
question
dict | answers
listlengths 1
27
| url
stringlengths 66
601
| tags
listlengths 1
15
⌀ |
|---|---|---|---|
{
"author": "Joel_B",
"title": "Change detection constantly triggering",
"body": "We are running Bamboo *9.2.14 build 90213* and during a set of builds the bamboo service crashed and restarted. After that four builds are being constantly triggered. The logs are:\n\n```\n2024-06-18 00:24:50,453 INFO [10-BAM::PlanExec:pool-13-thread-3] [DefaultChangeDetectionManager] : Excluding changeset 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' from change log. \n2024-06-18 00:24:50,454 INFO [10-BAM::PlanExec:pool-13-thread-3] [ChangeDetectionListenerAction] : Change detection found 1 change for plan KI-PLN \n2024-06-18 00:24:51,154 INFO [10-BAM::PlanExec:pool-13-thread-3] [ChainExecutionManagerImpl] Build KI-PLAN-JOB1-1187 has been dispatched\n```\n\nHow to I stop this from happening?\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Joel,\n\nWelcome to Atlassian community.\n\nIf you are just looking to stop few particular builds you can go to the plan configuration of that plans and go to triggers tab and remove all the triggers for the specific plan and see if that helps.\n\n<https://confluence.atlassian.com/bamboo/triggering-builds-289276897.html>\n\nIf that does not help, we'll need to investigate if there is something else which is triggering the plans.\n\nRegards,\n\nShashank kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Change-detection-constantly-triggering/qaq-p/2729257 | null |
{
"author": "NealPorter",
"title": "Problems with LDAP connection on Old Bamboo 5.10.1",
"body": "Hi folks. I've had a recent security update within my company causing havoc with my existing (old/ancient Bamboo 5.10 CI system).\n\nThe security change has been to set the\n\nDomain Controller : LDAP server channel binding token requirements: to Always\n\nAnd\n\nDomain Controller : LDAP server signing requirements : to Require signing.\n\nAs a result we are getting error logs when attempting to log in of\n\n2024-06-14 16:04:24,062 ERROR \\[http-apr-8085-exec-13\\] \\[LDAPUserManagerReadOnly\\] Error retrieving user: '**XXXX** ' from LDAP server OURSERVER.LOCAL\\[**XX.XX.XX.XX**\\] com.atlassian.user.impl.ldap.repository.LdapConnectionFailedException: javax.naming.AuthenticationNotSupportedException: \\[LDAP: error code 8 - 00002028: LdapErr: DSID-0C09032F, comment: The server requires binds to turn on integrity checking if SSL\\\\TLS are not already active on the connection, data 0, v4563 \\]\n\nWe've tried changing over to the LDAPS port from 389 -\\> 636, but it then appears unable to find the system at all.\n\nDoes anyone know if there is a way to get the old Bamboo 5.10 etc, using the new LDAPS settings?\n\nI've looked over\n\n<https://confluence.atlassian.com/bamboo0510/integrating-bamboo-with-ldap-824480440.html>\n\nBut I've not been able to get any of its suggestions to help so far.\n"
} | [
{
"author": "Khushboo Gupta",
"body": "Hello [@NealPorter](/t5/user/viewprofilepage/user-id/1168903)\n\nWelcome to the Atlassian Community!\n\nMicrosoft has released a security advisory for LDAP channel binding and LDAP signing to be implemented as a way to increase security of the network communication between an Active Directory Domain Services (AD DS) or an Active Directory Lightweight Directory Services (AD LDS) and its clients. Please refer to the below article from Microsoft for complete details.\n\n[How to enable LDAP signing in Windows Server 2008](https://support.microsoft.com/en-us/help/4520412/2020-ldap-channel-binding-and-ldap-signing-requirement-for-windows)\n\nAs the LDAP server is now configured to require signed communication, simple bind request are rejected by the LDAP server.\n\nPlease try following the below steps:\n\n* Locked out of application. Try login as an administrator accounts and Configure User directories to use SSL.\n* For LDAPS to function, your LDAP server must have a valid SSL certificate installed. Ensure Bamboo server trust those certificates.\n* Make sure your LDAP server (e.g., Active Directory) is configured to support LDAPS on port 636. This might involve configuring the certificate on the LDAP server and ensuring the service is running and accessible over this port.\n* Since you mentioned that switching to port 636 makes the LDAP server unreachable, verify that there are no network firewalls or security groups blocking access to this port from your Bamboo server. Use tools like `telnet` or `openssl s_client -connect YOUR_LDAP_SERVER:636` to test connectivity from the Bamboo server to the LDAP server over port 636.\n* Adjust your Bamboo LDAP configuration to use `ldaps://` in the server URL and specify port 636.\n\nThe issue you're facing is due to the security policies being tightened on your domain controller, requiring LDAP communications to be signed or encrypted.\n\nHope it helps!\n\nRegards,\n\nKhushboo Gupta\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Problems-with-LDAP-connection-on-Old-Bamboo-5-10-1/qaq-p/2726908 | [
"bamboo-server",
"server"
] |
{
"author": "Rakesh Singh",
"title": "How to enable repository tagging via Bamboo if GPG key is enabled in repository ?",
"body": "We have enabled our repository with GPG key, but we observed that through Bamboo its not able to tag the the repository as GPG key is enabled.\n\nIs there a process to tag our repository via Bamboo?\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Rakesh,\n\nWelcome to Atlassian Community.\n\nI am not sure on the ask here can you provide some details\n\n1. What is the repository type? ( Bitbucket, Github ? )\n\n2. What is the error which you are seeing on Bamboo.\n\n3. How are you trying to tag the repository, are you using a repository tag task in Bamboo and trying to create a new tag when the build comletes?\n\nRegards,\n\nShashank kumar\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-enable-repository-tagging-via-Bamboo-if-GPG-key-is/qaq-p/2726812 | null |
{
"author": "K_ Scheel",
"title": "Licensing of Ephemeral agents",
"body": "The wording regarding licensing is a bit ambiguous. All the licensing info pages mention the number of \"Remote Agents\". Since there are three different types of agents (remote, ephemeral, elastic), it sounds like only true \"Remote Agents\" would count towards the license.\n\nBut I'm assuming that's not actually the case, and elastic/ephemeral agents consume the license just like a regular remote agent?\n\nThe [elastic instance documentation](https://confluence.atlassian.com/bamboo/starting-an-elastic-instance-289277132.html) confirms this:\n> An elastic agent is counted as a remote agent for licensing purposes\n\nBut I couldn't find anything specific about ephemeral agents.\n"
} | [
{
"author": "Steffen Opel _Utoolity_",
"body": "You are assuming correctly, all three different types of agents (remote, ephemeral, elastic) are technically 'remote', which basically means that they are running in their own JVM and thus need to communicate with the Bamboo host via the network.\n\nThis contrast with the long deprecated 'local' agents that are running inside the same JVM as the Bamboo host - local agents are no longer available as of [Bamboo 9.6](https://confluence.atlassian.com/bambooreleases/bamboo-9-6-release-notes-1376026732.html#Bamboo9.6releasenotes-ChangesintroducedinBamboo9.6), see [Difference between Bamboo Local agents and Remote Agents](https://confluence.atlassian.com/bamkb/difference-between-bamboo-local-agents-and-remote-agents-457703602.html) if you want to learn more regardless.\n\nYou've already confirmed the 'remote' license aspect of [Elastic agents](https://confluence.atlassian.com/bamboo/starting-an-elastic-instance-289277132.html), and while section [Ephemeral agents](https://confluence.atlassian.com/bamboo/ephemeral-agents-1236444139.html) does not mention licensing explicitly, it still confirms the 'remote' characteristics that will use a license slot per running agent:\n> Anephemeral agent is a short-lived remote agent that starts on-demand inside a [Kubernetes](https://kubernetes.io/) cluster to carry out a single build or deployment before being shut down.\n",
"comments": null
},
{
"author": "Shashank Kumar",
"body": "Hello [K_ Scheel](https://community.atlassian.com/t5/user/viewprofilepage/user-id/1817062),\n\nWelcome to Atlassian community.\n\nYou can read through the licensing query at <https://www.atlassian.com/licensing/bamboo> and let me know if this answers your above query. If you have any specific do let me know.\n\nRegards,\n\nShashank kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/Licensing-of-Ephemeral-agents/qaq-p/2726183 | null |
{
"author": "Madhu",
"title": "Move files from bamboo working directory to Network directory in Powershell",
"body": "Hi Team,\n\nCan you please help me to move files from bamboo working directory to network directory in PowerShell\n"
} | [
{
"author": "Khushboo Gupta",
"body": "Hello [@Madhu](/t5/user/viewprofilepage/user-id/5179315)\n\nWelcome to the Atlassian Community!\n\nTo move files from a Bamboo working directory to a network directory using PowerShell, you can use the `Move-Item` cmdlet.\n\nThe working directory is where Bamboo temporarily places the checked-out files it's building. By default, this directory is located at <bamboo-home-dir>`/local-working-dir`, where <bamboo-home-dir> is the [Bamboo home directory](https://confluence.atlassian.com/bamboo/locating-important-directories-and-files-289277247.html).\n\nThe checked-out files for each job are stored in a sub-directory relative to the configured working directory:\n\n<bamboo-home-dir>`/local-working-dir/<job-key>`\n\nIncase if you want to change the location of Bamboo working directory, you can refer to a KB: <https://confluence.atlassian.com/bamboo/specifying-bamboo-s-working-directory-289277246.html>\n\nHope it helps!\n\nRegards,\n\nKhushboo Gupta\n",
"comments": [
{
"author": "Madhu",
"body": "Hi Khushboo Gupta,\n\nI'm trying both Copy-Item and Move-Item but getting error. Please find the below script i'm using and error log.\n\nSet Location \"D:\\\\Bamboo_New\\\\xml-data\\\\build-dir\\\\PROBOTS-RPASIT-JOB1\\\\\"\n\npwd\n\nMove-Item -Path .\\\\\\*.log -Destination \\\\\\\\xxxxx.corp.choosehmc.com\\\\Public\\\\twf\\\\xxxxx\\\\Test\n\nCopy-Item D:\\\\Bamboo_New\\\\xml-data\\\\build-dir\\\\PROBOTS-RPASIT-JOB1 -Destination \\\\\\\\xxxxx.corp.choosehmc.com\\\\Public\\\\twf\\\\xxxxx\\\\Test\n\nMove-Item Error\n\n---------------------\n\n```\nPath build 12-Jun-2024 00:02:01 ---- build 12-Jun-2024 00:02:01 D:\\Bamboo_New\\xml-data\\build-dir\\PROBOTS-RPASIT-JOB1error 12-Jun-2024 00:02:01 Move-Item : The user name or password is incorrect.error 12-Jun-2024 00:02:01 At D:\\Bamboo_New\\temp\\PROBOTS-RPASIT-JOB1-137-ScriptBuildTask-16213514140262231error 12-Jun-2024 00:02:01 16.ps1:8 char:1error 12-Jun-2024 00:02:01 + Move-Item -Path .\\*.log -Destination \\\\hmcnt3.corp.choosehmc.com\\Publ ...error 12-Jun-2024 00:02:01 + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~error 12-Jun-2024 00:02:01 + CategoryInfo : WriteError: (D:\\Bamboo_New\\x...amboo-agent.log:F error 12-Jun-2024 00:02:01 ileInfo) [Move-Item], IOExceptionerror 12-Jun-2024 00:02:01 + FullyQualifiedErrorId : MoveFileInfoItemIOError,Microsoft.PowerShell.Com error 12-Jun-2024 00:02:01 mands.MoveItemCommand\n\n\nCopy-Item Error\n--------------------\n\n```\n\n```\nPath build 12-Jun-2024 00:00:00 ---- build 12-Jun-2024 00:00:00 D:\\Bamboo_New\\xml-data\\build-dir\\PROBOTS-RPASIT-JOB1error 12-Jun-2024 00:00:00 Copy-Item : The user name or password is incorrect.error 12-Jun-2024 00:00:00 At D:\\Bamboo_New\\temp\\PROBOTS-RPASIT-JOB1-136-ScriptBuildTask-56319914737823582error 12-Jun-2024 00:00:00 53.ps1:10 char:1error 12-Jun-2024 00:00:00 + Copy-Item D:\\Bamboo_New\\xml-data\\build-dir\\PROBOTS-RPASIT-JOB1 -Desti ...error 12-Jun-2024 00:00:00 + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~error 12-Jun-2024 00:00:00 + CategoryInfo : WriteError: (\\\\hmcnt3.corp.c...wf\\AG82090\\Test:S error 12-Jun-2024 00:00:00 tring) [Copy-Item], IOExceptionerror 12-Jun-2024 00:00:00 + FullyQualifiedErrorId : CreateDirectoryIOError,Microsoft.PowerShell.Comm error 12-Jun-2024 00:00:00 ands.CopyItemCommanderror 12-Jun-2024 00:00:00 \n```\n\nCan you please suggest what causing the issue.\n\nThanks in advance!!\n\nMadhu\n"
},
{
"author": "Khushboo Gupta",
"body": "Hello [@Madhu](/t5/user/viewprofilepage/user-id/5179315) ,\n\nThe errors you're encountering, specifically \"The user name or password is incorrect,\" suggest an issue with network authentication. When you're trying to access a network share (like `\\\\xxxxx.corp.choosehmc.com\\Public\\twf\\xxxxx\\Test` in your case), your script needs to have the correct permissions to access that location.\n\n* Ensure that the user account under which the Bamboo agent (or the PowerShell script) is running has the necessary permissions to access the network share.\n\nIf the direct `Move-Item` or `Copy-Item` still faces permission issues even after mapping the drive, consider using other tools or cmdlets that might handle credentials differently, such as \\`robocopy\\` for copying files, which you can call from PowerShell. Below is the example:\n\n```\nrobocopy \"D:\\Bamboo_New\\xml-data\\build-dir\\PROBOTS-RPASIT-JOB1\" \"\\\\xxxxx.corp.choosehmc.com\\Public\\twf\\xxxxx\\Test\" *.log /Z /COPYALL /R:5 /W:5\n```\n\nHope it helps!\n\nRegards,\n\nKhushboo Gupta\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/Move-files-from-bamboo-working-directory-to-Network-directory-in/qaq-p/2724060 | null |
{
"author": "Shanmuga Sundaram",
"title": "How to skip bamboo stage based on inject variable",
"body": "Hi,\n\nWe have bamboo plan with multiple stages and we would like to skip package stage is there is no pull request. Pipeline is running for every commit now and we would like to create package only when we have PR. i can put a condition in every task to skip, but is there a way we can do it at stage level?\n\nBamboo Version: 8.0.3 build 80011 - 08 Oct 21\n"
} | [
{
"author": "Khushboo Gupta",
"body": "Hello [@Shanmuga Sundaram](/t5/user/viewprofilepage/user-id/5518118) ,\n\nWelcome to the Atlassian community!\n\nYou can have your task run based on a [condition](https://confluence.atlassian.com/bamkb/conditional-tasks-in-bamboo-1077907046.html) that checks for a variable. You need to add an [Inject Variables Task](https://confluence.atlassian.com/bamboo/configuring-a-variables-task-687213475.html#Configuringavariablestask-InjectBamboovariablestask) to your plan that would consume a properties file. Hence, once the variable(s) are set, you can enable the condition on the task so it knows if it should run or not.\n\n#### This is the workflow: {#toc-hId-345844012}\n\n1. Modify the \"*PREVIOUS_TASK* \" and have it create a properties file with a set of *key=value* lines\n2. The \"*PREVIOUS_TASK*\" should always succeed (return 0), even if it had failed. For that you'd have to wrap it in a script to force it to succeed, otherwise Bamboo will not advance to the next task\n3. Add an [Inject Variables Task](https://confluence.atlassian.com/bamboo/configuring-a-variables-task-687213475.html#Configuringavariablestask-InjectBamboovariablestask) to the Plan that would consume the properties file from step #1 and set them as variables\n4. On Tasks \"*DO A* \" and \"*DO B* \" check the \"*Add condition to task\"* box. That would evaluate the injected variables from step #3 and make the decision to execute that task or skip it.\n\nAdditionally there in our marketplace, we have a plugin offering conditional tasks: [Conditional tasks for Bamboo](https://marketplace.atlassian.com/apps/1219706/conditional-tasks-for-bamboo?hosting=server&tab=overview) you can find more information on its usage and limitation in this community post: [How we can configure job with conditional tasks for bamboo Plug-in.](https://community.atlassian.com/t5/Bamboo-questions/How-we-can-configure-job-with-conditional-tasks-for-bamboo-Plug/qaq-p/1105461)\n\nKind regards,\n\nKhushboo Gupta \nAtlassian Support\n\n**--please don't forget to Accept the answer if the reply is helpful--**\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-skip-bamboo-stage-based-on-inject-variable/qaq-p/2723868 | null |
{
"author": "rizwansiddiqu1",
"title": "getting error while connection to the database",
"body": "Error accessing database: org.postgresql.util.PSQLException: Connection to localhost:5432 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.\n\n\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello [rizwansiddiqu1](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5517568)\n\nThe above error means the Postgres Database is not accesible on port 5432, please refer [How to troubleshoot Bamboo connectivity issues with Databases](https://confluence.atlassian.com/bamkb/how-to-troubleshoot-bamboo-connectivity-issues-with-databases-1388151792.html) to understand how to troubleshoot this.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/getting-error-while-connection-to-the-database/qaq-p/2723111 | null |
{
"author": "pp",
"title": "How to create maven build on bamboo ? Unable to create by using profile as in pom.xml",
"body": "I have already configured job with maven command as \"clean install -Psample\" (sample is my profile name in pom.xml as shown below) . But I started running the build it is giving issue as \" Non-readable POM /appl/bamboo-agent/xml-data/build-dir/project/pom.xml (No such file or directory) The build could not read the project \\[Help 1\\]\"\n\n\n\n1) How to configure bamboo job to generate maven build ?\n\n2) How to run build with sample profile as shown below ?\n\n3) Can we run \"clean install\" only to generate bamboo build ?\n\nBelow is my pom.xml \n\n```\n<profile>\n <id>sample</id>\n <groupId>org.codehaus.mojo</groupId>\n <artifactId>exec-maven-plugin</artifactId>\n <goals>\n <goal>exec</goal>\n </goals>\n <activation>\n <activeByDefault>true</activeByDefault>\n </activation>\n</profile>\n```\n"
} | [
{
"author": "Khushboo Gupta",
"body": "Hello [@pp](/t5/user/viewprofilepage/user-id/5517909)\n\nWelcome to the Atlassian Community!\n\nThe error message you're encountering, `Non-readable POM /appl/bamboo-agent/xml-data/build-dir/project/pom.xml (No such file or directory)`, indicates that the Maven build process cannot find or access the `pom.xml` file in the specified directory.\n\n* Check that the POM is available, and readable by the Bamboo user\n* Try running the Maven build outside of Bamboo to see if the error persists.\n* Ensure that the job or task in Bamboo that runs the Maven command is configured to use the correct working directory.\n\nPost checking the pom.xml that you have provided profiles do not directly contain `groupId` and `artifactId` elements. Instead, these should be part of a `<plugin>` configuration within a `<plugins>` element. \n\n```\n`<profile> <id>sample</id> <activation> <activeByDefault>true</activeByDefault> </activation> <build> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>`exec-maven-plugin</artifactId>\n<version>1.6.0</version> <!-- Specify the version you're using --> \n<executions> \n<execution> \n<goals> \n<goal>exec</goal> \n</goals>\n</execution> \n</executions>\n</plugin> \n</plugins> \n</build> \n</profile>\n```\n\nTo answer your next query:\n> How to configure bamboo job to generate maven build ?\n\n`Please refer a Document which describe `[how to configure bamboo task to use Maven](https://confluence.atlassian.com/bamboo/maven-289277038.html)`.`\n> 2) How to run build with sample profile as shown below ?\n\nTo run your Maven build with a specific profile, such as the \"sample\" profile you mentioned, you would include the profile in the \"Goal\" field of your Maven task configuration as you did:\n\n* In the \"Goal\" field, append `-Psample` to your existing command, making it `clean install -Psample`.\n\n3) Can we run \"clean install\" only to generate bamboo build ? \nYes, you can use just \"clean install\" as your Maven goals for generating a Bamboo build. The `clean` goal will ensure that any previously compiled files or test results are removed, providing a fresh start for the build. The `install` goal compiles your project's code, packages it into a distributable format (like a JAR), and then installs it into your local Maven repository. \nHope it helps! \nRegards, \nKhushboo Gupta \n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "pp",
"body": "Hello ,\n\nI tried with above solutions but it is failing again. I have changed my pom.xml involving \\<plugin\\>\\</plugin\\> as well. but no success.\n\nI am using maven version 3.0.5 locally as per requirement. I am unable to upgrade it. On bamboo , I am configuring maven version 3.9.6. Is this main reason for my build failure ?\n\n**1.** I am unable to run bamboo build with maven 3.0.5 same as local. When I start to run it, it taking too much time \\& getting failed. How to resolve this ? It was showing bamboo agent can not support this job.\n\n**2.**When I trying to upgrade maven locally my application getting failed. What need to add locally so that I can run with bamboo ?\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/How-to-create-maven-build-on-bamboo-Unable-to-create-by-using/qaq-p/2723571 | null |
{
"author": "Mahesh",
"title": "NVM command not found from bamboo plan but works in local",
"body": "Hi There,\n\nI have installed NVM in my ubuntu build agent. I am able to use nvm and node commands in my local.\n\nBut when I run nvm or node commands from bamboo plan, Plan fails with error as node command not found. Same for nvm also. \n\nWhen I use full path for node it works.\n\n/opt/bamboo-agent-home/.nvm/versions/node/v12.21.0/bin/node -v\n\nBut nvm is not working. please suggest.\n\nError : \n/opt/bamboo-agent-home/temp/TEST-SCR-LT-71-ScriptBuildTask-47945519012.sh: 9: /opt/bamboo-agent-home/temp/TEST-SCR-LT-71-ScriptBuildTask-47945519012.sh: nvm: not found\n"
} | [
{
"author": "Shashank Kumar",
"body": "Hello Mahesh,\n\nWelcome to Atlassian community\n\nYou can try the below 2 things.\n\n1. Install nvm in a location using the user which is running the Bamboo agent and is location is accesible to the bamboo user which is running the agent.\n\n2. After Installing check if nvm is getting listed in the capabilities of the agent, if not try restarting the agent and check.\n\n3. If that does not work too, try defining the capabilities manually\n\nPost all the above steps try a simple script task with command nvm --version and let me know the results.\n\nRegards,\n\nShashank Kumar\n",
"comments": [
{
"author": "Mahesh",
"body": "Hi [@Shashank Kumar](/t5/user/viewprofilepage/user-id/4693340) , \nThanks for the reply.\n\nI installed nvm using command \"curl -o- <https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.3/install.sh> \\| bash\" \n\nIt is not listed in capabilities. After restart also same it is not listed.\n\nTried to add nvm path in capabilities but i am not able to find the nvm executable. Which one to be added as executable ???\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Mahesh,\n\nnvm is a shell function and not a shell ***executable*** file so you'll not be able to add it as a executable.\n\nThere are few options which you can work with.\n\n1. Add the below entry in .profile file in your linux box.\n\n```\nexport NVM_DIR=\"$HOME/.nvm\"\n[ -s \"$NVM_DIR/nvm.sh\" ] && \\. \"$NVM_DIR/nvm.sh\"\n```\n\n2. Or add it in the script task ( like attached )\n\n\n\nWhen you run this script task, you should be able to see the results.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n"
},
{
"author": "Mahesh",
"body": "Hi [@Shashank Kumar](/t5/user/viewprofilepage/user-id/4693340) ,\n\nBy adding this I can see nvm version, When I use ++**node**++ command again it says command not found. In local can see node version. and it can be managed by only ++**\"nvm use --delete-prefix v16.20.2\"**++ simple ++**nvm use 16**++ command is not working.\n\nIt throws error as below. \n\nbam:\\~$ nvm use 16 \nnvm is not compatible with the npm config \"prefix\" option: currently set to \"/data/home/bambooagent/.nvm/versions/node/v16.20.2\" \nRun \\`nvm use --delete-prefix v16.20.2\\` to unset it. \nbam:\\~$ \n\nnode command error : 848876677.sh: node: not found\n"
},
{
"author": "Mahesh",
"body": "[@Shashank Kumar](/t5/user/viewprofilepage/user-id/4693340)\n\nAny suggestions here\n"
}
]
}
] | https://community.atlassian.com/t5/Bamboo-questions/NVM-command-not-found-from-bamboo-plan-but-works-in-local/qaq-p/2722259 | [
"linux",
"node",
"node.js",
"nvm",
"ubuntu"
] |
{
"author": "Mark C_ Duncan",
"title": "sudo: start: command not found",
"body": "Deploying Bamboo as a service on AWS Linux 2 instance using Terraform with remote-exec provisioner. The start and stop command cannot be found.\n\nCode snippet: \n\"sudo touch bamboo.service\", \n\"echo '\\[Unit\\]' \\| sudo tee -a bamboo.service\", \n\"echo 'Description=Atlassian Bamboo Agent' \\| sudo tee -a bamboo.service\", \n\"echo 'After=syslog.target network.target' \\| sudo tee -a bamboo.service\", \n\"echo ' ' \\| sudo tee -a bamboo.service\", \n\"echo '\\[Service\\]' \\| sudo tee -a bamboo.service\", \n\"echo 'Type=forking' \\| sudo tee -a bamboo.service\", \n\"echo 'User=bamboo-agent' \\| sudo tee -a bamboo.service\", \n\"echo 'Group=bamboo-agent' \\| sudo tee -a bamboo.service\", \n/\\*\"echo 'Environment=CATALINA_PID=/bamboo-install/atlassian-bamboo-9.6.2/atlassian-bamboo/bin/Catalina.pid' \\| sudo tee -a bamboo.service\", \n\"echo 'PIDFile=/bamboo-install/atlassian/bamboo/bin/Catalina.pid' \\| sudo tee -a bamboo.service\",\\*/ \n\"echo 'ExecStart=/root/ec2-user/bamboo-install/atlassian-bamboo-9.6.2/bin/start-bamboo.sh start sysd' \\| sudo tee -a bamboo.service\", \n\"echo 'ExecStop=//root/ec2-user/bamboo-install/atlassian-bamboo-9.6.2/bin/stop-bamboo.sh stop sysd' \\| sudo tee -a bamboo.service\", \n\"echo 'KillMode=control-group' \\| sudo tee -a bamboo.service\", \n\"echo 'Environment=SYSTEMD_KILLMODE_WARNING=true' \\| sudo tee -a bamboo.service\", \n\"echo 'SuccessExitStatus=143' \\| sudo tee -a bamboo.service\", \n\"echo ' ' \\| sudo tee -a bamboo.service\", \n\"echo '\\[Install\\]' \\| sudo tee -a bamboo.service\", \n\"echo 'WantedBy=multi-user.target' \\| sudo tee -a bamboo.service\", \n\"sudo mv bamboo.service /etc/systemd/system/\", \n\"sudo systemctl daemon-reload\", \n\"sudo start bamboo\", \nAlso may be related that when installing the agent software, the following error is displayed: \nnull_resource.name (remote-exec): Installing file: /generic/bin/bamboo-agent.sh to: /root/bamboo-agent-home/bin/bamboo-agent.sh \nnull_resource.name (remote-exec): Installing file: /root/bamboo-agent-home/conf/wrapper.conf \nnull_resource.name (remote-exec): Installing file: /generic/lib/bamboo-agent-bootstrap-jar-with-dependencies.jar to: /root/bamboo-agent-home/lib/bamboo-agent-bootstrap.jar \nnull_resource.name (remote-exec): Unzipping /classpath.zip to /root/bamboo-agent-home/classpath \nnull_resource.name (remote-exec): Could not find source file /classpath.zip \nnull_resource.name (remote-exec): Agent installed \nAny suggestions are appreciated. New to Linux and Bamboo. \nThanks!\n"
} | [
{
"author": "Khushboo Gupta",
"body": "Hello [@Mark C_ Duncan](/t5/user/viewprofilepage/user-id/5515518)\n\nWelcome to Atlassian Community!\n\nBased on your description, there are a couple of key issues that need to be addressed to get your Bamboo agent running as a service on AWS Linux 2 instance using Terraform with the `remote-exec` provisioner.\n\n* Fixing the Systemd Service File and Start/Stop Commands: It looks like there's a typo in your `ExecStop` command (an extra slash at the beginning), and your `ExecStart` and `ExecStop` paths seem to be incorrect. You've mixed `/root/` with `ec2-user/` in the paths, which are typically home directories for different users on a Linux system. By default, `ec2-user` is the default user on AWS Linux instances, not `root`, so if you've installed Bamboo in the `ec2-user`'s home directory, ensure the paths are correct. Assuming Bamboo is installed in the `ec2-user` home directory, update the paths accordingly. It should look like below:\n * \"echo 'ExecStart=/home/ec2-user/bamboo-install/atlassian-bamboo-9.6.2/bin/start-bamboo.sh start sysd' \\| sudo tee -a /etc/systemd/system/bamboo.service\"\n * \"echo 'ExecStop=/home/ec2-user/bamboo-install/atlassian-bamboo-9.6.\n* Additionally, the command to start the service should be **`sudo systemctl start bamboo`** , not `sudo start bamboo`. It should look like below:\n * \"sudo systemctl enable bamboo\",\n * \"sudo systemctl start bamboo\",\n\nTo resolve the \"Could not find source file /classpath.zip\" issue, you'll need to ensure that `classpath.zip` is indeed available and in the correct location expected by your installation script.\n\nHope it helps!\n\nRegards,\n\nKhushboo Gupta\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bamboo-questions/sudo-start-command-not-found/qaq-p/2720918 | [
"start"
] |
{
"author": "Greg Davis",
"title": "URL for direct link to a statuspage.io component",
"body": "Is there a way to get the URL that when clicked on opens a browser tab to that component on a statuspage.io? Right now, I just have the main URL so a user will have to scroll down to a component.\n"
} | [
{
"author": "Tejaswi G",
"body": "Hi [@Greg Davis](/t5/user/viewprofilepage/user-id/5104690)\n\nThank you for contacting the Atlassian Community. I am Tejaswi from the Support team. At present, we don't offer an option to directly obtain links to the status page components. I have created a new feature request, STATUS-851, to address this issue. I encourage you to monitor the status page community for any updates on this feature request.\n\nBest regards,\n\nTejaswi\n",
"comments": [
{
"author": "Greg Davis",
"body": "Thanks. We have some users who want to jump to a certain component instead of having to scroll down to it. I thought a specific URL to that component would solve that issue.\n"
}
]
},
{
"author": "Kevin Patterson",
"body": "Hi [@Greg Davis](/t5/user/viewprofilepage/user-id/5104690) ,\n\nWhile waiting for STATUS-851 to be delivered, there is some configuration work you could do today that will solve this using HTMl/CSS overrides in statuspage if you are comfortable with a little javascript.\n\nI have a client with over 100 components that had the same requirement to have a link go directly to the component on the page. To accomplish this we used a javascript embedded in the Custom footer HTML through the customize HTML \\& CSS feature of statuspage. below is the script we are using:\n\n```\n<script>\n\ndocument.addEventListener(\"DOMContentLoaded\", function() {\n// Parse URL parameters\nconst urlParams = new URLSearchParams(window.location.search);\nconst componentName = urlParams.get('component');\n\n// Check if the componentName is present in the URL\nif (componentName) {\n// Attempt to find the span with the corresponding text\nconst spans = document.querySelectorAll('span.name');\nlet found = false;\nspans.forEach(function(span) {\nif (span.textContent.trim() === componentName) {\nspan.scrollIntoView({ behavior: 'smooth' });\nfound = true;\n}\n});\nif (!found) {\nconsole.error('Component not found: ', componentName);\n}\n}\n});\n\n</script>\n```\n\nOnce you've added the script to the custom footer HTML you can provide a link to your users directly to the component using a query after the url. The format you can use is below (just replace YOURPAGE with your statuspage \\& Component_Name with the name of your component)\n\n```\n https://YOURPAGE.statuspage.io/?component=Component_Name\n```\n\nI hope this helps while we await the enhancement from Atlassian.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/URL-for-direct-link-to-a-statuspage-io-component/qaq-p/2782621 | [
"cloud"
] |
{
"author": "shivam_singla",
"title": "Status Page service to initially test in staging environment and then publish to Production",
"body": "Currently, we need to use Atlassian's customization support, which allows for the addition of custom HTML, CSS, and JavaScript. Our goal is to have two pages---one for staging (testing) and one for production---that are connected in such a way that we can first publish customizations in the staging environment for testing. Once these changes are verified, we can then deploy the exact same customizations to the production environment.\n\nWe are aware that we can create two separate pages and manually copy and paste changes from the staging page to the live page once verified. However, this approach risks missing some changes during the copying process. Therefore, we are looking for a solution that enables us to deploy and manage both pages efficiently, ensuring that the changes made in staging are accurately and consistently reflected in production.\n"
} | [
{
"author": "Shashwat Khare",
"body": "Hi [@shivam_singla](/t5/user/viewprofilepage/user-id/5538502) , \n\nThis is Shashwat, from Statuspage support and here to help! :) \n\nI understand you're inquiring about how to create a Sandbox for your Statuspage account. \n\nPlease note that we, unfortunately, don't have a sandbox feature in Statuspage as of now. \n\nYou will need to create a trial page whether it be public, private, or audience-specific that is separate from your main production page. \n\nAt this moment, we don't have a Sandbox feature that we can enable on your behalf. However, we do have an internal feature request that I can share with you as \"**STATUS-140** \" \n\nI have added this request to the above feature request for the Product team. \n\n<br />\n\nBest, \nShashwat\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Status-Page-service-to-initially-test-in-staging-environment-and/qaq-p/2781784 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "prnaruka",
"title": "Maintenance notifications not getting delivered to subscribers",
"body": "We are not receiving the email notifications for the created maintenance of different components. Earlier we receiving the email notifications but on 02-08-2024 we didn't receive emails for all the maintenance. However, we receive notifications for some applications but after 02-08 we didn't receive any email for maintenance .Can anyone suggest.. what is needs to be fixed ? or what can we do in such a case?\n"
} | [
{
"author": "Mubeen Mohammed",
"body": "Hello [@prnaruka](/t5/user/viewprofilepage/user-id/5564763)\n\nThank you for contacting the Atlassian Community!\n\nThanks for bringing this to our attention. We understand how important it is to receive timely Statuspage maintenance notifications. To have this investigated further, please reach out to the Statuspage support team directly at <https://support.atlassian.com/contact/>.\n\nWhen creating your support ticket, please include the following information:\n\n* **Maintenance Incident Details:** Briefly describe the maintenance incidents for which you did not receive email notifications (date, time, any specific details you recall).\n* **User Email Addresses:** Provide the email addresses that should have received these notifications.\n\nSharing these details directly with the support team will help them investigate the issue and provide you with a solution.\n\nPlease refrain from posting any specific incident or email details on this public community forum.\n\nWe appreciate your understanding and patience.\n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Maintenance-notifications-not-getting-delivered-to-subscribers/qaq-p/2780680 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Jill Olson",
"title": "Is act of sending Scheduled Maintenance notification TIED directly to the Maintenance Start Date",
"body": "We're using the Scheduled Maintenance message type to send an informaitonal message to all our users. We set it up to start maintenance on Aug 14th as that date is key to our updated message. HOWEVER we wanted the email notification to send immediately. Is the message send date/time TIED directly to the Scheduled Date/Time Field? And maybe that's why our message isn't sending???\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Jill Olson](/t5/user/viewprofilepage/user-id/5564966)\n\nIt is possible to send the maintenance notification on creation of the maintenance record, as well as sending a reminder before the start of the scheduled maintenace.\n\nThe section \"Maintenance notifications and automation\" in the following link should be helpful. <https://support.atlassian.com/statuspage/docs/schedule-maintenance/> \n",
"comments": [
{
"author": "Kevin Patterson",
"body": "Here is an example from my statuspage for a maintenance schedule. i have select 3 additional notifications for subscribers. one an hour before the scheduled start, one at the scheduled start, and a final notification when the maintenance schedule time has elapsed. I hope this is helpful.\n\n\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Is-act-of-sending-Scheduled-Maintenance-notification-TIED/qaq-p/2780980 | null |
{
"author": "mchuecos",
"title": "How to check status custom API endpoint",
"body": "The Development Team has published an internal API (I.e. <https://myprivateendpointdata.com/health>).\n\nI have tried to add the endpoint in Atlassian StatusPage to be able to check the status each 1 minute but I couldn't find the place to configure it from the Component section.\n\nWhere and how can I implement/apply this? Or is not possible?\n\nCurrently, I am using New Relic with Synthetic Monitoring to monitorize the endpoint but I would like to add it to Statuspage tool.\n\nAm I on the right track and should I now integrate it into Statuspage for that component to show the status of Synthetics, or should this endpoint check be done in StatusPage?\n"
} | [
{
"author": "Jesse Klein",
"body": "Hello!\n\nThis is Jesse from the Statuspage support team. Welcome, and thanks for reaching out to the community. Statuspage doesn't do any monitoring on its own and is only an incident communication tool. We can, however, work with New Relic to change Statuspage components when New Relic sends emails out:\n\n<https://support.atlassian.com/statuspage/docs/set-up-new-relic-alerts-parsing/>\n\nI would take a look at this to see if this would meet your needs. Essentially, New Relic will send an alert, which sends an email to the component automation endpoint, and the status changes for you on Statuspage. Hopefully, that helps point you in the right direction.\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-to-check-status-custom-API-endpoint/qaq-p/2778260 | [
"cloud",
"new-relic",
"statuspage-cloud"
] |
{
"author": "Jo?o Henrique Finisguerra Pereira",
"title": "Can I transfer and migrate from one statuspage to another statuspage?",
"body": "Can I transfer and migrate from one statuspage to another statuspage?\n\nToday I have a statuspage account. In this account I have my history of open and closed statuses. I would like to know if I can migrate this history to another statuspage? Is this possible? Because I would not like to lose my status history.\n"
} | [
{
"author": "Vincent Kopa _Ovyka_",
"body": "Hello Jo?o,\n\nTransferring and migrating the history from one Statuspage to another directly within the platform is not supported. Unfortunately, there isn't a built-in feature to move your status history from one Statuspage to another.\n\nHowever, you can achieve this using the **Statuspage REST API**. By creating a script, you can programmatically extract the data from your current Statuspage and import it into the new one. Please note that this can be quite complex and requires a good understanding of scripting and using APIs.\n\nHere are the steps you would need to follow:\n\n1. **Export Data**: Use the Statuspage API to fetch your current data (incidents, components, etc.).\n2. **Transform Data**: Format the data as required by the new Statuspage.\n3. **Import Data**: Use the API to create the new entries in the new Statuspage.\n\nFor detailed API documentation, you can refer to the Statuspage API Documentation.\n\nThis process can import both \"configurations\" (like component definitions), and incidents/maintenance (as they can be \"backdated\").\n\nGiven the complexity, this approach might be quite labor-intensive for a one-time migration. If maintaining the history is critical, you might want to consider if it's worth the effort or if there are alternative solutions that might meet your needs.\n\nFeel free to ask if you have any more questions or need further assistance!\n\nBest regards\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Can-I-transfer-and-migrate-from-one-statuspage-to-another/qaq-p/2777253 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Daniel Winter",
"title": "Private Statuspage for customers",
"body": "Hey,\n\nI wanted to check with the community if anyone is using a private statuspage for customers.\n\nAtm we do not want to provide public insights into the Statuspage which is why we are looking into a way to provide a statuspage to a smaller customer audience behind SSO.\n\nFrom all the documentation it sounds more like the private Statuspage is for internal employees but I wanted to double-check if anyone has set this up as I mentioned.\n"
} | [
{
"author": "Jesse Klein",
"body": "Hi Daniel,\n\nJesse from the Statuspage support team here. I wanted to chime in on this to share my experience of what I see folks using private pages for.\n\nGenerally speaking, it's mostly internal users. The reason for this is our authentication methods. We have SAML, Google Auth, and IP allowlisting. These tend to favor internal teams because you have control over these configurations and no external users that can complicate the setup.\n\nDespite the more widely used use case, there are some teams that have private pages for external users. As long as you use one of the authentication methods, it'll work.\n\nWhat's more common for external customers, though, are [audience specific pages](https://support.atlassian.com/statuspage/docs/what-are-audience-specific-pages/). This allows customers to be added to certain groups and see what's relevant to them. It also supports username and password instead of requiring the other methods.\n\nHopefully, that helps! If anyone else in the community does use this, please feel free to share!\n\nRegards, \nJesse\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Private-Statuspage-for-customers/qaq-p/2775756 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Aaron Jones",
"title": "Hello, It appears Jira (under Confluence) now no longer supports pre iOS 16. I have been trying to u",
"body": "Hello, It appears Jira now no longer supports pre iOS 16. I have been trying to use the mobile web desktop version since I can no longer use the app. Now the web pages won't load. Particularly, the actual \"Issues\" page. When I get to the Issue, the page's load bar stops at 20%\n"
} | [
{
"author": "Hans Polder",
"body": "Hey [@Aaron Jones](/t5/user/viewprofilepage/user-id/5557844) ,\n\nIt could be that your organization admin updated the 'mobile app policy' on <https://admin.atlassian.com> which allows them to block certain versions of iOS/Android to use the app for their organization. Since iOS16 is pretty recent, I expect that it's not a 'unsupported matter' on Atlassian side, but might have been disabled by your admin.\n\nIf this is not the case, can you share more information on which error you're getting when trying to use the app?\n",
"comments": [
{
"author": "Aaron Jones",
"body": "I spoke with admin and they said it's not something they can fix on their end.\n\nAlso, I'm not using the mobile app because it no longer supports anything pre iOS 16. \n\nSince my iOS (15.8) is no longer supported, I have to use the \"desktop version\" in Chrome. It works fine until I get to an actual \"Issue\" page and then it just stalls like this.\n\nPlease advise.\n"
},
{
"author": "Hans Polder",
"body": "Ah, I missed the '**pre** ' part. I just read the documentation and noticed the same (<https://support.atlassian.com/jira-cloud-ios/docs/support-for-app-versions-and-operating-systems/>).\n\nI don't think you'll get any support from Atlassian since they ditched pre-ios16 for a reason. Neither for the app, nor for the browser that goes with it. I assume updating to iOS16 or later is not an option for you?\n\nThere is not much I can do from my end, other than stating some standard tips like cleaning your browser cache, restarting the device, and asking others with the same ios version/browser to see if they have the same issue. Hopefully that helps!\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Hello-It-appears-Jira-under-Confluence-now-no-longer-supports/qaq-p/2772201 | [
"atlassian-accounts",
"cloud",
"not-applicable",
"statuspage-cloud"
] |
{
"author": "ifarley",
"title": "How to update the org admin?",
"body": "Hello,\n\nWe only have one org admin on our account and that person is no longer with our organization. I don't have the necessary permissions to suspend that person or replace that existing org admin with myself or one of my colleagues. I just get a\n\n'some actions aren't available to your role' message when I attempt to do it.\n\nThanks for your help.\n"
} | [
{
"author": "shib saha",
"body": "Hi [@ifarley](/t5/user/viewprofilepage/user-id/5557719) , Only ORG admin can add or remove a user to/from the organisation, in your case only org admin has left. No body from your side will be able to perform this change.\n\nI would suggest raise a support ticket with atlassian they will do the changes in the background and add some of you at the org level for further changes.\n\nI hope you get the solution form them. Thanks\n",
"comments": [
{
"author": "ifarley",
"body": "Thank you [@shib saha](/t5/user/viewprofilepage/user-id/4610701) . I've opened a ticket with Atlassian about this.\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-to-update-the-org-admin/qaq-p/2772019 | [
"atlassian-cloud"
] |
{
"author": "Adnan Tatar",
"title": "Can I monitor myown API using Statuspage and how?",
"body": "I need a way to monitor myown APIs and see the performance and updates on Statuspage\n"
} | [
{
"author": "Tejaswi G",
"body": "Hi [@Adnan Tatar](/t5/user/viewprofilepage/user-id/5556532)\n\nThis is Tejaswi from the statuspage team.\n\nYou can monitor APIs via the statuspage and only show the uptime status of it via the statuspage.\n\nI recommend you to write a custom script using our [statuspage APIs](https://developer.statuspage.io/#operation/getPagesPageIdComponentsComponentIdUptime) which would monitor the status of your API and push the statusupdates to Statuspage components via the APIs.\n\nIf you have any further queries, Feel free to log a ticket with us at <https://support.atlassian.com/contact>\n\nKind Regards, \nTejaswi\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Can-I-monitor-myown-API-using-Statuspage-and-how/qaq-p/2770412 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "zrk",
"title": "How can I cancel the configuration of the Webhook interface",
"body": "\n"
} | [
{
"author": "Mubeen Mohammed",
"body": "Hello [@zrk](/t5/user/viewprofilepage/user-id/5556283)\n\nThank you for contacting the Atlassian Community!\n\nAs I understand you would like to remove the \"Webhook\" subscription option for your Statuspage.\n\nAs discussed in the [documentation,](https://support.atlassian.com/statuspage/docs/enable-webhook-notifications/) you will have the option to enable or disable the Webhook subscription option for your Statuspage. You can follow the instructions below to disable the Webhook subscription option\n\n1. from your <http://manage.statuspage.io> settings click **Subscribers** from the left sidebar.\n\n2. Click **Options**.\n\n3. Click **Settings** from the Options dropdown menu.\n\n4. Unchek **Webhook** in the list of delivery types.\n\n5. Click **Save changes** . \n\n\n\nI hope the details provided are helpful.\n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-can-I-cancel-the-configuration-of-the-Webhook-interface/qaq-p/2770122 | [
"cloud"
] |
{
"author": "Kumar Ankit",
"title": "How can I integrate my custom k8s application to status page?",
"body": "My main aim is to get the status of my application on hourly basis, and I'm unable to understand how exactly my application will be monitored? \nIs there a way where I can put in the IP Address, or any way out that helps me know how an actual application's status is being tracked?\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Kumar Ankit](/t5/user/viewprofilepage/user-id/5555631) ,\n\nStatuspage is primarily for **Communication** of Application Health, Maintenance \\& Incident information. It does not handle the monitoring of your applications directly, but instead can be updated by monitoring tools Like Newrelic or pingdom. Another popular way to update status page is alert aggregation tools like Opsgenie or pagerduty.\n\nYou could write your own integration to fetch data from your application and send updates directly to statuspage via the restAPI and update components status or log an incident or maintenance details. <https://developer.statuspage.io/>\n\nI hope this helps.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-can-I-integrate-my-custom-k8s-application-to-status-page/qaq-p/2769405 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Manubam13",
"title": "Does localise translate the content of the incident ?",
"body": "Hi ,\n\nI understand localise will download the phrases/ strings and import to localise where we can add the translations.\n\nhow can we translate the content of the incidents from one language to other .Is it like we add incident content in English and later it's detected by localise and we add the translations in localise ? \nplease share the steps as this is very important factor to consider purchasing status page\n"
} | [
{
"author": "Alex Koxaras _Relational_",
"body": "Hi [@Manubam13](/t5/user/viewprofilepage/user-id/5552648) and welcome,\n\nPlease take a look at this post <https://community.atlassian.com/t5/Statuspage-questions/Translation-of-Statuspage-UI-and-incidents/qaq-p/2588998>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Does-localise-translate-the-content-of-the-incident/qaq-p/2765724 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Suman Sarkar",
"title": "Customise Create incident form in status page",
"body": "Hi Team,\n\nI want to customize the create incident form, is it possible with the current status page. I can customise the status page but is there a way to customise the create incident form?\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Suman Sarkar](/t5/user/viewprofilepage/user-id/5550096)\n\nCurrently there are no configuration options available for the create incident form. What specifically are you trying to customize on the create incident form?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Customise-Create-incident-form-in-status-page/qaq-p/2762304 | null |
{
"author": "Darren.Burrows",
"title": "Opsgenie to statuspage, unable to set impact",
"body": "Hey all, \n\nwe've started to use opsgenies statuspage integration, but something we've spotted is that irrespective of what tags are used or what priority the OG alert comes in as, the impact always shows as major. \n\nDocumentation shows no way of adjusting this that I Can see also. \n\nI'm aware that statuspage defaults to Major for the impact when creating a new Incident via its manage area, is their anyway to change this or any tags that may. not be documented that we could use? \n\nHas anyone found a solution to this at all? \n\nIt seems odd that you can send impact from statuspage to opsgenie, but not the other way around according to the docs.\n\n<https://support.atlassian.com/opsgenie/docs/integrate-opsgenie-with-statuspage/>\n"
} | [
{
"author": "Kevin Patterson",
"body": "Hi [@Darren.Burrows](/t5/user/viewprofilepage/user-id/5260381) ,\n\nUsing the Outgoing rules in Opsgenie I do not believe it is possible to update the Impact field of the statuspage Incident. The statuspage API supports setting the impact so i'm not sure why this was overlooked in the Opsgenie Integration.\n\nAre you using the Opsgenie standalone product or the Jira Service Management Team Operations Opsgenie features? If you are using JSM you could use an send web request action in an automation rule to create the statuspage incident and set impact to your desired value.\n\nIf you are using the Opsgenie standalone product my best guess would be to look into setting up an Action Channel with statuspage being the rest endpoint. I don't recall how flexible actions are with regards to customizing the json payload, but i remember trying to do something similar a couple years ago and finding actions in opsgenie not very useful.\n\nLet us know if you figure out a workaround here as I'm sure others are also struggling with this integration.\n",
"comments": [
{
"author": "Darren.Burrows",
"body": "Thanks [@Kevin Patterson](/t5/user/viewprofilepage/user-id/5497084) I had a feeling this may be the case. \n\nTime to see what I can try to get out of Opsgenie actions until we finally migrate to JSMO. \n\nIf I crack it, ill be sure to share.\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/Opsgenie-to-statuspage-unable-to-set-impact/qaq-p/2764365 | [
"cloud",
"opsgenie",
"statuspage-cloud"
] |
{
"author": "Anvesh Singamsetty",
"title": "How can we integrate Atlassian status page and Microsoft teams",
"body": "**Office 365 Connectors within Teams will be retired soon. The Workflows app provides similar functionality with more scalability and security.**\n\n**How can i post status page message to microsoft teams channel?**\n\n**These integration steps in below atlassian page are not working**\n\n<https://support.atlassian.com/statuspage/docs/set-up-microsoft-teams-integration/>\n\nCould you help us with new solution or how to do with power automate tool as suggested by microsoft here\n\n<https://devblogs.microsoft.com/microsoft365dev/retirement-of-office-365-connectors-within-microsoft-teams/>\n"
} | [
{
"author": "Elelta D",
"body": "Hey there\n\nWelcome to the community and thank you for your question.\n\nWe are aware of these changes and will be working on providing a solution, at the moment MS have shared that until 15th Aug you should be able to use the current connectors and once created they will be supported until December 2024.\n\nI will open a ticket on your behalf so I can share your concerned with our product team internally.\n\nElelta\n",
"comments": [
{
"author": "Elelta D",
"body": "A quick follow up question ++[Anvesh,](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5553001)++ I cant seem to find your Statuspage url in our system.\n\nCould you you please open a ticket on <https://support.atlassian.com/contact> so I can share your query with our product team.\n\nThanks\n"
}
]
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-can-we-integrate-Atlassian-status-page-and-Microsoft-teams/qaq-p/2766358 | [
"cloud",
"jira",
"jira-cloud",
"ms-teams"
] |
{
"author": "?????? ?????????",
"title": "?????",
"body": "????? ?? ???????? ?????? ????? ???\n"
} | [
{
"author": "Chris DeGidio",
"body": "Hi there,\n\nFeel free to open a support ticket at support.atlassian.com in order for us to assist you with your report. Thanks\n\n- Chris\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/%D8%A7%D8%A8%D9%84%D8%A7%D8%BA/qaq-p/2757740 | null |
{
"author": "Deepak Kumar",
"title": "How to update status page histogram, is there any API for that?",
"body": "I want to update the status page histogram bar using API. I am able to update the status page histogram bar manually but want to update using restful API. is it possible to update the status page histogram bar using API?\n"
} | [
{
"author": "Shashwat Khare",
"body": "Hello [@Deepak Kumar](/t5/user/viewprofilepage/user-id/5545699), \n\nThis is Shashwat from Statuspage support and here to help! :smile:\n\nNo, unfortunately, we don't yet have the API endpoint to update the update status age histogram, rather only the below API endpoint to get a histogram of subscribers by type and then state: \n<https://developer.statuspage.io/#operation/getPagesPageIdSubscribersHistogramByState>\n\nWe have an existing feature request raised to the Product team on this functionality as **STATUS-109** \nI have gone ahead and added your details to the existing feature request. \n\nBest, \nShashwat\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/How-to-update-status-page-histogram-is-there-any-API-for-that/qaq-p/2756774 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Esteban Diaz",
"title": "Statuspage API not working?",
"body": "Hi Team,\n\nI?m trying to use the Statuspage API endpoints, but when I try to reach:\n\n<https://developer.statuspage.io/>\n\nI got stuck on the page showing \"Loading\" .. forever.\n\n\n\nDoes anybody know if it is still working?\n\nThanks!\n"
} | [
{
"author": "Alan Violada",
"body": "Hey Esteban, Alan from the Statuspage Support team here.\n\nI'm not seeing any issues with loading the page on my end, and we have not gotten reports of any issues with the site - I would recommend trying with a different browser, or clearing out your browser cache/cookies and trying again.\n\nMight also be worth testing on a different network, just in case.\n\nRegards,\n\nAlan\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Statuspage-API-not-working/qaq-p/2756195 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Brianna Johnson",
"title": "Customize Maintenance Notification Times",
"body": "Hi,\n\nWe would like to send a maintenance notification 5 minutes before the maintenance starts, is this possible or are we only able to do so 1 hour before?\n"
} | [
{
"author": "Brant Schroeder",
"body": "[@Brianna Johnson](/t5/user/viewprofilepage/user-id/5544393) Welcome to the Atlassian community\n\nAt this time there is not a way to change that. The application automatically sends the notification 60min before the maintenance is scheduled to occur. You would have to submit an Atlassian support issue here: <https://support.atlassian.com/contact/> to recommend the feature enhancement.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Customize-Maintenance-Notification-Times/qaq-p/2755284 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "dan.panainte",
"title": "Backfile Outage",
"body": "Hi team,\n\nI want to backfill an outage, so I created an incident and marked it as major. The incident is now on the status page, but the uptime percentage is still 100%. How can I backfill an outage and have it reflected in the uptime percentage?\n\nBest regards,\n\nDan\n"
} | [
{
"author": "Mubeen Mohammed",
"body": "Hello [@dan.panainte](/t5/user/viewprofilepage/user-id/5541555)\n\nThank you for contacting the Atlassian Community!\n\nThe uptime update process allows you to manually adjust a component's uptime percentage for a specific month directly on your Statuspage. This feature is particularly useful for reflecting historical outages or downtime that weren't recorded in real-time. You can follow the detailed instructions in the documentation [here](https://support.atlassian.com/statuspage/docs/display-historical-uptime-of-components/#Editing-uptime-downtime)\n\nYou can follow these simplified steps discussed in the documentation.\n\n1. **Access Your Statuspage**: Log in to your Statuspage management interface.\n\n2. **Navigate to Components**: Go to \"Components\" from the left-hand navigation menu.\n\n3. **Select the Component**: Choose the component you wish to backfill an outage for.\n\n4. **Edit Component**: Click on the \"Edit\" button next to the component.\n\n5. **Adjust Uptime**: In the component settings, you will find a section for \"Uptime\". Here, you can manually adjust the uptime percentage to reflect the historical outage. This is done by specifying the downtime in terms of the percentage of uptime you want to display for a given month.\n\n6. **Save Changes**: After adjusting the uptime percentage to account for the outage, remember to save your changes.\n\nI hope the details provided are helpful.\n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Backfile-Outage/qaq-p/2751778 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "souvik.chowdhury",
"title": "Time line question",
"body": "Can we not increase the visibility time frame to 180n days rather than 90 days in the statuspage ?\n"
} | [
{
"author": "Dave Mathijs",
"body": "Hi [@souvik.chowdhury](/t5/user/viewprofilepage/user-id/4126686) welcome to the Atlassian Community!\n\nIf found this snipped in the documentation article [Display historical uptime of components](https://support.atlassian.com/statuspage/docs/display-historical-uptime-of-components/):\n\n*\"Enabling this feature will add a 90-day uptime display to your status page, and a full historical account on the \"/uptime\" page.\"*\n\nI don't have Statuspage installed, but what happens if you add this after the URL of the component?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Time-line-question/qaq-p/2744554 | [
"cloud",
"statuspage-cloud"
] |
{
"author": "Siddharth Dalal",
"title": "Email automation- cloudflare",
"body": "I have health checks set up on Cloudflare that sends me an email anytime the server is down/not reachable. I can add one more recipient as the component email. \n\nThe subject line does not contain the word UP/DOWN. it says something like: \n\nHealth check status changed: Mailing \\| Unhealthy \\| HTTP invalid response {#toc-hId--353369619}\n------------------------------------------------------------------------------------------------\n\nCloudflare does not give me an option to change the subject. What do i do?\n"
} | [
{
"author": "Mubeen Mohammed",
"body": "Hello [@Siddharth Dalal](/t5/user/viewprofilepage/user-id/5536125)\n\nThank you for contacting the Atlassian Community!\n\nUnfortunately, this is not a feasible option in the current product design. As of right now, our system will only look for the words \"UP\" or \"DOWN\" in the email subject line. If your tool can't be configured to use the \"UP\" and \"DOWN\" keywords, you would need to send the emails to a third party first, where the subject can be modified, and then sent to Statuspage.\n\nHowever, please note we do have an open feature request with our engineering team to consider supporting more email automation keywords, or even a fully customizable list. STATUS-32 is the ticket ID for your reference. Please note that Statuspage Feature Requests are for internal access only as of right now, so you will not be able to access the ticket. \n\nyou can read a bit more about how this process works in the below document:\n\n[Feature implementation policy](https://confluence.atlassian.com/support/implementation-of-new-features-policy-201294576.html)\n\nI hope the information provided is helpful. \n\nRegards\n\nMubeen Mohammed\n\nCloud Support Engineer\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Email-automation-cloudflare/qaq-p/2744541 | [
"cloud",
"cloudflare",
"statuspage-cloud"
] |
{
"author": "Shad Hinds",
"title": "Can I configure status embed per component?",
"body": "I would like to utilize status embed but I would like to utilize it at the component level. Not sure if this is supported utilizing the component API key or something like that. I have multiple applications within the same platform and don't want an in app notification on all applications if I have a single component having an issue.\n"
} | [
{
"author": "Jesse Klein",
"body": "Hi Shad,\n\nThis is Jesse from the Statuspage support team. Welcome to the community and thanks for reaching out about configuring status embed. The status embed feature does not have the granularity to function based on specific components.\n\nWhat you may be able to do is create one using the build-your-own as a starting point. Maybe there's a way to use the Status API to see which components are down and then only show the status embed when it matches. This would likely require extra scripting to accomplish this. Hopefully, that helps get you started.\n\nRegards, \nJesse\n",
"comments": null
},
{
"author": "Kevin Patterson",
"body": "Hi [@Shad Hinds](/t5/user/viewprofilepage/user-id/5534583)\n\nThe Status Embed \"Recommend Embed\" option does not have the flexibility to restrict down to the component level. For this you will need to select the \"Build your own\" option.\n\nI used the build your own option to create an embedded status for a single component and next scheduled maintenance details for that component. To do this I wrote a simple javascript that fetches the component details via the statuspage restapi. I'm display the Component Status, a link to an incident if one is associated to the component and then display the next scheduled maintenance activity if their is one associated to the component in statuspage. I used the link at the bottom of the page \"your page API docs\" as a guide to write my own script. If you haven't already i'd recommend looking at the your page API docs link on your statuspage or review the public documentation here: <https://developer.statuspage.io/>\n\nHere is a screenshot of what the end result was using the \"build your own\" option. I hope this helps put you on the right track.\n\n\n",
"comments": null
}
] | https://community.atlassian.com/t5/Statuspage-questions/Can-I-configure-status-embed-per-component/qaq-p/2742683 | [
"cloud"
] |
{
"author": "Adam Frankowski",
"title": "Is Crowd server 5.2.1 vulnerable to CVE-2023-50164",
"body": "Hi,\n\nAccording to CVE-2023-50164, Apache Struts has a Remote Code Execution vulnerability, present in version 2.5.32 of their library.\n\nFor more details see the following: \n- <https://nvd.nist.gov/vuln/detail/CVE-2023-50164> \n- <https://cwiki.apache.org/confluence/display/WW/s2-066>\n\nWe have conducted a security scan of our systems which has detected Apache Struts 2.5.32 JAR files in Crowd Server 5.2.1.\n\nOur question is simple, is Atlassian Crowd (Server Edition) vulnerable to CVE-2023-50164? If it is, when will a fix be released?\n\nThank you to anyone who responds,\n\nAdam\n"
} | [
{
"author": "Geoff Seeley",
"body": "This details a patched 2.5.33 drop-in-replacement:\n\n<https://lists.apache.org/thread/yh09b3fkf6vz5d6jdgrlvmg60lfwtqhj>\n\nObviously an official update from Atlassian would be best but this can make do until then as I suspect the holidays are going to delay vendor responses to this CVE.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/Is-Crowd-server-5-2-1-vulnerable-to-CVE-2023-50164/qaq-p/2557889 | [
"security",
"server"
] |
{
"author": "seho_lim_hanafn_com",
"title": "apache struts version in crowd",
"body": "hello,\n\ncan i get a apache struts version in crowd?\n\nwe are using crowd version 5.1.2.\n\nPlease let me know if crowd is using Apache Struts and, if so, what version it is using.\n"
} | [
{
"author": "Srinivas Sakali",
"body": "Crowd 5.2.x version using below jar\n\nfind -name \\\\\\*struts\\*.jar\n\n./crowd-webapp/WEB-INF/lib/struts2-core-2.5.33-atlassian-1.jar\n\n./crowd-webapp/WEB-INF/lib/struts2-sitemesh-plugin-2.5.33.jar\n\n./crowd-openidclient-webapp/WEB-INF/lib/struts2-core-2.5.33-atlassian-1.jar\n\n./crowd-openidclient-webapp/WEB-INF/lib/struts2-sitemesh-plugin-2.5.30.jar\n\n./crowd-openidclient-webapp/WEB-INF/lib/struts2-spring-plugin-2.5.30.jar\n\n./crowd-openidserver-webapp/WEB-INF/lib/struts2-spring-plugin-2.5.33.jar\n\n./crowd-openidserver-webapp/WEB-INF/lib/struts2-sitemesh-plugin-2.5.33.jar\n\n./crowd-openidserver-webapp/WEB-INF/lib/struts2-core-2.5.30-atlassian-1.jar\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/apache-struts-version-in-crowd/qaq-p/2550531 | [
"server"
] |
{
"author": "Adrien MINTZ",
"title": "Can't connect to confluence",
"body": "Good morning,\n\nNoone can connect to confluence anymore but everyone still succeeds to connect to JIRA. \nEverything was fine just a couple weeks ago and nothing has changed.\n\nCan you please help me invistigate and/or solve this issue please? I really don't know where to start.\n\nThank you!\n"
} | [
{
"author": "Ashtoo",
"body": "Good morning,\n\nIt sounds like there's an issue specifically with Confluence, while JIRA is still accessible. To help troubleshoot, you could use tools like [Bright White Screen](http://whitescreen.io) to test if your device's display is functioning correctly, ensuring there are no screen issues interfering with accessing Confluence. However, it's more likely an issue with Confluence's server or network settings, so I'd recommend checking those first. It may also help to review recent changes in your network or Confluence configurations that could have affected access.\n\nLet me know how it goes!\n",
"comments": null
},
{
"author": "Adrien MINTZ",
"body": "Can someone help me please?\n",
"comments": null
},
{
"author": "Michael Yaroshefsky - Visor for Jira",
"body": "Hi [@Adrien MINTZ](/t5/user/viewprofilepage/user-id/4229583) , \n\nHas anything changed since this morning? \n\nI searched to see if Confluence was down; currently, all systems are operational. (Source: <https://confluence.status.atlassian.com/>) \n\nYou mentioned nothing has changed on your end, but if you're still having an issue with Confluence being down, you can: \n\n1. Double check that you don't have any firewall or security restrictions \n2. Double check that nothing has changed with user permissions or acccess \n\nOther steps you can take: \n**You can also try troubleshooting your Confluence server logs** . This Confluence article explains more <https://confluence.atlassian.com/doc/working-with-confluence-logs-108364721.html> \n\n**Atlassian also offers support if any of the above is complicated. You can create a support ticket here:** [https://support.atlassian.com/contact/#/?inquiry_category=technical_issues\\&is_cloud=false\\&product_key=confluence\\&support_type=customer](https://support.atlassian.com/contact/#/?inquiry_category=technical_issues&is_cloud=false&product_key=confluence&support_type=customer) \n\n<br />\n",
"comments": [
{
"author": "Adrien MINTZ",
"body": "Hi Michael,\n\nNothing has changed. I am still unable to connect to Confluence.\n\nConfluence is up and running but it does NOT recognize my credentials anymore (nor anyone else for that matter).\n"
}
]
}
] | https://community.atlassian.com/t5/Crowd-questions/Can-t-connect-to-confluence/qaq-p/2539837 | [
"confluence",
"confluence-server",
"server"
] |
{
"author": "Lorenzo Raras",
"title": "Will Disabling Autocommit in the MySQL Database Adversely Affect Crowd?",
"body": "We have a Crowd 5.0 instance and a Jira 9.1 instance connected to it. Their databases are both hosted in the same MySQL instance.\n\nWe recently upgraded to MySQL 8.0 and everything seems to be functioning normally. However, in the documentation [here](https://confluence.atlassian.com/adminjiraserver/connecting-jira-applications-to-mysql-8-0-1018775461.html), it specifies that Jira requires the \"autocommit\" field in the my.cnf to be set to **false** . In the documentation [here](https://confluence.atlassian.com/crowd/mysql-4030924.html), it does **not** specify to disable that setting explicitly when configuring the database for Crowd.\n\nWill having autocommit turned off in the database adversely affect Crowd in any way?\n"
} | [
{
"author": "Nic Brough -Adaptavist-",
"body": "Welcome to the Atlassian Community!\n\nNo, it needs to be set that way, otherwise you may find you get deadlocks in the database, which will stop people from logging in. It won't happen often, and the symptom is a hung login, which the users can refresh the page and probably be able to log in again, but it can happen.\n",
"comments": [
{
"author": "Lorenzo Raras",
"body": "Thank you very much!\n"
}
]
}
] | https://community.atlassian.com/t5/Crowd-questions/Will-Disabling-Autocommit-in-the-MySQL-Database-Adversely-Affect/qaq-p/2449174 | null |
{
"author": "Manjunath Patil",
"title": "How long does it take to update the reset password ?",
"body": "How long does it take to update the reset password ?\n"
} | [
{
"author": "Dave Mathijs",
"body": "Hello [@Manjunath Patil](/t5/user/viewprofilepage/user-id/5254360) welcome to the Atlassian Community!\n\nAfter you request to reset your password, we'll send you an email with a recovery link with the subject line **Reset your Atlassian password.** You should receive this email within 10 minutes. If not:\n\n1. Check that you've entered your email address correctly and that it's for an existing Atlassian account. Contact your organization's admin if you're unsure of what email address to use.\n\n2. Check your spam folder for an email from [email protected].\n\n3. Try using the **Resend recovery link** button.\n\n4. Contact your email administrator to check that emails from @am.atlassian.com are not being blocked.\n\nIf you have a managed account -- for example, if your organization uses Google or Microsoft to help you log in -- you may not be able to use our password reset link. You'll need to reset the account password for your single sign-on provider (for example, Google or Microsoft etc) instead or contact your organization admin if you're still having trouble logging in.\n",
"comments": [
{
"author": "Manjunath Patil",
"body": "Hi [@Dave Mathijs](/t5/user/viewprofilepage/user-id/2662590) , Thanks for the replay.\n\nI have successfully reset the Atlassian password, Able to login too using the new password.\n\nBut The issue is GIT, jFrog, Jenkins applications are not recognizing my credentials from CROWD.\n"
},
{
"author": "Dave Mathijs",
"body": "Hi [@Manjunath Patil](/t5/user/viewprofilepage/user-id/5254360) that is a totally different question. I would suggest to create a new question for GIT specifically.\n\nThanks for clicking the Accept answer button as your Atlassian account password is now reset.\n"
}
]
}
] | https://community.atlassian.com/t5/Crowd-questions/How-long-does-it-take-to-update-the-reset-password/qaq-p/2401165 | null |
{
"author": "Albert",
"title": "install crowd failed",
"body": "The following required plugins are not available: \\[com.atlassian.auiplugin, com.atlassian.soy.soy-template-plugin, com.atlassian.plugins.atlassian-plugins-webresource-plugin, crowd-rest-plugin, crowd.system.passwordencoders\\]. See Crowd server logs for details. The setup process cannot continue until the problem has been solved. If you require further assistance, you can contact Atlassian support.\n"
} | [
{
"author": "Kurt Klinner",
"body": "[@Albert](/t5/user/viewprofilepage/user-id/5246422)\n\nWelcome to the Atlassian community.\n\nAre there any additional entries in the log files\n\n?\n\nHave you had a look at similar reports in the forum?\n\n<https://community.atlassian.com/t5/Crowd-questions/Unable-to-install-crowd/qaq-p/741844>\n\nCheers\n\nKurt\n",
"comments": [
{
"author": "Albert",
"body": "yes, but it doesn't works.\n"
},
{
"author": "Albert",
"body": "2023-06-18 16:59:11,915 http-nio-8095-exec-12 INFO \\[crowd.manager.cluster.NodePanicHandler\\] Propagating node panic event as johnson event \n2023-06-18 16:59:11,919 http-nio-8095-exec-12 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down schedulers on node panic \n2023-06-18 16:59:11,919 http-nio-8095-exec-12 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down the scheduler com.atlassian.crowd.scheduling.InternalLocalScheduler@1b88c49f \n2023-06-18 16:59:11,920 http-nio-8095-exec-12 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down the scheduler com.atlassian.crowd.scheduling.CrowdSchedulerService@42018740 \n2023-06-18 16:59:11,921 http-nio-8095-exec-12 ERROR \\[atlassian.event.internal.AsynchronousAbleEventDispatcher\\] There was an exception thrown trying to dispatch event \\[com.atlassian.config.lifecycle.events.ApplicationStartedEvent@24f311d6\\] from the invoker \\[SingleParameterMethodListenerInvoker{method=public void com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(com.atlassian.config.lifecycle.events.ApplicationStartedEvent) throws com.atlassian.scheduler.SchedulerServiceException, listener=com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle@6a7cfb5a}\\] \njava.lang.RuntimeException: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet. Listener: com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle event: com.atlassian.config.lifecycle.events.ApplicationStartedEvent \nat com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:55) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher$1$1.run(AsynchronousAbleEventDispatcher.java:38) \nat com.google.common.util.concurrent.MoreExecutors$DirectExecutorService.execute(MoreExecutors.java:299) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher.dispatch(AsynchronousAbleEventDispatcher.java:88) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.lambda$dispatch$0(TransactionAwareEventDispatcher.java:31) \nat org.springframework.transaction.support.TransactionTemplate.execute(TransactionTemplate.java:133) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.dispatch(TransactionAwareEventDispatcher.java:30) \nat com.atlassian.event.internal.EventPublisherImpl.invokeListeners(EventPublisherImpl.java:204) \nat com.atlassian.event.internal.EventPublisherImpl.publish(EventPublisherImpl.java:115) \nat com.atlassian.crowd.core.event.TransactionAwareEventPublisher.publish(TransactionAwareEventPublisher.java:35) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.postBootstrapDatabase(CrowdBootstrapManagerImpl.java:94) \nat com.atlassian.config.bootstrap.DefaultAtlassianBootstrapManager.bootstrapDatabase(DefaultAtlassianBootstrapManager.java:285) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.bootstrapDatabase(CrowdBootstrapManagerImpl.java:74) \nat com.atlassian.crowd.console.action.setup.Database.configureJdbc(Database.java:238) \nat com.atlassian.crowd.console.action.setup.Database.update(Database.java:99) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat ognl.OgnlRuntime.invokeMethod(OgnlRuntime.java:899) \nat ognl.OgnlRuntime.callAppropriateMethod(OgnlRuntime.java:1544) \nat ognl.ObjectMethodAccessor.callMethod(ObjectMethodAccessor.java:68) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethodWithDebugInfo(XWorkMethodAccessor.java:98) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethod(XWorkMethodAccessor.java:90) \nat ognl.OgnlRuntime.callMethod(OgnlRuntime.java:1620) \nat ognl.ASTMethod.getValueBody(ASTMethod.java:91) \nat ognl.SimpleNode.evaluateGetValueBody(SimpleNode.java:212) \nat ognl.SimpleNode.getValue(SimpleNode.java:258) \nat ognl.Ognl.getValue(Ognl.java:470) \nat ognl.Ognl.getValue(Ognl.java:434) \nat com.opensymphony.xwork2.ognl.OgnlUtil$3.execute(OgnlUtil.java:374) \nat com.opensymphony.xwork2.ognl.OgnlUtil.compileAndExecuteMethod(OgnlUtil.java:426) \nat com.opensymphony.xwork2.ognl.OgnlUtil.callMethod(OgnlUtil.java:372) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeAction(DefaultActionInvocation.java:438) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeActionOnly(DefaultActionInvocation.java:293) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:254) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept(ParametersInterceptor.java:137) \nat com.opensymphony.xwork2.interceptor.MethodFilterInterceptor.intercept(MethodFilterInterceptor.java:99) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.StaticParametersInterceptor.intercept(StaticParametersInterceptor.java:201) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ModelDrivenInterceptor.intercept(ModelDrivenInterceptor.java:101) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ChainingInterceptor.intercept(ChainingInterceptor.java:160) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.xwork.interceptors.XWorkTransactionInterceptor.intercept(XWorkTransactionInterceptor.java:52) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.console.interceptor.SetupCheckInterceptor.intercept(SetupCheckInterceptor.java:24) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.factory.StrutsActionProxy.execute(StrutsActionProxy.java:48) \nat org.apache.struts2.dispatcher.Dispatcher.serviceAction(Dispatcher.java:574) \nat org.apache.struts2.dispatcher.ExecuteOperations.executeAction(ExecuteOperations.java:79) \nat org.apache.struts2.dispatcher.filter.StrutsExecuteFilter.doFilter(StrutsExecuteFilter.java:86) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.obtainContent(SiteMeshFilter.java:125) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.doFilter(SiteMeshFilter.java:76) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.struts2.dispatcher.filter.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:92) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.johnson.filters.AbstractJohnsonFilter.doFilter(AbstractJohnsonFilter.java:67) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdOpenSessionInViewFilter.doFilterInternal(CrowdOpenSessionInViewFilter.java:25) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.RequestCacheThreadLocalFilter.doFilter(RequestCacheThreadLocalFilter.java:27) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.security.BlockOpenSocialRequestFilter.doFilter(BlockOpenSocialRequestFilter.java:39) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdCachingFilter.doFilter(CrowdCachingFilter.java:25) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:197) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.webapp.filter.CrowdSecurityHeadersFilter.doFilter(CrowdSecurityHeadersFilter.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpRequestLoggingFilter.doFilter(HttpRequestLoggingFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpContextFilter.doFilter(HttpContextFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:198) \nat org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) \nat org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140) \nat org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:80) \nat org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87) \nat org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:342) \nat org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:799) \nat org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66) \nat org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:868) \nat org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1457) \nat org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) \nat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) \nat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) \nat org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) \nat java.lang.Thread.run(Thread.java:748) \nCaused by: java.lang.RuntimeException: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(CrowdSchedulerLifecycle.java:53) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:40) \n... 133 more \nCaused by: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:147) \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:155) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1423) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.lambda$getIdsToNextRunTimes$7(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.util.persistence.hibernate.StatelessDao.withStatelessSession(StatelessDao.java:26) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.getIdsToNextRunTimes(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.scheduling.ClusterJobDAODecorator.refresh(ClusterJobDAODecorator.java:109) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsFromDao(SchedulerQueueImpl.java:139) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsUnderLock(SchedulerQueueImpl.java:130) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobs(SchedulerQueueImpl.java:117) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.refreshClusteredJobs(CaesiumSchedulerService.java:359) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.startImpl(CaesiumSchedulerService.java:275) \nat com.atlassian.scheduler.core.AbstractSchedulerService.start(AbstractSchedulerService.java:180) \nat com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(CrowdSchedulerLifecycle.java:48) \n... 138 more \nCaused by: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.exception.internal.SQLExceptionTypeDelegate.convert(SQLExceptionTypeDelegate.java:63) \nat org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:42) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:111) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:97) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:80) \nat org.hibernate.loader.Loader.getResultSet(Loader.java:2123) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1911) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1887) \nat org.hibernate.loader.Loader.doQuery(Loader.java:932) \nat org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:349) \nat org.hibernate.loader.Loader.doList(Loader.java:2615) \nat org.hibernate.loader.Loader.doList(Loader.java:2598) \nat org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2430) \nat org.hibernate.loader.Loader.list(Loader.java:2425) \nat org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:502) \nat org.hibernate.hql.internal.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:379) \nat org.hibernate.engine.query.spi.HQLQueryPlan.performList(HQLQueryPlan.java:216) \nat org.hibernate.internal.StatelessSessionImpl.list(StatelessSessionImpl.java:461) \nat org.hibernate.query.internal.AbstractProducedQuery.doList(AbstractProducedQuery.java:1445) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1414) \n... 149 more \nCaused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'crowd.cwd_cluster_job' doesn't exist \nat sun.reflect.GeneratedConstructorAccessor158.newInstance(Unknown Source) \nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) \nat java.lang.reflect.Constructor.newInstance(Constructor.java:423) \nat com.mysql.jdbc.Util.handleNewInstance(Util.java:411) \nat com.mysql.jdbc.Util.getInstance(Util.java:386) \nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1054) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4237) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4169) \nat com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617) \nat com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778) \nat com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2825) \nat com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2156) \nat com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2323) \nat com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:116) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:71) \n... 164 more \n2023-06-18 16:59:11,930 http-nio-8095-exec-12 WARN \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] No plugins present. \n2023-06-18 16:59:11,930 http-nio-8095-exec-12 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.auiplugin \n2023-06-18 16:59:11,931 http-nio-8095-exec-12 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.soy.soy-template-plugin \n2023-06-18 16:59:11,931 http-nio-8095-exec-12 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.plugins.atlassian-plugins-webresource-plugin \n2023-06-18 16:59:11,931 http-nio-8095-exec-12 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd-rest-plugin \n2023-06-18 16:59:11,931 http-nio-8095-exec-12 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd.system.passwordencoders \n2023-06-18 16:59:11,931 http-nio-8095-exec-12 ERROR \\[console.action.setup.Database\\] Setup cannot continue because some required plugins are not available: \\[com.atlassian.auiplugin, com.atlassian.soy.soy-template-plugin, com.atlassian.plugins.atlassian-plugins-webresource-plugin, crowd-rest-plugin, crowd.system.passwordencoders\\] [@Kurt Klinner](/t5/user/viewprofilepage/user-id/734136)\n"
},
{
"author": "Kurt Klinner",
"body": "[@Albert](/t5/user/viewprofilepage/user-id/5246422) can you share the log files?\n"
},
{
"author": "Albert",
"body": "2023-06-18 17:48:33,025 http-nio-8095-exec-9 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Starting scheduler com.atlassian.crowd.scheduling.InternalLocalScheduler@38ad943b \n2023-06-18 17:48:33,028 http-nio-8095-exec-9 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Starting scheduler com.atlassian.crowd.scheduling.CrowdSchedulerService@10fa4625 \n2023-06-18 17:48:33,058 http-nio-8095-exec-9 WARN \\[engine.jdbc.spi.SqlExceptionHelper\\] SQL Error: 1146, SQLState: 42S02 \n2023-06-18 17:48:33,058 http-nio-8095-exec-9 ERROR \\[engine.jdbc.spi.SqlExceptionHelper\\] Table 'crowd.cwd_cluster_job' doesn't exist \n2023-06-18 17:48:33,059 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Error starting scheduler com.atlassian.crowd.scheduling.CrowdSchedulerService@10fa4625 \njavax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:147) \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:155) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1423) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.lambda$getIdsToNextRunTimes$7(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.util.persistence.hibernate.StatelessDao.withStatelessSession(StatelessDao.java:26) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.getIdsToNextRunTimes(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.scheduling.ClusterJobDAODecorator.refresh(ClusterJobDAODecorator.java:109) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsFromDao(SchedulerQueueImpl.java:139) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsUnderLock(SchedulerQueueImpl.java:130) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobs(SchedulerQueueImpl.java:117) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.refreshClusteredJobs(CaesiumSchedulerService.java:359) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.startImpl(CaesiumSchedulerService.java:275) \nat com.atlassian.scheduler.core.AbstractSchedulerService.start(AbstractSchedulerService.java:180) \nat com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(CrowdSchedulerLifecycle.java:48) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:40) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher$1$1.run(AsynchronousAbleEventDispatcher.java:38) \nat com.google.common.util.concurrent.MoreExecutors$DirectExecutorService.execute(MoreExecutors.java:299) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher.dispatch(AsynchronousAbleEventDispatcher.java:88) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.lambda$dispatch$0(TransactionAwareEventDispatcher.java:31) \nat org.springframework.transaction.support.TransactionTemplate.execute(TransactionTemplate.java:133) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.dispatch(TransactionAwareEventDispatcher.java:30) \nat com.atlassian.event.internal.EventPublisherImpl.invokeListeners(EventPublisherImpl.java:204) \nat com.atlassian.event.internal.EventPublisherImpl.publish(EventPublisherImpl.java:115) \nat com.atlassian.crowd.core.event.TransactionAwareEventPublisher.publish(TransactionAwareEventPublisher.java:35) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.postBootstrapDatabase(CrowdBootstrapManagerImpl.java:94) \nat com.atlassian.config.bootstrap.DefaultAtlassianBootstrapManager.bootstrapDatabase(DefaultAtlassianBootstrapManager.java:285) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.bootstrapDatabase(CrowdBootstrapManagerImpl.java:74) \nat com.atlassian.crowd.console.action.setup.Database.configureJdbc(Database.java:238) \nat com.atlassian.crowd.console.action.setup.Database.update(Database.java:99) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat ognl.OgnlRuntime.invokeMethod(OgnlRuntime.java:899) \nat ognl.OgnlRuntime.callAppropriateMethod(OgnlRuntime.java:1544) \nat ognl.ObjectMethodAccessor.callMethod(ObjectMethodAccessor.java:68) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethodWithDebugInfo(XWorkMethodAccessor.java:98) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethod(XWorkMethodAccessor.java:90) \nat ognl.OgnlRuntime.callMethod(OgnlRuntime.java:1620) \nat ognl.ASTMethod.getValueBody(ASTMethod.java:91) \nat ognl.SimpleNode.evaluateGetValueBody(SimpleNode.java:212) \nat ognl.SimpleNode.getValue(SimpleNode.java:258) \nat ognl.Ognl.getValue(Ognl.java:470) \nat ognl.Ognl.getValue(Ognl.java:434) \nat com.opensymphony.xwork2.ognl.OgnlUtil$3.execute(OgnlUtil.java:374) \nat com.opensymphony.xwork2.ognl.OgnlUtil.compileAndExecuteMethod(OgnlUtil.java:426) \nat com.opensymphony.xwork2.ognl.OgnlUtil.callMethod(OgnlUtil.java:372) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeAction(DefaultActionInvocation.java:438) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeActionOnly(DefaultActionInvocation.java:293) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:254) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept(ParametersInterceptor.java:137) \nat com.opensymphony.xwork2.interceptor.MethodFilterInterceptor.intercept(MethodFilterInterceptor.java:99) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.StaticParametersInterceptor.intercept(StaticParametersInterceptor.java:201) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ModelDrivenInterceptor.intercept(ModelDrivenInterceptor.java:101) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ChainingInterceptor.intercept(ChainingInterceptor.java:160) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.xwork.interceptors.XWorkTransactionInterceptor.intercept(XWorkTransactionInterceptor.java:52) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.console.interceptor.SetupCheckInterceptor.intercept(SetupCheckInterceptor.java:24) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.factory.StrutsActionProxy.execute(StrutsActionProxy.java:48) \nat org.apache.struts2.dispatcher.Dispatcher.serviceAction(Dispatcher.java:574) \nat org.apache.struts2.dispatcher.ExecuteOperations.executeAction(ExecuteOperations.java:79) \nat org.apache.struts2.dispatcher.filter.StrutsExecuteFilter.doFilter(StrutsExecuteFilter.java:86) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.obtainContent(SiteMeshFilter.java:125) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.doFilter(SiteMeshFilter.java:76) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.struts2.dispatcher.filter.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:92) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.johnson.filters.AbstractJohnsonFilter.doFilter(AbstractJohnsonFilter.java:67) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdOpenSessionInViewFilter.doFilterInternal(CrowdOpenSessionInViewFilter.java:25) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.RequestCacheThreadLocalFilter.doFilter(RequestCacheThreadLocalFilter.java:27) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.security.BlockOpenSocialRequestFilter.doFilter(BlockOpenSocialRequestFilter.java:39) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdCachingFilter.doFilter(CrowdCachingFilter.java:25) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:197) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.webapp.filter.CrowdSecurityHeadersFilter.doFilter(CrowdSecurityHeadersFilter.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpRequestLoggingFilter.doFilter(HttpRequestLoggingFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpContextFilter.doFilter(HttpContextFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:198) \nat org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) \nat org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140) \nat org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:80) \nat org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87) \nat org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:342) \nat org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:799) \nat org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66) \nat org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:868) \nat org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1457) \nat org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) \nat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) \nat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) \nat org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) \nat java.lang.Thread.run(Thread.java:748) \nCaused by: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.exception.internal.SQLExceptionTypeDelegate.convert(SQLExceptionTypeDelegate.java:63) \nat org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:42) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:111) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:97) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:80) \nat org.hibernate.loader.Loader.getResultSet(Loader.java:2123) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1911) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1887) \nat org.hibernate.loader.Loader.doQuery(Loader.java:932) \nat org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:349) \nat org.hibernate.loader.Loader.doList(Loader.java:2615) \nat org.hibernate.loader.Loader.doList(Loader.java:2598) \nat org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2430) \nat org.hibernate.loader.Loader.list(Loader.java:2425) \nat org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:502) \nat org.hibernate.hql.internal.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:379) \nat org.hibernate.engine.query.spi.HQLQueryPlan.performList(HQLQueryPlan.java:216) \nat org.hibernate.internal.StatelessSessionImpl.list(StatelessSessionImpl.java:461) \nat org.hibernate.query.internal.AbstractProducedQuery.doList(AbstractProducedQuery.java:1445) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1414) \n... 149 more \nCaused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'crowd.cwd_cluster_job' doesn't exist \nat sun.reflect.GeneratedConstructorAccessor105.newInstance(Unknown Source) \nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) \nat java.lang.reflect.Constructor.newInstance(Constructor.java:423) \nat com.mysql.jdbc.Util.handleNewInstance(Util.java:411) \nat com.mysql.jdbc.Util.getInstance(Util.java:386) \nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1054) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4237) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4169) \nat com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617) \nat com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778) \nat com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2825) \nat com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2156) \nat com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2323) \nat com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:116) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:71) \n... 164 more \n2023-06-18 17:48:33,061 http-nio-8095-exec-9 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down schedulers on node panic \n2023-06-18 17:48:33,062 http-nio-8095-exec-9 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down the scheduler com.atlassian.crowd.scheduling.InternalLocalScheduler@38ad943b \n2023-06-18 17:48:33,062 http-nio-8095-exec-9 INFO \\[atlassian.crowd.scheduling.CrowdSchedulerLifecycle\\] Shutting down the scheduler com.atlassian.crowd.scheduling.CrowdSchedulerService@10fa4625 \n2023-06-18 17:48:33,064 http-nio-8095-exec-9 INFO \\[crowd.manager.cluster.NodePanicHandler\\] Propagating node panic event as johnson event \n2023-06-18 17:48:33,065 http-nio-8095-exec-9 ERROR \\[atlassian.event.internal.AsynchronousAbleEventDispatcher\\] There was an exception thrown trying to dispatch event \\[com.atlassian.config.lifecycle.events.ApplicationStartedEvent@431c5e7c\\] from the invoker \\[SingleParameterMethodListenerInvoker{method=public void com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(com.atlassian.config.lifecycle.events.ApplicationStartedEvent) throws com.atlassian.scheduler.SchedulerServiceException, listener=com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle@549ab91}\\] \njava.lang.RuntimeException: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet. Listener: com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle event: com.atlassian.config.lifecycle.events.ApplicationStartedEvent \nat com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:55) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher$1$1.run(AsynchronousAbleEventDispatcher.java:38) \nat com.google.common.util.concurrent.MoreExecutors$DirectExecutorService.execute(MoreExecutors.java:299) \nat com.atlassian.event.internal.AsynchronousAbleEventDispatcher.dispatch(AsynchronousAbleEventDispatcher.java:88) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.lambda$dispatch$0(TransactionAwareEventDispatcher.java:31) \nat org.springframework.transaction.support.TransactionTemplate.execute(TransactionTemplate.java:133) \nat com.atlassian.crowd.core.event.TransactionAwareEventDispatcher.dispatch(TransactionAwareEventDispatcher.java:30) \nat com.atlassian.event.internal.EventPublisherImpl.invokeListeners(EventPublisherImpl.java:204) \nat com.atlassian.event.internal.EventPublisherImpl.publish(EventPublisherImpl.java:115) \nat com.atlassian.crowd.core.event.TransactionAwareEventPublisher.publish(TransactionAwareEventPublisher.java:35) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.postBootstrapDatabase(CrowdBootstrapManagerImpl.java:94) \nat com.atlassian.config.bootstrap.DefaultAtlassianBootstrapManager.bootstrapDatabase(DefaultAtlassianBootstrapManager.java:285) \nat com.atlassian.crowd.manager.bootstrap.CrowdBootstrapManagerImpl.bootstrapDatabase(CrowdBootstrapManagerImpl.java:74) \nat com.atlassian.crowd.console.action.setup.Database.configureJdbc(Database.java:238) \nat com.atlassian.crowd.console.action.setup.Database.update(Database.java:99) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat ognl.OgnlRuntime.invokeMethod(OgnlRuntime.java:899) \nat ognl.OgnlRuntime.callAppropriateMethod(OgnlRuntime.java:1544) \nat ognl.ObjectMethodAccessor.callMethod(ObjectMethodAccessor.java:68) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethodWithDebugInfo(XWorkMethodAccessor.java:98) \nat com.opensymphony.xwork2.ognl.accessor.XWorkMethodAccessor.callMethod(XWorkMethodAccessor.java:90) \nat ognl.OgnlRuntime.callMethod(OgnlRuntime.java:1620) \nat ognl.ASTMethod.getValueBody(ASTMethod.java:91) \nat ognl.SimpleNode.evaluateGetValueBody(SimpleNode.java:212) \nat ognl.SimpleNode.getValue(SimpleNode.java:258) \nat ognl.Ognl.getValue(Ognl.java:470) \nat ognl.Ognl.getValue(Ognl.java:434) \nat com.opensymphony.xwork2.ognl.OgnlUtil$3.execute(OgnlUtil.java:374) \nat com.opensymphony.xwork2.ognl.OgnlUtil.compileAndExecuteMethod(OgnlUtil.java:426) \nat com.opensymphony.xwork2.ognl.OgnlUtil.callMethod(OgnlUtil.java:372) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeAction(DefaultActionInvocation.java:438) \nat com.opensymphony.xwork2.DefaultActionInvocation.invokeActionOnly(DefaultActionInvocation.java:293) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:254) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.interceptor.ServletConfigInterceptor.intercept(ServletConfigInterceptor.java:167) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ParametersInterceptor.doIntercept(ParametersInterceptor.java:137) \nat com.opensymphony.xwork2.interceptor.MethodFilterInterceptor.intercept(MethodFilterInterceptor.java:99) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.StaticParametersInterceptor.intercept(StaticParametersInterceptor.java:201) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ModelDrivenInterceptor.intercept(ModelDrivenInterceptor.java:101) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.opensymphony.xwork2.interceptor.ChainingInterceptor.intercept(ChainingInterceptor.java:160) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.xwork.interceptors.XWorkTransactionInterceptor.intercept(XWorkTransactionInterceptor.java:52) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat com.atlassian.crowd.console.interceptor.SetupCheckInterceptor.intercept(SetupCheckInterceptor.java:24) \nat com.opensymphony.xwork2.DefaultActionInvocation.invoke(DefaultActionInvocation.java:249) \nat org.apache.struts2.factory.StrutsActionProxy.execute(StrutsActionProxy.java:48) \nat org.apache.struts2.dispatcher.Dispatcher.serviceAction(Dispatcher.java:574) \nat org.apache.struts2.dispatcher.ExecuteOperations.executeAction(ExecuteOperations.java:79) \nat org.apache.struts2.dispatcher.filter.StrutsExecuteFilter.doFilter(StrutsExecuteFilter.java:86) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.obtainContent(SiteMeshFilter.java:125) \nat com.opensymphony.sitemesh.webapp.SiteMeshFilter.doFilter(SiteMeshFilter.java:76) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.struts2.dispatcher.filter.StrutsPrepareFilter.doFilter(StrutsPrepareFilter.java:92) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.johnson.filters.AbstractJohnsonFilter.doFilter(AbstractJohnsonFilter.java:67) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdOpenSessionInViewFilter.doFilterInternal(CrowdOpenSessionInViewFilter.java:25) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.RequestCacheThreadLocalFilter.doFilter(RequestCacheThreadLocalFilter.java:27) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.plugin.servlet.filter.IteratingFilterChain.doFilter(IteratingFilterChain.java:39) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:70) \nat com.atlassian.plugin.servlet.filter.ServletFilterModuleContainerFilter.doFilter(ServletFilterModuleContainerFilter.java:58) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.security.BlockOpenSocialRequestFilter.doFilter(BlockOpenSocialRequestFilter.java:39) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdCachingFilter.doFilter(CrowdCachingFilter.java:25) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:197) \nat org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.console.filter.CrowdDelegatingFilterProxy.doFilter(CrowdDelegatingFilterProxy.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.webapp.filter.CrowdSecurityHeadersFilter.doFilter(CrowdSecurityHeadersFilter.java:38) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpRequestLoggingFilter.doFilter(HttpRequestLoggingFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat com.atlassian.crowd.plugin.web.filter.HttpContextFilter.doFilter(HttpContextFilter.java:30) \nat org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) \nat org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) \nat org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:198) \nat org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) \nat org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:140) \nat org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:80) \nat org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:87) \nat org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:342) \nat org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:799) \nat org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66) \nat org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:868) \nat org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1457) \nat org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) \nat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) \nat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) \nat org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) \nat java.lang.Thread.run(Thread.java:748) \nCaused by: java.lang.RuntimeException: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(CrowdSchedulerLifecycle.java:53) \nat sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) \nat sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) \nat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) \nat java.lang.reflect.Method.invoke(Method.java:498) \nat com.atlassian.event.internal.SingleParameterMethodListenerInvoker.invoke(SingleParameterMethodListenerInvoker.java:40) \n... 133 more \nCaused by: javax.persistence.PersistenceException: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:147) \nat org.hibernate.internal.ExceptionConverterImpl.convert(ExceptionConverterImpl.java:155) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1423) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.lambda$getIdsToNextRunTimes$7(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.util.persistence.hibernate.StatelessDao.withStatelessSession(StatelessDao.java:26) \nat com.atlassian.crowd.dao.scheduling.ClusterJobDAOHibernate.getIdsToNextRunTimes(ClusterJobDAOHibernate.java:84) \nat com.atlassian.crowd.scheduling.ClusterJobDAODecorator.refresh(ClusterJobDAODecorator.java:109) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsFromDao(SchedulerQueueImpl.java:139) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobsUnderLock(SchedulerQueueImpl.java:130) \nat com.atlassian.scheduler.caesium.impl.SchedulerQueueImpl.refreshClusteredJobs(SchedulerQueueImpl.java:117) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.refreshClusteredJobs(CaesiumSchedulerService.java:359) \nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.startImpl(CaesiumSchedulerService.java:275) \nat com.atlassian.scheduler.core.AbstractSchedulerService.start(AbstractSchedulerService.java:180) \nat com.atlassian.crowd.scheduling.CrowdSchedulerLifecycle.onApplicationStarted(CrowdSchedulerLifecycle.java:48) \n... 138 more \nCaused by: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.exception.internal.SQLExceptionTypeDelegate.convert(SQLExceptionTypeDelegate.java:63) \nat org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:42) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:111) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:97) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:80) \nat org.hibernate.loader.Loader.getResultSet(Loader.java:2123) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1911) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1887) \nat org.hibernate.loader.Loader.doQuery(Loader.java:932) \nat org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:349) \nat org.hibernate.loader.Loader.doList(Loader.java:2615) \nat org.hibernate.loader.Loader.doList(Loader.java:2598) \nat org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2430) \nat org.hibernate.loader.Loader.list(Loader.java:2425) \nat org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:502) \nat org.hibernate.hql.internal.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:379) \nat org.hibernate.engine.query.spi.HQLQueryPlan.performList(HQLQueryPlan.java:216) \nat org.hibernate.internal.StatelessSessionImpl.list(StatelessSessionImpl.java:461) \nat org.hibernate.query.internal.AbstractProducedQuery.doList(AbstractProducedQuery.java:1445) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1414) \n... 149 more \nCaused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'crowd.cwd_cluster_job' doesn't exist \nat sun.reflect.GeneratedConstructorAccessor105.newInstance(Unknown Source) \nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) \nat java.lang.reflect.Constructor.newInstance(Constructor.java:423) \nat com.mysql.jdbc.Util.handleNewInstance(Util.java:411) \nat com.mysql.jdbc.Util.getInstance(Util.java:386) \nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1054) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4237) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4169) \nat com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617) \nat com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778) \nat com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2825) \nat com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2156) \nat com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2323) \nat com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:116) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:71) \n... 164 more \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 WARN \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] No plugins present. \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.auiplugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.soy.soy-template-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.plugins.atlassian-plugins-webresource-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd-rest-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd.system.passwordencoders \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[console.action.setup.Database\\] Setup cannot continue because some required plugins are not available: \\[com.atlassian.auiplugin, com.atlassian.soy.soy-template-plugin, com.atlassian.plugins.atlassian-plugins-webresource-plugin, crowd-rest-plugin, crowd.system.passwordencoders\\]\n"
},
{
"author": "Albert",
"body": "Caused by: org.hibernate.exception.SQLGrammarException: could not extract ResultSet \nat org.hibernate.exception.internal.SQLExceptionTypeDelegate.convert(SQLExceptionTypeDelegate.java:63) \nat org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:42) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:111) \nat org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:97) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:80) \nat org.hibernate.loader.Loader.getResultSet(Loader.java:2123) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1911) \nat org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1887) \nat org.hibernate.loader.Loader.doQuery(Loader.java:932) \nat org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:349) \nat org.hibernate.loader.Loader.doList(Loader.java:2615) \nat org.hibernate.loader.Loader.doList(Loader.java:2598) \nat org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2430) \nat org.hibernate.loader.Loader.list(Loader.java:2425) \nat org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:502) \nat org.hibernate.hql.internal.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:379) \nat org.hibernate.engine.query.spi.HQLQueryPlan.performList(HQLQueryPlan.java:216) \nat org.hibernate.internal.StatelessSessionImpl.list(StatelessSessionImpl.java:461) \nat org.hibernate.query.internal.AbstractProducedQuery.doList(AbstractProducedQuery.java:1445) \nat org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1414) \n... 149 more \nCaused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'crowd.cwd_cluster_job' doesn't exist \nat sun.reflect.GeneratedConstructorAccessor105.newInstance(Unknown Source) \nat sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) \nat java.lang.reflect.Constructor.newInstance(Constructor.java:423) \nat com.mysql.jdbc.Util.handleNewInstance(Util.java:411) \nat com.mysql.jdbc.Util.getInstance(Util.java:386) \nat com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1054) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4237) \nat com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4169) \nat com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617) \nat com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778) \nat com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2825) \nat com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2156) \nat com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2323) \nat com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:116) \nat org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:71) \n... 164 more \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 WARN \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] No plugins present. \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.auiplugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.soy.soy-template-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: com.atlassian.plugins.atlassian-plugins-webresource-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd-rest-plugin \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[atlassian.crowd.plugin.RequiredPluginsStartupCheck\\] Required plugin is missing: crowd.system.passwordencoders \n2023-06-18 17:48:33,068 http-nio-8095-exec-9 ERROR \\[console.action.setup.Database\\] Setup cannot continue because some required plugins are not available: \\[com.atlassian.auiplugin, com.atlassian.soy.soy-template-plugin, com.atlassian.plugins.atlassian-plugins-webresource-plugin, crowd-rest-plugin, crowd.system.passwordencoders\\] \n2023-06-18 18:05:24,437 http-nio-8095-exec-12 INFO \\[atlassian.johnson.filters.JohnsonFilter\\] The application is still starting up, or there are errors. Redirecting request from '/console/setup/setupdatabase!update.action' to '/console/error/error.action'\n"
},
{
"author": "Kurt Klinner",
"body": "[@Albert](/t5/user/viewprofilepage/user-id/5246422) can you confirm you followed the steps at <https://confluence.atlassian.com/crowd/mysql-4030924.html>?\n"
},
{
"author": "Albert",
"body": "[@Kurt Klinner](/t5/user/viewprofilepage/user-id/734136)thanks so much, I followed the steps to create database, it works.\n\nmy steps are:\n\nCREATE DATABASE crowd CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;\n\ngrant all on crowd.\\* to 'crowd'@'%' identified by 'crowdpasswd' with grant option;\n\nthe right steps are:\n\n create database crowd character set utf8 collate utf8_bin;\n\n GRANT ALL PRIVILEGES ON crowd.* TO 'crowduser'@'localhost' IDENTIFIED BY 'crowdpass';\n\nthanks again.\n"
}
]
},
{
"author": "Kurt Klinner",
"body": "[@Albert](/t5/user/viewprofilepage/user-id/5246422) can you confirm that you followed the steps in <https://confluence.atlassian.com/crowd/mysql-4030924.html>?\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/install-crowd-failed/qaq-p/2392571 | null |
{
"author": "aerochaz",
"title": "Crowd Clustering not showing both nodes",
"body": "I'm trying to set up crowd clustering. I think I have it set up. However, it only shows both nodes when one node is offline and the other is still online. When the second node comes back online again, only one node is shown (the active one). Is this how it is supposed to be? Jira clustering shows all active nodes at the same time. Is crowd supposed to show all active nodes at the same time as well? If so, how do I fix it to where both are shown.\n"
} | [
{
"author": "Fabio Racobaldo _Herzum_",
"body": "Hi [@aerochaz](/t5/user/viewprofilepage/user-id/5228256) and welcome,\n\ncurrently, on crowd side, when a node goes offline it is removed form the list (on jira side it remains visible in the list with status offline). It is a different management.\n\nFabio\n",
"comments": [
{
"author": "aerochaz",
"body": "Thank you. I'm specifically wondering why I cannot view both nodes when they both are online. I can only view both when one goes offline and the other is online. It will show both temporarily and be removed like you said, but when they are both online, it doesn't show both online at the same time like on the Jira side.\n"
}
]
}
] | https://community.atlassian.com/t5/Crowd-questions/Crowd-Clustering-not-showing-both-nodes/qaq-p/2370946 | null |
{
"author": "Jakob KN",
"title": "Single Crowd directory for both Jira and Confluence.",
"body": "Hello folks!\n\nWe're looking into adding Crowd as a single point of authentication and SSO for Jira and Confluence. And, to be able to manage group memberships for both Jira and Confluence directly in Crowd going forwards.\n\nI'm considering adding a single directory in Crowd, called \"Atlassian-users\" which will authenticate for both Jira and Confluence.\n\nWe've got existing users and groups in both Confluence and Jira, the majority of users and groups are identical between the two, but there are a number of users and groups which only exist in Jira/Confluence. \nEventually, the groups will be streamlined to be the same on systems, but that's a rather large undertaking and adding Crowd takes priority over that.\n\nIn relation to this, i have a few questions:\n\n1) If i import Users and groups first from Confluence and then from Jira, I assume that duplicate users/groups will not exist twice in the \"Atlassian-users\" directory?\n\n2) Groups and users that only exist in Jira will only be created in the \"Atlassian-users\" directory, but not directly in Confluence? \n(and vice versa for groups/users only existing Confluence)\n\n3) Is this a viable approach, or is it better to have a two separate directories in Crowd, for Jira and Confluence?\n\nWe're on Data Center for both Jira, Confluence and Crowd.\n\nAny answers, tips or advice is much appreciated. \nThanks in advance!\n"
} | [
{
"author": "Arnav Ghatage",
"body": "Hello Jakob!\n\nI'd be happy to help with your questions regarding using Crowd as a single point of authentication and SSO for Jira and Confluence.\n\n**1) If i import Users and groups first from Confluence and then from Jira, I assume that duplicate users/groups will not exist twice in the \"Atlassian-users\" directory?**\n\n\\>\\> If you import users and groups from Confluence and then from Jira into the \"Atlassian-users\" directory in Crowd, any duplicate users or groups should not exist twice in the directory. Crowd should recognize and merge the duplicate entries during the import process.\n\n**2) Groups and users that only exist in Jira will only be created in the \"Atlassian-users\" directory, but not directly in Confluence?** \n**(and vice versa for groups/users only existing Confluence)**\n\nThat's correct, but as you've synced the Crowd directory to confluence and jira, all the users synced in the Crowd directory will be visible in Jira and Confluence.\n\n**3) Is this a viable approach, or is it better to have a two separate directories in Crowd, for Jira and Confluence?**\n\nUsing a single directory in Crowd for both Jira and Confluence is a viable approach and is actually recommended by Atlassian. It simplifies user management and allows for centralized control over authentication and authorization across the two systems. However, it's important to ensure that the user and group data is kept in sync between Jira and Confluence to avoid any issues.\n\nI hope this helps! Let me know if you have any further questions or concerns.\n\n**P.S - I work for miniOrange, the exclusive Crowd SSO vendor on the Atlassian Marketplace** \n\nThanks,\n\n**Arnav Ghatage**\n",
"comments": null
}
] | https://community.atlassian.com/t5/Crowd-questions/Single-Crowd-directory-for-both-Jira-and-Confluence/qaq-p/2342714 | [
"server"
] |
{
"author": "gijs_kruize",
"title": "Retrieving all customers (including private email)",
"body": "Dear Community, \n\nI have been tasked to automate creation of customers in our Service Desk Management. \n\nAfter some research I started using the Servicedesk API from which i can correctly all customers of our servicedesks. The only problem there is is that some emailAdress fields are empty since these users have their email visability on **only me and admins**.\n\nAfter making the same user that is used as credentials for the Servicedesk API Organization admin on the organization SDM lives on. I still could not see users' emailAdress (and yes i have verified that this user can see all users' email adresses under **atlassian admin \\> organization \\> directory** ) \n\nI have tried all admin API's but i never succeseeded in getting the users via atlassian admin. \n\nSo my final question is, is there a way to make all email adresses visable in the Servicedesk API? **or** what endpoint can i use to get the users from the Admin API \n\nThanks in advance\n"
} | [
{
"author": "Vijay Dadi",
"body": "Hello [@gijs_kruize](/t5/user/viewprofilepage/user-id/5601275) ,\n\nYou can search the Atlassian user using the api\n\n<http://xxx.atlassian.net/rest/api/user/search?query={{emaill> address}.\n\nHope this helps,\n\nVijay\n",
"comments": [
{
"author": "gijs_kruize",
"body": "The whole point is that i am not able to get a **List of users including email adresses**from the admin api. I also cannot search on email since i cannot retrieve the email adresses via the servicedesk api\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Retrieving-all-customers-including-private-email/qaq-p/2821350 | [
"administration",
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Serkan G?ltepe",
"title": "How to prevent agents from adding new customers?",
"body": "In Jira Service Desk, when an agent creates an issue on behalf of a customer in the customer portal, and if the customer doesn't exist as a user, it shows an option like \"Add new customer xxx[@XXXX](/t5/user/viewprofilepage/user-id/3340408).com.\"\n\nHow can I prevent agents from adding new customers? I want them to create issues on behalf of a customer only if the customer already exists as a user. Is there a way to prevent this?\n\n\n"
} | [
{
"author": "Ollie Guan",
"body": "Hi [@Serkan G?ltepe](/t5/user/viewprofilepage/user-id/5097825) ,\n\nVote for this issue <https://jira.atlassian.com/browse/JSDCLOUD-4088>\n\nAlso you can find some alternatives in the comments.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/How-to-prevent-agents-from-adding-new-customers/qaq-p/2821284 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Vinoth Senthilvel",
"title": "JIRA Service Portal Login Redirects to JIRA Project Page",
"body": "Dear Community,\n\nWe have JIRA service management portal to create tickets for our users(customers). For some reason couple of our users when they try to login the JIRA redirecting them to JIRA login page then it shows access denied message \"No Access\". but when i see in the customer list the users is already existing and active.\n\n.png\")\n"
} | [
{
"author": "Umut Ekin AL",
"body": "Hello [@Vinoth Senthilvel](/t5/user/viewprofilepage/user-id/5601107) ,\n\nyou might control permission scheme the projects.\n\nAlso give one person an extra role is already in the permissions to testing the problem. If it is the problem you should edit permission scheme. \n\n<br />\n\nHope it helps!\n\nUmut\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/JIRA-Service-Portal-Login-Redirects-to-JIRA-Project-Page/qaq-p/2821187 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Shaikh Abdul Rehman",
"title": "We are getting charged in monthly billing for JSM as we haven't using it.",
"body": "We are getting charged in monthly billing for JSM as we haven't using it. As i am using standard version of Jira with monthly billing plan. \n\nThis month bill generated included JSM subsrciption in it, how to resolve this ?\n"
} | [
{
"author": "Rilwan Ahmed",
"body": "Hi [@Shaikh Abdul Rehman](/t5/user/viewprofilepage/user-id/5471218) ,\n\n1. Go to product details and see if there is active subscription for JSM. i.e. go to <https://admin.atlassian.com/> and see how many users are active in JSM.\n2. If you had used JSM before and now if you are not using, then first you need to unsubscribe from JSM. Details in <https://support.atlassian.com/subscriptions-and-billing/docs/cancel-a-subscription/>\n3. Raise a ticket with Atlassian if you feel you are wrongly billed in <https://www.atlassian.com/company/contact/purchasing-licensing?redirectSource=sac-wac-redirect#/> **OR** <https://support.atlassian.com/contact/#/>\n",
"comments": [
{
"author": "Shaikh Abdul Rehman",
"body": "[@Rilwan Ahmed](/t5/user/viewprofilepage/user-id/716861) Thanks for the quick response. Noted i will follow on the same.\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/We-are-getting-charged-in-monthly-billing-for-JSM-as-we-haven-t/qaq-p/2821167 | [
"jira-service-desk-cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Tom Mikelin",
"title": "assets edit service missing service relationships",
"body": "Hi,\n\nIn cloud JSM Assets unable to edit service relationships.\n\nScreenshots attached. Regards, Tom\n\n\n"
} | [
{
"author": "Mark Higgins",
"body": "Hi [@Tom Mikelin](/t5/user/viewprofilepage/user-id/5298102)\n\nIf you go to a project and Select Services do you see something similar to\n\n\n\nIf I select Customer Support it opens up to be:\n\n\n\nFrom here you can add/remove the Service relationship.\n\nHope that helps\n\nMark\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/assets-edit-service-missing-service-relationships/qaq-p/2821114 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "yanchiu_octopus_com_hk",
"title": "How to adjust the height of a textarea by ScriptRunner Behaviour?",
"body": "Hi there,\n\nI want to make one of textarea (not all textarea) shorter, can it be set in Behaviour in ScriptRunner\n"
} | [
{
"author": "yanchiu_octopus_com_hk",
"body": "\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/How-to-adjust-the-height-of-a-textarea-by-ScriptRunner-Behaviour/qaq-p/2821044 | [
"jira-service-desk-data-center",
"jira-service-management",
"jira-service-management-data-center",
"jira-service-management-server"
] |
{
"author": "Danielle David",
"title": "JSM and Jira project -reportin system that allows us to understand the overall impact of each enhanc",
"body": "I'm seeking assistance with managing our enhancements across our Finance division. Currently, we have a central project that encompasses all our enhancement requests this is a **JSM service** **Project** . Once an enhancement is approved, the corresponding ticket is duplicated and transferred to a specific **Jira Project** project based on the nature of the enhancement. For instance, enhancements related to taxation issues are moved into the Tax project as an epic, to which we then add associated tasks and stories.\n\nOur goal is to establish a reporting system that allows us to understand the overall impact of each enhancement. Specifically, we want to track the number of epics generated per enhancement, as well as the subsequent stories and tasks created within those epics.\n\nCould you please advise if there's a way to report on these upstream and downstream flows accurately and efficiently?\n"
} | [
{
"author": "Alex Ortiz",
"body": "\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/JSM-and-Jira-project-reportin-system-that-allows-us-to/qaq-p/2821037 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "John Voita",
"title": "Looking to have a form generated in Jira Service Management automate to a Scrum Porject.",
"body": "I am looking for assistance with the following scenario:\n\nI have a form the is visible to users via a JSM portal. When the user clicks, \"Submit\", it generates a ticket. I have automated for that ticket to clone into a Scrum project, as that is the team that will then process the request. Automation also includes deleting the ticket in the JSM project.\n\nThe challenge I'm having is that when the cloning occurs, the completed form does not migrate with the automation. Essentially, the new ticket is created, but the form is not present, so it is just a ticket.\n\nHow do I automate the moving of the form?\n"
} | [
{
"author": "Camilo Galleguillos",
"body": "Hi, John!\n\nForms data from Jira Service Management cannot be moved or copied to other projects. There would be two options to access the form data:\n\n* **Don't delete the JSM issue, and link it to the JSW Scrum issue** \n This would allow the Scrum project users to access the data from the form without needing extra steps. Note that JSW users won't need to have a JSM license as long as they don't need to post comment replies to the customer.\n* **Generate a PDF export of the form data and attach it to the JSW Scrum issue** \n Check [this community article](https://community.atlassian.com/t5/Jira-Service-Management/Clone-a-ticket-and-form-to-another-project/qaq-p/2309180) describing a process to automatically attach the form data as PDF.\n\nBest,\n\n|----------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n|  | #### Camilo Galleguillos {#toc-hId-374382860} Sr. Technical Consultant [**ServiceRocket**](https://servicerocket.com/) [[email protected]](mailto:[email protected]) Santiago, Chile |\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Looking-to-have-a-form-generated-in-Jira-Service-Management/qaq-p/2821013 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Adolfo Mendez",
"title": "Google Sheets integration - missing issue",
"body": "Hello,\n\nI have created several Google Sheets reports based on the Jira Cloud for Sheets extension/add-on for a while, without any trouble.\n\nToday, I found that one of the reports failed to import one of the records/issues. It basically skipped that particular issue for unknown reasons.\n\nI tried to build the report again, from scratch, using the Basic, JQL and Filter import types, and all of them failed to import that particular record. In the Jira filter it does show correctly. I have also examined the issue and found nothing that makes it different from others.\n\nCould it be that the issue is corrupted somehow? What else could be causing this inconsistency?\n"
} | [
{
"author": "MobilityStream",
"body": "Hi [@Adolfo Mendez](/t5/user/viewprofilepage/user-id/5600807) ,\n\nUnfortunately I don't have an answer for you. Jira Cloud for Sheets is notoriously unreliable. The user community is full of post by users that lose connectivity, see frequent errors, experience various data issues (duplication, missing data, etc.). At this point it is basically unsupported (background [here](https://mobilitystream.com/why-move-from-free-app-jira-cloud-for-sheets-to-paid-google-sheets-integration/)).\n\nIf reliable exports are important to you, we recommend to try our [Google Sheet Integration](https://marketplace.atlassian.com/apps/1216313/google-sheets-integration) add-on. It works fundamentally different by exporting directly out of Jira via API calls. It is much more reliable and used by the largest organizations. Exports can be one-time, scheduled, or real-time You can also export much richer data to create more sophisticated reports (Assets, Changelogs, Projects, Sprints, Users, Time-in-Status, etc.). Everything directly controlled within Jira. Give it a try.\n\nKind regards,\n\nThe Mobility Team\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Google-Sheets-integration-missing-issue/qaq-p/2820843 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Kritika Buttan",
"title": "Need help with Show Field in Confiform",
"body": "I am working on Show field which is validated from the drop down value.\n\nIf Request Type = New Feature Request, then Feature Request field should appear.\n\n*** ** * ** ***\n\n\n"
} | [
{
"author": "Alex Medved _ConfiForms_",
"body": "Hi [@Kritika Buttan](/t5/user/viewprofilepage/user-id/5507896)\n\nSet the condition to be either\n\n```\nTypeOfWork:10\n```\n\nor\n\n```\nTypeOfWork.label:New Feature Request\n```\n\nFields and functions in ConfiForms are case sensitive\n\nAlex\n",
"comments": [
{
"author": "Kritika Buttan",
"body": "It worked. Thanks\n"
}
]
},
{
"author": "Vijay Dadi",
"body": "Hello [@Kritika Buttan](/t5/user/viewprofilepage/user-id/5507896) ,\n\nIf you have not tried the forms in JSM, i suggest you take a look at it. They provide the capability to show/hide fields depending the field value selection and this really helps you to build your portal request types. You can find more information on forms on this documentation. Hope this helps.\n\nRegards,\n\nVijay\n\n[Use forms in Jira Service Management \\| Jira Service Management Cloud \\| Atlassian Support](https://support.atlassian.com/jira-service-management-cloud/docs/use-forms-in-jira-service-management/)\n",
"comments": [
{
"author": "Kritika Buttan",
"body": "Sorry, this is for Confluence as Confiform not in Jira.\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Need-help-with-Show-Field-in-Confiform/qaq-p/2820944 | [
"addon-com.vertuna.confluence.plugins.confiforms",
"cloud",
"confiforms",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Caressa DeQuardo",
"title": "Automation: Need to count words across fields and total amount notated in another field",
"body": "Goal: create an automation to count the amount of times the word \"yes\" has been selected across custom drop-down fields in an issue and inputting the total amount of the word \"yes\" into another custom number field on the same issue.\n\n++Context:++\n\n* I have confirmed that the custom field ids I am mentioning in my smart value equation are accurate\n* all the custom fields apart of this automation have been confirmed to exist on the issue\n* the dropdown field options are \"Yes\" or \"No\"\n\n* I have changed the smart value equation many times but continue to hit a similar error message in the automation audit log it states *\"Error rendering smart-values when executing this rule: Missing parameter(s) for operator +u: + + +\"* when I was utilizing \"*.match()*\" in my equation\n* I also attempted a direct value comparison and that returned similar errors.\n\n\n\nHere is the most recent version of my smart value equation that's experiencing errors.\n\n{{#=}} ({{issue.customfield_10630.value == \"Yes\" ? 1 : 0}} + {{issue.customfield_10633.value == \"Yes\" ? 1 : 0}} + {{issue.customfield_10631.value == \"Yes\" ? 1 : 0}} + {{issue.customfield_10632.value == \"Yes\" ? 1 : 0}}) {{/}}\n"
} | [
{
"author": "Vijay Dadi",
"body": "Hello [@Caressa DeQuardo](/t5/user/viewprofilepage/user-id/5461641) ,\n\nYou can use the trigger \"Value Changed\" and provide all the field which are eligible for this requirement.\n\nWhen \"Yes\" is selected for any of the selected field, you can have a counter defined on another field, increment it by 1 and if selected as \"No\", decrement it by 1.\n\nBy this, you can have the actual count of Yes selected for all the available fields with such option. Hops this helps.\n\nRegards,\n\nVijay\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Automation-Need-to-count-words-across-fields-and-total-amount/qaq-p/2820830 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Ryan Bullock",
"title": "Can the automation option to send an email parse a user input that is multiple email addresses?",
"body": "One of our teams has a need to email to an external client. The clients are not customers of our Jira site and maybe be multiple emails to send to at once. I'd like to avoid adding all these various users as customers of the project and having to share the issues with them in order to just send one email.\n\nI am trying to create an automation that is manually triggered from the issue and prompts the user for an email address. I place this smart value into the 'to\" field on the send email automation option. When entering one email address, it works great, however, I cannot seem to get it to accept multiple emails. I've tried various formats of entering the addresses, but it always fails, like it can't parse them.\n\nIs there anyone to get this to work to manually send an email to multiple addresses directly from the issue?\n"
} | [
{
"author": "David Freitez",
"body": "Hi [@Ryan Bullock](/t5/user/viewprofilepage/user-id/4343687) ,\n\nI tested creating an automation rule that prompted a short text field type variable and added the emails separated by a comma and it worked.\n\nI am attaching screenshots of the rule so you can compare.\n\n\n\nLet me know if you have any follow up questions, hopefully my answer helps you so you can achieve what you are trying to achieve.\n\nKind regards, \nDavid \nServiceRocket\n",
"comments": [
{
"author": "Ryan Bullock",
"body": "Oh geez, I had the paragraph field type selected and switching to short text worked. Thank you!\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Can-the-automation-option-to-send-an-email-parse-a-user-input/qaq-p/2820815 | [
"automation",
"cloud",
"email",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Angelo Cigna",
"title": "Message approvers via slack",
"body": "Hi Team,\n\nI am guessing someone has asked this in the past but I cant find a step by step article. I would like set up a system where when a user is added as an approver for a JIRA ticket, the approver will automatically receive a slack message with a link to the ticket, the subject of the ticket and the ability to approve or decline (or even add a comment) in slack that will filter to the JIRA ticket. Does anyone know of a document or youtube video that explains how to set this up?\n"
} | [
{
"author": "Mark Higgins",
"body": "Hi [@Angelo Cigna](/t5/user/viewprofilepage/user-id/5600707)\n\nWelcome to the community!\n\nIn the Admin -\\> Product Settings -\\> Jira Service Management there is an Incident Management Section.\n\n\n\nClick on the Looking for Slack :-)\n\nThis takes you to the OPEATIONS area:\n\n\n\nThis is, I believe the 'new area' as OPSGEnie moves into JSM Operations.\n\nHope that helps\n\nMark\n",
"comments": null
},
{
"author": "Chris Rainey",
"body": "Hi there,\n\nCheck out the information below that I found in [this article](https://support.atlassian.com/jira-service-management-cloud/docs/manage-chat-settings/#Disable-request-approvals:~:text=Select%20Save%20changes.-,Manage%20request%20approvals,-By%20default%2C%20request).\n\n---\n\nManage request approvals {#toc-hId--326681658}\n----------------------------------------------\n\nBy default, request approvals are active in chat. This means approvers receive a message from Assist when a request requires their approval, and [they can take action directly from Slack](https://support.atlassian.com/jira-service-management-cloud/docs/work-on-issues-in-slack/#Approve-or-decline-requests).\n\nIf an approver group is assigned a request, they won't receive notification in Slack and need to take action from email or Jira Service Management.\n\nTo turn off request approvals:\n\n1. From your service project, select **Project settings** , then **Channels** , then **Chat** .\n\n2. From the **Settings** tab, turn off **Approvals in chat.**\n\n[Discover more about approvals in Jira Service Management](https://support.atlassian.com/jira-service-management-cloud/docs/what-are-approvals/).\n",
"comments": [
{
"author": "Angelo Cigna",
"body": "Hi Chris,\n\nThanks for your reply. I had found that article but I am wondering if my setup is missing an option or if I possibility do not have permissions. If I go to 'Project Settings' I do not have a 'Channels' options, but I do have a 'Chat' option in project settings. From 'Project Settings' \\> 'Chat' I have the option to \"Add to Slack\" or \"Add to Teams\". Is the \"Add to Slack\" option the one you are referring to? \n\nIf so, do you know if this will turn on the Slack option for our entire organization or just my board? I am working right now in a test board so as to not make any changes in our production environment so need to know if there will be visible changes to the team or users.\n\nThanks!!\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Message-approvers-via-slack/qaq-p/2820800 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Aidan Armstrong",
"title": "How do I ensure requesters are not required to create an account",
"body": "Hi there,\n\nMy team created a JIRA Service desk with the purpose of routing communication requests through the portal. As it stands, requesters (or \"customers\") are not able to create requests without creating an account.\n\nIs there a way to format these desks so that requesters do not require an account?\n"
} | [
{
"author": "Allen Chen",
"body": "Hi Aidan,\n\nPlease refer to the below link.\n\n<https://confluence.atlassian.com/servicedeskcloud/blog/2017/04/introducing-the-login-free-portal-for-jira-service-desk-cloud>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/How-do-I-ensure-requesters-are-not-required-to-create-an-account/qaq-p/2820794 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Fabiano Rocha",
"title": "Criar resposta pronta Compartilhada",
"body": "Em meu projeto n?o estou conseguindo compartilhar repostas pr?-definidas. Como mostrado abaixo, a op??o de compartilhar a resposta pr?-definida n?o aparece. Sabem me dizer se isso ? configurado em algum outro lugar?\n\n\n"
} | [
{
"author": "Camilo Galleguillos",
"body": "Ol?, Fabiano!\n\nA captura de tela que voc? est? mostrando ? o formul?rio para criar as respostas prontas. Depois de cri?r a resposta pronta e atribuir um nome a ela, voc? poder? selecion?-la ao responder a um ticket.\n\n|----------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n|  | #### Camilo Galleguillos {#toc-hId-374382922} Sr. Technical Consultant [**ServiceRocket**](https://servicerocket.com/) [[email protected]](mailto:[email protected]) Santiago, Chile |\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Criar-resposta-pronta-Compartilhada/qaq-p/2820716 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Zekeriya Spoth",
"title": "Why does a customer still show up as a reporter option after they've been removed from JSM?",
"body": "I removed a customer so they no longer show up in the customer list or the 'people' list in the project settings. However, when I open up an issue and change the reporter with in the 'details' section of the issue, the removed customer name still shows up as an option.\n\nIs there a way to remove them as an option as a reporter?\n"
} | [
{
"author": "Samuel Gatica",
"body": "Hi [@Zekeriya Spoth](/t5/user/viewprofilepage/user-id/5512989)\n\nPlease ensure the customer is removed from the Portal-only customer section in your Jira Product administration\n\n* [Delete portal-only customers](https://support.atlassian.com/user-management/docs/delete-portal-only-customers/)\n\n\n\nBest regards\n\nSam\n",
"comments": [
{
"author": "Zekeriya Spoth",
"body": "My side bar looks a little different and it does not have the \"Portal-only customers\" option. I am a user access admin but maybe this is something only an organization admin can access?\n"
},
{
"author": "Samuel Gatica",
"body": "Hi [@Zekeriya Spoth](/t5/user/viewprofilepage/user-id/5512989)\n\nOnly Organization admins and site admins can delete a customer's portal-only account.\n\nBest regards\n\nSam\n"
}
]
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Why-does-a-customer-still-show-up-as-a-reporter-option-after/qaq-p/2820688 | [
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Mia Litman",
"title": "Custom Text Field suddenly converting to links",
"body": "We have a custom filed (\"crawl domain\") with type \"text field (single line)\". At some point in the last 1-2 weeks, these are now all converting to links. I actually first noticed the urls had \\\\\\\\ in front of them (presumably to prevent the links from occurring). We didn't change anything but now they're links (which is not what I want). But I can't figure out how to not make them links.\n\n\n\n\n"
} | [
{
"author": "Walter Buggenhout",
"body": "Hi [@Mia Litman](/t5/user/viewprofilepage/user-id/3161008),\n\nThese are smart links. While about Confluence, [this support article](https://support.atlassian.com/confluence-cloud/docs/insert-links-and-anchors/) explains quite extensively what they are and how they behave. I expect that Atlassian has extended them to other types of fields or new types of content, which probably explains why so see this now.\n\nAs described in the article, smart links usually have different ways of displaying - ranging from the actual URL as you entered it to rich interactive previews with a lot of detail. Clicking on a smart link when you are editing a field usually displays the different viewing options.\n\nHope this helps!\n",
"comments": null
}
] | https://community.atlassian.com/t5/Jira-Service-Management/Custom-Text-Field-suddenly-converting-to-links/qaq-p/2820666 | [
"custom-field",
"jira-cloud"
] |
{
"author": "Eloise Taylor",
"title": "Auto assigning custom field \"Developer\" keeps breaking",
"body": "When I try to update \"Developer\" custom field in an automation script it fails with:\n\n\\`Additional fields contains invalid field(s) in 'update' or 'fields' section: Developer\\`\n\nI had been using a different field called \"Original Developer\" which worked well until one day it started failing to update the field. Thereafter any permutation of the json to update the custom field failed with the error above.\n\nI created a new field in the project called Developer, and same error.\n\n\\`\\`\\`\n\n{ \"fields\": { \"Developer\" : { \"id\":\"{{initiator.accountId}}\" } } }\n\n\\`\\`\\`\n\nIn another project I have created the Developer field and also a Tester field.\n\nIn this other project, Developer fails to save, whereas Tester works fine:\n\n\\`\\`\\`\n\n{ \"fields\": { \"Tester\" : { \"id\":\"{{initiator.accountId}}\" } } }\n\n\\`\\`\\`\n\nBoth Developer and Tester fields are set to allow only one assignee\n\nAlso to note that I tried suggestions from other posts on this forum, and not found an answer that resolved my issue despite the same error message\n"
} | [
{
"author": "Rilwan Ahmed",
"body": "Hi [@Eloise Taylor](/t5/user/viewprofilepage/user-id/5420883) ,\n\nWelcome to the community !!\n\n1. Smart values are case and space sensitive. So did you confirm you have the correct name for that field? You can check that using an example issue with the field <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n2. Did you try using the field id in the rule ?\n\nExample:\n\n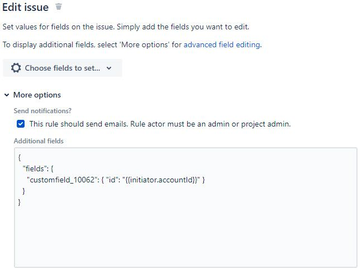\n",
"comments": [
{
"author": "Eloise Taylor",
"body": "The casing was the same as the field. I did try all lowercase as well which also didn't work\n\n<br />\n\nThis allowed me to save the automation rule:\n\n```\n\n{\n\"fields\": {\n\"customfield_10245\" : { \"id\":\"{{initiator.accountId}}\" } \n}\n}\n```\n\nBut then errored when a ticket was updated\n> Error editing issues \n> E1-501 (data was not an array (customfield_10245))\n"
},
{
"author": "Rilwan Ahmed",
"body": "Hi [@Eloise Taylor](/t5/user/viewprofilepage/user-id/5420883) ,\n\nPlease share the screenshot from custom field page for \"Developer\" and \"Original Developer\" fields and and the Automation rule setup.\n\nAlso let me know where are you creating the rule ? In team managed project OR company managed project OR in global automation section.\n"
},
{
"author": "Eloise Taylor",
"body": "It's a team managed project.\n\nThe field used to be multi-select, and is now single user. Could the current tickets on the board still have the multi-select variant?\n\n\n\nTo resolve, I have 2 automation rules: one that updates the field as if it's an array, and the other that updates as if it's not an array. If jira decides the field is no longer an array, the field should still update by the other rule. This means that one will always error. Once Jira knows the field can only have one user I can delete the unnecessary rule.\n\nThis approach only works now because of the custom field name, with the friendly name it won't save\n\n\n\n```\n{\n\"fields\": {\n\"customfield_10244\": { \"id\": \"{{initiator.accountId}}\" }\n}\n}\n\n{\n\"fields\": {\n\"customfield_10244\": [{ \"id\": \"{{initiator.accountId}}\" }]\n}\n}\n```\n"
},
{
"author": "Bill Sheboy",
"body": "Hi [@Eloise Taylor](/t5/user/viewprofilepage/user-id/5420883)\n\nJust an FYI...\n\nRegardless of what the UX indicates, all People-type fields in team-managed projects use the JSON array syntax (i.e., multiple-selection) even when a single-selection, user option is enabled.\n\nWhen in doubt what automation rules (and the REST API) are needing, please use this how-to article to view an example issue's smart value / JSON structure: <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nKind regards, \nBill\n"
}
]
},
{
"author": "Manon Soubies-Camy",
"body": "Hi [@Eloise Taylor](/t5/user/viewprofilepage/user-id/5420883) and welcome to Community!\n\nIf Developer is a user picker custom field, you can directly set it to {{initiator}} in the automation rule:\n\n\n\nHope this helps!\n\n- Manon\n",
"comments": [
{
"author": "Eloise Taylor",
"body": "I don't see the field in the List of available fields, either when scrolling through, or searching\n\n\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Auto-assigning-custom-field-quot-Developer-quot-keeps-breaking/qaq-p/2809020 | [
"custom-field"
] |
{
"author": "Edie Hovermale",
"title": "Need to get 'Components' data from an Xray Test when it is added to a Test Execution",
"body": "This might be a long shot, but I'm going to ask the community in case someone has already figured this out.\n\nI'm trying to use Jira Automation to retrieve the 'Components' data from an Xray Test when it is added to an Xray Test Execution and then add those 'Components' to the Test Execution.\n\nSince Xray doesn't use the 'Link Issue' functionality to connect Xray Test tickets to the Xray Test Execution ticket, I'm unsure how to trigger the event or capture the data.\n\nAny assistance would be greatly appreciated.\n\nFor context, I've already spoken with Xray support, but the agent wasn't aware of a solution. They opened a support ticket for the engineering team to investigate, but I'm hoping to find a quicker answer from the community if possible.\n"
} | [
{
"author": "Marc - Devoteam",
"body": "HI [@Edie Hovermale](/t5/user/viewprofilepage/user-id/5185278)\n\nThere has been a similar question on the community related to this subject, around Xray.\n\nThis was around adding Tests to a Test Set based on editing of a Test.\n\nThere is no data action in relation to this that's recorded by JIra, the same applies to your request.\n\nJira doesn't see this as an edit action os there is no option in automaton to use this as a trigger.\n\nThis is pure Xray functionality and only related to Xray. Automation is not able to use this as a trigger.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Need-to-get-Components-data-from-an-Xray-Test-when-it-is-added/qaq-p/2807183 | [
"cloud-automation",
"xray"
] |
{
"author": "venkata naram",
"title": "Confluence automation for Iterative/loop",
"body": "Could you set a rule to run only on pages not modified in the last 'n' number of days? Build a rule to list the number of pages and send just one email notification to all the pages.\n\nI have a Confluence automation rule for a page branch where the last modified date is less than a specified number of days.\n\nIn the email notification handling the loop, I have given the below code\n\n{{#Page}} {{title}} ((/Page}}\n"
} | [
{
"author": "Manon Soubies-Camy",
"body": "Hi [@venkata naram](/t5/user/viewprofilepage/user-id/5574537) and welcome to Community!\n\nYou can add a page branch to perform actions on pages updated more than x days ago, for example:\n\n\n\nHope this helps!\n\n- Manon\n",
"comments": [
{
"author": "venkata naram",
"body": "Hi [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212)\n\nThank you for your immediate response. I seek an iterative process to avoid sending multiple emails for each page. I will try to rephrase my question.\n\nI have created a page branch that returns multiple pages when they satisfy the condition of being updated more than 15 days ago. Currently, I have an action that sends an email notification for each page, resulting in multiple emails.\n\nFor example, if the page branch returns four wiki pages, it will send four separate emails. I want to send only one email that consolidates all the pages into the email content. How can I achieve this using an iterative process or loop in the email content?\n\nIf you refer to the template that notifies people about inactive pages, I want to achieve the same result using that method.\n\nThanks\n\nVenkata\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Hi [@venkata naram](/t5/user/viewprofilepage/user-id/5574537), ah, ok, I get it now, thanks for the additional context!\n\nThe Lookup action searches for pages meeting your condition:\n\n\n\nAnd you can then use the result in other actions, such as:\n\n\n\nIs that what you are trying to achieve?\n"
},
{
"author": "venkata naram",
"body": "The given solution with lookupPages is not working. Below is the error I'm facing:\n\n\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Can you please share a screenshot of your rule as well?\n"
},
{
"author": "venkata naram",
"body": "Sorry for the delayed response. Below is the screenshot.\n\n\n"
},
{
"author": "venkata naram",
"body": "Hi [@Manon Soubies-Camy](/t5/user/viewprofilepage/user-id/1215212) , Any update.\n"
},
{
"author": "Manon Soubies-Camy",
"body": "Hi [@venkata naram](/t5/user/viewprofilepage/user-id/5574537), I cannot reproduce your issue. I seem to run into the same bug than this [Community post](https://community.atlassian.com/t5/Confluence-questions/Smart-Values-in-Lookup-Pages-not-working/qaq-p/2651192) though, as the email I receive is blank, so I'd recommend reaching out to [Confluence's support team](https://support.atlassian.com/contact).\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Confluence-automation-for-Iterative-loop/qaq-p/2807312 | null |
{
"author": "Philip Kroos - TEAM XALT",
"title": "Creating multiple Confluence Pages with dynamic content from Jira issues via Jira Automation and",
"body": "Hi community,\n\nI'm trying to set up an Automation to achieve the following;\n\n* I have an Epic in Jira with multiple child issues (stories) that are all in a specific sprint\n* I want to create Confluence pages, with the Epic being the parent page and its title being the sprint name, sprint start date and sprint end date\n* For each of the child issues, the automation should create a confluence page, with the title being the (child) issue's summary\n* I would also like to set the labels of the created confluence pages based on field values of the jira issues. For example, if there is a fixversion \"1.00\", I want to automatically add a label to the confluence page named \"release-1.00\". The \"release\" part of the label is fixed, so if in a follow up sprint with new stories the fixversion is 1.01, the automation should create new pages with the label \"release-1.01\"\n\nI managed to create the parent page (for the Epic) and the child pages (for each of the child issues/stories of the Epic) and I was also able to populate the confluence pages with content by using web requests. For example, I created a new variable in the automation and can use this variable to be included on the confluence pages of the child issues, so that they are correctly nested under the parent page. I followed the [official documentation here](https://developer.atlassian.com/cloud/confluence/rest/v2/api-group-custom-content/#api-custom-content-post) and utilized the \"custom data\" section for the \"web request body\". In other words, the web request body to create the confluence pages sets aspects like the space where the confluence page should be created, the title, the parent etc.\n\nHowever, I could not find any information on setting labels for confluence pages created via web requests from a Jira automation. Is there a way to set labels for confluence pages via Jira automation and the method of using web requests that I'm using?\n"
} | [
{
"author": "Darryl Lee",
"body": "Hi [@Philip Kroos - TEAM XALT](/t5/user/viewprofilepage/user-id/3965067) - your automation sounds pretty cool!\n\nTo add labels, you have to use a v1 API endpoint:\n\n* <https://developer.atlassian.com/cloud/confluence/rest/v1/api-group-content-labels/#api-wiki-rest-api-content-id-label-post>\n\nIt seems like the v1 Content Create endpoint would allow you to set labels (under the \"metadata\" section) when you create the page, but that endpoint is supposed tagged as deprecated:\n\n* <https://developer.atlassian.com/cloud/confluence/rest/v1/api-group-content/#api-wiki-rest-api-content-post>\n\nReferences:\n\n* [How to add a label to a Confluence page using the v2 API?](https://community.atlassian.com/t5/Confluence-questions/How-to-add-a-label-to-a-Confluence-page-using-the-v2-API/qaq-p/2618944)\n* [Creating a confluence page via rest api with a label](https://community.atlassian.com/t5/Answers-Developer-Questions/Creating-a-confluence-page-via-rest-api-with-a-label/qaq-p/469849)\n",
"comments": null
},
{
"author": "Armin Meyer (Seibert - Coderay)",
"body": "Hi Philip,\n\nseems that Darryl provided the missing part.\n\nI just want to add. If you don't mind using an App. We developed AutoPage that is pretty much designed for such use cases as yours.\n\nIn addition to the initial creation of a page the content stays always in sync with the jira issue or it can be defined at which time of the jira workflow the page will be updated.\n\nIf synchronization later on is not a point for you, your solution sounds valid too :)\n\n[https://marketplace.atlassian.com/apps/1218503/autopage-create-confluence-page-from-jira-issue?tab=overview\\&hosting=cloud](https://marketplace.atlassian.com/apps/1218503/autopage-create-confluence-page-from-jira-issue?tab=overview&hosting=cloud)\n\ncheers\n\nArmin\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Creating-multiple-Confluence-Pages-with-dynamic-content-from/qaq-p/2806920 | [
"confluence",
"html",
"post",
"smart-value",
"variable",
"webhook"
] |
{
"author": "Samrudhi Shete",
"title": "How to create this automation for adding assignee of sub-task as a watcher to isse?",
"body": "Whenever a sub-task is assigned to someone, they should be added as a watcher to the regular issue that the sub-task is a part of.\n"
} | [
{
"author": "Kelly Arrey",
"body": "Hi [@Samrudhi Shete](/t5/user/viewprofilepage/user-id/5572382), to copy the Assignee from the Trigger issue to the Watchers list of the Parent, you should try the \"Add watchers\" action with the smart value: {{*triggerIssue.assignee* }}.\n\n\n\nHope this helps,\n\nKel\n",
"comments": [
{
"author": "Samrudhi Shete",
"body": "Thank you! [@Kelly Arrey](/t5/user/viewprofilepage/user-id/510430) , It's working!\n"
}
]
},
{
"author": "Manoj Gangwar",
"body": "Hi [@Samrudhi Shete](/t5/user/viewprofilepage/user-id/5572382) ,\n\nYou can create an automation similar like below:\n\n\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/How-to-create-this-automation-for-adding-assignee-of-sub-task-as/qaq-p/2806588 | null |
{
"author": "Myles Boyd",
"title": "Round robin assignment",
"body": "Has anyone found a way to do round robin assignments based, not on shift hours, but agent availability?\n\nWe have 3 agents working 8-6 Monday to Friday; but we have to accommodate annual leave and sickness.\n\nThe 3 agents are all on par with skill sets, so there is no particular SME for different services.\n"
} | [
{
"author": "Manoj Gangwar",
"body": "Hi [@Myles Boyd](/t5/user/viewprofilepage/user-id/4266693) ,\n\nAs per my knowledge, It is not feasible with Jira native functionality but you can achieve this using the [plugins](https://marketplace.atlassian.com/apps/1218305/out-of-office-issue-calendar-automation-for-team-workflow?hosting=cloud&tab=overview). Or you can use some workaround.\n\n<https://confluence.atlassian.com/jirakb/automatically-reassign-issues-of-agents-who-are-on-vacation-with-user-properties-1277100927.html>\n\n<br />\n\n<br />\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Round-robin-assignment/qaq-p/2806369 | null |
{
"author": "Joanna",
"title": "Link Request with Alert",
"body": "Hey!\n\nI would like to link an Ops alert (which I successfully created via a web request in the previous automation step) to the corresponding ticket that triggered this alert in the automation.\n\nSomething like: \"Alert #9 is caused by Ticket-17\" or \"Alert #9 blocks Ticket-17\". Is this possible?\n\nAlternatively, is there a manual trigger that can link both together?\n\nI would appreciate your help.\n"
} | [
{
"author": "Ken Young",
"body": "Hi [@Joanna von Boulderado](/t5/user/viewprofilepage/user-id/5585321)\n\nIn Automation, you can do the \"link\" between an incident ticket and the alert using this REST API and the **Sent Web Request** automation component\n\n<https://developer.atlassian.com/cloud/incidents/rest/api-group-linked-alerts/#api-jsm-incidents-cloudid-cloudid-v1-incident-issueid-alert-add-post>\n\nThe specific URL I use is\n\n```\nhttps://api.atlassian.com/jsm/incidents/cloudId/{{jsmCloudId}}/v1/incident/{{issue.id}}/alert/add\n```\n\nIn the URL, I am passing our cloudID of our jsm instances, as well as the issue id of the incident that was created.\n\nIn my use cast, the custom data that I pass is the alert\n\n```\n{\n\"alertIds\": [\n\"{{alertId}}\"\n]\n}\n```\n\nSince it is an experimental API at the moment, the headers you need to added to the web request\n\nExperimentalApi: opt-in\n\nAccept: application/json\n\nContent-Type: application/json\n\nAuthorization: {{Your Authorization method i.e. basic, token, etc.}}\n\nRemember to delay the execution of subsequent rule actions until you get your response. It is an asych operation to \"link\" the alerts so you may to add a delay or some other way to pause if you wish to confirm that the alert is linked to the incident.\n\nGood luck. Hopeful there will be a \"lookup alert\" or edit alert that makes this easier.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Link-Request-with-Alert/qaq-p/2804476 | null |
{
"author": "Patrick",
"title": "Set Assignee based on Custom Field",
"body": "Hi I have a custom single user picker field called \"Manager\" I also know the customfield ID \n\nI want to create an automation that creates a subtask when the task transitions (thats no problem). \nAfter that it should get the Value from Manager and Assign the new Issue to the Manager. \n\nI can extract things like the display name, for example issue.customfield_123.displayName. \nBut if I put this into the Assign Action, via Smart Value is doesnt work. \nI tried .name, .value, .emailAdress \n\n**Basically how can I copy the user from Manager Custom Field to Assignee Field.** \n\nThanks for any ideas\n"
} | [
{
"author": "Duc Thang TRAN",
"body": "Hello [@Patrick](/t5/user/viewprofilepage/user-id/4658238)\n\nYou can use this smart value for \"Assgin action\"\n\n{{issue.customfield_123.accountId}} or\n\n{{issue.Manager.accountId}}\n",
"comments": [
{
"author": "Patrick",
"body": "yes this also works now, but the main issue was that the user selected in Manager couldnt be found, because he wasnt added to the project.\n"
}
]
},
{
"author": "Patrick",
"body": "nvm, it was my mistake : ) \n\n{{issue.customfield_123}} this was correct the problem was the user wasn't invited to the project so that why it can't be found from the assignee field. \nThe customer user picker field can pick any user.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Set-Assignee-based-on-Custom-Field/qaq-p/2804116 | [
"jira-cloud"
] |
{
"author": "marafado88",
"title": "On JIRA service desk how can I get a date from ticket summary with format DD/MM/YYYY",
"body": "Hello everyone,\n\nOn JIRA service desk how can I get a date from ticket summary with format DD/MM/YYYY, have any one did this before? \n\nHave tried with Summary contains and Issue fiedls condition steps, but nothing: \n\n\n\nFrom audit logs: \n\n<br />\n\n##### [{{smart values}} condition](https://raketechgroup.atlassian.net/jira/servicedesk/projects/IS/settings/automate#/rule/21712305/584603837) {#toc-hId--1424353878}\n\nError rendering smart-values when executing this rule: \nFailed to get value for ('(\\\\\\\\d{2}/\\\\\\\\d{2}/\\\\\\\\d{4})') \nIs there here someone experienced within JIRA automation? I am really fresh with this :(\n"
} | [
{
"author": "Mikael Sandberg",
"body": "Because you are using regex you cannot use the Issue field condition, instead you would have to use {{smart values}} condition and the contains regular expression like this:\n\n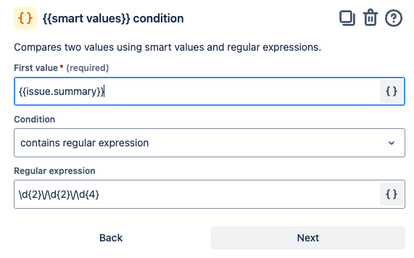\n\nAlso note that your regex has to look like this:\n\n\\\\d{2}\\\\/\\\\d{2}\\\\/\\\\d{4}\n",
"comments": [
{
"author": "marafado88",
"body": "Ah ok, worked, thank you! \n\nBy any chance, with \"Edit Issue\" action, what expression should be used with {{issue.summary}} to get that match? \n\nHAve tried with {{issue.summary.match('\\\\d{2}\\\\/\\\\d{2}\\\\/\\\\d{4}')}} but no luck.\n\nDo you have a good documentation source from where I could use as reference just for this level of JIRA automations?\n"
},
{
"author": "Mikael Sandberg",
"body": "You can't use regex with Edit issue, instead you would have to use [substringAfter()](https://support.atlassian.com/cloud-automation/docs/jira-smart-values-text-fields/#substringAfter--String-separator-) like this:\n\n{{issue.summary.substringAfter(\" - \")}}\n\nThis assume that the format for the summary is always the same.\n"
},
{
"author": "marafado88",
"body": "Have changed the date to duedate format, and it worked but there was no changes made/applied on the ticket that triggered the automation, do you know what could be?\n\n\n"
},
{
"author": "Mikael Sandberg",
"body": "Without knowing what your automation looks like I cannot say why you get an error on IS-904.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/On-JIRA-service-desk-how-can-I-get-a-date-from-ticket-summary/qaq-p/2803286 | [
"cloud",
"jira-service-desk"
] |
{
"author": "Wayne_Reilly",
"title": "Automation on adding users to groups",
"body": "Is it possible to create an automation where a user is added to a group that then triggers to add that same user to another group?\n"
} | [
{
"author": "Mohamed Benziane",
"body": "Hi,\n\nYou will need to use the REST API to achieve this. Be aware that there is no event/trigger about the user groups.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Automation-on-adding-users-to-groups/qaq-p/2802417 | null |
{
"author": "Sowjanya Mupparaju",
"title": "How to fetch the last comment on the Lookup issues?",
"body": "I wrote an automation rule and used a JQL query in Lookup Issues which will have more than 4 issues as a result of the JQL query. Now I need to send the details of the Lookup issues in a table format with Columns Issue Key, Priority, Assignee, Last Comment on the issue etc., in an email to the initiator of this automation rule. I wrote html tags to build in the Email \"Content\" field like below\n\n\\<table\\>\n\n\\<tbody\\>\n\n\\<tr\\>\n\n\\<th\\>Jira Key\\</th\\>\n\n\\</tr\\>\n\n\\<tr\\>\n\n\\<td\\>{{lookupIssues.key}}\\</d\\>\n\n\\</tr\\>\n\n\\</tbody\\>\n\n\\</table\\>\n\nThe problem is when I use {{lookupIssues.comments.body}} I could see all the comments on the Jira issue being populated but I want only the last comment on each Lookup issue.. I tried using {{lookupIssues.comments.last.body}} but this is not giving me any results in the Last Comment column.. Any solution?\n"
} | [
{
"author": "Samuel Gatica",
"body": "Hi [@Sowjanya Mupparaju](/t5/user/viewprofilepage/user-id/5316576)\n\nKindly refer to the similar post at the following link: [Getting last comment with lookupissue](https://community.atlassian.com/t5/Jira-questions/Getting-last-comment-with-lookupissue/qaq-p/2642550)\n\nBest regards\n\nSam\n",
"comments": [
{
"author": "Sowjanya Mupparaju",
"body": "[@Samuel Gatica](/t5/user/viewprofilepage/user-id/753028) : Thanks for sharing the link.. Even I used #lookupissues and it worked..\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-to-fetch-the-last-comment-on-the-Lookup-issues/qaq-p/2801415 | null |
{
"author": "Chris M.",
"title": "Using plusWeeks() and nextDayOfWeek(\" \") in one arguement",
"body": "Hello everyone,\n\nI want to calculate a field using automation. Starting from the start date, I want to calculate 20 weeks into the future and if it is not a Monday, I want to use the next Monday. Atlassian has introduced the two commands mentioned above, but it seems that they cannot be used in one command. I have tried the following so far:\n\ndirekt way:\n\n{{issue.start Date.plusWeeks(20).withNextDayOfWeek(\"TUE\")}}\n\n{{issue.start Date.withNextDayOfWeek(\"TUE\").plusWeeks(20)}}\n\nand indirekt way:\n\nCreate variable:\n\nVar: {{varPlusWeek}} which has the following smart value included: {{issue.start Date.plusWeeks(20)}}\n\nAnd in the next step with extention:\n\n{{varPlusWeek.withNextDayOfWeek(\"TUE\")}}\n\nBut nothing has worked. Is it simply not possible, e.g. due to the format or other reasons, or am I making a mistake here? Thank you very much.\n\nBest regards\n\nChris\n"
} | [
{
"author": "Gaurav",
"body": "Hello [@Chris M_](/t5/user/viewprofilepage/user-id/5574840)\n\nWelcome to the community!!\n\nI have gone through the post and in my understanding, you intend to add 20 weeks from the date of creation. If that is the case, please try the below operation: \n{{issue.created.plusWeeks(20).withNextDayOfWeek(\"TUE\")}}\n\nI have replaced 'start Date' with 'created' which is the smart value to fetch the created date of a ticket.\n\nPlease feel free to share your thoughts and feedback on this, including if there is any other usage.\n\n-GG\n",
"comments": [
{
"author": "Chris M.",
"body": "Hello [@Gaurav](/t5/user/viewprofilepage/user-id/1248589)\n\nthank you for posting your suggestion. But I realy mean issue.start date. It's a field of Jira by default oder of tempo. Process: The ticket is created in the past. After a while the project lead negotiated the final project start with our customers (start date) and has also to enter the due date manually with the constraints mentioned above. Due to Jiras ability to calculate dates I will calculate the due date automatically.\n\nBut I do not understand which Jira has problems with the expression of plusWeeks.withNextDayOfWeek.\n\nThank you in advance.\n\nChris\n"
},
{
"author": "Gaurav",
"body": "Thanks for sharing the context [@Chris M_](/t5/user/viewprofilepage/user-id/5574840)\n\nPlease see if the below calculation helps: \n{{issue.Start date.plusWeeks(20).withNextDayOfWeek(\"TUE\")}}\n"
},
{
"author": "Chris M.",
"body": "Thanks for your help [@Gaurav](/t5/user/viewprofilepage/user-id/1248589)!\n\nNow, it works!!! :) But I don't understand why. I can also use start Date for a single calculation but if I use it for a chain the is no result. With your help I used Start date and now it is possible to calculate the result.\n\n\n"
},
{
"author": "Bill Sheboy",
"body": "Hi [@Chris M_](/t5/user/viewprofilepage/user-id/5574840)\n\nThe reasons some of your early attempts did not work could be...\n\nSmart values are name, spacing, and case-sensitive, and you were using the incorrect case for the field. To learn the correct smart values for a field, please use this how-to article: <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nVariables are text. When you want to use a date saved as text, it must be converted to a \"date type\" using toDate: <https://support.atlassian.com/cloud-automation/docs/examples-of-using-smart-values-with-dates/#Converting-text-to-dates>\n\nKind regards, \nBill\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Using-plusWeeks-and-nextDayOfWeek-quot-quot-in-one-arguement/qaq-p/2800729 | [
"time"
] |
{
"author": "Stephen Herrmann",
"title": "Automating copying field value from trigger ticket to LookUp ticket",
"body": "Hello, I am running into an issue with getting this automation to update the indicated field in the Lookup issue. it currently only re updates the current ticket, even though the lookup successfully finds the ticket I am looking for. \n\n\n\nCurrent logic (as I understand it): Rule triggered when any ticket is created \\> Re fetch the ticket info \\> If ticket has \"Manager Form\" Proceed \\> Lookup ticket that matches specific criteria \\> In the ticket that was looked up, update the \"Distro List\" field\n\n\n\nEverything looks good, until the last step where it just updates itself and not the looked up ticket. I'm hoping I am just missing something simple here :)\n"
} | [
{
"author": "Trudy Claspill",
"body": "Hello [@Stephen Herrmann](/t5/user/viewprofilepage/user-id/5580164)\n\nWelcome to the Atlassian community.\n\nYou need to change the focus of the rule to the issues that you found. As your rule is currently structured the focus is still on the issue that triggered the rule.\n\nRather than using a Lookup Issues action I recommend that you use a For Each branch selecting Related Issues / JQL. Branching changes the focus to the issues that are found by the branch criteria and executes the specified actions for each issue found by that criteria. In the branch configuration you would use the JQL that you currently have in your Lookup Issues action.\n\nKeep the steps you currently have between the trigger and the Lookup Issue action. Replace the Lookup Issues action with the For Each branch. Pull the edit action into the branch.\n\n\n",
"comments": [
{
"author": "Stephen Herrmann",
"body": "Hey Trudy, \n\nThank you for this. Adding a single branch with my search did indeed select the desired ticket :) This allowed me to use the copy form function as well, instead of me copying the fields out of the form. So win win here :)\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Automating-copying-field-value-from-trigger-ticket-to-LookUp/qaq-p/2798891 | null |
{
"author": "Alexis Galicia Trevi?o",
"title": "Como le puedo hacer para que los usuarios nada mas vean sus tareas asignadas y no las de los demas j",
"body": "Solo quiero que el usuario cuando se mete al proyecto vea nada mas sus tareas asignadas y no las de los dem?s.\n"
} | [
{
"author": "Trudy Claspill",
"body": "Hola [@Alexis Galicia Trevi?o](/t5/user/viewprofilepage/user-id/5580830)\n\nBienvenido a la comunidad Atlassian.\n\n?Cu?l es el tipo de alojamiento o implementaci?n de tu instancia? ?Es un centro de datos o una nube?\n\n?Esto se aplica a Jira o Confluence?\n\nEn Jira, deber?s investigar el uso de la seguridad de problemas. Se puede usar la automatizaci?n para configurar la seguridad de problemas para un problema, pero primero se debe realizar un trabajo de configuraci?n.\n\nCuando nos confirmes el tipo de alojamiento y el producto, podremos brindarte m?s informaci?n.\n\n---\n\nHello [@Alexis Galicia Trevi?o](/t5/user/viewprofilepage/user-id/5580830)\n\nWelcome to the Atlassian community.\n\nWhat is the hosting/deployment type for your instance? Is it Data Center or Cloud?\n\nDoes this concern Jira or Confluence?\n\nIn Jira you would need to investigate the use of Issue Security. Automation might be used to set the issue security for an issue, but there is configuration work that would need to be done first.\n\nWhen you confirm for us the hosting type and product we can provide more information.\n> How can I make it so that users only see their assigned tasks and not those of others?\n>\n> I only want the user to see only their assigned tasks and not those of others when they enter the project.\n",
"comments": [
{
"author": "Alexis Galicia Trevi?o",
"body": "Hola, gracias por la respuesta.\n\nEstoy utilizando Jira en la nube para la gesti?n de proyectos. Me interesa saber c?mo configurar la seguridad de problemas para que los usuarios solo puedan ver las tareas que se les asignan y no las de los dem?s.\n\nAgradezco cualquier orientaci?n o pasos espec?ficos que me puedan proporcionar.\n"
},
{
"author": "Trudy Claspill",
"body": "Gracias por la informaci?n adicional.\n\n?Cu?l es el tipo de proyecto del proyecto que est?s usando? Encuentra esa informaci?n en la p?gina Ver todos los proyectos, en el men? Proyectos.\n\n\n\nPara los proyectos administrados por la empresa, consulta esta documentaci?n:\n\n<https://support.atlassian.com/jira-cloud-administration/docs/configure-issue-security-schemes/>\n\nPara los proyectos administrados por el equipo, consulta esta documentaci?n:\n\n<https://community.atlassian.com/t5/Jira-articles/Announcement-Control-access-to-your-issues-on-next-gen-using/ba-p/1430115>\n\n---\n\nThank you for that additional information.\n\nWhat is the project type for the project you are using? Find that information on the View All Projects page under the Projects menu.\n\nFor Company-managed projects refer to this documentation:\n\n<https://support.atlassian.com/jira-cloud-administration/docs/configure-issue-security-schemes/>\n\nFor Team-managed projects refer to this documentation:\n\n<https://community.atlassian.com/t5/Jira-articles/Announcement-Control-access-to-your-issues-on-next-gen-using/ba-p/1430115>\n\n> Hello, thanks for the response.\n>\n> I'm using Jira in the cloud for project management. I'm interested in knowing how to configure issue security so that users can only see the tasks assigned to them and not those of others.\n>\n> I appreciate any guidance or specific steps you can provide.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Como-le-puedo-hacer-para-que-los-usuarios-nada-mas-vean-sus/qaq-p/2799669 | null |
{
"author": "Markus Zimmermann",
"title": "Is it possible to create sub-tasks based on labels?",
"body": "Hi together,\n\nI need a logic that creates subtasks based on label entries!\n\n**Create-/Edit View Screen** : \n{Custom field} = \\[Label field\\]\n\nWhen I update the {Custom field} with 3 label entries it should create automatically 3 sub-tasks.\n\n**For example**: Labels (DEV - TEST - PROD)\n\nSub-task1: Summary (DEV - Sub-task) \nSub-task2: Summary (TEST - Sub-task) \nSub-task3: Summary (PROD - Sub-task)\n\nI have absolutely no idea how I could realize this with Jira Automation. Any little help is welcome.\n\nThank you in advance ...\n"
} | [
{
"author": "Trudy Claspill",
"body": "Hello [@Markus Zimmermann](/t5/user/viewprofilepage/user-id/1927545)\n\nWelcome to the Atlassian community.\n\nAre you working with self-hosted Jira (Jira Data center) or SaaS Jira (Jira Cloud)?\n\nHave you reviewed the Automation Rules documentation?\n\nHave you worked with Automation Rules at all?\n\nDo I correctly understand that DEV is on value, TEST is another separate value, and PROD is a third separate value?\n\nWhen are the labels being added? Is that done only when the issue is created, or at a later date?\n\nIs it possible that one label will be added, and then at a later date another label will be added, and you want subtask for each label?\n\nIs it possible that a subtask with the matching summary might already exist? What should happen in that case?\n",
"comments": [
{
"author": "Markus Zimmermann",
"body": "Hi,\n\nfirst at all it's Jira Datacenter! \n\nOnly if I create new Issues then I need a automated rule which creates automatically new sub-tasks.\n\nFor example, if I add a label with the value \\[INTERFACE\\] or \\[PANIC\\] or both in this specific {Custom field} and select create only in this case I want 2 new sub-tasks. And it would be great if I could add the label value also in the summary from each sub-task.\n\n**Sub-task1** : \nSummary: INTERFACE - Sub-task\n\n**Sub-task2** : \nSummary: PANIC - Sub-task\n\nTo answer your question, I have no experience with Automation. \n\nAny little support is welcome! \n???\n"
},
{
"author": "Trudy Claspill",
"body": "Hello [@Markus Zimmermann](/t5/user/viewprofilepage/user-id/1927545)\n\nUnfortunately the functionality you need is not yet available in Jira Data Center:\n\n<https://jira.atlassian.com/browse/JIRAAUTOSERVER-749>\n\nAdvanced Branching to iterate over a list of values in a field is not available.\n\nDo you expect the values to be in a known set of values? If so then you could set up rules to check if your custom field contains value X and create a subtask if it does. You would need to set up a rule for each possible value in the field.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Is-it-possible-to-create-sub-tasks-based-on-labels/qaq-p/2798530 | null |
{
"author": "Steve Y",
"title": "Need to automate scheduled review of assets with multiple attribute filters",
"body": "I need to implement a monthly automation (on Data Center) that creates Tasks for assets that have not been reviewed in the past 2 years (giving them a 90 day window to complete). There are a total of three Attribute fields that comprise the logic for this IF command.\n\n1. \"Active\" attribute is TRUE\n\n2. \"In Periodic Review\" is FALSE\n\n3. \"Last Reviewed\" is \\< 95 weeks ago\n\nI've tried this in both Jira automation using \"in aqlfunction(\"\") format, using compound JQL query syntax, like this:\n\n\"Selections/s\" in aqlFunction (\"Active=TRUE\") AND \"Selections/s\" in aqlFunction (\"In Periodic Review=FAlSE\") AND \"Selections/s\" in aqlFunction(\"Last Reviewed \\< now(-95w)\")\n\nand in Assets automation directly, using AQL.\n\nobjectType=Annex AND \"Active\" = TRUE AND \"Last Reviewed\" \\< now(-95w) AND \"In Period Review\" = FALSE\n\nI can't get results from either.\n\nI've built the query through the Basic builder in the Assets Object viewer, and it works just fine. When I put it into Automation, the automation runs, but it doesn't find anything.\n\nIn addition to creating the issue, I'd also need to change the \"In Periodic Review\" attribute to TRUE, to prevent duplication of issue creation.\n\nAny thoughts? I've hit a dead end.\n\nThank you!\n"
} | [
{
"author": "Zamin Ali Panhwar",
"body": "O\n",
"comments": [
{
"author": "Zamin Ali Panhwar",
"body": "O\n"
},
{
"author": "Steve Y",
"body": "Hi Zamin,\n\nWhat is the intent of your O comments? I'm not following.\n\nThanks,\n\n\\~Steve\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Need-to-automate-scheduled-review-of-assets-with-multiple/qaq-p/2798451 | [
"aql",
"asset-management",
"assets",
"attribute",
"data-center"
] |
{
"author": "Claire Mayer",
"title": "Help Needed with Jira Automation Error: \"Actor does not have permission to view one or more issues\"",
"body": "Hello Jira Community,\n\nI'm encountering an issue with a Jira automation rule, and I'm hoping someone can help me figure out what's going wrong. Here's the setup for the rule:\n\n### **Automation Rule Details:** {#toc-hId--2145585072}\n\n* **Steps:**\n * **When:** The rule is triggered on **All comments**\n * **Project:** The project is set to \"Team project (TES)\"\n * **Branch:** For Linked Issues with the type \"created by\"\n * **If Condition:** Compares two values to check if `{{comment.visibility.value}}` equals `Customers Visibility`\n * **Then Action:** Add a comment to the linked issue\n* **Actor:** User who triggered the event\n* **Scope:** Global\n\n### **Steps to Reproduce:** {#toc-hId-341927761}\n\n1. Issue **TES-22** has a linked issue **BSM-23** (Note: BSM is a Jira Service Management project).\n2. A user comments on **BSM-23** via the customer portal.\n3. The automation rule is triggered and ends with the following error:\n * `\"Actor does not have permission to view one or more issues, or the issue was deleted (please check permissions and issue security levels): Comment (id:67615) for issue BSM-31 (id:33084)\"`\n\n### **The Problem:** {#toc-hId--1465526702}\n\nI want to prevent this automation rule from being triggered in this scenario, as the BSM project should make the condition inapplicable. While the error doesn't seem to have a functional impact (since no action should occur), something is incorrectly configured.\n\n**Question:** \nDo you have suggestion how can I solve this?\n"
} | [
{
"author": "Jim Knepley - ReleaseTEAM",
"body": "The user has permission to access the BSM project, do they have permission to access the linked TES project as well?\n\nAssuming that it's a permissions problem, I think the most straightforward approach would be to give appropriate (and minimal) project permissions to a new, dedicated user and use that as the actor on the rule.\n",
"comments": [
{
"author": "Claire Mayer",
"body": "The user is a Jira Service Management Portal-only access. He doesn't have Jira Software access, so no project permissions.\n\nI also don't want it to be \"jira automation\" as i'll lose the benefit of the automation i'm trying to configure.\n"
}
]
},
{
"author": "Victor Law",
"body": "Hi [@Claire Mayer](/t5/user/viewprofilepage/user-id/5579894)\n\nWelcome to the community.\n\nBased on the error provided, it is clear that the **customer** who commented on the **BSM** project does NOT have permission to browse or view the linked **TES** Jira project.\n\nIn this case, you may resolve the issue by updating the **actor** user to someone with permission to **browse** and **edit** the **BSM** and**TES** Jira projects.\n\nThank you.\n",
"comments": [
{
"author": "Claire Mayer",
"body": "The actor is the JSM portal user. I cannot grant him the access needed. \nI tried conditions to trigger the rule only for some users, but still without any success. \nAlso triggering it with only 1 project doesn't work, as the linked issue is in another project.\n"
}
]
},
{
"author": "Marc - Devoteam",
"body": "Hi [@Claire Mayer](/t5/user/viewprofilepage/user-id/5579894)\n\nDoes the role scope need to be global, you could change the scope to the project only.\n\nOr you could branch on JQL (issueLinkType = \"created by\" and project != BSM)\n",
"comments": null
},
{
"author": "Claire Mayer",
"body": "The user only has access to the Jira Service Management Portal and lacks Jira Software access, so they don't have the necessary project permissions.\n\nI prefer not to use 'jira automation' as the actor, as that would compromise the benefits of the automation I'm trying to implement. I need a solution that doesn't involve changing the actor.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Help-Needed-with-Jira-Automation-Error-quot-Actor-does-not-have/qaq-p/2798476 | [
"cloud",
"jsm"
] |
{
"author": "Marco Calluso",
"title": "Can I filter to see all issues a certain user has approved?",
"body": "Hi\n\nI need to create a filter, which shows me all issues a certain user has approved. Even though the approval step might not be done yet, because other users have to approve first.\n\nIst this somehow possible? All users are in different approval groups.\n\nThank you\n"
} | [
{
"author": "Neil Fletcher",
"body": "Hi [@Marco Calluso](/t5/user/viewprofilepage/user-id/5539737) \n\nGive this JQL a try... it works for me in cloud; \n\nproject = **abc123** and \"Approvals\\[Approvals\\]\" = approver('**firstname lastname** ') OR \"Approvals\\[Approvals\\]\" = pendingBy(\"**firstname lastname** \") \n\nsubstitute the bold values with whatever you're looking for - this will return issues approved and issues waiting to be approved.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Can-I-filter-to-see-all-issues-a-certain-user-has-approved/qaq-p/2794460 | [
"approval",
"filter",
"jira-service-management"
] |
{
"author": "Devender Singh",
"title": "How to send an email to the team on addition of a calender event?",
"body": "I am looking for automation to update the team with email when a calendar event such as a project timeline, individual leave plan, etc is added to the confluence calendar.\n"
} | [
{
"author": "Darryl Lee",
"body": "Hi [@Devender Singh](/t5/user/viewprofilepage/user-id/5576003) - it looks like there's an open request for Calendar integration with Automation for Confluence:\n\n* [CONFCLOUD-75074 - Automation for confluence to integrate with Team calendar](https://jira.atlassian.com/browse/CONFCLOUD-75074)\n\nBut an easy \"hack\" to accomplishing what you want might be to embed a Team Calendar on a page, and then have your team members Watch that page (you could provide some instructions at the top of the page).\n\n(Yes, team members can go to the calendar and choose to Watch it there, but I feel that linking to and watching page is just easier to find.)\n\n* [Embed calendars on Confluence pages](https://support.atlassian.com/confluence-cloud/docs/embed-calendars-on-confluence-pages/)\n* [Watch a calendar](https://support.atlassian.com/confluence-cloud/docs/watch-a-calendar/)\n",
"comments": [
{
"author": "Darryl Lee",
"body": "In retrospect, perhaps explicitly subscribing to the Calendar (again, you could have a page that links to this) might be better, as I forgot that there's a common issue of people getting notifications about Calendars from spaces/pages they are watching, and the notification does not inform them what space/page contains the calendar.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-to-send-an-email-to-the-team-on-addition-of-a-calender-event/qaq-p/2793963 | null |
{
"author": "Hassan Azhar",
"title": "Pulling ISSUES from key to JSON",
"body": "I want to pull all the issues for web. I have API Key.\n\nLooking for query to pull issues using CURL command.\n"
} | [
{
"author": "Mohamed Benziane",
"body": "Hello,\n\nif you want to get the issue using their key you can use this REST API\n\n<https://developer.atlassian.com/cloud/jira/platform/rest/v2/api-group-issues/#api-rest-api-2-issue-issueidorkey-get>\n",
"comments": null
}
] | https://community.atlassian.com/t5/Automation-questions/Pulling-ISSUES-from-key-to-JSON/qaq-p/2793642 | null |
{
"author": "divya krishna",
"title": "Due date is crossed ? configure pop-up drop-down for project manager to choose the reason",
"body": "Hi \nDue date is crossed. configure the pop-up drop-down for the project manager to choose the reason, and if due is not crossed, they should not get the pop-up. Could you please provide suggestions for this case? \n"
} | [
{
"author": "Darryl Lee",
"body": "SO... I don't think Atlassian provides a mechanism for creating \"pop-ups\".\n\nI'm thinking one thing you could do (and you properly tagged this question) is create a Validator that forces the **Reason** field to be required if **Due Date** has past, and include a message explaining that.\n\nThe trick is that Validators only happen with specific transitions. So maybe you add this before somebody can Close a ticket. (\"Hey you closed this ticket after it was due. Therefore you have to provide a reason why.\")\n\nCan you please let us know if you are on Cloud or Data Center so I could give a recomendation on how to create such a Validator?\n",
"comments": [
{
"author": "divya krishna",
"body": "I am using cloud version\n"
},
{
"author": "divya krishna",
"body": "[@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322) Could you please reply me\n"
},
{
"author": "divya krishna",
"body": null
},
{
"author": "Darryl Lee",
"body": "Hi [@divya krishna](/t5/user/viewprofilepage/user-id/1598824) - so what you're actually need is a *conditional* Validator.\n\nAnd for that, you're going to need an add-on that allows you to implement a Jira Expressions. I wrote about this here:\n\n* [Jira Expressions - But Why?](https://community.atlassian.com/t5/Jira-articles/Jira-Expressions-But-Why/ba-p/1694545)\n\nNow, I wrote that a while ago, so it's possible there's an now add-on that provides a nice UI so you don't have to learn Jira Expressions, but under the covers, that's what really is happening.\n\nGive me a little time and I'll come up with what you need.\n"
},
{
"author": "Darryl Lee",
"body": "Got it. So I used the FREE [Custom Workflow Condition, Validator \\& Postfunctions](https://marketplace.atlassian.com/apps/1231933/extensions-for-jira-workflow-conditions-validators-free?hosting=cloud&tab=overview) to create Validator, but it would work with any of these (pricing for 100 users as of Jan 29, 2024):\n\n* [Cloud Workflows](https://marketplace.atlassian.com/apps/1220407/cloud-workflows?hosting=cloud&tab=pricing&utm_source=docs&utm_medium=navbar&utm_campaign=cloud_workflows_docs): $500\n* [JSU Automation Suite for Jira Workflows](https://marketplace.atlassian.com/apps/5048/jsu-automation-suite-for-jira-workflows?tab=pricing&hosting=cloud): $1,190\n* [Jira Workflow Toolbox](https://marketplace.atlassian.com/apps/29496/jira-workflow-toolbox?tab=pricing&hosting=cloud): $1,250\n* [Jira Misc Workflow Extensions (JMWE)](https://marketplace.atlassian.com/apps/292/jira-misc-workflow-extensions-jmwe?tab=pricing&hosting=cloud): $1,500\n* [Power Scripts - Jira Workflow Automation](https://marketplace.atlassian.com/apps/43318/power-scripts-jira-workflow-automation?hosting=cloud&tab=pricing): $1,550\n* [ScriptRunner for Jira](https://marketplace.atlassian.com/apps/6820/scriptrunner-for-jira?tab=pricing&hosting=cloud): $2,500\n\nHere's the Jira Expression:\n> new Date(issue.dueDate.toISOString() + 'T00:00:00') \\>= new Date() \\|\\| issue.customfield_10151 != null\n\nWhere my customfield_10151 is a Single Select field. I think if your **Reason** field was text, you might be able to use **''** , but maybe **null** will work too.\n\nAnyways, the ISO date thing was annoying. You might have to fiddle with it or tack on your timezone.)\n\nBut basically this is saying that for the transition to go through, one of these statements must be true:\n\n* Due Date (at 00:00:00) \\>= Current Date/Time\n* Reason field must not be empty\n\nHere's what it looked like in my workflow editor:\n\n\n\nHey [@Krzysztof Bogdan](/t5/user/viewprofilepage/user-id/1256398) - what does that green checkmark and 1 mean?\n\nWhew, it's been a long time since I've written a Jira Expression. Painful. But fun stuff.\n"
},
{
"author": "Krzysztof Bogdan",
"body": "[@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322)? - means expression syntax is ok. \n\nThe number show expression complexity: \n<https://developer.atlassian.com/cloud/jira/software/jira-expressions/#expensive-operations> \n\n(There are limit how many operations expression execute)\n"
}
]
},
{
"author": "divya krishna",
"body": "we can implement this function in validator or conditions without using free add-on\n",
"comments": null
},
{
"author": "divya krishna",
"body": "[@Maciej Dudziak _Forgappify_](/t5/user/viewprofilepage/user-id/5267224) [@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322)\n\nWithout using free add-on we can implement this function in validator or conditions\n",
"comments": [
{
"author": "Darryl Lee",
"body": "Hi - are you asking whether you can implement this without an add-on?\n\nThe answer is no.\n"
}
]
},
{
"author": "Maciej Dudziak _Forgappify_",
"body": "Hi [@divya krishna](/t5/user/viewprofilepage/user-id/1598824)\n\nI agree with [@Darryl Lee](/t5/user/viewprofilepage/user-id/1365322)\n\nWhat you need is a Jira expression-based validator, which allows you to create conditional validations.\n\nIf you're interested in learning how to build expressions related to dates, our team has created the Dates Compare Validator, which is part of the [Workflow Building Blocks for Jira](https://marketplace.atlassian.com/apps/1233642/workflow-building-blocks-for-jira?hosting=cloud&tab=overview) free app. With a wizard-like UI, you can select options that match your case. We provide a Jira expression preview section where you can see the expression generated by the UI. It looks like this:\n\n\n\nThen, you can use the generated expression, expand upon it, and apply it with our [Jira Expression Validator](https://docs.forgappify.com/workflow-building-blocks-for-jira/jira-administrator/validators/jira-expression-validator) to handle your case:\n\n```\n(issue.dueDate != null \n && new Date(issue.dueDate.toISOString()+'T00:00:00+00:00') >= new Date()) \n ? true\n : issue.customfield_xxxxx != null\n```\n\nYou need to change the ID of the custom field to a valid one. In the editor, after 'issue.', start typing the name of the field, and you will get suggestions with the correct value.\n\nIf your field is a customfield, then in most cases checking against null is correct way to make it required. In other cases you can check our Fields Required Validator, which also has a preview section to learn how to make it right.\n\nI hope it will help.\n\nCheers\n",
"comments": [
{
"author": "Darryl Lee",
"body": "Oh man, [@Maciej Dudziak _Forgappify_](/t5/user/viewprofilepage/user-id/5267224) your app is very very cool! I should've figured that given enough time, clever developers would make apps that would alleviate users from having to learn Jira Expressions (as much \"fun\" as it can be.)\n"
},
{
"author": "Maciej Dudziak _Forgappify_",
"body": "Thank you Darryl :)\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/Due-date-is-crossed-configure-pop-up-drop-down-for-project/qaq-p/2797216 | [
"condition",
"validator"
] |
{
"author": "Jonathan Chatfield",
"title": "How to send a weekly email update with uncompleted issues on a project?",
"body": "Hello,\n\nWe are going to move to a jira data center as I am testing out functionality for my company.\n\nI want to send a weekly email update with uncompleted issues on a project.\n\nI want to have the unresolved issues (epics, stories, and subtasks).\n\nIt would be amazing if I could categorize it the unresolved issues by assignee.\n\nI have looked through multiple threads and got a successful email to send to me on any tasks that have been updated since the last search was done. I want to see all the unresolved tasks even if it repeats itself.\n\nOn the screenshot I know it is 5 minutes as I will change it to seven days when the automation is completed.\n\nCan someone help with this ask? \n"
} | [
{
"author": "Darryl Lee",
"body": "Hi [@Jonathan Chatfield](/t5/user/viewprofilepage/user-id/5489117) !\n\nThe advice and template from [@Kalyan Sattaluri](/t5/user/viewprofilepage/user-id/5312306) looks spot on.\n\nOne thing to add:\n> I have looked through multiple threads and got a successful email to send to me on any tasks that have been updated since the last search was done. I want to see all the unresolved tasks even if it repeats itself.\n\nThe key to this is to uncheck \"Only include issues that have changed since the last time this rule executed\":\n\n\n",
"comments": [
{
"author": "Jonathan Chatfield",
"body": "Thank you for the extra bit of information! [@Kalyan Sattaluri](/t5/user/viewprofilepage/user-id/5312306) has really helped me get that information and I love your bit as well!\n"
}
]
},
{
"author": "Kalyan Sattaluri",
"body": "Hello [@Jonathan Chatfield](/t5/user/viewprofilepage/user-id/5489117)\n\nTo categorize by assignees, you need to know/hardcode their names in your email template.\n\nI dont think thats useful as team members move/added etc and its maintenance nightmare.\n\nAlso, open Epic/Story/Subtasks in 1 email gets wild ... as sub-tasks are special kind of issue type..\n\nYou could, instead think of adding a column where, for each story, you list count of open sub-tasks.\n\nBut the last part is little advanced and we are better off focussing on making your email template be more helpful in other ways, such asm instead of assignee, catgegorize by issue type..\n\nSo to summarize, categorizing by assignee needs you to either hard code assignees in your email.. OR, simply sort the JQL so assignee is listed by the clause you have shared.\n\nsuch as project = HOC and status != Done ORDER BY assignee\n\nHope it helps and share your thoughts.. Thanks!\n",
"comments": [
{
"author": "Kalyan Sattaluri",
"body": "Here is a template, will need to be customized for your Jira set up .. for example, confirm your Epic is infact called Epic and not Feature etc... but should get you started with email.. Trigger your rule and see the output and you can customize as needed...\n\n++**Open Epics**++\n\n\\<table border=\"1\"\\> \n\\<tr\\> \n\\<th style=\"width:100px\"\\>Key\\</th\\> \n\\<th style=\"width:150px\"\\>Issue Type\\</th\\> \n\\<th style=\"width:150px\"\\>Assignee\\</th\\> \n\\<th style=\"width:150px\"\\>Summary\\</th\\> \n\\<th style=\"width:1000px\"\\>Created\\</th\\> \n\\</tr\\>\n\n**{{#issues}}**\n\n**{{#if(equals(issueType.name, \"Epic\"))}}** \n\\<tr\\> \n\\<td\\>\\<a href=\"{{url}}\"\\>{{Key}}\\</a\\>\\</td\\> \n\\<td\\>{{fields.issuetype.name}}\\</td\\> \n\\<td\\>{{assignee.displayName}}\\</td\\> \n\\<td\\>{{summary}}\\</td\\> \n\\<td\\>{{created}}\\</td\\> \n\\</tr\\> \n{{/}} \n{{/}}\\</table\\>\n\n-----------------------------------------------------------------\n\n++**Open Stories**++\n\n\\<table border=\"1\"\\> \n\\<tr\\> \n\\<th style=\"width:100px\"\\>Key\\</th\\> \n\\<th style=\"width:150px\"\\>Issue Type\\</th\\> \n\\<th style=\"width:150px\"\\>Assignee\\</th\\> \n\\<th style=\"width:150px\"\\>Summary\\</th\\> \n\\<th style=\"width:1000px\"\\>Created\\</th\\> \n\\</tr\\>\n\n**{{#issues}}**\n\n**{{#if(equals(issueType.name, \"Story\"))}}** \n\\<tr\\> \n\\<td\\>\\<a href=\"{{url}}\"\\>{{Key}}\\</a\\>\\</td\\> \n\\<td\\>{{fields.issuetype.name}}\\</td\\> \n\\<td\\>{{assignee.displayName}}\\</td\\> \n\\<td\\>{{summary}}\\</td\\> \n\\<td\\>{{created}}\\</td\\> \n\\</tr\\> \n{{/}} \n{{/}}\\</table\\>\n\n-----------------------------------------------------------------\n\n++**Open Defects**++\n\n\\<table border=\"1\"\\> \n\\<tr\\> \n\\<th style=\"width:100px\"\\>Key\\</th\\> \n\\<th style=\"width:150px\"\\>Issue Type\\</th\\> \n\\<th style=\"width:150px\"\\>Assignee\\</th\\> \n\\<th style=\"width:150px\"\\>Summary\\</th\\> \n\\<th style=\"width:1000px\"\\>Created\\</th\\> \n\\</tr\\>\n\n**{{#issues}}**\n\n**{{#if(equals(issueType.name, \"Defect\"))}}** \n\\<tr\\> \n\\<td\\>\\<a href=\"{{url}}\"\\>{{Key}}\\</a\\>\\</td\\> \n\\<td\\>{{fields.issuetype.name}}\\</td\\> \n\\<td\\>{{assignee.displayName}}\\</td\\> \n\\<td\\>{{summary}}\\</td\\> \n\\<td\\>{{created}}\\</td\\> \n\\</tr\\> \n{{/}} \n{{/}}\\</table\\>\n\n-----------------------------------------------------------------\n"
},
{
"author": "Jonathan Chatfield",
"body": "This has been amazing help! I love the template email you have given me as I have added columns to it and so much information can be sent out from it! I really appreciate this!\n"
}
]
},
{
"author": "Trudy Claspill",
"body": "Hello [@Jonathan Chatfield](/t5/user/viewprofilepage/user-id/5489117)\n\nRather than use an Automation for this, you could use a [Saved Filter](https://confluence.atlassian.com/jirasoftwareserver/saving-your-search-as-a-filter-939938748.html) and ask each person to [subscribe](https://confluence.atlassian.com/jirasoftwareserver/working-with-search-results-939938808.html) to it.\n\nThe filter you would use is:\n\nproject=XXX and Resolution is empty and assignee=currentuser()\n\nEach person subscribed to the filter would get a list of the unresolved issues in project XXX where they are the Assignee.\n\nIf you have a reason that you **must** use an Automation rule then, depending on the version of Jira you currently are using, you could use a Lookup Issues action inside the Scheduled rule rather than have your filter in the Scheduled trigger. Then you could use branching to look at each distinct Assignee in that results set, do another Lookup Issues action for that Assignee, and send the results in an email to that Assignee.\n\nYou can find information on the Lookup Issue action in the documentation about actions:\n\n<https://confluence.atlassian.com/automation/jira-automation-actions-993924834.html>\n\nAnd there is a separate page for documentation on Branches:\n\n<https://confluence.atlassian.com/automation/branch-automation-rules-to-perform-actions-on-related-issues-993924648.html>\n",
"comments": [
{
"author": "Jonathan Chatfield",
"body": "Thank you for this insight for the search option, but this will mainly be for my manager and director to get a easy reminder of how the team is doing! I appreciate the links and insight!! =D\n"
},
{
"author": "Kelly Arrey",
"body": "Hi [@Jonathan Chatfield](/t5/user/viewprofilepage/user-id/5489117),\n\n[@Trudy Claspill](/t5/user/viewprofilepage/user-id/3569011)'s suggestion sounds like exactly what you need. Once you get the filter right, create a subscription to the filter for your manager and director, and they'll get a weekly email with the full report.\n"
}
]
}
] | https://community.atlassian.com/t5/Automation-questions/How-to-send-a-weekly-email-update-with-uncompleted-issues-on-a/qaq-p/2794029 | [
"email",
"jira-data-center"
] |
{
"author": "Aluvalu Manjunatha",
"title": "Unable to make the payment",
"body": "Hi atlasian team,\n\nWe have updated the credit card details for the below Bitbucket cloud subscription. Kindly deduct the amount and enable user access to update the codebase.\n\nbitbucket.org/\\[REDACTED\\]\n\nRegards,\n\nManjunath\n"
} | [
{
"author": "Ben",
"body": "Hi [@Aluvalu Manjunatha](/t5/user/viewprofilepage/user-id/5517259)\n\nI've noticed your plan appears to be updated, can you confirm if there are any issues?\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Unable-to-make-the-payment/qaq-p/2818907 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Moritz Friedrich",
"title": "Connect to service container from a Pipe",
"body": "**TL;DR: I cannot reach a service container from a custom Pipe. Is this by design, and what can I do about it?** \n\n\n*** ** * ** ***\n\nWe're using [Tailscale](https://tailscale.com) to connect to our internal services. Usually, this doesn't really affect Bitbucket deployments, but recently, we started tracking dependencies and vulnerabilities using [Dependency Track,](https://dependencytrack.org) which is hosted in our Tailnet exclusively---so, not reachable from the outside.\n\nEssentially, this means we want to collect information from a built Docker image as an [SBOM](https://www.cisa.gov/sbom), and send that in an API request to our Dependency Track instance. I actually created a new (public) Pipe for this: [matchory/dependency-track-pipe](https://bitbucket.org/matchory/dependency-track-pipe/). It can be used like so:\n\n```\n- pipe: matchory/dependency-track-pipe:0.4.2 variables: SERVER_URL: \"https://dtrack.example.com\" API_KEY: $DTRACK_API_KEY\n```\n\nSince we cannot connect directly, we need to [run the Tailscale client in the pipeline](https://tailscale.com/kb/1282/docker), and use its [SOCKS 5 proxy](https://en.wikipedia.org/wiki/SOCKS) to forward requests from our pipeline to the server. \nThe easiest way to do this is to run a Tailscale service container: \n\n```\ndefinitions:\n services:\n tailscale:\n image: tailscale/tailscale:latest\n variables:\n KUBERNETES_SERVICE_HOST: \"\"\n? TS_KUBE_SECRET: \"\" TS_ACCEPT_DNS: \"true\"\n TS_AUTHKEY: $TAILSCALE_AUTHKEY\n TS_SOCKS5_SERVER: \"localhost:1055\"\n```\n\n*(If you're also trying to get Tailscale to work, note the Kubernetes variables. These are required to avoid Tailscale detecting the Bitbucket k8s network, which breaks connectivity for your pipeline.)*\n\nThis allows connecting to all Tailnet services via the SOCKS5 proxy at `socks5://localhost:1055`. You can verify this by passing the proxy address to curl, for example:\n\n```\nALL_PROXY=socks5://localhost:1055 \\\n curl https://some-internal-service.your-tailnet.ts.net/\n```\n\nPlugging all of this together, we want to\n\n1. set up a proxy into our Tailscale network,\n2. collect an SBOM from the container we've just built, and\n3. send that SBOM to our Dependency Track instance via the proxy.\n\nThe following pipeline should be able to achieve this: \n\n```\ndefinitions:\n services:\n tailscale:\n image: tailscale/tailscale:latest\n variables:\n KUBERNETES_SERVICE_HOST: \"\"\n TS_KUBE_SECRET: \"\"\n TS_ACCEPT_DNS: \"true\"\n TS_AUTHKEY: $TAILSCALE_AUTHKEY\n TS_SOCKS5_SERVER: \"localhost:1055\"\n\n build-and-push: &build-and-push\n # ...\n\npipelines:\n branches:\n main:\n - step:\n name: Build and push\n services:\n - docker\n script:\n - *build-and-push\n - step:\n name: Collect SBOM\n services:\n - docker\n - tailscale\n script:\n - pipe: matchory/dependency-track-pipe:0.4.2\n variables:\n ALL_PROXY: socks5://localhost:1055\n SERVER_URL: https://dtrack.your-tailnet.ts.net/\n # ...\n```\n\n**This does not work, however, because the proxy cannot be reached from within the pipe container:** \n\n```\nSBOM Upload failed TypeError: fetch failed\n at fetch (/pipe/node_modules/undici/index.js:112:13)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)\n at async main (file:///pipe/upload.mjs:80:22) {\n [cause]: SocksClientError: connect ECONNREFUSED 127.0.0.1:1055\n at SocksClient.closeSocket (/pipe/node_modules/socks/build/client/socksclient.js:390:32)\n at SocksClient.onErrorHandler (/pipe/node_modules/socks/build/client/socksclient.js:363:14)\n at Socket.onError (/pipe/node_modules/socks/build/client/socksclient.js:225:38)\n at Object.onceWrapper (node:events:634:26)\n at Socket.emit (node:events:519:28)\n at emitErrorNT (node:internal/streams/destroy:170:8)\n at emitErrorCloseNT (node:internal/streams/destroy:129:3)\n at process.processTicksAndRejections (node:internal/process/task_queues:90:21) {\n options: {\n command: 'connect',\n proxy: [Object],\n timeout: 10000,\n destination: [Object],\n existing_socket: undefined\n }\n }\n}\n```\n\nI think this may be related to the way pipe networking is set up, but there is nothing in the documentation mentioning limitations in this regard, neither in [\"Databases and Service containers\"](https://support.atlassian.com/bitbucket-cloud/docs/databases-and-service-containers), nor in [\"Use Pipes in Bitbucket Pipelines\"](https://support.atlassian.com/bitbucket-cloud/docs/use-pipes-in-bitbucket-pipelines/).\n\nI could include Tailscale in the Dependency Track pipe container, but that would make it way too specialised for everyone else to use, and I think that'd be a sad state of affairs for Pipelines.\n"
} | [
{
"author": "Patrik S",
"body": "Hey [@Moritz Friedrich](/t5/user/viewprofilepage/user-id/4209820) ,\n\nthanks for reaching out!\n\nPipes containers in a build essentially run in the docker service.\n\nWhen you try to access another service using the localhost IP (127.0.0.1) from within a pipe, that IP is actually referred to within the step's docker service scope, so it won't be able to connect.\n\nWe have the following article that cover a sscenario on how to connect to a service container while inside a Docker container on Bitbucket Cloud Pipelines :\n\n* <https://confluence.atlassian.com/bbkb/connecting-to-a-service-container-while-inside-a-docker-container-on-bitbucket-cloud-pipelines-1217200735.html>\n\nThat article can be expanded to pipes as well, if you take into consideration that a pipe is a docker container spun up in the docker service.\n\nSo the same solution proposed in that article should be applicable to your use case.\n\nThe pipe start command already includes the --add-host argument by default: \n\n --add-host=\"host.docker.internal:$BITBUCKET_DOCKER_HOST_INTERNAL\"\n\nwhich will map the `host.docker.internal` to the build container's network.\n\nYou should then be able to use the `host.docker.internal` address to access your service container that has the socks 5 proxy.\n\nThat being said, could you try replacing the IP/port from ***127.0.0.1:1055*** to ***host.docker.internal:1055*** and let us know how it goes?\n\nThank you, [@Moritz Friedrich](/t5/user/viewprofilepage/user-id/4209820) !\n\nPatrik S\n",
"comments": [
{
"author": "Moritz Friedrich",
"body": "Hey Patrik,\n\nthat's interesting, the [page on variables and secrets](https://support.atlassian.com/bitbucket-cloud/docs/variables-and-secrets/) doesn't include BITBUCKET_DOCKER_HOST_INTERNAL. However, I tried it, and while host.docker.internal indeed seems to resolve to another host, it still refuses the connection:\n\n```\nECONNREFUSED 10.39.25.100:1055\n```\n\nThat's weird.\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Connect-to-service-container-from-a-Pipe/qaq-p/2818887 | [
"bitbucket-cloud",
"bitbucket-pipelines",
"cloud",
"network",
"pipes",
"service"
] |
{
"author": "magnolia099",
"title": "error when login to bit bucket account",
"body": "i am getting following error when login to bit bucket account.\n\n\"You may run into this issue when you use specific browsers or add-ons that hide the referer header for id.atlassian.com and other Atlassian sites. Check for these and then try logging in again.\"\n"
} | [
{
"author": "Patrik S",
"body": "Hello [@magnolia099](/t5/user/viewprofilepage/user-id/5598933) ,\n\nThank you for reaching out to us. We will reach out to you via a support ticket shortly.\n\nPlease be on a lookup for the email notification and a link to the ticket. Thank you for your patience.\n\nPatrik S\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/error-when-login-to-bit-bucket-account/qaq-p/2818768 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Fifi Chau",
"title": "Forking repositories under same project",
"body": "Hi, we are migrating from Bitbucket DC to Bitbucket cloud and I found that the forking behavior is a bit different from what we are currently doing in DC.\n\nWhen forking in cloud, it appears that we need to choose workspace and project as well, which would have two outcomes:\n\n1. All forked repos would fall into the project, which is what we don't want to see;\n\n2. Developers need to create their own project to save those forked repos, however they would need to be granted as workspace admin to create project, which also does not make sense to us.\n\nMay I know if any better ideas? Thanks a lot.\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Fifi,\n\nEvery repository in Bitbucket Cloud needs to belong to a workspace and a project within that workspace.\n\nYou could create a separate project only for forks within your workspace and grant developers **Create** access to that project. The developers will then be able to create their forks in that project.\n\nWhen a developer creates a fork in that project, they will have admin access to the fork they create, and write access to other repositories (not created by them) in that project.\n\nWould that work for you?\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Forking-repositories-under-same-project/qaq-p/2818626 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Alfrey",
"title": "Why am I unable to create/track issues?",
"body": "Please see the attached screenshots. GAM305 repository has the option to create/track issues (as circled in blue), but GAM495 does not. How can I enable this feature for GAM495? \n\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Alfrey and welcome to the community!\n\nEach of these two repositories belongs to a different workspace. We recently changed the workspace creation process, and now workspaces can only be created via <https://admin.atlassian.com/> and they need to be linked to an organization. It is no longer possible to create an issue tracker for repositories belonging to such workspaces. This is the case for the workspace the second repo belongs to.\n\nThe first repo belongs to an older workspace that is not linked with an Atlassian organization, so it is possible to enable an issue tracker from **Repository settings**.\n\nYou can look into using [Jira](https://www.atlassian.com/software/jira) for the repo in the second screenshot, or you could tranfer the repo to the workspace where the first repo belongs. You will then be able to enable an issue tracker from **Repository settings** \\> section **FEATURES** \\> **Issue tracker**. You can find steps on how to transfer a repository on this page:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/transfer-repository-ownership/>\n\nPlease feel free to reach out if you have any questions.\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Why-am-I-unable-to-create-track-issues/qaq-p/2818437 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "David W",
"title": "Need Garbage Collection on a repo",
"body": "I need a garbage collection on a repo as it's saying it is over sized but locally it's only 1.6GB. I was told I have to make a question here to have it done serverside because there's no more ticketing. Repo is private but to identify it the first word is **dark** and last word is **sdk**\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi David and welcome to the community!\n\nI ran a git gc on your repository and its size has been reduced to 754.6 MB.\n\nDoes it look ok on your end?\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "David W",
"body": "Thank you Theodora, everything works great now! Sorry for the delayed response.\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Need-Garbage-Collection-on-a-repo/qaq-p/2818314 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Michael Potter",
"title": "How to turn off billing",
"body": "I am getting billed $15/mo for bitbucket and I can't find the screen where I can turn off billing.\n\nI was able to find the screen on Jira (where I was paying $20/mo), but I can't find it on bitbucket.\n\nThe Jira payment management screen was kind enough to have a link to bitbucket, but the link did not go to the bitbucket payment screen.\n\nI have spent at least an hour going down every rabbit hole on the bitbucket site and looking at the FAQ but I still can't find it. The FAQ has information about adding paypal as a payment method so I would expect it to also have information about updating a credit card; but alas, there are not such instructions.\n"
} | [
{
"author": "Aron Gombas _Midori_",
"body": "[@Michael Potter](/t5/user/viewprofilepage/user-id/470749) It is available on a Bitbucket settings page, not on the integrated Billing page! See my screenshot below.\n\n(Reason: Bitbucket is not an original Atlassian product. It was acquired by them, and it has not been yet integrated to the integrated billing system.)\n\n\n",
"comments": [
{
"author": "Michael Potter",
"body": "I can't get to this screen. I think it is because I deleted all the repos in my account and then deleted the \"workspace\".\n"
}
]
},
{
"author": "Carlos Garcia Navarro",
"body": "Hi [@Michael Potter](/t5/user/viewprofilepage/user-id/470749) ,\n\nWelcome to the Community! Have you checked this article with details about how to access billing information?\n\n<https://support.atlassian.com/subscriptions-and-billing/docs/manage-your-bill-for-standard-and-premium-plans/>\n\nIf there is an issue with billing or payment, you can also contact Atlasian support here: <https://support.atlassian.com/contact/#/> (select the option billing, payment and pricing)\n",
"comments": [
{
"author": "Michael Potter",
"body": "I followed those instructions previously and I double checked right now.\n\nbitbucket is not listed on that page. Only jira is listed on that page.\n\nI have opened a ticket with support.\n"
}
]
},
{
"author": "Michael Potter",
"body": "Here is what I think happened:\n\nI deleted all the repos in my account and then deleted all the workspaces.\n\nDeleting the workspace turned off billing and removed the billing screens from my view of bitbucket.\n\nSupport told me that billing is turned off and I asked them for a confirmation that deleting the workspace turns off billing.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/How-to-turn-off-billing/qaq-p/2818273 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Ivan Lee",
"title": "Unable to log into Bitbucket",
"body": "Hi,\n\nI just signed up for the different atlassian products, Confluence, Jira, Jira Service Management, and lastly tried to register for BitBucket, all linking to my google ID After setting it up however, when trying to login, it keeps giving \"We couldn't log you in\".\n\nI've tried multiple browsers and it's still the same issue.\n\nI know I had a bitbucket account in 2016, but it's been inactive for a while. Is there a way to reactivate my account?\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Ivan and welcome to the community!\n\nYour Bitbucket Cloud account was indeed in a dormant state. I went ahead and reactivated it.\n\nCan you please try logging in when you have some time, and let me know if the issue is resolved?\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Unable-to-log-into-Bitbucket/qaq-p/2818205 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "rokgregoric",
"title": "I've enabled 2fa and it's not working",
"body": "every time I want to login is asking me to enter a verification code but when I enter it .. it doesn't work .. I tried 5 times, something is really broken\n"
} | [
{
"author": "rokgregoric",
"body": "I figured it out. I've enabled atlassian 2fa, but after logging in it was also asking me for bitbucket 2fa - there are 2 different - super confusing.\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/I-ve-enabled-2fa-and-it-s-not-working/qaq-p/2818270 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "kosamaria1",
"title": "Can't login to Bitbucket. \"We couldn't log you in\"",
"body": "Hi\n\nI tried to login to my bitbucket cloud but failed with error\n\n\"You may run into this issue when you use specific browsers or add-ons that hide the referer header for id.atlassian.com and other Atlassian sites. Check for these and then try logging in again.\"\n\nWhat should I do?\n"
} | [
{
"author": "Ben",
"body": "Hi [@kosamaria1](/t5/user/viewprofilepage/user-id/5597956)\n\nThank you for reaching out to us. We will reach out to you shortly via a support ticket.\n\nPlease be on a lookup for the email notification and a link to the ticket.\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Can-t-login-to-Bitbucket-quot-We-couldn-t-log-you-in-quot/qaq-p/2817966 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "David Ayodele",
"title": "Can't upgrade my bitbucket Account from Free to Standard",
"body": "Hi,\n\nWe want to upgrade our bitbucket plan from (Free) to (Standard). An error occured. We don't understand the reason. Please can you help us.\n\nError Message \nTitle: Unable to change plan \nBody: There was an issue changing your plan.\n\nOur subscription expired and we were stepped down to free. Now we are trying to renew the plan and we can't.\n\nWe recently canceled our products on Jira (Confluence, Jira Software and Jira Service Management). We don't know if this could be the cause.\n\nThanks.\n"
} | [
{
"author": "Syahrul",
"body": "G'day, [@David Ayodele](/t5/user/viewprofilepage/user-id/5597533)\n\nWelcome to the community!\n\nIt appears that your card has insufficient funds, which caused the automated payment to fail. This is likely why any charges on this card are not going through.\n\nHowever, I can see that your workspace is now on the Standard plan, so it seems this issue has been resolved. If that's the case, please remember to update your billing contact information at my.atlassian.com. This will ensure you receive email notifications if there are any issues with your billing.\n\nRegards, \nSyahrul\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Can-t-upgrade-my-bitbucket-Account-from-Free-to-Standard/qaq-p/2817375 | [
"bitbucket-cloud",
"cloud",
"not-applicable",
"subscriptions-and-billing"
] |
{
"author": "Yogesh Kumar",
"title": "How can I restrict a user with write access from approving a pipeline step that has a trigger applie",
"body": "I have given a user with write access in a repo i want to restrict it to approve a step that has a trigger : manual in it . Please help\n"
} | [
{
"author": "Syahrul",
"body": "G'day, [@Yogesh Kumar](/t5/user/viewprofilepage/user-id/5572153)\n\nIf I understand correctly, you want to restrict manual pipeline triggers to specific users. If so, what you're looking for are deployment restrictions.\n\nThese restrictions will ensure that only administrators can execute manual deployment steps. For more details, please refer to our documentation:\n\n[Deployment Permissions in Bitbucket Pipelines](https://bitbucket.org/blog/deployment-permissions-now-available-in-bitbucket-pipelines)\n\nRegards, \nSyahrul\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/How-can-I-restrict-a-user-with-write-access-from-approving-a/qaq-p/2817360 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Akshay Makwana",
"title": "sonarQube reports are not generating in Bitbucket",
"body": "after the pipeline runs successfully, sonarQube reports are not generated in the Bitbucket repository.\n"
} | [
{
"author": "Syahrul",
"body": "G'day, [@Akshay Makwana](/t5/user/viewprofilepage/user-id/5597468)\n\nWe are not experts in SonarQube integration, so I recommend contacting the [SonarQube community](https://community.sonarsource.com/) for further assistance. They should be able to provide you with the help you need.\n\nAlso, I suggest you review the SonarQube documentation to understand how their reporting works. You can find more information on their Bitbucket integration and reporting your quality gate status here: [SonarQube Documentation](https://docs.sonarsource.com/sonarqube/latest/devops-platform-integration/bitbucket-integration/bitbucket-cloud-integration/#reporting-your-quality-gate-status-in-bitbucket-cloud).\n\nRegards, \nSyahrul\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/sonarQube-reports-are-not-generating-in-Bitbucket/qaq-p/2817323 | [
"bitbucket-cloud",
"cloud",
"sonarqube"
] |
{
"author": "Nick de Pal?zieux",
"title": "Custom merge check based on Jira ticket status",
"body": "I'm looking into custom merge checks with forge.\n\nWhat I want to implement is a merge check that prevents merging a PR if the linked Jira issue is not in the correct status. Only once a Jira ticket has gone through approval do we want to merge the PRs.\n\nLooking at the documentation for custom merge checks, I see that there are triggers to evaluate the merge check when code is pushed to the PR branch etc.\n\nFor my check to work, I need to also be able to trigger based on events in jira, i.e. I need to re-evaluate the merge check when the linked jira issue changes its status.\n\nIs this possible?\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Nick,\n\nThere is no trigger to invoke the merge check based on the linked Jira tickets' status. You can see the available triggers here:\n\n* <https://developer.atlassian.com/platform/forge/manifest-reference/modules/bitbucket-merge-check/#triggers>\n\nHowever, the **on-merge** trigger can be used, which is invoked when someone tries to merge a PR. If this type of check fails and if the check was configured to be **Required**, then the merge will be aborted.\n\nWould this work for you?\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "Nick de Pal?zieux",
"body": "Thanks for your response Theodora.\n\nIt's not great since it requires that the developer tries to merge and then gets rejected. It would be much better if they can know ahead of time whether this is good to merge or not. I'd even want to notify them somehow (e.g. through an automated comment on the PR) that the result of the check has changed.\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Custom-merge-check-based-on-Jira-ticket-status/qaq-p/2817220 | [
"bitbucket-cloud",
"cloud",
"jira-cloud"
] |
{
"author": "Richard Creek",
"title": "Cannot access bitbucket.org website, or push to git repo",
"body": "```\nAtlassian's status page is showing Bitbucket as up, but I'm unable to see the bitbucket.org website and I can't push to my git repo.\nI've been working with repos in bitbucket for years and have never had this issue before, and I haven't changed any firewall settings or anything like that.\n\nWhen I try to do an ssh push whilst on my fibre connection I see:\nkex_exchange_identification: read: Connection reset by peer\n\nWhen I switch to using a 4g connection via my phone as a hotspot I see:\nssh: connect to host bitbucket.org port 22: Network is unreachable\n\nThe website gives: ERR_ADDRESS_UNREACHABLE\n\nI don't think my IPs can be the problem as both my phone and fibre connection have dynamic ips.\n\nI've tried: telnet bitbucket.org 22, that gives: Connection closed by foreign host.\n\nI'm not having any trouble accessing atlassian's site, or Trello, it's just bitbucket.org that I can't access.\n\nAny one else having this problem?\n\nP.S. I'm in the UK\n\nP.P.S Three days later and still no access to website or repos. I've looked at whois for bitbucket.org and found the primary nameserver, tried dig on that and got the A record and put it in my hosts file and it makes no difference\n```\n"
} | [
{
"author": "Richard Creek",
"body": "Note to self: Always check the hosts file properly.\n",
"comments": null
},
{
"author": "Theodora Boudale",
"body": "Hi Richard and welcome to the community!\n\nThere hasn't been any incident that would make our website inaccessible or affect SSH connections during the last three days.\n\nIf you have tried two different networks, the issue may be specific to that computer. Can you open bitbucket.org from your mobile device's browser, when it is connected to one of the two networks you have tried with your computer?\n\nWe have deprecated certain IPs for Bitbucket Cloud. You can see in the link below which IPs we have deprecated and which ones we currently use:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall/>\n\nI suggest removing from the hosts file all entries (check if there are additional ones, other than the one you recently added) that map bitbucket.org to a specific IP address and try again.\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "Richard Creek",
"body": "Thanks Theodora,\n\nI've tried with a browser directly in my phone and that is seeing the site - even using the same connection as the desktop.\n\nMy desktop still wont open the site though, I've tried with Chrome, Firefox and Opera - all the same.\n\nI've looked at that list of IP's you linked to. My DNS is pulling in one of the deprecated ones: 104.192.141.1\n\nSo, I've tried the non-deprecated ips in my hosts file and that made no difference either. I removed the host file entries and that made no difference.\n\nping bitbucket.org works and it's using 104.192.141.1\n\ntraceroute bitbucket.org is failing after a few hops e.g.\n\ntraceroute to bitbucket.org (104.192.141.1), 30 hops max, 60 byte packets \n1 _gateway (192.168.1.254) 0.769 ms 1.049 ms 1.287 ms \n2 \\* \\* \\* \n3 \\* \\* \\* \n4 31.55.187.176 (31.55.187.176) 12.043 ms 12.101 ms 31.55.187.180 (31.55.187.180) 12.270 ms \n5 core1-hu0-12-0-3.southbank.ukcore.bt.net (195.99.127.44) 12.335 ms core1-hu0-16-0-8.southbank.ukcore.bt.net (213.121.192.92) 12.617 ms host213-121-192-106.ukcore.bt.net (213.121.192.106) 12.098 ms \n6 peer8-et-4-0-5.telehouse.ukcore.bt.net (194.72.16.162) 12.345 ms peer1-et7-0-2.interxion.ukcore.bt.net (194.72.16.118) 9.427 ms peer2-et-0-1-2.slough.ukcore.bt.net (109.159.252.124) 15.502 ms \n7 195.99.126.11 (195.99.126.11) 10.133 ms 99.82.181.174 (99.82.181.174) 10.971 ms \\* \n8 \\* \\* \\* \n... \n30 \\* \\* \\*\n\nI've used the tool recommended in the Atlassian trouble shooting: **Customer Routing from NTT**\n\nThat's showing:\n\n inet.0: 966785 destinations, 8394080 routes (965494 active, 15192 holddown, 1341538 hidden)+ = Active Route, - = Last Active, * = BothA V Destination P Prf Metric 1 Metric 2 Next hop AS path* ? 81.128.0.0/11 B 170 100 4294967294 1299 5400 2856 I unverified >129.250.4.23 ? B 170 100 4294967294 1299 5400 2856 I unverified >129.250.4.23 ? B 170 100 4294967294 1299 5400 2856 I unverified >129.250.4.23 ? B 170 100 4294967294 3356 5400 2856 I unverified >129.250.2.125 ? B 170 100 4294967294 3356 5400 2856 I unverified >129.250.2.125 ? B 170 100 4294967294 3356 5400 2856 I unverified >129.250.2.125\n\nI'm using Ubuntu 20.04 on the desktop. Do you know of any recent Ubuntu updates that could have caused three different browsers to only have trouble connecting to bitbucket.org?\n\nthanks again for your help.\n"
},
{
"author": "Richard Creek",
"body": "I've tried checking the connection to <https://bitbucket.org> with curl\n\n```\n$ curl -v https://bitbucket.org \n* Trying 104.192.141.1:443...\n* TCP_NODELAY set\n* Connected to bitbucket.org (104.192.141.1) port 443 (#0)\n* ALPN, offering h2\n* ALPN, offering http/1.1\n* successfully set certificate verify locations:\n* CAfile: /etc/ssl/certs/ca-certificates.crt\n CApath: /etc/ssl/certs\n* TLSv1.3 (OUT), TLS handshake, Client hello (1):\n* OpenSSL SSL_connect: Connection reset by peer in connection to bitbucket.org:443 \n* Closing connection 0\ncurl: (35) OpenSSL SSL_connect: Connection reset by peer in connection to bitbucket.org:443\n```\n\nA similar curl against Trello.com works, Trello is also using TLSv1.3\n\nCould bitbucket have been changed to use a different cypher set recently that is making it inaccessible to ubuntu 20.04 with openssl 1.1.1f?\n"
},
{
"author": "Richard Creek",
"body": "Testing with openssl I'm seeing the following.\n\n```\nopenssl s_client -connect bitbucket.org:443 -prexit -servername bitbucket.org\nCONNECTED(00000003)\nwrite:errno=104\n---\nno peer certificate available\n---\nNo client certificate CA names sent\n---\nSSL handshake has read 0 bytes and written 305 bytes\nVerification: OK\n---\nNew, (NONE), Cipher is (NONE)\nSecure Renegotiation IS NOT supported\nCompression: NONE\nExpansion: NONE\nNo ALPN negotiated\nEarly data was not sent\nVerify return code: 0 (ok)\n---\n---\nno peer certificate available\n---\nNo client certificate CA names sent\n---\nSSL handshake has read 0 bytes and written 305 bytes\nVerification: OK\n---\nNew, (NONE), Cipher is (NONE)\nSecure Renegotiation IS NOT supported\nCompression: NONE\nExpansion: NONE\nNo ALPN negotiated\nEarly data was not sent\nVerify return code: 0 (ok)\n---\n\n\n```\n"
},
{
"author": "Richard Creek",
"body": "Oh boy, how embarrassing. I'd added the hosts file entry at the bottom of my host file when I started having the problem, then commented it out.\n\nThere was another entry at the top of the file for one of the deprecated IPs.\n"
},
{
"author": "Theodora Boudale",
"body": "Hi Richard,\n\nI was about to reply, when I saw your update. It's good to hear that you found the entry!\n\nEven though the issue was not related to security protocols, you can find supported TLS protocols and cipher suites on this page:\n\n* <https://support.atlassian.com/security-and-access-policies/docs/supported-security-protocols-for-atlassian-cloud-products/>\n\nPlease feel free to reach out if you ever need anything else.\n\nKind regards, \nTheodora\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Cannot-access-bitbucket-org-website-or-push-to-git-repo/qaq-p/2817299 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "JimmingO",
"title": "bitbucket new pipline ip address list",
"body": "My server use a firewall, access list, security group to restrict incoming access to particular IP's or IP ranges,\n\nI already set new ip list in my firewall but it still not work, i found incoming ip as follow\n\n98.81.221.97\n\n3.82.41.188\n\nbut it not found in pipline ip list\n\nplease help me to check and give me full ip list\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi and welcome to the community!\n\nAll Pipelines steps that run on Atlassian's Cloud infrastructure are hosted on Amazon Web Services. An exhaustive list of the IPs used for all steps can be found here, filtering to records where the **service** equals **EC2** or **S3** , and using the **us-east-1** and **us-west-2** regions:\n\n* <https://ip-ranges.amazonaws.com/ip-ranges.json>\n\n<br />\n\nThis is a large number of IP ranges. If you prefer to use a more limited or narrowed IP range, you can use the **runtime** option with **atlassian-ip-ranges** in your bitbucket-pipelines.yml file for a certain step:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/step-options/#Runtime>\n\nThis is only possible for steps with size 4x and 8x. Then, this step will use a more limited set of IPs and the number of IP ranges you will need to allowlist is smaller. You can find this limited set of IP ranges here:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/what-are-the-bitbucket-cloud-ip-addresses-i-should-use-to-configure-my-corporate-firewall/#Atlassian-IP-ranges>\n\nPlease feel free to reach out if you have any questions!\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "Jonathan Duncan",
"body": "Those lists are not complete. I found one that was not on any of the lists.\n"
},
{
"author": "Renato Lima",
"body": "[@Jonathan Duncan](/t5/user/viewprofilepage/user-id/1170081) we've just found 34.207.135.242 which is not in the lists, could you please share the address that you've found? I guess there s something wrong going on\n"
},
{
"author": "Jonathan Duncan",
"body": "[@Renato Lima](/t5/user/viewprofilepage/user-id/3290100), see this thread: <https://community.atlassian.com/t5/Bitbucket-questions/Unknown-New-Bitbucket-Pipeline-IP-Address/qaq-p/2819738#M107994>\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/bitbucket-new-pipline-ip-address-list/qaq-p/2817058 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Riley Davidson-Evans",
"title": "App install url has outdated workspace icon",
"body": "Our AI Powered Code Review app still has our old icon in the install url \n\n<br />\n\n<https://bitbucket.org/site/addons/authorize?addon_key=korbit-ai-mentor>\n\nHow can I get this updated to reflect the new icon ?\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Riley and welcome to the community!\n\nI haven't been involved with app development so I don't know the answer, but you can ask our Marketplace team. You can create a ticket via the following link (select **App listing** on this page):\n\n* <https://developer.atlassian.com/support>\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/App-install-url-has-outdated-workspace-icon/qaq-p/2816813 | [
"addon",
"app",
"application",
"bitbucket-cloud",
"cloud"
] |
{
"author": "Francois Grondin",
"title": "How to push modifications on website",
"body": "Hi,\n\nI'm new to this platform and I'm trying to figure out things, but I can't find something.\n\nI make some changes in the code, hire, but those changes don't appear on the live website. Do I have to push them once I saved them? If yes, how do I do it?\n\nThanks in advance,\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Francois and welcome to the community!\n\nIf you are hosting a website on another provider, then yes, you will need to copy/deploy the website's source code to this server. This is typically done with a CI/CD tool and the way you push depends on what that server supports (it might be ftp, sftp, scp, rsync).\n\nBitbucket offers such a CI/CD tool, it's called Pipelines:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/build-test-and-deploy-with-pipelines/>\n\nYou can use Bitbucket Pipelines either on Atlassian's infrastructure, or if you have a server where you can run builds, you can use a self-hosted runner:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/runners/>\n\nIf you use Pipelines on Atlassian's infrastructure or with a self-hosted Linux Docker runner, you can use one of the pipes to deploy (depending on what is possible with the hosting server):\n\n* <https://bitbucket.org/atlassian/rsync-deploy/src/master/>\n* <https://bitbucket.org/atlassian/sftp-deploy/src/master/>\n* <https://bitbucket.org/atlassian/scp-deploy/src/master/>\n* <https://bitbucket.org/atlassian/ftp-deploy/src/master/>\n\nIf you use a Linux Shell, MacOS, or Windows runner, the builds will run on Bash (Linux Shell and MacOS) or PowerShell (Windows) on the host machine. So, any tools you need to use (e.g. rsync, ftp, scp, etc) need to be installed on the runner's host machine.\n\nPlease feel free to reach out if you have any questions.\n\nKind regards, \nTheodora\n",
"comments": null
}
] | https://community.atlassian.com/t5/Bitbucket-questions/How-to-push-modifications-on-website/qaq-p/2816812 | [
"bitbucket-cloud",
"cloud"
] |
{
"author": "Brett Geibel",
"title": "Slack notifications sporadically work",
"body": "We've had Slack notifications configured for some time without issues in all of our repos.\n\nHowever, we've noticed recently that sometimes they work, and sometimes they don't.\n\nIn some cases, an engineers first pull request won't notify, but their second will, and we've seen this in reverse will the first PR will notify, but the second won't. It doesn't seem to have an affect on approvals, or merging, however.\n\nWe've tried removing the configuration from the repo and replacing, reauthorizing, clearing cache, etc, but to no avail.\n\nHas anyone else experienced anything like this before?\n\nAny additional steps I might be able to take to isolate further?\n"
} | [
{
"author": "Theodora Boudale",
"body": "Hi Brett,\n\nLast week we received one report about a similar issue via a support ticket and we are currently investigating this. I don't know if the issue you see is related to what the other customer reported, we would need to check logs. You can create a ticket with the support team for further investigation.\n\nYou can create a ticket via <https://support.atlassian.com/contact/#/>, in \"What can we help you with?\" select \"Technical issues and bugs\" and then Bitbucket Cloud as product. When you are asked to provide the workspace URL, please make sure you enter the URL of the workspace that is on a paid billing plan to proceed with ticket creation.\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "Brett Geibel",
"body": "Thank you, Theodora, for taking the time to reply. Very much appreciated. I've followed your guidance above.\n"
}
]
}
] | https://community.atlassian.com/t5/Bitbucket-questions/Slack-notifications-sporadically-work/qaq-p/2816705 | [
"bitbucket-cloud",
"cloud",
"slack"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.