
question
dict | answers
listlengths 1
27
| url
stringlengths 66
601
| tags
listlengths 1
15
⌀ |
|---|---|---|---|
{
"author": "Sandro Quartieri",
"title": "Notification translation does not translate ticket status",
"body": "Hi,\n\nI have a portal in italian language, which is set as the default language.\n\nDuring the normal workflow, when a ticket changes status, the customer receives a notification via email like this.\n\n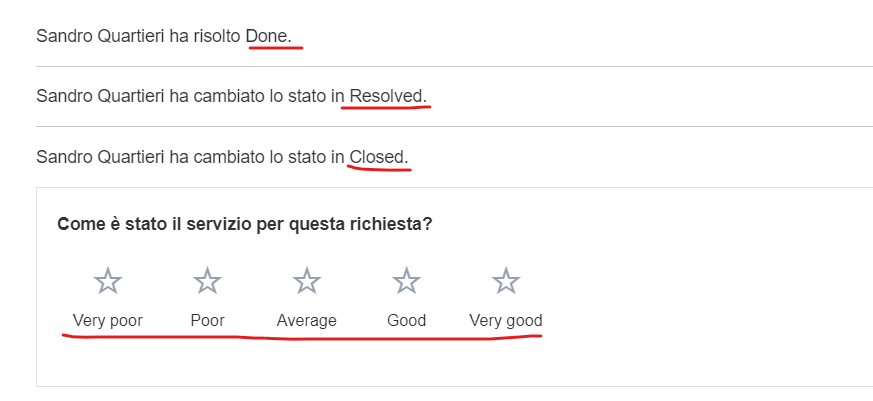\n\nThe notification is mostly in italian, except for the ticket status (Closed, Resolved, Done etc.) and the survey.\n\nAny advice?\n\nThanks\n\nSandro\n"
}
|
[
{
"author": "Lisa Forstberg",
"body": "Hi [@Sandro Quartieri](/t5/user/viewprofilepage/user-id/5590580) ,\n\nYou can translate statuses in the Status list. Settings \\> Issues \\>Statuses\n\nYou can translate Resolutions under Settings \\> Issues\\> Resolutions\n\n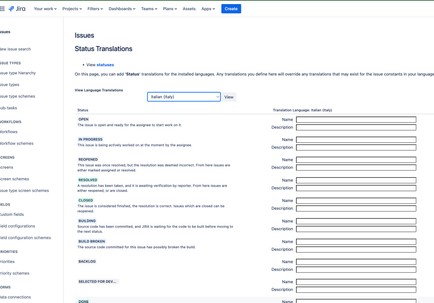\n\nall the best\n\nLisa\n",
"comments": [
{
"author": "Sandro Quartieri",
"body": "Hi [@Lisa Forstberg](/t5/user/viewprofilepage/user-id/5101516) ,\n\nthanks for your answer.\n\nThe tickets are already correctly translated in italian (the default language)\n\n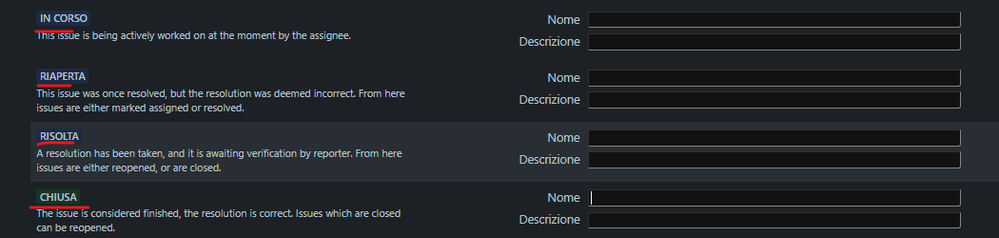\n\nIn fact, if I go to the portal, I can see them in italian\n\n\n\nThe only problem is with the mail notifications.\n\nBR\n"
},
{
"author": "Lisa Forstberg",
"body": "Hmm..\n\nYour project is default Italian, but how about your site?\n\nIs that default language Italian or English? Settings \\> General Configuration \\> Default language\n\nSuspecting that the site is english and the email template is bringing in the sites default language statuses.\n\nSee also instructions on this closed bug: <https://jira.atlassian.com/browse/JSDCLOUD-5887>\n\nall the best\n\nLisa\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Notification-translation-does-not-translate-ticket-status/qaq-p/2817496
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Folco",
"title": "Is it possible to create a confluence account within a claimed domain?",
"body": "We have a few claimed domains. External Confluence URL's are hidden for search engines. And yet is it possible to create an account without getting an invite?\n\nif it is possible: how is this done? and what can we do to prevent?\n\nThanks!\n"
}
|
[
{
"author": "Ashok Shembde",
"body": "### Yes, it is possible to create a Confluence account within a claimed domain, but only under certain conditions. Here's an overview of the process: {#toc-hId--2124374777}\n\n### Creating a Confluence Account Within a Claimed Domain: {#toc-hId-363138056}\n\n1. **Administrator Setup**: The organization's admin first needs to claim the domain by verifying ownership through Atlassian's Admin Hub. Once a domain is claimed, the organization has control over any accounts associated with it.\n\n2. **Account Creation Process**:\n\n * **User Creation**: After the domain is claimed, users with email addresses on that domain can still create Atlassian accounts, including for Confluence, by signing up through the standard process (e.g., using their work email).\n * **Domain Controls**: The organization that controls the domain can enforce additional security requirements (e.g., mandatory SSO, 2FA) on those accounts.\n * Account**Claiming**: In some cases, if a user tries to create an account within a claimed domain, the organization's admin may need to approve the account or enforce security measures before the account becomes fully active.\n3. **Managed Accounts** : Once an account is created under the claimed domain, it will become a **managed account**, meaning the organization can enforce policies, security settings, and other controls.\n",
"comments": null
},
{
"author": "Folco",
"body": "hi Ashok,\n\nThanks for your reply. It seems that an account within a claimed domain has created a confluence account. and after that a JSM account was created. We are still investigating.\n\ni was just curious ;)\n",
"comments": null
},
{
"author": "Ed Letifov _TechTime - New Zealand_",
"body": "[@Folco](/t5/user/viewprofilepage/user-id/5233254)\n\nPlease note, anyone can create an Atlassian Cloud in your domain. Just show up on id.atlassian.com and start registering with a completely fake email in your account -- this will trigger a creation of an unverified user record. Unless they are able to receive an email on the address they enter -- this is what it will stay as. This is why we (as a Solution Partner) usually recommend to NOT make the SSO policy default for anyone in your domain -- this way all these rubbish accounts will fall into some other default policy (e.g. unbillable) which you can regularly review and clean up.\n\nIt's possible that in your case JSM account was created first -- would be if you allow anyone to register there. See: <https://support.atlassian.com/jira-service-management-cloud/docs/change-global-customer-permissions/>\n\nAnd then if your KB is private, but allows any JSM logged-in customer free access -- that's how you get the same account in Confluence. They shouldn't be licensed, but account will be there. See: <https://support.atlassian.com/jira-service-management-cloud/docs/restrict-access-to-knowledge-base-articles/>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Is-it-possible-to-create-a-confluence-account-within-a-claimed/qaq-p/2817392
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Jasper Hovenga",
"title": "How to create issues from email using a shared mailbox",
"body": "We have a Exchange online environment where we storage and manage our emailadresses.\n\nWe have a shared support mailbox that we want to connect to JSM so the emails automatically convert to a JSM-issue. \n\nWe allready tried the option in this article and got it working: <https://support.atlassian.com/jira-cloud-administration/docs/create-issues-and-comments-from-email/>\n\nHowever, in this case, one specific user needs to login / connect using MFA all the time (or disable MFA and only use password, but thats agains our policy), so thats not working on the long term.\n\nIs there a cloud configuration, simular to the Data center option described here: <https://confluence.atlassian.com/adminjiraserver/configure-an-outgoing-link-1115659066.html>\n"
}
|
[
{
"author": "Dirk Ronsmans",
"body": "For JSM you should be able to using this documentation\n\n<https://support.atlassian.com/jira-service-management-cloud/docs/receive-requests-from-an-email-address/>\n\n(the one you linked is using the email handler)\n\nEither way, using OAuth2 the user only needs to connect once and authorize the permissions. After that the OAuth2 link should take over.\n\nI would still suggest using a generic/service account otherwise if the authorizing user goes away or changes their password the authorization has to be redone too.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-create-issues-from-email-using-a-shared-mailbox/qaq-p/2817373
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Barbara Fornes Ginard",
"title": "Quisiera poderme meter con mi correo a ver una factura que me han enviado",
"body": "* Quisiera poder acceder a jira a ver una factura que me han enviado y no me deja entrar con mi correo [email protected]\n"
}
|
[
{
"author": "Jack Brickey",
"body": "Hi [@Barbara Fornes Ginard](/t5/user/viewprofilepage/user-id/5593322) ,\n\nPrimero, al ser este un foro p?blico, no publicar?a mi correo electr?nico. Dicho esto, ?est?s diciendo que no puedes iniciar sesi?n en Jira o que no puedes acceder a la secci?n de facturaci?n? Para acceder a la facturaci?n tienes que tener las misiones necesarias. Si no puedes iniciar sesi?n, ?es por una contrase?a olvidada o algo m?s? Si no eres el administrador de la organizaci?n, te recomendar?a que primero te pongas en contacto con ellos para ayudarme a resolver este problema.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Quisiera-poderme-meter-con-mi-correo-a-ver-una-factura-que-me/qaq-p/2817356
|
[
"atlassian-accounts",
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"not-applicable"
] |
{
"author": "Lee Hutchinson",
"title": "Raise a request web form",
"body": "I have created a handful of request types to use for raise support tickets in our business.\n\nI want to create a web form I can share internally with staff and the can use it to raise tickets based on these request types.\n\nWhat is the best way to do this?\n"
}
|
[
{
"author": "John Funk",
"body": "Hi Lee,\n\nYou can create an easy form for each Request Type by simply going to Project Settings \\> Request Types. Then click on the Request Type which will bring you to the form where you can add the fields you want. Then you can simply share the URL for the form with the staff.\n",
"comments": [
{
"author": "Lee Hutchinson",
"body": "Thanks John, I think I was over egging it. I had a request type for each possible issue people might have rather than one request type for support and then the issues in a dropdown box.\n"
},
{
"author": "John Funk",
"body": "You are welcome. Glad it was helpful!\n"
},
{
"author": "Lee Hutchinson",
"body": "Is there a way that in a drop down that only certain members of staff can select certain options?\n\nWe have some issues that can only be raised by managers of teams\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Raise-a-request-web-form/qaq-p/2817337
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Ophelia Tao",
"title": "Error for LDAP synchronize in User Directory",
"body": "Dear Support,\n\nWe recently triggered the following error while LDAP synchronize in User Directory. We guess it's about the amendment of user_name field of user data source. However, we cannot reproduce this issue in another environment.\n\nCan you help estimate the impact and the further action we should take while facing this error.\n"
}
|
[
{
"author": "Dirk Ronsmans",
"body": "[@Ophelia Tao](/t5/user/viewprofilepage/user-id/5597463) ,\n\nCan you post the actual error or a bit more info?\n\nKeep in mind we are a volunteer run support community. if you require Atlassian engineer support you can reach out to them at <https://support.atlassian.com/contact>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Error-for-LDAP-synchronize-in-User-Directory/qaq-p/2817320
|
[
"jira-service-management",
"jira-service-management-server",
"server"
] |
{
"author": "maomaocui",
"title": "jira asset/insight automatically associate referencing object when edit a object",
"body": "Managing the assets of a central data center involves numerous racks, with each rack accommodating a standard of 20 servers and switches. Each switch has 24 ports. I have established an object architecture where servers and network devices are categorized under racks; within the network devices, there are switches and routers. Ports are defined as an independent object type, with two additional object types: port type and port status. The attributes of the port object include port number, port type, port status, and connected server. Except for the port number, the other three are object references to facilitate management. In the properties of the switch object type, I added a port information attribute, which is a multi-value reference to the port object. I want the effect that when creating an instance of the switch object, selecting the corresponding port object instance would trigger a pop-up to continue filling in the corresponding port type, port status, and the connected server. However, despite trying various methods, I can only select the port object instance without the pop-up for entering the corresponding type, status, and connected server.\n"
}
|
[
{
"author": "Mark Higgins",
"body": "Hi [@maomaocui](/t5/user/viewprofilepage/user-id/3656128)\n\nWelcome to the Community!\n\nI'm a picture person :-) Are you able to provide a screen shot of your schema?\n\nPop-ups are not native, but forms can have sections that are conditional, and custom fields can use other custom fields to filter results, so I'm trying to get a picture of what you are attempting.\n\nCheers\n\nMark\n",
"comments": [
{
"author": "maomaocui",
"body": "I tried two solutions, this is solution one\n\n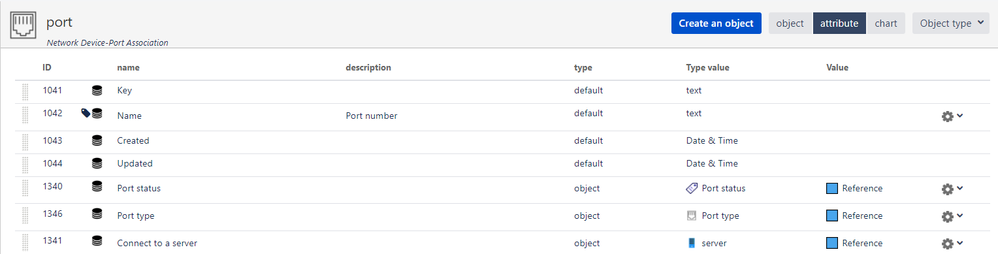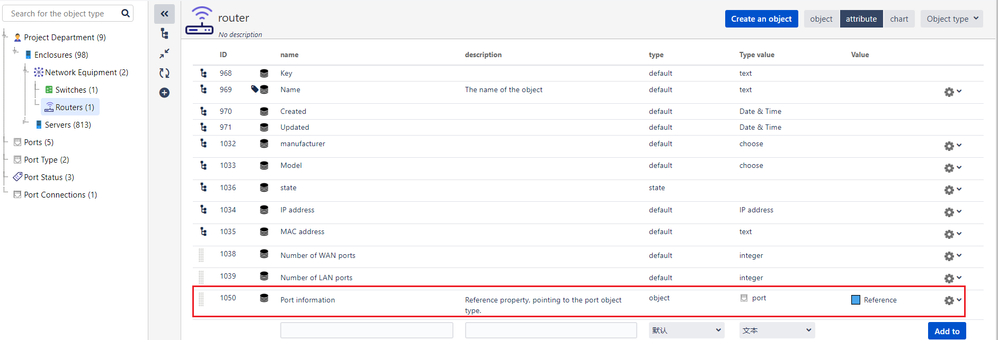\n\nand this is solution two\n\n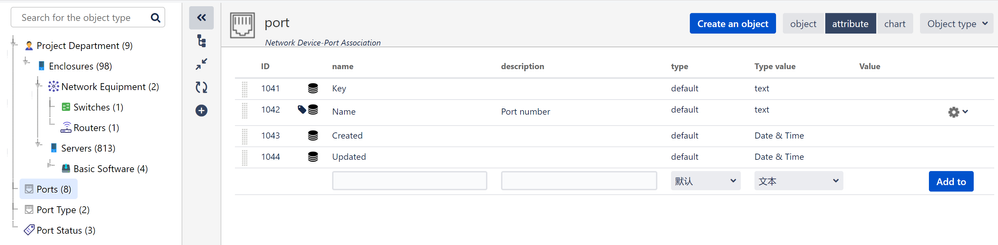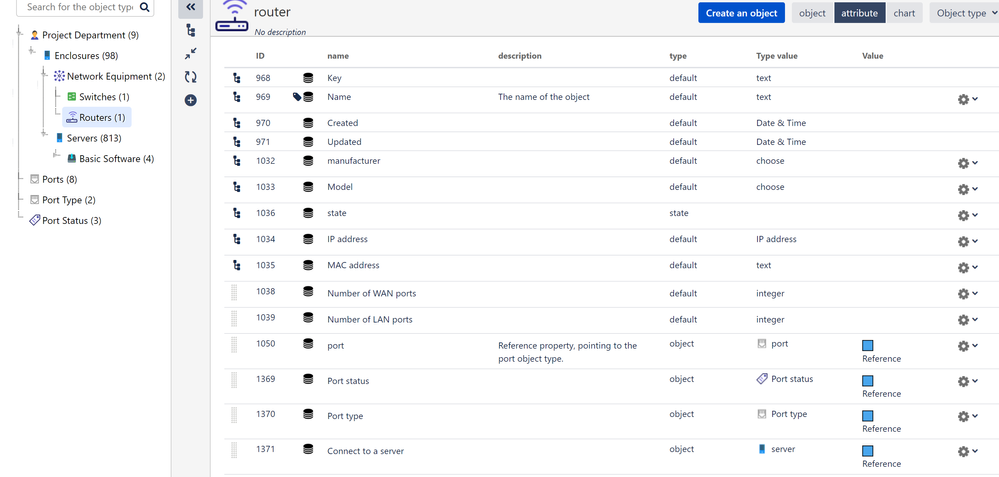\n"
},
{
"author": "Mark Higgins",
"body": "Hi [@maomaocui](/t5/user/viewprofilepage/user-id/3656128)\n\nThanks for the info. I'm going to go away and think on that.\n\nHow are you creating the instance of the switch object?\n\nCheers\n\nMark\n"
},
{
"author": "maomaocui",
"body": "The attributes of a switch are almost the same as those of a router.\n\n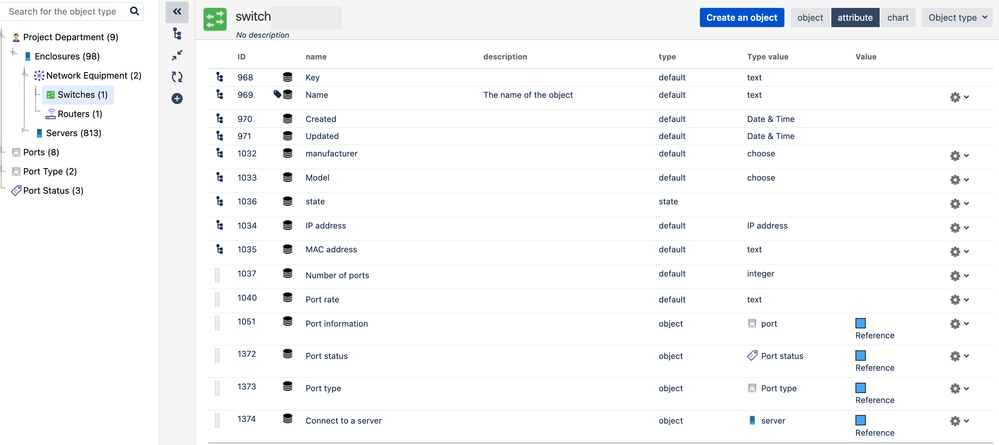\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/jira-asset-insight-automatically-associate-referencing-object/qaq-p/2817131
|
[
"assets",
"insight",
"jira-service-management-data-center",
"jira-software-data-center"
] |
{
"author": "Bernd Anderer",
"title": "How can I create a parent page and multiple Sub-Pages with automation?",
"body": "When an Issue is create in Jira, I want to create a NewPage in a Confluence space, plus a list of sub-pages underneath the newly created page. The result should look like this:\n\nSpace\n\n-NewPage\n\n-- Page1 - x\n\n-- Page2 -x\n\n-NewPage2\n\n--Page1-y\n\n--Page2-y\n\nthe name of NewPage is based on the issue created in Jira. The Subpages will have a name that consists of a fixed part (e.g. Page1) + some individual part (e.g. -x)\n\nThe idea is, that with each new Jira Issue, I want to setup a documentation structure in Confluence, that will be the same for each new Issue.\n\nHow can I do that? I tried it in Jira automation - but don't really know on how to use the\n\n{{createdPage}} variable, to reference the first page as parent for all the sub-pages\n\nAny idea on how I can achieve this?\n\nThanks in advance\n\nBernd\n"
}
|
[
{
"author": "Rick Westbrock",
"body": "The way we solved this was to create a smart value named parentPageId and set it to {{createdPage.Id}} from the NewPage.\n\nThe person who created the automation just has the child pages created under the same parent that NewPage was created under then used a web request action to move the child page under NewPage by calling <https://24hf.atlassian.net/wiki/rest/api/content/{{createdPage.Id}}/move/append/{{parentPageId>}}\n\nWe had to use the web request as a workaround due to the fact that the Parent Page field of the action will not accept a smart value.\n",
"comments": null
},
{
"author": "Nikola Perisic",
"body": "Hello [@Bernd Anderer](/t5/user/viewprofilepage/user-id/565597)\n\n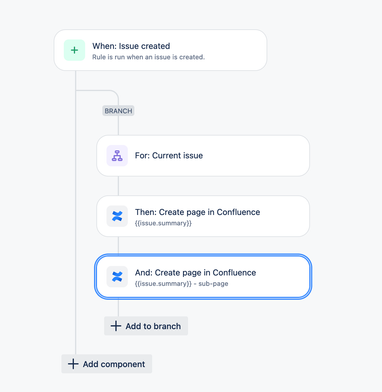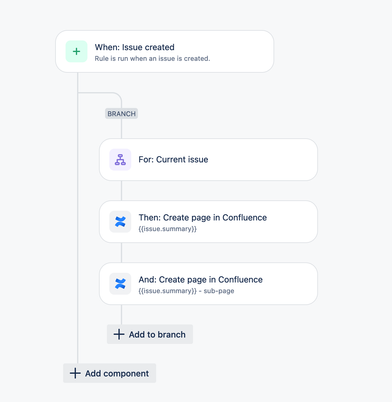\n\nYou can test this automation rule, where a page in first action is being created based on the summary of the issue, the second action is creating a sub-page and in the \"Parent page\" field, the page that was made from the first automation is being selected.\n",
"comments": [
{
"author": "Bernd Anderer",
"body": "Hi [@Nikola Perisic](/t5/user/viewprofilepage/user-id/5166624)\n\nthank you for your feedback.\n\nI am not able to add anything meaningful in \"Parent Page\".\n\nWhat did you add there? I can not add any variable... I can only select existing pages... am I doing something wrong?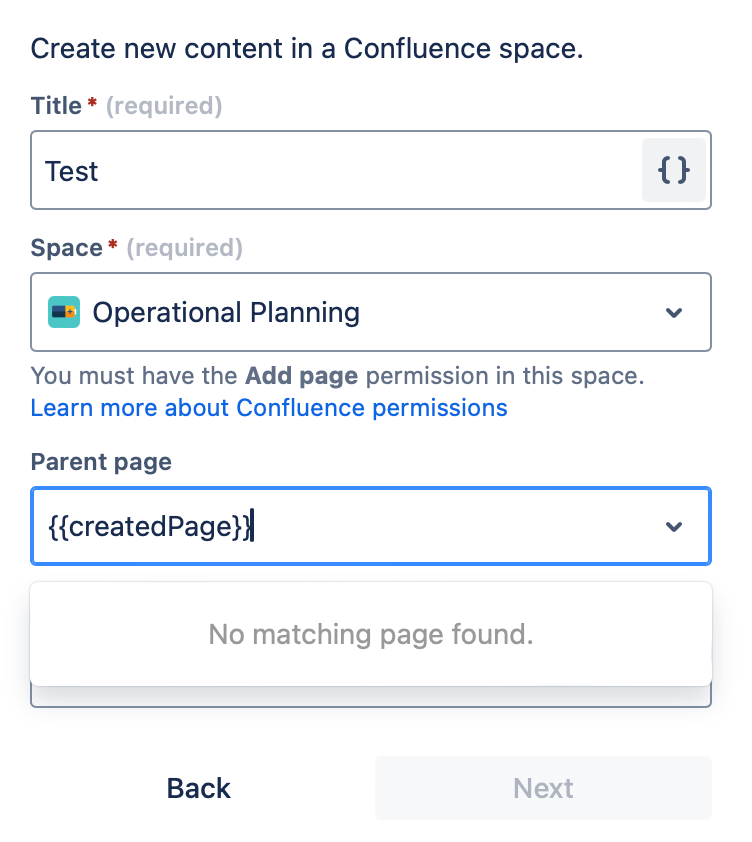\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-can-I-create-a-parent-page-and-multiple-Sub-Pages-with/qaq-p/2742042
| null |
{
"author": "Steeve Piette",
"title": "Create an automatic \"Side conversation\"",
"body": "Hi Everyone,\n\nNewbie to Jira here , but trying to convince company that it could fit to everything we need.\n\nLet me explain the issues.\n\nOur customer Service already use Zendesk , if I want the company to migrate everything to Jira we must at least find everything they already do inside.\n\nMostly...i think there is a way to handle everything, except this particular thing they got wich is \"Side Conversation\"\n\nBasically they can add a Side conv. to any ticket wich allow them to discuss with someone by Email.\n\n- This personn won't have access to the ticket, only E-mail discussion , and can see what the personn show them (Copy the ticket content if they want)\n\n- Discussion will not be shown isinde the Ticket. (Likely , a \"secret\" conversation)\n\n- Can be done as well with a known user , or someone totally new.\n\nSo far, and after a topic in other community.\n\nI think this can be related to\n\n\"There is the Main ticket , an automation rule create a second Ticket (or Subtask? not sure of difference) linked to the first one.\n\n-Agent can share the second one wth someone, and \"reply\" to it, while the person won't receive any invitation , but just E-mail.\n\n- If main ticket is closed, the second will also be.\n\n- \"Side ticket\" can't be closed if the main one is one\"\n\n- Agent can add / Link thing from the main one to the second ,( Attachements, comments...?)\n\n- If the person on the \"Side ticket\" reply to the E-mail i will add a comment on it as well and notify agent.\n\nHope it's clear enough on what i'm looking to do.\n\nIf not, feel free to ask, i'll try to answer as clearly as I can.\n\nRegards;\n\nSteeve\n"
}
|
[
{
"author": "John Funk",
"body": "Hi Steeve,\n\nNot sure you are completely going to be able to duplicate this, but that mostly depends on what type of person it is that the issue is getting shared with. If they are not a Jira user in that they do not have a Jira license, they could be added to the original request in the portal as a Request Participant. You could also add them to an Organization that is linked to the ticket.\n\nThen they could offer comments, but everyone would see those comments.\n\nIf the intent is that they can provide some private comments that the user who submitted the ticket can't see this can also be done. But that user would have to be a licensed Jira user. Then on the Agent view of the issue, the user could add \"Internal\" comments that the originator of the ticket cannot see. The Jira user would only be able to add comments - not change any other data.\n\nOr if the user is also an Agent, then they could also provide comments which are not seen by the individual who submitted the ticket originally.\n\nThis call all be done without creating a second ticket and sharing that. Creating a second ticket would still require that the user have a Jira license.\n",
"comments": [
{
"author": "Steeve Piette",
"body": "Hi [@John Funk](/t5/user/viewprofilepage/user-id/7148)\n\nThanks for the answer.\n\nLet say that the user who the ticket will be shared with won't have a license (basically can be anyone here for example)\n\nBy discussing this point seems there was a way by using a \"second\" ticket, wich as you tell can have public comment, don\"t really mind about that as soon as the second one is not visible for the customer who requested the first one.\n\nThe creation of the second ticket would be done b a licensed agent for sure, but in my idea, by an auto task like \"Create side Conv\" . \n\nthis would create second ticket linked to the first one (Or as i told... a sub-task? not sure?)\n\nAnd this one would be shared , not the main one\n\nAs well the personn who the ticket is shared with will need to lg in the portal? can't just \"reply\" to an E-mail?\n"
},
{
"author": "John Funk",
"body": "The problem is the no license thing. Your best best would be for the user to have a free Customer license. Then you can add them as a Request Participant on the issue so they can comment. But they cannot do it anonymously, and then need an account - though it would be free.\n"
},
{
"author": "Steeve Piette",
"body": "Thanks for that\n\nI'll dig into this and make few test to see how it can fit their need (hopefully...) or not\n\nHave a great day\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Create-an-automatic-quot-Side-conversation-quot/qaq-p/2741896
| null |
{
"author": "Eran Roiter",
"title": "how to create Integration between Jira and Slack to notify watchers ?",
"body": "Hey all,\n\nDoes anyone have an idea how do I perform an integration between Jira and Slack, so that every time there's an update of a ticket (task, bug) all the watchers will receive a notification in Slack.\n\nThanks !\n"
}
|
[
{
"author": "Josh_Unito",
"body": "[@Eran Roiter](/t5/user/viewprofilepage/user-id/5289455) You could set up a simple flow with Unito to send [Slack messages based on Jira issues](https://bit.ly/ATL-Jira-Slack-Int) that does this. I'm not sure about the updates, but at the very least you could have a flow that sends a message to a specific channel every time an issue is created and/or reaches a specific state (e.g., when the label is set to XYZ).\n",
"comments": null
},
{
"author": "Gaurav",
"body": "Hi [@Eran Roiter](/t5/user/viewprofilepage/user-id/5289455) , \n\nIf you are open for 3rd party, You can try[http://slackjira.com/](http://slackjira.com/%20) for the same, we have solved this problem for lot's of companies \nWe also provide custom workflow or changes whatever you require\n",
"comments": null
},
{
"author": "Jim Knepley - ReleaseTEAM",
"body": "There's an app to use [Jira Cloud with Slack](https://support.atlassian.com/jira-software-cloud/docs/use-jira-cloud-for-slack/) and similar for [Jira Data Center](https://marketplace.atlassian.com/apps/1220099/jira-data-center-for-slack-official?tab=overview&hosting=datacenter).\n\nFrom my experience, using Slack gives rise to the same alert fatigue as using email, but some users might prefer it.\n",
"comments": [
{
"author": "Eran Roiter",
"body": "Hey Jim, \nThanks for your answer, we do use it. But i can't find a way to send personal messages via slack to the watchers...\n\nAs you can see, there are very limited options.\n\n\n"
},
{
"author": "Jim Knepley - ReleaseTEAM",
"body": "Apologies, I misinterpreted what you're asking for. I don't think it's possible to configure Jira to notify individuals, only channels.\n\nYou could try to do it by writing up a function with ScriptRunner to interact with the Slack API, which is reasonably friendly. One challenge, targeting a Slack user directly or via a \"@mention\" requires that you know the Slack member ID and not their username.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/how-to-create-Integration-between-Jira-and-Slack-to-notify/qaq-p/2741311
|
[
"integration",
"slack",
"watcher"
] |
{
"author": "mrhodes",
"title": "AI Trigger Error: \"Your input is too long to be processed.\"",
"body": "I tried using this AI trigger in rules today, and got this error: \"Your input is too long to be processed\" I had a sentence in the AI text for the trigger, and am using the AI on the page content (instead of the title which is the other option here)\n\nMy first instinct was to shorten the AI trigger text to two words, vs the sentence I started with.... but the error is still occurring.\n\n1. Is this error about the page input size (instead of the AI parameter)?\n2. Is this a known issue?\n3. Can we perhaps make this error message more meaningful/useful?\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@mrhodes](/t5/user/viewprofilepage/user-id/5531660) -- Welcome to the Atlassian Community!\n\nIs this question regarding the new AI feature for rules which is in Beta: <https://community.atlassian.com/t5/Automation-articles/New-AI-feature-in-Beta-Natural-Language-for-Jira-Automation/ba-p/2651640>\n\nIf so, I recommend contacting Atlassian support for assistance through your Jira Site Admin or posting your question on that article thread. Your Jira Site Admin can submit a support ticket here: <https://support.atlassian.com/contact/#/>\n\nIf instead this is a question for an automation rule which is not working as expected, please add to your question:\n\n* describe the problem you are trying to solve (that is, \"why do this\");\n* an image of your complete automation rule;\n* images of any relevant actions / conditions / branches;\n* an image of the audit log details showing the rule execution; and\n* explain what is not working as expected.\n\nThose will provide context for the community to offer ideas. Thanks!\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/AI-Trigger-Error-quot-Your-input-is-too-long-to-be-processed/qaq-p/2739678
|
[
"cloud",
"confluence",
"confluence-cloud"
] |
{
"author": "caglad",
"title": "Automation - Inherit a date from trigger issue and add X days",
"body": "We are building an automation rule that takes an epic and uses different types of dates from that to make it a due date on the \"standard issue type\" children of the epic..\n\nSince I dont have all dates captured in the epic, I want to be able to do something like \"configuration due date\" plus 5 days. I know if I just want to NOT pull from the trigger date I could do something like\n\nnow.plusBusinessDays(5)\n\nMy question is how can I do date on the new issue by saying tiggerissue.configurationduedate-5days. Is this even possible.\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@caglad](/t5/user/viewprofilepage/user-id/3616945)\n\nYes, that is possible.\n\nYou will want to use the {{triggerIssue}} smart value as a start: <https://support.atlassian.com/cloud-automation/docs/jira-smart-values-issues/#--triggerIssue-->\n\nThen you need to identify the correct smart value (or custom field id) for your field: <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nAnd finally, use the correct function and units of measure to adjust the date value: <https://support.atlassian.com/cloud-automation/docs/jira-smart-values-date-and-time/#Date-minus-unit--->\n\nIf that does not help, please post images of the complete rule, the action where you are performing the date adjustment, and of the audit log details showing the rule execution. Those will provide context for the community to make suggestions.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "caglad",
"body": "So, it would be....\n\n{{triggerIssue.customfield_10226.plusbusinessDays(5)}}\n"
},
{
"author": "caglad",
"body": "THANK YOU!!! that worked! should know to ask before spending 2 hours...\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-Inherit-a-date-from-trigger-issue-and-add-X-days/qaq-p/2739643
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "caglad",
"title": "Automation thinks field is unavailable for project type",
"body": "I have a field that I am using in global automation to fill in the value. But error log suggests this field is not available for my project type. However, the issue type shows available for all issue types and available globally for all projects. I am able to use it in an import for project type but automation doesnt like it.\n\nI have to be missing something.. welp\n"
}
|
[
{
"author": "caglad",
"body": "Jira Cloud -\n\nHere is the rule.. Create issue - from trigger issue - and everything is being created with the correct values except for this.\n\n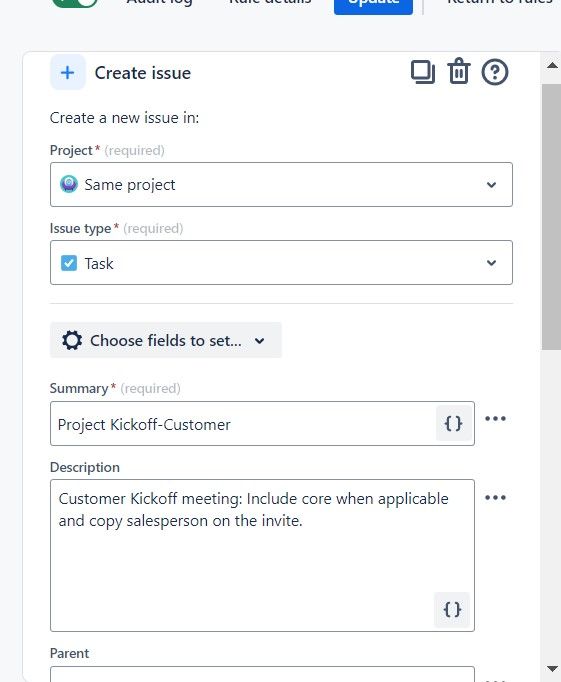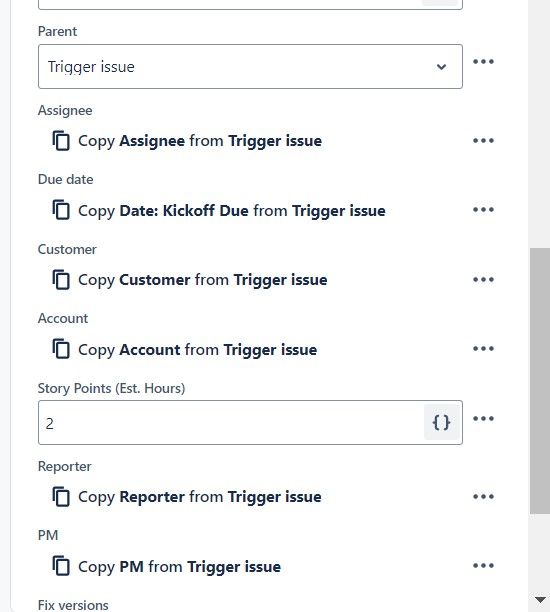\n\nomg dont tell me its because I didnt put the brackets in\n",
"comments": [
{
"author": "Julian Governale",
"body": "Since it works from Import i assume it is on your create screen for that project and the task issue type but here are a few aspects to double confirm.\n\n1. The field **Story points (Est. Hours)** is present on the task issue type create screen\n2. If it's not present\n 1. Ensure it's added to the Create screen\n 2. Ensure it's not marked as hidden in the field config\n3. Confirm you don't have two fields with the same name in the system\n 1. If you do, confirm you have selected the right field in the automation (customfield_10014)\n\nIf all the above is confirmed, try to set the field through the additional field section. First, remove it from the \"Choose fields to set\" area to avoid any conflicts.\n\n```\n{\n\"fields\": {\n \"customfield_10014\": 2\n }\n}\n\n\n```\n"
}
]
},
{
"author": "Bill Sheboy",
"body": "Hi [@caglad](/t5/user/viewprofilepage/user-id/3616945)\n\nPlease post an image of your complete rule and the Create Issue action. These will provide context to compare to the audit log details you show.\n\nAnd, which version of Jira are you using: Cloud, Server, or Data Center?\n\nUntil we know that information...\n\nI wonder: does the Create Issue action select the project and issue type explicitly? If not, that may be causing a problem with the field.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Bill Sheboy",
"body": "[@caglad](/t5/user/viewprofilepage/user-id/3616945) please try to stay in *one thread when responding*. That will help others reading this question in the future know if there are multiple solution approaches. Thanks!\n\nPlease post your complete automation rule, in one single image. That will provide context for where the Create Issue action is happening within the rule.\n\nWhich version of Jira are you using: Cloud, Server, or Data Center?\n\nIf Jira Cloud, what type of project is this: company-managed, team-managed, etc.?\n\nIs your custom field visible on the views for creating an issue?\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-thinks-field-is-unavailable-for-project-type/qaq-p/2739753
|
[
"error"
] |
{
"author": "Dipen",
"title": "Pointers on why the Completed Sprint trigger does not run",
"body": "Team\n\nThe **problem I am trying to solve** is 2 fold\n\na.Get a count of Story points for a completed Sprint.\n\nb.Get a count of Story points for issues that are in Done status, for that Completed Sprint.\n\n**Previous completed Sprint** ( the one that i would like to run this rule against) is listed in the JQL query as shown below by the custom field name cf\\[10113\\].\n\nI have Tested the output of JQL using the Validate query button.\n\nI have limited the scope of the output of JQL to 2 rows to test this functionality before expanding the scope.\n\nHave the following **Automation rule** in place\n\n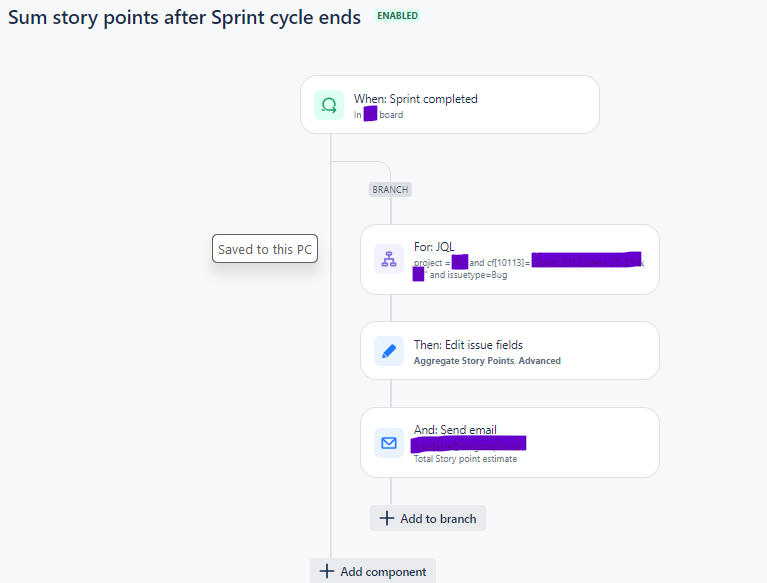\n\n**Issue**: The rule does not run. it appears that the trigger - Sprint completed for the previous Sprint is not getting picked up.\n\nAudit log shows just the Configuration changes I made but there is nothing else that indicates whether the Rule is failing or why it is not executing.\n\n\n\nAny pointers on what I could be doing wrong would be super helpful.\n\n**Final expected result** is that the Edit issue fields will aggregate the story point values for each issue in the JQL and send an email with the final count.\n\nHope this information helps\n\nPlease let me know if there is any additional information required to figure out the root cause.\n\nThanks\n\nKD\n"
}
|
[
{
"author": "Joseph Chung Yin",
"body": "[@Dipen](/t5/user/viewprofilepage/user-id/5462529) -\n\nNeed some additional information from you -\n\nIn JSM, by default that issue management is done via \"Queue\" process and not managed by \"Sprint\" via Scrum board process. Sprint management is typically used for Jira Software application projects and not for JSM.\n\nCan you provide your reasoning behind the usage of Sprints? Also, when you executed your JQL, did the JQL returned the issues that you wanted? (not just simply validating the JQL in the automation rule.\n\nHere is a link on how one can troubleshoot automation rule by using the action of \"log action\" and one can review the audit log of the rule's steps -\n\n<https://support.atlassian.com/cloud-automation/docs/debug-an-automation-rule/>\n\nPlease advise, so we can assist you further.\n\nBest, Joseph Chung Yin\n",
"comments": [
{
"author": "Dipen",
"body": "Joseph\n\nThank you for your response.\n\nResponding to the questions you posted above\n\n1.\"when you executed your JQL, did the JQL returned the issues that you wanted? (not just simply validating the JQL in the automation rule.\" - Yes, it returned exactly 2 rows, which was the scope of my testing.\n\n2. For the time being I am running the automation on a schedule every so often to see what else is broken.\n\nI agree with your comment: \" In JSM, by default that issue management is done via \"Queue\" process and not managed by \"Sprint\" via Scrum board process. Sprint management is typically used for Jira Software application projects and not for JSM.\"\n\nThis is a team managed software project hence the use of Sprint.\n\nI also want to thank you for sharing the link that shows how to use debug. That should help me find out why the Sprint story point estimate values are not adding up and showing in the Aggregated Story points.\n\nThe one additional challenge that I am running into is with the syntax of this statement:\n\n{{lookupIssues.Story point estimate.sum\\|0}} - It is not recording any errors, however the Story point values are not adding up.\n\nI am trying to add the Story points estimate for both the issues returned by JQL and show the aggregated value under a new custom field of type Numeric.\n\nPlease let me know if I can be of any additional help.\n\nThanks\n\nKD\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Pointers-on-why-the-Completed-Sprint-trigger-does-not-run/qaq-p/2739356
|
[
"jira-service-desk-cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Marc - Devoteam",
"title": "Copy form from trigger issue to created sub-task",
"body": "Hi all,\n\nI have a challenge. I have a request type on a portal with a form.\n\nBased on values set in the form there is an automation that creates sub-tasks from the selected options.\n\nThese selected options are based on a Jira custom field, also based that multiple options can be set I branched the rule so that based on the options selected a sub-task is created.\n\n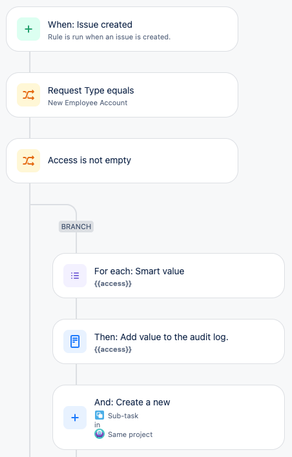\n\nThis is all working fine.\n\nHere is the challenge, I want to have a copy of the form on each of the sub-task created.\n\nI have tried to do an issue lookup after the branch, I looked up the sub-tasks created. These I can slo find, but then I made another branch based upon the lookup and using the key of the found sub-tasks and then have an action to copy the form based on the trigger issue.\n\n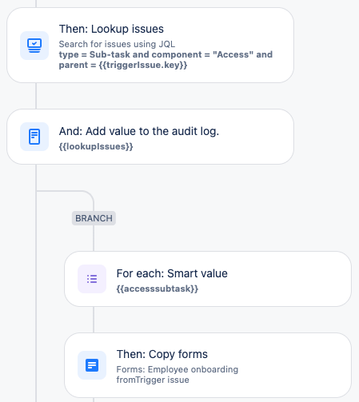\n\nBut the log always comes up with no form to copy, all issues are in the same project.\n\nAny ideas here in the community? \n\nThanks in advance.\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Marc - Devoteam](/t5/user/viewprofilepage/user-id/3796976)\n\nI am guessing a bit here as I cannot see your entire rule in one image, and...\n\nThe problem is likely because you are using two branches in the rule and assuming the first completes before the second one.\n\nBranches which could be on more-than-one-thing are run in parallel and asynchronously, and there is no guarantee of when the branch will complete, up until the last step of the rule. For your scenario, this means the first branch is still running when you try that Lookup Issue action and when the second branch starts running.\n\nA possible workaround for your scenario is to use two rules:\n\n* first rule adds the subtasks\n* the second rule...\n * enables the option in the details \"Check to allow other rule actions to trigger this rule...\"\n * triggered on issue created\n * adds lots of conditions to ensure this is a subtask, and has the other criteria to decide when to proceed\n * copy the form from the parent issue\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Marc - Devoteam",
"body": "Hi [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313)\n\nIt's in fact the complete rule. The 1st part is the initial rule and the 2nd part is what I added.\n\nAn I do agree in your thinking that it relates that branched run in parallel and they run asynchronously.\n\nI tried to see if anyone had a solution, as I know you can juts create sub tasks one by one in a rule and then brach with the lookup. But then I wold have to create 5 rules instead on the one I have now, due to the options that can be selected in the form.\n\nI will take a look at your suggestion this week and see if this will do the trick.\n\nThanks for looking and the suggestion.\n"
},
{
"author": "Marc - Devoteam",
"body": "Hi Bill,\n\nThis solution works. I had to think about this myself!!!\n"
}
]
},
{
"author": "Nicolas Grossi",
"body": "[@Marc - Devoteam](/t5/user/viewprofilepage/user-id/3796976) Maybe this is helpful for you: <https://community.atlassian.com/t5/Jira-Service-Management/Jira-Automation-Creating-Subtasks-and-Copying-Values-from-Parent/qaq-p/2001391>\n\nHTH\n\nNicolas\n",
"comments": [
{
"author": "Marc - Devoteam",
"body": "Hi [@Nicolas Grossi](/t5/user/viewprofilepage/user-id/676185)\n\nThanks for the suggestion.\n\nThis Article I have seen and is the basics, if I would implement this I would have to transform my branch from one rule to 5 rules.\n\nThe form in the request has many options to choose from, so this I wanted to circumvent.\n\nThanks for the reply anyway.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Copy-form-from-trigger-issue-to-created-sub-task/qaq-p/2739225
|
[
"cloud",
"forms",
"jira",
"jira-service-management",
"jira-service-management-cloud",
"smart-value"
] |
{
"author": "Eran Roiter",
"title": "How to use smart values for automation that take values from the Description.",
"body": "Hey all, i have automation that triggered every time the description is updated.\n\nThen it creates a variable and uses smart values to edit a custom field and add tagged users from the description to the custom field.\n\nWhen i edit the description at first and tag a user its working, but when i edit the description again and add another user it won't add him. \n\nany ideas what I'm missing?\n\nThanks !\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Eran Roiter](/t5/user/viewprofilepage/user-id/5289455)\n\nFor a question like this, please post an image of your complete automation rule, images of any relevant actions / conditions / branches, an image of the audit log details showing the rule execution, and explain what is not working as expected. Those will provide context for the community to offer ideas. Thanks!\n\nUntil we see those...\n\nFrom what you describe, I hypothesize there is an error in using the match() function to parse out the mentioned users.\n\nThe match() function can have problems if there are newlines or multiple matches not handled properly. Perhaps try this expression to get the account id values from the mentions:\n\n```\n{{issue.description.replace(\"\\n\",\" \").split(\" \").match(\"\\[~accountid:(.*)\\]\").distinct}}\n```\n\nThat replaces the newlines and then splits on spaces first, reducing the scope the match needs to check. Then it returns only the distinct values in case someone is mentioned multiple times.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Eran Roiter",
"body": "Thanks for you answer! \n\nI will try what you suggested.\n"
},
{
"author": "Eran Roiter",
"body": "It worked !!! thanks :)\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-use-smart-values-for-automation-that-take-values-from-the/qaq-p/2739202
|
[
"cloud",
"custom-field",
"jira",
"jira-cloud",
"smart-value"
] |
{
"author": "Mihir Vibhu",
"title": "Add all of Custom field (Numerical Fields) within linked issue",
"body": "Hi,\n\nI am trying to calculate sum of customfield for all of linked issue into 1 field which will show common value for all of linked issue by Duplicates or Is duplicated by.\n\nFor eg:\n\nTicket 1 is linked to ticket 2 and 3 with IS Duplicated by. Has a field1 in all of linked issue with ARR, and we wish to show sum of Field1 from all of linked ticket1/2/3 into Field 2 for all of linked issues.\n\nI used:\n\nBrachned\\> For Linked issue\\> Then LookUp Issue \\> then edit field: Field1\n\n{{lookupIssues.customfield_12864.sum}}. But it's not giving me the sum exactly.\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Mihir Vibhu](/t5/user/viewprofilepage/user-id/5464869)\n\nFor a question like this, please post an image of your complete automation rule, images of any relevant actions / conditions / branches, an image of the audit log details showing the rule execution, and explain what is not working as expected. Those will provide context for the community to offer ideas. Thanks!\n\nUntil we see those...\n\nIf you are trying to update a single issue's field with that sum, you likely do not need a branch in the rule. Instead only the lookup issues action is needed.\n\nSeeing your complete rule and knowing the types of the fields (e.g., number, text, etc.) will help to confirm this.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Add-all-of-Custom-field-Numerical-Fields-within-linked-issue/qaq-p/2739090
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Cedric Ahrend",
"title": "remove label after editing",
"body": "Hey all,\n\nI'm just starting with Jira as Product Owner and I'm trying use automation to speed up my work process. Every time a story is created a lable \"toBeRefined\" is automatically added, to help me with Backlog Refinement.\n\nThen I have to manually remove the label, once refined which is a source for errors and confusion, if I forget to do it. So I tried the JSON field with automation to remove the label every time I edit an issue and enter a value in Story Points.\n\nThe Audit logs keeps telling me there's an 'Error while parsing additional fields. Not valid JSON.'\n\n{ \"fields\":\n\n{ \"environment\": \"Thanks for raising {{issue.key}}.\",\n\n\"labels\": \\[\n\n\"bugfix\",\n\n\"blitz_test\" \\],\n\n\"update\":{\n\n\"labels\": \\[ { \"remove\": \"toBeRefined\" } \\] },\n\n\"Custom Field Name\": { \"value\": \"red\" }\n\n}\n\n}\n\nFor automation I use\n\nWhen: Value changes for Story point estimate, Story Points\n\nThen: Edit issue fields Labels, Advanced\n\nWhat am I doing wrong here?\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Cedric Ahrend](/t5/user/viewprofilepage/user-id/5531579) -- Welcome to the Atlassian Community!\n\nThere appears to be both some leftover JSON, from the field template, and incorrect syntax for label updates. Please look here for the correct syntax to add / remove labels: <https://support.atlassian.com/cloud-automation/docs/advanced-field-editing-using-json/#Labels>\n\nAnd...from what you describe, **you do not need JSON for this scenario** . Instead, you may remove the JSON, select the Labels field from the dropdown list, and at the right side ... menu select the ADDREMOVE option. That will allow you to enter the specific label in the *Values to Remove* field.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Cedric Ahrend",
"body": "Hi [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) -- thank you :)\n\nthe ... menu solution did the trick, thank you very much!\n\nKind regards\n\nCedric\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/remove-label-after-editing/qaq-p/2739197
|
[
"label",
"remove"
] |
{
"author": "Madar_ Andrew",
"title": "How to get approval dates",
"body": "Hi everyone,\n\nI need to get the approvers approval date. I can get the name and decision using the following but cannot figure out how to get the approval date. I checked the API get and I should be able to. Any ideas?\n\nThis gets the approval area, final decision, approver name and their decision.\n\n{{#issue.Approvals}} Approving Area: {{name}} Final Decision: {{finalDecision}} {{#approvers}} Name: {{approver.displayName}} Approver Decision: {{approverDecision}} {{/}} {{/}}\n\nThis area I cannot get the date the approval was created.\n\n{{#issue.Approvals}} {{createdDate.epochMillis}} {{createdDate.friendly}} {{createdDate.iso8601}} {{createdDate.jira}} {{#createdDate}} {{epochMillis}} {{friendly}} {{iso8601}} {{jira}} {{/}} {{/}}\n\nIn the API call, I can see createdDate but when I pass various keys none seem to work as expected. Anyone have a luck getting this or suggestions on my format?\n\n{ \"_expands\": \\[\\], \"size\": 3, \"start\": 3, \"limit\": 3, \"isLastPage\": false, \"_links\": { \"base\": \"<https://your-domain.atlassian.net/rest/servicedeskapi>\", \"context\": \"context\", \"next\": \"[https://your-domain.atlassian.net/rest/servicedeskapi/request/2/approval?start=6\\&limit=3](https://your-domain.atlassian.net/rest/servicedeskapi/request/2/approval?start=6&limit=3)\", \"prev\": \"[https://your-domain.atlassian.net/rest/servicedeskapi/request/2/approval?start=0\\&limit=3](https://your-domain.atlassian.net/rest/servicedeskapi/request/2/approval?start=0&limit=3)\" }, \"values\": \\[ { \"id\": \"1\", \"name\": \"Please approve this request\", \"finalDecision\": \"approved\", \"canAnswerApproval\": false, \"approvers\": \\[ { \"approver\": { \"accountId\": \"qm:a713c8ea-1075-4e30-9d96-891a7d181739:5ad6d3581db05e2a66fa80b\", \"name\": \"qm:a713c8ea-1075-4e30-9d96-891a7d181739:5ad6d3581db05e2a66fa80b\", \"key\": \"qm:a713c8ea-1075-4e30-9d96-891a7d181739:5ad6d3581db05e2a66fa80b\", \"emailAddress\": \"[email protected]\", \"displayName\": \"Fred F. User\", \"active\": true, \"timeZone\": \"Australia/Sydney\", \"_links\": { \"jiraRest\": \"<https://your-domain.atlassian.net/rest/api/2/user?username=qm:a713c8ea-1075-4e30-9d96-891a7d181739:5ad6d3581db05e2a66fa80b>\", \"avatarUrls\": { \"16x16\": \"[https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=16\\&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D16%26noRedirect%3Dtrue](https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=16&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D16%26noRedirect%3Dtrue)\", \"24x24\": \"[https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=24\\&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D24%26noRedirect%3Dtrue](https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=24&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D24%26noRedirect%3Dtrue)\", \"32x32\": \"[https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=32\\&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D32%26noRedirect%3Dtrue](https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=32&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D32%26noRedirect%3Dtrue)\", \"48x48\": \"[https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=48\\&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D48%26noRedirect%3Dtrue](https://avatar-cdn.atlassian.com/9bc3b5bcb0db050c6d7660b28a5b86c9?s=48&d=https%3A%2F%2Fsecure.gravatar.com%2Favatar%2F9bc3b5bcb0db050c6d7660b28a5b86c9%3Fd%3Dmm%26s%3D48%26noRedirect%3Dtrue)\" }, \"self\": \"<https://your-domain.atlassian.net/rest/api/2/user?username=qm:a713c8ea-1075-4e30-9d96-891a7d181739:5ad6d3581db05e2a66fa80b>\" } }, \"approverDecision\": \"approved\" } \\], \"createdDate\": { \"epochMillis\": 1475046060000, \"friendly\": \"Monday 14:01 PM\", \"iso8601\": \"2016-09-28T14:01:00+0700\", \"jira\": \"2016-09-28T14:01:00.000+0700\" }, \"completedDate\": { \"epochMillis\": 1475134200000, \"friendly\": \"Today 14:30 PM\", \"iso8601\": \"2016-09-29T14:30:00+0700\", \"jira\": \"2016-09-29T14:30:00.000+0700\" }, \"_links\": { \"self\": \"<https://your-domain.atlassian.net/rest/servicedeskapi/request/2/approval/1>\" } },\n\n<https://developer.atlassian.com/cloud/jira/service-desk/rest/api-group-request/#api-rest-servicedeskapi-request-issueidorkey-approval-get>\n"
}
|
[
{
"author": "Julian Governale",
"body": "A workaround that might work and is what we do since we have a three-stage approval is the following.\n\nWhen the approval happens \"Approved/Denied\" the issue can be automatically transitioned, what you can do to capture that approval date and time is the following\n\nFirst Option\n\n1. Trigger: Approval Complete\n2. Condition: If-Else\n 1. If status = \"Apprvoed Status\"\n 1. Edit Issue: set field \"Approval Date/Time\": {{now}}\n 2. If status = \"Declined status\"\n 1. Edit Issue: set field \"Approval Date/Time\": {{now}}\n\nSecond Option\n\n1. In your workflow transition for an approved and declined transition\n2. Set a Post Function to set the \"Approval Date/Time Field\" to {{now}}\n\nThis works well for us as we capture this field as read-only on an approval tab, and capture the initiator. (Who approved or declined). If you set this into a date/time field, the system will automatically convert that date time to the local of the user viewing. \n\nSince ours is a three-stage approval process (Service Owner, Business Owner, Change Board Approval) after each approval (approved) we transition to routing status to evaluate if the ticket needs to go to Business approval or can go right to our Change board approval so instead of doing the trigger on \"Approval complete\" we do it from \"Service Owner Approval\" to \"Routing\" and so on.\n",
"comments": null
},
{
"author": "Darryl Lee",
"body": "Hey [@Madar_ Andrew](/t5/user/viewprofilepage/user-id/5149198) - yeah I'm running into the same problem. What a bummer.\n\nWhen I try outputting**{{issue.Approvals}}** or even **{{issue.customfield_10042}}** I get the same output, which does NOT appear to contain the **createdDate** or I think what you really wanted, **completedDate** for the approvals. This is what I get:\n\n```\nServiceDeskApprovalsBean{\nid='1', \nname='Authorize', \nfinalDecision='approved', \ncanAnswerApproval=false, \napprovers=[ApprovalDecision{\napproverDecision='approved', \napprover=UserBean{name='null', \nkey='null', \naccountId='557058:55df3d50-d179-4d17-b747-bf1484246c4f', \nemailAddress='null', \ndisplayName='Darryl Lee', \nactive=true, \ntimeZone='America/Los_Angeles', \nlocale='null'}}]}\n```\n\nWhile it's not much fun, you ***could***use web requests within Automation to query the API yourself and get what you want from there. This is well-documented here:\n\n* [Automation for Jira - Send web request using Jira REST API](https://community.atlassian.com/t5/Jira-articles/Automation-for-Jira-Send-web-request-using-Jira-REST-API/ba-p/1443828)\n\nI would just update those instructions to advise that you check the \"Hidden\" checkbox next to the Authorization header.\n\n* [Automation: Hidden headers](https://community.atlassian.com/t5/Automation-articles/Automation-Hidden-headers/ba-p/2138236)\n",
"comments": [
{
"author": "Madar_ Andrew",
"body": "Thank you, I will try this approach.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-get-approval-dates/qaq-p/2738644
| null |
{
"author": "Robin Specht",
"title": "Automating Link Between Cloned Support and Development Tickets in Jira",
"body": "**Hello Community,**\n\nI am seeking assistance with automating the linking of cloned tickets between our Support and Development projects in Jira. Here is the scenario and the steps I have taken so far:\n\n### Scenario {#toc-hId-2143837062}\n\n1. **Support Ticket Creation:**\n\n * A support ticket is created in our Support project (team-managed Kanban project).\n2. **Cloning to Development:**\n\n * The support ticket is automatically cloned into our Development project (team-managed Scrum project) using an automation rule.\n3. **Linking Tickets:**\n\n * I need the cloned development ticket to be automatically linked back to the original support ticket.\n\n### Steps Taken {#toc-hId-336382599}\n\n#### Step 1: Automation in Support Project {#toc-hId-1026944073}\n\n1. **Created Automation Rule in Support Project:**\n * **Trigger:** Issue Created\n * **Condition:** Issue Type = Support\n * **Action:** Clone Issue to Development Project\n * **Summary:** `SupportKlon - {{issue.summary}}: {{issue.key}}`\n\nThis automation works perfectly. The support ticket is successfully cloned into the Development project with the correct data, including the issue key and summary.\n\n#### Step 2: Automation in Development Project {#toc-hId--780510390}\n\n1. **Created Automation Rule in Development Project:**\n * **Trigger:** Issue Created\n * **Condition:** Summary contains `SupportKlon -`\n * **Action 1:** Create Variable\n * **Variable Name:** `originalIssueKey`\n * **Smart Value:** `{{issue.summary.substringAfterLast(\": \").trim()}}`\n * **Action 2:** Find Issue\n * **JQL:** `key = {{originalIssueKey}}`\n * **Action 3:** Link Issues\n * **Link to:** Trigger Issue\n * **Link Type:** `relates to`\n\n### Issues Encountered {#toc-hId--791013494}\n\n1. **Automation Not Triggering:**\n\n * The automation rule in the Development project is not triggering as expected. The audit log shows that the rule execution is successful, but it also reports the following error:\n * **Error Message:** \n java \n Code kopieren \n `Issue did not match the specified `JQL` `(most likely)`. The selected rule actor does not have permission to view the `issue` `(or its security level)`. The issue was deleted by Jira or was not yet `indexed` `(rare)`. We recommend using the `\"Issue Fields Condition\"` `for` more consistent results. `\n2. **Permissions:**\n\n * The error message suggests a potential permissions issue. I have ensured that the rule actor has the necessary permissions in both projects:\n * **Browse Projects**\n * **Edit Issues**\n * **Link Issues**\n3. **JQL Validation:**\n\n * Manually running the JQL query `key = {{originalIssueKey}}` in Jira finds the issue correctly, indicating that the smart value extraction and JQL are likely correct.\n\n### Request for Assistance {#toc-hId-1696499339}\n\nCould anyone provide guidance or suggestions on how to resolve this issue? Specifically:\n\n* How to ensure the automation rule in the Development project triggers and correctly links the cloned issue back to the original support issue.\n* Any potential misconfigurations or overlooked steps that might be causing the automation to fail.\n* Could this issue be related to permissions, and if so, what specific permissions should I verify or modify?\n\nAny help or insights from the community would be greatly appreciated!\n\n**Thank you,**\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Robin Specht](/t5/user/viewprofilepage/user-id/5523330)\n\nFirst, some ideas to fix the rule symptoms and then a simplification...\n\nBy default, the actions of one rule do not trigger others. When you want the actions of one rule (e.g., your support project rule) to trigger other rules (e.g., your development project rule), the *downstream* rule should enable the option in the details at the top for \"Check to allow other rule actions to trigger this rule...\"\n\nNext, rules have scope...that is, which projects they can access / impact. Project-scope rules can only create / clone issues in other projects, but they cannot view or edit them. When a rule needs to impact multiple project issues, it needs to be global or multiple-project in scope. If your Development Project rule was multiple-project, it would work (with some adjustments). Rules with global or multiple-project scope must be configured by your Jira Site Admin in the global automation area.\n\nOkay, now for a simplification: if your Support Project rule was multiple-project in scope, I believe it can do this without the need for the Development Project rule. For example:\n\n* trigger: issue created\n* action: re-fetch issues *(I recommend always adding this action after the Issue Created trigger to prevent timing / racetrack error problems.)*\n* smart value condition: check if the project field is your Support Project\n* condition: issue type equals Support\n* action: clone the issue to your Development Project\n* branch: to most recently created issue\n * action: link to the trigger issue\n\nDoing this will eliminate the need to store the Support Project issue's key in the summary of the other one.\n\nKind regards, \nBill\n",
"comments": null
},
{
"author": "Luka Hummel - codefortynine",
"body": "Hi [@Robin Specht](/t5/user/viewprofilepage/user-id/5523330)\n\nIf you are willing to try a third-party app for your cloning needs, you could try our [Deep Clone for Jira](https://marketplace.atlassian.com/apps/1218652?utm_source=atlassian&utm_medium=referral&utm_campaign=deepj-new-reach-com-2738010).\n\nDeep Clone can link the cloned issues to the original issue and can be included in your existing [automation with a looping transition](https://documentation.codefortynine.com/deep-clone-for-jira/jira-automation?utm_source=atlassian&utm_medium=referral&utm_campaign=deepj-new-reach-com-2738010).\n",
"comments": [
{
"author": "Robin Specht",
"body": "Hi Luka,\n\nThanks for your response. Unfortunately, a third-party solution is not an option, as I don't have the permissions to set this up (I am not the Global Admin of our Jira environment). Additionally, it won't work due to internal policies.\n\nI'm from Germany, and the company I work for takes data protection and GDPR very seriously. I will look into implementing Bill Sheboy's approach instead.\n\nBest regards, \nRobin\n"
},
{
"author": "Luka Hummel - codefortynine",
"body": "Hallo [@Robin Specht](/t5/user/viewprofilepage/user-id/5523330)\n\nKein Problem :)\n\nWir sind auch aus Deutschland und verstehen die Limitationen der DSGVO nat?rlich, aber ich denke, jedes Unternehmen kann unsere Apps DSGVO-konform verwenden. Unsere Apps werden, je nach Standort der Jira Instanz, auf Servern in der EU betrieben, sogar in Deutschland, um genau zu sein.\n\nWir erlauben es auch, die Informationen, die wir speichern, auf ein absolut technisches Minimum zu reduzieren. Mehr dazu [hier](https://documentation.codefortynine.com/deep-clone-for-jira/logging).\n\nGr??e aus Karlsruhe.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automating-Link-Between-Cloned-Support-and-Development-Tickets/qaq-p/2738010
|
[
"connection",
"link",
"team-managed-projects",
"ticket"
] |
{
"author": "Tyler Giles",
"title": "split() - Smart value from field not splitting correctly",
"body": "I have a custom field that contains first and last name: \n\n**\"displayName\": \"John Doe\",** \n\nIf I do either of these-\n\n{{issue.fields.customfield_10173.displayName.split(\" \").get(0)}} \n{{issue.fields.customfield_10173.displayName.split(\" \").first}} \n\nIt will return **John, Doe**\n\nI want just **John**\n\nWhat am I doing wrong? Thank you!\n"
}
|
[
{
"author": "Tyler Giles",
"body": "Ok, I figured it out. Because my **customfield_10173** is originally a *list* of names, whether or not one or multiple are added, I had to do as follows: \n\n{{issue.fields.customfield_10173.displayName**.first** .split(\" \").get(0)}} \n\n**.first** selects the first name of the list and *then* I can split up that name. Even if it's only one name to begin with. \n\nThank you so much [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) and [@Duc Thang TRAN](/t5/user/viewprofilepage/user-id/5371199) for assisting me!\n",
"comments": null
},
{
"author": "Duc Thang TRAN",
"body": "Hello [@Tyler Giles](/t5/user/viewprofilepage/user-id/5525501)\n\nIf you want to get only John for John Doe\n\nI can suggest you this smart value\n\n{{issue.fields.customfield_10173.displayName.split(\" \").first}} \n",
"comments": [
{
"author": "Tyler Giles",
"body": "[@Duc Thang TRAN](/t5/user/viewprofilepage/user-id/5371199) Sadly, this does not appear to be working: \n\n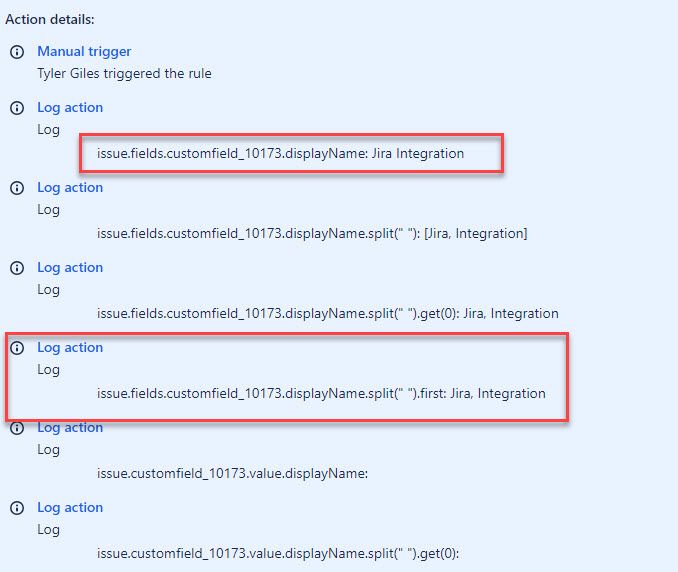\n"
},
{
"author": "Duc Thang TRAN",
"body": "It strange, work perfectly for me\n\n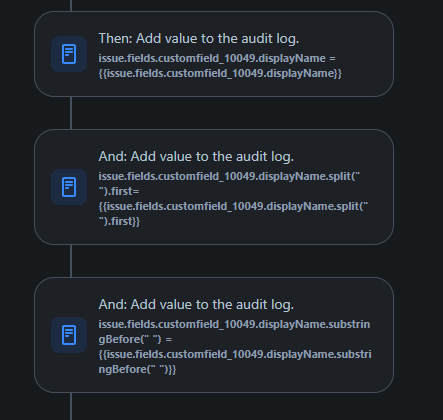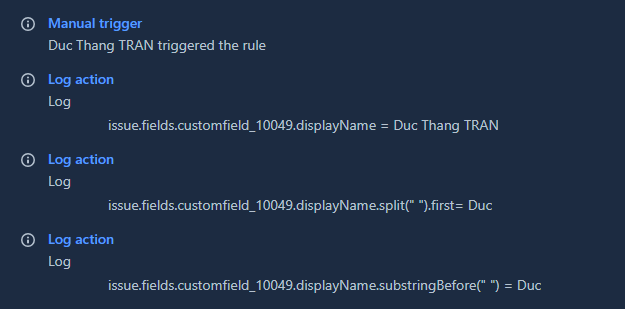\n"
},
{
"author": "Tyler Giles",
"body": "[@Duc Thang TRAN](/t5/user/viewprofilepage/user-id/5371199) Thank you for the assistance Duc! Can you do my a huge favor and see what this returns for you: \n\n{{issue.fields.customfield_10049.displayName.split(\" \")}}\n\nI am interested in seeing what a just a split will return vs what I am seeing. I see: \n**\\[John, Doe\\]** or **\\[Jira, Integration\\]**\n\nFor troubleshooting purposes, I am interested to see if yours returns: \n**\\[Duc, Thang, TRAN\\]** or something else.\n\nThank you for your time!\n"
}
]
},
{
"author": "Bill Sheboy",
"body": "Hi [@Tyler Giles](/t5/user/viewprofilepage/user-id/5525501)\n\nFirst, and guessing the field type is user select, perhaps try writing this to the audit log to observe what it returns:\n\n```\ndisplay name for selection: {{issue.customfield_10173.value.displayName}}\n\nfirst name for selection: {{issue.customfield_10173.value.displayName.split(\" \").get(0)}}\n```\n\nIf that does not help, please answer the following:\n\n* What is the type of your field: user selection, text, something else?\n* What type of project are you using: company-managed, or team-managed?\n* And if team-managed, where was the custom field defined: at the global context or within the team-managed project?\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Tyler Giles",
"body": "[@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) --Will try! I am brand new to Atlassian, but not to software development or ITSM in general. \n\nHow exactly can I \"try writing this to the audit log to observe what it returns\"?\n\nI have heard others mention this and I have been looking for documentation on how to do so. Right now, I am trying to familiarize myself with all of the smart values that I will need for my project, and to test returning values, I just have an automation that is emailing me per every issue opened.\n\nSo I am opening up a brand new test issue every time. If there is a way to test these without opening a new **test issue**, I am all ears! Thank you so much for your time!\n"
},
{
"author": "Bill Sheboy",
"body": "There is a **Log Action** which allows writing information to the audit log for debugging / informational purposes: <https://support.atlassian.com/cloud-automation/docs/jira-automation-actions/#Log-action>\n\nIf you add that action in your rule, you may paste in the expression, run the rule, and review the audit log details to see what happens. You may add multiple log actions, at different points in the rule, when trying to assess progress.\n\nRegarding your question about testing issue date, some tips are...\n\n* Please note well: some rule testing can consume \"usage limits\". As you are on a Standard license, consider only writing to the audit log during testing, rather than editing issues, to help manage that. To learn more about your limits, and what counts / does not count, please look here: <https://support.atlassian.com/cloud-automation/docs/how-is-my-usage-calculated/#What-are-my-usage-limits>\n* With complex / risky rules, consider creating a test project specifically for rule experiments. When it works as needed, you may copy or re-assign it to the correct project from the global rule settings. This test project may also act as a library of rules for reuse later.\n* In some cases, such as rules triggered on Issue Created, you may not want to repeatedly create new issues in the project. A workaround for that is:\n * Remove the current rule trigger of Issue Created, replacing with the Scheduled Trigger. This trigger allows manually executing the rule from the ... menu as often as needed.\n * In the Scheduled Trigger, add JQL for your test issue's key. For example:\n * key = TEST-123\n * Test and improve your rule...\n * When done, replace the Scheduled Trigger with Issue Created again\n * Test one last time, and then claim victory :\\^)\n"
},
{
"author": "Tyler Giles",
"body": "[@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) Ok, I found out how to manual trigger to the log, this is huge! \n\nThe removal of **.fields** and the addition of **.value** seem to not be returning any data. Please see screenshot of my returns: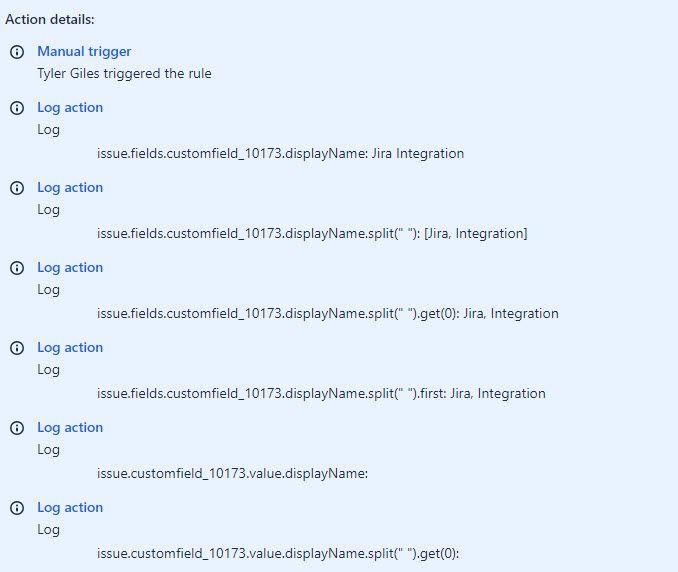\n"
},
{
"author": "Tyler Giles",
"body": "[@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) I am assuming that this is a user selection field, as the request form only accepts users that we have in our JSM.\n"
},
{
"author": "Bill Sheboy",
"body": "Before anything else, I recommend pausing to identify the *type of field* in the global custom field list, and its scope (i.e., JSM, Jira, both). That will clarify how to access its attributes in the rule.\n"
},
{
"author": "Tyler Giles",
"body": "This custom field type is a User Picker: \n\n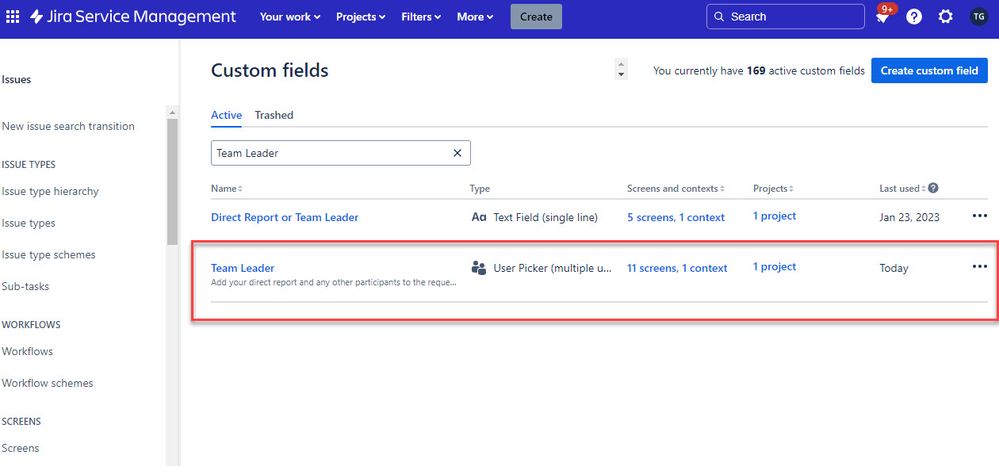 \n\nThis seems to be defined outside of my current project, as it appears it can be assigned to multiple projects.\n"
},
{
"author": "Bill Sheboy",
"body": "The key here is it is a **multiple-select**, user field.\n\nAnd so the specifics of *how you want to use the information* will determine how to proceed:\n\n* iterate over the selected values; or\n* select one specific, selected value, and then parse the name into first and last.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/split-Smart-value-from-field-not-splitting-correctly/qaq-p/2739285
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Hank Church",
"title": "Does viewing a page count as \"activity?\"",
"body": "I am trying to set up an automation rule in Confluence that is based on a certain period of \"inactivity\" on a page. Does simply viewing the page count as activity, and negate the rule? Also, if someone has a tab open to that page, but is not actually looking at it, does that count as viewing / activity as well?\n"
}
|
[
{
"author": "Benjamin",
"body": "HI [@Hank Church](/t5/user/viewprofilepage/user-id/5309416) ,\n\nI know that the viewing page is tracked in insights. However, I don't recall viewing as part of an automation rules set. Rules are usually around keeping the content up to date and lifecycle of documentation\n",
"comments": [
{
"author": "Hank Church",
"body": "My rule was supposed to change a page's status from Verified to Needs Review IF the page was \"Inactive\" for a certain period of time. Then it was going to send an email notification to the page owner that their status had changed and that page needs to be reviewed.\n\nOn two of the spaces i was testing, the rule did not work. On another space i was testing the rule worked, and i am trying to figure out why the rule worked on one space and not on the other two.\n"
},
{
"author": "Hank Church",
"body": "The one rule was set to run on the three spaces at the same time.\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Does-viewing-a-page-count-as-quot-activity-quot/qaq-p/2737510
|
[
"cloud",
"confluence",
"confluence-automation",
"confluence-cloud"
] |
{
"author": "hasungjoo",
"title": "How to make a automation rule which copy the most recently created page among child pages?",
"body": "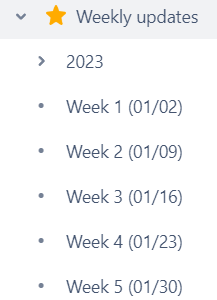\n\nHow to make a automation rule which copy the most recently created page among child pages?\n\nWhen Monday 9 am every week, make \"week 6\" named child pages copy from \"week 5\" page.\n\nis it possible to make by automation rule?\n"
}
|
[
{
"author": "Trev Angle",
"body": "Hi [@hasungjoo](/t5/user/viewprofilepage/user-id/5530539), this is Trevor from the Confluence automation team. Here's a rule that I think would work for you:\n\n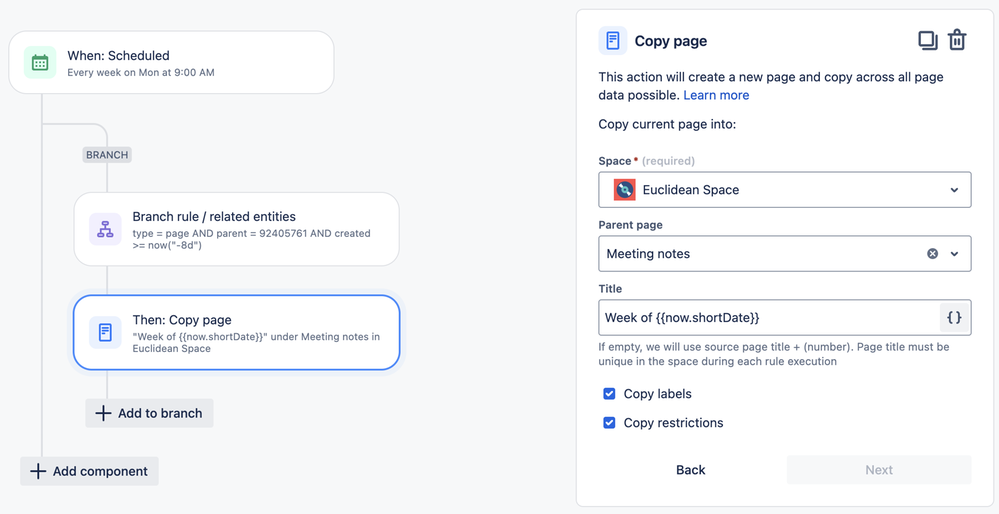\n\nThis rules runs every Monday at 9 AM, finds pages which were published within the last 8 days that have a certain parent page, and then publishes a copy with the title \"Week of 6/24/24\" (for example). So the rule assumes that no more than one page gets published each week under the parent.\n\nHere's the CQL that I used to configure the \"related entities\" branch component: **type = page AND parent = 92405761 AND created \\>= now(\"-8d\")**\n\nYou would just replace the number there with the ID of your parent page.\n\nAnother approach you could consider is having a single template page that gets copied every week. Then your CQL would be even simpler: **type = page AND id = 123456** (where the number is the ID of your template page)\n",
"comments": [
{
"author": "hasungjoo",
"body": "Thanks [@Trev Angle](/t5/user/viewprofilepage/user-id/5027568) ,\n"
}
]
},
{
"author": "Bill Sheboy",
"body": "Hi [@hasungjoo](/t5/user/viewprofilepage/user-id/5530539) -- Welcome to the Atlassian Community!\n\n*First thing, I am not using Confluence automation rules, and so my suggestions are based on what I know about automation rules in general. With that out of the way...*\n\nI do not believe there is a \"lookup pages\" rule action to use CQL to find the pages, and so identify the most recent one.\n\nHowever I hypothesize a rule could use the Send Web Request action to call the Confluence REST API to get the pages in your space, identify the most recently created one, and then use that for the copy page action.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "hasungjoo",
"body": "Thanks!\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/How-to-make-a-automation-rule-which-copy-the-most-recently/qaq-p/2737944
| null |
{
"author": "Dipen",
"title": "Story point estimate type can it be used for mathematical computations",
"body": "Hello Atlassian Team\n\nWe have a Custom field called Story point estimate (Locked field) that is of type: Story point estimate Value.\n\nI have another Custom field called Aggregate Story points which is of type: Number.\n\nI am trying to compute the total number of Story points that were Committed at the end of the Sprint cycle.\n\nWrote an automation rule that would do the following:\n\nTotal Story points: {{issue.customfield_10369.plus(issue.customfield_10236)}}\n\nI have printed the value of customfield_10236 prior to doing this computation for the 2 issues that I am testing with.\n\nBut it has'nt helped. Implying that the Aggregate Story point value is Empty.\n\nJust trying to figure out what am i doing wrong?\n\nAny pointers would be greatly appreciated.\n\nThanks\n\nKD\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Dipen](/t5/user/viewprofilepage/user-id/5462529)\n\nFor a question like this, please post an image of your complete automation rule, images of any relevant actions / conditions / branches, an image of the audit log details showing the rule execution, and explain what is not working as expected. Those will provide context for the community to offer ideas. Thanks!\n\nUntil we see those...\n\nYou note the \"Story point estimate\" field, and so I am assuming you are using a *team-managed project*.\n\nWhat is your rule trigger? For example, you seem to be doing this one-by-one for the issues rather than for the set of issues in the sprint.\n\nIf instead this happened when Sprint Completed triggered, you could use a Lookup Issues action with JQL to gather and sum the storing points for the completed issues to set the field:\n\n```\n{{lookupIssues.Story point estimate.sum|0}}\n```\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Dipen",
"body": "Bill\n\nThank you for your response back.\n\nI totally agree with your response. However teh automation rule that I have in place is bare bones wherein I am testing if the matematical computation will work or not. And for that I have limited the # of issues to 2 only.\n\nOnce the rule works then I can try and implement what you have suggested.\n\nHowever it appears that the computation that I am testing with may not work at all since\n\nCustom field: Aggregated Story points which is of type Number field and\n\nCustom field: Story point estimate (locked) which is of type Story point estimate value are 2 different types. Is that the correct understanding.\n\nAlso as you rightly pointed out this is a team managed project. Sorry I should have been more specific in my initial ticket request.\n\nAnd I am hoping to add all the Story points that were committed at the end of the sprint for all issue types.\n\nThe one question that I would like to run by you is with the solution is presented above:\n\n```\n{{lookupIssues.Story point estimate.sum|0}}\n\n```\n\nIf I were to implement this which variable stores the value of all the Story point estimates for all Issue types ?\n\nThank you for your help in advance.\n\nSorry for not posting the Automation rule as I don't want to mis-lead anyone.\n\nThanks\n\nKD\n"
},
{
"author": "Bill Sheboy",
"body": "There should only be one field named \"Story point estimate\" in your team-managed project, and it is numeric.\n\nRegarding your earlier expression, assuming that customfield_10236 is your \"Story point estimate\" field:\n\n```\n{{issue.customfield_10369.plus(issue.customfield_10236)}}\n```\n\nThat will only produce a number if customfield_10369 already contains a number. If it is null, it will collapse to null. A workaround for that is to use this math expression, with a 0 default at the front:\n\n```\n{{#=}}0{{issue.customfield_10369}} + 0{{issue.customfield_10236}}{{/}}\n```\n\nRegarding my example using lookup issues, the result could be stored directly in your custom *Aggregate Story Points* field by pasting it into the edit field, or written to the log, etc.\n"
},
{
"author": "Dipen",
"body": "Joe\n\nYou have been very kind to reply back to my messages. Really appreciate your feedback.\n\nHere are some responses to your comments\n\n\"There should only be one field named \"Story point estimate\" in your team-managed project, and it is numeric.\"\n\nYou are correct there is only 1 field Story poitn estimate, however the way this project was built before me stepping on board is the that type of that custom field is Story point estimate value and not Numeric.\n\nYou are also correct in stating these 2 things\n\ncustomfield_10236 is \"Story point estimate\" field where as\n\ncustomfield_10369 is \"Aggregated Story Points\" Type is Number field. And is Empty. Hence I tried both the variations with the workaround default value of 0\n\nJust a couple of quick things to check with you.\n\nI tried running 2 variations of this piece of code as per suggestion above, however I am getting the following message\n\nPiece of code you suggested\n\n```\n{{#=}}0{{issue.customfield_10369}} + 0{{issue.customfield_10236}}{{/}}\n```\n\n2 Variations of this\n\n{{#=}}0{{issue.customfield_10369}} + 0{(issue.customfield_10236}} {{/}}{{#=}}0{{issue.customfield_10369}} plus{(issue.customfield_10236}} {{/}}\n\nNone seem to work.\n\nError I get\n\nUnknown operator { at character position 7: 0. + 0{(issue.customfield_10236}}\n\nAm I missing something from a syntax perspective. Tried google searching but have'nt had much luck.\n\nThanks\n\nKD\n"
},
{
"author": "Bill Sheboy",
"body": "I do not believe it is possible to change the type of the built-in \"Story point estimate\" field from numeric to anything else.\n\nIf someone has created another field with the same name, that will certainly cause problems. I recommend pausing to learn why they added another field.\n\nUntil then, first use this how-to article to confirm you are using the correct custom field id values for the fields: <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nNext, please review that error message and you will observe you used a parenthesis rather than a curly-bracket at one location.\n\nPlease use **exactly** what I posted and it should work if those are the correct custom field id values.\n"
},
{
"author": "Dipen",
"body": "Bill\n\nYou are right on target. That was it. Replaced the parenthesis with curly-bracket that resolved the error.\n\nHere's the response to the some of your other comments\n\n1. Story point estimate - only 1 field exists for the Team-managed projects. Again re-iterating just for clarity - The type for that field is set to Story point estimate value. That field is locked status\n\n\n\n2. This piece of code works now\n\n```\n{{#=}}0{{issue.customfield_10369}} + 0{{issue.customfield_10236}}{{/}}\n```\n\nMoving on to the next phase of this automation code. since the value of the aggregate story points is not cumulating.\n\nThank you for pointing out the bug. Much appreciate.\n\n--Dipen\n"
},
{
"author": "Bill Sheboy",
"body": "Sounds like progress is being made!\n\nHow are you trying to accumulate the story points, and when would you do so?\n\nOften this is done when an issue completes, or when a sprint completes. Then the Lookup Issues action is used with JQL to gather all of issues to sum:\n\n<https://support.atlassian.com/cloud-automation/docs/jira-automation-actions/#Lookup-issues>\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Story-point-estimate-type-can-it-be-used-for-mathematical/qaq-p/2737414
|
[
"jira-service-desk-cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Neil Womack",
"title": "Linking a cloned issue to the original via automation",
"body": "Hello, I am trying to configure a rule that automatically clones a ticket to another project, assigns the clone to the same user as the original and then links the cloned ticket back to the original. I have it working except for the last step, as it never links back to the original. Here is my automation:\n\n\n\nFrom researching the other posts in this forum I have verified that the rule is scoped for multiple projects and includes both the source and destination projects in the scope.\n\nI have also confirmed that the Link issues outlined in the last step of the automation exist in the source project (below): \n\n\n\nThe issue is automatically cloned with the proper assignee, but still does not link back to the original issue. Is there something else I'm missing?\n"
}
|
[
{
"author": "Clara Belin-Brosseau",
"body": "Hello [@Neil Womack](/t5/user/viewprofilepage/user-id/5530099)\n\nIf you're seeking for an easy way to **clone an issue to another project and link them together while keeping the same assignee** , you can try our app [Elements Copy \\& Sync](https://marketplace.atlassian.com/apps/1211111/elements-copy-sync-clone-jira-issues?tab=overview&hosting=cloud?&utm_source=community&utm_medium=answer&utm_campaign=question_2737352&utm_keyword=CS&utm_vendorID=4952) that allows you to clone and sync a full hierarchy of issues with all their content (summary, description, custom fields, comments, attachments, etc).\n\nYou can check our guide [here](https://doc.elements-apps.com/copy-and-sync-jira-cloud/copy-all-issues-from-one-project-to-another?&utm_source=community&utm_medium=answer&utm_campaign=question_2737352&utm_keyword=CS&utm_vendorID=4952).\n\n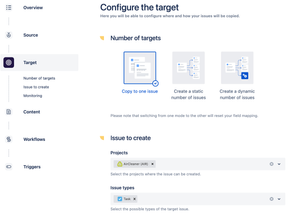\n\nThe app is for **free during 30 days** (and it stays free under 10 users).\n",
"comments": null
},
{
"author": "Bill Sheboy",
"body": "Hi [@Neil Womack](/t5/user/viewprofilepage/user-id/5530099) -- Welcome to the Atlassian Community!\n\nAfter you clone the issue, add a branch to Most Recently Created Issue before the Link Issue action. That will change the context to the new issue, rather than the trigger one.\n\n* trigger: issue created\n* **action: re-fetch issue** (I recommend always adding this action after the Issue Created trigger to prevent timing problems where some data may not be ready when the rule starts.)\n* condition: assignee is ... (your check on the trigger issue assignees)\n* action: clone issue\n* **branch: to most recently created issue**\n * action: link issue\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Neil Womack",
"body": "Thank you very much Bill, that solved the problem! For anyone else who may benefit, here is the final automation: \n\n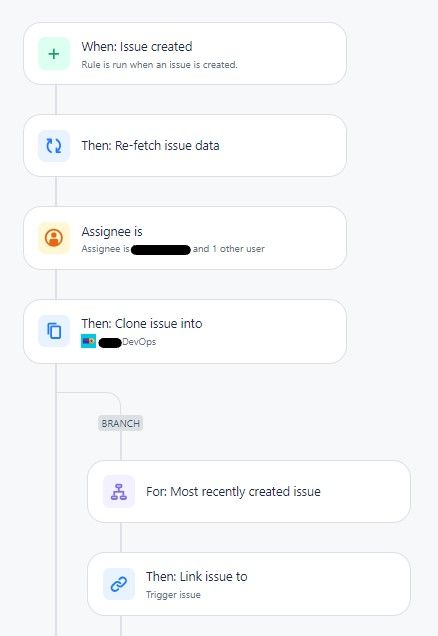\n"
},
{
"author": "Shivani Saran",
"body": "Hi [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) I implemented this automation in same way, but this is not working for in my case\n\nissue is getting cloned, but it is not getting linked with original issue\n"
},
{
"author": "Bill Sheboy",
"body": "Hi [@Shivani Saran](/t5/user/viewprofilepage/user-id/5597298) -- Welcome to the Atlassian Community!\n\nPlease post images of your complete automation rule, the action where the linking occurs, and of the audit log details showing the rule execution. Those will provide context for the community to offer suggestions. Thanks!\n\nUntil we see those...\n\nAre the issues all in the same Jira project or different projects?\n\nKind regards, \nBill\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Linking-a-cloned-issue-to-the-original-via-automation/qaq-p/2737352
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Shiyao Ling",
"title": "Pulling the latest comment for each issue with Automation",
"body": "Hello,\n\nI am very new to Jira. We are trying to auto populate a custom field with the last comment for each issue in a project.\n\nI have followed the steps from various existing resolved posts out there: create custom field \\> create automation rule to populate the field with the latest comment. The rule works when I only have the custom field in 1 type of issue, but as soon as I add the same custom field to another issue type, I run into problems. What am I doing wrong? Does each issue type within the same project require its own unique custom field name?\n\nHere is the rule I set up:\n\n\n\nThis is the error I get if I add the same custom field to more than one issue type.\n\n\n\nThanks!\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Shiyao Ling](/t5/user/viewprofilepage/user-id/5530095) -- Welcome to the Atlassian Community!\n\nDid you confirm there is only one field by that name, Last comment text, in your team-managed project for the different issue types?\n\nFor the trigger issue's type in that example, did you confirm the field was added to the views?\n\nTo help confirm both of those, please use this how-to article with example issues to check the field is present, unique, and has the same custom field id: <https://support.atlassian.com/cloud-automation/docs/find-the-smart-value-for-a-field/>\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Shiyao Ling",
"body": "Thank you Bill! The how-to article was super helpful, I found out the problem and now the automation rule is working properly!\n"
},
{
"author": "Bill Sheboy",
"body": "Awesome; I am glad to learn that helped!\n\nWhat was the root cause of the problem?\n"
},
{
"author": "Shiyao Ling",
"body": "It was such a rookie mistake. For each issue type, instead of just creating a new custom field for the first issue type then drag and drop from the \"suggested fields\" bar for the remaining, I was creating a new custom field and typing in the name for every single one of them. This indeed resulted in several custom fields with the same name, and the only way I discovered/confirmed that was by looking at the smart value. So thank you!\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Pulling-the-latest-comment-for-each-issue-with-Automation/qaq-p/2737337
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Sagi Gueta",
"title": "Ensuring Sub-tasks Inherit \"On Hold\" Status from Parent",
"body": "Hello,\n\nI need help setting up an automation rule that transitions all sub-tasks to **On Hold** whenever their parent issue is transitioned to \"On Hold,\" as long as these sub-tasks are not already in \"On Hold\" or \"Done\" statuses.\n\nCurrently, if there is at least one sub-task that is not in the relevant statuses I've specified, the rule is blocked. However, the automation should only transition sub-tasks that are not \"Done\" or already \"On Hold.\"\n\nIn the other hand, when I removed the issue field condition, the automation worked fine, and transitioned each and every subtask to On Hold, even if it was Done.\n\n++**Automation Rule**++ **:**\n\n**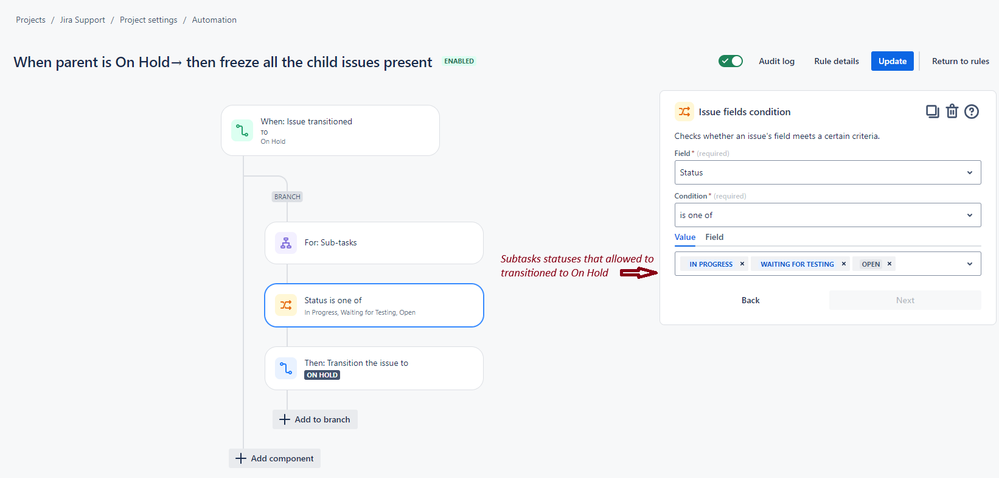**\n\n++**Audit Log**++ **:**\n\n**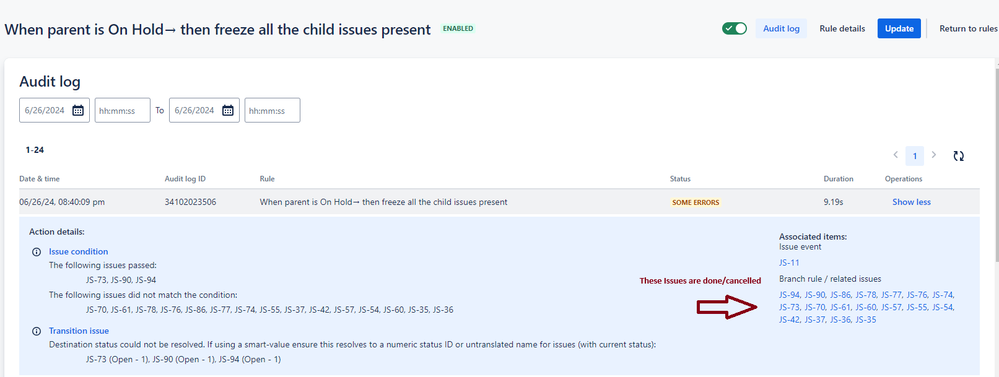**\n\nAny assistance would be greatly appreciated!\n\nThanks!\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Sagi Gueta](/t5/user/viewprofilepage/user-id/4493828)\n\nIs this a company-managed or a team-managed project? You may find that information at the bottom-left of the page expanding area.\n\nI hypothesize this is a team-managed project and that the id values for the statuses are different for your different issue types, such as Story and Subtask.\n\nWith the condition, the rule looks like it was going to work based on the issues selected in the audit log, but it tried to use the parent's \"On Hold\" id rather than the one for the child, Subtask type.\n\nI recall a workaround is to create a variable with the id value of the Subtask's status and use that in the transition rather than using the status name from the dropdown list.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "Sagi Gueta",
"body": "Hey [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) ,\n\nThanks for reply!\n\nActually, this is a company managed project. I'd like to understand why does it matter for the solution (as I didn't work much with team managed project).\n\nAdditionally, can you please share how would you do it with variables?\n"
},
{
"author": "Bill Sheboy",
"body": "First back to your original question, would you please post an image of the audit log for the case when the rule worked as expected? That may clarify what is happening.\n\nCan you manually move an example Subtask to \"On Hold\" on your board, or in the issue views?\n\nFor your follow-up questions...\n\nEach team-managed project has unique configurations for issue types, status values, fields, etc. And so there could be different id values representing \"On Hold\" for a Story versus a Subtask.\n\nWhen necessary, a workaround is to store the id value for the status with the Create Variable action:\n\n* create variable\n * name: varOnHoldForSubtask\n * smart value: 12345\n\nThen that smart value may be used as the status in the transition action, typing in {{varOnHoldForSubtask}}\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Ensuring-Sub-tasks-Inherit-quot-On-Hold-quot-Status-from-Parent/qaq-p/2737269
|
[
"jira-cloud"
] |
{
"author": "Sean McConell",
"title": "Automation - ASC order in Linking Tickets",
"body": "I have an Automation Build for a Mail Handler. Is there a way to when Linking and Closing the duplicate tickets to Order by created ASC. I basically need to close the newest ticket and link everything back to the oldest ticket.\n\n\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@Sean McConell](/t5/user/viewprofilepage/user-id/5530039) -- Welcome to the Atlassian Community!\n\nOne way to do that would be to use Lookup Issues with JQL and an ORDER BY Created DESC clause, and branch using JQL to just the first item by the key to close it:\n\n```\nkey = {{lookupIssues.first.key}}\n```\n\nThe reason I suggest inverting the ORDER BY and using the first one is to handle the possibility there are more than 100 issues as that is the maximum a lookup can return.\n\nThen branch to the other issues separately, perhaps using the lookup results and excluding the first one. That will prevent the possibility of the parallel processing for branches colliding.\n\nKind regards, \nBill\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-ASC-order-in-Linking-Tickets/qaq-p/2737255
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "kkimak",
"title": "Trigger automation when version with specific name is created",
"body": "HI,\n\nI'm setting up automation in JIRA where creating a new version triggers the update of the 'Fix Version' field for specific issues.\n\nI'd like to include a condition to only update issues when the new version name starts with 'XYZ'. I tried using the expression `{{version.name.startsWith(\"XYZ\")}}` in the Version name filter, but it's not working as expected. Could you help me identify the issue and suggest a solution?\n\n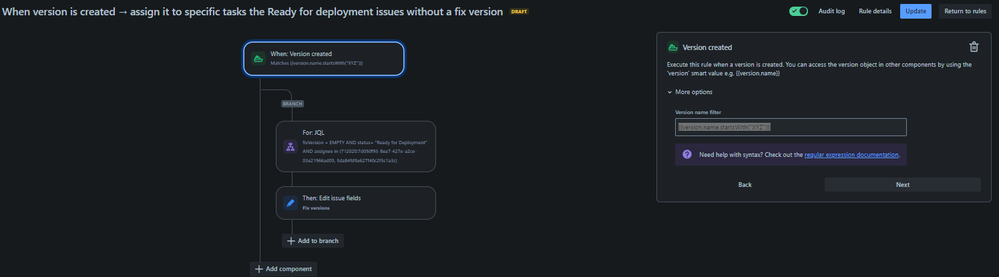\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@kkimak](/t5/user/viewprofilepage/user-id/5529838) -- Welcome to the Atlassian Community!\n\nWhen you added that trigger, it offered a link to help using a regular expression to test the *version name*. Please review that for more information.\n\nAs that check is specifically on the version name, the only thing you would need to enter in the field is this:\n\n```\nXYZ.*\n```\n\nThat would check for version names starting with XYZ followed by zero-to-many other characters.\n\nKind regards, \nBill\n",
"comments": null
},
{
"author": "Duc Thang TRAN",
"body": "Hello [@kkimak](/t5/user/viewprofilepage/user-id/5529838)\n\nCan can suggest this solution\n\nTrigger : when Version created\n\nIf : smart value comparaison\n\n{{version.name.startsWith(\"XYZ\")}} equal true\n\nThen for jql -\\> action\n\n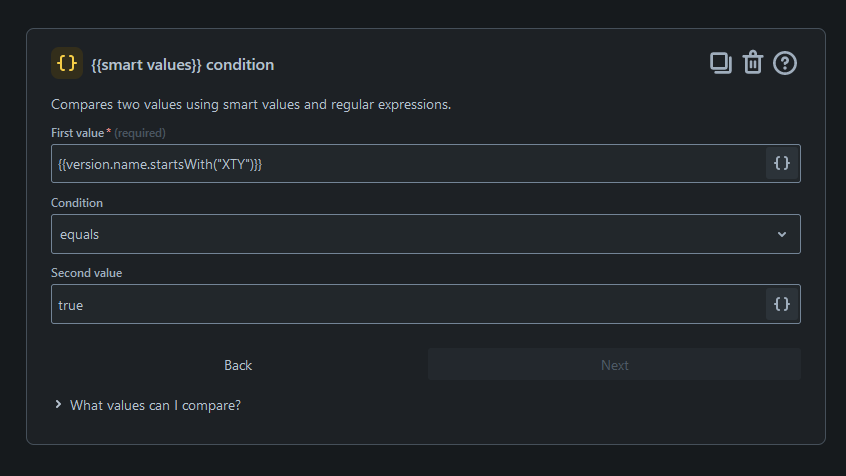\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Trigger-automation-when-version-with-specific-name-is-created/qaq-p/2737077
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "LynnG",
"title": "Automation auto-assign 10% of tickets to skip testing",
"body": "Hello,\n\nMy goal is to transition 10% of tickets directly to Acceptance, skipping Testing by way to automation.\n\nThere is not enough information to get this to work...\n\nI'm stuck on the RandomNumber Variable. In this case, I am just trying to get from 1 to 2 to work, before moving up to 1 to 10.\n\nThen I want the automation to compare the random number (1 to 10) to compare it to 1. If it equals 1, probably 10% of the time, then move it to Acceptance.\n\nIf there is an easier way to identify 10% of tickets, please let me know.\n\nThank you\n\n\n\n\n\n\n"
}
|
[
{
"author": "Bill Sheboy",
"body": "Hi [@LynnG](/t5/user/viewprofilepage/user-id/5278762)\n\nRegarding the math...you could use the [random() function](https://support.atlassian.com/cloud-automation/docs/jira-smart-values-math-expressions/#Functions), which returns a value between 0 and 1, and then adjust to get your range. For example for 1 to 2:\n\n```\n{{#=}}round(random()*2+0.49,0){{/}}\n```\n\nAlthough that may not do what you asked...\n\nInstead it will have a X% chance of skipping something (and will actually skip more / less) as the checks are *independent for each rule triggering*.\n\nIt seems you want to identify 10% of the items to skip at the time the first item enters Ready for Testing. I do not believe that is easy to do in a rule for a *random 10% selection of items without replacement*.\n\nThe rule could be adjusted to *select up to 10% and no more* by adding a \"skipped\" indicator to items (e.g. with a custom field, label, issue property), and checking if 10% have been skipped yet using Lookup Issues and JQL. If not at 10% yet, perform the random check to decide about skipping, and add the indictor when skipped. Else, do not skip.\n\nKind regards, \nBill\n",
"comments": [
{
"author": "LynnG",
"body": "Hello [@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313)\n\nI will check will my requester and get back to you.\n\nThanks!\n"
}
]
}
] |
https://community.atlassian.com/t5/Automation-questions/Automation-auto-assign-10-of-tickets-to-skip-testing/qaq-p/2736315
|
[
"cloud",
"jira",
"jira-cloud"
] |
{
"author": "Mkrtich Tono",
"title": "Create confluence page with jira automation by syncing info from jira ticket",
"body": "Hello community\n\nI have created an automation to create confluence page from jira but I need to sync some data from the ticket to the confluence page.\n\nIs there a way to sync the custom fields and update them automatically without any addon?\n"
}
|
[
{
"author": "Lukas Nicolai_Seibert_Media_",
"body": "Hey [@Mkrtich Tono](/t5/user/viewprofilepage/user-id/5351215) , I am the Product Marketing Manager at Seibert Media, and I think our app, AutoPage, is the perfect solution for what you're looking for.\n\nWith AutoPage, you can automatically create Confluence pages from Jira issues. That means you can display Jira content on a Confluence page, which will be linked and also synchronized live. AutoPage can also be used with Jira automation. It provides webhooks you can easily add as an action.\n\nHope that helps!\n\n[AutoPage - Display Jira data in Confluence with automation \\| Atlassian Marketplace](https://marketplace.atlassian.com/apps/1218503/autopage-display-jira-data-in-confluence-with-automation?hosting=cloud&tab=overview)\n\nIf you'd like to discuss your use case a bit further or if we can help you with the setup, feel free to[**jump on a call**](https://calendly.com/coderay) with us!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Automation-questions/Create-confluence-page-with-jira-automation-by-syncing-info-from/qaq-p/2736035
|
[
"cloud",
"cloud-automation",
"confluence",
"confluence-cloud"
] |
{
"author": "???",
"title": "Malfunction in 'Create a Pull Request'",
"body": "Hi, I'm a Bitbucket user. \n\nI'm not sure when this got patched, but there's been a bug in the 'Create a Pull Request' feature for a few months now. \n\nWhen I switch the 'Source Branch,' the description doesn't reset. \n\nIt used to show the commit messages for the branch, right? And it should only keep the message if I've edited the description myself. \n\nI think it's a bug because only the 'Title' works correctly! \n\nCould you take a look and fix this as soon as you can? Thanks!\n"
}
|
[
{
"author": "Syahrul",
"body": "G'day, [@???](/t5/user/viewprofilepage/user-id/5588229)\n\nWelcome to the community!\n\nI have tried to reproduce a similar issue to what you explained and am unable to. Could you please raise a support ticket with us on our [Support portal](https://support.atlassian.com/contact) so we can investigate this issue further?\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Malfunction-in-Create-a-Pull-Request/qaq-p/2807570
|
[
"cloud"
] |
{
"author": "John Kelly",
"title": "Issue connecting to bitbucket with IP allowlisting?",
"body": "We have historically used IP allowlisting to limit access to machines in our org. This afternoon we've seen issues where folks connected via VPN have been blocked, and where two build systems have stumbled when trying to collect changes. Locally (via VPN) users have seen this issue resolve. In one of two build systems we've seen the same. But we're still seeing issues in the second.\n\nI don't see any issues reported on the bitbucket status page, but perhaps there is an issue with this allowlisting feature?\n"
}
|
[
{
"author": "Patrik S",
"body": "Hello [@John Kelly](/t5/user/viewprofilepage/user-id/5137230) ,\n\nBased on your description, it seems your team was impacted by an incident on Bitbucket Cloud that was affecting git operations over SSH for some customers :\n\n* <https://bitbucket.status.atlassian.com/incidents/jfhrnk0m1jc9>\n\nThe issue has already been resolved by our engineering team, and the git operations should be working as usual again.\n\nLet us know in case you are still facing issues.\n\nThank you!\n\nPatrik S\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Issue-connecting-to-bitbucket-with-IP-allowlisting/qaq-p/2807365
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Kimberling Yarihuaman",
"title": "Bitbucket Pipeline does not finish the tests with firefox browser",
"body": "Hi!\n\nI have an issue when I try to run the tests with firefox browser in Bitbucket Pipeline, the tests never finish and after 2 hours shows the error -\\> **\"Exceeded build time limit of 120 minutes\",**I don?t know why is happening that, because I?ve tried with Edge and Chrome browsers and they?re okay.\n\nThis issue has been happening for 5 days so I think it?s the last version of Firefox, because the previous time it was working. Also, I?ve tried with old versions but I?ve got the same problem.\n\nPlease, can you help me with that?\n\nThanks in advance.\n\n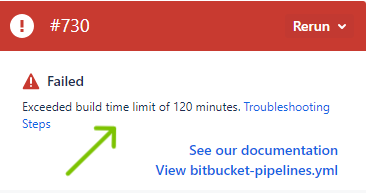\n"
}
|
[
{
"author": "Patrik S",
"body": "Hey [@Kimberling Yarihuaman](/t5/user/viewprofilepage/user-id/5587991) ,\n\nand welcome to the Community!\n\nMy understanding is that you have some tests implemented on your pipelines that test your code in different browsers, but for firefox specifically, it started to fail recently.\n\nWould you mind elaborate on how you're executing these tests in pipelines? Are you using a [service container](https://support.atlassian.com/bitbucket-cloud/docs/databases-and-service-containers/) in your pipelines step to emulate the browser, or using a different approach ?\n\nIf you feel comfortable in sharing here on community, it would greatly assist the investigation to see your YAML file. If you can share the particular step in YAML that is currently failing/stuck, it may help us to suggest possible next steps.\n\nOn a side note, I see you have access to a workspace with Premium subscription which is entitled to Premium support. If you'd like fast responses/turnaround, you can [create a support ticket here](https://support.atlassian.com/contact/) providing the link of the Premium workspace you're member of.\n\nThank you, [@Kimberling Yarihuaman](/t5/user/viewprofilepage/user-id/5587991) !\n\nPatrik S\n",
"comments": [
{
"author": "kimberling yarihuaman",
"body": "Hi [@Patrik S](/t5/user/viewprofilepage/user-id/4603309) !\n\nThanks for your answer, so I?m using bitbucket-pipelines.yml file, I attached a screenshot about my steps in that file. I?m working with Cypress, Cucumber, Gherkin and Javascript to automate the tests.\n\nI?am going to take into account the possibility to create a support ticket. In this case, should I provide the repository link of the Premium workspace? (sorry, but I don?t understand this part)\n\n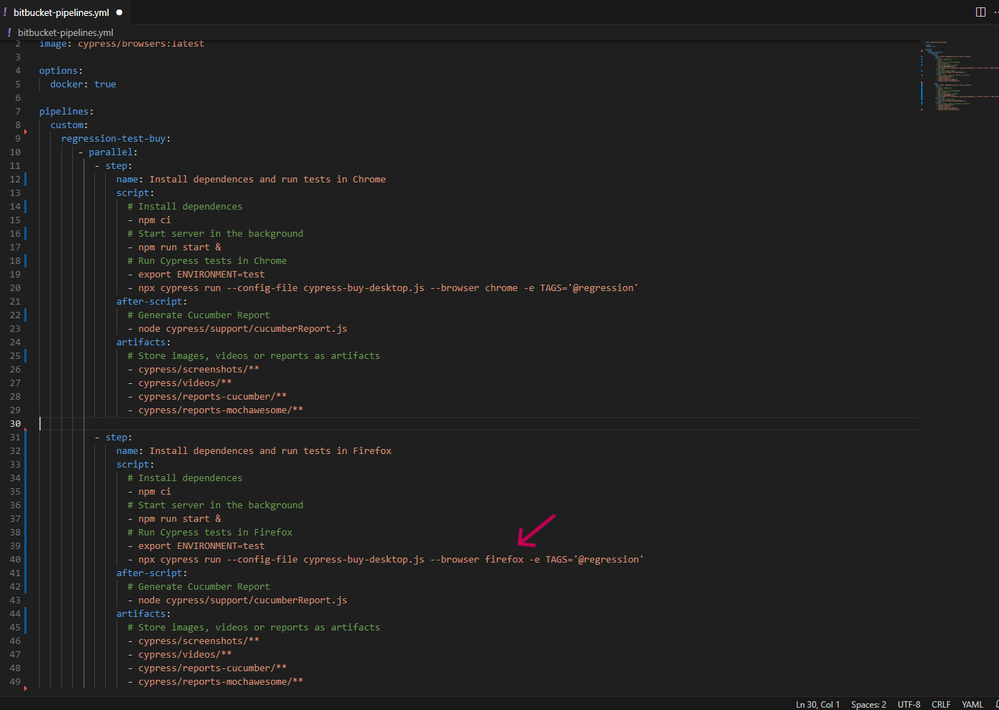\n\nThanks in advance.\n"
},
{
"author": "Patrik S",
"body": "Hello [@Kimberling Yarihuaman](/t5/user/viewprofilepage/user-id/5587991) ,\n\nThanks for sharing the screenshot.\n\nI'm not really familiar with cypress, but one thing I can think of is your step running close to the memory limit, and somehow causing the tests to get stuck hence resulting in the build to timeout.\n\nFor that, I would suggest trying increasing the [step size](https://support.atlassian.com/bitbucket-cloud/docs/step-options/#Size) to 2x, so it will get 8GB of memory (compared to 4GB by default):\n\n```\n- step:\n name: Install dependencies and run tests in Firefox\n size: 2x\n script:\n - <your script commands>\n```\n\nIf that doesn't work, you may want to try troubleshooting the pipeline locally to see if the same error happens and isolate if it only happens on the pipelines environment, or in your local environment as well:\n\n* [Troubleshoot failed Bitbucket Pipelines locally with Docker](https://confluence.atlassian.com/bbkb/debug-failed-bitbucket-pipelines-locally-with-docker-1318882094.html)\n\nThank you, [@Kimberling Yarihuaman](/t5/user/viewprofilepage/user-id/5587991) !\n\nPatrik S\n"
},
{
"author": "kimberling yarihuaman",
"body": "Hi [@Patrik S](/t5/user/viewprofilepage/user-id/4603309) !\n\nMy pipeline is working well with the memory increase.\n\nThanks so much!\n"
},
{
"author": "Patrik S",
"body": "You're very welcome [@Kimberling Yarihuaman](/t5/user/viewprofilepage/user-id/5587991) !\n\nHappy to hear that increasing the memory did the trick :)\n"
},
{
"author": "kimberling yarihuaman",
"body": "Yeah! [@Patrik S](/t5/user/viewprofilepage/user-id/4603309) I have a question. Why could it be happening that? Because it?s working with size: 4x.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Bitbucket-Pipeline-does-not-finish-the-tests-with-firefox/qaq-p/2807360
|
[
"bitbucket-cloud",
"browser",
"cloud",
"firefox",
"test"
] |
{
"author": "Lily Poon",
"title": "Jira no longer shows the pull request and branches created or merged to the ticket",
"body": "All my jira tickets used to show details with branch name and pull request information. Now, all the tickets are blank. I'm not sure how to link that information from my bitbucket back to the jira tickets. They were working a couple months ago.\n"
}
|
[
{
"author": "Lily Poon",
"body": "HI Patrik, Thanks for your response. I think the issue is my bitbucket account and jira account have 2 different emails. When i login to bitbucket, workspace settings under Atlassian integrations, Jira--- it shows me a \"Try Jira Cloud now\" button. I already have Jira with a different email. Both bitbucket and Jira account belongs to the same company. If i sign up for a new Jira cloud account, is there a way to port all existing Jira tickets to this new Jira cloud?\n",
"comments": null
},
{
"author": "Patrik S",
"body": "Hey [@Lily Poon](/t5/user/viewprofilepage/user-id/2675425) ,\n\nand welcome to the Community!\n\nFor development data from Bitbucket Cloud to be linked to Jira issues, you first need to connect your workspace to your Jira instance. If you haven't already, you can follow the steps outlined in the below article to connect the products:\n\n* [Connect Bitbucket Cloud to Jira Cloud](https://support.atlassian.com/bitbucket-cloud/docs/connect-bitbucket-cloud-to-jira-software-cloud/)\n\nOnce the instances are connected, you need to include the issue key information either on commit messages, branch names or Pull request title for that information to appear on the jira ticket.\n\nI hope that helps! Let us know in case you have any questions.\n\nThank you, [@Lily Poon](/t5/user/viewprofilepage/user-id/2675425) !\n\nPatrik S\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Jira-no-longer-shows-the-pull-request-and-branches-created-or/qaq-p/2807243
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Adam Brunt",
"title": "Tests are failing but pipeline step still passes ??",
"body": "Hi all,\n\nWe have a situation where a pipeline step is passing even though Bitbucket detects failing tests for that step. \n\nThe step *summary* says \"1 / 1894 tests failed\", the console log has a \"Tests\" tab on it which shows the failing test and the *build teardown* log shows \"Merged test suites, total number tests is 1894, with **1 failures** and 0 errors.\" but the step is still green.\n\nIf it makes a difference we write our test results to a file called **test-reports/results.xml** . though I notice the teardown log says \"Searching for test report files in directories named \\[test-results, failsafe-reports, test-reports, TestResults, surefire-reports\\]\". Does anyone know if the folder name makes a difference ? \n\nDoes anyone have any idea what our problem might be ? Or is it a bug with Bitbucket Pipelines ?\n"
}
|
[
{
"author": "Patrik S",
"body": "Hey [@Adam Brunt](/t5/user/viewprofilepage/user-id/5152789) ,\n\nand welcome to the Community!\n\nThe way that Bitbucket Pipelines defines whether a step was successful or not is based on the exit code returned by the commands you're executing in your script.\n\nAn exit code of zero is interpret as the command being successful, and pipelines follow to the next command, which then returns it's own exit code as well, and so on.\n\nIf all commands in a step return exit code zero, the step will be considered successful. On the other hand, if any command returns a non-zero exit code, Pipelines will stop that step immediately and consider it as a failure.\n\nThat being said, and bringing this to your scenario of tests results, the test results contents itself doesn't impact whether the pipeline will consider the step as failed on not. What actually matter is what exit code your test framework has returned once it complete its execution. If your test suite identified failed tests but still returned a zero exit code, pipelines will understand that command succeeded.\n\nI'd suggest including the following command right after your test execution command to print the exit code:\n\n```\n- echo $?\n```\n\nThis command outputs the exit code of the last command executed in the script. If it's zero, that would explain why the pipelines considered it successfully.\n\nIn that case, I would suggest looking for any configuration/setting in your test framework to enable it return a non-zero exit code for failed tests.\n\nI hope that helps! Let us know in case you have any questions.\n\nThank you, [@Adam Brunt](/t5/user/viewprofilepage/user-id/5152789) !\n\nPatrik S\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Tests-are-failing-but-pipeline-step-still-passes/qaq-p/2807103
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Girish Bramhane",
"title": "API to repos updated in last 7 days",
"body": "I just want to integrate API which will provide me information like Give repo list which updated in last 7 days ( anything activity like commits / merge / pr happened on that repo in last 7 days)\n"
}
|
[
{
"author": "Patrik S",
"body": "Hey [@Girish Bramhane](/t5/user/viewprofilepage/user-id/5587647) ,\n\nand welcome to the Community!\n\nBased on your use case, I would suggest using Bitbucket's public API endpoint to [List repositories in a workspace](https://developer.atlassian.com/cloud/bitbucket/rest/api-group-repositories/#api-repositories-workspace-get) while sorting by the updated_on attribute. \n\nExample request: \n\n```\ncurl -u USERNAME:APP_PASSWORD --location 'https://api.bitbucket.org/2.0/repositories/WORKSPACE?sort=-updated_on'\n```\n\nThis should return a list of repositories order by the most recent updated ones.\n\nI hope that helps! Let us know in case you have any questions.\n\nThank you, [@Girish Bramhane](/t5/user/viewprofilepage/user-id/5587647) !\n\nPatrik S\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/API-to-repos-updated-in-last-7-days/qaq-p/2806922
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Toan Duong",
"title": "Security Risk? Bitbucket integration with Vanta",
"body": "Hi All,\n\nWe are working with a vendor on a compliance project. One of their tools integrates with Bitbucket and checks for misconfigured settings/etc. I was wondering if anyone has come across this and could offer some advice as far as security risks regarding the integration? We obviously don't want to make something more secure by opening up another hole :)\n\nFrom their website:\n\n***Overview*** \n*Automates the collection of evidence for your code repository configurations, pull request workflows, and security issue tracking.* \n\n***Automation*** \n*Automates 11 tests and 7 controls* \n\n***Permissions*** \n*Vanta requires read-only access to your account information, team membership, repositories, issues, pull requests.* \n\n*We also request permission to administer your repositories to check branch protection. There is currently no read-only access for this.*\n\nAny insights are helpful. Thank you!\n"
}
|
[
{
"author": "Aron Gombas _Midori_",
"body": "We are using Vanta and allowed them to access our Bitbucket Cloud workspace. It is obviously a security risk, but as [@marc -Collabello--Phase Locked-](/t5/user/viewprofilepage/user-id/1205132) noted these tools need access to check for misconfigured settings and such. We just accepted it and trust them.\n\nNote that Vanta will ask for access to a lot of other possibly even more critical systems in your infrastructure, not only e.g. Jira Cloud, but even on the PaaS level (AWS)!\n",
"comments": [
{
"author": "Toan Duong",
"body": "Yes, we are aware that they will have access to more critical systems. As far as Bitbucket goes, do you know if their integration actually has access to the code files?\n"
}
]
},
{
"author": "marc -Collabello--Phase Locked-",
"body": "Obviously adding Vanta is an additional security risk. However maybe Vanta catches other security risks and implements required audit controls. This might be a net positive.\n",
"comments": [
{
"author": "Toan Duong",
"body": "Yep. We are trying to assess pros/cons of this integration. Thank you for your input.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Security-Risk-Bitbucket-integration-with-Vanta/qaq-p/2807315
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "???SA",
"title": "Issue with 401 Error for api.bitbucket.org/2.0/repositories/{workspace}/{repository}/commits",
"body": "Hi,\n\nWhen configuring a Bamboo plan environment, the repository to be used was added under the Default plan configuration \\> Repositories menu. \nCurrently, the method to connect Bamboo to Bitbucket Cloud involves adding an app password from the Bitbucket Cloud account, and then adding this key under the Bamboo Shared Credentials menu, which allowed successful registration. \nHowever, as of September 6th, repository registration is failing for all IDs except for a specific ID's Shared Credentials. My account has admin privileges on both Bitbucket and Bamboo, but I am still unable to register repositories (this was previously working without any issues). \nThe currently applied plans are still functional, but there is a problem when trying to register additional repositories.\n\nUpon checking, the account that works can query the URL without any issues, but the app password of the problematic account returns a 401 error with the following request: <https://api.bitbucket.org/2.0/repositories/{workspace}/{repository}/commits>\n\nI would like to know the reason for the 401 error and the solution, even though both accounts have the same permissions.\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi [@???SA](/t5/user/viewprofilepage/user-id/5152256),\n\nA 401 error means that the credentials provided are not valid.\n\nAre you also using a username along with the app password? An app password cannot be used by itself for authentication. You need to provide the Bitbucket username of the account that you generated the app password for. The username can be found on the following page, after you log in to the account:\n\n* <https://bitbucket.org/account/settings/>\n\nI suggest the following steps to confirm if the credentials are correct and work:\n\n**1.** Log in to <https://bitbucket.org> with the account you generated the app password for\n\n**2.** Double check the username listed here: <https://bitbucket.org/account/settings/>\n\n**3.** Then, run the following curl command from a terminal application on your computer:\n\n```\ncurl -u username:app_password --request GET \\\n--url https://api.bitbucket.org/2.0/repositories/workspace-id/repo-slug/commits \\\n--header 'Accept: application/json'\n```\n\nwhere\n\n**username** replace with the Bitbucket username from step 2 \n**app_password** replace with the app password you generated for this account \n**workspace-id** replace with the id of the workspace where this repo belongs \n**repo-slug** replace with the slug for the repo\n\nDo you get the repo's commits when you execute this curl call?\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "???SA",
"body": "Hi, [@Theodora Boudale](/t5/user/viewprofilepage/user-id/818086)\n\nI try to curl, but it occur 401 error\n"
},
{
"author": "Theodora Boudale",
"body": "Hi [@???SA](/t5/user/viewprofilepage/user-id/5152256),\n\nThank you for your reply.\n\nSince the curl command also fails, then the credentials are not correct.\n\nIf you have ensured that the username is correct, please generate a new app password from\n\n* <https://bitbucket.org/account/settings/app-passwords/>\n\nand then try the **curl** command with the new app password. Does it succeed then?\n\nIf you only need to perform a GET to the commits endpoint, then **Repositories - Read** permissions for the app password are enough. For Bamboo, if Bamboo makes additional operations other than cloning or getting commits, then additional permissions may be needed for the app password.\n\nKind regards, \nTheodora\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Issue-with-401-Error-for-api-bitbucket-org-2-0-repositories/qaq-p/2806763
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "gld",
"title": "Need to run the garbage collection on the reposotory \"<repo-slug-redacted>\"",
"body": "Hi,\n\nWe need to run the garbage collection on the repository **\\[REDACTED\\]**.\n\nCan you please run it manually on your end?\n\nThank you!\n"
}
|
[
{
"author": "Robert Wen_ReleaseTEAM_",
"body": "Hello [@gld](/t5/user/viewprofilepage/user-id/1998997) ! Welcome to the Atlassian Community!\n\nI've sent word to Atlassian Support team. Hold on.\n",
"comments": [
{
"author": "Ben",
"body": "Hi [@gld](/t5/user/viewprofilepage/user-id/1998997)\n\nThe repository you've mentioned is only 10mb in size, I executed the gc and it reduced the size by 400kb.\n\nHope this helps.\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n"
}
]
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Need-to-run-the-garbage-collection-on-the-reposotory-quot-lt/qaq-p/2806743
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "artem",
"title": "Error during workspace creation",
"body": "Yesterday and today, Im trying to create a workspace (fresh created account) and I'm receiving the following error\n\nSomething went wrong on our end. Please try again. If this keeps happening, [contact support](https://support.atlassian.com/contact/).\n\nI tried Chrome, Opera, duckduckgo and safari browsers. The account is corporate\n\nUPD: the error is highly informative but I believe it was a corporate account's restrictions. I managed to do it through admin panel\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi artem and welcome to the community!\n\nApologies for the inconvenience caused by this. There seems to be a bug when a workspace is created from <https://www.atlassian.com/try/cloud/signup?bundle=bitbucket> and we are looking into this.\n\nIn the meantime, Bitbucket workspaces can be created from <https://admin.atlassian.com/> as you have already figured out.\n\nKind regards, \nTheodora\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Error-during-workspace-creation/qaq-p/2806437
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Morgan Mutugi",
"title": "Port 22 Being Filtered for My IP Address ? Need Help",
"body": "I'm currently facing an issue where it seems that **port 22 (SSH)** is being filtered for my IP address, and I'm unable to establish a connection to pull or push code. I've tried connecting from different networks, and the issue seems to be isolated to my specific IP. I haven't made any recent changes to my firewall or network configurations.\n\nHas anyone encountered a similar issue with port 22 filtering? Could this be related to any security measures on the Atlassian side, or is there something I should look into on my network setup? Any insights on how to troubleshoot or resolve this would be greatly appreciated.\n\nThanks in advance! \n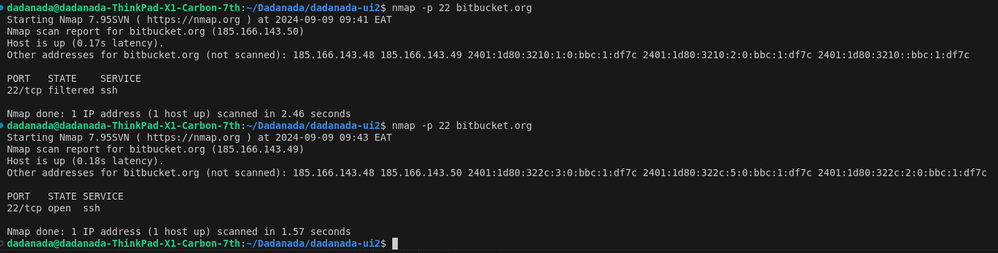\n"
}
|
[
{
"author": "Ben",
"body": "Hi [@Morgan Mutugi](/t5/user/viewprofilepage/user-id/5587245)\n\nIt is unlikely that your IP address would be blocked by us unless your IP address originates from a country sanctioned by the US (ie Crimea Region of Ukraine, Cuba, Iran, North Korea, Syria, Sudan). This is especially true if you have tried connecting from different networks as they would each have their own unique IP address.\n\nI would suggest checking your firewall/VPN configuration (especially if using ZScaler). You can also use [telnet](https://learn.microsoft.com/en-us/windows-server/administration/windows-commands/telnet) to determine if the port is open:\n\n*\n\n ```\n telnet bitbucket.org 22\n ```\n\nIf you need further support, you can also raise a ticket directly with our support team so we can check to ensure your IP address is not being blocked and also suggest further troubleshooting commands. The output of both would not be appropriate to share in a public forum such as community. You can do so by raising a ticket with **Bitbucket Cloud**as the product and your companies full paid workspace URL:\n\n* <https://support.atlassian.com/contact>\n\nIf you have any issues raising a ticket, please let me know your timezone so I can raise one on your behalf in the appropriate support timezone.\n\nI hope this helps.\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Port-22-Being-Filtered-for-My-IP-Address-Need-Help/qaq-p/2806426
|
[
"cloud"
] |
{
"author": "noriyukiichijo",
"title": "Why relative path in readme.md in repo is resolved under bytebucket.org instead of bitbucket.org?",
"body": "I thought I can use relative path in readme.md in a repo after reading [this](https://stackoverflow.com/questions/28766550/add-images-to-readme-md-on-bitbucket) .\n\nBut if I use relative path for image, it is not shown.\n\nAs I use dev tool of Chrome, I found its path is resolved under bytebucket.org domain instead of bitbucket.org domain.\n\nIf I swap the domain and paste full URL of the image on the address bar of Chrome, it is shown.\n\nIt's strange but relates to <https://jira.atlassian.com/browse/BCLOUD-15949> ?\n"
}
|
[
{
"author": "Samuel Tan",
"body": "I think that is a bug from bitbucket, there is another thread mentioned the image is not shown.\n\n[Bitbucket not display image from a Markdown (atlassian.com)](https://community.atlassian.com/t5/Bitbucket-questions/Bitbucket-not-display-image-from-a-Markdown/qaq-p/2806128)\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Why-relative-path-in-readme-md-in-repo-is-resolved-under/qaq-p/2806261
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "meteograms",
"title": "Taking forever to fetch dependency from bitbucket (specified in package.json)",
"body": "I have a dependency in the package.json file for a node.js app deployed using a Dockerfile that itself calls \\`RUN npm install\\`. The dependency is expressed in the following form in package.json:\n\n\"dependencies\": { \n\"myrepo\": \"git+<https://myusername:[email protected]/myusername/myrepo.git#v123>\" \n},\n\nThis has worked fine for years. It still works, but I'm finding that recently that the docker build process hangs for a looong time (around 10 mins) on the \\`RUN npm install\\` step. In the past it was maybe a few seconds... not really sure but never enough to notice particularly.\n\nThe bitbucket repo dependency is the only dependency, so it must relate to that? When I view the server stats, it seems like nothing is really going on... CPU and network activity flatlining... so it seems like it is just waiting.\n\nAny ideas why it's taking so long recently?\n"
}
|
[
{
"author": "Syahrul",
"body": "G'day, [@meteograms](/t5/user/viewprofilepage/user-id/1157589)\n\nIt's hard to say without viewing your build to understand the issue. So I suggest try to reproduce them locally following the guide [here](https://confluence.atlassian.com/bbkb/debug-pipelines-locally-with-docker-1167698072.html) and see if it's showing the same behavior.\n\nLet me know the results.\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Taking-forever-to-fetch-dependency-from-bitbucket-specified-in/qaq-p/2806138
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Peter",
"title": "Runner upgrade to 3.0",
"body": "Is there a possibility that this could lead to data exfiltration since runner now communicates directly with file storage in AWS S3 \n\n<br />\n\n<https://bitbucket.org/blog/bitbucket-pipelines-runner-upgrade-required>\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi Peter and welcome to the community!\n\nAWS S3 is used to upload files that you define as artifacts in your bitbucket-pipelines.yml file:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/use-artifacts-in-steps/>\n\nor caches you define in your bitbucket-pipelines.yml file:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/cache-dependencies/>\n\nFor every Pipelines step that downloads artifacts or cache, we have unique tokens that are used to authenticate with S3, so the artifacts and cache are not publicly accessible.\n\nKind regards, \nTheodora\n",
"comments": [
{
"author": "Peter",
"body": "Hi [@Theodora Boudale](/t5/user/viewprofilepage/user-id/818086) \n\nUpload works but it's failing when other step is trying to download the artifact \n\nArtifact \"target/\\*\\*\": Downloading Artifact \"target/\\*\\*\": Error downloading. Please contact support if this error persists.\n"
},
{
"author": "Theodora Boudale",
"body": "Hi Peter,\n\nWe'll need to check the build logs and runner logs to investigate, so I suggest creating a ticket with the support team for this issue. The support ticket will be visible only to you and Atlassian staff, so anything you post there won't be publicly visible.\n\nYou can create a ticket via <https://support.atlassian.com/contact/#/>, in \"What can we help you with?\" select \"Technical issues and bugs\" and then Bitbucket Cloud as product. When you are asked to provide the workspace URL, please make sure you enter the URL of the workspace that is on a paid billing plan to proceed with ticket creation.\n\nPlease feel free to let me know if you have any questions.\n\nKind regards, \nTheodora\n"
}
]
},
{
"author": "Peter",
"body": "Is there a possibility that this could lead to data exfiltration since runner now communicates directly with file storage in AWS S3 \n\nWe're using self hosted runners\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Runner-upgrade-to-3-0/qaq-p/2806253
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "mbazli7",
"title": "Bitbucket not display image from a Markdown",
"body": "Hi,\n\nI noticed since yesterday that my Bitbucket cloud not render any image from Markdown file even though the image file exists and can be viewed when clicking on the image itself.\n\nI'm using this method to render the image from the Markdown file (README.md)\n\n```\n\n```\n\nThe path used in the Markdown never changed and its work before. Any idea why this happen?\n\nThanks!\n"
}
|
[
{
"author": "Ben",
"body": "Hi [@mbazli7](/t5/user/viewprofilepage/user-id/4169250) [@Samuel Tan](/t5/user/viewprofilepage/user-id/5587109)\n\nThank you for bringing this to our attention. A few other users have reported this same issue, and we escalated it to our engineering team for further investigation.\n\nA root cause is believed to have been found, and a deployment to fix the issue is currently in progress.\n\nWe will keep you posted once we have have further updates.\n\nRegards,\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": [
{
"author": "mbazli7",
"body": "Hi Ben,\n\nI would like to inform that the issue has been resolved on my side. Images appear again in the Bitbucket repo.\n\nThanks!\n"
}
]
},
{
"author": "Samuel Tan",
"body": "I also facing this issue, should be a bug from bitbucket cloud\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Bitbucket-not-display-image-from-a-Markdown/qaq-p/2806128
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Buday_Gergely_Istvan",
"title": "How can I re-enable Bitbucket issues in an Atlassian workspace?",
"body": "<https://support.atlassian.com/bitbucket-cloud/docs/understand-bitbucket-issues/> writes that\n\n\\> Bitbucket issue tracker is not available in all workspaces\n\n\"Issue Tracker is not supported in workspaces administered through admin.atlassian.com. The Issue Tracker and issues will be disabled when you create or following a transfer to a workspace administered through admin.atlassian.com. \\*\\*If you have already transferred the repository, you can transfer it back to the original workspace to regain access to the issues.\\*\\* Issues can be exported as a zip file or migrated to Jira.\"\n\nHow can I transfer a repository \"back\" so that I would have a Bitbucket issue tracker?\n"
}
|
[
{
"author": "Syahrul",
"body": "G'day, [@Buday_Gergely_Istvan](/t5/user/viewprofilepage/user-id/5175410)\n\nUnfortunately, there are no features to revert to the old workspace. Instead, I suggest you use Jira as it has a free plan that can be utilised up to 10 users.\n\nCheck them out at:\n\n<https://www.atlassian.com/software/jira/pricing>\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/How-can-I-re-enable-Bitbucket-issues-in-an-Atlassian-workspace/qaq-p/2805870
|
[
"cloud",
"issue",
"issue-create"
] |
{
"author": "geoff_roddick",
"title": "Bitbucket Pipeline build a pyinstaller binary",
"body": "I am looking to use a pipeline to build my python project, but it doesn't look like I can have it build my python project using pyinstaller targeting macOS x86 - is this correct?\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi Geoff and welcome to the community!\n\nPipelines builds on Atlassian's infrastructure run on a Kubernetes cluster of Linux Docker hosts. Every step of the build runs in a separate Docker container, and you can specify the Docker image used for each step.\n\nIf your build needs to run on macOS, this is not currently supported on Atlassian's infrastructure. However, if you have a Mac where you can run builds, you can use a macOS self-hosted runner:\n\n* <https://support.atlassian.com/bitbucket-cloud/docs/runners/>\n* <https://support.atlassian.com/bitbucket-cloud/docs/set-up-runners-for-macos/>\n\nRunners allow you to run builds in Pipelines on your own infrastructure. You'll be able to see build logs on the repo's page on Bitbucket's site, and you won't be charged for the build minutes used by your self-hosted runners.\n\nWe have the following feature request for supporting macOS builds on our own infrastructure:\n\n* <https://jira.atlassian.com/browse/BCLOUD-22154>\n\nKind regards, \nTheodora\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Bitbucket-Pipeline-build-a-pyinstaller-binary/qaq-p/2805869
|
[
"bitbucket-cloud",
"bitbucket-pipelines",
"cloud",
"python"
] |
{
"author": "HarryBroeders",
"title": "Link to pdf on wiki causes ERR_TOO_MANY_REDIRECTS",
"body": "All links on my wiki's which point to documents (.pdf or .docx) don't work anymore. They all produce an ERR_TOO_MANY_REDIRECTS error. Please help.\n\nExample link:\n\n<https://bytebucket.org/HR_ELEKTRO/rts10/wiki/LEGv7/LEGv7-Pinky_ebook.pdf>\n"
}
|
[
{
"author": "Ben",
"body": "Hi [@HarryBroeders](/t5/user/viewprofilepage/user-id/2232471) [@baroy](/t5/user/viewprofilepage/user-id/5586836) [@VersD](/t5/user/viewprofilepage/user-id/5586829)\n\nThank you for bringing this to our attention. A few other users have reported this same issue, and we escalated it to our engineering team for further investigation.\n\nA root cause is believed to have been found, and a deployment to fix the issue is currently in progress.\n\nWe will keep you posted once we have have further updates.\n\nRegards,\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": [
{
"author": "HarryBroeders",
"body": "Thanks, the problem is fixed now.\n"
},
{
"author": "Ben",
"body": "Thankyou for the confirmation [@HarryBroeders](/t5/user/viewprofilepage/user-id/2232471) ! :)\n\n- Ben (Bitbucket Cloud Support)\n"
}
]
},
{
"author": "baroy",
"body": "I am experiencing the same issue on wiki documents and images.\n",
"comments": null
},
{
"author": "VersD",
"body": "I second this. Things like pictures also don't load. Seems to be a CSP configuration error on the bytebucket server?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Link-to-pdf-on-wiki-causes-ERR-TOO-MANY-REDIRECTS/qaq-p/2805825
|
[
"bitbucket-cloud",
"cloud",
"wiki"
] |
{
"author": "isiljanovski",
"title": "Did a Bitbucket creation process change and became centralized with Jira?",
"body": "I'm an Atlassian admin in my team and responsible for setting up new workspaces. This week I tried to create a workspace following my usual steps (creating frim Bitbucket), but found out that the 'Create Workspace' button disappeared and now I need to create a new workspace from Jira/Atlassian site.\n\nAnd as I do it, it's unclear how Bitbucket workspace permissions\n\n* 'can administer all workspaces, projects and repository settings' enabled/disabled\n* 'can create projects for this workspace' enable/disable\n* user will be assigned Write access on all future repos\n\ntranslates to only 2 new permissions:\n\n* Create\n* Admin\n\nCan anybody please help me to understand what happened, is it only me who sees the change (maybe I did something wrong)?\n\nThanks!\n"
}
|
[
{
"author": "Syahrul",
"body": "*G'day, [@isiljanovski](/t5/user/viewprofilepage/user-id/4209906)*\n\n*Welcome to the community!*\n\nI understand how there might be some confusion, and I'm happy to provide additional context.\n\nWith the integration of the new workspace and Admin Hub, you no longer need to grant permissions at the workspace level. Instead, user and group management is handled within each project, allowing you to organize users based on the projects they are working on.\n\nIn summary, you grant groups a product access through the Admin Hub, create a project within the Bitbucket workspace, and then assign the groups to that project with the necessary read, write, or admin permissions. Please refer to our documentation below for detailed information on project permission levels:\n\n[Configure project permissions for users and groups](https://support.atlassian.com/bitbucket-cloud/docs/configure-project-permissions-for-users-and-groups/)\n\nIf you require more explanation please raise a support ticket with us in our [Support portal](https://support.atlassian.com/contact)\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Did-a-Bitbucket-creation-process-change-and-became-centralized/qaq-p/2805591
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Yossi Geretz",
"title": "Error on workspace creation, but then workspace is already taken on second attempt!",
"body": "I'm getting an error on workspace creation but then I'm finding that on a subsequent attempt, the feedback reports that the workspace is already taken. I'm rapidly burning through all of the names I'd like to reasonably give my workspace, but the most pressing issue is that I'm not able to create a workspace and very little direction is provided in the feedback to let me know what is the problem, and how I can mitigate it.\n\nThanks for any help which you can provide!\n\n\n"
}
|
[
{
"author": "Theodora Boudale",
"body": "Hi Yossi and welcome to the community!\n\nApologies for the inconvenience caused by this. There seems to be a bug when a workspace is created from this page and we are looking into this.\n\nIn the meantime, if you want to create another workspace, you can do it from <https://admin.atlassian.com/> to avoid these errors.\n\n1. Open <https://admin.atlassian.com/>\n2. Select an Atlassian organization on this page (in case you are a member of multiple orgs)\n3. Select **Products** from the top menu\n4. Select the option **Add product** near the top right corner\n5. Select **Bitbucket**, and then provide the workspace details on the next page\n\nKind regards, \nTheodora\n",
"comments": null
},
{
"author": "Yossi Geretz",
"body": "BTW, when I go to to <https://bitbucket.org/blahdeblahbla> the workspace is there! So the workspace is actually created.\n\nIt routes me to <https://bitbucket.org/blahdeblahbla/workspace/overview/>\n\nSo my workspace which I need has actually been created (the blahdeblahbla workspace was just an example) and I have no idea why I was getting the failure message for every workspace. Annoying, but hopefully I can move past it.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Error-on-workspace-creation-but-then-workspace-is-already-taken/qaq-p/2805528
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Nan_Zhang",
"title": "Get users and groups from workspace",
"body": "Is there a way to get all of the users and groups in Bitbucket org using RestAPI version 2?\n\nThere is a /members endpoint but it doesn't return the user's email address, only the name and display name and uuid. And the /users/{select_user} endpoint doesn't return email address either and it requires the user id which the response from /members endpoint doesn't contain.\n\nI see that /groups endpoint in version 1 and it returns the groups but version 1 is not supported and this endpoint is not supported in version 2.\n"
}
|
[
{
"author": "Syahrul",
"body": "G'day, [@Nan_Zhang](/t5/user/viewprofilepage/user-id/5586247)\n\nWelcome to the community!\n\nOur API endpoint doesn't return user email addresses, but you can export the list from your workspace \\> User directory.\n\nWe have an existing feature request to add an email address in the API response; please Vote and Watch them to receive an update at:\n\n<https://jira.atlassian.com/browse/BCLOUD-22643>\n\nRegards, \nSyahrul\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Get-users-and-groups-from-workspace/qaq-p/2805684
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "Griffin Katrivesis Brown",
"title": "Contact Support for Garbage Collection",
"body": "Hi,\n\nI uploaded to many large files to my repo and have now set back those commits but now need to [contact our Support team](https://support.atlassian.com/contact/#/) to run GC for me and I can't seem to find out how to do that.\n"
}
|
[
{
"author": "Ben",
"body": "Hi [@Griffin Katrivesis Brown](/t5/user/viewprofilepage/user-id/5586441)\n\nWelcome to the Bitbucket Cloud community! :)\n\nI've just executed a gc against the repository and it has reduced the size from 2.9GB to 392MB.\n\nPlease double check this on your end, hopefully this helps :)\n\nCheers!\n\n- Ben (Bitbucket Cloud Support)\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bitbucket-questions/Contact-Support-for-Garbage-Collection/qaq-p/2805803
|
[
"bitbucket-cloud",
"cloud"
] |
{
"author": "revathink",
"title": "Unable to link crucible to jira cloud",
"body": "I have only started , I cannot get this working. When I create application link to jira, I get the below error (image 1). Then if i continue anyways and create one manually at both crucible and Jira. image 2 is what i am seeing on crucible end.\n\n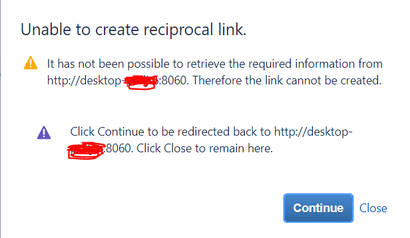\n\n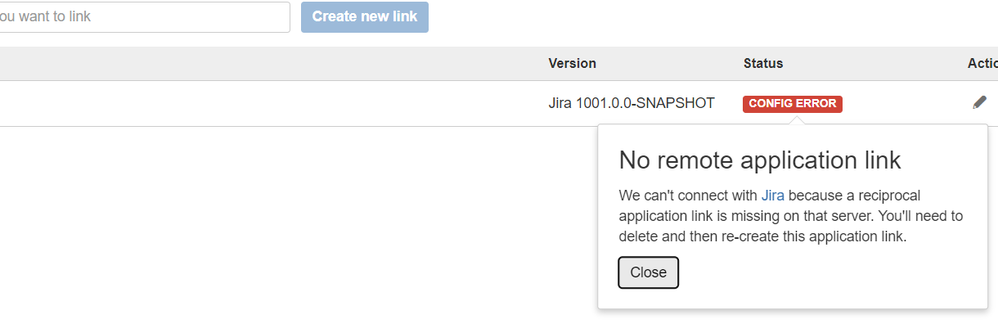\n\non jira end\n\n\n\n\n\nI am stuck and not sure what to do. Any help is much apreciated. Thanks\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "A 503 error means that Jira tried to reach your Fisheye/Crucible, and was successful in the sense that something responded with \"I'm here\", but it got no further, Fisheye/Crucible did not respond further.\n\nThis means that either Fisheye/Crucible has failed (check the service is running) or that it is running on a service that is not set up to be fully accessible to the internet (which is where Jira Cloud is running from)\n\nA very quick test - can you get to Fisheye Crucible on your computer, and see if that 503s. If it works ok, then try exactly the same url from an address outside your network - go to a coffee shop or internet cafe, or shared workspace and try to log into it (without using any VPNs)\n",
"comments": [
{
"author": "revathink",
"body": "Crucible is running on my computer and the url i am accessing for crucible is localhost. There is no error on 503 when i try to access cruible alone. The jira is not behind vpn or anything nor is crucible. I thought it might be firewall issue. I have also added rule to firewall. That did not help either.\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "Localhost means \"this computer\", you can't get to it from a remote computer.\n\nYou will need to turn your local installation into a server, and put it somewhere that Atlassian Cloud can access it.\n\nYou can do this with your current machine if you want, \"server\" just means \"computer that runs a service for other computers to talk to\" in this answer. To do that, you will need to\n\n* Work out what your current external IP address or domain name is\n* Make sure the outside world can see it on the internet\n* Route incoming connections to your Fisheye/Crucible server\n* Run your Fisheye/Crucible on the external IP address or domain name (change the base url)\n\nAs an example, I run some Atlassian stuff at home.\n\n* My home has a router, and the internet knows the IP for it, so when I'm away from home, I can use that IP address to connect to my router.\n* My router knows to pass all inbound HTTPS traffic to a machine that is running a proxying web server.\n* My web server proxies my Atlassian from their servers (running on other machines) to relevant URLs, so that I can say:\n\nhttps://\\<my home ip address\\>/jira\n\nhttps://\\<my home ip address\\>/confluence\n\nand so-on\n"
}
]
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Unable-to-link-crucible-to-jira-cloud/qaq-p/1897660
|
[
"integration"
] |
{
"author": "Marilynn Zayan",
"title": "Crucible/Fisheye AWS EC2 Instance Size",
"body": "What is the recommended instance type for a Crucible/Fisheye deployment on EC2?\n\nAlso, I would like to confirm that Crucible/Fisheye does not support clustering/scaling above 1 node.\n"
}
|
[
{
"author": "Marek Parfianowicz",
"body": "There is no single answer for this as it really depends on your requirements.\n\nYou have to answer yourself the following questions:\n\n\\* how many repositories do I expect to index? - this will affect disk space and disk IO required \n\\* how quickly new repositories will be added? - this will affect number of initial indexing threads and amount of RAM \n\\* how frequently I need to check for new updates in repositories, how many commits are being pushed between checks, how large are they? - this will affect number of incremental indexing threads, amount of RAM and CPU speed\n\n\\* how many users will be stored in a directory? how many active (licensed) users will be? how many concurrent users I expect? - this will affect CPU speed, database connection pool size, RAM requirements\n\nI suggest to experiment, e.g. spin up a test instance and fill with some test data (real or synthetic).\n\nThe general advice I can give is:\n\n\\* if you do not expect heavy load on the instance, the m5.xlarge with SSD disk might be sufficient and will not cost you too much\n\n\\* if you expect heavy load and seek for maximum performance, consider c5.xlarge or bigger with high IOOPS SSD disk (e.g. io2)\n\nFor example, a few years ago we tested indexing of a Linux kernel code repository. It took about 2 weeks to complete on M4, while it finished in just 3 days on C4.\n\n<br />\n\nHaving said this, I strongly encourage to run your own tests, as this will strongly depend on usage patterns.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Crucible-Fisheye-AWS-EC2-Instance-Size/qaq-p/1893483
|
[
"server"
] |
{
"author": "Robin Hochteil",
"title": "Where in Jira database tables is fisheye link information stored",
"body": "We are connected to Fisheye from Jira. If I hover over the commit header, I can see a link to my info in fisheye. Where is this link stored in Jira? What table? I have looked thru all the documentation I can find and there is no reference to what plugin table in Jira contains this information.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Jira connects to Fisheye to get some of the information, and it indexes some of it.\n\nSo some, possibly all, of what you see on screen is not held in the database.\n\nI would want to question what problem you are trying to solve with this. Reading a Jira database is almost certainly the worst possible way to do whatever it is, so we may be able to point you at something that will work better! (Or even just work)\n",
"comments": [
{
"author": "Robin Hochteil",
"body": "The project in one instance of Jira is being moved to another instance of Jira where the fisheye plugin is not being allowed. So we need to pull those links in from the legacy site and put them into the target Jira instance remotelink table as plain links.\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "Ok, the best thing to do would be to read the current Jira over REST, getting the development data. You may then need to read Fisheye to get all of what you need. Then, post-migration, poke the remote link data into the moved issues over REST (I can't recommend touching the database - it often fails, and leaves you unsupported)\n"
}
]
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Where-in-Jira-database-tables-is-fisheye-link-information-stored/qaq-p/1864653
| null |
{
"author": "Tommy",
"title": "Is Fisheye version 4.5.3 compatible to Jira version 7.6.6?",
"body": "Hi,\n\nIs Fisheye version 4.5.3 compatible to Jira version 7.6.6?\n\nJira is running with a MySQL database version 5.7.33.\n\nThanks\n\nBest regards\n\nTom\n"
}
|
[
{
"author": "Steffen Opel _Utoolity_",
"body": "Hi [@Tommy](/t5/user/viewprofilepage/user-id/4639415) - welcome to the Atlassian Community!\n\nAccording to the [Fisheye 4.5 supported platforms documentation](https://confluence.atlassian.com/fisheye045/getting-started/supported-platforms), you are good to go:\n> Fisheye to Jira communication requires Jira 6.4.x or later. Communication the other way, from Jira to Fisheye, depends on the Jira Fisheye Plugin.\n>\n> Note that the Jira Fisheye Plugin is bundled with Jira. If you are using a version of Jira earlier than Jira 6.4 you can upgrade the plugin in Jira to get support for Fisheye.\n\nCheers, \nSteffen\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Is-Fisheye-version-4-5-3-compatible-to-Jira-version-7-6-6/qaq-p/1864130
|
[
"jira",
"mysql"
] |
{
"author": "Kalvin G?hring",
"title": "Docker Images For Fisheye/Crucible Are Out of Date",
"body": "Good day,\n\nAfter receiving the vulnerability notification this morning I went to update our Atlassian products to find that [crucible docker images](https://hub.docker.com/r/atlassian/crucible) are no longer being updated from versions 4.8.6. Is it possible to get the official images updated to the fixed version 4.8.8 mentioned in this article:\n\n<https://confluence.atlassian.com/security/multiple-products-security-advisory-unrendered-unicode-bidirectional-override-characters-cve-2021-42574-1086419475.html>\n\nKind regards,\n\nKalvin G.\n"
}
|
[
{
"author": "Daniel Eads",
"body": "Hi [@Kalvin G?hring](/t5/user/viewprofilepage/user-id/2384610) ,\n\nWe pushed 4.8.8 to Docker hub a couple days ago - just wanted to make sure you saw. Running **docker pull atlassian/crucible:latest** will currently pull the 4.8.8 ubuntu image.\n\nCheers, \nDaniel \\| Atlassian Support\n",
"comments": [
{
"author": "Kalvin G?hring",
"body": "Hi [@Daniel Eads](/t5/user/viewprofilepage/user-id/1527694)\n\nI had not seen the updates so thanks for checking in with me. I have updated and all looks good.\n\nThanks, \nKalvin G.\n"
}
]
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Docker-Images-For-Fisheye-Crucible-Are-Out-of-Date/qaq-p/1851361
|
[
"cve-2021-42574",
"docker",
"server"
] |
{
"author": "Balaji Rathakrishnan",
"title": "Atlassian Fisheye service would not start on Windows 10",
"body": "Hi,\n\nI just installed Fisheye.\n\nI have already installed Java on a folder (under my /Users/\\<username\\> folder) which doesn't have spaces.\n\nWhen I open in localhost:8060, it doesn't work.\n\nWindows Service Control Manager shows 'Atlassian Fisheye' service, but when I start it, it fails with the message:\n\n\"The Atlassian Fisheye service terminated with the following service-specific error: \nIncorrect function.\"\n\nCan someone help how to troubleshoot this?\n\nThanks,\n\nBalaji\n"
}
|
[
{
"author": "Balaji Rathakrishnan",
"body": "I think the issue was that I had installed Fisheye and Java in the users folder. When I installed both Java and then Atlassian in the root folder of the OS drive, Fisheye started working.\n\nBalaji\n",
"comments": null
},
{
"author": "Naveed ullah khan",
"body": "I am also facing the same issue, please do suggest for solution\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Atlassian-Fisheye-service-would-not-start-on-Windows-10/qaq-p/1846575
| null |
{
"author": "Robbin Bonthond",
"title": "NullPointerException",
"body": "crucible (4.8.6) seems to be having issues with a particular changelist from perforce, any suggestions here?\n\nTue Oct 26 14:46:28 GMT 2021: Repository paused due to error com.cenqua.fisheye.perforce.client.P4ClientException: \\[p4.company.com:1666//depot/project\\] Problem executing describe -dn 317587: com.atlassian.utils.process.ProcessException:java.lang.NullPointerException\n"
}
|
[
{
"author": "Suvarna Gaikwad",
"body": "[@Robbin Bonthond](/t5/user/viewprofilepage/user-id/4612264) Welcome to Community. Perforce repo needs to be Unicode. Else you would have to follow below workaround to handle ClientException in Fisheye.\n\n1. Please add the following to the $FISHEYE_INST/system.properties file \n fisheye.ignore.p4.client.errors=true\n2. add the following to the FISHEYE_OPTS environment variable \n -Dfisheye.ignore.p4.client.errors=true\n3. Restart Fisheye\n4. Restart Repository and Reindex\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/NullPointerException/qaq-p/1845832
| null |
{
"author": "Mahmoud Eltahawy",
"title": "New license is not working!!!",
"body": "Hi I have purchased a license yesterday for my server, and when I applied to my server, the admin page says:\n\n**The license key you have entered terminated on September 16, 2021. Please enter a current license key.**\n"
}
|
[
{
"author": "Fabian Lim",
"body": "Hi [@Mahmoud Eltahawy](/t5/user/viewprofilepage/user-id/1071456),\n\nYou should open a support ticket with atlassian support so that they can take a look.\n\nGood luck\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/New-license-is-not-working/qaq-p/1808749
|
[
"server"
] |
{
"author": "Kevin Paulus",
"title": "Where is the Frontpage of my FishEye instance?",
"body": "I have entered custom info into both the Welcome Message and Support message on the FishEye Server (version 4.8.7) Front Page Customization page. No one in our organization has seen or can figure out where this frontpage or support message is. Where is the Frontpage of my FishEye instance? How do we get it to be visible?\n"
}
|
[
{
"author": "Steffen Opel _Utoolity_",
"body": "Good question - according to [Customizing the front page](https://confluence.atlassian.com/fisheye/customizing-the-front-page-960155656.html), both messages are (only?) *displayed to users when they first log in*.\n\nSo depending on the interpretation of 'first log in', I could imagine that this is literally just once, and possibly not even that in typical Enterprise single sign-on scenarios where you may not even need to actively log in at all.\n\n* Random data point: While we presumably have an SSO setup, I oddly still managed to log out and log back in via the Fisheye login form, and indeed didn't see either message despite being configured.\n",
"comments": [
{
"author": "Kevin Paulus",
"body": "Thanks Steffen; \nWe don't use SSO in this instance \\& in the 3 years since we set this one up, no one has seen the FishEye/Crucible \"Front Page\" I have a second instance with the same problem -- except its been more than 5 years. I am thinking there must be a setting at install that bypasses this page.\n"
}
]
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Where-is-the-Frontpage-of-my-FishEye-instance/qaq-p/1781028
|
[
"server"
] |
{
"author": "Derek Halvey",
"title": "Cannot upgrade SAML SingleSignOn for Fisheye/Crucible",
"body": "I cannot see the 'Update' button to upgrade *SAML SingleSignOn for Fisheye/Crucible* from version 2.4.7 to version **2.5.9**. I have also tried installing the app from a downloaded .obr file via the marketplace but that did not install (it just hung on installing).\n\n\n\nWe are on Fisheye/Crucible version 4.8.1 (Server). Does anyone have any advice on how I can upgrade *SAML SingleSignOn for Fisheye/Crucible*?\n"
}
|
[
{
"author": "Derek Halvey",
"body": "Resolved after upgrading to Fisheye 4.8.7.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Cannot-upgrade-SAML-SingleSignOn-for-Fisheye-Crucible/qaq-p/1768139
| null |
{
"author": "John Efstathiades",
"title": "Fisheye support for Perforce 2020.x and above",
"body": "The Fisheye [supported platforms page](https://confluence.atlassian.com/fisheye/supported-platforms-960155252.html) lists Perforce 2018.x and 2019.x but not later versions. Will support for newer versions of Perforce be added to upcoming Fisheye releases?\n\nThanks, \nJohn\n"
}
|
[
{
"author": "Marek Parfianowicz",
"body": "Hi John! I raised a feature request for this: <https://jira.atlassian.com/browse/FE-7373>. I can't give you ETA at the moment, feel free to add yourself as a watcher of the issue to receive notifications.\n\nFrom my experience, we had no compatibility issues with Perforce for years, so there's a high chance that current version of Fisheye will index Perforce 2020.x correctly. You might want to try. Having said this, please keep in mind that our Atlassian support team might not be able to help you in case of troubles, as this is an unsupported version.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Fisheye-Crucible-questions/Fisheye-support-for-Perforce-2020-x-and-above/qaq-p/1765802
|
[
"perforce"
] |
{
"author": "Richard_Donnell",
"title": "Roadmap Question: Adminy data?",
"body": "Thinking about easier ways to manage\\\\govern instances in Jira with data on Custom Fields definitions, Projects, Issuetypes, stuff like that.\n\nIs that on the roadmap?\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi Richard,\n\nAtlassian Data Lake already includes data on the parts of Jira you described - custom fields, projects, issue types, and more.\n\nYou can check out the full schema documentation here: <https://support.atlassian.com/analytics/docs/schema-for-jira-family-of-products/>.\n\nLet me know if you have further questions.\n",
"comments": [
{
"author": "piotr.x.zyrek",
"body": "I think Richard meant to access the dictionaries of these parts (statuses, issue types etc) to better manage them. I am also looking for this.\n\nNow in the schema there are indeed the above parameters, but they refer to the issues in which these parameters were used.\n\nIf in my project we have 10 statuses available, and only 3 of them are used then I am not able in the current schema to show which statuses are available in which project.\n"
},
{
"author": "Richard_Donnell",
"body": "yeah, exactly this - I am using a combination of analytics and the PowerBI connector plug in (great add on) to get lists of stuff to focus my substantial Jira tidy up campaign.\n\nEdit: so, for example, it would be good to pull out the data shown on the custom field definition screen in the Administrative section of the tool - what the field looks like, radio buttons, text field etc\n"
},
{
"author": "Tracy Chow",
"body": "Thanks for the additional context on your question. The way the Data Lake tables are currently built, only Jira issue types and custom fields etc that *are* being used are populated in the tables. So while you can identify fields with low usage, you won't be able to identify those with no usage.\n\nI definitely understand your use case though for administrative purposes. Your feedback has been shared with our product and data team to consider for future iterations of the Atlassian Data Lake schema.\n"
},
{
"author": "Richard_Donnell",
"body": "Hi [@Tracy Chow](/t5/user/viewprofilepage/user-id/4461730) - thanks for responding. Yes, I am using the Analytics data to identify low usage fields very successfully. I am cross referencing with data from Alpha Serves PowerBI connector to find defined fields with no usage, that tool has a table specifically for the field definition, whereas Analytics, as you point out, is a value based approach, multiple rows containing the individual value of the field linked to the ticket.\n\nNeither tool gives me 100% of the picture, including an understandable definition of the field as displayed on the custom field administration pages.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Roadmap-Question-Adminy-data/qaq-p/2339043
| null |
{
"author": "Javier Pascual arribas",
"title": "Alg?n experto de atlassian cerca de Segovia que pueda hecharme una mano?",
"body": "Mi n?mero es 646864198 si es as? poneos en contacto con migo, gracias un saludo.\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi Javier,\n\nCan you clarify what you need help with, or if you have a particular question about Atlassian Analytics?\n\nLook forward to hearing from you.\n\nThanks, \nTracy\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Alg%C3%BAn-experto-de-atlassian-cerca-de-Segovia-que-pueda-hecharme/qaq-p/2334848
| null |
{
"author": "Luis Crespo",
"title": "Is there a way to bring in parent field or epic link into the datalake?",
"body": "Trying to display the parent field or epic link as a column into my chart but cannot see this as part of my schema.\n"
}
|
[
{
"author": "Talar Pavlovic",
"body": "Hey there Luis,\n\nThanks for writing into the Atlassian Analytics Community, I'm Talar from the Atlassian team, happy to help.\n\nThere absolutely is - let me direct you over to our how-to guide here: <https://confluence.atlassian.com/analyticskb/query-parent-and-child-issues-from-jira-1206787653.html>\n\nRegards, \nTalar\n",
"comments": [
{
"author": "David Green",
"body": "Talar I followed the above instructions for linking parent and child but I have a issue with the first query. Namely that i can get a PARENT value for stories to Epics but I cannot get one for Epics to Initiatives. I have added the Initiative Project into my Projects drop down filter, and the initiative shows up in my SQL results, and the Epic I'm trying to find a parent for has a parent Initiative in JIRA, so where is that link stored in the Enterprise Data Lake? \n\nHere's my SQL... \n\nSELECT \\`Issue\\`.\\`issue_key\\` AS \\`Issue key\\`, \n\\`Issue field\\`.\\`name\\` AS \\`Issue field Name\\`, \n\\`Issue field\\`.\\`value\\` AS \\`Value\\`, \n\\`Project\\`.\\`name\\` AS \\`Project Name\\`, \n\\`Issue\\`.\\`issue_type\\` AS \\`Issue type\\` \nFROM \\`jira_project\\` AS \\`Project\\` \nINNER JOIN \\`jira_issue\\` AS \\`Issue\\` \nON \\`Issue\\`.\\`project_id\\` = \\`Project\\`.\\`project_id\\` \nLEFT JOIN \\`jira_issue_field\\` AS \\`Issue field\\` \nON \\`Issue field\\`.\\`issue_id\\` = \\`Issue\\`.\\`issue_id\\` \n-- AND (\\`Issue field\\`.\\`name\\` = 'Parent') \nWHERE {PROJECT_ID.IN('\\`Project\\`.\\`project_id\\`')} \nAND {ISSUE_TYPE.IN('\\`Issue\\`.\\`issue_type\\`')} \nAND \\`Issue\\`.\\`issue_key\\` = 'APPGG-999' \nORDER BY \\`Issue field\\`.\\`name\\` ASC \nLIMIT 100000; \n\nNote that if I test this on a story I DO get the Epic parent value.\n"
},
{
"author": "David Green",
"body": "actually I just found this - <https://support.atlassian.com/jira-software-cloud/docs/upcoming-changes-epic-link-replaced-with-parent/> \n\nWhen will this be done?\n"
},
{
"author": "Talar Pavlovic",
"body": "Hey there David,\n\nWhat you're seeing would be expected - we don't support parent hierarchy data above Epics just yet, but there should be an update posted in Community in the next week or so on this.\n\nRegards, \nTalar\n"
},
{
"author": "David Green",
"body": "Thanks Talar. I'm loving Analytics BTW. I followed the instructions above for getting Parent but I found just doing everything in SQL is far easier than the Visual mode especially as I used to be a SQL Dev :-) \n\nThere are a few other things in the schema that I can't find ie I can't seem to find any way of getting to the 'Team' in an Issue. Are there more tables to be added to the lake at some point or am I missing something?\n"
},
{
"author": "Talar Pavlovic",
"body": "So very glad to hear you're enjoying Analytics!! And it sounds like a \"welcome home\" (back to SQL world) is in order haha\n\nRe Custom Fields, this doco should help you find what you're looking for: <https://confluence.atlassian.com/analyticskb/query-jira-custom-fields-1188411074.html>\n\nIf you're not seeing the data you should be (and the projects with this field are enabled for Analytics), please [pop in a ticket](https://support.atlassian.com/contact/) so we can take a look at your data specifically and help out.\n\nRegards, \nTalar\n"
},
{
"author": "Talar Pavlovic",
"body": "[@David Green](/t5/user/viewprofilepage/user-id/4858396) - a correction from my response yesterday.\n\nAlthough that doco does detail the way to get *most* custom fields, the \"Team\" field is not yet available in the data lake yet. We do have a Feature Request for it to be added - <https://jira.atlassian.com/browse/ANALYTICS-27>\n\n- Talar\n"
},
{
"author": "David Green",
"body": "Thanks Talar,\n\nThe custom fields are easy - \n\nLEFT JOIN jira_issue_field AS IFS \nON IFS.issue_id = ISS.issue_id \nAND IFS.name = 'Sponsor' \nhistory requires a aggregation to get the latest value - \n\nLEFT JOIN (SELECT \nissue_id \n, MAX(TRY_CAST(value AS DATE)) AS value \nFROM jira_issue_history \nWHERE field = 'Start date' \nGROUP BY issue_id \n) AS IHS \nON IHS.issue_id = ISS.issue_id \nalso interesting to note is that I have to use TRY_CAST because for some reason Start date is in the format YYYY-MM-DD whereas every other date field is the long DATETIME format :-\\| \n\nAnd one last thing - history has a couple of extra fields that would be handy - like Tempo account and Tempo team. However these are only in history if someone actually changed the field (obviously). I notice that there is no history for these in an issue IF the issue was cloned from a previous issue that did have these values in history (which is fair enough given they were not changed in the clone). \n\nI'm going to try recursion to go back down the chain of clones in history (using the Link name and searching for 'this issue clones' in value) until I got to the one where these values were added :-) if I can remember how!\n"
},
{
"author": "David Green",
"body": "No recursive CTEs in apache spark sql :-(\n"
},
{
"author": "Talar Pavlovic",
"body": "Hey there David,\n\nTempo data in the Atlassian data lake is a feature request <https://jira.atlassian.com/browse/ANALYTICS-70>\n\nRe the recursive CTE's - is the goal here to use recursive CTEs to get the parent/child relationships? Is so, this may not be possible anyway until we get some more data / fields added to the tables.\n\n-Talar\n"
},
{
"author": "David Green",
"body": "Yes. I want to find the Tempo 'account' field in an Epic (under the Tempo tab). This isn't doable in the jira_issue table because this field isn't in the datalake (yet). \n\nI can however find it in Jira_issue_history table when it's been changed either by the user or the jira bot adding it in if the Epic was added to an account in Tempo. BUT... if an Epic is cloned then the account field may have been changed in the Epic the current Epic was cloned from. \n\nSo I need to scan down the jira_issue_history table to get the previous epic that the current one was cloned from and see if account was changed in that Epic. That part is easy. But there are clones of clones of clones, so I need to do a recursive search until I get back to original epic that DOES have the account value change. Hence the need for recursion. \n\nI did it the hard way instead (up to 5 repeat clones) cumbersome but it works :-\\|\n\n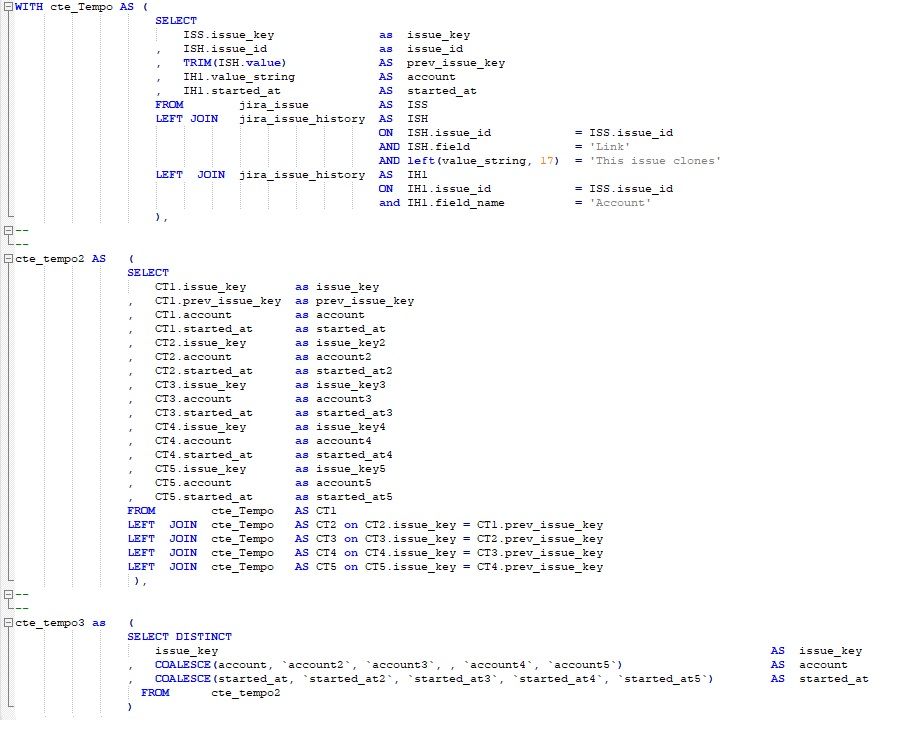\n"
}
]
},
{
"author": "David Green",
"body": "OK so I managed to get the desired result but there was a lot of jiggery-pokery. I ran it all past ChatGPT and he/she/they/them couldn't help either. We are stymied on a couple of things. The main one being unable to create temporary tables (which solves the problem of non-recursive CTEs). \n\nIs there a reason why we can't CREATE anything in Spark SQL in Analytics?\n",
"comments": [
{
"author": "Talar Pavlovic",
"body": "Hey David,\n\nYes indeed - CREATE is one of the restricted SQL commands in Analytics. Take a look here to see the others: <https://support.atlassian.com/analytics/docs/restricted-sql-commands/>\n\nRegards, \nTalar\n"
},
{
"author": "David Green",
"body": "OK I can understand the need to prevent users from creating objects and other things in Analytics that would damage the integrity of the data structures and/or the data, but unfortunately that limits the usability of the SQL because we can't use the CREATE TEMPORARY TABLE command, which would be very handy (and also can help with performance. \n\nAlthough I note that Spark SQL doesn't allow INSERT INTO so that limits the use of temporary tables somewhat. \n\nIs there a way we can run a python script against the Data Lake so I can do something like the following? - \n\nfrom pyspark.sql import SparkSession # Initialize Spark session spark = SparkSession.builder.appName(\"RecursiveExample\").getOrCreate() # Register the DataFrame as a temporary view initial_df = spark.createDataFrame(\\[(\"your_target_issue_key\",)\\], \\[\"Issue_key\"\\]) initial_df.createOrReplaceTempView(\"InitialView\") \n\n<br />\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Is-there-a-way-to-bring-in-parent-field-or-epic-link-into-the/qaq-p/2336910
| null |
{
"author": "Svante Esbj?rnsson",
"title": "I want to join in Team ID for an Issue ID",
"body": "So, \ntotally new to this tool. \nI have selected a few columns and they appear in my table as I want. Now I want to join in Team ID (or Team Name). When I scroll down I see Team -\\> Team ID under OPSGENIE but I have no idea how to get that into my table... \nsuggestions welcome\n"
}
|
[
{
"author": "Karin van Driel",
"body": "[@Svante Esbj?rnsson](/t5/user/viewprofilepage/user-id/5182929) \n\nWe don't use OPSGENIE in my org, so I don't have any data for that and cannot give you a specific solution for your scenario, but thought maybe this general steer might help.\n\nIf you go into the Data menu and select your data source, you should see a menu item called Schema. Click on that and then click the Visualize button. This should give you a diagram of all your tables, with lines of how they connect to eachother. Find the OPSGENIE data table you mention and see which field has a line going out of it and to which table. If this is a table you use in your query already, you can simply create a join between those tables where OPSGENIE data point = main table data point.\n\nHope that might help you find your answer on how to connect your data...\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/I-want-to-join-in-Team-ID-for-an-Issue-ID/qaq-p/2314695
|
[
"issue",
"team"
] |
{
"author": "piotr.x.zyrek",
"title": "Jira Product Discovery data available in Atlassian Analytics",
"body": "Hey guys,\n\nWe're currently exploring two new products - Atlassian Analytics and Jira Product Discovery.\n\nWe'd like to measure the effectiveness of our discovery process from the moment an idea is registered until the decision to include it in development plans.\n\nIt appears that currently Jira Product Discovery data is not available in Atlassian Analytics. Can you confirm my assumption?\n\nIf this is the case, are there plans to make this type of data available in the data lake?\n\nThanks a lot!\n"
}
|
[
{
"author": "Kevin Minnick",
"body": "Hello, Jira Product Discovery data should be available to add now. You will need to edit any existing connections and add any projects you'd like to see data for. Let us know if you have any questions.\n",
"comments": [
{
"author": "piotr.x.zyrek",
"body": "Lovely, thanks for keeping us updated!\n"
}
]
},
{
"author": "Kevin Minnick",
"body": "Hello, that assumption is correct. However, Jira Product Discovery data is currently being tested internally and should be released soon. I can update this thread when it's available.\n",
"comments": [
{
"author": "piotr.x.zyrek",
"body": "Thanks!\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Jira-Product-Discovery-data-available-in-Atlassian-Analytics/qaq-p/2309737
|
[
"jira-product-discovery"
] |
{
"author": "piotr.x.zyrek",
"title": "DevOps metrics (DORA) in Atlassian Analytics",
"body": "Hi guys,\n\nWe're going to improve our DevOps processes and architecture, for this purpose we are considering using DORA metrics to indicate areas for improvement.\n\n<br />\n\nDORA metrics are the four benchmarks for software teams:\n\n* Deployment Frequency\n* Mean Lead Time for Changes (MLT)\n* Mean Time to Recovery (MTTR)\n* Change Failure Rate (CFR)\n\nI know Atlassian's Compass offers the ability to automatically calculate DORA metrics based on integration with GitHub. Unfortunately, this is only possible with GitHub repositories in the cloud and ours are on the server.\n\nSoI started looking for alternatives and Atlassian Analytics looks promising. For this purpose, in the jira project, we have connected our repositories with GitHub and we can see the number of branches, commits, pull requests, etc. All this information can be found in the \"Development\" field.\n\nI tried to find this information in the tables in Atlassian Analytics, but unfortunately I couldn't find this field.\n\nCan you advise how to access this data? Do you know of any other solutions that would allow us to measure DORA metrics in the Jira environment?\n\nThanks!\n"
}
|
[
{
"author": "Inder Singh",
"body": "Hi [@piotr.x.zyrek](/t5/user/viewprofilepage/user-id/5171900) ,\n\nDevOps data is not available in Atlassian Data Lake but that is something we are actively working on. However, if your data is in a [supported 3rd party database](https://support.atlassian.com/analytics/docs/connect-to-a-third-party-data-source/), then you can try to connect to it directly from within Analytics. You will find details on how to establish the connection in the above link.\n\nAnother option might be to use Jira Software's [DevOps deployment frequency and cycle time reports](https://community.atlassian.com/t5/DevOps-articles/Introducing-Deployment-Frequency-and-Cycle-Time-metrics-in-Jira/ba-p/1616129) (though this will only cover 2 out of 4 DORA metrics).\n\nThanks!\n",
"comments": [
{
"author": "Steven Drury",
"body": "Hey [@Inder Singh](/t5/user/viewprofilepage/user-id/4829066)\n\nYou mentioned this was being worked on, any updates?\n\nThanks, \nSteve\n"
},
{
"author": "Inder Singh",
"body": "Hey [@Steven Drury](/t5/user/viewprofilepage/user-id/5208097)\n\nWe are planning to launch an Early Access Program (EAP) for DevOps data. This will allow you to view data tables related to DevOps in Atlassian Analytics. If you are interested in taking part in this EAP, please let us know via the feedback form in Atlassian Analytics. You can access this form by clicking the help icon on the top right of Atlassian Analytics page and selecting \"Give feedback\". Remember to select the option \"Atlassian can contact me about this feedback\" so that we can get back to you.\n\nPlease note that since this is an EAP, data tables can change based on the feedback that we will be receiving.\n\nThanks,\n\nInder\n"
},
{
"author": "Inder Singh",
"body": "[@piotr.x.zyrek](/t5/user/viewprofilepage/user-id/5171900) [@Steven Drury](/t5/user/viewprofilepage/user-id/5208097) : Devops data tables are now available in Atlassian Data Lake. You can read more about it in this [community post](https://community.atlassian.com/t5/Atlassian-Analytics-articles/DevOps-data-is-now-available-in-Atlassian-Analytics/ba-p/2547451).\n"
}
]
},
{
"author": "Jyo Khan",
"body": "[@piotr.x.zyrek](/t5/user/viewprofilepage/user-id/5171900) Haystack connects with JIRA + Github enterprise - <https://support.usehaystack.io/en/articles/5264860-setup-github-enterprise-self-hosted> to get you dora metrics.\n",
"comments": null
},
{
"author": "Dilan Anuruddha",
"body": "The closest thing I have come up so far for DORA in jira is using <https://linearb.io/>\n",
"comments": [
{
"author": "John Kinmonth",
"body": "Hi Dilan,\n\nLinearB is a good option, but have you also checked out Compass from Atlassian? \n\nStarts auto-populating deployment activity and DORA metrics using one of our GitHub, Bitbucket, or GitLab importers. In addition, it automatically populates your software component catalog to help track all of your services (and critical details about them) in one spot. \n\nIt's got a generous free tier, and we'd love any feedback.\n\n<https://www.atlassian.com/software/compass>\n\n<br />\n\nThanks! \n\n-John\n"
},
{
"author": "Daniel Konold",
"body": "How you get the DORA Metrics into atlassian compass? We are trying it and don't fully get it to work using Bitbucket and Compass, maybe you got an hint or two :)\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/DevOps-metrics-DORA-in-Atlassian-Analytics/qaq-p/2313390
|
[
"atl-gruland"
] |
{
"author": "Don Pierce",
"title": "What are the other databases I can connect to using Atlassian Analytics?",
"body": "Is there a page that points to all the databases that are available to add into Atlassian Analytics?\n"
}
|
[
{
"author": "Matthew Lempitsky",
"body": "The [supported third party data sources](https://support.atlassian.com/analytics/docs/what-is-a-data-source/) include: \n* Amazon Athena\n\n* Amazon Aurora\n\n* Amazon Redshift\n\n* Google BigQuery\n\n* Microsoft SQL Server\n\n* MySQL\n\n* PostgreSQL\n\n* Snowflake\n\n[You can learn more about connecting to third party data sources here](https://support.atlassian.com/analytics/docs/connect-to-a-third-party-data-source/) \n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/What-are-the-other-databases-I-can-connect-to-using-Atlassian/qaq-p/2301595
| null |
{
"author": "Ste Wright",
"title": "Re: Extract data from Atlassian datalake to other solutions",
"body": "Hi [@Aymeric Douyere](/t5/user/viewprofilepage/user-id/4416916)\n\nAs far as I know the Data Lake is in Open Beta - see: <https://www.atlassian.com/platform/analytics/what-is-atlassian-data-lake#what-is-the-atlassian-data-lake>\n\nFor when it will be released, you could check out the [public roadmap](https://www.atlassian.com/roadmap/cloud)? See these specific sections:\n\n* Atlassian Data Lake: [https://www.atlassian.com/wac/roadmap/cloud/atlassian-data-lake?search=data%20lake\\&p=9624c9d0-15](https://www.atlassian.com/wac/roadmap/cloud/atlassian-data-lake?search=data%20lake&p=9624c9d0-15)\n* Data Lake Export: [https://www.atlassian.com/wac/roadmap/cloud/atlassian-data-lake-export?search=data%20lake\\&p=f6a1d2fe-09](https://www.atlassian.com/wac/roadmap/cloud/atlassian-data-lake-export?search=data%20lake&p=f6a1d2fe-09)\n\nSte\n"
}
|
[
{
"author": "Aymeric Douyere",
"body": "Thanks a lot for the quick answer\n\nIndeed I should have checked the roadmap !\n",
"comments": null
},
{
"author": "Jonathan Smith",
"body": "Is anyone in the EAP hooked up to Power BI yet?\n\nI'd like to get some feedback on this feature!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Re-Extract-data-from-Atlassian-datalake-to-other-solutions/qaq-p/2239223
| null |
{
"author": "Aymeric Douyere",
"title": "Extract data from Atlassian datalake to other solutions",
"body": "Hello\n\nHappy new year to all\n\nThanks for the work done on Analytics :)\n\nWe'd like to extract data coming from our platform and stored in the Atlassian datalake if I understood well. I think that today it's not possible, do you know when this feature will be released ?\n\nThank you\n"
}
|
[
{
"author": "Tracy Chow",
"body": "This post accidentally got split into two. Reply located here :) <https://community.atlassian.com/t5/Atlassian-Analytics-questions/Re-Extract-data-from-Atlassian-datalake-to-other-solutions/qaq-p/2239223>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Extract-data-from-Atlassian-datalake-to-other-solutions/qaq-p/2239119
| null |
{
"author": "piotr.x.zyrek",
"title": "How often is the data updated in the data lake?",
"body": "Hello,\n\nI'm using Atlassian Analytics to get some insights regarding our performance.\n\nI'd like to ask how often is the data refreshed in the data lake ?\n\nI created a new ticket in JSM about 4 hours ago but there is still no info about this issue in any of the tables in data lake.\n\nI found the paragraph in the documentation which states: \"Data freshness - These tables rapidly reflect changes in your products, typically within **half an hour.** \"\n\nHowever it does not seem to be the case for me.\n\nThanks!\n"
}
|
[
{
"author": "Riley Venable",
"body": "The frequency of data updates in Atlassian Analytics depends on the cache duration, which varies depending on the dashboard settings. The cache for each chart is updated every 1 hour, 30 minutes, or 24 hours, depending on the dashboard settings, unless someone manually overrides the cache. Additionally, Atlassian Analytics queries all rows in the data source when performing calculations, but only returns up to a certain number of rows for the final result set.\n",
"comments": [
{
"author": "piotr.x.zyrek",
"body": "Thank you very much, this is very helpful. I have my dashboard cache settings set to 30 minutes, so it's not a dashboard refresh issue.\n\nWhen creating a new chart and querying these tables, there is no information there about this ticket created a few hours ago. So I'm afraid we should distinguish between two issues.\n\n1) How fast the data appears in the data lake.\n\n2) How often the dashboard is updated.\n\nThe latter you have explained very well! For some reason, however, this data is still not in the data lake. Do you have any idea what could be the reason?\n"
}
]
},
{
"author": "Jessie Turpin",
"body": "Hey Piotr! Would you mind creating a [support ticket](https://support.atlassian.com/contact/#/) and select Atlassian Analytics as the affected product. This would allow our team to investigate further why your data isn't appearing in the Atlassian Data Lake.\n\nThanks!\n\nJessie\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/How-often-is-the-data-updated-in-the-data-lake/qaq-p/2301149
| null |
{
"author": "Erin Quick-Laughlin",
"title": "Possible to pull succinct changelogs of when Story Points change?",
"body": "We're very new to the AAOB, and would like to pull data specific to the timestamp of when the Story Point field changes, plus what Issue it changes for. Where would we start to find that information? Even a quick pointer to general concepts within AAOB would be helpful to jump start us.\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi [@Erin Quick-Laughlin](/t5/user/viewprofilepage/user-id/4299733),\n\nChange logs for the story point field can be found in the Jira [\"Issue history\" table](https://support.atlassian.com/analytics/docs/schema-for-jira-family-of-products/#Issue-history). You can filter on \"Field name\"='Story Points' and also grab the timestamps of the change and story point values.\n\nI've attached an example of what this could look like.\n\n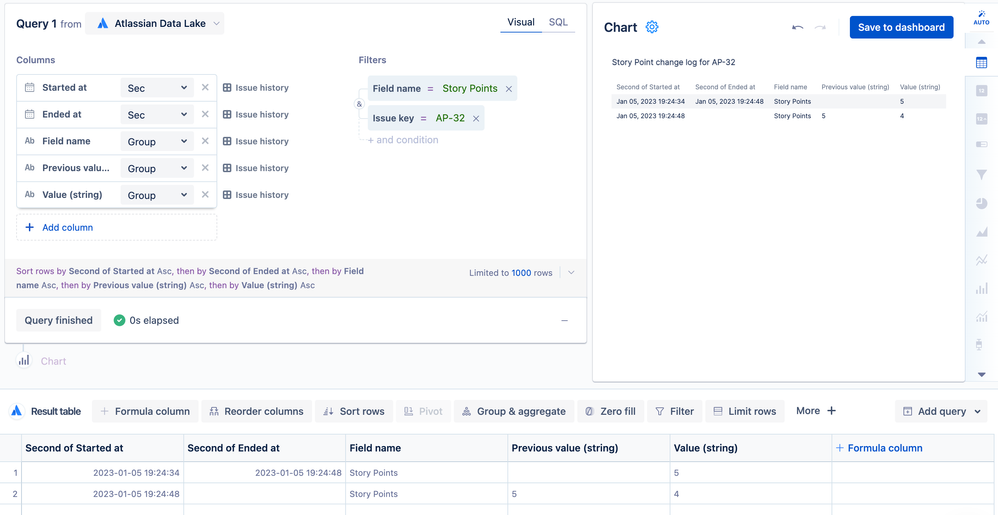\n\nHope this helps! Let me know if you have additional questions.\n",
"comments": [
{
"author": "Erin Quick-Laughlin",
"body": "Thank you so much [@Tracy Chow](/t5/user/viewprofilepage/user-id/4461730) ! I get it now!\n\nNext question: can third party apps connect to the data lake? We'd like to pull results into Domo.\n"
},
{
"author": "Tracy Chow",
"body": "No problem, [@Erin Quick-Laughlin](/t5/user/viewprofilepage/user-id/4299733)!\n\nWe don't support that yet but you can follow this ticket for updates: <https://jira.atlassian.com/browse/ANALYTICS-4>. It's currently on the roadmap: <https://www.atlassian.com/wac/roadmap/cloud/atlassian-data-lake-export?p=f6a1d2fe-09>.\n"
}
]
},
{
"author": "Steve Hooczko",
"body": "How do you access the [\"Issue history\" table](https://support.atlassian.com/analytics/docs/schema-for-jira-family-of-products/#Issue-history). ?\n\nDoes the table hold the history for all tickets within a JIRA Project?\n",
"comments": [
{
"author": "Tracy Chow",
"body": "If you have access to Atlassian Analytics, you can query the table in the Atlassian Data Lake as long as Jira product data is selected in the Data Lake connection.\n\nI believe it captures all changes that show up in the issue history within Jira itself.\n"
}
]
},
{
"author": "Erin Quick-Laughlin",
"body": "Thanks [@Deepak Rai](/t5/user/viewprofilepage/user-id/4482538) , but we're specifically looking for an automated solution using Atlassian Analytics data if possible. We already pull the data we need via a connector to Jira, however we have to pull all change logs, then filter down to just changes for Story Points.\n\nWe'd like to establish a table or dataset in AAOB, that has only the changelog records we need, and connect to that instead.\n\nThis will help us take our automated reporting updates from once a day, to multiple times a day.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Possible-to-pull-succinct-changelogs-of-when-Story-Points-change/qaq-p/2230913
| null |
{
"author": "Marcio C_",
"title": "Can I create Portfolio Management dashboards with AR + AAC ?",
"body": "Thanks for reading. \n\nCurrently, what I know is that the following cannot be achieved with Jira AR. \n\nCreate a single dashboard with % of deviations from schedule and % of deviations from the budget to track Portfolio Management changes live. \n\nThe question is, Would it be possible to achieve the above by using AR + AAC? If so, could you share any information that would help get started? \n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi [@Marcio C_](/t5/user/viewprofilepage/user-id/4580002),\n\nWe don't have Advanced Roadmap data in the Atlassian Data Lake just yet, so it sounds like what you're looking for wouldn't be possible right now.\n\nHere's the feature suggestion ticket: <https://jira.atlassian.com/browse/ANALYTICS-33>.\n\nFeel free to reach out to chat further.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Can-I-create-Portfolio-Management-dashboards-with-AR-AAC/qaq-p/2211226
|
[
"advanced-roadmaps",
"cost"
] |
{
"author": "Adam Kassoff",
"title": "Public Dashboard Viewing",
"body": "Is there a way to make a dashboard publicly accessible to be embedded on another webpage to be viewed by non atlas users? Have dynamic filters set up so they can see Issues related to them or the company they are associated with?\n"
}
|
[
{
"author": "Aaron Geister",
"body": "Hello [@Adam Kassoff](/t5/user/viewprofilepage/user-id/4769810)\n\nTypically I have used an add-on to do this. You can use any logged user but I believe they still need a license to view data.\n\nI know custom charts for Jira made by old street solutions is about to release this feature soon by end of year.\n\nAlso you can use some dashboarding in Confluence. You can leave a page or space public or use guests.\n\nHope this helps.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Public-Dashboard-Viewing/qaq-p/2189403
| null |
{
"author": "Esther Strom",
"title": "Pricing and availability",
"body": "I may have missed this, but has there been any announcement of how the product will be priced and who it will be available to when it's released into production? I had a video chat with a few Atlassian people and was told that because we have Jira Premium and are on Enterprise licensing we will have access at no additional charge.\n\nWe do have sister brands that are not on enterprise; will the Analytics product be available at a cost, or will it only be available to enterprise users?\n"
}
|
[
{
"author": "Sid Bhatia",
"body": "Hi Esther, thanks for reaching out about this. We haven't made any public announcements about pricing yet as we collect EAP feedback and get ready for the next phase of launch. That being said, it's currently available at no additional cost to Cloud Enterprise users of Jira Software or Jira Service Management and will continue to be so in the near future.\n\nWe don't yet have a plan to share that includes a cost model for other editions but are working on how and when non-enterprise users can access Analytics sometime in the new year. Any feedback on this would be greatly appreciated. Thanks!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Pricing-and-availability/qaq-p/2073403
| null |
{
"author": "Krzysztof Achinger",
"title": "Using Atlassian Datalake data in external tools",
"body": "Hello, I was wondering if the feature to use Atlassian Datalake date in external tools (Power BI, Tableau etc.) is available and if not, will it be available and when?\n"
}
|
[
{
"author": "Brant Schroeder",
"body": "[@Krzysztof Achinger](/t5/user/viewprofilepage/user-id/4103008) this is from Atlassian's data lake page \"Near real-time access to data in your BI tool of choice with standardized connectors rather than relying on slow, bulky data export APIs COMING SOON\" <https://www.atlassian.com/platform/analytics/what-is-atlassian-data-lake#why-use-the-atlassian-data-lake>\n\nI would suggest submitting a support issue so as they expand the product you could potentially be used to test new features that you are interested in.\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "Yeah, I thought I heard about that in the EAP but I was not sure, thank you for sharing the page.\n"
},
{
"author": "Tracy Chow",
"body": "[@Krzysztof Achinger](/t5/user/viewprofilepage/user-id/4103008) Here is the Jira ticket you can watch for updates: <https://jira.atlassian.com/browse/ANALYTICS-4>\n\ncc [@Hendrik Thomas](/t5/user/viewprofilepage/user-id/4508181)\n"
}
]
},
{
"author": "Jason Miller",
"body": "We are directly connecting to Atlassian Data Lake through Visual Studio / SSIS but the connection is an old ODBC. We're trying to migrate to a better connection but have not heard back from Atlassian Data Lake Support/team on direction or documentation.\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "I didn't know that any connection is possible at the moment. Anyhow, it sounds like waiting for the official release of the feature is the way to go.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Using-Atlassian-Datalake-data-in-external-tools/qaq-p/2133606
| null |
{
"author": "Krzysztof Achinger",
"title": "Stuck building table with issues list and their linked epics",
"body": "This will be a generic question because I am not even sure how to start. My goal is to build a table with issues and their corresponding Epic Names if the issue is linked to an epic.\n\nI found that some data lives in Jira Issue Field table where I can find Epic Name and Epic Link in the Name column and some values in Value column, however Epic Link corresponding values are some numbers and I am not sure how to make a connection between those numbers and epic names to be displayed in a table.\n\nExample\n\nI have issue ABC-123 that has Epic Link to an epic XYZ-321 with an Epic Name \"Test\". I want a table that displays following columns and corresponding values: \n\n\\| Issue Key \\| Linked Epic Name \\| \n\\| ABC-123 \\| Test \\|\n"
}
|
[
{
"author": "Matthew Lempitsky",
"body": "So I started looking at this, and I believe I have come up with a solution. It looks like the \"value\" for the Issue Link field will be the \"Issue Ref\" value of the Issue. I have created what I hope is what you're after: \n\n\nLet me know if you have any questions or concerns with this approach.\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "[@Matthew Lempitsky](/t5/user/viewprofilepage/user-id/4736217) this is exactly how I wanted it to work. Thank you! I am yet to wrap my head around how Issue Ref links with Value, but it is secondary now. I can move on with building the dashboard. One comment is that I used Join Inner instead of Outer, perhaps because not all my issues have epics linked.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Stuck-building-table-with-issues-list-and-their-linked-epics/qaq-p/2048723
| null |
{
"author": "Hakan Bahadir",
"title": "Flow Metrics",
"body": "Hello,\n\nI saw Flow Metrics Dashboard in one of the demos. Is it available for us also? I created a new data source definition which I was expecting to see new Dashboards to pop up. Is there another way to find the details of Flow Metrics?\n\nThank you\n\nHakan\n"
}
|
[
{
"author": "Inder Singh",
"body": "Hi [@Hakan Bahadir](/t5/user/viewprofilepage/user-id/3641841) : Flow metrics dashboards are now available as part of the dashboard templates. You can access them when you create a new dashboard. Here is the documentation for the flow metrics dashboards: <https://support.atlassian.com/analytics/docs/starter-dashboards-for-jira-software-flow-metrics/>\n\nThanks!\n",
"comments": [
{
"author": "Hakan Bahadir",
"body": "Thank you [@Inder Singh](/t5/user/viewprofilepage/user-id/4829066) this is great news.\n"
}
]
},
{
"author": "Tracy Chow",
"body": "Hi Hakan,\n\nThe Flow Metrics Dashboard isn't available as a starter dashboard yet in Atlassian Analytics, but we are be watching out for more feedback on how many customers are interested in Flow/DORA metrics.\n\n[@Inder Singh](/t5/user/viewprofilepage/user-id/4829066) can walk you through the details when you meet with him, but currently it's more complex to build these charts with the current Data Lake schema. In the next few months, we will be rolling out a new schema that will make it easier to build these types of charts.\n\nTracy\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Flow-Metrics/qaq-p/2014831
| null |
{
"author": "Krzysztof Achinger",
"title": "Weird behavior for text control on Summary field",
"body": "I have a text control that is attached to two visualizations for Summary field. Using wildcard-like expression with % symbol I am getting different results on different visualizations.\n\nI enter \"%TM Update%\" in the text filter control and one visualization shows results, the other one does not. Both have similar data, only difference is that one concerns open tickets and another closed tickets. Changing search string to %TM update% gives some results in second visualization and the number of results in the first one is different.\n\nBoth visualizations use\n\nfilter Summary like {TEXT_INPUT}\n\nIt is true that both visualizations should return different results but when I verify with JQL the second one has many more results regardless of using \"TM update\" or \"TM first Update\"\n\n\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi [@Krzysztof Achinger](/t5/user/viewprofilepage/user-id/4103008), based on the screenshots you provided of the filters, the other difference between the two other than the Issue Status is that the first is \"Labels does not contain one of\" and the 2nd is \"Labels contains one of\".\n\nIs it possible the difference in the Label filters is responsible for the differing results?\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "Ohh crap! yeah that will be it, thanks! (facepalm)\n"
},
{
"author": "Tracy Chow",
"body": "Great, no problem. Happy to help!\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Weird-behavior-for-text-control-on-Summary-field/qaq-p/2009587
| null |
{
"author": "Esther Strom",
"title": "Are there data available on Jira dashboard and filter use",
"body": "My co-admin brought up an interesting question. Are there analytics data points (or will there be) about dashboard (Jira, not analytics) and filter use? One thing we struggle with is a ton of abandoned dashboards and filters, and it would be really great if we could run queries on them.\n\nThings we'd specifically be interested in being able to figure out from analytics:\n\n* The last date a dashboard or filter was viewed\n* The number of views a dashboard or filter has had in the last *x* days/weeks/months\n* Which filters are being used in which dashboards\n"
}
|
[
{
"author": "Skyler Ataide",
"body": "Hi Esther!\n\nThank you for the feedback. At this time, there is not any Jira reporting data in the Data Lake. More on the current schema for the Jira family of products can be found in our EAP documentation here: <https://analytics-docs.atlassian.net/l/c/his0kwms>\n\nIn Atlassian Analytics, however, you do get the options to sort all dashboards by either total view count or by date of last view date. This can be done from the **Dashboards** homepage by switching to list view:\n\n\n\nFurther analytics data points about dashboard and filter use currently do not exist, though I will be happy to raise this request based on the use case you've described.\n\nBest regards,\n\nSkyler\n",
"comments": [
{
"author": "Esther Strom",
"body": "Thanks, Skyler, but those are Analytics dashboards. We are looking for info on Jira dashboards - i.e. the ones created by users in Jira itself and accessible via https://\\<mysite\\>.atlassian.net/jira/dashboards, not the Analyics product.\n\nI know the data lake was designed to provide info to end users, but there's real potential to help admins as well if we can get access to metadata like filter use.\n"
},
{
"author": "Ben Jackson",
"body": "Hi [@Esther Strom](/t5/user/viewprofilepage/user-id/2991092) we wanting to add usage data into the lake in time yes. Intially we were looking at the data that powers Admin hub around product usage and login information but we'll have a look at product specific usage like ticket views, filter usage etc and come back to you.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Are-there-data-available-on-Jira-dashboard-and-filter-use/qaq-p/1997484
| null |
{
"author": "Krzysztof Achinger",
"title": "How to build dropdown control with custom values?",
"body": "I am trying to build a dropdown control that has manually defined values, e.g. user names that belong to a group of users, so that I can with one click filter issues that are assigned to any of those users.\n\nIs something like that possible at all?\n\nMore info\n\nMy use case is that I have two groups of users defined in Jira. Call them Reds and Blues. Reds has 5 users, Blues has 8 users. I want to filter my dashboard based on assignee that belongs to Reds or Blues. Imagine control that reads: \n\nAssignee belongs to group:\n\n* Red\n* Blue\n\nUpon selecting Red, all my data is filtered by the 5 assignees from the Red group.\n\nIn JQL there is something like\n\n```\nassignee in membersOf(\"Red\")\n```\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi [@Krzysztof Achinger](/t5/user/viewprofilepage/user-id/4103008), group data is not yet in the Data Lake. So I imagine one way to achieve this in the meantime would be setting up an automation rule such that whenever the issue's Assignee is updated, it adds a Label or custom field to note which group the assignee is in, and then you can report on that.\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "Thank's Tracy. This workaround will do me :-)\n"
}
]
},
{
"author": "Steven Drury",
"body": "Something like the 'Quick Filters' in a Kanban board would be phenomenal to have on a dashboard. If I am reporting across a portfolio, I want to have a button I can click that will automatically apply a set of filters to existing controls (e.g. project, issue type)\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/How-to-build-dropdown-control-with-custom-values/qaq-p/1992501
| null |
{
"author": "Esther Strom",
"title": "Why am I seeing JSM tables when my data source is only selecting Jira Software?",
"body": "I've set up a new data source that's only selecting from our Jira Software data (we also have JSM and JWM available). I would expect this data source to only pull in tables from JSW, but when I view the scema diagram, I'm seeing JSM tables.\n\n\n\nI know I can uncheck the Visible checkbox before generating the diagram:\n\n\n\nBut why are those tables even being included in the data source in the first place?\n"
}
|
[
{
"author": "Tracy Chow",
"body": "Hi Esther,\n\nThanks for calling this out. I agree it's confusing that JSM tables are being shown even when Jira Service Management data is not selected and brought into the data source. Our team will be looking at ways to improve this going forward.\n\nBest, \nTracy\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Why-am-I-seeing-JSM-tables-when-my-data-source-is-only-selecting/qaq-p/1993564
|
[
"table"
] |
{
"author": "Krzysztof Achinger",
"title": "How to build filter with user names?",
"body": "I am trying to filter my dashboard data by assignee or reporter name but the only place I am finding user names are in **Jira Issue History** table **To String** column for raws where field is **assignee**.\n\nWhat is the best practice/way of building such filter? I am quite worried that I will have to filter **To String** column where **Field**is assignee and get unique values.\n"
}
|
[
{
"author": "Matthew Lempitsky",
"body": "Currently there is not a way to map Atlassian user ids to actual user names because the required user data is not yet available in the Data lake. The process of getting this data into the lake is ongoing and we hope to have that user data in the data lake soon.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/How-to-build-filter-with-user-names/qaq-p/1992493
| null |
{
"author": "Krzysztof Achinger",
"title": "Adding text filter to filter summary column gives 0 results",
"body": "I am trying to filter a table by partial summary, just like in JQL with \"summary \\~ xyz\" but oddly when I add text filter to the table, I get zero results: Summary like (case insensitive) {SUMMARY_TEXT_INPUT}.\n\n\n"
}
|
[
{
"author": "Jessie Turpin",
"body": "Hi Krzysztof! [Text input controls](https://analytics-docs.atlassian.net/wiki/spaces/ANALYTICS/pages/12746757/Set+up+a+Text+input+control) require an exact string match, so you'd need to type out the issue summary completely within your control to have results returned by your query.\n\nHowever, you could use the % wildcard with your control to use a partial string match, which would function similar to the JQL contains. This [page](https://analytics-docs.atlassian.net/wiki/spaces/ANALYTICS/pages/16252937/Use+wildcards+in+Text+input+controls) has instructions on how to use partial string matches with your Text input control. I hope that helps!\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "[@Tracy Chow](/t5/user/viewprofilepage/user-id/4461730) has mentioned that there is some issue with \"like\" query. I will also try your suggestions and update here if that solves my issue. Thank you.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Adding-text-filter-to-filter-summary-column-gives-0-results/qaq-p/1978535
| null |
{
"author": "Krzysztof Achinger",
"title": "How to filter by labels?",
"body": "I am stuck again trying to add a filter based on labels. It must have sth. to do with the fact that Labels is an array data type. When trying to add a text based or dropdown based control I get empty preview table.\n\n\n"
}
|
[
{
"author": "Matthew Lempitsky",
"body": "When creating your {LABELS_DROPDOWN}, a good approach would be to ensure you're creating a dropdown with all of the potential labels. \n\nTo create a dropdown control of all the labels you can simply select the \"Labels\" column from the Jira Issue table and then use the \"Explode\" aggregation. You will then need a \"Group \\& Aggregate\" step to remove any duplicate labels: \n\n\nYou can then change your Control Settings so that you can select and filter on multiple labels: \n\n\n\nHowever, there does appear to be an issue with the Empty state setting; if there are no labels selected, no results are returning, so a minimum of one label will need to be selected in the control.\n\nYou can connect your newly created dropdown control to your chart using the same method you used in your screenshot:\n\n \n\n<br />\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "[@math](/t5/user/viewprofilepage/user-id/4737998)\n\nThis is quite helpful and as a matter of fact I have done all those steps but it did not solve the problem. Preview table still returns 0 rows. I think I managed to narrow down the issue to the fact that I am also using History table. For results where history is not involved adding filter based on exploded labels work.\n\nSo my entire Visual query looks like this (not working)\n\n\n\nWhen I remove Jira Issue History to String = Closed, and Status = Closed it starts working. I need those fields as I want to operate on Closed tickets only for this data visualization.\n\n\n\nEDIT: I am now thinking that I might need to implement additional query and join tables before doing filtering. Will update here if that resolves the case.\n\nEDIT 2: Confirmed, I had to build the table from two queries with Inner Join and only then results could be properly filtered by labels.\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/How-to-filter-by-labels/qaq-p/1965281
| null |
{
"author": "Hondaman900",
"title": "What am I doing wrong - cannot add my local dev project to my Bitbucket repositories",
"body": "I have a local dev project that started out as test code that is now important enough to make a repository.\n\nTo that end, as I have done before, I created a new repository in my Bitbucket account. I cloned that empty repo to my local hard drive using HTTP option, then copied all my dev files into the new empty folder. However, none of the copied-in files show up in SourceTree, so I can't sync this project. No idea why this is not working and I'm not getting any errors.\n\nAny suggestions? I must be missing something.\n"
}
|
[
{
"author": "Hondaman900",
"body": "Ok, looks like I wasn't doing anything wrong after all.\n\nIn the Workspace/File Status in SourceTree \"Pending files, sorted by file status\" was selected in the dropdown, and none of my files were showing. However, selecting that same option again from the dropdown caused my files to appear for staging. All is now working well.\n\nLooks like it may be a bug...?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/What-am-I-doing-wrong-cannot-add-my-local-dev-project-to-my/qaq-p/2687306
|
[
"bitbucket",
"bitbucket-cloud",
"cloud"
] |
{
"author": "Brian postow",
"title": "Connecting source tree to a remote computer",
"body": "I have a mac, but the actual code is on a remote (AWS I assume) unix box. I ssh into the unix box and do all of my work there. Is there a way to get sourcetree on my mac to connect to the repo on the unix box?\n"
}
|
[
{
"author": "Brian postow",
"body": "Is the only way to do this to make a copy of the repo on my local machine, pull from the repo on the unix box, and then push to bitbucket? \n\nI haven't tried to do that, because it seems hard, and dumb, so I'm not even sure if that will work, but is that the way?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Connecting-source-tree-to-a-remote-computer/qaq-p/2687592
|
[
"bitbucket",
"cloud"
] |
{
"author": "Krzysztof Achinger",
"title": "Ticket open duration in days",
"body": "Hello EAP Team,\n\nI am trying to show a table with tickets' open duration in days. The column should show days between Issue Created At date and now. Is it possible, is there an easier way to achieve that?\n\nI was looking to add a column that stores now date but that did not seem to be possible.\n"
}
|
[
{
"author": "Tracy Chow",
"body": "You can add a formula column with a custom formula using the SQLite datediff function and the relative date variable {TODAY}.\n\n\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "It did the trick. I was actually playing with {TODAY} after reading the documentation but I did not know I need to use Custom formula for it to work. Thank you.\n"
}
]
},
{
"author": "Kamal Rajpal",
"body": "Is there any way to get this calculation done in JQL, which I am using to create filter in JIRA\n",
"comments": [
{
"author": "Cat Africa",
"body": "Hi, [@Kamal Rajpal](/t5/user/viewprofilepage/user-id/5016115)! It may be better to ask this question in Jira's Community group: <https://community.atlassian.com/t5/Jira/ct-p/jira>\n"
}
]
},
{
"author": "Cat Africa",
"body": "Hey, Krzysztof! You can use the `{TODAY}` [relative date variable](https://analytics-docs.atlassian.net/wiki/spaces/ANALYTICS/pages/11173917/Relative+date+variables) to get today's date.\n\nFor what you're trying to do, you can do the following (assuming you've made your initial query with the \"Created At\" column):\n\n1. Add a **Formula column** step.\n\n2. Select **Custom** as the formula type.\n\n3. Enter `{TODAY}` as the formula.\n\n4. Select **Save**. You should now have a new column where all the rows are today's date.\n\n5. Add another **Formula column** step.\n\n6. Select **Date difference** as the formula type.\n\n7. For the parameters, first select the **Created At** column, then select the new today column you created, then select **Day** as the time unit.\n\n8. Select **Save**. This should give you the date difference you're looking for.\n\nHope that helps a bit!\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "It did help, thank you.\n"
}
]
},
{
"author": "Adam Nichols (DISH)",
"body": "We have run into the same issue and had to create a custom script\n",
"comments": [
{
"author": "Krzysztof Achinger",
"body": "No way! How do you create custom script and where do you store the data if that is not too much to ask? Any additional pointers will help.\n"
},
{
"author": "Adam Nichols (DISH)",
"body": "Here is the script we used in Automation for Jira\n\n{{now.diff(issue.created).abs.days}}\n"
},
{
"author": "Krzysztof Achinger",
"body": "Right, all my previous data issues I was also resolving with Automation for Jira. I was hoping that I will not have to do it in Atlassian Analytics.\n\n[@Matt David](/t5/user/viewprofilepage/user-id/4301097) [@Cat Africa](/t5/user/viewprofilepage/user-id/4430495) hope you are reading :)\n"
},
{
"author": "Adam Nichols (DISH)",
"body": "Actually this is for our Jira Software, not Analytics, so that actually may be a different solution, I will defer to EAP\n"
},
{
"author": "Vinci Louise Morales",
"body": "Is there a way to change the format of {TODAY} into Date and Time?\n"
},
{
"author": "Rohit Kavuluru",
"body": "In Atlassian Analytics, you can't change the {TODAY} format as it's a pre-defined system variable representing the current date. There isn't a built-in feature to change its format.\n\nYou can, however, add an additional\"Created At\" column below to display the date and time separately in your results table. You can also manually query for the date or time and display them as separate columns using our SQL editor. Hopefully, this addresses your question!\n\n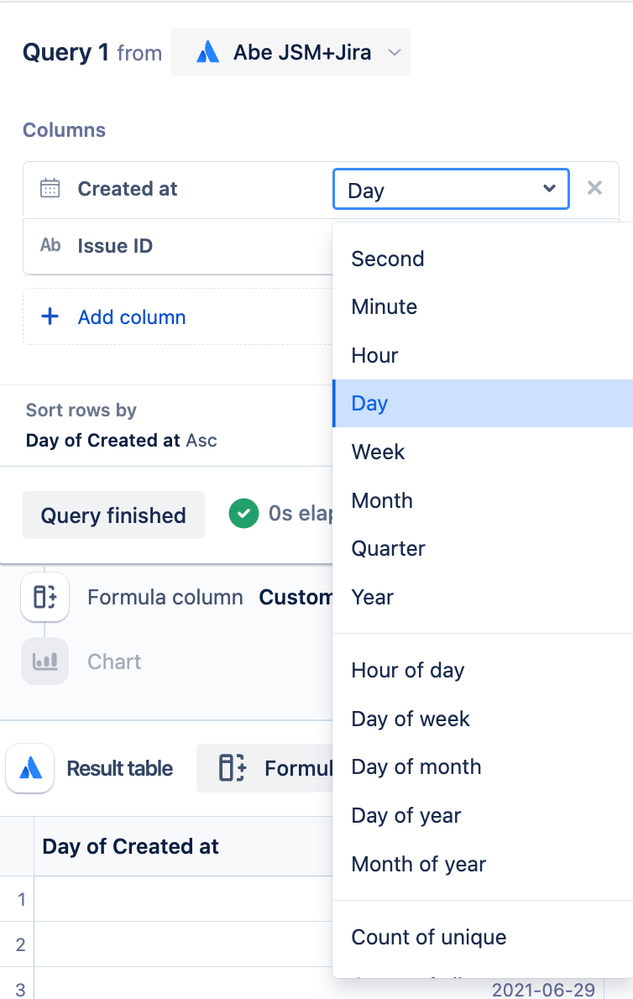\n"
}
]
}
] |
https://community.atlassian.com/t5/Atlassian-Analytics-questions/Ticket-open-duration-in-days/qaq-p/1963109
|
[
"date"
] |
{
"author": "gilgen-zt",
"title": "Sourcetree opens remote in Microsoft Edge (instead of default browser)",
"body": "When I click on the Remote button (in a repo in Sourcetree 3.4.17 for Windows) to open the remote repo in the internet browser, Sourcetree opens it with Microsoft Edge instead of my default internet browser.\n\nIt was not always like this. Is there any setting, where I can change that (couldn't find any so far)?\n"
}
|
[
{
"author": "Brant Schroeder",
"body": "[@gilgen-zt](/t5/user/viewprofilepage/user-id/1317766) have you tried reviewing the default browser setting and making sure that all file types are pointing to your default browser?\n",
"comments": [
{
"author": "gilgen-zt",
"body": "Setting of default browser did not help.\n\nBut as this topic already is some months old, I'm not sure any more if I did any canges of setting for the file types or if I reinstalled Sourcetree.\n\nBut at the moment it ist working.\n"
},
{
"author": "Brant Schroeder",
"body": "[@gilgen-zt](/t5/user/viewprofilepage/user-id/1317766) What version are you on?\n"
},
{
"author": "gilgen-zt",
"body": "Windows 3.4.19 (latest version)\n"
},
{
"author": "Brant Schroeder",
"body": "[@gilgen-zt](/t5/user/viewprofilepage/user-id/1317766) I found an older bug for 3.2 but the fix was to update. If you are on the latest version then that will not help unless you just reinstalled.\n\nOn another similar issue one user did this: If you go to Settings, then Remotes. Right click on your repository path and then hit Edit. Then just hit OK (or change it if it's wrong). That was enough to make it work for me and must retrigger a save of some kind.\n\nDon't know if either of those will work for you.\n"
},
{
"author": "gilgen-zt",
"body": "[@Brant Schroeder](/t5/user/viewprofilepage/user-id/769100) thank you for your solutions. This may help other when they search for this problem.\n\nBut for me it is already solved (without knowing exactly what helped)\n"
}
]
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Sourcetree-opens-remote-in-Microsoft-Edge-instead-of-default/qaq-p/2681638
|
[
"server"
] |
{
"author": "Scott Rappold",
"title": "Unable to cache the server's host key",
"body": "I have set up a new work machine and I am having an issue with Sourcetree.\n\nI have been able to log in and see my repos. When I try to Pull or Fetch I get the following:\n\n\\>\\>\n\ngit -c diff.mnemonicprefix=false -c core.quotepath=false fetch -v --no-tags origin \nThe server's host key is not cached. You have no guarantee \nthat the server is the computer you think it is. \nThe server's rsa2 key fingerprint is: \nssh-rsa 2048 SHA256:*\\<key\\>* \nIf you trust this host, enter \"y\" to add the key to\n\n<br />\n\nCompleted with errors, see above. \nPuTTY's cache and carry on connecting. \nIf you want to carry on connecting just once, without \nadding the key to the cache, enter \"n\". \nIf you do not trust this host, press Return to abandon the \nconnection. \nStore key in cache? (y/n, Return cancels connection, i for more info) fatal: Could not read from remote repository.\n\nPlease make sure you have the correct access rights \nand the repository exists\n\n\\>\\>\n\n.\n\nI have tried to follow the steps in issues answered elsewhere but none seem to work. If I try to run \"plink bitbucket.org\" I then press Y to cache and I get an error trying to enter a log in: \"FATAL ERROR: No supported authentication methods available (server sent: publickey)\"\n\nI know I am missing something somewhere, but I can not seem to identify what that may be. Any suggestions would be greatly appreciated. Thank you.\n"
}
|
[
{
"author": "gilgen-zt",
"body": "For me it helped to open an SSH-connection to bitbucket.org with PuTTY and then to accept to trust the connection.\n\n\n\n\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Unable-to-cache-the-server-s-host-key/qaq-p/2681275
| null |
{
"author": "thivya",
"title": "Sourcetree is not generating userhosts and password file",
"body": "Hi,\n\nWhen a user tries to install source tree application after the login, the user hosts and password files are not generating in appdata folder. We tried to re-install the application but still not working. Is there any workaround to solve this issue?\n\nWe have tried to clone the repo and getting \"Error: fatal: authentication failed\"\n\nversion 3.4.15\n\nThanks!\n"
}
|
[
{
"author": "thivya",
"body": "Could someone please help on this issue?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Sourcetree-is-not-generating-userhosts-and-password-file/qaq-p/2679286
| null |
{
"author": "Vitalii Vorobiov",
"title": "Memory issues",
"body": "When I open one of my repos, the Sourcetree freezes after a few seconds, and after some time I receive an OS pop-up that my system is running out of memory and I can see how my Sourcetree memory usage instantly grows from several GB to almost 100GB of RAM.\n"
}
|
[
{
"author": "Nikola Perisic",
"body": "Welcome to the community [@Vitalii Vorobiov](/t5/user/viewprofilepage/user-id/5475974)\n\nI have tagged Atlassian for this question. Also, you can post that question here: <https://community.developer.atlassian.com/c/jira/5>, as this is more question that is more technically oriented.\n",
"comments": [
{
"author": "Vitalii Vorobiov",
"body": "Thanks\n"
},
{
"author": "Dmytro Ivakhnenko",
"body": "Hello. Do you have any updates about this issue? I've faced with same one few days ago\n"
}
]
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Memory-issues/qaq-p/2670916
|
[
"atlassian"
] |
{
"author": "andreaExo",
"title": "Help Needed: SourceTree Authentication Failure with Bitbucket over HTTPS, but Terminal Works Fine",
"body": "Hello Atlassian Community,\n\nI'm reaching out for assistance with an issue I'm experiencing with SourceTree and Bitbucket authentication over HTTPS. While I can successfully use SSH within SourceTree, and HTTPS via the terminal for Git operations (prompting for my Bitbucket password works fine), both OAuth and App Password fail within SourceTree.\n\nI have tried the following steps to resolve the issue:\n\n1. Verified the default Bitbucket account in SourceTree.\n2. Generated and used a new app password in Bitbucket for Basic authentication.\n3. Cleared outdated credentials from both the Windows Credential Manager and within SourceTree.\n4. Refreshed OAuth tokens and re-entered app password in SourceTree.\n5. Checked the global `.gitconfig` for any old settings and made sure it is updated with the current user information.\n\nThe terminal-based Git operations with HTTPS work perfectly when I am prompted for my Bitbucket password. However, the same operations fail within SourceTree, suggesting a potential issue with SourceTree's handling of credentials.\n\nHas anyone encountered a similar problem or have suggestions to resolve this authentication dilemma? Any help or pointers would be greatly appreciated, as this is impacting my workflow significantly.\n\nThank you in advance for your time and help!\n"
}
|
[
{
"author": "Michael Sarafidis",
"body": "Same problem here,\n\nI have tried both creating an SSH key and App Password and both fail to clone a repo at Sourcetree GUI version 3.4.17 from bitbucket cloud.\n\nThe App Password works fine Sourcetree git terminal and also Github desktop that I have tried.\n\nThus, it is a Sourcetree GUI problem.\n\nI would also be glad to hear a solution here.\n",
"comments": [
{
"author": "Joseph DeAngelo",
"body": "I'm seeing what seems to be the same problem.\n"
},
{
"author": "Peter Busk",
"body": "I have been fighting the same problem with SourceTree, not being able to clone.\n\nHave now installed git and it has no problem cloning same repository.\n\nWhat to do ?\n"
},
{
"author": "Peter Busk",
"body": "I solved this issue by closing all programs, renaming: c:\\\\Users\\\\\\<USER\\>\\\\AppData\\\\Local\\\\Atlassian folder to something else and reinstall Sourcetree.\n\nNow all worked fine :-)\n"
}
]
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Help-Needed-SourceTree-Authentication-Failure-with-Bitbucket/qaq-p/2663145
|
[
"bitbucket",
"bitbucket-cloud",
"cloud"
] |
{
"author": "b12kab",
"title": "Stash list is empty - feature or bug?",
"body": "Hi,\n\nVersion: Sourcetree v 4.2.7 (263) OSX (Intel).\n\nStash list shows empty under Sourcetree (i.e. the disclosure triangle is un-selectable and there is nothing showing beneath it). I can see the stashes via a command line git stash list which shows a list of 256.\n\nIf I drop one via command line git, it shows up again on Sourcetree (i.e. the disclosure triangle is selectable and the stash list shows beneath it).\n\nThis is stored on a private repo, not on bitbucket, if that is a question.\n\nWhen there is 256 stashed items and Sourcetree doesn't show anything - is this by design or is it a bug?\n\nThanks!\n"
}
|
[
{
"author": "b12kab",
"body": "Looking at this [post](https://stackoverflow.com/questions/4600037/is-there-a-maximum-number-of-git-stashes) on SO, there is not a limit to number of stashes, so this appears to be a bug.\n\nWhere does one report bugs at (if not here)?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Sourcetree-questions/Stash-list-is-empty-feature-or-bug/qaq-p/2651401
| null |
{
"author": "Radu Dumitriu",
"title": "Can we do something about spam (really?)",
"body": "It's hard to say it again, but I'm again upset with the quantity of spam. I know, you made it easy to instaban users, but this is ridiculous.\n\nI mean, it makes sense for a spammer to target this community considering the subjects we're spammed with:\n\n1. washing machines repairs (right, geeks are too busy coding, so they do not wash, but when they wash their underware, they pile up too many t-shirts)\n2. astrologer (again, correct, geeks suck when it comes to relationships, so this is just normal, right?)\n3. penis enlargement (let's face it, we, the geeks, are in denial)\n\nYou can't fight the popular culture, but I believe we can fight these posts. All these have in common some phone numbers and nono keywords. I think it should be pretty trivial to filter such questions ... please.\n"
}
|
[
{
"author": "Joe Clark",
"body": "Hi Radu,\n\nThanks for your feedback and passion. We've made a number of changes recently in an attempt to defend against the spam we're receiving:\n\n1. We lowered the entitlements (such as posts per day) available to users with only 1 karma\n2. We implemented an automatic spam detection service (it picks up about 50-60% of the total spam, IMO, and unfortunately it also picks up some false positives)\n3. Atlassian ID recently added a CAPTCHA on user sign-up, so once a user is insta-banned they will have to pass this hurdle to start spamming again.\n\nAs is always the way with these things, new defensive techniques are initially very effective, but then eventually they become less effective as the attackers learn how they work and how they can circumvent them. When the Atlassian ID CAPTCHA was turned on, we had about 7 days straight of no spam (a new record!), however we're now climbing back up to the original levels.\n\nI think the next logical step is a manually maintained blacklist of words, phrases or URLs, but we've been shying away from that so far since we're really going to have to commit to someone spending a fair bit of time looking after this blacklist in order for it to remain effective. We've been investigating automated solutions before resorting to this.\n\nI'll have a chat about this with the team and I'll come back to this Question when we decide what the next step will be.\n",
"comments": [
{
"author": "Radu Dumitriu",
"body": "And, of course, thanks.\n"
},
{
"author": "Radu Dumitriu",
"body": "How about this: when a power user instabans a user, take the texts and parse for their meaning using [](http://nlp.stanford.edu/software/lex-parser.shtml)<http://nlp.stanford.edu/software/lex-parser.shtml>\n\nFor a medium-sized text, it will take 5-8 seconds to parse it. You can safely extract keywords from there, including URLs, because you will know the part of speech and how it is used. Hence, your list will be maintained automatically.\n\nI played with it, it is really useful, but on the other side, it consumes quite a lot of memory. Have fun.\n"
},
{
"author": "Radu Dumitriu",
"body": "Again, removed the same spam today.\n"
},
{
"author": "Joe Clark",
"body": "Looks like we had another big pile of spam overnight! I've just cleaned up some of it now.\n\nJust giving you an udpate, we're continuing to work out the best way to stop this for good. Dennis is actually going to be splitting his time with the Atlassian ID team for a couple of months to see if we can develop some better anti-spam tools further upstream (stop the spammers from creating an Atlassian ID account, before they even get to Answers).\n"
}
]
}
] |
https://community.atlassian.com/t5/Announcement-questions/Can-we-do-something-about-spam-really/qaq-p/322926
|
[
"community",
"feedback-forum"
] |
{
"author": "Jeff MacDonald",
"title": "How can I unfollow everything on this website?",
"body": "It seems I somehow followed everything at one point. Now i get a lot of notifications I don't want and have to individually unfollow each topic. :)\n\nHow can I unfollow everything :)\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Click on your picture (top right) Settings -\\> Notifications\n",
"comments": [
{
"author": "Jeremy Largman",
"body": "Yeah - unfortunately I think there's a bug in 'stop notifications' so you have to manually uncheck things.\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "Ah, ok. It's worked for me, but I only stopped the general \"follow everything\" when I went on holiday last year, so I probably haven't run into that bug.\n"
},
{
"author": "Michelle Larson",
"body": "I don't see notifications under settings\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "The software has changed in the last couple of years since this was posted.\n"
}
]
},
{
"author": "Carl DiClementi",
"body": "To manage the spaces and pages you are watching (and therefore receiving notifications for) in Confluence, you will want to go to the following URL: <https://blockfi.atlassian.net/wiki/users/viewnotifications.action>\n",
"comments": null
},
{
"author": "Jeff MacDonald",
"body": "Yeah, I still want to be notified if there is an update on a page i'm subscribed to. I just don't want to be subscribed to everything. It seems slightly better now.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Announcement-questions/How-can-I-unfollow-everything-on-this-website/qaq-p/80635
|
[
"community",
"feedback-forum"
] |
{
"author": "Michael Johnston",
"title": "How do I report an issue with the Atlassian Blogs?",
"body": "I was trying to share the following blog with teammates, but the format is clearly broken. I'd like to see it formatted properly before I share it.\n\n[](http://blogs.atlassian.com/2009/06/getting_started_with_agile_daily_standup_meetings/)<http://blogs.atlassian.com/2009/06/getting_started_with_agile_daily_standup_meetings/>\n"
}
|
[
{
"author": "Michael Johnston",
"body": "Comments are closed unfortunately, I guess because it's an older article.\n",
"comments": null
},
{
"author": "Frank Stiller",
"body": "You could always starting commenting under that blog. Maybe someone is picking it up, but probably not that fast as its quite an old article.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Announcement-questions/How-do-I-report-an-issue-with-the-Atlassian-Blogs/qaq-p/326761
|
[
"blog"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.