
prompt
stringlengths 501
4.98M
| target
stringclasses 1
value | chunk_prompt
bool 1
class | kind
stringclasses 2
values | prob
float64 0.2
0.97
⌀ | path
stringlengths 10
394
⌀ | quality_prob
float64 0.4
0.99
⌀ | learning_prob
float64 0.15
1
⌀ | filename
stringlengths 4
221
⌀ |
|---|---|---|---|---|---|---|---|---|
Corrigir versao de scipy para Inception
```
pip install scipy==1.3.3
```
Importar bibliotecas
```
from __future__ import division, print_function
from torchvision import datasets, models, transforms
import copy
import matplotlib.pyplot as plt
import numpy as np
import os
import shutil
import time
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import zipfile
```
Montar Google Drive
```
from google.colab import drive
drive.mount('/content/drive')
```
Definir constantes
```
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
ZIP_FILE_PATH = './dataset.zip'
DATASET_PATH = './dataset'
INCEPTION = 'inception'
VGG19 = 'vgg-19'
MODEL = INCEPTION # Define o tipo de modelo a ser usado.
IMG_SIZE = {
INCEPTION: 299,
VGG19: 224,
}[MODEL]
NORMALIZE_MEAN = [0.485, 0.456, 0.406]
NORMALIZE_STD = [0.229, 0.224, 0.225]
BATCH_SIZE = 4
NUM_WORKERS = 4
TRAIN = 'train'
VAL = 'val'
TEST = 'test'
PHASES = {
TRAIN: 'train',
VAL: 'val',
TEST: 'test',
}
print(DEVICE)
```
Limpar diretorio do dataset
```
shutil.rmtree(DATASET_PATH)
```
Extrair dataset
```
zip_file = zipfile.ZipFile(ZIP_FILE_PATH)
zip_file.extractall()
zip_file.close()
```
Carregar dataset
```
# Augmentacao de dados para treinamento,
# apenas normalizacao para validacao e teste.
data_transforms = {
TRAIN: transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),
]),
VAL: transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),
]),
TEST: transforms.Compose([
transforms.Resize(IMG_SIZE),
transforms.ToTensor(),
transforms.Normalize(NORMALIZE_MEAN, NORMALIZE_STD),
]),
}
data_sets = {
phase: datasets.ImageFolder(
os.path.join(DATASET_PATH, PHASES[phase]),
data_transforms[phase],
) for phase in PHASES
}
data_loaders = {
phase: torch.utils.data.DataLoader(
data_sets[phase],
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = NUM_WORKERS,
) for phase in PHASES
}
data_sizes = {
phase: len(data_sets[phase]) for phase in PHASES
}
class_names = data_sets[TRAIN].classes
print(data_sets)
print(data_loaders)
print(data_sizes)
print(class_names)
```
Helper functions
```
# Exibe uma imagem a partir de um Tensor.
def imshow(data):
mean = np.array(NORMALIZE_MEAN)
std = np.array(NORMALIZE_STD)
image = data.numpy().transpose((1, 2, 0))
image = std * image + mean
image = np.clip(image, 0, 1)
plt.imshow(image)
# Treina o modelo e retorna o modelo treinado.
def train_model(model_type, model, optimizer, criterion, num_epochs = 25):
start_time = time.time()
num_epochs_without_improvement = 0
best_acc = 0.0
best_model = copy.deepcopy(model.state_dict())
torch.save(best_model, 'model.pth')
for epoch in range(num_epochs):
print('Epoch {}/{} ...'.format(epoch + 1, num_epochs))
for phase in PHASES:
if phase == TRAIN:
model.train()
elif phase == VAL:
model.eval()
else:
continue
running_loss = 0.0
running_corrects = 0
for data, labels in data_loaders[phase]:
data = data.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == TRAIN):
outputs = model(data)
if phase == TRAIN and model_type == INCEPTION:
outputs = outputs.logits
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == TRAIN:
loss.backward()
optimizer.step()
running_loss += loss.item() * data.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / data_sizes[phase]
epoch_acc = running_corrects.double() / data_sizes[phase]
print('{} => Loss: {:.4f}, Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == VAL:
if epoch_acc > best_acc:
num_epochs_without_improvement = 0
best_acc = epoch_acc
best_model = copy.deepcopy(model.state_dict())
torch.save(best_model, 'model.pth')
else:
num_epochs_without_improvement += 1
if num_epochs_without_improvement == 50:
print('Exiting early...')
break
elapsed_time = time.time() - start_time
print('Took {:.0f}m {:.0f}s'.format(elapsed_time // 60, elapsed_time % 60))
print('Best Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model)
return model
# Visualiza algumas predicoes do modelo.
def visualize_model(model, num_images = 6):
was_training = model.training
model.eval()
fig = plt.figure()
images_so_far = 0
with torch.no_grad():
for i, (data, labels) in enumerate(data_loaders[TEST]):
data = data.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(data)
_, preds = torch.max(outputs, 1)
for j in range(data.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images // 2, 2, images_so_far)
ax.axis('off')
ax.set_title('Predicted: {}'.format(class_names[preds[j]]))
imshow(data.cpu().data[j])
if images_so_far == num_images:
model.train(mode = was_training)
return
model.train(mode = was_training)
# Testa o modelo.
def test_model(model, criterion):
was_training = model.training
model.eval()
running_loss = 0.0
running_corrects = 0
with torch.no_grad():
for data, labels in data_loaders[TEST]:
data = data.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(data)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * data.size(0)
running_corrects += torch.sum(preds == labels.data)
loss = running_loss / data_sizes[TEST]
acc = running_corrects.double() / data_sizes[TEST]
print('Loss: {:4f}, Acc: {:4f}'.format(loss, acc))
model.train(mode = was_training)
```
Exibir amostra do dataset
```
data, labels = next(iter(data_loaders[TRAIN]))
grid = torchvision.utils.make_grid(data)
imshow(grid)
```
Definir modelo
```
if MODEL == INCEPTION:
model = models.inception_v3(pretrained = True, progress = True)
print(model.fc)
for param in model.parameters():
param.requires_grad = False
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, len(class_names))
model = model.to(DEVICE)
optimizer = optim.SGD(model.fc.parameters(), lr = 0.001, momentum = 0.9)
elif MODEL == VGG19:
model = models.vgg19(pretrained = True, progress = True)
print(model.classifier[6])
for param in model.parameters():
param.requires_grad = False
num_features = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_features, len(class_names))
model = model.to(DEVICE)
optimizer = optim.SGD(model.classifier[6].parameters(), lr = 0.001, momentum = 0.9)
else:
print('ERRO: Nenhum tipo de modelo definido!')
criterion = nn.CrossEntropyLoss()
print(model)
```
Treinar modelo
```
model = train_model(MODEL, model, optimizer, criterion)
```
Visualizar modelo
```
visualize_model(model)
```
Testar modelo
```
model.load_state_dict(torch.load('model.pth'))
test_model(model, criterion)
```
Salvar modelo para CPU
```
model = model.cpu()
torch.save(model.state_dict(), 'model-cpu.pth')
```
Salvar no Google Drive
```
torch.save(model.state_dict(), '/content/drive/My Drive/model-inception.pth')
```
| true |
code
| 0.75656 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/flych3r/IA025_2022S1/blob/main/ex04/matheus_xavier/IA025_A04.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Regressão Softmax com dados do MNIST utilizando gradiente descendente estocástico por minibatches
Este exercicío consiste em treinar um modelo de uma única camada linear no MNIST **sem** usar as seguintes funções do pytorch:
- torch.nn.Linear
- torch.nn.CrossEntropyLoss
- torch.nn.NLLLoss
- torch.nn.LogSoftmax
- torch.optim.SGD
- torch.utils.data.Dataloader
## Importação das bibliotecas
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import random
import torch
import torchvision
from torchvision.datasets import MNIST
```
## Fixando as seeds
```
random.seed(123)
np.random.seed(123)
torch.manual_seed(123)
```
## Dataset e dataloader
### Definição do tamanho do minibatch
```
batch_size = 50
```
### Carregamento, criação dataset e do dataloader
```
dataset_dir = '../data/'
dataset_train_full = MNIST(
dataset_dir, train=True, download=True,
transform=torchvision.transforms.ToTensor()
)
print(dataset_train_full.data.shape)
print(dataset_train_full.targets.shape)
```
### Usando apenas 1000 amostras do MNIST
Neste exercício utilizaremos 1000 amostras de treinamento.
```
indices = torch.randperm(len(dataset_train_full))[:1000]
dataset_train = torch.utils.data.Subset(dataset_train_full, indices)
# Escreva aqui o equivalente do código abaixo:
# loader_train = torch.utils.data.DataLoader(dataset_train, batch_size=batch_size, shuffle=False)
import math
class DataLoader:
def __init__(self, dataset: torch.utils.data.Dataset, batch_size: int = 1, shuffle: bool = True):
self.dataset = dataset
self.batch_size = batch_size
self.shuffle = shuffle
self.idx = 0
self.indexes = np.arange(len(dataset))
self._size = math.ceil(len(dataset) / self.batch_size)
def __iter__(self):
self.idx = 0
return self
def __next__(self):
if self.idx < len(self):
if self.idx == 0 and self.shuffle:
np.random.shuffle(self.indexes)
batch = self.indexes[self.idx * self.batch_size: (self.idx + 1) * self.batch_size]
self.idx += 1
x_batch, y_batch = [], []
for b in batch:
x, y = self.dataset[b]
x_batch.append(x)
y_batch.append(y)
return torch.stack(x_batch), torch.tensor(y_batch)
raise StopIteration
def __len__(self):
return self._size
loader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=False)
print('Número de minibatches de trenamento:', len(loader_train))
x_train, y_train = next(iter(loader_train))
print("\nDimensões dos dados de um minibatch:", x_train.size())
print("Valores mínimo e máximo dos pixels: ", torch.min(x_train), torch.max(x_train))
print("Tipo dos dados das imagens: ", type(x_train))
print("Tipo das classes das imagens: ", type(y_train))
```
## Modelo
```
# Escreva aqui o codigo para criar um modelo cujo o equivalente é:
# model = torch.nn.Linear(28*28, 10)
# model.load_state_dict(dict(weight=torch.zeros(model.weight.shape), bias=torch.zeros(model.bias.shape)))
class Model:
def __init__(self, in_features: int, out_features: int):
self.weight = torch.zeros(out_features, in_features, requires_grad=True)
self.bias = torch.zeros(out_features, requires_grad=True)
def __call__(self, x: torch.Tensor) -> torch.Tensor:
y_pred = x.mm(torch.t(self.weight)) + self.bias.unsqueeze(0)
return y_pred
def parameters(self):
return self.weight, self.bias
model = Model(28*28, 10)
```
## Treinamento
### Inicialização dos parâmetros
```
n_epochs = 50
lr = 0.1
```
## Definição da Loss
```
# Escreva aqui o equivalente de:
# criterion = torch.nn.CrossEntropyLoss()
class CrossEntropyLoss:
def __init__(self):
self.loss = 0
def __call__(self, inputs: torch.Tensor, targets: torch.Tensor):
log_sum_exp = torch.log(torch.sum(torch.exp(inputs), dim=1, keepdim=True))
logits = inputs.gather(dim=1, index=targets.unsqueeze(dim=1))
return torch.mean(-logits + log_sum_exp)
criterion = CrossEntropyLoss()
```
# Definição do Optimizer
```
# Escreva aqui o equivalente de:
# optimizer = torch.optim.SGD(model.parameters(), lr)
from typing import Iterable
class SGD:
def __init__(self, parameters: Iterable[torch.Tensor], learning_rate: float):
self.parameters = parameters
self.learning_rate = learning_rate
def step(self):
for p in self.parameters:
p.data -= self.learning_rate * p.grad
def zero_grad(self):
for p in self.parameters:
p.grad = torch.zeros_like(p.data)
optimizer = SGD(model.parameters(), lr)
```
### Laço de treinamento dos parâmetros
```
epochs = []
loss_history = []
loss_epoch_end = []
total_trained_samples = 0
for i in range(n_epochs):
# Substitua aqui o loader_train de acordo com sua implementação do dataloader.
for x_train, y_train in loader_train:
# Transforma a entrada para uma dimensão
inputs = x_train.view(-1, 28 * 28)
# predict da rede
outputs = model(inputs)
# calcula a perda
loss = criterion(outputs, y_train)
# zero, backpropagation, ajusta parâmetros pelo gradiente descendente
# Escreva aqui o código cujo o resultado é equivalente às 3 linhas abaixo:
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_trained_samples += x_train.size(0)
epochs.append(total_trained_samples / len(dataset_train))
loss_history.append(loss.item())
loss_epoch_end.append(loss.item())
print(f'Epoch: {i:d}/{n_epochs - 1:d} Loss: {loss.item()}')
```
### Visualizando gráfico de perda durante o treinamento
```
plt.plot(epochs, loss_history)
plt.xlabel('época')
```
### Visualização usual da perda, somente no final de cada minibatch
```
n_batches_train = len(loader_train)
plt.plot(epochs[::n_batches_train], loss_history[::n_batches_train])
plt.xlabel('época')
# Assert do histórico de losses
target_loss_epoch_end = np.array([
1.1979684829711914,
0.867622971534729,
0.7226786613464355,
0.6381281018257141,
0.5809749960899353,
0.5387411713600159,
0.5056464076042175,
0.4786270558834076,
0.4558936357498169,
0.4363219141960144,
0.4191650450229645,
0.4039044976234436,
0.3901679515838623,
0.3776799440383911,
0.3662314713001251,
0.35566139221191406,
0.34584277868270874,
0.33667415380477905,
0.32807353138923645,
0.31997355818748474,
0.312318354845047,
0.3050611615180969,
0.29816246032714844,
0.29158851504325867,
0.28531041741371155,
0.2793029546737671,
0.273544579744339,
0.2680158317089081,
0.26270008087158203,
0.2575823664665222,
0.25264936685562134,
0.24788929522037506,
0.24329163134098053,
0.23884665966033936,
0.23454584181308746,
0.23038141429424286,
0.22634628415107727,
0.22243399918079376,
0.2186385989189148,
0.21495483815670013,
0.21137762069702148,
0.20790249109268188,
0.20452524721622467,
0.20124195516109467,
0.19804897904396057,
0.1949428766965866,
0.19192075729370117,
0.188979372382164,
0.18611609935760498,
0.1833282858133316])
assert np.allclose(np.array(loss_epoch_end), target_loss_epoch_end, atol=1e-6)
```
## Exercício
Escreva um código que responda às seguintes perguntas:
Qual é a amostra classificada corretamente, com maior probabilidade?
Qual é a amostra classificada erradamente, com maior probabilidade?
Qual é a amostra classificada corretamente, com menor probabilidade?
Qual é a amostra classificada erradamente, com menor probabilidade?
```
# Escreva o código aqui:
loader_eval = DataLoader(dataset_train, batch_size=len(dataset_train), shuffle=False)
x, y = next(loader_eval)
logits = model(x.view(-1, 28 * 28))
exp_logits = torch.exp(logits)
sum_exp_logits = torch.sum(exp_logits, dim=1, keepdim=True)
softmax = (exp_logits / sum_exp_logits).detach()
y_pred = torch.argmax(softmax, dim=1)
y_proba = softmax.gather(-1, y_pred.view(-1, 1)).ravel()
corret_preditions = (y == y_pred)
wrong_predictions = (y != y_pred)
def plot_image_and_proba(images, probas, idx, title):
plt.figure(figsize=(16, 8))
x_labels = list(range(10))
plt.subplot(121)
plt.imshow(images[idx][0])
plt.subplot(122)
plt.bar(x_labels, probas[idx])
plt.xticks(x_labels)
plt.suptitle(title)
plt.show()
# Qual é a amostra classificada corretamente, com maior probabilidade?
mask = corret_preditions
idx = torch.argmax(y_proba[mask])
title = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(
y_pred[mask][idx],
y_proba[mask][idx],
y[mask][idx],
)
plot_image_and_proba(x[mask], softmax[mask], idx, title)
# Qual é a amostra classificada erradamente, com maior probabilidade?
mask = wrong_predictions
idx = torch.argmax(y_proba[mask])
title = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(
y_pred[mask][idx],
y_proba[mask][idx],
y[mask][idx],
)
plot_image_and_proba(x[mask], softmax[mask], idx, title)
# Qual é a amostra classificada corretamente, com menor probabilidade?
mask = corret_preditions
idx = torch.argmin(y_proba[mask])
title = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(
y_pred[mask][idx],
y_proba[mask][idx],
y[mask][idx],
)
plot_image_and_proba(x[mask], softmax[mask], idx, title)
# Qual é a amostra classificada erradamente, com menor probabilidade?
mask = wrong_predictions
idx = torch.argmin(y_proba[mask])
title = 'Predita: {} | Probabilidate: {:.4f} | Correta: {}'.format(
y_pred[mask][idx],
y_proba[mask][idx],
y[mask][idx],
)
plot_image_and_proba(x[mask], softmax[mask], idx, title)
```
## Exercício Bonus
Implemente um dataloader que aceite como parâmetro de entrada a distribuição probabilidade das classes que deverão compor um batch.
Por exemplo, se a distribuição de probabilidade passada como entrada for:
`[0.01, 0.01, 0.72, 0.2, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]`
Em média, 72% dos exemplos do batch deverão ser da classe 2, 20% deverão ser da classe 3, e os demais deverão ser das outras classes.
Mostre também que sua implementação está correta.
| true |
code
| 0.697145 | null | null | null | null |
|
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
# Deploying a web service to Azure Kubernetes Service (AKS)
This notebook shows the steps for deploying a service: registering a model, creating an image, provisioning a cluster (one time action), and deploying a service to it.
We then test and delete the service, image and model.
```
from azureml.core import Workspace
from azureml.core.compute import AksCompute, ComputeTarget
from azureml.core.webservice import Webservice, AksWebservice
from azureml.core.image import Image
from azureml.core.model import Model
import azureml.core
print(azureml.core.VERSION)
```
# Get workspace
Load existing workspace from the config file info.
```
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep = '\n')
```
# Register the model
Register an existing trained model, add descirption and tags.
```
#Register the model
from azureml.core.model import Model
model = Model.register(model_path = "sklearn_regression_model.pkl", # this points to a local file
model_name = "sklearn_regression_model.pkl", # this is the name the model is registered as
tags = {'area': "diabetes", 'type': "regression"},
description = "Ridge regression model to predict diabetes",
workspace = ws)
print(model.name, model.description, model.version)
```
# Create an image
Create an image using the registered model the script that will load and run the model.
```
%%writefile score.py
import pickle
import json
import numpy
from sklearn.externals import joblib
from sklearn.linear_model import Ridge
from azureml.core.model import Model
def init():
global model
# note here "sklearn_regression_model.pkl" is the name of the model registered under
# this is a different behavior than before when the code is run locally, even though the code is the same.
model_path = Model.get_model_path('sklearn_regression_model.pkl')
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
# note you can pass in multiple rows for scoring
def run(raw_data):
try:
data = json.loads(raw_data)['data']
data = numpy.array(data)
result = model.predict(data)
# you can return any data type as long as it is JSON-serializable
return result.tolist()
except Exception as e:
error = str(e)
return error
from azureml.core.conda_dependencies import CondaDependencies
myenv = CondaDependencies.create(conda_packages=['numpy','scikit-learn'])
with open("myenv.yml","w") as f:
f.write(myenv.serialize_to_string())
from azureml.core.image import ContainerImage
image_config = ContainerImage.image_configuration(execution_script = "score.py",
runtime = "python",
conda_file = "myenv.yml",
description = "Image with ridge regression model",
tags = {'area': "diabetes", 'type': "regression"}
)
image = ContainerImage.create(name = "myimage1",
# this is the model object
models = [model],
image_config = image_config,
workspace = ws)
image.wait_for_creation(show_output = True)
```
# Provision the AKS Cluster
This is a one time setup. You can reuse this cluster for multiple deployments after it has been created. If you delete the cluster or the resource group that contains it, then you would have to recreate it.
```
# Use the default configuration (can also provide parameters to customize)
prov_config = AksCompute.provisioning_configuration()
aks_name = 'my-aks-9'
# Create the cluster
aks_target = ComputeTarget.create(workspace = ws,
name = aks_name,
provisioning_configuration = prov_config)
%%time
aks_target.wait_for_completion(show_output = True)
print(aks_target.provisioning_state)
print(aks_target.provisioning_errors)
```
## Optional step: Attach existing AKS cluster
If you have existing AKS cluster in your Azure subscription, you can attach it to the Workspace.
```
'''
# Use the default configuration (can also provide parameters to customize)
resource_id = '/subscriptions/92c76a2f-0e1c-4216-b65e-abf7a3f34c1e/resourcegroups/raymondsdk0604/providers/Microsoft.ContainerService/managedClusters/my-aks-0605d37425356b7d01'
create_name='my-existing-aks'
# Create the cluster
aks_target = AksCompute.attach(workspace=ws, name=create_name, resource_id=resource_id)
# Wait for the operation to complete
aks_target.wait_for_completion(True)
'''
```
# Deploy web service to AKS
```
#Set the web service configuration (using default here)
aks_config = AksWebservice.deploy_configuration()
%%time
aks_service_name ='aks-service-1'
aks_service = Webservice.deploy_from_image(workspace = ws,
name = aks_service_name,
image = image,
deployment_config = aks_config,
deployment_target = aks_target)
aks_service.wait_for_deployment(show_output = True)
print(aks_service.state)
```
# Test the web service
We test the web sevice by passing data.
```
%%time
import json
test_sample = json.dumps({'data': [
[1,2,3,4,5,6,7,8,9,10],
[10,9,8,7,6,5,4,3,2,1]
]})
test_sample = bytes(test_sample,encoding = 'utf8')
prediction = aks_service.run(input_data = test_sample)
print(prediction)
```
# Clean up
Delete the service, image and model.
```
%%time
aks_service.delete()
image.delete()
model.delete()
```
| true |
code
| 0.369969 | null | null | null | null |
|
# Linear Regression
---
- Author: Diego Inácio
- GitHub: [github.com/diegoinacio](https://github.com/diegoinacio)
- Notebook: [regression_linear.ipynb](https://github.com/diegoinacio/machine-learning-notebooks/blob/master/Machine-Learning-Fundamentals/regression_linear.ipynb)
---
Overview and implementation of *Linear Regression* analysis.
```
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from regression__utils import *
# Synthetic data 1
x, yA, yB, yC, yD = synthData1()
```

## 1. Simple
---
$$ \large
y_i=mx_i+b
$$
Where **m** describes the angular coefficient (or line slope) and **b** the linear coefficient (or line y-intersept).
$$ \large
m=\frac{\sum_i^n (x_i-\overline{x})(y_i-\overline{y})}{\sum_i^n (x_i-\overline{x})^2}
$$
$$ \large
b=\overline{y}-m\overline{x}
$$
```
class linearRegression_simple(object):
def __init__(self):
self._m = 0
self._b = 0
def fit(self, X, y):
X = np.array(X)
y = np.array(y)
X_ = X.mean()
y_ = y.mean()
num = ((X - X_)*(y - y_)).sum()
den = ((X - X_)**2).sum()
self._m = num/den
self._b = y_ - self._m*X_
def pred(self, x):
x = np.array(x)
return self._m*x + self._b
lrs = linearRegression_simple()
%%time
lrs.fit(x, yA)
yA_ = lrs.pred(x)
lrs.fit(x, yB)
yB_ = lrs.pred(x)
lrs.fit(x, yC)
yC_ = lrs.pred(x)
lrs.fit(x, yD)
yD_ = lrs.pred(x)
```

$$ \large
MSE=\frac{1}{n} \sum_i^n (Y_i- \hat{Y}_i)^2
$$

## 2. Multiple
---
$$ \large
y=m_1x_1+m_2x_2+...+m_nx_n+b
$$
```
class linearRegression_multiple(object):
def __init__(self):
self._m = 0
self._b = 0
def fit(self, X, y):
X = np.array(X).T
y = np.array(y).reshape(-1, 1)
X_ = X.mean(axis = 0)
y_ = y.mean(axis = 0)
num = ((X - X_)*(y - y_)).sum(axis = 0)
den = ((X - X_)**2).sum(axis = 0)
self._m = num/den
self._b = y_ - (self._m*X_).sum()
def pred(self, x):
x = np.array(x).T
return (self._m*x).sum(axis = 1) + self._b
lrm = linearRegression_multiple()
%%time
# Synthetic data 2
M = 10
s, t, x1, x2, y = synthData2(M)
# Prediction
lrm.fit([x1, x2], y)
y_ = lrm.pred([x1, x2])
```


## 3. Gradient Descent
---
$$ \large
e_{m,b}=\frac{1}{n} \sum_i^n (y_i-(mx_i+b))^2
$$
To perform the gradient descent as a function of the error, it is necessary to calculate the gradient vector $\nabla$ of the function, described by:
$$ \large
\nabla e_{m,b}=\Big\langle\frac{\partial e}{\partial m},\frac{\partial e}{\partial b}\Big\rangle
$$
where:
$$ \large
\begin{aligned}
\frac{\partial e}{\partial m}&=\frac{2}{n} \sum_{i}^{n}-x_i(y_i-(mx_i+b)), \\
\frac{\partial e}{\partial b}&=\frac{2}{n} \sum_{i}^{n}-(y_i-(mx_i+b))
\end{aligned}
$$
```
class linearRegression_GD(object):
def __init__(self,
mo = 0,
bo = 0,
rate = 0.001):
self._m = mo
self._b = bo
self.rate = rate
def fit_step(self, X, y):
X = np.array(X)
y = np.array(y)
n = X.size
dm = (2/n)*np.sum(-x*(y - (self._m*x + self._b)))
db = (2/n)*np.sum(-(y - (self._m*x + self._b)))
self._m -= dm*self.rate
self._b -= db*self.rate
def pred(self, x):
x = np.array(x)
return self._m*x + self._b
%%time
lrgd = linearRegression_GD(rate=0.01)
# Synthetic data 3
x, x_, y = synthData3()
iterations = 3072
for i in range(iterations):
lrgd.fit_step(x, y)
y_ = lrgd.pred(x)
```

## 4. Non-linear analysis
---
```
# Synthetic data 4
# Anscombe's quartet
x1, y1, x2, y2, x3, y3, x4, y4 = synthData4()
%%time
lrs.fit(x1, y1)
y1_ = lrs.pred(x1)
lrs.fit(x2, y2)
y2_ = lrs.pred(x2)
lrs.fit(x3, y3)
y3_ = lrs.pred(x3)
lrs.fit(x4, y4)
y4_ = lrs.pred(x4)
```


| true |
code
| 0.603552 | null | null | null | null |
|
# Clusters as Knowledge Areas of Annotators
```
# import required packages
import sys
sys.path.append("../..")
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from annotlib import ClusterBasedAnnot
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score
```
A popular approach to simulate annotators is to use clustering methods.
By using clustering methods, we can emulate areas of knowledge.
The assumption is that the knowledge of an annotator is not constant for a whole classification problem, but there are areas where the annotator has a wider knowledge compared to areas of sparse knowledge.
As the samples lie in a feature space, we can model the area of knowledge as an area in the feature space.
The simulation of annotators by means of clustering is implemented by the class [ClusterBasedAnnot](../annotlib.cluster_based.rst).
To create such annotators, you have to provide the samples `X`, their corresponding true class labels `y_true` and the cluster labels `y_cluster`.
In this section, we introduce the following simulation options:
- class labels as clustering,
- clustering algorithms to find clustering,
- and feature space as a single cluster.
The code below generates a two-dimensional (`n_features=2`) artificial data set with `n_samples=500` samples and `n_classes=4` classes.
```
X, y_true = make_classification(n_samples=500, n_features=2,
n_informative=2, n_redundant=0,
n_repeated=0, n_classes=4,
n_clusters_per_class=1,
flip_y=0.1, random_state=4)
plt.figure(figsize=(5, 3), dpi=150)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y_true, s=10)
plt.title('artificial data set: samples with class labels', fontsize=7)
plt.xticks(fontsize=7)
plt.yticks(fontsize=7)
plt.show()
```
## 1. Class Labels as Clustering
If you do not provide any cluster labels `y_cluster`, the true class labels `y_true` are assumed to be a representive clustering.
As a result the class labels and cluster labels are equivalent `y_cluster = y_true` and define the knowledge areas of the simulated annotators.
To simulate annotators on this dataset, we create an instance of the [ClusterBasedAnnot](../annotlib.cluster_based.rst) class by providing the samples `X` with the true labels `y_true` as input.
```
# simulate annotators where the clusters are defined by the class labels
clust_annot_cls = ClusterBasedAnnot(X=X, y_true=y_true, random_state=42)
```
The above simulated annotators have knowledge areas defined by the class label distribution.
As a result, there are four knowledge areas respectively clusters.
In the default setting, the number of annotators is equal to the number of defined clusters.
Correspondingly, there are four simulated annotators in our example.
☝🏽An important aspect is the simulation of the labelling performances of the annotators on the different clusters.
By default, each annotator is assumed to be an expert on a single cluster.
Since we have four clusters and four annotators, each cluster has only one annotator as expert.
Being an expert means that an annotator has a higher probability for providing the correct class label for a sample than in the clusters of low expertise.
Let the number of clusters be $K$ (`n_clusters`) and the number of annotators be $A$ (`n_annotators`).
For the case $K=A$, an annotator $a_i$ is expert on cluster $c_i$ with $i \in \{0,\dots,A-1\}$, the probability of providing the correct class label $y^{\text{true}}_\mathbf{x}$ for sample $\mathbf{x} \in c_i$ is defined by
$$p(y^{\text{true}}_\mathbf{x} \mid \mathbf{x}, a_i, c_i) = U(0.8, 1.0)$$
where $U(a,b)$ means that a value is uniformly drawn from the interval $[0.8, 1.0]$.
In contrast for the clusters of low expertise, the default probability for providing a correct class label is defined by
$$p(y^{\text{true}}_\mathbf{x} \mid \mathbf{x}, a_i, c_j) = U\left(\frac{1}{C}, \text{min}(\frac{1}{C}+0.1,1)\right),$$
where $j=0,\dots,A-1$, $j\neq i$ and $C$ denotes the number of classes (`n_classes`).
These properties apply only for the default settings.
The actual labelling accuracies per cluster are exemplary plotted for annotator $a_0$ below.
```
acc_cluster = clust_annot_cls.labelling_performance_per_cluster(accuracy_score)
x = np.arange(len(np.unique(clust_annot_cls.y_cluster_)))
plt.figure(figsize=(4, 2), dpi=150)
plt.bar(x, acc_cluster[0])
plt.xticks(x, ('cluster $c_0$', 'cluster $c_1$', 'cluster $c_2$',
'cluster $c_3$'), fontsize=7)
plt.ylabel('labelling accuracy', fontsize=7)
plt.title('labelling accuracy of annotator $a_0$',
fontsize=7)
plt.show()
```
The above figure matches the description of the default behaviour.
We can see that the accuracy of annotator $a_0$ is high in cluster $c_0$, whereas the labelling accuracy on the remaining clusters is comparable to randomly guessing of class labels.
You can also manually define properties of the annotators.
This may be interesting when you want to evaluate the performance of a developed method coping with multiple uncertain annotators.
Let's see how the ranges of uniform distributions for correct class labels on the clusters can be defined manually. For the default setting, we observe the following ranges:
```
print('ranges of uniform distributions for correct'
+' class labels on the clusters:')
for a in range(clust_annot_cls.n_annotators()):
print('annotator a_' + str(a) + ':\n'
+ str(clust_annot_cls.cluster_labelling_acc_[a]))
```
The attribute `cluster_labelling_acc_` is an array with the shape `(n_annotators, n_clusters, 2)` and can be defined by means of the parameter `cluster_labelling_acc`.
This parameter may be either a `str` or array-like.
By default, `cluster_labelling_acc='one_hot'` is valid, which indicates that each annotator is expert on one cluster.
Another option is `cluster_labelling_acc='equidistant'` and is explained in one of the following examples.
The entry `cluster_labelling_acc_[i, j , 0]` indicates the lower limit of the uniform distribution for correct class labels of annotator $a_i$ on cluster $c_j$. Analogous, the entry `cluster_labelling_acc_[i, j ,1]` represents the upper limit.
The sampled probabilities for correct class labels are also the confidence scores of the annotators.
An illustration of the annotators $a_0$ and $a_1$ simulated with default values on the predefined data set is given in the following plots.
The confidence scores correspond to the size of the crosses and dots.
```
clust_annot_cls.plot_class_labels(X=X, y_true=y_true, annotator_ids=[0, 1],
plot_confidences=True)
print('The confidence scores correspond to the size of the crosses and dots.')
plt.tight_layout()
plt.show()
```
☝🏽To sum up, by using the true class labels `y_true` as proxy of a clustering and specifying the input parameter `cluster_labelling_acc`, annotators being experts on different classes can be simulated.
## 2. Clustering Algorithms to Find Clustering
There are several algorithms available for perfoming clustering on a data set. The framework *scikit-learn* provides many clustering algorithms, e.g.
- `sklearn.cluster.KMeans`,
- `sklearn.cluster.DBSCAN`,
- `sklearn.cluster.AgglomerativeClustering`,
- `sklearn.cluster.bicluster.SpectralBiclusterin`,
- `sklearn.mixture.BayesianGaussianMixture`,
- and `sklearn.mixture.GaussianMixture`.
We examplary apply the `KMeans` algorithm being a very popular clustering algorithm.
For this purpose, you have to specify the number of clusters.
By doing so, you determine the number of different knowledge areas in the feature space with reference to the simulation of annotators.
We set `n_clusters = 3` as number of clusters.
The clusters found by `KMeans` on the previously defined data set are given in the following:
```
# standardize features of samples
X_z = StandardScaler().fit_transform(X)
# apply k-means algorithm
y_cluster_k_means = KMeans(n_clusters=3).fit_predict(X_z)
# plot found clustering
plt.figure(figsize=(5, 3), dpi=150)
plt.scatter(X[:, 0], X[:, 1], c=y_cluster_k_means, s=10)
plt.title('samples with cluster labels of k-means algorithm', fontsize=7)
plt.xticks(fontsize=7)
plt.yticks(fontsize=7)
plt.show()
```
The clusters are found on the standardised data set, so that the mean of each feature is 0 and the variance is 1.
The computed cluster labels `y_cluster` are used as input parameter to simulate two annotators, where the annotator $a_0$ is expert on two clusters and the annotator $a_1$ is expert on one cluster.
```
# define labelling accuracy ranges on four clusters for three annotators
clu_label_acc_km = np.array([[[0.8, 1], [0.8, 1], [0.3, 0.5]],
[[0.3, 0.5], [0.3, 0.5], [0.8, 1]]])
# simulate annotators
cluster_annot_kmeans = ClusterBasedAnnot(X=X, y_true=y_true,
y_cluster=y_cluster_k_means,
n_annotators=2,
cluster_labelling_acc=clu_label_acc_km)
# scatter plots of annotators
cluster_annot_kmeans.plot_class_labels(X=X, y_true=y_true,
plot_confidences=True,
annotator_ids=[0, 1])
plt.tight_layout()
plt.show()
```
☝🏽The employment of different clustering allows to define almost arbitrarily knowledge areas and offers a huge flexibiility.
However, the clusters should reflect the actual regions within a feature space.
## 3. Feature Space as a Single Cluster
Finally, you can simulate annotators whose knowledge does not depend on clusters.
Hence, their knowledge level is constant over the whole feature space.
To emulate such a behaviour, you create a clustering array `y_cluster_const`, in which all samples in the feature space are assigned to the same cluster.
```
y_cluster_const = np.zeros(len(X), dtype=int)
cluster_annot_const = ClusterBasedAnnot(X=X, y_true=y_true,
y_cluster=y_cluster_const,
n_annotators=5,
cluster_labelling_acc='equidistant')
# plot labelling accuracies
cluster_annot_const.plot_labelling_accuracy(X=X, y_true=y_true,
figsize=(4, 2), fontsize=6)
plt.show()
# print predefined labelling accuracies
print('ranges of uniform distributions for correct class '
+ 'labels on the clusters:')
for a in range(cluster_annot_const.n_annotators()):
print('annotator a_' + str(a) + ': '
+ str(cluster_annot_const.cluster_labelling_acc_[a]))
```
Five annotators are simulated whose labelling accuracy intervals are increasing with the index number of the annotator.
☝🏽The input parameter `cluster_labelling_acc='equidistant'` means that the lower bounds of the labelling accuracy intervals between two annotators have always the same distance.
In general, the interval of the correct labelling probability for annotator $a_i$ is computed by
$$d = \frac{1 - \frac{1}{C}}{A+1},$$
$$p(y^{(\text{true})}_\mathbf{x} \mid \mathbf{x}, a_i, c_j) \in U(\frac{1}{C} + i \cdot d, \frac{1}{C} + 2 \cdot i \cdot d),$$
where $i=0,\dots,A-1$ and $j=0,\dots,K-1$ with $K$.
This procedure ensures that the intervals of the correct labelling probabilities are overlapping.
| true |
code
| 0.638835 | null | null | null | null |
|
# Cross-Validation
Cross-validation is a step where we take our training sample and further divide it in many folds, as in the illustration here:
```{image} ./img/feature_5_fold_cv.jpg
:alt: 5-fold
:width: 400px
:align: center
```
As we talked about in the last chapter, cross-validation allows us to test our models outside the training data more often. This trick reduces the likelihood of overfitting and improves generalization: It _should_ improve our model's performance when we apply it outside the training data.
```{warning}
I say "_should_" because the exact manner in which you create the folds matters.
```
- **If your data has groups** (i.e. repeated observations for a given firm), you should use [group-wise cross-validation](https://scikit-learn.org/stable/modules/cross_validation.html#group-cv), like `GroupKFold` to make sure no group is in the training and validation partitions of the fold
- **If your data and/or task is time dependent**, like predicting stock returns, you should use a [time-wise cross-validation](https://scikit-learn.org/stable/modules/cross_validation.html#timeseries-cv), like `TimeSeriesSplit` to ensure that the validation partitions are subsequent to the training sample
```{margin}
Illustration: If you emulate the simple folding method as depicted in the above graphic for stock return data, some folds will end up testing your model on data from _before_ the periods where the model was estimated!
```
---
## CV in practice
Like before, let's load the data. Notice I consolidated the import lines at the top.
```
import pandas as pd
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
url = 'https://github.com/LeDataSciFi/ledatascifi-2021/blob/main/data/Fannie_Mae_Plus_Data.gzip?raw=true'
fannie_mae = pd.read_csv(url,compression='gzip').dropna()
y = fannie_mae.Original_Interest_Rate
fannie_mae = (fannie_mae
.assign(l_credscore = np.log(fannie_mae['Borrower_Credit_Score_at_Origination']),
l_LTV = np.log(fannie_mae['Original_LTV_(OLTV)']),
)
.iloc[:,-11:] # limit to these vars for the sake of this example
)
```
### **STEP 1:** Set up your test and train split samples
```
rng = np.random.RandomState(0) # this helps us control the randomness so we can reproduce results exactly
X_train, X_test, y_train, y_test = train_test_split(fannie_mae, y, random_state=rng)
```
---
**An important digression:** Now that we've introduced some of the conceptual issues with how you create folds for CV, let's revisit this `test_train_split` code above. [This page](https://scikit-learn.org/stable/modules/cross_validation.html#using-cross-validation-iterators-to-split-train-and-test) says `train_test_split` uses [ShuffleSplit](https://scikit-learn.org/stable/modules/cross_validation.html#random-permutations-cross-validation-a-k-a-shuffle-split). This method does not divide by time or any group type.
```{dropdown} Q: Does this data need special attention to how we divide it up?
A question to ponder, in class perhaps...
```
If you want to use any other CV iterators to divide up your sample, you can:
```python
# Just replace "GroupShuffleSplit" with your CV of choice,
# and update the contents of split() as needed
train_idx, test_idx = next(
GroupShuffleSplit(random_state=7).split(X, y, groups)
)
X_train, X_test, y_train, y_test = X[train_idx], X[train_idx], y[test_idx], y[test_idx]
```
---
Back to our regularly scheduled "CV in Practice" programming.
### **STEP 2:** Set up the CV
SK-learn makes cross-validation pretty easy. The `cross_validate("estimator",X_train,y_train,cv,scoring,...)` function ([documentation here](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html)) will
1. Create folds in X_train and y_train using the method you put in the `cv` parameter. For each fold, it will create a smaller "training partition" and "testing partition" like in the figure at the top of this page.
1. For each fold,
1. It will fit your "estimator" (as if you ran `estimator.fit(X_trainingpartition,y_trainingpartition)`) on the smaller training partition it creates. **Your estimator will be a "pipeline" object** ([covered in detail on the next page](04e_pipelines)) that tells sklearn to apply a series of steps to the data (preprocessing, etc.), culminating in a model.
1. Use that fitted estimator on the testing partition (as if you ran `estimator.predict(X_testingpartition)` will apply all of the data transformations in the pipeline and use the estimated model on it)
1. Score those predictions with the function(s) you put in `scoring`
1. Output a dictionary object with performance data
You can even give it multiple scoring metrics to evaluate.
So, you need to set up
1. Your preferred folding method (and number of folds)
1. Your estimator
1. Your scoring method (you can specify this inside the cross_validate function)
```
from sklearn.model_selection import KFold, cross_validate
cv = KFold(5) # set up fold method
ridge = Ridge(alpha=1.0) # set up model/estimator
cross_validate(ridge,X_train,y_train,
cv=cv, scoring='r2') # tell it the scoring method here
```
```{note}
Wow, that was easy! Just 3 lines of code (and an import)
```
And we can output test score statistics like:
```
scores = cross_validate(ridge,X_train,y_train,cv=cv, scoring='r2')
print(scores['test_score'].mean()) # scores is just a dictionary
print(scores['test_score'].std())
```
## Next step: Pipelines
The model above
- Only uses a few continuous variables: what if we want to include other variable types (like categorical)?
- Uses the variables as given: ML algorithms often need you to transform your variables
- Doesn't deal with any data problems (e.g. missing values or outliers)
- Doesn't create any interaction terms or polynomial transformations
- Uses every variable I give it: But if your input data had 400 variables, you'd be in danger of overfitting!
At this point, you are capable of solving all of these problems. (For example, you could clean the data in pandas.)
But for our models to be robust to evil monsters like "data leakage", we need the fixes to be done within pipelines.
| true |
code
| 0.775387 | null | null | null | null |
|
# Stock Price Prediction From Employee / Job Market Information
## Modelling: Linear Model
Objective utilise the Thinknum LinkedIn and Job Postings datasets, along with the Quandl WIKI prices dataset to investigate the effect of hiring practices on stock price. In this notebook I'll begin exploring the increase in predictive power from historic employment data.
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
from glob import glob
# Utilities
from utils import *
%matplotlib inline
PATH = Path('D:\data\jobs')
%%capture #ignore output warnings for now
link, companies, stocks = data_load(PATH)
```
Let's start with some of the series that had the most promising cross correlations.
```
filtered = companies.sort_values('max_corr',ascending=False)[['dataset_id', 'company_name','MarketCap', 'Sector', 'Symbol',
'max_corr', 'best_lag']]
filtered = filtered.query('(max_corr > 0.95) & (best_lag < -50)')
filtered.head()
```
Modelling for the top stock here USA Truck Inc.
```
USAK = stocks.USAK
USAK_link = link[link['dataset_id']==929840]['employees_on_platform']
start = min(USAK_link.index)
end = max(USAK_link.index)
fig, ax = plt.subplots(figsize=(12,8))
ax.set_xlim(start,end)
ax.plot(USAK.index,USAK, label='Adjusted Close Price (USAK)')
ax.set_ylabel('Adjusted close stock price')
ax1=ax.twinx()
ax1.set_ylabel('LinkedIn employee count')
ax1.plot(USAK_link.index, USAK_link,color='r',label='LinkedIn employee data')
plt.legend();
# Error in this code leading to slightly different train time ranges
def build_t_feats(stock,employ,n, include_employ=True):
if include_employ:
X = pd.concat([stock,employ],axis=1)
X.columns = ['close','emps']
else:
X = pd.DataFrame(stock)
X.columns = ['close']
y=None
start = max(pd.datetime(2016,7,1),min(stock.dropna().index)) - pd.Timedelta(1, unit='d')
end = max(stock.dropna().index)
X = X.loc[start:end]
# Normalize
X = (X-X.mean())/X.std()
# Fill gaps
X = X.interpolate()
# Daily returns
X = X.diff()
# Create target variable
X['y'] = X.close.shift(-1)
# Create time shifted features
for t in range(n):
X['c'+str(t+1)] = X.close.shift(t+1)
if include_employ: X['e'+str(t+1)] = X.emps.shift(t+1)
X = X.dropna()
y = X.y
X.drop('y',axis=1,inplace=True)
return X,y
X, y = build_t_feats(USAK,USAK_link,180)
```
## Linear Model
Start with a basic linear model, so we can easily interpret the model outputs.
```
from sklearn.model_selection import TimeSeriesSplit, cross_val_score
from sklearn.linear_model import Ridge, LinearRegression
from sklearn.metrics import mean_absolute_error
reg = Ridge()
def fit_predict(reg, X, y, plot=True):
cv = TimeSeriesSplit(n_splits=10)
scores = cross_val_score(reg, X, y, cv=cv, scoring='neg_mean_absolute_error')
if plot: print('Mean absolute error: ', np.mean(-scores), '\nSplit scores: ',-scores)
cut = int(X.shape[0]*0.9)
X_train, y_train = X[:cut], y[:cut].values.reshape(-1,1)
X_dev, y_dev = X[cut:], y[cut:].values.reshape(-1,1)
reg.fit(X_train,y_train)
pred_dev = reg.predict(X_dev)
pred_train = reg.predict(X_train)
if plot:
f,ax = plt.subplots(nrows=1,ncols=2,figsize=(25,8))
ax[0].plot(y_train,pred_train,marker='.',linestyle='None',alpha=0.6,label='train')
ax[0].plot(y_dev,pred_dev,marker='.',linestyle='None',color='r',alpha=0.6,label='dev')
ax[0].set_title('Predicted v actual daily changes')
ax[0].legend()
ax[1].plot(X[cut:].index,y_dev,alpha=0.6,label='actual',marker='.')
ax[1].plot(X[cut:].index,pred_dev,color='r',alpha=0.6,label='predict',marker='.')
ax[1].set_title('Development set, predicted v actual daily changes')
ax[1].legend();
return reg, np.mean(-scores)
reg, _ = fit_predict(reg, X, y)
```
Using MAE (Mean Absolute Error) as the evaluation metric here. Around 0.05 MAE seems acceptable at predicting the daily changes.
```
coefs = reg.coef_.ravel()
idx = coefs.argsort()[-40:]
x = np.arange(len(coefs[idx]))
fig,ax = plt.subplots(figsize=(20,5))
plt.bar(x,coefs[idx])
plt.xticks(x,X.columns.values[idx])
plt.title('Importance of shifted feature in model')
plt.show();
```
Looks like most of the top features are time lagged versions of the daily price change rather than the employment data.
## Same model excluding employment data
I'll now rerun the same analysis but exluced the employment data.
```
X, y = build_t_feats(USAK,USAK_link,180,include_employ=False)
reg = Ridge()
reg, _ = fit_predict(reg, X, y)
coefs = reg.coef_.ravel()
idx = coefs.argsort()[-40:]
x = np.arange(len(coefs[idx]))
fig,ax = plt.subplots(figsize=(20,5))
plt.bar(x,coefs[idx])
plt.xticks(x,X.columns.values[idx])
plt.title('Importance of shifted feature in model')
plt.show();
```
Over a similar time period it looks like our model performed better using employment data.
## Rerun analysis for all top stocks
```
%%capture
def run_for_all(filtered):
MAEs = np.full((len(filtered),2),np.nan)
for i,ID in enumerate(filtered.dataset_id.values):
print(i, ID, filtered.set_index('dataset_id').loc[ID].company_name)
try:
sym = filtered.set_index('dataset_id').loc[ID].Symbol
tick = stocks[sym]
emp = link[link['dataset_id']==ID]['employees_on_platform']
except:
print('Symbol Error, Skipping')
# Including employee data
X, y = build_t_feats(tick,emp,180,True)
reg = Ridge()
reg, MAE = fit_predict(reg, X, y, plot=False)
MAEs[i][0] = MAE
# Excluding employee data
X, y = build_t_feats(tick,emp,180,False)
reg = Ridge()
reg, MAE = fit_predict(reg, X, y, plot=False)
MAEs[i][1] = MAE
# Create columns with mean absolute errors added
filtered['MAE_w_emp'] = MAEs[:,0]
filtered['MAE_wo_emp'] = MAEs[:,1]
return filtered
filtered = filtered[filtered.dataset_id != 868877].copy()
filtered = run_for_all(filtered)
from bokeh.plotting import figure, show, output_notebook
from bokeh.models import HoverTool
output_notebook()
def plot_predicts(filtered):
TOOLS="hover,save"
p1 = figure(plot_width=600, plot_height=600, title="Prediction score with and without LinkedIn data",tools=TOOLS)
p1.xgrid.grid_line_color = None
p1.circle(x='MAE_wo_emp', y='MAE_w_emp', size=12, alpha=0.5, source=filtered)
p1.line(x=np.arange(0,0.25,0.01),y=np.arange(0,0.25,0.01))
p1.xaxis.axis_label = 'MAE with employee data in model'
p1.yaxis.axis_label = 'MAE without employee data in model'
hover = p1.select(dict(type=HoverTool))
hover.tooltips = [
("Name", "@company_name"),
("Correlation", "@max_corr"),
("Optimal Lag", "@best_lag"),
]
show(p1)
plot_predicts(filtered)
```
The vast majority of points fall below the line, suggesting the predictions generated with a simple linear model were improved when Employee data was included in the model.
**However** upon further review of my methodology it looks like I'm using comparing prediction accuracy on slightly different time ranges. I'll re-run the code below this time fixing identical time ranges.
```
# Updated code for processing data
def build_t_feats(stock,employ,n, include_employ=True, norm_diff=True):
X = pd.concat([stock,employ],axis=1)
X.columns = ['close','emps']
y=None
#start = max(pd.datetime(2016,7,1),min(stock.dropna().index)) - pd.Timedelta(1, unit='d')
start = min(employ.dropna().index) - pd.Timedelta(1, unit='d')
end = max(stock.dropna().index)
#print(start,end)
X = X.loc[start:end]
if norm_diff:
# Normalize
X = (X-X.mean())/X.std()
# Fill gaps
X = X.interpolate()
if norm_diff:
# Daily returns
X = X.diff()
# Create target variable
X['y'] = X.close.shift(-1)
# Create time shifted features
for t in range(n):
X['c'+str(t+1)] = X.close.shift(t+1)
if include_employ: X['e'+str(t+1)] = X.emps.shift(t+1)
X = X.dropna()
if not include_employ: X = X.drop('emps',axis=1)
y = X.y
X.drop('y',axis=1,inplace=True)
return X,y
```
### With employment data
```
X, y = build_t_feats(USAK,USAK_link,180)
reg = Ridge()
reg, _ = fit_predict(reg, X, y)
```
### Without Employment Data
```
X, y = build_t_feats(USAK,USAK_link,180,include_employ=False)
reg = Ridge()
reg, _ = fit_predict(reg, X, y)
```
As you can see the results are a lot less clear here. It looks as if there is no improved predictive power from including employment data.
## Rerun on all stocks
```
%%capture
filtered = companies.sort_values('max_corr',ascending=False)[['dataset_id', 'company_name','MarketCap', 'Sector', 'Symbol',
'max_corr', 'best_lag']]
filtered = filtered.query('(max_corr > 0.95) & (best_lag < -50)')
filtered = filtered[filtered.dataset_id != 868877].copy()
filtered = run_for_all(filtered)
plot_predicts(filtered)
```
As you can see except for some noise most stocks fall along the line **suggesting that there is no improvement in prediction accuracy when including LinkedIn data**.
| true |
code
| 0.517998 | null | null | null | null |
|
# LassoRegresion with Scale & Power Transformer
This Code template is for the regression analysis using Lasso Regression, the feature transformation technique Power Transformer and rescaling technique Scale in a pipeline. Lasso stands for Least Absolute Shrinkage and Selection Operator is a type of linear regression that uses shrinkage.
### Required Packages
```
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as se
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PowerTransformer
from sklearn.preprocessing import scale
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
warnings.filterwarnings('ignore')
```
### Initialization
Filepath of CSV file
```
#filepath
file_path = ""
```
List of features which are required for model training .
```
#x_values
features = []
```
Target feature for prediction.
```
#y_value
target = ''
```
### Data Fetching
Pandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.
We will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry.
```
df=pd.read_csv(file_path)
df.head()
```
### Feature Selections
It is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.
We will assign all the required input features to X and target/outcome to Y.
```
X=df[features]
Y=df[target]
```
### Data Preprocessing
Since the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes.
```
def NullClearner(df):
if(isinstance(df, pd.Series) and (df.dtype in ["float64","int64"])):
df.fillna(df.mean(),inplace=True)
return df
elif(isinstance(df, pd.Series)):
df.fillna(df.mode()[0],inplace=True)
return df
else:return df
def EncodeX(df):
return pd.get_dummies(df)
```
Calling preprocessing functions on the feature and target set.
```
x=X.columns.to_list()
for i in x:
X[i]=NullClearner(X[i])
X=EncodeX(X)
Y=NullClearner(Y)
X.head()
```
#### Correlation Map
In order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns.
```
f,ax = plt.subplots(figsize=(18, 18))
matrix = np.triu(X.corr())
se.heatmap(X.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax, mask=matrix)
plt.show()
```
### Data Splitting
The train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data.
```
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123)
```
## Data Rescaling
### Scale:
Standardize a dataset along any axis.
Center to the mean and component wise scale to unit variance.
for more... [click here](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.scale.html)
```
x_train = scale(x_train)
x_test = scale(x_test)
```
### Model
Linear Model trained with L1 prior as regularizer (aka the Lasso)
The Lasso is a linear model that estimates sparse coefficients. It is useful in some contexts due to its tendency to prefer solutions with fewer non-zero coefficients, effectively reducing the number of features upon which the given solution is dependent. For this reason Lasso and its variants are fundamental to the field of compressed sensing.
#### Model Tuning Parameter
> **alpha** -> Constant that multiplies the L1 term. Defaults to 1.0. alpha = 0 is equivalent to an ordinary least square, solved by the LinearRegression object. For numerical reasons, using alpha = 0 with the Lasso object is not advised.
> **selection** -> If set to ‘random’, a random coefficient is updated every iteration rather than looping over features sequentially by default. This (setting to ‘random’) often leads to significantly faster convergence especially when tol is higher than 1e-4.
> **tol** -> The tolerance for the optimization: if the updates are smaller than tol, the optimization code checks the dual gap for optimality and continues until it is smaller than tol.
> **max_iter** -> The maximum number of iterations.
#### Feature Transformation
Power Transformers are a family of parametric, monotonic transformations that are applied to make data more Gaussian-like. This is useful for modeling issues related to heteroscedasticity (non-constant variance), or other situations where normality is desired
[More on PowerTransformer module and parameters](https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PowerTransformer.html)
```
model=make_pipeline(PowerTransformer(),Lasso(random_state=123))
model.fit(x_train,y_train)
```
#### Model Accuracy
We will use the trained model to make a prediction on the test set.Then use the predicted value for measuring the accuracy of our model.
> **score**: The **score** function returns the coefficient of determination <code>R<sup>2</sup></code> of the prediction.
```
print("Accuracy score {:.2f} %\n".format(model.score(x_test,y_test)*100))
```
> **r2_score**: The **r2_score** function computes the percentage variablility explained by our model, either the fraction or the count of correct predictions.
> **mae**: The **mean abosolute error** function calculates the amount of total error(absolute average distance between the real data and the predicted data) by our model.
> **mse**: The **mean squared error** function squares the error(penalizes the model for large errors) by our model.
```
y_pred=model.predict(x_test)
print("R2 Score: {:.2f} %".format(r2_score(y_test,y_pred)*100))
print("Mean Absolute Error {:.2f}".format(mean_absolute_error(y_test,y_pred)))
print("Mean Squared Error {:.2f}".format(mean_squared_error(y_test,y_pred)))
```
#### Prediction Plot
First, we make use of a plot to plot the actual observations, with x_train on the x-axis and y_train on the y-axis.
For the regression line, we will use x_train on the x-axis and then the predictions of the x_train observations on the y-axis.
```
plt.figure(figsize=(14,10))
plt.plot(range(20),y_test[0:20], color = "green")
plt.plot(range(20),model.predict(x_test[0:20]), color = "red")
plt.legend(["Actual","prediction"])
plt.title("Predicted vs True Value")
plt.xlabel("Record number")
plt.ylabel(target)
plt.show()
```
##### Creator - Vikas Mishra, Github: [Profile](https://github.com/Vikaas08)
| true |
code
| 0.500366 | null | null | null | null |
|
# 0. Setup
```
# Imports
import arviz as az
import io
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc3 as pm
import scipy
import scipy.stats as st
import theano.tensor as tt
# Helper functions
def plot_golf_data(data, ax=None):
"""Utility function to standardize a pretty plotting of the golf data."""
if ax is None:
_, ax = plt.subplots(figsize=(10, 6))
bg_color = ax.get_facecolor()
ax.vlines(
data["distance"],
ymin=data["p_hat"] - data["se"],
ymax=data["p_hat"] + data["se"],
label=None,
)
ax.plot(data["distance"], data["p_hat"], 'o', mfc=bg_color, label=None)
ax.set_xlabel("Distance from hole")
ax.set_ylabel("Proportion of putts made")
ax.set_ylim(bottom=0, top=1)
ax.set_xlim(left=0)
ax.grid(True, axis='y', alpha=0.7)
return ax
```
# 1. Introduction
The following example is based on a study by [Gelman and Nolan (2002)](http://www.stat.columbia.edu/~gelman/research/published/golf.pdf), where they use Bayesian methods to estimate the accuracy of pro golfers with respect to putting.
The data comes from Don Berry's textbook *Statistics: A Bayesian Perspective* (1995) and describes the number of tries and successes of golf putting from a range of distances.
This example is also featured in the case studies sections of the [Stan](https://mc-stan.org/users/documentation/case-studies/golf.html) and [PyMC3](https://docs.pymc.io/notebooks/putting_workflow.html) documentation. This notebook is based heavily on these two sources.
## 1.1 Data
```
# Putting data from Berry (1995)
data = pd.read_csv("golf_1995.csv", sep=",")
data["p_hat"] = data["successes"] / data["tries"]
data
```
The authors start by estimating the standard error of the estimated probability of success for each distance in order to get a sense of how closely the model should be expected to fit the data, given by
$SE(\hat{p}_i) = \sqrt{\dfrac{\hat{p}_i(1 - \hat{p}_i)}{n}}$
```
def se(data):
"""Calculate standard error of estimator."""
p_hat = data["p_hat"]
n = data["tries"]
return np.sqrt(p_hat * (1 - p_hat) / n)
data["se"] = se(data)
ax = plot_golf_data(data)
ax.set_title("Overview of data from Berry (1995)")
plt.show()
```
# 2. Baseline: Logit model
As a baseline model, we fit a simple logistic regression to the data, where the probability is give as a function of the distance $x_j$ from the hole. The data generating process for $y_j$ is assumed to be a [binomial distribution](https://en.wikipedia.org/wiki/Binomial_distribution):
$$y_j \sim \text{Binomial}(n_j, p_j),\\
p_j = \dfrac{1}{1 + e^{-(a + bx_j)}}, \quad \text{for} j = 1 \ldots J,\\
a, b \sim \text{Normal}(0, 1)$$
```
def logit_model(data):
"""Logistic regression model."""
with pm.Model() as logit_binomial:
# Priors
a = pm.Normal('a', mu=0, tau=1)
b = pm.Normal('b', mu=0, tau=1)
# Logit link
link = pm.math.invlogit(a + b*data["distance"])
# Likelihood
success = pm.Binomial(
'success',
n=data["tries"],
p=link,
observed=data["successes"]
)
return logit_binomial
# Visualise model as graph
pm.model_to_graphviz(logit_model(data))
# Sampling from posterior
with logit_model(data):
logit_trace = pm.sample(10000, tune=1000)
# Retrieving summaries from models
pm.summary(logit_trace)
# Plotting posterior distributions of a, b
pm.plot_posterior(logit_trace)
plt.show()
```
Our estimates seem to make sense. As the distance $x_j \rightarrow 0$, it seems intuitive that the probability of success is high. Conversely, if $x_j \rightarrow \infty$, the probability of success should be close to zero.
```
p_test = lambda x: scipy.special.expit(2.224 - 0.255*x)
print(f" x = 0 --> p = {p_test(0)}")
print(f" x = really big --> p = {p_test(10**5)}")
```
## 2.1 Baseline: Posterior predictive samples
We plot the our probability model by drawing 50 samples from the posterior distribution of $a$ and $b$ and calculating the inverse logit (expit) for each sample:
```
# Plotting
ax = plot_golf_data(data)
distances = np.linspace(0, data["distance"].max(), 200)
# Plotting individual predicted sigmoids for 50 random draws of (a, b)
for idx in np.random.randint(0, len(logit_trace), 50):
post_logit = scipy.special.expit(logit_trace["a"][idx] + logit_trace["b"][idx] * distances)
ax.plot(
distances,
post_logit,
lw=1,
color="tab:orange",
alpha=.7,
)
# Plotting average prediction over all sampled (a, b)
logit_average = scipy.special.expit(
logit_trace["a"].reshape(-1, 1) + logit_trace["b"].reshape(-1, 1) * distances,
).mean(axis=0)
ax.plot(
distances,
logit_average,
label = "Inverse logit mean",
color="k",
linestyle="--",
)
ax.set_title("Fitted logistic regression")
ax.legend()
plt.show()
```
We see that:
* The posterior uncertainty is relatively low.
* The fit is OK, but we tend to overestimate the difficulty of making short putts and underestimate the probability of making long puts.
# 3. Modelling from first principles
Not satisfied with the logistic regression, we contact a golf pro who also happens to have a background in mathematics. She suggests that as an alternative, we could build a model from first principles and fit it to the data.
She provides us with the following sketch (from the [Stan case study](https://mc-stan.org/users/documentation/case-studies/golf.html)):
> The graph below shows a simplified sketch of a golf shot. The dotted line represents the angle within which the ball of radius r must be hit so that it falls within the hole of radius R. This threshold angle is $sin^{−1}\Bigg(\dfrac{R−r}{x}\Bigg)$. The graph, which is not to scale, is intended to illustrate the geometry of the ball needing to go into the hole.

If the angle is less (in absolute value) than the threshold, the show will go in the cup. The mathematically inclined golf pro suggests that we can assume that the putter will attempt to shoot perfectly straight, but that external factors will interfere with this goal. She suggests modelling this uncertainty using a normal distribution centered at 0 (i.e. assume that shots don't deviate systematically to the right or left) with some variance in angle (in radians) given by $\sigma_{\text{angle}}$.
Since our golf expert is also a expert mathematician, she provides us with an expression for the probability that the ball goes in the cup (which is the probability that the angle is less than the threshold):
$$p\Bigg(\vert\text{angle}\vert < sin^{−1}\Bigg(\dfrac{R−r}{x}\Bigg)\Bigg) = 2\Theta\Bigg(\dfrac{1}{\sigma_{\text{angle}}}sin^{−1}\Bigg(\dfrac{R−r}{x}\Bigg)\Bigg) - 1,$$
where $\Theta$ is the cumulative normal distribution function.
The full model is then given by
$$y_j \sim \text{Binomial}(n_j, p_j)\\
p_j = 2\Theta\Bigg(\dfrac{1}{\sigma_{\text{angle}}}sin^{−1}\Bigg(\dfrac{R−r}{x}\Bigg)\Bigg) - 1, \quad \text{for} j = 1 \ldots J.$$
Prior to fitting the model, our expert provides us with the appropriate measurements for the golf ball and cup radii. We also plot the probabilities given by the above expression for different values of $\sigma_{\text{angle}}$ to get a feel for the model:
```
def forward_angle_model(variance_of_shot, distance):
"""Geometry-based probabilities."""
BALL_RADIUS = (1.68 / 2) / 12
CUP_RADIUS = (4.25 / 2) / 12
return 2 * st.norm(0, variance_of_shot).cdf(np.arcsin((CUP_RADIUS - BALL_RADIUS) / distance)) - 1
# Plotting
variance_of_shot = (0.01, 0.02, 0.05, 0.1, 0.2, 1)
distances = np.linspace(0, data["distance"].max(), 200)
ax = plot_golf_data(data)
for sigma in variance_of_shot:
ax.plot(distances, forward_angle_model(sigma, distances), label=f"$\sigma$ = {sigma}")
ax.set_title("Model prediction for selected amounts of variance")
ax.legend()
plt.show()
def phi(x):
"""Calculates the standard normal CDF."""
return 0.5 + 0.5 * tt.erf(x / tt.sqrt(2.))
def angle_model(data):
"""Geometry-based model."""
BALL_RADIUS = (1.68 / 2) / 12
CUP_RADIUS = (4.25 / 2) / 12
with pm.Model() as angle_model:
variance_of_shot = pm.HalfNormal('variance_of_shot')
prob = 2 * phi(tt.arcsin((CUP_RADIUS - BALL_RADIUS) / data["distance"]) / variance_of_shot) - 1
prob_success = pm.Deterministic('prob_success', prob)
success = pm.Binomial('success', n=data["tries"], p=prob_success, observed=data["successes"])
return angle_model
# Plotting model as graph
pm.model_to_graphviz(angle_model(data))
```
## 3.1 Geometry-based model: Prior predictive checks
```
# Drawing 500 samples from the prior predictive distribution
with angle_model(data):
angle_prior = pm.sample_prior_predictive(500)
# Use these variances to sample an equivalent amount of random angles from a normal distribution
angle_of_shot = np.random.normal(0, angle_prior['variance_of_shot'])
distance = 20
# Calculate possible end positions
end_positions = np.array([
distance * np.cos(angle_of_shot),
distance * np.sin(angle_of_shot)
])
# Plotting
fig, ax = plt.subplots(figsize=(10, 6))
for endx, endy in end_positions.T:
ax.plot([0, endx], [0, endy], 'k-o', lw=1, mfc='w', alpha=0.1);
ax.plot(0, 0, 'o', color="tab:blue", label='Start', ms=10)
ax.plot(distance, 0, 'o', color="tab:orange", label='Goal', ms=10)
ax.set_title(f"Prior distribution of putts from {distance}ft away")
ax.legend()
plt.show()
```
## 3.2 Fitting model
```
# Draw samples from posterior distribution
with angle_model(data):
angle_trace = pm.sample(10000, tune=1000)
pm.summary(angle_trace)
# Plotting posterior distribution of angle variance
pm.plot_posterior(angle_trace["variance_of_shot"])
pm.forestplot(angle_trace)
plt.show()
```
## 3.3 Logistic regression vs. geometry-based model
```
# Plot model
ax = plot_golf_data(data)
distances = np.linspace(0, data["distance"].max(), 200)
for idx in np.random.randint(0, len(angle_trace), 50):
ax.plot(
distances,
forward_angle_model(angle_trace['variance_of_shot'][idx], distances),
lw=1,
color="tab:orange",
alpha=0.7,
)
# Average of angle model
ax.plot(
distances,
forward_angle_model(angle_trace['variance_of_shot'].mean(), distances),
label='Geometry-based model',
color="tab:blue",
)
# Compare with average of logit model
ax.plot(distances, logit_average, color="tab:green", label='Logit-binomial model (avg.)')
ax.set_title("Comparing the fit of geometry-based and logit-binomial model")
ax.set_ylim([0, 1.05])
ax.legend()
plt.show()
# Comparing models using WAIC (Watanabe-Akaike Information Criterion)
models = {
"logit": logit_trace,
"geometry": angle_trace,
}
pm.compare(models)
```
## 3.4 Geometry-based model: Posterior predictive check
```
# Randomly sample a sigma from the posterior distribution
variances = np.random.choice(angle_trace['variance_of_shot'].flatten())
# Randomly sample 500 angles based on sample from posterior
angle_of_shot = np.random.normal(0, variances, 500) # radians
distance = 20
# Calculate end positions
end_positions = np.array([
distance * np.cos(angle_of_shot),
distance * np.sin(angle_of_shot)
])
# Plotting
fig, ax = plt.subplots(figsize=(10, 6))
for endx, endy in end_positions.T:
ax.plot([0, endx], [0, endy], '-o', color="gray", lw=1, mfc='w', alpha=0.05);
ax.plot(0, 0, 'o', color="tab:blue", label='Start', ms=10)
ax.plot(distance, 0, 'o', color="tab:orange", label='Goal', ms=10)
ax.set_xlim(-21, 21)
ax.set_ylim(-21, 21)
ax.set_title(f"Posterior distribution of putts from {distance}ft.")
ax.legend()
plt.show()
```
# 4. Further work
The [official](https://docs.pymc.io/notebooks/putting_workflow.html) [docs](https://mc-stan.org/users/documentation/case-studies/golf.html) further extend the angle model by accounting for distance and distance plus dispersion. Furthermore, the [PyMC3 docs](https://docs.pymc.io/notebooks/putting_workflow.html) show how you can model the final position of the putt, given starting distance from the cup, e.g.:


The authors show how this information can be leveraged to
> [...] work out how many putts a player may need to take from a given distance. This can influence strategic decisions like trying to reach the green in fewer shots, which may lead to a longer first putt, vs. a more conservative approach. We do this by simulating putts until they have all gone in.

| true |
code
| 0.827932 | null | null | null | null |
|
# RoadMap 16 - Classification 3 - Training & Validating [Custom CNN, Custom Dataset]
```
import torch
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from torchvision import datasets
```
# [NOTE: - The network, transformation and training parameters are not suited for the dataset. Hence, the training does not converge]
# Steps to take
1. Create a network
- Arrange layers
- Visualize layers
- Creating loss function module
- Creating optimizer module [Set learning rates here]
2. Data prepraration
- Creating a data transformer
- Downloading and storing dataset
- Applying transformation
- Understanding dataset
- Loading the transformed dataset [Set batch size and number of parallel processors here]
3. Setting up data - plotters
4. Training
- Set Epoch
- Train model
5. Validating
- Overall-accuracy validation
- Class-wise accuracy validation
```
# 1.1 Creating a custom neural network
import torch.nn as nn
import torch.nn.functional as F
'''
Network arrangement
Input -> Conv1 -> Relu -> Pool -> Conv2 -> Relu -> Pool -> FC1 -> Relu -> FC2 -> Relu -> FC3 -> Output
'''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.relu = nn.ReLU() # Activation function
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.fc1 = nn.Linear(16 * 53 * 53, 120) # In-channels, Out-Channels
self.fc2 = nn.Linear(120, 84) # In-channels, Out-Channels
self.fc3 = nn.Linear(84, 2) # In-channels, Out-Channels
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = x.view(-1, 16 * 53 * 53) #Reshaping - Like flatten in caffe
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
net = Net()
net.cuda()
# 1.2 Visualizing network
from torchsummary import summary
print("Network - ")
summary(net, (3, 224, 224))
# 1.3. Creating loss function module
cross_entropy_loss = nn.CrossEntropyLoss()
# 1.4. Creating optimizer module
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 2.1. Creating data trasnformer
data_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
```
### 2.2 Storing downloaded dataset
Data storage directory
[NOTE: Directory and File names can be anything]
Parent Directory [cat_dog]
|
|----Train
| |
| |----Class1 [cat]
| | |----img1.png
| | |----img2.png
| |----Class2 [dog]
| | |----img1.png
| |----img2.png
|-----Val
| |
| |----Class1 [cat]
| | |----img1.png
| | |----img2.png
| |----Class2 [dog]
| | |----img1.png
| | |----img2.png
```
# 2.2. Applying transformations simultaneously
trainset = datasets.ImageFolder(root='cat_dog/train',
transform=data_transform)
valset = datasets.ImageFolder(root='cat_dog/val',
transform=data_transform)
print(dir(trainset))
# 2.3. - Understanding dataset
print("Number of training images - ", len(trainset.imgs))
print("Number of testing images - ", len(valset.imgs))
print("Classes - ", trainset.classes)
# 2.4. - Loading the transformed dataset
batch = 4
parallel_processors = 3
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch,
shuffle=True, num_workers=parallel_processors)
valloader = torch.utils.data.DataLoader(valset, batch_size=batch,
shuffle=False, num_workers=parallel_processors)
# Class list
classes = tuple(trainset.classes)
# 3. Setting up data plotters
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, labels = next(iter(trainloader))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[classes[x] for x in labels])
from tqdm.notebook import tqdm
# 4. Training
num_epochs = 2
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
pbar = tqdm(total=len(trainloader))
for i, data in enumerate(trainloader):
pbar.update();
# get the inputs
inputs, labels = data
inputs = inputs.cuda()
labels = labels.cuda()
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = cross_entropy_loss(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 10 == 9: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 5.1 Overall-accuracy Validation
correct = 0
total = 0
with torch.no_grad():
for data in valloader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
# 5.2 Classwise-accuracy Validation
class_correct = list(0. for i in range(2))
class_total = list(0. for i in range(2))
with torch.no_grad():
for data in valloader:
images, labels = data
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(len(c)):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(2):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
```
## Author - Tessellate Imaging - https://www.tessellateimaging.com/
## Monk Library - https://github.com/Tessellate-Imaging/monk_v1
Monk is an opensource low-code tool for computer vision and deep learning
### Monk features
- low-code
- unified wrapper over major deep learning framework - keras, pytorch, gluoncv
- syntax invariant wrapper
### Enables
- to create, manage and version control deep learning experiments
- to compare experiments across training metrics
- to quickly find best hyper-parameters
### At present it only supports transfer learning, but we are working each day to incorporate
- GUI based custom model creation
- various object detection and segmentation algorithms
- deployment pipelines to cloud and local platforms
- acceleration libraries such as TensorRT
- preprocessing and post processing libraries
## To contribute to Monk AI or Pytorch RoadMap repository raise an issue in the git-repo or dm us on linkedin
- Abhishek - https://www.linkedin.com/in/abhishek-kumar-annamraju/
- Akash - https://www.linkedin.com/in/akashdeepsingh01/
| true |
code
| 0.822777 | null | null | null | null |
|
## Some fundamental elements of programming III
### Understanding and creating correlated datasets and how to create functions
As we said before, the core of data science is computer programming.
To really explore data, we need to be able to write code to
(1) wrangle or even generate data that has the properties needed for analysis and
(2) do actual data analysis and visualization.
If data science didn't involve programming – if it only involved clicking buttons in a statistics program like SPSS – it wouldn't be called data *science*. In fact, it wouldn't even be a "thing" at all.
Learning goals:
- Understand how to generate correlated variables.
- More indexing
- More experiments with loops
#### Generate correlated datasets
In thispart of the tutorial we will learn how generate datasets that are 'related.' While doing that we will practice a few things learned recently in previous tutorials:
- Plotting with matplotlib
- generating numpy arrays
- indexing into arrays
- using `while` loops
First thing first, we will import the basic libraries we need.
```
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
```
After that we will create a few datasets. More specifically, we will create `n` datasets each called `x` (say 5 datasets, where `n=5`). Each dataset will have the length of `m` (where for example, `m` could be 100), this means for example that each dataset will have the shape of (m,1) or in our example (100,1).
After that, we will create another group of `n` datasets called `y` of the same shape of `x`. Each one of the `y` datasets will have a corresponding `x` dataset that it will be correlated with.
This means that for each dataset in `x` there will be a dataset in `y` that is correlated with it.
Let's get started with a hands on method. Forst we will make the example of a single dataset `x` and a correlated dataset `y`.
```
# We first build the dataset `x`,
# we will use our standard method
# based on randn
m = 1000
mu = 5
sd = 1
x = mu + sd*np.random.randn(m,1)
# let take a look at it
plt.hist(x, 60)
```
OK. After generating the first dataset we will generate a second dataset, let's call it `y`. This second dataset will be correlated to the first.
To generate a dataset correlated to `x` we will indeed use `x` as our base for the data and add on top of `x` a small amount of noise, let's call it `noise`. `noise` represents the small (or larger) difference between `x` and `y`.
```
err = np.random.randn(m,1)
y = x + err
plt.hist(y,60)
```
OK. The two histograms seem similar (similar range and height), but it is difficult to judge if `x` and `y` are indeed correlated. To do that we need to make a scatter plot.
`matplotlib` has a convenient function for scatter plots, `plt.scatter()`, we will use that function to take a look at whether the two datasets are correlated.
```
plt.scatter(x,y)
```
Great, the symbols should be aligned along the major diagonal. This means that they are indeed correlated. To get to understand more what we did above, let's think about `err`.
Imagine, if there were no error, e.g., no `err`. That would mean that there would be no difference between `x` and `y`. Literally, the two datasets would be identical.
We can do that with the code above by setting `err` to `0`.
```
err = 0
y = x + err
plt.scatter(x,y)
```
The symbols should all lay on the major diagonal. So, `err` effectively controls the level of correlation between `x` and `y`. So if we set it to something small, in other words if we add only a small amount of error then the two arrays (`x` and `y`) would be very similar. For example, let's try setting it up to 10% of the original `err`.
```
err = np.random.randn(m,1);
err = err*0.1 # 0.1 -> scaling factor
y = x + err
plt.scatter(x,y)
```
OK. It should have worked. The error added is not large, the symbols should lay almost on the diagonal, but not quite.
As we increase the `err` the symbols should move away from the diagonal.
```
err = np.random.randn(m,1);
scaling_factor = 0.9
err = err*scaling_factor
y = x + err
plt.scatter(x,y)
```
One way to think about the scaling factor and `err` is that they are related to correlation. Indeed, they are not directly related to correlation (not a one-to-one relationship, but a proxy).
The scaling factor is inversely related to correlation because as the scaling factor increases the correlation decreases. Furthermore, they are not directly related to correlation because they both depend on a couple of variables, for example, the variance of the distributions (both `err` and `x` will affect the relationship between the correlation and the scaling factor).
Python has a method to generate couples of correlated arrays. We will now briefly explore it, but leave a deeper dive on each function to you. You are suggested to further explore the code below and its implications. It might come helpful to us later down the road, you never know!
#### A more principled way to make correlated datasets
NumPy has a function called `multivariate_normal` that generates pairs of correlated datasets. The correlation values can be specified conveniently. A little bit of thinking is required, though. The function uses the covariance matrix. The covariance matrix is composed of 4 numbers. Two of the numbers describe the variances of the two datasamples we want to generate. The other two values describe the correlation between the samples and are generally called `covariances` (co-variations or co-relations).
```
from numpy.random import multivariate_normal # we import the function
x_mu = 0; # we set up the mean of the first set of data points
y_mu = 0; # we set up the mean of the second sample
x_var = 1; # the variance of the first sample
y_var = 1; # the variance of the second sample
cov = 0.9; # this is the covariance (can be thought of as correlation)
# the function multivariate_normal will need a matrix to control
# the relation between the samples, this matrix is called covariance matrix
cov_m = [[x_var, cov],
[cov, y_var]]
# we now create the two data sets by setting the the proper
# means and passing the covariance matrix, we also pass the
# requested size of the sample
data = multivariate_normal([x_mu, y_mu], cov_m, size=1000)
# We can plot the two data sets
x, y = data[:,0], data[:,1]
plt.scatter(x, y)
```
#### Creating many correlated datasets
Imagine now if we were asked to create a series of correlated datasets. Not one, nottwo, more than that.
Once the basic code used to build one is known. The rest of the datasets can be generated reusing the same code and putting the code inside a loop. Below we will show how to create 5 datasets using a `while` loop.
```
counter = 0;
n_datasets = 5;
siz_datasets = 1000;
x_mu = 1; # mean of the first dataset
y_mu = 1; # mean of the second dataset
x_var = 2; # the variance of the first dataset
y_var = 2; # the variance of the second dataset
cov = 0.85; # this is the covariance (can be thought of as correlation)
# covariance matrix
cov_m = [[x_var, cov],
[cov, y_var]]
while counter < n_datasets :
data = multivariate_normal([x_mu, y_mu],
cov_m,
size=siz_datasets)
x, y = data[:,0], data[:,1]
counter = counter + 1
# Make a plot, show it, wait some time
print("Plotting dataset: ", counter)
plt.scatter(x, y);
plt.show() ;
plt.pause(0.05)
else:
print("DONE Plotting datasets!")
```
| true |
code
| 0.700716 | null | null | null | null |
|
# Modules
Python has a way to put definitions in a file so they can easily be reused.
Such files are called a modules. You can define your own module (for instance see [here](https://docs.python.org/3/tutorial/modules.html)) how to do this but in this course we will only discuss how to use
existing modules as they come with python as the [python standard library](https://docs.python.org/3.9/tutorial/stdlib.html?highlight=library) or as third party libraries as they for instance are distributed
through [anaconda](https://www.anaconda.com/) or your Linux distribution or you can install trough `pip` or from source.
Definitions from a module can be imported into your jupyter notebook, your python script, and into other modules.
The module is imported using the import statement. Here we import the mathematics library from the python standard library:
```
import math
```
You can find a list of the available functions, variables and classes using the `dir` method:
```
dir(math)
```
A particular function (or class or constant) can be called in the form `<module name>.<function name>`:
```
math.exp(1)
```
Documentation of a function (or class or constant) can be obtained using the `help` function (if the developer has written it):
```
help(math.exp)
```
You can also import a specific function (or a set of functions) so you can directly use them without a prefix:
```
from cmath import exp
exp(1j)
```
In python terminology that means that - in this case - the `exp` function is imported into the main *name space*.
This needs to be applied with care as existing functions (or class definition) with identical names are overwritten.
For instance the `math` and the `cmath` module have a function `exp`. Importing both will create a problem
in the main name space.
If you are conficdent in what you are doing you can import all functions and class definitions into the main name space:
```
from cmath import *
cos(1.)
```
Modules can contain submodules. The functions are then
accessed `<module name>.<sub-module name>.<function name>`:
```
import os
os.path.exists('FileHandling.ipynb')
```
In these cases it can be useful to use an alias to make the code easier to read:
```
import os.path as pth
pth.exists('FileHandling.ipynb')
```
# More on printing
Python provides a powerful way of formatting output using formatted string.
Basicly the ideas is that in a formatted string marked by a leading 'f' variable
names are replaced by the corresponding variable values. Here comes an example:
```
x, y = 2.124, 3
f"the value of x is {x} and of y is {y}."
```
python makes guesses on how to format the value of the variable but you can also be specific if values should be shown in a specific way. here we want to show `x` as a floating point numbers with a scientific number representation indicated by `e` and `y` to be shown as an integer indicated by `d`:
```
f"x={x} x={x:10f} x={x:e} y={y:d}"
```
More details on [Formatted string literals](https://docs.python.org/3.7/reference/lexical_analysis.html#index-24)
Formatted strings are used to prettify output when printing:
```
print(f"x={x:10f}")
print(f"y={y:10d}")
```
An alternative way of formatting is the `format` method of a string. You can use the
positional arguments:
```
guest='John'
'Hi {0}, welcome to {1}!"'.format(guest, 'Brisbane')
```
Or keyword arguments:
```
'Hi {guest}, welcome to {place}!'.format(guest='Mike', place='Brisbane')
```
and a combination of positional arguments and keyword arguments:
```
'Hi {guest}, welcome to {1}! Enjoy your stay for {0} days.'.format(10, 'Brisbane', guest="Bob")
```
You can also introduce some formatting on how values are represented:
```
'Hi {guest}, welcome to {0}! Enjoy your stay for {1:+10d} days.'.format('Brisbane', 10, guest="Bob")
```
More details in particular for formating numbers are found [here](https://docs.python.org/3.9/library/string.html).
# Writing and Reading files
To open a file for reading or writing use the `open` function. `open()`
returns a file object, and is most commonly used with two arguments: open(filename, mode).
```
outfile=open("myRicker.csv", 'wt')
```
It is commonly used with two arguments: `open(filename, mode)` where the `mode` takes the values:
- `w` open for writing. An existing file with the same name will be erased.
- `a` opens the file for appending; any data written to the file is automatically added to the end.
- `r` opens the file for both reading only.
By default text mode `t` is used that means, you read and write strings from and to the file, which are encoded in a specific encoding. `b` appended to the mode opens the file in binary mode: now the data is read and written in the form of bytes objects.
We want to write some code that writes the `Ricker` wavelet of a period of
`length` and given frequency `f` to the files `myRicker.csv` in the comma-separated-value (CSV) format. The time is incremented by `dt`.
```
length=0.128
f=25
dt=0.001
def ricker(t, f):
"""
return the value of the Ricker wavelet at time t for peak frequency f
"""
r = (1.0 - 2.0*(math.pi**2)*(f**2)*(t**2)) * math.exp(-(math.pi**2)*(f**2)*(t**2))
return r
t=-length/2
n=0
while t < length/2:
outfile.write("{0}, {1}\n".format(t, ricker(t, f)))
t+=dt
n+=1
print("{} records writen to {}.".format(n, outfile.name))
```
You can download/open the file ['myRicker.csv'](myRicker.csv).
** Notice ** There is an extra new line character `\n` at the of string in the `write` statement. This makes sure that separate rows can be identified in the file.
Don't forget to close the file at the end:
```
outfile.close()
```
Now we want to read this back. First we need to open the file for reading:
```
infile=open("myRicker.csv", 'r')
```
We then can read the entire file as a string:
```
content=infile.read()
content[0:100]
```
In some cases it is more easier to read the file row-by-row. First we need to move back to the beginning of the file:
```
infile.seek(0)
```
Now we read the file line by line. Each line is split into the time and wavelet value which are
collected as floats in two lists `times` and `ricker`:
```
infile.seek(0)
line=infile.readline()
times=[]
ricker=[]
n=0
while len(line)>0:
a, b=line.split(',')
times.append(float(a))
ricker.append(float(b))
line=infile.readline()
n+=1
print("{} records read from {}.".format(n, infile.name))
```
Notice that the end of file is reached when the read line is empty (len(line)=0). Then the loop is exited.
```
time[:10]
```
# JSON Files
JSON files (JavaScript Object Notation) is an open-standard file format that uses human-readable text to transmit data objects consisting of dictionaries and lists. It is a very common data format, with a diverse range of applications in particular when exchanging data between web browsers and web services.
A typical structure that is saved in JSON files are combinations of lists and dictionaries
with string, integer and float entries. For instance
```
course = [ { "name": "John", "age": 30, "id" : 232483948} ,
{ "name": "Tim", "age": 45, "id" : 3246284632} ]
course
```
The `json` module provides the necessary functionality to write `course` into file, here `course.json`:
```
import json
json.dump(course, open("course.json", 'w'), indent=4)
```
You can access the [course.json](course.json). Depending on your web browser the file is identified as JSON file
and presented accordingly.
We can easily read the file back using the `load` method:
```
newcourse=json.load(open("course.json", 'r'))
```
This recovers the original list+dictionary structure:
```
newcourse
```
We can recover the names of the persons in the course:
```
[ p['name'] for p in newcourse ]
```
We can add new person to `newcourse`:
```
newcourse.append({'age': 29, 'name': 'Jane', 'studentid': 2643746328})
newcourse
```
# Visualization
We would like to plot the Ricker wavelet.
The `matplotlib` library provides a convenient, flexible and powerful tool for visualization at least for 2D data sets. Here we can give only a very brief introduction with more functionality being presented as the course evolves.
For a comprehensive documentation and list of examples we refer to the [matplotlib web page](https://matplotlib.org).
Here we use the `matplotlib.pyplot` library which is a collection of command style functions but there
is also a more general API which gives a reacher functionality:
```
#%matplotlib notebook
import matplotlib.pyplot as plt
```
It is very easy to plot data point we have read:
```
plt.figure(figsize=(8,5))
plt.scatter(times, ricker)
```
We can also plot this as a function rather than just data point:
```
plt.figure(figsize=(8,5))
plt.plot(times, ricker)
```
Let's use proper labeling of the horizontal axis:
```
plt.xlabel('time [sec]')
```
and for the vertical axis:
```
plt.ylabel('aplitude')
```
And maybe a title:
```
plt.title('Ricker wavelet for frequency f = 25 hz')
```
We can also change the line style, eg. red doted line:
```
plt.figure(figsize=(8,5))
plt.plot(times, ricker, 'r:')
plt.xlabel('time [sec]')
plt.ylabel('aplitude')
```
We can put different data sets or representations into the plot:
```
plt.figure(figsize=(8,5))
plt.plot(times, ricker, 'r:', label="function")
plt.scatter(times, ricker, c='b', s=10, label="data")
plt.xlabel('time [sec]')
plt.ylabel('aplitude')
plt.legend()
```
You can also add grid line to make the plot easier to read:
```
plt.grid(True)
```
Save the plot to a file:
```
plt.savefig("ricker.png")
```
see [ricker.png](ricker.png) for the file.
| true |
code
| 0.375807 | null | null | null | null |
|
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
#from sklearn.metrics import precision_recall_curve
#from sklearn.metrics import plot_precision_recall_curve
from sklearn.metrics import average_precision_score
import matplotlib.pyplot as plt
%matplotlib inline
```
# demonstration of vectorizer in Scikit learn
```
# word counts
# list of text documents
text_test = ["This is a test document","this is a second text","and here is a third text", "this is a dum text!"]
# create the transform
vectorizer_test = CountVectorizer()
# tokenize and build vocab
vectorizer_test.fit(text_test)
# summarize
print(vectorizer_test.vocabulary_)
# encode document
vector_test = vectorizer_test.transform(text_test)
# show encoded vector
print(vector_test.toarray())
```
# Spam/Ham dataset
```
# import data from TSV
sms_data=pd.read_csv('SMSSpamCollection.txt', sep='\t')
sms_data.head()
# create a new column with inferred class
def f(row):
if row['Label'] == "ham":
val = 1
else:
val = 0
return val
sms_data['Class'] = sms_data.apply(f, axis=1)
sms_data.head()
vectorizer = CountVectorizer(
analyzer = 'word',
lowercase = True,
)
features = vectorizer.fit_transform(
sms_data['Text']
)
# split X and Y
X = features.toarray()
Y= sms_data['Class']
# split training and testing
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,test_size=0.20, random_state=1)
log_model = LogisticRegression(penalty='l2', solver='lbfgs', class_weight='balanced')
log_model = log_model.fit(X_train, Y_train)
# make predictions
Y_pred = log_model.predict(X_test)
# make predictions
pred_df = pd.DataFrame({'Actual': Y_test, 'Predicted': Y_pred.flatten()})
pred_df.head()
# compute accuracy of the spam filter
print(accuracy_score(Y_test, Y_pred))
# compute precision and recall
average_precision = average_precision_score(Y_test, Y_pred)
print('Average precision-recall score: {0:0.2f}'.format(
average_precision))
# precision-recall curve
disp = plot_precision_recall_curve(log_model, X_test, Y_test)
disp.ax_.set_title('2-class Precision-Recall curve: '
'AP={0:0.2f}'.format(average_precision))
# look at the words learnt and their coefficients
coeff_df = pd.DataFrame({'coeffs': log_model.coef_.flatten(), 'Words': vectorizer.get_feature_names()}, )
# Words with highest coefficients -> predictive of 'Ham'
coeff_df.nlargest(10, 'coeffs')
# Words with highest coefficients -> predictive of 'Spam'
coeff_df.nsmallest(10, 'coeffs')
```
# Upload review dataset
```
# import data from TSV
rev_data=pd.read_csv('book_reviews.csv')
rev_data.head()
# fix issues with format text
reviews = rev_data['reviewText'].apply(lambda x: np.str_(x))
# create a new column with inferred class
# count words in texts
# split X and Y
# split training and testing
# fit model (this takes a while)
# make predictions
# compute accuracy of the sentiment analysis
# compute precision and recall
# precision-recall curve
# look at the words learnt and their coefficients
coeff_df = pd.DataFrame({'coeffs': log_model.coef_.flatten(), 'Words': vectorizer.get_feature_names()}, )
# Words with highest coefficients -> predictive of 'good reviews'
coeff_df.nlargest(10, 'coeffs')
# Words with highest coefficients -> predictive of 'bad reviews'
coeff_df.nsmallest(10, 'coeffs')
```
| true |
code
| 0.541348 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/iamsoroush/DeepEEGAbstractor/blob/master/cv_hmdd_4s_proposed_gap.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#@title # Clone the repository and upgrade Keras {display-mode: "form"}
!git clone https://github.com/iamsoroush/DeepEEGAbstractor.git
!pip install --upgrade keras
#@title # Imports {display-mode: "form"}
import os
import pickle
import sys
sys.path.append('DeepEEGAbstractor')
import numpy as np
from src.helpers import CrossValidator
from src.models import SpatioTemporalWFB, TemporalWFB, TemporalDFB, SpatioTemporalDFB
from src.dataset import DataLoader, Splitter, FixedLenGenerator
from google.colab import drive
drive.mount('/content/gdrive')
#@title # Set data path {display-mode: "form"}
#@markdown ---
#@markdown Type in the folder in your google drive that contains numpy _data_ folder:
parent_dir = 'soroush'#@param {type:"string"}
gdrive_path = os.path.abspath(os.path.join('gdrive/My Drive', parent_dir))
data_dir = os.path.join(gdrive_path, 'data')
cv_results_dir = os.path.join(gdrive_path, 'cross_validation')
if not os.path.exists(cv_results_dir):
os.mkdir(cv_results_dir)
print('Data directory: ', data_dir)
print('Cross validation results dir: ', cv_results_dir)
#@title ## Set Parameters
batch_size = 80
epochs = 50
k = 10
t = 10
instance_duration = 4 #@param {type:"slider", min:3, max:10, step:0.5}
instance_overlap = 1 #@param {type:"slider", min:0, max:3, step:0.5}
sampling_rate = 256 #@param {type:"number"}
n_channels = 20 #@param {type:"number"}
task = 'hmdd'
data_mode = 'cross_subject'
#@title ## Spatio-Temporal WFB
model_name = 'ST-WFB-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = SpatioTemporalWFB(input_shape,
model_name=model_name)
scores = validator.do_cv(model_obj,
data,
labels)
#@title ## Temporal WFB
model_name = 'T-WFB-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = TemporalWFB(input_shape,
model_name=model_name)
scores = validator.do_cv(model_obj,
data,
labels)
#@title ## Spatio-Temporal DFB
model_name = 'ST-DFB-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = SpatioTemporalDFB(input_shape,
model_name=model_name)
scores = validator.do_cv(model_obj,
data,
labels)
#@title ## Spatio-Temporal DFB (Normalized Kernels)
model_name = 'ST-DFB-NK-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = SpatioTemporalDFB(input_shape,
model_name=model_name,
normalize_kernels=True)
scores = validator.do_cv(model_obj,
data,
labels)
#@title ## Temporal DFB
model_name = 'T-DFB-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = TemporalDFB(input_shape,
model_name=model_name)
scores = validator.do_cv(model_obj,
data,
labels)
#@title ## Temporal DFB (Normalized Kernels)
model_name = 'T-DFB-NK-GAP'
train_generator = FixedLenGenerator(batch_size=batch_size,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=True)
test_generator = FixedLenGenerator(batch_size=8,
duration=instance_duration,
overlap=instance_overlap,
sampling_rate=sampling_rate,
is_train=False)
params = {'task': task,
'data_mode': data_mode,
'main_res_dir': cv_results_dir,
'model_name': model_name,
'epochs': epochs,
'train_generator': train_generator,
'test_generator': test_generator,
't': t,
'k': k,
'channel_drop': True}
validator = CrossValidator(**params)
dataloader = DataLoader(data_dir,
task,
data_mode,
sampling_rate,
instance_duration,
instance_overlap)
data, labels = dataloader.load_data()
input_shape = (sampling_rate * instance_duration,
n_channels)
model_obj = TemporalDFB(input_shape,
model_name=model_name,
normalize_kernels=True)
scores = validator.do_cv(model_obj,
data,
labels)
```
| true |
code
| 0.63077 | null | null | null | null |
|
# Sonic The Hedgehog 1 with Advantage Actor Critic
## Step 1: Import the libraries
```
import time
import retro
import random
import torch
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
from IPython.display import clear_output
import math
%matplotlib inline
import sys
sys.path.append('../../')
from algos.agents import A2CAgent
from algos.models import ActorCnn, CriticCnn
from algos.preprocessing.stack_frame import preprocess_frame, stack_frame
```
## Step 2: Create our environment
Initialize the environment in the code cell below.
```
env = retro.make(game='SonicTheHedgehog-Genesis', state='GreenHillZone.Act1', scenario='contest')
env.seed(0)
# if gpu is to be used
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Device: ", device)
```
## Step 3: Viewing our Enviroment
```
print("The size of frame is: ", env.observation_space.shape)
print("No. of Actions: ", env.action_space.n)
env.reset()
plt.figure()
plt.imshow(env.reset())
plt.title('Original Frame')
plt.show()
possible_actions = {
# No Operation
0: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# Left
1: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
# Right
2: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
# Left, Down
3: [0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0],
# Right, Down
4: [0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0],
# Down
5: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
# Down, B
6: [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
# B
7: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}
```
### Execute the code cell below to play Pong with a random policy.
```
def random_play():
score = 0
env.reset()
for i in range(200):
env.render()
action = possible_actions[np.random.randint(len(possible_actions))]
state, reward, done, _ = env.step(action)
score += reward
if done:
print("Your Score at end of game is: ", score)
break
env.reset()
env.render(close=True)
random_play()
```
## Step 4:Preprocessing Frame
```
plt.figure()
plt.imshow(preprocess_frame(env.reset(), (1, -1, -1, 1), 84), cmap="gray")
plt.title('Pre Processed image')
plt.show()
```
## Step 5: Stacking Frame
```
def stack_frames(frames, state, is_new=False):
frame = preprocess_frame(state, (1, -1, -1, 1), 84)
frames = stack_frame(frames, frame, is_new)
return frames
```
## Step 6: Creating our Agent
```
INPUT_SHAPE = (4, 84, 84)
ACTION_SIZE = len(possible_actions)
SEED = 0
GAMMA = 0.99 # discount factor
ALPHA= 0.0001 # Actor learning rate
BETA = 0.0005 # Critic learning rate
UPDATE_EVERY = 100 # how often to update the network
agent = A2CAgent(INPUT_SHAPE, ACTION_SIZE, SEED, device, GAMMA, ALPHA, BETA, UPDATE_EVERY, ActorCnn, CriticCnn)
```
## Step 7: Watching untrained agent play
```
env.viewer = None
# watch an untrained agent
state = stack_frames(None, env.reset(), True)
for j in range(200):
env.render(close=False)
action, _, _ = agent.act(state)
next_state, reward, done, _ = env.step(possible_actions[action])
state = stack_frames(state, next_state, False)
if done:
env.reset()
break
env.render(close=True)
```
## Step 8: Loading Agent
Uncomment line to load a pretrained agent
```
start_epoch = 0
scores = []
scores_window = deque(maxlen=20)
```
## Step 9: Train the Agent with Actor Critic
```
def train(n_episodes=1000):
"""
Params
======
n_episodes (int): maximum number of training episodes
"""
for i_episode in range(start_epoch + 1, n_episodes+1):
state = stack_frames(None, env.reset(), True)
score = 0
# Punish the agent for not moving forward
prev_state = {}
steps_stuck = 0
timestamp = 0
while timestamp < 10000:
action, log_prob, entropy = agent.act(state)
next_state, reward, done, info = env.step(possible_actions[action])
score += reward
timestamp += 1
# Punish the agent for standing still for too long.
if (prev_state == info):
steps_stuck += 1
else:
steps_stuck = 0
prev_state = info
if (steps_stuck > 20):
reward -= 1
next_state = stack_frames(state, next_state, False)
agent.step(state, log_prob, entropy, reward, done, next_state)
state = next_state
if done:
break
scores_window.append(score) # save most recent score
scores.append(score) # save most recent score
clear_output(True)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_window)), end="")
return scores
scores = train(1000)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
```
## Step 10: Watch a Smart Agent!
```
env.viewer = None
# watch an untrained agent
state = stack_frames(None, env.reset(), True)
for j in range(10000):
env.render(close=False)
action, _, _ = agent.act(state)
next_state, reward, done, _ = env.step(possible_actions[action])
state = stack_frames(state, next_state, False)
if done:
env.reset()
break
env.render(close=True)
```
| true |
code
| 0.522811 | null | null | null | null |
|
# Objected-Oriented Simulation
Up to this point we have been using Python generators and shared resources as the building blocks for simulations of complex systems. This can be effective, particularly if the individual agents do not require access to the internal state of other agents. But there are situations where the action of an agent depends on the state or properties of another agent in the simulation. For example, consider this discussion question from the Grocery store checkout example:
>Suppose we were to change one or more of the lanes to a express lanes which handle only with a small number of items, say five or fewer. How would you expect this to change average waiting time? This is a form of prioritization ... are there other prioritizations that you might consider?
The customer action depends the item limit parameter associated with a checkout lane. This is a case where the action of one agent depends on a property of another. The shared resources builtin to the SimPy library provide some functionality in this regard, but how do add this to the simulations we write?
The good news is that Python offers a rich array of object oriented programming features well suited to this purpose. The SymPy documentation provides excellent examples of how to create Python objects for use in SymPy. The bad news is that object oriented programming in Python -- while straightforward compared to many other programming languages -- constitutes a steep learning curve for students unfamiliar with the core concepts.
Fortunately, since the introduction of Python 3.7 in 2018, the standard libraries for Python have included a simplified method for creating and using Python classes. Using [dataclass](https://realpython.com/python-data-classes/), it easy to create objects for SymPy simulations that retain the benefits of object oriented programming without all of the coding overhead.
The purpose of this notebook is to introduce the use of `dataclass` in creating SymPy simulations. To the best of the author's knowledge, this is a novel use of `dataclass` and the only example of which the author is aware.
## Installations and imports
```
!pip install sympy
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import random
import simpy
import pandas as pd
from dataclasses import dataclass
import sys
print(sys.version)
```
Additional imports are from the `dataclasses` library that has been part of the standard Python distribution since version 3.7. Here we import `dataclass` and `field`.
```
from dataclasses import dataclass, field
```
## Introduction to `dataclass`
Tutorials and additional documentation:
* [The Ultimate Guide to Data Classes in Python 3.7](https://realpython.com/python-data-classes/): Tutorial article from ReaalPython.com
* [dataclasses — Data Classes](https://docs.python.org/3/library/dataclasses.html): Official Python documentation.
* [Data Classes in Python](https://towardsdatascience.com/data-classes-in-python-8d1a09c1294b): Tutorial from TowardsDataScience.com
### Creating a `dataclass`
A `dataclass` defines a new class of Python objects. A `dataclass` object takes care of several routine things that you would otherwise have to code, such as creating instances of an object, testing for equality, and other aspects.
As an example, the following cell shows how to define a dataclass corresponding to a hypothetical Student object. The Student object maintains data associated with instances of a student. The dataclass also defines a function associated with the object.
```
from dataclasses import dataclass
@dataclass
class Student():
name: str
graduation_class: int
dorm: str
def print_name(self):
print(f"{self.name} (Class of {self.graduation_class})")
```
Let's create an instance of the Student object.
```
sam = Student("Sam Jones", 2024, "Alumni")
```
Let's see how the `print_name()` function works.
```
sam.print_name()
```
The next cell shows how to create a list of students, and how to iterate over a list of students.
```
# create a list of students
students = [
Student("Sam Jones", 2024, "Alumni"),
Student("Becky Smith", 2023, "Howard"),
]
# iterate over the list of students to print all of their names
for student in students:
student.print_name()
print(student.dorm)
```
Here are a few details you need to use `dataclass` effectively:
* The `class` statement is standard statement for creating a new class of Python objects. The preceding `@dataclass` is a Python 'decorator'. Decorators are Python functions that modify the behavior of subsequent statements. In this case, the `@dataclass` decorator modifies `class` to provide a streamlined syntax for implementing classes.
* A Python class names begin with a capital letter. In this case `Student` is the class name.
* The lines following the the class statement declare parameters that will be used by the new class. The parameters can be specified when you create an instance of the dataclass.
* Each paraameter is followed by type 'hint'. Commonly used type hints are `int`, `float`, `bool`, and `str`. Use the keyword `any` you don't know or can't specify a particular type. Type hints are actually used by type-checking tools and ignored by the python interpreter.
* Following the parameters, write any functions or generators that you may wish to define for the new class. To access variables unique to an instance of the class, preceed the parameter name with `self`.
### Specifying parameter values
There are different ways of specifying the parameter values assigned to an instance of a dataclass. Here are three particular methods:
* Specify the parameter value when creating a new instance. This is what was done in the Student example above.
* Provide a default values determined when the dataclass is defined.
* Provide a default_factory method to create a parameter value when an instance of the dataclass is created.
#### Specifying a parameter value when creating a new instance
Parameter values can be specified when creating an instance of a dataclass. The parameter values can be specified by position or by name as shown below.
```
from dataclasses import dataclass
@dataclass
class Student():
name: str
graduation_year: int
dorm: str
def print_name(self):
print(f"{self.name} (Class of {self.graduation_year})")
sam = Student("Sam Jones", 2031, "Alumni")
sam.print_name()
gilda = Student(name="Gilda Radner", graduation_year=2030, dorm="Howard")
gilda.print_name()
```
#### Setting default parameter values
Setting a default value for a parameter can save extra typing or coding. More importantly, setting default values makes it easier to maintain and adapt code for other applications, and is a convenient way to handle missing data.
There are two ways to set default parameter values. For str, int, float, bool, tuple (the immutable types in Python), a default value can be set using `=` as shown in the next cell.
```
from dataclasses import dataclass
@dataclass
class Student():
name: str = None
graduation_year: int = None
dorm: str = None
def print_name(self):
print(f"{self.name} (Class of {self.graduation_year})")
jdoe = Student(name="John Doe", dorm="Alumni")
jdoe.print_name()
```
Default parameter values are restricted to 'immutable' types. This technical restriction eliminiates the error-prone practice of use mutable objects, such as lists, as defaults. The difficulty with setting defaults for mutable objects is that all instances of the dataclass share the same value. If one instance of the object changes that value, then all other instances are affected. This leads to unpredictable behavior, and is a particularly nasty bug to uncover and fix.
There are two ways to provide defaults for mutable parameters such as lists, sets, dictionaries, or arbitrary Python objects.
The more direct way is to specify a function for constucting the default parameter value using the `field` statement with the `default_factory` option. The default_factory is called when a new instance of the dataclass is created. The function must take no arguments and must return a value that will be assigned to the designated parameter. Here's an example.
```
from dataclasses import dataclass
@dataclass
class Student():
name: str = None
graduation_year: int = None
dorm: str = None
majors: list = field(default_factory=list)
def print_name(self):
print(f"{self.name} (Class of {self.graduation_year})")
def print_majors(self):
for n, major in enumerate(self.majors):
print(f" {n+1}. {major}")
jdoe = Student(name="John Doe", dorm="Alumni", majors=["Math", "Chemical Engineering"])
jdoe.print_name()
jdoe.print_majors()
Student().print_majors()
```
#### Initializing a dataclass with __post_init__(self)
Frequently there are additional steps to complete when creating a new instance of a dataclass. For that purpose, a dataclass may contain an
optional function with the special name `__post_init__(self)`. If present, that function is run automatically following the creation of a new instance. This feature will be demonstrated in following reimplementation of the grocery store checkout operation.
## Using `dataclass` with Simpy
### Step 0. A simple model
To demonstrate the use of classes in SimPy simulations, let's begin with a simple model of a clock using generators.
```
import simpy
def clock(id="", t_step=1.0):
while True:
print(id, env.now)
yield env.timeout(t_step)
env = simpy.Environment()
env.process(clock("A"))
env.process(clock("B", 1.5))
env.run(until=5.0)
```
### Step 1. Embed the generator inside of a class
As a first step, we rewrite the generator as a Python dataclass named `Clock`. The parameters are given default values, and the generator is incorporated within the Clock object. Note the use of `self` to refer to parameters specific to an instance of the class.
```
import simpy
from dataclasses import dataclass
@dataclass
class Clock():
id: str = ""
t_step: float = 1.0
def process(self):
while True:
print(self.id, env.now)
yield env.timeout(self.t_step)
env = simpy.Environment()
env.process(Clock("A").process())
env.process(Clock("B", 1.5).process())
env.run(until=5)
```
### Step 2. Eliminate (if possible) global variables
Our definition of clock requires the simulation environment to have a specific name `env`, and assumes env is a global variable. That's generally not a good coding practice because it imposes an assumption on any user of the class, and exposes the internal coding of the class. A much better practice is to use class parameters to pass this data through a well defined interface to the class.
```
import simpy
from dataclasses import dataclass
@dataclass
class Clock():
env: simpy.Environment
id: str = ""
t_step: float = 1.0
def process(self):
while True:
print(self.id, self.env.now)
yield self.env.timeout(self.t_step)
env = simpy.Environment()
env.process(Clock(env, "A").process())
env.process(Clock(env, "B", 1.5).process())
env.run(until=10)
```
### Step 3. Encapsulate initializations inside __post_init__
```
import simpy
from dataclasses import dataclass
@dataclass
class Clock():
env: simpy.Environment
id: str = ""
t_step: float = 1.0
def __post_init__(self):
self.env.process(self.process())
def process(self):
while True:
print(self.id, self.env.now)
yield self.env.timeout(self.t_step)
env = simpy.Environment()
Clock(env, "A")
Clock(env, "B", 1.5)
env.run(until=5)
```
## Grocery Store Model
Let's review our model for the grocery store checkout operations. There are multiple checkout lanes, each with potentially different characteristics. With generators we were able to implement differences in the time required to scan items. But another parameter, a limit on number of items that could be checked out in a lane, required a new global list. The reason was the need to access that parameter, something that a generator doesn't allow. This is where classes become important building blocks in creating more complex simulations.
Our new strategy will be encapsulate the generator inside of a dataclass object. Here's what we'll ask each class definition to do:
* Create a parameter corresponding to the simulation environment. This makes our classes reusable in other simulations by eliminating a reference to a globall variable.
* Create parameters with reasonable defaults values.
* Initialize any objects used within the class.
* Register the class generator with the simulation environment.
```
from dataclasses import dataclass
# create simulation models
@dataclass
class Checkout():
env: simpy.Environment
lane: simpy.Store = None
t_item: float = 1/10
item_limit: int = 25
t_payment: float = 2.0
def __post_init__(self):
self.lane = simpy.Store(self.env)
self.env.process(self.process())
def process(self):
while True:
customer_id, cart, enter_time = yield self.lane.get()
wait_time = env.now - enter_time
yield env.timeout(self.t_payment + cart*self.t_item)
customer_log.append([customer_id, cart, enter_time, wait_time, env.now])
@dataclass
class CustomerGenerator():
env: simpy.Environment
rate: float = 1.0
customer_id: int = 1
def __post_init__(self):
self.env.process(self.process())
def process(self):
while True:
yield env.timeout(random.expovariate(self.rate))
cart = random.randint(1, 25)
available_checkouts = [checkout for checkout in checkouts if cart <= checkout.item_limit]
checkout = min(available_checkouts, key=lambda checkout: len(checkout.lane.items))
yield checkout.lane.put([self.customer_id, cart, env.now])
self.customer_id += 1
def lane_logger(t_sample=0.1):
while True:
lane_log.append([env.now] + [len(checkout.lane.items) for checkout in checkouts])
yield env.timeout(t_sample)
# create simulation environment
env = simpy.Environment()
# create simulation objects (agents)
CustomerGenerator(env)
checkouts = [
Checkout(env, t_item=1/5, item_limit=25),
Checkout(env, t_item=1/5, item_limit=25),
Checkout(env, item_limit=5),
Checkout(env),
Checkout(env),
]
env.process(lane_logger())
# run process
customer_log = []
lane_log = []
env.run(until=600)
def visualize():
# extract lane data
lane_df = pd.DataFrame(lane_log, columns = ["time"] + [f"lane {n}" for n in range(0, len(checkouts))])
lane_df = lane_df.set_index("time")
customer_df = pd.DataFrame(customer_log, columns = ["customer id", "cart items", "enter", "wait", "leave"])
customer_df["elapsed"] = customer_df["leave"] - customer_df["enter"]
# compute kpi's
print(f"Average waiting time = {customer_df['wait'].mean():5.2f} minutes")
print(f"\nAverage lane queue \n{lane_df.mean()}")
print(f"\nOverall aaverage lane queue \n{lane_df.mean().mean():5.4f}")
# plot results
fig, ax = plt.subplots(3, 1, figsize=(12, 7))
ax[0].plot(lane_df)
ax[0].set_xlabel("time / min")
ax[0].set_title("length of checkout lanes")
ax[0].legend(lane_df.columns)
ax[1].bar(customer_df["customer id"], customer_df["wait"])
ax[1].set_xlabel("customer id")
ax[1].set_ylabel("minutes")
ax[1].set_title("customer waiting time")
ax[2].bar(customer_df["customer id"], customer_df["elapsed"])
ax[2].set_xlabel("customer id")
ax[2].set_ylabel("minutes")
ax[2].set_title("total elapsed time")
plt.tight_layout()
visualize()
```
## Customers as agents
```
from dataclasses import dataclass
# create simulation models
@dataclass
class Checkout():
env: simpy.Environment
lane: simpy.Store = None
t_item: float = 1/10
item_limit: int = 25
t_payment: float = 2.0
def __post_init__(self):
self.lane = simpy.Store(self.env)
self.env.process(self.process())
def process(self):
while True:
customer_id, cart, enter_time = yield self.lane.get()
wait_time = env.now - enter_time
yield env.timeout(self.t_payment + cart*self.t_item)
customer_log.append([customer_id, cart, enter_time, wait_time, env.now])
@dataclass
class CustomerGenerator():
env: simpy.Environment
rate: float = 1.0
customer_id: int = 1
def __post_init__(self):
self.env.process(self.process())
def process(self):
while True:
yield env.timeout(random.expovariate(self.rate))
Customer(self.env, self.customer_id)
self.customer_id += 1
@dataclass
class Customer():
env: simpy.Environment
id: int = 0
def __post_init__(self):
self.cart = random.randint(1, 25)
self.env.process(self.process())
def process(self):
available_checkouts = [checkout for checkout in checkouts if self.cart <= checkout.item_limit]
checkout = min(available_checkouts, key=lambda checkout: len(checkout.lane.items))
yield checkout.lane.put([self.id, self.cart, env.now])
def lane_logger(t_sample=0.1):
while True:
lane_log.append([env.now] + [len(checkout.lane.items) for checkout in checkouts])
yield env.timeout(t_sample)
# create simulation environment
env = simpy.Environment()
# create simulation objects (agents)
CustomerGenerator(env)
checkouts = [
Checkout(env, t_item=1/5, item_limit=25),
Checkout(env, t_item=1/5, item_limit=25),
Checkout(env, item_limit=5),
Checkout(env),
Checkout(env),
]
env.process(lane_logger())
# run process
customer_log = []
lane_log = []
env.run(until=600)
visualize()
```
## Creating Smart Objects
```
from dataclasses import dataclass, field
import pandas as pd
# create simulation models
@dataclass
class Checkout():
lane: simpy.Store
t_item: float = 1/10
item_limit: int = 25
def process(self):
while True:
customer_id, cart, enter_time = yield self.lane.get()
wait_time = env.now - enter_time
yield env.timeout(t_payment + cart*self.t_item)
customer_log.append([customer_id, cart, enter_time, wait_time, env.now])
@dataclass
class CustomerGenerator():
rate: float = 1.0
customer_id: int = 1
def process(self):
while True:
yield env.timeout(random.expovariate(self.rate))
cart = random.randint(1, 25)
available_checkouts = [checkout for checkout in checkouts if cart <= checkout.item_limit]
checkout = min(available_checkouts, key=lambda checkout: len(checkout.lane.items))
yield checkout.lane.put([self.customer_id, cart, env.now])
self.customer_id += 1
@dataclass
class LaneLogger():
lane_log: list = field(default_factory=list) # this creates a variable that can be modified
t_sample: float = 0.1
lane_df: pd.DataFrame = field(default_factory=pd.DataFrame)
def process(self):
while True:
self.lane_log.append([env.now] + [len(checkout.lane.items) for checkout in checkouts])
yield env.timeout(self.t_sample)
def report(self):
self.lane_df = pd.DataFrame(self.lane_log, columns = ["time"] + [f"lane {n}" for n in range(0, N)])
self.lane_df = self.lane_df.set_index("time")
print(f"\nAverage lane queue \n{self.lane_df.mean()}")
print(f"\nOverall average lane queue \n{self.lane_df.mean().mean():5.4f}")
def plot(self):
self.lane_df = pd.DataFrame(self.lane_log, columns = ["time"] + [f"lane {n}" for n in range(0, N)])
self.lane_df = self.lane_df.set_index("time")
fig, ax = plt.subplots(1, 1, figsize=(12, 3))
ax.plot(self.lane_df)
ax.set_xlabel("time / min")
ax.set_title("length of checkout lanes")
ax.legend(self.lane_df.columns)
# create simulation environment
env = simpy.Environment()
# create simulation objects (agents)
customer_generator = CustomerGenerator()
checkouts = [
Checkout(simpy.Store(env), t_item=1/5),
Checkout(simpy.Store(env), t_item=1/5),
Checkout(simpy.Store(env), item_limit=5),
Checkout(simpy.Store(env)),
Checkout(simpy.Store(env)),
]
lane_logger = LaneLogger()
# register agents
env.process(customer_generator.process())
for checkout in checkouts:
env.process(checkout.process())
env.process(lane_logger.process())
# run process
env.run(until=600)
# plot results
lane_logger.report()
lane_logger.plot()
```
| true |
code
| 0.40536 | null | null | null | null |
|
# 01 - Introduction to numpy: why does numpy exist?
You might have read somewhere that Python is "slow" in comparison to some other languages. While generally true, this statement has only little meaning without context. As a scripting language (e.g. simplify tasks such as file renaming, data download, etc.), python is fast enough. For *numerical computations* (like the computations done by an atmospheric model or by a machine learning algorithm), "pure" Python is very slow indeed. Fortunately, there is a way to overcome this problem!
In this chapter we are going to explain why the [numpy](http://numpy.org) library was created. Numpy is the fundamental library which transformed the general purpose python language into a scientific language like Matlab, R or IDL.
Before introducing numpy, we will discuss some of the differences between python and compiled languages widely used in scientific software development (like C and FORTRAN).
## Why is python "slow"?
In the next unit about numbers, we'll learn that the memory consumption of a python ``int`` is larger than the memory needed to store the binary number alone. This overhead in memory consumption is due to the nature of python data types, which are all **objects**. We've already learned that these objects come with certain "services".
Everything is an object in Python. Yes, even functions are objects! Let me prove it to you:
```
def useful_function(a, b):
"""This function adds two objects together.
Parameters
----------
a : an object
b : another object
Returns
-------
The sum of the two
"""
return a + b
type(useful_function)
print(useful_function.__doc__)
```
Functions are objects of type ``function``, and one of their attributes (``__doc__``) gives us access to their **docstring**. During the course of the semester you are going to learn how to use more and more of these object features, and hopefully you are going to like them more and more (at least this is what happened to me).
Now, why does this make python "slow"? Well, in simple terms, these "services" tend to increase the complexity and the number of operations an interpreter has to perform when running a program. More specialized languages will be less flexible than python, but will be faster at running specialized operations and be less memory hungry (because they don't need this overhead of flexible memory on top of every object).
Python's high-level of abstraction (i.e. python's flexibility) makes it slower than its lower-level counterparts like C or FORTRAN. But, why is that so?
## Dynamically versus statically typed languages
Python is a so-called **dynamically typed** language, which means that the **type** of a variable is determined by the interpreter *at run time*. To understand what that means in practice, let's have a look at the following code snippet:
```
a = 2
b = 3
c = a + b
```
The line ``c = a + b`` is valid python syntax. The *operation* that has to be applied by the ``+`` operator, however, depends on the type of the variables to be added. Remember what happens when adding two lists for example:
```
a = [2]
b = [3]
a + b
```
In this simple example it would be theoretically possible for the interpreter to predict which operation to apply beforehand (by parsing all lines of code prior to the action). In most cases, however, this is impossible: for example, a function taking arguments does not know beforehand the type of the arguments it will receive.
Languages which assess the type of variables *at run time* are called [dynamically typed programming languages](https://en.wikipedia.org/wiki/Category:Dynamically_typed_programming_languages). Matlab, Python or R are examples falling in this category.
**Statically typed languages**, however, require the *programmer* to provide the type of variables while writing the code. Here is an example of a program written in C:
```c
#include <stdio.h>
int main ()
{
int a = 2;
int b = 3;
int c = a + b;
printf ("Sum of two numbers : %d \n", c);
}
```
The major difference with the Python code above is that the programmer indicated the type of the variables when they are assigned. Variable type definition in the code script is an integral part of the C syntax. This applies to the variables themselves, but also to the output of computations. This is a fundamental difference to python, and comes with several advantages. Static typing usually results in code that executes faster: since the program knows the exact data types that are in use, it can predict the memory consumption of operations beforehand and produce optimized machine code. Another advantage is code documentation: the statement ``int c = a + b`` makes it clear that we are adding two numbers while the python equivalent ``c = a + b`` could produce a number, a string, a list, etc.
## Compiled versus interpreted languages
Statically typed languages often require **compilation**. To run the C code snippet I had to create a new text file (``example.c``), write the code, compile it (``$ gcc -o myprogram example.c``), before finally being able to execute it (``$ ./myprogram``).
[gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection) is the compiler I used to translate the C source code (a text file) to a low level language (machine code) in order to create an **executable** (``myprogram``). Later changes to the source code require a new compilation step for the changes to take effect.
Because of this "edit-compile-run" cycle, compiled languages are not interactive: in the C language, there is no equivalent to python's command line interpreter. Compiling complex programs can take up to several hours in some extreme cases. This compilation time, however, is usually associated with faster execution times: as mentioned earlier, the compiler's task is to optimize the program for memory consumption by source code analysis. Often, a compiled program is optimized for the machine architecture it is compiled onto. Like interpreters, there can be different compilers for the same language. They differ in the optimization steps they undertake to make the program faster, and in their support of various hardware architectures.
**Interpreters** do not require compilation: they analyze the code at run time. The following code for example is syntactically correct:
```
def my_func(a, b):
return a + b
```
but the *execution* of this code results in a `TypeError` when the variables have the wrong type:
```
my_func(1, '2')
```
The interpreter cannot detect these errors before runtime: they happen when the variables are finally added together, not when they are created.
**Parenthesis I: python bytecode**
When executing a python program from the command line, the CPython interpreter creates a hidden directory called ``__pycache__``. This directory contains [bytecode](https://en.wikipedia.org/wiki/Bytecode) files, which are your python source code files translated to binary files. This is an optimization step which makes subsequent executions of the program run faster. While this conversion step is sometimes called "compilation", it should not be mistaken with a C-program compilation: indeed, python bytecode still needs an interpreter to run, while compiled executables can be run without C interpreter.
**Parenthesis II: static typing and compilation**
Statically typed languages are often compiled, and dynamically typed languages are often interpreted. While this is a good rule of thumb, this is not always true and the vast landscape of programming languages contains many exceptions. This lecture is only a very short introduction to these concepts: you'll have to refer to more advanced computer science lectures if you want to learn about these topics in more detail.
## Here comes numpy
Let's summarize the two previous chapters:
- Python is flexible, interactive and slow
- C is less flexible, non-interactive and fast
This is a simplification, but not far from the truth.
Now, let's add another obstacle to using python for science: the built-in `list` data type in python is mostly useless for arithmetics or vector computations. Indeed, to add two lists together element-wise (a behavior that you would expect as a scientist), you must write:
```
def add_lists(A, B):
"""Element-wise addition of two lists."""
return [a + b for a, b in zip(A, B)]
add_lists([1, 2, 3], [4, 5, 6])
```
The numpy equivalent is much more intuitive and straightforward:
```
import numpy as np
def add_arrays(A, B):
return np.add(A, B)
add_arrays([1, 2, 3], [4, 5, 6])
```
Let's see which of the two functions runs faster:
```
n = 10
A = np.random.randn(n)
B = np.random.randn(n)
%timeit add_lists(A, B)
%timeit add_arrays(A, B)
```
Numpy is approximately 5-6 times faster.
```{exercise}
Repeat the performance test with n=100 and n=10000. How does the performance scale with the size of the array? Now repeat the test but make the input arguments ``A`` and ``B`` *lists* instead of numpy arrays. How is the performance comparison in this case? Why?
```
Why is numpy so much faster than pure python? One of the major reasons is **vectorization**, which is the process of applying mathematical operations to *all* elements of an array ("vector") at once instead of looping through them like we would do in pure python. "for loops" in python are slow because for each addition, python has to:
- access the elements a and b in the lists A and B
- check the type of both a and b
- apply the ``+`` operator on the data they store
- store the result.
Numpy skips the first two steps and does them only once before the actual operation. What does numpy know about the addition operation that the pure python version can't infer?
- the type of all numbers to add
- the type of the output
- the size of the output array (same as input)
Numpy can use this information to optimize the computation, but this isn't possible without trade-offs. See the following for example:
```
add_lists([1, 'foo'], [3, 'bar']) # works fine
add_arrays([1, 'foo'], [3, 'bar']) # raises a TypeError
```
$\rightarrow$ **numpy can only be that fast because the input and output data types are uniform and known before the operation**.
Internally, numpy achieves vectorization by relying on a lower-level, statically typed and compiled language: C! At the time of writing, about 35% of the [numpy codebase](https://github.com/numpy/numpy) is written in C/C++. The rest of the codebase offers an interface (a "layer") between python and the internal C code.
As a result, numpy has to be *compiled* at installation. Most users do not notice this compilation step anymore (recent pip and conda installations are shipped with pre-compiled binaries), but installing numpy used to require several minutes on my laptop when I started to learn python myself.
## Take home points
- The process of "type checking" may occur either at compile-time (statically typed language) or at runtime (dynamically typed language). These terms are not usually used in a strict sense.
- Statically typed languages are often compiled, while dynamically typed languages are interpreted.
- There is a trade-off between the flexibility of a language and its speed: static typing allows programs to be optimized at compilation time, thus allowing them to run faster. But writing code in a statically typed language is slower, especially for interactive data exploration (not really possible in fact).
- When speed matters, python allows to use compiled libraries under a python interface. numpy is using C under the hood to optimize its computations.
- numpy arrays use a continuous block of memory of homogenous data type. This allows for faster memory access and easy vectorization of mathematical operations.
## Further reading
I highly recommend to have a look at the first part of Jake Vanderplas' blog post, [Why python is slow](https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/) (up to the "hacking" part). It provides more details and a good visual illustration of the ``c = a + b`` example. The second part is a more involved read, but very interesting too!
## Addendum: is python really *that* slow?
The short answer is: yes, python is slower than a number of other languages. You'll find many benchmarks online illustrating it.
Is it bad?
No. Jake Vanderplas (a well known contributor of the scientific python community) [writes](https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/#So-Why-Use-Python?):
*As well, it comes down to this: dynamic typing makes Python easier to use than C. It's extremely flexible and forgiving, this flexibility leads to efficient use of development time, and on those occasions that you really need the optimization of C or Fortran, Python offers easy hooks into compiled libraries. It's why Python use within many scientific communities has been continually growing. With all that put together, Python ends up being an extremely efficient language for the overall task of doing science with code.*
It's the flexibility and readability of python that makes it so popular. Python is the language of choice for major actors like [instagram](https://www.youtube.com/watch?v=66XoCk79kjM) or [spotify](https://labs.spotify.com/2013/03/20/how-we-use-python-at-spotify/), and it has become the high-level interface to highly optimized machine learning libraries like [TensorFlow](https://github.com/tensorflow/tensorflow) or [Torch](http://pytorch.org/).
For a scientist, writing code efficiently is *much* more important than writing efficient code. Or [is it](https://xkcd.com/1205/)?
| true |
code
| 0.868465 | null | null | null | null |
|
# Prescient Tutorial
## Getting Started
This is a tutorial to demonstration the basic functionality of Prescient. Please follow the installation instructions in the [README](https://github.com/grid-parity-exchange/Prescient/blob/master/README.md) before proceeding. This tutorial will assume we are using the CBC MIP solver, however, we will point out where one could use a different solver (CPLEX, Gurobi, Xpress).
## RTS-GMLC
We will use the RTS-GMLC test system as a demonstration. Prescient comes included with a translator for the RTS-GMLC system data, which is publically available [here](https://github.com/GridMod/RTS-GMLC). To find out more about the RTS-GMLC system, or if you use the RTS-GMLC system in published research, please see or cite the [RTS-GMLC paper](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8753693&isnumber=4374138&tag=1).
## IMPORTANT NOTE
In the near future, the dev-team will allow more-direct reading of data in the "RTS-GMLC" format directly into the simulator. In the past, we have created one-off scripts for each data set to put then in the format required by the populator.
### Downloading the RTS-GMLC data
```
# first, we'll use the built-in function to download the RTS-GMLC system to Prescicent/downloads/rts_gmlc
import prescient.downloaders.rts_gmlc as rts_downloader
# the download function has the path Prescient/downloads/rts_gmlc hard-coded.
# All it does is a 'git clone' of the RTS-GMLC repo
rts_downloader.download()
# we should be able to see the RTS-GMLC data now
import os
rts_gmlc_dir = rts_downloader.rts_download_path+os.sep+'RTS-GMLC'
print(rts_gmlc_dir)
os.listdir(rts_gmlc_dir)
```
### Converting RTS-GMLC data into the format for the "populator"
```
# first thing we'll do is to create a *.dat file template for the "static" data, e.g.,
# branches, buses, generators, to Prescicent/downloads/rts_gmlc/templates/rts_with_network_template_hotstart.dat
from prescient.downloaders.rts_gmlc_prescient.rtsgmlc_to_dat import write_template
write_template(rts_gmlc_dir=rts_gmlc_dir,
file_name=rts_downloader.rts_download_path+os.sep+'templates'+os.sep+'rts_with_network_template_hotstart.dat')
# next, we'll convert the included time-series data into input for the populator
# (this step can take a while because we set up an entire year's worth of data)
from prescient.downloaders.rts_gmlc_prescient.process_RTS_GMLC_data import create_timeseries
create_timeseries(rts_downloader.rts_download_path)
# Lastly, Prescient comes with some pre-made scripts and templates to help get up-and-running with RTS-GMLC.
# This function just puts those in rts_downloader.rts_download_path from
# Prescient/prescient/downloaders/rts_gmlc_prescient/runners
rts_downloader.copy_templates()
os.listdir(rts_downloader.rts_download_path)
```
NOTE: the above steps are completely automated in the `__main__` function of Prescient/prescient/downloaders/rts_gmlc.py
### Running the populator
Below we'll show how the populator is set-up by the scripts above an subsequently run.
```
# we'll work in the directory we've set up now for
# running the populator and simulator
# If prescient is properly installed, this could be
# a directory anywhere on your system
os.chdir(rts_downloader.rts_download_path)
os.getcwd()
# helper for displaying *.txt files in jupyter
def print_file(file_n):
'''prints file contents to the screen'''
with open(file_n, 'r') as f:
for l in f:
print(l.strip())
```
Generally, one would call `runner.py populate_with_network_deterministic.txt` to set-up the data for the simulator. We'll give a brief overview below as to how that is orchestrated.
```
print_file('populate_with_network_deterministic.txt')
```
First, notice the `command/exec` line, which tells `runner.py` which command to execute. These `*.txt` files could be replaced with bash scripts, or run from the command line directly. In this case,
`populator.py --start-date 2020-07-10 --end-date 2020-07-16 --source-file sources_with_network.txt --output-directory deterministic_with_network_scenarios --scenario-creator-options-file deterministic_scenario_creator_with_network.txt
--traceback`
would give the same result. The use of the `*.txt` files enables saving these complex commands in a cross-platform compatable manner.
The `--start-date` and `--end-date` specify the date range for which we'll generate simulator input. The `--ouput-directory` gives the path (relative in this case) where the simulator input (the output of this script) should go. The `--sources-file` and `--scenario-creator-options-file` point to other `*.txt` files.
#### --scenario-creator-options-file
```
print_file('deterministic_scenario_creator_with_network.txt')
```
This file points the `scenario_creator` to the templates created/copied above, which store the "static" prescient data, e.g., `--sceneario-template-file` points to the bus/branch/generator data. The `--tree-template-file` is depreciated at this point, pending re-introdcution of stochastic unit commitment capabilities.
```
# This prints out the files entire contents, just to look at.
# See if you can find the set "NondispatchableGenerators"
print_file('templates/rts_with_network_template_hotstart.dat')
```
#### --sources-file
```
print_file('sources_with_network.txt')
```
This file connects each "Source" (e.g., `122_HYDRO_1`) in the file `templates/rts_with_network_template_hotstart.dat` to the `*.csv` files generated above for both load and renewable generation. Other things controlled here are whether a renewable resource is dispatchable at all.
```
# You could also run 'runner.py populate_with_network_deterministic.txt' from the command line
import prescient.scripts.runner as runner
runner.run('populate_with_network_deterministic.txt')
```
This creates the "input deck" for July 10, 2020 -- July 16, 2020 for the simulator in the ouput directory `determinstic_with_network_scenarios`.
```
sorted(os.listdir('deterministic_with_network_scenarios'+os.sep+'pyspdir_twostage'))
```
Inside each of these directories are the `*.dat` files specifying the simulation for each day.
```
sorted(os.listdir('deterministic_with_network_scenarios'+os.sep+'pyspdir_twostage'+os.sep+'2020-07-10'))
```
`Scenario_actuals.dat` contains the "actuals" for the day, which is used for the SCED problems, and `Scenario_forecast.dat` contains the "forecasts" for the day. The other `*.dat` files are hold-overs from stochastic mode.
`scenarios.csv` has forecast and actuals data for every uncertain generator in an easy-to-process format.
### Running the simulator
Below we show how to set-up and run the simulator.
Below is the contents of the included `simulate_with_network_deterministic.txt`:
```
print_file('simulate_with_network_deterministic.txt')
```
Description of the options included are as follows:
- `--data-directory`: Where the source data is (same as outputs for the populator).
- `--simulate-out-of-sample`: This option directs the simulator to use different forecasts from actuals. Without it, the simulation is run with forecasts equal to actuals
- `--run-sced-with-persistent-forecast-errors`: This option directs the simulator to use forecasts (adjusted by the current forecast error) for sced look-ahead periods, instead of using the actuals for sced look-ahead periods.
- `--output-directory`: Where to write the output data.
- `--run-deterministic-ruc`: Directs the simualtor to run a deterministic (as opposed to stochastic) unit commitment problem. Required for now as stochastic unit commitment is currently deprecated.
- `--start-date`: Day to start the simulation on. Must be in the data-directory.
- `--num-days`: Number of days to simulate, including the start date. All days must be included in the data-directory.
- `--sced-horizon`: Number of look-ahead periods (in hours) for the real-time economic dispatch problem.
- `--traceback`: If enabled, the simulator will print a trace if it failed.
- `--random-seed`: Unused currently.
- `--output-sced-initial-conditions`: Prints the initial conditions for the economic dispatch problem to the screen.
- `--output-sced-demands`: Prints the demands for the economic dispatch problem to the screen.
- `--output-sced-solutions`: Prints the solution for the economic dispatch problem to the screen.
- `--output-ruc-initial-conditions`: Prints the initial conditions for the unit commitment problem to the screen.
- `--output-ruc-solutions`: Prints the commitment solution for the unit commitment problem to the screen.
- `--output-ruc-dispatches`: Prints the dispatch solution for the unit commitment problem to the screen.
- `--output-solver-logs`: Prints the logs from the optimization solver (CBC, CPLEX, Gurobi, Xpress) to the screen.
- `--ruc-mipgap`: Optimality gap to use for the unit commitment problem. Default is 1% used here -- can often be tighted for commerical solvers.
- `--symbolic-solver-labels`: If set, `symbolic_solver_labels` is used when writing optimization models from Pyomo to the solver. Only useful for low-level debugging.
- `--reserve-factor`: If set, overwrites any basic reserve factor included in the test data.
- `--deterministic-ruc-solver`: The optimization solver ('cbc', 'cplex', 'gurobi', 'xpress') used for the unit commitment problem.
- `--sced-solver`: The optimization solver ('cbc', 'cplex', 'gurobi', 'xpress') used for the economic dispatch problem.
Other options not included in this file, which may be useful:
- `--compute-market-settlements`: (True/False) If enabled, solves a day-ahead pricing problem (in addition to the real-time pricing problem) and computes generator revenue based on day-ahead and real-time prices.
- `--day-ahead-pricing`: ('LMP', 'ELMP', 'aCHP') Specifies the type of day-ahead price to use. Default is 'aCHP'.
- `--price-threashold`: The maximum value for the energy price ($/MWh). Useful for when market settlements are computed to avoid very large LMP values when load shedding occurs.
- `--reserve-price-threashold`: The maximum value for the reserve price (\$/MW). Useful for when market settlements are computed to avoid very large LMP values when reserve shortfall occurs.
- `--deterministic-ruc-solver-options`: Options to pass into the unit commitment solver (specific to the solver used) for every unit commitment solve.
- `--sced-solver-options`: Options to pass into the economic dispatch solve (specific to the solver used) for every economic dispatch solve.
- `--plugin`: Path to a Python module to modify Prescient behavior.
```
# You could also run 'runner.py simulate_with_network_deterministic.txt' from the command line
# This runs a week of RTS-GMLC, which with the open-source cbc solver will take several (~12) minutes
import prescient.scripts.runner as runner
runner.run('simulate_with_network_deterministic.txt')
```
### Analyzing results
Summary and detailed `*.csv` files are written to the specified output directory (in this case, `deterministic_with_network_simulation_output`).
```
sorted(os.listdir('deterministic_with_network_simulation_output/'))
```
Below we give a breif description of the contents of each file.
- `bus_detail.csv`: Detailed results (demand, LMP, etc.) by bus.
- `daily_summary.csv`: Summary results by day. Demand, renewables data, costs, load shedding/over generation, etc.
- `hourly_gen_summary.csv`: Gives total thermal headroom and data on reserves (shortfall, price) by hour.
- `hourly_summary.csv`: Summary results by hour. Similar to `daily_summary.csv`.
- `line_detail.csv`: Detailed results (flow in MW) by bus.
- `overall_simulation_output.csv`: Summary results for the entire simulation run. Similar to `daily_summary.csv`.
- `plots`: Directory containing stackgraphs for every day of the simulation.
- `renewables_detail.csv`: Detailed results (output, curtailment) by renewable generator.
- `runtimes.csv`: Runtimes for each economic dispatch problem.
- `thermal_detail.csv`: Detailed results (dispatch, commitment, costs) per thermal generator.
Generally, the first think to look at, as a sanity check is the stackgraphs:
```
dates = [f'2020-07-1{i}' for i in range(0,7)]
from IPython.display import Image
for date in dates:
display(Image('deterministic_with_network_simulation_output'+os.sep+'plots'+os.sep+'stackgraph_'+date+'.png',
width=500))
```
Due to the non-deterministic nature of most MIP solvers, your results may be slightly different than mine. For my simulation, two things stand out:
1. The load-shedding at the end of the day (hour 23) on July 12th.
2. The renewables curtailed the evening of July 15th into the morning of July 16th.
For this tutorial, let's hypothesize about the cause of (2). Often renewables are curtailed either because of a binding transmission constraint, or because some or all of the thermal generators are operating at minimum power. Let's investigate the first possibility.
#### Examining Loaded Transmission Lines
```
import pandas as pd
# load in the output data for the lines
line_flows = pd.read_csv('deterministic_with_network_simulation_output'+os.sep+'line_detail.csv', index_col=[0,1,2,3])
# load in the source data for the lines
line_attributes = pd.read_csv('RTS-GMLC'+os.sep+'RTS_Data'+os.sep+'SourceData'+os.sep+'branch.csv', index_col=0)
# get the line limits
line_limits = line_attributes['Cont Rating']
# get a series of flows
line_flows = line_flows['Flow']
line_flows
# rename the line_limits to match the
# index of line_flows
line_limits.index.name = "Line"
line_limits
lines_relative_flow = line_flows/line_limits
lines_near_limits_time = lines_relative_flow[ (lines_relative_flow > 0.99) | (lines_relative_flow < -0.99) ]
lines_near_limits_time
```
As we can see, near the end of the day on July 15th and the beginning of the day July 16th, several transmission constraints are binding, which correspond exactly to the periods of renewables curtailment in the stackgraphs above.
| true |
code
| 0.257812 | null | null | null | null |
|
# Prédiction à l'aide de forêts aléatoires
Les forêts aléatoires sont des modèles de bagging ne nécessitant pas beaucoup de *fine tuning* pour obtenir des performances correctes. De plus, ces méthodes sont plus résitances au surapprentissage par rapport à d'autres méthodes.
```
from google.colab import drive
drive.mount('/content/drive')
dossier_donnees = "/content/drive/My Drive/projet_info_Ensae"
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
import numpy as np
from matplotlib import pyplot as plt
```
## Lecture des données de train et validation
```
donnees = pd.read_csv(dossier_donnees + "/donnees_model/donnees_train.csv", index_col = 1)
donnees_validation = pd.read_csv(dossier_donnees + "/donnees_model/donnees_validation.csv", index_col = 1)
donnees.drop(columns= "Unnamed: 0", inplace = True)
donnees_validation.drop(columns= "Unnamed: 0", inplace = True)
```
On va faire quelques petites modifications sur les donnees :
- Les variables `arrondissement`, `pp`, `mois` vont être considérées comme variable catégorielle
- Les variables `datemut` vont être supprimées
- La variable `sbati_squa` est retirée en suivant les recommandations de Maître Wenceslas Sanchez.
```
donnees["arrondissement"] = donnees["arrondissement"].astype("object")
donnees["pp"] = donnees["pp"].astype("object")
donnees["mois"] = donnees["datemut"].str[5:7].astype("object")
donnees_train = donnees.drop(columns = ["nblot", "nbpar", "nblocmut", "nblocdep","datemut","sbati_squa"])
donnees_validation["arrondissement"] = donnees_validation["arrondissement"].astype("object")
donnees_validation["pp"] = donnees_validation["pp"].astype("object")
donnees_validation["mois"] = donnees_validation["datemut"].str[5:7].astype("object")
donnees_validation.drop(columns = ["nblot", "nbpar", "nblocmut", "nblocdep","datemut","sbati_squa"], inplace = True)
donnees_train.rename(columns = {"valfoncact2" : "valfoncact"}, inplace = True)
donnees_validation.rename(columns = {"valfoncact2" : "valfoncact"}, inplace = True)
def preparation(table):
#Restriction à certains biens
table = table[(table["valfoncact"] > 1e5) & (table["valfoncact"] < 3*(1e6))]
#Ajout données brut
men_brut = table.loc[:, "Men":"Men_mais"].apply(lambda x : x*table["Men"], axis = 0).add_suffix("_brut")
ind_brut = table.loc[:, "Ind_0_3":"Ind_80p"].apply(lambda x : x*table["Ind"], axis = 0).add_suffix("_brut")
table = pd.concat([table, men_brut, ind_brut],axis = 1)
table_X = table.drop(columns = ["valfoncact"]).to_numpy()
table_Y = table["valfoncact"].to_numpy()
nom = table.drop(columns = ["valfoncact"]).columns
return(table_X,table_Y,nom)
donnees_validation_prep_X,donnees_validation_prep_Y,nom = preparation(donnees_validation)
donnees_train_prep_X,donnees_train_prep_Y,nom = preparation(donnees_train)
```
## Modélisation
```
rf = RandomForestRegressor(random_state=42,n_jobs = -1)
```
Pour le choix du nombre de variables testés à chaque split, Breiman [2000] recommande qu'utiliser dans les problèmes de régression $\sqrt{p}$ comme valeur où p désigne le nombre de covariables. Ici $p$ vaut 67. On prendra donc $p = 8$ ainsi que $6$ et $16$.
Le nombre d'arbres (`n_estimators`) n'est *a priori* pas le critère le plus déterminant dans la performance des forêts aléatoires au delà d'un certain seuil. Nous essayons ici des valeurs *conventionnelles*.
Pour contrôler la profondeur des feuilles de chaque arbre CART, nous utilisons le nombre d'individus minimums dans chaque feuille de l'arbre. Plus il est grand, plus l'arbre sera petit. Notons que les arbres ne sont pas élagués ici.
```
param_grid = {
'n_estimators': [100,200,500,1000],
'max_features': [6,8,16],
'min_samples_leaf' : [1,2,5,10]
}
rf_grid_search = GridSearchCV(estimator = rf, param_grid = param_grid,cv = 3, verbose=2, n_jobs = -1)
rf_grid_search.fit(donnees_train_prep_X, donnees_train_prep_Y)
print(rf_grid_search.best_params_)
rf2 = RandomForestRegressor(random_state=42,n_jobs = -1, max_features = 16, min_samples_leaf= 2, n_estimators= 1000)
rf2.fit(donnees_train_prep_X,donnees_train_prep_Y)
pred = rf2.predict(donnees_validation_prep_X)
np.sqrt(metrics.mean_squared_error(donnees_validation_prep_Y,pred))
```
## Visualisation de l'importance des variables
Afin de savoir quelles sont les variables les plus importantes dans la prédiction, nous allons utiliser l'importance des variables. Il s'agit ici d'une importance basée sur la diminution de l'indice de Gini.
```
sorted_idx = rf2.feature_importances_.argsort()
plt.figure(figsize=(10,15))
plt.barh(nom[sorted_idx], rf2.feature_importances_[sorted_idx])
plt.xlabel("Random Forest Feature Importance")
```
On note que les variables les plus importantes pour la prédiction sont :
- sbati : la surface du bien
- pp : le nombre de pièces
- nv_par_hab : le niveau de vie par habitant du carreaux de 200 mètres dans lequel le bien se situe
- Men_mai : Part de ménages en maison
- arrondissement : Arrondissement dans lequel se situe le bien
- Men_prop : Part de ménages propriétaires
- Ind_80p : Part de plus de 80 ans
- Ind_65_79 : Part d'individus âgés entre 65 et 79 ans
- Men_mai_brut : Nombre bruts de ménages en maison
| true |
code
| 0.41049 | null | null | null | null |
|
# 🌋 Quick Feature Tour
[](https://colab.research.google.com/github/RelevanceAI/RelevanceAI-readme-docs/blob/v2.0.0/docs/getting-started/_notebooks/RelevanceAI-ReadMe-Quick-Feature-Tour.ipynb)
### 1. Set up Relevance AI
Get started using our RelevanceAI SDK and use of [Vectorhub](https://hub.getvectorai.com/)'s [CLIP model](https://hub.getvectorai.com/model/text_image%2Fclip) for encoding.
```
# remove `!` if running the line in a terminal
!pip install -U RelevanceAI[notebook]==2.0.0
# remove `!` if running the line in a terminal
!pip install -U vectorhub[clip]
```
Follow the signup flow and get your credentials below otherwise, you can sign up/login and find your credentials in the settings [here](https://auth.relevance.ai/signup/?callback=https%3A%2F%2Fcloud.relevance.ai%2Flogin%3Fredirect%3Dcli-api)

```
from relevanceai import Client
"""
You can sign up/login and find your credentials here: https://cloud.relevance.ai/sdk/api
Once you have signed up, click on the value under `Activation token` and paste it here
"""
client = Client()
```

### 2. Create a dataset and insert data
Use one of our sample datasets to upload into your own project!
```
import pandas as pd
from relevanceai.utils.datasets import get_ecommerce_dataset_clean
# Retrieve our sample dataset. - This comes in the form of a list of documents.
documents = get_ecommerce_dataset_clean()
pd.DataFrame.from_dict(documents).head()
ds = client.Dataset("quickstart")
ds.insert_documents(documents)
```
See your dataset in the dashboard

### 3. Encode data and upload vectors into your new dataset
Encode a new product image vector using [Vectorhub's](https://hub.getvectorai.com/) `Clip2Vec` models and update your dataset with the resulting vectors. Please refer to [Vectorhub](https://github.com/RelevanceAI/vectorhub) for more details.
```
from vectorhub.bi_encoders.text_image.torch import Clip2Vec
model = Clip2Vec()
# Set the default encode to encoding an image
model.encode = model.encode_image
documents = model.encode_documents(fields=["product_image"], documents=documents)
ds.upsert_documents(documents=documents)
ds.schema
```
Monitor your vectors in the dashboard

### 4. Run clustering on your vectors
Run clustering on your vectors to better understand your data!
You can view your clusters in our clustering dashboard following the link which is provided after the clustering is finished!
```
from sklearn.cluster import KMeans
cluster_model = KMeans(n_clusters=10)
ds.cluster(cluster_model, ["product_image_clip_vector_"])
```
You can see the new `_cluster_` field that is added to your document schema.
Clustering results are uploaded back to the dataset as an additional field.
The default `alias` of the cluster will be the `kmeans_<k>`.
```
ds.schema
```
See your cluster centers in the dashboard

### 4. Run a vector search
Encode your query and find your image results!
Here our query is just a simple vector query, but our search comes with out of the box support for features such as multi-vector, filters, facets and traditional keyword matching to combine with your vector search. You can read more about how to construct a multivector query with those features [here](https://docs.relevance.ai/docs/vector-search-prerequisites).
See your search results on the dashboard here https://cloud.relevance.ai/sdk/search.
```
query = "gifts for the holidays"
query_vector = model.encode(query)
multivector_query = [{"vector": query_vector, "fields": ["product_image_clip_vector_"]}]
results = ds.vector_search(multivector_query=multivector_query, page_size=10)
```
See your multi-vector search results in the dashboard

Want to quickly create some example applications with Relevance AI? Check out some other guides below!
- [Text-to-image search with OpenAI's CLIP](https://docs.relevance.ai/docs/quickstart-text-to-image-search)
- [Hybrid Text search with Universal Sentence Encoder using Vectorhub](https://docs.relevance.ai/docs/quickstart-text-search)
- [Text search with Universal Sentence Encoder Question Answer from Google](https://docs.relevance.ai/docs/quickstart-question-answering)
| true |
code
| 0.63023 | null | null | null | null |
|
# CHEM 1000 - Spring 2022
Prof. Geoffrey Hutchison, University of Pittsburgh
## 1. Functions and Coordinate Sets
Chapter 1 in [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/)
By the end of this session, you should be able to:
- Handle 2D polar and 3D spherical coordinates
- Understand area elements in 2D polar coordinates
- Understand volume eleements in 3D spherical coordinates
### X/Y Cartesian 2D Coordinates
We've already been using the x/y 2D Cartesian coordinate set to plot functions.
Beyond `sympy`, we're going to use two new modules:
- `numpy` which lets us create and handle arrays of numbers
- `matplotlib` which lets us plot things
It's a little bit more complicated. For now, you can just consider these as **demos**. We'll go into code (and make our own plots) in the next recitation period.
```
# import numpy
# the "as np" part is giving a shortcut so we can write "np.function()" instead of "numpy.function()"
# (saving typing is nice)
import numpy as np
# similarly, we import matplotlib's 'pyplot' module
# and "as plt" means we can use "plt.show" instead of "matplotlib.pyplot.show()"
import matplotlib.pyplot as plt
# insert any graphs into our notebooks directly
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# once we've done that import (once) - we just need to create our x/y values
x = np.arange(0, 4*np.pi, 0.1) # start, stop, resolution
y = np.sin(x) # creates an array with sin() of all the x values
plt.plot(x,y)
plt.show()
```
Sometimes, we need to get areas in the Cartesian xy system, but this is very easy - we simply multiply an increment in x ($dx$) and an increment in y ($dy$).
(Image from [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/))
<img src="../images/cartesian-area.png" width="400" />
### Polar (2D) Coordinates
Of course, not all functions work well in xy Cartesian coordinates. A function should produce one y value for any x value. Thus, a circle isn't easily represented as $y = f(x)$.
Instead, polar coordinates, use radius $r$ and angle $\theta$. (Image from [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/))
<img src="../images/cartesian-polar.png" width="343" />
As a reminder, we can interconvert x,y into r, theta:
$$
r = \sqrt{x^2 + y^2}
$$
$$
\theta = \arctan \frac{y}{x} = \tan^{-1} \frac{y}{x}
$$
```
x = 3.0
y = 1.0
r = np.sqrt(x**2 + y**2)
theta = np.arctan(y / x)
print('r =', round(r, 4), 'theta = ', round(theta, 4))
```
Okay, we can't express a circle as an easy $y = f(x)$ expression. Can we do that in polar coordinates? Sure. The radius will be constant, and theta will go from $0 .. 2\pi$.
```
theta = np.arange(0, 2*np.pi, 0.01) # set up an array of radii from 0 to 2π with 0.01 rad
# create a function r(theta) = 1.5 .. a constant
r = np.full(theta.size, 1.5)
# create a new polar plot
ax = plt.subplot(111, projection='polar')
ax.plot(theta, r, color='blue')
ax.set_rmax(3)
ax.set_rticks([1, 2]) # Less radial ticks
ax.set_rlabel_position(22.5) # Move radial labels away from plotted line
ax.grid(True)
plt.show()
```
Anything else? Sure - we can create spirals, etc. that are parametric functions in the XY Cartesian coordinates.
```
r = np.arange(0, 2, 0.01) # set up an array of radii from 0 to 2 with 0.01 resolution
# this is a function theta(r) = 2π * r
theta = 2 * np.pi * r # set up an array of theta angles - spiraling outward .. from 0 to 2*2pi = 4pi
# create a polar plot
ax = plt.subplot(111, projection='polar')
ax.plot(theta, r, color='red')
ax.set_rmax(3)
ax.set_rticks([1, 2]) # Less radial ticks
ax.set_rlabel_position(22.5) # Move radial labels away from plotted line
ax.grid(True)
plt.show()
```
Just like with xy Cartesian, we will eventually need to consider the area of functions in polar coordinates. (Image from [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/))
<img src="../images/polar_area.png" width=375 />
Note that the area depends on the radius. Even if we sweep out the same $\Delta r$ and $\Delta \theta$ an area further out from the center is larger:
```
# create a polar plot
ax = plt.subplot(111, projection='polar')
# first arc at r = 1.0
r1 = np.full(20, 1.0)
theta1 = np.linspace(1.0, 1.3, 20)
ax.plot(theta1, r1)
# second arc at r = 1.2
r2 = np.full(20, 1.2)
theta2 = np.linspace(1.0, 1.3, 20)
ax.plot(theta2, r2)
# first radial line at theta = 1.0 radians
r3 = np.linspace(1.0, 1.2, 20)
theta3 = np.full(20, 1.0)
ax.plot(theta3, r3)
# first radial line at theta = 1.3 radians
r4 = np.linspace(1.0, 1.2, 20)
theta4 = np.full(20, 1.3)
ax.plot(theta4, r4)
# smaller box
# goes from r = 0.4-> 0.6
# sweeps out theta = 1.0-1.3 radians
r5 = np.full(20, 0.4)
r6 = np.full(20, 0.6)
r7 = np.linspace(0.4, 0.6, 20)
r8 = np.linspace(0.4, 0.6, 20)
ax.plot(theta1, r5)
ax.plot(theta2, r6)
ax.plot(theta3, r7)
ax.plot(theta4, r8)
ax.set_rmax(1.5)
ax.set_rticks([0.5, 1, 1.5]) # Less radial ticks
ax.set_rlabel_position(-22.5) # Move radial labels away from plotted line
ax.grid(True)
plt.show()
```
Thus the area element will be $r dr d\theta$. While it's not precisely rectangular, the increments are very small and it's a reasonable approximation.
### 3D Cartesian Coordinates
Of course there are many times when we need to express functions like:
$$ z = f(x,y) $$
These are a standard extension of 2D Cartesian coordinates, and so the volume is simply defined as that of a rectangular solid.
<img src="../images/cartesian-volume.png" width="360" />
```
from sympy import symbols
from sympy.plotting import plot3d
x, y = symbols('x y')
plot3d(-0.5 * (x**2 + y**2), (x, -3, 3), (y, -3, 3))
```
### 3D Spherical Coordinates
Much like two dimensions we sometimes need to use spherical coordinates — atoms are spherical, after all.
<div class="alert alert-block alert-danger">
**WARNING** Some math courses use a different [convention](https://en.wikipedia.org/wiki/Spherical_coordinate_system#Conventions) than chemistry and physics.
- Physics and chemistry use $(r, \theta, \varphi)$ where $\theta$ is the angle down from the z-axis (e.g., latitude)
- Some math courses use $\theta$ as the angle in the XY 2D plane.
</div>
(Image from [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/))
<img src="../images/spherical.png" width="330" />
Where:
- $r$ is the radius, from 0 to $\infty$
- $\theta$ is the angle down from the z-axis
- e.g., think of N/S latitude on the Earth's surface) from 0° at the N pole to 90° (π/2) at the equator and 180° (π) at the S pole
- $\varphi$ is the angle in the $xy$ plane
- e.g., think of E/W longitude on the Earth), from 0 to 360° / 0..2π
We can interconvert xyz and $r\theta\varphi$
$$x = r\sin \theta \cos \varphi$$
$$y = r\sin \theta \sin \varphi$$
$$z = r \cos \theta$$
Or vice-versa:
$$
\begin{array}{l}r=\sqrt{x^{2}+y^{2}+z^{2}} \\ \theta=\arccos \left(\frac{z}{r}\right)=\cos ^{-1}\left(\frac{z}{r}\right) \\ \varphi=\tan ^{-1}\left(\frac{y}{x}\right)\end{array}
$$
The code below might look a little complicated. That's okay. I've added comments for the different sections and each line.
You don't need to understand all of it - it's intended to plot the function:
$$ r = |\cos(\theta^2) | $$
```
# import some matplotlib modules for 3D and color scales
import mpl_toolkits.mplot3d.axes3d as axes3d
import matplotlib.colors as mcolors
cmap = plt.get_cmap('jet') # pick a red-to-blue color map
fig = plt.figure() # create a figure
ax = fig.add_subplot(1,1,1, projection='3d') # set up some axes for a 3D projection
# We now set up the grid for evaluating our function
# particularly the angle portion of the spherical coordinates
theta = np.linspace(0, np.pi, 100)
phi = np.linspace(0, 2*np.pi, 100)
THETA, PHI = np.meshgrid(theta, phi)
# here's the function to plot
R = np.abs(np.cos(THETA**2))
# now convert R(phi, theta) to x, y, z coordinates to plot
X = R * np.sin(THETA) * np.cos(PHI)
Y = R * np.sin(THETA) * np.sin(PHI)
Z = R * np.cos(THETA)
# set up some colors based on the Z range .. from red to blue
norm = mcolors.Normalize(vmin=Z.min(), vmax=Z.max())
# plot the surface
plot = ax.plot_surface(X, Y, Z, rstride=1, cstride=1, facecolors=cmap(norm(Z)),
linewidth=0, antialiased=True, alpha=0.4) # no lines, smooth graphics, semi-transparent
plt.show()
```
The volume element in spherical coordinates is a bit tricky, since the distances depend on the radius and angles:
(Image from [*Mathematical Methods for Chemists*](http://sites.bu.edu/straub/mathematical-methods-for-molecular-science/))
$$ dV = r^2 dr \sin \theta d\theta d\phi$$
<img src="../images/spherical-volume.png" width="414" />
-------
This notebook is from Prof. Geoffrey Hutchison, University of Pittsburgh
https://github.com/ghutchis/chem1000
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a>
| true |
code
| 0.716454 | null | null | null | null |
|
# Zipline Pipeline
### Introduction
On any given trading day, the entire universe of stocks consists of thousands of securities. Usually, you will not be interested in investing in all the stocks in the entire universe, but rather, you will likely select only a subset of these to invest. For example, you may only want to invest in stocks that have a 10-day average closing price of \$10.00 or less. Or you may only want to invest in the top 500 securities ranked by some factor.
In order to avoid spending a lot of time doing data wrangling to select only the securities you are interested in, people often use **pipelines**. In general, a pipeline is a placeholder for a series of data operations used to filter and rank data according to some factor or factors.
In this notebook, you will learn how to work with the **Zipline Pipeline**. Zipline is an open-source algorithmic trading simulator developed by *Quantopian*. We will learn how to use the Zipline Pipeline to filter stock data according to factors.
### Install Packages
```
conda install -c Quantopian zipline
import sys
!{sys.executable} -m pip install -r requirements.txt
```
# Loading Data with Zipline
Before we build our pipeline with Zipline, we will first see how we can load the stock data we are going to use into Zipline. Zipline uses **Data Bundles** to make it easy to use different data sources. A data bundle is a collection of pricing data, adjustment data, and an asset database. Zipline employs data bundles to preload data used to run backtests and store data for future runs. Zipline comes with a few data bundles by default but it also has the ability to ingest new bundles. The first step to using a data bundle is to ingest the data. Zipline's ingestion process will start by downloading the data or by loading data files from your local machine. It will then pass the data to a set of writer objects that converts the original data to Zipline’s internal format (`bcolz` for pricing data, and `SQLite` for split/merger/dividend data) that hs been optimized for speed. This new data is written to a standard location that Zipline can find. By default, the new data is written to a subdirectory of `ZIPLINE_ROOT/data/<bundle>`, where `<bundle>` is the name given to the bundle ingested and the subdirectory is named with the current date. This allows Zipline to look at older data and run backtests on older copies of the data. Running a backtest with an old ingestion makes it easier to reproduce backtest results later.
In this notebook, we will be using stock data from **Quotemedia**. In the Udacity Workspace you will find that the stock data from Quotemedia has already been ingested into Zipline. Therefore, in the code below we will use Zipline's `bundles.load()` function to load our previously ingested stock data from Quotemedia. In order to use the `bundles.load()` function we first need to do a couple of things. First, we need to specify the name of the bundle previously ingested. In this case, the name of the Quotemedia data bundle is `eod-quotemedia`:
```
# Specify the bundle name
bundle_name = 'eod-quotemedia'
```
Second, we need to register the data bundle and its ingest function with Zipline, using the `bundles.register()` function. The ingest function is responsible for loading the data into memory and passing it to a set of writer objects provided by Zipline to convert the data to Zipline’s internal format. Since the original Quotemedia data was contained in `.csv` files, we will use the `csvdir_equities()` function to generate the ingest function for our Quotemedia data bundle. In addition, since Quotemedia's `.csv` files contained daily stock data, we will set the time frame for our ingest function, to `daily`.
```
from zipline.data import bundles
from zipline.data.bundles.csvdir import csvdir_equities
# Create an ingest function
ingest_func = csvdir_equities(['daily'], bundle_name)
# Register the data bundle and its ingest function
bundles.register(bundle_name, ingest_func);
```
Once our data bundle and ingest function are registered, we can load our data using the `bundles.load()` function. Since this function loads our previously ingested data, we need to set `ZIPLINE_ROOT` to the path of the most recent ingested data. The most recent data is located in the `cwd/../../data/project_4_eod/` directory, where `cwd` is the current working directory. We will specify this location using the `os.environ[]` command.
```
import os
# Set environment variable 'ZIPLINE_ROOT' to the path where the most recent data is located
os.environ['ZIPLINE_ROOT'] = os.path.join(os.getcwd(),'project_4_eod')
# Load the data bundle
bundle_data = bundles.load(bundle_name)
```
# Building an Empty Pipeline
Once we have loaded our data, we can start building our Zipline pipeline. We begin by creating an empty Pipeline object using Zipline's `Pipeline` class. A Pipeline object represents a collection of named expressions to be compiled and executed by a Pipeline Engine. The `Pipeline(columns=None, screen=None)` class takes two optional parameters, `columns` and `screen`. The `columns` parameter is a dictionary used to indicate the intial columns to use, and the `screen` parameter is used to setup a screen to exclude unwanted data.
In the code below we will create a `screen` for our pipeline using Zipline's built-in `.AverageDollarVolume()` class. We will use the `.AverageDollarVolume()` class to produce a 60-day Average Dollar Volume of closing prices for every stock in our universe. We then use the `.top(10)` attribute to specify that we want to filter down our universe each day to just the top 10 assets. Therefore, this screen will act as a filter to exclude data from our stock universe each day. The average dollar volume is a good first pass filter to avoid illiquid assets.
```
from zipline.pipeline import Pipeline
from zipline.pipeline.factors import AverageDollarVolume
# Create a screen for our Pipeline
universe = AverageDollarVolume(window_length = 60).top(10)
# Create an empty Pipeline with the given screen
pipeline = Pipeline(screen = universe)
```
In the code above we have named our Pipeline object `pipeline` so that we can identify it later when we make computations. Remember a Pipeline is an object that represents computations we would like to perform every day. A freshly-constructed pipeline, like the one we just created, is empty. This means it doesn’t yet know how to compute anything, and it won’t produce any values if we ask for its outputs. In the sections below, we will see how to provide our Pipeline with expressions to compute.
# Factors and Filters
The `.AverageDollarVolume()` class used above is an example of a factor. In this section we will take a look at two types of computations that can be expressed in a pipeline: **Factors** and **Filters**. In general, factors and filters represent functions that produce a value from an asset in a moment in time, but are distinguished by the types of values they produce. Let's start by looking at factors.
### Factors
In general, a **Factor** is a function from an asset at a particular moment of time to a numerical value. A simple example of a factor is the most recent price of a security. Given a security and a specific moment in time, the most recent price is a number. Another example is the 10-day average trading volume of a security. Factors are most commonly used to assign values to securities which can then be combined with filters or other factors. The fact that you can combine multiple factors makes it easy for you to form new custom factors that can be as complex as you like. For example, constructing a Factor that computes the average of two other Factors can be simply illustrated usingthe pseudocode below:
```python
f1 = factor1(...)
f2 = factor2(...)
average = (f1 + f2) / 2.0
```
### Filters
In general, a **Filter** is a function from an asset at a particular moment in time to a boolean value (True of False). An example of a filter is a function indicating whether a security's price is below \$5. Given a security and a specific moment in time, this evaluates to either **True** or **False**. Filters are most commonly used for selecting sets of securities to include or exclude from your stock universe. Filters are usually applied using comparison operators, such as <, <=, !=, ==, >, >=.
# Viewing the Pipeline as a Diagram
Zipline's Pipeline class comes with the attribute `.show_graph()` that allows you to render the Pipeline as a Directed Acyclic Graph (DAG). This graph is specified using the DOT language and consequently we need a DOT graph layout program to view the rendered image. In the code below, we will use the Graphviz pakage to render the graph produced by the `.show_graph()` attribute. Graphviz is an open-source package for drawing graphs specified in DOT language scripts.
```
import graphviz
# Render the pipeline as a DAG
pipeline.show_graph()
```
Right now, our pipeline is empty and it only contains a screen. Therefore, when we rendered our `pipeline`, we only see the diagram of our `screen`:
```python
AverageDollarVolume(window_length = 60).top(10)
```
By default, the `.AverageDollarVolume()` class uses the `USEquityPricing` dataset, containing daily trading prices and volumes, to compute the average dollar volume:
```python
average_dollar_volume = np.nansum(close_price * volume, axis=0) / len(close_price)
```
The top of the diagram reflects the fact that the `.AverageDollarVolume()` class gets its inputs (closing price and volume) from the `USEquityPricing` dataset. The bottom of the diagram shows that the output is determined by the expression `x_0 <= 10`. This expression reflects the fact that we used `.top(10)` as a filter in our `screen`. We refer to each box in the diagram as a Term.
# Datasets and Dataloaders
One of the features of Zipline's Pipeline is that it separates the actual source of the stock data from the abstract description of that dataset. Therefore, Zipline employs **DataSets** and **Loaders** for those datasets. `DataSets` are just abstract collections of sentinel values describing the columns/types for a particular dataset. While a `loader` is an object which, given a request for a particular chunk of a dataset, can actually get the requested data. For example, the loader used for the `USEquityPricing` dataset, is the `USEquityPricingLoader` class. The `USEquityPricingLoader` class will delegate the loading of baselines and adjustments to lower-level subsystems that know how to get the pricing data in the default formats used by Zipline (`bcolz` for pricing data, and `SQLite` for split/merger/dividend data). As we saw in the beginning of this notebook, data bundles automatically convert the stock data into `bcolz` and `SQLite` formats. It is important to note that the `USEquityPricingLoader` class can also be used to load daily OHLCV data from other datasets, not just from the `USEquityPricing` dataset. Simliarly, it is also possible to write different loaders for the same dataset and use those instead of the default loader. Zipline contains lots of other loaders to allow you to load data from different datasets.
In the code below, we will use `USEquityPricingLoader(BcolzDailyBarWriter, SQLiteAdjustmentWriter)` to create a loader from a `bcolz` equity pricing directory and a `SQLite` adjustments path. Both the `BcolzDailyBarWriter` and `SQLiteAdjustmentWriter` determine the path of the pricing and adjustment data. Since we will be using the Quotemedia data bundle, we will use the `bundle_data.equity_daily_bar_reader` and the `bundle_data.adjustment_reader` as our `BcolzDailyBarWriter` and `SQLiteAdjustmentWriter`, respectively.
```
from zipline.pipeline.loaders import USEquityPricingLoader
# Set the dataloader
pricing_loader = USEquityPricingLoader(bundle_data.equity_daily_bar_reader, bundle_data.adjustment_reader)
```
# Pipeline Engine
Zipline employs computation engines for executing Pipelines. In the code below we will use Zipline's `SimplePipelineEngine()` class as the engine to execute our pipeline. The `SimplePipelineEngine(get_loader, calendar, asset_finder)` class associates the chosen data loader with the corresponding dataset and a trading calendar. The `get_loader` parameter must be a callable function that is given a loadable term and returns a `PipelineLoader` to use to retrieve the raw data for that term in the pipeline. In our case, we will be using the `pricing_loader` defined above, we therefore, create a function called `choose_loader` that returns our `pricing_loader`. The function also checks that the data that is being requested corresponds to OHLCV data, otherwise it retunrs an error. The `calendar` parameter must be a `DatetimeIndex` array of dates to consider as trading days when computing a range between a fixed `start_date` and `end_date`. In our case, we will be using the same trading days as those used in the NYSE. We will use Zipline's `get_calendar('NYSE')` function to retrieve the trading days used by the NYSE. We then use the `.all_sessions` attribute to get the `DatetimeIndex` from our `trading_calendar` and pass it to the `calendar` parameter. Finally, the `asset_finder` parameter determines which assets are in the top-level universe of our stock data at any point in time. Since we are using the Quotemedia data bundle, we set this parameter to the `bundle_data.asset_finder`.
```
from zipline.utils.calendars import get_calendar
from zipline.pipeline.data import USEquityPricing
from zipline.pipeline.engine import SimplePipelineEngine
# Define the function for the get_loader parameter
def choose_loader(column):
if column not in USEquityPricing.columns:
raise Exception('Column not in USEquityPricing')
return pricing_loader
# Set the trading calendar
trading_calendar = get_calendar('NYSE')
# Create a Pipeline engine
engine = SimplePipelineEngine(get_loader = choose_loader,
calendar = trading_calendar.all_sessions,
asset_finder = bundle_data.asset_finder)
```
# Running a Pipeline
Once we have chosen our engine we are ready to run or execute our pipeline. We can run our pipeline by using the `.run_pipeline()` attribute of the `SimplePipelineEngine` class. In particular, the `SimplePipelineEngine.run_pipeline(pipeline, start_date, end_date)` implements the following algorithm for executing pipelines:
1. Build a dependency graph of all terms in the `pipeline`. In this step, the graph is sorted topologically to determine the order in which we can compute the terms.
2. Ask our AssetFinder for a “lifetimes matrix”, which should contain, for each date between `start_date` and `end_date`, a boolean value for each known asset indicating whether the asset existed on that date.
3. Compute each term in the dependency order determined in step 1, caching the results in a a dictionary so that they can be fed into future terms.
4. For each date, determine the number of assets passing the `pipeline` screen. The sum, $N$, of all these values is the total number of rows in our output Pandas Dataframe, so we pre-allocate an output array of length $N$ for each factor in terms.
5. Fill in the arrays allocated in step 4 by copying computed values from our output cache into the corresponding rows.
6. Stick the values computed in step 5 into a Pandas DataFrame and return it.
In the code below, we run our pipeline for a single day, so our `start_date` and `end_date` will be the same. We then print some information about our `pipeline_output`.
```
import pandas as pd
# Set the start and end dates
start_date = pd.Timestamp('2016-01-05', tz = 'utc')
end_date = pd.Timestamp('2016-01-05', tz = 'utc')
# Run our pipeline for the given start and end dates
pipeline_output = engine.run_pipeline(pipeline, start_date, end_date)
# We print information about the pipeline output
print('The pipeline output has type:', type(pipeline_output), '\n')
# We print whether the pipeline output is a MultiIndex Dataframe
print('Is the pipeline output a MultiIndex Dataframe:', isinstance(pipeline_output.index, pd.core.index.MultiIndex), '\n')
# If the pipeline output is a MultiIndex Dataframe we print the two levels of the index
if isinstance(pipeline_output.index, pd.core.index.MultiIndex):
# We print the index level 0
print('Index Level 0:\n\n', pipeline_output.index.get_level_values(0), '\n')
# We print the index level 1
print('Index Level 1:\n\n', pipeline_output.index.get_level_values(1), '\n')
```
We can see above that the return value of `.run_pipeline()` is a `MultiIndex` Pandas DataFrame containing a row for each asset that passed our pipeline’s screen. We can also see that the 0th level of the index contains the date and the 1st level of the index contains the tickers. In general, the returned Pandas DataFrame will also contain a column for each factor and filter we add to the pipeline using `Pipeline.add()`. At this point we haven't added any factors or filters to our pipeline, consequently, the Pandas Dataframe will have no columns. In the following sections we will see how to add factors and filters to our pipeline.
# Get Tickers
We saw in the previous section, that the tickers of the stocks that passed our pipeline’s screen are contained in the 1st level of the index. Therefore, we can use the Pandas `.get_level_values(1).values.tolist()` method to get the tickers of those stocks and save them to a list.
```
# Get the values in index level 1 and save them to a list
universe_tickers = pipeline_output.index.get_level_values(1).values.tolist()
# Display the tickers
universe_tickers
```
# Get Data
Now that we have the tickers for the stocks that passed our pipeline’s screen, we can get the historical stock data for those tickers from our data bundle. In order to get the historical data we need to use Zipline's `DataPortal` class. A `DataPortal` is an interface to all of the data that a Zipline simulation needs. In the code below, we will create a `DataPortal` and `get_pricing` function to get historical stock prices for our tickers.
We have already seen most of the parameters used below when we create the `DataPortal`, so we won't explain them again here. The only new parameter is `first_trading_day`. The `first_trading_day` parameter is a `pd.Timestamp` indicating the first trading day for the simulation. We will set the first trading day to the first trading day in the data bundle. For more information on the `DataPortal` class see the [Zipline documentation](https://www.zipline.io/appendix.html?highlight=dataportal#zipline.data.data_portal.DataPortal)
```
from zipline.data.data_portal import DataPortal
# Create a data portal
data_portal = DataPortal(bundle_data.asset_finder,
trading_calendar = trading_calendar,
first_trading_day = bundle_data.equity_daily_bar_reader.first_trading_day,
equity_daily_reader = bundle_data.equity_daily_bar_reader,
adjustment_reader = bundle_data.adjustment_reader)
```
Now that we have created a `data_portal` we will create a helper function, `get_pricing`, that gets the historical data from the `data_portal` for a given set of `start_date` and `end_date`. The `get_pricing` function takes various parameters:
```python
def get_pricing(data_portal, trading_calendar, assets, start_date, end_date, field='close')
```
The first two parameters, `data_portal` and `trading_calendar`, have already been defined above. The third paramter, `assets`, is a list of tickers. In our case we will use the tickers from the output of our pipeline, namely, `universe_tickers`. The fourth and fifth parameters are strings specifying the `start_date` and `end_date`. The function converts these two strings into Timestamps with a Custom Business Day frequency. The last parameter, `field`, is a string used to indicate which field to return. In our case we want to get the closing price, so we set `field='close`.
The function returns the historical stock price data using the `.get_history_window()` attribute of the `DataPortal` class. This attribute returns a Pandas Dataframe containing the requested history window with the data fully adjusted. The `bar_count` parameter is an integer indicating the number of days to return. The number of days determines the number of rows of the returned dataframe. Both the `frequency` and `data_frequency` parameters are strings that indicate the frequency of the data to query, *i.e.* whether the data is in `daily` or `minute` intervals.
```
def get_pricing(data_portal, trading_calendar, assets, start_date, end_date, field='close'):
# Set the given start and end dates to Timestamps. The frequency string C is used to
# indicate that a CustomBusinessDay DateOffset is used
end_dt = pd.Timestamp(end_date, tz='UTC', freq='C')
start_dt = pd.Timestamp(start_date, tz='UTC', freq='C')
# Get the locations of the start and end dates
end_loc = trading_calendar.closes.index.get_loc(end_dt)
start_loc = trading_calendar.closes.index.get_loc(start_dt)
# return the historical data for the given window
return data_portal.get_history_window(assets=assets, end_dt=end_dt, bar_count=end_loc - start_loc,
frequency='1d',
field=field,
data_frequency='daily')
# Get the historical data for the given window
historical_data = get_pricing(data_portal, trading_calendar, universe_tickers,
start_date='2011-01-05', end_date='2016-01-05')
# Display the historical data
historical_data
```
# Date Alignment
When pipeline returns with a date of, e.g., `2016-01-07` this includes data that would be known as of before the **market open** on `2016-01-07`. As such, if you ask for latest known values on each day, it will return the closing price from the day before and label the date `2016-01-07`. All factor values assume to be run prior to the open on the labeled day with data known before that point in time.
# Adding Factors and Filters
Now that you know how build a pipeline and execute it, in this section we will see how we can add factors and filters to our pipeline. These factors and filters will determine the computations we want our pipeline to compute each day.
We can add both factors and filters to our pipeline using the `.add(column, name)` method of the `Pipeline` class. The `column` parameter represetns the factor or filter to add to the pipeline. The `name` parameter is a string that determines the name of the column in the output Pandas Dataframe for that factor of fitler. As mentioned earlier, each factor and filter will appear as a column in the output dataframe of our pipeline. Let's start by adding a factor to our pipeline.
### Factors
In the code below, we will use Zipline's built-in `SimpleMovingAverage` factor to create a factor that computes the 15-day mean closing price of securities. We will then add this factor to our pipeline and use `.show_graph()` to see a diagram of our pipeline with the factor added.
```
from zipline.pipeline.factors import SimpleMovingAverage
# Create a factor that computes the 15-day mean closing price of securities
mean_close_15 = SimpleMovingAverage(inputs = [USEquityPricing.close], window_length = 15)
# Add the factor to our pipeline
pipeline.add(mean_close_15, '15 Day MCP')
# Render the pipeline as a DAG
pipeline.show_graph()
```
In the diagram above we can clearly see the factor we have added. Now, we can run our pipeline again and see its output. The pipeline is run in exactly the same way we did before.
```
# Set starting and end dates
start_date = pd.Timestamp('2014-01-06', tz='utc')
end_date = pd.Timestamp('2016-01-05', tz='utc')
# Run our pipeline for the given start and end dates
output = engine.run_pipeline(pipeline, start_date, end_date)
# Display the pipeline output
output.head()
```
We can see that now our output dataframe contains a column with the name `15 Day MCP`, which is the name we gave to our factor before. This ouput dataframe from our pipeline gives us the 15-day mean closing price of the securities that passed our `screen`.
### Filters
Filters are created and added to the pipeline in the same way as factors. In the code below, we create a filter that returns `True` whenever the 15-day average closing price is above \$100. Remember, a filter produces a `True` or `False` value for each security every day. We will then add this filter to our pipeline and use `.show_graph()` to see a diagram of our pipeline with the filter added.
```
# Create a Filter that returns True whenever the 15-day average closing price is above $100
high_mean = mean_close_15 > 100
# Add the filter to our pipeline
pipeline.add(high_mean, 'High Mean')
# Render the pipeline as a DAG
pipeline.show_graph()
```
In the diagram above we can clearly see the fiter we have added. Now, we can run our pipeline again and see its output. The pipeline is run in exactly the same way we did before.
```
# Set starting and end dates
start_date = pd.Timestamp('2014-01-06', tz='utc')
end_date = pd.Timestamp('2016-01-05', tz='utc')
# Run our pipeline for the given start and end dates
output = engine.run_pipeline(pipeline, start_date, end_date)
# Display the pipeline output
output.head()
```
We can see that now our output dataframe contains a two columns, one for the filter and one for the factor. The new column has the name `High Mean`, which is the name we gave to our filter before. Notice that the filter column only contains Boolean values, where only the securities with a 15-day average closing price above \$100 have `True` values.
| true |
code
| 0.582907 | null | null | null | null |
|
# Machine Learning for Telecom with Naive Bayes
# Introduction
Machine Learning for CallDisconnectReason is a notebook which demonstrates exploration of dataset and CallDisconnectReason classification with Spark ml Naive Bayes Algorithm.
```
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from sagemaker import get_execution_role
import sagemaker_pyspark
role = get_execution_role()
# Configure Spark to use the SageMaker Spark dependency jars
jars = sagemaker_pyspark.classpath_jars()
classpath = ":".join(sagemaker_pyspark.classpath_jars())
spark = SparkSession.builder.config("spark.driver.extraClassPath", classpath)\
.master("local[*]").getOrCreate()
```
Using S3 Select, enables applications to retrieve only a subset of data from an object by using simple SQL expressions. By using S3 Select to retrieve only the data, you can achieve drastic performance increases – in many cases you can get as much as a 400% improvement.
- _We first read a parquet compressed format of CDR dataset using s3select which has already been processed by Glue._
```
cdr_start_loc = "<%CDRStartFile%>"
cdr_stop_loc = "<%CDRStopFile%>"
cdr_start_sample_loc = "<%CDRStartSampleFile%>"
cdr_stop_sample_loc = "<%CDRStopSampleFile%>"
df = spark.read.format("s3select").parquet(cdr_stop_sample_loc)
df.createOrReplaceTempView("cdr")
durationDF = spark.sql("SELECT _c13 as CallServiceDuration FROM cdr where _c0 = 'STOP'")
durationDF.count()
```
# Exploration of Data
- _We see how we can explore and visualize the dataset used for processing. Here we create a bar chart representation of CallServiceDuration from CDR dataset._
```
import matplotlib.pyplot as plt
durationpd = durationDF.toPandas().astype(int)
durationpd.plot(kind='bar',stacked=True,width=1)
```
- _We can represent the data and visualize with a box plot. The box extends from the lower to upper quartile values of the data, with a line at the median._
```
color = dict(boxes='DarkGreen', whiskers='DarkOrange',
medians='DarkBlue', caps='Gray')
durationpd.plot.box(color=color, sym='r+')
from pyspark.sql.functions import col
durationDF = durationDF.withColumn("CallServiceDuration", col("CallServiceDuration").cast(DoubleType()))
```
- _We can represent the data and visualize the data with histograms partitioned in different bins._
```
import matplotlib.pyplot as plt
bins, counts = durationDF.select('CallServiceDuration').rdd.flatMap(lambda x: x).histogram(durationDF.count())
plt.hist(bins[:-1], bins=bins, weights=counts,color=['green'])
sqlDF = spark.sql("SELECT _c2 as Accounting_ID, _c19 as Calling_Number,_c20 as Called_Number, _c14 as CallDisconnectReason FROM cdr where _c0 = 'STOP'")
sqlDF.show()
```
# Featurization
```
from pyspark.ml.feature import StringIndexer
accountIndexer = StringIndexer(inputCol="Accounting_ID", outputCol="AccountingIDIndex")
accountIndexer.setHandleInvalid("skip")
tempdf1 = accountIndexer.fit(sqlDF).transform(sqlDF)
callingNumberIndexer = StringIndexer(inputCol="Calling_Number", outputCol="Calling_NumberIndex")
callingNumberIndexer.setHandleInvalid("skip")
tempdf2 = callingNumberIndexer.fit(tempdf1).transform(tempdf1)
calledNumberIndexer = StringIndexer(inputCol="Called_Number", outputCol="Called_NumberIndex")
calledNumberIndexer.setHandleInvalid("skip")
tempdf3 = calledNumberIndexer.fit(tempdf2).transform(tempdf2)
from pyspark.ml.feature import StringIndexer
# Convert target into numerical categories
labelIndexer = StringIndexer(inputCol="CallDisconnectReason", outputCol="label")
labelIndexer.setHandleInvalid("skip")
from pyspark.sql.functions import rand
trainingFraction = 0.75;
testingFraction = (1-trainingFraction);
seed = 1234;
trainData, testData = tempdf3.randomSplit([trainingFraction, testingFraction], seed=seed);
# CACHE TRAIN AND TEST DATA
trainData.cache()
testData.cache()
trainData.count(),testData.count()
```
# Analyzing the label distribution
- We analyze the distribution of our target labels using a histogram where 16 represents Normal_Call_Clearing.
```
import matplotlib.pyplot as plt
negcount = trainData.filter("CallDisconnectReason != 16").count()
poscount = trainData.filter("CallDisconnectReason == 16").count()
negfrac = 100*float(negcount)/float(negcount+poscount)
posfrac = 100*float(poscount)/float(poscount+negcount)
ind = [0.0,1.0]
frac = [negfrac,posfrac]
width = 0.35
plt.title('Label Distribution')
plt.bar(ind, frac, width, color='r')
plt.xlabel("CallDisconnectReason")
plt.ylabel('Percentage share')
plt.xticks(ind,['0.0','1.0'])
plt.show()
import matplotlib.pyplot as plt
negcount = testData.filter("CallDisconnectReason != 16").count()
poscount = testData.filter("CallDisconnectReason == 16").count()
negfrac = 100*float(negcount)/float(negcount+poscount)
posfrac = 100*float(poscount)/float(poscount+negcount)
ind = [0.0,1.0]
frac = [negfrac,posfrac]
width = 0.35
plt.title('Label Distribution')
plt.bar(ind, frac, width, color='r')
plt.xlabel("CallDisconnectReason")
plt.ylabel('Percentage share')
plt.xticks(ind,['0.0','1.0'])
plt.show()
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import VectorAssembler
vecAssembler = VectorAssembler(inputCols=["AccountingIDIndex","Calling_NumberIndex", "Called_NumberIndex"], outputCol="features")
```
__Spark ML Naive Bayes__:
Naive Bayes is a simple multiclass classification algorithm with the assumption of independence between every pair of features. Naive Bayes can be trained very efficiently. Within a single pass to the training data, it computes the conditional probability distribution of each feature given label, and then it applies Bayes’ theorem to compute the conditional probability distribution of label given an observation and use it for prediction.
- _We use Spark ML Naive Bayes Algorithm and spark Pipeline to train the data set._
```
from pyspark.ml.classification import NaiveBayes
from pyspark.ml.clustering import KMeans
from pyspark.ml import Pipeline
# Train a NaiveBayes model
nb = NaiveBayes(smoothing=1.0, modelType="multinomial")
# Chain labelIndexer, vecAssembler and NBmodel in a
pipeline = Pipeline(stages=[labelIndexer,vecAssembler, nb])
# Run stages in pipeline and train model
model = pipeline.fit(trainData)
# Run inference on the test data and show some results
predictions = model.transform(testData)
predictions.printSchema()
predictions.show()
predictiondf = predictions.select("label", "prediction", "probability")
pddf_pred = predictions.toPandas()
pddf_pred
```
- _We use Scatter plot for visualization and represent the dataset._
```
import matplotlib.pyplot as plt
import numpy as np
# Set the size of the plot
plt.figure(figsize=(14,7))
# Create a colormap
colormap = np.array(['red', 'lime', 'black'])
# Plot CDR
plt.subplot(1, 2, 1)
plt.scatter(pddf_pred.Calling_NumberIndex, pddf_pred.Called_NumberIndex, c=pddf_pred.prediction)
plt.title('CallDetailRecord')
plt.show()
```
# Evaluation
```
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction",
metricName="accuracy")
accuracy = evaluator.evaluate(predictiondf)
print(accuracy)
```
# Confusion Matrix
```
from sklearn.metrics import confusion_matrix
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sn
outdataframe = predictiondf.select("prediction", "label")
pandadf = outdataframe.toPandas()
npmat = pandadf.values
labels = npmat[:,0]
predicted_label = npmat[:,1]
cnf_matrix = confusion_matrix(labels, predicted_label)
import numpy as np
def plot_confusion_matrix(cm,
target_names,
title='Confusion matrix',
cmap=None,
normalize=True):
import matplotlib.pyplot as plt
import numpy as np
import itertools
accuracy = np.trace(cm) / float(np.sum(cm))
misclass = 1 - accuracy
if cmap is None:
cmap = plt.get_cmap('Blues')
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
if normalize:
plt.text(j, i, "{:0.4f}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
else:
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('label')
plt.xlabel('Predicted \naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))
plt.show()
plot_confusion_matrix(cnf_matrix,
normalize = False,
target_names = ['Positive', 'Negative'],
title = "Confusion Matrix")
from pyspark.mllib.evaluation import MulticlassMetrics
# Create (prediction, label) pairs
predictionAndLabel = predictiondf.select("prediction", "label").rdd
# Generate confusion matrix
metrics = MulticlassMetrics(predictionAndLabel)
print(metrics.confusionMatrix())
```
# Cross Validation
```
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# Create ParamGrid and Evaluator for Cross Validation
paramGrid = ParamGridBuilder().addGrid(nb.smoothing, [0.0, 0.2, 0.4, 0.6, 0.8, 1.0]).build()
cvEvaluator = MulticlassClassificationEvaluator(metricName="accuracy")
# Run Cross-validation
cv = CrossValidator(estimator=pipeline, estimatorParamMaps=paramGrid, evaluator=cvEvaluator)
cvModel = cv.fit(trainData)
# Make predictions on testData. cvModel uses the bestModel.
cvPredictions = cvModel.transform(testData)
cvPredictions.select("label", "prediction", "probability").show()
# Evaluate bestModel found from Cross Validation
evaluator.evaluate(cvPredictions)
```
| true |
code
| 0.648188 | null | null | null | null |
|
# Recommending products with RetailRocket event logs
This IPython notebook illustrates the usage of the [ctpfrec](https://github.com/david-cortes/ctpfrec/) Python package for _Collaborative Topic Poisson Factorization_ in recommender systems based on sparse count data using the [RetailRocket](https://www.kaggle.com/retailrocket/ecommerce-dataset) dataset, consisting of event logs (view, add to cart, purchase) from an online catalog of products plus anonymized text descriptions of items.
Collaborative Topic Poisson Factorization is a probabilistic model that tries to jointly factorize the user-item interaction matrix along with item-word text descriptions (as bag-of-words) of the items by the product of lower dimensional matrices. The package can also extend this model to add user attributes in the same format as the items’.
Compared to competing methods such as BPR (Bayesian Personalized Ranking) or weighted-implicit NMF (non-negative matrix factorization of the non-probabilistic type that uses squared loss), it only requires iterating over the data for which an interaction was observed and not over data for which no interaction was observed (i.e. it doesn’t iterate over items not clicked by a user), thus being more scalable, and at the same time producing better results when fit to sparse count data (in general). Same for the word counts of items.
The implementation here is based on the paper _Content-based recommendations with poisson factorization (Gopalan, P.K., Charlin, L. and Blei, D., 2014)_.
For a similar package for explicit feedback data see also [cmfrec](https://github.com/david-cortes/cmfrec/). For Poisson factorization without side information see [hpfrec](https://github.com/david-cortes/hpfrec/).
**Small note: if the TOC here is not clickable or the math symbols don't show properly, try visualizing this same notebook from nbviewer following [this link](http://nbviewer.jupyter.org/github/david-cortes/ctpfrec/blob/master/example/ctpfrec_retailrocket.ipynb).**
** *
## Sections
* [1. Model description](#p1)
* [2. Loading and processing the dataset](#p2)
* [3. Fitting the model](#p3)
* [4. Common sense checks](#p4)
* [5. Comparison to model without item information](#p5)
* [6. Making recommendations](#p6)
* [7. References](#p7)
** *
<a id="p1"></a>
## 1. Model description
The model consists in producing a low-rank non-negative matrix factorization of the item-word matrix (a.k.a. bag-of-words, a matrix where each row represents an item and each column a word, with entries containing the number of times each word appeared in an item’s text, ideally with some pre-processing on the words such as stemming or lemmatization) by the product of two lower-rank matrices
$$ W_{iw} \approx \Theta_{ik} \beta_{wk}^T $$
along with another low-rank matrix factorization of the user-item activity matrix (a matrix where each entry corresponds to how many times each user interacted with each item) that shares the same item-factor matrix above plus an offset based on user activity and not based on items’ words
$$ Y_{ui} \approx \eta_{uk} (\Theta_{ik} + \epsilon_{ik})^T $$
These matrices are assumed to come from a generative process as follows:
* Items:
$$ \beta_{wk} \sim Gamma(a,b) $$
$$ \Theta_{ik} \sim Gamma(c,d)$$
$$ W_{iw} \sim Poisson(\Theta_{ik} \beta_{wk}^T) $$
_(Where $W$ is the item-word count matrix, $k$ is the number of latent factors, $i$ is the number of items, $w$ is the number of words)_
* User-Item interactions
$$ \eta_{uk} \sim Gamma(e,f) $$
$$ \epsilon_{ik} \sim Gamma(g,h) $$
$$ Y_{ui} \sim Poisson(\eta_{uk} (\Theta_{ik} + \epsilon_{ik})^T) $$
_(Where $u$ is the number of users, $Y$ is the user-item interaction matrix)_
The model is fit using mean-field variational inference with coordinate ascent. For more details see the paper in the references.
** *
<a id="p2"></a>
## 2. Loading and processing the data
Reading and concatenating the data. First the event logs:
```
import numpy as np, pandas as pd
events = pd.read_csv("events.csv")
events.head()
events.event.value_counts()
```
In order to put all user-item interactions in one scale, I will arbitrarily assign values as follows:
* View: +1
* Add to basket: +3
* Purchase: +3
Thus, if a user clicks an item, that `(user, item)` pair will have `value=1`, if she later adds it to cart and purchases it, will have `value=7` (plus any other views of the same item), and so on.
The reasoning behind this scale is because the distributions of counts and sums of counts seem to still follow a nice exponential distribution with these values, but different values might give better results in terms of models fit to them.
```
%matplotlib inline
equiv = {
'view':1,
'addtocart':3,
'transaction':3
}
events['count']=events.event.map(equiv)
events.groupby('visitorid')['count'].sum().value_counts().hist(bins=200)
events = events.groupby(['visitorid','itemid'])['count'].sum().to_frame().reset_index()
events.rename(columns={'visitorid':'UserId', 'itemid':'ItemId', 'count':'Count'}, inplace=True)
events.head()
```
Now creating a train and test split. For simplicity purposes and in order to be able to make a fair comparison with a model that doesn't use item descriptions, I will try to only take users that had >= 3 items in the training data, and items that had >= 3 users.
Given the lack of user attributes and the fact that it will be compared later to a model without side information, the test set will only have users from the training data, but it's also possible to use user attributes if they follow the same format as the items', in which case the model can also recommend items to new users.
In order to compare it later to a model without items' text, I will also filter out the test set to have only items that were in the training set. **This is however not a model limitation, as it can also recommend items that have descriptions but no user interactions**.
```
from sklearn.model_selection import train_test_split
events_train, events_test = train_test_split(events, test_size=.2, random_state=1)
del events
## In order to find users and items with at least 3 interactions each,
## it's easier and faster to use a simple heuristic that first filters according to one criteria,
## then, according to the other, and repeats.
## Finding a real subset of the data in which each item has strictly >= 3 users,
## and each user has strictly >= 3 items, is a harder graph partitioning or optimization
## problem. For a similar example of finding such subsets see also:
## http://nbviewer.ipython.org/github/david-cortes/datascienceprojects/blob/master/optimization/dataset_splitting.ipynb
users_filter_out = events_train.groupby('UserId')['ItemId'].agg(lambda x: len(tuple(x)))
users_filter_out = np.array(users_filter_out.index[users_filter_out < 3])
items_filter_out = events_train.loc[~np.in1d(events_train.UserId, users_filter_out)].groupby('ItemId')['UserId'].agg(lambda x: len(tuple(x)))
items_filter_out = np.array(items_filter_out.index[items_filter_out < 3])
users_filter_out = events_train.loc[~np.in1d(events_train.ItemId, items_filter_out)].groupby('UserId')['ItemId'].agg(lambda x: len(tuple(x)))
users_filter_out = np.array(users_filter_out.index[users_filter_out < 3])
events_train = events_train.loc[~np.in1d(events_train.UserId.values, users_filter_out)]
events_train = events_train.loc[~np.in1d(events_train.ItemId.values, items_filter_out)]
events_test = events_test.loc[np.in1d(events_test.UserId.values, events_train.UserId.values)]
events_test = events_test.loc[np.in1d(events_test.ItemId.values, events_train.ItemId.values)]
print(events_train.shape)
print(events_test.shape)
```
Now processing the text descriptions of the items:
```
iteminfo = pd.read_csv("item_properties_part1.csv")
iteminfo2 = pd.read_csv("item_properties_part2.csv")
iteminfo = iteminfo.append(iteminfo2, ignore_index=True)
iteminfo.head()
```
The item's description contain many fields and have a mixture of words and numbers. The numeric variables, as per the documentation, are prefixed with an "n" and have three digits decimal precision - I will exclude them here since this model is insensitive to numeric attributes such as price. The words are already lemmazed, and since we only have their IDs, it's not possible to do any other pre-processing on them.
Although the descriptions don't say anything about it, looking at the contents and the lengths of the different fields, here I will assume that the field $283$ is the product title and the field $888$ is the product description. I will just concatenate them to obtain an overall item text, but there might be better ways of doing this (such as having different IDs for the same word when it appears in the title or the body, or multiplying those in the title by some number, etc.)
As the descriptions vary over time, I will only take the most recent version for each item:
```
iteminfo = iteminfo.loc[iteminfo.property.isin(('888','283'))]
iteminfo = iteminfo.loc[iteminfo.groupby(['itemid','property'])['timestamp'].idxmax()]
iteminfo.reset_index(drop=True, inplace=True)
iteminfo.head()
```
**Note that for simplicity I am completely ignoring the categories (these are easily incorporated e.g. by adding a count of +1 for each category to which an item belongs) and important factors such as the price. I am also completely ignoring all the other fields.**
```
from sklearn.feature_extraction.text import CountVectorizer
from scipy.sparse import coo_matrix
import re
def concat_fields(x):
x = list(x)
out = x[0]
for i in x[1:]:
out += " " + i
return out
class NonNumberTokenizer(object):
def __init__(self):
pass
def __call__(self, txt):
return [i for i in txt.split(" ") if bool(re.search("^\d", i))]
iteminfo = iteminfo.groupby('itemid')['value'].agg(lambda x: concat_fields(x))
t = CountVectorizer(tokenizer=NonNumberTokenizer(), stop_words=None,
dtype=np.int32, strip_accents=None, lowercase=False)
bag_of_words = t.fit_transform(iteminfo)
bag_of_words = coo_matrix(bag_of_words)
bag_of_words = pd.DataFrame({
'ItemId' : iteminfo.index[bag_of_words.row],
'WordId' : bag_of_words.col,
'Count' : bag_of_words.data
})
del iteminfo
bag_of_words.head()
```
In this case, I will not filter it out by only items that were in the training set, as other items can still be used to get better latent factors.
** *
<a id="p3"></a>
## 3. Fitting the model
Fitting the model - note that I'm using some enhancements (passed as arguments to the class constructor) over the original version in the paper:
* Standardizing item counts so as not to favor items with longer descriptions.
* Initializing $\Theta$ and $\beta$ through hierarchical Poisson factorization instead of latent Dirichlet allocation.
* Using a small step size for the updates for the parameters obtained from hierarchical Poisson factorization at the beginning, which then grows to one with increasing iteration numbers (informally, this achieves to somehwat "preserve" these fits while the user parameters are adjusted to these already-fit item parameters - then as the user parameters are already defined towards them, the item and word parameters start changing too).
I'll be also fitting two slightly different models: one that takes (and can make recommendations for) all the items for which there are either descriptions or user clicks, and another that uses all the items for which there are descriptions to initialize the item-related parameters but discards the ones without clicks (can only make recommendations for items that users have clicked).
For more information about the parameters and what they do, see the online documentation:
[http://ctpfrec.readthedocs.io](http://ctpfrec.readthedocs.io)
```
print(events_train.shape)
print(events_test.shape)
print(bag_of_words.shape)
%%time
from ctpfrec import CTPF
recommender_all_items = CTPF(k=70, step_size=lambda x: 1-1/np.sqrt(x+1),
standardize_items=True, initialize_hpf=True, reindex=True,
missing_items='include', allow_inconsistent_math=True, random_seed=1)
recommender_all_items.fit(counts_df=events_train.copy(), words_df=bag_of_words.copy())
%%time
recommender_clicked_items_only = CTPF(k=70, step_size=lambda x: 1-1/np.sqrt(x+1),
standardize_items=True, initialize_hpf=True, reindex=True,
missing_items='exclude', allow_inconsistent_math=True, random_seed=1)
recommender_clicked_items_only.fit(counts_df=events_train.copy(), words_df=bag_of_words.copy())
```
Most of the time here was spent in fitting the model to items that no user in the training set had clicked. If using instead a random initialization, it would have taken a lot less time to fit this model (there would be only a fraction of the items - see above time spent in each procedure), but the results are slightly worse.
_Disclaimer: this notebook was run on a Google cloud server with Skylake CPU using 8 cores, and memory usage tops at around 6GB of RAM for the first model (including all the objects loaded before). In a desktop computer, it would take a bit longer to fit._
** *
<a id="p4"></a>
## 4. Common sense checks
There are many different metrics to evaluate recommendation quality in implicit datasets, but all of them have their drawbacks. The idea of this notebook is to illustrate the package usage and not to introduce and compare evaluation metrics, so I will only perform some common sense checks on the test data.
For implementations of evaluation metrics for implicit recommendations see other packages such as [lightFM](https://github.com/lyst/lightfm).
As some common sense checks, the predictions should:
* Be higher for this non-zero hold-out sample than for random items.
* Produce a good discrimination between random items and those in the hold-out sample (very related to the first point).
* Be correlated with the numer of events per user-item pair in the hold-out sample.
* Follow an exponential distribution rather than a normal or some other symmetric distribution.
Here I'll check these four conditions:
#### Model with all items
```
events_test['Predicted'] = recommender_all_items.predict(user=events_test.UserId, item=events_test.ItemId)
events_test['RandomItem'] = np.random.choice(events_train.ItemId.unique(), size=events_test.shape[0])
events_test['PredictedRandom'] = recommender_all_items.predict(user=events_test.UserId,
item=events_test.RandomItem)
print("Average prediction for combinations in test set: ", events_test.Predicted.mean())
print("Average prediction for random combinations: ", events_test.PredictedRandom.mean())
from sklearn.metrics import roc_auc_score
was_clicked = np.r_[np.ones(events_test.shape[0]), np.zeros(events_test.shape[0])]
score_model = np.r_[events_test.Predicted.values, events_test.PredictedRandom.values]
roc_auc_score(was_clicked[~np.isnan(score_model)], score_model[~np.isnan(score_model)])
np.corrcoef(events_test.Count[~events_test.Predicted.isnull()], events_test.Predicted[~events_test.Predicted.isnull()])[0,1]
import matplotlib.pyplot as plt
%matplotlib inline
_ = plt.hist(events_test.Predicted, bins=200)
plt.xlim(0,5)
plt.show()
```
#### Model with clicked items only
```
events_test['Predicted'] = recommender_clicked_items_only.predict(user=events_test.UserId, item=events_test.ItemId)
events_test['PredictedRandom'] = recommender_clicked_items_only.predict(user=events_test.UserId,
item=events_test.RandomItem)
print("Average prediction for combinations in test set: ", events_test.Predicted.mean())
print("Average prediction for random combinations: ", events_test.PredictedRandom.mean())
was_clicked = np.r_[np.ones(events_test.shape[0]), np.zeros(events_test.shape[0])]
score_model = np.r_[events_test.Predicted.values, events_test.PredictedRandom.values]
roc_auc_score(was_clicked, score_model)
np.corrcoef(events_test.Count, events_test.Predicted)[0,1]
_ = plt.hist(events_test.Predicted, bins=200)
plt.xlim(0,5)
plt.show()
```
** *
<a id="p5"></a>
## 5. Comparison to model without item information
A natural benchmark to compare this model is to is a Poisson factorization model without any item side information - here I'll do the comparison with a _Hierarchical Poisson factorization_ model with the same metrics as above:
```
%%time
from hpfrec import HPF
recommender_no_sideinfo = HPF(k=70)
recommender_no_sideinfo.fit(events_train.copy())
events_test_comp = events_test.copy()
events_test_comp['Predicted'] = recommender_no_sideinfo.predict(user=events_test_comp.UserId, item=events_test_comp.ItemId)
events_test_comp['PredictedRandom'] = recommender_no_sideinfo.predict(user=events_test_comp.UserId,
item=events_test_comp.RandomItem)
print("Average prediction for combinations in test set: ", events_test_comp.Predicted.mean())
print("Average prediction for random combinations: ", events_test_comp.PredictedRandom.mean())
was_clicked = np.r_[np.ones(events_test_comp.shape[0]), np.zeros(events_test_comp.shape[0])]
score_model = np.r_[events_test_comp.Predicted.values, events_test_comp.PredictedRandom.values]
roc_auc_score(was_clicked, score_model)
np.corrcoef(events_test_comp.Count, events_test_comp.Predicted)[0,1]
```
As can be seen, adding the side information and widening the catalog to include more items using only their text descriptions (no clicks) results in an improvemnet over all 3 metrics, especially correlation with number of clicks.
More important than that however, is its ability to make recommendations from a far wider catalog of items, which in practice can make a much larger difference in recommendation quality than improvement in typicall offline metrics.
** *
<a id="p6"></a>
## 6. Making recommendations
The package provides a simple API for making predictions and Top-N recommended lists. These Top-N lists can be made among all items, or across some user-provided subset only, and you can choose to discard items with which the user had already interacted in the training set.
Here I will:
* Pick a random user with a reasonably long event history.
* See which items would the model recommend to them among those which he has not yet clicked.
* Compare it with the recommended list from the model without item side information.
Unfortunately, since all the data is anonymized, it's not possible to make a qualitative evaluation of the results by looking at the recommended lists as it is in other datasets.
```
users_many_events = events_train.groupby('UserId')['ItemId'].agg(lambda x: len(tuple(x)))
users_many_events = np.array(users_many_events.index[users_many_events > 20])
np.random.seed(1)
chosen_user = np.random.choice(users_many_events)
chosen_user
%%time
recommender_all_items.topN(chosen_user, n=20)
```
*(These numbers represent the IDs of the items being recommended as they appeared in the `events_train` data frame)*
```
%%time
recommender_clicked_items_only.topN(chosen_user, n=20)
%%time
recommender_no_sideinfo.topN(chosen_user, n=20)
```
** *
<a id="p7"></a>
## 7. References
* Gopalan, Prem K., Laurent Charlin, and David Blei. "Content-based recommendations with poisson factorization." Advances in Neural Information Processing Systems. 2014.
| true |
code
| 0.496338 | null | null | null | null |
|
# Continuous Control
---
In this notebook, you will learn how to use the Unity ML-Agents environment for the second project of the [Deep Reinforcement Learning Nanodegree](https://www.udacity.com/course/deep-reinforcement-learning-nanodegree--nd893) program.
### 1. Start the Environment
We begin by importing the necessary packages. If the code cell below returns an error, please revisit the project instructions to double-check that you have installed [Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Installation.md) and [NumPy](http://www.numpy.org/).
```
import torch
import numpy as np
import pandas as pd
from collections import deque
from unityagents import UnityEnvironment
import random
import matplotlib.pyplot as plt
%matplotlib inline
from ddpg_agent import Agent
```
Next, we will start the environment! **_Before running the code cell below_**, change the `file_name` parameter to match the location of the Unity environment that you downloaded.
- **Mac**: `"path/to/Reacher.app"`
- **Windows** (x86): `"path/to/Reacher_Windows_x86/Reacher.exe"`
- **Windows** (x86_64): `"path/to/Reacher_Windows_x86_64/Reacher.exe"`
- **Linux** (x86): `"path/to/Reacher_Linux/Reacher.x86"`
- **Linux** (x86_64): `"path/to/Reacher_Linux/Reacher.x86_64"`
- **Linux** (x86, headless): `"path/to/Reacher_Linux_NoVis/Reacher.x86"`
- **Linux** (x86_64, headless): `"path/to/Reacher_Linux_NoVis/Reacher.x86_64"`
For instance, if you are using a Mac, then you downloaded `Reacher.app`. If this file is in the same folder as the notebook, then the line below should appear as follows:
```
env = UnityEnvironment(file_name="Reacher.app")
```
```
env = UnityEnvironment(file_name="Reacher1.app")
```
Environments contain **_brains_** which are responsible for deciding the actions of their associated agents. Here we check for the first brain available, and set it as the default brain we will be controlling from Python.
```
# get the default brain
brain_name = env.brain_names[0]
brain = env.brains[brain_name]
```
### 2. Examine the State and Action Spaces
In this environment, a double-jointed arm can move to target locations. A reward of `+0.1` is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of `33` variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector must be a number between `-1` and `1`.
Run the code cell below to print some information about the environment.
```
# reset the environment
env_info = env.reset(train_mode=True)[brain_name]
# number of agents
num_agents = len(env_info.agents)
print('Number of agents:', num_agents)
# size of each action
action_size = brain.vector_action_space_size
print('Size of each action:', action_size)
# examine the state space
states = env_info.vector_observations
state_size = states.shape[1]
print('There are {} agents. Each observes a state with length: {}'.format(states.shape[0], state_size))
print('The state for the first agent looks like:', states[0])
```
### 3. Take Random Actions in the Environment
In the next code cell, you will learn how to use the Python API to control the agent and receive feedback from the environment.
Once this cell is executed, you will watch the agent's performance, if it selects an action at random with each time step. A window should pop up that allows you to observe the agent, as it moves through the environment.
Of course, as part of the project, you'll have to change the code so that the agent is able to use its experience to gradually choose better actions when interacting with the environment!
```
env_info = env.reset(train_mode=False)[brain_name] # reset the environment
states = env_info.vector_observations # get the current state (for each agent)
scores = np.zeros(num_agents) # initialize the score (for each agent)
while True:
actions = np.random.randn(num_agents, action_size) # select an action (for each agent)
actions = np.clip(actions, -1, 1) # all actions between -1 and 1
env_info = env.step(actions)[brain_name] # send all actions to tne environment
next_states = env_info.vector_observations # get next state (for each agent)
rewards = env_info.rewards # get reward (for each agent)
dones = env_info.local_done # see if episode finished
scores += env_info.rewards # update the score (for each agent)
states = next_states # roll over states to next time step
if np.any(dones): # exit loop if episode finished
break
print('Total score (averaged over agents) this episode: {}'.format(np.mean(scores)))
```
### 4. It's Your Turn!
Now it's your turn to train your own agent to solve the environment! When training the environment, set `train_mode=True`, so that the line for resetting the environment looks like the following:
```python
env_info = env.reset(train_mode=True)[brain_name]
```
```
agent = Agent(state_size=state_size, action_size=action_size,
n_agents=num_agents, random_seed=42)
def plot_scores(scores, rolling_window=10, save_fig=False):
"""Plot scores and optional rolling mean using specified window."""
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(len(scores)), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.title(f'scores')
rolling_mean = pd.Series(scores).rolling(rolling_window).mean()
plt.plot(rolling_mean);
if save_fig:
plt.savefig(f'figures_scores.png', bbox_inches='tight', pad_inches=0)
def ddpg(n_episodes=10000, max_t=1000, print_every=100):
scores_deque = deque(maxlen=print_every)
scores = []
for i_episode in range(1, n_episodes+1):
env_info = env.reset(train_mode=True)[brain_name]
states = env_info.vector_observations
agent.reset()
score = np.zeros(num_agents)
for t in range(max_t):
actions = agent.act(states)
env_info = env.step(actions)[brain_name]
next_states = env_info.vector_observations # get next state (for each agent)
rewards = env_info.rewards # get reward (for each agent)
dones = env_info.local_done # see if episode finished
agent.step(states, actions, rewards, next_states, dones)
states = next_states
score += rewards
if any(dones):
break
scores_deque.append(np.mean(score))
scores.append(np.mean(score))
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)), end="")
torch.save(agent.actor_local.state_dict(), './weights/checkpoint_actor.pth')
torch.save(agent.critic_local.state_dict(), './weights/checkpoint_critic.pth')
if i_episode % print_every == 0:
print('\rEpisode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))
plot_scores(scores)
if np.mean(scores_deque) >= 30.0:
print('\nEnvironment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode - print_every, np.mean(scores_deque)))
torch.save(agent.actor_local.state_dict(), './weights/checkpoint_actor.pth')
torch.save(agent.critic_local.state_dict(), './weights/checkpoint_critic.pth')
break
return scores
scores = ddpg()
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(1, len(scores)+1), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
plot_scores(scores)
```
When finished, you can close the environment.
```
env.close()
```
| true |
code
| 0.679737 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/Eurus-Holmes/PyTorch-Tutorials/blob/master/Training_a__Classifier.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
%matplotlib inline
```
Training a Classifier
=====================
This is it. You have seen how to define neural networks, compute loss and make
updates to the weights of the network.
Now you might be thinking,
What about data?
----------------
Generally, when you have to deal with image, text, audio or video data,
you can use standard python packages that load data into a numpy array.
Then you can convert this array into a ``torch.*Tensor``.
- For images, packages such as Pillow, OpenCV are useful
- For audio, packages such as scipy and librosa
- For text, either raw Python or Cython based loading, or NLTK and
SpaCy are useful
Specifically for vision, we have created a package called
``torchvision``, that has data loaders for common datasets such as
Imagenet, CIFAR10, MNIST, etc. and data transformers for images, viz.,
``torchvision.datasets`` and ``torch.utils.data.DataLoader``.
This provides a huge convenience and avoids writing boilerplate code.
For this tutorial, we will use the CIFAR10 dataset.
It has the classes: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’,
‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’. The images in CIFAR-10 are of
size 3x32x32, i.e. 3-channel color images of 32x32 pixels in size.
Training an image classifier
----------------------------
We will do the following steps in order:
1. Load and normalizing the CIFAR10 training and test datasets using
``torchvision``
2. Define a Convolution Neural Network
3. Define a loss function
4. Train the network on the training data
5. Test the network on the test data
1. Loading and normalizing CIFAR10
----------------------------
# 1. Loading and normalizing CIFAR10
Using ``torchvision``, it’s extremely easy to load CIFAR10.
```
import torch
import torchvision
import torchvision.transforms as transforms
```
The output of torchvision datasets are PILImage images of range [0, 1].
We transform them to Tensors of normalized range [-1, 1].
```
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
```
Let us show some of the training images, for fun.
```
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
# 2. Define a Convolution Neural Network
----
Copy the neural network from the Neural Networks section before and modify it to
take 3-channel images (instead of 1-channel images as it was defined).
```
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
```
# 3. Define a Loss function and optimizer
----
Let's use a Classification Cross-Entropy loss and SGD with momentum.
```
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
```
# 4. Train the network
----
This is when things start to get interesting.
We simply have to loop over our data iterator, and feed the inputs to the
network and optimize.
```
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
```
# 5. Test the network on the test data
----
We have trained the network for 2 passes over the training dataset.
But we need to check if the network has learnt anything at all.
We will check this by predicting the class label that the neural network
outputs, and checking it against the ground-truth. If the prediction is
correct, we add the sample to the list of correct predictions.
Okay, first step. Let us display an image from the test set to get familiar.
```
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
```
Okay, now let us see what the neural network thinks these examples above are:
```
outputs = net(images)
```
The outputs are energies for the 10 classes.
Higher the energy for a class, the more the network
thinks that the image is of the particular class.
So, let's get the index of the highest energy:
```
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
```
The results seem pretty good.
Let us look at how the network performs on the whole dataset.
```
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
```
That looks waaay better than chance, which is 10% accuracy (randomly picking
a class out of 10 classes).
Seems like the network learnt something.
Hmmm, what are the classes that performed well, and the classes that did
not perform well:
```
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
```
Okay, so what next?
How do we run these neural networks on the GPU?
Training on GPU
----------------
Just like how you transfer a Tensor on to the GPU, you transfer the neural
net onto the GPU.
Let's first define our device as the first visible cuda device if we have
CUDA available:
```
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assume that we are on a CUDA machine, then this should print a CUDA device:
print(device)
```
The rest of this section assumes that `device` is a CUDA device.
Then these methods will recursively go over all modules and convert their
parameters and buffers to CUDA tensors:
`net.to(device)`
Remember that you will have to send the inputs and targets at every step
to the GPU too:
`inputs, labels = inputs.to(device), labels.to(device)`
Why dont I notice MASSIVE speedup compared to CPU? Because your network
is realllly small.
**Exercise:** Try increasing the width of your network (argument 2 of
the first ``nn.Conv2d``, and argument 1 of the second ``nn.Conv2d`` –
they need to be the same number), see what kind of speedup you get.
**Goals achieved**:
- Understanding PyTorch's Tensor library and neural networks at a high level.
- Train a small neural network to classify images
Training on multiple GPUs
-------------------------
If you want to see even more MASSIVE speedup using all of your GPUs,
please check out :doc:`data_parallel_tutorial`.
Where do I go next?
-------------------
- `Train neural nets to play video games`
- `Train a state-of-the-art ResNet network on imagenet`
- `Train a face generator using Generative Adversarial Networks`
- `Train a word-level language model using Recurrent LSTM networks`
- `More examples`
- `More tutorials`
- `Discuss PyTorch on the Forums`
- `Chat with other users on Slack`
| true |
code
| 0.77994 | null | null | null | null |
|
# Direct Outcome Prediction Model
Also known as standardization
```
%matplotlib inline
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import GradientBoostingRegressor
from causallib.datasets import load_smoking_weight
from causallib.estimation import Standardization, StratifiedStandardization
from causallib.evaluation import OutcomeEvaluator
```
#### Data:
The effect of quitting to smoke on weight loss.
Data example is taken from [Hernan and Robins Causal Inference Book](https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/)
```
data = load_smoking_weight()
data.X.join(data.a).join(data.y).head()
```
## "Standard" Standardization
A single model is trained with the treatment assignment as an additional feature.
During inference, the model assigns a treatment value for all samples,
thus predicting the potential outcome of all samples.
```
std = Standardization(LinearRegression())
std.fit(data.X, data.a, data.y)
```
##### Outcome Prediction
The model can be used to predict individual outcomes:
The potential outcome under each intervention
```
ind_outcomes = std.estimate_individual_outcome(data.X, data.a)
ind_outcomes.head()
```
The model can be used to predict population outcomes,
By aggregating the individual outcome prediction (e.g., mean or median).
Providing `agg_func` which is defaulted to `'mean'`
```
median_pop_outcomes = std.estimate_population_outcome(data.X, data.a, agg_func="median")
median_pop_outcomes.rename("median", inplace=True)
mean_pop_outcomes = std.estimate_population_outcome(data.X, data.a, agg_func="mean")
mean_pop_outcomes.rename("mean", inplace=True)
pop_outcomes = mean_pop_outcomes.to_frame().join(median_pop_outcomes)
pop_outcomes
```
##### Effect Estimation
Similarly, Effect estimation can be done on either individual or population level, depending on the outcomes provided.
Population level effect using population outcomes:
```
std.estimate_effect(mean_pop_outcomes[1], mean_pop_outcomes[0])
```
Population level effect using individual outcome, but asking for aggregation (default behaviour):
```
std.estimate_effect(ind_outcomes[1], ind_outcomes[0], agg="population")
```
Individual level effect using inidiviual outcomes:
Since we're using a binary treatment with logistic regression on a standard model,
the difference is same for all individuals, and is equal to the coefficient of the treatment varaible
```
print(std.learner.coef_[0])
std.estimate_effect(ind_outcomes[1], ind_outcomes[0], agg="individual").head()
```
Multiple types of effect are also supported:
```
std.estimate_effect(ind_outcomes[1], ind_outcomes[0],
agg="individual", effect_types=["diff", "ratio"]).head()
```
### Treament one-hot encoded
For multi-treatment cases, where treatments are coded as 0, 1, 2, ... but have no ordinal interpretation,
It is possible to make the model encode the treatment assignment vector as one hot matrix.
```
std = Standardization(LinearRegression(), encode_treatment=True)
std.fit(data.X, data.a, data.y)
pop_outcomes = std.estimate_population_outcome(data.X, data.a, agg_func="mean")
std.estimate_effect(mean_pop_outcomes[1], mean_pop_outcomes[0])
```
## Stratified Standarziation
While standardization can be viewed as a **"complete pooled"** estimator,
as it includes both treatment groups together,
Stratified Standardization can viewed as **"complete unpooled"** one,
as it completly stratifies the dataset by treatment values and learns a different model for each treatment group.
```
std = StratifiedStandardization(LinearRegression())
std.fit(data.X, data.a, data.y)
```
Checking the core `learner` we can see that it actually has two models, indexed by the treatment value:
```
std.learner
```
We can apply same analysis as above.
```
pop_outcomes = std.estimate_population_outcome(data.X, data.a, agg_func="mean")
std.estimate_effect(mean_pop_outcomes[1], mean_pop_outcomes[0])
```
We can see that internally, when asking for some potential outcome,
the model simply applies the model trained on the group of that treatment:
```
potential_outcome = std.estimate_individual_outcome(data.X, data.a)[1]
direct_prediction = std.learner[1].predict(data.X)
(potential_outcome == direct_prediction).all()
```
#### Providing complex scheme of learners
When supplying a single learner to the standardization above,
the model simply duplicates it for each treatment value.
However, it is possible to specify a different model for each treatment value explicitly.
For example, in cases where the treated are more complex than the untreated
(because, say, background of those choosed to be treated),
it is possible to specify them with a more expressive model:
```
learner = {0: LinearRegression(),
1: GradientBoostingRegressor()}
std = StratifiedStandardization(learner)
std.fit(data.X, data.a, data.y)
std.learner
ind_outcomes = std.estimate_individual_outcome(data.X, data.a)
ind_outcomes.head()
std.estimate_effect(ind_outcomes[1], ind_outcomes[0])
```
## Evaluation
#### Simple evaluation
```
plots = ["common_support", "continuous_accuracy"]
evaluator = OutcomeEvaluator(std)
evaluator._regression_metrics.pop("msle") # We have negative values and this is log transforms
results = evaluator.evaluate_simple(data.X, data.a, data.y, plots=plots)
```
Results show the results for each treatment group separetly and also combined:
```
results.scores
```
#### Thorough evaluation
```
plots=["common_support", "continuous_accuracy", "residuals"]
evaluator = OutcomeEvaluator(Standardization(LinearRegression()))
results = evaluator.evaluate_cv(data.X, data.a, data.y,
plots=plots)
results.scores
results.models
```
| true |
code
| 0.674908 | null | null | null | null |
|
# Accessing data in a DataSet
After a measurement is completed all the acquired data and metadata around it is accessible via a `DataSet` object. This notebook presents the useful methods and properties of the `DataSet` object which enable convenient access to the data, parameters information, and more. For general overview of the `DataSet` class, refer to [DataSet class walkthrough](DataSet-class-walkthrough.ipynb).
## Preparation: a DataSet from a dummy Measurement
In order to obtain a `DataSet` object, we are going to run a `Measurement` storing some dummy data (see [Dataset Context Manager](Dataset%20Context%20Manager.ipynb) notebook for more details).
```
import tempfile
import os
import numpy as np
import qcodes
from qcodes import initialise_or_create_database_at, \
load_or_create_experiment, Measurement, Parameter, \
Station
from qcodes.dataset.plotting import plot_dataset
db_path = os.path.join(tempfile.gettempdir(), 'data_access_example.db')
initialise_or_create_database_at(db_path)
exp = load_or_create_experiment(experiment_name='greco', sample_name='draco')
x = Parameter(name='x', label='Voltage', unit='V',
set_cmd=None, get_cmd=None)
t = Parameter(name='t', label='Time', unit='s',
set_cmd=None, get_cmd=None)
y = Parameter(name='y', label='Voltage', unit='V',
set_cmd=None, get_cmd=None)
y2 = Parameter(name='y2', label='Current', unit='A',
set_cmd=None, get_cmd=None)
q = Parameter(name='q', label='Qredibility', unit='$',
set_cmd=None, get_cmd=None)
meas = Measurement(exp=exp, name='fresco')
meas.register_parameter(x)
meas.register_parameter(t)
meas.register_parameter(y, setpoints=(x, t))
meas.register_parameter(y2, setpoints=(x, t))
meas.register_parameter(q) # a standalone parameter
x_vals = np.linspace(-4, 5, 50)
t_vals = np.linspace(-500, 1500, 25)
with meas.run() as datasaver:
for xv in x_vals:
for tv in t_vals:
yv = np.sin(2*np.pi*xv)*np.cos(2*np.pi*0.001*tv) + 0.001*tv
y2v = np.sin(2*np.pi*xv)*np.cos(2*np.pi*0.001*tv + 0.5*np.pi) - 0.001*tv
datasaver.add_result((x, xv), (t, tv), (y, yv), (y2, y2v))
q_val = np.max(yv) - np.min(y2v) # a meaningless value
datasaver.add_result((q, q_val))
dataset = datasaver.dataset
```
For the sake of demonstrating what kind of data we've produced, let's use `plot_dataset` to make some default plots of the data.
```
plot_dataset(dataset)
```
## DataSet indentification
Before we dive into what's in the `DataSet`, let's briefly note how a `DataSet` is identified.
```
dataset.captured_run_id
dataset.exp_name
dataset.sample_name
dataset.name
```
## Parameters in the DataSet
In this section we are getting information about the parameters stored in the given `DataSet`.
> Why is that important? Let's jump into *data*!
As it turns out, just "arrays of numbers" are not enough to reason about a given `DataSet`. Even comping up with a reasonable deafult plot, which is what `plot_dataset` does, requires information on `DataSet`'s parameters. In this notebook, we first have a detailed look at what is stored about parameters and how to work with this information. After that, we will cover data access methods.
### Run description
Every dataset comes with a "description" (aka "run description"):
```
dataset.description
```
The description, an instance of `RunDescriber` object, is intended to describe the details of a dataset. In the future releases of QCoDeS it will likely be expanded. At the moment, it only contains an `InterDependencies_` object under its `interdeps` attribute - which stores all the information about the parameters of the `DataSet`.
Let's look into this `InterDependencies_` object.
### Interdependencies
`Interdependencies_` object inside the run description contains information about all the parameters that are stored in the `DataSet`. Subsections below explain how the individual information about the parameters as well as their relationships are captured in the `Interdependencies_` object.
```
interdeps = dataset.description.interdeps
interdeps
```
#### Dependencies, inferences, standalones
Information about every parameter is stored in the form of `ParamSpecBase` objects, and the releationship between parameters is captured via `dependencies`, `inferences`, and `standalones` attributes.
For example, the dataset that we are inspecting contains no inferences, and one standalone parameter `q`, and two dependent parameters `y` and `y2`, which both depend on independent `x` and `t` parameters:
```
interdeps.inferences
interdeps.standalones
interdeps.dependencies
```
`dependencies` is a dictionary of `ParamSpecBase` objects. The keys are dependent parameters (those which depend on other parameters), and the corresponding values in the dictionary are tuples of independent parameters that the dependent parameter in the key depends on. Coloquially, each key-value pair of the `dependencies` dictionary is sometimes referred to as "parameter tree".
`inferences` follows the same structure as `dependencies`.
`standalones` is a set - an unordered collection of `ParamSpecBase` objects representing "standalone" parameters, the ones which do not depend on other parameters, and no other parameter depends on them.
#### ParamSpecBase objects
`ParamSpecBase` object contains all the necessary information about a given parameter, for example, its `name` and `unit`:
```
ps = list(interdeps.dependencies.keys())[0]
print(f'Parameter {ps.name!r} is in {ps.unit!r}')
```
`paramspecs` property returns a tuple of `ParamSpecBase`s for all the parameters contained in the `Interdependencies_` object:
```
interdeps.paramspecs
```
Here's a trivial example of iterating through dependent parameters of the `Interdependencies_` object and extracting information about them from the `ParamSpecBase` objects:
```
for d in interdeps.dependencies.keys():
print(f'Parameter {d.name!r} ({d.label}, {d.unit}) depends on:')
for i in interdeps.dependencies[d]:
print(f'- {i.name!r} ({i.label}, {i.unit})')
```
#### Other useful methods and properties
`Interdependencies_` object has a few useful properties and methods which make it easy to work it and with other `Interdependencies_` and `ParamSpecBase` objects.
For example, `non_dependencies` returns a tuple of all dependent parameters together with standalone parameters:
```
interdeps.non_dependencies
```
`what_depends_on` method allows to find what parameters depend on a given parameter:
```
t_ps = interdeps.paramspecs[2]
t_deps = interdeps.what_depends_on(t_ps)
print(f'Following parameters depend on {t_ps.name!r} ({t_ps.label}, {t_ps.unit}):')
for t_dep in t_deps:
print(f'- {t_dep.name!r} ({t_dep.label}, {t_dep.unit})')
```
### Shortcuts to important parameters
For the frequently needed groups of parameters, `DataSet` object itself provides convenient methods and properties.
For example, use `dependent_parameters` property to get only dependent parameters of a given `DataSet`:
```
dataset.dependent_parameters
```
This is equivalent to:
```
tuple(dataset.description.interdeps.dependencies.keys())
```
### Note on inferences
Inferences between parameters is a feature that has not been used yet within QCoDeS. The initial concepts around `DataSet` included it in order to link parameters that are not directly dependent on each other as "dependencies" are. It is very likely that "inferences" will be eventually deprecated and removed.
### Note on ParamSpec's
> `ParamSpec`s originate from QCoDeS versions prior to `0.2.0` and for now are kept for backwards compatibility. `ParamSpec`s are completely superseded by `InterDependencies_`/`ParamSpecBase` bundle and will likely be deprecated in future versions of QCoDeS together with the `DataSet` methods/properties that return `ParamSpec`s objects.
In addition to the `Interdependencies_` object, `DataSet` also holds `ParamSpec` objects (not to be confused with `ParamSpecBase` objects from above). Similar to `Interdependencies_` object, the `ParamSpec` objects hold information about parameters and their interdependencies but in a different way: for a given parameter, `ParamSpec` object itself contains information on names of parameters that it depends on, while for the `InterDependencies_`/`ParamSpecBase`s this information is stored only in the `InterDependencies_` object.
`DataSet` exposes `paramspecs` property and `get_parameters()` method, both of which return `ParamSpec` objects of all the parameters of the dataset, and are not recommended for use:
```
dataset.paramspecs
dataset.get_parameters()
dataset.parameters
```
To give an example of what it takes to work with `ParamSpec` objects as opposed to `Interdependencies_` object, here's a function that one needs to write in order to find standalone `ParamSpec`s from a given list of `ParamSpec`s:
```
def get_standalone_parameters(paramspecs):
all_independents = set(spec.name
for spec in paramspecs
if len(spec.depends_on_) == 0)
used_independents = set(d for spec in paramspecs for d in spec.depends_on_)
standalones = all_independents.difference(used_independents)
return tuple(ps for ps in paramspecs if ps.name in standalones)
all_parameters = dataset.get_parameters()
standalone_parameters = get_standalone_parameters(all_parameters)
standalone_parameters
```
## Getting data from DataSet
In this section methods for retrieving the actual data from the `DataSet` are discussed.
### `get_parameter_data` - the powerhorse
`DataSet` provides one main method of accessing data - `get_parameter_data`. It returns data for groups of dependent-parameter-and-its-independent-parameters in a form of a nested dictionary of `numpy` arrays:
```
dataset.get_parameter_data()
```
#### Avoid excessive calls to loading data
Note that this call actually reads the data of the `DataSet` and in case of a `DataSet` with a lot of data can take noticable amount of time. Hence, it is recommended to limit the number of times the same data gets loaded in order to speed up the user's code.
#### Loading data of selected parameters
Sometimes data only for a particular parameter or parameters needs to be loaded. For example, let's assume that after inspecting the `InterDependencies_` object from `dataset.description.interdeps`, we concluded that we want to load data of the `q` parameter and the `y2` parameter. In order to do that, we just pass the names of these parameters, or their `ParamSpecBase`s to `get_parameter_data` call:
```
q_param_spec = list(interdeps.standalones)[0]
q_param_spec
y2_param_spec = interdeps.non_dependencies[-1]
y2_param_spec
dataset.get_parameter_data(q_param_spec, y2_param_spec)
```
### `get_data_as_pandas_dataframe` - for `pandas` fans
`DataSet` provides one main method of accessing data - `get_data_as_pandas_dataframe`. It returns data for groups of dependent-parameter-and-its-independent-parameters in a form of a dictionary of `pandas.DataFrame` s:
```
dfs = dataset.get_data_as_pandas_dataframe()
# For the sake of making this article more readable,
# we will print the contents of the `dfs` dictionary
# manually by calling `.head()` on each of the DataFrames
for parameter_name, df in dfs.items():
print(f"DataFrame for parameter {parameter_name}")
print("-----------------------------")
print(f"{df.head()!r}")
print("")
```
Similar to `get_parameter_data`, `get_data_as_pandas_dataframe` also supports retrieving data for a given parameter(s), as well as `start`/`stop` arguments.
`get_data_as_pandas_dataframe` is implemented based on `get_parameter_data`, hence the performance considerations mentioned above for `get_parameter_data` apply to `get_data_as_pandas_dataframe` as well.
For more details on `get_data_as_pandas_dataframe` refer to [Working with pandas and xarray article](Working-With-Pandas-and-XArray.ipynb).
### Data extraction into "other" formats
If the user desires to export a QCoDeS `DataSet` into a format that is not readily supported by `DataSet` methods, we recommend to use `get_data_as_pandas_dataframe` first, and then convert the resulting `DataFrame` s into a the desired format. This is becuase `pandas` package already implements converting `DataFrame` to various popular formats including comma-separated text file (`.csv`), HDF (`.hdf5`), xarray, Excel (`.xls`, `.xlsx`), and more; refer to [Working with pandas and xarray article](Working-With-Pandas-and-XArray.ipynb), and [`pandas` documentation](https://pandas.pydata.org/pandas-docs/stable/reference/frame.html#serialization-io-conversion) for more information.
Nevertheless, `DataSet` also provides the following convenient methods:
* `DataSet.write_data_to_text_file`
Refer to the docstrings of those methods for more information on how to use them.
### Not recommended data access methods
The following tree methods of accessing data in a dataset are not recommended for use, and will be deprecated soon:
* `DataSet.get_data`
* `DataSet.get_values`
* `DataSet.get_setpoints`
| true |
code
| 0.402187 | null | null | null | null |
|
```
from fastai.vision.all import *
from moving_mnist.models.conv_rnn import *
from moving_mnist.data import *
if torch.cuda.is_available():
torch.cuda.set_device(1)
print(torch.cuda.get_device_name())
```
# Train Example:
We wil predict:
- `n_in`: 5 images
- `n_out`: 5 images
- `n_obj`: up to 3 objects
```
DATA_PATH = Path.cwd()/'data'
ds = MovingMNIST(DATA_PATH, n_in=5, n_out=5, n_obj=[1,2,3])
train_tl = TfmdLists(range(7500), ImageTupleTransform(ds))
valid_tl = TfmdLists(range(100), ImageTupleTransform(ds))
dls = DataLoaders.from_dsets(train_tl, valid_tl, bs=32,
after_batch=[Normalize.from_stats(imagenet_stats[0][0],
imagenet_stats[1][0])]).cuda()
loss_func = StackLoss(MSELossFlat())
```
Left: Input, Right: Target
```
dls.show_batch()
b = dls.one_batch()
explode_types(b)
```
`StackUnstack` takes cares of stacking the list of images into a fat tensor, and unstacking them at the end, we will need to modify our loss function to take a list of tensors as input and target.
## Simple model
```
model = StackUnstack(SimpleModel())
```
As the `ImageSeq` is a `tuple` of images, we will need to stack them to compute loss.
```
learn = Learner(dls, model, loss_func=loss_func, cbs=[]).to_fp16()
```
I have a weird bug that if I use `nn.LeakyReLU` after doing `learn.lr_find()` the model does not train (the loss get stucked).
```
x,y = dls.one_batch()
learn.lr_find()
learn.fit_one_cycle(10, 1e-4)
p,t = learn.get_preds()
```
As you can see, the results is a list of 5 tensors with 100 samples each.
```
len(p), p[0].shape
def show_res(t, idx):
im_seq = ImageSeq.create([t[i][idx] for i in range(5)])
im_seq.show(figsize=(8,4));
k = random.randint(0,100)
show_res(t,k)
show_res(p,k)
```
## A bigger Decoder
We will pass:
- `blur`: to use blur on the upsampling path (this is done by using and a poolling layer and a replication)
- `attn`: to include a self attention layer on the decoder
```
model2 = StackUnstack(SimpleModel(szs=[16,64,96], act=partial(nn.LeakyReLU, 0.2, inplace=True),blur=True, attn=True))
```
We have to reduce batch size as the self attention layer is heavy.
```
dls = DataLoaders.from_dsets(train_tl, valid_tl, bs=8,
after_batch=[Normalize.from_stats(imagenet_stats[0][0],
imagenet_stats[1][0])]).cuda()
learn2 = Learner(dls, model2, loss_func=loss_func, cbs=[]).to_fp16()
learn2.lr_find()
learn2.fit_one_cycle(10, 1e-4)
p,t = learn2.get_preds()
```
As you can see, the results is a list of 5 tensors with 100 samples each.
```
len(p), p[0].shape
def show_res(t, idx):
im_seq = ImageSeq.create([t[i][idx] for i in range(5)])
im_seq.show(figsize=(8,4));
k = random.randint(0,100)
show_res(t,k)
show_res(p,k)
```
| true |
code
| 0.793506 | null | null | null | null |
|
***
***
# Introduction to Gradient Descent
The Idea Behind Gradient Descent 梯度下降
***
***
<img src='./img/stats/gradient_descent.gif' align = "middle" width = '400px'>
<img align="left" style="padding-right:10px;" width ="400px" src="./img/stats/gradient2.png">
**如何找到最快下山的路?**
- 假设此时山上的浓雾很大,下山的路无法确定;
- 假设你摔不死!
- 你只能利用自己周围的信息去找到下山的路径。
- 以你当前的位置为基准,寻找这个位置最陡峭的方向,从这个方向向下走。
<img style="padding-right:10px;" width ="500px" src="./img/stats/gradient.png" align = 'right'>
**Gradient is the vector of partial derivatives**
One approach to maximizing a function is to
- pick a random starting point,
- compute the gradient,
- take a small step in the direction of the gradient, and
- repeat with a new staring point.
<img src='./img/stats/gd.webp' width = '700' align = 'middle'>
Let's represent parameters as $\Theta$, learning rate as $\alpha$, and gradient as $\bigtriangledown J(\Theta)$,
To the find the best model is an optimization problem
- “minimizes the error of the model”
- “maximizes the likelihood of the data.”
We’ll frequently need to maximize (or minimize) functions.
- to find the input vector v that produces the largest (or smallest) possible value.
# Mathematics behind Gradient Descent
A simple mathematical intuition behind one of the commonly used optimisation algorithms in Machine Learning.
https://www.douban.com/note/713353797/
The cost or loss function:
$$Cost = \frac{1}{N} \sum_{i = 1}^N (Y' -Y)^2$$
<img src='./img/stats/x2.webp' width = '700' align = 'center'>
Parameters with small changes:
$$ m_1 = m_0 - \delta m, b_1 = b_0 - \delta b$$
The cost function J is a function of m and b:
$$J_{m, b} = \frac{1}{N} \sum_{i = 1}^N (Y' -Y)^2 = \frac{1}{N} \sum_{i = 1}^N Error_i^2$$
$$\frac{\partial J}{\partial m} = 2 Error \frac{\partial}{\partial m}Error$$
$$\frac{\partial J}{\partial b} = 2 Error \frac{\partial}{\partial b}Error$$
Let's fit the data with linear regression:
$$\frac{\partial}{\partial m}Error = \frac{\partial}{\partial m}(Y' - Y) = \frac{\partial}{\partial m}(mX + b - Y)$$
Since $X, b, Y$ are constant:
$$\frac{\partial}{\partial m}Error = X$$
$$\frac{\partial}{\partial b}Error = \frac{\partial}{\partial b}(Y' - Y) = \frac{\partial}{\partial b}(mX + b - Y)$$
Since $X, m, Y$ are constant:
$$\frac{\partial}{\partial m}Error = 1$$
Thus:
$$\frac{\partial J}{\partial m} = 2 * Error * X$$
$$\frac{\partial J}{\partial b} = 2 * Error$$
Let's get rid of the constant 2 and multiplying the learning rate $\alpha$, who determines how large a step to take:
$$\frac{\partial J}{\partial m} = Error * X * \alpha$$
$$\frac{\partial J}{\partial b} = Error * \alpha$$
Since $ m_1 = m_0 - \delta m, b_1 = b_0 - \delta b$:
$$ m_1 = m_0 - Error * X * \alpha$$
$$b_1 = b_0 - Error * \alpha$$
**Notice** that the slope b can be viewed as the beta value for X = 1. Thus, the above two equations are in essence the same.
Let's represent parameters as $\Theta$, learning rate as $\alpha$, and gradient as $\bigtriangledown J(\Theta)$, we have:
$$\Theta_1 = \Theta_0 - \alpha \bigtriangledown J(\Theta)$$
<img src='./img/stats/gd.webp' width = '800' align = 'center'>
Hence,to solve for the gradient, we iterate through our data points using our new $m$ and $b$ values and compute the partial derivatives.
This new gradient tells us
- the slope of our cost function at our current position
- the direction we should move to update our parameters.
- The size of our update is controlled by the learning rate.
```
import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
# source:https://www.jianshu.com/p/c7e642877b0e
optimal = gradient_descent(X, y, alpha)
print('Optimal parameters Theta:', optimal[0][0], optimal[1][0])
print('Error function:', error_function(optimal, X, y)[0,0])
```
# This is the End!
# Estimating the Gradient
If f is a function of one variable, its derivative at a point x measures how f(x) changes when we make a very small change to x.
> It is defined as the limit of the difference quotients:
差商(difference quotient)就是因变量的改变量与自变量的改变量两者相除的商。
```
def difference_quotient(f, x, h):
return (f(x + h) - f(x)) / h
```
For many functions it’s easy to exactly calculate derivatives.
For example, the square function:
def square(x):
return x * x
has the derivative:
def derivative(x):
return 2 * x
```
def square(x):
return x * x
def derivative(x):
return 2 * x
derivative_estimate = lambda x: difference_quotient(square, x, h=0.00001)
def sum_of_squares(v):
"""computes the sum of squared elements in v"""
return sum(v_i ** 2 for v_i in v)
# plot to show they're basically the same
import matplotlib.pyplot as plt
x = range(-10,10)
plt.plot(x, list(map(derivative, x)), 'rx') # red x
plt.plot(x, list(map(derivative_estimate, x)), 'b+') # blue +
plt.show()
```
When f is a function of many variables, it has multiple partial derivatives.
```
def partial_difference_quotient(f, v, i, h):
# add h to just the i-th element of v
w = [v_j + (h if j == i else 0)
for j, v_j in enumerate(v)]
return (f(w) - f(v)) / h
def estimate_gradient(f, v, h=0.00001):
return [partial_difference_quotient(f, v, i, h)
for i, _ in enumerate(v)]
```
# Using the Gradient
```
def step(v, direction, step_size):
"""move step_size in the direction from v"""
return [v_i + step_size * direction_i
for v_i, direction_i in zip(v, direction)]
def sum_of_squares_gradient(v):
return [2 * v_i for v_i in v]
from collections import Counter
from linear_algebra import distance, vector_subtract, scalar_multiply
from functools import reduce
import math, random
print("using the gradient")
# generate 3 numbers
v = [random.randint(-10,10) for i in range(3)]
print(v)
tolerance = 0.0000001
n = 0
while True:
gradient = sum_of_squares_gradient(v) # compute the gradient at v
if n%50 ==0:
print(v, sum_of_squares(v))
next_v = step(v, gradient, -0.01) # take a negative gradient step
if distance(next_v, v) < tolerance: # stop if we're converging
break
v = next_v # continue if we're not
n += 1
print("minimum v", v)
print("minimum value", sum_of_squares(v))
```
# Choosing the Right Step Size
Although the rationale for moving against the gradient is clear,
- how far to move is not.
- Indeed, choosing the right step size is more of an art than a science.
Methods:
1. Using a fixed step size
1. Gradually shrinking the step size over time
1. At each step, choosing the step size that minimizes the value of the objective function
```
step_sizes = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001, 0.00001]
```
It is possible that certain step sizes will result in invalid inputs for our function.
So we’ll need to create a “safe apply” function
- returns infinity for invalid inputs:
- which should never be the minimum of anything
```
def safe(f):
"""define a new function that wraps f and return it"""
def safe_f(*args, **kwargs):
try:
return f(*args, **kwargs)
except:
return float('inf') # this means "infinity" in Python
return safe_f
```
# Putting It All Together
- **target_fn** that we want to minimize
- **gradient_fn**.
For example, the target_fn could represent the errors in a model as a function of its parameters,
To choose a starting value for the parameters `theta_0`.
```
def minimize_batch(target_fn, gradient_fn, theta_0, tolerance=0.000001):
"""use gradient descent to find theta that minimizes target function"""
step_sizes = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001, 0.00001]
theta = theta_0 # set theta to initial value
target_fn = safe(target_fn) # safe version of target_fn
value = target_fn(theta) # value we're minimizing
while True:
gradient = gradient_fn(theta)
next_thetas = [step(theta, gradient, -step_size)
for step_size in step_sizes]
# choose the one that minimizes the error function
next_theta = min(next_thetas, key=target_fn)
next_value = target_fn(next_theta)
# stop if we're "converging"
if abs(value - next_value) < tolerance:
return theta
else:
theta, value = next_theta, next_value
# minimize_batch"
v = [random.randint(-10,10) for i in range(3)]
v = minimize_batch(sum_of_squares, sum_of_squares_gradient, v)
print("minimum v", v)
print("minimum value", sum_of_squares(v))
```
Sometimes we’ll instead want to maximize a function, which we can do by minimizing its negative
```
def negate(f):
"""return a function that for any input x returns -f(x)"""
return lambda *args, **kwargs: -f(*args, **kwargs)
def negate_all(f):
"""the same when f returns a list of numbers"""
return lambda *args, **kwargs: [-y for y in f(*args, **kwargs)]
def maximize_batch(target_fn, gradient_fn, theta_0, tolerance=0.000001):
return minimize_batch(negate(target_fn),
negate_all(gradient_fn),
theta_0,
tolerance)
```
Using the batch approach, each gradient step requires us to make a prediction and compute the gradient for the whole data set, which makes each step take a long time.
Error functions are additive
- The predictive error on the whole data set is simply the sum of the predictive errors for each data point.
When this is the case, we can instead apply a technique called **stochastic gradient descent**
- which computes the gradient (and takes a step) for only one point at a time.
- It cycles over our data repeatedly until it reaches a stopping point.
# Stochastic Gradient Descent
During each cycle, we’ll want to iterate through our data in a random order:
```
def in_random_order(data):
"""generator that returns the elements of data in random order"""
indexes = [i for i, _ in enumerate(data)] # create a list of indexes
random.shuffle(indexes) # shuffle them
for i in indexes: # return the data in that order
yield data[i]
```
This approach avoids circling around near a minimum forever
- whenever we stop getting improvements we’ll decrease the step size and eventually quit.
```
def minimize_stochastic(target_fn, gradient_fn, x, y, theta_0, alpha_0=0.01):
data = list(zip(x, y))
theta = theta_0 # initial guess
alpha = alpha_0 # initial step size
min_theta, min_value = None, float("inf") # the minimum so far
iterations_with_no_improvement = 0
# if we ever go 100 iterations with no improvement, stop
while iterations_with_no_improvement < 100:
value = sum( target_fn(x_i, y_i, theta) for x_i, y_i in data )
if value < min_value:
# if we've found a new minimum, remember it
# and go back to the original step size
min_theta, min_value = theta, value
iterations_with_no_improvement = 0
alpha = alpha_0
else:
# otherwise we're not improving, so try shrinking the step size
iterations_with_no_improvement += 1
alpha *= 0.9
# and take a gradient step for each of the data points
for x_i, y_i in in_random_order(data):
gradient_i = gradient_fn(x_i, y_i, theta)
theta = vector_subtract(theta, scalar_multiply(alpha, gradient_i))
return min_theta
def maximize_stochastic(target_fn, gradient_fn, x, y, theta_0, alpha_0=0.01):
return minimize_stochastic(negate(target_fn),
negate_all(gradient_fn),
x, y, theta_0, alpha_0)
print("using minimize_stochastic_batch")
x = list(range(101))
y = [3*x_i + random.randint(-10, 20) for x_i in x]
theta_0 = random.randint(-10,10)
v = minimize_stochastic(sum_of_squares, sum_of_squares_gradient, x, y, theta_0)
print("minimum v", v)
print("minimum value", sum_of_squares(v))
```
Scikit-learn has a Stochastic Gradient Descent module http://scikit-learn.org/stable/modules/sgd.html
| true |
code
| 0.702938 | null | null | null | null |
|
# *Quick, Draw!* GAN
In this notebook, we use Generative Adversarial Network code (adapted from [Rowel Atienza's](https://github.com/roatienza/Deep-Learning-Experiments/blob/master/Experiments/Tensorflow/GAN/dcgan_mnist.py) under [MIT License](https://github.com/roatienza/Deep-Learning-Experiments/blob/master/LICENSE)) to create sketches in the style of humans who have played the [*Quick, Draw!* game](https://quickdraw.withgoogle.com) (data available [here](https://github.com/googlecreativelab/quickdraw-dataset) under [Creative Commons Attribution 4.0 license](https://creativecommons.org/licenses/by/4.0/)).
#### Load dependencies
```
# for data input and output:
import numpy as np
import os
# for deep learning:
import keras
from keras.models import Model
from keras.layers import Input, Dense, Conv2D, Dropout
from keras.layers import BatchNormalization, Flatten
from keras.layers import Activation
from keras.layers import Reshape # new!
from keras.layers import Conv2DTranspose, UpSampling2D # new!
from keras.optimizers import RMSprop # new!
# for plotting:
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
```
#### Load data
NumPy bitmap files are [here](https://console.cloud.google.com/storage/browser/quickdraw_dataset/full/numpy_bitmap) -- pick your own drawing category -- you don't have to pick *apples* :)
```
input_images = "../quickdraw_data/apple.npy"
data = np.load(input_images) # 28x28 (sound familiar?) grayscale bitmap in numpy .npy format; images are centered
data.shape
data[4242]
data = data/255
data = np.reshape(data,(data.shape[0],28,28,1)) # fourth dimension is color
img_w,img_h = data.shape[1:3]
data.shape
data[4242]
plt.imshow(data[4242,:,:,0], cmap='Greys')
```
#### Create discriminator network
```
def build_discriminator(depth=64, p=0.4):
# Define inputs
image = Input((img_w,img_h,1))
# Convolutional layers
conv1 = Conv2D(depth*1, 5, strides=2,
padding='same', activation='relu')(image)
conv1 = Dropout(p)(conv1)
conv2 = Conv2D(depth*2, 5, strides=2,
padding='same', activation='relu')(conv1)
conv2 = Dropout(p)(conv2)
conv3 = Conv2D(depth*4, 5, strides=2,
padding='same', activation='relu')(conv2)
conv3 = Dropout(p)(conv3)
conv4 = Conv2D(depth*8, 5, strides=1,
padding='same', activation='relu')(conv3)
conv4 = Flatten()(Dropout(p)(conv4))
# Output layer
prediction = Dense(1, activation='sigmoid')(conv4)
# Model definition
model = Model(inputs=image, outputs=prediction)
return model
discriminator = build_discriminator()
discriminator.summary()
discriminator.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.0008,
decay=6e-8,
clipvalue=1.0),
metrics=['accuracy'])
```
#### Create generator network
```
z_dimensions = 32
def build_generator(latent_dim=z_dimensions,
depth=64, p=0.4):
# Define inputs
noise = Input((latent_dim,))
# First dense layer
dense1 = Dense(7*7*depth)(noise)
dense1 = BatchNormalization(momentum=0.9)(dense1) # default momentum for moving average is 0.99
dense1 = Activation(activation='relu')(dense1)
dense1 = Reshape((7,7,depth))(dense1)
dense1 = Dropout(p)(dense1)
# De-Convolutional layers
conv1 = UpSampling2D()(dense1)
conv1 = Conv2DTranspose(int(depth/2),
kernel_size=5, padding='same',
activation=None,)(conv1)
conv1 = BatchNormalization(momentum=0.9)(conv1)
conv1 = Activation(activation='relu')(conv1)
conv2 = UpSampling2D()(conv1)
conv2 = Conv2DTranspose(int(depth/4),
kernel_size=5, padding='same',
activation=None,)(conv2)
conv2 = BatchNormalization(momentum=0.9)(conv2)
conv2 = Activation(activation='relu')(conv2)
conv3 = Conv2DTranspose(int(depth/8),
kernel_size=5, padding='same',
activation=None,)(conv2)
conv3 = BatchNormalization(momentum=0.9)(conv3)
conv3 = Activation(activation='relu')(conv3)
# Output layer
image = Conv2D(1, kernel_size=5, padding='same',
activation='sigmoid')(conv3)
# Model definition
model = Model(inputs=noise, outputs=image)
return model
generator = build_generator()
generator.summary()
```
#### Create adversarial network
```
z = Input(shape=(z_dimensions,))
img = generator(z)
discriminator.trainable = False
pred = discriminator(img)
adversarial_model = Model(z, pred)
adversarial_model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.0004,
decay=3e-8,
clipvalue=1.0),
metrics=['accuracy'])
```
#### Train!
```
def train(epochs=2000, batch=128, z_dim=z_dimensions):
d_metrics = []
a_metrics = []
running_d_loss = 0
running_d_acc = 0
running_a_loss = 0
running_a_acc = 0
for i in range(epochs):
# sample real images:
real_imgs = np.reshape(
data[np.random.choice(data.shape[0],
batch,
replace=False)],
(batch,28,28,1))
# generate fake images:
fake_imgs = generator.predict(
np.random.uniform(-1.0, 1.0,
size=[batch, z_dim]))
# concatenate images as discriminator inputs:
x = np.concatenate((real_imgs,fake_imgs))
# assign y labels for discriminator:
y = np.ones([2*batch,1])
y[batch:,:] = 0
# train discriminator:
d_metrics.append(
discriminator.train_on_batch(x,y)
)
running_d_loss += d_metrics[-1][0]
running_d_acc += d_metrics[-1][1]
# adversarial net's noise input and "real" y:
noise = np.random.uniform(-1.0, 1.0,
size=[batch, z_dim])
y = np.ones([batch,1])
# train adversarial net:
a_metrics.append(
adversarial_model.train_on_batch(noise,y)
)
running_a_loss += a_metrics[-1][0]
running_a_acc += a_metrics[-1][1]
# periodically print progress & fake images:
if (i+1)%100 == 0:
print('Epoch #{}'.format(i))
log_mesg = "%d: [D loss: %f, acc: %f]" % \
(i, running_d_loss/i, running_d_acc/i)
log_mesg = "%s [A loss: %f, acc: %f]" % \
(log_mesg, running_a_loss/i, running_a_acc/i)
print(log_mesg)
noise = np.random.uniform(-1.0, 1.0,
size=[16, z_dim])
gen_imgs = generator.predict(noise)
plt.figure(figsize=(5,5))
for k in range(gen_imgs.shape[0]):
plt.subplot(4, 4, k+1)
plt.imshow(gen_imgs[k, :, :, 0],
cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()
return a_metrics, d_metrics
a_metrics_complete, d_metrics_complete = train()
ax = pd.DataFrame(
{
'Adversarial': [metric[0] for metric in a_metrics_complete],
'Discriminator': [metric[0] for metric in d_metrics_complete],
}
).plot(title='Training Loss', logy=True)
ax.set_xlabel("Epochs")
ax.set_ylabel("Loss")
ax = pd.DataFrame(
{
'Adversarial': [metric[1] for metric in a_metrics_complete],
'Discriminator': [metric[1] for metric in d_metrics_complete],
}
).plot(title='Training Accuracy')
ax.set_xlabel("Epochs")
ax.set_ylabel("Accuracy")
```
| true |
code
| 0.655942 | null | null | null | null |
|
# Tutorial 3 of 3: Advanced Topics and Usage
**Learning Outcomes**
* Use different methods to add boundary pores to a network
* Manipulate network topology by adding and removing pores and throats
* Explore the ModelsDict design, including copying models between objects, and changing model parameters
* Write a custom pore-scale model and a custom Phase
* Access and manipulate objects associated with the network
* Combine multiple algorithms to predict relative permeability
## Build and Manipulate Network Topology
For the present tutorial, we'll keep the topology simple to help keep the focus on other aspects of OpenPNM.
```
import warnings
import numpy as np
import scipy as sp
import openpnm as op
%matplotlib inline
np.random.seed(10)
ws = op.Workspace()
ws.settings['loglevel'] = 40
np.set_printoptions(precision=4)
pn = op.network.Cubic(shape=[10, 10, 10], spacing=0.00006, name='net')
```
## Adding Boundary Pores
When performing transport simulations it is often useful to have 'boundary' pores attached to the surface(s) of the network where boundary conditions can be applied. When using the **Cubic** class, two methods are available for doing this: ``add_boundaries``, which is specific for the **Cubic** class, and ``add_boundary_pores``, which is a generic method that can also be used on other network types and which is inherited from **GenericNetwork**. The first method automatically adds boundaries to ALL six faces of the network and offsets them from the network by 1/2 of the value provided as the network ``spacing``. The second method provides total control over which boundary pores are created and where they are positioned, but requires the user to specify to which pores the boundary pores should be attached to. Let's explore these two options:
```
pn.add_boundary_pores(labels=['top', 'bottom'])
```
Let's quickly visualize this network with the added boundaries:
```
#NBVAL_IGNORE_OUTPUT
fig = op.topotools.plot_connections(pn, c='r')
fig = op.topotools.plot_coordinates(pn, c='b', fig=fig)
fig.set_size_inches([10, 10])
```
### Adding and Removing Pores and Throats
OpenPNM uses a list-based data storage scheme for all properties, including topological connections. One of the benefits of this approach is that adding and removing pores and throats from the network is essentially as simple as adding or removing rows from the data arrays. The one exception to this 'simplicity' is that the ``'throat.conns'`` array must be treated carefully when trimming pores, so OpenPNM provides the ``extend`` and ``trim`` functions for adding and removing, respectively. To demonstrate, let's reduce the coordination number of the network to create a more random structure:
```
Ts = np.random.rand(pn.Nt) < 0.1 # Create a mask with ~10% of throats labeled True
op.topotools.trim(network=pn, throats=Ts) # Use mask to indicate which throats to trim
```
When the ``trim`` function is called, it automatically checks the health of the network afterwards, so logger messages might appear on the command line if problems were found such as isolated clusters of pores or pores with no throats. This health check is performed by calling the **Network**'s ``check_network_health`` method which returns a **HealthDict** containing the results of the checks:
```
a = pn.check_network_health()
print(a)
```
The **HealthDict** contains several lists including things like duplicate throats and isolated pores, but also a suggestion of which pores to trim to return the network to a healthy state. Also, the **HealthDict** has a ``health`` attribute that is ``False`` is any checks fail.
```
op.topotools.trim(network=pn, pores=a['trim_pores'])
```
Let's take another look at the network to see the trimmed pores and throats:
```
#NBVAL_IGNORE_OUTPUT
fig = op.topotools.plot_connections(pn, c='r')
fig = op.topotools.plot_coordinates(pn, c='b', fig=fig)
fig.set_size_inches([10, 10])
```
## Define Geometry Objects
The boundary pores we've added to the network should be treated a little bit differently. Specifically, they should have no volume or length (as they are not physically representative of real pores). To do this, we create two separate **Geometry** objects, one for internal pores and one for the boundaries:
```
Ps = pn.pores('*boundary', mode='not')
Ts = pn.throats('*boundary', mode='not')
geom = op.geometry.StickAndBall(network=pn, pores=Ps, throats=Ts, name='intern')
Ps = pn.pores('*boundary')
Ts = pn.throats('*boundary')
boun = op.geometry.Boundary(network=pn, pores=Ps, throats=Ts, name='boun')
```
The **StickAndBall** class is preloaded with the pore-scale models to calculate all the necessary size information (pore diameter, pore.volume, throat lengths, throat.diameter, etc). The **Boundary** class is speciall and is only used for the boundary pores. In this class, geometrical properties are set to small fixed values such that they don't affect the simulation results.
## Define Multiple Phase Objects
In order to simulate relative permeability of air through a partially water-filled network, we need to create each **Phase** object. OpenPNM includes pre-defined classes for each of these common fluids:
```
air = op.phases.Air(network=pn)
water = op.phases.Water(network=pn)
water['throat.contact_angle'] = 110
water['throat.surface_tension'] = 0.072
```
### Aside: Creating a Custom Phase Class
In many cases you will want to create your own fluid, such as an oil or brine, which may be commonly used in your research. OpenPNM cannot predict all the possible scenarios, but luckily it is easy to create a custom **Phase** class as follows:
```
from openpnm.phases import GenericPhase
class Oil(GenericPhase):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.add_model(propname='pore.viscosity',
model=op.models.misc.polynomial,
prop='pore.temperature',
a=[1.82082e-2, 6.51E-04, -3.48E-7, 1.11E-10])
self['pore.molecular_weight'] = 116 # g/mol
```
* Creating a **Phase** class basically involves placing a series of ``self.add_model`` commands within the ``__init__`` section of the class definition. This means that when the class is instantiated, all the models are added to *itself* (i.e. ``self``).
* ``**kwargs`` is a Python trick that captures all arguments in a *dict* called ``kwargs`` and passes them to another function that may need them. In this case they are passed to the ``__init__`` method of **Oil**'s parent by the ``super`` function. Specifically, things like ``name`` and ``network`` are expected.
* The above code block also stores the molecular weight of the oil as a constant value
* Adding models and constant values in this way could just as easily be done in a run script, but the advantage of defining a class is that it can be saved in a file (i.e. 'my_custom_phases') and reused in any project.
```
oil = Oil(network=pn)
print(oil)
```
## Define Physics Objects for Each Geometry and Each Phase
In the tutorial #2 we created two **Physics** object, one for each of the two **Geometry** objects used to handle the stratified layers. In this tutorial, the internal pores and the boundary pores each have their own **Geometry**, but there are two **Phases**, which also each require a unique **Physics**:
```
phys_water_internal = op.physics.GenericPhysics(network=pn, phase=water, geometry=geom)
phys_air_internal = op.physics.GenericPhysics(network=pn, phase=air, geometry=geom)
phys_water_boundary = op.physics.GenericPhysics(network=pn, phase=water, geometry=boun)
phys_air_boundary = op.physics.GenericPhysics(network=pn, phase=air, geometry=boun)
```
> To reiterate, *one* **Physics** object is required for each **Geometry** *AND* each **Phase**, so the number can grow to become annoying very quickly Some useful tips for easing this situation are given below.
### Create a Custom Pore-Scale Physics Model
Perhaps the most distinguishing feature between pore-network modeling papers is the pore-scale physics models employed. Accordingly, OpenPNM was designed to allow for easy customization in this regard, so that you can create your own models to augment or replace the ones included in the OpenPNM *models* libraries. For demonstration, let's implement the capillary pressure model proposed by [Mason and Morrow in 1994](http://dx.doi.org/10.1006/jcis.1994.1402). They studied the entry pressure of non-wetting fluid into a throat formed by spheres, and found that the converging-diverging geometry increased the capillary pressure required to penetrate the throat. As a simple approximation they proposed $P_c = -2 \sigma \cdot cos(2/3 \theta) / R_t$
Pore-scale models are written as basic function definitions:
```
def mason_model(target, diameter='throat.diameter', theta='throat.contact_angle',
sigma='throat.surface_tension', f=0.6667):
proj = target.project
network = proj.network
phase = proj.find_phase(target)
Dt = network[diameter]
theta = phase[theta]
sigma = phase[sigma]
Pc = 4*sigma*np.cos(f*np.deg2rad(theta))/Dt
return Pc[phase.throats(target.name)]
```
Let's examine the components of above code:
* The function receives a ``target`` object as an argument. This indicates which object the results will be returned to.
* The ``f`` value is a scale factor that is applied to the contact angle. Mason and Morrow suggested a value of 2/3 as a decent fit to the data, but we'll make this an adjustable parameter with 2/3 as the default.
* Note the ``pore.diameter`` is actually a **Geometry** property, but it is retrieved via the network using the data exchange rules outlined in the second tutorial.
* All of the calculations are done for every throat in the network, but this pore-scale model may be assigned to a ``target`` like a **Physics** object, that is a subset of the full domain. As such, the last line extracts values from the ``Pc`` array for the location of ``target`` and returns just the subset.
* The actual values of the contact angle, surface tension, and throat diameter are NOT sent in as numerical arrays, but rather as dictionary keys to the arrays. There is one very important reason for this: if arrays had been sent, then re-running the model would use the same arrays and hence not use any updated values. By having access to dictionary keys, the model actually looks up the current values in each of the arrays whenever it is run.
* It is good practice to include the dictionary keys as arguments, such as ``sigma = 'throat.contact_angle'``. This way the user can control where the contact angle could be stored on the ``target`` object.
### Copy Models Between Physics Objects
As mentioned above, the need to specify a separate **Physics** object for each **Geometry** and **Phase** can become tedious. It is possible to *copy* the pore-scale models assigned to one object onto another object. First, let's assign the models we need to ``phys_water_internal``:
```
mod = op.models.physics.hydraulic_conductance.hagen_poiseuille
phys_water_internal.add_model(propname='throat.hydraulic_conductance',
model=mod)
phys_water_internal.add_model(propname='throat.entry_pressure',
model=mason_model)
```
Now make a copy of the ``models`` on ``phys_water_internal`` and apply it all the other water **Physics** objects:
```
phys_water_boundary.models = phys_water_internal.models
```
The only 'gotcha' with this approach is that each of the **Physics** objects must be *regenerated* in order to place numerical values for all the properties into the data arrays:
```
phys_water_boundary.regenerate_models()
phys_air_internal.regenerate_models()
phys_air_internal.regenerate_models()
```
### Adjust Pore-Scale Model Parameters
The pore-scale models are stored in a **ModelsDict** object that is itself stored under the ``models`` attribute of each object. This arrangement is somewhat convoluted, but it enables integrated storage of models on the object's wo which they apply. The models on an object can be inspected with ``print(phys_water_internal)``, which shows a list of all the pore-scale properties that are computed by a model, and some information about the model's *regeneration* mode.
Each model in the **ModelsDict** can be individually inspected by accessing it using the dictionary key corresponding to *pore-property* that it calculates, i.e. ``print(phys_water_internal)['throat.capillary_pressure'])``. This shows a list of all the parameters associated with that model. It is possible to edit these parameters directly:
```
phys_water_internal.models['throat.entry_pressure']['f'] = 0.75 # Change value
phys_water_internal.regenerate_models() # Regenerate model with new 'f' value
```
More details about the **ModelsDict** and **ModelWrapper** classes can be found in :ref:`models`.
## Perform Multiphase Transport Simulations
### Use the Built-In Drainage Algorithm to Generate an Invading Phase Configuration
```
inv = op.algorithms.Porosimetry(network=pn)
inv.setup(phase=water)
inv.set_inlets(pores=pn.pores(['top', 'bottom']))
inv.run()
```
* The inlet pores were set to both ``'top'`` and ``'bottom'`` using the ``pn.pores`` method. The algorithm applies to the entire network so the mapping of network pores to the algorithm pores is 1-to-1.
* The ``run`` method automatically generates a list of 25 capillary pressure points to test, but you can also specify more pores, or which specific points to tests. See the methods documentation for the details.
* Once the algorithm has been run, the resulting capillary pressure curve can be viewed with ``plot_drainage_curve``. If you'd prefer a table of data for plotting in your software of choice you can use ``get_drainage_data`` which prints a table in the console.
### Set Pores and Throats to Invaded
After running, the ``mip`` object possesses an array containing the pressure at which each pore and throat was invaded, stored as ``'pore.inv_Pc'`` and ``'throat.inv_Pc'``. These arrays can be used to obtain a list of which pores and throats are invaded by water, using Boolean logic:
```
Pi = inv['pore.invasion_pressure'] < 5000
Ti = inv['throat.invasion_pressure'] < 5000
```
The resulting Boolean masks can be used to manually adjust the hydraulic conductivity of pores and throats based on their phase occupancy. The following lines set the water filled throats to near-zero conductivity for air flow:
```
Ts = phys_water_internal.map_throats(~Ti, origin=water)
phys_water_internal['throat.hydraulic_conductance'][Ts] = 1e-20
```
* The logic of these statements implicitly assumes that transport between two pores is only blocked if the throat is filled with the other phase, meaning that both pores could be filled and transport is still permitted. Another option would be to set the transport to near-zero if *either* or *both* of the pores are filled as well.
* The above approach can get complicated if there are several **Geometry** objects, and it is also a bit laborious. There is a pore-scale model for this under **Physics.models.multiphase** called ``conduit_conductance``. The term conduit refers to the path between two pores that includes 1/2 of each pores plus the connecting throat.
### Calculate Relative Permeability of Each Phase
We are now ready to calculate the relative permeability of the domain under partially flooded conditions. Instantiate an **StokesFlow** object:
```
water_flow = op.algorithms.StokesFlow(network=pn, phase=water)
water_flow.set_value_BC(pores=pn.pores('left'), values=200000)
water_flow.set_value_BC(pores=pn.pores('right'), values=100000)
water_flow.run()
Q_partial, = water_flow.rate(pores=pn.pores('right'))
```
The *relative* permeability is the ratio of the water flow through the partially water saturated media versus through fully water saturated media; hence we need to find the absolute permeability of water. This can be accomplished by *regenerating* the ``phys_water_internal`` object, which will recalculate the ``'throat.hydraulic_conductance'`` values and overwrite our manually entered near-zero values from the ``inv`` simulation using ``phys_water_internal.models.regenerate()``. We can then re-use the ``water_flow`` algorithm:
```
phys_water_internal.regenerate_models()
water_flow.run()
Q_full, = water_flow.rate(pores=pn.pores('right'))
```
And finally, the relative permeability can be found from:
```
K_rel = Q_partial/Q_full
print(f"Relative permeability: {K_rel:.5f}")
```
* The ratio of the flow rates gives the normalized relative permeability since all the domain size, viscosity and pressure differential terms cancel each other.
* To generate a full relative permeability curve the above logic would be placed inside a for loop, with each loop increasing the pressure threshold used to obtain the list of invaded throats (``Ti``).
* The saturation at each capillary pressure can be found be summing the pore and throat volume of all the invaded pores and throats using ``Vp = geom['pore.volume'][Pi]`` and ``Vt = geom['throat.volume'][Ti]``.
| true |
code
| 0.572902 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/DingLi23/s2search/blob/pipelining/pipelining/exp-cshc/exp-cshc_cshc_1w_ale_plotting.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
### Experiment Description
> This notebook is for experiment \<exp-cshc\> and data sample \<cshc\>.
### Initialization
```
%load_ext autoreload
%autoreload 2
import numpy as np, sys, os
in_colab = 'google.colab' in sys.modules
# fetching code and data(if you are using colab
if in_colab:
!rm -rf s2search
!git clone --branch pipelining https://github.com/youyinnn/s2search.git
sys.path.insert(1, './s2search')
%cd s2search/pipelining/exp-cshc/
pic_dir = os.path.join('.', 'plot')
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
```
### Loading data
```
sys.path.insert(1, '../../')
import numpy as np, sys, os, pandas as pd
from getting_data import read_conf
from s2search_score_pdp import pdp_based_importance
sample_name = 'cshc'
f_list = [
'title', 'abstract', 'venue', 'authors',
'year',
'n_citations'
]
ale_xy = {}
ale_metric = pd.DataFrame(columns=['feature_name', 'ale_range', 'ale_importance', 'absolute mean'])
for f in f_list:
file = os.path.join('.', 'scores', f'{sample_name}_1w_ale_{f}.npz')
if os.path.exists(file):
nparr = np.load(file)
quantile = nparr['quantile']
ale_result = nparr['ale_result']
values_for_rug = nparr.get('values_for_rug')
ale_xy[f] = {
'x': quantile,
'y': ale_result,
'rug': values_for_rug,
'weird': ale_result[len(ale_result) - 1] > 20
}
if f != 'year' and f != 'n_citations':
ale_xy[f]['x'] = list(range(len(quantile)))
ale_xy[f]['numerical'] = False
else:
ale_xy[f]['xticks'] = quantile
ale_xy[f]['numerical'] = True
ale_metric.loc[len(ale_metric.index)] = [f, np.max(ale_result) - np.min(ale_result), pdp_based_importance(ale_result, f), np.mean(np.abs(ale_result))]
# print(len(ale_result))
print(ale_metric.sort_values(by=['ale_importance'], ascending=False))
print()
```
### ALE Plots
```
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.ticker import MaxNLocator
categorical_plot_conf = [
{
'xlabel': 'Title',
'ylabel': 'ALE',
'ale_xy': ale_xy['title']
},
{
'xlabel': 'Abstract',
'ale_xy': ale_xy['abstract']
},
{
'xlabel': 'Authors',
'ale_xy': ale_xy['authors'],
# 'zoom': {
# 'inset_axes': [0.3, 0.3, 0.47, 0.47],
# 'x_limit': [89, 93],
# 'y_limit': [-1, 14],
# }
},
{
'xlabel': 'Venue',
'ale_xy': ale_xy['venue'],
# 'zoom': {
# 'inset_axes': [0.3, 0.3, 0.47, 0.47],
# 'x_limit': [89, 93],
# 'y_limit': [-1, 13],
# }
},
]
numerical_plot_conf = [
{
'xlabel': 'Year',
'ylabel': 'ALE',
'ale_xy': ale_xy['year'],
# 'zoom': {
# 'inset_axes': [0.15, 0.4, 0.4, 0.4],
# 'x_limit': [2019, 2023],
# 'y_limit': [1.9, 2.1],
# },
},
{
'xlabel': 'Citations',
'ale_xy': ale_xy['n_citations'],
# 'zoom': {
# 'inset_axes': [0.4, 0.65, 0.47, 0.3],
# 'x_limit': [-1000.0, 12000],
# 'y_limit': [-0.1, 1.2],
# },
},
]
def pdp_plot(confs, title):
fig, axes_list = plt.subplots(nrows=1, ncols=len(confs), figsize=(20, 5), dpi=100)
subplot_idx = 0
plt.suptitle(title, fontsize=20, fontweight='bold')
# plt.autoscale(False)
for conf in confs:
axes = axes if len(confs) == 1 else axes_list[subplot_idx]
sns.rugplot(conf['ale_xy']['rug'], ax=axes, height=0.02)
axes.axhline(y=0, color='k', linestyle='-', lw=0.8)
axes.plot(conf['ale_xy']['x'], conf['ale_xy']['y'])
axes.grid(alpha = 0.4)
# axes.set_ylim([-2, 20])
axes.xaxis.set_major_locator(MaxNLocator(integer=True))
axes.yaxis.set_major_locator(MaxNLocator(integer=True))
if ('ylabel' in conf):
axes.set_ylabel(conf.get('ylabel'), fontsize=20, labelpad=10)
# if ('xticks' not in conf['ale_xy'].keys()):
# xAxis.set_ticklabels([])
axes.set_xlabel(conf['xlabel'], fontsize=16, labelpad=10)
if not (conf['ale_xy']['weird']):
if (conf['ale_xy']['numerical']):
axes.set_ylim([-1.5, 1.5])
pass
else:
axes.set_ylim([-7, 20])
pass
if 'zoom' in conf:
axins = axes.inset_axes(conf['zoom']['inset_axes'])
axins.xaxis.set_major_locator(MaxNLocator(integer=True))
axins.yaxis.set_major_locator(MaxNLocator(integer=True))
axins.plot(conf['ale_xy']['x'], conf['ale_xy']['y'])
axins.set_xlim(conf['zoom']['x_limit'])
axins.set_ylim(conf['zoom']['y_limit'])
axins.grid(alpha=0.3)
rectpatch, connects = axes.indicate_inset_zoom(axins)
connects[0].set_visible(False)
connects[1].set_visible(False)
connects[2].set_visible(True)
connects[3].set_visible(True)
subplot_idx += 1
pdp_plot(categorical_plot_conf, f"ALE for {len(categorical_plot_conf)} categorical features")
# plt.savefig(os.path.join('.', 'plot', f'{sample_name}-1wale-categorical.png'), facecolor='white', transparent=False, bbox_inches='tight')
pdp_plot(numerical_plot_conf, f"ALE for {len(numerical_plot_conf)} numerical features")
# plt.savefig(os.path.join('.', 'plot', f'{sample_name}-1wale-numerical.png'), facecolor='white', transparent=False, bbox_inches='tight')
```
| true |
code
| 0.484563 | null | null | null | null |
|
# (Optional) Testing the Function Endpoint with your Own Audio Clips
Instead of using pre-recorded clips we show you in this notebook how to invoke the deployed Function
with your **own** audio clips.
In the cells below, we will use the [PyAudio library](https://pypi.org/project/PyAudio/) to record a short 1 second clip. we will then submit
that short clip to the Function endpoint on Oracle Functions. **Make sure PyAudio is installed on your laptop** before running this notebook.
The helper function defined below will record a 1-sec audio clip when executed. Speak into the microphone
of your computer and say one of the words `cat`, `eight`, `right`.
I'd recommend double-checking that you are not muted and that you are using the internal computer mic. No
headset.
```
# we will use pyaudio and wave in the
# bottom half of this notebook.
import pyaudio
import wave
print(pyaudio.__version__)
def record_wave(duration=1.0, output_wave='./output.wav'):
"""Using the pyaudio library, this function will record a video clip of a given duration.
Args:
- duration (float): duration of the recording in seconds
- output_wave (str) : filename of the wav file that contains your recording
Returns:
- frames : a list containing the recorded waveform
"""
# number of frames per buffer
frames_perbuff = 2048
# 16 bit int
format = pyaudio.paInt16
# mono sound
channels = 1
# Sampling rate -- CD quality (44.1 kHz). Standard
# for most recording devices.
sampling_rate = 44100
# frames contain the waveform data:
frames = []
# number of buffer chunks:
nchunks = int(duration * sampling_rate / frames_perbuff)
p = pyaudio.PyAudio()
stream = p.open(format=format,
channels=channels,
rate=sampling_rate,
input=True,
frames_per_buffer=frames_perbuff)
print("RECORDING STARTED ")
for i in range(0, nchunks):
data = stream.read(frames_perbuff)
frames.append(data)
print("RECORDING ENDED")
stream.stop_stream()
stream.close()
p.terminate()
# Write the audio clip to disk as a .wav file:
wf = wave.open(output_wave, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(format))
wf.setframerate(sampling_rate)
wf.writeframes(b''.join(frames))
wf.close()
# let's record your own, 1-sec clip
my_own_clip = "./my_clip.wav"
frames = record_wave(output_wave=my_own_clip)
# Playback
ipd.Audio("./my_clip.wav")
```
Looks good? Now let's try to send that clip to our model API endpoint. We will repeat the same process we adopted when we submitted pre-recorded clips.
```
# oci:
import oci
from oci.config import from_file
from oci import pagination
import oci.functions as functions
from oci.functions import FunctionsManagementClient, FunctionsInvokeClient
# Lets specify the location of our OCI configuration file:
oci_config = from_file("/home/datascience/block_storage/.oci/config")
# Lets specify the compartment OCID, and the application + function names:
compartment_id = 'ocid1.compartment.oc1..aaaaaaaafl3avkal72rrwuy4m5rumpwh7r4axejjwq5hvwjy4h4uoyi7kzyq'
app_name = 'machine-learning-models'
fn_name = 'speech-commands'
fn_management_client = FunctionsManagementClient(oci_config)
app_result = pagination.list_call_get_all_results(
fn_management_client.list_applications,
compartment_id,
display_name=app_name
)
fn_result = pagination.list_call_get_all_results(
fn_management_client.list_functions,
app_result.data[0].id,
display_name=fn_name
)
invoke_client = FunctionsInvokeClient(oci_config, service_endpoint=fn_result.data[0].invoke_endpoint)
# here we need to be careful. `my_own_clip` was recorded at a 44.1 kHz sampling rate.
# Yet the training sample has data at a 16 kHz rate. To ensure that we feed data of the same
# size, we will downsample the data to a 16 kHz rate (sr=16000)
waveform, _ = librosa.load(my_own_clip, mono=True, sr=16000)
```
Below we call the deployed Function. Note that the first call could take 60 sec. or more. This is due to the cold start problem of Function. Subsequent calls are much faster. Typically < 1 sec.
```
%%time
resp = invoke_client.invoke_function(fn_result.data[0].id,
invoke_function_body=json.dumps({"input": waveform.tolist()}))
print(resp.data.text)
```
| true |
code
| 0.672224 | null | null | null | null |
|

<font size=3 color="midnightblue" face="arial">
<h1 align="center">Escuela de Ciencias Básicas, Tecnología e Ingeniería</h1>
</font>
<font size=3 color="navy" face="arial">
<h1 align="center">ECBTI</h1>
</font>
<font size=2 color="darkorange" face="arial">
<h1 align="center">Curso:</h1>
</font>
<font size=2 color="navy" face="arial">
<h1 align="center">Introducción al lenguaje de programación Python</h1>
</font>
<font size=1 color="darkorange" face="arial">
<h1 align="center">Febrero de 2020</h1>
</font>
<h2 align="center">Sesión 08 - Manipulación de archivos JSON</h2>
## Introducción
`JSON` (*JavaScript Object Notation*) es un formato ligero de intercambio de datos que los humanos pueden leer y escribir fácilmente. También es fácil para las computadoras analizar y generar. `JSON` se basa en el lenguaje de programación [JavaScript](https://www.javascript.com/ 'JavaScript'). Es un formato de texto que es independiente del lenguaje y se puede usar en `Python`, `Perl`, entre otros idiomas. Se utiliza principalmente para transmitir datos entre un servidor y aplicaciones web. `JSON` se basa en dos estructuras:
- Una colección de pares nombre / valor. Esto se realiza como un objeto, registro, diccionario, tabla hash, lista con clave o matriz asociativa.
- Una lista ordenada de valores. Esto se realiza como una matriz, vector, lista o secuencia.
## JSON en Python
Hay una serie de paquetes que admiten `JSON` en `Python`, como [metamagic.json](https://pypi.org/project/metamagic.json/ 'metamagic.json'), [jyson](http://opensource.xhaus.com/projects/jyson/wiki 'jyson'), [simplejson](https://simplejson.readthedocs.io/en/latest/ 'simplejson'), [Yajl-Py](http://pykler.github.io/yajl-py/ 'Yajl-Py'), [ultrajson](https://github.com/esnme/ultrajson 'ultrajson') y [json](https://docs.python.org/3.6/library/json.html 'json'). En este curso, utilizaremos [json](https://docs.python.org/3.6/library/json.html 'json'), que es compatible de forma nativa con `Python`. Podemos usar [este sitio](https://jsonlint.com/ 'jsonlint') que proporciona una interfaz `JSON` para verificar nuestros datos `JSON`.
A continuación se muestra un ejemplo de datos `JSON`.
```
{
"nombre": "Jaime",
"apellido": "Perez",
"aficiones": ["correr", "ciclismo", "caminar"],
"edad": 35,
"hijos": [
{
"nombre": "Pedro",
"edad": 6
},
{
"nombre": "Alicia",
"edad": 8
}
]
}
```
Como puede verse, `JSON` admite tanto tipos primitivos, cadenas de caracteres y números, como listas y objetos anidados.
Notamos que la representación de datos es muy similar a los diccionarios de `Python`
```
{
"articulo": [
{
"id":"01",
"lenguaje": "JSON",
"edicion": "primera",
"autor": "Derrick Mwiti"
},
{
"id":"02",
"lenguaje": "Python",
"edicion": "segunda",
"autor": "Derrick Mwiti"
}
],
"blog":[
{
"nombre": "Datacamp",
"URL":"datacamp.com"
}
]
}
```
Reescribámoslo en una forma más familiar
```
{"articulo":[{"id":"01","lenguaje": "JSON","edicion": "primera","author": "Derrick Mwiti"},
{"id":"02","lenguaje": "Python","edicion": "segunda","autor": "Derrick Mwiti"}],
"blog":[{"nombre": "Datacamp","URL":"datacamp.com"}]}
```
## `JSON` nativo en `Python`
`Python` viene con un paquete incorporado llamado `json` para codificar y decodificar datos `JSON`.
```
import json
```
## Un poco de vocabulario
El proceso de codificación de `JSON` generalmente se llama serialización. Este término se refiere a la transformación de datos en una serie de bytes (por lo tanto, en serie) para ser almacenados o transmitidos a través de una red. También puede escuchar el término de clasificación, pero esa es otra discusión. Naturalmente, la deserialización es el proceso recíproco de decodificación de datos que se ha almacenado o entregado en el estándar `JSON`.
De lo que estamos hablando aquí es leer y escribir. Piénselo así: la codificación es para escribir datos en el disco, mientras que la decodificación es para leer datos en la memoria.
### Serialización en `JSON`
¿Qué sucede después de que una computadora procesa mucha información? Necesita tomar un volcado de datos. En consecuencia, la biblioteca `json` expone el método `dump()` para escribir datos en archivos. También hay un método `dumps()` (pronunciado como "*dump-s*") para escribir en una cadena de `Python`.
Los objetos simples de `Python` se traducen a `JSON` de acuerdo con una conversión bastante intuitiva.
Comparemos los tipos de datos en `Python` y `JSON`.
|**Python** | **JSON** |
|:---------:|:----------------:|
|dict |object |
|list|array |
|tuple| array|
|str| string|
|int| number|
|float| number|
|True| true|
|False| false|
|None| null|
### Serialización, ejemplo
tenemos un objeto `Python` en la memoria que se parece a algo así:
```
data = {
"president": {
"name": "Zaphod Beeblebrox",
"species": "Betelgeusian"
}
}
print(type(data))
```
Es fundamental que se guarde esta información en el disco, por lo que la tarea es escribirla en un archivo.
Con el administrador de contexto de `Python`, puede crear un archivo llamado `data_file.json` y abrirlo en modo de escritura. (Los archivos `JSON` terminan convenientemente en una extensión `.json`).
```
with open("data_file.json", "w") as write_file:
json.dump(data, write_file)
```
Tenga en cuenta que `dump()` toma dos argumentos posicionales:
1. el objeto de datos que se va a serializar y
2. el objeto tipo archivo en el que se escribirán los bytes.
O, si estaba tan inclinado a seguir usando estos datos `JSON` serializados en su programa, podría escribirlos en un objeto `str` nativo de `Python`.
```
json_string = json.dumps(data)
print(type(json_string))
```
Tenga en cuenta que el objeto similar a un archivo está ausente ya que no está escribiendo en el disco. Aparte de eso, `dumps()` es como `dump()`.
Se ha creado un objeto `JSON` y está listo para trabajarlo.
### Algunos argumentos útiles de palabras clave
Recuerde, `JSON` está destinado a ser fácilmente legible por los humanos, pero la sintaxis legible no es suficiente si se aprieta todo junto. Además, probablemente tenga un estilo de programación diferente a éste presentado, y puede que le resulte más fácil leer el código cuando está formateado a su gusto.
***NOTA:*** Los métodos `dump()` y `dumps()` usan los mismos argumentos de palabras clave.
La primera opción que la mayoría de la gente quiere cambiar es el espacio en blanco. Puede usar el argumento de sangría de palabras clave para especificar el tamaño de sangría para estructuras anidadas. Compruebe la diferencia por sí mismo utilizando los datos, que definimos anteriormente, y ejecutando los siguientes comandos en una consola:
```
json.dumps(data)
json.dumps(data, indent=4)
```
Otra opción de formato es el argumento de palabra clave de separadores. Por defecto, esta es una tupla de 2 de las cadenas de separación (`","`, `": "`), pero una alternativa común para `JSON` compacto es (`","`, `":"`). observe el ejemplo `JSON` nuevamente para ver dónde entran en juego estos separadores.
Hay otros, como `sort_keys`. Puede encontrar una lista completa en la [documentación](https://docs.python.org/3/library/json.html#basic-usage) oficial.
### Deserializando JSON
Hemos trabajado un poco de `JSON` muy básico, ahora es el momento de ponerlo en forma. En la biblioteca `json`, encontrará `load()` y `loads()` para convertir datos codificados con `JSON` en objetos de `Python`.
Al igual que la serialización, hay una tabla de conversión simple para la deserialización, aunque probablemente ya puedas adivinar cómo se ve.
|**JSON** | **Python** |
|:---------:|:----------------:|
|object |dict |
|array |list|
|array|tuple |
|string|str |
|number|int |
|number|float |
|true|True |
|false|False |
|null|None |
Técnicamente, esta conversión no es un inverso perfecto a la tabla de serialización. Básicamente, eso significa que si codifica un objeto de vez en cuando y luego lo decodifica nuevamente más tarde, es posible que no recupere exactamente el mismo objeto. Me imagino que es un poco como teletransportación: descomponga mis moléculas aquí y vuelva a unirlas allí. ¿Sigo siendo la misma persona?
En realidad, probablemente sea más como hacer que un amigo traduzca algo al japonés y que otro amigo lo traduzca nuevamente al inglés. De todos modos, el ejemplo más simple sería codificar una tupla y recuperar una lista después de la decodificación, así:
```
blackjack_hand = (8, "Q")
encoded_hand = json.dumps(blackjack_hand)
decoded_hand = json.loads(encoded_hand)
blackjack_hand == decoded_hand
type(blackjack_hand)
type(decoded_hand)
blackjack_hand == tuple(decoded_hand)
```
### Deserialización, ejemplo
Esta vez, imagine que tiene algunos datos almacenados en el disco que le gustaría manipular en la memoria. Todavía usará el administrador de contexto, pero esta vez abrirá el archivo de datos existente `archivo_datos.json` en modo de lectura.
```
with open("data_file.json", "r") as read_file:
data = json.load(read_file)
```
Hasta ahora las cosas son bastante sencillas, pero tenga en cuenta que el resultado de este método podría devolver cualquiera de los tipos de datos permitidos de la tabla de conversión. Esto solo es importante si está cargando datos que no ha visto antes. En la mayoría de los casos, el objeto raíz será un diccionario o una lista.
Si ha extraído datos `JSON` de otro programa o ha obtenido una cadena de datos con formato `JSON` en `Python`, puede deserializarlo fácilmente con `loads()`, que naturalmente se carga de una cadena:
```
my_json_string = """{
"article": [
{
"id":"01",
"language": "JSON",
"edition": "first",
"author": "Derrick Mwiti"
},
{
"id":"02",
"language": "Python",
"edition": "second",
"author": "Derrick Mwiti"
}
],
"blog":[
{
"name": "Datacamp",
"URL":"datacamp.com"
}
]
}
"""
to_python = json.loads(my_json_string)
print(type(to_python))
```
Ahora ya estamos trabajando con `JSON` puro. Lo que se hará de ahora en adelante dependerá del usuario, por lo que hay qué estar muy atentos con lo que se quiere hacer, se hace, y el resultado que se obtiene.
## Un ejemplo real
Para este ejemplo introductorio, utilizaremos [JSONPlaceholder](https://jsonplaceholder.typicode.com/ "JSONPlaceholder"), una excelente fuente de datos `JSON` falsos para fines prácticos.
Primero cree un archivo de script llamado `scratch.py`, o como desee llamarlo.
Deberá realizar una solicitud de `API` al servicio `JSONPlaceholder`, así que solo use el paquete de solicitudes para realizar el trabajo pesado. Agregue estas importaciones en la parte superior de su archivo:
```
import json
import requests
```
Ahora haremos una solicitud a la `API` `JSONPlaceholder`, si no está familiarizado con las solicitudes, existe un práctico método `json()` que hará todo el trabajo, pero puede practicar el uso de la biblioteca `json` para deserializar el atributo de texto del objeto de respuesta. Debería verse más o menos así:
```
response = requests.get("https://jsonplaceholder.typicode.com/todos")
todos = json.loads(response.text)
```
Para saber si lo anterior funcionó (por lo menos no sacó ningún error), verifique el tipo de `todos` y luego hacer una consulta a los 10 primeros elementos de la lista.
```
todos == response.json()
type(todos)
todos[:10]
len(todos)
```
Puede ver la estructura de los datos visualizando el archivo en un navegador, pero aquí hay un ejemplo de parte de él:
```
# parte del archivo JSON - TODO
{
"userId": 1,
"id": 1,
"title": "delectus aut autem",
"completed": false
}
```
Hay varios usuarios, cada uno con un ID de usuario único, y cada tarea tiene una propiedad booleana completada. ¿Puedes determinar qué usuarios han completado la mayoría de las tareas?
```
# Mapeo de userID para la cantidad completa de TODOS para cada usuario
todos_by_user = {}
# Incrementa el recuento completo de TODOs para cada usuario.
for todo in todos:
if todo["completed"]:
try:
# Incrementa el conteo del usuario existente.
todos_by_user[todo["userId"]] += 1
except KeyError:
# Este usuario no ha sido visto, se inicia su conteo en 1.
todos_by_user[todo["userId"]] = 1
# Crea una lista ordenada de pares (userId, num_complete).
top_users = sorted(todos_by_user.items(),
key=lambda x: x[1], reverse=True)
# obtiene el número máximo completo de TODO
max_complete = top_users[0][1]
# Cree una lista de todos los usuarios que hayan completado la cantidad máxima de TODO
users = []
for user, num_complete in top_users:
if num_complete < max_complete:
break
users.append(str(user))
max_users = " y ".join(users)
```
Ahora se pueden manipular los datos `JSON` como un objeto `Python` normal.
Al ejecutar el script se obtienen los siguientes resultados:
```
s = "s" if len(users) > 1 else ""
print(f"usuario{s} {max_users} completaron {max_complete} TODOs")
```
Continuando, se creará un archivo `JSON` que contiene los *TODO* completos para cada uno de los usuarios que completaron el número máximo de *TODO*.
Todo lo que necesita hacer es filtrar todos y escribir la lista resultante en un archivo. llamaremos al archivo de salida `filter_data_file.json`. Hay muchas maneras de hacerlo, pero aquí hay una:
```
# Defina una función para filtrar TODO completos de usuarios con TODOS máximos completados.
def keep(todo):
is_complete = todo["completed"]
has_max_count = str(todo["userId"]) in users
return is_complete and has_max_count
# Escriba el filtrado de TODO a un archivo.
with open("filtered_data_file.json", "w") as data_file:
filtered_todos = list(filter(keep, todos))
json.dump(filtered_todos, data_file, indent=2)
```
Se han filtrado todos los datos que no se necesitan y se han guardado los necesarios en un archivo nuevo! Vuelva a ejecutar el script y revise `filter_data_file.json` para verificar que todo funcionó. Estará en el mismo directorio que `scratch.py` cuando lo ejecutes.
```
s = "s" if len(users) > 1 else ""
print(f"usuario{s} {max_users} completaron {max_complete} TODOs")
```
Por ahora estamos viendo los aspectos básicos de la manipulación de datos en `JSON`. Ahora vamos a tratar de avanzar un poco más en profundidad.
## Codificación y decodificación de objetos personalizados de `Python`
Veamos un ejemplo de una clase de un juego muy famoso (Dungeons & Dragons) ¿Qué sucede cuando intentamos serializar la clase `Elf` de esa aplicación?
```
class Elf:
def __init__(self, level, ability_scores=None):
self.level = level
self.ability_scores = {
"str": 11, "dex": 12, "con": 10,
"int": 16, "wis": 14, "cha": 13
} if ability_scores is None else ability_scores
self.hp = 10 + self.ability_scores["con"]
elf = Elf(level=4)
json.dumps(elf)
```
`Python` indica que `Elf` no es serializable
Aunque el módulo `json` puede manejar la mayoría de los tipos de `Python` integrados, no comprende cómo codificar los tipos de datos personalizados de forma predeterminada. Es como tratar de colocar una clavija cuadrada en un orificio redondo: necesita una sierra circular y la supervisión de los padres.
## Simplificando las estructuras de datos
cómo lidiar con estructuras de datos más complejas?. Se podría intentar codificar y decodificar el `JSON` "*manualmente*", pero hay una solución un poco más inteligente que ahorrará algo de trabajo. En lugar de pasar directamente del tipo de datos personalizado a `JSON`, puede lanzar un paso intermedio.
Todo lo que se necesita hacer es representar los datos en términos de los tipos integrados que `json` ya comprende. Esencialmente, traduce el objeto más complejo en una representación más simple, que el módulo `json` luego traduce a `JSON`. Es como la propiedad transitiva en matemáticas: si `A = B` y `B = C`, entonces `A = C`.
Para entender esto, necesitarás un objeto complejo con el que jugar. Puede usar cualquier clase personalizada que desee, pero `Python` tiene un tipo incorporado llamado `complex` para representar números complejos, y no es serializable por defecto.
```
z = 3 + 8j
type(z)
json.dumps(z)
```
Una buena pregunta que debe hacerse al trabajar con tipos personalizados es ¿Cuál es la cantidad mínima de información necesaria para recrear este objeto? En el caso de números complejos, solo necesita conocer las partes real e imaginaria, a las que puede acceder como atributos en el objeto `complex`:
```
z.real
z.imag
```
Pasar los mismos números a un constructor `complex` es suficiente para satisfacer el operador de comparación `__eq__`:
```
complex(3, 8) == z
```
Desglosar los tipos de datos personalizados en sus componentes esenciales es fundamental para los procesos de serialización y deserialización.
## Codificación de tipos personalizados
Para traducir un objeto personalizado a `JSON`, todo lo que necesita hacer es proporcionar una función de codificación al parámetro predeterminado del método `dump()`. El módulo `json` llamará a esta función en cualquier objeto que no sea serializable de forma nativa. Aquí hay una función de decodificación simple que puede usar para practicar ([aquí](https://www.programiz.com/python-programming/methods/built-in/isinstance "isinstance") encontrará información acerca de la función `isinstance`):
```
def encode_complex(z):
if isinstance(z, complex):
return (z.real, z.imag)
else:
type_name = z.__class__.__name__
raise TypeError(f"Object of type '{type_name}' is not JSON serializable")
```
Tenga en cuenta que se espera que genere un `TypeError` si no obtiene el tipo de objeto que esperaba. De esta manera, se evita serializar accidentalmente a cualquier `Elfo`. Ahora ya podemos intentar codificar objetos complejos.
```
json.dumps(9 + 5j, default=encode_complex)
json.dumps(elf, default=encode_complex)
```
¿Por qué codificamos el número complejo como una tupla? es la única opción, es la mejor opción? Qué pasaría si necesitáramos decodificar el objeto más tarde?
El otro enfoque común es subclasificar el `JSONEncoder` estándar y anular el método `default()`:
```
class ComplexEncoder(json.JSONEncoder):
def default(self, z):
if isinstance(z, complex):
return (z.real, z.imag)
else:
return super().default(z)
```
En lugar de subir el `TypeError` usted mismo, simplemente puede dejar que la clase base lo maneje. Puede usar esto directamente en el método `dump()` a través del parámetro `cls` o creando una instancia del codificador y llamando a su método `encode()`:
```
json.dumps(2 + 5j, cls=ComplexEncoder)
encoder = ComplexEncoder()
encoder.encode(3 + 6j)
```
## Decodificación de tipos personalizados
Si bien las partes reales e imaginarias de un número complejo son absolutamente necesarias, en realidad no son suficientes para recrear el objeto. Esto es lo que sucede cuando intenta codificar un número complejo con `ComplexEncoder` y luego decodifica el resultado:
```
complex_json = json.dumps(4 + 17j, cls=ComplexEncoder)
json.loads(complex_json)
```
Todo lo que se obtiene es una lista, y se tendría que pasar los valores a un constructor complejo si se quiere ese objeto complejo nuevamente. Recordemos el comentario sobre *teletransportación*. Lo que falta son metadatos o información sobre el tipo de datos que está codificando.
La pregunta que realmente debería hacerse es ¿Cuál es la cantidad mínima de información necesaria y suficiente para recrear este objeto?
El módulo `json` espera que todos los tipos personalizados se expresen como objetos en el estándar `JSON`. Para variar, puede crear un archivo `JSON` esta vez llamado `complex_data.json` y agregar el siguiente objeto que representa un número complejo:
```
# JSON
{
"__complex__": true,
"real": 42,
"imag": 36
}
```
¿Ves la parte inteligente? Esa clave "`__complex__`" son los metadatos de los que acabamos de hablar. Realmente no importa cuál sea el valor asociado. Para que este pequeño truco funcione, todo lo que necesitas hacer es verificar que exista la clave:
```
def decode_complex(dct):
if "__complex__" in dct:
return complex(dct["real"], dct["imag"])
return dct
```
Si "`__complex__`" no está en el diccionario, puede devolver el objeto y dejar que el decodificador predeterminado se encargue de él.
Cada vez que el método `load()` intenta analizar un objeto, se le da la oportunidad de interceder antes de que el decodificador predeterminado se adapte a los datos. Puede hacerlo pasando su función de decodificación al parámetro `object_hook`.
Ahora regresemos a lo de antes
```
with open("complex_data.json") as complex_data:
data = complex_data.read()
z = json.loads(data, object_hook=decode_complex)
type(z)
```
Si bien `object_hook` puede parecer la contraparte del parámetro predeterminado del método `dump()`, la analogía realmente comienza y termina allí.
```
# JSON
[
{
"__complex__":true,
"real":42,
"imag":36
},
{
"__complex__":true,
"real":64,
"imag":11
}
]
```
Esto tampoco funciona solo con un objeto. Intente poner esta lista de números complejos en `complex_data.json` y vuelva a ejecutar el script:
```
with open("complex_data.json") as complex_data:
data = complex_data.read()
numbers = json.loads(data, object_hook=decode_complex)
```
Si todo va bien, obtendrá una lista de objetos complejos:
```
type(z)
numbers
```
## Finalizando...
Ahora puede ejercer el poderoso poder de JSON para todas y cada una de las necesidades de `Python`.
Si bien los ejemplos con los que ha trabajado aquí son ciertamente demasiado simplistas, ilustran un flujo de trabajo que puede aplicar a tareas más generales:
- Importa el paquete json.
- Lea los datos con `load()` o `loads()`.
- Procesar los datos.
- Escriba los datos alterados con `dump()` o `dumps()`.
Lo que haga con los datos una vez que se hayan cargado en la memoria dependerá de su caso de uso. En general, el objetivo será recopilar datos de una fuente, extraer información útil y transmitir esa información o mantener un registro de la misma.
| true |
code
| 0.249379 | null | null | null | null |
|
## Import a model from ONNX and run using PyTorch
We demonstrate how to import a model from ONNX and convert to PyTorch
#### Imports
```
import os
import operator as op
import warnings; warnings.simplefilter(action='ignore', category=FutureWarning)
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
import onnx
import gamma
from gamma import convert, protobuf, utils
```
#### 1: Download the model
```
fpath = utils.get_file('https://s3.amazonaws.com/download.onnx/models/squeezenet.tar.gz')
onnx_model = onnx.load(os.path.join(fpath, 'squeezenet/model.onnx'))
inputs = [i.name for i in onnx_model.graph.input if
i.name not in {x.name for x in onnx_model.graph.initializer}]
outputs = [o.name for o in onnx_model.graph.output]
```
#### 2: Import into Gamma
```
graph = convert.from_onnx(onnx_model)
constants = {k for k, (v, i) in graph.items() if v['type'] == 'Constant'}
utils.draw(gamma.strip(graph, constants))
```
#### 3: Convert to PyTorch
```
make_node = gamma.make_node_attr
def torch_padding(params):
padding = params.get('pads', [0,0,0,0])
assert (padding[0] == padding[2]) and (padding[1] == padding[3])
return (padding[0], padding[1])
torch_ops = {
'Add': lambda params: op.add,
'Concat': lambda params: (lambda *xs: torch.cat(xs, dim=params['axis'])),
'Constant': lambda params: nn.Parameter(torch.FloatTensor(params['value'])),
'Dropout': lambda params: nn.Dropout(params.get('ratio', 0.5)).eval(), #.eval() sets to inference mode. where should this logic live?
'GlobalAveragePool': lambda params: nn.AdaptiveAvgPool2d(1),
'MaxPool': lambda params: nn.MaxPool2d(params['kernel_shape'], stride=params.get('strides', [1,1]),
padding=torch_padding(params),
dilation=params.get('dilations', [1,1])),
'Mul': lambda params: op.mul,
'Relu': lambda params: nn.ReLU(),
'Softmax': lambda params: nn.Softmax(dim=params.get('axis', 1)),
}
def torch_op(node, inputs):
if node['type'] in torch_ops:
op = torch_ops[node['type']](node['params'])
return make_node('Torch_op', {'op': op}, inputs)
return (node, inputs)
def torch_conv_node(params, x, w, b):
ko, ki, kh, kw = w.shape
group = params.get('group', 1)
ki *= group
conv = nn.Conv2d(ki, ko, (kh,kw),
stride=tuple(params.get('strides', [1,1])),
padding=torch_padding(params),
dilation=tuple(params.get('dilations', [1,1])),
groups=group)
conv.weight = nn.Parameter(torch.FloatTensor(w))
conv.bias = nn.Parameter(torch.FloatTensor(b))
return make_node('Torch_op', {'op': conv}, [x])
def convert_to_torch(graph):
v, _ = gamma.var, gamma.Wildcard
conv_pattern = {
v('conv'): make_node('Conv', v('params'), [v('x'), v('w'), v('b')]),
v('w'): make_node('Constant', {'value': v('w_val')}, []),
v('b'): make_node('Constant', {'value': v('b_val')}, [])
}
matches = gamma.search(conv_pattern, graph)
g = gamma.union(graph, {m[v('conv')]:
torch_conv_node(m[v('params')], m[v('x')], m[v('w_val')], m[v('b_val')])
for m in matches})
remove = {m[x] for m in matches for x in (v('w'), v('b'))}
g = {k: torch_op(v, i) for k, (v, i) in g.items() if k not in remove}
return g
def torch_graph(graph):
return gamma.FuncCache(lambda k: graph[k][0]['params']['op'](*[tg[x] for x in graph[k][1]]))
g = convert_to_torch(graph)
utils.draw(g)
```
#### 4: Load test example and check PyTorch output
```
def load_onnx_tensor(fname):
tensor = onnx.TensorProto()
with open(fname, 'rb') as f:
tensor.ParseFromString(f.read())
return protobuf.unwrap(tensor)
input_0 = load_onnx_tensor(os.path.join(fpath, 'squeezenet/test_data_set_0/input_0.pb'))
output_0 = load_onnx_tensor(os.path.join(fpath, 'squeezenet/test_data_set_0/output_0.pb'))
tg = torch_graph(g)
tg[inputs[0]] = Variable(torch.Tensor(input_0))
torch_outputs = tg[outputs[0]]
np.testing.assert_almost_equal(output_0, torch_outputs.data.numpy(), decimal=5)
print('Success!')
```
| true |
code
| 0.679019 | null | null | null | null |
|
```
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import math
%matplotlib inline
```
# Volunteer 1
## 3M Littmann Data
```
image = Image.open('3Ms.bmp')
image
x = image.size[0]
y = image.size[1]
print(x)
print(y)
matrix = []
points = []
integrated_density = 0
for i in range(x):
matrix.append([])
for j in range(y):
matrix[i].append(image.getpixel((i,j)))
#integrated_density += image.getpixel((i,j))[1]
#points.append(image.getpixel((i,j))[1])
```
### Extract Red Line Position
```
redMax = 0
xStore = 0
yStore = 0
for xAxis in range(x):
for yAxis in range(y):
currentPoint = matrix[xAxis][yAxis]
if currentPoint[0] ==255 and currentPoint[1] < 10 and currentPoint[2] < 10:
redMax = currentPoint[0]
xStore = xAxis
yStore = yAxis
print(xStore, yStore)
```
- The redline position is located at y = 252.
### Extract Blue Points
```
redline_pos = 51
absMax = 0
littmannArr = []
points_vertical = []
theOne = 0
for xAxis in range(x):
for yAxis in range(y):
currentPoint = matrix[xAxis][yAxis]
# Pickup Blue points
if currentPoint[2] == 255 and currentPoint[0] < 220 and currentPoint[1] < 220:
points_vertical.append(yAxis)
#print(points_vertical)
# Choose the largest amplitude
for item in points_vertical:
if abs(item-redline_pos) > absMax:
absMax = abs(item-redline_pos)
theOne = item
littmannArr.append((theOne-redline_pos)*800)
absMax = 0
theOne = 0
points_vertical = []
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(littmannArr, linewidth=0.6, color='blue')
```
# Ascul Pi Data
```
pathBase = 'C://Users//triti//OneDrive//Dowrun//Text//Manuscripts//Data//YangChuan//AusculPi//'
filename = 'Numpy_Array_File_2020-06-21_07_54_16.npy'
line = pathBase + filename
arr = np.load(line)
arr
arr.shape
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(arr[0], linewidth=1.0, color='black')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(arr[:,100], linewidth=1.0, color='black')
start = 1830
end = 2350
start_adj = int(start * 2583 / 3000)
end_adj = int(end * 2583 / 3000)
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(arr[start_adj:end_adj,460], linewidth=0.6, color='black')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(littmannArr, linewidth=0.6, color='blue')
asculArr = arr[start_adj:end_adj,460]
```
## Preprocess the two array
```
asculArr_processed = []
littmannArr_processed = []
for item in asculArr:
asculArr_processed.append(abs(item))
for item in littmannArr:
littmannArr_processed.append(abs(item))
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(asculArr_processed, linewidth=0.6, color='black')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(littmannArr_processed, linewidth=0.6, color='blue')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(asculArr_processed[175:375], linewidth=1.0, color='black')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(littmannArr_processed[:200], linewidth=1.0, color='blue')
len(littmannArr)
len(asculArr)
```
### Coeffient
```
stats.pearsonr(asculArr_processed, littmannArr_processed)
stats.pearsonr(asculArr_processed[176:336], littmannArr_processed[:160])
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(arr[start_adj:end_adj,460][176:336], linewidth=0.6, color='black')
fig = plt.figure()
s = fig.add_subplot(111)
s.plot(littmannArr[:160], linewidth=0.6, color='blue')
```
### Fitness
```
stats.chisquare(asculArr_processed[174:334], littmannArr_processed[:160])
def cosCalculate(a, b):
l = len(a)
sumXY = 0
sumRootXSquare = 0
sumRootYSquare = 0
for i in range(l):
sumXY = sumXY + a[i]*b[i]
sumRootXSquare = sumRootXSquare + math.sqrt(a[i]**2)
sumRootYSquare = sumRootYSquare + math.sqrt(b[i]**2)
cosValue = sumXY / (sumRootXSquare * sumRootYSquare)
return cosValue
cosCalculate(asculArr_processed[175:335], littmannArr_processed[:160])
```
| true |
code
| 0.313617 | null | null | null | null |
|
# How do distributions transform under a change of variables ?
Kyle Cranmer, March 2016
```
%pylab inline --no-import-all
```
We are interested in understanding how distributions transofrm under a change of variables.
Let's start with a simple example. Think of a spinner like on a game of twister.
<!--<img src="http://cdn.krrb.com/post_images/photos/000/273/858/DSCN3718_large.jpg?1393271975" width=300 />-->
We flick the spinner and it stops. Let's call the angle of the pointer $x$. It seems a safe assumption that the distribution of $x$ is uniform between $[0,2\pi)$... so $p_x(x) = 1/\sqrt{2\pi}$
Now let's say that we change variables to $y=\cos(x)$ (sorry if the names are confusing here, don't think about x- and y-coordinates, these are just names for generic variables). The question is this:
**what is the distribution of y?** Let's call it $p_y(y)$
Well it's easy to do with a simulation, let's try it out
```
# generate samples for x, evaluate y=cos(x)
n_samples = 100000
x = np.random.uniform(0,2*np.pi,n_samples)
y = np.cos(x)
# make a histogram of x
n_bins = 50
counts, bins, patches = plt.hist(x, bins=50, density=True, alpha=0.3)
plt.plot([0,2*np.pi], (1./2/np.pi, 1./2/np.pi), lw=2, c='r')
plt.xlim(0,2*np.pi)
plt.xlabel('x')
plt.ylabel('$p_x(x)$')
```
Ok, now let's make a histogram for $y=\cos(x)$
```
counts, y_bins, patches = plt.hist(y, bins=50, density=True, alpha=0.3)
plt.xlabel('y')
plt.ylabel('$p_y(y)$')
```
It's not uniform! Why is that? Let's look at the $x-y$ relationship
```
# make a scatter of x,y
plt.scatter(x[:300],y[:300]) #just the first 300 points
xtest = .2
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='r')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='r')
xtest = xtest+.1
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='r')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='r')
xtest = 2*np.pi-xtest
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='g')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='g')
xtest = xtest+.1
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='g')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='g')
xtest = np.pi/2
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='r')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='r')
xtest = xtest+.1
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='r')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='r')
xtest = 2*np.pi-xtest
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='g')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='g')
xtest = xtest+.1
plt.plot((-1,xtest),(np.cos(xtest),np.cos(xtest)), c='g')
plt.plot((xtest,xtest),(-1.5,np.cos(xtest)), c='g')
plt.ylim(-1.5,1.5)
plt.xlim(-1,7)
```
The two sets of vertical lines are both separated by $0.1$. The probability $P(a < x < b)$ must equal the probability of $P( cos(b) < y < cos(a) )$. In this example there are two different values of $x$ that give the same $y$ (see green and red lines), so we need to take that into account. For now, let's just focus on the first part of the curve with $x<\pi$.
So we can write (this is the important equation):
\begin{equation}
\int_a^b p_x(x) dx = \int_{y_b}^{y_a} p_y(y) dy
\end{equation}
where $y_a = \cos(a)$ and $y_b = \cos(b)$.
and we can re-write the integral on the right by using a change of variables (pure calculus)
\begin{equation}
\int_a^b p_x(x) dx = \int_{y_b}^{y_a} p_y(y) dy = \int_a^b p_y(y(x)) \left| \frac{dy}{dx}\right| dx
\end{equation}
notice that the limits of integration and integration variable are the same for the left and right sides of the equation, so the integrands must be the same too. Therefore:
\begin{equation}
p_x(x) = p_y(y) \left| \frac{dy}{dx}\right|
\end{equation}
and equivalently
\begin{equation}
p_y(y) = p_x(x) \,/ \,\left| \, {dy}/{dx}\, \right |
\end{equation}
The factor $\left|\frac{dy}{dx} \right|$ is called a Jacobian. When it is large it is stretching the probability in $x$ over a large range of $y$, so it makes sense that it is in the denominator.
```
plt.plot((0.,1), (0,.3))
plt.plot((0.,1), (0,0), lw=2)
plt.plot((1.,1), (0,.3))
plt.ylim(-.1,.4)
plt.xlim(-.1,1.6)
plt.text(0.5,0.2, '1', color='b')
plt.text(0.2,0.03, 'x', color='black')
plt.text(0.5,-0.05, 'y=cos(x)', color='g')
plt.text(1.02,0.1, '$\sin(x)=\sqrt{1-y^2}$', color='r')
```
In our case:
\begin{equation}
\left|\frac{dy}{dx} \right| = \sin(x)
\end{equation}
Looking at the right-triangle above you can see $\sin(x)=\sqrt{1-y^2}$ and finally there will be an extra factor of 2 for $p_y(y)$ to take into account $x>\pi$. So we arrive at
\begin{equation}
p_y(y) = 2 \times \frac{1}{2 \pi} \frac{1}{\sin(x)} = \frac{1}{\pi} \frac{1}{\sin(\arccos(y))} = \frac{1}{\pi} \frac{1}{\sqrt{1-y^2}}
\end{equation}
Notice that when $y=\pm 1$ the pdf is diverging. This is called a [caustic](http://www.phikwadraat.nl/huygens_cusp_of_tea/) and you see them in your coffee and rainbows!
| | |
|---|---|
| <img src="http://www.nanowerk.com/spotlight/id19915_1.jpg" size=200 /> | <img src="http://www.ams.org/featurecolumn/images/february2009/caustic.gif" size=200> |
**Let's check our prediction**
```
counts, y_bins, patches = plt.hist(y, bins=50, density=True, alpha=0.3)
pdf_y = (1./np.pi)/np.sqrt(1.-y_bins**2)
plt.plot(y_bins, pdf_y, c='r', lw=2)
plt.ylim(0,5)
plt.xlabel('y')
plt.ylabel('$p_y(y)$')
```
Perfect!
## A trick using the cumulative distribution function (cdf) to generate random numbers
Let's consider a different variable transformation now -- it is a special one that we can use to our advantage.
\begin{equation}
y(x) = \textrm{cdf}(x) = \int_{-\infty}^x p_x(x') dx'
\end{equation}
Here's a plot of a distribution and cdf for a Gaussian.
(NOte: the axes are different for the pdf and the cdf http://matplotlib.org/examples/api/two_scales.html
```
from scipy.stats import norm
x_for_plot = np.linspace(-3,3, 30)
fig, ax1 = plt.subplots()
ax1.plot(x_for_plot, norm.pdf(x_for_plot), c='b')
ax1.set_ylabel('p(x)', color='b')
for tl in ax1.get_yticklabels():
tl.set_color('b')
ax2 = ax1.twinx()
ax2.plot(x_for_plot, norm.cdf(x_for_plot), c='r')
ax2.set_ylabel('cdf(x)', color='r')
for tl in ax2.get_yticklabels():
tl.set_color('r')
```
Ok, so let's use our result about how distributions transform under a change of variables to predict the distribution of $y=cdf(x)$. We need to calculate
\begin{equation}
\frac{dy}{dx} = \frac{d}{dx} \int_{-\infty}^x p_x(x') dx'
\end{equation}
Just like particles and anti-particles, when derivatives meet anti-derivatives they annihilate. So $\frac{dy}{dx} = p_x(x)$, which shouldn't be a surprise.. the slope of the cdf is the pdf.
So putting these together we find the distribution for $y$ is:
\begin{equation}
p_y(y) = p_x(x) \, / \, \frac{dy}{dx} = p_x(x) /p_x(x) = 1
\end{equation}
So it's just a uniform distribution from $[0,1]$, which is perfect for random numbers.
We can turn this around and generate a uniformly random number between $[0,1]$, take the inverse of the cdf and we should have the distribution we want for $x$.
Let's try it for a Gaussian. The inverse of the cdf for a Gaussian is called [ppf](http://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.stats.norm.html)
```
norm.ppf.__doc__
#check it out
norm.cdf(0), norm.ppf(0.5)
```
Ok, let's use CDF trick to generate Normally-distributed (aka Gaussian-distributed) random numbers
```
rand_cdf = np.random.uniform(0,1,10000)
rand_norm = norm.ppf(rand_cdf)
_ = plt.hist(rand_norm, bins=30, density=True, alpha=0.3)
plt.xlabel('x')
```
**Pros**: The great thing about this technique is it is very efficient. You only generate one random number per random $x$.
**Cons**: the downside is you need to know how to compute the inverse cdf for $p_x(x)$ and that can be difficult. It works for a distribution like a Gaussian, but for some random distribution this might be even more computationally expensive than the accept/reject approach. This approach also doesn't really work if your distribution is for more than one variable.
## Going full circle
Ok, let's try it for our distribution of $y=\cos(x)$ above. We found
\begin{equation}
p_y(y) = \frac{1}{\pi} \frac{1}{\sqrt{1-y^2}}
\end{equation}
So the CDF is (see Wolfram alpha for [integral](http://www.wolframalpha.com/input/?i=integrate%5B1%2Fsqrt%5B1-x%5E2%5D%2FPi%5D) )
\begin{equation}
cdf(y') = \int_{-1}^{y'} \frac{1}{\pi} \frac{1}{\sqrt{1-y^2}} = \frac{1}{\pi}\arcsin(y') + C
\end{equation}
and we know that for $y=-1$ the CDF must be 0, so the constant is $1/2$ and by looking at the plot or remembering some trig you know that it's also $cdf(y') = (1/\pi) \arccos(y')$.
So to apply the trick, we need to generate uniformly random variables $z$ between 0 and 1, and then take the inverse of the cdf to get $y$. Ok, so what would that be:
\begin{equation}
y = \textrm{cdf}^{-1}(z) = \cos(\pi z)
\end{equation}
**Of course!** that's how we started in the first place, we started with a uniform $x$ in $[0,2\pi]$ and then defined $y=\cos(x)$. So we just worked backwards to get where we started. The only difference here is that we only evaluate the first half: $\cos(x < \pi)$
| true |
code
| 0.608652 | null | null | null | null |
|
# Distributed Training with Keras
## Import dependencies
```
import tensorflow_datasets as tfds
import tensorflow as tf
from tensorflow import keras
import os
print(tf.__version__)
```
## Dataset - Fashion MNIST
```
#datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
#mnist_train, mnist_test = datasets['train'], datasets['test']
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
```
## Define a distribution Strategy
```
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
num_train_examples = len(train_images)#info.splits['train'].num_examples
print(num_train_examples)
num_test_examples = len(test_images) #info.splits['test'].num_examples
print(num_test_examples)
BUFFER_SIZE = 10000
BATCH_SIZE_PER_REPLICA = 64
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
#train_dataset = train_images.map(scale).cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
#eval_dataset = test_images.map(scale).batch(BATCH_SIZE)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
with strategy.scope():
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=['accuracy'])
# Define the checkpoint directory to store the checkpoints
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
# Function for decaying the learning rate.
# You can define any decay function you need.
def decay(epoch):
if epoch < 3:
return 1e-3
elif epoch >= 3 and epoch < 7:
return 1e-4
else:
return 1e-5
class PrintLR(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
print('\nLearning rate for epoch {} is {}'.format(epoch + 1,
model.optimizer.lr.numpy()))
from tensorflow.keras.callbacks import ModelCheckpoint
#checkpoint = ModelCheckpoint(ckpt_model,
# monitor='val_accuracy',
# verbose=1,
# save_best_only=True,
# mode='max')
callbacks = [
tf.keras.callbacks.TensorBoard(log_dir='./logs'),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_prefix,
save_weights_only=True),
tf.keras.callbacks.LearningRateScheduler(decay),
PrintLR()
]
#model.fit(train_dataset, epochs=12, callbacks=callbacks)
history = model.fit(train_images, train_labels,validation_data=(test_images, test_labels),
epochs=15,callbacks=callbacks)
history.history.keys
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'])
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'])
plt.show()
```
| true |
code
| 0.779574 | null | null | null | null |
|
```
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
```
Manually Principal Component Analysis
```
#Reading wine data
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/wine/wine.data',
header=None)
# in the data first column is class label and rest
# 13 columns are different features
X,y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
#Splitting Data into training set and test set
#using scikit-learn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.3,
stratify=y, random_state=0)
#Standardarising all the columns
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
# covariance matrix using numpy
cov_mat = np.cov(X_train_std.T)
# eigen pair
eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)
print('\nEigenvalues \n%s' % eigen_vecs[:3])
# only three rows are printed
# representing relative importance of features
tot = eigen_vals.sum()
var_exp = [(i/tot) for i in sorted(eigen_vals, reverse=True)]
cum_var_exp = np.cumsum(var_exp)
import matplotlib.pyplot as plt
plt.bar(range(1,14), var_exp, alpha=0.5, align='center',
label='Individual explained variance')
plt.step(range(1,14), cum_var_exp, where='mid',
label='CUmmulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal component index')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
# plots explained variance ration of the features
# Explained variance is variance of one feature / sum of all the variances
# sorting the eigenpairs by decreasing order of the eigenvalues:
# list of (eigenvalue, eigenvector) tuples
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i])
for i in range(len(eigen_vals))]
# Sort the (eigenvalue, eigenvector) tuples from high to low
eigen_pairs.sort(key=lambda k:k[0], reverse=True)
# We take first two features which account for about 60% of variance
w = np.hstack((eigen_pairs[0][1][:, np.newaxis],
eigen_pairs[1][1][:, np.newaxis]))
# w is projection matrix
print('Matrix W:\n', w)
# converting 13 feature data to 2 feature data
X_train_pca = X_train_std.dot(w)
# Plotting the features on
colors = ['r', 'b', 'g']
markers = ['s', 'x', 'o']
for l,c,m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_pca[y_train==l, 0],
X_train_pca[y_train==l, 1],
c = c, label=l, marker = m)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
```
Using Scikit Learn
```
# Class to plot decision region
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min()-1, X[:, 0].max()+1
x2_min, x2_max = X[:, 1].min()-1, X[:, 1].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x = X[y==cl, 0],
y = X[y==cl, 1],
alpha = 0.6,
color = cmap(idx),
edgecolor='black',
marker=markers[idx],
label=cl)
# Plotting decision region of training set after applying PCA
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
lr = LogisticRegression(multi_class='ovr',
random_state=1,
solver = 'lbfgs')
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.transform(X_test_std)
lr.fit(X_train_pca, y_train)
plot_decision_regions(X_train_pca, y_train, classifier=lr)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
# plotting decision regions of test data set after applying PCA
plot_decision_regions(X_test_pca, y_test, classifier=lr)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
# finding explained variance ratio using scikit learn
pca1 = PCA(n_components=None)
X_train_pca1 = pca1.fit_transform(X_train_std)
pca1.explained_variance_ratio_
```
| true |
code
| 0.664268 | null | null | null | null |
|
### 6. Python API Training - Continuous Model Training [Solution]
<b>Author:</b> Thodoris Petropoulos <br>
<b>Contributors:</b> Rajiv Shah
This is the 6th exercise to complete in order to finish your `Python API Training for DataRobot` course! This exercise teaches you how to deploy a trained model, make predictions (**Warning**: Multiple ways of getting predictions out of DataRobot), and monitor drift to replace a model.
Here are the actual sections of the notebook alongside time to complete:
1. Connect to DataRobot. [3min]<br>
2. Retrieve the first project created in `Exercise 4 - Model Factory`. [5min]
3. Search for the `recommended for deployment` model and deploy it as a rest API. [20min]
4. Create a scoring procedure using dataset (1) that will force data drift on that deployment. [25min]
5. Check data drift. Does it look like data is drifting?. [3min]
6. Create a new project using data (2). [5min]
7. Replace the previously deployed model with the new `recommended for deployment` model from the new project. [10min]
Each section will have specific instructions so do not worry if things are still blurry!
As always, consult:
- [API Documentation](https://datarobot-public-api-client.readthedocs-hosted.com)
- [Samples](https://github.com/datarobot-community/examples-for-data-scientists)
- [Tutorials](https://github.com/datarobot-community/tutorials-for-data-scientists)
The last two links should provide you with the snippets you need to complete most of these exercises.
<b>Data</b>
(1) The dataset we will be using throughout these exercises is the well-known `readmissions dataset`. You can access it or directly download it through DataRobot's public S3 bucket [here](https://s3.amazonaws.com/datarobot_public_datasets/10k_diabetes.csv).
(2) This dataset will be used to retrain the model. It can be accessed [here](https://s3.amazonaws.com/datarobot_public_datasets/10k_diabetes_scoring.csv) through DataRobot's public S3 bucket.
### Import Libraries
Import libraries here as you start finding out what libraries are needed. The DataRobot package is already included for your convenience.
```
import datarobot as dr
#Proposed Libraries needed
import pandas as pd
```
### 1. Connect to DataRobot [3min]
```
#Possible solution
dr.Client(config_path='../../github/config.yaml')
```
### 2. Retrieve the first project created in `Exercise 4 - Model Factory` . [5min]
This should be the first project created during the exercise. Not one of the projects created using a sample of `readmission_type_id`.
```
#Proposed Solution
project = dr.Project.get('YOUR_PROJECT_ID')
```
### 3. Search for the `recommended for deployment` model and deploy it as a rest API. [10min]
**Hint**: The recommended model can be found using the `DataRobot.ModelRecommendation` method.
**Hint 2**: Use the `update_drift_tracking_settings` method on the DataRobot Deployment object to enable data drift tracking.
```
# Proposed Solution
#Find the recommended model
recommended_model = dr.ModelRecommendation.get(project.id).get_model()
#Deploy the model
prediction_server = dr.PredictionServer.list()[0]
deployment = dr.Deployment.create_from_learning_model(recommended_model.id, label='Readmissions Deployment', default_prediction_server_id=prediction_server.id)
deployment.update_drift_tracking_settings(feature_drift_enabled=True)
```
### 4. Create a scoring procedure using dataset (1) that will force data drift on that deployment. [25min]
**Instructions**
1. Take the first 100 rows of dataset (1) and save them to a Pandas DataFrame
2. Score 5 times using these observations to force drift.
3. Use the deployment you created during `question 3`.
**Hint**: The easiest way to score using a deployed model in DataRobot is to go to the `Deployments` page within DataRobot and navigate to the `Integrations` and `scoring code` tab. There you will find sample code for Python that you can use to score.
**Hint 2**: The only thing you will have to change for the code to work is change the filename variable to point to the csv file to be scored and create a for loop.
```
# Proposed Solution
#Save the dataset that is going to be scored as a csv file
scoring_dataset = pd.read_csv('https://s3.amazonaws.com/datarobot_public_datasets/10k_diabetes.csv').head(100)
scoring_dataset.to_csv('scoring_dataset.csv', index=False)
#This has been copied from the `integrations` tab.
#The only thing you actually have to do is change the filename variable in the bottom of the script and
#create the for loop.
"""
Usage:
python datarobot-predict.py <input-file.csv>
This example uses the requests library which you can install with:
pip install requests
We highly recommend that you update SSL certificates with:
pip install -U urllib3[secure] certifi
"""
import sys
import json
import requests
DATAROBOT_KEY = ''
API_KEY = ''
USERNAME = ''
DEPLOYMENT_ID = ''
MAX_PREDICTION_FILE_SIZE_BYTES = 52428800 # 50 MB
class DataRobotPredictionError(Exception):
"""Raised if there are issues getting predictions from DataRobot"""
def make_datarobot_deployment_predictions(data, deployment_id):
"""
Make predictions on data provided using DataRobot deployment_id provided.
See docs for details:
https://app.eu.datarobot.com/docs/users-guide/predictions/api/new-prediction-api.html
Parameters
----------
data : str
Feature1,Feature2
numeric_value,string
deployment_id : str
The ID of the deployment to make predictions with.
Returns
-------
Response schema:
https://app.eu.datarobot.com/docs/users-guide/predictions/api/new-prediction-api.html#response-schema
Raises
------
DataRobotPredictionError if there are issues getting predictions from DataRobot
"""
# Set HTTP headers. The charset should match the contents of the file.
headers = {'Content-Type': 'text/plain; charset=UTF-8', 'datarobot-key': DATAROBOT_KEY}
url = 'https://cfds.orm.eu.datarobot.com/predApi/v1.0/deployments/{deployment_id}/'\
'predictions'.format(deployment_id=deployment_id)
# Make API request for predictions
predictions_response = requests.post(
url,
auth=(USERNAME, API_KEY),
data=data,
headers=headers,
)
_raise_dataroboterror_for_status(predictions_response)
# Return a Python dict following the schema in the documentation
return predictions_response.json()
def _raise_dataroboterror_for_status(response):
"""Raise DataRobotPredictionError if the request fails along with the response returned"""
try:
response.raise_for_status()
except requests.exceptions.HTTPError:
err_msg = '{code} Error: {msg}'.format(
code=response.status_code, msg=response.text)
raise DataRobotPredictionError(err_msg)
def main(filename, deployment_id):
"""
Return an exit code on script completion or error. Codes > 0 are errors to the shell.
Also useful as a usage demonstration of
`make_datarobot_deployment_predictions(data, deployment_id)`
"""
if not filename:
print(
'Input file is required argument. '
'Usage: python datarobot-predict.py <input-file.csv>')
return 1
data = open(filename, 'rb').read()
data_size = sys.getsizeof(data)
if data_size >= MAX_PREDICTION_FILE_SIZE_BYTES:
print(
'Input file is too large: {} bytes. '
'Max allowed size is: {} bytes.'
).format(data_size, MAX_PREDICTION_FILE_SIZE_BYTES)
return 1
try:
predictions = make_datarobot_deployment_predictions(data, deployment_id)
except DataRobotPredictionError as exc:
print(exc)
return 1
print(json.dumps(predictions, indent=4))
return 0
for i in range(0,5):
filename = 'scoring_dataset.csv'
main(filename, DEPLOYMENT_ID)
```
### 5. Check data drift. Does it look like data is drifting?. [3min]
Check data drift from within the `Deployments` page in the UI. Is data drift marked as red?
### 6. Create a new project using data (2). [5min]
Link to data: https://s3.amazonaws.com/datarobot_public_datasets/10k_diabetes_scoring.csv
```
#Proposed solution
new_project = dr.Project.create(sourcedata = 'https://s3.amazonaws.com/datarobot_public_datasets/10k_diabetes_scoring.csv',
project_name = '06_New_Project')
new_project.set_target(target = 'readmitted', mode = 'quick', worker_count = -1)
new_project.wait_for_autopilot()
```
### 7. Replace the previously deployed model with the new `recommended for deployment` model from the new project. [10min]
**Hint**: You will have to provide a reason why you are replacing the model. Try: `dr.enums.MODEL_REPLACEMENT_REASON.DATA_DRIFT`.
```
#Proposed Solution
new_recommended_model = dr.ModelRecommendation.get(new_project.id).get_model()
deployment.replace_model(new_recommended_model.id, dr.enums.MODEL_REPLACEMENT_REASON.DATA_DRIFT)
```
| true |
code
| 0.67077 | null | null | null | null |
|
# Lightweight python components
Lightweight python components do not require you to build a new container image for every code change. They're intended to use for fast iteration in notebook environment.
**Building a lightweight python component**
To build a component just define a stand-alone python function and then call kfp.components.func_to_container_op(func) to convert it to a component that can be used in a pipeline.
There are several requirements for the function:
- The function should be stand-alone. It should not use any code declared outside of the function definition. Any imports should be added inside the main function. Any helper functions should also be defined inside the main function.
- The function can only import packages that are available in the base image. If you need to import a package that's not available you can try to find a container image that already includes the required packages. (As a workaround you can use the module subprocess to run pip install for the required package. There is an example below in my_divmod function.)
- If the function operates on numbers, the parameters need to have type hints. Supported types are [int, float, bool]. Everything else is passed as string.
- To build a component with multiple output values, use the typing.NamedTuple type hint syntax: NamedTuple('MyFunctionOutputs', [('output_name_1', type), ('output_name_2', float)])
```
# Install the dependency packages
!pip install --upgrade pip
!pip install numpy tensorflow kfp-tekton
```
**Important**: If you are running this notebook using the Kubeflow Jupyter Server, you need to restart the Python **Kernel** because the packages above overwrited some default packages inside the Kubeflow Jupyter image.
```
import kfp
import kfp.components as comp
```
Simple function that just add two numbers:
```
#Define a Python function
def add(a: float, b: float) -> float:
'''Calculates sum of two arguments'''
return a + b
```
Convert the function to a pipeline operation
```
add_op = comp.func_to_container_op(add)
```
A bit more advanced function which demonstrates how to use imports, helper functions and produce multiple outputs.
```
#Advanced function
#Demonstrates imports, helper functions and multiple outputs
from typing import NamedTuple
def my_divmod(dividend: float, divisor:float) -> NamedTuple('MyDivmodOutput', [('quotient', float), ('remainder', float), ('mlpipeline_ui_metadata', 'UI_metadata'), ('mlpipeline_metrics', 'Metrics')]):
'''Divides two numbers and calculate the quotient and remainder'''
#Pip installs inside a component function.
#NOTE: installs should be placed right at the beginning to avoid upgrading a package
# after it has already been imported and cached by python
import sys, subprocess;
subprocess.run([sys.executable, '-m', 'pip', 'install', 'tensorflow==1.8.0'])
#Imports inside a component function:
import numpy as np
#This function demonstrates how to use nested functions inside a component function:
def divmod_helper(dividend, divisor):
return np.divmod(dividend, divisor)
(quotient, remainder) = divmod_helper(dividend, divisor)
from tensorflow.python.lib.io import file_io
import json
# Exports a sample tensorboard:
metadata = {
'outputs' : [{
'type': 'tensorboard',
'source': 'gs://ml-pipeline-dataset/tensorboard-train',
}]
}
# Exports two sample metrics:
metrics = {
'metrics': [{
'name': 'quotient',
'numberValue': float(quotient),
},{
'name': 'remainder',
'numberValue': float(remainder),
}]}
from collections import namedtuple
divmod_output = namedtuple('MyDivmodOutput', ['quotient', 'remainder', 'mlpipeline_ui_metadata', 'mlpipeline_metrics'])
return divmod_output(quotient, remainder, json.dumps(metadata), json.dumps(metrics))
```
Test running the python function directly
```
my_divmod(100, 7)
```
#### Convert the function to a pipeline operation
You can specify an alternative base container image (the image needs to have Python 3.5+ installed).
```
divmod_op = comp.func_to_container_op(my_divmod, base_image='tensorflow/tensorflow:1.11.0-py3')
```
#### Define the pipeline
Pipeline function has to be decorated with the `@dsl.pipeline` decorator
```
import kfp.dsl as dsl
@dsl.pipeline(
name='Calculation pipeline',
description='A toy pipeline that performs arithmetic calculations.'
)
# Currently kfp-tekton doesn't support pass parameter to the pipelinerun yet, so we hard code the number here
def calc_pipeline(
a='7',
b='8',
c='17',
):
#Passing pipeline parameter and a constant value as operation arguments
add_task = add_op(a, 4) #Returns a dsl.ContainerOp class instance.
#Passing a task output reference as operation arguments
#For an operation with a single return value, the output reference can be accessed using `task.output` or `task.outputs['output_name']` syntax
divmod_task = divmod_op(add_task.output, b)
#For an operation with a multiple return values, the output references can be accessed using `task.outputs['output_name']` syntax
result_task = add_op(divmod_task.outputs['quotient'], c)
```
Compile and run the pipeline into Tekton yaml using kfp-tekton SDK
```
# Specify pipeline argument values
arguments = {'a': '7', 'b': '8'}
# Specify Kubeflow Pipeline Host
host=None
# Submit a pipeline run using the KFP Tekton client.
from kfp_tekton import TektonClient
TektonClient(host=host).create_run_from_pipeline_func(calc_pipeline, arguments=arguments)
# For Argo users, submit the pipeline run using the below client.
# kfp.Client(host=host).create_run_from_pipeline_func(calc_pipeline, arguments=arguments)
```
| true |
code
| 0.71729 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/JoanesMiranda/Machine-learning/blob/master/Autoenconder.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
### Importando as bibliotecas necessárias
```
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.datasets import mnist
```
### Carregando a base de dados
```
(x_train, y_train),(x_test, y_test) = mnist.load_data()
```
### Plotando uma amostra das imagens
```
plt.imshow(x_train[10], cmap="gray")
```
### Aplicando normalização nos dados de treino e teste
```
x_train = x_train / 255.0
x_test = x_test / 255.0
print(x_train.shape)
print(x_test.shape)
```
### Adicionando ruido a base de treino
```
noise = 0.3
noise_x_train = []
for img in x_train:
noisy_image = img + noise * np.random.randn(*img.shape)
noisy_image = np.clip(noisy_image, 0., 1.)
noise_x_train.append(noisy_image)
noise_x_train = np.array(noise_x_train)
print(noise_x_train.shape)
```
### Plotando uma amostra da imagem com o ruido aplicado
```
plt.imshow(noise_x_train[10], cmap="gray")
```
### Adicionando ruido a base de teste
```
noise = 0.3
noise_x_test = []
for img in x_train:
noisy_image = img + noise * np.random.randn(*img.shape)
noisy_image = np.clip(noisy_image, 0., 1.)
noise_x_test.append(noisy_image)
noise_x_test = np.array(noise_x_test)
print(noise_x_test.shape)
```
### Plotando uma amostra da imagem com o ruido aplicado
```
plt.imshow(noise_x_test[10], cmap="gray")
noise_x_train = np.reshape(noise_x_train,(-1, 28, 28, 1))
noise_x_test = np.reshape(noise_x_test,(-1, 28, 28, 1))
print(noise_x_train.shape)
print(noise_x_test.shape)
```
### Autoencoder
```
x_input = tf.keras.layers.Input((28,28,1))
# encoder
x = tf.keras.layers.Conv2D(filters=16, kernel_size=3, strides=2, padding='same')(x_input)
x = tf.keras.layers.Conv2D(filters=8, kernel_size=3, strides=2, padding='same')(x)
# decoder
x = tf.keras.layers.Conv2DTranspose(filters=16, kernel_size=3, strides=2, padding='same')(x)
x = tf.keras.layers.Conv2DTranspose(filters=1, kernel_size=3, strides=2, activation='sigmoid', padding='same')(x)
model = tf.keras.models.Model(inputs=x_input, outputs=x)
model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(lr=0.001))
model.summary()
```
### Treinando os dados
```
model.fit(noise_x_train, x_train, batch_size=100, validation_split=0.1, epochs=10)
```
### Realizando a predição das imagens usando os dados de teste com o ruido aplicado
```
predicted = model.predict(noise_x_test)
predicted
```
### Plotando as imagens com ruido e depois de aplicar o autoencoder
```
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
for images, row in zip([noise_x_test[:10], predicted], axes):
for img, ax in zip(images, row):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
```
| true |
code
| 0.685265 | null | null | null | null |
|
# Explicit Feedback Neural Recommender Systems
Goals:
- Understand recommender data
- Build different models architectures using Keras
- Retrieve Embeddings and visualize them
- Add metadata information as input to the model
```
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import os.path as op
from zipfile import ZipFile
try:
from urllib.request import urlretrieve
except ImportError: # Python 2 compat
from urllib import urlretrieve
ML_100K_URL = "http://files.grouplens.org/datasets/movielens/ml-100k.zip"
ML_100K_FILENAME = ML_100K_URL.rsplit('/', 1)[1]
ML_100K_FOLDER = 'ml-100k'
if not op.exists(ML_100K_FILENAME):
print('Downloading %s to %s...' % (ML_100K_URL, ML_100K_FILENAME))
urlretrieve(ML_100K_URL, ML_100K_FILENAME)
if not op.exists(ML_100K_FOLDER):
print('Extracting %s to %s...' % (ML_100K_FILENAME, ML_100K_FOLDER))
ZipFile(ML_100K_FILENAME).extractall('.')
```
### Ratings file
Each line contains a rated movie:
- a user
- an item
- a rating from 1 to 5 stars
```
import pandas as pd
raw_ratings = pd.read_csv(op.join(ML_100K_FOLDER, 'u.data'), sep='\t',
names=["user_id", "item_id", "rating", "timestamp"])
raw_ratings.head()
```
### Item metadata file
The item metadata file contains metadata like the name of the movie or the date it was released. The movies file contains columns indicating the movie's genres. Let's only load the first five columns of the file with `usecols`.
```
m_cols = ['item_id', 'title', 'release_date', 'video_release_date', 'imdb_url']
items = pd.read_csv(op.join(ML_100K_FOLDER, 'u.item'), sep='|',
names=m_cols, usecols=range(5), encoding='latin-1')
items.head()
```
Let's write a bit of Python preprocessing code to extract the release year as an integer value:
```
def extract_year(release_date):
if hasattr(release_date, 'split'):
components = release_date.split('-')
if len(components) == 3:
return int(components[2])
# Missing value marker
return 1920
items['release_year'] = items['release_date'].map(extract_year)
items.hist('release_year', bins=50);
```
Enrich the raw ratings data with the collected items metadata:
```
all_ratings = pd.merge(items, raw_ratings)
all_ratings.head()
```
### Data preprocessing
To understand well the distribution of the data, the following statistics are computed:
- the number of users
- the number of items
- the rating distribution
- the popularity of each movie
```
max_user_id = all_ratings['user_id'].max()
max_user_id
max_item_id = all_ratings['item_id'].max()
max_item_id
all_ratings['rating'].describe()
```
Let's do a bit more pandas magic compute the popularity of each movie (number of ratings):
```
popularity = all_ratings.groupby('item_id').size().reset_index(name='popularity')
items = pd.merge(popularity, items)
items.nlargest(10, 'popularity')
```
Enrich the ratings data with the popularity as an additional metadata.
```
all_ratings = pd.merge(popularity, all_ratings)
all_ratings.head()
```
Later in the analysis we will assume that this popularity does not come from the ratings themselves but from an external metadata, e.g. box office numbers in the month after the release in movie theaters.
Let's split the enriched data in a train / test split to make it possible to do predictive modeling:
```
from sklearn.model_selection import train_test_split
ratings_train, ratings_test = train_test_split(
all_ratings, test_size=0.2, random_state=0)
user_id_train = np.array(ratings_train['user_id'])
item_id_train = np.array(ratings_train['item_id'])
rating_train = np.array(ratings_train['rating'])
user_id_test = np.array(ratings_test['user_id'])
item_id_test = np.array(ratings_test['item_id'])
rating_test = np.array(ratings_test['rating'])
```
# Explicit feedback: supervised ratings prediction
For each pair of (user, item) try to predict the rating the user would give to the item.
This is the classical setup for building recommender systems from offline data with explicit supervision signal.
## Predictive ratings as a regression problem
The following code implements the following architecture:
<img src="images/rec_archi_1.svg" style="width: 600px;" />
```
from tensorflow.keras.layers import Embedding, Flatten, Dense, Dropout
from tensorflow.keras.layers import Dot
from tensorflow.keras.models import Model
# For each sample we input the integer identifiers
# of a single user and a single item
class RegressionModel(Model):
def __init__(self, embedding_size, max_user_id, max_item_id):
super().__init__()
self.user_embedding = Embedding(output_dim=embedding_size, input_dim=max_user_id + 1,
input_length=1, name='user_embedding')
self.item_embedding = Embedding(output_dim=embedding_size, input_dim=max_item_id + 1,
input_length=1, name='item_embedding')
# The following two layers don't have parameters.
self.flatten = Flatten()
self.dot = Dot(axes=1)
def call(self, inputs):
user_inputs = inputs[0]
item_inputs = inputs[1]
user_vecs = self.flatten(self.user_embedding(user_inputs))
item_vecs = self.flatten(self.item_embedding(item_inputs))
y = self.dot([user_vecs, item_vecs])
return y
model = RegressionModel(30, max_user_id, max_item_id)
model.compile(optimizer='adam', loss='mae')
# Useful for debugging the output shape of model
initial_train_preds = model.predict([user_id_train, item_id_train])
initial_train_preds.shape
```
### Model error
Using `initial_train_preds`, compute the model errors:
- mean absolute error
- mean squared error
Converting a pandas Series to numpy array is usually implicit, but you may use `rating_train.values` to do so explicitly. Be sure to monitor the shapes of each object you deal with by using `object.shape`.
```
# %load solutions/compute_errors.py
squared_differences = np.square(initial_train_preds[:,0] - rating_train)
absolute_differences = np.abs(initial_train_preds[:,0] - rating_train)
print("Random init MSE: %0.3f" % np.mean(squared_differences))
print("Random init MAE: %0.3f" % np.mean(absolute_differences))
# You may also use sklearn metrics to do so using scikit-learn:
from sklearn.metrics import mean_squared_error, mean_absolute_error
print("Random init MSE: %0.3f" % mean_squared_error(initial_train_preds, rating_train))
print("Random init MAE: %0.3f" % mean_absolute_error(initial_train_preds, rating_train))
```
### Monitoring runs
Keras enables to monitor various variables during training.
`history.history` returned by the `model.fit` function is a dictionary
containing the `'loss'` and validation loss `'val_loss'` after each epoch
```
%%time
# Training the model
history = model.fit([user_id_train, item_id_train], rating_train,
batch_size=64, epochs=6, validation_split=0.1,
shuffle=True)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='validation')
plt.ylim(0, 2)
plt.legend(loc='best')
plt.title('Loss');
```
**Questions**:
- Why is the train loss higher than the first loss in the first few epochs?
- Why is Keras not computing the train loss on the full training set at the end of each epoch as it does on the validation set?
Now that the model is trained, the model MSE and MAE look nicer:
```
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
test_preds = model.predict([user_id_test, item_id_test])
print("Final test MSE: %0.3f" % mean_squared_error(test_preds, rating_test))
print("Final test MAE: %0.3f" % mean_absolute_error(test_preds, rating_test))
train_preds = model.predict([user_id_train, item_id_train])
print("Final train MSE: %0.3f" % mean_squared_error(train_preds, rating_train))
print("Final train MAE: %0.3f" % mean_absolute_error(train_preds, rating_train))
```
## A Deep recommender model
Using a similar framework as previously, the following deep model described in the course was built (with only two fully connected)
<img src="images/rec_archi_2.svg" style="width: 600px;" />
To build this model we will need a new kind of layer:
```
from tensorflow.keras.layers import Concatenate
```
### Exercise
- The following code has **4 errors** that prevent it from working correctly. **Correct them and explain** why they are critical.
```
# For each sample we input the integer identifiers
# of a single user and a single item
class DeepRegressionModel(Model):
def __init__(self, embedding_size, max_user_id, max_item_id):
super().__init__()
self.user_embedding = Embedding(output_dim=embedding_size, input_dim=max_user_id + 1,
input_length=1, name='user_embedding')
self.item_embedding = Embedding(output_dim=embedding_size, input_dim=max_item_id + 1,
input_length=1, name='item_embedding')
# The following two layers don't have parameters.
self.flatten = Flatten()
self.concat = Concatenate()
self.dropout = Dropout(0.99)
self.dense1 = Dense(64, activation="relu")
self.dense2 = Dense(2, activation="tanh")
def call(self, inputs):
user_inputs = inputs[0]
item_inputs = inputs[1]
user_vecs = self.flatten(self.user_embedding(user_inputs))
item_vecs = self.flatten(self.item_embedding(item_inputs))
input_vecs = self.concat([user_vecs, item_vecs])
y = self.dropout(input_vecs)
y = self.dense1(y)
y = self.dense2(y)
return y
model = DeepRegressionModel(30, max_user_id, max_item_id)
model.compile(optimizer='adam', loss='binary_crossentropy')
initial_train_preds = model.predict([user_id_train, item_id_train])
# %load solutions/deep_explicit_feedback_recsys.py
# For each sample we input the integer identifiers
# of a single user and a single item
class DeepRegressionModel(Model):
def __init__(self, embedding_size, max_user_id, max_item_id):
super().__init__()
self.user_embedding = Embedding(output_dim=embedding_size, input_dim=max_user_id + 1,
input_length=1, name='user_embedding')
self.item_embedding = Embedding(output_dim=embedding_size, input_dim=max_item_id + 1,
input_length=1, name='item_embedding')
# The following two layers don't have parameters.
self.flatten = Flatten()
self.concat = Concatenate()
## Error 1: Dropout was too high, preventing any training
self.dropout = Dropout(0.5)
self.dense1 = Dense(64, activation="relu")
## Error 2: output dimension was 2 where we predict only 1-d rating
## Error 3: tanh activation squashes the outputs between -1 and 1
## when we want to predict values between 1 and 5
self.dense2 = Dense(1)
def call(self, inputs):
user_inputs = inputs[0]
item_inputs = inputs[1]
user_vecs = self.flatten(self.user_embedding(user_inputs))
item_vecs = self.flatten(self.item_embedding(item_inputs))
input_vecs = self.concat([user_vecs, item_vecs])
y = self.dropout(input_vecs)
y = self.dense1(y)
y = self.dense2(y)
return y
model = DeepRegressionModel(30, max_user_id, max_item_id)
## Error 4: A binary crossentropy loss is only useful for binary
## classification, while we are in regression (use mse or mae)
model.compile(optimizer='adam', loss='mae')
initial_train_preds = model.predict([user_id_train, item_id_train])
%%time
history = model.fit([user_id_train, item_id_train], rating_train,
batch_size=64, epochs=5, validation_split=0.1,
shuffle=True)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='validation')
plt.ylim(0, 2)
plt.legend(loc='best')
plt.title('Loss');
train_preds = model.predict([user_id_train, item_id_train])
print("Final train MSE: %0.3f" % mean_squared_error(train_preds, rating_train))
print("Final train MAE: %0.3f" % mean_absolute_error(train_preds, rating_train))
test_preds = model.predict([user_id_test, item_id_test])
print("Final test MSE: %0.3f" % mean_squared_error(test_preds, rating_test))
print("Final test MAE: %0.3f" % mean_absolute_error(test_preds, rating_test))
```
### Home assignment:
- Add another layer, compare train/test error
- What do you notice?
- Try adding more dropout and modifying layer sizes: should you increase
or decrease the number of parameters
### Model Embeddings
- It is possible to retrieve the embeddings by simply using the Keras function `model.get_weights` which returns all the model learnable parameters.
- The weights are returned the same order as they were build in the model
- What is the total number of parameters?
```
# weights and shape
weights = model.get_weights()
[w.shape for w in weights]
# Solution:
model.summary()
user_embeddings = weights[0]
item_embeddings = weights[1]
print("First item name from metadata:", items["title"][1])
print("Embedding vector for the first item:")
print(item_embeddings[1])
print("shape:", item_embeddings[1].shape)
```
### Finding most similar items
Finding k most similar items to a point in embedding space
- Write in numpy a function to compute the cosine similarity between two points in embedding space
- Write a function which computes the euclidean distance between a point in embedding space and all other points
- Write a most similar function, which returns the k item names with lowest euclidean distance
- Try with a movie index, such as 181 (Return of the Jedi). What do you observe? Don't expect miracles on such a small training set.
Notes:
- you may use `np.linalg.norm` to compute the norm of vector, and you may specify the `axis=`
- the numpy function `np.argsort(...)` enables to compute the sorted indices of a vector
- `items["name"][idxs]` returns the names of the items indexed by array idxs
```
# %load solutions/similarity.py
EPSILON = 1e-07
def cosine(x, y):
dot_pdt = np.dot(x, y.T)
norms = np.linalg.norm(x) * np.linalg.norm(y)
return dot_pdt / (norms + EPSILON)
# Computes cosine similarities between x and all item embeddings
def cosine_similarities(x):
dot_pdts = np.dot(item_embeddings, x)
norms = np.linalg.norm(x) * np.linalg.norm(item_embeddings, axis=1)
return dot_pdts / (norms + EPSILON)
# Computes euclidean distances between x and all item embeddings
def euclidean_distances(x):
return np.linalg.norm(item_embeddings - x, axis=1)
# Computes top_n most similar items to an idx,
def most_similar(idx, top_n=10, mode='euclidean'):
sorted_indexes=0
if mode == 'euclidean':
dists = euclidean_distances(item_embeddings[idx])
sorted_indexes = np.argsort(dists)
idxs = sorted_indexes[0:top_n]
return list(zip(items["title"][idxs], dists[idxs]))
else:
sims = cosine_similarities(item_embeddings[idx])
# [::-1] makes it possible to reverse the order of a numpy
# array, this is required because most similar items have
# a larger cosine similarity value
sorted_indexes = np.argsort(sims)[::-1]
idxs = sorted_indexes[0:top_n]
return list(zip(items["title"][idxs], sims[idxs]))
# sanity checks:
print("cosine of item 1 and item 1: %0.3f"
% cosine(item_embeddings[1], item_embeddings[1]))
euc_dists = euclidean_distances(item_embeddings[1])
print(euc_dists.shape)
print(euc_dists[1:5])
print()
# Test on movie 181: Return of the Jedi
print("Items closest to 'Return of the Jedi':")
for title, dist in most_similar(181, mode="euclidean"):
print(title, dist)
# We observe that the embedding is poor at representing similarities
# between movies, as most distance/similarities are very small/big
# One may notice a few clusters though
# it's interesting to plot the following distributions
# plt.hist(euc_dists)
# The reason for that is that the number of ratings is low and the embedding
# does not automatically capture semantic relationships in that context.
# Better representations arise with higher number of ratings, and less overfitting
# in models or maybe better loss function, such as those based on implicit
# feedback.
```
### Visualizing embeddings using TSNE
- we use scikit learn to visualize items embeddings
- Try different perplexities, and visualize user embeddings as well
- What can you conclude ?
```
from sklearn.manifold import TSNE
item_tsne = TSNE(perplexity=30).fit_transform(item_embeddings)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.scatter(item_tsne[:, 0], item_tsne[:, 1]);
plt.xticks(()); plt.yticks(());
plt.show()
```
Alternatively with [Uniform Manifold Approximation and Projection](https://github.com/lmcinnes/umap):
```
!pip install umap-learn
import umap
item_umap = umap.UMAP().fit_transform(item_embeddings)
plt.figure(figsize=(10, 10))
plt.scatter(item_umap[:, 0], item_umap[:, 1]);
plt.xticks(()); plt.yticks(());
plt.show()
```
## Using item metadata in the model
Using a similar framework as previously, we will build another deep model that can also leverage additional metadata. The resulting system is therefore an **Hybrid Recommender System** that does both **Collaborative Filtering** and **Content-based recommendations**.
<img src="images/rec_archi_3.svg" style="width: 600px;" />
```
from sklearn.preprocessing import QuantileTransformer
meta_columns = ['popularity', 'release_year']
scaler = QuantileTransformer()
item_meta_train = scaler.fit_transform(ratings_train[meta_columns])
item_meta_test = scaler.transform(ratings_test[meta_columns])
class HybridModel(Model):
def __init__(self, embedding_size, max_user_id, max_item_id):
super().__init__()
self.user_embedding = Embedding(output_dim=embedding_size, input_dim=max_user_id + 1,
input_length=1, name='user_embedding')
self.item_embedding = Embedding(output_dim=embedding_size, input_dim=max_item_id + 1,
input_length=1, name='item_embedding')
# The following two layers don't have parameters.
self.flatten = Flatten()
self.concat = Concatenate()
self.dense1 = Dense(64, activation="relu")
self.dropout = Dropout(0.5)
self.dense2 = Dense(32, activation='relu')
self.dense3 = Dense(2, activation="tanh")
def call(self, inputs):
user_inputs = inputs[0]
item_inputs = inputs[1]
meta_inputs = inputs[2]
user_vecs = self.flatten(self.user_embedding(user_inputs))
item_vecs = self.flatten(self.item_embedding(item_inputs))
input_vecs = self.concat([user_vecs, item_vecs, meta_inputs])
y = self.dense1(input_vecs)
y = self.dropout(y)
y = self.dense2(y)
y = self.dense3(y)
return y
model = DeepRecoModel(30, max_user_id, max_item_id)
model.compile(optimizer='adam', loss='mae')
initial_train_preds = model.predict([user_id_train, item_id_train, item_meta_train])
%%time
history = model.fit([user_id_train, item_id_train, item_meta_train], rating_train,
batch_size=64, epochs=15, validation_split=0.1,
shuffle=True)
test_preds = model.predict([user_id_test, item_id_test, item_meta_test])
print("Final test MSE: %0.3f" % mean_squared_error(test_preds, rating_test))
print("Final test MAE: %0.3f" % mean_absolute_error(test_preds, rating_test))
```
The additional metadata seem to improve the predictive power of the model a bit at least in terms of MAE.
### A recommendation function for a given user
Once the model is trained, the system can be used to recommend a few items for a user, that he/she hasn't already seen:
- we use the `model.predict` to compute the ratings a user would have given to all items
- we build a reco function that sorts these items and exclude those the user has already seen
```
indexed_items = items.set_index('item_id')
def recommend(user_id, top_n=10):
item_ids = range(1, max_item_id)
seen_mask = all_ratings["user_id"] == user_id
seen_movies = set(all_ratings[seen_mask]["item_id"])
item_ids = list(filter(lambda x: x not in seen_movies, item_ids))
print("User %d has seen %d movies, including:" % (user_id, len(seen_movies)))
for title in all_ratings[seen_mask].nlargest(20, 'popularity')['title']:
print(" ", title)
print("Computing ratings for %d other movies:" % len(item_ids))
item_ids = np.array(item_ids)
user_ids = np.zeros_like(item_ids)
user_ids[:] = user_id
items_meta = scaler.transform(indexed_items[meta_columns].loc[item_ids])
rating_preds = model.predict([user_ids, item_ids, items_meta])
item_ids = np.argsort(rating_preds[:, 0])[::-1].tolist()
rec_items = item_ids[:top_n]
return [(items["title"][movie], rating_preds[movie][0])
for movie in rec_items]
for title, pred_rating in recommend(5):
print(" %0.1f: %s" % (pred_rating, title))
```
### Home assignment: Predicting ratings as a classification problem
In this dataset, the ratings all belong to a finite set of possible values:
```
import numpy as np
np.unique(rating_train)
```
Maybe we can help the model by forcing it to predict those values by treating the problem as a multiclassification problem. The only required changes are:
- setting the final layer to output class membership probabities using a softmax activation with 5 outputs;
- optimize the categorical cross-entropy classification loss instead of a regression loss such as MSE or MAE.
```
# %load solutions/classification.py
class ClassificationModel(Model):
def __init__(self, embedding_size, max_user_id, max_item_id):
super().__init__()
self.user_embedding = Embedding(output_dim=embedding_size, input_dim=max_user_id + 1,
input_length=1, name='user_embedding')
self.item_embedding = Embedding(output_dim=embedding_size, input_dim=max_item_id + 1,
input_length=1, name='item_embedding')
# The following two layers don't have parameters.
self.flatten = Flatten()
self.concat = Concatenate()
self.dropout1 = Dropout(0.5)
self.dense1 = Dense(128, activation="relu")
self.dropout2 = Dropout(0.2)
self.dense2 = Dense(128, activation='relu')
self.dense3 = Dense(5, activation="softmax")
def call(self, inputs):
user_inputs = inputs[0]
item_inputs = inputs[1]
user_vecs = self.flatten(self.user_embedding(user_inputs))
item_vecs = self.flatten(self.item_embedding(item_inputs))
input_vecs = self.concat([user_vecs, item_vecs])
y = self.dropout1(input_vecs)
y = self.dense1(y)
y = self.dropout2(y)
y = self.dense2(y)
y = self.dense3(y)
return y
model = ClassificationModel(16, max_user_id, max_item_id)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
initial_train_preds = model.predict([user_id_train, item_id_train]).argmax(axis=1) + 1
print("Random init MSE: %0.3f" % mean_squared_error(initial_train_preds, rating_train))
print("Random init MAE: %0.3f" % mean_absolute_error(initial_train_preds, rating_train))
history = model.fit([user_id_train, item_id_train], rating_train - 1,
batch_size=64, epochs=15, validation_split=0.1,
shuffle=True)
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='validation')
plt.ylim(0, 2)
plt.legend(loc='best')
plt.title('loss');
test_preds = model.predict([user_id_test, item_id_test]).argmax(axis=1) + 1
print("Final test MSE: %0.3f" % mean_squared_error(test_preds, rating_test))
print("Final test MAE: %0.3f" % mean_absolute_error(test_preds, rating_test))
```
| true |
code
| 0.60212 | null | null | null | null |
|
```
"""The purpose of this tutorial is to introduce you to:
(1) how gradient-based optimization of neural networks
operates in concrete practice, and
(2) how different forms of learning rules lead to more or less
efficient learning as a function of the shape of the optimization
landscape
This tutorial should be used in conjunction with the lecture:
http://cs375.stanford.edu/lectures/lecture6_optimization.pdf
""";
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
#the above imports the plotting library matplotlib
#standard imports
import time
import numpy as np
import h5py
#We're not using the GPU here, so we set the
#"CUDA_VISIBLE_DEVICES" environment variable to -1
#which tells tensorflow to only use the CPU
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1"
import tensorflow as tf
```
## Gradient Descent
```
#let's define a model which "believes" that the output data
#is scalar power of a scalar input, e.g. :
# y ~ x^p
#defining the scalar input data variable
batch_size = 200
#the "placeholder" mechanis is similar in effect to
# x = tf.get_variable('x', shape=(batch_size,), dtype=tf.float32)
#except we don't have to define a fixed name "x"
x = tf.placeholder(shape=(batch_size,), dtype=tf.float32)
#define the scalar power variable
initial_power = tf.zeros(shape=())
power = tf.get_variable('pow', initializer=initial_power, dtype=tf.float32)
#define the model
model = x**power
#the output data needs a variable too
y = tf.placeholder(shape=(batch_size,), dtype=tf.float32)
#the error rate of the model is mean L2 distance across
#the batch of data
power_loss = tf.reduce_mean((model - y)**2)
#now, our goal is to use gradient descent to
#figure out the parameter of our model -- namely, the power variable
grad = tf.gradients(power_loss, power)[0]
#Let's fit (optimize) the model.
#to do that we'll have to first of course define a tensorflow session
sess = tf.Session()
#... and initialize the power variable
initializer = tf.global_variables_initializer()
sess.run(initializer)
#ok ... so let's test the case where the true input-output relationship
#is x --> x^2
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**2
#OK
initial_guess = 0
assign_op = tf.assign(power, initial_guess)
sess.run(assign_op)
gradval = sess.run(grad, feed_dict={x: xval, y: yval})
gradval
#ok so this is telling us to do:
new_guess = initial_guess + -1 * (gradval)
print(new_guess)
#ok so let's assign the new guess to the power variable
assign_op = tf.assign(power, new_guess)
sess.run(assign_op)
#... and get the gradient again
gradval = sess.run(grad, feed_dict={x: xval, y: yval})
gradval
new_guess = new_guess + -1 * (gradval)
print(new_guess)
#... and one more time ...
assign_op = tf.assign(power, new_guess)
sess.run(assign_op)
#... get the gradient again
gradval = sess.run(grad, feed_dict={x: xval, y: yval})
print('gradient: %.3f', gradval)
#... do the update
new_guess = new_guess + -1 * (gradval)
print('power: %.3f', new_guess)
#ok so we're hovering back and forth around guess of 2.... which is right!
#OK let's do this in a real loop and keep track of useful stuff along the way
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**2
#start the guess off at 0 again
assign_op = tf.assign(power, 0)
sess.run(assign_op)
#let's keep track of the guess along the way
powers = []
#and the loss, which should go down
losses = []
#and the grads just for luck
grads = []
#let's iterate the gradient descent process 20 timesteps
num_iterations = 20
#for each timestep ...
for i in range(num_iterations):
#... get the current derivative (grad), the current guess of "power"
#and the loss, given the input and output training data (xval & yval)
cur_power, cur_loss, gradval = sess.run([power, power_loss, grad],
feed_dict={x: xval, y: yval})
#... keep track of interesting stuff along the way
powers.append(cur_power)
losses.append(cur_loss)
grads.append(gradval)
#... now do the gradient descent step
new_power = cur_power - gradval
#... and actually update the value of the power variable
assign_op = tf.assign(power, new_power)
sess.run(assign_op)
#and then, the loop runs again
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.plot(grads, label='gradients')
plt.xlabel('iterations')
plt.legend(loc='lower right')
plt.title('Estimating a quadratic')
##ok now let's try that again except where y ~ x^3
#all we need to do is change the data
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**3
#The rest of the code remains the same
assign_op = tf.assign(power, 0)
sess.run(assign_op)
powers = []
losses = []
grads = []
num_iterations = 20
for i in range(num_iterations):
cur_power, cur_loss, gradval = sess.run([power, power_loss, grad],
feed_dict={x: xval, y: yval})
powers.append(cur_power)
losses.append(cur_loss)
grads.append(gradval)
new_power = cur_power - gradval
assign_op = tf.assign(power, new_power)
sess.run(assign_op)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.xlabel('iterations')
plt.legend(loc='center right')
plt.title('Failing to estimate a cubic')
#wait ... this did *not* work. why?
#whoa ... the loss must have diverged to infinity (or close) really early
losses
#why?
#let's look at the gradients
grads
#hm. the gradient was getting big at the end.
#after all, the taylor series only works in the close-to-the-value limit.
#we must have been been taking too big steps.
#how do we fix this?
```
### With Learning Rate
```
def gradient_descent(loss,
target,
initial_guess,
learning_rate,
training_data,
num_iterations):
#assign initial value to the target
initial_op = tf.assign(target, initial_guess)
#get the gradient
grad = tf.gradients(loss, target)[0]
#actually do the gradient descent step directly in tensorflow
newval = tf.add(target, tf.multiply(-grad, learning_rate))
#the optimizer step actually performs the parameter update
optimizer_op = tf.assign(target, newval)
#NB: none of the four steps above are actually running anything yet
#They are just formal graph computations.
#to actually do anything, you have to run stuff in a session.
#set up containers for stuff we want to keep track of
targetvals = []
losses = []
gradvals = []
#first actually run the initialization operation
sess.run(initial_op)
#now take gradient steps in a loop
for i in range(num_iterations):
#just by virtue of calling "run" on the "optimizer" op,
#the optimization occurs ...
output = sess.run({'opt': optimizer_op,
'grad': grad,
'target': target,
'loss': loss
},
feed_dict=training_data)
targetvals.append(output['target'])
losses.append(output['loss'])
gradvals.append(output['grad'])
return losses, targetvals, gradvals
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**3
data_dict = {x: xval, y:yval}
losses, powers, grads = gradient_descent(loss=power_loss,
target=power,
initial_guess=0,
learning_rate=.25, #chose learning rate < 1
training_data=data_dict,
num_iterations=20)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='upper right')
plt.title('Estimating a cubic')
#ok -- now the result stably converges!
#and also for a higher power ....
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**4
data_dict = {x: xval, y:yval}
losses, powers, grads = gradient_descent(loss=power_loss,
target=power,
initial_guess=0,
learning_rate=0.1,
training_data=data_dict,
num_iterations=100)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='upper right')
plt.title('Estimating a quartic')
#what about when the data is actually not of the right form?
xval = np.arange(0, 2, .01)
yval = np.sin(xval)
data_dict = {x: xval, y:yval}
losses, powers, grads = gradient_descent(loss=power_loss,
target=power,
initial_guess=0,
learning_rate=0.1,
training_data=data_dict,
num_iterations=20)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='center right')
plt.title('Estimating sine with a power, not converged yet')
#doesn't look like it's converged yet -- maybe we need to run it longer?
#sine(x) now with more iterations
xval = np.arange(0, 2, .01)
yval = np.sin(xval)
data_dict = {x: xval, y:yval}
losses, powers, grads = gradient_descent(loss=power_loss,
target=power,
initial_guess=0,
learning_rate=0.1,
training_data=data_dict,
num_iterations=100) #<-- more iterations
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='center right')
plt.title('Estimating sine with a power (badly)')
#ok it's converged but not to a great loss. This is unsurprising
#since x^p is a bad model for sine(x)
#how should we improve?
#THE MACHINE LEARNING ANSWER: well, let's have more parameters in our model!
#actually, let's write a model using the Taylor series idea more explicitly:
# y ~ sum_i a_i x^i
#for some coefficients a_i that we have to learn
#let's go out to x^5, so approx_order = 7 (remember, we're 0-indexing in python)
approximation_order = 6
#ok so now let's define the variabe we'll be using
#instead of "power" this will be coefficients of the powers
#with one coefficient for each power from 0 to approximation_order-1
coefficients = tf.get_variable('coefficients',
initializer = tf.zeros(shape=(approximation_order,)),
dtype=tf.float32)
#gotta run the initializer again b/c we just defined a new trainable variable
initializer = tf.global_variables_initializer()
sess.run(initializer)
sess.run(coefficients)
#Ok let's define the model
#here's the vector of exponents
powervec = tf.range(0, approximation_order, dtype=tf.float32)
#we want to do essentially:
# sum_i coefficient_i * x^powervec[i]
#but to do x^powervec, we need to create an additional dimension on x
x_expanded = tf.expand_dims(x, axis=1)
#ok, now we can actually do x^powervec
x_exponentiated = x_expanded**powervec
#now multiply by the coefficient variable
x_multiplied_by_coefficients = coefficients * x_exponentiated
#and add up over the 1st dimension e.g. dong the sum_i
polynomial_model = tf.reduce_sum(x_multiplied_by_coefficients, axis=1)
#the loss is again l2 difference between prediction and desired output
polynomial_loss = tf.reduce_mean((polynomial_model - y)**2)
xval = np.arange(-2, 2, .02)
yval = np.sin(xval)
data_dict = {x: xval, y:yval}
#starting out at 0 since the coefficients were all intialized to 0
sess.run(polynomial_model, feed_dict=data_dict)
#ok let's try it
losses, coefvals, grads = gradient_descent(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
learning_rate=0.1,
training_data=data_dict,
num_iterations=100)
#ok, so for each timstep we have 6 values -- the coefficients
print(len(coefvals))
coefvals[-1].shape
#here's the last set of coefficients learned
coefvals[-1]
#whoa -- what's going on?
#let's lower the learning rate
losses, coefvals, grads = gradient_descent(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
learning_rate=0.005, #<-- lowered learning rate
training_data=data_dict,
num_iterations=100)
#ok not quite as bad
coefvals[-1]
#let's visualize what we learned
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.plot(xval, yval)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
#ok, fine, but not great
#what if we let it run longer?
losses, coefvals, grads = gradient_descent(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
learning_rate=0.005,
training_data=data_dict,
num_iterations=5000) #<-- more iterations
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Gradient Descent')
#ok much better
coefvals[-1]
tf.Variable(np.zeros(6))
```
### With momentum
```
def gradient_descent_with_momentum(loss,
target,
initial_guess,
learning_rate,
momentum,
training_data,
num_iterations):
#set target to initial guess
initial_op = tf.assign(target, initial_guess)
#get gradient
grad = tf.gradients(loss, target)[0]
#set up the variable for the gradient accumulation
grad_shp = grad.shape.as_list()
#needs to be specified as float32 to interact properly with other things (but numpy defaults to float64)
grad_accum = tf.Variable(np.zeros(grad_shp).astype(np.float32))
#gradplus = grad + momentum * grad_accum
gradplus = tf.add(grad, tf.multiply(grad_accum, momentum))
#newval = oldval - learning_rate * gradplus
newval = tf.add(target, tf.multiply(-gradplus, learning_rate))
#the optimizer step actually performs the parameter update
optimizer_op = tf.assign(target, newval)
#this step updates grad_accum
update_accum = tf.assign(grad_accum, gradplus)
#run initialization
sess.run(initial_op)
#necessary b/c we've defined a new variable ("grad_accum") above
init_op = tf.global_variables_initializer()
sess.run(init_op)
#run the loop
targetvals = []
losses = []
gradvals = []
times = []
for i in range(num_iterations):
t0 = time.time()
output = sess.run({'opt': optimizer_op, #have to have this for optimization to occur
'accum': update_accum, #have to have this for grad_accum to update
'grad': grad, #the rest of these are just for keeping track
'target': target,
'loss': loss
},
feed_dict=training_data)
times.append(time.time() - t0)
targetvals.append(output['target'])
losses.append(output['loss'])
gradvals.append(output['grad'])
print('Average time per iteration --> %.5f' % np.mean(times))
return losses, targetvals, gradvals
losses, coefvals, grads = gradient_descent_with_momentum(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
learning_rate=0.01, #<-- can use higher learning rate!
momentum=0.9,
training_data=data_dict,
num_iterations=250) #<-- can get away from fewer iterations!
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Gradient Descent')
#so momentum is really useful
```
### Tensorflow's Built-In Optimizers
```
def tf_builtin_optimization(loss,
optimizer_class,
target,
training_data,
num_iterations,
optimizer_args=(),
optimizer_kwargs={},
):
#construct the optimizer
optimizer = optimizer_class(*optimizer_args,
**optimizer_kwargs)
#formal tensorflow optimizers will always have a "minimize" method
#this is how you actually get the optimizer op
optimizer_op = optimizer.minimize(loss)
init_op = tf.global_variables_initializer()
sess.run(init_op)
targetvals = []
losses = []
times = []
for i in range(num_iterations):
t0 = time.time()
output = sess.run({'opt': optimizer_op,
'target': target,
'loss': loss},
feed_dict=training_data)
times.append(time.time() - t0)
targetvals.append(output['target'])
losses.append(output['loss'])
print('Average time per iteration --> %.5f' % np.mean(times))
return np.array(losses), targetvals
xval = np.arange(-2, 2, .02)
yval = np.sin(xval)
data_dict = {x: xval, y:yval}
losses, coefvals = tf_builtin_optimization(loss=polynomial_loss,
optimizer_class=tf.train.GradientDescentOptimizer,
target=coefficients,
training_data=data_dict,
num_iterations=5000,
optimizer_args=(0.005,),
) #<-- more iterations
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Gradient Descent')
#right ok, we recovered what we did before by hand, now using
#the standard tensorflow tools
#Let's use the Momentum Optimizer. standard parameters for learning
#are learning_rate = 0.01 and momentum = 0.9
xval = np.arange(-2, 2, .02)
yval = np.sin(xval )
data_dict = {x: xval, y:yval}
losses, coefvals = tf_builtin_optimization(loss=polynomial_loss,
optimizer_class=tf.train.MomentumOptimizer,
target=coefficients,
training_data=data_dict,
num_iterations=250,
optimizer_kwargs={'learning_rate': 0.01,
'momentum': 0.9})
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Momentum Optimizer')
#again reproducing what we see before by hand
#and we can try some other stuff, such as the Adam Optimizer
losses, coefvals = tf_builtin_optimization(loss=polynomial_loss,
optimizer_class=tf.train.AdamOptimizer,
target=coefficients,
training_data=data_dict,
num_iterations=500,
optimizer_kwargs={'learning_rate': 0.01})
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Adam optimizer')
#Adam as usualy requires a bit more steps than Momentum -- but the advantage of Adam
#is that sometimes Momentum blows up and Adam is usually more stable
#(compare the loss traces! even though Momentum didn't below up above, it's
#loss is much more jaggedy -- signs up potential blowup)
#so hm ... maybe because Adam is more stable we can jack up the
#initial learning rate and thus converge even faster than with Momentum
losses, coefvals = tf_builtin_optimization(loss=polynomial_loss,
optimizer_class=tf.train.AdamOptimizer,
target=coefficients,
training_data=data_dict,
num_iterations=150,
optimizer_kwargs={'learning_rate': 0.5})
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.plot(xval, yval)
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Adam optimizer\nhigh initial learning rate')
#indeed we can!
```
### Newton's Method (Second Order)
```
def newtons_method(loss,
target,
initial_guess,
training_data,
num_iterations,
grad2clip=1.):
#create initialization operation
initial_op = tf.assign(target, initial_guess)
grad = tf.gradients(loss, target)[0]
#to actually compute the second order correction
#we split the one-variable and multi-variable cases up -- for ease of working
if len(target.shape) == 0: #one-variable case
#actually get the second derivative
grad2 = tf.gradients(grad, target)[0]
#now morally we want to compute:
# newval = target - grad / grad2
#BUT there is often numerical instability caused by dividing
#by grad2 if grad2 is small... so we have to clip grad2 by a clip value
clippedgrad2 = tf.maximum(grad2, grad2clip)
#and now we can do the newton's formula update
newval = tf.add(target, -tf.divide(grad, clippedgrad2))
else:
#in the multi-variable case, we first compute the hessian matrix
#thank gosh tensorflow has this built in finally!
hess = tf.hessians(loss, target)[0]
#now we take it's inverse
hess_inv = tf.matrix_inverse(hess)
#now we get H^{-1} grad, e.g. multiple the matrix by the vector
hess_inv_grad = tf.tensordot(hess_inv, grad, 1)
#again we have to clip for numerical stability
hess_inv_grad = tf.clip_by_value(hess_inv_grad, -grad2clip, grad2clip)
#and get the new value for the parameters
newval = tf.add(target, -hess_inv_grad)
#the rest of the code is just as in the gradient descent case
optimizer_op = tf.assign(target, newval)
targetvals = []
losses = []
gradvals = []
sess.run(initial_op)
for i in range(num_iterations):
output = sess.run({'opt': optimizer_op,
'grad': grad,
'target': target,
'loss': loss},
feed_dict=training_data)
targetvals.append(output['target'])
losses.append(output['loss'])
gradvals.append(output['grad'])
return losses, targetvals, gradvals
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**2
data_dict = {x: xval, y:yval}
losses, powers, grads = newtons_method(loss=power_loss,
target=power,
initial_guess=0,
training_data=data_dict,
num_iterations=20,
grad2clip=1)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='upper right')
plt.title("Newton's Method on Quadractic")
#whoa -- much faster than before
xval = np.arange(0, 2, .01)
yval = np.arange(0, 2, .01)**3
data_dict = {x: xval, y:yval}
losses, powers, grads = newtons_method(loss=power_loss,
target=power,
initial_guess=0,
training_data=data_dict,
num_iterations=20,
grad2clip=1)
plt.plot(powers, label='estimated power')
plt.plot(losses, label='loss')
plt.legend(loc='upper right')
plt.title("Newton's Method on a Cubic")
xval = np.arange(-2, 2, .02)
yval = np.sin(xval)
data_dict = {x: xval, y:yval}
losses, coefvals, grads = newtons_method(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
training_data=data_dict,
num_iterations=2)
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, yval)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
#no joke -- the error goes to 0 after 1 update step
#let's try something a little more complicated
xval = np.arange(-2, 2, .02)
yval = np.cos(2 * xval) + np.sin(xval + 1)
data_dict = {x: xval, y:yval}
losses, coefvals, grads = newtons_method(loss=polynomial_loss,
target=coefficients,
initial_guess=np.zeros(approximation_order),
training_data=data_dict,
num_iterations=5)
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, yval)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
#really fast -- actually Newton's method always converges this fast if
#the model is polynomial
#just to put the above in context, let's compare to momentum
xval = np.arange(-2, 2, .02)
yval = np.cos(2 * xval) + np.sin(xval + 1)
data_dict = {x: xval, y:yval}
losses, coefvals = tf_builtin_optimization(loss=polynomial_loss,
optimizer_class=tf.train.MomentumOptimizer,
target=coefficients,
training_data=data_dict,
num_iterations=200,
optimizer_kwargs={'learning_rate': 0.01,
'momentum': 0.9},
)
x0 = coefvals[-1]
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, yval)
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}))
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
```
### Using External Optimizers
```
#actually, let's use an *external* optimizer -- not do
#the optimization itself in tensorflow
from scipy.optimize import minimize
#you can see all the methods for optimization here:
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html#scipy.optimize.minimize
#Ok here's the model we want to learn
xval = np.arange(-2, 2, .02)
yval = np.cosh(2 * xval) + np.sin(xval + 1)
plt.plot(xval, yval)
plt.title("Target to Learn")
polynomial_loss
#we need to make a python function from our tensorflow model
#(actually we could simply write the model directly in numpy
#but ... since we already have it in Tensorflow might as well use it
def func_loss(vals):
data_dict = {x: xval,
y: yval,
coefficients: vals}
lossval = sess.run(polynomial_loss, feed_dict=data_dict)
losses.append(lossval)
return lossval
#Ok, so let's use a method that doesn't care about the derivative
#specifically "Nelder-Mead" -- this is a simplex-based method
losses = []
result = minimize(func_loss,
x0=np.zeros(6),
method='Nelder-Mead')
x0 = result.x
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, yval, label='True')
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}), label='Appox.')
plt.legend(loc='upper center')
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with Nelder-Mead')
#OK now let's try a method that *does* care about the derivative
#specifically, a method called L-BFGS -- this is basically
#an approximate version of the newton's method.
#It's called a "quasi-second-order" method because it uses only
#first derivatives to get an approximation to the second derivative
#to use it, we need *do* need to calculate the derivative
#... and here's why tensorflow STILL matters even if we're using
#an external optimizer
polynomial_grad = tf.gradients(polynomial_loss, coefficients)[0]
#we need to create a function that returns loss and loss derivative
def func_loss_with_grad(vals):
data_dict = {x: xval,
y:yval,
coefficients: vals}
lossval, g = sess.run([polynomial_loss, polynomial_grad],
feed_dict=data_dict)
losses.append(lossval)
return lossval, g.astype(np.float64)
#Ok, so let's see what happens with L-BFGS
losses = []
result = minimize(func_loss_with_grad,
x0=np.zeros(6),
method='L-BFGS-B', #approximation of newton's method
jac=True #<-- meaning, we're telling minimizer
#to use the derivative info -- the so-called
#"jacobian"
)
x0 = result.x
assign_op = tf.assign(coefficients, x0)
sess.run(assign_op)
plt.figure(figsize=(10, 3))
plt.subplot(1, 2, 1)
plt.plot(xval, yval, label='True')
plt.plot(xval, sess.run(polynomial_model, feed_dict={x:xval}), label='Appox.')
plt.legend(loc='upper center')
plt.subplot(1, 2, 2)
plt.plot(losses)
plt.xlabel('iterations')
plt.ylabel('loss')
plt.title('Loss with L-BFGS')
#substantially better than the non-derivative-based method
#-- fewer interations are needed, loss curve is stabler, and final
#results are better
```
## Deploying it in a real case
```
#ok let's load the neural data
DATA_PATH = "/home/chengxuz/Class/psych253_2018/data/ventral_neural_data.hdf5"
Ventral_Dataset = h5py.File(DATA_PATH)
categories = Ventral_Dataset['image_meta']['category'][:] #array of category labels for all images --> shape == (5760,)
unique_categories = np.unique(categories) #array of unique category labels --> shape == (8,)
var_levels = Ventral_Dataset['image_meta']['variation_level'][:]
Neural_Data = Ventral_Dataset['time_averaged_trial_averaged'][:]
num_neurons = Neural_Data.shape[1]
num_categories = 8
categories[:10]
#we'll construct 8 one-vs-all vectors with {-1, 1} values
category_matrix = np.array([2 * (categories == c) - 1 for
c in unique_categories]).T.astype(int)
category_matrix[0]
sess = tf.Session()
#first, get initializers for W and b
initial_weights = tf.random_uniform(shape=(num_neurons, num_categories),
minval=-1,
maxval=1,
seed=0)
initial_bias = tf.zeros(shape=(num_categories,))
#now construct the TF variables
weights = tf.get_variable('weights',
dtype=tf.float32,
initializer=initial_weights)
bias = tf.get_variable('bias',
dtype=tf.float32,
initializer=initial_bias)#initialize variables
init_op = tf.global_variables_initializer()
sess.run(init_op)
#input slots for data and labels
#note the batch size is "None" -- effectively meaning batches of
#varying sizes can be used
neural_data = tf.placeholder(shape=(None, num_neurons),
dtype=tf.float32)
category_labels = tf.placeholder(shape=(None, num_categories),
dtype=tf.float32)
#now construct margins
margins = tf.matmul(neural_data, weights) + bias
#the hinge loss
hinge_loss = tf.maximum(0., 1. - category_labels * margins)
#and take the mean of the loss over the batch
hinge_loss_mean = tf.reduce_mean(hinge_loss)
#simple interface for using tensorflow built-in optimizer
#as seen yesterclass
def tf_optimize(loss,
optimizer_class,
target,
training_data,
num_iterations,
optimizer_args=(),
optimizer_kwargs=None,
sess=None,
initial_guesses=None):
if sess is None:
sess = tf.Session()
if optimizer_kwargs is None:
optimizer_kwargs = {}
#construct the optimizer
optimizer = optimizer_class(*optimizer_args,
**optimizer_kwargs)
optimizer_op = optimizer.minimize(loss)
#initialize variables
init_op = tf.global_variables_initializer()
sess.run(init_op)
if initial_guesses is not None:
for k, v in initial_guesses.items():
op = tf.assign(k, v)
sess.run(op)
targetvals = []
losses = []
times = []
for i in range(num_iterations):
t0 = time.time()
output = sess.run({'opt': optimizer_op,
'target': target,
'loss': loss},
feed_dict=training_data)
times.append(time.time() - t0)
targetvals.append(output['target'])
losses.append(output['loss'])
print('Average time per iteration --> %.5f' % np.mean(times))
return np.array(losses), targetvals
#let's just focus on one batch of data for the moment
batch_size = 640
data_batch = Neural_Data[0: batch_size]
label_batch = category_matrix[0: batch_size]
data_dict = {neural_data: data_batch,
category_labels: label_batch}
#let's look at the weights and biases before training
weight_vals, bias_vals = sess.run([weights, bias])
#right, it's num_neurons x num_categories
print('weights shape:', weight_vals.shape)
#let's look at some of the weights
plt.hist(weight_vals[:, 0])
plt.xlabel('Weight Value')
plt.ylabel('Neuron Count')
plt.title('Weights for Animals vs All')
print('biases:', bias_vals)
#ok so we'll use the Momentum optimizer to find weights and bias
#for this classification problem
losses, targs = tf_optimize(loss=hinge_loss_mean,
optimizer_class=tf.train.MomentumOptimizer,
target=[],
training_data=data_dict,
num_iterations=100,
optimizer_kwargs={'learning_rate': 1, 'momentum': 0.9},
sess=sess)
#losses decrease almost to 0
plt.plot(losses)
weight_vals, bias_vals = sess.run([weights, bias])
#right, it's num_neurons x num_categories
weight_vals.shape
#let's look at some of the weights
plt.hist(weight_vals[:, 2])
plt.xlabel('Weight Value')
plt.ylabel('Neuron Count')
plt.title('Weights for Faces vs All')
print('biases:', bias_vals)
#ok so things have been learned!
#how good are the results on training?
#actually get the predictions by first getting the margins
margin_vals = sess.run(margins, feed_dict = data_dict)
#now taking the argmax across categories
pred_inds = margin_vals.argmax(axis=1)
#compare prediction to actual
correct = pred_inds == label_batch.argmax(axis=1)
pct = correct.sum() / float(len(correct)) * 100
print('Training accuracy: %.2f%%' % pct)
#Right, very accurate on training
```
### Stochastic Gradient Descent
```
class BatchReader(object):
def __init__(self, data_dict, batch_size, shuffle=True, shuffle_seed=0, pad=True):
self.data_dict = data_dict
self.batch_size = batch_size
_k = data_dict.keys()[0]
self.data_length = data_dict[_k].shape[0]
self.total_batches = (self.data_length - 1) // self.batch_size + 1
self.curr_batch_num = 0
self.curr_epoch = 1
self.pad = pad
self.shuffle = shuffle
self.shuffle_seed = shuffle_seed
if self.shuffle:
self.rng = np.random.RandomState(seed=self.shuffle_seed)
self.perm = self.rng.permutation(self.data_length)
def __iter__(self):
return self
def next(self):
return self.get_next_batch()
def get_next_batch(self):
data = self.get_batch(self.curr_batch_num)
self.increment_batch_num()
return data
def increment_batch_num(self):
m = self.total_batches
if (self.curr_batch_num >= m - 1):
self.curr_epoch += 1
if self.shuffle:
self.perm = self.rng.permutation(self.data_length)
self.curr_batch_num = (self.curr_batch_num + 1) % m
def get_batch(self, cbn):
data = {}
startv = cbn * self.batch_size
endv = (cbn + 1) * self.batch_size
if self.pad and endv > self.data_length:
startv = self.data_length - self.batch_size
endv = startv + self.batch_size
for k in self.data_dict:
if self.shuffle:
data[k] = self.data_dict[k][self.perm[startv: endv]]
else:
data[k] = self.data_dict[k][startv: endv]
return data
class TF_Optimizer(object):
"""Make the tensorflow SGD-style optimizer into a scikit-learn compatible class
Uses BatchReader for stochastically getting data batches.
model_func: function which returns tensorflow nodes for
predictions, data_input
loss_func: function which takes model_func prediction output node and
returns tensorflow nodes for
loss, label_input
optimizer_class: which tensorflow optimizer class to when learning the model parameters
batch_size: which batch size to use in training
train_iterations: how many iterations to run the optimizer for
--> this should really be picked automatically by like when the training
error plateaus
model_kwargs: dictionary of additional arguments for the model_func
loss_kwargs: dictionary of additional arguments for the loss_func
optimizer_args, optimizer_kwargs: additional position and keyword args for the
optimizer class
sess: tf session to use (will be constructed if not passed)
train_shuffle: whether to shuffle example order during training
"""
def __init__(self,
model_func,
loss_func,
optimizer_class,
batch_size,
train_iterations,
model_kwargs=None,
loss_kwargs=None,
optimizer_args=(),
optimizer_kwargs=None,
sess=None,
train_shuffle=False
):
self.model_func = model_func
if model_kwargs is None:
model_kwargs = {}
self.model_kwargs = model_kwargs
self.loss_func = loss_func
if loss_kwargs is None:
loss_kwargs = {}
self.loss_kwargs = loss_kwargs
self.train_shuffle=train_shuffle
self.train_iterations = train_iterations
self.batch_size = batch_size
if sess is None:
sess = tf.Session()
self.sess = sess
if optimizer_kwargs is None:
optimizer_kwargs = {}
self.optimizer = optimizer_class(*optimizer_args,
**optimizer_kwargs)
def fit(self, train_data, train_labels):
self.model, self.data_holder = self.model_func(**self.model_kwargs)
self.loss, self.labels_holder = self.loss_func(self.model, **self.loss_kwargs)
self.optimizer_op = self.optimizer.minimize(self.loss)
data_dict = {self.data_holder: train_data,
self.labels_holder: train_labels}
train_data = BatchReader(data_dict=data_dict,
batch_size=self.batch_size,
shuffle=self.train_shuffle,
shuffle_seed=0,
pad=True)
init_op = tf.global_variables_initializer()
sess.run(init_op)
self.losses = []
for i in range(self.train_iterations):
data_batch = train_data.next()
output = self.sess.run({'opt': self.optimizer_op,
'loss': self.loss},
feed_dict=data_batch)
self.losses.append(output['loss'])
def predict(self, test_data):
data_dict = {self.data_holder: test_data}
test_data = BatchReader(data_dict=data_dict,
batch_size=self.batch_size,
shuffle=False,
pad=False)
preds = []
for i in range(test_data.total_batches):
data_batch = test_data.get_batch(i)
pred_batch = self.sess.run(self.model, feed_dict=data_batch)
preds.append(pred_batch)
return np.row_stack(preds)
def binarize_labels(labels):
"""takes discrete-valued labels and binarizes them into {-1, 1}-value format
returns:
binarized_labels: of shape (num_stimuli, num_categories)
unique_labels: actual labels indicating order of first axis in binarized_labels
"""
unique_labels = np.unique(labels)
num_classes = len(unique_labels)
binarized_labels = np.array([2 * (labels == c) - 1 for
c in unique_labels]).T.astype(int)
return binarized_labels, unique_labels
class TF_OVA_Classifier(TF_Optimizer):
"""
Subclass of TFOptimizer for use with categorizers. Basically, this class
handles data binarization (in the fit method) and un-binarization
(in the predict method), so that we can use the class with the function:
train_and_test_scikit_classifier
that we've previously defined.
The predict method here implements a one-vs-all approach for multi-class problems.
"""
def fit(self, train_data, train_labels):
#binarize labels
num_features = train_data.shape[1]
binarized_labels, classes_ = binarize_labels(train_labels)
#set .classes_ attribute, since this is needed by train_and_test_scikit_classifier
self.classes_ = classes_
num_classes = len(classes_)
#pass number of features and classes to the model construction
#function that will be called when the fit method is called
self.model_kwargs['num_features'] = num_features
self.model_kwargs['num_classes'] = num_classes
#now actually call the optimizer fit method
TF_Optimizer.fit(self, train_data=train_data,
train_labels=binarized_labels)
def decision_function(self, test_data):
#returns what are effectively the margins (for a linear classifier)
return TF_Optimizer.predict(self, test_data)
def predict(self, test_data):
#use the one-vs-all rule for multiclass prediction.
preds = self.decision_function(test_data)
preds = np.argmax(preds, axis=1)
classes_ = self.classes_
return classes_[preds]
def linear_classifier(num_features, num_classes):
"""generic form of a linear classifier, e.g. the model
margins = np.dot(data, weight) + bias
"""
initial_weights = tf.zeros(shape=(num_features,
num_classes),
dtype=tf.float32)
weights = tf.Variable(initial_weights,
dtype=tf.float32,
name='weights')
initial_bias = tf.zeros(shape=(num_classes,))
bias = tf.Variable(initial_bias,
dtype=tf.float32,
name='bias')
data = tf.placeholder(shape=(None, num_features), dtype=tf.float32, name='data')
margins = tf.add(tf.matmul(data, weights), bias, name='margins')
return margins, data
def hinge_loss(margins):
"""standard SVM hinge loss
"""
num_classes = margins.shape.as_list()[1]
category_labels = tf.placeholder(shape=(None, num_classes),
dtype=tf.float32,
name='labels')
h = tf.maximum(0., 1. - category_labels * margins, name='hinge_loss')
hinge_loss_mean = tf.reduce_mean(h, name='hinge_loss_mean')
return hinge_loss_mean, category_labels
#construct the classifier instance ... just like with scikit-learn
cls = TF_OVA_Classifier(model_func=linear_classifier,
loss_func=hinge_loss,
batch_size=2500,
train_iterations=1000,
train_shuffle=True,
optimizer_class=tf.train.MomentumOptimizer,
optimizer_kwargs = {'learning_rate':10.,
'momentum': 0.99
},
sess=sess
)
#ok let's try out our classifier on medium-variation data
data_subset = Neural_Data[var_levels=='V3']
categories_subset = categories[var_levels=='V3']
cls.fit(data_subset, categories_subset)
plt.plot(cls.losses)
plt.xlabel('number of iterations')
plt.ylabel('Hinge loss')
#ok how good was the actual training accuracy?
preds = cls.predict(data_subset)
acc = (preds == categories_subset).sum()
pct = acc / float(len(preds)) * 100
print('Training accuracy was %.2f%%' % pct)
```
#### Side note on getting relevant tensors
```
#here's the linear mode constructed above:
lin_model = cls.model
print(lin_model)
#suppose we want to access the weights / bias used in this model?
#these can be accessed by the "op.inputs" attribute in TF
#first, we see that this is the stage of the caluation
#where the linear model (the margins) is put together by adding
#the result of the matrix multiplication ("MatMul_[somenumber]")
#to the bias
list(lin_model.op.inputs)
#so bias is just the first of these inputs
bias_tensor = lin_model.op.inputs[1]
bias_tensor
#if we follow up the calculation graph by taking apart
#whatever was the inputs to the matmul stage, we see
#the data and the weights
matmul_tensor = lin_model.op.inputs[0]
list(matmul_tensor.op.inputs)
#so the weights tensor is just the first of *these* inputs
weights_tensor = matmul_tensor.op.inputs[1]
weights_tensor
#putting this together, we could have done:
weights_tensor = lin_model.op.inputs[0].op.inputs[1]
weights_tensor
```
#### Regularization
```
#we can define other loss functions -- such as L2 regularization
def hinge_loss_l2reg(margins, C, square=False):
#starts off the same as regular hinge loss
num_classes = margins.shape.as_list()[1]
category_labels = tf.placeholder(shape=(None, num_classes),
dtype=tf.float32,
name='labels')
h = tf.maximum(0., 1 - category_labels * margins)
#allows for squaring the hinge_loss optionally, as done in sklearn
if square:
h = h**2
hinge_loss = tf.reduce_mean(h)
#but how let's get the weights from the margins,
#using the method just explored above
weights = margins.op.inputs[0].op.inputs[1]
#and get sum-square of the weights -- the 0.5 is for historical reasons
reg_loss = 0.5*tf.reduce_mean(weights**2)
#total up the loss from the two terms with constant C for weighting
total_loss = C * hinge_loss + reg_loss
return total_loss, category_labels
cls = TF_OVA_Classifier(model_func=linear_classifier,
loss_func=hinge_loss_l2reg,
loss_kwargs={'C':1},
batch_size=2500,
train_iterations=1000,
train_shuffle=True,
optimizer_class=tf.train.MomentumOptimizer,
optimizer_kwargs = {'learning_rate':10.,
'momentum': 0.99
},
sess=sess,
)
data_subset = Neural_Data[var_levels=='V3']
categories_subset = categories[var_levels=='V3']
cls.fit(data_subset, categories_subset)
plt.plot(cls.losses)
plt.xlabel('number of iterations')
plt.ylabel('Regularized Hinge loss')
preds = cls.predict(data_subset)
acc = (preds == categories_subset).sum()
pct = acc / float(len(preds)) * 100
print('Regularized training accuracy was %.2f%%' % pct)
#unsuprisingly training accuracy goes down a bit with regularization
#compared to before w/o regularization
```
### Integrating with cross validation tools
```
import cross_validation as cv
meta_array = np.core.records.fromarrays(Ventral_Dataset['image_meta'].values(),
names=Ventral_Dataset['image_meta'].keys())
#the whole point of creating the TF_OVA_Classifier above
#was that we could simply stick it into the cross-validation regime
#that we'd previously set up for scikit-learn style classifiers
#so now let's test it out
#create some train/test splits
splits = cv.get_splits(meta_array,
lambda x: x['object_name'], #we're balancing splits by object
5,
5,
35,
train_filter=lambda x: (x['variation_level'] == 'V3'),
test_filter=lambda x: (x['variation_level'] == 'V3'),)
#here are the arguments to the classifier
model_args = {'model_func': linear_classifier,
'loss_func': hinge_loss_l2reg,
'loss_kwargs': {'C':5e-2, #<-- a good regularization value
},
'batch_size': 2500,
'train_iterations': 1000, #<-- about the right number of steps
'train_shuffle': True,
'optimizer_class':tf.train.MomentumOptimizer,
'optimizer_kwargs': {'learning_rate':.1,
'momentum': 0.9},
'sess': sess}
#so now it should work just like before
res = cv.train_and_test_scikit_classifier(features=Neural_Data,
labels=categories,
splits=splits,
model_class=TF_OVA_Classifier,
model_args=model_args)
#yep!
res[0]['test']['mean_accuracy']
#### Logistic Regression with Softmax loss
def softmax_loss_l2reg(margins, C):
"""this shows how to write softmax logistic regression
using tensorflow
"""
num_classes = margins.shape.as_list()[1]
category_labels = tf.placeholder(shape=(None, num_classes),
dtype=tf.float32,
name='labels')
#get the softmax from the margins
probs = tf.nn.softmax(margins)
#extract just the prob value for the correct category
#(we have the (cats + 1)/2 thing because the category_labels
#come in as {-1, +1} values but we need {0,1} for this purpose)
probs_cat_vec = probs * ((category_labels + 1.) / 2.)
#sum up over categories (actually only one term, that for
#the correct category, contributes on each row)
probs_cat = tf.reduce_mean(probs_cat_vec, axis=1)
#-log
neglogprob = -tf.log(probs_cat)
#average over the batch
log_loss = tf.reduce_mean(neglogprob)
weights = cls.model.op.inputs[0].op.inputs[1]
reg_loss = 0.5*tf.reduce_mean(tf.square(weights))
total_loss = C * log_loss + reg_loss
return total_loss, category_labels
model_args={'model_func': linear_classifier,
'model_kwargs': {},
'loss_func': softmax_loss_l2reg,
'loss_kwargs': {'C': 5e-3},
'batch_size': 2500,
'train_iterations': 1000,
'train_shuffle': True,
'optimizer_class':tf.train.MomentumOptimizer,
'optimizer_kwargs': {'learning_rate': 1.,
'momentum': 0.9
},
'sess': sess}
res = cv.train_and_test_scikit_classifier(features=Neural_Data,
labels=categories,
splits=splits,
model_class=TF_OVA_Classifier,
model_args=model_args)
res[0]['test']['mean_accuracy']
#ok works reasonably well
```
| true |
code
| 0.766076 | null | null | null | null |
|
## Problem Statement
An experimental drug was tested on 2100 individual in a clinical trial. The ages of participants ranged from thirteen to hundred. Half of the participants were under the age of 65 years old, the other half were 65 years or older.
Ninety five percent patients that were 65 years or older experienced side effects. Ninety five percent patients under 65 years experienced no side effects.
You have to build a program that takes the age of a participant as input and predicts whether this patient has suffered from a side effect or not.
Steps:
• Generate a random dataset that adheres to these statements
• Divide the dataset into Training (90%) and Validation (10%) set
• Build a Simple Sequential Model
• Train and Validate the Model on the dataset
• Randomly choose 20% data from dataset as Test set
• Plot predictions made by the Model on Test set
## Generating Dataset
```
import numpy as np
from random import randint
from sklearn.utils import shuffle
from sklearn.preprocessing import MinMaxScaler
train_labels = [] # one means side effect experienced, zero means no side effect experienced
train_samples = []
for i in range(50):
# The 5% of younger individuals who did experience side effects
random_younger = randint(13, 64)
train_samples.append(random_younger)
train_labels.append(1)
# The 5% of older individuals who did not experience side effects
random_older = randint(65, 100)
train_samples.append(random_older)
train_labels.append(0)
for i in range(1000):
# The 95% of younger individuals who did not experience side effects
random_younger = randint(13, 64)
train_samples.append(random_younger)
train_labels.append(0)
# The 95% of older individuals who did experience side effects
random_older = randint(65, 100)
train_samples.append(random_older)
train_labels.append(1)
train_labels = np.array(train_labels)
train_samples = np.array(train_samples)
train_labels, train_samples = shuffle(train_labels, train_samples) # randomly shuffles each individual array, removing any order imposed on the data set during the creation process
scaler = MinMaxScaler(feature_range = (0, 1)) # specifying scale (range: 0 to 1)
scaled_train_samples = scaler.fit_transform(train_samples.reshape(-1,1)) # transforms our data scale (range: 13 to 100) into the one specified above (range: 0 to 1), we use the reshape fucntion as fit_transform doesnot accept 1-D data by default hence we need to reshape accordingly here
```
## Building a Sequential Model
```
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
model = Sequential([
Dense(units = 16, input_shape = (1,), activation = 'relu'),
Dense(units = 32, activation = 'relu'),
Dense(units = 2, activation = 'softmax')
])
model.summary()
```
## Training the Model
```
model.compile(optimizer = Adam(learning_rate = 0.0001), loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'])
model.fit(x = scaled_train_samples, y = train_labels, validation_split = 0.1, batch_size = 10, epochs = 30, shuffle = True, verbose = 2)
```
## Preprocessing Test Data
```
test_labels = []
test_samples = []
for i in range(10):
# The 5% of younger individuals who did experience side effects
random_younger = randint(13, 64)
test_samples.append(random_younger)
test_labels.append(1)
# The 5% of older individuals who did not experience side effects
random_older = randint(65, 100)
test_samples.append(random_older)
test_labels.append(0)
for i in range(200):
# The 95% of younger individuals who did not experience side effects
random_younger = randint(13, 64)
test_samples.append(random_younger)
test_labels.append(0)
# The 95% of older individuals who did experience side effects
random_older = randint(65, 100)
test_samples.append(random_older)
test_labels.append(1)
test_labels = np.array(test_labels)
test_samples = np.array(test_samples)
test_labels, test_samples = shuffle(test_labels, test_samples)
scaled_test_samples = scaler.fit_transform(test_samples.reshape(-1,1))
```
## Testing the Model using Predictions
```
predictions = model.predict(x = scaled_test_samples, batch_size = 10, verbose = 0)
rounded_predictions = np.argmax(predictions, axis = -1)
```
## Preparing Confusion Matrix
```
from sklearn.metrics import confusion_matrix
import itertools
import matplotlib.pyplot as plt
cm = confusion_matrix(y_true = test_labels, y_pred = rounded_predictions)
# This function has been taken from the website of scikit Learn. link: https://scikit-learn.org/0.18/auto_examples/model_selection/plot_confusion_matrix.html
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
```
## Plotting Predictions using Confusion Matrix
```
cm_plot_labels = ['no_side_effects', 'had_side_effects']
plot_confusion_matrix(cm = cm, classes = cm_plot_labels, title = 'Confusion Matrix')
```
| true |
code
| 0.614568 | null | null | null | null |
|
# Riemannian Optimisation with Pymanopt for Inference in MoG models
The Mixture of Gaussians (MoG) model assumes that datapoints $\mathbf{x}_i\in\mathbb{R}^d$ follow a distribution described by the following probability density function:
$p(\mathbf{x}) = \sum_{m=1}^M \pi_m p_\mathcal{N}(\mathbf{x};\mathbf{\mu}_m,\mathbf{\Sigma}_m)$ where $\pi_m$ is the probability that the data point belongs to the $m^\text{th}$ mixture component and $p_\mathcal{N}(\mathbf{x};\mathbf{\mu}_m,\mathbf{\Sigma}_m)$ is the probability density function of a multivariate Gaussian distribution with mean $\mathbf{\mu}_m \in \mathbb{R}^d$ and psd covariance matrix $\mathbf{\Sigma}_m \in \{\mathbf{M}\in\mathbb{R}^{d\times d}: \mathbf{M}\succeq 0\}$.
As an example consider the mixture of three Gaussians with means
$\mathbf{\mu}_1 = \begin{bmatrix} -4 \\ 1 \end{bmatrix}$,
$\mathbf{\mu}_2 = \begin{bmatrix} 0 \\ 0 \end{bmatrix}$ and
$\mathbf{\mu}_3 = \begin{bmatrix} 2 \\ -1 \end{bmatrix}$, covariances
$\mathbf{\Sigma}_1 = \begin{bmatrix} 3 & 0 \\ 0 & 1 \end{bmatrix}$,
$\mathbf{\Sigma}_2 = \begin{bmatrix} 1 & 1 \\ 1 & 3 \end{bmatrix}$ and
$\mathbf{\Sigma}_3 = \begin{bmatrix} 0.5 & 0 \\ 0 & 0.5 \end{bmatrix}$
and mixture probability vector $\boldsymbol{\pi}=\left[0.1, 0.6, 0.3\right]^\top$.
Let's generate $N=1000$ samples of that MoG model and scatter plot the samples:
```
import autograd.numpy as np
np.set_printoptions(precision=2)
import matplotlib.pyplot as plt
%matplotlib inline
# Number of data points
N = 1000
# Dimension of each data point
D = 2
# Number of clusters
K = 3
pi = [0.1, 0.6, 0.3]
mu = [np.array([-4, 1]), np.array([0, 0]), np.array([2, -1])]
Sigma = [np.array([[3, 0],[0, 1]]), np.array([[1, 1.], [1, 3]]), 0.5 * np.eye(2)]
components = np.random.choice(K, size=N, p=pi)
samples = np.zeros((N, D))
# For each component, generate all needed samples
for k in range(K):
# indices of current component in X
indices = k == components
# number of those occurrences
n_k = indices.sum()
if n_k > 0:
samples[indices, :] = np.random.multivariate_normal(mu[k], Sigma[k], n_k)
colors = ['r', 'g', 'b', 'c', 'm']
for k in range(K):
indices = k == components
plt.scatter(samples[indices, 0], samples[indices, 1], alpha=0.4, color=colors[k%K])
plt.axis('equal')
plt.show()
```
Given a data sample the de facto standard method to infer the parameters is the [expectation maximisation](https://en.wikipedia.org/wiki/Expectation-maximization_algorithm) (EM) algorithm that, in alternating so-called E and M steps, maximises the log-likelihood of the data.
In [arXiv:1506.07677](http://arxiv.org/pdf/1506.07677v1.pdf) Hosseini and Sra propose Riemannian optimisation as a powerful counterpart to EM. Importantly, they introduce a reparameterisation that leaves local optima of the log-likelihood unchanged while resulting in a geodesically convex optimisation problem over a product manifold $\prod_{m=1}^M\mathcal{PD}^{(d+1)\times(d+1)}$ of manifolds of $(d+1)\times(d+1)$ symmetric positive definite matrices.
The proposed method is on par with EM and shows less variability in running times.
The reparameterised optimisation problem for augmented data points $\mathbf{y}_i=[\mathbf{x}_i^\top, 1]^\top$ can be stated as follows:
$$\min_{(\mathbf{S}_1, ..., \mathbf{S}_m, \boldsymbol{\nu}) \in \mathcal{D}}
-\sum_{n=1}^N\log\left(
\sum_{m=1}^M \frac{\exp(\nu_m)}{\sum_{k=1}^M\exp(\nu_k)}
q_\mathcal{N}(\mathbf{y}_n;\mathbf{S}_m)
\right)$$
where
* $\mathcal{D} := \left(\prod_{m=1}^M \mathcal{PD}^{(d+1)\times(d+1)}\right)\times\mathbb{R}^{M-1}$ is the search space
* $\mathcal{PD}^{(d+1)\times(d+1)}$ is the manifold of symmetric positive definite
$(d+1)\times(d+1)$ matrices
* $\mathcal{\nu}_m = \log\left(\frac{\alpha_m}{\alpha_M}\right), \ m=1, ..., M-1$ and $\nu_M=0$
* $q_\mathcal{N}(\mathbf{y}_n;\mathbf{S}_m) =
2\pi\exp\left(\frac{1}{2}\right)
|\operatorname{det}(\mathbf{S}_m)|^{-\frac{1}{2}}(2\pi)^{-\frac{d+1}{2}}
\exp\left(-\frac{1}{2}\mathbf{y}_i^\top\mathbf{S}_m^{-1}\mathbf{y}_i\right)$
**Optimisation problems like this can easily be solved using Pymanopt – even without the need to differentiate the cost function manually!**
So let's infer the parameters of our toy example by Riemannian optimisation using Pymanopt:
```
import sys
sys.path.insert(0,"../..")
import autograd.numpy as np
from autograd.scipy.special import logsumexp
import pymanopt
from pymanopt.manifolds import Product, Euclidean, SymmetricPositiveDefinite
from pymanopt import Problem
from pymanopt.solvers import SteepestDescent
# (1) Instantiate the manifold
manifold = Product([SymmetricPositiveDefinite(D+1, k=K), Euclidean(K-1)])
# (2) Define cost function
# The parameters must be contained in a list theta.
@pymanopt.function.Autograd
def cost(S, v):
# Unpack parameters
nu = np.append(v, 0)
logdetS = np.expand_dims(np.linalg.slogdet(S)[1], 1)
y = np.concatenate([samples.T, np.ones((1, N))], axis=0)
# Calculate log_q
y = np.expand_dims(y, 0)
# 'Probability' of y belonging to each cluster
log_q = -0.5 * (np.sum(y * np.linalg.solve(S, y), axis=1) + logdetS)
alpha = np.exp(nu)
alpha = alpha / np.sum(alpha)
alpha = np.expand_dims(alpha, 1)
loglikvec = logsumexp(np.log(alpha) + log_q, axis=0)
return -np.sum(loglikvec)
problem = Problem(manifold=manifold, cost=cost, verbosity=1)
# (3) Instantiate a Pymanopt solver
solver = SteepestDescent()
# let Pymanopt do the rest
Xopt = solver.solve(problem)
```
Once Pymanopt has finished the optimisation we can obtain the inferred parameters as follows:
```
mu1hat = Xopt[0][0][0:2,2:3]
Sigma1hat = Xopt[0][0][:2, :2] - mu1hat.dot(mu1hat.T)
mu2hat = Xopt[0][1][0:2,2:3]
Sigma2hat = Xopt[0][1][:2, :2] - mu2hat.dot(mu2hat.T)
mu3hat = Xopt[0][2][0:2,2:3]
Sigma3hat = Xopt[0][2][:2, :2] - mu3hat.dot(mu3hat.T)
pihat = np.exp(np.concatenate([Xopt[1], [0]], axis=0))
pihat = pihat / np.sum(pihat)
```
And convince ourselves that the inferred parameters are close to the ground truth parameters.
The ground truth parameters $\mathbf{\mu}_1, \mathbf{\Sigma}_1, \mathbf{\mu}_2, \mathbf{\Sigma}_2, \mathbf{\mu}_3, \mathbf{\Sigma}_3, \pi_1, \pi_2, \pi_3$:
```
print(mu[0])
print(Sigma[0])
print(mu[1])
print(Sigma[1])
print(mu[2])
print(Sigma[2])
print(pi[0])
print(pi[1])
print(pi[2])
```
And the inferred parameters $\hat{\mathbf{\mu}}_1, \hat{\mathbf{\Sigma}}_1, \hat{\mathbf{\mu}}_2, \hat{\mathbf{\Sigma}}_2, \hat{\mathbf{\mu}}_3, \hat{\mathbf{\Sigma}}_3, \hat{\pi}_1, \hat{\pi}_2, \hat{\pi}_3$:
```
print(mu1hat)
print(Sigma1hat)
print(mu2hat)
print(Sigma2hat)
print(mu3hat)
print(Sigma3hat)
print(pihat[0])
print(pihat[1])
print(pihat[2])
```
Et voilà – this was a brief demonstration of how to do inference for MoG models by performing Manifold optimisation using Pymanopt.
## When Things Go Astray
A well-known problem when fitting parameters of a MoG model is that one Gaussian may collapse onto a single data point resulting in singular covariance matrices (cf. e.g. p. 434 in Bishop, C. M. "Pattern Recognition and Machine Learning." 2001). This problem can be avoided by the following heuristic: if a component's covariance matrix is close to being singular we reset its mean and covariance matrix. Using Pymanopt this can be accomplished by using an appropriate line search rule (based on [LineSearchBackTracking](https://github.com/pymanopt/pymanopt/blob/master/pymanopt/solvers/linesearch.py)) -- here we demonstrate this approach:
```
class LineSearchMoG:
"""
Back-tracking line-search that checks for close to singular matrices.
"""
def __init__(self, contraction_factor=.5, optimism=2,
suff_decr=1e-4, maxiter=25, initial_stepsize=1):
self.contraction_factor = contraction_factor
self.optimism = optimism
self.suff_decr = suff_decr
self.maxiter = maxiter
self.initial_stepsize = initial_stepsize
self._oldf0 = None
def search(self, objective, manifold, x, d, f0, df0):
"""
Function to perform backtracking line-search.
Arguments:
- objective
objective function to optimise
- manifold
manifold to optimise over
- x
starting point on the manifold
- d
tangent vector at x (descent direction)
- df0
directional derivative at x along d
Returns:
- stepsize
norm of the vector retracted to reach newx from x
- newx
next iterate suggested by the line-search
"""
# Compute the norm of the search direction
norm_d = manifold.norm(x, d)
if self._oldf0 is not None:
# Pick initial step size based on where we were last time.
alpha = 2 * (f0 - self._oldf0) / df0
# Look a little further
alpha *= self.optimism
else:
alpha = self.initial_stepsize / norm_d
alpha = float(alpha)
# Make the chosen step and compute the cost there.
newx, newf, reset = self._newxnewf(x, alpha * d, objective, manifold)
step_count = 1
# Backtrack while the Armijo criterion is not satisfied
while (newf > f0 + self.suff_decr * alpha * df0 and
step_count <= self.maxiter and
not reset):
# Reduce the step size
alpha = self.contraction_factor * alpha
# and look closer down the line
newx, newf, reset = self._newxnewf(x, alpha * d, objective, manifold)
step_count = step_count + 1
# If we got here without obtaining a decrease, we reject the step.
if newf > f0 and not reset:
alpha = 0
newx = x
stepsize = alpha * norm_d
self._oldf0 = f0
return stepsize, newx
def _newxnewf(self, x, d, objective, manifold):
newx = manifold.retr(x, d)
try:
newf = objective(newx)
except np.linalg.LinAlgError:
replace = np.asarray([np.linalg.matrix_rank(newx[0][k, :, :]) != newx[0][0, :, :].shape[0]
for k in range(newx[0].shape[0])])
x[0][replace, :, :] = manifold.rand()[0][replace, :, :]
return x, objective(x), True
return newx, newf, False
```
| true |
code
| 0.633212 | null | null | null | null |
|
# Programming_Assingment17
```
Question1.
Create a function that takes three arguments a, b, c and returns the sum of the
numbers that are evenly divided by c from the range a, b inclusive.
Examples
evenly_divisible(1, 10, 20) ➞ 0
# No number between 1 and 10 can be evenly divided by 20.
evenly_divisible(1, 10, 2) ➞ 30
# 2 + 4 + 6 + 8 + 10 = 30
evenly_divisible(1, 10, 3) ➞ 18
# 3 + 6 + 9 = 18
def sumDivisibles(a, b, c):
sum = 0
for i in range(a, b + 1):
if (i % c == 0):
sum += i
return sum
a = int(input('Enter a : '))
b = int(input('Enter b : '))
c = int(input('Enter c : '))
print(sumDivisibles(a, b, c))
```
### Question2.
Create a function that returns True if a given inequality expression is correct and
False otherwise.
Examples
correct_signs("3 > 7 < 11") ➞ True
correct_signs("13 > 44 > 33 > 1") ➞ False
correct_signs("1 < 2 < 6 < 9 > 3") ➞ True
```
def correct_signs ( txt ) :
return eval ( txt )
print(correct_signs("3 > 7 < 11"))
print(correct_signs("13 > 44 > 33 > 1"))
print(correct_signs("1 < 2 < 6 < 9 > 3"))
```
### Question3.
Create a function that replaces all the vowels in a string with a specified character.
Examples
replace_vowels('the aardvark, '#') ➞ 'th# ##rdv#rk'
replace_vowels('minnie mouse', '?') ➞ 'm?nn?? m??s?'
replace_vowels('shakespeare', '*') ➞ 'sh*k*sp**r*'
```
def replace_vowels(str, s):
vowels = 'AEIOUaeiou'
for ele in vowels:
str = str.replace(ele, s)
return str
input_str = input("enter a string : ")
s = input("enter a vowel replacing string : ")
print("\nGiven Sting:", input_str)
print("Given Specified Character:", s)
print("Afer replacing vowels with the specified character:",replace_vowels(input_str, s))
```
### Question4.
Write a function that calculates the factorial of a number recursively.
Examples
factorial(5) ➞ 120
factorial(3) ➞ 6
factorial(1) ➞ 1
factorial(0) ➞ 1
```
def factorial(n):
if n == 0:
return 1
return n * factorial(n-1)
num = int(input('enter a number :'))
print("Factorial of", num, "is", factorial(num))
```
### Question 5
Hamming distance is the number of characters that differ between two strings.
To illustrate:
String1: 'abcbba'
String2: 'abcbda'
Hamming Distance: 1 - 'b' vs. 'd' is the only difference.
Create a function that computes the hamming distance between two strings.
Examples
hamming_distance('abcde', 'bcdef') ➞ 5
hamming_distance('abcde', 'abcde') ➞ 0
hamming_distance('strong', 'strung') ➞ 1
```
def hamming_distance(str1, str2):
i = 0
count = 0
while(i < len(str1)):
if(str1[i] != str2[i]):
count += 1
i += 1
return count
# Driver code
str1 = "abcde"
str2 = "bcdef"
# function call
print(hamming_distance(str1, str2))
print(hamming_distance('strong', 'strung'))
hamming_distance('abcde', 'abcde')
```
| true |
code
| 0.550184 | null | null | null | null |
|
# Simulating a Predator and Prey Relationship
Without a predator, rabbits will reproduce until they reach the carrying capacity of the land. When coyotes show up, they will eat the rabbits and reproduce until they can't find enough rabbits. We will explore the fluctuations in the two populations over time.
# Using Lotka-Volterra Model
## Part 1: Rabbits without predators
According to [Mother Earth News](https://www.motherearthnews.com/homesteading-and-livestock/rabbits-on-pasture-intensive-grazing-with-bunnies-zbcz1504), a rabbit eats six square feet of pasture per day. Let's assume that our rabbits live in a five acre clearing in a forest: 217,800 square feet/6 square feet = 36,300 rabbit-days worth of food. For simplicity, let's assume the grass grows back in two months. Thus, the carrying capacity of five acres is 36,300/60 = 605 rabbits.
Female rabbits reproduce about six to seven times per year. They have six to ten children in a litter. According to [Wikipedia](https://en.wikipedia.org/wiki/Rabbit), a wild rabbit reaches sexual maturity when it is about six months old and typically lives one to two years. For simplicity, let's assume that in the presence of unlimited food, a rabbit lives forever, is immediately sexually mature, and has 1.5 children every month.
For our purposes, then, let $x_t$ be the number of rabbits in our five acre clearing on month $t$.
$$
\begin{equation*}
R_t = R_{t-1} + 1.5\frac{605 - R_{t-1}}{605} R_{t-1}
\end{equation*}
$$
The formula could be put into general form
$$
\begin{equation*}
R_t = R_{t-1} + growth_{R} \times \big( \frac{capacity_{R} - R_{t-1}}{capacity_{R}} \big) R_{t-1}
\end{equation*}
$$
By doing this, we allow users to interact with growth rate and the capacity value visualize different interaction
```
from __future__ import print_function
from ipywidgets import interact, interactive, fixed, interact_manual
from IPython.display import display, clear_output
import ipywidgets as widgets
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
style = {'description_width': 'initial'}
capacity_R = widgets.FloatText(description="Capacity", value=605)
growth_rate_R = widgets.FloatText(description="Growth rate", value=1.5)
initial_R = widgets.FloatText(description="Initial population",style=style, value=1)
button_R = widgets.Button(description="Plot Graph")
display(initial_R, capacity_R, growth_rate_R, button_R)
def plot_graph_r(b):
print("helo")
clear_output()
display(initial_R, capacity_R, growth_rate_R, button_R)
fig = plt.figure()
ax = fig.add_subplot(111)
t = np.arange(0, 20, 1)
s = np.zeros(t.shape)
R = initial_R.value
for i in range(t.shape[0]):
s[i] = R
R = R + growth_rate_R.value * (capacity_R.value - R)/(capacity_R.value) * R
if R < 0.0:
R = 0.0
ax.plot(t, s)
ax.set(xlabel='time (months)', ylabel='number of rabbits',
title='Rabbits Without Predators')
ax.grid()
button_R.on_click(plot_graph_r)
```
**Exercise 1** (1 point). Complete the following functions, find the number of rabbits at time 5, given $x_0$ = 10, population capcity =100, and growth rate = 0.8
```
R_i = 10
for i in range(5):
R_i = int(R_i + 0.8 * (100 - R_i)/(100) * R_i)
print(f'There are {R_i} rabbits in the system at time 5')
```
## Tweaking the Growth Function
The growth is regulated by this part of the formula:
$$
\begin{equation*}
\frac{capacity_{R} - R_{t-1}}{capacity_{R}}
\end{equation*}
$$
That is, this fraction (and thus growth) goes to zero when the land is at capacity. As the number of rabbits goes to zero, this fraction goes to 1.0, so growth is at its highest speed. We could substitute in another function that has the same values at zero and at capacity, but has a different shape. For example,
$$
\begin{equation*}
\left( \frac{capacity_{R} - R_{t-1}}{capacity_{R}} \right)^{\beta}
\end{equation*}
$$
where $\beta$ is a positive number. For example, if $\beta$ is 1.3, it indicates that the rabbits can sense that food supplies are dwindling and pre-emptively slow their reproduction.
```
#### %matplotlib inline
import math
style = {'description_width': 'initial'}
capacity_R_2 = widgets.FloatText(description="Capacity", value=605)
growth_rate_R_2 = widgets.FloatText(description="Growth rate", value=1.5)
initial_R_2 = widgets.FloatText(description="Initial population",style=style, value=1)
shaping_R_2 = widgets.FloatText(description="Shaping", value=1.3)
button_R_2 = widgets.Button(description="Plot Graph")
display(initial_R_2, capacity_R_2, growth_rate_R_2, shaping_R_2, button_R_2)
def plot_graph_r(b):
clear_output()
display(initial_R_2, capacity_R_2, growth_rate_R_2, shaping_R_2, button_R_2)
fig = plt.figure()
ax = fig.add_subplot(111)
t = np.arange(0, 20, 1)
s = np.zeros(t.shape)
R = initial_R_2.value
beta = float(shaping_R_2.value)
for i in range(t.shape[0]):
s[i] = R
reserve_ratio = (capacity_R_2.value - R)/capacity_R_2.value
if reserve_ratio > 0.0:
R = R + R * growth_rate_R_2.value * reserve_ratio**beta
else:
R = R - R * growth_rate_R_2.value * (-1.0 * reserve_ratio)**beta
if R < 0.0:
R = 0
ax.plot(t, s)
ax.set(xlabel='time (months)', ylabel='number of rabbits',
title='Rabbits Without Predators (Shaped)')
ax.grid()
button_R_2.on_click(plot_graph_r)
```
**Exercise 2** (1 point). Repeat Exercise 1, with $\beta$ = 1.5 Complete the following functions, find the number of rabbits at time 5. Should we expect to see more rabbits or less?
```
R_i = 10
b=1.5
for i in range(5):
R_i = int(R_i + 0.8 * ((100 - R_i)/(100))**b * R_i)
print(f'There are {R_i} rabbits in the system at time 5, less rabbits compare to exercise 1, where beta = 1')
```
## Part 2: Coyotes without Prey
According to [Huntwise](https://www.besthuntingtimes.com/blog/2020/2/3/why-you-should-coyote-hunt-how-to-get-started), coyotes need to consume about 2-3 pounds of food per day. Their diet is 90 percent mammalian. The perfect adult cottontail rabbits weigh 2.6 pounds on average. Thus, we assume the coyote eats one rabbit per day.
For coyotes, the breeding season is in February and March. According to [Wikipedia](https://en.wikipedia.org/wiki/Coyote#Social_and_reproductive_behaviors), females have a gestation period of 63 days, with an average litter size of 6, though the number fluctuates depending on coyote population density and the abundance of food. By fall, the pups are old enough to hunt for themselves.
In the absence of rabbits, the number of coyotes will drop, as their food supply is scarce.
The formula could be put into general form:
$$
\begin{align*}
C_t & \sim (1 - death_{C}) \times C_{t-1}\\
&= C_{t-1} - death_{C} \times C_{t-1}
\end{align*}
$$
```
%matplotlib inline
style = {'description_width': 'initial'}
initial_C=widgets.FloatText(description="Initial Population",style=style,value=200.0)
declining_rate_C=widgets.FloatText(description="Death rate",value=0.5)
button_C=widgets.Button(description="Plot Graph")
display(initial_C, declining_rate_C, button_C)
def plot_graph_c(b):
clear_output()
display(initial_C, declining_rate_C, button_C)
fig = plt.figure()
ax = fig.add_subplot(111)
t1 = np.arange(0, 20, 1)
s1 = np.zeros(t1.shape)
C = initial_C.value
for i in range(t1.shape[0]):
s1[i] = C
C = (1 - declining_rate_C.value)*C
ax.plot(t1, s1)
ax.set(xlabel='time (months)', ylabel='number of coyotes',
title='Coyotes Without Prey')
ax.grid()
button_C.on_click(plot_graph_c)
```
**Exercise 3** (1 point). Assume the system has 100 coyotes at time 0, the death rate is 0.5 if there are no prey. At what point in time, coyotes become extinct.
```
ti = 0
coyotes_init = 100
c_i = coyotes_init
d_r = 0.5
while c_i > 10:
c_i= int((1 - d_r)*c_i)
ti =ti + 1
print(f'At time t={ti}, the coyotes become extinct')
```
## Part 3: Interaction Between Coyotes and Rabbit
With the simple interaction from the first two parts, now we can combine both interaction and come out with simple interaction.
$$
\begin{align*}
R_t &= R_{t-1} + growth_{R} \times \big( \frac{capacity_{R} - R_{t-1}}{capacity_{R}} \big) R_{t-1} - death_{R}(C_{t-1})\times R_{t-1}\\\\
C_t &= C_{t-1} - death_{C} \times C_{t-1} + growth_{C}(R_{t-1}) \times C_{t-1}
\end{align*}
$$
In equations above, death rate of rabbit is a function parameterized by the amount of coyote. Similarly, the growth rate of coyotes is a function parameterized by the amount of the rabbit.
The death rate of the rabbit should be $0$ if there are no coyotes, while it should approach $1$ if there are many coyotes. One of the formula fulfilling this characteristics is hyperbolic function.
$$
\begin{equation}
death_R(C) = 1 - \frac{1}{xC + 1}
\end{equation}
$$
where $x$ determines how quickly $death_R$ increases as the number of coyotes ($C$) increases. Similarly, the growth rate of the coyotes should be $0$ if there are no rabbits, while it should approach infinity if there are many rabbits. One of the formula fulfilling this characteristics is a linear function.
$$
\begin{equation}
growth_C(R) = yC
\end{equation}
$$
where $y$ determines how quickly $growth_C$ increases as number of rabbit ($R$) increases.
Putting all together, the final equtions are
$$
\begin{align*}
R_t &= R_{t-1} + growth_{R} \times \big( \frac{capacity_{R} - R_{t-1}}{capacity_{R}} \big) R_{t-1} - \big( 1 - \frac{1}{xC_{t-1} + 1} \big)\times R_{t-1}\\\\
C_t &= C_{t-1} - death_{C} \times C_{t-1} + yR_{t-1}C_{t-1}
\end{align*}
$$
**Exercise 4** (3 point). The model we have created above is a variation of the Lotka-Volterra model, which describes various forms of predator-prey interactions. Complete the following functions, which should generate the state variables plotted over time. Blue = prey, Orange = predators.
```
%matplotlib inline
initial_rabbit = widgets.FloatText(description="Initial Rabbit",style=style, value=1)
initial_coyote = widgets.FloatText(description="Initial Coyote",style=style, value=1)
capacity = widgets.FloatText(description="Capacity rabbits", style=style,value=5)
growth_rate = widgets.FloatText(description="Growth rate rabbits", style=style,value=1)
death_rate = widgets.FloatText(description="Death rate coyotes", style=style,value=1)
x = widgets.FloatText(description="Death rate ratio due to coyote",style=style, value=1)
y = widgets.FloatText(description="Growth rate ratio due to rabbit",style=style, value=1)
button = widgets.Button(description="Plot Graph")
display(initial_rabbit, initial_coyote, capacity, growth_rate, death_rate, x, y, button)
def plot_graph(b):
clear_output()
display(initial_rabbit, initial_coyote, capacity, growth_rate, death_rate, x, y, button)
fig = plt.figure()
ax = fig.add_subplot(111)
t = np.arange(0, 20, 0.5)
s = np.zeros(t.shape)
p = np.zeros(t.shape)
R = initial_rabbit.value
C = initial_coyote.value
for i in range(t.shape[0]):
s[i] = R
p[i] = C
R = R + growth_rate.value * (capacity.value - R)/(capacity.value) * R - (1 - 1/(x.value*C + 1))*R
C = C - death_rate.value * C + y.value*s[i]*C
ax.plot(t, s, label="rabit")
ax.plot(t, p, label="coyote")
ax.set(xlabel='time (months)', ylabel='population size',
title='Coyotes-Rabbit (Predator-Prey) Relationship')
ax.grid()
ax.legend()
button.on_click(plot_graph)
```
The system shows an oscillatory behavior. Let's try to verify the nonlinear oscillation in phase space visualization.
## Part 4: Trajectories and Direction Fields for a system of equations
To further demonstrate the predator numbers rise and fall cyclically with their preferred prey, we will be using the Lotka-Volterra equations, which is based on differential equations. The Lotka-Volterra Prey-Predator model involves two equations, one describes the changes in number of preys and the second one decribes the changes in number of predators. The dynamics of the interaction between a rabbit population $R_t$ and a coyotes $C_t$ is described by the following differential equations:
$$
\begin{align*}
\frac{dR}{dt} = aR_t - bR_tC_t
\end{align*}
$$
$$
\begin{align*}
\frac{dC}{dt} = bdR_tC_t - cC_t
\end{align*}
$$
with the following notations:
R$_t$: number of preys(rabbits)
C$_t$: number of predators(coyotes)
a: natural growing rate of rabbits, when there is no coyotes
b: natural dying rate of rabbits, which is killed by coyotes per unit of time
c: natural dying rate of coyotes, when ther is not rabbits
d: natural growing rate of coyotes with which consumed prey is converted to predator
We start from defining the system of ordinary differential equations, and then find the equilibrium points for our system. Equilibrium occurs when the frowth rate is 0, and we can see that we have two equilibrium points in our example, the first one happens when theres no preys or predators, which represents the extinction of both species, the second equilibrium happens when $R_t=\frac{c}{b d}$ $C_t=\frac{a}{b}$. Move on, we will use the scipy to help us integrate the differential equations, and generate the plot of evolution for both species:
**Exercise 5** (3 point). As we can tell from the simulation results of predator-prey model, the system shows an oscillatory behavior. Find the equilibrium points of the system and generate the phase space visualization to demonstrate the oscillation seen previously is nonlinear with distorted orbits.
```
from scipy import integrate
#using the same input number from the previous example
input_a = widgets.FloatText(description="a",style=style, value=1)
input_b = widgets.FloatText(description="b",style=style, value=1)
input_c = widgets.FloatText(description="c",style=style, value=1)
input_d = widgets.FloatText(description="d",style=style, value=1)
# Define the system of ODEs
# P[0] is prey, P[1] is predator
def dP_dt(P,t=0):
return np.array([a*P[0]-b*P[0]*P[1], d*b*P[0]*P[1]-c*P[1]])
button_draw_trajectories = widgets.Button(description="Plot Graph")
display(input_a, input_b, input_c, input_d, button_draw_trajectories)
def plot_trajectories(graph):
global a, b, c, d, eq1, eq2
clear_output()
display(input_a, input_b, input_c, input_d, button_draw_trajectories)
a = input_a.value
b = input_b.value
c = input_c.value
d = input_d.value
# Define the Equilibrium points
eq1 = np.array([0. , 0.])
eq2 = np.array([c/(d*b),a/b])
values = np.linspace(0.1, 3, 10)
# Colors for each trajectory
vcolors = plt.cm.autumn_r(np.linspace(0.1, 1., len(values)))
f = plt.figure(figsize=(10,6))
t = np.linspace(0, 150, 1000)
for v, col in zip(values, vcolors):
# Starting point
P0 = v*eq2
P = integrate.odeint(dP_dt, P0, t)
plt.plot(P[:,0], P[:,1],
lw= 1.5*v, # Different line width for different trajectories
color=col, label='P0=(%.f, %.f)' % ( P0[0], P0[1]) )
ymax = plt.ylim(bottom=0)[1]
xmax = plt.xlim(left=0)[1]
nb_points = 20
x = np.linspace(0, xmax, nb_points)
y = np.linspace(0, ymax, nb_points)
X1,Y1 = np.meshgrid(x, y)
DX1, DY1 = dP_dt([X1, Y1])
M = (np.hypot(DX1, DY1))
M[M == 0] = 1.
DX1 /= M
DY1 /= M
plt.title('Trajectories and direction fields')
Q = plt.quiver(X1, Y1, DX1, DY1, M, pivot='mid', cmap=plt.cm.plasma)
plt.xlabel('Number of rabbits')
plt.ylabel('Number of coyotes')
plt.legend()
plt.grid()
plt.xlim(0, xmax)
plt.ylim(0, ymax)
print(f"\n\nThe equilibrium pointsof the system are:", list(eq1), list(eq2))
plt.show()
button_draw_trajectories.on_click(plot_trajectories)
```
The model here is described in continuous differential equations, thus there is no jump or intersections between the trajectories.
## Part 5: Multiple Predators and Preys Relationship
The previous relationship could be extended to multiple predators and preys relationship
**Exercise 6** (3 point). Develop a discrete-time mathematical model of four species, and each two of them competing for the same resource, and simulate its behavior. Plot the simulation results.
```
%matplotlib inline
initial_rabbit2 = widgets.FloatText(description="Initial Rabbit", style=style,value=2)
initial_coyote2 = widgets.FloatText(description="Initial Coyote",style=style, value=2)
initial_deer2 = widgets.FloatText(description="Initial Deer", style=style,value=1)
initial_wolf2 = widgets.FloatText(description="Initial Wolf", style=style,value=1)
population_capacity = widgets.FloatText(description="capacity",style=style, value=10)
population_capacity_rabbit = widgets.FloatText(description="capacity rabbit",style=style, value=3)
growth_rate_rabbit = widgets.FloatText(description="growth rate rabbit",style=style, value=1)
death_rate_coyote = widgets.FloatText(description="death rate coyote",style=style, value=1)
growth_rate_deer = widgets.FloatText(description="growth rate deer",style=style, value=1)
death_rate_wolf = widgets.FloatText(description="death rate wolf",style=style, value=1)
x1 = widgets.FloatText(description="death rate ratio due to coyote",style=style, value=1)
y1 = widgets.FloatText(description="growth rate ratio due to rabbit", style=style,value=1)
x2 = widgets.FloatText(description="death rate ratio due to wolf",style=style, value=1)
y2 = widgets.FloatText(description="growth rate ratio due to deer", style=style,value=1)
plot2 = widgets.Button(description="Plot Graph")
display(initial_rabbit2, initial_coyote2,initial_deer2, initial_wolf2, population_capacity,
population_capacity_rabbit, growth_rate_rabbit, growth_rate_deer, death_rate_coyote,death_rate_wolf,
x1, y1,x2, y2, plot2)
def plot_graph(b):
clear_output()
display(initial_rabbit2, initial_coyote2,initial_deer2, initial_wolf2, population_capacity,
population_capacity_rabbit, growth_rate_rabbit, growth_rate_deer, death_rate_coyote,death_rate_wolf,
x1, y1,x2, y2, plot2)
fig = plt.figure()
ax = fig.add_subplot(111)
t_m = np.arange(0, 20, 0.5)
r_m = np.zeros(t_m.shape)
c_m = np.zeros(t_m.shape)
d_m = np.zeros(t_m.shape)
w_m = np.zeros(t_m.shape)
R_m = initial_rabbit2.value
C_m = initial_coyote2.value
D_m = initial_deer2.value
W_m = initial_wolf2.value
population_capacity_deer = population_capacity.value - population_capacity_rabbit.value
for i in range(t_m.shape[0]):
r_m[i] = R_m
c_m[i] = C_m
d_m[i] = D_m
w_m[i] = W_m
R_m = R_m + growth_rate_rabbit.value * (population_capacity_rabbit.value - R_m)\
/(population_capacity_rabbit.value) * R_m - (1 - 1/(x1.value*C_m + 1))*R_m - (1 - 1/(x2.value*W_m + 1))*R_m
D_m = D_m + growth_rate_deer.value * (population_capacity_deer - D_m) \
/(population_capacity_deer) * D_m - (1 - 1/(x1.value*C_m + 1))*D_m - (1 - 1/(x2.value*W_m + 1))*D_m
C_m = C_m - death_rate_coyote.value * C_m + y1.value*r_m[i]*C_m + y2.value*d_m[i]*C_m
W_m = W_m - death_rate_wolf.value * W_m + y1.value*r_m[i]*W_m + y2.value*d_m[i]*W_m
ax.plot(t_m, r_m, label="rabit")
ax.plot(t_m, c_m, label="coyote")
ax.plot(t_m, d_m, label="deer")
ax.plot(t_m, w_m, label="wolf")
ax.set(xlabel='time (months)', ylabel='population',
title='Multiple Predator Prey Relationship')
ax.grid()
ax.legend()
plot2.on_click(plot_graph)
```
| true |
code
| 0.723786 | null | null | null | null |
|
## Imports
```
from __future__ import print_function, division
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
import patsy
import seaborn as sns
import matplotlib.pyplot as plt
import scipy.stats as stats
%matplotlib inline
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import RidgeCV
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
from sklearn.pipeline import Pipeline
from sklearn import cross_validation
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNetCV
from sklearn.linear_model import LassoCV
from sklearn.linear_model import RidgeCV
from sklearn.metrics import mean_squared_error as MSE
```
## Reading and preparing the df
```
horsey = pd.read_csv('finalmerged_clean').drop('Unnamed: 0', axis=1)
```
#### Smaller data set (maiden females)
```
MaidenFems = horsey.iloc[42:49]
MaidenFems
```
#### Larger data set (without maiden females)
```
horse_fast = horsey.drop(horsey.index[42:49]).reset_index(drop=True)
horse_fast
horse_fast = horse_fast.drop('Final_Time',1).drop('Horse Name',1)
horse_fast
```
## Splitting into Master Test-Train
```
ttest = horse_fast.iloc[[1,5,10,15,20,25,30,35,40,45,50]].reset_index(drop=True)
ttrain = horse_fast.drop(axis = 0, index = [1,5,10,15,20,25,30,35,40,45,50]).sample(frac=1).reset_index(drop=True)
ttrain
y_ttrain = ttrain['Final_Time_Hund']
y_ttest = ttest['Final_Time_Hund'] #extract dependent variable
X_ttrain = ttrain.drop('Final_Time_Hund',1)
X_ttest = ttest.drop('Final_Time_Hund',1) # Get rid of ind. variables
```
## Testing Assumptions
Didn't complete for sake of time
#### Assumption 1
```
XAssum = X_ttrain
yAssum = y_ttrain
XAssum_train, XAssum_test, yAssum_train, yAssum_test = train_test_split(XAssum, yAssum, test_size=0.2)
def diagnostic_plot(x, y):
plt.figure(figsize=(20,5))
rgr = LinearRegression()
rgr.fit(XAssum_train, yAssum_train)
pred = rgr.predict(XAssum_test, yAssum_test)
#Regression plot
plt.subplot(1, 3, 1)
plt.scatter(XAssum_train,yAssum_train)
plt.plot(XAssum_train, pred, color='blue',linewidth=1)
plt.title("Regression fit")
plt.xlabel("x")
plt.ylabel("y")
#Residual plot (true minus predicted)
plt.subplot(1, 3, 2)
res = yAssum_train - pred
plt.scatter(pred, res)
plt.title("Residual plot")
plt.xlabel("prediction")
plt.ylabel("residuals")
#A Q-Q plot (for the scope of today), it's a percentile, percentile plot. When the predicted and actual distributions
#are the same, they Q-Q plot has a diagonal 45degree line. When stuff diverges, the kertosis between predicted and actual are different,
#your line gets wonky.
plt.subplot(1, 3, 3)
#Generates a probability plot of sample data against the quantiles of a
# specified theoretical distribution
stats.probplot(res, dist="norm", plot=plt)
plt.title("Normal Q-Q plot")
diagnostic_plot(XAssum_train, yAssum_train)
modelA = ElasticNet(1, l1_ratio=.5)
fit = modelA.fit(XAssum_train, yAssum_train)
rsq = fit.score(XAssum_train, yAssum_train)
adj_rsq = 1 - (1-rsq)*(len(yAssum_train)-1)/(len(yAssum_train)-XAssum_train.shape[1]-1)
print(rsq)
print(adj_rsq)
```
#### Assumption 2
```
# develop OLS with Sklearn
X = ttrain[1:]
y = ttrain[0] # predictor
lr = LinearRegression()
fit = lr.fit(X,y)
t['predict']=fit.predict(X)
data['resid']=data.cnt-data.predict
with sns.axes_style('white'):
plot=data.plot(kind='scatter',
x='predict',y='resid',alpha=0.2,figsize=(10,6))
```
## Model 0 - Linear Regression
Working with the training data that doesn't include the maiden-filly race.
```
horsey = ttrain
Xlin = X_ttrain
ylin = y_ttrain
```
#### Regplots
```
sns.regplot('Gender','Final_Time_Hund', data=horsey);
#Makes sense! Male horses tend to be a little faster.
sns.regplot('Firsts','Final_Time_Hund', data=horsey);
#Makes sense! Horses that have won more races tend to be faster.
sns.regplot('Seconds','Final_Time_Hund', data=horsey);
#Similar to the result for "firsts", but slightly less apparent.
sns.regplot('Thirds','Final_Time_Hund', data=horsey);
#Similar to the results above.
sns.regplot('PercentWin','Final_Time_Hund', data=horsey);
#Not a great correlation...
sns.regplot('Starts','Final_Time_Hund', data=horsey);
#This seems pretty uncorrelated...
sns.regplot('Date','Final_Time_Hund', data=horsey);
#Horses with more practice have faster times. But pretty uncorrelated...
sns.regplot('ThreeF','Final_Time_Hund', data=horsey);
#Really no correlation!
sns.regplot('FourF','Final_Time_Hund', data=horsey);
#Huh, not great either.
sns.regplot('FiveF','Final_Time_Hund', data=horsey);
#Slower practice time means slower finaltime. But yeah... pretty uncorrelated...
```
#### Correlations
```
horsey.corr()
%matplotlib inline
import matplotlib
matplotlib.rcParams["figure.figsize"] = (12, 10)
sns.heatmap(horsey.corr(), vmin=-1,vmax=1,annot=True, cmap='seismic');
```
Pretty terrible... but it seems like FiveF, Date, Gender and Percent win are the best... (in that order).
```
sns.pairplot(horsey, size = 1.2, aspect=1.5);
plt.hist(horsey.Final_Time_Hund);
```
#### Linear Regression (All inputs)
```
#Gotta add the constant... without it my r^2 was 1.0!
Xlin = sm.add_constant(Xlin)
#Creating the model
lin_model = sm.OLS(ylin,Xlin)
# Fitting the model to the training set
fit_lin = lin_model.fit()
# Print summary statistics of the model's performance
fit_lin.summary()
```
- r2 could be worse...
- adj r2 also could be worse...
- Inputs that seem significant based on pvalue : Gender... that's about it! The other lowests are Firsts, seconds and date (though they're quite crappy). But I guess if 70% of data lies within the level of confidence... that's better than none...
** TESTING! **
```
Xlin = X_ttrain
ylin = y_ttrain
lr_train = LinearRegression()
lr_fit = lr_train.fit(Xlin, ylin)
r2_training = lr_train.score(Xlin, ylin)
r2adj_training = 1 - (1-r2_training)*(len(ylin)-1)/(len(ylin)-Xlin.shape[1]-1)
preds = lr_fit.predict(X_ttest)
rmse = np.sqrt(MSE(y_ttest, preds))
print('R2:', r2_training)
print('R2 Adjusted:', r2adj_training)
print('Output Predictions', preds)
print('RMSE:', rmse)
```
#### Linear Regression (Updated Inputs)
Below is the best combination of features to drop: Thirds, ThreeF & PrecentWin
```
Xlin2 = Xlin.drop(labels ='Thirds', axis = 1).drop(labels ='ThreeF', axis = 1).drop(labels ='PercentWin', axis = 1)
ylin2 = y_ttrain
#Gotta add the constant... without it my r^2 was 1.0!
Xlin2 = sm.add_constant(Xlin2)
#Creating the model
lin_model = sm.OLS(ylin,Xlin2)
# Fitting the model to the training set
fit_lin = lin_model.fit()
# Print summary statistics of the model's performance
fit_lin.summary()
```
Slightly better...
## Model A - Elastic Net (no frills)
```
## Establishing x and y
XA = X_ttrain
yA = y_ttrain
#Checking the predictability of the model with this alpha = 1
modelA = ElasticNet(1, l1_ratio=.5)
fit = modelA.fit(XA, yA)
rsq = fit.score(XA, yA)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yA)-XA.shape[1]-1)
print(rsq)
print(adj_rsq)
```
** 0.3073 ** not great... but not terrible. 30% of the variance is explained by the model.
```
#Let's see if I play around with the ratios of L1 and L2
modelA = ElasticNet(1, l1_ratio=.2)
fit = modelA.fit(XA, yA)
rsq = fit.score(XA, yA)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yA)-XA.shape[1]-1)
print(rsq)
print(adj_rsq)
```
** Looks slightly worse. I guess there wasn't much need to compress complexity, or fix colinearity. **
```
#Let's check it in the other direction, with L1 getting more weight.
modelA = ElasticNet(1, l1_ratio=.98)
fit = modelA.fit(XA, yA)
rsq = fit.score(XA, yA)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yA)-XA.shape[1]-1)
print(rsq)
print(adj_rsq)
```
** Seems like l1 of 0.98 really takes the cake! Let's check out alpha... Might be worth it to switch to a
Lasso model... something to keep in mind**
```
#Let's see if we can find a better alpha...
kf = KFold(n_splits=5, shuffle = True, random_state = 40 )
alphas = [1e-9,1e-8,1e-7,1e-6,1e-5,1e-4,1e-3,1e-2,1e-1,1,10,100,1000,10000, 100000, 1000000]
#alphas = [0,.001,.01,.1,.2,.5,.9,1,5,10,50,100,1000,10000]
errors = []
for i in alphas:
err_list = []
for train_index, test_index in kf.split(XA):
#print("TRAIN:", train_index, "TEST:", test_index) #This gives the index of the rows you're training and testing.
XA_train, XA_test = XA.loc[train_index], XA.loc[test_index]
yA_train, yA_test = yA[train_index], yA[test_index]
ef = ElasticNet(i, l1_ratio = 0.5)
ef.fit(XA_train,yA_train)
#print(ef.coef_) #This prints the coefficients of each of the input variables.
preds = ef.predict(XA_test) #Predictions for the y value.
error = np.sqrt(MSE(preds,yA_test))
err_list.append(error)
error = np.mean(err_list)
errors.append(error)
print("The RMSE for alpha = {0} is {1}".format(i,error))
```
** Looks like the best alpha is around 1000! Lets see if we can get even more granular. **
```
kf = KFold(n_splits=5, shuffle = True, random_state = 40)
alphas = [500, 600, 800, 900, 1000, 1500, 2000, 3000]
#alphas = [0,.001,.01,.1,.2,.5,.9,1,5,10,50,100,1000,10000]
errors = []
for i in alphas:
err_list = []
for train_index, test_index in kf.split(XA):
#print("TRAIN:", train_index, "TEST:", test_index) #This gives the index of the rows you're training and testing.
XA_train, XA_test = XA.loc[train_index], XA.loc[test_index]
yA_train, yA_test = yA[train_index], yA[test_index]
ef = ElasticNet(i)
ef.fit(XA_train,yA_train)
#print(ef.coef_) #This prints the coefficients of each of the input variables.
preds = ef.predict(XA_test) #Predictions for the y value.
error = np.sqrt(MSE(preds,yA_test))
err_list.append(error)
error = np.mean(err_list)
errors.append(error)
print("The RMSE for alpha = {0} is {1}".format(i,error))
```
** I'm going to settle on an alpha of 800 **
```
#Checking the predictability of the model again with the new alpha of 90.
modelA = ElasticNet(alpha = 800)
fit = modelA.fit(XA, yA)
fit.score(XA, yA)
```
Hm. Not really sure what that did, but definitely didn't work...
** TESTING **
Doing ElasticNetCV (withouth any modifications)
```
## Letting it do it's thing on it's own.
encvA = ElasticNetCV()
fitA = encvA.fit(XA, yA)
r2_training = encvA.score(XA, yA)
y= np.trim_zeros(encvA.fit(XA,yA).coef_)
#r2adj_training = 1 - (1-r2_training)*(XA.shape[1]-1)/(XA.shape[1]-len(y)-1)
adj_rsq = 1 - (1-r2_training)*(len(XA)-1)/(len(XA)-XA.shape[1]-len(y)-1)
preds = fitA.predict(X_ttest)
rmse = np.sqrt(MSE(preds, y_ttest))
print('R2:', r2_training)
print('R2 Adjusted:', adj_rsq)
print('Output Predictions', preds)
print('RMSE:', rmse)
print('Alpha:',encvA.alpha_)
print('L1:',encvA.l1_ratio_)
print('Coefficients:',fitA.coef_)
elastic_coef = encvA.fit(XA, yA).coef_
_ = plt.bar(range(len(XA.columns)), elastic_coef)
_ = plt.xticks(range(len(XA.columns)), XA.columns, rotation=45)
_ = plt.ylabel('Coefficients')
plt.show()
```
Doing ElasticNet CV - changing the l1 ratio
```
encvA2 = ElasticNetCV(l1_ratio = .99)
fitA2 = encvA2.fit(XA, yA)
r2_training = encvA2.score(XA, yA)
y= np.trim_zeros(encvA2.fit(XA,yA).coef_)
adj_rsq = 1 - (1-r2_training)*(len(XA)-1)/(len(XA)-XA.shape[1]-len(y)-1)
preds = fitA2.predict(X_ttest)
rmse = np.sqrt(MSE(y_ttest, preds))
print('R2:', r2_training)
print('R2 Adjusted:', adj_rsq)
print('Output Predictions', preds)
print('RMSE:', rmse)
print('Alpha:',encvA2.alpha_)
print('L1:',encvA2.l1_ratio_)
print('Coefficients:',fitA.coef_)
elastic_coef = encvA2.fit(XA, yA).coef_
_ = plt.bar(range(len(XA.columns)), elastic_coef)
_ = plt.xticks(range(len(XA.columns)), XA.columns, rotation=45)
_ = plt.ylabel('Coefficients')
plt.show()
```
### Extras
```
## L1 is 0.98
encvA2 = ElasticNetCV(l1_ratio = 0.98)
fitA2 = encvA2.fit(XA_train, yA_train)
rsq = fitA2.score(XA_test, yA_test)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yA)-XA.shape[1]-1)
preds = fitA2.predict(XA_test)
mserror = np.sqrt(MSE(preds,yA_test))
print(rsq)
print(adj_rsq)
print(preds)
print(mserror)
print(encvA2.alpha_)
print(encvA2.l1_ratio_)
```
Still weird...
```
## Trying some alphas...
encvA3 = ElasticNetCV(alphas = [80,800,1000])
fitA3 = encvA3.fit(XA_train, yA_train)
rsq = fitA3.score(XA_test, yA_test)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yA)-XA.shape[1]-1)
preds = fitA3.predict(XA_test)
mserror = np.sqrt(MSE(preds,yA_test))
print(rsq)
print(adj_rsq)
print(preds)
print(mserror)
print(encvA3.alpha_)
print(encvA3.l1_ratio_)
```
Still confused...
## Model B - Elastic Net (polynomial transformation)
```
## Establishing x and y
XB = X_ttrain
yB = y_ttrain
ModelB = make_pipeline(PolynomialFeatures(2), LinearRegression())
fit = ModelB.fit(XB, yB)
rsq = fit.score(XB, yB)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yB)-XB.shape[1]-1)
print(rsq)
print(adj_rsq)
ModelB = make_pipeline(PolynomialFeatures(3), ElasticNetCV(l1_ratio = .5))
fit = ModelB.fit(XB, yB)
rsq = fit.score(XB, yB)
adj_rsq = 1 - (1-rsq)*(len(yA)-1)/(len(yB)-XB.shape[1]-1)
print(rsq)
print(adj_rsq)
```
... Hm ... Not great. But we'll test it anyway.
** TESTING **
```
encvB = make_pipeline(PolynomialFeatures(2), LinearRegression())
fitB = encvB.fit(XB, yB)
r2_training = encvB.score(X_ttest, y_ttest)
#y= np.trim_zeros(encvB.fit(XB,yB).coef_)
#r2adj_training = 1 - (1-r2_training)*(XB.shape[1]-1)/(XB.shape[1]-len(y)-1)
preds = fitB.predict(X_ttest)
rmse = np.sqrt(MSE(y_ttest, preds))
print('R2:', r2_training)
print('R2 Adjusted:', r2adj_training)
print('Output Predictions', preds)
print('RMSE:', rmse)
print('Alpha:',encvB_steps.elasticnetcv.alpha_)
print('L1:',encvB.named_steps.elasticnetcv.l1_ratio_)
#Testing the predictability of the model with this alpha = 0.5
XB_train, XB_test, yB_train, yB_test = train_test_split(XB, yB, test_size=0.2)
modelB = make_pipeline(PolynomialFeatures(2), ElasticNetCV(l1_ratio = .5))
modelB.fit(XB_train, yB_train)
rsq = modelB.score(XB_train,yB_train)
adj_rsq = 1 - (1-rsq)*(len(yB_train)-1)/(len(yB_train)-XB_train.shape[1]-1)
preds = fitA3.predict(XB_test)
mserror = np.sqrt(MSE(preds,yB_test))
print(rsq)
print(adj_rsq)
print(preds)
print(mserror)
print(modelB.named_steps.elasticnetcv.alpha_)
print(modelB.named_steps.elasticnetcv.l1_ratio_)
```
## Model C - Elastic Net CV with transformations
On second review, none of the inputs would benefit from transformations
```
C_train = ttrain
C_train['new_firsts_log']=np.log(C_train.Firsts)
C_train
#C_train.new_firsts_log.str.replace('-inf', '0')
```
## Predicting Today's Race!
```
todays_race = pd.read_csv('big_race_day').drop('Unnamed: 0', axis = 1).drop('Horse Name', axis =1)
## today_race acting as testing x
todays_race
```
### Maiden Fems Prediction
```
ym_train = MaidenFems['Final_Time_Hund']
xm_train = MaidenFems.drop('Final_Time_Hund',1).drop('Horse Name',1).drop('Final_Time',1)
enMaid = ElasticNetCV(.90)
fitMaid = enMaid.fit(xm_train, ym_train)
preds = fitMaid.predict(todays_race)
r2_training = enMaid.score(xm_train, ym_train)
y= np.trim_zeros(enMaid.fit(xm_train,ym_train).coef_)
adj_rsq = 1 - (1-r2_training)*(len(xm_train)-1)/(len(xm_train)-xm_train.shape[1]-len(y)-1)
print('Output Predictions', preds)
print('R2:', r2_training)
print('R2 Adjusted:', adj_rsq)
print('Alpha:',enMaid.alpha_)
print('L1:',enMaid.l1_ratio_)
print('Coefficients:',fitMaid.coef_)
elastic_coef = enMaid.fit(xm_train, ym_train).coef_
_ = plt.bar(range(len(xm_train.columns)), elastic_coef)
_ = plt.xticks(range(len(xm_train.columns)), xm_train.columns, rotation=45)
_ = plt.ylabel('Coefficients')
plt.show()
finalguesses_Maiden = [{'Horse Name': 'Lady Lemon Drop' ,'Maiden Horse Guess': 10116.53721999},
{'Horse Name': 'Curlins Prize' ,'Maiden Horse Guess': 10097.09521978},
{'Horse Name': 'Luminoso' ,'Maiden Horse Guess':10063.11500294},
{'Horse Name': 'Party Dancer' ,'Maiden Horse Guess': 10069.32339855},
{'Horse Name': 'Bring on the Band' ,'Maiden Horse Guess': 10054.64900894},
{'Horse Name': 'Rockin Ready' ,'Maiden Horse Guess': 10063.67940254},
{'Horse Name': 'Rattle' ,'Maiden Horse Guess': 10073.93665433},
{'Horse Name': 'Curlins Journey' ,'Maiden Horse Guess': 10072.45966259},
{'Horse Name': 'Heaven Escape' ,'Maiden Horse Guess':10092.43120946}]
```
### EN-CV prediction
```
encvL = ElasticNetCV(l1_ratio = 0.99)
fiten = encvL.fit(X_ttrain, y_ttrain)
preds = fiten.predict(todays_race)
r2_training = encvL.score(X_ttrain, y_ttrain)
y = np.trim_zeros(encvL.fit(X_ttrain,y_ttrain).coef_)
adj_rsq = 1 - (1-r2_training)*(len(X_ttrain)-1)/(len(X_ttrain)-X_ttrain.shape[1]-len(y)-1)
print('Output Predictions', preds)
print('R2:', r2_training)
print('R2 Adjusted:', adj_rsq)
print('Alpha:',encv.alpha_)
print('L1:',encv.l1_ratio_)
print('Coefficients:',fiten.coef_)
elastic_coef = encvL.fit(X_ttrain, y_ttrain).coef_
_ = plt.bar(range(len(X_ttrain.columns)), elastic_coef)
_ = plt.xticks(range(len(X_ttrain.columns)), X_ttrain.columns, rotation=45)
_ = plt.ylabel('Coefficients')
plt.show()
finalguesses_EN = [{'Horse Name': 'Lady Lemon Drop' ,'Guess': 9609.70585871},
{'Horse Name': 'Curlins Prize' ,'Guess': 9645.82659915},
{'Horse Name': 'Luminoso' ,'Guess':9558.93257549},
{'Horse Name': 'Party Dancer' ,'Guess': 9564.01963654},
{'Horse Name': 'Bring on the Band' ,'Guess': 9577.9212198},
{'Horse Name': 'Rockin Ready' ,'Guess': 9556.46879067},
{'Horse Name': 'Rattle' ,'Guess': 9549.09508205},
{'Horse Name': 'Curlins Journey' ,'Guess': 9546.58621572},
{'Horse Name': 'Heaven Escape' ,'Guess':9586.917829}]
```
### Linear Regression prediction
```
Xlin = X_ttrain
ylin = y_ttrain
lr = LinearRegression()
lrfit = lr.fit(Xlin, ylin)
preds = lrfit.predict(todays_race)
r2_training = lr.score(Xlin, ylin)
r2adj_training = 1 - (1-r2_training)*(len(ylin)-1)/(len(ylin)-Xlin.shape[1]-1)
print('Output Predictions', preds)
print('R2:', r2_training)
print('R2 Adjusted:', r2adj_training)
elastic_coef = lrfit.fit(Xlin, ylin).coef_
_ = plt.bar(range(len(Xlin.columns)), elastic_coef)
_ = plt.xticks(range(len(Xlin.columns)), Xlin.columns, rotation=45)
_ = plt.ylabel('Coefficients')
plt.show()
finalguesses_Lin = [{'Horse Name': 'Lady Lemon Drop' ,'Guess': 9720.65585682},
{'Horse Name': 'Curlins Prize' ,'Guess': 9746.17852003},
{'Horse Name': 'Luminoso' ,'Guess':9608.10444379},
{'Horse Name': 'Party Dancer' ,'Guess': 9633.58532183},
{'Horse Name': 'Bring on the Band' ,'Guess': 9621.04698335},
{'Horse Name': 'Rockin Ready' ,'Guess': 9561.82026773},
{'Horse Name': 'Rattle' ,'Guess': 9644.13062968},
{'Horse Name': 'Curlins Journey' ,'Guess': 9666.24092249},
{'Horse Name': 'Heaven Escape' ,'Guess':9700.56665335}]
```
### Setting the data frames
```
GuessLin = pd.DataFrame(finalguesses_Lin)
GuessMaid = pd.DataFrame(finalguesses_Maiden)
GuessEN = pd.DataFrame(finalguesses_EN)
GuessLin.sort_values('Guess')
GuessMaid.sort_values('Maiden Horse Guess')
GuessEN.sort_values('Guess')
```
| true |
code
| 0.737158 | null | null | null | null |
|
```
from sympy import pi, cos, sin, symbols
from sympy.utilities.lambdify import implemented_function
import pytest
from sympde.calculus import grad, dot
from sympde.calculus import laplace
from sympde.topology import ScalarFunctionSpace
from sympde.topology import element_of
from sympde.topology import NormalVector
from sympde.topology import Square
from sympde.topology import Union
from sympde.expr import BilinearForm, LinearForm, integral
from sympde.expr import Norm
from sympde.expr import find, EssentialBC
from sympde.expr.expr import linearize
from psydac.fem.basic import FemField
from psydac.api.discretization import discretize
x,y,z = symbols('x1, x2, x3')
```
# Non-Linear Poisson in 2D
In this section, we consider the non-linear Poisson problem:
$$
-\nabla \cdot \left( (1+u^2) \nabla u \right) = f, \Omega
\\
u = 0, \partial \Omega
$$
where $\Omega$ denotes the unit square.
For testing, we shall take a function $u$ that fulfills the boundary condition, the compute $f$ as
$$
f(x,y) = -\nabla^2 u - F(u)
$$
The weak formulation is
$$
\int_{\Omega} (1+u^2) \nabla u \cdot \nabla v ~ d\Omega = \int_{\Omega} f v ~d\Omega, \quad \forall v \in \mathcal{V}
$$
For the sack of generality, we shall consider the linear form
$$
G(v;u,w) := \int_{\Omega} (1+w^2) \nabla u \cdot \nabla v ~ d\Omega, \quad \forall u,v,w \in \mathcal{V}
$$
Our problem is then
$$
\mbox{Find } u \in \mathcal{V}, \mbox{such that}\\
G(v;u,u) = l(v), \quad \forall v \in \mathcal{V}
$$
where
$$
l(v) := \int_{\Omega} f v ~d\Omega, \quad \forall v \in \mathcal{V}
$$
#### Topological domain
```
domain = Square()
B_dirichlet_0 = domain.boundary
```
#### Function Space
```
V = ScalarFunctionSpace('V', domain)
```
#### Defining the Linear form $G$
```
u = element_of(V, name='u')
v = element_of(V, name='v')
w = element_of(V, name='w')
# Linear form g: V --> R
g = LinearForm(v, integral(domain, (1+w**2)*dot(grad(u), grad(v))))
```
#### Defining the Linear form L
```
solution = sin(pi*x)*sin(pi*y)
f = 2*pi**2*(sin(pi*x)**2*sin(pi*y)**2 + 1)*sin(pi*x)*sin(pi*y) - 2*pi**2*sin(pi*x)**3*sin(pi*y)*cos(pi*y)**2 - 2*pi**2*sin(pi*x)*sin(pi*y)**3*cos(pi*x)**2
# Linear form l: V --> R
l = LinearForm(v, integral(domain, f * v))
```
### Picard Method
$$
\mbox{Find } u_{n+1} \in \mathcal{V}_h, \mbox{such that}\\
G(v;u_{n+1},u_n) = l(v), \quad \forall v \in \mathcal{V}_h
$$
### Newton Method
Let's define
$$
F(v;u) := G(v;u,u) -l(v), \quad \forall v \in \mathcal{V}
$$
Newton method writes
$$
\mbox{Find } u_{n+1} \in \mathcal{V}_h, \mbox{such that}\\
F^{\prime}(\delta u,v; u_n) = - F(v;u_n), \quad \forall v \in \mathcal{V} \\
u_{n+1} := u_{n} + \delta u, \quad \delta u \in \mathcal{V}
$$
#### Computing $F^{\prime}$ the derivative of $F$
**SymPDE** allows you to linearize a linear form and get a bilinear form, using the function **linearize**
```
F = LinearForm(v, g(v,w=u)-l(v))
du = element_of(V, name='du')
Fprime = linearize(F, u, trials=du)
```
## Picard Method
#### Abstract Model
```
un = element_of(V, name='un')
# Bilinear form a: V x V --> R
a = BilinearForm((u, v), g(v, u=u,w=un))
# Dirichlet boundary conditions
bc = [EssentialBC(u, 0, B_dirichlet_0)]
# Variational problem
equation = find(u, forall=v, lhs=a(u, v), rhs=l(v), bc=bc)
# Error norms
error = u - solution
l2norm = Norm(error, domain, kind='l2')
```
#### Discretization
```
# Create computational domain from topological domain
domain_h = discretize(domain, ncells=[16,16], comm=None)
# Discrete spaces
Vh = discretize(V, domain_h, degree=[2,2])
# Discretize equation using Dirichlet bc
equation_h = discretize(equation, domain_h, [Vh, Vh])
# Discretize error norms
l2norm_h = discretize(l2norm, domain_h, Vh)
```
#### Picard solver
```
def picard(niter=10):
Un = FemField( Vh, Vh.vector_space.zeros() )
for i in range(niter):
Un = equation_h.solve(un=Un)
# Compute error norms
l2_error = l2norm_h.assemble(u=Un)
print('l2_error = ', l2_error)
return Un
Un = picard(niter=5)
from matplotlib import pyplot as plt
from utilities.plot import plot_field_2d
nbasis = [w.nbasis for w in Vh.spaces]
p1,p2 = Vh.degree
x = Un.coeffs._data[p1:-p1,p2:-p2]
u = x.reshape(nbasis)
plot_field_2d(Vh.knots, Vh.degree, u) ; plt.colorbar()
```
## Newton Method
#### Abstract Model
```
# Dirichlet boundary conditions
bc = [EssentialBC(du, 0, B_dirichlet_0)]
# Variational problem
equation = find(du, forall=v, lhs=Fprime(du, v,u=un), rhs=-F(v,u=un), bc=bc)
```
#### Discretization
```
# Create computational domain from topological domain
domain_h = discretize(domain, ncells=[16,16], comm=None)
# Discrete spaces
Vh = discretize(V, domain_h, degree=[2,2])
# Discretize equation using Dirichlet bc
equation_h = discretize(equation, domain_h, [Vh, Vh])
# Discretize error norms
l2norm_h = discretize(l2norm, domain_h, Vh)
```
#### Newton Solver
```
def newton(niter=10):
Un = FemField( Vh, Vh.vector_space.zeros() )
for i in range(niter):
delta_x = equation_h.solve(un=Un)
Un = FemField( Vh, delta_x.coeffs + Un.coeffs )
# Compute error norms
l2_error = l2norm_h.assemble(u=Un)
print('l2_error = ', l2_error)
return Un
un = newton(niter=5)
nbasis = [w.nbasis for w in Vh.spaces]
p1,p2 = Vh.degree
x = un.coeffs._data[p1:-p1,p2:-p2]
u = x.reshape(nbasis)
plot_field_2d(Vh.knots, Vh.degree, u) ; plt.colorbar()
```
| true |
code
| 0.679046 | null | null | null | null |
|
# A simple DNN model built in Keras.
Let's start off with the Python imports that we need.
```
import os, json, math
import numpy as np
import shutil
import tensorflow as tf
print(tf.__version__)
```
## Locating the CSV files
We will start with the CSV files that we wrote out in the [first notebook](../01_explore/taxifare.iypnb) of this sequence. Just so you don't have to run the notebook, we saved a copy in ../data
```
!ls -l ../data/*.csv
```
## Use tf.data to read the CSV files
We wrote these cells in the [third notebook](../03_tfdata/input_pipeline.ipynb) of this sequence.
```
CSV_COLUMNS = ['fare_amount', 'pickup_datetime',
'pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude',
'passenger_count', 'key']
LABEL_COLUMN = 'fare_amount'
DEFAULTS = [[0.0],['na'],[0.0],[0.0],[0.0],[0.0],[0.0],['na']]
def features_and_labels(row_data):
for unwanted_col in ['pickup_datetime', 'key']:
row_data.pop(unwanted_col)
label = row_data.pop(LABEL_COLUMN)
return row_data, label # features, label
# load the training data
def load_dataset(pattern, batch_size=1, mode=tf.estimator.ModeKeys.EVAL):
dataset = (tf.data.experimental.make_csv_dataset(pattern, batch_size, CSV_COLUMNS, DEFAULTS)
.map(features_and_labels) # features, label
.cache())
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(1000).repeat()
dataset = dataset.prefetch(1) # take advantage of multi-threading; 1=AUTOTUNE
return dataset
## Build a simple Keras DNN using its Functional API
def rmse(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_pred - y_true)))
def build_dnn_model():
INPUT_COLS = ['pickup_longitude', 'pickup_latitude',
'dropoff_longitude', 'dropoff_latitude',
'passenger_count']
# input layer
inputs = {
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='float32')
for colname in INPUT_COLS
}
feature_columns = {
colname : tf.feature_column.numeric_column(colname)
for colname in INPUT_COLS
}
# the constructor for DenseFeatures takes a list of numeric columns
# The Functional API in Keras requires that you specify: LayerConstructor()(inputs)
dnn_inputs = tf.keras.layers.DenseFeatures(feature_columns.values())(inputs)
# two hidden layers of [32, 8] just in like the BQML DNN
h1 = tf.keras.layers.Dense(32, activation='relu', name='h1')(dnn_inputs)
h2 = tf.keras.layers.Dense(8, activation='relu', name='h2')(h1)
# final output is a linear activation because this is regression
output = tf.keras.layers.Dense(1, activation='linear', name='fare')(h2)
model = tf.keras.models.Model(inputs, output)
model.compile(optimizer='adam', loss='mse', metrics=[rmse, 'mse'])
return model
model = build_dnn_model()
print(model.summary())
tf.keras.utils.plot_model(model, 'dnn_model.png', show_shapes=False, rankdir='LR')
```
## Train model
To train the model, call model.fit()
```
TRAIN_BATCH_SIZE = 32
NUM_TRAIN_EXAMPLES = 10000 * 5 # training dataset repeats, so it will wrap around
NUM_EVALS = 5 # how many times to evaluate
NUM_EVAL_EXAMPLES = 10000 # enough to get a reasonable sample, but not so much that it slows down
trainds = load_dataset('../data/taxi-train*', TRAIN_BATCH_SIZE, tf.estimator.ModeKeys.TRAIN)
evalds = load_dataset('../data/taxi-valid*', 1000, tf.estimator.ModeKeys.EVAL).take(NUM_EVAL_EXAMPLES//1000)
steps_per_epoch = NUM_TRAIN_EXAMPLES // (TRAIN_BATCH_SIZE * NUM_EVALS)
history = model.fit(trainds,
validation_data=evalds,
epochs=NUM_EVALS,
steps_per_epoch=steps_per_epoch)
# plot
import matplotlib.pyplot as plt
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(['loss', 'rmse']):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history['val_{}'.format(key)])
plt.title('model {}'.format(key))
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left');
```
## Predict with model
This is how you'd predict with this model.
```
model.predict({
'pickup_longitude': tf.convert_to_tensor([-73.982683]),
'pickup_latitude': tf.convert_to_tensor([40.742104]),
'dropoff_longitude': tf.convert_to_tensor([-73.983766]),
'dropoff_latitude': tf.convert_to_tensor([40.755174]),
'passenger_count': tf.convert_to_tensor([3.0]),
})
```
Of course, this is not realistic, because we can't expect client code to have a model object in memory. We'll have to export our model to a file, and expect client code to instantiate the model from that exported file.
## Export model
Let's export the model to a TensorFlow SavedModel format. Once we have a model in this format, we have lots of ways to "serve" the model, from a web application, from JavaScript, from mobile applications, etc.
```
# This doesn't work yet.
shutil.rmtree('./export/savedmodel', ignore_errors=True)
tf.keras.experimental.export_saved_model(model, './export/savedmodel')
# Recreate the exact same model
new_model = tf.keras.experimental.load_from_saved_model('./export/savedmodel')
# try predicting with this model
new_model.predict({
'pickup_longitude': tf.convert_to_tensor([-73.982683]),
'pickup_latitude': tf.convert_to_tensor([40.742104]),
'dropoff_longitude': tf.convert_to_tensor([-73.983766]),
'dropoff_latitude': tf.convert_to_tensor([40.755174]),
'passenger_count': tf.convert_to_tensor([3.0]),
})
```
In the next notebook, we will improve this model through feature engineering.
Copyright 2019 Google Inc.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| true |
code
| 0.580233 | null | null | null | null |
|
# Multivariate Dependencies Beyond Shannon Information
This is a companion Jupyter notebook to the work *Multivariate Dependencies Beyond Shannon Information* by Ryan G. James and James P. Crutchfield. This worksheet was written by Ryan G. James. It primarily makes use of the ``dit`` package for information theory calculations.
## Basic Imports
We first import basic functionality. Further functionality will be imported as needed.
```
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from dit import ditParams, Distribution
from dit.distconst import uniform
ditParams['repr.print'] = ditParams['print.exact'] = True
```
## Distributions
Here we define the two distributions to be compared.
```
from dit.example_dists.mdbsi import dyadic, triadic
dists = [('dyadic', dyadic), ('triadic', triadic)]
```
## I-Diagrams and X-Diagrams
Here we construct the I- and X-Diagrams of both distributions. The I-Diagram is constructed by considering how the entropies of each variable interact. The X-Diagram is similar, but considers how the extropies of each variable interact.
```
from dit.profiles import ExtropyPartition, ShannonPartition
def print_partition(dists, partition):
ps = [str(partition(dist)).split('\n') for _, dist in dists ]
print('\t' + '\t\t\t\t'.join(name for name, _ in dists))
for lines in zip(*ps):
print('\t\t'.join(lines))
print_partition(dists, ShannonPartition)
```
Both I-Diagrams are the same. This implies that *no* Shannon measure (entropy, mutual information, conditional mutual information [including the transfer entropy], co-information, etc) can differentiate these patterns of dependency.
```
print_partition(dists, ExtropyPartition)
```
Similarly, the X-Diagrams are identical and so no extropy-based measure can differentiate the distributions.
## Measures of Mutual and Common Information
We now compute several measures of mutual and common information:
```
from prettytable import PrettyTable
from dit.multivariate import (entropy,
coinformation,
total_correlation,
dual_total_correlation,
independent_information,
caekl_mutual_information,
interaction_information,
intrinsic_total_correlation,
gk_common_information,
wyner_common_information,
exact_common_information,
functional_common_information,
mss_common_information,
tse_complexity,
)
from dit.other import (extropy,
disequilibrium,
perplexity,
LMPR_complexity,
renyi_entropy,
tsallis_entropy,
)
def print_table(title, table, dists):
pt = PrettyTable(field_names = [''] + [name for name, _ in table])
for name, _ in table:
pt.float_format[name] = ' 5.{0}'.format(3)
for name, dist in dists:
pt.add_row([name] + [measure(dist) for _, measure in table])
print("\n{}".format(title))
print(pt.get_string())
```
### Entropies
Entropies generally capture the uncertainty contained in a distribution. Here, we compute the Shannon entropy, the Renyi entropy of order 2 (also known as the collision entropy), and the Tsallis entropy of order 2. Though we only compute the order 2 values, any order will produce values identical for both distributions.
```
entropies = [('H', entropy),
('Renyi (α=2)', lambda d: renyi_entropy(d, 2)),
('Tsallis (q=2)', lambda d: tsallis_entropy(d, 2)),
]
print_table('Entropies', entropies, dists)
```
The entropies for both distributions are indentical. This is not surprising: they have the same probability mass function.
### Mutual Informations
Mutual informations are multivariate generalizations of the standard Shannon mutual information. By far, the most widely used (and often simply assumed to be the only) generalization is the total correlation, sometimes called the multi-information. It is defined as:
$$
T[\mathbf{X}] = \sum H[X_i] - H[\mathbf{X}] = \sum p(\mathbf{x}) \log_2 \frac{p(\mathbf{x})}{p(x_1)p(x_2)\ldots p(x_n)}
$$
Other generalizations exist, though, including the co-information, the dual total correlation, and the CAEKL mutual information.
```
mutual_informations = [('I', coinformation),
('T', total_correlation),
('B', dual_total_correlation),
('J', caekl_mutual_information),
('II', interaction_information),
]
print_table('Mutual Informations', mutual_informations, dists)
```
The equivalence of all these generalizations is not surprising: Each of them can be defined as a function of the I-diagram, and so must be identical here.
### Common Informations
Common informations are generally defined using an auxilliary random variable which captures some amount of information shared by the variables of interest. For all but the Gács-Körner common information, that shared information is the dual total correlation.
```
common_informations = [('K', gk_common_information),
('C', lambda d: wyner_common_information(d, niter=1, polish=False)),
('G', lambda d: exact_common_information(d, niter=1, polish=False)),
('F', functional_common_information),
('M', mss_common_information),
]
print_table('Common Informations', common_informations, dists)
```
As it turns out, only the Gács-Körner common information, `K`, distinguishes the two.
### Other Measures
Here we list a variety of other information measures.
```
other_measures = [('IMI', lambda d: intrinsic_total_correlation(d, d.rvs[:-1], d.rvs[-1])),
('X', extropy),
('R', independent_information),
('P', perplexity),
('D', disequilibrium),
('LMRP', LMPR_complexity),
('TSE', tse_complexity),
]
print_table('Other Measures', other_measures, dists)
```
Several other measures fail to differentiate our two distributions. For many of these (`X`, `P`, `D`, `LMRP`) this is because they are defined relative to the probability mass function. For the others, it is due to the equality of the I-diagrams. Only the intrinsic mutual information, `IMI`, can distinguish the two.
## Information Profiles
Lastly, we consider several "profiles" of the information.
```
from dit.profiles import *
def plot_profile(dists, profile):
n = len(dists)
plt.figure(figsize=(8*n, 6))
ent = max(entropy(dist) for _, dist in dists)
for i, (name, dist) in enumerate(dists):
ax = plt.subplot(1, n, i+1)
profile(dist).draw(ax=ax)
if profile not in [EntropyTriangle, EntropyTriangle2]:
ax.set_ylim((-0.1, ent + 0.1))
ax.set_title(name)
```
### Complexity Profile
```
plot_profile(dists, ComplexityProfile)
```
Once again, these two profiles are identical due to the I-Diagrams being identical. The complexity profile incorrectly suggests that there is no information at the scale of 3 variables.
### Marginal Utility of Information
```
plot_profile(dists, MUIProfile)
```
The marginal utility of information is based on a linear programming problem with constrains related to values from the I-Diagram, and so here again the two distributions are undifferentiated.
### Connected Informations
```
plot_profile(dists, SchneidmanProfile)
```
The connected informations are based on differences between maximum entropy distributions with differing $k$-way marginal distributions fixed. Here, the two distributions are differentiated
### Multivariate Entropy Triangle
```
plot_profile(dists, EntropyTriangle)
```
Both distributions are at an idential location in the multivariate entropy triangle.
## Partial Information
We next consider a variety of partial information decompositions.
```
from dit.pid.helpers import compare_measures
for name, dist in dists:
compare_measures(dist, name=name)
```
Here we see that the PID determines that in dyadic distribution two random variables uniquely contribute a bit of information to the third, whereas in the triadic distribution two random variables redundantly influene the third with one bit, and synergistically with another.
## Multivariate Extensions
```
from itertools import product
outcomes_a = [
(0,0,0,0),
(0,2,3,2),
(1,0,2,1),
(1,2,1,3),
(2,1,3,3),
(2,3,0,1),
(3,1,1,2),
(3,3,2,0),
]
outcomes_b = [
(0,0,0,0),
(0,0,1,1),
(0,1,0,1),
(0,1,1,0),
(1,0,0,1),
(1,0,1,0),
(1,1,0,0),
(1,1,1,1),
]
outcomes = [ tuple([2*a+b for a, b in zip(a_, b_)]) for a_, b_ in product(outcomes_a, outcomes_b) ]
quadradic = uniform(outcomes)
dyadic2 = uniform([(4*a+2*c+e, 4*a+2*d+f, 4*b+2*c+f, 4*b+2*d+e) for a, b, c, d, e, f in product([0,1], repeat=6)])
dists2 = [('dyadic2', dyadic2), ('quadradic', quadradic)]
print_partition(dists2, ShannonPartition)
print_partition(dists2, ExtropyPartition)
print_table('Entropies', entropies, dists2)
print_table('Mutual Informations', mutual_informations, dists2)
print_table('Common Informations', common_informations, dists2)
print_table('Other Measures', other_measures, dists2)
plot_profile(dists2, ComplexityProfile)
plot_profile(dists2, MUIProfile)
plot_profile(dists2, SchneidmanProfile)
plot_profile(dists2, EntropyTriangle)
```
| true |
code
| 0.445107 | null | null | null | null |
|
```
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from nn_interpretability.interpretation.lrp.lrp_0 import LRP0
from nn_interpretability.interpretation.lrp.lrp_eps import LRPEpsilon
from nn_interpretability.interpretation.lrp.lrp_gamma import LRPGamma
from nn_interpretability.interpretation.lrp.lrp_ab import LRPAlphaBeta
from nn_interpretability.interpretation.lrp.lrp_composite import LRPMix
from nn_interpretability.model.model_trainer import ModelTrainer
from nn_interpretability.model.model_repository import ModelRepository
from nn_interpretability.visualization.mnist_visualizer import MnistVisualizer
from nn_interpretability.dataset.mnist_data_loader import MnistDataLoader
model_name = 'model_cnn.pt'
train = False
mnist_data_loader = MnistDataLoader()
MnistVisualizer.show_dataset_examples(mnist_data_loader.trainloader)
model = ModelRepository.get_general_mnist_cnn(model_name)
if train:
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0005)
model.train()
ModelTrainer.train(model, criterion, optimizer, mnist_data_loader.trainloader)
ModelRepository.save(model, model_name)
```
# I. LRP-0
```
images = []
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRP0(model, target_class, transforms, visualize_layer)
interpretor = LRP0(model, i, None, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
## Comparison between LRP gradient and LRP convolution transpose implementation
For **convolution layers** there is no difference, we will obtain the same numerical results with either approach. However, for **pooling layers** the result from convolution transpose approach is **4^(n)** as large as for those from gradient approach, where n is the number of pooling layers. The reason is because in every average unpooling operation, s will be unpooled directly without multiplying any scaling factor. For gradient approach, every input activation influence the output equally therefore the gradient for every activation entrices is 0.25. The operation is an analog of first unpooling and then multiplying a scale of 0.25 to s.
The gradient approach will be more reasonable to the equation described in Montavon's paper. As we treat pooling layers like convolutional layers, the scaling factor 0.25 from pooling should be considered in the steps that we multiply weights in convolutional layers (step1 and step3).
# II. LRP-ε
```
images = []
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRPEpsilon(model, target_class, transforms, visualize_layer)
interpretor = LRPEpsilon(model, i, None, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
# III. LRP- γ
```
images = []
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRPGamma(model, target_class, transforms, visualize_layer)
interpretor = LRPGamma(model, i, None, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
# IV. LRP-αβ
## 1. LPP-α1β0
```
images = []
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRPAlphaBeta(model, target_class, transforms, alpha, beta, visualize_layer)
interpretor = LRPAlphaBeta(model, i, None, 1, 0, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
## 2. LPP-α2β1
```
images = []
img_shape = (28, 28)
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRPAlphaBeta(model, target_class, transforms, alpha, beta, visualize_layer)
interpretor = LRPAlphaBeta(model, i, None, 2, 1, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
# IV. Composite LRP
```
images = []
img_shape = (28, 28)
for i in range(10):
img = mnist_data_loader.get_image_for_class(i)
# LRPMix(model, target_class, transforms, alpha, beta, visualize_layer)
interpretor = LRPMix(model, i, None, 1, 0, 0)
endpoint = interpretor.interpret(img)
images.append(endpoint[0].detach().cpu().numpy().sum(axis=0))
MnistVisualizer.display_heatmap_for_each_class(images)
```
| true |
code
| 0.642825 | null | null | null | null |
|
# Project 1: Linear Regression Model
This is the first project of our data science fundamentals. This project is designed to solidify your understanding of the concepts we have learned in Regression and to test your knowledge on regression modelling. There are four main objectives of this project.
1\. Build Linear Regression Models
* Use closed form solution to estimate parameters
* Use packages of choice to estimate parameters<br>
2\. Model Performance Assessment
* Provide an analytical rationale with choice of model
* Visualize the Model performance
* MSE, R-Squared, Train and Test Error <br>
3\. Model Interpretation
* Intepret the results of your model
* Intepret the model assement <br>
4\. Model Dianostics
* Does the model meet the regression assumptions
#### About this Notebook
1\. This notebook should guide you through this project and provide started code
2\. The dataset used is the housing dataset from Seattle homes
3\. Feel free to consult online resources when stuck or discuss with data science team members
Let's get started.
### Packages
Importing the necessary packages for the analysis
```
# Necessary Packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Model and data preprocessing
from sklearn import linear_model
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.feature_selection import RFE
from sklearn import preprocessing
%matplotlib inline
```
Now that you have imported your packages, let's read the data that we are going to be using. The dataset provided is a titled *housing_data.csv* and contains housing prices and information about the features of the houses. Below, read the data into a variable and visualize the top 8 rows of the data.
```
# Initiliazing seed
np.random.seed(42)
data1 = pd.read_csv('housing_data.csv')
data = pd.read_csv('housing_data_2.csv')
data.head(8)
```
### Split data into train and test
In the code below, we need to split the data into the train and test for modeling and validation of our models. We will cover the Train/Validation/Test as we go along in the project. Fill the following code.
1\. Subset the features to the variable: features <br>
2\. Subset the target variable: target <br>
3\. Set the test size in proportion in to a variable: test_size <br>
```
features = data[['lot_area', 'firstfloor_sqft', 'living_area', 'bath', 'garage_area', 'price']]
target = data['price']
test_size = .33
x_train, x_test, y_train, y_test = train_test_split(features, target, test_size=test_size, random_state=42)
```
### Data Visualization
The best way to explore the data we have is to build some plots that can help us determine the relationship of the data. We can use a scatter matrix to explore all our variables. Below is some starter code to build the scatter matrix
```
features = pd.plotting.scatter_matrix(x_train, figsize=(14,8), alpha=1, diagonal='kde')
#columns = pd.plotting.scatter_matrix(columns, figsize=(14,8), alpha=1, diagonal='kde')
```
Based on the scatter matrix above, write a brief description of what you observe. In thinking about the description, think about the relationship and whether linear regression is an appropriate choice for modelling this data.
#### a. lot_area
My initial intutions tell me that lot_area would be the best indicator of price; that being said, there is a weak correlation between lot_area and the other features, which is a good sign! However, the distribution is dramatically skewed-right indicating that the mean lot_area is greater than the median. This tells me that lot_area stays around the same size while price increases. In turn, that tells me that some other feature is helping determine the price bceause if lot_area we're determining the increase in price, we'd see a linear distribution. In determining the best feature for my linear regression model, I think lot_area may be one of the least fitting to use.
#### b. firstfloor_sqft
There is a stronger correlation between firstfloor_sqft and the other features. The distrubution is still skewed-right making the median a better measure of center. firstfloor_sqft would be a good candidate for the linear regression model becuse of the stronger correlation and wider distribution; however, there appears to be a overly strong, linear correlation between firstfloor_sqft and living_area. Given that this linear correlation goes against the Regression Assumption that "all inputs are linearly independent," I would not consider using both in my model. I could, however, use one or the other.
#### c. living_area
There is a similarly strong correlation between living_area (as compared to firstfloor_sqft) and the other features, but these plots are better distributed than firstfloor_sqft. A right skew still exists, but less so than the firstfloor_sqft. However, the observation of a strong, linear correlation between firstfloor_sqft and living_area (or living_area and firstfloor_sqft) is reinforced here. Thus, I would not use both of these in my final model and having to choose between the two, I will likely choose living_area since it appears to be more well-distributed.
#### d. bath
Baths are static numbers, so the plots are much less distributed; however, the length and the clustering of the bath to living_area & bath to garage_area may indicate a correlation. Since I cannot use both living_area and firstfloor_sqft, and I think living_area has a better distribution, I would consider using bath in conjunction with living_area.
#### e. garage_area
Garage_area appears to be well-distributed with the lowest correlation between the other features. This could make it a great fit for the final regression model. It's also the least skewed right distribution.
#### Correlation Matrix
In the code below, compute the correlation matrix and write a few thoughts about the observations. In doing so, consider the interplay in the features and how their correlation may affect your modeling.
The correlation matrix below is in-line with my thought process. Lot_area has the lowest correlation between it and the other features, but it's not well distributed. firstfloor_sqft has a strong correlation between it and living_area. Given that the correlation is just over 0.5, both features may be able to be used in the model given that the correlation isn't overly strong; however, to be most accurate, I plan to leave out one of them (likely firstfloor_sqft). living_area also reflects this strong correlation between it and firstfloor_sqft. Surprisingly, there is a strong correlation between living_area and bath. Looking solely at the scatter matrix, I did not see this strong correlation. This changes my approach slighltly, which I will outline below. garage_area, again, has the lowest correlations while being the most well-distributed.
#### Approach
Given this new correlation information, I will approach the regression model in one of the following ways:
1. Leave out bath as a feature and use living_area + garage_area.
2. Swap firstfloor_sqft for living_area and include bath + garage area.
#### Conclusion
I'm not 100% sure if more features are better than less in this situation; however, I am sure that I want linearly independet features.
```
# Use pandas correlation function
x_train.corr(method='pearson').style.format("{:.2}").background_gradient(cmap=plt.get_cmap('coolwarm'), axis=1)
```
## 1. Build Your Model
Now that we have explored the data at a high level, let's build our model. From our sessions, we have discussed both closed form solution, gradient descent and using packages. In this section you will create your own estimators. Starter code is provided to makes this easier.
#### 1.1. Closed Form Solution
Recall: <br>
$$\beta_0 = \bar {y} - \beta_1 \bar{x}$$ <br>
$$\beta_1 = \frac {cov(x, y)} {var(x)}$$ <br>
Below, let's define functions that will compute these parameters
```
# Pass the necessary arguments in the function to calculate the coefficients
def compute_estimators(feature, target):
n1 = np.sum(feature*target) - np.mean(target)*np.sum(feature)
d1 = np.sum(feature*feature) - np.mean(feature)*np.sum(feature)
# Compute the Intercept and Slope
beta1 = n1/d1
beta0 = np.mean(target) - beta1*np.mean(feature)
return beta0, beta1 # Return the Intercept and Slope
```
Run the compute estimators function above and display the estimated coefficients for any of the predictors/input variables.
```
# Remember to pass the correct arguments
x_array = np.array(data1['living_area'])
normalized_X = preprocessing.normalize([x_array])
beta0, beta1 = compute_estimators(normalized_X, data1['price'])
print(beta0, beta1)
#### Computing coefficients for our model by hand using the actual mathematical equations
#y = beta1x + beta0
#print(y)
```
#### 1.2. sklearn solution
Now that we know how to compute the estimators, let's leverage the sklearn module to compute the metrics for us. We have already imported the linear model, let's initialize the model and compute the coefficients for the model with the input above.
```
# Initilize the linear Regression model here
model = linear_model.LinearRegression()
# Pass in the correct inputs
model.fit(data1[['living_area']], data1['price'])
# Print the coefficients
print("This is beta0:", model.intercept_)
print("This is beta1:", model.coef_)
#### Computing coefficients for our model using the sklearn package
```
Do the results from the cell above and your implementation match? They should be very close to each other.
#### Yes!! They match!
### 2. Model Evaluation
Now that we have estimated our single model. We are going to compute the coefficients for all the inputs. We can use a for loop for multiple model estimation. However, we need to create a few functions:
1\. Prediction function: Functions to compute the predictions <br>
2\. MSE: Function to compute Mean Square Error <br>
```
#Function that computes predictions of our model using the betas above + the feature data we've been using
def model_predictions(intercept, slope, feature):
""" Compute Model Predictions """
y_hat = intercept+(slope*feature)
return y_hat
y_hat = model_predictions(beta0, beta1, data1['living_area'])
#Function to compute MSE which determines the total loss for each predicted data point in our model
def mean_square_error(y_outcome, predictions):
""" Compute the mean square error """
mse = (np.sum((y_outcome - predictions) ** 2))/np.size(predictions)
return mse
mse = mean_square_error(target, y_hat)
print(mse)
```
The last function we need is a plotting function to visualize our predictions relative to our data.
```
#Function used to plot the data
def plotting_model(feature, target, predictions, name):
""" Create a scatter and predictions """
fig = plt.figure(figsize=(10,8))
plot_model = model.fit(feature, target)
plt.scatter(x=feature, y=target, color='blue')
plt.plot(feature, predictions, color='red')
plt.xlabel(name)
plt.ylabel('Price')
return model
model = plotting_model(data1[['living_area']], data1['price'], y_hat, data1['living_area'].name)
```
## Considerations/Reasoning
#### Data Integrity
After my inital linear model based on the feature "living area," I've eliminated 8 data points. If you look at the graph above, there are 4 outliers that are clear, and at least 4 others that follow a similar trend based on the x, y relationship. I used ~3500 sqft of living area as my cutoff for being not predictive of the model, and any price above 600000. Given the way these data points skew the above model, they intuitively appear to be outliers with high leverage. I determined this by comparing these high leverag points with points similar to it in someway and determined whether it was an outlier (i.e. if point A's price was abnormally high, I found a point (B) with living area at or close to point A's living area and compared the price. vice versa if living area was abnormally high).
#### Inital Feature Analysis - "Best" Feature (a priori)
Living area is the best metric to use to train the linear model because it incorporates multiple of the other features within it: first floor living space & bath. Living area has a high correlation with both first floor sq ft (0.53) and baths (0.63). Based on the other correlations, these are the two highest, and thus should immediately be eliminated. Additionally, based on initial intuition, one would assume that an increase in the metric "firstfloor sqft" will lead to an increase in the "living area" metric; if both firstfloor sqft and overall living area are increased, the "bath" metric will likely also increase to accommodate the additional living area/sqft in a home. Thus, I will not need to use them in my model because these can be accurately represented by the feature "living area."
### Single Feature Assessment
```
#Running each feature through to determine which has best linear fit
features = data[['living_area', 'garage_area', 'lot_area', 'firstfloor_sqft', 'bath']]
count = 0
for feature in features:
feature = features.iloc[:, count]
# Compute the Coefficients
beta0, beta1 = compute_estimators(feature, target)
count+=1
# Print the Intercept and Slope
print(feature.name)
print('beta0:', beta0)
print('beta1:', beta1)
# Compute the Train and Test Predictions
y_hat = model_predictions(beta0, beta1, feature)
# Plot the Model Scatter
name = feature.name
model = plotting_model(feature.values.reshape(-1, 1), target, y_hat, name)
# Compute the MSE
mse = mean_square_error(target, y_hat)
print('mean squared error:', mse)
print()
```
#### Analysis of Feature Linear Models
After eliminating these 8 data points, MSE for Living Area drop significantly from 8957196059.803959 to 2815789647.7664313. In fact, Living Area has the lowest MSE 2815789647.7664313 of all the individual models, and the best linear fit.
Garage Area is the next lowest MSE 3466639234.8407283, and the model is mostly linear; however, the bottom left of the model is concerning. You'll notice that a large number of data points go vertically upward indicating an increase in price with 0 garage area. That says to me that garage area isn't predicting the price of these homes, which indicates that it may be a good feature to use in conjunction with another feature (i.e. Living Area) or since those data points do not fit in with the rest of the population, they may need to be removed.
#### Run Model Assessment
Now that we have our functions ready, we can build individual models, compute preductions, plot our model results and determine our MSE. Notice that we compute our MSE on the test set and not the train set
### Dot Product (multiple feature) Assessment
```
#Models Living Area alone and compares it to the Dot Product of Living Area with each other feature
##Determining if a MLR would be a better way to visualize the data
features = data[['living_area', 'garage_area', 'lot_area', 'firstfloor_sqft', 'bath']]
count = 0
for feature in features:
feature = features.iloc[:, count]
#print(feature.head(0))
if feature.name == 'living_area':
x = data['living_area']
else:
x = feature * data['living_area']
# Compute the Coefficients
beta0, beta1 = compute_estimators(x, target)
# Print the Intercept and Slope
if feature.name == 'living_area':
print('living_area')
print('beta0:', beta0)
print('beta1:', beta1)
else:
print(feature.name, "* living_area")
print('beta0:', beta0)
print('beta1:', beta1)
# Compute the Train and Test Predictions
y_hat = model_predictions(beta0, beta1, x)
# Plot the Model Scatter
if feature.name == 'living_area':
name = 'living_area'
else:
name = feature.name + " " + "* living_area"
model = plotting_model(x.values.reshape(-1, 1), target, y_hat, name)
# Compute the MSE
mse = mean_square_error(target, y_hat)
print('mean squared error:', mse)
print()
count+=1
```
## Analysis
Based on the models, it appears that two of the dot products provide a more accurate model:
1. Living Area * First Floor SqFt
2. Living Area * Garage Area
These two dot products provide a lower MSE and thus lowers the loss per prediction point.
#1.
My intuition says that since Living Area, as a feature, will include First Floor SqFt in its data. The FirstFloor SqFt can be captured by Living Area, so it can be left out. Additionally, since one is included within the other, we cannot say anything in particular about Living Area or FirstFloor SqFt individually. Also, the correlation (Ln 24 & Out 24) between Living Area and FirstFloor SqFt is 0.53, which is the highest apart from Bath. This correlation is low in comparison to the "standard;" however, that standard is arbitrary. I've lowered it to be in context with data sets I'm working with in this notebook.
#2.
The dot product of Living Area & Garage Area provides doesn't allow us to make a statement about each individually, unless we provide a model of each, which I will do below. This dot product is a better model. Garage Area is advertised as 'bonus' space and CANNOT be included in the overall square footage of the home (i.e. living area). Thus, garage area vector will not be included as an implication within the living area vector making them linearly independent.
Garage Area can be a sought after feature depending on a buyer's desired lifestlye; more garage space would be sought after by buyers with more cars, which allows us to draw a couple possible inferences about the buyers:
1. enough net worth/monthly to make payments on multiple vehicles plus make payments on a house/garage
2. enough disposable income to outright buy multiple vehicles plus make payments on a house/garage
Additionally, it stands to reason that garage area would scale with living area for pragmatic reasons (more living area implies more people and potentially more vehicles) and for aesthetic reasons (more living area makes home look larger and would need larger garage).
Homes with more living area and garage area may be sought after by buyers with the ability to spend more on a home, and thus the market would bear a higher price for those homes, which helps explain why living area * garage area is a better indicator of home price.
#### Conclusion
Combining living area with other features lowered the MSE for each. The lowest MSE is living area * garage area, which confirms my hypothesis: Living Area is the best feature to predict price, and garage area is good when used in conjunction.
```
#Modeling Living Area & Garage Area separately.
features = data[['living_area', 'garage_area']]
count = 0
for feature in features:
feature = features.iloc[:, count]
if feature.name == 'living_area':
x = data['living_area']
elif feature.name == 'garage_area':
x = data['garage_area']
beta0, beta1 = compute_estimators(x, target)
count+=1
if feature.name == 'living_area':
print('living_area')
print('beta0:', beta0)
print('beta1:', beta1)
elif feature.name == 'garage_area':
print('garage_area')
print('beta0:', beta0)
print('beta1:', beta1)
y_hat = model_predictions(beta0, beta1, x)
if feature.name == 'living_area':
name = 'living_area'
elif feature.name == 'garage_area':
name = 'garage_area'
model = plotting_model(x.values.reshape(-1, 1), target, y_hat, name)
mse = mean_square_error(target, y_hat)
print('mean squared error:', mse)
print()
#Modeling dot product of Living Area * Garage Area
features = data[['living_area']]
x = features.iloc[:, 0]
x2 = x * data['garage_area']
#x3 = x2 * data['bath']
# Compute the Coefficients
beta0, beta1 = compute_estimators(x2, target)
# Print the Intercept and Slope
print('Name: garage_area * living_area')
print('beta0:', beta0)
print('beta1:', beta1)
# Compute the Train and Test Predictions
y_hat_1 = model_predictions(beta0, beta1, x2)
# Plot the Model Scatter
name = 'garage_area * living_area'
model = plotting_model(x2.values.reshape(-1, 1), target, y_hat_1, name)
# Compute the MSE
mse = mean_square_error(target, y_hat_1)
print('mean squared error:', mse)
print()
```
## Reasoning
Above, I modeled both living area and garage area by themselves then the dot product of Living Area * Garage Area to highlight the MSE of each vs. the MSE of the dot product. Garage Area, much more so than Living Area, has a high MSE indicating that on its own, Garage Area isn't the best predictor of a home's price; we must take the data in context with reality, and intuitively speaking, one wouldn't assume that the garage area, on its own, would be a feature indicative of price.
This fact combined with the assumption/implication that garage may scale with living area implies some correlation between the features, which would go against the linear assumption of feature independence. As a matter of fact, there is a correlation between them (Ln 24 & Out 24) of 0.44; however, this isn't problematic for two reasons:
1. 0.44 is quite low in regard to typical correlation standards.
2. Data must be seen in context.
#1.
Although I eliminated First Floor SqFt due, in part, to a high correlation and that correclation is only 0.09 points lower. The main reason why First Floor SqFt is eliminated is due to its inclusion within the living area vector. Additionally, the main reason why I'm including garage area is because it is not included with the living area vector.
#2.
Similar to my #1 explanation, knowing that garage area is 'bonus space' and, as such, is NOT included in a home's advertised square feet indicates that it isn't within the Living Area data set in the same way FF SqFt or Baths would be. It will most likely to scale with the living area independently of the living area making it a good fit for a MLR.
### 3. Model Interpretation
Now that you have calculated all the individual models in the dataset, provide an analytics rationale for which model has performed best. To provide some additional assessment metrics, let's create a function to compute the R-Squared.
#### Mathematically:
$$R^2 = \frac {SS_{Regression}}{SS_{Total}} = 1 - \frac {SS_{Error}}{SS_{Total}}$$<br>
where:<br>
$SS_{Regression} = \sum (\widehat {y_i} - \bar {y_i})^2$<br>
$SS_{Total} = \sum ({y_i} - \bar {y_i})^2$<br>
$SS_{Error} = \sum ({y_i} - \widehat {y_i})^2$
```
#ssr = sum of squares of regression --> variance of prediction from the mean
#sst = sum of squares total --> variance of the actuals from the prediction
#sse = sume of squares error --> variance of the atuals from the mean
def r_squared(y_outcome, predictions):
""" Compute the R Squared """
ssr = np.sum((predictions - np.mean(y_outcome))**2)
sst = np.sum((y_outcome - np.mean(y_outcome))**2)
sse = np.sum((y_outcome - predictions)**2)
# print(sse, "/", sst)
print("1 - SSE/SST =", round((1 - (sse/sst))*100), "%")
rss = (ssr/sst) * 100
return rss
```
Now that you we have R Squared calculated, evaluate the R Squared for the test group across all models and determine what model explains the data best.
```
rss = r_squared(target, y_hat_1)
print("R-Squared =", round(rss), "%")
count += 1
```
### R-Squared Adjusted
$R^2-adjusted = 1 - \frac {(1-R^2)(n-1)}{n-k-1}$
```
def r_squared_adjusted(rss, sample_size, regressors):
n = np.size(sample_size)
k = regressors
numerator = (1-rss)*(n)
denominator = n-k-1
rssAdj = 1 - (numerator / denominator)
return rssAdj
rssAdj = r_squared_adjusted(rss, y_hat_1, 2)
print(round(rssAdj), "%")
```
### 4. Model Diagnostics
Linear regressions depends on meetings assumption in the model. While we have not yet talked about the assumptions, you goal is to research and develop an intuitive understanding of why the assumptions make sense. We will walk through this portion on Multiple Linear Regression Project
| true |
code
| 0.631708 | null | null | null | null |
|
[SCEC BP3-QD](https://strike.scec.org/cvws/seas/download/SEAS_BP3.pdf) document is here.
# [DRAFT] Quasidynamic thrust fault earthquake cycles (plane strain)
## Summary
* Most of the code here follows almost exactly from [the previous section on strike-slip/antiplane earthquake cycles](c1qbx/part6_qd).
* Since the fault motion is in the same plane as the fault normal vectors, we are no longer operating in an antiplane approximation. Instead, we use plane strain elasticity, a different 2D reduction of full 3D elasticity.
* One key difference is the vector nature of the displacement and the tensor nature of the stress. We must always make sure we are dealing with tractions on the correct surface.
* We construct a mesh, build our discrete boundary integral operators, step through time and then compare against other benchmark participants' results.
Does this section need detailed explanation or is it best left as lonely code? Most of the explanation would be redundant with the antiplane QD document.
```
from tectosaur2.nb_config import setup
setup()
import sympy as sp
import numpy as np
import matplotlib.pyplot as plt
from tectosaur2 import gauss_rule, refine_surfaces, integrate_term, panelize_symbolic_surface
from tectosaur2.elastic2d import elastic_t, elastic_h
from tectosaur2.rate_state import MaterialProps, qd_equation, solve_friction, aging_law
surf_half_L = 1000000
fault_length = 40000
max_panel_length = 400
n_fault = 400
mu = shear_modulus = 3.2e10
nu = 0.25
quad_rule = gauss_rule(6)
sp_t = sp.var("t")
angle_rad = sp.pi / 6
sp_x = (sp_t + 1) / 2 * sp.cos(angle_rad) * fault_length
sp_y = -(sp_t + 1) / 2 * sp.sin(angle_rad) * fault_length
fault = panelize_symbolic_surface(
sp_t, sp_x, sp_y,
quad_rule,
n_panels=n_fault
)
free = refine_surfaces(
[
(sp_t, -sp_t * surf_half_L, 0 * sp_t) # free surface
],
quad_rule,
control_points = [
# nearfield surface panels and fault panels will be limited to 200m
# at 200m per panel, we have ~40m per solution node because the panels
# have 5 nodes each
(0, 0, 1.5 * fault_length, max_panel_length),
(0, 0, 0.2 * fault_length, 1.5 * fault_length / (n_fault)),
# farfield panels will be limited to 200000 m per panel at most
(0, 0, surf_half_L, 50000),
]
)
print(
f"The free surface mesh has {free.n_panels} panels with a total of {free.n_pts} points."
)
print(
f"The fault mesh has {fault.n_panels} panels with a total of {fault.n_pts} points."
)
plt.plot(free.pts[:,0]/1000, free.pts[:,1]/1000, 'k-o')
plt.plot(fault.pts[:,0]/1000, fault.pts[:,1]/1000, 'r-o')
plt.xlabel(r'$x ~ \mathrm{(km)}$')
plt.ylabel(r'$y ~ \mathrm{(km)}$')
plt.axis('scaled')
plt.xlim([-100, 100])
plt.ylim([-80, 20])
plt.show()
```
And, to start off the integration, we'll construct the operators necessary for solving for free surface displacement from fault slip.
```
singularities = np.array(
[
[-surf_half_L, 0],
[surf_half_L, 0],
[0, 0],
[float(sp_x.subs(sp_t,1)), float(sp_y.subs(sp_t,1))],
]
)
(free_disp_to_free_disp, fault_slip_to_free_disp), report = integrate_term(
elastic_t(nu), free.pts, free, fault, singularities=singularities, safety_mode=True, return_report=True
)
fault_slip_to_free_disp = fault_slip_to_free_disp.reshape((-1, 2 * fault.n_pts))
free_disp_to_free_disp = free_disp_to_free_disp.reshape((-1, 2 * free.n_pts))
free_disp_solve_mat = (
np.eye(free_disp_to_free_disp.shape[0]) + free_disp_to_free_disp
)
from tectosaur2.elastic2d import ElasticH
(free_disp_to_fault_stress, fault_slip_to_fault_stress), report = integrate_term(
ElasticH(nu, d_cutoff=8.0),
# elastic_h(nu),
fault.pts,
free,
fault,
tol=1e-12,
safety_mode=True,
singularities=singularities,
return_report=True,
)
fault_slip_to_fault_stress *= shear_modulus
free_disp_to_fault_stress *= shear_modulus
```
**We're not achieving the tolerance we asked for!!**
Hypersingular integrals can be tricky but I think this is solvable.
```
report['integration_error'].max()
A = -fault_slip_to_fault_stress.reshape((-1, 2 * fault.n_pts))
B = -free_disp_to_fault_stress.reshape((-1, 2 * free.n_pts))
C = fault_slip_to_free_disp
Dinv = np.linalg.inv(free_disp_solve_mat)
total_fault_slip_to_fault_stress = A - B.dot(Dinv.dot(C))
nx = fault.normals[:, 0]
ny = fault.normals[:, 1]
normal_mult = np.transpose(np.array([[nx, 0 * nx, ny], [0 * nx, ny, nx]]), (2, 0, 1))
total_fault_slip_to_fault_traction = np.sum(
total_fault_slip_to_fault_stress.reshape((-1, 3, fault.n_pts, 2))[:, None, :, :, :]
* normal_mult[:, :, :, None, None],
axis=2,
).reshape((-1, 2 * fault.n_pts))
```
## Rate and state friction
```
siay = 31556952 # seconds in a year
density = 2670 # rock density (kg/m^3)
cs = np.sqrt(shear_modulus / density) # Shear wave speed (m/s)
Vp = 1e-9 # Rate of plate motion
sigma_n0 = 50e6 # Normal stress (Pa)
# parameters describing "a", the coefficient of the direct velocity strengthening effect
a0 = 0.01
amax = 0.025
H = 15000
h = 3000
fx = fault.pts[:, 0]
fy = fault.pts[:, 1]
fd = -np.sqrt(fx ** 2 + fy ** 2)
a = np.where(
fd > -H, a0, np.where(fd > -(H + h), a0 + (amax - a0) * (fd + H) / -h, amax)
)
mp = MaterialProps(a=a, b=0.015, Dc=0.008, f0=0.6, V0=1e-6, eta=shear_modulus / (2 * cs))
plt.figure(figsize=(3, 5))
plt.plot(mp.a, fd/1000, label='a')
plt.plot(np.full(fy.shape[0], mp.b), fd/1000, label='b')
plt.xlim([0, 0.03])
plt.ylabel('depth')
plt.legend()
plt.show()
mesh_L = np.max(np.abs(np.diff(fd)))
Lb = shear_modulus * mp.Dc / (sigma_n0 * mp.b)
hstar = (np.pi * shear_modulus * mp.Dc) / (sigma_n0 * (mp.b - mp.a))
mesh_L, Lb, np.min(hstar[hstar > 0])
```
## Quasidynamic earthquake cycle derivatives
```
from scipy.optimize import fsolve
import copy
init_state_scalar = fsolve(lambda S: aging_law(mp, Vp, S), 0.7)[0]
mp_amax = copy.copy(mp)
mp_amax.a=amax
tau_amax = -qd_equation(mp_amax, sigma_n0, 0, Vp, init_state_scalar)
init_state = np.log((2*mp.V0/Vp)*np.sinh((tau_amax - mp.eta*Vp) / (mp.a*sigma_n0))) * mp.a
init_tau = np.full(fault.n_pts, tau_amax)
init_sigma = np.full(fault.n_pts, sigma_n0)
init_slip_deficit = np.zeros(fault.n_pts)
init_conditions = np.concatenate((init_slip_deficit, init_state))
class SystemState:
V_old = np.full(fault.n_pts, Vp)
state = None
def calc(self, t, y, verbose=False):
# Separate the slip_deficit and state sub components of the
# time integration state.
slip_deficit = y[: init_slip_deficit.shape[0]]
state = y[init_slip_deficit.shape[0] :]
# If the state values are bad, then the adaptive integrator probably
# took a bad step.
if np.any((state < 0) | (state > 2.0)):
print("bad state")
return False
# The big three lines solving for quasistatic shear stress, slip rate
# and state evolution
sd_vector = np.stack((slip_deficit * -ny, slip_deficit * nx), axis=1).ravel()
traction = total_fault_slip_to_fault_traction.dot(sd_vector).reshape((-1, 2))
delta_sigma_qs = np.sum(traction * np.stack((nx, ny), axis=1), axis=1)
delta_tau_qs = -np.sum(traction * np.stack((-ny, nx), axis=1), axis=1)
tau_qs = init_tau + delta_tau_qs
sigma_qs = init_sigma + delta_sigma_qs
V = solve_friction(mp, sigma_qs, tau_qs, self.V_old, state)
if not V[2]:
print("convergence failed")
return False
V=V[0]
if not np.all(np.isfinite(V)):
print("infinite V")
return False
dstatedt = aging_law(mp, V, state)
self.V_old = V
slip_deficit_rate = Vp - V
out = (
slip_deficit,
state,
delta_sigma_qs,
sigma_qs,
delta_tau_qs,
tau_qs,
V,
slip_deficit_rate,
dstatedt,
)
self.data = out
return self.data
def plot_system_state(t, SS, xlim=None):
"""This is just a helper function that creates some rough plots of the
current state to help with debugging"""
(
slip_deficit,
state,
delta_sigma_qs,
sigma_qs,
delta_tau_qs,
tau_qs,
V,
slip_deficit_rate,
dstatedt,
) = SS
slip = Vp * t - slip_deficit
fd = -np.linalg.norm(fault.pts, axis=1)
plt.figure(figsize=(15, 9))
plt.suptitle(f"t={t/siay}")
plt.subplot(3, 3, 1)
plt.title("slip")
plt.plot(fd, slip)
plt.xlim(xlim)
plt.subplot(3, 3, 2)
plt.title("slip deficit")
plt.plot(fd, slip_deficit)
plt.xlim(xlim)
# plt.subplot(3, 3, 2)
# plt.title("slip deficit rate")
# plt.plot(fd, slip_deficit_rate)
# plt.xlim(xlim)
# plt.subplot(3, 3, 2)
# plt.title("strength")
# plt.plot(fd, tau_qs/sigma_qs)
# plt.xlim(xlim)
plt.subplot(3, 3, 3)
# plt.title("log V")
# plt.plot(fd, np.log10(V))
plt.title("V")
plt.plot(fd, V)
plt.xlim(xlim)
plt.subplot(3, 3, 4)
plt.title(r"$\sigma_{qs}$")
plt.plot(fd, sigma_qs)
plt.xlim(xlim)
plt.subplot(3, 3, 5)
plt.title(r"$\tau_{qs}$")
plt.plot(fd, tau_qs, 'k-o')
plt.xlim(xlim)
plt.subplot(3, 3, 6)
plt.title("state")
plt.plot(fd, state)
plt.xlim(xlim)
plt.subplot(3, 3, 7)
plt.title(r"$\Delta\sigma_{qs}$")
plt.plot(fd, delta_sigma_qs)
plt.hlines([0], [fd[-1]], [fd[0]])
plt.xlim(xlim)
plt.subplot(3, 3, 8)
plt.title(r"$\Delta\tau_{qs}$")
plt.plot(fd, delta_tau_qs)
plt.hlines([0], [fd[-1]], [fd[0]])
plt.xlim(xlim)
plt.subplot(3, 3, 9)
plt.title("dstatedt")
plt.plot(fd, dstatedt)
plt.xlim(xlim)
plt.tight_layout()
plt.show()
def calc_derivatives(state, t, y):
"""
This helper function calculates the system state and then extracts the
relevant derivatives that the integrator needs. It also intentionally
returns infinite derivatives when the `y` vector provided by the integrator
is invalid.
"""
if not np.all(np.isfinite(y)):
return np.inf * y
state_vecs = state.calc(t, y)
if not state_vecs:
return np.inf * y
derivatives = np.concatenate((state_vecs[-2], state_vecs[-1]))
return derivatives
```
## Integrating through time
```
%%time
from scipy.integrate import RK23, RK45
# We use a 5th order adaptive Runge Kutta method and pass the derivative function to it
# the relative tolerance will be 1e-11 to make sure that even
state = SystemState()
derivs = lambda t, y: calc_derivatives(state, t, y)
integrator = RK45
atol = Vp * 1e-6
rtol = 1e-11
rk = integrator(derivs, 0, init_conditions, 1e50, atol=atol, rtol=rtol)
# Set the initial time step to one day.
rk.h_abs = 60 * 60 * 24
# Integrate for 1000 years.
max_T = 1000 * siay
n_steps = 500000
t_history = [0]
y_history = [init_conditions.copy()]
for i in range(n_steps):
# Take a time step and store the result
if rk.step() != None:
raise Exception("TIME STEPPING FAILED")
t_history.append(rk.t)
y_history.append(rk.y.copy())
# Print the time every 5000 steps
if i % 5000 == 0:
print(f"step={i}, time={rk.t / siay} yrs, step={(rk.t - t_history[-2]) / siay}")
if rk.t > max_T:
break
y_history = np.array(y_history)
t_history = np.array(t_history)
```
## Plotting the results
Now that we've solved for 1000 years of fault slip evolution, let's plot some of the results. I'll start with a super simple plot of the maximum log slip rate over time.
```
derivs_history = np.diff(y_history, axis=0) / np.diff(t_history)[:, None]
max_vel = np.max(np.abs(derivs_history), axis=1)
plt.plot(t_history[1:] / siay, np.log10(max_vel))
plt.xlabel('$t ~~ \mathrm{(yrs)}$')
plt.ylabel('$\log_{10}(V)$')
plt.show()
```
And next, we'll make the classic plot showing the spatial distribution of slip over time:
- the blue lines show interseismic slip evolution and are plotted every fifteen years
- the red lines show evolution during rupture every three seconds.
```
plt.figure(figsize=(10, 4))
last_plt_t = -1000
last_plt_slip = init_slip_deficit
event_times = []
for i in range(len(y_history) - 1):
y = y_history[i]
t = t_history[i]
slip_deficit = y[: init_slip_deficit.shape[0]]
should_plot = False
# Plot a red line every three second if the slip rate is over 0.1 mm/s.
if (
max_vel[i] >= 0.0001 and t - last_plt_t > 3
):
if len(event_times) == 0 or t - event_times[-1] > siay:
event_times.append(t)
should_plot = True
color = "r"
# Plot a blue line every fifteen years during the interseismic period
if t - last_plt_t > 15 * siay:
should_plot = True
color = "b"
if should_plot:
# Convert from slip deficit to slip:
slip = -slip_deficit + Vp * t
plt.plot(slip, fd / 1000.0, color + "-", linewidth=0.5)
last_plt_t = t
last_plt_slip = slip
plt.xlim([0, np.max(last_plt_slip)])
plt.ylim([-40, 0])
plt.ylabel(r"$\textrm{z (km)}$")
plt.xlabel(r"$\textrm{slip (m)}$")
plt.tight_layout()
plt.savefig("halfspace.png", dpi=300)
plt.show()
```
And a plot of recurrence interval:
```
plt.title("Recurrence interval")
plt.plot(np.diff(event_times) / siay, "k-*")
plt.xticks(np.arange(0, 10, 1))
plt.yticks(np.arange(75, 80, 0.5))
plt.xlabel("Event number")
plt.ylabel("Time between events (yr)")
plt.show()
```
## Comparison against SCEC SEAS results
```
ozawa_data = np.loadtxt("ozawa7500.txt")
ozawa_slip_rate = 10 ** ozawa_data[:, 2]
ozawa_stress = ozawa_data[:, 3]
t_start_idx = np.argmax(max_vel > 1e-4)
t_end_idx = np.argmax(max_vel[t_start_idx:] < 1e-6)
n_steps = t_end_idx - t_start_idx
t_chunk = t_history[t_start_idx : t_end_idx]
shear_chunk = []
slip_rate_chunk = []
for i in range(n_steps):
system_state = SystemState().calc(t_history[t_start_idx + i], y_history[t_start_idx + i])
slip_deficit, state, delta_sigma_qs, sigma_qs, delta_tau_qs, tau_qs, V, slip_deficit_rate, dstatedt = system_state
shear_chunk.append((tau_qs - mp.eta * V))
slip_rate_chunk.append(V)
shear_chunk = np.array(shear_chunk)
slip_rate_chunk = np.array(slip_rate_chunk)
fault_idx = np.argmax((-7450 > fd) & (fd > -7550))
VAvg = np.mean(slip_rate_chunk[:, fault_idx:(fault_idx+2)], axis=1)
SAvg = np.mean(shear_chunk[:, fault_idx:(fault_idx+2)], axis=1)
fault_idx
t_align = t_chunk[np.argmax(VAvg > 0.2)]
ozawa_t_align = np.argmax(ozawa_slip_rate > 0.2)
for lims in [(-1, 1), (-15, 30)]:
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
plt.plot(t_chunk - t_align, SAvg / 1e6, "k-o", markersize=0.5, linewidth=0.5, label='here')
plt.plot(
ozawa_data[:, 0] - ozawa_data[ozawa_t_align, 0],
ozawa_stress,
"b-*",
markersize=0.5,
linewidth=0.5,
label='ozawa'
)
plt.legend()
plt.xlim(lims)
plt.xlabel("Time (s)")
plt.ylabel("Shear Stress (MPa)")
# plt.show()
plt.subplot(2, 1, 2)
plt.plot(t_chunk - t_align, VAvg, "k-o", markersize=0.5, linewidth=0.5, label='here')
plt.plot(
ozawa_data[:, 0] - ozawa_data[ozawa_t_align, 0],
ozawa_slip_rate[:],
"b-*",
markersize=0.5,
linewidth=0.5,
label='ozawa'
)
plt.legend()
plt.xlim(lims)
plt.xlabel("Time (s)")
plt.ylabel("Slip rate (m/s)")
plt.tight_layout()
plt.show()
```
| true |
code
| 0.591959 | null | null | null | null |
|
# BLU02 - Learning Notebook - Data wrangling workflows - Part 2 of 3
```
import matplotlib.pyplot as plt
import pandas as pd
import os
```
# 2 Combining dataframes in Pandas
## 2.1 How many programs are there per season?
How many different programs does the NYP typically present per season?
Programs are under `/data/programs/` which contains a file per Season.
### Concatenate
To analyze how many programs there are per season, over time, we need a single dataframe containing *all* seasons.
Concatenation means, in short, to unite multiple dataframes (or series) in one.
The `pd.concat()` function performs concatenation operations along an axis (`axis=0` for index and `axis=1` for columns).
```
season_0 = pd.read_csv('./data/programs/1842-43.csv')
season_1 = pd.read_csv('./data/programs/1843-44.csv')
seasons = [season_0, season_1]
pd.concat(seasons, axis=1)
```
Concatenating like this makes no sense, as we no longer have a single observation per row.
What we want to do instead is to concatenate the dataframe along the index.
```
pd.concat(seasons, axis=0)
```
This dataframe looks better, but there's something weird with the index: it's not unique anymore.
Different observations share the same index. Not cool.
For dataframes that don't have a meaningful index, you may wish to ignore the indexes altogether.
```
pd.concat(seasons, axis=0, ignore_index=True)
```
Now, let's try something different.
Let's try to change the name of the columns, so that each dataframe has different ones, before concatenating.
```
season_0_ = season_0.copy()
season_0_.columns = [0, 1, 2, 'Season']
seasons_ = [season_0_, season_1]
pd.concat(seasons_, axis=0)
```
What a mess! What did we learn?
* When the dataframes have different columns, `pd.concat()` will take the union of all dataframes by default (no information loss)
* Concatenation will fill columns that are not present for specific dataframes with `np.NaN` (missing values).
The good news is that you can set how you want to glue the dataframes in regards to the other axis, the one not being concatenated.
Setting `join='inner'` will take the intersection, i.e., the columns that are present in all dataframes.
```
pd.concat(seasons_, axis=0, join='inner')
```
There you go. Concatenation complete.
### Append
The method `df.append()` is a shortcut for `pd.concat()`, that can be called on either a `pd.DataFrame` or a `pd.Series`.
```
season_0.append(season_1)
```
It can take multiple objects to concatenate as well. Please note the `ignore_index=True`.
```
season_2 = pd.read_csv('./data/programs/1844-45.csv')
more_seasons = [season_1, season_2]
season_0.append(more_seasons, ignore_index=True)
```
We are good to go. Let's use `pd.concat` to combine all seasons into a great dataframe.
```
def read_season(file):
path = os.path.join('.', 'data', 'programs', file)
return pd.read_csv(path)
files = os.listdir('./data/programs/')
files = [f for f in files if '.csv' in f]
```
A logical approach would be to iterate over all files and appending all of them to a single dataframe.
```
%%timeit
programs = pd.DataFrame()
for file in files:
season = read_season(file)
programs = programs.append(season, ignore_index=True)
```
It is worth noting that both `pd.concat()` and `df.append()` make a full copy of the data and continually reusing this function can create a significant performance hit.
Instead, use a list comprehension if you need to use the operation several times.
This way, you only call `pd.concat()` or `df.append()` once.
```
%%timeit
seasons = [read_season(f) for f in files if '.csv' in f]
programs = pd.concat(seasons, axis=0, ignore_index=True)
seasons = [read_season(f) for f in files if '.csv' in f]
programs = pd.concat(seasons, axis=0, ignore_index=True)
```
Now that we have the final `programs` dataframe, we can see how the number of distinct programs changes over time.
```
programs['Season'] = pd.to_datetime(programs['Season'].str[:4])
(programs.groupby('Season')
.size()
.plot(legend=False, use_index=True, figsize=(10, 7),
title='Number of programs per season (from 1842-43 to 2016-17)'));
```
The NYP appears to be investing in increasing the number of distinct programs per season since '95.
## 2.2 How many concerts are there per season?
What about the number of concerts? The first thing we need to do is to import the `concerts.csv` data.
```
concerts = pd.read_csv('./data/concerts.csv')
concerts.head()
```
We will use the Leon Levy Digital Archives ID (`GUID`) to identify each program.
Now, we have information regarding all the concerts that took place and the season for each program.
The problem? Information about the concert and the season are in different tables, and the program is the glue between the two. Familiar?
### Merge
Pandas provides high-performance join operations, very similar to SQL.
The method `df.merge()` method provides an interface for all database-like join methods.
```
?pd.merge
```
We can call `pd.merge` to join both tables on the `GUID` (and the `ProgramID`, that provides similar info).
```
# Since GUID and ProgramID offer similar info, we will drop the later.
programs = programs.drop(columns='ProgramID')
df = pd.merge(programs, concerts, on='GUID')
df.head()
```
Or, alternatively, we can call `merge()` directly on the dataframe.
```
df_ = programs.merge(concerts, on='GUID')
df_.head()
```
The critical parameter here is the `how`. Since we are not explicitly using it, the merge default to `inner` (for inner-join) by default.
But, in fact, you can use any join, just like you did in SQL: `left`, `right`, `outer` and `inner`.
Remember?

*Fig. 1 - Types of joins in SQL, note how left, right, outer and inner translate directly to Pandas.*
A refresher on different types of joins, all supported by Pandas:
| Pandas | SQL | What it does |
| ---------------------------------------------- | ---------------- | ----------------------------------------- |
| `pd.merge(right, left, on='key', how='left')` | LEFT OUTER JOIN | Use all keys from left frame only |
| `pd.merge(right, left, on='key', how='right')` | RIGHT OUTER JOIN | Use all keys from right frame only |
| `pd.merge(right, left, on='key', how='outer')` | FULL OUTER JOIN | Use union of keys from both frames |
| `pd.merge(right, left, on='key', how='inner')` | INNER JOIN | Use intersection of keys from both frames |
In this particular case, we have:
* A one-to-many relationship (i.e., one program to many concerts)
* Since every single show in `concerts` has a match in `programs`, the type of join we use doesn't matter.
We can use the `validate` argument to automatically check whether there are unexpected duplicates in the merge keys and check their uniqueness.
```
df__ = pd.merge(programs, concerts, on='GUID', how='outer', validate="one_to_many")
assert(concerts.shape[0] == df_.shape[0] == df__.shape[0])
```
Back to our question, how is the number of concerts per season evolving?
```
(programs.merge(concerts, on='GUID')
.groupby('Season')
.size()
.plot(legend=False, use_index=True, figsize=(10, 7),
title='Number of concerts per season (from 1842-43 to 2016-17)'));
```
Likewise, the number of concerts seems to be trending upwards since about 1995, which could be a sign of growing interest in the genre.
### Join
Now, we want the top-3 composer in total appearances.
Without surprise, we start by importing `works.csv`.
```
works = pd.read_csv('./data/works.csv',index_col='GUID')
```
Alternatively, we can use `df.join()` instead of `df.merge()`.
There are, however, differences in the default behavior: for example `df.join` uses `how='left'` by default.
Let's try to perform the merge.
```
(programs.merge(works, on="GUID")
.head(n=3))
programs.merge(works, on="GUID").shape
(programs.join(works, on='GUID')
.head(n=3))
# equivalent to
# pd.merge(programs, works, left_on='GUID', right_index=True,
# how='left').head(n=3)
programs.join(works, on="GUID").shape
```
We noticed that the shape of the results is diferent, we have a different number of lines in each one of the methods.
Typically, you would use `df.join()` when you want to do a left join or when you want to join on the index of the dataframe on the right.
Now for our goal: what are the top-3 composers?
```
(programs.join(works, on='GUID')
.groupby('ComposerName')
.size()
.nlargest(n=3))
```
Wagner wins!
What about the top-3 works?
```
(programs.join(works, on='GUID')
.groupby(['ComposerName', 'WorkTitle'])
.size()
.nlargest(n=3))
```
Wagner wins three times!
| true |
code
| 0.228974 | null | null | null | null |
|
Wayne H Nixalo - 09 Aug 2017
This JNB is an attempt to do the neural artistic style transfer and super-resolution examples done in class, on a GPU using PyTorch for speed.
Lesson NB: [neural-style-pytorch](https://github.com/fastai/courses/blob/master/deeplearning2/neural-style-pytorch.ipynb)
## Neural Style Transfer
Style Transfer / Super Resolution Implementation in PyTorch
```
%matplotlib inline
import importlib
import os, sys; sys.path.insert(1, os.path.join('../utils'))
from utils2 import *
import torch, torch.nn as nn, torch.nn.functional as F, torch.optim as optim
from torch.autograd import Variable
from torch.utils.serialization import load_lua
from torch.utils.data import DataLoader
from torchvision import transforms, models, datasets
```
### Setup
```
path = '../data/nst/'
fnames = pickle.load(open(path+'fnames.pkl','rb'))
img = Image.open(path + fnames[0]); img
rn_mean = np.array([123.68, 116.779, 103.939], dtype=np.float32).reshape((1,1,1,3))
preproc = lambda x: (x - rn_mean)[:,:,:,::-1]
img_arr = preproc(np.expand_dims(np.array(img),0))
shp = img_arr.shape
deproc = lambda x: x[:,:,:,::-1] + rn_mena
```
### Create Model
```
def download_convert_vgg16_model():
model_url = 'http://cs.stanford.edu/people/jcjohns/fast-neural-style/models/vgg16.t7'
file = get_file(model_url, cache_subdir='models')
vgglua = load_lua(file).parameters()
vgg = models.VGGFeature()
for (src, dst) in zip(vgglua[0], vgg.parameters()): dst[:] = src[:]
torch.save(vgg.state_dict(), path + 'vgg16_feature.pth')
url = 'https://s3-us-west-2.amazonaws.com/jcjohns-models/'
fname = 'vgg16-00b39a1b.pth'
file = get_file(fname, url+fname, cache_subdir='models')
vgg = models.vgg.vgg16()
vgg.load_state_dict(torch.load(file))
optimizer = optim.Adam(vgg.parameters())
vgg.cuda();
arr_lr = bcolz.open(path + 'trn_resized_72.bc')[:]
arr_hr = bcolz.open(path + 'trn_resized_288.bc')[:]
arr = bcolz.open(dpath + 'trn_resized.bc')[:]
x = Variable(arr[0])
y = model(x)
url = 'http://www.files.fast.ai/models/'
fname = 'imagenet_class_index.json'
fpath = get_file(fname, url + fname, cache_subdir='models')
class ResidualBlock(nn.Module):
def __init__(self, num):
super(ResideualBlock, self).__init__()
self.c1 = nn.Conv2d(num, num, kernel_size=3, stride=1, padding=1)
self.c2 = nn.Conv2d(num, num, kernel_size=3, stride=1, padding=1)
self.b1 = nn.BatchNorm2d(num)
self.b2 = nn.BatchNorm2d(num)
def forward(self, x):
h = F.relu(self.b1(self.c1(x)))
h = self.b2(self.c2(h))
return h + x
class FastStyleNet(nn.Module):
def __init__(self):
super(FastStyleNet, self).__init__()
self.cs = [nn.Conv2d(3, 32, kernel_size=9, stride=1, padding=4),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding1)]
self.b1s = [nn.BatchNorm2d(i) for i in [32, 64, 128]]
self.rs = [ResidualBlock(128) for i in range(5)]
self.ds = [nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1)]
self.b2s = [nn.BatchNorm2d(i) for i in [64, 32]]
self.d3 = nn.Conv2d(32, 3, kernel_size=9, stride=1, padding=4)
def forward(self, h):
for i in range(3): h = F.relu(self.b1s[i](self.cs[i](x)))
for r in self.rs: h = r(h)
for i in range(2): h = F.relu(self.b2s[i](self.ds[i](x)))
return self.d3(h)
```
### Loss Functions and Processing
| true |
code
| 0.773799 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/gabilodeau/INF6804/blob/master/FeatureVectorsComp.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
INF6804 Vision par ordinateur
Polytechnique Montréal
Distances entre histogrammes (L1, L2, MDPA, Bhattacharyya)
```
import numpy as np
import cv2
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
```
Fonction pour calculer la distance MDPA
```
def distMDPA(V1, V2):
Dist=0;
for i in range(0,len(V1)):
dint=0;
for j in range(0,i):
dint=dint+V1[j]-V2[j]
Dist=Dist+abs(dint)
return Dist;
```
Création de 5 vecteurs. On comparera avec Vecteur1 comme base.
```
Vecteur1 = np.array([3.0, 4.0, 3.0, 1.0, 6.0])
Vecteur2 = np.array([2.0, 5.0, 3.0, 1.0, 6.0])
Vecteur3 = np.array([2.0, 4.0, 3.0, 1.0, 7.0])
Vecteur4 = np.array([1.0, 5.0, 4.0, 1.0, 6.0])
Vecteur5 = np.array([3.0, 5.0, 2.0, 2.0, 5.0])
```
Distance ou norme L1. Les résultats seront affichés sur un graphique.
```
dist1 = cv2.norm(Vecteur1, Vecteur2, cv2.NORM_L1)
dist2 = cv2.norm(Vecteur1, Vecteur3, cv2.NORM_L1)
dist3 = cv2.norm(Vecteur1, Vecteur4, cv2.NORM_L1)
dist4 = cv2.norm(Vecteur1, Vecteur5, cv2.NORM_L1)
#Pour affichage...
x = [0, 0.1, 0.2, 0.3]
color = ['r','g','b','k']
dist = [dist1, dist2, dist3, dist4]
```
Distance ou norme L2.
```
dist1 = cv2.norm(Vecteur1, Vecteur2, cv2.NORM_L2)
dist2 = cv2.norm(Vecteur1, Vecteur3, cv2.NORM_L2)
dist3 = cv2.norm(Vecteur1, Vecteur4, cv2.NORM_L2)
dist4 = cv2.norm(Vecteur1, Vecteur5, cv2.NORM_L2)
x = x + [1, 1.1, 1.2, 1.3]
dist = dist + [dist1, dist2, dist3, dist4]
color = color + ['r','g','b','k']
```
Distance MDPA (Maximum distance of pair assignments).
```
dist1 = distMDPA(Vecteur1, Vecteur2)
dist2 = distMDPA(Vecteur1, Vecteur3)
dist3 = distMDPA(Vecteur1, Vecteur4)
dist4 = distMDPA(Vecteur1, Vecteur5)
x = x + [2, 2.1, 2.2, 2.3]
dist = dist + [dist1, dist2, dist3, dist4]
color = color + ['r','g','b','k']
```
Distance de Bhattacharyya avec les valeurs normalisées entre 0 et 1.
```
Vecteur1 = Vecteur1/np.sum(Vecteur1)
Vecteur2 = Vecteur2/np.sum(Vecteur2)
Vecteur3 = Vecteur3/np.sum(Vecteur3)
Vecteur4 = Vecteur4/np.sum(Vecteur3)
dist1 = cv2.compareHist(Vecteur1.transpose().astype('float32'), Vecteur2.transpose().astype('float32'), cv2.HISTCMP_BHATTACHARYYA)
dist2 = cv2.compareHist(Vecteur1.transpose().astype('float32'), Vecteur3.transpose().astype('float32'), cv2.HISTCMP_BHATTACHARYYA)
dist3 = cv2.compareHist(Vecteur1.transpose().astype('float32'), Vecteur4.transpose().astype('float32'), cv2.HISTCMP_BHATTACHARYYA)
dist4 = cv2.compareHist(Vecteur1.transpose().astype('float32'), Vecteur5.transpose().astype('float32'), cv2.HISTCMP_BHATTACHARYYA)
x = x + [3, 3.1, 3.2, 3.3]
dist = dist + [dist1, dist2, dist3, dist4]
color = color + ['r','g','b', 'k']
```
Similarité cosinus.
```
dist1 = cosine_similarity(Vecteur1.reshape(1, -1), Vecteur2.reshape(1, -1))
dist2 = cosine_similarity(Vecteur1.reshape(1, -1), Vecteur3.reshape(1, -1))
dist3 = cosine_similarity(Vecteur1.reshape(1, -1), Vecteur4.reshape(1, -1))
dist4 = cosine_similarity(Vecteur1.reshape(1, -1), Vecteur5.reshape(1, -1))
x = x + [4, 4.1, 4.2, 4.3]
dist = dist + [dist1, dist2, dist3, dist4]
color = color + ['r','g','b', 'k']
```
Affichage des distances.
```
plt.scatter(x, dist, c = color)
plt.text(0,0, 'Distance L1')
plt.text(0.8,1, 'Distance L2')
plt.text(1.6,0, 'Distance MDPA')
plt.text(2.6,0.5, 'Bhattacharyya')
plt.text(3.8,0.3, 'Similarité\n cosinus')
plt.show()
```
| true |
code
| 0.473353 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/kuriousk516/HIST4916a-Stolen_Bronzes/blob/main/Stolen_Bronzes.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Stolen Bronzes: Western Museums and Repatriation
## Introduction
>"*Walk into any European museum today and you will see the curated spoils of Empire. They sit behind plate glass: dignified, tastefully lit. Accompanying pieces of card offer a name, date and place of origin. They do not mention that the objects are all stolen*."
>
> 'Radicals in Conversation': The Brutish Museums
Public history and digital humanities offers a locus point of contending with difficult pasts. Museums, often considered bastions of knowledge, learning, and public good have fallen under an increasingly critical gaze -- and rightfully so. Public museums have been tools of colonialism, racism, and superiority centred around the supremacy of the west and its history.
Digital repositories of museum archives and websites can be used to subvert the exclusionary practices employed by museums and provide tools for marginalized peoples --. The purpose of this notebook is to act as a digital tool for real life change, and it is focused on Dan Hick's [Tweet](https://twitter.com/profdanhicks/status/1375421209265983488) and book, *The Brutish Museum*.
```
%%html
<iframe src="https://drive.google.com/file/d/1txSH3UkjJgLTeQW47MGLfrht7AHCEkGC/preview" width="640" height="480"></iframe>
```
What I read in Dan Hicks' Tweet was a call to action. Not necessarily for the average citizen to take the bronzes back, but to start an important discussion about the nature of artifact aqcuisition and confronting how museums procure these items in the first place.
The appendix' list is a small fraction of the stolen artifacts found in hundreds of museums all over the world but it is a powerful point of focus. I want to create something, however small, that can give others the tools to have a visual representation of stolen artifacts distribution and interrogate why (mostly) western museums are the institutions holding these artifacts, what effect this has, and what's being done with them. Can anyone own art? Who has the power to decide? How do we give that power back to those who were stolen from?
To learn more about the Benin bronzes and their history, a good place to start is with the ['Radicals in Conversation'](https://www.plutobooks.com/blog/podcast-brutish-museums-benin-bronzes-decolonisation/) podcast.
And now, what I have here is a helpful tool for all of us to answer, **"*How close are you right this second to a looted Benin Bronze*?"**
# Data
I have compiled a dataframe of all the museums listed in Hicks' appendix'; you can see the original above in his Tweet. The data is in a .CSV file stored in my [GitHub repository](https://github.com/kuriousk516/HIST4916a-Stolen_Bronzes), and you can also find screenshots of the errors I encountered and advice I recieved through the HIST4916a Discord server, some of which I will reference here when discussing data limitations.
## Mapping with Folium
Folium seemed the best choice for this project since it doesn't rely on Google Maps for the map itself or the data entry process. [This is the tutorial](https://craftingdh.netlify.app/tutorials/folium/) that I used for the majority of the data coding, and this is the [Point Map alternative](https://handsondataviz.org/mymaps.html) I considered but decided against.
```
import lxml
import pandas as pd
pd.set_option("max_rows", 400)
pd.set_option("max_colwidth", 400)
import pandas, os
os.listdir()
['.config', 'benin_bronze_locations2.csv', 'sample_data']
```
Here is where I ran into some trouble. I was having great difficulty in loading my .CSV file into the notebook, so I uploaded the file from my computer. Here is the alternative code to upload it using the RAW link from GitHub:
url = 'copied_raw_GH_link'
df1 = pd.read_csv(url)
If you have another (simpler) way of getting the job done, I fully encourage you altering the code to make it happen.
```
from google.colab import files
uploaded = files.upload()
```
In the .CSV file, I only had the name of the museums, cities, and countries. Manually inputting the necessary data for plotting the locations would be time-consuming and tedious, but I have an example using geopy and Nomatim to pull individual location info for the cases when "NaN" pops up when expanding the entire dataframe.
```
df1=pandas.read_csv('benin_bronze_locations2.csv', encoding = "ISO-8859-1", engine ='python')
df1
!pip install geopy
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="BENIN-BRONZES", timeout=2)
location = geolocator.geocode("Ulster Museum United Kingdom")
location
```
Great! Now we have the means of finding the relevant map information for individual entires. But to process the large amount of data, I followed [this YouTube tutorial](https://www.youtube.com/watch?v=0IjdfgmWzMk) for some extra help.
```
def find_location(row):
place = row['place']
location = geolocator.geocode(place)
if location != None:
return location.address, location.latitude, location.longitude, location.raw['importance']
else:
return "Not Found", "Not Found", "Not Found", "Not Found"
```
To expand on my data, I needed to add a new column to my dataframe -- the addresses of the museums.
```
df1["Address"]=df1["Place"]+", "+df1["City"]+", "+df1["Country"]
df1
#Then I added this string to the geocode to create a coordinates column.
df1["Coordinates"]=df1["Address"].apply(geolocator.geocode)
df1
```
After compiling the addresses and coordinates, the dataframe needed the latitude and longitudes for Folium to plot the locations on the map.
```
df1["Latitude"]=df1["Coordinates"].apply(lambda x: x.latitude if x !=None else None)
df1["Longitude"]=df1["Coordinates"].apply(lambda x: x.longitude if x !=None else None)
df1
!pip install folium
import folium
beninbronze_map = folium.Map(location=[6.3350, 5.6037], zoom_start=7)
beninbronze_map
```
I want Benin City to be the centre of this map, a rough point of origin. The Kingdom of Benin existed in modern day Nigeria, and it's where the looted bronzes belong. Only *nine* locations in Nigeria have collections of the bronzes, as opposed to the 152 others all over Europe, America, Canada, Russia, and Japan. Nigeria needs to be the centre of the conversation of the looted bronzes and repatriation, and so it is the centre of the map being created.
```
def create_map_markers(row, beninbronze_map):
folium.Marker(location=[row['lat'], row['lon']], popup=row['place']).add_to(beninbronze_map)
folium.Marker(location=[6.3350, 5.6037], popup="Send the bronzes home").add_to(beninbronze_map)
beninbronze_map
def create_map_markers(row, beninbronze_map):
folium.Marker(location=[row['Latitude'], row['Longitude']], popup=row['Place']).add_to(beninbronze_map)
```
Many of the data entries came up as "NaN" when the code was trying to find their latitude and longitude. It's an invalid entry and needs to be dropped in order for the map markers to function. This is very important to note: out of the 156 data entries, only 86 were plotted on the map. The missing coordinates need to be added to the dataframe, but that's a bit beyond the scope of this project. I invite anyone with the time to complete the map markers using the code examples above.
```
df1.dropna(subset = ["Latitude"], inplace=True)
df1.dropna(subset = ["Longitude"], inplace=True)
nan_value = float("NaN")
df1.replace("",nan_value, inplace=True)
df1.dropna(subset = ["Latitude"], inplace=True)
df1.dropna(subset = ["Longitude"], inplace=True)
df1
df1.apply(lambda row:folium.CircleMarker(location=[row["Latitude"],
row["Longitude"]]).add_to(beninbronze_map),
axis=1)
beninbronze_map
beninbronze_map.save("stolen-bronzes-map.html")
```
# Conclusion
Now we have a map showing (some of) the locations of the looted Benin bronzes. It needs to be expanded to include the other locations, but I hope it helped you to think about what Dan Hicks' asked: how close are you, right this minute, to a looted Benin bronze?
# Recommended Reading and Points of Reference
Abt, Jeffrey. “The Origins of the Public Museum.” In A Companion to Museum Studies, 115–134. Malden, MA, USA: Blackwell Publishing Ltd, 2006.
Bennett, Tony. 1990. “The Political Rationality of the Museum,” Continuum: The Australian Journal of Media and Culture 2, no. 1 (1990).
Bivens, Joy, and Ben Garcia, Porchia Moore, nikhil trivedi, Aletheia Wittman. 2019. ‘Collections: How We Hold the Stuff We Hold in Trust’ in MASSAction, Museums As Site for Social Action, toolkit, https://static1.squarespace.com/static/58fa685dff7c50f78be5f2b2/t/59dcdd27e5dd5b5a1b51d9d8/1507646780650/TOOLKIT_10_2017.pdf
DW.com. "'A matter of fairness': New debate about Benin Bronzes in Germany." Published March 26, 2021. https://www.dw.com/en/a-matter-of-fairness-new-debate-about-benin-bronzes-in-germany/a-57013604
Hudson, David J. 2016. “On Dark Continents and Digital Divides: Information Inequality and the Reproduction of Racial Otherness in Library and Information Studies” https://atrium.lib.uoguelph.ca/xmlui/handle/10214/9862.
Kreps, Christina. 2008. ‘Non-western Models of Museums and Curation in Cross-cultural Perspective’in Sharon Macdonald, ed. ‘Companion to Museum Studies’.
MacDonald, Sharon. 2008. “Collecting Practices” in Sharon Macdonald, ed. ‘Companion to Museum Studies’.
Sentance, Nathan mudyi. 2018. “Why Do We Collect,” Archival Decolonist blog, August 18, 2018, https://archivaldecolonist.com/2018/08/18/why-do-we-collect/
https://www.danhicks.uk/brutishmuseums
https://www.plutobooks.com/blog/podcast-brutish-museums-benin-bronzes-decolonisation/
| true |
code
| 0.312232 | null | null | null | null |
|
##### Copyright 2020 The OpenFermion Developers
```
```
# Introduction to OpenFermion
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://quantumai.google/openfermion/tutorials/intro_to_openfermion"><img src="https://quantumai.google/site-assets/images/buttons/quantumai_logo_1x.png" />View on QuantumAI</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/quantumlib/OpenFermion/blob/master/docs/tutorials/intro_to_openfermion.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/colab_logo_1x.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/quantumlib/OpenFermion/blob/master/docs/tutorials/intro_to_openfermion.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/github_logo_1x.png" />View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/OpenFermion/docs/tutorials/intro_to_openfermion.ipynb"><img src="https://quantumai.google/site-assets/images/buttons/download_icon_1x.png" />Download notebook</a>
</td>
</table>
Note: The examples below must be run sequentially within a section.
## Setup
Install the OpenFermion package:
```
try:
import openfermion
except ImportError:
!pip install git+https://github.com/quantumlib/OpenFermion.git@master#egg=openfermion
```
## Initializing the FermionOperator data structure
Fermionic systems are often treated in second quantization where arbitrary operators can be expressed using the fermionic creation and annihilation operators, $a^\dagger_k$ and $a_k$. The fermionic ladder operators play a similar role to their qubit ladder operator counterparts, $\sigma^+_k$ and $\sigma^-_k$ but are distinguished by the canonical fermionic anticommutation relations, $\{a^\dagger_i, a^\dagger_j\} = \{a_i, a_j\} = 0$ and $\{a_i, a_j^\dagger\} = \delta_{ij}$. Any weighted sums of products of these operators are represented with the FermionOperator data structure in OpenFermion. The following are examples of valid FermionOperators:
$$
\begin{align}
& a_1 \nonumber \\
& 1.7 a^\dagger_3 \nonumber \\
&-1.7 \, a^\dagger_3 a_1 \nonumber \\
&(1 + 2i) \, a^\dagger_4 a^\dagger_3 a_9 a_1 \nonumber \\
&(1 + 2i) \, a^\dagger_4 a^\dagger_3 a_9 a_1 - 1.7 \, a^\dagger_3 a_1 \nonumber
\end{align}
$$
The FermionOperator class is contained in $\textrm{ops/_fermion_operator.py}$. In order to support fast addition of FermionOperator instances, the class is implemented as hash table (python dictionary). The keys of the dictionary encode the strings of ladder operators and values of the dictionary store the coefficients. The strings of ladder operators are encoded as a tuple of 2-tuples which we refer to as the "terms tuple". Each ladder operator is represented by a 2-tuple. The first element of the 2-tuple is an int indicating the tensor factor on which the ladder operator acts. The second element of the 2-tuple is Boole: 1 represents raising and 0 represents lowering. For instance, $a^\dagger_8$ is represented in a 2-tuple as $(8, 1)$. Note that indices start at 0 and the identity operator is an empty list. Below we give some examples of operators and their terms tuple:
$$
\begin{align}
I & \mapsto () \nonumber \\
a_1 & \mapsto ((1, 0),) \nonumber \\
a^\dagger_3 & \mapsto ((3, 1),) \nonumber \\
a^\dagger_3 a_1 & \mapsto ((3, 1), (1, 0)) \nonumber \\
a^\dagger_4 a^\dagger_3 a_9 a_1 & \mapsto ((4, 1), (3, 1), (9, 0), (1, 0)) \nonumber
\end{align}
$$
Note that when initializing a single ladder operator one should be careful to add the comma after the inner pair. This is because in python ((1, 2)) = (1, 2) whereas ((1, 2),) = ((1, 2),). The "terms tuple" is usually convenient when one wishes to initialize a term as part of a coded routine. However, the terms tuple is not particularly intuitive. Accordingly, OpenFermion also supports another user-friendly, string notation below. This representation is rendered when calling "print" on a FermionOperator.
$$
\begin{align}
I & \mapsto \textrm{""} \nonumber \\
a_1 & \mapsto \textrm{"1"} \nonumber \\
a^\dagger_3 & \mapsto \textrm{"3^"} \nonumber \\
a^\dagger_3 a_1 & \mapsto \textrm{"3^}\;\textrm{1"} \nonumber \\
a^\dagger_4 a^\dagger_3 a_9 a_1 & \mapsto \textrm{"4^}\;\textrm{3^}\;\textrm{9}\;\textrm{1"} \nonumber
\end{align}
$$
Let's initialize our first term! We do it two different ways below.
```
from openfermion.ops import FermionOperator
my_term = FermionOperator(((3, 1), (1, 0)))
print(my_term)
my_term = FermionOperator('3^ 1')
print(my_term)
```
The preferred way to specify the coefficient in openfermion is to provide an optional coefficient argument. If not provided, the coefficient defaults to 1. In the code below, the first method is preferred. The multiplication in the second method actually creates a copy of the term, which introduces some additional cost. All inplace operands (such as +=) modify classes whereas binary operands such as + create copies. Important caveats are that the empty tuple FermionOperator(()) and the empty string FermionOperator('') initializes identity. The empty initializer FermionOperator() initializes the zero operator.
```
good_way_to_initialize = FermionOperator('3^ 1', -1.7)
print(good_way_to_initialize)
bad_way_to_initialize = -1.7 * FermionOperator('3^ 1')
print(bad_way_to_initialize)
identity = FermionOperator('')
print(identity)
zero_operator = FermionOperator()
print(zero_operator)
```
Note that FermionOperator has only one attribute: .terms. This attribute is the dictionary which stores the term tuples.
```
my_operator = FermionOperator('4^ 1^ 3 9', 1. + 2.j)
print(my_operator)
print(my_operator.terms)
```
## Manipulating the FermionOperator data structure
So far we have explained how to initialize a single FermionOperator such as $-1.7 \, a^\dagger_3 a_1$. However, in general we will want to represent sums of these operators such as $(1 + 2i) \, a^\dagger_4 a^\dagger_3 a_9 a_1 - 1.7 \, a^\dagger_3 a_1$. To do this, just add together two FermionOperators! We demonstrate below.
```
from openfermion.ops import FermionOperator
term_1 = FermionOperator('4^ 3^ 9 1', 1. + 2.j)
term_2 = FermionOperator('3^ 1', -1.7)
my_operator = term_1 + term_2
print(my_operator)
my_operator = FermionOperator('4^ 3^ 9 1', 1. + 2.j)
term_2 = FermionOperator('3^ 1', -1.7)
my_operator += term_2
print('')
print(my_operator)
```
The print function prints each term in the operator on a different line. Note that the line my_operator = term_1 + term_2 creates a new object, which involves a copy of term_1 and term_2. The second block of code uses the inplace method +=, which is more efficient. This is especially important when trying to construct a very large FermionOperator. FermionOperators also support a wide range of builtins including, str(), repr(), ==, !=, *=, *, /, /=, +, +=, -, -=, - and **. Note that since FermionOperators involve floats, == and != check for (in)equality up to numerical precision. We demonstrate some of these methods below.
```
term_1 = FermionOperator('4^ 3^ 9 1', 1. + 2.j)
term_2 = FermionOperator('3^ 1', -1.7)
my_operator = term_1 - 33. * term_2
print(my_operator)
my_operator *= 3.17 * (term_2 + term_1) ** 2
print('')
print(my_operator)
print('')
print(term_2 ** 3)
print('')
print(term_1 == 2.*term_1 - term_1)
print(term_1 == my_operator)
```
Additionally, there are a variety of methods that act on the FermionOperator data structure. We demonstrate a small subset of those methods here.
```
from openfermion.utils import commutator, count_qubits, hermitian_conjugated
from openfermion.transforms import normal_ordered
# Get the Hermitian conjugate of a FermionOperator, count its qubit, check if it is normal-ordered.
term_1 = FermionOperator('4^ 3 3^', 1. + 2.j)
print(hermitian_conjugated(term_1))
print(term_1.is_normal_ordered())
print(count_qubits(term_1))
# Normal order the term.
term_2 = normal_ordered(term_1)
print('')
print(term_2)
print(term_2.is_normal_ordered())
# Compute a commutator of the terms.
print('')
print(commutator(term_1, term_2))
```
## The QubitOperator data structure
The QubitOperator data structure is another essential part of openfermion. As the name suggests, QubitOperator is used to store qubit operators in almost exactly the same way that FermionOperator is used to store fermion operators. For instance $X_0 Z_3 Y_4$ is a QubitOperator. The internal representation of this as a terms tuple would be $((0, \textrm{"X"}), (3, \textrm{"Z"}), (4, \textrm{"Y"}))$. Note that one important difference between QubitOperator and FermionOperator is that the terms in QubitOperator are always sorted in order of tensor factor. In some cases, this enables faster manipulation. We initialize some QubitOperators below.
```
from openfermion.ops import QubitOperator
my_first_qubit_operator = QubitOperator('X1 Y2 Z3')
print(my_first_qubit_operator)
print(my_first_qubit_operator.terms)
operator_2 = QubitOperator('X3 Z4', 3.17)
operator_2 -= 77. * my_first_qubit_operator
print('')
print(operator_2)
```
## Jordan-Wigner and Bravyi-Kitaev
openfermion provides functions for mapping FermionOperators to QubitOperators.
```
from openfermion.ops import FermionOperator
from openfermion.transforms import jordan_wigner, bravyi_kitaev
from openfermion.utils import hermitian_conjugated
from openfermion.linalg import eigenspectrum
# Initialize an operator.
fermion_operator = FermionOperator('2^ 0', 3.17)
fermion_operator += hermitian_conjugated(fermion_operator)
print(fermion_operator)
# Transform to qubits under the Jordan-Wigner transformation and print its spectrum.
jw_operator = jordan_wigner(fermion_operator)
print('')
print(jw_operator)
jw_spectrum = eigenspectrum(jw_operator)
print(jw_spectrum)
# Transform to qubits under the Bravyi-Kitaev transformation and print its spectrum.
bk_operator = bravyi_kitaev(fermion_operator)
print('')
print(bk_operator)
bk_spectrum = eigenspectrum(bk_operator)
print(bk_spectrum)
```
We see that despite the different representation, these operators are iso-spectral. We can also apply the Jordan-Wigner transform in reverse to map arbitrary QubitOperators to FermionOperators. Note that we also demonstrate the .compress() method (a method on both FermionOperators and QubitOperators) which removes zero entries.
```
from openfermion.transforms import reverse_jordan_wigner
# Initialize QubitOperator.
my_operator = QubitOperator('X0 Y1 Z2', 88.)
my_operator += QubitOperator('Z1 Z4', 3.17)
print(my_operator)
# Map QubitOperator to a FermionOperator.
mapped_operator = reverse_jordan_wigner(my_operator)
print('')
print(mapped_operator)
# Map the operator back to qubits and make sure it is the same.
back_to_normal = jordan_wigner(mapped_operator)
back_to_normal.compress()
print('')
print(back_to_normal)
```
## Sparse matrices and the Hubbard model
Often, one would like to obtain a sparse matrix representation of an operator which can be analyzed numerically. There is code in both openfermion.transforms and openfermion.utils which facilitates this. The function get_sparse_operator converts either a FermionOperator, a QubitOperator or other more advanced classes such as InteractionOperator to a scipy.sparse.csc matrix. There are numerous functions in openfermion.utils which one can call on the sparse operators such as "get_gap", "get_hartree_fock_state", "get_ground_state", etc. We show this off by computing the ground state energy of the Hubbard model. To do that, we use code from the openfermion.hamiltonians module which constructs lattice models of fermions such as Hubbard models.
```
from openfermion.hamiltonians import fermi_hubbard
from openfermion.linalg import get_sparse_operator, get_ground_state
from openfermion.transforms import jordan_wigner
# Set model.
x_dimension = 2
y_dimension = 2
tunneling = 2.
coulomb = 1.
magnetic_field = 0.5
chemical_potential = 0.25
periodic = 1
spinless = 1
# Get fermion operator.
hubbard_model = fermi_hubbard(
x_dimension, y_dimension, tunneling, coulomb, chemical_potential,
magnetic_field, periodic, spinless)
print(hubbard_model)
# Get qubit operator under Jordan-Wigner.
jw_hamiltonian = jordan_wigner(hubbard_model)
jw_hamiltonian.compress()
print('')
print(jw_hamiltonian)
# Get scipy.sparse.csc representation.
sparse_operator = get_sparse_operator(hubbard_model)
print('')
print(sparse_operator)
print('\nEnergy of the model is {} in units of T and J.'.format(
get_ground_state(sparse_operator)[0]))
```
## Hamiltonians in the plane wave basis
A user can write plugins to openfermion which allow for the use of, e.g., third-party electronic structure package to compute molecular orbitals, Hamiltonians, energies, reduced density matrices, coupled cluster amplitudes, etc using Gaussian basis sets. We may provide scripts which interface between such packages and openfermion in future but do not discuss them in this tutorial.
When using simpler basis sets such as plane waves, these packages are not needed. openfermion comes with code which computes Hamiltonians in the plane wave basis. Note that when using plane waves, one is working with the periodized Coulomb operator, best suited for condensed phase calculations such as studying the electronic structure of a solid. To obtain these Hamiltonians one must choose to study the system without a spin degree of freedom (spinless), one must the specify dimension in which the calculation is performed (n_dimensions, usually 3), one must specify how many plane waves are in each dimension (grid_length) and one must specify the length scale of the plane wave harmonics in each dimension (length_scale) and also the locations and charges of the nuclei. One can generate these models with plane_wave_hamiltonian() found in openfermion.hamiltonians. For simplicity, below we compute the Hamiltonian in the case of zero external charge (corresponding to the uniform electron gas, aka jellium). We also demonstrate that one can transform the plane wave Hamiltonian using a Fourier transform without effecting the spectrum of the operator.
```
from openfermion.hamiltonians import jellium_model
from openfermion.utils import Grid
from openfermion.linalg import eigenspectrum
from openfermion.transforms import jordan_wigner, fourier_transform
# Let's look at a very small model of jellium in 1D.
grid = Grid(dimensions=1, length=3, scale=1.0)
spinless = True
# Get the momentum Hamiltonian.
momentum_hamiltonian = jellium_model(grid, spinless)
momentum_qubit_operator = jordan_wigner(momentum_hamiltonian)
momentum_qubit_operator.compress()
print(momentum_qubit_operator)
# Fourier transform the Hamiltonian to the position basis.
position_hamiltonian = fourier_transform(momentum_hamiltonian, grid, spinless)
position_qubit_operator = jordan_wigner(position_hamiltonian)
position_qubit_operator.compress()
print('')
print (position_qubit_operator)
# Check the spectra to make sure these representations are iso-spectral.
spectral_difference = eigenspectrum(momentum_qubit_operator) - eigenspectrum(position_qubit_operator)
print('')
print(spectral_difference)
```
## Basics of MolecularData class
Data from electronic structure calculations can be saved in an OpenFermion data structure called MolecularData, which makes it easy to access within our library. Often, one would like to analyze a chemical series or look at many different Hamiltonians and sometimes the electronic structure calculations are either expensive to compute or difficult to converge (e.g. one needs to mess around with different types of SCF routines to make things converge). Accordingly, we anticipate that users will want some way to automatically database the results of their electronic structure calculations so that important data (such as the SCF integrals) can be looked up on-the-fly if the user has computed them in the past. OpenFermion supports a data provenance strategy which saves key results of the electronic structure calculation (including pointers to files containing large amounts of data, such as the molecular integrals) in an HDF5 container.
The MolecularData class stores information about molecules. One initializes a MolecularData object by specifying parameters of a molecule such as its geometry, basis, multiplicity, charge and an optional string describing it. One can also initialize MolecularData simply by providing a string giving a filename where a previous MolecularData object was saved in an HDF5 container. One can save a MolecularData instance by calling the class's .save() method. This automatically saves the instance in a data folder specified during OpenFermion installation. The name of the file is generated automatically from the instance attributes and optionally provided description. Alternatively, a filename can also be provided as an optional input if one wishes to manually name the file.
When electronic structure calculations are run, the data files for the molecule can be automatically updated. If one wishes to later use that data they either initialize MolecularData with the instance filename or initialize the instance and then later call the .load() method.
Basis functions are provided to initialization using a string such as "6-31g". Geometries can be specified using a simple txt input file (see geometry_from_file function in molecular_data.py) or can be passed using a simple python list format demonstrated below. Atoms are specified using a string for their atomic symbol. Distances should be provided in angstrom. Below we initialize a simple instance of MolecularData without performing any electronic structure calculations.
```
from openfermion.chem import MolecularData
# Set parameters to make a simple molecule.
diatomic_bond_length = .7414
geometry = [('H', (0., 0., 0.)), ('H', (0., 0., diatomic_bond_length))]
basis = 'sto-3g'
multiplicity = 1
charge = 0
description = str(diatomic_bond_length)
# Make molecule and print out a few interesting facts about it.
molecule = MolecularData(geometry, basis, multiplicity,
charge, description)
print('Molecule has automatically generated name {}'.format(
molecule.name))
print('Information about this molecule would be saved at:\n{}\n'.format(
molecule.filename))
print('This molecule has {} atoms and {} electrons.'.format(
molecule.n_atoms, molecule.n_electrons))
for atom, atomic_number in zip(molecule.atoms, molecule.protons):
print('Contains {} atom, which has {} protons.'.format(
atom, atomic_number))
```
If we had previously computed this molecule using an electronic structure package, we can call molecule.load() to populate all sorts of interesting fields in the data structure. Though we make no assumptions about what electronic structure packages users might install, we assume that the calculations are saved in OpenFermion's MolecularData objects. Currently plugins are available for [Psi4](http://psicode.org/) [(OpenFermion-Psi4)](http://github.com/quantumlib/OpenFermion-Psi4) and [PySCF](https://github.com/sunqm/pyscf) [(OpenFermion-PySCF)](http://github.com/quantumlib/OpenFermion-PySCF), and there may be more in the future. For the purposes of this example, we will load data that ships with OpenFermion to make a plot of the energy surface of hydrogen. Note that helper functions to initialize some interesting chemical benchmarks are found in openfermion.utils.
```
# Set molecule parameters.
basis = 'sto-3g'
multiplicity = 1
bond_length_interval = 0.1
n_points = 25
# Generate molecule at different bond lengths.
hf_energies = []
fci_energies = []
bond_lengths = []
for point in range(3, n_points + 1):
bond_length = bond_length_interval * point
bond_lengths += [bond_length]
description = str(round(bond_length,2))
print(description)
geometry = [('H', (0., 0., 0.)), ('H', (0., 0., bond_length))]
molecule = MolecularData(
geometry, basis, multiplicity, description=description)
# Load data.
molecule.load()
# Print out some results of calculation.
print('\nAt bond length of {} angstrom, molecular hydrogen has:'.format(
bond_length))
print('Hartree-Fock energy of {} Hartree.'.format(molecule.hf_energy))
print('MP2 energy of {} Hartree.'.format(molecule.mp2_energy))
print('FCI energy of {} Hartree.'.format(molecule.fci_energy))
print('Nuclear repulsion energy between protons is {} Hartree.'.format(
molecule.nuclear_repulsion))
for orbital in range(molecule.n_orbitals):
print('Spatial orbital {} has energy of {} Hartree.'.format(
orbital, molecule.orbital_energies[orbital]))
hf_energies += [molecule.hf_energy]
fci_energies += [molecule.fci_energy]
# Plot.
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(0)
plt.plot(bond_lengths, fci_energies, 'x-')
plt.plot(bond_lengths, hf_energies, 'o-')
plt.ylabel('Energy in Hartree')
plt.xlabel('Bond length in angstrom')
plt.show()
```
The geometry data needed to generate MolecularData can also be retreived from the PubChem online database by inputting the molecule's name.
```
from openfermion.chem import geometry_from_pubchem
methane_geometry = geometry_from_pubchem('methane')
print(methane_geometry)
```
## InteractionOperator and InteractionRDM for efficient numerical representations
Fermion Hamiltonians can be expressed as $H = h_0 + \sum_{pq} h_{pq}\, a^\dagger_p a_q + \frac{1}{2} \sum_{pqrs} h_{pqrs} \, a^\dagger_p a^\dagger_q a_r a_s$ where $h_0$ is a constant shift due to the nuclear repulsion and $h_{pq}$ and $h_{pqrs}$ are the famous molecular integrals. Since fermions interact pairwise, their energy is thus a unique function of the one-particle and two-particle reduced density matrices which are expressed in second quantization as $\rho_{pq} = \left \langle p \mid a^\dagger_p a_q \mid q \right \rangle$ and $\rho_{pqrs} = \left \langle pq \mid a^\dagger_p a^\dagger_q a_r a_s \mid rs \right \rangle$, respectively.
Because the RDMs and molecular Hamiltonians are both compactly represented and manipulated as 2- and 4- index tensors, we can represent them in a particularly efficient form using similar data structures. The InteractionOperator data structure can be initialized for a Hamiltonian by passing the constant $h_0$ (or 0), as well as numpy arrays representing $h_{pq}$ (or $\rho_{pq}$) and $h_{pqrs}$ (or $\rho_{pqrs}$). Importantly, InteractionOperators can also be obtained by calling MolecularData.get_molecular_hamiltonian() or by calling the function get_interaction_operator() (found in openfermion.transforms) on a FermionOperator. The InteractionRDM data structure is similar but represents RDMs. For instance, one can get a molecular RDM by calling MolecularData.get_molecular_rdm(). When generating Hamiltonians from the MolecularData class, one can choose to restrict the system to an active space.
These classes inherit from the same base class, PolynomialTensor. This data structure overloads the slice operator [] so that one can get or set the key attributes of the InteractionOperator: $\textrm{.constant}$, $\textrm{.one_body_coefficients}$ and $\textrm{.two_body_coefficients}$ . For instance, InteractionOperator[(p, 1), (q, 1), (r, 0), (s, 0)] would return $h_{pqrs}$ and InteractionRDM would return $\rho_{pqrs}$. Importantly, the class supports fast basis transformations using the method PolynomialTensor.rotate_basis(rotation_matrix).
But perhaps most importantly, one can map the InteractionOperator to any of the other data structures we've described here.
Below, we load MolecularData from a saved calculation of LiH. We then obtain an InteractionOperator representation of this system in an active space. We then map that operator to qubits. We then demonstrate that one can rotate the orbital basis of the InteractionOperator using random angles to obtain a totally different operator that is still iso-spectral.
```
from openfermion.chem import MolecularData
from openfermion.transforms import get_fermion_operator, jordan_wigner
from openfermion.linalg import get_ground_state, get_sparse_operator
import numpy
import scipy
import scipy.linalg
# Load saved file for LiH.
diatomic_bond_length = 1.45
geometry = [('Li', (0., 0., 0.)), ('H', (0., 0., diatomic_bond_length))]
basis = 'sto-3g'
multiplicity = 1
# Set Hamiltonian parameters.
active_space_start = 1
active_space_stop = 3
# Generate and populate instance of MolecularData.
molecule = MolecularData(geometry, basis, multiplicity, description="1.45")
molecule.load()
# Get the Hamiltonian in an active space.
molecular_hamiltonian = molecule.get_molecular_hamiltonian(
occupied_indices=range(active_space_start),
active_indices=range(active_space_start, active_space_stop))
# Map operator to fermions and qubits.
fermion_hamiltonian = get_fermion_operator(molecular_hamiltonian)
qubit_hamiltonian = jordan_wigner(fermion_hamiltonian)
qubit_hamiltonian.compress()
print('The Jordan-Wigner Hamiltonian in canonical basis follows:\n{}'.format(qubit_hamiltonian))
# Get sparse operator and ground state energy.
sparse_hamiltonian = get_sparse_operator(qubit_hamiltonian)
energy, state = get_ground_state(sparse_hamiltonian)
print('Ground state energy before rotation is {} Hartree.\n'.format(energy))
# Randomly rotate.
n_orbitals = molecular_hamiltonian.n_qubits // 2
n_variables = int(n_orbitals * (n_orbitals - 1) / 2)
numpy.random.seed(1)
random_angles = numpy.pi * (1. - 2. * numpy.random.rand(n_variables))
kappa = numpy.zeros((n_orbitals, n_orbitals))
index = 0
for p in range(n_orbitals):
for q in range(p + 1, n_orbitals):
kappa[p, q] = random_angles[index]
kappa[q, p] = -numpy.conjugate(random_angles[index])
index += 1
# Build the unitary rotation matrix.
difference_matrix = kappa + kappa.transpose()
rotation_matrix = scipy.linalg.expm(kappa)
# Apply the unitary.
molecular_hamiltonian.rotate_basis(rotation_matrix)
# Get qubit Hamiltonian in rotated basis.
qubit_hamiltonian = jordan_wigner(molecular_hamiltonian)
qubit_hamiltonian.compress()
print('The Jordan-Wigner Hamiltonian in rotated basis follows:\n{}'.format(qubit_hamiltonian))
# Get sparse Hamiltonian and energy in rotated basis.
sparse_hamiltonian = get_sparse_operator(qubit_hamiltonian)
energy, state = get_ground_state(sparse_hamiltonian)
print('Ground state energy after rotation is {} Hartree.'.format(energy))
```
## Quadratic Hamiltonians and Slater determinants
The general electronic structure Hamiltonian
$H = h_0 + \sum_{pq} h_{pq}\, a^\dagger_p a_q + \frac{1}{2} \sum_{pqrs} h_{pqrs} \, a^\dagger_p a^\dagger_q a_r a_s$ contains terms that act on up to 4 sites, or
is quartic in the fermionic creation and annihilation operators. However, in many situations
we may fruitfully approximate these Hamiltonians by replacing these quartic terms with
terms that act on at most 2 fermionic sites, or quadratic terms, as in mean-field approximation theory.
These Hamiltonians have a number of
special properties one can exploit for efficient simulation and manipulation of the Hamiltonian, thus
warranting a special data structure. We refer to Hamiltonians which
only contain terms that are quadratic in the fermionic creation and annihilation operators
as quadratic Hamiltonians, and include the general case of non-particle conserving terms as in
a general Bogoliubov transformation. Eigenstates of quadratic Hamiltonians can be prepared
efficiently on both a quantum and classical computer, making them amenable to initial guesses for
many more challenging problems.
A general quadratic Hamiltonian takes the form
$$H = \sum_{p, q} (M_{pq} - \mu \delta_{pq}) a^\dagger_p a_q + \frac{1}{2} \sum_{p, q} (\Delta_{pq} a^\dagger_p a^\dagger_q + \Delta_{pq}^* a_q a_p) + \text{constant},$$
where $M$ is a Hermitian matrix, $\Delta$ is an antisymmetric matrix,
$\delta_{pq}$ is the Kronecker delta symbol, and $\mu$ is a chemical
potential term which we keep separate from $M$ so that we can use it
to adjust the expectation of the total number of particles.
In OpenFermion, quadratic Hamiltonians are conveniently represented and manipulated
using the QuadraticHamiltonian class, which stores $M$, $\Delta$, $\mu$ and the constant. It is specialized to exploit the properties unique to quadratic Hamiltonians. Like InteractionOperator and InteractionRDM, it inherits from the PolynomialTensor class.
The BCS mean-field model of superconductivity is a quadratic Hamiltonian. The following code constructs an instance of this model as a FermionOperator, converts it to a QuadraticHamiltonian, and then computes its ground energy:
```
from openfermion.hamiltonians import mean_field_dwave
from openfermion.transforms import get_quadratic_hamiltonian
# Set model.
x_dimension = 2
y_dimension = 2
tunneling = 2.
sc_gap = 1.
periodic = True
# Get FermionOperator.
mean_field_model = mean_field_dwave(
x_dimension, y_dimension, tunneling, sc_gap, periodic=periodic)
# Convert to QuadraticHamiltonian
quadratic_hamiltonian = get_quadratic_hamiltonian(mean_field_model)
# Compute the ground energy
ground_energy = quadratic_hamiltonian.ground_energy()
print(ground_energy)
```
Any quadratic Hamiltonian may be rewritten in the form
$$H = \sum_p \varepsilon_p b^\dagger_p b_p + \text{constant},$$
where the $b_p$ are new annihilation operators that satisfy the fermionic anticommutation relations, and which are linear combinations of the old creation and annihilation operators. This form of $H$ makes it easy to deduce its eigenvalues; they are sums of subsets of the $\varepsilon_p$, which we call the orbital energies of $H$. The following code computes the orbital energies and the constant:
```
orbital_energies, constant = quadratic_hamiltonian.orbital_energies()
print(orbital_energies)
print()
print(constant)
```
Eigenstates of quadratic hamiltonians are also known as fermionic Gaussian states, and they can be prepared efficiently on a quantum computer. One can use OpenFermion to obtain circuits for preparing these states. The following code obtains the description of a circuit which prepares the ground state (operations that can be performed in parallel are grouped together), along with a description of the starting state to which the circuit should be applied:
```
from openfermion.circuits import gaussian_state_preparation_circuit
circuit_description, start_orbitals = gaussian_state_preparation_circuit(quadratic_hamiltonian)
for parallel_ops in circuit_description:
print(parallel_ops)
print('')
print(start_orbitals)
```
In the circuit description, each elementary operation is either a tuple of the form $(i, j, \theta, \varphi)$, indicating the operation $\exp[i \varphi a_j^\dagger a_j]\exp[\theta (a_i^\dagger a_j - a_j^\dagger a_i)]$, which is a Givens rotation of modes $i$ and $j$, or the string 'pht', indicating the particle-hole transformation on the last fermionic mode, which is the operator $\mathcal{B}$ such that $\mathcal{B} a_N \mathcal{B}^\dagger = a_N^\dagger$ and leaves the rest of the ladder operators unchanged. Operations that can be performed in parallel are grouped together.
In the special case that a quadratic Hamiltonian conserves particle number ($\Delta = 0$), its eigenstates take the form
$$\lvert \Psi_S \rangle = b^\dagger_{1}\cdots b^\dagger_{N_f}\lvert \text{vac} \rangle,\qquad
b^\dagger_{p} = \sum_{k=1}^N Q_{pq}a^\dagger_q,$$
where $Q$ is an $N_f \times N$ matrix with orthonormal rows. These states are also known as Slater determinants. OpenFermion also provides functionality to obtain circuits for preparing Slater determinants starting with the matrix $Q$ as the input.
| true |
code
| 0.795906 | null | null | null | null |
|
**Pix-2-Pix Model using TensorFlow and Keras**
A port of pix-2-pix model built using TensorFlow's high level `tf.keras` API.
Note: GPU is required to make this model train quickly. Otherwise it could take hours.
Original : https://www.kaggle.com/vikramtiwari/pix-2-pix-model-using-tensorflow-and-keras/notebook
## Installations
```
requirements = """
tensorflow
drawSvg
matplotlib
numpy
scipy
pillow
#urllib
#skimage
scikit-image
#gzip
#pickle
"""
%store requirements > requirements.txt
!pip install -r requirements.txt
```
## Data Import
```
# !mkdir datasets
# URL="https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facade.tar.gz"
# TAR_FILE="./datasets/facade.tar.gz"
# TARGET_DIR="./datasets/facade/"
# !wget -N URL -O TAR_FILE
# !mkdir TARGET_DIR
# !tar -zxvf TAR_FILE -C ./datasets/
# !rm TAR_FILE
#_URL = 'https://drive.google.com/uc?export=download&id=1dnLTTT19YROjpjwZIZpJ1fxAd91cGBJv'
#path_to_zip = tf.keras.utils.get_file('pix2pix.zip', origin=_URL,extract=True)
#PATH = os.path.join(os.path.dirname(path_to_zip), 'pix2pix/')
```
## Imports
```
import os
import datetime
import imageio
import skimage
import scipy #
# from PIL import Image as Img
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from glob import glob
from IPython.display import Image
tf.logging.set_verbosity(tf.logging.ERROR)
datafolderpath = "/content/drive/My Drive/ToDos/Research/MidcurveNN/code/data/"
datasetpath = datafolderpath+ "pix2pix/datasets/pix2pix/"
# # datasetpath = "./"
# Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
!ls $datafolderpath
class DataLoader():
def __init__(self, dataset_name, img_res=(256, 256)):
self.dataset_name = dataset_name
self.img_res = img_res
def binarize(self, image):
h, w = image.shape
for i in range(h):
for j in range(w):
if image[i][j] < 195:
image[i][j] = 0
return image
def load_data(self, batch_size=1, is_testing=False):
data_type = "train" if not is_testing else "test"
path = glob(datafolderpath+'%s/datasets/%s/%s/*' % (self.dataset_name, self.dataset_name, data_type))
#path = glob(PATH + '%s/*' % (data_type))
batch_images = np.random.choice(path, size=batch_size)
imgs_A = []
imgs_B = []
for img_path in batch_images:
img = self.imread(img_path)
img = self.binarize(img)
img = np.expand_dims(img, axis=-1)
h, w, _ = img.shape
_w = int(w/2)
img_A, img_B = img[:, :_w, :], img[:, _w:, :]
# img_A = scipy.misc.imresize(img_A, self.img_res)
# img_A = np.array(Img.fromarray(img_A).resize(self.img_res))
#img_A = np.array(skimage.transform.resize(img_A,self.img_res))
# img_B = scipy.misc.imresize(img_B, self.img_res)
# img_B = np.array(Img.fromarray(img_B).resize(self.img_res))
#img_B = np.array(skimage.transform.resize(img_B,self.img_res))
# If training => do random flip
if not is_testing and np.random.random() < 0.5:
img_A = np.fliplr(img_A)
img_B = np.fliplr(img_B)
imgs_A.append(img_A)
imgs_B.append(img_B)
imgs_A = np.array(imgs_A)/127.5 - 1.
imgs_B = np.array(imgs_B)/127.5 - 1.
return imgs_A, imgs_B
def load_batch(self, batch_size=1, is_testing=False):
data_type = "train" if not is_testing else "val"
path = glob(datafolderpath+'%s/datasets/%s/%s/*' % (self.dataset_name, self.dataset_name, data_type))
#path = glob(PATH + '%s/*' % (data_type))
self.n_batches = int(len(path) / batch_size)
for i in range(self.n_batches-1):
batch = path[i*batch_size:(i+1)*batch_size]
imgs_A, imgs_B = [], []
for img in batch:
img = self.imread(img)
img = self.binarize(img)
img = np.expand_dims(img, axis=-1)
h, w, _ = img.shape
half_w = int(w/2)
img_A = img[:, :half_w, :]
img_B = img[:, half_w:, :]
# img_A = scipy.misc.imresize(img_A, self.img_res)
# img_A = np.array(Img.fromarray(img_A).resize(self.img_res))
#img_A = np.array(skimage.transform.resize(img_A,self.img_res))
# img_B = scipy.misc.imresize(img_B, self.img_res)
# img_B = np.array(Img.fromarray(img_B).resize(self.img_res))
#img_B = np.array(skimage.transform.resize(img_B,self.img_res))
if not is_testing and np.random.random() > 0.5:
img_A = np.fliplr(img_A)
img_B = np.fliplr(img_B)
imgs_A.append(img_A)
imgs_B.append(img_B)
imgs_A = np.array(imgs_A)/127.5 - 1.
imgs_B = np.array(imgs_B)/127.5 - 1.
yield imgs_A, imgs_B
def imread(self, path):
return imageio.imread(path).astype(np.float)
class Pix2Pix():
def __init__(self):
# Input shape
self.img_rows = 256
self.img_cols = 256
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# Configure data loader
self.dataset_name = 'pix2pix'
self.data_loader = DataLoader(dataset_name=self.dataset_name,
img_res=(self.img_rows, self.img_cols))
# Calculate output shape of D (PatchGAN)
patch = int(self.img_rows / 2**4)
self.disc_patch = (patch, patch, 1)
# Number of filters in the first layer of G and D
self.gf = int(self.img_rows/4) # 64
self.df = int(self.img_rows/4) # 64
optimizer = tf.keras.optimizers.Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
#-------------------------
# Construct Computational
# Graph of Generator
#-------------------------
# Build the generator
self.generator = self.build_generator()
# Input images and their conditioning images
img_A = tf.keras.layers.Input(shape=self.img_shape)
img_B = tf.keras.layers.Input(shape=self.img_shape)
# By conditioning on B generate a fake version of A
#fake_A = self.generator(img_B)
#By conditioning on A generate a fake version of B
fake_B = self.generator(img_A)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# Discriminators determines validity of translated images / condition pairs
#valid = self.discriminator([fake_A, img_B])
valid = self.discriminator([img_A, fake_B])
self.combined = tf.keras.models.Model(inputs=[img_A, img_B], outputs=[valid, fake_B])
self.combined.compile(loss=['mse', 'mae'],
loss_weights=[1, 100],
optimizer=optimizer)
def build_generator(self):
"""U-Net Generator"""
def conv2d(layer_input, filters, f_size=4, bn=True):
"""Layers used during downsampling"""
d = tf.keras.layers.Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = tf.keras.layers.LeakyReLU(alpha=0.2)(d)
if bn:
d = tf.keras.layers.BatchNormalization(momentum=0.8)(d)
return d
def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
"""Layers used during upsampling"""
u = tf.keras.layers.UpSampling2D(size=2)(layer_input)
u = tf.keras.layers.Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
if dropout_rate:
u = tf.keras.layers.Dropout(dropout_rate)(u)
u = tf.keras.layers.BatchNormalization(momentum=0.8)(u)
u = tf.keras.layers.Concatenate()([u, skip_input])
return u
# Image input
d0 = tf.keras.layers.Input(shape=self.img_shape)
# Downsampling
d1 = conv2d(d0, self.gf, bn=False)
d2 = conv2d(d1, self.gf*2)
d3 = conv2d(d2, self.gf*4)
d4 = conv2d(d3, self.gf*8)
d5 = conv2d(d4, self.gf*8)
d6 = conv2d(d5, self.gf*8)
d7 = conv2d(d6, self.gf*8)
# Upsampling
u1 = deconv2d(d7, d6, self.gf*8)
u2 = deconv2d(u1, d5, self.gf*8)
u3 = deconv2d(u2, d4, self.gf*8)
u4 = deconv2d(u3, d3, self.gf*4)
u5 = deconv2d(u4, d2, self.gf*2)
u6 = deconv2d(u5, d1, self.gf)
u7 = tf.keras.layers.UpSampling2D(size=2)(u6)
output_img = tf.keras.layers.Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u7)
return tf.keras.models.Model(d0, output_img)
def build_discriminator(self):
def d_layer(layer_input, filters, f_size=4, bn=True):
"""Discriminator layer"""
d = tf.keras.layers.Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = tf.keras.layers.LeakyReLU(alpha=0.2)(d)
if bn:
d = tf.keras.layers.BatchNormalization(momentum=0.8)(d)
return d
img_A = tf.keras.layers.Input(shape=self.img_shape)
img_B = tf.keras.layers.Input(shape=self.img_shape)
# Concatenate image and conditioning image by channels to produce input
combined_imgs = tf.keras.layers.Concatenate(axis=-1)([img_A, img_B])
d1 = d_layer(combined_imgs, self.df, bn=False)
d2 = d_layer(d1, self.df*2)
d3 = d_layer(d2, self.df*4)
d4 = d_layer(d3, self.df*8)
validity = tf.keras.layers.Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
return tf.keras.models.Model([img_A, img_B], validity)
def train(self, epochs, batch_size=1, sample_interval=50):
start_time = datetime.datetime.now()
# Adversarial loss ground truths
valid = np.ones((batch_size,) + self.disc_patch)
fake = np.zeros((batch_size,) + self.disc_patch)
for epoch in range(epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
# ---------------------
# Train Discriminator
# ---------------------
# Condition on B and generate a translated version
#fake_A = self.generator.predict(imgs_B)
#Condition on A and generate a translated version
fake_B = self.generator.predict(imgs_A)
# Train the discriminators (original images = real / generated = Fake)
d_loss_real = self.discriminator.train_on_batch([imgs_A, imgs_B], valid)
d_loss_fake = self.discriminator.train_on_batch([imgs_A, fake_B], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# -----------------
# Train Generator
# -----------------
# Train the generators
g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, imgs_B])
elapsed_time = datetime.datetime.now() - start_time
# Plot the progress
print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %f] time: %s" % (epoch, epochs,
batch_i, self.data_loader.n_batches,
d_loss[0], 100*d_loss[1],
g_loss[0],
elapsed_time))
# If at save interval => save generated image samples
if batch_i % sample_interval == 0:
self.sample_images(epoch, batch_i)
def sample_images(self, epoch, batch_i):
os.makedirs(datafolderpath+'images/%s' % self.dataset_name, exist_ok=True)
r, c = 3, 3
imgs_A, imgs_B = self.data_loader.load_data(batch_size=3, is_testing=True)
fake_B = self.generator.predict(imgs_A)
gen_imgs = np.concatenate([imgs_A, fake_B, imgs_B])
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
titles = ['Condition', 'Generated', 'Original']
fig, axs = plt.subplots(r, c, figsize=(15,15))
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt][:,:,0], cmap='gray')
axs[i, j].set_title(titles[i])
axs[i,j].axis('off')
cnt += 1
fig.savefig(datafolderpath+"images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
plt.close()
gan = Pix2Pix()
# gan.train(epochs=200, batch_size=1, sample_interval=200)
gan.train(epochs=2, batch_size=1, sample_interval=200)
# training logs are hidden in published notebook
```
Let's see how our model performed over time.
```
from PIL import Image as Img
Image('/content/drive/My Drive/ToDos/Research/MidcurveNN/code/data/images/pix2pix/0_0.png')
Img('/content/drive/My Drive/ToDos/Research/MidcurveNN/code/data/images/pix2pix/0_200.png')
```
This is the result of 2 iterations. You can train the model for more than 2 iterations and it will produce better results. Also, try this model with different datasets.
```
```
| true |
code
| 0.562777 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/lucianaribeiro/filmood/blob/master/SentimentDetectionRNN.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# Installing Tensorflow
! pip install --upgrade tensorflow
# Installing Keras
! pip install --upgrade keras
# Install other packages
! pip install --upgrade pip nltk numpy
# Importing the libraries
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras import Sequential
from keras.layers import Embedding, LSTM, Dense, Dropout
from numpy import array
# Disable tensor flow warnings for better view
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = False
# Loading dataset from IMDB
vocabulary_size = 10000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = vocabulary_size)
# Inspect a sample review and its label
print('Review')
print(X_train[6])
print('Label')
print(y_train[6])
# Review back to the original words
word2id = imdb.get_word_index()
id2word = {i: word for word, i in word2id.items()}
print('Review with words')
print([id2word.get(i, ' ') for i in X_train[6]])
print('Label')
print(y_train[6])
# Ensure that all sequences in a list have the same length
X_train = sequence.pad_sequences(X_train, maxlen=500)
X_test = sequence.pad_sequences(X_test, maxlen=500)
# Initialising the RNN
regressor=Sequential()
# Adding a first Embedding layer and some Dropout regularization
regressor.add(Embedding(vocabulary_size, 32, input_length=500))
regressor.add(Dropout(0.2))
# Adding a second LSTM layer and some Dropout regularization
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
# Adding a third LSTM layer and some Dropout regularization
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout(0.2))
# Adding a fourth LSTM layer and some Dropout regularization
regressor.add(LSTM(units = 50))
regressor.add(Dropout(0.2))
# Adding the output layer
regressor.add(Dense(1, activation='sigmoid'))
# Compiling the RNN
regressor.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
X_valid, y_valid = X_train[:64], y_train[:64]
X_train2, y_train2 = X_train[64:], y_train[64:]
regressor.fit(X_train2, y_train2, validation_data=(X_valid, y_valid), batch_size=64, epochs=25)
! pip install --upgrade nltk
import nltk
nltk.download('punkt')
from nltk import word_tokenize
# A value close to 0 means the sentiment was negative and a value close to 1 means its a positive review
word2id = imdb.get_word_index()
test=[]
for word in word_tokenize("this is simply one of the best films ever made"):
test.append(word2id[word])
test=sequence.pad_sequences([test],maxlen=500)
regressor.predict(test)
# A value close to 0 means the sentiment was negative and a value close to 1 means its a positive review
word2id = imdb.get_word_index()
test=[]
for word in word_tokenize( "the script is a real insult to the intelligence of those watching"):
test.append(word2id[word])
test=sequence.pad_sequences([test],maxlen=500)
regressor.predict(test)
```
| true |
code
| 0.660665 | null | null | null | null |
|
## Prediction sine wave function using Gaussian Process
An example for Gaussian process algorithm to predict sine wave function.
This example is from ["Gaussian Processes regression: basic introductory example"](http://scikit-learn.org/stable/auto_examples/gaussian_process/plot_gp_regression.html).
```
import numpy as np
from sklearn.gaussian_process import GaussianProcess
from matplotlib import pyplot as pl
%matplotlib inline
np.random.seed(1)
# The function to predict
def f(x):
return x*np.sin(x)
# --------------------------
# First the noiseless case
# --------------------------
# Obervations
X = np.atleast_2d([0., 1., 2., 3., 5., 6., 7., 8., 9.5]).T
y = f(X).ravel()
#X = np.atleast_2d(np.linspace(0, 100, 200)).T
# Mesh the input space for evaluations of the real function, the prediction and its MSE
x = np.atleast_2d(np.linspace(0, 10, 1000)).T
# Instanciate a Gaussian Process model
gp = GaussianProcess(corr='cubic', theta0=1e-2, thetaL=1e-4, thetaU=1e-1,
random_start=100)
# Fit to data using Maximum Likelihood Estimation of the parameters
gp.fit(X, y)
# Make the prediction on the meshed x-axis (ask for MSE as well)
y_pred, MSE = gp.predict(x, eval_MSE=True)
sigma = np.sqrt(MSE)
# Plot the function, the prediction and the 95% confidence interval based on the MSE
fig = pl.figure()
pl.plot(x, f(x), 'r:', label=u'$f(x) = x\,\sin(x)$')
pl.plot(X, y, 'r.', markersize=10, label=u'Observations')
pl.plot(x, y_pred, 'b-', label=u'Prediction')
pl.fill(np.concatenate([x, x[::-1]]),
np.concatenate([y_pred - 1.9600 * sigma,
(y_pred + 1.9600 * sigma)[::-1]]),
alpha=.5, fc='b', ec='None', label='95% confidence interval')
pl.xlabel('$x$')
pl.ylabel('$f(x)$')
pl.ylim(-10, 20)
pl.legend(loc='upper left')
# now the noisy case
X = np.linspace(0.1, 9.9, 20)
X = np.atleast_2d(X).T
# Observations and noise
y = f(X).ravel()
dy = 0.5 + 1.0 * np.random.random(y.shape)
noise = np.random.normal(0, dy)
y += noise
# Mesh the input space for evaluations of the real function, the prediction and
# its MSE
x = np.atleast_2d(np.linspace(0, 10, 1000)).T
# Instanciate a Gaussian Process model
gp = GaussianProcess(corr='squared_exponential', theta0=1e-1,
thetaL=1e-3, thetaU=1,
nugget=(dy / y) ** 2,
random_start=100)
# Fit to data using Maximum Likelihood Estimation of the parameters
gp.fit(X, y)
# Make the prediction on the meshed x-axis (ask for MSE as well)
y_pred, MSE = gp.predict(x, eval_MSE=True)
sigma = np.sqrt(MSE)
# Plot the function, the prediction and the 95% confidence interval based on
# the MSE
fig = pl.figure()
pl.plot(x, f(x), 'r:', label=u'$f(x) = x\,\sin(x)$')
pl.errorbar(X.ravel(), y, dy, fmt='r.', markersize=10, label=u'Observations')
pl.plot(x, y_pred, 'b-', label=u'Prediction')
pl.fill(np.concatenate([x, x[::-1]]),
np.concatenate([y_pred - 1.9600 * sigma,
(y_pred + 1.9600 * sigma)[::-1]]),
alpha=.5, fc='b', ec='None', label='95% confidence interval')
pl.xlabel('$x$')
pl.ylabel('$f(x)$')
pl.ylim(-10, 20)
pl.legend(loc='upper left')
pl.show()
```
| true |
code
| 0.77694 | null | null | null | null |
|
### Convolutional autoencoder
Since our inputs are images, it makes sense to use convolutional neural networks (convnets) as encoders and decoders. In practical settings, autoencoders applied to images are always convolutional autoencoders --they simply perform much better.
Let's implement one. The encoder will consist in a stack of Conv2D and MaxPooling2D layers (max pooling being used for spatial down-sampling), while the decoder will consist in a stack of Conv2D and UpSampling2D layers.
```
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras import backend as K
import numpy as np
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras import backend as K
input_img = Input(shape=(32, 32, 3)) # adapt this if using `channels_first` image data format
x1 = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x2 = MaxPooling2D((2, 2), padding='same')(x1)
x3 = Conv2D(8, (6, 6), activation='relu', padding='same')(x2)
x4 = MaxPooling2D((2, 2), padding='same')(x3)
x5 = Conv2D(8, (9, 9), activation='relu', padding='same')(x4)
encoded = MaxPooling2D((2, 2), padding='same')(x5)
# at this point the representation is (4, 4, 8) i.e. 128-dimensional
x6 = Conv2D(8, (9, 9), activation='relu', padding='same')(encoded)
x7 = UpSampling2D((2, 2))(x6)
x8 = Conv2D(8, (6, 6), activation='relu', padding='same')(x7)
x9 = UpSampling2D((2, 2))(x8)
x10 = Conv2D(16, (3, 3), activation='relu', padding='same')(x9)
x11 = UpSampling2D((2, 2))(x10)
decoded = Conv2D(3, (3, 3), activation='sigmoid', padding='same')(x11)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adagrad', loss='binary_crossentropy')
from keras.datasets import cifar10
import numpy as np
(x_train, _), (x_test, _) = cifar10.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 32, 32, 3)) # adapt this if using `channels_first` image data format
x_test = np.reshape(x_test, (len(x_test), 32, 32, 3)) # adapt this if using `channels_first` image data format
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test))
from keras.models import load_model
#autoencoder.save('cifar10_autoencoders.h5') # creates a HDF5 file 'my_model.h5'
#del model # deletes the existing model.
# returns a compiled model
# identical to the previous one
autoencoder = load_model('cifar10_autoencoders.h5')
import matplotlib.pyplot as plt
decoded_imgs = autoencoder.predict(x_test)
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(32, 32, 3))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + n + 1)
plt.imshow(decoded_imgs[i].reshape(32, 32, 3))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
```
### Plotting the weights from the first layer
```
import matplotlib.pyplot as plt
n = 8
for i in range(n):
fig = plt.figure(figsize=(1,1))
conv_1 = np.asarray(autoencoder.layers[1].get_weights())[0][:,:,0,i]
ax = fig.add_subplot(111)
plt.imshow(conv_1.transpose(), cmap = 'gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
autoencoder.layers[3].get_weights()
from keras import backend as K
# K.learning_phase() is a flag that indicates if the network is in training or
# predict phase. It allow layer (e.g. Dropout) to only be applied during training
inputs = [K.learning_phase()] + autoencoder.inputs
_layer1_f = K.function(inputs, [x2])
def convout1_f(X):
# The [0] is to disable the training phase flag
return _layer1_f([0] + [X])
#_lay_f = K.function(inputs, [x1])
#def convout1_f(X):
# The [0] is to disable the training phase flag
# return _layer1_f([0] + [X])
_layer2_f = K.function(inputs, [x4])
def convout2_f(X):
# The [0] is to disable the training phase flag
return _layer2_f([0] + [X])
_layer3_f = K.function(inputs, [encoded])
def convout3_f(X):
# The [0] is to disable the training phase flag
return _layer3_f([0] + [X])
_up_layer1_f = K.function(inputs, [x6])
def convout4_f(X):
# The [0] is to disable the training phase flag
return _up_layer1_f([0] + [X])
_up_layer2_f = K.function(inputs, [x8])
def convout5_f(X):
# The [0] is to disable the training phase flag
return _up_layer2_f([0] + [X])
_up_layer3_f = K.function(inputs, [x10])
def convout6_f(X):
# The [0] is to disable the training phase flag
return _up_layer3_f([0] + [X])
_up_layer4_f = K.function(inputs, [decoded])
def convout7_f(X):
# The [0] is to disable the training phase flag
return _up_layer4_f([0] + [X])
x2
i = 1
x = x_test[i:i+1]
```
### Visualizing the first convnet/output layer_1 with sample first test image
```
np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0).shape
#Plotting conv_1
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(4, 4, figsize=(5, 5))
for i in range(4):
for j in range(4):
axes[i,j].imshow(check[:,:,k], cmap = 'gray')
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
check.shape
```
### Visualizing the second convnet/output layer_2 with sample test image
```
i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout2_f(x)),0),0)
check.shape
#Plotting conv_2
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(2, 4, figsize=(5, 5))
for i in range(2):
for j in range(4):
axes[i,j].imshow(check[:,:,k])
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
```
### Plotting the third convnet/output layer_3 with sample test image
```
i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout3_f(x)),0),0)
check.shape
#Plotting conv_3
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(2, 4, figsize=(5, 5))
for i in range(2):
for j in range(4):
axes[i,j].imshow(check[:,:,k])
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
```
### Visualizing the fourth convnet/decoded/output layer_4 with sample test image
```
i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout4_f(x)),0),0)
check.shape
#Plotting conv_4
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(2, 4, figsize=(5, 5))
for i in range(2):
for j in range(4):
axes[i,j].imshow(check[:,:,k])
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
```
### Visualizing the fifth convnet/decoded/output layer_5 with sample test image
```
i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout5_f(x)),0),0)
check.shape
#Plotting conv_5
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(2, 4, figsize=(5, 5))
for i in range(2):
for j in range(4):
axes[i,j].imshow(check[:,:,k])
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
```
### Visualizing the sixth convnet/decoded/output layer_6 with sample test image
```
i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout6_f(x)),0),0)
check.shape
#Plotting conv_6
for i in range(4):
#i = 3
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout1_f(x)),0),0)
temp = x[0,:,:,:]
fig, axes = plt.subplots(1, 1, figsize=(3, 3))
plt.imshow(temp)
plt.show()
k = 0
while k < check.shape[2]:
#plt.figure()
#plt.subplot(231 + i)
fig, axes = plt.subplots(4, 4, figsize=(5, 5))
for i in range(4):
for j in range(4):
axes[i,j].imshow(check[:,:,k])
k += 1
#axes[0, 0].imshow(R, cmap='jet')
#plt.imshow(check[:,:,i])
plt.show()
```
### Visualizing the final decoded/output layer with sample test image
```
i = 1
x = x_test[i:i+1]
check = np.squeeze(np.squeeze(np.array(convout7_f(x)),0),0)
check.shape
#Plot final decoded layer
decoded_imgs = autoencoder.predict(x_test)
n = 4
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(32, 32, 3))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + n + 1)
plt.imshow(decoded_imgs[i].reshape(32, 32, 3))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
```
| true |
code
| 0.834693 | null | null | null | null |
|
```
%matplotlib inline
```
Sequence-to-Sequence Modeling with nn.Transformer and TorchText
===============================================================
This is a tutorial on how to train a sequence-to-sequence model
that uses the
`nn.Transformer <https://pytorch.org/docs/master/nn.html?highlight=nn%20transformer#torch.nn.Transformer>`__ module.
PyTorch 1.2 release includes a standard transformer module based on the
paper `Attention is All You
Need <https://arxiv.org/pdf/1706.03762.pdf>`__. The transformer model
has been proved to be superior in quality for many sequence-to-sequence
problems while being more parallelizable. The ``nn.Transformer`` module
relies entirely on an attention mechanism (another module recently
implemented as `nn.MultiheadAttention <https://pytorch.org/docs/master/nn.html?highlight=multiheadattention#torch.nn.MultiheadAttention>`__) to draw global dependencies
between input and output. The ``nn.Transformer`` module is now highly
modularized such that a single component (like `nn.TransformerEncoder <https://pytorch.org/docs/master/nn.html?highlight=nn%20transformerencoder#torch.nn.TransformerEncoder>`__
in this tutorial) can be easily adapted/composed.

Define the model
----------------
In this tutorial, we train ``nn.TransformerEncoder`` model on a
language modeling task. The language modeling task is to assign a
probability for the likelihood of a given word (or a sequence of words)
to follow a sequence of words. A sequence of tokens are passed to the embedding
layer first, followed by a positional encoding layer to account for the order
of the word (see the next paragraph for more details). The
``nn.TransformerEncoder`` consists of multiple layers of
`nn.TransformerEncoderLayer <https://pytorch.org/docs/master/nn.html?highlight=transformerencoderlayer#torch.nn.TransformerEncoderLayer>`__. Along with the input sequence, a square
attention mask is required because the self-attention layers in
``nn.TransformerEncoder`` are only allowed to attend the earlier positions in
the sequence. For the language modeling task, any tokens on the future
positions should be masked. To have the actual words, the output
of ``nn.TransformerEncoder`` model is sent to the final Linear
layer, which is followed by a log-Softmax function.
```
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
from torch.nn import TransformerEncoder, TransformerEncoderLayer
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, src_mask):
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, src_mask)
output = self.decoder(output)
return output
```
``PositionalEncoding`` module injects some information about the
relative or absolute position of the tokens in the sequence. The
positional encodings have the same dimension as the embeddings so that
the two can be summed. Here, we use ``sine`` and ``cosine`` functions of
different frequencies.
```
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
```
Load and batch data
-------------------
This tutorial uses ``torchtext`` to generate Wikitext-2 dataset. The
vocab object is built based on the train dataset and is used to numericalize
tokens into tensors. Starting from sequential data, the ``batchify()``
function arranges the dataset into columns, trimming off any tokens remaining
after the data has been divided into batches of size ``batch_size``.
For instance, with the alphabet as the sequence (total length of 26)
and a batch size of 4, we would divide the alphabet into 4 sequences of
length 6:
\begin{align}\begin{bmatrix}
\text{A} & \text{B} & \text{C} & \ldots & \text{X} & \text{Y} & \text{Z}
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
\begin{bmatrix}\text{A} \\ \text{B} \\ \text{C} \\ \text{D} \\ \text{E} \\ \text{F}\end{bmatrix} &
\begin{bmatrix}\text{G} \\ \text{H} \\ \text{I} \\ \text{J} \\ \text{K} \\ \text{L}\end{bmatrix} &
\begin{bmatrix}\text{M} \\ \text{N} \\ \text{O} \\ \text{P} \\ \text{Q} \\ \text{R}\end{bmatrix} &
\begin{bmatrix}\text{S} \\ \text{T} \\ \text{U} \\ \text{V} \\ \text{W} \\ \text{X}\end{bmatrix}
\end{bmatrix}\end{align}
These columns are treated as independent by the model, which means that
the dependence of ``G`` and ``F`` can not be learned, but allows more
efficient batch processing.
```
import io
import torch
from torchtext.utils import download_from_url, extract_archive
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
url = 'https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip'
test_filepath, valid_filepath, train_filepath = extract_archive(download_from_url(url))
tokenizer = get_tokenizer('basic_english')
vocab = build_vocab_from_iterator(map(tokenizer,
iter(io.open(train_filepath,
encoding="utf8"))))
def data_process(raw_text_iter):
data = [torch.tensor([vocab[token] for token in tokenizer(item)],
dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
train_data = data_process(iter(io.open(train_filepath, encoding="utf8")))
val_data = data_process(iter(io.open(valid_filepath, encoding="utf8")))
test_data = data_process(iter(io.open(test_filepath, encoding="utf8")))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def batchify(data, bsz):
# Divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size)
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
```
Functions to generate input and target sequence
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
``get_batch()`` function generates the input and target sequence for
the transformer model. It subdivides the source data into chunks of
length ``bptt``. For the language modeling task, the model needs the
following words as ``Target``. For example, with a ``bptt`` value of 2,
we’d get the following two Variables for ``i`` = 0:

It should be noted that the chunks are along dimension 0, consistent
with the ``S`` dimension in the Transformer model. The batch dimension
``N`` is along dimension 1.
```
bptt = 35
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].reshape(-1)
return data, target
```
Initiate an instance
--------------------
The model is set up with the hyperparameter below. The vocab size is
equal to the length of the vocab object.
```
ntokens = len(vocab.stoi) # the size of vocabulary
emsize = 200 # embedding dimension
nhid = 200 # the dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # the number of heads in the multiheadattention models
dropout = 0.2 # the dropout value
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
```
Run the model
-------------
`CrossEntropyLoss <https://pytorch.org/docs/master/nn.html?highlight=crossentropyloss#torch.nn.CrossEntropyLoss>`__
is applied to track the loss and
`SGD <https://pytorch.org/docs/master/optim.html?highlight=sgd#torch.optim.SGD>`__
implements stochastic gradient descent method as the optimizer. The initial
learning rate is set to 5.0. `StepLR <https://pytorch.org/docs/master/optim.html?highlight=steplr#torch.optim.lr_scheduler.StepLR>`__ is
applied to adjust the learn rate through epochs. During the
training, we use
`nn.utils.clip_grad_norm\_ <https://pytorch.org/docs/master/nn.html?highlight=nn%20utils%20clip_grad_norm#torch.nn.utils.clip_grad_norm_>`__
function to scale all the gradient together to prevent exploding.
```
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
import time
def train():
model.train() # Turn on the train mode
total_loss = 0.
start_time = time.time()
src_mask = model.generate_square_subsequent_mask(bptt).to(device)
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
optimizer.zero_grad()
if data.size(0) != bptt:
src_mask = model.generate_square_subsequent_mask(data.size(0)).to(device)
output = model(data, src_mask)
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
log_interval = 200
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
src_mask = model.generate_square_subsequent_mask(bptt).to(device)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
data, targets = get_batch(data_source, i)
if data.size(0) != bptt:
src_mask = model.generate_square_subsequent_mask(data.size(0)).to(device)
output = eval_model(data, src_mask)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
```
Loop over epochs. Save the model if the validation loss is the best
we've seen so far. Adjust the learning rate after each epoch.
```
best_val_loss = float("inf")
epochs = 3 # The number of epochs
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train()
val_loss = evaluate(model, val_data)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
scheduler.step()
```
Evaluate the model with the test dataset
-------------------------------------
Apply the best model to check the result with the test dataset.
```
test_loss = evaluate(best_model, test_data)
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
test_loss, math.exp(test_loss)))
print('=' * 89)
```
| true |
code
| 0.807271 | null | null | null | null |
|
# Plus proches voisins - évaluation
Comment évaluer la pertinence d'un modèle des plus proches voisins.
```
%matplotlib inline
from papierstat.datasets import load_wines_dataset
df = load_wines_dataset()
X = df.drop(['quality', 'color'], axis=1)
y = df['quality']
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=1)
knn.fit(X, y)
prediction = knn.predict(X)
```
Le modèle ne fait pas d'erreur sur tous les exemples de la base de vins. C'est normal puisque le plus proche voisin d'un vin est nécessairement lui-même, la note prédite et la sienne.
```
min(prediction - y), max(prediction - y)
```
Il est difficile dans ces conditions de dire si la prédiction et de bonne qualité. On pourrait estimer la qualité de la prédiction sur un vin nouveau mais il n'y en a aucun pour le moment et ce n'est pas l'ordinateur qui va les fabriquer. On peut peut-être regarder combien de fois le plus proche voisin d'un vin autre que le vin lui-même partage la même note.
```
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=2)
nn.fit(X)
distance, index = nn.kneighbors(X)
proche = index[:, 1].ravel()
note_proche = [y[i] for i in proche]
```
Il ne reste plus qu'à calculer la différence entre la note d'un vin et celle de son plus proche voisin autre que lui-même.
```
diff = y - note_proche
ax = diff.hist(bins=20, figsize=(3,3))
ax.set_title('Histogramme des différences\nde prédiction')
```
Ca marche pour les deux tiers de la base, pour le tiers restant, les notes diffèrent. On peut maintenant regarder si la distance entre ces deux voisins pourrait être corrélée à cette différence.
```
import pandas
dif = pandas.DataFrame(dict(dist=distance[:,1], diff=diff))
ax = dif.plot(x="dist", y="diff", kind='scatter', figsize=(3,3))
ax.set_title('Graphe XY - distance / différence');
```
Ce n'est pas très lisible. Essayons un autre type de graphique.
```
from seaborn import violinplot, boxplot
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(8,3))
violinplot(x="diff", y="dist", data=dif, ax=ax[0])
ax[0].set_ylim([0,25])
ax[0].set_title('Violons distribution\ndifférence / distance')
boxplot(x="diff", y="dist", data=dif, ax=ax[1])
ax[1].set_title('Boxplots distribution\ndifférence / distance')
ax[1].set_ylim([0,25]);
```
A priori le modèle n'est pas si mauvais, les voisins partageant la même note ont l'air plus proches que ceux qui ont des notes différentes.
```
import numpy
dif['abs_diff'] = numpy.abs(dif['diff'])
from seaborn import jointplot
ax = jointplot("dist", "abs_diff", data=dif[dif.dist <= 10],
kind="kde", space=0, color="g", size=4)
ax.ax_marg_y.set_title('Heatmap distribution distance / différence');
```
Les vins proches se ressemblent pour la plupart. C'est rassurant pour la suite. 61% des vins ont un voisin proche partageant la même note.
```
len(dif[dif['abs_diff'] == 0]) / dif.shape[0]
```
| true |
code
| 0.62498 | null | null | null | null |
|
# Introducción a Python: Sintaxis, Funciones y Booleanos
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://www.python.org/static/community_logos/python-logo.png" width="200px" height="200px" />
> Bueno, ya que sabemos qué es Python, y que ya tenemos las herramientas para trabajarlo, veremos cómo usarlo.
Referencias:
- https://www.kaggle.com/learn/python
___
# 1. Sintaxis básica
## 1.1 Hello, Python!
¿Qué mejor para empezar que analizar el siguiente pedazo de código?
```
work_hours = 0
print(work_hours)
# ¡A trabajar! Como una hora, no menos, como cinco
work_hours = work_hours + 5
if work_hours > 0:
print("Mucho trabajo!")
rihanna_song = "Work " * work_hours
print(rihanna_song)
```
¿Alguien adivina qué salida produce el código anterior?
Bueno, veamos línea por línea qué está pasando:
```
work_hours = 0
```
**Asignación de variable:** la línea anterior crea una variable llamada `work_hours` y le asigna el valor de `0` usando el símbolo `=`.
A diferencia de otros lenguajes (como Java o `C++`), la asignación de variables en Python:
- no necesita que la variable `work_hours` sea declarada antes de asignarle un valor;
- no necesitamos decirle a Python qué tipo de valor tendrá la variable `work_hours` (int, float, str, list...). De hecho, podríamos luego asignarle a `work_hours` otro tipo de valor como un string (cadena de caracteres) o un booleano (`True` o `False`).
```
print(work_hours)
```
**Llamado a una función**: print es una función de Python que imprime el valor pasado a su argumento. Las funciones son llamadas poniendo paréntesis luego de su nombre, y escribiendo sus argumentos (entradas) dentro de dichos paréntesis.
```
# ¡A trabajar! Como una hora, no menos, como cinco
work_hours = work_hours + 5
# work_hours += 5 # Esto es completamente equivalente a la linea de arriba
print(work_hours)
```
La primer línea es un **comentario**, los cuales en Python comienzan con el símbolo `#`.
A continuación se hace una reasignación. En este caso, estamos asignando a la variable `work_hours` un nuevo valor que involucra una operación aritmética en su propio valor previo.
```
if work_hours > 0:
print("Mucho trabajo!")
if work_hours > 10:
print("Mucho trabajo!")
```
Todavía no es tiempo de ver **condicionales**, sin embargo, se puede adivinar fácilmente lo que este pedazo de código hace, ya que se puede leer casi literal.
Notemos que la *indentación* es muy importante acá, y especifica qué parte del código pertenece al `if`. Lo que pertenece al `if` empieza por los dos puntos (`:`) y debe ir indentado en el renglón de abajo. Así que mucho cuidado con la indentación, sobretodo si han programado en otros lenguajes en los que este detalle no implica nada.
Acá vemos un tipo de variable string (cadena de caracteres). Se especifica a Python un objeto tipo string poniendo doble comilla ("") o comilla simple ('').
```
"Work " == 'Work '
rihanna_song = "Work " * work_hours
print(rihanna_song)
a = 5
a
type(a)
a *= "A "
a
type(a)
```
El operador `*` puede ser usado para multiplicar dos números (`3 * 4 evalua en 12`), pero también podemos multiplicar strings por números enteros, y obtenemos un nuevo string que repite el primero esa cantidad de veces.
En Python suceden muchas cosas de este estilo, muchos "truquillos" que ahorran mucho tiempo.
## 1.2 Tipos de números en Python y operaciones aritméticas
Ya vimos un ejemplo de una variable que contenía un número:
```
work_hours = 0
```
Sin embargo, hay varios tipos de "números". Si queremos ser más tecnicos, preguntémosle a Python qué tipo de variable es `work_hours`:
```
type(work_hours)
```
Vemos que es un entero (`int`). Hay otro tipo de número que encontramos en Python:
```
type(0.5)
```
Un número de punto flotante (float) es un número con decimales.
Ya conocemos dos funciones estándar de Python: `print()` y `type()`. La última es bien útil para preguntarle a Python "¿Qué es esto?".
Ahora veamos operaciones aritméticas:
```
# Operación suma(+)/resta(-)
5 + 8, 9 - 3
# Operación multiplicación(*)
5 * 8
# Operación división(/)
6 / 7
# Operación división entera(//)
5 // 2
# Operación módulo(%)
5 % 2
# Exponenciación(**)
2**5
# Bitwise XOR (^)
## 2 == 010
## 5 == 101
## 2^5 == 111 == 1 * 2**2 + 1 * 2**1 + 1 * 2**0 == 7
2^5
```
El orden en que se efectúan las operaciones es justo como nos lo enseñaron en primaria/secundaria:
- PEMDAS: Parentesis, Exponentes, Multiplicación/División, Adición/Sustracción.
Ante la duda siempre usar paréntesis.
```
# Ejemplo de altura con sombrero
altura_sombrero_cm = 20
mi_altura_cm = 183
# Que tan alto soy cuando me pongo sombrero?
altura_total_metros = altura_sombrero_cm + mi_altura_cm / 100
print("Altura total en metros =", altura_total_metros, "?")
# Que tan alto soy cuando me pongo sombrero?
altura_total_metros = (altura_sombrero_cm + mi_altura_cm) / 100
print("Altura total en metros =", altura_total_metros)
import this
```
### 1.2.1 Funciones para trabajar con números
`min()` y `max()` devuelven el mínimo y el máximo de sus argumentos, respectivamente...
```
# min
min(1, 8, -5, 4.4, 4.89)
# max
max(1, 8, -5, 4.4, 4.89)
```
`abs()` devuelve el valor absoluto de su argumeto:
```
# abs
abs(5), abs(-5)
```
Aparte de ser tipos de variable, `float()` e `int()` pueden ser usados como función para convertir su argumento al tipo especificado (esto lo veremos mejor cuando veamos programación orientada a objetos):
```
print(float(10))
print(int(3.33))
# They can even be called on strings!
print(int('807') + 1)
int(8.99999)
```
___
# 2. Funciones y ayuda en Python
## 2.1 Pidiendo ayuda
Ya vimos algunas funciones en la sección anterior (`print()`, `abs()`, `min()`, `max()`), pero, ¿y si se nos olvida que hace alguna de ellas?
Que no pande el cúnico, ahí estará siempre la función `help()` para venir al rescate...
```
# Usar la función help sobre la función round
help(round)
help(max)
# Función round
round(8.99999)
round(8.99999, 2)
round(146, -2)
```
### ¡CUIDADO!
A la función `help()` se le pasa como argumento el nombre de la función, **no la función evaluada**.
Si se le pasa la función evaluada, `help()` dará la ayuda sobre el resultado de la función y no sobre la función como tal.
Por ejemplo,
```
# Help de una función
help(round)
a = round(10.85)
type(a)
# Help de una función evaluada
help(round(10.85))
```
Intenten llamar la función `help()` sobre otras funciones a ver si se encuentran algo interesante...
```
# Help sobre print
help(print)
# Print
print(1, 'a', "Hola, ¿Cómo están?", sep="_este es un separador_", end=" ")
print(56)
```
## 2.2 Definiendo funciones
Las funciones por defecto de Python son de mucha utilidad. Sin embargo, pronto nos daremos cuenta que sería más útil aún definir nuestras propias funciones para reutilizarlas cada vez que las necesitemos.
Por ejemplo, creemos una función que dados tres números, devuelva la mínima diferencia absoluta entre ellos
```
# Explicar acá la forma de definir una función
def diferencia_minima(a, b, c):
diff1 = abs(a - b)
diff2 = abs(a - c)
diff3 = abs(b - c)
return min(diff1, diff2, diff3)
```
Las funciones comienzan con la palabra clave `def`, y el código indentado luego de los dos puntos `:` se corre cuando la función es llamada.
`return` es otra parablra clave que sólo se asocia con funciones. Cuando Python se encuentra un `return`, termina la función inmediatamente y devuelve el valor que hay seguido del `return`.
¿Qué hace específicamente la función que escribimos?
```
# Ejemplo: llamar la función unas 3 veces
diferencia_minima(7, -5, 8)
diferencia_minima(7.4, 7, 0)
diferencia_minima(7, 6, 8)
type(diferencia_minima)
```
Intentemos llamar `help` sobre la función
```
help(diferencia_minima)
```
Bueno, Python tampoco es tan listo como para leer código y entregar una buena descripción de la función. Esto es trabajo del diseñador de la función: incluir la documentación.
¿Cómo se hace? (Recordar añadir un ejemplo)
```
# Copiar y pegar la función, pero esta vez, incluir documentación de la misma
def diferencia_minima(a, b, c):
"""
This function determines the minimum difference between the
three arguments passed a, b, c.
Example:
>>> diferencia_minima(7, -5, 8)
1
"""
diff1 = abs(a - b)
diff2 = abs(a - c)
diff3 = abs(b - c)
return min(diff1, diff2, diff3)
# Volver a llamar el help
help(diferencia_minima)
```
Muy bien. Ahora, podemos observar que podemos llamar esta función sobre diferentes números, incluso de diferentes tipos:
- Si todos son enteros, entonces nos retornará un entero.
- Si hay algún float, nos retornará un float.
```
# Todos enteros
diferencia_minima(1, 1, 4)
# Uno o más floats
diferencia_minima(0., 0., 1)
```
Sin embargo, no todas las entradas son válidas:
```
# String: TypeError
diferencia_minima('a', 'b', 'c')
```
### 2.2.1 Funciones que no devuelven
¿Qué pasa si no incluimos el `return` en nuestra función?
```
# Ejemplo de función sin return
def imprimir(a):
print(a)
# Llamar la función un par de veces
imprimir('Hola a todos')
var = imprimir("Hola a todos")
print(var)
def write_file(a):
with open("file.txt", 'w') as f:
f.write(a)
write_file("Hola a todos")
```
### 2.2.2 Argumentos por defecto
Modificar la función `saludo` para que tenga un argumento por defecto.
```
# Función saludo con argumento por defecto
def greetings(name="Ashwin"):
# print(f"Welcome, {name}!")
# print("Welcome, " + name + "!")
# print("Welcome, ", name, "!", sep="")
print("Welcome, {}!".format(name))
# print("Welcome, %s!" %name)
greetings("Alejandro")
greetings()
```
___
# 3. Booleanos y condicionales
## 3.1 Booleanos
Python tiene un tipo de objetos de tipo `bool` los cuales pueden tomar uno de dos valores: `True` o `False`.
Ejemplo:
```
x = True
print(x)
print(type(x))
```
Normalmente no ponemos `True` o `False` directamente en nuestro código, sino que más bien los obtenemos luego de una operación booleana (operaciones que dan como resultado `True` o `False`).
Ejemplos de operaciones:
```
# ==
3 == 3.
# !=
2.99999 != 3
# <
8 < 5
# >
8 > 5
# <=
4 <= 4
# >=
5 >= 8
```
**Nota:** hay una diferencia enorme entre `==` e `=`. Con el primero estamos preguntando acerca del valor (`n==2`: ¿es `n` igual a `2`?), mientras que con el segundo asignamos un valor (`n=2`: `n` guarda el valor de `2`).
Ejemplo: escribir una función que dado un número nos diga si es impar
```
# Función para encontrar números impares
def odd(num_int):
return (num_int % 2) != 0
def odd(num_int):
if (num_int % 2) != 0:
return True
return False
# Probar la función
odd(5), odd(32)
(5, 4, 3) == ((5, 4, 3))
```
### 3.1.1 Combinando valores booleanos
Python también nos provee operadores básicos para operar con valores booleanos: `and`, `or`, y `not`.
Por ejemplo, podemos definir una función para ver si vale la pena llegar a la taquería de la esquina:
```
# Función: ¿vale la pena ir a la taquería? distancia, clima, paraguas ...
def vale_la_pena_ir_taqueria(distancia, clima, paraguas):
return (distancia <= 100) and (clima != 'lluvioso' or paraguas == True)
# Probar función
vale_la_pena_ir_taqueria(distancia=50,
clima="soleado",
paraguas=False)
vale_la_pena_ir_taqueria(distancia=50,
clima="lluvioso",
paraguas=False)
```
También podemos combinar más de dos valores: ¿cuál es el resultado de la siguiente expresión?
```
(True or True) and False
```
Uno puede tratar de memorizarse el orden de las operaciones lógicas, así como el de las aritméticas. Sin embargo, en línea con la filosofía de Python, el uso de paréntesis enriquece mucho la legibilidad y no quedan lugares a dudas.
Los siguientes códigos son equivalentes, pero, ¿cuál se lee mejor?
```
have_umbrella = True
rain_level = 4
have_hood = True
is_workday = False
prepared_for_weather = have_umbrella or rain_level < 5 and have_hood or not rain_level > 0 and is_workday
prepared_for_weather
prepared_for_weather = have_umbrella or (rain_level < 5 and have_hood) or not (rain_level > 0 and is_workday)
prepared_for_weather
prepared_for_weather = have_umbrella or ((rain_level < 5) and have_hood) or (not (rain_level > 0 and is_workday))
prepared_for_weather
prepared_for_weather = (
have_umbrella
or ((rain_level < 5) and have_hood)
or (not (rain_level > 0 and is_workday))
)
prepared_for_weather
```
___
## 3.2 Condicionales
Aunque los booleanos son útiles en si, dan su verdadero salto a la fama cuando se combinan con cláusulas condicionales, usando las palabras clave `if`, `elif`, y `else`.
Los condicionales nos permiten ejecutar ciertas partes de código dependiendo de alguna condición booleana:
```
# Función de inspección de un número
def inspeccion(num):
if num == 0:
print('El numero', num, 'es cero')
elif num > 0:
print('El numero', num, 'es positivo')
elif num < 0:
print('El numero', num, 'es negativo')
else:
print('Nunca he visto un numero como', num)
# Probar la función
inspeccion(1), inspeccion(-1), inspeccion(0)
```
- `if` y `else` se utilizan justo como en otros lenguajes.
- Por otra parte, la palabra clave `elif` es una contracción de "else if".
- El uso de `elif` y de `else` son opcionales.
- Adicionalmente, se pueden incluir tantos `elif` como se requieran.
Como en las funciones, el bloque de código correspondiente al condicional empieza luego de los dos puntos (`:`), y lo que sigue está indentado 4 espacios (tabulador). Pertenece al condicional todo lo que esté indentado hasta que encontremos una línea sin indentación.
Por ejemplo, analicemos la siguiente función:
```
def f(x):
if x > 0:
print("Only printed when x is positive; x =", x)
print("Also only printed when x is positive; x =", x)
print("Always printed, regardless of x's value; x =", x)
f(-1)
```
### 3.2.1 Conversión a booleanos
Ya vimos que la función `int()` convierte sus argumentos en enteros, y `float()` los convierte en números de punto flotante.
De manera similar `bool()` convierte sus argumentos en booleanos.
```
print(bool(1)) # Todos los números excepto el cero 0 se tratan como True
print(bool(0))
print(bool("asf")) # Todos los strings excepto el string vacío "" se tratan como True
print(bool("")) # No confundir el string vacío "" con un espacio " "
bool(" ")
```
Por ejemplo, ¿qué imprime el siguiente código?
```
if 0:
print(0)
elif "tocino":
print("tocino")
```
Las siguientes celdas son equivalentes. Sin embargo, por la legibilidad preferimos la primera:
```
x = 10
if x != 0:
print('Estoy contento')
else:
print('No estoy tan contento')
if x:
print('Estoy contento')
else:
print('No estoy tan contento')
```
### 3.2.2 Expresiones condicionales
Es muy común que una variable pueda tener dos valores, dependiendo de alguna condición:
```
# Función para ver si pasó o no dependiendo de la nota
def mensaje_calificacion(nota):
"""
Esta función imprime si pasaste o no de acuerdo a la nota obtenida.
La minima nota aprobatoria es de 6.
>>> mensaje_calificacion(9)
Pasaste la materia, con una nota de 9
>>> mensaje_calificacion(5)
Reprobaste la materia, con una nota de 5
"""
if nota >= 6:
print('Pasaste la materia, con una nota de', nota)
else:
print('Reprobaste la materia, con una nota de', nota)
mensaje_calificacion(5)
mensaje_calificacion(7)
mensaje_calificacion(10)
```
Por otra parte, Python permite escribir este tipo de expresiones en una sola línea, lo que resulta muy últil y muy legible:
```
# Función para ver si pasó o no dependiendo de la nota
def mensaje_calificacion(nota):
"""
Esta función imprime si pasaste o no de acuerdo a la nota obtenida.
>>> mensaje_calificacion(9)
Pasaste la materia, con una nota de 9
>>> mensaje_calificacion(5)
Reprobaste la materia, con una nota de 5
"""
resultado = 'Pasaste' if nota >= 6 else 'Reprobaste'
print(resultado + ' la materia, con una nota de', nota)
mensaje_calificacion(5)
mensaje_calificacion(7)
```
___
Hoy vimos:
- La sintaxis básica de Python, los tipos de variable int, float y str, y algunas funciones básicas.
- Cómo pedir ayuda de las funciones, y como construir nuestras propias funciones.
- Variables Booleanas y condicionales.
Para la próxima clase:
- Tarea 1 para el miércoles (23:59).
<script>
$(document).ready(function(){
$('div.prompt').hide();
$('div.back-to-top').hide();
$('nav#menubar').hide();
$('.breadcrumb').hide();
$('.hidden-print').hide();
});
</script>
<footer id="attribution" style="float:right; color:#808080; background:#fff;">
Created with Jupyter by jfraustro.
</footer>
| true |
code
| 0.328775 | null | null | null | null |
|
## Assigning gender based on first name
A straightforward task in natural language processing is to assign gender based on first name. Social scientists are often interested in gender inequalities and may have a dataset that lists name but not gender, such as a list of journal articles with authors in a study of gendered citation practices.
Assigning gender based on name is usually done by comparing a given name with the name's gender distribution on official records, such as the US Social Security baby name list. While this works for most names, some names, such as Gershun or Hunna, are too rare to have reliable estimates based on most available official records. Other names, such as Jian or Blake, are common among both men and women. A fourth category of names are those which are dispropriately one gender or another, but do have non-trivial numbers of a different gender, such as Cody or Kyle. For both these names and androgynous names, their are often generational differences in the gendered distribution.
The most efficient way to gender names in Python is with the `gender_guesser` library, which is based on Jörg Michael's multinational list of more than 48,000 names. The first time you use the library, you may need to install it:
`%pip install gender_guesser`
The `gender_guesser` library is set up so that first you import the gender function and then create a detector. In my case, the detector is named `d` and one parameter is passed, which instructors the detector to ignore capitalization.
```
import gender_guesser.detector as gender
d = gender.Detector(case_sensitive=False)
```
When passed a name, the detector's `get_gender` returns either 'male', 'female', 'mostly_male', 'mostly_female', 'andy' (for androgenous names), or 'unknown' (for names not in the dataset).
```
d.get_gender("Barack")
d.get_gender("Theresa")
d.get_gender("JAMIE")
d.get_gender("sidney")
d.get_gender("Tal")
```
In almost all cases, you will want to analyze a large list of names, rather than a single name. For example, the University of North Carolina, Chapel Hill makes available salary information on employees. The dataset includes name, department, position salary and years of employment, but not gender.
```
import pandas as pd
df = pd.read_csv("data/unc_salaries.csv")
df.head(10)
```
A column with name-based gender assignment can be created by applying `d.get_gender` to the first name column.
```
df["Gender"] = df["First Name"].apply(d.get_gender)
df["Gender"].value_counts(normalize=True)
```
For this dataset, the majority of the names can be gendered, while less than ten percent of names are not in the dataset.
Selecting the rows in the dataframe where gender is unknown and the listing the values can be useful for inspecting cases and evaluating the gender-name assignment process.
```
cases = df["Gender"] == "unknown"
df[cases]["First Name"].values
```
My quick interpreation of this list is that it names that are certainly rare in the US, and some are likely transliterated using a non-common English spelling. The name with missing gender are not-random and the process of creating missingness is likely correlated with other variables of interest, such as salary. This might impact a full-analysis of gender patterns, but I'll ignore that in the preliminary analysis.
If you were conducted your analysis in another statistical package, you could export your dataframe with the new gender column.
```
df.to_csv("unc_salaries_gendered.csv")
```
You could also produce some summary statistics in your notebook. For example, the pandas `groupby` method can be used to estimate median salary by gender.
```
df.groupby("Gender")["Salary"].median()
```
Comparing the male and female-coded names, this shows evidence of a large salary gap based on gender. The "mostly" and unknown categories are in the middle, but interesting the androgynous names are associated with the lowest salaries.
Grouping by gender and position may be useful in understanding the mechanisms that produce the gender gap. I also focus on just the individuals with names that are coded as male or female.
```
subset = df["Gender"].isin(["male", "female"])
df[subset].groupby(["Position", "Gender"])["Salary"].median()
```
This summary dataframe can also be plotted, which clearly shows that the median salary for male Assistant Professors is higher than the median salary of the higher ranked female Associate Professors.
```
%matplotlib inline
df[subset].groupby(['Position','Gender'])['Salary'].median().plot(kind='barh');
```
Sometimes the first name will not be it's own field, but included as part of the name column that includes the full name. In that case, you will need to create a function that extracts the first name.
In this dataframe, the `name` column is the last name, followed by a comma, and then the first name and possibly a middle name or initial. A brief function extracts the first name,
```
def gender_name(name):
"""
Extracts and genders first name when the original name is formatted "Last, First M".
Assumes a gender.Detector named `d` is already declared.
"""
first_name = name.split(", ")[-1] # grab the slide after the comma
first_name = first_name.split(" ")[0] # remove middle name/initial
gender = d.get_gender(first_name)
return gender
```
This function can now be applied to the full name column.
```
df["Gender"] = df["Full Name"].apply(gender_name)
df["Gender"].value_counts()
```
The results are the same as original gender column.
| true |
code
| 0.440048 | null | null | null | null |
|
# Day 1
```
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(np.c_[iris['data'], iris['target']], columns = iris['feature_names'] + ['species'])
df['species'] = df['species'].replace([0,1,2], iris.target_names)
df.head()
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
x
plt.scatter(x, y)
plt.show()
# 1
from sklearn.linear_model import LinearRegression
# 2
LinearRegression?
model_lr = LinearRegression(fit_intercept=True)
# 3
# x = data feature
# y = data target
x.shape
x_matriks = x[:, np.newaxis]
x_matriks.shape
# 4
# model_lr.fit(input_data, output_data)
model_lr.fit(x_matriks, y)
# Testing
x_test = np.linspace(10, 12, 15)
x_test = x_test[:, np.newaxis]
x_test
# 5
y_test = model_lr.predict(x_test)
y_test
y_train = model_lr.predict(x_matriks)
plt.scatter(x, y, color='r')
plt.plot(x, y_train, label="Model Training")
plt.plot(x_test, y_test, label="Test Result/hasil Prediksi")
plt.legend()
plt.show()
```
# Day 2
```
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(np.c_[iris['data'], iris['target']], columns = iris['feature_names'] + ['species'])
df.head()
iris
from scipy import stats
z = stats.zscore(df)
z
print(np.where(z>3))
# import class model
from sklearn.neighbors import KNeighborsClassifier
z[15][1]
# Membuat objek model dan memilih hyperparameter
# KNeighborsClassifier?
model_knn = KNeighborsClassifier(n_neighbors=6, weights='distance')
# Memisahkan data feature dan target
X = df.drop('species', axis=1)
y = df['species']
X
# Perintahkan model untuk mempelajari data dengan menggunakan method .fit()
model_knn.fit(X, y)
# predict
x_new = np.array([
[2.5, 4, 3, 0.1],
[1, 3.5, 1.7, 0.4],
[4, 1, 3, 0.3]
])
y_new = model_knn.predict(x_new)
y_new
# 0 = sentosa
# 1 = versicolor
# 2 = virginica
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.RandomState(1)
x = 10*rng.rand(50)
y = 5*x + 10 + rng.rand(50)
plt.scatter(x, y)
plt.show()
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression(fit_intercept=True)
model_lr.fit(x[:, np.newaxis], y)
y_predict = model_lr.predict(x[:, np.newaxis])
plt.plot(x, y_predict, color='r', label='Model Predicted Data')
plt.scatter(x, y, label='Actual Data')
plt.legend()
plt.show()
model_lr.coef_
model_lr.intercept_
# y = 5*x + 10 + rng.rand(50)
x = rng.rand(50, 3)
y = np.dot(x, [4, 2, 7]) + 20 # sama dengan x*4 + x*2 + x*7 + 20
x.shape
y
model_lr2 = LinearRegression(fit_intercept=True)
model_lr2.fit(x, y)
y_predict = model_lr2.predict(x)
model_lr2.coef_
model_lr2.intercept_
```
# Day 3
```
from sklearn.neighbors import KNeighborsClassifier
model_knn = KNeighborsClassifier(n_neighbors=2)
x_train = df.drop('species', axis=1)
y_train = df['species']
model_knn.fit(x_train, y_train)
# cara salah dalam mengevaluasi model
y_prediksi = model_knn.predict(x_train)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_train, y_prediksi)
score
# cara yang benar
x = df.drop('species', axis=1)
y = df['species']
y.value_counts()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=21, stratify=y)
# x -> x_train, x_test -0.3-0.2
# y -> y_train, y_test -0.3-0.2
# valuenya sama karena stratify
y_train.value_counts()
print(x_train.shape)
print(x_test.shape)
model_knn = KNeighborsClassifier(n_neighbors=2)
model_knn.fit(x_train, y_train)
y_predik = model_knn.predict(x_test)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_test, y_predik)
score
from sklearn.model_selection import cross_val_score
model_knn = KNeighborsClassifier(n_neighbors=2)
cv_result = cross_val_score(model_knn, x, y, cv=10)
cv_result.mean()
import pandas as pd
import numpy as np
colnames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
df = pd.read_csv('pima-indians-diabetes.csv', names=colnames)
df.head()
df['class'].value_counts()
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import scale
X = df.drop('class', axis=1)
Xs = scale(X)
y = df['class']
X_train, X_test, y_train, y_test = train_test_split(Xs, y, random_state=21, stratify=y, test_size=0.2)
model_lr = LogisticRegression(random_state=21)
params_grid = {
'C':np.arange(0.1, 1, 0.1), 'class_weight':[{0:x, 1:1-x} for x in np.arange(0.1, 0.9, 0.1)]
}
gscv = GridSearchCV(model_lr, params_grid, cv=10, scoring='f1')
gscv.fit(X_train, y_train)
X_test
y_pred = gscv.predict(X_test)
y_pred
from sklearn.metrics import confusion_matrix, classification_report
confusion_matrix(y_test, y_pred, labels=[1, 0])
TP = 39
FN = 15
FP = 25
TN = 75
print(classification_report(y_test, y_pred))
# menghitung nilai precisi, recall, f-1 score dari model kita dalam memprediksi data yang positif
precision = TP/(TP+FP)
recall = TP/(TP+FN)
f1score = 2 * precision * recall / (precision + recall)
print(precision)
print(recall)
print(f1score)
# menghitung nilai precisi, recall, f-1 score dari model kita dalam memprediksi data yang negatif
precision = TN/(TN+FN)
recall = TN/(TN+FP)
f1score = (precision * recall * 2) / (precision + recall)
print(precision)
print(recall)
print(f1score)
```
# Day 4
```
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
colnames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
df = pd.read_csv('pima-indians-diabetes.csv', names=colnames)
df.head()
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_validate, cross_val_score
X = df.drop('class', axis=1)
y = df['class']
model = KNeighborsClassifier(n_neighbors=5)
cv_score1 = cross_validate(model, X, y, cv=10, return_train_score=True)
cv_score2 = cross_val_score(model, X, y, cv=10)
cv_score1
cv_score2
cv_score1['test_score'].mean()
cv_score2.mean()
def knn_predict(k):
model = KNeighborsClassifier(n_neighbors=k)
score = cross_validate(model, X, y, cv=10, return_train_score=True)
train_score = score['train_score'].mean()
test_score = score['test_score'].mean()
return train_score, test_score
train_scores = []
test_scores = []
for k in range(2, 100):
# lakukan fitting
# kemudian scoring
train_score, test_score = knn_predict(k)
train_scores.append(train_score)
test_scores.append(test_score)
train_scores
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(14, 8))
ax.plot(range(2, 100), train_scores, marker='x', color='b', label='Train Scores')
ax.plot(range(2, 100), test_scores, marker='o', color='g', label='Test Scores')
ax.set_xlabel('Nilai K')
ax.set_ylabel('Score')
fig.legend()
plt.show()
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
model = KNeighborsClassifier()
param_grid = {'n_neighbors':np.arange(5, 50), 'weights':['distance', 'uniform']}
gscv = GridSearchCV(model, param_grid=param_grid, scoring='accuracy', cv=5)
gscv.fit(X, y)
gscv.best_params_
gscv.best_score_
rscv = RandomizedSearchCV(model, param_grid, n_iter=15, scoring='accuracy', cv=5)
rscv.fit(X, y)
rscv.best_params_
rscv.best_score_
```
# Day 5
```
data = {
'pendidikan_terakhir' : ['SD', 'SMP', 'SMA', 'SMP', 'SMP'],
'tempat_tinggal' : ['Bandung', 'Garut', 'Bandung', 'Cirebon', 'Jakarta'],
'status' : ['Menikah', 'Jomblo', 'Janda', 'Jomblo', 'Duda'],
'tingkat_ekonomi' : ['Kurang Mampu', 'Berkecukupan', 'Mampu', 'Sangat Mampu', 'Mampu'],
'jumlah_anak' : [1, 4, 2, 0, 3]
}
import pandas as pd
df = pd.DataFrame(data)
df.head()
df = pd.get_dummies(df, columns=['tempat_tinggal', 'status'])
df
obj_dict = {
'Kurang Mampu' : 0,
'Berkecukupan' : 1,
'Mampu' : 2,
'Sangat Mampu' : 3
}
df['tingkat_ekonomi'] = df['tingkat_ekonomi'].replace(obj_dict)
df['tingkat_ekonomi']
import numpy as np
data = {
'pendidikan_terakhir' : [np.nan, 'SMP', 'SD', 'SMP', 'SMP', 'SD', 'SMP', 'SMA', 'SD'],
'tingkat_ekonomi' : [0, 1, 2, 3, 2, 2, 1, 1, 3],
# 'jumlah_anak' : [1, np.nan, np.nan, np.nan, np.nan, np.nan, np.nan, 1, 2]
'jumlah_anak' : [1, np.nan, np.nan, 1, 1, 1, 3, 1, 2]
}
data_ts = {
'Hari' : [1, 2, 3, 4, 5],
'Jumlah' : [12, 23, np.nan, 12, 20]
}
df = pd.DataFrame(data)
df_ts = pd.DataFrame(data_ts)
df
```
5 Cara dalam menghandle missing value:
1. Drop missing value : Jumlah missing value data banyak
2. Filling with mean/median : berlaku untuk data yang bertipe numerik
3. Filling with modus : berlaku untuk data yang bertipe kategori
4. Filling with bffill atau ffill
5. KNN
```
1. # drop berdasarkan row
df.dropna(axis=0)
# 1. drop berdasarkan column
df.drop(['jumlah_anak'], axis=1)
# 2 kelemahannya kurang akurat
df['jumlah_anak'] = df['jumlah_anak'].fillna(df['jumlah_anak'].mean())
df['jumlah_anak']
df['jumlah_anak'] = df['jumlah_anak'].astype(int)
df['jumlah_anak']
df
# 3
df['pendidikan_terakhir'].value_counts()
df['pendidikan_terakhir'] = df['pendidikan_terakhir'].fillna('SMP')
df
# 4 bfill nan diisi dengan nilai sebelumnya
df_ts.fillna(method='bfill')
# 4 ffill nan diisi dengan nilai sebelumnya
df_ts.fillna(method='ffill')
df
from sklearn.impute import KNNImputer
imp = KNNImputer(n_neighbors=5)
# imp.fit_transform(df['jumlah_anak'][:, np.newaxis])
imp.fit_transform(df[['jumlah_anak', 'tingkat_ekonomi']])
import pandas as pd
colnames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
df = pd.read_csv('pima-indians-diabetes.csv', names=colnames)
df.head()
df.describe()
X = df.drop('class', axis=1)
X.head()
from sklearn.preprocessing import StandardScaler
stdscalar = StandardScaler()
datascale = stdscalar.fit_transform(X)
colnames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age']
dfscale = pd.DataFrame(datascale, columns=colnames)
dfscale
dfscale.describe()
from sklearn.preprocessing import Normalizer
normscaler = Normalizer()
datanorm = normscaler.fit_transform(X)
colnames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age']
dfnorm = pd.DataFrame(datanorm, columns=colnames)
dfnorm
dfnorm.describe()
```
1. Normalization digunakan ketika kita tidak tahu bahwa kita tidak harus memiliki asumsi bahwa data kita itu memiliki distribusi normal, dan kita memakai algoritma ML yang tidak harus mengasumsikan bentuk distribusi dari data... contohnya KNN, neural network, dll
2. Standardization apabila data kita berasumsi memiliki distribusi normal
| true |
code
| 0.617599 | null | null | null | null |
|
# Table of Contents
<p><div class="lev1 toc-item"><a href="#Simulated-annealing-in-Python" data-toc-modified-id="Simulated-annealing-in-Python-1"><span class="toc-item-num">1 </span>Simulated annealing in Python</a></div><div class="lev2 toc-item"><a href="#References" data-toc-modified-id="References-11"><span class="toc-item-num">1.1 </span>References</a></div><div class="lev2 toc-item"><a href="#See-also" data-toc-modified-id="See-also-12"><span class="toc-item-num">1.2 </span>See also</a></div><div class="lev2 toc-item"><a href="#About" data-toc-modified-id="About-13"><span class="toc-item-num">1.3 </span>About</a></div><div class="lev2 toc-item"><a href="#Algorithm" data-toc-modified-id="Algorithm-14"><span class="toc-item-num">1.4 </span>Algorithm</a></div><div class="lev2 toc-item"><a href="#Basic-but-generic-Python-code" data-toc-modified-id="Basic-but-generic-Python-code-15"><span class="toc-item-num">1.5 </span>Basic but generic Python code</a></div><div class="lev2 toc-item"><a href="#Basic-example" data-toc-modified-id="Basic-example-16"><span class="toc-item-num">1.6 </span>Basic example</a></div><div class="lev2 toc-item"><a href="#Visualizing-the-steps" data-toc-modified-id="Visualizing-the-steps-17"><span class="toc-item-num">1.7 </span>Visualizing the steps</a></div><div class="lev2 toc-item"><a href="#More-visualizations" data-toc-modified-id="More-visualizations-18"><span class="toc-item-num">1.8 </span>More visualizations</a></div>
# Simulated annealing in Python
This small notebook implements, in [Python 3](https://docs.python.org/3/), the [simulated annealing](https://en.wikipedia.org/wiki/Simulated_annealing) algorithm for numerical optimization.
## References
- The Wikipedia page: [simulated annealing](https://en.wikipedia.org/wiki/Simulated_annealing).
- It was implemented in `scipy.optimize` before version 0.14: [`scipy.optimize.anneal`](https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.optimize.anneal.html).
- [This blog post](http://apmonitor.com/me575/index.php/Main/SimulatedAnnealing).
- These Stack Overflow questions: [15853513](https://stackoverflow.com/questions/15853513/) and [19757551](https://stackoverflow.com/questions/19757551/).
## See also
- For a real-world use of simulated annealing, this Python module seems useful: [perrygeo/simanneal on GitHub](https://github.com/perrygeo/simanneal).
## About
- *Date:* 20/07/2017.
- *Author:* [Lilian Besson](https://GitHub.com/Naereen), (C) 2017.
- *Licence:* [MIT Licence](http://lbesson.mit-license.org).
----
> This notebook should be compatible with both Python versions, [2](https://docs.python.org/2/) and [3](https://docs.python.org/3/).
```
from __future__ import print_function, division # Python 2 compatibility if needed
import numpy as np
import numpy.random as rn
import matplotlib.pyplot as plt # to plot
import matplotlib as mpl
from scipy import optimize # to compare
import seaborn as sns
sns.set(context="talk", style="darkgrid", palette="hls", font="sans-serif", font_scale=1.05)
FIGSIZE = (19, 8) #: Figure size, in inches!
mpl.rcParams['figure.figsize'] = FIGSIZE
```
----
## Algorithm
The following pseudocode presents the simulated annealing heuristic.
- It starts from a state $s_0$ and continues to either a maximum of $k_{\max}$ steps or until a state with an energy of $e_{\min}$ or less is found.
- In the process, the call $\mathrm{neighbour}(s)$ should generate a randomly chosen neighbour of a given state $s$.
- The annealing schedule is defined by the call $\mathrm{temperature}(r)$, which should yield the temperature to use, given the fraction $r$ of the time budget that has been expended so far.
> **Simulated Annealing**:
>
> - Let $s$ = $s_0$
> - For $k = 0$ through $k_{\max}$ (exclusive):
> + $T := \mathrm{temperature}(k ∕ k_{\max})$
> + Pick a random neighbour, $s_{\mathrm{new}} := \mathrm{neighbour}(s)$
> + If $P(E(s), E(s_{\mathrm{new}}), T) \geq \mathrm{random}(0, 1)$:
> * $s := s_{\mathrm{new}}$
> - Output: the final state $s$
----
## Basic but generic Python code
Let us start with a very generic implementation:
```
def annealing(random_start,
cost_function,
random_neighbour,
acceptance,
temperature,
maxsteps=1000,
debug=True):
""" Optimize the black-box function 'cost_function' with the simulated annealing algorithm."""
state = random_start()
cost = cost_function(state)
states, costs = [state], [cost]
for step in range(maxsteps):
fraction = step / float(maxsteps)
T = temperature(fraction)
new_state = random_neighbour(state, fraction)
new_cost = cost_function(new_state)
if debug: print("Step #{:>2}/{:>2} : T = {:>4.3g}, state = {:>4.3g}, cost = {:>4.3g}, new_state = {:>4.3g}, new_cost = {:>4.3g} ...".format(step, maxsteps, T, state, cost, new_state, new_cost))
if acceptance_probability(cost, new_cost, T) > rn.random():
state, cost = new_state, new_cost
states.append(state)
costs.append(cost)
# print(" ==> Accept it!")
# else:
# print(" ==> Reject it...")
return state, cost_function(state), states, costs
```
----
## Basic example
We will use this to find the global minimum of the function $x \mapsto x^2$ on $[-10, 10]$.
```
interval = (-10, 10)
def f(x):
""" Function to minimize."""
return x ** 2
def clip(x):
""" Force x to be in the interval."""
a, b = interval
return max(min(x, b), a)
def random_start():
""" Random point in the interval."""
a, b = interval
return a + (b - a) * rn.random_sample()
def cost_function(x):
""" Cost of x = f(x)."""
return f(x)
def random_neighbour(x, fraction=1):
"""Move a little bit x, from the left or the right."""
amplitude = (max(interval) - min(interval)) * fraction / 10
delta = (-amplitude/2.) + amplitude * rn.random_sample()
return clip(x + delta)
def acceptance_probability(cost, new_cost, temperature):
if new_cost < cost:
# print(" - Acceptance probabilty = 1 as new_cost = {} < cost = {}...".format(new_cost, cost))
return 1
else:
p = np.exp(- (new_cost - cost) / temperature)
# print(" - Acceptance probabilty = {:.3g}...".format(p))
return p
def temperature(fraction):
""" Example of temperature dicreasing as the process goes on."""
return max(0.01, min(1, 1 - fraction))
```
Let's try!
```
annealing(random_start, cost_function, random_neighbour, acceptance_probability, temperature, maxsteps=30, debug=True);
```
Now with more steps:
```
state, c, states, costs = annealing(random_start, cost_function, random_neighbour, acceptance_probability, temperature, maxsteps=1000, debug=False)
state
c
```
----
## Visualizing the steps
```
def see_annealing(states, costs):
plt.figure()
plt.suptitle("Evolution of states and costs of the simulated annealing")
plt.subplot(121)
plt.plot(states, 'r')
plt.title("States")
plt.subplot(122)
plt.plot(costs, 'b')
plt.title("Costs")
plt.show()
see_annealing(states, costs)
```
----
## More visualizations
```
def visualize_annealing(cost_function):
state, c, states, costs = annealing(random_start, cost_function, random_neighbour, acceptance_probability, temperature, maxsteps=1000, debug=False)
see_annealing(states, costs)
return state, c
visualize_annealing(lambda x: x**3)
visualize_annealing(lambda x: x**2)
visualize_annealing(np.abs)
visualize_annealing(np.cos)
visualize_annealing(lambda x: np.sin(x) + np.cos(x))
```
In all these examples, the simulated annealing converges to a global minimum.
It can be non-unique, but it is found.
----
> That's it for today, folks!
More notebooks can be found on [my GitHub page](https://GitHub.com/Naereen/notebooks).
| true |
code
| 0.86511 | null | null | null | null |
|
# Hyper parameters
The goal here is to demonstrate how to optimise hyper-parameters of various models
The kernel is a short version of https://www.kaggle.com/mlisovyi/featureengineering-basic-model
```
max_events = None
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # needed for 3D scatter plots
%matplotlib inline
import seaborn as sns
import gc
import warnings
warnings.filterwarnings("ignore")
PATH='../input/'
import os
print(os.listdir(PATH))
```
Read in data
```
train = pd.read_csv('{}/train.csv'.format(PATH), nrows=max_events)
test = pd.read_csv('{}/test.csv'.format(PATH), nrows=max_events)
y = train['Cover_Type']
train.drop('Cover_Type', axis=1, inplace=True)
train.drop('Id', axis=1, inplace=True)
test.drop('Id', axis=1, inplace=True)
print('Train shape: {}'.format(train.shape))
print('Test shape: {}'.format(test.shape))
train.info(verbose=False)
```
## OHE into LE
Helper function to transfer One-Hot Encoding (OHE) into a Label Encoding (LE). It was taken from https://www.kaggle.com/mlisovyi/lighgbm-hyperoptimisation-with-f1-macro
The reason to convert OHE into LE is that we plan to use a tree-based model and such models are dealing well with simple interger-label encoding. Note, that this way we introduce an ordering between categories, which is not there in reality, but in practice in most use cases GBMs handle it well anyway.
```
def convert_OHE2LE(df):
tmp_df = df.copy(deep=True)
for s_ in ['Soil_Type', 'Wilderness_Area']:
cols_s_ = [f_ for f_ in df.columns if f_.startswith(s_)]
sum_ohe = tmp_df[cols_s_].sum(axis=1).unique()
#deal with those OHE, where there is a sum over columns == 0
if 0 in sum_ohe:
print('The OHE in {} is incomplete. A new column will be added before label encoding'
.format(s_))
# dummy colmn name to be added
col_dummy = s_+'_dummy'
# add the column to the dataframe
tmp_df[col_dummy] = (tmp_df[cols_s_].sum(axis=1) == 0).astype(np.int8)
# add the name to the list of columns to be label-encoded
cols_s_.append(col_dummy)
# proof-check, that now the category is complete
sum_ohe = tmp_df[cols_s_].sum(axis=1).unique()
if 0 in sum_ohe:
print("The category completion did not work")
tmp_df[s_ + '_LE'] = tmp_df[cols_s_].idxmax(axis=1).str.replace(s_,'').astype(np.uint16)
tmp_df.drop(cols_s_, axis=1, inplace=True)
return tmp_df
def train_test_apply_func(train_, test_, func_):
xx = pd.concat([train_, test_])
xx_func = func_(xx)
train_ = xx_func.iloc[:train_.shape[0], :]
test_ = xx_func.iloc[train_.shape[0]:, :]
del xx, xx_func
return train_, test_
train_x, test_x = train_test_apply_func(train, test, convert_OHE2LE)
```
One little caveat: looking through the OHE, `Soil_Type 7, 15`, are present in the test, but not in the training data
The head of the training dataset
```
train_x.head()
```
# Let's do some feature engineering
```
def preprocess(df_):
df_['fe_E_Min_02HDtH'] = (df_['Elevation']- df_['Horizontal_Distance_To_Hydrology']*0.2).astype(np.float32)
df_['fe_Distance_To_Hydrology'] = np.sqrt(df_['Horizontal_Distance_To_Hydrology']**2 +
df_['Vertical_Distance_To_Hydrology']**2).astype(np.float32)
feats_sub = [('Elevation_Min_VDtH', 'Elevation', 'Vertical_Distance_To_Hydrology'),
('HD_Hydrology_Min_Roadways', 'Horizontal_Distance_To_Hydrology', 'Horizontal_Distance_To_Roadways'),
('HD_Hydrology_Min_Fire', 'Horizontal_Distance_To_Hydrology', 'Horizontal_Distance_To_Fire_Points')]
feats_add = [('Elevation_Add_VDtH', 'Elevation', 'Vertical_Distance_To_Hydrology')]
for f_new, f1, f2 in feats_sub:
df_['fe_' + f_new] = (df_[f1] - df_[f2]).astype(np.float32)
for f_new, f1, f2 in feats_add:
df_['fe_' + f_new] = (df_[f1] + df_[f2]).astype(np.float32)
# The feature is advertised in https://douglas-fraser.com/forest_cover_management.pdf
df_['fe_Shade9_Mul_VDtH'] = (df_['Hillshade_9am'] * df_['Vertical_Distance_To_Hydrology']).astype(np.float32)
# this mapping comes from https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.info
climatic_zone = {}
geologic_zone = {}
for i in range(1,41):
if i <= 6:
climatic_zone[i] = 2
geologic_zone[i] = 7
elif i <= 8:
climatic_zone[i] = 3
geologic_zone[i] = 5
elif i == 9:
climatic_zone[i] = 4
geologic_zone[i] = 2
elif i <= 13:
climatic_zone[i] = 4
geologic_zone[i] = 7
elif i <= 15:
climatic_zone[i] = 5
geologic_zone[i] = 1
elif i <= 17:
climatic_zone[i] = 6
geologic_zone[i] = 1
elif i == 18:
climatic_zone[i] = 6
geologic_zone[i] = 7
elif i <= 21:
climatic_zone[i] = 7
geologic_zone[i] = 1
elif i <= 23:
climatic_zone[i] = 7
geologic_zone[i] = 2
elif i <= 34:
climatic_zone[i] = 7
geologic_zone[i] = 7
else:
climatic_zone[i] = 8
geologic_zone[i] = 7
df_['Climatic_zone_LE'] = df_['Soil_Type_LE'].map(climatic_zone).astype(np.uint8)
df_['Geologic_zone_LE'] = df_['Soil_Type_LE'].map(geologic_zone).astype(np.uint8)
return df_
train_x = preprocess(train_x)
test_x = preprocess(test_x)
```
# Optimise various classifiers
```
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
from sklearn.linear_model import LogisticRegression
import lightgbm as lgb
```
We subtract 1 to have the labels starting with 0, which is required for LightGBM
```
y = y-1
X_train, X_test, y_train, y_test = train_test_split(train_x, y, test_size=0.15, random_state=315, stratify=y)
```
Parameters to be used in optimisation for various models
```
def learning_rate_decay_power_0995(current_iter):
base_learning_rate = 0.15
lr = base_learning_rate * np.power(.995, current_iter)
return lr if lr > 1e-2 else 1e-2
clfs = {'rf': (RandomForestClassifier(n_estimators=200, max_depth=1, random_state=314, n_jobs=4),
{'max_depth': [20,25,30,35,40,45,50]},
{}),
'xt': (ExtraTreesClassifier(n_estimators=200, max_depth=1, max_features='auto',random_state=314, n_jobs=4),
{'max_depth': [20,25,30,35,40,45,50]},
{}),
'lgbm': (lgb.LGBMClassifier(max_depth=-1, min_child_samples=400,
random_state=314, silent=True, metric='None',
n_jobs=4, n_estimators=5000, learning_rate=0.1),
{'colsample_bytree': [0.75], 'min_child_weight': [0.1,1,10], 'num_leaves': [18, 20,22], 'subsample': [0.75]},
{'eval_set': [(X_test, y_test)],
'eval_metric': 'multi_error', 'verbose':500, 'early_stopping_rounds':100,
'callbacks':[lgb.reset_parameter(learning_rate=learning_rate_decay_power_0995)]}
)
}
gss = {}
for name, (clf, clf_pars, fit_pars) in clfs.items():
print('--------------- {} -----------'.format(name))
gs = GridSearchCV(clf, param_grid=clf_pars,
scoring='accuracy',
cv=5,
n_jobs=1,
refit=True,
verbose=True)
gs = gs.fit(X_train, y_train, **fit_pars)
print('{}: train = {:.4f}, test = {:.4f}+-{:.4f} with best params {}'.format(name,
gs.cv_results_['mean_train_score'][gs.best_index_],
gs.cv_results_['mean_test_score'][gs.best_index_],
gs.cv_results_['std_test_score'][gs.best_index_],
gs.best_params_
))
print("Valid+-Std Train : Parameters")
for i in np.argsort(gs.cv_results_['mean_test_score'])[-5:]:
print('{1:.3f}+-{3:.3f} {2:.3f} : {0}'.format(gs.cv_results_['params'][i],
gs.cv_results_['mean_test_score'][i],
gs.cv_results_['mean_train_score'][i],
gs.cv_results_['std_test_score'][i]))
gss[name] = gs
# gss = {}
# for name, (clf, clf_pars, fit_pars) in clfs.items():
# if name == 'lgbm':
# continue
# print('--------------- {} -----------'.format(name))
# gs = GridSearchCV(clf, param_grid=clf_pars,
# scoring='accuracy',
# cv=5,
# n_jobs=1,
# refit=True,
# verbose=True)
# gs = gs.fit(X_train, y_train, **fit_pars)
# print('{}: train = {:.4f}, test = {:.4f}+-{:.4f} with best params {}'.format(name,
# gs.cv_results_['mean_train_score'][gs.best_index_],
# gs.cv_results_['mean_test_score'][gs.best_index_],
# gs.cv_results_['std_test_score'][gs.best_index_],
# gs.best_params_
# ))
# print("Valid+-Std Train : Parameters")
# for i in np.argsort(gs.cv_results_['mean_test_score'])[-5:]:
# print('{1:.3f}+-{3:.3f} {2:.3f} : {0}'.format(gs.cv_results_['params'][i],
# gs.cv_results_['mean_test_score'][i],
# gs.cv_results_['mean_train_score'][i],
# gs.cv_results_['std_test_score'][i]))
# gss[name] = gs
```
| true |
code
| 0.221624 | null | null | null | null |
|
<img src="data/photutils_banner.svg">
## Photutils
- Code: https://github.com/astropy/photutils
- Documentation: http://photutils.readthedocs.org/en/stable/
- Issue Tracker: https://github.com/astropy/photutils/issues
## Photutils Overview
- Background and background noise estimation
- Source Detection and Extraction
- DAOFIND and IRAF's starfind
- **Image segmentation**
- local peak finder
- **Aperture photometry**
- PSF photometry
- PSF matching
- Centroids
- Morphological properties
- Elliptical isophote analysis
## Preliminaries
```
# initial imports
import numpy as np
import matplotlib.pyplot as plt
# change some default plotting parameters
import matplotlib as mpl
mpl.rcParams['image.origin'] = 'lower'
mpl.rcParams['image.interpolation'] = 'nearest'
mpl.rcParams['image.cmap'] = 'viridis'
# Run the %matplotlib magic command to enable inline plotting
# in the current notebook. Choose one of these:
%matplotlib inline
# %matplotlib notebook
```
### Load the data
We'll start by reading data and error arrays from FITS files. These are cutouts from the HST Extreme-Deep Field (XDF) taken with WFC3/IR in the F160W filter.
```
from astropy.io import fits
sci_fn = 'data/xdf_hst_wfc3ir_60mas_f160w_sci.fits'
rms_fn = 'data/xdf_hst_wfc3ir_60mas_f160w_rms.fits'
sci_hdulist = fits.open(sci_fn)
rms_hdulist = fits.open(rms_fn)
sci_hdulist[0].header['BUNIT'] = 'electron/s'
```
Print some info about the data.
```
sci_hdulist.info()
```
Define the data and error arrays.
```
data = sci_hdulist[0].data.astype(np.float)
error = rms_hdulist[0].data.astype(np.float)
```
Extract the data header and create a WCS object.
```
from astropy.wcs import WCS
hdr = sci_hdulist[0].header
wcs = WCS(hdr)
```
Display the data.
```
from astropy.visualization import simple_norm
norm = simple_norm(data, 'sqrt', percent=99.5)
plt.imshow(data, norm=norm)
plt.title('XDF F160W Cutout')
```
## Part 1: Aperture Photometry
Photutils provides circular, elliptical, and rectangular aperture shapes (plus annulus versions of each). These are names of the aperture classes, defined in pixel coordinates:
* `CircularAperture`
* `CircularAnnulus`
* `EllipticalAperture`
* `EllipticalAnnulus`
* `RectangularAperture`
* `RectangularAnnulus`
Along with variants of each, defined in celestial coordinates:
* `SkyCircularAperture`
* `SkyCircularAnnulus`
* `SkyEllipticalAperture`
* `SkyEllipticalAnnulus`
* `SkyRectangularAperture`
* `SkyRectangularAnnulus`
## Methods for handling aperture/pixel intersection
In general, the apertures will only partially overlap some of the pixels in the data.
There are three methods for handling the aperture overlap with the pixel grid of the data array.
<img src="data/photutils_aperture_methods.svg">
NOTE: the `subpixels` keyword is ignored for the **'exact'** and **'center'** methods.
### Perform circular-aperture photometry on some sources in the XDF
First, we define a circular aperture at a given position and radius (in pixels).
```
from photutils import CircularAperture
position = (90.73, 59.43) # (x, y) pixel position
radius = 5. # pixels
aperture = CircularAperture(position, r=radius)
aperture
print(aperture)
```
We can plot the aperture on the data using the aperture `plot()` method:
```
plt.imshow(data, norm=norm)
aperture.plot(color='red', lw=2)
```
Now let's perform photometry on the data using the `aperture_photometry()` function. **The default aperture method is 'exact'.**
Also note that the input data is assumed to have zero background. If that is not the case, please see the documentation for the `photutils.background` subpackage for tools to help subtract the background.
See the `photutils_local_background.ipynb` notebook for examples of local background subtraction.
The background was already subtracted for our XDF example data.
```
from photutils import aperture_photometry
phot = aperture_photometry(data, aperture)
phot
```
The output is an Astropy `QTable` (Quantity Table) with sum of data values within the aperture (using the defined pixel overlap method).
The table also contains metadata, which is accessed by the `meta` attribute of the table. The metadata is stored as a python (ordered) dictionary:
```
phot.meta
phot.meta['version']
```
Aperture photometry using the **'center'** method gives a slightly different (and less accurate) answer:
```
phot = aperture_photometry(data, aperture, method='center')
phot
```
Now perform aperture photometry using the **'subpixel'** method with `subpixels=5`:
These parameters are equivalent to SExtractor aperture photometry.
```
phot = aperture_photometry(data, aperture, method='subpixel', subpixels=5)
phot
```
## Photometric Errors
We can also input an error array to get the photometric errors.
```
phot = aperture_photometry(data, aperture, error=error)
phot
```
The error array in our XDF FITS file represents only the background error. If we want to include the Poisson error of the source we need to calculate the **total** error:
$\sigma_{\mathrm{tot}} = \sqrt{\sigma_{\mathrm{b}}^2 +
\frac{I}{g}}$
where $\sigma_{\mathrm{b}}$ is the background-only error,
$I$ are the data values, and $g$ is the "effective gain".
The "effective gain" is the value (or an array if it's variable across an image) needed to convert the data image to count units (e.g. electrons or photons), where Poisson statistics apply.
Photutils provides a `calc_total_error()` function to perform this calculation.
```
# this time include the Poisson error of the source
from photutils.utils import calc_total_error
# our data array is in units of e-/s
# so the "effective gain" should be the exposure time
eff_gain = hdr['TEXPTIME']
tot_error = calc_total_error(data, error, eff_gain)
phot = aperture_photometry(data, aperture, error=tot_error)
phot
```
The total error increased only slightly because this is a small faint source.
## Units
We can also input the data (and error) units via the `unit` keyword.
```
# input the data units
import astropy.units as u
unit = u.electron / u.s
phot = aperture_photometry(data, aperture, error=tot_error, unit=unit)
phot
phot['aperture_sum']
```
Instead of inputting units via the units keyword, `Quantity` inputs for data and error are also allowed.
```
phot = aperture_photometry(data * unit, aperture, error=tot_error * u.adu)
phot
```
The `unit` will not override the data or error unit.
```
phot = aperture_photometry(data * unit, aperture, error=tot_error * u.adu, unit=u.photon)
phot
```
## Performing aperture photometry at multiple positions
Now let's perform aperture photometry for three sources (all with the same aperture size). We simply define three (x, y) positions.
```
positions = [(90.73, 59.43), (73.63, 139.41), (43.62, 61.63)]
radius = 5.
apertures = CircularAperture(positions, r=radius)
```
Let's plot these three apertures on the data.
```
plt.imshow(data, norm=norm)
apertures.plot(color='red', lw=2)
```
Now let's perform aperture photometry.
```
phot = aperture_photometry(data, apertures, error=tot_error, unit=unit)
phot
```
Each source is a row in the table and is given a unique **id** (the first column).
## Adding columns to the photometry table
We can add columns to the photometry table. Let's calculate the signal-to-noise (SNR) ratio of our sources and add it as a new column to the table.
```
snr = phot['aperture_sum'] / phot['aperture_sum_err'] # units will cancel
phot['snr'] = snr
phot
```
Now calculate the F160W AB magnitude and add it to the table.
```
f160w_zpt = 25.9463
# NOTE that the log10() function can be applied only to dimensionless quantities
# so we use the value() method to get the number value of the aperture sum
abmag = -2.5 * np.log10(phot['aperture_sum'].value) + f160w_zpt
phot['abmag'] = abmag
phot
```
Now, using the WCS defined above, calculate the sky coordinates for these objects and add it to the table.
```
from astropy.wcs.utils import pixel_to_skycoord
# convert pixel positions to sky coordinates
x, y = np.transpose(positions)
coord = pixel_to_skycoord(x, y, wcs)
# we can add the astropy SkyCoord object directly to the table
phot['sky coord'] = coord
phot
```
We can also add separate RA and Dec columns, if preferred.
```
phot['ra_icrs'] = coord.icrs.ra
phot['dec_icrs'] = coord.icrs.dec
phot
```
If we write the table to an ASCII file using the ECSV format we can read it back in preserving all of the units, metadata, and SkyCoord objects.
```
phot.write('my_photometry.txt', format='ascii.ecsv')
# view the table on disk
!cat my_photometry.txt
```
Now read the table in ECSV format.
```
from astropy.table import QTable
tbl = QTable.read('my_photometry.txt', format='ascii.ecsv')
tbl
tbl.meta
tbl['aperture_sum'] # Quantity array
tbl['sky coord'] # SkyCoord array
```
## Aperture photometry using Sky apertures
First, let's define the sky coordinates by converting our pixel coordinates.
```
positions = [(90.73, 59.43), (73.63, 139.41), (43.62, 61.63)]
x, y = np.transpose(positions)
coord = pixel_to_skycoord(x, y, wcs)
coord
```
Now define circular apertures in sky coordinates.
For sky apertures, the aperture radius must be a `Quantity`, in either pixel or angular units.
```
from photutils import SkyCircularAperture
radius = 5. * u.pix
sky_apers = SkyCircularAperture(coord, r=radius)
sky_apers.r
radius = 0.5 * u.arcsec
sky_apers = SkyCircularAperture(coord, r=radius)
sky_apers.r
```
When using a sky aperture in angular units, `aperture_photometry` needs the WCS transformation, which can be provided in two ways.
```
# via the wcs keyword
phot = aperture_photometry(data, sky_apers, wcs=wcs)
phot
# or via a FITS hdu (i.e. header and data) as the input "data"
phot = aperture_photometry(sci_hdulist[0], sky_apers)
phot
```
## More on Aperture Photometry in the Extended notebook:
- Bad pixel masking
- Encircled flux
- Aperture photometry at multiple positions using multiple apertures
Also see the local background subtraction notebook (`photutils_local_backgrounds.ipynb`).
## Part 2: Image Segmentation
Image segmentation is the process where sources are identified and labeled in an image.
The sources are detected by using a S/N threshold level and defining the minimum number of pixels required within a source.
First, let's define a threshold image at 2$\sigma$ (per pixel) above the background.
```
bkg = 0. # background level in this image
nsigma = 2.
threshold = bkg + (nsigma * error) # this should be background-only error
```
Now let's detect "8-connected" sources of minimum size 5 pixels where each pixel is 2$\sigma$ above the background.
"8-connected" pixels touch along their edges or corners. "4-connected" pixels touch along their edges. For reference, SExtractor uses "8-connected" pixels.
The result is a segmentation image (`SegmentationImage` object). The segmentation image is the isophotal footprint of each source above the threshold.
```
from photutils import detect_sources
npixels = 5
segm = detect_sources(data, threshold, npixels)
print('Found {0} sources'.format(segm.nlabels))
```
Display the segmentation image.
```
from photutils.utils import random_cmap
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
ax1.imshow(data, norm=norm)
lbl1 = ax1.set_title('Data')
ax2.imshow(segm, cmap=segm.cmap())
lbl2 = ax2.set_title('Segmentation Image')
```
It is better to filter (smooth) the data prior to source detection.
Let's use a 5x5 Gaussian kernel with a FWHM of 2 pixels.
```
from astropy.convolution import Gaussian2DKernel
from astropy.stats import gaussian_fwhm_to_sigma
sigma = 2.0 * gaussian_fwhm_to_sigma # FWHM = 2 pixels
kernel = Gaussian2DKernel(sigma, x_size=5, y_size=5)
kernel.normalize()
ssegm = detect_sources(data, threshold, npixels, filter_kernel=kernel)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
ax1.imshow(segm, cmap=segm.cmap())
lbl1 = ax1.set_title('Original Data')
ax2.imshow(ssegm, cmap=ssegm.cmap())
lbl2 = ax2.set_title('Smoothed Data')
```
### Source deblending
Note above that some of our detected sources were blended. We can deblend them using the `deblend_sources()` function, which uses a combination of multi-thresholding and watershed segmentation.
```
from photutils import deblend_sources
segm2 = deblend_sources(data, ssegm, npixels, filter_kernel=kernel,
contrast=0.001, nlevels=32)
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15, 8))
ax1.imshow(data, norm=norm)
ax1.set_title('Data')
ax2.imshow(ssegm, cmap=ssegm.cmap())
ax2.set_title('Original Segmentation Image')
ax3.imshow(segm2, cmap=segm2.cmap())
ax3.set_title('Deblended Segmentation Image')
print('Found {0} sources'.format(segm2.max))
```
## Measure the photometry and morphological properties of detected sources
```
from photutils import source_properties
catalog = source_properties(data, segm2, error=error, wcs=wcs)
```
`catalog` is a `SourceCatalog` object. It behaves like a list of `SourceProperties` objects, one for each source.
```
catalog
catalog[0] # the first source
catalog[0].xcentroid # the xcentroid of the first source
```
Please go [here](http://photutils.readthedocs.org/en/latest/api/photutils.segmentation.SourceProperties.html#photutils.segmentation.SourceProperties) to see the complete list of available source properties.
We can create a Table of isophotal photometry and morphological properties using the ``to_table()`` method of `SourceCatalog`:
```
tbl = catalog.to_table()
tbl
```
Additional properties (not stored in the table) can be accessed directly via the `SourceCatalog` object.
```
# get a single object (id=12)
obj = catalog[11]
obj.id
obj
```
Let's plot the cutouts of the data and error images for this source.
```
fig, ax = plt.subplots(figsize=(12, 8), ncols=3)
ax[0].imshow(obj.make_cutout(segm2.data))
ax[0].set_title('Source id={} Segment'.format(obj.id))
ax[1].imshow(obj.data_cutout_ma)
ax[1].set_title('Source id={} Data'.format(obj.id))
ax[2].imshow(obj.error_cutout_ma)
ax[2].set_title('Source id={} Error'.format(obj.id))
```
## More on Image Segmentation in the Extended notebook:
- Define a subset of source labels
- Define a subset of source properties
- Additional sources properties, such a cutout images
- Define the approximate isophotal ellipses for each source
## Also see the two notebooks on Photutils PSF-fitting photometry:
- `gaussian_psf_photometry.ipynb`
- `image_psf_photometry_withNIRCam.ipynb`
| true |
code
| 0.69333 | null | null | null | null |
|
# cadCAD Tutorials: The Robot and the Marbles, part 3
In parts [1](../robot-marbles-part-1/robot-marbles-part-1.ipynb) and [2](../robot-marbles-part-2/robot-marbles-part-2.ipynb) we introduced the 'language' in which a system must be described in order for it to be interpretable by cadCAD and some of the basic concepts of the library:
* State Variables
* Timestep
* State Update Functions
* Partial State Update Blocks
* Simulation Configuration Parameters
* Policies
In this notebook we'll look at how subsystems within a system can operate in different frequencies. But first let's copy the base configuration with which we ended Part 2. Here's the description of that system:
__The robot and the marbles__
* Picture a box (`box_A`) with ten marbles in it; an empty box (`box_B`) next to the first one; and __two__ robot arms capable of taking a marble from any one of the boxes and dropping it into the other one.
* The robots are programmed to take one marble at a time from the box containing the largest number of marbles and drop it in the other box. They repeat that process until the boxes contain an equal number of marbles.
* The robots act simultaneously; in other words, they assess the state of the system at the exact same time, and decide what their action will be based on that information.
```
%%capture
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# List of all the state variables in the system and their initial values
genesis_states = {
'box_A': 10, # as per the description of the example, box_A starts out with 10 marbles in it
'box_B': 0 # as per the description of the example, box_B starts out empty
}
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# Settings of general simulation parameters, unrelated to the system itself
# `T` is a range with the number of discrete units of time the simulation will run for;
# `N` is the number of times the simulation will be run (Monte Carlo runs)
# In this example, we'll run the simulation once (N=1) and its duration will be of 10 timesteps
# We'll cover the `M` key in a future article. For now, let's omit it
sim_config_dict = {
'T': range(10),
'N': 1,
#'M': {}
}
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# We specify the robot arm's logic in a Policy Function
def robot_arm(params, step, sH, s):
add_to_A = 0
if (s['box_A'] > s['box_B']):
add_to_A = -1
elif (s['box_A'] < s['box_B']):
add_to_A = 1
return({'add_to_A': add_to_A, 'add_to_B': -add_to_A})
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# We make the state update functions less "intelligent",
# ie. they simply add the number of marbles specified in _input
# (which, per the policy function definition, may be negative)
def increment_A(params, step, sH, s, _input):
y = 'box_A'
x = s['box_A'] + _input['add_to_A']
return (y, x)
def increment_B(params, step, sH, s, _input):
y = 'box_B'
x = s['box_B'] + _input['add_to_B']
return (y, x)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# In the Partial State Update Blocks,
# the user specifies if state update functions will be run in series or in parallel
# and the policy functions that will be evaluated in that block
partial_state_update_blocks = [
{
'policies': { # The following policy functions will be evaluated and their returns will be passed to the state update functions
'robot_arm_1': robot_arm,
'robot_arm_2': robot_arm
},
'variables': { # The following state variables will be updated simultaneously
'box_A': increment_A,
'box_B': increment_B
}
}
]
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#imported some addition utilities to help with configuration set-up
from cadCAD.configuration.utils import config_sim
from cadCAD.configuration import Experiment
from cadCAD import configs
del configs[:] # Clear any prior configs
exp = Experiment()
c = config_sim(sim_config_dict)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# The configurations above are then packaged into a `Configuration` object
exp.append_configs(initial_state=genesis_states, #dict containing variable names and initial values
partial_state_update_blocks=partial_state_update_blocks, #dict containing state update functions
sim_configs=c #preprocessed dictionaries containing simulation parameters
)
from cadCAD.engine import ExecutionMode, ExecutionContext, Executor
exec_mode = ExecutionMode()
local_mode_ctx = ExecutionContext(exec_mode.local_mode)
simulation = Executor(local_mode_ctx, configs) # Pass the configuration object inside an array
raw_result, tensor, sessions = simulation.execute() # The `execute()` method returns a tuple; its first elements contains the raw results
%matplotlib inline
import pandas as pd
df = pd.DataFrame(raw_result)
df.plot('timestep', ['box_A', 'box_B'], grid=True,
xticks=list(df['timestep'].drop_duplicates()),
colormap = 'RdYlGn',
yticks=list(range(1+(df['box_A']+df['box_B']).max())));
```
# Asynchronous Subsystems
We have defined that the robots operate simultaneously on the boxes of marbles. But it is often the case that agents within a system operate asynchronously, each having their own operation frequencies or conditions.
Suppose that instead of acting simultaneously, the robots in our examples operated in the following manner:
* Robot 1: acts once every 2 timesteps
* Robot 2: acts once every 3 timesteps
One way to simulate the system with this change is to introduce a check of the current timestep before the robots act, with the definition of separate policy functions for each robot arm.
```
%%capture
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# We specify each of the robots logic in a Policy Function
robots_periods = [2,3] # Robot 1 acts once every 2 timesteps; Robot 2 acts once every 3 timesteps
def get_current_timestep(cur_substep, s):
if cur_substep == 1:
return s['timestep']+1
return s['timestep']
def robot_arm_1(params, step, sH, s):
_robotId = 1
if get_current_timestep(step, s)%robots_periods[_robotId-1]==0: # on timesteps that are multiple of 2, Robot 1 acts
return robot_arm(params, step, sH, s)
else:
return({'add_to_A': 0, 'add_to_B': 0}) # for all other timesteps, Robot 1 doesn't interfere with the system
def robot_arm_2(params, step, sH, s):
_robotId = 2
if get_current_timestep(step, s)%robots_periods[_robotId-1]==0: # on timesteps that are multiple of 3, Robot 2 acts
return robot_arm(params, step, sH, s)
else:
return({'add_to_A': 0, 'add_to_B': 0}) # for all other timesteps, Robot 2 doesn't interfere with the system
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# In the Partial State Update Blocks,
# the user specifies if state update functions will be run in series or in parallel
# and the policy functions that will be evaluated in that block
partial_state_update_blocks = [
{
'policies': { # The following policy functions will be evaluated and their returns will be passed to the state update functions
'robot_arm_1': robot_arm_1,
'robot_arm_2': robot_arm_2
},
'variables': { # The following state variables will be updated simultaneously
'box_A': increment_A,
'box_B': increment_B
}
}
]
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
del configs[:] # Clear any prior configs
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# The configurations above are then packaged into a `Configuration` object
exp.append_configs(initial_state=genesis_states, #dict containing variable names and initial values
partial_state_update_blocks=partial_state_update_blocks, #dict containing state update functions
sim_configs=c #preprocessed dictionaries containing simulation parameters
)
executor = Executor(local_mode_ctx, configs) # Pass the configuration object inside an array
raw_result, tensor, sessions = executor.execute() # The `execute()` method returns a tuple; its first elements contains the raw results
simulation_result = pd.DataFrame(raw_result)
simulation_result.plot('timestep', ['box_A', 'box_B'],
grid=True,
xticks=list(simulation_result['timestep'].drop_duplicates()),
yticks=list(range(1+max(simulation_result['box_A'].max(),simulation_result['box_B'].max()))),
colormap = 'RdYlGn'
)
```
Let's take a step-by-step look at what the simulation tells us:
* Timestep 1: the number of marbles in the boxes does not change, as none of the robots act
* Timestep 2: Robot 1 acts, Robot 2 doesn't; resulting in one marble being moved from box A to box B
* Timestep 3: Robot 2 acts, Robot 1 doesn't; resulting in one marble being moved from box A to box B
* Timestep 4: Robot 1 acts, Robot 2 doesn't; resulting in one marble being moved from box A to box B
* Timestep 5: the number of marbles in the boxes does not change, as none of the robots act
* Timestep 6: Robots 1 __and__ 2 act, as 6 is a multiple of 2 __and__ 3; resulting in two marbles being moved from box A to box B and an equilibrium being reached.
| true |
code
| 0.371051 | null | null | null | null |
|
# Deep Convolutional Neural Networks
In this assignment, we will be using the Keras library to build, train, and evaluate some *relatively simple* Convolutional Neural Networks to demonstrate how adding layers to a network can improve accuracy, yet are more computationally expensive.
The purpose of this assignment is for you to demonstrate understanding of the appropriate structure of a convolutional neural network and to give you an opportunity to research any parameters or elements of CNNs that you don't fully understand.
We will be using the cifar100 dataset for this assignment, however, in order to keep the dataset size small enough to be trained in a reasonable amount of time in a Google Colab, we will only be looking at two classes from the dataset - cats and dogs.

```
# Import important libraries and methods
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras import backend as K
if K.backend()=='tensorflow':
K.set_image_dim_ordering("th")
# input image dimensions
img_rows, img_cols = 32, 32
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# Important Hyperparameters
batch_size = 32
num_classes = 2
epochs = 100
# Plot sample image from each cifar10 class.
class_names = ['airplane','automobile','bird','cat','deer','dog','frog','horse','shop','truck']
fig = plt.figure(figsize=(8,3))
for i in range(10):
ax = fig.add_subplot(2, 5, 1 + i, xticks=[], yticks=[])
idx = np.where(y_train[:]==i)[0]
features_idx = x_train[idx,::]
img_num = np.random.randint(features_idx.shape[0])
im = np.transpose(features_idx[img_num,::],(1,2,0))
ax.set_title(class_names[i])
plt.imshow(im)
plt.show()
# Only look at cats [=3] and dogs [=5]
train_picks = np.ravel(np.logical_or(y_train==3,y_train==5))
test_picks = np.ravel(np.logical_or(y_test==3,y_test==5))
y_train = np.array(y_train[train_picks]==5,dtype=int)
y_test = np.array(y_test[test_picks]==5,dtype=int)
x_train = x_train[train_picks]
x_test = x_test[test_picks]
# check for image_data format and format image shape accordingly
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 3, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 3, img_rows, img_cols)
input_shape = (3, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 3)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 3)
input_shape = (img_rows, img_cols, 3)
# Normalize pixel values between 0 and 1
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# Convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(np.ravel(y_train), num_classes)
y_test = keras.utils.to_categorical(np.ravel(y_test), num_classes)
# Check train and test lengths
print('y_train length:', len(y_train))
print('x_train length:', len(x_train))
print('y_test length:', len(y_test))
print('x_test length:', len(x_test))
```
# Model #1
This model will be almost as simple as we can make it. It should look something like:
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final dropout layer
---
* Flatten
* Fully-Connected (Dense)
* Dropout - use .5 this time
* Fully-Connected (Dense layer where # neurons = # final classes/labels)
Then compile the model using categorical_crossentropy as your loss metric. Use the Adam optimizer, and accuracy as your overall scoring metric.
If you're lost when you get to this point, make sure you look at the lecture colab for somewhat similar sample code.
```
x_train.shape
model1 = Sequential()
model1.add(Conv2D(8, (3,3), activation='relu', input_shape=(3, 32, 32)))
model1.add(Dropout(.25))
model1.add(Conv2D(16, (3,3), activation='relu'))
model1.add(Dropout(.25))
model1.add(MaxPooling2D((2,2)))
model1.add(Flatten())
model1.add(Dense(64, activation='relu'))
model1.add(Dropout(0.5))
model1.add(Dense(2, activation='softmax'))
model1.summary()
model1.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
```
## Fit your model
Fit your model and save it to a new variable so that we can access the .history value to make a plot of our training and validation accuracies by epoch.
```
model1_training = model1.fit(x_train, y_train, epochs=50, batch_size=128, validation_split=0.1)
```
## Plot Training and Validation Accuracies
Use your matplotlib skills to give us a nice line graph of both training and validation accuracies as the number of epochs increases. Don't forget your legend, axis and plot title.
```
def train_val_metrics(epochs, model_training):
epochs = range(1, epochs+1)
metrics = model_training.history
train_loss = metrics['loss']
train_acc = metrics['acc']
val_loss = metrics['val_loss']
val_acc = metrics['val_acc']
ax = plt.subplot(211)
train, = ax.plot(epochs, train_loss)
val, = ax.plot(epochs, val_loss)
ax.legend([train, val], ['training', 'validation'])
ax.set(xlabel='epochs', ylabel='categorical cross-entropy loss')
ax2 = plt.subplot(212)
train2, = ax2.plot(epochs, train_acc)
val2, = ax2.plot(epochs, val_acc)
ax2.legend([train2, val2], ['training', 'validation'])
ax2.set(xlabel='epochs', ylabel='accuracy')
train_val_metrics(50, model1_training)
```
The model begins to overfit around epoch 20 or so. Early stopping would be useful here.

# Model #2
Lets add an additional set of convolutional->activation->pooling to this model:
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final layer
---
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final layer
---
* Flatten
* Fully-Connected (Dense)
* Dropout - use .5 this time
* Fully-Connected (Dense layer where # neurons = # final classes/labels)
Again, compile the model using categorical_crossentropy as your loss metric and use the Adam optimizer, and accuracy as your overall scoring metric.
```
model2 = Sequential()
model2.add(Conv2D(8, (3,3), activation='relu', input_shape=(3, 32, 32)))
model2.add(Dropout(.25))
model2.add(Conv2D(16, (3,3), activation='relu'))
model2.add(Dropout(.25))
model2.add(MaxPooling2D((2,2)))
model2.add(Conv2D(16, (3,3), activation='relu', input_shape=(3, 32, 32)))
model2.add(Dropout(.25))
model2.add(Conv2D(32, (3,3), activation='relu'))
model2.add(Dropout(.25))
model2.add(MaxPooling2D((2,2)))
model2.add(Flatten())
model2.add(Dense(64, activation='relu'))
model2.add(Dropout(0.5))
model2.add(Dense(2, activation='softmax'))
model2.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model2.summary()
```
## Fit your model
Fit your model and save it to a new variable so that we can access the .history value to make a plot of our training and validation accuracies by epoch.
```
model2_training = model2.fit(x_train, y_train, epochs=50, batch_size=128, validation_split=0.1)
```
## Plot Training and Validation Accuracies
Use your matplotlib skills to give us a nice line graph of both training and validation accuracies as the number of epochs increases. Don't forget your legend, axis and plot title.
```
train_val_metrics(50, model2_training)
```
The model continues to find loss and accuracy improvements, suggesting that it could be trained for more epochs.

# Model #3
Finally, one more set of convolutional/activation/pooling:
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final layer
---
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final layer
---
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Conv2D - kernel_size = (3,3)
* Relu Activation
* Max Pooling - pool_size = (2,2)
* Dropout - use .25 for all layers but the final layer
---
* Flatten
* Fully-Connected (Dense)
* Dropout - use .5 this time
* Fully-Connected (Dense layer where # neurons = # final classes/labels)
Again, compile the model using categorical_crossentropy as your loss metric and use the Adam optimizer, and accuracy as your overall scoring metric.
```
model3 = Sequential()
model3.add(Conv2D(8, (3,3), activation='relu', input_shape=(3, 32, 32)))
model3.add(Dropout(.25))
model3.add(Conv2D(16, (3,3), activation='relu'))
model3.add(Dropout(.25))
model3.add(MaxPooling2D((2,2), strides=1))
model3.add(Conv2D(16, (3,3), activation='relu', input_shape=(3, 32, 32)))
model3.add(Dropout(.25))
model3.add(Conv2D(32, (3,3), activation='relu'))
model3.add(Dropout(.25))
model3.add(MaxPooling2D((2,2), strides=1))
model3.add(Conv2D(32, (3,3), activation='relu', input_shape=(3, 32, 32)))
model3.add(Dropout(.25))
model3.add(Conv2D(64, (3,3), activation='relu'))
model3.add(Dropout(.25))
model3.add(MaxPooling2D(2,2))
model3.add(Flatten())
model3.add(Dense(128, activation='relu'))
model3.add(Dropout(0.5))
model3.add(Dense(2, activation='softmax'))
model3.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model3.summary()
```
## Fit your model
Fit your model and save it to a new variable so that we can access the .history value to make a plot of our training and validation accuracies by epoch.
```
model3_training = model3.fit(x_train, y_train, epochs=50, batch_size=128, validation_split=0.1)
```
## Plot Training and Validation Accuracies
Use your matplotlib skills to give us a nice line graph of both training and validation accuracies as the number of epochs increases. Don't forget your legend, axis and plot title.
```
train_val_metrics(50, model3_training)
```
# Stretch Goal:
## Use other classes from Cifar10
Try using different classes from the Cifar10 dataset or use all 10. You might need to sample the training data or limit the number of epochs if you decide to use the entire dataset due to processing constraints.
## Hyperparameter Tune Your Model
If you have successfully complete shown how increasing the depth of a neural network can improve its accuracy, and you feel like you have a solid understanding of all of the different parts of CNNs, try hyperparameter tuning your strongest model to see how much additional accuracy you can squeeze out of it. This will also give you a chance to research the different hyperparameters as well as their significance/purpose. (There are lots and lots)
---
Here's a helpful article that will show you how to get started using GridSearch to hyperaparameter tune your CNN. (should you desire to use that method):
[Grid Search Hyperparameters for Deep Learning Models in Python With Keras](https://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/)
| true |
code
| 0.698329 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/spyrosviz/Injury_Prediction_MidLong_Distance_Runners/blob/main/ML%20models/Models_Runners_Injury_Prediction.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# Import Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import GradientBoostingClassifier, BaggingClassifier
from xgboost.sklearn import XGBClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV, StratifiedKFold
from sklearn.metrics import accuracy_score, confusion_matrix, roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
import itertools
from collections import Counter
!pip install imbalanced-learn
from imblearn.over_sampling import SMOTE, RandomOverSampler, ADASYN
from imblearn.under_sampling import RandomUnderSampler, TomekLinks
import tensorflow as tf
```
**Use the following split if you want to hold out a specified number of athletes for train and test set. The last 10 athletes instances were kept for test set.**
```
'''Import data and hold out a specified test set'''
# Import data from excel, select the first 63 athletes events for train set and the last 10 athletes for test set
df = pd.read_excel(r'/content/drive/MyDrive/Runners_Injury_MLproject/Daily_Injury_Clean.xlsx',index_col = [0])
df_train = df[df['Athlete ID'] <= 63]
df_train.drop(['Date','Athlete ID'],axis=1,inplace=True)
df_test = df[df['Athlete ID'] > 63]
df_test.drop(['Date','Athlete ID'],axis=1,inplace=True)
# Check if df_train has any equal instances with df_test. We expect to return an empty dataframe if they do not share common instances
print(df_train[df_test.eq(df_train).all(axis=1)==True])
''' Set y '''
y_train = df_train['injury'].values
y_test = df_test['injury'].values
''' Set all columns for X except injury which is the target'''
X_train = df_train.drop(['injury'],axis=1).values
X_test = df_test.drop(['injury'],axis=1).values
column_names = df_train.drop(['injury'],axis=1).columns
#selected_features = ['Total Weekly Distance','Acute Load','Strain','Monotony','injury']
''' Set X after dropping selected features '''
#X_test = df_test.drop(selected_features,axis=1).values
#X_train = df_train.drop(selected_features,axis=1).values
#column_names = df_train.drop(selected_features,axis=1).columns
''' Set selected features as X '''
#X_train = df_train.loc[:,selected_features].values
#X_test = df_test.loc[:,selected_features].values
#column_names = df_train.loc[:,selected_features].columns
# Print dataframes shapes and respective number of healthy and injury events
print(column_names)
print(Counter(df_train['injury'].values))
print(Counter(df_test['injury'].values))
```
**Use the following dataset split if you want to hold out 2000 random healthy instancies and 50 random injury instancies**
```
'''Import data and holdout a random test set'''
# Import data from excel and drop Date and Athlete ID column
df = pd.read_excel(r'/content/drive/MyDrive/Runners_Injury_MLproject/run_injur_with_acuteloads.xlsx',index_col = [0])
# Hold out a test set with 100 random injury events and 100 random healthy events
df_copy = df.copy()
df_copy.drop(['Date','Athlete ID'],axis=1,inplace=True)
df_inj = df_copy[df_copy['injury']==1].sample(50,random_state=42)
df_uninj = df_copy[df_copy['injury']==0].sample(2000,random_state=42)
df_test = pd.concat([df_inj,df_uninj],ignore_index=True)
# Drop the test set from the original dataframe
df_train = pd.concat([df_copy,df_test],ignore_index=True).drop_duplicates(keep=False)
# Set X and y
y_train = df_train['injury'].values
y_test = df_test['injury'].values
selected_features = ['Total Weekly Distance','Acute Load','Strain','Monotony','injury']
X_test = df_test.drop(selected_features,axis=1).values
X_train = df_train.drop(selected_features,axis=1).values
#X_train = df_train.loc[:,selected_features].values
#X_test = df_test.loc[:,selected_features].values
# Check if df_train has any equal instances with df_test. We expect to return an empty dataframe if they do not share common instances
# Print dataframe shapes and respective number of healthy and injury events
print(df_train[df_test.eq(df_train).all(axis=1)==True])
#print(df_train.drop(['Acute Load','Total Weekly Distance','Monotony','Strain','injury'],axis=1).columns)
print(df_train.shape)
print(Counter(df_train['injury'].values))
print(df_test.shape)
print(Counter(df_test['injury'].values))
class_imbalance = len(df_train[df_train['injury']==1].values)/len(df_train[df_train['injury']==0].values)
print(f'Class imbalance is {class_imbalance}')
```
**Write a function to pretiffy confusion matrix results.
The function was found from Daniel Bourke's Tensorflow course**
```
def plot_confusion_matrix(y_true,y_pred,class_names,figsize=(10,10),text_size=15):
# create the confusion matrix
cm = confusion_matrix(y_true,y_pred)
cm_norm = cm.astype('float') / cm.sum(axis=1)[:,np.newaxis] # normalize confusion matrix
n_classes = cm.shape[0]
fig, ax = plt.subplots(figsize=figsize)
matrix_plot = ax.matshow(cm, cmap=plt.cm.Blues)
fig.colorbar(matrix_plot)
# Set labels to be classes
if class_names:
labels = class_names
else:
labels = np.arange(cm.shape[0])
# Label the axes
ax.set(title='Confusion Matrix',
xlabel = 'Predicted Label',
ylabel = 'True Label',
xticks = np.arange(n_classes),
yticks = np.arange(n_classes),
xticklabels = labels,
yticklabels = labels)
# Set x axis labels to bottom
ax.xaxis.set_label_position('bottom')
ax.xaxis.tick_bottom()
# Adjust label size
ax.yaxis.label.set_size(text_size)
ax.xaxis.label.set_size(text_size)
ax.title.set_size(text_size)
# Set threshold for different colors
threshold = (cm.max() + cm.min()) / 2
# Plot the text on each cell
for i, j in itertools.product(range(cm.shape[0]),range(cm.shape[1])):
plt.text(j,i,f'{cm[i,j]} ({cm_norm[i,j] * 100:.1f}%)',
horizontalalignment='center',
color='white' if cm[i,j] > threshold else 'black',
size = text_size)
```
Because there is very high class imbalance in the injury variable that we want to predict, we will try the following techniques to overcome this problem and see what works best:
* **Weighted XGBoost**
* **XGBoost with Smote algorithm for Resampling**
* **XGBoost model with Random Resampling**
* **Bagging XGBoost model with Random Resampling**
* **Neural Networks model with Random Undersampling**
```
# Set X and y with different resampling methods
'''SMOTE algorithm for oversampling 15% ratio and random undersampling 1-1 ratio'''
# Oversample the minority class to have number of instances equal with the 15% of the majority class
smote = SMOTE(sampling_strategy=0.15,random_state=1)
X_sm,y_sm = smote.fit_resample(X_train,y_train)
# Downsample the majority class to have number of instances equal with the minority class
undersamp = RandomUnderSampler(sampling_strategy=1,random_state=1)
X_smus,y_smus = undersamp.fit_resample(X_sm,y_sm)
'''Random oversampling 10% ratio and random undersampling 1-1 ratio'''
# Random over sampler for minority class to 1:10 class ratio
ros = RandomOverSampler(sampling_strategy=0.1,random_state=21)
X_ros,y_ros = ros.fit_resample(X_train,y_train)
# Undersample the majority class to have number of instances equal with the minority class
undersamp = RandomUnderSampler(sampling_strategy=1,random_state=21)
X_rosus,y_rosus = undersamp.fit_resample(X_ros,y_ros)
'''Random undersampling 1-1 ratio'''
# Random under sampler for majority class to 1:1 class ratio
rus = RandomUnderSampler(sampling_strategy=1,random_state=21)
X_rus,y_rus = rus.fit_resample(X_train,y_train)
'''Tomek Links Undersampling'''
tmkl = TomekLinks()
X_tmk, y_tmk = tmkl.fit_resample(X_train,y_train)
'''ADASYN for oversampling 15% ratio and random undersampler 1-1 ratio'''
# ADASYN oversample minority class to 15% of the majority class
adasyn = ADASYN(sampling_strategy=0.15,random_state=21)
X_ada, y_ada = adasyn.fit_resample(X_train,y_train)
# Random undersample the majority class to have equal instances with minority class
adarus = RandomUnderSampler(sampling_strategy=1,random_state=21)
X_adarus,y_adarus = adarus.fit_resample(X_ada,y_ada)
# Stratify crossvalidation
cv = StratifiedKFold(n_splits=5,shuffle=True,random_state=21)
```
## 1) Weighted XGBoost Model
```
'''Weighted XGBoost'''
# We will use scale_pos_weight argument in xgboost algorithm which increases the error for wrong positive class prediction.
# From xgboost documentation it's suggested that the optimal value for scale_pos_weight argument is usually around the
# sum(negative instances)/sum(positive instances). We will use randomizedsearchcv to find optimal value
xgb_weight = XGBClassifier()
param_grid_weight = {"gamma":[0.01,0.1,1,10,50,100,1000],'reg_lambda':[1,5,10,20],
'learning_rate':np.arange(0.01,1,0.01),'eta':np.arange(0.1,1,0.1),'scale_pos_weight':[60,70,80,90,100]}
gscv_weight = RandomizedSearchCV(xgb_weight,param_distributions=param_grid_weight,cv=cv,scoring='roc_auc')
gscv_weight.fit(X_train,y_train)
print("Best param is {}".format(gscv_weight.best_params_))
print("Best score is {}".format(gscv_weight.best_score_))
optimal_gamma = gscv_weight.best_params_['gamma']
optimal_reg_lambda = gscv_weight.best_params_['reg_lambda']
optim_lr = gscv_weight.best_params_['learning_rate']
optimal_eta = gscv_weight.best_params_['eta']
optimal_scale_pos_weight = gscv_weight.best_params_['scale_pos_weight']
tuned_xgb_weight = XGBClassifier(gamma=optimal_gamma,learning_rate=optim_lr,eta=optimal_eta,reg_lambda=optimal_reg_lambda,scale_pos_weight=optimal_scale_pos_weight,
colsample_bytree=0.5,min_child_weight=90,objective='binary:logistic',subsample=0.5)
tuned_xgb_weight.fit(X_train,y_train,early_stopping_rounds=10,eval_metric='auc',eval_set=[(X_test,y_test)])
# Evaluate model's performance on the test set, with AUC, confusion matrix, sensitivity and specificity
y_pred = tuned_xgb_weight.predict(X_test)
print(f'Area under curve score is {roc_auc_score(y_test,tuned_xgb_weight.predict_proba(X_test)[:,1])}')
# Compute true positives, true neagatives, false negatives and false positives
tp = confusion_matrix(y_test,y_pred)[1,1]
tn = confusion_matrix(y_test,y_pred)[0,0]
fn = confusion_matrix(y_test,y_pred)[1,0]
fp = confusion_matrix(y_test,y_pred)[0,1]
# Compute sensitivity and specificity
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
print(f'Sensitivity is {sensitivity*100}% and specificity is {specificity*100}%')
plot_confusion_matrix(y_true=y_test, y_pred=y_pred, class_names=['Healthy events','Injury events'])
```
##2) XGBoost Model with SMOTE combined with Random Undersampling
```
'''XGBoost Classifier and SMOTE (Synthetic Minority Oversampling Technique) combined with Random Undersampling'''
# Check the number of instances for each class before and after resampling
print(Counter(y_train))
print(Counter(y_smus))
xgb_sm = XGBClassifier()
param_grid_sm = {"gamma":[0.01,0.1,1,10,50,100,1000],'learning_rate':np.arange(0.01,1,0.01),'eta':np.arange(0.1,1,0.1),'reg_lambda':[1,5,10,20]}
gscv_sm = RandomizedSearchCV(xgb_sm,param_distributions=param_grid_sm,cv=5,scoring='roc_auc')
gscv_sm.fit(X_smus,y_smus)
print("Best param is {}".format(gscv_sm.best_params_))
print("Best score is {}".format(gscv_sm.best_score_))
optimal_gamma = gscv_sm.best_params_['gamma']
optim_lr = gscv_sm.best_params_['learning_rate']
optimal_eta = gscv_sm.best_params_['eta']
optimal_lambda = gscv_sm.best_params_['reg_lambda']
tuned_xgb_sm = XGBClassifier(gamma=optimal_gamma,learning_rate=optim_lr,eta=optimal_eta,reg_lambda=optimal_lambda,subsample=0.4,
colsample_bytree=0.6,min_child_weight=90,objective='binary:logistic')
tuned_xgb_sm.fit(X_smus,y_smus,early_stopping_rounds=10,eval_metric='auc',eval_set=[(X_test,y_test)])
# Evaluate model's performance on the test set, with AUC, confusion matrix, sensitivity and specificity
y_pred = tuned_xgb_sm.predict(X_test)
print(f'Area under curve score is {roc_auc_score(y_test,tuned_xgb_sm.predict_proba(X_test)[:,1])}')
# Compute true positives, true neagatives, false negatives and false positives
tp = confusion_matrix(y_test,y_pred)[1,1]
tn = confusion_matrix(y_test,y_pred)[0,0]
fn = confusion_matrix(y_test,y_pred)[1,0]
fp = confusion_matrix(y_test,y_pred)[0,1]
# Compute sensitivity and specificity
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
print(f'Sensitivity is {sensitivity*100}% and specificity is {specificity*100}%')
plot_confusion_matrix(y_true=y_test, y_pred=y_pred, class_names=['Healthy events','Injury events'])
```
## 3) XGBoost Model with Random Resampling
```
'''XGBoost Classifier and Random Undersampling'''
# Check the number of instances for each class before and after resampling
print(Counter(y_train))
print(Counter(y_rosus))
xgb_rus = XGBClassifier()
param_grid_rus = {"gamma":[0.01,0.1,1,10,50,100,1000],'reg_lambda':[1,5,10,20],'learning_rate':np.arange(0.01,1,0.01),'eta':np.arange(0.1,1,0.1)}
gscv_rus = RandomizedSearchCV(xgb_rus,param_distributions=param_grid_rus,cv=5,scoring='roc_auc')
gscv_rus.fit(X_rosus,y_rosus)
print("Best param is {}".format(gscv_rus.best_params_))
print("Best score is {}".format(gscv_rus.best_score_))
optimal_gamma = gscv_rus.best_params_['gamma']
optimal_reg_lambda = gscv_rus.best_params_['reg_lambda']
optim_lr = gscv_rus.best_params_['learning_rate']
optimal_eta = gscv_rus.best_params_['eta']
tuned_xgb_rus = XGBClassifier(gamma=optimal_gamma,reg_lambda=optimal_reg_lambda,learning_rate=optim_lr,eta=optimal_eta,
colsample_bytree=0.7,min_child_weight=9,objective='binary:logistic',subsample=0.8)
tuned_xgb_rus.fit(X_rosus,y_rosus,early_stopping_rounds=10,eval_metric='auc',eval_set=[(X_test,y_test)])
# Evaluate model's performance on the test set, with AUC, confusion matrix, sensitivity and specificity
y_pred = tuned_xgb_rus.predict(X_test)
print(f'Area under curve score is {roc_auc_score(y_test,tuned_xgb_rus.predict_proba(X_test)[:,1])}')
# Compute true positives, true neagatives, false negatives and false positives
tp = confusion_matrix(y_test,y_pred)[1,1]
tn = confusion_matrix(y_test,y_pred)[0,0]
fn = confusion_matrix(y_test,y_pred)[1,0]
fp = confusion_matrix(y_test,y_pred)[0,1]
# Compute sensitivity and specificity
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
print(f'Sensitivity is {sensitivity*100}% and specificity is {specificity*100}%')
plot_confusion_matrix(y_true=y_test, y_pred=y_pred, class_names=['Healthy events','Injury events'])
```
## 4) Bagging Model with XGBoost base estimators and Random Resampling
```
'''Bagging Classifier with XGBoost base estimators and Random Undersampling with combined Oversampling'''
# Check the number of instances for each class before and after resampling
print(Counter(y_train))
print(Counter(y_rosus))
base_est = XGBClassifier(gamma=optimal_gamma,reg_lambda=optimal_reg_lambda,learning_rate=optim_lr,eta=optimal_eta,
colsample_bytree=0.6,min_child_weight=90,objective='binary:logistic',subsample=0.8,n_estimators=11)
# XGBoost base classifier
#base_est = XGBClassifier(n_estimators=512,learning_rate=0.01,max_depth=3)
# Bagging XGBoost Classifier
bagg = BaggingClassifier(base_estimator=base_est,n_estimators=9,max_samples=2048,random_state=21)
# Platt's Scaling to get probabilities outputs
calib_clf = CalibratedClassifierCV(bagg,cv=5)
# Evaluate model's performance on the test set, with AUC, confusion matrix, sensitivity and specificity
# You can switch threshold prob in order to bias sensitivity at the cost of specificity. It is set to default 0.5
calib_clf.fit(X_rosus,y_rosus)
y_pred_calib = calib_clf.predict_proba(X_test)
threshold_prob = 0.5
y_pred = []
for y_hat in y_pred_calib:
if y_hat[1] > threshold_prob:
y_pred.append(1)
else:
y_pred.append(0)
print(f'Area under curve score is {roc_auc_score(y_test,calib_clf.predict_proba(X_test)[:,1])}')
# Compute true positives, true neagatives, false negatives and false positives
tp = confusion_matrix(y_test,np.array(y_pred))[1,1]
tn = confusion_matrix(y_test,np.array(y_pred))[0,0]
fn = confusion_matrix(y_test,np.array(y_pred))[1,0]
fp = confusion_matrix(y_test,np.array(y_pred))[0,1]
# Compute sensitivity and specificity
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
print(f'Sensitivity is {sensitivity*100}% and specificity is {specificity*100}%')
# Plot confusion matrix
plot_confusion_matrix(y_true=y_test, y_pred=np.array(y_pred), class_names=['Healthy events','Injury events'])
```
## 5) Neural Networks Model
```
'''Neural Networks Model'''
# Check the number of instances for each class before and after resampling
print(Counter(y_train))
print(Counter(y_rus))
# Scale X data
X_scaled_rus = MinMaxScaler().fit_transform(X_rus)
X_scaled_test = MinMaxScaler().fit_transform(X_test)
# set random seed for reproducibility
tf.random.set_seed(24)
# create model with 9 hidden layers with 50 neurons each and 1 output layer
nn_model = tf.keras.Sequential([tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(1,activation="sigmoid")
])
# compile model
nn_model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(learning_rate=0.002),
metrics=['AUC'])
# set callback to stop after 10 epochs if model doesn't improve and fit training data
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',patience=3)
history = nn_model.fit(X_scaled_rus,y_rus,epochs=10,batch_size=32,callbacks=[callback])
# Evaluate model performance on test set, with AUC, confusion matrix, sensitivity and specificity
y_prob_pred = nn_model.predict(X_scaled_test)
y_pred = []
for i in y_prob_pred:
if i <=0.5:
y_pred.append(0)
else:
y_pred.append(1)
y_pred = np.array(y_pred)
print(y_pred[y_pred>1])
# Compute true positives, true neagatives, false negatives and false positives
tp = confusion_matrix(y_test,np.array(y_pred))[1,1]
tn = confusion_matrix(y_test,np.array(y_pred))[0,0]
fn = confusion_matrix(y_test,np.array(y_pred))[1,0]
fp = confusion_matrix(y_test,np.array(y_pred))[0,1]
# Compute sensitivity and specificity
sensitivity = tp / (tp + fn)
specificity = tn / (tn + fp)
print(f'Sensitivity is {sensitivity*100}% and specificity is {specificity*100}%')
# Plot confusion matrix
plot_confusion_matrix(y_true=y_test, y_pred=np.array(y_pred), class_names=['Healthy events','Injury events'])
# evaluate the model
print(f'Area Under Curve is {nn_model.evaluate(X_scaled_test,y_test)[1]}')
'''Find optimal Learning Rate for nn_model'''
# set random seed for reproducibility
tf.random.set_seed(24)
# create model with 2 hidden layers and 1 output layer
nn_model = tf.keras.Sequential([tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(1,activation="sigmoid")
])
# compile model
nn_model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["AUC"])
# set callback to stop after 5 epochs if model doesn't improve and fit training data
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-4 * 10 ** (epoch/20))
history = nn_model.fit(X_scaled_rus,y_rus,epochs=30,callbacks=[lr_scheduler])
# plot accuracy vs learning rate to find optimal learning rate
plt.figure(figsize=[10,10])
plt.semilogx(1e-4 * (10 ** (tf.range(30)/20)),history.history["loss"])
plt.ylabel("Loss")
plt.title("Learning Rate vs Loss")
plt.show()
'''Crossvalidation on nn_model'''
from keras.wrappers.scikit_learn import KerasClassifier
tf.random.set_seed(24)
def create_nn_model():
# create model with 2 hidden layers and 1 output layer
nn_model = tf.keras.Sequential([tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(128,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(64,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(32,activation="relu"),
#tf.keras.layers.Dropout(0.1),
tf.keras.layers.Dense(1,activation="sigmoid")
])
# compile model
nn_model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(learning_rate=0.002),
metrics=["AUC"])
return nn_model
neural_network = KerasClassifier(build_fn=create_nn_model,
epochs=10)
# Evaluate neural network using 5-fold cross-validation
cv = StratifiedKFold(n_splits=5,shuffle=True,random_state=1)
cross_val_score(neural_network, X_scaled_rus, y_rus, scoring='roc_auc', cv=cv)
```
| true |
code
| 0.5867 | null | null | null | null |
|
```
import pandas as pd
import numpy as np
from datetime import datetime
import os
```
# Define Which Input Files to Use
The default settings will use the input files recently produced in Step 1) using the notebook `get_eia_demand_data.ipynb`. For those interested in reproducing the exact results included in the repository, you will need to point to the files containing the original `raw` EIA demand data that we querried on 10 Sept 2019.
```
merge_with_step1_files = False # used to run step 2 on the most recent files
merge_with_10sept2019_files = True # used to reproduce the documented results
assert((merge_with_step1_files != merge_with_10sept2019_files) and
(merge_with_step1_files == True or merge_with_10sept2019_files == True)), "One of these must be true: 'merge_with_step1_files' and 'merge_with_10sept2019_files'"
if merge_with_step1_files:
input_path = './data'
if merge_with_10sept2019_files:
# input_path is the path to the downloaded data from Zenodo: https://zenodo.org/record/3517197
input_path = '/BASE/PATH/TO/ZENODO'
input_path += '/data/release_2019_Oct/original_eia_files'
assert(os.path.exists(input_path)), f"You must set the base directory for the Zenodo data {input_path} does not exist"
# If you did not run step 1, make the /data directory
if not os.path.exists('./data'):
os.mkdir('./data')
```
# Make the output directories
```
# Make output directories
out_base = './data/final_results'
if not os.path.exists(out_base):
os.mkdir(out_base)
for subdir in ['balancing_authorities', 'regions', 'interconnects', 'contiguous_US']:
os.mkdir(f"{out_base}/{subdir}")
print(f"Final results files will be located here: {out_base}/{subdir}")
```
# Useful functions
```
# All 56 balancing authorities that have demand (BA)
def return_all_regions():
return [
'AEC', 'AECI', 'CPLE', 'CPLW',
'DUK', 'FMPP', 'FPC',
'FPL', 'GVL', 'HST', 'ISNE',
'JEA', 'LGEE', 'MISO', 'NSB',
'NYIS', 'PJM', 'SC',
'SCEG', 'SOCO',
'SPA', 'SWPP', 'TAL', 'TEC',
'TVA', 'ERCO',
'AVA', 'AZPS', 'BANC', 'BPAT',
'CHPD', 'CISO', 'DOPD',
'EPE', 'GCPD', 'IID',
'IPCO', 'LDWP', 'NEVP', 'NWMT',
'PACE', 'PACW', 'PGE', 'PNM',
'PSCO', 'PSEI', 'SCL', 'SRP',
'TEPC', 'TIDC', 'TPWR', 'WACM',
'WALC', 'WAUW',
'OVEC', 'SEC',
]
# All 54 "usable" balancing authorities (BA) (excludes OVEC and SEC)
# These 2 have significant
# enough reporting problems that we do not impute cleaned data for them.
def return_usable_BAs():
return [
'AEC', 'AECI', 'CPLE', 'CPLW',
'DUK', 'FMPP', 'FPC',
'FPL', 'GVL', 'HST', 'ISNE',
'JEA', 'LGEE', 'MISO', 'NSB',
'NYIS', 'PJM', 'SC',
'SCEG', 'SOCO',
'SPA', 'SWPP', 'TAL', 'TEC',
'TVA', 'ERCO',
'AVA', 'AZPS', 'BANC', 'BPAT',
'CHPD', 'CISO', 'DOPD',
'EPE', 'GCPD', 'IID',
'IPCO', 'LDWP', 'NEVP', 'NWMT',
'PACE', 'PACW', 'PGE', 'PNM',
'PSCO', 'PSEI', 'SCL', 'SRP',
'TEPC', 'TIDC', 'TPWR', 'WACM',
'WALC', 'WAUW',
# 'OVEC', 'SEC',
]
# mapping of each balancing authority (BA) to its associated
# U.S. interconnect (IC).
def return_ICs_from_BAs():
return {
'EASTERN_IC' : [
'AEC', 'AECI', 'CPLE', 'CPLW',
'DUK', 'FMPP', 'FPC',
'FPL', 'GVL', 'HST', 'ISNE',
'JEA', 'LGEE', 'MISO', 'NSB',
'NYIS', 'PJM', 'SC',
'SCEG', 'SOCO',
'SPA', 'SWPP', 'TAL', 'TEC',
'TVA',
'OVEC', 'SEC',
],
'TEXAS_IC' : [
'ERCO',
],
'WESTERN_IC' : [
'AVA', 'AZPS', 'BANC', 'BPAT',
'CHPD', 'CISO', 'DOPD',
'EPE', 'GCPD',
'IID',
'IPCO', 'LDWP', 'NEVP', 'NWMT',
'PACE', 'PACW', 'PGE', 'PNM',
'PSCO', 'PSEI', 'SCL', 'SRP',
'TEPC', 'TIDC', 'TPWR', 'WACM',
'WALC', 'WAUW',
]
}
# Defines a mapping between the balancing authorities (BAs)
# and their locally defined region based on EIA naming.
# This uses a json file defining the mapping.
def return_BAs_per_region_map():
regions = {
'CENT' : 'Central',
'MIDW' : 'Midwest',
'TEN' : 'Tennessee',
'SE' : 'Southeast',
'FLA' : 'Florida',
'CAR' : 'Carolinas',
'MIDA' : 'Mid-Atlantic',
'NY' : 'New York',
'NE' : 'New England',
'TEX' : 'Texas',
'CAL' : 'California',
'NW' : 'Northwest',
'SW' : 'Southwest'
}
rtn_map = {}
for k, v in regions.items():
rtn_map[k] = []
# Load EIA's Blancing Authority Acronym table
# https://www.eia.gov/realtime_grid/
df = pd.read_csv('data/balancing_authority_acronyms.csv',
skiprows=1) # skip first row as it is source info
# Loop over all rows and fill map
for idx in df.index:
# Skip Canada and Mexico
if df.loc[idx, 'Region'] in ['Canada', 'Mexico']:
continue
reg_acronym = ''
# Get region to acronym
for k, v in regions.items():
if v == df.loc[idx, 'Region']:
reg_acronym = k
break
assert(reg_acronym != '')
rtn_map[reg_acronym].append(df.loc[idx, 'Code'])
tot = 0
for k, v in rtn_map.items():
tot += len(v)
print(f"Total US48 BAs mapped {tot}. Recall 11 are generation only.")
return rtn_map
# Assume the MICE results file is a subset of the original hours
def trim_rows_to_match_length(mice, df):
mice_start = mice.loc[0, 'date_time']
mice_end = mice.loc[len(mice.index)-1, 'date_time']
to_drop = []
for idx in df.index:
if df.loc[idx, 'date_time'] != mice_start:
to_drop.append(idx)
else: # stop once equal
break
for idx in reversed(df.index):
if df.loc[idx, 'date_time'] != mice_end:
to_drop.append(idx)
else: # stop once equal
break
df = df.drop(to_drop, axis=0)
df = df.reset_index()
assert(len(mice.index) == len(df.index))
return df
# Load balancing authority files already containing the full MICE results.
# Aggregate associated regions into regional, interconnect, or CONUS files.
# Treat 'MISSING' and 'EMPTY' values as zeros when aggregating.
def merge_BAs(region, bas, out_base, folder):
print(region, bas)
# Remove BAs which are generation only as well as SEC and OVEC.
# See main README regarding SEC and OVEC.
usable_BAs = return_usable_BAs()
good_bas = []
for ba in bas:
if ba in usable_BAs:
good_bas.append(ba)
first_ba = good_bas.pop()
master = pd.read_csv(f'{out_base}/balancing_authorities/{first_ba}.csv', na_values=['MISSING', 'EMPTY'])
master = master.fillna(0)
master = master.drop(['category', 'forecast demand (MW)'], axis=1)
for ba in good_bas:
df = pd.read_csv(f'{out_base}/balancing_authorities/{ba}.csv', na_values=['MISSING', 'EMPTY'])
df = df.fillna(0)
master['raw demand (MW)'] += df['raw demand (MW)']
master['cleaned demand (MW)'] += df['cleaned demand (MW)']
master.to_csv(f'{out_base}/{folder}/{region}.csv', index=False)
# Do both the distribution of balancing authority level results to new BA files
# and generate regional, interconnect, and CONUS aggregate files.
def distribute_MICE_results(raw_demand_file_loc, screening_file, mice_results_csv, out_base):
# Load screening results
screening = pd.read_csv(screening_file)
# Load MICE results
mice = pd.read_csv(mice_results_csv)
screening = trim_rows_to_match_length(mice, screening)
# Distribute to single BA results files first
print("Distribute MICE results per-balancing authority:")
for ba in return_usable_BAs():
print(ba)
df = pd.read_csv(f"{raw_demand_file_loc}/{ba}.csv")
df = trim_rows_to_match_length(mice, df)
df_out = pd.DataFrame({
'date_time': df['date_time'],
'raw demand (MW)': df['demand (MW)'],
'category': screening[f'{ba}_category'],
'cleaned demand (MW)': mice[ba],
'forecast demand (MW)': df['forecast demand (MW)']
})
df_out.to_csv(f'./{out_base}/balancing_authorities/{ba}.csv', index=False)
# Aggregate balancing authority level results into EIA regions
print("\nEIA regional aggregation:")
for region, bas in return_BAs_per_region_map().items():
merge_BAs(region, bas, out_base, 'regions')
# Aggregate balancing authority level results into CONUS interconnects
print("\nCONUS interconnect aggregation:")
for region, bas in return_ICs_from_BAs().items():
merge_BAs(region, bas, out_base, 'interconnects')
# Aggregate balancing authority level results into CONUS total
print("\nCONUS total aggregation:")
merge_BAs('CONUS', return_usable_BAs(), out_base, 'contiguous_US')
```
# Run the distribution and aggregation
```
# The output file generated by Step 2 listing the categories for each time step
screening_file = './data/csv_MASTER.csv'
# The output file generated by Step 3 which runs the MICE algo and has the cleaned demand values
mice_file = 'MICE_output/mean_impute_csv_MASTER.csv'
distribute_MICE_results(input_path, screening_file, mice_file, out_base)
```
# Test distribution and aggregation
This cell simply checks that the results all add up.
```
# Compare each value in the vectors
def compare(vect1, vect2):
cnt = 0
clean = True
for v1, v2 in zip(vect1, vect2):
if v1 != v2:
print(f"Error at idx {cnt} {v1} != {v2}")
clean = False
cnt += 1
return clean
def test_aggregation(raw_demand_file_loc, screening_file, mice_results_csv, out_base):
# Load MICE results
usable_BAs = return_usable_BAs()
mice = pd.read_csv(mice_results_csv)
# Sum all result BAs
tot_imp = np.zeros(len(mice.index))
for col in mice.columns:
if col not in usable_BAs:
continue
tot_imp += mice[col]
# Sum Raw
tot_raw = np.zeros(len(mice.index))
for ba in return_usable_BAs():
df = pd.read_csv(f"{raw_demand_file_loc}/{ba}.csv", na_values=['MISSING', 'EMPTY'])
df = trim_rows_to_match_length(mice, df)
df = df.fillna(0)
tot_raw += df['demand (MW)']
# Check BA results distribution
print("\nBA Distribution:")
new_tot_raw = np.zeros(len(mice.index))
new_tot_clean = np.zeros(len(mice.index))
for ba in return_usable_BAs():
df = pd.read_csv(f"{out_base}/balancing_authorities/{ba}.csv", na_values=['MISSING', 'EMPTY'])
df = df.fillna(0)
new_tot_raw += df['raw demand (MW)']
new_tot_clean += df['cleaned demand (MW)']
assert(compare(tot_raw, new_tot_raw)), "Error in raw sums."
assert(compare(tot_imp, new_tot_clean)), "Error in imputed values."
print("BA Distribution okay!")
# Check aggregate balancing authority level results into EIA regions
print("\nEIA regional aggregation:")
new_tot_raw = np.zeros(len(mice.index))
new_tot_clean = np.zeros(len(mice.index))
for region, bas in return_BAs_per_region_map().items():
df = pd.read_csv(f"{out_base}/regions/{region}.csv")
new_tot_raw += df['raw demand (MW)']
new_tot_clean += df['cleaned demand (MW)']
assert(compare(tot_raw, new_tot_raw)), "Error in raw sums."
assert(compare(tot_imp, new_tot_clean)), "Error in imputed values."
print("Regional sums okay!")
# Aggregate balancing authority level results into CONUS interconnects
print("\nCONUS interconnect aggregation:")
new_tot_raw = np.zeros(len(mice.index))
new_tot_clean = np.zeros(len(mice.index))
for region, bas in return_ICs_from_BAs().items():
df = pd.read_csv(f"{out_base}/interconnects/{region}.csv")
new_tot_raw += df['raw demand (MW)']
new_tot_clean += df['cleaned demand (MW)']
assert(compare(tot_raw, new_tot_raw)), "Error in raw sums."
assert(compare(tot_imp, new_tot_clean)), "Error in imputed values."
print("Interconnect sums okay!")
# Aggregate balancing authority level results into CONUS total
print("\nCONUS total aggregation:")
new_tot_raw = np.zeros(len(mice.index))
new_tot_clean = np.zeros(len(mice.index))
df = pd.read_csv(f"{out_base}/contiguous_US/CONUS.csv")
new_tot_raw += df['raw demand (MW)']
new_tot_clean += df['cleaned demand (MW)']
assert(compare(tot_raw, new_tot_raw)), "Error in raw sums."
assert(compare(tot_imp, new_tot_clean)), "Error in imputed values."
print("CONUS sums okay!")
test_aggregation(input_path, screening_file, mice_file, out_base)
```
| true |
code
| 0.31295 | null | null | null | null |
|
```
import torch
from torch.distributions import Normal
import math
```
Let us revisit the problem of predicting if a resident of Statsville is female based on the height. For this purpose, we have collected a set of height samples from adult female residents in Statsville. Unfortunately, due to unforseen circumstances we have collected a very small sample from the residents. Armed with our knowledge of Bayesian inference, we do not want to let this deter us from trying to build a model.
From physical considerations, we can assume that the distribution of heights is Gaussian. Our goal is to estimate the parameters ($\mu$, $\sigma$) of this Gaussian.
Let us first create the dataset by sampling 5 points from a Gaussian distribution with $\mu$=152 and $\sigma$=8. In real life scenarios, we do not know the mean and standard deviation of the true distribution. But for the sake of this example, let's assume that the mean height is 152cm and standard deviation is 8cm.
```
torch.random.manual_seed(0)
num_samples = 5
true_dist = Normal(152, 8)
X = true_dist.sample((num_samples, 1))
print('Dataset shape: {}'.format(X.shape))
```
### Maximum Likelihood Estimate
If we relied on Maximum Likelihood estimation, our approach would be simply to compute the mean and standard deviation of the dataset, and use this normal distribution as our model.
$$\mu_{MLE} = \frac{1}{N}\sum_{i=1}^nx_i$$
$$\sigma_{MLE} = \frac{1}{N}\sum_{i=1}^n(x_i - \mu)^2$$
Once we estimate the parameters, we can find out the probability that a sample lies in the range using the following formula
$$ p(a < X <= b) = \int_{a}^b p(X) dX $$
However, when the amount of data is low, the MLE estimates are not as reliable.
```
mle_mu, mle_std = X.mean(), X.std()
mle_dist = Normal(mle_mu, mle_std)
print(f"MLE: mu {mle_mu:0.2f} std {mle_std:0.2f}")
```
## Bayesian Inference
Can we do better than MLE?
One potential method to do this is to use Bayesian inference with a good prior. How does one go about selecting a good prior? Well, lets say from another survey, we know that the average and the standard deviation of height of adult female residents in Neighborville, the neighboring town. Additionally, we have no reason to believe that the distribution of heights at Statsville is significantly different. So we can use this information to "initialize" our prior.
Lets say the the mean height of adult female resident in Neighborville is 150 cm with a standard deviation of 9 cm.
We can use this information as our prior. The prior distribution encodes our beliefs on the parameter values.
Given that we are dealing with an unknown mean, and unknown variance, we will model the prior as a Normal Gamma distribution.
$$p\left( \theta \middle\vert X \right) = p \left( X \middle\vert \theta \right) p \left( \theta \right)\\
p\left( \theta \middle\vert X \right) = Normal-Gamma\left( \mu_{n}, \lambda_{n}, \alpha_{n}, \beta_{n} \right) \\
p \left( X \middle\vert \theta \right) = \mathbb{N}\left( \mu, \lambda^{ -\frac{1}{2} } \right) \\
p \left( \theta \right) = Normal-Gamma\left( \mu_{0}, \lambda_{0}, \alpha_{0}, \beta_{0} \right)$$
We will choose a prior, $p \left(\theta \right)$, such that
$$ \mu_{0} = 150 \\
\lambda_{0} = 100 \\
\alpha_{0} = 100.5 \\
\beta_{0} = 8100 $$
$$p \left( \theta \right) = Normal-Gamma\left( 150, 100, 100.5 , 8100 \right)$$
We will compute the posterior, $p\left( \theta \middle\vert X \right)$, using Bayesian inference.
$$\mu_{n} = \frac{ \left( n \bar{x} + \mu_{0} \lambda_{0} \right) }{ n + \lambda_{0} } \\
\lambda_{n} = n + \lambda_{0} \\
\alpha_{n} = \frac{n}{2} + \alpha_{0} \\
\beta_{n} = \frac{ ns }{ 2 } + \beta_{ 0 } + \frac{ n \lambda_{0} } { 2 \left( n + \lambda_{0} \right) } \left( \bar{x} - \mu_{0} \right)^{ 2 }$$
$$p\left( \theta \middle\vert X \right) = Normal-Gamma\left( \mu_{n}, \lambda_{n}, \alpha_{n}, \beta_{n} \right)$$
```
class NormalGamma():
def __init__(self, mu_, lambda_, alpha_, beta_):
self.mu_ = mu_
self.lambda_ = lambda_
self.alpha_ = alpha_
self.beta_ = beta_
@property
def mean(self):
return self.mu_, self.alpha_/ self.beta_
@property
def mode(self):
return self.mu_, (self.alpha_-0.5)/ self.beta_
def inference_unknown_mean_variance(X, prior_dist):
mu_mle = X.mean()
sigma_mle = X.std()
n = X.shape[0]
# Parameters of the prior
mu_0 = prior_dist.mu_
lambda_0 = prior_dist.lambda_
alpha_0 = prior_dist.alpha_
beta_0 = prior_dist.beta_
# Parameters of posterior
mu_n = (n * mu_mle + mu_0 * lambda_0) / (lambda_0 + n)
lambda_n = n + lambda_0
alpha_n = n / 2 + alpha_0
beta_n = (n / 2 * sigma_mle ** 2) + beta_0 + (0.5* n * lambda_0 * (mu_mle - mu_0) **2 /(n + lambda_0))
posterior_dist = NormalGamma(mu_n, lambda_n, alpha_n, beta_n)
return posterior_dist
# Let us initialize the prior based on our beliefs
prior_dist = NormalGamma(150, 100, 10.5, 810)
# We compute the posterior distribution
posterior_dist = inference_unknown_mean_variance(X, prior_dist)
```
How do we use the posterior distribution?
Note that the posterior distribution is a distribution on the parameters $\mu$ and $\lambda$. It is important to note that the posterior and prior are distributions in the parameter space. The likelihood is a distribution on the data space.
Once we learn the posterior distribution, one way to use the distribution is to look at the mode of the distribution i.e the parameter values which have the highest probability density. Using these point estimates leads us to Maximum A Posteriori / MAP estimation.
As usual, we will obtain the maxima of the posterior probability density function $p\left( \mu, \sigma \middle\vert X \right) = Normal-Gamma\left( \mu, \sigma ; \;\; \mu_{n}, \lambda_{n}, \alpha_{n}, \beta_{n} \right) $.
This function attains its maxima when
$$\mu = \mu_{n} \\
\lambda = \frac{ \alpha_{n} - \frac{1}{2} } { \beta_{n} }$$
We notice that the MAP estimates for $\mu$ and $\sigma$ are better than the MLE estimates.
```
# With the Normal Gamma formulation, the unknown parameters are mu and precision
map_mu, map_precision = posterior_dist.mode
# We can compute the standard deviation using precision.
map_std = math.sqrt(1 / map_precision)
map_dist = Normal(map_mu, map_std)
print(f"MAP: mu {map_mu:0.2f} std {map_std:0.2f}")
```
How did we arrive at the values of the parameters for the prior distribution?
Let us consider the case when we have 0 data points. In this case, posterior will become equal to the prior. If we use the mode of this posterior for our MAP estimate, we see that the mu and std parameters are the same as the $\mu$ and $\sigma$ of adult female residents in Neighborville.
```
prior_mu, prior_precision = prior_dist.mode
prior_std = math.sqrt(1 / prior_precision)
print(f"Prior: mu {prior_mu:0.2f} std {prior_std:0.2f}")
```
## Inference
Let us say we want to find out the probability that a height between 150 and 155 belongs to an adult female resident. We can now use the the MAP estimates for $\mu$ and $\sigma$ to compute this value.
Since our prior was good, we notice that the MAP serves as a better estimator than MLE at low values of n
```
a, b = torch.Tensor([150]), torch.Tensor([155])
true_prob = true_dist.cdf(b) - true_dist.cdf(a)
print(f'True probability: {true_prob}')
map_prob = map_dist.cdf(b) - map_dist.cdf(a)
print(f'MAP probability: {map_prob}')
mle_prob = mle_dist.cdf(b) - mle_dist.cdf(a)
print('MLE probability: {}'.format(mle_prob))
```
Let us say we receive more samples, how do we incorporate this information into our model? We can now set the prior to our current posterior and run inference again to obtain the new posterior. This process can be done interatively.
$$ p \left( \theta \right)_{n} = p\left( \theta \middle\vert X \right)_{n-1}$$
$$ p\left( \theta \middle\vert X \right)_{n}=inference\_unknown\_mean\_variance(X_{n}, p \left( \theta \right)_{n})$$
We also notice that as the number of data points increases, the MAP starts to converge towards the true values of $\mu$ and $\sigma$ respectively
```
num_batches, batch_size = 20, 10
for i in range(num_batches):
X_i = true_dist.sample((batch_size, 1))
prior_i = posterior_dist
posterior_dist = inference_unknown_mean_variance(X_i, prior_i)
map_mu, map_precision = posterior_dist.mode
# We can compute the standard deviation using precision.
map_std = math.sqrt(1 / map_precision)
map_dist = Normal(map_mu, map_std)
if i % 5 == 0:
print(f"MAP at batch {i}: mu {map_mu:0.2f} std {map_std:0.2f}")
print(f"MAP at batch {i}: mu {map_mu:0.2f} std {map_std:0.2f}")
```
| true |
code
| 0.86293 | null | null | null | null |
|
```
!pip install plotly -U
import numpy as np
import matplotlib.pyplot as plt
from plotly import graph_objs as go
import plotly as py
from scipy import optimize
print("hello")
```
Generate the data
```
m = np.random.rand()
n = np.random.rand()
num_of_points = 100
x = np.random.random(num_of_points)
y = x*m + n + 0.15*np.random.random(num_of_points)
fig = go.Figure(data=[go.Scatter(x=x, y=y, mode='markers', name='all points')],
layout=go.Layout(
xaxis=dict(range=[np.min(x), np.max(x)], autorange=False),
yaxis=dict(range=[np.min(y), np.max(y)], autorange=False)
)
)
fig.show()
print("m=" + str(m) + " n=" + str(n) )
# fmin
def stright_line_fmin(x,y):
dist_func = lambda p: (((y-x*p[0]-p[1])**2).mean())
p_opt = optimize.fmin(dist_func, np.array([0,0]))
return p_opt
stright_line_fmin(x,y)
# PCA
def straight_line_pca(x,y):
X = np.append(x-x.mean(),y-y.mean(), axis=1)
# Data matrix X, assumes 0-centered
n, m = X.shape
# Compute covariance matrix
C = np.dot(X.T, X) / (n-1)
# Eigen decomposition
eigen_vals, eigen_vecs = np.linalg.eig(C)
# Project X onto PC space
X_pca_inv = np.dot(np.array([[1,0],[-1,0]]), np.linalg.inv(eigen_vecs))
X_pca = np.dot(X, eigen_vecs)
x_min = (x-x.mean()).min()
x_max = (x-x.mean()).max()
fig = go.Figure(data=[
go.Scatter(x=x.ravel(), y=y.ravel(), mode='markers', name='all points'),
go.Scatter(x=X_pca_inv[:, 0]+x.mean(), y=X_pca_inv[:,1]+y.mean(), mode='lines', name='pca estimation')])
fig.show()
return X_pca_inv[1, 1]/X_pca_inv[1, 0], y.mean() - x.mean()*X_pca_inv[1, 1]/X_pca_inv[1, 0]
c = straight_line_pca(x[:, np.newaxis],y[:, np.newaxis])
c
#leaset squares
def least_square_fit(x, y):
# model: y_i = h*x_i
# cost: (Y-h*X)^T * (Y-h*X)
# solution: h = (X^t *X)^-1 * X^t * Y
return np.dot(np.linalg.inv(np.dot(x.transpose(), x)), np.dot(x.transpose() , y))
least_square_fit(np.append(x[:, np.newaxis], np.ones_like(x[:, np.newaxis]), axis=1), y)
# SVd
def svd_fit(x, y):
# model: y_i = h*x_i
# minimize: [x_0, 1, -y_0; x1, 1, -y_1; ...]*[h, 1] = Xh = 0
# do so by: eigenvector coresponds to smallest eigenvalue of X
X = np.append(x, -y, axis=1)
u, s, vh = np.linalg.svd(X)
return vh[-1, :2]/vh[-1,-1]
m_, n_ = svd_fit(np.append(x[:, np.newaxis], np.ones_like(x[:, np.newaxis]), axis=1), y[:, np.newaxis])
print(m_, n_)
#Ransac
def ransac(src_pnts, distance_func, model_func, num_of_points_to_determine_model,
dist_th, inliers_ratio=0.7, p=0.95):
"""Summary or Description of the Function
Parameters:
src_pnt : data points used by Ransac to find the model
distance_func : a function pointer to a distance function.
The distance function takes a model and a point and calculate the cost
p : success probabilaty
Returns:
int:Returning value
"""
min_x = src_pnts[:, 0].min()
max_x = src_pnts[:, 0].max()
print(min_x, max_x)
num_of_points = src_pnts.shape[0]
num_of_iter = int(np.ceil(np.log(1-p)/np.log(1-inliers_ratio**num_of_points_to_determine_model)))
proposed_line = []
max_num_of_inliers = 0
for i in range(num_of_iter):
indx = np.random.permutation(num_of_points)[:num_of_points_to_determine_model]
curr_model = model_func(src_pnts[indx, :])
x=np.array([min_x, max_x])
y=curr_model(x)
print(y)
d = distance_func(curr_model, src_pnts)
num_of_inliers = np.sum(d<dist_th)
proposed_line.append((curr_model, x, y, indx, d, num_of_inliers))
if num_of_inliers > max_num_of_inliers:
max_num_of_inliers = num_of_inliers
best_model = curr_model
return best_model, proposed_line
def stright_line_from_two_points(pnts):
m = (pnts[1, 1]-pnts[0,1])/(pnts[1,0]-pnts[0,0])
n = (pnts[1,0]*pnts[0,1]-pnts[0,0]*pnts[1,1])/(pnts[1,0]-pnts[0,0])
mod_func = lambda x : x*m + n
return mod_func
src_pnts = np.array([x, y]).transpose()
distance_func = lambda model, pnts : (model(pnts[:, 0]) - pnts[:, 1])**2
model_func = stright_line_from_two_points
num_of_points_to_determine_model = 2
dist_th = 0.2
best_model, ransac_run = ransac(src_pnts, distance_func, model_func, num_of_points_to_determine_model, dist_th)
print(x.min())
print(x.max())
x_ransac = np.array([x.min(), x.max()])
y_ransac = best_model(x_ransac)
print(y_ransac)
scatter_xy = go.Scatter(x=x, y=y, mode='markers', name="all points")
frames=[go.Frame(
data=[scatter_xy,
go.Scatter(x=x[item[3]], y=y[item[3]], mode='markers', line=dict(width=2, color="red"), name="selected points"),
go.Scatter(x=item[1], y=item[2], mode='lines', name='current line')]) for item in ransac_run]
fig = go.Figure(
data=[go.Scatter(x=x, y=y, mode='markers', name='all points'),
go.Scatter(x=x, y=y, mode='markers', name="selected points"),
go.Scatter(x=x, y=y, mode='markers', name="current line"),
go.Scatter(x=x_ransac, y=y_ransac, mode='lines', name="best selection")],
layout=go.Layout(
xaxis=dict(range=[np.min(x), np.max(x)], autorange=False),
yaxis=dict(range=[np.min(y), np.max(y)], autorange=False),
title="Ransac guesses",
updatemenus=[dict(
type="buttons",
buttons=[dict(label="Play",
method="animate",
args=[None])])]
),
frames=frames
)
fig.show()
```
| true |
code
| 0.717804 | null | null | null | null |
|
# Cycle-GAN
## Model Schema Definition
The purpose of this notebook is to create in a simple format the schema of the solution proposed to colorize pictures with a Cycle-GAN accelerated with FFT convolutions.<p>To create a simple model schema this notebook will present the code for a Cycle-GAN built as a MVP (Minimum Viable Product) that works with the problem proposed.
```
import re
import os
import urllib.request
import numpy as np
import random
import pickle
from PIL import Image
from skimage import color
import matplotlib.pyplot as plt
from glob import glob
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model
from keras.layers import Conv2D, MaxPooling2D, Activation, BatchNormalization, UpSampling2D, Dropout, Flatten, Dense, Input, LeakyReLU, Conv2DTranspose,AveragePooling2D, Concatenate
from keras.models import load_model
from keras.optimizers import Adam
from keras.models import Sequential
from tensorflow.compat.v1 import set_random_seed
import numpy as np
import matplotlib.pyplot as plt
import pickle
import keras.backend as K
import boto3
import time
from copy import deepcopy
%%time
%matplotlib inline
#import tqdm seperately and use jupyter notebooks %%capture
%%capture
from tqdm import tqdm_notebook as tqdm
#enter your bucket name and use boto3 to identify your region if you don't know it
bucket = None
region = boto3.Session().region_name
#add your bucket then creat the containers to download files and send to bucket
role = get_execution_role()
bucket = None # customize to your bucket
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/image-classification:latest',
'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/image-classification:latest',
'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/image-classification:latest',
'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/image-classification:latest'}
training_image = containers[boto3.Session().region_name]
def download(url):
'''
Downloads the file of a given url
'''
filename = url.split("/")[-1]
if not os.path.exists(filename):
urllib.request.urlretrieve(url, filename)
def upload_to_s3(channel, file):
'''
Save file in a given folder in the S3 bucket
'''
s3 = boto3.resource('s3')
data = open(file, "rb")
key = channel + '/' + file
s3.Bucket(bucket).put_object(Key=key, Body=data)
# MPII Human Pose
download('https://datasets.d2.mpi-inf.mpg.de/andriluka14cvpr/mpii_human_pose_v1.tar.gz')
upload_to_s3('people', 'mpii_human_pose_v1.tar.gz')
#untar the file
!tar xvzf mpii_human_pose_v1.tar.gz
#MIT coastal
download('http://cvcl.mit.edu/scenedatabase/coast.zip')
upload_to_s3('coast', 'coast.zip')
#unzip the file
!unzip coast.zip -d ./data
def image_read(file, size=(256,256)):
'''
This function loads and resizes the image to the passed size.
Default image size is set to be 256x256
'''
image = image.load_img(file, target_size=size)
image = image.img_to_array(img)
return image
def image_convert(file_paths,size=256,channels=3):
'''
Redimensions images to Numpy arrays of a certain size and channels. Default values are set to 256x256x3 for coloured
images.
Parameters:
file_paths: a path to the image files
size: an int or a 2x2 tuple to define the size of an image
channels: number of channels to define in the numpy array
'''
# If size is an int
if isinstance(size, int):
# build a zeros matrix of the size of the image
all_images_to_array = np.zeros((len(file_paths), size, size, channels), dtype='int64')
for ind, i in enumerate(file_paths):
# reads image
img = image_read(i)
all_images_to_array[ind] = img.astype('int64')
print('All Images shape: {} size: {:,}'.format(all_images_to_array.shape, all_images_to_array.size))
else:
all_images_to_array = np.zeros((len(file_paths), size[0], size[1], channels), dtype='int64')
for ind, i in enumerate(file_paths):
img = read_img(i)
all_images_to_array[ind] = img.astype('int64')
print('All Images shape: {} size: {:,}'.format(all_images_to_array.shape, all_images_to_array.size))
return all_images_to_array
file_paths = glob(r'./images/*.jpg')
X_train = image_convert(file_paths)
def rgb_to_lab(img, l=False, ab=False):
"""
Takes in RGB channels in range 0-255 and outputs L or AB channels in range -1 to 1
"""
img = img / 255
l = color.rgb2lab(img)[:,:,0]
l = l / 50 - 1
l = l[...,np.newaxis]
ab = color.rgb2lab(img)[:,:,1:]
ab = (ab + 128) / 255 * 2 - 1
if l:
return l
else: return ab
def lab_to_rgb(img):
"""
Takes in LAB channels in range -1 to 1 and out puts RGB chanels in range 0-255
"""
new_img = np.zeros((256,256,3))
for i in range(len(img)):
for j in range(len(img[i])):
pix = img[i,j]
new_img[i,j] = [(pix[0] + 1) * 50,(pix[1] +1) / 2 * 255 - 128,(pix[2] +1) / 2 * 255 - 128]
new_img = color.lab2rgb(new_img) * 255
new_img = new_img.astype('uint8')
return new_img
L = np.array([rgb_to_lab(image,l=True)for image in X_train])
AB = np.array([rgb_to_lab(image,ab=True)for image in X_train])
L_AB_channels = (L,AB)
with open('l_ab_channels.p','wb') as f:
pickle.dump(L_AB_channels,f)
def resnet_block(x ,num_conv=2, num_filters=512,kernel_size=(3,3),padding='same',strides=2):
'''
This function defines a ResNet Block composed of two convolution layers and that returns the sum of the inputs and the
convolution outputs.
Parameters
x: is the tensor which will be used as input to the convolution layer
num_conv: is the number of convolutions inside the block
num_filters: is an int that describes the number of output filters in the convolution
kernel size: is an int or tuple that describes the size of the convolution window
padding: padding with zeros the image so that the kernel fits the input image or not. Options: 'valid' or 'same'
strides: is the number of pixels shifts over the input matrix.
'''
input=x
for i in num_conv:
input=Conv2D(num_filters,kernel_size=kernel_size,padding=padding,strides=strides)(input)
input=InstanceNormalization()(input)
input=LeakyReLU(0.2)(input)
return (input + x)
```
### Generator
```
def generator(input,filters=64,num_enc_layers=4,num_resblock=4,name="Generator"):
'''
The generator per se is an autoencoder built by a series of convolution layers that initially extract features of the
input image.
'''
# defining input
input=Input(shape=(256,256,1))
x=input
'''
Adding first layer of the encoder model: 64 filters, 5x5 kernel size, 2 so the input size is reduced to half,
input size is the image size: (256,256,1), number of channels 1 for the luminosity channel.
We will use InstanceNormalization through the model and Leaky Relu with and alfa of 0.2
as activation function for the encoder, while relu as activation for the decoder.
between both of them, in the latent space we insert 4 resnet blocks.
'''
for lay in num_enc_layers:
x=Conv2D(filters*lay,(5,5),padding='same',strides=2,input_shape=(256,256,1))(x)
x=InstanceNormalization()(x)
x=LeakyReLU(0.2)(x)
x=Conv2D(128,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=LeakyReLU(0.2)(x)
x=Conv2D(256,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=LeakyReLU(0.2)(x)
x=Conv2D(512,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=LeakyReLU(0.2)(x)
'''
----------------------------------LATENT SPACE---------------------------------------------
'''
for r in num_resblock:
x=resnet_block(x)
'''
----------------------------------LATENT SPACE---------------------------------------------
'''
x=Conv2DTranspose(256,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=Activation('relu')(x)
x=Conv2DTranspose(128,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=Activation('relu')(x)
x=Conv2DTranspose(64,(3,3),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=Activation('relu')(x)
x=Conv2DTranspose(32,(5,5),padding='same',strides=2)(x)
x=InstanceNormalization()(x)
x=Activation('relu')(x)
x=Conv2D(2,(3,3),padding='same')(x)
output=Activation('tanh')(x)
model=Model(input,output,name=name)
return model
```
## Discriminator
```
def discriminator(input,name="Discriminator"):
# importing libraries
from keras.layers import Conv2D, MaxPooling2D, Activation, BatchNormalization, UpSampling2D, Dropout, Flatten, Dense, Input, LeakyReLU, Conv2DTranspose,AveragePooling2D, Concatenate
from tensorflow_addons import InstanceNormalization
# defining input
input=Input(shape=(256,256,2))
x=input
x=Conv2D(32,(3,3), padding='same',strides=2,input_shape=(256,256,2))(x)
x=LeakyReLU(0.2)(x)
x=Dropout(0.25)(x)
x=Conv2D(64,(3,3),padding='same',strides=2)(x)
x=BatchNormalization()
x=LeakyReLU(0.2)(x)
x=Dropout(0.25)(x)
x=Conv2D(128,(3,3), padding='same', strides=2)(x)
x=BatchNormalization()(x)
x=LeakyReLU(0.2)(x)
x=Dropout(0.25)(x)
x=Conv2D(256,(3,3), padding='same',strides=2)(x)
x=BatchNormalization()(x)
x=LeakyReLU(0.2)(x)
x=Dropout(0.25)(x)
x=Flatten()(x)
x=Dense(1)(x)
output=Activation('sigmoid')(x)
model=Model(input,output,name=name)
return model
```
## Building GAN Model
```
# Building discriminators
discriminator_A=discriminator(input_a,"discriminator_A")
discriminator_B=discriminator(input_b,"discriminator_A")
discriminator_A.trainable = False
discriminator_B.trainable = False
# Building generator
generator_B = generator(input_a,"Generator_A_B")
generator_A = generator(input_b,"Generator_B_A")
decision_A=discriminator(generator_a,"Discriminator_A")
decision_B=discriminator(generator_B,"Discriminator_B")
cycle_A=generator(generator_b,"Generator_B_A")
cycle_B=generator(generator_A,"Generator_A_B")
#creates lists to log the losses and accuracy
gen_losses = []
disc_real_losses = []
disc_fake_losses=[]
disc_acc = []
#train the generator on a full set of 320 and the discriminator on a half set of 160 for each epoch
#discriminator is given real and fake y's while generator is always given real y's
n = 320
y_train_fake = np.zeros([160,1])
y_train_real = np.ones([160,1])
y_gen = np.ones([n,1])
#Optional label smoothing
#y_train_real -= .1
#Pick batch size and number of epochs, number of epochs depends on the number of photos per epoch set above
num_epochs=1500
batch_size=32
#run and train until photos meet expectations (stop & restart model with tweaks if loss goes to 0 in discriminator)
for epoch in tqdm(range(1,num_epochs+1)):
#shuffle L and AB channels then take a subset corresponding to each networks training size
np.random.shuffle(X_train_L)
l = X_train_L[:n]
np.random.shuffle(X_train_AB)
ab = X_train_AB[:160]
fake_images = generator.predict(l[:160], verbose=1)
#Train on Real AB channels
d_loss_real = discriminator.fit(x=ab, y= y_train_real,batch_size=32,epochs=1,verbose=1)
disc_real_losses.append(d_loss_real.history['loss'][-1])
#Train on fake AB channels
d_loss_fake = discriminator.fit(x=fake_images,y=y_train_fake,batch_size=32,epochs=1,verbose=1)
disc_fake_losses.append(d_loss_fake.history['loss'][-1])
#append the loss and accuracy and print loss
disc_acc.append(d_loss_fake.history['acc'][-1])
#Train the gan by producing AB channels from L
g_loss = combined_network.fit(x=l, y=y_gen,batch_size=32,epochs=1,verbose=1)
#append and print generator loss
gen_losses.append(g_loss.history['loss'][-1])
#every 50 epochs it prints a generated photo and every 100 it saves the model under that epoch
if epoch % 50 == 0:
print('Reached epoch:',epoch)
pred = generator.predict(X_test_L[2].reshape(1,256,256,1))
img = lab_to_rgb(np.dstack((X_test_L[2],pred.reshape(256,256,2))))
plt.imshow(img)
plt.show()
if epoch % 100 == 0:
generator.save('generator_' + str(epoch)+ '_v3.h5')
img_height = 256
img_width = 256
img_layer = 3
img_size = img_height * img_width
to_train = True
to_test = False
to_restore = False
output_path = "./output"
check_dir = "./output/checkpoints/"
temp_check = 0
max_epoch = 1
max_images = 100
h1_size = 150
h2_size = 300
z_size = 100
batch_size = 1
pool_size = 50
sample_size = 10
save_training_images = True
ngf = 32
ndf = 64
class CycleGAN():
def input_setup(self):
'''
This function basically setup variables for taking image input.
filenames_A/filenames_B -> takes the list of all training images
self.image_A/self.image_B -> Input image with each values ranging from [-1,1]
'''
filenames_A = tf.train.match_filenames_once("./input/horse2zebra/trainA/*.jpg")
self.queue_length_A = tf.size(filenames_A)
filenames_B = tf.train.match_filenames_once("./input/horse2zebra/trainB/*.jpg")
self.queue_length_B = tf.size(filenames_B)
filename_queue_A = tf.train.string_input_producer(filenames_A)
filename_queue_B = tf.train.string_input_producer(filenames_B)
image_reader = tf.WholeFileReader()
_, image_file_A = image_reader.read(filename_queue_A)
_, image_file_B = image_reader.read(filename_queue_B)
self.image_A = tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(image_file_A),[256,256]),127.5),1)
self.image_B = tf.subtract(tf.div(tf.image.resize_images(tf.image.decode_jpeg(image_file_B),[256,256]),127.5),1)
def input_read(self, sess):
'''
It reads the input into from the image folder.
self.fake_images_A/self.fake_images_B -> List of generated images used for calculation of loss function of Discriminator
self.A_input/self.B_input -> Stores all the training images in python list
'''
# Loading images into the tensors
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
num_files_A = sess.run(self.queue_length_A)
num_files_B = sess.run(self.queue_length_B)
self.fake_images_A = np.zeros((pool_size,1,img_height, img_width, img_layer))
self.fake_images_B = np.zeros((pool_size,1,img_height, img_width, img_layer))
self.A_input = np.zeros((max_images, batch_size, img_height, img_width, img_layer))
self.B_input = np.zeros((max_images, batch_size, img_height, img_width, img_layer))
for i in range(max_images):
image_tensor = sess.run(self.image_A)
if(image_tensor.size() == img_size*batch_size*img_layer):
self.A_input[i] = image_tensor.reshape((batch_size,img_height, img_width, img_layer))
for i in range(max_images):
image_tensor = sess.run(self.image_B)
if(image_tensor.size() == img_size*batch_size*img_layer):
self.B_input[i] = image_tensor.reshape((batch_size,img_height, img_width, img_layer))
coord.request_stop()
coord.join(threads)
def model_setup(self):
''' This function sets up the model to train
self.input_A/self.input_B -> Set of training images.
self.fake_A/self.fake_B -> Generated images by corresponding generator of input_A and input_B
self.lr -> Learning rate variable
self.cyc_A/ self.cyc_B -> Images generated after feeding self.fake_A/self.fake_B to corresponding generator. This is use to calcualte cyclic loss
'''
self.input_A = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name="input_A")
self.input_B = tf.placeholder(tf.float32, [batch_size, img_width, img_height, img_layer], name="input_B")
self.fake_pool_A = tf.placeholder(tf.float32, [None, img_width, img_height, img_layer], name="fake_pool_A")
self.fake_pool_B = tf.placeholder(tf.float32, [None, img_width, img_height, img_layer], name="fake_pool_B")
self.global_step = tf.Variable(0, name="global_step", trainable=False)
self.num_fake_inputs = 0
self.lr = tf.placeholder(tf.float32, shape=[], name="lr")
with tf.variable_scope("Model") as scope:
self.fake_B = build_generator_resnet_9blocks(self.input_A, name="g_A")
self.fake_A = build_generator_resnet_9blocks(self.input_B, name="g_B")
self.rec_A = build_gen_discriminator(self.input_A, "d_A")
self.rec_B = build_gen_discriminator(self.input_B, "d_B")
scope.reuse_variables()
self.fake_rec_A = build_gen_discriminator(self.fake_A, "d_A")
self.fake_rec_B = build_gen_discriminator(self.fake_B, "d_B")
self.cyc_A = build_generator_resnet_9blocks(self.fake_B, "g_B")
self.cyc_B = build_generator_resnet_9blocks(self.fake_A, "g_A")
scope.reuse_variables()
self.fake_pool_rec_A = build_gen_discriminator(self.fake_pool_A, "d_A")
self.fake_pool_rec_B = build_gen_discriminator(self.fake_pool_B, "d_B")
def loss_calc(self):
''' In this function we are defining the variables for loss calcultions and traning model
d_loss_A/d_loss_B -> loss for discriminator A/B
g_loss_A/g_loss_B -> loss for generator A/B
*_trainer -> Variaous trainer for above loss functions
*_summ -> Summary variables for above loss functions'''
cyc_loss = tf.reduce_mean(tf.abs(self.input_A-self.cyc_A)) + tf.reduce_mean(tf.abs(self.input_B-self.cyc_B))
disc_loss_A = tf.reduce_mean(tf.squared_difference(self.fake_rec_A,1))
disc_loss_B = tf.reduce_mean(tf.squared_difference(self.fake_rec_B,1))
g_loss_A = cyc_loss*10 + disc_loss_B
g_loss_B = cyc_loss*10 + disc_loss_A
d_loss_A = (tf.reduce_mean(tf.square(self.fake_pool_rec_A)) + tf.reduce_mean(tf.squared_difference(self.rec_A,1)))/2.0
d_loss_B = (tf.reduce_mean(tf.square(self.fake_pool_rec_B)) + tf.reduce_mean(tf.squared_difference(self.rec_B,1)))/2.0
optimizer = tf.train.AdamOptimizer(self.lr, beta1=0.5)
self.model_vars = tf.trainable_variables()
d_A_vars = [var for var in self.model_vars if 'd_A' in var.name]
g_A_vars = [var for var in self.model_vars if 'g_A' in var.name]
d_B_vars = [var for var in self.model_vars if 'd_B' in var.name]
g_B_vars = [var for var in self.model_vars if 'g_B' in var.name]
self.d_A_trainer = optimizer.minimize(d_loss_A, var_list=d_A_vars)
self.d_B_trainer = optimizer.minimize(d_loss_B, var_list=d_B_vars)
self.g_A_trainer = optimizer.minimize(g_loss_A, var_list=g_A_vars)
self.g_B_trainer = optimizer.minimize(g_loss_B, var_list=g_B_vars)
for var in self.model_vars: print(var.name)
#Summary variables for tensorboard
self.g_A_loss_summ = tf.summary.scalar("g_A_loss", g_loss_A)
self.g_B_loss_summ = tf.summary.scalar("g_B_loss", g_loss_B)
self.d_A_loss_summ = tf.summary.scalar("d_A_loss", d_loss_A)
self.d_B_loss_summ = tf.summary.scalar("d_B_loss", d_loss_B)
def save_training_images(self, sess, epoch):
if not os.path.exists("./output/imgs"):
os.makedirs("./output/imgs")
for i in range(0,10):
fake_A_temp, fake_B_temp, cyc_A_temp, cyc_B_temp = sess.run([self.fake_A, self.fake_B, self.cyc_A, self.cyc_B],feed_dict={self.input_A:self.A_input[i], self.input_B:self.B_input[i]})
imsave("./output/imgs/fakeB_"+ str(epoch) + "_" + str(i)+".jpg",((fake_A_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/fakeA_"+ str(epoch) + "_" + str(i)+".jpg",((fake_B_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/cycA_"+ str(epoch) + "_" + str(i)+".jpg",((cyc_A_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/cycB_"+ str(epoch) + "_" + str(i)+".jpg",((cyc_B_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/inputA_"+ str(epoch) + "_" + str(i)+".jpg",((self.A_input[i][0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/inputB_"+ str(epoch) + "_" + str(i)+".jpg",((self.B_input[i][0]+1)*127.5).astype(np.uint8))
def fake_image_pool(self, num_fakes, fake, fake_pool):
''' This function saves the generated image to corresponding pool of images.
In starting. It keeps on feeling the pool till it is full and then randomly selects an
already stored image and replace it with new one.'''
if(num_fakes < pool_size):
fake_pool[num_fakes] = fake
return fake
else :
p = random.random()
if p > 0.5:
random_id = random.randint(0,pool_size-1)
temp = fake_pool[random_id]
fake_pool[random_id] = fake
return temp
else :
return fake
def train(self):
''' Training Function '''
# Load Dataset from the dataset folder
self.input_setup()
#Build the network
self.model_setup()
#Loss function calculations
self.loss_calc()
# Initializing the global variables
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
#Read input to nd array
self.input_read(sess)
#Restore the model to run the model from last checkpoint
if to_restore:
chkpt_fname = tf.train.latest_checkpoint(check_dir)
saver.restore(sess, chkpt_fname)
writer = tf.summary.FileWriter("./output/2")
if not os.path.exists(check_dir):
os.makedirs(check_dir)
# Training Loop
for epoch in range(sess.run(self.global_step),100):
print ("In the epoch ", epoch)
saver.save(sess,os.path.join(check_dir,"cyclegan"),global_step=epoch)
# Dealing with the learning rate as per the epoch number
if(epoch < 100) :
curr_lr = 0.0002
else:
curr_lr = 0.0002 - 0.0002*(epoch-100)/100
if(save_training_images):
self.save_training_images(sess, epoch)
# sys.exit()
for ptr in range(0,max_images):
print("In the iteration ",ptr)
print("Starting",time.time()*1000.0)
# Optimizing the G_A network
_, fake_B_temp, summary_str = sess.run([self.g_A_trainer, self.fake_B, self.g_A_loss_summ],feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr})
writer.add_summary(summary_str, epoch*max_images + ptr)
fake_B_temp1 = self.fake_image_pool(self.num_fake_inputs, fake_B_temp, self.fake_images_B)
# Optimizing the D_B network
_, summary_str = sess.run([self.d_B_trainer, self.d_B_loss_summ],feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr, self.fake_pool_B:fake_B_temp1})
writer.add_summary(summary_str, epoch*max_images + ptr)
# Optimizing the G_B network
_, fake_A_temp, summary_str = sess.run([self.g_B_trainer, self.fake_A, self.g_B_loss_summ],feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr})
writer.add_summary(summary_str, epoch*max_images + ptr)
fake_A_temp1 = self.fake_image_pool(self.num_fake_inputs, fake_A_temp, self.fake_images_A)
# Optimizing the D_A network
_, summary_str = sess.run([self.d_A_trainer, self.d_A_loss_summ],feed_dict={self.input_A:self.A_input[ptr], self.input_B:self.B_input[ptr], self.lr:curr_lr, self.fake_pool_A:fake_A_temp1})
writer.add_summary(summary_str, epoch*max_images + ptr)
self.num_fake_inputs+=1
sess.run(tf.assign(self.global_step, epoch + 1))
writer.add_graph(sess.graph)
def test(self):
''' Testing Function'''
print("Testing the results")
self.input_setup()
self.model_setup()
saver = tf.train.Saver()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
self.input_read(sess)
chkpt_fname = tf.train.latest_checkpoint(check_dir)
saver.restore(sess, chkpt_fname)
if not os.path.exists("./output/imgs/test/"):
os.makedirs("./output/imgs/test/")
for i in range(0,100):
fake_A_temp, fake_B_temp = sess.run([self.fake_A, self.fake_B],feed_dict={self.input_A:self.A_input[i], self.input_B:self.B_input[i]})
imsave("./output/imgs/test/fakeB_"+str(i)+".jpg",((fake_A_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/test/fakeA_"+str(i)+".jpg",((fake_B_temp[0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/test/inputA_"+str(i)+".jpg",((self.A_input[i][0]+1)*127.5).astype(np.uint8))
imsave("./output/imgs/test/inputB_"+str(i)+".jpg",((self.B_input[i][0]+1)*127.5).astype(np.uint8))
def main():
model = CycleGAN()
if to_train:
model.train()
elif to_test:
model.test()
if __name__ == '__main__':
main()
```
| true |
code
| 0.661595 | null | null | null | null |
|
**KNN model of 10k dataset**
_using data found on kaggle from Goodreads_
_books.csv contains information for 10,000 books, such as ISBN, authors, title, year_
_ratings.csv is a collection of user ratings on these books, from 1 to 5 stars_
```
# imports
import numpy as pd
import pandas as pd
import pickle
from sklearn.neighbors import NearestNeighbors
from scipy.sparse import csr_matrix
import re
```
**Books dataset**
```
books = pd.read_csv('https://raw.githubusercontent.com/zygmuntz/goodbooks-10k/master/books.csv')
print(books.shape)
books.head()
```
**Ratings dataset**
```
ratings = pd.read_csv('https://raw.githubusercontent.com/zygmuntz/goodbooks-10k/master/ratings.csv')
print(ratings.shape)
ratings.head()
```
**Trim down the data**
_In order to make a user rating matrix we will only need bood_id and title._
```
cols = ['book_id', 'title']
books = books[cols]
books.head()
```
**Clean up book titles**
_Book titles are messy, special characters, empty spaces, brackets clutter up the titles_
```
def clean_book_titles(title):
title = re.sub(r'\([^)]*\)', '', title) # handles brackets
title = re.sub(' + ', ' ', title) #compresses multi spaces into a single space
title = title.strip() # handles special characters
return title
books['title'] = books['title'].apply(clean_book_titles)
books.head()
```
**neat-o**
**Create feature matrix**
_Combine datasets to get a new dataset of user ratings for each book_
```
books_ratings = pd.merge(ratings, books, on='book_id')
print(books_ratings.shape)
books_ratings.head()
```
**Remove rows with same user_id and book title**
```
user_ratings = books_ratings.drop_duplicates(['user_id', 'title'])
print(user_ratings.shape)
user_ratings.head()
```
**Pivot table to create user_ratings matrix**
_Each column is a user and each row is a book. The entries in the martix are the user's rating for that book._
```
user_matrix = user_ratings.pivot(index='title', columns='user_id', values='rating').fillna(0)
user_matrix.head()
user_matrix.shape
```
**Compress the matrix since it is extremely sparse**
_Whole lotta zeros_
_
```
compressed = csr_matrix(user_matrix.values)
# build and train knn
# unsupervised learning
# using cosine to measure space/distance
knn = NearestNeighbors(algorithm='brute', metric='cosine')
knn.fit(compressed)
def get_recommendations(book_title, matrix=user_matrix, model=knn, topn=2):
book_index = list(matrix.index).index(book_title)
distances, indices = model.kneighbors(matrix.iloc[book_index,:].values.reshape(1,-1), n_neighbors=topn+1)
print('Recommendations for {}:'.format(matrix.index[book_index]))
for i in range(1, len(distances.flatten())):
print('{}. {}, distance = {}'.format(i, matrix.index[indices.flatten()[i]], "%.3f"%distances.flatten()[i]))
print()
get_recommendations("Harry Potter and the Sorcerer's Stone")
get_recommendations("Pride and Prejudice")
get_recommendations("Matilda")
pickle.dump(knn, open('knn_model.pkl','wb'))
```
| true |
code
| 0.439868 | null | null | null | null |
|
# Wind Statistics
### Introduction:
The data have been modified to contain some missing values, identified by NaN.
Using pandas should make this exercise
easier, in particular for the bonus question.
You should be able to perform all of these operations without using
a for loop or other looping construct.
1. The data in 'wind.data' has the following format:
```
"""
Yr Mo Dy RPT VAL ROS KIL SHA BIR DUB CLA MUL CLO BEL MAL
61 1 1 15.04 14.96 13.17 9.29 NaN 9.87 13.67 10.25 10.83 12.58 18.50 15.04
61 1 2 14.71 NaN 10.83 6.50 12.62 7.67 11.50 10.04 9.79 9.67 17.54 13.83
61 1 3 18.50 16.88 12.33 10.13 11.17 6.17 11.25 NaN 8.50 7.67 12.75 12.71
"""
```
The first three columns are year, month and day. The
remaining 12 columns are average windspeeds in knots at 12
locations in Ireland on that day.
More information about the dataset go [here](wind.desc).
### Step 1. Import the necessary libraries
```
import pandas as pd
import datetime
```
### Step 2. Import the dataset from this [address](https://github.com/guipsamora/pandas_exercises/blob/master/06_Stats/Wind_Stats/wind.data)
### Step 3. Assign it to a variable called data and replace the first 3 columns by a proper datetime index.
```
# parse_dates gets 0, 1, 2 columns and parses them as the index
data_url = 'https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/06_Stats/Wind_Stats/wind.data'
data = pd.read_csv(data_url, sep = "\s+", parse_dates = [[0,1,2]])
data.head()
```
### Step 4. Year 2061? Do we really have data from this year? Create a function to fix it and apply it.
```
# The problem is that the dates are 2061 and so on...
# function that uses datetime
def fix_century(x):
year = x.year - 100 if x.year > 1989 else x.year
return datetime.date(year, x.month, x.day)
# apply the function fix_century on the column and replace the values to the right ones
data['Yr_Mo_Dy'] = data['Yr_Mo_Dy'].apply(fix_century)
# data.info()
data.head()
```
### Step 5. Set the right dates as the index. Pay attention at the data type, it should be datetime64[ns].
```
# transform Yr_Mo_Dy it to date type datetime64
data["Yr_Mo_Dy"] = pd.to_datetime(data["Yr_Mo_Dy"])
# set 'Yr_Mo_Dy' as the index
data = data.set_index('Yr_Mo_Dy')
data.head()
# data.info()
```
### Step 6. Compute how many values are missing for each location over the entire record.
#### They should be ignored in all calculations below.
```
# "Number of non-missing values for each location: "
data.isnull().sum()
```
### Step 7. Compute how many non-missing values there are in total.
```
#number of columns minus the number of missing values for each location
data.shape[0] - data.isnull().sum()
#or
data.notnull().sum()
```
### Step 8. Calculate the mean windspeeds of the windspeeds over all the locations and all the times.
#### A single number for the entire dataset.
```
data.sum().sum() / data.notna().sum().sum()
```
### Step 9. Create a DataFrame called loc_stats and calculate the min, max and mean windspeeds and standard deviations of the windspeeds at each location over all the days
#### A different set of numbers for each location.
```
data.describe(percentiles=[])
```
### Step 10. Create a DataFrame called day_stats and calculate the min, max and mean windspeed and standard deviations of the windspeeds across all the locations at each day.
#### A different set of numbers for each day.
```
# create the dataframe
day_stats = pd.DataFrame()
# this time we determine axis equals to one so it gets each row.
day_stats['min'] = data.min(axis = 1) # min
day_stats['max'] = data.max(axis = 1) # max
day_stats['mean'] = data.mean(axis = 1) # mean
day_stats['std'] = data.std(axis = 1) # standard deviations
day_stats.head()
```
### Step 11. Find the average windspeed in January for each location.
#### Treat January 1961 and January 1962 both as January.
```
data.loc[data.index.month == 1].mean()
```
### Step 12. Downsample the record to a yearly frequency for each location.
```
data.groupby(data.index.to_period('A')).mean()
```
### Step 13. Downsample the record to a monthly frequency for each location.
```
data.groupby(data.index.to_period('M')).mean()
```
### Step 14. Downsample the record to a weekly frequency for each location.
```
data.groupby(data.index.to_period('W')).mean()
```
### Step 15. Calculate the min, max and mean windspeeds and standard deviations of the windspeeds across all locations for each week (assume that the first week starts on January 2 1961) for the first 52 weeks.
```
# resample data to 'W' week and use the functions
weekly = data.resample('W').agg(['min','max','mean','std'])
# slice it for the first 52 weeks and locations
weekly.loc[weekly.index[1:53], "RPT":"MAL"] .head(10)
```
| true |
code
| 0.57075 | null | null | null | null |
|
# Mark and Recapture
Think Bayes, Second Edition
Copyright 2020 Allen B. Downey
License: [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
```
# If we're running on Colab, install empiricaldist
# https://pypi.org/project/empiricaldist/
import sys
IN_COLAB = 'google.colab' in sys.modules
if IN_COLAB:
!pip install empiricaldist
# Get utils.py
import os
if not os.path.exists('utils.py'):
!wget https://github.com/AllenDowney/ThinkBayes2/raw/master/soln/utils.py
from utils import set_pyplot_params
set_pyplot_params()
```
This chapter introduces "mark and recapture" experiments, in which we sample individuals from a population, mark them somehow, and then take a second sample from the same population. Seeing how many individuals in the second sample are marked, we can estimate the size of the population.
Experiments like this were originally used in ecology, but turn out to be useful in many other fields. Examples in this chapter include software engineering and epidemiology.
Also, in this chapter we'll work with models that have three parameters, so we'll extend the joint distributions we've been using to three dimensions.
But first, grizzly bears.
## The Grizzly Bear Problem
In 1996 and 1997 researchers deployed bear traps in locations in British Columbia and Alberta, Canada, in an effort to estimate the population of grizzly bears. They describe the experiment in [this article](https://www.researchgate.net/publication/229195465_Estimating_Population_Size_of_Grizzly_Bears_Using_Hair_Capture_DNA_Profiling_and_Mark-Recapture_Analysis).
The "trap" consists of a lure and several strands of barbed wire intended to capture samples of hair from bears that visit the lure. Using the hair samples, the researchers use DNA analysis to identify individual bears.
During the first session, the researchers deployed traps at 76 sites. Returning 10 days later, they obtained 1043 hair samples and identified 23 different bears. During a second 10-day session they obtained 1191 samples from 19 different bears, where 4 of the 19 were from bears they had identified in the first batch.
To estimate the population of bears from this data, we need a model for the probability that each bear will be observed during each session. As a starting place, we'll make the simplest assumption, that every bear in the population has the same (unknown) probability of being sampled during each session.
With these assumptions we can compute the probability of the data for a range of possible populations.
As an example, let's suppose that the actual population of bears is 100.
After the first session, 23 of the 100 bears have been identified.
During the second session, if we choose 19 bears at random, what is the probability that 4 of them were previously identified?
I'll define
* $N$: actual population size, 100.
* $K$: number of bears identified in the first session, 23.
* $n$: number of bears observed in the second session, 19 in the example.
* $k$: number of bears in the second session that were previously identified, 4.
For given values of $N$, $K$, and $n$, the probability of finding $k$ previously-identified bears is given by the [hypergeometric distribution](https://en.wikipedia.org/wiki/Hypergeometric_distribution):
$$\binom{K}{k} \binom{N-K}{n-k}/ \binom{N}{n}$$
where the [binomial coefficient](https://en.wikipedia.org/wiki/Binomial_coefficient), $\binom{K}{k}$, is the number of subsets of size $k$ we can choose from a population of size $K$.
To understand why, consider:
* The denominator, $\binom{N}{n}$, is the number of subsets of $n$ we could choose from a population of $N$ bears.
* The numerator is the number of subsets that contain $k$ bears from the previously identified $K$ and $n-k$ from the previously unseen $N-K$.
SciPy provides `hypergeom`, which we can use to compute this probability for a range of values of $k$.
```
import numpy as np
from scipy.stats import hypergeom
N = 100
K = 23
n = 19
ks = np.arange(12)
ps = hypergeom(N, K, n).pmf(ks)
```
The result is the distribution of $k$ with given parameters $N$, $K$, and $n$.
Here's what it looks like.
```
import matplotlib.pyplot as plt
from utils import decorate
plt.bar(ks, ps)
decorate(xlabel='Number of bears observed twice',
ylabel='PMF',
title='Hypergeometric distribution of k (known population 100)')
```
The most likely value of $k$ is 4, which is the value actually observed in the experiment.
That suggests that $N=100$ is a reasonable estimate of the population, given this data.
We've computed the distribution of $k$ given $N$, $K$, and $n$.
Now let's go the other way: given $K$, $n$, and $k$, how can we estimate the total population, $N$?
## The Update
As a starting place, let's suppose that, prior to this study, an expert estimates that the local bear population is between 50 and 500, and equally likely to be any value in that range.
I'll use `make_uniform` to make a uniform distribution of integers in this range.
```
import numpy as np
from utils import make_uniform
qs = np.arange(50, 501)
prior_N = make_uniform(qs, name='N')
prior_N.shape
```
So that's our prior.
To compute the likelihood of the data, we can use `hypergeom` with constants `K` and `n`, and a range of values of `N`.
```
Ns = prior_N.qs
K = 23
n = 19
k = 4
likelihood = hypergeom(Ns, K, n).pmf(k)
```
We can compute the posterior in the usual way.
```
posterior_N = prior_N * likelihood
posterior_N.normalize()
```
And here's what it looks like.
```
posterior_N.plot(color='C4')
decorate(xlabel='Population of bears (N)',
ylabel='PDF',
title='Posterior distribution of N')
```
The most likely value is 109.
```
posterior_N.max_prob()
```
But the distribution is skewed to the right, so the posterior mean is substantially higher.
```
posterior_N.mean()
```
And the credible interval is quite wide.
```
posterior_N.credible_interval(0.9)
```
This solution is relatively simple, but it turns out we can do a little better if we model the unknown probability of observing a bear explicitly.
## Two Parameter Model
Next we'll try a model with two parameters: the number of bears, `N`, and the probability of observing a bear, `p`.
We'll assume that the probability is the same in both rounds, which is probably reasonable in this case because it is the same kind of trap in the same place.
We'll also assume that the probabilities are independent; that is, the probability a bear is observed in the second round does not depend on whether it was observed in the first round. This assumption might be less reasonable, but for now it is a necessary simplification.
Here are the counts again:
```
K = 23
n = 19
k = 4
```
For this model, I'll express the data in a notation that will make it easier to generalize to more than two rounds:
* `k10` is the number of bears observed in the first round but not the second,
* `k01` is the number of bears observed in the second round but not the first, and
* `k11` is the number of bears observed in both rounds.
Here are their values.
```
k10 = 23 - 4
k01 = 19 - 4
k11 = 4
```
Suppose we know the actual values of `N` and `p`. We can use them to compute the likelihood of this data.
For example, suppose we know that `N=100` and `p=0.2`.
We can use `N` to compute `k00`, which is the number of unobserved bears.
```
N = 100
observed = k01 + k10 + k11
k00 = N - observed
k00
```
For the update, it will be convenient to store the data as a list that represents the number of bears in each category.
```
x = [k00, k01, k10, k11]
x
```
Now, if we know `p=0.2`, we can compute the probability a bear falls in each category. For example, the probability of being observed in both rounds is `p*p`, and the probability of being unobserved in both rounds is `q*q` (where `q=1-p`).
```
p = 0.2
q = 1-p
y = [q*q, q*p, p*q, p*p]
y
```
Now the probability of the data is given by the [multinomial distribution](https://en.wikipedia.org/wiki/Multinomial_distribution):
$$\frac{N!}{\prod x_i!} \prod y_i^{x_i}$$
where $N$ is actual population, $x$ is a sequence with the counts in each category, and $y$ is a sequence of probabilities for each category.
SciPy provides `multinomial`, which provides `pmf`, which computes this probability.
Here is the probability of the data for these values of `N` and `p`.
```
from scipy.stats import multinomial
likelihood = multinomial.pmf(x, N, y)
likelihood
```
That's the likelihood if we know `N` and `p`, but of course we don't. So we'll choose prior distributions for `N` and `p`, and use the likelihoods to update it.
## The Prior
We'll use `prior_N` again for the prior distribution of `N`, and a uniform prior for the probability of observing a bear, `p`:
```
qs = np.linspace(0, 0.99, num=100)
prior_p = make_uniform(qs, name='p')
```
We can make a joint distribution in the usual way.
```
from utils import make_joint
joint_prior = make_joint(prior_p, prior_N)
joint_prior.shape
```
The result is a Pandas `DataFrame` with values of `N` down the rows and values of `p` across the columns.
However, for this problem it will be convenient to represent the prior distribution as a 1-D `Series` rather than a 2-D `DataFrame`.
We can convert from one format to the other using `stack`.
```
from empiricaldist import Pmf
joint_pmf = Pmf(joint_prior.stack())
joint_pmf.head(3)
type(joint_pmf)
type(joint_pmf.index)
joint_pmf.shape
```
The result is a `Pmf` whose index is a `MultiIndex`.
A `MultiIndex` can have more than one column; in this example, the first column contains values of `N` and the second column contains values of `p`.
The `Pmf` has one row (and one prior probability) for each possible pair of parameters `N` and `p`.
So the total number of rows is the product of the lengths of `prior_N` and `prior_p`.
Now we have to compute the likelihood of the data for each pair of parameters.
## The Update
To allocate space for the likelihoods, it is convenient to make a copy of `joint_pmf`:
```
likelihood = joint_pmf.copy()
```
As we loop through the pairs of parameters, we compute the likelihood of the data as in the previous section, and then store the result as an element of `likelihood`.
```
observed = k01 + k10 + k11
for N, p in joint_pmf.index:
k00 = N - observed
x = [k00, k01, k10, k11]
q = 1-p
y = [q*q, q*p, p*q, p*p]
likelihood[N, p] = multinomial.pmf(x, N, y)
```
Now we can compute the posterior in the usual way.
```
posterior_pmf = joint_pmf * likelihood
posterior_pmf.normalize()
```
We'll use `plot_contour` again to visualize the joint posterior distribution.
But remember that the posterior distribution we just computed is represented as a `Pmf`, which is a `Series`, and `plot_contour` expects a `DataFrame`.
Since we used `stack` to convert from a `DataFrame` to a `Series`, we can use `unstack` to go the other way.
```
joint_posterior = posterior_pmf.unstack()
```
And here's what the result looks like.
```
from utils import plot_contour
plot_contour(joint_posterior)
decorate(title='Joint posterior distribution of N and p')
```
The most likely values of `N` are near 100, as in the previous model. The most likely values of `p` are near 0.2.
The shape of this contour indicates that these parameters are correlated. If `p` is near the low end of the range, the most likely values of `N` are higher; if `p` is near the high end of the range, `N` is lower.
Now that we have a posterior `DataFrame`, we can extract the marginal distributions in the usual way.
```
from utils import marginal
posterior2_p = marginal(joint_posterior, 0)
posterior2_N = marginal(joint_posterior, 1)
```
Here's the posterior distribution for `p`:
```
posterior2_p.plot(color='C1')
decorate(xlabel='Probability of observing a bear',
ylabel='PDF',
title='Posterior marginal distribution of p')
```
The most likely values are near 0.2.
Here's the posterior distribution for `N` based on the two-parameter model, along with the posterior we got using the one-parameter (hypergeometric) model.
```
posterior_N.plot(label='one-parameter model', color='C4')
posterior2_N.plot(label='two-parameter model', color='C1')
decorate(xlabel='Population of bears (N)',
ylabel='PDF',
title='Posterior marginal distribution of N')
```
With the two-parameter model, the mean is a little lower and the 90% credible interval is a little narrower.
```
print(posterior_N.mean(),
posterior_N.credible_interval(0.9))
print(posterior2_N.mean(),
posterior2_N.credible_interval(0.9))
```
The two-parameter model yields a narrower posterior distribution for `N`, compared to the one-parameter model, because it takes advantage of an additional source of information: the consistency of the two observations.
To see how this helps, consider a scenario where `N` is relatively low, like 138 (the posterior mean of the two-parameter model).
```
N1 = 138
```
Given that we saw 23 bears during the first trial and 19 during the second, we can estimate the corresponding value of `p`.
```
mean = (23 + 19) / 2
p = mean/N1
p
```
With these parameters, how much variability do you expect in the number of bears from one trial to the next? We can quantify that by computing the standard deviation of the binomial distribution with these parameters.
```
from scipy.stats import binom
binom(N1, p).std()
```
Now let's consider a second scenario where `N` is 173, the posterior mean of the one-parameter model. The corresponding value of `p` is lower.
```
N2 = 173
p = mean/N2
p
```
In this scenario, the variation we expect to see from one trial to the next is higher.
```
binom(N2, p).std()
```
So if the number of bears we observe is the same in both trials, that would be evidence for lower values of `N`, where we expect more consistency.
If the number of bears is substantially different between the two trials, that would be evidence for higher values of `N`.
In the actual data, the difference between the two trials is low, which is why the posterior mean of the two-parameter model is lower.
The two-parameter model takes advantage of additional information, which is why the credible interval is narrower.
## Joint and Marginal Distributions
Marginal distributions are called "marginal" because in a common visualization they appear in the margins of the plot.
Seaborn provides a class called `JointGrid` that creates this visualization.
The following function uses it to show the joint and marginal distributions in a single plot.
```
import pandas as pd
from seaborn import JointGrid
def joint_plot(joint, **options):
"""Show joint and marginal distributions.
joint: DataFrame that represents a joint distribution
options: passed to JointGrid
"""
# get the names of the parameters
x = joint.columns.name
x = 'x' if x is None else x
y = joint.index.name
y = 'y' if y is None else y
# make a JointGrid with minimal data
data = pd.DataFrame({x:[0], y:[0]})
g = JointGrid(x=x, y=y, data=data, **options)
# replace the contour plot
g.ax_joint.contour(joint.columns,
joint.index,
joint,
cmap='viridis')
# replace the marginals
marginal_x = marginal(joint, 0)
g.ax_marg_x.plot(marginal_x.qs, marginal_x.ps)
marginal_y = marginal(joint, 1)
g.ax_marg_y.plot(marginal_y.ps, marginal_y.qs)
joint_plot(joint_posterior)
```
A `JointGrid` is a concise way to represent the joint and marginal distributions visually.
## The Lincoln Index Problem
In [an excellent blog post](http://www.johndcook.com/blog/2010/07/13/lincoln-index/), John D. Cook wrote about the Lincoln index, which is a way to estimate the
number of errors in a document (or program) by comparing results from
two independent testers.
Here's his presentation of the problem:
> "Suppose you have a tester who finds 20 bugs in your program. You
want to estimate how many bugs are really in the program. You know
there are at least 20 bugs, and if you have supreme confidence in your
tester, you may suppose there are around 20 bugs. But maybe your
tester isn't very good. Maybe there are hundreds of bugs. How can you
have any idea how many bugs there are? There's no way to know with one
tester. But if you have two testers, you can get a good idea, even if
you don't know how skilled the testers are."
Suppose the first tester finds 20 bugs, the second finds 15, and they
find 3 in common; how can we estimate the number of bugs?
This problem is similar to the Grizzly Bear problem, so I'll represent the data in the same way.
```
k10 = 20 - 3
k01 = 15 - 3
k11 = 3
```
But in this case it is probably not reasonable to assume that the testers have the same probability of finding a bug.
So I'll define two parameters, `p0` for the probability that the first tester finds a bug, and `p1` for the probability that the second tester finds a bug.
I will continue to assume that the probabilities are independent, which is like assuming that all bugs are equally easy to find. That might not be a good assumption, but let's stick with it for now.
As an example, suppose we know that the probabilities are 0.2 and 0.15.
```
p0, p1 = 0.2, 0.15
```
We can compute the array of probabilities, `y`, like this:
```
def compute_probs(p0, p1):
"""Computes the probability for each of 4 categories."""
q0 = 1-p0
q1 = 1-p1
return [q0*q1, q0*p1, p0*q1, p0*p1]
y = compute_probs(p0, p1)
y
```
With these probabilities, there is a
68% chance that neither tester finds the bug and a
3% chance that both do.
Pretending that these probabilities are known, we can compute the posterior distribution for `N`.
Here's a prior distribution that's uniform from 32 to 350 bugs.
```
qs = np.arange(32, 350, step=5)
prior_N = make_uniform(qs, name='N')
prior_N.head(3)
```
I'll put the data in an array, with 0 as a place-keeper for the unknown value `k00`.
```
data = np.array([0, k01, k10, k11])
```
And here are the likelihoods for each value of `N`, with `ps` as a constant.
```
likelihood = prior_N.copy()
observed = data.sum()
x = data.copy()
for N in prior_N.qs:
x[0] = N - observed
likelihood[N] = multinomial.pmf(x, N, y)
```
We can compute the posterior in the usual way.
```
posterior_N = prior_N * likelihood
posterior_N.normalize()
```
And here's what it looks like.
```
posterior_N.plot(color='C4')
decorate(xlabel='Number of bugs (N)',
ylabel='PMF',
title='Posterior marginal distribution of n with known p1, p2')
print(posterior_N.mean(),
posterior_N.credible_interval(0.9))
```
With the assumption that `p0` and `p1` are known to be `0.2` and `0.15`, the posterior mean is 102 with 90% credible interval (77, 127).
But this result is based on the assumption that we know the probabilities, and we don't.
## Three-parameter Model
What we need is a model with three parameters: `N`, `p0`, and `p1`.
We'll use `prior_N` again for the prior distribution of `N`, and here are the priors for `p0` and `p1`:
```
qs = np.linspace(0, 1, num=51)
prior_p0 = make_uniform(qs, name='p0')
prior_p1 = make_uniform(qs, name='p1')
```
Now we have to assemble them into a joint prior with three dimensions.
I'll start by putting the first two into a `DataFrame`.
```
joint2 = make_joint(prior_p0, prior_N)
joint2.shape
```
Now I'll stack them, as in the previous example, and put the result in a `Pmf`.
```
joint2_pmf = Pmf(joint2.stack())
joint2_pmf.head(3)
```
We can use `make_joint` again to add in the third parameter.
```
joint3 = make_joint(prior_p1, joint2_pmf)
joint3.shape
```
The result is a `DataFrame` with values of `N` and `p0` in a `MultiIndex` that goes down the rows and values of `p1` in an index that goes across the columns.
```
joint3.head(3)
```
Now I'll apply `stack` again:
```
joint3_pmf = Pmf(joint3.stack())
joint3_pmf.head(3)
```
The result is a `Pmf` with a three-column `MultiIndex` containing all possible triplets of parameters.
The number of rows is the product of the number of values in all three priors, which is almost 170,000.
```
joint3_pmf.shape
```
That's still small enough to be practical, but it will take longer to compute the likelihoods than in the previous examples.
Here's the loop that computes the likelihoods; it's similar to the one in the previous section:
```
likelihood = joint3_pmf.copy()
observed = data.sum()
x = data.copy()
for N, p0, p1 in joint3_pmf.index:
x[0] = N - observed
y = compute_probs(p0, p1)
likelihood[N, p0, p1] = multinomial.pmf(x, N, y)
```
We can compute the posterior in the usual way.
```
posterior_pmf = joint3_pmf * likelihood
posterior_pmf.normalize()
```
Now, to extract the marginal distributions, we could unstack the joint posterior as we did in the previous section.
But `Pmf` provides a version of `marginal` that works with a `Pmf` rather than a `DataFrame`.
Here's how we use it to get the posterior distribution for `N`.
```
posterior_N = posterior_pmf.marginal(0)
```
And here's what it looks look.
```
posterior_N.plot(color='C4')
decorate(xlabel='Number of bugs (N)',
ylabel='PDF',
title='Posterior marginal distributions of N')
posterior_N.mean()
```
The posterior mean is 105 bugs, which suggests that there are still many bugs the testers have not found.
Here are the posteriors for `p0` and `p1`.
```
posterior_p1 = posterior_pmf.marginal(1)
posterior_p2 = posterior_pmf.marginal(2)
posterior_p1.plot(label='p1')
posterior_p2.plot(label='p2')
decorate(xlabel='Probability of finding a bug',
ylabel='PDF',
title='Posterior marginal distributions of p1 and p2')
posterior_p1.mean(), posterior_p1.credible_interval(0.9)
posterior_p2.mean(), posterior_p2.credible_interval(0.9)
```
Comparing the posterior distributions, the tester who found more bugs probably has a higher probability of finding bugs. The posterior means are about 23% and 18%. But the distributions overlap, so we should not be too sure.
This is the first example we've seen with three parameters.
As the number of parameters increases, the number of combinations increases quickly.
The method we've been using so far, enumerating all possible combinations, becomes impractical if the number of parameters is more than 3 or 4.
However there are other methods that can handle models with many more parameters, as we'll see in <<_MCMC>>.
## Summary
The problems in this chapter are examples of [mark and recapture](https://en.wikipedia.org/wiki/Mark_and_recapture) experiments, which are used in ecology to estimate animal populations. They also have applications in engineering, as in the Lincoln index problem. And in the exercises you'll see that they are used in epidemiology, too.
This chapter introduces two new probability distributions:
* The hypergeometric distribution is a variation of the binomial distribution in which samples are drawn from the population without replacement.
* The multinomial distribution is a generalization of the binomial distribution where there are more than two possible outcomes.
Also in this chapter, we saw the first example of a model with three parameters. We'll see more in subsequent chapters.
## Exercises
**Exercise:** [In an excellent paper](http://chao.stat.nthu.edu.tw/wordpress/paper/110.pdf), Anne Chao explains how mark and recapture experiments are used in epidemiology to estimate the prevalence of a disease in a human population based on multiple incomplete lists of cases.
One of the examples in that paper is a study "to estimate the number of people who were infected by hepatitis in an outbreak that occurred in and around a college in northern Taiwan from April to July 1995."
Three lists of cases were available:
1. 135 cases identified using a serum test.
2. 122 cases reported by local hospitals.
3. 126 cases reported on questionnaires collected by epidemiologists.
In this exercise, we'll use only the first two lists; in the next exercise we'll bring in the third list.
Make a joint prior and update it using this data, then compute the posterior mean of `N` and a 90% credible interval.
The following array contains 0 as a place-holder for the unknown value of `k00`, followed by known values of `k01`, `k10`, and `k11`.
```
data2 = np.array([0, 73, 86, 49])
```
These data indicate that there are 73 cases on the second list that are not on the first, 86 cases on the first list that are not on the second, and 49 cases on both lists.
To keep things simple, we'll assume that each case has the same probability of appearing on each list. So we'll use a two-parameter model where `N` is the total number of cases and `p` is the probability that any case appears on any list.
Here are priors you can start with (but feel free to modify them).
```
qs = np.arange(200, 500, step=5)
prior_N = make_uniform(qs, name='N')
prior_N.head(3)
qs = np.linspace(0, 0.98, num=50)
prior_p = make_uniform(qs, name='p')
prior_p.head(3)
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
```
**Exercise:** Now let's do the version of the problem with all three lists. Here's the data from Chou's paper:
```
Hepatitis A virus list
P Q E Data
1 1 1 k111 =28
1 1 0 k110 =21
1 0 1 k101 =17
1 0 0 k100 =69
0 1 1 k011 =18
0 1 0 k010 =55
0 0 1 k001 =63
0 0 0 k000 =??
```
Write a loop that computes the likelihood of the data for each pair of parameters, then update the prior and compute the posterior mean of `N`. How does it compare to the results using only the first two lists?
Here's the data in a NumPy array (in reverse order).
```
data3 = np.array([0, 63, 55, 18, 69, 17, 21, 28])
```
Again, the first value is a place-keeper for the unknown `k000`. The second value is `k001`, which means there are 63 cases that appear on the third list but not the first two. And the last value is `k111`, which means there are 28 cases that appear on all three lists.
In the two-list version of the problem we computed `ps` by enumerating the combinations of `p` and `q`.
```
q = 1-p
ps = [q*q, q*p, p*q, p*p]
```
We could do the same thing for the three-list version, computing the probability for each of the eight categories. But we can generalize it by recognizing that we are computing the cartesian product of `p` and `q`, repeated once for each list.
And we can use the following function (based on [this StackOverflow answer](https://stackoverflow.com/questions/58242078/cartesian-product-of-arbitrary-lists-in-pandas/58242079#58242079)) to compute Cartesian products:
```
def cartesian_product(*args, **options):
"""Cartesian product of sequences.
args: any number of sequences
options: passes to `MultiIndex.from_product`
returns: DataFrame with one column per sequence
"""
index = pd.MultiIndex.from_product(args, **options)
return pd.DataFrame(index=index).reset_index()
```
Here's an example with `p=0.2`:
```
p = 0.2
t = (1-p, p)
df = cartesian_product(t, t, t)
df
```
To compute the probability for each category, we take the product across the columns:
```
y = df.prod(axis=1)
y
```
Now you finish it off from there.
```
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
# Solution goes here
```
| true |
code
| 0.791363 | null | null | null | null |
|
```
#hide
#skip
! [ -e /content ] && pip install -Uqq fastai # upgrade fastai on colab
# default_exp losses
# default_cls_lvl 3
#export
from fastai.imports import *
from fastai.torch_imports import *
from fastai.torch_core import *
from fastai.layers import *
#hide
from nbdev.showdoc import *
```
# Loss Functions
> Custom fastai loss functions
```
# export
class BaseLoss():
"Same as `loss_cls`, but flattens input and target."
activation=decodes=noops
def __init__(self, loss_cls, *args, axis=-1, flatten=True, floatify=False, is_2d=True, **kwargs):
store_attr("axis,flatten,floatify,is_2d")
self.func = loss_cls(*args,**kwargs)
functools.update_wrapper(self, self.func)
def __repr__(self): return f"FlattenedLoss of {self.func}"
@property
def reduction(self): return self.func.reduction
@reduction.setter
def reduction(self, v): self.func.reduction = v
def _contiguous(self,x):
return TensorBase(x.transpose(self.axis,-1).contiguous()) if isinstance(x,torch.Tensor) else x
def __call__(self, inp, targ, **kwargs):
inp,targ = map(self._contiguous, (inp,targ))
if self.floatify and targ.dtype!=torch.float16: targ = targ.float()
if targ.dtype in [torch.int8, torch.int16, torch.int32]: targ = targ.long()
if self.flatten: inp = inp.view(-1,inp.shape[-1]) if self.is_2d else inp.view(-1)
return self.func.__call__(inp, targ.view(-1) if self.flatten else targ, **kwargs)
```
Wrapping a general loss function inside of `BaseLoss` provides extra functionalities to your loss functions:
- flattens the tensors before trying to take the losses since it's more convenient (with a potential tranpose to put `axis` at the end)
- a potential `activation` method that tells the library if there is an activation fused in the loss (useful for inference and methods such as `Learner.get_preds` or `Learner.predict`)
- a potential <code>decodes</code> method that is used on predictions in inference (for instance, an argmax in classification)
The `args` and `kwargs` will be passed to `loss_cls` during the initialization to instantiate a loss function. `axis` is put at the end for losses like softmax that are often performed on the last axis. If `floatify=True`, the `targs` will be converted to floats (useful for losses that only accept float targets like `BCEWithLogitsLoss`), and `is_2d` determines if we flatten while keeping the first dimension (batch size) or completely flatten the input. We want the first for losses like Cross Entropy, and the second for pretty much anything else.
```
# export
@delegates()
class CrossEntropyLossFlat(BaseLoss):
"Same as `nn.CrossEntropyLoss`, but flattens input and target."
y_int = True
@use_kwargs_dict(keep=True, weight=None, ignore_index=-100, reduction='mean')
def __init__(self, *args, axis=-1, **kwargs): super().__init__(nn.CrossEntropyLoss, *args, axis=axis, **kwargs)
def decodes(self, x): return x.argmax(dim=self.axis)
def activation(self, x): return F.softmax(x, dim=self.axis)
tst = CrossEntropyLossFlat()
output = torch.randn(32, 5, 10)
target = torch.randint(0, 10, (32,5))
#nn.CrossEntropy would fail with those two tensors, but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.CrossEntropyLoss()(output,target))
#Associated activation is softmax
test_eq(tst.activation(output), F.softmax(output, dim=-1))
#This loss function has a decodes which is argmax
test_eq(tst.decodes(output), output.argmax(dim=-1))
#In a segmentation task, we want to take the softmax over the channel dimension
tst = CrossEntropyLossFlat(axis=1)
output = torch.randn(32, 5, 128, 128)
target = torch.randint(0, 5, (32, 128, 128))
_ = tst(output, target)
test_eq(tst.activation(output), F.softmax(output, dim=1))
test_eq(tst.decodes(output), output.argmax(dim=1))
```
[Focal Loss](https://arxiv.org/pdf/1708.02002.pdf) is the same as cross entropy except easy-to-classify observations are down-weighted in the loss calculation. The strength of down-weighting is proportional to the size of the `gamma` parameter. Put another way, the larger `gamma` the less the easy-to-classify observations contribute to the loss.
```
# export
class FocalLossFlat(CrossEntropyLossFlat):
"""
Same as CrossEntropyLossFlat but with focal paramter, `gamma`. Focal loss is introduced by Lin et al.
https://arxiv.org/pdf/1708.02002.pdf. Note the class weighting factor in the paper, alpha, can be
implemented through pytorch `weight` argument in nn.CrossEntropyLoss.
"""
y_int = True
@use_kwargs_dict(keep=True, weight=None, ignore_index=-100, reduction='mean')
def __init__(self, *args, gamma=2, axis=-1, **kwargs):
self.gamma = gamma
self.reduce = kwargs.pop('reduction') if 'reduction' in kwargs else 'mean'
super().__init__(*args, reduction='none', axis=axis, **kwargs)
def __call__(self, inp, targ, **kwargs):
ce_loss = super().__call__(inp, targ, **kwargs)
pt = torch.exp(-ce_loss)
fl_loss = (1-pt)**self.gamma * ce_loss
return fl_loss.mean() if self.reduce == 'mean' else fl_loss.sum() if self.reduce == 'sum' else fl_loss
#Compare focal loss with gamma = 0 to cross entropy
fl = FocalLossFlat(gamma=0)
ce = CrossEntropyLossFlat()
output = torch.randn(32, 5, 10)
target = torch.randint(0, 10, (32,5))
test_close(fl(output, target), ce(output, target))
#Test focal loss with gamma > 0 is different than cross entropy
fl = FocalLossFlat(gamma=2)
test_ne(fl(output, target), ce(output, target))
#In a segmentation task, we want to take the softmax over the channel dimension
fl = FocalLossFlat(gamma=0, axis=1)
ce = CrossEntropyLossFlat(axis=1)
output = torch.randn(32, 5, 128, 128)
target = torch.randint(0, 5, (32, 128, 128))
test_close(fl(output, target), ce(output, target), eps=1e-4)
test_eq(fl.activation(output), F.softmax(output, dim=1))
test_eq(fl.decodes(output), output.argmax(dim=1))
# export
@delegates()
class BCEWithLogitsLossFlat(BaseLoss):
"Same as `nn.BCEWithLogitsLoss`, but flattens input and target."
@use_kwargs_dict(keep=True, weight=None, reduction='mean', pos_weight=None)
def __init__(self, *args, axis=-1, floatify=True, thresh=0.5, **kwargs):
if kwargs.get('pos_weight', None) is not None and kwargs.get('flatten', None) is True:
raise ValueError("`flatten` must be False when using `pos_weight` to avoid a RuntimeError due to shape mismatch")
if kwargs.get('pos_weight', None) is not None: kwargs['flatten'] = False
super().__init__(nn.BCEWithLogitsLoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
self.thresh = thresh
def decodes(self, x): return x>self.thresh
def activation(self, x): return torch.sigmoid(x)
tst = BCEWithLogitsLossFlat()
output = torch.randn(32, 5, 10)
target = torch.randn(32, 5, 10)
#nn.BCEWithLogitsLoss would fail with those two tensors, but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
output = torch.randn(32, 5)
target = torch.randint(0,2,(32, 5))
#nn.BCEWithLogitsLoss would fail with int targets but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
tst = BCEWithLogitsLossFlat(pos_weight=torch.ones(10))
output = torch.randn(32, 5, 10)
target = torch.randn(32, 5, 10)
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
#Associated activation is sigmoid
test_eq(tst.activation(output), torch.sigmoid(output))
# export
@use_kwargs_dict(weight=None, reduction='mean')
def BCELossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.BCELoss`, but flattens input and target."
return BaseLoss(nn.BCELoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
tst = BCELossFlat()
output = torch.sigmoid(torch.randn(32, 5, 10))
target = torch.randint(0,2,(32, 5, 10))
_ = tst(output, target)
test_fail(lambda x: nn.BCELoss()(output,target))
# export
@use_kwargs_dict(reduction='mean')
def MSELossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.MSELoss`, but flattens input and target."
return BaseLoss(nn.MSELoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
tst = MSELossFlat()
output = torch.sigmoid(torch.randn(32, 5, 10))
target = torch.randint(0,2,(32, 5, 10))
_ = tst(output, target)
test_fail(lambda x: nn.MSELoss()(output,target))
#hide
#cuda
#Test losses work in half precision
if torch.cuda.is_available():
output = torch.sigmoid(torch.randn(32, 5, 10)).half().cuda()
target = torch.randint(0,2,(32, 5, 10)).half().cuda()
for tst in [BCELossFlat(), MSELossFlat()]: _ = tst(output, target)
# export
@use_kwargs_dict(reduction='mean')
def L1LossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.L1Loss`, but flattens input and target."
return BaseLoss(nn.L1Loss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
#export
class LabelSmoothingCrossEntropy(Module):
y_int = True
def __init__(self, eps:float=0.1, weight=None, reduction='mean'):
store_attr()
def forward(self, output, target):
c = output.size()[1]
log_preds = F.log_softmax(output, dim=1)
if self.reduction=='sum': loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=1) #We divide by that size at the return line so sum and not mean
if self.reduction=='mean': loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target.long(), weight=self.weight, reduction=self.reduction)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)
lmce = LabelSmoothingCrossEntropy()
output = torch.randn(32, 5, 10)
target = torch.randint(0, 10, (32,5))
test_eq(lmce(output.flatten(0,1), target.flatten()), lmce(output.transpose(-1,-2), target))
```
On top of the formula we define:
- a `reduction` attribute, that will be used when we call `Learner.get_preds`
- `weight` attribute to pass to BCE.
- an `activation` function that represents the activation fused in the loss (since we use cross entropy behind the scenes). It will be applied to the output of the model when calling `Learner.get_preds` or `Learner.predict`
- a <code>decodes</code> function that converts the output of the model to a format similar to the target (here indices). This is used in `Learner.predict` and `Learner.show_results` to decode the predictions
```
#export
@delegates()
class LabelSmoothingCrossEntropyFlat(BaseLoss):
"Same as `LabelSmoothingCrossEntropy`, but flattens input and target."
y_int = True
@use_kwargs_dict(keep=True, eps=0.1, reduction='mean')
def __init__(self, *args, axis=-1, **kwargs): super().__init__(LabelSmoothingCrossEntropy, *args, axis=axis, **kwargs)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)
```
## Export -
```
#hide
from nbdev.export import *
notebook2script()
```
| true |
code
| 0.799442 | null | null | null | null |
|

# _*Qiskit Finance: Pricing Fixed-Income Assets*_
The latest version of this notebook is available on https://github.com/Qiskit/qiskit-iqx-tutorials.
***
### Contributors
Stefan Woerner<sup>[1]</sup>, Daniel Egger<sup>[1]</sup>, Shaohan Hu<sup>[1]</sup>, Stephen Wood<sup>[1]</sup>, Marco Pistoia<sup>[1]</sup>
### Affiliation
- <sup>[1]</sup>IBMQ
### Introduction
We seek to price a fixed-income asset knowing the distributions describing the relevant interest rates. The cash flows $c_t$ of the asset and the dates at which they occur are known. The total value $V$ of the asset is thus the expectation value of:
$$V = \sum_{t=1}^T \frac{c_t}{(1+r_t)^t}$$
Each cash flow is treated as a zero coupon bond with a corresponding interest rate $r_t$ that depends on its maturity. The user must specify the distribution modeling the uncertainty in each $r_t$ (possibly correlated) as well as the number of qubits he wishes to use to sample each distribution. In this example we expand the value of the asset to first order in the interest rates $r_t$. This corresponds to studying the asset in terms of its duration.
<br>
<br>
The approximation of the objective function follows the following paper:<br>
<a href="https://arxiv.org/abs/1806.06893">Quantum Risk Analysis. Woerner, Egger. 2018.</a>
```
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from qiskit import BasicAer
from qiskit.aqua.algorithms.single_sample.amplitude_estimation.ae import AmplitudeEstimation
from qiskit.aqua.components.uncertainty_models import MultivariateNormalDistribution
from qiskit.finance.components.uncertainty_problems import FixedIncomeExpectedValue
backend = BasicAer.get_backend('statevector_simulator')
```
### Uncertainty Model
We construct a circuit factory to load a multivariate normal random distribution in $d$ dimensions into a quantum state.
The distribution is truncated to a given box $\otimes_{i=1}^d [low_i, high_i]$ and discretized using $2^{n_i}$ grid points, where $n_i$ denotes the number of qubits used for dimension $i = 1,\ldots, d$.
The unitary operator corresponding to the circuit factory implements the following:
$$\big|0\rangle_{n_1}\ldots\big|0\rangle_{n_d} \mapsto \big|\psi\rangle = \sum_{i_1=0}^{2^n_-1}\ldots\sum_{i_d=0}^{2^n_-1} \sqrt{p_{i_1,...,i_d}}\big|i_1\rangle_{n_1}\ldots\big|i_d\rangle_{n_d},$$
where $p_{i_1, ..., i_d}$ denote the probabilities corresponding to the truncated and discretized distribution and where $i_j$ is mapped to the right interval $[low_j, high_j]$ using the affine map:
$$ \{0, \ldots, 2^{n_{j}}-1\} \ni i_j \mapsto \frac{high_j - low_j}{2^{n_j} - 1} * i_j + low_j \in [low_j, high_j].$$
In addition to the uncertainty model, we can also apply an affine map, e.g. resulting from a principal component analysis. The interest rates used are then given by:
$$ \vec{r} = A * \vec{x} + b,$$
where $\vec{x} \in \otimes_{i=1}^d [low_i, high_i]$ follows the given random distribution.
```
# can be used in case a principal component analysis has been done to derive the uncertainty model, ignored in this example.
A = np.eye(2)
b = np.zeros(2)
# specify the number of qubits that are used to represent the different dimenions of the uncertainty model
num_qubits = [2, 2]
# specify the lower and upper bounds for the different dimension
low = [0, 0]
high = [0.12, 0.24]
mu = [0.12, 0.24]
sigma = 0.01*np.eye(2)
# construct corresponding distribution
u = MultivariateNormalDistribution(num_qubits, low, high, mu, sigma)
# plot contour of probability density function
x = np.linspace(low[0], high[0], 2**num_qubits[0])
y = np.linspace(low[1], high[1], 2**num_qubits[1])
z = u.probabilities.reshape(2**num_qubits[0], 2**num_qubits[1])
plt.contourf(x, y, z)
plt.xticks(x, size=15)
plt.yticks(y, size=15)
plt.grid()
plt.xlabel('$r_1$ (%)', size=15)
plt.ylabel('$r_2$ (%)', size=15)
plt.colorbar()
plt.show()
```
### Cash flow, payoff function, and exact expected value
In the following we define the cash flow per period, the resulting payoff function and evaluate the exact expected value.
For the payoff function we first use a first order approximation and then apply the same approximation technique as for the linear part of the payoff function of the [European Call Option](european_call_option_pricing.ipynb).
```
# specify cash flow
cf = [1.0, 2.0]
periods = range(1, len(cf)+1)
# plot cash flow
plt.bar(periods, cf)
plt.xticks(periods, size=15)
plt.yticks(size=15)
plt.grid()
plt.xlabel('periods', size=15)
plt.ylabel('cashflow ($)', size=15)
plt.show()
# estimate real value
cnt = 0
exact_value = 0.0
for x1 in np.linspace(low[0], high[0], pow(2, num_qubits[0])):
for x2 in np.linspace(low[1], high[1], pow(2, num_qubits[1])):
prob = u.probabilities[cnt]
for t in range(len(cf)):
# evaluate linear approximation of real value w.r.t. interest rates
exact_value += prob * (cf[t]/pow(1 + b[t], t+1) - (t+1)*cf[t]*np.dot(A[:, t], np.asarray([x1, x2]))/pow(1 + b[t], t+2))
cnt += 1
print('Exact value: \t%.4f' % exact_value)
# specify approximation factor
c_approx = 0.125
# get fixed income circuit appfactory
fixed_income = FixedIncomeExpectedValue(u, A, b, cf, c_approx)
# set number of evaluation qubits (samples)
m = 5
# construct amplitude estimation
ae = AmplitudeEstimation(m, fixed_income)
# result = ae.run(quantum_instance=LegacySimulators.get_backend('qasm_simulator'), shots=100)
result = ae.run(quantum_instance=backend)
print('Exact value: \t%.4f' % exact_value)
print('Estimated value:\t%.4f' % result['estimation'])
print('Probability: \t%.4f' % result['max_probability'])
# plot estimated values for "a" (direct result of amplitude estimation, not rescaled yet)
plt.bar(result['values'], result['probabilities'], width=0.5/len(result['probabilities']))
plt.xticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.yticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.title('"a" Value', size=15)
plt.ylabel('Probability', size=15)
plt.xlim((0,1))
plt.ylim((0,1))
plt.grid()
plt.show()
# plot estimated values for fixed-income asset (after re-scaling and reversing the c_approx-transformation)
plt.bar(result['mapped_values'], result['probabilities'], width=3/len(result['probabilities']))
plt.plot([exact_value, exact_value], [0,1], 'r--', linewidth=2)
plt.xticks(size=15)
plt.yticks([0, 0.25, 0.5, 0.75, 1], size=15)
plt.title('Estimated Option Price', size=15)
plt.ylabel('Probability', size=15)
plt.ylim((0,1))
plt.grid()
plt.show()
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
| true |
code
| 0.699229 | null | null | null | null |
|
```
#hide
#skip
! [ -e /content ] && pip install -Uqq fastai # upgrade fastai on colab
# default_exp losses
# default_cls_lvl 3
#export
from fastai.imports import *
from fastai.torch_imports import *
from fastai.torch_core import *
from fastai.layers import *
#hide
from nbdev.showdoc import *
```
# Loss Functions
> Custom fastai loss functions
```
F.binary_cross_entropy_with_logits(torch.randn(4,5), torch.randint(0, 2, (4,5)).float(), reduction='none')
funcs_kwargs
# export
class BaseLoss():
"Same as `loss_cls`, but flattens input and target."
activation=decodes=noops
def __init__(self, loss_cls, *args, axis=-1, flatten=True, floatify=False, is_2d=True, **kwargs):
store_attr("axis,flatten,floatify,is_2d")
self.func = loss_cls(*args,**kwargs)
functools.update_wrapper(self, self.func)
def __repr__(self): return f"FlattenedLoss of {self.func}"
@property
def reduction(self): return self.func.reduction
@reduction.setter
def reduction(self, v): self.func.reduction = v
def __call__(self, inp, targ, **kwargs):
inp = inp .transpose(self.axis,-1).contiguous()
targ = targ.transpose(self.axis,-1).contiguous()
if self.floatify and targ.dtype!=torch.float16: targ = targ.float()
if targ.dtype in [torch.int8, torch.int16, torch.int32]: targ = targ.long()
if self.flatten: inp = inp.view(-1,inp.shape[-1]) if self.is_2d else inp.view(-1)
return self.func.__call__(inp, targ.view(-1) if self.flatten else targ, **kwargs)
```
Wrapping a general loss function inside of `BaseLoss` provides extra functionalities to your loss functions:
- flattens the tensors before trying to take the losses since it's more convenient (with a potential tranpose to put `axis` at the end)
- a potential `activation` method that tells the library if there is an activation fused in the loss (useful for inference and methods such as `Learner.get_preds` or `Learner.predict`)
- a potential <code>decodes</code> method that is used on predictions in inference (for instance, an argmax in classification)
The `args` and `kwargs` will be passed to `loss_cls` during the initialization to instantiate a loss function. `axis` is put at the end for losses like softmax that are often performed on the last axis. If `floatify=True`, the `targs` will be converted to floats (useful for losses that only accept float targets like `BCEWithLogitsLoss`), and `is_2d` determines if we flatten while keeping the first dimension (batch size) or completely flatten the input. We want the first for losses like Cross Entropy, and the second for pretty much anything else.
```
# export
@delegates()
class CrossEntropyLossFlat(BaseLoss):
"Same as `nn.CrossEntropyLoss`, but flattens input and target."
y_int = True
@use_kwargs_dict(keep=True, weight=None, ignore_index=-100, reduction='mean')
def __init__(self, *args, axis=-1, **kwargs): super().__init__(nn.CrossEntropyLoss, *args, axis=axis, **kwargs)
def decodes(self, x): return x.argmax(dim=self.axis)
def activation(self, x): return F.softmax(x, dim=self.axis)
tst = CrossEntropyLossFlat()
output = torch.randn(32, 5, 10)
target = torch.randint(0, 10, (32,5))
#nn.CrossEntropy would fail with those two tensors, but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.CrossEntropyLoss()(output,target))
#Associated activation is softmax
test_eq(tst.activation(output), F.softmax(output, dim=-1))
#This loss function has a decodes which is argmax
test_eq(tst.decodes(output), output.argmax(dim=-1))
#In a segmentation task, we want to take the softmax over the channel dimension
tst = CrossEntropyLossFlat(axis=1)
output = torch.randn(32, 5, 128, 128)
target = torch.randint(0, 5, (32, 128, 128))
_ = tst(output, target)
test_eq(tst.activation(output), F.softmax(output, dim=1))
test_eq(tst.decodes(output), output.argmax(dim=1))
# export
@delegates()
class BCEWithLogitsLossFlat(BaseLoss):
"Same as `nn.BCEWithLogitsLoss`, but flattens input and target."
@use_kwargs_dict(keep=True, weight=None, reduction='mean', pos_weight=None)
def __init__(self, *args, axis=-1, floatify=True, thresh=0.5, **kwargs):
if kwargs.get('pos_weight', None) is not None and kwargs.get('flatten', None) is True:
raise ValueError("`flatten` must be False when using `pos_weight` to avoid a RuntimeError due to shape mismatch")
if kwargs.get('pos_weight', None) is not None: kwargs['flatten'] = False
super().__init__(nn.BCEWithLogitsLoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
self.thresh = thresh
def decodes(self, x): return x>self.thresh
def activation(self, x): return torch.sigmoid(x)
tst = BCEWithLogitsLossFlat()
output = torch.randn(32, 5, 10)
target = torch.randn(32, 5, 10)
#nn.BCEWithLogitsLoss would fail with those two tensors, but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
output = torch.randn(32, 5)
target = torch.randint(0,2,(32, 5))
#nn.BCEWithLogitsLoss would fail with int targets but not our flattened version.
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
tst = BCEWithLogitsLossFlat(pos_weight=torch.ones(10))
output = torch.randn(32, 5, 10)
target = torch.randn(32, 5, 10)
_ = tst(output, target)
test_fail(lambda x: nn.BCEWithLogitsLoss()(output,target))
#Associated activation is sigmoid
test_eq(tst.activation(output), torch.sigmoid(output))
# export
@use_kwargs_dict(weight=None, reduction='mean')
def BCELossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.BCELoss`, but flattens input and target."
return BaseLoss(nn.BCELoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
tst = BCELossFlat()
output = torch.sigmoid(torch.randn(32, 5, 10))
target = torch.randint(0,2,(32, 5, 10))
_ = tst(output, target)
test_fail(lambda x: nn.BCELoss()(output,target))
# export
@use_kwargs_dict(reduction='mean')
def MSELossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.MSELoss`, but flattens input and target."
return BaseLoss(nn.MSELoss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
tst = MSELossFlat()
output = torch.sigmoid(torch.randn(32, 5, 10))
target = torch.randint(0,2,(32, 5, 10))
_ = tst(output, target)
test_fail(lambda x: nn.MSELoss()(output,target))
#hide
#cuda
#Test losses work in half precision
output = torch.sigmoid(torch.randn(32, 5, 10)).half().cuda()
target = torch.randint(0,2,(32, 5, 10)).half().cuda()
for tst in [BCELossFlat(), MSELossFlat()]: _ = tst(output, target)
# export
@use_kwargs_dict(reduction='mean')
def L1LossFlat(*args, axis=-1, floatify=True, **kwargs):
"Same as `nn.L1Loss`, but flattens input and target."
return BaseLoss(nn.L1Loss, *args, axis=axis, floatify=floatify, is_2d=False, **kwargs)
#export
class LabelSmoothingCrossEntropy(Module):
y_int = True
def __init__(self, eps:float=0.1, reduction='mean'): self.eps,self.reduction = eps,reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
if self.reduction=='sum': loss = -log_preds.sum()
else:
loss = -log_preds.sum(dim=-1) #We divide by that size at the return line so sum and not mean
if self.reduction=='mean': loss = loss.mean()
return loss*self.eps/c + (1-self.eps) * F.nll_loss(log_preds, target.long(), reduction=self.reduction)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)
```
On top of the formula we define:
- a `reduction` attribute, that will be used when we call `Learner.get_preds`
- an `activation` function that represents the activation fused in the loss (since we use cross entropy behind the scenes). It will be applied to the output of the model when calling `Learner.get_preds` or `Learner.predict`
- a <code>decodes</code> function that converts the output of the model to a format similar to the target (here indices). This is used in `Learner.predict` and `Learner.show_results` to decode the predictions
```
#export
@delegates()
class LabelSmoothingCrossEntropyFlat(BaseLoss):
"Same as `LabelSmoothingCrossEntropy`, but flattens input and target."
y_int = True
@use_kwargs_dict(keep=True, eps=0.1, reduction='mean')
def __init__(self, *args, axis=-1, **kwargs): super().__init__(LabelSmoothingCrossEntropy, *args, axis=axis, **kwargs)
def activation(self, out): return F.softmax(out, dim=-1)
def decodes(self, out): return out.argmax(dim=-1)
```
## Export -
```
#hide
from nbdev.export import *
notebook2script()
```
| true |
code
| 0.745054 | null | null | null | null |
|
# Finding Outliers with k-Means
## Setup
```
import numpy as np
import pandas as pd
import sqlite3
with sqlite3.connect('../../ch_11/logs/logs.db') as conn:
logs_2018 = pd.read_sql(
"""
SELECT *
FROM logs
WHERE datetime BETWEEN "2018-01-01" AND "2019-01-01";
""",
conn, parse_dates=['datetime'], index_col='datetime'
)
logs_2018.head()
def get_X(log, day):
"""
Get data we can use for the X
Parameters:
- log: The logs dataframe
- day: A day or single value we can use as a datetime index slice
Returns:
A pandas DataFrame
"""
return pd.get_dummies(log[day].assign(
failures=lambda x: 1 - x.success
).query('failures > 0').resample('1min').agg(
{'username':'nunique', 'failures': 'sum'}
).dropna().rename(
columns={'username':'usernames_with_failures'}
).assign(
day_of_week=lambda x: x.index.dayofweek,
hour=lambda x: x.index.hour
).drop(columns=['failures']), columns=['day_of_week', 'hour'])
X = get_X(logs_2018, '2018')
X.columns
```
## k-Means
Since we want a "normal" activity cluster and an "anomaly" cluster, we need to make 2 clusters.
```
from sklearn.cluster import KMeans
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
kmeans_pipeline = Pipeline([
('scale', StandardScaler()),
('kmeans', KMeans(random_state=0, n_clusters=2))
]).fit(X)
```
The cluster label doesn't mean anything to us, but we can examine the size of each cluster. We don't expect the clusters to be of equal size because anomalous activity doesn't happen as often as normal activity (we presume).
```
preds = kmeans_pipeline.predict(X)
pd.Series(preds).value_counts()
```
### Evaluating the clustering
#### Step 1: Get the true labels
```
with sqlite3.connect('../../ch_11/logs/logs.db') as conn:
hackers_2018 = pd.read_sql(
'SELECT * FROM attacks WHERE start BETWEEN "2018-01-01" AND "2019-01-01";',
conn, parse_dates=['start', 'end']
).assign(
duration=lambda x: x.end - x.start,
start_floor=lambda x: x.start.dt.floor('min'),
end_ceil=lambda x: x.end.dt.ceil('min')
)
def get_y(datetimes, hackers, resolution='1min'):
"""
Get data we can use for the y (whether or not a hacker attempted a log in during that time).
Parameters:
- datetimes: The datetimes to check for hackers
- hackers: The dataframe indicating when the attacks started and stopped
- resolution: The granularity of the datetime. Default is 1 minute.
Returns:
A pandas Series of booleans.
"""
date_ranges = hackers.apply(
lambda x: pd.date_range(x.start_floor, x.end_ceil, freq=resolution),
axis=1
)
dates = pd.Series()
for date_range in date_ranges:
dates = pd.concat([dates, date_range.to_series()])
return datetimes.isin(dates)
is_hacker = get_y(X.reset_index().datetime, hackers_2018)
```
### Step 2: Calculate Fowlkes Mallows Score
This indicates percentage of the observations belong to the same cluster in the true labels and in the predicted labels.
```
from sklearn.metrics import fowlkes_mallows_score
fowlkes_mallows_score(is_hacker, preds)
```
| true |
code
| 0.650634 | null | null | null | null |
|
# Detecting malaria in blood smear images
### The Problem
Malaria is a mosquito-borne disease caused by the parasite _Plasmodium_. There are an estimated 219 million cases of malaria annually, with 435,000 deaths, many of whom are children. Malaria is prevalent in sub-tropical regions of Africa.
Microscopy is the most common and reliable method for diagnosing malaria and computing parasitic load.
With this technique, malaria parasites are identified by examining a drop of the patient’s blood, spread out as a “blood smear” on a slide. Prior to examination, the specimen is stained (most often with the Giemsa stain) to give the parasites a distinctive appearance. This technique remains the gold standard for laboratory confirmation of malaria.
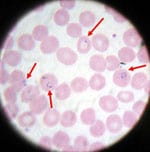
Blood smear from a patient with malaria; microscopic examination shows _Plasmodium falciparum_ parasites (arrows) infecting some of the patient’s red blood cells. (CDC photo)
However, the diagnostic accuracy of this technique is dependent on human expertise and can be affectived by and observer's variability.
### Deep learning as a diagnostic aid
Recent advances in computing and deep learning techniques have led to the applications of large-scale medical image analysis. Here, we aim to use a convolutional neural network (CNN) in order to quickly and accurately classify parasitized from healthy cells from blood smears.
This notebook is based on the work presented by [Dipanjan Sarkar](https://towardsdatascience.com/detecting-malaria-with-deep-learning-9e45c1e34b60)
### About the dataset
A [dataset](https://ceb.nlm.nih.gov/repositories/malaria-datasets/) of parasitized and unparasitized cells from blood smear slides was collected and annotated by [Rajaraman et al](https://doi.org/10.7717/peerj.4568). The dataset contains a total of 27,558 cell images with equal instances of parasitized and uninfected cells from Giemsa-stained thin blood smear slides from 150 P. falciparum-infected and 50 healthy patients collected and photographed at Chittagong Medical College Hospital, Bangladesh. There are also CSV files containing the Patient-ID to cell mappings for the parasitized and uninfected classes. The CSV file for the parasitized class contains 151 patient-ID entries. The slide images for the parasitized patient-ID “C47P8thinOriginal” are read from two different microscope models (Olympus and Motif). The CSV file for the uninfected class contains 201 entries since the normal cells from the infected patients’ slides also make it to the normal cell category (151+50 = 201).
The data appears along with the publication:
Rajaraman S, Antani SK, Poostchi M, Silamut K, Hossain MA, Maude, RJ, Jaeger S, Thoma GR. (2018) Pre-trained convolutional neural networks as feature extractors toward improved Malaria parasite detection in thin blood smear images. PeerJ6:e4568 https://doi.org/10.7717/peerj.4568
## Malaria Dataset
Medium post:
https://towardsdatascience.com/detecting-malaria-using-deep-learning-fd4fdcee1f5a
Data:
https://ceb.nlm.nih.gov/repositories/malaria-datasets/
## Data preprocessing
The [cell images](https://ceb.nlm.nih.gov/proj/malaria/cell_images.zip) dataset can be downloaded from the [NIH repository](https://ceb.nlm.nih.gov/repositories/malaria-datasets/).
Parasitized and healthy cells are sorted into their own folders.
```
# mkdir ../data/
# wget https://ceb.nlm.nih.gov/proj/malaria/cell_images.zip
# unzip cell_images.zip
import os
os.listdir('../data/cell_images/')
import random
import glob
# Get file paths for files
base_dir = os.path.join('../data/cell_images')
infected_dir = os.path.join(base_dir, 'Parasitized')
healthy_dir = os.path.join(base_dir, 'Uninfected')
# Glob is used to identify filepath patterns
infected_files = glob.glob(infected_dir+'/*.png')
healthy_files = glob.glob(healthy_dir+'/*.png')
# View size of dataset
len(infected_files), len(healthy_files)
```
Our data is evenly split between parasitized and healthy cells/images so we won't need to further balance our data.
## Split data into train, test, split sets
We can aggregate all of our images by adding the filepaths and labels into a single dataframe.
We'll then shuffle and split the data into a 60/30/10 train/test/validation set.
```
import numpy as np
import pandas as pd
np.random.seed(1)
# Build a dataframe of filenames with labels
files = pd.DataFrame(data={'filename': infected_files, 'label': ['malaria' for i in range(len(infected_files))]})
files = pd.concat([files, pd.DataFrame(data={'filename': healthy_files, 'label': ['healthy' for i in range(len(healthy_files))]})])
files = files.sample(frac=1).reset_index(drop=True) # Shuffle rows
files.head()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(files.filename.values, files.label.values, test_size=0.3, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
X_train.shape, X_val.shape, y_test.shape
```
As the dimensions of each image will vary, we will resize the images to be 125 x 125 pixels. The cv2 module can be used to load and resize images.
```
import cv2
# Read and resize images
nrows = 125
ncols = 125
channels = 3
cv2.imread(X_train[0], cv2.IMREAD_COLOR)
cv2.resize(cv2.imread(X_train[0], cv2.IMREAD_COLOR), (nrows, ncols), interpolation=cv2.INTER_CUBIC).shape
import threading
from concurrent import futures
# Resize images
IMG_DIMS = (125, 125)
def get_img_data_parallel(idx, img, total_imgs):
if idx % 5000 == 0 or idx == (total_imgs - 1):
print('{}: working on img num: {}'.format(threading.current_thread().name,
idx))
img = cv2.imread(img)
img = cv2.resize(img, dsize=IMG_DIMS,
interpolation=cv2.INTER_CUBIC)
img = np.array(img, dtype=np.float32)
return img
ex = futures.ThreadPoolExecutor(max_workers=None)
X_train_inp = [(idx, img, len(X_train)) for idx, img in enumerate(X_train)]
X_val_inp = [(idx, img, len(X_val)) for idx, img in enumerate(X_val)]
X_test_inp = [(idx, img, len(X_test)) for idx, img in enumerate(X_test)]
print('Loading Train Images:')
X_train_map = ex.map(get_img_data_parallel,
[record[0] for record in X_train_inp],
[record[1] for record in X_train_inp],
[record[2] for record in X_train_inp])
X_train = np.array(list(X_train_map))
print('\nLoading Validation Images:')
X_val_map = ex.map(get_img_data_parallel,
[record[0] for record in X_val_inp],
[record[1] for record in X_val_inp],
[record[2] for record in X_val_inp])
X_val = np.array(list(X_val_map))
print('\nLoading Test Images:')
X_test_map = ex.map(get_img_data_parallel,
[record[0] for record in X_test_inp],
[record[1] for record in X_test_inp],
[record[2] for record in X_test_inp])
X_test = np.array(list(X_test_map))
X_train.shape, X_val.shape, X_test.shape
```
Using the matplotlib module, we can view a sample of the resized cell images. A brief inspection shows the presence of purple-stained parasites only in malaria-labeled samples.
```
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(1 , figsize = (8 , 8))
n = 0
for i in range(16):
n += 1
r = np.random.randint(0 , X_train.shape[0] , 1)
plt.subplot(4 , 4 , n)
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
plt.imshow(X_train[r[0]]/255.)
plt.title('{}'.format(y_train[r[0]]))
plt.xticks([]) , plt.yticks([])
```
## Model training
We can set some initial parameters for our model, including batch size, the number of classes, number of epochs, and image dimensions.
We'll encode the text category labels as 0 or 1.
```
from sklearn.preprocessing import LabelEncoder
BATCH_SIZE = 64
NUM_CLASSES = 2
EPOCHS = 25
INPUT_SHAPE = (125, 125, 3)
X_train_imgs_scaled = X_train / 255.
X_val_imgs_scaled = X_val / 255.
le = LabelEncoder()
le.fit(y_train)
y_train_enc = le.transform(y_train)
y_val_enc = le.transform(y_val)
print(y_train[:6], y_train_enc[:6])
```
### Simple CNN model
To start with, we'll build a simple CNN model with 2 convolution and pooling layers and a dense dropout layer for regularization.
```
from keras.models import Sequential
from keras.utils import to_categorical
from keras.layers import Conv2D, Dense, MaxPooling2D, Flatten
# Build a simple CNN
model = Sequential()
model.add(Conv2D(32, kernel_size=(5,5), strides=(1,1), activation='relu', input_shape=INPUT_SHAPE))
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1000, activation='relu'))
model.add(Dense(1, activation='softmax'))
# out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
# model = tf.keras.Model(inputs=inp, outputs=out)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
```
We can evaluate the accuracy of model
```
import datetime
from keras import callbacks
# View accuracy
logdir = os.path.join('../tensorboard_logs',
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = callbacks.TensorBoard(logdir, histogram_freq=1)
reduce_lr = callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
patience=2, min_lr=0.000001)
callbacks = [reduce_lr, tensorboard_callback]
history = model.fit(x=X_train_imgs_scaled, y=y_train_enc,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(X_val_imgs_scaled, y_val_enc),
callbacks=callbacks,
verbose=1)
```
| true |
code
| 0.487307 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/MIT-LCP/sccm-datathon/blob/master/04_timeseries.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# eICU Collaborative Research Database
# Notebook 4: Timeseries for a single patient
This notebook explores timeseries data for a single patient.
## Load libraries and connect to the database
```
# Import libraries
import numpy as np
import os
import pandas as pd
import matplotlib.pyplot as plt
# Make pandas dataframes prettier
from IPython.display import display, HTML
# Access data using Google BigQuery.
from google.colab import auth
from google.cloud import bigquery
# authenticate
auth.authenticate_user()
# Set up environment variables
project_id='sccm-datathon'
os.environ["GOOGLE_CLOUD_PROJECT"]=project_id
```
## Selecting a single patient stay
### The patient table
The patient table includes general information about the patient admissions (for example, demographics, admission and discharge details). See: http://eicu-crd.mit.edu/eicutables/patient/
```
# Display the patient table
%%bigquery
SELECT *
FROM `physionet-data.eicu_crd_demo.patient`
patient.head()
```
### The `vitalperiodic` table
The `vitalperiodic` table comprises data that is consistently interfaced from bedside vital signs monitors into eCareManager. Data are generally interfaced as 1 minute averages, and archived into the `vitalperiodic` table as 5 minute median values. For more detail, see: http://eicu-crd.mit.edu/eicutables/vitalPeriodic/
```
# Get periodic vital signs for a single patient stay
%%bigquery vitalperiodic
SELECT *
FROM `physionet-data.eicu_crd_demo.vitalperiodic`
WHERE patientunitstayid = 210014
vitalperiodic.head()
# sort the values by the observationoffset (time in minutes from ICU admission)
vitalperiodic = vitalperiodic.sort_values(by='observationoffset')
vitalperiodic.head()
# subselect the variable columns
columns = ['observationoffset','temperature','sao2','heartrate','respiration',
'cvp','etco2','systemicsystolic','systemicdiastolic','systemicmean',
'pasystolic','padiastolic','pamean','icp']
vitalperiodic = vitalperiodic[columns].set_index('observationoffset')
vitalperiodic.head()
# plot the data
plt.rcParams['figure.figsize'] = [12,8]
title = 'Vital signs (periodic) for patientunitstayid = {} \n'.format(patientunitstayid)
ax = vitalperiodic.plot(title=title, marker='o')
ax.legend(loc='center left', bbox_to_anchor=(1.0, 0.5))
ax.set_xlabel("Minutes after admission to the ICU")
ax.set_ylabel("Absolute value")
```
## Questions
- Which variables are available for this patient?
- What is the peak heart rate during the period?
### The vitalaperiodic table
The vitalAperiodic table provides invasive vital sign data that is recorded at irregular intervals. See: http://eicu-crd.mit.edu/eicutables/vitalAperiodic/
```
# Get aperiodic vital signs
%%bigquery vitalaperiodic
SELECT *
FROM `physionet-data.eicu_crd_demo.vitalaperiodic`
WHERE patientunitstayid = 210014
# display the first few rows of the dataframe
vitalaperiodic.head()
# sort the values by the observationoffset (time in minutes from ICU admission)
vitalaperiodic = vitalaperiodic.sort_values(by='observationoffset')
vitalaperiodic.head()
# subselect the variable columns
columns = ['observationoffset','noninvasivesystolic','noninvasivediastolic',
'noninvasivemean','paop','cardiacoutput','cardiacinput','svr',
'svri','pvr','pvri']
vitalaperiodic = vitalaperiodic[columns].set_index('observationoffset')
vitalaperiodic.head()
# plot the data
plt.rcParams['figure.figsize'] = [12,8]
title = 'Vital signs (aperiodic) for patientunitstayid = {} \n'.format(patientunitstayid)
ax = vitalaperiodic.plot(title=title, marker='o')
ax.legend(loc='center left', bbox_to_anchor=(1.0, 0.5))
ax.set_xlabel("Minutes after admission to the ICU")
ax.set_ylabel("Absolute value")
```
## Questions
- What do the non-invasive variables measure?
- How do you think the mean is calculated?
## 3.4. The lab table
```
# Get labs
%%bigquery lab
SELECT *
FROM `physionet-data.eicu_crd_demo.lab`
WHERE patientunitstayid = 210014
lab.head()
# sort the values by the offset time (time in minutes from ICU admission)
lab = lab.sort_values(by='labresultoffset')
lab.head()
lab = lab.set_index('labresultoffset')
columns = ['labname','labresult','labmeasurenamesystem']
lab = lab[columns]
lab.head()
# list the distinct labnames
lab['labname'].unique()
# pivot the lab table to put variables into columns
lab = lab.pivot(columns='labname', values='labresult')
lab.head()
# plot laboratory tests of interest
labs_to_plot = ['creatinine','pH','BUN', 'glucose', 'potassium']
lab[labs_to_plot].head()
# plot the data
plt.rcParams['figure.figsize'] = [12,8]
title = 'Laboratory test results for patientunitstayid = {} \n'.format(patientunitstayid)
ax = lab[labs_to_plot].plot(title=title, marker='o',ms=10, lw=0)
ax.legend(loc='center left', bbox_to_anchor=(1.0, 0.5))
ax.set_xlabel("Minutes after admission to the ICU")
ax.set_ylabel("Absolute value")
```
| true |
code
| 0.629006 | null | null | null | null |
|
# Random Signals
*This jupyter notebook is part of a [collection of notebooks](../index.ipynb) on various topics of Digital Signal Processing. Please direct questions and suggestions to [[email protected]](mailto:[email protected]).*
## Auto Power Spectral Density
The (auto-) [power spectral density](https://en.wikipedia.org/wiki/Spectral_density#Power_spectral_density) (PSD) is defined as the Fourier transformation of the [auto-correlation function](correlation_functions.ipynb) (ACF).
### Definition
For a continuous-amplitude, real-valued, wide-sense stationary (WSS) random signal $x[k]$ the PSD is given as
\begin{equation}
\Phi_{xx}(\mathrm{e}^{\,\mathrm{j}\,\Omega}) = \mathcal{F}_* \{ \varphi_{xx}[\kappa] \},
\end{equation}
where $\mathcal{F}_* \{ \cdot \}$ denotes the [discrete-time Fourier transformation](https://en.wikipedia.org/wiki/Discrete-time_Fourier_transform) (DTFT) and $\varphi_{xx}[\kappa]$ the ACF of $x[k]$. Note that the DTFT is performed with respect to $\kappa$. The ACF of a random signal of finite length $N$ can be expressed by way of a linear convolution
\begin{equation}
\varphi_{xx}[\kappa] = \frac{1}{N} \cdot x_N[k] * x_N[-k].
\end{equation}
Taking the DTFT of the left- and right-hand side results in
\begin{equation}
\Phi_{xx}(\mathrm{e}^{\,\mathrm{j}\,\Omega}) = \frac{1}{N} \, X_N(\mathrm{e}^{\,\mathrm{j}\,\Omega})\, X_N(\mathrm{e}^{-\,\mathrm{j}\,\Omega}) =
\frac{1}{N} \, | X_N(\mathrm{e}^{\,\mathrm{j}\,\Omega}) |^2.
\end{equation}
The last equality results from the definition of the magnitude and the symmetry of the DTFT for real-valued signals. The spectrum $X_N(\mathrm{e}^{\,\mathrm{j}\,\Omega})$ quantifies the amplitude density of the signal $x_N[k]$. It can be concluded from above result that the PSD quantifies the squared amplitude or power density of a random signal. This explains the term power spectral density.
### Properties
The properties of the PSD can be deduced from the properties of the ACF and the DTFT as:
1. From the link between the PSD $\Phi_{xx}(\mathrm{e}^{\,\mathrm{j}\,\Omega})$ and the spectrum $X_N(\mathrm{e}^{\,\mathrm{j}\,\Omega})$ derived above it can be concluded that the PSD is real valued
$$\Phi_{xx}(\mathrm{e}^{\,\mathrm{j}\,\Omega}) \in \mathbb{R}$$
2. From the even symmetry $\varphi_{xx}[\kappa] = \varphi_{xx}[-\kappa]$ of the ACF it follows that
$$ \Phi_{xx}(\mathrm{e}^{\,\mathrm{j} \, \Omega}) = \Phi_{xx}(\mathrm{e}^{\,-\mathrm{j}\, \Omega}) $$
3. The PSD of an uncorrelated random signal is given as
$$ \Phi_{xx}(\mathrm{e}^{\,\mathrm{j} \, \Omega}) = (\sigma_x^2 + \mu_x^2) \cdot {\bot \!\! \bot \!\! \bot}\left( \frac{\Omega}{2 \pi} \right) ,$$
which can be deduced from the [ACF of an uncorrelated signal](correlation_functions.ipynb#Properties).
4. The quadratic mean of a random signal is given as
$$ E\{ x[k]^2 \} = \varphi_{xx}[\kappa=0] = \frac{1}{2\pi} \int\limits_{-\pi}^{\pi} \Phi_{xx}(\mathrm{e}^{\,\mathrm{j}\, \Omega}) \,\mathrm{d} \Omega $$
The last relation can be found by expressing the ACF via the inverse DTFT of $\Phi_{xx}$ and considering that $\mathrm{e}^{\mathrm{j} \Omega \kappa} = 1$ when evaluating the integral for $\kappa=0$.
### Example - Power Spectral Density of a Speech Signal
In this example the PSD $\Phi_{xx}(\mathrm{e}^{\,\mathrm{j} \,\Omega})$ of a speech signal of length $N$ is estimated by applying a discrete Fourier transformation (DFT) to its ACF. For a better interpretation of the PSD, the frequency axis $f = \frac{\Omega}{2 \pi} \cdot f_s$ has been chosen for illustration, where $f_s$ denotes the sampling frequency of the signal. The speech signal constitutes a recording of the vowel 'o' spoken from a German male, loaded into variable `x`.
In Python the ACF is stored in a vector with indices $0, 1, \dots, 2N - 2$ corresponding to the lags $\kappa = (0, 1, \dots, 2N - 2)^\mathrm{T} - (N-1)$. When computing the discrete Fourier transform (DFT) of the ACF numerically by the fast Fourier transform (FFT) one has to take this shift into account. For instance, by multiplying the DFT $\Phi_{xx}[\mu]$ by $\mathrm{e}^{\mathrm{j} \mu \frac{2 \pi}{2N - 1} (N-1)}$.
```
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
%matplotlib inline
# read audio file
fs, x = wavfile.read('../data/vocal_o_8k.wav')
x = np.asarray(x, dtype=float)
N = len(x)
# compute ACF
acf = 1/N * np.correlate(x, x, mode='full')
# compute PSD
psd = np.fft.fft(acf)
psd = psd * np.exp(1j*np.arange(2*N-1)*2*np.pi*(N-1)/(2*N-1))
f = np.fft.fftfreq(2*N-1, d=1/fs)
# plot PSD
plt.figure(figsize = (10, 4))
plt.plot(f, np.real(psd))
plt.title('Estimated power spectral density')
plt.ylabel(r'$\hat{\Phi}_{xx}(e^{j \Omega})$')
plt.xlabel(r'$f / Hz$')
plt.axis([0, 500, 0, 1.1*max(np.abs(psd))])
plt.grid()
```
**Exercise**
* What does the PSD tell you about the average spectral contents of a speech signal?
Solution: The speech signal exhibits a harmonic structure with the dominant fundamental frequency $f_0 \approx 100$ Hz and a number of harmonics $f_n \approx n \cdot f_0$ for $n > 0$. This due to the fact that vowels generate random signals which are in good approximation periodic. To generate vowels, the sound produced by the periodically vibrating vowel folds is filtered by the resonance volumes and articulators above the voice box. The spectrum of periodic signals is a line spectrum.
## Cross-Power Spectral Density
The cross-power spectral density is defined as the Fourier transformation of the [cross-correlation function](correlation_functions.ipynb#Cross-Correlation-Function) (CCF).
### Definition
For two continuous-amplitude, real-valued, wide-sense stationary (WSS) random signals $x[k]$ and $y[k]$, the cross-power spectral density is given as
\begin{equation}
\Phi_{xy}(\mathrm{e}^{\,\mathrm{j} \, \Omega}) = \mathcal{F}_* \{ \varphi_{xy}[\kappa] \},
\end{equation}
where $\varphi_{xy}[\kappa]$ denotes the CCF of $x[k]$ and $y[k]$. Note again, that the DTFT is performed with respect to $\kappa$. The CCF of two random signals of finite length $N$ and $M$ can be expressed by way of a linear convolution
\begin{equation}
\varphi_{xy}[\kappa] = \frac{1}{N} \cdot x_N[k] * y_M[-k].
\end{equation}
Note the chosen $\frac{1}{N}$-averaging convention corresponds to the length of signal $x$. If $N \neq M$, care should be taken on the interpretation of this normalization. In case of $N=M$ the $\frac{1}{N}$-averaging yields a [biased estimator](https://en.wikipedia.org/wiki/Bias_of_an_estimator) of the CCF, which consistently should be denoted with $\hat{\varphi}_{xy,\mathrm{biased}}[\kappa]$.
Taking the DTFT of the left- and right-hand side from above cross-correlation results in
\begin{equation}
\Phi_{xy}(\mathrm{e}^{\,\mathrm{j}\,\Omega}) = \frac{1}{N} \, X_N(\mathrm{e}^{\,\mathrm{j}\,\Omega})\, Y_M(\mathrm{e}^{-\,\mathrm{j}\,\Omega}).
\end{equation}
### Properties
1. The symmetries of $\Phi_{xy}(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ can be derived from the symmetries of the CCF and the DTFT as
$$ \underbrace {\Phi_{xy}(\mathrm{e}^{\,\mathrm{j}\, \Omega}) = \Phi_{xy}^*(\mathrm{e}^{-\,\mathrm{j}\, \Omega})}_{\varphi_{xy}[\kappa] \in \mathbb{R}} =
\underbrace {\Phi_{yx}(\mathrm{e}^{\,- \mathrm{j}\, \Omega}) = \Phi_{yx}^*(\mathrm{e}^{\,\mathrm{j}\, \Omega})}_{\varphi_{yx}[-\kappa] \in \mathbb{R}},$$
from which $|\Phi_{xy}(\mathrm{e}^{\,\mathrm{j}\, \Omega})| = |\Phi_{yx}(\mathrm{e}^{\,\mathrm{j}\, \Omega})|$ can be concluded.
2. The cross PSD of two uncorrelated random signals is given as
$$ \Phi_{xy}(\mathrm{e}^{\,\mathrm{j} \, \Omega}) = \mu_x^2 \mu_y^2 \cdot {\bot \!\! \bot \!\! \bot}\left( \frac{\Omega}{2 \pi} \right) $$
which can be deduced from the CCF of an uncorrelated signal.
### Example - Cross-Power Spectral Density
The following example estimates and plots the cross PSD $\Phi_{xy}(\mathrm{e}^{\,\mathrm{j}\, \Omega})$ of two random signals $x_N[k]$ and $y_M[k]$ of finite lengths $N = 64$ and $M = 512$.
```
N = 64 # length of x
M = 512 # length of y
# generate two uncorrelated random signals
np.random.seed(1)
x = 2 + np.random.normal(size=N)
y = 3 + np.random.normal(size=M)
N = len(x)
M = len(y)
# compute cross PSD via CCF
acf = 1/N * np.correlate(x, y, mode='full')
psd = np.fft.fft(acf)
psd = psd * np.exp(1j*np.arange(N+M-1)*2*np.pi*(M-1)/(2*M-1))
psd = np.fft.fftshift(psd)
Om = 2*np.pi * np.arange(0, N+M-1) / (N+M-1)
Om = Om - np.pi
# plot results
plt.figure(figsize=(10, 4))
plt.stem(Om, np.abs(psd), basefmt='C0:', use_line_collection=True)
plt.title('Biased estimator of cross power spectral density')
plt.ylabel(r'$|\hat{\Phi}_{xy}(e^{j \Omega})|$')
plt.xlabel(r'$\Omega$')
plt.grid()
```
**Exercise**
* What does the cross PSD $\Phi_{xy}(\mathrm{e}^{\,\mathrm{j} \, \Omega})$ tell you about the statistical properties of the two random signals?
Solution: The cross PSD $\Phi_{xy}(\mathrm{e}^{\,\mathrm{j} \, \Omega})$ is essential only non-zero for $\Omega=0$. It hence can be concluded that the two random signals are not mean-free and uncorrelated to each other.
**Copyright**
This notebook is provided as [Open Educational Resource](https://en.wikipedia.org/wiki/Open_educational_resources). Feel free to use the notebook for your own purposes. The text is licensed under [Creative Commons Attribution 4.0](https://creativecommons.org/licenses/by/4.0/), the code of the IPython examples under the [MIT license](https://opensource.org/licenses/MIT). Please attribute the work as follows: *Sascha Spors, Digital Signal Processing - Lecture notes featuring computational examples*.
| true |
code
| 0.625896 | null | null | null | null |
|
Notebook to plot the histogram of the power criterion values of Rel-UME test.
```
%matplotlib inline
%load_ext autoreload
%autoreload 2
#%config InlineBackend.figure_format = 'svg'
#%config InlineBackend.figure_format = 'pdf'
import freqopttest.tst as tst
import kmod
import kgof
import kgof.goftest as gof
# submodules
from kmod import data, density, kernel, util, plot, glo, log
from kmod.ex import cifar10 as cf10
import kmod.ex.exutil as exu
from kmod import mctest as mct
import matplotlib
import matplotlib.pyplot as plt
import pickle
import os
import autograd.numpy as np
import scipy.stats as stats
import numpy.testing as testing
# plot.set_default_matplotlib_options()
# font options
font = {
#'family' : 'normal',
#'weight' : 'bold',
'size' : 20,
}
plt.rc('font', **font)
plt.rc('lines', linewidth=2)
matplotlib.rcParams['pdf.fonttype'] = 42
matplotlib.rcParams['ps.fonttype'] = 42
# def store_path(fname):
# """
# Construct a full path for saving/loading files.
# """
# return os.path.join('cifar10', fname)
display(list(zip(range(10), cf10.cifar10_classes)))
```
# Histogram of power criterion values
First construct four samples: $X \sim P, Y \sim Q, Z \sim R$, and a pool W to be used as test location candidates.
```
# class_spec = [
# # (class, #points for p, #points for q, #points for r, #points for the pool)
# ('airplane', 2000, 0, 0, 1500),
# ('cat', 0, 2000, 2000, 1500),
# ('truck', 1500, 1500, 1500, 1500),
# ]
# class_spec = [
# # (class, #points for p, #points for q, #points for r, #points for the pool)
# ('airplane', 1000, 0, 0, 300),
# ('cat', 0, 1000, 1000, 300),
# ('truck', 1500, 1500, 1500, 300),
# ]
class_spec = [
# (class, #points for p, #points for q, #points for r, #points for the pool)
('ship', 2000, 0, 0, 1000),
('airplane', 0, 2000, 1500, 1000),
('dog', 1500, 1500, 1500, 1000),
('bird', 0, 0, 500, 1000),
]
# class_spec = [
# # (class, #points for p, #points for q, #points for r, #points for the pool)
# ('horse', 2000, 0, 0, 1000),
# ('deer', 0, 2000, 1500, 1000),
# ('dog', 1500, 1500, 1500, 1000),
# ('automobile', 0, 0, 500, 1000),
# ]
# class_spec = [
# # (class, #points for p, #points for q, #points for r, #points for the pool)
# ('airplane', 2000, 0, 0, 1000),
# ('automobile', 0, 2000, 1500, 1000),
# ('cat', 1500, 1500, 1500, 1000),
# ('frog', 0, 0, 500, 1000),
# ]
#class_spec = [
# (class, #points for p, #points for q, #points for r, #points for the pool)
# ('airplane', 2000, 0, 0, 1000),
# ('automobile', 0, 2000, 2000, 1000),
# ('cat', 1500, 1500, 1500, 1000),
#]
# class_spec = [
# # (class, #points for p, #points for q, #points for r, #points for the pool)
# ('airplane', 200, 0, 0, 150),
# ('cat', 0, 200, 200, 150),
# ('truck', 150, 150, 150, 150),
# ]
# check sizes
hist_classes = [z[0] for z in class_spec]
p_sizes = [z[1] for z in class_spec]
q_sizes = [z[2] for z in class_spec]
r_sizes = [z[3] for z in class_spec]
pool_sizes = [z[4] for z in class_spec]
# make sure p,q,r have the same sample size
assert sum(p_sizes) == sum(q_sizes)
assert sum(q_sizes) == sum(r_sizes)
# cannot use more than 6000 from each class
for i, cs in enumerate(class_spec):
class_used = sum(cs[1:])
if class_used > 6000:
raise ValueError('class "{}" requires more than 6000 points. Was {}.'.format(cs[0], class_used))
# images as numpy arrays
list_Ximgs = []
list_Yimgs = []
list_Zimgs = []
list_poolimgs = []
# features
list_X = []
list_Y = []
list_Z = []
list_pool = []
# class labels
list_Xlabels = []
list_Ylabels = []
list_Zlabels = []
list_poollabels = []
# seed used for subsampling
seed = 368
with util.NumpySeedContext(seed=seed):
for i, cs in enumerate(class_spec):
# load class data
class_i = cs[0]
imgs_i = cf10.load_data_array(class_i)
feas_i = cf10.load_feature_array(class_i)
# split each class according to the spec
class_sizes_i = cs[1:]
# imgs_i, feas_i may contain more than what we need in total for a class. Subsample
sub_ind = util.subsample_ind(imgs_i.shape[0], sum(class_sizes_i), seed=seed+1)
sub_ind = list(sub_ind)
assert len(sub_ind) == sum(class_sizes_i)
xyzp_imgs_i = util.multi_way_split(imgs_i[sub_ind,:], class_sizes_i)
xyzp_feas_i = util.multi_way_split(feas_i[sub_ind,:], class_sizes_i)
# assignment
list_Ximgs.append(xyzp_imgs_i[0])
list_Yimgs.append(xyzp_imgs_i[1])
list_Zimgs.append(xyzp_imgs_i[2])
list_poolimgs.append(xyzp_imgs_i[3])
list_X.append(xyzp_feas_i[0])
list_Y.append(xyzp_feas_i[1])
list_Z.append(xyzp_feas_i[2])
list_pool.append(xyzp_feas_i[3])
# class labels
class_ind_i = cf10.cifar10_class_ind_dict[class_i]
list_Xlabels.append(np.ones(class_sizes_i[0])*class_ind_i)
list_Ylabels.append(np.ones(class_sizes_i[1])*class_ind_i)
list_Zlabels.append(np.ones(class_sizes_i[2])*class_ind_i)
list_poollabels.append(np.ones(class_sizes_i[3])*class_ind_i)
```
Finally we have the samples (features and images)
```
# stack the lists. For the "histogram" purpose, we don't actually need
# images for X, Y, Z. Only images for the pool.
Ximgs = np.vstack(list_Ximgs)
Yimgs = np.vstack(list_Yimgs)
Zimgs = np.vstack(list_Zimgs)
poolimgs = np.vstack(list_poolimgs)
# features
X = np.vstack(list_X)
Y = np.vstack(list_Y)
Z = np.vstack(list_Z)
pool = np.vstack(list_pool)
# labels
Xlabels = np.hstack(list_Xlabels)
Ylabels = np.hstack(list_Ylabels)
Zlabels = np.hstack(list_Zlabels)
poollabels = np.hstack(list_poollabels)
# sanity check
XYZP = [(X, Ximgs, Xlabels), (Y, Yimgs, Ylabels), (Z, Zimgs, Zlabels), (pool, poolimgs, poollabels)]
for f, fimgs, flabels in XYZP:
assert f.shape[0] == fimgs.shape[0]
assert fimgs.shape[0] == flabels.shape[0]
assert X.shape[0] == sum(p_sizes)
assert Y.shape[0] == sum(q_sizes)
assert Z.shape[0] == sum(r_sizes)
assert pool.shape[0] == sum(pool_sizes)
```
## The actual histogram
```
def eval_test_locations(X, Y, Z, loc_pool, k, func_inds, reg=1e-6):
"""
Use X, Y, Z to estimate the Rel-UME power criterion function and evaluate
the function at each point (individually) in loc_pool (2d numpy array).
* k: a kernel
* func_inds: list of indices of the functions to evaluate. See below.
* reg: regularization parameter in the power criterion
Return an m x (up to) 5 numpy array where m = number of candidates in the
pool. The columns can be (as specified in func_inds):
0. power criterion
1. evaluation of the relative witness (or the test statistic of UME_SC)
2. evaluation of MMD witness(p, r) (not squared)
3. evaluation of witness(q, r)
4. evaluate of witness(p, q)
"""
datap = data.Data(X)
dataq = data.Data(Y)
datar = data.Data(Z)
powcri_func = mct.SC_UME.get_power_criterion_func(datap, dataq, datar, k, k, reg=1e-7)
relwit_func = mct.SC_UME.get_relative_sqwitness(datap, dataq, datar, k, k)
witpr = tst.MMDWitness(k, X, Z)
witqr = tst.MMDWitness(k, Y, Z)
witpq = tst.MMDWitness(k, X, Y)
funcs = [powcri_func, relwit_func, witpr, witqr, witpq]
# select the functions according to func_inds
list_evals = [funcs[i](loc_pool) for i in func_inds]
stack_evals = np.vstack(list_evals)
return stack_evals.T
# Gaussian kernel with median heuristic
medxz = util.meddistance(np.vstack((X, Z)), subsample=1000)
medyz = util.meddistance(np.vstack((Y, Z)), subsample=1000)
k = kernel.KGauss(np.mean([medxz, medyz])**2)
print('Gaussian width: {}'.format(k.sigma2**0.5))
# histogram. This will take some time.
func_inds = np.array([0, 1, 2, 3, 4])
pool_evals = eval_test_locations(X, Y, Z, loc_pool=pool, k=k, func_inds=func_inds, reg=1e-6)
pow_cri_values = pool_evals[:, func_inds==0].reshape(-1)
test_stat_values = pool_evals[:, func_inds==1].reshape(-1)
witpr_values = pool_evals[:, func_inds==2]
witqr_values = pool_evals[:, func_inds==3]
witpq_values = pool_evals[:, func_inds==4].reshape(-1)
plt.figure(figsize=(6, 4))
a = 0.6
plt.figure(figsize=(4,4))
plt.hist(pow_cri_values, bins=15, label='Power Criterion', alpha=a);
plt.hist(witpr_values, bins=15, label='Power Criterion', alpha=a);
plt.hist(witqr_values, bins=15, label='Power Criterion', alpha=a);
plt.hist(witpq_values, bins=15, label='Power Criterion', alpha=a);
# Save the results
# package things to save
datapack = {
'class_spec': class_spec,
'seed': seed,
'poolimgs': poolimgs,
'X': X,
'Y': Y,
'Z': Z,
'pool': pool,
'medxz': medxz,
'medyz': medyz,
'func_inds': func_inds,
'pool_evals': pool_evals,
}
lines = [ '_'.join(str(x) for x in cs) for cs in class_spec]
fname = '-'.join(lines) + '-seed{}.pkl'.format(seed)
with open(fname, 'wb') as f:
# expect result to be a dictionary
pickle.dump(datapack, f)
```
Code for running the experiment ends here.
## Plot the results
This section can be run by loading the previously saved results.
```
# load the results
# fname = 'airplane_2000_0_0_1000-automobile_0_2000_1500_1000-cat_1500_1500_1500_1000-frog_0_0_500_1000-seed368.pkl'
# fname = 'ship_2000_0_0_1000-airplane_0_2000_1500_1000-automobile_1500_1500_1500_1000-bird_0_0_500_1000-seed368.pkl'
# fname = 'ship_2000_0_0_1000-dog_0_2000_1500_1000-automobile_1500_1500_1500_1000-bird_0_0_500_1000-seed368.pkl'
fname = 'ship_2000_0_0_1000-airplane_0_2000_1500_1000-dog_1500_1500_1500_1000-bird_0_0_500_1000-seed368.pkl'
# fname = 'horse_2000_0_0_1000-deer_0_2000_1500_1000-dog_1500_1500_1500_1000-airplane_0_0_500_1000-seed368.pkl'
# fname = 'horse_2000_0_0_1000-deer_0_2000_1500_1000-dog_1500_1500_1500_1000-automobile_0_0_500_1000-seed368.pkl'
# fname = 'horse_2000_0_0_1000-deer_0_2000_2000_1000-dog_1500_1500_1500_1000-seed368.pkl'
#fname = 'airplane_2000_0_0_1000-automobile_0_2000_2000_1000-cat_1500_1500_1500_1000-seed368.pkl'
with open(fname, 'rb') as f:
# expect a dictionary
L = pickle.load(f)
# load the variables
class_spec = L['class_spec']
seed = L['seed']
poolimgs = L['poolimgs']
X = L['X']
Y = L['Y']
Z = L['Z']
pool = L['pool']
medxz = L['medxz']
medyz = L['medyz']
func_inds = L['func_inds']
pool_evals = L['pool_evals']
pow_cri_values = pool_evals[:, func_inds==0].reshape(-1)
test_stat_values = pool_evals[:, func_inds==1].reshape(-1)
witpq_values = pool_evals[:, func_inds==4].reshape(-1)
# plot the histogram
plt.figure(figsize=(6, 4))
a = 0.6
plt.figure(figsize=(4,4))
plt.hist(pow_cri_values, bins=15, label='Power Criterion', alpha=a);
# plt.hist(test_stat_values, label='Stat.', alpha=a);
# plt.legend()
plt.savefig('powcri_hist_locs_pool.pdf', bbox_inches='tight')
plt.figure(figsize=(12, 4))
plt.hist(test_stat_values, label='Stat.', alpha=a);
plt.legend()
def reshape_3c_rescale(img_in_stack):
img = img_in_stack.reshape([3, 32, 32])
# h x w x c
img = img.transpose([1, 2, 0])/255.0
return img
def plot_lowzerohigh(images, values, text_in_title='', grid_rows=2,
grid_cols=10, figsize=(13, 3)):
"""
Sort the values in three different ways (ascending, descending, absolute ascending).
Plot the images corresponding to the top-k sorted values. k is determined
by the grid size.
"""
low_inds, zeros_inds, high_inds = util.top_lowzerohigh(values)
plt.figure(figsize=figsize)
exu.plot_images_grid(images[low_inds], reshape_3c_rescale, grid_rows, grid_cols)
# plt.suptitle('{} Low'.format(text_in_title))
plt.savefig('powcri_low_region.pdf', bbox_inches='tight')
plt.figure(figsize=figsize)
exu.plot_images_grid(images[zeros_inds], reshape_3c_rescale, grid_rows, grid_cols)
# plt.suptitle('{} Near Zero'.format(text_in_title))
plt.savefig('powcri_zero_region.pdf', bbox_inches='tight')
plt.figure(figsize=figsize)
exu.plot_images_grid(images[high_inds], reshape_3c_rescale, grid_rows, grid_cols)
# plt.suptitle('{} High'.format(text_in_title))
plt.savefig('powcri_high_region.pdf', bbox_inches='tight')
grid_rows = 2
grid_cols = 5
figsize = (5, 3)
plot_lowzerohigh(poolimgs, pow_cri_values, 'Power Criterion.', grid_rows, grid_cols, figsize)
# plot_lowzerohigh(poolimgs, rel_wit_values, 'Test statistic.', grid_rows, grid_cols, figsize)
import matplotlib.gridspec as gridspec
def plot_images_grid_witness(images, func_img=None, grid_rows=4, grid_cols=4, witness_pq=None, scale=100.):
"""
Plot images in a grid, starting from index 0 to the maximum size of the
grid.
images: stack of images images[i] is one image
func_img: function to run on each image before plotting
"""
gs1 = gridspec.GridSpec(grid_rows, grid_cols)
gs1.update(wspace=0.2, hspace=0.8) # set the spacing between axes.
wit_sign = np.sign(witness_pq)
for i in range(grid_rows*grid_cols):
if func_img is not None:
img = func_img(images[i])
else:
img = images[i]
if witness_pq is not None:
sign = wit_sign[i]
if sign > 0:
color = 'red'
else:
color = 'blue'
# plt.subplot(grid_rows, grid_cols, i+1)
ax = plt.subplot(gs1[i])
if witness_pq is not None:
ax.text(0.5, -0.6, "{:1.2f}".format(scale*witness_pq[i]), ha="center",
color=color, transform=ax.transAxes)
plt.imshow(img)
plt.axis('off')
def plot_lowzerohigh(images, values, text_in_title='', grid_rows=2,
grid_cols=10, figsize=(13, 3), wit_pq=None, skip_length=1):
"""
Sort the values in three different ways (ascending, descending, absolute ascending).
Plot the images corresponding to the top-k sorted values. k is determined
by the grid size.
"""
low_inds, zeros_inds, high_inds = util.top_lowzerohigh(values)
low_inds = low_inds[::skip_length]
zeros_inds = zeros_inds[::skip_length]
high_inds = high_inds[::skip_length]
plt.figure(figsize=figsize)
plot_images_grid_witness(images[low_inds], reshape_3c_rescale, grid_rows, grid_cols, wit_pq[low_inds])
# plt.suptitle('{} Low'.format(text_in_title))
# plt.savefig('powcri_low_region.pdf', bbox_inches='tight')
plt.figure(figsize=figsize)
plot_images_grid_witness(images[zeros_inds], reshape_3c_rescale, grid_rows, grid_cols, wit_pq[zeros_inds])
# plt.suptitle('{} Near Zero'.format(text_in_title))
# plt.savefig('powcri_zero_region.pdf', bbox_inches='tight')
plt.figure(figsize=figsize)
plot_images_grid_witness(images[high_inds[:]], reshape_3c_rescale, grid_rows, grid_cols, wit_pq[high_inds])
# plt.suptitle('{} High'.format(text_in_title))
# plt.savefig('powcri_high_region.pdf', bbox_inches='tight')
grid_rows = 3
grid_cols = 5
figsize = (8, 3)
plot_lowzerohigh(poolimgs, pow_cri_values, 'Power Criterion.', grid_rows, grid_cols, figsize, witpq_values, skip_length=40)
```
| true |
code
| 0.36642 | null | null | null | null |
|
# Integrated gradients for text classification on the IMDB dataset
In this example, we apply the integrated gradients method to a sentiment analysis model trained on the IMDB dataset. In text classification models, integrated gradients define an attribution value for each word in the input sentence. The attributions are calculated considering the integral of the model gradients with respect to the word embedding layer along a straight path from a baseline instance $x^\prime$ to the input instance $x.$ A description of the method can be found [here](https://docs.seldon.io/projects/alibi/en/latest/methods/IntegratedGradients.html). Integrated gradients was originally proposed in Sundararajan et al., ["Axiomatic Attribution for Deep Networks"](https://arxiv.org/abs/1703.01365)
The IMDB data set contains 50K movie reviews labelled as positive or negative.
We train a convolutional neural network classifier with a single 1-d convolutional layer followed by a fully connected layer. The reviews in the dataset are truncated at 100 words and each word is represented by 50-dimesional word embedding vector. We calculate attributions for the elements of the embedding layer.
```
import tensorflow as tf
import numpy as np
import os
import pandas as pd
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Embedding, Conv1D, GlobalMaxPooling1D, Dropout
from tensorflow.keras.utils import to_categorical
from alibi.explainers import IntegratedGradients
import matplotlib.pyplot as plt
print('TF version: ', tf.__version__)
print('Eager execution enabled: ', tf.executing_eagerly()) # True
```
## Load data
Loading the imdb dataset.
```
max_features = 10000
maxlen = 100
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
test_labels = y_test.copy()
train_labels = y_train.copy()
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
print('Pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
index = imdb.get_word_index()
reverse_index = {value: key for (key, value) in index.items()}
```
A sample review from the test set. Note that unknown words are replaced with 'UNK'
```
def decode_sentence(x, reverse_index):
# the `-3` offset is due to the special tokens used by keras
# see https://stackoverflow.com/questions/42821330/restore-original-text-from-keras-s-imdb-dataset
return " ".join([reverse_index.get(i - 3, 'UNK') for i in x])
print(decode_sentence(x_test[1], reverse_index))
```
## Train Model
The model includes one convolutional layer and reaches a test accuracy of 0.85. If `save_model = True`, a local folder `../model_imdb` will be created and the trained model will be saved in that folder. If the model was previously saved, it can be loaded by setting `load_model = True`.
```
batch_size = 32
embedding_dims = 50
filters = 250
kernel_size = 3
hidden_dims = 250
load_model = False
save_model = True
filepath = './model_imdb/' # change to directory where model is downloaded
if load_model:
model = tf.keras.models.load_model(os.path.join(filepath, 'model.h5'))
else:
print('Build model...')
inputs = Input(shape=(maxlen,), dtype='int32')
embedded_sequences = Embedding(max_features,
embedding_dims)(inputs)
out = Conv1D(filters,
kernel_size,
padding='valid',
activation='relu',
strides=1)(embedded_sequences)
out = Dropout(0.4)(out)
out = GlobalMaxPooling1D()(out)
out = Dense(hidden_dims,
activation='relu')(out)
out = Dropout(0.4)(out)
outputs = Dense(2, activation='softmax')(out)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train,
batch_size=256,
epochs=3,
validation_data=(x_test, y_test))
if save_model:
if not os.path.exists(filepath):
os.makedirs(filepath)
model.save(os.path.join(filepath, 'model.h5'))
```
## Calculate integrated gradients
The integrated gradients attributions are calculated with respect to the embedding layer for 10 samples from the test set. Since the model uses a word to vector embedding with vector dimensionality of 50 and sequence length of 100 words, the dimensionality of the attributions is (10, 100, 50). In order to obtain a single attribution value for each word, we sum all the attribution values for the 50 elements of each word's vector representation.
The default baseline is used in this example which is internally defined as a sequence of zeros. In this case, this corresponds to a sequence of padding characters (**NB:** in general the numerical value corresponding to a "non-informative" baseline such as the PAD token will depend on the tokenizer used, make sure that the numerical value of the baseline used corresponds to your desired token value to avoid surprises). The path integral is defined as a straight line from the baseline to the input image. The path is approximated by choosing 50 discrete steps according to the Gauss-Legendre method.
```
n_steps = 50
method = "gausslegendre"
internal_batch_size = 100
nb_samples = 10
ig = IntegratedGradients(model,
layer=model.layers[1],
n_steps=n_steps,
method=method,
internal_batch_size=internal_batch_size)
x_test_sample = x_test[:nb_samples]
predictions = model(x_test_sample).numpy().argmax(axis=1)
explanation = ig.explain(x_test_sample,
baselines=None,
target=predictions)
# Metadata from the explanation object
explanation.meta
# Data fields from the explanation object
explanation.data.keys()
# Get attributions values from the explanation object
attrs = explanation.attributions[0]
print('Attributions shape:', attrs.shape)
```
## Sum attributions
```
attrs = attrs.sum(axis=2)
print('Attributions shape:', attrs.shape)
```
## Visualize attributions
```
i = 1
x_i = x_test_sample[i]
attrs_i = attrs[i]
pred = predictions[i]
pred_dict = {1: 'Positive review', 0: 'Negative review'}
print('Predicted label = {}: {}'.format(pred, pred_dict[pred]))
```
We can visualize the attributions for the text instance by mapping the values of the attributions onto a matplotlib colormap. Below we define some utility functions for doing this.
```
from IPython.display import HTML
def hlstr(string, color='white'):
"""
Return HTML markup highlighting text with the desired color.
"""
return f"<mark style=background-color:{color}>{string} </mark>"
def colorize(attrs, cmap='PiYG'):
"""
Compute hex colors based on the attributions for a single instance.
Uses a diverging colorscale by default and normalizes and scales
the colormap so that colors are consistent with the attributions.
"""
import matplotlib as mpl
cmap_bound = np.abs(attrs).max()
norm = mpl.colors.Normalize(vmin=-cmap_bound, vmax=cmap_bound)
cmap = mpl.cm.get_cmap(cmap)
# now compute hex values of colors
colors = list(map(lambda x: mpl.colors.rgb2hex(cmap(norm(x))), attrs))
return colors
```
Below we visualize the attribution values (highlighted in the text) having the highest positive attributions. Words with high positive attribution are highlighted in shades of green and words with negative attribution in shades of pink. Stronger shading corresponds to higher attribution values. Positive attributions can be interpreted as increase in probability of the predicted class ("Positive sentiment") while negative attributions correspond to decrease in probability of the predicted class.
```
words = decode_sentence(x_i, reverse_index).split()
colors = colorize(attrs_i)
HTML("".join(list(map(hlstr, words, colors))))
```
| true |
code
| 0.754819 | null | null | null | null |
|
# A practical introduction to Reinforcement Learning
Most of you have probably heard of AI learning to play computer games on their own, a very popular example being Deepmind. Deepmind hit the news when their AlphaGo program defeated the South Korean Go world champion in 2016. There had been many successful attempts in the past to develop agents with the intent of playing Atari games like Breakout, Pong, and Space Invaders.
You know what's common in most of these programs? A paradigm of Machine Learning known as **Reinforcement Learning**. For those of you that are new to RL, let's get some understand with few analogies.
## Reinforcement Learning Analogy
Consider the scenario of teaching a dog new tricks. The dog doesn't understand our language, so we can't tell him what to do. Instead, we follow a different strategy. We emulate a situation (or a cue), and the dog tries to respond in many different ways. If the dog's response is the desired one, we reward them with snacks. Now guess what, the next time the dog is exposed to the same situation, the dog executes a similar action with even more enthusiasm in expectation of more food. That's like learning "what to do" from positive experiences. Similarly, dogs will tend to learn what not to do when face with negative experiences.
That's exactly how Reinforcement Learning works in a broader sense:
- Your dog is an "agent" that is exposed to the **environment**. The environment could in your house, with you.
- The situations they encounter are analogous to a **state**. An example of a state could be your dog standing and you use a specific word in a certain tone in your living room
- Our agents react by performing an **action** to transition from one "state" to another "state," your dog goes from standing to sitting, for example.
- After the transition, they may receive a **reward** or **penalty** in return. You give them a treat! Or a "No" as a penalty.
- The **policy** is the strategy of choosing an action given a state in expectation of better outcomes.
Reinforcement Learning lies between the spectrum of Supervised Learning and Unsupervised Learning, and there's a few important things to note:
1. Being greedy doesn't always work
There are things that are easy to do for instant gratification, and there's things that provide long term rewards
The goal is to not be greedy by looking for the quick immediate rewards, but instead to optimize for maximum rewards over the whole training.
2. Sequence matters in Reinforcement Learning
The reward agent does not just depend on the current state, but the entire history of states. Unlike supervised and unsupervised learning, time is important here.
### The Reinforcement Process
In a way, Reinforcement Learning is the science of making optimal decisions using experiences.
Breaking it down, the process of Reinforcement Learning involves these simple steps:
1. Observation of the environment
2. Deciding how to act using some strategy
3. Acting accordingly
4. Receiving a reward or penalty
5. Learning from the experiences and refining our strategy
6. Iterate until an optimal strategy is found
Let's now understand Reinforcement Learning by actually developing an agent to learn to play a game automatically on its own.
## Example Design: Self-Driving Cab
Let's design a simulation of a self-driving cab. The major goal is to demonstrate, in a simplified environment, how you can use RL techniques to develop an efficient and safe approach for tackling this problem.
The Smartcab's job is to pick up the passenger at one location and drop them off in another. Here are a few things that we'd love our Smartcab to take care of:
- Drop off the passenger to the right location.
- Save passenger's time by taking minimum time possible to drop off
- Take care of passenger's safety and traffic rules
There are different aspects that need to be considered here while modeling an RL solution to this problem: rewards, states, and actions.
### 1. Rewards
Since the agent (the imaginary driver) is reward-motivated and is going to learn how to control the cab by trial experiences in the environment, we need to decide the **rewards** and/or **penalties** and their magnitude accordingly. Here a few points to consider:
- The agent should receive a high positive reward for a successful dropoff because this behavior is highly desired
- The agent should be penalized if it tries to drop off a passenger in wrong locations
- The agent should get a slight negative reward for not making it to the destination after every time-step. "Slight" negative because we would prefer our agent to reach late instead of making wrong moves trying to reach to the destination as fast as possible
### 2. State Space
In Reinforcement Learning, the agent encounters a state, and then takes action according to the state it's in.
The **State Space** is the set of all possible situations our taxi could inhabit. The state should contain useful information the agent needs to make the right action.
Let's say we have a training area for our Smartcab where we are teaching it to transport people in a parking lot to four different locations (R, G, Y, B):
Let's assume Smartcab is the only vehicle in this parking lot. We can break up the parking lot into a 5x5 grid, which gives us 25 possible taxi locations. These 25 locations are one part of our state space. Notice the current location state of our taxi is coordinate (3, 1).
You'll also notice there are four (4) locations that we can pick up and drop off a passenger: R, G, Y, B or `[(0,0), (0,4), (4,0), (4,3)] ` in (row, col) coordinates. Our illustrated passenger is in location **Y** and they wish to go to location **R**.
When we also account for one (1) additional passenger state of being inside the taxi, we can take all combinations of passenger locations and destination locations to come to a total number of states for our taxi environment; there's four (4) destinations and five (4 + 1) passenger locations.
So, our taxi environment has $5 \times 5 \times 5 \times 4 = 500$ total possible states.
### 3. Action Space
The agent encounters one of the 500 states and it takes an action. The action in our case can be to move in a direction or decide to pickup/dropoff a passenger.
In other words, we have six possible actions:
1. `south`
2. `north`
3. `east`
4. `west`
5. `pickup`
6. `dropoff`
This is the **action space**: the set of all the actions that our agent can take in a given state.
You'll notice in the illustration above, that the taxi cannot perform certain actions in certain states due to walls. In environment's code, we will simply provide a -1 penalty for every wall hit and the taxi won't move anywhere. This will just rack up penalties causing the taxi to consider going around the wall.
## Implementation with Python
Fortunately, [OpenAI Gym](https://gym.openai.com/) has this exact environment already built for us.
Gym provides different game environments which we can plug into our code and test an agent. The library takes care of API for providing all the information that our agent would require, like possible actions, score, and current state. We just need to focus just on the algorithm part for our agent.
We'll be using the Gym environment called `Taxi-V3`, which all of the details explained above were pulled from. The objectives, rewards, and actions are all the same.
### Gym's interface
We need to install `gym` first. Executing the following in a Jupyter notebook should work:
```
!pip install cmake 'gym[atari]' scipy
```
Once installed, we can load the game environment and render what it looks like:
```
import gym
env = gym.make("Taxi-v3").env
env.render()
```
The core gym interface is `env`, which is the unified environment interface. The following are the `env` methods that would be quite helpful to us:
- `env.reset`: Resets the environment and returns a random initial state.
- `env.step(action)`: Step the environment by one timestep. Returns
+ **observation**: Observations of the environment
+ **reward**: If your action was beneficial or not
+ **done**: Indicates if we have successfully picked up and dropped off a passenger, also called one *episode*
+ **info**: Additional info such as performance and latency for debugging purposes
- `env.render`: Renders one frame of the environment (helpful in visualizing the environment)
Note: We are using the `.env` on the end of `make` to avoid training stopping at 200 iterations, which is the default for the new version of Gym ([reference](https://stackoverflow.com/a/42802225)).
### Reminder of our problem
Here's our restructured problem statement (from Gym docs):
> There are 4 locations (labeled by different letters), and our job is to pick up the passenger at one location and drop him off at another. We receive +20 points for a successful drop-off and lose 1 point for every time-step it takes. There is also a 10 point penalty for illegal pick-up and drop-off actions.
Let's dive more into the environment.
```
env.reset() # reset environment to a new, random state
env.render()
print("Action Space {}".format(env.action_space))
print("State Space {}".format(env.observation_space))
```
- The **filled square** represents the taxi, which is yellow without a passenger and green with a passenger.
- The **pipe ("|")** represents a wall which the taxi cannot cross.
- **R, G, Y, B** are the possible pickup and destination locations. The **blue letter** represents the current passenger pick-up location, and the **purple letter** is the current destination.
As verified by the prints, we have an **Action Space** of size 6 and a **State Space** of size 500. As you'll see, our RL algorithm won't need any more information than these two things. All we need is a way to identify a state uniquely by assigning a unique number to every possible state, and RL learns to choose an action number from 0-5 where:
- 0 = south
- 1 = north
- 2 = east
- 3 = west
- 4 = pickup
- 5 = dropoff
Recall that the 500 states correspond to a encoding of the taxi's location, the passenger's location, and the destination location.
Reinforcement Learning will learn a mapping of **states** to the optimal **action** to perform in that state by *exploration*, i.e. the agent explores the environment and takes actions based off rewards defined in the environment.
The optimal action for each state is the action that has the **highest cumulative long-term reward**.
#### Back to our illustration
We can actually take our illustration above, encode its state, and give it to the environment to render in Gym. Recall that we have the taxi at row 3, column 1, our passenger is at location 2, and our destination is location 0. Using the Taxi-v2 state encoding method, we can do the following:
```
state = env.encode(3, 1, 2, 0) # (taxi row, taxi column, passenger index, destination index)
print("State:", state)
env.s = state
env.render()
```
We are using our illustration's coordinates to generate a number corresponding to a state between 0 and 499, which turns out to be **328** for our illustration's state.
Then we can set the environment's state manually with `env.env.s` using that encoded number. You can play around with the numbers and you'll see the taxi, passenger, and destination move around.
#### The Reward Table
When the Taxi environment is created, there is an initial Reward table that's also created, called `P`. We can think of it like a matrix that has the number of states as rows and number of actions as columns, i.e. a $states \ \times \ actions$ matrix.
Since every state is in this matrix, we can see the default reward values assigned to our illustration's state:
```
for I in range(10,20):
print(env.P[I],'\n')
```
This dictionary has the structure `{action: [(probability, nextstate, reward, done)]}`.
A few things to note:
- The 0-5 corresponds to the actions (south, north, east, west, pickup, dropoff) the taxi can perform at our current state in the illustration.
- In this env, `probability` is always 1.0.
- The `nextstate` is the state we would be in if we take the action at this index of the dict
- All the movement actions have a -1 reward and the pickup/dropoff actions have -10 reward in this particular state. If we are in a state where the taxi has a passenger and is on top of the right destination, we would see a reward of 20 at the dropoff action (5)
- `done` is used to tell us when we have successfully dropped off a passenger in the right location. Each successfull dropoff is the end of an **episode**
Note that if our agent chose to explore action two (2) in this state it would be going East into a wall. The source code has made it impossible to actually move the taxi across a wall, so if the taxi chooses that action, it will just keep acruing -1 penalties, which affects the **long-term reward**.
### Solving the environment without Reinforcement Learning
Let's see what would happen if we try to brute-force our way to solving the problem without RL.
Since we have our `P` table for default rewards in each state, we can try to have our taxi navigate just using that.
We'll create an infinite loop which runs until one passenger reaches one destination (one **episode**), or in other words, when the received reward is 20. The `env.action_space.sample()` method automatically selects one random action from set of all possible actions.
Let's see what happens:
```
env.s = 328 # set environment to illustration's state
epochs = 0
penalties, reward = 0, 0
frames = [] # for animation
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
# Put each rendered frame into dict for animation
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
from IPython.display import clear_output
from time import sleep
def print_frames(frames):
for i, frame in enumerate(frames):
clear_output(wait=True)
#print(frame['frame'].getvalue())
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
print_frames(frames)
```
Not good. Our agent takes thousands of timesteps and makes lots of wrong drop offs to deliver just one passenger to the right destination.
This is because we aren't *learning* from past experience. We can run this over and over, and it will never optimize. The agent has no memory of which action was best for each state, which is exactly what Reinforcement Learning will do for us.
### Enter Reinforcement Learning
We are going to use a simple RL algorithm called *Q-learning* which will give our agent some memory.
#### Intro to Q-learning
Essentially, Q-learning lets the agent use the environment's rewards to learn, over time, the best action to take in a given state.
In our Taxi environment, we have the reward table, `P`, that the agent will learn from. It does thing by looking receiving a reward for taking an action in the current state, then updating a *Q-value* to remember if that action was beneficial.
The values store in the Q-table are called a *Q-values*, and they map to a `(state, action)` combination.
A Q-value for a particular state-action combination is representative of the "quality" of an action taken from that state. Better Q-values imply better chances of getting greater rewards.
For example, if the taxi is faced with a state that includes a passenger at its current location, it is highly likely that the Q-value for `pickup` is higher when compared to other actions, like `dropoff` or `north`.
Q-values are initialized to an arbitrary value, and as the agent exposes itself to the environment and receives different rewards by executing different actions, the Q-values are updated using the equation:
$$\Large Q({\small state}, {\small action}) \leftarrow (1 - \alpha) Q({\small state}, {\small action}) + \alpha \Big({\small reward} + \gamma \max_{a} Q({\small next \ state}, {\small all \ actions})\Big)$$
Where:
- $\Large \alpha$ (alpha) is the learning rate ($0 < \alpha \leq 1$) - Just like in supervised learning settings, $\alpha$ is the extent to which our Q-values are being updated in every iteration.
- $\Large \gamma$ (gamma) is the discount factor ($0 \leq \gamma \leq 1$) - determines how much importance we want to give to future rewards. A high value for the discount factor (close to **1**) captures the long-term effective award, whereas, a discount factor of **0** makes our agent consider only immediate reward, hence making it greedy.
**What is this saying?**
We are assigning ($\leftarrow$), or updating, the Q-value of the agent's current *state* and *action* by first taking a weight ($1-\alpha$) of the old Q-value, then adding the learned value. The learned value is a combination of the reward for taking the current action in the current state, and the discounted maximum reward from the next state we will be in once we take the current action.
Basically, we are learning the proper action to take in the current state by looking at the reward for the current state/action combo, and the max rewards for the next state. This will eventually cause our taxi to consider the route with the best rewards strung together.
The Q-value of a state-action pair is the sum of the instant reward and the discounted future reward (of the resulting state).
The way we store the Q-values for each state and action is through a **Q-table**
##### Q-Table
The Q-table is a matrix where we have a row for every state (500) and a column for every action (6). It's first initialized to 0, and then values are updated after training. Note that the Q-table has the same dimensions as the reward table, but it has a completely different purpose.
<img src="assets/q-matrix-initialized-to-learned.png" width=500px>
#### Summing up the Q-Learning Process
Breaking it down into steps, we get
- Initialize the Q-table by all zeros.
- Start exploring actions: For each state, select any one among all possible actions for the current state (S).
- Travel to the next state (S') as a result of that action (a).
- For all possible actions from the state (S') select the one with the highest Q-value.
- Update Q-table values using the equation.
- Set the next state as the current state.
- If goal state is reached, then end and repeat the process.
##### Exploiting learned values
After enough random exploration of actions, the Q-values tend to converge serving our agent as an action-value function which it can exploit to pick the most optimal action from a given state.
There's a tradeoff between exploration (choosing a random action) and exploitation (choosing actions based on already learned Q-values). We want to prevent the action from always taking the same route, and possibly overfitting, so we'll be introducing another parameter called $\Large \epsilon$ "epsilon" to cater to this during training.
Instead of just selecting the best learned Q-value action, we'll sometimes favor exploring the action space further. Lower epsilon value results in episodes with more penalties (on average) which is obvious because we are exploring and making random decisions.
### Implementing Q-learning in python
#### Training the Agent
First, we'll initialize the Q-table to a $500 \times 6$ matrix of zeros:
```
import numpy as np
q_table = np.zeros([env.observation_space.n, env.action_space.n])
q_table
```
We can now create the training algorithm that will update this Q-table as the agent explores the environment over thousands of episodes.
In the first part of `while not done`, we decide whether to pick a random action or to exploit the already computed Q-values. This is done simply by using the `epsilon` value and comparing it to the `random.uniform(0, 1)` function, which returns an arbitrary number between 0 and 1.
We execute the chosen action in the environment to obtain the `next_state` and the `reward` from performing the action. After that, we calculate the maximum Q-value for the actions corresponding to the `next_state`, and with that, we can easily update our Q-value to the `new_q_value`:
```
%%time
"""Training the agent"""
import random
from IPython.display import clear_output
import matplotlib.pyplot as plt
import seaborn as sns
from time import sleep
%matplotlib inline
# Hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.1
# For plotting metrics
all_epochs = []
all_penalties = []
for i in range(1, 1000):
state = env.reset()
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Explore action space Sub sample
else:
action = np.argmax(q_table[state]) # Values Funcation
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action] # Q-values Funcation
next_max = np.max(q_table[next_state])
new_value = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
if i % 100 == 0:
clear_output(wait=True)
print(f"Episode: {i}")
print("Training finished.\n")
```
Now that the Q-table has been established over 100,000 episodes, let's see what the Q-values are at our illustration's state:
```
q_table[328]
```
The max Q-value is "north" (-1.971), so it looks like Q-learning has effectively learned the best action to take in our illustration's state!
### Evaluating the agent
Let's evaluate the performance of our agent. We don't need to explore actions any further, so now the next action is always selected using the best Q-value:
```
"""Evaluate agent's performance after Q-learning"""
total_epochs, total_penalties = 0, 0
episodes = 100
for _ in range(episodes):
state = env.reset()
epochs, penalties, reward = 0, 0, 0
done = False
while not done:
action = np.argmax(q_table[state]) # Values
Funcation
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
epochs += 1
total_penalties += penalties
total_epochs += epochs
print(f"Results after {episodes} episodes:")
print(f"Average timesteps per episode: {total_epochs / episodes}")
print(f"Average penalties per episode: {total_penalties / episodes}")
```
We can see from the evaluation, the agent's performance improved significantly and it incurred no penalties, which means it performed the correct pickup/dropoff actions with 100 different passengers.
#### Comparing our Q-learning agent to no Reinforcement Learning
With Q-learning agent commits errors initially during exploration but once it has explored enough (seen most of the states), it can act wisely maximizing the rewards making smart moves. Let's see how much better our Q-learning solution is when compared to the agent making just random moves.
We evaluate our agents according to the following metrics,
- **Average number of penalties per episode:** The smaller the number, the better the performance of our agent. Ideally, we would like this metric to be zero or very close to zero.
- **Average number of timesteps per trip:** We want a small number of timesteps per episode as well since we want our agent to take minimum steps(i.e. the shortest path) to reach the destination.
- **Average rewards per move:** The larger the reward means the agent is doing the right thing. That's why deciding rewards is a crucial part of Reinforcement Learning. In our case, as both timesteps and penalties are negatively rewarded, a higher average reward would mean that the agent reaches the destination as fast as possible with the least penalties"
| Measure | Random agent's performance | Q-learning agent's performance |
|----------------------------------------- |-------------------------- |-------------------------------- |
| Average rewards per move | -3.9012092102214075 | 0.6962843295638126 |
| Average number of penalties per episode | 920.45 | 0.0 |
| Average number of timesteps per trip | 2848.14 | 12.38 | |
These metrics were computed over 100 episodes. And as the results show, our Q-learning agent nailed it!
#### Hyperparameters and optimizations
The values of `alpha`, `gamma`, and `epsilon` were mostly based on intuition and some "hit and trial", but there are better ways to come up with good values.
Ideally, all three should decrease over time because as the agent continues to learn, it actually builds up more resilient priors;
- $\Large \alpha$: (the learning rate) should decrease as you continue to gain a larger and larger knowledge base.
- $\Large \gamma$: as you get closer and closer to the deadline, your preference for near-term reward should increase, as you won't be around long enough to get the long-term reward, which means your gamma should decrease.
- $\Large \epsilon$: as we develop our strategy, we have less need of exploration and more exploitation to get more utility from our policy, so as trials increase, epsilon should decrease.
#### Tuning the hyperparameters
A simple way to programmatically come up with the best set of values of the hyperparameter is to create a comprehensive search function (similar to [grid search](https://en.wikipedia.org/wiki/Hyperparameter_optimization#Grid_search)) that selects the parameters that would result in best `reward/time_steps` ratio. The reason for `reward/time_steps` is that we want to choose parameters which enable us to get the maximum reward as fast as possible. We may want to track the number of penalties corresponding to the hyperparameter value combination as well because this can also be a deciding factor (we don't want our smart agent to violate rules at the cost of reaching faster). A more fancy way to get the right combination of hyperparameter values would be to use Genetic Algorithms.
## Conclusion and What's Ahead
Alright! We began with understanding Reinforcement Learning with the help of real-world analogies. We then dived into the basics of Reinforcement Learning and framed a Self-driving cab as a Reinforcement Learning problem. We then used OpenAI's Gym in python to provide us with a related environment, where we can develop our agent and evaluate it. Then we observed how terrible our agent was without using any algorithm to play the game, so we went ahead to implement the Q-learning algorithm from scratch. The agent's performance improved significantly after Q-learning. Finally, we discussed better approaches for deciding the hyperparameters for our algorithm.
Q-learning is one of the easiest Reinforcement Learning algorithms. The problem with Q-earning however is, once the number of states in the environment are very high, it becomes difficult to implement them with Q table as the size would become very, very large. State of the art techniques uses Deep neural networks instead of the Q-table (Deep Reinforcement Learning). The neural network takes in state information and actions to the input layer and learns to output the right action over the time. Deep learning techniques (like Convolutional Neural Networks) are also used to interpret the pixels on the screen and extract information out of the game (like scores), and then letting the agent control the game.
We have discussed a lot about Reinforcement Learning and games. But Reinforcement learning is not just limited to games. It is used for managing stock portfolios and finances, for making humanoid robots, for manufacturing and inventory management, to develop general AI agents, which are agents that can perform multiple things with a single algorithm, like the same agent playing multiple Atari games. Open AI also has a platform called universe for measuring and training an AI's general intelligence across myriads of games, websites and other general applications.
| true |
code
| 0.358086 | null | null | null | null |
|
<a href="https://colab.research.google.com/github/MonitSharma/Learn-Quantum-Computing/blob/main/Circuit_Basics.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!pip install qiskit
```
# Qiskit Basics
```
import numpy as np
from qiskit import QuantumCircuit
# building a circuit
qc = QuantumCircuit(3)
# adding gates
qc.h(0)
qc.cx(0,1)
qc.cx(0,2)
qc.draw('mpl')
```
## Simulating the Circuits
```
from qiskit.quantum_info import Statevector
# setting the initial state to 0
state = Statevector.from_int(0,2**3)
state = state.evolve(qc)
state.draw('latex')
from qiskit.quantum_info import Statevector
# setting the initial state to 1
state = Statevector.from_int(1,2**3)
state = state.evolve(qc)
state.draw('latex')
```
Below we use the visualization function to plot the bloch sphere and a hinton representing the real and the imaginary components of the state density matrix $\rho$
```
state.draw('qsphere')
state.draw('hinton')
```
## Unitary Representation of a Circuit
The quant_info module of qiskit has an operator method that can be used to make unitary operator for the circuit.
```
from qiskit.quantum_info import Operator
U = Operator(qc)
U.data
```
## Open QASM backend
The simulators above are useful, as they help us in providing information about the state output and matrix representation of the circuit.
Here we would learn about more simulators that will help us in measuring the circuit
```
qc2 = QuantumCircuit(3,3)
qc2.barrier(range(3))
# do the measurement
qc2.measure(range(3), range(3))
qc2.draw('mpl')
# now, if we want to add both the qc and qc2 circuit
circ = qc2.compose(qc, range(3), front = True)
circ.draw('mpl')
```
This circuit adds a classical register , and three measurement that are used to map the outcome of qubits to the classical bits.
To simulate this circuit we use the 'qasm_simulator' in Qiskit Aer. Each single run will yield a bit string $000$ or $111$. To build up the statistics about the distribution , we need to repeat the circuit many times.
The number of times the circuit is repeated is specified in the 'execute' function via the 'shots' keyword.
```
from qiskit import transpile
# import the qasm simulator
from qiskit.providers.aer import QasmSimulator
backend = QasmSimulator()
# first transpile the quantum circuit to low level QASM instructions
qc_compiled = transpile(circ, backend)
# execute the circuit
job_sim = backend.run(qc_compiled, shots=1024)
# get the result
result_sim = job_sim.result()
```
Since, the code has run, we can count the number of specific ouputs it recieved and plot it too.
```
counts = result_sim.get_counts(qc_compiled)
print(counts)
from qiskit.visualization import plot_histogram
plot_histogram(counts)
```
| true |
code
| 0.644141 | null | null | null | null |
|
# A case study in screening for new enzymatic reactions
In this example, we show how to search the KEGG database for a reaction of interest based on user requirements. At specific points we highlight how our code could be used for arbitrary molecules that the user is interested in. This is crucial because the KEGG database is not exhaustive, and we only accessed a portion of the database that has no ambiguities (to avoid the need for manual filtering).
Requirements to run this script:
* rdkit (2019.09.2.0)
* matplotlib (3.1.1)
* numpy (1.17.4)
* enzyme_screen
* Clone source code and run this notebook in its default directory.
# This notebook requires data from screening, which is not uploaded!
## The idea:
We want to screen all collected reactions for a reaction that fits these constraints (automatic or manual application is noted):
1. Maximum component size within 5-7 Angstrom (automatic)
2. *One* component on *one* side of the reaction contains a nitrile group (automatic)
3. Value added from reactant to product (partially manual) e.g.:
- cost of the reactants being much less than the products
- products being unpurchasable and reactants being purchasable
Constraint *2* affords potential reaction monitoring through the isolated FT-IR signal of the nitrile group.
Constraint *3* is vague, but generally aims to determine some value-added by using an enzyme for a given reaction. This is often based on overcoming the cost of purchasing/synthesising the product through some non-enzymatic pathway by using an encapsulate enzyme. In this case, we use the primary literature on a selected reaction and some intuition to guide our efforts (i.e. we select a reaction (directionality determined from KEGG) where a relatively cheap (fair assumption) amino acid is the reactant).
The alternative to this process would be to select a target reactant or product and search all reactions that include that target and apply similar constraints to test the validity of those reactions.
### Provide directory to reaction data and molecule data, and parameter file.
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
import sys
reaction_dir = (
'/data/atarzia/projects/psp_phd/production/rxn_collection'
)
molecule_dir = (
'/data/atarzia/projects/psp_phd/molecules/molecule_DBs/production'
)
# Handle import directories.
module_path = os.path.abspath(os.path.join('../src'))
if module_path not in sys.path:
sys.path.append(module_path)
import utilities
param_file = '../data/param_file.txt'
params = utilities.read_params(param_file)
```
### Find reaction systems with max component sizes within threshold
Using a threshold of 5 to 7 angstrom.
Results in a plot of reaction distributions.
```
import plotting_fn as pfn
threshold_min = 5
threshold_max = 7
# Read in reaction collection CSV: rs_properties.csv
# from running RS_analysis.py.
rs_properties = pd.read_csv(
os.path.join(reaction_dir, 'rs_properties.csv')
)
rs_within_threshold = rs_properties[
rs_properties['max_mid_diam'] < threshold_max
]
rs_within_threshold = rs_within_threshold[
rs_within_threshold['max_mid_diam'] >= threshold_min
]
print(f'{len(rs_within_threshold)} reactions in threshold')
fig, ax = plt.subplots()
alpha = 1.0
width = 0.25
X_bins = np.arange(0, 20, width)
# All reactions.
hist, bin_edges = np.histogram(
a=list(rs_properties['max_mid_diam']),
bins=X_bins
)
ax.bar(
bin_edges[:-1],
hist,
align='edge',
alpha=alpha,
width=width,
color='lightgray',
edgecolor='lightgray',
label='all reactions'
)
# Within threshold.
hist, bin_edges = np.histogram(
a=list(rs_within_threshold['max_mid_diam']),
bins=X_bins
)
ax.bar(
bin_edges[:-1],
hist,
align='edge',
alpha=alpha,
width=width,
color='firebrick',
edgecolor='firebrick',
label='within threshold'
)
pfn.define_standard_plot(
ax,
xtitle='$d$ of largest component [$\mathrm{\AA}$]',
ytitle='count',
xlim=(0, 20),
ylim=None
)
fig.legend(fontsize=16)
fig.savefig(
os.path.join(reaction_dir, 'screen_example_distribution.pdf'),
dpi=720,
bbox_inches='tight'
)
plt.show()
```
### Find reaction systems with at least one nitrile functionality on one side of the reaction
```
import reaction
from rdkit.Chem import AllChem as rdkit
from rdkit.Chem import Fragments
# Handle some warnings for flat molecules.
from rdkit import RDLogger
RDLogger.DisableLog('rdApp.*')
# Needed to show molecules
from rdkit.Chem import Draw
from rdkit.Chem.Draw import IPythonConsole
def has_nitrile(mol_file):
"""
Returns False if nitrile fragment is not found using RDKIT.
"""
mol = rdkit.MolFromMolFile(mol_file)
no_frag = Fragments.fr_nitrile(mol)
if no_frag > 0:
return True
else:
return False
# Define generator over reactions.
generator = reaction.yield_rxn_syst(
output_dir=reaction_dir,
pars=params,
)
# Iterate over reactions, checking for validity.
target_reaction_ids = []
molecules_with_nitriles = []
for i, (count, rs) in enumerate(generator):
if 'KEGG' not in rs.pkl:
continue
if rs.skip_rxn:
continue
if rs.components is None:
continue
# Check components for nitrile groups.
reactants_w_nitriles = 0
products_w_nitriles = 0
for m in rs.components:
mol_file = os.path.join(
molecule_dir,
m.name+'_opt.mol'
)
if has_nitrile(mol_file):
if mol_file not in molecules_with_nitriles:
molecules_with_nitriles.append(mol_file)
if m.role == 'reactant':
reactants_w_nitriles += 1
elif m.role == 'product':
products_w_nitriles += 1
# Get both directions.
if products_w_nitriles == 1 and reactants_w_nitriles == 0:
target_reaction_ids.append(rs.DB_ID)
if products_w_nitriles == 0 and reactants_w_nitriles == 1:
target_reaction_ids.append(rs.DB_ID)
```
### Draw nitrile containing molecules
```
print(
f'There are {len(molecules_with_nitriles)} molecules '
f'with nitrile groups, corresponding to '
f'{len(target_reaction_ids)} reactions '
'out of all.'
)
molecules = [
rdkit.MolFromSmiles(rdkit.MolToSmiles(rdkit.MolFromMolFile(i)))
for i in molecules_with_nitriles
]
mol_names = [
i.replace(molecule_dir+'/', '').replace('_opt.mol', '')
for i in molecules_with_nitriles
]
img = Draw.MolsToGridImage(
molecules,
molsPerRow=6,
subImgSize=(100, 100),
legends=mol_names,
)
img
```
## Update dataframe to have target reaction ids only.
```
target_reactions = rs_within_threshold[
rs_within_threshold['db_id'].isin(target_reaction_ids)
]
print(
f'There are {len(target_reactions)} reactions '
'that fit all constraints so far.'
)
target_reactions
```
## Select reaction based on bertzCT and SAScore, plus intuition from visualisation
Plotting the measures of reaction productivity is useful, but so is looking manually through the small subset.
Both methods highlight R02846 (https://www.genome.jp/dbget-bin/www_bget?rn:R02846) as a good candidate:
- High deltaSA and deltaBertzCT
- The main reactant is a natural amino acid (cysteine). Note that the chirality is not defined in this specific KEGG Reaction, however, the chirality is defined as L-cysteine in the Enzyme entry (https://www.genome.jp/dbget-bin/www_bget?ec:4.4.1.9)
```
fig, ax = plt.subplots()
ax.scatter(
target_reactions['deltasa'],
target_reactions['deltabct'],
alpha=1.0,
c='#ff3b3b',
edgecolor='none',
label='target reactions',
s=100,
)
pfn.define_standard_plot(
ax,
xtitle=r'$\Delta$ SAscore',
ytitle=r'$\Delta$ BertzCT',
xlim=(-10, 10),
ylim=None,
)
fig.legend(fontsize=16)
fig.savefig(
os.path.join(
reaction_dir,
'screen_example_complexity_targets.pdf'
),
dpi=720,
bbox_inches='tight'
)
plt.show()
fig, ax = plt.subplots()
ax.scatter(
rs_properties['deltasa'],
rs_properties['deltabct'],
alpha=1.0,
c='lightgray',
edgecolor='none',
label='all reactions',
s=40,
)
ax.scatter(
rs_within_threshold['deltasa'],
rs_within_threshold['deltabct'],
alpha=1.0,
c='#2c3e50',
edgecolor='none',
label='within threshold',
s=40,
)
ax.scatter(
target_reactions['deltasa'],
target_reactions['deltabct'],
alpha=1.0,
c='#ff3b3b',
edgecolor='k',
label='target reactions',
marker='P',
s=60,
)
pfn.define_standard_plot(
ax,
xtitle=r'$\Delta$ SAscore',
ytitle=r'$\Delta$ BertzCT',
xlim=(-10, 10),
ylim=(-850, 850),
)
fig.legend(fontsize=16)
fig.savefig(
os.path.join(
reaction_dir,
'screen_example_complexity_all.pdf'
),
dpi=720,
bbox_inches='tight'
)
plt.show()
```
## Visualise properties of chosen reaction
Reaction: R02846 (https://www.genome.jp/dbget-bin/www_bget?rn:R02846)
```
# Read in reaction system.
rs = reaction.get_RS(
filename=os.path.join(
reaction_dir, 'sRS-4_4_1_9-KEGG-R02846.gpkl'
),
output_dir=reaction_dir,
pars=params,
verbose=True
)
# Print properties and collate components.
print(rs)
if rs.skip_rxn:
print(f'>>> {rs.skip_reason}')
print(
f'max intermediate diameter = {rs.max_min_mid_diam} angstrom'
)
print(
f'deltaSA = {rs.delta_SA}'
)
print(
f'deltaBertzCT = {rs.delta_bCT}'
)
print('--------------------------\n')
print('Components:')
# Output molecular components and their properties.
reacts = []
reactstr = []
prodstr = []
prods = []
for rsc in rs.components:
prop_dict = rsc.read_prop_file()
print(rsc)
print(f"SA = {round(prop_dict['Synth_score'], 3)}")
print(f"BertzCT = {round(prop_dict['bertzCT'], 3)}")
print('\n')
if rsc.role == 'product':
prods.append(
rdkit.MolFromMolFile(rsc.structure_file)
)
prodstr.append(f'{rsc.name}')
if rsc.role == 'reactant':
reacts.append(
rdkit.MolFromMolFile(rsc.structure_file)
)
reactstr.append(f'{rsc.name}')
img = Draw.MolsToGridImage(
reacts,
molsPerRow=2,
subImgSize=(300, 300),
legends=reactstr,
)
img.save(
os.path.join(
reaction_dir,
'screen_example_reactants.png'
)
)
img
img = Draw.MolsToGridImage(
prods,
molsPerRow=2,
subImgSize=(300, 300),
legends=prodstr,
)
img.save(
os.path.join(
reaction_dir,
'screen_example_products.png'
)
)
img
```
## Manually obtaining the cost of molecules
In this example, we will assume C00283 and C00177 are obtainable/purchasable through some means and that only C00736 and C02512 are relevant to the productivity of the reaction.
Note that the synthetic accessibility is 'large' for these molecules due to the two small molecules, while the change in BertzCT comes from the two larger molecules.
- Get CAS number from KEGG Compound pages:
- KEGG: C00736, CAS: 3374-22-9
- KEGG: C02512, CAS: 6232-19-5
- Use CAS number in some supplier website (using http://astatechinc.com/ here for no particular reason)
- KEGG: C00736, Price: \\$69 for 10 gram = \\$6.9 per gram
- KEGG: C02512, Price: \\$309 for 1 gram = \\$309 per gram
| true |
code
| 0.553566 | null | null | null | null |
|
# API demonstration for paper of v1.0
_the LSST-DESC CLMM team_
Here we demonstrate how to use `clmm` to estimate a WL halo mass from observations of a galaxy cluster when source galaxies follow a given distribution (The LSST DESC Science Requirements Document - arXiv:1809.01669, implemented in `clmm`). It uses several functionalities of the support `mock_data` module to produce mock datasets.
- Setting things up, with the proper imports.
- Computing the binned reduced tangential shear profile, for the 2 datasets, using logarithmic binning.
- Setting up a model accounting for the redshift distribution.
- Perform a simple fit using `scipy.optimize.curve_fit` included in `clmm` and visualize the results.
## Setup
First, we import some standard packages.
```
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.family'] = ['gothambook','gotham','gotham-book','serif']
```
## Generating mock data
`clmm` has a support code to generate a mock catalog given a input cosmology and cluster parameters. We will use this to generate a data sample to be used in this example:
```
from clmm import Cosmology
import clmm.support.mock_data as mock
np.random.seed(14) # For reproducibility
# Set cosmology of mock data
cosmo = Cosmology(H0=70.0, Omega_dm0=0.27-0.045, Omega_b0=0.045, Omega_k0=0.0)
# Cluster info
cluster_m = 1.e15 # Cluster mass - ($M200_m$) [Msun]
concentration = 4 # Cluster concentration
cluster_z = 0.3 # Cluster redshift
cluster_ra = 0. # Cluster Ra in deg
cluster_dec = 0. # Cluster Dec in deg
# Catalog info
field_size = 10 # i.e. 10 x 10 Mpc field at the cluster redshift, cluster in the center
# Make mock galaxies
mock_galaxies = mock.generate_galaxy_catalog(
cluster_m=cluster_m, cluster_z=cluster_z, cluster_c=concentration, # Cluster data
cosmo=cosmo, # Cosmology object
zsrc='desc_srd', # Galaxy redshift distribution,
zsrc_min=0.4, # Minimum redshift of the galaxies
shapenoise=0.05, # Gaussian shape noise to the galaxy shapes
photoz_sigma_unscaled=0.05, # Photo-z errors to source redshifts
field_size=field_size,
ngal_density=20 # number of gal/arcmin2 for z in [0, infty]
)['ra', 'dec', 'e1', 'e2', 'z', 'ztrue', 'pzbins', 'pzpdf', 'id']
print(f'Catalog table with the columns: {", ".join(mock_galaxies.colnames)}')
ngals_init = len(mock_galaxies)
print(f'Initial number of galaxies: {ngals_init:,}')
# Keeping only galaxies with "measured" redshift greater than cluster redshift
mock_galaxies = mock_galaxies[(mock_galaxies['z']>cluster_z)]
ngals_good = len(mock_galaxies)
if ngals_good < ngals_init:
print(f'Number of excluded galaxies (with photoz < cluster_z): {ngals_init-ngals_good:,}')
# reset galaxy id for later use
mock_galaxies['id'] = np.arange(ngals_good)
# Check final density
from clmm.utils import convert_units
field_size_arcmin = convert_units(field_size, 'Mpc', 'arcmin', redshift=cluster_z, cosmo=cosmo)
print(f'Background galaxy density = {ngals_good/field_size_arcmin**2:.2f} gal/arcmin2\n')
```
We can extract the column of this mock catalog to show explicitely how the quantities can be used on `clmm` functionality and how to add them to a `GalaxyCluster` object:
```
# Put galaxy values on arrays
gal_ra = mock_galaxies['ra'] # Galaxies Ra in deg
gal_dec = mock_galaxies['dec'] # Galaxies Dec in deg
gal_e1 = mock_galaxies['e1'] # Galaxies elipticipy 1
gal_e2 = mock_galaxies['e2'] # Galaxies elipticipy 2
gal_z = mock_galaxies['z'] # Galaxies observed redshift
gal_ztrue = mock_galaxies['ztrue'] # Galaxies true redshift
gal_pzbins = mock_galaxies['pzbins'] # Galaxies P(z) bins
gal_pzpdf = mock_galaxies['pzpdf'] # Galaxies P(z)
gal_id = mock_galaxies['id'] # Galaxies ID
```
## Measuring shear profiles
From the source galaxy quantities, we can compute the elepticities and corresponding radial profile usimg `clmm.dataops` functions:
```
import clmm.dataops as da
# Convert elipticities into shears
gal_ang_dist, gal_gt, gal_gx = da.compute_tangential_and_cross_components(cluster_ra, cluster_dec,
gal_ra, gal_dec,
gal_e1, gal_e2,
geometry="flat")
# Measure profile
profile = da.make_radial_profile([gal_gt, gal_gx, gal_z],
gal_ang_dist, "radians", "Mpc",
bins=da.make_bins(0.01, field_size/2., 50),
cosmo=cosmo,
z_lens=cluster_z,
include_empty_bins=False)
print(f'Profile table has columns: {", ".join(profile.colnames)},')
print('where p_(0, 1, 2) = (gt, gx, z)')
```
The other possibility is to use the `GalaxyCluster` object. This is the main approach to handle data with `clmm`, and also the simpler way. For that you just have to provide the following information of the cluster:
* Ra, Dec [deg]
* Mass - ($M200_m$) [Msun]
* Concentration
* Redshift
and the source galaxies:
* Ra, Dec [deg]
* 2 axis of eliptticities
* Redshift
```
import clmm
# Create a GCData with the galaxies
galaxies = clmm.GCData([gal_ra, gal_dec, gal_e1, gal_e2, gal_z,
gal_ztrue, gal_pzbins, gal_pzpdf, gal_id],
names=['ra', 'dec', 'e1', 'e2', 'z',
'ztrue', 'pzbins', 'pzpdf', 'id'])
# Create a GalaxyCluster
cluster = clmm.GalaxyCluster("Name of cluster", cluster_ra, cluster_dec,
cluster_z, mock_galaxies)
# Convert elipticities into shears for the members
cluster.compute_tangential_and_cross_components(geometry="flat")
print(cluster.galcat.colnames)
# Measure profile and add profile table to the cluster
seps = convert_units(cluster.galcat['theta'], 'radians', 'mpc',cluster.z, cosmo)
cluster.make_radial_profile(bins=da.make_bins(0.1, field_size/2., 25, method='evenlog10width'),
bin_units="Mpc",
cosmo=cosmo,
include_empty_bins=False,
gal_ids_in_bins=True,
)
print(cluster.profile.colnames)
```
This results in an attribute `table` added to the `cluster` object.
```
from paper_formating import prep_plot
prep_plot(figsize=(9, 9))
errorbar_kwargs = dict(linestyle='', marker='o',
markersize=1, elinewidth=.5, capthick=.5)
plt.errorbar(cluster.profile['radius'], cluster.profile['gt'],
cluster.profile['gt_err'], c='k', **errorbar_kwargs)
plt.xlabel('r [Mpc]', fontsize = 10)
plt.ylabel(r'$g_t$', fontsize = 10)
plt.xscale('log')
plt.yscale('log')
```
## Theoretical predictions
We consider 3 models:
1. One model where all sources are considered at the same redshift
2. One model using the overall source redshift distribution to predict the reduced tangential shear
3. A more accurate model, relying on the fact that we have access to the individual redshifts of the sources, where the average reduced tangential shear is averaged independently in each bin, accounting for the acutal population of sources in each bin.
All models rely on `clmm.predict_reduced_tangential_shear` to make a prediction that accounts for the redshift distribution of the galaxies in each radial bin:
### Model considering all sources located at the average redshift
\begin{equation}
g_{t,i}^{\rm{avg(z)}} = g_t(R_i, \langle z \rangle)\;,
\label{eq:wrong_gt_model}
\end{equation}
```
def predict_reduced_tangential_shear_mean_z(profile, logm):
return clmm.compute_reduced_tangential_shear(
r_proj=profile['radius'], # Radial component of the profile
mdelta=10**logm, # Mass of the cluster [M_sun]
cdelta=4, # Concentration of the cluster
z_cluster=cluster_z, # Redshift of the cluster
z_source=np.mean(cluster.galcat['z']), # Mean value of source galaxies redshift
cosmo=cosmo,
delta_mdef=200,
halo_profile_model='nfw'
)
```
### Model relying on the overall redshift distribution of the sources N(z), not using individual redshift information (eq. (6) from Applegate et al. 2014, MNRAS, 439, 48)
\begin{equation}
g_{t,i}^{N(z)} = \frac{\langle\beta_s\rangle \gamma_t(R_i, z\rightarrow\infty)}{1-\frac{\langle\beta_s^2\rangle}{\langle\beta_s\rangle}\kappa(R_i, z\rightarrow\infty)}
\label{eq:approx_model}
\end{equation}
```
z_inf = 1000
dl_inf = cosmo.eval_da_z1z2(cluster_z, z_inf)
d_inf = cosmo.eval_da(z_inf)
def betas(z):
dls = cosmo.eval_da_z1z2(cluster_z, z)
ds = cosmo.eval_da(z)
return dls * d_inf / (ds * dl_inf)
def predict_reduced_tangential_shear_approx(profile, logm):
bs_mean = np.mean(betas(cluster.galcat['z']))
bs2_mean = np.mean(betas(cluster.galcat['z'])**2)
gamma_t_inf = clmm.compute_tangential_shear(
r_proj=profile['radius'], # Radial component of the profile
mdelta=10**logm, # Mass of the cluster [M_sun]
cdelta=4, # Concentration of the cluster
z_cluster=cluster_z, # Redshift of the cluster
z_source=z_inf, # Redshift value at infinity
cosmo=cosmo,
delta_mdef=200,
halo_profile_model='nfw')
convergence_inf = clmm.compute_convergence(
r_proj=profile['radius'], # Radial component of the profile
mdelta=10**logm, # Mass of the cluster [M_sun]
cdelta=4, # Concentration of the cluster
z_cluster=cluster_z, # Redshift of the cluster
z_source=z_inf, # Redshift value at infinity
cosmo=cosmo,
delta_mdef=200,
halo_profile_model='nfw')
return bs_mean*gamma_t_inf/(1-(bs2_mean/bs_mean)*convergence_inf)
```
### Model using individual redshift and radial information, to compute the averaged shear in each radial bin, based on the galaxies actually present in that bin.
\begin{equation}
g_{t,i}^{z, R} = \frac{1}{N_i}\sum_{{\rm gal\,}j\in {\rm bin\,}i} g_t(R_j, z_j)
\label{eq:exact_model}
\end{equation}
```
cluster.galcat['theta_mpc'] = convert_units(cluster.galcat['theta'], 'radians', 'mpc',cluster.z, cosmo)
def predict_reduced_tangential_shear_exact(profile, logm):
return np.array([np.mean(
clmm.compute_reduced_tangential_shear(
# Radial component of each source galaxy inside the radial bin
r_proj=cluster.galcat[radial_bin['gal_id']]['theta_mpc'],
mdelta=10**logm, # Mass of the cluster [M_sun]
cdelta=4, # Concentration of the cluster
z_cluster=cluster_z, # Redshift of the cluster
# Redshift value of each source galaxy inside the radial bin
z_source=cluster.galcat[radial_bin['gal_id']]['z'],
cosmo=cosmo,
delta_mdef=200,
halo_profile_model='nfw'
)) for radial_bin in profile])
```
## Mass fitting
We estimate the best-fit mass using `scipy.optimize.curve_fit`. The choice of fitting $\log M$ instead of $M$ lowers the range of pre-defined fitting bounds from several order of magnitude for the mass to unity. From the associated error $\sigma_{\log M}$ we calculate the error to mass as $\sigma_M = M_{fit}\ln(10)\sigma_{\log M}$.
#### First, identify bins with sufficient galaxy statistics to be kept for the fit
For small samples, error bars should not be computed using the simple error on the mean approach available so far in CLMM)
```
mask_for_fit = cluster.profile['n_src'] > 5
data_for_fit = cluster.profile[mask_for_fit]
```
#### Perform the fits
```
from clmm.support.sampler import fitters
def fit_mass(predict_function):
popt, pcov = fitters['curve_fit'](predict_function,
data_for_fit,
data_for_fit['gt'],
data_for_fit['gt_err'], bounds=[10.,17.])
logm, logm_err = popt[0], np.sqrt(pcov[0][0])
return {'logm':logm, 'logm_err':logm_err,
'm': 10**logm, 'm_err': (10**logm)*logm_err*np.log(10)}
fit_mean_z = fit_mass(predict_reduced_tangential_shear_mean_z)
fit_approx = fit_mass(predict_reduced_tangential_shear_approx)
fit_exact = fit_mass(predict_reduced_tangential_shear_exact)
print(f'Input mass = {cluster_m:.2e} Msun\n')
print(f'Best fit mass for average redshift = {fit_mean_z["m"]:.3e} +/- {fit_mean_z["m_err"]:.3e} Msun')
print(f'Best fit mass for N(z) model = {fit_approx["m"]:.3e} +/- {fit_approx["m_err"]:.3e} Msun')
print(f'Best fit mass for individual redshift and radius = {fit_exact["m"]:.3e} +/- {fit_exact["m_err"]:.3e} Msun')
```
As expected, the reconstructed mass is biased when the redshift distribution is not accounted for in the model
## Visualization of the results
For visualization purpose, we calculate the reduced tangential shear predicted by the model with estimated masses for noisy and ideal data.
```
def get_predicted_shear(predict_function, fit_values):
gt_est = predict_function(data_for_fit, fit_values['logm'])
gt_est_err = [predict_function(data_for_fit, fit_values['logm']+i*fit_values['logm_err'])
for i in (-3, 3)]
return gt_est, gt_est_err
gt_mean_z, gt_err_mean_z = get_predicted_shear(predict_reduced_tangential_shear_mean_z, fit_mean_z)
gt_approx, gt_err_approx = get_predicted_shear(predict_reduced_tangential_shear_approx, fit_approx)
gt_exact, gt_err_exact = get_predicted_shear(predict_reduced_tangential_shear_exact, fit_exact)
```
Check reduced chi2 values of the best-fit model
```
chi2_mean_z_dof = np.sum((gt_mean_z-data_for_fit['gt'])**2/(data_for_fit['gt_err'])**2)/(len(data_for_fit)-1)
chi2_approx_dof = np.sum((gt_approx-data_for_fit['gt'])**2/(data_for_fit['gt_err'])**2)/(len(data_for_fit)-1)
chi2_exact_dof = np.sum((gt_exact-data_for_fit['gt'])**2/(data_for_fit['gt_err'])**2)/(len(data_for_fit)-1)
print(f'Reduced chi2 (mean z model) = {chi2_mean_z_dof}')
print(f'Reduced chi2 (N(z) model) = {chi2_approx_dof}')
print(f'Reduced chi2 (individual (R,z) model) = {chi2_exact_dof}')
```
We compare to tangential shear obtained with theoretical mass. We plot the reduced tangential shear models first when redshift distribution is accounted for in the model then for the naive approach, with respective best-fit masses.
```
from matplotlib.ticker import MultipleLocator
prep_plot(figsize=(9 , 9))
gt_ax = plt.axes([.25, .42, .7, .55])
gt_ax.errorbar(data_for_fit['radius'],data_for_fit['gt'], data_for_fit['gt_err'],
c='k', label=rf'$M_{{input}} = {cluster_m*1e-15}\times10^{{{15}}} M_\odot$',
**errorbar_kwargs)
# Points in grey have not been used for the fit
gt_ax.errorbar(cluster.profile['radius'][~mask_for_fit], cluster.profile['gt'][~mask_for_fit],
cluster.profile['gt_err'][~mask_for_fit],
c='grey',**errorbar_kwargs)
pow10 = 15
mlabel = lambda name, fits: fr'$M_{{fit}}^{{{name}}} = {fits["m"]/10**pow10:.3f}\pm{fits["m_err"]/10**pow10:.3f}\times 10^{{{pow10}}} M_\odot$'
# Avg z
gt_ax.loglog(data_for_fit['radius'], gt_mean_z,'-C0',
label=mlabel('avg(z)', fit_mean_z),lw=.5)
gt_ax.fill_between(data_for_fit['radius'], *gt_err_mean_z, lw=0, color='C0', alpha=.2)
# Approx model
gt_ax.loglog(data_for_fit['radius'], gt_approx,'-C1',
label=mlabel('N(z)', fit_approx),
lw=.5)
gt_ax.fill_between(data_for_fit['radius'], *gt_err_approx, lw=0, color='C1', alpha=.2)
# Exact model
gt_ax.loglog(data_for_fit['radius'], gt_exact,'-C2',
label=mlabel('z,R', fit_exact),
lw=.5)
gt_ax.fill_between(data_for_fit['radius'], *gt_err_exact, lw=0, color='C2', alpha=.2)
gt_ax.set_ylabel(r'$g_t$', fontsize = 8)
gt_ax.legend(fontsize=6)
gt_ax.set_xticklabels([])
gt_ax.tick_params('x', labelsize=8)
gt_ax.tick_params('y', labelsize=8)
#gt_ax.set_yscale('log')
errorbar_kwargs2 = {k:v for k, v in errorbar_kwargs.items() if 'marker' not in k}
errorbar_kwargs2['markersize'] = 3
errorbar_kwargs2['markeredgewidth'] = .5
res_ax = plt.axes([.25, .2, .7, .2])
delta = (cluster.profile['radius'][1]/cluster.profile['radius'][0])**.25
res_err = data_for_fit['gt_err']/data_for_fit['gt']
res_ax.errorbar(data_for_fit['radius']/delta, gt_mean_z/data_for_fit['gt']-1,
yerr=res_err, marker='.', c='C0', **errorbar_kwargs2)
errorbar_kwargs2['markersize'] = 1.5
res_ax.errorbar(data_for_fit['radius'], gt_approx/data_for_fit['gt']-1,
yerr=res_err, marker='s', c='C1', **errorbar_kwargs2)
errorbar_kwargs2['markersize'] = 3
errorbar_kwargs2['markeredgewidth'] = .5
res_ax.errorbar(data_for_fit['radius']*delta, gt_exact/data_for_fit['gt']-1,
yerr=res_err, marker='*', c='C2', **errorbar_kwargs2)
res_ax.set_xlabel(r'$R$ [Mpc]', fontsize = 8)
res_ax.set_ylabel(r'$g_t^{mod.}/g_t^{data}-1$', fontsize = 8)
res_ax.set_xscale('log')
res_ax.set_xlim(gt_ax.get_xlim())
res_ax.set_ylim(-0.65,0.65)
res_ax.yaxis.set_minor_locator(MultipleLocator(.1))
res_ax.tick_params('x', labelsize=8)
res_ax.tick_params('y', labelsize=8)
for p in (gt_ax, res_ax):
p.xaxis.grid(True, which='major', lw=.5)
p.yaxis.grid(True, which='major', lw=.5)
p.xaxis.grid(True, which='minor', lw=.1)
p.yaxis.grid(True, which='minor', lw=.1)
plt.savefig('r_gt.png')
```
| true |
code
| 0.581065 | null | null | null | null |
|
<img width="10%" alt="Naas" src="https://landen.imgix.net/jtci2pxwjczr/assets/5ice39g4.png?w=160"/>
# CI/CD - Make sure all notebooks respects our format policy
**Tags:** #naas
**Author:** [Maxime Jublou](https://www.linkedin.com/in/maximejublou/)
# Input
### Import libraries
```
import json
import glob
from rich import print
import pydash
import re
```
## Model
### Utility functions
These functions are used by other to not repeat ourselves.
```
def tag_exists(tagname, cells):
for cell in cells:
if tagname in pydash.get(cell, 'metadata.tags', []):
return True
return False
def regexp_match(regex, string):
matches = re.finditer(regex, string, re.MULTILINE)
return len(list(matches)) >= 1
def check_regexp(cells, regex, source):
cell_str = pydash.get(cells, source, '')
return regexp_match(regex, cell_str)
def check_title_exists(cells, title):
for cell in cells:
if pydash.get(cell, 'cell_type') == 'markdown' and regexp_match(rf"^## *{title}", pydash.get(cell, 'source[0]')):
return True
return False
```
### Check functions
This functions are used to check if a notebook contains the rights cells with proper formatting.
```
def check_naas_logo(cells):
logo_content = '<img width="10%" alt="Naas" src="https://landen.imgix.net/jtci2pxwjczr/assets/5ice39g4.png?w=160"/>'
if pydash.get(cells, '[0].cell_type') == 'markdown' and pydash.get(cells, '[0].source[0]', '').startswith(logo_content):
return (True, '')
return (False, f'''
Requirements:
- Cell number: 1
- Cell type: Markdown
- Shape: {logo_content}
''')
def check_title_match_regexp(cells):
return (check_regexp(cells, r"markdown", '[1].cell_type') and check_regexp(cells, r"^#.*-.*", '[1].source[0]'), '''
Requirements:
- Cell number: 2
- Cell type: Markdown
- Shape: "# something - some other thing"
''')
def check_tool_tags(cells):
return (check_regexp(cells, r"markdown", '[2].cell_type') and check_regexp(cells, r"^\*\*Tags:\*\* (#[1-9,a-z,A-Z]*( *|$))*", '[2].source[0]'), '''
Requirements:
- Cell number: 3
- Cell type: Markdown
- Shape: "**Tags:** #atLeastOneTool"
''')
def check_author(cells):
return (check_regexp(cells, r"markdown", '[3].cell_type') and check_regexp(cells, r"^\*\*Author:\*\* *.*", '[3].source[0]'), '''
Requirements:
- Cell number: 4
- Cell type: Markdown
- Shape: "**Author:** At least one author name"
''')
def check_input_title_exists(cells):
return (check_title_exists(cells, 'Input'), '''
Requirements:
- Cell number: Any
- Cell type: Markdown
- Shape: "## Input"
''')
def check_model_title_exists(cells):
return (check_title_exists(cells, 'Model'), '''
Requirements:
- Cell number: Any
- Cell type: Markdown
- Shape: "## Model"
''')
def check_output_title_exists(cells):
return (check_title_exists(cells, 'Output'), '''
Requirements:
- Cell number: Any
- Cell type: Markdown
- Shape: "## Output"
''')
```
## Output
```
got_errors = False
error_counter = 0
for file in glob.glob('../../**/*.ipynb', recursive=True):
# Do not check notebooks in .github or at the root of the project.
if '.github' in file or len(file.split('/')) == 3:
continue
notebook = json.load(open(file))
cells = notebook.get('cells')
filename = "[dark_orange]" + file.replace("../../", "") + "[/dark_orange]"
outputs = [f'Errors found in: {filename}']
should_display_debug = False
for checkf in [
check_naas_logo,
check_title_match_regexp,
check_tool_tags,
check_author,
check_input_title_exists,
check_model_title_exists,
check_output_title_exists]:
result, msg = checkf(cells)
if result is False:
should_display_debug = True
status_msg = "[bright_green]OK[/bright_green]" if result is True else f"[bright_red]KO {msg}[/bright_red]"
outputs.append(f'{checkf.__name__} ... {status_msg}')
if should_display_debug:
got_errors = True
error_counter += 1
for msg in outputs:
print(msg)
print("\n")
if got_errors == True:
print(f'[bright_red]You have {error_counter} notebooks having errors!')
exit(1)
```
| true |
code
| 0.306767 | null | null | null | null |
|
# Predict H1N1 and Seasonal Flu Vaccines
## Preprocessing
### Import libraries
```
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
```
### Import data
```
features_raw_df = pd.read_csv("data/training_set_features.csv", index_col="respondent_id")
labels_raw_df = pd.read_csv("data/training_set_labels.csv", index_col="respondent_id")
print("features_raw_df.shape", features_raw_df.shape)
features_raw_df.head()
features_raw_df.dtypes
print("labels_raw_df.shape", labels_raw_df.shape)
labels_raw_df.head()
labels_raw_df.dtypes
features_df = features_raw_df.copy()
labels_df = labels_raw_df.copy()
```
### Exploratory Data Analysis
```
fig, ax = plt.subplots(2, 1, sharex=True)
n_entries = labels_df.shape[0]
(labels_df['h1n1_vaccine'].value_counts().div(n_entries)
.plot.barh(title="Proportion of H1N1 Vaccine", ax=ax[0]))
ax[0].set_ylabel("seasonal_vaccine")
(labels_df['seasonal_vaccine'].value_counts().div(n_entries)
.plot.barh(title="Proportion of H1N1 Vaccine", ax=ax[1]))
ax[1].set_ylabel("seasonal_vaccine")
fig.tight_layout()
pd.crosstab(
labels_df["h1n1_vaccine"],
labels_df["seasonal_vaccine"],
margins=True,
normalize=True
)
(labels_df["h1n1_vaccine"]
.corr(labels_df["seasonal_vaccine"], method="pearson")
)
```
### Features
```
df = features_df.join(labels_df)
print(df.shape)
df.head()
h1n1_concern_vaccine = df[['h1n1_concern', 'h1n1_vaccine']].groupby(['h1n1_concern', 'h1n1_vaccine']).size().unstack()
h1n1_concern_vaccine
ax = h1n1_concern_vaccine.plot.barh()
ax.invert_yaxis()
h1n1_concern_counts = h1n1_concern_vaccine.sum(axis='columns')
h1n1_concern_counts
h1n1_concern_vaccine_prop = h1n1_concern_vaccine.div(h1n1_concern_counts, axis='index')
h1n1_concern_vaccine_prop
ax = h1n1_concern_vaccine_prop.plot.barh(stacked=True)
ax.invert_yaxis()
ax.legend(loc='center left', bbox_to_anchor=(1.05, 0.5), title='h1n1_vaccine')
plt.show()
def vaccination_rate_plot(vaccine, feature, df, ax=None):
feature_vaccine = df[[feature, vaccine]].groupby([feature, vaccine]).size().unstack()
counts = feature_vaccine.sum(axis='columns')
proportions = feature_vaccine.div(counts, axis='index')
ax = proportions.plot.barh(stacked=True, ax=ax)
ax.invert_yaxis()
ax.legend(loc='center left', bbox_to_anchor=(1.05, 0.5), title=vaccine)
ax.legend().remove()
vaccination_rate_plot('seasonal_vaccine', 'h1n1_concern', df)
cols_to_plot = [
'h1n1_concern',
'h1n1_knowledge',
'opinion_h1n1_vacc_effective',
'opinion_h1n1_risk',
'opinion_h1n1_sick_from_vacc',
'opinion_seas_vacc_effective',
'opinion_seas_risk',
'opinion_seas_sick_from_vacc',
'sex',
'age_group',
'race',
]
fig, ax = plt.subplots(len(cols_to_plot), 2, figsize=(10,len(cols_to_plot)*2.5))
for idx, col in enumerate(cols_to_plot):
vaccination_rate_plot('h1n1_vaccine', col, df, ax=ax[idx, 0])
vaccination_rate_plot('seasonal_vaccine', col, df, ax=ax[idx, 1])
ax[0, 0].legend(loc='lower center', bbox_to_anchor=(0.5, 1.05), title='h1n1_vaccine')
ax[0, 1].legend(loc='lower center', bbox_to_anchor=(0.5, 1.05), title='seasonal_vaccine')
fig.tight_layout()
```
### Categorical columns
```
features_df = features_raw_df.copy()
labels_df = labels_raw_df.copy()
features_df.dtypes == object
# All categorical columns considered apart from employment-related
categorical_cols = features_df.columns[features_df.dtypes == "object"].values[:-2]
categorical_cols
categorical_cols = np.delete(categorical_cols, np.where(categorical_cols == 'hhs_geo_region'))
categorical_cols
features_df.employment_occupation.unique()
features_df.hhs_geo_region.unique()
features_df[categorical_cols].head()
for col in categorical_cols:
col_dummies = pd.get_dummies(features_df[col], drop_first = True)
features_df = features_df.drop(col, axis=1)
features_df = pd.concat([features_df, col_dummies], axis=1)
features_df.head()
features_df.isna().sum()
def preprocess_categorical(df):
categorical_cols = df.columns[df.dtypes == "object"].values[:-2]
categorical_cols = np.delete(categorical_cols, np.where(categorical_cols == 'hhs_geo_region'))
for col in categorical_cols:
col_dummies = pd.get_dummies(df[col], drop_first = True)
df = df.drop(col, axis=1)
df = pd.concat([df, col_dummies], axis=1)
df = df.drop(['hhs_geo_region', 'employment_industry', 'employment_occupation'], axis=1)
return df
```
## MACHINE LEARNING
### Machine Learning Model
```
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.multioutput import MultiOutputClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, roc_auc_score
RANDOM_SEED = 6
features_raw_df.dtypes != "object"
numeric_cols = features_raw_df.columns[features_raw_df.dtypes != "object"].values
print(numeric_cols)
```
### Features Preprocessing
```
# chain preprocessing into a Pipeline object
numeric_preprocessing_steps = Pipeline([
('standard_scaler', StandardScaler()),
('simple_imputer', SimpleImputer(strategy='median'))
])
# create the preprocessor stage of final pipeline
preprocessor = ColumnTransformer(
transformers = [
("numeric", numeric_preprocessing_steps, numeric_cols)
],
remainder = "passthrough"
)
estimators = MultiOutputClassifier(
estimator=LogisticRegression(penalty="l2", C=1)
)
full_pipeline = Pipeline([
("preprocessor", preprocessor),
("estimators", estimators),
])
features_df_trans = preprocess_categorical(features_df)
X_train, X_test, y_train, y_test = train_test_split(
features_df_trans,
labels_df,
test_size=0.33,
shuffle=True,
stratify=labels_df,
random_state=RANDOM_SEED
)
X_train
# Train model
full_pipeline.fit(X_train, y_train)
# Predict on evaluation set
# This competition wants probabilities, not labels
preds = full_pipeline.predict_proba(X_test)
preds
print("test_probas[0].shape", preds[0].shape)
print("test_probas[1].shape", preds[1].shape)
y_pred = pd.DataFrame(
{
"h1n1_vaccine": preds[0][:, 1],
"seasonal_vaccine": preds[1][:, 1],
},
index = y_test.index
)
print("y_pred.shape:", y_pred.shape)
y_pred.head()
fig, ax = plt.subplots(1, 2, figsize=(7, 3.5))
fpr, tpr, thresholds = roc_curve(y_test['h1n1_vaccine'], y_pred['h1n1_vaccine'])
ax[0].plot(fpr, tpr)
ax[0].plot([0, 1], [0, 1], color='grey', linestyle='--')
ax[0].set_ylabel('TPR')
ax[0].set_xlabel('FPR')
ax[0].set_title(f"{'h1n1_vaccine'}: AUC = {roc_auc_score(y_test['h1n1_vaccine'], y_pred['h1n1_vaccine']):.4f}")
fpr, tpr, thresholds = roc_curve(y_test['seasonal_vaccine'], y_pred['seasonal_vaccine'])
ax[1].plot(fpr, tpr)
ax[1].plot([0, 1], [0, 1], color='grey', linestyle='--')
ax[1].set_xlabel('FPR')
ax[1].set_title(f"{'seasonal_vaccine'}: AUC = {roc_auc_score(y_test['seasonal_vaccine'], y_pred['seasonal_vaccine']):.4f}")
fig.tight_layout()
roc_auc_score(y_test, y_pred)
```
### Retrain on full Dataset
```
full_pipeline.fit(features_df_trans, labels_df);
```
## PREDICTIONS FOR THE TEST SET
```
test_features_df = pd.read_csv('data/test_set_features.csv', index_col='respondent_id')
test_features_df
test_features_df_trans = preprocess_categorical(test_features_df)
test_preds = full_pipeline.predict_proba(test_features_df_trans)
submission_df = pd.read_csv('data/submission_format.csv', index_col='respondent_id')
# Save predictions to submission data frame
submission_df["h1n1_vaccine"] = test_preds[0][:, 1]
submission_df["seasonal_vaccine"] = test_preds[1][:, 1]
submission_df.head()
submission_df.to_csv('data/my_submission.csv', index=True)
```
| true |
code
| 0.572484 | null | null | null | null |
|
# QUANTUM PHASE ESTIMATION
This tutorial provides a detailed implementation of the Quantum Phase Estimation (QPE) algorithm using the Amazon Braket SDK.
The QPE algorithm is designed to estimate the eigenvalues of a unitary operator $U$ [1, 2];
it is a very important subroutine to many quantum algorithms, most famously Shor's algorithm for factoring and the HHL algorithm (named after the physicists Harrow, Hassidim and Lloyd) for solving linear systems of equations on a quantum computer [1, 2].
Moreover, eigenvalue problems can be found across many disciplines and application areas, including (for example) principal component analysis (PCA) as used in machine learning or the solution of differential equations as relevant across mathematics, physics, engineering and chemistry.
We first review the basics of the QPE algorithm.
We then implement the QPE algorithm in code using the Amazon Braket SDK, and we illustrate the application thereof with simple examples.
This notebook also showcases the Amazon Braket `circuit.subroutine` functionality, which allows us to use custom-built gates as if they were any other built-in gates.
This tutorial is set up to run either on the local simulator or the managed simulators; changing between these devices merely requires changing one line of code as demonstrated as follows in cell [4].
## TECHNICAL BACKGROUND OF QPE
__Introduction__: A unitary matrix is a complex, square matrix whose adjoint (or conjugate transpose) is equal to its inverse. Unitary matrices have many nice properties, including the fact that their eigenvalues are always roots of unity (that is, phases). Given a unitary matrix $U$ (satisfying $U^{\dagger}U=\mathbb{1}=UU^{\dagger}$) and an eigenstate $|\psi \rangle$ with $U|\psi \rangle = e^{2\pi i\varphi}|\psi \rangle$, the Quantum Phase Estimation (QPE) algorithm provides an estimate $\tilde{\varphi} \approx \varphi$ for the phase $\varphi$ (with $\varphi \in [0,1]$ since the eigenvalues $\lambda = \exp(2\pi i\varphi)$ of a unitary have modulus one).
The QPE works with high probability within an additive error $\varepsilon$ using $O(\log(1/\varepsilon))$ qubits (without counting the qubits used to encode the eigenstate) and $O(1/\varepsilon)$ controlled-$U$ operations [1].
__Quantum Phase Estimation Algorithm__:
The QPE algorithm takes a unitary $U$ as input. For the sake of simplicity (we will generalize the discussion below), suppose that the algorithm also takes as input an eigenstate $|\psi \rangle$ fulfilling
$$U|\psi \rangle = \lambda |\psi \rangle,$$
with $\lambda = \exp(2\pi i\varphi)$.
QPE uses two registers of qubits: we refer to the first register as *precision* qubits (as the number of qubits $n$ in the first register sets the achievable precision of our results) and the second register as *query* qubits (as the second register hosts the eigenstate $|\psi \rangle$).
Suppose we have prepared this second register in $|\psi \rangle$. We then prepare a uniform superposition of all basis vectors in the first register using a series of Hadamard gates.
Next, we apply a series of controlled-unitaries $C-U^{2^{k}}$ for different powers of $k=0,1,\dots, n-1$ (as illustrated in the circuit diagram that follows).
For example, for $k=1$ we get
\begin{equation}
\begin{split}
(|0 \rangle + |1 \rangle) |\psi \rangle & \rightarrow |0 \rangle |\psi \rangle + |1 \rangle U|\psi \rangle \\
& = (|0 \rangle + e^{2\pi i \varphi}|1 \rangle) |\psi \rangle.
\end{split}
\end{equation}
Note that the second register remains unaffected as it stays in the eigenstate $|\psi \rangle$.
However, we managed to transfer information about the phase of the eigenvalue of $U$ (that is, $\varphi$) into the first *precision* register by encoding it as a relative phase in the state of the qubits in the first register.
Similarly, for $k=2$ we obtain
\begin{equation}
\begin{split}
(|0 \rangle + |1 \rangle) |\psi \rangle & \rightarrow |0 \rangle |\psi \rangle + |1 \rangle U^{2}|\psi \rangle \\
& = (|0 \rangle + e^{2\pi i 2\varphi}|1 \rangle) |\psi \rangle,
\end{split}
\end{equation}
where this time we wrote $2\varphi$ into the precision register. The process is similar for all $k>2$.
Introducing the following notation for binary fractions
$$[0. \varphi_{l}\varphi_{l+1}\dots \varphi_{m}] = \frac{\varphi_{l}}{2^{1}} + \frac{\varphi_{l+1}}{2^{2}} + \frac{\varphi_{m}}{2^{m-l+1}},$$
one can show that the application of a controlled unitary $C-U^{2^{k}}$ leads to the following transformation
\begin{equation}
\begin{split}
(|0 \rangle + |1 \rangle) |\psi \rangle & \rightarrow |0 \rangle |\psi \rangle + |1 \rangle U^{2^{k}}|\psi \rangle \\
& = (|0 \rangle + e^{2\pi i 2^{k}\varphi}|1 \rangle) |\psi \rangle \\
& = (|0 \rangle + e^{2\pi i [0.\varphi_{k+1}\dots \varphi_{n}]}|1 \rangle) |\psi \rangle,
\end{split}
\end{equation}
where the first $k$ bits of precision in the binary expansion (that is, those bits to the left of the decimal) can be dropped, because $e^{2\pi i \theta} = 1$ for any whole number $\theta$.
The QPE algorithm implements a series of these transformations for $k=0, 1, \dots, n-1$, using $n$ qubits in the precision register.
In its entirety, this sequence of controlled unitaries leads to the transformation
$$ |0, \dots, 0 \rangle \otimes |\psi \rangle \longrightarrow
(|0 \rangle + e^{2\pi i [0.\varphi_{n}]}|1 \rangle)
\otimes (|0 \rangle + e^{2\pi i [0.\varphi_{n-1}\varphi_{n}]}|1 \rangle)
\otimes \dots
\otimes (|0 \rangle + e^{2\pi i [0.\varphi_{1}\dots\varphi_{n}]}|1 \rangle)
\otimes |\psi \rangle.
$$
By inspection, one can see that the state of the register qubits above corresponds to a quantum Fourier transform of the state $|\varphi_1,\dots,\varphi_n\rangle$. Thus, the final step of the QPE algorithm is to run the *inverse* Quantum Fourier Transform (QFT) algorithm on the precision register to extract the phase information from this state. The resulting state is
$$|\varphi_{1}, \varphi_{2}, \dots, \varphi_{n} \rangle \otimes |\psi\rangle.$$
Measuring the precision qubits in the computational basis then gives the classical bitstring $\varphi_{1}, \varphi_{2}, \dots, \varphi_{n}$, from which we can readily infer the phase estimate $\tilde{\varphi} = 0.\varphi_{1} \dots \varphi_{n}$ with the corresponding eigenvalue $\tilde{\lambda} = \exp(2\pi i \tilde{\varphi})$.
__Simple example for illustration__: For concreteness, consider a simple example with the unitary given by the Pauli $X$ gate, $U=X$, for which $|\Psi \rangle = |+\rangle = (|0 \rangle + |1 \rangle)/\sqrt{2}$ is an eigenstate with eigenvalue $\lambda = 1$, i.e., $\varphi=0$.
This state can be prepared with a Hadamard gate as $|\Psi \rangle = H|0 \rangle$.
We take a precision register consisting of just two qubits ($n=2$).
Thus, after the first layer of Hadamard gates, the quantum state is
$$|0,0,0 \rangle \rightarrow |+,+,+\rangle.$$
Next, the applications of the controlled-$U$ gates (equal to $C-X$ operations, or CNOT gates in this example) leave this state untouched, because $|+\rangle$ is an eigenstate of $X$ with eigenvalue $+1$.
Finally, applying the inverse QFT leads to
$$\mathrm{QFT}^{\dagger}|+++\rangle=\mathrm{QFT}^\dagger\frac{|00\rangle + |01\rangle + |10\rangle + |11\rangle}{4}\otimes |+\rangle = |00\rangle \otimes |+\rangle,$$
from which we deduce $\varphi = [0.00]=0$ and therefore $\lambda=1$, as expected.
Here, in the last step we have used $|00\rangle + |01\rangle + |10\rangle + |11\rangle = (|0\rangle + e^{2\pi i[0.0]}|1\rangle)(|0\rangle + e^{2\pi i[0.00]}|1\rangle)$, which makes the effect of the inverse QFT more apparent.
__Initial state of query register__: So far, we have assumed that the query register is prepared in an eigenstate $|\Psi\rangle$ of $U$. What happens if this is not the case? Let's reconsider the simple example given previously.
Suppose now that the query register is instead prepared in the state $|\Psi\rangle = |1\rangle$.
We can always express this state in the eigenbasis of $U$, that is, $|1\rangle = \frac{1}{\sqrt{2}}(|+\rangle - |-\rangle)$.
By linearity, application of the QPE algorithm then gives (up to normalization)
\begin{equation}
\begin{split}
\mathrm{QPE}(|0,0,\dots\rangle \otimes |1\rangle) & = \mathrm{QPE}(|0,0,\dots\rangle \otimes |+\rangle)
- \mathrm{QPE}(|0,0,\dots\rangle \otimes |-\rangle) \\
& = |\varphi_{+}\rangle \otimes |+\rangle - |\varphi_{-}\rangle \otimes |-\rangle. \\
\end{split}
\end{equation}
When we measure the precision qubits in this state, 50% of the time we will observe the eigenphase $\varphi_{+}$ and 50% of the time we will measure $\varphi_{-}$. We illustrate this example numerically as follows.
This example motivates the general case: we can pass a state that is not an eigenstate of $U$ to the QPE algorithm, but we may need to repeat our measurements several times in order to obtain an estimate of the desired phase.
## CIRCUIT IMPLEMENTATION OF QPE
The QPE circuit can be implemented using Hadamard gates, controlled-$U$ unitaries, and the inverse QFT (denoted as $\mathrm{QFT}^{-1}$).
The details of the calculation can be found in a number of resources (such as, [1]); we omit them here.
Following the previous discussion, the circuit that implements the QPE algorithm reads as below, where m is the size of lower query register and n is the size of upper precision register.

## IMPORTS and SETUP
```
# general imports
import numpy as np
import math
import matplotlib.pyplot as plt
# magic word for producing visualizations in notebook
%matplotlib inline
# AWS imports: Import Amazon Braket SDK modules
from braket.circuits import Circuit, circuit
from braket.devices import LocalSimulator
from braket.aws import AwsDevice
# local imports
from utils_qpe import qpe, run_qpe
%load_ext autoreload
%autoreload 2
```
__NOTE__: Enter your desired device and S3 location (bucket and key) in the following area. If you are working with the local simulator ```LocalSimulator()``` you do not need to specify any S3 location. However, if you are using the managed (cloud-based) device or any QPU devices, you must specify the S3 location where your results will be stored. In this case, you must replace the API call ```device.run(circuit, ...)``` in the example that follows with ```device.run(circuit, s3_folder, ...)```.
```
# set up device: local simulator or the managed cloud-based simulator
# device = LocalSimulator()
device = AwsDevice("arn:aws:braket:::device/quantum-simulator/amazon/sv1")
# Enter the S3 bucket you created during onboarding into the code that follows
my_bucket = "amazon-braket-Your-Bucket-Name" # the name of the bucket
my_prefix = "Your-Folder-Name" # the name of the folder in the bucket
s3_folder = (my_bucket, my_prefix)
```
### Pauli Matrices:
In some of our examples, we choose the unitary $U$ to be given by the **Pauli Matrices**, which we thus define as follows:
```
# Define Pauli matrices
Id = np.eye(2) # Identity matrix
X = np.array([[0., 1.],
[1., 0.]]) # Pauli X
Y = np.array([[0., -1.j],
[1.j, 0.]]) # Pauli Y
Z = np.array([[1., 0.],
[0., -1.]]) # Pauli Z
```
## IMPLEMENTATION OF THE QPE CIRCUIT
In ```utils_qpe.py``` we provide simple helper functions to implement the quantum circuit for the QPE algorithm.
Specifically, we demonstrate that such modular building blocks can be registered as subroutines, using ```@circuit.subroutine(register=True)```.
Moreover, we provide a helper function (called ```get_qpe_phases```) to perform postprocessing based on the measurement results to extract the phase. The details of ```utils_qpe.py``` are shown in the Appendix.
To implement the unitary $C-U^{2^k}$, one can use the fact that $C-U^{2} = (C-U)(C-U)$, so that $C-U^{2^{k}}$ can be constructed by repeatedly applying the core building block $C-U$.
However, the circuit generated using this approach will have a significantly larger depth. In our implementation, we instead define the matrix $U^{2^k}$ and create the controlled $C-(U^{2^k})$ gate from that.
## VISUALIZATION OF THE QFT CIRCUIT
To check our implementation of the QPE circuit, we visualize this circuit for a small number of qubits.
```
# set total number of qubits
precision_qubits = [0, 1]
query_qubits = [2]
# prepare query register
my_qpe_circ = Circuit().h(query_qubits)
# set unitary
unitary = X
# show small QPE example circuit
my_qpe_circ = my_qpe_circ.qpe(precision_qubits, query_qubits, unitary)
print('QPE CIRCUIT:')
print(my_qpe_circ)
```
As shown in the folllowing code, the two registers can be distributed anywhere across the circuit, with arbitrary indices for the precision and the query registers.
```
# set qubits
precision_qubits = [1, 3]
query_qubits = [5]
# prepare query register
my_qpe_circ = Circuit().i(range(7))
my_qpe_circ.h(query_qubits)
# set unitary
unitary = X
# show small QPE example circuit
my_qpe_circ = my_qpe_circ.qpe(precision_qubits, query_qubits, unitary)
print('QPE CIRCUIT:')
print(my_qpe_circ)
```
As follows, we set up the same circuit, this time implementing the unitary $C-U^{2^k}$, by repeatedly applying the core building block $C-U$.
This operation can be done by setting the parameter ```control_unitary=False``` (default is ```True```).
```
# set qubits
precision_qubits = [1, 3]
query_qubits = [5]
# prepare query register
my_qpe_circ = Circuit().i(range(7))
my_qpe_circ.h(query_qubits)
# set unitary
unitary = X
# show small QPE example circuit
my_qpe_circ = my_qpe_circ.qpe(precision_qubits, query_qubits, unitary, control_unitary=False)
print('QPE CIRCUIT:')
print(my_qpe_circ)
```
In the circuit diagram, we can visually infer the exponents for $k=0,1$, at the expense of a larger circuit depth.
## NUMERICAL TEST EXPERIMENTS
In the following section, we verify that our QFT implementation works as expected with a few test examples:
1. We run QPE with $U=X$ and prepare the eigenstate $|\Psi\rangle = |+\rangle = H|0\rangle$ with phase $\varphi=0$ and eigenvalue $\lambda=1$.
2. We run QPE with $U=X$ and prepare the eigenstate $|\Psi\rangle = |-\rangle = HX|0\rangle$ with phase $\varphi=0.5$ and eigenvalue $\lambda=-1$.
3. We run QPE with $U=X$ and prepare $|\Psi\rangle = |1\rangle = X|0\rangle$ which is *not* an eigenstate of $U$.
Because $|1\rangle = (|+\rangle - |-\rangle)/\sqrt{2}$, we expect to measure both $\varphi=0$ and $\varphi=0.5$ associated with the two eigenstates $|\pm\rangle$.
4. We run QPE with unitary $U=X \otimes Z$, and prepare the query register in the eigenstate $|\Psi\rangle = |+\rangle \otimes |1\rangle = H|0\rangle \otimes Z|0\rangle$.
Here, we expect to measure the phase $\varphi=0.5$ (giving the corresponding eigenvalue $\lambda=-1$).
5. We run QPE with a _random_ two qubit unitary, diagonal in the computational basis, and prepare the query register in the eigenstate $|11\rangle$.
In this case, we should be able to read off the eigenvalue and phase from $U$ and verify QPE gives the right answer (with high probability) up to a small error (that depends on the number of qubits in the precision register).
## HELPER FUNCTIONS FOR NUMERICAL TESTS
Because we will run the same code repeatedly, let's first create a helper function we can use to keep the notebook clean.
```
def postprocess_qpe_results(out):
"""
Function to postprocess dictionary returned by run_qpe
Args:
out: dictionary containing results/information associated with QPE run as produced by run_qpe
"""
# unpack results
circ = out['circuit']
measurement_counts = out['measurement_counts']
bitstring_keys = out['bitstring_keys']
probs_values = out['probs_values']
precision_results_dic = out['precision_results_dic']
phases_decimal = out['phases_decimal']
eigenvalues = out['eigenvalues']
# print the circuit
print('Printing circuit:')
print(circ)
# print measurement results
print('Measurement counts:', measurement_counts)
# plot probabalities
plt.bar(bitstring_keys, probs_values);
plt.xlabel('bitstrings');
plt.ylabel('probability');
plt.xticks(rotation=90);
# print results
print('Results in precision register:', precision_results_dic)
print('QPE phase estimates:', phases_decimal)
print('QPE eigenvalue estimates:', np.round(eigenvalues, 5))
```
### NUMERICAL TEST EXAMPLE 1
First, apply the QPE algorithm to the simple single-qubit unitary $U=X$, with eigenstate $|\Psi\rangle = |+\rangle = H|0\rangle$. Here, we expect to measure the phase $\varphi=0$ (giving the corresponding eigenvalue $\lambda=1$).
We show that this result stays the same as we increase the number of qubits $n$ for the top register.
```
# Set total number of precision qubits: 2
number_precision_qubits = 2
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits]
# State preparation for eigenstate of U=X
query = Circuit().h(query_qubits)
# Run the test with U=X
out = run_qpe(X, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
postprocess_qpe_results(out)
```
Next, check that we get the same result for a larger precision (top) register.
```
# Set total number of precision qubits: 3
number_precision_qubits = 3
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits]
# State preparation for eigenstate of U=X
query = Circuit().h(query_qubits)
# Run the test with U=X
out = run_qpe(X, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
postprocess_qpe_results(out)
```
### NUMERICAL TEST EXAMPLE 2
Next, apply the QPE algorithm to the simple single-qubit unitary $U=X$, with eigenstate $|\Psi\rangle = |-\rangle = HX|0\rangle$.
Here, we expect to measure the phase $\varphi=0.5$ (giving the corresponding eigenvalue $\lambda=-1$).
```
# Set total number of precision qubits: 2
number_precision_qubits = 2
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits]
# State preparation for eigenstate of U=X
query = Circuit().x(query_qubits).h(query_qubits)
# Run the test with U=X
out = run_qpe(X, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
postprocess_qpe_results(out)
```
### NUMERICAL TEST EXAMPLE 3
Next, apply the QPE algorithm again to the simple single-qubit unitary $U=X$, but we initialize the query register in the state $|\Psi\rangle = |1\rangle$ which is *not* an eigenstate of $U$.
Here, following the previous discussion, we expect to measure the phases $\varphi=0, 0.5$ (giving the corresponding eigenvalue $\lambda=\pm 1$). Accordingly, here we set ```items_to_keep=2```.
```
# Set total number of precision qubits: 2
number_precision_qubits = 2
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits]
# State preparation for |1>, which is not an eigenstate of U=X
query = Circuit().x(query_qubits)
# Run the test with U=X
out = run_qpe(X, precision_qubits, query_qubits, query, device, s3_folder, items_to_keep=2)
# Postprocess results
postprocess_qpe_results(out)
```
### NUMERICAL TEST EXAMPLE 4
Next, apply the QPE algorithm to the two-qubit unitary $U=X \otimes Z$, and prepare the query register in the eigenstate $|\Psi\rangle = |+\rangle \otimes |1\rangle = H|0\rangle \otimes Z|0\rangle$.
Here, we expect to measure the phase $\varphi=0.5$ (giving the corresponding eigenvalue $\lambda=-1$).
```
# set unitary matrix U
u1 = np.kron(X, Id)
u2 = np.kron(Id, Z)
unitary = np.dot(u1, u2)
print('Two-qubit unitary (XZ):\n', unitary)
# get example eigensystem
eig_values, eig_vectors = np.linalg.eig(unitary)
print('Eigenvalues:', eig_values)
# print('Eigenvectors:', eig_vectors)
# Set total number of precision qubits: 2
number_precision_qubits = 2
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits, number_precision_qubits+1]
# State preparation for eigenstate |+,1> of U=X \otimes Z
query = Circuit().h(query_qubits[0]).x(query_qubits[1])
# Run the test with U=X
out = run_qpe(unitary, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
postprocess_qpe_results(out)
```
### NUMERICAL TEST EXAMPLE 5
In this example, we choose the unitary to be a _random_ two-qubit unitary, diagonal in the computational basis. We initialize the query register to be in the eigenstate $|11\rangle$ of $U$, which we can prepare using that $|11\rangle = X\otimes X|00\rangle$.
In this case we should be able to read off the eigenvalue and phase from $U$ and verify that QPE gives the right answer.
```
# Generate a random 2 qubit unitary matrix:
from scipy.stats import unitary_group
# Fix random seed for reproducibility
np.random.seed(seed=42)
# Get random two-qubit unitary
random_unitary = unitary_group.rvs(2**2)
# Let's diagonalize this
evals = np.linalg.eig(random_unitary)[0]
# Since we want to be able to read off the eigenvalues of the unitary in question
# let's choose our unitary to be diagonal in this basis
unitary = np.diag(evals)
# Check that this is indeed unitary, and print it out:
print('Two-qubit random unitary:\n', np.round(unitary, 3))
print('Check for unitarity: ', np.allclose(np.eye(len(unitary)), unitary.dot(unitary.T.conj())))
# Print eigenvalues
print('Eigenvalues:', np.round(evals, 3))
```
When we execute the QPE circuit, we expect the following (approximate) result for the eigenvalue estimate:
```
print('Target eigenvalue:', np.round(evals[-1], 3))
# Set total number of precision qubits
number_precision_qubits = 3
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits, number_precision_qubits+1]
# State preparation for eigenstate |1,1> of diagonal U
query = Circuit().x(query_qubits[0]).x(query_qubits[1])
# Run the test with U=X
out = run_qpe(unitary, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
postprocess_qpe_results(out)
# compare output to exact target values
print('Target eigenvalue:', np.round(evals[-1], 3))
```
We can easily improve the precision of our parameter estimate by increasing the number of qubits in the precision register, as shown in the following example.
```
# Set total number of precision qubits
number_precision_qubits = 10
# Define the set of precision qubits
precision_qubits = range(number_precision_qubits)
# Define the query qubits. We'll have them start after the precision qubits
query_qubits = [number_precision_qubits, number_precision_qubits+1]
# State preparation for eigenstate |1,1> of diagonal U
query = Circuit().x(query_qubits[0]).x(query_qubits[1])
# Run the test with U=X
out = run_qpe(unitary, precision_qubits, query_qubits, query, device, s3_folder)
# Postprocess results
eigenvalues = out['eigenvalues']
print('QPE eigenvalue estimates:', np.round(eigenvalues, 5))
# compare output to exact target values
print('Target eigenvalue:', np.round(evals[-1], 5))
```
---
## APPENDIX
```
# Check SDK version
# alternative: braket.__version__
!pip show amazon-braket-sdk | grep Version
```
## Details of the ```utiles_qpe.py``` module
### Imports, including inverse QFT
```python
# general imports
import numpy as np
import math
from collections import Counter
from datetime import datetime
import pickle
# AWS imports: Import Braket SDK modules
from braket.circuits import Circuit, circuit
# local imports
from utils_qft import inverse_qft
```
### QPE Subroutine
```python
@circuit.subroutine(register=True)
def controlled_unitary(control, target_qubits, unitary):
"""
Construct a circuit object corresponding to the controlled unitary
Args:
control: The qubit on which to control the gate
target_qubits: List of qubits on which the unitary U acts
unitary: matrix representation of the unitary we wish to implement in a controlled way
"""
# Define projectors onto the computational basis
p0 = np.array([[1., 0.],
[0., 0.]])
p1 = np.array([[0., 0.],
[0., 1.]])
# Instantiate circuit object
circ = Circuit()
# Construct numpy matrix
id_matrix = np.eye(len(unitary))
controlled_matrix = np.kron(p0, id_matrix) + np.kron(p1, unitary)
# Set all target qubits
targets = [control] + target_qubits
# Add controlled unitary
circ.unitary(matrix=controlled_matrix, targets=targets)
return circ
@circuit.subroutine(register=True)
def qpe(precision_qubits, query_qubits, unitary, control_unitary=True):
"""
Function to implement the QPE algorithm using two registers for precision (read-out) and query.
Register qubits need not be contiguous.
Args:
precision_qubits: list of qubits defining the precision register
query_qubits: list of qubits defining the query register
unitary: Matrix representation of the unitary whose eigenvalues we wish to estimate
control_unitary: Optional boolean flag for controlled unitaries,
with C-(U^{2^k}) by default (default is True),
or C-U controlled-unitary (2**power) times
"""
qpe_circ = Circuit()
# Get number of qubits
num_precision_qubits = len(precision_qubits)
num_query_qubits = len(query_qubits)
# Apply Hadamard across precision register
qpe_circ.h(precision_qubits)
# Apply controlled unitaries. Start with the last precision_qubit, and end with the first
for ii, qubit in enumerate(reversed(precision_qubits)):
# Set power exponent for unitary
power = ii
# Alterantive 1: Implement C-(U^{2^k})
if control_unitary:
# Define the matrix U^{2^k}
Uexp = np.linalg.matrix_power(unitary,2**power)
# Apply the controlled unitary C-(U^{2^k})
qpe_circ.controlled_unitary(qubit, query_qubits, Uexp)
# Alterantive 2: One can instead apply controlled-unitary (2**power) times to get C-U^{2^power}
else:
for _ in range(2**power):
qpe_circ.controlled_unitary(qubit, query_qubits, unitary)
# Apply inverse qft to the precision_qubits
qpe_circ.inverse_qft(precision_qubits)
return qpe_circ
```
### QPE postprocessing helper functions
```python
# helper function to remove query bits from bitstrings
def substring(key, precision_qubits):
"""
Helper function to get substring from keys for dedicated string positions as given by precision_qubits.
This function is necessary to allow for arbitary qubit mappings in the precision and query registers
(that is, so that the register qubits need not be contiguous.)
Args:
key: string from which we want to extract the substring supported only on the precision qubits
precision_qubits: List of qubits corresponding to precision_qubits.
Currently assumed to be a list of integers corresponding to the indices of the qubits
"""
short_key = ''
for idx in precision_qubits:
short_key = short_key + key[idx]
return short_key
# helper function to convert binary fractional to decimal
# reference: https://www.geeksforgeeks.org/convert-binary-fraction-decimal/
def binaryToDecimal(binary):
"""
Helper function to convert binary string (example: '01001') to decimal
Args:
binary: string which to convert to decimal fraction
"""
length = len(binary)
fracDecimal = 0
# Convert fractional part of binary to decimal equivalent
twos = 2
for ii in range(length):
fracDecimal += ((ord(binary[ii]) - ord('0')) / twos);
twos *= 2.0
# return fractional part
return fracDecimal
# helper function for postprocessing based on measurement shots
def get_qpe_phases(measurement_counts, precision_qubits, items_to_keep=1):
"""
Get QPE phase estimate from measurement_counts for given number of precision qubits
Args:
measurement_counts: measurement results from a device run
precision_qubits: List of qubits corresponding to precision_qubits.
Currently assumed to be a list of integers corresponding to the indices of the qubits
items_to_keep: number of items to return (topmost measurement counts for precision register)
"""
# Aggregate the results (that is, ignore the query register qubits):
# First get bitstrings with corresponding counts for precision qubits only
bitstrings_precision_register = [substring(key, precision_qubits) for key in measurement_counts.keys()]
# Then keep only the unique strings
bitstrings_precision_register_set = set(bitstrings_precision_register)
# Cast as a list for later use
bitstrings_precision_register_list = list(bitstrings_precision_register_set)
# Now create a new dict to collect measurement results on the precision_qubits.
# Keys are given by the measurement count substrings on the register qubits. Initialize the counts to zero.
precision_results_dic = {key: 0 for key in bitstrings_precision_register_list}
# Loop over all measurement outcomes
for key in measurement_counts.keys():
# Save the measurement count for this outcome
counts = measurement_counts[key]
# Generate the corresponding shortened key (supported only on the precision_qubits register)
count_key = substring(key, precision_qubits)
# Add these measurement counts to the corresponding key in our new dict
precision_results_dic[count_key] += counts
# Get topmost values only
c = Counter(precision_results_dic)
topmost= c.most_common(items_to_keep)
# get decimal phases from bitstrings for topmost bitstrings
phases_decimal = [binaryToDecimal(item[0]) for item in topmost]
# Get decimal phases from bitstrings for all bitstrings
# number_precision_qubits = len(precision_qubits)
# Generate binary decimal expansion
# phases_decimal = [int(key, 2)/(2**number_precision_qubits) for key in precision_results_dic]
# phases_decimal = [binaryToDecimal(key) for key in precision_results_dic]
return phases_decimal, precision_results_dic
```
### Run QPE experiments:
```python
def run_qpe(unitary, precision_qubits, query_qubits, query_circuit,
device, s3_folder, items_to_keep=1, shots=1000, save_to_pck=False):
"""
Function to run QPE algorithm end-to-end and return measurement counts.
Args:
precision_qubits: list of qubits defining the precision register
query_qubits: list of qubits defining the query register
unitary: Matrix representation of the unitary whose eigenvalues we wish to estimate
query_circuit: query circuit for state preparation of query register
items_to_keep: (optional) number of items to return (topmost measurement counts for precision register)
device: Braket device backend
shots: (optional) number of measurement shots (default is 1000)
save_to_pck: (optional) save results to pickle file if True (default is False)
"""
# get size of precision register and total number of qubits
number_precision_qubits = len(precision_qubits)
num_qubits = len(precision_qubits) + len(query_qubits)
# Define the circuit. Start by copying the query_circuit, then add the QPE:
circ = query_circuit
circ.qpe(precision_qubits, query_qubits, unitary)
# Add desired results_types
circ.probability()
# Run the circuit with all zeros input.
# The query_circuit subcircuit generates the desired input from all zeros.
# The following code executes the correct device.run call, depending on whether the backend is local or managed (cloud-based)
if device.name == 'DefaultSimulator':
task = device.run(circ, shots=shots)
else:
task = device.run(circ, s3_folder, shots=shots)
# get result for this task
result = task.result()
# get metadata
metadata = result.task_metadata
# get output probabilities (see result_types above)
probs_values = result.values[0]
# get measurement results
measurements = result.measurements
measured_qubits = result.measured_qubits
measurement_counts = result.measurement_counts
measurement_probabilities = result.measurement_probabilities
# bitstrings
format_bitstring = '{0:0' + str(num_qubits) + 'b}'
bitstring_keys = [format_bitstring.format(ii) for ii in range(2**num_qubits)]
# QPE postprocessing
phases_decimal, precision_results_dic = get_qpe_phases(measurement_counts, precision_qubits, items_to_keep)
eigenvalues = [np.exp(2*np.pi*1j*phase) for phase in phases_decimal]
# aggregate results
out = {'circuit': circ,
'task_metadata': metadata,
'measurements': measurements,
'measured_qubits': measured_qubits,
'measurement_counts': measurement_counts,
'measurement_probabilities': measurement_probabilities,
'probs_values': probs_values,
'bitstring_keys': bitstring_keys,
'precision_results_dic': precision_results_dic,
'phases_decimal': phases_decimal,
'eigenvalues': eigenvalues}
if save_to_pck:
# store results: dump output to pickle with timestamp in filename
time_now = datetime.strftime(datetime.now(), '%Y%m%d%H%M%S')
results_file = 'results-'+time_now+'.pck'
pickle.dump(out, open(results_file, "wb"))
# you can load results as follows
# out = pickle.load(open(results_file, "rb"))
return out
```
---
## REFERENCES
[1] Wikipedia: https://en.wikipedia.org/wiki/Quantum_phase_estimation_algorithm
[2] Nielsen, Michael A., Chuang, Isaac L. (2010). Quantum Computation and Quantum Information (2nd ed.). Cambridge: Cambridge University Press.
| true |
code
| 0.662687 | null | null | null | null |
|
## Computer Vision Learner
[`vision.learner`](/vision.learner.html#vision.learner) is the module that defines the [`cnn_learner`](/vision.learner.html#cnn_learner) method, to easily get a model suitable for transfer learning.
```
from fastai.gen_doc.nbdoc import *
from fastai.vision import *
```
## Transfer learning
Transfer learning is a technique where you use a model trained on a very large dataset (usually [ImageNet](http://image-net.org/) in computer vision) and then adapt it to your own dataset. The idea is that it has learned to recognize many features on all of this data, and that you will benefit from this knowledge, especially if your dataset is small, compared to starting from a randomly initialized model. It has been proved in [this article](https://arxiv.org/abs/1805.08974) on a wide range of tasks that transfer learning nearly always give better results.
In practice, you need to change the last part of your model to be adapted to your own number of classes. Most convolutional models end with a few linear layers (a part will call head). The last convolutional layer will have analyzed features in the image that went through the model, and the job of the head is to convert those in predictions for each of our classes. In transfer learning we will keep all the convolutional layers (called the body or the backbone of the model) with their weights pretrained on ImageNet but will define a new head initialized randomly.
Then we will train the model we obtain in two phases: first we freeze the body weights and only train the head (to convert those analyzed features into predictions for our own data), then we unfreeze the layers of the backbone (gradually if necessary) and fine-tune the whole model (possibly using differential learning rates).
The [`cnn_learner`](/vision.learner.html#cnn_learner) factory method helps you to automatically get a pretrained model from a given architecture with a custom head that is suitable for your data.
```
show_doc(cnn_learner)
```
This method creates a [`Learner`](/basic_train.html#Learner) object from the [`data`](/vision.data.html#vision.data) object and model inferred from it with the backbone given in `arch`. Specifically, it will cut the model defined by `arch` (randomly initialized if `pretrained` is False) at the last convolutional layer by default (or as defined in `cut`, see below) and add:
- an [`AdaptiveConcatPool2d`](/layers.html#AdaptiveConcatPool2d) layer,
- a [`Flatten`](/layers.html#Flatten) layer,
- blocks of \[[`nn.BatchNorm1d`](https://pytorch.org/docs/stable/nn.html#torch.nn.BatchNorm1d), [`nn.Dropout`](https://pytorch.org/docs/stable/nn.html#torch.nn.Dropout), [`nn.Linear`](https://pytorch.org/docs/stable/nn.html#torch.nn.Linear), [`nn.ReLU`](https://pytorch.org/docs/stable/nn.html#torch.nn.ReLU)\] layers.
The blocks are defined by the `lin_ftrs` and `ps` arguments. Specifically, the first block will have a number of inputs inferred from the backbone `arch` and the last one will have a number of outputs equal to `data.c` (which contains the number of classes of the data) and the intermediate blocks have a number of inputs/outputs determined by `lin_frts` (of course a block has a number of inputs equal to the number of outputs of the previous block). The default is to have an intermediate hidden size of 512 (which makes two blocks `model_activation` -> 512 -> `n_classes`). If you pass a float then the final dropout layer will have the value `ps`, and the remaining will be `ps/2`. If you pass a list then the values are used for dropout probabilities directly.
Note that the very last block doesn't have a [`nn.ReLU`](https://pytorch.org/docs/stable/nn.html#torch.nn.ReLU) activation, to allow you to use any final activation you want (generally included in the loss function in pytorch). Also, the backbone will be frozen if you choose `pretrained=True` (so only the head will train if you call [`fit`](/basic_train.html#fit)) so that you can immediately start phase one of training as described above.
Alternatively, you can define your own `custom_head` to put on top of the backbone. If you want to specify where to split `arch` you should so in the argument `cut` which can either be the index of a specific layer (the result will not include that layer) or a function that, when passed the model, will return the backbone you want.
The final model obtained by stacking the backbone and the head (custom or defined as we saw) is then separated in groups for gradual unfreezing or differential learning rates. You can specify how to split the backbone in groups with the optional argument `split_on` (should be a function that returns those groups when given the backbone).
The `kwargs` will be passed on to [`Learner`](/basic_train.html#Learner), so you can put here anything that [`Learner`](/basic_train.html#Learner) will accept ([`metrics`](/metrics.html#metrics), `loss_func`, `opt_func`...)
```
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learner = cnn_learner(data, models.resnet18, metrics=[accuracy])
learner.fit_one_cycle(1,1e-3)
learner.save('one_epoch')
show_doc(unet_learner)
```
This time the model will be a [`DynamicUnet`](/vision.models.unet.html#DynamicUnet) with an encoder based on `arch` (maybe `pretrained`) that is cut depending on `split_on`. `blur_final`, `norm_type`, `blur`, `self_attention`, `y_range`, `last_cross` and `bottle` are passed to unet constructor, the `kwargs` are passed to the initialization of the [`Learner`](/basic_train.html#Learner).
```
jekyll_warn("The models created with this function won't work with pytorch `nn.DataParallel`, you have to use distributed training instead!")
```
### Get predictions
Once you've actually trained your model, you may want to use it on a single image. This is done by using the following method.
```
show_doc(Learner.predict)
img = learner.data.train_ds[0][0]
learner.predict(img)
```
Here the predict class for our image is '3', which corresponds to a label of 0. The probabilities the model found for each class are 99.65% and 0.35% respectively, so its confidence is pretty high.
Note that if you want to load your trained model and use it on inference mode with the previous function, you should export your [`Learner`](/basic_train.html#Learner).
```
learner.export()
```
And then you can load it with an empty data object that has the same internal state like this:
```
learn = load_learner(path)
```
### Customize your model
You can customize [`cnn_learner`](/vision.learner.html#cnn_learner) for your own model's default `cut` and `split_on` functions by adding them to the dictionary `model_meta`. The key should be your model and the value should be a dictionary with the keys `cut` and `split_on` (see the source code for examples). The constructor will call [`create_body`](/vision.learner.html#create_body) and [`create_head`](/vision.learner.html#create_head) for you based on `cut`; you can also call them yourself, which is particularly useful for testing.
```
show_doc(create_body)
show_doc(create_head, doc_string=False)
```
Model head that takes `nf` features, runs through `lin_ftrs`, and ends with `nc` classes. `ps` is the probability of the dropouts, as documented above in [`cnn_learner`](/vision.learner.html#cnn_learner).
```
show_doc(ClassificationInterpretation, title_level=3)
```
This provides a confusion matrix and visualization of the most incorrect images. Pass in your [`data`](/vision.data.html#vision.data), calculated `preds`, actual `y`, and your `losses`, and then use the methods below to view the model interpretation results. For instance:
```
learn = cnn_learner(data, models.resnet18)
learn.fit(1)
preds,y,losses = learn.get_preds(with_loss=True)
interp = ClassificationInterpretation(learn, preds, y, losses)
```
The following factory method gives a more convenient way to create an instance of this class:
```
show_doc(ClassificationInterpretation.from_learner, full_name='from_learner')
```
You can also use a shortcut `learn.interpret()` to do the same.
```
show_doc(Learner.interpret, full_name='interpret')
```
Note that this shortcut is a [`Learner`](/basic_train.html#Learner) object/class method that can be called as: `learn.interpret()`.
```
show_doc(ClassificationInterpretation.plot_top_losses, full_name='plot_top_losses')
```
The `k` items are arranged as a square, so it will look best if `k` is a square number (4, 9, 16, etc). The title of each image shows: prediction, actual, loss, probability of actual class. When `heatmap` is True (by default it's True) , Grad-CAM heatmaps (http://openaccess.thecvf.com/content_ICCV_2017/papers/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.pdf) are overlaid on each image. `plot_top_losses` should be used with single-labeled datasets. See `plot_multi_top_losses` below for a version capable of handling multi-labeled datasets.
```
interp.plot_top_losses(9, figsize=(7,7))
show_doc(ClassificationInterpretation.top_losses)
```
Returns tuple of *(losses,indices)*.
```
interp.top_losses(9)
show_doc(ClassificationInterpretation.plot_multi_top_losses, full_name='plot_multi_top_losses')
```
Similar to `plot_top_losses()` but aimed at multi-labeled datasets. It plots misclassified samples sorted by their respective loss.
Since you can have multiple labels for a single sample, they can easily overlap in a grid plot. So it plots just one sample per row.
Note that you can pass `save_misclassified=True` (by default it's `False`). In such case, the method will return a list containing the misclassified images which you can use to debug your model and/or tune its hyperparameters.
```
show_doc(ClassificationInterpretation.plot_confusion_matrix)
```
If [`normalize`](/vision.data.html#normalize), plots the percentages with `norm_dec` digits. `slice_size` can be used to avoid out of memory error if your set is too big. `kwargs` are passed to `plt.figure`.
```
interp.plot_confusion_matrix()
show_doc(ClassificationInterpretation.confusion_matrix)
interp.confusion_matrix()
show_doc(ClassificationInterpretation.most_confused)
```
#### Working with large datasets
When working with large datasets, memory problems can arise when computing the confusion matrix. For example, an error can look like this:
RuntimeError: $ Torch: not enough memory: you tried to allocate 64GB. Buy new RAM!
In this case it is possible to force [`ClassificationInterpretation`](/train.html#ClassificationInterpretation) to compute the confusion matrix for data slices and then aggregate the result by specifying slice_size parameter.
```
interp.confusion_matrix(slice_size=10)
interp.plot_confusion_matrix(slice_size=10)
interp.most_confused(slice_size=10)
```
## Undocumented Methods - Methods moved below this line will intentionally be hidden
## New Methods - Please document or move to the undocumented section
| true |
code
| 0.845688 | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.