [September 2022](https://openai.com/blog/whisper/) by the authors Alec Radford et al. from OpenAI. Unlike
its CTC predecessors, which were pre-trained entirely on **un-labelled** audio data, Whisper is pre-trained on a vast quantity of
**labelled** audio-transcription data, 680,000 hours to be precise.
This is an order of magnitude more data than the un-labelled audio data used to train Wav2Vec 2.0 (60,000 hours). What is
more, 117,000 hours of this pre-training data is multilingual (or "non-English") data. This results in checkpoints that can be applied to
over 96 languages, many of which are considered _low-resource_, meaning the language lacks a large corpus of data suitable for training.
When scaled to 680,000 hours of labelled pre-training data, Whisper models demonstrate a strong ability to generalise to
many datasets and domains. The pre-trained checkpoints achieve competitive results to state-of-the-art pipe systems, with
near 3% word error rate (WER) on the test-clean subset of LibriSpeech pipe and a new state-of-the-art on TED-LIUM with
4.7% WER (_c.f._ Table 8 of the [Whisper paper](https://cdn.openai.com/papers/whisper.pdf)).
Of particular importance is Whisper's ability to handle long-form audio samples, its robustness to input noise and ability
to predict cased and punctuated transcriptions. This makes it a viable candidate for real-world speech recognition systems.
The remainder of this section will show you how to use the pre-trained Whisper models for speech recognition using 🤗
Transformers. In many situations, the pre-trained Whisper checkpoints are extremely performant and give great results,
thus we encourage you to try using the pre-trained checkpoints as a first step to solving any speech recognition problem.
Through fine-tuning, the pre-trained checkpoints can be adapted for specific datasets and languages to further improve
upon these results. We'll demonstrate how to do this in the upcoming subsection on [fine-tuning](fine-tuning).
The Whisper checkpoints come in five configurations of varying model sizes. The smallest four are trained on either
English-only or multilingual data. The largest checkpoint is multilingual only. All nine of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The checkpoints are
summarised in the following table with links to the models on the Hub. "VRAM" denotes the required GPU memory to run the
model with the minimum batch size of 1. "Rel Speed" is the relative speed of a checkpoint compared to the largest model.
Based on this information, you can select a checkpoint that is best suited to your hardware.
| Size | Parameters | VRAM / GB | Rel Speed | English-only | Multilingual |
|--------|------------|-----------|-----------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | 1.4 | 32 | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | 1.5 | 16 | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | 2.3 | 6 | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | 4.2 | 2 | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | 7.5 | 1 | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
Let's load the [Whisper Base](https://huggingface.co/openai/whisper-base) checkpoint, which is of comparable size to the
Wav2Vec2 checkpoint we used previously. Preempting our move to multilingual speech recognition, we'll load the multilingual
variant of the base checkpoint. We'll also load the model on the GPU if available, or CPU otherwise. The `pipeline()` will
subsequently take care of moving all inputs / outputs from the CPU to the GPU as required:
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
Great! Now let's transcribe the audio as before. The only change we make is passing an extra argument, `max_new_tokens`,
which tells the model the maximum number of tokens to generate when making its prediction:
```python
pipe(sample["audio"], max_new_tokens=256)
```
**Output:**
```
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}
```
Easy enough! The first thing you'll notice is the presence of both casing and punctuation. Immediately this makes the
transcription easier to read compared to the un-cased and un-punctuated transcription from Wav2Vec2. Let's put the transcription
side-by-side with the target:
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.
```
Whisper has done a great job at correcting the phonetic errors we saw from Wav2Vec2 - both _Christmas_ and _roast_ are
spelled correctly. We see that the model still struggles with _SIMILES_, being incorrectly transcribed as _similarly_, but
this time the prediction is a valid word from the English vocabulary. Using a larger Whisper checkpoint can help further
reduce transcription errors, at the expense of requiring more compute and a longer transcription time.
We've been promised a model that can handle 96 languages, so lets leave English speech recognition for now and go global 🌎!
The [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) (MLS) dataset is
the multilingual equivalent of the LibriSpeech dataset, with labelled audio data in six languages. We'll load one sample
from the Spanish split of the MLS dataset, making use of _streaming_ mode so that we don't have to download the entire dataset:
```python
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))
```
Again, we'll inspect the text transcription and take a listen to the audio segment:
```python
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Output:**
```
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha hablado
```
This is the target text that we're aiming for with our Whisper transcription. Although we now know that we can
probably do better this, since our model is also going to predict punctuation and casing, neither of which are present in the
reference. Let's forward the audio sample to the pipeline to get our text prediction. One thing to note is that the
pipeline _consumes_ the dictionary of audio inputs that we input, meaning the dictionary can't be re-used. To circumvent
this, we'll pass a _copy_ of the audio sample, so that we can re-use the same audio sample in the proceeding code examples:
```python
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})
```
**Output:**
```
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}
```
Great - this looks very similar to our reference text (arguably better since it has punctuation and casing!). You'll notice
that we forwarded the `"task"` as a _generate key-word argument_ (generate kwarg). Setting the `"task"` to `"transcribe"`
forces Whisper to perform the task of _speech recognition_, where the audio is transcribed in the same language that the
speech was spoken in. Whisper is also capable of performing the closely related task of _speech translation_, where the
audio in Spanish can be translated to text in English. To achieve this, we set the `"task"` to `"translate"`:
```python
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})
```
**Output:**
```
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}
```
Now that we know we can toggle between speech recognition and speech translation, we can pick our task depending on our
needs. Either we recognise from audio in language X to text in the same language X (e.g. Spanish audio to Spanish text),
or we translate from audio in any language X to text in English (e.g. Spanish audio to English text).
To read more about how the `"task"` argument is used to control the properties of the generated text, refer to the
[model card](https://huggingface.co/openai/whisper-base#usage) for the Whisper base model.
## Long-Form Transcription and Timestamps
So far, we've focussed on transcribing short audio samples of less than 30 seconds. We mentioned that one of the appeals
of Whisper was its ability to work on long audio samples. We'll tackle this task here!
Let's create a long audio file by concatenating sequential samples from the MLS dataset. Since the MLS dataset is
curated by splitting long audiobook recordings into shorter segments, concatenating samples is one way of reconstructing
longer audiobook passages. Consequently, the resulting audio should be coherent across the entire sample.
We'll set our target audio length to 5 minutes, and stop concatenating samples once we hit this value:
```python
import numpy as np
target_length_in_m = 5
# convert from minutes to seconds (* 60) to num samples (* sampling rate)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# iterate over our streaming dataset, concatenating samples until we hit our target
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# how did we do?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")
```
**Output:**
```
Length of audio sample is 5.0 minutes 17.22 seconds
```
Alright! 5 minutes and 17 seconds of audio to transcribe. There are two problems with forwarding this long audio sample
directly to the model:
1. Whisper is inherently designed to work with 30 second samples: anything shorter than 30s is padded to 30s with silence, anything longer than 30s is truncated to 30s by cutting of the extra audio, so if we pass our audio directly we'll only get the transcription for the first 30s
2. Memory in a transformer network scales with the sequence length squared: doubling the input length quadruples the memory requirement, so passing super long audio files is bound to lead to an out-of-memory (OOM) error
The way long-form transcription works in 🤗 Transformers is by _chunking_ the input audio into smaller, more manageable segments.
Each segment has a small amount of overlap with the previous one. This allows us to accurately stitch the segments back together
at the boundaries, since we can find the overlap between segments and merge the transcriptions accordingly:
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/49_asr_chunking/Striding.png" alt="🤗 Transformers chunking algorithm. Source: https://huggingface.co/blog/asr-chunking.">
</div>
The advantage of chunking the samples is that we don't need the result of chunk \\( i \\) to transcribe the subsequent
chunk \\( i + 1 \\). The stitching is done after we have transcribed all the chunks at the chunk boundaries, so it doesn't
matter which order we transcribe chunks in. The algorithm is entirely **stateless**, so we can even do chunk \\( i + 1 \\)
at the same time as chunk \\( i \\)! This allows us to _batch_ the chunks and run them through the model in parallel,
providing a large computational speed-up compared to transcribing them sequentially. To read more about chunking in 🤗 Transformers,
you can refer to this [blog post](https://huggingface.co/blog/asr-chunking).
To activate long-form transcriptions, we have to add one additional argument when we call the pipeline. This argument,
`chunk_length_s`, controls the length of the chunked segments in seconds. For Whisper, 30 second chunks are optimal,
since this matches the input length Whisper expects.
To activate batching, we need to pass the argument `batch_size` to the pipeline. Putting it all together, we can transcribe the
long audio sample with chunking and batching as follows:
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)
```
**Output:**
```
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...
```
We won't print the entire output here since it's pretty long (312 words total)! On a 16GB V100 GPU, you can expect the above
line to take approximately 3.45 seconds to run, which is pretty good for a 317 second audio sample. On a CPU, expect
closer to 30 seconds.
Whisper is also able to predict segment-level _timestamps_ for the audio data. These timestamps indicate the start and end
time for a short passage of audio, and are particularly useful for aligning a transcription with the input audio. Suppose
we want to provide closed captions for a video - we need these timestamps to know which part of the transcription corresponds
to a certain segment of video, in order to display the correct transcription for that time.
Activating timestamp prediction is straightforward, we just need to set the argument `return_timestamps=True`. Timestamps
are compatible with both the chunking and batching methods we used previously, so we can simply append the timestamp
argument to our previous call:
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]
```
**Output:**
```
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...
```
And voila! We have our predicted text as well as corresponding timestamps.
## Summary
Whisper is a strong pre-trained model for speech recognition and translation. Compared to Wav2Vec2, it has higher
transcription accuracy, with outputs that contain punctuation and casing. It can be used to transcribe speech in English
as well as 96 other languages, both on short audio segments and longer ones through _chunking_. These attributes make it
a viable model for many speech recognition and translation tasks without the need for fine-tuning. The `pipeline()` method
provides an easy way of running inference in one-line API calls with control over the generated predictions.
While the Whisper model performs extremely well on many high-resource languages, it has lower transcription and translation
accuracy on low-resource languages, i.e. those with less readily available training data. There is also varying performance
across different accents and dialects of certain languages, including lower accuracy for speakers of different genders,
races, ages or other demographic criteria (_c.f._ [Whisper paper](https://arxiv.org/pdf/2212.04356.pdf)).
To boost the performance on low-resource languages, accents or dialects, we can take the pre-trained Whisper model and
train it on a small corpus of appropriately selected data, in a process called _fine-tuning_. We'll show that with
as little as ten hours of additional data, we can improve the performance of the Whisper model by over 100% on a low-resource
language. In the next section, we'll cover the process behind selecting a dataset for fine-tuning.
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/demo.mdx | # Build a demo with Gradio
Now that we've fine-tuned a Whisper model for Dhivehi speech recognition, let's go ahead and build a [Gradio](https://gradio.app)
demo to showcase it to the community!
The first thing to do is load up the fine-tuned checkpoint using the `pipeline()` class - this is very familiar now from
the section on [pre-trained models](asr_models). You can change the `model_id` to the namespace of your fine-tuned
model on the Hugging Face Hub, or one of the pre-trained [Whisper models](https://huggingface.co/models?sort=downloads&search=openai%2Fwhisper-)
to perform zero-shot speech recognition:
```python
from transformers import pipeline
model_id = "sanchit-gandhi/whisper-small-dv" # update with your model id
pipe = pipeline("automatic-speech-recognition", model=model_id)
```
Secondly, we'll define a function that takes the filepath for an audio input and passes it through the pipeline. Here,
the pipeline automatically takes care of loading the audio file, resampling it to the correct sampling rate, and running
inference with the model. We can then simply return the transcribed text as the output of the function. To ensure our
model can handle audio inputs of arbitrary length, we'll enable *chunking* as described in the section
on [pre-trained models](asr_models):
```python
def transcribe_speech(filepath):
output = pipe(
filepath,
max_new_tokens=256,
generate_kwargs={
"task": "transcribe",
"language": "sinhalese",
}, # update with the language you've fine-tuned on
chunk_length_s=30,
batch_size=8,
)
return output["text"]
```
We'll use the Gradio [blocks](https://gradio.app/docs/#blocks) feature to launch two tabs on our demo: one for microphone
transcription, and the other for file upload.
```python
import gradio as gr
demo = gr.Blocks()
mic_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(sources="microphone", type="filepath"),
outputs=gr.components.Textbox(),
)
file_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(sources="upload", type="filepath"),
outputs=gr.components.Textbox(),
)
```
Finally, we launch the Gradio demo using the two blocks that we've just defined:
```python
with demo:
gr.TabbedInterface(
[mic_transcribe, file_transcribe],
["Transcribe Microphone", "Transcribe Audio File"],
)
demo.launch(debug=True)
```
This will launch a Gradio demo similar to the one running on the Hugging Face Space:
<iframe src="https://course-demos-whisper-small.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Should you wish to host your demo on the Hugging Face Hub, you can use this Space as a template for your fine-tuned model.
Click the link to duplicate the template demo to your account: https://huggingface.co/spaces/course-demos/whisper-small?duplicate=true
We recommend giving your space a similar name to your fine-tuned model (e.g. whisper-small-dv-demo) and setting the visibility to "Public".
Once you've duplicated the Space to your account, click "Files and versions" -> "app.py" -> "edit". Then change the
model identifier to your fine-tuned model (line 6). Scroll to the bottom of the page and click "Commit changes to main".
The demo will reboot, this time using your fine-tuned model. You can share this demo with your friends and family so that
they can use the model that you've trained!
Checkout our video tutorial to get a better understanding of how to duplicate the Space 👉️ [YouTube Video](https://www.youtube.com/watch?v=VQYuvl6-9VE)
We look forward to seeing your demos on the Hub!
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/introduction.mdx | # What you'll learn and what you'll build
In this section, we’ll take a look at how Transformers can be used to convert spoken speech into text, a task known _speech recognition_.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/asr_diagram.png" alt="Diagram of speech to text">
</div>
Speech recognition, also known as automatic speech recognition (ASR) or speech-to-text (STT), is one of the most popular
and exciting spoken language processing tasks. It’s used in a wide range of applications, including dictation, voice assistants,
video captioning and meeting transcriptions.
You’ve probably made use of a speech recognition system many times before without realising! Consider the digital
assistant in your smartphone device (Siri, Google Assistant, Alexa). When you use these assistants, the first thing that
they do is transcribe your spoken speech to written text, ready to be used for any downstream tasks (such as finding you
the weather 🌤️).
Have a play with the speech recognition demo below. You can either record yourself using your microphone, or drag and
drop an audio sample for transcription:
<iframe src="https://course-demos-whisper-small.hf.space" frameborder="0" width="850" height="450"> </iframe>
Speech recognition is a challenging task as it requires joint knowledge of audio and text. The input audio might have
lots of background noise and be spoken by speakers with different accents, making it difficult to pick out the spoken
speech. The written text might have characters which don’t have an acoustic sound, such as punctuation, which are difficult
to infer from audio alone. These are all hurdles we have to tackle when building effective speech recognition systems!
Now that we’ve defined our task, we can begin looking into speech recognition in more detail. By the end of this Unit,
you'll have a good fundamental understanding of the different pre-trained speech recognition models available and how to
use them with the 🤗 Transformers library. You'll also know the procedure for fine-tuning an ASR model on a domain or
language of choice, enabling you to build a performant system for whatever task you encounter. You'll be able to showcase
your model to your friends and family by building a live demo, one that takes any spoken speech and converts it to text!
Specifically, we’ll cover:
* [Pre-trained models for speech recognition](asr_models)
* [Choosing a dataset](choosing_dataset)
* [Evaluation and metrics for speech recognition](evaluation)
* [How to fine-tune an ASR system with the Trainer API](fine-tuning)
* [Building a demo](demo)
* [Hands-on exercise](hands_on)
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/fine-tuning.mdx | # Fine-tuning the ASR model
In this section, we'll cover a step-by-step guide on fine-tuning Whisper for speech recognition on the Common Voice 13
dataset. We'll use the 'small' version of the model and a relatively lightweight dataset, enabling you to run fine-tuning
fairly quickly on any 16GB+ GPU with low disk space requirements, such as the 16GB T4 GPU provided in the Google Colab free
tier.
Should you have a smaller GPU or encounter memory issues during training, you can follow the suggestions provided for
reducing memory usage. Conversely, should you have access to a larger GPU, you can amend the training arguments to maximise
your throughput. Thus, this guide is accessible regardless of your GPU specifications!
Likewise, this guide outlines how to fine-tune the Whisper model for the Dhivehi language. However, the steps covered here
generalise to any language in the Common Voice dataset, and more generally to any ASR dataset on the Hugging Face Hub.
You can tweak the code to quickly switch to a language of your choice and fine-tune a Whisper model in your native tongue 🌍
Right! Now that's out the way, let's get started and kick-off our fine-tuning pipeline!
## Prepare Environment
We strongly advise you to upload model checkpoints directly the [Hugging Face Hub](https://huggingface.co/) while training.
The Hub provides:
- Integrated version control: you can be sure that no model checkpoint is lost during training.
- Tensorboard logs: track important metrics over the course of training.
- Model cards: document what a model does and its intended use cases.
- Community: an easy way to share and collaborate with the community! 🤗
Linking the notebook to the Hub is straightforward - it simply requires entering your Hub authentication token when prompted.
Find your Hub authentication token [here](https://huggingface.co/settings/tokens) and enter it when prompted:
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```bash
Login successful
Your token has been saved to /root/.huggingface/token
```
## Load Dataset
[Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) contains approximately ten
hours of labelled Dhivehi data, three of which is held-out test data. This is extremely little data for fine-tuning, so
we'll be relying on leveraging the extensive multilingual ASR knowledge acquired by Whisper during pre-training for the
low-resource Dhivehi language.
Using 🤗 Datasets, downloading and preparing data is extremely simple. We can download and prepare the Common Voice 13
splits in just one line of code. Since Dhivehi is very low-resource, we'll combine the `train` and `validation` splits
to give approximately seven hours of training data. We'll use the three hours of `test` data as our held-out test set:
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="train+validation"
)
common_voice["test"] = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
print(common_voice)
```
**Output:**
```
DatasetDict({
train: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 4904
})
test: Dataset({
features: ['client_id', 'path', 'audio', 'sentence', 'up_votes', 'down_votes', 'age', 'gender', 'accent', 'locale', 'segment', 'variant'],
num_rows: 2212
})
})
```
<Tip>
You can change the language identifier from `"dv"` to a language identifier of your choice. To see all possible languages
in Common Voice 13, check out the dataset card on the Hugging Face Hub: https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0
</Tip>
Most ASR datasets only provide input audio samples (`audio`) and the corresponding transcribed text (`sentence`).
Common Voice contains additional metadata information, such as `accent` and `locale`, which we can disregard for ASR.
Keeping the notebook as general as possible, we only consider the input audio and transcribed text for fine-tuning,
discarding the additional metadata information:
```python
common_voice = common_voice.select_columns(["audio", "sentence"])
```
## Feature Extractor, Tokenizer and Processor
The ASR pipeline can be de-composed into three stages:
1. The feature extractor which pre-processes the raw audio-inputs to log-mel spectrograms
2. The model which performs the sequence-to-sequence mapping
3. The tokenizer which post-processes the predicted tokens to text
In 🤗 Transformers, the Whisper model has an associated feature extractor and tokenizer, called [WhisperFeatureExtractor](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperFeatureExtractor) and [WhisperTokenizer](https://huggingface.co/docs/transformers/main/model_doc/whisper#transformers.WhisperTokenizer)
respectively. To make our lives simple, these two objects are wrapped under a single class, called the [WhisperProcessor](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor).
We can call the WhisperProcessor to perform both the audio pre-processing and the text token post-processing. In doing
so, we only need to keep track of two objects during training: the processor and the model.
When performing multilingual fine-tuning, we need to set the `"language"` and `"task"` when instantiating the processor.
The `"language"` should be set to the source audio language, and the task to `"transcribe"` for speech recognition or
`"translate"` for speech translation. These arguments modify the behaviour of the tokenizer, and should be set correctly
to ensure the target labels are encoded properly.
We can see all possible languages supported by Whisper by importing the list of languages:
```python
from transformers.models.whisper.tokenization_whisper import TO_LANGUAGE_CODE
TO_LANGUAGE_CODE
```
If you scroll through this list, you'll notice that many languages are present, but Dhivehi is one of few that is not!
This means that Whisper was not pre-trained on Dhivehi. However, this doesn't mean that we can't fine tune Whisper on it.
In doing so, we'll be teaching Whisper a new language, one that the pre-trained checkpoint does not support. That's pretty
cool, right!
When you fine-tune it on a new language, Whisper does a good job at leveraging its knowledge of the other 96 languages
it’s pre-trained on. Largely speaking, all modern languages will be linguistically similar to at least one of the
96 languages Whisper already knows, so we'll fall under this paradigm of cross-lingual knowledge representation.
What we need to do to fine-tune Whisper on a new language is find the language **most similar** that Whisper was
pre-trained on. The Wikipedia article for Dhivehi states that Dhivehi is closely related to the Sinhalese language of Sri Lanka.
If we check the language codes again, we can see that Sinhalese is present in the Whisper language set,
so we can safely set our language argument to `"sinhalese"`.
Right! We'll load our processor from the pre-trained checkpoint, setting the language to `"sinhalese"` and task to `"transcribe"`
as explained above:
```python
from transformers import WhisperProcessor
processor = WhisperProcessor.from_pretrained(
"openai/whisper-small", language="sinhalese", task="transcribe"
)
```
It's worth reiterating that in most circumstances, you'll find that the language you want to fine-tune on is in the set of
pre-training languages, in which case you can simply set the language directly as your source audio language! Note that
both of these arguments should be omitted for English-only fine-tuning, where there is only one option for the language
(`"English"`) and task (`"transcribe"`).
## Pre-Process the Data
Let's have a look at the dataset features. Pay particular attention to the `"audio"` column - this details the sampling
rate of our audio inputs:
```python
common_voice["train"].features
```
**Output:**
```
{'audio': Audio(sampling_rate=48000, mono=True, decode=True, id=None),
'sentence': Value(dtype='string', id=None)}
```
Since our input audio is sampled at 48kHz, we need to _downsample_ it to 16kHz prior to passing it to the Whisper feature
extractor, 16kHz being the sampling rate expected by the Whisper model.
We'll set the audio inputs to the correct sampling rate using dataset's [`cast_column`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.cast_column)
method. This operation does not change the audio in-place, but rather signals to datasets to resample audio samples
on-the-fly when they are loaded:
```python
from datasets import Audio
sampling_rate = processor.feature_extractor.sampling_rate
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=sampling_rate))
```
Now we can write a function to prepare our data ready for the model:
1. We load and resample the audio data on a sample-by-sample basis by calling `sample["audio"]`. As explained above, 🤗 Datasets performs any necessary resampling operations on the fly.
2. We use the feature extractor to compute the log-mel spectrogram input features from our 1-dimensional audio array.
3. We encode the transcriptions to label ids through the use of the tokenizer.
```python
def prepare_dataset(example):
audio = example["audio"]
example = processor(
audio=audio["array"],
sampling_rate=audio["sampling_rate"],
text=example["sentence"],
)
# compute input length of audio sample in seconds
example["input_length"] = len(audio["array"]) / audio["sampling_rate"]
return example
```
We can apply the data preparation function to all of our training examples using 🤗 Datasets' `.map` method. We'll
remove the columns from the raw training data (the audio and text), leaving just the columns returned by the
`prepare_dataset` function:
```python
common_voice = common_voice.map(
prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=1
)
```
Finally, we filter any training data with audio samples longer than 30s. These samples would otherwise be truncated by
the Whisper feature-extractor which could affect the stability of training. We define a function that returns `True` for
samples that are less than 30s, and `False` for those that are longer:
```python
max_input_length = 30.0
def is_audio_in_length_range(length):
return length < max_input_length
```
We apply our filter function to all samples of our training dataset through 🤗 Datasets' `.filter` method:
```python
common_voice["train"] = common_voice["train"].filter(
is_audio_in_length_range,
input_columns=["input_length"],
)
```
Let's check how much training data we removed through this filtering step:
```python
common_voice["train"]
```
**Output**
```
Dataset({
features: ['input_features', 'labels', 'input_length'],
num_rows: 4904
})
```
Alright! In this case we actually have the same number of samples as before, so there were no samples longer than 30s.
This might not be the case if you switch languages, so it's best to keep this filter step in-place for robustness. With
that, we have our data fully prepared for training! Let's continue and take a look at how we can use this data to fine-tune
Whisper.
## Training and Evaluation
Now that we've prepared our data, we're ready to dive into the training pipeline.
The [🤗 Trainer](https://huggingface.co/transformers/master/main_classes/trainer.html?highlight=trainer)
will do much of the heavy lifting for us. All we have to do is:
- Define a data collator: the data collator takes our pre-processed data and prepares PyTorch tensors ready for the model.
- Evaluation metrics: during evaluation, we want to evaluate the model using the word error rate (WER) metric. We need to define a `compute_metrics` function that handles this computation.
- Load a pre-trained checkpoint: we need to load a pre-trained checkpoint and configure it correctly for training.
- Define the training arguments: these will be used by the 🤗 Trainer in constructing the training schedule.
Once we've fine-tuned the model, we will evaluate it on the test data to verify that we have correctly trained it
to transcribe speech in Dhivehi.
### Define a Data Collator
The data collator for a sequence-to-sequence speech model is unique in the sense that it treats the `input_features`
and `labels` independently: the `input_features` must be handled by the feature extractor and the `labels` by the tokenizer.
The `input_features` are already padded to 30s and converted to a log-Mel spectrogram of fixed dimension, so all we
have to do is convert them to batched PyTorch tensors. We do this using the feature extractor's `.pad` method with
`return_tensors=pt`. Note that no additional padding is applied here since the inputs are of fixed dimension, the
`input_features` are simply converted to PyTorch tensors.
On the other hand, the `labels` are un-padded. We first pad the sequences to the maximum length in the batch using
the tokenizer's `.pad` method. The padding tokens are then replaced by `-100` so that these tokens are **not** taken
into account when computing the loss. We then cut the start of transcript token from the beginning of the label sequence
as we append it later during training.
We can leverage the `WhisperProcessor` we defined earlier to perform both the feature extractor and the tokenizer operations:
```python
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need different padding methods
# first treat the audio inputs by simply returning torch tensors
input_features = [
{"input_features": feature["input_features"][0]} for feature in features
]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
# get the tokenized label sequences
label_features = [{"input_ids": feature["labels"]} for feature in features]
# pad the labels to max length
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(
labels_batch.attention_mask.ne(1), -100
)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
```
We can now initialise the data collator we've just defined:
```python
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
```
Onwards!
### Evaluation Metrics
Next, we define the evaluation metric we'll use on our evaluation set. We'll use the Word Error Rate (WER) metric introduced
in the section on [Evaluation](evaluation), the 'de-facto' metric for assessing ASR systems.
We'll load the WER metric from 🤗 Evaluate:
```python
import evaluate
metric = evaluate.load("wer")
```
We then simply have to define a function that takes our model predictions and returns the WER metric. This function, called
`compute_metrics`, first replaces `-100` with the `pad_token_id` in the `label_ids` (undoing the step we applied in the
data collator to ignore padded tokens correctly in the loss). It then decodes the predicted and label ids to strings. Finally,
it computes the WER between the predictions and reference labels. Here, we have the option of evaluating with the 'normalised'
transcriptions and predictions, which have punctuation and casing removed. We recommend you follow this to benefit
from the WER improvement obtained by normalising the transcriptions.
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = processor.tokenizer.pad_token_id
# we do not want to group tokens when computing the metrics
pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
label_str = processor.batch_decode(label_ids, skip_special_tokens=True)
# compute orthographic wer
wer_ortho = 100 * metric.compute(predictions=pred_str, references=label_str)
# compute normalised WER
pred_str_norm = [normalizer(pred) for pred in pred_str]
label_str_norm = [normalizer(label) for label in label_str]
# filtering step to only evaluate the samples that correspond to non-zero references:
pred_str_norm = [
pred_str_norm[i] for i in range(len(pred_str_norm)) if len(label_str_norm[i]) > 0
]
label_str_norm = [
label_str_norm[i]
for i in range(len(label_str_norm))
if len(label_str_norm[i]) > 0
]
wer = 100 * metric.compute(predictions=pred_str_norm, references=label_str_norm)
return {"wer_ortho": wer_ortho, "wer": wer}
```
### Load a Pre-Trained Checkpoint
Now let's load the pre-trained Whisper small checkpoint. Again, this is trivial through use of 🤗 Transformers!
```python
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
```
We'll set `use_cache` to `False` for training since we're using [gradient checkpointing](https://huggingface.co/docs/transformers/v4.18.0/en/performance#gradient-checkpointing)
and the two are incompatible. We'll also override two generation arguments to control the behaviour of the model during inference:
we'll force the language and task tokens during generation by setting the `language` and `task` arguments, and also re-enable
cache for generation to speed-up inference time:
```python
from functools import partial
# disable cache during training since it's incompatible with gradient checkpointing
model.config.use_cache = False
# set language and task for generation and re-enable cache
model.generate = partial(
model.generate, language="sinhalese", task="transcribe", use_cache=True
)
```
## Define the Training Configuration
In the final step, we define all the parameters related to training. Here, we set the number of training steps to 500.
This is enough steps to see a big WER improvement compared to the pre-trained Whisper model, while ensuring that fine-tuning can
be run in approximately 45 minutes on a Google Colab free tier. For more detail on the training arguments, refer to the
Seq2SeqTrainingArguments [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments).
```python
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-dv", # name on the HF Hub
per_device_train_batch_size=16,
gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
lr_scheduler_type="constant_with_warmup",
warmup_steps=50,
max_steps=500, # increase to 4000 if you have your own GPU or a Colab paid plan
gradient_checkpointing=True,
fp16=True,
fp16_full_eval=True,
evaluation_strategy="steps",
per_device_eval_batch_size=16,
predict_with_generate=True,
generation_max_length=225,
save_steps=500,
eval_steps=500,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=True,
)
```
<Tip>
If you do not want to upload the model checkpoints to the Hub, set `push_to_hub=False`.
</Tip>
We can forward the training arguments to the 🤗 Trainer along with our model, dataset, data collator and `compute_metrics` function:
```python
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=processor,
)
```
And with that, we're ready to start training!
### Training
To launch training, simply execute:
```python
trainer.train()
```
Training will take approximately 45 minutes depending on your GPU or the one allocated to the Google Colab. Depending on
your GPU, it is possible that you will encounter a CUDA `"out-of-memory"` error when you start training. In this case,
you can reduce the `per_device_train_batch_size` incrementally by factors of 2 and employ [`gradient_accumulation_steps`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Seq2SeqTrainingArguments.gradient_accumulation_steps)
to compensate.
**Output:**
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.136 | 1.63 | 500 | 0.1727 | 63.8972 | 14.0661 |
Our final WER is 14.1% - not bad for seven hours of training data and just 500 training steps! That amounts to a 112%
improvement versus the pre-trained model! That means we've taken a model that previously had no knowledge about Dhivehi,
and fine-tuned it to recognise Dhivehi speech with adequate accuracy in under one hour 🤯
The big question is how this compares to other ASR systems. For that, we can view the autoevaluate [leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=mozilla-foundation%2Fcommon_voice_13_0&only_verified=0&task=automatic-speech-recognition&config=dv&split=test&metric=wer),
a leaderboard that categorises models by language and dataset, and subsequently ranks them according to their WER.
Looking at the leaderboard, we see that our model trained for 500 steps convincingly beats the pre-trained [Whisper Small](https://huggingface.co/openai/whisper-small)
checkpoint that we evaluated in the previous section. Nice job 👏
We see that there are a few checkpoints that do better than the one we trained. The beauty of the Hugging Face Hub is that
it's a *collaborative* platform - if we don't have the time or resources to perform a longer training run ourselves, we
can load a checkpoint that someone else in the community has trained and been kind enough to share (making sure to thank them for it!).
You'll be able to load these checkpoints in exactly the same way as the pre-trained ones using the `pipeline` class as we
did previously! So there's nothing stopping you cherry-picking the best model on the leaderboard to use for your task!
We can automatically submit our checkpoint to the leaderboard when we push the training results to the Hub - we simply
have to set the appropriate key-word arguments (kwargs). You can change these values to match your dataset, language and
model name accordingly:
```python
kwargs = {
"dataset_tags": "mozilla-foundation/common_voice_13_0",
"dataset": "Common Voice 13", # a 'pretty' name for the training dataset
"language": "dv",
"model_name": "Whisper Small Dv - Sanchit Gandhi", # a 'pretty' name for your model
"finetuned_from": "openai/whisper-small",
"tasks": "automatic-speech-recognition",
}
```
The training results can now be uploaded to the Hub. To do so, execute the `push_to_hub` command:
```python
trainer.push_to_hub(**kwargs)
```
This will save the training logs and model weights under `"your-username/the-name-you-picked"`. For this example, check
out the upload at `sanchit-gandhi/whisper-small-dv`.
While the fine-tuned model yields satisfactory results on the Common Voice 13 Dhivehi test data, it is by no means optimal.
The purpose of this guide is to demonstrate how to fine-tune an ASR model using the 🤗 Trainer for multilingual speech
recognition.
If you have access to your own GPU or are subscribed to a Google Colab paid plan, you can increase `max_steps` to 4000 steps
to improve the WER further by training for more steps. Training for 4000 steps will take approximately 3-5 hours depending
on your GPU and yield WER results approximately 3% lower than training for 500 steps. If you decide to train for 4000 steps,
we also recommend changing the learning rate scheduler to a *linear* schedule (set `lr_scheduler_type="linear"`), as this will
yield an additional performance boost over long training runs.
The results could likely be improved further by optimising the training hyperparameters, such as _learning rate_ and
_dropout_, and using a larger pre-trained checkpoint (`medium` or `large`). We leave this as an exercise to the reader.
## Sharing Your Model
You can now share this model with anyone using the link on the Hub. They can load it with the identifier `"your-username/the-name-you-picked"`
directly into the `pipeline()` object. For instance, to load the fine-tuned checkpoint ["sanchit-gandhi/whisper-small-dv"](https://huggingface.co/sanchit-gandhi/whisper-small-dv):
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="sanchit-gandhi/whisper-small-dv")
```
## Conclusion
In this section, we covered a step-by-step guide on fine-tuning the Whisper model for speech recognition 🤗 Datasets,
Transformers and the Hugging Face Hub. We first loaded the Dhivehi subset of the Common Voice 13 dataset and pre-processed
it by computing log-mel spectrograms and tokenising the text. We then defined a data collator, evaluation metric and
training arguments, before using the 🤗 Trainer to train and evaluate our model. We finished by uploading the fine-tuned
model to the Hugging Face Hub, and showcased how to share and use it with the `pipeline()` class.
If you followed through to this point, you should now have a fine-tuned checkpoint for speech recognition, well done! 🥳
Even more importantly, you're equipped with all the tools you need to fine-tune the Whisper model on any speech recognition
dataset or domain. So what are you waiting for! Pick one of the datasets covered in the section [Choosing a Dataset](choosing_dataset)
or select a dataset of your own, and see whether you can get state-of-the-art performance! The leaderboard is waiting for you...
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter5/hands_on.mdx | # Hands-on exercise
In this unit, we explored the challenges of fine-tuning ASR models, acknowledging the time and resources required to
fine-tune a model like Whisper (even a small checkpoint) on a new language. To provide a hands-on experience, we have
designed an exercise that allows you to navigate the process of fine-tuning an ASR model while using a smaller dataset.
The main goal of this exercise is to familiarize you with the process rather than expecting production-level results.
We have intentionally set a low metric to ensure that even with limited resources, you should be able to achieve it.
Here are the instructions:
* Fine-tune the `”openai/whisper-tiny”` model using the American English ("en-US") subset of the `”PolyAI/minds14”` dataset.
* Use the first **450 examples for training**, and the rest for evaluation. Ensure you set `num_proc=1` when pre-processing the dataset using the `.map` method (this will ensure your model is submitted correctly for assessment).
* To evaluate the model, use the `wer` and `wer_ortho` metrics as described in this Unit. However, *do not* convert the metric into percentages by multiplying by 100 (E.g. if WER is 42%, we’ll expect to see the value of 0.42 in this exercise).
Once you have fine-tuned a model, make sure to upload it to the 🤗 Hub with the following `kwargs`:
```
kwargs = {
"dataset_tags": "PolyAI/minds14",
"finetuned_from": "openai/whisper-tiny",
"tasks": "automatic-speech-recognition",
}
```
You will pass this assignment if your model’s normalised WER (`wer`) is lower than **0.37**.
Feel free to build a demo of your model, and share it on Discord! If you have questions, post them in the #audio-study-group channel.
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter2/asr_pipeline.mdx | # Automatic speech recognition with a pipeline
Automatic Speech Recognition (ASR) is a task that involves transcribing speech audio recording into text.
This task has numerous practical applications, from creating closed captions for videos to enabling voice commands
for virtual assistants like Siri and Alexa.
In this section, we'll use the `automatic-speech-recognition` pipeline to transcribe an audio recording of a person
asking a question about paying a bill using the same MINDS-14 dataset as before.
To get started, load the dataset and upsample it to 16kHz as described in [Audio classification with a pipeline](audio_classification_pipeline),
if you haven't done that yet.
To transcribe an audio recording, we can use the `automatic-speech-recognition` pipeline from 🤗 Transformers. Let's
instantiate the pipeline:
```py
from transformers import pipeline
asr = pipeline("automatic-speech-recognition")
```
Next, we'll take an example from the dataset and pass its raw data to the pipeline:
```py
example = minds[0]
asr(example["audio"]["array"])
```
**Output:**
```out
{"text": "I WOULD LIKE TO PAY MY ELECTRICITY BILL USING MY COD CAN YOU PLEASE ASSIST"}
```
Let's compare this output to what the actual transcription for this example is:
```py
example["english_transcription"]
```
**Output:**
```out
"I would like to pay my electricity bill using my card can you please assist"
```
The model seems to have done a pretty good job at transcribing the audio! It only got one word wrong ("card") compared
to the original transcription, which is pretty good considering the speaker has an Australian accent, where the letter "r"
is often silent. Having said that, I wouldn't recommend trying to pay your next electricity bill with a fish!
By default, this pipeline uses a model trained for automatic speech recognition for English language, which is fine in
this example. If you'd like to try transcribing other subsets of MINDS-14 in different language, you can find a pre-trained
ASR model [on the 🤗 Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&language=fr&sort=downloads).
You can filter the models list by task first, then by language. Once you have found the model you like, pass it's name as
the `model` argument to the pipeline.
Let's try this for the German split of the MINDS-14. Load the "de-DE" subset:
```py
from datasets import load_dataset
from datasets import Audio
minds = load_dataset("PolyAI/minds14", name="de-DE", split="train")
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
Get an example and see what the transcription is supposed to be:
```py
example = minds[0]
example["transcription"]
```
**Output:**
```out
"ich möchte gerne Geld auf mein Konto einzahlen"
```
Find a pre-trained ASR model for German language on the 🤗 Hub, instantiate a pipeline, and transcribe the example:
```py
from transformers import pipeline
asr = pipeline("automatic-speech-recognition", model="maxidl/wav2vec2-large-xlsr-german")
asr(example["audio"]["array"])
```
**Output:**
```out
{"text": "ich möchte gerne geld auf mein konto einzallen"}
```
Also, stimmt's!
When working on solving your own task, starting with a simple pipeline like the ones we've shown in this unit is a valuable
tool that offers several benefits:
- a pre-trained model may exist that already solves your task really well, saving you plenty of time
- pipeline() takes care of all the pre/post-processing for you, so you don't have to worry about getting the data into
the right format for a model
- if the result isn't ideal, this still gives you a quick baseline for future fine-tuning
- once you fine-tune a model on your custom data and share it on Hub, the whole community will be able to use it quickly
and effortlessly via the `pipeline()` method making AI more accessible.
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/mixtral.md | ---
title: "欢迎 Mixtral - 当前 Hugging Face 上最先进的 MoE 模型"
thumbnail: /blog/assets/mixtral/thumbnail.jpg
authors:
- user: lewtun
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: olivierdehaene
- user: lvwerra
- user: ybelkada
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 欢迎 Mixtral - 当前 Hugging Face 上最先进的 MoE 模型
最近,Mistral 发布了一个激动人心的大语言模型: Mixtral 8x7b,该模型把开放模型的性能带到了一个新高度,并在许多基准测试上表现优于 GPT-3.5。我们很高兴能够在 Hugging Face 生态系统中全面集成 Mixtral 以对其提供全方位的支持 🔥!
Hugging Face 对 Mixtral 的全方位支持包括:
- [Hub 上的模型](https://huggingface.co/models?search=mistralai/Mixtral),包括模型卡以及相应的许可证 (Apache 2.0)
- [🤗 transformers 的集成](https://github.com/huggingface/transformers/releases/tag/v4.36.0)
- 推理终端的集成
- [TGI](https://github.com/huggingface/text-generation-inference) 的集成,以支持快速高效的生产级推理
- 使用 🤗 TRL 在单卡上对 Mixtral 进行微调的示例
## 目录
- [欢迎 Mixtral - 当前 Hugging Face 上最先进的 MoE 模型](#欢迎-mixtral---当前-hugging-face-上最先进的-moe-模型)
- [目录](#目录)
- [Mixtral 8x7b 是什么?](#mixtral-8x7b-是什么)
- [关于命名](#关于命名)
- [提示格式](#提示格式)
- [我们不知道的事](#我们不知道的事)
- [演示](#演示)
- [推理](#推理)
- [使用 🤗 transformers](#使用-transformers)
- [使用 TGI](#使用-tgi)
- [用 🤗 TRL 微调](#用-trl-微调)
- [量化 Mixtral](#量化-mixtral)
- [使用 4 比特量化加载 Mixtral](#使用-4-比特量化加载-mixtral)
- [使用 GPTQ 加载 Mixtral](#使用-gptq-加载-mixtral)
- [免责声明及正在做的工作](#免责声明及正在做的工作)
- [更多资源](#更多资源)
- [总结](#总结)
## Mixtral 8x7b 是什么?
Mixtral 的架构与 Mistral 7B 类似,但有一点不同: 它实际上内含了 8 个“专家”模型,这要归功于一种称为“混合专家”(Mixture of Experts,MoE) 的技术。当 MoE 与 transformer 模型相结合时,我们会用稀疏 MoE 层替换掉某些前馈层。MoE 层包含一个路由网络,用于选择将输入词元分派给哪些专家处理。Mixtral 模型为每个词元选择两名专家,因此,尽管其有效参数量是 12B 稠密模型的 4 倍,但其解码速度却能做到与 12B 的稠密模型相当!
欲了解更多有关 MoE 的知识,请参阅我们之前的博文: [hf.co/blog/zh/moe](https://huggingface.co/blog/zh/moe)。
**本次发布的 Mixtral 模型的主要特点:**
- 模型包括基础版和指令版
- 支持高达 32k 词元的上下文
- 性能优于 Llama 2 70B,在大多数基准测试上表现不逊于 GPT3.5
- 支持英语、法语、德语、西班牙语及意大利语
- 擅长编码,HumanEval 得分为 40.2%
- 可商用,Apache 2.0 许可证
那么,Mixtral 模型效果到底有多好呢?下面列出了 Mixtral 基础模型与其他先进的开放模型在 [LLM 排行榜](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) 上表现 (分数越高越好):
| 模型 | 许可证 | 是否可商用 | 预训练词元数 | 排行榜得分 ⬇️ |
| --------------------------------------------------------------------------------- | --------------- | --------------- | ------------------------- | -------------------- |
| [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) | Apache 2.0 | ✅ | 不详 | 68.42 |
| [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 许可证 | ✅ | 2,000B | 67.87 |
| [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 |
| [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | Apache 2.0 | ✅ | 不详 | 60.97 |
| [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 许可证 | ✅ | 2,000B | 54.32 |
我们还用 MT-Bench 及 AlpacaEval 等基准对指令版和其它聊天模型进行了对比。下表列出了 [Mixtral Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) 与顶级闭源或开放模型相比的表现 (分数越高越好):
| 模型 | 可得性 | 上下文窗口(词元数) | MT-Bench 得分 ⬇️ |
| --------------------------------------------------------------------------------------------------- | --------------- | ----------------------- | ---------------- |
| [GPT-4 Turbo](https://openai.com/blog/new-models-and-developer-products-announced-at-devday) | 私有 | 128k | 9.32 |
| [GPT-3.5-turbo-0613](https://platform.openai.com/docs/models/gpt-3-5) | 私有 | 16k | 8.32 |
| [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) | Apache 2.0 | 32k | 8.30 |
| [Claude 2.1](https://www.anthropic.com/index/claude-2-1) | 私有 | 200k | 8.18 |
| [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5) | Apache 2.0 | 8k | 7.81 |
| [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | MIT | 8k | 7.34 |
| [meta-llama/Llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | Llama 2 许可证 | 4k | 6.86 |
令人印象深刻的是,Mixtral Instruct 的性能优于 MT-Bench 上的所有其他开放模型,且是第一个与 GPT-3.5 性能相当的开放模型!
### 关于命名
Mixtral MoE 模型虽然名字是 **Mixtral-8x7B**,但它其实并没有 56B 参数。发布后不久,我们就发现不少人被名字误导了,认为该模型的行为类似于 8 个模型的集合,其中每个模型有 7B 个参数,但这种想法其实与 MoE 模型的工作原理不符。实情是,该模型中只有某些层 (前馈层) 是各专家独有的,其余参数与稠密 7B 模型情况相同,是各专家共享的。所以,参数总量并不是 56B,而是 45B 左右。所以可能叫它 [`Mixtral-45-8e`](https://twitter.com/osanseviero/status/1734248798749159874) 更贴切,更能符合其架构。更多有关 MoE 如何运行的详细信息,请参阅我们之前发表的 [《MoE 详解》](https://huggingface.co/blog/zh/moe) 一文。
### 提示格式
[基础模型](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) 没有提示格式,与其他基础模型一样,它可用于序列补全或零样本/少样本推理。你可以对基础模型进行微调,将其适配至自己的应用场景。[指令模型](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) 有一个非常简单的对话格式。
```bash
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]
```
你必须准确遵循此格式才能有效使用指令模型。稍后我们将展示,使用 `transformers` 的聊天模板能很轻易地支持这类自定义指令提示格式。
### 我们不知道的事
与之前的 Mistral 7B 版本一样,对这一新的模型家族,我们也有几个待澄清的问题。比如,我们不知道用于预训练的数据集大小,也不知道它的组成信息以及预处理方式信息。
同样,对于 Mixtral 指令模型,我们对微调数据集或 SFT 和 DPO 使用的超参也知之甚少。
## 演示
你可以在 Hugging Face Chat 上与 Mixtral Instruct 模型聊天!点击 [此处](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1) 开始体验吧。
## 推理
我们主要提供两种对 Mixtral 模型进行推理的方法:
- 通过 🤗 transformers 的 `pipeline()` 接口。
- 通过 TGI,其支持连续组批、张量并行等高级功能,推理速度极快。
以上两种方法均支持半精度 (float16) 及量化权重。由于 Mixtral 模型的参数量大致相当于 45B 参数的稠密模型,因此我们可以对所需的最低显存量作一个估计,如下:
| 精度 | 显存需求 |
| --------- | ------------- |
| float16 | >90 GB |
| 8-bit | >45 GB |
| 4-bit | >23 GB |
### 使用 🤗 transformers
从 transformers [4.36 版](https://github.com/huggingface/transformers/releases/tag/v4.36.0) 开始,用户就可以用 Hugging Face 生态系统中的所有工具处理 Mixtral 模型,如:
- 训练和推理脚本及示例
- 安全文件格式 (`safetensors` )
- 与 bitsandbytes (4 比特量化) 、PEFT (参数高效微调) 和 Flash Attention 2 等工具的集成
- 使用文本生成任务所提供的工具及辅助方法
- 导出模型以进行部署
用户唯一需要做的是确保 `transformers` 的版本是最新的:
```bash
pip install --upgrade transformers
```
下面的代码片段展示了如何使用 🤗 transformers 及 4 比特量化来运行推理。由于模型尺寸较大,你需要一张显存至少为 30GB 的卡才能运行,符合要求的卡有 A100 (80 或 40GB 版本) 、A6000 (48GB) 等。
```python
from transformers import pipeline
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
pipe = pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
outputs = pipe(messages, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"][-1]["content"])
```
> \<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A
Mixture of Experts is an ensemble learning method that combines multiple models,
or "experts," to make more accurate predictions. Each expert specializes in a
different subset of the data, and a gating network determines the appropriate
expert to use for a given input. This approach allows the model to adapt to
complex, non-linear relationships in the data and improve overall performance.
>
### 使用 TGI
**[TGI](https://github.com/huggingface/text-generation-inference)** 是 Hugging Face 开发的生产级推理容器,可用于轻松部署大语言模型。其功能主要有: 连续组批、流式词元输出、多 GPU 张量并行以及生产级的日志记录和跟踪等。
你可在 Hugging Face 的 [推理终端](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000) 上部署 Mixtral,其使用 TGI 作为后端。要部署 Mixtral 模型,可至 [模型页面](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1),然后单击 [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf) 按钮即可。
_注意: 如你的账号 A100 配额不足,可发送邮件至 **[[email protected]](mailto:[email protected])** 申请升级。_
你还可以阅读我们的博文 **[用 Hugging Face 推理终端部署 LLM](https://huggingface.co/blog/inference-endpoints-llm)** 以深入了解如何部署 LLM,该文包含了推理终端支持的超参以及如何使用 Python 和 Javascript 接口来流式生成文本等信息。
你还可以使用 Docker 在 2 张 A100 (80GB) 上本地运行 TGI,如下所示:
```bash
docker run --gpus all --shm-size 1g -p 3000:80 -v /data:/data ghcr.io/huggingface/text-generation-inference:1.3.0 \
--model-id mistralai/Mixtral-8x7B-Instruct-v0.1 \
--num-shard 2 \
--max-batch-total-tokens 1024000 \
--max-total-tokens 32000
```
## 用 🤗 TRL 微调
训练 LLM 在技术和算力上都有较大挑战。本节我们将了解在 Hugging Face 生态系统中如何在单张 A100 GPU 上高效训练 Mixtral。
下面是在 OpenAssistant 的 [聊天数据集](https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25) 上微调 Mixtral 的示例命令。为了节省内存,我们对注意力块中的所有线性层执行 4 比特量化和 [QLoRA](https://arxiv.org/abs/2305.14314)。请注意,与稠密 transformer 模型不同,我们不对专家网络中的 MLP 层进行量化,因为它们很稀疏并且量化后 PEFT 效果不好。
首先,安装 🤗 TRL 的每日构建版并下载代码库以获取 [训练脚本](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py):
```bash
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl
```
然后,运行脚本:
```bash
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name trl-lib/ultrachat_200k_chatml \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 200_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit
```
在单张 A100 上训练大约需要 48 小时,但我们可以通过 `--num_processes` 来调整 GPU 的数量以实现并行。
## 量化 Mixtral
如上所见,该模型最大的挑战是如何实现普惠,即如何让它能够在消费级硬件上运行。因为即使以半精度 ( `torch.float16` ) 加载,它也需要 90GB 显存。
借助 🤗 transformers 库,我们支持用户开箱即用地使用 QLoRA 和 GPTQ 等最先进的量化方法进行推理。你可以阅读 [相应的文档](https://huggingface.co/docs/transformers/quantization) 以获取有关我们支持的量化方法的更多信息。
### 使用 4 比特量化加载 Mixtral
用户还可以通过安装 `bitsandbytes` 库 ( `pip install -U bitsandbytes` ) 并将参数 `load_in_4bit=True` 传给 `from_pretrained` 方法来加载 4 比特量化的 Mixtral。为了获得更好的性能,我们建议用户使用 `bnb_4bit_compute_dtype=torch.float16` 来加载模型。请注意,你的 GPU 显存至少得有 30GB 才能正确运行下面的代码片段。
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
该 4 比特量化技术由 [QLoRA 论文](https://huggingface.co/papers/2305.14314) 提出,你可以通过 [相应的 Hugging Face 文档](https://huggingface.co/docs/transformers/quantization#4-bit) 或 [这篇博文](https://huggingface.co/blog/zh/4bit-transformers-bitsandbytes) 获取更多相关信息。
### 使用 GPTQ 加载 Mixtral
GPTQ 算法是一种训后量化技术,其中权重矩阵的每一行都是独立量化的,以获取误差最小的量化权重。这些权重被量化为 int4,但在推理过程中会即时恢复为 fp16。与 4 比特 QLoRA 相比,GPTQ 的量化模型是通过对某个数据集进行校准而得的。[TheBloke](https://huggingface.co/TheBloke) 在 🤗 Hub 上分享了很多量化后的 GPTQ 模型,这样大家无需亲自执行校准就可直接使用量化模型。
对于 Mixtral,为了获得更好的性能,我们必须调整一下校准方法,以确保我们 **不会** 量化那些专家门控层。量化模型的最终困惑度 (越低越好) 为 `4.40` ,而半精度模型为 `4.25` 。你可在 [此处](https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GPTQ) 找到量化模型,要使用 🤗 transformers 运行它,你首先需要更新 `auto-gptq` 和 `optimum` 库:
```bash
pip install -U optimum auto-gptq
```
然后是从源代码安装 transformers:
```bash
pip install -U git+https://github.com/huggingface/transformers.git
```
安装好后,只需使用 `from_pretrained` 方法加载 GPTQ 模型即可:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "TheBloke/Mixtral-8x7B-v0.1-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
请注意,你的 GPU 显存至少得有 30GB 才能运行 Mixtral 模型的 QLoRA 和 GPTQ 版本。如果你如上例一样使用了 `device_map="auto"` ,则其在 24GB 显存时也可以运行,因此会有一些层被自动卸载到 CPU。
## 免责声明及正在做的工作
- **量化**: 围绕 MoE 的量化还有许多研究正如火如荼地展开。上文展示了我们基于 TheBloke 所做的一些初步实验,但我们预计随着对该架构研究的深入,会涌现出更多进展!这一领域的进展将会是日新月异的,我们翘首以盼。此外,最近的工作,如 [QMoE](https://arxiv.org/abs/2310.16795),实现了 MoE 的亚 1 比特量化,也是值得尝试的方案。
- **高显存占用**: MoE 运行推理速度较快,但对显存的要求也相对较高 (因此需要昂贵的 GPU)。这对本地推理提出了挑战,因为本地推理所拥有的设备显存一般较小。MoE 非常适合多设备大显存的基础设施。对 Mixtral 进行半精度推理需要 90GB 显存 🤯。
## 更多资源
- [MoE 详解](https://huggingface.co/blog/zh/moe)
- [Mistral 的 Mixtral 博文](https://mistral.ai/news/mixtral-of-experts/)
- [Hub 上的模型](https://huggingface.co/models?other=mixtral)
- [开放 LLM 排行榜](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [基于 Mixtral 的 Hugging Chat 聊天演示应用](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1)
## 总结
我们对 Mixtral 的发布感到欢欣鼓舞!我们正围绕 Mixtral 准备更多关于微调和部署文章,尽请期待。 | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/time-series-transformers.md | ---
title: "使用 🤗 Transformers 进行概率时间序列预测"
thumbnail: /blog/assets/118_time-series-transformers/thumbnail.png
authors:
- user: nielsr
- user: kashif
translators:
- user: zhongdongy
---
# 使用 🤗 Transformers 进行概率时间序列预测
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## 介绍
时间序列预测是一个重要的科学和商业问题,因此最近通过使用 [基于深度学习](https://dl.acm.org/doi/abs/10.1145/3533382) 而不是 [经典方法](https://otexts.com/fpp3/) 的模型也涌现出诸多创新。ARIMA 等经典方法与新颖的深度学习方法之间的一个重要区别如下。
## 概率预测
通常,经典方法针对数据集中的每个时间序列单独拟合。这些通常被称为“单一”或“局部”方法。然而,当处理某些应用程序的大量时间序列时,在所有可用时间序列上训练一个“全局”模型是有益的,这使模型能够从许多不同的来源学习潜在的表示。
一些经典方法是点值的 (point-valued)(意思是每个时间步只输出一个值),并且通过最小化关于基本事实数据的 L2 或 L1 类型的损失来训练模型。然而,由于预测经常用于实际决策流程中,甚至在循环中有人的干预,让模型同时也提供预测的不确定性更加有益。这也称为“概率预测”,而不是“点预测”。这需要对可以采样的概率分布进行建模。
所以简而言之,我们希望训练 **全局概率模型**,而不是训练局部点预测模型。深度学习非常适合这一点,因为神经网络可以从几个相关的时间序列中学习表示,并对数据的不确定性进行建模。
在概率设定中学习某些选定参数分布的未来参数很常见,例如高斯分布 (Gaussian) 或 Student-T,或者学习条件分位数函数 (conditional quantile function),或使用适应时间序列设置的共型预测 (Conformal Prediction) 框架。方法的选择不会影响到建模,因此通常可以将其视为另一个超参数。通过采用经验均值或中值,人们总是可以将概率模型转变为点预测模型。
## 时间序列 Transformer
正如人们所想象的那样,在对本来就连续的时间序列数据建模方面,研究人员提出了使用循环神经网络 (RNN) (如 LSTM 或 GRU) 或卷积网络 (CNN) 的模型,或利用最近兴起的基于 Transformer 的训练方法,都很自然地适合时间序列预测场景。
在这篇博文中,我们将利用传统 vanilla Transformer (参考 [(Vaswani et al., 2017)](https://arxiv.org/abs/1706.03762)) 进行单变量概率预测 (**univariate** probabilistic forecasting) 任务 (即预测每个时间序列的一维分布)。由于 Encoder-Decoder Transformer 很好地封装了几个归纳偏差,所以它成为了我们预测的自然选择。
首先,使用 Encoder-Decoder 架构在推理时很有帮助。通常对于一些记录的数据,我们希望提前预知未来的一些预测步骤。可以认为这个过程类似于文本生成任务,即给定上下文,采样下一个词元 (token) 并将其传回解码器 (也称为“自回归生成”) 。类似地,我们也可以在给定某种分布类型的情况下,从中抽样以提供预测,直到我们期望的预测范围。这被称为贪婪采样 (Greedy Sampling)/搜索,[此处](https://huggingface.co/blog/zh/how-to-generate) 有一篇关于 NLP 场景预测的精彩博文。
其次,Transformer 帮助我们训练可能包含成千上万个时间点的时间序列数据。由于注意力机制的时间和内存限制,一次性将 *所有* 时间序列的完整历史输入模型或许不太可行。因此,在为随机梯度下降 (SGD) 构建批次时,可以考虑适当的上下文窗口大小,并从训练数据中对该窗口和后续预测长度大小的窗口进行采样。可以将调整过大小的上下文窗口传递给编码器、预测窗口传递给 *ausal-masked* 解码器。这样一来,解码器在学习下一个值时只能查看之前的时间步。这相当于人们训练用于机器翻译的 vanilla Transformer 的过程,称为“教师强制 (Teacher Forcing)”。
Transformers 相对于其他架构的另一个好处是,我们可以将缺失值 (这在时间序列场景中很常见) 作为编码器或解码器的额外掩蔽值 (mask),并且仍然可以在不诉诸于填充或插补的情况下进行训练。这相当于 Transformers 库中 BERT 和 GPT-2 等模型的 `attention_mask`,在注意力矩阵 (attention matrix) 的计算中不包括填充词元。
由于传统 vanilla Transformer 的平方运算和内存要求,Transformer 架构的一个缺点是上下文和预测窗口的大小受到限制。关于这一点,可以参阅 [Tay et al., 2020](https://arxiv.org/abs/2009.06732)。此外,由于 Transformer 是一种强大的架构,与 [其他方法](https://openreview.net/pdf?id=D7YBmfX_VQy) 相比,它可能会过拟合或更容易学习虚假相关性。
🤗 Transformers 库带有一个普通的概率时间序列 Transformer 模型,简称为 [Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)。在这篇文章后面的内容中,我们将展示如何在自定义数据集上训练此类模型。
## 设置环境
首先,让我们安装必要的库: 🤗 Transformers、🤗 Datasets、🤗 Evaluate、🤗 Accelerate 和 [GluonTS](https://github.com/awslabs/gluonts)。
正如我们将展示的那样,GluonTS 将用于转换数据以创建特征以及创建适当的训练、验证和测试批次。
```python
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujson
```
## 加载数据集
在这篇博文中,我们将使用 [Hugging Face Hub](https://huggingface.co/datasets/monash_tsf) 上提供的 `tourism_monthly` 数据集。该数据集包含澳大利亚 366 个地区的每月旅游流量。
此数据集是 [Monash Time Series Forecasting](https://forecastingdata.org/) 存储库的一部分,该存储库收纳了是来自多个领域的时间序列数据集。它可以看作是时间序列预测的 GLUE 基准。
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")
```
可以看出,数据集包含 3 个片段: 训练、验证和测试。
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})
```
每个示例都包含一些键,其中 `start` 和 `target` 是最重要的键。让我们看一下数据集中的第一个时间序列:
```python
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
`start` 仅指示时间序列的开始 (类型为 `datetime`) ,而 `target` 包含时间序列的实际值。
`start` 将有助于将时间相关的特征添加到时间序列值中,作为模型的额外输入 (例如“一年中的月份”) 。因为我们已经知道数据的频率是 `每月`,所以也能推算第二个值的时间戳为 `1979-02-01`,等等。
```python
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]
```
验证集包含与训练集相同的数据,只是数据时间范围延长了 `prediction_length` 那么多。这使我们能够根据真实情况验证模型的预测。
与验证集相比,测试集还是比验证集多包含 `prediction_length` 时间的数据 (或者使用比训练集多出数个 `prediction_length` 时长数据的测试集,实现在多重滚动窗口上的测试任务)。
```python
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
验证的初始值与相应的训练示例完全相同:
```python
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]
```
但是,与训练示例相比,此示例具有 `prediction_length=24` 个额外的数据。让我们验证一下。
```python
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)
```
让我们可视化一下:
```python
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()
```
下面拆分数据:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## 将 `start` 更新为 `pd.Period`
我们要做的第一件事是根据数据的 `freq` 值将每个时间序列的 `start` 特征转换为 pandas 的 `Period` 索引:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
这里我们使用 `datasets` 的 [`set_transform`](https://huggingface.co/docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) 来实现:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
## 定义模型
接下来,让我们实例化一个模型。该模型将从头开始训练,因此我们不使用 `from_pretrained` 方法,而是从 [`config`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerConfig) 中随机初始化模型。
我们为模型指定了几个附加参数:
- `prediction_length` (在我们的例子中是 `24` 个月) : 这是 Transformer 的解码器将学习预测的范围;
- `context_length`: 如果未指定 `context_length`,模型会将 `context_length` (编码器的输入) 设置为等于 `prediction_length`;
- 给定频率的 `lags`(滞后): 这将决定模型“回头看”的程度,也会作为附加特征。例如对于 `Daily` 频率,我们可能会考虑回顾 `[1, 2, 7, 30, ...]`,也就是回顾 1、2……天的数据,而对于 Minute数据,我们可能会考虑 `[1, 30, 60, 60*24, ...]` 等;
- 时间特征的数量: 在我们的例子中设置为 `2`,因为我们将添加 `MonthOfYear` 和 `Age` 特征;
- 静态类别型特征的数量: 在我们的例子中,这将只是 `1`,因为我们将添加一个“时间序列 ID”特征;
- 基数: 将每个静态类别型特征的值的数量构成一个列表,对于本例来说将是 `[366]`,因为我们有 366 个不同的时间序列;
- 嵌入维度: 每个静态类别型特征的嵌入维度,也是构成列表。例如 `[3]` 意味着模型将为每个 `366` 时间序列 (区域) 学习大小为 `3` 的嵌入向量。
让我们使用 GluonTS 为给定频率 (“每月”) 提供的默认滞后值:
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]
```
这意味着我们每个时间步将回顾长达 37 个月的数据,作为附加特征。
我们还检查 GluonTS 为我们提供的默认时间特征:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]
```
在这种情况下,只有一个特征,即“一年中的月份”。这意味着对于每个时间步长,我们将添加月份作为标量值 (例如,如果时间戳为 "january",则为 `1`;如果时间戳为 "february",则为 `2`,等等) 。
我们现在准备好定义模型需要的所有内容了:
```python
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags coming from helper given the freq:
lags_sequence=lags_sequence,
# we'll add 2 time features ("month of year" and "age", see further):
num_time_features=len(time_features) + 1,
# we have a single static categorical feature, namely time series ID:
num_static_categorical_features=1,
# it has 366 possible values:
cardinality=[len(train_dataset)],
# the model will learn an embedding of size 2 for each of the 366 possible values:
embedding_dimension=[2],
# transformer params:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)
```
请注意,与 🤗 Transformers 库中的其他模型类似,[`TimeSeriesTransformerModel`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerModel) 对应于没有任何顶部前置头的编码器-解码器 Transformer,而 [`TimeSeriesTransformerForPrediction`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction) 对应于顶部有一个分布前置头 (**distribution head**) 的 `TimeSeriesTransformerForPrediction`。默认情况下,该模型使用 Student-t 分布 (也可以自行配置):
```python
model.config.distribution_output
>>> student_t
```
这是具体实现层面与用于 NLP 的 Transformers 的一个重要区别,其中头部通常由一个固定的分类分布组成,实现为 `nn.Linear` 层。
## 定义转换
接下来,我们定义数据的转换,尤其是需要基于样本数据集或通用数据集来创建其中的时间特征。
同样,我们用到了 GluonTS 库。这里定义了一个 `Chain` (有点类似于图像训练的 `torchvision.transforms.Compose`) 。它允许我们将多个转换组合到一个流水线中。
```python
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
下面的转换代码带有注释供大家查看具体的操作步骤。从全局来说,我们将迭代数据集的各个时间序列并添加、删除某些字段或特征:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# a bit like torchvision.transforms.Compose
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# month of year in the case when freq="M"
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in its life the value of the time series is,
# sort of a running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## 定义 `InstanceSplitter`
对于训练、验证、测试步骤,接下来我们创建一个 `InstanceSplitter`,用于从数据集中对窗口进行采样 (因为由于时间和内存限制,我们无法将整个历史值传递给 Transformer)。
实例拆分器从数据中随机采样大小为 `context_length` 和后续大小为 `prediction_length` 的窗口,并将 `past_` 或 `future_` 键附加到各个窗口的任何临时键。这确保了 `values` 被拆分为 `past_values` 和后续的 `future_values` 键,它们将分别用作编码器和解码器的输入。同样我们还需要修改 `time_series_fields` 参数中的所有键:
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## 创建 PyTorch 数据加载器
有了数据,下一步需要创建 PyTorch DataLoaders。它允许我们批量处理成对的 (输入, 输出) 数据,即 (`past_values`, `future_values`)。
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from the 366 possible transformed time series)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(
stream, is_train=True
)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# we create a Test Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "test")
# we apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_test_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)
```
让我们检查第一批:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensor
```
可以看出,我们没有将 `input_ids` 和 `attention_mask` 提供给编码器 (训练 NLP 模型时也是这种情况),而是提供 `past_values`,以及 `past_observed_mask`、`past_time_features`、`static_categorical_features` 和 `static_real_features` 几项数据。
解码器的输入包括 `future_values`、`future_observed_mask` 和 `future_time_features`。`future_values` 可以看作等同于 NLP 训练中的 `decoder_input_ids`。
我们可以参考 [Time Series Transformer 文档](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction.forward.past_values) 以获得对它们中每一个的详细解释。
## 前向传播
让我们对刚刚创建的批次执行一次前向传播:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: 9.069628715515137
```
目前,该模型返回了损失值。这是由于解码器会自动将 `future_values` 向右移动一个位置以获得标签。这允许计算预测结果和标签值之间的误差。
另请注意,解码器使用 Causal Mask 来避免预测未来,因为它需要预测的值在 `future_values` 张量中。
## 训练模型
是时候训练模型了!我们将使用标准的 PyTorch 训练循环。
这里我们用到了 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) 库,它会自动将模型、优化器和数据加载器放置在适当的 `device` 上。
```python
from accelerate import Accelerator
from torch.optim import AdamW
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(40):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
if idx % 100 == 0:
print(loss.item())
```
## 推理
在推理时,建议使用 `generate()` 方法进行自回归生成,类似于 NLP 模型。
预测的过程会从测试实例采样器中获得数据。采样器会将数据集的每个时间序列的最后 `context_length` 那么长时间的数据采样出来,然后输入模型。请注意,这里需要把提前已知的 `future_time_features` 传递给解码器。
该模型将从预测分布中自回归采样一定数量的值,并将它们传回解码器最终得到预测输出:
```python
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())
```
该模型输出一个表示结构的张量 (`batch_size`, `number of samples`, `prediction length`)。
下面的输出说明: 对于大小为 `64` 的批次中的每个示例,我们将获得接下来 `24` 个月内的 `100` 个可能的值:
```python
forecasts[0].shape
>>> (64, 100, 24)
```
我们将垂直堆叠它们,以获得测试数据集中所有时间序列的预测:
```python
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)
```
我们可以根据测试集中存在的样本值,根据真实情况评估生成的预测。这里我们使用数据集中的每个时间序列的 [MASE](https://huggingface.co/spaces/evaluate-metric/mase) 和 [sMAPE](https://huggingface.co/spaces/evaluate-metric/smape) 指标 (metrics) 来评估:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549
```
我们还可以单独绘制数据集中每个时间序列的结果指标,并观察到其中少数时间序列对最终测试指标的影响很大:
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```
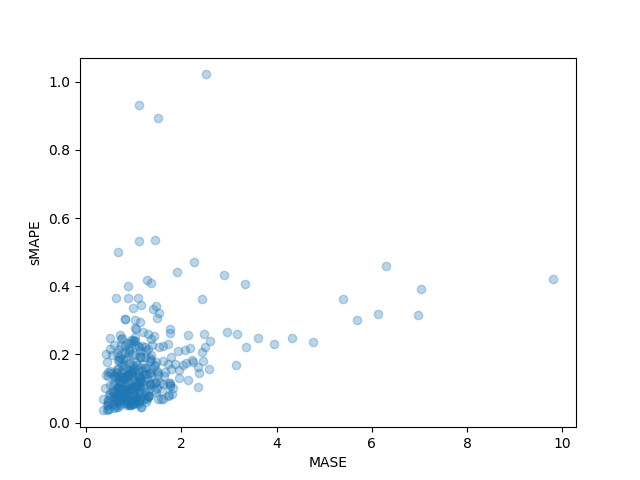
为了根据基本事实测试数据绘制任何时间序列的预测,我们定义了以下辅助绘图函数:
```python
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Major ticks every half year, minor ticks every month,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()
```
例如:
```python
plot(334)
```
我们如何与其他模型进行比较?[Monash Time Series Repository](https://forecastingdata.org/#results) 有一个测试集 MASE 指标的比较表。我们可以将自己的结果添加到其中作比较:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| **Transformer** (Our) |
|:------------------:|:-----------------:|:--:|:--:|:--:|:--:|:--:|:--:|:---:|:---:|:--:|:--:|:--:|
|Tourism Monthly | 3.306 | 1.649 | 1.751 | 1.526| 1.589| 1.678 |1.699| 1.582 | 1.409 | 1.574| 1.482 | **1.256**|
请注意,我们的模型击败了所有已知的其他模型 (另请参见相应 [论文](https://openreview.net/pdf?id=wEc1mgAjU-) 中的表 2) ,并且我们没有做任何超参数优化。我们仅仅花了 40 个完整训练调参周期来训练 Transformer。
当然,我们应该谦虚。从历史发展的角度来看,现在认为神经网络解决时间序列预测问题是正途,就好比当年的论文得出了 “[你需要的就是 XGBoost](https://www.sciencedirect.com/science/article/pii/S0169207021001679)” 的结论。我们只是很好奇,想看看神经网络能带我们走多远,以及 Transformer 是否会在这个领域发挥作用。这个特定的数据集似乎表明它绝对值得探索。
## 下一步
我们鼓励读者尝试我们的 [Jupyter Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) 和来自 Hugging Face [Hub](https://huggingface.co/datasets/monash_tsf) 的其他时间序列数据集,并替换适当的频率和预测长度参数。对于您的数据集,需要将它们转换为 GluonTS 的惯用格式,在他们的 [文档](https://ts.gluon.ai/stable/tutorials/forecasting/extended_tutorial.html#What-is-in-a-dataset?) 里有非常清晰的说明。我们还准备了一个示例 Notebook,向您展示如何将数据集转换为 [🤗 Hugging Face 数据集格式](https://github.com/huggingface/notebooks/blob/main/examples/time_series_datasets.ipynb)。
正如时间序列研究人员所知,人们对“将基于 Transformer 的模型应用于时间序列”问题很感兴趣。传统 vanilla Transformer 只是众多基于注意力 (Attention) 的模型之一,因此需要向库中补充更多模型。
目前没有什么能妨碍我们继续探索对多变量时间序列 (multivariate time series) 进行建模,但是为此需要使用多变量分布头 (multivariate distribution head) 来实例化模型。目前已经支持了对角独立分布 (diagonal independent distributions),后续会增加其他多元分布支持。请继续关注未来的博客文章以及其中的教程。
路线图上的另一件事是时间序列分类。这需要将带有分类头的时间序列模型添加到库中,例如用于异常检测这类任务。
当前的模型会假设日期时间和时间序列值都存在,但在现实中这可能不能完全满足。例如 [WOODS](https://woods-benchmarks.github.io/) 给出的神经科学数据集。因此,我们还需要对当前模型进行泛化,使某些输入在整个流水线中可选。
最后,NLP/CV 领域从 [大型预训练模型](https://arxiv.org/abs/1810.04805) 中获益匪浅,但据我们所知,时间序列领域并非如此。基于 Transformer 的模型似乎是这一研究方向的必然之选,我们迫不及待地想看看研究人员和从业者会发现哪些突破!
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/xethub-joins-hf.md | ---
title: "XetHub 加入 Hugging Face!"
thumbnail: /blog/assets/xethub-joins-hf/thumbnail.png
authors:
- user: yuchenglow
org: xet-team
- user: julien-c
translators:
- user: AdinaY
---
# XetHub 加入 Hugging Face!
我们非常激动地正式宣布,Hugging Face 已收购 XetHub 🔥
XetHub 是一家位于西雅图的公司,由 Yucheng Low、Ajit Banerjee 和 Rajat Arya 创立,他们之前在 Apple 工作,构建和扩展了 Apple 的内部机器学习基础设施。XetHub 的使命是为 AI 开发提供软件工程的最佳实践。XetHub 开发了技术,能够使 Git 扩展到 TB 级别的存储库,并使团队能够探索、理解和共同处理大型不断变化的数据集和模型。不久之后,他们加入了一支由 12 名才华横溢的团队成员组成的团队。你可以在他们的新组织页面关注他们:[hf.co/xet-team](https://huggingface.co/xet-team)。
## 我们在 Hugging Face 的共同目标
> XetHub 团队将帮助我们通过切换到我们自己的、更好的 LFS 版本作为 Hub 存储库的存储后端,解锁 Hugging Face 数据集和模型的未来五年增长。
>
> —— Julien Chaumond, Hugging Face CTO
早在 2020 年,当我们构建第一个 Hugging Face Hub 版本时,我们决定将其构建在 Git LFS 之上,因为它相当知名,并且是启动 Hub 使用的合理选择。
然而,我们当时就知道,某个时候我们会希望切换到我们自己的、更优化的存储和版本控制后端。Git LFS——即使它代表的是大文件存储——也从未适合我们在 AI 中处理的那种类型的大文件,这些文件不仅大,而且非常大 😃。
## 未来的示例用例 🔥 – 这将如何在 Hub 上实现
假设你有一个 10GB 的 Parquet 文件。你添加了一行。今天你需要重新上传 10GB。使用 XetHub 的分块文件和重复数据删除技术,你只需要重新上传包含新行的几个块。
另一个例子是 GGUF 模型文件:假设 [@bartowski](https://huggingface.co/bartowski) 想要更新 Llama 3.1 405B 存储库的 GGUF 头部中的一个元数据值。将来,bartowski 只需重新上传几千字节的单个块,使这个过程更加高效 🔥。
随着该领域在未来几个月内转向万亿参数模型(感谢 Maxime Labonne 提供新的 [BigLlama-3.1-1T](https://huggingface.co/mlabonne/BigLlama-3.1-1T-Instruct) 🤯),我们希望这种新技术将解锁社区和企业内部的新规模。
最后,随着大数据集和大模型的
出现,协作也面临挑战。团队如何共同处理大型数据、模型和代码?用户如何理解他们的数据和模型是如何演变的?我们将努力找到更好的解决方案来回答这些问题。
## Hub 存储库的有趣当前统计数据 🤯🤯
- 存储库数量:130 万个模型,45 万个数据集,68 万个空间
- 累计总大小:LFS 中存储了 12PB(2.8 亿个文件)/ git(非 LFS)中存储了 7.3TB
- Hub 每日请求次数:10 亿次
- Cloudfront 每日带宽:6PB 🤯
## 来自 [@ylow](https://huggingface.co/yuchenglow) 的个人话语
我在 AI/ML 领域工作了 15 年以上,见证了深度学习如何慢慢接管视觉、语音、文本,甚至越来越多的每个数据领域。
我严重低估了数据的力量。几年前看起来不可能的任务(如图像生成),实际上通过数量级更多的数据和能够吸收这些数据的模型变得可能。从历史上看,这是一再重复的机器学习历史教训。
自从我的博士学位以来,我一直在数据领域工作。首先在初创公司(GraphLab/Dato/Turi)中,我使结构化数据和机器学习算法在单机上扩展。之后被 Apple 收购,我致力于将 AI 数据管理扩展到超过 100PB,支持数十个内部团队每年发布数百个功能。2021 年,与我的联合创始人们一起,在 Madrona 和其他天使投资者的支持下,创立了 XetHub,将我们在实现大规模协作方面的经验带给全世界。
XetHub 的目标是使 ML 团队像软件团队一样运作,通过将 Git 文件存储扩展到 TB 级别,无缝实现实验和可重复性,并提供可视化功能来理解数据集和模型的演变。
我和整个 XetHub 团队都非常高兴能够加入 Hugging Face,并继续我们的使命,通过将 XetHub 技术整合到 Hub 中,使 AI 协作和开发更加容易,并向全球最大的 ML 社区发布这些功能!
## 最后,我们的基础设施团队正在招聘 👯
如果你喜欢这些主题,并希望为开源 AI 运动构建和扩展协作平台,请联系我们!
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/intel-starcoder-quantization.md | ---
title: "使用 🤗 Optimum Intel 在英特尔至强上加速 StarCoder:Q8/Q4 及投机解码"
thumbnail: /blog/assets/optimum_intel/intel_thumbnail.png
authors:
- user: ofirzaf
guest: true
- user: echarlaix
- user: imargulis
guest: true
- user: danielkorat
guest: true
- user: jmamou
guest: true
- user: guybd
guest: true
- user: orenpereg
guest: true
- user: moshew
guest: true
- user: Haihao
guest: true
- user: aayasin
guest: true
- user: FanZhao
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 使用 🤗 Optimum Intel 在英特尔至强上加速 StarCoder: Q8/Q4 及投机解码
## 引言
近来,随着 BigCode 的 [StarCoder](https://huggingface.co/blog/starcoder) 以及 Meta AI 的 [Code Llama](https://ai.meta.com/blog/code-llama-large-language-model-coding) 等诸多先进模型的发布,代码生成模型变得炙手可热。同时,业界也涌现出了大量的致力于优化大语言模型 (LLM) 的运行速度及易用性的工作。我们很高兴能够分享我们在英特尔至强 CPU 上优化 LLM 的最新结果,本文我们主要关注 StarCoder 这一流行的代码生成 LLM。
StarCoder 模型是一个专为帮助用户完成各种编码任务而设计的先进 LLM,其可用于代码补全、错误修复、代码摘要,甚至根据自然语言生成代码片段等用途。 StarCoder 模型是 StarCoder 模型家族的一员,该系列还有 StarCoderBase。这些代码大模型 (代码 LLM) 使用 GitHub 上的许可代码作为训练数据,其中涵盖了 80 多种编程语言、Git 提交、GitHub 问题以及 Jupyter Notebook。本文,我们将 8 比特、4 比特量化以及 [辅助生成](https://huggingface.co/blog/assisted-generation) 结合起来,在英特尔第四代至强 CPU 上对 StarCoder-15B 模型实现了 7 倍以上的推理加速。
欢迎到 Hugging Face Spaces 上尝试我们的 [演示应用](https://huggingface.co/spaces/Intel/intel-starcoder-playground),其运行在第四代英特尔至强可扩展处理器上。
<figure class="image table text-center m-0 w-full">
<video
alt="Generating DOI"
style="max-width: 80%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/starcoder-demo.mov" type="video/mp4">
</video>
</figure>
## 第 1 步: 基线与评估方法
首先,我们在 PyTorch 和 [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) 上运行 StarCoder (15B),并将其作为基线。
至于评估方法,目前已有不少数据集可用于评估自动代码补全的质量。本文,我们使用流行的 [Huggingface.co/datasets/openai_humaneval] 数据集来评估模型的质量和性能。HumanEval 由 164 个编程问题组成,其内容为函数接口及其对应的函数功能的文档字符串,需要模型基于此补全函数体的代码。其提示的平均长度为 139。我们使用 Bigcode Evaluation Harness 运行评估并报告 pass@1 指标。我们通过测量 HumanEval 测试集上的首词元延迟 (Time To First Token,TTFT) 和每词元延迟 (Time Per Output Token,TPOT) 来度量模型性能,并报告平均 TTFT 和 TPOT。
第四代英特尔至强处理器内置人工智能加速器,称为英特尔® 高级矩阵扩展 (Intel® Advanced Matrix Extensions,英特尔® AMX) 指令集。具体来说,其在每个 CPU 核中内置了 [BFloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) (BF16) 和 Int8 GEMM 加速器,以加速深度学习训练和推理工作负载。AMX 推理加速已集成入 PyTorch 2.0 及 [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX),同时这两个软件还针对其他 LLM 中常见的操作 (如层归一化、SoftMax、缩放点积等) 进行了更多的优化。
我们使用 PyTorch 和 IPEX 对 BF16 模型进行推理,以确定基线。图 1 展示了模型推理延迟的基线,表 1 展示了延迟及其对应的准确率。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_baseline_model.png" alt="baseline latency"><br>
<em>图 1: 模型延迟基线</em>
</p>
### LLM 量化
LLM 中的文本生成是以自回归的方式进行的,因此在生成每个新词元时都需要把整个模型从内存加载到 CPU。我们发现内存 (DRAM) 和 CPU 之间的带宽是词元生成的最大性能瓶颈。量化是缓解这一问题的通用方法,其可减小模型尺寸,进而减少模型权重加载时间。
本文,我们关注两种量化方法:
1. 仅权重量化 (Weight Only Quantization,WOQ) - 仅量化模型的权重,但不量化激活值,且使用高精度 (如 BF16) 进行计算,因此在计算时需要对权重进行反量化。
2. 静态量化 (Static Quantization,SQ) - 对权重和激活都进行量化。量化过程包括通过校准预先计算量化参数,从而使得计算能够以较低精度 (如 INT8) 执行。图 2 所示为 INT8 静态量化的计算流程。
## 第 2 步: 8 比特量化 (INT8)
[SmoothQuant](https://huggingface.co/blog/generative-ai-models-on-intel-cpu) 是一种训后量化算法,其能以最小的精度损失把 LLM 量化至 INT8。由于激活的特定通道存在大量异常值,常规静态量化方法在 LLM 上表现不佳。这是因为激活是按词元量化的,因此常规静态量化会导致大的激活值截断以及小的激活值下溢。SmoothQuant 算法通过引入预量化解决了这个问题,其引入了一个额外的平滑缩放因子,将其应用于激活和权重能达到平滑激活中的异常值的作用,从而最大化量化阶数的利用率。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/int8_diagram.png" alt="INT8 quantization"><br>
<em>图 2:INT8 静态量化模型的计算流程</em>
</p>
我们利用 IPEX 对 StarCoder 模型进行 SmoothQuant 量化。我们使用 [MBPP](https://huggingface.co/datasets/nuprl/MultiPL-E) 的测试子集作为校准数据集,并基于此生成了 Q8-StarCoder。评估表明,Q8-StarCoder 相对于基线没有精度损失 (事实上,甚至还有轻微的改进)。在性能方面,Q8-StarCoder 的 TTFT 有 **~2.19x** 的加速,TPOT 有 **~2.20x** 的加速。图 3 展示了 Q8-StarCoder 与 BF16 基线模型的延迟 (TPOT) 对比。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int8_model.png" alt="INT8 latency"><br>
<em>图 3:8 比特量化模型的延迟加速</em>
</p>
## 第 3 步: 4 比特量化 (INT4)
尽管与 BF16 相比,INT8 将模型尺寸减小了 2 倍 (每权重 8 比特,之前每权重 16 比特),但内存带宽仍然是最大的瓶颈。为了进一步减少模型的内存加载时间,我们使用 WOQ 将模型的权重量化为 4 比特。请注意,4 比特 WOQ 需要在计算之前反量化回 16 比特 (图 4),这意味着存在额外的计算开销。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/int4_diagram.png" alt="INT4 quantization"><br>
<em>图 4:INT4 量化模型的计算流程</em>
</p>
张量级的非对称最近舍入 (Round To Nearest,RTN) 量化是一种基本的 WOQ 技术,但它经常会面临精度降低的挑战。[这篇论文](https://arxiv.org/pdf/2206.01861.pdf) (Zhewei Yao,2022) 表明对模型权重进行分组量化有助于保持精度。为了避免精度下降,我们沿输入通道将若干个连续值 (如 128 个) 分为一组,对分组后的数据执行 4 比特量化,并按组计算缩放因子。我们发现分组 4 比特 RTN 在 HumanEval 数据集上足以保持 StarCoder 的准确性。与 BF16 基线相比,4 比特模型的 TPOT 有 **3.35 倍** 的加速 (图 5),但由于在计算之前需要将 4 比特反量化为 16 比特,该操作带来的额外开销使得其 TTFT 出现了 0.84 倍的减速 (表 1),这也是符合预期的。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int4_model.png" alt="INT4 latency"><br>
<em>图 5:4 比特量化模型的延迟加速。</em>
</p>
## 首词元和后续词元的性能瓶颈不同
生成首词元时会涉及到对整个输入提示的并行处理,当提示长度很长时,需要大量的计算资源。因此,计算成为这一阶段的瓶颈。此时,与基线 (以及引入反量化计算开销的 4 比特 WOQ) 相比,将精度从 BF16 切至 INT8 能提高性能。然而,从第二个词元开始,系统需以自回归的方式逐一生成剩下的词元,而每新生成一个词元都需要从内存中再次加载模型。此时,内存带宽变成了瓶颈,而不再是可执行操作数 (FLOPS),此时 INT4 优于 INT8 和 BF16。
## 第 4 步: 辅助生成 (Assisted Generation,AG)
另一种能提高推理延迟、缓解内存带宽瓶颈的方法是 [辅助生成](https://huggingface.co/blog/assisted-generation) (Assisted Generation,AG),其实际上是 [投机解码](https://arxiv.org/pdf/2211.17192.pdf) 的一种实现。AG 通过更好地平衡内存和计算来缓解上述压力,其基于如下假设: 更小、更快的辅助草稿模型生成的词元与更大的目标模型生成的词元重合的概率比较高。
AG 先用小而快的草稿模型基于贪心算法生成 K 个候选词元。这些词元的生成速度更快,但其中一些可能与原始目标模型的输出词元不一致。因此,下一步,目标模型会通过一次前向传播并行检查所有 K 个候选词元的有效性。这种做法加快了解码速度,因为并行解码 K 个词元的延迟比自回归生成 K 个词元的延迟要小。
为了加速 StarCoder,我们使用 [bigcode/tiny_starcoder_py](https://huggingface.co/bigcode/tiny_starcoder_py) 作为草稿模型。该模型与 StarCoder 架构相似,但参数量仅为 164M - 比 StarCoder 小 **~95** 倍,因此速度更快。为了实现更大的加速,除了量化目标模型之外,我们还对草稿模型进行了量化。我们对草稿模型和目标模型均实验了两种量化方案: 8 比特 SmoothQuant 和 4 比特 WOQ 量化。评估结果表明,对草稿模型和目标模型均采用 8 比特 SmoothQuant 量化得到的加速最大: TPOT 加速达 **~7.30** 倍 (图 6)。
我们认为该结果是合理的,分析如下:
1. 草稿模型量化: 当使用 164M 参数的 8 比特量化 StarCoder 作为草稿模型时,大部分权重均可驻留在 CPU 缓存中,内存带宽瓶颈得到缓解,因为在生成每个词元时无需重复从内存中读取模型。此时,已不存在内存瓶颈,所以进一步量化为 4 比特意义已不大。同时,与量化为 4 比特 WOQ 的 StarCoder-164M 相比,我们发现量化为 8 比特的 StarCoder-164M 加速比更大。这是因为,4 比特 WOQ 虽然在内存带宽成为瓶颈的情况下具有优势,因为它的内存占用较小,但 其会带来额外的计算开销,因为需要在计算之前执行 4 比特到 16 比特的反量化操作。
2. 目标模型量化: 在辅助生成场景下,目标模型需要处理草稿模型生成的 K 个词元序列。通过目标模型一次性 (并行) 对 K 个词元进行推理,而不是一个一个顺序地进行自回归处理,工作负载已从内存带宽瓶颈型转变成了计算瓶颈型。此时,我们观察到,使用 8 比特量化的目标模型比使用 4 比特模型加速比更高,因为从 4 比特到 16 比特的反量化会产生额外的计算开销。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int8_ag_model.png" alt="IN8 AG"><br>
<em>图 6: 最终优化模型的延迟加速</em>
</p>
| StarCoder | 量化方案 | 精度 | HumanEval (pass@1)| TTFT (ms) | TTFT 加速 | TPOT (ms) | TPOT 加速 |
| --------- | ------------ | --------- | ----------------- | --------- | ------------ | --------- | ------------ |
| 基线 | 无 | A16W16 | 33.54 | 357.9 | 1.00x | 181.0 | 1.00x |
| INT8 | SmoothQuant | A8W8 | 33.96 | 163.4 | 2.19x | 82.4 | 2.20x |
| INT4 | RTN (g128) | A16W4 | 32.80 | 425.1 | 0.84x | 54.0 | 3.35x |
|INT8 + AG | SmoothQuant | A8W8 | 33.96 | 183.6 | 1.95x | 24.8 | 7.30x |
表 1: 在英特尔第四代至强处理器上测得的 StarCoder 模型的准确率及延迟
如果您想要加载优化后的模型,并执行推理,可以用 [optimum-intel](https://github.com/huggingface/optimum-intel) 提供的 `IPEXModelForXxx` 类来替换对应的 `AutoModelForXxx` 类。
在开始之前,还需要确保已经安装了所需的库:
```bash
pip install --upgrade-strategy eager optimum[ipex]
```
```diff
- from transformers import AutoModelForCausalLM
+ from optimum.intel import IPEXModelForCausalLM
from transformers import AutoTokenizer, pipeline
- model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = IPEXModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")
```
| 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/embedding-quantization.md | ---
title: "用于显著提高检索速度和降低成本的二进制和标量嵌入量化"
thumbnail: /blog/assets/embedding-quantization/thumbnail.png
authors:
- user: aamirshakir
guest: true
- user: tomaarsen
- user: SeanLee97
guest: true
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 用于显著提高检索速度和降低成本的二进制和标量嵌入量化
我们引入了嵌入量化的概念,并展示了它们对检索速度、内存使用、磁盘空间和成本的影响。我们将讨论理论上和实践中如何对嵌入进行量化,然后介绍一个 [演示](https://huggingface.co/spaces/sentence-transformers/quantized-retrieval),展示了 4100 万维基百科文本的真实检索场景。
## 目录
* [为什么使用嵌入?](#为什么使用嵌入?)
+ [嵌入可能难以扩展](#嵌入可能难以扩展)
* [提高可扩展性](#提高可扩展性)
+ [二进制量化](#二进制量化)
- [Sentence Transformers 中的二进制量化](#sentence-transformers-中的二进制量化)
- [向量数据库中的二进制量化](#向量数据库中的二进制量化)
+ [标量(int8)量化](#标量_int8_量化
)
- [Sentence Transformers 中的标量量化](#sentence-transformers-中的标量量化)
- [向量数据库中的标量量化](#向量数据库中的标量量化)
+ [结合二进制和标量量化](#结合二进制和标量量化)
+ [量化实验](#量化实验)
+ [重打分的影响](#重打分的影响)
- [二进制重打分](#二进制重打分)
- [标量(Int8)重打分](#标量-Int8-重打分)
- [检索速度](#检索速度)
+ [性能汇总](#性能汇总)
+ [演示](#演示)
+ [自己尝试](#自己尝试)
+ [未来工作](#未来工作)
+ [致谢](#致谢)
+ [引用](#引用)
+ [参考文献](#参考文献)
## 为什么使用嵌入?
嵌入是自然语言处理中最多样化的工具之一,支持各种设置和使用场景。本质上,嵌入是对更复杂对象 (如文本、图像、音频等) 的数值表示。具体来说,这些对象被表示为 n 维向量。
在转换了复杂对象之后,你可以通过计算相应嵌入的相似性来确定它们的相似性!这对于许多使用场景至关重要: 它为推荐系统、检索、单次学习或少样本学习、异常检测、相似性搜索、释义检测、聚类、分类等提供了基础。
### 嵌入可能难以扩展
但是,当我们在实际应用中使用嵌入时,可能会遇到一些问题。比如,现在很多先进的模型产生的嵌入都是 1024 维的,每个维度需要 4 字节的空间来存储 (float 32 编码)。如果你要处理 2.5 亿个这样的向量,那就需要大约 1TB 的内存,这既花钱又可能导致处理速度变慢。
下表展示了一些不同的模型,它们的维度大小、需要的内存量以及相应的成本。成本是按照 AWS 上一种叫做 x2gd 的实例来估算的,大概每个月每 GB 需要 3.8 美元。
| 嵌入维数| 模型样例 | 100M 嵌入 | 250M 嵌入 | 1B 嵌入 |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------|-----------------|-------------------------|
| 384 | [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)<br>[bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 143.05GB<br>$543 / mo | 357.62GB<br>$1,358 / mo | 1430.51GB<br>$5,435 / mo |
| 768 | [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)<br>[bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5)<br>[jina-embeddings-v2-base-en](https://huggingface.co/jinaai/jina-embeddings-v2-base-en)<br>[nomic-embed-text-v1](https://huggingface.co/nomic-ai/nomic-embed-text-v1) |286.10GB<br>$1,087 / mo|715.26GB<br>$2,717 / mo|2861.02GB<br>$10,871 / mo|
| 1024 | [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5)<br>[mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1)<br>[Cohere-embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/) |381.46GB<br>$1,449 / mo|953.67GB<br>$3,623 / mo|3814.69GB<br>$14,495 / mo|
| 1536 | [OpenAI text-embedding-3-small](https://openai.com/blog/new-embedding-models-and-api-updates) |572.20GB<br>$2,174 / mo|1430.51GB<br>$5,435 / mo|5722.04GB<br>$21,743 / mo|
| 3072 | [OpenAI text-embedding-3-large](https://openai.com/blog/new-embedding-models-and-api-updates) |1144.40GB<br>$4,348 / mo|2861.02GB<br>$10,871 / mo|11444.09GB<br>$43,487 / mo|
## 提高可扩展性
有几种方法可以应对嵌入扩展的挑战。最常见的方法是降维,比如使用 [主成分分析 (PCA)](https://en.wikipedia.org/wiki/Principal_component_analysis)。然而,传统的降维方法——比如 PCA ——在处理嵌入时往往效果不佳。
最近,有关于 [ Matryoshka 表征学习](https://arxiv.org/abs/2205.13147) (MRL) 的新闻 ([博客](https://huggingface.co/blog/matryoshka)),这种方法由 [OpenAI](https://openai.com/blog/new-embedding-models-and-api-updates) 使用,允许更经济的嵌入。使用 MRL 时,只使用前 `n` 个嵌入维度。这种方法已经被一些开源模型采用,比如 [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) 和 [mixedbread-ai/mxbai-embed-2d-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-2d-large-v1)。对于 OpenAI 的 `text-embedding-3-large` 模型,我们看到在 12 倍压缩下性能保留了 93.1 %,而对于 nomic 的模型,在 3 倍压缩下保留了 95.8% 的性能,在 6 倍压缩下保留了 90% 的性能。
然而,还有一种新的方法可以在这个挑战上取得进展; 它不涉及降维,而是减少嵌入中每个个体值的尺寸大小: **量化**。我们的量化实验将展示,我们可以在显著加快计算速度并节省内存、存储和成本的同时,保持大量的性能。让我们进一步了解一下吧!
### 二进制量化
与在模型中减少权重精度的量化不同,嵌入的量化是指对嵌入本身进行的一个后处理步骤。特别是,二进制量化指的是将嵌入中的 `float32` 值转换为 1 bit ,从而在内存和存储使用上实现 32 倍的减少。
要将 `float32` 嵌入量化为二进制,我们只需将归一化的嵌入在 0 处进行阈值处理:
$$
f(x)=
\begin{cases}
0 & \text{如果 } x\leq 0\\
1 & \text{如果 } x \gt 0
\end{cases}
$$
我们可以使用汉明距离来高效地检索这些二进制嵌入。汉明距离是指两个二进制嵌入在位上不同的位置数量。汉明距离越低,嵌入越接近; 因此,文档的相关性越高。汉明距离的一个巨大优势是它可以用 2 个 CPU 周期轻松计算,允许极快的性能。
[Yamada 等人 (2021)](https://arxiv.org/abs/2106.00882) 引入了一个重打分步骤,他们称之为 _rerank_ ,以提高性能。他们提议可以使用点积将 `float32` 查询嵌入与二进制文档嵌入进行比较。在实践中,我们首先使用二进制查询嵌入和二进制文档嵌入检索 `rescore_multiplier * top_k` 的结果——即双二进制检索的前 k 个结果的列表——然后使用 `float32` 查询嵌入对这个二进制文档嵌入列表进行重打分。
通过应用这种新颖的重打分步骤,我们能够在减少内存和磁盘空间使用 32 倍的同时,保留高达 ~96% 的总检索性能,并使检索速度提高多达 32 倍。如果没有重打分,我们能够保留大约 ~92.5% 的总检索性能。
#### Sentence Transformers 中的二进制量化
将一个维度为 1024 的嵌入量化为二进制将得到 1024 比特。实际上,将比特存储为字节要常见得多,因此当我们量化为二进制嵌入时,我们使用 `np.packbits` 将比特打包成字节。
因此,将一个维度为 1024 的 `float32` 嵌入量化后,得到一个维度为 128 的 `int8` 或 `uint8` 嵌入。下面是两种使用 [Sentence Transformers](https://sbert.net/) 生成量化嵌入的方法:
```python
from sentence_transformers import SentenceTransformer
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2a. Encode some text using "binary" quantization
binary_embeddings = model.encode(
["I am driving to the lake.", "It is a beautiful day."],
precision="binary",
)
```
或者
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2b. or, encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
binary_embeddings = quantize_embeddings(embeddings, precision="binary")
```
**参考:**
<a href="https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1"><code>mixedbread-ai/mxbai-embed-large-v1</code></a><a href="https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode"><code>SentenceTransformer.encode</code></a><a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.quantize_embeddings"><code>quantize_embeddings</code></a>
在这里,你可以看到默认的 `float32` 嵌入和二进制嵌入在形状、大小和 `numpy` 数据类型方面的差异:
```python
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> binary_embeddings.shape
(2, 128)
>>> binary_embeddings.nbytes
256
>>> binary_embeddings.dtype
int8
```
请注意,你还可以选择 `"ubinary"` 来使用无符号的 `uint8` 数据格式将嵌入量化为二进制。这可能取决于你的向量库/数据库的要求。
#### 向量数据库中的二进制量化
| 向量数据库 | 是否支持 |
| --- | --- |
| Faiss | [是](https://github.com/facebookresearch/faiss/wiki/Binary-indexes) |
| USearch | [是](https://github.com/unum-cloud/usearch) |
| Vespa AI | [是](https://docs.vespa.ai/en/reference/schema-reference.html) |
| Milvus | [是](https://milvus.io/docs/index.md) |通过
| Qdrant | [二进制量化](https://qdrant.tech/documentation/guides/quantization/#binary-quantization) |通过
| Weaviate | [二进制量化](https://weaviate.io/developers/weaviate/configuration/bq-compression) |
### 标量 (int8) 量化
我们使用标量量化过程将 `float32` 嵌入转换为 `int8` 。这涉及到将 `float32` 值的连续范围映射到可以表示 256 个不同级别 (从 -128 到 127) 的 `int8` 值的离散集合,如下面的图像所示。这是通过使用大量的嵌入校准数据集来完成的。我们计算这些嵌入的范围,即每个嵌入维度的 `min` 和 `max` 。从这里,我们计算将每个值分类的步骤 (桶)。
为了进一步提高检索性能,你可以可选地应用与二进制嵌入相同的重打分步骤。重要的是要注意,校准数据集极大地影响性能,因为它定义了量化桶。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/embedding-quantization/scalar-quantization.png">
<em><small>Source: <a href="https://qdrant.tech/articles/scalar-quantization/">https://qdrant.tech/articles/scalar-quantization/</a></small></em>
</p>
通过将标量量化为 `int8` ,我们将原始 `float32` 嵌入的精度降低,使得每个值都用一个 8 位整数表示 (缩小 4 倍)。请注意,这与二进制量化情况不同,在二进制量化中,每个值由一个单比特表示 (缩小 32 倍)。
#### Sentence Transformers 中的标量量化
将一个维度为 1024 的嵌入量化为 `int8` 将得到 1024 字节。在实际应用中,我们可以选择 `uint8` 或 `int8` 。这个选择通常取决于你的向量库/数据库支持哪种格式。
在实践中,建议为标量量化提供以下之一:
1. 一大组嵌入,以便一次性全部量化,或者
2. 每个嵌入维度的 `min` 和 `max` 范围,或者
3. 一大组嵌入的校准数据集,从中可以计算 `min` 和 `max` 范围。
如果这些情况都不适用,你将收到如下警告:
`Computing int8 quantization buckets based on 2 embeddings. int8 quantization is more stable with 'ranges' calculated from more embeddings or a 'calibration_embeddings' that can be used to calculate the buckets.`
大意是如果你只使用很少量的嵌入 (在这个例子中是 2 个嵌入) 来计算这些量化桶,那么量化可能不会那么稳定或准确,因为少量的数据可能无法很好地代表整个数据分布。因此,如果你有一个很大的数据集来计算这些范围,或者有一个校准数据集,那么你可以得到更好的量化结果。
请看下面如何使用 [Sentence Transformers](https://sbert.net/) 生成标量量化嵌入:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.quantization import quantize_embeddings
from datasets import load_dataset
# 1. Load an embedding model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
# 2. Prepare an example calibration dataset
corpus = load_dataset("nq_open", split="train[:1000]")["question"]
calibration_embeddings = model.encode(corpus)
# 3. Encode some text without quantization & apply quantization afterwards
embeddings = model.encode(["I am driving to the lake.", "It is a beautiful day."])
int8_embeddings = quantize_embeddings(
embeddings,
precision="int8",
calibration_embeddings=calibration_embeddings,
)
```
**参考文献:**
<a href="https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1"><code>mixedbread-ai/mxbai-embed-large-v1</code></a><a href="https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode"><code>SentenceTransformer.encode</code></a><a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.quantize_embeddings"><code>quantize_embeddings</code></a>
在这里,你可以看到默认的 `float32` 嵌入和 `int8` 标量嵌入在形状、大小和 `numpy` 数据类型方面的差异:
```python
>>> embeddings.shape
(2, 1024)
>>> embeddings.nbytes
8192
>>> embeddings.dtype
float32
>>> int8_embeddings.shape
(2, 1024)
>>> int8_embeddings.nbytes
2048
>>> int8_embeddings.dtype
int8
```
#### 向量数据库中的标量量化
| 向量数据库 | 是否支持标量量化 |
| --- | --- |
| Faiss | [IndexHNSWSQ](https://faiss.ai/cpp_api/struct/structfaiss_1_1IndexHNSWSQ.html) |
| USearch | [是](https://github.com/unum-cloud/usearch) |
| Vespa AI | [是](https://docs.vespa.ai/en/reference/tensor.html) |
| OpenSearch | [是](https://opensearch.org/docs/latest/field-types/supported-field-types/knn-vector) |
| ElasticSearch | [是](https://www.elastic.co/de/blog/save-space-with-byte-sized-vectors) |间接通过
| Milvus | [IVF_SQ8](https://milvus.io/docs/index.md) |间接通过
| Qdrant | [Scalar Quantization](https://qdrant.tech/documentation/guides/quantization/#scalar-quantization) |
### 结合二进制和标量量化
结合二进制和标量量化可以兼得两者的优点: 二进制嵌入的极快速度和标量嵌入在重打分后的优良性能的保留。请查看下面的 [演示](#demo),这是一个涉及维基百科 4100 万文本的真实实现。该设置的流程如下:
1. 使用 [`mixedbread-ai/mxbai-embed-large-v1`](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) SentenceTransformer 模型对查询进行嵌入。
2. 使用 `sentence-transformers` 库中的 <a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.quantize_embeddings"><code>quantize_embeddings</code></a> 函数将查询量化为二进制。
3. 使用量化查询在二进制索引 (4100 万个二进制嵌入; 5.2GB 内存/磁盘空间) 中搜索前 40 个文档。
4. 从磁盘上的 int8 索引 (4100 万个 int8 嵌入; 0 字节内存,47.5GB 磁盘空间) 动态加载前 40 个文档。
5. 使用 float32 查询和 int8 嵌入对前 40 个文档进行重打分,以获得前 10 个文档。
6. 按分数对前 10 个文档进行排序并显示。
通过这种方法,我们为索引使用了 5.2GB 内存和 52GB 磁盘空间。这比通常的检索所需的 200GB 内存和 200GB 磁盘空间要少得多。尤其是当你进一步扩展时,这将显著减少延迟和成本。
### 量化实验
我们在 [MTEB](https://huggingface.co/spaces/mteb/leaderboard) 的检索子集上进行了实验,该子集包含 15 个基准测试。首先,我们使用 `rescore_multiplier` 为 4 来检索前 k (k=100) 个搜索结果。因此,我们总共检索了 400 个结果,并对这前 400 个结果进行了重打分。对于 `int8` 性能,我们直接使用了点积,而没有进行任何重打分。
| 模型 | 嵌入维度 | 250M 嵌入 | MTEB 检索(NDCG@10) | 默认性能的百分比 |
| - | -: | -: | -: | -: |
| **开源模型** | | | | |
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1): float32 | 1024 | 953.67GB<br>$3623 / mo | 54.39 | 100% |
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1): int8 | 1024 | 238.41GB<br>$905 / mo | 52.79 | 97% |
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1): binary | 1024 | 29.80GB<br>$113.25 / mo |52.46 | 96.45% |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2): float32 | 768 | 286.10GB<br>$1087 / mo |50.77 | 100% |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2): int8 | 768 | 178.81GB<br>$679 / mo| 47.54 | 94.68% |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2): binary | 768 | 22.35GB<br>$85 / mo | 37.96 |74.77% |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2): float32 | 384 | 357.62GB<br>$1358 / mo | 41.66 |100%
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2): int8 | 384 | 89.40GB<br>$339 / mo| 37.82 | 90.79%
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2): binary | 384 | 11.18GB<br>$42 / mo |39.07| 93.79%|
| **专有模型** | | | | |
| [Cohere-embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/): float32 | 1024 | 953.67GB<br>$3623 / mo | 55.0 | 100% |
| [Cohere-embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/): int8 | 1024 | 238.41GB<br>$905 / mo | 55.0 | 100% |
| [Cohere-embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/): binary | 1024 | 29.80GB<br>$113.25 / mo | 52.3 | 94.6% |
从我们的量化实验结果中,可以识别出几个关键趋势和好处。正如预期的那样,维度更高的嵌入模型通常每计算生成的存储成本更高,但能实现最佳性能。然而,令人惊讶的是,量化到 `int8` 已经帮助 `mxbai-embed-large-v1` 和 `Cohere-embed-english-v3.0` 在存储使用低于较小维度基模型的情况下实现了更高的性能。
量化好处的显现,在查看二进制模型的结果时更为明显。在这种情况下,1024 维度的模型仍然优于现在存储需求高 10 倍的基模型,而 `mxbai-embed-large-v1` 在资源需求减少 32 倍后仍能保持超过 96% 的性能。从 `int8` 进一步量化到二进制的性能损失几乎可以忽略不计。
有趣的是,我们还可以看到 `all-MiniLM-L6-v2` 在二进制量化上的性能比 `int8` 量化更强。这可能的原因是校准数据的选择。在 `e5-base-v2` 上,我们观察到了 [维度坍缩](https://arxiv.org/abs/2110.09348) 效应,导致模型只使用潜在空间的子空间; 当进行量化时,整个空间进一步坍缩,导致性能损失很大。
这表明量化并不适用于所有嵌入模型。考虑现有基准测试结果并开展实验以确定给定模型与量化的兼容性仍然至关重要。
### 重打分的影响
在本节中,我们探讨了重打分对检索性能的影响。我们基于 [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) 评估了结果。
#### 二进制重打分
使用二进制嵌入,[mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) 在 MTEB 检索上保留了 92.53% 的性能。仅进行重打分而无需检索更多样本,性能提升到了 96.45%。我们实验设置了 `rescore_multiplier` 从 1 到 10,但没有观察到进一步的性能提升。这表明 `top_k` 搜索已经检索到了最顶级的候选项,而重打分则正确地重新排列了这些好的候选项。
#### 标量 (Int8) 重打分
我们还评估了 [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) 模型与 `int8` 重打分,因为 Cohere 表明 [Cohere-embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/) 在 `int8` 量化后可以达到 `float32` 模型的 100% 性能。在这个实验中,我们将 `rescore_multiplier` 设置为 [1, 4, 10],并得到了以下结果:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/embedding-quantization/rescoring-influence.png">
</p>
从图表中我们可以看到,更高的重打分乘数意味着量化后性能的更好保留。从我们的结果推断,我们假设这种关系可能是双曲线的,随着重打分乘数的增加,性能接近 100%。使用 `int8` 时,重打分乘数为 4-5 已经导致令人瞩目的 99% 的性能保留。
#### 检索速度
我们使用 Google Cloud Platform 的 `a2-highgpu-4g` 实例,在整个 MTEB 检索中测量了 [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) 嵌入的检索速度,该嵌入的维度为 1024。对于 `int8` ,我们使用了 [USearch](https://github.com/unum-cloud/usearch) (版本 2.9.2) 和二进制量化 [Faiss](https://github.com/facebookresearch/faiss) (版本 1.8.0)。所有计算都在 CPU 上使用精确搜索完成。
| 量化 | 最小 | 均值 | 最大 |
|--------------|----------------|--------------------|---------------|
| `float32` | 1x (baseline) | **1x** (baseline) | 1x (baseline) |
| `int8` | 2.99x speedup | **3.66x** speedup | 4.8x speedup |
| `binary` | 15.05x speedup | **24.76x** speedup | 45.8x speedup |
如表中所示,应用 `int8` 标量量化相比全尺寸 `float32` 嵌入实现了平均速度提升 3.66 倍。此外,二进制量化实现了平均速度提升 24.76 倍。对于标量和二进制量化,即使在最坏的情况下,也实现了非常显著的速度提升。
### 性能汇总
量化在资源使用、检索速度和检索性能方面的实验结果和影响可以总结如下:
| | float32 | int8/uint8 | binary/ubinary |
|-------------------------------|---------:|------------:|----------------:|
| **内存和索引空间节省** | 1x | 精确 4x | 精确 32x |
| **检索速度** | 1x | 多达 4x | 多达 45x |
| **默认性能百分比** | 100% | ~99.3% | ~96% |
### 演示
以下 [演示](https://huggingface.co/spaces/sentence-transformers/quantized-retrieval) 展示了通过结合二进制搜索和标量 ( `int8` ) 重打分来提高检索效率。该解决方案需要 5GB 的内存用于二进制索引和 50GB 的磁盘空间用于二进制和标量索引,这比常规的 `float32` 检索所需的 200GB 内存和磁盘空间要少得多。此外,检索速度也更快。
<iframe
src="https://sentence-transformers-quantized-retrieval.hf.space"
frameborder="0"
width="100%"
height="1000"
></iframe>
### 自己尝试
以下脚本可用于实验性地进行检索和其他用途的嵌入量化。它们分为三个类别:
- **推荐检索**:
- [semantic_search_recommended.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/embedding-quantization/semantic_search_recommended.py): 此脚本结合了二进制搜索和标量重打分,与上面的演示类似,以实现廉价、高效且性能良好的检索。
- **使用**:
- [semantic_search_faiss.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/embedding-quantization/semantic_search_faiss.py): 此脚本展示了使用 FAISS 的常规二进制或标量量化、检索和重打分的使用方式,通过使用 <a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.semantic_search_faiss"><code>semantic_search_faiss</code></a> 实用函数。
- [semantic_search_usearch.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/embedding-quantization/semantic_search_usearch.py): 此脚本展示了使用 USearch 的常规二进制或标量量化、检索和重打分的使用方式,通过使用 <a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.semantic_search_usearch"><code>semantic_search_usearch</code></a> 实用函数。
- **基准测试**:
- [semantic_search_faiss_benchmark.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/embedding-quantization/semantic_search_faiss_benchmark.py): 此脚本包括了对 `float32` 检索、二进制检索加重打分和标量检索加重打分的检索速度基准测试,使用 FAISS。它使用了 <a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.semantic_search_faiss"><code>semantic_search_faiss</code></a> 实用函数。我们的基准测试特别显示了 `ubinary` 的速度提升。
- [semantic_search_usearch_benchmark.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/embedding-quantization/semantic_search_usearch_benchmark.py): 此脚本包括了对 `float32` 检索、二进制检索加重打分和标量检索加重打分的检索速度基准测试,使用 USearch。它使用了 <a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.semantic_search_usearch"><code>semantic_search_usearch</code></a> 实用函数。我们的实验在新硬件上显示了巨大的速度提升,特别是对于 `int8` 。
### 未来工作
我们期待二进制量化技术的进一步发展。要提到的一些潜在改进,我们怀疑可能还有比 `int8` 更小的标量量化空间,即使用 128 或 64 个桶而不是 256 个。
此外,我们也很兴奋地发现,嵌入量化与 Matryoshka 表征学习 (MRL) 完全垂直。换句话说,可以将 MRL 嵌入从例如 1024 减少到 128 (通常与 2% 的性能降低相对应),然后应用二进制或标量量化。我们怀疑这可能会将检索速度提高多达 32 倍,质量降低约 3%,或者质量降低约 10% 时检索速度提高多达 256 倍。
最后,我们意识到,使用嵌入量化进行检索可以与一个独立的重新排序模型结合起来使用。我们设想了一个三步流水线: 首先进行二进制搜索,然后对结果进行标量 (int8) 重打分,最后使用交叉编码模型进行重新排序。这样的流水线可以实现高效的检索性能,同时降低延迟、内存使用、磁盘空间和成本。
### 致谢
这个项目得益于我们与 [mixedbread.ai](https://mixedbread.ai) 的合作以及 [SentenceTransformers](https://www.sbert.net/) 库,该库允许你轻松创建句子嵌入并进行量化。如果你想在你的项目中使用量化嵌入,你现在知道该怎么做了!
### 引用
```bibtex
@article{shakir2024quantization,
author = { Aamir Shakir and
Tom Aarsen and
Sean Lee
},
title = { Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval },
journal = {Hugging Face Blog},
year = {2024},
note = {https://huggingface.co/blog/embedding-quantization},
}
```
### 参考文献
<a href="https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1"><code>mixedbread-ai/mxbai-embed-large-v1</code></a><a href="https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode"><code>SentenceTransformer.encode</code></a><a href="https://sbert.net/docs/package_reference/quantization.html#sentence_transformers.quantization.quantize_embeddings"><code>quantize_embeddings</code></a>
- [Sentence Transformers docs - Embedding Quantization](https://sbert.net/examples/applications/embedding-quantization/README.html)
- https://txt.cohere.com/int8-binary-embeddings/
- https://qdrant.tech/documentation/guides/quantization
- https://zilliz.com/learn/scalar-quantization-and-product-quantization
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/game-jam-first-edition-results.md | ---
title: "首届开源 AI 游戏挑战赛事结果"
thumbnail: /blog/assets/game-jam-first-edition-results/thumbnail.jpg
authors:
- user: ThomasSimonini
- user: dylanebert
- user: osanseviero
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 首届开源 AI 游戏挑战赛事结果
北京时间 7 月 8 日到 7 月 10 日, **我们举办了 [首届开源 AI 游戏开发挑战赛](https://itch.io/jam/open-source-ai-game-jam)**。这是一场激动人心的赛事活动,游戏开发者在紧迫的 48 小时内使用 AI 创造、创新有创意的游戏。
本次赛事活动的主要目标是 **至少使用一个开源 AI 工具来创建游戏**,可以嵌入到工作流中辅助游戏开发,也可以集成到游戏内增加趣味玩法。尽管规则允许使用私有的 AI 工具,不过我们更鼓励参与者使用开源的 AI 工具。
活动的反响超出了我们的预期,全球范围内注册数超过 1300 人,共 **提交了 88 款精彩游戏!**
**所有游戏试玩地址:** 👉 https://itch.io/jam/open-source-ai-game-jam/entries
<iframe width="560" height="315" src="https://www.youtube.com/embed/UG9-gOAs2-4" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
## 主题: Expanding
为了激发创造力, **我们决定以 “EXPANDING” 为主题**。我们对其进行开放性解释,让开发者能够探索、试验他们的新奇想法,从而创造出多样化的游戏。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/theme.jpeg" alt="Game Jam Theme"/>
最终游戏由从业者和贡献者根据三个关键标准进行评估: **趣味性 , 创造性 , 扣题度。**
排名前 10 的游戏将提交给三位评委 ([Dylan Ebert](https://twitter.com/dylan_ebert_), [Thomas Simonini](https://twitter.com/ThomasSimonini) 和 [Omar Sanseviero](https://twitter.com/osanseviero)), **由他们评选出最佳游戏。**
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/jury.jpg" alt="Game Jam Judges"/>
## 最佳游戏 🏆🥇
经过认真审议,评委们将 **本届开源 AI 游戏挑战赛最佳游戏** 颁给了:
**由 [ohmlet](https://itch.io/profile/ohmlet) 开发的 [Snip It](https://ohmlet.itch.io/snip-it)** 👏👏👏。
代码: Ruben Gres
AI 资产: Philippe Saade
音乐 / SFX: Matthieu Deloffre
在这款 AI 生成的游戏中,你将参观一座博物馆,馆内布满了栩栩如生的画作。 **剪下画中的物体,揭开它们背后隐藏的秘密**。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/snipit.jpg" alt="Snip it"/>
在线试玩地址: 👉 https://ohmlet.itch.io/snip-it
## 参赛者评选: Top 10 🥈🥉🏅
88 款精彩游戏作品中,最终有 Top 11 款 (有两款并列第 10 ) 游戏留下了深刻印象。
### #1: Snip It
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/snipit2.jpg" alt="Snip it"/>
除了被评委会颁为最佳游戏之外,Snip it 还荣获参赛者评选的 Top 1 游戏。
🤖 使用了开源模型 Stable Diffusion 生成游戏资产
🎮👉 https://ohmlet.itch.io/snip-it
### #2: Yabbit Attack
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/yabbit.jpg" alt="Yabbit Attack"/>
在 Yabbit Attack 中,你的目标是 **击败自适应神经网络中不断增长的 Yabbit**。
🤖 使用了自然选择和进化背景下的遗传算法
🤖 使用了 Stable Diffusion 生成游戏背景视觉效果
🎮👉 https://visionistx.itch.io/yabbit-attack
### #3: Fish Dang Bot Rolling Land (机甲鱼壳郎: 滚滚赞)
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/fish.jpg" alt="Fish Dang Bot Rolling Land"/>
在这款游戏中,你将控制一个被遗弃在废旧垃圾堆里、拥有机械腿的鱼形机器人 Fein。Fein 偶然间醒来,觉醒出了自我意识,看到一只屎壳郎在推粪球。Fein 很自然地把自己幻想成屎壳郎,并梦想推出世界上最大的粪球。怀揣着这个梦想,Fein 决定踏上自己的冒险之旅。
🤖 使用了 Text To Speech 模型生成游戏旁白
🎮👉 https://zeenaz.itch.io/fish-dang-rolling-laud
### #4: Everchanging Quest
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/everchanging.jpg" alt="Everchanging Quest"/>
在这款游戏中,你是全村最后的希望。在踏上冒险之旅前,你要做好万全的准备,佩戴精良的装备,与村民对话并寻求指引。村外的世界充满了变数,加油击败敌人收集积分,找到通往终点的路。
🤖 使用了 GPT-4 放置瓦片图块和其他对象 (专有) 组件,以及使用了 Starcoder 编写代码 (开源)
🎮👉 https://jofthomas.itch.io/everchanging-quest
### #5: Word Conquest (词汇量大作战)
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/word.gif" alt="Word"/>
在这款游戏中,你需要尽可能多地写出 (语义或词性) 不相关的词语,来征服词汇地图。词语之间相关性越低,它们在词汇地图中的距离就越远,你获得的分数就越高。
🤖 使用了 all-MiniLM-L6-v2 模型和 GloVe 计算的 embeddings 来生成词汇地图
🎮👉 https://danielquelali.itch.io/wordconquest
### #6: Expanding Universe
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/universe.jpg" alt="Universe"/>
在这款沙盒引力游戏中,你将创建一个不断扩展的宇宙,并尝试完成目标。
🤖 使用了 Dream Textures Blender (Stable Diffusion) 附加组件生成恒星和行星的纹理贴图,以及使用了 LLM 模型生成恒星和行星的描述内容
🎮👉 https://carsonkatri.itch.io/expanding-universe
### #7: Hexagon Tactics: The Expanding Arena
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/hexagon.gif" alt="Hexagon"/>
在这款游戏中,你将陷入一场竞技场战斗。击败你的对手,升级你的牌组,扩大你的竞技场。
🤖 使用了 Stable Diffusion 1.5 生成定制角色 (可执行版本游戏提供该功能)
🎮👉 https://dgeisert.itch.io/hextactics
### #8: Galactic Domination
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/galactic.gif" alt="Galactic"/>
在这款游戏中,你扮演宇宙飞船的船长。你将踏上星际之旅,与强大的宇宙飞船争夺宇宙的统治地位。你的目标是建造宇宙中第一个强力空间站,以扩大影响力并巩固你在浩瀚宇宙中的霸主地位。在宇宙战场叱诧时,你需要收集必要的资源来升级空间站。这是一场建筑竞赛!
🤖 使用了 Unity ML-Agents (bot-AI 与强化学习配合使用)
🤖 使用了 CharmedAI 提供的 Texture Generator 工具生成纹理资产
🤖 使用了 Soundful 提供的 Music generator 生成音乐
🤖 使用了 Elevenlabs 提供的 Voice generator 生成旁白
🤖 使用了 Scenario 提供的 Image generator 生成图像
🎮👉 https://blastergames.itch.io/galactic-domination
### #9: Apocalypse Expansion
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/appocalypse.jpg" alt="Apocalypse"/>
在这款游戏中,你将扮演一位腐蚀僵尸,并对人肉有着疯狂的渴望。你的目标是组建史上规模最大的僵尸部落,同时注意躲避警察坚持不懈地无情追捕。
🤖 使用了 Stable Diffusion 生成图像
🤖 使用了 MusicGen (melody 1.5B) 生成音乐
🎮👉 https://mad25.itch.io/apocalypse-expansion
### #10: Galactic Bride: Bullet Ballet
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/bride.jpg" alt="Bride"/>
在这款游戏中,你将成为星球王子的新娘,踏上一段劲爽的弹幕地狱冒险,并实现伟大夙愿。
🎮👉 https://n30hrtgdv.itch.io/galactic-bride-bullet-ballet
### #10: Singularity
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/game-jam-first-edition-results/singularity.gif" alt="Singularity"/>
这款游戏 demo 是一个概念演示,你可能很快在不久的将来看到它孕育的游戏或者其他体验。
🤖 使用了 Stable Diffusion
🎮👉 https://ilumine-ai.itch.io/dreamlike-hugging-face-open-source-ai-game-jam
除了 Top 10 游戏之外,其他精彩游戏 (Ghost In Smoke、Outopolis、Dungeons and Decoders…) 也不容错过。 **查看完整游戏列表可点击此处** 👉 https://itch.io/jam/open-source-ai-game-jam/entries
---
事实证明,首届开源 AI 游戏挑战赛取得了惊人的成功,在社区参与度和产出游戏质量方面均超出了我们的预期。强烈的反响 **增强了我们对开源 AI 工具彻底改变游戏行业潜力的信念。**
我们渴望继续这一举措,并计划在未来举办更多活动,为广大游戏开发者提供展示技能的机会,并充分探索 AI 在游戏开发中的影响力。
如果你对 AI for games 感兴趣,我们这里整理了一系列有价值的资源,包括游戏开发中可用的 AI 工具集、以及将 AI 集成到 Unity 等游戏引擎中的教程:
- **[游戏开发 AI 工具集](https://github.com/simoninithomas/awesome-ai-tools-for-game-dev)**
- 如何安装和使用 Hugging Face Unity API: **https://huggingface.co/blog/zh/unity-api**
- 如何在 Unity 游戏中集成 AI 语音识别: **https://huggingface.co/blog/zh/unity-asr**
- 使用 Transformers.js 制作 ML 驱动的网页游戏: **https://huggingface.co/blog/ml-web-games**
- 使用 Hugging Face 🤗 and Unity 构建一个智能机器人 AI: **https://thomassimonini.substack.com/p/building-a-smart-robot-ai-using-hugging**
想了解未来活动的最新动态,可以访问我们的 Discord 服务器,在这里你可以找到 AI for games 专用频道,与更多同好一起交流更加新奇的想法。
加入我们的 Discord Server 👉 **https://hf.co/join/discord**
**感谢所有参与者、贡献者和支持者,是你们让本次活动取得了令人难忘的成功!**
| 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/quanto-diffusers.md | ---
title: "基于 Quanto 和 Diffusers 的内存高效 transformer 扩散模型"
thumbnail: /blog/assets/quanto-diffusers/thumbnail.png
authors:
- user: sayakpaul
- user: dacorvo
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 基于 Quanto 和 Diffusers 的内存高效 transformer 扩散模型
过去的几个月,我们目睹了使用基于 transformer 模型作为扩散模型的主干网络来进行高分辨率文生图 (text-to-image,T2I) 的趋势。和一开始的许多扩散模型普遍使用 UNet 架构不同,这些模型使用 transformer 架构作为扩散过程的主模型。由于 transformer 的性质,这些主干网络表现出了良好的可扩展性,模型参数量可从 0.6B 扩展至 8B。
随着模型越变越大,内存需求也随之增加。对扩散模型而言,这个问题愈加严重,因为扩散流水线通常由多个模型串成: 文本编码器、扩散主干模型和图像解码器。此外,最新的扩散流水线通常使用多个文本编码器 - 如: Stable Diffusion 3 有 3 个文本编码器。使用 FP16 精度对 SD3 进行推理需要 18.765GB 的 GPU 显存。
这么高的内存要求使得很难将这些模型运行在消费级 GPU 上,因而减缓了技术采纳速度并使针对这些模型的实验变得更加困难。本文,我们展示了如何使用 Diffusers 库中的 Quanto 量化工具脚本来提高基于 transformer 的扩散流水线的内存效率。
### 目录
- [基于 Quanto 和 Diffusers 的内存高效 transformer 扩散模型](#基于-quanto-和-diffusers-的内存高效-transformer-扩散模型)
- [目录](#目录)
- [基础知识](#基础知识)
- [用 Quanto 量化 `DiffusionPipeline` ](#用-quanto-量化-diffusionpipeline)
- [上述攻略通用吗?](#上述攻略通用吗)
- [其他发现](#其他发现)
- [在 H100 上 `bfloat16` 通常表现更好](#在-h100-上-bfloat16-常表现更好)
- [`qint8` 的前途](#qint8-的前途)
- [INT4 咋样?](#int4-咋样)
- [加个鸡腿 - 在 Quanto 中保存和加载 Diffusers 模型](#加个鸡腿—在-quanto-中保存和加载-diffusers-模型)
- [小诀窍](#小诀窍)
- [总结](#总结)
## 基础知识
你可参考 [这篇文章](https://huggingface.co/blog/zh/quanto-introduction) 以获取 Quanto 的详细介绍。简单来说,Quanto 是一个基于 PyTorch 的量化工具包。它是 [Hugging Face Optimum](https://github.com/huggingface/optimum) 的一部分,Optimum 提供了一套硬件感知的优化工具。
模型量化是 LLM 从业者必备的工具,但在扩散模型中并不算常用。Quanto 可以帮助弥补这一差距,其可以在几乎不伤害生成质量的情况下节省内存。
我们基于 H100 GPU 配置进行基准测试,软件环境如下:
- CUDA 12.2
- PyTorch 2.4.0
- Diffusers (从源代码安装,参考 [此提交](https://github.com/huggingface/diffusers/commit/bce9105ac79636f68dcfdcfc9481b89533db65e5))
- Quanto (从源代码安装,参考 [此提交](https://github.com/huggingface/optimum-quanto/commit/285862b4377aa757342ed810cd60949596b4872b))
除非另有说明,我们默认使用 FP16 进行计算。我们不对 VAE 进行量化以防止数值不稳定问题。你可于 [此处](https://huggingface.co/datasets/sayakpaul/sample-datasets/blob/main/quanto-exps-2/benchmark.py) 找到我们的基准测试代码。
截至本文撰写时,以下基于 transformer 的扩散模型流水线可用于 Diffusers 中的文生图任务:
- [PixArt-Alpha](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart) 及 [PixArt-Sigma](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart_sigma)
- [Stable Diffusion 3](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_3)
- [Hunyuan DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/hunyuandit)
- [Lumina](https://huggingface.co/docs/diffusers/main/en/api/pipelines/lumina)
- [Aura Flow](https://huggingface.co/docs/diffusers/main/en/api/pipelines/aura_flow)
另外还有一个基于 transformer 的文生视频流水线: [Latte](https://huggingface.co/docs/diffusers/main/en/api/pipelines/latte)。
为简化起见,我们的研究仅限于以下三个流水线: PixArt-Sigma、Stable Diffusion 3 以及 Aura Flow。下表显示了它们各自的扩散主干网络的参数量:
| **模型** | **Checkpoint** | **参数量(Billion)** |
|:-----------------:|:--------------------------------------------------------:|:----------------------:|
| PixArt | https://huggingface.co/PixArt-alpha/PixArt-Sigma-XL-2-1024-MS | 0.611 |
| Stable Diffusion 3| https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers | 2.028 |
| Aura Flow | https://huggingface.co/fal/AuraFlow/ | 6.843 |
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
请记住,本文主要关注内存效率,因为量化对推理延迟的影响很小或几乎可以忽略不计。
</div>
## 用 Quanto 量化 `DiffusionPipeline`
使用 Quanto 量化模型非常简单。
```python
from optimum.quanto import freeze, qfloat8, quantize
from diffusers import PixArtSigmaPipeline
import torch
pipeline = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to("cuda")
quantize(pipeline.transformer, weights=qfloat8)
freeze(pipeline.transformer)
```
我们对需量化的模块调用 `quantize()` ,以指定我们要量化的部分。上例中,我们仅量化参数,保持激活不变,量化数据类型为 FP8。最后,调用 `freeze()` 以用量化参数替换原始参数。
然后,我们就可以如常调用这个 `pipeline` 了:
```python
image = pipeline("ghibli style, a fantasy landscape with castles").images[0]
```
<table>
<tr style="text-align: center;">
<th>FP16</th>
<th> 将 transformer 扩散主干网络量化为 FP8</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptpixart-bs1-dtypefp16-qtypenone-qte0.png" width=512 alt="FP16 image."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptpixart-bs1-dtypefp16-qtypefp8-qte0.png" width=512 alt="FP8 quantized image."/></td>
</tr>
</table>
我们注意到使用 FP8 可以节省显存,且几乎不影响生成质量; 我们也看到量化模型的延迟稍有变长:
| **Batch Size** | **量化** | **内存 (GB)** | **延迟 (秒)** |
|:--------------:|:----------------:|:---------------:|:--------------------:|
| 1 | 无 | 12.086 | 1.200 |
| 1 | FP8 | **11.547** | 1.540 |
| 4 | 无 | 12.087 | 4.482 |
| 4 | FP8 | **11.548** | 5.109 |
我们可以用相同的方式量化文本编码器:
```python
quantize(pipeline.text_encoder, weights=qfloat8)
freeze(pipeline.text_encoder)
```
文本编码器也是一个 transformer 模型,我们也可以对其进行量化。同时量化文本编码器和扩散主干网络可以带来更大的显存节省:
| **Batch Size** | **量化** | **是否量化文本编码器** | **显存 (GB)** | **延迟 (秒)** |
|:--------------:|:----------------:|:---------------:|:---------------:|:--------------------:|
| 1 | FP8 | 否 | 11.547 | 1.540 |
| 1 | FP8 | 是 | **5.363** | 1.601 |
| 4 | FP8 | 否 | 11.548 | 5.109 |
| 4 | FP8 | 是 | **5.364** | 5.141 |
量化文本编码器后生成质量与之前的情况非常相似:
![ckpt@pixart-bs@1-dtype@fp16-qtype@[email protected]](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptpixart-bs1-dtypefp16-qtypefp8-qte1.png)
## 上述攻略通用吗?
将文本编码器与扩散主干网络一起量化普遍适用于我们尝试的很多模型。但 Stable Diffusion 3 是个特例,因为它使用了三个不同的文本编码器。我们发现 _ 第二个 _ 文本编码器量化效果不佳,因此我们推荐以下替代方案:
- 仅量化第一个文本编码器 ([`CLIPTextModelWithProjection`](https://huggingface.co/docs/transformers/en/model_doc/clip#transformers.CLIPTextModelWithProjection)) 或
- 仅量化第三个文本编码器 ([`T5EncoderModel`](https://huggingface.co/docs/transformers/en/model_doc/t5#transformers.T5EncoderModel)) 或
- 同时量化第一个和第三个文本编码器
下表给出了各文本编码器量化方案的预期内存节省情况 (扩散 transformer 在所有情况下均被量化):
| **Batch Size** | **量化** | **量化文本编码器 1** | **量化文本编码器 2** | **量化文本编码器 3** | **显存 (GB)** | **延迟 (秒)** |
|:--------------:|:----------------:|:-----------------:|:-----------------:|:-----------------:|:---------------:|:--------------------:|
| 1 | FP8 | 1 | 1 | 1 | 8.200 | 2.858 |
| 1 ✅ | FP8 | 0 | 0 | 1 | 8.294 | 2.781 |
| 1 | FP8 | 1 | 1 | 0 | 14.384 | 2.833 |
| 1 | FP8 | 0 | 1 | 0 | 14.475 | 2.818 |
| 1 ✅ | FP8 | 1 | 0 | 0 | 14.384 | 2.730 |
| 1 | FP8 | 0 | 1 | 1 | 8.325 | 2.875 |
| 1 ✅ | FP8 | 1 | 0 | 1 | 8.204 | 2.789 |
| 1 | 无 | - | - | - | 16.403 | 2.118 |
<table>
<tr style="text-align: center;">
<th> 量化文本编码器: 1</th>
<th> 量化文本编码器: 3</th>
<th> 量化文本编码器: 1 和 3</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptsd3-bs1-dtypefp16-qtypefp8-qte1-first1.png" width=300 alt="Image with quantized text encoder 1."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptsd3-bs1-dtypefp16-qtypefp8-qte1-third1.png" width=300 alt="Image with quantized text encoder 3."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckptsd3-bs1-dtypefp16-qtypefp8-qte1-first1-third1%201.png" width=300 alt="Image with quantized text encoders 1 and 3."/></td>
</tr>
</table>
## 其他发现
### 在 H100 上 `bfloat16` 通常表现更好
对于支持 `bfloat16` 的 GPU 架构 (如 H100 或 4090),使用 `bfloat16` 速度更快。下表列出了在我们的 H100 参考硬件上测得的 PixArt 的一些数字: **Batch Size** **精度** **量化** **显存 (GB)** **延迟 (秒)** **是否量化文本编码器**
| **Batch Size** | **精度** | **量化** | **显存(GB)** | **延迟(秒)** | **是否量化文本编码器** |
|:--------------:|:-------------:|:----------------:|:---------------:|:--------------------:|:---------------:|
| 1 | FP16 | INT8 | 5.363 | 1.538 | 是 |
| 1 | BF16 | INT8 | 5.364 | **1.454** | 是 |
| 1 | FP16 | FP8 | 5.363 | 1.601 | 是 |
| 1 | BF16 | FP8 | 5.363 | **1.495** | 是 |
### `qint8` 的前途
我们发现使用 `qint8` (而非 `qfloat8` ) 进行量化,推理延迟通常更好。当我们对注意力 QKV 投影进行水平融合 (在 Diffusers 中调用 `fuse_qkv_projections()` ) 时,效果会更加明显,因为水平融合会增大 int8 算子的计算维度从而实现更大的加速。我们基于 PixArt 测得了以下数据以证明我们的发现:
| **Batch Size** | **量化** | **显存 (GB)** | **延迟 (秒)** | **是否量化文本编码器** | **QKV 融合** |
|:--------------:|:----------------:|:---------------:|:--------------------:|:---------------:|:------------------:|
| 1 | INT8 | 5.363 | 1.538 | 是 | 否 |
| 1 | INT8 | 5.536 | **1.504** | 是 | 是 |
| 4 | INT8 | 5.365 | 5.129 | 是 | 否 |
| 4 | INT8 | 5.538 | **4.989** | 是 | 是 |
### INT4 咋样?
在使用 `bfloat16` 时,我们还尝试了 `qint4` 。目前我们仅支持 H100 上的 `bfloat16` 的 `qint4` 量化,其他情况尚未支持。通过 `qint4` ,我们期望看到内存消耗进一步降低,但代价是推理延迟变长。延迟增加的原因是硬件尚不支持 int4 计算 - 因此权重使用 4 位,但计算仍然以 `bfloat16` 完成。下表展示了 PixArt-Sigma 的结果:
| **Batch Size** | **是否量化文本编码器** | **显存 (GB)** | **延迟 (秒)** |
|:--------------:|:---------------:|:---------------:|:--------------------:|
| 1 | 否 | 9.380 | 7.431 |
| 1 | 是 | **3.058** | 7.604 |
但请注意,由于 INT4 量化比较激进,最终结果可能会受到影响。所以,一般对于基于 transformer 的模型,我们通常不量化最后一个投影层。在 Quanto 中,我们做法如下:
```python
quantize(pipeline.transformer, weights=qint4, exclude="proj_out")
freeze(pipeline.transformer)
```
`"proj_out"` 对应于 `pipeline.transformer` 的最后一层。下表列出了各种设置的结果:
<table>
<tr style="text-align: center;">
<th> 量化文本编码器: 否 , 不量化的层: 无 </th>
<th> 量化文本编码器: 否 , 不量化的层: "proj_out"</th>
<th> 量化文本编码器: 是 , 不量化的层: 无 </th>
<th> 量化文本编码器: 是 , 不量化的层: "proj_out"</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckpt%40pixart-bs%401-dtype%40bf16-qtype%40int4-qte%400-fuse%400.png" width=300 alt="Image 1 without text encoder quantization."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckpt%40pixart-bs%401-dtype%40bf16-qtype%40int4-qte%400-fuse%400-exclude%40proj_out.png" width=300 alt="Image 2 without text encoder quantization but with proj_out excluded in diffusion transformer quantization."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckpt%40pixart-bs%401-dtype%40bf16-qtype%40int4-qte%401-fuse%400.png" width=300 alt="Image 3 with text encoder quantization."/></td>
<td><img class="mx-auto" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/quanto-diffusers/ckpt%40pixart-bs%401-dtype%40bf16-qtype%40int4-qte%401-fuse%400-exclude%40proj_out.png" width=300 alt="Image 3 with text encoder quantization but with proj_out excluded in diffusion transformer quantization.."/></td>
</tr>
</table>
为了恢复损失的图像质量,常见的做法是进行量化感知训练,Quanto 也支持这种训练。这项技术超出了本文的范围,如果你有兴趣,请随时与我们联系!
本文的所有实验结果都可以在 [这里](https://huggingface.co/datasets/sayakpaul/sample-datasets/tree/main/quanto-exps-2) 找到。
## 加个鸡腿 - 在 Quanto 中保存和加载 Diffusers 模型
以下代码可用于对 Diffusers 模型进行量化并保存量化后的模型:
```python
from diffusers import PixArtTransformer2DModel
from optimum.quanto import QuantizedPixArtTransformer2DModel, qfloat8
model = PixArtTransformer2DModel.from_pretrained("PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", subfolder="transformer")
qmodel = QuantizedPixArtTransformer2DModel.quantize(model, weights=qfloat8)
qmodel.save_pretrained("pixart-sigma-fp8")
```
此代码生成的 checkpoint 大小为 _**587MB**_ ,而不是原本的 2.44GB。然后我们可以加载它:
```python
from optimum.quanto import QuantizedPixArtTransformer2DModel
import torch
transformer = QuantizedPixArtTransformer2DModel.from_pretrained("pixart-sigma-fp8")
transformer.to(device="cuda", dtype=torch.float16)
```
最后,在 `DiffusionPipeline` 中使用它:
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
transformer=None,
torch_dtype=torch.float16,
).to("cuda")
pipe.transformer = transformer
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt).images[0]
```
将来,我们计划支持在初始化流水线时直接传入 `transformer` 就可以工作:
```diff
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
- transformer=None,
+ transformer=transformer,
torch_dtype=torch.float16,
).to("cuda")
```
`QuantizedPixArtTransformer2DModel` 实现可参考 [此处](https://github.com/huggingface/optimum-quanto/blob/601dc193ce0ed381c479fde54a81ba546bdf64d1/optimum/quanto/models/diffusers_models.py#L184)。如果你希望 Quanto 支持对更多的 Diffusers 模型进行保存和加载,请在 [此处](https://github.com/huggingface/optimum-quanto/issues/new) 提出需求并 `@sayakpaul` 。
## 小诀窍
- 根据应用场景的不同,你可能希望对流水线中不同的模块使用不同类型的量化。例如,你可以对文本编码器进行 FP8 量化,而对 transformer 扩散模型进行 INT8 量化。由于 Diffusers 和 Quanto 的灵活性,你可以轻松实现这类方案。
- 为了优化你的用例,你甚至可以将量化与 Diffuser 中的其他 [内存优化技术]((https://huggingface.co/docs/diffusers/main/en/optimization/memory)) 结合起来,如 `enable_model_cpu_offload() ` 。
## 总结
本文,我们展示了如何量化 Diffusers 中的 transformer 模型并优化其内存消耗。当我们同时对文本编码器进行量化时,效果变得更加明显。我们希望大家能将这些工作流应用到你的项目中并从中受益🤗。
感谢 [Pedro Cuenca](https://github.com/pcuenca) 对本文的细致审阅。 | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/llama31.md | ---
title: "Llama 3.1:405B/70B/8B 模型的多语言与长上下文能力解析"
thumbnail: /blog/assets/llama31/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: alvarobartt
- user: lvwerra
- user: dvilasuero
- user: reach-vb
- user: marcsun13
- user: pcuenq
translators:
- user: AdinaY
---
# Llama 3.1 - 405B、70B 和 8B 的多语言与长上下文能力解析
Llama 3.1 发布了!今天我们迎来了 Llama 家族的新成员 Llama 3.1 进入 Hugging Face 平台。我们很高兴与 Meta 合作,确保在 Hugging Face 生态系统中实现最佳集成。Hub 上现有八个开源权重模型 (3 个基础模型和 5 个微调模型)。
Llama 3.1 有三种规格: 8B 适合在消费者级 GPU 上进行高效部署和开发,70B 适合大规模 AI 原生应用,而 405B 则适用于合成数据、大语言模型 (LLM) 作为评判者或蒸馏。这三个规格都提供基础版和指令调优版。
除了六个生成模型,Meta 还发布了两个新模型: Llama Guard 3 和 Prompt Guard。Prompt Guard 是一个小型分类器,可以检测提示注入和越狱。Llama Guard 3 是一个保护模型,能够分类 LLM 输入和生成的内容。
此次发布的一些功能和集成包括:
- [Hub 上的模型](https://huggingface.co/collections/meta-llama/llama-31-669fc079a0c406a149a5738f)
- Hugging Face Transformers 和 TGI 集成
- [Meta Llama 3.1 405B Instruct 的 Hugging Chat 集成](https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-405b-instruct/)
- 使用推理端点、Google Cloud、Amazon SageMaker 和 DELL Enterprise Hub 进行推理和部署集成
- FP8、AWQ 和 GPTQ 的量化,便于推理
- 使用 🤗 TRL 在单个 GPU 上微调 Llama 3.1 8B
- 使用 Distilabel 生成 Llama 3.1 70B 和 405B 的合成数据
## 目录
- [Llama 3.1 的新功能](#whats-new-with-llama-31)
- [Llama 3.1 需要多少内存?](#how-much-memory-does-llama-31-need)
- [推理内存需求](#inference-memory-requirements)
- [训练内存需求](#training-memory-requirements)
- [Llama 3.1 评估](#llama-31-evaluation)
- [使用 Hugging Face Transformers](#using-hugging-face-transformers)
- [如何使用 Llama 3.1](#how-to-prompt-llama-31)
- [内置工具调用](#built-in-tool-calling)
- [自定义工具调用](#custom-tool-calling)
- [演示](#demo)
- [Llama 3.1 405B 的 FP8、AWQ 和 GPTQ 量化](#llama-31-405b-quantization-with-fp8-awq-and-gptq)
- [推理集成](#inference-integrations)
- [Hugging Face 推理 API](#hugging-face-inference-api)
- [Hugging Face 推理端点](#hugging-face-inference-endpoints)
- [Hugging Face 合作伙伴集成](#hugging-face-partner-integrations)
- [使用 Hugging Face TRL 进行微调](#fine-tuning-with-hugging-face-trl)
- [使用 distilabel 生成合成数据](#synthetic-data-generation-with-distilabel)
- [附加资源](#additional-resources)
- [致谢](#acknowledgments)
## Llama 3.1 的新功能
Llama 3.1 为什么令人兴奋?在前代产品的基础上,Llama 3.1 增加了一些关键新功能:
- 128K token 的长上下文能力 (相较于原来的 8K)
- 多语言支持
- 工具使用功能
- 拥有 4050 亿参数的超大稠密模型
- 更宽松的许可证
让我们深入了解这些新功能!
Llama 3.1 版本引入了基于 Llama 3 架构的六个新开源 LLM 模型。它们有三种规格: 8B、70B 和 405B 参数,每种都有基础版 (预训练) 和指令调优版。所有版本都支持 128K token 的上下文长度和 8 种语言,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。Llama 3.1 继续使用分组查询注意力 (GQA),这是一种高效的表示方式,有助于处理更长的上下文。
- [Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B): 基础 8B 模型
- [Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct): 基础 8B 模型的指令调优版
- [Meta-Llama-3.1-70B](https://huggingface.co/meta-llama/Meta-Llama-3.1-70B): 基础 70B 模型
- [Meta-Llama-3.1-70B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct): 基础 70B 模型的指令调优版
- [Meta-Llama-3.1-405B](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B): 基础 405B 模型
- [Meta-Llama-3.1-405B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct): 基础 405B 模型的指令调优版
除了这六个语言模型,还发布了 Llama Guard 3 和 Prompt Guard。
- [Llama Guard 3](https://huggingface.co/meta-llama/Llama-Guard-3-8B) 是 Llama Guard 家族的最新版本,基于 Llama 3.1 8B 进行微调。它为生产用例而设计,具有 128k 的上下文长度和多语言能力。Llama Guard 3 可以分类 LLM 的输入 (提示) 和输出,以检测在风险分类中被认为不安全的内容。
- [Prompt Guard](https://huggingface.co/meta-llama/Prompt-Guard-86M),另一方面,是一个小型 279M 参数的基于 BERT 的分类器,可以检测提示注入和越狱。它在大规模攻击语料库上训练,并建议使用特定应用的数据进行进一步微调。
与 Llama 3 相比,Llama 3.1 的新特点是指令模型在工具调用方面进行了微调,适用于智能体用例。内置了两个工具 (搜索,使用 Wolfram Alpha 进行数学推理),可以扩展为自定义 JSON 功能。
Llama 3.1 模型在定制 GPU 集群上训练了超过 15 万亿 token,总计 39.3M GPU 小时 (8B 1.46M,70B 7.0M,405B 30.84M)。我们不知道训练数据集混合的具体细节,但我们猜测它在多语言方面有更广泛的策划。Llama 3.1 Instruct 已优化用于指令跟随,并在公开可用的指令数据集以及超过 2500 万合成生成的示例上进行监督微调 (SFT) 和人类反馈的强化学习 (RLHF)。Meta 开发了基于 LLM 的分类器,以在数据混合创建过程中过滤和策划高质量的提示和响应。
关于许可条款,Llama 3.1 具有非常相似的许可证,但有一个关键区别: **它允许使用模型输出来改进其他 LLM**。这意味着合成数据生成和蒸馏是允许的,即使是不同的模型!这对 405B 模型尤其重要,如后面所讨论的。许可证允许再分发、微调和创建衍生作品,仍然要求派生模型在其名称的开头包括 “Llama”,并且任何衍生作品或服务必须提及 “Built with Llama”。有关完整详情,请确保阅读 [官方许可证](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct/blob/main/LICENSE)。
## Llama 3.1 需要多少内存?
Llama 3.1 带来了令人兴奋的进步。然而,运行它需要仔细考虑硬件资源。我们分解了三种模型规格在训练和推理中的内存需求。
### 推理内存需求
对于推理,内存需求取决于模型规格和权重的精度。以下是不同配置所需的近似内存:
<table>
<tr>
<td><strong> 模型规格 </strong>
</td>
<td><strong>FP16</strong>
</td>
<td><strong>FP8</strong>
</td>
<td><strong>INT4</strong>
</td>
</tr>
<tr>
<td>8B
</td>
<td>16 GB
</td>
<td>8 GB
</td>
<td>4 GB
</td>
</tr>
<tr>
<td>70B
</td>
<td>140 GB
</td>
<td>70 GB
</td>
<td>35 GB
</td>
</tr>
<tr>
<td>405B
</td>
<td>810 GB
</td>
<td>405 GB
</td>
<td>203 GB
</td>
</tr>
</table>
_注意: 上面引用的数字表示仅加载模型检查点所需的 GPU VRAM。它们不包括内核或 CUDA 图形的 torch 保留空间。_
例如,一个 H100 节点 (8x H100) 有约 640GB 的 VRAM,因此 405B 模型需要在多节点设置中运行或以较低精度 (例如 FP8) 运行,这是推荐的方法。
请记住,较低精度 (例如 INT4) 可能会导致一些精度损失,但可以显著减少内存需求并提高推理速度。除了模型权重外,您还需要将 KV 缓存保持在内存中。它包含模型上下文中所有 token 的键和值,以便在生成新 token 时不需要重新计算。特别是当利用可用的长上下文长度时,它变得至关重要。在 FP16 中,KV 缓存内存需求如下:
<table>
<tr>
<td><strong> 模型规格 </strong>
</td>
<td><strong>1k token</strong>
</td>
<td><strong>16k token</strong>
</td>
<td><strong>128k token</strong>
</td>
</tr>
<tr>
<td>8B
</td>
<td>0.125 GB
</td>
<td>1.95 GB
</td>
<td>15.62 GB
</td>
</tr>
<tr>
<td>70B
</td>
<td>0.313 GB
</td>
<td>4.88 GB
</td>
<td>39.06 GB
</td>
</tr>
<tr>
<td>405B
</td>
<td>0.984 GB
</td>
<td>15.38
</td>
<td>123.05 GB
</td>
</tr>
</table>
特别是对于小规格模型,当接近上下文长度上限时,缓存使用的内存与权重一样多。
### 训练内存需求
以下表格概述了使用不同技术训练 Llama 3.1 模型的大致内存需求:
<table>
<tr>
<td><strong> 模型规格 </strong>
</td>
<td><strong> 全量微调 </strong>
</td>
<td><strong>LoRA</strong>
</td>
<td><strong>Q-LoRA</strong>
</td>
</tr>
<tr>
<td>8B
</td>
<td>60 GB
</td>
<td>16 GB
</td>
<td>6 GB
</td>
</tr>
<tr>
<td>70B
</td>
<td>500 GB
</td>
<td>160 GB
</td>
<td>48 GB
</td>
</tr>
<tr>
<td>405B
</td>
<td>3.25 TB
</td>
<td>950 GB
</td>
<td>250 GB
</td>
</tr>
</table>
_注意: 这些是估计值,可能会根据具体实现细节和优化情况有所不同。_
## Llama 3.1 评估
_注意: 我们目前正在新的 [Open LLM Leaderboard 2](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) 上单独评估 Llama 3.1,并将在今天晚些时候更新此部分。以下是 Meta 官方评估的摘录。_
<table>
<tr>
<td><strong><em>类别</em></strong>
</td>
<td><strong><em>基准</em></strong>
</td>
<td><strong><em>样本数</em></strong>
</td>
<td><strong><em>指标</em></strong>
</td>
<td><strong><em>Llama 3 8B</em></strong>
</td>
<td><strong><em>Llama 3.1 8B</em></strong>
</td>
<td><strong><em>Llama 3 70B</em></strong>
</td>
<td><strong><em>Llama 3.1 70B</em></strong>
</td>
<td><strong><em>Llama 3.1 405B</em></strong>
</td>
</tr>
<tr>
<td><em>综合</em>
</td>
<td><em>MMLU</em>
</td>
<td><em>5</em>
</td>
<td><em>宏观平均/字符准确率</em></td>
<td><em>66.7</em>
</td>
<td><em>66.7</em>
</td>
<td><em>79.5</em>
</td>
<td><em>79.3</em>
</td>
<td><em>85.2</em></td>
</tr>
<tr>
<td></td>
<td><em>MMLU PRO(CoT)</em></td>
<td><em>5</em></td>
<td><em>宏观平均/字符准确率</em></td>
<td><em>36.2</em></td>
<td><em>37.1</em></td>
<td><em>55.0</em></td>
<td><em>53.8</em></td>
<td><em>61.6</em></td>
</tr>
<tr>
<td></td>
<td><em>AGIEval 英语</em></td>
<td><em>3-5</em></td>
<td><em>平均/字符准确率</em></td>
<td><em>47.1</em></td>
<td><em>47.8</em></td>
<td><em>63.0</em></td>
<td><em>64.6</em></td>
<td><em>71.6</em></td>
</tr>
<tr>
<td></td>
<td><em>CommonSenseQA</em></td>
<td><em>7</em></td>
<td><em>字符准确率</em></td>
<td><em>72.6</em></td>
<td><em>75.0</em></td>
<td><em>83.8</em></td>
<td><em>84.1</em></td>
<td><em>85.8</em></td>
</tr>
<tr>
<td></td>
<td><em>Winogrande</em></td>
<td><em>5</em></td>
<td><em>字符准确率</em></td>
<td><em>-</em></td>
<td><em>60.5</em></td>
<td><em>-</em></td>
<td><em>83.3</em></td>
<td><em>86.7</em></td>
</tr>
<tr>
<td></td>
<td><em>BIG-Bench Hard(CoT)</em></td>
<td><em>3</em></td>
<td><em>平均/完全匹配</em></td>
<td><em>61.1</em></td>
<td><em>64.2</em></td>
<td><em>81.3</em></td>
<td><em>81.6</em></td>
<td><em>85.9</em></td>
</tr>
<tr>
<td></td>
<td><em>ARC-Challenge</em></td>
<td><em>25</em></td>
<td><em>字符准确率</em></td>
<td><em>79.4</em></td>
<td><em>79.7</em></td>
<td><em>93.1</em></td>
<td><em>92.9</em></td>
<td><em>96.1</em></td>
</tr>
<tr>
<td><em>知识推理</em></td>
<td><em>TriviaQA-Wiki</em></td>
<td><em>5</em></td>
<td><em>完全匹配</em></td>
<td><em>78.5</em></td>
<td><em>77.6</em></td>
<td><em>89.7</em></td>
<td><em>89.8</em></td>
<td><em>91.8</em></td>
</tr>
<tr>
<td></td>
<td><em>SQuAD</em></td>
<td><em>1</em></td>
<td><em>完全匹配</em></td>
<td><em>76.4</em></td>
<td><em>77.0</em></td>
<td><em>85.6</em></td>
<td><em>81.8</em></td>
<td><em>89.3</em></td>
</tr>
<tr>
<td><em>阅读理解</em></td>
<td><em>QuAC(F1)</em></td>
<td><em>1</em></td>
<td><em>F1</em></td>
<td><em>44.4</em></td>
<td><em>44.9</em></td>
<td><em>51.1</em></td>
<td><em>51.1</em></td>
<td><em>53.6</em></td>
</tr>
<tr>
<td></td>
<td><em>BoolQ</em></td>
<td><em>0
</em></td>
<td><em>字符准确率</em></td>
<td><em>75.7</em></td>
<td><em>75.0</em></td>
<td><em>79.0</em></td>
<td><em>79.4</em></td>
<td><em>80.0</em></td>
</tr>
<tr>
<td></td>
<td><em>DROP(F1)</em></td>
<td><em>3</em></td>
<td><em>F1</em></td>
<td><em>58.4</em></td>
<td><em>59.5</em></td>
<td><em>79.7</em></td>
<td><em>79.6</em></td>
<td><em>84.8</em></td>
</tr>
</table>
## 使用 Hugging Face Transformers
Llama 3.1 需要进行少量建模更新,以有效处理 RoPE 缩放。使用 Transformers [4.43 版](https://github.com/huggingface/transformers/tags),您可以使用新的 Llama 3.1 模型,并利用 Hugging Face 生态系统中的所有工具。确保使用最新的 `transformers` 版本:
```bash
pip install "transformers>=4.43" --upgrade
```
几个细节:
- Transformers 默认以 bfloat16 加载模型。这是 Meta 发布的原始检查点使用的类型,因此这是确保最佳精度或进行评估的推荐方法。
- 助手响应可能以特殊 token `<|eot_id|>` 结尾,但我们还必须在找到常规 EOS token 时停止生成。我们可以通过在 `eos_token_id` 参数中提供终止符列表来提前停止生成。
- 我们使用了 Meta 代码库中的默认采样参数 (`temperature` 和 `top_p` )。我们还没有时间进行广泛测试,请随意探索!
以下代码段显示了如何使用 `meta-llama/Meta-Llama-3.1-8B-Instruct` 。它大约需要 16 GB 的 VRAM,适合许多消费者级 GPU。相同的代码段适用于 `meta-llama/Meta-Llama-3.1-70B-Instruct` ,在 140GB VRAM 和 `meta-llama/Meta-Llama-3.1-405B-Instruct` (需要 810GB VRAM),使其成为生产用例的非常有趣的模型。可以通过以 8 位或 4 位模式加载进一步减少内存消耗。
```python
from transformers import pipeline
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
do_sample=False,
)
assistant_response = outputs[0]["generated_text"][-1]["content"]
print(assistant_response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?
```
您还可以自动量化模型,以 8 位甚至 4 位模式加载,使用 bitsandbytes。4 位加载大 70B 版本大约需要 34 GB 的内存运行。这是如何以 4 位模式加载生成管道:
```python
pipeline = pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.bfloat16,
"quantization_config": {"load_in_4bit": True}
},
)
```
有关使用 `transformers` 模型的更多详细信息,请查看 [模型卡片](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)。
_注意: Transformers 处理所有棘手的提示模板问题,如果您想了解更多关于提示的信息,请查看下一部分。_
## 如何使用 Llama 3.1
基础模型没有提示格式。像其他基础模型一样,它们可以用于继续输入序列并进行合理的延续或零样本/少样本推理。它们也是微调您自己用例的绝佳基础。
指令版本支持具有 4 个角色的对话格式:
1. **system:** 设置对话的上下文。它允许包括规则、指南或必要的信息,帮助有效响应。它也用于在适当情况下启用工具使用。
2. **user:** 用户输入、命令和对模型的问题。
3. **assistant:** 助手的响应,基于 `system` 和 `user` 提示中提供的上下文。
4. **ipython:** Llama 3.1 中引入的新角色。当工具调用返回给 LLM 时作为输出使用。
指令版本使用以下对话结构进行简单对话:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_msg_1 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1 }}<|eot_id|>
```
Llama 3.1 指令模型现在支持工具调用,包括三个内置工具 (brave_search、wolfram_alpha 和 code_interpreter) 和通过 JSON 函数调用的自定义工具调用。内置工具使用 Python 语法。生成 Python 代码以进行函数调用是代码解释器工具的一部分,必须在系统提示中使用 `Environment` 关键字启用,如下所示。
### 内置工具调用
包括 "Environment: ipython" 会打开代码解释器模式,模型可以生成它期望被执行的 Python 代码。助手响应的消息体以特殊标记 `<|python_tag|>` 开头,以 `<|eom_id|>` 结尾,而不是标准 `<|eot_id|>`。后者表示回合结束,而前者表示继续多步推理。
<details close>
<summary>内置工具调用示例</summary>
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Environment: ipython
Tools: brave_search, wolfram_alpha
Cutting Knowledge Date: 01 March 2023
Today's Date: 13 July 2024
You are a helpful Assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Weather in Menlo Park, California<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
此时模型的响应将包括调用其中一个支持的工具 (在本例中为 `brave_search` ) 的 Python 代码:
```
<|python_tag|>brave_search.call(query="current weather in Menlo Park, California")<|eom_id|>
```
执行调用的响应然后发送回模型以检索最终响应。为了简洁,以下内容将附加到前面代码段中显示的消息:
```
<|python_tag|>brave_search.call(query="Menlo Park California weather")<|eom_id|><|start_header_id|>ipython<|end_header_id|>
{"query": "Menlo Park California weather", "top_k": [{"title": "10-Day Weather Forecast for West Menlo Park, CA - The Weather Channel | weather.com", "url": "https://weather.com/weather/tenday/l/West+Menlo+Park+CA?canonicalCityId=b2375713aa1943aad7d1a13a85e1c0adad13c1b10563b2bbaad70734dc61cf11", "description": "Be prepared with the most accurate 10-day forecast for West <strong>Menlo</strong> <strong>Park</strong>, CA with highs, lows, chance of precipitation from The <strong>Weather</strong> Channel and <strong>Weather</strong>.com", "type": "search_result"},....}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
LLM 的最终响应将是:
```
The current weather in Menlo Park, California is mostly sunny with a high of 77°F and a low of 56°F.<|eot_id|>
```
</details>
## 自定义工具调用
Llama 3.1 指令支持从单个用户消息中调用自定义函数。以下提示提供了如何从模型输出调用自定义函数的示例。在自定义函数调用中,模型输出 `<|eot_id|>` 而不是 `<|eom_id|>` 。需要调整系统提示以告知模型如何处理函数调用输出。
<details close>
<summary>自定义工具调用 JSON 函数</summary>
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant with tool calling capabilities. When you receive a tool call response, use the output to format an answer to the orginal user question.<|eot_id|><|start_header_id|>user<|end_header_id|>
Given the following functions, please respond with a JSON for a function call with its proper arguments that best answers the given prompt.
Respond in the format {"name": function name, "parameters": dictionary of argument name and its value}. Do not use variables.
{
"type": "function",
"function": {
"name": "get_current_conditions",
"description": "Get the current weather conditions for a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["Celsius", "Fahrenheit"],
"description": "The temperature unit to use. Infer this from the user's location."
}
},
"required": ["location", "unit"]
}
}
}
Question: what is the weather like in Menlo Park?<|eot_id|><|start_header_id|>assitant<|end_header_id|>
{"name": "get_current_conditions", "parameters": {"location": "Menlo Park, CA", "unit": "Fahrenheit"}}<|eot_id|><|start_header_id|>ipython<|end_header_id|>
```
当我们从选定的工具检索输出时,我们将其传回模型,使用相同的 `<|python_tag|>` 分隔符。`<|python_tag|>` 不意味着使用 Python。它仅用于表示任何工具的输出开始。
```
<|python_tag|>{
"tool_call_id": "get_current_conditions"
"output": "Clouds giving way to sun Hi: 76° Tonight: Mainly clear early, then areas of low clouds forming Lo: 56°"
}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The weather in Menlo Park is currently cloudy with a high of 76° and a low of 56°, with clear skies expected tonight.<|eot_id|>
```
这种格式必须精确复制才能有效使用。transformers 中可用的聊天模板使其易于正确格式化提示。
</details>
## 演示
您可以在以下演示中试验三种指令模型:
- Llama 3.1 405B 的 Hugging Chat [https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-405b-instruct/](https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-405b-instruct/)
- Llama 3.1 70B 的 Hugging Chat [https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-70b-instruct/](https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-70b-instruct/)
- Llama 3.1 8B 演示的 Gradio 驱动的 Space [https://huggingface.co/spaces/ysharma/Chat_with_Meta_llama3_1_8b](https://huggingface.co/spaces/ysharma/Chat_with_Meta_llama3_1_8b)
整个堆栈都是开源的。Hugging Chat 由 [chat-ui](https://github.com/huggingface/chat-ui) 和 [text-generation-inference](https://github.com/huggingface/text-generation-inference) 提供支持。
## Llama 3.1 405B 的 FP8、AWQ 和 GPTQ 量化
Meta 创建了 [Llama 3.1 405B 的官方 FP8 量化版本](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8),精度损失最小。为实现这一目标,FP8 量化仅应用于模型的主要线性运算符,例如 FFNs 的门和上升及下降投影 (涵盖 75% 的推理 FLOPs)。我们共同努力,确保此 FP8 量化检查点在社区中兼容 (transformers, TGI, VLLM)。
此外,我们使用 AutoAWQ 和 AutoGPTQ 创建了 INT4 的 AWQ 和 GPTQ 量化变体。对于 AWQ,所有线性层都使用 GEMM 内核进行量化,将零点量化到 4 位,组大小为 128; 对于 GPTQ,相同的设置仅使用 GPTQ 内核。我们确保 INT4 检查点与 transformers 和 TGI 兼容,包括 Marlin 内核支持,以加快 TGI 中 GPTQ 量化的推理速度。
可用的 Llama 3.1 405B 的量化权重:
- [meta-llama/Meta-Llama-3.1-405B-Base-FP8](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-FP8): 官方 FP8 量化权重,可在 8xH100 上运行
- [meta-llama/Meta-Llama-3.1-405B-Instruct-FP8](https://huggingface.co/sllhf/Meta-Llama-3.1-405B-Instruct-FP8): 官方 FP8 量化权重,可在 8xH100 上运行
- [hugging-quants/Meta-Llama-3.1-405B-Instruct-AWQ-INT4](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-AWQ-INT4): Hugging Face 量化权重,可在 8xA100 80GB, 8xH100 80GB 和 8xA100 40GB (减少 KV 缓存且无 CUDA 图形) 上运行
- [hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4:](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4): Hugging Face 量化权重,可在 8xA100 80GB, 8xH100 80GB 和 8xA100 40GB (减少 KV 缓存且无 CUDA 图形) 上运行
- [hugging-quants/Meta-Llama-3.1-405B-BNB-NF4](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-BNB-NF4): Hugging Face 量化权重,适用于 QLoRA 微调
- [hugging-quants/Meta-Llama-3.1-405B-Instruct-BNB-NF4](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-BNB-NF4): Hugging Face 量化权重,适用于在 8xA100 和 4xH100 上推理
[Hugging Quants 组织](https://huggingface.co/hugging-quants) 还包含 70B 和 8B 版本的量化检查点。
## 推理集成
### Hugging Face 推理 API
[Hugging Face PRO 用户现在可以访问独家 API 端点](https://huggingface.co/blog/inference-pro),托管 Llama 3.1 8B Instruct、Llama 3.1 70B Instruct 和 Llama 3.1 405B Instruct AWQ,由 [text-generation-inference](https://github.com/huggingface/text-generation-inference) 提供支持。所有版本都支持 Messages API,因此与 OpenAI 客户端库兼容,包括 LangChain 和 LlamaIndex。
_注意: 使用 `pip install "huggingface_hub>=0.24.1"` 更新到最新的 `huggingface_hub` 版本。_
```python
from huggingface_hub import InferenceClient
# 初始化客户端,指向一个可用的模型
client = InferenceClient()
chat_completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
messages=[
{"role": "system", "content": "You are a helpful and honest programming assistant."},
{"role": "user", "content": "Is Rust better than Python?"},
],
stream=True,
max_tokens=500
)
# 迭代并打印流
for message in chat_completion:
print(message.choices[0].delta.content, end="")
```
有关使用 Messages API 的更多详细信息,请查看 [此帖子](https://huggingface.co/blog/tgi-messages-api)。
### Hugging Face 推理端点
您可以在 Hugging Face 的 [推理端点](https://ui.endpoints.huggingface.co/) 上部署 Llama 3.1,它使用 Text Generation Inference 作为后端。Text Generation Inference 是 Hugging Face 开发的生产就绪推理容器,支持 FP8、连续批处理、token 流、张量并行,以便在多个 GPU 上快速推理。要部署 Llama 3.1,请转到 [模型页面](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct) 并点击部署 -> 推理端点小部件:
- [Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) 推荐在 1x NVIDIA A10G 或 L4 GPU 上运行
- [Meta-Llama-3.1-70B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct) 推荐在 4x NVIDIA A100 或量化为 AWQ/GPTQ 在 2x A100 上运行
- [Meta-Llama-3.1-405B-Instruct-FP8](https://huggingface.co/sllhf/Meta-Llama-3.1-405B-Instruct-FP8) 推荐在 8x NVIDIA H100 上以 FP 运行或量化为 [AWQ](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-AWQ-INT4)/[GPTQ](https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4) 在 8x A100 上运行
```python
from huggingface_hub import InferenceClient
# 初始化客户端,指向一个可用的模型
client = InferenceClient(
base_url="<ENDPOINT_URL>",
)
# 创建一个聊天完成
chat_completion = client.chat.completions.create(
model="ENDPOINT",
messages=[
{"role": "system", "content": "You are a helpful and honest programming assistant."},
{"role": "user", "content": "Is Rust better than Python?"},
],
stream=True,
max_tokens=500
)
# 迭代并打印流
for message in chat_completion:
print(message.choices[0].delta.content, end="")
```
## Hugging Face 合作伙伴集成
_注意: 我们目前正在与我们的合作伙伴 AWS、Google Cloud、Microsoft Azure 和 DELL 合作,将 Llama 3.1 8B、70B 和 405B 添加到 Amazon SageMaker、Google Kubernetes Engine、Vertex AI Model Catalog、Azure AI Studio、DELL Enterprise Hub。我们将在容器可用时更新此部分 - 您可以 [订阅 Hugging Squad 以获取电子邮件更新](https://mailchi.mp/huggingface/squad)。_
## 使用 Hugging Face TRL 进行微调
在本节中,我们将查看 Hugging Face 生态系统中可用的工具,以便在消费者级 GPU 上高效训练 Llama 3.1。下面是一个示例命令,用于在 OpenAssistant 的 [chat 数据集](https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25) 上微调 Llama 3.1 8B。我们使用 4 位量化和 [QLoRA](https://arxiv.org/abs/2305.14314) 来节省内存,以针对所有注意力块的线性层。
<details close>
<summary>使用 Hugging Face TRL 的微调示例</summary>
首先,安装最新版本的 🤗 TRL 并克隆 repo 以访问 [训练脚本](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py):
```
pip install "transformers>=4.43" --upgrade
pip install --upgrade bitsandbytes
pip install --ugprade peft
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl
```
然后你可以运行脚本:
```
python \
examples/scripts/sft.py \
--model_name meta-llama/Meta-Llama-3.1-8B \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--dataset_text_field="text" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--learning_rate 2e-4 \
--report_to "none" \
--bf16 \
--max_seq_length 1024 \
--lora_r 16 --lora_alpha 32 \
--lora_target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit \
--use_peft \
--attn_implementation "flash_attention_2" \
--logging_steps=10 \
--gradient_checkpointing \
--output_dir llama31
```
如果您有更多的 GPU,可以使用 DeepSpeed 和 ZeRO Stage 3 运行训练:
```
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft.py \
--model_name meta-llama/Meta-Llama-3.1-8B \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--dataset_text_field="text" \
--per_device train batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--learning_rate 2e-5 \
--report_to wandb \
--bf16 \
--max_seq_length 1024 \
--attn_implementation eager \
--logging_steps=10 \
--gradient_checkpointing \
--output_dir models/llama
```
</details>
## 使用 distilabel 生成合成数据
Llama 3.1 许可证的一个重大变化是,它允许使用模型输出来改进其他 LLM,这意味着您可以使用 Llama 3.1 模型生成合成数据集,并使用它们来微调更小、更专业的模型。
让我们看一个示例,如何使用 [distilabel](https://github.com/argilla-io/distilabel),一个用于生成合成数据的开源框架,生成一个偏好数据集。该数据集可用于使用 TRL 提供的偏好优化方法 (如 DPO 或 KTO) 微调模型。
首先安装最新的 `distilabel` 版本,包括 `hf-inference-endpoints` 额外组件,使用 `pip` 如下:
```bash
pip install “distilabel[hf-inference-endpoints]” --upgrade
```
然后定义一个管道:
- 从 Hugging Face Hub 加载带有指令的数据集。
- 使用 Hugging Face 推理端点,通过 Llama 3.1 70B Instruct 和 Llama 3.1 405B Instruct 生成响应。
- 最后,使用 Llama 3.1 405B Instruct 作为裁判,使用 UltraFeedback 提示对响应进行评分。从这些评分中,可以选择和拒绝响应,并使用偏好优化方法微调模型。
请参阅下面的代码以定义管道,或使用此 [Colab 笔记本](https://colab.research.google.com/drive/1o0ALge7DHBmcKgdyrk59yOL70tcGS3v4?usp=sharing) 自行运行并探索生成的数据集。
```python
from distilabel.llms import InferenceEndpointsLLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromHub, CombineColumns
from distilabel.steps.tasks import TextGeneration, UltraFeedback
llama70B = InferenceEndpointsLLM(
model_id="meta-llama/Meta-Llama-3.1-70B-Instruct"
)
llama405B = InferenceEndpointsLLM(
model_id="meta-llama/Meta-Llama-3.1-405B-Instruct-FP8"
)
with Pipeline(name="synthetic-data-with-llama3") as pipeline:
# 加载带有提示的数据集
load_dataset = LoadDataFromHub(
repo_id="argilla/10Kprompts-mini"
)
# 为每个提示生成两个响应
generate = [
TextGeneration(llm=llama70B),
TextGeneration(llm=llama405B)
]
# 将响应组合到一个列中
combine = CombineColumns(
columns=["generation", "model_name"],
output_columns=["generations", "model_names"]
)
# 使用 405B LLM-as-a-judge 对响应进行评分
rate = UltraFeedback(aspect="overall-rating", llm=llama405B)
# 定义管道
load_dataset >> generate >> combine >> rate
if __name__ == "__main__":
distiset = pipeline.run()
```
接下来是什么?除了上述示例, `distilabel` 还提供了使用 LLM 在广泛的场景和主题中生成合成数据的令人兴奋的方法。它包括当前 SOTA 文献中的实现,用于任务如使用 LLM-as-a-judge 方法评估输出、进化指令、数据过滤以及定义自定义组件。
## 附加资源
- [Hub 上的模型](https://huggingface.co/collections/meta-llama/llama-31-669fc079a0c406a149a5738f)
- [Hugging Face Llama Recipes](https://github.com/huggingface/huggingface-llama-recipes)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Llama 3.1 405B Instruct 的 Hugging Chat 演示](https://huggingface.co/chat/models/meta-llama/Meta-Llama-3.1-405b-instruct/)
- [Meta 博客](https://ai.meta.com/blog/meta-llama-3-1/)
## 致谢
没有成千上万社区成员对 transformers、tgi、vllm、pytorch、LM Eval Harness 和许多其他项目的贡献,这些模型的发布和生态系统中的支持与评估是不可能实现的。这次发布离不开 [Clémentine](https://huggingface.co/clefourrier) 和 [Nathan](https://huggingface.co/SaylorTwift) 对 LLM 评估的支持; [Nicolas](https://huggingface.co/Narsil)、[Olivier Dehaene](https://huggingface.co/olivierdehaene) 和 [Daniël de Kok](https://huggingface.co/danieldk) 对 Text Generation Inference 支持的贡献; [Arthur](https://huggingface.co/ArthurZ)、[Matthew Carrigan](https://huggingface.co/Rocketknight1)、[Zachary Mueller](https://huggingface.co/muellerzr)、[Joao](https://huggingface.co/joaogante)、[Joshua Lochner](https://huggingface.co/Xenova) 和 [Lysandre](https://huggingface.co/lysandre) 对 Llama 3.1 集成到 `transformers` 的贡献; [Matthew Douglas](https://huggingface.co/mdouglas) 对量化支持的贡献; [Gabriel Martín Blázquez](https://huggingface.co/gabrielmbmb) 对 `distilabel` 支持的贡献; [Merve Noyan](https://huggingface.co/merve) 和 [Aymeric Roucher](https://huggingface.co/m-ric) 对审核的贡献; [hysts](huggingface.co/hysts) 和 [Yuvi](huggingface.co/ysharma) 对演示的贡献; [Ellie](https://huggingface.co/eliebak) 对微调测试的贡献; [Brigitte Tousignant](https://huggingface.co/BrigitteTousi) 和 [Florent Daudens](https://huggingface.co/fdaudens) 对沟通的贡献; [Nathan](https://huggingface.co/nsarrazin) 和 [Victor](https://huggingface.co/victor) 对 Hugging Chat 中 Llama 3.1 的可用性的贡献。
感谢 Meta 团队发布 Llama 3.1 并使其在开源 AI 社区中可用!
| 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/intro-graphml.md | ---
title: "一文带你入门图机器学习"
thumbnail: /blog/assets/125_intro-to-graphml/thumbnail.png
authors:
- user: clefourrier
translators:
- user: MatrixYao
- user: inferjay
proofreader: true
---
# 一文带你入门图机器学习
本文主要涉及图机器学习的基础知识。
我们首先学习什么是图,为什么使用图,以及如何最佳地表示图。然后,我们简要介绍大家如何在图数据上学习,从神经网络以前的方法 (同时我们会探索图特征) 到现在广为人知的图神经网络 (Graph Neural Network,GNN)。最后,我们将一窥图数据上的 Transformers 世界。
## 什么是图?
本质上来讲,图描述了由关系互相链接起来的实体。
现实中有很多图的例子,包括社交网络 (如推特,长毛象,以及任何链接论文和作者的引用网络) 、分子、知识图谱 (如 UML 图,百科全书,以及那些页面之间有超链接的网站) 、被表示成句法树的句子、3D 网格等等。因此,可以毫不夸张地讲,图无处不在。
图 (或网络) 中的实体称为 *节点* (或顶点) ,它们之间的连接称为 *边* (或链接) 。举个例子,在社交网络中,节点是用户,而边是他 (她) 们之间的连接关系;在分子中,节点是原子,而边是它们之间的分子键。
* 可以存在不止一种类型的节点或边的图称为 **异构图 (heterogeneous graph)** (例子:引用网络的节点有论文和作者两种类型,含有多种关系类型的 XML 图的边是多类型的) 。异构图不能仅由其拓扑结构来表征,它需要额外的信息。本文主要讨论同构图 (homogeneous graph) 。
* 图还可以是 **有向 (directed)** 的 (如一个关注网络中,A 关注了 B,但 B 可以不关注 A) 或者是 **无向 (undirected)** 的 (如一个分子中,原子间的关系是双向的) 。边可以连接不同的节点,也可以自己连接自己 (自连边,self-edges) ,但不是所有的节点都必须有连接。
如果你想使用自己的数据,首先你必须考虑如何最佳地刻画它 (同构 / 异构,有向 / 无向等) 。
## 图有什么用途?
我们一起看看在图上我们可以做哪些任务吧。
在 **图层面**,主要的任务有:
- 图生成,可在药物发现任务中用于生成新的可能的药物分子,
- 图演化 (给定一个图,预测它会如何随时间演化) ,可在物理学中用于预测系统的演化,
- 图层面预测 (基于图的分类或回归任务) ,如预测分子毒性。
在 **节点层面**,通常用于预测节点属性。举个例子,[Alphafold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology) 使用节点属性预测方法,在给定分子总体图的条件下预测原子的 3D 坐标,并由此预测分子在 3D 空间中如何折叠,这是个比较难的生物化学问题。
在 **边层面**,我们可以做边属性预测或缺失边预测。边属性预测可用于在给定药物对 (pair) 的条件下预测药物的不良副作用。缺失边预测被用于在推荐系统中预测图中的两个节点是否相关。
另一种可能的工作是在 **子图层面** 的,可用于社区检测或子图属性预测。社交网络用社区检测确定人们之间如何连接。我们可以在行程系统 (如 [Google Maps](https://www.deepmind.com/blog/traffic-prediction-with-advanced-graph-neural-networks)) 中发现子图属性预测的身影,它被用于预测到达时间。
完成这些任务有两种方式。
当你想要预测特定图的演化时,你工作在 **直推 (transductive)** 模式,直推模式中所有的训练、验证和推理都是基于同一张图。**如果这是你的设置,要多加小心!在同一张图上创建训练 / 评估 / 测试集可不容易。** 然而,很多任务其实是工作在不同的图上的 (不同的训练 / 评估 / 测试集划分) ,我们称之为 **归纳 (inductive)** 模式。
## 如何表示图?
常用的表示图以用于后续处理和操作的方法有 2 种:
* 表示成所有边的集合 (很有可能也会加上所有节点的集合用以补充) 。
* 或表示成所有节点间的邻接矩阵。邻接矩阵是一个 $node\_size \times node\_size$ 大小的方阵,它指明图上哪些节点间是直接相连的 (若 $n\_i$ 和 $n\_j$ 相连则 $A_{ij} = 1$,否则为 0) 。
>注意:多数图的边连接并不稠密,因此它们的邻接矩阵是稀疏的,这个会让计算变得困难。
虽然这些表示看上去很熟悉,但可别被骗了!
图与机器学习中使用的典型对象大不相同,因为它们的拓扑结构比序列 (如文本或音频) 或有序网格 (如图像和视频) 复杂得多:即使它们可以被表示成链表或者矩阵,但它们并不能被当作有序对象来处理。
这究竟意味着什么呢?如果你有一个句子,你交换了这个句子的词序,你就创造了一个新句子。如果你有一张图像,然后你重排了这个图像的列,你就创造了一张新图像。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_hf.png" width="500" />
<figcaption>左图是 Hugging Face 的标志。右图是一个重排后的 Hugging Face 标志,已经是一张不同的新图像了。</figcaption>
</figure>
</div>
但图并不会如此。如果你重排了图的边列表或者邻接矩阵的列,图还是同一个图 (一个更正式的叫法是置换不变性 (permutation invariance) ) 。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_graphs.png" width="1000" />
<figcaption>左图,一个小型图 (黄色是节点,橙色是边) 。 中图,该图的邻接矩阵,行与列的节点按字母排序:可以看到第一行的节点 A,与 E 和 C 相连。右图,重排后的邻接矩阵 (列不再按字母序排了) ,但这还是该图的有效表示:A 节点仍然与 E 和 C 相连。</figcaption>
</figure>
</div>
## 基于机器学习的图表示
使用机器学习处理图的一般流程是:首先为你感兴趣的对象 (根据你的任务,可以是节点、边或是全图) 生成一个有意义的表示,然后使用它们训练一个目标任务的预测器。与其他模态数据一样,我们想要对这些对象的数学表示施加一些约束,使得相似的对象在数学上是相近的。然而,这种相似性在图机器学习上很难严格定义,举个例子,具有相同标签的两个节点和具有相同邻居的两个节点哪两个更相似?
> *注意:在随后的部分,我们将聚焦于如何生成节点的表示。一旦你有了节点层面的表示,就有可能获得边或图层面的信息。你可以通过把边所连接的两个节点的表示串联起来或者做一个点积来得到边层面的信息。至于图层面的信息,可以通过对图上所有节点的表示串联起来的张量做一个全局池化 (平均,求和等) 来获得。当然,这么做会平滑掉或丢失掉整图上的一些信息,使用迭代的分层池化可能更合理,或者增加一个连接到图上所有其他节点的虚拟节点,然后使用它的表示作为整图的表示。*
### 神经网络以前的方法
#### 只使用手工设计特征
在神经网络出现之前,图以及图中的感兴趣项可以被表示成特征的组合,这些特征组合是针对特定任务的。尽管现在存在 [更复杂的特征生成方法](https://arxiv.org/abs/2208.11973),这些特征仍然被用于数据增强和 [半监督学习](https://arxiv.org/abs/2202.08871)。这时,你主要的工作是根据目标任务,找到最佳的用于后续网络训练的特征。
**节点层面特征** 可以提供关于其重要性 (该节点对于图有多重要?) 以及 / 或结构性 (节点周围的图的形状如何?) 信息,两者可以结合。
节点 **中心性 (centrality)** 度量图中节点的重要性。它可以递归计算,即不断对每个节点的邻节点的中心性求和直到收敛,也可以通过计算节点间的最短距离来获得,等等。节点的 **度 (degree)** 度量节点的直接邻居的数量。**聚类系数 (clustering coefficient)** 度量一个节点的邻节点之间相互连接的程度。**图元度向量 (Graphlets degree vectors,GDV)** 计算给定根节点的不同图元的数目,这里图元是指给定数目的连通节点可创建的所有迷你图 (如:3 个连通节点可以生成一个有两条边的线,或者一个 3 条边的三角形) 。
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/graphlets.png" width="700" />
<figcaption>2 个节点到 5 个节点的图元 (Pržulj, 2007)</figcaption>
</figure>
</div>
**边层面特征** 带来了关于节点间连通性的更多细节信息,有效地补充了图的表示,有:两节点间的 最短距离 (shortest distance),它们的公共邻居 (common neighbours),以及它们的 卡兹指数 (Katz index) (表示两节点间从所有长度小于某个值的路径的数目,它可以由邻接矩阵直接算得) 。
**图层面特征** 包含了关于图相似性和规格的高层信息。总 **图元数** 尽管计算上很昂贵,但提供了关于子图形状的信息。**核方法** 通过不同的 “节点袋 (bag of nodes) ” (类似于词袋 (bag of words) ) 方法度量图之间的相似性。
### 基于游走的方法
[**基于游走的方法**](https://en.wikipedia.org/wiki/Random_walk) 使用在随机游走时从节点j访问节点i的可能性来定义相似矩阵;这些方法结合了局部和全局的信息。举个例子,[**Node2Vec**](https://snap.stanford.edu/node2vec/)模拟图中节点间的随机游走,把这些游走路径建模成跳字 (skip-gram) ,这 [与我们处理句子中的词很相似](https://arxiv.org/abs/1301.3781),然后计算嵌入。基于随机游走的方法也可被用于 [加速](https://arxiv.org/abs/1208.3071) [**Page Rank 方法**](http://infolab.stanford.edu/pub/papers/google.pdf),帮助计算每个节点的重要性得分 (举个例子:如果重要性得分是基于每个节点与其他节点的连通度的话,我们可以用随机游走访问到每个节点的频率来模拟这个连通度) 。
然而,这些方法也有限制:它们不能得到新的节点的嵌入向量,不能很好地捕获节点间的结构相似性,也使用不了新加入的特征。
## 图神经网络
神经网络可泛化至未见数据。我们在上文已经提到了一些图表示的约束,那么一个好的神经网络应该有哪些特性呢?
它应该:
- 满足置换不变性:
- 等式:\\(f(P(G))=f(G)\\),这里 f 是神经网络,P 是置换函数,G 是图。
- 解释:置换后的图和原图经过同样的神经网络后,其表示应该是相同的。
- 满足置换等价性
- 公式:\\(P(f(G))=f(P(G))\\),同样 f 是神经网络,P 是置换函数,G 是图。
- 解释:先置换图再传给神经网络和对神经网络的输出图表示进行置换是等价的。
典型的神经网络,如循环神经网络 (RNN) 或卷积神经网络 (CNN) 并不是置换不变的。因此,[图神经网络 (Graph Neural Network, GNN) ](https://ieeexplore.ieee.org/abstract/document/1517930) 作为新的架构被引入来解决这一问题 (最初是作为状态机使用) 。
一个 GNN 由连续的层组成。一个 GNN 层通过 **消息传递 (message passing)** 过程把一个节点表示成其邻节点及其自身表示的组合 (**聚合 (aggregation)**) ,然后通常我们还会使用一个激活函数去增加一些非线性。
**与其他模型相比**:CNN 可以看作一个邻域 (即滑动窗口) 大小和顺序固定的 GNN,也就是说 CNN 不是置换等价的。一个没有位置嵌入 (positional embedding) 的 [Transformer](https://arxiv.org/abs/1706.03762v3) 模型可以被看作一个工作在全连接的输入图上的 GNN。
### 聚合与消息传递
多种方式可用于聚合邻节点的消息,举例来讲,有求和,取平均等。一些值得关注的工作有:
- [图卷积网络](https://tkipf.github.io/graph-convolutional-networks/) 对目标节点的所有邻节点的归一化表示取平均来做聚合 (大多数 GNN 其实是 GCN) ;
- [图注意力网络](https://petar-v.com/GAT/) 会学习如何根据邻节点的重要性不同来加权聚合邻节点 (与 transformer 模型想法相似) ;
- [GraphSAGE](https://snap.stanford.edu/graphsage/) 先在不同的跳数上进行邻节点采样,然后基于采样的子图分多步用最大池化 (max pooling) 方法聚合信息;
- [图同构网络](https://arxiv.org/pdf/1810.00826v3.pdf) 先计算对邻节点的表示求和,然后再送入一个 MLP 来计算最终的聚合信息。
**选择聚合方法**:一些聚合技术 (尤其是均值池化和最大池化) 在遇到在邻节点上仅有些微差别的相似节点的情况下可能会失败 (举个例子:采用均值池化,一个节点有 4 个邻节点,分别表示为 1,1,-1,-1,取均值后变成 0;而另一个节点有 3 个邻节点,分别表示为 - 1,0,1,取均值后也是 0。两者就无法区分了。) 。
### GNN 的形状和过平滑问题
每加一个新层,节点表示中就会包含越来越多的节点信息。
一个节点,在第一层,只会聚合它的直接邻节点的信息。到第二层,它们仍然只聚合直接邻节点信息,但这次,他们的直接邻节点的表示已经包含了它们各自的邻节点信息 (从第一层获得) 。经过 n 层后,所有节点的表示变成了它们距离为 n 的所有邻节点的聚合。如果全图的直径小于 n 的话,就是聚合了全图的信息!
如果你的网络层数过多,就有每个节点都聚合了全图所有节点信息的风险 (并且所有节点的表示都收敛至相同的值) ,这被称为 **过平滑问题 (the oversmoothing problem)**。
这可以通过如下方式来解决:
- 在设计 GNN 的层数时,要首先分析图的直径和形状,层数不能过大,以确保每个节点不聚合全图的信息
- 增加层的复杂性
- 增加非消息传递层来处理消息 (如简单的 MLP 层)
- 增加跳跃连接 (skip-connections)
过平滑问题是图机器学习的重要研究领域,因为它阻止了 GNN 的变大,而在其他模态数据上 Transformers 之类的模型已经证明了把模型变大是有很好的效果的。
## 图 Transformers
没有位置嵌入 (positional encoding) 层的 Transformer 模型是置换不变的,再加上 Transformer 模型已被证明扩展性很好,因此最近大家开始看如何改造 Transformer 使之适应图数据 ([综述](https://github.com/ChandlerBang/awesome-graph-transformer)) 。多数方法聚焦于如何最佳表示图,如找到最好的特征、最好的表示位置信息的方法以及如何改变注意力以适应这一新的数据。
这里我们收集了一些有意思的工作,截至本文写作时为止,这些工作在现有的最难的测试基准之一 [斯坦福开放图测试基准 (Open Graph Benchmark, OGB)](https://ogb.stanford.edu/) 上取得了最高水平或接近最高水平的结果:
- [*Graph Transformer for Graph-to-Sequence Learning*](https://arxiv.org/abs/1911.07470) (Cai and Lam, 2020) 介绍了一个图编码器,它把节点表示为它本身的嵌入和位置嵌入的级联,节点间关系表示为它们间的最短路径,然后用一个关系增强的自注意力机制把两者结合起来。
- [*Rethinking Graph Transformers with Spectral Attention*](https://arxiv.org/abs/2106.03893) (Kreuzer et al, 2021) 介绍了谱注意力网络 (Spectral Attention Networks, SANs) 。它把节点特征和学习到的位置编码 (从拉普拉斯特征值和特征向量中计算得到) 结合起来,把这些作为注意力的键 (keys) 和查询 (queries) ,然后把边特征作为注意力的值 (values) 。
- [*GRPE: Relative Positional Encoding for Graph Transformer*](https://arxiv.org/abs/2201.12787) (Park et al, 2021) 介绍了图相对位置编码 Transformer。它先在图层面的位置编码中结合节点信息,在边层面的位置编码中也结合节点信息,然后在注意力机制中进一步把两者结合起来。
- [*Global Self-Attention as a Replacement for Graph Convolution*](https://arxiv.org/abs/2108.03348) (Hussain et al, 2021) 介绍了边增强 Transformer。该架构分别对节点和边进行嵌入,并通过一个修改过的注意力机制聚合它们。
- [*Do Transformers Really Perform Badly for Graph Representation*](https://arxiv.org/abs/2106.05234) (Ying et al, 2021) 介绍了微软的 [**Graphormer**](https://www.microsoft.com/en-us/research/project/graphormer/), 该模型在面世时赢得了 OGB 第一名。这个架构使用节点特征作为注意力的查询 / 键 / 值 (Q/K/V) ,然后在注意力机制中把这些表示与中心性,空间和边编码信息通过求和的方式结合起来。
最新的工作是 [*Pure Transformers are Powerful Graph Learners*](https://arxiv.org/abs/2207.02505) (Kim et al, 2022),它引入了 **TokenGT**。这一方法把输入图表示为一个节点和边嵌入的序列 (并用正交节点标识 (orthonormal node identifiers) 和可训练的类型标识 (type identifiers) 增强它) ,而不使用位置嵌入,最后把这个序列输入给 Tranformer 模型。超级简单,但很聪明!
稍有不同的是,[*Recipe for a General, Powerful, Scalable Graph Transformer*](https://arxiv.org/abs/2205.12454) (Rampášek et al, 2022) 引入的不是某个模型,而是一个框架,称为 **GraphGPS**。它允许把消息传递网络和线性 (长程的) transformer 模型结合起来轻松地创建一个混合网络。这个框架还包含了不少工具,用于计算位置编码和结构编码 (节点、图、边层面的) 、特征增强、随机游走等等。
在图数据上使用 transformer 模型还是一个非常初生的领域,但是它看上去很有前途,因为它可以减轻 GNN 的一些限制,如扩展到更大 / 更稠密的图,抑或是增加模型尺寸而不必担心过平滑问题。
## 更进阶的资源
如果你想钻研得更深入,可以看看这些课程:
- 学院课程形式
- [斯坦福大学图机器学习](https://web.stanford.edu/class/cs224w/)
- [麦吉尔大学图表示学习](https://cs.mcgill.ca/~wlh/comp766/)
- 视频形式
- [几何深度学习课程](https://www.youtube.com/playlist?list=PLn2-dEmQeTfSLXW8yXP4q_Ii58wFdxb3C)
- 相关书籍
- [图表示学习*,汉密尔顿著](https://www.cs.mcgill.ca/~wlh/grl_book/)
不错的处理图数据的库有 [PyGeometric](https://pytorch-geometric.readthedocs.io/en/latest/) (用于图机器学习) 以及 [NetworkX](https://networkx.org/) (用于更通用的图操作)。
如果你需要质量好的测试基准,你可以试试看:
- [OGB, 开放图测试基准 (the Open Graph Benchmark) ](https://ogb.stanford.edu/):一个可用于不同的任务和数据规模的参考图测试基准数据集。
- [Benchmarking GNNs](https://github.com/graphdeeplearning/benchmarking-gnns): 用于测试图机器学习网络和他们的表现力的库以及数据集。相关论文特地从统计角度研究了哪些数据集是相关的,它们可被用于评估图的哪些特性,以及哪些图不应该再被用作测试基准。
- [长程图测试基准 (Long Range Graph Benchmark)](https://github.com/vijaydwivedi75/lrgb): 最新的 (2022 年 10 月份) 测试基准,主要关注长程的图信息。
- [Taxonomy of Benchmarks in Graph Representation Learning](https://openreview.net/pdf?id=EM-Z3QFj8n): 发表于 2022 年 Learning on Graphs 会议,分析并对现有的测试基准数据集进行了排序。
如果想要更多的数据集,可以看看:
- [Paper with code 图任务排行榜](https://paperswithcode.com/area/graphs):
公开数据集和测试基准的排行榜,请注意,不是所有本排行榜上的测试基准都仍然适宜。
- [TU 数据集](https://chrsmrrs.github.io/datasets/docs/datasets/): 公开可用的数据集的合辑,现在以类别和特征排序。大多数数据集可以用 PyG 加载,而且其中一些已经被集成进 PyG 的 Datsets。
- [SNAP 数据集 (Stanford Large Network Dataset Collection)](https://snap.stanford.edu/data/):
- [MoleculeNet 数据集](https://moleculenet.org/datasets-1)
- [关系数据集仓库](https://relational.fit.cvut.cz/)
### 外部图像来源
缩略图中的 Emoji 表情来自于 Openmoji (CC-BY-SA 4.0),图元的图片来自于 *Biological network comparison using graphlet degree distribution* (Pržulj, 2007)。
| 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/the_n_implementation_details_of_rlhf_with_ppo.md | ---
title: "使用 PPO 算法进行 RLHF 的 N 步实现细节"
thumbnail: /blog/assets/167_the_n_implementation_details_of_rlhf_with_ppo/thumbnail.png
authors:
- user: vwxyzjn
- user: tianlinliu0121
guest: true
- user: lvwerra
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 使用 PPO 算法进行 RLHF 的 N 步实现细节
当下,RLHF/ChatGPT 已经变成了一个非常流行的话题。我们正在致力于更多有关 RLHF 的研究,这篇博客尝试复现 OpenAI 在 2019 年开源的原始 RLHF 代码库,其仓库位置位于 [_openai/lm-human-preferences_](https://github.com/openai/lm-human-preferences)。尽管它具有 “tensorflow-1.x” 的特性,但 OpenAI 的原始代码库评估和基准测试非常完善,使其成为研究 RLHF 实现工程细节的好地方。
我们的目标是:
1. 复现 OAI 在风格化任务中的结果,并匹配 [_openai/lm-human-preferences_](https://github.com/openai/lm-human-preferences) 的学习曲线。
2. 提供一个实现细节的清单,类似于 [近端优化策略的 37 个实施细节 (_The 37 Implementation Details of Proximal Policy Optimization_)](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/) 和 [没有痛苦折磨的调试 RL (_Debugging RL, Without the Agonizing Pain_)](https://andyljones.com/posts/rl-debugging.html) 的风格;
3. 提供一个易于阅读且简洁的 RLHF 参考实现;
这项工作仅适用于以教育/学习为目的的。对于需要更多功能的高级用户,例如使用 PEFT 运行更大的模型, [_huggingface/trl_](https://github.com/huggingface/trl) 将是一个不错的选择。
- 在 [匹配学习曲线](#匹配学习曲线) 中,我们展示了我们的主要贡献: 创建一个代码库,能够在风格化任务中复现 OAI 的结果,并且与 [_openai/lm-human-preferences_](https://github.com/openai/lm-human-preferences) 的学习曲线非常接近地匹配。
- 然后我们深入探讨了与复现 OAI 的工作相关的实现细节。在 [总体实现细节](#总体实现细节) 中,我们讨论了基本细节,像如何生成奖励/值和如何生成响应。在 [奖励模型实现细节](#奖励模型实现细节) 中,我们讨论了诸如奖励标准化之类的细节。在 [策略训练实现细节](#策略训练实现细节) 中,我们讨论了拒绝采样和奖励“白化”等细节。
- 在 [**PyTorch Adam 优化器在处理 RLHF 时的数值问题**](https://www.notion.so/PyTorch-Adam-optimizer-numerical-issues-w-r-t-RLHF-c48b1335349941c6992a04a2c8069f2b?pvs=21) 中,我们强调了 TensorFlow 和 PyTorch 之间 Adam 的一个非常有趣的实现区别,其导致了模型训练中的激进更新。
- 接下来,我们检查了在奖励标签由 `gpt2-large` 生成的情况下,训练不同基础模型 (例如 gpt2-xl, falcon-1b) 的效果。
- 最后,我们通过讨论一些限制来总结我们的研究工作。
**以下是一些重要链接:**
- 💾 我们的复现代码库 [_https://github.com/vwxyzjn/lm-human-preference-details_](https://github.com/vwxyzjn/lm-human-preference-details)
- 🤗 RLHF 模型比较示例: [_https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo_](https://huggingface.co/spaces/lm-human-preference-details/rlhf-demo)
- 🐝 所有的 w&b 训练日志 [_https://wandb.ai/openrlbenchmark/lm_human_preference_details_](https://wandb.ai/openrlbenchmark/lm_human_preference_details)
# 匹配学习曲线
我们的主要贡献是在风格化任务中复现 OAI 的结果,例如情感和描述性。如下图所示,我们的代码库 (橙色曲线) 能够产生与 OAI 的代码库 (蓝色曲线) 几乎相同的学习曲线。
## 关于运行 openai/lm-human-preferences 的说明
为了直观比较,我们运行了原始的 RLHF 代码,其仓库位置位于 [_openai/lm-human-preferences_](https://github.com/openai/lm-human-preferences),它将提供宝贵的指标,以帮助验证和诊断我们的复现。我们能够设置原始的 TensorFlow 1.x 代码,但它需要一个非常特定的设置:
- OAI 的数据集部分损坏/丢失 (所以我们用类似的 HF 数据集替换了它们,这可能会或可能不会导致性能差异)
- 具体来说,它的书籍数据集在 OpenAI 的 GCP - Azure 迁移过程中丢失了 ([https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496))。我用 Hugging Face 的 `bookcorpus` 数据集替换了书籍数据集,原则上,这是类似 OAI 使用的数据集。
- 它不能在 1 个 V100 上运行,因为它没有实现梯度累积。相反,它使用一个大的 BS (批量大小),并在 8 个 GPU 上分割 batch (批量),仅在 1 个 GPU 上就会出现 OOM (内存溢出)。
- 它不能在 8 个 A100 上运行,因为它使用的是 TensorFlow 1.x,与 Cuda 8+ 不兼容。
- 它不能在 8 个 V100 (16GB) 上运行,因为它会 OOM (内存溢出)。
- 它只能在 8 个 V100 (32GB) 上运行,这种配置仅由 AWS 以 `p3dn.24xlarge` 实例的形式提供。
# 总体实现细节
我们现在深入探讨与复现 OAI 工作相关的技术实现细节。在这个部分,我们讨论了一些基本细节,例如奖励/值是如何生成的,以及响应是如何生成的。以下是这些细节,不按特定顺序列出:
1. **奖励模型和策略的价值头将 `query` 和 `response` 的连接作为输入**
1. 奖励模型和策略的价值头 _不_ 仅仅查看响应。相反,它将 `query` 和 `response` 连接在一起,作为 `query_response` ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107))。
2. 举例来说,如果 `query = "他在想某事,但他的眼神很难读懂"。` ,和 `response = "他看着他的左手,手臂伸在他的前面。"` ,那么奖励模型和策略的价值会对`query_response = "他在想某事,但他的眼神很难读懂。他看着他的左手,手臂伸在他的前面。"` 进行前向传递,并产生形状为 `(B, T, 1)` 的奖励和价值,其中 `B` 是 BS (批量大小),`T` 是序列长度,而 `1` 代表奖励头的输出结构的维度为 1 ([lm_human_preferences/rewards.py#L105-L107](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L105-L107), [lm_human_preferences/policy.py#L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L111))。
3. `T` 意味着每个 token 都有与其和前文关联的奖励。例如,`eyes` token 将有一个与`他在想某事,但他的眼神很难读懂` 相对应的奖励。
2. **使用特殊的填充 token 来填充和截断输入。**
1. OAI 为查询 `query_length` 设置了固定的输入长度; 它使用 `pad_token` **填充** 过短的序列 ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67)),并 **截断** 过长的序列 ([lm_human_preferences/language/datasets.py#L57](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L57))。详见 [此处](https://huggingface.co/docs/transformers/pad_truncation) 以获取该概念的通用介绍。在填充输入时,OAI 使用了词汇表之外的 token ([lm_human_preferences/language/encodings.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/encodings.py#L56))。
1. **关于 HF 的 transformers — 填充 token 的注解。** 根据 ([transformers#2630#issuecomment-578159876](https://github.com/huggingface/transformers/issues/2630#issuecomment-578159876)),在 GPT 和 GPT-2 的预训练期间没有使用填充 token; 因此,transformer 的 gpt2 模型与其分词器没有关联的官方填充 token。通常的做法是设置 `tokenizer.pad_token = tokenizer.eos_token` ,但在这项工作中,我们将区分这两个特殊 token 以匹配 OAI 的原始设置,所以我们将使用 `tokenizer.add_special_tokens({"pad_token": "[PAD]"})` 。
注意,没有填充 token 是解码器模型的默认设置,因为它们在预训练期间使用“打包”训练,这意味着许多序列被连接并由 EOS token 分隔,这些序列的块在预训练期间始终具有最大长度并被馈送到模型中。
2. 当把所有事物放在一起时,这里有一个例子
```python
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
query_length = 5
texts = [
"usually, he would",
"she thought about it",
]
tokens = []
for text in texts:
tokens.append(tokenizer.encode(text)[:query_length])
print("tokens", tokens)
inputs = tokenizer.pad(
{"input_ids": tokens},
padding="max_length",
max_length=query_length,
return_tensors="pt",
return_attention_mask=True,
)
print("inputs", inputs)
"""prints are
tokens [[23073, 11, 339, 561], [7091, 1807, 546, 340]]
inputs {'input_ids': tensor([[23073, 11, 339, 561, 50257],
[ 7091, 1807, 546, 340, 50257]]), 'attention_mask': tensor([[1, 1, 1, 1, 0],
[1, 1, 1, 1, 0]])}
"""
```
3. **相应地调整填充 token 的位置索引**
1. 在计算 logits 时,OAI 的代码通过适当地屏蔽填充 token 来工作。这是通过找出与填充 token 相对应的 token 索引来实现的 ([lm_human_preferences/language/model.py#L296-L297](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L296-L297)),然后相应地调整它们的位置索引 ([lm_human_preferences/language/model.py#L320](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L320))。
2. 例如,如果 `query=[23073, 50259, 50259]` 和 `response=[11, 339, 561]` ,其中 ( `50259` 是 OAI 的填充 token),它会创建位置索引为 `[[0 1 1 1 2 3]]` 并且如下的 logits。注意填充 token 对应的 logits 如何保持不变!这是我们在复制过程中应该追求的效果。
```python
all_logits [[[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[ -35.28693 -34.2875 -38.16074 ... -41.595802 -41.082108
-35.36577 ]
[-111.303955 -110.94471 -112.90624 ... -113.13064 -113.7788
-109.17345 ]
[-111.51512 -109.61077 -114.90231 ... -118.43514 -111.56671
-112.12478 ]
[-122.69775 -121.84468 -128.27417 ... -132.28055 -130.39604
-125.707756]]] (1, 6, 50257)
```
3. **关于 HF 的 transformers — `position_ids` 和 `padding_side` 的注解。** 我们可以通过 1) 左填充和 2) 传入适当的 `position_ids` ,使用 Hugging Face 的 transformer 复制精确的 logits:
```python
import torch
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
pad_id = tokenizer.pad_token_id
query = torch.tensor([
[pad_id, pad_id, 23073],
])
response = torch.tensor([
[11, 339, 561],
])
temperature = 1.0
query = torch.tensor(query)
response = torch.tensor(response).long()
context_length = query.shape[1]
query_response = torch.cat((query, response), 1)
pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2")
def forward(policy, query_responses, tokenizer):
attention_mask = query_responses != tokenizer.pad_token_id
position_ids = attention_mask.cumsum(1) - attention_mask.long() # exclusive cumsum
input_ids = query_responses.clone()
input_ids[~attention_mask] = 0
return policy(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
return_dict=True,
output_hidden_states=True,
)
output = forward(pretrained_model, query_response, tokenizer)
logits = output.logits
logits /= temperature
print(logits)
"""
tensor([[[ -26.9395, -26.4709, -30.0456, ..., -33.2208, -33.2884,
-27.4360],
[ -27.1677, -26.7330, -30.2386, ..., -33.6813, -33.6931,
-27.5928],
[ -35.2869, -34.2875, -38.1608, ..., -41.5958, -41.0821,
-35.3658],
[-111.3040, -110.9447, -112.9062, ..., -113.1306, -113.7788,
-109.1734],
[-111.5152, -109.6108, -114.9024, ..., -118.4352, -111.5668,
-112.1248],
[-122.6978, -121.8447, -128.2742, ..., -132.2805, -130.3961,
-125.7078]]], grad_fn=<DivBackward0>)
"""
```
4. **关于 HF 的 transformers ——在 `生成` 过程中的 `position_ids` 的注解:** 在生成过程中,我们不应传入 `position_ids` ,因为在 `transformers` 中, `position_ids` 已经以某种方式被调整了。当我在生成过程中也传入 `position_ids` 时,性能会灾难性地恶化。
通常情况下,我们几乎从不在 transformers 中传递 `position_ids` 。所有的遮蔽 (masking) 和移位 (shifting) logic 已经实现,例如,在 `generate` 函数中 (需要永久的代码链接)。
4. **生成固定长度响应的响应生成不需要填充。**
1. 在响应生成期间,OAI 使用 `top_k=0, top_p=1.0` 并仅在词汇表上做分类样本 ([lm_human_preferences/language/sample.py#L43](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/sample.py#L43)),代码会一直采样,直到生成固定长度的响应 ([lm_human_preferences/policy.py#L103](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L103))。值得注意的是,即使遇到 EOS (序列结束) token ,它也会继续采样。
2. **关于 HF 的 transformers 的注解 — 在 `eos_token` 处采样可能会停止:** 在 `transformers` 中,生成可能会在 `eos_token` 处停止 ([src/transformers/generation/utils.py#L2248-L2256](https://github.com/huggingface/transformers/blob/67b85f24def79962ce075353c2627f78e0e53e9f/src/transformers/generation/utils.py#L2248-L2256)),这与 OAI 的设置不同。为了对齐设置,我们需要设置 `pretrained_model.generation_config.eos_token_id = None, pretrained_model.generation_config.pad_token_id = None` 。请注意, `transformers.GenerationConfig(eos_token_id=None, pad_token_id=None, ...)` 不起作用,因为 `pretrained_model.generation_config` 会覆盖并设置一个 `eos_token` 。
```python
import torch
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("gpt2", padding_side="right")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
pad_id = tokenizer.pad_token_id
query = torch.tensor([
[pad_id, pad_id, 23073],
])
response = torch.tensor([
[11, 339, 561],
])
response_length = 4
temperature = 0.7
pretrained_model = transformers.AutoModelForCausalLM.from_pretrained("gpt2")
pretrained_model.generation_config.eos_token_id = None # disable `pad_token_id` and `eos_token_id` because we just want to
pretrained_model.generation_config.pad_token_id = None # generate tokens without truncation / padding
generation_config = transformers.GenerationConfig(
max_new_tokens=response_length,
min_new_tokens=response_length,
temperature=temperature,
top_k=0.0,
top_p=1.0,
do_sample=True,
)
context_length = query.shape[1]
attention_mask = query != tokenizer.pad_token_id
input_ids = query.clone()
input_ids[~attention_mask] = 0 # set padding tokens to 0
output = pretrained_model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
# position_ids=attention_mask.cumsum(1) - attention_mask.long(), # generation collapsed if this was turned on. TODO: why does generation collapse with this?
generation_config=generation_config,
return_dict_in_generate=True,
)
print(output.sequences)
"""
tensor([[ 0, 0, 23073, 16851, 11, 475, 991]])
"""
```
3. 请注意,在较新的代码库 https://github.com/openai/summarize-from-feedback 中,当遇到 EOS token 时,OAI 确实会停止采样 ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19))。然而,在这项工作中,我们的目标是进行 1:1 的复刻,所以我们调整了设置,即使遇到 eos_token 也可以继续采样。
5. **奖励模型和策略训练的学习率退火。**
1. 正如 Ziegler 等人 (2019) 建议的,奖励模型只训练一个 epcho,以避免过度拟合有限量的人类注释数据 (例如,`descriptiveness` 任务只有大约 5000 个标签)。在这个单一的 epcho 中,学习率会退火至零 ([lm_human_preferences/train_reward.py#L249](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L249))。
2. 类似于奖励模型训练,策略训练的学习率也会退火至零 ([lm_human_preferences/train_policy.py#L172-L173](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L172-L173))。
6. **为不同的进程使用不同的种子**
1. 在生成 8 个 GPU 进程进行数据并行时,OAI 为每个进程设置了不同的随机种子 ([lm_human_preferences/utils/core.py#L108-L111](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/utils/core.py#L108-L111))。在实现上,这是通过 `local_seed = args.seed + process_rank * 100003` 完成的。种子会让模型产生不同的响应并得到不同的分数,例如。
1. 注: 我认为数据集的洗牌 (shuffling) 存在一个错误——由于某种原因,数据集是使用相同的种子进行洗牌的 ([lm_human_preferences/lm_tasks.py#L94-L97](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/lm_tasks.py#L94-L97))。
# 奖励模型实现细节
在本节中,我们讨论了奖励模型特定的实现细节。我们讨论了诸如奖励归一化和层初始化等细节。以下是这些细节,不按特定顺序排列:
1. **奖励模型只输出最后一个 token 的值。**
1. 请注意,在对 `query` 和 `response` 的连接进行前向传递后获得的奖励将具有形状 `(B, T, 1)` ,其中 `B` 是 BS(批量大小),`T` 是序列长度 (始终相同; 在 OAI 的设置中,它是 `query_length + response_length = 64 + 24 = 88` ,用于风格任务,参见 [launch.py#L9-L11](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L9-L11)),`1` 是奖励头其维度为 1。对于 RLHF (Reinforcement Learning from Human Feedback,通过人类反馈进行强化学习) 的目的,原始代码库提取最后一个 token 的奖励 ([lm_human_preferences/rewards.py#L132](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L132)),因此奖励将只具有形状 `(B, 1)` 。
2. 请注意,在较新的代码库 [_openai/summarize-from-feedback_](https://github.com/openai/summarize-from-feedback) 中,OAI 在遇到 EOS token 时停止采样 ([summarize_from_feedback/utils/experiment_helpers.py#L19](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/utils/experiment_helpers.py#L19))。在提取奖励时,它将确定 `last_response_index` ,即 EOS token 之前的索引 ([#L11-L13](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L11-L13)),并在该索引处提取奖励 ([summarize_from_feedback/reward_model.py#L59](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/reward_model.py#L59))。但在此工作中,我们只是坚持原始设置。
2. **奖励头层初始化**
1. 奖励头的权重是根据 \( \mathcal{N}\left(0,1 /\left(\sqrt{d_{\text {model }}+1}\right)\right) \) 初始化的 ([lm_human_preferences/language/model.py#L368,](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368) [lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252))。这与 Stiennon 等人的设置相符,2020 年 ([summarize_from_feedback/query_response_model.py#L106-L107](https://github.com/openai/summarize-from-feedback/blob/8af822a428c93432aa80ffbe5b065a8f93895669/summarize_from_feedback/query_response_model.py#L106-L107)) (附注,Stiennon 等人,2020 年在第 17 页上有一个错字,表示分布是 \( \mathcal{N}\left(0,1 /\left(d_{\text {model }}+1\right)\right) \) 没有平方根)
2. 奖励头的 bias (偏置) 设为 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254))。
3. **奖励模型的前后归一化**
1. 在论文中,Ziegler 等人 (2019) 提到“为了保持训练过程中奖励模型的规模一致,我们将其归一化,使其在 \( x \sim \mathcal{D}, y \sim \rho(·|x) \) 的情况下,均值为 0,方差为 1”。为了执行归一化过程,代码首先创建了 `reward_gain` 和 `reward_bias` ,以便可以通过 `reward = reward * reward_gain + reward_bias` 来计算奖励值 ([lm_human_preferences/rewards.py#L50-L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/rewards.py#L50-L51))。
2. 在执行归一化过程时,代码首先设置 `reward_gain=1, reward_bias=0` ([lm_human_preferences/train_reward.py#L211](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L211)),然后从目标数据集 (例如,`bookcorpus, tldr, cnndm` ) 中收集采样查询、完成的响应和评估的奖励。接着,它得到评估奖励的 **实证均值和标准差** ([lm_human_preferences/train_reward.py#L162-L167](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L162-L167)),并尝试计算 `reward_gain` 和 `reward_bias` 应该是什么。
3. 我们用\( \mu_{\mathcal{D}} \) 来表示实证均值,用\( \sigma_{\mathcal{D}} \) 表示实证标准差,用\(g\) 表示 `reward_gain` ,用\(b\) 表示 `reward_bias` ,用\( \mu_{\mathcal{T}} = 0\) 表示 **目标均值**,用\( \sigma_{\mathcal{T}}=1\) 表示 **目标标准差**。然后我们有以下公式。
$$
\begin{aligned}g*\mathcal{N}(\mu_{\mathcal{D}}, \sigma_{\mathcal{D}}) + b &= \mathcal{N}(g*\mu_{\mathcal{D}}, g*\sigma_{\mathcal{D}}) + b\\&= \mathcal{N}(g*\mu_{\mathcal{D}} + b, g*\sigma_{\mathcal{D}}) \\&= \mathcal{N}(\mu_{\mathcal{T}}, \sigma_{\mathcal{T}}) \\g &= \frac{\sigma_{\mathcal{T}}}{\sigma_{\mathcal{D}}} \\b &= \mu_{\mathcal{T}} - g*\mu_{\mathcal{D}}\end{aligned}
$$
4. 然后在奖励模型训练的 **前** 和 **后** 应用归一化过程 ([lm_human_preferences/train_reward.py#L232-L234](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L232-L234),[lm_human_preferences/train_reward.py#L252-L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_reward.py#L252-L254))。
5. 请注意,我们为归一化目的生成的响应 \( y \sim \rho(·|x) \) 来自预训练的语言模型 \(\rho \)。模型 \(\rho \) 被固定为参考,并且在奖励学习中不会更新 ([lm_human_preferences/train_reward.py#L286C1-L286C31](https://github.com/openai/lm-human-preferences/blob/master/lm_human_preferences/train_reward.py#L286C1-L286C31))。
# 策略训练实现细节
在本节中,我们将深入探讨诸如层初始化、数据后处理和 dropout 设置等细节。我们还将探讨一些技术,如拒绝采样和奖励 “白化”,以及自适应 KL。以下是这些细节,排列不分先后:
1. **通过采样温度来缩放 logits**
1. 在计算响应的对数概率时,模型首先输出响应中 token 的 logits,然后用采样温度除以这些 logits ([lm_human_preferences/policy.py#L121](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L121))。即 `logits /= self.temperature`
2. 在一个非正式的测试中,我们发现如果不进行此缩放,KL 散度会比预期更快地上升,性能会下降。
2. **价值头层的初始化**
1. 价值头的权重是根据 \(\mathcal{N}(0,0)\) 进行初始化的 ([lm_human_preferences/language/model.py#L368](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L368)、[lm_human_preferences/language/model.py#L251-L252](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L251-L252))。
2. 奖励头的 bias (偏置) 设置为 0 ([lm_human_preferences/language/model.py#L254](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/model.py#L254))。
3. **选择以句号开始和结束的查询文本**
1. 这是数据预处理的一部分:
1. 尝试仅在 `start_text="."` 之后选择文本 ([lm_human_preferences/language/datasets.py#L51](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L51))
2. 尝试在 `end_text="."` 之前选择文本 ([lm_human_preferences/language/datasets.py#L61](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L61))
3. 然后填充文本 ([lm_human_preferences/language/datasets.py#L66-L67](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/language/datasets.py#L66-L67))
2. 在运行 `openai/lm-human-preferences` 时,OAI 的数据集部分损坏/丢失 ([openai/lm-human-preferences/issues/17#issuecomment-104405149](https://github.com/openai/lm-human-preferences/issues/17#issuecomment-1044051496)),因此我们不得不用类似的 HF 数据集替换它们,这可能会或可能不会导致性能差异。
3. 对于书籍数据集,我们使用 [https://huggingface.co/datasets/bookcorpus](https://huggingface.co/datasets/bookcorpus),我们发现没有必要提取以句号开始和结束的句子,因为数据集已经是这样预处理过的 (例如,`"usually , he would be tearing around the living room , playing with his toys."` ) 为此,我们为 `sentiment` 和 `descriptiveness` 任务设置 `start_text=None, end_text=None` 。
4. **禁用 dropout**
1. Ziegler 等人 (2019) 建议,“我们在策略训练中不使用 dropout。” 这也在代码中实现了 ([lm_human_preferences/policy.py#L48](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/policy.py#L48))。
5. **拒绝采样**
1. Ziegler 等人 (2019) 建议: “我们使用拒绝采样来确保在第 16 和 24 个 token 之间有一个句号,然后在那个句号处截断 (这是‘句子结束’的粗略近似。我们选择它是因为它很容易集成到 RL 循环中,即使是粗略的近似也足以使人类评估任务变得稍微容易一些)。在 RL 微调期间,我们对没有这样的句号的延续给予固定奖励 -1。”
2. 具体来说,通过以下步骤实现此目的:
1. **token 截断**: 我们想要在第一个出现在响应的 `truncate_after` 位置之后的 `truncate_token` 处截断 ([lm_human_preferences/train_policy.py#L378](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L378))。
1. 代码注释: “中心示例: 将截断 token 后的所有 token 替换为填充 token”
2. **在截断响应上运行奖励模型**: 在 token 截断过程将响应截断后,代码然后在 **截断的响应** 上运行奖励模型。
3. **拒绝采样**: 如果在第 16 和 24 个 token 之间没有句号,那么将响应的分数替换为固定的低值 (例如 -1) ([lm_human_preferences/train_policy.py#L384](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384)、[lm_human_preferences/train_policy.py#L384-L402](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L384-L402))。
1. 代码注释: “中心示例: 确保样本包含 `truncate_token` “
2. 代码注释: “只对通过该功能的响应进行人类查询”
4. 在 `descriptiveness` 中举一些例子:
从我们的复制中提取的样本 [https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs](https://wandb.ai/openrlbenchmark/lm_human_preference_details/runs/djf8yymv/logs?workspace=user-costa-huang)。请注意,第 1 和第 3 个示例在句号后有太多 token,因此其分数被替换为 -1。
6. **折现因子 (discount factor) = 1**
1. 折现因子 \(\gamma\) 设置为 1 ([lm_human_preferences/train_policy.py#L56](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L56)),这意味着未来的奖励与即时奖励具有相同的权重。
7. **训练循环的术语: PPO 中的批次和小批次**
1. OAI 使用以下训练循环 ([lm_human_preferences/train_policy.py#L184-L192](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L184-L192))。注意: 我们额外添加了 `micro_batch_size` 来帮助处理梯度累积的情况。在每个时期,它都会洗牌批次索引。
```python
import numpy as np
batch_size = 8
nminibatches = 2
gradient_accumulation_steps = 2
mini_batch_size = batch_size // nminibatches
micro_batch_size = mini_batch_size // gradient_accumulation_steps
data = np.arange(batch_size).astype(np.float32)
print("data:", data)
print("batch_size:", batch_size)
print("mini_batch_size:", mini_batch_size)
print("micro_batch_size:", micro_batch_size)
for epoch in range(4):
batch_inds = np.random.permutation(batch_size)
print("epoch:", epoch, "batch_inds:", batch_inds)
for mini_batch_start in range(0, batch_size, mini_batch_size):
mini_batch_end = mini_batch_start + mini_batch_size
mini_batch_inds = batch_inds[mini_batch_start:mini_batch_end]
# `optimizer.zero_grad()` set optimizer to zero for gradient accumulation
for micro_batch_start in range(0, mini_batch_size, micro_batch_size):
micro_batch_end = micro_batch_start + micro_batch_size
micro_batch_inds = mini_batch_inds[micro_batch_start:micro_batch_end]
print("____⏩ a forward pass on", data[micro_batch_inds])
# `optimizer.step()`
print("⏪ a backward pass on", data[mini_batch_inds])
# data: [0. 1. 2. 3. 4. 5. 6. 7.]
# batch_size: 8
# mini_batch_size: 4
# micro_batch_size: 2
# epoch: 0 batch_inds: [6 4 0 7 3 5 1 2]
# ____⏩ a forward pass on [6. 4.]
# ____⏩ a forward pass on [0. 7.]
# ⏪ a backward pass on [6. 4. 0. 7.]
# ____⏩ a forward pass on [3. 5.]
# ____⏩ a forward pass on [1. 2.]
# ⏪ a backward pass on [3. 5. 1. 2.]
# epoch: 1 batch_inds: [6 7 3 2 0 4 5 1]
# ____⏩ a forward pass on [6. 7.]
# ____⏩ a forward pass on [3. 2.]
# ⏪ a backward pass on [6. 7. 3. 2.]
# ____⏩ a forward pass on [0. 4.]
# ____⏩ a forward pass on [5. 1.]
# ⏪ a backward pass on [0. 4. 5. 1.]
# epoch: 2 batch_inds: [1 4 5 6 0 7 3 2]
# ____⏩ a forward pass on [1. 4.]
# ____⏩ a forward pass on [5. 6.]
# ⏪ a backward pass on [1. 4. 5. 6.]
# ____⏩ a forward pass on [0. 7.]
# ____⏩ a forward pass on [3. 2.]
# ⏪ a backward pass on [0. 7. 3. 2.]
# epoch: 3 batch_inds: [7 2 4 1 3 0 6 5]
# ____⏩ a forward pass on [7. 2.]
# ____⏩ a forward pass on [4. 1.]
# ⏪ a backward pass on [7. 2. 4. 1.]
# ____⏩ a forward pass on [3. 0.]
# ____⏩ a forward pass on [6. 5.]
# ⏪ a backward pass on [3. 0. 6. 5.]
```
8. **基于每个标记的 KL 惩罚**
- 代码为奖励添加了每个标记的 KL 惩罚 ([lm_human_preferences/train_policy.py#L150-L153](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L150-L153)),以阻止策略与原始策略差异过大。
- 以 “usually, he would” 为例,它被标记化为 `[23073, 11, 339, 561]` 。假设我们使用 `[23073]` 作为查询,`[11, 339, 561]` 作为响应。然后在默认的 `gpt2` 参数下,响应标记将具有参考策略的对数概率 `logprobs=[-3.3213, -4.9980, -3.8690]` 。
- 在第一个 PPO 更新时期和小批次更新时,激活策略将具有相同的对数概率`new_logprobs=[-3.3213, -4.9980, -3.8690]` 。因此,每个标记的 KL 惩罚将为 `kl = new_logprobs - logprobs = [0., 0., 0.]` 。
- 但是,在第一个梯度反向传播后,我们可能会得到 `new_logprob=[3.3213, -4.9980, -3.8690]` ,因此每个标记的 KL 惩罚变为 `kl = new_logprobs - logprobs = [-0.3315, -0.0426, 0.6351]` 。
- 随后,`non_score_reward = beta * kl` ,其中 `beta` 是 KL 惩罚系数 \(\beta\),它被添加到从奖励模型获得的 `score` 中,以创建用于训练的 `rewards` 。`score` 仅在每个回合 ( episode ) 结束时给出,可能类似于 `[0.4]` ,然后我们有 `rewards = [beta * -0.3315, beta * -0.0426, beta * 0.6351 + 0.4]` 。
9. **每个小批次的奖励和优势白化,可选择均值平移**
1. OAI 实现了一个名为 `whiten` 的函数,如下所示,基本上通过减去其均值然后除以其标准差来对 `values` 进行归一化。可选地,`whiten` 可以通过 `shift_mean=True` 将白化后的 `values` 平移到均值。
```python
def whiten(values, shift_mean=True):
mean, var = torch.mean(values), torch.var(values, unbiased=False)
whitened = (values - mean)* torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
```
2. 在每个小批次中,OAI 使用 `whiten(rewards, shift_mean=False)` 对奖励进行白化,不对均值进行平移处理 ([lm_human_preferences/train_policy.py#L325](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L325)),并使用平移后的均值对优势进行白化 `whiten(advantages)` ([lm_human_preferences/train_policy.py#L338](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L338))。
3. **优化注意事项:** 如果小批次的数量为一 (在此复现中是这种情况),我们只需要对奖励进行白化、计算并对优势进行一次白化,因为它们的值不会改变。
4. **TensorFlow vs PyTorch 注意事项:** `tf.moments` 与 `torch.var` 的不同行为: 由于方差计算方式不同,Torch 和 TensorFlow 中的白化行为不同:
```jsx
import numpy as np
import tensorflow as tf
import torch
def whiten_tf(values, shift_mean=True):
mean, var = tf.nn.moments(values, axes=list(range(values.shape.rank)))
mean = tf.Print(mean, [mean], 'mean', summarize=100)
var = tf.Print(var, [var], 'var', summarize=100)
whitened = (values - mean)* tf.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
def whiten_pt(values, shift_mean=True, unbiased=True):
mean, var = torch.mean(values), torch.var(values, unbiased=unbiased)
print("mean", mean)
print("var", var)
whitened = (values - mean)* torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
rewards = np.array([
[1.2, 1.3, 1.4],
[1.5, 1.6, 1.7],
[1.8, 1.9, 2.0],
])
with tf.Session() as sess:
print(sess.run(whiten_tf(tf.constant(rewards, dtype=tf.float32), shift_mean=False)))
print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=True))
print(whiten_pt(torch.tensor(rewards), shift_mean=False, unbiased=False))
```
```jsx
mean[1.5999999]
var[0.0666666627]
[[0.05080712 0.4381051 0.8254035 ]
[1.2127019 1.6000004 1.9872988 ]
[2.3745968 2.7618952 3.1491938 ]]
mean tensor(1.6000, dtype=torch.float64)
var tensor(0.0750, dtype=torch.float64)
tensor([[0.1394, 0.5046, 0.8697],
[1.2349, 1.6000, 1.9651],
[2.3303, 2.6954, 3.0606]], dtype=torch.float64)
mean tensor(1.6000, dtype=torch.float64)
var tensor(0.0667, dtype=torch.float64)
tensor([[0.0508, 0.4381, 0.8254],
[1.2127, 1.6000, 1.9873],
[2.3746, 2.7619, 3.1492]], dtype=torch.float64)
```
10. **裁剪值函数**
1. 与原始的 PPO 一样 ([baselines/ppo2/model.py#L68-L75](https://github.com/openai/baselines/blob/ea25b9e8b234e6ee1bca43083f8f3cf974143998/baselines/ppo2/model.py#L68-L75)),值函数被裁剪 ([lm_human_preferences/train_policy.py#L343-L348](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L343-L348)),方式与策略目标类似。
11. **自适应 KL 散度**
- KL 散度惩罚系数 \(\beta\) 根据当前策略与先前策略之间的 KL 散度自适应修改。如果 KL 散度超出预定的目标范围,则调整惩罚系数以使其更接近目标范围 ([lm_human_preferences/train_policy.py#L115-L124](https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/lm_human_preferences/train_policy.py#L115-L124))。它的实现如下:
```python
class AdaptiveKLController:
def __init__(self, init_kl_coef, hparams):
self.value = init_kl_coef
self.hparams = hparams
def update(self, current, n_steps):
target = self.hparams.target
proportional_error = np.clip(current / target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.hparams.horizon
self.value *= mult
```
- 对于本工作中研究的 `sentiment` 和 `descriptiveness` 任务,我们使用了 `init_kl_coef=0.15, hparams.target=6, hparams.horizon=10000` 。
## **PyTorch Adam 优化器与 RLHF 相关的数值问题**
- 这个实现细节非常有趣,值得专门一节来讨论。
- PyTorch 的 Adam 优化器 ([torch.optim.Adam.html](https://pytorch.org/docs/stable/generated/torch.optim.Adam.html)) 与 TensorFlow 的 Adam 优化器 (TF1 Adam 在 [tensorflow/v1.15.2/adam.py](https://github.com/tensorflow/tensorflow/blob/v1.15.2/tensorflow/python/training/adam.py),TF2 Adam 在 [keras/adam.py#L26-L220](https://github.com/keras-team/keras/blob/v2.13.1/keras/optimizers/adam.py#L26-L220)) 有不同的实现方式。具体来说, **PyTorch 遵循了 Kingma 和 Ba 的 Adam 论文中的算法 1** ([arxiv/1412.6980](https://arxiv.org/pdf/1412.6980.pdf)),而 **TensorFlow 使用了该论文第 2.1 节前的公式**,这里提到的 `epsilon` 在论文中称为 `epsilon hat` 。在伪代码比较中,我们有以下内容:
```python
### pytorch adam implementation:
bias_correction1 = 1 - beta1 ** step
bias_correction2 = 1 - beta2 ** step
step_size = lr / bias_correction1
bias_correction2_sqrt = _dispatch_sqrt(bias_correction2)
denom = (exp_avg_sq.sqrt() / bias_correction2_sqrt).add_(eps)
param.addcdiv_(exp_avg, denom, value=-step_size)
### tensorflow adam implementation:
lr_t = lr * _dispatch_sqrt((1 - beta2 ** step)) / (1 - beta1 ** step)
denom = exp_avg_sq.sqrt().add_(eps)
param.addcdiv_(exp_avg, denom, value=-lr_t)
```
- 让我们比较一下 PyTorch 风格和 TensorFlow 风格 Adam 的更新方程。按照 Adam 论文 [(Kingma 和 Ba,2014)](https://arxiv.org/abs/1412.6980) 的符号表示,我们可以得到 PyTorch Adam (Kingma 和 Ba 论文的算法 1) 和 TensorFlow 风格 Adam (Kingma 和 Ba 论文第 2.1 节前的公式) 的梯度更新规则如下:
$$\begin{aligned}\text{pytorch adam :}\quad \theta_t & =\theta_{t-1}-\alpha \cdot \hat{m} _t /\left(\sqrt{\hat{v} _t}+\varepsilon\right) \& =\theta_ {t-1}- \alpha \underbrace{\left[m_t /\left(1-\beta_1^t\right)\right]}_ {=\hat{m} _t} /\left[\sqrt{\underbrace{v_t /\left(1-\beta_2^t\right)}_ {=\hat{v} _t} }+\varepsilon\right]\& =\theta_ {t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right]\frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\varepsilon \sqrt{1-\beta_2^t}}}\end{aligned}$$
$$\begin{aligned}\text{tensorflow adam:}\quad \theta_t & =\theta_{t-1}-\alpha_t m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \& =\theta_{t-1}-\underbrace{\left[\alpha \sqrt{1-\beta_2^t} /\left(1-\beta_1^t\right)\right]} _{=\alpha_t} m_t /\left(\sqrt{v_t}+\hat{\varepsilon}\right) \& =\theta_ {t-1}- \alpha\left[m_t /\left(1-\beta_1^t\right)\right] \frac{\sqrt{1-\beta_2^t}}{\sqrt{v_t}+\color{green}{\hat{\varepsilon}}} \end{aligned}$$
- 上面的方程强调了 PyTorch 和 TensorFlow 实现之间的区别在于它们的 **归一化项**,即 \(\color{green}{\varepsilon \sqrt{1-\beta_2^t}}\) 和 \(\color{green}{\hat{\varepsilon}}\)。如果我们设置 \(\hat{\varepsilon} = \varepsilon \sqrt{1-\beta_2^t}\),则这两个版本是等价的。然而,在 PyTorch 和 TensorFlow 的 API 中,我们只能通过 `eps` 参数设置 \(\varepsilon\) (PyTorch) 和 \(\hat{\varepsilon}\) (TensorFlow),从而导致它们的更新方程存在差异。如果我们将 \(\varepsilon\) 和 \(\hat{\varepsilon}\) 都设置为相同的值,比如 1e-5 会发生什么?那么对于 TensorFlow Adam,归一化项 \(\hat{\varepsilon} = \text{1e-5}\) 就是一个常数。但对于 PyTorch Adam,归一化项 \({\varepsilon \sqrt{1-\beta_2^t}}\) 随着时间的推移而变化。重要的是,当时间步 \(t\) 较小时,该项 \({\varepsilon \sqrt{1-\beta_2^t}}\) 明显小于 1e-5,随着时间步增加,逐渐接近 1e-5。下面的图表比较了这两个归一化项随着时间步的变化情况:
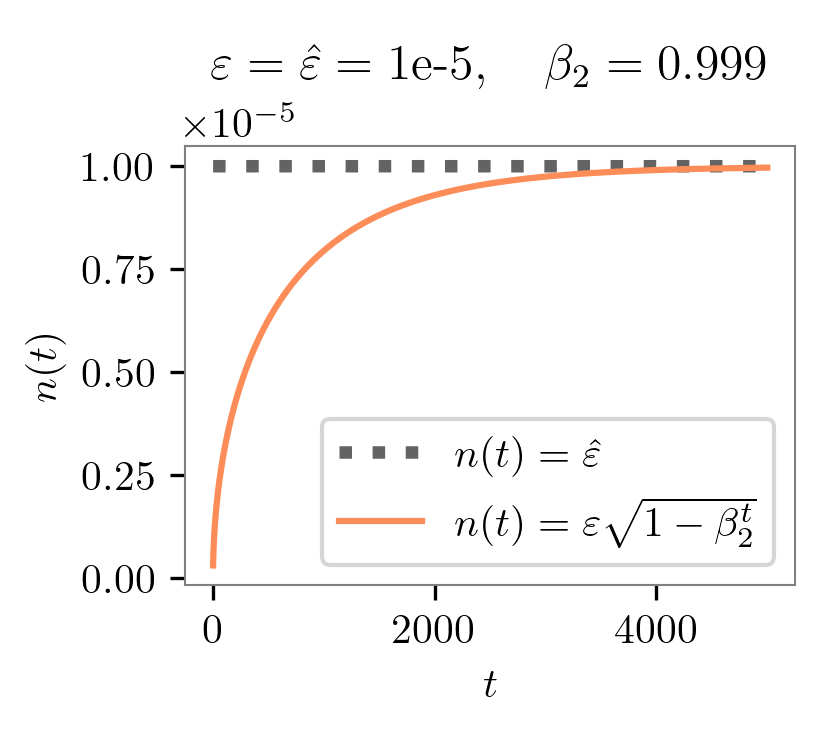
- 上图显示,如果我们在 PyTorch Adam 和 TensorFlow Adam 中设置相同的 `eps` ,那么在训练的早期阶段,PyTorch Adam 使用的归一化项要比 TensorFlow Adam 小得多。换句话说,PyTorch Adam 在训练的早期采用了 **更激进的梯度更新**。我们的实验证明了这一发现,如下所示。
- 这对复现性和性能有何影响?为了保持设置一致,我们记录了来自 [https://github.com/openai/lm-human-preferences](https://github.com/openai/lm-human-preferences) 的原始查询、响应和奖励,并将它们保存在 [https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main](https://huggingface.co/datasets/vwxyzjn/lm-human-preferences-debug/tree/main) 中。我还记录了使用 TF1 的 `AdamOptimizer` 优化器的前两个训练周期的指标作为基准。以下是一些关键指标:
| | OAI 的 TF1 Adam | PyTorch 的 Adam | 我们自定义的类似 TensorFlow 风格的 Adam|
| --- | --- | --- | --- |
| policy/approxkl | 0.00037167023 | 0.0023672834504395723 | 0.000374998344341293 |
| policy/clipfrac | 0.0045572915 | 0.02018229104578495 | 0.0052083334885537624 |
| ratio_mean | 1.0051285 | 1.0105520486831665 | 1.0044583082199097 |
| ratio_var | 0.0007716546 | 0.005374275613576174 | 0.0007942612282931805 |
| ratio_max | 1.227216 | 1.8121057748794556 | 1.250215768814087 |
| ratio_min | 0.7400441 | 0.4011387825012207 | 0.7299948930740356 |
| logprob_diff_mean | 0.0047487603 | 0.008101251907646656 | 0.004073789343237877 |
| logprob_diff_var | 0.0007207897 | 0.004668936599045992 | 0.0007334011606872082 |
| logprob_diff_max | 0.20474821 | 0.594489574432373 | 0.22331619262695312 |
| logprob_diff_min | -0.30104542 | -0.9134478569030762 | -0.31471776962280273 |
- 由于某种原因, **PyTorch 的 Adam 生成了更激进的更新**。以下是一些证据:
- **PyTorch 的 Adam 的 logprob_diff_var 高出 6 倍**。这里的 `logprobs_diff = new_logprobs - logprobs` 是经过两个训练周期后,初始策略和当前策略之间的标记对数概率差异。具有更大的 `logprob_diff_var` 意味着对数概率变化的幅度比 OAI 的 TF1 Adam 大。
- **PyTorch 的 Adam 呈现更极端的最大和最小比率**。这里的 `ratio = torch.exp(logprobs_diff)` 。具有 `ratio_max=1.8121057748794556` 意味着对于某些标记,在当前策略下抽取该标记的概率要比 OAI 的 TF1 Adam 高 1.8 倍,而后者仅为 1.2 倍。
- **更大的 `policy/approxkl` 和 `policy/clipfrac`**。由于激进的更新,比率被剪切的次数 **多 4.4 倍,近似的 KL 散度大 6 倍**。
- 这种激进的更新可能会导致进一步的问题。例如,PyTorch 的 `Adam` 中的`logprob_diff_mean` 要大 1.7 倍,这将对下一个奖励计算中的 KL 惩罚产生 1.7 倍大的影响; 这可能会被累积。实际上,这可能与著名的 KL 散度问题有关—— KL 惩罚远大于它应该的值,模型可能会更多地关注它并进行更多优化,从而导致负的 KL 散度。
- **更大的模型受到更多影响**。我们进行了一些实验,比较了 PyTorch 的 `Adam` (代号 `pt_adam` ) 和我们自定义的类似 TensorFlow 风格的 Adam (代号 `tf_adam` ) 在 `gpt2` 和 `gpt2-xl` 上的性能。我们发现在 `gpt2` 下性能大致相似; 但是在 `gpt2-xl` 下,我们观察到了更激进的更新,这意味着更大的模型受到了更多的影响。
- 当在 `gpt2-xl` 中初始策略更新更为激进时,训练动态会受到影响。例如,我们发现使用 `pt_adam` 时,`sentiment` 的 `objective/kl` 和 `objective/scores` 峰值要大得多, _在其中一个随机种子中,最大的 KL 值达到了 17.5_ ,这表明了不希望的过度优化。
- 此外,由于 KL 更大,许多其他训练指标也受到影响。例如,我们观察到更大的 `clipfrac` (`ratio` 被 PPO 的目标裁剪系数 0.2 裁剪的时间比例) 和 `approxkl` 。
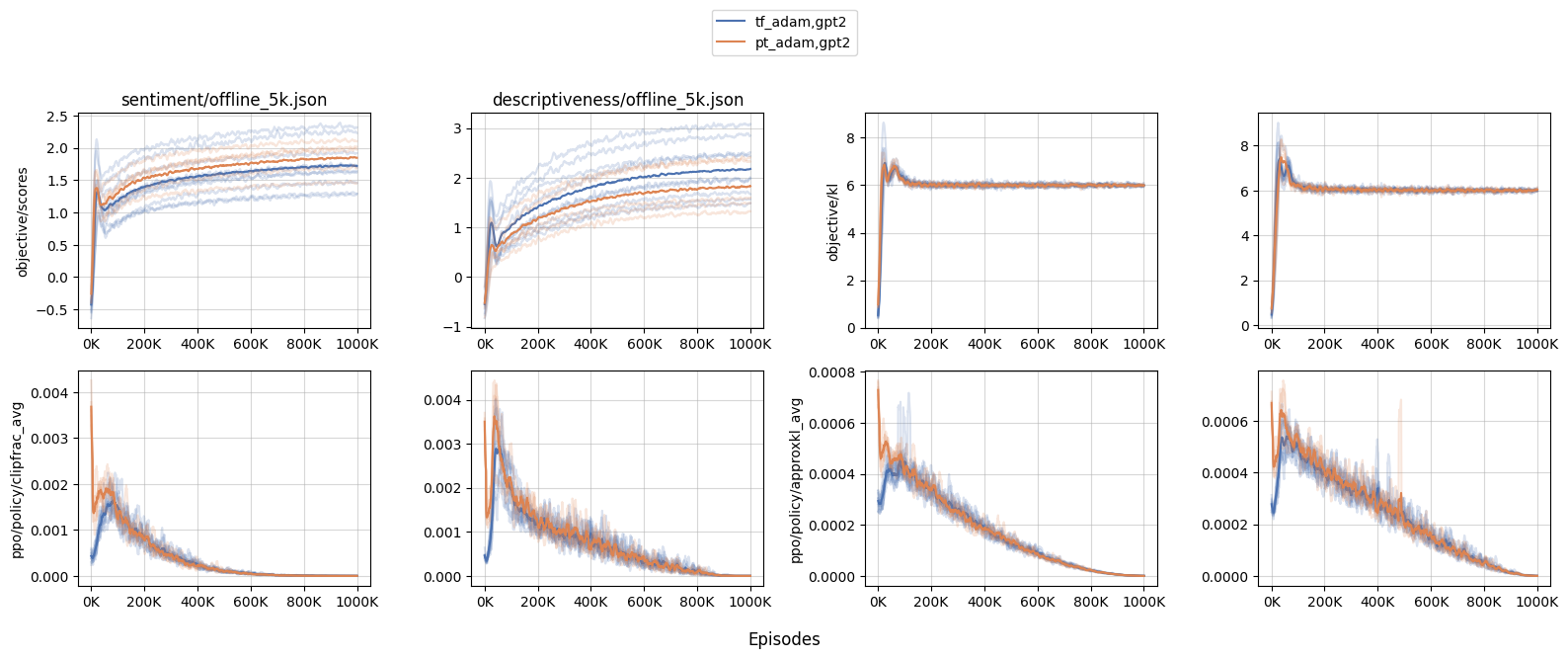
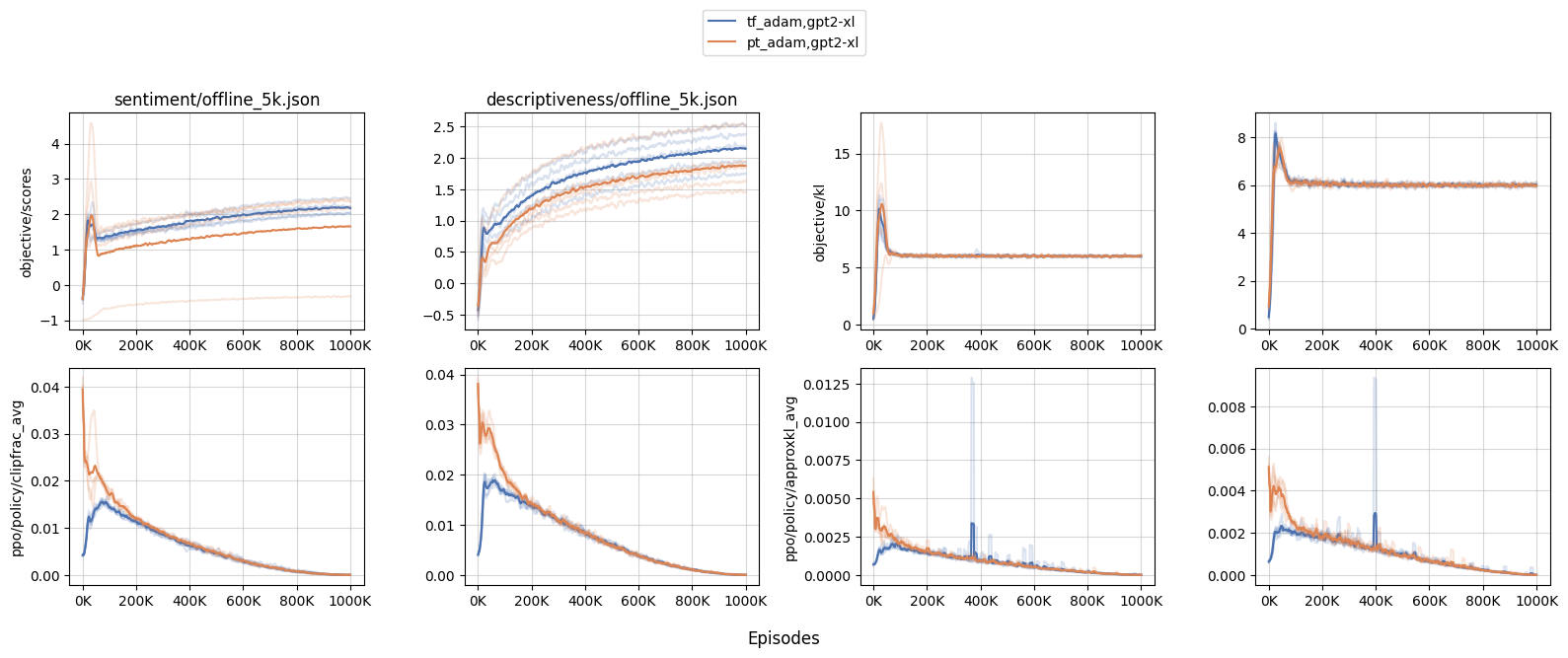
# 局限性
注意到这项工作没有尝试复现 CNN DM 中的摘要工作。这是因为我们发现训练耗时且不稳定。
我们的特定训练运行显示 GPU 利用率较低 (约 30%),因此一个训练运行需要近 4 天的时间,这非常昂贵 (只有 AWS 销售 p3dn.24xlarge,每小时费用为 31.212 美元)。
此外,训练也很不稳定。虽然奖励值上升,但我们发现难以复现 Ziegler 等人 (2019 年) 报告的“智能复制”行为。以下是一些样本输出 — 显然,智能体出现了某种程度的过拟合。请查看 [https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs](https://wandb.ai/openrlbenchmark/lm-human-preferences/runs/1ab47rqi/logs?workspace=user-costa-huang) 以获取更完整的日志。
# 总结
在这项工作中,我们深入研究了 OpenAI 的原始 RLHF (Reinforcement Learning from Human Feedback) 代码库,并编制了其实施细节的列表。我们还创建了一个最小的基础版本,当数据集和超参数受控制时,可以复现与 OpenAI 原始 RLHF 代码库相同的学习曲线。此外,我们还识别了一些令人惊讶的实施细节,比如 Adam 优化器的设置,它会导致在 RLHF 训练的早期出现激进的更新。
# 致谢
这项工作得到了 Hugging Face 的 Big Science 集群的支持 🤗。我们还感谢 @lewtun 和 @natolambert 的建设性讨论。
# Bibtex
```bibtex
@article{Huang2023implementation,
author = {Huang, Shengyi and Liu, Tianlin and von Werra, Leandro},
title = {The N Implementation Details of RLHF with PPO},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo},
}
```
| 9 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced-api/Dockerfile | FROM huggingface/autotrain-advanced:latest
CMD autotrain api --port 7860 --host 0.0.0.0
| 0 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/setup.cfg | [isort]
default_section = FIRSTPARTY
ensure_newline_before_comments = True
force_grid_wrap = 0
include_trailing_comma = True
known_first_party = alignment
known_third_party =
transformers
datasets
fugashi
git
h5py
matplotlib
nltk
numpy
packaging
pandas
psutil
pytest
rouge_score
sacrebleu
seqeval
sklearn
streamlit
torch
tqdm
line_length = 119
lines_after_imports = 2
multi_line_output = 3
use_parentheses = True
[flake8]
ignore = E203, E501, E741, W503, W605
max-line-length = 119
per-file-ignores =
# imported but unused
__init__.py: F401
[tool:pytest]
doctest_optionflags=NUMBER NORMALIZE_WHITESPACE ELLIPSIS | 1 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/setup.py | # Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Adapted from huggingface/transformers: https://github.com/huggingface/transformers/blob/21a2d900eceeded7be9edc445b56877b95eda4ca/setup.py
import re
import shutil
from pathlib import Path
from setuptools import find_packages, setup
# Remove stale alignment.egg-info directory to avoid https://github.com/pypa/pip/issues/5466
stale_egg_info = Path(__file__).parent / "alignment.egg-info"
if stale_egg_info.exists():
print(
(
"Warning: {} exists.\n\n"
"If you recently updated alignment, this is expected,\n"
"but it may prevent alignment from installing in editable mode.\n\n"
"This directory is automatically generated by Python's packaging tools.\n"
"I will remove it now.\n\n"
"See https://github.com/pypa/pip/issues/5466 for details.\n"
).format(stale_egg_info)
)
shutil.rmtree(stale_egg_info)
# IMPORTANT: all dependencies should be listed here with their version requirements, if any.
# * If a dependency is fast-moving (e.g. transformers), pin to the exact version
_deps = [
"accelerate>=0.29.2",
"bitsandbytes>=0.43.0",
"black>=24.4.2",
"datasets>=2.18.0",
"deepspeed>=0.14.4",
"einops>=0.6.1",
"evaluate==0.4.0",
"flake8>=6.0.0",
"hf-doc-builder>=0.4.0",
"hf_transfer>=0.1.4",
"huggingface-hub>=0.19.2,<1.0",
"isort>=5.12.0",
"ninja>=1.11.1",
"numpy>=1.24.2",
"packaging>=23.0",
"parameterized>=0.9.0",
"peft>=0.9.0",
"protobuf<=3.20.2", # Needed to avoid conflicts with `transformers`
"pytest",
"safetensors>=0.3.3",
"sentencepiece>=0.1.99",
"scipy",
"tensorboard",
"torch>=2.1.2",
"transformers>=4.39.3",
"trl>=0.9.6",
"jinja2>=3.0.0",
"tqdm>=4.64.1",
]
# this is a lookup table with items like:
#
# tokenizers: "tokenizers==0.9.4"
# packaging: "packaging"
#
# some of the values are versioned whereas others aren't.
deps = {b: a for a, b in (re.findall(r"^(([^!=<>~ \[\]]+)(?:\[[^\]]+\])?(?:[!=<>~ ].*)?$)", x)[0] for x in _deps)}
def deps_list(*pkgs):
return [deps[pkg] for pkg in pkgs]
extras = {}
extras["tests"] = deps_list("pytest", "parameterized")
extras["torch"] = deps_list("torch")
extras["quality"] = deps_list("black", "isort", "flake8")
extras["docs"] = deps_list("hf-doc-builder")
extras["dev"] = extras["docs"] + extras["quality"] + extras["tests"]
# core dependencies shared across the whole project - keep this to a bare minimum :)
install_requires = [
deps["accelerate"],
deps["bitsandbytes"],
deps["einops"],
deps["evaluate"],
deps["datasets"],
deps["deepspeed"],
deps["hf_transfer"],
deps["huggingface-hub"],
deps["jinja2"],
deps["ninja"],
deps["numpy"],
deps["packaging"], # utilities from PyPA to e.g., compare versions
deps["peft"],
deps["protobuf"],
deps["safetensors"],
deps["sentencepiece"],
deps["scipy"],
deps["tensorboard"],
deps["tqdm"], # progress bars in model download and training scripts
deps["transformers"],
deps["trl"],
]
setup(
name="alignment-handbook",
version="0.4.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
author="The Hugging Face team (past and future)",
author_email="[email protected]",
description="The Alignment Handbook",
long_description=open("README.md", "r", encoding="utf-8").read(),
long_description_content_type="text/markdown",
keywords="nlp deep learning rlhf llm",
license="Apache",
url="https://github.com/huggingface/alignment-handbook",
package_dir={"": "src"},
packages=find_packages("src"),
zip_safe=False,
extras_require=extras,
python_requires=">=3.10.9",
install_requires=install_requires,
classifiers=[
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
)
| 2 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/LICENSE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 3 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/Makefile | .PHONY: style quality
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
export PYTHONPATH = src
check_dirs := src tests scripts
style:
black --line-length 119 --target-version py310 $(check_dirs) setup.py
isort $(check_dirs) setup.py
quality:
black --check --line-length 119 --target-version py310 $(check_dirs) setup.py
isort --check-only $(check_dirs) setup.py
flake8 --max-line-length 119 $(check_dirs) setup.py
# Release stuff
pre-release:
python src/alignment/release.py
pre-patch:
python src/alignment/release.py --patch
post-release:
python src/alignment/release.py --post_release
post-patch:
python src/alignment/release.py --post_release --patch
wheels:
python setup.py bdist_wheel && python setup.py sdist
wheels_clean:
rm -rf build && rm -rf dist
pypi_upload:
python -m pip install twine
twine upload dist/* -r pypi
pypi_test_upload:
python -m pip install twine
twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
| 4 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/CITATION.cff | cff-version: 1.2.0
title: The Alignment Handbook
message: >-
Robust recipes to align language models with human and AI
preferences.
type: software
authors:
- given-names: Lewis
family-names: Tunstall
- given-names: Edward
family-names: Beeching
- given-names: Nathan
family-names: Lambert
- given-names: Nazneen
family-names: Rajani
- given-names: Shengyi
family-names: Huang
- given-names: Kashif
family-names: Rasul
- given-names: Alvaro
family-names: Bartolome
- given-names: Alexander
name-particle: M.
family-names: Rush
- given-names: Thomas
family-names: Wolf
repository-code: 'https://github.com/huggingface/alignment-handbook'
license: Apache-2.0
version: 0.3.0.dev0
| 5 |
0 | hf_public_repos | hf_public_repos/alignment-handbook/README.md | <p align="center">
<img src="https://raw.githubusercontent.com/huggingface/alignment-handbook/main/assets/handbook.png">
</p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/alignment-handbook/handbook-v01-models-and-datasets-654e424d22e6880da5ebc015" target="_blank">Models & Datasets</a> | 📃 <a href="https://arxiv.org/abs/2310.16944" target="_blank">Technical Report</a>
</p>
# The Alignment Handbook
Robust recipes to continue pretraining and to align language models with human and AI preferences.
## What is this?
Just one year ago, chatbots were out of fashion and most people hadn't heard about techniques like Reinforcement Learning from Human Feedback (RLHF) to align language models with human preferences. Then, OpenAI broke the internet with ChatGPT and Meta followed suit by releasing the Llama series of language models which enabled the ML community to build their very own capable chatbots. This has led to a rich ecosystem of datasets and models that have mostly focused on teaching language models to follow instructions through supervised fine-tuning (SFT).
However, we know from the [InstructGPT](https://huggingface.co/papers/2203.02155) and [Llama2](https://huggingface.co/papers/2307.09288) papers that significant gains in helpfulness and safety can be had by augmenting SFT with human (or AI) preferences. At the same time, aligning language models to a set of preferences is a fairly novel idea and there are few public resources available on how to train these models, what data to collect, and what metrics to measure for best downstream performance.
The Alignment Handbook aims to fill that gap by providing the community with a series of robust training recipes that span the whole pipeline.
## News 🗞️
* **November 21, 2024**: We release the [recipe](recipes/smollm2/README.md) for finet-uning SmolLM2-Instruct.
* **August 18, 2024**: We release SmolLM-Instruct v0.2, along with the [recipe](recipes/smollm/README.md) to fine-tuning small LLMs 💻
* **April 12, 2024**: We release Zephyr 141B (A35B), in collaboration with Argilla and Kaist AI, along with the recipe to fine-tune Mixtral 8x22B with ORPO 🪁
* **March 12, 2024:** We release StarChat2 15B, along with the recipe to train capable coding assistants 🌟
* **March 1, 2024:** We release Zephyr 7B Gemma, which is a new recipe to align Gemma 7B with RLAIF 🔥
* **February 1, 2024:** We release a recipe to align open LLMs with Constitutional AI 📜! See the [recipe](https://github.com/huggingface/alignment-handbook/tree/main/recipes/constitutional-ai) and the [blog post](https://huggingface.co/blog/constitutional_ai) for details.
* **January 18, 2024:** We release a suite of evaluations of DPO vs KTO vs IPO, see the [recipe](recipes/pref_align_scan/README.md) and the [blog post](https://huggingface.co/blog/pref-tuning) for details.
* **November 10, 2023:** We release all the training code to replicate Zephyr-7b-β 🪁! We also release [No Robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots), a brand new dataset of 10,000 instructions and demonstrations written entirely by skilled human annotators.
## Links 🔗
* [Zephyr 7B models, datasets, and demos](https://huggingface.co/collections/HuggingFaceH4/zephyr-7b-6538c6d6d5ddd1cbb1744a66)
## How to navigate this project 🧭
This project is simple by design and mostly consists of:
* [`scripts`](./scripts/) to train and evaluate models. Four steps are included: continued pretraining, supervised-finetuning (SFT) for chat, preference alignment with DPO, and supervised-finetuning with preference alignment with ORPO. Each script supports distributed training of the full model weights with DeepSpeed ZeRO-3, or LoRA/QLoRA for parameter-efficient fine-tuning.
* [`recipes`](./recipes/) to reproduce models like Zephyr 7B. Each recipe takes the form of a YAML file which contains all the parameters associated with a single training run. A `gpt2-nl` recipe is also given to illustrate how this handbook can be used for language or domain adaptation, e.g. by continuing to pretrain on a different language, and then SFT and DPO tuning the result.
We are also working on a series of guides to explain how methods like direct preference optimization (DPO) work, along with lessons learned from gathering human preferences in practice. To get started, we recommend the following:
1. Follow the [installation instructions](#installation-instructions) to set up your environment etc.
2. Replicate Zephyr-7b-β by following the [recipe instructions](./recipes/zephyr-7b-beta/README.md).
If you would like to train chat models on your own datasets, we recommend following the dataset formatting instructions [here](./scripts/README.md#fine-tuning-on-your-datasets).
## Contents
The initial release of the handbook will focus on the following techniques:
* **Continued pretraining:** adapt language models to a new language or domain, or simply improve it by continued pretraining (causal language modeling) on a new dataset.
* **Supervised fine-tuning:** teach language models to follow instructions and tips on how to collect and curate your training dataset.
* **Reward modeling:** teach language models to distinguish model responses according to human or AI preferences.
* **Rejection sampling:** a simple, but powerful technique to boost the performance of your SFT model.
* **Direct preference optimisation (DPO):** a powerful and promising alternative to PPO.
* **Odds Ratio Preference Optimisation (ORPO)**: a technique to fine-tune language models with human preferences, combining SFT and DPO in a single stage.
## Installation instructions
To run the code in this project, first, create a Python virtual environment using e.g. Conda:
```shell
conda create -n handbook python=3.10 && conda activate handbook
```
Next, install PyTorch `v2.1.2` - the precise version is important for reproducibility! Since this is hardware-dependent, we
direct you to the [PyTorch Installation Page](https://pytorch.org/get-started/locally/).
You can then install the remaining package dependencies as follows:
```shell
git clone https://github.com/huggingface/alignment-handbook.git
cd ./alignment-handbook/
python -m pip install .
```
You will also need Flash Attention 2 installed, which can be done by running:
```shell
python -m pip install flash-attn --no-build-isolation
```
> **Note**
> If your machine has less than 96GB of RAM and many CPU cores, reduce the `MAX_JOBS` arguments, e.g. `MAX_JOBS=4 pip install flash-attn --no-build-isolation`
Next, log into your Hugging Face account as follows:
```shell
huggingface-cli login
```
Finally, install Git LFS so that you can push models to the Hugging Face Hub:
```shell
sudo apt-get install git-lfs
```
You can now check out the `scripts` and `recipes` directories for instructions on how to train some models 🪁!
## Project structure
```
├── LICENSE
├── Makefile <- Makefile with commands like `make style`
├── README.md <- The top-level README for developers using this project
├── chapters <- Educational content to render on hf.co/learn
├── recipes <- Recipe configs, accelerate configs, slurm scripts
├── scripts <- Scripts to train and evaluate chat models
├── setup.cfg <- Installation config (mostly used for configuring code quality & tests)
├── setup.py <- Makes project pip installable (pip install -e .) so `alignment` can be imported
├── src <- Source code for use in this project
└── tests <- Unit tests
```
## Citation
If you find the content of this repo useful in your work, please cite it as follows via `\usepackage{biblatex}`:
```bibtex
@software{Tunstall_The_Alignment_Handbook,
author = {Tunstall, Lewis and Beeching, Edward and Lambert, Nathan and Rajani, Nazneen and Huang, Shengyi and Rasul, Kashif and Bartolome, Alvaro and M. Rush, Alexander and Wolf, Thomas},
license = {Apache-2.0},
title = {{The Alignment Handbook}},
url = {https://github.com/huggingface/alignment-handbook},
version = {0.3.0.dev0}
}
```
| 6 |
0 | hf_public_repos/alignment-handbook | hf_public_repos/alignment-handbook/scripts/run_sft.py | #!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Supervised fine-tuning script for decoder language models.
"""
import logging
import random
import sys
import datasets
import torch
import transformers
from transformers import AutoModelForCausalLM, set_seed
from alignment import (
DataArguments,
H4ArgumentParser,
ModelArguments,
SFTConfig,
apply_chat_template,
decontaminate_humaneval,
get_checkpoint,
get_datasets,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
get_tokenizer,
)
from trl import SFTTrainer, setup_chat_format
logger = logging.getLogger(__name__)
def main():
parser = H4ArgumentParser((ModelArguments, DataArguments, SFTConfig))
model_args, data_args, training_args = parser.parse()
# Set seed for reproducibility
set_seed(training_args.seed)
###############
# Setup logging
###############
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process a small summary
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f" distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Model parameters {model_args}")
logger.info(f"Data parameters {data_args}")
logger.info(f"Training/evaluation parameters {training_args}")
# Check for last checkpoint
last_checkpoint = get_checkpoint(training_args)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint=}.")
###############
# Load datasets
###############
raw_datasets = get_datasets(
data_args,
splits=data_args.dataset_splits,
configs=data_args.dataset_configs,
columns_to_keep=["messages", "chosen", "rejected", "prompt", "completion", "label"],
)
logger.info(
f"Training on the following datasets and their proportions: {[split + ' : ' + str(dset.num_rows) for split, dset in raw_datasets.items()]}"
)
column_names = list(raw_datasets["train"].features)
################
# Load tokenizer
################
tokenizer = get_tokenizer(model_args, data_args)
#######################
# Load pretrained model
#######################
logger.info("*** Load pretrained model ***")
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = model_args.model_name_or_path
# For ChatML we need to add special tokens and resize the embedding layer
if "<|im_start|>" in tokenizer.chat_template and "gemma-tokenizer-chatml" not in tokenizer.name_or_path:
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, **model_kwargs)
model, tokenizer = setup_chat_format(model, tokenizer)
model_kwargs = None
#####################
# Apply chat template
#####################
raw_datasets = raw_datasets.map(
apply_chat_template,
fn_kwargs={
"tokenizer": tokenizer,
"task": "sft",
"auto_insert_empty_system_msg": data_args.auto_insert_empty_system_msg,
},
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
desc="Applying chat template",
)
##########################
# Decontaminate benchmarks
##########################
num_raw_train_samples = len(raw_datasets["train"])
raw_datasets = raw_datasets.filter(decontaminate_humaneval, batched=True, batch_size=10_000, num_proc=1)
num_filtered_train_samples = num_raw_train_samples - len(raw_datasets["train"])
logger.info(
f"Decontaminated {num_filtered_train_samples} ({num_filtered_train_samples/num_raw_train_samples * 100:.2f}%) samples from the training set."
)
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
with training_args.main_process_first(desc="Log a few random samples from the processed training set"):
for index in random.sample(range(len(raw_datasets["train"])), 3):
logger.info(f"Sample {index} of the processed training set:\n\n{raw_datasets['train'][index]['text']}")
########################
# Initialize the Trainer
########################
trainer = SFTTrainer(
model=model,
model_init_kwargs=model_kwargs,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text",
max_seq_length=training_args.max_seq_length,
tokenizer=tokenizer,
packing=True,
peft_config=get_peft_config(model_args),
dataset_kwargs=training_args.dataset_kwargs,
)
###############
# Training loop
###############
logger.info("*** Train ***")
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
metrics["train_samples"] = len(train_dataset)
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
trainer.save_model(training_args.output_dir)
logger.info(f"Model saved to {training_args.output_dir}")
# Save everything else on main process
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"dataset": list(data_args.dataset_mixer.keys()),
"dataset_tags": list(data_args.dataset_mixer.keys()),
"tags": ["alignment-handbook"],
}
if trainer.accelerator.is_main_process:
trainer.create_model_card(**kwargs)
# Restore k,v cache for fast inference
trainer.model.config.use_cache = True
trainer.model.config.save_pretrained(training_args.output_dir)
##########
# Evaluate
##########
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(eval_dataset)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.push_to_hub is True:
logger.info("Pushing to hub...")
trainer.push_to_hub(**kwargs)
logger.info("*** Training complete ***")
if __name__ == "__main__":
main()
| 7 |
0 | hf_public_repos/alignment-handbook | hf_public_repos/alignment-handbook/scripts/run_orpo.py | #!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import random
import sys
from typing import Any, Dict
import torch
import transformers
from transformers import AutoModelForCausalLM, set_seed
from alignment import (
DataArguments,
H4ArgumentParser,
ModelArguments,
apply_chat_template,
decontaminate_humaneval,
get_checkpoint,
get_datasets,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
get_tokenizer,
)
from trl import ORPOConfig, ORPOTrainer, setup_chat_format
logger = logging.getLogger(__name__)
def main():
parser = H4ArgumentParser((ModelArguments, DataArguments, ORPOConfig))
model_args, data_args, training_args = parser.parse()
#######
# Setup
#######
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.info(f"Model parameters {model_args}")
logger.info(f"Data parameters {data_args}")
logger.info(f"Training/evaluation parameters {training_args}")
# Check for last checkpoint
last_checkpoint = get_checkpoint(training_args)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint=}.")
# Set seed for reproducibility
set_seed(training_args.seed)
###############
# Load datasets
###############
raw_datasets = get_datasets(
data_args,
splits=data_args.dataset_splits,
configs=data_args.dataset_configs,
columns_to_keep=[
"prompt",
"chosen",
"rejected",
],
)
logger.info(
f"Training on the following splits: {[split + ' : ' + str(dset.num_rows) for split, dset in raw_datasets.items()]}"
)
column_names = list(raw_datasets["train"].features)
#####################################
# Load tokenizer and process datasets
#####################################
data_args.truncation_side = "left" # Truncate from left to ensure we don't lose labels in final turn
tokenizer = get_tokenizer(model_args, data_args)
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args)
model = AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
# For ChatML we need to add special tokens and resize the embedding layer
if "<|im_start|>" in tokenizer.chat_template:
model, tokenizer = setup_chat_format(model, tokenizer)
#####################
# Apply chat template
#####################
raw_datasets = raw_datasets.map(
apply_chat_template,
fn_kwargs={
"tokenizer": tokenizer,
"task": "orpo",
"auto_insert_empty_system_msg": data_args.auto_insert_empty_system_msg,
},
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
desc="Formatting comparisons with prompt template",
)
#############################
# Filter out seq > max_length
#############################
if training_args.max_prompt_length is not None:
unfiltered_train_samples = len(raw_datasets["train"])
if "test" in raw_datasets:
unfiltered_test_samples = len(raw_datasets["test"])
def filter_fn(sample: Dict[str, Any]) -> Dict[str, Any]:
prompt_length = tokenizer(
sample["text_prompt"],
return_tensors="pt",
)[
"input_ids"
].size(dim=-1)
return prompt_length < training_args.max_prompt_length
raw_datasets = raw_datasets.filter(
filter_fn,
desc="Filtering out the samples where len(text_prompt) > max_prompt_length",
)
filtered_train_samples = unfiltered_train_samples - len(raw_datasets["train"])
logger.info(
f"Filtered out {filtered_train_samples} training samples out of the {unfiltered_train_samples} samples."
)
if "test" in raw_datasets:
filtered_test_samples = unfiltered_test_samples - len(raw_datasets["test"])
logger.info(
f"Filtered out {filtered_test_samples} test samples out of the {unfiltered_test_samples} samples."
)
##########################
# Decontaminate benchmarks
##########################
num_raw_train_samples = len(raw_datasets["train"])
raw_datasets = raw_datasets.filter(
decontaminate_humaneval,
fn_kwargs={"text_column": "text_chosen"},
batched=True,
batch_size=10_000,
num_proc=1,
desc="Decontaminating HumanEval samples",
)
num_filtered_train_samples = num_raw_train_samples - len(raw_datasets["train"])
logger.info(
f"Decontaminated {num_filtered_train_samples} ({num_filtered_train_samples/num_raw_train_samples * 100:.2f}%) samples from the training set."
)
# Replace column names with what TRL needs, text_prompt -> prompt, text_chosen -> chosen and text_rejected -> rejected
for split in raw_datasets.keys():
raw_datasets[split] = raw_datasets[split].rename_columns(
{
"text_prompt": "prompt",
"text_chosen": "chosen",
"text_rejected": "rejected",
}
)
# Log a few random samples from the training set:
for index in random.sample(range(len(raw_datasets["train"])), 3):
logger.info(f"Prompt sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['prompt']}")
logger.info(f"Chosen sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['chosen']}")
logger.info(f"Rejected sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['rejected']}")
##########################
# Instantiate ORPO trainer
##########################
trainer = ORPOTrainer(
model,
args=training_args,
train_dataset=raw_datasets["train"],
eval_dataset=raw_datasets["test"] if "test" in raw_datasets else None,
tokenizer=tokenizer,
peft_config=get_peft_config(model_args), # type: ignore
)
###############
# Training loop
###############
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
metrics["train_samples"] = len(raw_datasets["train"])
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
logger.info("*** Training complete ***")
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(training_args.output_dir)
logger.info(f"Model saved to {training_args.output_dir}")
# Save everything else on main process
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"dataset": list(data_args.dataset_mixer.keys()),
"dataset_tags": list(data_args.dataset_mixer.keys()),
"tags": ["alignment-handbook"],
}
if trainer.accelerator.is_main_process:
trainer.create_model_card(**kwargs)
# Restore k,v cache for fast inference
trainer.model.config.use_cache = True
trainer.model.config.save_pretrained(training_args.output_dir)
##########
# Evaluate
##########
if training_args.do_eval and "test" in raw_datasets:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(raw_datasets["test"])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.push_to_hub is True:
logger.info("Pushing to hub...")
trainer.push_to_hub(**kwargs)
logger.info("*** Training complete! ***")
if __name__ == "__main__":
main()
| 8 |
0 | hf_public_repos/alignment-handbook | hf_public_repos/alignment-handbook/scripts/run_dpo.py | #!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import random
import sys
import torch
import transformers
from transformers import AutoModelForCausalLM, set_seed
from alignment import (
DataArguments,
DPOConfig,
H4ArgumentParser,
ModelArguments,
apply_chat_template,
decontaminate_humaneval,
get_checkpoint,
get_datasets,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
get_tokenizer,
is_adapter_model,
)
from peft import PeftConfig, PeftModel
from trl import DPOTrainer
logger = logging.getLogger(__name__)
def main():
parser = H4ArgumentParser((ModelArguments, DataArguments, DPOConfig))
model_args, data_args, training_args = parser.parse()
#######
# Setup
#######
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.info(f"Model parameters {model_args}")
logger.info(f"Data parameters {data_args}")
logger.info(f"Training/evaluation parameters {training_args}")
# Check for last checkpoint
last_checkpoint = get_checkpoint(training_args)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint=}.")
# Set seed for reproducibility
set_seed(training_args.seed)
###############
# Load datasets
###############
raw_datasets = get_datasets(
data_args,
splits=data_args.dataset_splits,
configs=data_args.dataset_configs,
columns_to_keep=["messages", "chosen", "rejected", "prompt", "completion", "label"],
)
logger.info(
f"Training on the following splits: {[split + ' : ' + str(dset.num_rows) for split, dset in raw_datasets.items()]}"
)
column_names = list(raw_datasets["train"].features)
#####################################
# Load tokenizer and process datasets
#####################################
data_args.truncation_side = "left" # Truncate from left to ensure we don't lose labels in final turn
tokenizer = get_tokenizer(model_args, data_args)
#####################
# Apply chat template
#####################
raw_datasets = raw_datasets.map(
apply_chat_template,
fn_kwargs={
"tokenizer": tokenizer,
"task": "dpo",
"auto_insert_empty_system_msg": data_args.auto_insert_empty_system_msg,
},
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
desc="Formatting comparisons with prompt template",
)
##########################
# Decontaminate benchmarks
##########################
num_raw_train_samples = len(raw_datasets["train"])
raw_datasets = raw_datasets.filter(
decontaminate_humaneval,
fn_kwargs={"text_column": "text_chosen"},
batched=True,
batch_size=10_000,
num_proc=1,
desc="Decontaminating HumanEval samples",
)
num_filtered_train_samples = num_raw_train_samples - len(raw_datasets["train"])
logger.info(
f"Decontaminated {num_filtered_train_samples} ({num_filtered_train_samples/num_raw_train_samples * 100:.2f}%) samples from the training set."
)
# Replace column names with what TRL needs, text_chosen -> chosen and text_rejected -> rejected
for split in ["train", "test"]:
raw_datasets[split] = raw_datasets[split].rename_columns(
{"text_prompt": "prompt", "text_chosen": "chosen", "text_rejected": "rejected"}
)
# Log a few random samples from the training set:
for index in random.sample(range(len(raw_datasets["train"])), 3):
logger.info(f"Prompt sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['prompt']}")
logger.info(f"Chosen sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['chosen']}")
logger.info(f"Rejected sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['rejected']}")
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = model_args.model_name_or_path
if is_adapter_model(model, model_args.model_revision) is True:
logger.info(f"Loading SFT adapter for {model_args.model_name_or_path=}")
peft_config = PeftConfig.from_pretrained(model_args.model_name_or_path, revision=model_args.model_revision)
model_kwargs = dict(
revision=model_args.base_model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
base_model = AutoModelForCausalLM.from_pretrained(
peft_config.base_model_name_or_path,
**model_kwargs,
)
model = PeftModel.from_pretrained(
base_model,
model_args.model_name_or_path,
revision=model_args.model_revision,
)
model_kwargs = None
ref_model = model
ref_model_kwargs = model_kwargs
if model_args.use_peft is True:
ref_model = None
ref_model_kwargs = None
#########################
# Instantiate DPO trainer
#########################
trainer = DPOTrainer(
model,
ref_model,
model_init_kwargs=model_kwargs,
ref_model_init_kwargs=ref_model_kwargs,
args=training_args,
beta=training_args.beta,
train_dataset=raw_datasets["train"],
eval_dataset=raw_datasets["test"],
tokenizer=tokenizer,
max_length=training_args.max_length,
max_prompt_length=training_args.max_prompt_length,
peft_config=get_peft_config(model_args),
loss_type=training_args.loss_type,
)
###############
# Training loop
###############
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
metrics["train_samples"] = len(raw_datasets["train"])
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
logger.info("*** Training complete ***")
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
trainer.save_model(training_args.output_dir)
logger.info(f"Model saved to {training_args.output_dir}")
# Save everything else on main process
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"dataset": list(data_args.dataset_mixer.keys()),
"dataset_tags": list(data_args.dataset_mixer.keys()),
"tags": ["alignment-handbook"],
}
if trainer.accelerator.is_main_process:
trainer.create_model_card(**kwargs)
# Restore k,v cache for fast inference
trainer.model.config.use_cache = True
trainer.model.config.save_pretrained(training_args.output_dir)
##########
# Evaluate
##########
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(raw_datasets["test"])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.push_to_hub is True:
logger.info("Pushing to hub...")
trainer.push_to_hub(**kwargs)
logger.info("*** Training complete! ***")
if __name__ == "__main__":
main()
| 9 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/phi/phiWorker.js | import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "phi-mixformer-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
async function concatenateArrayBuffers(urls) {
const arrayBuffers = await Promise.all(urls.map(url => fetchArrayBuffer(url)));
let totalLength = arrayBuffers.reduce((acc, arrayBuffer) => acc + arrayBuffer.byteLength, 0);
let concatenatedBuffer = new Uint8Array(totalLength);
let offset = 0;
arrayBuffers.forEach(buffer => {
concatenatedBuffer.set(new Uint8Array(buffer), offset);
offset += buffer.byteLength;
});
return concatenatedBuffer;
}
class Phi {
static instance = {};
static async getInstance(
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized
) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8, configArrayU8] =
await Promise.all([
weightsURL instanceof Array ? concatenateArrayBuffers(weightsURL) : fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
fetchArrayBuffer(configURL),
]);
this.instance[modelID] = new Model(
weightsArrayU8,
tokenizerArrayU8,
configArrayU8,
quantized
);
}
return this.instance[modelID];
}
}
let controller = null;
self.addEventListener("message", (event) => {
if (event.data.command === "start") {
controller = new AbortController();
generate(event.data);
} else if (event.data.command === "abort") {
controller.abort();
}
});
async function generate(data) {
const {
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized,
prompt,
temp,
top_p,
repeatPenalty,
seed,
maxSeqLen,
} = data;
try {
self.postMessage({ status: "loading", message: "Starting Phi" });
const model = await Phi.getInstance(
weightsURL,
modelID,
tokenizerURL,
configURL,
quantized
);
self.postMessage({ status: "loading", message: "Initializing model" });
const firstToken = model.init_with_prompt(
prompt,
temp,
top_p,
repeatPenalty,
64,
BigInt(seed)
);
const seq_len = 2048;
let sentence = firstToken;
let maxTokens = maxSeqLen ? maxSeqLen : seq_len - prompt.length - 1;
let startTime = performance.now();
let tokensCount = 0;
while (tokensCount < maxTokens) {
await new Promise(async (resolve) => {
if (controller && controller.signal.aborted) {
self.postMessage({
status: "aborted",
message: "Aborted",
output: prompt + sentence,
});
return;
}
const token = await model.next_token();
if (token === "<|endoftext|>") {
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
return;
}
const tokensSec =
((tokensCount + 1) / (performance.now() - startTime)) * 1000;
sentence += token;
self.postMessage({
status: "generating",
message: "Generating token",
token: token,
sentence: sentence,
totalTime: performance.now() - startTime,
tokensSec,
prompt: prompt,
});
setTimeout(resolve, 0);
});
tokensCount++;
}
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
} catch (e) {
self.postMessage({ error: e });
}
}
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/phi/README.md | ## Running [Microsoft phi 1.5](https://huggingface.co/microsoft/phi-1_5) Example
Here, we provide two examples of how to run [Microsoft phi 1.5](https://huggingface.co/microsoft/phi-1_5) written in Rust using a Candle-compiled WASM binary and runtime.
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./index.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/index.html` in your browser.
| 1 |
0 | hf_public_repos/candle/candle-wasm-examples/phi | hf_public_repos/candle/candle-wasm-examples/phi/src/lib.rs | use wasm_bindgen::prelude::*;
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples/phi/src | hf_public_repos/candle/candle-wasm-examples/phi/src/bin/m.rs | use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use candle_transformers::models::mixformer::{Config, MixFormerSequentialForCausalLM as MixFormer};
use candle_transformers::models::quantized_mixformer::MixFormerSequentialForCausalLM as QMixFormer;
use candle_wasm_example_phi::console_log;
use js_sys::Date;
use serde::Deserialize;
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
enum SelectedModel {
MixFormer(MixFormer),
Quantized(QMixFormer),
}
#[wasm_bindgen]
pub struct Model {
model: SelectedModel,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
tokens: Vec<u32>,
repeat_penalty: f32,
repeat_last_n: usize,
}
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct ModelName {
pub _name_or_path: String,
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn load(
weights: Vec<u8>,
tokenizer: Vec<u8>,
config: Vec<u8>,
quantized: bool,
) -> Result<Model, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let device = Device::Cpu;
let name: ModelName = serde_json::from_slice(&config)?;
let config: Config = serde_json::from_slice(&config)?;
console_log!("config loaded {:?}", name);
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let start = Date::now();
console_log!("weights len: {:?}", weights.len());
let model = if quantized {
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf_buffer(
&weights, &device,
)?;
console_log!("weights loaded");
if name._name_or_path == "microsoft/phi-2" {
let model = QMixFormer::new_v2(&config, vb)?;
SelectedModel::Quantized(model)
} else {
let model = QMixFormer::new(&config, vb)?;
SelectedModel::Quantized(model)
}
} else {
let device = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, device)?;
let model = MixFormer::new(&config, vb)?;
SelectedModel::MixFormer(model)
};
console_log!("model loaded in {:?}s", (Date::now() - start) / 1000.);
let logits_processor = LogitsProcessor::new(299792458, None, None);
Ok(Self {
model,
tokenizer,
tokens: vec![],
logits_processor,
repeat_penalty: 1.,
repeat_last_n: 64,
})
}
#[wasm_bindgen]
pub fn init_with_prompt(
&mut self,
prompt: String,
temp: f64,
top_p: f64,
repeat_penalty: f32,
repeat_last_n: usize,
seed: u64,
) -> Result<String, JsError> {
match &mut self.model {
SelectedModel::MixFormer(m) => m.clear_kv_cache(),
SelectedModel::Quantized(m) => m.clear_kv_cache(),
};
let temp = if temp <= 0. { None } else { Some(temp) };
let top_p = if top_p <= 0. || top_p >= 1. {
None
} else {
Some(top_p)
};
self.logits_processor = LogitsProcessor::new(seed, temp, top_p);
self.repeat_penalty = repeat_penalty;
self.repeat_last_n = repeat_last_n;
self.tokens.clear();
let tokens = self
.tokenizer
.encode(prompt, true)
.map_err(|m| JsError::new(&m.to_string()))?
.get_ids()
.to_vec();
let text = self
.process(&tokens)
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
#[wasm_bindgen]
pub fn next_token(&mut self) -> Result<String, JsError> {
let last_token = *self.tokens.last().unwrap();
let text = self
.process(&[last_token])
.map_err(|m| JsError::new(&m.to_string()))?;
Ok(text)
}
}
impl Model {
fn process(&mut self, tokens: &[u32]) -> candle::Result<String> {
let dev = Device::Cpu;
let input = Tensor::new(tokens, &dev)?.unsqueeze(0)?;
let logits = match &mut self.model {
SelectedModel::MixFormer(m) => m.forward(&input)?,
SelectedModel::Quantized(m) => m.forward(&input)?,
};
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
self.tokens.push(next_token);
let token = match self.tokenizer.decode(&[next_token], false) {
Ok(token) => token,
Err(e) => {
console_log!("error decoding token: {:?}", e);
"".to_string()
}
};
// console_log!("token: {:?}: {:?}", token, next_token);
Ok(token)
}
}
fn main() {
console_error_panic_hook::set_once();
}
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/index.html | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Welcome to Candle!</title>
<link data-trunk rel="copy-file" href="yolov8s.safetensors" />
<link data-trunk rel="copy-file" href="bike.jpeg" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="app" data-type="main" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="worker" data-type="worker" />
<link rel="stylesheet" href="https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css">
</head>
<body></body>
</html>
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/Cargo.toml | [package]
name = "candle-wasm-example-yolo"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
num-traits = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
image = { workspace = true }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
log = { workspace = true }
rand = { workspace = true }
safetensors = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
getrandom = { version = "0.2", features = ["js"] }
gloo = "0.11"
js-sys = "0.3.64"
wasm-bindgen = "0.2.87"
wasm-bindgen-futures = "0.4.37"
wasm-logger = "0.2"
yew-agent = "0.2.0"
yew = { version = "0.20.0", features = ["csr"] }
[dependencies.web-sys]
version = "=0.3.70"
features = [
'Blob',
'CanvasRenderingContext2d',
'Document',
'Element',
'HtmlElement',
'HtmlCanvasElement',
'HtmlImageElement',
'ImageData',
'Node',
'Window',
'Request',
'RequestCache',
'RequestInit',
'RequestMode',
'Response',
'Performance',
'TextMetrics',
]
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/lib-example.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle YOLOv8 Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
code,
output,
select,
pre {
font-family: "Source Code Pro", monospace;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script
src="https://cdn.jsdelivr.net/gh/huggingface/hub-js-utils/share-canvas.js"
type="module"
></script>
<script type="module">
const MODEL_BASEURL =
"https://huggingface.co/lmz/candle-yolo-v8/resolve/main/";
const MODELS = {
yolov8n: {
model_size: "n",
url: "yolov8n.safetensors",
},
yolov8s: {
model_size: "s",
url: "yolov8s.safetensors",
},
yolov8m: {
model_size: "m",
url: "yolov8m.safetensors",
},
yolov8l: {
model_size: "l",
url: "yolov8l.safetensors",
},
yolov8x: {
model_size: "x",
url: "yolov8x.safetensors",
},
yolov8n_pose: {
model_size: "n",
url: "yolov8n-pose.safetensors",
},
yolov8s_pose: {
model_size: "s",
url: "yolov8s-pose.safetensors",
},
yolov8m_pose: {
model_size: "m",
url: "yolov8m-pose.safetensors",
},
yolov8l_pose: {
model_size: "l",
url: "yolov8l-pose.safetensors",
},
yolov8x_pose: {
model_size: "x",
url: "yolov8x-pose.safetensors",
},
};
const COCO_PERSON_SKELETON = [
[4, 0], // head
[3, 0],
[16, 14], // left lower leg
[14, 12], // left upper leg
[6, 12], // left torso
[6, 5], // top torso
[6, 8], // upper arm
[8, 10], // lower arm
[1, 2], // head
[1, 3], // right head
[2, 4], // left head
[3, 5], // right neck
[4, 6], // left neck
[5, 7], // right upper arm
[7, 9], // right lower arm
[5, 11], // right torso
[11, 12], // bottom torso
[11, 13], // right upper leg
[13, 15], // right lower leg
];
// init web worker
const yoloWorker = new Worker("./yoloWorker.js", { type: "module" });
let hasImage = false;
//add event listener to image examples
document.querySelector("#image-select").addEventListener("click", (e) => {
const target = e.target;
if (target.nodeName === "IMG") {
const href = target.src;
drawImageCanvas(href);
}
});
//add event listener to file input
document.querySelector("#file-upload").addEventListener("change", (e) => {
const target = e.target;
if (target.files.length > 0) {
const href = URL.createObjectURL(target.files[0]);
drawImageCanvas(href);
}
});
// add event listener to drop-area
const dropArea = document.querySelector("#drop-area");
dropArea.addEventListener("dragenter", (e) => {
e.preventDefault();
dropArea.classList.add("border-blue-700");
});
dropArea.addEventListener("dragleave", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
});
dropArea.addEventListener("dragover", (e) => {
e.preventDefault();
});
dropArea.addEventListener("drop", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
const url = e.dataTransfer.getData("text/uri-list");
const files = e.dataTransfer.files;
if (files.length > 0) {
const href = URL.createObjectURL(files[0]);
drawImageCanvas(href);
} else if (url) {
drawImageCanvas(url);
}
});
document.querySelector("#clear-btn").addEventListener("click", () => {
drawImageCanvas();
});
function drawImageCanvas(imgURL) {
const canvas = document.querySelector("#canvas");
const canvasResult = document.querySelector("#canvas-result");
canvasResult
.getContext("2d")
.clearRect(0, 0, canvas.width, canvas.height);
const ctx = canvas.getContext("2d");
ctx.clearRect(0, 0, canvas.width, canvas.height);
document.querySelector("#share-btn").classList.add("invisible");
document.querySelector("#clear-btn").classList.add("invisible");
document.querySelector("#detect").disabled = true;
hasImage = false;
canvas.parentElement.style.height = "auto";
if (imgURL && imgURL !== "") {
const img = new Image();
img.crossOrigin = "anonymous";
img.onload = () => {
canvas.width = img.width;
canvas.height = img.height;
ctx.drawImage(img, 0, 0);
canvas.parentElement.style.height = canvas.offsetHeight + "px";
hasImage = true;
document.querySelector("#detect").disabled = false;
document.querySelector("#clear-btn").classList.remove("invisible");
};
img.src = imgURL;
}
}
async function classifyImage(
imageURL, // URL of image to classify
modelID, // ID of model to use
modelURL, // URL to model file
modelSize, // size of model
confidence, // confidence threshold
iou_threshold, // IoU threshold
updateStatus // function receives status updates
) {
return new Promise((resolve, reject) => {
yoloWorker.postMessage({
imageURL,
modelID,
modelURL,
modelSize,
confidence,
iou_threshold,
});
function handleMessage(event) {
console.log("message", event.data);
if ("status" in event.data) {
updateStatus(event.data.status);
}
if ("error" in event.data) {
yoloWorker.removeEventListener("message", handleMessage);
reject(new Error(event.data.error));
}
if (event.data.status === "complete") {
yoloWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
}
yoloWorker.addEventListener("message", handleMessage);
});
}
// add event listener to detect button
document.querySelector("#detect").addEventListener("click", async () => {
if (!hasImage) {
return;
}
const modelID = document.querySelector("#model").value;
const modelURL = MODEL_BASEURL + MODELS[modelID].url;
const modelSize = MODELS[modelID].model_size;
const confidence = parseFloat(
document.querySelector("#confidence").value
);
const iou_threshold = parseFloat(
document.querySelector("#iou_threshold").value
);
const canvasInput = document.querySelector("#canvas");
const canvas = document.querySelector("#canvas-result");
canvas.width = canvasInput.width;
canvas.height = canvasInput.height;
const scale = canvas.width / canvas.offsetWidth;
const ctx = canvas.getContext("2d");
ctx.drawImage(canvasInput, 0, 0);
const imageURL = canvas.toDataURL();
const results = await await classifyImage(
imageURL,
modelID,
modelURL,
modelSize,
confidence,
iou_threshold,
updateStatus
);
const { output } = results;
ctx.lineWidth = 1 + 2 * scale;
ctx.strokeStyle = "#3c8566";
ctx.fillStyle = "#0dff9a";
const fontSize = 14 * scale;
ctx.font = `${fontSize}px sans-serif`;
for (const detection of output) {
// check keypoint for pose model data
let xmin, xmax, ymin, ymax, label, confidence, keypoints;
if ("keypoints" in detection) {
xmin = detection.xmin;
xmax = detection.xmax;
ymin = detection.ymin;
ymax = detection.ymax;
confidence = detection.confidence;
keypoints = detection.keypoints;
} else {
const [_label, bbox] = detection;
label = _label;
xmin = bbox.xmin;
xmax = bbox.xmax;
ymin = bbox.ymin;
ymax = bbox.ymax;
confidence = bbox.confidence;
}
const [x, y, w, h] = [xmin, ymin, xmax - xmin, ymax - ymin];
const text = `${label ? label + " " : ""}${confidence.toFixed(2)}`;
const width = ctx.measureText(text).width;
ctx.fillStyle = "#3c8566";
ctx.fillRect(x - 2, y - fontSize, width + 4, fontSize);
ctx.fillStyle = "#e3fff3";
ctx.strokeRect(x, y, w, h);
ctx.fillText(text, x, y - 2);
if (keypoints) {
ctx.save();
ctx.fillStyle = "magenta";
ctx.strokeStyle = "yellow";
for (const keypoint of keypoints) {
const { x, y } = keypoint;
ctx.beginPath();
ctx.arc(x, y, 3, 0, 2 * Math.PI);
ctx.fill();
}
ctx.beginPath();
for (const [xid, yid] of COCO_PERSON_SKELETON) {
//draw line between skeleton keypoitns
if (keypoints[xid] && keypoints[yid]) {
ctx.moveTo(keypoints[xid].x, keypoints[xid].y);
ctx.lineTo(keypoints[yid].x, keypoints[yid].y);
}
}
ctx.stroke();
ctx.restore();
}
}
});
function updateStatus(statusMessage) {
const button = document.querySelector("#detect");
if (statusMessage === "detecting") {
button.disabled = true;
button.classList.add("bg-blue-700");
button.classList.remove("bg-blue-950");
button.textContent = "Predicting...";
} else if (statusMessage === "complete") {
button.disabled = false;
button.classList.add("bg-blue-950");
button.classList.remove("bg-blue-700");
button.textContent = "Predict";
document.querySelector("#share-btn").classList.remove("invisible");
}
}
document.querySelector("#share-btn").addEventListener("click", () => {
shareToCommunity(
"lmz/candle-yolo",
"Candle + YOLOv8",
"YOLOv8 with [Candle](https://github.com/huggingface/candle)",
"canvas-result",
"share-btn"
);
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle YOLOv8</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
This demo showcases object detection and pose estimation models in
your browser using Rust/WASM. It utilizes
<a
href="https://huggingface.co/lmz/candle-yolo-v8"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>
safetensor's YOLOv8 models
</a>
and a WASM runtime built with
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>Candle </a
>.
</p>
<p>
To run pose estimation, select a yolo pose model from the dropdown
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light"
>
<option value="yolov8n" selected>yolov8n (6.37 MB)</option>
<option value="yolov8s">yolov8s (22.4 MB)</option>
<option value="yolov8m">yolov8m (51.9 MB)</option>
<option value="yolov8l">yolov8l (87.5 MB)</option>
<option value="yolov8x">yolov8x (137 MB)</option>
<!-- Pose models -->
<option value="yolov8n_pose">yolov8n_pose (6.65 MB)</option>
<option value="yolov8s_pose">yolov8s_pose (23.3 MB)</option>
<option value="yolov8m_pose">yolov8m_pose (53 MB)</option>
<option value="yolov8l_pose">yolov8l_pose (89.1 MB)</option>
<option value="yolov8x_pose">yolov8x_pose (139 MB)</option>
</select>
</div>
<div>
<button
id="detect"
disabled
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 px-4 rounded disabled:bg-gray-300 disabled:cursor-not-allowed"
>
Predict
</button>
</div>
<!-- drag and drop area -->
<div class="relative max-w-lg">
<div class="py-1">
<button
id="clear-btn"
class="text-xs bg-white rounded-md disabled:opacity-50 flex gap-1 items-center ml-auto invisible"
>
<svg
class=""
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 13 12"
height="1em"
>
<path
d="M1.6.7 12 11.1M12 .7 1.6 11.1"
stroke="#2E3036"
stroke-width="2"
/>
</svg>
Clear image
</button>
</div>
<div
id="drop-area"
class="flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative aspect-video w-full overflow-hidden"
>
<div
class="flex flex-col items-center justify-center space-y-1 text-center"
>
<svg
width="25"
height="25"
viewBox="0 0 25 25"
fill="none"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z"
fill="#000"
/>
</svg>
<div class="flex text-sm text-gray-600">
<label
for="file-upload"
class="relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700"
>
<span>Drag and drop your image here</span>
<span class="block text-xs">or</span>
<span class="block text-xs">Click to upload</span>
</label>
</div>
<input
id="file-upload"
name="file-upload"
type="file"
class="sr-only"
/>
</div>
<canvas
id="canvas"
class="absolute pointer-events-none w-full"
></canvas>
<canvas
id="canvas-result"
class="absolute pointer-events-none w-full"
></canvas>
</div>
<div class="text-right py-2">
<button
id="share-btn"
class="bg-white rounded-md hover:outline outline-orange-200 disabled:opacity-50 invisible"
>
<img
src="https://huggingface.co/datasets/huggingface/badges/raw/main/share-to-community-sm.svg"
/>
</button>
</div>
</div>
<div>
<div
class="flex gap-3 items-center overflow-x-scroll"
id="image-select"
>
<h3 class="font-medium">Examples:</h3>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/sf.jpg"
class="cursor-pointer w-24 h-24 object-cover"
/>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg"
class="cursor-pointer w-24 h-24 object-cover"
/>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/000000000077.jpg"
class="cursor-pointer w-24 h-24 object-cover"
/>
</div>
</div>
<div>
<div class="grid grid-cols-3 max-w-md items-center gap-3">
<label class="text-sm font-medium" for="confidence"
>Confidence Threshold</label
>
<input
type="range"
id="confidence"
name="confidence"
min="0"
max="1"
step="0.01"
value="0.25"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs font-light px-1 py-1 border border-gray-700 rounded-md w-min"
>0.25</output
>
<label class="text-sm font-medium" for="iou_threshold"
>IoU Threshold</label
>
<input
type="range"
id="iou_threshold"
name="iou_threshold"
min="0"
max="1"
step="0.01"
value="0.45"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="font-extralight text-xs px-1 py-1 border border-gray-700 rounded-md w-min"
>0.45</output
>
</div>
</div>
</main>
</body>
</html>
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/README.md | ## Running Yolo Examples
Here, we provide two examples of how to run YOLOv8 using a Candle-compiled WASM binary and runtimes.
### Pure Rust UI
To build and test the UI made in Rust you will need [Trunk](https://trunkrs.dev/#install)
From the `candle-wasm-examples/yolo` directory run:
Download assets:
```bash
wget -c https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg
wget -c https://huggingface.co/lmz/candle-yolo-v8/resolve/main/yolov8s.safetensors
```
Run hot reload server:
```bash
trunk serve --release --public-url / --port 8080
```
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model, ModelPose } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/yolo/yoloWorker.js | //load the candle yolo wasm module
import init, { Model, ModelPose } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "yolo-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Yolo {
static instance = {};
// Retrieve the YOLO model. When called for the first time,
// this will load the model and save it for future use.
static async getInstance(modelID, modelURL, modelSize) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: `loading model ${modelID}:${modelSize}` });
const weightsArrayU8 = await fetchArrayBuffer(modelURL);
if (/pose/.test(modelID)) {
// if pose model, use ModelPose
this.instance[modelID] = new ModelPose(weightsArrayU8, modelSize);
} else {
this.instance[modelID] = new Model(weightsArrayU8, modelSize);
}
} else {
self.postMessage({ status: "model already loaded" });
}
return this.instance[modelID];
}
}
self.addEventListener("message", async (event) => {
const { imageURL, modelID, modelURL, modelSize, confidence, iou_threshold } =
event.data;
try {
self.postMessage({ status: "detecting" });
const yolo = await Yolo.getInstance(modelID, modelURL, modelSize);
self.postMessage({ status: "loading image" });
const imgRes = await fetch(imageURL);
const imgData = await imgRes.arrayBuffer();
const imageArrayU8 = new Uint8Array(imgData);
self.postMessage({ status: `running inference ${modelID}:${modelSize}` });
const bboxes = yolo.run(imageArrayU8, confidence, iou_threshold);
// Send the output back to the main thread as JSON
self.postMessage({
status: "complete",
output: JSON.parse(bboxes),
});
} catch (e) {
self.postMessage({ error: e });
}
});
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/granite/main.rs | // An implementation of different Granite models https://www.ibm.com/granite
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use anyhow::{bail, Error as E, Result};
use clap::{Parser, ValueEnum};
use candle::{DType, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::{LogitsProcessor, Sampling};
use hf_hub::{api::sync::Api, Repo, RepoType};
use std::io::Write;
use candle_transformers::models::granite as model;
use model::{Granite, GraniteConfig};
use std::time::Instant;
const EOS_TOKEN: &str = "</s>";
const DEFAULT_PROMPT: &str = "How Fault Tolerant Quantum Computers will help humanity?";
#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]
enum GraniteModel {
Granite7bInstruct,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// The temperature used to generate samples.
#[arg(long, default_value_t = 0.8)]
temperature: f64,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// Only sample among the top K samples.
#[arg(long)]
top_k: Option<usize>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(short = 'n', long, default_value_t = 10000)]
sample_len: usize,
/// Disable the key-value cache.
#[arg(long)]
no_kv_cache: bool,
/// The initial prompt.
#[arg(long)]
prompt: Option<String>,
/// Use different dtype than f16
#[arg(long)]
dtype: Option<String>,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long, default_value = "granite7b-instruct")]
model_type: GraniteModel,
#[arg(long)]
use_flash_attn: bool,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 128)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
use tokenizers::Tokenizer;
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
let device = candle_examples::device(args.cpu)?;
let dtype = match args.dtype.as_deref() {
Some("f16") => DType::F16,
Some("bf16") => DType::BF16,
Some("f32") => DType::F32,
Some(dtype) => bail!("Unsupported dtype {dtype}"),
None => DType::F16,
};
let (granite, tokenizer_filename, mut cache, config) = {
let api = Api::new()?;
let model_id = args.model_id.unwrap_or_else(|| match args.model_type {
GraniteModel::Granite7bInstruct => "ibm-granite/granite-7b-instruct".to_string(),
});
println!("loading the model weights from {model_id}");
let revision = args.revision.unwrap_or("main".to_string());
let api = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let tokenizer_filename = api.get("tokenizer.json")?;
let config_filename = api.get("config.json")?;
let config: GraniteConfig = serde_json::from_slice(&std::fs::read(config_filename)?)?;
let config = config.into_config(args.use_flash_attn);
let filenames = match args.model_type {
GraniteModel::Granite7bInstruct => {
candle_examples::hub_load_safetensors(&api, "model.safetensors.index.json")?
}
};
let cache = model::Cache::new(!args.no_kv_cache, dtype, &config, &device)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
(
Granite::load(vb, &config)?,
tokenizer_filename,
cache,
config,
)
};
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let eos_token_id = config.eos_token_id.or_else(|| {
tokenizer
.token_to_id(EOS_TOKEN)
.map(model::GraniteEosToks::Single)
});
let default_prompt = match args.model_type {
GraniteModel::Granite7bInstruct => DEFAULT_PROMPT,
};
let prompt = args.prompt.as_ref().map_or(default_prompt, |p| p.as_str());
let mut tokens = tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);
println!("Starting the inference loop:");
print!("{prompt}");
let mut logits_processor = {
let temperature = args.temperature;
let sampling = if temperature <= 0. {
Sampling::ArgMax
} else {
match (args.top_k, args.top_p) {
(None, None) => Sampling::All { temperature },
(Some(k), None) => Sampling::TopK { k, temperature },
(None, Some(p)) => Sampling::TopP { p, temperature },
(Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },
}
};
LogitsProcessor::from_sampling(args.seed, sampling)
};
let mut start_gen = std::time::Instant::now();
let mut index_pos = 0;
let mut token_generated = 0;
let use_cache_kv = cache.use_kv_cache;
(0..args.sample_len)
.inspect(|index| {
if *index == 1 {
start_gen = Instant::now();
}
})
.try_for_each(|index| -> Result<()> {
let (context_size, context_index) = if use_cache_kv && index > 0 {
(1, index_pos)
} else {
(tokens.len(), 0)
};
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;
let logits = granite
.forward(&input, context_index, &mut cache)?
.squeeze(0)?;
let logits = if args.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(args.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
args.repeat_penalty,
&tokens[start_at..],
)?
};
index_pos += ctxt.len();
let next_token = logits_processor.sample(&logits)?;
token_generated += 1;
tokens.push(next_token);
if let Some(model::GraniteEosToks::Single(eos_tok_id)) = eos_token_id {
if next_token == eos_tok_id {
return Err(E::msg("EOS token found"));
}
} else if let Some(model::GraniteEosToks::Multiple(ref eos_ids)) = eos_token_id {
if eos_ids.contains(&next_token) {
return Err(E::msg("EOS token found"));
}
}
if let Some(t) = tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
Ok(())
})
.unwrap_or(());
if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
let dt = start_gen.elapsed();
println!(
"\n\n{} tokens generated ({} token/s)\n",
token_generated,
(token_generated - 1) as f64 / dt.as_secs_f64(),
);
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/granite/README.md | # candle-granite LLMs from IBM Research
[Granite](https://www.ibm.com/granite) is a family of Large Language Models built for business, to help drive trust and scalability in AI-driven applications.
## Running the example
```bash
$ cargo run --example granite --features metal -r -- --model-type "granite7b-instruct" \
--prompt "Explain how quantum computing differs from classical computing, focusing on key concepts like qubits, superposition, and entanglement. Describe two potential breakthroughs in the fields of drug discovery and cryptography. Offer a convincing argument for why businesses and governments should invest in quantum computing research now, emphasizing its future benefits and the risks of falling behind"
Explain how quantum computing differs from classical computing, focusing on key concepts like qubits, superposition, and entanglement. Describe two potential breakthroughs in the fields of drug discovery and cryptography. Offer a convincing argument for why businesses and governments should invest in quantum computing research now, emphasizing its future benefits and the risks of falling behind competitors.
In recent years, there has been significant interest in quantum computing due to its potential to revolutionize various fields, including drug discovery, cryptography, and optimization problems. Quantum computers, which leverage the principles of quantum mechanics, differ fundamentally from classical computers. Here are some of the key differences:
```
## Supported Models
There are two different modalities for the Granite family models: Language and Code.
### Granite for language
1. [Granite 7b Instruct](https://huggingface.co/ibm-granite/granite-7b-instruct)
| 1 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/setup.cfg | [metadata]
license_files = LICENSE
version = attr: autotrain.__version__
[isort]
ensure_newline_before_comments = True
force_grid_wrap = 0
include_trailing_comma = True
line_length = 119
lines_after_imports = 2
multi_line_output = 3
use_parentheses = True
[flake8]
ignore = E203, E501, W503
max-line-length = 119
per-file-ignores =
# imported but unused
__init__.py: F401, E402
src/autotrain/params.py: F401
exclude =
.git,
.venv,
__pycache__,
dist
build | 2 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/setup.py | # Lint as: python3
"""
HuggingFace / AutoTrain Advanced
"""
import os
from setuptools import find_packages, setup
DOCLINES = __doc__.split("\n")
this_directory = os.path.abspath(os.path.dirname(__file__))
with open(os.path.join(this_directory, "README.md"), encoding="utf-8") as f:
LONG_DESCRIPTION = f.read()
# get INSTALL_REQUIRES from requirements.txt
INSTALL_REQUIRES = []
requirements_path = os.path.join(this_directory, "requirements.txt")
with open(requirements_path, encoding="utf-8") as f:
for line in f:
# Exclude 'bitsandbytes' if installing on macOS
if "bitsandbytes" in line:
line = line.strip() + " ; sys_platform == 'linux'"
INSTALL_REQUIRES.append(line.strip())
else:
INSTALL_REQUIRES.append(line.strip())
QUALITY_REQUIRE = [
"black",
"isort",
"flake8==3.7.9",
]
TESTS_REQUIRE = ["pytest"]
CLIENT_REQUIRES = ["requests", "loguru"]
EXTRAS_REQUIRE = {
"base": INSTALL_REQUIRES,
"dev": INSTALL_REQUIRES + QUALITY_REQUIRE + TESTS_REQUIRE,
"quality": INSTALL_REQUIRES + QUALITY_REQUIRE,
"docs": INSTALL_REQUIRES
+ [
"recommonmark",
"sphinx==3.1.2",
"sphinx-markdown-tables",
"sphinx-rtd-theme==0.4.3",
"sphinx-copybutton",
],
"client": CLIENT_REQUIRES,
}
setup(
name="autotrain-advanced",
description=DOCLINES[0],
long_description=LONG_DESCRIPTION,
long_description_content_type="text/markdown",
author="HuggingFace Inc.",
author_email="[email protected]",
url="https://github.com/huggingface/autotrain-advanced",
download_url="https://github.com/huggingface/autotrain-advanced/tags",
license="Apache 2.0",
package_dir={"": "src"},
packages=find_packages("src"),
extras_require=EXTRAS_REQUIRE,
install_requires=INSTALL_REQUIRES,
entry_points={"console_scripts": ["autotrain=autotrain.cli.autotrain:main"]},
classifiers=[
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
keywords="automl autonlp autotrain huggingface",
data_files=[
(
"static",
[
"src/autotrain/app/static/logo.png",
"src/autotrain/app/static/scripts/fetch_data_and_update_models.js",
"src/autotrain/app/static/scripts/listeners.js",
"src/autotrain/app/static/scripts/utils.js",
"src/autotrain/app/static/scripts/poll.js",
"src/autotrain/app/static/scripts/logs.js",
],
),
(
"templates",
[
"src/autotrain/app/templates/index.html",
"src/autotrain/app/templates/error.html",
"src/autotrain/app/templates/duplicate.html",
"src/autotrain/app/templates/login.html",
],
),
],
include_package_data=True,
)
| 3 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/LICENSE |
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | 4 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/Makefile | .PHONY: quality style test
# Check that source code meets quality standards
quality:
black --check --line-length 119 --target-version py38 .
isort --check-only .
flake8 --max-line-length 119
# Format source code automatically
style:
black --line-length 119 --target-version py38 .
isort .
test:
pytest -sv ./src/
docker:
docker build -t autotrain-advanced:latest .
docker tag autotrain-advanced:latest huggingface/autotrain-advanced:latest
docker push huggingface/autotrain-advanced:latest
api:
docker build -t autotrain-advanced-api:latest -f Dockerfile.api .
docker tag autotrain-advanced-api:latest public.ecr.aws/z4c3o6n6/autotrain-api:latest
docker push public.ecr.aws/z4c3o6n6/autotrain-api:latest
ngc:
docker build -t autotrain-advanced:latest .
docker tag autotrain-advanced:latest nvcr.io/ycymhzotssoi/autotrain-advanced:latest
docker push nvcr.io/ycymhzotssoi/autotrain-advanced:latest
pip:
rm -rf build/
rm -rf dist/
make style && make quality
python setup.py sdist bdist_wheel
twine upload dist/* --verbose --repository autotrain-advanced | 5 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/requirements.txt | albumentations==1.4.21
datasets[vision]~=3.1.0
evaluate==0.4.3
ipadic==1.0.0
jiwer==3.0.5
joblib==1.4.2
loguru==0.7.2
pandas==2.2.3
nltk==3.9.1
optuna==4.0.0
Pillow==11.0.0
sacremoses==0.1.1
scikit-learn==1.5.2
sentencepiece==0.2.0
tqdm==4.67.0
werkzeug==3.1.2
xgboost==2.1.2
huggingface_hub==0.26.2
requests==2.32.3
einops==0.8.0
packaging==24.1
cryptography==43.0.3
nvitop==1.3.2
# latest versions
tensorboard==2.16.2
peft==0.13.2
trl==0.12.0
tiktoken==0.6.0
transformers==4.46.2
accelerate==1.1.1
bitsandbytes==0.44.1
# extras
rouge_score==0.1.2
py7zr==0.22.0
fastapi==0.115.4
uvicorn==0.32.0
python-multipart==0.0.17
pydantic==2.9.2
hf-transfer
pyngrok==7.2.1
authlib==1.3.2
itsdangerous==2.2.0
seqeval==1.2.2
httpx==0.27.2
pyyaml==6.0.2
timm==1.0.11
torchmetrics==1.5.1
pycocotools==2.0.8
sentence-transformers==3.2.1
| 6 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/Manifest.in | recursive-include src/autotrain/static *
recursive-include src/autotrain/templates * | 7 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/.dockerignore | build/
dist/
logs/
output/
output2/
test/
test.py
.DS_Store
.vscode/
op*
op_*
.git
*.db
autotrain-data*
autotrain-* | 8 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/Dockerfile | FROM nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04
ENV DEBIAN_FRONTEND=noninteractive \
TZ=UTC \
HF_HUB_ENABLE_HF_TRANSFER=1
ENV PATH="${HOME}/miniconda3/bin:${PATH}"
ARG PATH="${HOME}/miniconda3/bin:${PATH}"
ENV PATH="/app/ngc-cli:${PATH}"
ARG PATH="/app/ngc-cli:${PATH}"
RUN mkdir -p /tmp/model && \
chown -R 1000:1000 /tmp/model && \
mkdir -p /tmp/data && \
chown -R 1000:1000 /tmp/data
RUN apt-get update && \
apt-get upgrade -y && \
apt-get install -y \
build-essential \
cmake \
curl \
ca-certificates \
gcc \
git \
locales \
net-tools \
wget \
libpq-dev \
libsndfile1-dev \
git \
git-lfs \
libgl1 \
unzip \
libjpeg-dev \
libpng-dev \
libgomp1 \
&& rm -rf /var/lib/apt/lists/* && \
apt-get clean
RUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \
git lfs install
WORKDIR /app
RUN mkdir -p /app/.cache
ENV HF_HOME="/app/.cache"
RUN useradd -m -u 1000 user
RUN chown -R user:user /app
USER user
ENV HOME=/app
ENV PYTHONPATH=$HOME/app \
PYTHONUNBUFFERED=1 \
GRADIO_ALLOW_FLAGGING=never \
GRADIO_NUM_PORTS=1 \
GRADIO_SERVER_NAME=0.0.0.0 \
SYSTEM=spaces
RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& sh Miniconda3-latest-Linux-x86_64.sh -b -p /app/miniconda \
&& rm -f Miniconda3-latest-Linux-x86_64.sh
ENV PATH /app/miniconda/bin:$PATH
RUN conda create -p /app/env -y python=3.10
SHELL ["conda", "run","--no-capture-output", "-p","/app/env", "/bin/bash", "-c"]
RUN conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia && \
conda clean -ya && \
conda install -c "nvidia/label/cuda-12.1.1" cuda-nvcc && conda clean -ya && \
conda install xformers -c xformers && conda clean -ya
COPY --chown=1000:1000 . /app/
RUN pip install -e . && \
python -m nltk.downloader punkt && \
pip install -U ninja && \
pip install -U flash-attn --no-build-isolation && \
pip install -U deepspeed && \
pip install --upgrade --force-reinstall --no-cache-dir "unsloth[cu121-ampere-torch230] @ git+https://github.com/unslothai/unsloth.git" --no-deps && \
pip cache purge
| 9 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_classification/dataset.py | import numpy as np
import torch
class ImageClassificationDataset:
"""
A custom dataset class for image classification tasks.
Args:
data (list): A list of data samples, where each sample is a dictionary containing image and target information.
transforms (callable): A function/transform that takes in an image and returns a transformed version.
config (object): A configuration object containing the column names for images and targets.
Attributes:
data (list): The dataset containing image and target information.
transforms (callable): The transformation function to be applied to the images.
config (object): The configuration object with image and target column names.
Methods:
__len__(): Returns the number of samples in the dataset.
__getitem__(item): Retrieves the image and target at the specified index, applies transformations, and returns them as tensors.
Example:
dataset = ImageClassificationDataset(data, transforms, config)
image, target = dataset[0]
"""
def __init__(self, data, transforms, config):
self.data = data
self.transforms = transforms
self.config = config
def __len__(self):
return len(self.data)
def __getitem__(self, item):
image = self.data[item][self.config.image_column]
target = int(self.data[item][self.config.target_column])
image = self.transforms(image=np.array(image.convert("RGB")))["image"]
image = np.transpose(image, (2, 0, 1)).astype(np.float32)
return {
"pixel_values": torch.tensor(image, dtype=torch.float),
"labels": torch.tensor(target, dtype=torch.long),
}
| 0 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_classification/params.py | from typing import Optional
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class ImageClassificationParams(AutoTrainParams):
"""
ImageClassificationParams is a configuration class for image classification training parameters.
Attributes:
data_path (str): Path to the dataset.
model (str): Pre-trained model name or path. Default is "google/vit-base-patch16-224".
username (Optional[str]): Hugging Face account username.
lr (float): Learning rate for the optimizer. Default is 5e-5.
epochs (int): Number of epochs for training. Default is 3.
batch_size (int): Batch size for training. Default is 8.
warmup_ratio (float): Warmup ratio for learning rate scheduler. Default is 0.1.
gradient_accumulation (int): Number of gradient accumulation steps. Default is 1.
optimizer (str): Optimizer type. Default is "adamw_torch".
scheduler (str): Learning rate scheduler type. Default is "linear".
weight_decay (float): Weight decay for the optimizer. Default is 0.0.
max_grad_norm (float): Maximum gradient norm for clipping. Default is 1.0.
seed (int): Random seed for reproducibility. Default is 42.
train_split (str): Name of the training data split. Default is "train".
valid_split (Optional[str]): Name of the validation data split.
logging_steps (int): Number of steps between logging. Default is -1.
project_name (str): Name of the project for output directory. Default is "project-name".
auto_find_batch_size (bool): Automatically find optimal batch size. Default is False.
mixed_precision (Optional[str]): Mixed precision training mode (fp16, bf16, or None).
save_total_limit (int): Maximum number of checkpoints to keep. Default is 1.
token (Optional[str]): Hugging Face Hub token for authentication.
push_to_hub (bool): Whether to push the model to Hugging Face Hub. Default is False.
eval_strategy (str): Evaluation strategy during training. Default is "epoch".
image_column (str): Column name for images in the dataset. Default is "image".
target_column (str): Column name for target labels in the dataset. Default is "target".
log (str): Logging method for experiment tracking. Default is "none".
early_stopping_patience (int): Number of epochs with no improvement for early stopping. Default is 5.
early_stopping_threshold (float): Threshold for early stopping. Default is 0.01.
"""
data_path: str = Field(None, title="Path to the dataset")
model: str = Field("google/vit-base-patch16-224", title="Pre-trained model name or path")
username: Optional[str] = Field(None, title="Hugging Face account username")
lr: float = Field(5e-5, title="Learning rate for the optimizer")
epochs: int = Field(3, title="Number of epochs for training")
batch_size: int = Field(8, title="Batch size for training")
warmup_ratio: float = Field(0.1, title="Warmup ratio for learning rate scheduler")
gradient_accumulation: int = Field(1, title="Number of gradient accumulation steps")
optimizer: str = Field("adamw_torch", title="Optimizer type")
scheduler: str = Field("linear", title="Learning rate scheduler type")
weight_decay: float = Field(0.0, title="Weight decay for the optimizer")
max_grad_norm: float = Field(1.0, title="Maximum gradient norm for clipping")
seed: int = Field(42, title="Random seed for reproducibility")
train_split: str = Field("train", title="Name of the training data split")
valid_split: Optional[str] = Field(None, title="Name of the validation data split")
logging_steps: int = Field(-1, title="Number of steps between logging")
project_name: str = Field("project-name", title="Name of the project for output directory")
auto_find_batch_size: bool = Field(False, title="Automatically find optimal batch size")
mixed_precision: Optional[str] = Field(None, title="Mixed precision training mode (fp16, bf16, or None)")
save_total_limit: int = Field(1, title="Maximum number of checkpoints to keep")
token: Optional[str] = Field(None, title="Hugging Face Hub token for authentication")
push_to_hub: bool = Field(False, title="Whether to push the model to Hugging Face Hub")
eval_strategy: str = Field("epoch", title="Evaluation strategy during training")
image_column: str = Field("image", title="Column name for images in the dataset")
target_column: str = Field("target", title="Column name for target labels in the dataset")
log: str = Field("none", title="Logging method for experiment tracking")
early_stopping_patience: int = Field(5, title="Number of epochs with no improvement for early stopping")
early_stopping_threshold: float = Field(0.01, title="Threshold for early stopping")
| 1 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/generic/utils.py | import os
import subprocess
import requests
from huggingface_hub import HfApi, snapshot_download
from autotrain import logger
def create_dataset_repo(username, project_name, script_path, token):
"""
Creates a new dataset repository on Hugging Face and uploads the specified dataset.
Args:
username (str): The username of the Hugging Face account.
project_name (str): The name of the project for which the dataset repository is being created.
script_path (str): The local path to the dataset folder that needs to be uploaded.
token (str): The authentication token for the Hugging Face API.
Returns:
str: The repository ID of the newly created dataset repository.
"""
logger.info("Creating dataset repo...")
api = HfApi(token=token)
repo_id = f"{username}/autotrain-{project_name}"
api.create_repo(
repo_id=repo_id,
repo_type="dataset",
private=True,
)
logger.info("Uploading dataset...")
api.upload_folder(
folder_path=script_path,
repo_id=repo_id,
repo_type="dataset",
)
logger.info("Dataset uploaded.")
return repo_id
def pull_dataset_repo(params):
"""
Downloads a dataset repository from Hugging Face Hub.
Args:
params (object): An object containing the following attributes:
- data_path (str): The repository ID of the dataset.
- project_name (str): The local directory where the dataset will be downloaded.
- token (str): The authentication token for accessing the repository.
Returns:
None
"""
snapshot_download(
repo_id=params.data_path,
local_dir=params.project_name,
token=params.token,
repo_type="dataset",
)
def uninstall_requirements(params):
"""
Uninstalls the requirements specified in the requirements.txt file of a given project.
This function reads the requirements.txt file located in the project's directory,
extracts the packages to be uninstalled, writes them to an uninstall.txt file,
and then uses pip to uninstall those packages.
Args:
params (object): An object containing the project_name attribute, which specifies
the directory of the project.
Returns:
None
"""
if os.path.exists(f"{params.project_name}/requirements.txt"):
# read the requirements.txt
uninstall_list = []
with open(f"{params.project_name}/requirements.txt", "r", encoding="utf-8") as f:
for line in f:
if line.startswith("-"):
uninstall_list.append(line[1:])
# create an uninstall.txt
with open(f"{params.project_name}/uninstall.txt", "w", encoding="utf-8") as f:
for line in uninstall_list:
f.write(line)
pipe = subprocess.Popen(
[
"pip",
"uninstall",
"-r",
"uninstall.txt",
"-y",
],
cwd=params.project_name,
)
pipe.wait()
logger.info("Requirements uninstalled.")
return
def install_requirements(params):
"""
Installs the Python packages listed in the requirements.txt file located in the specified project directory.
Args:
params: An object containing the project_name attribute, which specifies the directory of the project.
Behavior:
- Checks if a requirements.txt file exists in the project directory.
- Reads the requirements.txt file and filters out lines starting with a hyphen.
- Rewrites the filtered requirements back to the requirements.txt file.
- Uses subprocess to run the pip install command on the requirements.txt file.
- Logs the installation status.
Returns:
None
"""
# check if params.project_name has a requirements.txt
if os.path.exists(f"{params.project_name}/requirements.txt"):
# install the requirements using subprocess, wait for it to finish
install_list = []
with open(f"{params.project_name}/requirements.txt", "r", encoding="utf-8") as f:
for line in f:
if not line.startswith("-"):
install_list.append(line)
with open(f"{params.project_name}/requirements.txt", "w", encoding="utf-8") as f:
for line in install_list:
f.write(line)
pipe = subprocess.Popen(
[
"pip",
"install",
"-r",
"requirements.txt",
],
cwd=params.project_name,
)
pipe.wait()
logger.info("Requirements installed.")
return
logger.info("No requirements.txt found. Skipping requirements installation.")
return
def run_command(params):
"""
Executes a Python script with optional arguments in a specified project directory.
Args:
params (object): An object containing the following attributes:
- project_name (str): The name of the project directory where the script is located.
- args (dict): A dictionary of arguments to pass to the script. Keys are argument names, and values are argument values.
Raises:
ValueError: If the script.py file is not found in the specified project directory.
Returns:
None
"""
if os.path.exists(f"{params.project_name}/script.py"):
cmd = ["python", "script.py"]
if params.args:
for arg in params.args:
cmd.append(f"--{arg}")
if params.args[arg] != "":
cmd.append(params.args[arg])
pipe = subprocess.Popen(cmd, cwd=params.project_name)
pipe.wait()
logger.info("Command finished.")
return
raise ValueError("No script.py found.")
def pause_endpoint(params):
"""
Pauses a specific endpoint using the Hugging Face API.
This function retrieves the endpoint ID from the environment variables,
extracts the username and project name from the endpoint ID, constructs
the API URL, and sends a POST request to pause the endpoint.
Args:
params (object): An object containing the token attribute for authorization.
Returns:
dict: The JSON response from the API call.
"""
endpoint_id = os.environ["ENDPOINT_ID"]
username = endpoint_id.split("/")[0]
project_name = endpoint_id.split("/")[1]
api_url = f"https://api.endpoints.huggingface.cloud/v2/endpoint/{username}/{project_name}/pause"
headers = {"Authorization": f"Bearer {params.token}"}
r = requests.post(api_url, headers=headers, timeout=120)
return r.json()
| 2 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/generic/__main__.py | import argparse
import json
from autotrain import logger
from autotrain.trainers.common import monitor, pause_space
from autotrain.trainers.generic import utils
from autotrain.trainers.generic.params import GenericParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--config", type=str, required=True)
return parser.parse_args()
@monitor
def run(config):
"""
Executes a series of operations based on the provided configuration.
This function performs the following steps:
1. Converts the configuration dictionary to a GenericParams object if necessary.
2. Downloads the data repository specified in the configuration.
3. Uninstalls any existing requirements specified in the configuration.
4. Installs the necessary requirements specified in the configuration.
5. Runs a command specified in the configuration.
6. Pauses the space as specified in the configuration.
Args:
config (dict or GenericParams): The configuration for the operations to be performed.
"""
if isinstance(config, dict):
config = GenericParams(**config)
# download the data repo
logger.info("Downloading data repo...")
utils.pull_dataset_repo(config)
logger.info("Unintalling requirements...")
utils.uninstall_requirements(config)
# install the requirements
logger.info("Installing requirements...")
utils.install_requirements(config)
# run the command
logger.info("Running command...")
utils.run_command(config)
pause_space(config)
if __name__ == "__main__":
args = parse_args()
_config = json.load(open(args.config))
_config = GenericParams(**_config)
run(_config)
| 3 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/generic/params.py | from typing import Dict, Optional
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class GenericParams(AutoTrainParams):
"""
GenericParams is a class that holds configuration parameters for an AutoTrain SpaceRunner project.
Attributes:
username (str): The username for your Hugging Face account.
project_name (str): The name of the project.
data_path (str): The file path to the dataset.
token (str): The authentication token for accessing Hugging Face Hub.
script_path (str): The file path to the script to be executed. Path to script.py.
env (Optional[Dict[str, str]]): A dictionary of environment variables to be set.
args (Optional[Dict[str, str]]): A dictionary of arguments to be passed to the script.
"""
username: str = Field(
None, title="Hugging Face Username", description="The username for your Hugging Face account."
)
project_name: str = Field("project-name", title="Project Name", description="The name of the project.")
data_path: str = Field(None, title="Data Path", description="The file path to the dataset.")
token: str = Field(None, title="Hub Token", description="The authentication token for accessing Hugging Face Hub.")
script_path: str = Field(
None, title="Script Path", description="The file path to the script to be executed. Path to script.py"
)
env: Optional[Dict[str, str]] = Field(
None, title="Environment Variables", description="A dictionary of environment variables to be set."
)
args: Optional[Dict[str, str]] = Field(
None, title="Arguments", description="A dictionary of arguments to be passed to the script."
)
| 4 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_regression/utils.py | import os
import albumentations as A
import numpy as np
from sklearn import metrics
from autotrain.trainers.image_regression.dataset import ImageRegressionDataset
VALID_METRICS = [
"eval_loss",
"eval_mse",
"eval_mae",
"eval_r2",
"eval_rmse",
"eval_explained_variance",
]
MODEL_CARD = """
---
tags:
- autotrain
- vision
- image-classification
- image-regression{base_model}
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace{dataset_tag}
---
# Model Trained Using AutoTrain
- Problem type: Image Regression
## Validation Metrics
{validation_metrics}
"""
def image_regression_metrics(pred):
"""
Calculate various regression metrics for image regression tasks.
Args:
pred (tuple): A tuple containing raw predictions and labels.
raw_predictions should be a list of lists or a list of numpy.float32 values.
labels should be a list of true values.
Returns:
dict: A dictionary containing the calculated metrics:
- 'mse': Mean Squared Error
- 'mae': Mean Absolute Error
- 'r2': R^2 Score
- 'rmse': Root Mean Squared Error
- 'explained_variance': Explained Variance Score
If an error occurs during the calculation of a metric, the value for that metric will be -999.
"""
raw_predictions, labels = pred
try:
raw_predictions = [r for preds in raw_predictions for r in preds]
except TypeError as err:
if "numpy.float32" not in str(err):
raise Exception(err)
pred_dict = {}
metrics_to_calculate = {
"mse": metrics.mean_squared_error,
"mae": metrics.mean_absolute_error,
"r2": metrics.r2_score,
"rmse": lambda y_true, y_pred: np.sqrt(metrics.mean_squared_error(y_true, y_pred)),
"explained_variance": metrics.explained_variance_score,
}
for key, func in metrics_to_calculate.items():
try:
pred_dict[key] = float(func(labels, raw_predictions))
except Exception:
pred_dict[key] = -999
return pred_dict
def process_data(train_data, valid_data, image_processor, config):
"""
Processes training and validation data by applying image transformations.
Args:
train_data (Dataset): The training dataset.
valid_data (Dataset or None): The validation dataset. If None, only training data is processed.
image_processor (ImageProcessor): An object containing image processing parameters such as size, mean, and std.
config (dict): Configuration dictionary containing additional parameters for the dataset.
Returns:
tuple: A tuple containing the processed training dataset and the processed validation dataset (or None if valid_data is None).
"""
if "shortest_edge" in image_processor.size:
size = image_processor.size["shortest_edge"]
else:
size = (image_processor.size["height"], image_processor.size["width"])
try:
height, width = size
except TypeError:
height = size
width = size
train_transforms = A.Compose(
[
A.RandomResizedCrop(height=height, width=width),
A.RandomRotate90(),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
val_transforms = A.Compose(
[
A.Resize(height=height, width=width),
A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
train_data = ImageRegressionDataset(train_data, train_transforms, config)
if valid_data is not None:
valid_data = ImageRegressionDataset(valid_data, val_transforms, config)
return train_data, valid_data
return train_data, None
def create_model_card(config, trainer):
"""
Generates a model card string based on the provided configuration and trainer.
Args:
config (object): Configuration object containing various settings such as
valid_split, data_path, project_name, and model.
trainer (object): Trainer object used to evaluate the model if validation
split is provided.
Returns:
str: A formatted model card string containing dataset information,
validation metrics, and base model details.
"""
if config.valid_split is not None:
eval_scores = trainer.evaluate()
eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items() if k in VALID_METRICS]
eval_scores = "\n\n".join(eval_scores)
else:
eval_scores = "No validation metrics available"
if config.data_path == f"{config.project_name}/autotrain-data" or os.path.isdir(config.data_path):
dataset_tag = ""
else:
dataset_tag = f"\ndatasets:\n- {config.data_path}"
if os.path.isdir(config.model):
base_model = ""
else:
base_model = f"\nbase_model: {config.model}"
model_card = MODEL_CARD.format(
dataset_tag=dataset_tag,
validation_metrics=eval_scores,
base_model=base_model,
)
return model_card
| 5 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_regression/__main__.py | import argparse
import json
from accelerate.state import PartialState
from datasets import load_dataset, load_from_disk
from huggingface_hub import HfApi
from transformers import (
AutoConfig,
AutoImageProcessor,
AutoModelForImageClassification,
EarlyStoppingCallback,
Trainer,
TrainingArguments,
)
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.common import (
ALLOW_REMOTE_CODE,
LossLoggingCallback,
TrainStartCallback,
UploadLogs,
monitor,
pause_space,
remove_autotrain_data,
save_training_params,
)
from autotrain.trainers.image_regression import utils
from autotrain.trainers.image_regression.params import ImageRegressionParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--training_config", type=str, required=True)
return parser.parse_args()
@monitor
def train(config):
if isinstance(config, dict):
config = ImageRegressionParams(**config)
valid_data = None
if config.data_path == f"{config.project_name}/autotrain-data":
train_data = load_from_disk(config.data_path)[config.train_split]
else:
if ":" in config.train_split:
dataset_config_name, split = config.train_split.split(":")
train_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
train_data = load_dataset(
config.data_path,
split=config.train_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
if config.valid_split is not None:
if config.data_path == f"{config.project_name}/autotrain-data":
valid_data = load_from_disk(config.data_path)[config.valid_split]
else:
if ":" in config.valid_split:
dataset_config_name, split = config.valid_split.split(":")
valid_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
valid_data = load_dataset(
config.data_path,
split=config.valid_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
logger.info(f"Train data: {train_data}")
logger.info(f"Valid data: {valid_data}")
model_config = AutoConfig.from_pretrained(
config.model,
num_labels=1,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
)
model_config._num_labels = 1
label2id = {"target": 0}
model_config.label2id = label2id
model_config.id2label = {v: k for k, v in label2id.items()}
try:
model = AutoModelForImageClassification.from_pretrained(
config.model,
config=model_config,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
ignore_mismatched_sizes=True,
)
except OSError:
model = AutoModelForImageClassification.from_pretrained(
config.model,
config=model_config,
from_tf=True,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
ignore_mismatched_sizes=True,
)
image_processor = AutoImageProcessor.from_pretrained(
config.model,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)
if config.logging_steps == -1:
if config.valid_split is not None:
logging_steps = int(0.2 * len(valid_data) / config.batch_size)
else:
logging_steps = int(0.2 * len(train_data) / config.batch_size)
if logging_steps == 0:
logging_steps = 1
if logging_steps > 25:
logging_steps = 25
config.logging_steps = logging_steps
else:
logging_steps = config.logging_steps
logger.info(f"Logging steps: {logging_steps}")
training_args = dict(
output_dir=config.project_name,
per_device_train_batch_size=config.batch_size,
per_device_eval_batch_size=2 * config.batch_size,
learning_rate=config.lr,
num_train_epochs=config.epochs,
eval_strategy=config.eval_strategy if config.valid_split is not None else "no",
logging_steps=logging_steps,
save_total_limit=config.save_total_limit,
save_strategy=config.eval_strategy if config.valid_split is not None else "no",
gradient_accumulation_steps=config.gradient_accumulation,
report_to=config.log,
auto_find_batch_size=config.auto_find_batch_size,
lr_scheduler_type=config.scheduler,
optim=config.optimizer,
warmup_ratio=config.warmup_ratio,
weight_decay=config.weight_decay,
max_grad_norm=config.max_grad_norm,
push_to_hub=False,
load_best_model_at_end=True if config.valid_split is not None else False,
ddp_find_unused_parameters=False,
)
if config.mixed_precision == "fp16":
training_args["fp16"] = True
if config.mixed_precision == "bf16":
training_args["bf16"] = True
if config.valid_split is not None:
early_stop = EarlyStoppingCallback(
early_stopping_patience=config.early_stopping_patience,
early_stopping_threshold=config.early_stopping_threshold,
)
callbacks_to_use = [early_stop]
else:
callbacks_to_use = []
callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])
args = TrainingArguments(**training_args)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks_to_use,
compute_metrics=utils.image_regression_metrics,
)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data,
)
trainer.remove_callback(PrinterCallback)
trainer.train()
logger.info("Finished training, saving model...")
trainer.save_model(config.project_name)
image_processor.save_pretrained(config.project_name)
model_card = utils.create_model_card(config, trainer)
# save model card to output directory as README.md
with open(f"{config.project_name}/README.md", "w") as f:
f.write(model_card)
if config.push_to_hub:
if PartialState().process_index == 0:
remove_autotrain_data(config)
save_training_params(config)
logger.info("Pushing model to hub...")
api = HfApi(token=config.token)
api.create_repo(
repo_id=f"{config.username}/{config.project_name}", repo_type="model", private=True, exist_ok=True
)
api.upload_folder(
folder_path=config.project_name, repo_id=f"{config.username}/{config.project_name}", repo_type="model"
)
if PartialState().process_index == 0:
pause_space(config)
if __name__ == "__main__":
_args = parse_args()
training_config = json.load(open(_args.training_config))
_config = ImageRegressionParams(**training_config)
train(_config)
| 6 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_regression/dataset.py | import numpy as np
import torch
class ImageRegressionDataset:
"""
A dataset class for image regression tasks.
Args:
data (list): A list of data points where each data point is a dictionary containing image and target information.
transforms (callable): A function/transform that takes in an image and returns a transformed version.
config (object): A configuration object that contains the column names for images and targets.
Attributes:
data (list): The input data.
transforms (callable): The transformation function.
config (object): The configuration object.
Methods:
__len__(): Returns the number of data points in the dataset.
__getitem__(item): Returns a dictionary containing the transformed image and the target value for the given index.
"""
def __init__(self, data, transforms, config):
self.data = data
self.transforms = transforms
self.config = config
def __len__(self):
return len(self.data)
def __getitem__(self, item):
image = self.data[item][self.config.image_column]
target = self.data[item][self.config.target_column]
image = self.transforms(image=np.array(image.convert("RGB")))["image"]
image = np.transpose(image, (2, 0, 1)).astype(np.float32)
return {
"pixel_values": torch.tensor(image, dtype=torch.float),
"labels": torch.tensor(target, dtype=torch.float),
}
| 7 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/image_regression/params.py | from typing import Optional
from pydantic import Field
from autotrain.trainers.common import AutoTrainParams
class ImageRegressionParams(AutoTrainParams):
"""
ImageRegressionParams is a configuration class for image regression training parameters.
Attributes:
data_path (str): Path to the dataset.
model (str): Name of the model to use. Default is "google/vit-base-patch16-224".
username (Optional[str]): Hugging Face Username.
lr (float): Learning rate. Default is 5e-5.
epochs (int): Number of training epochs. Default is 3.
batch_size (int): Training batch size. Default is 8.
warmup_ratio (float): Warmup proportion. Default is 0.1.
gradient_accumulation (int): Gradient accumulation steps. Default is 1.
optimizer (str): Optimizer to use. Default is "adamw_torch".
scheduler (str): Scheduler to use. Default is "linear".
weight_decay (float): Weight decay. Default is 0.0.
max_grad_norm (float): Max gradient norm. Default is 1.0.
seed (int): Random seed. Default is 42.
train_split (str): Train split name. Default is "train".
valid_split (Optional[str]): Validation split name.
logging_steps (int): Logging steps. Default is -1.
project_name (str): Output directory name. Default is "project-name".
auto_find_batch_size (bool): Whether to auto find batch size. Default is False.
mixed_precision (Optional[str]): Mixed precision type (fp16, bf16, or None).
save_total_limit (int): Save total limit. Default is 1.
token (Optional[str]): Hub Token.
push_to_hub (bool): Whether to push to hub. Default is False.
eval_strategy (str): Evaluation strategy. Default is "epoch".
image_column (str): Image column name. Default is "image".
target_column (str): Target column name. Default is "target".
log (str): Logging using experiment tracking. Default is "none".
early_stopping_patience (int): Early stopping patience. Default is 5.
early_stopping_threshold (float): Early stopping threshold. Default is 0.01.
"""
data_path: str = Field(None, title="Data path")
model: str = Field("google/vit-base-patch16-224", title="Model name")
username: Optional[str] = Field(None, title="Hugging Face Username")
lr: float = Field(5e-5, title="Learning rate")
epochs: int = Field(3, title="Number of training epochs")
batch_size: int = Field(8, title="Training batch size")
warmup_ratio: float = Field(0.1, title="Warmup proportion")
gradient_accumulation: int = Field(1, title="Gradient accumulation steps")
optimizer: str = Field("adamw_torch", title="Optimizer")
scheduler: str = Field("linear", title="Scheduler")
weight_decay: float = Field(0.0, title="Weight decay")
max_grad_norm: float = Field(1.0, title="Max gradient norm")
seed: int = Field(42, title="Seed")
train_split: str = Field("train", title="Train split")
valid_split: Optional[str] = Field(None, title="Validation split")
logging_steps: int = Field(-1, title="Logging steps")
project_name: str = Field("project-name", title="Output directory")
auto_find_batch_size: bool = Field(False, title="Auto find batch size")
mixed_precision: Optional[str] = Field(None, title="fp16, bf16, or None")
save_total_limit: int = Field(1, title="Save total limit")
token: Optional[str] = Field(None, title="Hub Token")
push_to_hub: bool = Field(False, title="Push to hub")
eval_strategy: str = Field("epoch", title="Evaluation strategy")
image_column: str = Field("image", title="Image column")
target_column: str = Field("target", title="Target column")
log: str = Field("none", title="Logging using experiment tracking")
early_stopping_patience: int = Field(5, title="Early stopping patience")
early_stopping_threshold: float = Field(0.01, title="Early stopping threshold")
| 8 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/seq2seq/utils.py | import os
import evaluate
import nltk
import numpy as np
ROUGE_METRIC = evaluate.load("rouge")
MODEL_CARD = """
---
tags:
- autotrain
- text2text-generation{base_model}
widget:
- text: "I love AutoTrain"{dataset_tag}
---
# Model Trained Using AutoTrain
- Problem type: Seq2Seq
## Validation Metrics
{validation_metrics}
"""
def _seq2seq_metrics(pred, tokenizer):
"""
Compute sequence-to-sequence metrics for predictions and labels.
Args:
pred (tuple): A tuple containing predictions and labels.
Predictions and labels are expected to be token IDs.
tokenizer (PreTrainedTokenizer): The tokenizer used for decoding the predictions and labels.
Returns:
dict: A dictionary containing the computed ROUGE metrics and the average length of the generated sequences.
The keys are the metric names and the values are the corresponding scores rounded to four decimal places.
"""
predictions, labels = pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
result = ROUGE_METRIC.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
result = {key: value * 100 for key, value in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
def create_model_card(config, trainer):
"""
Generates a model card string based on the provided configuration and trainer.
Args:
config (object): Configuration object containing the following attributes:
- valid_split (optional): If not None, the function will include evaluation scores.
- data_path (str): Path to the dataset.
- project_name (str): Name of the project.
- model (str): Path or identifier of the model.
trainer (object): Trainer object with an `evaluate` method that returns evaluation metrics.
Returns:
str: A formatted model card string containing dataset information, validation metrics, and base model details.
"""
if config.valid_split is not None:
eval_scores = trainer.evaluate()
eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items()]
eval_scores = "\n\n".join(eval_scores)
else:
eval_scores = "No validation metrics available"
if config.data_path == f"{config.project_name}/autotrain-data" or os.path.isdir(config.data_path):
dataset_tag = ""
else:
dataset_tag = f"\ndatasets:\n- {config.data_path}"
if os.path.isdir(config.model):
base_model = ""
else:
base_model = f"\nbase_model: {config.model}"
model_card = MODEL_CARD.format(
dataset_tag=dataset_tag,
validation_metrics=eval_scores,
base_model=base_model,
)
return model_card
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter0/introduction.mdx | # Добро пожаловать на аудиокурс Hugging Face!
Уважаемый слушатель,
Добро пожаловать на курс по использованию трансформеров в аудио. Трансформеры снова и снова доказывают, что они являются одной из
наиболее мощных и универсальных архитектур глубокого обучения, способных достигать передовых результатов в широком спектре
задач, включая обработку естественного языка, компьютерное зрение, а с недавних пор и аудио.
В этом курсе мы рассмотрим, как трансформеры могут быть применены к аудиоданным. Вы узнаете, как использовать их для решения
ряда задач, связанных с аудио. Если вас интересует распознавание речи, классификация аудиоданных или генерация речи
из текста, трансформеры и данный курс помогут вам в этом.
Чтобы вы могли оценить возможности этих моделей, произнесите несколько слов в демонстрации ниже и посмотрите, как модель транскрибирует их в режиме реального времени!
<iframe
src="https://openai-whisper.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
В ходе курса вы получите представление о специфике работы с аудиоданными, узнаете о различных
архитектурах трансформеров, а также обучите свои собственные аудио трансформеры, используя мощные предварительно обученные модели.
Этот курс рассчитан на слушателей, имеющих опыт глубокого обучения и общее представление о трансформерах.
Знаний в области обработки аудиоданных не требуется. Если вам нужно подтянуть свое понимание трансформеров, ознакомьтесь с
нашим [курсом по NLP](https://huggingface.co/course/chapter1/1), в котором очень подробно рассматриваются основы трансформеров.
## Знакомство с командой курса
**Санчит Ганди, инженер-исследователь в области машинного обучения в Hugging Face**
Привет! Меня зовут Санчит, и я работаю инженером-исследователем в области машинного обучения звука в Open Source команде компании Hugging Face 🤗.
Основным направлением моей работы является автоматическое распознавание речи и перевод, а текущей целью - сделать речевые модели более быстрыми,
более легкими и простыми в использовании.
**Маттиджс Холлеманс, инженер по машинному обучению в Hugging Face**
Меня зовут Маттиджс, я работаю инженером по машинному обучению аудио в команде Hugging Face с открытым исходным кодом. Я также являюсь автором
книги о том, как писать звуковые синтезаторы, а в свободное время создаю аудиоплагины.
**Мария Халусова, отдел документации и курсов в Hugging Face**
Меня зовут Мария, и я создаю образовательный контент и документацию, чтобы сделать библиотеку Transformers и другие инструменты с открытым исходным кодом еще более
доступными. Я раскрываю сложные технические концепции и помогаю людям начать работу с передовыми технологиями.
**Вайбхав Шривастав, ML-разработчик, инженер по продвижению интересов разработчиков в компании Hugging Face**
Меня зовут Вайбхав и я являюсь инженером по продвижению интересов разработчиков в области аудио в Open Source команде компании Hugging Face. Я занимаюсь исследованиями
в области аудио с низким потреблением ресурсов и помогаю продвигать передовые исследования в области обработки речи в массы.
## Структура курса
Курс состоит из нескольких разделов, в которых подробно рассматриваются различные темы:
* [Раздел 1](https://huggingface.co/learn/audio-course/chapter1): охватывает специфику работы с аудиоданными, включая методы обработки аудиоданных и их подготовку.
* [Раздел 2](https://huggingface.co/learn/audio-course/chapter2): познакомит с аудиоприложениями и научит использовать конвейеры 🤗 Transformers для решения различных задач, таких как
классификация аудио и распознавание речи.
* [Раздел 3](https://huggingface.co/learn/audio-course/chapter3): познакомит с архитектурами аудио трансформеров, расскажет, чем они отличаются и для каких задач лучше всего подходят.
* [Раздел 4](https://huggingface.co/learn/audio-course/chapter4): научит создавать собственный классификатор музыкальных жанров.
* [Раздел 5](https://huggingface.co/learn/audio-course/chapter5): углубится в распознавание речи и построение модель для расшифровки записей совещаний.
* [Раздел 6](https://huggingface.co/learn/audio-course/chapter6): научит генерировать речь из текста.
* [Раздел 7](https://huggingface.co/learn/audio-course/chapter7): научит создавать реальные аудиоприложения с использованием трансформеров.
Каждый раздел включает в себя теоретическую часть, где вы получите глубокое понимание основных концепций и методов.
На протяжении всего курса мы предлагаем тестовые задания, которые помогут вам проверить свои знания и закрепить полученные навыки.
Некоторые главы также включают практические упражнения, где вы сможете применить полученные знания.
К концу курса вы получите прочную базу в области использования трансформеров для аудиоданных и будете
хорошо подготовлены к применению этих методов для решения широкого круга задач, связанных с аудио.
Разделы курса будут выходить несколькими последовательными блоками со следующим графиком публикации:
| Раздел | Дата публикации |
|---|-----------------|
| Раздел 0, Раздел 1, и Раздел 2 | 14 июня 2023 |
| Раздел 3, Раздел 4 | 21 июня 2023 |
| Раздел 5 | 28 июня 2023 |
| Раздел 6 | 5 июля 2023 |
| Раздел 7, Раздел 8 | 12 июля 2023 |
## Траектории обучения и сертификация
Не существует правильного или неправильного способа изучения этого курса. Все материалы данного курса являются 100% бесплатными, общедоступными и открытыми.
Вы можете изучать курс в удобном для вас темпе, однако мы рекомендуем проходить его по порядку.
Если вы хотите получить сертификат по окончании курса, мы предлагаем два варианта:
| Тип сертификата | Требования |
|---|------------------------------------------------------------------------------------------------|
| Сертификат о прохождении обучения | Выполнить 80% практических заданий в соответствии с инструкциями. |
| Cертификат c отличием | Выполнить 100% практических заданий в соответствии с инструкциями. |
В каждом практическом упражнении указаны критерии его выполнения. Если вы выполнили достаточное количество практических упражнений, чтобы претендовать
на получение сертификата, обратитесь к последнему разделу курса, чтобы узнать, как его получить. Удачи!
## Зарегистрироваться на курс
Разделы этого курса будут выходить постепенно в течение нескольких недель. Мы рекомендуем вам подписаться на обновления курса,
чтобы не пропустить появление новых разделов. Учащиеся, подписавшиеся на обновления курса,
также первыми узнают о специальных социальных мероприятиях, которые мы планируем проводить.
[Зарегистрироваться](http://eepurl.com/insvcI)
Наслаждайтесь курсом!
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter0/community.mdx | # Присоединяйтесь к сообществу!
Мы приглашаем вас [присоединиться к нашему активному и поддерживающему сообществу в Discord](http://hf.co/join/discord). У вас появится
возможность общаться с единомышленниками, обмениваться идеями и получать ценные отзывы о своих практических занятиях. Вы сможете задавать вопросы,
делиться ресурсами и сотрудничать с другими.
Наша команда также активно работает в Discord и готова оказать поддержку и дать рекомендации, если они вам понадобятся.
Присоединяйтесь к нашему сообществу - это отличный способ поддерживать мотивацию, участие и связь, мы будем рады видеть
вас там!
## Что такое Discord?
Discord - это бесплатная платформа для общения. Если вы пользовались Slack, то найдете его очень похожим. Сервер Hugging Face Discord
является домом для процветающего сообщества из 18 000 экспертов, исследователей и энтузиастов ИИ, частью которого можете стать и вы.
## Навигация по Discord
После регистрации на нашем Discord-сервере вам нужно будет выбрать интересующие вас темы, нажав на кнопку `#role-assignment`
слева. Вы можете выбрать сколько угодно различных категорий. Чтобы присоединиться к другим слушателям этого курса, обязательно
нажмите "ML for Audio and Speech".
Изучите каналы и расскажите немного о себе на канале `#introduce-yourself`.
## Каналы аудиокурса
На нашем сервере Discord существует множество каналов, посвященных различным темам. Здесь можно найти людей, обсуждающих статьи, организующих
мероприятия, делящихся своими проектами и идеями, проводящих мозговые штурмы и многое другое.
Для слушателей аудиокурсов особенно актуальным может оказаться следующий набор каналов:
* `#audio-announcements`: обновления курса, новости из Hugging Face, связанные со всем тем, что касается работы с аудио, анонсы мероприятий и многое другое.
* `#audio-study-group`: место, где можно обменяться идеями, задать вопросы по курсу и начать дискуссию.
* `#audio-discuss`: общее место для обсуждения вопросов, связанных с аудио.
Помимо присоединения к `#audio-study-group`, не стесняйтесь создавать свою собственную учебную группу - учиться вместе всегда легче!
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/events/introduction.mdx | # Живые занятия и семинары
Новый курс "Аудиотрансформеры": Прямой эфир с Пейдж Бейли (DeepMind), Сеохван Ким (Amazon Alexa AI) и Брайаном Макфи (Librosa)
<Youtube id="wqkKResXWB8"/>
Запись Live AMA с командой аудиокурса Hugging Face:
<Youtube id="fbONSVoUneQ"/>
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter8/certification.mdx | # Получение сертификата о прохождении курса
Процесс сертификации является полностью бесплатным.
* Для получения сертификата об окончании курса необходимо сдать 3 из 4 практических заданий до 1 сентября 2023 года.
* Для получения сертификата с отличием об окончании курса необходимо сдать 4 из 4 практических заданий до 1 сентября 2023 года.
Требования к каждому заданию приведены в соответствующих разделах:
* [Раздел 4 Практическое занятие](../chapter4/hands_on)
* [Раздел 5 Практическое занятие](../chapter5/hands_on)
* [Раздел 6 Практическое занятие](../chapter6/hands_on)
* [Раздел 7 Практическое занятие](../chapter7/hands_on)
Для заданий, требующих обучения модели, убедитесь, что ваша модель, удовлетворяющая требованиям, выложена на HuggingFace хабе с соответствующими `kwargs`.
Для демонстрационного задания в Главе 7 убедитесь, что ваша демонстрация является `public`.
Для самооценки и для того, чтобы увидеть, какие разделы вы сдали/не сдали, вы можете использовать следующее пространство:
[Check My Progress - Audio Course](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course)
После того как вы сможете получить сертификат, перейдите в пространство [Audio Course Certification](https://huggingface.co/spaces/MariaK/Audio-Course-Certification).
В этом пространстве осуществляются дополнительные проверки на соответствие представленных материалов критериям оценки.
Введите свое имя пользователя Hugging Face, имя, фамилию в текстовые поля и нажмите на кнопку "Check if I pass and get the certificate".
Если вы сдали 3 из 4 практических заданий, то получите сертификат о прохождении курса.
Если вы сдали 4 из 4 практических заданий, вы получите сертификат о прохождении курса с отличием.
Вы можете скачать свой сертификат в формате pdf и png. Не стесняйтесь делиться своим сертификатом в Twitter
(тэгните меня @mariakhalusova и @huggingface) и на LinkedIn.
Если вы не соответствуете критериям сертификации, не отчаивайтесь! Вернитесь к пространству
[Check My Progress - Audio Course](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course), чтобы увидеть
какие блоки необходимо выполнить еще раз для получения сертификата. Если у вас возникнут какие-либо проблемы с любым из этих пространств,
сообщите нам об этом!
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter8/introduction.mdx | # Поздравляем!
Вы много работали, чтобы достичь этого момента, и мы хотели бы поздравить Вас с окончанием этого курса по обработке аудиоданных!
В ходе данного курса вы получили базовое представление об аудиоданных, изучили новые концепции и приобрели
практические навыки работы с аудио трансформерами.
Начиная с основ работы с аудиоданными и предварительно обученными контрольными точками моделей с помощью конвейеров и заканчивая созданием реальных
аудиоприложений, вы узнали, как можно создавать системы, способные не только понимать звук, но и создавать его.
Поскольку эта область является динамичной и постоянно развивающейся, мы призываем вас не терять любопытства и постоянно изучать новые модели, достижения в области исследований
и новые приложения. Создавая свои новые и интересные аудиоприложения, не забывайте об этических аспектах
и тщательно анализируйте потенциальное воздействие на человека и общество в целом.
Благодарим Вас за то, что Вы присоединились к этому курсу, мы надеемся, что Вы получили огромное удовольствие от этого образовательного процесса,
так же как и мы от его создания. Ваши отзывы и предложения приветствуются в
[репозитории курса на GitHub](https://github.com/huggingface/audio-transformers-course).
Чтобы узнать, как можно получить заслуженный сертификат об окончании курса, если вы успешно справились с практическими заданиями,
вы узнаете на [следующей странице](certification).
Наконец, чтобы оставаться на связи с командой курса по аудио, вы можете связаться с нами в Twitter:
* Мария Халусова: [@mariakhalusova](https://twitter.com/mariaKhalusova)
* Санчит Ганди: [@sanchitgandhi99](https://twitter.com/sanchitgandhi99)
* Матиас Холлеманс: [@mhollemans](https://twitter.com/mhollemans)
* Вайбхав Шривастав: [@reach_vb](https://twitter.com/reach_vb)
Оставайтесь любопытными и тренируйте трансформеров! :)
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter5/choosing_dataset.mdx | # Выбор набора данных
Как и в любой другой задаче машинного обучения, наша модель хороша лишь настолько, насколько хороши данные, на которых мы ее обучаем.
Наборы данных для распознавания речи существенно различаются по способу их формирования и областям, которые они охватывают.
Чтобы выбрать правильный набор данных, необходимо сопоставить наши критерии с возможностями, которые предоставляет набор данных.
Прежде чем выбрать набор данных, необходимо понять его ключевые определяющие характеристики.
## Характеристики речевых наборов данных
### 1. Количество часов
Проще говоря, количество часов обучения показывает, насколько велик набор данных. Это аналогично количеству обучающих примеров в наборе данных
для обработки естественного языка (NLP). Однако, большой набор данных не означает что этот набор лучший. Если мы хотим получить модель, которая
хорошо обобщает, нам нужна **разнообразный** набор данных с большим количеством различных дикторов, источников и стилей речи.
### 2. Источник данных
Источник данных означает, откуда были взяты данные, будь то аудиокниги, подкасты, YouTube или финансовые встречи. Для каждого источника характерно
свое распределение данных. Например, аудиокниги записываются в качественных студийных условиях (без посторонних шумов), а текст берется из
письменной литературы. В то время как для YouTube аудиозапись, скорее всего, содержит больше фонового шума и более неформальный стиль речи.
Мы должны соотнести наш источник с условиями, которые мы ожидаем в момент вывода. Например, если мы обучаем нашу модель на аудиокнигах, мы не можем
ожидать, что она будет хорошо работать в шумной обстановке.
### 3. Стиль речи
Стиль речи относится к одной из двух категорий:
* Дикторская: чтение по сценарию
* Спонтанная: речь без сценария, разговорная речь
Аудио- и текстовые данные отражают стиль речи. Поскольку дикторский текст написан по сценарию, он, как правило, произносится внятно и без ошибок:
```
“Рассмотрим задачу обучения модели на наборе данных распознавания речи”
```
В то время как для спонтанной речи можно ожидать более разговорного стиля речи, с повторениями, запинаниями и других речевых сбоев:
```
“Let’s uhh let's take a look at how you'd go about training a model on uhm a sp- speech recognition dataset”
```
### 4. Стиль транскрипции
Стиль транскрипции относится к тому, есть ли в целевом тексте пунктуация, регистр или и то, и другое. Если мы хотим, чтобы система
генерировала полностью отформатированный текст, который можно было бы использовать для публикации или транскрипции собрания, нам нужны
обучающие данные с пунктуацией и регистром. Если нам просто нужны произносимые слова в неформатированной структуре, ни пунктуация,
ни регистр не нужны. В этом случае мы можем либо выбрать набор данных без знаков препинания и регистра, либо выбрать тот, в котором
есть знаки препинания и регистр, а затем впоследствии удалить их из целевого текста с помощью предварительной обработки.
## Сводная информация о наборах данных на Hugging Face Hub
Ниже приведен обзор наиболее популярных наборов данных для распознавания английской речи на Hugging Face Hub:
| Dataset | Train Hours | Domain | Speaking Style | Casing | Punctuation | License | Recommended Use |
|-----------------------------------------------------------------------------------------|-------------|-----------------------------|-----------------------|--------|-------------|-----------------|----------------------------------|
| [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) | 960 | Audiobook | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) | 3000 | Wikipedia | Narrated | ✅ | ✅ | CC0-1.0 | Non-native speakers |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 540 | European Parliament | Oratory | ❌ | ✅ | CC0 | Non-native speakers |
| [TED-LIUM](https://huggingface.co/datasets/LIUM/tedlium) | 450 | TED talks | Oratory | ❌ | ❌ | CC-BY-NC-ND 3.0 | Technical topics |
| [GigaSpeech](https://huggingface.co/datasets/speechcolab/gigaspeech) | 10000 | Audiobook, podcast, YouTube | Narrated, spontaneous | ❌ | ✅ | apache-2.0 | Robustness over multiple domains |
| [SPGISpeech](https://huggingface.co/datasets/kensho/spgispeech) | 5000 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | User Agreement | Fully formatted transcriptions |
| [Earnings-22](https://huggingface.co/datasets/revdotcom/earnings22) | 119 | Financial meetings | Oratory, spontaneous | ✅ | ✅ | CC-BY-SA-4.0 | Diversity of accents |
| [AMI](https://huggingface.co/datasets/edinburghcstr/ami) | 100 | Meetings | Spontaneous | ✅ | ✅ | CC-BY-4.0 | Noisy speech conditions |
Эта таблица служит справочной информацией для выбора набора данных на основе вашего критерия. Ниже приведена эквивалентная таблица
для многоязычного распознавания речи. Обратите внимание, что мы опускаем столбец "Время обучения", поскольку оно зависит от языка для
каждого набора данных, и заменяем его на количество языков для каждого набора данных:
| Dataset | Languages | Domain | Speaking Style | Casing | Punctuation | License | Recommended Usage |
|-----------------------------------------------------------------------------------------------|-----------|---------------------------------------|----------------|--------|-------------|-----------|-------------------------|
| [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 6 | Audiobooks | Narrated | ❌ | ❌ | CC-BY-4.0 | Academic benchmarks |
| [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) | 108 | Wikipedia text & crowd-sourced speech | Narrated | ✅ | ✅ | CC0-1.0 | Diverse speaker set |
| [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) | 15 | European Parliament recordings | Spontaneous | ❌ | ✅ | CC0 | European languages |
| [FLEURS](https://huggingface.co/datasets/google/fleurs) | 101 | European Parliament recordings | Spontaneous | ❌ | ❌ | CC-BY-4.0 | Multilingual evaluation |
Подробную информацию о наборах аудиоданных, представленных в обеих таблицах, можно найти в блоге [Полное руководство по работе с наборами аудиоданных](https://huggingface.co/blog/audio-datasets#a-tour-of-audio-datasets-on-the-hub).
Хотя на Hugging Face Hub имеется более 180 наборов данных для распознавания речи, может оказаться, что среди них нет такого,
который соответствует вашим потребностям. Для создания пользовательского набора аудиоданных см. руководство [Создание набора аудиоданных](https://huggingface.co/docs/datasets/audio_dataset).
При создании пользовательского набора аудиоданных подумайте о том, чтобы опубликовать окончательный набор данных в Hugging Face Hub, чтобы
другие участники сообщества могли извлечь пользу из ваших усилий — сообщество аудио является обширно и многогранно, и другие оценят вашу
работу так же, как и вы.
Хорошо! Теперь, когда мы рассмотрели все критерии выбора набора данных ASR, давайте выберем один из них для целей данного руководства.
Мы знаем, что Whisper уже достаточно хорошо справляется с транскрибацией данных на ресурсоемких языках(таких как английский
и испанский), поэтому мы сосредоточимся на многоязычной транскрибации данных с низким уровнем ресурсов. Мы хотим сохранить способность Whisper
предсказывать знаки препинания и регистр, поэтому из второй таблицы видно, что Common Voice 13 является отличным набором данных!
## Common Voice 13
Common Voice 13 - это набор данных, созданный на основе краудсорсинга, в котором дикторы записывают текст из Википедии на разных языках.
Он является частью серии Common Voice - коллекции наборов данных Common Voice, выпускаемой Mozilla Foundation. На момент написания статьи
Common Voice 13 является последней редакцией набора данных, содержащей наибольшее количество языков и часов на один язык из всех выпущенных
на сегодняшний день.
Полный список языков для набора данных Common Voice 13 можно получить, заглянув на страницу набора данных на Hugging Face Hub:
[mozilla-foundation/common_voice_13_0](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0).
При первом просмотре этой страницы вам будет предложено принять условия использования. После этого вам будет предоставлен полный доступ к набору данных.
После того как мы выполнили аутентификацию для использования набора данных, нам будет представлен предварительный просмотр набора данных.
Предварительный просмотр набора данных показывает нам первые 100 образцов набора данных для каждого языка. Более того, в него загружены аудиообразцы,
которые мы можем прослушать в режиме реального времени. Для этого Раздела мы выберем [_Дивехи_](https://en.wikipedia.org/wiki/Maldivian_language)
или (_Мальдивский язык_), это индоарийский язык, на котором разговаривают в островном государстве Мальдивы, расположенном в Южной Азии. Хотя для данного
руководства мы выбрали Дивехи, описанные здесь шаги применимы к любому из 108 языков, входящих в набор данных Common Voice 13, и вообще к любому из 180
с лишним наборов аудиоданных на Hugging Face Hub, поэтому нет никаких ограничений по языку или диалекту.
Мы можем выбрать подмножество Дивехи в Common Voice 13, установив в выпадающем меню подмножество `dv` (`dv` - код идентификатора языка Dhivehi):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/cv_13_dv_selection.png" alt="Selecting the Dhivehi split from the Dataset's Preview">
</div>
Если мы нажмем кнопку воспроизведения на первом примере, то сможем прослушать звук и увидеть соответствующий текст. Пролистайте примеры обучающего
и тестового наборов, чтобы лучше понять, с какими аудио- и текстовыми данными мы имеем дело. По интонации и стилю можно определить, что записи
сделаны с дикторской речи. Вы также, вероятно, заметите большой разброс между дикторами и качеством записи, что является общей чертой что является
общей чертой краудсорсинговых данных.
Предварительный просмотр данных - это отличный способ ознакомиться с наборами аудиоданных, прежде чем приступить к их использованию. Вы можете
выбрать любой набор данных в Hugging Face Hub, просмотреть образцы и прослушать аудио для различных подмножеств и разбиений, оценив, подходит
ли этот набор данных для ваших нужд. Выбрав набор данных, можно загрузить их и начать использовать.
Итак, я лично не владею Дивехи, и предполагаю, что подавляющее большинство читателей тоже! Чтобы узнать, насколько хороша наша
дообученная модель, нам потребуется строгий способ _оценить_ ее на невидимых данных и измерить достоверность транскрипции. Именно об этом
мы расскажем в следующем разделе! | 5 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter5/evaluation.mdx | # Evaluation metrics for ASR
Если вы знакомы с [расстоянием Левенштейна](https://en.wikipedia.org/wiki/Levenshtein_distance) из NLP то метрики для оценки
систем распознавания речи будут вам знакомы! Не волнуйтесь, если нет, мы рассмотрим объяснения от начала до конца, чтобы
убедиться, что вы знаете различные метрики и понимаете, что они означают.
При оценке систем распознавания речи мы сравниваем предсказания системы с транскрипцией целевого текста, аннотируя все имеющиеся ошибки.
Мы относим эти ошибки к одной из трех категорий:
1. Замены (S - от англ. "Substitutions"): когда мы транскрибируем **неправильное слово** в нашем предсказании ("sit" вместо "sat")
2. Вставки (I - от англ. "Insertions"): когда мы добавляем **дополнительное слово** в наше предсказание
3. Удаления (D - от англ. "Deletions"): когда мы **удаляем слово** в нашем предсказании
Эти категории ошибок одинаковы для всех метрик распознавания речи. Различается лишь уровень, на котором мы вычисляем эти ошибки: мы
можем вычислять их либо на уровне _слова_, либо на уровне _символа_.
Для каждого из определений метрики мы будем использовать свой пример. Ниже мы видим _истину_ или _эталонную_ (_reference_) текстовую последовательность:
```python
reference = "the cat sat on the mat"
```
И предсказанную последовательность от системы распознавания речи, которую мы пытаемся оценить:
```python
prediction = "the cat sit on the"
```
Видно, что предсказание довольно близко, но некоторые слова не совсем верны. Оценим это предсказание в сравнении с эталоном для трех
наиболее популярных метрик распознавания речи и посмотрим, какие цифры мы получим для каждой из них.
## Частота ошибок в словах (Word Error Rate)
Метрика *word error rate (WER)* является "фактической" метрикой для распознавания речи. Она рассчитывает замены, вставки и удаления
на *уровне слова*. Это означает, что ошибки аннотируются на уровне каждого слова. Возьмем наш пример:
| Эталон: | the | cat | sat | on | the | mat |
|-------------|-----|-----|---------|-----|-----|-----|
| Предсказание: | the | cat | **sit** | on | the | | |
| Метка: | ✅ | ✅ | S | ✅ | ✅ | D |
Здесь:
* 1 замена (S) ("sit" вместо "sat")
* 0 вставок
* 1 удаление (D) ("mat" отсутствует)
Это дает 2 ошибки в сумме. Чтобы получить коэффициент ошибок, разделим количество ошибок на общее количество слов в эталонной
последовательности (N), которое для данного примера равно 6:
$$
\begin{aligned}
WER &= \frac{S + I + D}{N} \\
&= \frac{1 + 0 + 1}{6} \\
&= 0.333
\end{aligned}
$$
Отлично! Итак, WER равен 0,333, или 33,3%. Обратите внимание, что в слове "sit" ошибочным является только один символ,
но все слово помечено как неправильное. Это является отличительной особенностью WER: орфографические ошибки сильно штрафуются,
какими бы незначительными они ни были.
WER определяется так: чем меньше WER, тем меньше ошибок в прогнозе, поэтому для идеальной системы распознавания речи WER
был бы равен нулю (отсутствие ошибок).
Рассмотрим, как можно вычислить WER с помощью 🤗 Evaluate. Для вычисления метрики WER нам понадобятся два пакета: 🤗 Evaluate
для интерфейса API и JIWER для выполнения тяжелой работы по вычислению:
```
pip install --upgrade evaluate jiwer
```
Отлично! Теперь мы можем загрузить метрику WER и вычислить показатель для нашего примера:
```python
from evaluate import load
wer_metric = load("wer")
wer = wer_metric.compute(references=[reference], predictions=[prediction])
print(wer)
```
**Print Output:**
```
0.3333333333333333
```
0,33, или 33,3%, как и ожидалось! Теперь мы знаем, как именно производится расчет WER.
А теперь кое-что, что сбивает с толку... Как Вы думаете, какова верхняя граница WER? Вы ожидаете, что он будет равен 1 или
100%, верно? Так как WER - это отношение количества ошибок к количеству слов (N), то верхнего предела для WER не существует!
Возьмем пример, когда мы предсказали 10 слов, а у целевой фразы только 2 слова. Если бы все наши прогнозы оказались неверными
(10 ошибок), то WER был бы равен 10 / 2 = 5, или 500%! Об этом следует помнить, если вы обучаете ASR-систему и видите, что WER
превышает 100%. Хотя если вы видите это, то, скорее всего, что-то пошло не так... 😅
## Точность слов (Word Accuracy)
Мы можем перевернуть WER, чтобы получить метрику, в которой *больше - лучше*. Вместо того чтобы измерять частоту ошибок в словах,
мы можем измерить *точность слов (WAcc)* нашей системы:
$$
\begin{equation}
WAcc = 1 - WER \nonumber
\end{equation}
$$
WAcc также измеряется на уровне слов, просто WER представлен (сформулирован) как метрика точности, а не метрика ошибки. WAcc очень редко
встречается в речевой литературе - мы рассматриваем предсказания нашей системы в терминах ошибок в словах, и поэтому предпочитаем метрики
ошибок, которые больше ассоциируются с этими ошибками.
## Частота ошибок в символах (Character Error Rate)
Кажется немного несправедливым, что мы пометили все слово "sit" ошибочным, когда на самом деле неправильной была только одна буква.
Это объясняется тем, что мы оценивали нашу систему на уровне слов, тем самым аннотируя ошибки пословно (word-by-word). Показатель *частота ошибок
в символах (CER)* оценивает системы на *символьном уровне*. Это означает, что мы разбиваем слова на отдельные символы и аннотируем ошибки по каждому
символу:
| Эталон: | t | h | e | | c | a | t | | s | a | t | | o | n | | t | h | e | | m | a | t |
|-------------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
| Предсказание: | t | h | e | | c | a | t | | s | **i** | t | | o | n | | t | h | e | | | | |
| Метка: | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | S | ✅ | | ✅ | ✅ | | ✅ | ✅ | ✅ | | D | D | D |
Теперь мы видим, что в слове "sit" буквы "s" и "t" отмечены как правильные. И только "i" помечается как ошибка замены символа (S). Таким
образом, мы вознаграждаем нашу систему за частично верное предсказание 🤝.
В нашем примере мы имеем 1 замену символов, 0 вставок и 3 удаления. Всего у нас 14 символов. Таким образом, наш CER имеет вид:
$$
\begin{aligned}
CER &= \frac{S + I + D}{N} \\
&= \frac{1 + 0 + 3}{14} \\
&= 0.286
\end{aligned}
$$
Отлично! Мы получили CER, равный 0,286, или 28,6%. Обратите внимание, что это меньше, чем WER - мы гораздо меньше наказывали
за орфографическую ошибку.
## Какую метрику следует использовать?
В целом для оценки речевых систем WER используется гораздо чаще, чем CER. Это объясняется тем, что WER требует от систем более
глубокого понимания контекста прогнозов. В нашем примере слово "sit" находится в неправильном времени. Система, понимающая связь
между глаголом и временем, в котором употребляется слово, предсказала бы правильное время глагола "sat". Мы хотим поощрять такой
уровень понимания со стороны наших речевых систем. Таким образом, хотя WER менее щадящим, чем CER, он также более благоприятен
для тех видов разборчивых систем, которые мы хотим разработать. Поэтому мы обычно используем WER и рекомендуем вам это делать!
Однако существуют обстоятельства, при которых использование WER невозможно. В некоторых языках, таких как мандаринский (севернокитайский
язык) и японский, понятие "слова" отсутствует, и поэтому WER не имеет смысла. Здесь мы возвращаемся к использованию CER.
В нашем примере при расчете WER мы использовали только одно предложение. При оценке реальной системы мы обычно используем целый
тестовый набор, состоящий из нескольких тысяч предложений. При оценке по нескольким предложениям мы суммируем S, I, D и N по всем
предложениям, а затем вычисляем WER в соответствии с формулой, приведенной выше. Это дает более точную оценку WER для данных,
которые не были использованы ранее.
## Нормализация
Если мы обучим модель ASR на данных с пунктуацией и регистром букв, она научится предсказывать регистр и пунктуацию в своих транскрипциях.
Это отлично работает, когда нам нужно использовать нашу модель для реальных приложений распознавания речи, таких как транскрибирование
совещаний или диктовка, поскольку предсказанные транскрипции будут полностью отформатированы с учетом регистра и пунктуации, стиля,
называемого *орфографическим*.
Однако у нас также есть возможность *нормализовать* набор данных, чтобы убрать регистр и пунктуацию. Нормализация набора данных делает задачу
распознавания речи проще: модели больше не нужно различать символы верхнего и нижнего регистра или предсказывать пунктуацию только на основе
аудиоданных (например, какой звук издает точка с запятой?). Из-за этого показатели ошибки слов снижаются естественным образом (что означает,
что результаты лучше). В статье о модели Whisper продемонстрировано радикальное воздействие нормализации транскрипций на результаты WER
(см. раздел 4.4 в [статье Whisper](https://cdn.openai.com/papers/whisper.pdf)). Несмотря на более низкие показатели WER, модель не обязательно
становится лучше для промышленного использования. Отсутствие регистра и пунктуации делает предсказанный текст от модели значительно труднее
для чтения. Возьмем пример из [предыдущего раздела](asr_models), где мы применили модели Wav2Vec2 и Whisper к одному и тому же аудиофрагменту
из набора данных LibriSpeech. Модель Wav2Vec2 не предсказывает ни пунктуацию, ни регистр, в то время как Whisper предсказывает оба эти элемента.
Сравнив транскрипции рядом, мы видим, что транскрипция Whisper гораздо проще для чтения:
```
Wav2Vec2: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Whisper: He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.
```
Транскрипция Whisper с соблюдением орфографии и, следовательно, готова к использованию - она отформатирована так, как мы ожидаем для транскрипции совещания
или диктовки, с пунктуацией и регистром букв. Напротив, для восстановления пунктуации и регистра в наших предсказаниях Wav2Vec2 нам потребуется
дополнительная постобработка, если мы хотим использовать их в дальнейшем при разработке приложений.
Существует золотая середина между нормализацией и отсутствием нормализации: мы можем обучать наши системы на орфографических транскрипциях,
а затем нормализовать предсказания и целевые метки перед вычислением WER. Таким образом, мы обучаем наши системы предсказывать полностью
отформатированный текст, но также получаем выгоду от улучшений WER, которые мы получаем, нормализуя транскрипции.
Модель Whisper была выпущена с нормализатором, который эффективно обрабатывает нормализацию регистра, пунктуации и форматирования чисел, среди
прочего. Давайте применим нормализатор к транскрипциям Whisper, чтобы продемонстрировать, как мы можем их нормализовать:
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
prediction = " He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind."
normalized_prediction = normalizer(prediction)
normalized_prediction
```
**Output:**
```
' he tells us that at this festive season of the year with christmas and roast beef looming before us similarly is drawn from eating and its results occur most readily to the mind '
```
Отлично! Мы видим, что текст был полностью приведен к нижнему регистру и удалена вся пунктуация. Теперь давайте определим эталонную транскрипцию
и затем вычислим нормализованный WER между эталоном и предсказанием:
```python
reference = "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"
normalized_referece = normalizer(reference)
wer = wer_metric.compute(
references=[normalized_referece], predictions=[normalized_prediction]
)
wer
```
**Output:**
```
0.0625
```
6,25% - это примерно то, что мы ожидаем для базовой модели Whisper на наборе данных LibriSpeech для валидационной выборки. Как мы видим здесь, мы
предсказали орфографическую транскрипцию, но в то же время получили улучшение WER, полученное благодаря нормализации эталона и предсказания
перед вычислением WER.
Выбор способа нормализации транскрипций в конечном итоге зависит от ваших потребностей. Мы рекомендуем обучать модель на орфографическом тексте
и оценивать на нормализованном тексте, чтобы получить лучшее из обоих приемов.
### Собираем все воедино
Хорошо! Мы рассмотрели три темы в этом разделе: предварительно обученные модели, выбор набора данных и оценку. Давайте весело проведем время и
объединим их в одном примере end-to-end 🚀 Мы будем готовиться к следующему разделу по настройке модели путем оценки предварительно обученной
модели Whisper на тестовом наборе данных Common Voice 13 на Дивехи. Мы используем полученное число WER как _baseline_ для нашего процесса дообучения
или как целевое значение, которое мы постараемся превзойти 🥊.
Сначала мы загрузим предварительно обученную модель Whisper с помощью `pipeline()`. Этот процесс вам уже должен быть крайне знаком!
Единственное новое, что мы сделаем - это загрузим модель с использованием половинной точности (float16), если запускаем на GPU.
Это ускорит вывод, почти не влияя на точность WER.
```python
from transformers import pipeline
import torch
if torch.cuda.is_available():
device = "cuda:0"
torch_dtype = torch.float16
else:
device = "cpu"
torch_dtype = torch.float32
pipe = pipeline(
"automatic-speech-recognition",
model="openai/whisper-small",
torch_dtype=torch_dtype,
device=device,
)
```
Затем мы загрузим тестовую часть Дивехи из набора данных Common Voice 13. Вы помните из предыдущего раздела, что Common Voice 13 является
ограниченным, что означает, что мы должны согласиться с условиями использования набора данных, прежде чем получить доступ к нему. Теперь
мы можем связать нашу учетную запись Hugging Face с нашим блокнотом, чтобы получить доступ к набору данных с машины, которую мы сейчас используем.
Связать блокнот с Hugging Face Hub очень просто - это требует ввода вашего токена аутентификации, когда вас попросят. Найдите ваш токен аутентификации
Hugging Face Hub [здесь](https://huggingface.co/settings/tokens) и введите его, когда вас попросят:
```python
from huggingface_hub import notebook_login
notebook_login()
```
Отлично! После того как мы свяжем блокнот с нашей учетной записью Hugging Face, мы можем продолжить с загрузкой набора данных Common Voice.
Это займет несколько минут на загрузку и предварительную обработку, данные будут получены с Hub Hugging Face и подготовлены автоматически
в вашем блокноте:
```python
from datasets import load_dataset
common_voice_test = load_dataset(
"mozilla-foundation/common_voice_13_0", "dv", split="test"
)
```
<Tip>
Если вы столкнетесь с проблемой аутентификации при загрузке набора данных, убедитесь, что вы приняли условия использования набора данных на
Hub Hugging Face по следующей ссылке: https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0
</Tip>
Оценка по всему набору данных может быть выполнена так же, как и для одного примера - все, что нам нужно сделать, это **циклически** пройти по
входным аудиофайлам, вместо вывода только одного образца. Для этого мы сначала преобразуем наш набор данных в `KeyDataset`. При этом выбирается
определенный столбец набора данных, который мы хотим передать модели (в нашем случае это столбец `"audio"`), игнорируя остальные (например,
целевые транскрипции, которые мы не хотим использовать для вывода). Затем мы перебираем этот преобразованный набор данных, добавляя выходы
модели в список для сохранения предсказаний. Этот блок кода будет выполняться около пяти минут при использовании GPU с половинной точностью
и максимальной памятью 12 ГБ:
```python
from tqdm import tqdm
from transformers.pipelines.pt_utils import KeyDataset
all_predictions = []
# run streamed inference
for prediction in tqdm(
pipe(
KeyDataset(common_voice_test, "audio"),
max_new_tokens=128,
generate_kwargs={"task": "transcribe"},
batch_size=32,
),
total=len(common_voice_test),
):
all_predictions.append(prediction["text"])
```
<Tip>
Если вы столкнетесь с ошибкой "Out-of-Memory" (OOM) CUDA при выполнении вышеуказанной ячейки, уменьшайте размер пакета (`batch_size`)
последовательно вдвое, пока не найдете такой размер пакета, который подходит для вашего устройства.
</Tip>
И, наконец, мы можем вычислить WER. Давайте сначала вычислим орфографический WER, то есть WER без какой-либо дополнительной обработки:
```python
from evaluate import load
wer_metric = load("wer")
wer_ortho = 100 * wer_metric.compute(
references=common_voice_test["sentence"], predictions=all_predictions
)
wer_ortho
```
**Output:**
```
167.29577268612022
```
Ладно... 167% в основном означает, что наша модель выдает мусор 😜 Не беспокойтесь, нашей целью будет улучшить это путем настройки
модели на обучающем выборке Дивехи!
Затем мы оценим нормализованный WER, то есть WER с постобработкой в части нормализации. Нам придется исключить выборки, которые были бы пустыми
после нормализации, так как в противном случае общее количество слов в нашем эталоне (N) будет равно нулю, что вызовет ошибку деления на ноль в
нашем вычислении:
```python
from transformers.models.whisper.english_normalizer import BasicTextNormalizer
normalizer = BasicTextNormalizer()
# compute normalised WER
all_predictions_norm = [normalizer(pred) for pred in all_predictions]
all_references_norm = [normalizer(label) for label in common_voice_test["sentence"]]
# filtering step to only evaluate the samples that correspond to non-zero references
all_predictions_norm = [
all_predictions_norm[i]
for i in range(len(all_predictions_norm))
if len(all_references_norm[i]) > 0
]
all_references_norm = [
all_references_norm[i]
for i in range(len(all_references_norm))
if len(all_references_norm[i]) > 0
]
wer = 100 * wer_metric.compute(
references=all_references_norm, predictions=all_predictions_norm
)
wer
```
**Output:**
```
125.69809089960707
```
Снова мы видим резкое снижение WER при нормализации наших эталонов и предсказаний: базовая модель достигает орфографического
тестового WER 168%, в то время как нормализованный WER составляет 126%.
Итак, именно эти показатели мы хотим превзойти, когда будем дообучать модель, чтобы улучшить модель Whisper для распознавания речи для Дивехи.
Продолжайте чтение, чтобы получить практический опыт с примером дообучения модели 🚀. | 6 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter5/supplemental_reading.mdx | # Дополнительные материалы и ресурсы
Этот раздел предоставил практическое введение в распознавание речи, одну из самых популярных задач в области аудио.
Хотите узнать больше? Здесь вы найдете дополнительные ресурсы, которые помогут вам углубить свое понимание темы и повысить качество обучения.
* [Whisper Talk](https://www.youtube.com/live/fZMiD8sDzzg?feature=share) by Jong Wook Kim: презентация о модели Whisper, в которой объясняются мотивация, архитектура, обучение и результаты, представленные автором Whisper - Джонг Вук Кимом.
* [End-to-End Speech Benchmark (ESB)](https://arxiv.org/abs/2210.13352): научная статья, в которой обосновывается использование орфографического WER вместо нормализованного WER для оценки систем распознавания речи и представляется соответствующий бенчмарк.
* [Fine-Tuning Whisper for Multilingual ASR](https://huggingface.co/blog/fine-tune-whisper): подробный блог-пост, который объясняет, как работает модель Whisper, и подробно описывает пред- и пост-обработку с использованием извлекателя призников и токенизатора.
* [Fine-tuning MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters): полное руководство по дообучению новых многоязычных моделей распознавания речи Meta AI [MMS](https://ai.facebook.com/blog/multilingual-model-speech-recognition/), при этом замораживая веса базовой модели и обучая только небольшое количество *адаптерных* слоев.
* [Boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram): блог-пост о сочетании моделей CTC с внешними языковыми моделями (LM) для борьбы со смысловыми и пунктуационными ошибками. | 7 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter5/asr_models.mdx | # Предварительно обученные модели для распознавания речи
В этом разделе мы рассмотрим, как с помощью `pipeline()` использовать предварительно обученные модели для распознавания речи.
В [Разделе 2](../chapter2/asr_pipeline) мы представили `pipeline()` как простой способ выполнения задач распознавания речи с предварительной
и последующей обработкой "под капотом" и возможностью быстро экспериментировать с любой предварительно обученной контрольной точкой модели на Hugging Face Hub.
В этом разделе мы углубимся в изучение различных характеристик моделей распознавания речи и рассмотрим, как их можно использовать для решения различных задач.
Как подробно описано в Разделе 3, модели распознавания речи в целом относятся к одной из двух категорий:
1. Connectionist Temporal Classification (CTC) или Коннекционистская Временная Классификация: модели состящие только из энкодера, с головой линейного классификатора в вершине модели.
2. Sequence-to-sequence (Seq2Seq) или последовательность-в-последовательность: модели включающие в себя как энкодер, так и декодер с механизмом перекрестного внимания между ними (cross-attention).
До 2022 года более популярной из двух архитектур была CTC, а такие модели, работающие только с энкодером, как Wav2Vec2, HuBERT и XLSR, совершили прорыв в парадигме
предварительного обучения/дообучения в задачах с речью. Крупные корпорации, такие как Meta и Microsoft, предварительно обучали энкодер на огромных объемах
неразмеченных аудиоданных в течение многих дней или недель. Затем пользователи могли взять предварительно обученную контрольную точку и дообучить ее с помощью
головы CTC всего на **10 минутах** размеченных речевых данных для достижения высоких результатов в последующей задаче распознавания речи.
Однако модели CTC имеют свои недостатки. Присоединение простого линейного слоя к кодирующему устройству дает небольшую и быструю модель в целом, но она может
быть подвержена фонетическим ошибкам в написании. Ниже мы продемонстрируем это на примере модели Wav2Vec2.
## Анализ моделей CTC
Загрузим небольшой фрагмент набора данных [LibriSpeech ASR](hf-internal-testing/librispeech_asr_dummy) чтобы продемонстрировать возможности Wav2Vec2
по транскрибации речи:
```python
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
dataset
```
**Output:**
```
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})
```
Мы можем выбрать один из 73 аудиообразцов и просмотреть его, а также транскрипцию:
```python
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Output:**
```
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
Хорошо! Рождество и запеченная в духовке говядина, звучит здорово! 🎄 Сформировав выборку данных, мы теперь загружаем
дообученную контрольную точку в `pipeline()`. Для этого мы будем использовать официальную контрольную точку [Wav2Vec2 base](facebook/wav2vec2-base-100h)
дообученную на 100 часах данных LibriSpeech:
```python
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")
```
Далее мы возьмем пример из набора данных и передадим его исходные данные в конвейер. Поскольку `pipeline` *поглощает* любой словарь, который мы ему
передаем (то есть его нельзя использовать повторно), мы будем передавать копию данных. Таким образом, мы можем безопасно повторно использовать один
и тот же аудиообразец в следующих примерах:
```python
pipe(sample["audio"].copy())
```
**Output:**
```
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}
```
Видно, что модель Wav2Vec2 неплохо справляется с транскрибацией данного образца - на первый взгляд, все выглядит в целом корректно.
Давайте поставим целевое значение (target) и прогноз/предсказание модели (prediction) рядом и выделим различия:
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
```
Сравнивая целевой текст с предсказанной транскрибацией, мы видим, что все слова _звучат_ правильно, но некоторые написаны не совсем точно. Например:
* _CHRISTMAUS_ vs. _CHRISTMAS_
* _ROSE_ vs. _ROAST_
* _SIMALYIS_ vs. _SIMILES_
Это подчеркивает недостаток модели CTC. Модель CTC - это, по сути, "только акустическая" модель: она состоит из энкодера, который формирует представления
скрытых состояний из аудиовходов, и линейного слоя, который отображает скрытые состояния в символы:
<!--- Need U3 to be merged before this figure is available:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/wav2vec2-ctc.png" alt="Transformer encoder with a CTC head on top">
</div>
--->
Это означает, что система практически полностью основывает свое предсказание на акустических данных (фонетических звуках аудиозаписи) и поэтому склонна
транскрибировать аудиозапись фонетическим способом (например, _CHRISTMAUS_). В нем меньше внимания уделяется языковому моделирующему контексту предыдущих
и последующих букв, поэтому он склонен к фонетическим ошибкам в написании. Более интеллектуальная модель определила бы, что _CHRISTMAUS_ не является
правильным словом в английском словаре, и исправила бы его на _CHRISTMAS_, когда делала бы свои предсказания. Кроме того, в нашем прогнозировании отсутствуют
два важных признака - регистр и пунктуация, что ограничивает полезность транскрибации модели для реальных приложений.
## Переход к Seq2Seq
Модели Seq2Seq! Как было описано в Разделе 3, модели Seq2Seq состоят из энкодера и декодера, связанных между собой механизмом перекрестного внимания.
Энкодер играет ту же роль, что и раньше, вычисляя представления скрытых состояний аудиовходов, а декодер - роль **языковой модели**. Декодер обрабатывает
всю последовательность представлений скрытых состояний, полученных от энкодера, и формирует соответствующие текстовые транскрипции. Имея глобальный контекст
входного аудиосигнала, декодер может использовать контекст языкового моделирования при составлении своих прогнозов, исправляя орфографические ошибки
"на лету" и тем самым обходя проблему фонетических прогнозов.
У моделей Seq2Seq есть два недостатка:
1. Они изначально медленнее декодируют, поскольку процесс декодирования происходит по одному шагу за раз, а не все сразу
2. Они более требовательны к данным, для достижения сходимости им требуется значительно больше обучающих данных
В частности, узким местом в развитии архитектур Seq2Seq для задач с речью является потребность в больших объемах обучающих данных. Размеченные речевые данные
труднодоступны, самые большие аннотированные базы данных на тот момент составляли всего 10 000 часов. Все изменилось в 2022 году после выхода **Whisper**.
Whisper - это предварительно обученная модель для распознавания речи, опубликованная в [Сентябре 2022](https://openai.com/blog/whisper/) авторами Alec Radford
и др. из компании OpenAI. В отличие от предшественников CTC, которые обучались исключительно на **неразмеченных** аудиоданных, Whisper предварительно обучен
на огромном количестве **размеченных** данных аудиотранскрипции, а именно на 680 000 часов.
Это на порядок больше данных, чем неразмеченные аудиоданные, использованные для обучения Wav2Vec 2.0 (60 000 часов). Более того, 117 000 часов этих данных,
предназначенных для предварительного обучения, являются мультиязычными (или "не английскими") данными. В результате контрольные точки могут быть применены
к более чем 96 языкам, многие из которых считаются _низкоресурсными_, т.е. не имеющими большого корпуса данных, пригодных для обучения.
При масштабировании на 680 000 часов аннотированных данных для предварительного обучения модели Whisper демонстрируют высокую способность к обобщению
на многие наборы данных и области. Предварительно обученные контрольные точки достигают результатов, конкурентоспособных с state-of-the-art pipe systems,
с коэффициентом ошибок в словах (WER) около 3% на подмножестве чистых тестов LibriSpeech и новым рекордом на TED-LIUM с WER 4,7%
(см. табл. 8 [Whisper paper](https://cdn.openai.com/papers/whisper.pdf)).
Особое значение имеет способность Whisper работать с длинными аудиообразцами, устойчивость к входным шумам и возможность предсказывать транскрипцию с
использованием падежей и пунктуации. Это делает его перспективным для использования в реальных системах распознавания речи.
В оставшейся части этого раздела будет показано, как использовать предварительно обученные модели Whisper для распознавания речи с помощью 🤗 Transformers.
Во многих ситуациях предварительно обученные контрольные точки Whisper обладают высокой производительностью и дают отличные результаты, поэтому мы
рекомендуем вам попробовать использовать предварительно обученные контрольные точки в качестве первого шага к решению любой задачи распознавания речи.
Благодаря дообучению предварительно обученные контрольные точки могут быть адаптированы для конкретных наборов данных и языков с целью дальнейшего
улучшения результатов. Как это сделать, мы продемонстрируем в следующем подразделе, посвященном [дообучению] (fine-tuning).
Контрольные точки модели Whisper доступны в пяти конфигурациях с различными размерами модели. Наименьшие по параметрам четыре модели обучаются либо
только на английском, либо на многоязычных данных. Самая большая по параметрам контрольная точка была обучена только на мультиязычных данных.
Все девять предварительно обученных контрольных точек доступны на [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). Контрольные
точки приведены в следующей таблице со ссылками на модели на Hugging Face Hub. "VRAM" обозначает объем памяти GPU, необходимый для работы модели с
минимальным размером пакета = 1. "Rel Speed" - относительная скорость контрольной точки по сравнению с самой большой моделью. На основе этой информации
можно выбрать контрольную точку, наиболее подходящую для вашего оборудования.
| Size | Parameters | VRAM / GB | Rel Speed | English-only | Multilingual |
|--------|------------|-----------|-----------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | 1.4 | 32 | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | 1.5 | 16 | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | 2.3 | 6 | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | 4.2 | 2 | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | 7.5 | 1 | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
Загрузим контрольную точку [Whisper Base](https://huggingface.co/openai/whisper-base), которая по размеру сопоставима с контрольной точкой Wav2Vec2, которую
мы использовали ранее. Предваряя наш переход к многоязычному распознаванию речи, загрузим многоязычный вариант базовой контрольной точки. Мы также загрузим
модель на GPU, если он доступен, или на CPU в противном случае. В последствии `pipeline()` позаботится о перемещении всех входов/выходов с CPU на GPU по мере
необходимости:
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
Отлично! Теперь давайте транскрибируем аудиозапись, как и раньше. Единственное изменение - это передача дополнительного аргумента `max_new_tokens`, который
указывает модели максимальное количество токенов, которые нужно генерировать при предсказании:
```python
pipe(sample["audio"], max_new_tokens=256)
```
**Output:**
```
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}
```
Достаточно легко! Первое, на что вы обратите внимание, - это наличие как регистра, так и знаков препинания. Это сразу же делает транскрипцию более удобной для
чтения по сравнению с транскрипцией из Wav2Vec2, не содержащей ни регистра, ни пунктуации. Давайте поместим транскрипцию рядом с целевой меткой:
```
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.
```
Whisper проделал большую работу по исправлению фонетических ошибок, которые мы видели в Wav2Vec2 - и _Christmas_, и _roast_ написаны правильно.
Мы видим, что модель все еще испытывает трудности с _SIMILES_, которое неправильно транскрибируется как _similarly_, но на этот раз предсказание
является правильным словом из английского словаря. Использование контрольной точки Whisper большего размера позволяет еще больше снизить количество
ошибок в транскрибированном тексте, но при этом требует больше вычислений и увеличивает время транскрибации.
Нам обещали модель, способную работать с 96 языками, так что оставим пока распознавание английской речи и пойдем по миру 🌎! Набор данных [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech)
(MLS) представляет собой многоязычный аналог набора данных LibriSpeech, содержащий размеченные аудиоданные на шести языках. Мы загрузим одну
образец из испанской части набора данных MLS, используя режим _streaming_, чтобы не загружать весь набор данных:
```python
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))
```
Снова посмотрим текстовую транскрипцию и прослушаем аудиофрагмент:
```python
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
**Output:**
```
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha hablado
```
Это целевой текст, на который мы ориентируемся в нашей транскрипции Whisper. Хотя теперь мы знаем, что, вероятно, можем сделать это лучше,
поскольку наша модель будет предсказывать также пунктуацию и регистр, которые в выводе примера отсутствуют. Передадим образец звука в конвейер для
получения предсказания текста. Следует отметить, что конвейер _потребует_ словарь аудиовходов, который мы вводим, то есть словарь не может
быть использован повторно. Чтобы обойти эту проблему, мы будем передавать _копию_ аудиообразца, что позволит нам повторно использовать тот же самый
аудиообразец в последующих примерах кода:
```python
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})
```
**Output:**
```
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}
```
Отлично - это очень похоже на наш целевой текст (возможно, даже лучше, поскольку в нем есть пунктуация и регистр!). Обратите внимание, что мы передали
`"task"` в качестве аргумента _генерируемого ключевого слова_ (generate kwarg). Передача ключу `"task"` значения `"transcribe"` заставляет Whisper
выполнять задачу _распознавания речи_, при которой аудиозапись транскрибируется на том же языке, на котором была произнесена речь. Whisper также
способен выполнять тесно связанную с задачу - _перевода речи_, когда аудиозапись на испанском языке может быть переведена в текст на английском.
Для этого мы передаем ключу `"task"` значение `"translate"`:
```python
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})
```
**Output:**
```
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}
```
Теперь, когда мы знаем, что можем переключаться между распознаванием речи и ее переводом, мы можем выбирать задачу в зависимости от наших потребностей.
Либо мы распознаем звук на языке X в текст на том же языке X (например, испанский звук в испанский текст), либо переводим с любого языка X в текст
на английском языке (например, испанский звук в английский текст).
Подробнее о том, как аргумент `"task"` используется для управления свойствами генерируемого текста, см. в [карточке модели](https://huggingface.co/openai/whisper-base#usage)
для базовой модели Whisper.
## Длинноформатная транскрипция и временные метки
Пока мы были сосредоточены на транскрибации коротких аудиофрагментов длительностью менее 30 секунд. Мы уже упоминали, что одной из привлекательных
сторон Whisper является возможность работы с длинными аудиофрагментами. В этой части раздела мы рассмотрим эту задачу!
Создадим длинный аудиофайл путем конкатенации последовательных выборок из набора данных MLS. Поскольку набор данных MLS формируется путем разбиения
длинных записей аудиокниг на более короткие сегменты, конкатенация образцов является одним из способов реконструкции более длинных отрывков аудиокниг.
Следовательно, результирующий звук должен быть когерентным по всей выборке.
Мы установим целевую длительность звука в 5 минут и прекратим конкатенацию сэмплов, как только достигнем этого значения:
```python
import numpy as np
target_length_in_m = 5
# преобразование из минут в секунды (* 60) в число выборок (* частота дискретизации)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# итерируемся по нашему потоковому набору данных, конкатенируя выборки до тех пор, пока мы не достигнем нашей цели
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# что у нас получилось?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")
```
**Output:**
```
Length of audio sample is 5.0 minutes 17.22 seconds
```
Отлично! Осталось транскрибировать 5 минут 17 секунд аудиозаписи. При передаче такого длинного аудиофрагмента непосредственно в модель
возникают две проблемы:
1. Whisper изначально рассчитан на работу с 30-секундными образцами: все, что короче 30 секунд, заполняется тишиной, все, что длиннее 30 секунд, усекается до 30 секунд путем вырезания лишнего звука, поэтому если мы передадим наш звук напрямую, то получим транскрипцию только первых 30 секунд
2. Память в сети трансформера зависит от квадрата длины последовательности: удвоение длины входного сигнала увеличивает потребность в памяти в четыре раза, поэтому передача очень длинных аудиофайлов обязательно приведет к ошибке "вне памяти" (out-of-memory)
Длинная транскрибация в 🤗 Transformers осуществляется путем _фрагментации_ (от англ. chunking) входного аудио на более мелкие и управляемые фрагменты.
Каждый фрагмент имеет небольшое наложение с предыдущим. Это позволяет нам точно соединять фрагменты на границах,
так как мы можем найти наложение между фрагментами и соответствующим образом объединить транскрипции:
<div class="flex justify-center">
<img src="https://huggingface.co/blog/assets/49_asr_chunking/Striding.png" alt="🤗 Transformers chunking algorithm. Source: https://huggingface.co/blog/asr-chunking.">
</div>
Преимущество фрагментирования аудиообразцов на части заключается в том, что нам не нужен результат транскрибации небольшого фрагмента аудиосигнала \\( i \\)
для транскрибации последующего фрагмента \\( i + 1 \\). Соединение выполняется после того, как мы
транскрибировали все фрагменты на границах фрагментов, поэтому не имеет значения, в каком порядке мы их транскрибируем. Алгоритм полностью **нестационарный**,
поэтому мы можем даже обрабатывать фрагмент \\( i + 1 \\) одновременно с фрагментом \\( i \\)! Это позволяет нам _пакетировать_ (от англ. batch) фрагменты
и прогонять их через модель параллельно, обеспечивая значительное ускорение вычислений по сравнению с их последовательной транскрибацией. Более подробно
о фрагментированни в 🤗 Transformers можно прочитать в [посте из блога](https://huggingface.co/blog/asr-chunking).
Для активации длинных транскрипций необходимо добавить один дополнительный аргумент при вызове конвейера. Этот аргумент, `chunk_length_s`,
определяет длину фрагментов в секундах. Для Whisper оптимальной является 30-секундная длина фрагментов, поскольку она соответствует длине
входного сигнала, ожидаемого Whisper.
Чтобы активизировать пакетную обработку, необходимо передать конвейеру аргумент `batch_size`. Если собрать все это воедино,
то транскрибация длинного аудиообразца с использованием чанкинга и батчинга может быть выполнена следующим образом:
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)
```
**Output:**
```
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...
```
Мы не будем приводить здесь весь результат, поскольку он довольно длинный (всего 312 слов)! На графическом процессоре V100
с памятью 16 Гбайт выполнение приведенной выше строки займет примерно 3,45 секунды, что весьма неплохо для 317-секундного аудиообразца.
На CPU ожидается около 30 секунд.
Whisper также способен предсказывать _временные метки_ на уровне фрагментов для аудиоданных. Эти временные метки указывают на время начала
и окончания короткого отрывка аудиозаписи и особенно полезны для выравнивания транскрипции с входным аудиосигналом. Предположим, мы хотим
создать субтитры для видео - нам нужны эти временные метки, чтобы знать, какая часть транскрипции соответствует определенному
сегменту видео, чтобы отобразить правильную транскрипцию для этого времени.
Активировать предсказание временных меток очень просто, достаточно установить аргумент `return_timestamps=True`. Временные метки совместимы
с методами фрагментирования и пакетирования, которые мы использовали ранее, поэтому мы можем просто добавить аргумент timestamp к нашему
предыдущему вызову:
```python
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]
```
**Output:**
```
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...
```
И вуаля! У нас есть предсказанный текст и соответствующие временные метки.
## Итоги
Whisper - это сильная предварительно обученная модель для распознавания и перевода речи. По сравнению с Wav2Vec2, он обладает более
высокой точностью транскрибации, при этом выходные данные содержат знаки препинания и регистр. Он может использоваться для транскрибации
речи на английском и 96 других языках, как на коротких аудиофрагментах, так и на более длинных за счет _фрагментирования_. Эти качества делают
его подходящей моделью для многих задач распознавания речи и перевода без необходимости дообучения. Метод `pipeline()` обеспечивает простой
способ выполнения выводов в виде однострочных вызовов API с контролем над генерируемыми предсказаниями.
В то время как модель Whisper демонстрирует отличные результаты на многих языках с большим количеством ресурсов, она имеет более низкую
точность транскрибации и перевода на языках с малым количеством ресурсов, т.е. на языках с меньшим количеством доступных обучающих данных.
Кроме того, существуют различия в результатах работы с разными акцентами и диалектами некоторых языков, включая более низкую точность для
носителей разных полов, рас, возрастов и других демографических критериев (например, [Whisper paper](https://arxiv.org/pdf/2212.04356.pdf)).
Для повышения производительности при работе с языками, акцентами или диалектами, не имеющими достаточного количества ресурсов, мы можем взять
предварительно обученную модель Whisper и обучить ее на небольшом корпусе данных, подобранных соответствующим образом, в процессе,
называемом _дообучением_. Мы покажем, что всего десять часов дополнительных данных позволяют повысить производительность модели Whisper более
чем на 100% на языке с низким уровнем ресурсов. В следующей секции мы рассмотрим процесс выбора набора данных для дообучения модели.
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter5/demo.mdx | # Создание Демо с Gradio
Теперь, когда мы настроили модель Whisper для распознавания речи на Дивехи, давайте продолжим и создадим демо с использованием [Gradio](https://gradio.app),
чтобы показать ее сообществу!
Первое, что нам нужно сделать, это загрузить дообученную модель, используя класс `pipeline()` - это уже знакомо из раздела о [предварительно обученных моделях](asr_models).
Вы можете заменить идентификатор модели (`model_id`) на пространство имен вашей дообученной модели на Hugging Face Hub, или на одну из
предобученных [моделей Whisper](https://huggingface.co/models?sort=downloads&search=openai%2Fwhisper-) для выполнения распознавания речи без настройки (zero-shot):
```python
from transformers import pipeline
model_id = "sanchit-gandhi/whisper-small-dv" # update with your model id
pipe = pipeline("automatic-speech-recognition", model=model_id)
```
Во-вторых, мы определим функцию, которая принимает путь к аудиофайлу в качестве входных данных и передает его через конвейер (`pipeline`).
Здесь конвейер автоматически заботится о загрузке аудиофайла, пересэмплировании его до правильной частоты дискретизации и выполнении вывода модели.
Затем мы просто вернем преобразованный текст в качестве выходных данных функции. Чтобы обеспечить возможность нашей модели обрабатывать аудиофайлы
произвольной длины, мы включим *фрагментирование* (разбиение на фрагменты), как описано в разделе о [предварительно обученных моделях](asr_models):
```python
def transcribe_speech(filepath):
output = pipe(
filepath,
max_new_tokens=256,
generate_kwargs={
"task": "transcribe",
"language": "sinhalese",
}, # update with the language you've fine-tuned on
chunk_length_s=30,
batch_size=8,
)
return output["text"]
```
Мы будем использовать функцию [blocks](https://gradio.app/docs/#blocks) в Gradio, чтобы создать две вкладки в нашем демо: одну
для транскрипции с микрофона и другую для загрузки файла.
```python
import gradio as gr
demo = gr.Blocks()
mic_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.outputs.Textbox(),
)
file_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.outputs.Textbox(),
)
```
Наконец, мы запускаем демонстрацию Gradio, используя два только что определенных блока:
```python
with demo:
gr.TabbedInterface(
[mic_transcribe, file_transcribe],
["Transcribe Microphone", "Transcribe Audio File"],
)
demo.launch(debug=True)
```
Это запустит демонстрацию Gradio, подобную той, которая работает на пространстве Hugging Face:
<iframe src="https://course-demos-whisper-small.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Если вы хотите разместить своё демо на платформе Hugging Face Hub, вы можете использовать этот Space в качестве шаблона для своей модели.
Для этого выполните следующие шаги:
Щелкните по ссылке, чтобы дублировать шаблон демо в свою учетную запись: https://huggingface.co/spaces/course-demos/whisper-small?duplicate=true
Рекомендуем дать своему Space имя, подобное имени вашей обученной модели (например, whisper-small-dv-demo) и установить видимость на "Public" (Публичный).
После дублирования Space в вашей учетной записи перейдите в раздел "Files and versions" -> "app.py" -> "edit". Затем измените идентификатор модели
на идентификатор вашей обученной модели(строка 6). Прокрутите страницу вниз и нажмите "Commit changes to main" (Зафиксировать изменения в главной версии).
Демо перезагрузится, используя вашу обученную модель. Теперь вы можете поделиться этим демо со своими друзьями и родственниками, чтобы они могли использовать
модель, которую вы обучили!
Вы можете посмотреть наш видеоурок, чтобы лучше понять, как продублировать Space: [YouTube Video](https://www.youtube.com/watch?v=VQYuvl6-9VE)
Ожидаем с нетерпением увидеть ваши демо на Hugging Face Hub! | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.