
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Python one liner with explanation | a-number-after-a-double-reversal | 0 | 1 | False is when 2+ digit numbers have trailing zeroes, otherwise every other double reversal condition is True\n\n\n```\nclass Solution:\n def isSameAfterReversals(self, num: int) -> bool:\n return [False if len(str(num)) > 1 and str(num)[-1] == "0" else True][0]\n``` | 0 | **Reversing** an integer means to reverse all its digits.
* For example, reversing `2021` gives `1202`. Reversing `12300` gives `321` as the **leading zeros are not retained**.
Given an integer `num`, **reverse** `num` to get `reversed1`, **then reverse** `reversed1` to get `reversed2`. Return `true` _if_ `reversed2` _equals_ `num`. Otherwise return `false`.
**Example 1:**
**Input:** num = 526
**Output:** true
**Explanation:** Reverse num to get 625, then reverse 625 to get 526, which equals num.
**Example 2:**
**Input:** num = 1800
**Output:** false
**Explanation:** Reverse num to get 81, then reverse 81 to get 18, which does not equal num.
**Example 3:**
**Input:** num = 0
**Output:** true
**Explanation:** Reverse num to get 0, then reverse 0 to get 0, which equals num.
**Constraints:**
* `0 <= num <= 106` | Sort the array. For every index do a binary search to get the possible right end of the window and calculate the possible answer. |
[Python3] Clean Solution | execution-of-all-suffix-instructions-staying-in-a-grid | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def executeInstructions(self, n: int, startPos: List[int], s: str) -> List[int]:\n row,col,res=startPos[0],startPos[1],[]\n for i in range(len(s)):\n startPos[0],startPos[1],arr,count=row,col,s[i:],0\n for j in arr:\n if j=="R":\n if startPos[1]+1==n:break\n else:\n startPos[1]+=1\n count+=1\n elif j=="L":\n if startPos[1]-1==-1:break\n else:\n startPos[1]-=1\n count+=1\n elif j=="U":\n if startPos[0]-1==-1:break\n else:\n startPos[0]-=1\n count+=1\n elif j=="D":\n if startPos[0]+1==n:break\n else:\n startPos[0]+=1\n count+=1\n res.append(count)\n return res\n``` | 2 | There is an `n x n` grid, with the top-left cell at `(0, 0)` and the bottom-right cell at `(n - 1, n - 1)`. You are given the integer `n` and an integer array `startPos` where `startPos = [startrow, startcol]` indicates that a robot is initially at cell `(startrow, startcol)`.
You are also given a **0-indexed** string `s` of length `m` where `s[i]` is the `ith` instruction for the robot: `'L'` (move left), `'R'` (move right), `'U'` (move up), and `'D'` (move down).
The robot can begin executing from any `ith` instruction in `s`. It executes the instructions one by one towards the end of `s` but it stops if either of these conditions is met:
* The next instruction will move the robot off the grid.
* There are no more instructions left to execute.
Return _an array_ `answer` _of length_ `m` _where_ `answer[i]` _is **the number of instructions** the robot can execute if the robot **begins executing from** the_ `ith` _instruction in_ `s`.
**Example 1:**
**Input:** n = 3, startPos = \[0,1\], s = "RRDDLU "
**Output:** \[1,5,4,3,1,0\]
**Explanation:** Starting from startPos and beginning execution from the ith instruction:
- 0th: "**R**RDDLU ". Only one instruction "R " can be executed before it moves off the grid.
- 1st: "**RDDLU** ". All five instructions can be executed while it stays in the grid and ends at (1, 1).
- 2nd: "**DDLU** ". All four instructions can be executed while it stays in the grid and ends at (1, 0).
- 3rd: "**DLU** ". All three instructions can be executed while it stays in the grid and ends at (0, 0).
- 4th: "**L**U ". Only one instruction "L " can be executed before it moves off the grid.
- 5th: "U ". If moving up, it would move off the grid.
**Example 2:**
**Input:** n = 2, startPos = \[1,1\], s = "LURD "
**Output:** \[4,1,0,0\]
**Explanation:**
- 0th: "**LURD** ".
- 1st: "**U**RD ".
- 2nd: "RD ".
- 3rd: "D ".
**Example 3:**
**Input:** n = 1, startPos = \[0,0\], s = "LRUD "
**Output:** \[0,0,0,0\]
**Explanation:** No matter which instruction the robot begins execution from, it would move off the grid.
**Constraints:**
* `m == s.length`
* `1 <= n, m <= 500`
* `startPos.length == 2`
* `0 <= startrow, startcol < n`
* `s` consists of `'L'`, `'R'`, `'U'`, and `'D'`. | null |
[Python] Straight-forward O(n ^ 2) solution (still fast - 85%) | execution-of-all-suffix-instructions-staying-in-a-grid | 0 | 1 | # Complexity\n- Time complexity:\nO(N ^ 2)\n- Space complexity:\nO(N)\n\n# Code\n```python []\nclass Solution:\n def executeInstructions(self, n: int, startPos: list[int], s: str) -> list[int]:\n\n def num_of_valid_instructions(s, pos, start, end):\n row, colon = pos\n k = 0\n for i in range(start, end):\n cur = s[i]\n row += (cur == \'D\') - (cur == \'U\')\n colon += (cur == \'R\') - (cur == \'L\')\n if not (0 <= row < n and 0 <= colon < n):\n return k\n k += 1\n return k\n\n ans = []\n for i in range(len(s)):\n ans.append(num_of_valid_instructions(s, startPos, i, len(s)))\n return ans\n``` | 3 | There is an `n x n` grid, with the top-left cell at `(0, 0)` and the bottom-right cell at `(n - 1, n - 1)`. You are given the integer `n` and an integer array `startPos` where `startPos = [startrow, startcol]` indicates that a robot is initially at cell `(startrow, startcol)`.
You are also given a **0-indexed** string `s` of length `m` where `s[i]` is the `ith` instruction for the robot: `'L'` (move left), `'R'` (move right), `'U'` (move up), and `'D'` (move down).
The robot can begin executing from any `ith` instruction in `s`. It executes the instructions one by one towards the end of `s` but it stops if either of these conditions is met:
* The next instruction will move the robot off the grid.
* There are no more instructions left to execute.
Return _an array_ `answer` _of length_ `m` _where_ `answer[i]` _is **the number of instructions** the robot can execute if the robot **begins executing from** the_ `ith` _instruction in_ `s`.
**Example 1:**
**Input:** n = 3, startPos = \[0,1\], s = "RRDDLU "
**Output:** \[1,5,4,3,1,0\]
**Explanation:** Starting from startPos and beginning execution from the ith instruction:
- 0th: "**R**RDDLU ". Only one instruction "R " can be executed before it moves off the grid.
- 1st: "**RDDLU** ". All five instructions can be executed while it stays in the grid and ends at (1, 1).
- 2nd: "**DDLU** ". All four instructions can be executed while it stays in the grid and ends at (1, 0).
- 3rd: "**DLU** ". All three instructions can be executed while it stays in the grid and ends at (0, 0).
- 4th: "**L**U ". Only one instruction "L " can be executed before it moves off the grid.
- 5th: "U ". If moving up, it would move off the grid.
**Example 2:**
**Input:** n = 2, startPos = \[1,1\], s = "LURD "
**Output:** \[4,1,0,0\]
**Explanation:**
- 0th: "**LURD** ".
- 1st: "**U**RD ".
- 2nd: "RD ".
- 3rd: "D ".
**Example 3:**
**Input:** n = 1, startPos = \[0,0\], s = "LRUD "
**Output:** \[0,0,0,0\]
**Explanation:** No matter which instruction the robot begins execution from, it would move off the grid.
**Constraints:**
* `m == s.length`
* `1 <= n, m <= 500`
* `startPos.length == 2`
* `0 <= startrow, startcol < n`
* `s` consists of `'L'`, `'R'`, `'U'`, and `'D'`. | null |
Python3 O(N ^ 2) solution with simulation (92.80% Runtime) | execution-of-all-suffix-instructions-staying-in-a-grid | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nIteratively check for out of bounds while updating counts\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- From start location, iteratively check if the next position is out of bounds\n- For each start index "i", update "i"th possible movements before out of bounds\n\n# Complexity\n- Time complexity: O(N ^ 2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\nIf this solution is similar to yours or helpful, upvote me if you don\'t mind\n```\nclass Solution:\n def executeInstructions(self, n: int, startPos: List[int], s: str) -> List[int]:\n l = len(s)\n ans = [0] * l\n\n for i in range(l):\n cnt = 0\n y, x = startPos\n\n for c in s[i:]:\n if c == "U":\n y -= 1\n elif c == "D":\n y += 1\n elif c == "R":\n x += 1\n else:\n x -= 1\n\n if x >= n or y >= n or x < 0 or y < 0:\n break\n cnt += 1\n\n ans[i] = cnt\n \n return ans\n``` | 0 | There is an `n x n` grid, with the top-left cell at `(0, 0)` and the bottom-right cell at `(n - 1, n - 1)`. You are given the integer `n` and an integer array `startPos` where `startPos = [startrow, startcol]` indicates that a robot is initially at cell `(startrow, startcol)`.
You are also given a **0-indexed** string `s` of length `m` where `s[i]` is the `ith` instruction for the robot: `'L'` (move left), `'R'` (move right), `'U'` (move up), and `'D'` (move down).
The robot can begin executing from any `ith` instruction in `s`. It executes the instructions one by one towards the end of `s` but it stops if either of these conditions is met:
* The next instruction will move the robot off the grid.
* There are no more instructions left to execute.
Return _an array_ `answer` _of length_ `m` _where_ `answer[i]` _is **the number of instructions** the robot can execute if the robot **begins executing from** the_ `ith` _instruction in_ `s`.
**Example 1:**
**Input:** n = 3, startPos = \[0,1\], s = "RRDDLU "
**Output:** \[1,5,4,3,1,0\]
**Explanation:** Starting from startPos and beginning execution from the ith instruction:
- 0th: "**R**RDDLU ". Only one instruction "R " can be executed before it moves off the grid.
- 1st: "**RDDLU** ". All five instructions can be executed while it stays in the grid and ends at (1, 1).
- 2nd: "**DDLU** ". All four instructions can be executed while it stays in the grid and ends at (1, 0).
- 3rd: "**DLU** ". All three instructions can be executed while it stays in the grid and ends at (0, 0).
- 4th: "**L**U ". Only one instruction "L " can be executed before it moves off the grid.
- 5th: "U ". If moving up, it would move off the grid.
**Example 2:**
**Input:** n = 2, startPos = \[1,1\], s = "LURD "
**Output:** \[4,1,0,0\]
**Explanation:**
- 0th: "**LURD** ".
- 1st: "**U**RD ".
- 2nd: "RD ".
- 3rd: "D ".
**Example 3:**
**Input:** n = 1, startPos = \[0,0\], s = "LRUD "
**Output:** \[0,0,0,0\]
**Explanation:** No matter which instruction the robot begins execution from, it would move off the grid.
**Constraints:**
* `m == s.length`
* `1 <= n, m <= 500`
* `startPos.length == 2`
* `0 <= startrow, startcol < n`
* `s` consists of `'L'`, `'R'`, `'U'`, and `'D'`. | null |
[Python3, Java, C++] Dictionary/Map and Prefix Sum O(n) | intervals-between-identical-elements | 1 | 1 | Dictionary/Hashmap is used to store all the occurences of a given number as {num: [indexes of occurences in arr]}\n\n***Explanation for the use of prefix array***:\nPrefix array `pre` is first used to fetch the sum of numbers uptil index i (for a given number arr[i]). We know that the numbers in the list are sorted thus these numbers will be smaller than i.\n\n`v * (i + 1) - pre[i + 1]` finds the `\u2211 (l[i] - (numbers smaller than or equal to l[i] in list))`\nLet\'s say for given list 1, 3, 5, 7, 9:\nFor example, we choose `i` = 3 or the number `l[i]` = 7.\nTo find abs difference for numbers smaller than equal to 7:\n7 - 1 + 7 - 3 + 7 - 5 + 7 - 7\nor\n7 * 4 - (1 + 3 + 5 + 7)\nor\n7 * `(i + 1)` - `pre[i + 1]`\n\nSimilarly\n`((pre[len(l)] - pre[i]) - v * (len(l) - (i)))` calculates abs difference between` l[i]` and numbers greater than `l[i]`\n\n**Python3**:\n```\ndef getDistances(self, arr: List[int]) -> List[int]:\n m, res = {}, [0] * len(arr)\n for i, v in enumerate(arr):\n if v not in m: m[v] = list()\n m[v].append(i)\n \n for x in m:\n l = m[x]\n pre = [0] * (len(l) + 1)\n for i in range(len(l)):\n pre[i + 1] = pre[i] + l[i]\n for i, v in enumerate(l):\n res[v] = (v * (i + 1) - pre[i + 1]) + ((pre[len(l)] - pre[i]) - v * (len(l) - (i)))\n return res\n```\n\n<iframe src="https://leetcode.com/playground/EYjsLmzB/shared" frameBorder="0" width="800" height="410"></iframe>\n\n | 45 | You are given a **0-indexed** array of `n` integers `arr`.
The **interval** between two elements in `arr` is defined as the **absolute difference** between their indices. More formally, the **interval** between `arr[i]` and `arr[j]` is `|i - j|`.
Return _an array_ `intervals` _of length_ `n` _where_ `intervals[i]` _is **the sum of intervals** between_ `arr[i]` _and each element in_ `arr` _with the same value as_ `arr[i]`_._
**Note:** `|x|` is the absolute value of `x`.
**Example 1:**
**Input:** arr = \[2,1,3,1,2,3,3\]
**Output:** \[4,2,7,2,4,4,5\]
**Explanation:**
- Index 0: Another 2 is found at index 4. |0 - 4| = 4
- Index 1: Another 1 is found at index 3. |1 - 3| = 2
- Index 2: Two more 3s are found at indices 5 and 6. |2 - 5| + |2 - 6| = 7
- Index 3: Another 1 is found at index 1. |3 - 1| = 2
- Index 4: Another 2 is found at index 0. |4 - 0| = 4
- Index 5: Two more 3s are found at indices 2 and 6. |5 - 2| + |5 - 6| = 4
- Index 6: Two more 3s are found at indices 2 and 5. |6 - 2| + |6 - 5| = 5
**Example 2:**
**Input:** arr = \[10,5,10,10\]
**Output:** \[5,0,3,4\]
**Explanation:**
- Index 0: Two more 10s are found at indices 2 and 3. |0 - 2| + |0 - 3| = 5
- Index 1: There is only one 5 in the array, so its sum of intervals to identical elements is 0.
- Index 2: Two more 10s are found at indices 0 and 3. |2 - 0| + |2 - 3| = 3
- Index 3: Two more 10s are found at indices 0 and 2. |3 - 0| + |3 - 2| = 4
**Constraints:**
* `n == arr.length`
* `1 <= n <= 105`
* `1 <= arr[i] <= 105` | null |
[Python3] prefix sum | intervals-between-identical-elements | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/338b3e50d12cc0067b8b85e8e27c1b0c10fd91c6) for solutions of weely 273. \n\n```\nclass Solution:\n def getDistances(self, arr: List[int]) -> List[int]:\n loc = defaultdict(list)\n for i, x in enumerate(arr): loc[x].append(i)\n \n for k, idx in loc.items(): \n prefix = list(accumulate(idx, initial=0))\n vals = []\n for i, x in enumerate(idx): \n vals.append(prefix[-1] - prefix[i] - prefix[i+1] - (len(idx)-2*i-1)*x)\n loc[k] = deque(vals)\n \n return [loc[x].popleft() for x in arr]\n```\n\n**Explanation on the formula**\nGiven an array, say `nums = [3,2,1,5,4]`. Calculate its prefix sum `[0,3,5,6,11,15]` (note the leading zero). Now let\'s loop through `nums` by index. At `i`, there are \n1) `i` numbers whose indices are below `i` with sum `prefix[i]`;\n2) `len(nums)-i-1` numbers whose indices are above `i` with sum `prefix[-1] - prefix[i+1]`. \n\nSo the desired value in this case is `i*x - prefix[i] + prefix[-1] - prefix[i+1] - (len(nums)-i-1)*x`. Rearranging the terms one would arrive at the formula used in this implementation. | 10 | You are given a **0-indexed** array of `n` integers `arr`.
The **interval** between two elements in `arr` is defined as the **absolute difference** between their indices. More formally, the **interval** between `arr[i]` and `arr[j]` is `|i - j|`.
Return _an array_ `intervals` _of length_ `n` _where_ `intervals[i]` _is **the sum of intervals** between_ `arr[i]` _and each element in_ `arr` _with the same value as_ `arr[i]`_._
**Note:** `|x|` is the absolute value of `x`.
**Example 1:**
**Input:** arr = \[2,1,3,1,2,3,3\]
**Output:** \[4,2,7,2,4,4,5\]
**Explanation:**
- Index 0: Another 2 is found at index 4. |0 - 4| = 4
- Index 1: Another 1 is found at index 3. |1 - 3| = 2
- Index 2: Two more 3s are found at indices 5 and 6. |2 - 5| + |2 - 6| = 7
- Index 3: Another 1 is found at index 1. |3 - 1| = 2
- Index 4: Another 2 is found at index 0. |4 - 0| = 4
- Index 5: Two more 3s are found at indices 2 and 6. |5 - 2| + |5 - 6| = 4
- Index 6: Two more 3s are found at indices 2 and 5. |6 - 2| + |6 - 5| = 5
**Example 2:**
**Input:** arr = \[10,5,10,10\]
**Output:** \[5,0,3,4\]
**Explanation:**
- Index 0: Two more 10s are found at indices 2 and 3. |0 - 2| + |0 - 3| = 5
- Index 1: There is only one 5 in the array, so its sum of intervals to identical elements is 0.
- Index 2: Two more 10s are found at indices 0 and 3. |2 - 0| + |2 - 3| = 3
- Index 3: Two more 10s are found at indices 0 and 2. |3 - 0| + |3 - 2| = 4
**Constraints:**
* `n == arr.length`
* `1 <= n <= 105`
* `1 <= arr[i] <= 105` | null |
Python | Simple Solution | intervals-between-identical-elements | 0 | 1 | # Intuition\nThis question is very similar to [1685. Sum of Absolute Differences in a Sorted Array](https://leetcode.com/problems/sum-of-absolute-differences-in-a-sorted-array/description/)\n\n# Approach\n[Click Here](https://leetcode.com/problems/sum-of-absolute-differences-in-a-sorted-array/solutions/4329588/python-simple-intutive-solution-with-explanation-formula-derivation/) for the explanation\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def getDistances(self, arr: List[int]) -> List[int]:\n lookup = {}\n for idx, num in enumerate(arr):\n if num not in lookup:\n lookup[num] = []\n lookup[num].append(idx)\n \n intervalsSum = {}\n for num, indexes in lookup.items():\n n = len(indexes)\n prefixSum = [i for i in indexes]\n for i in range(1, n):\n prefixSum[i] += prefixSum[i-1]\n intervalSum = {}\n for i in range(n):\n eq1 = prefixSum[-1] - prefixSum[i] - (n-(i+1))*indexes[i]\n eq2 = (i+1)*indexes[i] - prefixSum[i]\n intervalSum[indexes[i]] = eq1 + eq2\n intervalsSum[num] = intervalSum\n\n intervals = [-1] * len(arr)\n for idx, num in enumerate(arr):\n intervals[idx] = intervalsSum[num][idx]\n return intervals\n\n\n```\n\n**If you liked the above solution then please upvote!** | 0 | You are given a **0-indexed** array of `n` integers `arr`.
The **interval** between two elements in `arr` is defined as the **absolute difference** between their indices. More formally, the **interval** between `arr[i]` and `arr[j]` is `|i - j|`.
Return _an array_ `intervals` _of length_ `n` _where_ `intervals[i]` _is **the sum of intervals** between_ `arr[i]` _and each element in_ `arr` _with the same value as_ `arr[i]`_._
**Note:** `|x|` is the absolute value of `x`.
**Example 1:**
**Input:** arr = \[2,1,3,1,2,3,3\]
**Output:** \[4,2,7,2,4,4,5\]
**Explanation:**
- Index 0: Another 2 is found at index 4. |0 - 4| = 4
- Index 1: Another 1 is found at index 3. |1 - 3| = 2
- Index 2: Two more 3s are found at indices 5 and 6. |2 - 5| + |2 - 6| = 7
- Index 3: Another 1 is found at index 1. |3 - 1| = 2
- Index 4: Another 2 is found at index 0. |4 - 0| = 4
- Index 5: Two more 3s are found at indices 2 and 6. |5 - 2| + |5 - 6| = 4
- Index 6: Two more 3s are found at indices 2 and 5. |6 - 2| + |6 - 5| = 5
**Example 2:**
**Input:** arr = \[10,5,10,10\]
**Output:** \[5,0,3,4\]
**Explanation:**
- Index 0: Two more 10s are found at indices 2 and 3. |0 - 2| + |0 - 3| = 5
- Index 1: There is only one 5 in the array, so its sum of intervals to identical elements is 0.
- Index 2: Two more 10s are found at indices 0 and 3. |2 - 0| + |2 - 3| = 3
- Index 3: Two more 10s are found at indices 0 and 2. |3 - 0| + |3 - 2| = 4
**Constraints:**
* `n == arr.length`
* `1 <= n <= 105`
* `1 <= arr[i] <= 105` | null |
UGLY BUT BEGINNER FRIENDLY || BOTH SUFFIX & PREFIX || Python || LONG EXPLAINED | intervals-between-identical-elements | 0 | 1 | # Intuition\nSo, to find the intervals we can find the summ of all index seen from left side (prefix) and summ of all index seen from right side (suffix)\nnow the formula will be\n(prefix sum - (distance from left * index val)) + (suffix sum - (distance from right * index val))\n\n`now what is distance from left and distance from right and why we need to calculate it?`\nSo, to find intervals we need to subtract the current index value to all the index value of that arr[i] thus, we must know how many current index value we need to subtract from left and from right.\n\n`why during subtraction we are using left distance as j + 1 instead pf j?` take a measure unlike other problems we are doing prefix[i][j] instead of prefix[i-1][j] thus we need to subtract the current value once more.\n\n`we are also subtracting n-j instead of n - 1 - j` again for the same reason being but the question arise isnt we subtracting the same index value twice? well it doesnt matter because the current index shouldnt be even considered as curr idx - curridx = 0 in interval\n\nIt is not a very effecient solution as u can do it using only prefix array too (read top solutions) but it is bit easy to ready for beginners like me.\n\n\n\n# Code\n```\nclass Solution:\n def getDistances(self, arr: List[int]) -> List[int]:\n # formula -> suffix - (distance from right * index value) + prefix - (distance from left * index value)\n d = defaultdict(list)\n prefix = defaultdict(list)\n suffix = defaultdict(list)\n for i in range(len(arr)):\n if arr[i] in d:\n prefix[arr[i]].append(prefix[arr[i]][-1] + i)\n else:\n prefix[arr[i]].append(i)\n d[arr[i]].append(i)\n\n for i, val in d.items():\n summ = 0\n for idx in range(len(val)-1, -1, -1):\n summ += val[idx]\n suffix[i].append(summ)\n suffix[i] = suffix[i][::-1]\n\n ans = [0] * len(arr)\n for i, val in suffix.items():\n n = len(val)\n for j in range(n):\n summ = (abs(prefix[i][j] - ((j + 1) * d[i][j])) + abs(suffix[i][j] - ((n - j)* d[i][j])))\n ans[d[i][j]] = summ\n return ans\n\n\n\n \n\n\n \n``` | 0 | You are given a **0-indexed** array of `n` integers `arr`.
The **interval** between two elements in `arr` is defined as the **absolute difference** between their indices. More formally, the **interval** between `arr[i]` and `arr[j]` is `|i - j|`.
Return _an array_ `intervals` _of length_ `n` _where_ `intervals[i]` _is **the sum of intervals** between_ `arr[i]` _and each element in_ `arr` _with the same value as_ `arr[i]`_._
**Note:** `|x|` is the absolute value of `x`.
**Example 1:**
**Input:** arr = \[2,1,3,1,2,3,3\]
**Output:** \[4,2,7,2,4,4,5\]
**Explanation:**
- Index 0: Another 2 is found at index 4. |0 - 4| = 4
- Index 1: Another 1 is found at index 3. |1 - 3| = 2
- Index 2: Two more 3s are found at indices 5 and 6. |2 - 5| + |2 - 6| = 7
- Index 3: Another 1 is found at index 1. |3 - 1| = 2
- Index 4: Another 2 is found at index 0. |4 - 0| = 4
- Index 5: Two more 3s are found at indices 2 and 6. |5 - 2| + |5 - 6| = 4
- Index 6: Two more 3s are found at indices 2 and 5. |6 - 2| + |6 - 5| = 5
**Example 2:**
**Input:** arr = \[10,5,10,10\]
**Output:** \[5,0,3,4\]
**Explanation:**
- Index 0: Two more 10s are found at indices 2 and 3. |0 - 2| + |0 - 3| = 5
- Index 1: There is only one 5 in the array, so its sum of intervals to identical elements is 0.
- Index 2: Two more 10s are found at indices 0 and 3. |2 - 0| + |2 - 3| = 3
- Index 3: Two more 10s are found at indices 0 and 2. |3 - 0| + |3 - 2| = 4
**Constraints:**
* `n == arr.length`
* `1 <= n <= 105`
* `1 <= arr[i] <= 105` | null |
Prefix - Map | intervals-between-identical-elements | 0 | 1 | # Complexity\n```haskell\nTime complexity: O(n)\nSpace complexity: O(n)\n```\n\n# Code\n```python\nclass Solution:\n def getDistances(self, A: List[int]) -> List[int]:\n # Returns s.t. R[i] = sum(|i - j| for j in [0..i] if A[j] == 0)\n def f(A: List[int]) -> List[int]:\n R = [0 for _ in range(len(A))]\n P = {} # map: n -> (prev_idx, count_so_far, interval_so_far)\n for (i, a) in enumerate(A):\n (j, c, v) = P.get(a, (i, 0, 0))\n R[i] += v + (i - j) * c\n P[a] = (i, c + 1, v + (i - j) * c)\n return R\n\n # get prefix and suffix counts\n return [a + b for a, b in zip(f(A), f(A[::-1])[::-1])]\n``` | 0 | You are given a **0-indexed** array of `n` integers `arr`.
The **interval** between two elements in `arr` is defined as the **absolute difference** between their indices. More formally, the **interval** between `arr[i]` and `arr[j]` is `|i - j|`.
Return _an array_ `intervals` _of length_ `n` _where_ `intervals[i]` _is **the sum of intervals** between_ `arr[i]` _and each element in_ `arr` _with the same value as_ `arr[i]`_._
**Note:** `|x|` is the absolute value of `x`.
**Example 1:**
**Input:** arr = \[2,1,3,1,2,3,3\]
**Output:** \[4,2,7,2,4,4,5\]
**Explanation:**
- Index 0: Another 2 is found at index 4. |0 - 4| = 4
- Index 1: Another 1 is found at index 3. |1 - 3| = 2
- Index 2: Two more 3s are found at indices 5 and 6. |2 - 5| + |2 - 6| = 7
- Index 3: Another 1 is found at index 1. |3 - 1| = 2
- Index 4: Another 2 is found at index 0. |4 - 0| = 4
- Index 5: Two more 3s are found at indices 2 and 6. |5 - 2| + |5 - 6| = 4
- Index 6: Two more 3s are found at indices 2 and 5. |6 - 2| + |6 - 5| = 5
**Example 2:**
**Input:** arr = \[10,5,10,10\]
**Output:** \[5,0,3,4\]
**Explanation:**
- Index 0: Two more 10s are found at indices 2 and 3. |0 - 2| + |0 - 3| = 5
- Index 1: There is only one 5 in the array, so its sum of intervals to identical elements is 0.
- Index 2: Two more 10s are found at indices 0 and 3. |2 - 0| + |2 - 3| = 3
- Index 3: Two more 10s are found at indices 0 and 2. |3 - 0| + |3 - 2| = 4
**Constraints:**
* `n == arr.length`
* `1 <= n <= 105`
* `1 <= arr[i] <= 105` | null |
[Python3] brute-force | recover-the-original-array | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/338b3e50d12cc0067b8b85e8e27c1b0c10fd91c6) for solutions of weely 273. \n\n```\nclass Solution:\n def recoverArray(self, nums: List[int]) -> List[int]:\n nums.sort()\n cnt = Counter(nums)\n for i in range(1, len(nums)): \n diff = nums[i] - nums[0]\n if diff and diff&1 == 0: \n ans = []\n freq = cnt.copy()\n for k, v in freq.items(): \n if v: \n if freq[k+diff] < v: break \n ans.extend([k+diff//2]*v)\n freq[k+diff] -= v\n else: return ans \n``` | 12 | Given a 0-indexed integer array nums, return the number of distinct quadruplets (a, b, c, d) such that: | N is very small, how can we use that? Can we check every possible quadruplet? |
85+ in speed and memory using Python3 | recover-the-original-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import Counter\nclass Solution:\n def recoverArray(self, nums: List[int]) -> List[int]:\n nums.sort()\n smallest, largest = nums[0], nums[-1]\n nums_counter = Counter(nums)\n knums = list(nums_counter.keys())\n\n for knum in knums[1:]:\n K = knum - smallest\n if K & 1 or smallest + K not in nums_counter or largest - K not in nums_counter:\n continue\n \n ans = []\n numsc = nums_counter.copy()\n \n for num in knums:\n if numsc[num] == 0:\n continue\n if num + K not in numsc or numsc[num + K] == 0:\n break\n \n count = min(numsc[num], numsc[num + K]) \n numsc[num] -= count\n numsc[num + K] -= count\n\n ans += [num + K//2]*count\n \n if len(ans) == len(nums) // 2:\n return ans\n``` | 0 | Given a 0-indexed integer array nums, return the number of distinct quadruplets (a, b, c, d) such that: | N is very small, how can we use that? Can we check every possible quadruplet? |
Python (Simple Maths) | recover-the-original-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def recoverArray(self, nums):\n n = len(nums)\n\n nums.sort()\n\n def dfs(k):\n dict1, res = Counter(nums), []\n\n for num in nums:\n if dict1[num] and dict1[num+2*k]:\n res.append(num+k)\n dict1[num] -= 1\n dict1[num+2*k] -= 1\n\n if len(res) == n//2: return res\n\n return []\n\n for i in range(n):\n if (nums[i]-nums[0]) > 0 and (nums[i]-nums[0])%2 == 0:\n res = dfs((nums[i]-nums[0])//2)\n if res: return res\n\n return []\n\n\n \n\n\n\n\n\n\n\n\n\n \n\n\n\n\n\n\n\n\n``` | 0 | Given a 0-indexed integer array nums, return the number of distinct quadruplets (a, b, c, d) such that: | N is very small, how can we use that? Can we check every possible quadruplet? |
Python Counter: Use it to its fullest. 98ms, fastest solution yet... for slow python. | recover-the-original-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nMany solutions here cleverly create a counter, and yet iterate through each num in the full array to subtract matching pairs. We can do a little better though. Since we *have* the counter, we can iterate through that instead and remove whole chunks of matched sets in one step\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe same basic O(n^2) solution in most other posts, with a twist. Iterate through counter keys rather than the num array. Subtract counter vals to account for EVERY match of num and num + k in one step.\n\nIts a pretty minor optimization, but is neat and you may as well. \n\n\nOriginally I did try deleting key:val pairs in the dict so the dictionary actually gets smaller, and we can exit once its empty (knowing we have the right answer), but this is slower than just checking if the value in the dict == 0. \n\n# Complexity\nInstead of O(n^2), this is technically O(len(counter.keys())^2), though worst case that IS O(n^2). It improves the average and best case analysis though. \n\n\n# Code\n```\nfrom collections import Counter\n\n\nclass Solution:\n def recoverArray(self, nums: List[int]) -> List[int]:\n nums.sort()\n smallest, largest = nums[0], nums[-1]\n nums_counter = Counter(nums)\n knums = list(nums_counter.keys())\n\n for knum in knums[1:]:\n #technically this is 2k here, but thats less useful.\n #Lets say K = 2k\n K = knum - smallest\n #We know smallest MUST be in the LOWER array, so smallest + K must exist or we have the wrong K. \n # Same logic for largest. We can directly test this and maybe stop early\n # This test accounts for hundreds of ms in runtime speedup\n if K & 1 or smallest + K not in nums_counter or largest - K not in nums_counter:\n continue\n \n #make new copies, dont recreate the counter each time. \n ans = []\n numsc = nums_counter.copy()\n \n for num in knums:\n #already accounted for all these\n if numsc[num] == 0:\n continue\n #Wrong K\n if num + K not in numsc or numsc[num + K] == 0:\n break\n\n #Update ALL matched pairs in one step \n count = min(numsc[num], numsc[num + K]) \n numsc[num] -= count\n numsc[num + K] -= count\n\n # Need to add count many copies of our new num\n ans += [num + K//2]*count\n \n if len(ans) == len(nums) // 2:\n return ans \n\n\n``` | 0 | Given a 0-indexed integer array nums, return the number of distinct quadruplets (a, b, c, d) such that: | N is very small, how can we use that? Can we check every possible quadruplet? |
Python. Beats 100%. | recover-the-original-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nsort nums\n\ncreate a dictionary with Counter of all vals\n\ncreate a test array testing abs(nums[0] - nums[i]) for i in range(1,n//2+1)\n\nthe n//2+1 upperbound is included because if n == 10, and nums is sorted, for nums[0], the maximum index for which nums[0] could be paired up with is nums[5]. \n\nThen run a for loop testing each possibility. the difference has to be divisible by 2 and > 1. Divisible by 2 because the differences we are testing are 2*k, so if the differnece is 7, k would have to be 3.5 which is not an integer and invalid.\n\ni copy the dicitonary, and -=1 in the copied dictionary for each [val] and [val + c], and i break the forloop as soon i encounter a [val+c] either not in dictionary or with value 0. \n\nbreak the testing for loop as soon as you identify a value that will work, then build the array bestans.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def recoverArray(self, nums: List[int]) -> List[int]:\n from collections import Counter\n nums.sort()\n n = len(nums)\n vals = Counter(nums)\n \n test = [abs(x-nums[0]) for x in nums[1:len(nums)//2+1]]\n \n ans = 0\n for c in test:\n if c % 2 != 0 or c==0:\n continue\n cvals = dict(vals)\n flag = 0\n for num in nums:\n if cvals[num] > 0:\n if num+c in cvals and cvals[num + c] > 0:\n cvals[num] -= 1\n cvals[num+c] -= 1\n else:\n flag = 1\n break\n if not flag:\n ans = c\n break\n \n bestans = []\n for num in nums:\n if vals[num] > 0:\n bestans.append(num+ans//2)\n vals[num] -= 1\n vals[num+c] -= 1\n \n return bestans\n \n \n \n``` | 0 | Given a 0-indexed integer array nums, return the number of distinct quadruplets (a, b, c, d) such that: | N is very small, how can we use that? Can we check every possible quadruplet? |
Python Solution | check-if-all-as-appears-before-all-bs | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkString(self, s: str) -> bool:\n st = \'\'.join(sorted(s))\n if st==s:\n return True\n return False\n``` | 2 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
Python3||O(n)|| easy | check-if-all-as-appears-before-all-bs | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n- O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n- O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkString(self, s: str) -> bool:\n c=s[0]\n if s[0]==\'b\' and \'a\' in s:\n return False\n n=len(s)\n for i in range(n):\n if c==s[i]:\n continue\n elif c in s[i+1:]:\n return False\n return True\n``` | 1 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
[Java/Python 3] Check if 'b' followed by 'a'. | check-if-all-as-appears-before-all-bs | 1 | 1 | **Method 1**\n\n```java\n public boolean checkString(String s) {\n for (int i = 1; i < s.length(); ++i) {\n if (s.charAt(i - 1) == \'b\' && s.charAt(i) == \'a\') {\n return false;\n }\n }\n return true;\n }\n```\n```python\n def checkString(self, s: str) -> bool:\n for i, c in enumerate(s):\n if i > 0 and s[i - 1] == \'b\' and c == \'a\':\n return False\n return True\n```\n\n----\n\n**Method 2:**\n\n```java\n public boolean checkString(String s) {\n return !s.contains("ba");\n }\n```\n```python\n def checkString(self, s: str) -> bool:\n return \'ba\' not in s\n```\n**Analysis**\n\nTime: `O(n)`, space: `O(1)`, where `n = s.length()`. | 42 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
Python3 || Easy and simple solution. | check-if-all-as-appears-before-all-bs | 0 | 1 | # **Please \u2191(upvote) if you like the solution.**\n# Code\n```\nclass Solution:\n def checkString(self, s: str) -> bool:\n for i in range(len(s)):\n if s[i]==\'b\':\n if \'a\' in s[i+1:]:\n return False\n return True\n elif \'b\' not in s:\n return True \n``` | 1 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
Easy python solution 1 liner (Multiple approach) | check-if-all-as-appears-before-all-bs | 0 | 1 | ```\ndef checkString(self, s: str) -> bool:\n return (\'\'.join(sorted(list(s))))==s\n```\n\n```\ndef checkString(self, s: str) -> bool:\n return "ba" not in s\n``` | 21 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
OneLiner Python3 | check-if-all-as-appears-before-all-bs | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def checkString(self, s: str) -> bool:\n return (s.count(\'ba\')) < 1\n``` | 1 | Given a string `s` consisting of **only** the characters `'a'` and `'b'`, return `true` _if **every**_ `'a'` _appears before **every**_ `'b'` _in the string_. Otherwise, return `false`.
**Example 1:**
**Input:** s = "aaabbb "
**Output:** true
**Explanation:**
The 'a's are at indices 0, 1, and 2, while the 'b's are at indices 3, 4, and 5.
Hence, every 'a' appears before every 'b' and we return true.
**Example 2:**
**Input:** s = "abab "
**Output:** false
**Explanation:**
There is an 'a' at index 2 and a 'b' at index 1.
Hence, not every 'a' appears before every 'b' and we return false.
**Example 3:**
**Input:** s = "bbb "
**Output:** true
**Explanation:**
There are no 'a's, hence, every 'a' appears before every 'b' and we return true.
**Constraints:**
* `1 <= s.length <= 100`
* `s[i]` is either `'a'` or `'b'`. | The only way to get to room i+1 is when you are visiting room i and room i has been visited an even number of times. After visiting room i an odd number of times, you are required to visit room nextVisit[i] where nextVisit[i] <= i. It takes a fixed amount of days for you to come back from room nextVisit[i] to room i. Then, you have visited room i even number of times.nextVisit[i] Can you use Dynamic Programming to avoid recomputing the number of days it takes to visit room i from room nextVisit[i]? |
Python3 | number-of-laser-beams-in-a-bank | 0 | 1 | ```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n su = 0\n a = []\n for i in range(len(bank)):\n count = 0\n for j in range(len(bank[i])):\n if bank[i][j]==\'1\':\n count+=1\n if count>0:\n a.append(count)\n if len(a)<=1:\n return 0\n else:\n for i in range(len(a)-1):\n su+=a[i]*a[i+1]\n return su\n``` | 2 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Easily understanding Python Code with Detailed Explanation... | number-of-laser-beams-in-a-bank | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->Counting the no-of **ones** in each floor and appending hem to a list.\nIf only one floor has the security devices it is not possible to form a **Laser Beam** \nso a min of 2 floors are required t form a **Laser Beam**.\n\n**EG:** if there are 2 devices in floor 1 and 1 device in any floor.\nThen only two lasers can be formed like that if **3** are on first floor and **2** on the next floor then only 6 beams can be formed..\n# Approach \n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n li=[]\n for i in bank:\n x=i.count("1")\n if x>0:\n li.append(x)\n if(len(li))<2:\n return 0\n else:\n s=0\n for i in range(len(li)-1):\n s+=li[i]*li[i+1]\n return s\n\n \n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Basic PYTHON STACK solution (If, elif approach) (beats 60% solutions) | number-of-laser-beams-in-a-bank | 0 | 1 | # Intuition\nBasic Python approach using Stack to keep track of previous laser device count\n\n# Approach\nmajor If Else approach using a stack to maintain the previous device count to generate the number of lasers between r1 and r2.\n\n# Complexity\n- Time complexity:\no(n*n)\n\n- Space complexity:\n- o(n)\n\n# Code\n```\nclass Solution:\n def numberOfBeams(self, arr: List[str]) -> int:\n li=[-1]\n flag=0\n summ=0\n for i in range(len(arr)):\n laser=arr[i].count(\'1\')\n if li[-1]==-1:\n li.append(laser)\n elif li[-1]==0 and laser==0:\n li.append(-1)\n elif laser==0:\n pass\n else:\n summ+=li[-1]*laser\n li.append(laser)\n return summ\n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Python || Easy To Understand || Beats 99% Time Complexity 🔥 | number-of-laser-beams-in-a-bank | 0 | 1 | # Code\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n arr = []\n for i in range(len(bank)):\n temp = bank[i].count("1")\n if temp > 0: arr.append(temp)\n cnt = 0\n for i in range(len(arr)-1):\n cnt += (arr[i] * arr[i+1])\n return cnt\n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Solution of number of laser beams in a bank problem || two-pointer algorithm | number-of-laser-beams-in-a-bank | 0 | 1 | # Approach\nSolved using two-pointer algorithm\n\n# Complexity\n- Time complexity:\n$$O(n^2)$$ - as two-pointer algorithm takes linear time and \n.count() function takes linear time --> $$O(n*n)$$ == $$O(n^2)\n$$.\n- Space complexity:\n$$O(1)$$ - as, no extra space is required.\n\n# Code\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n left, right = 0, 0\n count = 0\n while right != len(bank) - 1:\n right += 1\n if bank[right].count("1") != 0:\n count += bank[left].count("1") * bank[right].count("1")\n left = right\n return count\n \n\n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
[Python3, Java, C++] Simple O(mn) | number-of-laser-beams-in-a-bank | 1 | 1 | **Explanation**:\nTo find the total number of `laser beams` we have to do 2 things:\n1. Find the `number of laser beams` between \'adjacent rows\'. A row here is considered only if it has atleast 1 `security device`. Otherwise the row is simply ignored. \nThus if: \nRow `1`: 3 security devices \nRow `2`: 0 security devices \nRow `3`: 2 security devices\nWe can ignore row `2` and say that row `1` is adjacent to row `3`. To find the `number of laser beams` between \'adjacent rows\' we can multiply the number of security devices in the first row of the pair to the number of security devices in the second row of the pair.\n2. Doing step 1 only solves a part of the problem. We now need to find the sum of all the `laser beams` from each pair of \'adjacent rows\'.\n\n**Algorithm**:\nFor each string in bank:\n* `count` = number of ones in string\n* Multiply `count` by the non-zero `count` of previous string and add it to `ans`\n<iframe src="https://leetcode.com/playground/CfnEimzJ/shared" frameBorder="0" width="500" height="275"></iframe>\n\nTime Complexity: `O(mn)`, `m` = length of bank, `n` = length of string | 66 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Python3 Code: Runtime Beats 91% O(n) Memory Beats 90% | number-of-laser-beams-in-a-bank | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n res = []\n s = 0\n for i in bank:\n if i.count("1")>0:\n res.append(i.count("1"))\n i,j=0,1\n while j<len(res):\n s+= res[i]*res[j]\n j+=1\n i+=1\n return s\n\n \n\n\n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
2125. Number of Laser Beams in a Bank | number-of-laser-beams-in-a-bank | 0 | 1 | **EASY TO UNDERSTAND || BEGINNER FRIENDLY**\n```\n arr=[]\n \n for i in range(len(bank)):\n count=0\n for j in range(len(bank[i])):\n if bank[i][j]==\'1\':\n count+=1\n arr.append(count)\n\n ans=[]\n \n for ii in range(len(arr)):\n if arr[ii]!=0:\n ans.append(arr[ii])\n \n anss=0\n \n for x in range(len(ans)-1):\n anss+=ans[x]*ans[x+1]\n return anss\n \n``` | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
very simple solution | easy to understand | number-of-laser-beams-in-a-bank | 0 | 1 | ```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n prev, ans = 0, 0\n for i in bank:\n current = i.count(\'1\')\n if current:\n ans += prev * current\n prev = current\n return ans\n``` | 2 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
Python3 Simple Solution | number-of-laser-beams-in-a-bank | 0 | 1 | ```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n pre = 0\n nn = 0\n ans = 0\n for i in bank:\n nn= 0\n for j in i:\n if j == \'1\':\n nn+=1\n if nn:\n ans+=nn*pre\n pre= nn\n return ans\n## PLease upvote if you like the Solution | 1 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
[Python3] simulation | number-of-laser-beams-in-a-bank | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/18f88320ffb2c2a06e86fad46d82ebd17dadad64) for solutions of weekly 274. \n\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n ans = prev = 0 \n for row in bank: \n curr = row.count(\'1\')\n if curr: \n ans += prev * curr\n prev = curr \n return ans \n``` | 7 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
[Java/Python 3] Product of neighboring row devices number. | number-of-laser-beams-in-a-bank | 1 | 1 | **Q & A**\n\nQ1: How we got to know that we are required to do product of adjacent rows with count of 1s? \nA1: According to the problem:\nThere is one laser beam between any two security devices if both conditions are met:\n\n1. The two devices are located on two different rows: r1 and r2, where r1 < r2.\n2. For each row i where r1 < i < r2, there are no security devices in the ith row.\n\n**End of Q & A**\n\n----\n\nGet rid of empty rows and then sum the product of each pair of neighbors.\n```java\n public int numberOfBeams(String[] bank) {\n int cnt = 0, prev = 0;\n for (String devs : bank) {\n // devs.chars() cost more than O(1) space. - credit to @bharathkalyans.\n // int cur = devs.chars().map(i -> i == \'1\' ? 1 : 0).sum();\n int cur = 0;\n for (int i = 0; i < devs.length(); ++i) {\n cur += devs.charAt(i) == \'1\' ? 1 : 0;\n }\n cnt += prev * cur;\n if (cur > 0) {\n prev = cur;\n }\n }\n return cnt;\n }\n```\n```python\n def numberOfBeams(self, bank: List[str]) -> int:\n cnt = prev = 0\n for devs in bank:\n cur = devs.count(\'1\')\n cnt += cur * prev\n if cur > 0:\n prev = cur\n return cnt\n```\n**Analysis:**\n\nTime: `O(n)`, space: `O(1)`, where `n` is the **total** number of characters in `bank`. | 5 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
[PYTHON 3] 99.13% LESS MEMORY | 94.93% FASTER | EXPLANATION | number-of-laser-beams-in-a-bank | 0 | 1 | Runtime: **87 ms, faster than 94.93%** of Python3 online submissions for Number of Laser Beams in a Bank.\nMemory Usage: **15.9 MB, less than 99.13%** of Python3 online submissions for Number of Laser Beams in a Bank.\n\n```\nclass Solution:\n def numberOfBeams(self, bank: List[str]) -> int:\n a, s = [x.count("1") for x in bank if x.count("1")], 0\n\n\t\t# ex: bank is [[00101], [01001], [00000], [11011]]\n\t\t# a would return [2, 2, 4]\n\n for c in range(len(a)-1):\n s += (a[c]*a[c+1])\n\n\t\t\t# basic math to find the total amount of lasers\n\t\t\t# for the first iteration: s += 2*2\n\t\t\t# for the second iteration: s += 2*4\n\t\t\t# returns s = 12\n\n return s\n \n | 9 | Anti-theft security devices are activated inside a bank. You are given a **0-indexed** binary string array `bank` representing the floor plan of the bank, which is an `m x n` 2D matrix. `bank[i]` represents the `ith` row, consisting of `'0'`s and `'1'`s. `'0'` means the cell is empty, while`'1'` means the cell has a security device.
There is **one** laser beam between any **two** security devices **if both** conditions are met:
* The two devices are located on two **different rows**: `r1` and `r2`, where `r1 < r2`.
* For **each** row `i` where `r1 < i < r2`, there are **no security devices** in the `ith` row.
Laser beams are independent, i.e., one beam does not interfere nor join with another.
Return _the total number of laser beams in the bank_.
**Example 1:**
**Input:** bank = \[ "011001 ", "000000 ", "010100 ", "001000 "\]
**Output:** 8
**Explanation:** Between each of the following device pairs, there is one beam. In total, there are 8 beams:
\* bank\[0\]\[1\] -- bank\[2\]\[1\]
\* bank\[0\]\[1\] -- bank\[2\]\[3\]
\* bank\[0\]\[2\] -- bank\[2\]\[1\]
\* bank\[0\]\[2\] -- bank\[2\]\[3\]
\* bank\[0\]\[5\] -- bank\[2\]\[1\]
\* bank\[0\]\[5\] -- bank\[2\]\[3\]
\* bank\[2\]\[1\] -- bank\[3\]\[2\]
\* bank\[2\]\[3\] -- bank\[3\]\[2\]
Note that there is no beam between any device on the 0th row with any on the 3rd row.
This is because the 2nd row contains security devices, which breaks the second condition.
**Example 2:**
**Input:** bank = \[ "000 ", "111 ", "000 "\]
**Output:** 0
**Explanation:** There does not exist two devices located on two different rows.
**Constraints:**
* `m == bank.length`
* `n == bank[i].length`
* `1 <= m, n <= 500`
* `bank[i][j]` is either `'0'` or `'1'`. | Can we build a graph with all the prime numbers and the original array? We can use union-find to determine which indices are connected (i.e., which indices can be swapped). |
[Java/Python 3] Sort then apply greedy algorithm. | destroying-asteroids | 1 | 1 | ```java\n public boolean asteroidsDestroyed(int mass, int[] asteroids) {\n long m = mass;\n Arrays.sort(asteroids);\n for (int ast : asteroids) {\n if (m < ast) {\n return false;\n }\n m += ast;\n }\n return true;\n }\n```\nIn case you do NOT like using `long`, we can use the constraints: `1 <= asteroids[i] <= 10^5`: once mass is greater than all asteroids, we can conclude all can be destroyed.\u3000-- inspired by **@Zudas**.\n\n```java\n public boolean asteroidsDestroyed(int mass, int[] asteroids) {\n Arrays.sort(asteroids);\n for (int ast : asteroids) {\n if (mass < ast) {\n return false;\n }else if (mass > 100_000) { // now we can conclude all can be destroyed.\n return true;\n }\n mass += ast;\n }\n return true;\n }\n```\n```python\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n for a in sorted(asteroids):\n if mass < a:\n return False\n mass += a\n return True\n```\n**Analysis:**\n\nTime: `O(n * log(n))`, space: `O(n)` - including sorting space. | 23 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
Python | 90% faster than other... | Greedy Solution very intuitive | Using sorting technique | destroying-asteroids | 0 | 1 | \n***Please don\'t forget to upvote if found it helpful!!!***\n```\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n # ///// TC O(nlogn) //////\n asteroids.sort()\n \n for asteroid in asteroids:\n if mass >= asteroid:\n mass += asteroid\n else:\n return False\n return True\n``` | 1 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
✔Simple python solution | 85% lesser memory | destroying-asteroids | 0 | 1 | ```\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n asteroids = sorted(asteroids)\n for i in asteroids:\n if i <= mass:\n mass += i\n else:\n return False\n return True\n``` | 2 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
BEATS 98.72% RUNTIME! My Solution :) | destroying-asteroids | 0 | 1 | # Intuition\nThe problem asks us to determine whether a given mass of asteroids can be destroyed by a spaceship. We can assume that the spaceship destroys asteroids by colliding with them. If an asteroid has a mass greater than the spaceship\'s current mass, it cannot destroy the asteroid, and the spaceship fails. Otherwise, the spaceship\'s mass increases by the mass of the destroyed asteroid. We need to find out if the spaceship can destroy all the asteroids.\n\n# Approach\nStep 1:\nSort the list of asteroids in ascending order. Sorting the asteroids allows us to consider the smallest asteroids first, which helps optimize the spaceship\'s chances of destroying them.\n\nStep 2:\nInitialize a variable mass with the initial mass of the spaceship.\n\nStep 3:\nIterate through the sorted list of asteroids.\n\nFor each asteroid x:\nIf x is greater than the spaceship\'s mass (mass), it means the spaceship cannot destroy the asteroid, and we return False.\nOtherwise, we add the mass of the asteroid x to mass to represent the spaceship destroying the asteroid.\n\nStep 4:\nIf we successfully iterate through all the asteroids without encountering an asteroid that the spaceship cannot destroy, it means the spaceship can destroy all the asteroids. In this case, we return True.\n\nStep 5:\nFinally, if the spaceship successfully destroys all the asteroids, the total mass of the spaceship is returned.\n\n# Complexity\n- Time complexity:\nO(n log n)\n\n- Space complexity:\nO(n)\n\n# Code\n```\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n asteroids.sort()\n for x in asteroids:\n if x > mass:\n return False\n else:\n mass += x\n return mass\n\n\n``` | 0 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
Simple Sort. Python3 | destroying-asteroids | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport heapq\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n\n asteroids.sort()\n\n for ast in asteroids:\n if mass >= ast:\n mass+= ast\n else:\n return False\n return True\n \n # heapq.heapify(asteroids)\n\n # for _ in range(len(asteroids)):\n # astr = heapq.heappop(asteroids)\n # if mass >= astr:\n # mass += astr\n # else:\n # return False\n # return True\n \n``` | 0 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
Heap. Python3. 95%+ mem | destroying-asteroids | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport heapq\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n \n heapq.heapify(asteroids)\n\n for _ in range(len(asteroids)):\n astr = heapq.heappop(asteroids)\n if mass >= astr:\n mass += astr\n else:\n return False\n return True\n \n``` | 0 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
Easy Python Solution | destroying-asteroids | 0 | 1 | # Code\n```\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n\n asteroids.sort()\n \n while asteroids:\n if mass >= asteroids[0]: \n mass = mass + asteroids[0]\n asteroids.pop(0)\n else: return False\n\n return True\n``` | 0 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
Easy Python 3 solution | destroying-asteroids | 0 | 1 | \n# Code\n```\nclass Solution:\n def asteroidsDestroyed(self, mass: int, asteroids: List[int]) -> bool:\n asteroids.sort()\n for i in asteroids:\n if mass < i:\n return False\n else:\n mass += i\n return True\n\n``` | 0 | You are given an integer `mass`, which represents the original mass of a planet. You are further given an integer array `asteroids`, where `asteroids[i]` is the mass of the `ith` asteroid.
You can arrange for the planet to collide with the asteroids in **any arbitrary order**. If the mass of the planet is **greater than or equal to** the mass of the asteroid, the asteroid is **destroyed** and the planet **gains** the mass of the asteroid. Otherwise, the planet is destroyed.
Return `true` _if **all** asteroids can be destroyed. Otherwise, return_ `false`_._
**Example 1:**
**Input:** mass = 10, asteroids = \[3,9,19,5,21\]
**Output:** true
**Explanation:** One way to order the asteroids is \[9,19,5,3,21\]:
- The planet collides with the asteroid with a mass of 9. New planet mass: 10 + 9 = 19
- The planet collides with the asteroid with a mass of 19. New planet mass: 19 + 19 = 38
- The planet collides with the asteroid with a mass of 5. New planet mass: 38 + 5 = 43
- The planet collides with the asteroid with a mass of 3. New planet mass: 43 + 3 = 46
- The planet collides with the asteroid with a mass of 21. New planet mass: 46 + 21 = 67
All asteroids are destroyed.
**Example 2:**
**Input:** mass = 5, asteroids = \[4,9,23,4\]
**Output:** false
**Explanation:**
The planet cannot ever gain enough mass to destroy the asteroid with a mass of 23.
After the planet destroys the other asteroids, it will have a mass of 5 + 4 + 9 + 4 = 22.
This is less than 23, so a collision would not destroy the last asteroid.
**Constraints:**
* `1 <= mass <= 105`
* `1 <= asteroids.length <= 105`
* `1 <= asteroids[i] <= 105` | Can we reuse previously calculated information? How can we calculate the sum of the current subtree using the sum of the child's subtree? |
[Python3] Solution with using DFS approach and cycle detecting | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Code\n```\nclass Solution: \n def get_max_cycle_length(self, favorite: List[int]) -> int:\n person_cnt = len(favorite)\n max_cycle_length = 0\n\n seen = set()\n\n # for each person\n for i in range(person_cnt):\n # i - person i\n\n # if person not part of any chain (chain with cycle)\n if i in seen:\n continue\n \n # begin of chain (chain with cycle)\n begin_person = i\n\n # visited nodes inside of chain (chain with cycle)\n cur_visited = set()\n\n # cur_person\n cur_person = i\n\n # try to build chain with cycle\n while cur_person not in seen:\n seen.add(cur_person)\n cur_visited.add(cur_person)\n cur_person = favorite[cur_person]\n \n # if cycle exists\n if cur_person in cur_visited:\n # length of chain with cycle\n visited_person_cnt = len(cur_visited)\n\n # try to find length of cycle\n while begin_person != cur_person:\n visited_person_cnt -= 1\n begin_person = favorite[begin_person]\n \n max_cycle_length = max(max_cycle_length, visited_person_cnt)\n \n return max_cycle_length\n \n def get_max_chain_without_cycle_length(self, favorite: List[int]) -> int:\n person_cnt = len(favorite)\n max_chain_len = 0\n\n # find mutal-favorite (a <-> b) pairs\n pairs = []\n visited = set()\n\n for i in range(person_cnt):\n if i not in visited and favorite[favorite[i]] == i:\n pairs.append((i, favorite[i]))\n visited.add(i)\n visited.add(favorite[i])\n\n # build deps list, list that consits from deps from i (a -> b and c -> b, we shoul build such list [a,c] for b)\n deps = collections.defaultdict(list)\n for i in range(person_cnt):\n deps[favorite[i]].append(i)\n\n for src, dst in pairs:\n # max chain length to src\n max_dist_to_src = 0\n \n q = collections.deque()\n for dep in deps[src]:\n if dep != dst: q.append((dep, 1)) # dependent node and dist to dependent node\n \n while q:\n cur_dependency, dist = q.popleft()\n max_dist_to_src = max(max_dist_to_src, dist)\n for next_dep in deps[cur_dependency]:\n q.append((next_dep, dist + 1))\n \n max_dist_to_dst = 0\n q = collections.deque()\n for dep in deps[dst]:\n if dep != src: q.append((dep, 1))\n \n while q:\n cur_dependency, dist = q.popleft()\n max_dist_to_dst = max(max_dist_to_dst, dist)\n for next_dep in deps[cur_dependency]:\n q.append((next_dep, dist + 1)) \n\n max_chain_len += 2 + max_dist_to_src + max_dist_to_dst\n\n return max_chain_len\n\n def maximumInvitations(self, favorite: List[int]) -> int:\n return max(self.get_max_cycle_length(favorite), self.get_max_chain_without_cycle_length(favorite))\n``` | 3 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
[Python 3] Self-Explainatory Code — O(N) | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Intuition\nOnly 2 candidates for an answer:\n* Longest cycle\n* Combination of cycles of length 2 with longest tails\n\n# Code\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n ans = 0\n n = len(favorite)\n cycles_of_2 = []\n seen = [False for _ in range(n)]\n for node in range(n):\n if seen[node]:\n continue\n if favorite[favorite[node]] == node:\n cycles_of_2.append((node, favorite[node]))\n seen[node] = True\n seen[favorite[node]] = True\n for node in range(n):\n if seen[node]:\n continue\n cycle_length = self.find_cycle(node, 1, {}, seen, favorite)\n ans = max(ans, cycle_length)\n \n if len(cycles_of_2) != 0:\n revfavorite = defaultdict(list)\n for node, fav in enumerate(favorite):\n if favorite[fav] != node:\n revfavorite[fav].append(node)\n total_tail = 0\n for x, y in cycles_of_2:\n max_tail = self.max_depth(x, revfavorite) + self.max_depth(y, revfavorite)\n total_tail += max_tail\n ans = max(ans, 2 * len(cycles_of_2) + total_tail)\n return ans\n\n def find_cycle(self, node, length, path, seen, favorite):\n if seen[node]:\n return -1\n seen[node] = True\n path[node] = length\n if favorite[node] in path:\n return path[node] - path[favorite[node]] + 1\n return self.find_cycle(favorite[node], length+1, path, seen, favorite)\n \n def max_depth(self, node, graph, depth=0):\n res = depth\n for neigh in graph[node]:\n res = max(res, self.max_depth(neigh, graph, depth+1))\n return res\n\n``` | 2 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
[Python3] quite a tedious solution | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/18f88320ffb2c2a06e86fad46d82ebd17dadad64) for solutions of weekly 274. \n\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n n = len(favorite)\n graph = [[] for _ in range(n)]\n for i, x in enumerate(favorite): graph[x].append(i)\n \n def bfs(x, seen): \n """Return longest arm of x."""\n ans = 0 \n queue = deque([x])\n while queue: \n for _ in range(len(queue)): \n u = queue.popleft()\n for v in graph[u]: \n if v not in seen: \n seen.add(v)\n queue.append(v)\n ans += 1\n return ans \n \n ans = 0 \n seen = [False]*n\n for i, x in enumerate(favorite): \n if favorite[x] == i and not seen[i]: \n seen[i] = seen[x] = True \n ans += bfs(i, {i, x}) + bfs(x, {i, x})\n \n dp = [0]*n\n for i, x in enumerate(favorite): \n if dp[i] == 0: \n ii, val = i, 0\n memo = {}\n while ii not in memo: \n if dp[ii]: \n cycle = dp[ii]\n break\n memo[ii] = val\n val += 1\n ii = favorite[ii]\n else: cycle = val - memo[ii]\n for k in memo: dp[k] = cycle\n return max(ans, max(dp))\n``` | 5 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
Python, intutive approach. Beats 99% runtime and 100% space | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Intuition\nI looked at a couple of [solutions](https://leetcode.com/problems/maximum-employees-to-be-invited-to-a-meeting/submissions/1115462421/?source=submission-ac) to get this understanding. \n\nIn a levelwise visit we won\'t be able to visit nodes that form a circle\n\n\n# Approach\nWe visit levelwise and store level info for each node as we do this,\n- Level 0: Nodes with 0 indegree,\n- Level 1: Nodes with 1 indegree ......\n- We will visit all nodes except those are present in a circle \n- We can realize two kinds of circles,\n1. Circle of 2, node and fav[node] are connected reverse as well.\n2. Circle >= 3 nodes\n- For case 1, we can use the levels information.\n- For case 2, can loop over circle and count perimeter of the circle.\n\n# Complexity\nTime:\n- Indegree: $$O(n)$$\n- Levelwise visit + cycle visit: $$O(n)$$\n- Total complexity: $$O(n)$$\n\nSpace complexity:\n- Levels, indegree, queue = $$O(n)$$\n\n# Code\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n n = len(favorite)\n levels = [1]*n\n indegree = [0]*n\n \n # Compute indegrees\n for i in range(n):\n indegree[favorite[i]] += 1\n \n # Begin traversal with 0 indegree nodes\n queue = deque()\n for i in range(n):\n if indegree[i] == 0:\n queue.append(i)\n\n # Visit all possible nodes level wise, store level info for each node.\n while queue:\n node = queue.popleft()\n neighbor = favorite[node]\n indegree[neighbor] -= 1\n levels[neighbor] = levels[node]+1 \n if indegree[neighbor] == 0:\n queue.append(neighbor)\n \n # Visit circle forming nodes, update answer based on circle type.\n longest_path = max_perimeter = 0\n for i in range(n):\n if indegree[i] != 0:\n circle_start = circle_node = i\n indegree[circle_node] -= 1\n circle_perimeter = 1\n while favorite[circle_node]!=circle_start:\n circle_node = favorite[circle_node]\n indegree[circle_node] -= 1\n circle_perimeter += 1\n\n if circle_perimeter == 2:\n longest_path += levels[circle_start] + levels[circle_node]\n else:\n max_perimeter = max(max_perimeter, circle_perimeter) \n return max(max_perimeter, longest_path)\n``` | 0 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
Brief Python | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nAs stated in the most voted solutions, there are two things we need to consider in the graph formed by the employee favorites\n1 - The largest cycle\n2 - The segments that are self-contained\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFor finding the largest cycle we apply a Breadth-First-Search algorithm.\nFor Finding the largest segments, we find the total indegree of all nodes and only consider the nodes that are mutually favorites of one-another. These people can come to the party and be happy and sit beside other happy groups with no problems. But these people cannot sit beside cycles (because cycles are not self-contained and need the whole table.)\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n def get_largest_cycle(favorites):\n visited = [False] * len(favorites)\n res = 0\n for at in range(len(favorites)):\n if not visited[at]:\n seen = {}\n while not visited[at]:\n visited[at] = True\n seen[at] = len(seen)\n at = favorites[at]\n if at in seen:\n res = max(res, len(seen) - seen[at])\n break\n return res\n \n def calculate_indegree(favorite):\n indegree = Counter(favorite)\n rank = defaultdict(lambda: 1)\n explore = list(set(range(len(favorite))) - set(favorite))\n for at in explore:\n rank[favorite[at]] = max(rank[favorite[at]], rank[at] + 1)\n indegree[favorite[at]] -= 1\n if indegree[favorite[at]] == 0:\n explore.append(favorite[at])\n return rank\n \n largest_cycle = get_largest_cycle(favorite)\n segments = 0\n indegrees = calculate_indegree(favorite)\n for i in range(len(favorite)):\n if i < favorite[i] and i == favorite[favorite[i]]:\n segments += indegrees[i] + indegrees[favorite[i]]\n\n return max(largest_cycle, segments)\n``` | 0 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
Fast solution without additional graph, using Floyd's cycle detection algorithm | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe\'re given an oriented graph in which every vertex has exactly one vertex coming out of it. In the final arrangement of employees, each vertex must sit next to its child.\n\nAfter a bit of thinking one realizes that the only possible arrangement is either a cycle or multiple chains one after the other.\nBy chain here we mean a chain with the last vertex going into the one before, i.e. a cycle of length two with a tail.\n\nThere is also a tricky case where we could have one cycle of length 2, say (0, 1) and chains (3, 2, 0, 1), (5, 4, 1, 0). In this case we can arrange them like (3, 2, 0, 1, 4, 5).\n\nSo the answer is max(max cycle, sum of cyc of len 2),\nwhere for cycles of length 2 we sum over longest tails, and the tails may originate from both ends of the 2-cycle.\n\n**Useful observations:**\n1. If the graph is not connected, then the answer is the maximum among all connected components.\n2. In one connected component there is exactly one cycle.\n\nWe use Floyd\'s algorithm to detect cycles. See more at https://en.wikipedia.org/wiki/Cycle_detection\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe detect cycles, find its length and update the max cycle if larger cycle is found. The tricky part comes with the addition of 2-cycles, there we store the "tail length" from each node going into the two cycle while updating the maximum tail length for each particular 2-cycle. We treat (a, b) differently from (b, a) for reasons described earlier, and later subtract len(pairs) to account for counting pairs twice.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n# Code\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n n = len(favorite)\n pairs = set()\n for i, j in enumerate(favorite):\n if favorite[j] == i:\n pairs.add((i, j))\n chain_lens_from_elem = {}\n chain_lens_from_pair = {(i, j): 2 for (i, j) in pairs}\n\n seen = set()\n type_cyc = 1\n for i in range(n):\n if i in seen: continue\n slow_iter, fast_iter = i, i\n skip = False\n while True:\n slow_iter = favorite[slow_iter]\n fast_iter = favorite[favorite[fast_iter]]\n if slow_iter in seen:\n skip = True\n break\n if slow_iter == fast_iter: break\n if skip:\n iter = i\n tail = 0\n while iter not in seen:\n seen.add(iter)\n iter = favorite[iter]\n tail += 1\n \n if iter in chain_lens_from_elem:\n seen_start = iter\n old_len, pair = chain_lens_from_elem[seen_start]\n if seen_start == pair[1]:\n pair = (pair[1], pair[0])\n chain_lens_from_pair[pair] = max(chain_lens_from_pair[pair], old_len + tail)\n iter = i\n while iter != seen_start:\n chain_lens_from_elem[iter] = (old_len + tail, pair)\n iter = favorite[iter]\n tail -= 1\n\n continue\n\n cycle_start = i\n tail_len = 0\n while cycle_start != slow_iter:\n seen.add(cycle_start)\n cycle_start = favorite[cycle_start]\n slow_iter = favorite[slow_iter]\n tail_len += 1\n seen.add(cycle_start)\n \n iter = favorite[cycle_start]\n cyc_len = 1\n while iter != cycle_start:\n seen.add(iter)\n cyc_len += 1\n iter = favorite[iter]\n \n type_cyc = max(type_cyc, cyc_len)\n\n if cyc_len == 2:\n pair = (cycle_start, favorite[cycle_start])\n chain_lens_from_pair[pair] = max(chain_lens_from_pair[pair], 2 + tail_len)\n chain_lens_from_elem[pair[0]] = (2, pair)\n chain_lens_from_elem[pair[1]] = (2, pair)\n iter = i\n while iter != cycle_start:\n chain_lens_from_elem[iter] = (2 + tail_len, pair)\n iter = favorite[iter]\n tail_len -= 1\n \n type_chain = sum(tail_len for (pair, tail_len) in chain_lens_from_pair.items()) - len(pairs)\n \n return max(type_cyc, type_chain)\n\n\n``` | 0 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
Reverse graph | maximum-employees-to-be-invited-to-a-meeting | 0 | 1 | # Intuition\nCatch loops and cycles, there can be only one cycle or many loops.\n\n# Approach\nFirstly create a reverse graph and catch pairs (the ones that are friends two each other)\nThen run the graph (dfs) starting from pairs, collecting loops depth.\nLastly run through all not vivsited people, catching biggest cycle.\n\n# Complexity\n- Time complexity:\n1174 ms\n\n- Space complexity:\n60.6 MB\n\n# Code\n```\nclass Solution:\n def maximumInvitations(self, favorite: List[int]) -> int:\n\n loop_heads = set()\n graph: dict[int, set[int]] = {}\n for vertex in range(len(favorite)):\n try:\n graph[vertex].remove(favorite[vertex])\n loop = True\n except KeyError:\n loop = False\n\n if loop:\n loop_heads.add(favorite[vertex])\n loop_heads.add(vertex)\n else:\n graph.setdefault(favorite[vertex], set()).add(vertex)\n\n seen = [False for _ in range(len(favorite))]\n loops_depth = 0\n for head in loop_heads:\n max_depth, cur_depth = 0, 0\n stack = [(head, cur_depth)]\n while stack:\n cur_v, cur_depth = stack.pop()\n seen[cur_v] = True\n cur_depth += 1\n if max_depth < cur_depth: max_depth = cur_depth\n try:\n for parent in graph[cur_v]:\n stack.append((parent, cur_depth))\n except KeyError:\n continue\n loops_depth += max_depth\n\n max_cycle_depth = 0\n for vertex in range(len(seen)):\n\n if not seen[vertex]:\n done = set()\n cur_depth = 0\n stack = []\n while not seen[vertex]:\n done.add(vertex)\n cur_depth += 1\n seen[vertex] = True\n try:\n for vert in graph[vertex]:\n if not seen[vert] or vert in done:\n stack.append((vert, cur_depth))\n except KeyError:\n pass\n if stack:\n vertex, cur_depth = stack.pop()\n else:\n cur_depth = 0\n if cur_depth > max_cycle_depth:\n max_cycle_depth = cur_depth\n\n return max((loops_depth, max_cycle_depth))\n\n\n\n\n``` | 0 | A company is organizing a meeting and has a list of `n` employees, waiting to be invited. They have arranged for a large **circular** table, capable of seating **any number** of employees.
The employees are numbered from `0` to `n - 1`. Each employee has a **favorite** person and they will attend the meeting **only if** they can sit next to their favorite person at the table. The favorite person of an employee is **not** themself.
Given a **0-indexed** integer array `favorite`, where `favorite[i]` denotes the favorite person of the `ith` employee, return _the **maximum number of employees** that can be invited to the meeting_.
**Example 1:**
**Input:** favorite = \[2,2,1,2\]
**Output:** 3
**Explanation:**
The above figure shows how the company can invite employees 0, 1, and 2, and seat them at the round table.
All employees cannot be invited because employee 2 cannot sit beside employees 0, 1, and 3, simultaneously.
Note that the company can also invite employees 1, 2, and 3, and give them their desired seats.
The maximum number of employees that can be invited to the meeting is 3.
**Example 2:**
**Input:** favorite = \[1,2,0\]
**Output:** 3
**Explanation:**
Each employee is the favorite person of at least one other employee, and the only way the company can invite them is if they invite every employee.
The seating arrangement will be the same as that in the figure given in example 1:
- Employee 0 will sit between employees 2 and 1.
- Employee 1 will sit between employees 0 and 2.
- Employee 2 will sit between employees 1 and 0.
The maximum number of employees that can be invited to the meeting is 3.
**Example 3:**
**Input:** favorite = \[3,0,1,4,1\]
**Output:** 4
**Explanation:**
The above figure shows how the company will invite employees 0, 1, 3, and 4, and seat them at the round table.
Employee 2 cannot be invited because the two spots next to their favorite employee 1 are taken.
So the company leaves them out of the meeting.
The maximum number of employees that can be invited to the meeting is 4.
**Constraints:**
* `n == favorite.length`
* `2 <= n <= 105`
* `0 <= favorite[i] <= n - 1`
* `favorite[i] != i` | null |
Beats 99% | CodeDominar Solution | capitalize-the-title | 0 | 1 | # Code\n```\nclass Solution:\n def capitalizeTitle(self, title: str) -> str:\n li = title.split()\n for i,l in enumerate(li):\n if len(l) <= 2:\n li[i] = l.lower()\n else:\n li[i] = l[0].upper() + l[1:].lower()\n return \' \'.join(li)\n``` | 1 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
Python | 95% Beats | Using Lower and Capitalize | capitalize-the-title | 0 | 1 | # Submission Details:\nhttps://leetcode.com/problems/capitalize-the-title/submissions/881960588/\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def capitalizeTitle(self, title: str) -> str:\n ls=title.split(" ")\n a=[]\n for i in ls:\n if len(i)==1 or len(i)==2: a.append(i.lower())\n else: a.append(i.capitalize())\n b=\' \'.join([str(elem) for elem in a])\n return b\n``` | 1 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
🏔Capitalization || 🔥Beat 100% in 9 lines🔥 || 😎Enjoy LeetCode... | capitalize-the-title | 0 | 1 | # KARRAR\n> Capitalize the TITLE of letters in the sentence...\n>> Optimized code...\n>>> Easily understand able...\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach:\n Lowest time complexity...\n If you want to beat the most PLEASE UPVOTE...\n\n\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity:\n- Time complexity: Beats 100% (3 ms)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: Beats 64% (13 MB)\n\n\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code:\n```\nclass Solution(object):\n def capitalizeTitle(self, title):\n title=title.lower()\n title=title.split()\n for i in range(len(title)):\n if(len(title[i])<3):\n title[i]=title[i].lower()\n else:\n title[i]=title[i].title()\n for i in range(1,len(title)):\n title[0]+=" "\n title[0]+=title[i]\n \n return title[0]\n``` | 2 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
[Java/Python 3] Clean code w/ brief analysis. | capitalize-the-title | 1 | 1 | **Q & A**\nQ1: Where can I find the material about togglling letter cases in Java?\nA1: You can find [here](https://www.techiedelight.com/bit-hacks-part-4-playing-letters-english-alphabet/). - credit to **@Aaditya_Burujwale**\n\n**End of Q & A**\n\n----\n\n```java\n public String capitalizeTitle(String title) {\n List<String> ans = new ArrayList<>();\n for (String w : title.split(" ")) {\n if (w.length() < 3) {\n ans.add(w.toLowerCase());\n }else {\n char[] ca = w.toLowerCase().toCharArray();\n ca[0] ^= 32; // toggle letter case.\n ans.add(String.valueOf(ca));\n }\n }\n return String.join(" ", ans);\n }\n```\n```python\n def capitalizeTitle(self, title: str) -> str:\n ans = []\n for s in title.split():\n if len(s) < 3:\n ans.append(s.lower())\n else:\n ans.append(s.capitalize())\n return \' \'.join(ans) \n```\n**Analysis:**\n\nTime & space: `O(n)`, where `n = title.length()`. | 11 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
Python | Easy Solution✅ | capitalize-the-title | 0 | 1 | ```\ndef capitalizeTitle(self, title: str) -> str:\n output = list()\n word_arr = title.split()\n for word in word_arr:\n output.append(word.title()) if len(word) > 2 else output.append(word.lower())\n return " ".join(output)\n``` | 6 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
Python Easy Solution | capitalize-the-title | 0 | 1 | ```\nclass Solution:\n def capitalizeTitle(self, title: str) -> str:\n title = title.split()\n word = ""\n for i in range(len(title)):\n if len(title[i]) < 3:\n word = word + title[i].lower() + " "\n else:\n word = word + title[i].capitalize() + " "\n return word[:-1]\n```\nOr \n```\nclass Solution:\n def capitalizeTitle(self, title: str) -> str:\n title = title.split()\n word = []\n for i in range(len(title)):\n if len(title[i]) < 3:\n word.append(title[i].lower())\n else:\n word.append(title[i].capitalize())\n return " ".join(word)\n``` | 5 | You are given a string `title` consisting of one or more words separated by a single space, where each word consists of English letters. **Capitalize** the string by changing the capitalization of each word such that:
* If the length of the word is `1` or `2` letters, change all letters to lowercase.
* Otherwise, change the first letter to uppercase and the remaining letters to lowercase.
Return _the **capitalized**_ `title`.
**Example 1:**
**Input:** title = "capiTalIze tHe titLe "
**Output:** "Capitalize The Title "
**Explanation:**
Since all the words have a length of at least 3, the first letter of each word is uppercase, and the remaining letters are lowercase.
**Example 2:**
**Input:** title = "First leTTeR of EACH Word "
**Output:** "First Letter of Each Word "
**Explanation:**
The word "of " has length 2, so it is all lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Example 3:**
**Input:** title = "i lOve leetcode "
**Output:** "i Love Leetcode "
**Explanation:**
The word "i " has length 1, so it is lowercase.
The remaining words have a length of at least 3, so the first letter of each remaining word is uppercase, and the remaining letters are lowercase.
**Constraints:**
* `1 <= title.length <= 100`
* `title` consists of words separated by a single space without any leading or trailing spaces.
* Each word consists of uppercase and lowercase English letters and is **non-empty**. | Store the rectangle height and width ratio in a hashmap. Traverse the ratios, and for each ratio, use the frequency of the ratio to add to the total pair count. |
Image Explanation🏆- [Fastest, Easiest & Concise] - C++/Java/Python | maximum-twin-sum-of-a-linked-list | 1 | 1 | # Video Solution (`Aryan Mittal`) - Link in LeetCode Profile\n`Maximum Twin Sum of a Linked List` by `Aryan Mittal`\n\n\n\n# Approach & Intution\n\n\n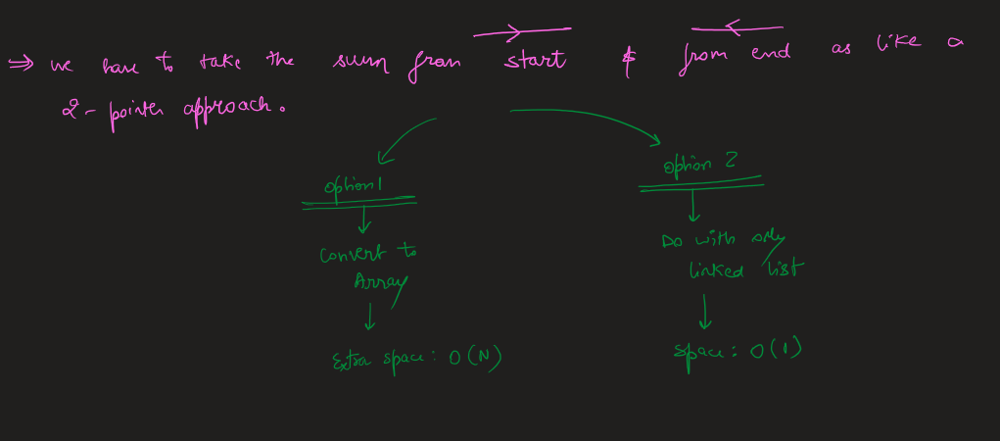\n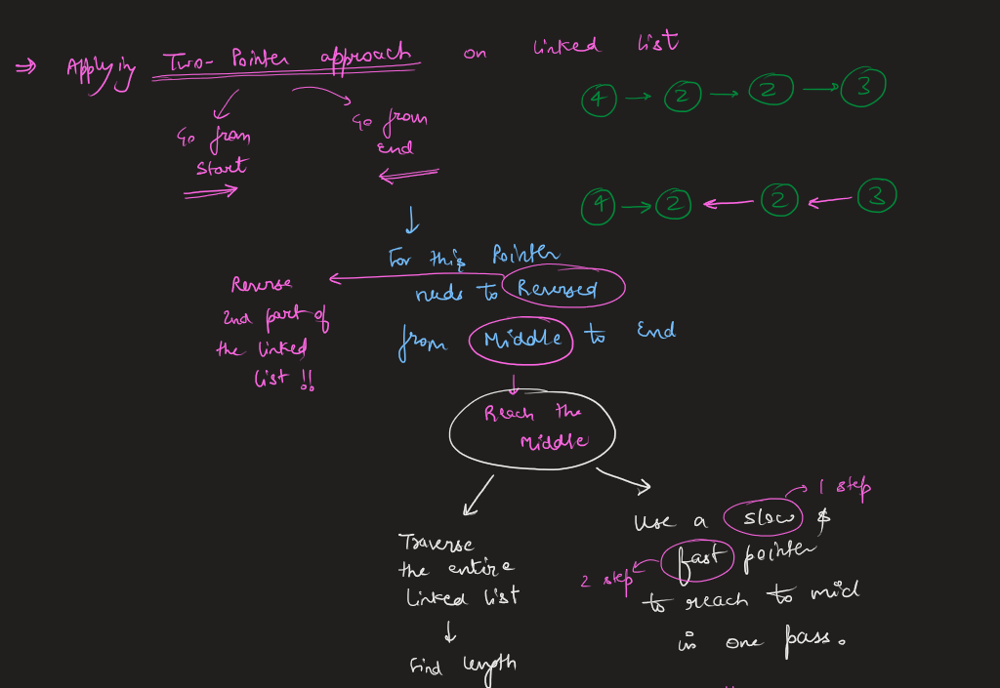\n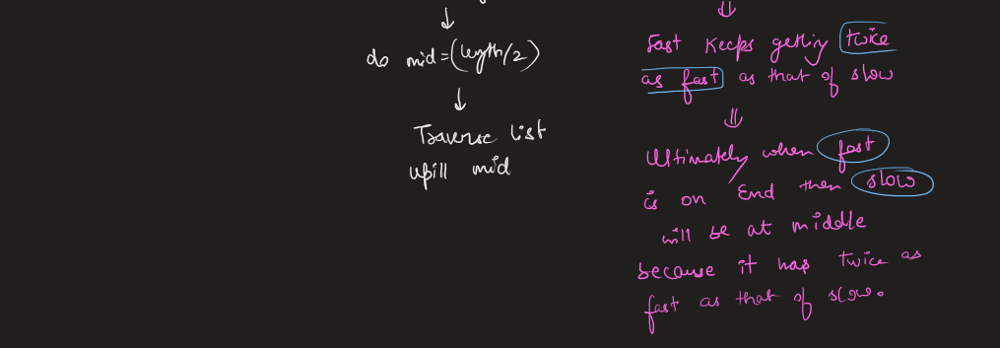\n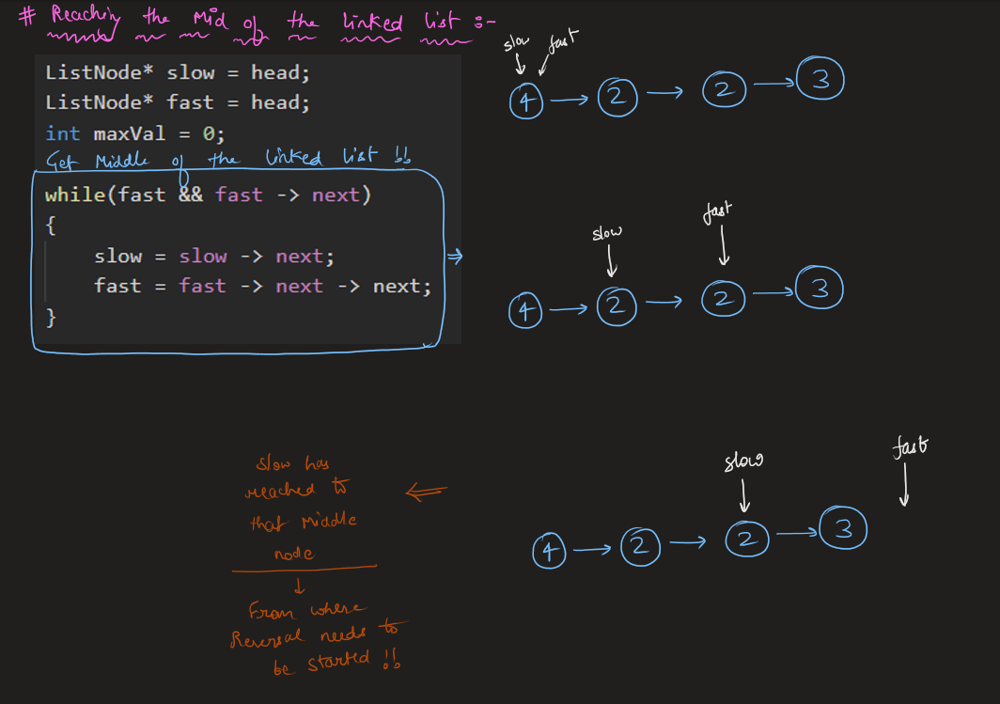\n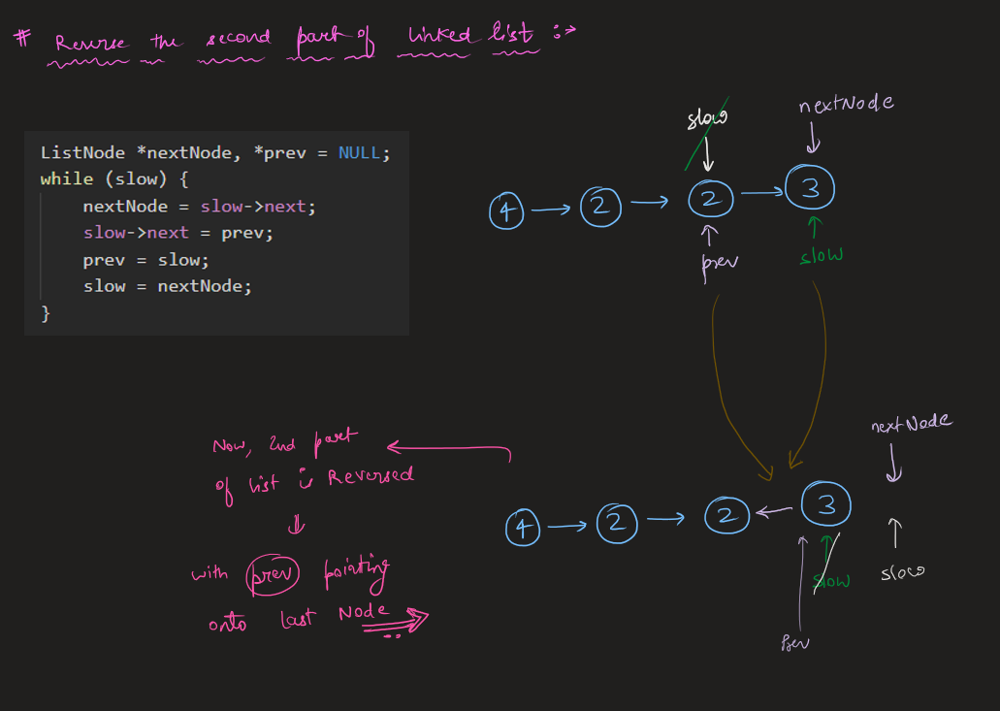\n\n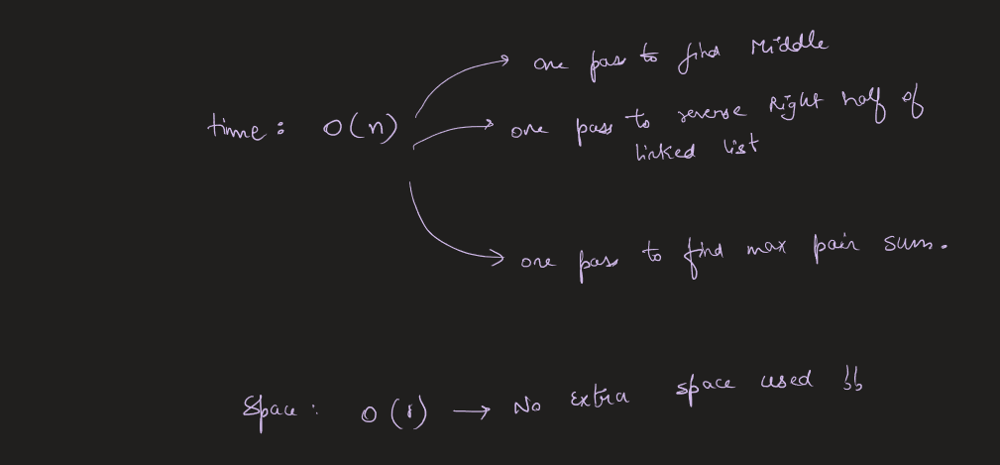\n\n\n\n# Code\n```C++ []\nclass Solution {\n public:\n int pairSum(ListNode* head) {\n ListNode* slow = head;\n ListNode* fast = head;\n int maxVal = 0;\n\n while(fast && fast -> next)\n {\n slow = slow -> next;\n fast = fast -> next -> next;\n }\n\n ListNode *nextNode, *prev = NULL;\n while (slow) {\n nextNode = slow->next;\n slow->next = prev;\n prev = slow;\n slow = nextNode;\n }\n\n while(prev)\n {\n maxVal = max(maxVal, head -> val + prev -> val);\n prev = prev -> next;\n head = head -> next;\n }\n\n return maxVal;\n }\n};\n```\n```Java []\nclass Solution {\n public int pairSum(ListNode head) {\n ListNode slow = head;\n ListNode fast = head;\n int maxVal = 0;\n\n while (fast != null && fast.next != null) {\n slow = slow.next;\n fast = fast.next.next;\n }\n\n ListNode nextNode, prev = null;\n while (slow != null) {\n nextNode = slow.next;\n slow.next = prev;\n prev = slow;\n slow = nextNode;\n }\n\n while (prev != null) {\n maxVal = Math.max(maxVal, head.val + prev.val);\n prev = prev.next;\n head = head.next;\n }\n\n return maxVal;\n }\n}\n```\n```Python []\nclass Solution:\n def pairSum(self, head):\n slow = head\n fast = head\n maxVal = 0\n\n while fast and fast.next:\n slow = slow.next\n fast = fast.next.next\n\n nextNode, prev = None, None\n while slow:\n nextNode = slow.next\n slow.next = prev\n prev = slow\n slow = nextNode\n\n while prev:\n maxVal = max(maxVal, head.val + prev.val)\n prev = prev.next\n head = head.next\n\n return maxVal\n``` | 76 | In a linked list of size `n`, where `n` is **even**, the `ith` node (**0-indexed**) of the linked list is known as the **twin** of the `(n-1-i)th` node, if `0 <= i <= (n / 2) - 1`.
* For example, if `n = 4`, then node `0` is the twin of node `3`, and node `1` is the twin of node `2`. These are the only nodes with twins for `n = 4`.
The **twin sum** is defined as the sum of a node and its twin.
Given the `head` of a linked list with even length, return _the **maximum twin sum** of the linked list_.
**Example 1:**
**Input:** head = \[5,4,2,1\]
**Output:** 6
**Explanation:**
Nodes 0 and 1 are the twins of nodes 3 and 2, respectively. All have twin sum = 6.
There are no other nodes with twins in the linked list.
Thus, the maximum twin sum of the linked list is 6.
**Example 2:**
**Input:** head = \[4,2,2,3\]
**Output:** 7
**Explanation:**
The nodes with twins present in this linked list are:
- Node 0 is the twin of node 3 having a twin sum of 4 + 3 = 7.
- Node 1 is the twin of node 2 having a twin sum of 2 + 2 = 4.
Thus, the maximum twin sum of the linked list is max(7, 4) = 7.
**Example 3:**
**Input:** head = \[1,100000\]
**Output:** 100001
**Explanation:**
There is only one node with a twin in the linked list having twin sum of 1 + 100000 = 100001.
**Constraints:**
* The number of nodes in the list is an **even** integer in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Could you generate all possible pairs of disjoint subsequences? Could you find the maximum length palindrome in each subsequence for a pair of disjoint subsequences? |
C++ / Python mid and reverse solution | maximum-twin-sum-of-a-linked-list | 0 | 1 | **C++ :**\n\n```\nint pairSum(ListNode* head) {\n\tListNode* slow = head;\n\tListNode* fast = head;\n\tint maxVal = 0;\n\n\t// Get middle of linked list\n\twhile(fast && fast -> next)\n\t{\n\t\tfast = fast -> next -> next;\n\t\tslow = slow -> next;\n\t}\n\n\t// Reverse second part of linked list\n\tListNode *nextNode, *prev = NULL;\n\twhile (slow) {\n\t\tnextNode = slow->next;\n\t\tslow->next = prev;\n\t\tprev = slow;\n\t\tslow = nextNode;\n\t}\n\n\t// Get max sum of pairs\n\twhile(prev)\n\t{\n\t\tmaxVal = max(maxVal, head -> val + prev -> val);\n\t\tprev = prev -> next;\n\t\thead = head -> next;\n\t}\n\n\treturn maxVal;\n}\n```\n\n\n**Python :**\n\n```\ndef pairSum(self, head: Optional[ListNode]) -> int:\n\tslow, fast = head, head\n\tmaxVal = 0\n\n\t# Get middle of linked list\n\twhile fast and fast.next:\n\t\tfast = fast.next.next\n\t\tslow = slow.next\n\n\t# Reverse second part of linked list\n\tcurr, prev = slow, None\n\n\twhile curr: \n\t\tcurr.next, prev, curr = prev, curr, curr.next \n\n\t# Get max sum of pairs\n\twhile prev:\n\t\tmaxVal = max(maxVal, head.val + prev.val)\n\t\tprev = prev.next\n\t\thead = head.next\n\n\treturn maxVal\n```\n\n**Like it ? please upvote !** | 212 | In a linked list of size `n`, where `n` is **even**, the `ith` node (**0-indexed**) of the linked list is known as the **twin** of the `(n-1-i)th` node, if `0 <= i <= (n / 2) - 1`.
* For example, if `n = 4`, then node `0` is the twin of node `3`, and node `1` is the twin of node `2`. These are the only nodes with twins for `n = 4`.
The **twin sum** is defined as the sum of a node and its twin.
Given the `head` of a linked list with even length, return _the **maximum twin sum** of the linked list_.
**Example 1:**
**Input:** head = \[5,4,2,1\]
**Output:** 6
**Explanation:**
Nodes 0 and 1 are the twins of nodes 3 and 2, respectively. All have twin sum = 6.
There are no other nodes with twins in the linked list.
Thus, the maximum twin sum of the linked list is 6.
**Example 2:**
**Input:** head = \[4,2,2,3\]
**Output:** 7
**Explanation:**
The nodes with twins present in this linked list are:
- Node 0 is the twin of node 3 having a twin sum of 4 + 3 = 7.
- Node 1 is the twin of node 2 having a twin sum of 2 + 2 = 4.
Thus, the maximum twin sum of the linked list is max(7, 4) = 7.
**Example 3:**
**Input:** head = \[1,100000\]
**Output:** 100001
**Explanation:**
There is only one node with a twin in the linked list having twin sum of 1 + 100000 = 100001.
**Constraints:**
* The number of nodes in the list is an **even** integer in the range `[2, 105]`.
* `1 <= Node.val <= 105` | Could you generate all possible pairs of disjoint subsequences? Could you find the maximum length palindrome in each subsequence for a pair of disjoint subsequences? |
using dictnory in TC=N | longest-palindrome-by-concatenating-two-letter-words | 0 | 1 | ```\nclass Solution:\n def longestPalindrome(self, words: List[str]) -> int:\n dc=defaultdict(lambda:0)\n for a in words:\n dc[a]+=1\n count=0\n palindromswords=0\n inmiddle=0\n wds=set(words)\n for a in wds:\n if(a==a[::-1]):\n if(dc[a]%2==1):\n inmiddle=1\n palindromswords+=(dc[a]//2)*2\n elif(dc[a[::-1]]>0):\n count+=(2*(min(dc[a],dc[a[::-1]])))\n dc[a]=0\n return (palindromswords+count+inmiddle)*2\n ``\n``` | 5 | You are given an array of strings `words`. Each element of `words` consists of **two** lowercase English letters.
Create the **longest possible palindrome** by selecting some elements from `words` and concatenating them in **any order**. Each element can be selected **at most once**.
Return _the **length** of the longest palindrome that you can create_. If it is impossible to create any palindrome, return `0`.
A **palindrome** is a string that reads the same forward and backward.
**Example 1:**
**Input:** words = \[ "lc ", "cl ", "gg "\]
**Output:** 6
**Explanation:** One longest palindrome is "lc " + "gg " + "cl " = "lcggcl ", of length 6.
Note that "clgglc " is another longest palindrome that can be created.
**Example 2:**
**Input:** words = \[ "ab ", "ty ", "yt ", "lc ", "cl ", "ab "\]
**Output:** 8
**Explanation:** One longest palindrome is "ty " + "lc " + "cl " + "yt " = "tylcclyt ", of length 8.
Note that "lcyttycl " is another longest palindrome that can be created.
**Example 3:**
**Input:** words = \[ "cc ", "ll ", "xx "\]
**Output:** 2
**Explanation:** One longest palindrome is "cc ", of length 2.
Note that "ll " is another longest palindrome that can be created, and so is "xx ".
**Constraints:**
* `1 <= words.length <= 105`
* `words[i].length == 2`
* `words[i]` consists of lowercase English letters. | If the subtree doesn't contain 1, then the missing value will always be 1. What data structure allows us to dynamically update the values that are currently not present? |
Python3 Hash map approach | longest-palindrome-by-concatenating-two-letter-words | 0 | 1 | \n**Main idea:**\n\nTo look at all possible types of variations of palindrome construction let\'s use the example: \n\n\twords = ["ab", "ee", "cc", "ba", "ee", "cc", "cc"]\n\nTo construct a palindrome we can use three types of "words":\n1. The same "word" as we met before, but at reversed order: \n\n\t\t"ab" + ... + "ba"\n2. An even number of "words" which consist of the same letter: \n\n\t\t"ee" + ... + "ee" \n3. Odd number of "words" which consist of the same letter: \n\n\t\t"cc" + ... + "cc" + ... + "cc" \n\n\t(i.e we put one "word" in the middle of the palindrome, **but** we can do that only for **one** "word" of that type).\n\nSo, for that list of **words**, based on the above, we can construct a palindrome:\n\n\t\t"ab" + "ee" + "cc" + "cc" + "cc" + "ee" + "ba"\nor\n\n\t\t "cc" + "ab" + "ee" + "cc" + "ee" + "ba" + "cc"\nor any other, based on the same logic.\n\n**Algorithm:**\n\nWhile we going through the list of **words** let\'s reverse them and put them as a key of the dict, where value is the number of such words. If we will meet a "word" from the dict then we already met his unreversed "brother" therefore we can use both of them as the part of palindrome. All those pairs give **+4** to the length of the palindrome. \n\nAs a result when we go through the whole list of words we will calculate all types of "word" which were mentioned at the points 1 and 2. \n\nTo take into account a "word" which we could place in the middle, we will go through the dict and check if there is any "word" consisting of the same letter left.\n\n**Complexity:**\nTime complexity: O(n)\nSpace complexity: O(n)\n\n\n```\n\nclass Solution:\n\tdef longestPalindrome(self, words: List[str]) -> int:\n\t\tans, rev = 0, defaultdict(int)\n\t\tfor word in words:\n\t\t\tif rev[word] > 0:\n\t\t\t\tans += 4\n\t\t\t\trev[word] -= 1\n\t\t\telse:\n\t\t\t\trev[word[::-1]] += 1\n \n\t return ans + (2 if any(k[0] == k[1] and v > 0 for k, v in rev.items()) else 0)\n```\n | 2 | You are given an array of strings `words`. Each element of `words` consists of **two** lowercase English letters.
Create the **longest possible palindrome** by selecting some elements from `words` and concatenating them in **any order**. Each element can be selected **at most once**.
Return _the **length** of the longest palindrome that you can create_. If it is impossible to create any palindrome, return `0`.
A **palindrome** is a string that reads the same forward and backward.
**Example 1:**
**Input:** words = \[ "lc ", "cl ", "gg "\]
**Output:** 6
**Explanation:** One longest palindrome is "lc " + "gg " + "cl " = "lcggcl ", of length 6.
Note that "clgglc " is another longest palindrome that can be created.
**Example 2:**
**Input:** words = \[ "ab ", "ty ", "yt ", "lc ", "cl ", "ab "\]
**Output:** 8
**Explanation:** One longest palindrome is "ty " + "lc " + "cl " + "yt " = "tylcclyt ", of length 8.
Note that "lcyttycl " is another longest palindrome that can be created.
**Example 3:**
**Input:** words = \[ "cc ", "ll ", "xx "\]
**Output:** 2
**Explanation:** One longest palindrome is "cc ", of length 2.
Note that "ll " is another longest palindrome that can be created, and so is "xx ".
**Constraints:**
* `1 <= words.length <= 105`
* `words[i].length == 2`
* `words[i]` consists of lowercase English letters. | If the subtree doesn't contain 1, then the missing value will always be 1. What data structure allows us to dynamically update the values that are currently not present? |
Easy python solution | longest-palindrome-by-concatenating-two-letter-words | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def longestPalindrome(self, words: List[str]) -> int:\n ### count the frequency of each word in words\n counter = Counter(words)\n \n ### initialize res and mid. \n ### mid represent if result is in case1 (mid=1) or case2 (mid=0)\n res = mid = 0 \n\n for word in counter.keys():\n \n if word[0]==word[1]:\n \t### increase the result by the word frequency\n res += counter[word] if counter[word]%2==0 else counter[word]-1\n ### set mid to 1 if frequency is odd (using bit-wise OR to make it short)\n mid |= counter[word]%2\n \n elif word[::-1] in counter:\n \t### increase the result by the minimum frequency of the word and its reverse\n \t### we do not do *2 because we will see its reverse later\n res += min(counter[word],counter[word[::-1]])\n \n ### since we only count the frequency of the selected word\n ### times 2 to get the length of the palindrome\n return (res + mid) * 2\n``` | 1 | You are given an array of strings `words`. Each element of `words` consists of **two** lowercase English letters.
Create the **longest possible palindrome** by selecting some elements from `words` and concatenating them in **any order**. Each element can be selected **at most once**.
Return _the **length** of the longest palindrome that you can create_. If it is impossible to create any palindrome, return `0`.
A **palindrome** is a string that reads the same forward and backward.
**Example 1:**
**Input:** words = \[ "lc ", "cl ", "gg "\]
**Output:** 6
**Explanation:** One longest palindrome is "lc " + "gg " + "cl " = "lcggcl ", of length 6.
Note that "clgglc " is another longest palindrome that can be created.
**Example 2:**
**Input:** words = \[ "ab ", "ty ", "yt ", "lc ", "cl ", "ab "\]
**Output:** 8
**Explanation:** One longest palindrome is "ty " + "lc " + "cl " + "yt " = "tylcclyt ", of length 8.
Note that "lcyttycl " is another longest palindrome that can be created.
**Example 3:**
**Input:** words = \[ "cc ", "ll ", "xx "\]
**Output:** 2
**Explanation:** One longest palindrome is "cc ", of length 2.
Note that "ll " is another longest palindrome that can be created, and so is "xx ".
**Constraints:**
* `1 <= words.length <= 105`
* `words[i].length == 2`
* `words[i]` consists of lowercase English letters. | If the subtree doesn't contain 1, then the missing value will always be 1. What data structure allows us to dynamically update the values that are currently not present? |
Simple and Easy, Python, O(n) time and space | longest-palindrome-by-concatenating-two-letter-words | 0 | 1 | # Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def longestPalindrome(self, words: List[str]) -> int:\n map = {}\n occur = False\n count = 0\n for word in words:\n map[word] = (map[word]+1) if word in map else 1\n for key in map:\n rev = key[1] + key[0]\n if key!=rev and rev in map:\n count+= min(map[key],map[rev])*2\n map[key] = 0\n elif key == rev:\n if map[key]%2!=0:\n occur = True\n map[key] -= 1\n count += map[key] + (-1 if map[key]%2!=0 else 0)\n map[key] = 0\n return count*2 + (2 if occur else 0)\n\n\n``` | 3 | You are given an array of strings `words`. Each element of `words` consists of **two** lowercase English letters.
Create the **longest possible palindrome** by selecting some elements from `words` and concatenating them in **any order**. Each element can be selected **at most once**.
Return _the **length** of the longest palindrome that you can create_. If it is impossible to create any palindrome, return `0`.
A **palindrome** is a string that reads the same forward and backward.
**Example 1:**
**Input:** words = \[ "lc ", "cl ", "gg "\]
**Output:** 6
**Explanation:** One longest palindrome is "lc " + "gg " + "cl " = "lcggcl ", of length 6.
Note that "clgglc " is another longest palindrome that can be created.
**Example 2:**
**Input:** words = \[ "ab ", "ty ", "yt ", "lc ", "cl ", "ab "\]
**Output:** 8
**Explanation:** One longest palindrome is "ty " + "lc " + "cl " + "yt " = "tylcclyt ", of length 8.
Note that "lcyttycl " is another longest palindrome that can be created.
**Example 3:**
**Input:** words = \[ "cc ", "ll ", "xx "\]
**Output:** 2
**Explanation:** One longest palindrome is "cc ", of length 2.
Note that "ll " is another longest palindrome that can be created, and so is "xx ".
**Constraints:**
* `1 <= words.length <= 105`
* `words[i].length == 2`
* `words[i]` consists of lowercase English letters. | If the subtree doesn't contain 1, then the missing value will always be 1. What data structure allows us to dynamically update the values that are currently not present? |
Limited Premium Explained Solution | stamping-the-grid | 1 | 1 | \n```\nclass Solution:\n def possibleToStamp(self, grid, H, W):\n def acc_2d(grid):\n dp = [[0] * (n+1) for _ in range(m+1)] \n for c, r in product(range(n), range(m)):\n dp[r+1][c+1] = dp[r+1][c] + dp[r][c+1] - dp[r][c] + grid[r][c]\n return dp\n\n def sumRegion(r1, c1, r2, c2):\n return dp[r2+1][c2+1] - dp[r1][c2+1] - dp[r2+1][c1] + dp[r1][c1] \n\n m, n = len(grid), len(grid[0])\n dp = acc_2d(grid)\n\n diff = [[0] * (n+1) for _ in range(m+1)] \n for c in range(n - W + 1):\n for r in range(m - H + 1):\n if sumRegion(r, c, r + H - 1, c + W - 1) == 0:\n diff[r][c] += 1\n diff[r][c+W] -= 1\n diff[r+H][c] -= 1\n diff[r+H][c+W] += 1\n \n dp2 = acc_2d(diff)\n for c, r in product(range(n), range(m)):\n if dp2[r+1][c+1] == 0 and grid[r][c] != 1: return False\n\n return True\n``` | 0 | You are given an `m x n` binary matrix `grid` where each cell is either `0` (empty) or `1` (occupied).
You are then given stamps of size `stampHeight x stampWidth`. We want to fit the stamps such that they follow the given **restrictions** and **requirements**:
1. Cover all the **empty** cells.
2. Do not cover any of the **occupied** cells.
3. We can put as **many** stamps as we want.
4. Stamps can **overlap** with each other.
5. Stamps are not allowed to be **rotated**.
6. Stamps must stay completely **inside** the grid.
Return `true` _if it is possible to fit the stamps while following the given restrictions and requirements. Otherwise, return_ `false`.
**Example 1:**
**Input:** grid = \[\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\]\], stampHeight = 4, stampWidth = 3
**Output:** true
**Explanation:** We have two overlapping stamps (labeled 1 and 2 in the image) that are able to cover all the empty cells.
**Example 2:**
**Input:** grid = \[\[1,0,0,0\],\[0,1,0,0\],\[0,0,1,0\],\[0,0,0,1\]\], stampHeight = 2, stampWidth = 2
**Output:** false
**Explanation:** There is no way to fit the stamps onto all the empty cells without the stamps going outside the grid.
**Constraints:**
* `m == grid.length`
* `n == grid[r].length`
* `1 <= m, n <= 105`
* `1 <= m * n <= 2 * 105`
* `grid[r][c]` is either `0` or `1`.
* `1 <= stampHeight, stampWidth <= 105` | When is it possible to convert original into a 2D array and when is it impossible? It is possible if and only if m * n == original.length If it is possible to convert original to a 2D array, keep an index i such that original[i] is the next element to add to the 2D array. |
An incorrect but accepted solution,and the hacking testcase. | stamping-the-grid | 0 | 1 | ### Source Code\n```Python\nclass Solution:\n def possibleToStamp(self, grid: List[List[int]], sh: int, sw: int) -> bool:\n n, m = len(grid) + 1, len(grid[0])\n grid.append([1] * m)\n\n f1 = [0] * m\n for row in grid:\n f2 = [0] * m\n l, r = 0, 0\n for j in range(m):\n if f1[j] < sh:\n l = r = j + 1\n else:\n while r < m and f1[r] >= sh:\n r += 1\n\n if row[j] == 0:\n f2[j] = f1[j] + 1\n elif f1[j] and r - l < sw:\n return False\n f1 = f2\n\n return True\n```\n### Hacking testcase:\n```text\n[[0,0,0],[0,0,0],[0,1,0],[0,0,0],[0,0,0]]\n2\n2\n```\nOutput: `true`. Expected: `false`\n | 0 | You are given an `m x n` binary matrix `grid` where each cell is either `0` (empty) or `1` (occupied).
You are then given stamps of size `stampHeight x stampWidth`. We want to fit the stamps such that they follow the given **restrictions** and **requirements**:
1. Cover all the **empty** cells.
2. Do not cover any of the **occupied** cells.
3. We can put as **many** stamps as we want.
4. Stamps can **overlap** with each other.
5. Stamps are not allowed to be **rotated**.
6. Stamps must stay completely **inside** the grid.
Return `true` _if it is possible to fit the stamps while following the given restrictions and requirements. Otherwise, return_ `false`.
**Example 1:**
**Input:** grid = \[\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\],\[1,0,0,0\]\], stampHeight = 4, stampWidth = 3
**Output:** true
**Explanation:** We have two overlapping stamps (labeled 1 and 2 in the image) that are able to cover all the empty cells.
**Example 2:**
**Input:** grid = \[\[1,0,0,0\],\[0,1,0,0\],\[0,0,1,0\],\[0,0,0,1\]\], stampHeight = 2, stampWidth = 2
**Output:** false
**Explanation:** There is no way to fit the stamps onto all the empty cells without the stamps going outside the grid.
**Constraints:**
* `m == grid.length`
* `n == grid[r].length`
* `1 <= m, n <= 105`
* `1 <= m * n <= 2 * 105`
* `grid[r][c]` is either `0` or `1`.
* `1 <= stampHeight, stampWidth <= 105` | When is it possible to convert original into a 2D array and when is it impossible? It is possible if and only if m * n == original.length If it is possible to convert original to a 2D array, keep an index i such that original[i] is the next element to add to the 2D array. |
[Java/Python 3] Two codes w/ brief analysis. | check-if-every-row-and-column-contains-all-numbers | 1 | 1 | **Q & A**\n\nQ: How does declaring sets inside 1st loop different from declaring ouside the loops?\nA: They only exist during each iteration of the outer loop; Therefore, we do NOT need to clear them after each iteration. Otherwise their life cycle will NOT terminate till the end of the whole code, and also we have to clear them after each iteration of outer for loop.\n\n**End of Q & A**\n\n----\n\n**Method 1: Use HashSet to check each row / column**\n\nCredit to **@uprightclear** for improvement of Java code.\n```java\n public boolean checkValid(int[][] matrix) {\n for (int r = 0, n = matrix.length; r < n; ++r) {\n Set<Integer> row = new HashSet<>();\n Set<Integer> col = new HashSet<>();\n for (int c = 0; c < n; ++c) {\n if (!row.add(matrix[r][c]) || !col.add(matrix[c][r])) {\n return false;\n }\n }\n }\n return true;\n }\n```\n```python\n def checkValid(self, matrix: List[List[int]]) -> bool:\n n = len(matrix)\n for row, col in zip(matrix, zip(*matrix)):\n if len(set(row)) != n or len(set(col)) != n:\n return False\n return True\n```\n\n----\n\n**Method 2: BitSet/bytearray**\n\n```java\n public boolean checkValid(int[][] matrix) {\n for (int r = 0, n = matrix.length; r < n; ++r) {\n BitSet row = new BitSet(n + 1), col = new BitSet(n + 1);\n for (int c = 0; c < n; ++c) {\n if (row.get(matrix[r][c]) || col.get(matrix[c][r])) {\n return false;\n }\n row.set(matrix[r][c]);\n col.set(matrix[c][r]);\n }\n } \n return true;\n }\n```\n```python\n def checkValid(self, matrix: List[List[int]]) -> bool:\n n = len(matrix)\n for r in range(n):\n row = bytearray(n + 1) \n col = bytearray(n + 1) \n for c in range(n):\n ro, co = matrix[r][c], matrix[c][r]\n row[ro] += 1\n col[co] += 1\n if row[ro] > 1 or col[co] > 1:\n return False\n return True\n```\n**Analysis:**\n\nTime: `O(n * n)`, space: O(n), where `n = matrix.length`. | 69 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
use DP tabulation | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n\n dp_col = [[False for _ in range(len(matrix[0]))] for _ in range(len(matrix))]\n dp_row = [[False for _ in range(len(matrix[0]))] for _ in range(len(matrix))]\n\n for i in range(len(matrix)):\n for j in range(len(matrix[0])):\n if dp_row[i][matrix[i][j]-1] or dp_col[j][matrix[i][j]-1]:\n return False\n dp_row[i][matrix[i][j]-1] = True\n dp_col[j][matrix[i][j]-1] = True\n return True\n\n\n``` | 1 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
Python3 simple 2 lines | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | Create a set containing the integers from `1...n` then check that each set of rows and columns is equal to this set.\n\n`zip(*matrix)` is a convenient way of obtaining the columns of a matrix\n\n```python\n def checkValid(self, matrix: List[List[int]]) -> bool:\n set_ = set(range(1,len(matrix)+1))\n return all(set_ == set(x) for x in matrix+list(zip(*matrix)))\n``` | 26 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
Python One-Liner | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n return all(i == set(range(1,len(matrix)+1)) for i in ([frozenset(i) for i in matrix ])) and all(i == set(range(1,len(matrix)+1)) for i in [frozenset(i) for i in [[i[j] for i in matrix] for j in range(len(matrix))]])\n``` | 2 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
Python (Simple Hashmap) | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkValid(self, matrix):\n m, n = len(matrix), len(matrix[0])\n\n rows, cols = defaultdict(set), defaultdict(set)\n\n for i in range(m):\n for j in range(n):\n if (matrix[i][j] in rows[i]) or (matrix[i][j] in cols[j]):\n return False\n else:\n rows[i].add(matrix[i][j])\n cols[j].add(matrix[i][j])\n\n return True\n\n\n\n``` | 4 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
A simple and CORRECT XOR method | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | As suggested by @kartik135065, \nsimple XOR method can be wrong as the code could not pass the test case such as [[1,2,2,4,5,6,6],[2,2,4,5,6,6,1],[2,4,5,6,6,1,2],[4,5,6,6,1,2,2],[5,6,6,1,2,2,4],[6,6,1,2,2,4,5],[6,1,2,2,4,5,6]]\n\nI crafted the correct codes using the XOR idea and easily passed the above test case. Pls upvote is you find it helpful. \n\nTime complexity O(N^2)\nSpace complexity O(1)\n\nInitial Code: May have overflow issue if n is too large\n```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n # bitmask\n n = len(matrix)\n\n for i in range(n):\n row_bit, col_bit, bitmask = 1, 1, 1\n for j in range(n):\n row_bit ^= 1 << matrix[i][j]\n col_bit ^= 1 << matrix[j][i]\n bitmask |= 1 << j + 1\n\n if row_bit ^ bitmask or col_bit ^ bitmask:\n return False\n \n return True\n```\n\nUsing the third bitmask to avoid the overflow issue\n```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n # bitmask\n n = len(matrix)\n\n for i in range(n):\n row_bit, col_bit, bitmask = 1, 1, 1\n for j in range(n):\n row_bit ^= 1 << matrix[i][j]\n col_bit ^= 1 << matrix[j][i]\n bitmask |= 1 << j + 1\n\n if row_bit ^ bitmask or col_bit ^ bitmask:\n return False\n \n return True\n``` | 5 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
✔Python 3 | 7 Line solution | 87% Faster runtime | 92.99% lesser memory | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | ```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n lst = [0]*len(matrix)\n for i in matrix:\n if len(set(i)) != len(matrix):\n return False\n for j in range(len(i)):\n lst[j] += i[j]\n return len(set(lst)) == 1\n``` | 12 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
Python easy | Set | 98% faster and memory efficient | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | ```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n for r in range(len(matrix)):\n colSet = set()\n rowSet = set()\n for c in range(len(matrix)):\n if matrix[r][c] in colSet or matrix[c][r] in rowSet:\n return False\n colSet.add(matrix[r][c])\n rowSet.add(matrix[c][r])\n \n return True\n``` | 3 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
[Python3] 1-line | check-if-every-row-and-column-contains-all-numbers | 0 | 1 | Please checkout this [commit](https://github.com/gaosanyong/leetcode/commit/36536bdcdd42d372f17893d27ffbe283d970e24f) for solutions of weekly 275. \n\n```\nclass Solution:\n def checkValid(self, matrix: List[List[int]]) -> bool:\n return all(len(set(row)) == len(matrix) for row in matrix) and all(len(set(col)) == len(matrix) for col in zip(*matrix))\n``` | 5 | An `n x n` matrix is **valid** if every row and every column contains **all** the integers from `1` to `n` (**inclusive**).
Given an `n x n` integer matrix `matrix`, return `true` _if the matrix is **valid**._ Otherwise, return `false`.
**Example 1:**
**Input:** matrix = \[\[1,2,3\],\[3,1,2\],\[2,3,1\]\]
**Output:** true
**Explanation:** In this case, n = 3, and every row and column contains the numbers 1, 2, and 3.
Hence, we return true.
**Example 2:**
**Input:** matrix = \[\[1,1,1\],\[1,2,3\],\[1,2,3\]\]
**Output:** false
**Explanation:** In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3.
Hence, we return false.
**Constraints:**
* `n == matrix.length == matrix[i].length`
* `1 <= n <= 100`
* `1 <= matrix[i][j] <= n` | Try to concatenate every two different strings from the list. Count the number of pairs with concatenation equals to target. |
[Python3, Java, C++] Easy Sliding Window O(n) | minimum-swaps-to-group-all-1s-together-ii | 1 | 1 | *Intuition*: \nWhenever you are faced with a circular array question, you can just append the array to itself to get rid of the circular array part of the problem\n\n***Explanation***:\n* Count number of ones in nums, let the number of ones be stored in the variable `ones`\n* Append nums to nums because we have to look at it as a circular array\n* Find the maximum number of ones in a window of size `ones` in the new array\n* Number of swaps = `ones` - maximum number of ones in a window of size `ones`\n<iframe src="https://leetcode.com/playground/kCYY9jmQ/shared" frameBorder="0" width="600" height="300"></iframe>\n\nWe can also solve the same in O(1) space. Loop through the array twice:\n```\ndef minSwaps(self, nums: List[int]) -> int:\n\tones, n = nums.count(1), len(nums)\n\tx, onesInWindow = 0, 0\n\tfor i in range(n * 2):\n\t\tif i >= ones and nums[i % n - ones]: x -= 1\n\t\tif nums[i % n] == 1: x += 1\n\t\tonesInWindow = max(x, onesInWindow)\n\treturn ones - onesInWindow\n``` | 210 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
Sliding window approach | minimum-swaps-to-group-all-1s-together-ii | 0 | 1 | **Approch Sliding window**\n\n* the main idea is that when it says it\'s circular you can use of doubling the array by it\'s self \n\n* another is that then main intuision is that it says `"to group all the one\'s"` well you have to ask how many `one\'s(1\'s)` there are in the orginal array then that will tell you the `size of your window` \n\n* thirdly if you think to group all the ones well you have know how many zero\'s (0\'s) are there in the window size example `[1, 0, 0, 1, 1, 0]` there are 3 1\'s so our window size is k = 3 because we need to group all those 3 1\'s together so first it will be `[1,0,0] zeros = 2 0\'s` 0\'s so our minimum becames 2 and then goes for the rest of all the `doubled array`\n\n\n```\nclass Solution:\n def minSwaps(self, nums: List[int]) -> int:\n l = r = 0\n zero = 0\n k = nums.count(1) + 1 #our window size #O(n)\n nums+=nums #double the array\n \n mi = len(nums)*3 #just random higher number\n \n while r < len(nums):\n if (r - l + 1) == k: #if our window size is k increment left and add the minimum size\n mi = min(mi, zero)\n if nums[l] == 0:\n zero-=1\n l+=1\n \n if nums[r] == 0:\n zero+=1\n r+=1\n print(mi)\n \n return mi\n\t\t\n```\n**T = O(n)\nS = O(n)**\n | 1 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
Sliding window with comments, Python | minimum-swaps-to-group-all-1s-together-ii | 0 | 1 | First, by appending nums to nums, you can ignore the effect of split case.\nThen, you look at the window whose width is `width`. Here, `width` = the number of 1\'s in the original nums. This is because you have to gather all 1\'s in this window at the end of some swap operations. Therefore, the number of swap operation is the number of 0\'s in this window. \nThe final answer should be the minimum value of this.\n\n```\nclass Solution:\n def minSwaps(self, nums: List[int]) -> int:\n width = sum(num == 1 for num in nums) #width of the window\n nums += nums\n res = width\n curr_zeros = sum(num == 0 for num in nums[:width]) #the first window is nums[:width]\n \n for i in range(width, len(nums)):\n curr_zeros -= (nums[i - width] == 0) #remove the leftmost 0 if exists\n curr_zeros += (nums[i] == 0) #add the rightmost 0 if exists\n res = min(res, curr_zeros) #update if needed\n \n return res\n``` | 22 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
✔ Python3 Solution | Sliding Window | O(n) Time | minimum-swaps-to-group-all-1s-together-ii | 0 | 1 | `Time Complexity` : `O(n)`\n`Space Complexity` : `O(1)`\n```\nclass Solution:\n def minSwaps(self, nums):\n n, k, ans = len(nums), nums.count(1), float(\'inf\')\n c = nums[:k].count(1)\n for i in range(n):\n ans = min(ans, k - c)\n c += nums[(i + k) % n] - nums[i]\n return ans\n``` | 1 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
[Java/Python 3] Sliding Window O(n) code w/ brief explanation and analysis. | minimum-swaps-to-group-all-1s-together-ii | 1 | 1 | Denote as `winWidth` the total number of `1`\'s in the input array, then the goal of swaps is to get a window of size `winWidth` full of `1`\'s. Therefore, we can maintain a sliding window of size `winWidth` to find the maximum `1`\'s inside, and accordingly the minimum number of `0`\'s inside the sliding window is the solution.\n\n```java\n public int minSwaps(int[] nums) {\n int winWidth = 0;\n for (int n : nums) {\n winWidth += n;\n }\n int mx = 0;\n for (int lo = -1, hi = 0, onesInWin = 0, n = nums.length; hi < 2 * n; ++hi) {\n onesInWin += nums[hi % n];\n if (hi - lo > winWidth) {\n onesInWin -= nums[++lo % n];\n }\n mx = Math.max(mx, onesInWin);\n }\n return winWidth - mx;\n }\n```\n```python\n def minSwaps(self, nums: List[int]) -> int:\n win_width = sum(nums)\n lo, mx, ones_in_win = -1, 0, 0\n n = len(nums)\n for hi in range(2 * n):\n ones_in_win += nums[hi % n]\n if hi - lo > win_width:\n lo += 1\n ones_in_win -= nums[lo % n]\n mx = max(mx, ones_in_win) \n return win_width - mx\n```\n\n**Analysis:**\n\nTime: `O(n)`, space: `O(1)`, where `n = nums.length`. | 8 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
Simple sliding window with Python | minimum-swaps-to-group-all-1s-together-ii | 0 | 1 | # Intuition\nWhen all ones are next to each other, they will form a subarray of the size of the total number of ones.\nWe can count the number of ones, divide the array into subarrays of this size and then count the number of ones in each subarray. The number of \'missing\' ones will be the number of needed swaps.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nWe will count the total number of ones in the array.\nWe will create a sliding window of the same size.\nWe will iterate through the array to find which sliding window has the most amount of ones.\nThe final answer will be the number of ones in the array subtracted by the maximum number of ones in our sliding window.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minSwaps(self, nums: List[int]) -> int:\n \n #Create sliding window\n k = nums.count(1)\n sliding_window = nums[-k:].count(1)\n maxi = sliding_window\n\n #Iterate through the array\n n = len(nums)\n for i in range(n):\n sliding_window += nums[i] - nums[i-k]\n maxi = max(maxi, sliding_window)\n\n return k - maxi\n``` | 1 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
Python sliding window O(n) | minimum-swaps-to-group-all-1s-together-ii | 0 | 1 | ```\nclass Solution:\n def minSwaps(self, nums: List[int]) -> int:\n ones = nums.count(1)\n n = len(nums)\n res = ones\n start = 0\n end = ones-1\n zeroesInWindow = sum(num==0 for num in nums[start:end+1])\n \n while start < n:\n # print(start, end , zeroesInWindow)\n res = min(res, zeroesInWindow)\n if nums[start] == 0: zeroesInWindow -= 1 \n start += 1\n end += 1\n if nums[end%n] == 0: zeroesInWindow += 1\n \n return res\n``` | 2 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
Sliding Window Beginner Friendly | minimum-swaps-to-group-all-1s-together-ii | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public int minSwaps(int[] nums) {\n\n int noOfOnes = 0;\n for (int i = 0; i < nums.length; i++) {\n if (nums[i] == 1)\n noOfOnes++;\n }\n if (noOfOnes == 0 || noOfOnes == nums.length) {\n return 0; // No swaps needed if all elements are 0 or all elements are 1.\n }\n System.out.println(noOfOnes);\n int arr[] = new int[2 * nums.length];\n for (int y = 0; y < nums.length; y++) {\n arr[y] = nums[y];\n }\n for (int z = nums.length; z < nums.length + noOfOnes; z++) {\n arr[z] = nums[z - nums.length];\n }\n\n int i = 0;\n int j = 0;\n int sum = 0;\n int min = Integer.MIN_VALUE;\n System.out.println(Arrays.toString(arr));\n while (j < arr.length) {\n sum += arr[j];\n if ((j - i + 1) < noOfOnes) {\n j++;\n } else if ((j - i + 1) == noOfOnes) {\n min = Math.max(min, (sum));\n sum -= arr[i];\n i++;\n j++;\n }\n\n }\n return noOfOnes - min;\n\n }\n}\n``` | 0 | A **swap** is defined as taking two **distinct** positions in an array and swapping the values in them.
A **circular** array is defined as an array where we consider the **first** element and the **last** element to be **adjacent**.
Given a **binary** **circular** array `nums`, return _the minimum number of swaps required to group all_ `1`_'s present in the array together at **any location**_.
**Example 1:**
**Input:** nums = \[0,1,0,1,1,0,0\]
**Output:** 1
**Explanation:** Here are a few of the ways to group all the 1's together:
\[0,0,1,1,1,0,0\] using 1 swap.
\[0,1,1,1,0,0,0\] using 1 swap.
\[1,1,0,0,0,0,1\] using 2 swaps (using the circular property of the array).
There is no way to group all 1's together with 0 swaps.
Thus, the minimum number of swaps required is 1.
**Example 2:**
**Input:** nums = \[0,1,1,1,0,0,1,1,0\]
**Output:** 2
**Explanation:** Here are a few of the ways to group all the 1's together:
\[1,1,1,0,0,0,0,1,1\] using 2 swaps (using the circular property of the array).
\[1,1,1,1,1,0,0,0,0\] using 2 swaps.
There is no way to group all 1's together with 0 or 1 swaps.
Thus, the minimum number of swaps required is 2.
**Example 3:**
**Input:** nums = \[1,1,0,0,1\]
**Output:** 0
**Explanation:** All the 1's are already grouped together due to the circular property of the array.
Thus, the minimum number of swaps required is 0.
**Constraints:**
* `1 <= nums.length <= 105`
* `nums[i]` is either `0` or `1`. | Can we use the maximum length at the previous position to help us find the answer for the current position? Can we use binary search to find the maximum consecutive same answer at every position? |
[Python3] bitmask | count-words-obtained-after-adding-a-letter | 0 | 1 | Please checkout this [commit](https://github.com/gaosanyong/leetcode/commit/36536bdcdd42d372f17893d27ffbe283d970e24f) for solutions of weekly 275. \n\n```\nclass Solution:\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n seen = set()\n for word in startWords: \n m = 0\n for ch in word: m ^= 1 << ord(ch)-97\n seen.add(m)\n \n ans = 0 \n for word in targetWords: \n m = 0 \n for ch in word: m ^= 1 << ord(ch)-97\n for ch in word: \n if m ^ (1 << ord(ch)-97) in seen: \n ans += 1\n break \n return ans \n``` | 94 | You are given two **0-indexed** arrays of strings `startWords` and `targetWords`. Each string consists of **lowercase English letters** only.
For each string in `targetWords`, check if it is possible to choose a string from `startWords` and perform a **conversion operation** on it to be equal to that from `targetWords`.
The **conversion operation** is described in the following two steps:
1. **Append** any lowercase letter that is **not present** in the string to its end.
* For example, if the string is `"abc "`, the letters `'d'`, `'e'`, or `'y'` can be added to it, but not `'a'`. If `'d'` is added, the resulting string will be `"abcd "`.
2. **Rearrange** the letters of the new string in **any** arbitrary order.
* For example, `"abcd "` can be rearranged to `"acbd "`, `"bacd "`, `"cbda "`, and so on. Note that it can also be rearranged to `"abcd "` itself.
Return _the **number of strings** in_ `targetWords` _that can be obtained by performing the operations on **any** string of_ `startWords`.
**Note** that you will only be verifying if the string in `targetWords` can be obtained from a string in `startWords` by performing the operations. The strings in `startWords` **do not** actually change during this process.
**Example 1:**
**Input:** startWords = \[ "ant ", "act ", "tack "\], targetWords = \[ "tack ", "act ", "acti "\]
**Output:** 2
**Explanation:**
- In order to form targetWords\[0\] = "tack ", we use startWords\[1\] = "act ", append 'k' to it, and rearrange "actk " to "tack ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "act ".
Note that "act " does exist in startWords, but we **must** append one letter to the string before rearranging it.
- In order to form targetWords\[2\] = "acti ", we use startWords\[1\] = "act ", append 'i' to it, and rearrange "acti " to "acti " itself.
**Example 2:**
**Input:** startWords = \[ "ab ", "a "\], targetWords = \[ "abc ", "abcd "\]
**Output:** 1
**Explanation:**
- In order to form targetWords\[0\] = "abc ", we use startWords\[0\] = "ab ", add 'c' to it, and rearrange it to "abc ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "abcd ".
**Constraints:**
* `1 <= startWords.length, targetWords.length <= 5 * 104`
* `1 <= startWords[i].length, targetWords[j].length <= 26`
* Each string of `startWords` and `targetWords` consists of lowercase English letters only.
* No letter occurs more than once in any string of `startWords` or `targetWords`. | A pivot point splits the array into equal prefix and suffix. If no change is made to the array, the goal is to find the number of pivot p such that prefix[p-1] == suffix[p]. Consider how prefix and suffix will change when we change a number nums[i] to k. When sweeping through each element, can you find the total number of pivots where the difference of prefix and suffix happens to equal to the changes of k-nums[i]. |
Easy Python solution with comments | count-words-obtained-after-adding-a-letter | 0 | 1 | # Intuition\n- Words should be sorted to help match the different permutations. \n- It will be easier to remove letters from targetWords to match startWords than to add letters to startWords to match targetWords. \n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n) * klog(k)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(m)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nn = len(targetWords)\nk = len(targetWords[i])\nm = len(startWords)\n\n# Code\n```\nclass Solution:\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n\n #Make a set of sorted startWords\n start = set([\'\'.join(sorted(item)) for item in startWords])\n\n count = 0\n for item in targetWords:\n\n #Sort letters for each targetWord to match them with startWords\n word = \'\'.join(sorted(item))\n\n #Remove letters one by one to see if any of the startWords match\n n = len(item)\n for i in range(n):\n if word[:i] + word[i+1:] in start:\n count += 1\n break\n\n return count\n``` | 1 | You are given two **0-indexed** arrays of strings `startWords` and `targetWords`. Each string consists of **lowercase English letters** only.
For each string in `targetWords`, check if it is possible to choose a string from `startWords` and perform a **conversion operation** on it to be equal to that from `targetWords`.
The **conversion operation** is described in the following two steps:
1. **Append** any lowercase letter that is **not present** in the string to its end.
* For example, if the string is `"abc "`, the letters `'d'`, `'e'`, or `'y'` can be added to it, but not `'a'`. If `'d'` is added, the resulting string will be `"abcd "`.
2. **Rearrange** the letters of the new string in **any** arbitrary order.
* For example, `"abcd "` can be rearranged to `"acbd "`, `"bacd "`, `"cbda "`, and so on. Note that it can also be rearranged to `"abcd "` itself.
Return _the **number of strings** in_ `targetWords` _that can be obtained by performing the operations on **any** string of_ `startWords`.
**Note** that you will only be verifying if the string in `targetWords` can be obtained from a string in `startWords` by performing the operations. The strings in `startWords` **do not** actually change during this process.
**Example 1:**
**Input:** startWords = \[ "ant ", "act ", "tack "\], targetWords = \[ "tack ", "act ", "acti "\]
**Output:** 2
**Explanation:**
- In order to form targetWords\[0\] = "tack ", we use startWords\[1\] = "act ", append 'k' to it, and rearrange "actk " to "tack ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "act ".
Note that "act " does exist in startWords, but we **must** append one letter to the string before rearranging it.
- In order to form targetWords\[2\] = "acti ", we use startWords\[1\] = "act ", append 'i' to it, and rearrange "acti " to "acti " itself.
**Example 2:**
**Input:** startWords = \[ "ab ", "a "\], targetWords = \[ "abc ", "abcd "\]
**Output:** 1
**Explanation:**
- In order to form targetWords\[0\] = "abc ", we use startWords\[0\] = "ab ", add 'c' to it, and rearrange it to "abc ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "abcd ".
**Constraints:**
* `1 <= startWords.length, targetWords.length <= 5 * 104`
* `1 <= startWords[i].length, targetWords[j].length <= 26`
* Each string of `startWords` and `targetWords` consists of lowercase English letters only.
* No letter occurs more than once in any string of `startWords` or `targetWords`. | A pivot point splits the array into equal prefix and suffix. If no change is made to the array, the goal is to find the number of pivot p such that prefix[p-1] == suffix[p]. Consider how prefix and suffix will change when we change a number nums[i] to k. When sweeping through each element, can you find the total number of pivots where the difference of prefix and suffix happens to equal to the changes of k-nums[i]. |
[Java/Python 3] Group anagrams by hash w/ brief explanation and analysis. | count-words-obtained-after-adding-a-letter | 1 | 1 | 1. Use HashMap/dict to group the hashs of the anagrams in `startWords` by their lengths;\n2. Traverse `targetWords`, for each word, compute its hashs after remove one character; Then check if we can find the hashs among the HashMap/dict corresponding to `startWord`; If yes, increase the counter `cnt` by `1`;\n\n**Method 1: Use char[]/String as hash**\n\n```java\n public int wordCount(String[] startWords, String[] targetWords) {\n Map<Integer, Set<String>> groups = new HashMap<>();\n for (String w : startWords) {\n char[] ca = getHash(w);\n groups.computeIfAbsent(w.length(), s -> new HashSet<>()).add(String.valueOf(ca));\n }\n int cnt = 0;\n outer:\n for (String w : targetWords) {\n int sz = w.length() - 1;\n if (groups.containsKey(sz)) {\n char[] ca = getHash(w);\n for (char c : w.toCharArray()) {\n --ca[c - \'a\'];\n if (groups.get(sz).contains(String.valueOf(ca))) {\n ++cnt;\n continue outer;\n }\n ++ca[c - \'a\'];\n }\n }\n }\n return cnt;\n }\n private char[] getHash(String w) {\n char[] ca = new char[26];\n for (char c : w.toCharArray()) {\n ++ca[c - \'a\'];\n }\n return ca;\n }\n```\n```python\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n \n def getHash(w: str) -> List[int]:\n h = [0] * 26\n for c in w:\n h[ord(c) - ord(\'a\')] = 1\n return h\n \n groups = defaultdict(set)\n for w in startWords:\n h = getHash(w)\n groups[len(w)].add(tuple(h))\n cnt = 0\n for w in targetWords:\n if groups[len(w) - 1]:\n h = getHash(w)\n for c in w:\n h[ord(c) - ord(\'a\')] = 0\n if tuple(h) in groups[len(w) - 1]:\n cnt += 1\n break\n h[ord(c) - ord(\'a\')] = 1\n return cnt\n```\n\n----\n\n**Method 2: Use int as hash - bit manipulation**\n\n```java\n public int wordCount(String[] startWords, String[] targetWords) {\n Map<Integer, Set<Integer>> groups = new HashMap<>();\n for (String w : startWords) {\n groups.computeIfAbsent(w.length(), s -> new HashSet<>()).add(getHash(w));\n }\n int cnt = 0;\n for (String w : targetWords) {\n int hash = getHash(w), len = w.length() - 1;\n for (char c : w.toCharArray()) {\n if (groups.containsKey(len) && groups.get(len).contains(hash ^ (1 << c - \'a\'))) {\n ++cnt;\n break;\n }\n }\n }\n return cnt;\n }\n private int getHash(String w) {\n int hash = 0;\n for (char c : w.toCharArray()) {\n hash |= 1 << c - \'a\';\n }\n return hash;\n }\n```\n```python\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n \n def getHash(w: str) -> int:\n h = 0\n for c in w:\n h |= 1 << ord(c) - ord(\'a\')\n return h \n \n cnt, groups = 0, defaultdict(set)\n for w in startWords:\n groups[len(w)].add(getHash(w))\n for w in targetWords:\n h = getHash(w)\n if any((h ^ (1 << ord(c) - ord(\'a\'))) in groups[len(w) - 1] for c in w):\n cnt += 1\n return cnt\n```\n\n**Analysis:**\n\nDenote `S = startWords.length` and `T = targetWords.length`. Let `m` and `n` be the average sizes of the words in `startWords` and `targetWords` respectively, then,\n\nTime & space: `O(S * m + T * n)`. | 27 | You are given two **0-indexed** arrays of strings `startWords` and `targetWords`. Each string consists of **lowercase English letters** only.
For each string in `targetWords`, check if it is possible to choose a string from `startWords` and perform a **conversion operation** on it to be equal to that from `targetWords`.
The **conversion operation** is described in the following two steps:
1. **Append** any lowercase letter that is **not present** in the string to its end.
* For example, if the string is `"abc "`, the letters `'d'`, `'e'`, or `'y'` can be added to it, but not `'a'`. If `'d'` is added, the resulting string will be `"abcd "`.
2. **Rearrange** the letters of the new string in **any** arbitrary order.
* For example, `"abcd "` can be rearranged to `"acbd "`, `"bacd "`, `"cbda "`, and so on. Note that it can also be rearranged to `"abcd "` itself.
Return _the **number of strings** in_ `targetWords` _that can be obtained by performing the operations on **any** string of_ `startWords`.
**Note** that you will only be verifying if the string in `targetWords` can be obtained from a string in `startWords` by performing the operations. The strings in `startWords` **do not** actually change during this process.
**Example 1:**
**Input:** startWords = \[ "ant ", "act ", "tack "\], targetWords = \[ "tack ", "act ", "acti "\]
**Output:** 2
**Explanation:**
- In order to form targetWords\[0\] = "tack ", we use startWords\[1\] = "act ", append 'k' to it, and rearrange "actk " to "tack ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "act ".
Note that "act " does exist in startWords, but we **must** append one letter to the string before rearranging it.
- In order to form targetWords\[2\] = "acti ", we use startWords\[1\] = "act ", append 'i' to it, and rearrange "acti " to "acti " itself.
**Example 2:**
**Input:** startWords = \[ "ab ", "a "\], targetWords = \[ "abc ", "abcd "\]
**Output:** 1
**Explanation:**
- In order to form targetWords\[0\] = "abc ", we use startWords\[0\] = "ab ", add 'c' to it, and rearrange it to "abc ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "abcd ".
**Constraints:**
* `1 <= startWords.length, targetWords.length <= 5 * 104`
* `1 <= startWords[i].length, targetWords[j].length <= 26`
* Each string of `startWords` and `targetWords` consists of lowercase English letters only.
* No letter occurs more than once in any string of `startWords` or `targetWords`. | A pivot point splits the array into equal prefix and suffix. If no change is made to the array, the goal is to find the number of pivot p such that prefix[p-1] == suffix[p]. Consider how prefix and suffix will change when we change a number nums[i] to k. When sweeping through each element, can you find the total number of pivots where the difference of prefix and suffix happens to equal to the changes of k-nums[i]. |
Help with the testcase | count-words-obtained-after-adding-a-letter | 0 | 1 | My output is 253 and result is 254.\nCan every one tell me where\'s wrong logic?\n\n```\n["mgxfkirslbh","wpmsq","pxfouenr","lnq","vcomefldanb","gdsjz","xortwlsgevidjpc","kynjtdlpg","hmofavtbgykidw","bsefprtwxuamjih","yvuxreobngjp","ihbywqkteusjxl","ugh","auydixmtogrkve","ox","wvknsj","pyekgfcab","zsunrh","ecrpmxuw","mtvpdgwr","kpbmwlxgus","ob","gfhqz","qvjkgtxecdoafpi","rnufgtom","vijqecrny","lkgtqcxbrfhay","eq","mbhf","iv","bzevwoxrnjp","wgusokd","cnkexvsquwlgbfp","zebrwf","gdxleczutofajir","x","mtraowpeschbkxi","daickygrp","p","xjlwcbapyszdtv","hgab","nlgf","z","mt","oumqabs","alf","whfruolazjdcb","tf","dxngwmft","ibuvnosrqdgjyp","hftpg","jcnah","recavwlgfxiuk","stjuiedvlfwbhpq","dqakvgfrc","nzqtouwbism","dwymhgcsx","zvqr","c","hevgr","jbsvmrtcnow","fptlcxg","wsiqcgnlfxb","zapnjquycdsxvi","lcvabg","hpuzsbgqkeixwr","ornd","eqgukchjnwids","ysxbhdzpvgcew","ji","ozna","be","muhikqnd","axlhyftvrpkucs","aedofvlhzqmxrt","g","leifus","i","qlgcrxsdnmytb","t","fbhlgrvozsyxajt","puyqhksclinob","vfbpcedhn","nqism","zi","qgb","qweg","sh","qmbunh","sp","cainjebqmvyslo","hya","ifyrxkgemqc","hmcrgabdlqkfs","o","abikmjqpr","hbzedog","yxijqknhl","g","jhbav","n","bvglmordite","r","ulmkqdwytxipvao","ngfkuvxatzqryl","wzmxuiyj","jguv","vzgmelrnjpsoa","lgndsxvuiq","cflwyxbezdgsqj","tiqznalvrdepws","znofuykwilps","srquzgomnlkcb","fuktdpbinwl","bevucxl","zgxahrynjqfsmu","digtkmachbrxven","zlkpqatvibr","awdilqtmbrvceg","oswhbncfx","ruzqfvtjphg","x","i","cydkbxnl","zprdiwholgm","bheaiprnvodm","ftihvlsjayw","agdub","v","ahlqydvnkgeju","jkv","bepnzdw","ogjuhltpnmaire","gojxtmraiqz","sfhv","pgmjzehnfxrbk","msat","aodegjbmt","n","fpanl","ghylfn","vzxysgwncmeb","onyeabqimcrtwp","dvcbqueixzfwgo","lafgbztpmdnyws","ydaixthclnjgkq","mgyajwfieus","jinvoyud","xrb","g","ceivybxtljdzu","ijrqzdegpxs","gjw","kczrpqbtwjulamv","alrvb","usftxanbdw","hitvrca","aybtr","kbxpwivucnley","tv","lgpbaytvjdfeowx","igmkqlnedjaxsc","qlvwszxhbrfe","bofcmzyvsg","gc","zojkdvixfbant","cstlvhpkfrdwney","nblsowtza","zjqthpwfbgsae","xqrvdfusnhcbwlj","lmsgtn","dvwyxbch","jagbesnvwhkfxoc","rs","ocyph","rgmfyvwbekxad","ynov","w","xlizrsf","lctpaxqizb","tmovsbjxqeh","aqcoslvfmkg","odpqkzlrxh","osyfzjwbthpamue","atihkjxbcmdfu","ocrjlfnug","psjwqyeibu","fgkjnmpc","bkljzrc","rfgwkp","kygcnhdu","zjmwei","lctvhjrngafo","ouvgm","kmcrx","y","r","anri","gtlrnepusmjbwh","rketigxb","zompxictdrqhy","nbcavygtpldwmsr","fdjbo","dokmrypczgnf","gjidtncwouer","gdclb","pbehgj","rmzgxscqolnh","pgwyiu","rozvjcekpgudl","ngzjyotwepavc","rexjomgdfblsu","ihjsz","uy","ivmx","fmewhrgsxj","ftdbcxpaglunhj","yxnatjghfbzd","rnqbmdhtwzgpsoi","kabsdq","aifosqdtmlxprjy","vzcnmyfu","zcogsdvrpy","maorzpfqus","jmxrhfgtepqoz","srkoghcuvewxfdz","jvrfdtgihb","ndg","kxtqhg","ftdlihv","gklsuycht","yxcv","axsydfeg","ayostk","fhrwkb","ezxauvsjfodit","gdzxkbcowtyrnqp","lxjraocfhi","idge","afptqjcvd","rpdagkqows","uvjregzl","vaeknyjci","ztuavj","qtodpfaxslmc","hxamecynpdq","nlzwr","owbzkhcqlnyd","axsioeklpbcuyq","xpczv","aruicpsw","ebolyfqshp","tuyjgbqxkcnav","mcnyewxfvsi","izb","w","ybrfj","yrpchjik","erljaoiyfxpkght","swjgimbzaqc","aiq","nstwhcabkd","pyrnahv","ckezagrnw","bqrxjysckmzife","cqeslp","bpcxfwy","z","eqypbakhzsdj","dijepvmtohsbg","tokfxvnzrsl","vnamdoblrqwfx","udfmzj","txornzeiykw","qzgjeidfybavhpc","bcnasehw","doqlptju","uciwskjzfpdtlr","orcayhmvgzx","wvyq","uixyfapoznleb","zsawrfun","ifjcovxalpmbryk","cdvajtmnyr","d","vyu","vwcknlphbite","xarzstglin","adm","ifpkuzhs","hlfrkscuzimb","kliwz","trcqxlmy","gidhkfcvmzab","cjxyoszh","bhunojsazwfxvi","l","mwqfzlsguaeoi","fqdomyght","j","swtqiovuaphm","unyjg","ieyxp","aolfrbg","pyovktzmrjuie","uew","l","npwisxm","a","rkexvymhaof","yuipgq","qzvnsx","bwatpdu","vthizgue","eh","oxubpyaqjmfsd","zxlsftu","dusl","rpdsmljtcoaqveg","jfgnilepzhc","nz","wftpvsijg","larx","ylv","drptekxzainhybo","kamdovjbsnizq","igoaprsznvjfkwb","jt","gcpfi","ihvkomuc","qnbgcdxviwulke","cxuhyvdkesprq","lixvrwskot","wngphsjztvx","wv","rcbsphoqijdtmv","nhprx","a","m","wctzuk","fingedrwyjsbl","kbyqad","xtgbyqovckn","xr","ygaenxqc","dnibrxzohft","jy","fbyxqadrewshu","rvfcdtgmkypwai","wr","csotefgijw","rabphzvwcndqil","zk","zwycqvaiubers","pty","qrgtk","kagdqfo","efharqwngoicds","tmgyub","fln","paqesokun","nilutckzejqxgdv","xtuzogl","htfzpqywla","wsmo","glbfvmjzs","brsc","ojcqrn","yqsncexfjumzgo","sunqiwjhvbtxokm","hw","gy","m","wfli","eqazhgjvfydtusr","bu","lwu","mnpobr","xtv","aysfkui","vwmjgknbxheu","ktabp","yqjpfxwen","podsig","erqdbxgckiwlht","emdbpfvzl","gauhjcvxrtmd","eykrotbig","qfhwydcn","njgtvwmzlk","n","urtnipf","c","ptdwigz","qgvutfsrxp","mczxv","whayfszc","wqcaskzb","ox","ngqpswbhd","tabc","lwtf","lbukxpzacyevw","tvsjzbaqohgwke","qspcakoudj","mho","jdw","situxhcgfnq","vhopwt","yqk","pblx","haxbyjvinrq","gbiehqudwprjn","hlg"]\n["nsewcbujhad","aeb","phvbaeinctkwl","cybwlsuzinvk","qwhxytpvefrjz","gvy","ixcalbqfz","igftodzvcnswjlm","thbdfgivurj","nbd","dgqolunivxs","bcsovemfldan","unhzrsd","skwlendhyucapzi","zyrmohljp","qum","btmzgfqaspwjeh","jgkmzqoyvtw","tlgrawcxkn","qdwogyrfs","gephoxvsdj","dfvxywjknm","wru","jnumkcfydo","ewhbxfqgkclsj","lz","ghxopqbey","xc","jiznkxvcues","uykrcxaofhm","vmqdipal","zjkmbqxtyefsicr","fiawpvldc","h","dompynwi","zbkynwmcxgves","mxi","ranoytupxb","pyaqedhvzgjcbifl","fy","nrobdxvspqyjgui","snrm","gfyknowupqrta","wivmt","qtxyhcblrakfdg","vfczbhtoa","reho","o","rzn","rabsgdfxij","gpyhft","jiv","ufqji","xe","pnifxjhmtosa","j","vzodg","cthzjspulafxiwb","ohbmuqn","rdliztsjukcwfpv","saoqpd","pxu","kxnguybvejfwo","fukagtlbndmpry","sqlpaytnvhkrmo","pm","umco","imjqrd","riq","vywxz","npiu","rvzjq","qso","epkloxmr","racvl","znkcwbg","sfp","mguztnorf","pnjogwuyztacev","qdyxcfzbhp","bcwhdqzjultrai","sfvheigw","vgqb","brsyjegvmhdc","xwuadlp","aft","pinl","gctwje","ufjzmdp","ohbxag","cdfamgpntkwu","ruaekpdbfqtzclj","cesowgvpltxjihdr","nfy","jftgxplc","zhlgtxou","tljanzupriodew","rlesyncqbkftuoh","eqslt","giotujnrwfdce","qldztvnyguwxso","vjkdfzuaseitxo","rdimnopgzhlw","ckrjyqwplitsfo","dwvj","wgje","qcmrxk","qgflbvxhn","qoniymsa","ftdcoxpqakigrejv","hrusofb","qcm","scwykazqb","riswegfoctj","tq","ekoc","sjpkg","dikj","sqigfbrel","eoknxfrup","ot","djfsbwkpuhl","yvafsiku","clnbxzg","ivbhygjqrxan","rit","msprwq","hfdjmckqzpulrw","hfwazycos","kdmnqztsi","nrhol","lctab","svf","crxngv","gczkqjs","agfqzhmy","dvoxgmh","ndvcuykgh","vct","nywvhcxbd","e","pbufvcszi","ql","agvpjizktbwsorfn","zxvgbkwca","omeayvfwhqzrpi","fmgcxeutzdk","ldpbcrayxztsjvw","nxt","ypluzeavsqw","zmbv","rucwispfa","iucj","jnhbzw","vqhetubalnf","poivetgflayxkjhr","tje","nr","spygwiqr","ewyuforkmpicnx","vg","hakjcn","aygvphcszitqwku","baovglc","qmurcdzbhy","wucgnfmlsjz","kslongxrqhcmz","pgfvquewxncalksb","drqhje","parmfuzhdkvb","orfwcqbsv","uoq","iocesyphtzxvuwk","oisafxherlpvjd","xrbw","iktsg","dag","ifpyer","onerqivbwmjz","ia","kemzasyxndgjhoc","ukvj","celxkzuhwypbva","y","agejbtoqislvh","xiopwdtfkba","fqbihmywglxdnc","cjmeizw","ghzfqw","eylv","jbuylhnfk","pkyfr","rf","dyvhipqjmgrezaf","kcolxfmgnqvyz","nphgbcujmo","fqupgtrxvis","f","drishmtobjqcapv","exutnvc","pkzcqhmgnf","ycgqbdtsenmlhf","k","wtgerl","lqa","ku","i","ydlzsgfirbjx","owecuxrpm","i","ekr","tglokjeyc","ckmfij","coxekquhwmd","kfsdwcq","hnpymjovxue","twqyv","demvwrtcsiabglq","y","kvnqszx","g","ewtuijhxyo","mwhrsfxjgeb","dwxfbntusoa","lhiboak","kune","ow","awzpn","jqesgiuzrdpx","rijvynudo","ycvutdmgkroiexa","qvo","wupmsxni","rcpnhx","wsbcanhpe","sdelrbyxqukzmw","qhrygcuabnv","fruaynbsedwqxh","flyhcwnaoej","ni","rbtopmn","jvtdensy","few","dn","a","chg","h","tiwdrbp","tdm","qghetodvsjimbp","hymzfvgsobc","kdqstyjznvhapb","oem","lb","mhod","adjhexcpqmny","ljsiq","whgdyxmzcs","tc","vyquexhzlwirbo","gykq","qhmjgo","wmcrasnoxf","xzrbwvpefnoj","eyhaqspxvkrdcu","ncbtsvzfr","kwal","slfyi","fz","nzbdmr","akpdhycirg","ofrbxuc","ajkyobq","tkxhd","tjcxrw","qiruxdljayvw","xhvakznmibru","shgizj","mtgbuokycqjwz","lbodjf","xbgmzwslkup","ix","tefw","szlqbfcrvewxh","yugjdax","aekjsruy","womqkfdny","jgzw","lavbxr","lijybwtshfva","fwvlt","abhvjc","ub","qew","kwimvrfxsn","mldvjhbsxkfqtp","gfewmbh","oe","adurofqsiwcyek","mrahvpzxqo","gxtbcrjvnayquk","agdukwhevqynjl","fal","jzrvwinkusldbot","qnia","kwhuiacrvobp","ewmr","rmwdsvtgp","zctjunxidevybl","ckuexlrgpn","dh","dczbrilvhnwpaqt","ustilnpkfowzy","bknrejhxopmgzf","uzvteaj","xnkie","dxbtswmrekfvncu","yeuaxkilbcshopq","ax","suchdoxfbn","iegrpnd","qetwovbjs","kxrobvsuwzd","suwj","xsgdcavhoeyrznl","fo","vtpyhaowszmq","hfwonijbvdzxsua","onatjk","sau","dvbwoatyjsxpgefl","na","mglfynh","ywlkdcbnx","qwvojklutydran","aql","gdol","m","ufskachixjtmbd","kxlwg","klgmyuparhtox","fvshdugarpyejqzt","ejidg","uknhpsfqdotvjya","novyphxwj","blxps","d","kc","cnaroqj","qu","incfrutp","ci","dtugyziblrqh","dsfoquxevlarht","zwmnptjau","ytecmgvjf","maoictxvjus","uwhxytnv","tbmzpscehxkarwoi","ztxv","kigyjb","frlapn","wcveqlpj","arz","bfqkiatlmvsueo","jkepaqwimx","jefodwbt","xcnqwdhtlkmiryp","xulkbnq","ot","m","jchodig","wcqgmilbajzs","zekqsxwgfdjyblc","nmxavdocguybrtp","bkyczmptogqiu","mastzincjxqb","nzm","dxpfaoelg","hygbrxamzcov","b","pkgvdzsrcyo","whqopvdgexfntaz","iowrnxkltsv","f","nvcuymzwf","sxevmktrdyqpga","ulwzsntvhgo","fkvzgxbadmihc","kmferiap","gnpylhidxqvre","zfunlhxpajsmte","psomxbu","tpyz","vrbnpzicehqlk","vut","hmosw","wrcoegynlmihktq","ehujpgb","teurhbpola","te","qmhvgazpy","qn","xgkevnmujhbcw","cednjuyzfrk","bl","tvjsdkzgbfrnolx","o","jeszr","lf","pxmrstykena","etkaqgywb","xitepcoqmywnabr","phfeo","tuzkb","ltcpynmzkhe","qf","jceaqor","vikewzdsflayrh","amipvtk","bqjxfctm","xyuflbwdni","zjn","avnyhxtgcbmsj","fyxztlw","rhiksqzwbncdu","jnsgkmxz","mbhfu","unrqvayjeiocsld","ugb","iu","orjyfb","cfxyv","dkrzslecipt","rh","otuwqevildhsfpbj","lsxrizef","ufwl","vpbsgxlucam","zldruejvg","qdszvjpgh","omqlsijg","zrjsyimekutopv","tqiwgkjxhp","pmldfswutjenyo","juzltnvkgwm","istbrgxek","zsekjfihrbmdgtl","ntxlkarzsfvo","tfzmsyn","junvwaoiy","iuehozgtv","gwpfkry","jyuwpvil","zor","mrxfkeiguqcy","tlops","jvratnwemgupsl","ufvrzmts","dpkjsfmthglwic","bhkandtjwvgpr","gbcmstwonrvj","gnsxietuyvohjc","np","rpjyhckie","tj","fhoxkpinujs","boq","vlytmzbcj","nboyucs","f","tmkrbvcequgolsi","inthajrleycopd","mzpkoteqjfhgxr","wifjoezhqlaydrg","dufr","zsg","rafzbmldtkc","uamgpkrzet","eajgftqzl","ifkgbcwn","mbgqnsrv","thgewzbiufdp","ng","oszkxyeritnw","npvryhas","gqwpnlft","gtbsreykoi","ytcuaefbkwo","whv","indxwfc","zqi","snvihkaglfxp","zjlefovgdby","jlkwuacx","jzkocbnaismqdv","qxnz","fehcipdbnv","qwhpxnejfy","lrnwjz","jfduoehpxgs","md","dej","erbipdhgnquwjc","utyabgm","mrghpwtnaiqkfc","mlcoq","smxavtwkeizo","j","anjwekzo","gvsoqdbwnc","ribnmhugpt","zxqgtkh","lh","zvib","ianrw","ozekxhrdqpl","gdns","fxymzdjbthang","vynmo","segtfrnjzuvd","h","x","qlfwdxjzna","jmlrotpyhcuv","zfwsqrgxk","lmq","qwdifkjecshung","utdihflv","mnuvsawckq","ucakhswdtbn","oaedpl","rohtbfdxnzei","cu","vdlcw","tsgudkwo","ugijehftmalzv","ehmkjblipgv","n","bd","sgko","neb","qxbuingv","fcvtpjadqz","zqnrskbme","ldgxwijqnkrfcp","cnj","lcqxgyena","hufobzqekpxvldm","ctxn","ab","aolvmzespbrnjg","io","kbhwspg","jwhomcr","npfl","zidqsvpunjbyaxc","bav","tmwrjlsed","jzibvwcstlgrk","hizmbwqyge","onyxbergpvjul","o","noigbrtqzhuwpsdm","wgyoitnkacj","cleatwzurifgdxoj","ydprewfczknlt","yjiemrltqhkfzd","qbhe","y","uhgq","a","eptlxqmoairfyjds","pytesjdvo","ulajndfgx","knvpfcmldwbios","ejqxawcop","c","xhloesfqypb","j","yflgq","vcyu","chqztuvn","vmwubperxk","samxt","po","t","exfdpatnwosk","xcqonaptfmlsd","tlmayecdkisrpbz","hgyvzlbxetufjmw","fsgakpcndiuzeb","m","luevtfj","avguom","afqwnblsomk","qlozdybwcfnhk","fosmbqua","afdmrgsqwxvo","lzdfjtbqc","qhagb","qeimns","xnhrs","xdtwiymhskqoa","hfbgnwjuzevlkpr","by","ogtlerhvdmbi","epcdgwajviourbx","pdohxc","oxqkbethrlwnpma","pwdhq","tkgnzbhverafc","zlpbvitakqrf","ynbfxwpc","ygmxtiv","ybtpaudw","nagxrepfl","rvp","rhbiavct","vmqspyzfuw","ajex","fgjrad","zr","wzk","jk","rkqzmjabip","ditpyqoxwnzgja","ybsnciveoakjlmq","ywverqzmujginxc","czvrm","bazyusfmdtjgie","yhmlbrtxskuwqa","pnqgesyzuvwkt","ahpntv","kmgcndrfyzpoj","zobskapmlj"]\n```\n\n```\nclass Solution:\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n sw = {}\n \n for ss in startWords:\n sw[ss] = Counter(ss)\n \n \n S = set()\n \n for target in targetWords:\n counter_t = Counter(target)\n \n for ss in sw:\n if len(target) == len(ss) + 1 and len(counter_t.keys()) == len(sw[ss].keys()) + 1:\n s = sum([val for key, val in (sw[ss] & counter_t).items()])\n if s == len(ss):\n S.add(target)\n break\n\n return len(S)\n``` | 10 | You are given two **0-indexed** arrays of strings `startWords` and `targetWords`. Each string consists of **lowercase English letters** only.
For each string in `targetWords`, check if it is possible to choose a string from `startWords` and perform a **conversion operation** on it to be equal to that from `targetWords`.
The **conversion operation** is described in the following two steps:
1. **Append** any lowercase letter that is **not present** in the string to its end.
* For example, if the string is `"abc "`, the letters `'d'`, `'e'`, or `'y'` can be added to it, but not `'a'`. If `'d'` is added, the resulting string will be `"abcd "`.
2. **Rearrange** the letters of the new string in **any** arbitrary order.
* For example, `"abcd "` can be rearranged to `"acbd "`, `"bacd "`, `"cbda "`, and so on. Note that it can also be rearranged to `"abcd "` itself.
Return _the **number of strings** in_ `targetWords` _that can be obtained by performing the operations on **any** string of_ `startWords`.
**Note** that you will only be verifying if the string in `targetWords` can be obtained from a string in `startWords` by performing the operations. The strings in `startWords` **do not** actually change during this process.
**Example 1:**
**Input:** startWords = \[ "ant ", "act ", "tack "\], targetWords = \[ "tack ", "act ", "acti "\]
**Output:** 2
**Explanation:**
- In order to form targetWords\[0\] = "tack ", we use startWords\[1\] = "act ", append 'k' to it, and rearrange "actk " to "tack ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "act ".
Note that "act " does exist in startWords, but we **must** append one letter to the string before rearranging it.
- In order to form targetWords\[2\] = "acti ", we use startWords\[1\] = "act ", append 'i' to it, and rearrange "acti " to "acti " itself.
**Example 2:**
**Input:** startWords = \[ "ab ", "a "\], targetWords = \[ "abc ", "abcd "\]
**Output:** 1
**Explanation:**
- In order to form targetWords\[0\] = "abc ", we use startWords\[0\] = "ab ", add 'c' to it, and rearrange it to "abc ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "abcd ".
**Constraints:**
* `1 <= startWords.length, targetWords.length <= 5 * 104`
* `1 <= startWords[i].length, targetWords[j].length <= 26`
* Each string of `startWords` and `targetWords` consists of lowercase English letters only.
* No letter occurs more than once in any string of `startWords` or `targetWords`. | A pivot point splits the array into equal prefix and suffix. If no change is made to the array, the goal is to find the number of pivot p such that prefix[p-1] == suffix[p]. Consider how prefix and suffix will change when we change a number nums[i] to k. When sweeping through each element, can you find the total number of pivots where the difference of prefix and suffix happens to equal to the changes of k-nums[i]. |
Clean Python, Using Set, No Sorting, Binary Char Representation | count-words-obtained-after-adding-a-letter | 0 | 1 | Let M be the number of startWords, N be the number of targetWords and 26 is the number of characters.\nRuntime is O(M x 26) to generate the startWords set\nRuntime is O(N x 26) to look up the targetWords in the startWords set\nRuntime O(M+N)\n\nThe next natural step would be to not use a binary tuple to represent the word, but use actual bits of e.g. an INT. Principle is the same, implementation of createWordTuple differs.\n```\nclass Solution:\n def wordCount(self, startWords: List[str], targetWords: List[str]) -> int:\n # represent chars in word with binary encoding "ca" = (1,0,1,...,0)\n def createWordTuple(word):\n ans = [0]*26\n for c in word:\n ans[ord(c) - ord(\'a\')] = 1\n return tuple(ans)\n \n # create set with binary encoded words\n words = set()\n for word in startWords:\n words.add(createWordTuple(word))\n \n # for each targetWord remove one char and look in the set whether \n # the reduced binary encoded character string is there\n ans = 0\n for word in targetWords:\n for i in range(len(word)):\n cutWord = word[:i] + word[i+1:]\n if createWordTuple(cutWord) in words:\n ans += 1\n break\n \n return ans\n``` | 6 | You are given two **0-indexed** arrays of strings `startWords` and `targetWords`. Each string consists of **lowercase English letters** only.
For each string in `targetWords`, check if it is possible to choose a string from `startWords` and perform a **conversion operation** on it to be equal to that from `targetWords`.
The **conversion operation** is described in the following two steps:
1. **Append** any lowercase letter that is **not present** in the string to its end.
* For example, if the string is `"abc "`, the letters `'d'`, `'e'`, or `'y'` can be added to it, but not `'a'`. If `'d'` is added, the resulting string will be `"abcd "`.
2. **Rearrange** the letters of the new string in **any** arbitrary order.
* For example, `"abcd "` can be rearranged to `"acbd "`, `"bacd "`, `"cbda "`, and so on. Note that it can also be rearranged to `"abcd "` itself.
Return _the **number of strings** in_ `targetWords` _that can be obtained by performing the operations on **any** string of_ `startWords`.
**Note** that you will only be verifying if the string in `targetWords` can be obtained from a string in `startWords` by performing the operations. The strings in `startWords` **do not** actually change during this process.
**Example 1:**
**Input:** startWords = \[ "ant ", "act ", "tack "\], targetWords = \[ "tack ", "act ", "acti "\]
**Output:** 2
**Explanation:**
- In order to form targetWords\[0\] = "tack ", we use startWords\[1\] = "act ", append 'k' to it, and rearrange "actk " to "tack ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "act ".
Note that "act " does exist in startWords, but we **must** append one letter to the string before rearranging it.
- In order to form targetWords\[2\] = "acti ", we use startWords\[1\] = "act ", append 'i' to it, and rearrange "acti " to "acti " itself.
**Example 2:**
**Input:** startWords = \[ "ab ", "a "\], targetWords = \[ "abc ", "abcd "\]
**Output:** 1
**Explanation:**
- In order to form targetWords\[0\] = "abc ", we use startWords\[0\] = "ab ", add 'c' to it, and rearrange it to "abc ".
- There is no string in startWords that can be used to obtain targetWords\[1\] = "abcd ".
**Constraints:**
* `1 <= startWords.length, targetWords.length <= 5 * 104`
* `1 <= startWords[i].length, targetWords[j].length <= 26`
* Each string of `startWords` and `targetWords` consists of lowercase English letters only.
* No letter occurs more than once in any string of `startWords` or `targetWords`. | A pivot point splits the array into equal prefix and suffix. If no change is made to the array, the goal is to find the number of pivot p such that prefix[p-1] == suffix[p]. Consider how prefix and suffix will change when we change a number nums[i] to k. When sweeping through each element, can you find the total number of pivots where the difference of prefix and suffix happens to equal to the changes of k-nums[i]. |
FASTEST GREEDY SOLUTION (7 LINES) | earliest-possible-day-of-full-bloom | 0 | 1 | ```\nclass Solution:\n def earliestFullBloom(self, plantTime: List[int], growTime: List[int]) -> int:\n comb=[(plantTime[i],growTime[i]) for i in range(len(plantTime))]\n mx,passed_days=0,0\n comb.sort(key=lambda x:(-x[1],x[0]))\n for i in range(len(plantTime)):\n mx=max(mx,(passed_days+comb[i][0]+comb[i][1]))\n passed_days+=comb[i][0]\n return mx\n``` | 5 | You have `n` flower seeds. Every seed must be planted first before it can begin to grow, then bloom. Planting a seed takes time and so does the growth of a seed. You are given two **0-indexed** integer arrays `plantTime` and `growTime`, of length `n` each:
* `plantTime[i]` is the number of **full days** it takes you to **plant** the `ith` seed. Every day, you can work on planting exactly one seed. You **do not** have to work on planting the same seed on consecutive days, but the planting of a seed is not complete **until** you have worked `plantTime[i]` days on planting it in total.
* `growTime[i]` is the number of **full days** it takes the `ith` seed to grow after being completely planted. **After** the last day of its growth, the flower **blooms** and stays bloomed forever.
From the beginning of day `0`, you can plant the seeds in **any** order.
Return _the **earliest** possible day where **all** seeds are blooming_.
**Example 1:**
**Input:** plantTime = \[1,4,3\], growTime = \[2,3,1\]
**Output:** 9
**Explanation:** The grayed out pots represent planting days, colored pots represent growing days, and the flower represents the day it blooms.
One optimal way is:
On day 0, plant the 0th seed. The seed grows for 2 full days and blooms on day 3.
On days 1, 2, 3, and 4, plant the 1st seed. The seed grows for 3 full days and blooms on day 8.
On days 5, 6, and 7, plant the 2nd seed. The seed grows for 1 full day and blooms on day 9.
Thus, on day 9, all the seeds are blooming.
**Example 2:**
**Input:** plantTime = \[1,2,3,2\], growTime = \[2,1,2,1\]
**Output:** 9
**Explanation:** The grayed out pots represent planting days, colored pots represent growing days, and the flower represents the day it blooms.
One optimal way is:
On day 1, plant the 0th seed. The seed grows for 2 full days and blooms on day 4.
On days 0 and 3, plant the 1st seed. The seed grows for 1 full day and blooms on day 5.
On days 2, 4, and 5, plant the 2nd seed. The seed grows for 2 full days and blooms on day 8.
On days 6 and 7, plant the 3rd seed. The seed grows for 1 full day and blooms on day 9.
Thus, on day 9, all the seeds are blooming.
**Example 3:**
**Input:** plantTime = \[1\], growTime = \[1\]
**Output:** 2
**Explanation:** On day 0, plant the 0th seed. The seed grows for 1 full day and blooms on day 2.
Thus, on day 2, all the seeds are blooming.
**Constraints:**
* `n == plantTime.length == growTime.length`
* `1 <= n <= 105`
* `1 <= plantTime[i], growTime[i] <= 104` | null |
Simplest solution for beginners | divide-a-string-into-groups-of-size-k | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n res=[]\n for i in range(0,len(s),k):\n res.append(s[i:i+k])\n diff=abs(len(res[-1])-k)\n \n if len(res[-1])!=k:\n for i in range(diff):\n res[-1]+=fill \n return res\n \n \n\n\n \n``` | 1 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Simple python solution | divide-a-string-into-groups-of-size-k | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n lst=[]\n for i in range(0,len(s),k):\n a=s[i:i+k]\n if len(a)==k:\n lst.append(a)\n else:\n c=k-len(a)\n for j in range(c):\n a=a+fill\n lst.append(a)\n return lst\n``` | 1 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Easy Python Solution | Faster than 84% | divide-a-string-into-groups-of-size-k | 0 | 1 | ```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n ans = []\n no_of_groups = math.ceil(len(s)/k)\n start = 0\n while no_of_groups>0:\n if s[start:start+k]:\n ans.append(s[start:start+k])\n else:\n ans.append(s[start:])\n start+=k\n no_of_groups-=1\n while len(ans[-1])!=k:\n ans[-1]+=fill \n return ans\n``` | 1 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Easy python solution | divide-a-string-into-groups-of-size-k | 0 | 1 | ```\ndef divideString(self, s: str, k: int, fill: str) -> List[str]:\n l=[]\n if len(s)%k!=0:\n s+=fill*(k-len(s)%k)\n for i in range(0,len(s),k):\n l.append(s[i:i+k])\n return l\n``` | 10 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Python one liner | divide-a-string-into-groups-of-size-k | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(N)\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n return [s[i:i+k] + fill * (k-len(s[i:i+k])) for i in range(0, len(s), k)]\n``` | 3 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
[PYTHON] Comments | Clean | divide-a-string-into-groups-of-size-k | 0 | 1 | ```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n while len(s)%k != 0:\n s += fill\n # checking until the string is dividable into k groups\n # if not, it will add the filler until it is\n \n c = []\n for x in range(0, len(s), k): # starts at 0, goes to len(s), iteration value is k\n c.append(s[x:x+k]) # appends everything from x->x+k (iteration value)\n\n return c # return final list\n``` | 3 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
[Python3] simulation | divide-a-string-into-groups-of-size-k | 0 | 1 | Please check out this [commit](https://github.com/gaosanyong/leetcode/commit/210499523d9965e2d9dd5e1a6fbf67931233e41b) for solutions of weekly 276. \n\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n ans = []\n for i in range(0, len(s), k): \n ss = s[i:i+k]\n ans.append(ss + (k-len(ss))*fill)\n return ans \n``` | 5 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Easy python solution | divide-a-string-into-groups-of-size-k | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n l=[]\n for i in range(0,len(s),k):\n if len(s[i:i+k])!=k:\n m=k-len(s[i:i+k])\n a=s[i:i+k]+m*fill\n l.append(a)\n else:\n l.append(s[i:i+k]) \n return l\n \n``` | 0 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Easy and simple solution || python3 | divide-a-string-into-groups-of-size-k | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n b=[]\n for i in range(0,len(s),k):\n if len(s)%k==0:\n a=s[i:i+k]\n b.append(a)\n else:\n a=s[i:i+k]\n if len(a)==k:\n b.append(a)\n else:\n b.append(a+(k-len(a))*fill)\n return b\n\n \n``` | 0 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
2138. Divide a String Into Groups of Size k | divide-a-string-into-groups-of-size-k | 0 | 1 | # Intuition\nCheers\n\n# Approach\nString slicing\n\n# Complexity\n- Time complexity:\n $$O(n): 17.30 MB$$\n\n- Space complexity:\n $$O(n): 35ms$$\n\n# Code\n```\nclass Solution:\n def divideString(self, s: str, k: int, fill: str) -> List[str]:\n assert 1<=len(s) and len(s)<=100, \'constraint reached\'\n assert 97<=ord(fill) and ord(fill)<=122, \'constraint reached\'\n assert 1<=k and k<=100, \'constraint reached\'\n l=[]\n lf=len(s)%k\n for i in range(len(s)//k):\n l.append(s[k*i:k*(i+1)])\n if lf:\n l.append(s[-lf:]+fill*(k-lf))\n return l\n``` | 0 | A string `s` can be partitioned into groups of size `k` using the following procedure:
* The first group consists of the first `k` characters of the string, the second group consists of the next `k` characters of the string, and so on. Each character can be a part of **exactly one** group.
* For the last group, if the string **does not** have `k` characters remaining, a character `fill` is used to complete the group.
Note that the partition is done so that after removing the `fill` character from the last group (if it exists) and concatenating all the groups in order, the resultant string should be `s`.
Given the string `s`, the size of each group `k` and the character `fill`, return _a string array denoting the **composition of every group**_ `s` _has been divided into, using the above procedure_.
**Example 1:**
**Input:** s = "abcdefghi ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi "\]
**Explanation:**
The first 3 characters "abc " form the first group.
The next 3 characters "def " form the second group.
The last 3 characters "ghi " form the third group.
Since all groups can be completely filled by characters from the string, we do not need to use fill.
Thus, the groups formed are "abc ", "def ", and "ghi ".
**Example 2:**
**Input:** s = "abcdefghij ", k = 3, fill = "x "
**Output:** \[ "abc ", "def ", "ghi ", "jxx "\]
**Explanation:**
Similar to the previous example, we are forming the first three groups "abc ", "def ", and "ghi ".
For the last group, we can only use the character 'j' from the string. To complete this group, we add 'x' twice.
Thus, the 4 groups formed are "abc ", "def ", "ghi ", and "jxx ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters only.
* `1 <= k <= 100`
* `fill` is a lowercase English letter. | Use suffix/prefix arrays. prefix[i] records the maximum value in range (0, i - 1) inclusive. suffix[i] records the minimum value in range (i + 1, n - 1) inclusive. |
Simple python solution beats 90% | minimum-moves-to-reach-target-score | 0 | 1 | # Intuition\nThe problem involves reaching the target integer starting from 1 using two operations: incrementing by one or doubling the current integer. We need to find the minimum number of moves required to reach the target, with the restriction that we can only use the double operation at most maxDoubles times. \n\n# Approach\nTo solve the problem, we can use a greedy approach. We will keep dividing the target integer by 2 as long as it is even and we have remaining double operations available (maxDoubles > 0). After using all the possible double operations, we can simply decrement the target integer by 1 until it becomes 1.\n\n# Complexity\n- Time complexity: The time complexity of the solution is O(log(target)) since in each iteration, we divide the target by 2.\n\n- Space complexity: The space complexity is O(1) as we are only using a constant amount of extra space to store the count variable c.\n\n# Code\n```\nclass Solution:\n def minMoves(self, target: int, maxDoubles: int) -> int:\n c=0\n while maxDoubles and target > 1:\n if target%2 == 0 and maxDoubles :\n c+=1\n maxDoubles-=1\n target //=2\n else:\n target -=1\n c+=1\n if target>1:\n c+=target-1\n return c \n \n``` | 0 | You are playing a game with integers. You start with the integer `1` and you want to reach the integer `target`.
In one move, you can either:
* **Increment** the current integer by one (i.e., `x = x + 1`).
* **Double** the current integer (i.e., `x = 2 * x`).
You can use the **increment** operation **any** number of times, however, you can only use the **double** operation **at most** `maxDoubles` times.
Given the two integers `target` and `maxDoubles`, return _the minimum number of moves needed to reach_ `target` _starting with_ `1`.
**Example 1:**
**Input:** target = 5, maxDoubles = 0
**Output:** 4
**Explanation:** Keep incrementing by 1 until you reach target.
**Example 2:**
**Input:** target = 19, maxDoubles = 2
**Output:** 7
**Explanation:** Initially, x = 1
Increment 3 times so x = 4
Double once so x = 8
Increment once so x = 9
Double again so x = 18
Increment once so x = 19
**Example 3:**
**Input:** target = 10, maxDoubles = 4
**Output:** 4
**Explanation:** Initially, x = 1
Increment once so x = 2
Double once so x = 4
Increment once so x = 5
Double again so x = 10
**Constraints:**
* `1 <= target <= 109`
* `0 <= maxDoubles <= 100` | Maintain the frequency of all the points in a hash map. Traverse the hash map and if any point has the same y-coordinate as the query point, consider this point and the query point to form one of the horizontal lines of the square. |
🐍Python3 the 🔥most easy 🔥way || Beginner friendly🔥🔥 | solving-questions-with-brainpower | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n**Dynamic Programing or Memoization**\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- we have array in given question, so we can think of something related to index.\n- problem states that i can skip or take the question.\n- from this our first choice is recursion because we need to try all possible ways.\n- now in this we will encounter many overlaping sub-problems such as **if at index p we skip and go to index p+1, there might be a chance that it is previously computed by taking some index p-i**\n- so we make dp to store these problems, we have solution.\n\n# Complexity\n- Time complexity: O(2*N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(2*N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def mostPoints(self, qs: List[List[int]]) -> int:\n n = len(qs) # get length of questions\n # initialise dp with -1, this will work as flag that if we found answer of sub-problem or not\n dp = [-1 for _ in range(n)]\n def f(i):\n if i >= n: return 0 # if jump is too far then return 0, we cannot gain point at this\n else:\n if dp[i] + 1: return dp[i] # if this sub-problem is solved then return directly\n# now take the question to solve and move to next index which will be: brainpower + i + 1, because we have \'0\' based index\n# also if we take question then add the points of it.\n take = f(i+qs[i][1]+1) + qs[i][0]\n# miss the question and move to i+1 index and add point as 0\n miss = f(i+1) + 0\n# update the dp to max points and return it\n dp[i] = max(take, miss)\n return dp[i]\n return f(0) # ofcourse we will start from 0 index and get optimal solution\n```\n# Please like and Comment below ( \u0361\u2688\u202F\u035C\u0296 \u0361\u2688) \uD83D\uDC49 | 1 | You are given a **0-indexed** 2D integer array `questions` where `questions[i] = [pointsi, brainpoweri]`.
The array describes the questions of an exam, where you have to process the questions **in order** (i.e., starting from question `0`) and make a decision whether to **solve** or **skip** each question. Solving question `i` will **earn** you `pointsi` points but you will be **unable** to solve each of the next `brainpoweri` questions. If you skip question `i`, you get to make the decision on the next question.
* For example, given `questions = [[3, 2], [4, 3], [4, 4], [2, 5]]`:
* If question `0` is solved, you will earn `3` points but you will be unable to solve questions `1` and `2`.
* If instead, question `0` is skipped and question `1` is solved, you will earn `4` points but you will be unable to solve questions `2` and `3`.
Return _the **maximum** points you can earn for the exam_.
**Example 1:**
**Input:** questions = \[\[3,2\],\[4,3\],\[4,4\],\[2,5\]\]
**Output:** 5
**Explanation:** The maximum points can be earned by solving questions 0 and 3.
- Solve question 0: Earn 3 points, will be unable to solve the next 2 questions
- Unable to solve questions 1 and 2
- Solve question 3: Earn 2 points
Total points earned: 3 + 2 = 5. There is no other way to earn 5 or more points.
**Example 2:**
**Input:** questions = \[\[1,1\],\[2,2\],\[3,3\],\[4,4\],\[5,5\]\]
**Output:** 7
**Explanation:** The maximum points can be earned by solving questions 1 and 4.
- Skip question 0
- Solve question 1: Earn 2 points, will be unable to solve the next 2 questions
- Unable to solve questions 2 and 3
- Solve question 4: Earn 5 points
Total points earned: 2 + 5 = 7. There is no other way to earn 7 or more points.
**Constraints:**
* `1 <= questions.length <= 105`
* `questions[i].length == 2`
* `1 <= pointsi, brainpoweri <= 105` | The length of the longest subsequence does not exceed n/k. Do you know why? Find the characters that could be included in the potential answer. A character occurring more than or equal to k times can be used in the answer up to (count of the character / k) times. Try all possible candidates in reverse lexicographic order, and check the string for the subsequence condition. |
SORT SOLUTIONS🔥 PYTHON😊 CODE 👍UPVOTED | solving-questions-with-brainpower | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code SORT SOLUTIONS \uD83D\uDC4DUPVOTED\uD83D\uDD25\n```\nclass Solution:\n def mostPoints(self, questions: List[List[int]]) -> int:\n res=[0]*(len(questions)+1)\n for i in range(len(questions)-1,-1,-1):\n point,solve=questions[i][0],questions[i][1]\n res[i]=max(point+res[min(solve+i+1,len(questions))],res[i+1])\n return res[0]\n \n\n``` | 1 | You are given a **0-indexed** 2D integer array `questions` where `questions[i] = [pointsi, brainpoweri]`.
The array describes the questions of an exam, where you have to process the questions **in order** (i.e., starting from question `0`) and make a decision whether to **solve** or **skip** each question. Solving question `i` will **earn** you `pointsi` points but you will be **unable** to solve each of the next `brainpoweri` questions. If you skip question `i`, you get to make the decision on the next question.
* For example, given `questions = [[3, 2], [4, 3], [4, 4], [2, 5]]`:
* If question `0` is solved, you will earn `3` points but you will be unable to solve questions `1` and `2`.
* If instead, question `0` is skipped and question `1` is solved, you will earn `4` points but you will be unable to solve questions `2` and `3`.
Return _the **maximum** points you can earn for the exam_.
**Example 1:**
**Input:** questions = \[\[3,2\],\[4,3\],\[4,4\],\[2,5\]\]
**Output:** 5
**Explanation:** The maximum points can be earned by solving questions 0 and 3.
- Solve question 0: Earn 3 points, will be unable to solve the next 2 questions
- Unable to solve questions 1 and 2
- Solve question 3: Earn 2 points
Total points earned: 3 + 2 = 5. There is no other way to earn 5 or more points.
**Example 2:**
**Input:** questions = \[\[1,1\],\[2,2\],\[3,3\],\[4,4\],\[5,5\]\]
**Output:** 7
**Explanation:** The maximum points can be earned by solving questions 1 and 4.
- Skip question 0
- Solve question 1: Earn 2 points, will be unable to solve the next 2 questions
- Unable to solve questions 2 and 3
- Solve question 4: Earn 5 points
Total points earned: 2 + 5 = 7. There is no other way to earn 7 or more points.
**Constraints:**
* `1 <= questions.length <= 105`
* `questions[i].length == 2`
* `1 <= pointsi, brainpoweri <= 105` | The length of the longest subsequence does not exceed n/k. Do you know why? Find the characters that could be included in the potential answer. A character occurring more than or equal to k times can be used in the answer up to (count of the character / k) times. Try all possible candidates in reverse lexicographic order, and check the string for the subsequence condition. |
[Python] From recursive to iterative, easy to understand 🔥🔥🔥 | solving-questions-with-brainpower | 0 | 1 | # Complexity\n- Time complexity: O(n)\n\n- Space complexity: O(n)\n\n# Code\n```\nclass Solution:\n def mostPoints(self, questions: List[List[int]]) -> int:\n memo = [-1] * len(questions)\n def dp(i):\n if i >= len(questions):\n return 0\n \n if memo[i] != -1:\n return memo[i]\n\n # skip i th question and go to next \n skip = dp(i+1) \n # solve i th question and go to next available question\n solve = questions[i][0] + dp(i+questions[i][1]+1) \n\n memo[i] = max(skip, solve)\n return memo[i]\n \n return dp(0)\n```\n```\nclass Solution:\n def mostPoints(self, questions: List[List[int]]) -> int:\n dp = [-1] * len(questions)\n dp[-1] = questions[-1][0]\n for i in range(len(questions)-2, -1, -1):\n skip = dp[i+1]\n solve = questions[i][0] + (dp[i+1+questions[i][1]] if i+1+questions[i][1] < len(questions) else 0)\n dp[i] = max(dp[i], skip, solve)\n return dp[0]\n``` | 1 | You are given a **0-indexed** 2D integer array `questions` where `questions[i] = [pointsi, brainpoweri]`.
The array describes the questions of an exam, where you have to process the questions **in order** (i.e., starting from question `0`) and make a decision whether to **solve** or **skip** each question. Solving question `i` will **earn** you `pointsi` points but you will be **unable** to solve each of the next `brainpoweri` questions. If you skip question `i`, you get to make the decision on the next question.
* For example, given `questions = [[3, 2], [4, 3], [4, 4], [2, 5]]`:
* If question `0` is solved, you will earn `3` points but you will be unable to solve questions `1` and `2`.
* If instead, question `0` is skipped and question `1` is solved, you will earn `4` points but you will be unable to solve questions `2` and `3`.
Return _the **maximum** points you can earn for the exam_.
**Example 1:**
**Input:** questions = \[\[3,2\],\[4,3\],\[4,4\],\[2,5\]\]
**Output:** 5
**Explanation:** The maximum points can be earned by solving questions 0 and 3.
- Solve question 0: Earn 3 points, will be unable to solve the next 2 questions
- Unable to solve questions 1 and 2
- Solve question 3: Earn 2 points
Total points earned: 3 + 2 = 5. There is no other way to earn 5 or more points.
**Example 2:**
**Input:** questions = \[\[1,1\],\[2,2\],\[3,3\],\[4,4\],\[5,5\]\]
**Output:** 7
**Explanation:** The maximum points can be earned by solving questions 1 and 4.
- Skip question 0
- Solve question 1: Earn 2 points, will be unable to solve the next 2 questions
- Unable to solve questions 2 and 3
- Solve question 4: Earn 5 points
Total points earned: 2 + 5 = 7. There is no other way to earn 7 or more points.
**Constraints:**
* `1 <= questions.length <= 105`
* `questions[i].length == 2`
* `1 <= pointsi, brainpoweri <= 105` | The length of the longest subsequence does not exceed n/k. Do you know why? Find the characters that could be included in the potential answer. A character occurring more than or equal to k times can be used in the answer up to (count of the character / k) times. Try all possible candidates in reverse lexicographic order, and check the string for the subsequence condition. |
python3 Solution | solving-questions-with-brainpower | 0 | 1 | \n```\nclass Solution:\n def mostPoints(self, questions: List[List[int]]) -> int:\n n=len(questions)\n best=[0]*(n+1)\n @cache\n def go(i):\n if i>=n:\n return 0\n\n best=0\n best=max(go(i+1),best)\n best=max(go(i+questions[i][1]+1)+questions[i][0],best)\n return best\n\n\n return go(0) \n``` | 1 | You are given a **0-indexed** 2D integer array `questions` where `questions[i] = [pointsi, brainpoweri]`.
The array describes the questions of an exam, where you have to process the questions **in order** (i.e., starting from question `0`) and make a decision whether to **solve** or **skip** each question. Solving question `i` will **earn** you `pointsi` points but you will be **unable** to solve each of the next `brainpoweri` questions. If you skip question `i`, you get to make the decision on the next question.
* For example, given `questions = [[3, 2], [4, 3], [4, 4], [2, 5]]`:
* If question `0` is solved, you will earn `3` points but you will be unable to solve questions `1` and `2`.
* If instead, question `0` is skipped and question `1` is solved, you will earn `4` points but you will be unable to solve questions `2` and `3`.
Return _the **maximum** points you can earn for the exam_.
**Example 1:**
**Input:** questions = \[\[3,2\],\[4,3\],\[4,4\],\[2,5\]\]
**Output:** 5
**Explanation:** The maximum points can be earned by solving questions 0 and 3.
- Solve question 0: Earn 3 points, will be unable to solve the next 2 questions
- Unable to solve questions 1 and 2
- Solve question 3: Earn 2 points
Total points earned: 3 + 2 = 5. There is no other way to earn 5 or more points.
**Example 2:**
**Input:** questions = \[\[1,1\],\[2,2\],\[3,3\],\[4,4\],\[5,5\]\]
**Output:** 7
**Explanation:** The maximum points can be earned by solving questions 1 and 4.
- Skip question 0
- Solve question 1: Earn 2 points, will be unable to solve the next 2 questions
- Unable to solve questions 2 and 3
- Solve question 4: Earn 5 points
Total points earned: 2 + 5 = 7. There is no other way to earn 7 or more points.
**Constraints:**
* `1 <= questions.length <= 105`
* `questions[i].length == 2`
* `1 <= pointsi, brainpoweri <= 105` | The length of the longest subsequence does not exceed n/k. Do you know why? Find the characters that could be included in the potential answer. A character occurring more than or equal to k times can be used in the answer up to (count of the character / k) times. Try all possible candidates in reverse lexicographic order, and check the string for the subsequence condition. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.