
question
dict | answers
listlengths 1
27
| url
stringlengths 66
601
| tags
listlengths 1
15
⌀ |
|---|---|---|---|
{
"author": "pBogey",
"title": "How to disable automatic branch cleanup with bamboo yaml specs?",
"body": "I have a plan where the branch settings are defined as: \n\n```\nbranches: &branch_settings\n create: for-new-branch\n delete:\n after-deleted-days: 3\n after-inactive-days: 90\n link-to-jira: true\n```\n\nAnd I want to override this for certain branches and disable the automatic cleanup. I have tried: \n\n```\nbranch-overrides:\n - ^(whatever.*)$:\n branches:\n << : *branch_settings\n delete: never\n```\n\nBut this doesn't work.\n\nFrom the UI I can uncheck a checkbox (Clean up plan branch automatically) in the specific plan branch configuration, but I don't know how to define it in the yaml spec and I didn't find it in the documentation.\n\n\n\nAny suggestions? Thanks.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello pBogey,\n\nWelcome to Atlassian community.\n\nYou can use the below examples to disable the expiry for branches using YAML specs\n\n```\nbranch-overrides: - integration-branch: branch-config: disable-expiry: false - feature/.*: branch-config: disable-expiry: false\n```\n\nIn this example I am overriding the branch properties for two branches one with a name of integration-branch and another any branch starting with the name of feature, you can probably modify this to meet your requirement.\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n\nRegards,\n\nShashank Kumar\n",
"comments": [
{
"author": "pBogey",
"body": "That did the trick, thanks a lot. Seems it is documented as well, but I missed it.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-disable-automatic-branch-cleanup-with-bamboo-yaml-specs/qaq-p/2526807
| null |
{
"author": "Rafe G",
"title": "Data Centre: Trying to get Docker Server and Agent talking to each other",
"body": "I'm trialing Bamboo Data Centre - intentionally doing it inside of docker so that I can do comparisons against other products.... However I'm struggling to get this running, wondering if anyone has any ideas.\n\nI've tried this on several different hosts, ie I've changed the location of the server and the agent machines to different hosts with exactly the same results. Worth noting that I am running these on different hosts.\n\nFollowing on from the instructions on\n\n<https://hub.docker.com/r/atlassian/bamboo-agent-base>\n"
}
|
[
{
"author": "Eduardo Alvarenga",
"body": "Hello [@Rafe G](/t5/user/viewprofilepage/user-id/4413482)\n\nThe error message is not really clear about what's going on with your system, but that's an indicator that the Agent can't communicate with the Bamboo server.\n\nAs the Atlassian Community is a public forum and the troubleshooting of this issue may expose personal information from your system, I recommend you raise a ticket with Atlassian at <https://support.atlassian.com/contact> so our team can help you with this matter privately.\n\nSincerely,\n\nEduardo Alvarenga \nAtlassian Support APAC\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Data-Centre-Trying-to-get-Docker-Server-and-Agent-talking-to/qaq-p/2525179
| null |
{
"author": "Patrick Zenner",
"title": "Failure at upgrade from 9.2.4 to 9.2.7 LTS",
"body": "I want to upgrade our Bamboo Server from version 9.2.4 to 9.2.7. LTS but it stays on 9.2.4\n\nI did the following steps:\n\n- Copy .tar.gz to Server and unpack it with bamboo-user\n\n- Backup /conf/server.xml\n\n- stop Bamboo bamboo_9.2.4/bin/stop-bamboo.sh\n\n- Backup /var/opt/bamboo/bamboo.cfg.xml\n\n- DB Dump (Postgres)\n\n- Edit bamboo-init.properties bamboo.home=/var/opt/bamboo\n\n- Start Bamboo bamboo_9.2.7/bin/start-bamboo.sh\n\n- Bamboo starts again but it shows 9.2.4\n\nWhat am I doing wrong?\n"
}
|
[
{
"author": "brian_schrader",
"body": "I am also having this issue. I am running Bamboo Server on Windows and there is only one instance of Bamboo running and the footer of the page still says 9.2.4. I have retried the upgrade several times and confirmed that the installer says 9.2.7.\n\nWhat is going on?\n",
"comments": null
},
{
"author": "Alexey Chystoprudov",
"body": "Make sure previous Bamboo instance was stopped.\n\nCheck logs in $bamboo.home/logs\n",
"comments": [
{
"author": "brian_schrader",
"body": "I do not believe this is the solution as I noted in my comment I see the same thing.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Failure-at-upgrade-from-9-2-4-to-9-2-7-LTS/qaq-p/2529235
| null |
{
"author": "Rajat Roy",
"title": "DB Query to get list of active plans",
"body": "I want to extract some data like list of active plans used in last 6 months . {#toc-hId--412535379}\n---------------------------------------------------------------------------------------------------\n\nCan you help me with a DB Query to get this details ? {#toc-hId-2074977454}\n---------------------------------------------------------------------------\n"
}
|
[
{
"author": "Eduardo Alvarenga",
"body": "Hello **Rajat**,\n\nTry this KB article:\n\n* [How to query the database for build plans that have not been run](https://confluence.atlassian.com/bamkb/how-to-query-the-database-for-build-plans-that-have-not-been-run-942853255.html)\n\nCheers,\n\nEduardo Alvarenga \nAtlassian Support APAC\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/DB-Query-to-get-list-of-active-plans/qaq-p/2522484
| null |
{
"author": "David Rydg?rd",
"title": "Artifact seems to be removed during source code checkout",
"body": "I have an artifact dependency, the artifact being created by a previous stage in the plan. As 'destination directory' for the dependency, I have put 'Artifacts'.\n\nThere is a script task that just runs the line *dir Artifacts* . This works fine, and in the logs I can see that the artifact is in the 'Artifacts' directory. This task is followed by a source code checkout task. The source code checkout is then followed by a task which, again, just runs *dir Artifacts*. This time, it gives an error message because, as it seems, the 'Artifacts' directory does not exist anymore.\n\nI can see in the logs that, as part of the source code checkout, Bamboo \"cleans\" the build directory. I suppose this removes the 'Artifacts' directory. But if that is the case, how can I use Artifacts after doing a source code checkout?\n"
}
|
[
{
"author": "Eduardo Alvarenga",
"body": "Hello [@David Rydg?rd](/t5/user/viewprofilepage/user-id/5355301)\n\nWelcome to the **Atlassian Community**!\n\nThere's a possibility the \"Force Clean Build\" property is enabled in the \"Source Code Checkout\" task, which will instruct the Agent to remove everything from the build-dir before running the Git checkout during Stage 2 execution.\n\nAlso, the Checkout Task in Bamboo will retry the operation in case of failure, like having files or folders in the checkout folder that are not part of the repository. When retrying, Bamboo cleans up the folder to have a clean checkout. That action may be removing the files you expect to see in the second stage. As you check out the code in place, there's a chance that Bamboo is doing that.\n\nTo fix that, set the \"Checkout Directory\" in the \"Source Code Checkout\" task properties to a subfolder within the build directory. That will allow you to separate the repository data from the artifacts, which will not conflict with files from a different stage.\n\nIt is also possible to remove the Artifact Dependency and add an \"Artifact Download\" task in the Second Stage Jobs so you can control exactly what and when artifacts will be downloaded.\n\nMore information can be found on the link below:\n\n* [Sharing Artifacts](https://confluence.atlassian.com/bamboo/sharing-artifacts-359400060.html)\n\nThank you,\n\nEduardo Alvarenga \nAtlassian Support APAC\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": [
{
"author": "David Rydg?rd",
"body": "Great, thank you for a clear explanation!\n"
}
]
},
{
"author": "Shashank Kumar",
"body": "Hello David,\n\nWelcome to Atlassian Community\n\nI can understand you have the below structure for your plan.\n\n1. First script task just runs the dir Artifacts which lists the artifcats from the build directory.\n\n2. Source code checkout task checks out the repo\n\n3. Third script task fails to list the directory.\n\nYou have mentioned that the script task is cleans the build directory, so we'll need to stop that. To do that you can go to the script task in your plan configuration and uncheck the option of \"Force clean Build\", see below\n\n\n\nLet me know if this works for you.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Artifact-seems-to-be-removed-during-source-code-checkout/qaq-p/2522570
| null |
{
"author": "V gopi",
"title": "How to access path of a file in bamboo working directory using JAVA code",
"body": "Hi, I am currently in need of reading a file path which is present in bamboo build working directory. This is how i am doing currently. but im not able to get the path\n\n\n\nCan you help me to resolve this?\n"
}
|
[
{
"author": "alok m",
"body": "The snippet of code you've provided seems to be attempting to open a KeePass database file by constructing a file path that includes a system property for the Bamboo build working directory and a relative path to the KeePass file. Here's a breakdown of what the code does:\n\n1. **System.getenv(\"bamboo.build.working.directory\")** tries to access an environment variable named **bamboo.build.working.directory** which is expected to hold the path to the Bamboo build working directory.\n2. It then appends **\"\\\\Temp\\\\KEEPPASS\\\\mongodb.kdbx\"** to this path, which is the relative path to the KeePass file you want to access.\n3. The **.openDatabase(\"remove\\&credentials@1527\");** method is then called with a passphrase.\n\nIf you are not able to get the path, there might be a few reasons:\n\n* The environment variable **bamboo.build.working.directory** might not be set or could be incorrect.\n* There may be a typo or a mismatch in the case of the environment variable name.\n* The file path may not be correct, or the file might not exist at the specified location.\n* File permissions might be preventing access to the file.\n\nTo debug this issue, you could add logging to print out the constructed file path before trying to open the database. This way, you can verify whether the path is correct. Here's an example in Java:\n\nString workingDirectory = System.getenv(\"bamboo.build.working.directory\");\n\nString filePath = workingDirectory + \"\\\\\\\\Temp\\\\\\\\KEEPPASS\\\\\\\\mongodb.kdbx\";\n\nSystem.out.println(\"The constructed file path is: \" + filePath);\n\n// Now proceed to open the database with this file path\n\nKeePassFile database = KeePassDatabase.getInstance(filePath)\n\n.openDatabase(\"remove\\&credentials@1527\");\n\nMake sure the KeePass file exists at that path and that the application has the necessary permissions to access it.\n\nIf the environment variable isn't set, you may need to check your Bamboo configuration to ensure that it is being passed to your build environment correctly. Alternatively, if the Bamboo build working directory follows a consistent structure, you might be able to construct the path based on known values instead of relying on an environment variable.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-access-path-of-a-file-in-bamboo-working-directory-using/qaq-p/2520606
|
[
"bamboo-development"
] |
{
"author": "Suguna Tejaswini Nandakumara",
"title": "Trigger or start a new build on a bamboo plan using rest api from a powershell script",
"body": "In order to do the trigger I am using the below powershell commands(Also I don't want to use the username password for auth, is there any other way to to that? may be using a PAT or something):\n\n$url = \"https://\\<host\\>/rest/api/latest/queue/\\<ProjectKey\\>-\\<BuildKey\\>\" \n$header = @{ \n\"Content-Type\"=\"application/json\" \n} \n$body = @{ \n\"Authorization\"=\"Bearer \\<Key\\>\" \n} \\| ConvertTo-Json\n\n<br />\n\nInvoke-RestMethod -Uri (\\[Uri\\]$url) -Method Post -Headers $header -body $body\n\nBut I keep getting the below error:\n\nInvoke-RestMethod : Unable to connect to the remote server..\n\nWhat am I missing in the above line..or is there any other way to achieve this?\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Suguna,\n\nWelcome to Atlassian community.\n\nYou can use the use the below 2 links to get more information about this, instead of using userid password you can generate PAT tokens.\n\n1. <https://docs.atlassian.com/atlassian-bamboo/REST/8.2.5/#d2e5904>\n\n2. <https://developer.atlassian.com/server/bamboo/using-the-bamboo-rest-apis/>\n\nSample example ( replace the appropriate values accordingly )\n\ncurl -H \"Authorization: Bearer NDc4NDkyNDg3ODE3OstHYSeYC1UgXqRacSqvUbookcZk\" POST <http://localhost:8085/rest/api/latest/queue/PROJECTKEY-PLANKEY>\n\nRegards,\n\nShashank Kumar\n",
"comments": [
{
"author": "Suguna Tejaswini Nandakumara",
"body": "Thank you for the details.\n\nI tried doing below, by adding a powershell script task in a build plan.\n\n$token = \"\\<PAT\\>\" \n$headers = @{ \nAuthorization=\"Bearer $token\" \n} \nInvoke-RestMethod -Method Post -Headers $headers -Uri \"<http://localhost:8085/rest/api/latest/queue/>\\<[PROJECTKEY-PLANKEY\\>](http://localhost:8085/rest/api/latest/queue/PROJECTKEY-PLANKEY)\"\n\nI still get the error as below:\n\nInvoke-RestMethod : Unable to connect to the remote server\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Suguna,\n\nI was able to trigger a REST API with the exact same configurations, example below\n\n```\n$token = \"acd\"\n$headers = @{\nAuthorization=\"Bearer $token\"\n}\nInvoke-RestMethod -Method Post -Headers $headers -Uri \"http://localhost:8085/rest/api/latest/queue/BAM-BOO\"\n```\n\n<br />\n\nI think the error which are getting **Invoke-RestMethod : Unable to connect to the remote server ,**i think localhost is not being able to resolve by the agent where you are running the builds.\n\nAre you running this on a local agent or a remote agent and can you see if the URL you have put for your Bamboo Instance is correct?\n\nSimilar question is explained here \\> <https://stackoverflow.com/questions/38830912/powershell-invoke-restmethod-unable-to-connect-to-the-remote-server>\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "Suguna Tejaswini Nandakumara",
"body": "Hi,\n\nYes the URL is correct. May be its because of the authentication issues.\n\nI will look into the link you have added.\n\nThanks and regards,\n\nTejaswini N.S\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Trigger-or-start-a-new-build-on-a-bamboo-plan-using-rest-api/qaq-p/2521580
| null |
{
"author": "w.bos",
"title": "Subscriber maintenance: unconfirmed subscribers and subscribers that no longer exist",
"body": "Hello,\n\nI have two questions about subscriber maintenance.\n\nI know \"quarantined\" subscribers with no action are deleted after 90 days.\n\nBut what happens with:\n\n1. \"Unconfirmed\" subscribers?\n2. Subscribers where the mail address becomes at one point invalid?\n\nCannot find it in the documentation... who knows the ansers?\n\nKind regards,\n"
}
|
[
{
"author": "Kevin Paulovkin",
"body": "They stay in \"Unconfirmed\" - but the initial email confirmation that gets sent expires after 90 days and must be re-sent to the subscriber after this time.\n\n<https://support.atlassian.com/statuspage/docs/enable-subscribers/>\n\n\"When they subscribe, they will receive an email with a confirmation button. The confirmation link must be clicked in order to receive any notifications; it expires after 90 days.\"\n",
"comments": [
{
"author": "w.bos",
"body": "Thanks! This solves 50%.\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Subscriber-maintenance-unconfirmed-subscribers-and-subscribers/qaq-p/2582658
|
[
"cloud"
] |
{
"author": "Ashish Nigam",
"title": "Source code checkout failure in Bamboo",
"body": "|----------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| |\n| | |\n| 30-Oct-2023 13:16:21 | Fetching 'refs/heads/bugfix/191.4/SON5-69192-add-new-usm-oss-setting-attach-cells-to-ret-from-oss-data-always-set-to-true' from 'ssh://[email protected]:7999/son5/son5.git'. |\n| 30-Oct-2023 13:16:21 | error: cannot open .git/FETCH_HEAD: Permission denied |\n| 30-Oct-2023 13:16:21 | |\n| 30-Oct-2023 13:16:21 | Cannot fetch branch 'refs/heads/bugfix/191.4/SON5-69192-add-new-usm-oss-setting-attach-cells-to-ret-from-oss-data-always-set-to-true' from 'ssh://[email protected]:7999/son5/son5.git' to source directory '/home/bamboo/bamboo-agent-home/xml-data/build-dir/_git-repositories-cache/a5325ea61a0162099755c033861f1147d03a4c12'. command \\[/usr/bin/git fetch ssh://[email protected]:38645/son5/son5.git +refs/heads/bugfix/191.4/SON5-69192-add-new-usm-oss-setting-attach-cells-to-ret-from-oss-data-always-set-to-true:refs/heads/bugfix/191.4/SON5-69192-add-new-usm-oss-setting-attach-cells-to-ret-from-oss-data-always-set-to-true --update-head-ok\\] failed with code 255. Working directory was \\[/home/bamboo/bamboo-agent-home/xml-data/build-dir/_git-repositories-cache/a5325ea61a0162099755c033861f1147d03a4c12\\]., stderr:error: cannot open .git/FETCH_HEAD: Permission denied |\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Ashish,\n\nWelcome to Atlassian community.\n\nFrom the error which you have provided I can see the exception \\> \"**error: cannot open .git/FETCH_HEAD: Permission denied**\"\n\nThe Git \"Cannot open .git/FETCH_HEAD: Permission denied\" error occurs when you try to pull code from a remote repository when the .git/ directory in your server file system is inaccessible to your current user which is running the build.\n\nI am not sure if you are running this on local or remote agent, but if you are running this build on local agent, make sure the user which is running the Bamboo service has read/write access to the above folder. For remote agent you need to provide the similar permission for the user which is running the remote agent.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Source-code-checkout-failure-in-Bamboo/qaq-p/2519649
| null |
{
"author": "Des Armstrong",
"title": "Embed for private pages",
"body": "Hi - we'd like to be able to use the Embed feature for our private page. Is this on the roadmap? If so when can we expect to see it?\n\nI see there's an app for use with JIRA Service desk so I'm hoping there's something available or coming up for other applications.\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hi Des,\n\nThis is Jesse from the Statuspage support team. Welcome to the community. We don't have this on the roadmap at this time and the ticket is still in a state of gathering interest.\n\nI can add this community post to the feature request we have to show more interest but it might be a while before this gets prioritized. If you want to provide more details about your use case, please feel free to open a ticket with us so we can add the context. Thanks for your time!\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Embed-for-private-pages/qaq-p/2583033
| null |
{
"author": "Chris Milton",
"title": "StatusPage Attachments",
"body": "Hi team,\n\nIs it possible to add attachments to StatusPage notifications?\n\nThanks,\n\nChris\n"
}
|
[
{
"author": "G subramanyam",
"body": "Hi [@Chris Milton](/t5/user/viewprofilepage/user-id/5209274) welcome to the Atlassian community.\n\nI don't think, we can directly attach files to Atlassian Status page notifications.\n\nTheir are few workarounds, like: \n1. Proactively notifying users of downtime. \n2. Let end users opt-in to the subscriptions of the services they are interested in. \n3. Add links to relevant resources within the incident or maintenance page itself for easy access.\n\nIf you haven't already, check this [official status page](https://www.atlassian.com/software/statuspage/features/notifications) notifications link for helpful information.\n",
"comments": null
},
{
"author": "Kevin Paulovkin",
"body": "I don't believe so. Found this question answered by Atlassian here: <https://community.atlassian.com/t5/Statuspage-questions/Attach-files-to-scheduled-maintenance-or-incidents/qaq-p/2111786>\n\n\"With the current product design, we don't have the ability to attach files to incidents or maintenance details. The best workaround to do this would be to upload the document/file to a central \\& accessible location and add the document/file URL in the incident/maintenance message.\n\nPlease note we do have a feature request open with our engineering team to be able to achieve this request. STATUS-75 is the feature request ID for your reference.\"\n",
"comments": [
{
"author": "Chris Milton",
"body": "Thanks Kevin. Any idea how I can track the status of STATUS-75?\n"
},
{
"author": "Kevin Paulovkin",
"body": "For some reason, Atlassian's feature requests for StatusPage are not open publicly like they are for Jira or other products. So there isn't a link to vote or follow for updates unfortunately.\n"
},
{
"author": "Kevin Paulovkin",
"body": "Actually, just found this page - <https://jira.atlassian.com/projects/STATUS/issues/STATUS-373?filter=allopenissues> but I don't see STATUS-75 - looks like only Bugs are visible to the public\n"
},
{
"author": "Chris Milton",
"body": "Thanks Kevin. That's frustrating.\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/StatusPage-Attachments/qaq-p/2581581
|
[
"cloud"
] |
{
"author": "JS",
"title": "Atlassian user as Statuspage subscriber",
"body": "When I add a user to my Atlassian site, using admin.atlassian.com, is it possible to give that user subscription access to my private or audience-specific Statuspage?\n\nI want the user to be able to log in to both our service desk and Statuspage using their Atlassian account.\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello there,\n\nThis is Jesse from the Statuspage support team. Thanks for the question about users. The users through admin.atlassian.com are separated from adding subscribers with the pages.\n\nIf you want to have this user setup to be an admin in Statuspage and have access to the service desk, this can be accomplished by giving the user the correct group permissions within admin.atlassian.com\n\nIf, however, you want them to have access to the service desk and be a viewer of Stautspage, you wouldn't be able to use admin.atlassian.com to accomplish this. Statuspage page viewers are entirely managed within the product so if you needed to go this route, you would need to do it separately. Please let me know if you have any questions about this.\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Atlassian-user-as-Statuspage-subscriber/qaq-p/2579372
| null |
{
"author": "Pierre-Alain Galtier",
"title": "Change icon of page in the https://manage.statuspage.io/pages/<id>",
"body": "Hello Community,\n\nI have 3 different pages (=3 different web apps) in my statuspage.io application.\n\nI can change the page I want to manage by using the combo-box in the left part of the page. Each of them has an icon and a label.\n\nI'm wondering how I can change the icon before the label (using the web application icon)?\n\nThank you\n"
}
|
[
{
"author": "Kevin Paulovkin",
"body": "You can change the Favicon as well as the icon you are referring to by going to \"Your Page\" \\> \"Customize page and emails\" \\> \"Fav icon\"\n\nNote: this only changes the favicon when you are viewing the front end of your page. It does not change the Favicon or browser icon when you are in the back end (<https://manage.statuspage.io/pages/>\\<id\\>). However the icon next to the title of each page in the page dropdown will be updated.\n",
"comments": [
{
"author": "Pierre-Alain Galtier",
"body": "Thanks ! It works by changing the FavIcon\n"
}
]
},
{
"author": "Eugenio Onofre",
"body": "Hi [@Pierre-Alain Galtier](/t5/user/viewprofilepage/user-id/3537146)\n\nThis is only allowed on the paid-plans of Atlassian StatusPage that allow custom CSS/HTML.\n\nFont icons can be used by embedding the Fontawesome CDN code in the head section of \"Custom header HTML\". Once that is added, you can input your font icon code to your preference.\n\n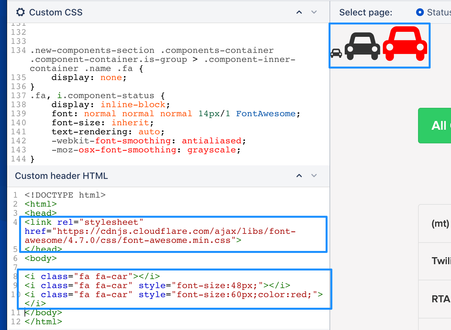\n\nPlease remember to accept this answer in case it helps you resolve your question as it may also help other community members in the future.\n\nRegards, \nEugenio\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Change-icon-of-page-in-the-https-manage-statuspage-io-pages-lt/qaq-p/2582611
|
[
"cloud"
] |
{
"author": "Roy Speier",
"title": "published API does not return data as documented and needed",
"body": "calling the API to return a list of component groups. \n\nusing curl: curl <https://api.statuspage.io/v1/pages/{page_id}/component-groups> \\\\ \n-H \"Authorization: OAuth your-api-key-goes-here\" \\\\ \n-X GET \n\napi-info page from <https://manage.statuspage.ioc> provided the your-api-key-goes-here \n\nThe data returned was NOT a list of component groups, the data looked like it contained information specific to the UI elements on the page, as included in the output were several element values, such as \n\"favicon_logo\", \"transactional_logo\", \"normal_url\", \"retina_url\", \"hero_cover\", \"email_logo\" and \"twitter_logo\" \nI'm looking to retrieve the list of current component groups. I'd REALLY like an API that would retrieve the data for a specific component group, specified by name in the query API call. That API call doesn't currently exist so I need to use the API to get the list of component groups and iterate over this list looking for a matching group name. This approach should work but only if the API call to fetch the list of component groups works as documented. \n\nI can provide the full response (after redacting any sensitive info if any) from the API call to retrieve the component group list if needed.\n"
}
|
[
{
"author": "Kevin Paulovkin",
"body": "Are you looking for a list of Components in your instance or Component Groups? If you don't have any Component groups created, perhaps that's the issue?\n\nWhen I run this API against my instance, it works fine and returns a Response similar to example seen below. Includes the name of each component group along with list of components underneath.\n\n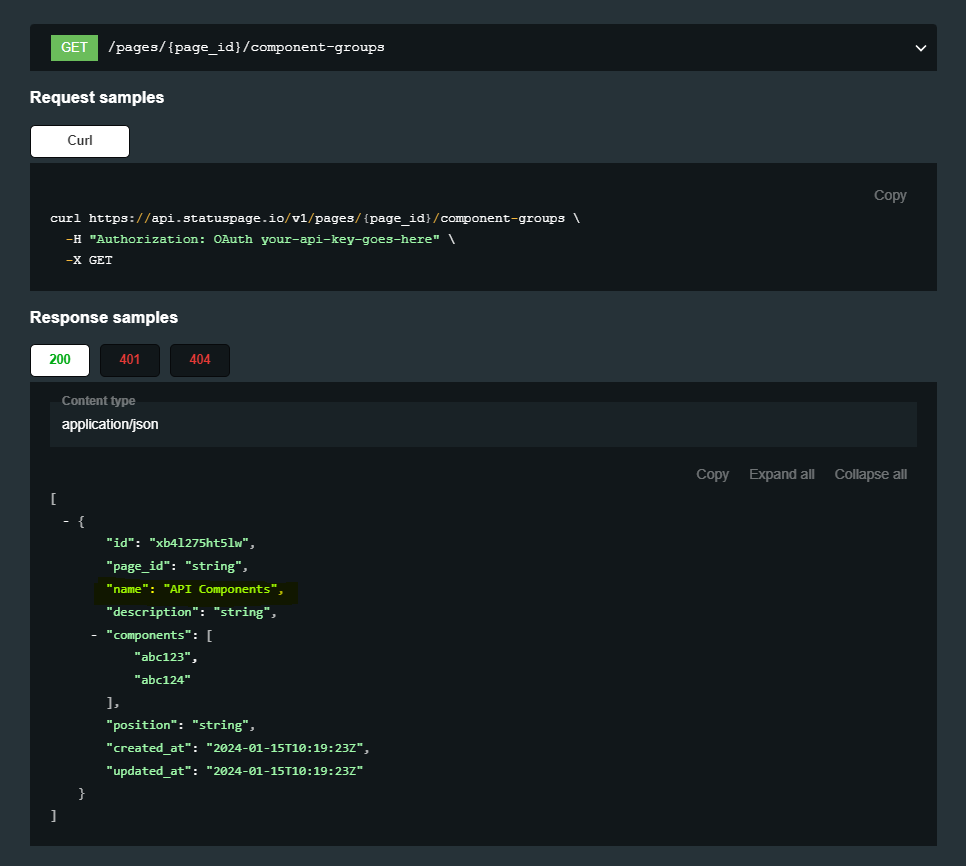\n",
"comments": [
{
"author": "Roy Speier",
"body": "I'm looking for a list of Component Groups - even better would be an API that returns a component group by name but that API is not available\n"
},
{
"author": "Roy Speier",
"body": "I found the source of my error - I thought I was executing this: \n\ncurl <https://api.statuspage.io/v1/pages/{page_id}/component-groups> \\\\ \n-H \"Authorization: OAuth your-api-key-goes-here\" \\\\ \n-X GET \n\nbut somehow I lost the component-groups at the end of the URL and then when I added it I originally spelled component-groups as component_groups \n\nrunning the API as I listed above succeeds returns the desired list of component groups!\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/published-API-does-not-return-data-as-documented-and-needed/qaq-p/2580578
| null |
{
"author": "reza_jugon",
"title": "Turn off Uptime report on Statuspage",
"body": "I'd like to hide the uptime reporting on our customer facing statuspage and leave just the Incidents tab viewable.\n\nI couldn't find an answer for this here : <https://support.atlassian.com/statuspage/docs/display-historical-uptime-of-components/>\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@reza_jugon](/t5/user/viewprofilepage/user-id/5324904)\n\nWelcome to the Atlassian Community. \nThis configuration resides under each component.\n\nTo disable it, simply uncheck this box:\n\n\n\nPlease remember to accept this response in case it helps you resolve your question as it may also help other community members in the future.\n\nBest Regards, \nEugenio\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Turn-off-Uptime-report-on-Statuspage/qaq-p/2579060
| null |
{
"author": "ami Provasi",
"title": "How can I report my opened issues using jira automations? I don't want to upgrade to the premium ver",
"body": "How can I report my opened issues using jira automations? I don't want to upgrade to the premium version of jira for now. I need to report my tasks regularly. Deadlines, dates and similar information will be critical. I dream of collecting all of them in one area and then a flow like an information e-mail. Is there anyone who can support?\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@ami Provasi](/t5/user/viewprofilepage/user-id/5399857)\n\nYou may use the Jira Automations to do so, but they may require custom coding / scripting.\n\nAutomations can have a scheduled trigger (every 24 hours, for example). The action would be to send an email and then you will need to customize the JSON of the email body. Please note, in this case, you will have limited access to look and feel customization.\n\nPlease remember to accept this answer in case it helps you resolve your question as it may also help other community members in the future.\n\nRegards, \nEugenio\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-can-I-report-my-opened-issues-using-jira-automations-I-don-t/qaq-p/2578234
|
[
"cloud"
] |
{
"author": "bhaueter",
"title": "Does Statuspage have a component for support of Symitar/Episys core?",
"body": "We are in the process of creating a status page using Atlassian's Statuspage app. But I do not see any components that support the Symitar Episys product, or any of the Symitar products for that matter. Nor do I support for Zoho's ManageEngine HelpDesk application.\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@bhaueter](/t5/user/viewprofilepage/user-id/4034109)\n\nThere are no out-of-the-box integrations with Symitar Episys or Zoho's application. \nIn case you need StatusPage to be automatically populated in case of incidents on these applications, my recommendation would be using StatusPage APIs.\n\nPlease find the official documentation below: \n<https://developer.statuspage.io/>\n\nPlease remember to accept this answer in case it helps resolve your query as it may also help other community members in the future.\n\nRegards, \nEugenio\n",
"comments": [
{
"author": "bhaueter",
"body": "Thank you Eugenio...\n\nDoes Statuspage offer PRTG network monitoring as an out of the box component?\n"
},
{
"author": "Eugenio Onofre",
"body": "Hi [@bhaueter](/t5/user/viewprofilepage/user-id/4034109)\n\nUnfortunately not.\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Does-Statuspage-have-a-component-for-support-of-Symitar-Episys/qaq-p/2577311
|
[
"cloud"
] |
{
"author": "Daniel Inderbinen",
"title": "Problem with Login",
"body": "I add the Saml over Azure AD. All good, works but every time someone try to login he got this error:\n\n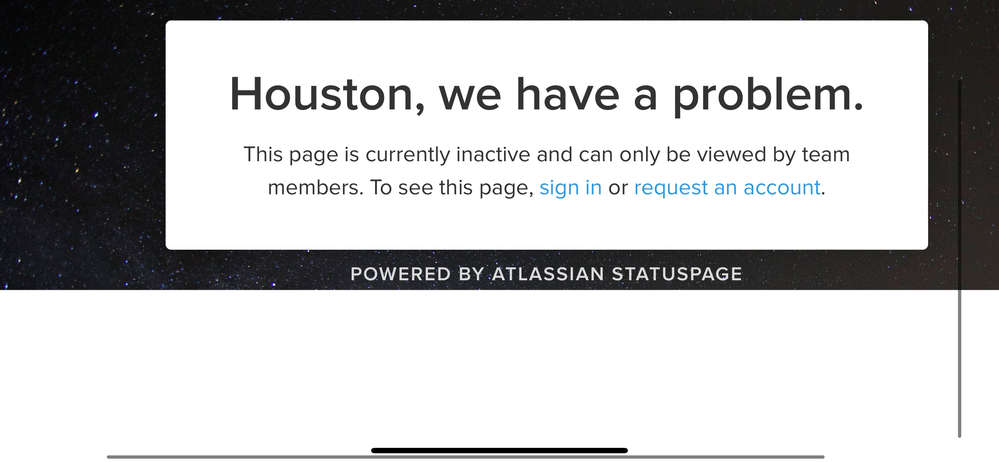\n\nWhen the Error is showing and you open the page: xxx.statuspage.io again it works ...\n\nThanks for the Help !\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@Daniel Inderbinen](/t5/user/viewprofilepage/user-id/5401161)\n\nThis issue usually happens when there is a misconfiguration in the SAML properties / redirects. I strongly suggest reviewing all the SAML configuration to make sure the values are all correct and, in case you are still facing the issue, raise a ticket with Atlassian Support at <https://support.atlassian.com>\n\nIn case this answer helps you resolve your query, please accept it so it can help other community users in the future.\n\nRegards, \nEugenio\n",
"comments": [
{
"author": "Daniel Inderbinen",
"body": "Hey [@Eugenio Onofre](/t5/user/viewprofilepage/user-id/4992586) can you please quick tell me witch part can be have inpact on the Setup?\n"
},
{
"author": "Eugenio Onofre",
"body": "Hi [@Daniel Inderbinen](/t5/user/viewprofilepage/user-id/5401161)\n\nI am not quite sure as I do not have access to your instance to check. \nI would strongly recommend getting in touch with Atlassian Support as they have access to your instance and may be able to debug it.\n\nRegards, \nEugenio\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Problem-with-Login/qaq-p/2574331
|
[
"cloud"
] |
{
"author": "w.bos",
"title": "Cannot update multiple component subscribtions through csv import",
"body": "I have a CSV with one subscriber and I want to update its subscriptions to components.\n\nI use this format:\n\n* **email,[email protected],yes,COMPONENTCODE1,COMPONENTCODE2**\n\nThe import only results in addressing the first component ID:\n\n* - when it is the same ID as the first component that is allready subscribed to, it does nothing;\n* - when it is not the same as the first component allready subscribed to, it changes it. (So the first component ID in de CSV is now the only one subscribed to.)\n\nIt ignores all compontents codes after the first one... what am I doing wrong?\n\nNote that in de documentation it says the list should be semi-colon seperated... but in the example CSV it is comma separated. Only comma works for the first component.\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@w.bos](/t5/user/viewprofilepage/user-id/5293493)\n\nWelcome to the Atlassian Community. \nAs stated on the official documentation, component codes column should be a semi-colon separated list of component codes that you want the subscriber to receive notifications for.\n\nYou should use a CSV file formated as below:\n\n* email,[email protected],yes,COMPONENTCODE1;COMPONENTCODE2;COMPONENTCODE3\n\nPlease remember to accept this answer in case it helps you resolve this issue as it may also help other community users in the future.\n\nRegards, \nEugenio\n",
"comments": [
{
"author": "w.bos",
"body": "Thanks Eugenio,\n\n* When I use \",\" as a seperator, at least it uses the first ID to subscribe to.\n* When I use \";\" as a seperator between the ID's, it does nothing (there is no update, even if there are different ID's used).\n\nNote that in the example upload file, the file has only \",\" a seperator...\n\n|-------------------------------------------------------------|--------------|\n| Email Subscribers,,,,,,,,,,,,,, ||\n| type,email address,skip confirmation notification,component codes (optional),,,,,,,,,,, ||\n| email,[email protected],yes,n097s9kg06ry | ,,,,,,,,,,, |\n| email,[email protected],yes,0bnr0wzc16dv | ,,,,,,,,,,, |\n| email,[email protected],yes,0bnr0wzc16dv | n097s9kg06ry |\n| ,,,,,,,,,,,,,, | |\n"
},
{
"author": "w.bos",
"body": "I have found the solution!\n\nUntil the first component ID it uses \",\" as a seperator.\n\nFrom the first component and beyond it uses \"tabs\".\n"
},
{
"author": "Eugenio Onofre",
"body": "Great it worked! Documentation says it is semicolon so I will report it back to atlassian.\n\nThanks for sharing!\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Cannot-update-multiple-component-subscribtions-through-csv/qaq-p/2576664
| null |
{
"author": "Daniel Inderbinen",
"title": "Deactivate Subscribe Option",
"body": "Hey Everyone,\n\nIs there a way to deactivate the Subscribe to Updates option? The Page should be only report to a small group. No buddy should be able to add his own Mail adress.\n"
}
|
[
{
"author": "Daniel Inderbinen",
"body": "Can be closed.\n",
"comments": null
},
{
"author": "Shiran Manor",
"body": "Hey I have the same question, is it possible?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Deactivate-Subscribe-Option/qaq-p/2574162
|
[
"cloud"
] |
{
"author": "Viktor",
"title": "How to check site availability?",
"body": "Hello, I'm using atlassian status page \nI just need to make status page show my site is available or not \nwhat is the simplest way to implement it? \n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Welcome to the Atlassian Community!\n\nWhat monitoring tools are you using? Statuspage can be configured to display monitoring information from a lot of them.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-to-check-site-availability/qaq-p/2566088
|
[
"cloud"
] |
{
"author": "Zyed Triki",
"title": "Auto Update 2 status page",
"body": "Hello Team\n\nCan we auto-update a status page from another status page ?\n\nFor eg When we publich an incident on a page status.ABC.com the same incident should be published on another page status.XYZ.com ?\n\nIf Yes how to configure this option\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Zyed,\n\nThis is Jesse from the Statuspage support team. Welcome to the community and thanks for the question about auto-updating another page.\n\nThere is no built-in way to update one page from another page but you can utilize the [Manage API](https://developer.statuspage.io/) and [Status API](https://support.atlassian.com/statuspage/docs/what-are-the-different-apis-under-statuspage/) to accomplish this.\n\nAt a high level, you can use the Status API on one page to grab incident and component information. Then, with some scripting and the Manage API, you can post the data you grabbed onto the second page. This would allow you to update one and then automatically update the other. It would take some time to set up but afterwards, it can be useful to keep things in sync.\n\nI would recommend looking through the different APIs to see how they work. Specifically, the create an incident endpoint and the update an incident endpoint in the Manage API would be the most useful. Also, for the Status APl, you can add /API to the end of your Statuspage URL to get the documentation. I hope this is useful for you.\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Auto-Update-2-status-page/qaq-p/2563139
| null |
{
"author": "Marcel Lindenbergh",
"title": "SSL is being provisioned for your account",
"body": "Hello,\n\nFor 4 days the SSL for our statuspage is still not working. The status keeps saying **SSL is being provisioned for your account**. What can we do to resolve this as this is preventing us to go live.\n\nThanks!\n"
}
|
[
{
"author": "eugenio_onofre",
"body": "Hi [@Marcel Lindenbergh](/t5/user/viewprofilepage/user-id/5388600)\n\nWelcome to the Atlassian Community. \nThis usually happens when there is an issue propagating the SSL certificate to you page.\n\nAre you using a paid plan? If yes, I strongly suggest you raise a ticket with Atlassian Support so they can better assist you.\n\nPlease do not forget to accept the answer in case it helps you resolve the issue!\n\nRegards!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/SSL-is-being-provisioned-for-your-account/qaq-p/2561624
|
[
"cloud"
] |
{
"author": "Captain",
"title": "Incident webhooks are not always sent",
"body": "I'm subscribed to discord.com status page's webhooks. Yesterday they had several incidents but I only received a small portion of them. Does discord need to be posting incident updates in a certain way to trigger a webhook? I thought that all incident updates would trigger. \n\nI don't have issues with we webhook receiver since I successfully received and logged a portion of them.\n"
}
|
[
{
"author": "Alan Violada",
"body": "Hey Kyle, Alan from the Statuspage Support team here.\n\nPage admins have the option to create and update incidents in Statuspage without sending out notifications, in which case you would indeed not get any POST requests sent to your endpoint, even if your subscription is configured correctly.\n\nFor pages that have the option to subscribe to specific components, you would be able to get notified about component status changes, regardless of incident notifications. However, this option does not seem to be enabled for the Discord page.\n\n[Webhook Notifications Documentation](https://support.atlassian.com/statuspage/docs/enable-webhook-notifications/)\n\nRegards,\n\nAlan\n",
"comments": [
{
"author": "Captain",
"body": "Thanks Alan. Can you suggest any documentation that will help me point the Discord team in the right direction to update their settings so that POST requests are always sent?\n"
},
{
"author": "Alan Violada",
"body": "Hey Kyle,\n\nEssentially, what defines this is whether the \"**Send notifications**\" box is checked in the incident creation/update window.\n\nIt is worth mentioning that if this is enabled, it will send out notifications to all types of subscribers(Webhook, E-MAIL, SMS, Slack) based on the below rules:\n\n[Notification event triggers](https://support.atlassian.com/statuspage/docs/notification-event-triggers/)\n\nAlso related:\n\n[Incident creation documentation](https://support.atlassian.com/statuspage/docs/create-an-incident/)\n\nRegards,\n\nAlan\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Incident-webhooks-are-not-always-sent/qaq-p/2561029
| null |
{
"author": "Joep Oomen",
"title": "Toggle for recaptcha",
"body": "Hi,\n\nour users run into Recapthca when trying to subscribe to our statuspage in such a degree that it's leading to them not subscribing at all. This in turn does not update them for later incidents. Is there a possibility to toggle Recaptcha off?\n"
}
|
[
{
"author": "Abraham Musalem",
"body": "Hey [@Joep Oomen](/t5/user/viewprofilepage/user-id/5386516) ,\n\nThanks for reaching out about this. Please submit a ticket with us via support.atlassian.com so we can help you out. \n\nRegards, \nAbraham, Statuspage Support\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Toggle-for-recaptcha/qaq-p/2559535
|
[
"cloud"
] |
{
"author": "Hitesh Gawhade",
"title": "Component uptime editor API access",
"body": "Hi Team Atlassian,\n\nWe are trying to fetch the automated daily status on a custom UI, for this we need an API that gives as daywise status for a component. I could see on the existing status page but not sure if this API is public, if not can this be used publicly :\n\n[component uptime editor](https://manage.statuspage.io/pages/9r52hp1jy3hf/component_uptime_editor/kr0qcbwc41z1?page_count=2&page_start=1)\n\nOr please help us on how to fetch day wise status for a component.\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Hitesh,\n\nThanks for reaching out to the community about wanting to access the component uptime editor API. This is not a public API and is used to help the UI when changing the uptime. In terms of making this public, I don't see them doing that specifically for this endpoint but I can make a feature request to add an endpoint that allows you to edit the uptime showcase.\n\nIf I understand your use case, though, it seems like you might be able to use the [Get uptime data](https://developer.statuspage.io/#operation/getPagesPageIdComponentsComponentIdUptime) for a component API endpoint. This endpoint allows you to grab the data from the uptime showcase. You could have it run every day to get the uptime of the components. This doesn't give you the ability to change component uptime but if your goal is just to read it, this might be the way to go. Hope this helps!\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Component-uptime-editor-API-access/qaq-p/2559504
|
[
"cloud"
] |
{
"author": "Terry Medearis",
"title": "\"Link this incident\" in Jira is not doing anything. \"Create new incident\" button produces error",
"body": "Greetings,\n\nI am experimenting with a trial instance of Statuspage and the integration with Jira. I have my Jira project connected to Statuspage. I have an issue in Jira that shows the \"Update status page\" field on the right side. When I click that, it shows the name of the incident that is currently open in Statuspage, a \"Link this incident\" button that is greyed out, and a blue \"Create new incident\" button. \n\nThe \"Link this incident\" button does nothing. The \"Create new incident\" button produces a \"Sorry you can't open this. Refresh this page or try again in the next couple of minutes.\" message. Any explanation? \n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Terry,\n\nThanks for reaching out to the Statuspage community! I setup the Jira Software Integration to try and recreate this but I was able to get mine to work properly. This might be a situation where we need more information and since it is on the Jira side of the integration, I would recommend opening a support ticket with them. On the surface, this looks like a permissions issue but they would be able to dig deeper to see if that is the case or if there is something that needs to be changed. Hopefully, that will help get the issue resolved.\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/quot-Link-this-incident-quot-in-Jira-is-not-doing-anything-quot/qaq-p/2558936
| null |
{
"author": "eric",
"title": "How do I specify the color of the 'confirm subscription' button in the email?",
"body": "I found the area where I can specify colors for the email and status page. The button on the status page is in my desired color, but not the button in the email.\n"
}
|
[
{
"author": "John M",
"body": "Hi [@eric](/t5/user/viewprofilepage/user-id/5384985)\n\nJohn from Statuspage support here.\n\nAt the moment, there isn't an option to customize the colors of the statuspage emails but we do have a feature request for there logged under STATUS-156 to add customization options to Statuspage emails.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-do-I-specify-the-color-of-the-confirm-subscription-button-in/qaq-p/2557684
|
[
"cloud"
] |
{
"author": "Laurie Sciutti",
"title": "Community Moderators: Can we add Atlassian's Status Page Hub link to the Community homepage?",
"body": "It would be super-helpful ?\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hi Laurie,\n\nThis is Jesse from the Statuspage support team. I'd be happy to reach out to the team on this but can you clarify something for me? Are you just looking to have the status.atlassian.com link posted on the community.atlassian.com home page or was there something more specific? Thanks for your time!\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Community-Moderators-Can-we-add-Atlassian-s-Status-Page-Hub-link/qaq-p/2557974
|
[
"cloud"
] |
{
"author": "Erin Azar",
"title": "Looking for documentation on Status Embed Widget / Incident Status Mapping",
"body": "Please point me to documentation for how the status page embedded widget maps to incident status? \n\nFor example, we created a Partial Outage (Incident = Major Severity) on our status page. The embed widget translated this to Minor Service Outage on our login page. \n\nTo ensure our communication plan is fully understood, we would like to better understand the mapping on the widget and if the mapping is configurable. \n\nThank you.\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Erin Azar](/t5/user/viewprofilepage/user-id/5040125) ,\n\nJohn from Statuspage support here - happy to help!\n\nThe default status embed feature will only show popups of any new incidents or maintenances added to your statuspage, but you can opt to [build your own status embed](https://support.atlassian.com/statuspage/docs/build-your-own-status-embed/) which is fully customizable.\n",
"comments": [
{
"author": "Erin Azar",
"body": "Will you please give me the Status Page status mapping logic that drives the embedded widget status?\n\n* Partial Degraded Service\n* Minor Service Outage\n* Partial System Outage\n* Major Outage\n"
},
{
"author": "John M",
"body": "Hi [@Erin Azar](/t5/user/viewprofilepage/user-id/5040125) ,\n\nHere is how the component outages map to system statuses:\n\nIncident with a component set to \"Degraded performance\":\n\n\"status\":{\"indicator\":\"minor\",\"description\":\"Partially Degraded Service\"}}\n\nIncident with a component set to \"Partial outage\":\n\n\"status\":{\"indicator\":\"minor\",\"description\":\"Minor Service Outage\"}}\n\nIncident with a component set to \"Major outage\":\n\n\"status\":{\"indicator\":\"major\",\"description\":\"Partial System Outage\"}}\n\nIncident with ALL components set to \"Major outage\":\n\n\"status\":{\"indicator\":\"critical\",\"description\":\"Major System Outage\"}}\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Looking-for-documentation-on-Status-Embed-Widget-Incident-Status/qaq-p/2556764
|
[
"cloud"
] |
{
"author": "Dieu Nguyen",
"title": "Could we restore a deleted component?",
"body": "I have deleted a component but I want to restore it. Could I know if I can do that or not?\n\nThanks\n"
}
|
[
{
"author": "Mubeen Mohammed",
"body": "Hello [@Dieu Nguyen](/t5/user/viewprofilepage/user-id/4020522)\n\nThank you for contacting the Atlassian Community. This is Mubeen from Statuspage support.\n\nI'm sorry, but as per the current product design, once a component is deleted from the Statuspage, it can't be restored. Statuspage doesn't offer a built-in feature to restore deleted components.\n\nWhen you delete a component, Statuspage warns you that this action is irreversible, and you must confirm the deletion. It is highly recommended to consider all implications before deleting a component, this includes how it might affect your incident communication, subscribers, and historical data.\n\nIf you've accidentally deleted a component, your best option is to recreate it manually. Please remember that this will not bring back any historical data associated with the deleted component.\n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": [
{
"author": "Dieu Nguyen",
"body": "Thanks Mubeen Mohammed\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Could-we-restore-a-deleted-component/qaq-p/2555863
| null |
{
"author": "Kunwar Vaibhav Singh",
"title": "Update Previous Status Page Incident",
"body": "Hi Team,\n\nI want to update the previous status page incident body record but how to get incident_update_id. I'm aware about incident_id but not incident_update_id.\n\nPlease guide me. \n\n<https://api.statuspage.io/v1>/pages/{page_id}/incidents/{incident_id}/incident_updates/{incident_update_id}\n"
}
|
[
{
"author": "Mubeen Mohammed",
"body": "Hello [@Kunwar Vaibhav Singh](/t5/user/viewprofilepage/user-id/5079236)\n\nThank you for contacting the Atlassian Community. This is Mubeen from Statuspage support team.\n\nTo use the [option](https://developer.statuspage.io/#operation/patchPagesPageIdIncidentsIncidentIdIncidentUpdatesIncidentUpdateId) to update a previous incident update you need incident_update_id to get it you will need to use the '[Get an Incident](https://developer.statuspage.io/#operation/getPagesPageIdIncidentsIncidentId)' endpoint from the Statuspage API.\n\n<br />\n\n- The initial requirement is you will make a GET request to the '/pages/{page_id}/incidents/{incident_id}' endpoint.\n\n- This will return a JSON object with details of the incident, including an \"incident_updates\" array section. Each item in the incident_updates array represents a previous update to the incident and includes an \"id\" field. This \"id\" is the \"incident_update_id\" you are looking for.\n\n- Once you have the \"incident_update_id\", you can use it in the 'PATCH /pages/{page_id}/incidents/{incident_id}/incident_updates/{incident_update_id}' endpoint to update the specific incident update. \n\nI hope the details provided are helpful\n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Update-Previous-Status-Page-Incident/qaq-p/2554940
|
[
"cloud"
] |
{
"author": "Drew Arnold",
"title": "How would you design a statuspage layout for multiple customers with their own specific subdomain?",
"body": "We wanted to investigate/research how we would be able to setup a statuspage that would be accessible publically, but would be tailored for each of our customers.\n\nWe provide a SaaS solution where we provide them an account with a subdomain of their own choice. An example of this would be customer1.example.com and another customer would have customer2.example.com. We want to have these customers to both have statuspages for their site available and not to be able to view the other customer's information. How should we design / layout these customer statuspages where our communication wouldn't need to be vague where they would contact our customer success team with whether their page is impacted.\n"
}
|
[
{
"author": "Alan Violada",
"body": "Hey Drew, Alan from the Statuspage Support team here.\n\nThe closest thing we have to the use case you provided would be the \"Audience-specific\" page type, which allows you to control what components each user has access to on a page, so that they only see the components that interest/affect them.\n\nWith that said, it is not possible to have multiple subdomains for one page - You would need a separate page for each customer for that, which would mean a separate billing plan for each one as well.\n\n[What are audience-specific pages?](https://support.atlassian.com/statuspage/docs/what-are-audience-specific-pages/)\n\nRegards,\n\nAlan\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-would-you-design-a-statuspage-layout-for-multiple-customers/qaq-p/2554429
| null |
{
"author": "Alan DAIBI",
"title": "Can't use the SSO tab",
"body": "Hi there,\n\nI am having problems with the SSO tab in all my applications. I can't access this tab and it seems to make the user interface sputter. This is regardless of the applications on Crowd (recently registered or not).\n\nHave any of you encountered this kind of problem? \nDo you have any suggestions for me?\n\nFor information, I am currently unable to restart Crowd.\n\nBest regards,\n\nAlan\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey Alan,\n\nBy applications - assuming you mean the Crowd Applications? Do you have any errors in your browsers network or Console tabs? \nWhat version of Crowd are you on?\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Can-t-use-the-SSO-tab/qaq-p/1769818
|
[
"sso"
] |
{
"author": "Frederick Washburn",
"title": "LDAP groups can define Customer User/Role in JSM but then Customers is just a list of names",
"body": "Hi Folks,\n\nWe are implementing JSM Data Center 8.16 and I've hit a snag. We use role based groups extensively throughout Jira/Confluence. I thought it would be the same in JSM as I can define Users and Roles - Role: Service Desk Customers with a group, just like in Jira/Confluence which is exactly what I want. So I was surprised that this alone does not provide access, and it appears individuals need to be added manually to the Customers on the Project? Also it seems that Customers actually controls the access and not the User and Roles Service Desk Customers - so not sure why that's even needed?\n\nCustomers does not take an LDAP group like Users and Roles which makes no sense to me. Do I really need to add a few hundred people to the each Portal project based on who can access the portal? And no, it cannot be everyone that has access to JSM on our system as we have different levels of user classification on our network.\n\nIf we can't use groups, then it also means that we now need to have a workflow for new users on the network that goes through each portal and adds users into the appropriate customer lists?\n\nI hope I'm missing something and this is solvable.\n\nThanks - Rick\n"
}
|
[
{
"author": "Mikael Sandberg",
"body": "Are your customers internal customers that have access to your Atlassian instance? If that is the case then you can add the LDAP group as Service Desk Customers in the project and that will add those users to the Customers list. This is how I am doing it, since all our customers are internal and everyone at the company have at least access to Confluence.\n",
"comments": [
{
"author": "Frederick Washburn",
"body": "Hi Mikael,\n\nThanks for the clarification, I hadn't realized that it would sync customers from the role. I've been playing around with that in various testing scenarios and hadn't picked up on what it was doing. I verified I can add users in customer role with permissions set to \"Who can raise requests?\" set to \"Customers who are added to the project\". This works the way I would expect.\n\nThanks again!\n"
},
{
"author": "Frederick Washburn",
"body": "Hi [@Mikael Sandberg](/t5/user/viewprofilepage/user-id/853579)\n\nI've ran into a related issue in that the group I'm using for service desk customers in Users and roles is 'mostly' brought into the Customers list in the project. There are 295 users in this group and only 287 get brought in as 'Customers'. If I go into Admin-\\>User Management I can see the missing individuals in the system and if I do 'View Project Roles for User' on them I see they they are in the project as Service Desk Customers. They are just not in the customer list within the project and cannot see the project in the portal. Could there be some other setting I'm missing?\n\nThanks - Rick\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/LDAP-groups-can-define-Customer-User-Role-in-JSM-but-then/qaq-p/1769980
|
[
"jira-service-desk"
] |
{
"author": "David Low",
"title": "What is the build number for Crowd 4.3.5?",
"body": "What is the build number for Crowd 4.3.5?\n\nI know this page list various version and build numbers but it is yet to be updated with 4.3.5\n\n<https://confluence.atlassian.com/crowdkb/crowd-build-and-version-numbers-reference-703401603.html>\n"
}
|
[
{
"author": "Jack Nolddor [Sweet Bananas]",
"body": "Have you a Crowd of that version installed? If so the build number is displayed on the footer.\n\n\n\nHope this helps.\n",
"comments": [
{
"author": "David Low",
"body": "1637\n\nYes. I know it is in the footer. I was just hoping not to stand up a instance of that version first to find out the number.\n\nOur setup is Infrastructure As Code, and we have a process to overwrite the crowd.cfg.xml settings on each deployment, with our preferred values. Within crowd.cfg.xml, the buildNumber is listed, hence I want the buildNumber so I overwrite that value with the correct number of this version of Crowd.\n\n\\<application-configuration\\> \n... \n\\<buildNumber\\>\\<%= [@Build](/t5/user/viewprofilepage/user-id/1568580)_number %\\>\\</buildNumber\\>\n\n...\n\n\\</application-configuration\\>\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/What-is-the-build-number-for-Crowd-4-3-5/qaq-p/1767688
|
[
"server"
] |
{
"author": "Hans Pesata",
"title": "Crowd UserDeletedEvent User Profile",
"body": "Hi! \n\nCrowd 3.7.0 \n\nI wrote a Plugin which implements an UserDeletedEvent Listener. \n\nUnfortunately when the Listener is called, the User Profile is no longer available only the Username. I would need the deleted Users data for the offboarding. \n\nWhen I look in the Crowd Audit Log, Crowd displays the User data in the User deleted audit record. \n\nIs there a way to get the data of the deleted user within the listener ? \n\nThanx \\& regards, \nHans\n"
}
|
[
{
"author": "Steffen Opel _Utoolity_",
"body": "Hi [@Hans Pesata](/t5/user/viewprofilepage/user-id/613670)\n\nApp development related questions are best asked in the [Crowd Development category](https://community.developer.atlassian.com/c/crowd-development/29) of the [Atlassian Developer Community](https://community.developer.atlassian.com/), you have a greater chance to get feedback from other app developers there.\n\nThat said, to set expectations, you'll note that there are comparatively few Crowd related questions and even less answers there - regardless, quite some Atlassian team members monitoring the community by now, so hopefully they can loop in someone from the Crowd team.\n\nCheers, \nSteffen \n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-UserDeletedEvent-User-Profile/qaq-p/1766618
|
[
"crowd-development",
"event",
"listener"
] |
{
"author": "Jan Holzbecher",
"title": "LDAPS Communication Through Loadbalancers",
"body": "Hello,\n\nI would like to use the LDAPS connector to my active directory. Since I have multiple active directory servers, I need to use a loadbalancer IP within the LDAPS connection string.\n\nNow obiously, this IP does not match the certificate installed on the active directory server. The active directory root ca certificates are yet installed on the crowd server.\n\n\n\nUnfortunately, I can not add any SAN IPs to the certificate as the CA does not support this.\n\nIs there any way to enable LDAPS without certificate checking?\n\nBest regards,\n\nJan\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey Jan,\n\nwondering if you're able to use a TCP level load balancer? this way it won't try and do the ldaps termination, it'll just pass it straight on to your AD nodes.\n\nCCM\n",
"comments": [
{
"author": "Jan Holzbecher",
"body": "Hello Craig,\n\nThanks for the suggestion, guess that might work.\n\nI finally was able to create an additional certificate and move it right onto the loadbalancer itself. Not a proper end-to-end solution, but working from the crowd server point of view.\n\nBest regards,\n\nJan\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/LDAPS-Communication-Through-Loadbalancers/qaq-p/1754423
|
[
"server"
] |
{
"author": "Martin Grulich",
"title": "Crowd is not able to connect to MySQL database after update from 4.3.0 to 4.3.5",
"body": "Hi,\n\nI've updated our crowd instance but its not able to connect to the MySQL database anymore. Im using the mysql-connector version 5.1.45, I've also tried 5.1.48 in this case.\n\n```\n2021-07-16 09:07:28,306 localhost-startStop-1 INFO [apache.jasper.servlet.TldScanner] At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time.\n2021-07-16 09:07:28,311 localhost-startStop-1 INFO [ContainerBase.[Catalina].[localhost].[/crowd]] No Spring WebApplicationInitializer types detected on classpath\n2021-07-16 09:07:29,067 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:07:29,067 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:07:29,116 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:07:29,820 localhost-startStop-1 INFO [ContainerBase.[Catalina].[localhost].[/crowd]] Initializing Spring root WebApplicationContext\n2021-07-16 09:07:31,563 localhost-startStop-1 INFO [persistence.hibernate.connection.DelegatingConnectionProvider] Configuring delegated connection provider: org.hibernate.c3p0.internal.C3P0ConnectionProvider@e904faf\n2021-07-16 09:07:31,577 MLog-Init-Reporter INFO [mchange.v2.log.MLog] MLog clients using slf4j logging.\n2021-07-16 09:07:31,628 localhost-startStop-1 INFO [mchange.v2.c3p0.C3P0Registry] Initializing c3p0-0.9.5.4 [built 23-March-2019 23:00:48 -0700; debug? true; trace: 10]\n2021-07-16 09:07:31,699 localhost-startStop-1 INFO [v2.c3p0.impl.AbstractPoolBackedDataSource] Initializing c3p0 pool... com.mchange.v2.c3p0.PoolBackedDataSource@81deed9d [ connectionPoolDataSource -> com.mchange.v2.c3p0.WrapperConnectionPoolDataSource@dcceb96e [ acquireIncrement -> 1, acquireRetryAttempts -> 30, acquireRetryDelay -> 1000, autoCommitOnClose -> false, automaticTestTable -> null, breakAfterAcquireFailure -> false, checkoutTimeout -> 0, connectionCustomizerClassName -> null, connectionTesterClassName -> com.mchange.v2.c3p0.impl.DefaultConnectionTester, contextClassLoaderSource -> caller, debugUnreturnedConnectionStackTraces -> false, factoryClassLocation -> null, forceIgnoreUnresolvedTransactions -> false, forceSynchronousCheckins -> false, identityToken -> 186xnslai1cbgbkm1pj4yyn|50779df3, idleConnectionTestPeriod -> 100, initialPoolSize -> 0, maxAdministrativeTaskTime -> 0, maxConnectionAge -> 0, maxIdleTime -> 30, maxIdleTimeExcessConnections -> 0, maxPoolSize -> 30, maxStatements -> 0, maxStatementsPerConnection -> 0, minPoolSize -> 0, nestedDataSource -> com.mchange.v2.c3p0.DriverManagerDataSource@82d5bc75 [ description -> null, driverClass -> null, factoryClassLocation -> null, forceUseNamedDriverClass -> false, identityToken -> 186xnslai1cbgbkm1pj4yyn|1e9c4c65, jdbcUrl -> jdbc:mysql://localhost/crowd?autoReconnect=true&characterEncoding=utf8&useUnicode=true&rewriteBatchedStatements=true, properties -> {handling_mode=DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION, user=******, password=******} ], preferredTestQuery -> null, privilegeSpawnedThreads -> false, propertyCycle -> 0, statementCacheNumDeferredCloseThreads -> 0, testConnectionOnCheckin -> false, testConnectionOnCheckout -> false, unreturnedConnectionTimeout -> 0, usesTraditionalReflectiveProxies -> false; userOverrides: {} ], dataSourceName -> null, extensions -> {}, factoryClassLocation -> null, identityToken -> 186xnslai1cbgbkm1pj4yyn|7c805302, numHelperThreads -> 3 ]\n2021-07-16 09:10:05,999 C3P0PooledConnectionPoolManager[identityToken->186xnslai1cbgbkm1pj4yyn|7c805302]-HelperThread-#1 WARN [mchange.v2.resourcepool.BasicResourcePool] com.mchange.v2.resourcepool.BasicResourcePool$ScatteredAcquireTask@9abc472 -- Acquisition Attempt Failed!!! Clearing pending acquires. While trying to acquire a needed new resource, we failed to succeed more than the maximum number of allowed acquisition attempts (30). Last acquisition attempt exception:\ncom.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.\nat sun.reflect.GeneratedConstructorAccessor73.newInstance(Unknown Source)\nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)\nat java.lang.reflect.Constructor.newInstance(Constructor.java:423)\nat com.mysql.jdbc.Util.handleNewInstance(Util.java:425)\nat com.mysql.jdbc.Util.getInstance(Util.java:408)\nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:919)\nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:898)\nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:887)\nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:861)\nat com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2094)\nat com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2019)\nat com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:776)\nat com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47)\nat sun.reflect.GeneratedConstructorAccessor71.newInstance(Unknown Source)\nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)\nat java.lang.reflect.Constructor.newInstance(Constructor.java:423)\nat com.mysql.jdbc.Util.handleNewInstance(Util.java:425)\nat com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:386)\nat com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:330)\nat com.mchange.v2.c3p0.DriverManagerDataSource.getConnection(DriverManagerDataSource.java:175)\nat com.mchange.v2.c3p0.WrapperConnectionPoolDataSource.getPooledConnection(WrapperConnectionPoolDataSource.java:220)\nat com.mchange.v2.c3p0.WrapperConnectionPoolDataSource.getPooledConnection(WrapperConnectionPoolDataSource.java:206)\nat com.mchange.v2.c3p0.impl.C3P0PooledConnectionPool$1PooledConnectionResourcePoolManager.acquireResource(C3P0PooledConnectionPool.java:203)\nat com.mchange.v2.resourcepool.BasicResourcePool.doAcquire(BasicResourcePool.java:1176)\nat com.mchange.v2.resourcepool.BasicResourcePool.doAcquireAndDecrementPendingAcquiresWithinLockOnSuccess(BasicResourcePool.java:1163)\nat com.mchange.v2.resourcepool.BasicResourcePool.access$700(BasicResourcePool.java:44)\nat com.mchange.v2.resourcepool.BasicResourcePool$ScatteredAcquireTask.run(BasicResourcePool.java:1908)\nat com.mchange.v2.async.ThreadPoolAsynchronousRunner$PoolThread.run(ThreadPoolAsynchronousRunner.java:696)\nCaused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure\nThe last packet successfully received from the server was 1 milliseconds ago. The last packet sent successfully to the server was 1 milliseconds ago.\nat sun.reflect.GeneratedConstructorAccessor65.newInstance(Unknown Source)\nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)\nat java.lang.reflect.Constructor.newInstance(Constructor.java:423)\nat com.mysql.jdbc.Util.handleNewInstance(Util.java:425)\nat com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:990)\nat com.mysql.jdbc.ExportControlled.transformSocketToSSLSocket(ExportControlled.java:203)\nat com.mysql.jdbc.MysqlIO.negotiateSSLConnection(MysqlIO.java:4901)\nat com.mysql.jdbc.MysqlIO.proceedHandshakeWithPluggableAuthentication(MysqlIO.java:1659)\nat com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1226)\nat com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2188)\nat com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2035)\n... 18 more\nCaused by: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)\nat sun.security.ssl.HandshakeContext.<init>(HandshakeContext.java:171)\nat sun.security.ssl.ClientHandshakeContext.<init>(ClientHandshakeContext.java:98)\nat sun.security.ssl.TransportContext.kickstart(TransportContext.java:220)\nat sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:428)\nat com.mysql.jdbc.ExportControlled.transformSocketToSSLSocket(ExportControlled.java:188)\n... 23 more\n2021-07-16 09:10:06,000 C3P0PooledConnectionPoolManager[identityToken->186xnslai1cbgbkm1pj4yyn|7c805302]-HelperThread-#1 WARN [mchange.v2.resourcepool.BasicResourcePool] Having failed to acquire a resource, com.mchange.v2.resourcepool.BasicResourcePool@6bd2704d is interrupting all Threads waiting on a resource to check out. Will try again in response to new client requests.\n2021-07-16 09:10:06,002 localhost-startStop-1 WARN [jdbc.env.internal.JdbcEnvironmentInitiator] HHH000342: Could not obtain connection to query metadata : Connections could not be acquired from the underlying database!\n```\n\nI tried a newser version of mysql connector (8.0.24) and get the following error:\n\n```\n2021-07-16 09:12:14,940 localhost-startStop-1 INFO [apache.jasper.servlet.TldScanner] At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time.\n2021-07-16 09:12:14,943 localhost-startStop-1 INFO [ContainerBase.[Catalina].[localhost].[/crowd]] No Spring WebApplicationInitializer types detected on classpath\n2021-07-16 09:12:15,636 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:12:15,636 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:12:15,685 localhost-startStop-1 INFO [atlassian.crowd.config.CrowdApplicationConfig] Using config directory : /var/atlassian/application-data/crowd/shared\n2021-07-16 09:12:16,374 localhost-startStop-1 INFO [ContainerBase.[Catalina].[localhost].[/crowd]] Initializing Spring root WebApplicationContext\n2021-07-16 09:12:18,027 localhost-startStop-1 INFO [persistence.hibernate.connection.DelegatingConnectionProvider] Configuring delegated connection provider: org.hibernate.c3p0.internal.C3P0ConnectionProvider@2018de93\n2021-07-16 09:12:18,040 MLog-Init-Reporter INFO [mchange.v2.log.MLog] MLog clients using slf4j logging.\n2021-07-16 09:12:18,121 localhost-startStop-1 INFO [mchange.v2.c3p0.C3P0Registry] Initializing c3p0-0.9.5.4 [built 23-March-2019 23:00:48 -0700; debug? true; trace: 10]\n2021-07-16 09:12:18,200 localhost-startStop-1 INFO [v2.c3p0.impl.AbstractPoolBackedDataSource] Initializing c3p0 pool... com.mchange.v2.c3p0.PoolBackedDataSource@399c905 [ connectionPoolDataSource -> com.mchange.v2.c3p0.WrapperConnectionPoolDataSource@5372d8c7 [ acquireIncrement -> 1, acquireRetryAttempts -> 30, acquireRetryDelay -> 1000, autoCommitOnClose -> false, automaticTestTable -> null, breakAfterAcquireFailure -> false, checkoutTimeout -> 0, connectionCustomizerClassName -> null, connectionTesterClassName -> com.mchange.v2.c3p0.impl.DefaultConnectionTester, contextClassLoaderSource -> caller, debugUnreturnedConnectionStackTraces -> false, factoryClassLocation -> null, forceIgnoreUnresolvedTransactions -> false, forceSynchronousCheckins -> false, identityToken -> 186xnslai1cbmgmi84j5bb|4b9b4b53, idleConnectionTestPeriod -> 100, initialPoolSize -> 0, maxAdministrativeTaskTime -> 0, maxConnectionAge -> 0, maxIdleTime -> 30, maxIdleTimeExcessConnections -> 0, maxPoolSize -> 30, maxStatements -> 0, maxStatementsPerConnection -> 0, minPoolSize -> 0, nestedDataSource -> com.mchange.v2.c3p0.DriverManagerDataSource@53af1266 [ description -> null, driverClass -> null, factoryClassLocation -> null, forceUseNamedDriverClass -> false, identityToken -> 186xnslai1cbmgmi84j5bb|6c6f7b62, jdbcUrl -> jdbc:mysql://localhost/crowd?autoReconnect=true&characterEncoding=utf8&useUnicode=true&rewriteBatchedStatements=true, properties -> {handling_mode=DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION, user=******, password=******} ], preferredTestQuery -> null, privilegeSpawnedThreads -> false, propertyCycle -> 0, statementCacheNumDeferredCloseThreads -> 0, testConnectionOnCheckin -> false, testConnectionOnCheckout -> false, unreturnedConnectionTimeout -> 0, usesTraditionalReflectiveProxies -> false; userOverrides: {} ], dataSourceName -> null, extensions -> {}, factoryClassLocation -> null, identityToken -> 186xnslai1cbmgmi84j5bb|776b4d09, numHelperThreads -> 3 ]\n2021-07-16 09:12:22,151 localhost-startStop-1 INFO [opensaml.core.config.InitializationService] Initializing OpenSAML using the Java Services API\n2021-07-16 09:12:23,113 localhost-startStop-1 INFO [crowd.console.listener.StartupListener] License is valid. Support Entitlement Number (SEN) is SEN-11352380\n2021-07-16 09:12:23,169 localhost-startStop-1 INFO [v2.c3p0.impl.AbstractPoolBackedDataSource] Initializing c3p0 pool... com.mchange.v2.c3p0.PoolBackedDataSource@5becbfa2 [ connectionPoolDataSource -> com.mchange.v2.c3p0.WrapperConnectionPoolDataSource@610baf38 [ acquireIncrement -> 1, acquireRetryAttempts -> 30, acquireRetryDelay -> 1000, autoCommitOnClose -> false, automaticTestTable -> null, breakAfterAcquireFailure -> false, checkoutTimeout -> 0, connectionCustomizerClassName -> null, connectionTesterClassName -> com.mchange.v2.c3p0.impl.DefaultConnectionTester, contextClassLoaderSource -> caller, debugUnreturnedConnectionStackTraces -> false, factoryClassLocation -> null, forceIgnoreUnresolvedTransactions -> false, forceSynchronousCheckins -> false, identityToken -> 186xnslai1cbmgmi84j5bb|4b1c586e, idleConnectionTestPeriod -> 100, initialPoolSize -> 0, maxAdministrativeTaskTime -> 0, maxConnectionAge -> 0, maxIdleTime -> 30, maxIdleTimeExcessConnections -> 0, maxPoolSize -> 30, maxStatements -> 0, maxStatementsPerConnection -> 0, minPoolSize -> 0, nestedDataSource -> com.mchange.v2.c3p0.DriverManagerDataSource@a582c860 [ description -> null, driverClass -> null, factoryClassLocation -> null, forceUseNamedDriverClass -> false, identityToken -> 186xnslai1cbmgmi84j5bb|3765de28, jdbcUrl -> jdbc:mysql://localhost/crowd?autoReconnect=true&characterEncoding=utf8&useUnicode=true&rewriteBatchedStatements=true, properties -> {user=******, password=******} ], preferredTestQuery -> null, privilegeSpawnedThreads -> false, propertyCycle -> 0, statementCacheNumDeferredCloseThreads -> 0, testConnectionOnCheckin -> false, testConnectionOnCheckout -> false, unreturnedConnectionTimeout -> 0, usesTraditionalReflectiveProxies -> false; userOverrides: {} ], dataSourceName -> null, extensions -> {}, factoryClassLocation -> null, identityToken -> 186xnslai1cbmgmi84j5bb|4b4c649f, numHelperThreads -> 3 ]\n2021-07-16 09:12:24,009 localhost-startStop-1 INFO [liquibase.lockservice.StandardLockService] Successfully acquired change log lock\n2021-07-16 09:12:24,012 localhost-startStop-1 INFO [liquibase.servicelocator.ServiceLocator] Can not use class liquibase.parser.core.yaml.YamlChangeLogParser as a Liquibase service because org.yaml.snakeyaml.constructor.BaseConstructor is not in the classpath\n2021-07-16 09:12:24,012 localhost-startStop-1 INFO [liquibase.servicelocator.ServiceLocator] Can not use class liquibase.parser.core.json.JsonChangeLogParser as a Liquibase service because org.yaml.snakeyaml.constructor.BaseConstructor is not in the classpath\n2021-07-16 09:12:24,565 localhost-startStop-1 INFO [liquibase.changelog.StandardChangeLogHistoryService] Reading from crowd.CWD_DATABASECHANGELOG\n2021-07-16 09:12:24,574 localhost-startStop-1 INFO [liquibase.lockservice.StandardLockService] Successfully released change log lock\n2021-07-16 09:12:24,576 localhost-startStop-1 ERROR [crowd.console.listener.StartupListener] Failed to initialise Crowd container\njava.lang.ClassCastException: java.time.LocalDateTime cannot be cast to java.lang.String\nat liquibase.changelog.StandardChangeLogHistoryService.getRanChangeSets(StandardChangeLogHistoryService.java:328)\nat liquibase.changelog.AbstractChangeLogHistoryService.upgradeChecksums(AbstractChangeLogHistoryService.java:66)\nat liquibase.changelog.StandardChangeLogHistoryService.upgradeChecksums(StandardChangeLogHistoryService.java:297)\nat liquibase.Liquibase.checkLiquibaseTables(Liquibase.java:1174)\nat liquibase.Liquibase.update(Liquibase.java:192)\nat liquibase.Liquibase.update(Liquibase.java:178)\nat com.atlassian.crowd.util.persistence.hibernate.LiquibaseSchemaHelper.runLiquibaseUpdate(LiquibaseSchemaHelper.java:154)\nat com.atlassian.crowd.util.persistence.hibernate.LiquibaseSchemaHelper.lambda$updateSchemaIfNeeded$1(LiquibaseSchemaHelper.java:76)\nat com.atlassian.crowd.util.persistence.hibernate.LiquibaseSchemaHelper.withServiceRegistry(LiquibaseSchemaHelper.java:178)\nat com.atlassian.crowd.util.persistence.hibernate.LiquibaseSchemaHelper.withServiceRegistry(LiquibaseSchemaHelper.java:164)\nat com.atlassian.crowd.util.persistence.hibernate.LiquibaseSchemaHelper.updateSchemaIfNeeded(LiquibaseSchemaHelper.java:75)\nat com.atlassian.crowd.console.listener.StartupListener.migrateAndUpgradeCrowd(StartupListener.java:194)\nat com.atlassian.crowd.console.listener.StartupListener.contextInitialized(StartupListener.java:61)\nat org.apache.catalina.core.StandardContext.listenerStart(StandardContext.java:4705)\nat org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5171)\nat org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:183)\nat org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:743)\nat org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:719)\nat org.apache.catalina.core.StandardHost.addChild(StandardHost.java:705)\nat org.apache.catalina.startup.HostConfig.deployDescriptor(HostConfig.java:672)\nat org.apache.catalina.startup.HostConfig$DeployDescriptor.run(HostConfig.java:1873)\nat java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)\nat java.util.concurrent.FutureTask.run(FutureTask.java:266)\nat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\nat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\nat java.lang.Thread.run(Thread.java:748)\n2021-07-16 09:12:24,579 localhost-startStop-1 ERROR [crowd.console.listener.StartupListener] Errors experienced during the Crowd upgrade process: []\n2021-07-16 09:12:24,579 localhost-startStop-1 INFO [com.atlassian.crowd.startup] System Information:\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Timezone: Central European Time\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Java Version: 1.8.0_292\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Java Vendor: AdoptOpenJDK\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] JVM Version: 25.292-b10\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] JVM Vendor: AdoptOpenJDK\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] JVM Runtime: OpenJDK 64-Bit Server VM\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Username: root\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Operating System: Linux4.19.0-17-amd64\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Architecture: amd64\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] File Encoding: UTF-8\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] JVM Statistics:\n2021-07-16 09:12:24,580 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Total Memory: 261MB\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Used Memory: 106MB\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Free Memory: 154MB\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Runtime Information:\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Version: 4.3.5\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Build Number: 1637\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [com.atlassian.crowd.startup] Build Date: 2021-07-02\n2021-07-16 09:12:24,581 localhost-startStop-1 INFO [crowd.console.listener.StartupListener] Upgrades not performed since the application has not been setup yet.\n2021-07-16 09:12:24,581 localhost-startStop-1 ERROR [crowd.console.listener.StartupListener] Stopping Crowd startup due to earlier errors\n2021-07-16 09:12:24,613 localhost-startStop-1 INFO [ContainerBase.[Catalina].[localhost].[/crowd]] org.tuckey.web.filters.urlrewrite.UrlRewriteFilter INFO: loaded (conf ok)\n```\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey [@Martin Grulich](/t5/user/viewprofilepage/user-id/1665646)\n\nHave you confirmed that the MySQL server is indeed running and accepting connections at localhost:3306?\n\nWhile this is basic troubleshooting, sometimes it's the easy things that are overlooked and based on the logs, it does indicate a basic connection issue and I'd be surprised if the mysql connector version came in to play.\n\nCCM\n",
"comments": [
{
"author": "Martin Grulich",
"body": "Hi CCM,\n\nthank you. But I've already checked this manually with manual connection on shell:\n\n```\nmysql -h localhost -P 3306 -u crowd -p crowd\nEnter password:\nReading table information for completion of table and column names\nYou can turn off this feature to get a quicker startup with -A\n\nWelcome to the MySQL monitor. Commands end with ; or \\g.\nYour MySQL connection id is 176763\nServer version: 5.7.34 MySQL Community Server (GPL)\n\nCopyright (c) 2000, 2021, Oracle and/or its affiliates.\n\nOracle is a registered trademark of Oracle Corporation and/or its\naffiliates. Other names may be trademarks of their respective\nowners.\n\nType 'help;' or '\\h' for help. Type '\\c' to clear the current input statement.\n\nmysql> SHOW TABLES;\n+-----------------------------+\n| Tables_in_crowd |\n+-----------------------------+\n| CWD_DATABASECHANGELOG |\n| CWD_DATABASECHANGELOGLOCK |\n| cwd_app_dir_default_groups |\n| cwd_app_dir_group_mapping |\n| cwd_app_dir_mapping |\n| cwd_app_dir_operation |\n| cwd_app_licensed_user |\n| cwd_app_licensing |\n| cwd_app_licensing_dir_info |\n| cwd_application |\n| cwd_application_address |\n| cwd_application_alias |\n| cwd_application_attribute |\n| cwd_application_saml_config |\n| cwd_audit_log_changeset |\n| cwd_audit_log_entity |\n| cwd_audit_log_entry |\n| cwd_cluster_heartbeat |\n| cwd_cluster_info |\n| cwd_cluster_job |\n| cwd_cluster_lock |\n| cwd_cluster_message |\n| cwd_cluster_message_id |\n| cwd_cluster_safety |\n| cwd_directory |\n| cwd_directory_attribute |\n| cwd_directory_operation |\n| cwd_expirable_user_token |\n| cwd_granted_perm |\n| cwd_group |\n| cwd_group_admin_group |\n| cwd_group_admin_user |\n| cwd_group_attribute |\n| cwd_membership |\n| cwd_property |\n| cwd_remember_me_token |\n| cwd_saml_trust_entity_idp |\n| cwd_synchronisation_status |\n| cwd_synchronisation_token |\n| cwd_token |\n| cwd_tombstone |\n| cwd_user |\n| cwd_user_attribute |\n| cwd_user_credential_record |\n| cwd_webhook |\n| hibernate_unique_key |\n+-----------------------------+\n46 rows in set (0.00 sec)\n\nmysql> QUIT\nBye\n```\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-is-not-able-to-connect-to-MySQL-database-after-update-from/qaq-p/1751848
|
[
"server"
] |
{
"author": "Brent Blish",
"title": "jira users change their own password within jira",
"body": "Our crowd system is down (AGAIN). i am wondering how to config jira so the users can change their own passwords or have admin change their password on jira.\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey [@Brent Blish](/t5/user/viewprofilepage/user-id/2849125)\n\nI'd recommend working on the reliability issues of your Crowd environment. We've been using Crowd for \\~\\> 9 years now and it's been rock solid. If you can supply any background on what issues you've been having, I'd be happy to see if I can give any recommendations.\n\nAs for allowing users to change their passwords in Jira, if Jira is using Crowd as a user directory, then this is not possible as the password change would need to sync to Crowd \"live\".\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/jira-users-change-their-own-password-within-jira/qaq-p/1750403
|
[
"server"
] |
{
"author": "Brent Blish",
"title": "after restore crowd will not startup.",
"body": "08-Jul-2021 14:41:03.892 WARNING \\[main\\] org.apache.coyote.http11.Http11Protocol.\\<init\\> The HTTP BIO connector has been removed in Tomcat 8.5.x onwards. The HTTP BIO connector configuration has been automatically switched to use the HTTP NIO connector instead. \n08-Jul-2021 14:41:04.023 INFO \\[main\\] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent Loaded APR based Apache Tomcat Native library \\[1.2.21\\] using APR version \\[1.6.5\\]. \n08-Jul-2021 14:41:04.024 INFO \\[main\\] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent APR capabilities: IPv6 \\[true\\], sendfile \\[true\\], accept filters \\[false\\], random \\[true\\]. \n08-Jul-2021 14:41:04.024 INFO \\[main\\] org.apache.catalina.core.AprLifecycleListener.lifecycleEvent APR/OpenSSL configuration: useAprConnector \\[false\\], useOpenSSL \\[true\\] \n08-Jul-2021 14:41:04.028 INFO \\[main\\] org.apache.catalina.core.AprLifecycleListener.initializeSSL OpenSSL successfully initialized \\[OpenSSL 1.1.1a 20 Nov 2018\\] \n08-Jul-2021 14:41:04.160 INFO \\[main\\] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler \\[\"http-nio-10.250.71.143-80\"\\] \n08-Jul-2021 14:41:04.191 INFO \\[main\\] org.apache.tomcat.util.net.NioSelectorPool.getSharedSelector Using a shared selector for servlet write/read \n08-Jul-2021 14:41:04.191 INFO \\[main\\] org.apache.coyote.AbstractProtocol.init Initializing ProtocolHandler \\[\"https-openssl-nio-10.250.71.143-443\"\\] \n08-Jul-2021 14:41:04.222 SEVERE \\[main\\] org.apache.catalina.core.StandardService.initInternal Failed to initialize connector \\[Connector\\[org.apache.coyote.http11.Http11Protocol-443\\]\\] \norg.apache.catalina.LifecycleException: Failed to initialize component \\[Connector\\[org.apache.coyote.http11.Http11Protocol-443\\]\\] \nat org.apache.catalina.util.LifecycleBase.init(LifecycleBase.java:112) \nat org.apache.catalina.core.StandardService.initInternal(StandardService.java:552) \nat org.apache.catalina.util.LifecycleBase.init(LifecycleBase.java:107) \nat org.apache.catalina.core.StandardServer.initInternal(StandardServer.java:875) \nat org.apache.catalina.util.LifecycleBase.init(LifecycleBase.java:107) \nat org.apache.catalina.startup.Catalina.load(Catalina.java:639) \nat org.apache.catalina.startup.Catalina.load(Catalina.java:662) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source) \nat java.lang.reflect.Method.invoke(Unknown Source) \nat org.apache.catalina.startup.Bootstrap.load(Bootstrap.java:309) \nat org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:492) \nCaused by: org.apache.catalina.LifecycleException: Protocol handler initialization failed \nat org.apache.catalina.connector.Connector.initInternal(Connector.java:995) \nat org.apache.catalina.util.LifecycleBase.init(LifecycleBase.java:107) \n... 12 more \nCaused by: java.lang.IllegalArgumentException: jsse.alias_no_key_entry \nat org.apache.tomcat.util.net.AbstractJsseEndpoint.createSSLContext(AbstractJsseEndpoint.java:100) \nat org.apache.tomcat.util.net.AbstractJsseEndpoint.initialiseSsl(AbstractJsseEndpoint.java:72) \nat org.apache.tomcat.util.net.NioEndpoint.bind(NioEndpoint.java:244) \nat org.apache.tomcat.util.net.AbstractEndpoint.init(AbstractEndpoint.java:1105) \nat org.apache.tomcat.util.net.AbstractJsseEndpoint.init(AbstractJsseEndpoint.java:224) \nat org.apache.coyote.AbstractProtocol.init(AbstractProtocol.java:581) \nat org.apache.coyote.http11.AbstractHttp11Protocol.init(AbstractHttp11Protocol.java:68) \nat org.apache.catalina.connector.Connector.initInternal(Connector.java:993)\n"
}
|
[
{
"author": "Bastian Stehmann",
"body": "Hi,\n\nI'm not sure, but I guess it has something to do with SSL Configuration.\n\njsse.alias_no_key_entry \nat org.apache.tomcat.util.net.AbstractJsseEndpoint.createSSLContext(AbstractJsseEndpoint.java:100)\n\nCan you check, if you have imported the certificate correct into the keystore?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/after-restore-crowd-will-not-startup/qaq-p/1745233
| null |
{
"author": "Kris Van Regenmortel",
"title": "I have now a Crowd account, how can I enter the KIA BRAND RELAUNCH application?",
"body": "I can enter CROWD and get to see several applications, but when I want to enter the KIA BRAND RELAUNCH application, nothing happens.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Is that application an Atlassian system branded with \"kia brand relaunch\"?\n\nIf not, then you'll need to talk to the administrators (or possibly developers) who set up the application for Crowd access.\n\nIf it is an Atlassian application, we'll need to see the browser error messages or a full description of \"nothing happens\" - is it a blank screen with a new url in the address bar? If so, what is the new address? Does the click on the application do nothing? If so, what is the link for the application actually pointing to?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/I-have-now-a-Crowd-account-how-can-I-enter-the-KIA-BRAND/qaq-p/1738842
| null |
{
"author": "Jonathan Bertossa",
"title": "Cannot remove alias from a user",
"body": "I have a crowd user with configured alias for bitbucket, jira and confluence.\n\nNow I need to remove this alias but give me an error when I click the button \"Remove alias\".\n\nThe error is *\"Alias \\[usernameX\\] already in use for application \\[jira\\] by user \\[usernameY\\]\"*\n\nHas it already happened to you too? Some solutions?\n\nJ.B.\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey [@Jonathan Bertossa](/t5/user/viewprofilepage/user-id/2049202)\n\nWhich version of Crowd are you running?\n\nAnd what happens if you go to the Jira application, usernameY? Can you see usernameX listed there?\n\n<br />\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Cannot-remove-alias-from-a-user/qaq-p/1731931
|
[
"alias",
"error"
] |
{
"author": "Aya AlJboor",
"title": "Compatibility of Crowd DC with Jira Software server",
"body": "if my customer has jira software and core hosted on server and want to use Crowd although it is only available on DC; can I use it with the current licenses? if yes, how?\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Crowd has a separate licence to Jira, so I'm not sure what you mean by \"use with the current licence\".\n\nYou can run Jira and other Crowd-using applications with Server or DC Crowd, they don't care what the licence is for Crowd.\n",
"comments": [
{
"author": "Aya AlJboor",
"body": "thanks [@Nic Brough -Adaptavist-](/t5/user/viewprofilepage/user-id/781454)\n\nmy question is: Can I activate a DC crowd with Jira applications hosted on server?\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "Again, the licence for Crowd is separate to Jira. They have nothing to do with each other.\n\nNeither system cares what the other one is licenced for.\n"
},
{
"author": "Aya AlJboor",
"body": "thanks [@Nic Brough -Adaptavist-](/t5/user/viewprofilepage/user-id/781454)\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Compatibility-of-Crowd-DC-with-Jira-Software-server/qaq-p/1729622
| null |
{
"author": "sim.sisavuthary",
"title": "how to integrate Confluence and Jira with SSO with OAuth?",
"body": "Dear Support,\n\nwe are using Confluence and Jira on cloud, and we plan to integrate with SSO with OAuth.\n\ncould you help guide us on how to do it? and what do we need to do?\n\nwhat is my IT support need to have in order to do the integration?\n\nCan you use the free trial plugin before we pushing the license for SSO with OAuth?\n\nnormally how is the effort to make it done?\n\nthanks,\n\nThary\n"
}
|
[
{
"author": "Roman Kovalov",
"body": "Hello [@sim.sisavuthary](/t5/user/viewprofilepage/user-id/4252215) and welcome to the community!\n\nI can recommend you [this guide](https://confluence.atlassian.com/crowd/crowd-sso-2-0-967322291.html) to use Crowd as entity provider for SSO. There is step by step instruction how to integrate Crowd with your application. \nTo do that ,make sure you're using Crowd version 3.4 or later, also you need to have Crowd DC license. \nTo integrate Crowd with your application you need about 15 minutes.\n\nHope I answered your question) \nRoman.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/how-to-integrate-Confluence-and-Jira-with-SSO-with-OAuth/qaq-p/1727688
| null |
{
"author": "Ashok Arunakiri",
"title": "Integrate Kibana authentication to Crowd",
"body": "Hello,\n\nWe looking to use Crowd as IDP or the directory to authenticate against to login to to Kibana +Logstash stack. As we already have integrated Crowd to SCM ,GIT and Jenkins in addition to Jira and confluence I m looking to centralise the authentication with crowd for Logstash as well. At the moment we using X-PACK with kibana. The realms supported for Kibana are listed under <https://www.elastic.co/guide/en/kibana/current/kibana-authentication.html#oidc>\n\nAny guidance is appreciated.\n"
}
|
[
{
"author": "Roman Kovalov",
"body": "Hello [@Ashok Arunakiri](/t5/user/viewprofilepage/user-id/246971) and welcome to the community.\n\nTo enable SSO in Crowd for ELK stack I used this [guide](https://www.elastic.co/guide/en/elasticsearch/reference/current/saml-guide-stack.html#saml-role-mapping). \nI did this steps, and everything worked fine for me:\n\n1) Create generic application in Crowd, and Download metadata file from it (don't forget to add Assertion Consumer URL and Entity ID, it should be default for Kibana): \n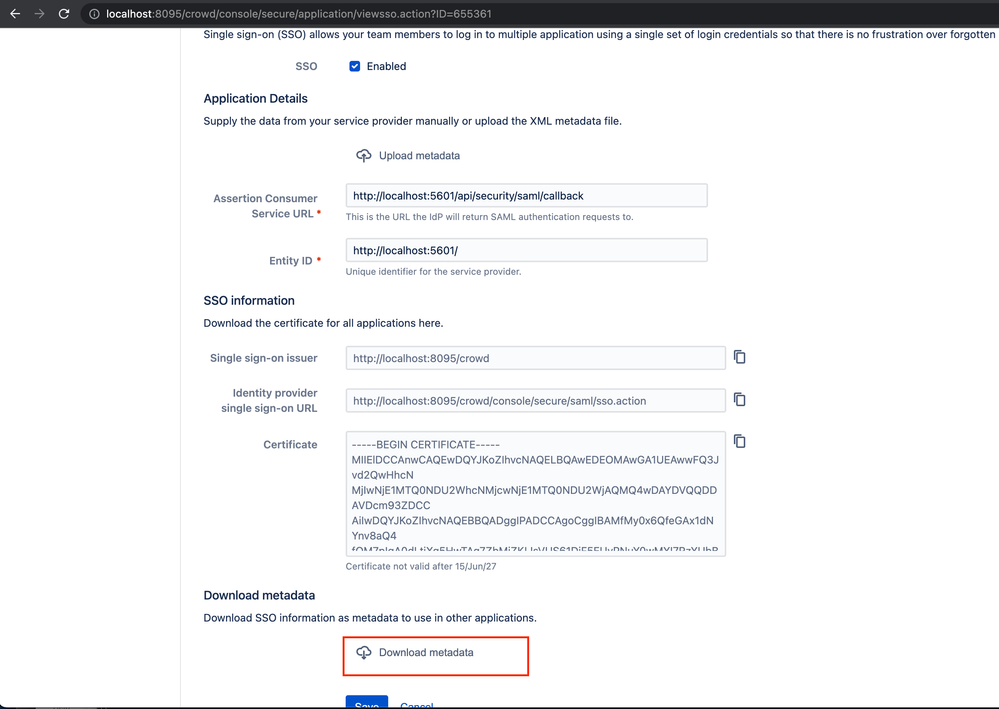\n\n2) Put metadata.xml file in your elasticsearch config folder. Then create new [realm](https://www.elastic.co/guide/en/elasticsearch/reference/current/saml-guide-stack.html#saml-create-realm) for saml authentication in *elasticsearch.yml*.\n\n3) Use created realm in [kibana](https://www.elastic.co/guide/en/kibana/master/security-settings-kb.html). You need to change kibana.yml file in kibana's config folder.\n\n4)If you did everything correct, you should see similar login page: \n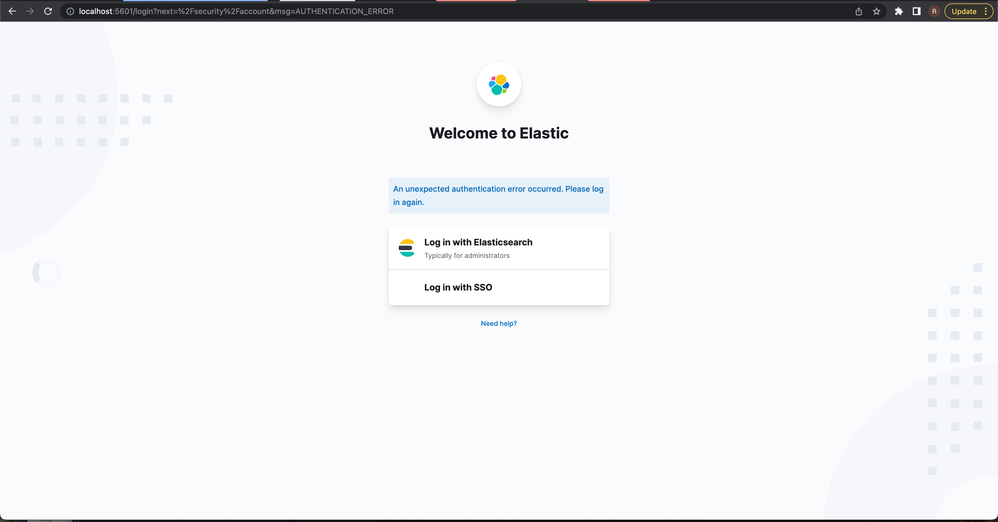 \n\nHope that will help you. \nIf you have any questions, please ask.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Integrate-Kibana-authentication-to-Crowd/qaq-p/1720092
|
[
"kibana",
"logstash",
"server"
] |
{
"author": "Dovid Bender",
"title": "Error on start up",
"body": "Hi,\n\nWe are trying to migrate crowd from an old server running CentOS6 to a new server running Oracle Linux. Here is what I did:\n\n1) Stopped crowd on current server.\n\n2) Copied over the application and data directories to the new server.\n\n3) Dumped the database and imported it to the new server.\n\n4) Updated the configs on the server to reflect the new DB and server name.\n\nWhen I start the crowd application on the new server I get an error of:\n\n|---------------------|-------|----------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| 2021-06-06 20:22:54 | fatal | Crowd has encountered errors while upgrading. Please resolve these errors and restart Crowd. | An error occurred when querying the database \\<ERROR: relation \"REMOTEGROUP\" does not exist Position: 26 Location: File: parse_relation.c, Routine: parserOpenTable, Line: 1160 Server SQLState: 42P01\\> |\n\nI am not doing an upgrade. I am merely moving it from one server to another. Any idea what I can be doing wrong?\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey [@Dovid Bender](/t5/user/viewprofilepage/user-id/3030611)\n\nIt looks like you may be seeing this issue - <https://confluence.atlassian.com/crowdkb/error-table-crowd-remotegroup-doesn-t-exist-after-migrating-crowd-database-from-another-server-726564970.html>\n\nFollow the Resolution steps from above and see if that helps\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Error-on-start-up/qaq-p/1716322
| null |
{
"author": "Kris",
"title": "Do I need Crowd for SSO with Jira+Confluence and external IDP",
"body": "Hello,\n\nI use an external IDP and would like to realize a SSO with my on-prem jira and confluence server. Should I use Crowd or directly configure jira and confluence with SSO 2.0 SAML?\n\nI would like to manage all my user access policy within the external IDP.\n\nThe jira and confluence server are behind a firewall and do not have direct access to internet.\n\nWhat is best practice?\n"
}
|
[
{
"author": "Kris",
"body": "additional I found out, that I have only Server licence and NOT Data Center.\n\nIs it possible with or without Crowd (Server) to have SAML SSO behind Firewall to connect to jira and confluence?\n\nOr is the only option upgrade to Data Center Version or get third party tools?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Do-I-need-Crowd-for-SSO-with-Jira-Confluence-and-external-IDP/qaq-p/1710637
|
[
"confluence",
"identity-provider",
"jira",
"sso"
] |
{
"author": "aas",
"title": "Can't start plugin with PageBuilderService",
"body": "I've made servlet plugin for crowd with template and when I try to add js and css resources like described here [https://developer.atlassian.com/server/confluence/web-resource-module/](https://developer.atlassian.com/server/confluence/web-resource-module/?) plugin can't start with that error in logs\n>\n> \\[INFO\\] \\[talledLocalContainer\\] 2021-05-19 12:25:37,553 QuickReload - Plugin Installer ERROR \\[plugin.osgi.factory.OsgiPlugin\\] Plugin 'com.example.crowd.plugin.crowdplugin2' never resolved service '\\&pageBuilderService' with filter '(\\&(objectClass=com.atlassian.webresource.api.assembler.PageBuilderService)(objectClass=com.atlassian.webresource.api.assembler.PageBuilderService))' \n> \\[INFO\\] \\[talledLocalContainer\\] 2021-05-19 12:25:37,553 FelixDispatchQueue INFO \\[osgi.container.felix.FelixOsgiContainerManager\\] Stopped bundle com.example.crowd.plugin.crowdplugin2 (70)\n\nhere is atlassian-plugin.xml\n\n```\n<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<atlassian-plugin key=\"${atlassian.plugin.key}\" name=\"${project.name}\" plugins-version=\"2\">\n <plugin-info> \n <description>${project.description}</description> \n <version>${project.version}</version> \n <vendor name=\"${project.organization.name}\" url=\"${project.organization.url}\"/> \n <param name=\"plugin-icon\">images/pluginIcon.png</param> \n <param name=\"plugin-logo\">images/pluginLogo.png</param> \n </plugin-info> \n <!-- add our i18n resource --> \n <resource type=\"i18n\" name=\"i18n\" location=\"crowdplugin2\"/> \n <!-- add our web resources --> \n <web-resource key=\"crowdplugin2-resources\" name=\"crowdplugin2 Web Resources\">\n <dependency>com.atlassian.auiplugin:ajs</dependency> \n <resource type=\"download\" name=\"crowdplugin2.css\" location=\"/css/crowdplugin2.css\"/>\n <resource type=\"download\" name=\"crowdplugin2.js\" location=\"/js/crowdplugin2.js\"/> \n <resource type=\"download\" name=\"images/\" location=\"/images\"/> \n <context>crowdplugin2</context> \n </web-resource> \n <web-item name=\"WebItem\" i18n-name-key=\"web-item.name\" key=\"web-item\" section=\"topnav\" weight=\"1000\"> \n <description key=\"web-item.description\">The WebItem Plugin</description> \n <label key=\"web-item.label\"/> \n <link linkId=\"web-item-link\">http://localhost:4990/crowd/plugins/servlet/userblock</link>\n </web-item> \n <servlet name=\"User Block\" i18n-name-key=\"user-block.name\" key=\"user-block\" class=\"com.example.crowd.plugin.servlet.UserBlock\"> \n <description key=\"user-block.description\">The User Block Plugin</description> \n <url-pattern>/userblock</url-pattern> \n </servlet>\n</atlassian-plugin>\n```\n\nhere is servlet class:\n\n```\nimport com.atlassian.plugin.spring.scanner.annotation.component.Scanned;\nimport com.atlassian.plugin.spring.scanner.annotation.imports.ComponentImport;\nimport com.atlassian.templaterenderer.TemplateRenderer;\nimport com.atlassian.webresource.api.assembler.PageBuilderService;\nimport javax.inject.Inject;\n\n@Scanned\npublic class UserBlock extends HttpServlet {\n@ComponentImport\n private final TemplateRenderer templateRenderer;\n@ComponentImport\n private PageBuilderService pageBuilderService;\n private static final Logger log = LoggerFactory.getLogger(UserBlock.class);\n\n@Inject\npublic UserBlock(TemplateRenderer templateRenderer, PageBuilderService pageBuilderService) {\n this.templateRenderer = templateRenderer;\n this.pageBuilderService = pageBuilderService;\n}\n\n@Override\n protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { \n resp.setContentType(\"text/html\");\n templateRenderer.render(\"template.vm\", resp.getWriter());\n pageBuilderService.assembler().resources().requireWebResource(\"ru.ftc.crowd.plugin.crowdplugin2:crowdplugin2-resources\");\n\n }\n}\n```\n\nIn pom.xml I have\n\n```\n<dependency>\n <groupId>com.atlassian.templaterenderer</groupId>\n <artifactId>atlassian-template-renderer-api</artifactId>\n <scope>provided</scope>\n</dependency>\n<dependency>\n <groupId>com.atlassian.plugins</groupId>\n <artifactId>atlassian-plugins-webresource-api</artifactId>\n <version>4.1.3</version>\n</dependency>\n```\n\nWhen I remove PageBuilderService from servlet class, plugin starts and I my template renders.\n\nWhat should I do to add js and css to my template?\n"
}
|
[
{
"author": "Steffen Opel _Utoolity_",
"body": "Hi [@aas](/t5/user/viewprofilepage/user-id/3441288)\n\nAs just answered on your previous question, just in case other Crowd users stumble over this question here:\n> App development related questions like this are best asked in the [Crowd Development category](https://community.developer.atlassian.com/c/crowd-development/29) of the [Atlassian Developer Community](https://community.developer.atlassian.com/), you have a greater chance to get feedback from other app developers there.\n>\n> That said, to set expectations, you'll note that there are comparatively few Crowd related questions and even less answers there - regardless, quite some Atlassian team members monitoring the community by now, so hopefully they can loop in someone from the Crowd team.\n\nCheers,\n\nSteffen\n",
"comments": [
{
"author": "aas",
"body": "Hi [@Steffen Opel _Utoolity_](/t5/user/viewprofilepage/user-id/781567)\n\nUnfortunately I don't know how ask questions in [Atlassian Developer Community](https://community.developer.atlassian.com/), there no any buttons to create topic or ask questions. I can only read topics\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Can-t-start-plugin-with-PageBuilderService/qaq-p/1696876
| null |
{
"author": "Carlos Chang",
"title": "Crowd user identification",
"body": "Hi guys,\n\nI'm using crowd internal user as authentication for Atlassian service like Jira and Confluence.\n\nNow I'd like to switch to external AD, but my concern here that if there exist any potential risk? for example, crowd user create an issue or become an assignee, after AD switch, could Jira recognize the new user in AD if they have the same username. What's the key value for user identification?\n\nSame question for confluence page/space creating and permission inherit.\n\n#data-center #crowd #jira #confluence\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey [@Carlos Chang](/t5/user/viewprofilepage/user-id/4087225)\n\nWe've done a significant amount of work with various Crowd directory types and can confirm the answer in <https://community.atlassian.com/t5/Crowd-questions/Crowd-Migrating-from-Crowd-internal-directory-to-Microsoft/qaq-p/131524> is correct. An application connected to Crowd will look at the Application \\> Directory mapping, and the first instance of a username that matches will be how that user is authenticated. If you have the same username in multiple mapped directories, then all group memberships are merged - eg: if [email protected] is in group A and B in the first directory and B, C and D in the second directory, while they auth against directory 1, the application will see them as being members of groups A,B,C and D\n\nCCM\n",
"comments": null
},
{
"author": "Brant Schroeder",
"body": "[@Carlos Chang](/t5/user/viewprofilepage/user-id/4087225) I belive this is the answer to your question. <https://community.atlassian.com/t5/Crowd-questions/Crowd-Migrating-from-Crowd-internal-directory-to-Microsoft/qaq-p/131524>\n\nAs with any major change, it is always good to test in a development environment beforehand and backup production prior to making the change.\n",
"comments": null
},
{
"author": "Carlos Chang",
"body": "[@Brant Schroeder](/t5/user/viewprofilepage/user-id/769100) Thank you for the info, I've get the idea but still have some questions and I leave comments in the thread.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-user-identification/qaq-p/1692464
|
[
"confluence",
"jira-software"
] |
{
"author": "John Halstead",
"title": "Prevent crowd from adding new users to active directory",
"body": "Hi,\n\nWe have crowd hooked up to an active directory:\n\nI'm ok with crowd manipulating existing users in the active directory as part of its own organisational unit (thus ensuring you can only manage users of Jira, confluence etc) what I'm not ok with is crowd being able to create new users within active directory. Can it be configured to prevent this?\n"
}
|
[
{
"author": "Brant Schroeder",
"body": "[@John Halstead](/t5/user/viewprofilepage/user-id/4381955) Welcome to the Atlassian Community.\n\nIt has been a while since I have used Crowd. I know when configuring crowd connector you have an option to manage local groups. This allows you to create groups in crowd. Here is information from the documentation.\n\nIf you select the **Manage Groups Locally** setting on the 'Connector' tab (available only if you've selected the **Cache Enabled** check box), new groups are created and updated in the Crowd database and not propagated to the LDAP server. Memberships of local groups are also stored locally. This makes it possible to augment the group structure with new groups even with a read-only LDAP server. When this option is enabled, only local groups can be created and updated, while groups synchronized from the remote directory cannot be locally modified.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Prevent-crowd-from-adding-new-users-to-active-directory/qaq-p/1685784
| null |
{
"author": "aas",
"title": "Crowd Rest API plugin",
"body": "I want to make plugin, which parse file with users from server, and make all that users inactive. I use 2 modules in plugin: Web Item and REST plugin modules. So when I click in to my web item I call my rest plugin module and in it I want to parse file with users and call crowd's rest api to change users PUT https://server/crowd/rest/usermanagment/1/user?username=userFromFile. Problem is that I can't call crowd's rest endpoint from my web plugin module, I always get code 400. Is it right way to call crowd rest endpoint from my rest endpoint or there is other way to make users inactive?\n"
}
|
[
{
"author": "Steffen Opel _Utoolity_",
"body": "Hi [@aas](/t5/user/viewprofilepage/user-id/3441288)\n\nYou have probably figured this out by now, just in case:\n\nApp development related questions like this are best asked in the [Crowd Development category](https://community.developer.atlassian.com/c/crowd-development/29) of the [Atlassian Developer Community](https://community.developer.atlassian.com/), you have a greater chance to get feedback from other app developers there.\n\nThat said, to set expectations, you'll note that there are comparatively few Crowd related questions and even less answers there - regardless, quite some Atlassian team members monitoring the community by now, so hopefully they can loop in someone from the Crowd team.\n\nCheers, \nSteffen\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-Rest-API-plugin/qaq-p/1681769
|
[
"app",
"rest-api"
] |
{
"author": "Admin Octavian",
"title": "Crowd account password attempt count for external directories.",
"body": "Hi there!\n\nWe use Crowd 4.2.2 server in our Enterprise. We have some MS AD directories, connected to Crowd as external. Each AD have own password lockout policy, but all have configured at least 3-4 invalid password attempts before lockout. We noticed, that in all Applications connected to Crowd, user from such directory is locked after 2 invalid attempts, that is much lover then configured in AD. Why Crowd account lock policy isn't equal to AD policy? How can i see \\& set it to corresponding values?? I can set password lockout attempts only for internal directory.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "It's because Crowd cannot read the policy from your AD server. You have to give Crowd the rules because your AD server does not publish them.\n",
"comments": [
{
"author": "Admin Octavian",
"body": "Hi Nic.\n\nThank you for answer, my next question is how to configure count of bad Password attempts for external directories in Crowd?\n\nAs i see, i can set this only for internal Crowd directory, external directory configuration doesn't have such option.\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-account-password-attempt-count-for-external-directories/qaq-p/1672772
|
[
"server"
] |
{
"author": "Muraleetharan Ramaraj",
"title": "Unable to delete users from Crowd",
"body": "I have crowd admin access, but unable to delete users. It says\n\norg.springframework.ldap.NoPermissionException: \\[LDAP: error code 50 - 00000005: SecErr: DSID-031526E9, problem 4003 (INSUFF_ACCESS_RIGHTS), data 0 \\]; nested exception is javax.naming.NoPermissionException: \\[LDAP: error code 50 - 00000005: SecErr: DSID-031526E9, problem 4003.\n\nCan you please help?\n"
}
|
[
{
"author": "Brant Schroeder",
"body": "[@Muraleetharan Ramaraj](/t5/user/viewprofilepage/user-id/4266534)\n\nLooks like crowd is using an LDAP directory. Even if you have it setup so you could manage users in crowd and it syncs back to LDAP you would need to ensure that the user performing the LDAP sync (delete/update) has access to do so in AD. I would suggest just making the change in AD and letting it sync to crowd.\n",
"comments": [
{
"author": "Muraleetharan Ramaraj",
"body": "Thanks Brant for your answer\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Unable-to-delete-users-from-Crowd/qaq-p/1667663
| null |
{
"author": "xyz",
"title": "where do I get the username and password of crowd application?",
"body": "I was trying to Authenticate Crowd rest Api using python code [https://python-crowd.readthedocs.io/en/latest/](https://python-crowd.readthedocs.io/en/latest/?) where i can get\n\n```\napp_user = 'testapp'app_pass = 'testpass'\n```\n\nHow can i find app_user and app_pass in my crowd.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "They will be whatever you set up in Crowd for the application you are creating.\n\nCrowd, like any secure system, does not store the password, it stores a hash to validate against. If you don't know what was set, you'll have to reset it.\n\nSee <https://confluence.atlassian.com/crowd/adding-an-application-18579591.html#AddinganApplication-add>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/where-do-I-get-the-username-and-password-of-crowd-application/qaq-p/1669748
|
[
"rest-api"
] |
{
"author": "Maurice Meyer",
"title": "JSM - Create a User in Active Directory via Request Type or Portal",
"body": "Dear Atlassian Community,\n\nI'm wondering, if there is a solution for HR projects in JSM to directly create/update a user in AD (active Directory) via the Portal or Ticket.\n\nDoes anyone have experience?\n\nThank you so much in advance!\n"
}
|
[
{
"author": "Prabhu Palanisamy _Onward_",
"body": "HI [@Maurice Meyer](/t5/user/viewprofilepage/user-id/5332387) - [OnLink](https://marketplace.atlassian.com/apps/1231655/onlink-hr-systems-integration-for-jira?hosting=cloud&tab=overview) supports this use case. You can automate user provisioning, de-provisioning, change roles, assign licenses etc based on the details from the ticket. \nHere is a demo [video](https://www.youtube.com/watch?v=e2jOwE_8spM)that walks through the new user provisioning in Azure AD as part new hire onboarding. Happy to do a demo if this of interest to you. \n\nDisclosure: I'm part of Onward who built OnLink.\n",
"comments": [
{
"author": "Maurice Meyer",
"body": "appreciate your suggestion Prabhu, I'm going to check it out. Thank you kind!\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/JSM-Create-a-User-in-Active-Directory-via-Request-Type-or-Portal/qaq-p/2816437
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Amber Truesdell",
"title": "Automation to Create Issues on a Reoccurring Day",
"body": "Goal: I want to create an automation that automatically creates a unique Jira Task issue for each of my direct reports on the last Monday of every month with a due date of the last business day of every month.\n\nI have scoured the internet and this community and everything suggests I utilize the \"When:Scheduled\" trigger but when I go to add the next component of creating a new Jira issue, it is not an option.\n\nTo answer some potential questions:\n\nYes I have the permission level required to create Jira issues on this specific project\n\n- Yes I have the permission level to create automations\n\nI have tried utilizing the basic and advanced versions of the \"When:Scheduled\" trigger and neither allow me to make the next component a \"Then: Create Issue\"\n\nI would like to refrain from downloading any external script/scheduler plugins from Atlassian Marketplace if I can avoid it.\n"
}
|
[
{
"author": "Manon Soubies-Camy",
"body": "Hi [@Amber Truesdell](/t5/user/viewprofilepage/user-id/5591175) and welcome to Community!\n\nHave you tried selecting \"All actions\":\n\n\n\nAnd then selecting the project and type of the new issue:\n\n\n\nI believe Jira categorizes the \"Create issue\" action as incompatible with the \"Scheduled\" trigger because it doesn't know in which project to create the new issue nor which issue type to choose.\n\nHope this helps!\n\n- Manon\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Automation-to-Create-Issues-on-a-Reoccurring-Day/qaq-p/2816407
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"jira-work-management"
] |
{
"author": "Ingo Syllwasschy",
"title": "Who can see tickets when using Customer and organization profiles",
"body": "Hi,\n\nwe want to use customer and organization profiles. If I understand correctly, all customers of an organization can view all tickets of their organization? Is that correct?\n\nThanks\n\nIngo\n"
}
|
[
{
"author": "John Funk",
"body": "Hi Ingo,\n\nYes, that is correct.\n",
"comments": [
{
"author": "Ingo Syllwasschy",
"body": "Hi John,\n\nthanks for your answer.\n\nIs there anything, what I can do to change this? I know the ticket security. With this function should it function, or not?\n\nI don't know why these concerns exist, but our customer management thinks that our customers don't want every customer to be able to see all tickets.\n"
},
{
"author": "John Funk",
"body": "Then you can implement Issue Level security to restrict visibility to those tickets.\n"
},
{
"author": "Ingo Syllwasschy",
"body": "Thanks for answer and Confirmation of my assumption.\n\nIngo\n"
},
{
"author": "John Funk",
"body": "You are welcome.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Who-can-see-tickets-when-using-Customer-and-organization/qaq-p/2816410
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Patryk Mucha",
"title": "Education Tracking in Jira Service Management",
"body": "Hi All,\n\nMy team and I have been working to implement Education Tracking and Documentation into Jira. We were hoping to receive some guidance/suggestions for how to structure this in a project. At this stage, we have a project dedicated to this function. The difficulty we are encountering is with the levels of documentation we require:\n\n1. High-level: The Education topic or roll-out itself\n2. Medium-level: Facilities' progress for the Education topic\n3. Low-level: The units' progress in each facility\n\nAdditionally, we need to capture the number of users educated and how many users need to be educated within each unit, and the dynamic threshold that unit needs to reach in order to be considered educated (e.g. 80%). We have been attempting to structure the project in this way and have been having much difficulty.\n\nSo far we have attempted to develop a structure of Epic-\\>Ticket-\\>Subtask, but this structure lead to difficulty in dashboarding and dynamically creating the tickets (and subtasks within those tickets) for each Facility and Unit.\n\nAny insight or suggestions are greatly appreciated while we develop this process through Jira.\n\nThank you!\n"
}
|
[
{
"author": "Danut M _StonikByte_",
"body": "Hi [@Patryk Mucha](/t5/user/viewprofilepage/user-id/5235712),\n\nThe structure Epic-\\>Ticket-\\>Subtask looks good to me. You could also track the *Number of Users to Be Educated* and the *Number of Users Educated* as numeric custom fields in these issues.\n\nNot sure what do you say that it is difficult to dynamically create the tickets. Could you please elaborate a bit?\n\nFor dashboarding it should be easy with the right gadgets in-place. Jira offers some useful gadgets (Pie Chart gadget, Two Dimensional Filter Statistics gadget, etc), but it might not be enough. In this case you could search on Atlassian Marketplace for apps that provides additional gadgets.\n\nIf you consider the idea of using apps, our [Great Gadgets](https://marketplace.atlassian.com/search?query=stonikbyte%20great%20gadgets%20agile) offers some gadgets that could be really helpful for your case.\n\nFor example, by using its **Pivot Table \\& Pivot Chart** gadget you can display stats at the epic level split by education topics, facilities and units.\n\n\n\nAnd by using the **Advanced Issue Filter Formula** gadget you could calculate various metrics based on like *Total Number of Users to Be Educated* and the *Total Number of Users Educated* or *Percent Completion*.\n\n\n\nAlso, by using the **Work Breakdown Structure gadget** you can visualize the entire structure of the educational project.\n\n\n\nSee more examples of these gadgets in these articles:\n\n* [An effective dashboard for Service Desk and Customer Support teams in Jira Service Management](https://community.atlassian.com/t5/App-Central-articles/An-effective-dashboard-for-Service-Desk-and-Customer-Support/ba-p/2360369)\n* [Building a powerful Kanban dashboard in Jira with Great Gadgets app](https://community.atlassian.com/t5/Jira-articles/Building-a-powerful-Kanban-dashboard-in-Jira-with-Great-Gadgets/ba-p/1664331)\n\nDanut.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Education-Tracking-in-Jira-Service-Management/qaq-p/2816401
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Terry Dance",
"title": "Cannot use \"access_token\" from my webhook response",
"body": "My webhook successfully gets a token back, but I cannot use it any anything as Jira just fails to grab it. I've tried putting it into a variable, a comment or directly into the next webhook but its always blank.\n\nMy response is this;\n\n### Response {#toc-hId--2124405624}\n\n200OK \n\n##### Headers (6) {#toc-hId-1064171787}\n\nContent-Type: application/vnd.appd.cntrl+json;v=1 \nx-content-type-options: nosniff \nx-frame-options: SAMEORIGIN \nx-xss-protection: 1; mode=block \nContent-Length: 700 \nConnection: keep-alive \n\n##### Payload {#toc-hId--743282676}\n\n```\n{ \"access_token\": \"xxx\", \"expires_in\": 5}\n```\n\nTo access the token I've tried\n\n{{webResponse.body.access_token}}\n\n{{webhookResponse.body.access_token}}\n\n{{webResponse.body.substringBetween(\"access_token\\\\\":\", \",\") }} - this works but leaves the \" marks at beginning an end of the token, and trying to find the token between the 2 \"'s doesnt work.\n\nAnyone have an idea?\n"
}
|
[
{
"author": "Terry Dance",
"body": "Managed to create a \"smart\" variable with this\n\n{{webhookresponse.body.substringBetween(\"access_token\\\\\": \\\\\"\", \"\\\\\",\\\\\"expires\") }}\n",
"comments": null
},
{
"author": "marc -Collabello--Phase Locked-",
"body": "Hi [@Terry Dance](/t5/user/viewprofilepage/user-id/5385711) ,\n\nProbably you'd need to follow the steps at: <https://confluence.atlassian.com/jirakb/manually-formatting-webresponse-to-json-in-automation-1252006605.html>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Cannot-use-quot-access-token-quot-from-my-webhook-response/qaq-p/2816266
|
[
"automation",
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"rest-api",
"smart-value",
"token",
"webhook"
] |
{
"author": "Anna Nguyen",
"title": "Customers do not receive the email when using the button \"Reply to customer\"",
"body": "Hi Team,\n\nPlease help to check this case:\n\nFor notification emails, customers can receive all of them. But if our customer service agent reply to customers by the button \"Reply to customer\", then no email is sent out to customer. In specific,\n\n- Outgoing email enabled\n\n- Notification email enabled (this is not the issue about notification email)\n\nThanks\n\n\n"
}
|
[
{
"author": "Jack Brickey",
"body": "Hi [@Anna Nguyen](/t5/user/viewprofilepage/user-id/5592979) , welcome to the community.\n\nI have a few questions or things for you to check.\n\n* can you verify that \"comment added\" notification is enabled under project settings \\> customer notifications\n* can you verify that the customer is the reporter?\n* Can you verify that the comment that is made is actually viewable by the customer in the portal?\n",
"comments": [
{
"author": "Anna Nguyen",
"body": "Thanks [@Jack Brickey](/t5/user/viewprofilepage/user-id/853369)\n\nIt's good now, the customers can receive the email from us\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Customers-do-not-receive-the-email-when-using-the-button-quot/qaq-p/2816231
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Kypta_ Jan_ Ing_",
"title": "How to setup permitions for anyone to assets Objets schema",
"body": "Portal Request type is setup where Anyone can raise request. I use form in this request type where is used Field Type Assets Object/s\n\nHow to setup permitions for anyone to assets Objets schema?\n\nThank\n\nJan\n"
}
|
[
{
"author": "sathishkumar_selvaraj",
"body": ".png\")\n",
"comments": [
{
"author": "sathishkumar_selvaraj",
"body": "<https://support.atlassian.com/jira-service-management-cloud/docs/building-an-object-schema-for-it-assets-management-itam/>\n\nRefer to the above URL\n"
}
]
},
{
"author": "Kumar_rajarapu",
"body": "Hi [@Kypta_ Jan_ Ing_](/t5/user/viewprofilepage/user-id/5028533) ,\n\nPlease take a look at below doc link:\n\n<https://help.refined.com/space/CLOUDDOCS/5175574529/Assets+fields+in+JSM+forms+and+requests>\n\nHope that helps.\n\nThanks\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-setup-permitions-for-anyone-to-assets-Objets-schema/qaq-p/2816171
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Faroek Sweet",
"title": "Automatic approval by authorized user",
"body": "Hello Atlassian Community,\n\nI would like to know if it's possible to automatically approve requests in Jira Service Management when the approval request is made by someone authorized based on their membership in a specific group.\n\nThe goal is to have certain approval requests automatically approved if the requester is already part of a predefined group, rather than requiring manual approval and notifications.\n\nHas anyone set up such automation in Jira?\n\nThanks in advance!\n"
}
|
[
{
"author": "Shatakshi Mete",
"body": "Hello Faroek,\n\nAs per my understanding, it is possible to set up automatic approvals in Jira Service Management based on the requester's group membership. You can create automation rules using Jira's **Automation for Jira** feature. The rule would check if the requester belongs to a specific group, and if they do, the request can be automatically approved without any manual process.\n\nTo follow the process, You need to configure the automation to:\n\n1. Trigger when an approval request is created.\n2. Check the requester's group.\n3. If the requester is in the predefined group, the system automatically approves the request.\n\nThis can save time by skipping manual approvals. \n\nI hope this information is helpful.\n",
"comments": [
{
"author": "Faroek Sweet",
"body": "Thank you for your thorough answer, I can continue with this information!\n"
}
]
},
{
"author": "Jakub Koc",
"body": "Hi [@Faroek Sweet](/t5/user/viewprofilepage/user-id/5070927)\n\nIt's just as easy as it sounds, your automation should look something like this:\n\n\n",
"comments": [
{
"author": "Faroek Sweet",
"body": "Thank you for providing the visual.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Automatic-approval-by-authorized-user/qaq-p/2816152
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Drishti Maharaj",
"title": "Clone issue multiple times using automation",
"body": "Hi,\n\nI am not too sure if this is possible but when an issue is created in Project A, and will transition to a specific status in the project, is it possible to create an automation to clone that issue to a different project - however, it would need to clone and create multiple new tickets based on the choices picked in a multi-choice picker field?\n\nExample - ticket created in Project A and the choices in the filed is \"System 1\" and \"System 3\" (as per attached image).\n\n\n\nWhen this ticket transitions to \"In Progress\", an automation should kick off to create 2 new tickets in a different project, one for \"System 1\" and one for \"System 3\".\n\nWould something like that be possible?\n\nThanks.\n"
}
|
[
{
"author": "Jakub Koc",
"body": "Hi [@Drishti Maharaj](/t5/user/viewprofilepage/user-id/4311470)\n\nYes, this is definitely possible, the automation should look like this:\n\n<br />\n\n<br />\n\nTrigger: Issue Transitioned (to your desired status)\n\nCondition: Check fields value (and make sure it's not empty)\n\nBranch 1 - For Current Issue\n\nCondition: Check if field contains System 1\n\nAction: Clone Issue to Project System 1\n\nBranch 2 - For Current Issue\n\nCondition: Check if field contains System 2\n\nAction: Clone Issue to Project System 2\n\nYou can do as many branches you need, if you need more help with that let me know:)\n",
"comments": [
{
"author": "Drishti Maharaj",
"body": "Thank you [@Jakub Koc](/t5/user/viewprofilepage/user-id/5446949) - I had attempted this but think I just need to check on adding the condition to make sure the field is not empty and I thought about branches as well! Much appreciated.\n"
}
]
},
{
"author": "Clara Belin-Brosseau",
"body": "Hello [@Drishti Maharaj](/t5/user/viewprofilepage/user-id/4311470)\n\nIf you're seeking for an easy way to **clone an issue into multiple ones in another project,** I suggest trying our app [Elements Copy \\& Sync](https://marketplace.atlassian.com/apps/1211111/elements-copy-sync-clone-jira-issues?tab=overview&hosting=cloud?&utm_source=community&utm_medium=answer&utm_campaign=question_2815994&utm_keyword=CS&utm_vendorID=4952) that allows you to clone and sync a full hierarchy of issues with all their content (summary, description, custom fields, comments, attachments, etc).\n\nYou can check our guide [here](https://doc.elements-apps.com/copy-and-sync-jira-cloud/create-multiple-issues-based-on-a-template?&utm_source=community&utm_medium=answer&utm_campaign=question_2815994&utm_keyword=CS&utm_vendorID=4952).\n\nThe app is compatible with both Automation and Post-functions.\n\nThe app is for **free during 30 days** (and it stays free under 10 users).\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Clone-issue-multiple-times-using-automation/qaq-p/2815994
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Mar Angelo L_ Tareno",
"title": "Getting the count days per Status?",
"body": "is possible to get the days spend per status?\n\nexample\n\nStatus: Days \nWaiting for support : 3days spend\n\nApproving: 1 day spend\n\nI need it to create a report\n"
}
|
[
{
"author": "Jakub Koc",
"body": "Hi Mar,\n\nYou won't be able to get that in Jira default settings, thought you might want to test some external tool like [Time in Status.](https://marketplace.atlassian.com/apps/1219732/time-in-status?tab=overview&hosting=cloud)\n",
"comments": [
{
"author": "Mar Angelo L_ Tareno",
"body": "is this free?\n"
},
{
"author": "Jakub Koc",
"body": "On the marketplace you can check that it's free up to 10 users.\n"
},
{
"author": "Valeriia_Havrylenko_SaaSJet",
"body": "[@Jakub Koc](/t5/user/viewprofilepage/user-id/5446949) Thank you for suggesting [Time in Status](https://marketplace.atlassian.com/apps/1219732?tab=overview&utm_campaign=Comment_Getting-the-count-days-per-Status_20240919&utm_medium=referral&utm_source=Atlassian_Community&hosting=cloud) !\n"
}
]
},
{
"author": "Valeriia_Havrylenko_SaaSJet",
"body": "Hi [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846) ? \n\n?f you consider installing third-party add-ons to help, you can try [Time in Status](https://marketplace.atlassian.com/apps/1219732?tab=overview&utm_campaign=Comment_Getting-the-count-days-per-Status_20240919&utm_medium=referral&utm_source=Atlassian_Community&hosting=cloud) that helps to get the count days per Status. For this just:\n\n1. Choose Time in Status report and sort by project (assignee, sprint, any JQL etc)\n2. Filter Issues by preferred time\n3. Get your report!\n\n\n\nYou can also [book a live demo](https://calendly.com/vitalii_meeting/time-in-status?utm_source=Atlassian_Marketplace&utm_medium=referral&utm_campaign=Button_more-info) - we'll show you the application inside out and answer all your questions. \nAdd-on developed by my team.\n\nHave a nice day ?\n",
"comments": null
},
{
"author": "Rahul_RVS_Support",
"body": "Hi [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846)\n\nYou can use Jira Automation to populate a custom field on status time every day. or you can also use Jira Rest API's to pull this data from issue change history.\n\nAnother option could be to use a mktplace app. If you would be interested in the same, you can try out our app\n\n[Time in Status Reports](https://marketplace.atlassian.com/apps/1226187/time-in-status-reports?hosting=cloud&tab=overview)\n\nThe below report will suffice the requirement. Also with this app you generate time in status for multiple issues with multiple filter and grouping options. You can also group your statuses to define your resolution times. The app can easily be added as a dashboard gadget.\n\n[More details here.](https://community.atlassian.com/t5/App-Central-articles/Reports-to-extract-Time-in-Status-data/ba-p/2348133)\n\nDisclaimer : I work for the vendor who built this app\n\n\n",
"comments": null
},
{
"author": "Gizem G?k?e _OBSS_",
"body": "Hello [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846) ,\n\nThere is no built in solution in Jira for this. So in order to track the time spent on each status I suggest you use a marketplace app. [Timepiece - Time in Status for Jira](https://marketplace.atlassian.com/apps/1211756/time-in-status?hosting=cloud&tab=overview&utm_source=community&utm_medium=answer) ,the oldest and the most comprehensive \"Time in Status\" app in Atlassian Marketplace, which is developed by my team at OBSS, has a report type that will meet your need. Our app is available for both Jira Cloud, and Data Center.\n\nTimepiece mainly allows you to see how much time each issue spent on each **status.**\n\n**Status Duration** report (please see the screenshot above) which shows how much time each issue spent on each status.\n\n\n\nThe app calculates its reports using already existing Jira issue histories so when you install the app, you don't need to add anything to your issue workflows and you can get reports on your past issues as well.\n\nTimepiece reports can be accessed through **its own reporting page, dashboard gadgets, and issue view screen tabs**.\n\nIf you wish, you can also [schedule a live demo.](https://calendar.app.google/faQYgsEekRdFxnPj7) We will provide a comprehensive overview of the application and address any inquiries you may have.\n\nHope it helps,\n\nGizem\n",
"comments": null
},
{
"author": "Mehmet A _Bloompeak_",
"body": "Hi [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846) ,\n\nWe developed [Status Time Reports](https://marketplace.atlassian.com/1221826) app for this exact need. It is free up to 10 users. \n\nIf you are looking for a complete**ly** **free** solution, you can try the limited version [Status Time Free](https://marketplace.atlassian.com/1222051).\n\n\n\nIf you have any questions, feel free to [schedule a free call](https://bloompeak.io/schedule-a-call) with us.\n",
"comments": null
},
{
"author": "Hannes Obweger - JXL for Jira",
"body": "Hi [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846)\n\nAs you can see from the previous answers, this is an area where many Jira users rely on apps from the Atlassian Marketplace to fulfil their reporting needs.\n\nIf a Marketplace app is an option for you, I think you'll like the app that my team and I are working on, [JXL for Jira](https://marketplace.atlassian.com/apps/1224710?hosting=cloud&tab=overview&utm_source=atlassian-community&utm_medium=referral&utm_content=2799215).\n\nJXL is a full-fledged spreadsheet/table view for your issues that allows viewing, inline-editing, sorting, and filtering by all your issue fields, much like you'd do in e.g. Excel or Google Sheets. It also comes with a number of so-called *history columns* that aren't natively available, including an issue's *time in \\[status\\].*\n\nThis is how it looks in action:\n\n\n\nAs you can see above, you can easily sort and filter by your history columns, and also use them across JXL's advanced features, such as support for (configurable) *issue hierarchies* , *issue grouping* by any issue field(s), *sum-ups* , or *conditional formatting.* You can also configure the cell format of your columns, if you prefer to see the number of *days* for a particular status.\n\nOf course, you can also export your data to XSLX (Excel, Google Sheets) or CSV in just two clicks.\n\nAny questions just let me know,\n\nBest,\n\nHannes\n",
"comments": null
},
{
"author": "Danut M _StonikByte_",
"body": "Hi [@Mar Angelo L_ Tareno](/t5/user/viewprofilepage/user-id/5544846),\n\nThe report you need need looks like a time-in-status report. As far as I know Jira does not have such chart or report. You could search on Atlassian Marketplace for an app that provides a time-in-status chart or report.\n\nIf you are open to the idea of using an app, our [Great Gadgets](https://marketplace.atlassian.com/search?query=great%20gadgets%20agile%20stonikbyte) app has a **Time in Status gadget** that offers this info as chart (pie, bar or column) or table.\n\n\n\nIt can be configured to calculate in **days**, hours or minutes.\n\nOn its **Data** tab, you can see details at the issue level. This report can be exported in CSV.\n\n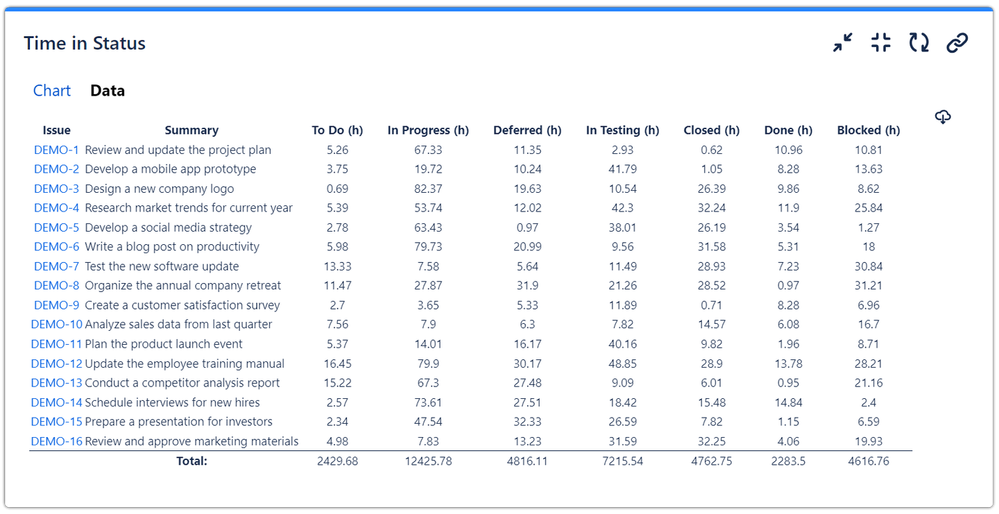\n\nDanut.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Getting-the-count-days-per-Status/qaq-p/2816013
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Hiep_Nguyen",
"title": "Inform Stakeholder feature",
"body": "Hello,\n\nI'm new to Jira. I have seen many organizations have the \"Inform Stakeholder\" tab under Comments. Ours only has Add Internal Note and Reply to Customer (attached screenshot).\n\n\n\nI would like to enable the \"Inform Stakeholder\" tab for our tickets.\n\nPlease advise! Thank you in advance!\n"
}
|
[
{
"author": "John Funk",
"body": "Hi Hiep - Welcome to the Atlassian Community!\n\nThis is a feature of Jira Service Management for Incident Management.\n\n<https://support.atlassian.com/jira-service-management-cloud/docs/how-can-i-add-and-manage-internal-stakeholders/>\n",
"comments": [
{
"author": "Hiep_Nguyen",
"body": "Hi [@John Funk](/t5/user/viewprofilepage/user-id/7148) ,\n\nI found the Incident Management feature in my Project Setting\n\n\n\nIs this what you referred to? I have turned on that feature, but I still don't see \"Inform Stakeholder\"\n\nPlease advise. Thank you!\n\n[@John Funk](/t5/user/viewprofilepage/user-id/7148)\n"
},
{
"author": "John Funk",
"body": "The issue must be related to Incident Management after it is created. You have to turn on Incident Management above, then create an issue against that, then you can see the Inform Stakeholder option. But you will not be able to see it for existing issues that are not related to Incident Management, even if you toggle that on.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Inform-Stakeholder-feature/qaq-p/2815990
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Danielle David",
"title": "Reporting how many tickets one enhancement has",
"body": "I'm seeking assistance with managing our enhancements across our Finance division. Currently, we have a central project that encompasses all our enhancement requests. Once an enhancement is approved, the corresponding ticket is duplicated and transferred to a specific project based on the nature of the enhancement. For instance, enhancements related to taxation issues are moved into the Tax project as an epic, to which we then add associated tasks and stories. \nOur goal is to establish a reporting system that allows us to understand the overall impact of each enhancement. Specifically, we want to track the number of epics generated per enhancement, as well as the subsequent stories and tasks created within those epics. \nCould you please advise if there's a way to report on these upstream and downstream flows accurately and efficiently? In Jira without an add-on? \nThank you for your assistance.\n"
}
|
[
{
"author": "Danut M _StonikByte_",
"body": "Hi [@Danielle David](/t5/user/viewprofilepage/user-id/4577696),\n\nI think you can achieve this by using the **Two Dimensional Filter Statistics gadget** of Jira.\n\n\n\nHere is how:\n\n- create a new filter in Jira that returns the Tasks and Stories from you projects and saved it as \"Issues under epic\". Filter's JQL should be something like this:\n\n*project in (Tax, Finance, ...) and parent is not EMPTY and issuetype IN (Task, Story)*\n\n- add the Two Dimensional Filter Statistics gadget to a dashboard and configure it to use the new filter. At xAxis choose Issue Type and at yAxis choose Parent.\n\nIf you need something more advanced, with data split by project or current status, you could also use the **Pivot Table \\& Pivot Chart gadget** offered by our [Great Gadgets](https://marketplace.atlassian.com/search?query=great%20gadgets%20agile%20stonikbyte) add-on.\n\n\n\nDanut.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Reporting-how-many-tickets-one-enhancement-has/qaq-p/2815934
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Anna Nguyen",
"title": "Language support error",
"body": "Hi every one,\n\nPlease help me with this issue\n\nI already set my language preference to be Vietnamese, but the language in Portal and notification email is displayed in English\n\nAlthough I set up the language is Vietnamese, but when I click on the Profile, the language is English, and when I click \"Edit account preferences\", then it shows Vietnamese :\\|\n\nI do not know what's wrong here, please help me to address this issue\n\nThanks\n"
}
|
[
{
"author": "Anna Nguyen",
"body": "Can anyone help me address this case?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Language-support-error/qaq-p/2815913
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Ali Moeen",
"title": "Error: You can't move this issue to this column due to workflow configurations or permissions.",
"body": "I am on a board and I am trying to move (drag) an item (it is a bug) from \"In progress\" to \"Resolved\"\n\nWhen I try to do that I get this error: \n\n<br />\n\nYou can't move this issue to this column due to workflow configurations or permissions.\n\nand a toaster at bottom left of the page popes with this message:\n\n**We couldn't update the issue**\n\nWe failed to reorder the issue or your admin has restricted how you can move it. Try moving the issue again or move it to a different drop zone.\n\nWhat does it takes for fix my my setup or the Jita item's setting so that I can drag it from the \"IN PROGRESS\" to the \"RESOLVED\" area?\n"
}
|
[
{
"author": "Trudy Claspill",
"body": "Hello [@Ali Moeen](/t5/user/viewprofilepage/user-id/5590289)\n\nWhat is the project type for the project whose issue you are trying to move? You can get that information from the Type column on the View All Projects page under the Projects menu.\n\nYou will have to contact the Project administrator for the project the issues belongs to, and possibly they will have to contact the Jira Administrators.\n\nThe problem could be that you don't have enough permissions in the project, and the Project Admin may be able to fix that.\n\nIf it is a Service Management project you will need to be a member of the Service Desk Team role. You also must have a Jira Service Management Agent license allocated to you.\n\nIf that is not the problem then it could be an issue in the Workflow. That may require intervention by a Jira Administrator to resolve.\n",
"comments": null
},
{
"author": "Alex Ortiz",
"body": "First, can you transition any other issue? Maybe of a different type? Also, can you transition from a different status into In Progress?\n\nNext:\n\n1) IF you are doing this on a JSM project, do make sure you have a valid JSM license (I'm assuming you do since you can access the project). But, also make sure you are in the Service Desk Team role as Trudy mentioned.\n\n2) The workflow may have an approval step. In which case, if you aren't the approver, Jira won't let you go to the next step.\n\n3) The workflow may have a condition that only allows certain folks to make the transition.\n\n4) Check the project permission to make sure you have the ability to resolve issues.\n",
"comments": null
},
{
"author": "Shawn Doyle - ReleaseTEAM",
"body": "You tagged this as JSM, but I'm kinda smelling this isn't a JSM thing, are you sure you are in JSM and not Jira?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Error-You-can-t-move-this-issue-to-this-column-due-to-workflow/qaq-p/2815782
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Dacian Voicu _WoiQ_",
"title": "How to edit / delete the \"Contact us about\" - from customer portal",
"body": "hello,\n\nis this text (\"contact us about\") from customer portal editable?\n\n\n\nthank you\n"
}
|
[
{
"author": "Christopher Yen",
"body": "Unfortunately I don't believe this can be changed\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-edit-delete-the-quot-Contact-us-about-quot-from-customer/qaq-p/2815653
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Sintia Pulido Sardi?as",
"title": "How to deal with 2 fields with the same name?",
"body": "#### Context: {#toc-hId-373584330}\n\nI am building an automation in a project and am getting the following error code: \nFound multiple fields with the same name and type: \nStart date (com.atlassian.jira.plugin.system.custom field types: date picker)\n\n*** ** * ** ***\n\n#### **Issue:** {#toc-hId--1433870133}\n\nAfter some digging, I realized we have two Start date fields. One is the \"out of the box\" option, and the other is a custom field that another team member made for their projects. I want to rename the custom field but don't want to break anything. From our understanding, they don't have any automation or scripts calling the custom field. However, the team member who originally built that project is no longer with the company, and the current owner doesn't have an in-depth understanding of Jira Service Management. \n\n*** ** * ** ***\n\n#### **Request:** {#toc-hId-1053642700}\n\nI want to know what issues might happen if I rename the custom field. Could I swap the custom field to the \"out-of-the-box\" one without breaking their project? Any recommendations on handling this situation while making a few project changes would be appreciated. Our company is very new to using Jira, and we don't have much internal knowledge yet.\n"
}
|
[
{
"author": "Nikola Perisic",
"body": "Welcome to the community [@Sintia Pulido Sardi?as](/t5/user/viewprofilepage/user-id/5595849) !\n\nDo you already have some issues that were created with the Start date value? Also, when you rename your custom field, the data that was stored in your custom field will not be lost.\n",
"comments": [
{
"author": "Nikola Perisic",
"body": "To add, you can distinguish your custom fields from your system fields when you see the LOCKED tag by the name of the field. LOCKED indicates that the field is a system field created by Jira.\n"
},
{
"author": "Sintia Pulido Sardi?as",
"body": "Yes, we already have issues created with the custom start date. Additionally, we can identify which field is the custom one, but the automation I am trying can't.\n"
},
{
"author": "Nikola Perisic",
"body": "I'd suggest renaming your custom field then, otherwise, you will keep getting the same errors.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-deal-with-2-fields-with-the-same-name/qaq-p/2815651
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Benjamin Peikes",
"title": "Multiple email addresses per service desk!",
"body": "I was sure I looked into this in the past and there was support for only one email address. Although maybe I was looking into being able to see the email that was in the \"To:\" field because we have a single mailbox that receives emails on several addresses and we wanted to add automation rules based on the To: field. \n\nI'm seeing that there is now support for multiple external emails. Is that something new?\n"
}
|
[
{
"author": "Susan Waldrip",
"body": "Hi [@Benjamin Peikes](/t5/user/viewprofilepage/user-id/551049) and welcome to the Community!\n\nThere have been some changes within the past year for allowing [multiple emails per service project](https://support.atlassian.com/jira-service-management-cloud/docs/connect-multiple-email-addresses-to-your-service-project/), is this what you're looking for?\n",
"comments": [
{
"author": "Benjamin Peikes",
"body": "Do you know when those changes were made? Also, how do you find out when there are new features like this added.\n"
},
{
"author": "Susan Waldrip",
"body": "I'm not sure when the feature I mentioned became available, if I can find it I'll add a follow-up post.\n\nAs for finding out about new features, you can check the [Atlassian Cloud Documentation blog posts](https://confluence.atlassian.com/cloud/blog) every week or subscribe to a weekly digest of them (link is at the top of that blog post page) for a run-down of changes that are being rolled out as well as new changes released that week. Atlassian's [Cloud Roadmap](https://www.atlassian.com/roadmap/cloud) may also be useful to you.\n\nIf you want something fun that covers more than the blog, you can check out @seddon Jimmy Seddon's Atlassian Community Round-up articles posted each month in the [Welcome Center](https://community.atlassian.com/t5/Welcome-Center/gh-p/WelcomeCenter) group. Hope this helps!\n"
},
{
"author": "Susan Waldrip",
"body": "Hi [@Benjamin Peikes](/t5/user/viewprofilepage/user-id/551049) , I found what I was thinking about, it's for Jira Service Management and it was posted in the [Atlassian Cloud changes Aug 12 to Aug 19, 2024](https://confluence.atlassian.com/cloud/blog/2024/08/atlassian-cloud-changes-aug-12-to-aug-19-2024) blog post:\n\n\n\n?\n"
},
{
"author": "Benjamin Peikes",
"body": "Thanks! Glad to know that it was recent, and that is wasn't something we could have done all along. :)\n\nWas just able to figure out how to signup for notifications on new features.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Multiple-email-addresses-per-service-desk/qaq-p/2815627
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Ricardo Acunzo",
"title": "How can I use advanced branching to loop through a lookup table to update user defined text?",
"body": "I'm trying to build an automation to will replace text within a user defined text field (could be in Jira or Confluence) by looping through a lookup table (with key value pairs) with an advanced branch.\n\nI have not been able to figure it out yet through I did try some variations per the explanations below:\n\n<https://community.atlassian.com/t5/Automation-articles/New-Automation-action-Create-lookup-table/ba-p/2311333/page/2>\n\n<https://community.atlassian.com/t5/Automation-articles/Update-Create-lookup-table-action-improvements/ba-p/2427798?anon_like=2451783>\n\nThe following screenshots are a simplified version of what I'm attempting to do (my text field and lookup table would be much larger)\n\n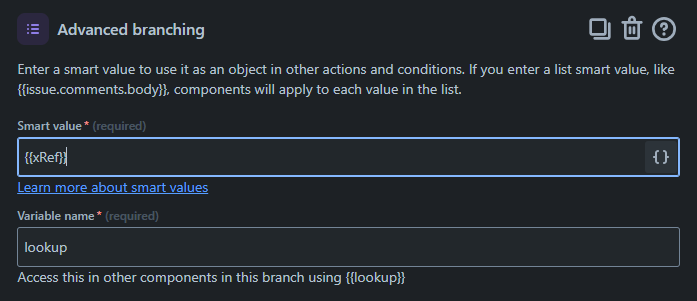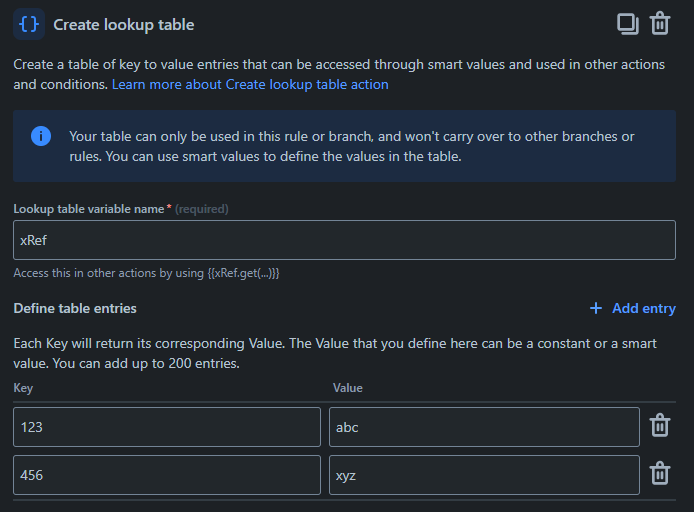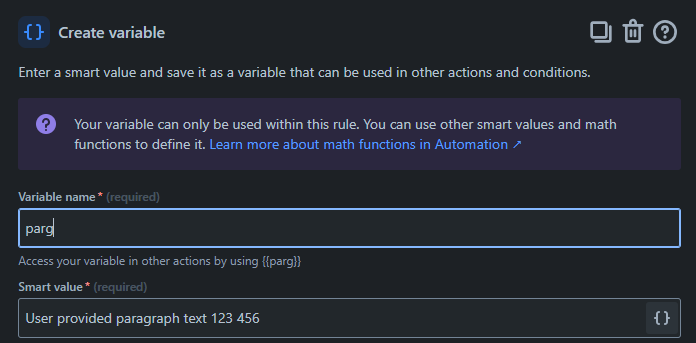\n\n\n\nThe desired outcome in the above would be that 123 and 456 are replaced with abc and xyz .\n\n[@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) Tagging since you had a lot of good info with many examples. This one I think is slightly different.\n\n[@denis.sheridan](/t5/user/viewprofilepage/user-id/5148233) I think you had a similar use case so I thought I'd tag you as well\n\nAny help is appreciated\n\nthanks\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Ricardo Acunzo](/t5/user/viewprofilepage/user-id/5523654) -- Welcome to the Atlassian Community!\n\nShort answer: at this time, *for a small number of replacement items* I recommend solving a multiple find / replace scenario using a chain of replace() calls or replaceAll if regular expressions are needed.\n\nFor example: {{parg.replace(\"123\",\"abc\").replace(\"456\",\"xyz\")}}\n\nWhen more items (or more complex replacement) is needed, do that outside of Jira, such as with an external custom service or export / import functions.\n\nSome more information...\n\nWhat you are trying to do with the advanced branch to \"update\" the variable cannot work that way.\n\nBranches which *could be on more than one thing / issue* (e.g., advanced branch) are executed in parallel and asynchronously, and so each pass through the loop is independent. There is no guarantee of when such branches will finish up until the last step in the rule, and so it is likely the branch is still running when the steps after the branch process. Thus your re-created variable just repeatedly goes out of scope and vanishes. ( There is an open suggestion to add an option for sequential versus parallel processing of branches / rules: <https://jira.atlassian.com/browse/AUTO-32> )\n\nThere are elaborate workarounds to perform sequential processing for rules using webhooks to repeatedly callback themselves. These have limitations and risks, and may not be a good fit for multiple find / replacement of text.\n\nSome other things I noticed in your rule...\n\nI recommend avoiding using variable names which could be confused (by a person or rule) with an existing thing, such as *lookup* . I normally do this by adding a prefix, such a *var* for variables and *tbl* for tables. And so your *lookup* one could be renamed *varLookup*.\n\nIf you review that [updated article on Lookup Tables](https://community.atlassian.com/t5/Automation-articles/Update-Create-lookup-table-action-improvements/ba-p/2427798), you will find the entries function / attribute, which returns the table as a list of rows. For your advanced branch, that smart value expression would be:\n\n```\n{{xRef.entries}}\n```\n\nAlthough due to the reasons noted earlier, that would not help solve the update scenario.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/How-can-I-use-advanced-branching-to-loop-through-a-lookup-table/qaq-p/2730433
|
[
"jira"
] |
{
"author": "Anthony Nguyen",
"title": "Building a string",
"body": "Is there some way to build a string with branching? I have a JSON and want to grab id from each entry and append them all together, i.e. id1\\&id2\\&id3.\n\nI created a variable {{ids}} with {{empty}} and set up advanced branching. With logging, I can see the ids, but my attempts to append to {{ids}} doesn't seem to work. Additionally, accessing {{ids}} outside of the loop reports that it is empty.\n"
}
|
[
{
"author": "Darryl Lee",
"body": "Hey [@Hariharan Iyer](/t5/user/viewprofilepage/user-id/5124435) the bigger problem for [@Anthony Nguyen](/t5/user/viewprofilepage/user-id/5508614) isn't going to be the lack of a concat function, but rather that he wants to build the strings as part of advanced branching.\n\nAutomation doesn't support \"global\" variables, and there's complications with scope of variables inside of branches. Additionally there's some confusing and interesting problems introduced because many rules (including Advanced branching across multiple issues) happen **asynchronously**and so may stomp on each other.\n\nBasically if you're thinking that everything runs sequentially... it doesn't. It's been a while since I've been down the rabbit hole, but [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) always seems to be able to explain it well.\n\nBut anyways [@Anthony Nguyen](/t5/user/viewprofilepage/user-id/5508614), that's probably why your variables are turning up empty.\n\nI suggest you take a look at these open issues:\n\n* [AUTO-19 - As a user I want to define a global variable that can be used in automation](https://jira.atlassian.com/browse/AUTO-19)\n* [AUTO-26 - Easier ways to set properties/variables for use within a rule, e.g. save JQL as smart value to support notifying of multiple issues, more ways to work with variable types, ability to edit a created variable with an action, increment a variable](https://jira.atlassian.com/browse/AUTO-26)\n* [AUTO-32 - Rule orchestration - allow switch between parallel and sequential execution of Automation Rules](https://jira.atlassian.com/browse/AUTO-32)\n* [AUTO-154 - Automation: Ability to use variable outside of a block - variable is not updated on main branch if created inside an if/else or branch block](https://jira.atlassian.com/browse/AUTO-154)\n",
"comments": null
},
{
"author": "Hariharan Iyer",
"body": "\\`concat\\` doesn't work with smart values, but if you're getting the ids as a jsonStringArray, you should be able to do something like this without branching\n\n```\n{{jsonStringArray.replaceAll(\",\\s+\", \"&\").replace(\"[\",\"\").replace(\"]\",\"\")}}\n```\n\nHope that helps!\n\n\\~ Hariharan\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Building-a-string/qaq-p/2730582
| null |
{
"author": "Christian Schneider",
"title": "Jira Automation: how to read the previous state of an issue?",
"body": "Dear community,\n\nI would like to now the *previous state* of an issue within a Jira Automation.\n\nI can get the change history of an issue via web request:\n\n\n\nI then read the response into a variable by **{{webhookResponse.body.changelog.histories.items}}**.\n\nThere are all the changes, which have been done to an issue.\n\n**Question** : how do I parse it down to the *previous state* of the issue?\n\nI tried to follow this approach by [@Erin Quick-Laughlin](/t5/user/viewprofilepage/user-id/4299733), but I am very much struggling with the {{smart values}}.\n\n<https://community.atlassian.com/t5/Automation-questions/Re-Re-How-to-parse-through-an-json-array-where-field-na/qaq-p/2297738/comment-id/6353#M6353>\n\nI have tried this, but get an empty audit log back:\n\n```\n{{#webhookResponse.body.changelog.histories.items}} {{#if(equals(field, \"status\"))}} {{fromString}} {{/}} {{/}}\n```\n\nAny help is very much appreciated.\n\nChris\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Christian Schneider](/t5/user/viewprofilepage/user-id/4404092)\n\nShort answer: in my opinion, there is no simple / elegant way to do this using the REST API functions in a rule, and saving the prior status in a custom field may be easier to implement and maintain.\n\nMore information...\n\nThe changelog for an issue could be quite long, and so you may not find your status field in the first 100 records returned. And so paging to repeatedly call the REST API may be required, increasing the rule complexity...and reducing the chances of success.\n\nLet's assume the rule trigger is *issue transitioned*, and so we can experiment and increase the chances of finding at least one match to the status field in the histories.\n\nNext, rules have problems processing lists-within-lists inside of iterators. In this case, the histories are a list and so are histories.items. Inside the iterator, the fields will not resolve correctly when conditional filtering is used: they collapse to *null*. Noting the earlier post you linked-to for your question, that is why I suggested using inline-iteration and the match() function.\n\nThus one possible workaround for this is to flatten the structure into a known, delimited format; split to a list; and then use match...returning only the first record. That will be the one with the prior status id information in the \"from\" attribute.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Bill Sheboy",
"body": "Here is a follow-up example with that workaround...assuming the answer is in the current response for the Send Web Request action.\n\n* create variable:\n * name: varHistory\n * smart value:\n\n```\n{{#webhookResponse.body.changelog.histories}}field:{{items.field}}@@@{{items.from}}~~{{/}}\n```\n\nThat would produce a delimited, text string like this:\n\n```\nfield:status@@@3~~field:Fix Version@@@null~~field:status@@@10003~~and so on...\n```\n\n* to parse out the status histories' \"from\" value with the status id, use this expression:\n\n```\n{{varHistory.split(\"~~\").match(\"field:status@@@(.*)\")}}\n```\n\n* and you want the most recent one, which should be the first in the list:\n\n```\n{{varHistory.split(\"~~\").match(\"field:status@@@(.*)\").first}}\n```\n"
},
{
"author": "Christian Schneider",
"body": "Dear [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313)\n\nThank you very much for your input. Up until now, I did not unterstand the **.split** , **.match** and **.first**, but I am a big fan of regex. :-)\n\nI very much value your inputs about the changelog. As it seems, the webresponse is ordered in a descending way -\\> newest entries come first. The webresponse from my current test ticket has 4000+ lines and I can still find all state-changes. I am confident, that the newest one should be available anyway, but I will try to implement a default behaviour, if no previous state could be found. (Trigger for my automation will be \"comment created\".)\n\nMy integration provider suggested a solution using **.substringBetween** to parse the webrequest response.\n\nAll your inputs got me going and I tried many different things.\n\n#### Regex to get the state-change history entries {#toc-hId-346737714}\n\nTo get a list of all state changes from the history, I found this:\n\n```\n{{response.match(\"((?=\\{field=status)\\{field=status, fieldtype=jira, fieldId=status, from=\\d*, fromString=(([\\w\\s]*)|(\\w)*), to=\\d*, toString=(([\\w\\s]*)|(\\w)*)\\})\")}}\n```\n\nThis will result in something like this:\n> {field=status, fieldtype=jira, fieldId=status, from=3, fromString=In Progress, to=10006, toString=Warten auf Kunden}, {field=status, fieldtype=jira, fieldId=status, from=10006, fromString=Warten auf Kunden, to=3, toString=In Progress}, {field=status, fieldtype=jira, fieldId=status, from=10005, fromString=Pendent, to=10006, toString=Warten auf Kunden}, {field=status, fieldtype=jira, fieldId=status, from=10016, fromString=Selected for Development, to=10005, toString=Pendent}, {field=status, fieldtype=jira, fieldId=status, from=10004, fromString=in Vorbereitung, to=10016, toString=Selected for Development}, {field=status, fieldtype=jira, fieldId=status, from=10003, fromString=Backlog, to=10004, toString=in Vorbereitung}, {field=status, fieldtype=jira, fieldId=status, from=10016, fromString=Selected for Development, to=10003, toString=Backlog}, {field=status, fieldtype=jira, fieldId=status, from=10003, fromString=Backlog, to=10016, toString=Selected for Development}\n\nby adding the **.first**, I can reduce it to the newest entry.\n\n\n\nThen, I would have to use **.split** and **.match** to read the \"from=\" or \"fromString\".\n\nDownsides are...\n\n* ... the big, long regex. It is designed for your state-names. (-\\> one word or several words with spaces) and\n* ... I have to use several steps with .match and .split to get the final result.\n\n#### Regex to get the newest from stateId {#toc-hId--1460716749}\n\nI then modified my approach a little bit.\n\nThis line directly provides the list of all from-status from all state-changes. (newest first)\n\n```\n{{response.match(\"((?<=\\{field=status, fieldtype=jira, fieldId=status, from=)\\d*)\")}}\n```\n\nAgain, by adding the **.first**, I get the ID I need directly into a variable.\n\n```\n{{response.match(\"((?<=\\{field=status, fieldtype=jira, fieldId=status, from=)\\d*)\").first}}\n```\n\n\n\nThe duration of the processing time is approx. 3-4 seconds.\n\nLooking forward to your feedback on this solution.\n\nChris\n\nEDIT: the original web response is a JSON. It would be so much easier, if the {{webhookResponse.body}} would be a JSON-object as well. Is there a way to read the response as JSON?\n"
},
{
"author": "Bill Sheboy",
"body": "Thanks for your extra analysis, Christian!\n\nAnswering your last question, first...no, there is no way to read *all possible* responses as JSON. I recall there is an open suggestion to add a text function for rules to correctly interpret as JSON, allowing dereferencing by attributes at all levels / structures.\n\nNext regarding use of more advanced, complicated regular expressions...the [documentation states this](https://support.atlassian.com/cloud-automation/docs/jira-smart-values-text-fields/#match--), with emphasis added by me:\n> The underlying implementation **is based on** Java's Pattern class and uses Matcher.find() to find matches.\n\nI have not found stated what is / is not supported in regular expressions for rules. Several community posts indicate expressions that work with other regular expression parsing tools do not work the same in automation rules. This can be caused by the parsing order, particularly when escaping characters is used. (One workaround for that is to store the expression in a created variable first, and then use it in the match() function.)\n\nI recommend using the simplest regular expression that can possibly work, testing, and incrementally adding to handle edge cases. And if you have something that works, save that expression / rule, before modifying to enhance it.\n\nRegarding the performance, I suspect at least 1 second of that time is for the Send Web Request call. And I have observed both complicated regular expressions and large text strings adding to rule run time. I cannot tell from your question if you are using Jira Cloud, Server, or Data Center. If Cloud, I have seen rule performance be inconsistent, even for trivially simple rules.\n\nPerhaps try removing rule steps to isolate where the time is going, and then trying to improve those.\n"
}
]
},
{
"author": "Arkadiusz Inglot",
"body": "Hi,\n\nI see two another solutions which may be helpful:\n\nA) Create hidden custom fields and put there your status names: <https://confluence.atlassian.com/jirakb/how-to-transition-to-the-previous-status-of-an-issue-using-automation-rules-in-jira-1236599919.html>\n\nB) Depending on complexity of your workflow you can rename all transitions to make the name uniques between statuses. You can create a combined Lookup Table inside automation rule with propper mappings as you will have transition names that defines \"from\" and \"to\" statuses.\n\nThis is more complex solution and it will not work if you want tyo globalise that rule across projects/workflows.\n",
"comments": [
{
"author": "Christian Schneider",
"body": "Thank you for your response. I have seen that approach as well, but I don't want to create another set of customfields, if I can get this done *on the fly*.\n\nMy automation should trigger, if a customer comments on an issue and then, the automation should transition the issue back to its previous state. As I have different workflows with different transitions in our Service Desk, I would like to solve this elegantly. :-)\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Jira-Automation-how-to-read-the-previous-state-of-an-issue/qaq-p/2729916
|
[
"history",
"json",
"rest-api",
"smart-value",
"webhook"
] |
{
"author": "Robin Specht",
"title": "Automation for Reopening Support Tickets Based on Linked Development Ticket Status",
"body": "Hello Jira Community,\n\nI'm new to the forum and have limited experience with Jira. Over the past few weeks, I've been learning through resources like Google and Chat-GPT, but I need some additional help.\n\nI need assistance with creating an automation for the following scenario:\n\nI have two team-managed projects: a Kanban project used for support and a Scrum project for development. Sometimes, a support ticket requires development work, so we create a linked development ticket and initially close the support ticket, as there is no active action needed from the support team until the development is completed.\n\nHere's what I need the automation to do:\n\n* When the linked development ticket reaches the status \"Development Completed\" or \"Cancelled,\" the corresponding support ticket should automatically change its status from \"Hypotheses Backlog\" to \"In Progress.\"\n\nAny guidance on how to set up this automation would be greatly appreciated!\n\nThank you in advance for your help!\n\nBest regards, \n\nRobin\n"
}
|
[
{
"author": "Mauricio Heberle",
"body": "Trigger: Issue transitioned from any status to \"Development Completed\" or \"Cancelled\"\n\nBranch for Linked issues. Choose the link type you are using when linking both tickets. \nCondition: check if status is not one of \"Hypotheses Backlog\" to \"In Progress\" \nAction: change status to \"Hypotheses Backlog\" to \"In Progress\".\n",
"comments": [
{
"author": "Robin Specht",
"body": "Hey Mauricio,\n\nI hope this message finds you well.\n\nThank you for your assistance with my query. However, I have encountered an issue with the suggested process. The current process doesn't work as intended because I am not checking the statuses within the same project. Instead, there are two separate projects where the tickets are merely linked together.\n\nI suspect that the issue might be related to permissions. I encountered a similar problem with another automation, and it seems likely that a global permission or the team-managed project setup might be responsible for this limitation.\n\nDo you have any idea if my assumption is correct, or what else might be causing this issue?\n\nThank you very much for your help and support.\n\nBest regards, \nRobin\n"
},
{
"author": "Mauricio Heberle",
"body": "Robin,\n\nWithin your automation, under \"Rule Details\", there's a field called \"Scope\", you need to set it to \"multiple projects\". Have you done that?\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-for-Reopening-Support-Tickets-Based-on-Linked/qaq-p/2729747
|
[
"reopen",
"team-managed-projects",
"ticket"
] |
{
"author": "Claudia Pillay",
"title": "Jira Product Discovery automation to keep stakeholders informed",
"body": "I am trying to find a way to keep stakeholders informed about a JPD issue's progress, even if they weren't necessarily the creator of an Idea.\n\nI've tested using the Watcher field and custom people picker fields, but I can't work out how to setup an email or comment automation that tags the correct people.\n\nThe email automation fails, and the comment automation lists out the emails or user names that are in Watchers however, it does not successfully tag them.\n\nHas anyone found a workaround to this?\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Claudia Pillay](/t5/user/viewprofilepage/user-id/5522861) -- Welcome to the Atlassian Community!\n\nFor a question like this, please post an image of your complete automation rule, images of any relevant actions / conditions / branches, an image of the audit log details showing the rule execution, and explain what is not working as expected. Those will provide context for the community to offer ideas. Thanks!\n\nUntil we see those...\n\nTo mention a user in a comment, the accountId is used. If you are getting those from a field like Watchers, multiple-selection fields contain a list of values. To mention all the watchers in a comment, [iterate over the values](https://support.atlassian.com/cloud-automation/docs/jira-smart-values-lists/#Combined-function-examples):\n\n```\nwatcher mentions: {{#issue.watchers.accountId}}[~accountId:{{.}}]{{^last}}, {{/}}{{/}}\n```\n\nIf you are trying to email, and using a custom People field, that is not possible. At this time, People type fields in team-managed projects (TMP), including JPD, [cannot access the email address](https://jira.atlassian.com/browse/AUTO-519). The only workaround I know of for JPD projects is to call the REST API with the accountId values to get the email address.\n\nIf your stakeholders are not Jira users, you could instead add a custom text field to store the email address, and then use that in the Send Email action.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Jira-Product-Discovery-automation-to-keep-stakeholders-informed/qaq-p/2729231
|
[
"cloud",
"jiraproductdiscovery",
"jpd",
"productdiscovery"
] |
{
"author": "Jose Ramon Sena Reynoso",
"title": "Send Form as PDF to email",
"body": "Hi.\n\nI have an Issue with a Form on it and i want to know if I can send a copy of the form or the info in the form can be send to an email, maybe as a PDF or something like it.\n\nThanks\n"
}
|
[
{
"author": "Summer Hogan",
"body": "Hi [@Jose Ramon Sena Reynoso](/t5/user/viewprofilepage/user-id/5522759) - Welcome to the community!\n\nI'm not sure which application you are asking about, but I suspect it is Jira or JSM. If so, hopefully one of these articles will help you - <https://confluence.atlassian.com/jirakb/export-forms-spreadsheets-in-jira-cloud-1369442328.html> or <https://support.atlassian.com/jira-service-management-cloud/docs/use-forms-in-jira-service-management/>. If not, please let me know.\n",
"comments": [
{
"author": "Jose Ramon Sena Reynoso",
"body": "Thanks a lot. Sorry I didn't specify, but as you assume, its JSM. As you send on the first link, a way to send that PDF by email as soon the request is created.\n"
},
{
"author": "Summer Hogan",
"body": "Hi [@Jose Ramon Sena Reynoso](/t5/user/viewprofilepage/user-id/5522759) if this helped you can you please accept my answer as that helps me? Thank you!\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Send-Form-as-PDF-to-email/qaq-p/2729046
| null |
{
"author": "Fede B.",
"title": "Automation branching variable scope",
"body": "Hi all,\n\nI'm using advanced branching in Cloud Automation, to setup a variable which I use later on, outside of the branch.\n\nBut apparently the variable exists only within the scope of the branch, and is null when the code exits the branch.\n\nExample:\n\n- In my Automation, I create an advanced branching by splitting the issue summary with separator \",\"\n\n- If I find the text \"example\" inside the branch, I create variable \"found\", with value \"true\"\n\n- Outside of the branch, I put a conditional statement: if {{found}} = true\n\n- apparently, this statement is always false, and the variable {{found}} is unset\n\nEDIT: forgot to mention that right now the only workaround I found for this problem, is to add a special label to the issue when I find \"example\", and re-fetch its data. So, outside of the branch, I just look for that label instead.\n\nCould anyone confirm that this is the expected behaviour?\n\nThanks\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Fede B.](/t5/user/viewprofilepage/user-id/5491099)\n\nYes, that is the expected behavior.\n\nBranches which could be on more than one thing / issue are run in parallel and asynchronously, and so any variable created inside the branch is gone by the end. And...there is no guarantee when such branches will complete, up until the last step of the rule. Thus you could not check such results after the branch (in the rule logic) as the branch is likely still executing.\n\nA workaround for the scenario you describe is to use the text function match(): <https://support.atlassian.com/cloud-automation/docs/jira-smart-values-text-fields/#match-->\n\nFor example, test the result of this:\n\n{{issue.summary.match(\"(example)\")}}\n\nPlease see the details of regular expressions to adjust for your needs.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Fede B.",
"body": "Hi [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) ,\n\nThank for your answer.\n\nYes, in my example the match() function would work, but in reality the automation I'm building is much more complex than that, and using match() results in a lot of work with smart variables and related frustration :-)\n\nIt would be nice to have a functionality for branching similar to that of web requests: a checkbox, to make sure that all branch code is processed before continuing to process the rest of the automation. I'm not sure if there's already a ticket to request this feature, I think it's something worth to be voted.\n\nRegards\n"
},
{
"author": "Bill Sheboy",
"body": "There are several open suggestions to add that option for branching, such as this one: <https://jira.atlassian.com/browse/AUTO-32>\n\nAlthough due to the potential to make longer running rules exceed the service limits, it might then halt all rule executions!\n\nIf you want additional help with alternatives for your more complex rule, for which match() may not be a good fit, please describe the problem you are trying to solve and post images of your complete rule and audit log details, and describe what does not work as expected. Those will provide context for the community to offer more suggestions. Thanks!\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-branching-variable-scope/qaq-p/2728614
|
[
"branch",
"smart-value"
] |
{
"author": "agnes BOURLON",
"title": "How to send only ONE email containing all the changes made at the end of an automation process?",
"body": "Here is an automate that add a label on some tickets retrieved from an SQL request.\n\nFor each change an email is sent. How to modify this automate to get only one email a the end?\n\n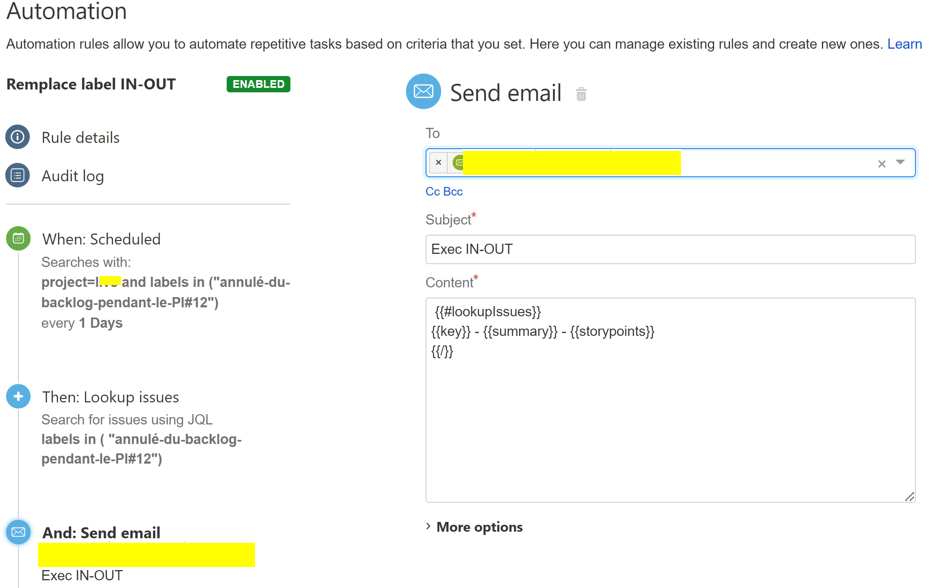\n\n\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@agnes BOURLON](/t5/user/viewprofilepage/user-id/5143057)\n\nWith the Scheduled Trigger using JQL, the rule is executed for each issue found.\n\nWhen you only want one email for your scenario, you may remove the JQL from the trigger and use that with the lookup instead:\n\n* trigger: scheduled, with no JQL\n* action: lookup issues, use the JQL that was in the trigger\n* action: send email\n\nKind regards, \nBill\n",
"comments": [
{
"author": "agnes BOURLON",
"body": "Hi Bill\n\nThanks for your answer; I removed the JQL in the trigger and I got this issue. It seems that if I need to use the edit issue later I can't remove the JQL part in the trigger ...\n\nIf I remove the For Current issue, I got the same issue\n\nI forgot to say something important, I would like to get if possible only the issues that as been changed by the action Edit Issue (I could have a condition saying that if I already have the label xxxxx I won't add the label otherwise I will add it.\n\nThx in advance,\n\nAgnes\n\n****\n"
},
{
"author": "Bill Sheboy",
"body": "That is correct; to edit an issue with a rule, either the trigger or a branch needs to provide it.\n\nIf you only want to trigger the rule on that condition, the rule would instead need to trigger on Field Value Changed for Labels, and then add a condition to check the value needed.\n\nNote this will operate on only one issue at a time, and so send an email for each one.\n\nWhat is the problem you are trying to solve with this rule? Knowing that may help confirm it solves it.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-send-only-ONE-email-containing-all-the-changes-made-at/qaq-p/2728561
| null |
{
"author": "Christopher Parker",
"title": "Check for issue updates, but ignore weekend dates",
"body": "Hi, I'm trying to resolve an issue with our Jira admins to fix an automation which needs to exclude weekend dates. \n\nIn simple terms, I need an automation which, once an issue is set to \"Review\", the requestor has 48 hours to respond in any way in the ticket, i.e with a comment or changing the status to \"Done\". If they don't, the ticket is set to \"Amber\" and \"Blocked\" status. This works during weekdays, but we cannot seem to work out how to exclude weekend working days. \n\nAny suggestions? Many thanks!\n"
}
|
[
{
"author": "Julian Governale",
"body": "Try the below.\n\n0 30 \\* ? \\* MON-FRI\n\nI saw an example in their documentation that 1 represents Sunday if 3 represents Tuesday. \n\n\n",
"comments": [
{
"author": "Christopher Parker",
"body": "Hi Julian, \n\nThanks for the suggestion. \n\nThe issue seems to be more about excluding weekend time from when a ticket hasn't been updated, rather than just when to run the automation rule. \n\nIf I run the rule on a Monday morning and it looks back 48 hours it thinks there have been no updates over the weekend, of course, we have a life! and it applies the automation anyway. My Jira admins say there is no way to deduct weekend time from a ticket when assessing if it has been updated or not.....\n"
}
]
},
{
"author": "Ste Wright",
"body": "Hi [@Christopher Parker](/t5/user/viewprofilepage/user-id/5441632)\n\nWelcome to the Community!\n\nCould you provide your current rule, so we can review/refine? That way, we can ensure we work to your specific needs, rather than make assumptions :)\n\nIt'd be good to understand the current rule including trigger, conditions, and actions.\n\nSte\n",
"comments": [
{
"author": "Christopher Parker",
"body": "Hi Ste, \n\nCurrent settings:- \n \n\nWe had someone update their issue at the weekend so it didn't register their update as I understand the entire weekend period is discounted. \n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Check-for-issue-updates-but-ignore-weekend-dates/qaq-p/2728399
|
[
"cloud",
"jira"
] |
{
"author": "Jacek",
"title": "Automation for JSM Assets - JSM",
"body": "Good Day\n\nI am a total beginner with JSM and JSM Assets, so excuse me if some questions are for dummies :)\n\nI have actually created our jsm asset schemas for Hardware, Business Partners, Employees. In the Assets everything is linked and referenced fine and everything looks good. The Objects Employees are all linked with their Atlassian ID.\n\nI have created the custom field and am able to search for the laptop of an employee in his created ticket and can add it manually.\n\nBut i do not have an clue how to proceed now with an automation. I like to keep it simplest possible. So my idea is to trigger the automation for each issue.reporter and the grab the informations from the assets laptops and link it to the custom field in the jsm ticket.\n\nI appreciate for your ideas and help.\n\nThank you in advance\n\nJ\n"
}
|
[
{
"author": "Rick Westbrock",
"body": "Editing an Assets field requires that you use a valid AQL query so I think you may need an Assets field for the Employees object type on your issues. From there your edit issue fields action would use an AQL query something like this:\n\nobjectType = Laptops AND \"Assigned User\" = {{issue.Employee}}\n",
"comments": [
{
"author": "Jacek",
"body": "Hi Rick\n\nThank you four your answer. Will try tomorrow when i am back at work.\n\nSo it looks that my idea with the aql for the devices in the custom field and the following automation was thought from the false perspective.\n"
}
]
},
{
"author": "Jacek",
"body": "Additonally here the attributes for Objects Laptops\n\n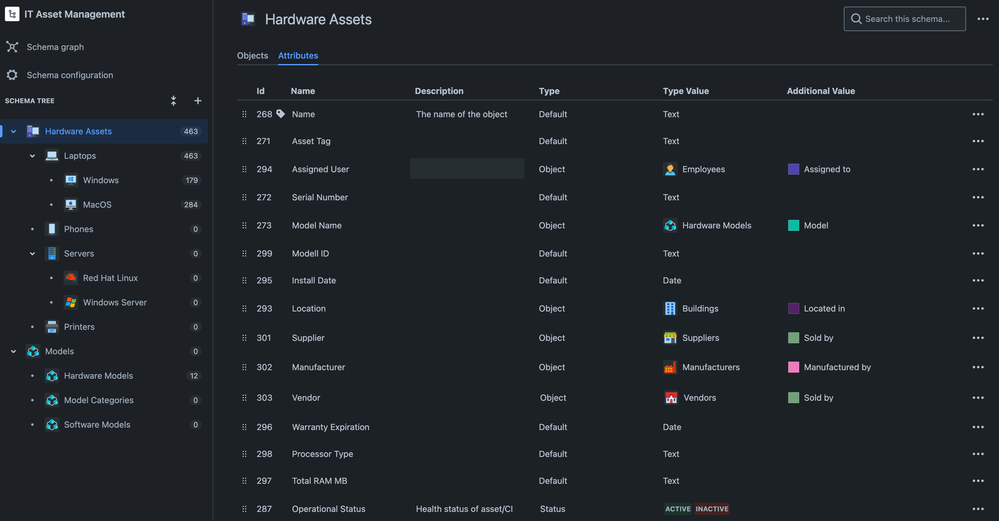\n\nCustomn Fiel Config\n\n\n\nAnd automation i tried today\n\n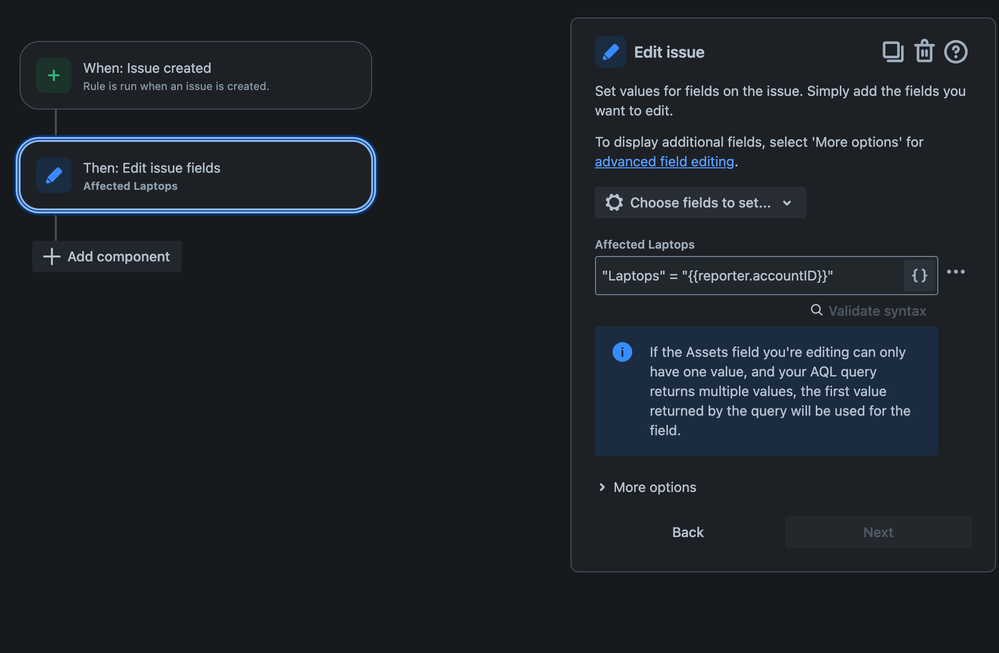\n\nAudit Logs\n\n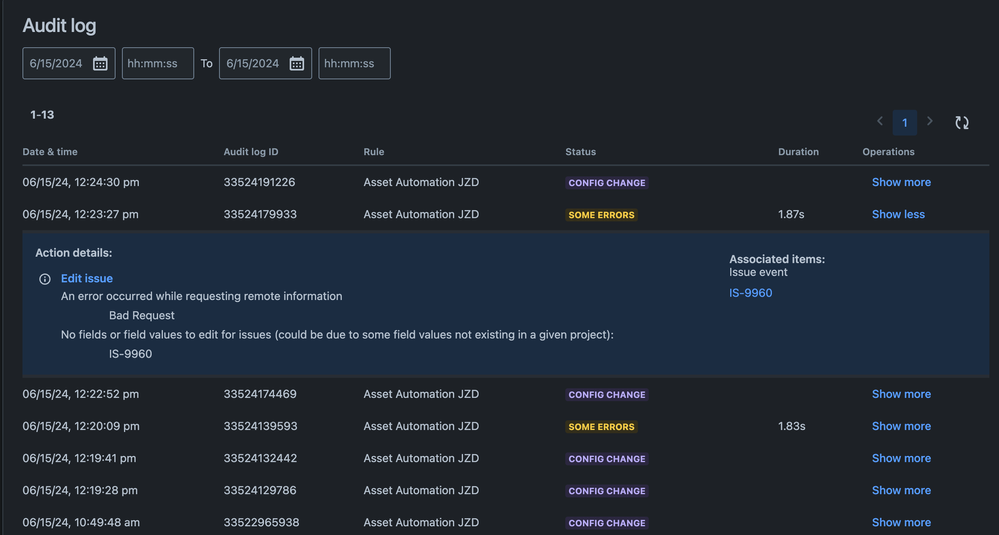\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-for-JSM-Assets-JSM/qaq-p/2727882
| null |
{
"author": "Jill Vieregge",
"title": "How to use Jia automation Slack message formatting to show cascading fields",
"body": "I have a cascading cf (Domain/Sub-Domain).\n\nI figured out how to report on slack via Jira automation the Domain\n\nIssue reported for Domain = {{customfield_12330.value}}\n\nAny idea how I can do this for the Sub-domain?\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Jill Vieregge](/t5/user/viewprofilepage/user-id/4540914)\n\nTo access the child of the cascading field, please try this:\n\n```\n{{issue.customfield_12330.child.value}}\n```\n\nAnd FYI...to learn about the content and structure of smart values available for an issue, this how-to article can help. The idea is to call the REST API function with a browser tab to query the issue with expanded names, and then review the results.\n\n<https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Jill Vieregge",
"body": "Worked great. thanks\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-use-Jia-automation-Slack-message-formatting-to-show/qaq-p/2727426
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Katherine Lord",
"title": "Using Automation to update field",
"body": "Struggling with the json to update a field.\n\nTrying to copy the value from a Label type field (text) to a asset field. Trying to use automation so we don't have to manually update all the tickets now that we have this information in assets.\n"
}
|
[
{
"author": "Nicolas Grossi",
"body": "[@Katherine Lord](/t5/user/viewprofilepage/user-id/5281149) You might take a look at this link: <https://community.atlassian.com/t5/Jira-questions/Jira-automation-using-quot-Edit-issue-quot-to-update-a-custom/qaq-p/2182398>\n\nHTH\n\nNicolas\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Using-Automation-to-update-field/qaq-p/2726541
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Syd Heller",
"title": "Automation related issues condition match JQL throws errors when checking for null/empty value",
"body": "Hi all,\n\nI have an Automation and I am trying to check on related issues that also meet another criteria (that they are not closed) but I am having trouble with the Matching JQL field.\n\nDoes anyone have any ideas what JQL I could use here?\n\n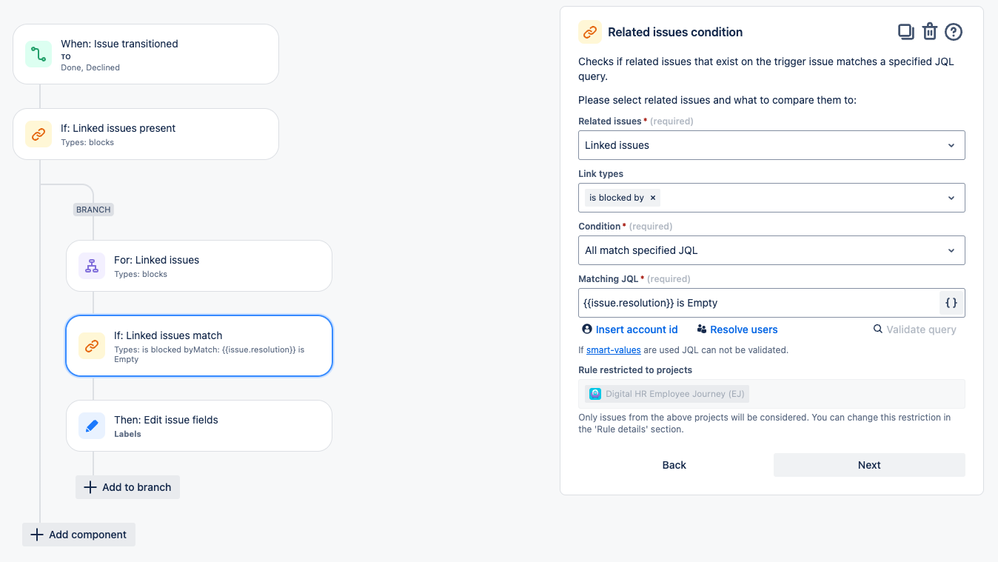\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Syd Heller](/t5/user/viewprofilepage/user-id/5330871)\n\nThe \"matching JQL\" for that Related Issues condition must be well-formed JQL. That is...\n\n```\n<some_Jira_field> <some_operator> <some_value> ...and so on\n```\n\n{{issue.resolution}} cannot be on the left-hand side of the JQL as that would try to compare a value to another value.\n\nPlease try this instead:\n\n```\nresolution IS EMPTY\n```\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Syd Heller",
"body": "Yup that worked, amazingly simple, thanks!\n"
}
]
},
{
"author": "Nicolas Grossi",
"body": "[@Syd Heller](/t5/user/viewprofilepage/user-id/5330871) Could please elaborate ? What errors are you getting ? Also Resolution is empty is different than Issues not closed .\n\nNicolas\n",
"comments": [
{
"author": "Syd Heller",
"body": "Sure, apologies, here is the error I get:\n\n\n\nSure, they are not the same. For us, Resolution is empty would be sufficient, or Issue is not \"Done\" or \"Declined\" would work too if it's easier.\n\nThanks for the help!\n"
},
{
"author": "Nicolas Grossi",
"body": "[@Syd Heller](/t5/user/viewprofilepage/user-id/5330871) Are you sure that the issue EJ-323 meets the criteria ?\n\nNicolas\n"
},
{
"author": "Syd Heller",
"body": "I don't know, because it throws that JQL error\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-related-issues-condition-match-JQL-throws-errors-when/qaq-p/2727543
| null |
{
"author": "Dimitri Cools",
"title": "Getting the issue linked to the parent with a specific linktype",
"body": "I'm really struggling trying to do something, what I thought was going to be rather easy..\n\nThe triggerissue has a parent, this parent has linked issues, with different lintypes, and I (simply) need to retrieve the issue which is linked (to the parent) with a particular link type. (in my case: \"External-Internal\")\n\nI've been trying multiple angles of logic but all fails.. \nMost hopeful I came up with was this, but it doesn't work:\n\nFor parent:\n\n{{issue.issuelinks.type.split(\",\").match(\"(External-Internal)\").outwardIssue.key}}\n\nany help or suggestions would be highly appreciated !\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Dimitri Cools](/t5/user/viewprofilepage/user-id/3928120)\n\nShort answer:\n\nFor this scenario, I recommend using a Lookup Issues action with JQL and the linkedIssues() function for the specify link type to find the issues, then get the keys from the lookup result:\n\n<https://support.atlassian.com/cloud-automation/docs/jira-automation-actions/#Lookup-issues> \n<https://support.atlassian.com/jira-software-cloud/docs/jql-functions/#linkedIssues-->\n\nMore information...\n\nFor the expression you show, {{issue.issuelinks.type}} would already be a list, and so the split() is not needed. But even then, the match() shown could not return the entire, linked issue record as it would only be matching on the \"type\" attribute.\n\nIn my experience, the smart value {{issue.issuelinks}} is one that does not load all of the data for the issues in all contexts. Sometimes the data must be loaded into a variable for parsing / filtering. Thus to perform that filtering on the type, the entire list of linked issues would need to be deserialized into a text string, stored in a created variable, filtered with a dynamic regular expression with match(), and then parsed to extract the keys.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Getting-the-issue-linked-to-the-parent-with-a-specific-linktype/qaq-p/2725904
| null |
{
"author": "shelleyc",
"title": "Calculating Number of Days within a Service Contract that are within a Fiscal Year",
"body": "Scenario:\n\nOur program has service contracts that don't necessarily follow our fiscal year (July 1 - June 30). The service contracts can be anything ranging from Jan 1 - Dec 31, 9/15 - 9/14 etc. They are all a year in length. We have a service fee (Biotics Fee) that we charge annually. This varies by program. What I need to know is how many days in the service period fall within the Fiscal Year so that I can calculate how much of that fee is captured in this Fiscal Year (and ultimately in either the previous or next FY as well). Once I have the days in Fiscal Year, I can pretty easily figure out the rest. I can either trigger this by an automation to run once a day or have some sort of calculated field (but I couldn't find that available to use)\n\nI have the following fields:\n\nService From: (DATE) Sept 01, 2024\n\nService To: (DATE) Aug 31, 2025\n\nFiscal Year Start Date: July 01, 2024\n\nFiscal Year End Date: June 30, 2025\n\nBiotics Fee: 18,000\n\nDays in Fiscal Year: ???\n\nFee in FY: ???\n\nI know from an Excel formula that the days in FY should be 303 and the Fee in FY should be 14942.47. I took the Excel Formula which was:\n\n=MAX(0,MIN($B2,DATE(2025,6,30))-MAX($A2,DATE(2024,7,1))+1)\n\nwhere B2 is Service To and A2 is Service From and tried to put that into jQL like this:\n\nMin({{issue.Service To}},{{Issue.Fiscal Year End Date}})) - MAX({{Issue.Service From}}, {{Issue.Fiscal Year Start Date}}+1)\n\nWhich actually does run, but the result isn't correct (it shows -31).\n\nAny help would be appreciated!\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@shelleyc](/t5/user/viewprofilepage/user-id/5131983)\n\nComparing what you show, your smart value expression does not match the spreadsheet formula: the first part is missing the outer MAX(0, ...) before performing the subtraction.\n\nI also recommend writing each part to the audit log in your rule and comparing that to the spreadsheet results. That may clarify where there are other differences.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Calculating-Number-of-Days-within-a-Service-Contract-that-are/qaq-p/2726268
|
[
"cloud",
"jira-work-management",
"jira-work-management-cloud"
] |
{
"author": "Alain BEAULIEU",
"title": "How to keep version on specific issues when version is released",
"body": "Hi,\n\nThis is a special/non-standard case.\n\nWhen we release a version, this pop-up appears and we normally choose to push undone issues up to the next version:\n\n\n\nI want to create an automation rule triggered on the Version Released event. I want the rule to check every issue included in that release, and if the issue contains a given XYZ label, then **do not increase the version number** **even if in the above screenshot the option to move unresolved issues to a given version is selected**.\n\nIf that is not possible BEFORE the release, then AFTER the release I want the automation rule to check all the issues again but this time if the Labels field contains a label called ABC_STATUS, then:\n\n1. Remove the Resolution value in the issue;\n2. Return the issue to the ABC_STATUS status (a real status in our workflow);\n3. Revert the FixVersion to the one it had before the release. Note that our tickets have multiple versions in FixVersion (e.g. 9.30.001, 9.31.005, 9.32.002), so I only want the version concerned to be reverted.\n\nBasically, I want some specially labeled tickets to not move when a version is released and I'm not sure how to use branching with the right conditions in Automation.\n\nAnd I'm using Labels but it could be any field that might be used to identify and prevent these special issues to move up.\n\nIce cream cone to the first one with an answer.\n"
}
|
[
{
"author": "Rick Westbrock",
"body": "Is there a project setting which causes that dialog box when manually releasing a version? I ask because I have an automation rule which releases the newest unreleased version every Sunday and for unresolved issues it just leaves them the version so it feels like the automation rule \"Release version\" action doesn't trigger that check for unresolved issues like manually releasing does.\n\nIf you have a sandbox tenant I suggest that you try building your automation rule there and testing to see that it works as desired as you may not have to even account for this special case at all. If you don't have a sandbox then maybe create a new version to use for testing this.\n",
"comments": [
{
"author": "Alain BEAULIEU",
"body": "Interesting, but we wouldn't be shielded from someone actually releasing manually. Many people in our organization have the right to release versions. Of course we could document the new procedure in our process.\n\nI'll give it a shot. Thanks for the suggestion [@Rick Westbrock](/t5/user/viewprofilepage/user-id/604528) .\n"
},
{
"author": "Rick Westbrock",
"body": "Ah I didn't consider manual releases because my team's projects all use automation rules to release our weekly versions. I know that you can access the previous value of a field when using something like ScriptRunner but I don't know if that's possible in automation rules.\n\nI have a feeling that you won't be able to check the labels before release because from what I have seen with automation rules they don't start executing until after the triggering event has completed in which case it's too late to check the labels.\n\nWhile you can have the automation rule simply remove the new version to which the issue was added I have no idea whether the issue gets removed from the version which was released when the user selects the \"Move unresolved issues to\" option.\n\nI guess another option would be to create an automation rule which does the following:\n\n1. Presents a user prompt for the version name\n\n2. Release the version entered by the user in step #1\n\nUsers would trigger that automation rule from any issue instead of using the normal process to release a version. I could see this causing some friction for your users but I think at least it would accomplish your goal of not disturbing the versions in the issues. The downside would be that if there are other unresolved issues in the version being released those won't get moved to another version either.\n"
},
{
"author": "Alain BEAULIEU",
"body": "Thanks Rick. I spent all day today testing several solutions that would work while preserving the usage of the prompt. None of them worked. We're going to have to change our process to work around this issue I believe.\n"
}
]
},
{
"author": "Alain BEAULIEU",
"body": "I checked the following posts and I still don't know how to do this.\n\n<https://community.atlassian.com/t5/Jira-questions/What-is-included-in-quot-all-issues-fixed-in-this-version-quot/qaq-p/2600661>\n\n<https://community.atlassian.com/t5/Jira-questions/How-to-create-and-release-version-using-Jira-Automation/qaq-p/2568966>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-keep-version-on-specific-issues-when-version-is-released/qaq-p/2726460
|
[
"fixversion",
"release",
"version"
] |
{
"author": "Casey Enderlein",
"title": "Project Lead Smart Values for at mention via Automations",
"body": "**1.) Is there a smart value available to allow at mentioning project lead via comment for a given issue?** For this automation I have setup, I am able to successfully email the project lead using {{triggerIssue.project.lead.displayName}}. I know I can at mention assignee by using \\[\\~accountid:{{issue.assignee.accountId}}\\], therefore I tried using \\[\\~accountid:{{triggerIssue.project.lead.displayName.accountId}}\\] to at mention project lead. The comment posted as expected when rule triggered, but did not at mention project lead in the comments.\n\n**2.) Is there a smart value to hard code users to be at mentioned via comment in automation rule setup?** I have the account IDs for the users I want to be at mentioned in the comment any time rule triggers.\n\nMy intended use case is:\n\n1.) To send an at mention comment to the project lead when rule is triggered, as well as,\n\n2.) hard coding the at mentioning for two admins when rule is triggered\n\nThanks!\n"
}
|
[
{
"author": "Darryl Lee",
"body": "Hi [@Casey Enderlein](/t5/user/viewprofilepage/user-id/5429919) - I believe what you want for #1 (how to mention the project lead in a comment) is: **\\[\\~accountid:{{triggerIssue.project.lead.accountId}}\\]**\n\nFor #2, you should just be able to do:**\\[\\~accountId:abcd-1234-abcd-1234\\]** (where abcd-1234-abcd-1234 is the account ID of the user you want mentioned every time).\n",
"comments": [
{
"author": "Casey Enderlein",
"body": "thank you kindly! this answered both my questions - appreciate it!\n"
},
{
"author": "Darryl Lee",
"body": "Hey [@Casey Enderlein](/t5/user/viewprofilepage/user-id/5429919) - glad this worked! Would appreciate if you can Accept this answer.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Project-Lead-Smart-Values-for-at-mention-via-Automations/qaq-p/2725425
| null |
{
"author": "Bobby Arvanitakis",
"title": "Team-managed project automation to change Preset Approvers based on custom field",
"body": "Depending on a selected \"Division\" custom field, with options: Group X, Group Y. \nI want a specific person added as a Preset Approver.\n\nI managed to find the *customfield_10700* id that stores the approvers for that Approval step (different approvers for different statuses).\n\nIn my automation, if Division = Group X, I want to populate the Preset approver field with the reporter (as an example):\n\n```\n{ \"fields\": { \"customfield_10700\": [ { \"value\": \"<accountid>\" } ] }}\n```\n\nWhere \\<accountid\\> is the approver's account id.\n\nIn my testing, if an approver is already in this custom field and I run this automation, the current approver is removed, but the new approver isn't added. The automation runs without reported errors.\n\nWould love some help! :)\n"
}
|
[
{
"author": "Bobby Arvanitakis",
"body": "Figured it out!\n\n```\n?{\"update\":{\"customfield_10700\":[{\"set\":[{\"accountId\":\"5f241224cdb7b4001bd41227\"}]}]}}\n```\n",
"comments": null
},
{
"author": "Bobby Arvanitakis",
"body": "I've tried the following without success:\n\n```\n{\"update\":{\"customfield_10700\":[{\"set\":[{\"approvers\":\"62b9844d268cac6e31c355ee\"}]}]}}\n```\n\n```\n{\"update\":{\"customfield_10700\":[{\"set\":[{\"value\":\"62b9844d268cac6e31c355ee\"}]}]}}\n```\n\nAll run without errors, but the approver doesn't change.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Team-managed-project-automation-to-change-Preset-Approvers-based/qaq-p/2725414
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Hiromichi Kikuchi",
"title": "Jira automation for upcoming due date",
"body": "I want to set up an automated email that will send you an email for the upcoming due dates in the beginning of the week for things that are due that week. for example I want to send out an individual email to each assignee on Monday of all of the issues they have due that week. I want each individual assignee to only get the issues due to them in that week.\n"
}
|
[
{
"author": "Aron Gombas _Midori_",
"body": "You can [create a saved filter](https://support.atlassian.com/jira-software-cloud/docs/manage-filters/) with a query something like:\n\n```\nassignee = currentUser() and dueDate > startOfWeek() and dueDate < startOfWeek(\"7d\")\n```\n\nand then subscribe it.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Jira-automation-for-upcoming-due-date/qaq-p/2725246
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Marc Schadee",
"title": "Help with how to use Jira Automation to find distinct sprints for an Epic's children",
"body": "Hi!\n\nI could use some help with finding all sprints that work for an epics children\n\nI use this lookup \"Epic Link\" = {{triggerIssue.key}} AND Sprint is not empty \n\n{then i create a variable {lookupIssues.sprint.name.distinct}}\n\nWhen i print to the audit log i get this \n\nRPT-2024_Sprint08, RPT-2024_Sprint09, RPT-2024_Sprint10, RPT-2024_Sprint08, RPT-2024_Sprint09, RPT-2024_Sprint10, RPT-2024_Sprint11, PM1 Backlog, RPT-2024_Sprint10, RPT-2024_Sprint11, RPT-2024_Sprint11, RPT-2024_Sprint08, RPT-2024_Sprint07, RPT-2024_Sprint08\n\nwhich is great except for the duplicates (work items that were in 2 sprints)\n\nSo the issue is I am trying to parse this list (or use substring) to find just unique sprints but nothing im doing is working so far.\n\nMy current idea was to use substring but that seems to not work with the list and returns \\[\\] \\[\\] \\[\\] \\[\\]\n\nAny suggestions on how to parse this list? my Thought was to use a character count as there is a standard naming length that does not change but open to help\n"
}
|
[
{
"author": "Marc Schadee",
"body": "so took some thought but for anyone trying to parse unique sprints that an epic has work that has been this is a way\n\nlookup -\\> \"Epic Link\" = {{triggerIssue.key}} AND Sprint is not empty\n\ncreate variable (smart value) {{#lookupIssues}}{{#sprint}}{{#if(not(equals(state,\"future\")))}}{{name}},{{/}}{{/}}{{/}}\n\n(I only wanted current/closed sprints youll need to play with above if you want different)\n\ncreate variable (smart value) {{firstvariablename.split(\",\").distinct}}\n",
"comments": [
{
"author": "Bill Sheboy",
"body": "Hi [@Marc Schadee](/t5/user/viewprofilepage/user-id/5377588)\n\nI am glad to learn you found the workaround, and...\n\nFYI, the distinct was working as expected: it just did not match your scenario because the sprint field can contain multiple values, and \"distinct\" was over the sets of values in this case.\n\nFor example, if the issues had these sprint values:\n\n* issue A: sprint 1, sprint 2, sprint 3\n* issue B: sprint 2\n* issue C: sprint 4\n* issue D: sprint 2\n\nThen using this:\n\n{{lookupIssues.sprint.name.distinct}}\n\nWould produce the following, with a list of arrays, and not necessarily in this ordering:\n\n\\[sprint 1, sprint 2, sprint 3\\], \\[sprint 2\\], \\[sprint 4\\]\n\nThe list of sprints for issue A is *distinct as a set*, even though it contained overlapping sprints with other issues.\n\nAs you found, the workaround is to expand everything into a variable so it can be reprocessed as a list for using distinct later. One gotcha for this technique is ensuring the delimiters are consistent, helping split() to work predictably later. The fix for that is often to replace(\", \", \",\") before the split attempt.\n\nKind regards, \nBill\n"
},
{
"author": "Marc Schadee",
"body": "Hey [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) !\n\nI missed mentioning a step! in the first variable i add commas (bolded below) deliberately to have a comma between each sprint iteration since you can get multiple sprints as 1 value but they are always separated as a comma (that im aware),\n\ne.x.\n\n\\[Sprint 1\\],\\[Sprint 1, Sprint 2\\],\\[Sprint 2\\]\n\n{{#lookupIssues}}{{#sprint}}{{#if(not(equals(state,\"future\")))}}{{name}}**,** {{/}}{{/}}{{/}} \n\nto get (because its now a string we lose the \\[\\])\n\nSprint 1,Sprint 1,Sprint 2,Sprint 2\n\nthen run {{firstvariablename.split(\",\").distinct}}\n\nSprint 1, Sprint 2\n\nand thank you! Im pretty certain i got that last bit off of one of your prior comments!\n"
},
{
"author": "Marc Schadee",
"body": "Really the best part was getting this to work outside of a for each branch\n"
},
{
"author": "Joanna Weir",
"body": "[@Marc Schadee](/t5/user/viewprofilepage/user-id/5377588) \\& [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) , I am having trouble getting this to work. Can you help.\n\nI am looking for a distinct list of sprints in the future. Note: since the sprint field can contain multiple values, I want a distinct list of sprints using the LAST Sprint value.\n\nHere is my automation rule:\n\n1. When: Scheduled Daily\n\n2. Then: Create Variable called \"SprintList\". Smart Value = {{#lookupIssues}}{{#sprint}}{{#if(equals(state,\"future\"))}}{{name}},{{/}}{{/}}{{/}}\n\n3. And: Create Variable called \"DistinctSprint\". Smart Value = {{SprintList.split(\",\").distinct}}\n\n4. And: Send email . In the content/body of the email i have: {{DistinctSprint}}\n\n**Result**: This produces an empty email.\n\nPlease advise.\n"
},
{
"author": "Marc Schadee",
"body": "[@Joanna Weir](/t5/user/viewprofilepage/user-id/5583441) Can you use the log action to return {{SprintList}} between step 2 and 3 and tell me what that says? \n\nits odd that its returning nothing.. it should return atleast 1 \",\"\n"
},
{
"author": "Marc Schadee",
"body": "[@Joanna Weir](/t5/user/viewprofilepage/user-id/5583441)\n\noh i think i see the issue now \nI dont see how you are looking up the information initially as you dont do it from a triggered epic like i did in step one\n\nExample \nLookup -\\> \"Epic Link\" = {{triggerIssue.key}} AND Sprint is not empty\n\nI would first create a lookup or post what lookup you are using before step 2\n"
},
{
"author": "Joanna Weir",
"body": "[@Marc Schadee](/t5/user/viewprofilepage/user-id/5377588) , Thank you so much for responding\n\nHere is my updated automation rule:\n\n1. When: Scheduled Daily, running a JQL search: \"++sprint in futureSprints()++\"\n\n2. Then: Create Variable called \"SprintList\". Smart Value = ++{{#lookupIssues}}{{#sprint}}{{#if(equals(state,\"future\"))}}{{name}},{{/}}{{/}}{{/}}++\n\n3. And: Create Variable called \"DistinctSprint\". Smart Value = ++{{SprintList.split(\",\").distinct}}++\n\n4. And: Send email . In the content/body of the email i have: ++{{DistinctSprint}}++\n\n**Result**: This produces an empty email.\n\nPlease advise.\n"
},
{
"author": "Marc Schadee",
"body": "[@Joanna Weir](/t5/user/viewprofilepage/user-id/5583441) \n\nI would like you to run the jql search in jira as close to the same as what you have in automation and tell me if you return any results\n"
},
{
"author": "Marc Schadee",
"body": "If you have results i would like you to add a log action to your script after step 2\n\n \n\nthen go to your log and tell me what it listed out \n\n<br />\n"
},
{
"author": "Joanna Weir",
"body": "[@Marc Schadee](/t5/user/viewprofilepage/user-id/5377588)\n\nThank you so much for responding. When I validate the Scheduled trigger using JQL, i get 126 results.\n\nHere is my updated automation rule \\& results, per your request:\n\n1. When: Scheduled Daily, running a JQL search: \"++sprint in futureSprints()++\"\n\n2. Then: Create Variable called \"SprintList\". Smart Value = ++{{#lookupIssues}}{{#sprint}}{{#if(equals(state,\"future\"))}}{{name}},{{/}}{{/}}{{/}}++\n\n3. And: Add value to the audit Log: ++SprintList: {{SprintList}}++\n\n4. And: Create Variable called \"DistinctSprint\". Smart Value = ++{{SprintList.split(\",\").distinct}}++\n\n5. And: Send email . In the content/body of the email i have: ++{{DistinctSprint}}++\n\n**Result**:\n\n1. This produces an empty email.\n2. The Audit Log says: \n\nPlease advise.\n"
},
{
"author": "Marc Schadee",
"body": "[@Joanna Weir](/t5/user/viewprofilepage/user-id/5583441)\n\nClick validate query on the when scheduled box for me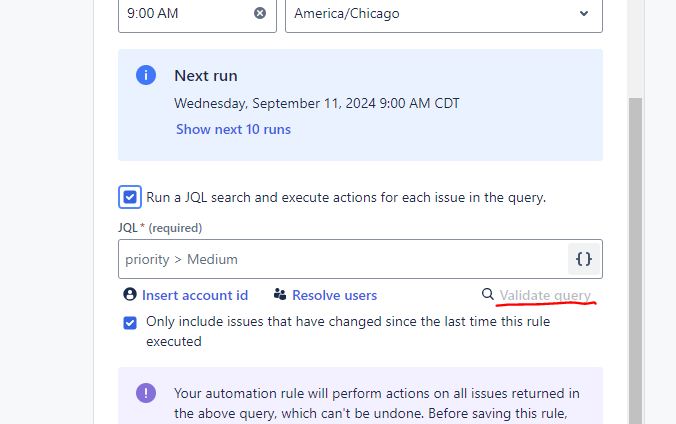\n\ndoes that return the same amount of results as the jql query?\n\nif so \nI would then move the lookup to a separate action rather than a part of the scheduled action and try again \nif you do this please add a log action for the lookup as well\n"
},
{
"author": "Marc Schadee",
"body": "Sorry if this is taking a bit I dont have a direct answer so im trying to troubleshoot why the lookup is not being parsed by the variable\n"
},
{
"author": "Joanna Weir",
"body": "[@Marc Schadee](/t5/user/viewprofilepage/user-id/5377588) , Thanks for you help Marc. I played around more and finally got it to work. My solution is posted here:\n\n1. Scheduled Trigger with JQL: sprint in futureSprints()\n\n2. Then: Create Variable called LastSprint: {{#Issues}}{{sprint.name.last}},{{/}}\n\n3. Then: Create Variable called Last SprintDistinct: {{LastSprint.split(\",\").distinct}}\n\n4. Send Email\n"
},
{
"author": "Marc Schadee",
"body": "Ah interesting! \n\nThank you for sharing and glad you got it to work!\n"
},
{
"author": "Bill Sheboy",
"body": "Hi [@Joanna Weir](/t5/user/viewprofilepage/user-id/5583441) -- Welcome to the Atlassian Community!\n\nSorry for the delay in responding as I have been offline for a few weeks.\n\nI am glad to learn you got something working, and as a follow-up...Are you using Jira Server / Data Center or Jira Cloud?\n\nI ask because the **{{issues}}** (please note the plural) smart value is only supported for Jira Server / Data Center automation, bulk-handling, and not for Jira Cloud. Using it may lead to unexpected results.\n\nFor Cloud, the Lookup Issues action is used for bulk-handling of issues.\n\nKind regards, \nBill\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Help-with-how-to-use-Jira-Automation-to-find-distinct-sprints/qaq-p/2725416
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Venkat",
"title": "Jira Automation: how to send a webrequest to an endpoint secured with OAuth authentication",
"body": "Hi,\n\nI have created an automation to run when an issue's priority is updated. The action is to reach an endpoint which is protected by OAuth Authorization. How can I achieve this? Is there a way to generate the access token and use it for the Send web request action\n\n\n"
}
|
[
{
"author": "Rick Westbrock",
"body": "Web request actions have smart values which allow you to access the response data so if the token is returned in the \"token\" element of the JSON response body then you can access it using this smart value: {{webResponse.body.token}}\n\nIf you expand the \"How do I access web request response values in subsequent rule actions?\" section at the bottom of the web request it mentions the {{webResponse.body}} smart value and how to access its elements (along with several other smart values). I tried pasting that text but it won't let me save my comment so here it is in an image instead:\n\n\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Jira-Automation-how-to-send-a-webrequest-to-an-endpoint-secured/qaq-p/2724629
| null |
{
"author": "Ewoud van der Werf",
"title": "Cannot push to bitbucket from Github Desktop",
"body": "Hi folks,\n\nI'm relatively new to git, I'm mostly used to Github with Github Desktop. I'm now collaborating with a team using Bitbucket, I had some trouble configuring everything but after following [this short video](https://youtu.be/FO-LLKc2GC8) I got Github Desktop working with Bitbucket.\n\nHowever I cannot push my changes.\n\nWhen I try in the Desktop client it says: \"Authentication failed. Some common reasons include:...\"\n\nWhen I try to do git push origin it says: \"remote: The requested repository either does not exist or you do not have access. If you believe this repository exists and you have access, make sure you're authenticated. fatal: unable to access '[https://bitbucket.org/\\*\\*\\*\\*\\*\\*\\*/\\*\\*\\*\\*\\*\\*\\*\\*\\*.git/](https://bitbucket.org/*******/*********.git/)': The requested URL returned error: 403\"\n\nCould you help me with this? It's probably a simple issue I'm overlooking. \nThe steps I used to clone the project with HTTPS are in the video I mentioned.\n"
}
|
[
{
"author": "Patrik S",
"body": "Hey [@Ewoud van der Werf](/t5/user/viewprofilepage/user-id/5583129) ,\n\nand welcome to the Community!\n\nBased on the error message you are receiving, the issue seems to be related to authentication.\n\nThe URL in the logs suggests you're using HTTPS to interact with the repository.\n\nIn this case, if you confirmed that you have write access to that repository, could you please verify if you're using an [app password](https://support.atlassian.com/bitbucket-cloud/docs/app-passwords/) (not your account password) in your Github Desktop configuration to authenticate the git operation ? The app password is used on behalf of your account password when authentication git activity and API calls.\n\nIf you haven't already, please create a new app password and try pushing the content again.\n\nThank you, [@Ewoud van der Werf](/t5/user/viewprofilepage/user-id/5583129) !\n\nPatrik S\n",
"comments": [
{
"author": "Ewoud van der Werf",
"body": "Hi Patrik,\n\nThank you for your help! I was able to resolve the issue yesterday, it turned out I simply didn't have the permissions to write to the repository yet.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Cannot-push-to-bitbucket-from-Github-Desktop/qaq-p/2801762
|
[
"bitbucket-cloud",
"cloud",
"github",
"push"
] |
{
"author": "Muhammad Hasham",
"title": "fatal: Could not read from remote repository.",
"body": "We are not able to pull any code change from remote origin\n\n\n\nWhen we checked the remote its already there\n\n\n\nAnd we haven't added any Access key or SSH key against our repository or workspace\n\n\n\nPlease kindly share, how can we resolve the issue.\n"
}
|
[
{
"author": "Syahrul",
"body": "G'day, [@Muhammad Hasham](/t5/user/viewprofilepage/user-id/5567037)\n\nI highly suggest you check our guidelines below on how to configure SSH with Bitbucket:\n\n[SSH key for Linux](https://support.atlassian.com/bitbucket-cloud/docs/set-up-personal-ssh-keys-on-linux/)\n\nPlease make sure to add your key under your Personal Bitbucket account and your local SSH agent by using the ssh config.\n\nLet me know how it goes.\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/fatal-Could-not-read-from-remote-repository/qaq-p/2801696
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "UShankar87",
"title": "Resolving merge conflict & Automatically marking PR as remotely merged.",
"body": "**Trying to understand why it works.**\n\nPre-Req: **Branch creation**: Main -\\> New Release Branch (release/2024-12-12) - \\> New feature Branch (feature/NewMenu)\n\nI add my changes to feature/NewMenu. Raise a PR from feature/NewMenu -\\> develop Where I'm asked to resolve the merge conflicts, since other developer would have merged their feature branch to develop branch.\n\nI follow below steps in git console:\n\n1. git branch o/p shows : feature/NewMenu\n2. git pull\n3. git checkout develop\n4. git pull\n5. git merge feature/NewMenu o/p: shows auto-merge conflicts I resolve the conflicts.\n6. git checkout -b mergefix/Resolved.\n7. git add \\& commit\n8. git push\n\nWhen PR is merged from mergefix/Resolved to develop. The other conflicted PR is not marked as remotely merged.\n\n++**If I modify the last 3 steps it works as expected:**++\n\n1. git add \\& commit\n2. git checkout -b mergefix/Resolved.\n3. git push\n\nWhy does this work? What is the difference ?\n"
}
|
[
{
"author": "Patrik S",
"body": "Hello [@UShankar87](/t5/user/viewprofilepage/user-id/3485351) ,\n\nand welcome to the Community!\n\n* **Original steps**\n\nIn the **original steps** you are creating a new branch `mergefix/Resolved` after resolving conflicts and then committing your changes only to this new branch.\n\nWhen you create a new branch, Git uses the current HEAD as the base for that branch. Hence, when you create `mergefix/Resolved`, it is based on the `develop` branch after resolving the merge, and your commit containing conflict resolutions is only on this new branch.\n\nHowever, because the conflicts were resolved and committed **after** switching to a new branch, Git does not recognize the original merge as having been completed on the `develop` branch. It essentially sees the conflict resolution as a separate line of development from the initial merge attempt from `feature/NewMenu`.\n\n* **Modified steps**\n\nOn the other hand, in the **modified sequence** , you resolve conflicts and commit the changes **while still on the** `develop` branch before creating the new branch `mergefix/Resolved`. When you commit after resolving conflicts on the `develop` branch, Git records the merge as having been completed on `develop`. Creating the branch `mergefix/Resolved` afterward is suitable for pushing and raising a PR, but it does not affect how the merge commit itself is perceived.\n\nThe modified steps work as expected because the merge resolution is committed directly on the `develop` branch. This allows Git to recognize that the conflict from `feature/NewMenu` to `develop` has been resolved.\n\nI hope that helps to clarify! Should you have any questions, let us know!\n\nThank you, [@UShankar87](/t5/user/viewprofilepage/user-id/3485351) !\n\nPatrik S\n",
"comments": [
{
"author": "UShankar87",
"body": "Thank you for the insights. [@Patrik S](/t5/user/viewprofilepage/user-id/4603309)\n"
},
{
"author": "Patrik S",
"body": "You're very welcome!\n\nFeel free to reach out if you ever need help in the future :)\n\nThank you, [@UShankar87](/t5/user/viewprofilepage/user-id/3485351) ! \nPatrik S\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Resolving-merge-conflict-amp-Automatically-marking-PR-as/qaq-p/2801689
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Karlen Kishmiryan",
"title": "How to create a reviewer group?",
"body": "Hi\n\nI just learned about the CODEOWNERS. However, I'm struggling to achieve the functionality I need. That is, to **require** at least one approval from each user group for merging the PR (2 user groups, 2 approvals in total).\n\nI have created a CODEOWNERS file, which has a single file pattern (\\*) mapped to two user groups. When I create a PR, I can see that one person from each team gets randomly added to the PR as a reviewer. In my repo settings, I have a \"merge to branch\" restriction, which requires at least 2 approvals. However, it doesn't force the approvals to be exactly from the same two people who have been randomly selected. In case ANY two people approve it, then it can be merged (this is what I want to avoid).\n\nI have also tried setting the restriction not on reviewers, but specifically on default reviewers. In this case it also didn't work, because the randomly selected two people never become part of the default reviewers \"on-the-fly\". So, even if they approve the PR, it's still pending on default reviewers' approvals.\n\nIs there any way at all to achieve this behavior? Am I missing anything?\n\nThanks\n"
}
|
[
{
"author": "Ben",
"body": "Hi Karlen,\n\nThe nature of code owners is that it will automatically assign users associated with the specific file path/pattern in your repository. When you use \\* it will mean that any users defined here are owners of all file paths within your repository - hence why it is randomly assigning users from this pool.\n\nI'd suggest more tightly defining paths to ensure that only certain users are added, rather than have this be random.\n\nThis is covered in our documentation:\n\n* <https://bitbucket.org/blog/code-owners>\n\nI would also suggest reviewing our custom merge checks documentation, as you may be able to write a Forge app to cover your merge check use case:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/set-up-and-use-custom-merge-checks/>\n\nIf you need more support, please raise a support ticket using the Premium company workspace URL that you are a member of, as community is a public forum which is not appropriate to share potentially sensitive information regarding your repo/users inside:\n\n* <https://support.atlassian.com/contact/#/>\n\nIf you have issues raising a support ticket, please let me know which timezone you are in so I may raise one on your behalf with a support team in your geolocation.\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": [
{
"author": "Karlen Kishmiryan",
"body": "Hi Ben, \nThank you for the reply.\n\nMy ultimate goal is to make sure that every change gets reviewed by two distinct teams before it can be merged. Who will review from each team is not important for me, hence I'm just specifying two user groups for all files with a random selection strategy.\n\nI think the shortcoming to achieve this is in the merge check functionality. If the people, who are selected via CODEOWNERS would become **default reviewers** rather than just reviewers, then I could use the merge check based on default reviewers. It would force the approvals to be from these people only in order to proceed with merge. But it's not the case and as you mentioned, perhaps I'll need a Forge app to perform the logic I need. Unfortunately, at this point of time, we don't have a capacity to work on it. So I guess I'll just have to give up on this and look for other approaches.\n\nThanks\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/How-to-create-a-reviewer-group/qaq-p/2801651
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "lukasz_wojcik",
"title": "How does the pricing work for large pipeline output",
"body": "Hi, I'm working on a project that is a PITA to build as it is resource intensive to build. I'd like to move that process to pipelines. I need help understanding pricing details. So let's assume, that output of the build stage is around 100GB in volume, and each build takes around 4h. I'm currently on free plan. Only 2 BB users need access to this feature. What would be my optimal plan, what would I be charged for. Is LFS the same as build artifacts size or does it refer to binaries that sometimes people include in their GIT repos ?\n"
}
|
[
{
"author": "Ben",
"body": "Hi lukasz_wojcik,\n\nMay I know what you mean by the \"output of the build stage is around 100GB in volume\"? Are you referring to storage in the repository, or storage as a build artifact?\n\nThe repository size limit is 4GB across all plans, LFS limit is 10GB for Premium (you can purchase additional 100GB chunks for an extra $10 per month, per 100GB chunk) - more on LFS below:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/use-git-lfs-with-bitbucket/>\n\nLFS is not the same as build artifact size. An artifact is simply something you store as a result of a build step so that it can be passed to another build step, the storage limit is 1GB for artifacts. LFS is storage outside the repository for large binary files.\n\nAdditionally, the maximum build time across all plans is 2 hours. If you need additional build resources to speed up the processing time - you can make use of 4x/8x pipelines steps which is a Premium feature (note that this consumes 4 times/8 times the build minutes as a regular step):\n\n* <https://bitbucket.org/blog/announcing-our-new-ci-cd-runtime-with-up-to-8x-faster-builds>\n\nPremium has the most amount of build minutes available per month (3500) and more can be purchased in chunks ($10 per month/1,000 minutes) - I'd highly recommend reviewing our plans page to determine the plan that is right for you:\n\n* <https://www.atlassian.com/software/bitbucket/pricing>\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/How-does-the-pricing-work-for-large-pipeline-output/qaq-p/2801637
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Venkat",
"title": "Jira Automation: Can we store the response of the web request and fetch it in the subsequent trigger",
"body": "Hi,\n\nIs there a way to store the web request response somewhere and fetch it during the next time this automation runs?\n\n**My use case**: I have generated an OAuth access token by sending a web request. If I am able to store it somewhere, then I need not generate it again, instead fetch it from where I have stored in the previous time when this automation was triggered.\n"
}
|
[
{
"author": "YY Brother",
"body": "Hi [@Venkat](/t5/user/viewprofilepage/user-id/5243251)\n\nWelcom to our Community.\n\nIt's not recommended to store OAuth access token in somewhere because it's a so sensitive information and usually is encrypted.\n\nI suggest each time you need, then you fetch it.\n\nThanks,\n\nYY?\n",
"comments": [
{
"author": "Venkat",
"body": "Hi [@YY Brother](/t5/user/viewprofilepage/user-id/4083879)\n\nI understand, but is there a way to store non sensitive data in automation rules?\n\nAnd is there a way to reach an endpoint which uses OAuth authentication, using \"Send Web Request\" Action?\n\nThanks,\n\nVenkat\n"
},
{
"author": "YY Brother",
"body": "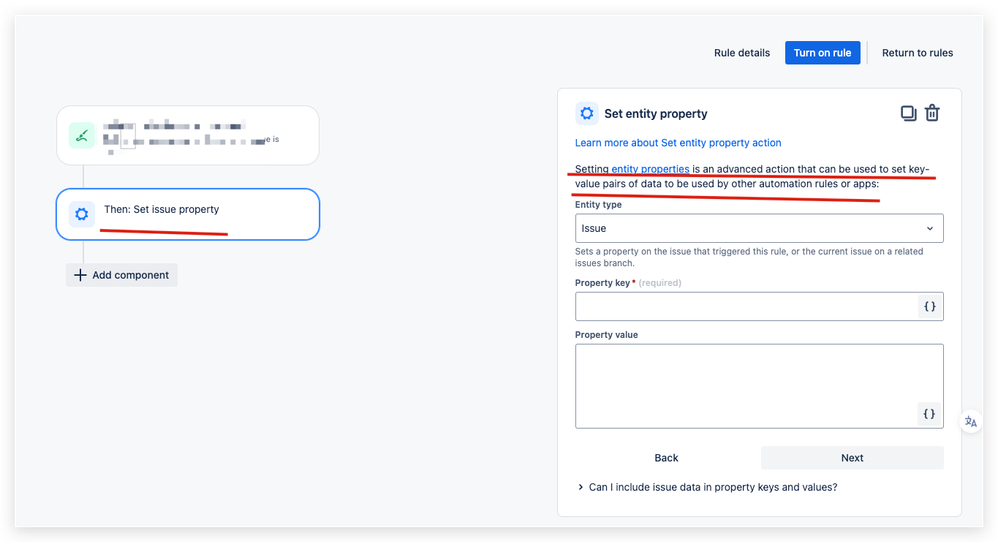\n"
},
{
"author": "Darryl Lee",
"body": "Yep, Issue Properties, Project Properties, these are all fine places to store non-sensitive data.\n\nBut IF YOU ARE TEMPTED to put an OAuth token in there, you should be aware that any user who has view access on the issue or project, can view all associated properties via the REST API.\n\nExamples:\n\n<https://YOURSITE.atlassian.net/rest/api/3/issue/BUG-6/properties>\n\n<https://YOURSITE.atlassian.net/rest/api/3/project/BUG/properties>\n\nSo again, you do not want to store anything like an Oauth token there, because it is definitely NOT protected.\n"
},
{
"author": "Venkat",
"body": "Hi [@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322)\n\nYes, I Agree as you said. Its not advisable to store sensitive values in entity properties.\n\nAs suggested by [@YY Brother](/t5/user/viewprofilepage/user-id/4083879), Fetching an Access access token every time is not suitable for my case as this automation will be triggered whenever a ticket's priority/status is updated (due to throttle limit)\n\nBut then, is there any other way to reach an endpoint which uses OAuth as authentication method through \"Send Web Request\"? Do you have any inbuilt OAuth Access token generation flow for Automations?\n\nRegards,\n\nVenkat\n"
},
{
"author": "YY Brother",
"body": "\"Fetching an Access access token every time is not suitable for my case as this automation will be triggered whenever a ticket's priority/status is updated (due to throttle limit)\"\n\nPlease detail your requirement so that we can assess if automation fits or not.\n"
},
{
"author": "Darryl Lee",
"body": "Doing some Googling, I found an interesting approach to this problem by [@Brandon Davies](/t5/user/viewprofilepage/user-id/5305960) , using Assets to manage and store the tokens.\n\n* [The Secure Way to Manage OAuth API requests in Jira Automation](https://www.linkedin.com/pulse/secure-way-manage-oauth-api-requests-jira-automation-brandon-davies-ublvc/)\n\nThe key is:\n> For security reasons, definitely remember to limit the access to the schema that this object resides in. You can access this by going to the Asset schema configuration and limit who can view the schema and edit it.\n\nBut I'm thinking, if you don't have Assets, what if you just created a very very small project called OAUTHKEYS to store the tokens, with access limited to you and other admins. If the automation runs as the Automation Account that also has access to that project, you could use it to store and rotate the tokens every 60-90 days or whatever works.\n"
}
]
},
{
"author": "Rick Westbrock",
"body": "See my answer linked below in another thread for how you can make a web request to send the OAuth credentials and access the returned token to use in the next web request action:\n\n<https://community.atlassian.com/t5/Automation-questions/Re-Jira-Automation-how-to-send-a-webrequest-to-an-endpo/qaq-p/2728931/comment-id/10862#M10862>\n",
"comments": [
{
"author": "Darryl Lee",
"body": "Hi [@Rick Westbrock](/t5/user/viewprofilepage/user-id/604528)\n\nYes, the {{webResponse}} smart value can be used in other web requests *in the same rule*.\n\nBut what [@Venkat](/t5/user/viewprofilepage/user-id/5243251) was asking for was a way to store an Oauth token so that it could be used in other rules.\n\nThat means storing it somewhere persistent, but also secure.\n"
},
{
"author": "Rick Westbrock",
"body": "Without seeing Venkat's automation rule my assumption was that they generated the token in some other fashion (such as Postman) instead of generating it with a web request action in the automation rule.\n\nI should have explained that in most cases the token has a limited lifetime so eventually that stored token will no longer be valid and the rule will need to request a new token anyway.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Jira-Automation-Can-we-store-the-response-of-the-web-request-and/qaq-p/2724637
| null |
{
"author": "Valeriu Ghisoiu",
"title": "Bitbucket Yaml file can contain Stages and Runners in the same time?",
"body": "Hello!\n\nBitbucket can support Stages also for Windows Runners?\n\n(more exactly to run runners under stages) \nMy idea is to have different steps for different actions without losing my already compiled data from the step before. (or lose time to compile it again).\n\n(I can't use a local Docker to transmit commands in the different steps and data not lose)\n\nThanks in advance,\n\nValeriu\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi Valeriu!\n\nYes, you can use stages with Windows self-hosted runners.\n\nYou still need to use the **runs-on** property in your yml for every step that you want to run on this runner. You can't define this on the stage level.\n> My idea is to have different steps for different actions without losing my already compiled data from the step before. (or lose time to compile it again).\n\nIf you're talking about files generated in a step, the stages are not going to help with this. Files generated in one step are not transferred to the next step (even if the steps are part of the same stage), unless you define them as artifacts.\n\nYou can check the documentation below for more info about artifacts and how you can define them in your yml file:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/use-artifacts-in-steps/>\n\nPlease feel free to reach out if you have any questions!\n\nKind regards, \nTheodora\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Bitbucket-Yaml-file-can-contain-Stages-and-Runners-in-the-same/qaq-p/2801543
|
[
"cicd",
"cloud",
"pipelines",
"runner",
"windows"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.