
question
dict | answers
listlengths 1
27
| url
stringlengths 66
601
| tags
listlengths 1
15
⌀ |
|---|---|---|---|
{
"author": "Thomas Teller",
"title": "How to modify Opsgenie Alert to add custom data/fields",
"body": "When a Incident or ticket is created in JIRA Service management it generates an OpsGenie alert. how do i embed a JSM Incident ticket link into the OPSgenie alert message.\n"
}
|
[
{
"author": "Nick H",
"body": "Hi [@Thomas Teller](/t5/user/viewprofilepage/user-id/5483661) ,\n\nYou can edit the integration's Create Alert action(s) to include something like the suggestion below, which will embed a link within an Opsgenie alert field:\n\n```\nhttps://sitename.atlassian.net/browse/{{key}}\n```\n\n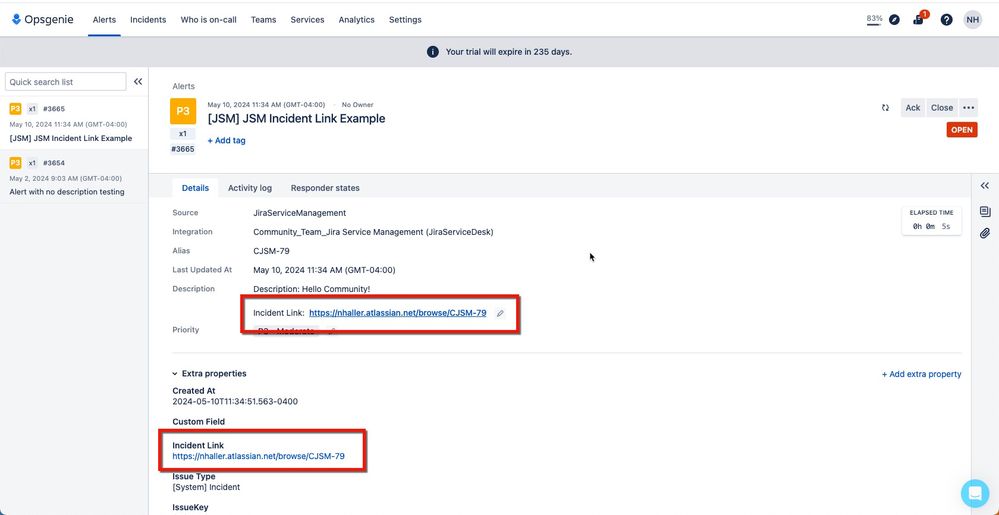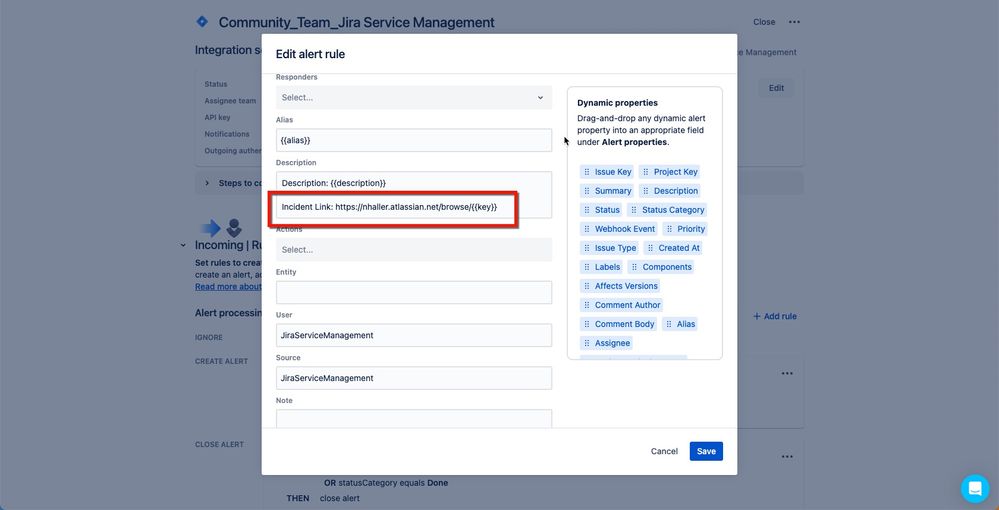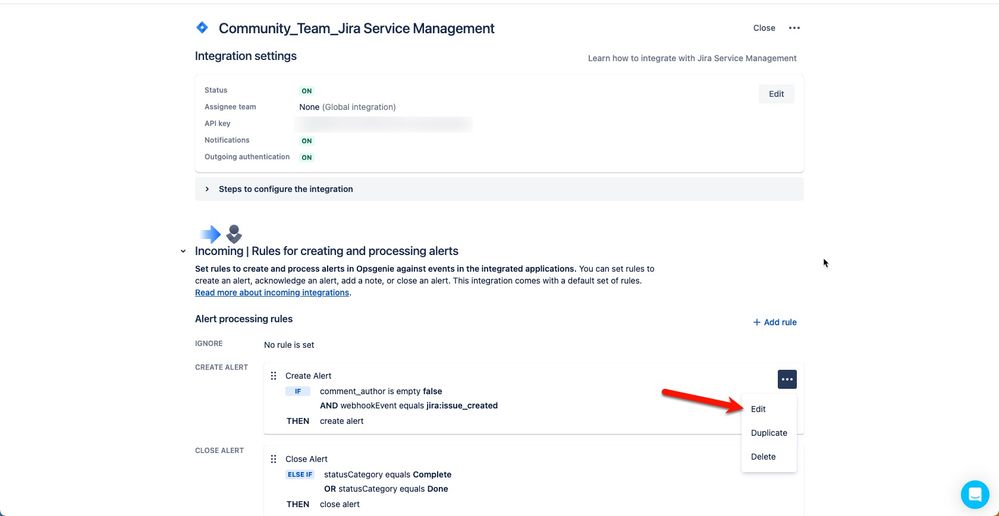\n",
"comments": [
{
"author": "Thomas Teller",
"body": "The screen shots are nice. how do i get to those pages?\n"
},
{
"author": "Nick H",
"body": "Within Opsgenie.\n\nIf you are subscribed to the Standard, Enterprise, JSM-Premium or JSM-Enterprise plans select the Settings \\>\\> Integrations tab, then select your JSM integration. Note only Opsgenie admins and owners will have access to this tab.\n\nOtherwise navigate to the Opsgenie team that has the integration configured, and select the Integrations tab.\n\nIf you are subscribed to the Free, Essentials, ~~JSM-Free~~ or JSM-Standard plans, the global Integrations tab found under the Settings / mentioned above does not exist. Integrations can only be configured under a team with these plans.\n\nSo you would need to navigate to the team that has the JSM integration configured, select the Integrations tab, and select the JSM integration.\n\nHope that helps.\n"
},
{
"author": "Thomas Teller",
"body": "we are currently on JSM Standard and Opsgenie Free. does that change anything you already provided?\n"
},
{
"author": "Nick H",
"body": "I'm actually not sure. I realized there seems to be some new user experience with the lower-tired JSM plans which does not redirected into Opsgenie anymore, but rather keeps you within JSM - so again, unsure where this could be configured, and if it's even possible any longer.\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/How-to-modify-Opsgenie-Alert-to-add-custom-data-fields/qaq-p/2694673
| null |
{
"author": "Will McCutchen",
"title": "DataDog integration with dynamic alert routing based on service or team",
"body": "My question is somewhat similar to <https://community.atlassian.com/t5/Opsgenie-questions/Datadog-integration-and-routing-best-practice-advice/qaq-p/2204954> but I'm hoping for a different solution.\n\nOn our in-house platform, we have deployed many independent services (100+), each owned by one of many different teams (10+).\n\nWe have a variety of platform-level monitors in DataDog, where one monitor (e.g. \"deployment failed\") will apply to ALL services, distinguished by tags (e.g. \\`env:production, service:foo, team:bar\\`).\n\nAssuming we create each of those teams and their services within OpsGenie, is it possible to create a single DataDog \\<\\> OpsGenie integration that *dynamically* routes alerts to the appropriate team based on the tags in the incoming alert? I.e. can we create a routing rule that says, basically, \"route this alert to the OpsGenie team named in the \\`team\\` tag\"?\n\nI believe, based on the question linked above, that we could do this somewhat manually, by manually constructing a large sequence of if/else rules. We would rather avoid that, if possible, as our system of services and teams changes fairly often (e.g. new services added, old ones decommissioned, service ownership moves from one team to another, team names change, etc), so keeping a complex set of routing rules updated will be tricky and likely to lead to missed alerts.\n\nThanks!\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Will McCutchen](/t5/user/viewprofilepage/user-id/4921340)\n\nYou could use the same general method shown in the link you posted, but to make it dynamic you could use a regex expression filter instead of a 'contains' or 'equals' filter. As long as your DataDog config uses consistent naming conventions, this method should allow you to dynamically match patterns and route to the appropriate teams. Here is more on regex in Opsgenie:\n\n<https://support.atlassian.com/opsgenie/docs/regular-expressions-for-improved-alert-filtering/>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/DataDog-integration-with-dynamic-alert-routing-based-on-service/qaq-p/2692712
|
[
"cloud"
] |
{
"author": "Syed, Najeeb",
"title": "Migrate Teams/users from Splunk on-call to Opsgenie",
"body": "We currently have Jira and confluence products. \n\ncan we list out the users in Splunk on-call and identify their Atlassian ID. Use that ID to grant access to those users to Opsgenie SSO ?\n"
}
|
[
{
"author": "Chris DeGidio",
"body": "hi [@Syed, Najeeb](/t5/user/viewprofilepage/user-id/5491296)\n\nThis definitely sounds like something that could be possible. It seems like you would be able to complete this by compiling the list of users that are within Splunk on-call (reference their API documentation for this.\n\nOn the Atlassian side as long as your org has the domain claimed and you manage the Atlassian accounts then you would be able to use the API to gather the Atlassian ID's\n\n<https://developer.atlassian.com/cloud/admin/organization/rest/api-group-users/#api-v1-orgs-orgid-users-get>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Migrate-Teams-users-from-Splunk-on-call-to-Opsgenie/qaq-p/2690175
|
[
"cloud"
] |
{
"author": "Maxim Chechenev",
"title": "Creating schedules without integrations and escalations",
"body": "I have a team schedule for our alerts and incidents. It works fine. \nNow I want to create another schedule but for internal support rotation, so it should not have integrations and alerts at all. I want to use Opsgenie as a tool to manage this process (we have daily rotation of people who is responsible of helping support team of our product). I cannot find how I can do it with existing team - I want this schedule to be excluded from any alerts. \n\nIt was straightforward when I used PagerDuty, but I cannot understand how to do it in Opsgenie/\n"
}
|
[
{
"author": "Tejaswi G",
"body": "Hi [@Maxim Chechenev](/t5/user/viewprofilepage/user-id/5489662),\n\nThis is Tejaswi here from the Opsgenie Team and here to help.\n\nYou can create an internal schedule for your internal support team and don't route any alerts to this newly created schedule. You can control the routing of alerts via routing rule and escalation policy and not route any alerts to this new created internal schedule and use it only for the tracking purpose.\n\nIf you have any further queries, Feel free to log a ticket at our [Support portal](https://support.atlassian.com/contact).\n\nKind Regards,\n\nTejaswi\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Creating-schedules-without-integrations-and-escalations/qaq-p/2688484
|
[
"cloud"
] |
{
"author": "Stefan Draber",
"title": "Current capabilities and plans for Service Relationships?",
"body": "Hi all,\n\ncan someone please explain the current capabilities of Service Relationships in Opsgenie to me?\n\nI had the expectation that when Service A is impacted the dependant Service B would be impacted as well, but in my tests (incident impacting Service A) I did not find anything which would even indicate that there could also be an impact to Service B.\n\nAlso, when I view Service A from the Services overview (top menu), I don't see any dependant services. When I view Service B, I can see that it's depending on Service A. That doesn't make sense, because when there's an incident impacting Service A and I want to know which other related services could be affected, I would drill down from affected Service A rather than click through all other services to check whether they're depending on Service A.\n\nSo, is the incident investigation feature really the only useful service relationship feature?\n\n(I'm aware of this article and actually I hoped that the functionality would have evolved since back then: <https://community.atlassian.com/t5/Opsgenie-questions/Services-relationship-and-teams-How-it-works/qaq-p/1382317> )\n\nAre there any plans to go one or more steps further with service relationships in the (near) future?\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Stefan Draber](/t5/user/viewprofilepage/user-id/4735559) ,\n\nYou can actually see the service relationship both ways, as long as services are assigned to team. You can view the relationship from the 'services' page on the team dashboard. Here is an example:\n\n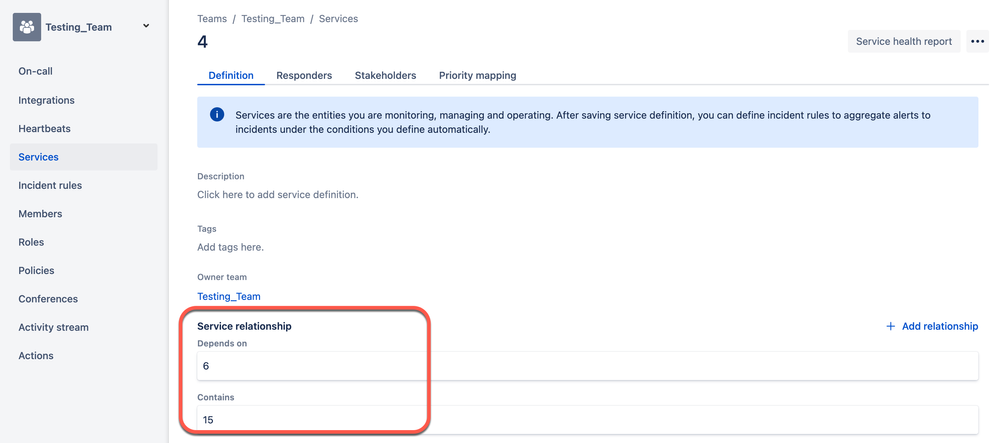\n",
"comments": [
{
"author": "Stefan Draber",
"body": "Hi [@John M](/t5/user/viewprofilepage/user-id/4625213)\n\nthanks for your feedback, unfortunately I cannot confirm for my instance.\n\nI have a demo-configuration where Service 2 depends on Service 1. This is shown on the Service 2 page, but not on the Service 1 page (please see screenshots below).\n\nWe're running on Opsgenie standalone, not on JSM-Opsgenie, if that makes a difference.\n\nApart from that, is it correct that the service relationship doesn't play any role in incident situations (e.g. there's an incident impacting Service 1, and because Service 2 depends on Service 1 it's impacted as well)?\n\n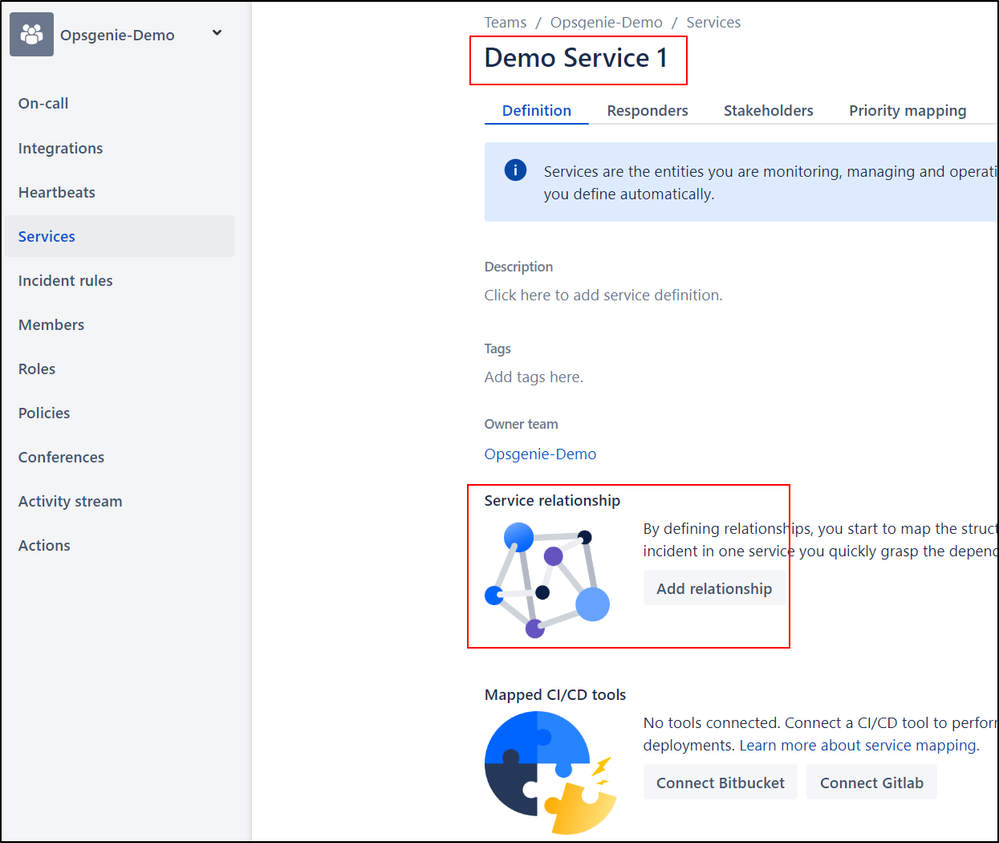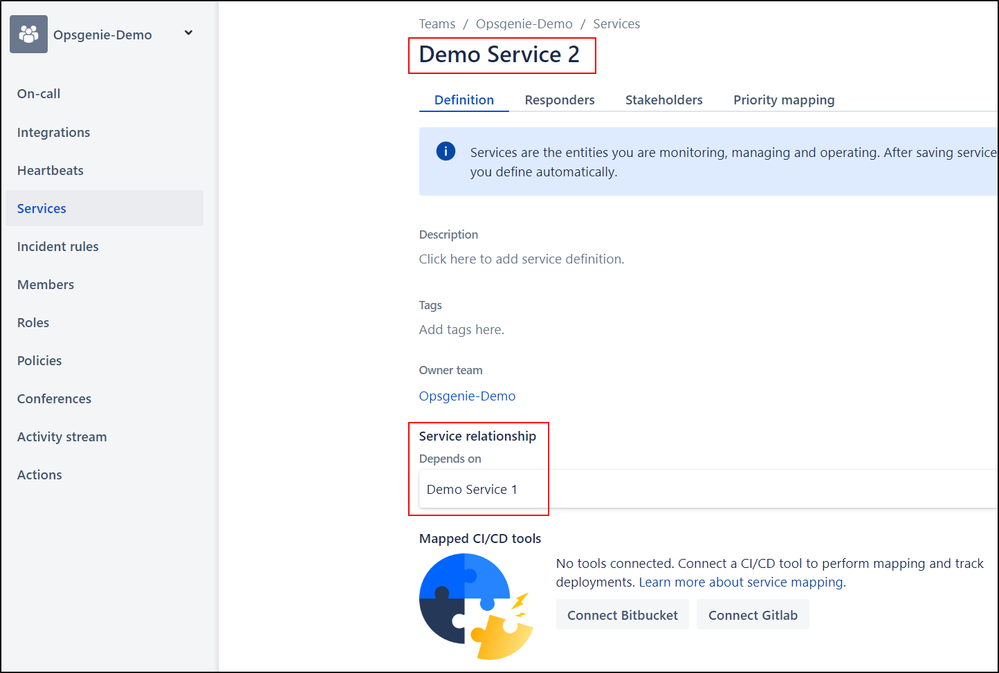\n"
},
{
"author": "John M",
"body": "Hi [@Stefan Draber](/t5/user/viewprofilepage/user-id/4735559)\n\nYou should be able to add the 'contains' relationship here:\n\n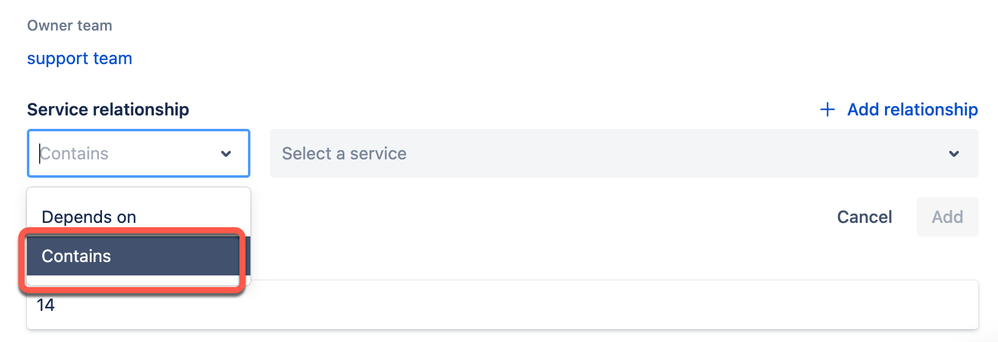\n\nThat is correct - the service relationships won't automatically affect related services. We do have some feature requests to change this functionality, though there is no ETA on them.\n"
},
{
"author": "Stefan Draber",
"body": "Hi [@John M](/t5/user/viewprofilepage/user-id/4625213)\n\nsure, I could add the relationship manually. I just expected that when I link a relationship from one side (Service 2 depends on Service 1) that the link would automatically also appear on the other side (Service 1 contains Service 2). Comparable to issue-linking in Jira.\n\n> We do have some feature requests to change this functionality, though there is no ETA on them.\n\nThat brings me back to the last question in my original post: Are there any plans to go one or more steps further with service relationships in the (near) future?\n\nCould you (or maybe a product manager) please share something like a roadmap for what's to be expected in (standalone) Opsgenie for the future?\n"
},
{
"author": "John M",
"body": "[@Stefan Draber](/t5/user/viewprofilepage/user-id/4735559) I agree, the it would make sense for the opposite relationship to automatically be added for to the other service.\n\nHowever, to be transparent, Standalone Opsgenie standalone likely won't see any significant updates to existing features, particularly with respect to services, as the current focus is on the JSM-integrated Opsgenie, which adds Opsgenie into the JSM UI. The Opsgenie roadmap is primarily focused on that.\n"
},
{
"author": "Stefan Draber",
"body": "Hi [@John M](/t5/user/viewprofilepage/user-id/4625213)\n\nthanks a lot for your transparent feedback, much appreciated.\n\nDoes JSM-Opsgenie handle this whole service-relationship thing better as of now?\n\nOr, maybe a bit more general, does JSM-Opsgenie have more advantages/features than Standalone Opsgenie, apart from JSM-functionalities and -integrations? Is there maybe an overview or something, comparing JSM- and Standalone Opsgenie?\n"
},
{
"author": "John M",
"body": "[@Stefan Draber](/t5/user/viewprofilepage/user-id/4735559) I believe the way the services work will be largely the same, with the addition of [Major incidents](https://support.atlassian.com/jira-service-management-cloud/docs/what-are-major-incidents/). We do have this doc that compares JSM- Opsgenie with Standalone:\n\n<https://confluence.atlassian.com/jirakb/main-differences-between-opsgenie-plans-when-bundled-with-jira-service-management-or-as-a-standalone-product-1163763012.html>\n\nThe above was actually created for the JSM-subordinate Opsgenie, which is not exactly the same as the consolidated experience, which adds Opsgenie to the JSM UI, but the points still apply.\n\nThis is also a good answer from Nick on this question:\n\n<https://community.atlassian.com/t5/Opsgenie-questions/What-are-the-biggest-differences-between-Opsgenie-Standalone-and/qaq-p/1958748>\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Current-capabilities-and-plans-for-Service-Relationships/qaq-p/2688169
|
[
"cloud",
"service-relationship"
] |
{
"author": "ian",
"title": "stop jsm automatically assigning incident ticket created via opsgenie integration",
"body": "Our OpsGenie is configured to receive alert emails from external services. Some of these will trigger the creation of JSM incident ticket using the OpsGenie-JSM integration.\n\nThis is working well except that the JSM ticket is being automatically assigned. It seems to the alphabetically first agent in the team associated with the OpsGenie alert. We don't specify assignee in the integration. Example:\n\n3 agents (Adam, Bob and Fred) are in the 'backup team'. OpsGenie receives an email alert from our backup service which triggers the creation of a JSM ticket. This ticket is always automatically assigned to Adam.\n\nAt this stage, we want agents to pick up the JSM incident themselves. Ticket can be re-assigned so it's not a big problem but would be nice if we could stop it auto assigning. As I can't really find any info about this, I thought I'd ask here.\n\nThanks.\n"
}
|
[
{
"author": "ian",
"body": "Worked it out. My OG\\<\\>JSM integration specifies a component. The component I'm specifying has its default assignee set to the component lead. And the component lead is Adam. Therefore, Adam gets auto-assigned the incident.\n\nA little embarrassing but hope this helps someone else.\n",
"comments": null
},
{
"author": "Shashwat Khare",
"body": "Hello [@ian](/t5/user/viewprofilepage/user-id/4591137) , \n\nThis is Shashwat from the Opsgenie support team and here to help! :) \n\nMay I know if you see the \"Assignee\" selected as Adam when you open the JSM integration in Opsgenie and check the below path: \n\n**JSM Integration \\> Outgoing automation rules \\> Create and update issues with Opsgenie alerts that are created by other integrations \\> Rule \\> Issue details and mandatory fields \\> Edit issue fields \\> Assignee** as in the below example screenshot:\n\n####  {#toc-hId-322909719}\n\nBest, \nShashwat\n",
"comments": [
{
"author": "ian",
"body": "Hello Shashwat. Thanks for your reply. I checked this. Nobody is selected as the Assignee:\n\n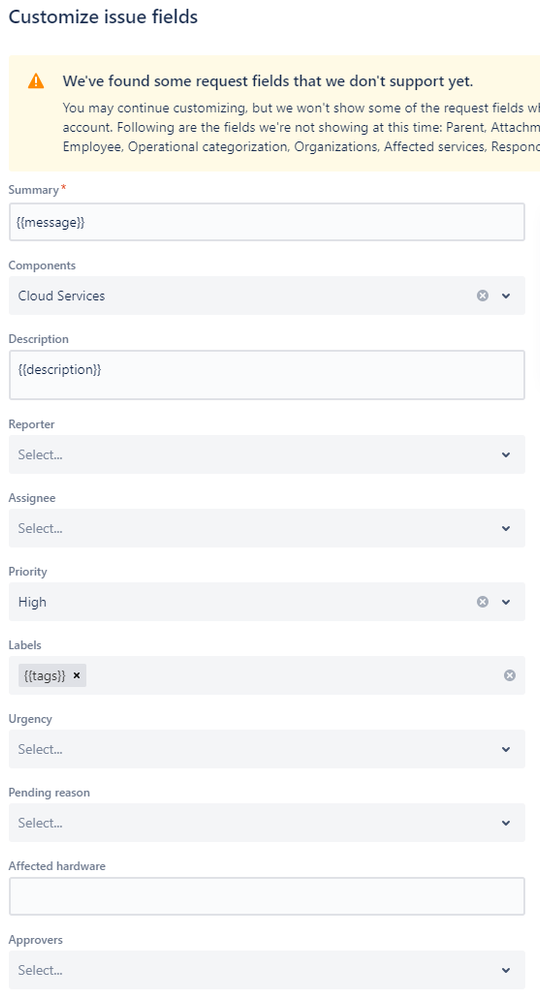\n\nI've removed Adam from the opsgenie team assigned to the email alert integration. Its made no difference - the jsm ticket is still being auto-assigned to Adam. Perhaps its simply that Adam is the alphabetically first jsm agent.\n\nI'm also wondering if I just need to wait until the new jsm incident integration is applied to our tenant before troubleshooting further.\n"
},
{
"author": "Shashwat Khare",
"body": "Hey [@ian](/t5/user/viewprofilepage/user-id/4591137) , \n\nCould you please log a ticket with us for the Jira Service Management Team for this to be investigated further using [this link](https://support.atlassian.com/contact/)? \n\nBest, \nShashwat\n"
},
{
"author": "ian",
"body": "Thanks Shashwat. I've logged a ticket with support.\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/stop-jsm-automatically-assigning-incident-ticket-created-via/qaq-p/2687943
|
[
"cloud",
"integration",
"jira-service-management"
] |
{
"author": "Anders_Bergenholtz",
"title": "Search for alerts that either have an empty message or empty description",
"body": "Is there a way to query alerts that either have an empty message or empty description in the alert view filter or through an API call? This could happen when alerts are originating from emails. I have read this page [Search queries for alerts \\| Opsgenie \\| Atlassian Support.](https://support.atlassian.com/opsgenie/docs/search-queries-for-alerts/) \n\nBtw, why is a alert message called subject in the configuration of an alert rule, and alert description is called alert message in the alert rule. This is confusing, or have I got it wrong? \n\nThanks in advance, Anders\n"
}
|
[
{
"author": "Shashwat Khare",
"body": "Hello [@Anders_Bergenholtz](/t5/user/viewprofilepage/user-id/5224785) , \n\nThis is Shashwat from Opsgenie support and here to help! :) \n\nKindly note that the \"null\" value isn't supported in the search queries for alerts in the Opsgenie Web UI. \n\nAlternatively, you can use the [List Alerts API endpoint](https://docs.opsgenie.com/docs/alert-api#list-alerts) to list out all alerts and then search through the results with the message/description value as blank. \n\nBest, \nShashwat\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Search-for-alerts-that-either-have-an-empty-message-or-empty/qaq-p/2687260
|
[
"cloud"
] |
{
"author": "Matt Osborne",
"title": "Who writes Opsgenie integrations.",
"body": "Hello, \n\nLooking for some details regarding the data security model of opsgenie integrations. I understand that they function as slightly more complex API endpoints, but who writes the code? And is there any opportunity for data to be sent to a third party when using an integration?\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Matt Osborne](/t5/user/viewprofilepage/user-id/5486956) ,\n\nJohn from Opsgenie support here - happy to help.\n\nOur development team writes all of the code for the integrations. We do have 2 options for sending data to a 3rd party:\n\nWebhooks, which send alert payloads to any endpoint you specify:\n\n<https://support.atlassian.com/opsgenie/docs/integrate-opsgenie-with-webhook/>\n\nOEC, which can send more customizable payloads to an AWS SQS queue, which is then retrieved by the OEC client, which can be installed on your local server:\n\n<https://support.atlassian.com/opsgenie/docs/opsgenie-edge-connector-as-an-extensibility-platform/>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Who-writes-Opsgenie-integrations/qaq-p/2685199
| null |
{
"author": "Robert Pawlak",
"title": "Unmerging Jira Service Management and Opsgenie",
"body": "We are going to ask for unmerging Jira Service Management and Opsgenie. My question is if our current setup and configuration of Opsgenie will stay the same as it is now (teams, users, integrations, on-call escalations and schedules).\n"
}
|
[
{
"author": "Robert Pawlak",
"body": "Answer from support:\n\n\"Please note that all settings, such as integrations, schedules, and teams within Opsgenie, will be preserved when the un-merge occurs. No features within Opsgenie will be lost by processing this un-merge. The changes you will experience as a result of splitting the merge include the restoration of features, such as:\n\n- Incoming call routing\n\n- Live chat support\n\n- Free Stakeholder roles\"\n",
"comments": [
{
"author": "Robert Pawlak",
"body": "But.. there is another issue:\n\n**\"Splitting Opsgenie instance is not available for the CCP sites\"**\n\nI don't understand, what actually happened here. We have never asked for Opsgenie related actions nor moving to CCP billing. It sounds very strange. I wonder how many Atlassian customers are affected.\n"
},
{
"author": "Robert Pawlak",
"body": "Issue fixed: [OPSGENIE-1633](https://jira.atlassian.com/browse/OPSGENIE-1633) (*\"Unable to split Opsgenie from JSM if it has been previously merged with JSM and Atlassian Site is Billed in CCP\"*).\n"
},
{
"author": "Shashwat Khare",
"body": "Hey [@Robert Pawlak](/t5/user/viewprofilepage/user-id/5444937) , \n\n<br />\n\nYes, this is fixed and our CA Team should be able to help you with the split. \n\nCould you please log a ticket with us for the same using [this link](https://www.atlassian.com/company/contact/purchasing-licensing?redirectSource=sac-wac-redirect#/)? \n\n<br />\n\nBest, \nShashwat\n"
}
]
},
{
"author": "Elelta D",
"body": "Hello there Robert!\n\nWelcome to the community :-)\n\nYes, you can split OpsGenie from Jira Service Management (JSM), but there are specific conditions and steps involved in the process and requires coordination with Atlassian support teams to ensure the process is completed correctly.\n\n<br />\n\nPlease open a ticket here: <https://support.atlassian.com/contact/>\n\nElelta\n",
"comments": [
{
"author": "Robert Pawlak",
"body": "Hi [@Elelta D](/t5/user/viewprofilepage/user-id/4767776) , thanks for info. I've already opened a ticket on 23/Apr/24, but got no answer up to now. Could you please check CA-2937816? Thanks!\n"
},
{
"author": "Robert Pawlak",
"body": "And I know there is an option, but my question is if after unmerge our current setup and configuration of Opsgenie will stay the same as it is now.\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Unmerging-Jira-Service-Management-and-Opsgenie/qaq-p/2685283
| null |
{
"author": "ACME MS",
"title": "Nested Rules",
"body": "Is it possible to create nested rules in opsgenie? For example, I have 2 rules in cloudwatch,\n\nCPU utilization exceeds 80%, then alerts should come as P1.\n\nCPU utilization exceeds 70%, then alerts should come as P2.\n\nI need the alerts to get suppressed rather than logging it as 2 seperate alerts/ tickets to jira. So, if its 70 then alert it as P2 and once it reaches 80 then alert it as P1 but not log it separately.\n\nPlease provide clarification on this.\n"
}
|
[
{
"author": "Egor",
"body": "Hey There, \nThanks for reaching out to Atlassian Community! \n\nTo achieve your goal of handling alerts based on CPU utilization and managing escalation without creating duplicate alerts, you can use OpsGenie's **Alert Policies** and **Integration settings**. Here's a simplified guide:\n\n1. **Create Integration with CloudWatch**: Set up your OpsGenie integration to receive alerts from AWS CloudWatch. Ensure both P1 and P2 conditions (CPU exceeds 80% and 70%, respectively) are configured in CloudWatch to send alerts to OpsGenie.\n\n2. **Use Alert Deduplication**: In OpsGenie, utilize the deduplication feature to manage multiple alerts triggered for the same incident. Configure deduplication to match alerts based on a common identifier (e.g., instance ID or alert name).\n\n3. **Define Priority-Based Policies**:\n\n * **Filter by Condition**: Use filtering rules in OpsGenie to categorize alerts into P1 or P2 based on the specifics in the alert message or custom fields sent by CloudWatch.\n * **Update Priority**: Use OpsGenie policies to automatically upgrade the priority of an existing alert (from P2 to P1) instead of creating a new alert, based on newer incoming data.\n\nI hope this helps! \n\nThank you,\n\nEgor\n",
"comments": [
{
"author": "ACME MS",
"body": "Thank you,\n\nCan you please elaborate on Update priority part please? maybe the steps or screenshots etc,.\n"
},
{
"author": "Muhammad Zeeshan",
"body": "Hey,\n\nThe updating priority works when for example, there is an existing Alert with priority P3 and alias 'test-alert-alias'. Then a new alert is created with the same alias 'test-alert-alias' but priority P1. In that case, that new alert will not be created as a separate alert, instead it will merged into the initial alert and raise its priority to P1.\n\nNow you can implement it via your Integration settings and via your Alert policies. Please feel free to open a ticket on our Support channel here: <https://support.atlassian.com/contact/> so we can assist you with a solution based on your current configuration and requirements.\n\nBR,\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Nested-Rules/qaq-p/2684549
| null |
{
"author": "Mert ?smail K?ro?lu",
"title": "Create Incident response Incident Id",
"body": "I am performing a \"Create Incident\" operation using Api Key. Then I want to close the Incident I created using the \"Close Incident\" feature. However, the \"Create Incident\" operation does not return the Id value of the created incident. How can I do \"Close Incident\" in this case? I am integrating processes into automation. Entering the application is not among my options.\n"
}
|
[
{
"author": "Egor",
"body": "Hey Mert, \nThanks for reaching out to Atlassian Community. \n\nI'm afraid that at the moment there's no possibility to get the needed data for the automation. \n\nOnce you create an incident, you won't see its ID. I filed a new ticket here for our engineering team - <https://jira.atlassian.com/browse/OPSGENIE-2085> \n\nPlease feel free to start watching it and also add public comments, if needed.\n\nBest Regards, \nEgor\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Create-Incident-response-Incident-Id/qaq-p/2684542
|
[
"cloud"
] |
{
"author": "Ioannis Karavasilis",
"title": "How to create an alert, from email integration, with a specific condition",
"body": "Hello, I have the following issue: \n\nI receive alerts in mail that have the following body format: \n\n**Total emails: \"number of mails\"** \n\nI want an alert to be created, only when the \"number of mails\" \\> specific threshold. \nIs there a way to achieve that? \nI have tried with regex, but I cannot make it work. \nThanks.\n\n<br />\n\n<br />\n"
}
|
[
{
"author": "Vijay Dadi",
"body": "Dear [@Ioannis Karavasilis](/t5/user/viewprofilepage/user-id/5484933) ,\n\nYou need think of ticket de-duplication which means any incoming alert from the same issue will not create a new ticket and increase the count for the same alert.\n\nIn the screenshot below, there is a number below alert it like x2 this means this alert was triggered 2 times. Hope this help.\n\nRegards,\n\nVijay\n\n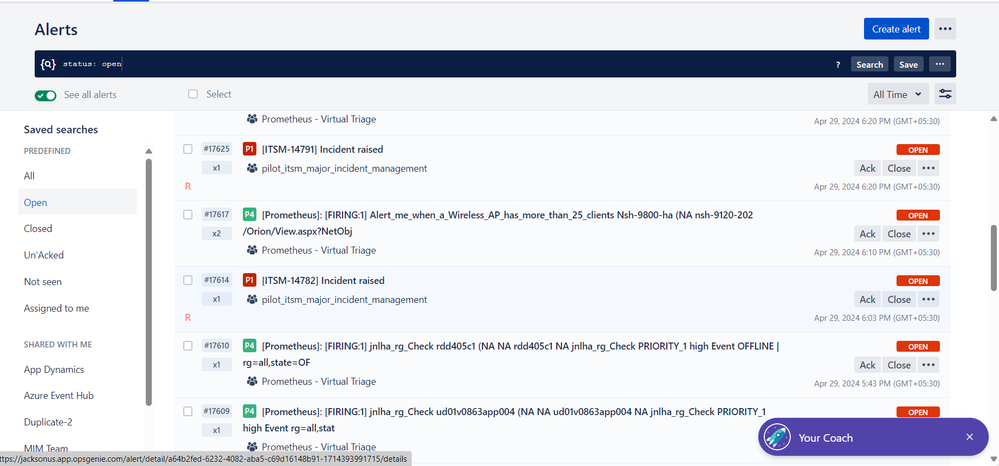\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/How-to-create-an-alert-from-email-integration-with-a-specific/qaq-p/2684527
|
[
"cloud"
] |
{
"author": "Dhary Almousa",
"title": "Get Schedule of Team Via Postman",
"body": "Dear Community,\n\nI have the postman apis for opsgenie and i am trying to get the on call schedule however i keep getting error could not authenticate even though i am using the API Key from my settings in ops genie.\n\nBr,\n"
}
|
[
{
"author": "Elelta D",
"body": "Hey there Dhary,\n\nThanks for getting in touch!\n\nCan you please tell me what error you see? There are a a few types possibilities for what is happening.\n\n|------------------------------------------|-------|--------------------------------------------------------------------------------|\n| 401 - Unauthenticated (Not Unauthorized) | | apiKey is invalid or integration is disabled |\n| 403 - Forbidden (Unauthorized) | 40301 | apiKey is valid but the apiKey cannot do this operation because of permissions |\n| 403 - Forbidden | 40302 | apiKey is valid and authorized but we do not support the request |\n\nIn the case of a 401, please check the api key is correct and that the integration is active/\n\nIn the case of 40301, it means the the API key is from the [API Key Management](https://support.atlassian.com/atlassian-account/docs/manage-api-tokens-for-your-atlassian-account/) and you need to get the API from [API integration](https://docs.opsgenie.com/docs/api-integration) by going to the Settings tab \\>\\> Integrations and selecting the API integration you would like to use.\n\nIn the case of 40302, it means that the request is not support, perhaps the endpoint is incorrect.\n",
"comments": [
{
"author": "Elelta D",
"body": "Dhary, a quick follow up to say that when you configure your api key in postman you can do it in the authorisation tab, chose the API key type and add the key as below where the Key = GenieKey and the Value = the API key from your integration.\n\n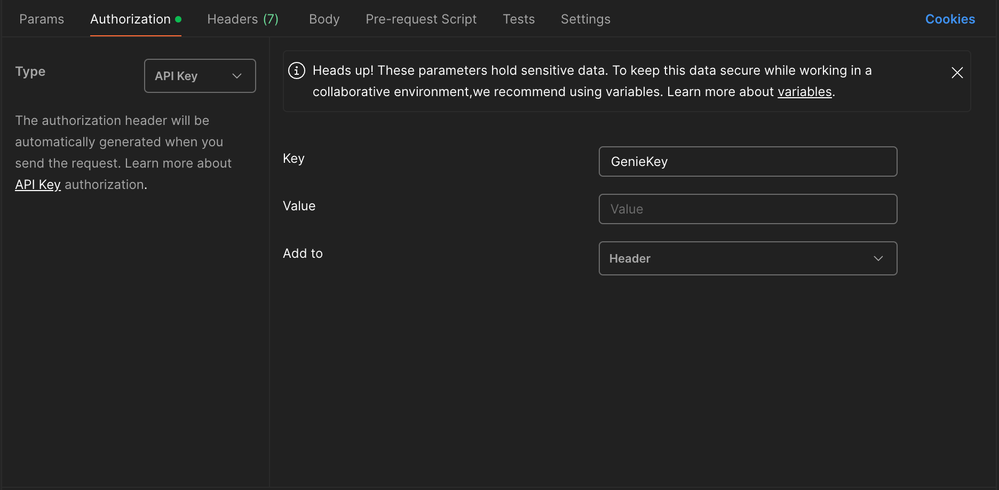\n\nLet me know how you go.\n"
}
]
}
] |
https://community.atlassian.com/t5/Opsgenie-questions/Get-Schedule-of-Team-Via-Postman/qaq-p/2683971
|
[
"cloud"
] |
{
"author": "Ismail Sanni",
"title": "Bamboo page just loading endlessly after upgrade to 9.2.7",
"body": "Hi Guys,\n\nI'm not a tech wiz but i just upgraded Bamboo to 9.2.7 on my staging environment, but after configuration it, the bamboo page keeps loading endlessly, please can anyone help?\n\nSteps i took\n\n- Download bamboo\n\n- Update setenv.sh - `vim` `/opt/atlassian/bamboo_new/bin/setenv``.sh`\n\n- Update server.xml - `vim` `/opt/atlassian/bamboo/conf/server``.xml`\n\n- Update bamboo-init.properties - `vim ``/opt/atlassian/bamboo/atlassian-bamboo/WEB-INF/classes/bamboo-init``.properties`\n\n- Update crowd.properties -\n\n|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| `vim` `/opt/atlassian/bamboo/atlassian-bamboo/WEB-INF/classes/crowd``.properties` `- `Update seraph-config.xml `- `Copy Oracle DB driver - Start Bamboo After a while, I got this (Screenshot)  |\n\nThanks\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Ismail,\n\nWelcome to Atlassian community.\n\nYou'll be able to see the possible errors under **\\<bamboo-home\\>logs\\>atlassian-bamboo.log**file to understand if there was any problem during the upgrade process.\n\nAs Atlassian community is a public forum I'll not advise you to upload the logs here, if you have a valid SEN you can raise a support request with Atlassian support to get this checked.\n\nRegards,\n\nShashank Kumar\n\n**\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Sharmila",
"body": "Hey Ismail,\n\nCan you confirm what is the version of Bamboo you upgraded Bamboo from?\n\nYou can have a look at the upgrade procedure to get more details on Bamboo upgrade steps that you will need to undertake: [Bamboo upgrade guide.](https://confluence.atlassian.com/bamboo0902/bamboo-upgrade-guide-1236931009.html)\n\nRegards,\n\nSharmila\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Bamboo-page-just-loading-endlessly-after-upgrade-to-9-2-7/qaq-p/2585896
| null |
{
"author": "Srinivasan Azhagar",
"title": "Installation Stuck on H2 Data",
"body": "Hi Team,\n\nNot able to complete the installation using H2 database\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Srinivasan,\n\nWelcome to Atlassian community\n\nThere might be multiple reasons why Bamboo installation would be stuck on H2 DB setup, we would need access to **\\<bamboo-home\\>atlassian-bamboo.log** file to understand this issue, as this is a public forum I would not advise you to directly put the logs here, if you have a valid SEN you can raise a support request with Atlassian support to get this checked.\n\nMeanwhile looking a past cases, this normally happens when the Bamboo user which you have used to start does not have **read/write** access to \\<bamboo-home\\> directory, you should provide full read/write access to bamboo-home directory to the user which is starting Bamboo and restart the installation, it will work.\n\nThis is just one hypothesis, you may have some other problem which can be confirmed by looking at the logs\n\nRegards,\n\nShashank Kumar\n\n**\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Installation-Stuck-on-H2-Data/qaq-p/2579952
| null |
{
"author": "velu",
"title": "How to configure test parser plugins like JUnit Parser, TestNG Parser in deployment environme",
"body": "Hi team, In build plan, test parser tasks are available. In deployment project environment there is no test parser task are available. How to configure test parser plugins in deployment project environment task. \nIs there any steps or plugins to configure test parsers like JUnit parser, TestNG parser, Nunit parser and so on. \nIf it is possible to add test parser tasks or any other method. Give me the solution to complete the task.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Velu,\n\nWelcome to Atlassian community.\n\nTest parser tasks are available under Build Plan \\> Job \\> Tasks, the reason for that is these test parser scans for test cases during the build time ( As part of CI process ), the result is then provided under Test tab for each build result. This is part of CI process\n\nDeployment projects and Deployment environments are designed to deploy the already completed builds, we don't expect to capture the status of test results here, hence you don't see any test case parsing tasks there.\n\nCan you explain me your flow why would you want a test case parsing task under deployment environments?\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-configure-test-parser-plugins-like-JUnit-Parser-TestNG/qaq-p/2576391
| null |
{
"author": "leegyu86",
"title": "Is there a way to not copy the trigger settings when performing a clone using restapi?",
"body": "The plan being executed periodically is copied.\n\nThe problem is that Tigger's 'Single daily build' settings are also being copied.\n\nIs there a way to not copy the trigger settings when performing a clone using restapi?\n\nOr please tell me about restapi where I can delete the trigger settings.\n\n(Please do not suggest methods using the Bamboo spec.)\n\nIf there is no solution, I have no choice but to find a 3rd party method... but I would like to solve it in Bamboo itself.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [leegyu86](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5325379),\n\nWelcome to Atlassian community.\n\nAs far as I am aware, I am not aware of any REST API to delete the Triggers settings for the plans or not copy the trigger settings which cloning using Rest API\n\nYou can try to use the Bulk action functionality from Bamboo GUI to achieve this, go to **?? \\> Overview \\> Bulk action** page\n\nYou can select all the plans which you want to change the trigger and click Next and select what kind of Trigger you want to choose, see example below of the page\n\n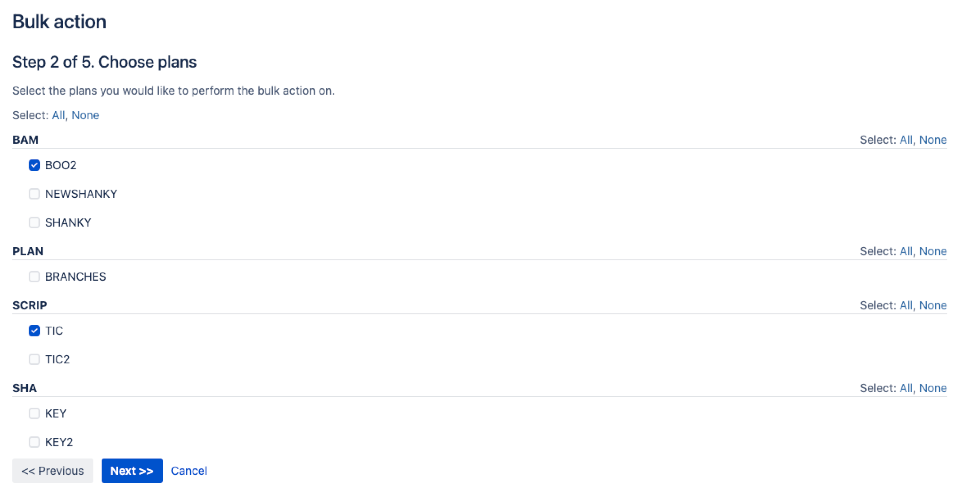\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Is-there-a-way-to-not-copy-the-trigger-settings-when-performing/qaq-p/2576381
| null |
{
"author": "velu",
"title": "How to display the test result in bamboo console using plugin or some other tasks ?",
"body": "Hi team, In bamboo pipeline task I have added a testing jobs for API testing using Newman, Performance Testing using JMeter, Selenium Testing.\n\nIs any possibilities like tasks or plugins to display the above three test results in the bamboo console to view the test reports.\n\nIs any possibilities is there to display the test results, Give me solution to resolve the above test tasks\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Velu,\n\nWelcome to Atlassian community.\n\nYou can view the test results for a particular build using by navigating to Build result and Tests tab, it will display all the test result for that particular build.\n\nPlease refer <https://confluence.atlassian.com/bamboo/viewing-test-results-for-a-build-289276936.html> for more details\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-display-the-test-result-in-bamboo-console-using-plugin-or/qaq-p/2576375
| null |
{
"author": "Matimba Mashaba",
"title": "Remote trigger and webhook",
"body": "Hi, I have a plan that I have enable a remote trigger but I get an error when i send a POST API request (Method Not Allowed). i do get results when i use GET method. Please note I have left the IP Address edit box blank as I am querying from Saas environment.\n\nRegarding webhook, How can I create a webhook that trigger a build. I saw the build webhook template but I did not understand how to go about it.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Matimba,\n\nWelcome to Atlassian community.\n> Regarding webhook, How can I create a webhook that trigger a build. I saw the build webhook template but I did not understand how to go about it. \n>\nI believe you are referring to <https://confluence.atlassian.com/bamboo/using-webhooks-1018270680.html> where the Build webhook is used to send information about the current build to third party apps. This will help you display Bamboo build information in for example in Teams where you can get to know if a Build passes or Fails.\n\nTo trigger the Build best way would be to use **Bamboo REST API** , you can refer <https://developer.atlassian.com/server/bamboo/rest/api-group-api/#api-api-latest-queue-projectkey-buildkey-post> for more details, the REST API would looks something like below\n\n```\ncurl --request POST \\ \n--url 'http://{baseurl}/rest/api/latest/queue/{projectKey}-{buildKey}' \\ \n--header 'Accept: application/json' \\ \n--header 'Content-Type: application/json' \\ \n--data '{ \"fakeParam\": \"<string>\" }'\n```\n\nIf you looking to use Webhook to Trigger builds from Github or BB Cloud you can refer the below documentation\n\n<https://confluence.atlassian.com/bamkb/how-to-trigger-bamboo-builds-with-github-webhook-1097179080.html>\n\n<https://confluence.atlassian.com/bamboo/triggering-a-bamboo-build-from-bitbucket-cloud-using-webhooks-873949130.html>\n\nRegarding your query related to Remote Trigger, can you explain the whole setup again, it's little confusing to understand currently.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Remote-trigger-and-webhook/qaq-p/2575816
| null |
{
"author": "sulekhak",
"title": "Sharing previous build artifact is failing",
"body": "I have a plan A and has Stage 1 and Stage 2 \nStage 1 has 1 Job which creates artifact in the working directory \nStage 2 has 1 Job which downloads those files and uses those files in the execution flow \n\nHave disabled Stage2 and ran stage 1 and files are shared in the working directory \nHave disabled stage 1 and ran Stage 2 but not able to use the shared files, shared files are present in the directory.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [sulekhak](https://community.atlassian.com/t5/user/viewprofilepage/user-id/3247597),\n\nWelcome to Atlassian community.\n\nWhen you run stage 1 Artifacts are created in the working directory of the agent where you ran the Build and once the Job is completed, these artifacts are then published to Bamboo server.\n\nYou can see this information in the build logs of the Job from Stage 1 as below\n\n```\n08-Jan-2024 06:22:34 Running post build plugin 'Artifact Copier'\n08-Jan-2024 06:22:34 Publishing an artifact: Artifact1\n08-Jan-2024 06:22:34 Finished publishing of artifact Required shared artifact Http Compression On : [Artifact1], patterns: [*.jar] in 64.49 ms\n```\n\nWhen you go to the Artifacts tab of the Job which created this artifacts, you'll see where it is stored on the Bamboo server\n\n**Shared artifacts can be found under:**\n\n```\n/var/atlassian/application-data/bamboo/shared/artifacts/plan-26705921/shared/build-00022\n```\n\nNow if you disable Stage 1, Artifcats won't be created for that particular run as Stage 1 is disable and Stage 2 won't able to download it.\n\nYou can't share artifacts across different build runs.\n\nSame concept is applicable if you are create dependency from Artifacts from Stage 1 to Stage 2 via <https://confluence.atlassian.com/bamboo/sharing-artifacts-359400060.html>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Sharing-previous-build-artifact-is-failing/qaq-p/2571351
| null |
{
"author": "Devendar Gangapuram",
"title": "Will BAMBOO server continue work after the 14th Jan, as the current license expires on Jan-13th,2023",
"body": "Hi Team,\n\nwhat will happen if we cannot migrate to Data center version and given that we cannot renew the existing server license. Will BAMBOO continue work after the 14th Jan, as the current license expires on Jan-13th,2023\n\n* SEN-20623233 - Bamboo (Server) 1 Remote Agent License - Jan 13, 2024\n\nPlease let us know, how to proceed on this BMABOO set up going further after Jan-13th, 2024.\n\nThank you,\n\nDev G\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Dev G,\n\nWelcome to Atlassian community.\n\nWith Server license post Effective **15th Feb 2024** , Atlassian will no longer offer **technical support** , **security updates** , or **bug fixes** . You'll not be able to upgrade Bamboo to **latest** version with the server license.\n\nYour current Bamboo instance will continue to run as the Server license is perpetual ( meaning it never expires ), you can read more about it at [What happens when a Bamboo license expires](https://confluence.atlassian.com/bamkb/what-happens-when-a-bamboo-license-expires-1114804458.html)\n\nYou can refer [Upgrade from Bamboo Server to Bamboo Data Center](https://confluence.atlassian.com/bamboo/upgrade-from-bamboo-server-to-bamboo-data-center-1189482373.html) for more details. In short you can just migrate by buying the DC License and applying it to your current Server instance, you'll need to take care of certain external app's or plugins which you have installed which are not supported on Bamboo Data center, read the above page for all the details.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Will-BAMBOO-server-continue-work-after-the-14th-Jan-as-the/qaq-p/2571345
|
[
"migration",
"migration-customer-care"
] |
{
"author": "Billy Sharpe",
"title": "Terminate Bamboo Job with Python Exception",
"body": "Hello all, \n\nI have a Bamboo job that runs a Python script, followed by a PowerShell script. What I am trying to figure out, is if the python script throws an exception (like below), how can I make the bamboo job terminate so it does not run the PowerShell script? I tried passing sys.exit(1) but bamboo still reads it as 0. \n\nexcept Exception as error: \nprint(f\"FAILED with the following error: {error} in the file: {filename}\") \nsys.exit(1)\n\n```\nbuild\t03-Jan-2024 16:18:49\tFAILED with the following error: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all(). in the file: Afilename.xlsxsimple\t03-Jan-2024 16:18:49\tFinished task 'Run Python: CreateUploadForm' with result: Success\n```\n\nThank you!\n\nBilly\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Billy,\n\nWelcome to Atlassian Community\n\nIf i understand correctly you have a single script task which contains Python and Powershell scripts.\n\nYou can try to use **set -e**at the beginning of the script task like below\n\n```\n#!/bin/bash\nset -e\n```\n\nBamboo will terminate the task when it sees any error and won't execute the next commands.\n\nYou can read similar information on this thread [https://community.atlassian.com/t5/Bamboo-questions/Bamboo-does-not-respect-exit-status-of-docker-compose/qaq-p/1197430?utm_source=atlcomm\\&utm_medium=email\\&utm_campaign=kudos_answer\\&utm_content=topic](https://community.atlassian.com/t5/Bamboo-questions/Bamboo-does-not-respect-exit-status-of-docker-compose/qaq-p/1197430?utm_source=atlcomm&utm_medium=email&utm_campaign=kudos_answer&utm_content=topic)\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "Billy Sharpe",
"body": "Hello! \n\nThanks for the info. \n\nBelow is my current bamboo task list.\n\nWhat I am looking to do is, if the script that runs python throws an exception, the powershell after it does not run.\n\nAccording to bamboo, despite the exception being thrown, the script ran \"successfully' and it continues running the powershell script. \n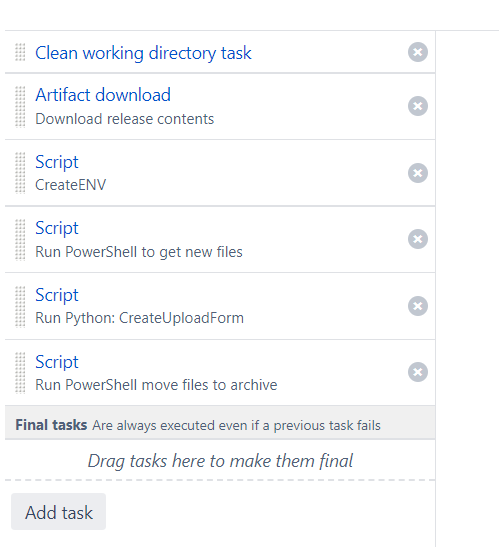\n\nI should mention that my bamboo servers are windows, not linux if that matters.\n\nWhere do I add the -e?\n\nIs it here?\n\n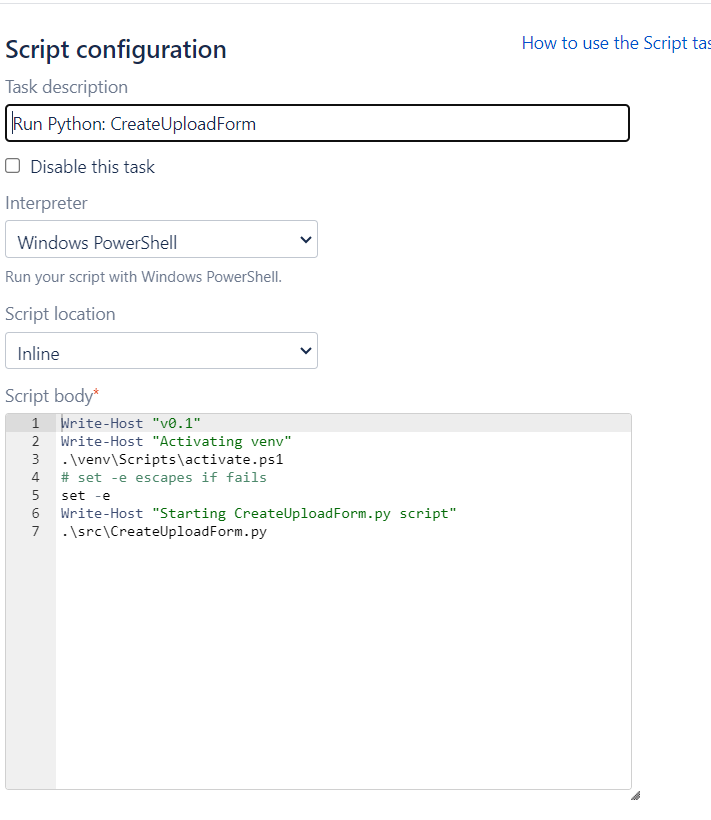\n\nThanks again!\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Billy,\n\nThanks for providing the clarification regarding the structure of your Job, now my understanding is clear.\n\nBasically you have 1 task which is Python script and if this Task fails, you don't want another Task which is Powershell script to be executed.\n\nIn your case somehow Bamboo is returning exit code as 0, hence marking your Python script task as success.\n\n**set -e**option will not work here as it is for Linux and your scripts are getting executed in Powershell environment.\n\nI am not an expert in Windows shell programming, you can try couple of Options.\n\n**Option 1:**\n\nYou'll need to exit with the exit code if it's non zero manually, you can try something\n\n```\nif ($lastexitcode -ne 0) { exit $lastexitcode }\n```\n\n**Option 2:**\n\nYou can try the below\n\n```\necho \"Exiting with return code: \" %ERRORLEVEL%\nexit %ERRORLEVEL%\n```\n\nYou can read more about these at\n\n<https://community.atlassian.com/t5/Bamboo-questions/How-do-you-capture-a-task-error-during-a-build/qaq-p/1238630>\n\n<https://stackoverflow.com/questions/15777492/why-are-my-powershell-exit-codes-always-0>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Terminate-Bamboo-Job-with-Python-Exception/qaq-p/2570173
| null |
{
"author": "Ankush Das",
"title": "Run Builds Sequentially trigger at the same time.",
"body": "When a Jira status change occurs, it triggers a Bamboo pipeline. However, in the current scenario, if two users simultaneously change the Jira status, only one build is executed, and the other is not.\n\nWhat I desire is for the first build to run immediately, while the second build enters a queue and runs after the completion of the first build.\n\nIs there any way to do the same? I do not want to run builds in parallel.\n"
}
|
[
{
"author": "alok m",
"body": "Ensuring that builds triggered by Jira status changes are queued sequentially in Bamboo, especially when multiple status changes occur simultaneously, requires configuring Bamboo's build queue and possibly using additional scripting or plugins to manage the build triggers more effectively. Here's a general approach to achieving this:\n\nStep 1: Configure Bamboo Build Plans \nConcurrency Settings: Check the plan configuration in Bamboo. Ensure that the plan is set not to run concurrent builds. This setting ensures that if a build is triggered while another is running, it will be queued.\n\nNavigate to your plan configuration in Bamboo. \nLook for settings related to Concurrency or Queueing. \nEnsure the configuration is set to avoid parallel executions of the same plan. \nThrottling Triggers: If Bamboo's built-in settings don't provide the level of control you need, consider adding a throttling mechanism to your build trigger process. This might involve custom scripting or using an intermediary service to manage the triggers.\n\nStep 2: Use an Intermediary Script or Service \nIf direct configuration in Bamboo is insufficient, you can use an intermediary script or service that receives the Jira webhook notifications and then triggers the Bamboo builds. This script can implement logic to check if a build is currently running and queue requests accordingly.\n\nWebhook Receiver: Create a simple web service or script that listens for Jira webhook events. \nCheck Bamboo's Build Status: Before triggering a new build, check if there is already a build running for the plan. Bamboo's REST API can be used to query the current status of builds. \nQueue Management: If a build is already running, your script can wait (polling at regular intervals) until the current build completes before triggering the next build. \nStep 3: Utilize Bamboo's REST API \nBamboo's REST API can be leveraged to check the status of a build plan and trigger builds. This can be integrated into your intermediary service:\n\nQuery Plan Status: Use the REST API to check if the plan is currently building. \nTrigger Build: If no builds are currently running, use the API to trigger a new build. If a build is running, queue the request. \nStep 4: Jira Integration \nConfigure Jira to send status change events to your intermediary service instead of directly to Bamboo. This setup allows your service to manage the build triggers. \nStep 5: Implement Queue Logic \nIn your service, implement logic to manage a queue of build requests. When a build completes, the service should automatically trigger the next build in the queue, if any. \nStep 6: Monitoring and Error Handling \nEnsure that your intermediary service includes robust logging, monitoring, and error handling. This is crucial for diagnosing issues and ensuring the reliability of the build process. \nAlternative: Explore Bamboo Plugins \nExplore Bamboo Marketplace: Check the Atlassian Marketplace for Bamboo plugins that might offer enhanced queue management or build trigger controls. Some plugins might provide the functionality you need out of the box. \nThis approach requires additional infrastructure and setup but offers a flexible solution to precisely manage how and when builds are triggered from Jira status changes.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Run-Builds-Sequentially-trigger-at-the-same-time/qaq-p/2570608
| null |
{
"author": "Ryan Mann",
"title": "Permissions issues with viewing the details of a new stage with jobs created from specs",
"body": "I have a working build configuration checked in with (Java) Specs on the master branch of my code, which has a single stage and a single job. I am attempting to break up the work into two stages. I am working on a branch from master, so that I can test the changes before merging them into master. I have added a stage (with a new key) before the existing stage, which has three jobs.\n\nWhen the branch comes off the queue on our bamboo server, the new jobs are queued. I can see the \"live activity log\" for each of the new jobs, but when I click on the link for each job, I'm given an \"access denied\" error. After the job is complete, I cannot see the live activity view, or see the results of the build.\n\nThe same is not true for the pre-existing stage and job (which exist with the same keys in the master branch specs): that job I can click into and see the details about.\n\nI even changed the user permissions (in the build specs) to make sure I have admin privileges, but makes no difference.\n\nIs this simply because I'm working on a branch? Is there no way to create and test new stages or jobs on a branch without first defining them in master?\n"
}
|
[
{
"author": "Ryan Mann",
"body": "I solved it by logging out of Bamboo and then back in again.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Permissions-issues-with-viewing-the-details-of-a-new-stage-with/qaq-p/2569998
| null |
{
"author": "Fernando Alonso",
"title": "How can one provide read-only/view permissions to a plan configuration?",
"body": "It seems that Bamboo 6.8.1 one is unable to provide view configuration permissions for Build Plans. How can one provide read-only/view permissions to a build plan configuration? The only way we have managed this is to allow the users 'admin' level rights.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Fernando,\n\nWelcome to Atlassian community\n\nOn Bamboo 6.8 to provide view permission for plans, you need to go to **configure plan \\> permissions tab** and provide permissions to the user and you can see from the dropdown all the options are available.\n\n\n\nOn Bamboo 6.8 the permission of plan is not dependent upon permission of the project, On the project level you can only provide below 2 permissions\n\n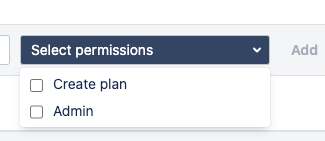d\n\nFrom **Bamboo 7.2** this has changed, The project View permission is a prerequisite for accessing all plans in the project. Without the project View permission, you won't be able to see, run, or administer any plans.\n\nHence you'll se the below options in project permissions after Bamboo 7.2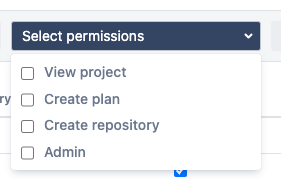\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-can-one-provide-read-only-view-permissions-to-a-plan/qaq-p/2564134
| null |
{
"author": "Mayur Maru",
"title": "Is there any native way where we can automate creation of Atlassian Bamboo Plans, Jobs and Tasks",
"body": "Hi All, \n\nLooking for a native way to automate creation of Atlassian Bamboo Plans, Jobs and Tasks. \nI am using Atlassian Bamboo v9.2.1. So Bamboo Specs would not be of much use - *\"This reference documentation is based on [Bamboo Specs](http://repo1.maven.org/maven2/com/atlassian/bamboo/bamboo-specs/) library version **9.4.2** , which is intended for Bamboo version **9.4.2** and higher.\"* \n\n<https://docs.atlassian.com/bamboo-specs-docs/9.4.2/specs.html?yaml#yaml4> \n\n<br />\n\nThanks, \nMayur \n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Mayur,\n\nWelcome to Atlassian community.\n\nWhat you are looking for can be done via Specs, Bamboo specs is available for version **9.2.1** , for reference you can refer \\> <https://docs.atlassian.com/bamboo-specs-docs/9.2.1/specs.html?yaml>.\n\nDo you see any problem using this on 9.2.1?\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Is-there-any-native-way-where-we-can-automate-creation-of/qaq-p/2562912
| null |
{
"author": "leegyu86",
"title": "Where is the output of tasks executed in Bamboo Agent stored?",
"body": "I am looking for a log where the output of the task is written on the server where the agent is running. \nI created a Script Task in Plan as shown below.\n\n---------------- \necho \"Here I am\" \nexit 3 \n----------------\n\nI also checked the following message in the Logs-Build log on the web.\n\n------------------------------------------------------------------------------------------------ \n18-Dec-2023 22:42:51 Here i am \n18-Dec-2023 22:42:51 Failing task since return code of \\[/hdd/bamboo-agent-home/bamboo-agent01/temp/VES-AKNBU2P2NINKV6U2HGJPUKVR7MZSWC5DVOJSS6VCFON2D6TKDKVPVGRZSL5CVMP2EJFLA-BJT-2-ScriptBuildTask-6285048483259833227.sh\\] was 3 while expected 0 \n------------------------------------------------------------------------------------------------\n\nHowever, there is no 'Here i am' message in the agent's bamboo-agent01/logs/atlassian-bamboo-agent.log file, as shown below.\n\n------------------------------------------------------------------------------------------------ \n13848 INFO \\| jvm 1 \\| 2023/12/18 22:42:51 \\| 2023-12-18 22:42:51,030 INFO \\[0-BAM::AP::Agent:pool-5-thread-1\\] \\[ProcessServiceImpl$2\\] Beginning to execute external process for build ... \n13849 INFO \\| jvm 1 \\| 2023/12/18 22:42:51 \\| 2023-12-18 22:42:51,040 INFO \\[0-BAM::AP::Agent:pool-5-thread-1\\] \\[TaskResultBuilder\\] Failing task since return code of \\[/hdd/bamboo-agent-home/bamboo-agent01/temp/VES-AKNBU2P2NINKV6U2HGJPUKVR7MZSWC5DVOJSS6VCFON2D6TKDKVPVGRZSL5CVMP2EJFLA-BJT-2-ScriptBuildTask -6285048483259833227.sh\\] was 3 while expected 0 \n------------------------------------------------------------------------------------------------\n\nThe only clue I found is when you timeout for a long time after the echo message. During the timeout, there was a bamboo-agent01/temp/log_spool/plan-153780472-BJT-2.log file, and that file had an echo message.\n\n-------------------------------------- \nbuild 18-Dec-2023 22:56:56 Here I am \n--------------------------------------\n\nHowever, this file is created 4 to 7 seconds after the execution of the echo command is seen on the web, so it does not seem to be the file being logged by the agent.\n\nI believe agent will have a complete log. (Or I think there is such a setting)\n\nI'm continuing to look. Please give me some advice. Thank you.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [leegyu86](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5325379),\n\nWelcome to Atlassian community.\n\nThe results of the echo command is part of build logs, these are first created on the bamboo-agent and later transmitted to the Bamboo server. The method of transferring logs as artifacts is used regardless if live logs are on. If the live logs are on, the partial logs are persisted on-the-fly on the server and replaced with the content of the full logs, once the build finishes.\n\nOn the Bamboo-agent you can find these under \\> **\\<bamboo-agent-home\\>/temp/log_spool**\n\nI just tested one in my local system and was able to see the logs there while the build was executing.\n\n**Note** : The logs would only be available here until the build is executing on the agent, once the build completes these logs would be moved to Bamboo server and you'll not be able to see these on the agent file system.\n\nThese would only be left on the agent file system if for some reason agent was not able to send these files to the Bamboo server.\n\nOn the Bamboo GUI, you are able to see these logs because of live log transmission, read more about it at <https://confluence.atlassian.com/bamboo/configuring-live-logs-transmission-1018270669.html>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Where-is-the-output-of-tasks-executed-in-Bamboo-Agent-stored/qaq-p/2561932
| null |
{
"author": "deependra97",
"title": "programaticlly set custom name for cloned plan",
"body": "I am using a bamboo rest api to clone existing plan to new plan, here is the api endpoint:\n\n```\n\ncurl --request PUT \\ --url 'http://{baseurl}/rest/api/latest/clone/{projectKey}-{buildKey}:{toProjectKey}-{toBuildKey}' \\ --header 'Accept: application/json'\n```\n\n<br />\n\n<br />\n\nIt's working fine, however the new plan(cloned from existing name) has the same plan name with appended([(dvcsci-cloned)](https://code.verisk.com/bamboo/browse/ISONA-FSTD)) , Is there any way to set a custom name in cloned plan?\n\nAny suggestions or recommendations are appreciated.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [deependra97](https://community.atlassian.com/t5/user/viewprofilepage/user-id/2739290),\n\nWelcome to Atlassian community.\n\nI don't think so you can pass Plan name in Clone REST API endpoint, as it does not accept plan name as input.\n\n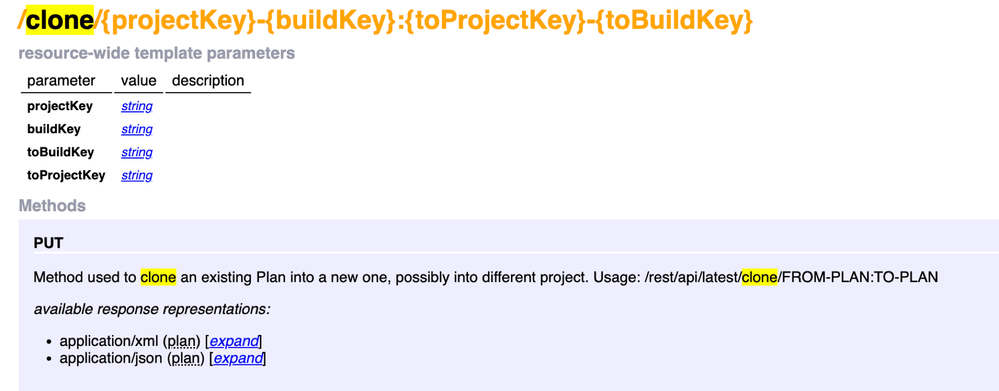\n\nThere is however a feature request raised for the same, kindly refer <https://jira.atlassian.com/browse/BAM-20098>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": [
{
"author": "deependra97",
"body": "Thanks, I have upvoted as well. Let's hope it will be available soon.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/programaticlly-set-custom-name-for-cloned-plan/qaq-p/2562864
| null |
{
"author": "Patrick Laubner",
"title": "Gather all the Jira Tickets in the lastest Bamboo Release using a Bamboo Script Task",
"body": "Hello everyone,\n\nI'm trying to automate the post release process inside of Bamboo, I have a the following structure in my build plan (upstream):\n\n* Build Project\n * Plan\n * Default Stage\n * Job Build JAR\n * Task Git Checkout\n * Task Maven\n * Task create Git Tag in repo\n\nAfter building my project I have a successful build with i.E. #14 and the tag 'v5.10.4.1' in ButBucket (Git).\n\nFollowing this I created a Deployment Project (downstream) that has these script tasks:\n\n* Create fixVersion in Jira\n* Gather all the Jira Tickets in the lastest Bamboo Release\n* Add all Bamboo Release Tickets to Jira Release\n\nThe steps use *curl* in some form or another and the REST API either from Jira or Bamboo, **Step 1** works with any problems as long as the **fixVersion** hasn't been created in Jira previously.\n\nFor **Step 2** I did a test from my workstation with success using this command to get the issues and save them as a text file for **Step 3** afterwards:\n\n```\n\ncurl -X GET --user ${bamboo.user}:${bamboo.password} -H 'X-Atlassian-Token: no-check' \"https://server-name/rest/api/latest/result/${bamboo.buildResultKey}.json?expand=jiraIssues\" -o >(grep -o -E '\"(Ticket-KEY)-\\d*\"' | tr -d '\"' > /tmp/issueKeys.txt) && cat /tmp/issueKeys.txt\n\n```\n\nI tried doing this as a Script Task during my deployment as either inline or file based, this is my script:\n\n```\n\n#!/bin/bash\n\n# Variables: ${bamboo.user}:${bamboo.password}; ${bamboo.buildResultKey}\n# Gather all the Jira Tickets in the lastest Bamboo Release as the second step\n\necho \"==> Gather all the Jira Tickets in the lastest Bamboo Release: yes\"\n\ncurl -X GET --user ${bamboo.user}:${bamboo.password} -H 'X-Atlassian-Token: no-check' \"https://server-name/rest/api/latest/result/${bamboo.buildResultKey}.json?expand=jiraIssues\" -o >(grep -o -E '\"(Ticket-KEY)-\\d*\"' | tr -d '\"' > /tmp/issueKeys.txt)\n\necho \"==> The following Jira Tickets from the lastest Bamboo Release have been gathered\"\n\n# for debugging run this to verfiy the results in the Bamboo deployment logs\ncd /tmp/ && ls -la && cat issueKeys.txt && nl issueKeys.txt\n\n```\n\nI ran into the following problems:\n\n* Using https in the curl command on Bamboo itself will log: **curl: (35) error:1408F10B:SSL routines:ssl3_get_record:wrong version number**\n* Using http in the curl command on Bamboo itself will log a **404**:\n\n```\n\n\n13-Dec.-2023 14:05:53 <!DOCTYPE HTML PUBLIC \"-//IETF//DTD HTML 2.0//EN\">\n13-Dec.-2023 14:05:53 <html><head>\n13-Dec.-2023 14:05:53 <title>404 Not Found</title>\n13-Dec.-2023 14:05:53 </head><body>\n13-Dec.-2023 14:05:53 <h1>Not Found</h1>\n13-Dec.-2023 14:05:53 <p>The requested URL was not found on this server.</p>\n13-Dec.-2023 14:05:53 <hr>\n\n```\n\nIt seems it is not possible to curl the Bamboo REST API from inside of Bamboo it's self but it should be possible, I found this in the Atlassian documentation:\n\n```\n\ncurl -u <ADMIN_USERNAME>:<PASSWORD> <BAMBOO_URL>/build/admin/ajax/getDashboardSummary.action\n```\n\nMaybe someone has solved this already but I can't find a thread or documentation. Many thanks for help or ideas!\n"
}
|
[
{
"author": "alok m",
"body": "Your issue with using **curl** to access the Bamboo REST API from within Bamboo itself appears to involve a couple of different problems: SSL issues and incorrect URL handling. Let's address each issue and propose a solution.\n\n**SSL Issue**\n\nThe error message **curl: (35) error:1408F10B:SSL routines:ssl3_get_record:wrong version number** suggests a mismatch in the SSL protocol between the **curl** client and the server. This can be caused by an outdated **curl** or OpenSSL library on the Bamboo server or by specific server configurations.\n\nPossible Solutions:\n\n1. **Update curl and OpenSSL** : Ensure that both **curl** and OpenSSL are up to date on the Bamboo server. This can often resolve SSL version mismatch issues.\n2. **Specify SSL Version** : You can explicitly specify the SSL version **curl** should use with the **--sslv3** , **--tlsv1.0** , **--tlsv1.1** , **--tlsv1.2** , or **--tlsv1.3** options, depending on what the server supports. Be cautious with this approach, as using older versions of SSL/TLS can introduce security vulnerabilities.\n3. **Disable SSL Verification** : As a last resort and only for internal, secure networks, you can disable SSL certificate verification in **curl** with the **-k** or **--insecure** option. **This is not recommended for production environments** due to security risks.\n\n**HTTP 404 Error**\n\nReceiving a 404 error with the HTTP URL might be due to incorrect API endpoint specification or server configuration that does not route HTTP traffic correctly.\n\nCheck the API Endpoint:\n\nEnsure that the API endpoint URL is correct. It's worth double-checking the base URL and the API path. Sometimes, path issues or typos can lead to 404 errors.\n\n**Script Adjustments**\n\nGiven the issues you're facing, here are some adjustments and considerations for your script:\n\n1. **Debugging SSL** :\n * Initially, try running **curl** with the **-v** (verbose) flag to get more insight into the SSL negotiation process.\n * Test the SSL version specification, e.g., **curl --tlsv1.2 ...**, to see if specifying the version resolves the issue.\n2. **Ensure Correct API Endpoint** :\n * Verify the API endpoint URL directly via a browser or Postman to ensure it's correct and accessible.\n3. **Use Internal Hostname** :\n * If the SSL issue persists, and you're accessing an internal service, consider using the internal hostname (without SSL) if security policies permit. Ensure the URL and port are correct for internal access.\n4. **Script Modification**:\n\nbash\n\n#!/bin/bash # Use -k for debugging purposes only; remove in production curl -k -v -X GET --user ${bamboo.user}:${bamboo.password} -H 'X-Atlassian-Token: no-check' \"<https://server-name/rest/api/latest/result/${bamboo.buildResultKey}.json?expand=jiraIssues>\" \\| grep -o -E '\"(Ticket-KEY)-\\\\d\\*\"' \\| tr -d '\"' \\> /tmp/issueKeys.txt echo \"==\\> The following Jira Tickets from the latest Bamboo Release have been gathered\" cat /tmp/issueKeys.txt\n\n1. **Environment Variables** :\n * Make sure **bamboo.user** , **bamboo.password** , and **bamboo.buildResultKey** are correctly set as environment variables in your Bamboo plan or deployment project.\n2. **Alternative Tools** : If **curl** continues to cause issues, consider alternative command-line tools like **wget** , or scripting languages like Python with the **requests** library, which may offer more flexibility and better error handling.\n\nLastly, always consult the latest Atlassian documentation and consider reaching out to Atlassian support or community forums if the problem persists. Custom situations like this can sometimes involve nuances specific to your environment or version of the tools you're using.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Gather-all-the-Jira-Tickets-in-the-lastest-Bamboo-Release-using/qaq-p/2561812
|
[
"jira",
"rest-api"
] |
{
"author": "leegyu86",
"title": "Is there a way to send complete logging when sending mail from a Task within a Plan?",
"body": "In Bamboo's final tasks, I am creating a task that sends Bamboo's execution results and logs by email.\n\n<br />\n\nBefore the plan ends, the task is downloading the log through the URL below. \n<https://bamboo.aev.com/download/VES-AEV-SJT/build_logs/VES-AEV-SJT-3.log>\n\nThe problem is, sometimes the last part of the log doesn't come out. \nI would like to see logs up to the task of sending an email.\n\n<br />\n\nIsn't there a better way?\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [leegyu86,](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5325379)\n\nWelcome to Atlassian community.\n\n<https://bamboo.aev.com/download/VES-AEV-SJT/build_logs/VES-AEV-SJT-3.log> link would display the running logs during the build process if live log transmission is on, please read more about it at <https://confluence.atlassian.com/bamboo/configuring-live-logs-transmission-1018270669.html>\n\nHow it works is that Build whey they are running on the agent would store it temporally on the agent server, if the Live log transmission is On, agent would keep on sending the partial logs to the Bamboo server during the process of the build and when the build completes it replaces the whole content on the Bamboo server and deletes the temporary file on the Bamboo agent.\n\nRead about all the scenarios on the above link.\n\nComing to your ask, I think the best idea to would be to split your plan into two stages.\n\n\\* Stage 1 - Have everything configured\n\n\\* Stage 2 - Configure the task to send the logs from the previous stage.\n\nWhen Stage 1 completes, Bamboo would transmit all the logs files to the Bamboo server, so that when you use the link <https://bamboo.aev.com/download/VES-AEV-SJT/build_logs/VES-AEV-SJT-3.log> to download it doesn't have partial logs and contains everything as the logs are now available on Bamboo server.\n\nMaybe you can setup some sleep in script task of stage 2, so that it gives enough time for Bamboo to transfer all the log files for stage1 ( normally in case there are huge build logs).\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Is-there-a-way-to-send-complete-logging-when-sending-mail-from-a/qaq-p/2561658
| null |
{
"author": "lee",
"title": "Bamboo build for modified files (only Updated Artifacts Shot)",
"body": "We have multiple projects in one solution. When we commit this to Bitbucket and perform a build and Shot in Bamboo, all projects in the solution are built and Shot. We want to take a snapshot only of the changed DLL files. Please advise on how to achieve this. \n\nfinally we want to take a Shot only of the updated artifacts \n\nplease Help us.....\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello [lee](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5386184),\n> 1. Are you saying that you can't only apply the modified artifacts with your reply? \n>\nArtifacts are defined at Job level and this definition is valid for each time the build is run, so Bamboo will try to find the artifacts during each build ( on the location which you have defined during the artifact definition ) and if it finds it it will display it under the artifact tab of the build results.\n\nIt does not check what has changed in the artifact from the previous build or even what has been newly built with the new code changes. Bamboo just collects all the artifacts matching the pattern and display there is no comparison functionality available.\n> 2. I don't have an \"Exclusion pattern\".Does it only exist in other versions?\n\nThis is available from Bamboo 9.0+ versions\n> 3. If there's an \"Exclusion pattern,\"What examples should I put in there? \n> Can you show me a sample?\n\nYou can see my example below, here I am instructing Bamboo to look into target folder and if it finds any files ( as per copy pattern which is \\* ) it should list it as an Artifact, now under Exclusion pattern I have instructed Bamboo to ignore any files with pattern of .jar, so now Bamboo will consider everything as an artifact except files with .jar pattern\n\n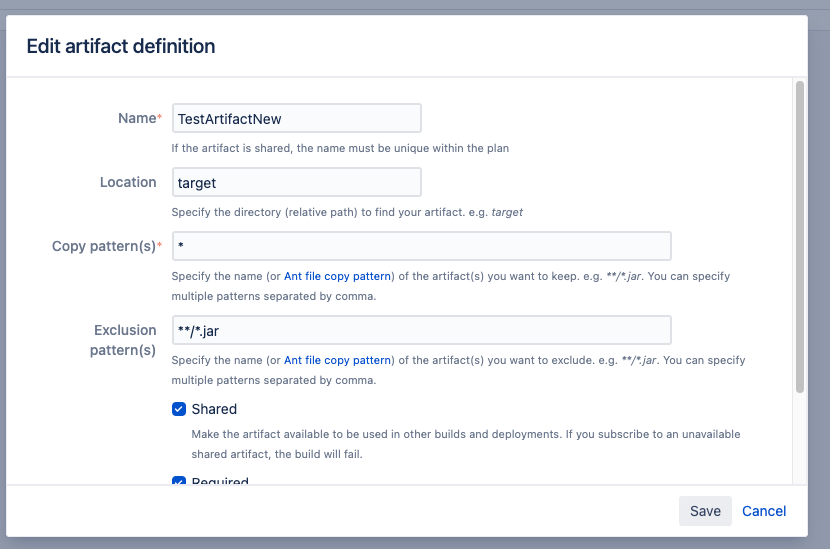\n\nRegards,\n\nShashank kumar\n",
"comments": null
},
{
"author": "Shashank Kumar",
"body": "Hello Lee,\n\nWelcome to Atlassian community.\n\nIf I understand your request correctly, you can check the **commit** tab of your build results tab to understand what changes were built for that particular code change in bitbucket, see below\n\n\n\nIf my understanding is incorrect can you explain your question with an example please.\n\nAlso I didn't understand your below question, can you please elaborate a little\n> Finally we want to take a Shot only of the updated artifacts \n\nRegards\n\nShashank Kumar\n",
"comments": [
{
"author": "lee",
"body": "thank you for your reply\n\nI'll explain again. This picture is a summary of bamboo.\n\nThe committed changes include modifications to A, F.\n\nbut All artifacts are applied.\n\n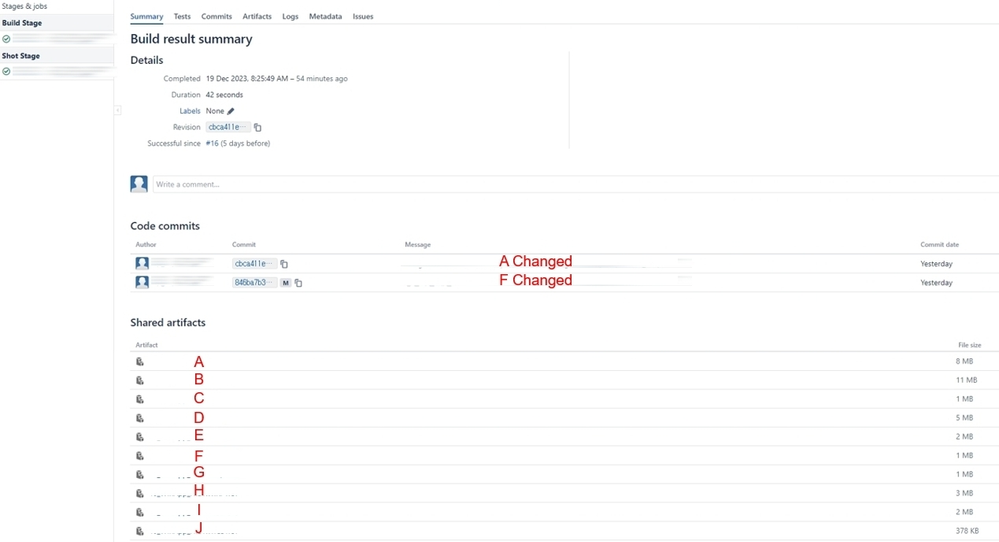\n"
},
{
"author": "Shashank Kumar",
"body": "Hello Lee,\n\nThanks for providing the attachment, this explains better now!\n\nWhile defining the artifact in Bamboo, You define it's name, Location, File pattern or any exclusion pattern, see below\n\n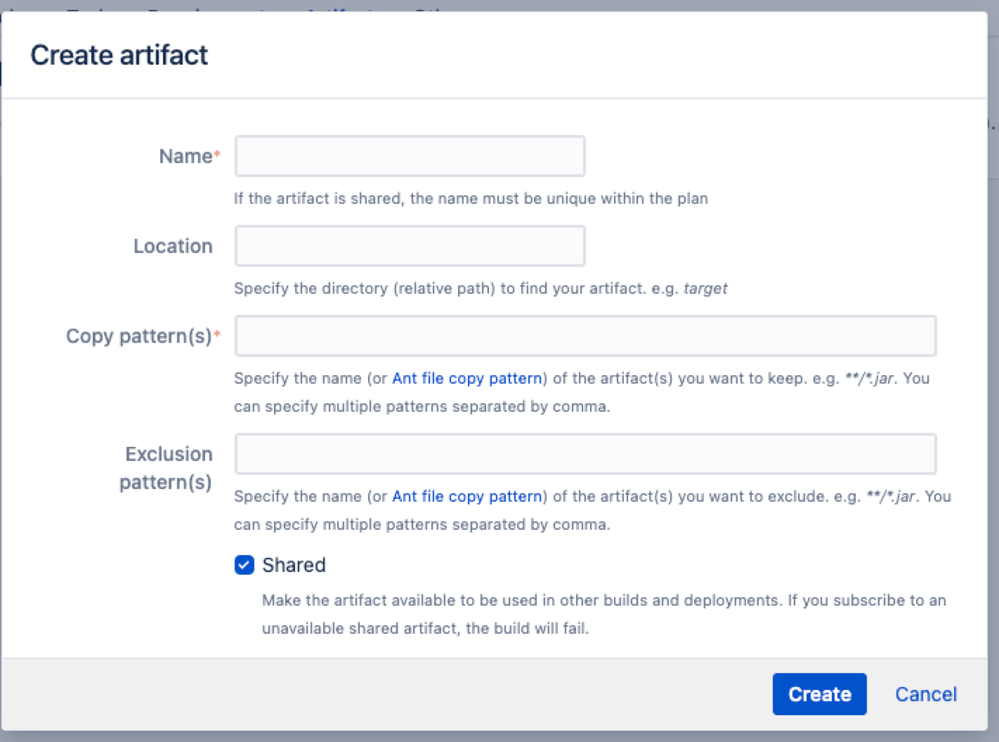 \n\nIf your source code is creating an artifact and it matches the filter above, Bamboo will create all the artifcats and list it under the artifacts tab.\n\nBamboo will not inform what are the artifacts which has changed based on source code ( Probably a worth feature request where Bamboo can compare the artifacts with the previous build result and inform of the differences), but this would be a overkill assuming in some case small files in the range of thousands are created as artifacts.\n\nRegards,\n\nShashank Kumar\n"
},
{
"author": "lee",
"body": "thank you for your reply\n\nI have a few inquiries. \n\n1. Are you saying that you can't only apply the modified artifacts with your reply? \n2. I don't have an \"Exclusion pattern\". \nDoes it only exist in other versions? \n3. If there's an \"Exclusion pattern,\" \nWhat examples should I put in there? \nCan you show me a sample? \n\n<br />\n\nIf you know anything, please help me. \n\n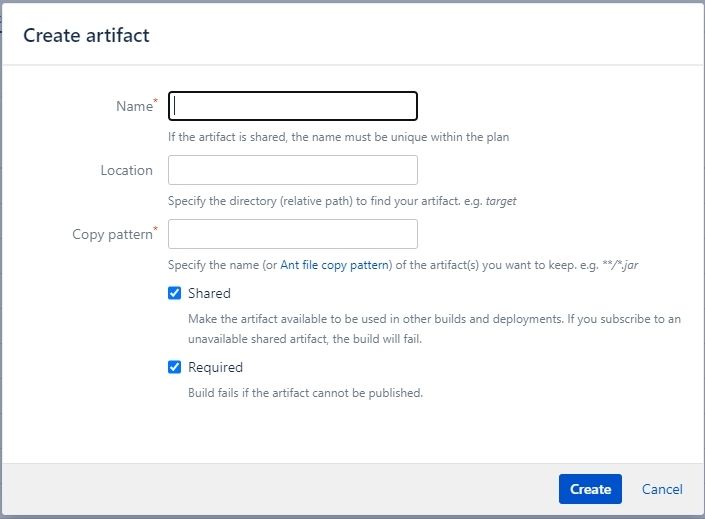 \n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Bamboo-build-for-modified-files-only-Updated-Artifacts-Shot/qaq-p/2559989
| null |
{
"author": "Ankush Das",
"title": "How to receive webhook notifications from Jira when the status changes in Bamboo?",
"body": "I want to trigger a Bamboo job based on Jira status changes. The first method I found is to create an application link between Jira and Bamboo and then set up a webhook in Jira to send notifications.\n\nMy issue is how to receive notifications in Bamboo to trigger the job. \n\nAlternatively, are there any other methods to trigger a Bamboo job based on Jira status changes?\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Ankush,\n\nWelcome to atlassian community.\n\nYou can refer <https://confluence.atlassian.com/bamboo/triggering-a-bamboo-build-from-jira-automation-1064091028.html> which explains the steps which you are looking for.\n\nPlease note this is not applicable for Jira cloud and will work for on Premise version.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-receive-webhook-notifications-from-Jira-when-the-status/qaq-p/2559346
|
[
"jira"
] |
{
"author": "leegyu86",
"title": "Is there a restapi that can tell plan to delete the local directory as well?",
"body": "Even if I delete the plan, the local directory where the plan was executed still exists. \nIs there a restapi that can tell plan to delete the local directory as well? Or is there a good way to delete the local directory?\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello leegyu86,\n\nWelcome to Atlassian community.\n\nI don't think so any REST API exists which would cleanup these directories, but once you delete a plan Bamboo will automatically cleanup the local working directory on the local agent if any, this process runs few mins after you have deleted a plan, I just tested this now and the folder was delete for me.\n\n```\n2023-12-13 07:39:39,849 INFO [DelayedDeletionThread] [DeletionServiceHelper] Deleting 1 job(s) marked for deletion\n2023-12-13 07:39:39,850 INFO [DelayedDeletionThread] [DeletionServiceHelper] Deleting SCRIP-TIC-JOB1\n2023-12-13 07:39:39,872 INFO [DelayedDeletionThread] [ImmutablePlanCacheServiceImpl] Skipping invalidation, plan is being deleted: SCRIP-TIC\n2023-12-13 07:39:39,873 INFO [scheduler_Worker-10] [DeletionServiceHelper] Completed background deletion in 38.66 ms\n2023-12-13 07:39:39,880 INFO [DelayedDeletionThread] [DeletionServiceHelper] Deleting 1 stage(s) marked for deletion\n2023-12-13 07:39:39,881 INFO [DelayedDeletionThread] [PlanManagerImpl] Removing 1 stage(s) for plan SCRIP-TIC\n2023-12-13 07:39:39,889 INFO [DelayedDeletionThread] [ImmutablePlanCacheServiceImpl] Skipping invalidation, plan is being deleted: SCRIP-TIC\n2023-12-13 07:39:39,890 INFO [AtlassianEvent::0-BAM::EVENTS:pool-2-thread-59] [DeletionServiceHelper] Completed background deletion in 15.60 ms\n```\n\nThe best option would be to delete these directories after each build completion ( if your build does not require files etc from previous build results you can go ahead with this ).\n\nPlease follow <https://confluence.atlassian.com/bamboo/deleting-a-job-s-current-working-files-1047534685.html> to get the exact steps\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Is-there-a-restapi-that-can-tell-plan-to-delete-the-local/qaq-p/2558015
| null |
{
"author": "Marciano",
"title": "Why does the Sonar Maven 3 Task fail in Bamboo",
"body": "Hi All, I'm having trouble with a Sonar Maven 3 task in our nightly build plan in Bamboo. \nIn the \"Default plan configuration\", I have a \"Default Job\" in the \"Default Stage\". In the \"Default Job\" there are 3 tasks: \n-Source Code Checkout \n-Maven 3.x (Build) \n-Sonar Maven 3\n\nNow, I created an additional \"Sonar Maven 3\" task with the same settings as the already existing task. The 1st task (created years ago) executes fine. The 2nd task with the exact same settings as task 1 doesn't! I disabled the 1st task that runs fine and let the 2nd one run during the plan run, but it fails! The error message.. I will come back to it. My question is why does the exact same task fail?! \nI see a difference in the build logs of the two identical tasks, which I think is the reason why the 2nd task fails! I hope you can explain why and how to solve it.\n\nLog task 1: \nsimple 12-Dec-2023 16:49:31 Starting task 'Sonar' of type 'ch.mibex.bamboo.sonar4bamboo:sonar4bamboo.maven3task' \ncommand 12-Dec-2023 16:49:31 Substituting password variable: ${bamboo.sonar.token.passphrase} \nsimple 12-Dec-2023 16:49:31 \nsimple 12-Dec-2023 16:49:31 SONAR4BAMBOO: Going to use executable home /usr/local/apache-maven-3.8 \ncommand 12-Dec-2023 16:49:31 Beginning to execute external process for build 'Com - flip - Default Job #628 (TRCK-NIGHT-JOB1-628)'\\\\n ... running command line: \\\\n/usr/local/apache-maven-3.8/bin/mvn sonar:sonar -Dsonar.projectKey=com.domain.flip:flip -Dsonar.projectName=com.domain.flip:flip -Dsonar.host.url=<https://sonar.compdomain.com> -Dsonar.login=\\*\\*\\*\\*\\*\\* ... in: /var/atlassian/bamboo-agent-home/xml-data/build-dir/TRCK-NIGHT-JOB1\\\\n\n\n<br />\n\nLog task 2: \nsimple 12-Dec-2023 16:16:06 Starting task 'sonar_marc' of type 'ch.mibex.bamboo.sonar4bamboo:sonar4bamboo.maven3task' \ncommand 12-Dec-2023 16:16:06 Substituting password variable: ${bamboo.sonar.token.passphrase} \nsimple 12-Dec-2023 16:16:06 \nsimple 12-Dec-2023 16:16:06 SONAR4BAMBOO: Will use develop as sonar.branch.name. \nsimple 12-Dec-2023 16:16:06 SONAR4BAMBOO: Going to use executable home /usr/local/apache-maven-3.8 \ncommand 12-Dec-2023 16:16:06 Beginning to execute external process for build 'CommonTrack - flip-nightly - Default Job #627 (TRCK-NIGHT-JOB1-627)'\\\\n ... running command line: \\\\n/usr/local/apache-maven-3.8/bin/mvn sonar:sonar -Dsonar.branch.name=develop -Dsonar.host.url=<https://sonar.compdomain.com> -Dsonar.login=\\*\\*\\*\\*\\*\\* ... in: /var/atlassian/bamboo-agent-home/xml-data/build-dir/TRCK-NIGHT-JOB1\\\\n\n\n<br />\n\nWhy in task 2 at \"Beginning to execute external process\" it is eventually NOT using command \"mvn sonar:sonar -Dsonar.projectKey=com.domain.flip:flip\" as in task 1, but is it using \"mvn sonar:sonar -Dsonar.branch.name=develop\"?!?\n\nI believe if task 2 would also use the \"-Dsonar.projectKey=com.domain.flip:flip\" parameter it will run successful! Any idea where I can configure this?\n\nThe use of Dsonar.branch.name=develop is evenutally causing the error, because this parameter is not allowed in Sonar Community Edition. \nThe error in the log of the buildplan with task nr 2 is: \nbuild 12-Dec-2023 16:16:11 \\[ERROR\\] Failed to execute goal org.sonarsource.scanner.maven:sonar-maven-plugin:3.7.0.1746:sonar (default-cli) on project flip: Validation of project reactor failed: \nbuild 12-Dec-2023 16:16:11 \\[ERROR\\] o To use the property \"sonar.branch.name\" and analyze branches, Developer Edition or above is required. See <https://redirect.sonarsource.com/doc/branches.html> for more information.\n\n<br />\n\nAn important note about the 2nd task I created: I get the same error with multiple applications when creating a 2nd task. Also, when my colleagues create this 2nd task they get the same error, so apparently it's not a permissions issue (unless it's on group level)!! Even if I remove the 1st task and only have the 2nd exist and run I get the same error.\n\nCurrently it is blocking my nightly build for application \"flip-core\". I don't have a 'task 1' anymore and I created a new \"2nd\" task that now fails with the details as mentioned before in the log. \nWho can help to solve why task 2 is running different and is using parameter \"-Dsonar.branch.name=develop\" instead of \"mvn sonar:sonar -Dsonar.projectKey=com.domain.flip:flip\"?\n"
}
|
[
{
"author": "Michael R?egg _Mibex Software_",
"body": "Hi [@Marciano Wong-Swie-San](/t5/user/viewprofilepage/user-id/5385571) and welcome to the Atlassian community!\n\nLooking at your problem description, I think task 2 is using a different server configuration in the task field \"Choose a server for this task (required)\". Is that possible?\n\nBecause that could be the reason why it is configuring the branch name with \"develop\", while task 1 is not.\n\nI guess you are on a Bamboo plan branch called \"develop\"?\n\nThanks,\n\nMichael (app vendor)\n",
"comments": [
{
"author": "Marciano",
"body": "Hi [@Michael R?egg _Mibex Software_](/t5/user/viewprofilepage/user-id/1135077)\n\nThank you for welcoming me. And, thank you for looking into this and replying!\n\nHmm.. I'm not seeing any task field with \"Choose a server for this task (required)\". I'm mostly having default settings in the task: \n\n \nAnd these settings are similar as task 1. \n"
},
{
"author": "Marciano",
"body": "I forgot to mention I choose the \"Sonar Maven 3\" Task from the 'templates'. \n\n\n"
},
{
"author": "Michael R?egg _Mibex Software_",
"body": "Hi [@Marciano Wong-Swie-San](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5385571)\n\nYou're very welcome, and thanks for your feedback.\n\nFor the field \"Choose a server for this task\", do you use \"community\" for both tasks 1+2?\n\nBest regards,\n\nMichael\n"
},
{
"author": "Marciano",
"body": "Ah, now I see what you mean. We are using the community edition in our company, So yes, for both tasks community is used.\n"
},
{
"author": "Michael R?egg _Mibex Software_",
"body": "Thanks for your feedback.\n\nWould you mind creating a support ticket at <https://support.mibexsoftware.com> so that you can share the task logs? That would help us a lot.\n"
}
]
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Why-does-the-Sonar-Maven-3-Task-fail-in-Bamboo/qaq-p/2558469
| null |
{
"author": "Dnyaneshwar Borase",
"title": "How to connect all Bamboo pipeline to Github after the migration from Bitbucket to Github",
"body": "Hi Team,\n\nWe are planning to do repository migration from Bitbucket to GitHub/Gitlab with all existing integrated tools with Bitbucket.\n\nCurrently, we are using Bamboo tool for Continuous Integration (CI) and Continuous deployment with Bitbucket. After the migration of SourceCode (Repositories) from Bitbucket to GitHub/Gitlab we need to do rewiring/all created or current (CI) builds with GitHub/Gitlab.\n\nCan you please guide me on this how we can perform this activity?\n\nYour valuable guidance is really appreciated.\n\nRegards,\n\nDnyaneshwar Borase\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Dnyaneshwar,\n\nWelcome to Atlassian community\n\nCurrently there is no option available at bulk to change all the Linked repositories from Bitbucket to Github. You'll need to setup these linked repositories one by one and then setup the triggers for each of these plans individually in Bamboo\n\nWhen you have Bamboo- Bitbucket integration, there are some triggers which are automatically setup if you have bitbucket connected via application links, this does not work so seamlessly with Github.\n\nYou can refer the below 2 documents to get more details about this process\n\n<https://confluence.atlassian.com/bamboo/github-289277001.html>\n\n<https://confluence.atlassian.com/bamkb/how-to-trigger-bamboo-builds-with-github-webhook-1097179080.html>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/How-to-connect-all-Bamboo-pipeline-to-Github-after-the-migration/qaq-p/2556316
|
[
"bamboo-administration",
"bamboo-development",
"bitbucket-administration",
"bitbucket-development",
"bitbucket-pipelines",
"bitbucket-server"
] |
{
"author": "Hemanth kumar kokkirala",
"title": "I am getting this error some one help me please \"Bamboo bootstrap failed: Could not make directory/\"",
"body": "You cannot access Bamboo at present. Look at the table below to identify the reasons:\n\n| Time | Level | Type | Description | Exception |\n|---------------------|-------|-----------|--------------------------------------------------------------------------------|-----------|\n| 2023-12-09 22:35:59 | fatal | bootstrap | Bamboo bootstrap failed: Could not make directory/ies: /Users/aref/Bamboo-Home | |\n\nPlease contact us at <https://support.atlassian.com/> if you have any queries.\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Hemanth,\n\nWelcome to Atlassian community.\n\nFor this error you'll need to make sure the user which is running the Bamboo application has got full **read/write** access to the directory **/Users/aref/Bamboo-Home**\n\nYou are getting this error because while starting up Bamboo, it will try to create files and folder under bamboo-home directory which you have defined and currently it does not have permissions to do do.\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/I-am-getting-this-error-some-one-help-me-please-quot-Bamboo/qaq-p/2555671
| null |
{
"author": "rolando.viado",
"title": "Do I need to run the setup wizard after upgrading Bamboo 7.0.6 to 8.0.12",
"body": "Hi everyone,\n\nI'm asking this question because the wizard launched after the installation of bamboo 8.0.12 in my cloned linux machine and then while completing the installation wizard I was stucked in the Postgres database setup as it does not accept the DB password from the original instance where the new linux bamboo clone came from. I am sure that the password I am using/entering is correct as I have checked this in the bamboo.cfg.xml file.\n\nAppreciate any help guys or am I doing something wrong after the upgrade from 7.0.6 to 8.0.12.\n\nthanks\n"
}
|
[
{
"author": "Shashank Kumar",
"body": "Hello Rolando,\n\nWelcome to Atlassian community.\n\nLooking the description it is very hard to tell where is the problem, this would be easier to tell after looking at **atlassian-bamboo.log** file to understand the sequence of events from the logs.\n\nAs this is a public forum, I would strongly advise against uploading log files here, if you have a valid **SEN** , you can raise a support request with Atlassian support to check your issue, refer <https://confluence.atlassian.com/support/create-a-support-request-790796816.html>\n\nRegards,\n\nShashank Kumar\n\n**\\*\\*please don't forget to Accept the answer if your query was answered\\*\\***\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Do-I-need-to-run-the-setup-wizard-after-upgrading-Bamboo-7-0-6/qaq-p/2555064
|
[
"cloud",
"jira-software",
"jira-software-cloud"
] |
{
"author": "Patrick Gibo",
"title": "Problem retrieving customRevision from Bamboo",
"body": "Normally, our builds are started via a TagTrigger in the PlanSpec.java. We can then get the Tag name in CMakeLists.txt using $ENV{bamboo_TagBuildTriggerReason_tagName}, then use that to construct the name of the generated Artifact.\n\nThere are some instances where we'd like to perform the same using Customized builds. I see the 'customRevision' variable and value getting set in the log, but when I try to retrieve the value using $ENV{bamboo_customRevision} nothing gets returned.\n\nIs there a different way to retrieve this variable? I'm on v 8.1.9\n\nAppreciate any help!\n"
}
|
[
{
"author": "Patrick Gibo",
"body": "Should've done more research before posting question. Appears problem is related to the way I'm trying to retrieve the value via CMake.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Bamboo-questions/Problem-retrieving-customRevision-from-Bamboo/qaq-p/2554488
| null |
{
"author": "Balamurugan Pasumpon",
"title": "Need format changes to the Components List in portal",
"body": "Hi,\n\nI would like to display the list of affected components on the portal, mirroring the format used in the incident notification email. Presently, it appears in a single row instead of a list. I intend to submit a feature request.\n\n**Portal format:**\n\nThis incident affected: Component Group 1 (Component 1, Component 2, Component 3) and Component Group 2 (Component 1, Component 2).\n\n**Email format:**\n\nComponent Group 1 - Component 1\n\nComponent Group 1 - Component 2\n\nComponent Group 1 - Component 3\n\nComponent Group 2 - Component 1\n\nComponent Group 2 - Component 2\n\nThanks,\n\nBala.\n"
}
|
[
{
"author": "Tejaswi G",
"body": "Hi Balaurugan,\n\nThank you for reaching out to the statuspage community. We don't have the option to change the affected components displayed in the notifications. However, I have logged an FR STATUS-743 for your request. The Statuspage feature requests are currently for internal access only. I would recommend keeping an eye out on our community page for any news about feature updates.\n\nKind Regards, \nTejaswi\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Need-format-changes-to-the-Components-List-in-portal/qaq-p/2609317
| null |
{
"author": "CMillard",
"title": "I have a component name \"xyz\" and it has 5 statuses Operational, Partial Outage, Degraded Performan",
"body": "Copied the Question from another forum but is similar in concept.\n\nOriginal Link: <https://community.atlassian.com/t5/Statuspage-questions/can-we-change-the-name-of-status-of-component-on-statuspage/qaq-p/2024117>\n\nI copied the script and it works for changing all status on all components, but want one component to be one set of information (On Time, Slightly Delayed, and Major Delayed) and then have the other component be \"Not Ready\" and \"Ready\". I've attempted to do this several different ways but am unable to do so.\n"
}
|
[
{
"author": "Abraham Musalem",
"body": "Hey [@CMillard](/t5/user/viewprofilepage/user-id/5429164) ,\n\nThanks for reaching out to the Statuspage Community. What sort of issues are you running into? Support doesn't have any specific code to do this but it might help if you share part of your code.\n\nI think it might not be working because the statuses apply to all components and I don't think there is a way to give different components a different number of corresponding statuses. \n\nBest, \nAbraham, Statuspage Support\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/I-have-a-component-name-quot-xyz-quot-and-it-has-5-statuses/qaq-p/2608456
|
[
"cloud"
] |
{
"author": "Heather Chism",
"title": "Is there a report of the users we have set up that's categorized by the Financial Institutions name",
"body": "Hi, I was trying to figure out how to pull a report to review all of the users that we have that have signed up, but trying to get a report that shows a column that has the Financial institution's name so that we can easily filter.\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Heather Chism](/t5/user/viewprofilepage/user-id/5428983) ,\n\nIs this question for Opsgenie? If so, there is a user management report that will list all of the users in the account.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Is-there-a-report-of-the-users-we-have-set-up-that-s-categorized/qaq-p/2608089
| null |
{
"author": "Estrat?gia Vencedora",
"title": "Indexa??o no analitcs",
"body": "? possivel colocar tags do Analitcs na minha pagina? Obg\n"
}
|
[
{
"author": "Skyler Ataide",
"body": "Ol?! Voc? consegue compartilhar mais informa??es sobre o tipo de tag anal?tica que est? tentando adicionar ? sua p?gina? Essas tags s?o do Google Analytics?\n\nHello! Are you able to share more information around the type of analytics tag that you are trying to add to your page? Are these Google Analytics tags?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Indexa%C3%A7%C3%A3o-no-analitcs/qaq-p/2607719
|
[
"cloud"
] |
{
"author": "michal.virgovic-ext",
"title": "Broken link on system metrics with datadog",
"body": "Hello,\n\nThe \"View this metric with Datadog\" link on System metrics page is broken since we don't use \"datadoghq.com\" but \"datadoghq.eu\" app.\n\nIt's a minor but annoying issue.\n\nIs there a place to open a bug?\n"
}
|
[
{
"author": "Abraham Musalem",
"body": "Hey [@michal.virgovic-ext](/t5/user/viewprofilepage/user-id/5428316) , \n\nThanks for reaching out to Statuspage community. You can submit a ticket via support.atlassian.com with more info and we can get the bug created. \n\nCheers, \nAbraham, Statuspage Support\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Broken-link-on-system-metrics-with-datadog/qaq-p/2607174
|
[
"cloud"
] |
{
"author": "Sam Wij",
"title": "How to segmenet Status Page by Region the way New Relic Status Page has?",
"body": "Hey Team,\n\nDoes anyone know how[New Relic](https://status.newrelic.com/) has managed to segment their status page by region?\n\nI've tried searching for custom css and jss snippets but couldn't find any. Can this be achieved by using a single public page and groups?\n\nAny help would be greatly appreciated. I have also seen [Monday](https://status.monday.com/) do a similar thing but with a drop-down.\n\n\n"
}
|
[
{
"author": "Abraham Musalem",
"body": "Hey Sam, \n\nAbraham here from Statuspage support. That is indeed just some custom HTML/CSS. You can try inspecting the page via developer mode on google chrome, which could give you some ideas as to what custom code they are using. \n\nRegards, \nAbraham\n",
"comments": [
{
"author": "Sam Wij",
"body": "Hey Abraham!\n\nThank you for getting back to me, this gives us hope that it is possible to do via the custom HTML/CSS editor in status page.\n\nIf we find any ideas, I will paste them here just in case anyone else wants to do something similar.\n\nThanks\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-to-segmenet-Status-Page-by-Region-the-way-New-Relic-Status/qaq-p/2603931
|
[
"cloud"
] |
{
"author": "Mohammed Rayyan",
"title": "How to get the subscriber list for each componenet in the status page?",
"body": "How to get the subscriber list for each componenet in the status page?\n"
}
|
[
{
"author": "Russell Chee",
"body": "Hey Mohammed,\n\nThanks for reaching out to the community about your Statuspage inquiry.\n\nIn order to obtain a subscriber list for each component in Statuspage, you will need to ensure that \"enable component subscriptions\" is enabled on your account as mentioned in our article [here](https://support.atlassian.com/statuspage/docs/enable-component-subscriptions/). Keep in mind this is only available to business plans or higher.\n\nOnce that has been enabled, you can [export the subscribers](https://support.atlassian.com/statuspage/docs/export-subscribers/) from your Statuspage and in the CSV file it should list what components a subscriber has been subscribed to. For example: \n\n\nI hope this helps point you in the right direction. Please let us know if you have any further questions we can assist on.\n\nKind regards, \nRussell\n",
"comments": [
{
"author": "Kevin Paulovkin",
"body": "[@Russell Chee](/t5/user/viewprofilepage/user-id/5276971) is there a feature request to update the CSV file to include the ID's of the components? Or is there a way to do this export with the API? I see there is an \"Incident Subscribers\" section but that's only for pulling those who are subscribing to individual incidents.\n\nReason I am asking - The current CSV export format isn't friendly for doing a bulk import adjusting users subscriptions. Have to get the ID's for the components and reformat the export before importing.\n\nGoal being something similar to the Jira Software CSV export where it's in the same format needed for doing an Import\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-to-get-the-subscriber-list-for-each-componenet-in-the-status/qaq-p/2602090
| null |
{
"author": "Harishankar V",
"title": "I need to enable multiple API endpoints on a single page, specifically on the status page",
"body": "Now I need to enable multiple API endpoints in the same environment. Is it possible to try a free version? I also need to pass some JSON data for those endpoints.\n"
}
|
[
{
"author": "Alan Violada",
"body": "Hey Harishankar, Alan from the Statuspage Support team here.\n\nCould you provide more details on the kind of requests you need to make to the Statuspage API, or the specific data you are looking to query?\n\nTo start with, I would recommend taking a look at the below docs:\n\n[What are the different APIs under Statuspage?](https://support.atlassian.com/statuspage/docs/what-are-the-different-apis-under-statuspage/)\n\n[Manage API Documentation](https://developer.statuspage.io/#section/Basics/HTTPS)\n\nCheers,\n\nAlan\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/I-need-to-enable-multiple-API-endpoints-on-a-single-page/qaq-p/2601448
|
[
"cloud"
] |
{
"author": "Andrew Conkling",
"title": "Is it possible to post updates to Mastodon etc.?",
"body": "Our team uses the StatusPage app connection to post updates to Twitter, and would be interested in posting updates to a Mastodon (or Threads) account as well.\n\nIs this possible? It doesn't seem like it. If that's the case, does this count as a feature request or should I submit one of those another way? Thanks!\n"
}
|
[
{
"author": "Russell Chee",
"body": "Hey [@Andrew Conkling](/t5/user/viewprofilepage/user-id/1167358)\n\nThank you for your community post, I hope you are well.\n\nAt this current time we do not have a direct Statuspage to Mastodon/Threads integration where Statuspage can update those third party platforms.\n\nWhat I can do is create an internal feature request to share with our engineers to show that there's an opportunity for a new feature.\n\nTo set expectations it will not be a public facing feature request however feel free to write in any time and we can check the progression of it. I'll also be adding this community post as part of the internal comments to showcase interest.\n\nAppreciate you reaching out and sharing your use case to have something like this hopefully implemented in the future. Reach out if you need anything else, all the best!\n\nRussell\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Is-it-possible-to-post-updates-to-Mastodon-etc/qaq-p/2600732
| null |
{
"author": "Balamurugan Pasumpon",
"title": "Adding New Page",
"body": "Hello,\n\nWe have audience specific statuspage license. Can i generate multiple pages under the \"Add New Page\" option, and will each page incur separate billing?\n\nThanks,\n\nBala.\n"
}
|
[
{
"author": "Talar Pavlovic",
"body": "Hi there Balamurugan,\n\nThanks for writing into Community, I'm Talar from the Atlassian Statuspage support team, happy to help!\n\nYou most certainly can - your current page will be in a Statuspage Organisation. Each Statuspage Organisation can hold up to 25 pages.\n\nSo, you can definitely click on \"Add Page\" there, to setup a new page of any type ([Public, Private or Audience-Specific)](https://support.atlassian.com/statuspage/docs/read-the-statuspage-user-guide/) and with its own contents and functionality, which will be billed based upon the plan chosen - <https://www.atlassian.com/software/statuspage/pricing>\n\nHope this helps! \nTalar\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Adding-New-Page/qaq-p/2597127
| null |
{
"author": "Kunwar Vaibhav Singh",
"title": "Is it possible 3 level grouping",
"body": "Hi Team,\n\nI want to create 2-level grouping histogram data but cannot. we monitor the city and update outages and maintenance of the city. The city comes under the country and the country group is under the region. \n\nRegion -\\> Country -\\> City\n\nBut I can create a 1-level grouping like Region -\\> Country-City. Please guide me. \n\nThanks \nkusingh\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@Kunwar Vaibhav Singh](/t5/user/viewprofilepage/user-id/5079236)\n\nUnfortunately StatusPage only allows Category \\> Subcategory relationship, which means you will not be able to add a 3rd level.\n\nPlease remember to accept this answer in case it helps you resolve your question as it may also help other community members in the future.\n\nRegards, \nEugenio\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Is-it-possible-3-level-grouping/qaq-p/2599127
|
[
"cloud"
] |
{
"author": "Prathamesh Anil More",
"title": "Historical status of the component",
"body": "Hello Team,\n\nIs there any way to change the Component historical uptime to 30 days instead of default 90 days?\n"
}
|
[
{
"author": "Skyler Ataide",
"body": "Hello Prathamesh,\n\nAt this time, it isn't possible to change the component historical uptime display to only 30 days. As a workaround, this may be something that is possible with [custom HTML](https://support.atlassian.com/statuspage/docs/use-custom-html-on-a-status-page/) [CSS and JS](https://support.atlassian.com/statuspage/docs/css-and-javascript-snippets-for-customizations/). Though specifics on custom coding solutions are not something that our Statuspage support team is able to provide support for.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Historical-status-of-the-component/qaq-p/2596261
|
[
"cloud"
] |
{
"author": "Derek Cazel",
"title": "Why am I unable to activate this statuspage?",
"body": "Why am I unable to activate this statuspage? This is my second statuspage and the first one activated just fine, but this is giving me a permissions error.\n"
}
|
[
{
"author": "Kevin Paulovkin",
"body": "Are these both Free pages? If so, how many admins/team members are in your plan? If more than 2, you will need to remove some users: <https://support.atlassian.com/statuspage/docs/what-do-i-get-on-a-free-plan/>\n",
"comments": [
{
"author": "Derek Cazel",
"body": "I only have one admin, and I just signed up and thought I got their $99/mo plan. Do you know if that prevents me from having more than one statuspage? I appreciate your help, this is new to me.\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Why-am-I-unable-to-activate-this-statuspage/qaq-p/2594869
|
[
"cloud"
] |
{
"author": "Paun, Cosmin",
"title": "Adding a Subscriber via API and skip the confirmation notification",
"body": "Hi StatusPage Team,\n\nWe try to inser a subscriber to our StatusPage via the API when an Incident is being created, and we have a weird behaviour. When an Incident is being created then:\n\n- the subscriber gets immediately the confirmation Email (although in the payload we have set \"skip_confirmation_notification\": true )\n\n- and right after that the subscriber gets a second email with the unsubscribe notification.\n\nWhat are we doing wrong?\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello there,\n\nThanks for reaching out to the community about how the skip confirmation email is not working. I did some investigating and it seems we currently have this off. The team should be creating a doc that talks more about why this change was made. For the second issue, I can't recreate this. Is this happening on every email or just select ones? If you have a paid account, I recommend reaching out to us at support.atlassian.com and we can dive deeper into the issue. Thanks for your time!\n\nRegards, \nJesse\n",
"comments": [
{
"author": "Roman Temekunidi",
"body": "Hi [@Jesse Klein](/t5/user/viewprofilepage/user-id/3659201) ,\n\nHave you got any updates on this?\n\nI'm having the same issue. When I set the **\"skip_confirmation_notification\": true**, the subscriber still gets the notification.\n"
},
{
"author": "Jesse Klein",
"body": "Hi Roman,\n\nThe team created this article that goes into more detail about the changes: <https://community.atlassian.com/t5/Statuspage-articles/Change-to-Skip-Confirmation-Notification-option-in-Statuspage/ba-p/2624654>\n\nHopefully, that helps!\n\nRegards, \nJesse\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Adding-a-Subscriber-via-API-and-skip-the-confirmation/qaq-p/2594130
|
[
"cloud"
] |
{
"author": "Marc Scheimann",
"title": "How to co-term billing periods for different pages",
"body": "Hi\n\nI have 2x pages that I've set up - and I would like to co-term their billing subscription dates, how do I do that? \n\nRegards, Marc\n"
}
|
[
{
"author": "Eugenio Onofre",
"body": "Hi [@Marc Scheimann](/t5/user/viewprofilepage/user-id/5417479)\n\nWelcome to the Atlassian Community. \nUnfortunately subscription dates (and their renewals) are set based on the StatusPage creation date.\n\nI am not aware of being able to change it, but you may reach out to Billing team at <https://support.atlassian.com> and raise a request to see if it is possible on their side.\n\nPlease remember to accept this answer as it may also help other community members in the future.\n\nRegards, \nEugenio\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/How-to-co-term-billing-periods-for-different-pages/qaq-p/2592429
| null |
{
"author": "Siddharth Verma",
"title": "Component status \"Degraded performance\" is not marked permanently",
"body": "When a component is marked \"Degraded performance\", it shown on UI. After marking component \"Operational\", check history of component and there is no sign of it being having \"Degraded performance\" in the past.\n\nUnlike \"Major Outage\" status, which can be seen in component past timeline.\n\nReferring to the attached screenshot, Can I see \"Degraded Performance\" in historical uptime timeline.\n"
}
|
[
{
"author": "Egor",
"body": "Hey Siddharth, \n\nThanks for reaching out to Atlassian Community! \n\nThe idea is that \"Degraded Performance\" is not considered an outage, that's why it's not shown on the uptime history. \n\nThis is correct if you set your incident to a major outage, then you'll see it as a downtime on your history graph. Please see the following article explaining how all the statuses work - <https://support.atlassian.com/statuspage/docs/top-level-status-and-incident-impact-calculations/>\n\nI hope this helps, please let me know if you have any other questions.\n\nBest Regards, \nEgor\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Component-status-quot-Degraded-performance-quot-is-not-marked/qaq-p/2590668
| null |
{
"author": "Rawan Elrifai",
"title": "Unable to select components for maintenance notifications via slack subscription",
"body": "We are unable to select components for channels subscribed via the Slack channel. Specifically maintenance notifications Is there a way we can choose a specific component to subscribe customers to? Following the instructions here <https://support.atlassian.com/statuspage/docs/set-up-a-slack-integration/> but still seeing all upgrade maintenance going to the channel and not the specified components. Any help would be appreciated!\n\nI opened a ticket already with support but still waiting for an answer. Thank you!\n"
}
|
[
{
"author": "Egor",
"body": "Hey Rawan,\n\nThanks for reaching out to Atlassian Community! \n\nMay I ask you please to raise a ticket with us using the following link - <https://support.atlassian.com/statuspage/> so that we can check that? \n\nBest Regards, \nEgor\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Unable-to-select-components-for-maintenance-notifications-via/qaq-p/2590419
| null |
{
"author": "Nicola Sacco",
"title": "Update status page using slack",
"body": "Hi, \n\nis there a way to manage (create/update etc) statuspage incidents directly from Slack. \n\nThe only thing I was able to find is was this question: <https://community.atlassian.com/t5/Statuspage-discussions/Managing-Statuspage-incidents-from-Slack/m-p/1099480#M173> \n\nHowever it looks like the company developing that tool is no longer active. \n\nDo you have any plan to support this? \nIs there any third party tool you would suggest for this?\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Nicola,\n\nThis is Jesse from the Statuspage support team. Welcome to the community and thanks for the question about a bi-directional Slack app.\n\nThis is not something that we currently have and is not currently on a roadmap. I see that there is a feature request so I added this community post to that request to show more interest.\n\nI don't have any other third parties that are working on this, either so I don't really have a recommendation. Ideally, I would want something that is similar to the Ospgenie Slack integration and this is something that is stated on the feature request. Hopefully, with more interest, this bi-directional app is something that can be worked on. For now, though, you'll either need to go through the UI or look into using the Manage API to create and update incidents. Thanks again for your interest in this.\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Update-status-page-using-slack/qaq-p/2589347
|
[
"slack"
] |
{
"author": "adrien.billot",
"title": "Component group / users update",
"body": "Hello, \n\nI'm trying the status page product (audience-specific), \nAnd I find that when I update (in edit) an audience group (add 2 components for example), \nusers in this group won't have their profile updated to include these 2 new groups. \nI need to go to the user profile to add the 2 new components. \nIs there a way to do it directly by updating the group? (avoid to manage the profile of hundred users in the future) \nThx \n"
}
|
[
{
"author": "Alan Violada",
"body": "Hey Adrien, Alan from the Statuspage Support team here.\n\nI believe you were looking to have users be automatically subscribed to all components that they have access to, is that correct?\n\nIf so, this functionality is unfortunately not currently available, but we do have an open feature request for it with the ID **STATUS-544** (Internal-access only)\n\nIf you are looking to automate this, it could be worth taking a look at using the API as an alternative:\n\n[\"Update a subscriber\" API Endpoint](https://developer.statuspage.io/#operation/patchPagesPageIdSubscribersSubscriberId)\n\nLet me know if you have any questions, or anything else we can try to assist with!\n\nRegards,?\n\nAlan\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Component-group-users-update/qaq-p/2589266
| null |
{
"author": "Jeremy Guillory",
"title": "Translation of Statuspage UI and incidents",
"body": "I need to localize/translate the Statuspage UI and the incident content. I do not want to use localize.js because our company already has its own language resources, processes, and tools. What other ways are there (using the Statuspage API or other means) to localize the content and to allow users to switch languages from Statuspage.\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Jeremy,\n\nThis is Jesse from the Statuspage support team. Thanks for your question about alternatives to using Localize.js.\n\nAll Localize is doing is using JavaScript to manipulate the page text from one language into another so the alternative would be to do that manually using the custom HTML, CSS, and JS features.\n\nI don't have any more details on how to accomplish this, mainly because customizations can be taken in so many directions and be accomplished in so many different ways. While I can't guarantee this will work for you, I found a jQuery plugin that can do translations:\n\n<https://github.com/tinoni/translate.js>\n\nThis might be a good starting point as an alternative.\n\nHopefully, this helps you out!\n\nRegards, \nJesse\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Translation-of-Statuspage-UI-and-incidents/qaq-p/2588998
|
[
"translation"
] |
{
"author": "Kunwar Vaibhav Singh",
"title": "Getting multiple captcha popup during subscribe.",
"body": "Hi Team,\n\nSome of my team members facing captcha popup issues during subscribe mail. It keeps coming multiple times. Can you please guide me or is there any way to disable it?\n\n\n\nThanks, \nKusingh\n"
}
|
[
{
"author": "Nikola Perisic",
"body": "Hello [@Kunwar Vaibhav Singh](/t5/user/viewprofilepage/user-id/5079236) ,\n\nThis indeed strange. Have you faced this issue before? Is this also happening in the incognito mode?\n\nAlso, captcha is showing for the unusual activity from that specific IP address. This is according to Google.\n\nNow, for the Atlassian, it may have this behavior appearing as well - but this is not necessarily the case for you. If you are concerned about this, you can ask Atlassian about this.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Getting-multiple-captcha-popup-during-subscribe/qaq-p/2588124
| null |
{
"author": "Caleb Bolden",
"title": "User not subscribed but still receiving emails",
"body": "A user was previously subscribed to statuspage, but has continued to receive emails after unsubscribing. How can we disable the email notifications for this user?\n"
}
|
[
{
"author": "John M",
"body": "Hi [@Caleb Bolden](/t5/user/viewprofilepage/user-id/4879346)\n\nThe user should get a confirmation email after unsubscribing like the one below:\n\n\n\nKeep in mind, it will be specific to the page they subscribed to. If the user was subscribed to more than one page, they would need to unsubscribe to each one, individually. If they did't get that email for the page that they are getting notifications from, have then try unsubscribing again. If the issue persists, please have the user [open a ticket with our support team](https://support.atlassian.com/contact/#/) so we can look up the email address.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/User-not-subscribed-but-still-receiving-emails/qaq-p/2587349
|
[
"cloud"
] |
{
"author": "Darren.Burrows",
"title": "Component Tags in Statuspage to OpsGenie integrations",
"body": "We're currently in the early phases of setting up integrations between OpsGenie and Statuspage, while we have no issues with going from OG to SP, we're finding some limitations in going the other way. \n\nThe biggest issue being that their seems to be no way to include information around the impacted Component on Statuspage in the OpsGenie alert, which will allow us to ensure that the relevant teams are alerted or actions are triggered. \n\nI've been toying with custom tags and raw parameters in the notes or for tags using <https://support.atlassian.com/statuspage/docs/enable-webhook-notifications/> as a guide to what Statuspage will send as part of its payload, however these never seem to populate in OpsGenie. \n\nAn example of a tag we're trying would be component_id:{{component_id}} assuming I've understood how the payloads work correctly, which is based on the formatting of some of the default tags that OpsGenie added when creating the integration. Checking in the OpsGenie logs, its suggesting that OpsGenie itself lacks any configuration for handling this with the log showing the following warning. \n\n\"Discarded incomingData, Reason:Discarding..Atlassian StatusPage integration does not support component updates.\" \n\nHas anyone managed to include components or their states from Statuspage in OpsGenie alerting using the default integration? Or are we going to have to build something bespoke that acts as a middleman for this?\n"
}
|
[
{
"author": "Alan Violada",
"body": "Hey Darren, Alan from the Statuspage/Opsgenie Support team here.\n\nI did some testing on my side to confirm, and you should be able to access the component data that comes in the payload from Statuspage to Opsgenie with this dynamic field value:\n\n{{_payload.incident.components}}\n\nKeep in mind that this value comes as an object array, so it might still take some tweaking to get the specific information you want from it.\n\nTo better test this kind of setup, I would recommend adding the {{_payload}} value to the description field in your integration alert creation rules, so that you can better see how the data comes in to Opsgenie, and have a better view of how to manipulate it.\n\nI hope that helps, and if you do need more detailed assistance for your instance, I would recommend creating a support ticket at [support.atlassian.com](http://support.atlassian.com) if possible.\n\nCheers,\n\nAlan\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Component-Tags-in-Statuspage-to-OpsGenie-integrations/qaq-p/2586988
|
[
"cloud",
"integration",
"opsgenie"
] |
{
"author": "Daniel Brix",
"title": "Is it possible to whitelist mail subscriptions per domain?",
"body": "Hello there, we have the following situation: \n\nWe want to limit the mail subscriptions to company mail addresses only, but leave the status page publicly accessible for everyone. \n\nIs this even possible? I've only found some documentations about limiting the whole page access to certain user groups. \n\nbest Daniel\n"
}
|
[
{
"author": "Jesse Klein",
"body": "Hello Daniel,\n\nThis is Jesse from the Statuspage support team. Welcome to the community and thanks for the question about limiting email subscriptions.\n\nThere is no native way to do this within Statuspage on public pages. Since these pages are publically available, we don't have any mechanisms to lock the subscriptions in place. One recommendation is to have a public page for all subscribers and then make a separate, private page for your employees that only they can see. You can be more detailed with incidents there as well for transparency within the company.\n\nIt might also be possible to use custom Javascript to check emails before allowing them to subscribe but I wouldn't have any specifics on how to do this but it could be an option to explore. Please also note, this would likely not work with SMS subscriptions unless you had a list of all the employee numbers.\n\nHopefully, that helps get you pointed in the right direction. I hope you have a great day!\n\nRegards, \nJesse\n",
"comments": [
{
"author": "Daniel Brix",
"body": "Thanks Jesse, that clears things up for me and might be an option for us.\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Is-it-possible-to-whitelist-mail-subscriptions-per-domain/qaq-p/2586442
| null |
{
"author": "Angelo Gouvis",
"title": "Is it possible to raise the Subscriber limit beyond 25,000?",
"body": "We currently license the Enterprise version of Atlassian Statuspage, and we have the potential to have more than 25,000 Subscribers.\n\nIs it possible to raise the Subscriber limit beyond 25,000? If so, would there be additional monthly licensing costs involved, and if so, how much?\n\nRegards,\n\nAngelo Gouvis\n"
}
|
[
{
"author": "Brant Schroeder",
"body": "[@Angelo Gouvis](/t5/user/viewprofilepage/user-id/5411628) Welcome to the Atlassian community\n\nYou would have to connect with support here: <https://support.atlassian.com/contact/> if you are unable to submit your question there then I can escalate here in community for you.\n",
"comments": [
{
"author": "Angelo Gouvis",
"body": "Thanks Brant for your reply.\n\nFor reference, the Atlassian Support ticket I've raised is: [SPSP-35029](https://support.atlassian.com/requests/SPSP-35029/).\n\nRegards,\n\nAngelo\n"
}
]
}
] |
https://community.atlassian.com/t5/Statuspage-questions/Is-it-possible-to-raise-the-Subscriber-limit-beyond-25-000/qaq-p/2585932
| null |
{
"author": "Val Scott",
"title": "Does Crowd support SSO across Jira Server, Jira Data Center and Jira CLoud",
"body": "On this page\n\n<https://confluence.atlassian.com/kb/single-sign-on-integration-with-the-atlassian-stack-794495126.html>\n\nThe following statement is made: Crowd SSO 2.0 offers one solution for Server, Data Center, and Cloud applications and setting it up takes only minutes. \nAre you are ready for the change? See [Crowd SSO 2.0](https://confluence.atlassian.com/crowd/crowd-sso-2-0-967322291.html).\n\nHowever, when I look at the documentation, it does not appear Crowd SSO 2.0 can be used for cloud.\n\nI am looking for a solution to have SSO across Jira Server and Jira Cloud. How can I accomplish this?\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hi Val,\n\nTo get SSO between terrestrial and Atlassian Cloud using Crowd, you're going to need to use Crowd as your SAML provider for both - this means using Atlassian Access to talk to your Crowd environment using SAML.\n\nFor your terrestrial apps (Server and DC) - DC has native SAML support, but Server does not. I believe there are third party/marketplace apps that will give you SAML for Server in their own way.\n\n\"However, when I look at the documentation, it does not appear Crowd SSO 2.0 can be used for cloud. \" - Crowd SSO (SAML) I believe was introduced in Crowd DC 4.0 - and Access should allow you to add a SAML connector. NB: you can only have one SAML provider per Atlassian Access Org - though <https://jira.atlassian.com/browse/ACCESS-572> indicates it may be available in the near future\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Does-Crowd-support-SSO-across-Jira-Server-Jira-Data-Center-and/qaq-p/1954612
| null |
{
"author": "Bastian Stehmann",
"title": "Integrate Crowd with ADFS",
"body": "Hi,\n\nWe are currently looking for a solution to integrate Crowd with ADFS.\n\nIs there any way to get the users via ADFS into crowd, and then use crowd as user directory for the other Atlassian Applications, so that groups can be managed in Crowd and the Applications use ADFS for authentication?\n"
}
|
[
{
"author": "Thomas Clemens",
"body": "The Answer would be very interesting for us..\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Integrate-Crowd-with-ADFS/qaq-p/1952781
|
[
"active-directory",
"sso"
] |
{
"author": "Yashasswini Gowda",
"title": "Can we add one group as admin to multiple groups at a time(bulk update) in crowd?",
"body": "I have to add one group as admin to multiple groups present in crowrd?\n\nDo we have any bulk process to do\n\nI have added manually now.\n"
}
|
[
{
"author": "Nikita",
"body": "Hello, Yashasswini \nCrowd don't provide any api to add group as admin to multiple groups\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Can-we-add-one-group-as-admin-to-multiple-groups-at-a-time-bulk/qaq-p/1937389
| null |
{
"author": "Mariner IT",
"title": "Log4J Vulnerability located in Atlassian/Crowd",
"body": "I am getting prompts that my version of Atalassian Crowd has vulnerable Log4J files in it - how can we remedy?\n"
}
|
[
{
"author": "Sloan",
"body": "Hi there\n\nYou should check out Atlassian's response to Log4Shell: [Multiple Products Security Advisory - Log4j Vulnerable To Remote Code Execution - CVE-2021-44228](https://confluence.atlassian.com/security/multiple-products-security-advisory-log4j-vulnerable-to-remote-code-execution-cve-2021-44228-1103069934.html)\n\nCrowd should not be affected to my knowledge. Out of curiosity, where do you get the prompt from?\n\nCheers \nNiklas\n",
"comments": [
{
"author": "Mariner IT",
"body": "Azure/Windows Defender security.\n"
},
{
"author": "Mariner IT",
"body": "That link does not seem to work for me.\n"
},
{
"author": "Sloan",
"body": "What does the link say? What do you mean by Azure/Windows Defender security?\n"
},
{
"author": "Ernest Dudley",
"body": "I'm getting flagged through Nessus. I downloaded the latest crowd version (5.0.0) and Nessus is flagging the Log4j package (1.2.17) as being an unsupported version of Log4j. Just an FYI, see: <https://confluence.atlassian.com/kb/faq-for-cve-2021-44228-1103069406.html>\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Log4J-Vulnerability-located-in-Atlassian-Crowd/qaq-p/1937727
| null |
{
"author": "Trevor Wood",
"title": "Unable to authenticate to LDAP. How can I get into products to reconfigure?",
"body": "This is not only in Crowd but in our other Atlassian products, too. I can't authenticate via our LDAP; getting very vague errors. Is there a way to restore a local administrator account or otherwise get into crowd through a back door, so I can test or fix the configuration? I have full access to the server and the database.\n"
}
|
[
{
"author": "Reneesh Kottakkalathil",
"body": "Hello [@Trevor Wood](/t5/user/viewprofilepage/user-id/3566329)\n\nMaybe problem with your user directory configuration. Here is an example for configuring user directories in Jira <https://confluence.atlassian.com/adminjiraserver/configuring-user-directories-938847049.html>\n\nWere you able to authenticate before? If so, check for all the recent changes in the environment.\n",
"comments": [
{
"author": "Trevor Wood",
"body": "Thank you for the reply!\n\nYes, this configuration was working. The only thing we know changed is the previous cert on the server expired, but we thought it was replaced properly. The web-facing side of things does show the updated cert.\n"
},
{
"author": "Reneesh Kottakkalathil",
"body": "Under User Directory setting, there is a test option. Have you tried the test to see if that works? Can you paste the logs if you see any error? On which Atlassian product did the previous cert got expired and you renewed it?\n\n\n"
},
{
"author": "Trevor Wood",
"body": "Unfortunately, I can't get that far, since the User Directories page is behind authentication and I can't authenticate. We have a CentOS server which has crowd, bamboo, confluence, jira, and bitbucket running on it. The db is on another server running MySQL. The LDAP I'm trying to authenticate from is Active Directory.\n\nCrowd log excerpt:\n\n2022-02-08 14:44:04,690 http-nio-8095-exec-6 ERROR \\[jdbc.batch.internal.BatchingBatch\\] HHH000315: Exception executing batch \\[java.sql.BatchUpdateException: Duplicate entry '\\[redacted\\]' for key 'uk_token_id_hash'\\], SQL: insert into cwd_token (directory_id, entity_name, random_number, identifier_hash, random_hash, created_date, last_accessed_date, last_accessed_time, duration, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)\n\n2022-02-08 14:44:04,691 http-nio-8095-exec-6 ERROR \\[engine.jdbc.spi.SqlExceptionHelper\\] Duplicate entry '\\[redacted\\]' for key 'uk_token_id_hash'\n\n2022-02-08 14:44:05,597 http-nio-8095-exec-7 ERROR \\[crowd.manager.application.ApplicationServiceGeneric\\] Directory '\\[redacted\\]' is not functional during authentication of '\\[redacted\\]'. Skipped.\n\nHere's a line from the jira log:\n\natlassian-jira.log:2022-02-08 14:44:05,687-0500 http-nio-8080-exec-1 ERROR anonymous 883x26x1 69m0nt 172.17.0.21,127.0.0.1 /rest/gadget/1.0/login \\[c.a.j.security.login.JiraSeraphAuthenticator\\] Error occurred while trying to authenticate user... \n"
},
{
"author": "Reneesh Kottakkalathil",
"body": "[@Trevor Wood](/t5/user/viewprofilepage/user-id/3566329)\n\nYou can use the local admin account(non-AD) of Jira or other products to login and explore the settings.\n"
},
{
"author": "Trevor Wood",
"body": "Admin account worked! Still having trouble but at least i can get to the User Directories area. For the test, most turned green, but this was an error at the bottom:\n\nTest user can authenticate : Failed \nError from Crowd server propagated to here via REST API (check the Crowd server logs for details): org.springframework.transaction.CannotCreateTransactionException: Could not create DirContext instance for transaction; nested exception is org.springframework.ldap.CommunicationException: admin-dc1.\\[redacted.server.domain\\]:636; nested exception is javax.naming.CommunicationException: admin-dc1.\\[redacted.server.domain\\]:636 \\[Root exception is javax.net.ssl.SSLHandshakeException: PKIX path validation failed: java.security.cert.CertPathValidatorException: validity check failed\\]\n"
},
{
"author": "Reneesh Kottakkalathil",
"body": "Good news that you are able to login with your admin account. I know this PKIX error. This is because your products are missing the intermediate(chain) certificate in the JDK cacerts file. Importing the chain certificate to the JDKs cacerts file will fix the issue.\n\nRefer this link <https://confluence.atlassian.com/kb/unable-to-connect-to-ssl-services-due-to-pkix-path-building-failed-error-779355358.html>\n"
},
{
"author": "Trevor Wood",
"body": "We are back up and connected. I believe it started working after we ran 'update-ca-trust extract' with the intermediate and chain certs in the anchors directory. Had to do a restart of each app.\n\nI guess the cacerts file that java used was not updated when we first updated the certs.\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Unable-to-authenticate-to-LDAP-How-can-I-get-into-products-to/qaq-p/1938028
| null |
{
"author": "Airbus DS",
"title": "When are the attribut of user updated ?",
"body": "We have a Crowd server set with a Jira server.\n\nWhile managing user, I've come up with some strange thing.\n\nIn Crowd profile of user, attributs of profile as like that\n\nLast active : 1643187736929 was GMT: Wednesday 26 January 2022 09:02:16.929 \nLast authenticated : 1643181881675 was GMT: Wednesday 26 January 2022 07:24:41.675\n\nWhile in Jira, for the same profile of user, we have for Loggin details\n\n**Last:** Yesterday 07:36 (so this should be 3rd february 07:36 GMT+2)\n\nHow can I explain this to security team ?\n\nIt's not the first time we have some difficulties understanding the values of Last active and Last authenticated.\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hi [@Airbus DS](/t5/user/viewprofilepage/user-id/4743292)\n\nAny chance that the user is able to login to your Jira environment using a Jira local account? This would explain a discrepancy between when Jira thinks a user last authenticated and when Crowd thinks a user last authenticated.\n\nCCM\n",
"comments": [
{
"author": "Airbus DS",
"body": "No that's shouldn't be the case. We only have users in Crowd and have check this.\n\nPlus those attribute are not set when only browsing and using the feature \"Connect as\" provided by Scriptrunner or while settings some Jira Automation ...\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/When-are-the-attribut-of-user-updated/qaq-p/1934324
|
[
"jira",
"jira-server",
"server"
] |
{
"author": "Deepu Kurup",
"title": "Users are unable to authenticate",
"body": "From the logs :- I find this error :-\n\nCrowd user authentication fails with 'Directory 'X' is not functional during authentication' error {#toc-hId--1187430975}\n-------------------------------------------------------------------------------------------------------------------------\n\nOn Checking the LDAP test connection I get the following error :-\n\nThere was a problem communicating with the LDAP server: simple bind failed: \\<Ixyz.com:3269\\>; nested exception is javax.naming.CommunicationException: simple bind failed: \\<Xyz.com\\> \\[Root exception is javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path validation failed: java.security.cert.CertPathValidatorException: validity check failed\\]\n\nNeed help asap\n"
}
|
[
{
"author": "Reneesh Kottakkalathil",
"body": "[@Deepu Kurup](/t5/user/viewprofilepage/user-id/4693338)\n\nWelcome to the community. This is because your products are missing the intermediate(chain) certificate in the JDK cacerts file. Importing the chain certificate to the JDKs cacerts file will fix the issue. I faced a similar issue and it was fixed after importing the intermediate certs.\n\nRefer this link <https://confluence.atlassian.com/kb/unable-to-connect-to-ssl-services-due-to-pkix-path-building-failed-error-779355358.html>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Users-are-unable-to-authenticate/qaq-p/1900290
| null |
{
"author": "Nicol?s Guzm?n",
"title": "Jira-Crowd: Synchronisation failed: Incremental synchronisation is not available. Falling back to f",
"body": "I have configured a unique Crowd directory in Jira Server with the following configuration:\n\n\n\nSince yesterday, when we try to synchronize we get the following error message:\n> Synchronisation failed. See server logs for details.\n\nWe have checked the atlassian-jira.log file and found out the following trace. We don?t understand what is going on and we really appreciate it if somebody her can give us an advice:\n\n```\n2-15 15:38:38,758+0100 Caesium-1-1 INFO ServiceRunner [c.a.crowd.directory.DbCachingRemoteDirectory] INCREMENTAL synchronisation for directory [ 10500 ] starting\n2021-12-15 15:38:38,758+0100 Caesium-1-1 INFO ServiceRunner [c.a.crowd.directory.DbCachingRemoteDirectory] Attempting INCREMENTAL synchronisation for directory [ 10500 ]\n2021-12-15 15:38:38,758+0100 Caesium-1-1 DEBUG ServiceRunner [c.a.c.d.ldap.cache.EventTokenChangedCacheRefresher] A full synchronisation is needed to obtain the current token event\n2021-12-15 15:38:38,758+0100 Caesium-1-1 INFO ServiceRunner [c.a.crowd.directory.DbCachingRemoteDirectory] Incremental synchronisation for directory [ 10500 ] was not completed, falling back to a full synchronisation\n2021-12-15 15:38:38,758+0100 Caesium-1-1 INFO ServiceRunner [c.a.crowd.directory.DbCachingRemoteDirectory] INCREMENTAL synchronisation for directory [ 10500 ] was not successful, attempting FULL\n2021-12-15 15:38:39,020+0100 Caesium-1-1 WARN ServiceRunner [c.a.c.d.ldap.cache.EventTokenChangedCacheRefresher] Incremental synchronisation is not available. Falling back to full synchronisation\ncom.atlassian.crowd.event.IncrementalSynchronisationNotAvailableException\nat com.atlassian.crowd.integration.rest.service.RestCrowdClient.getCurrentEventToken(RestCrowdClient.java:1002)\nat com.atlassian.crowd.directory.RemoteCrowdDirectory.getCurrentEventToken(RemoteCrowdDirectory.java:631)\nat com.atlassian.crowd.directory.ldap.cache.EventTokenChangedCacheRefresher.synchroniseAll(EventTokenChangedCacheRefresher.java:47)\nat com.atlassian.crowd.directory.DbCachingRemoteDirectory.synchroniseCache(DbCachingRemoteDirectory.java:978)\nat com.atlassian.crowd.manager.directory.DirectorySynchroniserImpl.synchronise(DirectorySynchroniserImpl.java:67)\nat com.atlassian.jira.crowd.embedded.JiraDirectorySynchroniser.synchronizeDirectory(JiraDirectorySynchroniser.java:77)\nat com.atlassian.jira.crowd.embedded.JiraDirectorySynchroniser.runJob(JiraDirectorySynchroniser.java:52)\nat com.atlassian.scheduler.core.JobLauncher.runJob(JobLauncher.java:134)\nat com.atlassian.scheduler.core.JobLauncher.launchAndBuildResponse(JobLauncher.java:106)\nat com.atlassian.scheduler.core.JobLauncher.launch(JobLauncher.java:90)\nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.launchJob(CaesiumSchedulerService.java:435)\nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.executeClusteredJob(CaesiumSchedulerService.java:430)\nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.executeClusteredJobWithRecoveryGuard(CaesiumSchedulerService.java:454)\nat com.atlassian.scheduler.caesium.impl.CaesiumSchedulerService.executeQueuedJob(CaesiumSchedulerService.java:382)\nat com.atlassian.scheduler.caesium.impl.SchedulerQueueWorker.executeJob(SchedulerQueueWorker.java:66)\nat com.atlassian.scheduler.caesium.impl.SchedulerQueueWorker.executeNextJob(SchedulerQueueWorker.java:60)\nat com.atlassian.scheduler.caesium.impl.SchedulerQueueWorker.run(SchedulerQueueWorker.java:35)\nat java.lang.Thread.run(Thread.java:748)\n```\n\nThanks,\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hi [@Nicol?s Guzm?n](/t5/user/viewprofilepage/user-id/3431495)\n\nI'd start by checking the Crowd Directories that are mapped to the Crowd Application Jira is configured to talk to to see if any of the directories are Delegated Authentication or don't have caching enabled\n\n\"Incremental synchronisation from a remote Crowd directory is only supported when all the remote directories are either local or fully synchronized, which does not currently include Delegated Authentication directories\"\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Jira-Crowd-Synchronisation-failed-Incremental-synchronisation-is/qaq-p/1888725
|
[
"jira"
] |
{
"author": "Redz",
"title": "Azure SSO issues with Atlassian Cloud",
"body": "I followed the instruction here ([Tutorial: Azure Active Directory integration with Atlassian Cloud \\| Microsoft Docs](https://docs.microsoft.com/en-us/azure/active-directory/saas-apps/atlassian-cloud-tutorial)) and the configuration seems correct. But I'm running into this issue when testing SSO:\n\n\n\nWhen I talked to our devops person, he thinks the issue is with API permissions in the app registration, but it is not clear what API permissions need to be set to grant admin approval. Am I missing something?\n"
}
|
[
{
"author": "Dominik Aigner",
"body": "Hi [@Redz](/t5/user/viewprofilepage/user-id/4725588) could you solve it? Got the same behaviour today and somehow I could solve it but only for me and two other test users. Another Test User is still being asked for approval.\n",
"comments": [
{
"author": "Redz",
"body": "[@Dominik Aigner](/t5/user/viewprofilepage/user-id/4991562) Yes we did. Our Azure admin blocked the permission on all apps, so we had to get our Azure admin to grant permission for the Atlassian app.\n\nAnother workaround is if your org uses SSO with Google Workspace, you can log into GWS and then \"Log in with Google\" at Confluence log in page.\n"
},
{
"author": "Samuel Alegre",
"body": "Hi [@Redz](/t5/user/viewprofilepage/user-id/4725588) what permission did you give to solve this? We are running into this same problem. Did you need to give rights to specific API\n"
},
{
"author": "Redz",
"body": "Hey [@Samuel Alegre](/t5/user/viewprofilepage/user-id/2822005) , it was basically blocked by our Azure admins. There are two types of permissions in Azure, User and Admin approval. Under user approval, a user has the ability to approve required permissions; under admin approvals, only Azure admins can approve requests. The problem is with Admin approval, it's basically all or nothing. In your org that might be acceptable, but for us, Confluence cloud is approved only for a limited number of users.\n\nWhat helped us get around that issue is we have Google Workspace and we instructed users to log into Google workspace first and then go to \\<company\\>.atlassian.net and select log in with Google option.\n\nOtherwise your Azure admin will have to approve Confluence app permissions at the Org level.\n"
}
]
},
{
"author": "Pramodh M",
"body": "Hi [@Redz](/t5/user/viewprofilepage/user-id/4725588)\n\nWelcome to the Community!!\n\nIt's referring to the one who created the App. That's it. You are allowing the app which you have just created in Azure to read the Profile data of the user such as username, email address so that it will be used for authentication, but before that, it requires permission to do so, and the screen which you have shared is the one.\n\nThanks, \nPramodh\n",
"comments": [
{
"author": "Redz",
"body": "Hi [@Pramodh M](/t5/user/viewprofilepage/user-id/3691224) , I created the app in Azure Enterprise apps following the instructions in the link above. The config is correct, however when I test the sso that's when I get the error going through Continue with Microsoft for SSO login. The screenshot does share permissions required, but that does not translate into what API permissions need to be set in Azure \\> App registrations \\> API permissions.\n\nWhat I concluded is that specific API permissions are needed but are not configured in Atlassian Cloud app in Azure, there were no API permissions that needed to be granted as Admin.\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Azure-SSO-issues-with-Atlassian-Cloud/qaq-p/1921704
|
[
"active-directory",
"azure",
"sso"
] |
{
"author": "Bongjoo Kim",
"title": "reset password",
"body": "Hello Crowd,\n\nthere are nomal user with Jira_user permisison and some users created by api and don't have any permission .\n\nbut they claimed when they get notification email from crowd to reset password.\n\nIs there any way not to send notification email to specifice user ?\n\nThanks,\n\nBongjoo\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "People get sent emails about resetting passwords when you add them or they request a reset. Crowd has no way to know that you're adding users who aren't going to use it!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/reset-password/qaq-p/1845586
| null |
{
"author": "charleslcso",
"title": "Application Links again",
"body": "Hello, I am seeing an issue, and I'm not sure if it has something to do with Application Links.\n\nFirst of all, Jira 8.20.0 -\\> Crowd 3.7.2 , Jenkins -\\> Jira 8.20.0 have been working.\n\nA few days ago I did a minor upgrade to Jenkins, and at the same time migrated it to a new server. All Jenkins' jobs no longer run. I get a 401 in Jenkins when I Test Connection to Jira.\n\nAt the same time, Jira's atlassian-jira-security.log says my Jira ID tried to login but I do not have USE permission or weren't found.\n\nIn Jira, under User Management, Jira can connect to Crowd, and I can authenticate and log into Jira using my ID.\n\nI checked Application Links in both Jira and Crowd. Jira to Crowd has Network Error (please see screen below), while Crowd to Jira is Connected!\n\nWhat is going on? The OAuth version mismatch between Jira 8.20 and Crowd 3.7?\n\n\n"
}
|
[
{
"author": "charleslcso",
"body": "Nevermind, it is really a problem with reverse proxy configuration.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Application-Links-again/qaq-p/1865052
|
[
"application-link",
"jenkins",
"jira-server",
"oauth",
"server"
] |
{
"author": "Shankar_1988",
"title": "While starting crowd tomcat not responding",
"body": "While starting crowd tomcat not responding\n"
}
|
[
{
"author": "Florian PEREZ",
"body": "Hello!\n\nTo be able to help you we will need more information:\n\n* Is this a new install\n* Have you made any modification on the software recently\n* Are you able to share with us some log ( <https://confluence.atlassian.com/crowd/logging-and-profiling-24248601.html>) or some screen shots of the problem.\n\nWhen we will have more information I will be able to help you more!\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/While-starting-crowd-tomcat-not-responding/qaq-p/1878612
| null |
{
"author": "v8lust",
"title": "Crowd Server upgrade from upgrade 3.3.3 ? 4.4.0 creating new install instead",
"body": "Followed the normal process (<https://confluence.atlassian.com/crowd/upgrading-crowd-via-automatic-database-upgrade-213519474.html>) and in atlassian-crowd.log I can see expected logging of my home (which I have unimaginitively set the Atlassian document example)\n\nUsing config directory : /var/crowd-home/shared\n\nReferences to migrating database tables and then accessing my Active Directory, with\n\nFULL synchronisation complete for directory \\[ 32770 \\] in \\[ 1835ms \\]\n\nSo it looked normal and no errors were reported, however, when I go to the URL, it's presenting the setup Crowd dialog\n"
}
|
[
{
"author": "v8lust",
"body": "I selected the set-up button, could not login with AD user, but could log in with the inbuilt admin user, and within the server I can see the user settings, so the migration does appear to have worked. We never use the self-service aspect of Crowd so the inabilty to login won't block us.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-Server-upgrade-from-upgrade-3-3-3-4-4-0-creating-new/qaq-p/1843652
|
[
"server"
] |
{
"author": "Andrew Dunn",
"title": "Is this the right place to get help with my minecraft loggin issues. i'm not reciving my reset link.",
"body": "A while ago Mojang decided to migrate everyone to Microsoft to give us better account security. since then I have not been able to sign in to my Minecraft account. Following all the stupid \"have you read these FAQ and then try this forum page\" I have ended up here. I don't believe anyone here will be able to help.\n\nMy issue is when i click on the reset password link i don't receive it.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "Actually, no.\n\nMojang uses Atlassian software for its documentation and help systems (Jira as the issue tracker for example). I think you (like a lot of others) have clicked on \"help with the doc/support tool\" instead of \"help with Minecraft\"\n\nI'm afraid we can't help you with Mojang's login system. You'll need to get in touch with them!\n",
"comments": [
{
"author": "Andrew Dunn",
"body": "I wish i could. The help system keeps sending me in circles. Thank you. I'll keep trying\n"
},
{
"author": "Andrew Dunn",
"body": "\n\nI keep getting this message to contact a Jira administrator\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "Ok, that makes some sense in that you need to contact a Jira admin to fix your account so it can log into Jira.\n\nBut we are a community of people here to talk about Atlassian stuff. We are not your Jira admins.\n\nThe best most of us here (for \"can't log in\" problems) can do is tell you to ask the admins of the system you are trying to get into.\n"
},
{
"author": "Andrew Dunn",
"body": "When i click on the links for help it sends me back here. Thanks again.\n"
},
{
"author": "Nic Brough -Adaptavist-",
"body": "I'm sorry, but we are not the admins of that system, so we can't do anything to help you.\n\nYou really do need to talk to Mojang, not us (for access to it anyway, please do feel free to talk to us about using Atlassian stuff in general, that's what we're here for!)\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Is-this-the-right-place-to-get-help-with-my-minecraft-loggin/qaq-p/1855833
| null |
{
"author": "Olaf Bonness",
"title": "What SSO plugins can I get for a Confluence Cloud installation?",
"body": "Most SSO plugins are only available for Server and DC installation. Is there any plugin out there that works / installs also for the Confluence Cloud product?\n"
}
|
[
{
"author": "Lisa Grau",
"body": "Hi Olaf,\n\nyou need Atlassian Access to use SSO in the Atlassian Cloud. You can find further information here: <https://www.atlassian.com/software/access/guide/elements/single-sign-on#how-it-works>\n",
"comments": [
{
"author": "Olaf Bonness",
"body": "Thx Lisa, will try ...\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/What-SSO-plugins-can-I-get-for-a-Confluence-Cloud-installation/qaq-p/1817116
|
[
"confluence-cloud",
"sso"
] |
{
"author": "Ben Radlinski",
"title": "Do we still need Crowd?",
"body": "We are using the Azure AD plugin for authentication to Confluence and Jira. Our onprem AD is fully integrated with our Azure AD and autosyncs. I've been trying to come up with a reason to keep using Crowd and I don't see it. I don't think the SSO ever worked in our setup (I didn't set it up). Do we still need Crowd?\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hey Ben, \nYour summary doesn't indicate whether you're using AzureAD as the only source for all of your groups/memberships, but if not, it may be of value retaining Crowd for this purpose. While you can use Jira as the user source for Confluence, as a more lightweight product, we have had much better uptime with Crowd than Jira. We source some key (authentication) groups from Azure AD but most authorisation groups live in Crowd for all of our products.\n\nCCM\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Do-we-still-need-Crowd/qaq-p/1811667
|
[
"server"
] |
{
"author": "Satish Bezawada",
"title": "How can i integrate Nexus IQ server to Crowd ?",
"body": "Hello,\n\nPlease help me steps or documentation on Nexus IQ integration with Crowd application.\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "What do you want from this \"integration\"? What is it supposed to do and what do the end users get from it?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/How-can-i-integrate-Nexus-IQ-server-to-Crowd/qaq-p/1805551
| null |
{
"author": "chappie",
"title": "Atlassian Crowd Version: 3.2.3 (Build:#954 - 2018-06-26) compatible with PostgreSQL version 13.2",
"body": "Atlassian Crowd Version: 3.2.3 (Build:#954 - 2018-06-26) compatible with PostgreSQL version 13.2\n"
}
|
[
{
"author": "Nic Brough -Adaptavist-",
"body": "See <https://confluence.atlassian.com/crowd/supported-platforms-191851.html> and select the version you are interested in\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Atlassian-Crowd-Version-3-2-3-Build-954-2018-06-26-compatible/qaq-p/1804887
|
[
"server"
] |
{
"author": "a111111",
"title": "check token isAuthenticated is false",
"body": "I was testing the crowd sso function.\n\nI generated token success.\n\nbut when I use the method httpAuthenticator.isAuthenticated(request,response) to check token,it always flase.How can I do to check the reason?\n"
}
|
[
{
"author": "Ruslan Tkachuk",
"body": "Hi [@a111111](/t5/user/viewprofilepage/user-id/4555752) \n\nThe most correct way to check a token (stored in cookies for SSO configuration) will be using the 'validate token' method in Crowd REST API. <https://docs.atlassian.com/atlassian-crowd/4.4.1/REST/#usermanagement/1/session-validateToken> \n\nExample: \n1. Create a new application in Crowd for SSO. Ex: Jira application type with name - jiraapp and password - jirapsw \n2. Add to jiraapp a new directory + group + user (ex: jirauser). User should be able to sing-in to jiraapp and crowd \n3. Sign-in into Crowd like jirauser. Check cookie and copy the token value.\n\n*** ** * ** ***\n\ncurl --location --request POST 'http://\\<host\\>:\\<port\\>/crowd/rest/usermanagement/1/session/\\<token value\\>' \\\\ \n--header 'Content-Type: application/json' \\\\ \n--header 'Accept: application/json' \\\\ \n--header 'Authorization: Basic \\<jiraapp:jirapsw to Base64\\>' \\\\ \n--data-raw '{ \n\"validationFactors\": \\[ \n{ \n\"name\": \"remote_address\", \n\"value\": \"\\<IP of Jira or 127.0.0.1 for locall instalation\\>\" \n} \n\\] \n} \n'\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/check-token-isAuthenticated-is-false/qaq-p/1804094
| null |
{
"author": "Ludmila Schemarow",
"title": "How to compile ApacheCrowd Connector",
"body": "Hello,\n\nI tried to compile the binary (on Centos 7) from that site\n\n<https://confluence.atlassian.com/crowd/installing-the-crowd-apache-connector-on-other-unix-like-systems-226790526.html> but I get errors after I try to start \"make\".\n\n\\[schemaro@mz-902-s-tronapp01 mod_authnz_crowd-2.2.2\\]$ sudo make \nmake all-recursive \nmake\\[1\\]: Entering directory \\`/home/schemaro/mod_authnz_crowd-2.2.2' \nMaking all in src \nmake\\[2\\]: Entering directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \ncd .. \\&\\& /bin/sh ./config.status config.h \nconfig.status: creating config.h \nconfig.status: config.h is unchanged \nmake\\[3\\]: Entering directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \ncd .. \\&\\& /bin/sh ./config.status config.h \nconfig.status: creating config.h \nconfig.status: config.h is unchanged \nmake\\[3\\]: Leaving directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \nmake all-recursive \nmake\\[3\\]: Entering directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \nMaking all in src \n/bin/sh: line 20: cd: src: No such file or directory \nmake\\[3\\]: \\*\\*\\* \\[all-recursive\\] Error 1 \nmake\\[3\\]: Leaving directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \nmake\\[2\\]: \\*\\*\\* \\[all\\] Error 2 \nmake\\[2\\]: Leaving directory \\`/home/schemaro/mod_authnz_crowd-2.2.2/src' \nmake\\[1\\]: \\*\\*\\* \\[all-recursive\\] Error 1 \nmake\\[1\\]: Leaving directory \\`/home/schemaro/mod_authnz_crowd-2.2.2' \nmake: \\*\\*\\* \\[all\\] Error 2\n\nHave you an idea, why? Or there are any other options to protect third part apps throught crowd or LDAP?\n\nBR, Ludmila\n"
}
|
[
{
"author": "Charlie Misonne",
"body": "Hi Ludmila, welcome to the Atlassian Community.\n\nTo be honest I have no idea but I found a fork for CentOS7 while yours seems to be for CentOS6. Perhaps the error is related to a mismatch in OS versions.\n\n<https://github.com/ferstl/cwdapache-rhel7>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/How-to-compile-ApacheCrowd-Connector/qaq-p/1801641
|
[
"apache",
"connector",
"server"
] |
{
"author": "sm.park",
"title": "Crowd username bulk change",
"body": "Hello \nI want to bulk change the user name of Crowd user. \nAttempted to change username using update user of crawd rest api, but got error 'ILLEGAL_ARGUMENT'. Is there a good way?\n"
}
|
[
{
"author": "sm.park",
"body": "I found it.\n\nit use rename user rest api.\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-username-bulk-change/qaq-p/1793954
|
[
"rest-api",
"user"
] |
{
"author": "???",
"title": "Can I add user information in crowd?",
"body": "i want to add company infomation to user detail in corwd.\n\nis it possible?\n"
}
|
[
{
"author": "DPKJ",
"body": "I think this can help you - <https://confluence.atlassian.com/crowd/specifying-a-user-s-attributes-18579612.html>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Can-I-add-user-information-in-crowd/qaq-p/1783947
| null |
{
"author": "sm.park",
"title": "Crowd username bulk change",
"body": "Hello \nI want to bulk change the user name of Crowd user. \nAttempted to change username using update user of crawd rest api, but got error 'ILLEGAL_ARGUMENT'. Is there a good way?\n"
}
|
[
{
"author": "sm.park",
"body": "I solved this problem. \ncan use the rename user restapi.\n",
"comments": [
{
"author": "Mugilan Sukumar",
"body": "Kindly send me the rest api link which one you used\n"
},
{
"author": "Shannon S",
"body": "Hi [@Mugilan Sukumar](/t5/user/viewprofilepage/user-id/4492228),\n\nIt will depend on you're Crowd version, but sm likely used\n\n```\nPOST /rest/usermanagement/1/user/rename\n```\n\nRefer to the documentation here:\n\n<https://docs.atlassian.com/atlassian-crowd/4.4.0/REST/#usermanagement/1/user-renameUser>\n\nTake care,\n\nShannon \\| Atlassian Community Support\n"
}
]
}
] |
https://community.atlassian.com/t5/Crowd-questions/Crowd-username-bulk-change/qaq-p/1793951
|
[
"rest-api"
] |
{
"author": "Christopher Del Rosario",
"title": "Adding Crowd User via API",
"body": "Hi All!\n\nI am utilizing the CROWD REST API and I am having difficulty with adding a user to a specific Directory.\n\nWhen I am sending the request with the below filled out.\n\n{ \n\"name\": \"sampleuser\", \n\"password\": { \n\"value\": \"secret\" \n}, \n\"active\": true, \n\"first-name\": \"Sample\", \n\"last-name\": \"User\", \n\"display-name\": \"Sample User\", \n\"email\": \"[email protected]\",\n\n\"directory-name\": \"sample\",\n\n\"directory-id\": 1 \n}\n\nEvery time the call is executed the user is being added to the first Directory on page.\n\nNote: Application has access to add/modify in multiple directories.\n\nAny help would be much appreciated!\n"
}
|
[
{
"author": "Craig Castle-Mead",
"body": "Hi,\n\nI don't believe directory-name or directory-id are parameters you can pass through (<https://docs.atlassian.com/atlassian-crowd/3.2.3/REST/#usermanagement/1/user-addUser>)\n\nCrowd will try and make the user in the first directory that application has access to. The way we work around this is by having an application per directory we want to create users in with a 1:1 relationship, then authenticate with the appropriate application user/pass for the directory you want to create the user in. \n\nCCM\n",
"comments": null
},
{
"author": "Chris Arnold",
"body": "How does suggestion actual work in practice? You no longer have the ability to use directory's. Only have one. Mutiple unique userids for each user one for each application?\n",
"comments": null
},
{
"author": "Chris Arnold",
"body": "Has this been fixed in 5.0.2?\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Crowd-questions/Adding-Crowd-User-via-API/qaq-p/1777497
|
[
"api"
] |
{
"author": "Marta Perez",
"title": "How to show/hide different tabs on the same issue type - subtask (without scripting if possible)",
"body": "Hello!\n\nI have added 3 tabs in my sub-task issue type and I need to be able to show certain tabs depending on some conditions.\n\nI have an automation in place that creates different sub-tasks with different names during some transitions and I need the sub-task to show a specific tab depending the on the name.\n\nLet's say: Sub-task A will show tab no1; Sub-task B will show tab no2, etc.\n\nIs it possible to accomplish this without creating a different sub-task issue type?\n\nPD. Client does not have Scritprunner or any other app, so ideally I would like to achieve this out of the box.\n\nThank you in advance.\n\nRegards\n\n\n"
}
|
[
{
"author": "Manoj Gangwar",
"body": "Hi [@Marta Perez](/t5/user/viewprofilepage/user-id/5489066)\n\nNormally it is not feasible but as a workaround, you do this:\n\nYou need to create three customfields and add one customfield on each tab apart from that you have to remove all other fields from the tabs. In the automation rule, you can set the field value based on the sub-task. For example- Sub-task1 then sets the field1 value to ABC, and Sub-task2 then field2 value DEF...using this it will show only that particular tab.\n",
"comments": [
{
"author": "Marta Perez",
"body": "Hey Manoj,\n\nthank you for your quick answer! Even if I set up the automation and set specific fields during the subtask creation, the tab will be still visibile in the issue layout. I guess i would still need to create different issue types...?\n"
},
{
"author": "Manoj Gangwar",
"body": "I think empty fields are not hidden thats why they are showing in the tab and tab is not hiding due to this.\n\nIf you have configured request type then under the request type click on issue view and move those fields under hide when field empty.\n\nElse you have to create the separate isaue types.\n"
},
{
"author": "Marta Perez",
"body": "Thank you Manoj. The issue type I need to configure is the subtask and it does not have a request type connected to it. In the end I created 2 more subtask issue types and configured the fields there.\n\nThank you for your feedback :)\n"
},
{
"author": "Manoj Gangwar",
"body": "Please accept the answer so it marked as resolved.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-show-hide-different-tabs-on-the-same-issue-type-subtask/qaq-p/2817109
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"sub-task",
"tabs"
] |
{
"author": "Jason Igari-Szabo",
"title": "Communication with external party",
"body": "Hello,\n\nI am new to Jira / Jira Service Management, we're evaluating it as a replacement for our current system.\n\nA feature I have found absent from JSM so far is contacting an external party from within an issue, other ITSM solutions do offer that functionality after all.\n\nI have searched through various other community questions, but haven't found a suitable solution. The only other similar question was asked here:\n\n[JIRA Service Desk: Can an external third party be involved via email?](https://community.atlassian.com/t5/Jira-Service-Management/JIRA-Service-Desk-Can-an-external-third-party-be-involved-via/qaq-p/613105)\n\nBut that question was asked in 2017, and the solution there does not work for us.\n\nOur situation is similar to the Requester's. \nWe work with external support companies in some of our areas. \nTo keep things aligned, I want to have all communication within the same ticket, or possibly subtasks of the ticket. It would already help a lot if we can define a different recipient in a \"To: \" field when adding a comment.\n\nIs there now, roughly 7 years later, a built-in solution to that situation?\n\nThank you very much in advance for your replies. \nSorry if that question does indeed have a current answer. \n"
}
|
[
{
"author": "victorfdezespada",
"body": "within the incidents there is the field of \"participants of the request\", it works for us.\n",
"comments": [
{
"author": "Jason Igari-Szabo",
"body": "Thank you for your reply! I already tried including external partners that way, but this way, the customer is also notified about every communication with the external party, which is not what we want and wish for.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Communication-with-external-party/qaq-p/2817101
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Harshit Grover",
"title": "Prevent closed transition from updating resolution date",
"body": "In a Jira project , we have a workflow transition from Resolved to Closed.\n\nDuring this status transition the resolution date is getting updated. However, we would like to preserve the date when the ticket was transitioned to Resolved.\n\nI suspect we might be able to update the post functions for the transition to Closed to prevent the resolution date update possibly.\n\nKindly provide a best possible way to do that ?\n"
}
|
[
{
"author": "Manoj Gangwar",
"body": "Hi [@Harshit Grover](/t5/user/viewprofilepage/user-id/4990036)\n\nAs far as I understand, a post function is currently applied to the closed transition to set the Resolution fields. You can remove that post function and use it on the Resolved transition to set the Resolution field.\n\nOn the Closed status, you can apply the below properties: \njira.issue.editable: Set to false to disable issue editing\n",
"comments": null
},
{
"author": "Hemalatha Balamurugan",
"body": "Hi [@Harshit Grover](/t5/user/viewprofilepage/user-id/4990036) ,\n\nThe Resolution Date will be set when you update the Resolution field in your workflow transition. In your case, please remove the post function to update resolution field in your transition to closed status.\n\nHope this helps.\n\nThanks \\& Regards,\n\nHema\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Prevent-closed-transition-from-updating-resolution-date/qaq-p/2817087
|
[
"data-center",
"jira-service-management",
"jira-service-management-data-center"
] |
{
"author": "Gabe Cz",
"title": "How to JSON import hyperlinks",
"body": "Hi\n\nHere is a sample i use a photo for if i insert text here it will get converted.\n\n\n\nbasically i have a json line with \"description\": with a n a href= hyperlink in it, and while importing it it does not get converted to an actually clickable hyperlink. i het the code adding a link to a ticket and exporting it to xml. what is the correct way if there is to import json with hyperlinked words in it?\n\nwhat i see after importing it, is this:\n\n\n\nultimately what we're trying to achieve here is a file:// that points to a folder on the network share containing the old system's ticket attachments that we couldn't export/import properly (i'll use something like \" file : / / network path / spiceworks / old-ticketnr / \" but that's formality i can figure out after finding out how to import \"a href\"\n\nthanks\n\nbtw it'd be a very helpful feature if one could export a ticket / tickets in json format.\n"
}
|
[
{
"author": "Anusha A",
"body": "Hi Gabe,\n\nThanks for posting this query.\n\nWe need to replicate this behavior and consult with our developers to determine if the description field supports HTML hyperlinks. I've created a ticket for you, and our experts will reach out shortly to assist you effectively. You'll receive the ticket details soon over the email.\n\nThanks for your cooperation, have a great day ahead.\n\nRegards,\n\nAnusha A\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-JSON-import-hyperlinks/qaq-p/2816994
|
[
"cloud",
"html",
"import",
"jira-service-management",
"jira-service-management-cloud",
"json"
] |
{
"author": "Gaurav Gupta",
"title": "8x8 Contact Center Integration",
"body": "Hello Experts,\n\nWe have a use case where we need to integrate 8X8 Contact Center with our Jira Service Management instance. We have explored the marketplace and do have a plugin but it does not enable the integration between the products.\n\nKindly share if someone has achieved the integration between 8X8 Contact Center with Jira Service Management and the process for the same.\n\nThanks\n\nGaurav\n"
}
|
[
{
"author": "Vijay Dadi",
"body": "Hello,\n\nI have built a integration with Service Now without any plugin or app from the market place for ticket exchange bi-directional.\n\nPlease provide more details on your usecase.\n\nRegards,\n\nVijay\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/8x8-Contact-Center-Integration/qaq-p/2817078
|
[
"cloud",
"jira",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "David Quiram",
"title": "How to handle automation actions when the data is a date within a text field.",
"body": "In our IdP (Okta) we have a custom text field to facilitate a specific date for people. I will be syncing this field over to a custom read-only text field in Atlassian, via MindPro Sync, so that it will be available on issues and for Automation.\n\nI would like to setup an automation where an issue is auto-closed with comment based on that \"date\". If it were a true date field, I could use a smart value time comparison, but since it's a text field, I feel that wont be possible via the exact same means.\n\nDue to the systems in place, we are locked into use text fields for this.\n\nDoes anyone have suggestions on this? Thank you for your time and consideration.\n"
}
|
[
{
"author": "Trudy Claspill",
"body": "Hello [@David Quiram](/t5/user/viewprofilepage/user-id/4501008)\n\nThere are functions that can be applied to smart values in automation to convert text to dates that can then be used in date-applicable functions.\n\n[@Bill Sheboy](/t5/user/viewprofilepage/user-id/1685313) provided an answer to a similar question on [this post](https://community.atlassian.com/t5/Jira-questions/Is-it-possible-to-convert-string-into-date-time-from-Jira/qaq-p/2354974) and [this post](https://community.atlassian.com/t5/Jira-questions/Smart-Values-String-type-conversion-to-Date/qaq-p/2106719) referencing the toDate function.\n",
"comments": [
{
"author": "David Quiram",
"body": "Amazing! Thank you so much. I'll def be digging into those posts next week!\n"
}
]
},
{
"author": "David Quiram",
"body": "So... I have been picking away at this for a few hours now trying different combinations to see if I could land on the solution and it's not quite catching. What am I missing?\n\nMy Okta variable has the value of March 26, 1990. I have tried this as both: \n1990-03-26 \n1990 03 26\n\nIn the automation, I store the data into a variable {{TestVariable}} and I give it the smart value of: \n{{issue.customfield_10385.toDate(\"yyyy-MM-dd\")}} \n{{issue.customfield_10385.toDate(\"yyyy MM dd\")}} \n{{issue.customfield_10385.toDate(jiraDate)}}\n\nI then log the action so I can visually inspect what is being used. I log both the variable and the smart value for comparison and for all three variants that I have tried we get: \n1990-03-26T00:00:00.0+0000\n\nIf I am reading documentation correctly, it is putting the time value in there because that is the default format for a date/time value. So, am I doing something incorrectly with my smart value?\n\nMoving on, the next thing I tried to log was adjusting the date/time value by doing a plus 1 month to it. I tried the following and both display no data, but don't error: \n{{issue.customfield_10385.toDate(\"yyyy-MM-dd\").plusMonth(1)}} \n{{TestVariable.plusMonth(1)}}\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-to-handle-automation-actions-when-the-data-is-a-date-within/qaq-p/2816975
|
[
"automation",
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "EDUARDO JOSUE ZAMORA VALVERDE",
"title": "extract the values from a status field via api",
"body": "\n\nThrough the API, how can I get these values ??(Active, Support Requested, Deleted)?, it is an attribute of an object\n"
}
|
[
{
"author": "Vijay Dadi",
"body": "Hello,\n\nyou can get it using smart values like {{status.name}}. If it is via api, it will be like\n\n{{webResponse.body.status.name}}. Hope this helps\n\nVijay\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/extract-the-values-from-a-status-field-via-api/qaq-p/2816962
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Giovanni Cardillo",
"title": "You don't have permission to access this service project for Email requests",
"body": "Hi,\n\nI'm in the trial period before the migration from server to Cloud and I'm in trouble with the mail request in the Service Project.\n\nEven if I've followed these steps:\n\n<https://confluence.atlassian.com/jirakb/enable-automatic-accounts-creation-through-email-requests-1167726016.html>\n\n++If a certain [email protected] sends a message to the [email protected] the operation fails because \"You don't have permission to access this service project\"++ \n\nI found another article where the solution is [email protected]++to join the jira-servicemanagement-customers group and it worked.\n\nBut I have more than 5.000 customer users and many others to come, how can I resolve without joining the group one by one?\n\nPlease help me\n\nThanks\n\n**INFO UPDATE**: it seems like this:\n\n* If the CUSTOMER_MAIL is a migrated one, it doesn't work as it should until I add manually the group jira-servicemanagement-customers\n* If the CUSTOMER_MAIL is a new one, it works as it should and it opens the request automatically\n\nThen, there is no official automation way to get an alert for the mail handler failings <https://jira.atlassian.com/browse/JSDCLOUD-2517>\n\nIt's a very big trouble for me\n\nPlease help me\n\nThanks\n"
}
|
[
{
"author": "Anusha A",
"body": "Hi [Giovanni,](https://community.atlassian.com/t5/user/viewprofilepage/user-id/5332543)\n\nI have created a ticket on your behalf as our support experts can dig in a bit from your instance and understand the configuration to efficiently help you further. You will be receiving an email with the details soon.\n\nRegards,\n\nAnusha A\n",
"comments": [
{
"author": "Giovanni Cardillo",
"body": "Hi [@Anusha A](/t5/user/viewprofilepage/user-id/4968529) and [@Kai Becker](/t5/user/viewprofilepage/user-id/1178079) ,\n\nthanks for your interest.\n\nMaybe I found a possible workaround:\n\ninstead of adding the group jira-servicemanagement-customers manually one by one I could use the BULKOPS app available in the store and get the customers joining the group by uploading a CSV file.\n\nI hope we can find a definitive solution and not necessarily a workaround.\n\nThanks for tour help\n"
}
]
},
{
"author": "Giovanni Cardillo",
"body": "Hi [@Kai Becker](/t5/user/viewprofilepage/user-id/1178079) ,\n\nyes, the MIGRATED CUSTOMERS have been created by cloud migration assistant and only emails sent by MIGRATED CUSTOMERS have the problem.\n\nI noticed something, hope it helps:\n\nMIGRATED CUSTOMER are present both in Customer section of JMS and in the admin.atlassian.com \\> Manage user section.\n\nMails sent by a NEW CUSTOMER open the request automatically and, once done, the NEW CUSTOMER is present in Customer section of JMS but NOT in the admin.atlassian.com \\> Manage user section\n\nThanks for your help\n",
"comments": [
{
"author": "Kai Becker",
"body": "are they assigned to the service management customer role and added to the project via people tab? \nMaybe this got messed up during cloud migration. I haven't done one for a while so I'm not fully aware of the current features and bugs.\n"
},
{
"author": "Giovanni Cardillo",
"body": "Hi,\n\n[@Kai Becker](/t5/user/viewprofilepage/user-id/1178079)\n\n* in the admin.atlassian.com \\> Manage user section they don't have any product access\n* in the people tab they are not present\n\nAccording to your opinion something's gone wrong with the migration?\n\nThanks again for your help\n"
},
{
"author": "Kai Becker",
"body": "[@Giovanni Cardillo](/t5/user/viewprofilepage/user-id/5332543) not a hundred percent sure at the moment. \nI think it definitely has something todo with the customers missing from the people tab. \nCould you try to add a few customers and try emailing with these addresses?\n"
}
]
},
{
"author": "Kai Becker",
"body": "Hi [@Giovanni Cardillo](/t5/user/viewprofilepage/user-id/5332543)\n\nthank you for your question. How do you identify these old customers? Are the created via cloud migration assistant? Or are only the requests copied over and they are not correctly associated with this service project? Your error usually comes from a missing permisson setting.\n\nRegarding you way to get notified for failing mail handler, make sure you take a look at this guide: <https://community.atlassian.com/t5/Jira-Service-Management-articles/An-unofficial-way-to-monitor-a-JSM-mail-handler-for-errors/ba-p/2132002#M2089>\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/You-don-t-have-permission-to-access-this-service-project-for/qaq-p/2816967
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud",
"jira-software"
] |
{
"author": "Alexander Steel",
"title": "Can I input a JQL query into an automated comment?",
"body": "I am attempting to make a simple automated message when a ticket is triaged in Jira Servicedesk.\n\nI want the message to say something like\n\n\"Hi {{issue.reporter.displayName}},\n\nYour issue has been read over and assigned a priority of {{issue.priority.name}}.\n\nWe currently have X outstanding tickets of that priority or higher and are already working on Y of them.\n\nWe will pick your issue up as soon as we have cleared these tickets ahead of you in the queue.\n\nRegards, the support team\"\n\nI can get JQL queries for the X and Y values fairly easily but can't find a way to enter it into the automated email.\n\nHas anyone come across a way to do something similar?\n"
}
|
[
{
"author": "Semih Tolga Yazici",
"body": "Hey Alexander, \n\nI will share with you a simple example to guide the solution that you can implement. \n\nX (All tickets that are not done) -\\> {{issue.priority.name}} AND statusCategory != Done \nY (In Progress) -\\> {{issue.priority.name}} AND status = 'In Progress' \n\nCreate an Automation. \nSelect the trigger according to when you want to calculate the number of issues and send an email. \nUse branch rule (you can select current issue) \nLookupIssues action. \nAnd provide the JQL in there for X and Y. \n{{lookupIssues.size}} smart value will give you the number of issues. \nAnd you can add one more action which is Send email and use that smart value. Or you can put it into a customfield. \n\nHowever, there might be a total limit for the JQL that gets the issues. \n\nIn that case, let's say the limit is 100. \n\nYou can say in the email like there are more than 100 issues that are in the queue currently. \n\n<br />\n\nThe other but not the best way is counting the issues in a customfield. It will decrease the number -1 whenever and issue goes to the statusCategory = Done. It will increase the number whenever an issue is created. \n",
"comments": [
{
"author": "Alexander Steel",
"body": "I did see some similar comments but jira isn't happy with the {{lookupissues.size}} and is simply skipping over it. \nIs there some specific licence or versioning that is required?\n\n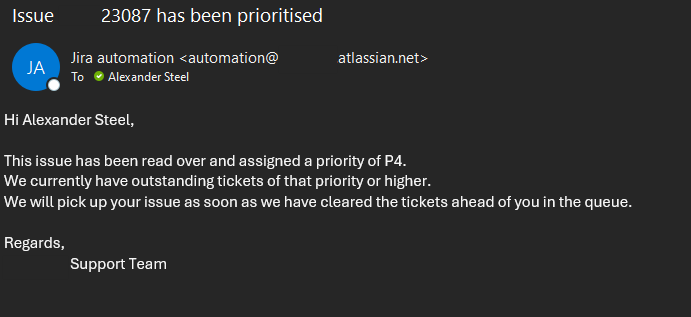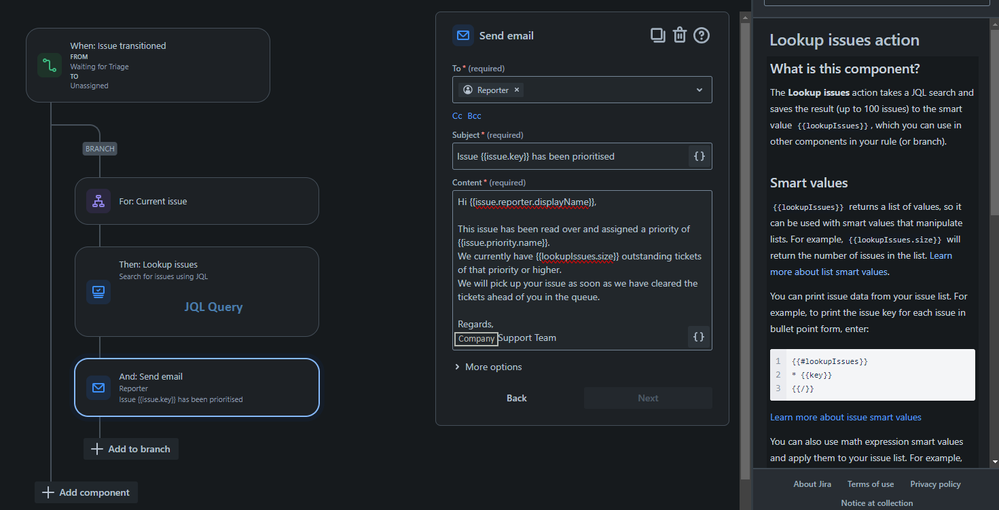\n"
},
{
"author": "Alexander Steel",
"body": "Strangely after trying again it worked, no change to any of the queries but it just seemed to work all of a sudden and since I have been able to test and it is working fine.\n\nThank you\n"
},
{
"author": "Alexander Steel",
"body": "The final section that allowed for the email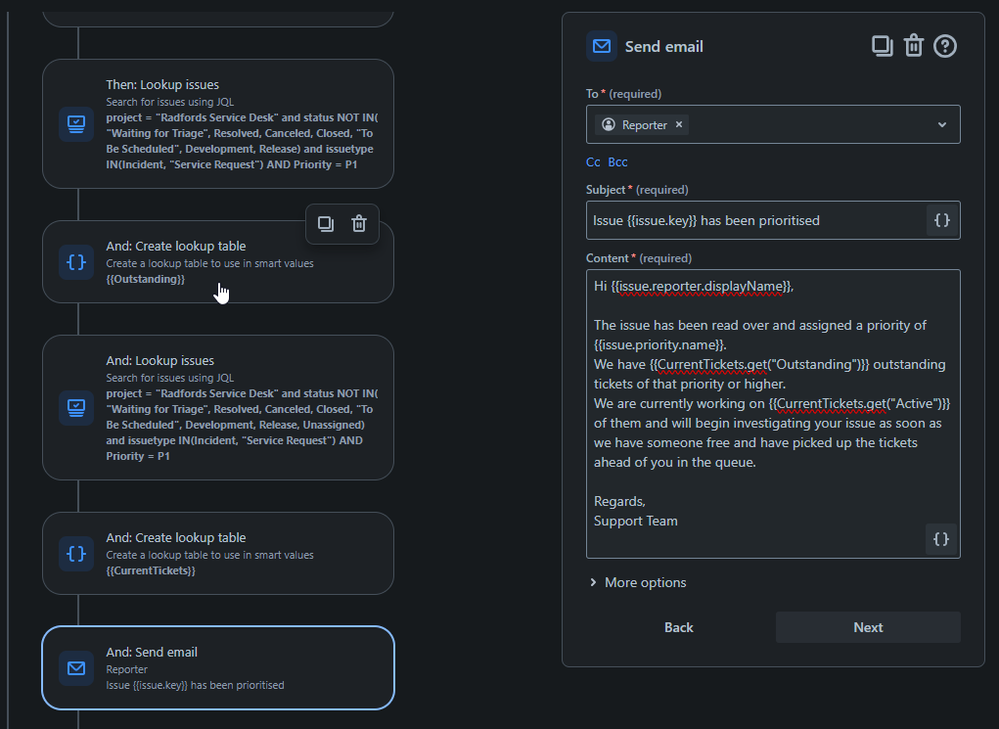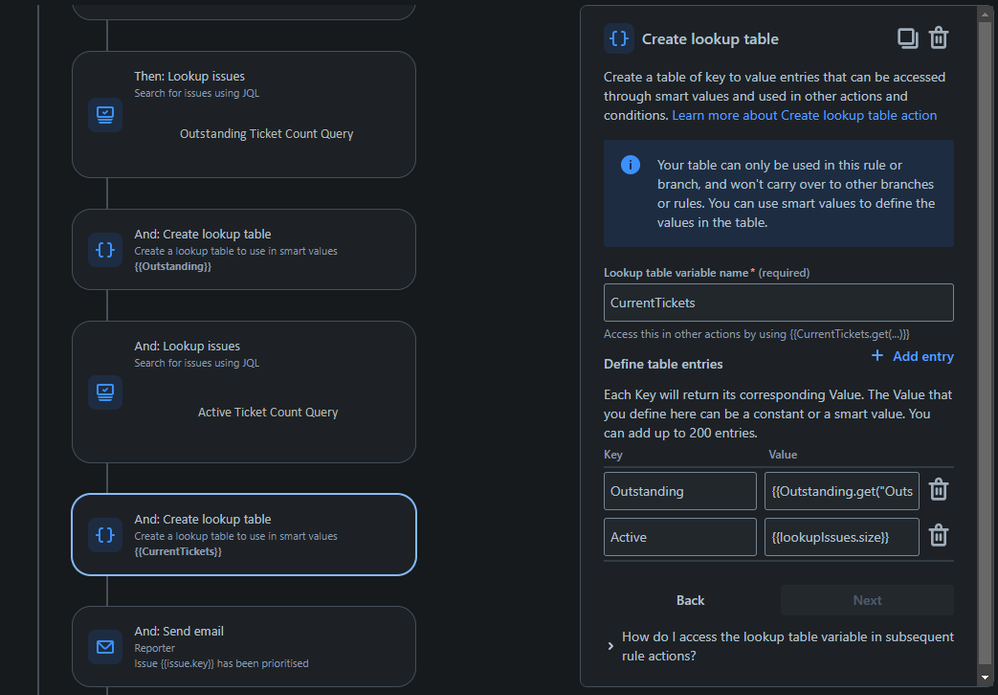\n"
}
]
},
{
"author": "Semih Tolga Yazici",
"body": "I have just tried for you {{lookupIssues.size}} yeah it still works fine and it gave the result actually.\n\n<br />\n\n\n",
"comments": [
{
"author": "Mark Higgins",
"body": "Hi,\n\nYes, it now works for me as well? Weird.\n\nI did add a log action inbetween but all is now good.\n\n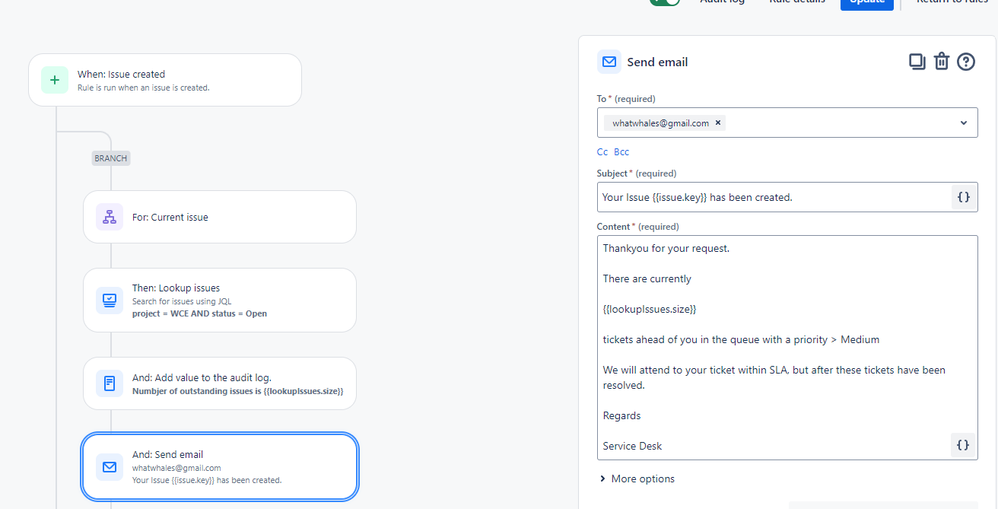\n\nEmail looks like:\n\n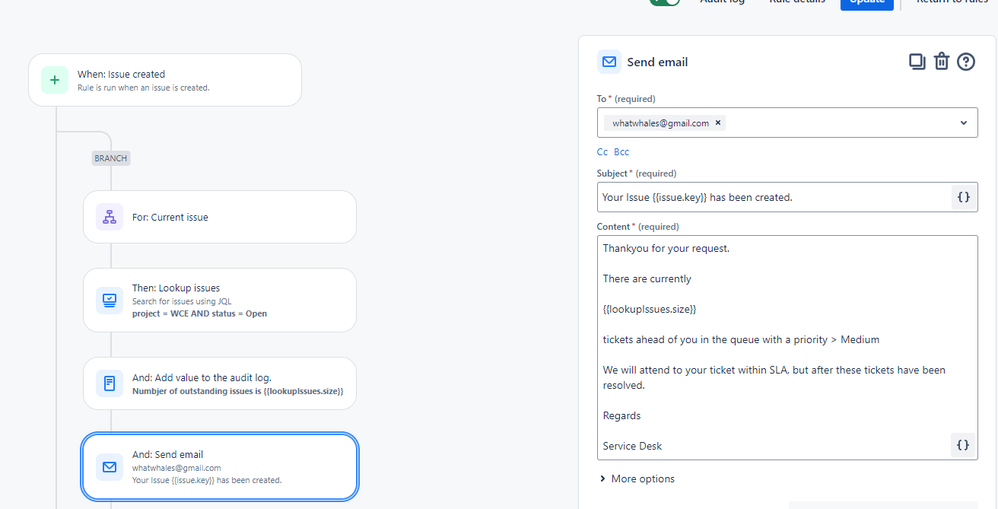\n\nThanks [@Alexander Steel](/t5/user/viewprofilepage/user-id/5597029) that is a very useful idea.\n\nMark\n"
}
]
},
{
"author": "Mark Higgins",
"body": "Hi [@Alexander Steel](/t5/user/viewprofilepage/user-id/5597029)\n\nI was curious to see if this did work in my environment and it did not.\n\nWhat did work (and I admit it's not ideal) is this:\n\n{{#lookupIssues}}\n\n\\* {{key}}\n\n{{/}}\n\nwhich lists ALL the issues that the JQL returned.\n\nTry as I might, I can not get the .size to work??\n\nMark\n",
"comments": null
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Can-I-input-a-JQL-query-into-an-automated-comment/qaq-p/2816953
|
[
"cloud",
"jira-automation",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Nancy Galvez",
"title": "AQL for Automation",
"body": "I am trying to create an automation. One ticket will trigger the creation of another ticket. I want to transfer the Asset Field to the new ticket. The asset field is called \"Customer Object\" or (customfield_10820).\n\nI have tried {\\[triggerIssue.Customer Object}} but this does not work. Since the field only takes AQL, what would be the AQL syntax to work?\n"
}
|
[
{
"author": "Mikael Sandberg",
"body": "Since the field holds the object key (what you see is the display name) then this AQL should do the trick for you:\n\nKey LIKE {{triggerIssue.Customer Object}}\n",
"comments": [
{
"author": "Nancy Galvez",
"body": "Thank you! That worked\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/AQL-for-Automation/qaq-p/2816944
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Rachel Frechette",
"title": "Filtering for all JIRA issues worked on within a timeframe.",
"body": "Hello all,\n\nI want to get a list of all of the JIRA tickets that we worked on for the current week.\n\nI need the ones that are in any status, even Done.\n\nI have no idea how to even begin to do this.\n\nI don't know what dates to use or how I would format the query.\n\nI've only got. \"Team Name\" = Team-1 AND ...\n\nCan this be done? T\n\nhanks so much.\n"
}
|
[
{
"author": "Manoj Gangwar",
"body": "Hi [@Rachel Frechette](/t5/user/viewprofilepage/user-id/5476530)\n\nproject = \"YourProjectKey\" AND updated \\>= startOfWeek() AND updated \\<= endOfWeek()\n\nReplace `\"YourProjectKey\"` with your actual project key. This query will return all issues that were updated during the current week.\n",
"comments": [
{
"author": "Rachel Frechette",
"body": "Thanks so much for your help Manoj!\n\nI really needed this today!\n"
}
]
},
{
"author": "Laura Campbell _Seibert Media_",
"body": "Hi [@Rachel Frechette](/t5/user/viewprofilepage/user-id/5476530) ,\n\nI recommend checking out this free course [https://university.atlassian.com/student/path/1687678-finding-information-with-search-and-filters-in-jira?sid=9a76b062-72d8-4bed-8cc5-2a71e89bdbb3\\&sid_i=0](https://university.atlassian.com/student/path/1687678-finding-information-with-search-and-filters-in-jira?sid=9a76b062-72d8-4bed-8cc5-2a71e89bdbb3&sid_i=0)\n\nas learning the basics of JQL is an essential skill when using Jira.\n",
"comments": [
{
"author": "Rachel Frechette",
"body": "Thank you.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/Filtering-for-all-JIRA-issues-worked-on-within-a-timeframe/qaq-p/2816922
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Atif Ul Aftab",
"title": "I just wanted to know if we can update the creation date after lodging any ticket ?",
"body": "Suppose I created a ticket and later on I realized it the issue was actually on going before the ticket creation date. Then is there any way to update the ticket creation date ?\n"
}
|
[
{
"author": "Aaron Pavez _ServiceRocket_",
"body": "Hi [@Atif Ul Aftab](/t5/user/viewprofilepage/user-id/5590297)\n\nSadly no, you can't. You could create a new issue by importing a CSV and setting the date to another date.\n\nOR you could create a custom field to hold the original date too.\n\nRegards\n\nAaron\n",
"comments": [
{
"author": "Atif Ul Aftab",
"body": "Hello \n\nThank you so much. I am really new to this community. I was thinking almost in the same way but thank you again for showing me the path.\n"
}
]
},
{
"author": "Mikael Sandberg",
"body": "Hi [@Atif Ul Aftab](/t5/user/viewprofilepage/user-id/5590297),\n\nWelcome to Atlassian Community!\n\nNo, the created date cannot be changed, that is set when the issue is created and you have no control over that. You could work around it by creating a custom date field that you use as discovery date.\n",
"comments": [
{
"author": "Atif Ul Aftab",
"body": "Hello \n\nThank you so much. I am really new to this community. I was think almost in the same way but thank you again for showing me the path.\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/I-just-wanted-to-know-if-we-can-update-the-creation-date-after/qaq-p/2816845
|
[
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
{
"author": "Rodney Estrada",
"title": "How is this schedule Assets import automation useful?",
"body": "Hi,\n\nJust wondering the purpose of this automation that [schedules Assets imports](https://confluence.atlassian.com/jirakb/how-to-schedule-assets-import-using-automation-for-assets-1155466867.html). It looks like it just runs the existing configured CSV file. How is running the same CSV file again useful?\n\nI'm trying to figure out a way to connect Assets with Jamf so changes in Jamf automatically get pushed to Assets, either via API or some app integration.\n\nExample: Laptop \"A\" is purchased and details entered into Jamf. Then Laptop \"A\" details are pushed automatically to Assets either immediately or next day.\n\nThanks,\n"
}
|
[
{
"author": "Dave Mathijs",
"body": "Yes, this. Unfortunately, these existing DC features are ~~not yet~~ still not available in Cloud. I mean, one simply doesn't use a CSV for synchronization. Database, JSON, LDAP are the ones we need for scheduling.\n",
"comments": [
{
"author": "Rodney Estrada",
"body": "[@Dave Mathijs](/t5/user/viewprofilepage/user-id/2662590) , Indeed!\n"
}
]
}
] |
https://community.atlassian.com/t5/Jira-Service-Management/How-is-this-schedule-Assets-import-automation-useful/qaq-p/2816600
|
[
"assets",
"cloud",
"jira-service-management",
"jira-service-management-cloud"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.