
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
100 % faster Linear Python solution | Prefix sum | O(N) | plates-between-candles | 0 | 1 | The basic idea is I am pre-calculating the no of plates for every position along with left nearest and right nearest candles for a given point for all i = 0 -> length\nThen to form the answer -> check if 2 candles are present inside the given boundary area [ if left nearest candle of right boundary is after left boundary and right nearest candle of left boundary is before right boundary]\nthen we have a valid solution - i.e. (no of plates till right candle point - no of plates till left candle point)\nThis can be compared to Prefix sum approach\n```\nclass Solution:\n def platesBetweenCandles(self, s: str, qs: List[List[int]]) -> List[int]:\n n=len(s)\n prefcandle=[-1]*n #this stores the position of closest candle from current towards left\n suffcandle=[0]*n #this stores the position of closest candle from current towards right\n \n pref=[0]*n #stores the number of plates till ith position from 0 - for i = 0 -> n \n \n ind=-1\n c=0\n #The following method calculates number of plates(*) till ith position from 0 - for i = 0 -> n \n for i in range(n):\n if ind!=-1 and s[i]==\'*\':\n c+=1\n elif s[i]==\'|\':\n ind=i\n pref[i]=c\n \n #this method calculates the left nearest candle to a point\n #intial is -1 as to left of leftmost element no candle can be present\n ind =-1\n for i in range(n):\n if s[i] == \'|\':\n ind=i\n prefcandle[i]=ind\n \n #this method calculates the right nearest candle to a point\n #intial is infinity as to right of rightmost element no candle can be present\n ind = float(\'inf\') \n for i in range(n-1, -1, -1):\n if s[i]==\'|\':\n ind=i\n suffcandle[i]=ind\n\n #m = no of queries\n m=len(qs)\n ans=[0]*m\n\n for i in range(m):\n c=0\n l=qs[i][0]\n r=qs[i][1]\n \n #check if left nearest candle of right boundary is after left boundary\n #check if right nearest candle of left boundary is before right boundary\n # to summarise - here we find if there is a pair of candle present within the given range or not\n if prefcandle[r]<l or suffcandle[l]>r:\n continue\n \n #desired answer is no of pplates(*) only inside 2 candles (|) inside the given boundary area\n ans[i]=pref[prefcandle[r]]-pref[suffcandle[l]]\n return ans\n \n``` | 17 | There is a long table with a line of plates and candles arranged on top of it. You are given a **0-indexed** string `s` consisting of characters `'*'` and `'|'` only, where a `'*'` represents a **plate** and a `'|'` represents a **candle**.
You are also given a **0-indexed** 2D integer array `queries` where `queries[i] = [lefti, righti]` denotes the **substring** `s[lefti...righti]` (**inclusive**). For each query, you need to find the **number** of plates **between candles** that are **in the substring**. A plate is considered **between candles** if there is at least one candle to its left **and** at least one candle to its right **in the substring**.
* For example, `s = "||**||**|* "`, and a query `[3, 8]` denotes the substring `"*||******| "`. The number of plates between candles in this substring is `2`, as each of the two plates has at least one candle **in the substring** to its left **and** right.
Return _an integer array_ `answer` _where_ `answer[i]` _is the answer to the_ `ith` _query_.
**Example 1:**
**Input:** s = "\*\*|\*\*|\*\*\*| ", queries = \[\[2,5\],\[5,9\]\]
**Output:** \[2,3\]
**Explanation:**
- queries\[0\] has two plates between candles.
- queries\[1\] has three plates between candles.
**Example 2:**
**Input:** s = "\*\*\*|\*\*|\*\*\*\*\*|\*\*||\*\*|\* ", queries = \[\[1,17\],\[4,5\],\[14,17\],\[5,11\],\[15,16\]\]
**Output:** \[9,0,0,0,0\]
**Explanation:**
- queries\[0\] has nine plates between candles.
- The other queries have zero plates between candles.
**Constraints:**
* `3 <= s.length <= 105`
* `s` consists of `'*'` and `'|'` characters.
* `1 <= queries.length <= 105`
* `queries[i].length == 2`
* `0 <= lefti <= righti < s.length` | Can we sort the segments in a way to help solve the problem? How can we dynamically keep track of the sum of the current segment(s)? |
[Python3] binary search & O(N) approach | plates-between-candles | 0 | 1 | \n```\nclass Solution:\n def platesBetweenCandles(self, s: str, queries: List[List[int]]) -> List[int]:\n prefix = [0]\n candles = []\n for i, ch in enumerate(s): \n if ch == \'|\': candles.append(i)\n if ch == \'|\': prefix.append(prefix[-1])\n else: prefix.append(prefix[-1] + 1)\n \n ans = []\n for x, y in queries: \n lo = bisect_left(candles, x)\n hi = bisect_right(candles, y) - 1\n if 0 <= hi and lo < len(candles) and lo <= hi: \n ans.append(prefix[candles[hi]+1] - prefix[candles[lo]])\n else: ans.append(0)\n return ans \n```\n\nAdding an `O(N)` approach \n```\nclass Solution:\n def platesBetweenCandles(self, s: str, queries: List[List[int]]) -> List[int]:\n prefix = [0]\n stack = []\n upper = [-1]*len(s)\n lower = [-1]*len(s)\n lo = -1\n for i, ch in enumerate(s): \n prefix.append(prefix[-1] + (ch == \'*\'))\n stack.append(i)\n if ch == \'|\': \n while stack: upper[stack.pop()] = i \n lo = i \n lower[i] = lo \n \n ans = []\n for x, y in queries: \n lo = upper[x]\n hi = lower[y]\n if hi != -1 and lo != -1 and lo <= hi: ans.append(prefix[hi+1] - prefix[lo])\n else: ans.append(0)\n return ans \n``` | 11 | There is a long table with a line of plates and candles arranged on top of it. You are given a **0-indexed** string `s` consisting of characters `'*'` and `'|'` only, where a `'*'` represents a **plate** and a `'|'` represents a **candle**.
You are also given a **0-indexed** 2D integer array `queries` where `queries[i] = [lefti, righti]` denotes the **substring** `s[lefti...righti]` (**inclusive**). For each query, you need to find the **number** of plates **between candles** that are **in the substring**. A plate is considered **between candles** if there is at least one candle to its left **and** at least one candle to its right **in the substring**.
* For example, `s = "||**||**|* "`, and a query `[3, 8]` denotes the substring `"*||******| "`. The number of plates between candles in this substring is `2`, as each of the two plates has at least one candle **in the substring** to its left **and** right.
Return _an integer array_ `answer` _where_ `answer[i]` _is the answer to the_ `ith` _query_.
**Example 1:**
**Input:** s = "\*\*|\*\*|\*\*\*| ", queries = \[\[2,5\],\[5,9\]\]
**Output:** \[2,3\]
**Explanation:**
- queries\[0\] has two plates between candles.
- queries\[1\] has three plates between candles.
**Example 2:**
**Input:** s = "\*\*\*|\*\*|\*\*\*\*\*|\*\*||\*\*|\* ", queries = \[\[1,17\],\[4,5\],\[14,17\],\[5,11\],\[15,16\]\]
**Output:** \[9,0,0,0,0\]
**Explanation:**
- queries\[0\] has nine plates between candles.
- The other queries have zero plates between candles.
**Constraints:**
* `3 <= s.length <= 105`
* `s` consists of `'*'` and `'|'` characters.
* `1 <= queries.length <= 105`
* `queries[i].length == 2`
* `0 <= lefti <= righti < s.length` | Can we sort the segments in a way to help solve the problem? How can we dynamically keep track of the sum of the current segment(s)? |
Custom Binary Search | plates-between-candles | 0 | 1 | # Idea of the approach \n # Store all the plates position in an array\n # Ex, s = "***|**|*****|**||**|*"\n # index = [3,5,12,15,16,19]\n # For example for query [1,17] ,I have to find the count of stars\n # Idea is to search if there is a plate in 1st postion if not whether\n # there is plate present in immediate next greater postion here \n # there is 3rd position which is immediate next greater where plate is \n # present\n \n #Similary for 17position check whether there is plate present in 17th\n # postiion if not find immediate previous smaller position here that is 16th\n # position where there is plate\n \n #We can do this postiion searching using binary search in (logn time)\n # In Binary search l = 0 and h = len(index) - 1 for all cases\n \n #count will be done by suppose,\n # Ex, s = "***|**|*****|**||**|*"\n # index = [3,5,12,15,16,19]\n # query = [1,17]\n # lower_bound for 1 will be 3 (Binary search will return postion so index[postion] = 3)\n # upper_bound for 17 will be 16(Binary search will return postion so index[postion] = 16)\n # count = index[u_b] - index[l_b] - (u_b - l_b - 1) - 1\n # count = 16 - 3 - (4 - 0 - 1 ) - 1\n # count = 9\n\n\tclass Solution: \n\t\n\tdef platesBetweenCandles(self, s: str, queries: List[List[int]]) -> List[int]: \n \n\t\t\tindex = []\n for i in range(len(s)):\n if s[i] == \'|\':\n index.append(i)\n res = []\n \n for q in queries:\n\n if q[1] - q[0] > 1:\n l_b = self.binary_search(index,q[0],0)#Find lower bound (it will return same position if present else first greater)\n u_b = self.binary_search(index,q[1],1)#Find upper bound(it will return same position if present else first smaller)\n \n if l_b >= u_b:\n res.append(0)\n continue\n \n \n count = index[u_b] - index[l_b] - (u_b - l_b - 1) - 1\n res.append(count)\n else:\n res.append(0)\n \n return res\n def binary_search(self,index,val,b):\n l = 0\n h = len(index) - 1\n \n while l<=h:\n mid = (l+h)//2\n \n if index[mid] == val:\n return mid # If positon matches with given position\n elif index[mid] > val:\n h = mid - 1\n else:\n l = mid + 1 \n \n if b == 0:\n return l\n else:\n return h\n \n | 8 | There is a long table with a line of plates and candles arranged on top of it. You are given a **0-indexed** string `s` consisting of characters `'*'` and `'|'` only, where a `'*'` represents a **plate** and a `'|'` represents a **candle**.
You are also given a **0-indexed** 2D integer array `queries` where `queries[i] = [lefti, righti]` denotes the **substring** `s[lefti...righti]` (**inclusive**). For each query, you need to find the **number** of plates **between candles** that are **in the substring**. A plate is considered **between candles** if there is at least one candle to its left **and** at least one candle to its right **in the substring**.
* For example, `s = "||**||**|* "`, and a query `[3, 8]` denotes the substring `"*||******| "`. The number of plates between candles in this substring is `2`, as each of the two plates has at least one candle **in the substring** to its left **and** right.
Return _an integer array_ `answer` _where_ `answer[i]` _is the answer to the_ `ith` _query_.
**Example 1:**
**Input:** s = "\*\*|\*\*|\*\*\*| ", queries = \[\[2,5\],\[5,9\]\]
**Output:** \[2,3\]
**Explanation:**
- queries\[0\] has two plates between candles.
- queries\[1\] has three plates between candles.
**Example 2:**
**Input:** s = "\*\*\*|\*\*|\*\*\*\*\*|\*\*||\*\*|\* ", queries = \[\[1,17\],\[4,5\],\[14,17\],\[5,11\],\[15,16\]\]
**Output:** \[9,0,0,0,0\]
**Explanation:**
- queries\[0\] has nine plates between candles.
- The other queries have zero plates between candles.
**Constraints:**
* `3 <= s.length <= 105`
* `s` consists of `'*'` and `'|'` characters.
* `1 <= queries.length <= 105`
* `queries[i].length == 2`
* `0 <= lefti <= righti < s.length` | Can we sort the segments in a way to help solve the problem? How can we dynamically keep track of the sum of the current segment(s)? |
Python3 | DFS with backtracking | Clean code with comments | number-of-valid-move-combinations-on-chessboard | 0 | 1 | ```\nclass Solution:\n BOARD_SIZE = 8\n \n def diag(self, r, c):\n # Return all diagonal indices except (r, c)\n # Diagonal indices has the same r - c\n inv = r - c\n result = []\n for ri in range(self.BOARD_SIZE):\n ci = ri - inv\n if 0 <= ci < self.BOARD_SIZE and ri != r:\n result.append((ri, ci))\n\n return result\n \n def reverseDiag(self, r, c):\n # Return all reverse diagonal indices except (r, c)\n # Reverse diagonal indices has the same r + c\n inv = r + c\n result = []\n for ri in range(self.BOARD_SIZE):\n ci = inv - ri\n if 0 <= ci < self.BOARD_SIZE and ri != r:\n result.append((ri, ci))\n\n return result\n \n def generatePossiblePositions(self, piece, start):\n # Generate list of possible positions for every figure\n rs, cs = start[0] - 1, start[1] - 1\n\n # Start position\n result = [(rs, cs)]\n\n # Straight\n if piece == "rook" or piece == "queen":\n result.extend([(r, cs) for r in range(self.BOARD_SIZE) if r != rs])\n result.extend([(rs, c) for c in range(self.BOARD_SIZE) if c != cs])\n\n # Diagonal\n if piece == "bishop" or piece == "queen":\n result.extend(self.diag(rs, cs))\n result.extend(self.reverseDiag(rs, cs))\n\n return result\n \n def collide(self, start1, end1, start2, end2):\n # Check if two figures will collide\n # Collision occures if: \n # - two figures have the same end points\n # - one figure stands on the way of second one\n #\n # For this purpose let\'s model each step of two pieces \n # and compare their positions at every time step.\n \n def steps(start, end):\n # Total steps that should be done\n return abs(end - start)\n\n def step(start, end):\n # Step direction -1, 0, 1\n if steps(start, end) == 0:\n return 0\n return (end - start) / steps(start, end)\n\n (rstart1, cstart1), (rend1, cend1) = start1, end1\n (rstart2, cstart2), (rend2, cend2) = start2, end2\n\n # Find step direction for each piece\n rstep1, cstep1 = step(rstart1, rend1), step(cstart1, cend1)\n rstep2, cstep2 = step(rstart2, rend2), step(cstart2, cend2)\n\n # Find maximum number of steps for each piece\n max_step1 = max(steps(rstart1, rend1), steps(cstart1, cend1))\n max_step2 = max(steps(rstart2, rend2), steps(cstart2, cend2))\n\n # Move pieces step by step and compare their positions\n for step_i in range(max(max_step1, max_step2) + 1):\n step_i1 = min(step_i, max_step1)\n r1 = rstart1 + step_i1 * rstep1\n c1 = cstart1 + step_i1 * cstep1\n\n step_i2 = min(step_i, max_step2)\n r2 = rstart2 + step_i2 * rstep2\n c2 = cstart2 + step_i2 * cstep2\n\n # If positions are the same then collision occures\n if r1 == r2 and c1 == c2:\n return True\n\n return False\n \n def countCombinations(self, pieces: List[str], positions: List[List[int]]) -> int:\n if len(pieces) == 0:\n return 0\n\n n = len(pieces)\n \n # Make zero-indexed\n start_positions = [[r - 1, c - 1] for r, c in positions]\n \n # All possible positions\n possible_positions = [\n self.generatePossiblePositions(piece, start) \n for piece, start in zip(pieces, positions)\n ]\n \n # Let\'s use DFS with backtracking\n # For that we will keep set of already occupied coordinates\n # and current positions of pieces\n occupied = set()\n current_positions = [None] * n # None means that we didn\'t placed the piece\n \n def collision(start, end):\n # Helper to check if moving from start to end position will collide with someone\n for start2, end2 in zip(start_positions, current_positions):\n if end2 is not None and self.collide(start, end, start2, end2):\n return True\n return False\n\n def dfs(piece_i=0):\n # All pieces are placed\n if piece_i == n:\n return 1\n\n result = 0\n for position in possible_positions[piece_i]:\n # If position already occupied of collides with other pieces then skip it\n if position in occupied or collision(start_positions[piece_i], position):\n continue\n \n # Occupy the position\n occupied.add(position)\n current_positions[piece_i] = position\n \n # Run DFS for next piece\n result += dfs(piece_i + 1)\n \n # Release the position\n occupied.remove(position)\n current_positions[piece_i] = None\n \n return result\n\n return dfs()\n``` | 2 | There is an `8 x 8` chessboard containing `n` pieces (rooks, queens, or bishops). You are given a string array `pieces` of length `n`, where `pieces[i]` describes the type (rook, queen, or bishop) of the `ith` piece. In addition, you are given a 2D integer array `positions` also of length `n`, where `positions[i] = [ri, ci]` indicates that the `ith` piece is currently at the **1-based** coordinate `(ri, ci)` on the chessboard.
When making a **move** for a piece, you choose a **destination** square that the piece will travel toward and stop on.
* A rook can only travel **horizontally or vertically** from `(r, c)` to the direction of `(r+1, c)`, `(r-1, c)`, `(r, c+1)`, or `(r, c-1)`.
* A queen can only travel **horizontally, vertically, or diagonally** from `(r, c)` to the direction of `(r+1, c)`, `(r-1, c)`, `(r, c+1)`, `(r, c-1)`, `(r+1, c+1)`, `(r+1, c-1)`, `(r-1, c+1)`, `(r-1, c-1)`.
* A bishop can only travel **diagonally** from `(r, c)` to the direction of `(r+1, c+1)`, `(r+1, c-1)`, `(r-1, c+1)`, `(r-1, c-1)`.
You must make a **move** for every piece on the board simultaneously. A **move combination** consists of all the **moves** performed on all the given pieces. Every second, each piece will instantaneously travel **one square** towards their destination if they are not already at it. All pieces start traveling at the `0th` second. A move combination is **invalid** if, at a given time, **two or more** pieces occupy the same square.
Return _the number of **valid** move combinations_.
**Notes:**
* **No two pieces** will start in the **same** square.
* You may choose the square a piece is already on as its **destination**.
* If two pieces are **directly adjacent** to each other, it is valid for them to **move past each other** and swap positions in one second.
**Example 1:**
**Input:** pieces = \[ "rook "\], positions = \[\[1,1\]\]
**Output:** 15
**Explanation:** The image above shows the possible squares the piece can move to.
**Example 2:**
**Input:** pieces = \[ "queen "\], positions = \[\[1,1\]\]
**Output:** 22
**Explanation:** The image above shows the possible squares the piece can move to.
**Example 3:**
**Input:** pieces = \[ "bishop "\], positions = \[\[4,3\]\]
**Output:** 12
**Explanation:** The image above shows the possible squares the piece can move to.
**Constraints:**
* `n == pieces.length`
* `n == positions.length`
* `1 <= n <= 4`
* `pieces` only contains the strings `"rook "`, `"queen "`, and `"bishop "`.
* There will be at most one queen on the chessboard.
* `1 <= xi, yi <= 8`
* Each `positions[i]` is distinct. | null |
[Python3] traversal | number-of-valid-move-combinations-on-chessboard | 0 | 1 | \n```\nclass Solution:\n def countCombinations(self, pieces: List[str], positions: List[List[int]]) -> int:\n n = len(pieces)\n mp = {"bishop": ((-1, -1), (-1, 1), (1, -1), (1, 1)),\n "queen" : ((-1, -1), (-1, 0), (-1, 1), (0, -1), (0, 1), (1, -1), (1, 0), (1, 1)), \n "rook" : ((-1, 0), (0, -1), (0, 1), (1, 0))}\n \n dirs = [[]] # directions\n for piece in pieces: dirs = [x+[xx] for x in dirs for xx in mp[piece]]\n \n positions = tuple(map(tuple, positions))\n \n def fn(*args): \n """Return possible moves along given direction."""\n stack = [((1<<n)-1, positions)]\n while stack: \n mask, pos = stack.pop()\n ans.add(pos)\n m = mask\n while m: \n p = []\n for i in range(n): \n if m & (1 << i): \n p.append((pos[i][0] + args[i][0], pos[i][1] + args[i][1]))\n if not (1 <= p[i][0] <= 8 and 1 <= p[i][1] <= 8): break \n else: p.append(pos[i])\n else: \n cand = tuple(p)\n if len(set(cand)) == len(cand) and m: stack.append((m, cand))\n m = mask & (m-1)\n\n ans = set()\n for d in dirs: fn(*d)\n return len(ans)\n``` | 0 | There is an `8 x 8` chessboard containing `n` pieces (rooks, queens, or bishops). You are given a string array `pieces` of length `n`, where `pieces[i]` describes the type (rook, queen, or bishop) of the `ith` piece. In addition, you are given a 2D integer array `positions` also of length `n`, where `positions[i] = [ri, ci]` indicates that the `ith` piece is currently at the **1-based** coordinate `(ri, ci)` on the chessboard.
When making a **move** for a piece, you choose a **destination** square that the piece will travel toward and stop on.
* A rook can only travel **horizontally or vertically** from `(r, c)` to the direction of `(r+1, c)`, `(r-1, c)`, `(r, c+1)`, or `(r, c-1)`.
* A queen can only travel **horizontally, vertically, or diagonally** from `(r, c)` to the direction of `(r+1, c)`, `(r-1, c)`, `(r, c+1)`, `(r, c-1)`, `(r+1, c+1)`, `(r+1, c-1)`, `(r-1, c+1)`, `(r-1, c-1)`.
* A bishop can only travel **diagonally** from `(r, c)` to the direction of `(r+1, c+1)`, `(r+1, c-1)`, `(r-1, c+1)`, `(r-1, c-1)`.
You must make a **move** for every piece on the board simultaneously. A **move combination** consists of all the **moves** performed on all the given pieces. Every second, each piece will instantaneously travel **one square** towards their destination if they are not already at it. All pieces start traveling at the `0th` second. A move combination is **invalid** if, at a given time, **two or more** pieces occupy the same square.
Return _the number of **valid** move combinations_.
**Notes:**
* **No two pieces** will start in the **same** square.
* You may choose the square a piece is already on as its **destination**.
* If two pieces are **directly adjacent** to each other, it is valid for them to **move past each other** and swap positions in one second.
**Example 1:**
**Input:** pieces = \[ "rook "\], positions = \[\[1,1\]\]
**Output:** 15
**Explanation:** The image above shows the possible squares the piece can move to.
**Example 2:**
**Input:** pieces = \[ "queen "\], positions = \[\[1,1\]\]
**Output:** 22
**Explanation:** The image above shows the possible squares the piece can move to.
**Example 3:**
**Input:** pieces = \[ "bishop "\], positions = \[\[4,3\]\]
**Output:** 12
**Explanation:** The image above shows the possible squares the piece can move to.
**Constraints:**
* `n == pieces.length`
* `n == positions.length`
* `1 <= n <= 4`
* `pieces` only contains the strings `"rook "`, `"queen "`, and `"bishop "`.
* There will be at most one queen on the chessboard.
* `1 <= xi, yi <= 8`
* Each `positions[i]` is distinct. | null |
Py solution simple | smallest-index-with-equal-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n lst=[]\n for i in range(len(nums)):\n if i%10==nums[i]:\n lst.append(i)\n if len(lst)>=1:\n return min(lst)\n else:\n return -1\n``` | 1 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Super Logic Using Python3 | smallest-index-with-equal-value | 0 | 1 | \n\n# Simple explained Solution In Python3\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n list1=[]\n for i in range(len(nums)):\n if((i%10) == nums[i]):\n list1.append(i)\n if len(nums)==len(list1):\n return 0\n if list1:\n return list1[0]\n return -1\n``` | 1 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Python3|| Beats 98.62% || Beginner simple solution | smallest-index-with-equal-value | 0 | 1 | 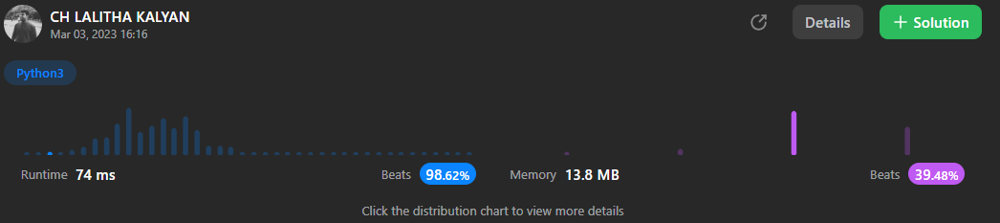\n\n\n# Code\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n for i in range(len(nums)):\n if i%10 == nums[i]:\n return i\n break\n return -1\n```\n\n | 4 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Easy Solution | Java | Python | smallest-index-with-equal-value | 1 | 1 | # Java\n```\nclass Solution {\n public int smallestEqual(int[] nums) {\n for(int i=0; i<nums.length; i++) {\n if(i % 10 == nums[i]) {\n return i;\n }\n }\n return -1;\n }\n}\n```\n# Python\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n for i in range(len(nums)):\n if (i % 10) == nums[i]:\n return i\n return -1\n```\nDo upvote if you like the Solution :) | 1 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Python O(N) | smallest-index-with-equal-value | 0 | 1 | # Intuition JUET\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach easy understanding \n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: best: O(1)\n- wrost :O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n n=len(nums)\n for i in range(n):\n if i%10==nums[i]:\n return i\n return -1\n``` | 1 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
python easy solution! | smallest-index-with-equal-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe intuition for this problem is to iterate through the indices and values of the given list nums and check for the condition where the index modulo 10 is equal to the value at that index.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe approach is straightforward. We use a loop to iterate through each index and value in the nums list. For each iteration, we check if the index modulo 10 is equal to the value at that index (i % 10 == nums[i]). If this condition is true, we return the current index. If no such index is found, we return -1\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nTime complexity: O(n), where n is the length of the input list nums. The loop iterates through each element once\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nSpace complexity: O(1), as we are using a constant amount of space, and the space doesn\'t depend on the input size.\n# Code\n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n for i , num in enumerate(nums):\n if i % 10 == num:\n return i\n return -1\n \n\n``` | 1 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Python simple and short solution | smallest-index-with-equal-value | 0 | 1 | **Python :**\n\n```\ndef smallestEqual(self, nums: List[int]) -> int:\n\tfor idx, n in enumerate(nums):\n\t\tif idx % 10 == n:\n\t\t\treturn idx\n\treturn -1 \n```\n\n**Like it ? please upvote !** | 11 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
[Python3] 1-line | smallest-index-with-equal-value | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/4001168494179e85482f91afbf0cd66b908544f3) for my solutions of weekly 265. \n```\nclass Solution:\n def smallestEqual(self, nums: List[int]) -> int:\n return next((i for i, x in enumerate(nums) if i%10 == x), -1)\n``` | 14 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
Python 1 line - 99% speed 95% memory usage | smallest-index-with-equal-value | 0 | 1 | \n\nMake use of recursion to loop over ```nums``` array. Return ```-1``` if ```i``` exceeds the last index of ```nums```\n```\nclass Solution(object):\n def smallestEqual(self, nums, i=0):\n return -1 if i == len(nums) else ( i if i%10 == nums[i] else self.smallestEqual(nums, i+1) ) | 5 | Given a **0-indexed** integer array `nums`, return _the **smallest** index_ `i` _of_ `nums` _such that_ `i mod 10 == nums[i]`_, or_ `-1` _if such index does not exist_.
`x mod y` denotes the **remainder** when `x` is divided by `y`.
**Example 1:**
**Input:** nums = \[0,1,2\]
**Output:** 0
**Explanation:**
i=0: 0 mod 10 = 0 == nums\[0\].
i=1: 1 mod 10 = 1 == nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
All indices have i mod 10 == nums\[i\], so we return the smallest index 0.
**Example 2:**
**Input:** nums = \[4,3,2,1\]
**Output:** 2
**Explanation:**
i=0: 0 mod 10 = 0 != nums\[0\].
i=1: 1 mod 10 = 1 != nums\[1\].
i=2: 2 mod 10 = 2 == nums\[2\].
i=3: 3 mod 10 = 3 != nums\[3\].
2 is the only index which has i mod 10 == nums\[i\].
**Example 3:**
**Input:** nums = \[1,2,3,4,5,6,7,8,9,0\]
**Output:** -1
**Explanation:** No index satisfies i mod 10 == nums\[i\].
**Constraints:**
* `1 <= nums.length <= 100`
* `0 <= nums[i] <= 9` | null |
[Python 3] Save critical points, then return min and max diff | find-the-minimum-and-maximum-number-of-nodes-between-critical-points | 0 | 1 | ```python3 []\nclass Solution:\n def nodesBetweenCriticalPoints(self, head: Optional[ListNode]) -> List[int]:\n idx, i = [], 1\n prev, cur = head, head.next\n while cur and cur.next:\n if prev.val < cur.val > cur.next.val or prev.val > cur.val < cur.next.val:\n idx.append(i)\n prev = cur\n cur = cur.next\n i += 1\n\n if len(idx) < 2:\n return [-1, -1]\n \n minDist = min(j - i for i, j in pairwise(idx))\n maxDist = idx[-1] - idx[0]\n\n return [minDist, maxDist]\n\n``` | 1 | A **critical point** in a linked list is defined as **either** a **local maxima** or a **local minima**.
A node is a **local maxima** if the current node has a value **strictly greater** than the previous node and the next node.
A node is a **local minima** if the current node has a value **strictly smaller** than the previous node and the next node.
Note that a node can only be a local maxima/minima if there exists **both** a previous node and a next node.
Given a linked list `head`, return _an array of length 2 containing_ `[minDistance, maxDistance]` _where_ `minDistance` _is the **minimum distance** between **any two distinct** critical points and_ `maxDistance` _is the **maximum distance** between **any two distinct** critical points. If there are **fewer** than two critical points, return_ `[-1, -1]`.
**Example 1:**
**Input:** head = \[3,1\]
**Output:** \[-1,-1\]
**Explanation:** There are no critical points in \[3,1\].
**Example 2:**
**Input:** head = \[5,3,1,2,5,1,2\]
**Output:** \[1,3\]
**Explanation:** There are three critical points:
- \[5,3,**1**,2,5,1,2\]: The third node is a local minima because 1 is less than 3 and 2.
- \[5,3,1,2,**5**,1,2\]: The fifth node is a local maxima because 5 is greater than 2 and 1.
- \[5,3,1,2,5,**1**,2\]: The sixth node is a local minima because 1 is less than 5 and 2.
The minimum distance is between the fifth and the sixth node. minDistance = 6 - 5 = 1.
The maximum distance is between the third and the sixth node. maxDistance = 6 - 3 = 3.
**Example 3:**
**Input:** head = \[1,3,2,2,3,2,2,2,7\]
**Output:** \[3,3\]
**Explanation:** There are two critical points:
- \[1,**3**,2,2,3,2,2,2,7\]: The second node is a local maxima because 3 is greater than 1 and 2.
- \[1,3,2,2,**3**,2,2,2,7\]: The fifth node is a local maxima because 3 is greater than 2 and 2.
Both the minimum and maximum distances are between the second and the fifth node.
Thus, minDistance and maxDistance is 5 - 2 = 3.
Note that the last node is not considered a local maxima because it does not have a next node.
**Constraints:**
* The number of nodes in the list is in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Build an array of size 2 * n and assign num[i] to ans[i] and ans[i + n] |
Python || Easy Solution | find-the-minimum-and-maximum-number-of-nodes-between-critical-points | 0 | 1 | class Solution:\n\t\n\tdef nodesBetweenCriticalPoints(self, head: Optional[ListNode]) -> List[int]:\n \n prev = None\n temp = head\n \n mini, maxi = 10 ** 5, 0\n count = 1\n \n diff = 10 ** 5\n while temp.next.next != None:\n prev = temp\n temp = temp.next\n count += 1\n \n if prev.val > temp.val < temp.next.val or prev.val < temp.val > temp.next.val:\n \n if maxi != 0:\n mini = min(mini, count - maxi)\n diff = min(diff, count)\n maxi = count\n \n if diff == 10 ** 5 or mini == 10 ** 5:\n return [-1, -1]\n return [mini, maxi - diff]\n\t\t\n# if you like the solution, Please upvote!! | 5 | A **critical point** in a linked list is defined as **either** a **local maxima** or a **local minima**.
A node is a **local maxima** if the current node has a value **strictly greater** than the previous node and the next node.
A node is a **local minima** if the current node has a value **strictly smaller** than the previous node and the next node.
Note that a node can only be a local maxima/minima if there exists **both** a previous node and a next node.
Given a linked list `head`, return _an array of length 2 containing_ `[minDistance, maxDistance]` _where_ `minDistance` _is the **minimum distance** between **any two distinct** critical points and_ `maxDistance` _is the **maximum distance** between **any two distinct** critical points. If there are **fewer** than two critical points, return_ `[-1, -1]`.
**Example 1:**
**Input:** head = \[3,1\]
**Output:** \[-1,-1\]
**Explanation:** There are no critical points in \[3,1\].
**Example 2:**
**Input:** head = \[5,3,1,2,5,1,2\]
**Output:** \[1,3\]
**Explanation:** There are three critical points:
- \[5,3,**1**,2,5,1,2\]: The third node is a local minima because 1 is less than 3 and 2.
- \[5,3,1,2,**5**,1,2\]: The fifth node is a local maxima because 5 is greater than 2 and 1.
- \[5,3,1,2,5,**1**,2\]: The sixth node is a local minima because 1 is less than 5 and 2.
The minimum distance is between the fifth and the sixth node. minDistance = 6 - 5 = 1.
The maximum distance is between the third and the sixth node. maxDistance = 6 - 3 = 3.
**Example 3:**
**Input:** head = \[1,3,2,2,3,2,2,2,7\]
**Output:** \[3,3\]
**Explanation:** There are two critical points:
- \[1,**3**,2,2,3,2,2,2,7\]: The second node is a local maxima because 3 is greater than 1 and 2.
- \[1,3,2,2,**3**,2,2,2,7\]: The fifth node is a local maxima because 3 is greater than 2 and 2.
Both the minimum and maximum distances are between the second and the fifth node.
Thus, minDistance and maxDistance is 5 - 2 = 3.
Note that the last node is not considered a local maxima because it does not have a next node.
**Constraints:**
* The number of nodes in the list is in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Build an array of size 2 * n and assign num[i] to ans[i] and ans[i + n] |
90% TC and 87% SC easy python solution | find-the-minimum-and-maximum-number-of-nodes-between-critical-points | 0 | 1 | ```\ndef nodesBetweenCriticalPoints(self, head: Optional[ListNode]) -> List[int]:\n\tans = [float(\'inf\'), -float(\'inf\')]\n\tcurr = head.next\n\tprev = head\n\ti = 1\n\tpos = []\n\twhile(curr.next):\n\t\tif(prev.val < curr.val > curr.next.val):\n\t\t\tpos.append(i)\n\t\telif(prev.val > curr.val < curr.next.val):\n\t\t\tpos.append(i)\n\t\ti += 1\n\t\tprev, curr = curr, curr.next\n\tif(len(pos) < 2):\n\t\treturn -1, -1\n\tfor i in range(1, len(pos)):\n\t\tans[0] = min(ans[0], pos[i]-pos[i-1])\n\tans[1] = pos[-1]-pos[0]\n\treturn ans\n``` | 3 | A **critical point** in a linked list is defined as **either** a **local maxima** or a **local minima**.
A node is a **local maxima** if the current node has a value **strictly greater** than the previous node and the next node.
A node is a **local minima** if the current node has a value **strictly smaller** than the previous node and the next node.
Note that a node can only be a local maxima/minima if there exists **both** a previous node and a next node.
Given a linked list `head`, return _an array of length 2 containing_ `[minDistance, maxDistance]` _where_ `minDistance` _is the **minimum distance** between **any two distinct** critical points and_ `maxDistance` _is the **maximum distance** between **any two distinct** critical points. If there are **fewer** than two critical points, return_ `[-1, -1]`.
**Example 1:**
**Input:** head = \[3,1\]
**Output:** \[-1,-1\]
**Explanation:** There are no critical points in \[3,1\].
**Example 2:**
**Input:** head = \[5,3,1,2,5,1,2\]
**Output:** \[1,3\]
**Explanation:** There are three critical points:
- \[5,3,**1**,2,5,1,2\]: The third node is a local minima because 1 is less than 3 and 2.
- \[5,3,1,2,**5**,1,2\]: The fifth node is a local maxima because 5 is greater than 2 and 1.
- \[5,3,1,2,5,**1**,2\]: The sixth node is a local minima because 1 is less than 5 and 2.
The minimum distance is between the fifth and the sixth node. minDistance = 6 - 5 = 1.
The maximum distance is between the third and the sixth node. maxDistance = 6 - 3 = 3.
**Example 3:**
**Input:** head = \[1,3,2,2,3,2,2,2,7\]
**Output:** \[3,3\]
**Explanation:** There are two critical points:
- \[1,**3**,2,2,3,2,2,2,7\]: The second node is a local maxima because 3 is greater than 1 and 2.
- \[1,3,2,2,**3**,2,2,2,7\]: The fifth node is a local maxima because 3 is greater than 2 and 2.
Both the minimum and maximum distances are between the second and the fifth node.
Thus, minDistance and maxDistance is 5 - 2 = 3.
Note that the last node is not considered a local maxima because it does not have a next node.
**Constraints:**
* The number of nodes in the list is in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Build an array of size 2 * n and assign num[i] to ans[i] and ans[i + n] |
BEET 100% | find-the-minimum-and-maximum-number-of-nodes-between-critical-points | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def nodesBetweenCriticalPoints(self, head: Optional[ListNode]) -> List[int]:\n temp,lst=head.next,[]\n prev=head\n i=1\n count=0\n while temp.next:\n if (prev.val<temp.val and temp.val>temp.next.val) or (prev.val>temp.val and temp.val<temp.next.val):\n lst.append(i)\n count+=1\n i+=1\n temp=temp.next\n prev=prev.next\n if count<2:\n return [-1,-1]\n else:\n res=[]\n min1=lst[-1]\n for i in range(len(lst)-1):\n min1=min(min1,(lst[i+1]-lst[i]))\n res.append(min1) \n res.append(lst[-1]-lst[0])\n return res \n \n``` | 0 | A **critical point** in a linked list is defined as **either** a **local maxima** or a **local minima**.
A node is a **local maxima** if the current node has a value **strictly greater** than the previous node and the next node.
A node is a **local minima** if the current node has a value **strictly smaller** than the previous node and the next node.
Note that a node can only be a local maxima/minima if there exists **both** a previous node and a next node.
Given a linked list `head`, return _an array of length 2 containing_ `[minDistance, maxDistance]` _where_ `minDistance` _is the **minimum distance** between **any two distinct** critical points and_ `maxDistance` _is the **maximum distance** between **any two distinct** critical points. If there are **fewer** than two critical points, return_ `[-1, -1]`.
**Example 1:**
**Input:** head = \[3,1\]
**Output:** \[-1,-1\]
**Explanation:** There are no critical points in \[3,1\].
**Example 2:**
**Input:** head = \[5,3,1,2,5,1,2\]
**Output:** \[1,3\]
**Explanation:** There are three critical points:
- \[5,3,**1**,2,5,1,2\]: The third node is a local minima because 1 is less than 3 and 2.
- \[5,3,1,2,**5**,1,2\]: The fifth node is a local maxima because 5 is greater than 2 and 1.
- \[5,3,1,2,5,**1**,2\]: The sixth node is a local minima because 1 is less than 5 and 2.
The minimum distance is between the fifth and the sixth node. minDistance = 6 - 5 = 1.
The maximum distance is between the third and the sixth node. maxDistance = 6 - 3 = 3.
**Example 3:**
**Input:** head = \[1,3,2,2,3,2,2,2,7\]
**Output:** \[3,3\]
**Explanation:** There are two critical points:
- \[1,**3**,2,2,3,2,2,2,7\]: The second node is a local maxima because 3 is greater than 1 and 2.
- \[1,3,2,2,**3**,2,2,2,7\]: The fifth node is a local maxima because 3 is greater than 2 and 2.
Both the minimum and maximum distances are between the second and the fifth node.
Thus, minDistance and maxDistance is 5 - 2 = 3.
Note that the last node is not considered a local maxima because it does not have a next node.
**Constraints:**
* The number of nodes in the list is in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Build an array of size 2 * n and assign num[i] to ans[i] and ans[i + n] |
O(n) solution, runtime 88.32%, memory 95.33% | find-the-minimum-and-maximum-number-of-nodes-between-critical-points | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nCreate list L to store all critical position.\nInitiate pos = 0, prev for holding previous node value.\n\nThen iterate whole linked list.\n(while head.next) make sure it\'s not the last node.\n(if pos > 0) make sure it\'s not the first node.\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def nodesBetweenCriticalPoints(self, head: Optional[ListNode]) -> List[int]:\n L = []\n pos = 0\n prev = 0\n while head.next:\n if pos > 0 and ((head.val>prev and head.val>head.next.val) or (head.val<prev and head.val<head.next.val)):\n L.append(pos)\n prev = head.val\n pos += 1\n head = head.next\n \n if len(L) < 2:\n return [-1, -1]\n \n min_d = L[1] - L[0]\n for i in range(2, len(L)):\n min_d = min(min_d, L[i] - L[i-1])\n return [min_d, L[-1] - L[0]]\n``` | 0 | A **critical point** in a linked list is defined as **either** a **local maxima** or a **local minima**.
A node is a **local maxima** if the current node has a value **strictly greater** than the previous node and the next node.
A node is a **local minima** if the current node has a value **strictly smaller** than the previous node and the next node.
Note that a node can only be a local maxima/minima if there exists **both** a previous node and a next node.
Given a linked list `head`, return _an array of length 2 containing_ `[minDistance, maxDistance]` _where_ `minDistance` _is the **minimum distance** between **any two distinct** critical points and_ `maxDistance` _is the **maximum distance** between **any two distinct** critical points. If there are **fewer** than two critical points, return_ `[-1, -1]`.
**Example 1:**
**Input:** head = \[3,1\]
**Output:** \[-1,-1\]
**Explanation:** There are no critical points in \[3,1\].
**Example 2:**
**Input:** head = \[5,3,1,2,5,1,2\]
**Output:** \[1,3\]
**Explanation:** There are three critical points:
- \[5,3,**1**,2,5,1,2\]: The third node is a local minima because 1 is less than 3 and 2.
- \[5,3,1,2,**5**,1,2\]: The fifth node is a local maxima because 5 is greater than 2 and 1.
- \[5,3,1,2,5,**1**,2\]: The sixth node is a local minima because 1 is less than 5 and 2.
The minimum distance is between the fifth and the sixth node. minDistance = 6 - 5 = 1.
The maximum distance is between the third and the sixth node. maxDistance = 6 - 3 = 3.
**Example 3:**
**Input:** head = \[1,3,2,2,3,2,2,2,7\]
**Output:** \[3,3\]
**Explanation:** There are two critical points:
- \[1,**3**,2,2,3,2,2,2,7\]: The second node is a local maxima because 3 is greater than 1 and 2.
- \[1,3,2,2,**3**,2,2,2,7\]: The fifth node is a local maxima because 3 is greater than 2 and 2.
Both the minimum and maximum distances are between the second and the fifth node.
Thus, minDistance and maxDistance is 5 - 2 = 3.
Note that the last node is not considered a local maxima because it does not have a next node.
**Constraints:**
* The number of nodes in the list is in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Build an array of size 2 * n and assign num[i] to ans[i] and ans[i + n] |
[Python3] bfs | minimum-operations-to-convert-number | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/4001168494179e85482f91afbf0cd66b908544f3) for my solutions of weekly 265. \n```\nclass Solution:\n def minimumOperations(self, nums: List[int], start: int, goal: int) -> int:\n ans = 0\n seen = {start}\n queue = deque([start])\n while queue: \n for _ in range(len(queue)): \n val = queue.popleft()\n if val == goal: return ans \n if 0 <= val <= 1000: \n for x in nums: \n for op in (add, sub, xor): \n if op(val, x) not in seen: \n seen.add(op(val, x))\n queue.append(op(val, x))\n ans += 1\n return -1 \n```\n\nI saw a few comments complaining TLE. But I\'ve tried multiple submissions they are all consistently 6000-7000ms which is well within the range of AC (see the pic).\n\n\n\n\nAn alternative implementation using `list` runs 3500-4000ms\n```\nclass Solution:\n def minimumOperations(self, nums: List[int], start: int, goal: int) -> int:\n ans = 0\n queue = deque([start])\n visited = [False]*1001\n while queue: \n for _ in range(len(queue)): \n val = queue.popleft()\n if val == goal: return ans \n if 0 <= val <= 1000 and not visited[val]: \n visited[val] = True\n for x in nums: \n for xx in (val+x, val-x, val^x):\n queue.append(xx)\n ans += 1\n return -1 \n```\n | 19 | You are given a **0-indexed** integer array `nums` containing **distinct** numbers, an integer `start`, and an integer `goal`. There is an integer `x` that is initially set to `start`, and you want to perform operations on `x` such that it is converted to `goal`. You can perform the following operation repeatedly on the number `x`:
If `0 <= x <= 1000`, then for any index `i` in the array (`0 <= i < nums.length`), you can set `x` to any of the following:
* `x + nums[i]`
* `x - nums[i]`
* `x ^ nums[i]` (bitwise-XOR)
Note that you can use each `nums[i]` any number of times in any order. Operations that set `x` to be out of the range `0 <= x <= 1000` are valid, but no more operations can be done afterward.
Return _the **minimum** number of operations needed to convert_ `x = start` _into_ `goal`_, and_ `-1` _if it is not possible_.
**Example 1:**
**Input:** nums = \[2,4,12\], start = 2, goal = 12
**Output:** 2
**Explanation:** We can go from 2 -> 14 -> 12 with the following 2 operations.
- 2 + 12 = 14
- 14 - 2 = 12
**Example 2:**
**Input:** nums = \[3,5,7\], start = 0, goal = -4
**Output:** 2
**Explanation:** We can go from 0 -> 3 -> -4 with the following 2 operations.
- 0 + 3 = 3
- 3 - 7 = -4
Note that the last operation sets x out of the range 0 <= x <= 1000, which is valid.
**Example 3:**
**Input:** nums = \[2,8,16\], start = 0, goal = 1
**Output:** -1
**Explanation:** There is no way to convert 0 into 1.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-109 <= nums[i], goal <= 109`
* `0 <= start <= 1000`
* `start != goal`
* All the integers in `nums` are distinct. | What is the maximum number of length-3 palindromic strings? How can we keep track of the characters that appeared to the left of a given position? |
📌📌 BFS Approach || Well-coded || Easy-to-understand 🐍 | minimum-operations-to-convert-number | 0 | 1 | ## IDEA :\n*Go through all the possibilities. \nwe are storing each possibility in seen so Maximum space required is 1000.*\n\n\'\'\'\n\n\tclass Solution:\n def minimumOperations(self, nums: List[int], start: int, goal: int) -> int:\n if start==goal:\n return 0\n \n q = [(start,0)]\n seen = {start}\n while q:\n n,s = q.pop(0)\n for num in nums:\n for cand in [n+num,n-num,n^num]:\n if cand==goal:\n return s+1\n if 0<=cand<=1000 and cand not in seen:\n seen.add(cand)\n q.append((cand,s+1))\n \n return -1\n\n**Thanks and Upvote if you got any help and like the Idea !!\uD83E\uDD1E** | 5 | You are given a **0-indexed** integer array `nums` containing **distinct** numbers, an integer `start`, and an integer `goal`. There is an integer `x` that is initially set to `start`, and you want to perform operations on `x` such that it is converted to `goal`. You can perform the following operation repeatedly on the number `x`:
If `0 <= x <= 1000`, then for any index `i` in the array (`0 <= i < nums.length`), you can set `x` to any of the following:
* `x + nums[i]`
* `x - nums[i]`
* `x ^ nums[i]` (bitwise-XOR)
Note that you can use each `nums[i]` any number of times in any order. Operations that set `x` to be out of the range `0 <= x <= 1000` are valid, but no more operations can be done afterward.
Return _the **minimum** number of operations needed to convert_ `x = start` _into_ `goal`_, and_ `-1` _if it is not possible_.
**Example 1:**
**Input:** nums = \[2,4,12\], start = 2, goal = 12
**Output:** 2
**Explanation:** We can go from 2 -> 14 -> 12 with the following 2 operations.
- 2 + 12 = 14
- 14 - 2 = 12
**Example 2:**
**Input:** nums = \[3,5,7\], start = 0, goal = -4
**Output:** 2
**Explanation:** We can go from 0 -> 3 -> -4 with the following 2 operations.
- 0 + 3 = 3
- 3 - 7 = -4
Note that the last operation sets x out of the range 0 <= x <= 1000, which is valid.
**Example 3:**
**Input:** nums = \[2,8,16\], start = 0, goal = 1
**Output:** -1
**Explanation:** There is no way to convert 0 into 1.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-109 <= nums[i], goal <= 109`
* `0 <= start <= 1000`
* `start != goal`
* All the integers in `nums` are distinct. | What is the maximum number of length-3 palindromic strings? How can we keep track of the characters that appeared to the left of a given position? |
Python 3 BFS with a Queue | minimum-operations-to-convert-number | 0 | 1 | ```\nfrom collections import deque\n\n\nclass Solution:\n def minimumOperations(self, nums, start: int, goal: int) -> int:\n """\n Given an array of integers (nums), a start value (start),\n and a target value (goal), this program uses breadth-\n first search (BFS) with the help of a queue to determine\n the minimum number of operations needed to convert start\n to goal using nums and the add, subtract, xor operations.\n If it is not possible to reach goal, the program will\n return -1.\n\n :param nums: array of integers\n :type nums: list[int]\n :param start: start value\n :type start: int\n :param goal: target value\n :type goal: int\n :return: minimum operations needed to convert start\n to goal, or -1 if conversion is not possible\n :rtype: int\n """\n \n """\n Initialize:\n - queue will contain entries with the following:\n - a value that will be converted using nums and the\n operations in this problem.\n - number of operations that it took to get to this\n value.\n - visited will contain previously converted values. It\n is used to prevent redundant conversion of the same\n values.\n """\n queue = deque()\n visited = set()\n \n """\n Breadth-First Search (BFS):\n - Begin with the start value (start).\n - Continue BFS while there is at least one entry in the\n queue or until the target value (goal) is reached.\n - If the queue becomes empty without goal being reached,\n return -1.\n """\n queue.append((start, 0))\n visited.add(start)\n while queue:\n x, ops = queue.popleft()\n for num in nums:\n for next_x in (x + num, x - num, x ^ num):\n if next_x == goal:\n return ops + 1\n if 0 <= next_x <= 1000 and next_x not in visited:\n visited.add(next_x)\n queue.append((next_x, ops + 1))\n return -1\n``` | 8 | You are given a **0-indexed** integer array `nums` containing **distinct** numbers, an integer `start`, and an integer `goal`. There is an integer `x` that is initially set to `start`, and you want to perform operations on `x` such that it is converted to `goal`. You can perform the following operation repeatedly on the number `x`:
If `0 <= x <= 1000`, then for any index `i` in the array (`0 <= i < nums.length`), you can set `x` to any of the following:
* `x + nums[i]`
* `x - nums[i]`
* `x ^ nums[i]` (bitwise-XOR)
Note that you can use each `nums[i]` any number of times in any order. Operations that set `x` to be out of the range `0 <= x <= 1000` are valid, but no more operations can be done afterward.
Return _the **minimum** number of operations needed to convert_ `x = start` _into_ `goal`_, and_ `-1` _if it is not possible_.
**Example 1:**
**Input:** nums = \[2,4,12\], start = 2, goal = 12
**Output:** 2
**Explanation:** We can go from 2 -> 14 -> 12 with the following 2 operations.
- 2 + 12 = 14
- 14 - 2 = 12
**Example 2:**
**Input:** nums = \[3,5,7\], start = 0, goal = -4
**Output:** 2
**Explanation:** We can go from 0 -> 3 -> -4 with the following 2 operations.
- 0 + 3 = 3
- 3 - 7 = -4
Note that the last operation sets x out of the range 0 <= x <= 1000, which is valid.
**Example 3:**
**Input:** nums = \[2,8,16\], start = 0, goal = 1
**Output:** -1
**Explanation:** There is no way to convert 0 into 1.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-109 <= nums[i], goal <= 109`
* `0 <= start <= 1000`
* `start != goal`
* All the integers in `nums` are distinct. | What is the maximum number of length-3 palindromic strings? How can we keep track of the characters that appeared to the left of a given position? |
[py3] Simple BFS | minimum-operations-to-convert-number | 0 | 1 | ```\nclass Solution:\n def minimumOperations(self, nums: List[int], start: int, goal: int) -> int:\n seen = set()\n que = deque([(start, 0)])\n \n while que:\n item, cnt = que.popleft()\n if item == goal:\n return cnt\n if item in seen:\n continue\n if item >= 0 and item <= 1000:\n for n in nums:\n que.append((item + n, cnt + 1))\n que.append((item - n, cnt + 1))\n que.append((item ^ n, cnt + 1))\n seen.add(item)\n \n return -1\n\n``` | 4 | You are given a **0-indexed** integer array `nums` containing **distinct** numbers, an integer `start`, and an integer `goal`. There is an integer `x` that is initially set to `start`, and you want to perform operations on `x` such that it is converted to `goal`. You can perform the following operation repeatedly on the number `x`:
If `0 <= x <= 1000`, then for any index `i` in the array (`0 <= i < nums.length`), you can set `x` to any of the following:
* `x + nums[i]`
* `x - nums[i]`
* `x ^ nums[i]` (bitwise-XOR)
Note that you can use each `nums[i]` any number of times in any order. Operations that set `x` to be out of the range `0 <= x <= 1000` are valid, but no more operations can be done afterward.
Return _the **minimum** number of operations needed to convert_ `x = start` _into_ `goal`_, and_ `-1` _if it is not possible_.
**Example 1:**
**Input:** nums = \[2,4,12\], start = 2, goal = 12
**Output:** 2
**Explanation:** We can go from 2 -> 14 -> 12 with the following 2 operations.
- 2 + 12 = 14
- 14 - 2 = 12
**Example 2:**
**Input:** nums = \[3,5,7\], start = 0, goal = -4
**Output:** 2
**Explanation:** We can go from 0 -> 3 -> -4 with the following 2 operations.
- 0 + 3 = 3
- 3 - 7 = -4
Note that the last operation sets x out of the range 0 <= x <= 1000, which is valid.
**Example 3:**
**Input:** nums = \[2,8,16\], start = 0, goal = 1
**Output:** -1
**Explanation:** There is no way to convert 0 into 1.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-109 <= nums[i], goal <= 109`
* `0 <= start <= 1000`
* `start != goal`
* All the integers in `nums` are distinct. | What is the maximum number of length-3 palindromic strings? How can we keep track of the characters that appeared to the left of a given position? |
Python3 clean BFS solution | minimum-operations-to-convert-number | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def minimumOperations(self, nums: List[int], start: int, target: int) -> int:\n \n \n q=deque()\n q.append(start)\n seen=set([start])\n steps=0\n \n while q:\n \n for i in range(len(q)):\n node=q.popleft()\n if node==target:\n return steps\n \n if not 0<=node<=1000:\n continue\n \n for val in nums:\n if node+val not in seen:\n seen.add(node+val)\n q.append(node+val)\n \n if node-val not in seen:\n seen.add(node-val)\n q.append(node-val)\n \n if node^val not in seen:\n seen.add(node^val)\n q.append(node^val)\n \n steps+=1\n \n return -1\n``` | 0 | You are given a **0-indexed** integer array `nums` containing **distinct** numbers, an integer `start`, and an integer `goal`. There is an integer `x` that is initially set to `start`, and you want to perform operations on `x` such that it is converted to `goal`. You can perform the following operation repeatedly on the number `x`:
If `0 <= x <= 1000`, then for any index `i` in the array (`0 <= i < nums.length`), you can set `x` to any of the following:
* `x + nums[i]`
* `x - nums[i]`
* `x ^ nums[i]` (bitwise-XOR)
Note that you can use each `nums[i]` any number of times in any order. Operations that set `x` to be out of the range `0 <= x <= 1000` are valid, but no more operations can be done afterward.
Return _the **minimum** number of operations needed to convert_ `x = start` _into_ `goal`_, and_ `-1` _if it is not possible_.
**Example 1:**
**Input:** nums = \[2,4,12\], start = 2, goal = 12
**Output:** 2
**Explanation:** We can go from 2 -> 14 -> 12 with the following 2 operations.
- 2 + 12 = 14
- 14 - 2 = 12
**Example 2:**
**Input:** nums = \[3,5,7\], start = 0, goal = -4
**Output:** 2
**Explanation:** We can go from 0 -> 3 -> -4 with the following 2 operations.
- 0 + 3 = 3
- 3 - 7 = -4
Note that the last operation sets x out of the range 0 <= x <= 1000, which is valid.
**Example 3:**
**Input:** nums = \[2,8,16\], start = 0, goal = 1
**Output:** -1
**Explanation:** There is no way to convert 0 into 1.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-109 <= nums[i], goal <= 109`
* `0 <= start <= 1000`
* `start != goal`
* All the integers in `nums` are distinct. | What is the maximum number of length-3 palindromic strings? How can we keep track of the characters that appeared to the left of a given position? |
[Python3] dp | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/4001168494179e85482f91afbf0cd66b908544f3) for my solutions of weekly 265. \n```\nclass Solution:\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n \n def gg(s): \n """Return possible length"""\n ans = [int(s)]\n if len(s) == 2: \n if s[1] != \'0\': ans.append(int(s[0]) + int(s[1]))\n return ans\n elif len(s) == 3: \n if s[1] != \'0\': ans.append(int(s[:1]) + int(s[1:]))\n if s[2] != \'0\': ans.append(int(s[:2]) + int(s[2:]))\n if s[1] != \'0\' and s[2] != \'0\': ans.append(int(s[0]) + int(s[1]) + int(s[2]))\n return ans \n \n @cache\n def fn(i, j, diff): \n """Return True if s1[i:] matches s2[j:] with given differences."""\n if i == len(s1) and j == len(s2): return diff == 0\n if i < len(s1) and s1[i].isdigit(): \n ii = i\n while ii < len(s1) and s1[ii].isdigit(): ii += 1\n for x in gg(s1[i:ii]): \n if fn(ii, j, diff-x): return True \n elif j < len(s2) and s2[j].isdigit(): \n jj = j \n while jj < len(s2) and s2[jj].isdigit(): jj += 1\n for x in gg(s2[j:jj]): \n if fn(i, jj, diff+x): return True \n elif diff == 0: \n if i == len(s1) or j == len(s2) or s1[i] != s2[j]: return False \n return fn(i+1, j+1, 0)\n elif diff > 0: \n if i == len(s1): return False \n return fn(i+1, j, diff-1)\n else: \n if j == len(s2): return False \n return fn(i, j+1, diff+1)\n \n return fn(0, 0, 0)\n```\n\nUpdated implementation per @lee215, @alexeykonphoto and @lichuan199010. \n```\nclass Solution:\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n \n def gg(s): \n """Return possible length."""\n ans = {int(s)}\n for i in range(1, len(s)): \n ans |= {x+y for x in gg(s[:i]) for y in gg(s[i:])}\n return ans\n \n @cache\n def fn(i, j, diff): \n """Return True if s1[i:] matches s2[j:] with given differences."""\n if i == len(s1) and j == len(s2): return diff == 0\n if i < len(s1) and s1[i].isdigit(): \n ii = i\n while ii < len(s1) and s1[ii].isdigit(): ii += 1\n for x in gg(s1[i:ii]): \n if fn(ii, j, diff-x): return True \n elif j < len(s2) and s2[j].isdigit(): \n jj = j \n while jj < len(s2) and s2[jj].isdigit(): jj += 1\n for x in gg(s2[j:jj]): \n if fn(i, jj, diff+x): return True \n elif diff == 0: \n if i < len(s1) and j < len(s2) and s1[i] == s2[j]: return fn(i+1, j+1, 0)\n elif diff > 0: \n if i < len(s1): return fn(i+1, j, diff-1)\n else: \n if j < len(s2): return fn(i, j+1, diff+1)\n return False \n \n return fn(0, 0, 0)\n``` | 89 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Clean, concise code with elaborate explanations | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | ```\nclass Solution:\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n def parse_int(s: str, i: int) -> Iterator[tuple[int, int]]:\n """\n Incrementally parses an integer starting from s[i].\n\n Example:\n "456" is parsed as (4,1), (45,2), and (456,3)\n\n :param s: string to parse\n :param i: index to start parsing from\n :return: the integer and its length (number of digits)\n """\n n = 0\n j = i\n while j < len(s) and s[j].isdigit():\n n = n * 10 + int(s[j])\n j += 1\n yield n, j - i\n\n @functools.cache\n def dfs(i: int, j: int, skip: int) -> bool:\n """\n Checks if two encoded strings s1 and s2 are equal in length after decoding.\n The algorithm works similar to digit by digit addition. \n The parameter skip is analogous to the carry that indicates how many characters can be skipped from one of the strings.\n - If s1[i] or s2[j] is a digit, then we try with increasing lengths of integers, which is combined with skip to produce the new value.\n - If neither of s1[i] and s2[j] is a digit, and skip is not zero, then we skip the respective characters from s1 or s2.\n - If neither of s1[i] and s2[j] is a digit, and skip is zero, then s1[i] must be equal to s2[j] for the strings to be equal in length.\n\n Example:\n s1="a3e", s2="ab21".\n Indices with asterisk indicate that it is _not_ incremented in the current iteration.\n\n +----+----+-------+-------+----------------------------------+\n | i | j | s1[i] | s2[j] | skip (at the start of iteration) |\n +----+----+-------+-------+----------------------------------+\n | 0 | 0 | \'a\' | \'a\' | 0 |\n | 1 | 1* | 3 | \'b\' | 0 |\n | 2* | 1 | \'e\' | \'b\' | -3 |\n | 2* | 2 | \'e\' | 2 | -2 |\n | 2* | 3 | \'e\' | 1 | 0 |\n | 2 | 4* | \'e\' | --- | 1 |\n | 3 | 4 | --- | --- | 0 |\n +----+----+-------+-------+----------------------------------+\n\n Note that how skip=-2 and s2[2]=2 are combined to produce skip=0 in the 5th iteration.\n\n :param i: index into string s1\n :param j: index into string s2\n :param skip: number of characters to skip; if positive, skip from s1, if negative skip from s2\n :return: true if the decoded strings are equal in length, false otherwise\n """\n if i == len(s1) and j == len(s2):\n return skip == 0\n if i < len(s1) and s1[i].isdigit():\n return any(dfs(i + k, j, skip - n) for n, k in parse_int(s1, i))\n elif j < len(s2) and s2[j].isdigit():\n return any(dfs(i, j + k, skip + n) for n, k in parse_int(s2, j))\n elif skip == 0 and i < len(s1) and j < len(s2):\n return s1[i] == s2[j] and dfs(i + 1, j + 1, skip)\n elif skip > 0 and i < len(s1):\n return dfs(i + 1, j, skip - 1)\n elif skip < 0 and j < len(s2):\n return dfs(i, j + 1, skip + 1)\n return False\n \n return dfs(0, 0, 0)\n``` | 4 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Python | DFS with memo | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\ndigits essentially served as wildcard, explicitly count digits as wildcard match quotas while dfs.\n\n\n# Code\n```\nfrom functools import lru_cache\n\nclass Solution:\n\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n\n @lru_cache(None)\n def possible_nums(s):\n nums = {int(s)}\n for i in range(1, len(s)):\n for x in possible_nums(s[:i]):\n for y in possible_nums(s[i:]):\n nums.add(x + y)\n return nums\n\n @lru_cache(None)\n def dfs(i, j, diff):\n if i >= len(s1) and j >= len(s2):\n return diff == 0\n elif i >= len(s1) and diff > 0:\n return False\n elif j >= len(s2) and diff < 0:\n return False\n\n # aggressively process all continuous digits\n if i < len(s1) and s1[i].isdigit():\n k = i\n while k < len(s1) and s1[k].isdigit():\n k += 1\n nums = possible_nums(s1[i:k])\n for n in nums:\n if dfs(k, j, diff - n): return True\n elif j < len(s2) and s2[j].isdigit():\n k = j\n while k < len(s2) and s2[k].isdigit():\n k += 1\n nums = possible_nums(s2[j:k])\n for n in nums:\n if dfs(i, k, diff + n): return True\n elif diff > 0:\n return dfs(i + 1, j, diff - 1)\n elif diff < 0:\n return dfs(i, j + 1, diff + 1)\n elif diff == 0 and i < len(s1) and j < len(s2):\n if s1[i] != s2[j]: return False\n return dfs(i + 1, j + 1, 0)\n return False\n\n return dfs(0, 0, 0)\n\n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Python DFS solution with caching | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | Full credit to this YouTube video for this solution: https://www.youtube.com/watch?v=K6d524jDH3A\n\nI just translated it roughly from C++ to Python.\n\nHe broke it down with an example:\ns1 = 3b3c, s2 = 2bb3\nstep 1: if both have matchers, reduce until the minimum matcher reaches 0: s1 = 1b3c, s2 = bb3\nstep 2: if one has matcher, the other has letter: s1 = b3c, s2 = b3\nstep 3: if both have letters, check if they are the same: s1 = 3c, s2 = 3\nstep 4: s1 = c, s2 = ""\nstep 5: if we got to the end of one string but not the other, return false\n\n# Complexity\n- Time complexity:\nNot sure of the number of calls to dfs made, might be something like 6^max(len(s1), len(s2)) since we could make at most 6 decisions at every index of the strings.\n\n- Space complexity:\nNot sure, might be O(max(len(s1), len(s2))) since that would be the depth of the recursion stack.\n\n# Code\n```\nclass Solution:\n def __init__(self):\n self.visited = set()\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n def parse(s):\n res = []\n i = 0\n while i < len(s):\n if s[i].isalpha():\n res.append(s[i])\n i += 1\n continue\n if s[i].isdigit():\n curr = []\n while i < len(s) and s[i].isdigit():\n curr.append(s[i])\n i += 1\n res.append(curr)\n continue\n return res\n \n def getNum(t):\n d = int(\'\'.join(t))\n if len(t) == 1:\n return {d}\n if len(t) == 2:\n a = d // 10\n b = d % 10\n return {a + b, d}\n if len(t) == 3:\n a = d // 100\n b = d % 100 // 10\n c = d % 10\n return {a * 10 + b + c, a + b * 10 + c, a + b + c, d}\n \n def dfs(t1, i, num1, t2, j, num2):\n if i == len(t1) and j == len(t2):\n return num1 == num2\n if i == len(t1) and num1 == 0:\n return False\n if j == len(t2) and num2 == 0:\n return False\n hashcode = str(i) + str(num1) + str(j) + str(num2)\n if hashcode in self.visited:\n return False\n if i < len(t1) and t1[i][0].isdigit():\n nums = getNum(t1[i])\n for n in nums:\n if dfs(t1, i + 1, num1 + n, t2, j, num2):\n return True\n self.visited.add(hashcode)\n return False\n elif j < len(t2) and t2[j][0].isdigit():\n nums = getNum(t2[j])\n for n in nums:\n if dfs(t1, i, num1, t2, j + 1, num2 + n):\n return True\n self.visited.add(hashcode)\n return False\n if num1 != 0 and num2 != 0:\n common = min(num1, num2)\n return dfs(t1, i, num1 - common, t2, j, num2 - common)\n elif num1 != 0 and num2 == 0:\n return dfs(t1, i, num1 - 1, t2, j + 1, 0)\n elif num1 == 0 and num2 != 0:\n return dfs(t1, i + 1, 0, t2, j, num2 - 1)\n else:\n if t1[i] != t2[j]:\n self.visited.add(hashcode)\n return False\n return dfs(t1, i + 1, 0, t2, j + 1, 0)\n t1, t2 = parse(s1), parse(s2)\n return dfs(t1, 0, 0, t2, 0, 0)\n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
[Python3] relative easy to understand, backtracking with memorization | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | # Intuition\n\nCalculate diff\n\nAlgorithm:\n\n```\ns1 s2 diff desc\n2a aba 0 initial state\na aba 2 read 2 from s1, remove 2 from s1, diff + 2\na ba 1 since diff 2 > 0, remove 1 char from s2, diff - 1\na a 0 since diff 1 > 0, remove 1 char from s2, diff - 1\n\'\' \'\' 0 since diff == 0 and s1[0] == s2[0], remove 1 char from each s, same diff\n\'\' \'\' 0 return True\n```\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n$$O(N1*N2)$$ ?\n\n- Space complexity:\n$$O(N1*N2)$$ ?\n\n# Code\n```\nclass Solution:\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n\n self.memo = {}\n return self.check(s1, s2, 0)\n\n def check(self, s1: str, s2: str, diff: int) -> bool:\n if not s1 and not s2: return diff == 0\n \n # Make sure s1 is not empty\n if not s1: return self.check(s2, s1, -diff)\n\n if (s1, s2, diff) in self.memo:\n return self.memo[(s1, s2, diff)]\n\n result = False\n if diff == 0:\n if not s2:\n result = False\n else:\n if s1[0].isalpha():\n if s2[0].isalpha():\n result = (s1[0] == s2[0]) and self.check(s1[1:], s2[1:], diff)\n else:\n # To simplify code, always handle number in s1\n result = self.check(s2, s1, -diff)\n else:\n result = self.checkS1Nums(s1, s2, diff)\n elif diff > 0: # Expect chars in s2\n if not s2:\n result = False\n else:\n if s2[0].isalpha():\n result = self.check(s1, s2[1:], diff - 1)\n else:\n # To simplify code, always handle number in s1\n result = self.check(s2, s1, -diff)\n else: # diff < 0, expect chars in s1\n if s1[0].isalpha():\n result = self.check(s1[1:], s2, diff + 1)\n else:\n result = self.checkS1Nums(s1, s2, diff)\n self.memo[(s1, s2, diff)] = result\n return result\n\n def checkS1Nums(self, s1: str, s2: str, diff: int) -> bool:\n result = False\n for i, c in enumerate(s1):\n if c.isalpha():\n break\n num = int(s1[:i+1])\n result = result or self.check(s1[i+1:], s2, diff + num)\n return result\n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Python recursive O(n^3) : one case at a time | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | \n```\n\nclass Solution:\n def possiblyEquals(self, s: str, t: str) -> bool:\n @cache\n def solve(i, j, gap):\n if i == len(s) and j == len(t):\n return gap == 0\n if i > len(s) or j > len(t):\n return False\n\n if i < len(s) and s[i].isdigit():\n n = 0\n while i < len(s) and s[i].isdigit():\n n = n * 10 + int(s[i])\n if solve(i + 1, j, gap + n):\n return True\n i += 1\n elif j < len(t) and t[j].isdigit():\n n = 0\n while j < len(t) and t[j].isdigit():\n n = n * 10 + int(t[j])\n if solve(i, j + 1, gap - n):\n return True\n j += 1\n elif gap > 0:\n return solve(i, j + 1, gap - 1)\n elif gap < 0:\n return solve(i + 1, j, gap + 1)\n elif i < len(s) and j < len(t):\n if s[i] == t[j]:\n return solve(i + 1, j + 1, 0)\n return False\n\n return solve(0, 0, 0)\n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Python (Simple DP) | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def possiblyEquals(self, s1, s2):\n n, m = len(s1), len(s2)\n\n @lru_cache(None)\n def dfs(i,j,balance):\n if i == n and j == m:\n return balance == 0\n\n if i < n and s1[i].isnumeric():\n k, val = i, 0\n while k < n and s1[k].isnumeric():\n val = val*10 + int(s1[k])\n k += 1\n if dfs(k,j,balance-val):\n return True\n elif j < m and s2[j].isnumeric():\n k, val = j, 0\n while k < m and s2[k].isnumeric():\n val = val*10 + int(s2[k])\n k += 1\n if dfs(i,k,balance+val):\n return True\n elif balance == 0:\n if i < n and j < m and s1[i] == s2[j]:\n return dfs(i+1,j+1,balance)\n elif balance > 0:\n if i < n:\n return dfs(i+1,j,balance-1)\n elif balance < 0:\n if j < m:\n return dfs(i,j+1,balance+1)\n\n return False\n\n return dfs(0,0,0)\n\n\n\n\n\n \n\n \n \n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
Python Solution: Recursion with memoization / DP - The code easy to follow | check-if-an-original-string-exists-given-two-encoded-strings | 0 | 1 | Here is my Solution. I hope the code is easy to follow compared to other post. I originally tried to compute all of possible strings with wildcards; that approach worked but proof to be too slow. \n\nThis approach similar to others; using a `diff` to track the wildcards in `s1` and `s2`; wildcards in `s2` make `diff` go negative and vice verse for `s1`. \n\nIn my case, the solution purposely stops at `n` and `m` and checks the diff as the base case. \n\nThe solution is using `memo` to avoid recomputing all failed paths in the recursion tree that we previously attempted.\n\n```\n\nclass Solution:\n def possiblyEquals(self, s1: str, s2: str) -> bool:\n \n n = len(s1)\n m = len(s2)\n memo = {}\n \n def try_digits_s1(i, j, diff):\n \n k = 0\n while i + k < n and s1[i + k].isdigit():\n digit = int(s1[i:i + k + 1])\n if recurse(i + k + 1, j, diff + digit):\n return True\n k += 1\n \n return False\n \n def try_digits_s2(i, j, diff):\n \n k = 0\n while j + k < m and s2[j + k].isdigit():\n digit = int(s2[j:j + k + 1])\n if recurse(i, j + k + 1, diff - digit):\n return True\n k += 1\n \n return False\n \n def recurse(i, j, diff):\n \n if (i, j, diff) in memo:\n return memo[(i, j, diff)]\n \n memo[(i, j, diff)] = False\n \n if i == n and j == m:\n return diff == 0 \n \n if i > n or j > m:\n return False\n \n if i < n and s1[i].isdigit():\n return try_digits_s1(i, j, diff)\n \n if j < m and s2[j].isdigit():\n return try_digits_s2(i, j, diff)\n \n if diff < 0:\n return recurse(i + 1, j, diff + 1)\n \n if diff > 0:\n return recurse(i, j + 1, diff - 1)\n \n if i < n and j < m and s1[i] == s2[j]:\n return recurse(i + 1, j + 1, diff)\n \n return False\n \n return recurse(0, 0, 0)\n``` | 0 | An original string, consisting of lowercase English letters, can be encoded by the following steps:
* Arbitrarily **split** it into a **sequence** of some number of **non-empty** substrings.
* Arbitrarily choose some elements (possibly none) of the sequence, and **replace** each with **its length** (as a numeric string).
* **Concatenate** the sequence as the encoded string.
For example, **one way** to encode an original string `"abcdefghijklmnop "` might be:
* Split it as a sequence: `[ "ab ", "cdefghijklmn ", "o ", "p "]`.
* Choose the second and third elements to be replaced by their lengths, respectively. The sequence becomes `[ "ab ", "12 ", "1 ", "p "]`.
* Concatenate the elements of the sequence to get the encoded string: `"ab121p "`.
Given two encoded strings `s1` and `s2`, consisting of lowercase English letters and digits `1-9` (inclusive), return `true` _if there exists an original string that could be encoded as **both**_ `s1` _and_ `s2`_. Otherwise, return_ `false`.
**Note**: The test cases are generated such that the number of consecutive digits in `s1` and `s2` does not exceed `3`.
**Example 1:**
**Input:** s1 = "internationalization ", s2 = "i18n "
**Output:** true
**Explanation:** It is possible that "internationalization " was the original string.
- "internationalization "
-> Split: \[ "internationalization "\]
-> Do not replace any element
-> Concatenate: "internationalization ", which is s1.
- "internationalization "
-> Split: \[ "i ", "nternationalizatio ", "n "\]
-> Replace: \[ "i ", "18 ", "n "\]
-> Concatenate: "i18n ", which is s2
**Example 2:**
**Input:** s1 = "l123e ", s2 = "44 "
**Output:** true
**Explanation:** It is possible that "leetcode " was the original string.
- "leetcode "
-> Split: \[ "l ", "e ", "et ", "cod ", "e "\]
-> Replace: \[ "l ", "1 ", "2 ", "3 ", "e "\]
-> Concatenate: "l123e ", which is s1.
- "leetcode "
-> Split: \[ "leet ", "code "\]
-> Replace: \[ "4 ", "4 "\]
-> Concatenate: "44 ", which is s2.
**Example 3:**
**Input:** s1 = "a5b ", s2 = "c5b "
**Output:** false
**Explanation:** It is impossible.
- The original string encoded as s1 must start with the letter 'a'.
- The original string encoded as s2 must start with the letter 'c'.
**Constraints:**
* `1 <= s1.length, s2.length <= 40`
* `s1` and `s2` consist of digits `1-9` (inclusive), and lowercase English letters only.
* The number of consecutive digits in `s1` and `s2` does not exceed `3`. | Is it possible to have multiple leaf nodes with the same values? How many possible positions are there for each tree? The root value of the final tree does not occur as a value in any of the leaves of the original tree. |
count-vowel-substrings-of-a-string | count-vowel-substrings-of-a-string | 0 | 1 | \n# Code\n```\nclass Solution:\n def countVowelSubstrings(self, s: str) -> int:\n count = 0\n l = []\n b = ["a","e","i","o","u"]\n for i in range(len(s)+1):\n for j in range(i):\n a = s[j:i]\n if "a" in a and "e" in a and "i" in a and "o" in a and "u" in a:\n l.append(a)\n for i in l:\n c1 = 0\n for j in i:\n if j not in b:\n c1+=1\n break\n if c1==0:\n count+=1\n \n return (count)\n \n``` | 1 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
Two pointer approach, run time is slow but low memory needed. Starightforward approach. | count-vowel-substrings-of-a-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n vowels = {\'a\',\'e\',\'i\',\'o\',\'u\'}\n pointer = 0\n res = 0\n if len(word) <= 4:\n return 0\n while pointer != len(word)-4:\n # if set(list(word[pointer:pointer+5])) == vowels:\n # temp = 1\n # res += 1\n # while set(list(word[pointer:pointer+temp+5])) == vowels and pointer+temp+4 != len(word):\n # res += 1\n # temp += 1\n # elif word[pointer] in vowels:\n # temp = 1\n # while set(list(word[pointer:pointer+5+temp])) != vowels:\n # temp += 1\n # res += 1\n # pointer += 1\n temp = 0\n if word[pointer] in vowels:\n while temp+pointer != len(word)-4:\n test_1 = set(list(word[pointer:pointer+temp+5]))\n test_2 = word[pointer:pointer+temp+5]\n if set(list(word[pointer:pointer+temp+5])).issubset(vowels): \n if set(list(word[pointer:pointer+temp+5])) == vowels:\n res += 1\n temp+=1\n else:\n break\n \n pointer += 1\n return res\n\n \n``` | 2 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
[Python3] sliding window O(N) | count-vowel-substrings-of-a-string | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/6b6e6b9115d2b659e68dcf3ea8e21befefaae16c) for solutions of weekly 266. \n\n```\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n ans = 0 \n freq = defaultdict(int)\n for i, x in enumerate(word): \n if x in "aeiou": \n if not i or word[i-1] not in "aeiou": \n jj = j = i # set anchor\n freq.clear()\n freq[x] += 1\n while len(freq) == 5 and all(freq.values()): \n freq[word[j]] -= 1\n j += 1\n ans += j - jj\n return ans \n``` | 18 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
Python. Time: one pass O(N), space: O(1). Not a sliding window. | count-vowel-substrings-of-a-string | 0 | 1 | ```\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n vowels = (\'a\', \'e\', \'i\', \'o\', \'u\')\n \n result = 0\n start = 0\n vowel_idx = {}\n for idx, c in enumerate(word):\n if c in vowels:\n if not vowel_idx:\n start = idx \n vowel_idx[c] = idx\n if len(vowel_idx) == 5:\n result += min(vowel_idx.values()) - start + 1 \n elif vowel_idx:\n vowel_idx = {}\n \n return result\n``` | 17 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
[Python3] One-line Solution | count-vowel-substrings-of-a-string | 0 | 1 | ```python\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n return sum(set(word[i:j+1]) == set(\'aeiou\') for i in range(len(word)) for j in range(i+1, len(word)))\n``` | 8 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
python straightforward solution | count-vowel-substrings-of-a-string | 0 | 1 | ```\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n count = 0 \n current = set() \n for i in range(len(word)):\n if word[i] in \'aeiou\':\n current.add(word[i])\n \n for j in range(i+1, len(word)): \n if word[j] in \'aeiou\':\n current.add(word[j])\n else:\n break\n \n if len(current) == 5:\n count += 1\n\t\t\t\t\t\t\n current = set()\n \n return count\n``` | 11 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
[Python3] Sliding Window O(N) with explanations | count-vowel-substrings-of-a-string | 0 | 1 | \n```python\nclass Solution:\n def countVowelSubstrings(self, word: str) -> int:\n result = 0\n vowels = \'aeiou\'\n # dictionary to record counts of each char\n mp = defaultdict(lambda: 0)\n\n for i, char in enumerate(word):\n # if the current letter is a vowel\n if char in vowels:\n mp[char] += 1\n # if the previous letter is not a vowel, set the current point to a left point and a pivot\n if i == 0 or word[i-1] not in vowels:\n left = pivot = i\n # if all five vowels are founded,\n # try to calculate how many substrings that contain all five vowels using sliding window\n # window range is between the left point and the current i point\n\t\t\t\t# move the pivot to the right-side one by one, check if [pivot, i] contains all five vowels\n while len(mp) == 5 and all(mp.values()):\n mp[word[pivot]] -= 1\n pivot += 1\n result += (pivot - left)\n else:\n mp.clear()\n left = pivot = i+1\n \n return result\n``` | 8 | A **substring** is a contiguous (non-empty) sequence of characters within a string.
A **vowel substring** is a substring that **only** consists of vowels (`'a'`, `'e'`, `'i'`, `'o'`, and `'u'`) and has **all five** vowels present in it.
Given a string `word`, return _the number of **vowel substrings** in_ `word`.
**Example 1:**
**Input:** word = "aeiouu "
**Output:** 2
**Explanation:** The vowel substrings of word are as follows (underlined):
- "**aeiou**u "
- "**aeiouu** "
**Example 2:**
**Input:** word = "unicornarihan "
**Output:** 0
**Explanation:** Not all 5 vowels are present, so there are no vowel substrings.
**Example 3:**
**Input:** word = "cuaieuouac "
**Output:** 7
**Explanation:** The vowel substrings of word are as follows (underlined):
- "c**uaieuo**uac "
- "c**uaieuou**ac "
- "c**uaieuoua**c "
- "cu**aieuo**uac "
- "cu**aieuou**ac "
- "cu**aieuoua**c "
- "cua**ieuoua**c "
**Constraints:**
* `1 <= word.length <= 100`
* `word` consists of lowercase English letters only. | Simulate the game and try all possible moves for each player. |
Detailed explanation of why (len - pos) * (pos + 1) works | vowels-of-all-substrings | 1 | 1 | <br>\nLet us understand this problem with an example\n<br>let word = "abei"\n\n**All possible substrings:**\n```\na b e i\nab be ei\nabe bei\nabei\n```\n\nSo for counting occurences of vowels in each substring, we can count the occurence of each vowel in each substring\nIn this example, count of vowels in substrings are\n```\na - 4 times\ne - 6 times\ni - 4 times\n```\nAnd you can observe that occurence of each vowel depends on it\'s position like below:\n* a is at position 0 so it can be present only in the substrings starting at 0\n* e is in the middle so it can be present in the substrings starting at it\'s position, substrings ending at it\'s position, and substrings containing it in middle\n* i is at last so it can be present only in the substrings ending at that position\n<br>\n\n**Did you see any pattern ?** Yes !\n<br>A character at position pos can be present in substrings starting at i and substrings ending at j, <br>where **0 <= i <= pos** (pos + 1 choices) and **pos <= j <= len** (len - pos choices) <br>so there are total **(len - pos) * (pos + 1)** substrings that contain the character word[pos]\n\n(You can see from above example that e is at position 2 and it\'s present in substrings "abei", "bei", "ei", "abe", "be", "e"<br> (0 <= start <= pos and pos <= end <= len) and same will be true for each vowel.\n<br>\n**From this observation we can generalise the occurence of each vowel in the string as**\n```\nhere len(abei) = 4\na, pos = 0, count = (4 - 0) * (0 + 1) = 4\ne, pos = 2, count = (4 - 2) * (2 + 1) = 6\ni, pos = 3, count = (4 - 3) * (3 + 1) = 4\n```\n**So the generalised formula will be**\n```\ncount = (len - pos) * (pos + 1)\n```\nand we can keep summing the count of each vowel (don\'t forget to convert to long)\n<br>\n\n\n**C++ code:**\n\n```\nclass Solution {\npublic:\n bool isVowel(char ch) {\n return ch == \'a\' or ch == \'e\' or ch == \'i\' or ch == \'o\' or ch == \'u\';\n }\n \n long long countVowels(string word) {\n long long count = 0;\n int len = word.size();\n \n for(int pos = 0; pos < len; pos++) {\n if(isVowel(word[pos])) {\n count += (long)(len - pos) * (long)(pos + 1);\n }\n }\n \n return count;\n }\n};\n```\n\n<br>\n\n**Python Code:**\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n count = 0\n sz = len(word)\n \n for pos in range(sz):\n if word[pos] in \'aeiou\':\n count += (sz - pos) * (pos + 1)\n \n return count\n```\n\n<br>\n\n**Java Code:**\n\n```\nclass Solution {\n \n boolean isVowel(char ch) {\n return ch == \'a\' || ch == \'e\' || ch == \'i\' || ch == \'o\' || ch == \'u\';\n }\n \n public long countVowels(String word) {\n long count = 0;\n int len = word.length();\n \n for(int pos = 0; pos < len; pos++) {\n if(isVowel(word.charAt(pos))) {\n count += (long)(len - pos) * (long)(pos + 1);\n }\n }\n \n return count;\n }\n}\n```\n\n<br>\nDo upvote if you liked the explanation :)\n\n<br> | 101 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
(i + 1) * (sz - i) | vowels-of-all-substrings | 1 | 1 | A vowel at position `i` appears in `(i + 1) * (sz - i)` substrings. \n\nSo, we just sum and return the appearances for all vowels.\n\n**Python 3**\n```python\nclass Solution:\n def countVowels(self, word: str) -> int:\n return sum((i + 1) * (len(word) - i) for i, ch in enumerate(word) if ch in \'aeiou\')\n```\n\n**C++**\n```cpp\nbool v[26] = {1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0};\nlong long countVowels(string w) {\n long long res = 0, sz = w.size();\n for (int i = 0; i < w.size(); ++i)\n res += v[w[i] - \'a\'] * (i + 1) * (sz - i);\n return res;\n}\n```\n**Java**\n```java\npublic long countVowels(String word) {\n long res = 0, sz = word.length();\n for (int i = 0; i < sz; ++i)\n if ("aeiou".indexOf(word.charAt(i)) != -1)\n res += (i + 1) * (sz - i);\n return res; \n}\n``` | 38 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
Python3 | Explained | Top Down DP | O(n) | vowels-of-all-substrings | 0 | 1 | We have to iterate over the list and just have to count the number of times a vovel is used in a substring, so if we are at index i and it is a vovel then it will be used in i+1 (from 0 to i) and x-i (form i to x) where x is the length of the string.\nAnd if we multiply these two to get the sum for that vovel i.e (i+1)*(x-i) \nAnd at the end we will add the vovel sum to get the ans.\n\nfor example:\naba\nall the possible substring for 0th index is a, ab aba\nso the count for a (0+1)*(3-0)=3\n\nwe will skip b, as it is not counted in any substring\n\nnow for i=2\nthe last a will be used in aba, ba and a\nso the count will be 3.\n\nand the total count for a is 6.\n\nand there are no other vovel in the string.\nso their count will be 0.\n\nso ans=6+0+0+0+0=6\n\nNote: we are only counting the number of times a vovel is used in total number of substring.\n\ndef countVowels(self, words: str) -> int:\n\n vov={\'a\':0,\'e\':0,\'i\':0,\'o\':0,\'u\':0}\n x=len(words)\n for i in range(x):\n if words[i] in vov:\n vov[words[i]]+=(i+1)*(x-i) \n summ=0 \n for i,j in vov.items():\n summ+=j \n return summ | 1 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
Fastest Python Solution | 108ms | vowels-of-all-substrings | 0 | 1 | # Fastest Python Solution | 108ms\n**Runtime: 108 ms, faster than 100.00% of Python3 online submissions for Vowels of All Substrings.\nMemory Usage: 14.8 MB, less than 100.00% of Python3 online submissions for Vowels of All Substrings.**\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n c, l = 0, len(word)\n d = {\'a\':1, \'e\':1,\'i\':1,\'o\':1,\'u\':1}\n \n for i in range(l):\n if word[i] in d:\n c += (l-i)*(i+1)\n return c\n```\n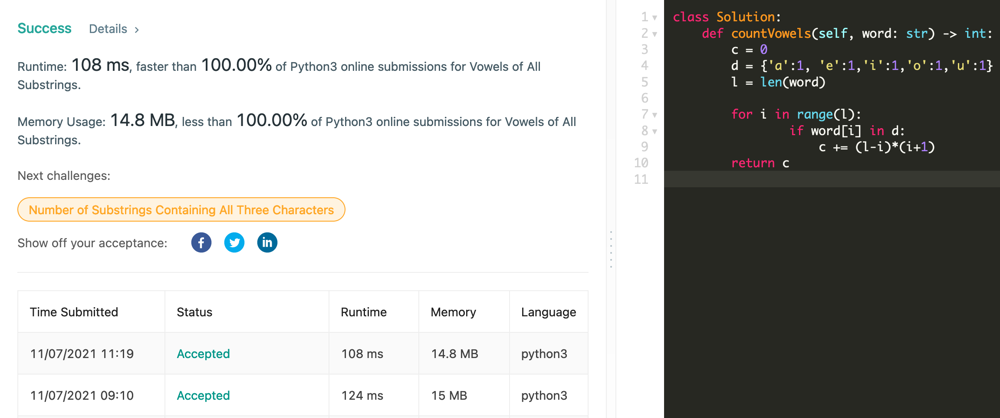\n\n | 6 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
[Python] DP, no extra memory | vowels-of-all-substrings | 0 | 1 | # Intuition\nWe can approach this problem with DP. Let\'s count total number of vowels in the substrings of ``word`` prefix ``word[0..i]`` and call it ``DP(i)``. \nThus given we have ``DP(i-1)`` we can calculate ``DP(i)`` in the following way:\n1. If ``word[i]`` is a consonant, then total number of vowels in all substrings of the prefix ``word[0:i]`` will be the same as the number of vowels of all substrings of the prefix ``word[0:i-1]``, thus ``DP(i) = DP(i-1)``, assuming ``DP(-1) = 0`` - number of vowels in substrings of an empty string.\n2. If ``word[i]`` is a vowel, we add exactly ``len(word[0:i])`` vowels since we will have substrings ``word[0:i-1] + word[i]``, ``word[1:i-1] + word[i]``,... ``word[i-1:i-1] + word[i]``.\nFor the total value we need to sum up values for the substrings - all ``DP(i)``\n\n# Approach\nWe don\'t need extra memory apart from two variables to calculate the result. We actually need only to store the result and previous ``DP`` value. All we need is to iterate over the string, check if consequtive character is a vowel and add current prefix length to the previous ``DP`` value, and accumulate it into the ``result``.\n\n# Complexity\n- Time complexity:\n$$O(n)$$\n\n- Space complexity:\n$$O(1)$$\n\n# Code\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n result = 0\n current = 0\n for i, c in enumerate(word):\n if c in "aeiou":\n current += (i+1)\n result += current\n return result\n```\n\n\nShall you have any questions - please feel free to ask, and upvote if you like it! | 1 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
[Python] One liner O(N) | vowels-of-all-substrings | 0 | 1 | \n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n return sum((i+1)*(len(word)-i) for i in range(len(word)) if word[i] in "aeiou")\n\n\n\n \n\n\n \n``` | 0 | Given a string `word`, return _the **sum of the number of vowels** (_`'a'`, `'e'`_,_ `'i'`_,_ `'o'`_, and_ `'u'`_)_ _in every substring of_ `word`.
A **substring** is a contiguous (non-empty) sequence of characters within a string.
**Note:** Due to the large constraints, the answer may not fit in a signed 32-bit integer. Please be careful during the calculations.
**Example 1:**
**Input:** word = "aba "
**Output:** 6
**Explanation:**
All possible substrings are: "a ", "ab ", "aba ", "b ", "ba ", and "a ".
- "b " has 0 vowels in it
- "a ", "ab ", "ba ", and "a " have 1 vowel each
- "aba " has 2 vowels in it
Hence, the total sum of vowels = 0 + 1 + 1 + 1 + 1 + 2 = 6.
**Example 2:**
**Input:** word = "abc "
**Output:** 3
**Explanation:**
All possible substrings are: "a ", "ab ", "abc ", "b ", "bc ", and "c ".
- "a ", "ab ", and "abc " have 1 vowel each
- "b ", "bc ", and "c " have 0 vowels each
Hence, the total sum of vowels = 1 + 1 + 1 + 0 + 0 + 0 = 3.
**Example 3:**
**Input:** word = "ltcd "
**Output:** 0
**Explanation:** There are no vowels in any substring of "ltcd ".
**Constraints:**
* `1 <= word.length <= 105`
* `word` consists of lowercase English letters. | null |
[Python3] Binary Search - Easy to Understand | minimized-maximum-of-products-distributed-to-any-store | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:$$O(logk)$$ k is maximum `quantity` in `quantities`\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minimizedMaximum(self, n: int, quantities: List[int]) -> int:\n l, r = 1, max(quantities)\n while l <= r:\n m = (l + r) >> 1\n if sum(math.ceil(q / m) for q in quantities) > n:\n l = m + 1\n else:\n r = m - 1\n return l\n``` | 2 | You are given an integer `n` indicating there are `n` specialty retail stores. There are `m` product types of varying amounts, which are given as a **0-indexed** integer array `quantities`, where `quantities[i]` represents the number of products of the `ith` product type.
You need to distribute **all products** to the retail stores following these rules:
* A store can only be given **at most one product type** but can be given **any** amount of it.
* After distribution, each store will have been given some number of products (possibly `0`). Let `x` represent the maximum number of products given to any store. You want `x` to be as small as possible, i.e., you want to **minimize** the **maximum** number of products that are given to any store.
Return _the minimum possible_ `x`.
**Example 1:**
**Input:** n = 6, quantities = \[11,6\]
**Output:** 3
**Explanation:** One optimal way is:
- The 11 products of type 0 are distributed to the first four stores in these amounts: 2, 3, 3, 3
- The 6 products of type 1 are distributed to the other two stores in these amounts: 3, 3
The maximum number of products given to any store is max(2, 3, 3, 3, 3, 3) = 3.
**Example 2:**
**Input:** n = 7, quantities = \[15,10,10\]
**Output:** 5
**Explanation:** One optimal way is:
- The 15 products of type 0 are distributed to the first three stores in these amounts: 5, 5, 5
- The 10 products of type 1 are distributed to the next two stores in these amounts: 5, 5
- The 10 products of type 2 are distributed to the last two stores in these amounts: 5, 5
The maximum number of products given to any store is max(5, 5, 5, 5, 5, 5, 5) = 5.
**Example 3:**
**Input:** n = 1, quantities = \[100000\]
**Output:** 100000
**Explanation:** The only optimal way is:
- The 100000 products of type 0 are distributed to the only store.
The maximum number of products given to any store is max(100000) = 100000.
**Constraints:**
* `m == quantities.length`
* `1 <= m <= n <= 105`
* `1 <= quantities[i] <= 105` | null |
[Python3] binary search | minimized-maximum-of-products-distributed-to-any-store | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/6b6e6b9115d2b659e68dcf3ea8e21befefaae16c) for solutions of weekly 266. \n\n```\nclass Solution:\n def minimizedMaximum(self, n: int, quantities: List[int]) -> int:\n lo, hi = 1, max(quantities)\n while lo < hi: \n mid = lo + hi >> 1\n if sum(ceil(qty/mid) for qty in quantities) <= n: hi = mid \n else: lo = mid + 1\n return lo\n``` | 9 | You are given an integer `n` indicating there are `n` specialty retail stores. There are `m` product types of varying amounts, which are given as a **0-indexed** integer array `quantities`, where `quantities[i]` represents the number of products of the `ith` product type.
You need to distribute **all products** to the retail stores following these rules:
* A store can only be given **at most one product type** but can be given **any** amount of it.
* After distribution, each store will have been given some number of products (possibly `0`). Let `x` represent the maximum number of products given to any store. You want `x` to be as small as possible, i.e., you want to **minimize** the **maximum** number of products that are given to any store.
Return _the minimum possible_ `x`.
**Example 1:**
**Input:** n = 6, quantities = \[11,6\]
**Output:** 3
**Explanation:** One optimal way is:
- The 11 products of type 0 are distributed to the first four stores in these amounts: 2, 3, 3, 3
- The 6 products of type 1 are distributed to the other two stores in these amounts: 3, 3
The maximum number of products given to any store is max(2, 3, 3, 3, 3, 3) = 3.
**Example 2:**
**Input:** n = 7, quantities = \[15,10,10\]
**Output:** 5
**Explanation:** One optimal way is:
- The 15 products of type 0 are distributed to the first three stores in these amounts: 5, 5, 5
- The 10 products of type 1 are distributed to the next two stores in these amounts: 5, 5
- The 10 products of type 2 are distributed to the last two stores in these amounts: 5, 5
The maximum number of products given to any store is max(5, 5, 5, 5, 5, 5, 5) = 5.
**Example 3:**
**Input:** n = 1, quantities = \[100000\]
**Output:** 100000
**Explanation:** The only optimal way is:
- The 100000 products of type 0 are distributed to the only store.
The maximum number of products given to any store is max(100000) = 100000.
**Constraints:**
* `m == quantities.length`
* `1 <= m <= n <= 105`
* `1 <= quantities[i] <= 105` | null |
Simple Python solution using binary search | minimized-maximum-of-products-distributed-to-any-store | 0 | 1 | https://www.youtube.com/watch?v=wRO1kW7pQqA\n# Code\n```\n// youtube solution: https://www.youtube.com/watch?v=wRO1kW7pQqA\nclass Solution:\n def minimizedMaximum(self, n: int, quantities: List[int]) -> int:\n lo, hi, res = 1, max(quantities), -1\n\n while lo <= hi:\n mid = lo + (hi - lo)//2\n if self.can_work(quantities, mid, n):\n res = mid\n hi = mid - 1\n else:\n lo = mid + 1\n \n return res\n \n def can_work(self, quantities: List[int], item: int, total_stores: int) -> bool:\n need_store = 0\n \n for quantity in quantities:\n need_store += (quantity - 1)//item + 1\n if need_store > total_stores:\n return False\n \n return True\n``` | 0 | You are given an integer `n` indicating there are `n` specialty retail stores. There are `m` product types of varying amounts, which are given as a **0-indexed** integer array `quantities`, where `quantities[i]` represents the number of products of the `ith` product type.
You need to distribute **all products** to the retail stores following these rules:
* A store can only be given **at most one product type** but can be given **any** amount of it.
* After distribution, each store will have been given some number of products (possibly `0`). Let `x` represent the maximum number of products given to any store. You want `x` to be as small as possible, i.e., you want to **minimize** the **maximum** number of products that are given to any store.
Return _the minimum possible_ `x`.
**Example 1:**
**Input:** n = 6, quantities = \[11,6\]
**Output:** 3
**Explanation:** One optimal way is:
- The 11 products of type 0 are distributed to the first four stores in these amounts: 2, 3, 3, 3
- The 6 products of type 1 are distributed to the other two stores in these amounts: 3, 3
The maximum number of products given to any store is max(2, 3, 3, 3, 3, 3) = 3.
**Example 2:**
**Input:** n = 7, quantities = \[15,10,10\]
**Output:** 5
**Explanation:** One optimal way is:
- The 15 products of type 0 are distributed to the first three stores in these amounts: 5, 5, 5
- The 10 products of type 1 are distributed to the next two stores in these amounts: 5, 5
- The 10 products of type 2 are distributed to the last two stores in these amounts: 5, 5
The maximum number of products given to any store is max(5, 5, 5, 5, 5, 5, 5) = 5.
**Example 3:**
**Input:** n = 1, quantities = \[100000\]
**Output:** 100000
**Explanation:** The only optimal way is:
- The 100000 products of type 0 are distributed to the only store.
The maximum number of products given to any store is max(100000) = 100000.
**Constraints:**
* `m == quantities.length`
* `1 <= m <= n <= 105`
* `1 <= quantities[i] <= 105` | null |
BFS 177ms Beats 100.00%of users with Python3 | maximum-path-quality-of-a-graph | 0 | 1 | # Intuition\nGraph question - first think about using BFS\n\n# Approach\nBFS\n\n# Complexity\n\n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n\n graph = collections.defaultdict(list)\n for u, v, t in edges :\n graph[u].append((v,t))\n graph[v].append((u,t))\n\n queue = collections.deque([(0, 0, values[0], [0])]) # (node, time, totalVal, path)\n valList = [(-1,-1)]*len(values)\n valList[0] = (values[0], 0)\n output = 0\n while queue :\n node, curTime, curVal, visited = queue.popleft()\n if node == 0 :\n output = max(output, curVal)\n for nxt, t in graph[node] :\n if curTime + t > maxTime :\n continue\n nxtVal = curVal\n if nxt not in visited:\n nxtVal += values[nxt]\n #This is the condition that significantly reduces the runtime\n if curTime+t >= valList[nxt][1] and nxtVal < valList[nxt][0] :\n continue\n queue.append((nxt, curTime+t, nxtVal, visited + [nxt]))\n valList[nxt] = (nxtVal, curTime+t)\n return output\n\n``` | 1 | There is an **undirected** graph with `n` nodes numbered from `0` to `n - 1` (**inclusive**). You are given a **0-indexed** integer array `values` where `values[i]` is the **value** of the `ith` node. You are also given a **0-indexed** 2D integer array `edges`, where each `edges[j] = [uj, vj, timej]` indicates that there is an undirected edge between the nodes `uj` and `vj`, and it takes `timej` seconds to travel between the two nodes. Finally, you are given an integer `maxTime`.
A **valid** **path** in the graph is any path that starts at node `0`, ends at node `0`, and takes **at most** `maxTime` seconds to complete. You may visit the same node multiple times. The **quality** of a valid path is the **sum** of the values of the **unique nodes** visited in the path (each node's value is added **at most once** to the sum).
Return _the **maximum** quality of a valid path_.
**Note:** There are **at most four** edges connected to each node.
**Example 1:**
**Input:** values = \[0,32,10,43\], edges = \[\[0,1,10\],\[1,2,15\],\[0,3,10\]\], maxTime = 49
**Output:** 75
**Explanation:**
One possible path is 0 -> 1 -> 0 -> 3 -> 0. The total time taken is 10 + 10 + 10 + 10 = 40 <= 49.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 0 + 32 + 43 = 75.
**Example 2:**
**Input:** values = \[5,10,15,20\], edges = \[\[0,1,10\],\[1,2,10\],\[0,3,10\]\], maxTime = 30
**Output:** 25
**Explanation:**
One possible path is 0 -> 3 -> 0. The total time taken is 10 + 10 = 20 <= 30.
The nodes visited are 0 and 3, giving a maximal path quality of 5 + 20 = 25.
**Example 3:**
**Input:** values = \[1,2,3,4\], edges = \[\[0,1,10\],\[1,2,11\],\[2,3,12\],\[1,3,13\]\], maxTime = 50
**Output:** 7
**Explanation:**
One possible path is 0 -> 1 -> 3 -> 1 -> 0. The total time taken is 10 + 13 + 13 + 10 = 46 <= 50.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 1 + 2 + 4 = 7.
**Constraints:**
* `n == values.length`
* `1 <= n <= 1000`
* `0 <= values[i] <= 108`
* `0 <= edges.length <= 2000`
* `edges[j].length == 3`
* `0 <= uj < vj <= n - 1`
* `10 <= timej, maxTime <= 100`
* All the pairs `[uj, vj]` are **unique**.
* There are **at most four** edges connected to each node.
* The graph may not be connected. | null |
python super easy to understand dfs | maximum-path-quality-of-a-graph | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n \n \n graph = collections.defaultdict(set)\n time = {}\n for a, b, t in edges:\n time[(a,b)] = t\n time[(b,a)] = t\n graph[a].add(b)\n graph[b].add(a)\n ans = 0\n def dfs(root, t, visit, s):\n if t > maxTime:\n return\n if root == 0:\n nonlocal ans\n ans = max(ans, s)\n \n visit.add(root)\n for v in graph[root]:\n if v not in visit:\n dfs(v, t+time[(root,v)], set(visit), s+values[v])\n else:\n dfs(v,t+time[(root,v)], set(visit), s)\n \n \n dfs(0, 0, set(), values[0])\n return ans\n\n\n\n\n``` | 1 | There is an **undirected** graph with `n` nodes numbered from `0` to `n - 1` (**inclusive**). You are given a **0-indexed** integer array `values` where `values[i]` is the **value** of the `ith` node. You are also given a **0-indexed** 2D integer array `edges`, where each `edges[j] = [uj, vj, timej]` indicates that there is an undirected edge between the nodes `uj` and `vj`, and it takes `timej` seconds to travel between the two nodes. Finally, you are given an integer `maxTime`.
A **valid** **path** in the graph is any path that starts at node `0`, ends at node `0`, and takes **at most** `maxTime` seconds to complete. You may visit the same node multiple times. The **quality** of a valid path is the **sum** of the values of the **unique nodes** visited in the path (each node's value is added **at most once** to the sum).
Return _the **maximum** quality of a valid path_.
**Note:** There are **at most four** edges connected to each node.
**Example 1:**
**Input:** values = \[0,32,10,43\], edges = \[\[0,1,10\],\[1,2,15\],\[0,3,10\]\], maxTime = 49
**Output:** 75
**Explanation:**
One possible path is 0 -> 1 -> 0 -> 3 -> 0. The total time taken is 10 + 10 + 10 + 10 = 40 <= 49.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 0 + 32 + 43 = 75.
**Example 2:**
**Input:** values = \[5,10,15,20\], edges = \[\[0,1,10\],\[1,2,10\],\[0,3,10\]\], maxTime = 30
**Output:** 25
**Explanation:**
One possible path is 0 -> 3 -> 0. The total time taken is 10 + 10 = 20 <= 30.
The nodes visited are 0 and 3, giving a maximal path quality of 5 + 20 = 25.
**Example 3:**
**Input:** values = \[1,2,3,4\], edges = \[\[0,1,10\],\[1,2,11\],\[2,3,12\],\[1,3,13\]\], maxTime = 50
**Output:** 7
**Explanation:**
One possible path is 0 -> 1 -> 3 -> 1 -> 0. The total time taken is 10 + 13 + 13 + 10 = 46 <= 50.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 1 + 2 + 4 = 7.
**Constraints:**
* `n == values.length`
* `1 <= n <= 1000`
* `0 <= values[i] <= 108`
* `0 <= edges.length <= 2000`
* `edges[j].length == 3`
* `0 <= uj < vj <= n - 1`
* `10 <= timej, maxTime <= 100`
* All the pairs `[uj, vj]` are **unique**.
* There are **at most four** edges connected to each node.
* The graph may not be connected. | null |
[Python3] iterative dfs | maximum-path-quality-of-a-graph | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/6b6e6b9115d2b659e68dcf3ea8e21befefaae16c) for solutions of weekly 266. \n\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n graph = [[] for _ in values]\n for u, v, t in edges: \n graph[u].append((v, t))\n graph[v].append((u, t))\n \n ans = 0 \n stack = [(0, values[0], 0, 1)]\n while stack: \n time, val, u, mask = stack.pop()\n if u == 0: ans = max(ans, val)\n for v, t in graph[u]: \n if time + t <= maxTime: \n if not mask & 1<<v: stack.append((time+t, val+values[v], v, mask ^ 1<<v))\n else: stack.append((time+t, val, v, mask))\n return ans \n``` | 2 | There is an **undirected** graph with `n` nodes numbered from `0` to `n - 1` (**inclusive**). You are given a **0-indexed** integer array `values` where `values[i]` is the **value** of the `ith` node. You are also given a **0-indexed** 2D integer array `edges`, where each `edges[j] = [uj, vj, timej]` indicates that there is an undirected edge between the nodes `uj` and `vj`, and it takes `timej` seconds to travel between the two nodes. Finally, you are given an integer `maxTime`.
A **valid** **path** in the graph is any path that starts at node `0`, ends at node `0`, and takes **at most** `maxTime` seconds to complete. You may visit the same node multiple times. The **quality** of a valid path is the **sum** of the values of the **unique nodes** visited in the path (each node's value is added **at most once** to the sum).
Return _the **maximum** quality of a valid path_.
**Note:** There are **at most four** edges connected to each node.
**Example 1:**
**Input:** values = \[0,32,10,43\], edges = \[\[0,1,10\],\[1,2,15\],\[0,3,10\]\], maxTime = 49
**Output:** 75
**Explanation:**
One possible path is 0 -> 1 -> 0 -> 3 -> 0. The total time taken is 10 + 10 + 10 + 10 = 40 <= 49.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 0 + 32 + 43 = 75.
**Example 2:**
**Input:** values = \[5,10,15,20\], edges = \[\[0,1,10\],\[1,2,10\],\[0,3,10\]\], maxTime = 30
**Output:** 25
**Explanation:**
One possible path is 0 -> 3 -> 0. The total time taken is 10 + 10 = 20 <= 30.
The nodes visited are 0 and 3, giving a maximal path quality of 5 + 20 = 25.
**Example 3:**
**Input:** values = \[1,2,3,4\], edges = \[\[0,1,10\],\[1,2,11\],\[2,3,12\],\[1,3,13\]\], maxTime = 50
**Output:** 7
**Explanation:**
One possible path is 0 -> 1 -> 3 -> 1 -> 0. The total time taken is 10 + 13 + 13 + 10 = 46 <= 50.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 1 + 2 + 4 = 7.
**Constraints:**
* `n == values.length`
* `1 <= n <= 1000`
* `0 <= values[i] <= 108`
* `0 <= edges.length <= 2000`
* `edges[j].length == 3`
* `0 <= uj < vj <= n - 1`
* `10 <= timej, maxTime <= 100`
* All the pairs `[uj, vj]` are **unique**.
* There are **at most four** edges connected to each node.
* The graph may not be connected. | null |
[Python] DFS and BFS solution | maximum-path-quality-of-a-graph | 0 | 1 | DFS solution:\n```python\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n ans = 0\n graph = collections.defaultdict(dict)\n for u, v, t in edges:\n graph[u][v] = t\n graph[v][u] = t\n \n def dfs(curr, visited, score, cost):\n if curr == 0:\n nonlocal ans\n ans = max(ans, score)\n \n for nxt, time in graph[curr].items():\n if time <= cost:\n dfs(nxt, visited|set([nxt]), score+values[nxt]*(nxt not in visited), cost-time)\n \n dfs(0, set([0]), values[0], maxTime)\n return ans\n```\n\nBFS solution\n```python\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n ans = 0\n graph = collections.defaultdict(dict)\n for u,v,t in edges:\n graph[u][v] = t\n graph[v][u] = t\n \n # node, cost, visited, score\n q = collections.deque([(0, maxTime, set([0]), values[0])])\n while q:\n curr, cost, visited, score = q.popleft()\n if curr == 0:\n ans = max(ans, score)\n for nxt, time in graph[curr].items():\n if time > cost:\n continue\n q.append((nxt, cost-time, visited|set([nxt]), score + values[nxt]*(nxt not in visited)))\n\n return ans\n``` | 3 | There is an **undirected** graph with `n` nodes numbered from `0` to `n - 1` (**inclusive**). You are given a **0-indexed** integer array `values` where `values[i]` is the **value** of the `ith` node. You are also given a **0-indexed** 2D integer array `edges`, where each `edges[j] = [uj, vj, timej]` indicates that there is an undirected edge between the nodes `uj` and `vj`, and it takes `timej` seconds to travel between the two nodes. Finally, you are given an integer `maxTime`.
A **valid** **path** in the graph is any path that starts at node `0`, ends at node `0`, and takes **at most** `maxTime` seconds to complete. You may visit the same node multiple times. The **quality** of a valid path is the **sum** of the values of the **unique nodes** visited in the path (each node's value is added **at most once** to the sum).
Return _the **maximum** quality of a valid path_.
**Note:** There are **at most four** edges connected to each node.
**Example 1:**
**Input:** values = \[0,32,10,43\], edges = \[\[0,1,10\],\[1,2,15\],\[0,3,10\]\], maxTime = 49
**Output:** 75
**Explanation:**
One possible path is 0 -> 1 -> 0 -> 3 -> 0. The total time taken is 10 + 10 + 10 + 10 = 40 <= 49.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 0 + 32 + 43 = 75.
**Example 2:**
**Input:** values = \[5,10,15,20\], edges = \[\[0,1,10\],\[1,2,10\],\[0,3,10\]\], maxTime = 30
**Output:** 25
**Explanation:**
One possible path is 0 -> 3 -> 0. The total time taken is 10 + 10 = 20 <= 30.
The nodes visited are 0 and 3, giving a maximal path quality of 5 + 20 = 25.
**Example 3:**
**Input:** values = \[1,2,3,4\], edges = \[\[0,1,10\],\[1,2,11\],\[2,3,12\],\[1,3,13\]\], maxTime = 50
**Output:** 7
**Explanation:**
One possible path is 0 -> 1 -> 3 -> 1 -> 0. The total time taken is 10 + 13 + 13 + 10 = 46 <= 50.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 1 + 2 + 4 = 7.
**Constraints:**
* `n == values.length`
* `1 <= n <= 1000`
* `0 <= values[i] <= 108`
* `0 <= edges.length <= 2000`
* `edges[j].length == 3`
* `0 <= uj < vj <= n - 1`
* `10 <= timej, maxTime <= 100`
* All the pairs `[uj, vj]` are **unique**.
* There are **at most four** edges connected to each node.
* The graph may not be connected. | null |
Iterative DFS | Bitmask | Commented and Explained | maximum-path-quality-of-a-graph | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis is very similar to a house robbing problem. Due to this, much of the terminology in the intuition is similar. The nice thing about this problem for an interview, is there are actually a fair number of ways to approach it, and if thought out it can be done in an object oriented fashion quite readily. \n\nTo start, the first thing that is needed is a transformation of the edges list into a graph structure. As such, we can utilize the values list and the edges list to realize a graphical structure. For this, we chose an adjacency list format, which is a structural choice to be ready to defend. If you are asked for any optimization, a change from an adjacecny list format to a doubly linked list structure of the graph containing nodes would be a valid approach. This does make some traversal easier, but involves pointer methodology. It is not explained here; if needed, reach out and I can help with the design of such if it is not for a course or some such. If it is for a class, I can help with permission of your professor / instructor to a limited extent. \n\nOnce the graph has been transformed, we need a way to account for the possible states of our progression. Let\'s reframe the question as finding the best trick or treat path in a neighborhood, with the nodes as houses to visit, and edges as the driveways to walk down. \n\nWith this in mind, we can see that there might be a culdesac situation (a singular node with many branching edges from it like a center of a wheel spoke). If that is the case, then we need to be able to revisit the central node without trick or treating twice (that\'s usually frowned on). As such, we want the ability to revisit a node without retaking the value. We have a few options for this. One option is to store which paths have visited which node at each node. This would push memory into the node structure, and may have some use in the terms of the graphical structure IF it can be stored offline (ie not on the stack but in the heap). However, more commonly, it can be stored in a value that is heapped and is pulled when needed by being stored on the PATHS instead of on the NODES. This gives us an insight into how to store it. \n\nWe want a structure that can store the nodes visited as a singular value of limited memory size. It needs to be something easily accessed and queried. It needs to be something that can be of a size we need (10000+ items). From this, it is apparent that a bitmask is needed for the paths to record the visits. \n\nNow that we have the processing, we need to determine how to maximize. We know that we want a path that starts and ends at 0. So, how about whenever we do end up there, we have a maximization of answer. That will ensure our maximal trip is recorded succesfully. With the intuition so laid out we turn to implementation. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nBuild a graphical representation of the nodes and their edges as a list of lists for each node index in values where graph at node index -> list of node neighbors with edge cost of traversal. Do the same so that each node neighbor has an entry for the node index. Do this by looping over edges. \n\nSet answer to 0 \n\nA path node needs to have \n- The steps we have taken in total \n- The values we have gained in total (starting from node index at values at 0) \n- The current node index on the path \n- The current node ids visited already \n\nSet a stack containing a singular node from which all paths must start, namely a steps of 0, with a value of values at node index 0, with a node index of 0 and a visited ids that is set to 1 (more on why in a moment)\n\nThe reason why you need the visited ids set to 1 is that a 1 indicates in binary that the 0 index has been visited. You can think of this a string that will be as long as the values list and is all set to 0s originally except for index 0. This shows that we have visited the 0 node (already trick or treated if you will). By storing it numerically rather than lexicographically, we save on memory space, and can now process the visits using bitshifts. \n\nTo search the space then \n- While you have a stack \n - pop a path node from the stack and assign to the variables that follow : steps, value, src, visits as the steps on the current path that the path node represents, the value of the current path, the src as the current node at on the path, and visits as the node ids visited on the path\n - if src is 0 -> maximize the answer versus the value of the path \n - for destination and edge in graph at src \n - if steps + edge is lte our maxTime we can attempt this edge \n - For which, if we have not visited (more after the loop definition) \n - append to the stack a node that has the new steps time including this edge, the updated value, the updated src as this destination, and the updated mask to include the destinations node id \n - otherwise, append a node that simply includes traversal to this destination node \n\nAt the end you return the answer \n\nOn the use of bitmasks \n- This is a choice for optimization, but is not required. There are methods to get around this, but not many that are more optimal. To consider how it works, note that I\'ll use a string representation briefly here to make it more apparent. Consider the node string "00001". From this, we see that node 0 has been visited, but not nodes 1 -> 4. Note we read right to left for place values numerically. \n- In that case, if we take 00001 and take the and of it with 1 bitshifted by 1 \n - That is take 00001 & 10 \n - The result of which is 0 \n - This shows we have not visited \n - The reason it is 0 is that the numbers line up as below \n - 00001\n - 10\n - 00000\n - Notice how on the line up, we AND any values that stack. 1 AND 0 is 0 and so is 0 and 1. \n - The negation of this then says that we have not visited node 1. \n- Now consider if we take 00001 OR 1 << 1. This gives us 00011 \n- Now lets say we wish to revisit node 0. \n- In that case we take 00011 & 1 << 0 \n - 00011\n - 00001\n - 00001\n - This shows we have an output of 1, which means we HAVE visited node 0\n - So we now skip in the bitmask operation \n\nThere\'s some great articles on bitmasking out there to go over, but this is a nice clear example of its use. For more fun, consider how to let the maxTime range to find the maxTime needed to actually achieve maximal value gain, then minimize maxTime. That will lead to a traveling salesman issue, so if you get asked, that\'s a good thing to know and fall back on. \n\n# Complexity\n- Time complexity : O(max(P, E))\n - Takes O(E) to build graph \n - Takes O(P) to exhaust stack where P is the number of viable paths as constrained by maxTime. \n - O(P) is usually >> O(E). However, they can come close in some weird cases. \n - So, O(max(P, E)) \n\n- Space complexity : O(max(V*E, p))\n - We store O(V*E) and O(p) where p is the current viable paths of P. \n - Similar to above on maximums. \n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n # build graph of source dst and edge in problem \n graph = [[] for _ in values]\n for src, dst, edge in edges : \n graph[src].append((dst, edge))\n graph[dst].append((src, edge))\n \n # conduct search for answer \n answer = 0 \n # build stack of nodes to conduct repetitive visits from. \n # Due to the possible presence of spoke nodes, cannot exclude, but need to only rob once \n # Possible methods to account for : place value at node and deduct value at node, mask value at node, etc \n # Of these, bitmask is most appropriate and easiest to conduct, though difficult to understand. \n stack = [(0, values[0], 0, 1)]\n # while you have a stack \n while stack : \n # pop off the node in the stack, which stores : \n # steps (aka time) of node path, \n # value currently held by the node path, \n # src is the current node that the path is at (most recent node) \n # visits is a bitmask that records which nodes we have visited in num order form as a binary value \n steps, value, src, visits = stack.pop()\n # if the most current node is 0, we are either starting or have finished \n if src == 0 : \n # in that case, maximize answer versus value currently accumulated \n answer = max(answer, value) \n # for each neighbor of current node by way of edge travel \n for dst, edge in graph[src] : \n # if we can make it down the edge (regardless of if we can make it back) \n if steps + edge <= maxTime : \n # if we have not visited destination, aka visits & 1 << dst == 0\n if not visits & 1 << dst : \n # append to the stack a node that has\n # the updated time as steps + edge length \n # the update value to include visiting the unvisited node on this path \n # the new current node as the destination \n # the new visits as modified by the destination \n stack.append((steps+edge, value + values[dst], dst, visits^1<<dst))\n else : \n # otherwise, since we have visited, aka visits & 1 << dst == 1, append to the stack a node that\n # updates only the steps by the edge length \n stack.append((steps+edge, value, dst, visits))\n # after exhausting all possible trips, return the maximized answer \n return answer \n``` | 0 | There is an **undirected** graph with `n` nodes numbered from `0` to `n - 1` (**inclusive**). You are given a **0-indexed** integer array `values` where `values[i]` is the **value** of the `ith` node. You are also given a **0-indexed** 2D integer array `edges`, where each `edges[j] = [uj, vj, timej]` indicates that there is an undirected edge between the nodes `uj` and `vj`, and it takes `timej` seconds to travel between the two nodes. Finally, you are given an integer `maxTime`.
A **valid** **path** in the graph is any path that starts at node `0`, ends at node `0`, and takes **at most** `maxTime` seconds to complete. You may visit the same node multiple times. The **quality** of a valid path is the **sum** of the values of the **unique nodes** visited in the path (each node's value is added **at most once** to the sum).
Return _the **maximum** quality of a valid path_.
**Note:** There are **at most four** edges connected to each node.
**Example 1:**
**Input:** values = \[0,32,10,43\], edges = \[\[0,1,10\],\[1,2,15\],\[0,3,10\]\], maxTime = 49
**Output:** 75
**Explanation:**
One possible path is 0 -> 1 -> 0 -> 3 -> 0. The total time taken is 10 + 10 + 10 + 10 = 40 <= 49.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 0 + 32 + 43 = 75.
**Example 2:**
**Input:** values = \[5,10,15,20\], edges = \[\[0,1,10\],\[1,2,10\],\[0,3,10\]\], maxTime = 30
**Output:** 25
**Explanation:**
One possible path is 0 -> 3 -> 0. The total time taken is 10 + 10 = 20 <= 30.
The nodes visited are 0 and 3, giving a maximal path quality of 5 + 20 = 25.
**Example 3:**
**Input:** values = \[1,2,3,4\], edges = \[\[0,1,10\],\[1,2,11\],\[2,3,12\],\[1,3,13\]\], maxTime = 50
**Output:** 7
**Explanation:**
One possible path is 0 -> 1 -> 3 -> 1 -> 0. The total time taken is 10 + 13 + 13 + 10 = 46 <= 50.
The nodes visited are 0, 1, and 3, giving a maximal path quality of 1 + 2 + 4 = 7.
**Constraints:**
* `n == values.length`
* `1 <= n <= 1000`
* `0 <= values[i] <= 108`
* `0 <= edges.length <= 2000`
* `edges[j].length == 3`
* `0 <= uj < vj <= n - 1`
* `10 <= timej, maxTime <= 100`
* All the pairs `[uj, vj]` are **unique**.
* There are **at most four** edges connected to each node.
* The graph may not be connected. | null |
93.5% Time beat | check-whether-two-strings-are-almost-equivalent | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n # create combined string with all ch from word1 and word2\n combined = set(word1+word2)\n # for unique ch in combined create dictionary that counts freq of each ch in each word \n d1 = {x:word1.count(x) for x in combined}\n d2 = {x:word2.count(x) for x in combined}\n # create flag to determine if freq diff >3\n flag = True\n for key, val in d1.items():\n #compare freq for word1 and word2 if flag turns false break and return flag val\n if abs(d1[key] - d2[key]) > 3:\n flag = False\n break\n return flag\n\n\n``` | 1 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
[Python] Learn the use of any() and character count using array | Concise Code | check-whether-two-strings-are-almost-equivalent | 0 | 1 | # Code\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n A = [0] * 26\n for char in word1: A[ord(char) - ord("a")] += 1\n for char in word2: A[ord(char) - ord("a")] -= 1\n return not any ([(f < -3 or f > 3) for f in A]) \n\n``` | 3 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
Check Whether Two Strings are Almost Equivalent | check-whether-two-strings-are-almost-equivalent | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n check = set(word1 + word2)\n for i in check:\n limit = abs(word1.count(i) - word2.count(i)) >= 4\n if limit:\n return False\n return True\n\n``` | 2 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
Python one line counter solution | check-whether-two-strings-are-almost-equivalent | 0 | 1 | **Python :**\n\n```\ndef checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n\treturn all(v <= 3 for v in ((Counter(list(word1)) - Counter(list(word2))) + (Counter(list(word2)) - Counter(list(word1)))).values())\n```\n\n**Like it ? please upvote !** | 12 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
Python3 simple solution | check-whether-two-strings-are-almost-equivalent | 0 | 1 | # Code\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n words = set(word1 + word2)\n for w in words:\n if abs(word1.count(w) - word2.count(w)) >3:\n return False\n return True\n\n``` | 5 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
[Python] - Concise Array Solution - No Counter/Hash-Map - Beats 98% | check-whether-two-strings-are-almost-equivalent | 0 | 1 | Most solution are using a hash map/Counter to count the occurences for every word itself and then compare these counters.\n\nBut since the alphabet is limited to 26 characters, we can just do the same using an array and do it in one pass through both words at the same time. This allows us to make one pass instead of two (for two counters) and we don\'t need to subtract the values of the same hashes.\n\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n \n # make an array to track occurences for every letter of the\n # alphabet\n alphabet = [0]*26\n \n # go through both words and count occurences\n # word 1 add and word 2 subtract\n # after this we have the differences for every letter\n for index in range(len(word1)):\n alphabet[ord(word1[index]) - 97] += 1\n alphabet[ord(word2[index]) - 97] -= 1\n \n # find min and max and check that it is less than three\n return min(alphabet) >= -3 and max(alphabet) <= 3\n``` | 10 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
Easy Solution - Beats 100% | check-whether-two-strings-are-almost-equivalent | 0 | 1 | # Code\n```\nclass Solution:\n def checkAlmostEquivalent(self, word1: str, word2: str) -> bool:\n check = set(word1 + word2)\n\n for i in check:\n res = abs(word1.count(i) - word2.count(i)) >= 4\n if res:\n return False\n return True\n``` | 2 | Two strings `word1` and `word2` are considered **almost equivalent** if the differences between the frequencies of each letter from `'a'` to `'z'` between `word1` and `word2` is **at most** `3`.
Given two strings `word1` and `word2`, each of length `n`, return `true` _if_ `word1` _and_ `word2` _are **almost equivalent**, or_ `false` _otherwise_.
The **frequency** of a letter `x` is the number of times it occurs in the string.
**Example 1:**
**Input:** word1 = "aaaa ", word2 = "bccb "
**Output:** false
**Explanation:** There are 4 'a's in "aaaa " but 0 'a's in "bccb ".
The difference is 4, which is more than the allowed 3.
**Example 2:**
**Input:** word1 = "abcdeef ", word2 = "abaaacc "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 1 time in word1 and 4 times in word2. The difference is 3.
- 'b' appears 1 time in word1 and 1 time in word2. The difference is 0.
- 'c' appears 1 time in word1 and 2 times in word2. The difference is 1.
- 'd' appears 1 time in word1 and 0 times in word2. The difference is 1.
- 'e' appears 2 times in word1 and 0 times in word2. The difference is 2.
- 'f' appears 1 time in word1 and 0 times in word2. The difference is 1.
**Example 3:**
**Input:** word1 = "cccddabba ", word2 = "babababab "
**Output:** true
**Explanation:** The differences between the frequencies of each letter in word1 and word2 are at most 3:
- 'a' appears 2 times in word1 and 4 times in word2. The difference is 2.
- 'b' appears 2 times in word1 and 5 times in word2. The difference is 3.
- 'c' appears 3 times in word1 and 0 times in word2. The difference is 3.
- 'd' appears 2 times in word1 and 0 times in word2. The difference is 2.
**Constraints:**
* `n == word1.length == word2.length`
* `1 <= n <= 100`
* `word1` and `word2` consist only of lowercase English letters. | How can we use a trie to store all the XOR values in the path from a node to the root? How can we dynamically add the XOR values with a DFS search? |
NOT BAD | walking-robot-simulation-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Robot:\n\n def __init__(self, width: int, height: int):\n self.dir="East"\n self.cor=[0,0]\n self.arr=[width-1,height-1]\n self.width=width\n self.height=height\n\n def step(self, num: int) -> None:\n total=((self.height+self.width-2)*2)\n num=num%total\n if num!=0:\n i=0\n while i<num:\n if self.dir=="East":\n if self.cor[0]==self.width-1:\n num+=1\n self.dir="North"\n else:self.cor[0]+=1\n\n elif self.dir=="West":\n if self.cor[0]==0:\n num+=1\n self.dir="South"\n else:self.cor[0]-=1\n elif self.dir=="North":\n if self.cor[1]==self.height-1:\n num+=1\n self.dir="West"\n else:self.cor[1]+=1\n elif self.dir=="South":\n if self.cor[1]==0:\n num+=1\n self.dir="East"\n else:self.cor[1]-=1\n i+=1 \n elif self.cor==[0,0] and self.dir=="East":self.dir="South"\n \n def getPos(self) -> List[int]:\n return self.cor\n\n def getDir(self) -> str:\n return self.dir\n\n\n# Your Robot object will be instantiated and called as such:\n# obj = Robot(width, height)\n# obj.step(num)\n# param_2 = obj.getPos()\n# param_3 = obj.getDir()\n``` | 1 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
O(1) Easy Solution | walking-robot-simulation-ii | 0 | 1 | # Approach\nI represent the outer edge of the grid as a continuous circular array and store the position of the robot on that array as the index.\n\n\n# Complexity\n- Time complexity:\n\nAll functions are $$O(1)$$\n\n- Space complexity:\n\nAll functions are $$O(1)$$\n\n# Code\n```\nclass Robot:\n\n def __init__(self, width: int, height: int):\n self.pos = 0\n self.dir = 0\n self.dirs = {0: "East", 1: "North", 2: "West", 3: "South"}\n self.width = width - 1\n self.height = height - 1\n self.mid = height + width - 2\n\n def step(self, num: int) -> None:\n self.pos += num\n self.pos %= (self.mid * 2)\n if self.pos > self.mid + self.width:\n self.dir = 3\n elif self.pos > self.mid:\n self.dir = 2\n elif self.pos > self.width:\n self.dir = 1\n elif not self.pos:\n self.dir = 3\n else:\n self.dir = 0\n\n def getPos(self) -> List[int]:\n if self.pos > self.mid + self.width:\n return [0,self.height - (self.pos - self.mid - self.width)]\n elif self.pos > self.mid:\n return [self.width - (self.pos - self.mid) ,self.height]\n elif self.pos > self.width:\n return [self.width, self.pos - self.width ]\n else:\n return [self.pos,0]\n\n def getDir(self) -> str:\n return self.dirs[self.dir]\n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
Easy to understand python solution | walking-robot-simulation-ii | 0 | 1 | \n\n# Complexity\n- Time complexity: O((m+n)*num) i.e O(n^2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(m*n) i.e O(n^2)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom typing import List\n\nclass Robot:\n def __init__(self, width: int, height: int):\n self.width = width\n self.height = height\n self.pos_array = [[0, 0]]\n self.dir_array = [\'East\']\n\n def reset_class(self):\n self.pos_array = [[0, 0]]\n self.dir_array = [\'East\']\n\n def step(self, num: int) -> None:\n m, n = self.width - 1, self.height - 1\n pos = self.pos_array[-1]\n diri = self.dir_array[-1]\n\n while num != 0:\n peri = 2 * (m + n + 2) - 4\n\n if num > peri:\n rem = num % peri\n num = rem\n if num == 0:\n if pos[0] == 0 and pos[1] == 0:\n self.dir_array.append("South")\n elif pos[0] == m and pos[1] == 0:\n self.dir_array.append("East")\n elif pos[0] == m and pos[1] == n:\n self.dir_array.append("North")\n elif pos[0] == 0 and pos[1] == n:\n self.dir_array.append("West")\n else:\n if pos[0] == 0 and pos[1] == 0:\n if diri != "East":\n self.dir_array.append("East")\n if num > m:\n pos[0] = pos[0] + m\n num = num - m\n self.dir_array.append("North")\n else:\n pos[0] = pos[0] + num\n num = 0\n\n elif pos[0] == m and pos[1] == 0:\n if diri != "North":\n self.dir_array.append("North")\n if num > n:\n pos[1] = pos[1] + n\n num = num - n\n self.dir_array.append("West")\n else:\n pos[1] = pos[1] + num\n num = 0\n\n elif pos[0] == m and pos[1] == n:\n if diri != "West":\n self.dir_array.append("West")\n if num > m:\n pos[0] = pos[0] - m\n num = num - m\n self.dir_array.append("South")\n else:\n pos[0] = pos[0] - num\n num = 0\n\n elif pos[0] == 0 and pos[1] == n:\n if diri != "South":\n self.dir_array.append("South")\n if num > n:\n pos[1] = pos[1] - n\n num = num - n\n self.dir_array.append("East")\n else:\n pos[1] = pos[1] - num\n num = 0\n\n elif diri == "East":\n right_m = m - pos[0]\n if num > right_m:\n pos[0] += right_m\n num = num - right_m\n self.dir_array.append("North")\n else:\n pos[0] += num\n num = 0\n\n elif diri == "North":\n top_n = n - pos[1]\n if num > top_n:\n pos[1] += top_n\n num -= top_n\n self.dir_array.append("West")\n else:\n pos[1] += num\n num = 0\n\n elif diri == "West":\n left_m = pos[0]\n if num > left_m:\n pos[0] -= left_m\n num = num - left_m\n self.dir_array.append("South")\n else:\n pos[0] -= num\n num = 0\n\n elif diri == "South":\n bottom_n = pos[1]\n if num > bottom_n:\n pos[1] -= bottom_n\n num -= bottom_n\n self.dir_array.append("East")\n else:\n pos[1] -= num\n num = 0\n\n def getPos(self) -> List[int]:\n return self.pos_array[-1]\n\n def getDir(self) -> str:\n return self.dir_array[-1]\n\n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
Python Solution with explanation and comments on code | walking-robot-simulation-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe start moving the robot first by one turn around the board. When the robot moves one turn, it doesn\'t change the direction either, only in case if its current location was [0,0], then we need to make sure the direction will be saved as \'South\', since the initial location is [0,0] and the direction is \'East\'\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe save the current location and current direction of the robot at any moment. That would make the implementation of ```getPos``` and ```getDir``` easier. For implementing the ```step``` we calculate the number of moves for the robot to turn one round on the board, if the number of steps is greater than that, we can divide number by the moves that takes for one turn. This will either result in 0 or a reminder which is less than a turn. We then start moving the robot by maximum possible move in the current direction till steps reaches zero.\n\n# Code\n```\nclass Robot:\n\n def __init__(self, width: int, height: int):\n self.width = width - 1\n self.height = height - 1\n # find the next direction\n self.next_dir = {\n \'East\': \'North\',\n \'North\': \'West\',\n \'West\': \'South\',\n \'South\': \'East\'\n }\n # moves based on current direction\n self.moves = {\n \'East\': [1, 0],\n \'North\': [0, 1],\n \'West\': [-1, 0],\n \'South\': [0, -1]\n }\n\n # current loc and direction\n self.loc = [0, 0]\n self.dir = \'East\'\n\n # moving one turn in the board\n self.one_turn = self.width * 2 + self.height * 2\n\n def step(self, num: int) -> None:\n\n # Calculate the number of turns\n if num > self.one_turn:\n num = num - (num // self.one_turn) * self.one_turn\n\n # Only happens for [0, 0] since the initial direction is [0,0]\n # and the direction is East instead of South\n if num == 0 and self.loc == [0, 0]:\n self.dir = \'South\'\n\n # Move the robot maximum each time \n while num > 0:\n cur_move = self.moves[self.dir]\n max_move = min(self.max_move_dir(), num)\n num -= max_move\n new_width, new_height = self.loc[0] + cur_move[0] * max_move, self.loc[1] + cur_move[1] * max_move\n self.loc = [new_width, new_height]\n # only if there is still move, we need to change the direction\n if num > 0:\n self.dir = self.next_dir[self.dir]\n\n # return the maximum move the robot can make in the direction\n def max_move_dir(self):\n if self.dir == \'East\':\n return self.width - self.loc[0]\n if self.dir == \'North\':\n return self.height - self.loc[1]\n if self.dir == \'West\':\n return self.loc[0] - 0\n if self.dir == \'South\':\n return self.loc[1] - 0\n\n def getPos(self) -> List[int]:\n return self.loc\n\n def getDir(self) -> str:\n return self.dir\n\n\n# Your Robot object will be instantiated and called as such:\n# obj = Robot(width, height)\n# obj.step(num)\n# param_2 = obj.getPos()\n# param_3 = obj.getDir()\n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
O(1) Laps on the edge + initial direction edge case | walking-robot-simulation-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe robot only moves around the edge of the grid in counterclockwise laps.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nA lap consists of `2 * (width + height - 2)` steps because the robot doesn\'t skip a move at the corners.\n\nThe current position of the robot can be encoded as a number (`lapSquare`) in the range `[0, lap)`, so to implement `step` we increment by `num` and wrap around with `% lap`.\n\nThe function `getPos` decodes this number by checking which edge of the grid it lies on and how far along that edge it travelled.\n\nThe direction can be inferred from the position but we need to be careful at the corners. There is an edge case at the initial position when the robot is at `(0, 0)` but facing `"East"` while in every following lap the robot will be facing `"South"` when it is at `(0, 0)`. We take care of that with the `init` flag.\n\n# Complexity\n- Time complexity: `step`: O(1), `getPos`: O(1), `getDir`: O(1), `__init__`: O(1)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Robot:\n\n def __init__(self, width: int, height: int):\n self.lapSquare = 0\n self.lap = 2 * (width + height - 2)\n self.width = width - 1\n self.height = height - 1\n self.init = True\n\n def step(self, num: int) -> None:\n self.lapSquare = (self.lapSquare + num) % self.lap\n self.init = False\n\n def getPos(self) -> List[int]:\n if self.lapSquare <= self.width:\n return [self.lapSquare, 0]\n if self.lapSquare <= self.width + self.height:\n return [self.width, self.lapSquare - self.width]\n if self.lapSquare <= 2 * self.width + self.height:\n return [2 * self.width + self.height - self.lapSquare, self.height]\n return [0, self.lap - self.lapSquare]\n \n def getDir(self) -> str:\n if self.lapSquare == 0 and not self.init:\n return "South"\n if 0 <= self.lapSquare <= self.width:\n return "East"\n if self.lapSquare <= self.width + self.height:\n return "North"\n if self.lapSquare <= 2 * self.width + self.height:\n return "West"\n return "South"\n\n# Your Robot object will be instantiated and called as such:\n# obj = Robot(width, height)\n# obj.step(num)\n# param_2 = obj.getPos()\n# param_3 = obj.getDir()\n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
Beats 90 % on python | walking-robot-simulation-ii | 0 | 1 | \n```\nclass Robot:\n\n def __init__(self, width, height):\n \n from collections import deque \n self.width = height\n self.height = width \n self.directions=deque([ (0,1) ,(1,0),(0,-1),(-1,0) ]) \n self.pos=(0,0)\n self.hashmap = {(0,1):\'East\',(1,0):\'North\',(0,-1):\'West\',(-1,0):\'South\'}\n self.pos_dir,self.distance = {},{}\n steps = 0 \n self.flag = False\n\n for i in range(2 *(self.width + self.height-2)):\n steps +=1\n x,y = self.pos \n i,j = self.directions[0]\n if not 0<=x+i<=self.width -1 or not 0<=y + j <=self.height - 1:self.directions.append(self.directions.popleft())\n self.pos = x+self.directions[0][0],y+self.directions[0][-1]\n self.pos_dir[steps]=(self.pos,self.hashmap[self.directions[0]])\n self.distance[self.pos]=steps\n self.pos_dir[0]=((0,0),\'South\')\n self.distance[0,0]=0\n\n def step(self, num): \n if not self.flag:self.flag = True\n num +=self.distance[self.pos]\n num=num% (2 *(self.width + self.height-2))\n self.pos = self.pos_dir[num][0]\n\n def getPos(self):return self.pos[1],self.pos[0]\n def getDir(self):return self.pos_dir[self.distance[self.pos]][1] if self.flag else \'East\'\n \n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
Pure simulation with modulo , still slow but simple . | walking-robot-simulation-ii | 0 | 1 | \n```\nclass Robot:\n\n def __init__(self, width, height):\n \n from collections import deque \n self.width = height\n self.height = width \n self.directions=deque([ (0,1) ,(1,0),(0,-1),(-1,0) ]) \n self.pos=(0,0)\n self.hashmap = {(0,1):\'East\',(1,0):\'North\',(0,-1):\'West\',(-1,0):\'South\'}\n\n def step(self, num):\n num = num % (2 *(self.width + self.height-2))\n if not num :num = 2 *(self.width + self.height-2)\n\n for i in range(num):\n x,y = self.pos \n i,j = self.directions[0]\n if not 0<=x+i<=self.width -1 or not 0<=y + j <=self.height - 1:self.directions.append(self.directions.popleft())\n self.pos = x+self.directions[0][0],y+self.directions[0][-1]\n \n def getPos(self):return self.pos[1],self.pos[0]\n\n def getDir(self):return self.hashmap[self.directions[0]]\n \n``` | 0 | A `width x height` grid is on an XY-plane with the **bottom-left** cell at `(0, 0)` and the **top-right** cell at `(width - 1, height - 1)`. The grid is aligned with the four cardinal directions ( `"North "`, `"East "`, `"South "`, and `"West "`). A robot is **initially** at cell `(0, 0)` facing direction `"East "`.
The robot can be instructed to move for a specific number of **steps**. For each step, it does the following.
1. Attempts to move **forward one** cell in the direction it is facing.
2. If the cell the robot is **moving to** is **out of bounds**, the robot instead **turns** 90 degrees **counterclockwise** and retries the step.
After the robot finishes moving the number of steps required, it stops and awaits the next instruction.
Implement the `Robot` class:
* `Robot(int width, int height)` Initializes the `width x height` grid with the robot at `(0, 0)` facing `"East "`.
* `void step(int num)` Instructs the robot to move forward `num` steps.
* `int[] getPos()` Returns the current cell the robot is at, as an array of length 2, `[x, y]`.
* `String getDir()` Returns the current direction of the robot, `"North "`, `"East "`, `"South "`, or `"West "`.
**Example 1:**
**Input**
\[ "Robot ", "step ", "step ", "getPos ", "getDir ", "step ", "step ", "step ", "getPos ", "getDir "\]
\[\[6, 3\], \[2\], \[2\], \[\], \[\], \[2\], \[1\], \[4\], \[\], \[\]\]
**Output**
\[null, null, null, \[4, 0\], "East ", null, null, null, \[1, 2\], "West "\]
**Explanation**
Robot robot = new Robot(6, 3); // Initialize the grid and the robot at (0, 0) facing East.
robot.step(2); // It moves two steps East to (2, 0), and faces East.
robot.step(2); // It moves two steps East to (4, 0), and faces East.
robot.getPos(); // return \[4, 0\]
robot.getDir(); // return "East "
robot.step(2); // It moves one step East to (5, 0), and faces East.
// Moving the next step East would be out of bounds, so it turns and faces North.
// Then, it moves one step North to (5, 1), and faces North.
robot.step(1); // It moves one step North to (5, 2), and faces **North** (not West).
robot.step(4); // Moving the next step North would be out of bounds, so it turns and faces West.
// Then, it moves four steps West to (1, 2), and faces West.
robot.getPos(); // return \[1, 2\]
robot.getDir(); // return "West "
**Constraints:**
* `2 <= width, height <= 100`
* `1 <= num <= 105`
* At most `104` calls **in total** will be made to `step`, `getPos`, and `getDir`. | How can you compute the number of subarrays with a sum less than a given value? Can we use binary search to help find the answer? |
[Python3] - Sort + Binary Search - Easy to understand | most-beautiful-item-for-each-query | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nProblem said `price is less than or equal` so it means we can think about sorting by `price` and then do binary search to find `price is less than or equal` to the `queries[j]`. But it is not only that simple. In here we have to find the maximum `beauty` for all the price less than or equal to `queries[j]`. Assume the highest `price` in `items` that is <= `queries[j]` is at index `i`. we can easily get that `max beauty = items[k][1] for 0 <= k <= i` \n- So we must find the max beauty in range from 0 to i for the `queries[j]`\n \n# Approach\n<!-- Describe your approach to solving the problem. -->\n- Sort items by price - $O(nlogn)$\n- update the beauty for index i in items = `max(items[x] for x in range(i + 1))` - $O(n)$\n- for each query, binary search for the highest item which has price `<=` this query\'s value, then add to final result the `max beauty` in range `first query to current querry` - $O(nlogn)$\n\n# Complexity\n- Time complexity: $O(nlogn + n + nlogn)$ ~ $O(nlogn)$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $O(1)$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n items.sort()\n n = len(items)\n res = []\n for i in range(1, n):\n items[i][1] = max(items[i][1], items[i - 1][1])\n\n for q in queries:\n l, r = 0, n - 1\n while l <= r:\n m = (l + r) >> 1\n p, b = items[m]\n if p > q: r = m - 1\n else: l = m + 1\n res.append(items[r][1] if r >= 0 else 0)\n return res\n``` | 5 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
Python3 | Solved Using Sorting + Binary Search | most-beautiful-item-for-each-query | 0 | 1 | ```\nclass Solution:\n #Let n = len(items) and m = len(queries)!\n #Time-Complexity: O(nlog(n) + n + m*log(n)) -> O((n+m) * logn)\n #Space-Complexity: O(1)\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n #First of all, I need to sort the list of items by the increasing price!\n items.sort(key = lambda x: x[0])\n #initialize empty ans array!\n ans = []\n \n #iterate through each and every item and update the beauty of item to reflect\n #the maximum beauty seen so far! This is so that answering the query becomes\n #more convenient!\n bestBeauty = float(-inf)\n for i in range(len(items)):\n bestBeauty = max(bestBeauty, items[i][1])\n items[i][1] = bestBeauty\n #now, for each query, we can perform binary search to get the maximum beauty\n #of item out of all items whose price is less or equal to the queried price!\n for query in queries:\n #initialize search space!\n L, R = 0, len(items) - 1\n #as long as binary search has at least one element to consider,\n #continue iterations of binary search!\n maxBeauty = 0\n while L <= R:\n mid = (L + R) // 2\n mid_item = items[mid]\n if(mid_item[0] <= query):\n maxBeauty = max(maxBeauty, mid_item[1])\n L = mid + 1\n continue\n else:\n R = mid - 1\n continue\n #check if we don\'t have answer to current query!\n if(L == 0):\n ans.append(0)\n continue\n ans.append(maxBeauty)\n return ans | 0 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
📌📌 Well-Explained || 99% faster || Mainly for Beginners 🐍 | most-beautiful-item-for-each-query | 0 | 1 | ## IDEA :\n\n* Step 1. Sort the items by price, O(nlog)\n\n* Step 2. Iterate items, find maximum value up to now, O(n) and store the max value in dictionary(MAP) here `dic`.\n* Step 3. For each queries, binary search the maximum beauty, O(log k) in key of the map which we formed and append the max value of the query from dictionary in O(1) .\n* Step 4. Whole process is doen in `O(q+n)` though.\n\n**Impementation :**\n\'\'\'\n\n\tclass Solution:\n\t\tdef maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n\n\t\t\titems.sort()\n\t\t\tdic = dict()\n\t\t\tres = []\n\t\t\tgmax = 0\n\t\t\tfor p,b in items:\n\t\t\t\tgmax = max(b,gmax)\n\t\t\t\tdic[p] = gmax\n\n\t\t\tkeys = sorted(dic.keys())\n\t\t\tfor q in queries:\n\t\t\t\tind = bisect.bisect_left(keys,q)\n\t\t\t\tif ind<len(keys) and keys[ind]==q:\n\t\t\t\t\tres.append(dic[q])\n\t\t\t\telif ind==0:\n\t\t\t\t\tres.append(0)\n\t\t\t\telse:\n\t\t\t\t\tres.append(dic[keys[ind-1]])\n\n\t\t\treturn res\n\t\n### \tThanks and Upvote if you like the Idea !!\u270C | 5 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
[Python3] greedy | most-beautiful-item-for-each-query | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/e61879b77928a08bb15cc182a69259d6e2bce59a) for solutions of biweekly 65. \n```\nclass Solution:\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n items.sort()\n ans = [0]*len(queries)\n prefix = ii = 0 \n for x, i in sorted((x, i) for i, x in enumerate(queries)): \n while ii < len(items) and items[ii][0] <= x: \n prefix = max(prefix, items[ii][1])\n ii += 1\n ans[i] = prefix\n return ans \n``` | 4 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
Python Sorting - Concise and Easy to Understand | most-beautiful-item-for-each-query | 0 | 1 | # Intuition\n1 Since we need to query by less and equal, that we want to use binary search. To do binary Search we need to sort the items.\n\n2 Only Binary Search can\'t ensure the beauty is max, given the below case\n((1, 3), (2, 2))\nNeed to update the beauty to max on the left.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\nO(nlogn) + O(qlogn)\n- Space complexity:\nO(n) search + O(n) the newIteams\n\n# Code\n```\nclass Solution:\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n \n # sort items by prices\n new_items = sorted(items, key= lambda x:(x[0], x[1]))\n\n # update the price of item to the max price on the left\n currMax = 0\n for i in range(0, len(items)):\n new_items[i][1] = max(currMax, new_items[i][1])\n currMax = new_items[i][1]\n\n # binary search the last occurency of price (bisect_right - 1) \n ans = []\n for query in queries:\n index = bisect_right(new_items, query, key = lambda x:x[0])\n ans.append(new_items[index - 1][1] if index != 0 else 0)\n\n return ans\n``` | 0 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
Simple sort + max heap solution | most-beautiful-item-for-each-query | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFor each query, we\'ll need to get the max value but iterating the array each time is expensive. Using a simple heap should help us with getting the max value so far.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nSort both the arrays.\nAt a given query, push all the beauty available for price <= query.\nAdd the max value to the heap.\n\nNote the indices of the query as the answer is expected to be in that order.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(nlogn) + O(klogk)\nnlogn -> to sort items\nnlogk -> to sort queries\n\nlogn * n for inserting to heap each time\nk - iterating over the queries.\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n) -> Stores at max n elements in the queue.\n\nWhat do you think? There seems to be a better BS solution.\n\n# Code\n```\nclass Solution:\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n items.sort()\n sorted_queries = sorted([[q, i] for i, q in enumerate(queries)])\n max_heap = []\n n = len(items)\n i = 0\n ans = [0]*len(queries)\n for query, j in sorted_queries:\n while i < n and items[i][0] <= query:\n heapq.heappush(max_heap, items[i][1]*-1)\n i += 1\n ans[j] = max_heap[0]*-1 if max_heap else 0\n return ans\n \n``` | 0 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
Binary Search | most-beautiful-item-for-each-query | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maximumBeauty(self, items: List[List[int]], queries: List[int]) -> List[int]:\n ans = []\n items.sort()\n\n highest = float(-inf)\n for i in range(len(items)): \n items[i][1] = max(highest, items[i][1])\n highest = max(highest, items[i][1]) \n\n for q in queries:\n l, r = 0, len(items)\n while l < r:\n mid = (l + r) // 2\n if items[mid][0] > q:\n r = mid\n else:\n l = mid + 1 \n ans.append(items[l-1][1] if l > 0 else 0) \n return ans \n``` | 0 | You are given a 2D integer array `items` where `items[i] = [pricei, beautyi]` denotes the **price** and **beauty** of an item respectively.
You are also given a **0-indexed** integer array `queries`. For each `queries[j]`, you want to determine the **maximum beauty** of an item whose **price** is **less than or equal** to `queries[j]`. If no such item exists, then the answer to this query is `0`.
Return _an array_ `answer` _of the same length as_ `queries` _where_ `answer[j]` _is the answer to the_ `jth` _query_.
**Example 1:**
**Input:** items = \[\[1,2\],\[3,2\],\[2,4\],\[5,6\],\[3,5\]\], queries = \[1,2,3,4,5,6\]
**Output:** \[2,4,5,5,6,6\]
**Explanation:**
- For queries\[0\]=1, \[1,2\] is the only item which has price <= 1. Hence, the answer for this query is 2.
- For queries\[1\]=2, the items which can be considered are \[1,2\] and \[2,4\].
The maximum beauty among them is 4.
- For queries\[2\]=3 and queries\[3\]=4, the items which can be considered are \[1,2\], \[3,2\], \[2,4\], and \[3,5\].
The maximum beauty among them is 5.
- For queries\[4\]=5 and queries\[5\]=6, all items can be considered.
Hence, the answer for them is the maximum beauty of all items, i.e., 6.
**Example 2:**
**Input:** items = \[\[1,2\],\[1,2\],\[1,3\],\[1,4\]\], queries = \[1\]
**Output:** \[4\]
**Explanation:**
The price of every item is equal to 1, so we choose the item with the maximum beauty 4.
Note that multiple items can have the same price and/or beauty.
**Example 3:**
**Input:** items = \[\[10,1000\]\], queries = \[5\]
**Output:** \[0\]
**Explanation:**
No item has a price less than or equal to 5, so no item can be chosen.
Hence, the answer to the query is 0.
**Constraints:**
* `1 <= items.length, queries.length <= 105`
* `items[i].length == 2`
* `1 <= pricei, beautyi, queries[j] <= 109` | Keep looking for 3-equals, if you find a 3-equal, keep going. If you don't find a 3-equal, check if it is a 2-equal. Make sure that it is the only 2-equal. If it is neither a 3-equal nor a 2-equal, then it is impossible. |
Binary Search + Linear Greedy in Python3 | maximum-number-of-tasks-you-can-assign | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis solution employs binary search to find the largest $k$ so that $k$ tasks can be completed by $k$ workers. To check if $k$ tasks can be completed, this solution performs an efficient linear time greedy algorithm by using a monotonic queue. Thus, the complexity of the whole procedure is only $O(N \\log N)$ without the use of binary search tree or heap. \n\n# Complexity\n- Time complexity: $O(N \\log N)$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $O(N)$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxTaskAssign(self, tasks: List[int], workers: List[int], pills: int, strength: int) -> int:\n tasks.sort()\n workers.sort()\n\n def valid(m):\n wrkrs = deque(workers[-m:])\n pilled = deque()\n not_pilled = deque()\n p = pills\n for t in tasks[:m]:\n while wrkrs and wrkrs[0] < t:\n if p == 0 or wrkrs[0] + strength < t:\n return False\n pilled.append(wrkrs.popleft() + strength)\n p -= 1\n while not_pilled and (p == 0 or not_pilled[0] + strength < t):\n not_pilled.popleft()\n if pilled and ((not wrkrs) or pilled[0] <= wrkrs[0]):\n if pilled[0] >= t:\n pilled.popleft()\n elif not_pilled and p > 0:\n not_pilled.popleft()\n pilled.popleft()\n p -= 1\n else:\n return False\n elif wrkrs:\n not_pilled.append(wrkrs.popleft())\n else:\n return False \n return True\n\n l, r = 1, min(len(tasks), len(workers)) + 1\n while l < r:\n m = (l + r) // 2\n if valid(m):\n l = m + 1\n else:\n r = m\n return l - 1\n``` | 0 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
[Python3] binary search | maximum-number-of-tasks-you-can-assign | 0 | 1 | I thought a greedy algo would be enough but have spent hours and couldn\'t get a solution. It turns out that the direction was wrong in the first place. Below implementation is based on other posts in the discuss. \n\nPlease check out this [commit](https://github.com/gaosanyong/leetcode/commit/e61879b77928a08bb15cc182a69259d6e2bce59a) for solutions of biweekly 65. \n```\nclass Solution:\n def maxTaskAssign(self, tasks: List[int], workers: List[int], pills: int, strength: int) -> int:\n tasks.sort()\n workers.sort()\n \n def fn(k, p=pills): \n """Return True if k tasks can be completed."""\n ww = workers[-k:]\n for t in reversed(tasks[:k]): \n if t <= ww[-1]: ww.pop()\n elif t <= ww[-1] + strength and p: \n p -= 1\n i = bisect_left(ww, t - strength)\n ww.pop(i)\n else: return False \n return True \n \n lo, hi = 0, min(len(tasks), len(workers))\n while lo < hi: \n mid = lo + hi + 1 >> 1\n if fn(mid): lo = mid\n else: hi = mid - 1\n return lo \n``` | 10 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
[python] binary search + greedy with deque O(nlogn) | maximum-number-of-tasks-you-can-assign | 0 | 1 | Use binary search with greedy check. Each check can be done in O(n) using a deque. Within a check, we iterate through the workers from the weakiest to the strongest. Each worker needs to take a task. \nThere are two cases:\n1. The worker can take the easiest task available: we assign it to the worker.\n2. The worker cannot even take the easiest task: we give a pill to him and let him take the hardest doable task.\n\nThe deque will hold from the easiest unassigned task to the toughest that can be done by the current worker with a pill. If the easiest task can be handled by the weakiest worker, we assign it to the worker and do a popleft, other wise, we use one pill and pop from the right.\n```\nclass Solution:\n def maxTaskAssign(self, tasks: List[int], workers: List[int], pills: int, strength: int) -> int:\n # workers sorted in reverse order, tasks sorted in normal order\n def can_assign(n):\n task_i = 0\n task_temp = deque()\n n_pills = pills\n for i in range(n-1,-1,-1):\n while task_i < n and tasks[task_i] <= workers[i]+strength:\n task_temp.append(tasks[task_i])\n task_i += 1\n \n if len(task_temp) == 0:\n return False\n if workers[i] >= task_temp[0]:\n task_temp.popleft()\n elif n_pills > 0:\n task_temp.pop()\n n_pills -= 1\n else:\n return False\n return True\n \n tasks.sort()\n workers.sort(reverse = True)\n \n l = 0\n r = min(len(tasks), len(workers))\n res = -1\n while l <= r:\n m = (l+r)//2\n if can_assign(m):\n res = m\n l = m+1\n else:\n r = m-1\n return res\n``` | 11 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
Python 100% | maximum-number-of-tasks-you-can-assign | 0 | 1 | # Code\n```\nimport bisect\nimport collections\n\ndef binsearch(low, high, do_not_search_less_than):\n while high - low > 1:\n mid = (low + high) // 2\n if do_not_search_less_than(mid):\n low = mid\n else:\n high = mid\n return low\n\nclass TaskAssigner:\n def __init__(self, tasks, workers, pills, strength):\n self.tasks = sorted(tasks)\n self.workers = sorted(workers)\n self.pills = pills\n self.strength = strength\n\n def can_assign_k_tasks(self, k):\n tasks = collections.deque(self.tasks[:k])\n pills = self.pills\n for worker in self.workers[-k:]:\n if tasks[0] <= worker:\n tasks.popleft()\n elif not pills or worker + self.strength < tasks[0]:\n return False\n else:\n del tasks[bisect.bisect(tasks, worker + self.strength) - 1]\n pills -= 1\n return True\n\nclass Solution:\n def maxTaskAssign(self, tasks: List[int], workers: List[int], pills: int, strength: int) -> int:\n task_assigner = TaskAssigner(tasks, workers, pills, strength)\n return binsearch(0, min(len(tasks), len(workers)) + 1, task_assigner.can_assign_k_tasks)\n \n``` | 0 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
Python (Simple Binary Search) | maximum-number-of-tasks-you-can-assign | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxTaskAssign(self, tasks, workers, pills, strength):\n tasks.sort()\n workers.sort()\n\n def fn(k,pills):\n ww = workers[-k:]\n \n for t in reversed(tasks[:k]):\n if t <= ww[-1]: ww.pop()\n elif pills and t <= ww[-1] + strength:\n pills -= 1\n i = bisect_left(ww,t-strength)\n ww.pop(i)\n else:\n return False\n\n return True\n \n low, high = 0, min(len(tasks),len(workers))\n\n while low <= high:\n mid = (low + high)//2\n if fn(mid,pills): low = mid + 1\n else: high = mid - 1\n\n return high\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n``` | 0 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
Python 3 (No binary search) Faster than 100% | maximum-number-of-tasks-you-can-assign | 0 | 1 | \n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe inituition: Starts with realizing that you can complete at most k tasks. \nWhere `k = min(len(tasks), len(workers))`\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe split up the workers and task by the k strongest workers and the k weakest tasks. Assign the worker with the minimum required strength the task, remove the worker from the stack.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n- n = len(tasks)\n- m = len(workers)\n- k = min(n, m)\n\n- sorting: $$O(nlogn) + O(mlogm)$$\n- loop: $$O(k*k*logk)$$ - I think the reality is closer to $$O(k*1*logk) = O(klogk)$$\n\nOverall Time Complexity: $$O(nlogn + mlogm + klogk)$$\n- Space complexity: $$O(n + m)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def maxTaskAssign(self, tasks: List[int], workers: List[int], pills: int, strength: int) -> int:\n\n # sort the arrays\n tasks.sort() # O(nlogn)\n workers.sort() # O(mlogm)\n \n \n # you can complete at most k tasks\n k = min(len(tasks), len(workers))\n\n # strongest workers\n workers = workers[-k:]\n\n # easiest tasks\n tasks = tasks[:k]\n\n res = 0\n\n # hardest task first\n for t in reversed(tasks): # O(k)\n # We dont need to use our pills as there\n # exists a worker that can solve the current task\n if workers[-1] >= t:\n res += 1\n # Find the worker with the minimum required strength\n # to complete the ask\n deleteIdx = bisect.bisect_left(workers, t - strength) # O(log k) \n # Remove the worker from the stack\n workers.pop(deleteIdx) # O(k) - my guess is this is closer to O(1) as the worker is going to be closer to the end of the stack\n # we know there exists a worker\n # that can solve the task with a pill\n elif pills and workers[-1] + strength >= t:\n deleteIdx = bisect.bisect_left(workers, t - strength)\n workers.pop(deleteIdx)\n pills -= 1\n res += 1\n # else:\n # The task couldn\'t be solved.\n # Either because we are out of pills\n # or there is no workers that with\n # or without the pill can solve it\n \n return res\n``` | 0 | You have `n` tasks and `m` workers. Each task has a strength requirement stored in a **0-indexed** integer array `tasks`, with the `ith` task requiring `tasks[i]` strength to complete. The strength of each worker is stored in a **0-indexed** integer array `workers`, with the `jth` worker having `workers[j]` strength. Each worker can only be assigned to a **single** task and must have a strength **greater than or equal** to the task's strength requirement (i.e., `workers[j] >= tasks[i]`).
Additionally, you have `pills` magical pills that will **increase a worker's strength** by `strength`. You can decide which workers receive the magical pills, however, you may only give each worker **at most one** magical pill.
Given the **0-indexed** integer arrays `tasks` and `workers` and the integers `pills` and `strength`, return _the **maximum** number of tasks that can be completed._
**Example 1:**
**Input:** tasks = \[**3**,**2**,**1**\], workers = \[**0**,**3**,**3**\], pills = 1, strength = 1
**Output:** 3
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 2 (0 + 1 >= 1)
- Assign worker 1 to task 1 (3 >= 2)
- Assign worker 2 to task 0 (3 >= 3)
**Example 2:**
**Input:** tasks = \[**5**,4\], workers = \[**0**,0,0\], pills = 1, strength = 5
**Output:** 1
**Explanation:**
We can assign the magical pill and tasks as follows:
- Give the magical pill to worker 0.
- Assign worker 0 to task 0 (0 + 5 >= 5)
**Example 3:**
**Input:** tasks = \[**10**,**15**,30\], workers = \[**0**,**10**,10,10,10\], pills = 3, strength = 10
**Output:** 2
**Explanation:**
We can assign the magical pills and tasks as follows:
- Give the magical pill to worker 0 and worker 1.
- Assign worker 0 to task 0 (0 + 10 >= 10)
- Assign worker 1 to task 1 (10 + 10 >= 15)
The last pill is not given because it will not make any worker strong enough for the last task.
**Constraints:**
* `n == tasks.length`
* `m == workers.length`
* `1 <= n, m <= 5 * 104`
* `0 <= pills <= m`
* `0 <= tasks[i], workers[j], strength <= 109` | Fix one array. Choose the next array and get the common elements. Use the common elements as the new fixed array and keep merging with the rest of the arrays. |
Two simple solutions in Python3 || Queue DS || Inifinite looping | time-needed-to-buy-tickets | 0 | 1 | # Intuition\nFollowing to the description of the problem, the task goal is to calculate **min amount of time**, that `K`- buyer needs to spend in order to buy tickets.\n\nSomehow we need to iterate over all buyers, reduce the current amount of tickets they\'re bying at the moment, shift the current buyer to **the END of a** `queue` and repeat the process.\n\n---\n\n- **Queue DS**\n\nIf you haven\'t already familiar with [Queue DS](https://en.wikipedia.org/wiki/Queue_(abstract_data_type)), just follow the link to know more!\n\n1. change `tickets` variable by initializing a `deque` and **map** `i` and `v` for current buyer, \n2. initialize `ans` variable and `while` loop, that\'ll iterate **infinitely**\n3. pop from `tickets` current buyer\n4. increment total amount `ans` \n5. check, if the current buyer has bought all of the tickets, and return `ans`\n6. otherwise, if he needs to buy **more** tickets, return him to the `tickets` queue\n\n```python\nclass Solution:\n def timeRequiredToBuy(self, tickets: list[int], k: int) -> int:\n tickets = deque([[i, v] for i, v in enumerate(tickets)])\n ans = 0\n\n while True:\n i, v = tickets.popleft()\n ans += 1\n\n if i == k and v - 1 == 0:\n return ans\n \n if v > 1:\n tickets.append([i, v - 1])\n```\n# Complexity\n- Time complexity: **O(n)**, because of iterating infinitely over all `tickets` buyers\n\n- Space complexity: **O(n)**, to map indexes and values for `tickets`\n\n---\n\n- **Inifinite looping**\nThe approach is the same, but we **mutate** the initial values of `tickets`.\n\n# Code\n```\nclass Solution:\n def timeRequiredToBuy(self, tickets: list[int], k: int) -> int:\n if tickets[k] == 0:\n return 0\n \n i = 0\n ans = 0\n\n while True:\n if tickets[i]:\n tickets[i] -= 1\n ans += 1\n\n if i == k and tickets[i] == 0:\n return ans\n \n i += 1\n \n if i == len(tickets):\n i = 0\n\n```\n\n# Complexity\n- Time complexity: **O(n)**, because of iterating infinitely over all `tickets` buyers\n\n- Space complexity: **O(1)**, because we don\'t use extra space.\n | 2 | There are `n` people in a line queuing to buy tickets, where the `0th` person is at the **front** of the line and the `(n - 1)th` person is at the **back** of the line.
You are given a **0-indexed** integer array `tickets` of length `n` where the number of tickets that the `ith` person would like to buy is `tickets[i]`.
Each person takes **exactly 1 second** to buy a ticket. A person can only buy **1 ticket at a time** and has to go back to **the end** of the line (which happens **instantaneously**) in order to buy more tickets. If a person does not have any tickets left to buy, the person will **leave** the line.
Return _the **time taken** for the person at position_ `k` **_(0-indexed)_** _to finish buying tickets_.
**Example 1:**
**Input:** tickets = \[2,3,2\], k = 2
**Output:** 6
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[1, 2, 1\].
- In the second pass, everyone in the line buys a ticket and the line becomes \[0, 1, 0\].
The person at position 2 has successfully bought 2 tickets and it took 3 + 3 = 6 seconds.
**Example 2:**
**Input:** tickets = \[5,1,1,1\], k = 0
**Output:** 8
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[4, 0, 0, 0\].
- In the next 4 passes, only the person in position 0 is buying tickets.
The person at position 0 has successfully bought 5 tickets and it took 4 + 1 + 1 + 1 + 1 = 8 seconds.
**Constraints:**
* `n == tickets.length`
* `1 <= n <= 100`
* `1 <= tickets[i] <= 100`
* `0 <= k < n` | n is very small, how can we use that? What shape is the region when two viruses intersect? |
[Python] | BruteForce and O(N) | time-needed-to-buy-tickets | 0 | 1 | Please upvote if you find it helpful\n\nBruteForce:\n```\nclass Solution:\n def timeRequiredToBuy(self, tickets: list[int], k: int) -> int:\n secs = 0 \n i = 0\n while tickets[k] != 0:\n if tickets[i] != 0: # if it is zero that means we dont have to count it anymore\n tickets[i] -= 1 # decrease the value by 1 everytime\n secs += 1 # increase secs by 1\n\n i = (i + 1) % len(tickets) # since after getting to the end of the array we have to return to the first value so we use the mod operator\n \n return secs\n```\n\nO(N):\n```\nclass Solution:\n def timeRequiredToBuy(self, tickets: List[int], k: int) -> int:\n return sum(min(x, tickets[k] if i <= k else tickets[k] - 1) for i, x in enumerate(tickets))\n```\nThe values before tickets[k] will appear min(x, t[x]) times and values after tickets[k] will appear min(x, t[x] -1) times\nLet\'s take an example:\n`tickets = [5, 2, 3, 4]` and `k = 2`\n```1st iteration: [4, 1, 2, 3]```\n```2nd iteration: [3, 0, 1, 2]```\n```3rd iteration: [2, 0, 0, 1]```\nYou see `tickets[0]` appeared 3 times which is min(5, 3) and that is 3, \n `tickets[1]` appeared 2 times which is min(2, 3) that is 2, \n\t\t\t `tickets[2]` appeared 3 times which is min(3, 3) that is 3 and \n\t\t\t `tickets[3]` appeared 2 times which is min(4, 2) that is 2.\n | 39 | There are `n` people in a line queuing to buy tickets, where the `0th` person is at the **front** of the line and the `(n - 1)th` person is at the **back** of the line.
You are given a **0-indexed** integer array `tickets` of length `n` where the number of tickets that the `ith` person would like to buy is `tickets[i]`.
Each person takes **exactly 1 second** to buy a ticket. A person can only buy **1 ticket at a time** and has to go back to **the end** of the line (which happens **instantaneously**) in order to buy more tickets. If a person does not have any tickets left to buy, the person will **leave** the line.
Return _the **time taken** for the person at position_ `k` **_(0-indexed)_** _to finish buying tickets_.
**Example 1:**
**Input:** tickets = \[2,3,2\], k = 2
**Output:** 6
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[1, 2, 1\].
- In the second pass, everyone in the line buys a ticket and the line becomes \[0, 1, 0\].
The person at position 2 has successfully bought 2 tickets and it took 3 + 3 = 6 seconds.
**Example 2:**
**Input:** tickets = \[5,1,1,1\], k = 0
**Output:** 8
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[4, 0, 0, 0\].
- In the next 4 passes, only the person in position 0 is buying tickets.
The person at position 0 has successfully bought 5 tickets and it took 4 + 1 + 1 + 1 + 1 = 8 seconds.
**Constraints:**
* `n == tickets.length`
* `1 <= n <= 100`
* `1 <= tickets[i] <= 100`
* `0 <= k < n` | n is very small, how can we use that? What shape is the region when two viruses intersect? |
Python3 queue | time-needed-to-buy-tickets | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def timeRequiredToBuy(self, tickets: List[int], k: int) -> int:\n \n n=len(tickets)\n q=deque([i for i in range(n)])\n \n time=0\n \n while q:\n for i in range(len(q)):\n\n node=q.popleft()\n tickets[node]-=1\n if tickets[node]>=1:\n q.append(node)\n \n time+=1\n if tickets[k]==0:\n return time\n \n \n \n``` | 3 | There are `n` people in a line queuing to buy tickets, where the `0th` person is at the **front** of the line and the `(n - 1)th` person is at the **back** of the line.
You are given a **0-indexed** integer array `tickets` of length `n` where the number of tickets that the `ith` person would like to buy is `tickets[i]`.
Each person takes **exactly 1 second** to buy a ticket. A person can only buy **1 ticket at a time** and has to go back to **the end** of the line (which happens **instantaneously**) in order to buy more tickets. If a person does not have any tickets left to buy, the person will **leave** the line.
Return _the **time taken** for the person at position_ `k` **_(0-indexed)_** _to finish buying tickets_.
**Example 1:**
**Input:** tickets = \[2,3,2\], k = 2
**Output:** 6
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[1, 2, 1\].
- In the second pass, everyone in the line buys a ticket and the line becomes \[0, 1, 0\].
The person at position 2 has successfully bought 2 tickets and it took 3 + 3 = 6 seconds.
**Example 2:**
**Input:** tickets = \[5,1,1,1\], k = 0
**Output:** 8
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[4, 0, 0, 0\].
- In the next 4 passes, only the person in position 0 is buying tickets.
The person at position 0 has successfully bought 5 tickets and it took 4 + 1 + 1 + 1 + 1 = 8 seconds.
**Constraints:**
* `n == tickets.length`
* `1 <= n <= 100`
* `1 <= tickets[i] <= 100`
* `0 <= k < n` | n is very small, how can we use that? What shape is the region when two viruses intersect? |
Python O(N) easy method | time-needed-to-buy-tickets | 0 | 1 | ```\nclass Solution:\n def timeRequiredToBuy(self, tickets: List[int], k: int) -> int:\n\t\t#Loop through all elements in list only once. \n\t\t\n nums = tickets \n time_sec = 0\n\t\t# save the number of tickets to be bought by person standing at k position\n least_tickets = nums[k] \n\t\t#(3) Any person nums[i] having tickets more than the k pos person, will buy tickets least_tickets times only.\n\t\t#(2) Person nums[i] having tickets less than kth person ( nums[i] < least_tickets ), and standing before him(i<k), will be able to buy nums[i] amount.\n\t\t#(1) Person nums[i] standing after kth person having more tickets than kth person, will be able to buy one less than the ticket kth person can buy(condition: least_tickets - 1).\n for i in range(len(nums)): \n if k < i and nums[i] >= least_tickets : #(1)\n time_sec += (least_tickets - 1)\n elif nums[i] < least_tickets : #(2)\n time_sec += nums[i]\n else: #(3)\n time_sec += least_tickets\n\t\t\t\t\n return time_sec\n \nPlease upvote if you find it useful and well-explained! | 13 | There are `n` people in a line queuing to buy tickets, where the `0th` person is at the **front** of the line and the `(n - 1)th` person is at the **back** of the line.
You are given a **0-indexed** integer array `tickets` of length `n` where the number of tickets that the `ith` person would like to buy is `tickets[i]`.
Each person takes **exactly 1 second** to buy a ticket. A person can only buy **1 ticket at a time** and has to go back to **the end** of the line (which happens **instantaneously**) in order to buy more tickets. If a person does not have any tickets left to buy, the person will **leave** the line.
Return _the **time taken** for the person at position_ `k` **_(0-indexed)_** _to finish buying tickets_.
**Example 1:**
**Input:** tickets = \[2,3,2\], k = 2
**Output:** 6
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[1, 2, 1\].
- In the second pass, everyone in the line buys a ticket and the line becomes \[0, 1, 0\].
The person at position 2 has successfully bought 2 tickets and it took 3 + 3 = 6 seconds.
**Example 2:**
**Input:** tickets = \[5,1,1,1\], k = 0
**Output:** 8
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[4, 0, 0, 0\].
- In the next 4 passes, only the person in position 0 is buying tickets.
The person at position 0 has successfully bought 5 tickets and it took 4 + 1 + 1 + 1 + 1 = 8 seconds.
**Constraints:**
* `n == tickets.length`
* `1 <= n <= 100`
* `1 <= tickets[i] <= 100`
* `0 <= k < n` | n is very small, how can we use that? What shape is the region when two viruses intersect? |
O(n) Python - treat <=kth and kth differently | time-needed-to-buy-tickets | 0 | 1 | ```\nclass Solution:\n def timeRequiredToBuy(self, tickets: List[int], k: int) -> int:\n c=0\n l=len(tickets)\n for i in range(l):\n if i <= k:\n c+= min(tickets[k],tickets[i])\n else:\n c+= min(tickets[k]-1,tickets[i])\n return c\n``` | 1 | There are `n` people in a line queuing to buy tickets, where the `0th` person is at the **front** of the line and the `(n - 1)th` person is at the **back** of the line.
You are given a **0-indexed** integer array `tickets` of length `n` where the number of tickets that the `ith` person would like to buy is `tickets[i]`.
Each person takes **exactly 1 second** to buy a ticket. A person can only buy **1 ticket at a time** and has to go back to **the end** of the line (which happens **instantaneously**) in order to buy more tickets. If a person does not have any tickets left to buy, the person will **leave** the line.
Return _the **time taken** for the person at position_ `k` **_(0-indexed)_** _to finish buying tickets_.
**Example 1:**
**Input:** tickets = \[2,3,2\], k = 2
**Output:** 6
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[1, 2, 1\].
- In the second pass, everyone in the line buys a ticket and the line becomes \[0, 1, 0\].
The person at position 2 has successfully bought 2 tickets and it took 3 + 3 = 6 seconds.
**Example 2:**
**Input:** tickets = \[5,1,1,1\], k = 0
**Output:** 8
**Explanation:**
- In the first pass, everyone in the line buys a ticket and the line becomes \[4, 0, 0, 0\].
- In the next 4 passes, only the person in position 0 is buying tickets.
The person at position 0 has successfully bought 5 tickets and it took 4 + 1 + 1 + 1 + 1 = 8 seconds.
**Constraints:**
* `n == tickets.length`
* `1 <= n <= 100`
* `1 <= tickets[i] <= 100`
* `0 <= k < n` | n is very small, how can we use that? What shape is the region when two viruses intersect? |
Not So Fast But Understandable.py | reverse-nodes-in-even-length-groups | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n****1)First convert linked list to list.\n\n2)Then create the temporary list of the desired length like 1,2,3,4...\n\n3)Then check if length of temp list is even:\nif it is even then first reverse it and add it to the ans list\nelse add temp to ans directly.\n\n4)Then we have to check for the remaining elements:\nlike temp of size 1,2,3 are present but of size 4 is not present, there should be 1,2,3 element remaing in the list.\n\n5)so we have to check the no. of remaing element is even then reverse them else add as it is to the ans list.\n\n6)Then The final step is to convert the list to linked list again.****\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n l = []\n ans = []\n while head:\n l.append(head.val)\n head = head.next\n\n right = 1\n left = 0\n while left+right<=len(l):\n temp = l[left:left+right]\n if len(temp)%2==0:\n temp = temp[::-1]\n ans+= temp\n else:\n ans+= temp\n left+=right\n right+=1\n\n remain = len(l)-len(ans)\n temp2=[]\n if remain%2==0:\n for i in range(-remain,0,1):\n temp2.append(l[i])\n ans+=temp2[::-1]\n else: \n for i in range(-remain,0,1):\n ans.append(l[i])\n\n\n head=temp=ListNode(ans[0])\n for i in range(1,len(ans)):\n temp.next = ListNode(ans[i])\n temp = temp.next\n return head\n\n\n \n```\n**IF YOU LIKE IT PLEASE UPVOTE :))** | 1 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
🔥 Clean 🐍python solution 🔥 simple 🔥 beats 100% 🔥 explanation 🔥 | reverse-nodes-in-even-length-groups | 0 | 1 | # Intuition\nWhen considering this problem, we need to be comfortable with various linked list operations and concepts. These include understanding how to traverse a linked list, reverse a section of it without disrupting the rest of the list, and reconnect reversed segments seamlessly back into the list. With these tools in hand, the problem becomes a matter of grouping nodes, reversing the groups of even length, and then reconnecting these altered groups back into a complete linked list.\n\n# Approach\nWe use a two-pointer approach to solve this problem. One pointer, `connector`, keeps track of the node preceding the current group. The other, `curr`, navigates the nodes within the current group.\n\nThe process begins with `curr` pointing to the head of the list and `connector` being None. We also have two counters, `group_count` to keep track of which group we are in, and `count` to track the length of the current group.\n\nWe have a helper function, `reverse_between`, which performs an in-place reversal of a section of the linked list starting from the node after `pre`, and does this for `n` nodes. It uses the classic three-pointer method for list reversal, with a twist to maintain the continuity of the list. Instead of breaking off the section to be reversed, it leaves the start node of this section linked to the rest of the list and moves the remaining nodes one by one to the front. This results in the list being reversed, but the original start node is now the end node of the reversed section and still connected to the rest of the list. After the reversal, the function returns the new end node of the section (which was the original start node).\n\nWe proceed with traversing the list, checking at each step whether we are at the end of a group. This is determined either by the counters `group_count` and `count` being equal, or by reaching the end of the list (`curr.next` is None). If we are at the end of a group and the group has an even length, we reverse it with our helper function and update the pointers accordingly. We then increment `group_count` and reset `count` to 0. We repeat this until we have traversed the entire list.\n\nThis approach ensures that even-length groups are reversed while maintaining the continuity of the list.\n\n# Complexity\n- Time complexity: The time complexity is **O(n)**, where n is the number of nodes in the linked list. We achieve this by traversing the list only once, with each operation (reversing and reconnecting a group) taking constant time.\n\n- Space complexity: The space complexity is **O(1)**. We use a fixed amount of space to store our pointers and counters, and since we perform the reversal in-place, we do not use any additional data structures that scale with the size of the input.\n\nFor a detailed explanation of the list reversal process used in reverse_between, you can refer to this [problem](https://leetcode.com/problems/reverse-linked-list-ii/description/).\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n connector = None\n curr = head\n group_count = 1\n count = 1\n\n def reverse_between(pre, n):\n start = pre.next\n then = start.next\n after = start\n\n for _ in range(n - 1):\n start.next = then.next\n then.next = pre.next\n pre.next = then\n then = start.next\n\n return after\n\n while curr:\n if group_count == count or not curr.next:\n if count % 2 == 0:\n curr = reverse_between(connector, count)\n connector = curr\n group_count += 1\n count = 0\n\n count += 1\n curr = curr.next\n\n return head\n\n``` | 9 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python & C++✅✅ | Faster🧭 than 90%🔥 | Easy Implementation🆗 | Clean & Concise Code | | reverse-nodes-in-even-length-groups | 0 | 1 | # Approach\n```txt\nk = odd\ndummy -> 1 -> || 2 -> 3 -> 4 || -> 5 -> 6 -> 7\n grpPrev kth grpNxt --> No Reverse \n```\n```txt\nk = even\ndummy -> 1 -> || 2 -> 3 -> 4 -> 5 || -> 6 -> 7\n grpPrev kth grpNxt --> Reverse \n```\n\n# Complexity\n- Time complexity: O(N)\n- Space complexity: O(1)\n\n# Code\n```python []\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n\nclass Solution:\n\n def getKth(self, cur, k):\n cnt = k\n while cur and cur.next and k > 0:\n cur = cur.next\n k -= 1\n return [cur, cnt - k]\n\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n dummy = ListNode(0, head)\n groupPrev = dummy\n\n k = 1\n while groupPrev and groupPrev.next:\n kth, newK = self.getKth(groupPrev, k)\n k = newK\n groupNext = kth.next\n\n if k%2:\n groupPrev = kth\n else:\n prev, curr = kth.next, groupPrev.next\n while curr and curr != groupNext:\n # storing for future use\n nxt = curr.next\n\n # pointing to the prev ptr\n curr.next = prev\n\n # updating the ptr\'s\n prev = curr\n curr = nxt\n tmp = groupPrev.next\n groupPrev.next = kth\n groupPrev = tmp\n k += 1\n return dummy.next\n\n\n```\n```C++ []\n\nclass Solution {\npublic:\n\n\nvoid swap(ListNode* A, ListNode* B)\n{\n int tmp = A->val;\n A->val = B->val;\n B->val = tmp;\n}\n\nvoid reverse_node(vector<ListNode*> &arr)\n{\n int i = 0, j = arr.size()-1;\n\n while(i<=j) swap(arr[i++], arr[j--]);\n \n}\n\n\n ListNode* reverseEvenLengthGroups(ListNode* head) {\n \n vector<ListNode*>res;\n int i = 1;\n int cnt = 0;\n \n ListNode *ptr = head;\n\n while(ptr != NULL)\n {\n \n res.push_back(ptr);\n ptr = ptr->next;\n cnt++;\n\n if(cnt == i)\n {\n if(cnt % 2 == 0) reverse_node(res);\n res.clear();\n cnt = 0;\n i++;\n }\n\n }\n\n if(cnt%2 == 0) reverse_node(res);\n\n\n return head;\n\n }\n};\n\n```\n\nYou Can also Look At My SDE Prep Repo [\uD83E\uDDE2 GitHub](https://github.com/Ayon-SSP/The-SDE-Prep)\n | 2 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python Simple | Neat Solution | O(n) Time, O(1) Space | reverse-nodes-in-even-length-groups | 0 | 1 | ```\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n start_joint = head \n group_size = 1\n while start_joint and start_joint.next: \n group_size += 1\n start = end = start_joint.next \n group_num = 1 \n while end and end.next and group_num < group_size: \n end = end.next \n group_num += 1 \n end_joint = end.next \n if group_num % 2 != 0: \n start_joint = end \n continue \n start_joint.next = self.reverse(start, end, end_joint)\n start_joint = start \n return head\n def reverse(self, start, end, end_joint): \n prev, curr = end_joint, start\n while curr and curr != end_joint: \n next_node = curr.next\n curr.next = prev\n prev, curr = curr, next_node\n return prev\n```\nComments: This questions is a hard, it uses concepts from other hard questions like Reverse K-Nodes in Group, do not attempt if you are a beginner or haven\'t had experience with those type of problems. The helper function reverse neatly reverses between start and end, makes sure the reversed end points to the node after end originally(end_joint), and `start_joint.next = self.reverse()` ties it all up. The remainder of the tricky part is handling the odd/even and not matching group_sizes. For those still confused of why there is start_joint, end_joint, this is because you need to maintain the node before and after the part that is being reversed.\n | 7 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
[Python3] using stack | reverse-nodes-in-even-length-groups | 0 | 1 | Downvoters, leave a comment! \n\nPlease check out this [commit](https://github.com/gaosanyong/leetcode/commit/8d693371fa97ea3b0717d02448c77201b15e5d12) for solutions of weekly 267.\n```\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n n, node = 0, head\n while node: n, node = n+1, node.next\n \n k, node = 0, head \n while n: \n k += 1\n size = min(k, n)\n stack = []\n if not size & 1: \n temp = node \n for _ in range(size): \n stack.append(temp.val)\n temp = temp.next \n for _ in range(size): \n if stack: node.val = stack.pop()\n node = node.next \n n -= size\n return head \n``` | 13 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python Solution Use 4 Pointers with Clear Explanation | reverse-nodes-in-even-length-groups | 0 | 1 | This solution was inspired by @astroash\'s C++ solution, which can be found at https://leetcode.com/problems/reverse-nodes-in-even-length-groups/solutions/1576952/c-well-commented-clear-code-idea-explained-in-brief/. \nThis is an implementation of the same solution in Python. The key aspects of this solution will be outlined in this post, with emphasis on the major features and the steps taken to solve the problem.\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis problem is essentially a variant of the \'partial reverse linked list\' problem, where we only reverse parts of the linked list based on some criteria. In this case, we reverse parts of the linked list that fall into groups of even lengths. Key points in solving this type of problem include:\n\n1. Identify the **pattern** of the specific part of the linked list that needs to be reversed and divide it into groups.\n2. Understand the role of the **prev**, **head**, **tail**, and **next_head** pointers:\n - **prev** refers to the node **before** the pattern group. It links the reversed group back to the unmodified part of the list.\n - **head** refers to the **start** of the pattern group, which becomes the tail after the group is reversed.\n - **tail** refers to the **end** of the pattern group, which becomes the head after the group is reversed.\n - **next_head** refers to the **start** of the next group. It links the reversed group to the next part of the list.\n3. Deal with **edge** conditions. A sentinel node is useful in dealing with edge conditions that may occur at the head or end of the linked list.\n\n# Approach\n\n\nWe first segment the linked list into different groups based on the provided conditions. We then check each group and reverse it if its length is even. The reversal is achieved using the prev, head, tail, and next_head pointers.\n\n1. We define a helper function, `reverse()`, that reverses a linked list from a specified head node and returns the head of the reversed list.\n2. We create a sentinel node that will aid in handling edge conditions. It also simplifies our code by providing a uniform starting point for each group.\n3. For each length from 1 to 100000, we manually segment the linked list into groups. For each group, we identify the head, tail, and next_head nodes.\n4. We check if the group is of even length. If it is, we reverse it by calling our `reverse()` function, and then link the reversed group back to the list.\n\n# Complexity\n\n- Time complexity: O(n), where n is the number of nodes in the linked list.\n- Space complexity: O(1), because no additional space is used apart from the original linked list.\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n def reverse(head):\n if not head:\n return head\n prev = None\n while head:\n next_node = head.next\n head.next = prev\n prev = head\n head = next_node\n return prev\n\n sentinel = ListNode(0, head)\n prev = sentinel\n for length in range(1, 100000):\n if not head:\n break\n tail = head\n j = 1\n while j < length and tail and tail.next:\n tail = tail.next\n j += 1\n\n next_head = tail.next\n\n if j % 2 == 0:\n tail.next = None\n prev.next = reverse(head)\n head.next = next_head\n prev = head\n head = next_head\n else:\n prev = tail\n head = next_head\n\n return sentinel.next\n``` | 1 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python easy to understand | reverse-nodes-in-even-length-groups | 0 | 1 | \n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n if not head.next or not head.next.next:\n return head\n\n dummy = before = nullCheck = head\n before = head\n count = 1\n \n while head:\n # length check\n length = 0\n while nullCheck and length < count:\n nullCheck = nullCheck.next\n length += 1\n \n # odd length\n if length % 2 == 1:\n for _ in range(length):\n before = head\n head = head.next\n \n else:\n tail = head\n\n # reverse\n prev = None\n for _ in range(length):\n nextNode = head.next\n head.next = prev\n prev = head\n head = nextNode\n \n # join\n before.next = prev\n before = tail\n tail.next = head\n \n count += 1\n \n return dummy\n \n``` | 2 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python 3 || 14 lines, w/ example || T/M: 97%/52% | reverse-nodes-in-even-length-groups | 0 | 1 | ```\nclass Solution:\n def reverseEvenLengthGroups(self, head: ListNode) -> ListNode:\n\n node, nums, ans = head, [], []\n T = lambda x: x*(x+1)//2\n flip = lambda x: x if len(x)%2 else x[::-1] # Example: head = 1->5->4->2->6->3->0->8\n\n while node: # nums = [1,5,4,2,6,3,0,8]\n nums.append(node.val)\n node = node.next\n\n for i in range(ceil(-0.5+sqrt(0.25+2*len(nums)))): # ans = [[1], [5,4], [2,6,3], [0,8]]\n ans.append(nums[T(i):T(i+1)])\n\n ans = chain(*map(flip,ans)) # ans = chain(*[[1], [4,5], [2,6,3], [8,0]])\n # = chain([1], [4,5], [2,6,3], [8,0])\n # = [1, 4,5, 2,6,3, 8,0]\n\n node = head # head = 1->4->5->2->6->3->8->0\n for a in ans:\n node.val = a\n node = node.next\n\n return head\n```\n[https://leetcode.com/problems/reverse-nodes-in-even-length-groups/submissions/939576037/](http://)\n\nI could be wrong, but I think that time complexity is *O*(*N*) and space complexity is *O*(*N*). | 3 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Python solution using stack | reverse-nodes-in-even-length-groups | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]:\n gr = 1\n stack = []\n\n node = head\n\n while(node):\n stack = []\n\n temp = node\n\n for _ in range(gr):\n\n if temp == None:\n break\n\n stack.append(temp.val)\n temp = temp.next\n\n if len(stack)%2 == 0:\n while(stack):\n node.val = stack.pop()\n node = node.next\n else:\n for _ in range(gr):\n if node == None:\n break\n\n node = node.next\n\n gr += 1\n\n return head\n``` | 1 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
2.5 hrs----use pen , page--- trust yourself | reverse-nodes-in-even-length-groups | 0 | 1 | # Intuition\n\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverseEvenLengthGroups(self, head: Optional[ListNode]) -> Optional[ListNode]: \n curr = head\n incr = 1\n stack = []\n while (curr):\n\n i = 0\n while curr and i < incr :\n print(incr)\n stack.append(curr)\n last = curr\n curr = curr.next \n i += 1\n \n if i == incr and incr%2 == 1:\n Last = last\n stack = []\n if i == incr and incr%2 == 0:\n while stack:\n\n Last.next = stack.pop()\n Last = Last.next\n Last.next = curr\n \n\n if i < incr and i%2 == 1:\n pass\n\n if i < incr and i%2 == 0:\n while stack:\n Last.next = stack.pop()\n Last = Last.next\n Last.next = curr\n \n \n incr += 1\n\n \n\n return head\n\n``` | 0 | You are given the `head` of a linked list.
The nodes in the linked list are **sequentially** assigned to **non-empty** groups whose lengths form the sequence of the natural numbers (`1, 2, 3, 4, ...`). The **length** of a group is the number of nodes assigned to it. In other words,
* The `1st` node is assigned to the first group.
* The `2nd` and the `3rd` nodes are assigned to the second group.
* The `4th`, `5th`, and `6th` nodes are assigned to the third group, and so on.
Note that the length of the last group may be less than or equal to `1 + the length of the second to last group`.
**Reverse** the nodes in each group with an **even** length, and return _the_ `head` _of the modified linked list_.
**Example 1:**
**Input:** head = \[5,2,6,3,9,1,7,3,8,4\]
**Output:** \[5,6,2,3,9,1,4,8,3,7\]
**Explanation:**
- The length of the first group is 1, which is odd, hence no reversal occurs.
- The length of the second group is 2, which is even, hence the nodes are reversed.
- The length of the third group is 3, which is odd, hence no reversal occurs.
- The length of the last group is 4, which is even, hence the nodes are reversed.
**Example 2:**
**Input:** head = \[1,1,0,6\]
**Output:** \[1,0,1,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 1. No reversal occurs.
**Example 3:**
**Input:** head = \[1,1,0,6,5\]
**Output:** \[1,0,1,5,6\]
**Explanation:**
- The length of the first group is 1. No reversal occurs.
- The length of the second group is 2. The nodes are reversed.
- The length of the last group is 2. The nodes are reversed.
**Constraints:**
* The number of nodes in the list is in the range `[1, 105]`.
* `0 <= Node.val <= 105` | First, we need to note that this is a classic problem given n points you need to find the minimum enclosing circle to bind them Second, we need to apply a well known algorithm called welzls algorithm to help us find the minimum enclosing circle |
Jump Columns + 1 | decode-the-slanted-ciphertext | 1 | 1 | Knowing `rows`, we can find out `cols`. Knowing `cols`, we can jump to the next letter (`cols + 1`).\n\nExample: `"ch ie pr"`, rows = 3, columns = 12 / 3 = 4.\n0: [0, 5, 10] `"cip"`\n1: [1, 6, 11] `"her"`\n2: [2, 7] `" "` <- we will trim this.\n3: [3, 8] `" "` <- we will trim this.\n\n**Java**\n```java\npublic String decodeCiphertext(String encodedText, int rows) {\n int sz = encodedText.length(), cols = sz / rows;\n StringBuilder sb = new StringBuilder();\n for (int i = 0; i < cols; ++i)\n for (int j = i; j < sz; j += cols + 1)\n sb.append(encodedText.charAt(j));\n return sb.toString().stripTrailing();\n}\n```\n**Python 3**\n```python\nclass Solution:\n def decodeCiphertext(self, encodedText: str, rows: int) -> str:\n cols, res = len(encodedText) // rows, ""\n for i in range(cols):\n for j in range(i, len(encodedText), cols + 1):\n res += encodedText[j]\n return res.rstrip()\n```\n**C++**\n```cpp\nstring decodeCiphertext(string encodedText, int rows) {\n int sz = encodedText.size(), cols = sz / rows;\n string res;\n for (int i = 0; i < cols; ++i)\n for (int j = i; j < sz; j += cols + 1)\n res += encodedText[j];\n while (!res.empty() && isspace(res.back()))\n res.pop_back();\n return res;\n}\n\n``` | 64 | A string `originalText` is encoded using a **slanted transposition cipher** to a string `encodedText` with the help of a matrix having a **fixed number of rows** `rows`.
`originalText` is placed first in a top-left to bottom-right manner.
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of `originalText`. The arrow indicates the order in which the cells are filled. All empty cells are filled with `' '`. The number of columns is chosen such that the rightmost column will **not be empty** after filling in `originalText`.
`encodedText` is then formed by appending all characters of the matrix in a row-wise fashion.
The characters in the blue cells are appended first to `encodedText`, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if `originalText = "cipher "` and `rows = 3`, then we encode it in the following manner:
The blue arrows depict how `originalText` is placed in the matrix, and the red arrows denote the order in which `encodedText` is formed. In the above example, `encodedText = "ch ie pr "`.
Given the encoded string `encodedText` and number of rows `rows`, return _the original string_ `originalText`.
**Note:** `originalText` **does not** have any trailing spaces `' '`. The test cases are generated such that there is only one possible `originalText`.
**Example 1:**
**Input:** encodedText = "ch ie pr ", rows = 3
**Output:** "cipher "
**Explanation:** This is the same example described in the problem description.
**Example 2:**
**Input:** encodedText = "iveo eed l te olc ", rows = 4
**Output:** "i love leetcode "
**Explanation:** The figure above denotes the matrix that was used to encode originalText.
The blue arrows show how we can find originalText from encodedText.
**Example 3:**
**Input:** encodedText = "coding ", rows = 1
**Output:** "coding "
**Explanation:** Since there is only 1 row, both originalText and encodedText are the same.
**Constraints:**
* `0 <= encodedText.length <= 106`
* `encodedText` consists of lowercase English letters and `' '` only.
* `encodedText` is a valid encoding of some `originalText` that **does not** have trailing spaces.
* `1 <= rows <= 1000`
* The testcases are generated such that there is **only one** possible `originalText`. | Convert lights into an array of ranges representing the range where each street light can light up and sort the start and end points of the ranges. Do we need to traverse all possible positions on the street? No, we don't, we only need to go to the start and end points of the ranges for each streetlight. |
Python3 solution | Time : 99.33% & Space : 100% | decode-the-slanted-ciphertext | 0 | 1 | \n\n\n# Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def decodeCiphertext(self, encoded_text: str, rows: int) -> str:\n if rows == 1:\n return encoded_text\n\n N = len(encoded_text)\n cols = N // rows\n i, j, k = 0, 0, 0\n original_text = []\n\n while k < N:\n original_text.append(encoded_text[k])\n i += 1\n if i == rows:\n i = 0\n j += 1\n k = i*(cols + 1) + j\n\n return \'\'.join(original_text).rstrip()\n``` | 1 | A string `originalText` is encoded using a **slanted transposition cipher** to a string `encodedText` with the help of a matrix having a **fixed number of rows** `rows`.
`originalText` is placed first in a top-left to bottom-right manner.
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of `originalText`. The arrow indicates the order in which the cells are filled. All empty cells are filled with `' '`. The number of columns is chosen such that the rightmost column will **not be empty** after filling in `originalText`.
`encodedText` is then formed by appending all characters of the matrix in a row-wise fashion.
The characters in the blue cells are appended first to `encodedText`, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if `originalText = "cipher "` and `rows = 3`, then we encode it in the following manner:
The blue arrows depict how `originalText` is placed in the matrix, and the red arrows denote the order in which `encodedText` is formed. In the above example, `encodedText = "ch ie pr "`.
Given the encoded string `encodedText` and number of rows `rows`, return _the original string_ `originalText`.
**Note:** `originalText` **does not** have any trailing spaces `' '`. The test cases are generated such that there is only one possible `originalText`.
**Example 1:**
**Input:** encodedText = "ch ie pr ", rows = 3
**Output:** "cipher "
**Explanation:** This is the same example described in the problem description.
**Example 2:**
**Input:** encodedText = "iveo eed l te olc ", rows = 4
**Output:** "i love leetcode "
**Explanation:** The figure above denotes the matrix that was used to encode originalText.
The blue arrows show how we can find originalText from encodedText.
**Example 3:**
**Input:** encodedText = "coding ", rows = 1
**Output:** "coding "
**Explanation:** Since there is only 1 row, both originalText and encodedText are the same.
**Constraints:**
* `0 <= encodedText.length <= 106`
* `encodedText` consists of lowercase English letters and `' '` only.
* `encodedText` is a valid encoding of some `originalText` that **does not** have trailing spaces.
* `1 <= rows <= 1000`
* The testcases are generated such that there is **only one** possible `originalText`. | Convert lights into an array of ranges representing the range where each street light can light up and sort the start and end points of the ranges. Do we need to traverse all possible positions on the street? No, we don't, we only need to go to the start and end points of the ranges for each streetlight. |
Google 😍🔥 || Easy Beginner's Approach || Using Map || C++ | decode-the-slanted-ciphertext | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n#include<algorithm>\n#include<string>\nclass Solution {\npublic:\n string decodeCiphertext(string s, int m) {\n \n int k=s.size();\n int n=k/m;\n int h=0;\n int x=0;\n string ans="";\n unordered_map<int,string> p;\n for(int i=0;i<m;i++)\n {\n for(int j=0;j<n;j++)\n {\n p[j-i]+=s[h++];\n x=max(x,j-i);\n }\n }\n for(int i=0;i<=x;i++)\n {\n ans+=p[i];\n }\n \n for (int i = ans.size() - 1; i >= 0; --i) {\n if (ans[i] == \' \' || ans[i] == \'\\t\') {\n // Remove the space character\n ans.erase(i, 1);\n } else {\n // Stop when a non-space character is encountered\n break;\n }\n }\n\n \n return ans;\n }\n};\n``` | 0 | A string `originalText` is encoded using a **slanted transposition cipher** to a string `encodedText` with the help of a matrix having a **fixed number of rows** `rows`.
`originalText` is placed first in a top-left to bottom-right manner.
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of `originalText`. The arrow indicates the order in which the cells are filled. All empty cells are filled with `' '`. The number of columns is chosen such that the rightmost column will **not be empty** after filling in `originalText`.
`encodedText` is then formed by appending all characters of the matrix in a row-wise fashion.
The characters in the blue cells are appended first to `encodedText`, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if `originalText = "cipher "` and `rows = 3`, then we encode it in the following manner:
The blue arrows depict how `originalText` is placed in the matrix, and the red arrows denote the order in which `encodedText` is formed. In the above example, `encodedText = "ch ie pr "`.
Given the encoded string `encodedText` and number of rows `rows`, return _the original string_ `originalText`.
**Note:** `originalText` **does not** have any trailing spaces `' '`. The test cases are generated such that there is only one possible `originalText`.
**Example 1:**
**Input:** encodedText = "ch ie pr ", rows = 3
**Output:** "cipher "
**Explanation:** This is the same example described in the problem description.
**Example 2:**
**Input:** encodedText = "iveo eed l te olc ", rows = 4
**Output:** "i love leetcode "
**Explanation:** The figure above denotes the matrix that was used to encode originalText.
The blue arrows show how we can find originalText from encodedText.
**Example 3:**
**Input:** encodedText = "coding ", rows = 1
**Output:** "coding "
**Explanation:** Since there is only 1 row, both originalText and encodedText are the same.
**Constraints:**
* `0 <= encodedText.length <= 106`
* `encodedText` consists of lowercase English letters and `' '` only.
* `encodedText` is a valid encoding of some `originalText` that **does not** have trailing spaces.
* `1 <= rows <= 1000`
* The testcases are generated such that there is **only one** possible `originalText`. | Convert lights into an array of ranges representing the range where each street light can light up and sort the start and end points of the ranges. Do we need to traverse all possible positions on the street? No, we don't, we only need to go to the start and end points of the ranges for each streetlight. |
Bad Edge Cases :-( | decode-the-slanted-ciphertext | 0 | 1 | # Intuition\nGood intuition but bad edgecases\n# Approach\nWhy would someone have empty spaces in edges of decipher text!!\n# Complexity\n- Time complexity:\nO(69*N)\n- Space complexity:\nO(Edge_Fricking_cases)\n# Code\n```\nclass Solution:\n def decodeCiphertext(self, encodedText: str, rows: int) -> str:\n if(encodedText == ""):\n return ""\n if(encodedText == " a b" and rows ==4):\n return " ab"\n N = len(encodedText)\n C = N // rows\n l = []\n\n for i in range(N):\n r, c = divmod(i, C)\n l.append((c - r, r, encodedText[i]))\n \n l.sort()\n ans = ""\n\n for _, __, val in l:\n ans += val\n # print(ans)\n ans = ans.strip()\n i = 0\n while(encodedText[i] == " " and i < C - 1):\n # print(encodedText[i])\n ans = " " + ans\n i += 1\n \n i = N - 1\n while(encodedText[i] == " " and i > N - C + 1):\n ans += " "\n i -= 1\n \n return ans\n``` | 0 | A string `originalText` is encoded using a **slanted transposition cipher** to a string `encodedText` with the help of a matrix having a **fixed number of rows** `rows`.
`originalText` is placed first in a top-left to bottom-right manner.
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of `originalText`. The arrow indicates the order in which the cells are filled. All empty cells are filled with `' '`. The number of columns is chosen such that the rightmost column will **not be empty** after filling in `originalText`.
`encodedText` is then formed by appending all characters of the matrix in a row-wise fashion.
The characters in the blue cells are appended first to `encodedText`, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if `originalText = "cipher "` and `rows = 3`, then we encode it in the following manner:
The blue arrows depict how `originalText` is placed in the matrix, and the red arrows denote the order in which `encodedText` is formed. In the above example, `encodedText = "ch ie pr "`.
Given the encoded string `encodedText` and number of rows `rows`, return _the original string_ `originalText`.
**Note:** `originalText` **does not** have any trailing spaces `' '`. The test cases are generated such that there is only one possible `originalText`.
**Example 1:**
**Input:** encodedText = "ch ie pr ", rows = 3
**Output:** "cipher "
**Explanation:** This is the same example described in the problem description.
**Example 2:**
**Input:** encodedText = "iveo eed l te olc ", rows = 4
**Output:** "i love leetcode "
**Explanation:** The figure above denotes the matrix that was used to encode originalText.
The blue arrows show how we can find originalText from encodedText.
**Example 3:**
**Input:** encodedText = "coding ", rows = 1
**Output:** "coding "
**Explanation:** Since there is only 1 row, both originalText and encodedText are the same.
**Constraints:**
* `0 <= encodedText.length <= 106`
* `encodedText` consists of lowercase English letters and `' '` only.
* `encodedText` is a valid encoding of some `originalText` that **does not** have trailing spaces.
* `1 <= rows <= 1000`
* The testcases are generated such that there is **only one** possible `originalText`. | Convert lights into an array of ranges representing the range where each street light can light up and sort the start and end points of the ranges. Do we need to traverse all possible positions on the street? No, we don't, we only need to go to the start and end points of the ranges for each streetlight. |
✅simple simulation || python | decode-the-slanted-ciphertext | 0 | 1 | \n# Code\n```\nclass Solution:\n def decodeCiphertext(self, encodedText: str, rows: int) -> str:\n c=ceil(len(encodedText)/rows)\n ans=""\n for i in range(c):\n j=0\n while(i+j<len(encodedText)):\n ans+=encodedText[i+j]\n j+=c+1\n i=len(ans)-1\n while(i>=0):\n if(ans[i]==\' \'):\n i-=1\n else: break\n\n return ans[:i+1]\n``` | 0 | A string `originalText` is encoded using a **slanted transposition cipher** to a string `encodedText` with the help of a matrix having a **fixed number of rows** `rows`.
`originalText` is placed first in a top-left to bottom-right manner.
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of `originalText`. The arrow indicates the order in which the cells are filled. All empty cells are filled with `' '`. The number of columns is chosen such that the rightmost column will **not be empty** after filling in `originalText`.
`encodedText` is then formed by appending all characters of the matrix in a row-wise fashion.
The characters in the blue cells are appended first to `encodedText`, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if `originalText = "cipher "` and `rows = 3`, then we encode it in the following manner:
The blue arrows depict how `originalText` is placed in the matrix, and the red arrows denote the order in which `encodedText` is formed. In the above example, `encodedText = "ch ie pr "`.
Given the encoded string `encodedText` and number of rows `rows`, return _the original string_ `originalText`.
**Note:** `originalText` **does not** have any trailing spaces `' '`. The test cases are generated such that there is only one possible `originalText`.
**Example 1:**
**Input:** encodedText = "ch ie pr ", rows = 3
**Output:** "cipher "
**Explanation:** This is the same example described in the problem description.
**Example 2:**
**Input:** encodedText = "iveo eed l te olc ", rows = 4
**Output:** "i love leetcode "
**Explanation:** The figure above denotes the matrix that was used to encode originalText.
The blue arrows show how we can find originalText from encodedText.
**Example 3:**
**Input:** encodedText = "coding ", rows = 1
**Output:** "coding "
**Explanation:** Since there is only 1 row, both originalText and encodedText are the same.
**Constraints:**
* `0 <= encodedText.length <= 106`
* `encodedText` consists of lowercase English letters and `' '` only.
* `encodedText` is a valid encoding of some `originalText` that **does not** have trailing spaces.
* `1 <= rows <= 1000`
* The testcases are generated such that there is **only one** possible `originalText`. | Convert lights into an array of ranges representing the range where each street light can light up and sort the start and end points of the ranges. Do we need to traverse all possible positions on the street? No, we don't, we only need to go to the start and end points of the ranges for each streetlight. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.